Настоящее изобретение относится к основанному на линейном предсказании кодированию аудио и, в частности, основанному на линейном предсказании кодированию аудио с использованием спектрального кодирования.
Классический подход для квантования и кодирования в частотной области состоит в том, чтобы брать (перекрывающиеся) окна сигнала, выполнять время-частотное преобразование, применять модель восприятия и квантовать индивидуальные частоты с использованием энтропийного кодера, такого как арифметический кодер [1]. Модель восприятия является в своей основе весовой функцией, которая умножается на спектральные линии, так что ошибки в каждой взвешенной спектральной линии имеют равное воспринимаемое влияние. Все взвешенные линии могут, таким образом, квантоваться с одной и той же точностью, и полная точность определяет компромисс между качеством восприятия и потреблением битов.
В AAC и режиме частотной области USAC (не-TCX), модель восприятия определена пополосно, так что группа спектральных линий (спектральная полоса) имеет один и тот же вес. Эти веса известны как коэффициенты масштабирования, так как они определяют, посредством какого коэффициента полоса масштабируется. Дополнительно, коэффициенты масштабирования кодируются разностным образом.
В области TCX веса не кодируются с использованием коэффициентов масштабирования, но посредством модели LPC [2], которая определяет огибающую спектра, то есть полную форму спектра. LPC используется, так как оно обеспечивает возможность гладкого переключения между TCX и ACELP. Однако LPC не соответствует хорошо модели восприятия, которая должна быть намного более гладкой, в силу чего обработка, известная как взвешивание, применяется к LPC, так что взвешенное LPC приблизительно соответствует требуемой модели восприятия.
В области TCX USAC спектральные линии кодируются посредством арифметического кодера. Арифметический кодер основывается на присвоении вероятностей всем возможным конфигурациям сигнала, так что высокие значения вероятностей могут кодироваться с малым количеством бит, так что потребление битов минимизируется. Чтобы оценить распределение вероятностей спектральных линий, кодек использует модель вероятностей, которая предсказывает распределение сигнала на основе предыдущих, уже кодированных линий во время-частотном пространстве. Предыдущие линии известны как контекст текущей линии для кодирования [3].
Недавно NTT предложила способ для улучшения контекста арифметического кодера (ср. [4]). Он основывается на использовании LTP, чтобы определять приблизительные положения гармонических линий (гребенчатый фильтр), и перегруппировке спектральных линий, так что предсказание амплитуды из контекста является более эффективным.
Вообще говоря, чем лучше оценка распределения вероятностей, тем более эффективное сжатие достигается посредством энтропийного кодирования. Было бы предпочтительным иметь под рукой концепцию, которая бы обеспечивала возможность достижения оценки распределения вероятностей аналогичного качества, которая достижима с использованием любого из вышеописанных способов, но при уменьшенной сложности.
Соответственно, целью настоящего изобретения является обеспечить схему основывающегося на линейном предсказании кодирования аудио, имеющую улучшенные характеристики. Эта цель достигается посредством сущности независимых пунктов формулы.
Базовой находкой настоящего изобретения является то, что основанное на линейном предсказании кодирование аудио может быть улучшено посредством кодирования спектра, составленного из упомянутого множества спектральных компонент, с использованием оценки распределения вероятностей, определенной для каждой из множества спектральных компонент из информации коэффициентов линейного предсказания. В частности, информация коэффициентов линейного предсказания является доступной в любом случае. Соответственно, она может использоваться для определения оценки распределений вероятностей как на кодирующей, так и декодирующей стороне. Последнее определение может осуществляться вычислительно простым способом посредством использования, например, соответствующей параметризации для оценки распределений вероятностей на множестве спектральных компонент. В общей сложности, эффективность кодирования, как обеспечивается посредством энтропийного кодирования, является совместимой с оценками распределений вероятностей, как достигаются с использованием выбора контекста, но ее вывод является менее сложным. Например, вывод может быть чисто аналитическим и/или не требует какой-либо информации об атрибутах соседних спектральных линий, как, например, ранее кодированных/декодированных спектральных значениях соседних спектральных линий, как имеет место в выборе пространственного контекста. Это, в свою очередь, обеспечивает распараллеливание процессов вычисления более легко, например. Более того, меньшие требования к памяти и меньшее количество доступов к памяти могут быть необходимы.
В соответствии с одним вариантом осуществления настоящей заявки спектр, спектральные значения которого энтропийно кодируются с использованием оценки вероятностей, определенной как только что описано, может быть возбуждением с кодированным преобразованием, полученным с использованием информации коэффициентов линейного предсказания.
В соответствии с одним вариантом осуществления настоящей заявки, например, спектр является возбуждением с кодированным преобразованием, определенным, однако в перцепционно взвешенной области. То есть, спектр, энтропийно кодированный с использованием определенной оценки распределений вероятностей, соответствует спектру аудиосигналов предварительно отфильтрованному с использованием функции преобразования, соответствующей перцепционно взвешенному синтезирующему фильтру линейного предсказания, определенному посредством информации коэффициентов линейного предсказания и для каждой из множества спектральных компонент параметр распределения вероятностей определяется так, что параметры распределений вероятностей спектрально следуют, например, являются масштабированной версией, функции, которая зависит от произведения передаточной функции синтезирующего фильтра линейного предсказания и инверсии передаточной функции перцепционно взвешенной модификации синтезирующего фильтра линейного предсказания. Для каждой из множества спектральных компонент, оценка распределения вероятностей тогда является параметризуемой функцией, параметризованной с использованием параметра распределения вероятностей соответствующей спектральной компоненты. Снова, информация коэффициентов линейного предсказания является доступной в любом случае, и вывод параметра распределения вероятностей может осуществляться как чисто аналитическая обработка и/или обработка, которая не требует какой-либо взаимной зависимости между спектральными значениями в разных спектральных компонентах спектра.
В соответствии с еще дополнительным вариантом осуществления параметр распределения вероятностей альтернативно или дополнительно определяется так, что параметры распределений вероятностей спектрально следуют функции, которая мультипликативно зависит от спектральной тонкой структуры, которая в свою очередь определяется с использованием долгосрочного предсказания (LTP). Снова, в некоторых основывающихся на линейном предсказании кодеках, информация LTP является доступной в любом случае, и более того, определение параметров распределений вероятностей все еще является реализуемым, чтобы выполняться чисто аналитически и/или без взаимных зависимостей между кодированием спектральных значений разных спектральных компонент спектра. При комбинировании использования LTP с перцепционным кодированием возбуждения с кодированным преобразованием, эффективность кодирования дополнительно улучшается при умеренном увеличении сложности.
Предпочтительные варианты реализации и варианты осуществления являются предметом зависимых пунктов формулы изобретения. Предпочтительные варианты осуществления настоящей заявки описываются дополнительно ниже по отношению к фигурам, на которых
Фиг. 1 показывает блок-схему основывающегося на линейном предсказании аудиокодера согласно одному варианту осуществления;
Фиг. 2 показывает блок-схему определителя спектра из фиг. 1 в соответствии с одним вариантом осуществления;
Фиг. 3a показывает разные передаточные функции, встречающиеся в описании режима работы элементов, показанных на фиг. 1 и 2, при осуществлении их с использованием перцепционного кодирования;
Фиг. 3b показывает функции из фиг. 3a, взвешенные, однако, с использованием инверсии модели восприятия;
Фиг. 4 показывает блок-схему, иллюстрирующую внутреннюю работу модуля 14 оценки распределений вероятностей из фиг. 1 в соответствии с одним вариантом осуществления с использованием перцепционного кодирования;
Фиг. 5a показывает график, иллюстрирующий исходный аудиосигнал после фильтрации с предыскажением и его оцененную огибающую;
Фиг. 5b показывает пример для функции LTP, используемой, чтобы более близко оценивать огибающую, в соответствии с одним вариантом осуществления;
Фиг. 5c показывает график, иллюстрирующий результат оценки огибающей посредством применения функции LTP из фиг. 5b к примеру из фиг. 5a;
Фиг. 6 показывает блок-схему внутренней работы модуля 14 оценки распределений вероятностей в дополнительном варианте осуществления с использованием перцепционного кодирования также как обработки LTP;
Фиг. 7 показывает блок-схему основывающегося на линейном предсказании аудиодекодера в соответствии с одним вариантом осуществления;
Фиг. 8 показывает блок-схему основывающегося на линейном предсказании аудиодекодера в соответствии с еще дополнительным вариантом осуществления;
Фиг. 9 показывает блок-схему фильтра из фиг. 8 в соответствии с одним вариантом осуществления;
Фиг. 10 показывает блок-схему более подробной структуры части кодера из фиг. 1, расположенной в каскаде квантования и энтропийного кодирования и модуле 14 оценки распределений вероятностей в соответствии с одним вариантом осуществления; и
Фиг. 11 показывает блок-схему части внутри основывающегося на линейном предсказании аудиодекодера из, например, фиг. 7 и 8, расположенной в его части, которая соответствует части из фиг. 10, которая расположена на кодирующей стороне, т.е. расположена в модуле 102 оценки распределений вероятностей и каскаде 104 энтропийного декодирования и деквантования, в соответствии с одним вариантом осуществления.
До описания различных вариантов осуществления настоящей заявки, идеи, лежащие в ее основе, иллюстративно описываются по отношению к уровню техники, описанному во вводной части описания настоящей заявки. Конкретные признаки, происходящие от сравнения с конкретными способами сравнения, как, например, USAC, не должны трактоваться как ограничивающие объем настоящей заявки и ее варианты осуществления.
В подходе USAC для арифметического кодирования, контекст в своей основе предсказывает распределение амплитуд последующих линий. То есть, спектральные линии или спектральные компоненты сканируются в спектральных измерениях при кодировании/декодировании, и распределение амплитуд предсказывается непрерывно в зависимости от ранее кодированных/декодированных спектральных значений. Однако LPC уже кодирует ту же информацию явно, без необходимости в предсказании. Соответственно, применение LPC вместо этого контекста должно приносить аналогичный результат, однако при более низкой вычислительной сложности или, по меньшей мере, с возможностью достижения более низкой сложности. Фактически, так как при низких битрейтах спектр, по существу, состоит из единиц и нулей, контекст будет почти всегда очень разреженным и лишенным полезной информации. Поэтому, в теории LPC должно фактически быть намного более хорошим источником для оценок амплитуд, так как шаблон соседних, уже кодированных/декодированных спектральных значений, используемых для оценки распределения вероятностей, просто разреженно заполнен полезной информацией. Кроме того, информация LPC уже является доступной в обоих кодере и декодере, в силу чего она получается при нулевых затратах в терминах потребления битов.
Модель LPC определяет только форму огибающей спектра, то есть относительные амплитуды каждой линии, но не абсолютную амплитуду. Чтобы определить распределение вероятностей для одиночной линии, нам всегда нужна абсолютная амплитуда, то есть значение для дисперсии сигнала (или аналогичная мера). Существенная часть большинства моделей модулей основывающегося на LPC спектрального квантования должна соответственно быть масштабированием огибающей LPC, так чтобы достигалась требуемая дисперсия (и, таким образом, требуемое потребление битов). Это масштабирование должно обычно выполняться в обоих кодере, также как декодере, так как распределения вероятностей для каждой линии тогда зависят от масштабированного LPC.
Как описано выше, модель восприятия (взвешенное LPC) может использоваться, чтобы определять модель восприятия, т.е. квантование может выполняться в перцепционной области, так что ожидаемая ошибка квантования в каждой спектральной линии вызывает приблизительно одинаковую величину воспринимаемого искажения. Соответственно, если это так, модель LPC преобразовывается в перцепционную область также посредством умножения ее на взвешенное LPC, как определяло ниже. В вариантах осуществления, описанных ниже, часто предполагается, что огибающая LPC преобразовывается в перцепционную область.
Таким образом, является возможным применять независимую модель вероятностей для каждой спектральной линии. Является разумным предполагать, что спектральные линии не имеют никакой предсказуемой корреляции фаз, в силу чего является достаточным моделировать только амплитуду. Так как можно предполагать, что LPC кодирует амплитуду эффективно, наличие основывающегося на контексте арифметического кодера, вероятно, не улучшит эффективность оценки амплитуды.
Соответственно, является возможным применять основанный на контексте энтропийный кодер, так что контекст зависит от, или даже состоит из, огибающей LPC.
В дополнение к огибающей LPC, LTP также может использоваться, чтобы выводить информацию огибающей. В конечном итоге, LTP может соответствовать гребенчатому фильтру в частотной области. Некоторые практические детали описываются дополнительно ниже.
После объяснения некоторых мыслей, которые ведут к идее, лежащей в основе вариантов осуществления, описанных дополнительно ниже, описание этих вариантов осуществления теперь начинается по отношению к фиг. 1, которая показывает один вариант осуществления для основанного на линейном предсказании аудиокодера согласно одному варианту осуществления настоящей заявки. Основанный на линейном предсказании аудиокодер из фиг. 1, в общем, показан с использованием ссылочной позиции 10 и содержит анализатор 12 линейного предсказания, оценку 14 распределений вероятностей, определитель 16 спектра и каскад 18 квантования и энтропийного кодирования. Основанный на линейном предсказании аудиокодер 10 из фиг. 1 принимает аудиосигнал, подлежащий кодированию, например, на входе 20, и выводит поток 22 данных, который соответственно имеет аудиосигнал, кодированный в нем. Анализатор 12 LP и определитель 16 спектра, как показано на фиг. 1, либо напрямую, либо косвенно соединены с входом 20. Модуль 14 оценки распределений вероятностей соединен между анализатором 12 LP и каскадом 18 квантования и энтропийного кодирования и каскад 18 квантования и энтропийного кодирования, в свою очередь, соединен с выходом определителя 16 спектра. Как можно видеть на фиг. 1, анализатор 12 LP и каскад 18 квантования и энтропийного кодирования вносят вклад в формирование/генерирование потока 22 данных. Как будет описываться более подробно ниже, кодер 10 может необязательно содержать фильтр 24 предыскажений, который может быть соединен между входом 20 и анализатором 12 LP и/или определителем 16 спектра. Дополнительно, определитель 16 спектра может необязательно быть соединен с выходом анализатора 12 LP.
В частности, анализатор 12 LP сконфигурирован с возможностью определять информацию коэффициентов линейного предсказания на основе аудиосигнала, входящего на входе 20. Как изображено на фиг. 1, анализатор 12 LP может либо выполнять анализ линейного предсказания над аудиосигналом на входе 20 напрямую или над его некоторой модифицированной версией, как, например, его предварительно искаженной версией, как получается посредством фильтра 24 предыскажений. Режим работы анализатора 12 LP может, например, включать в себя оконную обработку входящего сигнала, чтобы получать последовательность подвергнутых оконной обработке частей сигнала, подлежащего анализу LP, определение автокорреляции, чтобы определять автокорреляцию каждой подвергнутой оконной обработке части, и корреляционную оконную обработку, которая является необязательной, для применения функции корреляционного окна к автокорреляциям. Оценка параметров линейного предсказания может затем выполняться над автокорреляциями или выводом корреляционной оконной обработки, т.е. подвергнутыми оконной обработке функциями автокорреляции. Оценка параметров линейного предсказания может, например, включать в себя выполнение алгоритма Винера-Левинсона-Дурбина или другого подходящего алгоритма к (подвергнутым корреляционной оконной обработке) автокорреляциям, чтобы выводить коэффициенты линейного предсказания в расчете на автокорреляцию, т.е. в расчете на подвергнутую оконной обработке часть сигнала, подлежащего анализу LP. То есть на выходе анализатора 12 LP, в результате получаются коэффициенты LPC, которые, как описано дополнительно ниже, используются модулем 14 оценки распределений вероятностей и, необязательно, определителем 16 спектра. Анализатор 12 LP может быть сконфигурирован с возможностью квантовать коэффициент линейного предсказания для вставки в поток 22 данных. Квантование коэффициентов линейного предсказания может выполняться в другой области, нежели область коэффициентов линейного предсказания, как, например, в области пар спектральных линий или частот спектральных линий. Квантованные коэффициенты линейного предсказания могут кодироваться в поток 22 данных. Информация коэффициентов линейного предсказания, фактически используемая модулем 14 оценки распределений вероятностей и, необязательно, определителем 16 спектра, может учитывать потери квантования, т.е. может быть квантованной версией, которая передается без потерь посредством потока данных. То есть, последний может фактически использовать в качестве информации коэффициентов линейного предсказания квантованные коэффициенты линейного предсказания, как получаются посредством анализатора 12 линейного предсказания. Только ради полноты, следует отметить, что существует огромное количество возможностей выполнения определения информации коэффициентов линейного предсказания посредством анализатора 12 линейного предсказания. Например, могут использоваться другие алгоритмы, нежели алгоритм Винера-Левинсона-Дурбина. Более того, оценка локальной автокорреляции сигнала, подлежащего анализу LP, может получаться на основе спектрального разложения сигнала, подлежащего анализу LP. В WO 2012/110476 A1, например, описано, что автокорреляция может получаться посредством оконной обработки сигнала, подлежащего анализу LP, подвергания MDCT каждой подвергнутой оконной обработке части, определения спектра мощности в расчете на спектр MDCT и выполнения обратного ODFT для перехода от области MDCT к оценке автокорреляции. Чтобы подытожить, анализатор 12 LP обеспечивает информацию коэффициентов линейного предсказания и поток 22 данных передает или содержит эту информацию коэффициентов линейного предсказания. Например, поток 22 данных передает информацию коэффициентов линейного предсказания при временном разрешении, которое определяется посредством только что упомянутой скорости подвергнутых оконной обработке частей, при этом подвергнутые оконной обработке части могут, как известно в данной области техники, перекрывать друг друга, как, например, при 50% перекрытия.
