Уровень техники
Количество данных, управляемых и обрабатываемых в типичной среде предприятия, огромное и быстро увеличивается. Например, является обычным для отделов информационной технологии (IT) иметь дело с многими миллионами или даже миллиардами файлов в десятках форматов. Кроме того, существующее количество имеет тенденцию роста со значительной скоростью (например, с двузначным ежегодным приростом). Большая часть этих данных неактивно управляется и содержится в неструктурированном виде в общих каталогах.
Существующие инструментальные средства и практики управления данными не очень способны поддерживать различные и сложные сценарии, которые могут присутствовать. Такие сценарии включают в себя совместимость, безопасность и хранение и применяются к неструктурированным данным (например, файлам), полуструктурированным данным (например, файлам плюс дополнительные свойства / метаданные) и структурированным данным (например, в базах данных). Таким образом, желательна любая технология, которая снижает затраты на управление и риски неэффективного управления.
Сущность изобретения
Данный раздел «Сущность изобретения» предусматривается для введения выбора характерных принципов в упрощенном виде, которые дополнительно описываются ниже в разделе «Подробное описание». Данный раздел «Сущность изобретения» не предназначен для определения ключевых признаков или существенных признаков заявленного объекта изобретения и не предназначен для использования любым образом, который ограничил бы объем заявленного объекта изобретения.
Вкратце, различные аспекты объекта изобретения, описанные в данном документе, относятся к технологии, посредством которой элементы данных (например, файлы) обрабатываются посредством конвейера обработки данных, включающего в себя конвейер классификации, чтобы способствовать управлению элементами данных, основываясь на их классификации. В одном аспекте конвейер классификации получает метаданные (например, влияние на бизнес, уровень конфиденциальности и т.п.), ассоциированные с каждым обнаруженным элементом данных. Набор из одного или более классификаторов классифицирует элемент данных, если он вызван, в метаданные классификации (например, одно или более свойств), которые затем ассоциируются (сохраняются в ассоциативной связи) с элементом данных. Затем может быть применена политика для каждого элемента данных, основываясь на ассоциированных с ним метаданных классификации, например истечение срока хранения файла, изменение уровня защиты/доступа к файлу и т.п., основываясь на метаданных каждого файла.
В одном аспекте конвейер обработки элементов данных включает в себя модульные компоненты для независимых фаз обнаружения элементов, классификации и применения политики. Каждая фаза является расширяемой и может включать в себя один или более модулей (или ни одного), которые действуют в этой фазе. Метаданные/свойства классификации каждого элемента могут устанавливаться или получаться внешне посредством интерфейса установления или получения соответственно.
В одном аспекте в фазе классификации могут вызываться многочисленные модули классификатора. Может быть принято решение, вызывать ли каждый классификатор, основываясь на различных критериях, таких как были ли и/или когда был ранее классифицирован элемент данных. Классификатор может использовать любое из свойств, ассоциированное с элементом данных, и/или содержимое самого элемента данных при классификации элемента данных. Заданное упорядочение классификаторов, авторитетные классификаторы и/или механизм агрегирования являются из числа методов, которые могут быть использованы для обработки любых конфликтов в отношении того, как разные классификаторы классифицируют один и тот же элемент.
Могут обеспечиваться разные типы классификаторов, включая классификатор, который классифицирует элемент данных, основываясь на расположении элемента данных, основанный на глобальном репозитории классификатор (основанный на владельце и/или авторе) и/или основанный на содержимом классификатор, который классифицирует элемент, основываясь на содержимом, содержащимся в элементе. Каждый классификатор может соответствовать правилам автоматической классификации; классификатор может непосредственно изменить значение свойства или возвратить результат механизму соответствующего правила, так что механизм соответствующего правила может изменить свойство.
Другие преимущества могут стать очевидными из последующего подробного описания, рассматриваемого вместе с чертежами.
Краткое описание чертежей
Настоящее изобретение изображается посредством примеров и не ограничивается прилагаемыми фигурами, на которых подобные позиции указывают аналогичные элементы и на которых:
Фиг.1 представляет собой блок-схему, изображающую примерные модули в конвейерной службе для автоматической обработки элементов данных для управления данными, включая обнаружение элементов данных, классификацию этих элементов данных и применение политики, основываясь на классификации.
Фиг.2 представляет собой представление, изображающее примерные этапы, выполняемые конвейерной службой при обработки файлов файлового сервера в свойства, ассоциированные с файлами.
Фиг.3 представляет собой представление примерной архитектуры службы классификации, иллюстрирующей на примере, как свойства элемента данных могут передаваться между модулями для обработки посредством времени исполнения классификации.
Фиг.4А и 4В содержат блок-схему последовательности операций, изображающую примерные этапы, выполняемые для обработки элементов данных, включающие в себя этапы для классификации элементов для применения политики.
Фиг.5 изображает иллюстративный пример вычислительной среды, в которую могут быть встроены различные аспекты настоящего изобретения.
Подробное описание
Различные аспекты технологии, описанной в данном документе, относятся, в основном, к управлению данными (например, файлами на файловых серверах или т.п.) посредством классификации элементов данных (объектов) в классификацию и применения политик управления данными, основываясь на классификации. В одном аспекте это выполняется посредством модульного подхода для решений с возможностью классификации данных, основанных на конвейере классификации. В основном, конвейер содержит последовательность модульных программных компонентов, которые связываются через общий интерфейс. В различные моменты времени данные обнаруживаются и классифицируются, при этом политика применяется к данным, основываясь на классификации данных.
Хотя различные примеры используются в данном документе, такие как разные типы классификации файлов для классификации файлов/данных, хранимых на файловом сервере, необходимо понять, что любой из примеров, описанных в данном документе, является неограничивающим примером. Например, могут классифицироваться не только файлы, но другие структуры данных также могут классифицироваться в связанные «типы» классификации, например любые данные, которые являются структурированными (например, любая порция данных, которая придерживается абстрактной моделью, описывающей, как представлены данные и как к ним можно обращаться), могут классифицироваться, например, элементы электронной почты, таблицы базы данных, сетевые данные и т.п. Кроме того, могут использоваться другие пути хранения данных, например, вместо, или в дополнение к, файлового сервера, данные могут храниться в локальном запоминающем устройстве, распределенном запоминающем устройстве, сетях устройств хранения данных, запоминающем устройстве Интернета и т.п. По существу, настоящее изобретение не ограничивается какими-либо конкретными вариантами осуществления, аспектами, принципами, структурами, функциональными возможностями или примерами, описанными в данном документе. Скорее, любой вариант осуществления, аспект, принцип, структура, функциональная возможность или пример, описанный в данном документе, является неограничивающим, и настоящее изобретение может использоваться различными путями, которые, как правило, обеспечивают выгоду и преимущества при вычислении и управлении данными.
Фиг.1 изображает различные аспекты, относящиеся к технологии, описанной в данном документе, включая конвейер для обработки элементов данных, который, как приведено в качестве примера в данном документе, может использоваться для обработки файлов, но, как понятно, может использоваться для обработки одной или более других структур данных, таких как элементы электронной почты. В примере на фиг.1 конвейер реализован в виде службы 102, которая работает с любым набором данных, как представлено хранилищем 104 данных.
Обычно конвейерная служба 102 включает в себя модуль 106 обнаружения, службу 108 классификации и модуль 113 политики. Отметьте, что термин «служба» необязательно ассоциируется с единственной машиной, но вместо этого представляет собой механизм, который координирует некоторое исполнение конвейера. В данном примере, служба 108 классификации включает в себя другие модули, а именно модуль (или модули) 109 извлечения метаданных, модуль (или модули) 110 классификации и модуль (или модули) 111 хранения метаданных. Каждый из модулей, описанных ниже, может рассматриваться как фаза, и, действительно, нет необходимости, чтобы временная шкала для каждой операции была непрерывной, т.е. каждая фаза может выполняться относительно независимо и нет необходимости, чтобы она следовала непосредственно за предыдущей фазой. Например, фаза обнаружения может обнаруживать и сохранять элементы, которые фаза классификации классифицирует позже. В качестве другого примера, данные могут классифицироваться ежесуточно, при этом приложение управления данными (например, резервное копирование) выполняется один раз в неделю. Любая из фаз может выполняться независимо, при неавтономной обработке в реальном времени или автономной обработке, при работе в приоритетном режиме или в фоновом режиме (например, в отложенном режиме) или распределенным образом на отдельных машинах.
