Настоящее изобретение относится к основанному на линейном предсказании аудио кодеку, использующему формирование шума в частотной области, такому как режим TCX, известный из USAC.
В качестве относительно нового аудио кодека недавно был завершен USAC. USAC является кодеком, который поддерживает переключение между несколькими режимами кодирования, такими как AAC-подобный режим кодирования, режим кодирования во временной области, использующий кодирование с линейным предсказанием, а именно ACELP, и кодирование с возбуждением кодированным преобразованием, формирующее промежуточный режим кодирования, согласно которому формированием (изменением формы) спектральной области управляют, используя коэффициенты линейного предсказания, переданные с помощью потока данных. В документе WO2011147950 было сделано предложение представить схему кодирования USAC более подходящей для приложений с малыми задержками посредством исключения AAC-подобного режима кодирования из доступности и ограничения режимов кодирования только режимами ACELP и TCX. Кроме того, было предложено уменьшить длину кадра.
Однако было бы выгодно иметь под рукой возможность уменьшить сложность основанной на линейном предсказании схемы кодирования, используя формирование спектральной области, в то же время достигая аналогичной эффективности кодирования в терминах, например, восприятия отношения «частота следования битов/искажение».
Таким образом, задачей настоящего изобретения является обеспечить такую основанную на линейном предсказании схему кодирования, использующую формирование (изменение формы) спектральной области, позволяющую уменьшить сложность при сопоставимой или даже увеличенной эффективности кодирования.
Эта задача решается предметом изобретения согласно предложенным независимым пунктам формулы изобретения.
Основной идеей, лежащей в основе настоящего изобретения, является то, что понятие кодирования, которое является основанным на линейном предсказании и использует формирование (изменение формы) шума спектральной области, может быть обеспечено менее сложным при сопоставимой эффективности кодирования в терминах, например, отношения частоты следования битов/искажения, если спектральное разложение входного сигнала аудио в спектрограмму, содержащую последовательность спектров, используется как для вычислений коэффициентов линейного предсказания, так и для ввода для формирования (изменения формы) спектральной области, на основании коэффициентов линейного предсказания.
В этом отношении было установлено, что эффективность кодирования сохраняется, даже если такое перекрывающееся преобразование используется для спектрального разложения, которое вызывает наложение и требует отмены наложения во времени, такие как критически дискретизированные перекрывающиеся преобразования, например MDCT (модифицированное дискретное косинусное преобразование).
Выгодные реализации аспектов настоящего изобретения являются предметом зависимых пунктов формулы изобретения.
В частности, предпочтительные варианты осуществления настоящей заявки описаны со ссылками на чертежи, на которых
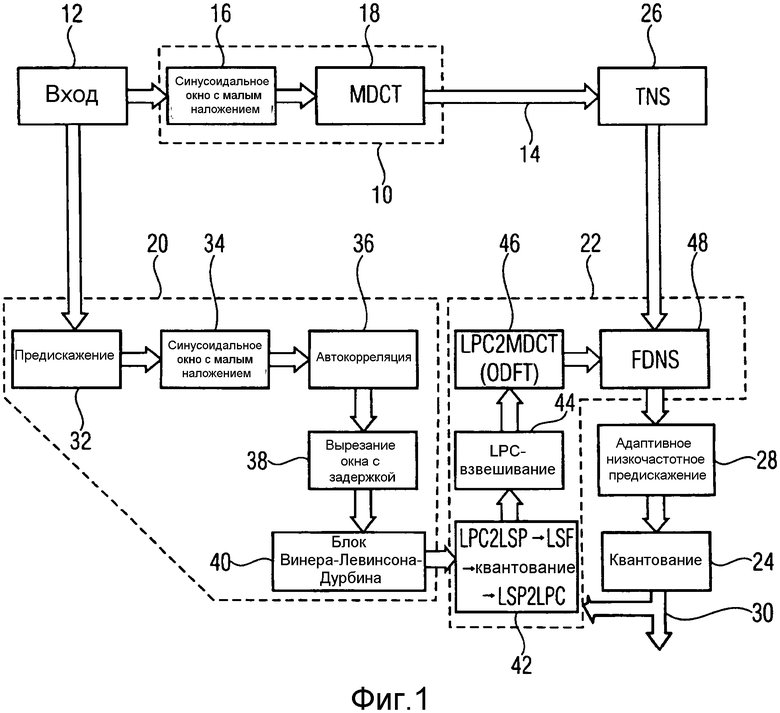
Фиг.1 показывает блок-схему аудио кодера в соответствии со сравнением или вариантом осуществления;
Фиг.2 показывает аудио кодер в соответствии с вариантом осуществления настоящей заявки;
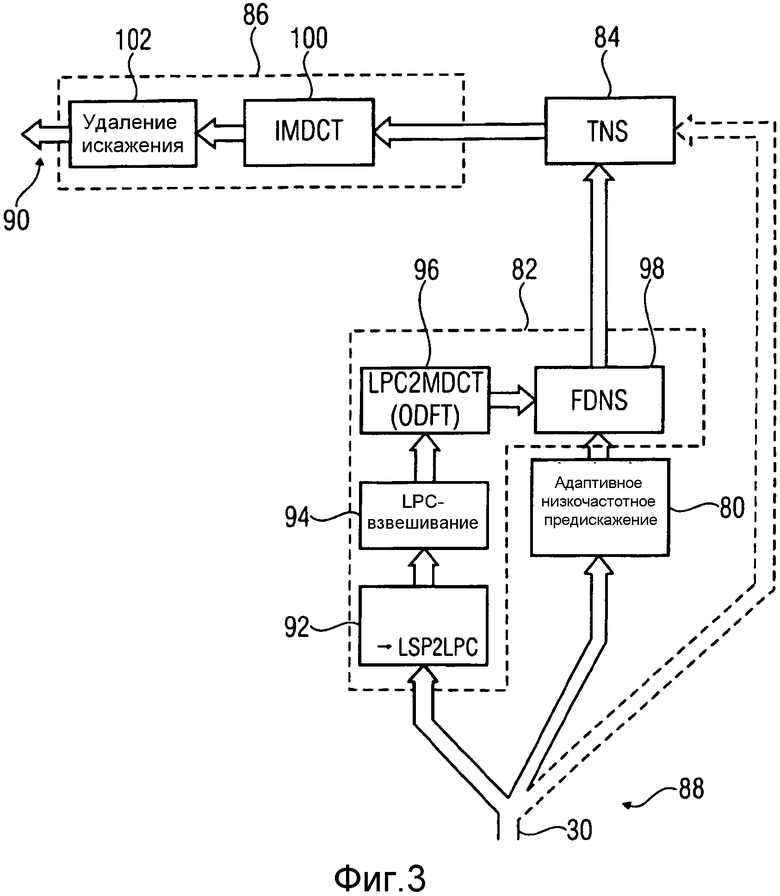
Фиг.3 показывает блок-схему возможного аудио декодера, соответствующего аудио кодеру согласно Фиг.2; и
Фиг.4 показывает блок-схему альтернативного аудио кодера в соответствии с вариантом осуществления настоящей заявки.
Чтобы облегчить понимание основных аспектов и преимуществ вариантов осуществления настоящего изобретения, дополнительно описанного ниже, ссылка предварительно делается на Фиг.1, которая показывает основанный на линейном предсказании аудио кодер, использующий формирование (изменение формы) шума спектральной области.
