Область техники
[0001] Настоящее изобретение относится к способам кодирования и синтеза речи.
Уровень техники
[0002] Современные статистико-параметрические синтезаторы речи демонстрируют способность производить естественно звучащие голоса с гибкой настройкой в рабочем диапазоне. К сожалению, качество звучания страдает от характерного «жужжания», связанного с тем, что речь создается вокодером.
[0003] В последнее десятилетие в синтезе речи отчетливо заявили о себе методы, основанные на выборе речевых единиц. Эти методы опираются на огромные корпусы (обычно в несколько сотен мегабайт), покрывающие как можно большее многообразие речевых сигналов. В процессе синтеза речь создается конкатенацией естественных единиц, извлекаемых из корпуса. Поскольку база данных содержит по несколько примеров для каждой единицы речи, возникает проблема нахождения оптимального пути в сетке потенциальных кандидатов, обеспечивающего сокращение затрат на выбор и конкатенацию.
[0004] Этот подход позволяет производить речь с высокой степенью естественности и разборчивости. Однако качество может значительно снижаться, если требуется недостаточно представленная в корпусе единица или когда нарушается плавность из-за плохого стыка между двумя выбранными единицами.
[0005] В последние годы в публикации Токуда К. (К.Tokuda) и др. «Система синтеза речи на основе скрытой марковской модели в применении к английскому языку» (An HMM-based speech synthesis system applied to English), Proc. IEEE Workshop on Speech Synthesis, 2002, с.227-230, был предложен новый способ синтеза: статистико-параметрический синтез речи. Этот подход опирается на статистическое моделирование параметров речи. Предполагается, что такая модель, пройдя обучение, может создавать реалистичные последовательности этих параметров. Наиболее известная методика в рамках такого подхода - это, разумеется, синтез речи на основе скрытой марковской модели СММ (НММ). Синтезаторы с использованием этой методики в недавних субъективных испытаниях продемонстрировали показатели, сопоставимые с системами на основе выбора единиц. Важным преимуществом такой методики является гибкость в управлении речевыми вариациями (например, эмоциями, экспрессивностью) и простота создания новых голосов (через статистическое преобразование голоса). К двум основным недостаткам, свойственным способу в силу его природы, относятся:
- недостаточная естественность создаваемых траекторий: при статистической обработке наблюдается тенденция к размыванию деталей при разработке признаков, из-за чего создаваемые траектории оказываются слишком сглаженными, что создает эффект приглушенности синтезированной речи;
- «жужжащий характер» создаваемой речи, связанный с обычным для вокодера качеством.
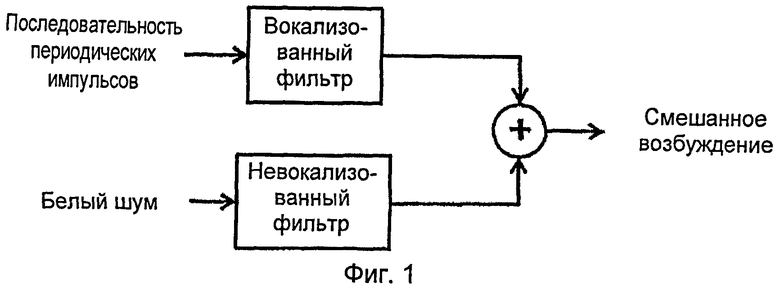
[0006] Хотя параметры, характеризующие спектр и просодию, достаточно хорошо определены, можно ожидать улучшений за счет выбора более подходящей модели возбуждения. Традиционный подход предполагает, что в качестве сигнала возбуждения используется либо белый шум, либо последовательность импульсов - для невокализованных и вокализованных сегментов, соответственно. Чтобы ближе воспроизвести физиологический процесс фонации, в котором голосовой сигнал состоит из комбинации периодических и непериодических компонент, было предложено использовать смешанное возбуждение СВ (ME). CB (ME) обычно получают так, как показано на фиг.1.
[0007] Авторы публикации Йосимура Т. (Т.Yoshimura) и др. «Смешанный источник возбуждения для синтеза речи на основе скрытой марковской модели» (Mixed-excitation for HMM-based speech synthesis), Proc. Eurospeech01, 2001, с.2259-2262, предлагают получать коэффициенты для фильтров из интенсивности вокализации их полос пропускания.
[0008] Публикация Майа Р. (R.Maia) и др. «Модель возбуждения, построенная по принципу остаточного моделирования для синтеза речи на основе скрытой марковской модели» (An excitation model for HMM-based speech synthesis based on residual modeling), Proc. ISCA SSW6, 2007, описывает прямое обучение многоступенчатых фильтров, зависимых от состояния, с использованием процессов обратной связи.
Цель изобретения
[0009] Цель настоящего изобретения состоит в обеспечении сигналов возбуждения для синтеза речи, которые не имеют недостатков, присущих уровню техники.
[0010] В частности, цель настоящего изобретения состоит в обеспечении сигнала возбуждения для вокализованных последовательностей, который уменьшает «жужжащий» или «металлический» характер синтезированной речи.
