Настоящая заявка относится к заполнению шумом при аудиокодировании с перцепционным преобразованием.
В кодировании с преобразованием часто осознается (ср. [1], [2], [3]), что квантование частей спектра в нули ведет к ухудшению восприятия. Такие части, квантованные в нуль, называются спектральными дырами. Решение для этой проблемы, представленное в [1], [2], [3] и [4], состоит в том, чтобы заменять квантованные в нуль спектральные линии на шум. Иногда, избегают вставки шума ниже некоторой частоты. Начальная частота для заполнения шумом является фиксированной, но разной среди известного предшествующего уровня техники.
Иногда, FDNS (Формирование шума частотной области) используется для формирования спектра (включая сюда вставленный шум) и для управления шумом квантования, как в USAC (ср. [4]). FDNS выполняется с использованием амплитудной характеристики фильтра LPC. Коэффициенты фильтра LPC вычисляются с использованием подвергнутого предыскажению входного сигнала.
В [1] было замечено, что добавление шума в непосредственной окрестности тональной компоненты ведет к ухудшению, и соответственно, точно так же как в [5] только длинные последовательности нулей заполняются шумом, чтобы избегать скрытия квантованных не в нуль значений вставленным окружающим шумом.
В [3] замечено, что имеется проблема компромисса между гранулярностью заполнения шумом и размером требуемой сторонней информации. В [1], [2], [3] и [5] передается один параметр заполнения шумом в расчете на полный спектр. Вставленный шум спектрально формируется с использованием LPC как в [2] или с использованием коэффициентов масштабирования как в [3]. В [3] описано как адаптировать коэффициенты масштабирования к заполнению шумом с одним уровнем заполнения шумом для всего спектра. В [3], коэффициенты масштабирования для диапазонов, которые полностью квантуются в нуль, модифицируются, чтобы избегать спектральных дыр и иметь корректный уровень шума.
Даже хотя решения в [1] и [5] избегают ухудшения тональных компонент в том, что они предлагают не заполнять малые спектральные дыры, все еще имеется необходимость, чтобы дополнительно улучшать качество аудиосигнала, кодированного с использованием заполнения шумом, особенно при очень низких битрейтах.
Имеются другие проблемы помимо описанных выше, которые проистекают из концепций заполнения шумом, известных до настоящего времени, согласно которым шум заполняется в спектр спектрально плоским способом.
Было бы предпочтительно иметь улучшенную концепцию заполнения шумом в наличии, которая увеличивает достижимое качество аудио, проистекающее из заполненного шумом спектра, по меньшей мере, в соединении с кодированием аудио с перцепционным преобразованием.
Соответственно, целью настоящего изобретения является обеспечить концепцию для заполнения шумом в кодировании аудио с перцепционным преобразованием с улучшенными характеристиками.
Эта цель достигается посредством сущности независимых пунктов формулы изобретения, содержащихся здесь, при этом предпочтительные аспекты настоящей заявки являются предметом зависимых пунктов формулы изобретения.
Является базовой находкой настоящей заявки, что заполнение шумом в аудиокодеках с перцепционным преобразованием может быть улучшено посредством выполнения заполнения шумом со спектрально глобальным наклоном, нежели спектрально плоским способом. Например, спектрально глобальный наклон может иметь отрицательный угловой коэффициент, то есть демонстрировать уменьшение от низких к высоким частотам, чтобы, по меньшей мере, частично обращать спектральный наклон, вызываемый подверганием заполненного шумом спектра спектральной перцепционной весовой функции. Положительный угловой коэффициент также может быть возможным, например, в случаях, когда кодированный спектр демонстрирует подобный высокочастотному характер. В частности, спектральные перцепционные весовые функции обычно имеют тенденцию демонстрировать увеличение от низких к высоким частотам. Соответственно, шум, заполняемый в спектр аудиокодеров с перцепционным преобразованием спектрально плоским способом, в конечном итоге дает минимальный уровень наклоненного шума в конечно восстановленном спектре. Изобретатели настоящей заявки, однако, осознали, что этот наклон в конечно восстановленном спектре отрицательно влияет на качество аудио, так как он ведет к спектральным дырам, остающимся в заполненных шумом частях спектра. Соответственно, вставка шума со спектрально глобальным наклоном, так что уровень шума уменьшается от низких к высоким частотам, по меньшей мере, частично компенсирует такой спектральный наклон, вызываемый последующим формированием заполненного шумом спектра с использованием спектральной перцепционной весовой функции, тем самым, улучшая качество аудио. В зависимости от обстоятельств, положительный угловой коэффициент может быть предпочтительным, как отмечено выше.
В соответствии с одним вариантом осуществления, угловой коэффициент спектрально глобального наклона изменяется в ответ на сигнализацию в потоке данных, в который спектр кодируется. Сигнализация может, например, явно сигнализировать крутизну и может адаптироваться, на стороне кодирования, к величине спектрального наклона, вызываемого спектральной перцепционной весовой функцией. Например, величина спектрального наклона, вызываемого спектральной перцепционной весовой функцией, может проистекать от предыскажения, которому аудиосигнал подвергается до применения анализа LPC на нем.
В соответствии с одним вариантом осуществления, заполнение шумом спектра аудиосигнала улучшается по качеству по отношению к заполненному шумом спектру даже дополнительно, так что воспроизведение заполненного шумом аудиосигнала является менее раздражающим, посредством выполнения заполнения шумом способом, зависящим от тональности аудиосигнала.
В соответствии с одним вариантом осуществления настоящей заявки, непрерывная спектральная нулевая часть спектра аудиосигнала заполняется шумом, спектрально сформированным с использованием функции, принимающей максимум во внутренней части непрерывной спектральной нулевой части, и имеющей спадающие кнаружи края, абсолютный угловой коэффициент которых отрицательно зависит от тональности, то есть угловой коэффициент уменьшается с увеличением тональности. Дополнительно или альтернативно, функция, используемая для заполнения, принимает максимум во внутренней части непрерывной спектральной нулевой части и имеет спадающие кнаружи края, спектральная ширина которых положительно зависит от тональности, то есть спектральная ширина увеличивается с увеличением тональности. Даже дополнительно, дополнительно или альтернативно, для заполнения может использоваться постоянная или унимодальная функция, интеграл которой - нормализованной к интегралу, равному 1 - по внешним четвертям непрерывной спектральной нулевой части отрицательно зависит от тональности, то есть интеграл уменьшается с увеличением тональности. Посредством всех из этих мер, заполнение шумом имеет тенденцию быть менее вредным для тональных частей аудиосигнала, однако, при этом является тем не менее эффективным для нетональных частей аудиосигнала в терминах уменьшения спектральных дыр. Другими словами, всякий раз, когда аудиосигнал имеет тональное содержимое, шум, заполняемый в спектр аудиосигнала, оставляет тональные пики спектра не затронутыми посредством поддержания достаточного расстояния от них, при этом, однако, нетональный характер временных фаз аудиосигнала с аудио-содержимым как нетональный тем не менее удовлетворяется заполнением шумом.
В соответствии с одним вариантом осуществления настоящей заявки, непрерывные спектральные нулевые части спектра аудиосигнала идентифицируются и идентифицированные нулевые части заполняются шумом, спектрально сформированным с помощью функций, так что для каждой непрерывной спектральной нулевой части соответствующая функция устанавливается в зависимости от ширины соответствующей непрерывной спектральной нулевой части и тональности аудиосигнала. Для легкости реализации, зависимость может достигаться посредством поиска в таблице поиска функций, или функции могут вычисляться аналитически с использованием математической формулы в зависимости от ширины непрерывной спектральной нулевой части и тональности аудиосигнала. В любом случае, усилие для реализации зависимости является относительно малым по сравнению с преимуществами, проистекающими от зависимости. В частности, зависимость может быть такой, что соответствующая функция устанавливается в зависимости от ширины непрерывной спектральной нулевой части, так что функция ограничивается соответствующей непрерывной спектральной нулевой частью, и в зависимости от тональности аудиосигнала, так что, для более высокой тональности аудиосигнала, масса функции становится более сосредоточенной во внутренней части соответствующей непрерывной спектральной нулевой части и отдаленной от краев соответствующей непрерывной спектральной нулевой части.
В соответствии с одним дополнительным вариантом осуществления, шум, спектрально формируемый и заполняемый в непрерывные спектральные нулевые части, обычно масштабируется с использованием спектрально глобального уровня заполнения шумом. В частности, шум масштабируется так, что интеграл по шуму в непрерывных спектральных нулевых частях или интеграл по функциям непрерывных спектральных нулевых частей соответствует, например, равен, глобальному уровню заполнения шумом. Предпочтительно, глобальный уровень заполнения шумом кодируется внутри существующих аудиокодеков в любом случае так, что никакой дополнительный синтаксис не должен обеспечиваться для таких аудиокодеков. То есть, глобальный уровень заполнения шумом может явно сигнализироваться в потоке данных, в который аудиосигнал кодируется, с малым усилием. В действительности, функции, с помощью которых шум непрерывной спектральной нулевой части спектрально формируется, могут масштабироваться так, что интеграл по шуму, с помощью которого все непрерывные спектральные нулевые части заполняются, соответствует глобальному уровню заполнения шумом.
В соответствии с одним вариантом осуществления настоящей заявки, тональность выводится из параметра кодирования, с использованием которого аудиосигнал кодируется. Посредством этой меры, никакая дополнительная информация не должна передаваться внутри существующего аудиокодека. В соответствии с конкретными вариантами осуществления, параметр кодирования является флагом или усилением LTP (долгосрочного предсказания), флагом активации или усилением TNS (временного формирования шума) и/или флагом активации перегруппировки спектра.
В соответствии с одним дополнительным вариантом осуществления, выполнение заполнения шумом ограничивается на высокочастотную спектральную часть, при этом низкочастотное начальное положение высокочастотной спектральной части устанавливается, соответствуя явной сигнализации в потоке данных, и в который аудиосигнал кодируется. Посредством этой меры, является возможной адаптивная к сигналу установка нижней границы высокочастотной спектральной части, в которой выполняется заполнение шумом. Посредством этой меры, в свою очередь, качество аудио, результирующее из заполнения шумом, может увеличиваться. Необходимая дополнительная сторонняя информация, в свою очередь, внесенная посредством явной сигнализации, является сравнительно малой.
Заполнение шумом может использоваться на стороне кодирования аудио и/или декодирования аудио. Когда используется на стороне кодирования аудио, заполненный шумом спектр может использоваться для целей анализа посредством синтеза.
В соответствии с одним вариантом осуществления, кодер определяет глобальный уровень масштабирования шума посредством учета зависимости от тональности.
Предпочтительные варианты осуществления настоящей заявки описываются ниже по отношению к фигурам, среди которых:
Фиг. 1А показывает блок-схему аудиокодера с перцепционным преобразованием в соответствии с одним вариантом осуществления;
Фиг. 1В показывает блок-схему аудиодекодера с перцепционным преобразованием в соответствии с одним вариантом осуществления;
Фиг. 1С показывает схематическую диаграмму, иллюстрирующую возможный способ достижения спектрально глобального наклона, вводимого в шум заполнения, в соответствии с одним вариантом осуществления;
Фиг. 2А показывает, выровненным по времени способом, одно над другим, сверху книзу, временной фрагмент из аудиосигнала, его спектрограмму с использованием схематически показанного спектрально-временного изменения "шкалы серого" спектральной энергии, и тональность аудиосигнала, для иллюстративных целей;
Фиг. 2В показывает блок-схему устройства заполнения шумом в соответствии с одним вариантом осуществления;
Фиг. 3 показывает схему спектра, подлежащего заполнению шумом, и функцию, используемую, чтобы спектрально формировать шум, используемый, чтобы заполнять непрерывную спектральную нулевую часть этого спектра, в соответствии с одним вариантом осуществления;
Фиг. 4 показывает схему спектра, подлежащего заполнению шумом, и функцию, используемую, чтобы спектрально формировать шум, используемый, чтобы заполнять непрерывную спектральную нулевую часть этого спектра, в соответствии с одним дополнительным вариантом осуществления;
Фиг. 5 показывает схему спектра, подлежащего заполнению шумом, и функцию, используемую, чтобы спектрально формировать шум, используемый, чтобы заполнять непрерывную спектральную нулевую часть этого спектра, в соответствии с одним еще дополнительным вариантом осуществления;
Фиг. 6 показывает блок-схему модуля заполнения шумом из фиг. 2 в соответствии с одним вариантом осуществления;
Фиг. 7 схематически показывает возможное отношение между определенной тональностью аудиосигнала с одной стороны и возможными функциями, доступными для спектрального формирования непрерывной спектральной нулевой части, с другой стороны в соответствии с одним вариантом осуществления;
Фиг. 8 схематически показывает спектр, подлежащий заполнению шумом, при этом дополнительно показывает функции, используемые, чтобы спектрально формировать шум для заполнения непрерывных спектральных нулевых частей спектра, чтобы проиллюстрировать то, как масштабировать уровень шума в соответствии с одним вариантом осуществления;
Фиг. 9 показывает блок-схему кодера, который может использоваться внутри аудиокодека, применяющего концепцию заполнения шумом, описанную по отношению к фиг. 1 по 8;
Фиг. 10 схематически показывает квантованный спектр, подлежащий заполнению шумом, как кодируется посредством кодера из фиг. 9 вместе с переданной сторонней информацией, именно коэффициентами масштабирования и глобальным уровнем шума, в соответствии с одним вариантом осуществления;
Фиг. 11 показывает блок-схему декодера, соответствующего кодеру из фиг. 9 и включающего в себя устройство заполнения шумом в соответствии с фиг. 2;
Фиг. 12 показывает схему спектрограммы с ассоциированными данными сторонней информации в соответствии с одним вариантом реализации кодера и декодера из фиг. 9 и 11;
Фиг. 13 показывает аудиокодер с преобразованием линейного предсказания, который может включаться в аудиокодек, использующий концепцию заполнения шумом из фиг. 1 по 8, в соответствии с одним вариантом осуществления;
Фиг. 14 показывает блок-схему декодера, соответствующего кодеру из фиг. 13;
Фиг. 15 показывает примеры фрагментов из спектра, подлежащего заполнению шумом;
Фиг. 16 показывает явный пример для функции для формирования шума, заполняемого в некоторую непрерывную спектральную нулевую часть спектра, подлежащего заполнению шумом, в соответствии с одним вариантом осуществления;
Фиг. 17А-D показывают различные примеры для функций для спектрального формирования шума, заполняемого в непрерывные спектральные нулевые части, для разных ширин нулевых частей и разных ширин переходов, используемых для разных тональностей.
Везде в последующем описании фигур, одинаковые ссылочные позиции используются для элементов, показанных на этих фигурах, описание, приведенное по отношению к одному элементу на одной фигуре, должно интерпретироваться как переносимое на элемент на другой фигуре, который указывается с использованием такой же ссылочной позиции. Посредством этой меры, обширное и повторяющееся описание избегается насколько возможно, тем самым, описание различных вариантов осуществления концентрируется на различиях друг между другом, нежели описываются все варианты осуществления снова сначала, снова и снова.
Фиг. 1А показывает аудиокодер с перцепционным преобразованием в соответствии с одним вариантом осуществления настоящей заявки, и фиг. 1b показывает аудиодекодер с перцепционным преобразованием в соответствии с одним вариантом осуществления настоящей заявки, оба соответствуют друг другу, чтобы формировать аудиокодек с перцепционным преобразованием.
Как показано на фиг. 1А, аудиокодер с перцепционным преобразованием содержит модуль 1 взвешивания спектра, сконфигурированный с возможностью спектрально взвешивать исходный спектр аудиосигнала, принимаемый модулем 1 взвешивания спектра, согласно обратной к перцепционной весовой функции спектрального взвешивания, определенной посредством модуля 1 взвешивания спектра предварительно определенным способом, для которого примеры показаны ниже. Модуль 1 спектрального взвешивания получает, посредством этой меры, взвешенный по восприятию спектр, который затем подвергается квантованию спектрально единообразным способом, то есть способом, одинаковым для спектральных линий, в модуле 2 квантования аудиокодера с перцепционным преобразованием. Результат, выводимый модулем 2 единообразного квантования, является квантованным спектром 34, который в заключение кодируется в поток данных, выводимый аудиокодером с перцепционным преобразованием.
Чтобы управлять заполнением шумом, подлежащим выполнению на стороне декодирования, чтобы улучшать спектр 34, по отношению к установке уровня шума, может необязательно присутствовать модуль 3 вычисления уровня шума аудиокодера с перцепционным преобразованием, который вычисляет параметр уровня шума посредством измерения уровня взвешенного по восприятию спектра 4 в частях 5, совместно расположенных с нулевыми частями 40 квантованного спектра 34. Таким образом, вычисленный параметр уровня шума также может кодироваться в вышеупомянутом потоке данных, чтобы прибывать в декодер.
Аудиодекодер с перцепционным преобразованием показан на фиг. 1В. Он содержит устройство 30 заполнения шумом, сконфигурированное с возможностью выполнять заполнение шумом над прибывающим спектром 34 аудиосигнала, как кодируется в поток данных, генерируемый посредством кодера из фиг. 1А, посредством заполнения спектра 34 с помощью шума, демонстрирующего спектрально глобальный наклон, так что уровень шума уменьшается от низких к высоким частотам, чтобы получать заполненный шумом спектр 36. Модуль формирования шума частотной области шума аудиодекодера с перцепционным преобразованием, показанный с использованием ссылочной позиции 6, сконфигурирован с возможностью подвергать заполненный шумом спектр спектральному формированию с использованием спектральной перцепционной весовой функции, полученной от стороны кодирования посредством потока данных, способом, описанным посредством конкретных примеров дополнительно ниже. Этот спектр, выводимый модулем 6 формирования шума частотной области, может передаваться в модуль 7 обратного преобразования, чтобы восстанавливать аудиосигнал во временной области и подобным образом, внутри аудиокодера с перцепционным преобразованием, модуль 8 преобразования может предшествовать модулю 1 взвешивания спектра, чтобы обеспечивать модуль 1 взвешивания спектра спектром аудиосигнала.
Смысл заполнения спектра 34 шумом 9, который демонстрирует спектрально глобальный наклон, является следующим: позже, когда заполненный шумом спектр 36 подвергается спектральному формированию посредством модуля 6 формирования шума частотной области, спектр 36 будет подвергаться наклоненной весовой функции. Например, спектр будет усиливаться на высоких частотах при сравнении с взвешиванием низких частот. То есть, уровень спектра 36 будет подниматься на более высоких частотах по отношению к более низким частотам. Это вызывает спектрально глобальный наклон с положительным угловым коэффициентом в исходно спектрально плоских частях спектра 36. Соответственно, если шум 9 будет заполняться в спектр 36, чтобы заполнять его нулевые части 40, спектрально плоским способом, то спектр, выводимый посредством FDNS 6, будет демонстрировать внутри этих частей 40 минимальный уровень шума, который имеет тенденцию увеличиваться от, например, низких к высоким частотам. То есть, при обследовании всего спектра или, по меньшей мере, части ширины полосы спектра, где заполнение шумом выполняется, можно видеть, что шум внутри частей 40 имеет тенденцию или функцию линейной регрессии с положительным угловым коэффициентом или отрицательным угловым коэффициентом. Так как устройство 30 заполнения шумом, однако, заполняет спектр 34 с помощью шума, демонстрирующего спектрально глобальный наклон положительного или отрицательного углового коэффициента, показанного как α на фиг. 1В, и который наклонен в противоположном направлении по сравнению с наклоном, вызываемым FDNS 9, спектральный наклон, вызываемый FDNS 6, компенсируется и минимальный уровень шума, таким образом, вводимый в конечно восстановленный спектр на выходе FDNS 6, является плоским или, по меньшей мере, более плоским, что, тем самым, увеличивает качество аудио посредством оставления менее глубоких дыр шума.
"Спектрально глобальный наклон" обозначает, что шум 9, заполняемый в спектр 34, имеет уровень, который имеет тенденцию уменьшаться (или увеличиваться) от низких к высоким частотам. Например, при размещении линии линейной регрессии через локальные максимумы шума 9, как заполняется, например, во взаимно спектрально отдаленные, непрерывные спектральные нулевые части 40, результирующая линия линейной регрессии имеет отрицательный (или положительный) угловой коэффициент α.
Хотя не обязательно, модуль вычисления уровня шума аудиокодера с перцепционным преобразованием может учитывать наклоненный способ заполнения шума в спектр 34 посредством измерения уровня взвешенного по восприятию спектра 4 в частях 5 способом, взвешенным со спектрально глобальным наклоном, имеющим, например, положительный угловой коэффициент в случае, когда α является отрицательным, и отрицательный угловой коэффициент, если α является положительным. Угловой коэффициент, применяемый модулем вычисления уровня шума, который показан как β на фиг. 1А, не должен быть таким же как упомянутый угловой коэффициент, применяемый на стороне декодирования, в отношении его абсолютного значения, но в соответствии с одним вариантом осуществления это может иметь место. Посредством этого, модуль 3 вычисления уровня шума является способным адаптировать уровень шума 9, вставляемого на стороне декодирования, более точно к уровню шума, который приближает исходный сигнал наилучшим способом и по всей спектральной ширине полосы.
Ниже будет описываться то, что может быть возможным управлять изменением углового коэффициента спектрально глобального наклона α посредством явной сигнализации в потоке данных или посредством неявной сигнализации в нем, например, устройство 30 заполнения шумом выводит крутизну из, например, самой спектральной перцепционной весовой функции или из переключения длины окна преобразования. Посредством упомянутого вывода, например, угловой коэффициент может адаптироваться к длине окна.