Обычно модуль (или модули) 106 обнаружения находят элементы для классификации (например, файлы) и могут использовать более одного механизма для выполнения этого. В качестве примера, есть два пути для обнаружения файлов на файловом сервере, один, который работает посредством сканирования файловой системы, и другой, который обнаруживает новые изменения в файлах из протокола удаленного доступа к файлу. Обычно обнаруженные данные обеспечиваются в виде элементов для фазы/службы 108 классификации или непосредственно, или через промежуточное хранение. Таким образом, обнаружение может логически быть отделено от классификации.
Обнаружение может инициироваться различными путями. Одним путем является по требованию, при котором элементы обнаруживаются после запроса. Другим путем является в реальном времени, когда изменение в одном или более элементах запускает операцию обнаружения. Еще другим путем является запланированное обнаружение, например, один раз в день, например, после обычного рабочего времени. Еще другим путем является отложенное обнаружение, при котором фоновый процесс или т.п. выполняется с низким приоритетом для обнаружения элементов, например, когда коэффициент использования сети или сервера является относительно низким. Кроме того, отметьте, что обнаружение может выполняться в неавтономной операции, т.е. над реальными данными или над автономной копией данных, такой как моментальный снимок исходных данных; (отметьте, что, как правило, моментальная копия ссылается на копию конкретных элементов данных, какими они были в некоторый заданный момент времени, посредством чего работа над моментальной копией помогает поддерживать элементы данных в постоянном состоянии, когда они обрабатываются, в противоположность реальной системе, в которой элементы данных могут изменяться в реальном времени).
После фазы/службы 108 классификации (описанной ниже) модуль (или модули) 113 политики применяют политику, основываясь на классификации каждого элемента. В качестве примера, продукт защиты от утечки информации может классифицировать некоторые файлы как имеющие «персональную идентифицируемую информацию» или т.п. Продукт резервного копирования файлов может быть выполнен с политикой, так что любой файл, классифицированный как имеющий «персональную идентифицируемую информацию» должен резервироваться на защищенное запоминающее устройство.
Обращаясь к различным аспектам, относящимся к классификации, как представлено на фиг.1, модуль (или модули) 109 извлечения метаданных находит метаданные, ассоциированные с элементами данных. Например, файловая система имеет многочисленные атрибуты, которые она ассоциирует с файлом, и они могут извлекаться известным образом. Модуль (или модули) 109 извлечения метаданных также извлекает текущие значения метаданных классификации, так что они могут использоваться в качестве входа в фазу классификации. Отметьте, что классификация может выполняться над реальными данными или данными резервного копирования.
Некоторые примеры метаданных включают в себя определения свойств классификации, имеющие различные элементы, такие как имя свойства (или идентификатор), тип значения свойства (который идентифицирует тип данных фактического значения, например простые типы данных, такие как строка, дата, булево выражение, упорядоченное множество или мультимножество значений) и сложные типы данных, такие как типы данных, описываемые иерархической таксономией (тип документа, организационная единица или географическое расположение). Значение свойства классификации (называемое «значением свойства» или просто «свойством») представляет собой некоторое значение, которое может быть присвоено элементу данных с целью классификации этого элемента данных. Это значение ассоциируется со свойством классификации и обычно соблюдает ограничения, налагаемые определением ассоциированного свойства.
Другие примеры включают в себя схему свойств (описывающую большее количество ограничений на возможные значения) и политику агрегирования, описывающую, как многочисленные значения могут агрегироваться в единственное в том случае, когда необходимо такое агрегирование во время исполнения конвейера. Кроме того, метаданные могут содержать дополнительные атрибуты, ассоциированные со свойствами, такие как зависимая от языка информация, дополнительные идентификаторы и т.п.
В качестве примера рассмотрим свойство, названное «влияние на бизнес» типа «упорядоченное множество значений», которое ограничено значениями HBI (сильное влияние на бизнес), MBI (среднее влияние на бизнес) и LBI (слабое влияние на бизнес), с политикой агрегирования, что HBI выигрывает у MBI, которое выигрывает у LBI. Отметьте, что в процессе классификации ассоциирование значения свойства с элементом данных автоматически «связывает» этот документ с классом (т.е. категорией) документов. Например, посредством присоединения свойства BusinessImpact=HBI” к элементу данных этот элемент данных неявно присваивается «категории» документов BusinesImpact=HBI”.
Метаданные также могут храниться во внешнем источнике данных или другом кэше. Один пример включает в себя разрешение пользователям, или клиентам, и/или одному или более другим механизмам устанавливать метаданные классификации, или саму классификацию, и сохранять их в хранилище данных, таком как база данных. Таким образом, например, пользователь может вручную установить файл как содержащий «персональную идентифицируемую информацию» или т.п. Автоматизированный процесс может выполнять подобную операцию, такую как посредством определения метаданных, основываясь на том, какая папка содержит файл, например процесс может автоматически устанавливать ассоциированные метаданные для файла, когда этот файл добавляется к восприимчивой папке.
Кроме того, метаданные для элемента могут сохраняться (кэшироваться) из предыдущей операции извлечения и/или классификации. Таким образом, извлечение метаданных может состоять из многочисленных частей, например извлечь существующие метаданные (извлечение) и извлечь новые метаданные. Как можно легко понять, извлечение существующих метаданных может повысить эффективность классификации, например, для файлов, которые редко изменяются. Кроме того, механизм эффективности может определить, вызывать ли классификатор, основываясь на последнем разе, когда метаданные классификатора были обновлены, например, основываясь на временной метке, принятой от классификатора. Изменение в конфигурации службы 108 классификации, такое как изменение правила или изменение классификатора, также может запустить новую классификацию.
Если метаданные получены для элемента, модуль или модули 110 классификации классифицируют элемент на основе его метаданных. Содержимое элемента также может оцениваться, например, для поиска некоторых ключевых слов (например, «конфиденциальный»), тегов или других индикаторов в отношении свойства файла, которое может использоваться для его классификации. Существуют различные пути для классификации данных. Например, при классификации файлов файл может быть вручную установлен пользователем для классификации и/или классифицировался посредством важного коммерческого (LOB) приложения (например, приложения по трудовым ресурсам), которое управляет файлом. Файл может быть установлен для классификации посредством выполнения сценариев администратора и/или автоматически классифицироваться с использованием набора правил классификации.
Обычно правила автоматической классификации обеспечивают обобщенный расширяемый механизм, который составляет часть фазы 108 конвейера классификации. Это позволяет администратору или т.п. определять правила автоматической классификации, которые применяются к элементам данных для классификации этих элементов. Каждое правило автоматической классификации активизирует модуль классификации (классификатор), который может определить классификацию некоторого набора объектов данных и установить свойства классификации. Отметьте, что один модуль классификатора может включать в себя несколько правил для определения разных свойств классификации для одного и того же элемента данных (или для разных элементов данных). Кроме того, многочисленные классификаторы могут применяться к одному и тому же элементу данных; например, каждый из двух разных классификаторов может определить, имеет ли файл «персональную идентифицируемую информацию». Оба классификатора могут быть использованы для оценки одного и того же файла, посредством чего, даже если только один классификатор определяет, что файл содержит «персональную идентифицируемую информацию», файл классифицируется как таковой.
В качестве примера, некоторые элементы, которые правило может содержать, включают в себя информацию управления правилами (имя правила, идентификаторы и т.п.), область действия правила (описание набора элементов данных, подлежащих управлению правилом, такое как «все файлы в c:\folder1») и варианты оценки правила, описывающие, как правило исполняется во время конвейера. Другие элементы включают в себя модуль классификатора (ссылка на классификатор, используемый данным правилом, для фактического присвоения значения свойства), свойство (необязательное описание, определяющее набор свойств, присвоенных данным правилом) и дополнительные параметры правила, такие как дополнительные политики исполнения (такие как дополнительные фильтры, подобные регулярным выражениям, используемым для классификации содержимого файла, и т.п.).
Примерные модули классификатора включают в себя (1) классификатор, который классифицирует элементы, основываясь на расположении элемента данных (например, каталог файла), (2) классификатор, который классифицирует посредством использования глобального репозитория, основываясь на некоторых характеристиках элемента данных (например, поиск организационной единицы в Active Directory® или AD, основываясь на владельце файла), и (3) классификатор, который классифицирует на основе содержимого данных и характеристик данных (например, поиск шаблона в данных элемента). Отметьте, что это только примеры, и специалист в данной области техники может оценить, что другие характеристики элементов также могут использоваться для классификации разных элементов, т.е. фактически любая относительная разность среди элементов может использоваться для целей классификации.