В частности, аудио кодер согласно Фиг.1 содержит модуль 10 спектрального разложения для того, чтобы спектрально разложить входной сигнал 12 аудио в спектрограмму, состоящую из последовательности спектров, которая обозначена 14 на Фиг.1. Как показано на Фиг.1, модуль 10 спектрального разложения может использовать MDCT, чтобы передать сигнал 10 ввода аудио из временной области в спектральную область. В частности, модуль 16 выреза окна предшествует модулю MDCT 18 модуля 10 спектрального разложения так, чтобы вырезать в виде окна взаимно накладывающееся части входного сигнала 12 аудио, причем эти части в виде вырезанных окон являются индивидуально подлежащими соответствующему преобразованию в модуле 18 MDCT, чтобы получить спектры последовательности спектров спектрограммы 14. Однако модуль 10 спектрального разложения может, альтернативно, использовать любое другое перекрывающееся преобразование, вызывающее наложение, например любое другое критически дискретизированное перекрывающееся преобразование.
Далее, аудио кодер согласно Фиг.1 содержит анализатор 20 линейного предсказания для того, чтобы анализировать входной сигнал 12 аудио, чтобы получить из него коэффициенты линейного предсказания. Формирователь (блок изменения формы) 22 спектральной области из аудио кодера согласно Фиг.1 конфигурируется, чтобы спектрально формировать (изменять форму) текущий спектр последовательности спектров спектрограммы 14, на основании коэффициентов линейного предсказания, предоставленных анализатором 20 линейного предсказания. В частности, формирователь 22 спектральной области конфигурируется, чтобы спектрально формировать текущий спектр, поступающий в формирователь 22 спектральной области в соответствии с функцией передачи, которая соответствует функции передачи анализирующего фильтра с линейным предсказанием посредством преобразования коэффициентов линейного предсказания из анализатора 20 в спектральные взвешивающие значения и применения последних взвешивающих значений в качестве делителей, чтобы спектрально придать форму или сформировать текущий спектр. Сформированный спектр является подлежащим квантованию в квантователе 24 аудио кодера согласно Фиг.1. Из-за формирования в формирователе 22 спектральной области шум квантования, который получается после удаления формирования (устранения изменения формы) квантованного спектра на стороне декодера, смещается так, что становится скрытым, то есть кодирование является таким прозрачным для восприятия, насколько возможно.
Ради законченности только следует отметить, что модуль 26 формирования (изменения формы) временного шума может необязательно подвергать спектры, направленные от модуля 10 спектрального разложения к формирователю 22 спектральной области формированию временного шума, и модуль 28 предыскажения (предыскажения) низких частот может адаптивно фильтровать каждый сформированный спектр, выведенный формирователем 22 спектральной области перед квантованием 24.
Квантованный и спектрально формованный спектр вставляется в поток 30 данных наряду с информацией относительно коэффициентов линейного предсказания, используемых при спектральном формировании так, чтобы на стороне декодирования удаление формирования и обратное квантование могли быть выполнены.
Большинство частей аудио кодека, за одним исключением, являющимся модулем 26 TNS, показанным на Фиг.1, например, воплощены и описаны в новом аудио кодеке USAC и, в частности, в его режиме TCX. Соответственно, для дальнейших деталей, ссылка сделана, например, на стандарт USAC, например [1].
Однако больший акцент делается на следующее относительно анализатора 20 линейного предсказания. Как показано на Фиг.1, анализатор 20 линейного предсказания непосредственно оперирует над входным сигналом 12 аудио. Модуль 32 предварительного выделения (предыскажения) предварительно фильтрует входной сигнал 12 аудио посредством, например, фильтрования FIR и затем непрерывно выводит автокорреляцию посредством объединения модуля 34 выреза окна, автокоррелятора 36 и модуля 38 выреза окна с задержкой. Модуль 34 выреза окна формирует вырезанные в виде окон части из предварительно фильтрованного входного сигнала аудио, причем вырезанные в виде окон части могут взаимно накладываться во времени. Автокоррелятор 36 вычисляет автокорреляцию для каждой вырезанной в виде окна части, выведенной модулем 34 выреза окна, и модуль 38 выреза окна с задержкой необязательно предоставляется, чтобы применить функцию окна с задержкой к автокорреляциям, чтобы обеспечить автокорреляцию, более подходящую для следующего алгоритма оценки параметров линейного предсказания. В частности, модуль 40 оценки параметров линейного предсказания принимает выведенный сигнал окна с задержкой и выполняет, например, алгоритм Винера-Левинсона-Дурбина (Wiener-Levinson-Durbin) или другой подходящий алгоритм в отношении вырезанных в виде окон автокорреляций так, чтобы вывести коэффициенты линейного предсказания для каждой автокорреляции. В формирователе 22 спектральной области получающиеся коэффициенты линейного предсказания передают через цепь модулей 42, 44, 46 и 48. Модуль 42 ответственен за передачу информации относительно коэффициентов линейного предсказания в пределах потока 30 данных к стороне декодирования. Как показано на Фиг.1, модуль 42 вставки в поток данных коэффициентов линейного предсказания может быть сконфигурирован, чтобы выполнять квантование коэффициентов линейного предсказания, определенных анализатором 20 линейного предсказания в линейной спектральной паре или линейной спектральной частотной области с кодированием квантованных коэффициентов в поток 30 данных и повторное преобразование квантованных значений предсказания снова в коэффициенты LPC. Необязательно, некоторая интерполяция может использоваться, чтобы уменьшить частоту обновления, с которой информация в коэффициентах линейного предсказания передается в пределах потока 30 данных. Соответственно, последующий модуль 44, который ответственен за подвергание коэффициентов линейного предсказания относительно текущего спектра, входящего в формирователь 22 спектральной области, некоторому процессу взвешивания, обращается к коэффициентам линейного предсказания, когда они также доступны на стороне декодирования, то есть обращается к квантованным коэффициентам линейного предсказания. Последующий модуль 46 преобразовывает взвешенные коэффициенты линейного предсказания в спектральные весовые коэффициенты, которые затем применяются формирователем (модулем изменения формы) 48 шума частотной области так, чтобы спектрально формировать входящий текущий спектр.
Как стало ясным из вышеупомянутого обсуждения, анализ линейного предсказания, выполненный анализатором 20, вызывает служебные расходы, которые полностью составляют в целом спектральное разложение и формирование в спектральной области, выполненные в блоках 10 и 22, и соответственно, вычислительные служебные расходы являются значительными.
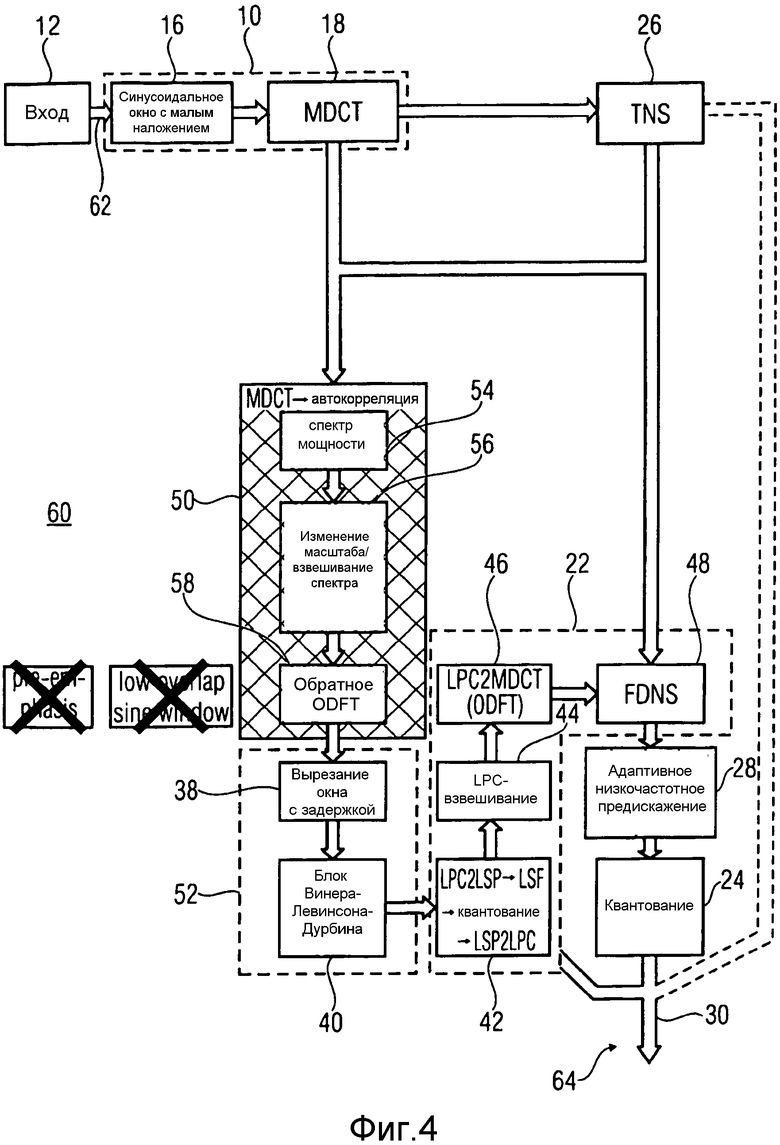
Фиг.2 показывает аудио кодер согласно варианту осуществления настоящей заявки, которая предлагает сопоставимую эффективность кодирования, но уменьшенную сложность кодирования.