В отношении использования фильтра 24 предыскажений, следует отметить, что он может, например, осуществляться с использованием фильтрации FIR. Фильтр 24 предыскажений может, например, иметь высокочастотную передаточную функцию. В соответствии с одним вариантом осуществления фильтр 24 предыскажений осуществлен как высокочастотный фильтр n-ого порядка, как, например, 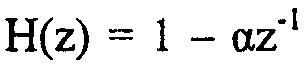 , где α установлен, например, на 0,68.
, где α установлен, например, на 0,68.
Далее описывается определитель спектра. Определитель 16 спектра сконфигурирован с возможностью определять спектр, составленный из множества спектральных компонент, на основе аудиосигнала на входе 20. Спектр должен описывать аудиосигнал. Аналогично анализатору 12 линейного предсказания, определитель 16 спектра может обрабатывать аудиосигнал 20 напрямую, или его некоторую модифицированную версию, как, например, его фильтрованную с предыскажением версию. Определитель 16 спектра может использовать любое преобразование, чтобы определять спектр, как, например, преобразование с перекрытием блоков или даже критически дискретизированное преобразование с перекрытием блоков, как, например, MDCT, хотя другие возможности также существуют. То есть, определитель 16 спектра может подвергать сигнал, подлежащий спектральному разложению, оконной обработке, чтобы получать последовательность подвергнутых оконной обработке частей, и подвергать каждую подвергнутую оконной обработке часть соответствующему преобразованию, такому как MDCT. Скорость подвергнутых оконной обработке частей определителя 16 спектра, т.е. временное разрешение спектрального разложения, может отличаться от временного разрешения, на котором анализатор 12 LP определяет информацию коэффициентов линейного предсказания.
Определитель 16 спектра, таким образом, выводит спектр, составленный из множества спектральных компонент. В частности, определитель 16 спектра может выводить, в расчете на подвергнутую оконной обработке часть, которая подвергается преобразованию, последовательность спектральных значений, именно одно спектральное значение в расчете на спектральную компоненту, например, в расчете на спектральную линию частоты. Спектральные значения могут быть комплекснозначными или действительнозначными. Спектральные значения являются действительнозначными в случае использования MDCT, например. В частности, спектральные значения могут иметь знак, т.е. они могут быть комбинацией знака и амплитуды.
Как описано выше, информация коэффициентов линейного предсказания формирует краткосрочное предсказание огибающей спектра сигнала, подвергнутого анализу LP, и может, таким образом, служить в качестве основы для определения, для каждой из множества спектральных компонент, оценки распределения вероятностей, т.е. оценки того, как, статистически, на области возможных спектральных значений изменяется вероятность того, что спектр в соответствующей спектральной компоненте, принимает некоторое возможное спектральное значение. Определение выполняется посредством модуля 14 оценки распределений вероятностей. Разные возможности существуют по отношению к деталям определения оценки распределений вероятностей. Например, хотя определитель 16 спектра может быть реализован, чтобы определять спектрограмму аудиосигнала или предварительно искаженной версии аудиосигнала, в соответствии с вариантами осуществления, дополнительно описанными ниже, определитель 16 спектра сконфигурирован с возможностью определять, в качестве спектра, сигнал возбуждения, т.е. остаточный сигнал, полученный посредством фильтрации на основе LP аудиосигнала, или его некоторой модифицированной версии, как, например, его фильтрованной с предыскажением версии. В частности, определитель 16 спектра может быть сконфигурирован с возможностью определять спектр сигнала, входящего в определитель 16 спектра, после фильтрации входящего сигнала с использованием передаточной функции, которая зависит от, или равна, инверсии синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания, т.е. фильтра анализа линейного предсказания. Альтернативно, основанный на LP аудиокодер может быть перцепционным основывающимся на LP аудиокодером и определитель 16 спектра может быть сконфигурирован с возможностью определять спектр сигнала, входящего в определитель 16 спектра, после фильтрации входящего сигнала с использованием передаточной функции, которая зависит от, или равна, инверсии синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания, но была модифицирована, чтобы, например, соответствовать инверсии оценки порога маскирования. То есть, определитель 16 спектра может быть сконфигурирован с возможностью определять спектр входящего сигнала, фильтрованного с помощью передаточной функции, которая соответствует инверсии перцепционно модифицированного синтезирующего фильтра линейного предсказания. В этом случае, определитель 16 спектра сравнительно уменьшает спектр в спектральных областях, где перцепционное маскирование является более высоким, по отношению к спектральным областям, где перцепционное маскирование является более низким. Посредством использования информации коэффициентов линейного предсказания, модуль 14 оценки распределений вероятностей, однако, все еще способен оценивать огибающую спектра, определенного посредством определителя 16 спектра, именно посредством учета перцепционной модификации синтезирующего фильтра линейного предсказания при определении оценки распределения вероятностей. Подробности в этом отношении дополнительно описываются ниже.
Дополнительно, как описано более подробно ниже, модуль 14 оценки распределений вероятностей способен использовать долгосрочное предсказание, чтобы получать информацию тонкой структуры о спектре, чтобы получать более хорошую оценку распределения вероятностей в расчете на спектральную компоненту. Параметр (параметры) LTP посылается/посылаются, например, в декодирование, чтобы обеспечивать возможность восстановления информации тонкой структуры. Подробности в этом отношении описываются дополнительно ниже.
В любом случае, каскад 18 квантования и энтропийного кодирования сконфигурирован с возможностью квантовать и осуществлять энтропийное кодирование спектра с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент посредством модуля 14 оценки распределений вероятностей. Чтобы быть более точными, каскад 18 квантования и энтропийного кодирования принимает от спектрального определителя 16 спектр 26, составленный из спектральных компонент k, или чтобы быть более точными, последовательность спектров 26 на некоторой временной скорости, соответствующей вышеупомянутой скорости подвергнутых оконной обработке частей для подвергнутых оконной обработке частей, подлежащих преобразованию. В частности, каскад 18 может принимать значение знака для спектрального значения в спектральной компоненте k и, соответствующую амплитуду 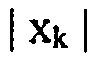 для спектральной компоненты k.
для спектральной компоненты k.
С другой стороны, каскад 18 квантования и энтропийного кодирования принимает, в расчете на спектральную компоненту k, оценку 28 распределения вероятностей, определяющую, для каждого возможного значения спектральное значение, которое может быть принято, оценку значения вероятности, определяющую вероятность спектрального значения в соответствующей спектральной компоненте k, имеющей это очень возможное значение. Например, оценка распределения вероятностей, определенная посредством модуля 14 оценки распределений вероятностей, концентрируется только на амплитудах спектральных значений и определяет, соответственно, значения вероятностей только для положительных значений, включающих в себя нуль. В частности, каскад 18 квантования и энтропийного кодирования квантует спектральные значения, например, с использованием правила квантования, которое одинаково для всех спектральных компонент. Уровни амплитуд для спектральных компонент k, таким образом, полученные, соответственно определены на области целых чисел, включающих в себя нуль, вплоть до, необязательно, некоторого максимального значения. Оценка распределения вероятностей может, для каждой спектральной компоненты k, определяться на этой области возможных целых чисел i, т.е. p(k, i) будет оценкой вероятностей для спектральной компоненты k, и определяться для целых чисел 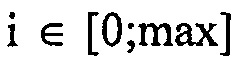 , где целое число
, где целое число 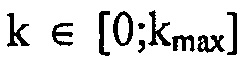 , где kmax является максимальной спектральной компонентой и
, где kmax является максимальной спектральной компонентой и 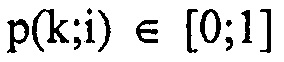 для всех k, i, и сумма p(k, i) по всем
для всех k, i, и сумма p(k, i) по всем 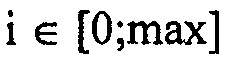 равна единице для всех k.
равна единице для всех k.
Каскад 18 квантования и энтропийного кодирования может, например, использовать постоянный размер шага квантования для квантования, при этом размер шага является одинаковым для всех спектральных компонент k. Чем лучше оценка 28 распределений вероятностей, тем лучше эффективность сжатия, достигаемая посредством каскада 18 квантования и энтропийного кодирования.
Откровенно говоря, модуль 14 оценки распределений вероятностей может использовать информацию коэффициентов линейного предсказания, обеспеченную посредством анализатора 12 LP, чтобы получать информацию об огибающей 30, или аппроксимировать форму, спектра 26. С использованием этой оценки 30 огибающей или формы, модуль 14 оценки может выводить меру 32 дисперсии для каждой спектральной компоненты k посредством, например, подходящим образом масштабирования огибающей, с использованием общего коэффициента масштабирования, одинакового для всех спектральных компонент. Эти меры дисперсии в спектральных компонентах k могут служить в качестве параметров для параметризаций оценок распределений вероятностей для каждой спектральной компоненты k. Например, p(k, i) может быть f(i, l(k)) для всех k, где l(i) является определенной мерой дисперсии в спектральной компоненте k, где f(i, l) является, для каждого фиксированного l, соответствующей функцией переменной i, такой как монотонная функция, как, например, как определено ниже, функцией Гаусса или Лапласа, определенной для положительных значений i, включающих в себя нуль, в то время как l является параметром функции, который измеряет "крутизну" или "ширину" функции, как будет описано ниже с более точной формулировкой. С использованием параметризованных параметризаций, каскад 18 квантования и энтропийного кодирования, таким образом, способен осуществлять эффективное энтропийное кодирование спектральных значений спектра в поток 22 данных. Как станет ясно из описания, приведенного далее ниже с большими деталями, определение оценки 28 распределений вероятностей может осуществляться чисто аналитически и/или без требования взаимных зависимостей между спектральными значениями разных спектральных компонент одного и того же спектра 26, т.е. независимо от спектральных значений разных спектральных компонент, относящихся к одному и тому же моменту времени. Каскад 18 квантования и энтропийного кодирования может соответственно выполнять энтропийное кодирование квантованных спектральных значений или уровней амплитуд, соответственно, параллельно. Фактическое энтропийное кодирование может в свою очередь быть арифметическим кодированием или кодированием с переменной длиной или некоторой другой формой энтропийного кодирования, как, например, энтропийным кодированием на основе разделения интервала вероятностей или подобным. В действительности, каскад 18 квантования и энтропийного кодирования осуществляет энтропийное кодирование каждого спектрального значения в некоторой спектральной компоненте k с использованием оценки 28 распределения вероятностей для этой спектральной компоненты k, так что потребление битов для соответствующего спектрального значения k для его кодирования в поток 22 данных является более низким внутри частей области возможных значений спектрального значения в спектральной компоненте k, где вероятность, показанная посредством оценки 28 распределения вероятностей, является более высокой, и потребление битов является более большим в частях области возможных значений, где вероятность, показанная посредством оценки 28 распределения вероятностей, является более низкой. В случае арифметического кодирования, например, может использоваться основанное на таблице арифметическое кодирование. В случае кодирования с переменной длиной, разные таблицы кодовых слов, отображающие возможные значения на кодовые слова, могут выбираться и применяться каскадом квантования и энтропийного кодирования в зависимости от оценки 28 распределения вероятностей, определенной посредством модуля 14 оценки распределений вероятностей для соответствующей спектральной компоненты k.
Фиг. 2 показывает возможный вариант осуществления определителя 16 спектра из фиг. 1. Согласно фиг. 2, определитель 16 спектра содержит определитель 34 коэффициентов масштабирования, модуль 36 преобразования и спектральный формирователь 38 (модуль придания формы спектру). Модуль 36 преобразования и спектральный формирователь 38 последовательно соединены друг с другом между входом и выходом спектрального определителя 16, через которые спектральный определитель 16 соединен между входом 20 и каскадом 18 квантования и энтропийного кодирования на фиг. 1. Определитель 34 коэффициентов масштабирования, в свою очередь, соединен между анализатором 12 LP и дополнительным входом спектрального формирователя 38 (см. фиг. 1).
Определитель 34 коэффициентов масштабирования сконфигурирован с возможностью использовать информацию коэффициентов линейного предсказания, чтобы определять коэффициенты масштабирования. Модуль 36 преобразования спектрально разлагает сигнал, который принимает, чтобы получать исходный спектр. Как описано выше, входящий сигнал может быть исходным аудиосигналом на входе 20 или, например, его предварительно искаженной версией. Как также уже описано выше, модуль 36 преобразования может внутренне подвергать сигнал, подлежащий преобразованию, оконной обработке, по частям, с использованием перекрывающихся частей, при индивидуальном преобразовании каждой подвергнутой оконной обработке части. Как уже описано выше, для преобразования может использоваться MDCT. То есть, модуль 36 преобразования выводит одно спектральное значение 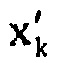 в расчете на спектральную компоненту k и спектральный формирователь 38 сконфигурирован с возможностью спектрально формировать этот исходный спектр посредством масштабирования спектра с использованием коэффициентов масштабирования, т.е. посредством масштабирования каждого исходного спектрального значения
в расчете на спектральную компоненту k и спектральный формирователь 38 сконфигурирован с возможностью спектрально формировать этот исходный спектр посредством масштабирования спектра с использованием коэффициентов масштабирования, т.е. посредством масштабирования каждого исходного спектрального значения 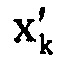 с использованием коэффициентов масштабирования sk, выведенных определителем 34 коэффициентов масштабирования, чтобы получать соответствующее спектральное значение xk, которое затем подвергается квантованию и энтропийному кодированию в каскаде 18 из фиг. 1.
с использованием коэффициентов масштабирования sk, выведенных определителем 34 коэффициентов масштабирования, чтобы получать соответствующее спектральное значение xk, которое затем подвергается квантованию и энтропийному кодированию в каскаде 18 из фиг. 1.
Спектральное разрешение, при котором определитель 34 коэффициентов масштабирования определяет коэффициенты масштабирования, не необходимо совпадает с разрешением, определенным посредством спектральной компоненты k. Например, перцепционно мотивированное группирование спектральных компонент в спектральные группы, как, например, полосы барков, может формировать спектральное разрешение, в котором определяются коэффициенты масштабирования, т.е. спектральные веса, посредством которых взвешиваются спектральные значения спектра, выведенные модулем 36 преобразования.