В одной реализации классификатор может работать в различных режимах. Например, один рабочий режим «явного классификатора» имеет установку классификатора на фактическое свойство или свойства, например, когда персональная информация обнаруживается в файле, классификатор устанавливает соответствующее свойство «PII» (персональная идентифицируемая информация) на «существует» или т.п. Другим подходящим режимом является «неявный классификатор», который может иметь возврат классификатора ИСТИНА или ЛОЖЬ, например, в отношении того, находится ли файл в некотором каталоге, таком как c:\debugger. В режиме ИСТИНА или ЛОЖЬ правило автоматической классификации ассоциируется со свойством и значением, которое должно быть установлено всякий раз, когда классификатор возвращает ИСТИНА. Таким образом, классификатор может устанавливать значение или значения свойства, или правило, которое вызывает классификатор, может выполнить так. Отметьте, что могут применяться классификаторы кроме типов ИСТИНА или ЛОЖЬ, например, тот, который возвращает числовое значение (например, значение вероятности) для обеспечения более детальной классификации и правила классификации.
После классификации результат классификации и, возможно, другие извлеченные метаданные необязательно сохраняются в ассоциативной связи с элементом. Как представлено на фиг.1, модуль 111 хранения метаданных выполняет данную операцию. Хранение позволят применять политику позже, основываясь на классификации.
Отметьте, что каждый из модулей конвейера классификации является расширяемым, так что различные предприятия могут настроить данную реализацию. Расширяемость позволяет подключать более одного модуля в одну и ту же фазу конвейера. Кроме того, любая из фаз может выполняться параллельно или последовательно, например, распределенным образом (по многочисленным машинам). Например, если классификация является дорогой в отношение вычислений, тогда элементы могут распределяться (например, используя методы выравнивания нагрузки) для распараллеливания наборов классификаторов, выполняющихся на разных машинах, при этом результаты каждого параллельного пути подаются на модуль политики.
Что касается политики, приложения (включая те, которые не являются непосредственно подключаемыми в конвейер) могут оценивать метаданные классификации, чтобы выполнить решение о политике в отношении того, как обрабатывать элемент. Такие приложения включает в себя те, которые выполняют операции для проверки истечения срока элемента, аудита, резервного копирования, удержания, поиска, согласованности, оптимизации и т.п. Отметьте, что любая такая находящаяся в процессе решения операция может запускать классификацию данных в случае, когда данные еще не классифицированы, или не классифицированы в отношении находящейся в процессе решения операции.
Как можно легко понять, разные классификаторы могут приводить к разным и возможно конфликтующим классификациям. В одном аспекте выполняется агрегирование значений классификации для свойств. С этой целью для каждого элемента данных оцениваются определенные правила классификации (например, посредством администратора или процесса) для определения свойств классификации. Если два правила классификации могут установить одно и то же значение для одного конкретного свойства классификации, процесс агрегирования определяет окончательное значение свойства классификации. Таким образом, например, если одно правило вызывает результат, в котором свойство устанавливается в «1», и другое правило вызывает результат, где это же свойство устанавливается в «2», тогда определенная политика агрегирования может в некоторых вариантах осуществления определять, каким должно быть фактическим значением для этого свойства, т.е. «1» или «2» или что-то еще. Отметьте, что в данном конкретном сценарии одно правило не перезаписывает установку свойства другого правила, но вместо этого вызывается политика агрегирования для управления конфликтом.
В другом сценарии могут использоваться авторитетные классификаторы. Авторитетные классификаторы представляют собой другой тип классификатора, который обычно представляет собой классификаторы, которые могут переопределять другие классификаторы без активизирования правил агрегирования. Такой классификатор может сигнализировать свой результат, например, так, что он выигрывает любые конфликты.
В другом аспекте обеспечивается механизм для автоматического определения порядка оценки для правил классификации. С этой целью порядок оценки правила может определяться администратором и/или определяться автоматически посредством определения любых зависимостей между разными правилами и классификаторами. Например, если Rule-R1 устанавливает свойство классификации Property-P1, и Rule-R2 использует Classifier-C1, который использует Property-P1 для определения значения Property-P2, тогда Rule-R1 необходимо оценивать перед Rule-R2.
Кроме того, выполнять ли классификатор, может зависеть от результата предыдущего классификатора. Таким образом, например, может использоваться один классификатор, который редко имеет ошибочные положительные выводы, и всякий раз используется его результат «ИСТИНА». Вторичный классификатор (например, предназначенный для устранения ошибочных отрицательных выводов) рассматривается только тогда, когда авторитетный классификатор не возвращает «ИСТИНА» (например, возвращает «ЛОЖЬ» или возможно результат, указывающий неопределенность). Другой пример должен упорядочивать некоторые классификаторы в конвейере, основываясь на заданной «высоте». Например, классификатор с меньшей высотой исполняется в конвейере перед классификатором с большей высотой. Поэтому в конвейере классификаторы сортируются в порядке возрастания высоты.
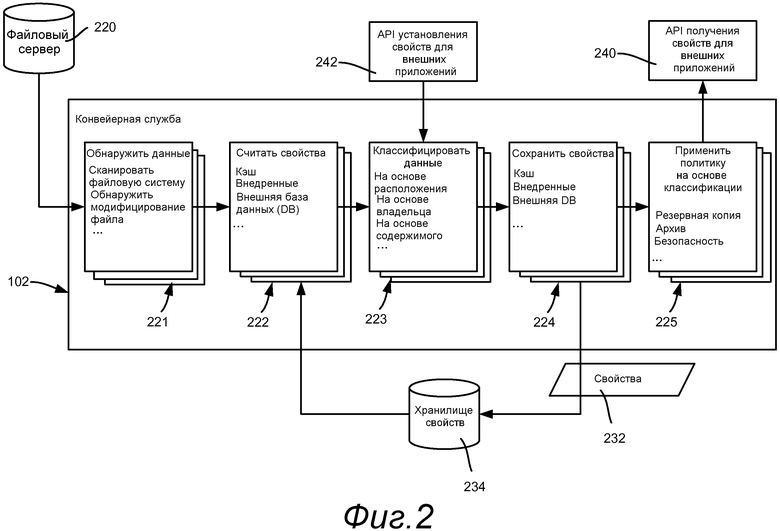
Фиг.2 изображает более конкретный пример, направленный на реализацию правил расширяемой автоматической классификации на файловом сервере 220. Как правило, вместо модулей фиг.2 представляет различные этапы 221-225 конвейерной службы; как можно видеть, эти этапы/модули 221-225 соответствуют модулям 106, 109-111 и 113 на фиг.1 соответственно. Таким образом, правила классификации применяются в конвейере классификации и включает в себя один или более модулей 221 обнаружения данных (или сканеры), один или более модулей 222 считывания метаданных (например, экстракторы и извлекатели), набор из одного или более модулей 223, которые определяют классификацию (классификаторы), один или более модулей 224, которые хранят метаданные (установщики), и один или более модулей 225, которые применяют политику, основываясь на классификации (модули политики).
Как также представлено на фиг.2, может увеличиваться количество модулей на любом данном этапе. Например, этапы классификации обеспечивают модель расширяемости для классификаторов; администраторы могут регистрировать новые классификаторы, перечислять существующие классификаторы и лишать регистрации классификаторы, которые больше не являются желательными.
Как, в основном, описано в данном документе, этапы для управления файлами на файловых серверах включают в себя классификацию файлов и применение политик управления данными, основываясь на классификации каждого файла. Отметьте, что файл может классифицироваться, так что к нему не применяется никакая политика.
В одной реализации процесс автоматической классификации для файлов на файловом сервере 220 управляется правилами классификации, определенными на этом сервере 220. Когда файл сохраняется на файловом сервере, на котором активна классификация, он классифицируется автоматически, т.е нет явного запроса от пользователя на классификацию файла. Различные критерии классификации, которые могут использоваться для классификации файла на этом конкретном файловом сервере, включают в себя (1) правила классификации и классификаторы, выполняющиеся на файловом сервере, (2) любые предыдущие результаты классификации, которые остаются ассоциированными с файлом, и/или (3) свойства, которые хранятся в самом файле (или его атрибуты). Эти критерии оцениваются при определении классификации данного файла для обеспечения результирующего набора свойств 232, которые хранятся в хранилище 234 свойств (но могут храниться в самом файле).