Имеются разные возможные способы, посредством которых устройство 30 заполнения шумом вызывает, чтобы шум 9 демонстрировал спектрально глобальный наклон. Фиг. 1С, например, иллюстрирует, что устройство 30 заполнения шумом выполняет умножение 11 по спектральным линиям между промежуточным сигналом 13 шума, представляющим промежуточное состояние в обработке заполнения шумом, и монотонно убывающей (или возрастающей) функцией 15, то есть функцией, которая монотонно спектрально убывает (или возрастает) по всему спектру или, по меньшей мере, части, где выполняется заполнение шумом, чтобы получать шум 9. Как проиллюстрировано на фиг. 1С, промежуточный сигнал 13 шума может быть уже спектрально сформированным. Детали в этом отношении относятся к конкретным вариантам осуществления, очерченным дополнительно ниже, согласно которым заполнение шумом также выполняется в зависимости от тональности. Спектральное формирование, однако, также может пропускаться или может выполняться после умножения 11. Сигнал параметра уровня шума и поток данных могут использоваться, чтобы устанавливать уровень промежуточного сигнала 13 шума, но альтернативно промежуточный сигнал шума может генерироваться с использованием стандартного уровня, применяя скалярный параметр уровня шума, чтобы масштабировать линию спектра после умножения 11. Монотонно убывающая функция 15 может, как проиллюстрировано на фиг. 1С, быть линейной функцией, кусочно-линейной функцией, полиномиальной функцией или любой другой функцией.
Как будет описываться более подробно ниже, является возможным адаптивно устанавливать часть всего спектра, внутри которой заполнение шумом выполняется посредством устройства 30 заполнения шумом.
В соединении с вариантами осуществления, очерченными дополнительно ниже, согласно которым непрерывные спектральные нулевые части в спектре 34, то есть спектральные дыры, заполняются конкретным неплоским и зависящим от тональности способом, будет описываться то, что имеются также альтернативы для умножения 11, проиллюстрированного на фиг. 1С, чтобы вызывать спектрально глобальный наклон, описанный до сих пор.
Последующее описание продолжается конкретными вариантами осуществления для выполнения заполнения шумом. Ниже, разные варианты осуществления представляются для различных аудиокодеков, где может встраиваться заполнение шумом, вместе с особенностями, которые могут применяться в соединении с соответствующим представленным аудиокодеком. Следует отметить, что заполнение шумом, описанное далее, может, в любом случае, выполняться на стороне декодирования. В зависимости от кодера, однако, заполнение шумом, как описано далее, также может выполняться на стороне кодирования, как, например, по причинам анализа посредством синтеза. Промежуточный случай, согласно которому модифицированный способ заполнения шумом в соответствии с вариантами осуществления, очерченными ниже, только частично изменяет способ работы кодера, как, например, чтобы определять спектрально глобальный уровень заполнения шумом, также описывается ниже.
Фиг. 2А показывает, для иллюстративных целей, аудиосигнал 10, то есть временное поведение его аудиовыборок, например, выровненную по времени спектрограмму 12 аудиосигнала, которая была выведена из аудиосигнала 10, по меньшей мере, среди прочего, посредством подходящего преобразования, такого как преобразование с перекрытиями, проиллюстрированного на 14 иллюстративно для двух последовательных окон 16 преобразования и ассоциированных спектров 18, которое, таким образом, представляет срез из спектрограммы 12 в момент времени, соответствующий середине ассоциированного окна 16 преобразования, например. Примеры для спектрограммы 12 и того, как она выводится, дополнительно представлены ниже. В любом случае, спектрограмма 12 подвергается некоторому типу квантования и, таким образом, имеет нулевые части, где спектральные значения, в которых спектрограмма 12 спектрально-временным образом дискретизирована, являются непрерывно нулевыми. Преобразование 14 с перекрытиями может, например, быть критически дискретизированным преобразованием, таким как MDCT. Окна 16 преобразования могут иметь перекрытие, равное 50%, друг с другом, но другие варианты осуществления также являются возможными. Дополнительно, спектрально-временное разрешение, при котором спектрограмма 12 дискретизируется в спектральные значения, может изменяться во времени. Другими словами, временное расстояние между последовательными спектрами 18 спектрограммы 12 может изменяться во времени, и то же применяется к спектральному разрешению каждого спектра 18. В частности, изменение во времени, в отношении временного расстояния между последовательными спектрами 18, может быть обратным к изменению спектрального разрешения спектров. Квантование использует, например, спектрально изменяющийся, адаптивный к сигналу размер шага квантования, изменяющийся, например, в соответствии с огибающей спектра LPC аудиосигнала, описываемой посредством коэффициентов LP, сигнализируемых в потоке данных, в который квантованные спектральные значения спектрограммы 12 со спектрами 18, подлежащими заполнению шумом, кодируются, или в соответствии с коэффициентами масштабирования, определяемыми, в свою очередь, в соответствии с психоакустической моделью, и сигнализируемыми в потоке данных.
Помимо этого, выровненным по времени способом фиг. 2А показывает характеристику аудиосигнала 10 и его временное изменение, именно тональность аудиосигнала. Вообще говоря, "тональность" указывает меру, описывающую то, как сконцентрирована энергия аудиосигнала в некоторой точке времени в соответствующем спектре 18, ассоциированном с этой точкой во времени. Если энергия рассеяна сильно, как, например, в зашумленных временных фазах аудиосигнала 10, то тональность является низкой. Но если энергия, по существу, сконцентрирована в одном или более спектральных пиках, то тональность является высокой.
Фиг. 2В показывает устройство 30 заполнения шумом, сконфигурированное с возможностью выполнять заполнение шумом над спектром аудиосигнала, в соответствии с одним вариантом осуществления настоящей заявки. Как будет описываться более подробно ниже, устройство сконфигурировано с возможностью выполнять заполнение шумом в зависимости от тональности аудиосигнала.
Устройство из фиг. 2В содержит модуль 32 заполнения шумом и модуль 34 определения тональности, который является необязательным.
Фактическое заполнение шумом выполняется посредством модуля 32 заполнения шумом. Модуль 32 заполнения шумом принимает спектр, к которому заполнение шумом должно применяться. Этот спектр проиллюстрирован на фиг. 2В как разреженный спектр 34. Разреженный спектр 34 может быть спектром 18 из спектрограммы 12. Спектры 18 входят в модуль 32 заполнения шумом последовательно. Модуль 32 заполнения шумом подвергает спектр 34 заполнению шумом и выводит "заполненный спектр" 36. Модуль 32 заполнения шумом выполняет заполнение шумом в зависимости от тональности аудиосигнала, как, например, тональности 20 из фиг. 2А. В зависимости от обстоятельств, тональность может не быть напрямую доступной. Например, существующие аудиокодеки не обеспечивают явную сигнализацию тональности аудиосигнала в потоке данных, так что если устройство 30 установлено на стороне декодирования, не будет возможным восстанавливать тональность без высокой степени ложной оценки. Например, спектр 34 может, вследствие его разреженности и/или из-за его адаптивного к сигналу изменяющегося квантования, не быть оптимальной основой для оценки тональности.
Соответственно, задачей модуля 34 определения тональности является обеспечивать модуль 32 заполнения шумом оценкой тональности на основе другого указания 38 тональности, как будет описываться более подробно ниже. В соответствии с вариантами осуществления, описанными ниже, указание 38 тональности может быть доступным на сторонах кодирования и декодирования в любом случае, посредством соответствующего параметра кодирования, передаваемого внутри потока данных аудиокодека, внутри которого устройство 30, например, используется. На фиг. 1В, устройство 30 используется на стороне декодирования, но альтернативно устройство 30 может использоваться на стороне кодирования также, как, например, в контуре обратной связи предсказания кодера из фиг. 1А, если присутствует.
Фиг. 3 показывает пример для разреженного спектра 34, то есть квантованного спектра, имеющего непрерывные части 40 и 42, состоящие из последовательностей спектрально соседних спектральных значений спектра 34, которые квантованы в нуль. Непрерывные части 40 и 42 являются, таким образом, спектрально раздельными или отдаленными друг от друга посредством, по меньшей мере, одной не квантованной в нуль спектральной линии в спектре 34.
Зависимость от тональности для заполнения шумом, в общем, описанного выше по отношению к фиг. 2В, может осуществляться следующим образом. Фиг. 3 показывает временную часть 44, включающую в себя непрерывную спектральную нулевую часть 40, увеличенную на 46. Модуль 32 заполнения шумом сконфигурирован с возможностью заполнять эту непрерывную спектральную нулевую часть 40 способом, зависящим от тональности аудиосигнала, во время, которому спектр 34 принадлежит. В частности, модуль 32 заполнения шумом заполняет непрерывную спектральную нулевую часть шумом, спектрально сформированным с использованием функции, принимающей максимум во внутренней части непрерывной спектральной нулевой части, и имеющей спадающие кнаружи края, абсолютный угловой коэффициент которых отрицательно зависит от тональности. Фиг. 3 иллюстративно показывает две функции 48 для двух разных тональностей. Обе функции являются "унимодальными", то есть принимают абсолютный максимум во внутренней части непрерывной спектральной нулевой части 40 и имеют всего только локальный максимум, который может быть плато или одиночной спектральной частотой. Здесь, локальный максимум принимается функциями 48 и 50 непрерывно над простирающимся интервалом 52, то есть плато, расположенное в центре нулевой части 40. Областью определения функций 48 и 50 является нулевая часть 40. Центральный интервал 52 покрывает только центральную часть нулевой части 40 и граничит сбоку с краевой частью 54 на стороне более высокой частоты интервала 52, и с краевой частью 56 более низкой частоты на стороне более низкой частоты интервала 52. Внутри краевой части 54, функции 48 и 52 имеют спадающий край 58, и внутри краевой части 56, поднимающийся край 60. Абсолютный угловой коэффициент может приписываться каждому краю 58 и 60, соответственно, как, например, средний угловой коэффициент внутри краевой части 54 и 56, соответственно. То есть, угловой коэффициент, приписанный спадающему краю 58, может быть средним угловым коэффициентом соответствующей функции 48 и 52, соответственно, внутри краевой части 54, и угловой коэффициент, приписанный поднимающемуся краю 60, может быть средним угловым коэффициентом функции 48 и 52, соответственно, внутри краевой части 56.
Как можно видеть, абсолютное значение углового коэффициента краев 58 и 60 является более высоким для функции 50, чем для функции 48. Модуль 32 заполнения шумом выбирает заполнять нулевую часть 40 с помощью функции 50 для тональностей, более низких, чем тональности, для которых модуль 32 заполнения шумом выбирает использовать функцию 48 для заполнения нулевой части 40. Посредством этой меры, модуль 32 заполнения шумом избегает кластеризации непосредственной периферии потенциально тональных спектральных пиков спектра 34, как, например, пика 62. Чем меньше абсолютный угловой коэффициент краев 58 и 60, тем дальше шум, заполняемый в нулевую часть 40, находится от ненулевых частей спектра 34, окружающих нулевую часть 40.
Модуль 32 заполнения шумом может, например, осуществлять выбор, чтобы выбирать функцию 48 в случае тональности аудиосигнала, равной τ2, и функцию 50 в случае тональности аудиосигнала, равной τ1, но описание, приведенное дополнительно ниже, показывает, что модуль 32 заполнения шумом может различать больше, чем два разных состояния тональности аудиосигнала, то есть может поддерживать более, чем две разных функции 48, 50 для заполнения некоторой непрерывной спектральной нулевой части и выбирать между ними в зависимости от тональности посредством сюръективного отображения из тональностей в функции.
В качестве незначительного замечания, следует отметить, что конструкция функций 48 и 50, согласно которой они имеют плато во внутреннем интервале 52, к которому примыкают края 58 и 60, чтобы давать результатом унимодальные функции, является только примером. Альтернативно, могут использоваться функции в форме колокола, например, в соответствии с альтернативой. Интервал 52 может альтернативно определяться как интервал, внутри которого функция является более высокой, чем 95% от ее максимального значения.
Фиг. 4 показывает альтернативу для изменения функции, используемой, чтобы спектрально формировать шум, с помощью которого некоторая непрерывная спектральная нулевая часть 40 заполняется посредством модуля 32 заполнения шумом, от тональности. В соответствии с фиг. 4, изменение имеет отношение к спектральной ширине краевых частей 54 и 56 и спадающим кнаружи краям 58 и 60, соответственно. Как показано на фиг. 4, в соответствии с примером из фиг. 4, угловой коэффициент краев 58 и 60 может даже быть независимым от, то есть не изменяться в соответствии с, тональности. В частности, в соответствии с примером из фиг. 4, модуль 32 заполнения шумом устанавливает функцию, с использованием которой спектрально формируется шум для заполнения нулевой части 40, так что спектральная ширина спадающих кнаружи краев 58 и 60 положительно зависит от тональности, то есть для более высоких тональностей, используется функция 48, для которой спектральная ширина спадающих кнаружи краев 58 и 60 является более большой, и для более низких тональностей, используется функция 50, для которой спектральная ширина спадающих кнаружи краев 58 и 60 является более малой.
Фиг. 4 показывает другой пример изменения функции, используемой посредством модуля 32 заполнения шумом для спектрального формирования шума, с помощью которого непрерывная спектральная нулевая часть 40 заполняется: здесь, характеристика функции, которая изменяется с тональностью, является интегралом по внешним четвертям нулевой части 40. Чем более высокой является тональность, тем более большим является интервал. Перед определением интервала, полный интервал функции по полной нулевой части 40 выравнивается/нормализуется, как, например, к 1.
Для описания этого, см. фиг. 5. Непрерывная спектральная нулевая часть 40 показана как разделенная на четыре четверти a, b, c, d равного размера, среди которых четверти a и d являются внешними четвертями. Как можно видеть, обе функции 50 и 48 имеют их центр масс во внутренней части, здесь иллюстративно в середине нулевой части 40, но обе из них простираются из внутренних четвертей b, c во внешние четверти a и d. Перекрывающая часть функций 48 и 50, перекрывающая внешние четверти a и d, соответственно, показана просто затененной.
На фиг. 5, обе функции имеют один и тот же интеграл по всей нулевой части 40, то есть по всем четырем четвертям a, b, c, d. Интеграл, например, нормализован к 1.
В этой ситуации, интеграл функции 50 по четвертям a, d является более большим, чем интеграл функции 48 по четвертям a, d и соответственно, модуль 32 заполнения шумом использует функцию 50 для более высоких тональностей и функцию 48 для более низких тональностей, то есть интеграл по внешним четвертям нормализованных функций 50 и 48 отрицательно зависит от тональности.
Для иллюстративных целей, в случае фиг. 5 обе функции 48 и 50 были иллюстративно показаны как постоянные или двоичные функции. Функция 50, например, является функцией, принимающей постоянное значение во всей области определения, то есть всей нулевой части 40, и функция 48 является двоичной функцией, равной нулю на внешних краях нулевой части 40, и принимающей ненулевое постоянное значение между ними. Должно быть ясно, что, вообще говоря, функции 50 и 48 в соответствии с примером из фиг. 5 могут быть любой постоянной или унимодальной функцией, как, например, функциями, соответствующими функциям, показанным на фиг. 3 и 4. Чтобы быть еще более точными, по меньшей мере, одна может быть унимодальной и, по меньшей мере, одна (кусочно-) постоянной и потенциально дополнительная одна какой-либо одной из унимодальной или постоянной.
Хотя тип изменения функций 48 и 50 в зависимости от тональности изменяется, все примеры из фиг. 3 по 5 имеют, в общем, то, что, для увеличения тональности, степень размытия непосредственного окружения тональных пиков в спектре 34 уменьшается или избегается, так что качество заполнения шумом увеличивается, так как заполнение шумом не влияет отрицательно на тональные фазы аудиосигнала и, тем не менее, это дает результатом приятное приближение нетональных фаз аудиосигнала.
До сих пор описание из фиг. 3 по 5 фокусировалось на заполнении одной непрерывной спектральной нулевой части. В соответствии с вариантом осуществления из фиг. 6, устройство из фиг. 2В сконфигурировано с возможностью идентифицировать непрерывные спектральные нулевые части спектра аудиосигнала и применять заполнение шумом на непрерывных спектральных нулевых частях, таким образом, идентифицированных. В частности, фиг. 6 показывает модуль 32 заполнения шумом из фиг. 2В более подробно, как содержащий модуль 70 идентификации нулевых частей и модуль 72 заполнения нулевых частей. Модуль идентификации нулевых частей осуществляет поиск в спектре 34 непрерывных спектральных нулевых частей, таких как 40 и 42 на фиг. 3. Как уже описано выше, непрерывные спектральные нулевые части могут определяться как последовательности спектральных значений, которые были квантованы в нуль. Модуль 70 идентификации нулевых частей может быть сконфигурирован с возможностью ограничивать идентификацию на высокочастотную спектральную часть спектра аудиосигнала, начинающуюся с, то есть лежащую выше, некоторой начальной частоты. Соответственно, устройство может быть сконфигурировано с возможностью ограничивать выполнение заполнения шумом на такую высокочастотную спектральную часть. Начальная частота, выше которой модуль 70 идентификации нулевых частей выполняет идентификацию непрерывных спектральных нулевых частей, и выше которой устройство сконфигурировано с возможностью ограничивать выполнение заполнения шумом, может быть фиксированной или может изменяться. Например, явная сигнализация в потоке данных аудиосигнала, в который аудиосигнал кодируется посредством его спектра, может использоваться, чтобы сигнализировать начальную частоту, подлежащую использованию.
Модуль 72 заполнения нулевых частей сконфигурирован с возможностью заполнять идентифицированные непрерывные спектральные нулевые части, идентифицированные посредством модуля 70 идентификации, шумом, спектрально сформированным в соответствии с некоторой функцией, как описано выше по отношению к фиг. 3, 4 или 5. Соответственно, модуль 72 заполнения нулевых частей заполняет непрерывные спектральные нулевые части, идентифицированные посредством модуля 70 идентификации, с помощью набора функций в зависимости от ширины соответствующей непрерывной спектральной нулевой части, как, например, количества спектральных значений, которые были квантованы в нуль из последовательности квантованных в нуль спектральных значений соответствующей непрерывной спектральной нулевой части, и тональности аудиосигнала.
В частности, индивидуальное заполнение каждой непрерывной спектральной нулевой части, идентифицированной посредством модуля 70 идентификации, может выполняться посредством модуля 72 заполнения следующим образом: функция устанавливается в зависимости от ширины непрерывной спектральной нулевой части, так что функция ограничивается соответствующей непрерывной спектральной нулевой частью, то есть область определения функции совпадает с шириной непрерывной спектральной нулевой части. Установка функции дополнительно зависит от тональности аудиосигнала, именно способом, описанным выше по отношению к фиг. 3 по 5, так что если тональность аудиосигнала увеличивается, масса функции становится более сосредоточенной во внутренней части соответствующей непрерывной нулевой части и отдаленной от краев соответствующей непрерывной спектральной нулевой части. С использованием этой функции, предварительно заполненное состояние непрерывной спектральной нулевой части, согласно которому каждое спектральное значение устанавливается на случайное, псевдослучайное или обеспечиваемое заплатой/скопированное значение, спектрально формируется, именно посредством умножения функции на предварительные спектральные значения.
Было уже очерчено выше, что зависимость заполнения шумом от тональности может различать между более, чем только двумя разными тональностями, как, например, 3, 4 или даже более чем 4. Фиг. 7, например, показывает область возможных тональностей, то есть интервал возможных значений между тональностями, как определяется посредством модуля 34 определения на ссылочной позиции 74. На 76, фиг. 7 иллюстративно показывает набор возможных функций, используемых для спектрального формирования шума, с помощью которого непрерывные спектральные нулевые части могут заполняться. Набор 76, как проиллюстрировано на фиг. 7, является набором экземпляров дискретных функций, взаимно отличающихся друг от друга посредством спектральной ширины или длины области определения и/или формы, то есть сосредоточенностью и расстоянием от внешних краев. На 78, фиг. 7 дополнительно показывает область возможных ширин нулевых частей. В то время как интервал 78 является интервалом дискретных значений, находящихся в диапазоне от некоторой минимальной ширины до некоторой максимальной ширины, значения тональности, выводимые посредством модуля 34 определения, чтобы измерять тональность аудиосигнала, могут либо быть целочисленными, либо некоторого другого типа, как, например, значениями с плавающей точкой. Отображение из пары интервалов 74 и 78 в набор возможных функций 76 может реализовываться посредством поиска в таблице или с использованием математической функции. Например, для некоторой непрерывной спектральной нулевой части, идентифицированной посредством модуля 70 идентификации, модуль 72 заполнения нулевых частей может использовать ширину соответствующей непрерывной спектральной нулевой части и текущую тональность, как определяется посредством модуля 34 определения, чтобы осуществлять поиск в таблице функции из набора 76, определенной, например, как последовательность значений функции, при этом длина последовательности совпадает с шириной непрерывной спектральной нулевой части. Альтернативно, модуль 72 заполнения нулевых частей ищет параметры функции и заполняет эти параметры функции в предварительно определенную функцию, чтобы выводить функцию, подлежащую использованию для спектрального формирования шума, подлежащего заполнению в соответствующую непрерывную спектральную нулевую часть. В другой альтернативе, модуль 72 заполнения нулевых частей может напрямую вставлять ширину соответствующей непрерывной спектральной нулевой части и текущую тональность в математическую формулу, чтобы получать параметры функции, чтобы строить соответствующую функцию в соответствии с математически вычисленным параметром функции.
До сих пор, описание некоторых вариантов осуществления настоящей заявки фокусировалось на форме функции, используемой, чтобы спектрально формировать шум, с помощью которого некоторые непрерывные спектральные нулевые части заполняются. Является предпочтительным, однако, управлять полным уровнем шума, добавляемого к некоторому спектру, подлежащему заполнению шумом, чтобы давать результатом приятное восстановление, или чтобы даже спектрально управлять уровнем введения шума.