Определитель 34 коэффициентов масштабирования сконфигурирован с возможностью определять коэффициенты масштабирования, так что они представляют, или аппроксимируют, передаточную функцию, которая зависит от инверсии синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания. Например, определитель 34 коэффициентов масштабирования может быть сконфигурирован с возможностью использовать коэффициенты линейного предсказания, как получены от анализатора 12 LP, например, в их квантованной форме, в которой они также являются доступными на декодирующей стороне, посредством потока 22 данных, в качестве основы для преобразования LPC в MDCT, которое, в свою очередь, может включать в себя ODFT. Естественно, также существуют альтернативы. В случае вышеописанных альтернатив, где аудиокодер из фиг. 1 является перцепционным основывающимся на линейном предсказании аудиокодером, определитель 34 коэффициентов масштабирования может быть сконфигурирован с возможностью выполнять перцепционно мотивированное взвешивание коэффициентов LPC сначала до выполнения преобразования в спектральные коэффициенты с использованием, например, ODFT. Однако другая возможность также может существовать. Как будет описано более подробно ниже, передаточная функция фильтрации, результирующей из спектрального масштабирования посредством спектрального формирователя 38, может зависеть, через определение коэффициентов масштабирования, выполняемое посредством определителя 34 коэффициентов масштабирования, от инверсии синтезирующего фильтра линейного предсказания 1/A(z), определенного посредством информации коэффициентов линейного предсказания, так что передаточная функция является инверсией передаточной функции 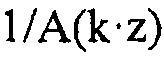 , где k здесь обозначает постоянную, которая может быть, например, равной 0,92.
, где k здесь обозначает постоянную, которая может быть, например, равной 0,92.
Чтобы более хорошо понимать взаимное отношение между функциональностью определителя спектра с одной стороны и модулем 14 оценки распределений вероятностей с другой стороны, и тем, как это отношение ведет к эффективной операции каскада 18 квантования и энтропийного кодирования в случае основывающегося на линейном предсказании аудиокодера, действующего как перцепционный основанный на линейном предсказании аудиокодер, ссылка делается на фиг. 3a и 3b. Фиг. 3a показывает исходный спектр 40. Здесь, он является иллюстративным спектром аудиосигнала, взвешенным посредством передаточной функции фильтра предыскажений. Чтобы быть более точными, фиг. 3a показывает амплитуду спектра 40, вычерченного над спектральными компонентами или спектральными линиями k. На том же графике, фиг. 3a показывает передаточную функцию синтезирующего фильтра линейного предсказания A(z), умноженную на передаточную функцию фильтра предыскажений 24, результирующее произведение обозначено 42. Как можно видеть, функция 42 аппроксимирует огибающую или грубую форму спектра 40. На фиг. 3a, перцепционно мотивированная модификация синтезирующего фильтра линейного предсказания показана, как A(0,92z) в иллюстративном случае, упомянутом выше. Эта "модель восприятия" обозначена посредством ссылочной позиции 44. Функция 44, таким образом, представляет упрощенную оценку порога маскирования аудиосигнала посредством учета, по меньшей мере, спектральных окклюзий. Определитель 34 спектральных коэффициентов определяет коэффициенты масштабирования так, чтобы аппроксимировать инверсию модели 44 восприятия. Результат умножения функций 40 по 44 из фиг. 3a на инверсию модели 44 восприятия показан на фиг. 3b. Например, 46 показывает результат умножения спектра 40 на инверсию 44 и, таким образом, соответствует перцепционно взвешенному спектру, как выводится посредством спектрального формирователя 38 в случае кодера 10, действующего как перцепционный основанный на линейном предсказании кодер, как описано выше. Так как умножение функции 44 на ее инверсию дает результатом постоянную функцию, результирующее произведение изображено как являющееся плоским на фиг. 3b, см. 50.
Теперь обращаясь к модулю 14 оценки распределений вероятностей, он также имеет доступ к информации коэффициентов линейного предсказания, как описано выше. Модуль 14 оценки является, таким образом, способным вычислять функцию 48, результирующую из умножения функции 42 на инверсию функции 44. Эта функция 48 может служить, как видно из фиг. 3b, в качестве оценки огибающей или грубой формы предварительно фильтрованного 46, как выводится спектральным формирователем 38.
Соответственно, модуль 14 оценки распределений вероятностей может работать, как проиллюстрировано на фиг. 4. В частности, модуль 14 оценки распределений вероятностей может подвергать коэффициенты линейного предсказания, определяющие синтезирующий фильтр линейного предсказания 1/A(z), перцепционному взвешиванию 64, чтобы он соответствовал перцепционно модифицированному синтезирующему фильтру линейного предсказания 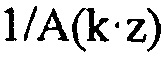 . Оба, невзвешенные коэффициенты линейного предсказания, также как взвешенные коэффициенты линейного предсказания подвергаются преобразованию 60 и 62 LPC в спектральный вес, соответственно, и результат подвергается, в расчете на спектральную компоненту k, делению. Результирующее частное необязательно подвергается некоторому выводу 68 параметров, где частные для спектральных компонент k индивидуально, т.е. для каждого k, подвергаются некоторой отображающей функции, чтобы давать результатом параметр распределения вероятностей, представляющий меру, например, для дисперсии оценки распределения вероятностей. Чтобы быть более точными, преобразования 60, 62 LPC в спектральный вес, примененные к невзвешенным и взвешенным коэффициентам линейного предсказания, дают результатом спектральные веса sk и
. Оба, невзвешенные коэффициенты линейного предсказания, также как взвешенные коэффициенты линейного предсказания подвергаются преобразованию 60 и 62 LPC в спектральный вес, соответственно, и результат подвергается, в расчете на спектральную компоненту k, делению. Результирующее частное необязательно подвергается некоторому выводу 68 параметров, где частные для спектральных компонент k индивидуально, т.е. для каждого k, подвергаются некоторой отображающей функции, чтобы давать результатом параметр распределения вероятностей, представляющий меру, например, для дисперсии оценки распределения вероятностей. Чтобы быть более точными, преобразования 60, 62 LPC в спектральный вес, примененные к невзвешенным и взвешенным коэффициентам линейного предсказания, дают результатом спектральные веса sk и 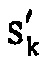 для спектральных компонент k. Преобразования 60, 62 могут, как уже описано выше, выполняться при более низком спектральном разрешении, чем спектральное разрешение, определенное посредством самих спектральных компонент k, но интерполяция может, например, использоваться, чтобы сглаживать результирующее частное qk над спектральной компонентой k. Вывод параметров затем дает результатом параметр распределения вероятностей
для спектральных компонент k. Преобразования 60, 62 могут, как уже описано выше, выполняться при более низком спектральном разрешении, чем спектральное разрешение, определенное посредством самих спектральных компонент k, но интерполяция может, например, использоваться, чтобы сглаживать результирующее частное qk над спектральной компонентой k. Вывод параметров затем дает результатом параметр распределения вероятностей 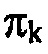 в расчете на спектральную компоненту k посредством, например, масштабирования всех qk с использованием коэффициента масштабирования, общего для всех k. Каскад 18 квантования и энтропийного кодирования может затем использовать эти параметры распределений вероятностей
в расчете на спектральную компоненту k посредством, например, масштабирования всех qk с использованием коэффициента масштабирования, общего для всех k. Каскад 18 квантования и энтропийного кодирования может затем использовать эти параметры распределений вероятностей 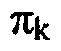 , чтобы осуществлять эффективное энтропийное кодирование спектрально сформированного спектра квантования. В частности, так как
, чтобы осуществлять эффективное энтропийное кодирование спектрально сформированного спектра квантования. В частности, так как 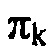 является мерой для дисперсии оценки распределения вероятностей значения спектра огибающей xk или, по меньшей мере, его амплитуды, параметризуемая функция, такая как вышеупомянутая f(i,l(k)), может использоваться каскадом 18 квантования и энтропийного кодирования, чтобы определять, для каждой спектральной компоненты k, оценку 28 распределения вероятностей посредством использования
является мерой для дисперсии оценки распределения вероятностей значения спектра огибающей xk или, по меньшей мере, его амплитуды, параметризуемая функция, такая как вышеупомянутая f(i,l(k)), может использоваться каскадом 18 квантования и энтропийного кодирования, чтобы определять, для каждой спектральной компоненты k, оценку 28 распределения вероятностей посредством использования 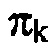 в качестве параметра для параметризуемой функции, т.е. в качестве l(k). Предпочтительно, параметризация параметризуемой функции является такой, что параметр распределения вероятностей, например, l(k), является фактически мерой для дисперсии оценки распределения вероятностей, т.е. параметр распределения вероятностей измеряет ширину параметризуемой функции распределения вероятностей. В конкретном варианте осуществления, описанном дополнительно ниже, используется распределение Лапласа в качестве параметризуемой функции, например, f(i, l(k)).
в качестве параметра для параметризуемой функции, т.е. в качестве l(k). Предпочтительно, параметризация параметризуемой функции является такой, что параметр распределения вероятностей, например, l(k), является фактически мерой для дисперсии оценки распределения вероятностей, т.е. параметр распределения вероятностей измеряет ширину параметризуемой функции распределения вероятностей. В конкретном варианте осуществления, описанном дополнительно ниже, используется распределение Лапласа в качестве параметризуемой функции, например, f(i, l(k)).
По отношению к фиг. 1, следует отметить, что модуль 14 оценки распределений вероятностей может дополнительно вставлять информацию в поток 22 данных, которая обеспечивает возможность декодирующей стороне увеличивать качество оценки 28 распределения вероятностей для индивидуальных спектральных компонент k по сравнению с качеством, единственно обеспеченным на основе информации LPC. В частности, в соответствии с этими конкретными иллюстративно описанными деталями осуществления, дополнительно описанными ниже, модуль 14 оценки распределений вероятностей может использовать долгосрочное предсказание, чтобы получать спектрально более тонкую оценку 30 огибающей или формы спектра 26 в случае спектра 26, представляющего возбуждение с кодированным преобразованием, как, например, спектра, результирующего из фильтрации с функцией преобразования, соответствующей инверсии модели восприятия или инверсии синтезирующего фильтра линейного предсказания.
Например, см. фиг. 5a по 5c для иллюстрации упомянутой последней, необязательной функциональности модуля 14 оценки распределений вероятностей. Фиг. 5a показывает, как фиг. 3a, спектр 40 исходных аудиосигналов и модель LPC A(z), включающую в себя предыскажение. То есть мы имеем исходный сигнал 40 и его огибающую 42 LPC, включающую в себя предыскажение. Фиг. 5b изображает, в качестве примера вывода анализа LTP, выполняемого посредством модуля 14 оценки распределений вероятностей, гребенчатый фильтр 70 LTP, т.е. гребенчатую функцию над спектральными компонентами k, параметризованными, например, посредством значения усиления LTP, описывающего отношение впадин к пикам a/b, и параметра задержки LTP, определяющего основной тон или расстояние между пиками гребенчатой функции 70, т.е. c. Модуль 14 оценки распределений вероятностей может определять только что упомянутые параметры LTP, чтобы умножение гребенчатой функции 70 LTP на основывающуюся на коэффициентах линейного предсказания оценку 30 спектра 26 более близко оценивало фактический спектр 26. Умножение гребенчатой функции 70 LTP на модель 42 LPC иллюстративно показано на фиг. 5c и можно видеть, что произведение 72 гребенчатой функции 70 LTP и модели 42 LPC более близко аппроксимирует фактическую форму спектра 40.
В случае комбинирования функциональности LTP модуля 14 оценки распределений вероятностей с использованием перцепционной области, модуль 14 оценки распределений вероятностей может работать, как показано на фиг. 6. Режим работы в значительной степени совпадает с режимом, показанным на фиг. 4. То есть, коэффициенты LPC, определяющие синтезирующий фильтр линейного предсказания 1/A(z), подвергаются преобразованию 60 и 62 LPC в спектральный вес, именно один раз напрямую и другой раз после перцепционного взвешивания 64. Результирующие коэффициенты масштабирования подвергаются делению 66 и результирующие частные qk умножаются с использованием множителя 47 на гребенчатую функцию 70 LTP, параметры усиления LTP и задержки LTP которой определяются посредством модуля 14 оценки распределений вероятностей соответствующим образом и вставляются в поток 22 данных для доступа для декодирующей стороны. Результирующее произведение 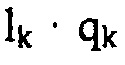 на lk, обозначающее гребенчатую функцию LTP в спектральной компоненте k, затем подвергается выводу 68 параметров распределений вероятностей, чтобы давать результатом параметры распределений вероятностей
на lk, обозначающее гребенчатую функцию LTP в спектральной компоненте k, затем подвергается выводу 68 параметров распределений вероятностей, чтобы давать результатом параметры распределений вероятностей 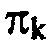 . Следует отметить, что в последующем описании декодирующей стороны, ссылка делается, среди прочего, на фиг. 6 по отношению к функциональности оценки распределений вероятностей стороны декодера. В этом отношении, следует отметить, что, на стороне кодера, параметр (параметры) LTP определяются посредством способа оптимизации и подобного и вставляются в поток 22 данных, в то время как декодирующая сторона всего лишь должна считывать параметры LTP из потока данных.
. Следует отметить, что в последующем описании декодирующей стороны, ссылка делается, среди прочего, на фиг. 6 по отношению к функциональности оценки распределений вероятностей стороны декодера. В этом отношении, следует отметить, что, на стороне кодера, параметр (параметры) LTP определяются посредством способа оптимизации и подобного и вставляются в поток 22 данных, в то время как декодирующая сторона всего лишь должна считывать параметры LTP из потока данных.
После описания различных вариантов осуществления для основанного на линейном предсказании аудиокодера по отношению к фиг. 1 по 6, последующее описание концентрируется на декодирующей стороне. Фиг. 7 показывает один вариант осуществления для основанного на линейном предсказании аудиодекодера 100. Он содержит модуль 102 оценки распределений вероятностей и каскад 104 энтропийного декодирования и деквантования. Основанный на линейном предсказании аудиодекодер имеет доступ к потоку 22 данных и, в то время как модуль 102 оценки распределений вероятностей сконфигурирован с возможностью определять, для каждой из множества спектральных компонент k, оценку 28 распределения вероятностей из информации коэффициентов линейного предсказания, содержащейся в потоке 22 данных, каскад 104 энтропийного декодирования и деквантования сконфигурирован с возможностью осуществлять энтропийное декодирование и деквантование спектра 26 из потока 22 данных с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент k посредством модуля 102 оценки распределений вероятностей. То есть как модуль 102 оценки распределений вероятностей, так и каскад 104 энтропийного декодирования и деквантования имеют доступ к потоку 22 данных и выход модуля 102 оценки распределений вероятностей соединен с входом каскада 104 энтропийного декодирования и деквантования. На выходе последнего, получается спектр 26.
Следует отметить, что, естественно, спектр, выводимый каскадом 104 энтропийного декодирования и деквантования, может подвергаться дополнительной обработке в зависимости от приложения. Вывод декодера 100 не необходимо должен, однако, быть аудиосигналом, который кодирован в поток 22 данных, во временной области, чтобы, например, воспроизводиться с использованием громкоговорителей. Скорее, основанный на линейном предсказании аудиодекодер 100 может осуществлять взаимодействовать с входом, например, смесителя системы конференц-связи, многоканальным или многообъектным декодером или подобным, и это взаимодействие может находиться в спектральной области. Альтернативно, спектр или его некоторая подвергнутая последующей обработке версия может подвергаться спектрально-временному преобразованию посредством преобразования спектрального разложения, как, например, обратного преобразования с использованием обработки перекрытия с суммированием, как описано дополнительно ниже.
Так как модуль 102 оценки распределений вероятностей имеет доступ к такой же информации LPC, что и модуль 14 оценки распределений вероятностей на кодирующей стороне, модуль 102 оценки распределений вероятностей обрабатывает то же, что и соответствующий модуль оценки на кодирующей стороне за исключением, например, определения дополнительного параметра LTP на кодирующей стороне, результат этого определения сигнализируется в декодирующую сторону посредством потока 22 данных. Каскад 104 энтропийного декодирования и деквантования сконфигурирован с возможностью использовать оценку распределений вероятностей в энтропийном декодировании спектральных значений спектра 62, как, например, уровней амплитуд из потока 22 данных, и деквантовать их одинаковым образом для всех спектральных компонент, чтобы получать спектр 26. В отношении различных возможностей для осуществления энтропийного кодирования, ссылка делается на вышеописанные утверждения, относительно энтропийного кодирования. Дополнительно, такое же правило квантования применяется в обратном направлении по отношению к правилу, используемому на кодирующей стороне, так что все альтернативы и детали, описанные выше по отношению к энтропийному кодированию и квантованию, должны также применяться для вариантов осуществления декодера соответственно. То есть, например, каскад энтропийного декодирования и деквантования может быть сконфигурирован с возможностью использовать постоянный размер шага квантования для деквантования уровней амплитуд и может использовать, например, арифметическое декодирование.