Сущность изобретения
[0011] Настоящее изобретение относится к способу кодирования сигнала возбуждения целевой речи, включающему в себя следующие шаги:
- извлечение из набора обучающих нормализованных остаточных кадров набора подходящих нормализованных остаточных кадров, при этом указанные обучающие остаточные кадры извлекают из обучающей речи, синхронизируют по моменту закрытия голосовой щели МЗГЩ (GCI) и нормализуют по основному тону и энергии;
- определение целевого сигнала возбуждения целевой речи;
- деление указанного целевого сигнала возбуждения на целевые кадры, синхронизированные по моментам МЗГЩ (GCI);
- определение локального основного тона и энергии для целевых кадров, синхронизированных по моментам МЗГЩ (GCI);
- нормализация целевых кадров, синхронизированных по моментам МЗГЩ (GCI), по энергии и по основному тону с получением целевых нормализованных остаточных кадров;
- определение коэффициентов линейной комбинации указанного извлеченного набора подходящих нормализованных остаточных кадров, чтобы построить для каждого из целевых нормализованных остаточных кадров наиболее близкие к ним синтезированные нормализованные остаточные кадры,
причем параметры кодирования для каждого из целевых остаточных кадров содержат определенные таким образом коэффициенты.
[0012] Целевой сигнал возбуждения может быть получен путем применения предварительно заданного фильтра синтеза, подвергнутого инверсии, к целевому сигналу.
[0013] Предпочтительно, указанный фильтр синтеза определен методом спектрального анализа, предпочтительно, методом линейного предсказания, примененным к целевой речи.
[0014] Под набором подходящих нормализованных остаточных кадров понимается минимальный набор нормализованных остаточных кадров, дающий максимальное количество информации для построения синтезированных нормализованных остаточных кадров посредством линейной комбинации соответствующих нормализованных остаточных кадров, наиболее близких к целевым нормализованным остаточным кадрам.
[0015] Предпочтительно, параметры кодирования дополнительно включают в себя просодические параметры.
[0016] Более предпочтительно, указанные просодические параметры содержат (состоят из) энергию и основной тон.
[0017] Указанный набор подходящих нормализованных остаточных кадров, предпочтительно, определяют статистическим методом, предпочтительно - выбранным из совокупности методов, включающей в себя метод К-средних и метод РСА.
[0018] Предпочтительно, набор подходящих нормализованных остаточных кадров определен посредством алгоритма К-средних, причем подходящие нормализованные остаточные кадры в указанном наборе соответствуют полученным центроидам кластеров. В этом случае коэффициент, связанный с центроидом кластера, ближайшим к целевому нормализованному остаточному кадру, предпочтительно будет равен единице, а другие - нулю, или, что эквивалентно, будет использоваться только один параметр, представляющий параметр ближайшего центроида.
[0019] Как вариант, указанный набор подходящих нормализованных остаточных кадров может представлять собой набор первых собственных остаточных векторов, определенных методом главных компонент МГК (РСА). Под собственными остаточными векторами здесь понимаются собственные векторы, получаемые методом МГК (РСА).
[0020] Предпочтительно, указанный набор первых собственных остаточных векторов выбран так, чтобы допустить понижение размерности.
[0021] Предпочтительно, указанный подходящий набор первых собственных остаточных векторов получен по критерию информационного коэффициента, где информационный коэффициент определяется следующим образом:

где λi обозначает i-e собственное значение, определяемое методом МГК (РСА) в убывающем порядке, и m - общее число собственных значений.
[0022] Набор обучающих нормализованных остаточных кадров, предпочтительно, определяют способом, который включает в себя следующие шаги:
- получение записи обучающей речи;
- деление указанного образца речи на подкадры, имеющие предварительно заданную продолжительность;
- анализ указанных обучающих подкадров для определения фильтров синтеза;
- применение инверсных фильтров синтеза к указанным обучающим подкадрам для определения обучающих остаточных сигналов;
- определение моментов закрытия голосовой щели МЗГЩ (GCI) указанных обучающих остаточных сигналов;
- определение локальных периода основного тона, и энергии указанных обучающих остаточных сигналов;
- деление указанных обучающих остаточных сигналов на обучающие остаточные кадры, продолжительность которых пропорциональна периоду локального основного тона, что позволяет синхронизировать эти обучающие остаточные кадры по найденным моментам МЗГЩ (GCI);
- повторная дискретизация указанных обучающих остаточных кадров в обучающие остаточные кадры с постоянным основным тоном;
- нормализация энергии указанных обучающих остаточных кадров с постоянным основным тоном для получения набора остаточных кадров, синхронизированных по моментам МЗГЩ (GCI) и нормализованных по основному тону и энергии.
[0023] Еще один аспект изобретения относится к способу синтеза сигнала возбуждения, в котором используется способ кодирования согласно настоящему изобретению, дополнительно включающий в себя следующие шаги:
- построение синтезированных нормализованных остаточных кадров посредством линейной комбинации указанного набора подходящих нормализованных остаточных кадров с использованием параметров кодирования;
- денормализация указанных синтезированных нормализованных остаточных кадров по основному тону и энергии для получения синтезированных остаточных кадров, имеющих целевые локальный период основного тона и энергию;
- перекомбинирование указанных синтезированных остаточных кадров методом синхронизированного по основному тону соединения с наложением, чтобы получить синтезированный сигнал возбуждения.