Фиг. 8 показывает спектр, подлежащий заполнению шумом, где части, не квантованные в нуль, и соответственно, не подлежащие заполнению шумом, показаны поперечно-заштрихованными, при этом три непрерывных спектральных нулевых части 90, 92 и 94 показаны в предварительно заполненном состоянии, что проиллюстрировано посредством того, что нулевые части имеют вписанные в них выбранные функции для спектрального формирования шума, заполняемого в эти части 90-94, без учета масштаба.
В соответствии с одним вариантом осуществления, доступный набор функций 48, 50 для спектрального формирования шума, подлежащего заполнению в части 90-94, все имеют предварительно определенный масштаб, который известен кодеру и декодеру. Спектрально глобальный коэффициент масштабирования сигнализируется явно внутри потока данных, в который аудиосигнал, то есть неквантованная часть спектра, кодируется. Этот коэффициент показывает, например, RMS или другую меру для уровня шума, то есть случайные или псевдослучайные значения спектральных линий, с помощью которых части 90-94 предварительно устанавливаются на стороне декодирования, при этом затем спектрально формируются с использованием выбранных в зависимости от тональности функций 48, 50, такими, какими они являются. То, как глобальный коэффициент масштабирования шума может определяться на стороне кодера, описывается дополнительно ниже. Пусть, например, A будет набором индексов i спектральных линий, где спектр квантуется в нуль и которые принадлежат любой из частей 90-94, и пусть N обозначает глобальный коэффициент масштабирования шума. Значения спектра будут обозначаться xi. Дополнительно, "random(N)" обозначает функцию, дающую случайное значение уровня, соответствующего уровню "N", и left(i) является функцией, показывающей для любого квантованного в нуль спектрального значения с индексом i индекс квантованного в нуль значения на низкочастотном конце нулевой части, которой i принадлежит, и Fi(j), где j=0 до Ji-1 обозначает функцию 48 или 50, назначаемую, в зависимости от тональности, нулевой части 90-94, начиная с индекса i, где Ji обозначает ширину этой нулевой части. Тогда, части 90-94 заполняются согласно xi=Fleft(i)(i-left(i))⋅random(N).
Дополнительно, заполнением шума в части 90-94, можно управлять так, чтобы уровень шума уменьшался от низких к высоким частотам. Это может делаться посредством спектрального формирования шума, с помощью которого части предварительно устанавливаются, или спектрального формирования компоновки функций 48, 50 в соответствии с передаточной функцией низкочастотного фильтра. Это может компенсировать спектральный наклон, вызываемый при изменении масштаба/деквантовании заполненного спектра вследствие, например, предыскажения, используемого в определении спектрального поведения размера шага квантования. Соответственно, крутизной уменьшения или передаточной функцией низкочастотного фильтра можно управлять согласно степени примененного предыскажения. Применяя терминологию, использованную выше, части 90-94 могут заполняться согласно xi=Fleft(i)(i-left(i))⋅random(N)⋅LPF(i), где LPF(i) обозначает передаточную функцию низкочастотного фильтра, которая может быть линейной. В зависимости от обстоятельств, функция LPF, которая соответствует функции 15, может иметь положительный угловой коэффициент и LPF изменяться, чтобы читаться как HPF соответственно.
Вместо использования фиксированного масштабирования функций, выбираемых в зависимости от тональности и ширины нулевой части, только что описанная коррекция спектрального наклона может напрямую учитываться посредством использования спектрального положения соответствующей непрерывной нулевой части также в качестве индекса в поиске или другого определения 80 функции, подлежащей использованию для спектрального формирования шума, с помощью которого соответствующая непрерывная спектральная нулевая часть должна заполняться. Например, среднее значение функции или ее предварительное масштабирование, используемое для спектрального формирования шума, подлежащего заполнению в некоторую нулевую часть 90-94, может зависеть от спектрального положения нулевой части 90-94 так, чтобы, по всей ширине полосы спектра, функции, используемые для непрерывных спектральных нулевых частей 90-94, предварительно масштабировались, чтобы эмулировать передаточную функцию низкочастотного фильтра, чтобы компенсировать любую передаточную функцию высокочастотного предыскажения, используемую, чтобы выводить квантованные не в нуль части спектра.
В заключение, следует отметить, что, в то время как фиг. 8 иллюстративно указывает на вариант осуществления с использованием заполнения спектрально сформированным шумом непрерывных спектральных нулевых частей, он может альтернативно модифицироваться, чтобы указывать на варианты осуществления, не использующие заполнение спектрально сформированным шумом, но заполнение непрерывных спектральных нулевых частей спектрально плоским способом, например. Таким образом, части 90-94 будут тогда заполняться согласно xi=LPF(i)⋅random(N).
После описания вариантов осуществления для выполнения заполнения шумом, в последующем представлены варианты осуществления для аудиокодеков, где заполнение шумом, очерченное выше, может предпочтительно встраиваться. Фиг. 9 и 10, например, показывают пару кодера и декодера, соответственно, вместе осуществляющую основывающийся на преобразовании перцепционный аудиокодек типа, формирующего основу, например, для AAC (усовершенствованного кодирования аудио). Кодер 100, показанный на фиг. 9, подвергает исходный аудиосигнал 102 преобразованию в модуле 104 преобразования. Преобразование, выполняемое посредством модуля 104 преобразования является, например, преобразованием с перекрытиями, которое соответствует преобразованию 14 из фиг. 1: оно спектрально разлагает прибывающий исходный аудиосигнал 102 посредством преобразования последовательных, взаимно перекрывающихся окон преобразования исходного аудиосигнала в последовательность спектров 18, вместе составляющих спектрограмму 12. Как обозначено выше, заплата между окнами преобразования, которая определяет временное разрешение спектрограммы 12, может изменяться во времени, точно так же как может делаться с временной длиной окон преобразования, что определяет спектральное разрешение каждого спектра 18. Кодер 100 дополнительно содержит модуль 106 перцепционного моделирования, который выводит из исходного аудиосигнала, на основе версии временной области, входящей в модуль 104 преобразования, или спектрально разложенной версии, выводимой посредством модуля 104 преобразования, перцепционный порог маскирования, определяющий спектральную кривую, ниже которой шум квантования может быть скрыт, так что он не является воспринимаемым.
Представление по спектральным линиям аудиосигнала, то есть спектрограмма 12, и порог маскирования входят в модуль 108 квантования, который является ответственным за квантование спектральных выборок спектрограммы 12 с использованием спектрально изменяющегося размера шага квантования, который зависит от порога маскирования: чем более большим является порог маскирования, тем более малым является размер шага квантования. В частности, модуль 108 квантования информирует сторону декодирования об изменении размера шага квантования в форме так называемых коэффициентов масштабирования, которые, посредством только что описанного отношения между размером шага квантования с одной стороны и перцепционным порогом маскирования с другой стороны, представляют тип представления самого перцепционного порога маскирования. Чтобы находить хороший компромисс между величиной сторонней информации, подлежащей использованию для передачи коэффициентов масштабирования стороне декодирования, и гранулярностью адаптации шума квантования к перцепционному порогу маскирования, модуль 108 квантования устанавливает/изменяет коэффициенты масштабирования в спектрально-временном разрешении, которое является более низким, чем, или более грубым, чем, спектрально-временное разрешение, при котором квантованные спектральные уровни описывают представление по спектральным линиям спектрограммы 12 аудиосигнала. Например, модуль 108 квантования подразделяет каждый спектр на диапазоны 110 коэффициентов масштабирования, как, например, диапазоны барков, и передает один коэффициент масштабирования в расчете на диапазон 110 коэффициентов масштабирования. Что касается временного разрешения, то оно также может быть более низким в отношении передачи коэффициентов масштабирования, по сравнению со спектральными уровнями спектральных значений спектрограммы 12.
Оба спектральных уровня спектральных значений спектрограммы 12, также как коэффициенты 112 масштабирования передаются в сторону декодирования. Однако, чтобы улучшать качество аудио, кодер 100 передает внутри потока данных также глобальный уровень шума, который сигнализирует в сторону декодирования уровень шума, вплоть до которого квантованные в нуль части представления 12 должны заполняться шумом до изменения масштаба, или деквантования, спектра посредством применения коэффициентов 112 масштабирования. Это показано на фиг. 10. Фиг. 10 показывает, с использованием поперечной штриховки, спектр аудиосигнала с еще не измененным масштабом, такой как 18 на фиг. 9. Он имеет непрерывные спектральные нулевые части 40a, 40b, 40c и 40d. Глобальный уровень 114 шума, который также может передаваться в потоке данных для каждого спектра 18, показывает декодеру уровень, вплоть до которого эти нулевые части 40a по 40d должны заполняться шумом до подвергания этого заполненного спектра изменению масштаба или повторному квантованию с использованием коэффициентов 112 масштабирования.
Как уже обозначено выше, заполнение шумом, на которое указывает глобальный уровень 114 шума, может подвергаться ограничению в том, что этот тип заполнения шумом указывает только на частоты выше некоторой начальной частоты, которая показана на фиг. 10 только для иллюстративных целей как fstart.
Фиг. 10 также иллюстрирует другой конкретный признак, который может осуществляться в кодере 100: так как могут иметься спектры 18, содержащие диапазоны 110 коэффициентов масштабирования, где все спектральные значения внутри соответствующих диапазонов коэффициентов масштабирования были квантованы в нуль, коэффициент 112 масштабирования, ассоциированный с таким диапазоном коэффициентов масштабирования, является фактически излишним. Соответственно, модуль 100 квантования использует этот самый коэффициент масштабирования для индивидуального заполнения диапазона коэффициентов масштабирования шумом в дополнение к шуму, заполняемому в диапазон коэффициентов масштабирования с использованием глобального уровня 114 шума, или в других терминах, чтобы масштабировать шум, приписанный соответствующему диапазону коэффициентов масштабирования, в ответ на глобальный уровень 114 шума. См., например, фиг. 10. Фиг. 10 показывает иллюстративное подразделение спектра 18 на диапазоны 110a по 110h коэффициентов масштабирования.
Диапазон 110e коэффициентов масштабирования является диапазоном коэффициентов масштабирования, спектральные значения которого все были квантованы в нуль. Соответственно, ассоциированный коэффициент 112 масштабирования является "свободным" и используется, чтобы определять 114 уровень шума, вплоть до которого этот диапазон коэффициентов масштабирования заполняется полностью. Другие диапазоны коэффициентов масштабирования, которые содержат спектральные значения, квантованные в ненулевые уровни, имеют коэффициенты масштабирования, ассоциированные с ними, которые используются, чтобы изменять масштаб спектральных значений спектра 18, не квантованных в нуль, включая сюда шум, с использованием которого нулевые части 40a по 40d заполняются, при этом это масштабирование показано с использованием стрелки 116, иллюстративно.
Кодер 100 из фиг. 9 может уже учитывать, что внутри стороны декодирования заполнение шумом с использованием глобального уровня 114 шума будет выполняться с использованием вариантов осуществления заполнения шумом, описанных выше, например, с использованием зависимости от тональности и/или наложения спектрально глобального наклона на шум и/или изменения начальной частоты заполнения шумом и так далее.
В отношении зависимости от тональности, кодер 100 может определять глобальный уровень 114 шума, и вставлять его в поток данных, посредством ассоциирования с нулевыми частями 40a по 40d функции для спектрального формирования шума для заполнения соответствующей нулевой части. В частности, кодер может использовать эти функции, чтобы взвешивать исходные, то есть взвешенные, но еще не квантованные, спектральные значения аудиосигнала в этих частях 40a по 40d, чтобы определять глобальный уровень 114 шума. Тем самым, глобальный уровень 114 шума, определенный и передаваемый внутри потока данных, ведет к заполнению шумом на стороне декодирования, которая более близко восстанавливает спектр исходного аудиосигнала.
Кодер 100 может, в зависимости от содержимого аудиосигнала, принимать решение в отношении использования некоторых вариантов выбора кодирования, которые, в свою очередь, могут использоваться в качестве указаний тональности, таких как указание 38 тональности, показанное на фиг. 2, чтобы обеспечивать возможность стороне декодирования корректно устанавливать функцию для спектрального формирования шума, используемого, чтобы заполнять части 40a по 40d. Например, кодер 100 может использовать временное предсказание, чтобы предсказывать один спектр 18 из предыдущего спектра с использованием так называемого параметра усиления долгосрочного предсказания. Другими словами, усиление долгосрочного предсказания может устанавливать степень, вплоть до которой такое временное предсказание используется или нет. Соответственно, усиление долгосрочного предсказания, или усиление LTP, является параметром, который может использоваться в качестве указания тональности, так как чем более высоким является усиление LTP, тем более высокой скорее всего будет тональность аудиосигнала. Таким образом, модуль 34 определения тональности из фиг. 2, например, может устанавливать тональность согласно монотонной положительной зависимости от усиления LTP. Вместо, или в дополнение к, усилению LTP, поток данных может содержать флаг активации LTP, сигнализирующий включение/выключение LTP, тем самым, также показывая двухзначное указание, касающееся тональности, например.
Дополнительно или альтернативно, кодер 100 может поддерживать временное формирование шума. То есть, на основе в расчете на спектр 18, например, кодер 100 может выбирать подвергать спектр 18 временному формированию шума с помощью индикации этого решения в декодер с использованием флага активации временного формирования шума. Флаг активации TNS указывает, формируют ли спектральные уровни спектра 18 остаток предсказания спектрального, то есть вдоль определенного направления частоты, линейного предсказания спектра, или спектр не является предсказанным на основе LP. Если сигнализируется, что TNS активировано, поток данных дополнительно содержит коэффициенты линейного предсказания для спектрально линейного предсказания спектра, так что декодер может восстанавливать спектр с использованием этих коэффициентов линейного предсказания посредством применения их на спектре до или после изменения масштаба или деквантования. Флаг активации TNS также является указанием тональности: если флаг активации TNS сигнализирует, что TNS должно быть включено, например, на неустановившемся состоянии, то аудиосигнал очень маловероятно является тональным, так как спектр кажется должен быть хорошо предсказуемым посредством линейного предсказания вдоль частотной оси и, следовательно, нестационарным. Соответственно, тональность может определяться на основе флага активации TNS, так что тональность является более высокой, если флаг активации TNS деактивирует TNS, и является более низкой, если флаг активации TNS сигнализирует активацию TNS. Вместо, или в дополнение к, флагу активации TNS, может являться возможным выводить из коэффициентов фильтра TNS усиление TNS, показывающее степень, вплоть до которой TNS может использоваться для предсказания спектра, тем самым, также показывая более, чем двухзначное указание, касающееся тональности.
Другие параметры кодирования также могут кодироваться внутри потока данных посредством кодера 100. Например, флаг активации спектральной перегруппировки может сигнализировать один вариант выбора кодирования, согласно которому спектр 18 кодируется посредством перегруппировки спектральных уровней, то есть квантованных спектральных значений, спектрально с дополнительной передачей внутри потока данных предписания перегруппировки, так что декодер может перегруппировать, или повторно скремблировать, спектральные уровни, чтобы восстанавливать спектр 18. Если флаг активации перегруппировки спектра активирован, то есть применяется перегруппировка спектра, это показывает, что аудиосигнал является скорей всего тональным, так как перегруппировка имеет тенденцию быть более эффективной по отношению к скорости/искажению в сжатии потока данных, если имеется много тональных пиков внутри спектра. Соответственно, дополнительно или альтернативно, флаг активации перегруппировки спектра может использоваться в качестве тонального указания, и тональность, используемая для заполнения шумом, может устанавливаться более большой в случае, когда флаг активации перегруппировки спектра активирован, и более низкой, если флаг активации компоновки спектра является деактивированным.
Ради полноты, и также как показано на фиг. 2В, следует отметить, что количество разных функций для спектрального формирования нулевой части 40a по 40d, то есть количество разных тональностей, различаемых для установки функции для спектрального формирования, может, например, быть более большим, чем четыре, или даже более большим, чем восемь, по меньшей мере, для ширин непрерывных спектральных нулевых частей выше предварительно определенной минимальной ширины.
В отношении концепции наложения спектрально глобального наклона на шум и учета его при вычислении параметра уровня шума на стороне кодирования, кодер 100 может определять глобальный уровень 114 шума, и вставлять его в поток данных, посредством взвешивания частей еще не квантованных, но с взвешенными с помощью обратной к перцепционной весовой функции спектральными значениями аудиосигнала, спектрально совместно расположенными с нулевыми частями 40a по 40d, с помощью функции, спектрально простирающейся, по меньшей мере, над всей частью заполнения шумом ширины полосы спектра и имеющей угловой коэффициент противоположного знака относительно функции 15, используемой на стороне декодирования для заполнения шумом, например, и измерения уровня на основе, таким образом, взвешенных неквантованных значений.
Фиг. 11 показывает декодер, соответствующий кодеру из фиг. 9. Декодер из фиг. 11, в общем, показан с использованием ссылочной позиции 130 и содержит модуль 30 заполнения шумом, соответствующий вышеописанным вариантам осуществления, модуль 132 деквантования и модуль 134 обратного преобразования. Модуль 30 заполнения шумом принимает последовательность спектров 18 внутри спектрограммы 12, то есть представление по спектральным линиям, включающее в себя квантованные спектральные значения, и, необязательно, указания тональности из потока данных, такие как один или несколько из параметров кодирования, описанных выше. Модуль 30 заполнения шумом затем заполняет непрерывные спектральные нулевые части 40a по 40d с помощью шума, как описано выше, как, например, с использованием зависимости от тональности, описанной выше, и/или посредством наложения спектрально глобального наклона на шум, и с использованием глобального уровня 114 шума для масштабирования уровня шума, как описано выше. Таким образом заполненные, эти спектры достигают модуля 132 деквантования, который в свою очередь деквантует или изменяет масштаб заполненного шумом спектра с использованием коэффициентов 112 масштабирования. Модуль 134 обратного преобразования, в свою очередь, подвергает деквантованный спектр обратному преобразованию, чтобы восстанавливать аудиосигнал. Как описано выше, обратное преобразование 134 также может содержать обработку добавления перекрывания, чтобы достигать аннулирования наложения временной области, вызываемого в случае преобразования, используемого модулем 104 преобразования, которое является критически дискретизированным преобразованием с перекрытиями, таким как MDCT, в этом случае обратное преобразование, применяемое модулем 134 обратного преобразования, будет IMDCT (обратным MDCT).
Как уже описано по отношению к фиг. 9 и 10, модуль 132 деквантования применяет коэффициенты масштабирования к предварительно заполненному спектру. То есть, спектральные значения внутри диапазонов коэффициентов масштабирования, не полностью квантованные в нуль, масштабируются с использованием коэффициента масштабирования независимо от спектрального значения, представляющего ненулевое спектральное значение или шум, который был спектрально сформирован посредством модуля 30 заполнения шумом, как описано выше. Полностью квантованные в нуль спектральные диапазоны имеют коэффициенты масштабирования, ассоциированные с ними, которые являются полностью свободными, чтобы управлять заполнением шумом, и модуль 30 заполнения шумом может либо использовать этот коэффициент масштабирования, чтобы индивидуально масштабировать шум, с помощью которого диапазон коэффициентов масштабирования был заполнен путем заполнения шумом модулем 30 заполнения шумом непрерывных спектральных нулевых частей, или модуль 30 заполнения шумом может использовать коэффициент масштабирования, чтобы дополнительно заполнять, то есть добавлять, дополнительный шум с учетом этих квантованных в нуль спектральных диапазонов.
Следует отметить, что шум, который модуль 30 заполнения шумом спектрально формирует зависящим от тональности способом, описанным выше, и/или подвергает спектрально глобальному наклону способом, описанным выше, может проистекать от псевдослучайного источника шума, или может выводиться из модуля 30 заполнения шумом на основе спектрального копирования или наложения заплат из других областей того же спектра или связанных спектров, как, например, выровненного по времени спектра другого канала, или предшествующего по времени спектра. Даже наложение заплат из того же спектра может быть возможным, как, например, копирование из областей более низких частот спектра 18 (спектральное копирование). Независимо от способа, каким модуль 30 заполнения шумом выводит шум, модуль 30 заполнения спектрально формирует шум для заполнения в непрерывные спектральные нулевые части 40a по 40d зависящим от тональности способом, описанным выше, и/или подвергает его спектрально глобальному наклону способом, описанным выше.
Только ради полноты, на фиг. 12 показано, что варианты осуществления кодера 100 и декодера 130 из фиг. 9 и 11 могут изменяться в том, что комбинирование между коэффициентами масштабирования с одной стороны и специальными для коэффициентов масштабирования уровнями шума осуществляется различным образом. В соответствии с примером из фиг. 12, кодер передает внутри потока данных информацию об огибающей шума, спектрально-временным образом дискретизированной при разрешении, более грубом, чем разрешение по спектральным линиям спектрограммы 12, как, например, при таком же спектрально-временном разрешении, что и коэффициенты 112 масштабирования, в дополнение к коэффициентам 112 масштабирования. Эта информация огибающей шума показывается с использованием ссылочной позиции 140 на фиг. 12. Посредством этой меры, для диапазонов коэффициентов масштабирования, не полностью квантованных в нуль, существуют два значения: коэффициент масштабирования для изменения масштаба или деквантования ненулевых спектральных значений внутри этого соответствующего диапазона коэффициентов масштабирования, также как уровень 140 шума для индивидуального масштабирования на основе диапазонов коэффициентов масштабирования уровня шума квантованных в нуль спектральных значений внутри этого диапазона коэффициентов масштабирования. Эта концепция иногда называется IGF (интеллектуальное заполнение промежутков).
Даже здесь, модуль 30 заполнения шумом может применять зависящее от тональности заполнение непрерывных спектральных нулевых частей 40a по 40d, как иллюстративно показано на фиг. 12.