Как уже описано выше, спектр 26 может представлять возбуждение с кодированным преобразованием и соответственно фиг. 8 показывает, что основанный на линейном предсказании аудиодекодер может дополнительно содержать фильтр 106, который также имеет доступ к информации LPC и потоку 22 данных и соединен с выходом каскада 104 энтропийного декодирования и деквантования, чтобы принимать спектр 26 и выводить спектр подвергнутого фильтрации/восстановленного аудиосигнала на его выходе. В частности, фильтр 106 сконфигурирован с возможностью формировать спектр 26 согласно передаточной функции, зависящей от синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания. Чтобы быть даже более точными, фильтр 106 может осуществляться посредством последовательного соединения определителя 34 коэффициентов масштабирования и спектрального формирователя 38, при этом спектральный формирователь 38 принимает спектр 26 от каскада 104 и выводит подвергнутый фильтрации сигнал, т.е. восстановленный аудиосигнал. Различие будет только том, что масштабирование, выполняемое внутри фильтра 106, будет в точности инверсией масштабирования, выполненного посредством спектрального формирователя 38 на кодирующей стороне, т.е. там, где спектральный формирователь 38 на кодирующей стороне выполняет, например, умножение с использованием коэффициентов масштабирования, а в фильтре 106 будет выполняться деление на коэффициенты масштабирования или наоборот.
Последнее обстоятельство показано на фиг. 9, которая показывает один вариант осуществления для фильтра 106 из фиг. 8. Как можно видеть, фильтр 108 может содержать определитель 110 коэффициентов масштабирования, работающий, например, как определитель 34 коэффициентов масштабирования из фиг. 2, и спектральный формирователь 112, который, как описано выше, применяет коэффициенты масштабирования из определителя 110 коэффициентов масштабирования к входящему спектру, обратным образом по отношению к спектральному формирователю 38.
Фиг. 9 иллюстрирует, что фильтр 106 может иллюстративно дополнительно содержать модуль 114 обратного преобразования, модуль 116 перекрытия с суммированием и фильтр 118 компенсации предыскажений. Последние компоненты 114 по 118 могут быть последовательно соединены с выходом спектрального формирователя 112 в порядке их упоминания, при этом фильтр 118 компенсации предыскажений или оба модуль 116 перекрытия с суммированием и фильтр 118 компенсации предыскажений могут, в соответствии с дополнительно альтернативой, исключаться.
Фильтр 118 компенсации предыскажений выполняет инверсию фильтрации с предыскажением фильтра 24 из фиг. 1 и модуль 116 перекрытия с суммированием может, как известно в данной области техники, давать результатом устранение наложения спектров в случае обратного преобразования, используемого внутри модуля 114 обратного преобразования, которое является критически дискретизированным преобразованием с перекрытием блоков. Например, модуль 114 обратного преобразования может подвергать каждый спектр 26, принимаемый от спектрального формирователя 112 на временной скорости, на которой эти спектры кодированы внутри потока 22 данных, обратному преобразованию, чтобы получать подвергнутые оконной обработке части, которые, в свою очередь, перекрываются с суммированием посредством модуля 116 перекрытия с суммированием, чтобы давать результатом версию сигнала временной области. Фильтр 118 компенсации предыскажений, в точности как фильтр 24 предыскажений, может осуществляться как фильтр FIR.
После описания вариантов осуществления настоящей заявки по отношению к фигурам, в последующем обеспечивается более математическое описание вариантов осуществления настоящей заявки, при этом это описание затем заканчивается соответствующим описанием фиг. 10 и 11. В частности, в вариантах осуществления, описанных ниже, предполагается, что используется унарное преобразование в двоичную форму спектральных значений спектра с двоичным арифметическим кодированием двоичных символов результирующих последовательностей двоичных символов, чтобы кодировать спектр.
В частности, в иллюстративных деталях, описанных ниже, которые должны пониматься, как которые могут быть перенесены на вышеописанные варианты осуществления, было решено в иллюстративных целях вычислять структуру огибающей 30 в 64 полосах, когда длина кадра, т.е. скорость спектра, на которой спектр 26 обновляется внутри потока 22 данных, равняется 256 выборкам, и в 80 полосах, когда длина кадра равняется 320 выборкам. Если модель LPC является A(z), то взвешенное LPC является, например, 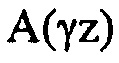 с
с 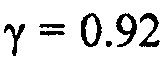 и ассоциированный член предыскажения фильтра 24 равняется
и ассоциированный член предыскажения фильтра 24 равняется 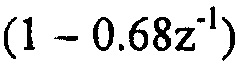 , например, при этом постоянные могут изменяться в зависимости от приложения. Огибающая 30 и перцепционная область является, таким образом,
, например, при этом постоянные могут изменяться в зависимости от приложения. Огибающая 30 и перцепционная область является, таким образом,
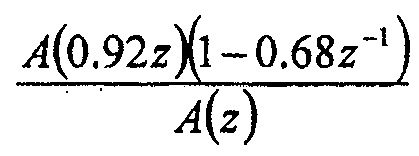 (1)
(1)
Таким образом, передаточная функция фильтра, определенного посредством формулы (1), соответствует функции 48 на фиг. 3b и является результатом вычисления на фиг. 4 и 6 на выходе делителя 66.
Следует отметить, что фиг. 4 и 6 представляют режим работы как модуля 14 оценки распределений вероятностей, так и модуля 102 оценки распределений вероятностей на фиг. 7. Более того, в случае использования фильтра 24 предыскажений и фильтра 118 компенсации предыскажений, преобразование 60 LPC в спектральный вес учитывает функцию фильтра предыскажений, так что, в конце, оно представляет произведение передаточных функций синтезирующего фильтра и фильтра предыскажений.
В любом случае, время-частотное преобразование фильтра, определенного посредством формулы (1), должно вычисляться так, что конечная огибающая частотно выравнивается со спектральным представлением входного сигнала. Более того, следует отметить снова, что модуль оценки распределений вероятностей может просто вычислять абсолютную амплитуду огибающей или передаточной функции фильтра из формулы (1). В этом случае, компонента фазы может отбрасываться.
В случае вычисления огибающей для спектральных полос и не индивидуальных линий, огибающая, примененная к спектральным линиям, будет ступенчато непрерывной. Чтобы получать более непрерывную огибающую, является возможным интерполировать или сглаживать огибающую. Однако следует заметить, что ступенчато непрерывные спектральные полосы обеспечивают уменьшение в вычислительной сложности. Поэтому, это является балансом между точностью по отношению к сложности.
Как отмечалось ранее, LTP также может использоваться, чтобы выводить более детальную огибающую. Некоторые из основных настоящих проблем применения гармонической информации к форме огибающей являются:
1) Выбор кодирования и точности информации LTP, как, например, задержки LTP и усиления LTP. Например, может использоваться такое же кодирование как в ACELP.
2) LTP может соответствовать гребенчатому фильтру в частотной области. Однако вышеописанные варианты осуществления или любой другой вариант осуществления согласно настоящему изобретению не ограничены использованием гребенчатого фильтра такой же формы как LTP. Другие функции также могут использоваться.
3) В дополнение к форме гребенчатого фильтра из LTP, является также возможным выбирать применять LTP различным образом в разных частотных областях. Например, гармонические пики являются обычно более выступающими при низких частотах. В таком случае имеет смысл применять гармоническую модель на низкой частоте с более высокой амплитудой, чем на высоких частотах.
4) Как отмечено выше, форма огибающей вычисляется пополосно. Однако гребенчатый фильтр в LTP будет определенно иметь намного более детальную структуру и частоту, чем то, что имеют значения пополосно оцененной огибающей. В варианте осуществления гармонической модели, тогда является предпочтительным уменьшать вычислительную сложность.
В вышеописанных вариантах осуществления, может использоваться предположение, согласно которому индивидуальные линии или более конкретно амплитуды спектра 26 в спектральных компонентах k, распределены согласно распределению Лапласа, то есть, экспоненциальному распределению со знаком. Другими словами, вышеупомянутая f(i, l(k)) может быть функцией Лапласа. Так как знак спектра 26 в спектральной компоненте k всегда может кодироваться посредством одного бита, и вероятность обоих знаков может надежно предполагаться равной 0,5, то знак может всегда кодироваться отдельно, и мы должны принимать во внимание только экспоненциальное распределение.
В общем, без какой-либо предварительной информации первым выбором для любого распределения будет нормальное распределение. Экспоненциальное распределение, однако имеет намного большую массу вероятности, близкую к нулю, чем нормальное распределение, и оно, таким образом, описывает более разреженный сигнал, чем нормальное распределение. Так как одной из основных целей время-частотных преобразований является достичь разреженного сигнала, то распределение вероятностей, которое описывает разреженные сигналы, является обоснованным. В дополнение, экспоненциальное распределение также обеспечивает уравнения, которые легко поддаются обработке в аналитической форме. Эти два аргумента обеспечивают основу для использования экспоненциального распределения. Последующие выводы могут быть естественно легко модифицированы для других распределений.
Экспоненциально распределенная переменная x имеет функцию плотности вероятности 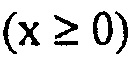 :
:
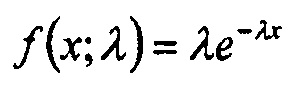 (2)
(2)
и кумулятивную функцию распределения
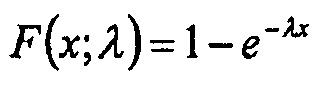 . (3)
. (3)
Энтропия экспоненциальной переменной равняется 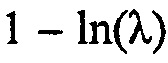 , в силу чего ожидаемое потребление битов одиночной линии, включая сюда знак, равно
, в силу чего ожидаемое потребление битов одиночной линии, включая сюда знак, равно 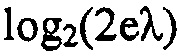 . Однако это является теоретическим значением, которое имеет место для дискретных переменных, только когда
. Однако это является теоретическим значением, которое имеет место для дискретных переменных, только когда 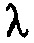 является большим.
является большим.
Фактическое потребление битов может оцениваться посредством моделирований, но точная аналитическая формула не доступна. Приблизительное потребление битов является, хотя, 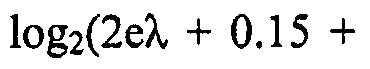
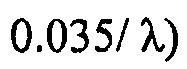 для
для 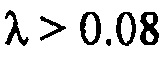 .
.
То есть, вышеописанные варианты осуществления с модулем оценки распределений вероятностей на кодирующей и декодирующей сторонах могут использовать распределение Лапласа в качестве параметризуемой функции для определения оценки распределения вероятностей. Параметр масштаба 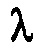 распределения Лапласа может служить в качестве вышеупомянутого параметра распределения вероятностей, т.е. в качестве
распределения Лапласа может служить в качестве вышеупомянутого параметра распределения вероятностей, т.е. в качестве 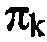 .
.
Далее, описывается возможность для выполнения масштабирования огибающей. Один подход основывается на выполнении первого предположения для масштабирования, вычислении его потребления битов и улучшении масштабирования итеративно до тех пор, когда достигается достаточная близость к требуемому уровню. Другими словами, вышеупомянутые модули оценки распределений вероятностей на кодирующей и декодирующей стороне могут выполнять следующие этапы.
Пусть fk будет значением огибающей для положения k. Среднее значение огибающей тогда 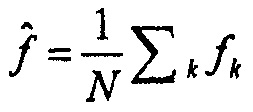 , где N является количеством спектральных линий. Если требуемое потребление битов равняется b, то масштабирование первого предположения g0 может легко решаться из
, где N является количеством спектральных линий. Если требуемое потребление битов равняется b, то масштабирование первого предположения g0 может легко решаться из 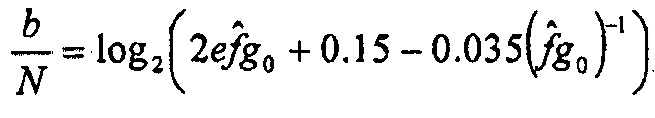 .
.
Оцененное потребление битов bk для итерации k и с масштабированием gk тогда
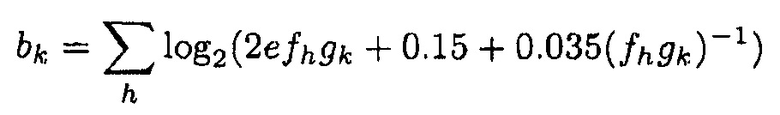 (4)
(4)
Логарифмическая операция является вычислительно сложной, таким образом, мы можем вместо этого вычислять
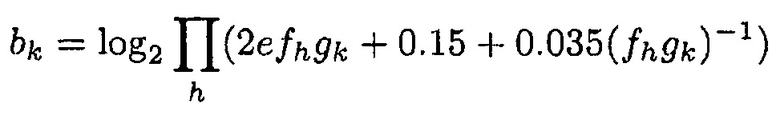 (5)
(5)
Даже хотя член произведения является очень большим числом и его вычисление с фиксированной точкой требует много операций, оно все еще является менее сложным, чем большое количество операций для 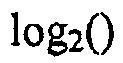 .
.
Чтобы дополнительно уменьшить сложность, мы можем оценивать потребление битов посредством 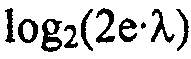 , в силу чего полное потребление битов равняется
, в силу чего полное потребление битов равняется 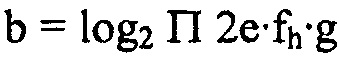 . Из этого уравнения, масштабный коэффициент g может легко решаться аналитически, при этом итерация масштабирования огибающей не требуется.
. Из этого уравнения, масштабный коэффициент g может легко решаться аналитически, при этом итерация масштабирования огибающей не требуется.
В общем, никакая аналитическая форма не существует для решения gk из уравнения 5, в силу чего должен использоваться итеративный способ. Если используется поиск на основе деления пополам, то если 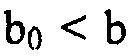 , то начальный размер шага равняется
, то начальный размер шага равняется 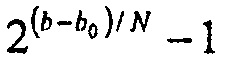 и в противном случае размер шага равняется
и в противном случае размер шага равняется 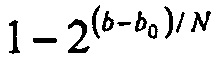 . Посредством этого подхода, поиск на основе деления пополам сходится обычно за 5-6 итераций.
. Посредством этого подхода, поиск на основе деления пополам сходится обычно за 5-6 итераций.
Огибающая должна масштабироваться одинаково в обоих кодере, и также декодере. Так как распределения вероятностей выводятся из огибающей, даже 1-битное различие в масштабировании в кодере и декодере будет вызывать, что арифметический декодер будет вырабатывать случайный вывод. Является поэтому очень важным, чтобы вариант осуществления работал в точности одинаково на всех платформах. На практике, это требует, чтобы алгоритм осуществлялся с операциями с целыми числами и фиксированной точкой.
В то время как огибающая уже была масштабирована, так что ожидание потребления битов равняется требуемому уровню, фактические спектральные линии будут, в общем, не соответствовать бюджету битов без масштабирования. Даже если сигнал будет масштабироваться, так что его дисперсия соответствует дисперсии огибающей, распределение выборок будет неизменно отличаться от распределения модели, в силу чего требуемое потребление битов не достигается. Является поэтому необходимым масштабировать сигнал, так что, когда он квантуется и кодируется, конечное потребление битов достигает требуемый уровень. Так как это обычно должно выполняться итеративным способом (никакого аналитического решения не существует), обработка известна как контур обратной связи по скорости.