Кратко говоря, в аудио кодере согласно Фиг.2, который представляет вариант осуществления настоящей заявки, анализатор линейного предсказания согласно Фиг.1 заменен объединением компьютера 50 автокорреляции и компьютера 52 коэффициентов линейного предсказания, последовательно включенных между модулем 10 спектрального разложения и формирователем 22 спектральной области. Мотивация для модификации от Фиг.1 к Фиг.2 и математическое объяснение, которое показывает подробные функциональные возможности модулей 50 и 52, предоставлены ниже. Однако очевидно, что вычислительные служебные расходы аудио кодера согласно Фиг.2 уменьшены по сравнению с аудио кодером согласно Фиг.1, рассматривая, что компьютер 50 автокорреляции вовлекает менее сложные вычисления по сравнению с последовательностью вычислений, связанных с автокорреляцией и вырезанием окна до автокорреляции.
Прежде, чем описать подробную и математическую структуру варианта осуществления согласно Фиг.2, кратко описана структура аудио кодера согласно Фиг.2. В частности, аудио кодер согласно Фиг.2, который в целом обозначен с использованием ссылочной позиции 60, содержит вход 62 для приема входного сигнала 12 аудио и выход 64 для вывода потока данных 30, в который аудио кодер кодирует входной сигнал 12 аудио. Модуль 10 спектрального разложения, формирователь 26 временного шума, формирователь 22 спектральной области, модуль 28 предыскажения низких частот и квантователь 24 соединены последовательно в порядке их упоминания между входом 62 и выходом 64. Формирователь 26 временного шума и модуль 28 предыскажения низких частот являются необязательными модулями и, в соответствии с альтернативным вариантом осуществления, могут быть опущены. Если имеется, формирователь 26 временного шума может быть сконфигурирован, чтобы быть активируемым адаптивно, то есть формирование временного шума формирователем 26 временного шума может быть активировано или дезактивировано в зависимости от характеристики входного сигнала аудио, например, с результатом решения, например, передаваемым стороне декодирования через поток 30 данных, как будет пояснено более подробно ниже.
Как показано на Фиг.1, формирователь 22 спектральной области согласно Фиг.2 внутренне сконструированы так, как это было описано относительно Фиг.1. Однако внутренняя структура согласно Фиг.2 не должна интерпретироваться как критическая проблема, и внутренняя структура формирователя 22 спектральной области может также быть отличной по сравнению с точной структурой, показанной на Фиг.2.
Компьютер 52 коэффициентов линейного предсказания согласно Фиг.2 содержит модуль 38 выреза окна с задержкой и модуль 40 оценки коэффициентов линейного предсказания, которые последовательно соединены между компьютером 50 автокорреляции с одной стороны и формирователем 22 спектральной области с другой стороны. Нужно отметить, что модуль выреза окна с задержкой, например, является также необязательным признаком. Если имеется, окно, примененное модулем 38 выреза окна с задержкой в отношении индивидуальных автокорреляций, предоставленных компьютером 50 автокорреляции, может быть Гауссовским окном или окном, имеющим биномиальную форму. Относительно модуля 40 оценки коэффициентов линейного предсказания следует отметить, что он не обязательно использует алгоритм Винера-Левинсона-Дурбина. Вместо этого другой алгоритм может использоваться, чтобы вычислять коэффициенты линейного предсказания.
Внутренне компьютер 50 автокорреляции содержит последовательность из компьютера 54 спектра мощности с последующим модулем 56 изменения масштаба/ спектрального взвешивания, за которым, в свою очередь, следует инверсный преобразователь 58. Детали и значение последовательности модулей 54-58 будут описаны более подробно ниже.
Чтобы понять то, почему возможно совместно использовать спектральное разложение модуля 10 разложения как для формирования шума спектральной области в формирователе 22 так и вычисления коэффициентов линейного предсказания, нужно рассмотреть теорему Винера-Хиничина (Wiener-Khinichin), которая показывает, что автокорреляция может быть вычислена, используя DFT (дискретное преобразование Фурье):
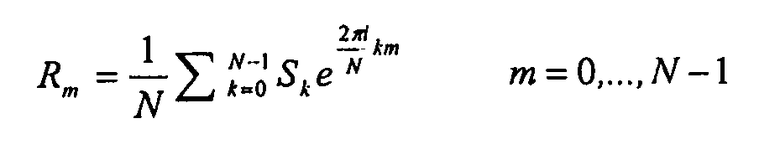 ,
,
где
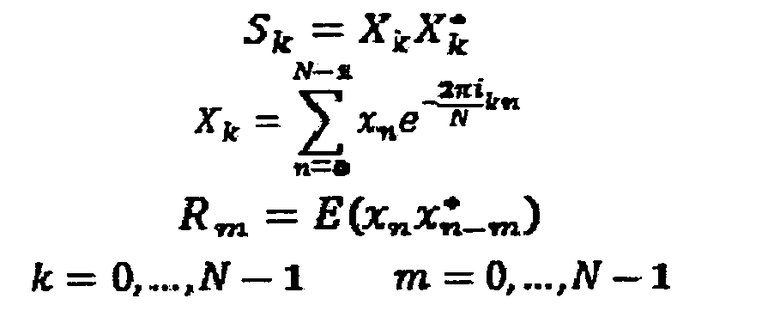
Таким образом, Rm являются коэффициентами автокорреляции для автокорреляции части xn сигнала, DFT которых является Xk.
Соответственно, если модуль 10 спектрального разложения использует DFT, чтобы реализовать перекрывающееся преобразование и генерирует последовательность спектров входного сигнала 12 аудио, то вычислитель 50 автокорреляции может быть в состоянии выполнить более быстрое вычисление автокорреляции при ее выводе, просто следуя только описанной в общих чертах теореме Винера-Хиничина.
Если требуются значения для всех задержек m автокорреляции, DFT модуля 10 спектрального разложения может быть выполнено, используя FFT (быстрое преобразование Фурье), и обратное FFT может быть использовано в компьютере 50 автокорреляции, чтобы вывести автокорреляцию из нее, используя упомянутую выше формулу. Когда, однако, необходимы только М<< N задержек, может быть быстрее использовать FFT для спектрального разложения и непосредственно применить обратное DFT, чтобы получить релевантные коэффициенты автокорреляции.
То же самое сохраняется истинным, когда упомянутое выше DFT заменяется на ODFT, то есть нечетно-частотное DFT, где обобщенное DFT временной последовательности x определяется как:
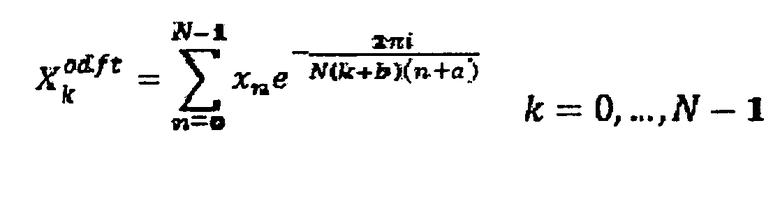
и
a=0 b=1/2
установлены для ODFT (нечетно-частотного DFT).