В соответствии с примерами аудиокодека, очерченными выше по отношению к фиг. 9 по 12, спектральное формирование шума квантования выполняется посредством передачи информации, касающейся перцепционного порога маскирования, с использованием спектрально-временного представления в форме коэффициентов масштабирования. Фиг. 13 и 14 показывают пару кодера и декодера, где также варианты осуществления заполнения шумом, описанные по отношению к фиг. 1 по 8, могут использоваться, но где шум квантования спектрально формируется в соответствии с описанием LP (линейного предсказания) спектра аудиосигнала. В обоих вариантах осуществления, спектр, подлежащий заполнению шумом, находится во взвешенной области, то есть он квантуется с использованием спектрально постоянного размера шага во взвешенной области или перцепционно взвешенной области.
Фиг. 13 показывает кодер 150, который содержит модуль 152 преобразования, модуль 154 квантования, модуль 156 введения предыскажения, модуль 158 анализа LPC, и модуль 160 преобразования LPC в спектральные линии. Модуль 156 введения предыскажения является необязательным. Модуль 156 введения предыскажения подвергает прибывающий аудиосигнал 12 предыскажению, именно высокочастотной фильтрации с неглубокой передаточной функцией высокочастотного фильтра с использованием, например, фильтра FIR или IIR. Высокочастотный фильтр первого порядка может, например, использоваться для модуля 156 введения предыскажения, как, например, 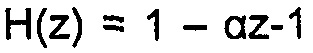 , где
, где 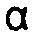 , устанавливает, например, величину или силу предыскажения, в соответствии с которым, в соответствии с одним из вариантов осуществления, спектрально глобальный наклон, которому подвергается шум для заполнения в спектр, изменяется. Возможная установка может быть 0.68. Предыскажение, вызванное посредством модуля 156 введения предыскажения, должно сдвигать энергию квантованных спектральных значений, переданных посредством кодера 150, из высоких в низкие частоты, тем самым, учитывая психоакустические законы, согласно которым человеческое восприятие является более высоким в области низкой частоты, чем в области высокой частоты. Подвергнут ли аудиосигнал предыскажению или нет, модуль 158 анализа LPC выполняет анализ LPC над прибывающим аудиосигналом 12, чтобы линейно предсказывать аудиосигнал или, чтобы быть более точными, оценивать его огибающую спектра. Модуль 158 анализа LPC определяет в единицах времени, например, подкадров, состоящих из некоторого количества аудиовыборок аудиосигнала 12, коэффициенты линейного предсказания и передает их, как показано на 162, в сторону декодирования внутри потока данных. Модуль 158 анализа LPC определяет, например, коэффициенты линейного предсказания с использованием автокорреляции в окнах анализа и с использованием, например, алгоритма Левинсона-Дурбина.
, устанавливает, например, величину или силу предыскажения, в соответствии с которым, в соответствии с одним из вариантов осуществления, спектрально глобальный наклон, которому подвергается шум для заполнения в спектр, изменяется. Возможная установка может быть 0.68. Предыскажение, вызванное посредством модуля 156 введения предыскажения, должно сдвигать энергию квантованных спектральных значений, переданных посредством кодера 150, из высоких в низкие частоты, тем самым, учитывая психоакустические законы, согласно которым человеческое восприятие является более высоким в области низкой частоты, чем в области высокой частоты. Подвергнут ли аудиосигнал предыскажению или нет, модуль 158 анализа LPC выполняет анализ LPC над прибывающим аудиосигналом 12, чтобы линейно предсказывать аудиосигнал или, чтобы быть более точными, оценивать его огибающую спектра. Модуль 158 анализа LPC определяет в единицах времени, например, подкадров, состоящих из некоторого количества аудиовыборок аудиосигнала 12, коэффициенты линейного предсказания и передает их, как показано на 162, в сторону декодирования внутри потока данных. Модуль 158 анализа LPC определяет, например, коэффициенты линейного предсказания с использованием автокорреляции в окнах анализа и с использованием, например, алгоритма Левинсона-Дурбина.
Коэффициенты линейного предсказания могут передаваться в потоке данных в квантованной и/или преобразованной версии, как, например, в форме пар спектральных линий или подобного. В любом случае, модуль 158 анализа LPC передает в модуль 160 преобразования LPC в спектральные линии коэффициенты линейного предсказания, как также доступные на стороне декодирования, посредством потока данных, и модуль 160 преобразования преобразовывает коэффициенты линейного предсказания в спектральную кривую, используемую модулем 154 квантования, чтобы спектрально изменять/устанавливать размер шага квантования. В частности, модуль 152 преобразования подвергает прибывающий аудиосигнал 12 преобразованию, как, например, таким же способом, который осуществляется модулем 104 преобразования. Таким образом, модуль 152 преобразования выводит последовательность спектров и модуль 154 квантования может, например, разделять каждый спектр посредством спектральной кривой, полученной от модуля 160 преобразования, при этом затем использовать спектрально постоянный размер шага квантования для всего спектра. Спектрограмма последовательности спектров, выводимых посредством модуля 154 квантования, показана на 164 на фиг. 13 и содержит также некоторые непрерывные спектральные нулевые части, которые могут заполняться на стороне декодирования. Глобальный параметр уровня шума может передаваться внутри потока данных посредством кодера 150.
Фиг. 14 показывает декодер, соответствующий кодеру из фиг. 13. Декодер из фиг. 14, в общем, показан с использованием ссылочной позиции 170 и содержит модуль 30 заполнения шумом, модуль 172 преобразования LPC в спектральные линии, модуль 174 деквантования и модуль 176 обратного преобразования. Модуль 30 заполнения шумом принимает квантованные спектры 164, выполняет заполнение шумом над непрерывными спектральными нулевыми частями, как описано выше, и передает, таким образом, заполненную спектрограмму в модуль 174 деквантования. Модуль 174 деквантования принимает от модуля 172 преобразования LPC в спектральные линии спектральную кривую, подлежащую использованию модулем 174 деквантования для повторного формирования заполненного спектра или, другими словами, для его деквантования. Эта обработка иногда называется FDNS (Формирование шума частотной области). Модуль 172 преобразования LPC в спектральные линии выводит спектральную кривую на основе информации 162 LPC в потоке данных. Деквантованный спектр, или повторно сформированный спектр, выведенный посредством модуля 174 деквантования, подвергается обратному преобразованию посредством модуля 176 обратного преобразования, чтобы восстанавливать аудиосигнал. Снова, последовательность повторно сформированных спектров может подвергаться модулем 176 обратного преобразования обратному преобразованию, за которым следует обработка добавления перекрывания, чтобы выполнять аннулирование наложения временной области между последовательными повторными преобразованиями в случае преобразования модуля 152 преобразования, которое является критически дискретизированным преобразованием с перекрытиями, таким как MDCT.
Посредством пунктирных линий на фиг. 13 и 14 показано, что предыскажение, применяемое модулем 156 введения предыскажения, может изменяться во времени, при этом изменение сигнализируется внутри потока данных. Модуль 30 заполнения шумом может, в этом случае, учитывать предыскажение при выполнении заполнения шумом, как описано выше по отношению к фиг. 8. В частности, предыскажение вызывает спектральный наклон в квантованном спектре, выводимом посредством модуля 154 квантования, в том, что квантованные спектральные значения, то есть спектральные уровни, имеют тенденцию уменьшаться от более низких частот к более высоким частотам, то есть они демонстрируют спектральный наклон. Этот спектральный наклон может компенсироваться, или более хорошо эмулироваться или к нему может осуществляться адаптация, посредством модуля 30 заполнения шумом способом, описанным выше. Если сигнализируется в потоке данных, сигнализируемая степень предыскажения может использоваться, чтобы выполнять адаптивный наклон заполненного шума способом, зависящим от степени предыскажения. То есть, степень предыскажения, сигнализируемая в потоке данных, может использоваться декодером, чтобы устанавливать степень спектрального наклона, наложенного на шум, заполняемый в спектр посредством модуля 30 заполнения шумом.
Вплоть до текущего времени, было описано несколько вариантов осуществления, и в дальнейшем представляются конкретные примеры осуществления. Детали, приведенные по отношению к этим примерам, должны пониматься как индивидуально переносимые на вышеописанные варианты осуществления, чтобы дополнительно их определять. Перед этим, однако, следует отметить, что все из вариантов осуществления, описанных выше, могут использоваться в кодировании аудио, также как речи. Они, в общем, указывают на кодирование с преобразованием и используют адаптивную к сигналу концепцию для замены нулей, введенных в обработке квантования, на спектрально сформированный шум с использованием очень малой величины сторонней информации. В вариантах осуществления, описанных выше, использовалось наблюдение, что спектральные дыры иногда также появляются только ниже начальной частоты заполнения шумом, если какая-либо такая начальная частота используется, и что такие спектральные дыры являются иногда перцепционно раздражающими. Вышеописанные варианты осуществления с использованием явной сигнализации начальной частоты обеспечивают возможность удаления дыр, которые приносят ухудшение, но обеспечивают возможность избегать вставки шума на низких частотах, когда вставка шума будет вводить искажения.
Более того, некоторые из вариантов осуществления, очерченных выше, используют управляемое предыскажением заполнение шумом, чтобы компенсировать спектральный наклон, вызываемый предыскажением. Эти варианты осуществления учитывают наблюдение, что если фильтр LPC вычисляется на сигнале предыскажения, только применение глобальной или средней амплитуды или средней энергии шума, подлежащего вставке, будет вызывать, что формирование шума будет вводить спектральный наклон во вставляемый шум, так как FDNS на стороне декодирования будет подвергать спектрально плоский вставленный шум спектральному формированию, все еще демонстрирующему спектральный наклон предыскажения. Соответственно, последние варианты осуществления выполняют заполнение шумом таким образом, что спектральный наклон от предыскажения учитывается и компенсируется.
Таким образом, другими словами, фиг. 11 и 14 каждая показывают аудиодекодер с перцепционным преобразованием. Он содержит модуль 30 заполнения шумом, сконфигурированный с возможностью выполнять заполнение шумом над спектром 18 аудиосигнала. Выполнение может осуществляться в зависимости от тональности, как описано выше. Выполнение может осуществляться посредством заполнения спектра с помощью шума, демонстрирующего спектрально глобальный наклон, чтобы получать заполненный шумом спектр, как описано выше. "Спектрально глобальный наклон", например, означает, что наклон проявляет себя, например, в огибающей, которая огибает шум по всем частям 40, подлежащим заполнению шумом, который наклонен, то есть имеет ненулевой угловой коэффициент. "Огибающая", например, определяется, чтобы быть кривой спектральной регрессии, такой как линейная функция или другой многочлен порядка два или три, например, ведущий через локальные максимумы шума, заполняемого в часть 40, которые все являются внутренне непрерывными, но спектрально отдаленными, "уменьшение от низких к высоким частотам" означает, что этот наклон имеет отрицательный угловой коэффициент, и "увеличение от низких к высоким частотам" означает, что этот наклон имеет положительный угловой коэффициент. Обе аспекта выполнения могут применяться параллельно или только один из них.
Дополнительно, аудиодекодер с перцепционным преобразованием содержит модуль 6 формирования шума частотной области в форме модуля 132, 174 деквантования, сконфигурированного с возможностью подвергать заполненный шумом спектр спектральному формированию с использованием спектральной перцепционной весовой функции. В случае фиг. 11, модуль 132 формирования шума частотной области сконфигурирован с возможностью определять спектральную перцепционную весовую функцию из информации 162 коэффициентов линейного предсказания, сигнализируемой в потоке данных, в который спектр кодируется. В случае фиг. 14, модуль 174 формирования шума частотной области сконфигурирован с возможностью определять спектральную перцепционную весовую функцию из коэффициентов 112 масштабирования, относящихся к диапазонам 110 коэффициентов масштабирования, сигнализируемых в потоке данных. Как описано по отношению к фиг. 8 и проиллюстрировано по отношению к фиг. 11, модуль 34 заполнения шумом может быть сконфигурирован с возможностью изменять угловой коэффициент спектрально глобального наклона в ответ на явную сигнализацию в потоке данных, или выводить его из части потока данных, которая сигнализирует спектральную перцепционную весовую функцию, как, например, посредством оценки огибающей спектра LPC или коэффициентов масштабирования, или выводить его из квантованного и переданного спектра 18.
Дополнительно, аудиодекодер с перцепционным преобразованием содержит модуль 134, 176 обратного преобразования, сконфигурированный с возможностью обратного преобразования заполненного шумом спектра, спектрально сформированного посредством модуля формирования шума частотной области, чтобы получать обратное преобразование, и подвергать обратное преобразование обработке добавления перекрывания.
Соответствующим образом, фиг. 13 и 9 обе показывают примеры для аудиокодера с перцепционным преобразованием, сконфигурированного с возможностью выполнять взвешивание 1 спектра и квантование 2, которые оба осуществляются в модулях 108, 154 квантования, показанных на фиг. 9 и 13. Взвешивание 1 спектра спектрально взвешивает исходный спектр аудиосигнала согласно обратной к спектральной перцепционной весовой функции, чтобы получать взвешенный по восприятию спектр, и квантование 2 квантует взвешенный по восприятию спектр спектрально единообразным способом, чтобы получать квантованный спектр. Аудиокодер с перцепционным преобразованием дополнительно выполняет вычисление 3 уровня шума внутри модулей 108, 154 квантования, например, вычисляя параметр уровня шума посредством измерения уровня взвешенного по восприятию спектра, совместно расположенного с нулевыми частями квантованного спектра, способом, взвешенным со спектрально глобальным наклоном, увеличивающимся от низких к высоким частотам. В соответствии с фиг. 13, аудиокодер с перцепционным преобразованием содержит модуль 158 анализа LPC, сконфигурированный с возможностью определять информацию 162 коэффициентов линейного предсказания, представляющую огибающую спектра LPC исходного спектра аудиосигнала, при этом модуль 154 спектрального взвешивания сконфигурирован с возможностью определять спектральную перцепционную весовую функцию, чтобы следовала за огибающей спектра LPC. Как описано, модуль 158 анализа LPC может быть сконфигурирован с возможностью определять информацию 162 коэффициентов линейного предсказания посредством выполнения анализа LP над версией аудиосигнала, подвергнутой фильтру 156 предыскажения. Как описано выше по отношению к фиг. 13, фильтр 156 предыскажения может быть сконфигурирован с возможностью подвергать высокочастотной фильтрации аудиосигнал с изменяющейся величиной предыскажения, чтобы получать версию аудиосигнала, подвергнутую фильтру предыскажения, при этом вычисление уровня шума может быть сконфигурировано с возможностью, чтобы устанавливать величину спектрально глобального наклона в зависимости от величины предыскажения. Может использоваться явная сигнализация величины спектрально глобального наклона или величины предыскажения в потоке данных. В случае фиг. 9, аудиокодер с перцепционным преобразованием содержит определение коэффициентов масштабирования, управляемое посредством модели 106 восприятия, которое определяет коэффициенты 112 масштабирования, относящиеся к диапазонам 110 коэффициентов масштабирования, чтобы следовали за порогом маскирования. Это определение осуществляется в модуле 108 квантования, например, который также действует как модуль спектрального взвешивания, сконфигурированный с возможностью определять спектральную перцепционную весовую функцию, чтобы следовала за коэффициентами масштабирования.
Все из вариантов осуществления, описанных выше, имеют, в общем, то, что избегаются спектральные дыры и что также избегается скрытие тональных квантованных не в нуль линий. Способом, описанным выше, энергия в зашумленных частях сигнала может сохраняться и добавление шума, который маскирует тональные компоненты, избегается способом, описанным выше.
В конкретных вариантах осуществления, описанных ниже, часть сторонней информации для выполнения зависящего от тональности заполнения шумом не добавляет что-либо к существующей сторонней информации кодека, где заполнение шумом используется. Вся информация из потока данных, которая используется для восстановления спектра, независимо от заполнения шумом, также может использоваться для формирования заполнения шумом.
В соответствии с одним примером осуществления, заполнение шумом в модуле 30 заполнения шумом выполняется следующим образом. Все спектральные линии выше индекса начала заполнения шумом, которые квантуются в нуль, заменяются на ненулевое значение. Это делается, например, случайным или псевдослучайным способом с использованием спектрально постоянной функцией плотности вероятности или с использованием наложения заплат из других спектральных местоположений спектрограммы (источников). См., например, фиг. 15. Фиг. 15 показывает два примера для спектра, подлежащего заполнению шумом, точно так же как спектр 34 или спектры 18 в спектрограмме 12, выводимой посредством модуля 108 квантования, или спектры 164, выводимые посредством модуля 154 квантования. Индекс начала заполнения шумом является индексом спектральной линии между iFreq0 и iFreq1 (0<iFreq0<=iFreq1), где iFreq0 и iFreq1 являются предварительно определенными, зависящими от битрейта и ширины полосы индексами спектральных линий. Индекс начала заполнения шумом равняется индексу iStart (iFreq0<=iStart<=iFreq1) спектральной линии, квантованной в ненулевое значение, где все спектральные линии с индексами j (iStart<j<=Freq1) квантованы в нуль. Разные значения для iStart, iFreq0 или iFreq1 также могут передаваться в битовом потоке, чтобы обеспечивать возможность вставки шума очень низкой частоты в некоторые сигналы (например, окружающего шума).
ВСТАВЛЕННЫЙ ШУМ ФОРМИРУЕТСЯ НА СЛЕДУЮЩИХ ЭТАПАХ:
1. В остаточной области или взвешенной области. Формирование в остаточной области или взвешенной области в значительной степени было описано выше по отношению к фиг. 1-14.
2. Спектральное формирование с использованием LPC или FDNS (формирование в области преобразования с использованием амплитудной характеристики LPC) было описано по отношению к фиг. 13 и 14. Спектр также может формироваться с использованием коэффициентов масштабирования (как в AAC) или с использованием любого другого способа спектрального формирования для формирования полного спектра, как описано по отношению к фиг. 9-12.
3. Необязательное формирование с использованием TNS (временного формирования шума) с использованием более малого количества битов, было описано кратко по отношению к фиг. 9-12.
Единственной дополнительной сторонней информацией, необходимой для заполнения шумом, является уровень, который передается с использованием 3 битов, например.
При использовании FDNS не имеется необходимости адаптировать его к конкретному заполнению шумом и оно формирует шум по полному спектру с использованием более малого количества битов, чем коэффициенты масштабирования.
Во вставленный шум может вводиться спектральный наклон, чтобы противодействовать спектральному наклону от предыскажения в основывающемся на LPC перцепционном формировании шума. Так как предыскажение представляет плавный высокочастотный фильтр, применяемый к входному сигналу, компенсация наклона может противодействовать ему посредством умножения эквивалента передаточной функции тонкого низкочастотного фильтра на спектр вставленного шума. Спектральный наклон этой низкочастотной операции зависит от коэффициента предыскажения и, предпочтительно, битрейта и ширины полосы. Это было описано со ссылкой на фиг. 8.
Для каждой спектральной дыры, составленной из 1 или более последовательных квантованных в нуль спектральных линий, вставленный шум может формироваться, как изображено на фиг. 16. Уровень заполнения шумом может находиться в кодере и передаваться в битовом потоке. Не имеется никакого заполнения шумом в квантованных не в нуль спектральных линиях и оно увеличивается в области перехода вплоть до полного заполнения шумом. В области полного заполнения шумом уровень заполнения шумом равняется уровню, передаваемому в битовом потоке, например. Это избегает вставки высокого уровня шума в непосредственной окрестности квантованных не в нуль спектральных линий, что может потенциально маскировать или искажать тональные компоненты. Однако все квантованные в нуль линии заменяются на шум, не оставляя никаких спектральных дыр.
Ширина перехода зависит от тональности входного сигнала. Тональность получается для каждого временного кадра. На фиг. 17А-D форма заполнения шумом иллюстративно изображена для разных размеров дыр и ширин переходов.
Мера тональности спектра может основываться на информации, доступной в битовом потоке:
- Усиление LTP
- Флаг активации перегруппировки спектра (см. [6])
- Флаг активации TNS
Ширина перехода пропорциональна тональности - малая для шумоподобных сигналов, большая для очень тональных сигналов.
В одном варианте осуществления, ширина перехода является пропорциональной усилению LTP, если усиление LTP > 0. Если усиление LTP равняется 0 и перегруппировка спектра активирована, то используется ширина перехода для среднего усиления LTP. Если TNS активировано, то не имеется никакой области перехода, но полное заполнение шумом должно применяться ко всем квантованным в нуль спектральным линиям. Если усиление LTP равняется 0 и TNS и перегруппировка спектра деактивирована, используется минимальная ширина перехода.
Если не имеется никакой информации тональности в битовом потоке мера тональности может вычисляться на декодированном сигнале без заполнения шумом. Если не имеется никакой информации TNS, временная мера плоскостности может вычисляться на декодированном сигнале. Если, однако, информация TNS является доступной, такая мера плоскостности может выводиться из коэффициентов фильтра TNS напрямую, например, посредством вычисления усиления предсказания фильтра.
В кодере, уровень заполнения шумом может вычисляться предпочтительно посредством учета ширины перехода. Являются возможными несколько способов, чтобы определять уровень заполнения шумом из квантованного спектра. Наиболее простым является сложить энергию (квадрат) всех линий нормализованного входного спектра в области заполнения шумом (то есть выше iStart), которые были квантованы в нуль, затем разделить эту сумму на количество таких линий, чтобы получить среднюю энергию в расчете на линию, и в заключение вычислить квантованный уровень шума из квадратного корня из средней энергии линии. Этим способом, уровень шума эффективно выводится из RMS спектральных компонент, квантованных в нуль. Пусть, например, A будет набором индексов i спектральных линий, где спектр квантован в нуль и которые принадлежат какой-либо из нулевых частей, например, находится выше начальной частоты, и пусть N обозначает глобальный коэффициент масштабирования шума. Значения спектра, как еще не квантованные, обозначаются как yi. Дополнительно, left(i) является функцией, показывающей для любого квантованного в нуль спектрального значения с индексом i индекс квантованного в нуль значения на низкочастотном конце нулевой части, которой i принадлежит, и Fi(j), где j=0 до Ji-1, обозначает функцию, назначенную, в зависимости от тональности, нулевой части, начинающейся с индекса i, где Ji обозначает ширину этой нулевой части. Тогда, N может определяться посредством N=sqrt( yi2/количество элементов(A)).
yi2/количество элементов(A)).