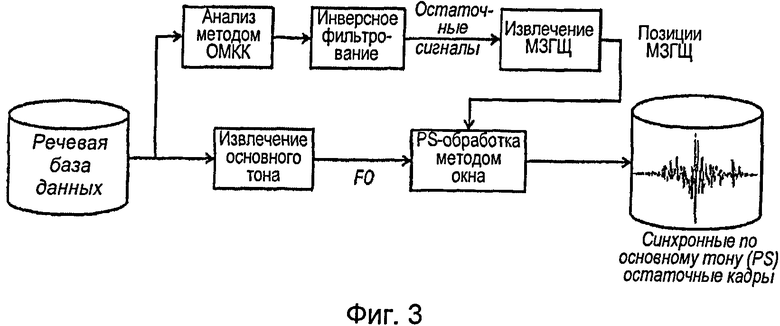
[0024] Предпочтительно, указанный набор подходящих нормализованных остаточных кадров представляет собой набор первых собственных остаточных векторов, определяемых методом МГК (РСА), и к указанным синтезированным остаточным кадрам добавлен высокочастотный шум. Указанный высокочастотный шум может иметь границу отсечки низких частот, составляющую от 2 до 6 кГц, предпочтительно - от 3 до 5 кГц, наиболее предпочтительно - приблизительно 4 кГц.
[0025] Еще один аспект заявленного изобретения относится к способу параметрического синтеза речи, в котором для определения сигнала возбуждения вокализованных последовательностей в синтезируемом сигнале речи используется способ синтеза сигнала возбуждения согласно настоящему изобретению.
[0026] Предпочтительно, способ параметрического синтеза речи дополнительно включает в себя шаг фильтрования указанного синтезированного сигнала возбуждения фильтрами синтеза, используемыми для извлечения целевых сигналов возбуждения.
[0027] Настоящее изобретение относится также к набору команд, записанных на машиночитаемом носителе, которые при их выполнении на компьютере реализуют способ согласно изобретению.
Краткое описание чертежей
[0028] На фиг.1 представлен смешанный способ возбуждения.
[0029] На фиг.2 представлен способ определения момента закрытия голосовой щели методом центра тяжести ЦТ (CoG).
[0030] На фиг.3 представлен способ получения набора синхронных по основному тону остаточных кадров, пригодных для статистического анализа.
[0031] На фиг.4 представлен способ возбуждения согласно настоящему изобретению.
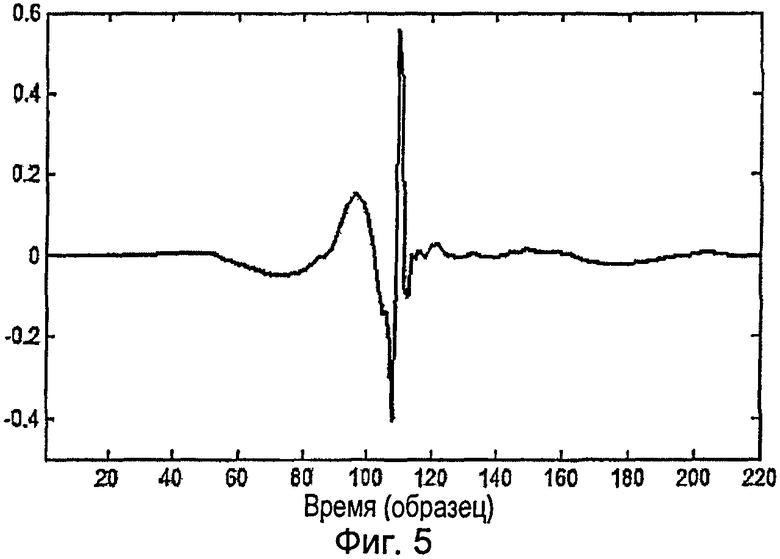
[0032] На фиг.5 представлен первый собственный остаточный вектор для диктора-женщины SLT.
[0033] На фиг.6 представлен «информационный коэффициент» при использовании k собственных остаточных векторов для диктора AWB.
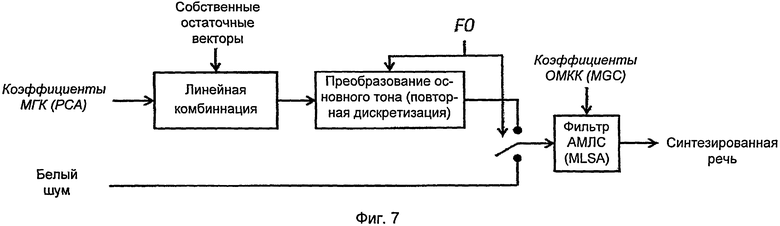
[0034] На фиг.7 представлен синтез возбуждения согласно настоящему изобретению, выполненный с использованием собственных остаточных векторов метода МГК (РСА).
[0035] На фиг.8 представлен пример декомпозиции по детерминированной/стохастической модели ДСМ (DSM) на остаточном кадре, синхронном по основному тону. Левый график: детерминированная часть. Средний график: стохастическая часть. Правый график: амплитудные спектры детерминированной части (штрихпунктирная линия), шумовой части (пунктирная линия) и реконструированный кадр возбуждения (сплошная линия), полученный совмещением обеих составляющих.