Если, однако, MDCT используется в варианте осуществления согласно Фиг.2, вместо DFT или FFT, ситуации отличаются. MDCT вовлекает дискретное косинусное преобразование типа IV и выявляет только спектр вещественных значений. Таким образом, информация фазы теряется этим преобразованием. MDCT может быть записано как:
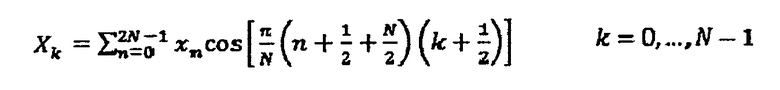 ,
,
где xn с n = 0... 2N-1 определяет текущую вырезанную в виде окна часть входного сигнала 12 аудио, которая выведена модулем 16 выреза окна, и Xk является, соответственно, k-м спектральным коэффициентом получающегося спектра для этой вырезанной в виде окна части.
Компьютер 54 спектра мощности вычисляет из выходного результата MDCT спектр мощности посредством возведения в квадрат каждого коэффициента Xk преобразования:
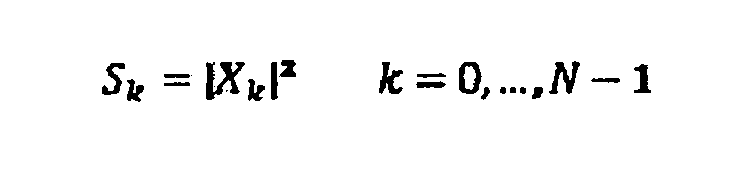
Отношение между спектром MDCT, который определен посредством Xk и ODFT- спектром X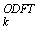
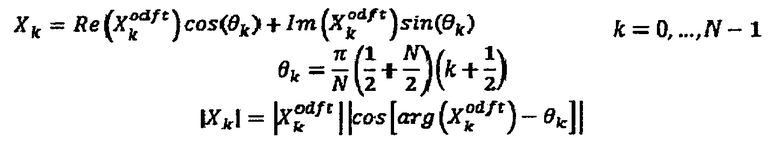
Это означает, что использование MDCT вместо ODFT в качестве входного сигнала для компьютера 50 автокорреляции, выполняющего MDCT к процедуре автокорреляции, эквивалентно автокорреляции, полученной из ODFT с взвешиванием спектра
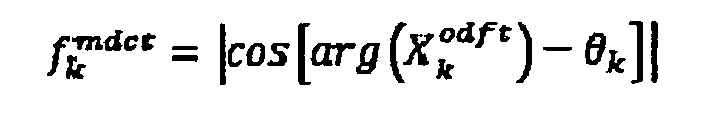
Это искажение определенной автокорреляции является, однако, прозрачным для стороны декодирования, поскольку формирование (изменение формы) спектральной области в формирователе 22 имеет место в точно той же самой спектральной области, что и для модуля 10 спектрального разложения, а именно MDCT. Другими словами, так как формирование шума частотной области формирователем 48 шума частотной области согласно Фиг.2 применяется в области MDCT, это фактически означает, что спектральное взвешивание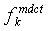
Соответственно, в компьютере 50 автокорреляции обратный преобразователь 58 выполняет обратное ODFT и обратное ODFT симметричного вещественного входного сигнала равно DCT типа II:
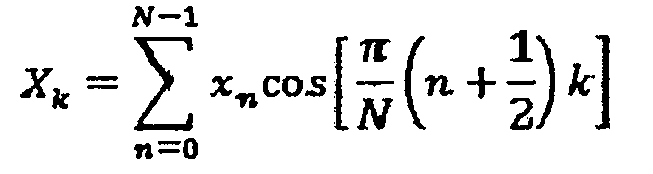
Таким образом, это позволяет осуществить быстрое вычисление LPC, основанное на MDCT, в компьютере 50 автокорреляции согласно Фиг.2, поскольку автокорреляция, как она определена обратным ODFT на выходе обратного преобразователя 58, приводит к относительно низкой вычислительной стоимости, поскольку просто менее значительные вычислительные этапы необходимы, такие как описанные выше в общих чертах возведение в квадрат и компьютер 54 спектра мощности и обратное ODFT в обратном преобразователе 58.
Детали относительно модуля 56 спектрального взвешивания/изменения масштаба еще не были описаны. В частности, этот модуль является необязательным и может быть удален или заменен прореживателем частотной области. Детали относительно возможных мер, выполняемых модулем 56, описаны ниже. Перед этим, однако, описаны в общих чертах некоторые детали относительно некоторых из других элементов, показанных на Фиг.2. Относительно модуля 38 выреза окна с задержкой, например, следует отметить, что он может выполнять компенсацию белого шума, чтобы улучшить приведение к требуемым условиям оценку коэффициентов линейного предсказания, выполняемую модулем 40 оценки. Взвешивание LPC, выполняемое в модуле 44, является необязательным, но если присутствует, оно может быть выполнено, чтобы достигнуть фактического расширения полосы частот. Таким образом, полюса LPC перемещаются к началу координат посредством константы согласно, например,
A'(z)=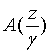
Таким образом, взвешивание LPC, выполненное таким образом, аппроксимирует одновременное маскирование. Константа γ, имеющая значение γ=0,92 или где-нибудь между 0,85 и 0,95, оба включительно, приводит к хорошим результатам.
Относительно модуля 42 следует отметить, что кодирование с переменной скоростью передачи в битах или некоторая другая схема статистического кодирования, могут использоваться, чтобы закодировать в поток 30 данных информацию относительно коэффициентов линейного предсказания. Как уже упомянуто выше, квантование может быть выполнено в области LSP/LSF, но область ISP/ISF также возможна.
Относительно модуля 46 LPC-в-MDCT, который преобразовывает LPC в значения спектрального взвешивания, которые называют, в случае области MDCT, коэффициентами передачи MDCT в нижеследующем, можно сослаться на, например, кодек USAC, где это преобразование поясняется подробно. Кратко говоря, коэффициенты LPC могут быть подлежащими обработке посредством ODFT, чтобы получить коэффициенты передачи MDCT, инверсия которых может затем использоваться в качестве весовых коэффициентов для формирования спектра в модуле 48, применяя получающиеся весовые коэффициенты на соответствующих частотных диапазонах спектра. Например, 16 коэффициентов LPC преобразуются в коэффициенты передачи MDCT. Естественно, вместо взвешивания с использованием инверсии, взвешивания с использованием коэффициентов передачи MDCT в неинвертированной форме используется на стороне декодера, чтобы получить функцию передачи, похожую на фильтр синтеза LPC, чтобы формировать шум квантования, как уже упомянуто выше. Таким образом, суммируя, в модуле 46 коэффициенты передачи, используемые посредством FDNS 48, получают из коэффициентов линейного предсказания, используя ODFT, и называют коэффициентами передачи MDCT в случае использования MDCT.
Для завершения рассмотрения, Фиг.3 показывает возможную реализацию для аудио декодера, который может использоваться, чтобы снова восстановить аудио сигнал из потока 30 данных. Декодер согласно Фиг.3 содержит модуль 80 удаления предыскажения низких частот, который является необязательным, модуль 82 удаления формирования (изменения формы) спектральной области, модуль 84 удаления временного шума, который является также необязательным, и преобразователь 86 из спектральной во временную область, которые последовательно соединены между входом 88 потока данных аудио декодера, на который поступает поток 30 данных, и выходом 90 аудио декодера, где восстановленный аудио сигнал выводится. Модуль удаления предыскажения низких частот принимает из потока 30 данных квантованный и спектрально сформированный спектр и выполняет его фильтрование, которое является обратным функции передачи модуля предыскажения низких частот согласно Фиг.2. Как уже упомянуто, модуль 80 удаления предыскажения является, однако, необязательным.