Мы выбрали начинать посредством масштабирования первого предположения, так что дисперсия огибающей и масштабированного сигнала соответствуют. Одновременно, мы можем обнаружить ту спектральную линию, которая имеет наименьшую вероятность согласно нашей модели вероятностей. Необходимо позаботиться о том, чтобы значение наименьшей вероятности не было ниже машинной точности. Это, таким образом, устанавливает предел на коэффициент масштабирования, который будет оцениваться в контуре обратной связи по скорости.
Для контура обратной связи по скорости, мы снова применяем поиск на основе деления пополам, так что размер шага начинается на половине начального коэффициента масштабирования. Затем потребление битов вычисляется на каждой итерации как сумма всех спектральных линий и точность квантования обновляется в зависимости от того, как близко к бюджету битов мы находимся.
На каждой итерации, сигнал сначала квантуется с текущим масштабированием. Во-вторых, каждая линия кодируется с помощью арифметического кодера. Согласно модели вероятностей, вероятность того, что линия xk квантуется в нуль, равняется 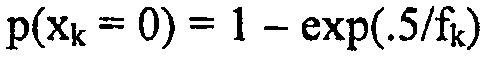 , где fk является значением огибающей (= стандартное отклонение спектральной линии). Потребление битов такой линии равняется естественно
, где fk является значением огибающей (= стандартное отклонение спектральной линии). Потребление битов такой линии равняется естественно 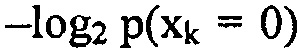 . Ненулевое значение xk имеет вероятность
. Ненулевое значение xk имеет вероятность 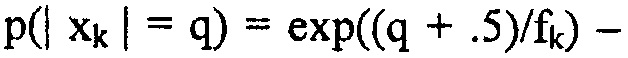
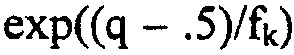 . Амплитуда может, таким образом, кодироваться с помощью
. Амплитуда может, таким образом, кодироваться с помощью 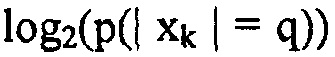 битов, плюс один бит для знака.
битов, плюс один бит для знака.
Этим способом, может вычисляться потребление битов для всего спектра. В дополнение, отметим, что мы можем устанавливать предел K, так что все линии k>K являются нулевыми. Тогда является достаточным кодировать K первых линий. Декодер может затем выводить, что, если K первых линий были декодированы, но никакие дополнительные биты не являются доступными, то оставшиеся линии должны все быть нулевыми. Поэтому, не является необходимым передавать предел K, но он может выводиться из битового потока. Этим способом, мы можем избегать кодирования линий, которые являются нулевыми, посредством чего мы сохраняем биты. Так как для сигналов речи и аудио часто происходит то, что верхняя часть спектра квантуется в нуль, является предпочтительным начинать с низких частот, и насколько возможно, использовать все биты для первых K линий.
Отметим, что, так как значения огибающей fk равны внутри полосы, мы можем легко уменьшать сложность посредством предварительного вычисления значений, которые необходимы для каждой линии в полосе. Конкретно, в кодировании линий, член exp(.5/fk) всегда необходим и он является одним и тем же внутри каждой полосы. Более того, это значение не изменяется внутри контура обратной связи по скорости, в силу чего он может вычисляться вне контура обратной связи по скорости и одно и то же значение может использоваться для конечного квантования также.
Более того, так как потребление битов линии равняется log2() от вероятности, мы можем, вместо вычисления суммы логарифмов, вычислять логарифм произведения. Этим способом сложность снова сохраняется. В дополнение, так как контур обратной связи по скорости является признаком только кодера, собственные операции с плавающей точкой могут использоваться вместо операций с фиксированной точкой.
Ссылаясь на вышеописанное, ссылка делается на фиг. 10, которая показывает подчасть из кодера, объясненного выше по отношению к фигурам, при этом упомянутая часть является ответственной за выполнение вышеупомянутого масштабирования огибающей и контура обратной связи по скорости в соответствии с одним вариантом осуществления. В частности, фиг. 10 показывает элементы из каскада 18 квантования и энтропийного кодирования с одной стороны и модуля 14 оценки распределений вероятностей с другой стороны. Модуль 130 унарного преобразования в двоичную форму подвергает амплитуды спектральных значений xk спектра 26 в спектральных компонентах k унарному преобразованию в двоичную форму, тем самым генерируя, для каждой амплитуды в спектральной компоненте k, последовательность двоичных символов. Двоичный арифметический кодер 132 принимает эти последовательности двоичных символов, т.е. одну в расчете на спектральную компоненту k, и подвергает ее двоичному арифметическому кодированию. Как модуль 130 унарного преобразования в двоичную форму, так и двоичный арифметический кодер 132 являются частью каскада 18 квантования и энтропийного кодирования. Фиг. 10 также показывает модуль 68 вывода параметров, который является ответственным за выполнение вышеупомянутого масштабирования, чтобы масштабировать значения оценок огибающей qk, или как они также были обозначены выше посредством fk, чтобы давать результатом корректно масштабированные параметры распределений вероятностей 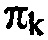 или с использованием системы обозначений только что использованной, gkfk. Как описано выше с использованием формулы (5), модуль 68 двоичного вывода определяет значение масштабирования gk итеративно, так что аналитическая оценка потребления битов, пример которой представлен посредством уравнения (5), удовлетворяет некоторому целевому битрейту для полного спектра 26. Как незначительное стороннее замечание, следует отметить, что k, как используется в соединении с уравнением (5), обозначало номер этапа итерации, в то время как в других местах предполагается, что переменная k обозначает спектральную линию или компоненту k. Далее, следует отметить, что модуль 68 вывода параметров не необходимо масштабирует исходные значения огибающей, иллюстративно выведенные, как показано на фиг. 4 и 6, но может альтернативно напрямую итеративно модифицировать значения огибающей с использованием, например, аддитивных модификаторов.
или с использованием системы обозначений только что использованной, gkfk. Как описано выше с использованием формулы (5), модуль 68 двоичного вывода определяет значение масштабирования gk итеративно, так что аналитическая оценка потребления битов, пример которой представлен посредством уравнения (5), удовлетворяет некоторому целевому битрейту для полного спектра 26. Как незначительное стороннее замечание, следует отметить, что k, как используется в соединении с уравнением (5), обозначало номер этапа итерации, в то время как в других местах предполагается, что переменная k обозначает спектральную линию или компоненту k. Далее, следует отметить, что модуль 68 вывода параметров не необходимо масштабирует исходные значения огибающей, иллюстративно выведенные, как показано на фиг. 4 и 6, но может альтернативно напрямую итеративно модифицировать значения огибающей с использованием, например, аддитивных модификаторов.
В любом случае, двоичный арифметический кодер 132 применяет, для каждой спектральной компоненты, оценку распределения вероятностей, как определено посредством параметра распределения вероятностей 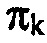 , или как альтернативно используется выше, gkfk, для всех двоичных символов унарного преобразования в двоичную форму соответствующей амплитуды спектральных значений xk.
, или как альтернативно используется выше, gkfk, для всех двоичных символов унарного преобразования в двоичную форму соответствующей амплитуды спектральных значений xk.
Как также описано выше, может обеспечиваться модуль 134 проверки контура обратной связи по скорости, чтобы проверять фактическое потребление битов, выработанное посредством использования параметров распределений вероятностей, как определены посредством модуля 68 вывода параметров как первое предположение. Модуль 134 проверки контура обратной связи по скорости проверяет предположение посредством того, что он соединен между двоичным арифметическим кодером 132 и модулем 68 вывода параметров.
Если фактическое потребление битов превосходит позволенное потребление битов несмотря на оценку, выполненную посредством модуля 68 вывода параметров, модуль 134 проверки контура обратной связи по скорости корректирует значения первого предположения параметров распределений параметров 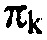 (или gkfk), и фактическое двоичное арифметическое кодирование 132 унарных преобразований в двоичную форму выполняется снова.
(или gkfk), и фактическое двоичное арифметическое кодирование 132 унарных преобразований в двоичную форму выполняется снова.
Фиг. 11 показывает ради полноты аналогичную часть из декодера из фиг. 8. В частности, модуль 68 вывода параметров работает на кодирующей и декодирующей стороне одинаковым образом и соответственно, как показано на фиг. 11. Вместо использования последовательного соединения модуля унарного преобразования в двоичную форму, за которым следует двоичный арифметический кодер, на декодирующей стороне используется обратная последовательная компоновка, т.е. каскад 104 энтропийного декодирования и деквантования в соответствии с фиг. 11 иллюстративно содержит двоичный арифметический декодер 136, за которым следует модуль 138 обращения унарного преобразования в двоичную форму. Двоичный арифметический декодер 136 принимает часть потока 22 данных, который арифметически кодирует спектр 26. Вывод двоичного арифметического декодера 136 является последовательностью последовательностей двоичных символов, именно последовательностью двоичных символов некоторой амплитуды спектрального значения в спектральной компоненте k, за которой следует последовательность двоичных символов амплитуды спектрального значения следующей спектральной компоненты k + 1, и так далее. Модуль 138 обращения унарного преобразования в двоичную форму выполняет преобразование из двоичной формы, т.е. выводит преобразованные из двоичной формы амплитуды спектральных значений в спектральной компоненте k и информирует двоичный арифметический декодер 136 о начале и конце последовательностей двоичных символов индивидуальных амплитуд спектральных значений. В точности как двоичный арифметический кодер 132, двоичный арифметический декодер 136 использует, при двоичном арифметическом декодировании, оценки распределений параметров, определенные посредством параметров распределений параметров, именно параметра распределения вероятностей 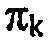 (gkfk), для всех двоичных символов, принадлежащих соответствующей амплитуде одного спектрального значения спектральной компоненты k.
(gkfk), для всех двоичных символов, принадлежащих соответствующей амплитуде одного спектрального значения спектральной компоненты k.
Как также было описано выше, кодер и декодер могут использовать тот факт, что обе стороны могут информироваться о максимальном битрейте, доступном в этих обеих сторонах, могут использовать то обстоятельство, что фактическое кодирование амплитуд спектральных значений спектра 26 может прекращаться при проходе по ним от наименьшей частоты к наивысшей частоте, как только достигается максимальный битрейт, доступный в битовом потоке 22. По соглашению, непереданная амплитуда может устанавливаться на нуль.
По отношению к только что описанным вариантам осуществления следует отметить, что, например, масштабирование первого предположения огибающей для получения параметров распределений вероятностей может использоваться без контура обратной связи по скорости для удовлетворения некоторому постоянному битрейту, как, например, если соответствие не требуется сценарием приложения, например.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствует этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все из этапов способа могут выполняться посредством (или с использованием) аппаратного устройства, как, например, микропроцессора, программируемого компьютера или электронной схемы. В некоторых вариантах осуществления, некоторые один или более из наиболее важных этапов способа могут выполняться посредством такого устройства.
Кодированный аудиосигнал согласно настоящему изобретению может сохраняться в цифровом запоминающем носителе или может передаваться по носителю передачи как, например, беспроводной носитель передачи или проводной носитель передачи, как, например, сеть Интернет.
В зависимости от некоторых требований реализации, варианты осуществления изобретения могут осуществляться в аппаратном обеспечении или в программном обеспечении. Вариант осуществления может выполняться с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего электронно-читаемые сигналы управления, сохраненные на нем, которые работают вместе (или являются способными работать вместе) с программируемой компьютерной системой, так что соответствующий способ выполняется. Поэтому, цифровой запоминающий носитель может быть машинно-читаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронно-читаемые сигналы управления, которые являются способными работать вместе с программируемой компьютерной системой, так что выполняется один из способов, здесь описанных.
В общем, варианты осуществления настоящего изобретения могут осуществляться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью для выполнения одного из способов, когда компьютерный программный продукт исполняется на компьютере. Программный код может, например, сохраняться на машинно-читаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, здесь описанных, сохраненную на машинно-читаемом носителе.
Другими словами, один вариант осуществления нового способа является поэтому компьютерной программой, имеющей программный код для выполнения одного из способов, здесь описанных, когда компьютерная программа исполняется на компьютере.
Дополнительный вариант осуществления новых способов является поэтому носителем данных (или цифровым запоминающим носителем, или машинно-читаемым носителем), содержащим, записанную на нем, компьютерную программу для выполнения одного из способов, здесь описанных. Носитель данных, цифровой запоминающий носитель или записывающий носитель являются обычно материальными и/или не-транзиторными.
Дополнительный вариант осуществления нового способа является поэтому потоком данных или последовательностью сигналов, представляющих компьютерную программу для выполнения одного из способов, здесь описанных. Поток данных или последовательность сигналов может, например, быть сконфигурированной с возможностью передачи через соединение передачи данных, например, через сеть Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, сконфигурированное с возможностью или выполненное с возможностью для выполнения одного из способов, здесь описанных.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, здесь описанных.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную с возможностью передавать (например, электронным образом или оптически) компьютерную программу для выполнения одного из способов, здесь описанных, в приемник. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством или подобным. Устройство или система может, например, содержать файловый сервер для передачи компьютерной программы в приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться, чтобы выполнять некоторые или все из функциональностей способов, здесь описанных. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может работать вместе с микропроцессором, чтобы выполнять один из способов, здесь описанных. В общем, способы предпочтительно выполняются посредством любого устройства аппаратного обеспечения.
Вышеописанные варианты осуществления являются всего лишь иллюстративными для принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и деталей, здесь описанных, должны быть очевидными для специалистов в данной области техники. Поэтому предполагается, что изобретение ограничено только посредством объема приложенной патентной формулы изобретения и не посредством конкретных деталей, представленных здесь в качестве описания и объяснения вариантов осуществления.
Ссылки
[1] ISO/IEC 23003-3:2012, "MPEG-D (MPEG audio technologies), Part 3: Unified speech and audio coding", 2012.
[2] J. Makhoul, "Linear prediction: A tutorial review", Proc. IEEE, vol. 63, no. 4, pp. 561-580, April 1975.
[3] G. Fuchs, V. Subbaraman, and M. Multrus, "Efficient context adaptive entropy coding for real-time applications", in Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on, May 2011, pp. 493-496.