В предпочтительном варианте осуществления, рассматриваются индивидуальные размеры дыр также как ширина перехода. С этой целью, последовательности последовательных квантованных в нуль линий группируются в области дыр. Каждая нормализованная входная спектральная линия в области дыр, то есть каждое спектральное значение исходного сигнала в спектральном положении внутри какой-либо непрерывной спектральной нулевой части, затем масштабируется посредством переходной функции, как описано в предыдущем разделе, и впоследствии вычисляется сумма энергий масштабированных линий. Как в предыдущем простом варианте осуществления, уровень заполнения шумом может затем вычисляться из RMS квантованных в нуль линий. Применяя вышеописанную терминологию, N может вычисляться как N=sqrt( (Fleft(i)(i-left(i))⋅yi)2/количество элементов(A)).
(Fleft(i)(i-left(i))⋅yi)2/количество элементов(A)).
Проблема с этим подходом, однако, состоит в том, что спектральная энергия в малых областях дыр (то есть областях с шириной намного меньшей, чем удвоенная ширина перехода) недооценивается, так как в вычислении RMS, количество спектральных линий в сумме, на которое сумма энергий разделяется, является неизменным. Другими словами, когда квантованные спектры демонстрируют главным образом много малых областей дыр, результирующий уровень заполнения шумом будет более низким, чем, когда спектр является разреженным и имеет только несколько длинных областей дыр. Чтобы обеспечивать, что в обоих из этих случаев находится аналогичный уровень шума, является, поэтому, предпочтительным адаптировать подсчет линий, используемый в знаменателе вычисления RMS, к ширине перехода. Наиболее важно, если размер области дыр является более малым, чем удвоенная ширина перехода, количество спектральных линий в этой области дыр не вычисляется, как есть, то есть как целое число линий, но как дробное число линий, которое меньше, чем целое число линий. В вышеописанной формуле, касающейся N, например, "количество элементов(A)" будет заменяться на более малое количество в зависимости от количества "малых" нулевых частей.
Дополнительно, компенсация спектрального наклона в заполнении шумом вследствие основывающегося на LPC перцепционного кодирования также должна учитываться во время вычисления уровня шума. Более конкретно, инверсия компенсации наклона заполнения шумом стороны декодера предпочтительно применяется к исходным неквантованным спектральным линиям, которые были квантованы в нуль, перед тем, как уровень шума вычисляется. В контексте основывающегося на LPC кодирования, использующего предыскажение, это имеет следствием, что линии более высокой частоты усиливаются незначительно по отношению к линиям более низкой частоты до оценки уровня шума. Применяя вышеописанную терминологию, N может вычисляться как N=sqrt( (Fleft(i)(i-left(i))⋅LPF(i)-1⋅yi)2/количество элементов(A)). Как упомянуто выше, в зависимости от обстоятельств, функция LPF, которая соответствует функции 15, может иметь положительный угловой коэффициент и LPF, изменяться, чтобы читаться как HPF соответственно. Необходимо кратко отметить, что во всех вышеописанных формулах, использующих "LPF", установка Fleft на постоянную функцию, как, например, чтобы была всеми единицами, будет показывать способ того, как применять концепцию подвергания шума, подлежащего заполнению в спектр 34, спектрально глобальному наклону без зависящего от тональности заполнения дыр.
(Fleft(i)(i-left(i))⋅LPF(i)-1⋅yi)2/количество элементов(A)). Как упомянуто выше, в зависимости от обстоятельств, функция LPF, которая соответствует функции 15, может иметь положительный угловой коэффициент и LPF, изменяться, чтобы читаться как HPF соответственно. Необходимо кратко отметить, что во всех вышеописанных формулах, использующих "LPF", установка Fleft на постоянную функцию, как, например, чтобы была всеми единицами, будет показывать способ того, как применять концепцию подвергания шума, подлежащего заполнению в спектр 34, спектрально глобальному наклону без зависящего от тональности заполнения дыр.
Возможные вычисления для N могут выполняться в кодере, таком как, например, в 108 или 154.
В заключение, было обнаружено, что когда гармоники очень тонального, стационарного сигнала квантованы в нуль, линии, представляющие эти гармоники, ведут к относительно высокому или нестабильному (то есть флуктуирующему во времени) уровню шума. Этот артефакт может уменьшаться посредством использования в вычислении уровня шума средней амплитуды квантованных в нуль линий вместо их RMS. В то время как этот альтернативный подход не всегда гарантирует, что энергия заполненных шумом линий в декодере воспроизводит энергию исходных линий в областях заполнения шумом, это действительно обеспечивает, что спектральные пики в областях заполнения шумом имеют только ограниченный вклад в полный уровень шума, тем самым, уменьшая риск переоценки уровня шума.
В заключение, следует отметить, что кодер может даже быть сконфигурирован с возможностью выполнять заполнение шумом полностью, чтобы держать себя в соответствии с декодером, как, например, для целей анализа посредством синтеза.
Таким образом, вышеописанный вариант осуществления, среди прочего, описывает адаптивный к сигналу способ для замены нулей, введенных в обработке квантования, на спектрально сформированный шум. Описывается расширение заполнения шумом для кодера и декодера, которые удовлетворяют вышеупомянутым требованиям посредством осуществления следующего:
- Индекс начала заполнения шумом может адаптироваться к результату квантования спектра, но ограничен некоторым диапазоном
- Во вставленный шум может вводиться спектральный наклон, чтобы противодействовать спектральному наклону от перцепционного формирования шума
- Все квантованные в нуль линии выше индекса начала заполнения шумом заменяются на шум
- Посредством переходной функции, вставленный шум ослабляется вблизи спектральных линий, не квантованных в нуль
- Переходная функция зависит от мгновенных характеристик входного сигнала
- Адаптация индекса начала заполнения шумом, спектральный наклон и переходная функция могут основываться на информации, доступной в декодере
Не имеется необходимости в дополнительной сторонней информации, за исключением уровня заполнения шумом.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторое или все из этапов способа могут выполняться посредством (или с использованием) устройства аппаратного обеспечения, такого, как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления, некоторые один или более из наиболее важных этапов способа могут выполняться посредством такого устройства.
В зависимости от некоторых требований осуществления, варианты осуществления изобретения могут осуществляться в аппаратном обеспечении или в программном обеспечении. Осуществление может выполняться с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронно-читаемые сигналы управления, сохраненные на нем, который работает вместе (или способен работать вместе) с программируемой компьютерной системой, так что соответствующий способ выполняется. Поэтому, цифровой запоминающий носитель может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно-читаемые сигналы управления, которые способны работать вместе с программируемой компьютерной системой, так что выполняется один из способов, здесь описанных.
В общем, варианты осуществления настоящего изобретения могут осуществляться как компьютерный программный продукт с программным кодом, при этом программный код является работоспособным для выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код может, например, сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, здесь описанных, сохраненную на машиночитаемом носителе.
Другими словами, один вариант осуществления нового способа является, поэтому, компьютерной программой, имеющей программный код для выполнения одного из способов, здесь описанных, когда компьютерная программа исполняется на компьютере.
Один дополнительный вариант осуществления новых способов является, поэтому, носителем данных (или цифровым запоминающим носителем, или машиночитаемым носителем), содержащим, записанную на нем, компьютерную программу для выполнения одного из способов, здесь описанных. Носитель данных, цифровой запоминающий носитель или записывающий носитель являются обычно материальными и/или нетранзиторными.
