ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСТИСЯ ИЗОБРЕТЕНИЕ
Варианты осуществления изобретения относятся к аудиодекодеру, который предоставляет декодированную аудиоинформацию на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), к способу предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), к компьютерной программе для выполнения такого способа, при этом компьютерная программа работает на компьютере, и к аудиосигналу или носителю данных, на котором сохранен такой аудиосигнал, где аудиосигнал обработан с помощью такого способа.
УРОВЕНЬ ТЕХНИКИ
Цифровые речевые кодеры с низкой скоростью передачи битов (битрейтом), основанные на принципе кодирования с линейным предсказанием с кодовым возбуждением (CELP), как правило страдают от артефактов разреженного сигнала, когда скорость передачи битов падает ниже приблизительно 0,5-1 бита на отсчет, что приводит к несколько искусственному, металлическому звуку. Низкоскоростные артефакты особенно ясно слышны, когда входящий сигнал речи загрязнен фоновым шумом окружающей среды: фоновый шум будет ослаблен во время участков, содержащих активную речь. Настоящее изобретение описывает схему вставки шума для кодеров, использующих алгоритм (A)CELP (линейное предсказание с возбуждением алгебраическим кодом), таких как AMR-WB [1] и G.718 [4, 7], которая, аналогично способам наполнения шумом, используемым в кодерах с преобразованием сигнала, таких как xHE-AAC [5, 6], добавляет выход генератора случайного шума в декодированный речевой сигнал, для воспроизведения фонового шума.
Международная публикация WO 2012/110476 A1 демонстрирует концепцию кодирования, которая основана на линейном предсказании и использует преобразование шума в спектральной области. Спектральная декомпозиция входящего аудиосигнала в спектрограмму, содержащую спектральную последовательность, используется как для вычисления коэффициента линейного предсказания, так и в качестве входа для преобразования частотной области, основанного на коэффициентах линейного предсказания. Согласно цитируемому документу аудиокодер содержит анализатор линейных предсказаний, анализирующий входящий аудиосигнал для того, чтобы вычислить оттуда коэффициенты линейного предсказания. Преобразователь частотной области аудиокодера сконфигурирован спектрально преобразовать текущий спектр спектральной последовательности спектрограммы на основе коэффициентов линейного предсказания полученных из анализатора линейных предсказаний. Квантованный и спектрально преобразованный спектр вставляется в поток данных наряду с информацией о коэффициентах линейного предсказания, использованных в спектральном преобразовании так, чтобы при декодировании можно было выполнить обратное преобразование и деквантизацию. Модуль временного преобразования шума также может присутствовать для выполнения временного преобразования шума.
Ввиду известного уровня техники сохраняется потребность в усовершенствованном аудиодекодере, усовершенствованном способе, усовершенствованной компьютерной программе для выполнения такого способа, и усовершенствованном аудиосигнале или носителе данных, на котором сохранен такой аудиосигнал, где аудиосигнал обработан с помощью такого способа. Точнее, желательно найти такие решения, которые усовершенствуют качество звука аудиоинформации, передаваемой в закодированном битовом потоке.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Ссылочные символы в формуле изобретения и в подробном описании предпочтительных вариантов осуществления изобретения были добавлены только для улучшения читабельности и никоим образом не подразумеваются как ограничения.
Задача изобретения решается посредством аудиодекодера, который предоставляет декодированную аудиоинформацию на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), причем аудиодекодер содержит средство регулирования отклонения, сконфигурированное для регулирования отклонения шума, используя коэффициенты линейного предсказания текущего кадра для получения информации об отклонении, и средство вставки шума, сконфигурированное для добавления шума к текущему кадру в зависимости от информации об отклонении, полученной средством вычисления (вычислителем) отклонения. Кроме того, задача настоящего изобретения решается посредством способа предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), при этом способ содержит регулирование отклонения шума, используя коэффициенты линейного предсказания текущего кадра, для получения информации об отклонении, и добавление шума к текущему кадру в зависимости от полученной информации об отклонении.
В качестве второго отвечающего изобретению технического решения, изобретение предлагает аудиодекодер, который предоставляет декодированную аудиоинформацию на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), причем аудиодекодер содержит средство оценки уровня шума, сконфигурированное для оценки уровня шума для текущего кадра, используя коэффициенты линейного предсказания по меньшей мере одного предыдущего кадра, для получения информации об уровне шума, и средство вставки шума, сконфигурированное для добавления шума к текущему кадру в зависимости от информации об уровне шума, полученной средством оценки уровня шума. Более того, задача настоящего изобретения решается посредством способа предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), при этом способ содержит оценку уровня шума текущего кадра, используя коэффициенты линейного предсказания по меньшей мере одного предыдущего кадра для получения информации об уровне шума, и добавление шума к текущему кадру в зависимости от информации об уровне шума, полученной путем оценки уровня шума. Кроме того, задача изобретения решается посредством компьютерной программой для выполнения такого способа, при этом компьютерная программа работает на компьютере, а также посредством аудиосигнала или носителя данных, на котором сохранен такой аудиосигнал, где аудиосигнал обработан с помощью такого способа.
Предложенные решения исключают необходимость предоставления побочной информации в битовом потоке CELP для того, чтобы регулировать шум, предоставляемый на стороне декодера во время процесса наполнения шумом. Это означает, что количество данных, передаваемых с битовым потоком, может быть уменьшено, в то время как качество вставляемого шума может быть только увеличено на основе коэффициентов линейного предсказания кадров, декодируемых в настоящий момент или декодированных прежде. Другими словами, побочная информация, касающаяся шума, которая увеличила бы количество данных, передаваемых с битовым потоком, может быть исключена. Изобретение позволяет создать цифровой кодер с низкой скоростью передачи битов и способ, который может потреблять меньший диапазон частот относительно битового потока и предоставлять улучшенное качество фонового шума по сравнению с решениями предшествующего уровня техники.
Предпочтительно, чтобы аудиодекодер содержал средство определения типа кадра, которое определяет тип кадра текущего кадра, при этом средство определения типа кадра выполнено с возможностью активации средства регулирования отклонения, которое регулирует отклонение шума, когда тип кадра текущего кадра определен как относящийся к типу речи. В некоторых вариантах осуществления, средство определения типа кадра сконфигурировано для определения того, относится ли кадр к кадру типа речи, когда кадр закодирован ACELP или CELP. Преобразование шума согласно отклонению текущего кадра может обеспечивать более естественный фоновый шум и может уменьшать нежелательные эффекты сжатия звука относительно фонового шума желаемого сигнала, закодированного в битовом потоке. Так как эти нежелательные эффекты и артефакты сжатия часто становятся заметны в отношении фонового шума речевой информации, может быть полезно увеличить качество шума, добавляемого к таким кадрам типа речи посредством регулирования отклонения шума до добавления шума к текущему кадру. Соответственно, средство вставки шума может быть сконфигурировано для добавления шума к текущему кадру, только если текущий кадр является кадром речевого сигнала, так как это может уменьшить рабочую нагрузку на стороне декодера, только если кадры речевого сигнала обрабатываются наполнением шумом.
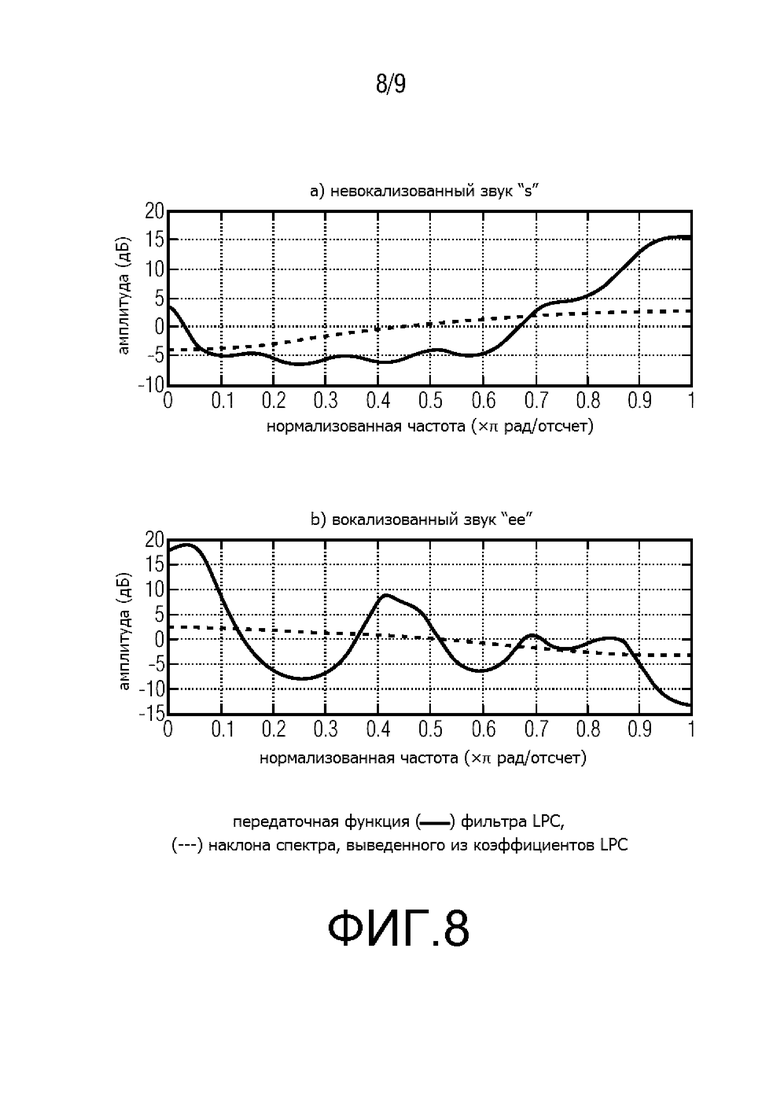
В предпочтительном варианте осуществления изобретения, средство регулирования отклонения сконфигурировано для использования результата анализа первого порядка коэффициентов линейного предсказания текущего кадра для получения информации об отклонении. Посредством использования такого анализа коэффициентов линейного предсказания первого порядка, становится возможным исключить побочную информацию для описания шума в битовом потоке. Более того, регулирование добавляемого шума может быть основано на коэффициентах линейного предсказания текущего кадра, которые в любом случае должны быть переданы с битовым потоком для того, чтобы сделать возможным декодирование аудиоинформации текущего кадра. Это означает, что коэффициенты линейного предсказания текущего кадра преимущественно используются повторно в процессе регулирования отклонения шума. Более того, анализ первого порядка достаточно прост, чтобы вычислительная сложность аудиодекодера не увеличивалась значительно.