Модуль 82 удаления формирования спектральной области имеет структуру, которая очень сходна с таковой у формирователя 22 спектральной области из Фиг.2. В частности, внутри она содержит объединение модуля 92 извлечения LPC, модуль 94 взвешивания LPC, который равен модулю 44 взвешивания LPC, преобразователь 96 LPC-в-MDCT, который также равен модулю 46 из Фиг.2, и формирователь 98 шума частотной области, который применяет коэффициенты передачи MDCT к поступающему (несформированному) спектру, инверсно по отношению к FDNS 48 из Фиг.2, то есть посредством умножения, а не деления, чтобы получить функцию передачи, которая соответствует синтезирующему фильтру с линейным предсказанием коэффициентов линейного предсказания, извлеченных из потока 30 данных модулем 92 извлечения LPC. Модуль 92 извлечения LPC может выполнить вышеупомянутое повторное преобразование из соответствующей области квантования, такой как LSP/LSF или ISP/ISF, чтобы получить коэффициенты линейного предсказания для индивидуальных спектров, закодированных в поток 30 данных, для последовательных взаимно накладывающихся частей аудио сигнала, который подлежит восстановлению.
Формирователь 84 шума временной области инвертирует фильтрование модуля 26 согласно Фиг.2, и возможные реализации для этих модулей описаны более подробно ниже. В любом случае, однако, модуль 84 TNS из Фиг.3 является необязательным и может быть опущен, как было также упомянуто относительно модуля 26 TNS из Фиг.2.
Спектральный составитель 86 содержит, внутренне, инверсный преобразователь 100, выполняющий, например, IMDCT индивидуально над поступающими несформированными спектрами, с последующим модулем удаления наложения, таким как сумматор 102 добавления наложения, сконфигурированный так, чтобы корректно временно регистрировать восстановленные версии вырезанных окон, выведенные повторным преобразователем 100, чтобы выполнять отмену наложения во времени между ними и вывести восстановленный аудио сигнал на выходе 90.
Как уже упомянуто выше, из-за формирования 22 спектральной области в соответствии с функцией передачи, соответствующей анализирующему фильтру LPC, определенному коэффициентами LPC, переданными в потоке данных 30, квантование в квантователе 24, которое имеет, например, спектрально плоский шум, формируется (изменяет форму) посредством модуля 82 удаления формирования спектральной области на стороне декодирования таким образом, чтобы быть скрытым ниже порога маскирования.
Различные возможности существуют для того, чтобы реализовать модуль 26 TNS и его инверсию в декодере, а именно модуле 84. Формирование временного шума предназначено для того, чтобы сформировать шум во временном смысле во временных частях, к которым относятся индивидуальные спектры, спектрально сформированные формирователем спектральным области. Формирование временного шума особенно полезно в случае переходных процессов, присутствующих в пределах соответствующей временной части, к которой относится текущий спектр. В соответствии с конкретным вариантом осуществления формирователь 26 временного шума конфигурируется как предсказатель спектра, сконфигурированный чтобы фильтровать с предсказанием текущий спектр или последовательность спектров, выведенных модулем 10 спектрального разложения вдоль спектрального измерения (размерности). Таким образом, предсказатель 26 спектра может также определить коэффициенты фильтра предсказания, которые могут быть вставлены в поток 30 данных. Это иллюстрируется пунктирной линией на Фиг.2. Как следствие, отфильтрованные по временному шуму спектры уплощаются вдоль спектрального измерения и вследствие соотношений между спектральной областью и временной областью, обратного фильтрования в модуле 84 удаления формирования временного шума в соответствии с переданными фильтрами с предсказанием формирования шума временной области в пределах потока данных 30, это удаление формирования приводит к сокрытию или сжатию шума в моменты времени или время, в которое происходят воздействие или переходные процессы. Так называемое сигналы опережающего эха таким образом избегаются.
Другими словами, посредством фильтрования с предсказанием текущего спектра в формирователе 26 шума временной области, формирователь шума временной области 26 получает в качестве остатка спектра, то есть фильтрованный с предсказанием спектр, который направляется к формирователю 22 спектральной области, причем соответствующие коэффициенты предсказания вставлены в поток 30 данных. Модуль 84 удаления формирования шума временной области, в свою очередь, принимает от модуля 82 удаления формирования спектральной области спектр с удаленным изменением формы и инвертирует фильтрование временной области вдоль спектральной области, посредством инверсного фильтрования этого спектра в соответствии с фильтрами с предсказанием, принятыми из потока данных, или извлеченными из потока 30 данных. Другими словами, формирователь 26 шума временной области использует анализирующий фильтр с предсказанием, такой как фильтр с линейным предсказанием, тогда как модуль 84 удаления формирования шума временной области использует соответствующий синтезирующий фильтр, на основании тех же самых коэффициентов предсказания.
Как уже упомянуто, аудио кодер может быть сконфигурирован, чтобы решать - разрешить или запретить формирование временного шума в зависимости от коэффициента усиления фильтра с предсказанием или тональности или изменяемости сигнала 12 аудио входа в соответствующей временной части, соответствующей текущему спектру. Снова, соответствующая информация относительно решения вставляется в поток 30 данных.
Ниже описана возможность, согласно которой компьютер 50 автокорреляции конфигурируется, чтобы вычислять автокорреляцию из фильтрованной с предсказанием, то есть TNS-фильтрованной, версии спектра, вместо нефильтрованного спектра, как показано на Фиг.2. Существуют две возможности: TNS-фильтрованные спектры могут использоваться всякий раз, когда TNS применяется, или способом, выбранном аудио кодером, на основании, например, характеристик входного сигнала 12 аудио, который должен быть кодирован. Соответственно, аудио кодер согласно Фиг.4 отличается от аудио кодера согласно Фиг.2 тем, что вход компьютера 50 автокорреляции соединен как с выходом спектрального модуля 10 разложения, так и с выводом модуля 26 TNS.
Как упомянуто выше, TNS-фильтрованный MDCT-спектр, как выводится спектральным модулем 10 разложения, может использоваться как входной сигнал или основание для вычисления автокорреляции в компьютере 50. Как упомянуто выше, TNS-фильтрованный спектр может использоваться всякий раз, когда TNS применяется, или аудио кодер мог решить для спектров, к которым TNS был применено, между использованием нефильтрованного спектра или TNS-фильтрованного спектра. Это решение может быть принято, как упомянуто выше, в зависимости от характеристик входного сигнала аудио. Решение может быть, однако, прозрачным для декодера, который просто применяет информацию коэффициентов LPC для удаления формирования (изменения формы) частотной области. Другая возможность может состоять в том, что аудио кодер переключается между TNS-фильтрованным спектром и нефильтрованным спектром для спектров, к которым было применено TNS, то есть чтобы принимать решение между этими двумя вариантами для этих спектров, в зависимости от выбранной длины преобразования спектрального модуля 10 разложения.