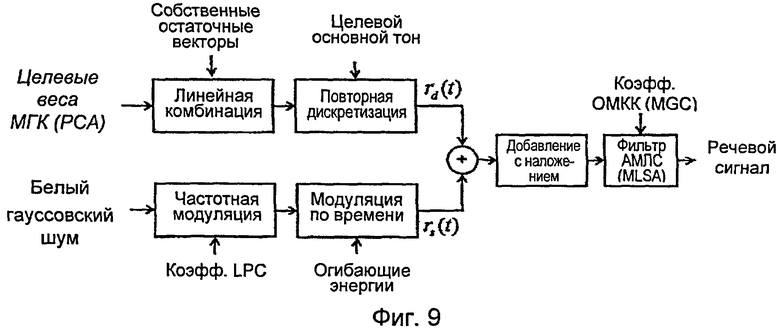
[0036] На фиг.9 представлена общая блок-схема синтеза сигнала возбуждения согласно настоящему изобретению с использованием метода детерминированной и стохастической составляющих.
[0037] На фиг.10 представлен способ определения кодовых книг для остаточных кадров по RN, и кадров, синхронизированных по основному тону, соответственно.
[0038] На фиг.11 представлена процедура кодирования и синтеза в случае применения метода К-средних.
[0039] На фиг.12 представлены результаты теста на предпочтение по отношению к эксперименту, где способ кодирования и синтеза согласно настоящему изобретению сравнивался с традиционным возбуждением импульсов.
Подробное раскрытие изобретения
[0040] В настоящем изобретении раскрывается новый способ возбуждения, обеспечивающий уменьшение «жужжащего характера» вокализованных сегментов параметрических синтезаторов речи.
[0041] Настоящее изобретение относится также к способам кодирования для кодирования такого возбуждения.
[0042] На первом шаге из образца речи (обучающего набора данных) извлекают набор остаточных кадров. Эта операция выполняется посредством деления образца речи на обучающие подкадры предварительно заданной продолжительности, анализа каждого обучающего подкадра для определения фильтров синтеза, например фильтров линейного предсказания, а затем применения соответствующего инверсного фильтра к каждому из подкадров в образце речи с получением остаточного сигнала, разделенного на остаточные кадры.
[0043] Для определения указанного фильтра предпочтительно используются обобщенные по мел кепстральные коэффициенты, (ОМКК (MGC)), которые позволяют точно и надежно отразить огибающие спектра речевого сигнала. Найденные таким образом коэффициенты затем используются для определения фильтра синтеза на основе линейного предсказания. Далее для извлечения остаточных кадров используется инверсия найденного фильтра синтеза.
[0044] Остаточные кадры делят таким образом, чтобы они были синхронизированы по моментам закрытия голосовой щели (МЗГЩ (GCI)). Для определения моментов МЗГЩ (GCI) может использоваться способ, основанный на центре тяжести (ЦТ (CoG)) энергии речевого сигнала. Предпочтительно, остаточные кадры центрованы по моментам МЗГЩ (GCI).
[0045] На фиг.2 показано, как можно улучшить обнаружение моментов МЗГЩ (GCI) методом выбора пиков и обнаружения точек прохождения нуля (от положительных к отрицательным значениям) в сигнале ЦТ (CoG).
[0046] Предпочтительно, остаточные кадры обработаны методом окна Хеннинга (Harming) протяженностью в два периода. Чтобы обеспечить точку сравнения между остаточными кадрами до извлечения большей части подходящих остаточных кадров, выравнивание по моментам МЗГЩ (GCI) будет недостаточным и потребуется нормализация по основному тону и энергии.
[0047] Нормализация по основному тону может достигаться повторной дискретизацией, при которой будут сохранены наиболее важные свойства остаточного кадра. Если исходить из того, что остаток, получаемый применением инверсного фильтра, может аппроксимировать первую производную потока в голосовой щели, повторная дискретизация этого сигнала позволит сохранить такие параметры, как отношение фазы открытия голосовой щели, коэффициент асимметрии (и, следовательно, соотношение Fg/F0, где Fg - частота глоттальной форманты, a F0 - частота основного тона), а также характеристики обратной фазы.
[0048] В процессе синтеза остаточные кадры будут получены в результате применения повторной дискретизации комбинации подходящих остаточных кадров, нормализованных по основному тону и энергии. Если основной тон этих кадров не будет достаточно низким, при последующей повышающей дискретизации спектр окажется сжатым и в области высоких частот появятся «энергетические дыры». Чтобы избежать этого, анализируют гистограмму основного тона P(F0) диктора, при этом выбранное нормализованное значение частоты основного тона F0* в общем случае должно удовлетворять следующему условию:
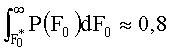
то есть в процессе синтеза незначительной повышающей дискретизации будут подвергнуты лишь 20% кадров.
[0049] Общая блок-схема извлечения остаточных кадров, синхронных по основному тону, представлена на фиг.3.
[0050] Таким образом, в рассматриваемый момент в нашем распоряжении имеется набор остаточных кадров, синхронизированных по моментам МЗГЩ (GCI) и нормализованных по основному тону и энергии (так называемые «RN-кадры»), к которым могут быть применены такие статистические методы кластеризации, как метод главных компонент МГК (РСА) или метод К-средних.