В одной реализации каждое правило классификации может иметь варианты оценки, например те, которые изложены ниже:
оценивать только тогда, когда файл еще не был классифицирован;
оценивать, даже если файл уже был классифицирован, и принять во внимание предыдущее значение или значения свойства классификации (например, из предыдущих выполнений процесса классификации над этим же файлом, если он существует);
оценивать, даже если файл уже был классифицирован, но не принимать во внимание никакое предыдущее значение свойства классификации.
В качестве примера рассмотрим документ (без присвоенных свойств), сохраненный пользователем в виде файла, в папке на сервере. Правило автоматической классификации классифицирует файл как имеющий среднее влияние на бизнес, т.е. BusinessImpact=MBI. Данная классификация также может сохраняться внутри документа (так как файловый сервер имеет синтаксический анализатор, установленный для данного типа документа).
Рассмотрим, что документ затем копируется на другой сервер (и в другую папку). Новая папка подпадает под правило классификации, которое, если оно выполняется, классифицирует файлы в папке как имеющие сильное влияние на бизнес BusinessImpact=HBI, если файл ранее не классифицирован. Однако так как свойства в данном файле указывают, что классификация BusinessImpact уже установлена на MBI, свойством BusinessImpact файла остается MBI.
Вышеупомянутое правило может быть модифицировано, чтобы оценивать файл, даже если файл уже классифицирован, и может принимать во внимание или может не принимать во внимание значение свойства в файле. При последующем выполнении классификации оценивается правило, и, так как HBI выше MBI, политика агрегирования определяет, что свойство файла должно быть установлено на HBI.
Как можно видеть, каждое правило классификации основывается на классификаторе, который используется для этого правила. В качестве другого примера, рассмотрим правило классификации, которое содержит <scope> (область действия), <classifier> (классификатор), <classification property> (свойство классификации), <value> (значение), в котором классификатор содержит конкретную реализацию, которая используется для классификации файла. Например, классификатор <classify by folder> (классифицировать по папке) позволяет выполнять классификацию файлов по их расположению. Данный классификатор рассматривает текущий путь файла и сопоставляет его с путем, заданным в <scope> правила классификации. Если путь находится в пределах <scope>, тогда правило указывает, что <classification property> может иметь <value>, заданное в правиле; (свойство необязательно установлено, так как может потребоваться агрегирование многочисленных правил для определения, каким является фактическое значение для данного свойства классификации). Отметьте, что это явный классификатор, так как он требует, чтобы было задано <value>.
В качестве примера другого типа классификатора файла классификатор «извлечь классификацию из AD по владельцу» считывает владельца файла и запрашивает активный каталог для вычисления, каким является правильное значение по владельцу для <classification property>, которое упомянуто в правиле. Отметьте, что им является неявный классификатор, так как он определяет <value>; таким образом, <value> не должно быть задано в правиле.
Каждый классификатор может необязательно указывать, какие свойства он использует для логики классификации. Эта информация является полезной при определении порядка, в котором процесс классификации вызывает классификаторы, а также для указания, какие свойства должны быть извлечены из хранилища 234 перед вызовом классификаторов.
Кроме того, каждый классификатор может необязательно указывать, какие свойства используются для установки. Эта информация может использоваться в пользовательском интерфейсе, чтобы показать, какие свойства являются подходящими для данного классификатора (если ни одно не упомянуто, тогда все свойства являются подходящими), а также в процессе классификации, где данная информация указывает, какие свойства должны быть извлечены из хранилища перед вызовом классификаторов. Информация является подходящей для явных и неявных классификаторов. Например, явный классификатор «классифицировать по папке» не имеет конкретные указанные свойства, ни неявный классификатор «извлечь классификацию из AD по владельцу». Однако неявный классификатор «определить организационную единицу» знает только, как установить свойство «организационная единица».
Для дополнительной идентификации необязательная информация может использоваться для описания классификатора, такая как название компании и обозначения версии.
Классификатору также может потребоваться использование дополнительных параметров. Например, если классификатор составлен для нахождения персональной информации в файле, основываясь на некоторых гранулярных выражений, тогда нет необходимости жестко закодировать эти гранулярные выражения в классификатор, но скорее могут предоставляться от внешнего источника, такого как файл расширяемого языка разметки (XML), который регулярно обновляется. В данном случае классификатор включает в себя указатель на этот XML-файл. Классификация, основанная на менеджере ресурсов файлового сервера (FSRM), позволяет задавать дополнительные параметры для классификатора, причем эти параметры передаются классификатору в качестве ввода, когда он вызывается.
Кроме того, поведение во время исполнения классификатора может быть разным между разными классификаторами из-за уровня разрешения, с которым исполняется классификатор. Одним уровнем разрешения является «локальная служба», однако могут потребоваться более высокий или более низкий уровень разрешения, например «локальная система» или «сетевая служба».
Другим аспектом является то, требуется ли классификатору обращение к содержимому файла. Например, вышеописанному классификатору папок нет необходимости обращаться к содержимому файла, так как он классифицирует на основе содержащей папки. В противоположность этому классификатору, который идентифицирует конкретный текст или шаблоны (например, номера кредитной карты) в файле, необходимо обрабатывать содержимое файла. Отметьте, что классификатор, которому необходимо обращаться к содержимому файла, нет необходимости для выполнения с увеличенным преимущественным правом, так как классификация FSRM выводит в виде потока содержимое файла для классификатора.
Нижеследующая таблица суммирует различные характеристики одной реализации классификатора:
Разрешен/запрещен (по умолчанию - разрешен)
Явный/неявный
Необходимо ли для классификатора, чтобы классификация FSRM выводила потоком содержимое файла для него? (по умолчанию: нет)
Преимущественное право времени исполнения классификатора (по умолчанию: локальная служба)
Свойства, которые он использует (необязательно)
Свойства, которые он устанавливает (необязательно)
Описание (необязательно)
Название компании (необязательно)
Версия (необязательно)
Уровень высоты
Дополнительные параметры (необязательно)
Фиг.2 также представляет интерфейсы 240, 242 прикладного программирования (API), которые позволяют другим внешним приложениям получать или устанавливать свойства для элемента данных соответственно. Как правило, API 240 получения свойств используется для того, чтобы «извлекать» свойства в произвольные моменты времени (в противоположность конвейеру, проталкивающему свойства в модули политики, когда он выполняется). Отметьте, что данное API 240 показано после фаз 223 и 224 классификации и сохранения соответственно, чтобы иметь возможность получить любые свойства, которые были установлены во время фазы 223 классификации данных.
API 242 установления свойств используется для «проталкивания» свойств в систему в произвольные моменты времени (хотя отметьте, что данный API 242 показан как работающий вместе с фазой 223 классификации данных, так что свойства могут быть сохранены позже, во время фазы 224 сохранения свойств; т.е. установка свойств, в основном, представляет собой управляемую пользователем ручную классификацию). Также отметьте, что в качестве части процесса классификации классификаторы могут иметь доступ к дополнительным заданным свойствам файла, которые извлекаются из файла для использования классификации (например, File.CreationTime …). Эти свойства могут не раскрываться в качестве свойств классификации посредством API классификации.
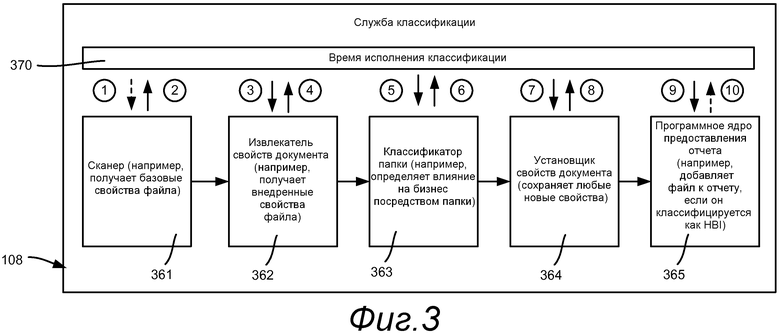
Возвращаясь к фиг.3, одна примерная архитектура для службы 108 классификации, которая включает в себя классификатор 363 папок, создана посредством сборки конвейерных модулей 361-365, которые связаны с временем 370 исполнения классификации при помощи общего потокового интерфейса, например, посредством операций, обозначенных один (1) - десять (10); сплошные стрелки представляют вызовы распределенной модели компонентных объектов (DCOM), например. В данном примере каждый конвейерный модуль 361-365 обрабатывает потоки объектов PropertyBag (одно мультимножество свойств на документ/файл), в котором каждый объект PropertyBag содержит список свойств, накопленных от предыдущих конвейерных модулей (если они есть). Обычно роль каждого конвейерного модуля 361-365 заключается в выполнении некоторых действий на основе этих свойств файла (например, добавить еще свойств) и передачи этого же мультимножества свойств обратно времени 370 исполнения. Время 370 исполнения передает поток мультимножества свойств на следующий конвейерный модуль до завершения.