В некоторых вариантах осуществления изобретения, средство регулирования отклонения сконфигурировано для получения информации об отклонении, с помощью вычисления приращения g коэффициентов линейного предсказания текущего кадра в качестве анализа первого порядка. Более предпочтительно, приращение g задается по формуле 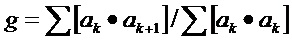
Предпочтительно, средство регулирования отклонения сконфигурировано для получения информации об отклонении с помощью вычисления передаточной функции прямой реализации фильтра 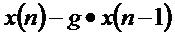
В предпочтительном варианте осуществления изобретения, средство вставки шума сконфигурировано для применения информации об отклонении текущего кадра к шуму для того, чтобы отрегулировать отклонение шума до добавления шума к текущему кадру. Если средство вставки шума сконфигурировано соответствующим образом, может быть создан упрощенный аудиодекодер. Сначала применив информацию об отклонении и затем добавив отрегулированный шум к текущему кадру, может быть предложен простой и эффективный способ работы аудиодекодера предоставлен.
В варианте осуществления изобретения, аудиодекодер, более того, содержит средство оценки уровня шума, сконфигурированное для оценки уровня шума текущего кадра, используя коэффициенты линейного предсказания по меньшей мере одного предыдущего кадра для получения информации об уровне шума, и средство вставки шума, сконфигурированное для добавления шума к текущему кадру в зависимости от информации об уровне шума, полученной средством оценки уровня шума. Таким способом, качество фонового шума и, таким образом, качество всей передачи звуковых сигналов может быть увеличено, так как шум, добавляемый к текущему кадру, может быть отрегулирован согласно уровню шума, который вероятно присутствует в текущем кадре. Например, если высокий уровень шума ожидается в текущем кадре, потому что высокий уровень шума был оценен из предыдущих кадров, средство вставки шума может быть сконфигурировано для повышения уровня шума, добавляемого к текущему кадру, до его добавления к текущему кадру. Таким образом, добавляемый шум может быть отрегулирован для того, чтобы не быть ни слишком тихим, ни слишком громким в сравнении с ожидаемым уровнем шума текущего кадра. Такое регулирование, также, не основано на выделенной побочной информации в битовом потоке, но только использует информацию о необходимых данных, передаваемых в битовый поток, в данном случае коэффициент линейного предсказания по меньшей мере одного предыдущего кадра, который также предоставляет информацию об уровне шума в предыдущем кадре. Таким образом, предпочтительно, чтобы шуму, добавляемому к текущему кадру, придавалась форма, используя выведенный из g отклонение, и чтобы его масштабировали с учетом оценки уровня шума. Наиболее предпочтительно, чтобы отклонение и уровень шума, добавляемого к текущему кадру, регулировались, когда текущий кадр относится к речевому типу. В некоторых вариантах осуществления, отклонение и/или уровень шума, добавляемого к текущему кадру, также регулируются, когда текущий кадр относится к типу обычного звука, например, типу TCX (возбуждение с преобразованием кода) или DTX (прерывистая передача).
Предпочтительно, аудиодекодер содержит средство определения типа кадра, которое определяет тип кадра текущего кадра, при этом средство определения типа кадра выполнено с возможностью распознавать, относится ли тип кадра текущего кадра к типу речи или к типу обычного звука для того, чтобы оценка уровня шума могла быть выполнена в зависимости от типа кадра текущего кадра. Например, средство определения типа кадра может быть сконфигурировано для определения, является ли текущий кадр кадром CELP или ACELP, который является типом речевого кадра, или кадром TCX/MDCT (модифицированное дискретное косинус-преобразование) или DTX, которые являются типами обычного звукового кадра. Так как эти форматы кодирования следуют разным принципам, желательно определять тип кадра до выполнения оценки уровня шума, чтобы подходящие вычисления могли быть выбраны в зависимости от типа кадра.
В некоторых вариантах осуществления изобретения аудиодекодер приспособлен вычислять первую информацию, представляющую спектрально бесформенное возбуждение текущего кадра, и вычислять вторую информацию, касающуюся спектрального масштабирования текущего кадра, для вычисления отношения первой информации и второй информации для получения информации об уровне шума. Таким способом, информация об уровне шума может быть получена без использования какой бы то ни было побочной информации. Таким образом, скорость передачи битов кодера может сохраняться низкой.
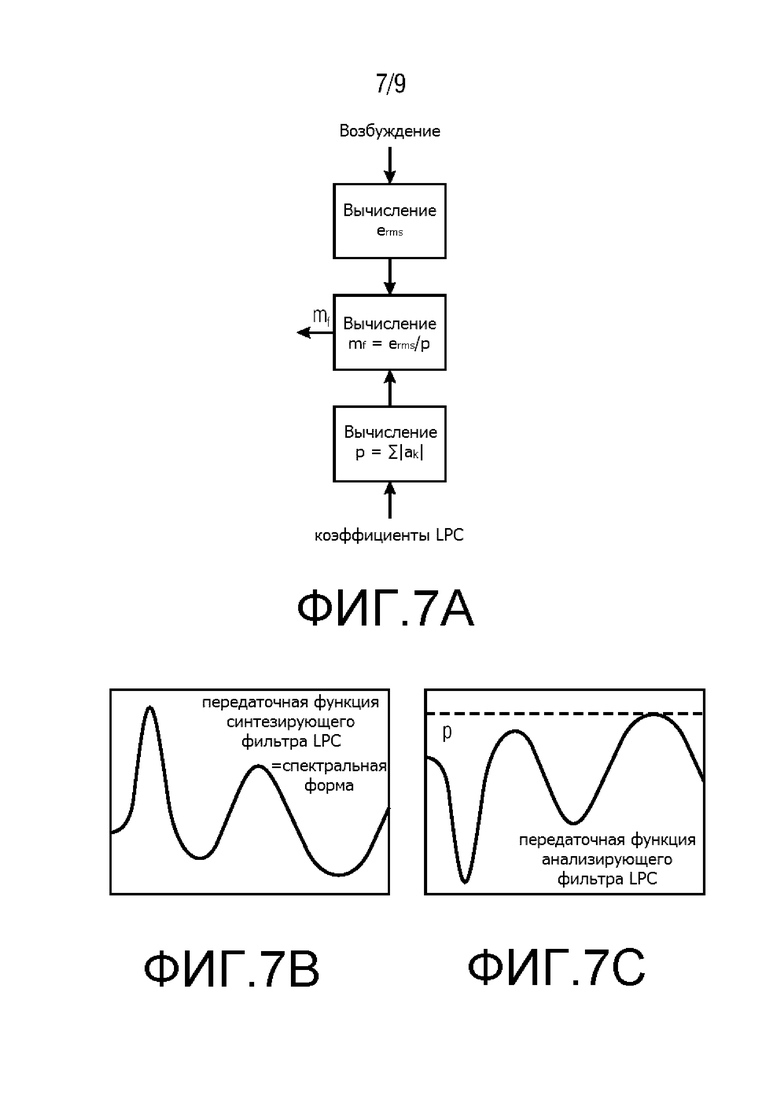
Предпочтительно, аудиодекодер приспособлен для декодирования сигнала возбуждения текущего кадра и для вычисления его среднего квадратичного erms из представления временной области текущего кадра в качестве первой информации для получения информации об уровне шума, при условии, что текущий кадр относится к типу речи. Для данного варианта осуществления предпочтительно, чтобы аудиодекодер был адаптирован функционировать соответствующим образом, если текущий кадр имеет тип CELP или ACELP. Спектрально выровненный сигнал возбуждения (в области восприятия) декодируется из битового потока и используется для обновления оценки уровня шума. Среднее квадратичное erms сигнала возбуждения текущего кадра вычисляется после считывания битового потока. Вычисления такого типа могут не нуждаться в высокой вычислительной мощности и, таким образом, даже могут быть выполнены аудиодекодерами с низкими вычислительными мощностями.