Чтобы быть более точным, модуль 10 разложения на Фиг.4 может быть сконфигурирован, чтобы переключаться между различными длинами преобразования в спектральном разложении входного сигнала аудио так, чтобы спектры, выведенные модулем 10 спектрального разложения, имели бы различное спектральное разрешение. Таким образом, модуль 10 спектрального разложения может, например, использовать перекрывающееся преобразование, такое как MDCT, чтобы преобразовать взаимно накладывающиеся временные части различной длины на преобразования или спектры также переменной длины, где длина преобразования спектров соответствует длине соответствующих накладывающихся временных частей. В этом случае компьютер 50 автокорреляции может быть сконфигурирован, чтобы вычислять автокорреляцию из фильтрованного с предсказанием или TNS-фильтрованного текущего спектра в случае спектрального разрешения текущего спектра, удовлетворяющего заранее определенному критерию, или из нефильтрованного с предсказанием, то есть нефильтрованного, текущего спектра в случае спектрального разрешения текущего спектра, не удовлетворяющего заранее определенному критерию. Заранее определенный критерий может быть таким, например, что спектральное разрешение текущего спектра превышает некоторый порог. Например, использование TNS-фильтрованного спектра, который выведен модулем 26 TNS для вычисления автокорреляции, является выгодным для более длинных кадров (временных частей), таких как кадры дольше чем 15 миллисекунд, но может быть невыгодным для коротких кадров (временных частей) короче чем, например, 15 миллисекунд, и соответственно, входной сигнал в компьютер 50 автокорреляции для более длинных кадров может быть TNS-фильтрованным спектром MDCT, тогда как для более коротких кадров MDCT-спектр, который выводится модулем 10 разложения, может использоваться непосредственно.
До сих пор это еще не было описано, какие перцепционные релевантные модификации могут быть выполнены над спектром мощности в модуле 56. Ниже поясняются различные меры, и они могут быть применены индивидуально или в комбинации ко всем вариантам осуществления и вариантам, описанным до сих пор. В частности, взвешивание спектра может быть применено модулем 56 к спектру мощности, выведенному компьютером 54 спектра мощности. Взвешивание спектра может быть:
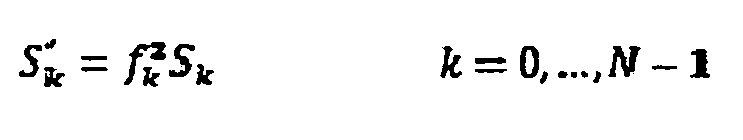 ,
,
где Sk являются коэффициентами спектра мощности, как уже упомянуто выше.
Спектральное взвешивание может использоваться как механизм для того, чтобы распределить шум квантования в соответствии с психоакустическими аспектами. Взвешивание спектра, соответствующее предварительному выделению в смысле Фиг.1, может быть определено как:
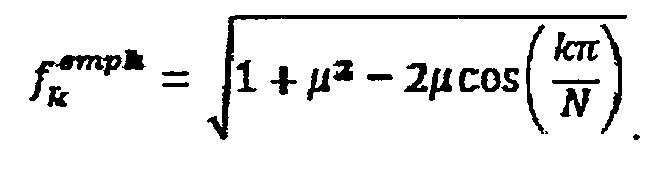
Кроме того, изменение масштаба может быть использовано в модуле 56. Полный спектр может быть разделен, например, на М частотных диапазонов для спектров, соответствующих кадрам или временным частям длины выборки l1 и 2M частотных диапазонов для спектров, соответствующих временным частям кадров, имеющих длину выборки l2, в котором l2 может быть двукратным от l1, причем l1 может быть 64, 128 или 256. В частности, деление может подчиняться:

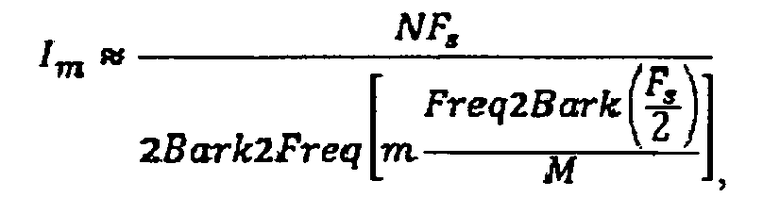
Деление частотного диапазона может включать в себя изменение частоты к аппроксимации шкалы Барка (Bark scale) согласно:
альтернативно, частотные диапазоны могут быть одинаково распределены, чтобы сформировать линейный масштаб (линейную шкалу) согласно:
lm=mN/M
Для спектров кадров длины l1, например, ряд частотных диапазонов могут находиться между 20 и 40 и между 48 и 72 для спектров, принадлежащих кадрам длины l2, в котором 32 частотных диапазона для спектров кадров длины l1 и 64 частотных диапазона для спектров кадров длины l2 являются предпочтительными.
Спектральное взвешивание и изменение частоты, как необязательно выполняется необязательным модулем 56, могут быть расценены как средство распределения битов (изменение формы шума квантования). Взвешивание спектра в линейном масштабе, соответствующем предварительному предыскажению, может быть выполнено, используя константу µ=0,9 или константу, лежащую где-нибудь между 0,8 и 0,95, так что соответствующее предварительное предыскажение (выделение) может приблизительно соответствовать изменению шкалы Барка.
Модификация спектра мощности в модуле 56 может включать в себя расширение по спектру спектра мощности, моделирование одновременного маскирования и таким образом заменить модули 44 и 94 LPC-взвешивания.
Если используется линейный масштаб и взвешивание спектра, соответствующее предварительному предыскажению, применяется, то результаты аудио кодера согласно Фиг.4, которые получают на стороне декодирования, то есть на выходе аудио декодера согласно Фиг.3, перцепционно очень подобны обычному результату реконструкции, который получают в соответствии с вариантом осуществления согласно Фиг.1.
Некоторые результаты тестов прослушивания были выполнены, используя варианты осуществления, идентифицированные выше. Из тестов оказалось, что обычный LPC-анализ, как показано на Фиг.1, и LPC-анализ, основанный на линейном масштабе MDCT, приводят к перцепционно эквивалентным результатам, когда
- взвешивание спектра в основанном на MDCT LPC-анализе соответствует предварительному предыскажению в обычном LPC-анализе,
- одно и то же вырезание окна используется в спектральном разложении, таком как синусоидальное окно с низкой степенью наложения, и
- линейный масштаб используется в основанном на MDCT LPC-анализе.
Незначительное различие между обычным LPC-анализом и основанным на линейном масштабе MDCT LPC-анализом, вероятно, происходит из факта, что LPC используется для формирования шума квантования и что есть достаточно битов при 48 кбит/сек, чтобы кодировать коэффициенты MDCT достаточно точно.
Далее, оказалось, что, использование масштаба Барка или нелинейного масштаба посредством применения изменения масштаба в модуле 56 приводит к эффективности кодирования или результатам тестов прослушивания, согласно которым масштаб Барка выигрывает у линейного масштаба для тестовых аудио частей “Applause”, “Fatboy”, “RockYou”, “Waiting”, “Bohemian”, “fuguepremikres”, “kraftwerk”, “lesvoleurs”, “teardrop”.
Масштаб Барка терпит неудачу для «хоккей» и «linchpin». Другим элементом, который имеет проблемы в масштабе Барка, является bibilolo, но он не был включен в тест, поскольку он придает экспериментальной музыке конкретную структуру спектра. Некоторые слушатели также выражали сильную неприязнь элементу “bibilolo”.
Однако для аудио кодера согласно Фиг.2 и 4 возможно переключаться между различными масштабами. Таким образом, модуль 56 может применить различное масштабирование для различных спектров в зависимости от характеристик аудио сигнала, таких как нестационарность или тональность, или использовать различные масштабы частоты, чтобы произвести множественные квантованные сигналы и меру для определения, какой из квантованных сигналов перцепционно лучше. Оказалось, что переключения масштаба приводят к усовершенствованиям в присутствии переходных процессов, таких как переходные процессы в «RockYou» и «linchpin» по сравнению с непереключенными версиями (Барка и линейным масштабом).