В одной службе классификации на основе FSRM конвейерные модули хостируются по-разному в зависимости от чувствительности. Более конкретно, конвейерные модули, которые не интерпретируют/синтаксически анализируют содержимое пользователя (например, приведенный в качестве примера классификатор «папка», который интерпретирует метаданные файловой системы, или классификатор «AD», который ориентирован на свойства AD), могут хостироваться непосредственно в службе классификации FSRM. Конвейерные модули, которые имеют дело с предоставленным пользователем содержимым и/или модулями третьей стороны / внешними модулями (такими как выполняющими синтаксический анализ документов редактора Word, хостированных в процессе хостирования с низким преимущественным правом, выполняющимся под неадминистраторской учетной записью пользователя.
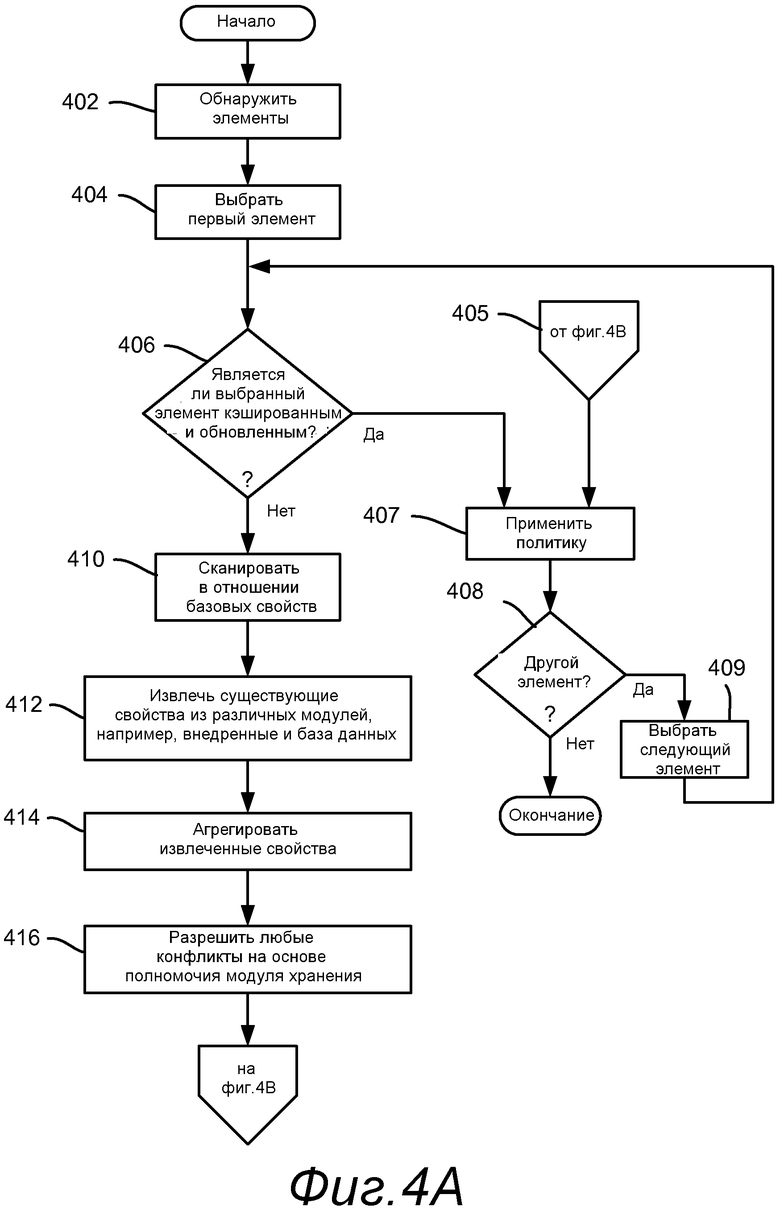
Фиг.4А и 4В суммируют различные конвейерные операции посредством примерных этапов блок-схемы последовательности операций, начинающихся на этапе 402, который представляет обнаружение элементов. Этап 404, который может работать, когда этап 402 предоставляет каждый новый элемент, или каждый раз после того, как этап 402 предоставит по меньшей мере один элемент, выбирает первый элемент.
Этап 406 оценивает, кэшируется ли выбранный элемент и обновляется ли в кэше. Если так, нет необходимости обработки элемента в остальной части конвейера, и, таким образом, выполняется переход на этап 407 для применения любой политики на основе свойств, как требуется; отметьте, что политика применяется к кэшированным/обновленным файлам соответствующим образом. Этапы 408 и 409, которые повторяют процесс для других элементов до тех пор, пока не останется ни одного.
Если элемент должен быть обработан в остальной части конвейера, этап 406 вместо этого выполняет переход на этап 410, который представляет сканирование элемента в отношении базовых свойств элемента. Ими могут быть метаданные файла, внедренные свойства и т.п.
Этап 412 представляет извлечение любых существующих свойств, ассоциированных с элементом. Они могут быть из различных модулей хранения, как описано выше, например встроенных модулей или модулей базы данных.
Этап 414 агрегирует различные свойства. Отметьте, что, возможно, что свойства могут конфликтовать, например, в примере выше, свойства классификации файла могут быть внедрены в файл и также могут внешне ассоциированы с файлом. Временная метка или другое правило разрешения конфликта может определять выигрывающую сторону, или классификация может принудительно задаваться, если иначе классификация должна быть пропущена из-за конфликтующего значения свойства. Этап 416 представляет разрешение любых таких конфликтов, например, на основе полномочия модуля хранения.
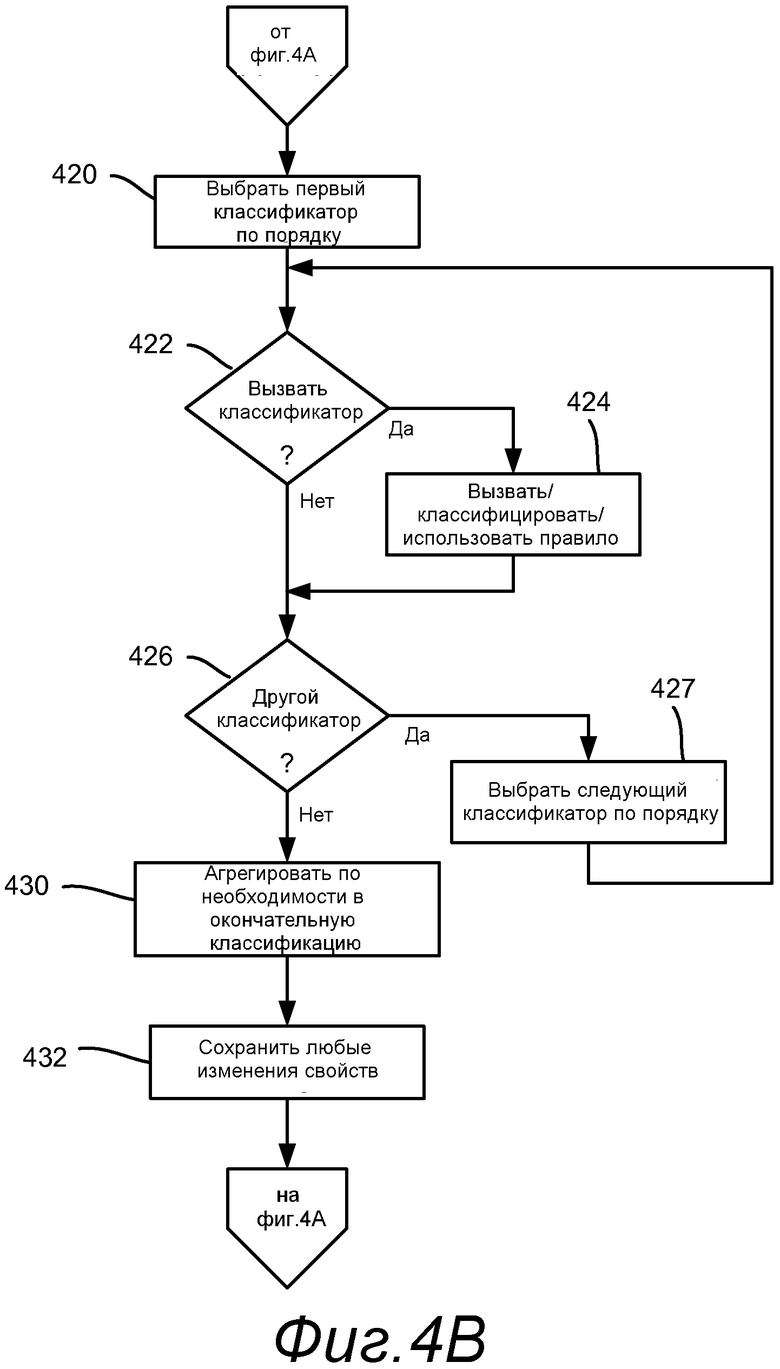
Процесс продолжается на этапе 420 фиг.4В, который представляет выбор первого классификатора, основываясь на упорядочении классификаторов, как описано выше; (отметьте, что может быть только один классификатор). Этап 422 представляет определение, вызывать ли выбранный классификатор. Как описано выше, существуют различные причины, почему может не выполняться конкретный классификатор, например, на основе существования предшествующей классификации, на основе временной метки или другого критерия и т.п. Если он не должен вызываться, этап 422 выполняет переход на этап 426 для проверки, должен ли рассматриваться другой классификатор.