В предпочтительном варианте осуществления аудиодекодер приспособлен для вычисления пикового уровня p передаточной функции фильтра LPC текущего кадра как второй информации, таким образом используя коэффициенты линейного предсказания для получения информации об уровне шума, при условии, что текущий кадр относится к типу речи. Вновь, предпочтительно, чтобы текущий кадр имел тип CELP или ACELP. Вычисление пикового уровня p достаточно экономно, и путем повторного использования коэффициентов линейного предсказания текущего кадра, которые также используются для декодирования аудиоинформации, содержащейся в данном кадре, побочная информация может быть исключена, и тихий фоновый шум может быть усилен без повышения скорости передачи данных в битовом потоке.
В предпочтительном варианте осуществления изобретения, аудиодекодер приспособлен для вычисления спектрального минимума mf текущего аудиокадра, путем вычисления отношения среднего квадратичного erms и пикового уровня p, для получения информации об уровне шума, при условии, что текущий кадр относится к типу речи. Данное вычисление достаточно простое и может предоставить числовое значение, которое может быть полезно при оценке уровня шума по диапазону многочисленных аудиокадров. Таким образом, спектральный минимум mf последовательности текущих аудиокадров может быть использован для оценки уровня шума в течении периода времени, покрываемого данной последовательностью аудиокадров. Это может позволить получать хорошую оценку уровня шума текущего кадра, вместе с тем сохраняя сложность достаточно низкой. Пиковый уровень p предпочтительно вычисляется, используя формулу 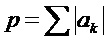
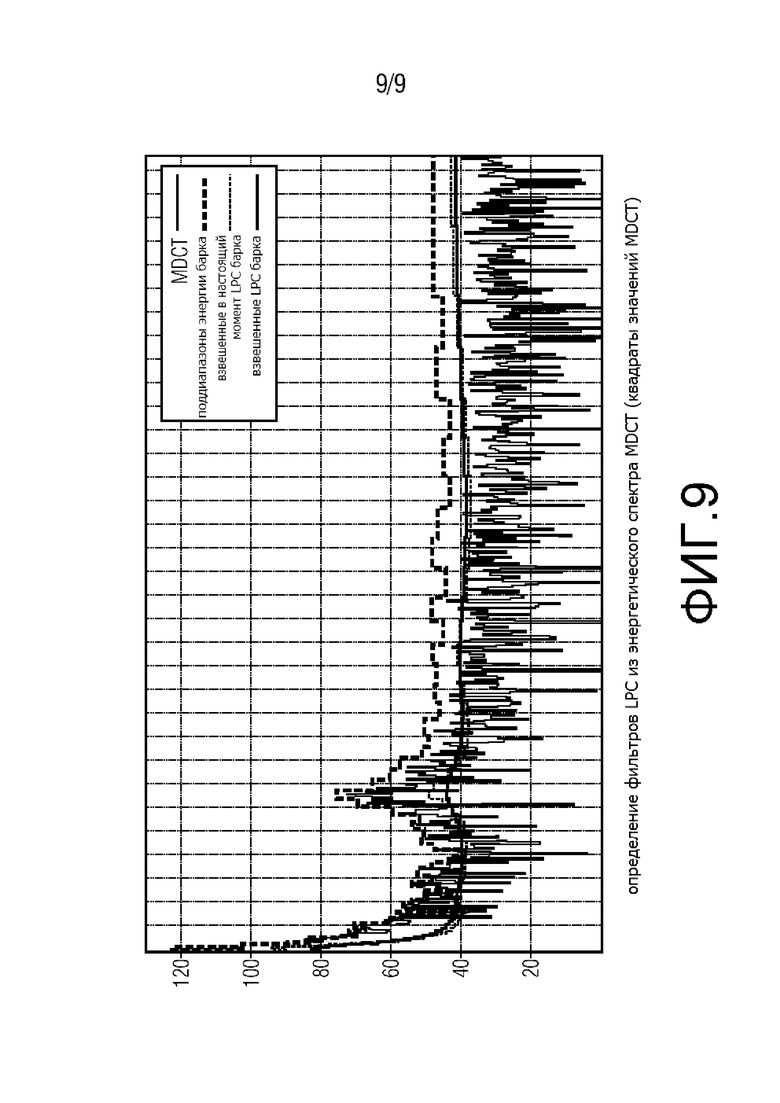
Предпочтительно, аудиодекодер приспособлен для декодирования бесформенного MDCT-возбуждения текущего кадра и для вычисления его средних квадратичных erms из представления спектральной области текущего кадра для получения информации об уровне шума в качестве первой информации, если текущий кадр относится к типу обычного звука. Это является предпочтительным вариантом осуществления изобретения всякий раз, когда текущий кадр не является кадром речевого сигнала, но является кадром обычного звука. Представление спектральной области в кадрах MDCT или DTX в значительной степени эквивалентно представлениям временной области в кадрах речевого сигнала, например, кадры CELP или (A)CELP. Отличие состоит в том, что MDCT не принимает во внимание теорему Парсеваля. Таким образом, предпочтительно среднее квадратичное erms для кадра обычного звука вычисляется аналогично среднему квадратичному erms для кадров речевого сигнала. Затем, предпочтительно вычисляются эквиваленты коэффициентов LPC кадров обычного звука, как изложено в WO 2012/110476 A1, например, используя энергетический спектр MDCT, который относится к квадрату значений MDCT на шкале Барка. В альтернативном варианте осуществления, диапазон частот энергетического спектра MDCT может иметь постоянную ширину, так что шкала спектра соответствует линейной шкале. С такой линейной шкалой вычисленные эквиваленты коэффициентов LPC похожи на коэффициенты LPC в представлении временной области того же кадра, как, например, вычисленные для кадров ACELP или CELP. Более того, предпочтительно чтобы, если текущий кадр относится к типу обычного звука, пиковый уровень p передаточной функции фильтра LPC текущего кадра, который был вычислен из кадра MDCT, как изложено в WO 2012/110476 A1, вычислялся как вторая информация, таким образом используя коэффициенты линейного предсказания для получения информации об уровне шума, при условии, что текущий кадр относится к типу обычного звука. Затем, если текущий кадр относится к типу обычного звука, предпочтительно вычислять спектральный минимум текущего аудиокадра, путем вычисления отношения среднего квадратичного erms и пикового уровня p, для получения информации об уровне шума, при условии, что текущий кадр относится к типу обычного звука. Таким образом, отношение, описывающее спектральный минимум mf текущего аудиокадра, может быть получено независимо от того, относится ли текущий кадр к типу речи или к типу обычного звука.
В предпочтительном варианте осуществления, аудиодекодер приспособлен ставить в очередь отношение, полученное из текущего аудиокадра в средстве оценки уровня шума, независимо от типа кадра, средство оценки уровня шума содержит хранилище уровня шума для двух или более отношений, полученных из различных аудиокадров. Это может быть полезным, если аудиодекодер приспособлен переключаться между декодированием кадров речевого сигнала и декодированием кадров обычного звука, например, когда применяется унифицированное декодирование речи и аудиос малой задержкой (LD-USAC, EVS). Таким способом, средний уровень шума множества кадров может быть получен независимо от типа кадра. Предпочтительно, хранилище уровня шума может удерживать десять или более отношений, полученных из десяти или более предыдущих аудиокадров. Например, хранилище уровня шума может содержать участки памяти для отношений 30 кадров. Таким образом, уровень шума может быть вычислен для длительного времени, предшествующего текущему кадру. В некоторых вариантах осуществления, отношение может ставиться в очередь только в средстве оценки уровня шума, когда текущий кадр определен как относящийся к типу речи. В других вариантах осуществления, отношение может ставится в очередь только в средстве оценки уровня шума, когда текущий кадр определен как относящийся к типу обычного звука.