[4] US8296134 and WO2012046685.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОДИРОВАНИЕ СПЕКТРАЛЬНЫХ КОЭФФИЦИЕНТОВ СПЕКТРА АУДИОСИГНАЛА | 2014 |
|
RU2638734C2 |
| ЗАПОЛНЕНИЕ ШУМОМ ПРИ АУДИОКОДИРОВАНИИ С ПЕРЦЕПЦИОННЫМ ПРЕОБРАЗОВАНИЕМ | 2014 |
|
RU2631988C2 |
| КОНЦЕПЦИЯ ЗАПОЛНЕНИЯ ШУМОМ | 2014 |
|
RU2660605C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2562375C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2015 |
|
RU2696292C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2008 |
|
RU2456682C2 |
| АУДИОКОДЕР И ДЕКОДЕР | 2019 |
|
RU2793725C2 |
| ОСНОВАННАЯ НА ЛИНЕЙНОМ ПРЕДСКАЗАНИИ СХЕМА КОДИРОВАНИЯ, ИСПОЛЬЗУЮЩАЯ ФОРМИРОВАНИЕ ШУМА В СПЕКТРАЛЬНОЙ ОБЛАСТИ | 2012 |
|
RU2575993C2 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ АУДИОСИГНАЛА, ИМЕЮЩЕГО ИМПУЛЬСОПОДОБНУЮ И СТАЦИОНАРНУЮ СОСТАВЛЯЮЩИЕ, СПОСОБЫ КОДИРОВАНИЯ, ДЕКОДЕР, СПОСОБ ДЕКОДИРОВАНИЯ И КОДИРОВАННЫЙ АУДИОСИГНАЛ | 2008 |
|
RU2439721C2 |
| МНОГОРЕЖИМНЫЙ АУДИО КОДИРОВЩИК И CELP КОДИРОВАНИЕ, АДАПТИРОВАННОЕ К НЕМУ | 2010 |
|
RU2586841C2 |
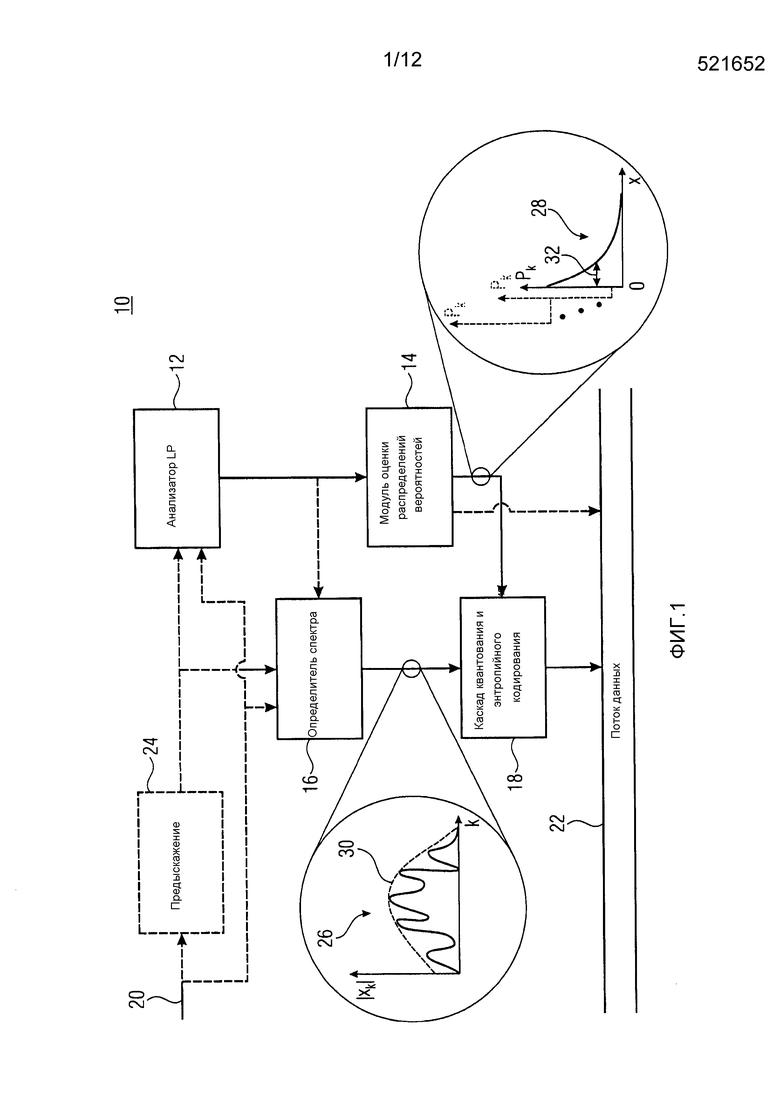
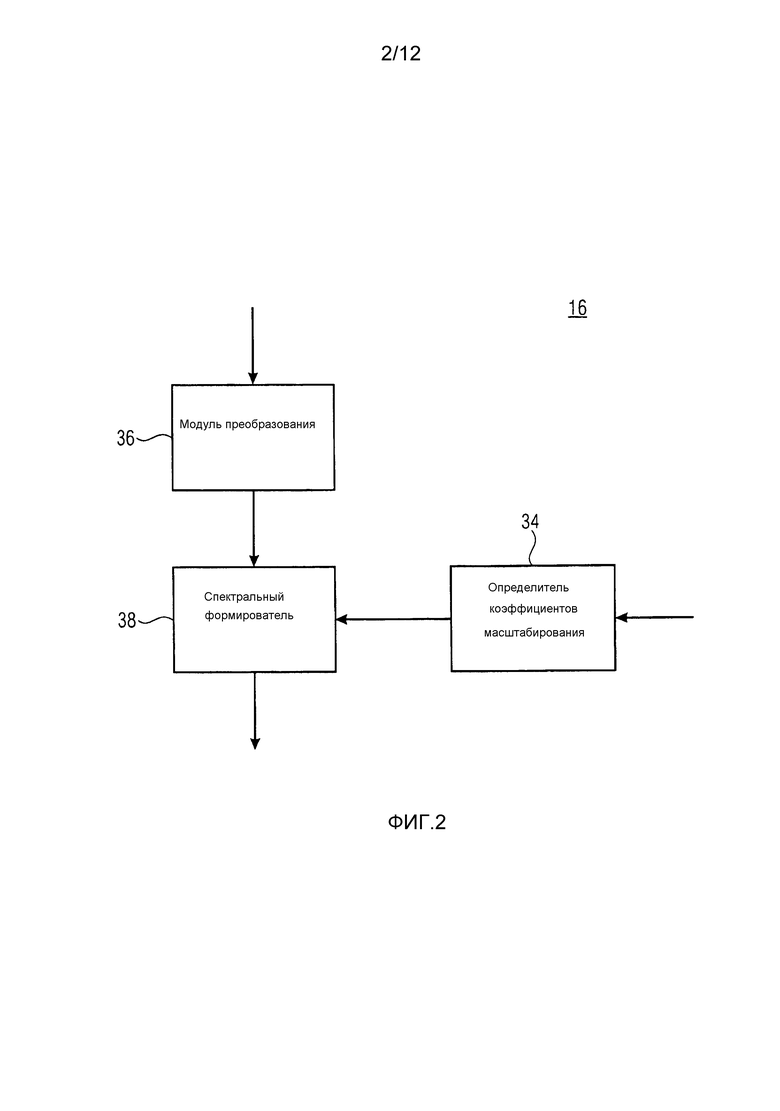
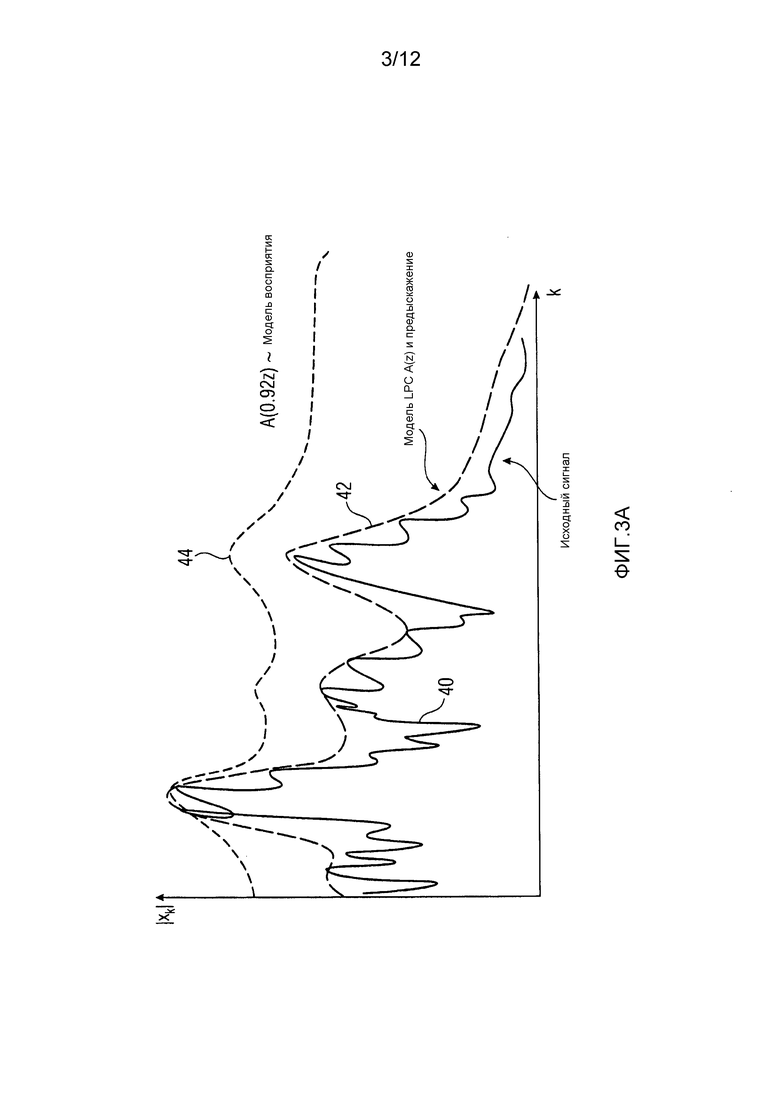
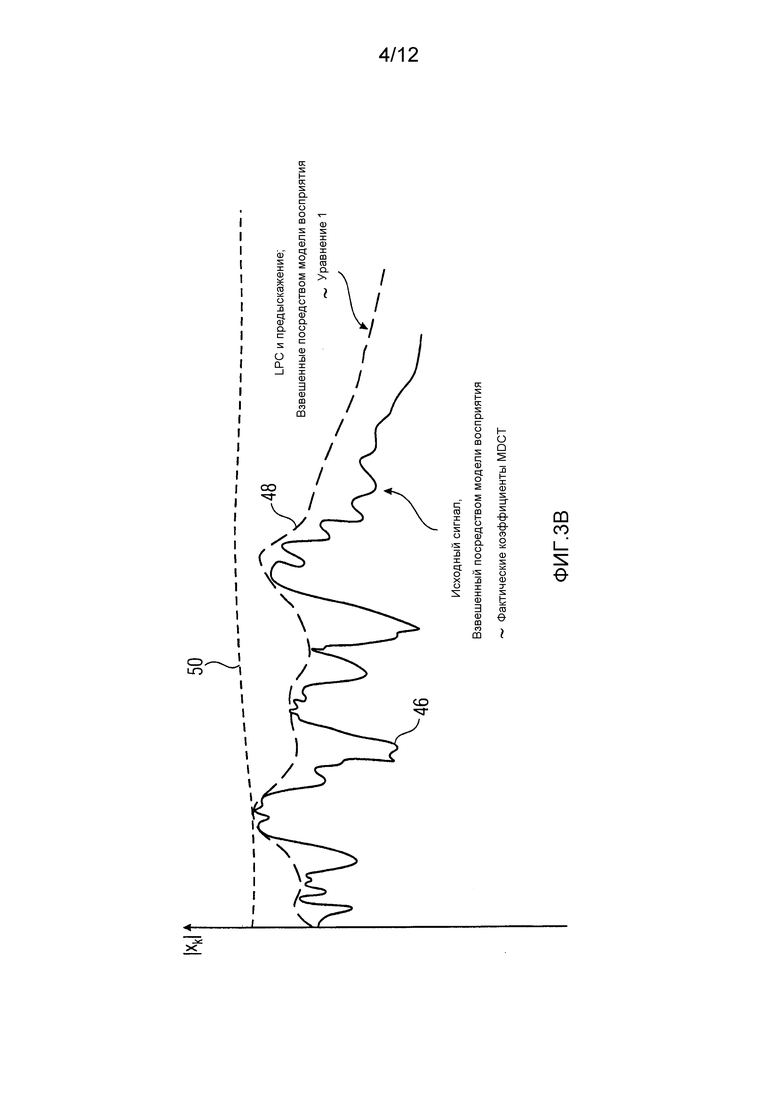
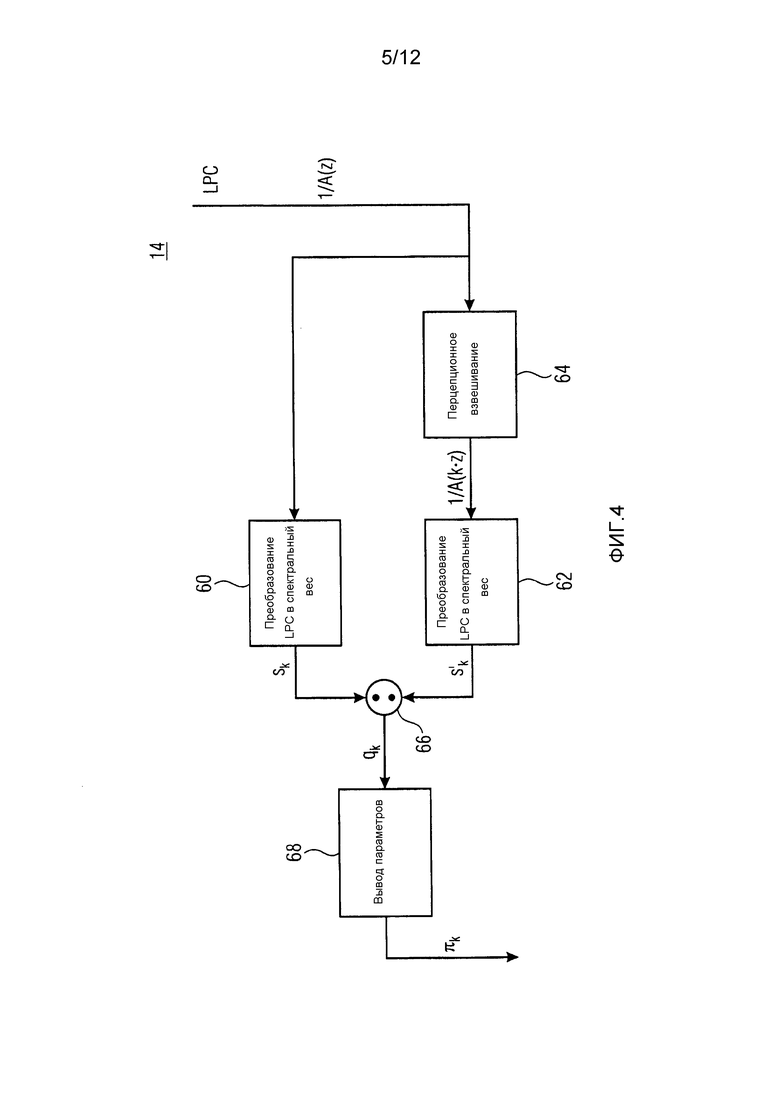
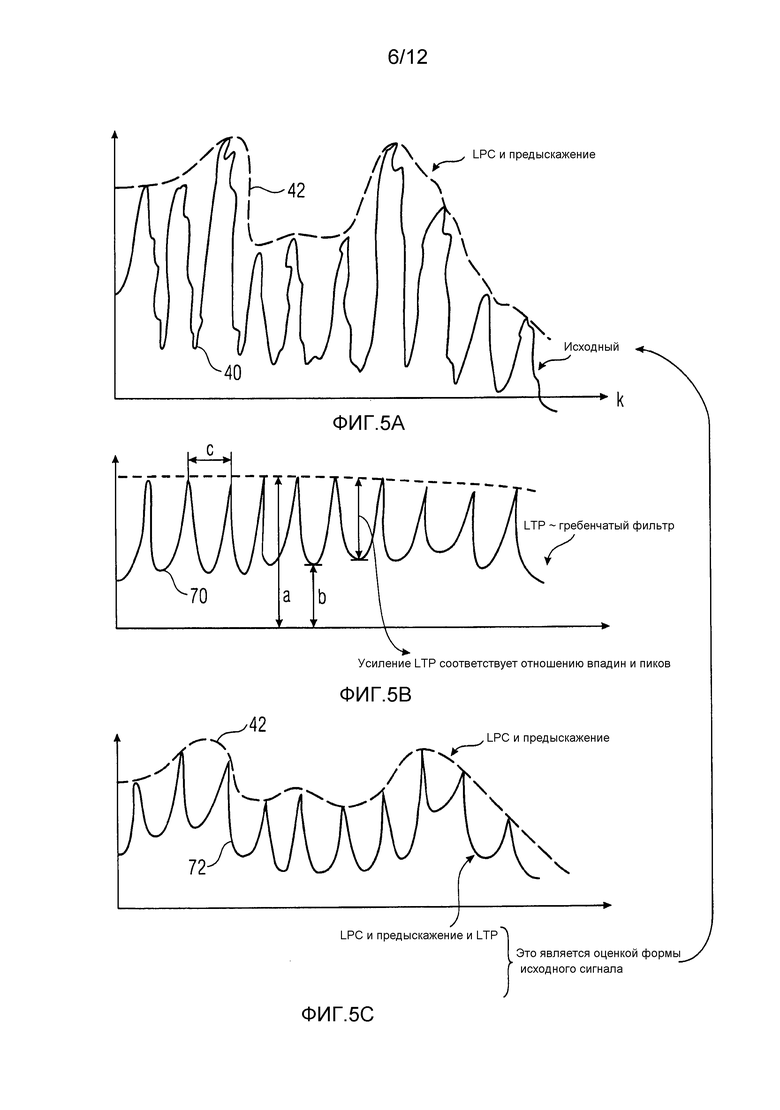
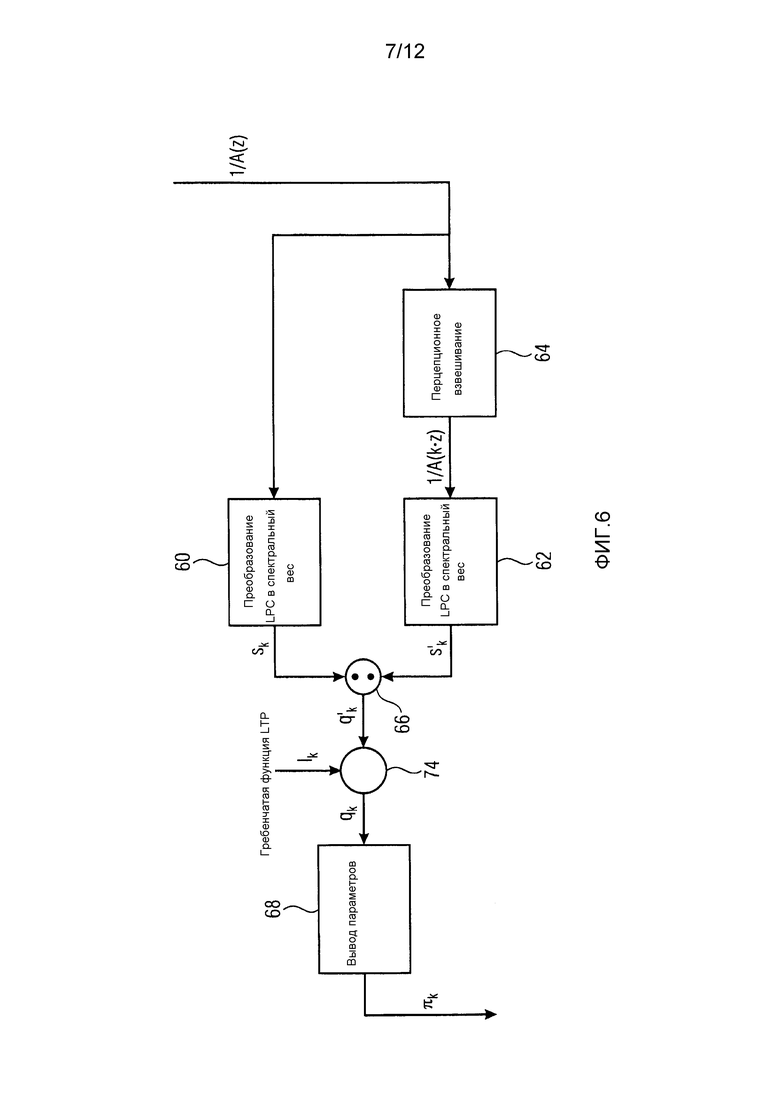
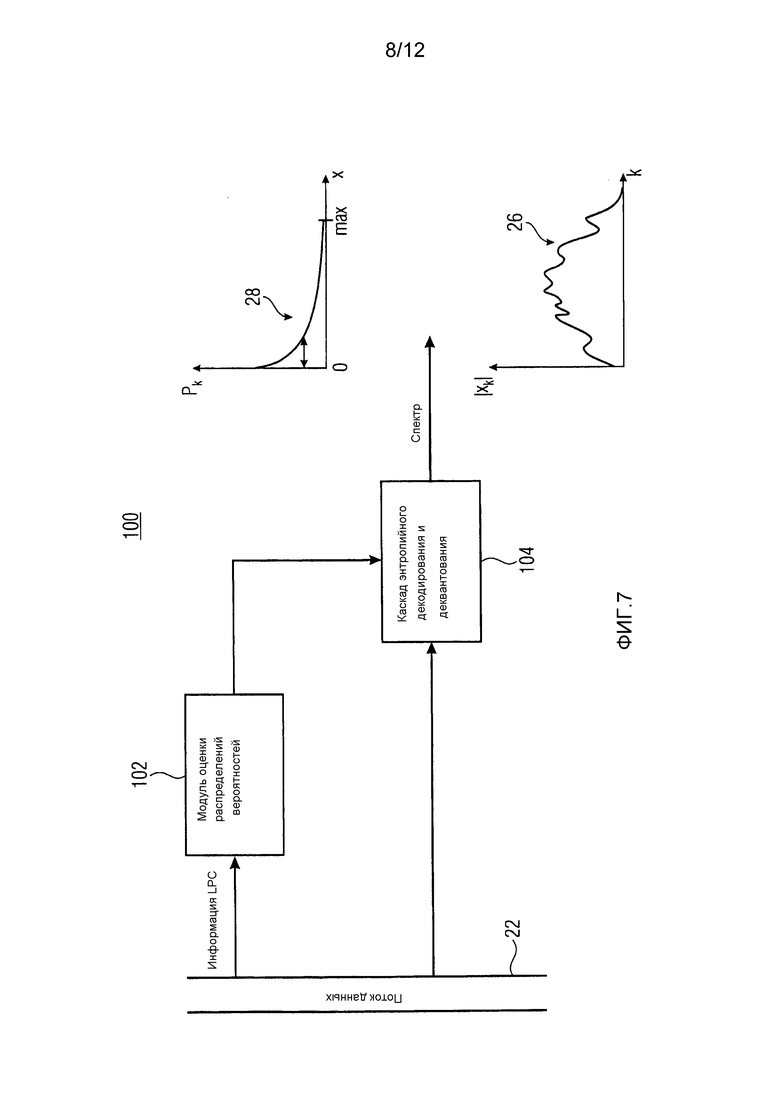
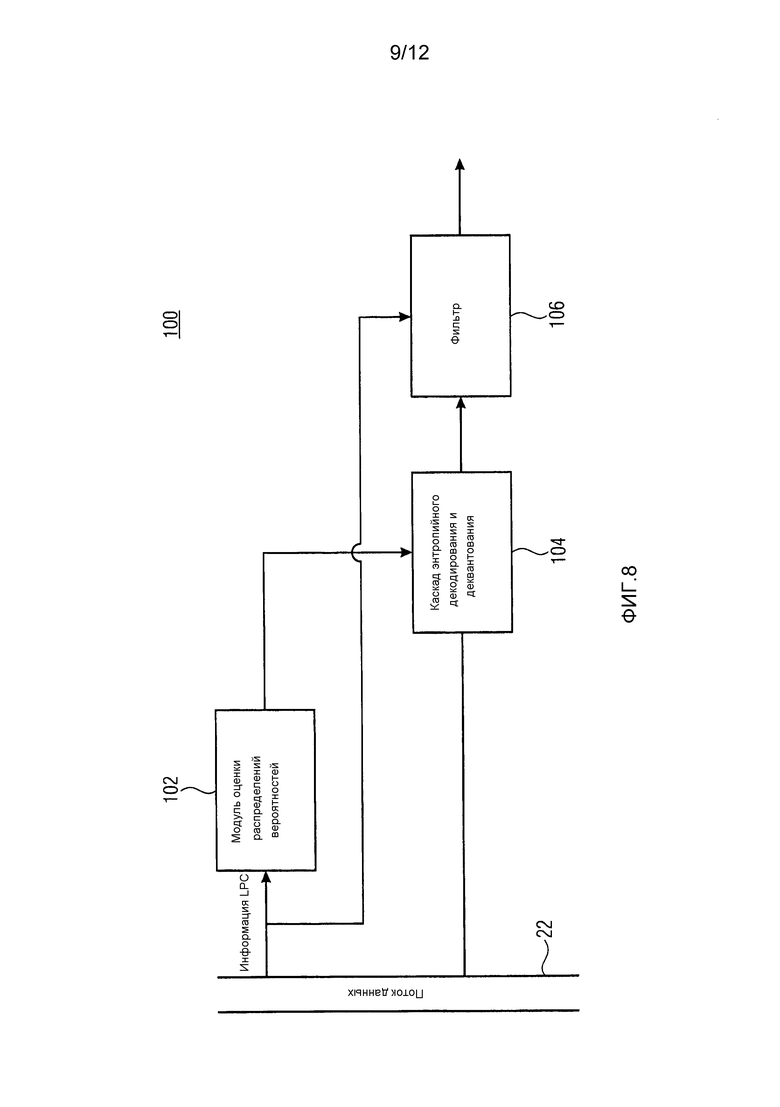
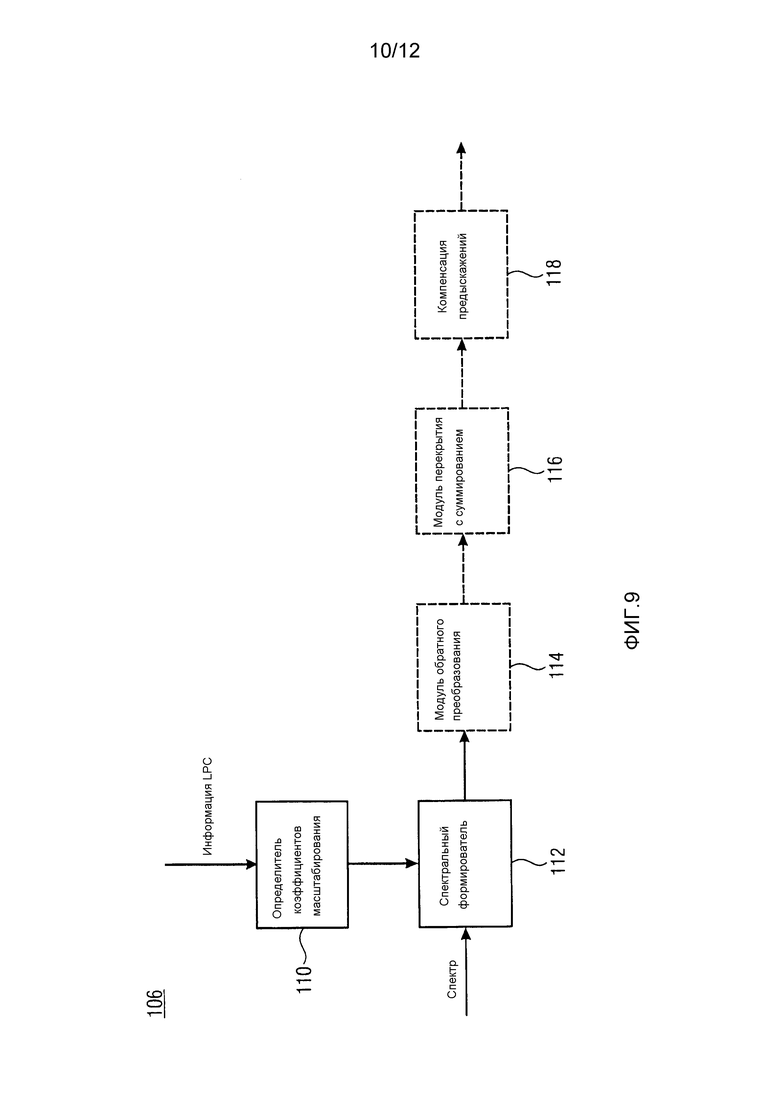
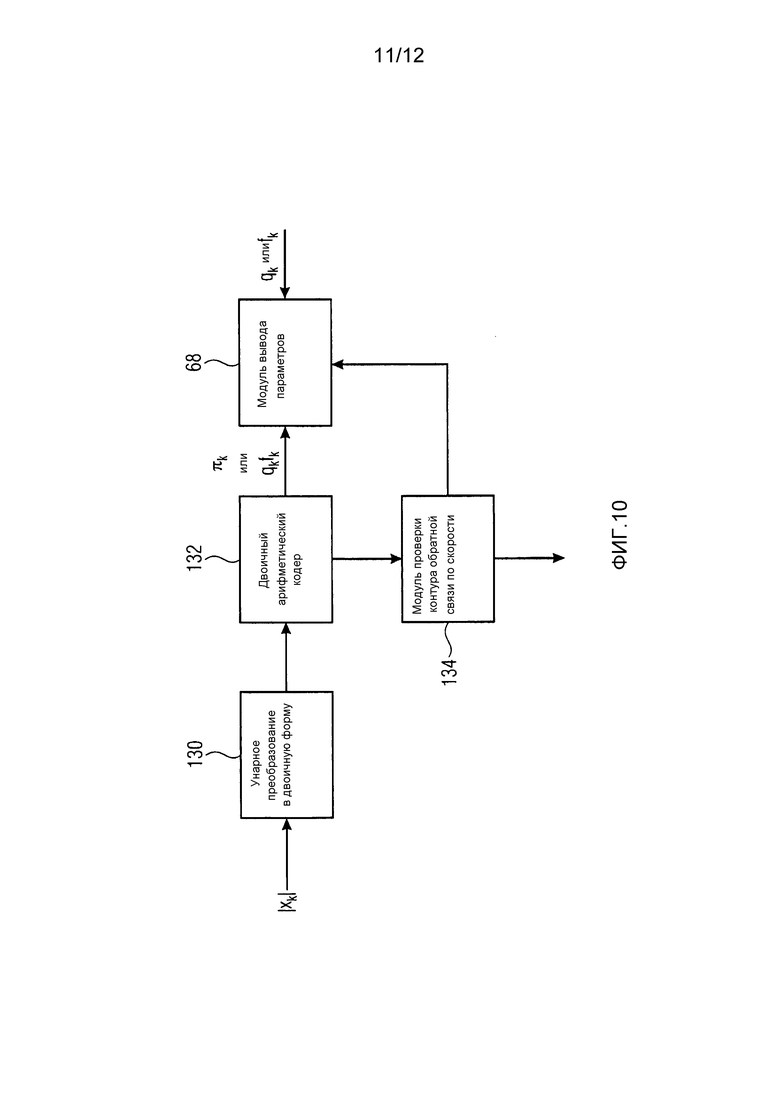
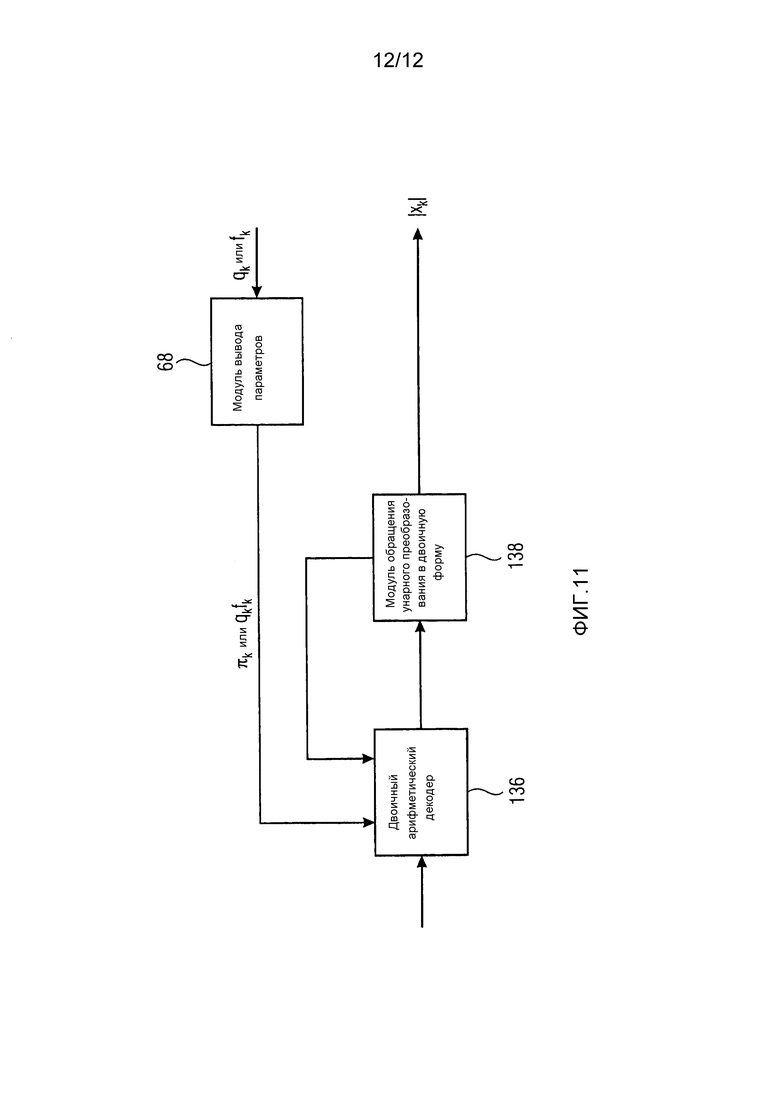
Изобретение относится к средствам для кодирования аудио. Технический результат заключается в повышении эффективности кодирования. Основанный на линейном предсказании аудиодекодер содержит: модуль оценки распределений вероятностей, сконфигурированный с возможностью определять, для каждой из множества спектральных компонент, оценку распределения вероятностей из информации коэффициентов линейного предсказания, содержащейся в потоке данных, в который закодирован аудиосигнал; каскад энтропийного декодирования и