Если выбранный классификатор должен быть вызван на этапе 422, выполняется этап 424, который представляет вызов классификатора, передачу любых параметров, как описано выше, который затем выполняет классификацию. Как также описано выше, если классификатор не устанавливает непосредственно свойство, тогда используется соответствующее правило на основе результата классификатора.
Этапы 426 и 427 повторяют процесс этапов 422 и 424 для любого другого классификатора. Каждый другой классификатор выбирается в соответствии с порядком оценки, определяемым высотой или другими методами упорядочения.
Этап 430 представляет агрегирование свойств соответствующим образом на основе классификаций. Как описано выше, оно включает в себя обработку любых конфликтов, хотя агрегирование не применяется к результатам классификации любого авторитетного классификатора.
Этап 432 представляет сохранение изменений свойств, если есть какие-либо, ассоциированных с файлом. Отметьте, что модули политики могут пропустить применение политики, если свойства файла не изменились. Процесс тогда может возвратиться на этап 405 на фиг.4А для применения любой политики (этап 407), выбора и обработки следующего элемента, если есть, до тех пор пока не останется ни одного.
Примерная операционная среда
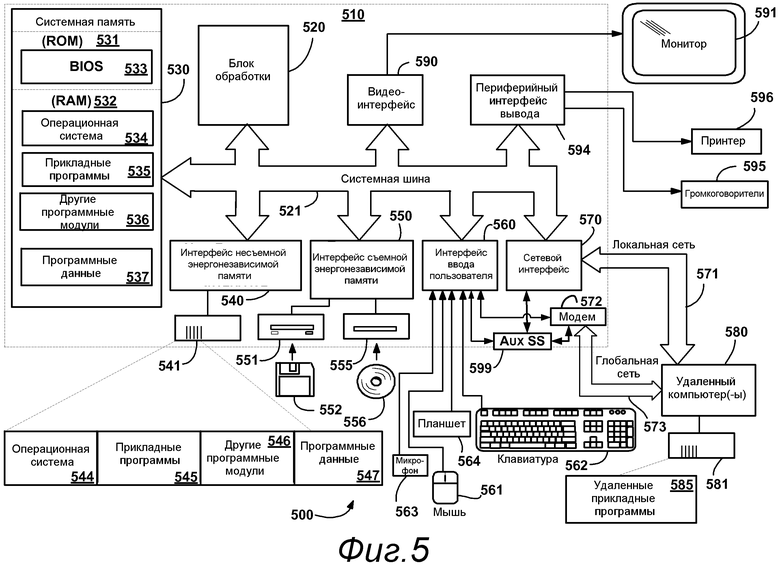
Фиг.5 изображает пример подходящей вычислительной и сетевой среды 500, на которой могут быть реализованы примеры по фиг.1-4. Вычислительная системная среда 500 представляет собой только один пример подходящей вычислительной среды и, как подразумевается, не предлагает никакого ограничения в отношении объема использования или функциональных возможностей изобретения. Вычислительная среда 500 также не должна интерпретироваться как имеющая какую-либо зависимость или требование, относящееся к любому одному или комбинации компонентов, изображенных в примерной операционной среде 500.
Изобретение является действующим с многочисленными другими вычислительными системными средами или конфигурациями общего назначения или специального назначения. Примеры общеизвестных вычислительных систем, сред и/или конфигураций, которые могут быть подходящими для использования с изобретением, включают в себя, но не ограничиваются ими: персональные компьютеры, серверные компьютеры, карманные или портативные устройства, планшетные устройства, мультипроцессорные системы, микропроцессорные системы, телевизионные абонентские приставки, программируемую бытовую электронику, сетевые персональные компьютеры (PC), миникомпьютеры, большие электронно-вычислительные машины, распределенные вычислительные среды, которые включают в себя любую из вышеупомянутых систем или устройств, и т.п.
Изобретение может быть описано в общем контексте исполняемых компьютером команд, таких как программные модули, исполняемые компьютером. Обычно программные модули включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и т.п., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Изобретение также может быть осуществлено на практике в распределенных вычислительных средах, где задачи выполняются удаленными устройствами обработки, которые связаны при помощи сети передачи данных. В распределенной вычислительной среде программные модули могут располагаться на локальных и/или удаленных носителях данных компьютера, включая запоминающие устройства памяти.
Как показано на фиг.5, примерная система для реализации различных аспектов изобретения может включать в себя вычислительное устройство общего назначения в виде компьютера 510. Компоненты компьютера 510 могут включать в себя, но не ограничиваются ими, блок 520 обработки, системную память 530 и системную шину 521, которая соединяет различные системные компоненты, включая системную память с блоком 520 обработки. Системная шина 521 может быть любой из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, используя любую из множества шинных архитектур. В качестве примера, а не ограничения, такие архитектуры включают в себя шину архитектуры промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), шину расширенной ISA (EISA), локальную шину Ассоциативной связи по стандартам в области видеоэлектроники (VESA) и шину межсоединений периферийных компонентов (PCI) также известную как шина расширения.
Компьютер 510 обычно включает в себя многочисленные считываемые компьютером носители. Считываемые компьютером носители могут представлять собой любой доступный носитель, к которому может обращаться компьютер 510 и который включает в себя как энергозависимые, так и энергонезависимые носители, как съемные, так и несъемные носители. В качестве примера, а не ограничения считываемые компьютером носители могут содержать носители данных компьютера и среды передачи данных. Носители данных компьютера включают в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные любым способом или по любой технологии для хранения информации, такой как считываемые компьютером команды, структуры данных, программные модули или другие данные. Носители данных компьютера включают в себя, но не ограничиваются ими, оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), электрически стираемое программируемое ROM (EEPROM), флэш-память или другую технологию памяти, компакт-диск (CD-ROM), цифровые многофункциональные диски (DVD) или другое запоминающее устройство на оптических дисках, магнитные кассеты, магнитную ленту, запоминающее устройство на магнитных дисках или другие магнитные запоминающие устройства, или любой другой носитель, который может использоваться для хранения требуемой информации и к которому может обращаться компьютер 510. Среды передачи данных обычно воплощают считываемые компьютером команды, структуры данных, программные модули или другие данные в модулированном данными сигнале, таком как несущая волна или другой транспортный механизм и включают в себя любую среду доставки информации. Термин «модулированный данными сигнал» означает сигнал, в котором одна или более из его характеристик устанавливается или изменяется таким образом, чтобы кодировать информацию в сигнале. В качестве примера, а не ограничения среды передачи данных включают в себя проводные среды, такие как проводная сеть или прямое проводное соединение, и беспроводные среды, такие как акустические, радиочастотные (RF), инфракрасные и другие беспроводные среды. Сочетание любых из вышеприведенных также должно быть включено в объем считываемых компьютером носителей.
Системная память 530 включает в себя носители данных компьютера в виде энергозависимой и/или энергонезависимой памяти, такой как постоянное запоминающее устройство (ROM) 531 и оперативное запоминающее устройство (RAM) 532. Базовая система 533 ввода-вывода (BIOS), содержащая базовые подпрограммы, которые способствуют переносу информации между элементами внутри компьютера 510, например, во время запуска, хранится обычно в ROM 531. RAM 532 обычно содержит данные и/или программные модули, которые являются немедленно доступными для блока 520 обработки и/или в данный момент обрабатываются им. В качестве примера, а не ограничения фиг.5 изображает операционную систему 534, прикладные программы 535, другие программные модули 536 и программные данные 537.