Нужно упомянуть, что вышеупомянутые обрисованные в общих чертах варианты осуществления могут использоваться в качестве режима TCX в многорежимном аудио кодеке, таком как кодек, поддерживающий ACELP, и вышеупомянутый описанный в общих чертах вариант осуществления в качестве TCX-подобного режима. В качестве создания кадров могут использоваться кадры постоянной длины, например, 20 миллисекунд. Таким образом, может быть получена своего рода версия с малой задержкой кодека USAC, которая является очень эффективной. В качестве TNS может использоваться TNS из AAC-ELD. Чтобы уменьшить количество битов, используемых для побочной информации, количество фильтров может быть фиксировано равным двум, один оперирующий от 600 Гц до 4500 Гц и второй от 4500 Гц до конца спектра основного кодера. Фильтры могут быть независимо включены и выключены. Фильтры могут быть применены и переданы как решетка, используя коэффициенты частичной автокорреляции. Максимальный порядок фильтра может быть установлен равным восьми, и четыре бита могут использоваться для каждого коэффициента фильтра. Кодирование Хаффмана может использоваться, чтобы сократить количество битов, используемых для порядка фильтра и для его коэффициентов.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все этапы способа могут быть выполнены (или использоваться) устройством аппаратного обеспечения, как, например, микропроцессором, программируемым компьютером или электронной схемой. В некоторых вариантах осуществления некоторые один или более самых важных этапов способа могут быть выполнены таким устройством.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратном обеспечении или в программном обеспечении. Реализация может быть выполнена, используя цифровой носитель данных, например дискета, DVD, Blue-ray, компакт-диск, ROM, PROM, стираемая программируемая постоянная память PROM, EEPROM или флэш-память, имеющие электронно считываемые управляющие сигналы на них, которые совместно работают (или способны совместно работать) с программируемой компьютерной системой таким образом, что соответствующий способ выполняется. Поэтому цифровой носитель данных может быть считываемым компьютером.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно считываемые управляющие сигналы, которые способны совместно работать с программируемой компьютерной системой таким образом, что один из способов, описанных здесь, выполняется.
В целом, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, причем программный код работает для того, чтобы выполнять один из способов, когда компьютерный программный продукт запускается на компьютере. Программный код может например быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для того, чтобы выполнять один из способов, описанных здесь, сохраненную на машиночитаемом носителе.
Другими словами, вариантом осуществления изобретательного способа является поэтому компьютерная программа, имеющая программный код для того, чтобы выполнять один из способов, описанных здесь, когда компьютерная программа запускается на компьютере.
Другой вариант осуществления изобретенных способов является поэтому носителем информации (или цифровым запоминающим носителем или считываемым компьютером носителем), содержащим записанную на нем компьютерную программу для того, чтобы выполнять один из способов, описанных здесь. Носитель информации, цифровой носитель данных или записанный носитель обычно являются материальными и/или невременными.
Другой вариант осуществления изобретательного способа является поэтому потоком данных или последовательностью сигналов, представляющих компьютерную программу для того, чтобы выполнять один из способов, описанных здесь. Поток данных или последовательность сигналов могут например конфигурироваться, чтобы быть переданными через соединение передачи данных, например через Интернет.
Другой вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, конфигурируемое или приспособленное, чтобы выполнять один из способов, описанных здесь.
Другой вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для того, чтобы выполнять один из способов, описанных здесь.
Другой вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную, чтобы передать (например, электронно или оптически) компьютерную программу для того, чтобы выполнять один из способов, описанных здесь, на приемник. Приемник может, например, быть компьютером, мобильным устройством, устройством памяти или подобным. Устройство или система могут, например, содержать файловый сервер для того, чтобы передать компьютерную программу приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться, чтобы выполнять некоторые или все функциональные возможности способов, описанных здесь. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может совместно работать с микропроцессором, чтобы выполнять один из способов, описанных здесь. В целом способы предпочтительно выполняются любым устройством аппаратного обеспечения.
Вышеупомянутые описанные варианты осуществления являются просто иллюстративными для принципов настоящего изобретения. Подразумевается, что модификации и изменения компоновок и деталей, описанных здесь, будут очевидны для специалистов в данной области техники. Поэтому изобретение предназначается быть ограниченным только объемом нижеследующей формулы изобретения, а не конкретными деталями, представленными здесь посредством описания и пояснениями вариантов осуществления.
Литература
[1]: US AC codec (Unified Speech and Audio Codec), ISO/IEC CD 23003-3 от 24 сентября 2010
| название | год | авторы | номер документа |
|---|---|---|---|
| ОСНОВАННОЕ НА ЛИНЕЙНОМ ПРЕДСКАЗАНИИ КОДИРОВАНИЕ АУДИО С ИСПОЛЬЗОВАНИЕМ УЛУЧШЕННОЙ ОЦЕНКИ РАСПРЕДЕЛЕНИЯ ВЕРОЯТНОСТЕЙ | 2013 |
|
RU2651187C2 |
| ЗАПОЛНЕНИЕ ШУМОМ ПРИ АУДИОКОДИРОВАНИИ С ПЕРЦЕПЦИОННЫМ ПРЕОБРАЗОВАНИЕМ | 2014 |
|
RU2631988C2 |
| КОНЦЕПЦИЯ ЗАПОЛНЕНИЯ ШУМОМ | 2014 |
|
RU2660605C2 |
| УПРАВЛЕНИЕ ПОЛОСОЙ ЧАСТОТ В КОДЕРАХ И/ИЛИ ДЕКОДЕРАХ | 2018 |
|
RU2752520C1 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ВЫРОВНЕННОЙ ЧАСТИ ОПЕРЕЖАЮЩЕГО ПРОСМОТРА | 2012 |
|
RU2574849C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕЙ ДИСКРЕТИЗАЦИИ ИЛИ ИНТЕРПОЛЯЦИИ МАСШТАБНЫХ ПАРАМЕТРОВ | 2018 |
|
RU2762301C2 |
| КОДИРОВАНИЕ СПЕКТРАЛЬНЫХ КОЭФФИЦИЕНТОВ СПЕКТРА АУДИОСИГНАЛА | 2014 |
|
RU2638734C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
| НАПОЛНЕНИЕ ШУМОМ БЕЗ ПОБОЧНОЙ ИНФОРМАЦИИ ДЛЯ CELP-ПОДОБНЫХ КОДЕРОВ | 2014 |
|
RU2648953C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
Изобретение относится к способу кодирования аудио сигнала и средствам для осуществления этого способа. Технический результат изобретения заключается в создании концепции кодирования, позволяющей уменьшить сложность при сопоставимой или даже увеличенной эффективности кодирования. Концепция кодирования, основанная на линейном предсказании при использовании спектрального разложения входного аудио сигнала для вычисления коэффициентов линейного предсказания, использует формирование шума в спектральной области на основании вычисленных коэффициентов линейного предсказания. Эффективность кодирования может сохраняться, даже если используется такое перекрывающееся преобразование для спектрального разложения, которое вызывает наложение и требует отмены наложения во времени, такое как критически дискретизированное перекрывающееся преобразование, например MDCT. 3 н. и 10 з.п. ф-лы, 4ил. 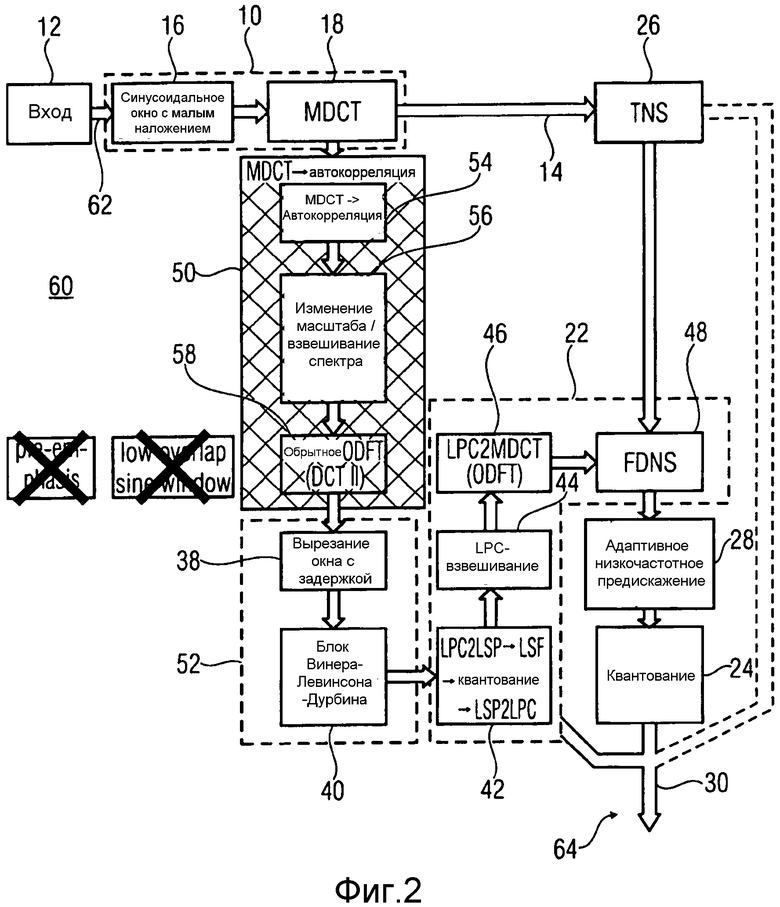
1. Аудио кодер, содержащий
модуль (10) спектрального разложения для того, чтобы спектрально разложить, используя MDCT, входной сигнал (12) аудио в спектрограмму (14) из последовательности спектров;
компьютер (50) автокорреляции, сконфигурированный, чтобы вычислять автокорреляцию из текущего спектра последовательности спектров;
компьютер (52) коэффициентов линейного предсказания, сконфигурированный, чтобы вычислять коэффициенты линейного предсказания на основании автокорреляции;
формирователь (22) спектральной области, сконфигурированный, чтобы спектрально формировать текущий спектр на основании коэффициентов линейного предсказания; и
каскад (24) квантования, сконфигурированный, чтобы квантовать спектрально сформированный спектр;
причем аудио кодер сконфигурирован, чтобы вставлять информацию относительно квантованного спектрально сформированного спектра и информацию относительно коэффициентов линейного предсказания в поток данных,
причем компьютер автокорреляции сконфигурирован, чтобы при вычислении автокорреляции из текущего спектра вычислять спектр мощности из текущего спектра и подвергать этот спектр мощности обратному ODFT преобразованию.