Один дополнительный вариант осуществления нового способа является, поэтому, потоком данных или последовательностью сигналов, представляющей компьютерную программу для выполнения одного из способов, здесь описанных. Поток данных или последовательность сигналов может, например, быть сконфигурирована с возможностью передаваться посредством соединения передачи данных, например, посредством сети Интернет.
Один дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, сконфигурированное с возможностью или выполненное с возможностью выполнять один из способов, здесь описанных.
Один дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, здесь описанных.
Один дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную с возможностью передавать (например, электронным образом или оптически) компьютерную программу для выполнения одного из способов, здесь описанных, в приемник. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством или подобным. Устройство или система может, например, содержать файловый сервер для передачи компьютерной программы в приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться, чтобы выполнять некоторые или все из функциональностей способов, здесь описанных. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может работать вместе с микропроцессором, чтобы выполнять один из способов, здесь описанных. В общем, способы предпочтительно выполняются посредством любого устройства аппаратного обеспечения.
Устройство, здесь описанное, может быть осуществлено с использованием устройства аппаратного обеспечения, или с использованием компьютера, или с использованием комбинации устройства аппаратного обеспечения и компьютера.
Способы, здесь описанные, могут выполняться с использованием устройства аппаратного обеспечения, или с использованием компьютера, или с использованием комбинации устройства аппаратного обеспечения и компьютера.
Вышеописанные варианты осуществления являются только иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и деталей, здесь описанных, должны быть ясны другим специалистам в данной области техники. Поэтому предполагается, что ограничение определяется только посредством объема приложенной патентной формулы изобретения и не посредством конкретных деталей, представленных посредством описания и объяснения вариантов осуществления отсюда.
ССЫЛКИ
[1] B. G. G. F. S. G. M. M. H. P. J. H. S. W. G. S. J. H. Nikolaus Rettelbach, "Noise Filler, Noise Filling Parameter Calculator Encoded Audio Signal Representation, Methods and Computer Program". Патент US 2011/0173012 A1.
[2] Extended Adaptive Multi-Rate-Wideband (AMR-WB+) codec, 3GPP TS 26.290 V6.3.0, 2005-2006.
[3] B. G. G. F. S. G. M. M. H. P. J. H. S. W. G. S. J. H. Nikolaus Rettelbach, "Audio encoder, audio decoder, methods for encoding and decoding an audio signal, audio stream and computer program". Патент WO 2010/003556 A1.
[4] M. M. N. R. G. F. J. R. J. L. S. W. S. B. S. D. C. H. R. L. P. G. B. B. J. L. K. K. H. Max Neuendorf, "MPEG Unified Speech and Audio Coding - The ISO/MPEG Standard for High-Efficiency Audio Coding of all Content Types", in 132nd Convention AES, Budapest, 2012. Также опубликовано в Journal of the AES, vol. 61, 2013.
[5] M. M. M. N. a. R. G. Guillaume Fuchs, "MDCT-Based Coder for Highly Adaptive Speech and Audio Coding", in 17th European Signal Processing Conference (EUSIPCO 2009), Glasgow, 2009.
[6] H. Y. K. Y. M. T. Harada Noboru, "Coding Method, Decoding Method, Coding Device, Decoding Device, Program, and Recording Medium". Патент WO 2012/046685 A1.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНЦЕПЦИЯ ЗАПОЛНЕНИЯ ШУМОМ | 2014 |
|
RU2660605C2 |
| ОСНОВАННАЯ НА ЛИНЕЙНОМ ПРЕДСКАЗАНИИ СХЕМА КОДИРОВАНИЯ, ИСПОЛЬЗУЮЩАЯ ФОРМИРОВАНИЕ ШУМА В СПЕКТРАЛЬНОЙ ОБЛАСТИ | 2012 |
|
RU2575993C2 |
| ОСНОВАННОЕ НА ЛИНЕЙНОМ ПРЕДСКАЗАНИИ КОДИРОВАНИЕ АУДИО С ИСПОЛЬЗОВАНИЕМ УЛУЧШЕННОЙ ОЦЕНКИ РАСПРЕДЕЛЕНИЯ ВЕРОЯТНОСТЕЙ | 2013 |
|
RU2651187C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ С ЗАПОЛНЕНИЕМ ПРОМЕЖУТКА В ПОЛНОЙ ПОЛОСЕ И ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ | 2015 |
|
RU2671997C2 |
| КОДЕР И ДЕКОДЕР АУДИОСИГНАЛА, ИСПОЛЬЗУЮЩИЕ ПРОЦЕССОР ЧАСТОТНОЙ ОБЛАСТИ, ПРОЦЕССОР ВРЕМЕННОЙ ОБЛАСТИ И КРОССПРОЦЕССОР ДЛЯ НЕПРЕРЫВНОЙ ИНИЦИАЛИЗАЦИИ | 2015 |
|
RU2668397C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ПОНИЖАЮЩЕЙ ДИСКРЕТИЗАЦИИ ИЛИ ИНТЕРПОЛЯЦИИ МАСШТАБНЫХ ПАРАМЕТРОВ | 2018 |
|
RU2762301C2 |
| АУДИОДЕКОДЕР, АУДИОКОДЕР И СВЯЗАННЫЕ СПОСОБЫ С ИСПОЛЬЗОВАНИЕМ ОБЪЕДИНЕННОГО КОДИРОВАНИЯ ПАРАМЕТРОВ МАСШТАБИРОВАНИЯ ДЛЯ КАНАЛОВ МНОГОКАНАЛЬНОГО АУДИОСИГНАЛА | 2021 |
|
RU2809981C1 |
| УСТРОЙСТВО КВАНТОВАНИЯ АУДИОДАННЫХ, УСТРОЙСТВО ДЕКВАНТОВАНИЯ АУДИОДАННЫХ И СООТВЕТСТВУЮЩИЕ СПОСОБЫ | 2021 |
|
RU2807462C1 |
| ИНТЕГРАЛЬНОЕ ПАРАМЕТРИЧЕСКОЕ АУДИОКОДИРОВАНИЕ ДЛЯ КАЖДОЙ ПОЛОСЫ ЧАСТОТ | 2022 |
|
RU2834366C2 |
| УПРАВЛЕНИЕ ПОЛОСОЙ ЧАСТОТ В КОДЕРАХ И/ИЛИ ДЕКОДЕРАХ | 2018 |
|
RU2752520C1 |
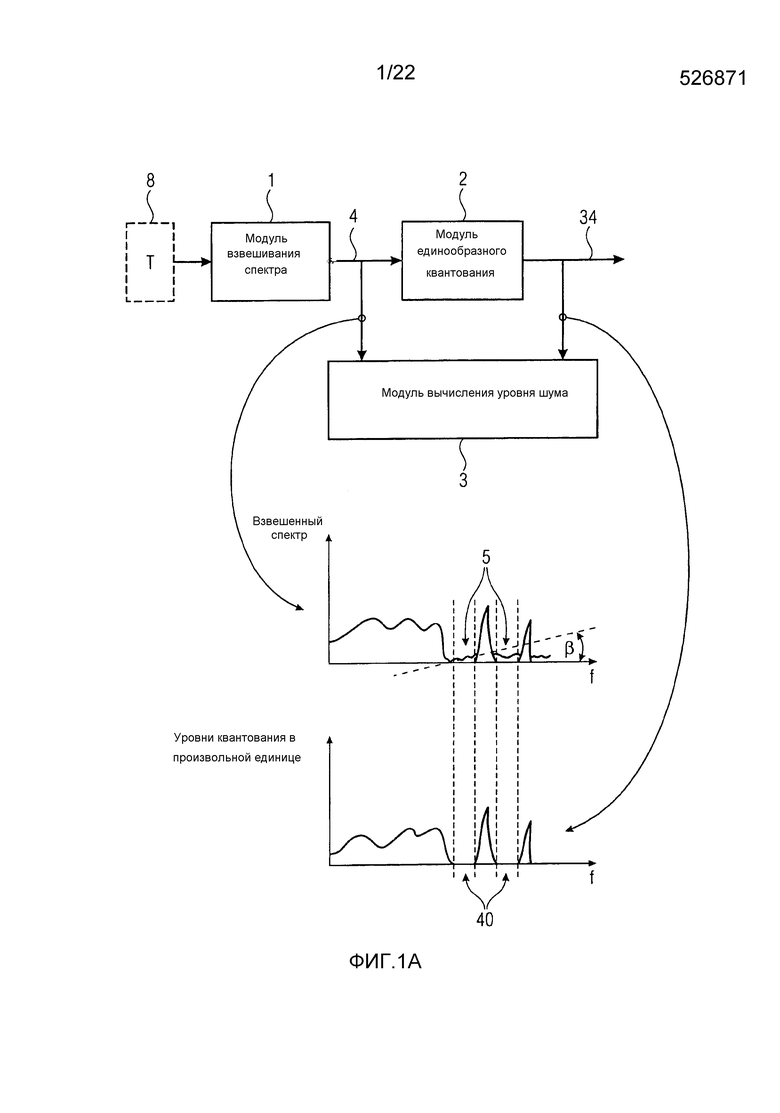
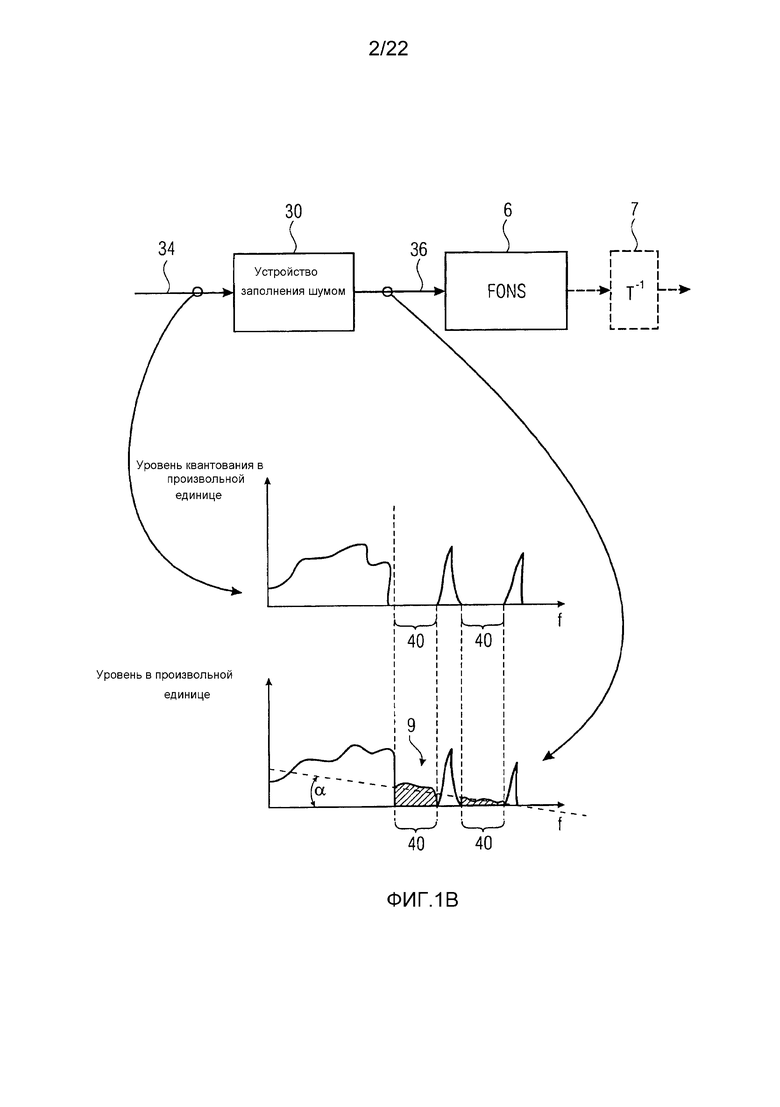
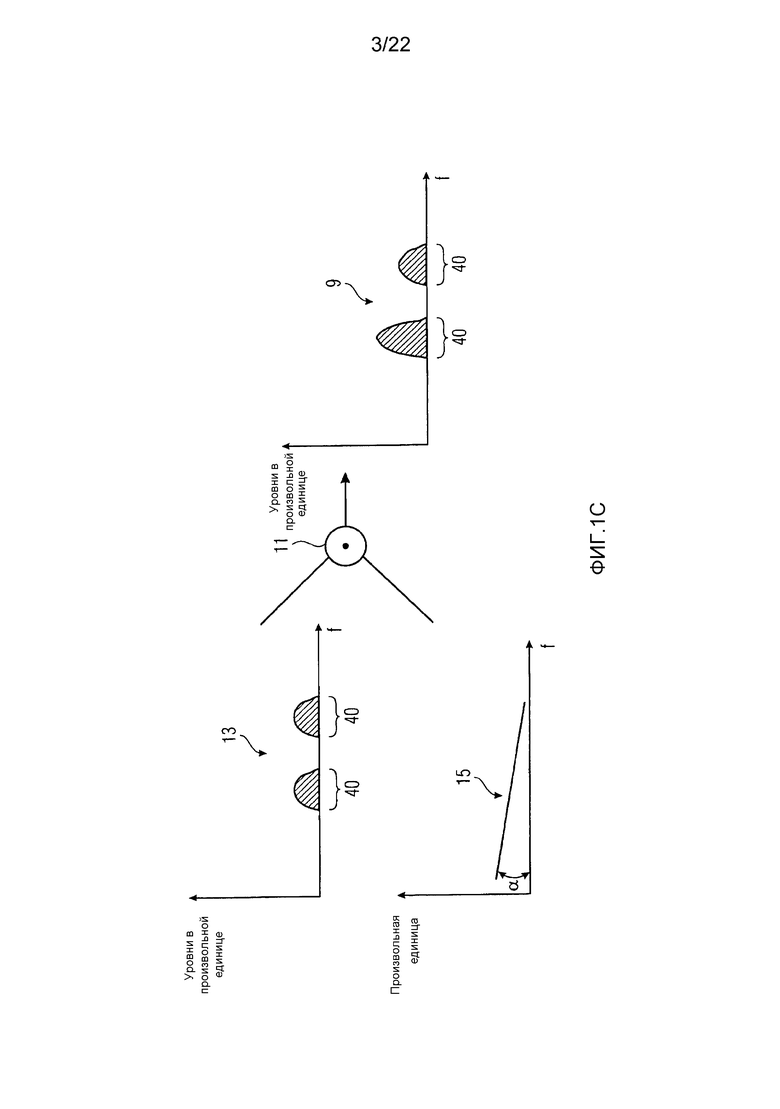
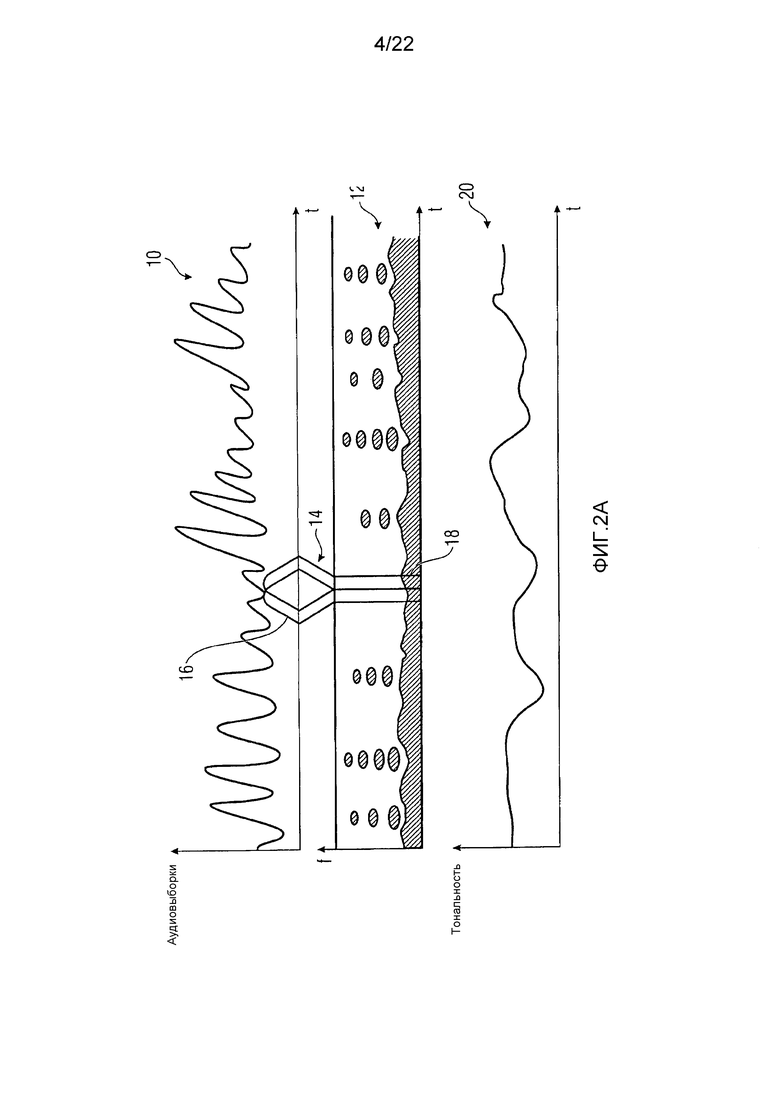
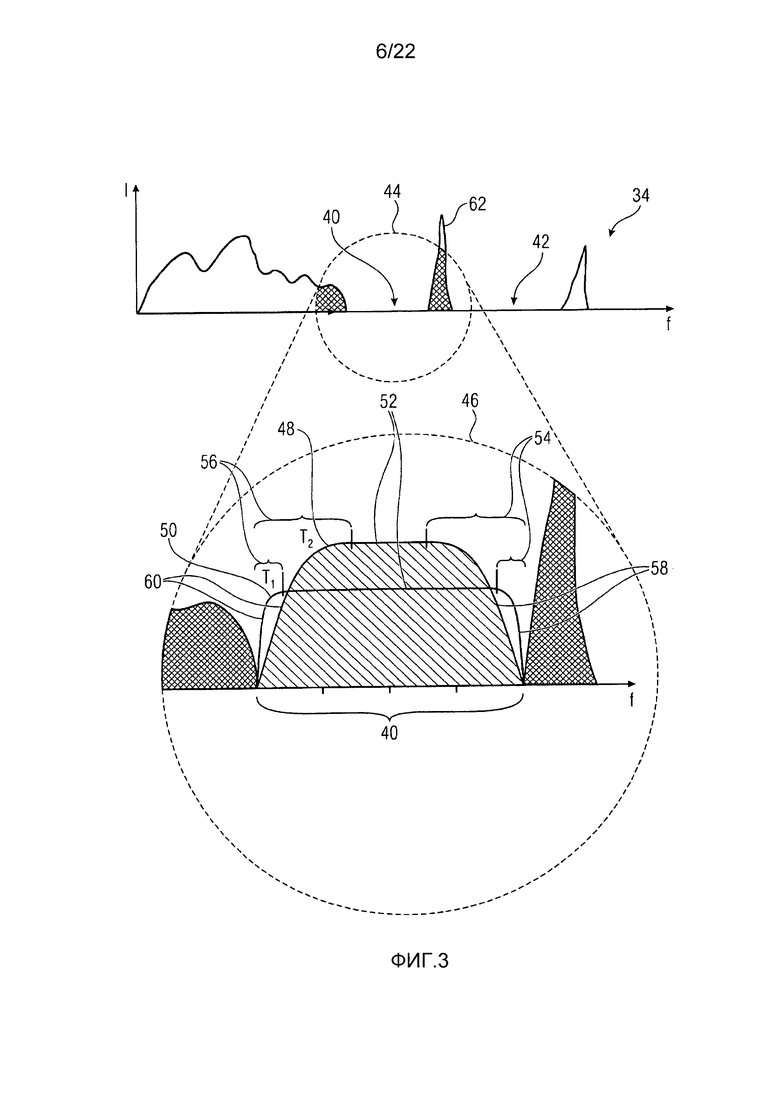
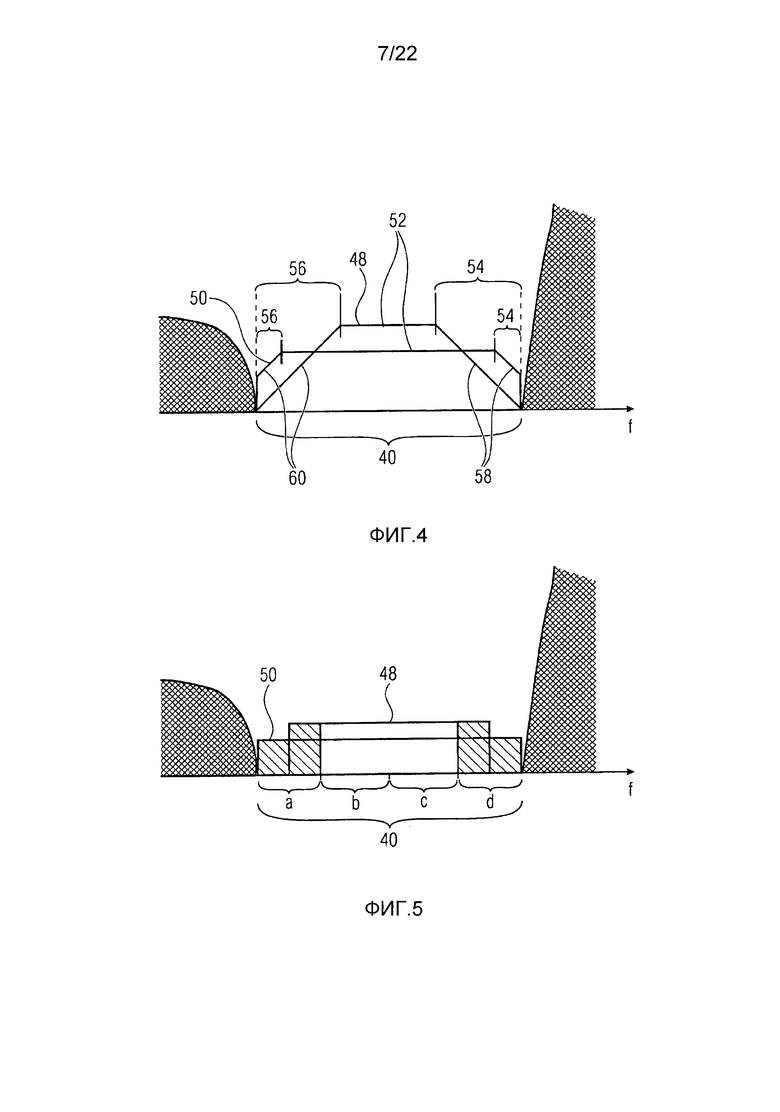
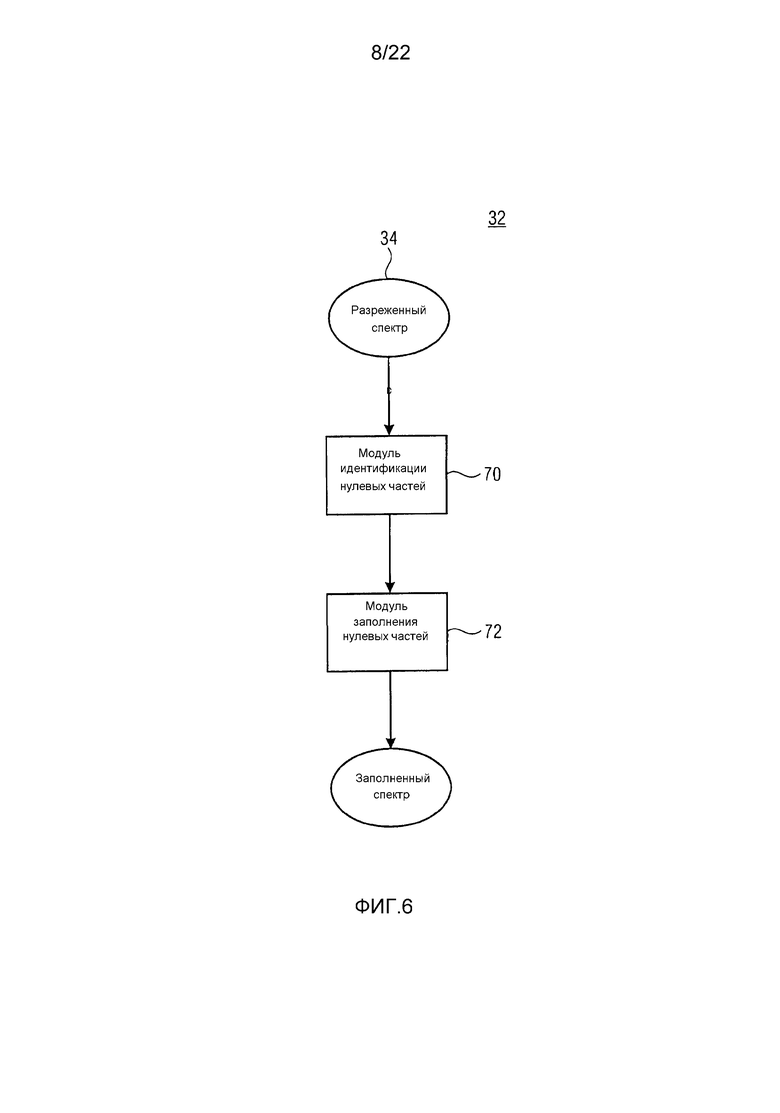
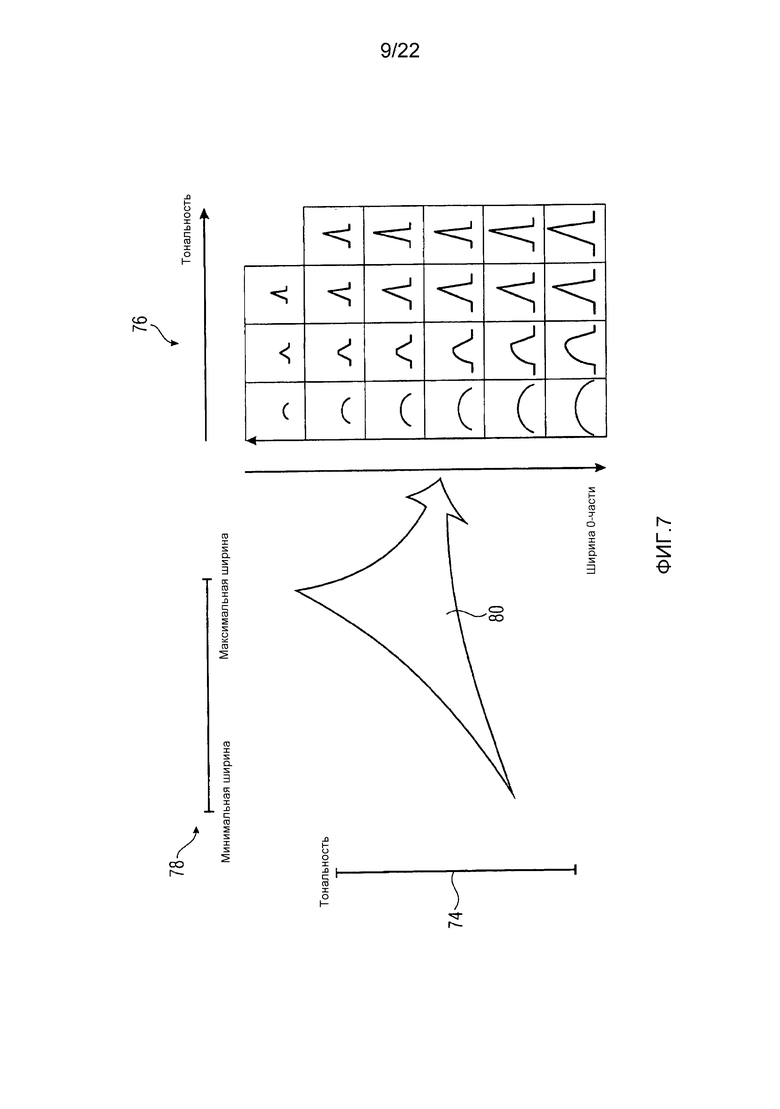
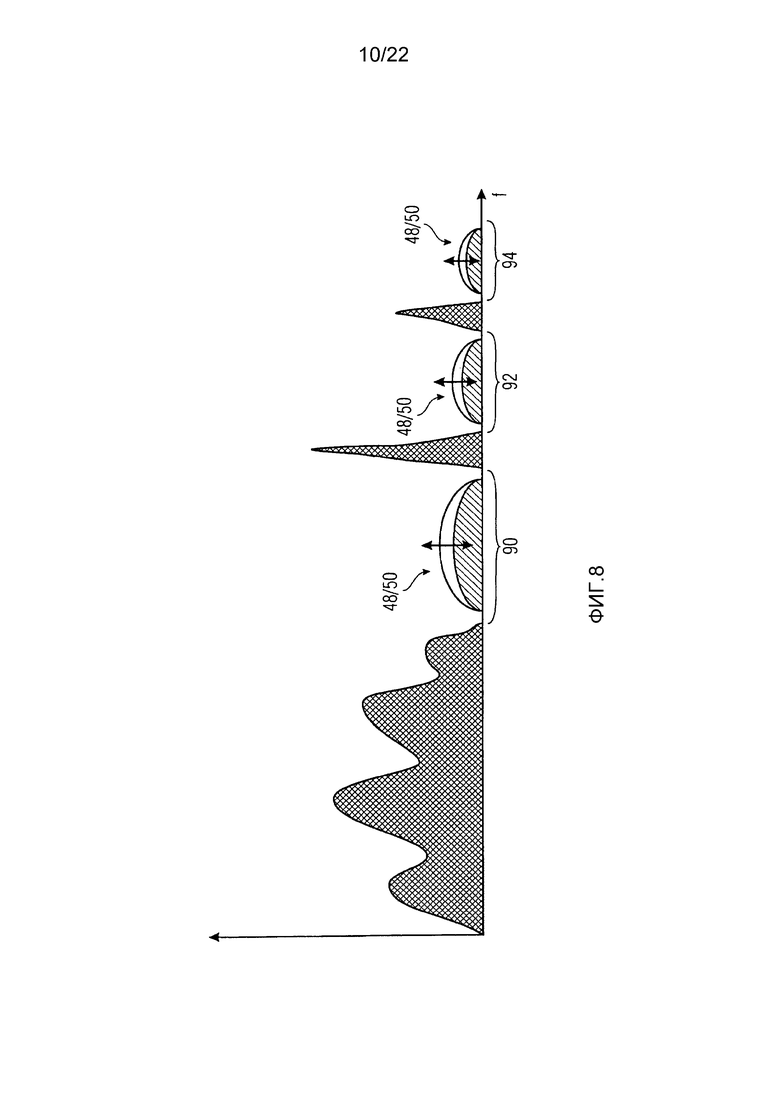
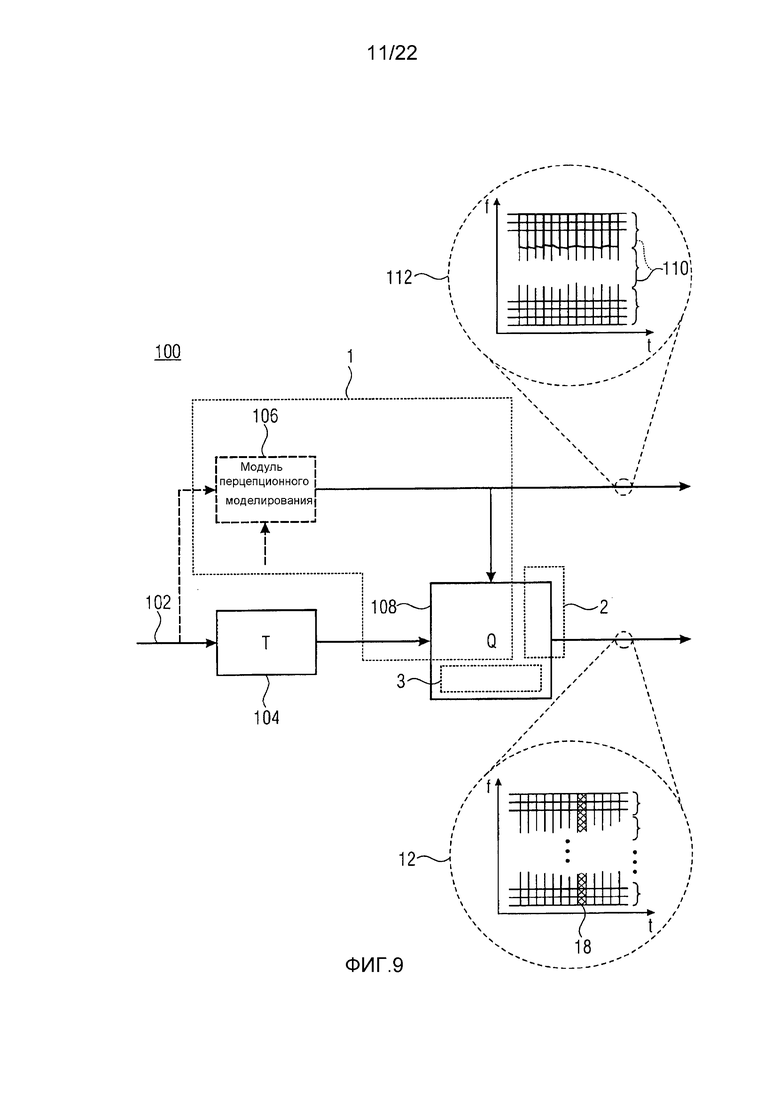
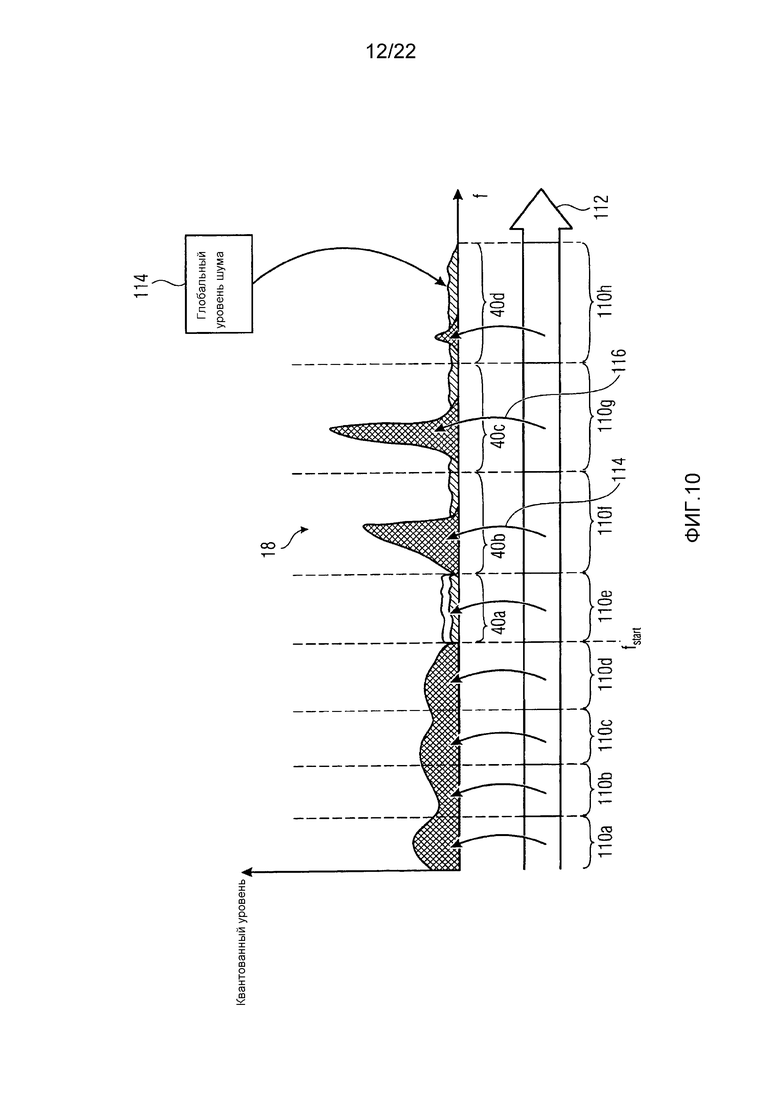
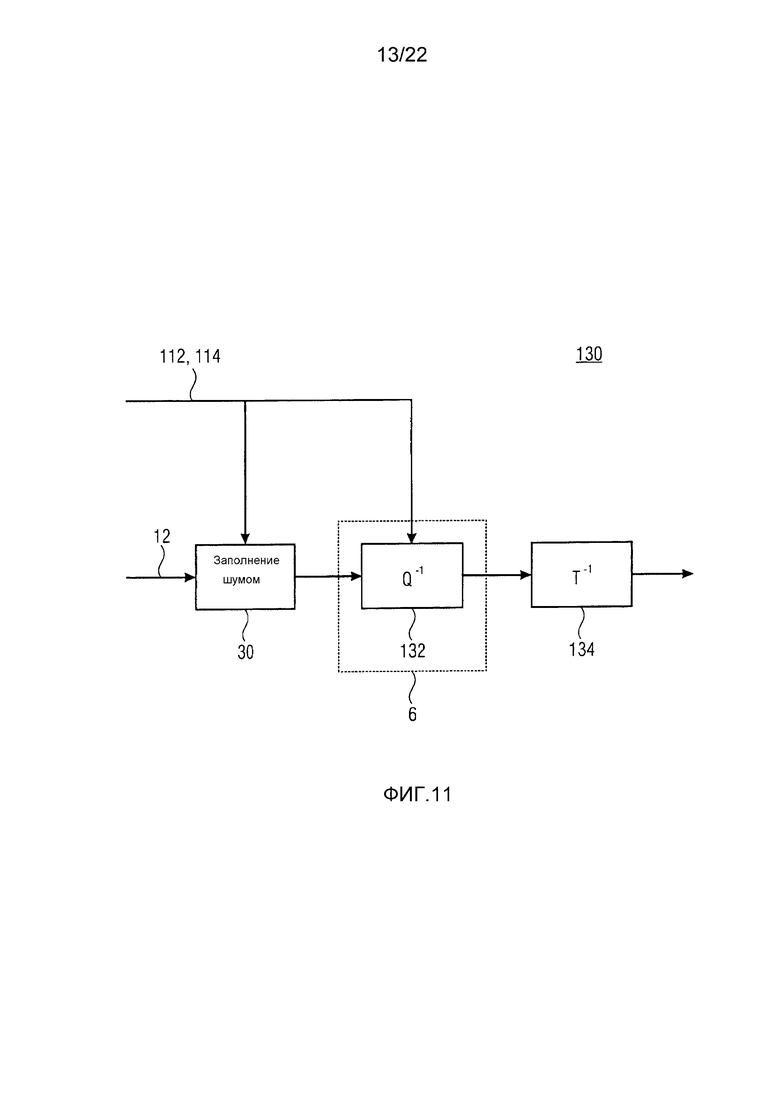
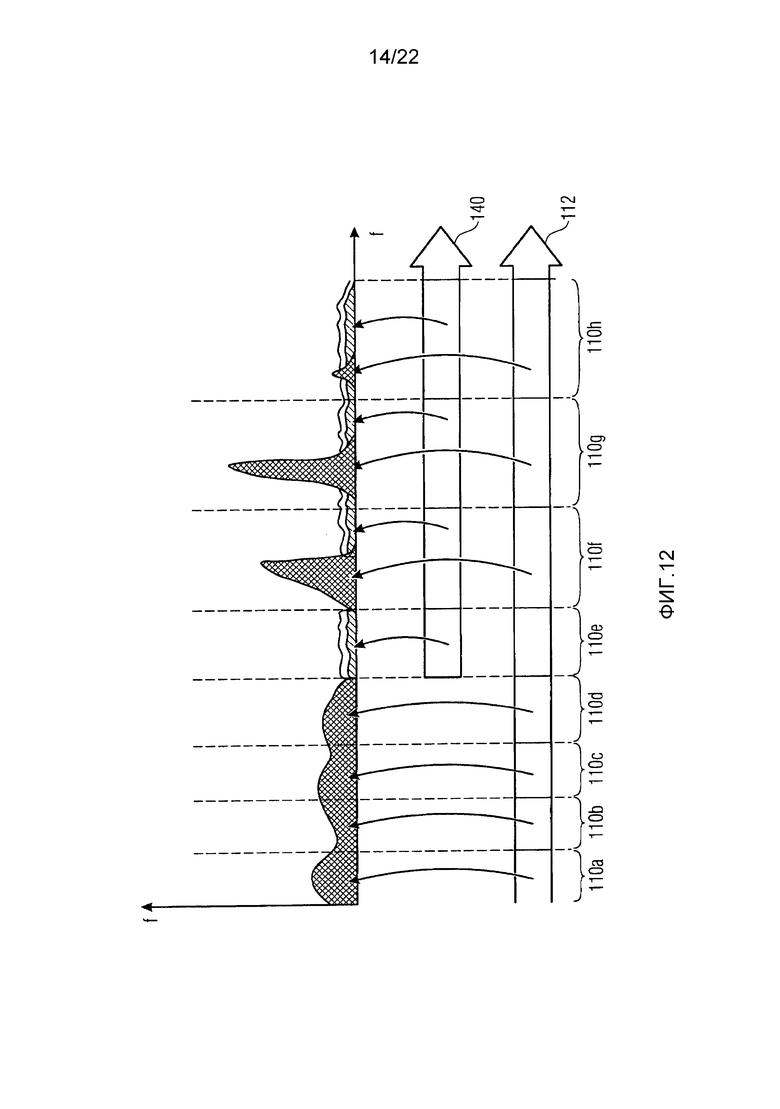
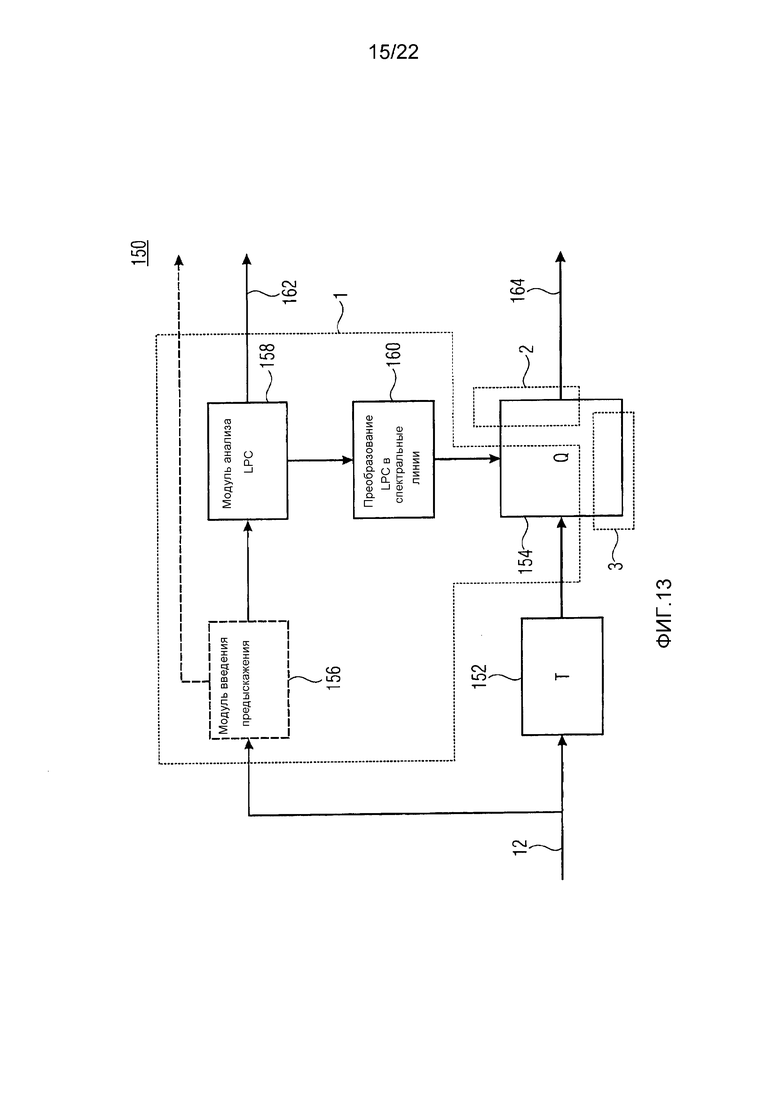
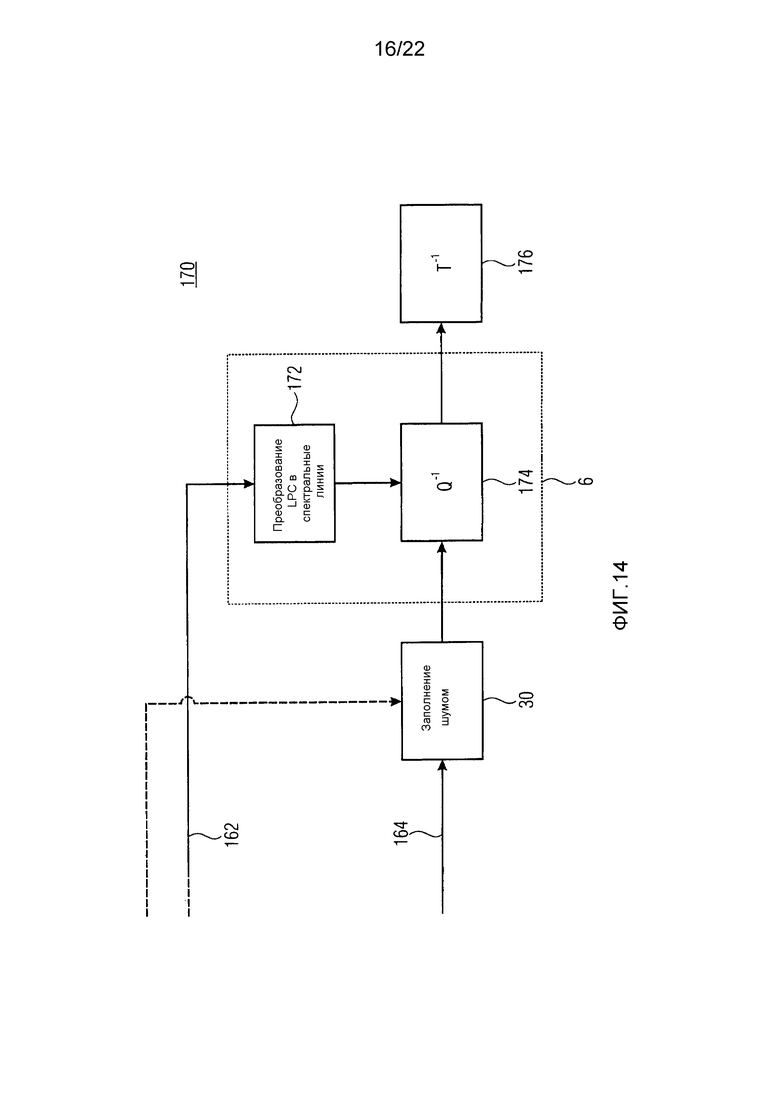
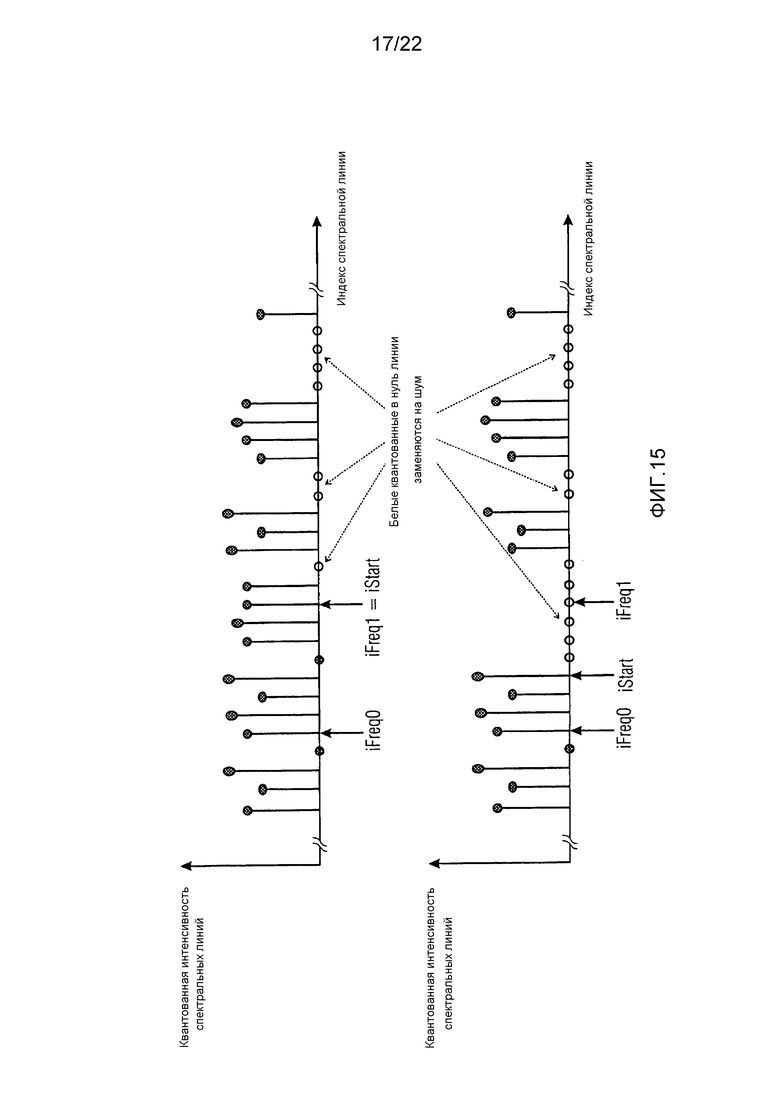
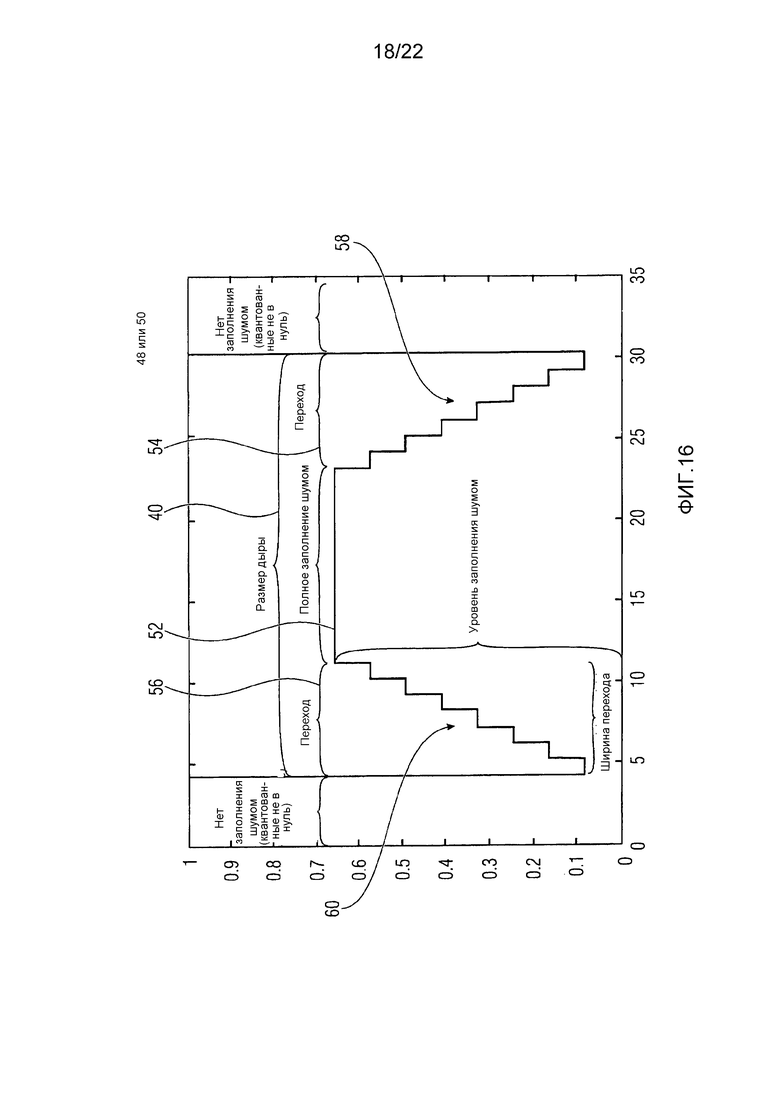

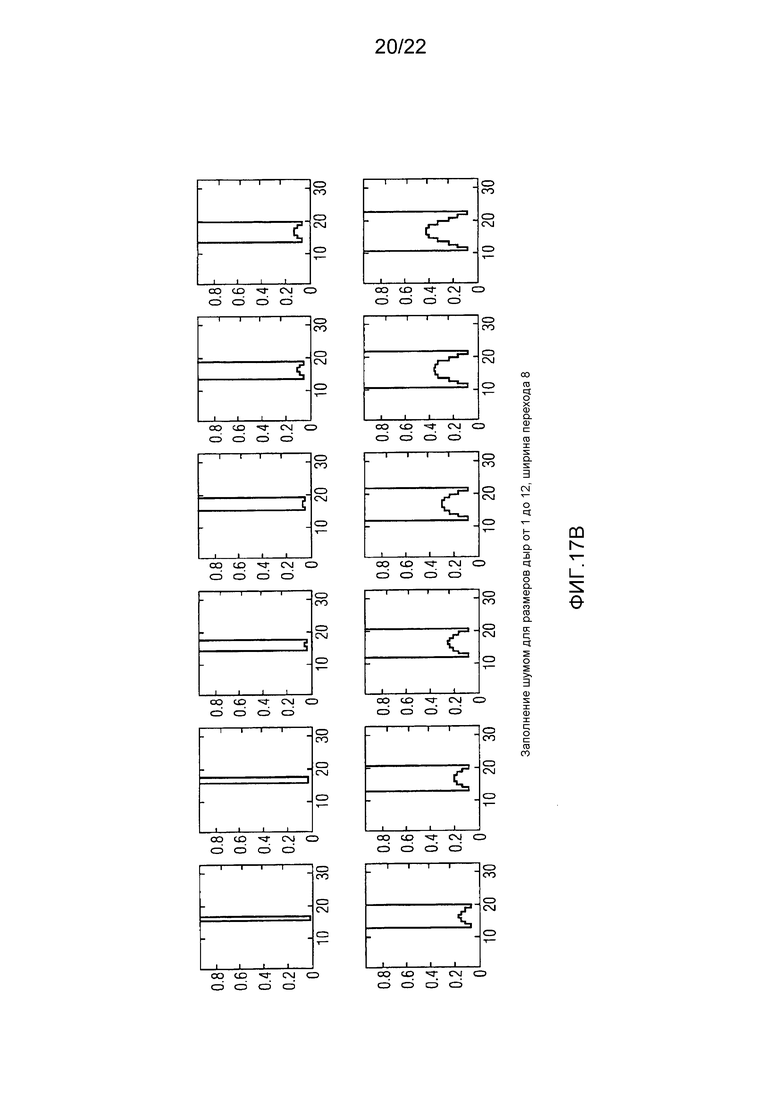
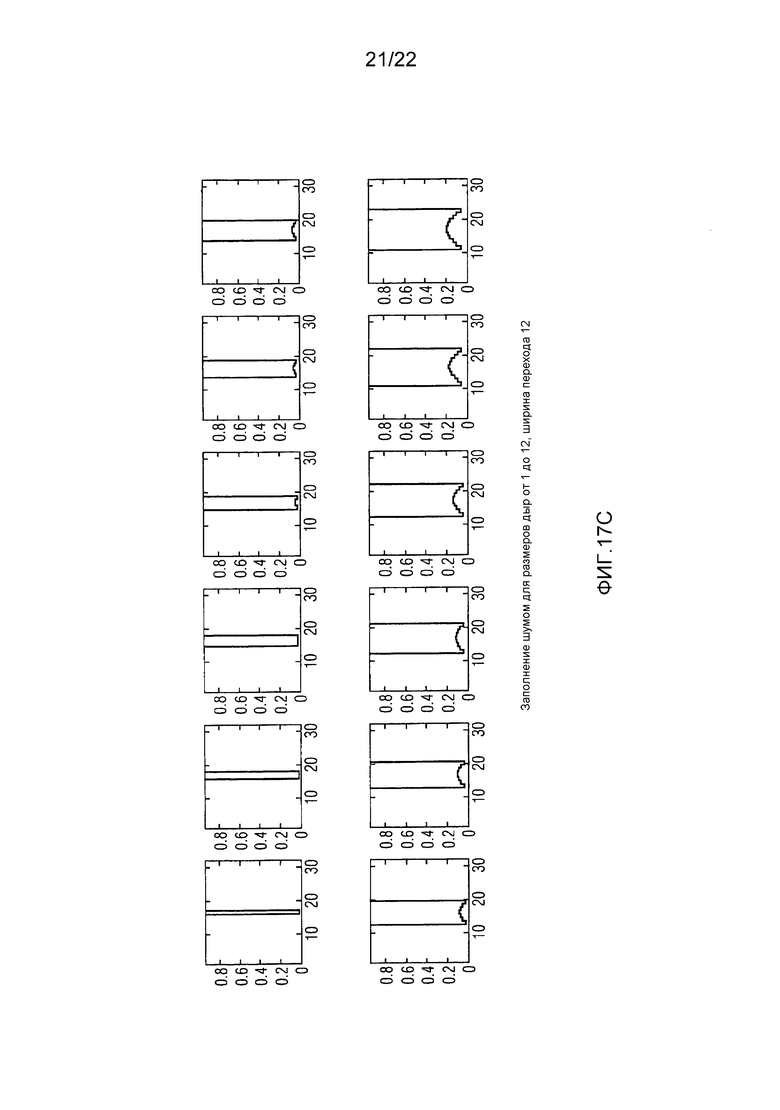
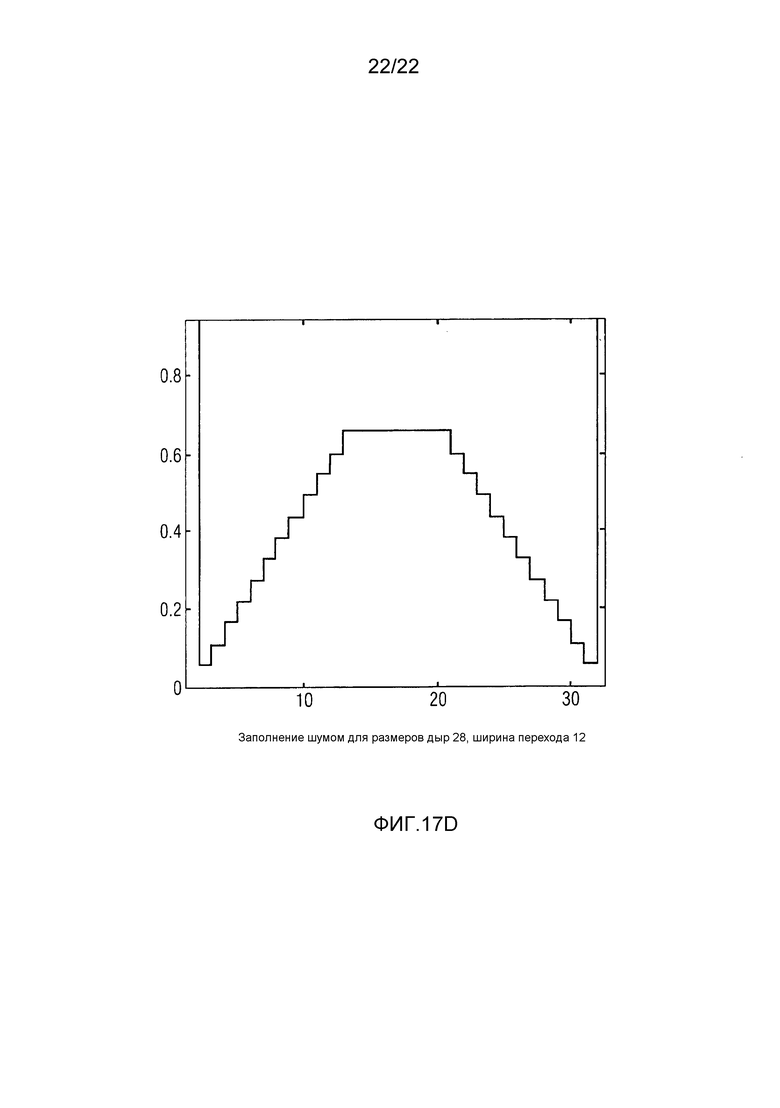
Изобретение относится к средствам для заполнения шумом при аудиокодировании. Технический результат заключается в повышении качества аудио после заполнения спектра шумом. Аудиодекодер с перцепционным преобразованием содержит: модуль заполнения шумом, модуль формирования шума частотной области, при этом модуль формирования шума частотной области сконфигурирован с возможностью: определять спектральную перцепционную весовую функцию из информации коэффициентов линейного предсказания, сигнализируемой в потоке данных, в который спектр кодируется, или определять спектральную перцепционную весовую функцию из коэффициентов масштабирования, относящихся к диапазонам коэффициентов масштабирования, сигнализируемых в потоке данных, в который спектр кодируется, при этом модуль заполнения шумом сконфигурирован с возможностью: генерировать промежуточный сигнал шума; идентифицировать непрерывные спектральные нулевые части спектра аудиосигнала; определять функцию для каждой непрерывной спектральной нулевой части в зависимости от ширины соответствующей непрерывной спектральной нулевой части, спектрального положения соответствующей непрерывной спектральной нулевой части; и формировать промежуточный сигнал шума. 6 н. и 20 з.п. ф-лы, 23 ил.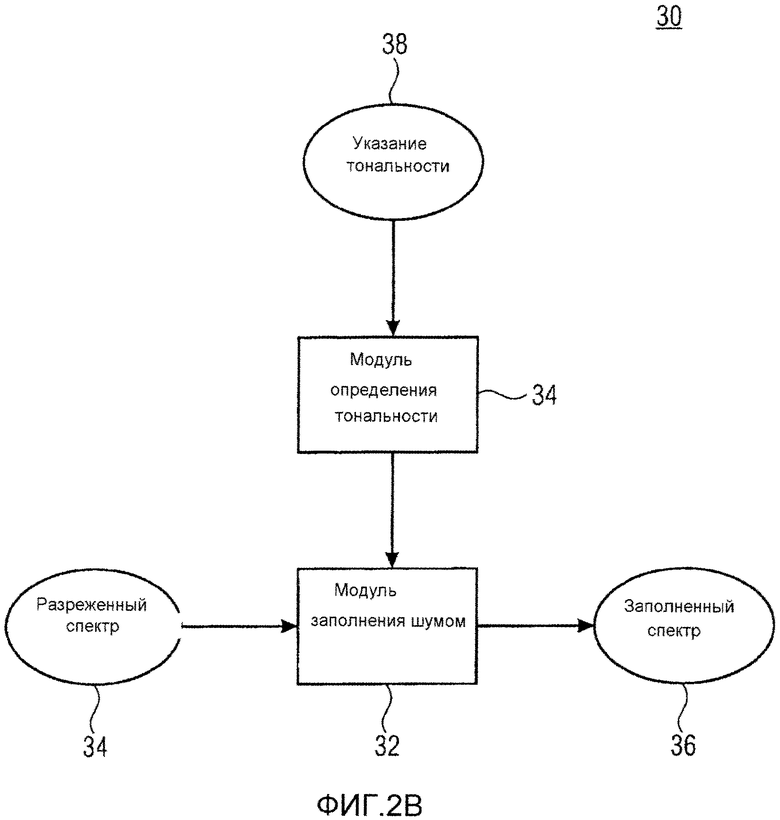
1. Аудиодекодер с перцепционным преобразованием, содержащий
модуль заполнения шумом, сконфигурированный с возможностью выполнять заполнение шумом над спектром (34) аудиосигнала посредством заполнения спектра с помощью шума для получения заполненного шумом спектра; и
модуль формирования шума частотной области, сконфигурированный с возможностью подвергать заполненный шумом спектр спектральному формированию с использованием спектральной перцепционной весовой функции,
при этом модуль формирования шума частотной области сконфигурирован с возможностью:
определять спектральную перцепционную весовую функцию из информации (162) коэффициентов линейного предсказания, сигнализируемой в потоке данных, в который спектр (34) кодируется (164), или
определять спектральную перцепционную весовую функцию из коэффициентов (112) масштабирования, относящихся к диапазонам (110) коэффициентов масштабирования, сигнализируемых в потоке данных, в который спектр (34) кодируется,
при этом модуль заполнения шумом сконфигурирован с возможностью:
генерировать промежуточный сигнал шума;