Предпочтительно, средство оценки уровня шума приспособлено для оценки уровня шума на основе статистического анализа двух или более отношений различных аудиокадров. В варианте осуществления изобретения, аудиодекодер приспособлен использовать слежение за спектральной плотностью мощности шума, основанное на минимальной средней квадратичной погрешности, для статистического анализа отношений. Такое слежение описано в публикации Hendriks, Heusdens и Jensen [2]. Если способ согласно [2] будет применяться, аудиодекодер приспособлен для использования квадратного корня отслеживаемой величины при статистическом анализе, как в настоящем случае амплитуда спектра ищется напрямую. В другом варианте осуществления изобретения, минимум статистики, известной из [3], используется для анализа двух или более отношений различных аудиокадров.
В предпочтительном варианте осуществления, аудиодекодер содержит ядро декодера, сконфигурированное для декодирования аудиоинформации текущего кадра, используя коэффициент линейного предсказания текущего кадра для получения декодированного выходного сигнала основного кодера, и средство вставки шума добавляет шум в зависимости от коэффициента линейного предсказания, использованного при декодировании аудиоинформации текущего кадра, и/или использованных при декодировании аудиоинформации одного или более предыдущих кадров. Таким образом, средство вставки шума использует такие же коэффициенты линейного предсказания, что используются при декодировании аудиоинформации текущего кадра. Побочная информация для инструктирования средства вставки шума может быть исключена.
Предпочтительно, аудиодекодер содержит фильтр компенсации предыскажений для компенсации предыскажений текущего кадра, аудиодекодер выполнен с возможностью применения фильтра компенсации предыскажений к текущему кадру после того, как средством вставки шума добавлен шум в текущий кадр. Так как компенсация предыскажений является БИХ-усилением (усилением с бесконечной импульсной характеристикой) первого порядка низких частот, это дает возможность для БИХ-фильтрации резких верхних частот с низкой сложностью в отношении добавляемого шума с устранением слышимых артефактов шума при низких частотах.
Предпочтительно, аудиодекодер содержит генератор шума, причем генератор шума приспособлен для генерации шума, который добавляется к текущему кадру средством вставки шума. Генератор шума, включенный в аудиодекодер, может обеспечивать более удобный аудиодекодер, так как не нужен внешний генератор шума. В альтернативном варианте, шум может быть предоставлен внешним генератором шума, который может быть соединен с аудиодекодером через интерфейс. Например, специальные типы генераторов шума могут быть применены, в зависимости от фонового шума, который должен быть усилен в текущем кадре.