2. Аудио кодер по п.1, дополнительно содержащий
предсказатель (26) спектра, сконфигурированный для фильтрования с предсказанием текущего спектра вдоль спектрального измерения, причем формирователь спектральной области сконфигурирован, чтобы спектрально формировать фильтрованный с предсказанием текущий спектр, и аудио кодер сконфигурирован, чтобы вставить информацию относительно того, как инвертировать фильтрование с предсказанием в поток данных.
3. Аудио кодер по п.2, в котором предсказатель спектра сконфигурирован, чтобы выполнять фильтрование с линейным предсказанием в отношении текущего спектра вдоль спектрального измерения, при этом шаблон потока данных сконфигурирован таким образом, что информация относительно того, как инвертировать фильтрование с предсказанием, содержит информацию относительно дополнительных коэффициентов линейного предсказания, лежащих в основе фильтрования с линейным предсказанием в отношении текущего спектра вдоль спектрального измерения.
4. Аудио кодер по п.2, в котором аудио кодер сконфигурирован, чтобы решать - разрешить или запретить предсказатель спектра в зависимости от тональности или нестационарности входного сигнала аудио или коэффициента предсказания фильтра, при этом аудио кодер сконфигурирован, чтобы вставить информацию относительно этого решения.
5. Аудио кодер по п.2, в котором компьютер автокорреляции сконфигурирован, чтобы вычислять автокорреляцию из фильтрованного с предсказанием текущего спектра.
6. Аудио кодер по п.2, в котором модуль (10) спектрального разложения сконфигурирован так, чтобы переключаться между различными длинами преобразования при спектральном разложении входного сигнала (12) аудио так, чтобы спектры имели различное спектральное разрешение, при этом компьютер (50) автокорреляции сконфигурирован так, чтобы вычислять автокорреляцию из фильтрованного с предсказанием текущего спектра в случае, если спектральное разрешение текущего спектра удовлетворяет заранее определенному критерию, или из не фильтрованного с предсказанием текущего спектра в случае, если спектральное разрешение текущего спектра не удовлетворяет заранее определенному критерию.
7. Аудио кодер по п.6, в котором компьютер автокорреляции сконфигурирован таким образом, что заранее определенный критерий удовлетворяется, если спектральное разрешение текущего спектра выше, чем порог спектрального разрешения.
8. Аудио кодер по п.1, в котором компьютер автокорреляции сконфигурирован для, при вычислении автокорреляции из текущего спектра, вычисления спектра мощности из текущего спектра, перцепционного взвешивания спектра мощности и подвергания перцепционно взвешенного спектра мощности инверсному преобразованию ODFT в качестве перцепционно взвешенного.
9. Аудио кодер по п.8, в котором компьютер автокорреляции сконфигурирован, чтобы изменять масштаб частоты текущего спектра и выполнять перцепционное взвешивание спектра мощности в измененном масштабе частоты.
10. Аудио кодер по п.1, в котором аудио кодер сконфигурирован, чтобы вставлять информацию относительно коэффициентов линейного предсказания в поток данных в квантованной форме, при этом формирователь спектральной области сконфигурирован, чтобы спектрально формировать текущий спектр на основании квантованных коэффициентов линейного предсказания.
11. Аудио кодер по п.9, в котором аудио кодер сконфигурирован, чтобы вставлять информацию относительно коэффициентов линейного предсказания в поток данных в форме, согласно которой квантование коэффициентов линейного предсказания имеет место в области LSF или LSP.
12. Способ кодирования аудио, содержащий:
спектральное разложение, используя MDCT, входного сигнала (12) аудио в спектрограмму (14) из последовательности спектров;
вычисление автокорреляции из текущего спектра последовательности спектров;
вычисление коэффициентов линейного предсказания на основании автокорреляции;
спектральное формирование текущего спектра на основании коэффициентов линейного предсказания;
квантование спектрально сформированного спектра; и
вставку информации относительно квантованного спектрально сформированного спектра и информации относительно коэффициентов линейного предсказания в поток данных, причем вычисление автокорреляции из текущего спектра содержит вычисление спектра мощности из текущего спектра и подвергание спектра мощности обратному ODFT преобразованию.
13. Машиночитаемый носитель, содержащий записанную на нем компьютерную программу, которая при запуске на компьютере выполняет способ по п.12.
| EP 1852851 A1, 07.11.2007 | |||
| СПОСОБЫ И УСТРОЙСТВА ДЛЯ ВВЕДЕНИЯ НИЗКОЧАСТОТНЫХ ПРЕДЫСКАЖЕНИЙ В ХОДЕ СЖАТИЯ ЗВУКА НА ОСНОВЕ ACELP/TCX | 2005 |
|
RU2389085C2 |
| MOTLICEK PETR et.al | |||
| AUDIO CODING BASED ON LONG TEMPORAL CONTEXTS, IDIAP-RR 06-30, AVRIL 2006 | |||
| АВТОМАТИЧЕСКОЕ СТРЕЛКОВОЕ ОРУЖИЕ (ВАРИАНТЫ), ПРОДОЛЬНО-МНОГОРЯДНЫЙ МАГАЗИН, КОМПЕНСАЦИОННОЕ УСТРОЙСТВО ОТПИРАНИЯ КАНАЛА СТВОЛА, КРИВОШИПНО-ПОЛЗУННОЕ ЗАПИРАЮЩЕЕ УСТРОЙСТВО, УСТРОЙСТВО БАЛАНСИРОВКИ МАСС ПОДВИЖНЫХ ЧАСТЕЙ И КОМПЕНСАЦИОННЫЙ СПОСОБ ОТПИРАНИЯ КАНАЛА СТВОЛА | 1998 |
|
RU2144171C1 |