[0051] Эти методы используются далее для определения набора подходящих RN-кадров, которые используются для воссоздания целевых остаточных кадров. Под набором подходящих кадров понимается минимальный набор кадров, обеспечивающих максимальное количество информации, чтобы воссоздать остаточные кадры, наиболее близкие к целевым остаточным кадрам, или, иными словами, набор RN-кадров, допускающий в описании целевых кадров максимальное понижение размерности с минимальной потерей информации.
[0052] В качестве первого варианта определение набора подходящих кадров основывается на получаемой методом главных компонент МГК (РСА) декомпозиции остаточных кадров, синхронных по основному тону, на ортонормированном базисе. Этот базис содержит ограниченное количество RN-кадров и вычисляется на относительно небольшой базе речевых данных (приблизительно 20 мин), из которой извлекают набор вокализованных кадров.
[0053] Метод главных компонент МГК (РСА) является ортогональным линейным преобразованием с применением поворота системы координат для получения наилучшего (по критерию наименьших квадратов НК (LS)) представления входных данных. Можно показать, что применение критерия НК (LS) эквивалентно максимизации дисперсии данных по новым осям координат. После этого может быть применен собственно метод МГК (РСА), посредством вычисления собственных значений и собственных векторов матрицы ковариации данных.
[0054] Для набора данных, состоящего из N остаточных кадров из m образцов, вычисления методом МГК (РСА) дадут m собственных значений λi с соответствующими им собственными векторами µi (обозначаемыми здесь «собственные остаточные векторы»). Например, первый собственный остаточный вектор для конкретного диктора-женщины представлен на фиг.5. λi представляет собой дисперсию данных по оси µi, то есть является мерой информации, которую рассматриваемый собственный остаточный вектор несет о наборе данных. Этот показатель важен для понижения размерности. Определим информационный коэффициент I(k) при использовании k первых собственных остаточных векторов как отношение дисперсии по этим k осям к общей дисперсии:
[0055] На фиг.6 эта переменная представлена для диктора-мужчины AWB (где m=280). Субъективные испытания с применением анализа/синтеза показали, что выбор k, при котором I(k) превышает приблизительно 0,75, оказывает практически неощутимое на слух воздействие на первоначальный файл. Если вернуться к примеру на фиг.6, это означает, что для рассматриваемого диктора может эффективно использоваться приблизительно 20 собственных остаточных векторов. Из этого следует, что целевые кадры могут быть эффективно описаны вектором, имеющим размерность 20, который будет определен преобразованием МГК (РСА) (проекция целевого кадра на 20 первых собственных остаточных векторов). Эти собственные остаточные векторы образуют набор подходящих RN-кадров.
[0056] После расчета преобразования методом МГК (РСА) анализируют весь корпус, извлекая параметры МГК (РСА) для кодирования сигнала возбуждения для целевой речи. Блок-схема синтеза для этого случая представлена на фиг.7.
[0057] Предпочтительно использование смешанной модели возбуждения в виде детерминированной/стохастической модели ДСМ (DSM). Это позволяет уменьшить количество собственных остаточных векторов для кодирования и синтеза возбуждения вокализованных сегментов без снижения качества синтеза. В этом случае сигнал возбуждения раскладывают на детерминированную низкочастотную составляющую rd(t) и стохастическую высокочастотную составляющую rs(t). Максимальная частота Fmax вокализованного участка обозначает границу между детерминированной и стохастической составляющими. Для Fmax могут использоваться значения от 2 до 6 кГц, предпочтительно, приблизительно равные 4 кГц/
[0058] В случае применения модели ДСМ (DSM) стохастическая часть сигнала rs(t) представляет собой белый шум, пропускаемый через высокочастотный полосовой фильтр с границей пропускания, равной Fmax. Для этого может использоваться, например, авторегрессивный фильтр. Предпочтительно, чтобы на усеченный по частоте белый шум накладывалась дополнительная временная зависимость. Может использоваться, например, треугольная огибающая, центрированная по моментам МЗГЩ (GCI).
[0059] С другой стороны, rd(t) рассчитывают так же, как описано выше, путем кодирования и синтезирования нормализованных остаточных кадров посредством линейной комбинации собственных остаточных векторов. Получаемый при этом остаточный нормализованный кадр затем денормализуют, приводя его к целевым значениям частоты основного тона и энергии.
[0060] Полученные детерминированные и стохастические компоненты представлены на фиг.8.
[0061] Конечный сигнал возбуждения при этом является суммой rd(t)+rs(t). Общая блок-схема данной модели возбуждения представлена на фиг.9.
[0062] Рассмотренная модель ДОМ (DSM) обеспечивает такое повышение качества, что для получения приемлемых результатов оказывается достаточным использование только одного собственного остаточного вектора. В этом случае возбуждение характеризуется только частотой основного тона, и поток весов, получаемых методом МГК (РСА), можно исключить. Это дает максимально простую модель, в которой сигнал возбуждения является (ниже Fmax) по существу привязанным к временной шкале колебательным сигналом, что почти не требует ощутимой вычислительной нагрузки, обеспечивая в то же время высокое качество синтеза.
[0063] В любом случае возбуждение для невокализованных сегментов представляет собой гауссовский белый шум.