Предпочтительно, генератор шума сконфигурирован для генерации случайного белого шума. Такой шум в достаточной мере напоминает обычные фоновые шумы, и такой генератор шума может быть легко предоставлен.
В предпочтительном варианте осуществления изобретения, средство вставки шума сконфигурировано для добавления шума в текущий кадр при условии, что скорость передачи битов закодированной аудиоинформации меньше, чем 1 бит на отсчет. Предпочтительно скорость передачи битов закодированной аудиоинформации меньше, чем 0,8 бит на отсчет. Даже еще более предпочтительно, чтобы средство вставки шума было сконфигурировано для добавления шума в текущий кадр при условии, что скорость передачи битов закодированной аудиоинформации меньше, чем 0,5 бит на отсчет.
В предпочтительном варианте осуществления, аудиодекодер сконфигурирован для использования кодера, который основан на одном или более кодерах AMR-WB, G.718 или LD-USAC (EVS), чтобы декодировать закодированную аудиоинформацию. Это хорошо известные и широко распространенные кодеры (A)CELP, в которых дополнительное использование таких способов наполнения шумом может быть весьма полезно.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления настоящего изобретения в последующем описаны по фигурам.
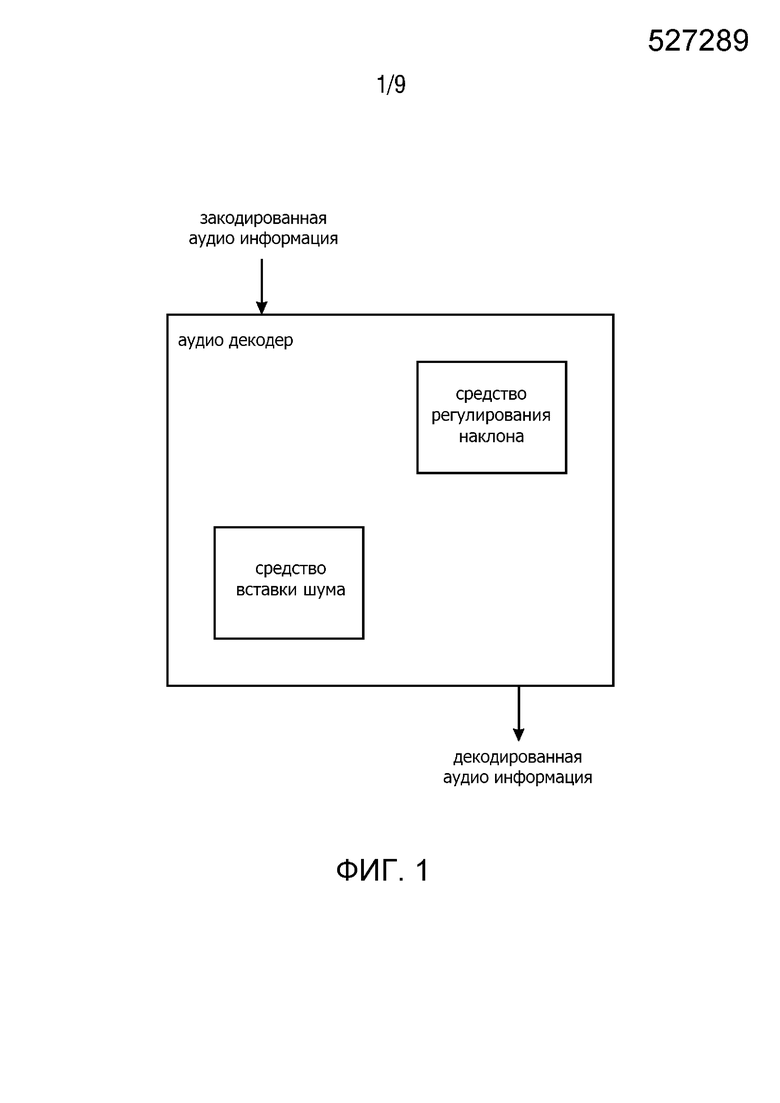
Фиг. 1 показывает первый вариант осуществления аудиодекодера согласно настоящему изобретению;
Фиг. 2 показывает первый способ выполнения декодирования аудио согласно настоящему изобретению, который может быть выполнен аудиодекодером согласно Фиг. 1;
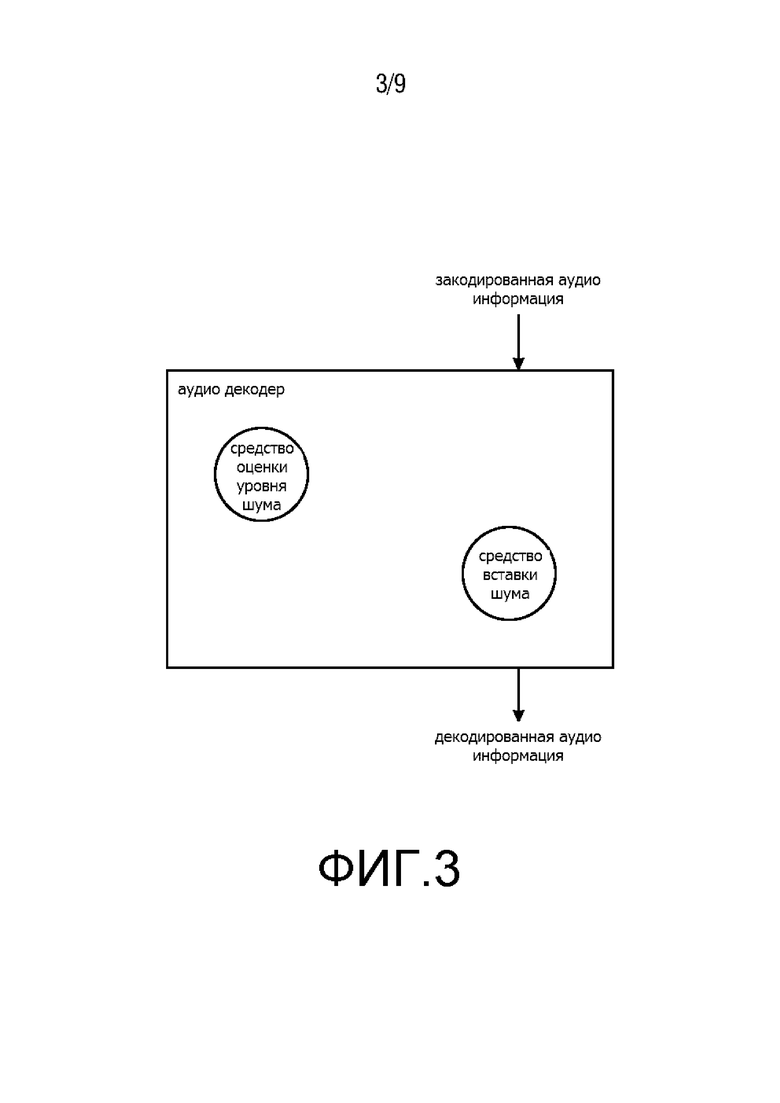
Фиг. 3 показывает второй вариант осуществления аудиодекодера согласно настоящему изобретению;
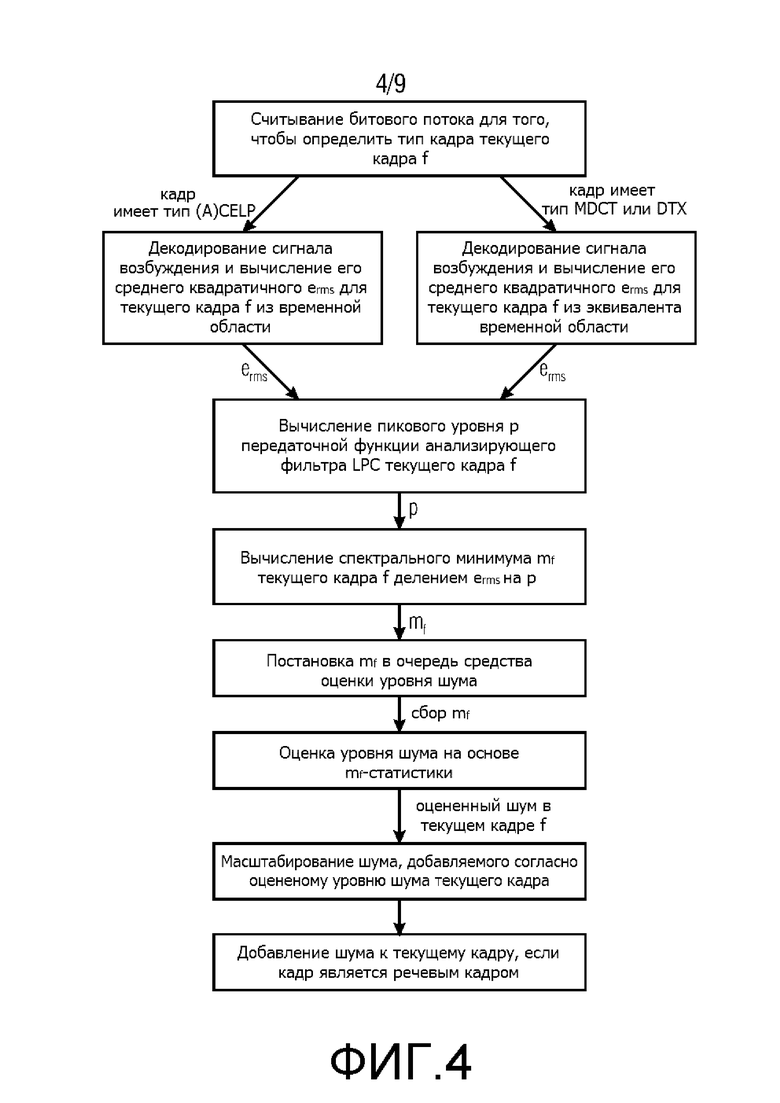
Фиг. 4 показывает второй способ выполнения декодирования аудио согласно настоящему изобретению, который может быть выполнен аудиодекодером согласно Фиг. 3;
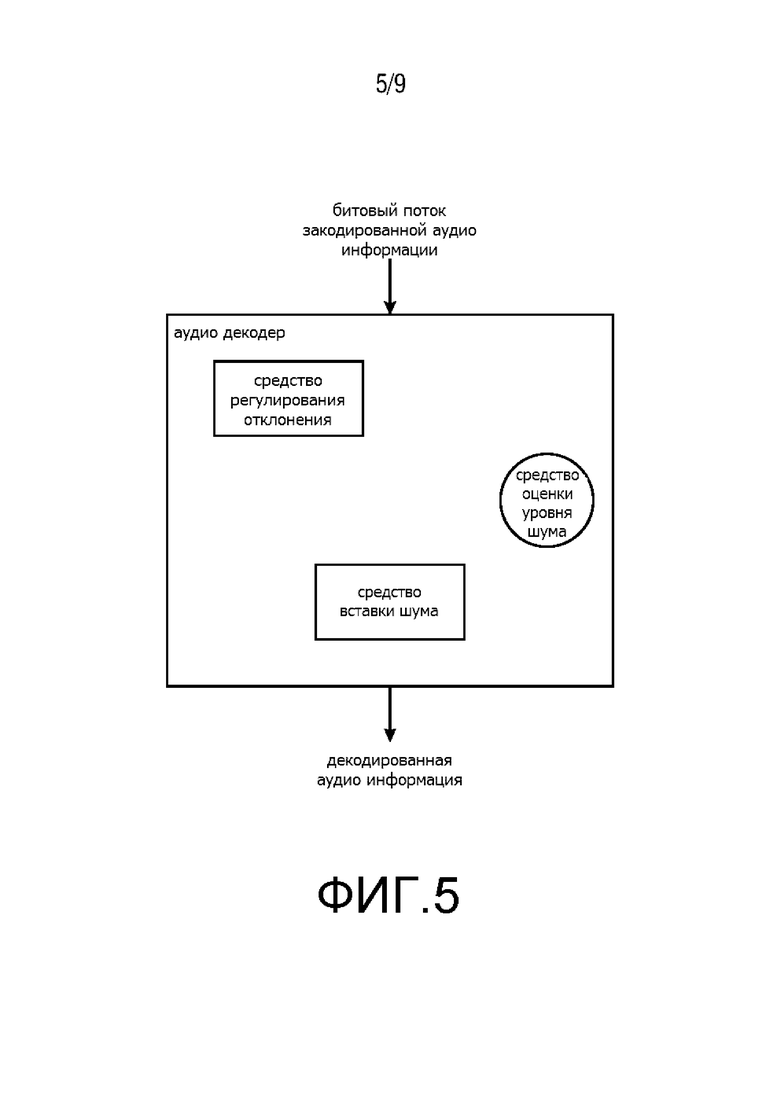
Фиг. 5 показывает третий вариант осуществления аудиодекодера согласно настоящему изобретению;
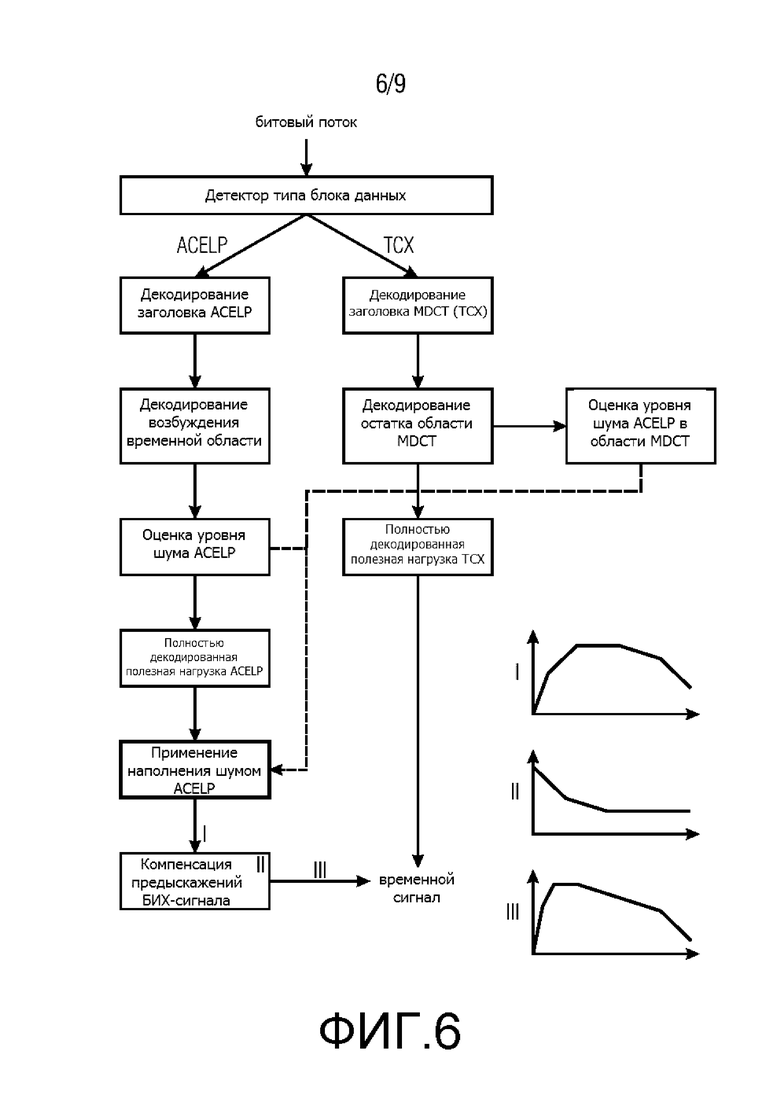
Фиг. 6 показывает третий способ выполнения декодирования аудио согласно настоящему изобретению, который может быть выполнен аудиодекодером согласно Фиг. 5;
Фиг. 7 показывает иллюстрацию способа вычисления спектральных минимумов mf для оценки уровня шума;
Фиг. 8 показывает схему, иллюстрирующую выведение отклонения из коэффициентов LPC; и
Фиг. 9 показывает схему, иллюстрирующую, каким образом эквиваленты фильтра LPC определяется из энергетического спектра MDCT.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Изобретение описано подробно в отношении фигур с 1 по 9. Изобретение никоим образом не подразумевается ограниченным показанными и описанными вариантами осуществления.