идентифицировать непрерывные спектральные нулевые части спектра аудиосигнала;
определять функцию для каждой непрерывной спектральной нулевой части в зависимости от
ширины соответствующей непрерывной спектральной нулевой части, так что функция ограничивается соответствующей непрерывной спектральной нулевой частью,
спектрального положения соответствующей непрерывной спектральной нулевой части, так что масштабирование функции зависит от спектрального положения соответствующей непрерывной спектральной нулевой части, так что величина масштабирования монотонно возрастает или убывает с возрастанием частоты спектрального положения соответствующей непрерывной спектральной нулевой части; и
спектрально формировать, для каждой непрерывной спектральной нулевой части, промежуточный сигнал шума с использованием функции, определенной для соответствующей непрерывной спектральной нулевой части, так что шум имеет глобальный спектральный наклон, имеющий отрицательный угловой коэффициент.
2. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом сконфигурирован с возможностью изменять крутизну глобального спектрального наклона в ответ на неявную или явную сигнализацию в потоке данных, в который спектр (34) кодируется (164).
3. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом сконфигурирован с возможностью выводить крутизну глобального спектрального наклона из части потока данных, которая сигнализирует спектральную перцепционную весовую функцию, или из потока данных, который сигнализирует длину окна преобразования.
4. Аудиодекодер с перцепционным преобразованием по п. 1, дополнительно содержащий
модуль обратного преобразования, сконфигурированный с возможностью выполнять обратное преобразование заполненного шумом спектра, спектрально сформированного посредством модуля формирования шума частотной области, чтобы получать обратное преобразование, и подвергать обратное преобразование обработке добавления перекрывания.
5. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом сконфигурирован так, что функция принимает максимум во внутренней части (52) непрерывной спектральной нулевой части (40), и имеет спадающие кнаружи края (58, 60), абсолютный угловой коэффициент которых отрицательно зависит от тональности.
6. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом сконфигурирован так, что функция принимает максимум во внутренней части (52) непрерывной спектральной нулевой части (40), и имеет спадающие кнаружи края (58, 60), спектральная ширина (54, 56) которых положительно зависит от тональности.
7. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом дополнительно сконфигурирован так, что функция является постоянной или унимодальной функцией (48, 50), интеграл которой - нормализованной к интегралу, равному 1 - по внешним четвертям (a, d) непрерывной спектральной нулевой части (40), отрицательно зависит от тональности.
8. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом дополнительно сконфигурирован так, что набор (80) функций зависит от тональности аудиосигнала, так что если тональность аудиосигнала увеличивается, масса функции становится более сосредоточенной во внутренней части соответствующей непрерывной спектральной нулевой части и отдаленной от внешних краев соответствующей непрерывной спектральной нулевой части.
9. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом дополнительно сконфигурирован с возможностью масштабировать шум с использованием параметра уровня шума, сигнализируемого в потоке данных, в который спектр кодируется, со спектральным единообразием.
10. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом дополнительно сконфигурирован с возможностью генерировать шум с использованием случайной или псевдослучайной обработки или с использованием наложения патчей из других спектральных местоположений спектрограммы.
11. Аудиодекодер с перцепционным преобразованием по п. 5, в котором модуль заполнения шумом дополнительно сконфигурирован с возможностью выводить тональность из параметра кодирования, с использованием которого аудиосигнал кодируется.
12. Аудиодекодер с перцепционным преобразованием по п. 11, в котором модуль заполнения шумом дополнительно сконфигурирован так, что параметр кодирования является флагом активации или усилением LTP (долгосрочного предсказания) или TNS (временного формирования шума) и/или флагом активации перегруппировки спектра, при этом флаг активации спектральной перегруппировки сигнализирует вариант выбора кодирования, согласно которому квантованные спектральные значения спектрально по-новому размещаются, с дополнительной передачей внутри потока данных предписания перегруппировки.
13. Аудиодекодер с перцепционным преобразованием по п. 1, в котором модуль заполнения шумом дополнительно сконфигурирован с возможностью ограничивать заполнение шумом на высокочастотную спектральную часть спектра аудиосигнала.
14. Аудиодекодер с перцепционным преобразованием по п. 13, в котором модуль заполнения шумом дополнительно сконфигурирован с возможностью устанавливать низкочастотное начальное положение высокочастотной спектральной части, соответствующее явной сигнализации в потоке данных, в который спектр аудиосигнала кодируется.
15. Аудиокодер с перцепционным преобразованием, содержащий
фильтр предыскажения;
модуль анализа LPC, сконфигурированный с возможностью определять информацию (162) коэффициентов линейного предсказания посредством выполнения анализа LP над версией аудиосигнала, подвергнутой фильтру предыскажения, при этом информация (162) коэффициентов линейного предсказания представляет собой огибающую спектра LPC спектра подвергнутой предыскажению версии аудиосигнала;
модуль преобразования, сконфигурированный с возможностью обеспечивать исходный спектр аудиосигнала;
модуль взвешивания спектра, сконфигурированный с возможностью спектрально взвешивать исходный спектр аудиосигнала согласно обратной к спектральной перцепционной весовой функции так, чтобы получать взвешенный по восприятию спектр,
при этом модуль спектрального взвешивания сконфигурирован с возможностью определять спектральную перцепционную весовую функцию так, чтобы следовать за огибающей спектра LPC;
модуль квантования, сконфигурированный с возможностью квантовать взвешенный по восприятию спектр способом, одинаковым для спектральных линий взвешенного по восприятию спектра так, чтобы получать квантованный спектр, при этом аудиокодер с перцепционным преобразованием сконфигурирован с возможностью кодировать квантованный спектр в поток данных, подлежащий выводу в аудиодекодер с перцепционным преобразованием, при этом информация коэффициентов линейного предсказания также сигнализируется в потоке данных;
модуль вычисления уровня шума, сконфигурированный с возможностью вычислять параметр уровня шума посредством
идентификации непрерывных спектральных нулевых частей спектра аудиосигнала и
измерения уровня взвешенного по восприятию спектра, совместно расположенного с непрерывными спектральными нулевыми частями квантованного спектра, способом, взвешенным со глобальным спектральным наклоном, имеющим положительный угловой коэффициент,
причем аудиокодер с перцепционным преобразованием сконфигурирован с возможностью осуществления заполнения шумом так, чтобы заполнить шумом непрерывные спектральные нулевые части,
генерирования промежуточного сигнала шума;
определения функции для каждой непрерывной спектральной нулевой части в зависимости от
ширины соответствующей непрерывной спектральной нулевой части, так что функция ограничивается соответствующей непрерывной спектральной нулевой частью,
спектрального положения соответствующей непрерывной спектральной нулевой части, так что масштабирование функции зависит от спектрального положения соответствующей непрерывной спектральной нулевой части, так что величина масштабирования монотонно возрастает или убывает с возрастанием частоты спектрального положения соответствующей непрерывной спектральной нулевой части; и
спектрального формирования, для каждой непрерывной спектральной нулевой части, промежуточного сигнала шума с использованием функции, определенной для соответствующей непрерывной спектральной нулевой части, так что шум имеет глобальный спектральный наклон.