Компьютер 510 также может включать в себя другие съемные/несъемные энергозависимые/энергонезависимые носители данных компьютера. Исключительно в качестве примера фиг.5 изображает накопитель 541 на жестком диске, который считывает с несъемного энергонезависимого магнитного носителя или записывает на него, накопитель 551 на магнитных дисках, который считывает со съемного энергонезависимого магнитного диска 552 или записывает на него, и накопитель 555 на оптическом диске, который считывает со съемного энергонезависимого оптического диска 556, такого как CD-ROM или другие оптические носители, или записывает на них. Другие съемные/несъемные энергозависимые/энергонезависимые носители данных компьютера, которые могут использоваться в примерной операционной среде, включают в себя, но не ограничиваются ими, кассеты с магнитной лентой, карты флэш-памяти, цифровые многофункциональные диски, цифровую видеоленту, твердотельное RAM, твердотельное ROM, и т.п. Накопитель 541 на жестком диске обычно соединен с системной шиной 521 посредством интерфейса несъемной памяти, такого как интерфейс 540, и накопитель 551 на магнитных дисках и накопитель 555 на оптических дисках обычно соединены с системной шиной 521 посредством интерфейса съемной памяти, такого как интерфейс 550.
Накопители и связанные с ними носители данных компьютера, описанные выше и изображенные на фиг.5, обеспечивают хранение считываемых компьютером команд, структур данных, программных модулей и других данных для компьютера 510. На фиг.5, например, накопитель 541 на жестком диске изображен как хранящий операционную систему 544, прикладные программы 545, другие программные модули 546 и программные данные 547. Отметьте, что эти компоненты могут или быть такими же или отличаться от операционной системы 534, прикладных программ 535, других программных модулей 536 и программных данных 537. Операционной системе 544, прикладным программам 545, другим программным модулям 546 и программным данным 547 присвоены другие позиции в данном документе, чтобы иллюстрировать, что как минимум они представляют собой разные копии. Пользователь может вводить команды и информацию в компьютер 510 при помощи устройств ввода, таких как планшет или электронный дигитайзер 564, микрофон 563, клавиатура 562 и указательное устройство 561, обычно упоминаемое как мышь, трекбол или сенсорная панель. Другие устройства ввода, не показанные на фиг.5, могут включать в себя джойстик, игровой планшет, антенну спутниковой связи, сканер или т. п. Эти и другие устройства ввода часто подключаются к блоку 520 обработки при помощи интерфейса 560 ввода пользователя, который соединен с системной шиной, но могут подключаться посредством другого интерфейса и шинных структур, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 591 или устройство отображения другого типа также подсоединен к системной шине 521 при помощи интерфейса, такого как видеоинтерфейс 590. В монитор 591 также может быть интегрирована сенсорная панель или т.п. Отметьте, что монитор и/или сенсорная панель могут быть физически соединены с корпусом, в который встроено вычислительное устройство 510, например в персональный компьютер планшетного типа. Кроме того, компьютеры, такие как вычислительное устройство 510, также могут включать в себя другие периферийные устройства вывода, такие как громкоговорители 595 и принтер 596, которые могут быть подсоединены при помощи периферийного интерфейса 594 вывода или т.п.
Компьютер 510 может работать в сетевой среде, используя логические соединения с одним или более удаленными компьютерам, такими как удаленный компьютер 580. Удаленным компьютером 580 может быть персональный компьютер, сервер, маршрутизатор, сетевой PC, одноранговое устройство или другой общий узел сети и обычно включает в себя многие или все из элементов, описанных выше в отношении компьютера 510, хотя только запоминающее устройство 581 памяти изображено на фиг.5. Логические соединения, изображенные на фиг.5, включают в себя одну или более локальных сетей (LAN) 571 и одну или более глобальных сетей (WAN) 573, но также могут включать в себя другие сети. Такие сетевые среды являются обычными в офисах, компьютерных сетях масштаба предприятия, интрасетях и Интернете.
Когда компьютер 510 используется в сетевой среде LAN, он соединяется с LAN 571 посредством сетевого интерфейса или адаптера 570. Когда компьютер 510 используется в сетевой среде WAN, он обычно включает в себя модем 572 или другое средство для установления связи по WAN 573, такой как Интернет. Модем 572, который может быть внутренним или внешним, может быть соединен с системной шиной 521 при помощи интерфейса 560 ввода пользователя или другого соответствующего механизма. Беспроводный сетевой компонент 574, такой как содержащий интерфейс и антенну, может быть соединен при помощи подходящего устройства, такого как точка доступа или одноранговый компьютер, с WAN или LAN. В сетевой среде программные модули, описанные в отношении компьютера 510 или его частей, могут храниться в удаленном запоминающем устройстве памяти. В качестве примера, а не ограничения фиг.5 изображает удаленные прикладные программы 585 как постоянно находящиеся на устройстве 581 памяти. Понятно, что показанные сетевые соединения являются примерными и могут использоваться другие средства установления линии связи между компьютерами.
Вспомогательная подсистема 599 (например, для вспомогательного отображения содержимого) может быть подсоединена при помощи пользовательского интерфейса 560, позволяя предоставлять пользователю данные, такие как содержание программы, статус системы и уведомления о событиях, даже если главные части компьютерной системы находятся в состоянии малой потребляемой мощности. Вспомогательная подсистема 599 может быть подсоединена к модему 572 и/или сетевому интерфейсу 570, позволяя выполнять связь между этими системами, когда главный блок 520 обработки находится в состоянии малой потребляемой мощности.
Заключение
Хотя изобретение допускает различные модификации и альтернативные конструкции, некоторые изображенные варианты его осуществления показаны на чертежах и были подробно описаны выше. Необходимо понять, однако, что нет никакого намерения ограничивать изобретение конкретными описанными видами, но наоборот, изобретение должно охватывать все модификации, альтернативные конструкции и эквиваленты, подпадающие под сущность и объем изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| КЛАССИФИКАЦИЯ ДОКУМЕНТОВ ПО УРОВНЯМ КОНФИДЕНЦИАЛЬНОСТИ | 2019 |
|
RU2732850C1 |
| КЛАССИФИКАЦИЯ ДАННЫХ ВЫБОРОК | 2009 |
|
RU2517286C2 |
| ПРЕДОСТАВЛЕНИЕ ВОЗМОЖНОСТИ КЛАССИФИКАЦИИ И УПРАВЛЕНИЯ ПРАВАМИ ДОСТУПА К ИНФОРМАЦИИ В ПРОГРАММНЫХ ПРИЛОЖЕНИЯХ | 2015 |
|
RU2701111C2 |
| КЛАССИФИКАЦИЯ КАСАНИЙ | 2015 |
|
RU2711029C2 |
| Система и способ классификации звонка | 2020 |
|
RU2763047C2 |
| Способ и система контроля доступа к конфиденциальной информации в операционной системе | 2023 |
|
RU2825554C1 |
| Система и способ перехвата файловых потоков | 2023 |
|
RU2816551C1 |
| Система и способ двухэтапной классификации файлов | 2018 |
|
RU2708356C1 |
| АВТОМАТИЧЕСКИЙ ВЫБОР ИНФОРМАЦИИ, ОСНОВАННЫЙ НА КЛАССИФИКАЦИИ ЗАИНТЕРЕСОВАННОСТИ | 2010 |
|
RU2553073C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ФОРМАЛИЗОВАННЫХ ТЕКСТОВЫХ ДОКУМЕНТОВ И АВТОРИЗОВАННЫХ ПОЛЬЗОВАТЕЛЕЙ СИСТЕМЫ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА | 2017 |
|
RU2692043C2 |
Изобретение относится к средствам управления данными. Технический результат заключается в уменьшении времени обработки элементов данных. Обнаруживают элемент данных. Классифицируют элемент данных с использованием одного или более свойств, связанных с элементом данных, для формирования связанного с ним набора свойств классификации, причем эти одно или более свойств включают в себя имеющиеся свойства классификации, связанные с элементом данных, при этом элемент данных классифицируется одним или более компонентами классификации. Агрегируют наборы свойств классификации, когда элемент данных классифицируется двумя или более компонентами классификации. Применяют политику к элементу данных на основе по меньшей мере одного из набора свойств классификации и агрегированных наборов свойств классификации. 3 н. и 17 з.п. ф-лы, 6 ил., 1 табл.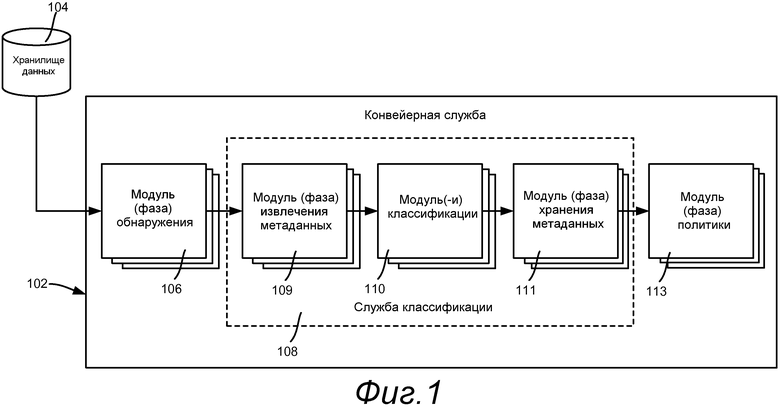
1. Система для управления элементами данных в вычислительной среде, содержащая:
один или более процессоров; и
память, подключенную к одному или более процессорам, при этом в памяти хранятся инструкции, которые при их исполнении одним или более процессорами предписывают одному или более процессорам:
обеспечивать конвейер классификации, включающий в себя компонент, который получает метаданные, связанные с элементом данных, и имеющиеся метаданные классификации, связанные с этим элементом данных, причем имеющиеся метаданные классификации включают в себя текущую классификацию элемента данных,
обеспечивать набор из одного или более модулей классификатора, при этом каждый модуль классификатора из данного набора модулей классификатора имеет связанные с ним правила классификации, причем каждым из этих правил классификации при его активации определяются метаданные классификации элемента данных с использованием упомянутых метаданных, связанных с элементом данных, и упомянутых имеющихся метаданных классификации, связанных с элементом данных,
обеспечивать компонент агрегирования для агрегирования различных результатов классификации от каждого модуля классификатора из упомянутого набора из одного или более модулей классификатора и
обеспечивать компонент, который связывает упомянутые метаданные классификации с элементом данных для использования при применении политики к элементу данных.