Фиг. 1 показывает первый вариант осуществления аудиодекодера согласно настоящему изобретению. Аудиодекодер приспособлен для предоставления декодированной аудиоинформации на основе закодированной аудиоинформации. Аудиодекодер сконфигурирован для использования кодера, который может быть основан на AMR-WB, G.718 и LD-USAC (EVS), чтобы декодировать закодированную аудиоинформацию. Закодированная аудиоинформация содержит коэффициенты линейного предсказания (LPC), которые могут быть индивидуально обозначены как коэффициенты ak. Аудиодекодер содержит средство регулирования отклонения, сконфигурированное для регулирования отклонения шума, используя коэффициенты линейного предсказания текущего кадра для получения информации об отклонении, и средство вставки шума, сконфигурированное для добавления шума к текущему кадру в зависимости от информации об отклонении, полученной вычислителем отклонения. Средство вставки шума сконфигурировано для добавления шума в текущий кадр при условии, что скорость передачи битов закодированной аудиоинформации меньше, чем 1 бит на отсчет. Более того, средство вставки шума может быть сконфигурировано для добавления шума в текущий кадр при условии, что текущий кадр является кадром речевого сигнала. Таким образом, шум может быть добавлен в текущий кадр для того, чтобы улучшить общее качество звука декодированной аудиоинформации, которое может быть ухудшено из-за артефактов кодирования, что особенно касается фонового шума в речевой информации. Когда отклонение шума отрегулировано с учетом отклонения текущего аудиокадра, общее качество звука может быть улучшено независимо от побочной информации в битовом потоке. Таким образом, количество данных, передаваемых с битовым потомком, может быть уменьшено.
Фиг. 2 показывает первый способ выполнения декодирования аудио согласно настоящему изобретению, который может быть выполнен аудиодекодером согласно Фиг. 1. Технические подробности аудиодекодера, изображенного на Фиг. 1, описаны вместе с признаками способа. Аудиодекодер приспособлен для чтения битового потока закодированной аудиоинформации. Аудиодекодер содержит средство определения типа кадра, которое определяет тип кадра текущего кадра, средство определения типа кадра выполнено с возможностью активации средства регулирования отклонения, которое регулирует отклонение шума, когда тип кадра текущего кадра определен как относящийся к типу речи. Таким образом, аудиодекодер определяет тип кадра текущего аудиокадра посредством применения средства определения типа кадра. Если текущий кадр является кадром ACELP, то средство определения типа кадра активирует средство регулирования отклонения. Средство регулирования отклонения сконфигурировано для использования результата анализа первого порядка коэффициентов линейного предсказания текущего кадра для получения информации об отклонении. Более точно, средство регулирования отклонения вычисляет приращение g, используя формулу 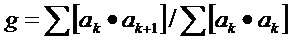
Фиг. 3 показывает второй вариант осуществления аудиодекодера согласно настоящему изобретению. Аудиодекодер также приспособлен для предоставления декодированной аудиоинформации на основе закодированной аудиоинформации. Аудиодекодер также сконфигурирован для использования кодера, который может быть основан на AMR-WB, G.718 и LD-USAC (EVS), чтобы декодировать закодированную аудиоинформацию. Закодированная аудиоинформация также содержит коэффициенты линейного предсказания (LPC), которые могут быть индивидуально обозначены как коэффициенты ak. Аудиодекодер согласно второму варианту осуществления содержит средство оценки уровня шума, сконфигурированное для оценки уровня шума текущего кадра, используя коэффициенты линейного предсказания по меньшей мере одного предыдущего кадра для получения информации об уровне шума, и средство вставки шума, сконфигурированное для добавления шума к текущему кадру в зависимости от информации об уровне шума, полученной средством оценки уровня шума. Средство вставки шума сконфигурировано для добавления шума в текущий кадр при условии, что скорость передачи битов закодированной аудиоинформации меньше, чем 0,5 бит на отсчет. Более того, средство вставки шума сконфигурировано для добавления шума в текущий кадр при условии, что текущий кадр является кадром речевого сигнала. Таким образом, шум также может быть добавлен в текущий кадр для того, чтобы улучшить общее качество звука декодированной аудиоинформации, которое может быть ухудшено из-за артефактов кодирования, что особенно касается фонового шума в речевой информации. Когда уровень шума в шуме отрегулирован с учетом уровня шума по меньшей мере одного предыдущего аудиокадра, общее качество звука может быть улучшено независимо от побочной информации в битовом потоке. Таким образом, количество данных, передаваемых с битовым потомком, может быть уменьшено.
Фиг. 4 показывает второй способ выполнения декодирования аудио согласно настоящему изобретению, который может быть выполнен аудиодекодером согласно Фиг. 3. Технические подробности аудиодекодера, изображенного на Фиг. 3, описаны вместе с признаками способа. Согласно Фиг. 4, аудиодекодер сконфигурирован для чтения битового потока для того, чтобы определять тип кадра текущего кадра. Более того, аудиодекодер содержит средство определения типа кадра, которое определяет тип кадра текущего кадра, средство определения типа кадра выполнено с возможностью распознавать, относится ли тип кадра текущего кадра к типу речи или к типу обычного звука, для того чтобы оценка уровня шума могла быть выполнена в зависимости от типа кадра текущего кадра. В общем, аудиодекодер приспособлен вычислять первую информацию, представляющую спектрально бесформенное возбуждение текущего кадра, и вычислять вторую информацию, касающуюся спектрального масштабирования текущего кадра, для вычисления отношения первой информации и второй информации для получения информации об уровне шума. Например, если кадр имеет тип ACELP, являющийся кадром типа речи, аудиодекодер декодирует сигнал возбуждения текущего кадра и вычисляет его среднее квадратичное erms для текущего кадра f из представления временной области сигнала возбуждения. Это означает, что аудиодекодер приспособлен для декодирования сигнала возбуждения текущего кадра и для вычисления его среднего квадратичного erms из представления временной области текущего кадра в качестве первой информации для получения информации об уровне шума, при условии, что текущий кадр относится к типу речи. В другом случае, если кадр имеет тип MDCT или DTX, являющиеся кадрами типа обычного звука, аудиодекодер декодирует сигнал возбуждения текущего кадра и вычисляет его среднее квадратичное erms для текущего кадра f из представления эквиваленты временной области сигнала возбуждения. Это означает, что аудиодекодер приспособлен для декодирования бесформенного MDCT-возбуждения текущего кадра и для вычисления его среднего квадратичного erms из представления спектральной области текущего кадра в качестве первой информации для получения информации об уровне шума, при условии, что текущий кадр относится к типу обычного звука. То, каким образом это делается, подробно описано в WO 2012/110476 A1. Более того, Фиг. 9 показывает диаграмму, иллюстрирующую, каким образом эквивалент фильтра LPC определяется из энергетического спектра MDCT. Пока изображенная шкала является шкалой Барка, эквиваленты коэффициентов LPC также могут быть получены из линейной шкалы. Особенно когда они получены из линейной шкалы, вычисленные эквиваленты коэффициентов LPC очень похожи на те, что вычислены из представления временной области того же кадра, например, когда кодируется при помощи ACELP.