[0064] В качестве другого варианта в определении набора подходящих кадров используются кодовые книги для остаточных кадров, которые определяют в соответствии с алгоритмом К-средних. Алгоритм К-средних представляет собой способ кластеризации n объектов на основе их признаков по k кластерам, k<n. При этом предполагается, что признаки объектов образуют векторное пространство. Ставится цель минимизировать общую дисперсию внутри отдельных кластеров или функцию квадратичной ошибки:

где имеется k кластеров Si, i=1, 2, …, k, и µi - их центроиды, или средние для всех точек xj∈Sj/
[0065] Как центроиды, получаемые методом К-средних, так и собственные векторы, получаемые методом МГК (РСА), представляют подходящие остаточные кадры, позволяющие получить целевые нормализованные остаточные кадры посредством линейной комбинации с минимальным количеством коэффициентов (параметров).
[0066] При применении алгоритма К-средних к ранее описанным RN-кадрам обычно оставляют 100 центроидов, поскольку было установлено, что 100 центроидов достаточно, чтобы компрессия не ощущалась на слух. Эти выбранные 100 центроидов образуют набор подходящих нормализованных остаточных кадров для кодовой книги.
[0067] Предпочтительно, каждый центроид может быть заменен наиболее близким RN-кадром из реального обучающего набора данных, формируя таким образом кодовую книгу RN-кадров. На фиг.10 представлена общая блок-схема для определения кодовых книг RN-кадров.
[0068] Действительно, если устранить вариативность, связанную с формантами и основным тоном, можно ожидать получения значительной компрессии. Тогда каждому центроиду может быть поставлен в соответствие реальный остаточный кадр. При этом следует принять во внимание сложности, которые проявятся при обратном преобразовании остаточных кадров в целевые кадры с основным тоном. Чтобы сократить возникновение «энергетических дыр» во время синтеза, кадры, составляющие компрессированный набор, должны иметь как можно более низкую частоту основного тона. Для каждого центроида отбирают N наиболее близких (по расстоянию после нормализации) кадров и сохраняют только самый длинный кадр. Выбранные таким образом наиболее близкие кадры далее обозначаются как «центроидные остаточные кадры».
[0069] Далее выполняется кодирование за счет определения ближайшего центроида для каждого целевого нормализованного остаточного кадра. Указанный ближайший центроид определяют, вычисляя на компьютере среднюю квадратичную ошибку между целевым нормализованным остаточным кадром и каждым центроидом и принимая за ближайший центроид тот, у которого вычисленная средняя квадратичная ошибка минимальна. Этот принцип разъясняется на фиг.11.
[0070] После этого подходящие нормализованные остаточные кадры могут использоваться для улучшения синтезатора речи, например, основывающегося на скрытой марковской модели (СММ (НММ)) с новым потоком параметров возбуждения в дополнение к традиционной характеристике основного тона.
[0071] Синтезируемые остаточные кадры создаются с помощью линейной комбинации подходящих RN-кадров (т.е. комбинации собственных остаточных векторов в случае МГК (РСА) или наиболее близких остаточных кадров центроидов в случае К-средних) с использованием параметров, которые были определены на этапе кодирования.
[0072] После этого синтезированные остаточные кадры адаптируют к целевым значениям просодических параметров (основного тона и энергии) и соединяют с наложением, чтобы получить целевой сигнал возбуждения.
[0073] В конечном счете, для производства синтезированного речевого сигнала может использоваться так называемая аппроксимация по меллогарифмическому спектру, АМЛС (MLSA), основывающаяся на созданных коэффициентах ОМКК (MGC).
Пример 1
[0074] Сначала к обучающему набору данных (образцу речи) был применен упомянутый выше метод К-средних. В первую очередь был выполнен анализ ОМКК (MGC) с α=0,42 (Fs=16 кГц) и γ=-1/3, поскольку эти значения обеспечили предпочтительный воспринимаемый результат. Указанный анализ ОМКК (MGC) позволил определить фильтры синтеза.
[0075] После этого анализу ОМКК (MGC) подвергли тестовые предложения (не содержащиеся в наборе данных), при этом были извлечены параметры для возбуждения и фильтров. Были найдены такие моменты МЗГЩ (GCI), чтобы кадры вокализованных участков оказались центрированы по этим моментам МЗГЩ (GCI) и имели продолжительность в два периода. Для выполнения отбора эти кадры подвергли повторной дискретизации и нормализовали, получив RN-кадры. Эти последние использовались в алгоритме реконструкции сигнала возбуждения, показанном на фиг.11.
[0076] После того как из набора подходящих нормализованных остаточных кадров были выбраны нормализованные по центроидам остаточные кадры, у них была изменена частота основного тона и энергия, и в таком виде они заменили первоначальные кадры.
[0077] Невокализованные сегменты заменили сегментами белого шума, характеризующимися той же энергией. Результирующий сигнал возбуждения был затем отфильтрован с использованием ранее извлеченных первоначальных коэффициентов ОМКК (MGC).
Эксперимент выполняли, используя кодовую книгу по 100 кластерам и 100 соответствующих остаточных кадров.