деквантования, сконфигурированный с возможностью осуществлять энтропийное декодирование и деквантование спектра, составленного из упомянутого множества спектральных компонент, из потока данных с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент; и фильтр, сконфигурированный с возможностью формировать спектр согласно передаточной функции, зависящей от синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания. 6 н. и 24 з.п. ф-лы, 14 ил.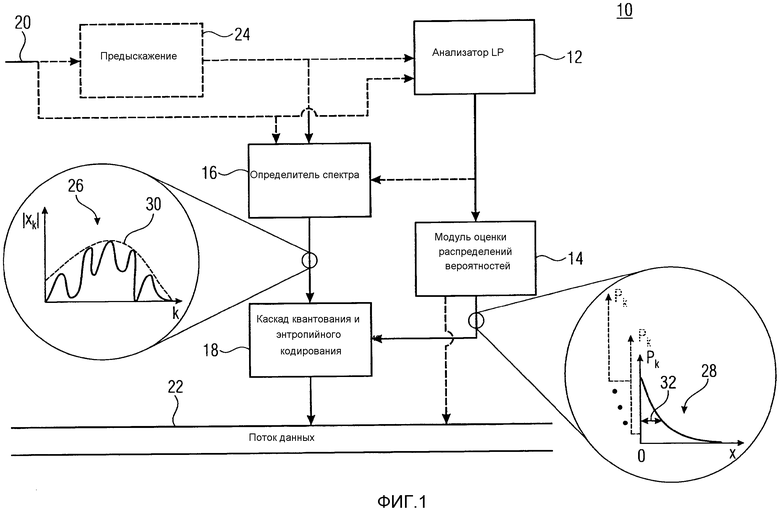
1. Основанный на линейном предсказании аудиодекодер, содержащий:
модуль (102) оценки распределений вероятностей, сконфигурированный с возможностью определять, для каждой из множества спектральных компонент, оценку (28) распределения вероятностей из информации коэффициентов линейного предсказания, содержащейся в потоке (22) данных, в который закодирован аудиосигнал;
каскад (104) энтропийного декодирования и деквантования, сконфигурированный с возможностью осуществлять энтропийное декодирование и деквантование спектра (26), составленного из упомянутого множества спектральных компонент, из потока (22) данных с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент; и
фильтр, сконфигурированный с возможностью формировать спектр (26) согласно передаточной функции, зависящей от синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания,
при этом модуль оценки распределений вероятностей сконфигурирован с возможностью выполнять определение оценки (28) распределения вероятностей для каждой из множества спектральных компонент посредством
определения спектральной тонкой структуры из параметров долгосрочного предсказания, содержащихся в потоке данных, и
определения, для каждой из упомянутого множества спектральных компонент, параметра, который осуществляет параметризацию параметризуемой функции, представляющей оценку распределения вероятностей соответствующей спектральной компоненты, так что параметры для упомянутого множества спектральных компонент формируют спектральную функцию, которая мультипликативно зависит от упомянутой спектральной тонкой структуры.