Кроме того, аудиодекодер согласно Фиг. 3, как показано на блок-схеме способа на Фиг. 4, приспособлен для вычисления пикового уровня p передаточной функции фильтра LPC текущего кадра в качестве второй информации, таким образом используя коэффициенты линейного предсказания для получения информации об уровне шума при условии, что текущий кадр относится к типу речи. Это означает, что аудиодекодер вычисляет пиковый уровень p передаточной функции анализирующего фильтра LPC текущего кадра f согласно формуле
Фиг. 5 показывает третий вариант осуществления аудиодекодера согласно настоящему изобретению. Аудиодекодер приспособлен для предоставления декодированной аудиоинформации на основе закодированной аудиоинформации. Аудиодекодер сконфигурирован для использования кодера, основанного на LD-USAC, чтобы декодировать закодированную аудиоинформацию. Закодированная аудиоинформация содержит коэффициенты линейного предсказания (LPC), которые могут быть индивидуально обозначены как коэффициенты ak. Аудиодекодер содержит средство регулирования отклонения, сконфигурированное для регулирования отклонения шума, используя коэффициенты линейного предсказания текущего кадра для получения информации об отклонении, и средство оценки уровня шума, сконфигурированное для оценки уровня шума текущего кадра, используя коэффициенты линейного предсказания по меньшей мере одного предыдущего кадра, для получения информации об уровне шума. Более того, аудиодекодер содержит средство вставки шума, сконфигурированное для добавления шума к текущему кадру в зависимости от информации об отклонении, полученной вычислителем отклонения, и в зависимости от информации об уровне шума, предоставленной средством оценки уровня шума. Таким образом, шум может быть добавлен в текущий кадр для того, чтобы улучшить общее качество звука декодированной аудиоинформации, которое может быть ухудшено из-за артефактов кодирования, что особенно касается фонового шума в речевой информации, в зависимости от информации об отклонении, полученной вычислителем отклонения, и в зависимости от информации об уровне шума, предоставленной средством оценки уровня шума. В данном варианте осуществления, генератор случайного шума (не показан), который содержится в аудиодекодере, генерирует спектрально белый шум, который затем и масштабируется согласно информации об уровне шума, и которому придается форма, используя выведенный из g отклонение, как описано ранее.
Фиг. 6 показывает третий способ выполнения декодирования аудио согласно настоящему изобретению, который может быть выполнен аудиодекодером согласно Фиг. 5. Битовый поток считывается, и средство определения типа кадра, называемое детектор типа кадра, определяет, является ли текущий кадр кадром речевого сигнала (ACELP) или кадром обычного звука (TCX/MDCT). Независимо от типа кадра, заголовок кадра декодируется и спектрально выравнивается, бесформенный сигнал возбуждения в области восприятия декодируется. В случае кадра речевого сигнала, сигнал возбуждения является возбуждением временной области, как описано ранее. Если кадр является кадром обычного звука, декодируется остаток области MDCT (спектральная область). Представление временной области и представление спектральной области соответственно используются для оценки уровня шума, как проиллюстрировано на Фиг. 7 и описано ранее, используя коэффициенты LPC, также использующиеся для декодирования битового потока, вместо использования какой-либо побочной информации или дополнительных коэффициентов LPC. Информация о шуме обоих типов кадров ставится в очередь для регулирования отклонения и уровня шума, который добавляется к текущему кадру при условии, что текущий кадр является кадром речевого сигнала. После добавления шума к кадру речевого сигнала ACELP (применения наполнения шумом ACELP) с помощью БИХ компенсируются предыскажения кадра речевого сигнала ACELP, и речевые кадры и кадры обычного звука объединяются в сигнал времени, представляющий декодированную аудиоинформацию. Эффект резких верхних частот при компенсации предыскажений спектра добавленного шума изображен на маленьких вставленных Фигурах I, II, III на Фиг. 6. Другими словами, согласно Фиг. 6 система наполнения шумом ACELP, описанная выше, реализована в LD-USAC (EVS) декодере, варианте xHE-AAC [6] с низкой задержкой, который может переключаться между ACELP (речь) и MDCT (музыка/шум) кодированием для каждого кадра. Процесс вставки согласно Фиг. 6 обобщается следующим образом:
1. Битовый поток считывается, и определяется, является ли текущий кадр кадром ACELP или MDCT, или DTX. Независимо от типа кадра, спектрально выровненный сигнал возбуждения (в области восприятия) декодируется и используется для обновления оценки уровня шума, как подробно описано ниже. Затем, сигнал полностью восстанавливается для компенсации предыскажений, что является последним этапом.
2. Если кадр закодирован при помощи ACELP, отклонение (общая форма спектра) для вставки шума вычисляется путем LPC-анализа первого порядка коэффициентов фильтра LPC. Отклонение выводится из приращения g 16 коэффициентов LPC ak, которое задано как
3. Если кадр закодирован при помощи ACELP, уровень и отклонение преобразования шума используются для выполнения добавления шума в декодированный кадр: генератор случайного шума генерирует сигнал спектрально белого шума, который затем масштабируется, и которому придается форма, используя выведенный из g отклонение.
4. Сформированный и выровненный шумовой сигнал кадра ACELP добавляется в декодированный сигнал непосредственно перед заключительным этапом фильтрования - компенсация предыскажений. Так как компенсация предыскажений является БИХ-усилением первого порядка низких частот, это дает возможность для БИХ-фильтрации резких верхних частот низкой сложности добавляемого шума, как на Фиг. 6, с устранением слышимых артефактов шума при низких частотах.
Оценка уровня шума на этапе 1 выполняется путем вычисления среднего квадратичного erms сигнала возбуждения текущего кадра (или, в случае возбуждения MDCT-области, эквиваленты временной области, значение erms, которое было бы вычислено для данного кадра так, как если бы он был кадром ACELP), и затем путем деления его на пиковый уровень p передаточной функции анализирующего фильтра LPC. Это дает уровень mf спектрального минимума кадра f, как на Фиг. 7. Наконец, mf ставится в очередь в средство оценки уровня шума, проводящее операции исходя, например, из минимума статистики [3]. Заметим, что так как преобразования времени/частоты не требуются, и, так как средство оценки уровня работает только один раз на кадр (не в нескольких поддиапазонах), описанная система наполнения шумом CELP демонстрирует очень низкую сложность, в то же время улучшая кодирование зашумленной речи с низкой скоростью передачи битов.
Хотя некоторые аспекты были описаны в контексте аудиодекодера, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапов способа, также представляют описание соответствующей схемы, или элемента или признака соответствующего аудиодекодера. Некоторые или все этапы способа могут быть выполнены (или использованы) аппаратными устройствами, такими как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления, некоторые, один или несколько самых важных этапов способа могут быть выполнены такими устройствами.
Закодированный аудиосигнал, отвечающий настоящему изобретению, может храниться на цифровом носителе данных или может передаваться средой передачи, такой как беспроводная среда передачи или проводная среда передачи, такая как сеть Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя данных, например, гибкий магнитный диск, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-память, содержащего электронным образом считываемые управляющие сигналы, хранимые на нем, которые взаимодействуют (или в состоянии взаимодействовать) с программируемой компьютерной системой, из условия чтобы выполнялся соответствующий способ. Следовательно, цифровой носитель данных может быть машинно-читаемым.
Некоторые варианты осуществления согласно изобретению содержат носители информации, содержащие электронно-читаемые управляющие сигналы, которые в состоянии взаимодействовать с программируемой компьютерной системой, из условия чтобы выполнялся один из способов, описанных в материалах настоящей заявки.
В общем смысле, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с управляющей программой, управляющая программа функционирует для выполнения одного из способов, когда компьютерный программный продукт работает на компьютере. Управляющая программа, например, может храниться на машинно-читаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки, сохраненную на машинно-читаемом носителе.
Другими словами, вариантом осуществления отвечающего настоящему изобретению способа, поэтому, является компьютерная программа, содержащая управляющую программу для выполнения одного из способов, описанных в материалах настоящей заявки, когда компьютерная программа работает на компьютере.
Дополнительным вариантом осуществления отвечающих настоящему изобретению способов, поэтому, является носитель информации (или цифровой носитель данных, или компьютерно-читаемый носитель), содержащий записанную на него компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки. Носитель информации, цифровой носитель данных или носитель записи типично материальные и/или не промежуточные.
Дополнительным вариантом осуществления отвечающего настоящему изобретению способа, поэтому, является поток данных или последовательность сигналов, представляющие компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки. Поток данных или последовательность сигналов, например, могут быть сконфигурированы так, чтобы передаваться через соединения передачи данных, например, сеть Интернет.
Дополнительный вариант осуществления содержит средства обработки, например, компьютер или программируемое логическое устройство, сконфигурированные или приспособленные для выполнения одного из способов, описанных в материалах настоящей заявки.
Дополнительный вариант осуществления содержит компьютер, содержащий установленную на нем компьютерную программу для выполнения одного из способов, описанных в материалах настоящей заявки.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированные для передачи (например, электронной или оптической) компьютерной программы для выполнения одного из способов, описанных в материалах настоящей заявки, на приемник. Приемником, например, может быть компьютер, мобильное устройство, запоминающее устройство или тому подобное. Устройство или система, например, могут содержать файловый сервер для передачи компьютерной программы на приемник.
В некоторых вариантах осуществления, программируемое логическое устройство (например, матрица логических элементов с эксплуатационным программированием) может быть использовано для выполнения некоторых или всех функциональных возможностей способов, описанных в материалах настоящей заявки. В некоторых вариантах осуществления, матрица логических элементов с эксплуатационным программированием может взаимодействовать с микропроцессором для того, чтобы выполнить один из способов, описанных в материалах настоящей заявки. В общем смысле, способы предпочтительно выполняются любыми аппаратными устройствами.