Пример 2
[0078] Во втором примере был определен статистический параметрический синтезатор речи. Векторы признаков представляли собой параметры ОМКК (MGC) 24-го порядка, логарифмическое выражение F0 и коэффициенты МГК (РСА), порядок которых был определен так, как пояснялось выше, и которые были подвергнуты конкатенации с их первыми и вторыми производными. Был выполнен анализ ОМКК (MCG) с α=0,42 (Fs=16 кГц) и γ=-1/3. Для обработки границ между вокализованными и невокализованными участками применялось многопространственное распределение (МПР (MSD)) (F0 в логарифмическом выражении и МГК (РСА) определялись только на вокализованных кадрах), что дало в общей сложности 7 потоков. Были применены фонемные контекстно-зависимые СММ (НММ) с 5 состояниями и проходом слева направо с использованием одинарных гауссовых распределений с диагональной матрицей ковариации. По статистике пребывания в отдельных состояниях СММ (НММ) была также определена модель длительности состояний. В процессе синтеза речи сначала с помощью модели длительности определили наиболее вероятную последовательность состояний. Затем построили наиболее вероятную последовательность векторов признаков, связанную с указанной последовательностью состояний. И, наконец, векторы признаков ввели в вокодер, чтобы произвести речевой сигнал.
[0079] Блок-схема вокодера изображена на фиг.7. Выбор вокализованного или невокализованного решения зависит от генерируемого значения F0. Во время невокализованных кадров используется белый шум. Что касается вокализованных кадров, то они строятся в соответствии с синтезированными коэффициентами МГК (РСА). Первую версию получают с помощью линейной комбинации с собственными остаточными векторами, которые были извлечены, как поясняется в настоящем описании. Поскольку эта версия нормализована по размеру, требуется преобразование в целевое значение частоты основного тона. Как уже указывалось, это может быть достигнуто повторной дискретизацией. Выбор достаточно низкого основного тона, сделанный при нормализации, теперь может быть явным образом истолкован как ограничение, позволяющее избежать «энергетических дыр» при высоких частотах. После этого кадры соединяют с наложением, получая сигнал возбуждения. В конечном счете, для получения синтезированного речевого сигнала используется так называемая аппроксимация по меллогарифмическому спектру, АМЛС (MLSA), основывающаяся на полученных коэффициентах ОМКК (MGC).
Пример 3
[0080] В третьем примере был использован тот же способ, что и во втором, за исключением того, что применялся только первый собственный остаточный вектор, и был добавлен высокочастотный шум, как описано выше в связи с моделью ДСМ (DSM). Частота Fmax была установлена на уровне 4 кГц, составляющая rs(t) представляла собой гауссовский белый шум n(t), модифицированный сверткой с авторегрессивной моделью h(τ,t) (высокочастотный полосовой фильтр), временная структура которого управлялась параметрической огибающей e(t):
rs(t)=e(t).(h(τ,t)*n(t))
где е(t) - треугольная функция, зависимая от основного тона. Некоторые дополнительные исследования показали, что e(t) не является ключевым признаком структуры шума и может быть сведено к плоской функции, например e(t)=1, не ухудшая ощутимым образом конечного результата.
[0081] В каждом примере оценивались три голоса: Бруно (мужчина, француз, не из базы данных CMU ARCTIC), AWB (мужчина, шотландец) и SLT (женщина, США) из базы данных CMU ARCTIC. Обучающий набор характеризовался продолжительностью приблизительно 50 мин для AWB и SLT и 2 часа для Бруно и был составлен из фонетически сбалансированных высказываний с частотой дискретизации 16 кГц.
[0082] Материал субъективного испытания был предложен 20 испытуемым-непрофессионалам. Он состоял из 4 синтезированных предложений длительностью приблизительно 7 секунд для каждого диктора. Для каждого предложения были представлены два варианта, с использованием традиционного возбуждения или возбуждения согласно настоящему изобретению, и испытуемые должны были указать, какой вариант они предпочитают. В традиционном методе при возбуждении вокализованных сегментов использовалась последовательность импульсов (то есть основной метод, применяемый при синтезе, основанном на СММ (НММ)). Но и в рамках этой традиционной методики для отражения микропросодических характеристик использовались импульсы, синхронизированные по моментам МЗГЩ (GCI), и создаваемая вокодером речь благодаря этому опиралась на качественную основу. Результаты приведены на фиг.12. Как видно из чертежа, в каждом из трех экспериментов, пронумерованных от 1 до 3, видны улучшения.