16. Аудиокодер с перцепционным преобразованием по п. 15, в котором фильтр предыскажения сконфигурирован с возможностью подвергать высокочастотной фильтрации аудиосигнал с изменяющейся величиной предыскажения, чтобы получать версию аудиосигнала, подвергнутую фильтру предыскажения, при этом модуль вычисления уровня шума сконфигурирован с возможностью устанавливать угловой коэффициент глобального спектрального наклона в зависимости от величины предыскажения.
17. Аудиокодер с перцепционным преобразованием по п. 16, сконфигурированный с возможностью явно кодировать величину глобального спектрального наклона или величину предыскажения в потоке данных, в который квантованный спектр (34) кодируется (164).
18. Аудиокодер с перцепционным преобразованием по п. 17, содержащий
модуль определения коэффициентов масштабирования, сконфигурированный с возможностью, под управлением модели восприятия, определять коэффициенты (112) масштабирования, относящиеся к диапазонам (110) коэффициентов масштабирования, в зависимости от порога маскирования, при этом модуль спектрального взвешивания сконфигурирован с возможностью определять спектральную перцепционную весовую функцию, чтобы следовала за коэффициентами масштабирования.
19. Аудиокодер с перцепционным преобразованием по п. 15, в котором модуль вычисления уровня шума сконфигурирован с возможностью определять, для каждой непрерывной спектральной нулевой части, функцию так, что
она принимает максимум во внутренней части (52) непрерывной спектральной нулевой части (40), и имеет спадающие кнаружи края (58, 60), абсолютный угловой коэффициент которых отрицательно зависит от тональности,
она принимает максимум во внутренней части (52) непрерывной спектральной нулевой части (40) и имеет спадающие кнаружи края (58, 60), спектральная ширина (54, 56) которых положительно зависит от тональности, и/или
она является постоянной или унимодальной функцией (48, 50), интеграл которой - нормализованной к интегралу, равному 1 - по внешним четвертям (a, d) непрерывной спектральной нулевой части (40) отрицательно зависит от тональности.
20. Аудиокодер с перцепционным преобразованием по п. 19, в котором модуль вычисления уровня шума сконфигурирован с возможностью выводить тональность из флага активации или усиления LTP (долгосрочного предсказания) или TNS (временного формирования шума) и/или флага активации перегруппировки спектра, используемого аудиокодером с перцепционным преобразованием, чтобы кодировать аудиосигнал, при этом флаг активации спектральной перегруппировки сигнализирует вариант выбора кодирования, согласно которому квантованные спектральные значения спектрально по-новому размещаются, с дополнительной передачей внутри потока данных предписания перегруппировки.
21. Аудиокодер с перцепционным преобразованием по п. 15, сконфигурированный с возможностью ограничивать заполнение шумом на высокочастотную спектральную часть спектра аудиосигнала.
22. Аудиокодер с перцепционным преобразованием по п. 15, в котором модуль вычисления уровня шума сконфигурирован с возможностью ограничивать упомянутое измерение высокочастотной спектральной частью с ее низкочастотным начальным положением, установленным явной сигнализацией, в потоке данных, в который кодируется аудиосигнал.
23. Способ декодирования аудио с перцепционным преобразованием, содержащий
выполнение заполнения шумом над спектром (34) аудиосигнала посредством заполнения спектра с помощью шума, чтобы получать заполненный шумом спектр; и
формирование шума частотной области, содержащее подвергание заполненного шумом спектра спектральному формированию с использованием спектральной перцепционной весовой функции, при этом формирование шума частотной области содержит определение спектральной перцепционной весовой функции из информации (162) коэффициентов линейного предсказания, сигнализируемой в потоке данных, в который спектр (34) кодируется (164), или определение спектральной перцепционной весовой функции из коэффициентов (112) масштабирования, относящихся к диапазонам (110) коэффициентов масштабирования, сигнализируемых в потоке данных, в который спектр (34) кодируется,
при этом заполнение шумом включает в себя
генерирование промежуточного сигнала шума;
идентификацию непрерывных спектральных нулевых частей спектра аудиосигнала;
определение функции для каждой непрерывной спектральной нулевой части в зависимости от
ширины соответствующей непрерывной спектральной нулевой части, так что функция ограничивается соответствующей непрерывной спектральной нулевой частью,
спектрального положения соответствующей непрерывной спектральной нулевой части, так что масштабирование функции зависит от спектрального положения соответствующей непрерывной спектральной нулевой части, так что величина масштабирования монотонно возрастает или убывает с возрастанием частоты спектрального положения соответствующей непрерывной спектральной нулевой части; и
спектрального формирования, для каждой непрерывной спектральной нулевой части, промежуточного сигнала шума с использованием функции, определенной для соответствующей непрерывной спектральной нулевой части, так что шум демонстрирует глобальный спектральный наклон, имеющий отрицательный угловой коэффициент.
24. Способ кодирования аудио с перцепционным преобразованием, содержащий
определение информации (162) коэффициентов линейного предсказания посредством выполнения анализа LP над версией аудиосигнала, подвергнутой фильтру предыскажения, при этом информация (162) коэффициентов линейного предсказания представляет огибающую спектра LPC спектра подвергнутой предыскажению версии аудиосигнала;
обеспечение исходного спектра аудиосигнала посредством модуля преобразования;
спектральное взвешивание исходного спектра аудиосигнала согласно обратной к спектральной перцепционной весовой функции, чтобы получать взвешенный по восприятию спектр, при этом функция спектрального взвешивания определяется, чтобы следовала за огибающей спектра LPC;
квантование взвешенного по восприятию спектра способом, одинаковым для спектральных линий взвешенного по восприятию спектра, чтобы получать квантованный спектр, при этом квантованный спектр кодируется в поток данных, подлежащий выводу в аудиодекодер с перцепционным преобразованием, при этом информация коэффициентов линейного предсказания также сигнализируется в потоке данных;
вычисление параметра уровня шума посредством
идентификации непрерывных спектральных нулевых частей спектра аудиосигнала и
измерения уровня взвешенного по восприятию спектра, совместно расположенного с непрерывными спектральными нулевыми частями квантованного спектра, способом, взвешенным с глобальным спектральным наклоном, имеющим положительный угловой коэффициент, и
осуществления заполнения шумом так, чтобы заполнить шумом непрерывные спектральные нулевые части,
генерирования промежуточного сигнала шума;
определения функции для каждой непрерывной спектральной нулевой части в зависимости от
ширины соответствующей непрерывной спектральной нулевой части, так что функция ограничивается соответствующей непрерывной спектральной нулевой частью,
спектрального положения соответствующей непрерывной спектральной нулевой части, так что масштабирование функции зависит от спектрального положения соответствующей непрерывной спектральной нулевой части, так что величина масштабирования монотонно возрастает или убывает с возрастанием частоты спектрального положения соответствующей непрерывной спектральной нулевой части; и
спектрального формирования, для каждой непрерывной спектральной нулевой части, промежуточного сигнала шума с использованием функции, определенной для соответствующей непрерывной спектральной нулевой части, так что шум имеет глобальный спектральный наклон.
25. Машиночитаемый носитель, на котором сохранена компьютерная программа, имеющая программный код для выполнения, когда исполняется на компьютере, способа по п. 23.
26. Машиночитаемый носитель, на котором сохранена компьютерная программа, имеющая программный код для выполнения, когда исполняется на компьютере, способа по п. 24.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 5692102 A, 25.11.1997 | |||
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ ВЗВЕШЕННОГО СЛОЖЕНИЯ С ПЕРЕКРЫТИЕМ | 2006 |
|
RU2405217C2 |