2. Система по п.1, в которой конвейер классификации встроен в конвейер обработки элементов данных, при этом конвейер обработки элементов данных включает в себя модуль обнаружения, который обнаруживает элемент данных.
3. Система по п.2, в которой элемент данных соответствует файлу, при этом модуль обнаружения выполнен с возможностью осуществлять по меньшей мере одно из (i) сканирования файловой системы для обнаружения в ней файлов и (ii) сканирования файла для обнаружения изменений в файле.
4. Система по п.1, в которой конвейер классификации встроен в конвейер обработки элементов данных, при этом конвейер обработки элементов данных включает в себя модуль политики, который оценивает метаданные классификации для применения политики к элементу данных.
5. Система по п.1, дополнительно содержащая модуль определения для определения того, вызывать ли один модуль классификатора из упомянутого набора модулей классификатора, основываясь на по меньшей мере одном из (i) любых имеющихся данных классификации и (ii) временной метки или другого идентификатора, который указывает предшествующие изменения в файле данных.
6. Система по п.1, дополнительно содержащая интерфейс для взаимодействия с конвейером классификации для внешней установки метаданных классификации.
7. Система по п.1, дополнительно содержащая интерфейс для взаимодействия с конвейером классификации для внешнего получения метаданных классификации.
8. Система по п.1, в которой компонент, который получает метаданные, связанные с элементом данных, и имеющиеся метаданные классификации, связанные с элементом данных, является по меньшей мере одним из (i) расширяемого, (ii) заменяемого и (iii) расширяемого и заменяемого, при этом каждый модуль классификатора из упомянутого набора модулей классификатора является по меньшей мере одним из (i) расширяемого, (ii) заменяемого и (iii) расширяемого и заменяемого, при этом компонент, который связывает метаданные классификации, является по меньшей мере одним из (i) расширяемого, (ii) заменяемого и (iii) расширяемого и заменяемого.
9. Система по п.1, в которой упомянутый набор модулей классификатора включает в себя классификатор, который выполняет по меньшей мере одно из (i) выдачи результата истина или ложь, (ii) явного задания по меньшей мере одного значения свойства, соответствующего метаданным классификации, и (iii) выдачи результата истина или ложь и явного задания по меньшей мере одного значения свойства, соответствующего метаданным классификации.
10. Система по п.1, в которой упомянутый набор модулей классификатора включает в себя классификатор, который классифицирует элемент данных на основе по меньшей мере одного из (i) расположения элемента данных, (ii) классификатора, основывающегося на глобальном репозитории, и (iii) классификатора, основывающегося на содержимом, который классифицирует элемент данных на основе содержимого, содержащегося в элементе данных.
11. Система по п.1, в которой упомянутый набор модулей классификатора включает в себя авторитетный классификатор, который переопределяет метаданные классификации другого классификатора в этом наборе классификаторов.
12. Способ управления элементами данных в вычислительной среде, содержащий этапы, на которых:
обнаруживают элемент данных;
посредством одного или более процессоров классифицируют элемент данных с использованием одного или более свойств, связанных с элементом данных, для формирования связанного с ним набора свойств классификации, причем эти одно или более свойств включают в себя имеющиеся свойства классификации, связанные с элементом данных, при этом элемент данных классифицируется одним или более компонентами классификации;
агрегируют наборы свойств классификации, когда элемент данных классифицируется двумя или более компонентами классификации; и
применяют политику к элементу данных на основе по меньшей мере одного из (i) набора свойств классификации и (ii) агрегированных наборов свойств классификации.
13. Способ по п.12, в котором при упомянутом использовании одного или более свойств, связанных с элементом данных, автоматически применяют правила классификации с использованием результата классификации от набора классификаторов, содержащего
по меньшей мере один классификатор.
14. Способ по п.12, дополнительно содержащий этап, на котором вызывают упомянутые два или более компонентов классификации в заранее заданном порядке и обеспечивают передачу набора свойств от одного из этих двух или более компонентов классификации другому одному из этих двух или более компонентов классификации.
15. Способ по п.12, дополнительно содержащий этап, на котором вызывают упомянутые два или более компонентов классификации в заранее заданном порядке и обеспечивают изменение последующим компонентом классификации в этом заранее заданном порядке набора свойств предыдущего компонента классификации в этом заранее заданном порядке.
16. Способ по п.12, дополнительно содержащий этап, на котором определяют, вызывать ли упомянутые один или более компонентов классификации, на основе одного или более заданных на текущий момент свойств классификации.
17. Способ по п.12, дополнительно содержащий этап, на котором определяют порядок оценивания агрегированных наборов свойств классификации.
18. Считываемый компьютером носитель, на котором имеются исполняемые компьютером команды, которыми при их исполнении одним или более процессорами выполняется способ, содержащий этапы, на которых:
обнаруживают один или более элементов данных;
получают набор свойств из свойств, связанных с элементом данных, при этом данный набор свойств включает в себя имеющиеся свойства метаданных, связанные с элементом данных;
определяют, классифицировать ли элемент данных с использованием одного или более классификаторов из набора классификаторов;
агрегируют результаты классификации от двух или более классификаторов из упомянутого набора классификаторов, когда эти два или более классификаторов вызваны;
обновляют набор свойств на основе любых изменений, выполненных по меньшей мере одним из (i) упомянутых одного или более классификаторов и (ii) упомянутых двух или более классификаторов; и
применяют политику к элементу данных на основе обновленного набора свойств.
19. Считываемый компьютером носитель по п.18, в котором упомянутое получение набора свойств содержит по меньшей мере одно из (i) извлечения метаданных, соответствующих элементу данных, (ii) нахождения имеющегося набора свойств, связанного с элементом данных, и (iii) извлечения метаданных, соответствующих элементу данных, и нахождения имеющегося набора свойств, связанного с элементом данных.
20. Считываемый компьютером носитель по п.18, в котором при упомянутом обновлении набора свойств набор свойств обновляют с использованием по меньшей мере одного из (i) упомянутых одного или более классификаторов, (ii) упомянутых двух или более классификаторов и (iii) механизма правил, сконфигурированного для обновления упомянутого набора свойств на основе результатов, предоставляемых из упомянутых одного или более классификаторов или упомянутых двух или более классификаторов.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| RU 61442 U1, 27.02.2007 | |||