Настоящее изобретение относится к способу кодирования сигнала возбуждения в целевой речи. Технический результат заключается в обеспечении сигналов возбуждения для синтеза речи без эффекта приглушенности синтезированной речи. Извлекают из набора обучающих нормализованных остаточных кадров набор подходящих нормализованных остаточных кадров, при этом указанные обучающие остаточные кадры извлекают из обучающей речи; синхронизируют по моменту закрытия голосовой щели (МЗГЩ (GCI)) и нормализуют по основному тону и энергии; определяют целевой сигнал возбуждения исходя из целевой речи. Разделяют указанный целевой сигнал возбуждения на целевые кадры, синхронизированные по моментам МЗГЩ (GCI). Определяют локальный основной тон и энергию целевых кадров, синхронизированных по моментам МЗГЩ (GCI). Нормализуют синхронизированные по моментам МЗГЩ (GCI) целевые кадры по энергии и по основному тону с получением целевых нормализованных остаточных кадров. Определяют коэффициенты линейной комбинации указанного извлеченного набора подходящих нормализованных остаточных кадров, чтобы построить для каждого из целевых нормализованных остаточных кадров близкие к ним синтезированные нормализованные остаточные кадры, при этом параметры кодирования для каждого из целевых остаточных кадров содержат полученные коэффициенты. 4 н. и 9 з.п. ф-лы, 12 ил., 3 пр.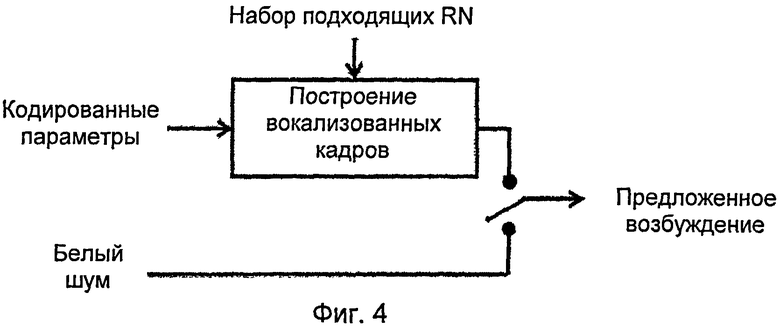
1. Способ кодирования сигнала возбуждения целевой речи, включающий в себя следующие шаги:
извлекают из набора обучающих нормализованных остаточных кадров набор подходящих нормализованных остаточных кадров, при этом указанные обучающие остаточные кадры извлекают из обучающей речи, синхронизируют по моменту закрытия голосовой щели (МЗГЩ (GCI)) и нормализуют по основному тону и энергии;
определяют целевой сигнал возбуждения из целевой речи;
разделяют указанный целевой сигнал возбуждения на целевые кадры, синхронизированные по моментам МЗГЩ (GCI);
определяют локальный основной тон и энергию целевых кадров, синхронизированных по моментам МЗГЩ (GCI);
нормализуют синхронизированные по моментам МЗГЩ (GCI) целевые кадры по энергии и по основному тону с получением целевых нормализованных остаточных кадров;
определяют коэффициенты линейной комбинации указанного извлеченного набора подходящих нормализованных остаточных кадров, чтобы построить для каждого из целевых нормализованных остаточных кадров близкие к ним синтезированные нормализованные остаточные кадры,
при этом параметры кодирования для каждого из целевых остаточных кадров содержат полученные коэффициенты.
2. Способ по п.1, в котором целевой сигнал возбуждения определяют путем применения инверсного фильтра синтеза к целевой речи.
3. Способ по п.2, отличающийся тем, что фильтр синтеза определяют методом спектрального анализа, предпочтительно методом линейного предсказания.
4. Способ по любому из пп.1-3, отличающийся тем, что указанный набор подходящих нормализованных остаточных кадров определяют посредством алгоритма К-средних или методом главных компонент (МГК (РСА)).
5. Способ по п.4, отличающийся тем, что указанный набор подходящих нормализованных остаточных кадров определяют посредством алгоритма К-средних, причем набор подходящих нормализованных остаточных кадров представляет собой полученные центроиды кластеров.
6. Способ по п.5, отличающийся тем, что коэффициент, связанный с центроидом кластера, ближайшим к целевому нормализованному остаточному кадру, равен единице, а другие коэффициенты равны нулю.
7. Способ по п.4, отличающийся тем, что указанный набор подходящих нормализованных остаточных кадров представляет собой набор первых собственных остаточных векторов, определенных методом МГК (РСА).
8. Способ синтеза сигнала возбуждения, использующий способ кодирования по любому из пп.1-7, дополнительно включающий в себя следующие шаги:
выполняют построение синтезированных нормализованных остаточных кадров посредством линейной комбинации указанного набора подходящих нормализованных остаточных кадров с использованием параметров кодирования;
денормализуют указанные синтезированные нормализованные остаточные кадры по основному тону и энергии для получения синтезированных остаточных кадров, имеющих целевые локальный период основного тона и энергию;
выполняют перекомбинацию указанных синтезированных остаточных кадров методом синхронизированного по основному тону соединения с наложением для получения синтезированного сигнала возбуждения.
9. Способ синтеза сигнала возбуждения по п.8, отличающийся тем, что указанный набор подходящих нормализованных остаточных кадров представляет собой набор первых собственных остаточных векторов, определяемых методом МГК (РСА), при этом к указанным синтезированным остаточным кадрам добавляют высокочастотный шум.
10. Способ по п.9, отличающийся тем, что указанный высокочастотный шум имеет границу отсечки низких частот, составляющую от 2 до 6 кГц.
11. Способ по п.10, отличающийся тем, что указанный высокочастотный шум имеет границу отсечки низких частот, составляющую приблизительно 4 кГц.
12. Способ параметрического синтеза речи, в котором для определения сигнала возбуждения вокализованных последовательностей используют способ по любому из пп.8, 9, 10 или 11.
13. Машиночитаемый носитель, на котором записан набор команд, который, при выполнении на компьютере, реализует способ по любому из пп.1-12.
| СПОСОБ И УСТРОЙСТВО ВОСПРОИЗВЕДЕНИЯ РЕЧЕВЫХ СИГНАЛОВ И СПОСОБ ИХ ПЕРЕДАЧИ | 1996 |
|
RU2255380C2 |