2. Основанный на линейном предсказании аудиодекодер по п. 1, дополнительно содержащий:
определитель (110) коэффициентов масштабирования, сконфигурированный с возможностью определять коэффициенты масштабирования на основе информации коэффициентов линейного предсказания; и
спектральный формирователь (112), сконфигурированный с возможностью спектрально формировать спектр посредством масштабирования спектра с использованием коэффициентов масштабирования,
при этом определитель коэффициентов масштабирования сконфигурирован с возможностью определять коэффициенты масштабирования, так что они представляют передаточную функцию, зависящую от синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания.
3. Основанный на линейном предсказании аудиодекодер по п. 1, в котором
зависимость передаточной функции от синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания, является такой, что передаточная функция является перцепционно взвешенной.
4. Основанный на линейном предсказании аудиодекодер по п. 1, в котором
зависимость передаточной функции от синтезирующего фильтра линейного предсказания 1/A(z), определенного посредством линейного предсказания, является такой, что передаточная функция является передаточной функцией 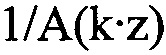 , где k является постоянной.
, где k является постоянной.
5. Основанный на линейном предсказании аудиодекодер по п. 1, в котором модуль оценки распределений вероятностей сконфигурирован так, что спектральная тонкая структура является гребенчатой функцией, определенной посредством параметров долгосрочного предсказания.
6. Основанный на линейном предсказании аудиодекодер по п. 1, в котором параметры долгосрочного предсказания содержат усиление долгосрочного предсказания и основной тон долгосрочного предсказания.
7. Основанный на линейном предсказании аудиодекодер по п. 1, в котором, для каждой из множества спектральных компонент, параметризуемая функция определена так, что параметр является мерой для дисперсии оценки распределения вероятностей.
8. Основанный на линейном предсказании аудиодекодер по п. 1, в котором, для каждой из множества спектральных компонент, параметризуемая функция является распределением Лапласа и параметр соответствующей спектральной компоненты формирует параметр масштаба соответствующего распределения Лапласа.
9. Основанный на линейном предсказании аудиодекодер по п. 1, дополнительно содержащий фильтр компенсации предыскажений.
10. Основанный на линейном предсказании аудиодекодер по п. 1, в котором каскад (104) энтропийного декодирования и деквантования сконфигурирован с возможностью, при деквантовании и энтропийном декодировании спектра из множества спектральных компонент, использовать оценку распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент для амплитуды спектра.
11. Основанный на линейном предсказании аудиодекодер по п. 1, в котором каскад (104) энтропийного декодирования и деквантования сконфигурирован с возможностью использовать оценку распределения вероятностей при энтропийном декодировании уровня амплитуды спектральных компонент и деквантовать уровни амплитуд одинаковым образом для всех спектральных компонент, чтобы получать спектр.
12. Основанный на линейном предсказании аудиодекодер по п. 11, в котором каскад (104) энтропийного декодирования и деквантования сконфигурирован с возможностью использовать постоянный размер шага квантования для деквантования уровней амплитуд.
13. Основанный на линейном предсказании аудиодекодер по п. 1, дополнительно содержащий
модуль обратного преобразования, сконфигурированный с возможностью подвергать спектр действительнозначному критически дискретизированному обратному преобразованию, чтобы получать часть сигнала временной области; и
модуль перекрытия с суммированием, сконфигурированный с возможностью подвергать часть сигнала временной области обработке перекрытия с суммированием с предшествующей и/или следующей частью временной области, чтобы восстанавливать аудиосигнал.
14. Основанный на линейном предсказании аудиокодер, содержащий:
анализатор (12) линейного предсказания, сконфигурированный с возможностью определять информацию коэффициентов линейного предсказания;
модуль (14) оценки распределений вероятностей, сконфигурированный с возможностью определять, для каждой из множества спектральных компонент, оценку распределения вероятностей из информации коэффициентов линейного предсказания; и
определитель (16) спектра, сконфигурированный с возможностью определять спектр, составленный из множества спектральных компонент, из аудиосигнала;
каскад (18) квантования и энтропийного кодирования, сконфигурированный с возможностью квантовать и осуществлять энтропийное кодирование спектра с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент,
при этом определитель (16) спектра сконфигурирован с возможностью формировать исходный спектр аудиосигнала согласно передаточной функции, которая зависит от инверсии синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания, и
при этом основанный на линейном предсказании аудиокодер дополнительно содержит долгосрочный предсказатель, сконфигурированный с возможностью определять параметры долгосрочного предсказания, и модуль оценки распределений вероятностей сконфигурирован с возможностью выполнять определение оценки распределения вероятностей для каждой из множества спектральных компонент посредством
определения спектральной тонкой структуры из параметров долгосрочного предсказания и
определения, для каждой из упомянутого множества спектральных компонент, параметра, который осуществляет параметризацию параметризуемой функции, представляющей оценку распределения вероятностей соответствующей спектральной компоненты, так что параметры для упомянутого множества спектральных компонент формируют спектральную функцию, которая зависит от произведения передаточной функции синтезирующего фильтра линейного предсказания, инверсии передаточной функции перцепционно взвешенной модификации синтезирующего фильтра линейного предсказания и упомянутой спектральной тонкой структуры.
15. Основанный на линейном предсказании аудиокодер по п. 14, в котором определитель (16) спектра содержит:
определитель (34) коэффициентов масштабирования, сконфигурированный с возможностью определять коэффициенты масштабирования на основе информации коэффициентов линейного предсказания;
модуль (36) преобразования, сконфигурированный с возможностью осуществлять спектральное разложение аудиосигнала, чтобы получать исходный спектр; и
спектральный формирователь (38), сконфигурированный с возможностью спектрально формировать исходный спектр посредством масштабирования спектра с использованием коэффициентов масштабирования,
при этом определитель (34) коэффициентов масштабирования сконфигурирован с возможностью определять коэффициенты масштабирования, так что спектральное формирование посредством спектрального формирователя с использованием коэффициентов масштабирования соответствует передаточной функции, которая зависит от инверсии синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания.
16. Основанный на линейном предсказании аудиокодер по п. 14, в котором
зависимость передаточной функции от инверсии синтезирующего фильтра линейного предсказания, определенного посредством линейного предсказания, является такой, что передаточная функция является перцепционно взвешенной.
17. Основанный на линейном предсказании аудиокодер по п. 14, в котором
зависимость передаточной функции от инверсии синтезирующего фильтра линейного предсказания 1/A(z), определенного посредством информации коэффициентов линейного предсказания, является такой, что передаточная функция является инверсией передаточной функции 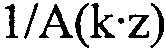 , где k является постоянной.
, где k является постоянной.
18. Основанный на линейном предсказании аудиокодер по п. 14, в котором модуль оценки распределений вероятностей сконфигурирован так, что спектральная тонкая структура является структурой, подобной гребенчатой структуре, определенной посредством параметров долгосрочного предсказания.
19. Основанный на линейном предсказании аудиокодер по п. 14, в котором параметры долгосрочного предсказания содержат усиление долгосрочного предсказания и основной тон долгосрочного предсказания.
20. Основанный на линейном предсказании аудиокодер по п. 14, в котором, для каждой из множества спектральных компонент, параметризуемая функция определена так, что параметр является мерой для дисперсии оценки распределения вероятностей.
21. Основанный на линейном предсказании аудиокодер по п. 14, в котором, для каждой из множества спектральных компонент, параметризуемая функция является распределением Лапласа и параметр соответствующей спектральной компоненты формирует параметр масштаба соответствующего распределения Лапласа.
22. Основанный на линейном предсказании аудиокодер по п. 14, дополнительно содержащий фильтр (24) предыскажений, сконфигурированный с возможностью подвергать аудиосигнал предыскажению.
23. Основанный на линейном предсказании аудиокодер по п. 14, в котором каскад квантования и энтропийного кодирования сконфигурирован с возможностью, при квантовании и энтропийном кодировании спектра из множества спектральных компонент, интерпретировать знак и амплитуду во множестве спектральных компонент по отдельности с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент для амплитуды.
24. Основанный на линейном предсказании аудиокодер по п. 14, в котором каскад (18) квантования и энтропийного кодирования сконфигурирован с возможностью квантовать спектр одинаковым образом для всех спектральных компонент, чтобы получать уровни амплитуд для спектральных компонент, и использовать оценку распределения вероятностей при энтропийном кодировании уровней амплитуд спектра в расчете на каждую спектральную компоненту.
25. Основанный на линейном предсказании аудиокодер по п. 24, в котором каскад квантования и энтропийного кодирования сконфигурирован с возможностью использовать постоянный размер шага квантования для квантования.
26. Основанный на линейном предсказании аудиокодер по п. 14, в котором модуль преобразования сконфигурирован с возможностью выполнять действительнозначное критически дискретизированное преобразование.
27. Способ для основанного на линейном предсказании декодирования аудио, содержащий:
определение, для каждой из множества спектральных компонент, оценки (28) распределения вероятностей из информации коэффициентов линейного предсказания, содержащейся в потоке (22) данных, в который закодирован аудиосигнал; и
энтропийное декодирование и деквантование спектра (26), составленного из упомянутого множества спектральных компонент, из потока (22) данных с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент,
способ также содержит формирование спектра (26) согласно передаточной функции, зависящей от синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания,
при этом определение оценки распределений вероятностей для каждой из множества спектральных компонент содержит
определение спектральной тонкой структуры из параметров долгосрочного предсказания, содержащихся в потоке данных, и
определение, для каждой из упомянутого множества спектральных компонент, параметра, который осуществляет параметризацию параметризуемой функции, представляющей оценку распределения вероятностей соответствующей спектральной компоненты, так что параметры для упомянутого множества спектральных компонент формируют спектральную функцию, которая мультипликативно зависит от упомянутой спектральной тонкой структуры.
28. Способ для основанного на линейном предсказании кодирования аудио содержащий:
определение информации коэффициентов линейного предсказания;
определение, для каждой из множества спектральных компонент, оценки распределения вероятностей из информации коэффициентов линейного предсказания; и
определение спектра, составленного из упомянутого множества спектральных компонент, из аудиосигнала;
квантование и энтропийное кодирование спектра с использованием оценки распределения вероятностей, которая определена для каждой из упомянутого множества спектральных компонент,
при этом определение спектра содержит формирование исходного спектра аудиосигнала согласно передаточной функции, которая зависит от инверсии синтезирующего фильтра линейного предсказания, определенного посредством информации коэффициентов линейного предсказания, и
при этом способ дополнительно содержит определение параметров долгосрочного предсказания, и определение оценки распределения вероятностей для каждой из множества спектральных компонент содержит
определение спектральной тонкой структуры из параметров долгосрочного предсказания и
определение, для каждой из упомянутого множества спектральных компонент, параметра, который осуществляет параметризацию параметризуемой функции, представляющей оценку распределения вероятностей соответствующей спектральной компоненты, так что параметры для упомянутого множества спектральных компонент формируют спектральную функцию, которая зависит от произведения передаточной функции синтезирующего фильтра линейного предсказания, инверсии передаточной функции перцепционно взвешенной модификации синтезирующего фильтра линейного предсказания, и упомянутой спектральной тонкой структуры.
29. Считываемый компьютером носитель, хранящий компьютерную программу, имеющую программный код для выполнения, когда исполняется на компьютере, способа по п. 27.
30. Считываемый компьютером носитель, хранящий компьютерную программу, имеющую программный код для выполнения, когда исполняется на компьютере, способа по п. 28.
| ТОПЛИВНАЯ КОМПОЗИЦИЯ | 1995 |
|
RU2077550C1 |
| Устройство для заточки сверл | 1985 |
|
SU1278184A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ ВЫДЕЛЕНИЯ СЕГМЕНТОВ ОБРАБОТКИ РЕЧИ НА ОСНОВЕ АНАЛИЗА КОРРЕЛЯЦИОННЫХ ЗАВИСИМОСТЕЙ В РЕЧЕВОМ СИГНАЛЕ | 2010 |
|
RU2445718C1 |