Устройства, описанные в материалах настоящей заявки, могут быть реализованы, используя аппаратные устройства, или используя комбинацию аппаратных устройств и компьютера.
Способы, описанные в материалах настоящей заявки, могут быть выполнены, используя аппаратные устройства, или используя комбинацию аппаратных устройств и компьютера.
Описанные выше варианты осуществления являются только иллюстрирующими для принципов настоящего изобретения. Понятно, что модификации и варианты компоновок и деталей, описанных в материалах настоящей заявки, будут очевидны другим специалистам в данной области техники. Замысел, поэтому, должен быть ограничен только объемом, определяемым формулой изобретения, приведенной ниже, но не специфичными деталями, представленными путем описаний и объяснений вариантов осуществления, описанных в материалах настоящей заявки.
СПИСОК НЕПАТЕНТНОЙ ЛИТЕРАТУРЫ
[1] B. Bessette et al., “The Adaptive Multi-rate Wideband Speech Codec (AMR-WB),” IEEE Trans. On Speech and Audio Processing, Vol. 10, No. 8, Nov. 2002.
[2] R. C. Hendriks, R. Heusdens and J. Jensen, “MMSE based noise PSD tracking with low complexity,” in IEEE Int. Conf. Acoust., Speech, Signal Processing, pp. 4266 – 4269, March 2010.
[3] R. Martin, “Noise Power Spectral Density Estimation Based on Optimal Smoothing and Minimum Statistics,” IEEE Trans. On Speech and Audio Processing, Vol. 9, No. 5, Jul. 2001.
[4] M. Jelinek and R. Salami, “Wideband Speech Coding Advances in VMR-WB Standard,” IEEE Trans. On Audio, Speech, and Language Processing, Vol. 15, No. 4, May 2007.
[5] J. Mäkinen et al., “AMR-WB+: A New Audio Coding Standard for 3rd Generation Mobile Audio Services,” in Proc. ICASSP 2005, Philadelphia, USA, Mar. 2005.
[6] M. Neuendorf et al., “MPEG Unified Speech and Audio Coding – The ISO/MPEG Standard for High-Efficiency Audio Coding of All Content Types,” in Proc. 132nd AES Convention, Budapest, Hungary, Apr. 2012. Also appears in the Journal of the AES, 2013.
[7] T. Vaillancourt et al., “ITU-T EV-VBR: A Robust 8 – 32 kbit/s Scalable Coder for Error Prone Telecommunications Channels,” in Proc. EUSIPCO 2008, Lausanne, Switzerland, Aug. 2008.

Изобретение относится к средствам для кодирования аудио. Технический результат заключается в повышении качества кодирования аудио. Аудиодекодер для предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания, содержит средство регулирования отклонения, сконфигурированное для регулирования отклонения фонового шума с использованием информации об отклонении; ядро декодера, сконфигурированное для декодирования аудиоинформации текущего кадра с использованием коэффициентов линейного предсказания текущего кадра для получения декодированного основного выходного сигнала кодера; и средство вставки шума, сконфигурированное для добавления отрегулированного фонового шума к текущему кадру, чтобы выполнить наполнение шумом, при этом средство регулирования отклонения сконфигурировано для получения информации об отклонении с помощью вычисления приращения g коэффициентов линейного предсказания текущего кадра. 6 н. и 11 з.п. ф-лы, 11 ил.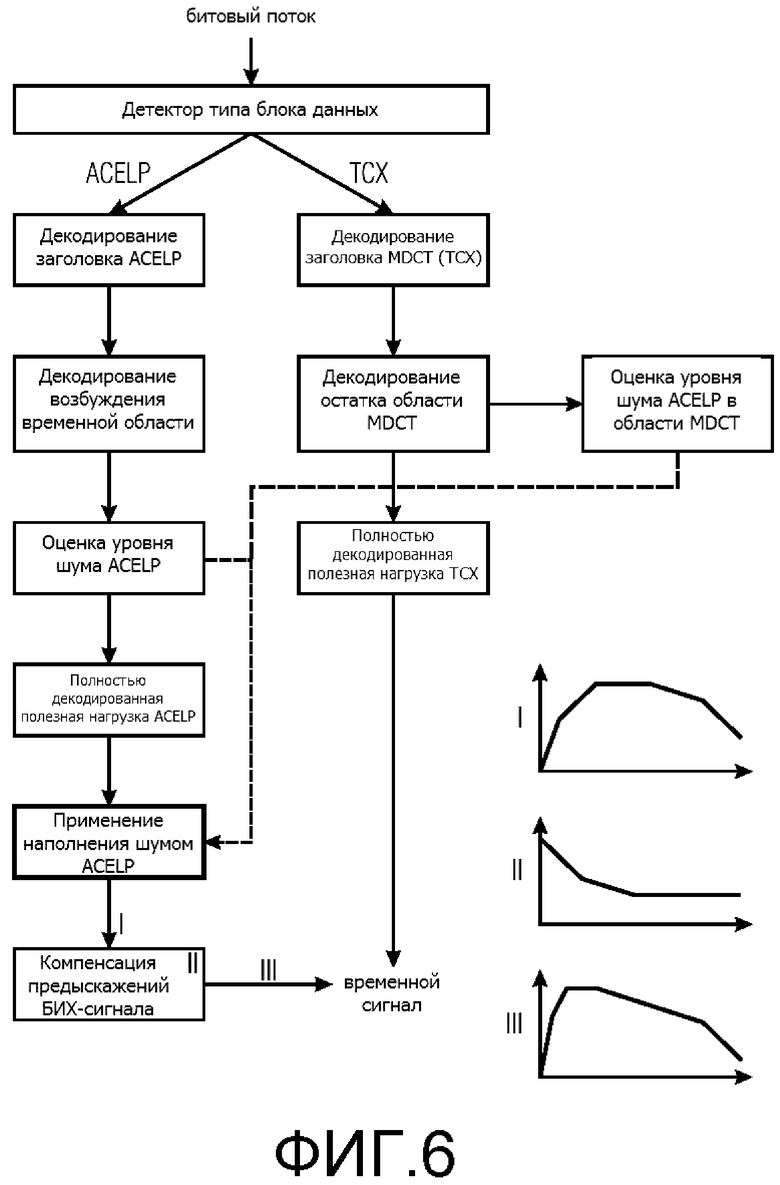
1. Аудиодекодер для предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), содержащий:
средство регулирования отклонения, сконфигурированное для регулирования отклонения фонового шума с использованием информации об отклонении, при этом средство регулирования отклонения сконфигурировано для использования коэффициентов линейного предсказания текущего кадра для получения информации об отклонении;
ядро декодера, сконфигурированное для декодирования аудиоинформации текущего кадра с использованием коэффициентов линейного предсказания текущего кадра для получения декодированного основного выходного сигнала кодера; и
средство вставки шума, сконфигурированное для добавления отрегулированного фонового шума к текущему кадру, чтобы выполнить наполнение шумом,
при этом средство регулирования отклонения сконфигурировано для использования результата анализа первого порядка линейных коэффициентов предсказания текущего кадра для получения информации об отклонении, и
при этом средство регулирования отклонения сконфигурировано для получения информации об отклонении с помощью вычисления приращения g коэффициентов линейного предсказания текущего кадра в качестве упомянутого анализа первого порядка, причем
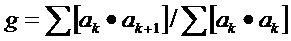
где ak - коэффициент линейного предсказания текущего кадра, находящийся по индексу k LPC.
2. Аудиодекодер по п.1, при этом аудиодекодер содержит средство определения типа кадра для определения типа кадра текущего кадра, причем средство определения типа кадра выполнено с возможностью активации средства регулирования отклонения для регулирования отклонения фонового шума, когда тип кадра текущего кадра определен как относящийся к типу речи.
3. Аудиодекодер по п.1, при этом аудиодекодер дополнительно содержит средство оценки уровня шума, сконфигурированное для оценки уровня шума текущего кадра с использованием множества коэффициентов линейного предсказания по меньшей мере одного предыдущего кадра для получения информации об уровне шума; при этом средство вставки шума сконфигурировано для добавления фонового шума к текущему кадру в зависимости от информации об уровне шума, предоставленной средством оценки уровня шума;
при этом аудиодекодер выполнен с возможностью декодировать сигнал возбуждения текущего кадра и вычислять его среднее квадратичное erms;
при этом аудиодекодер выполнен с возможностью вычисления пикового уровня p передаточной функции фильтра LPC текущего кадра;
при этом аудиодекодер выполнен с возможностью вычисления спектрального минимума mf текущего аудиокадра путем вычисления отношения среднего квадратичного erms и пикового уровня p для получения информации об уровне шума;
при этом средство оценки уровня шума выполнено с возможностью оценки уровня шума на основе двух или более отношений различных аудиокадров.
4. Аудиодекодер для предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), содержащий:
средство оценки уровня шума, сконфигурированное оценивать уровень шума для текущего кадра с использованием множества коэффициентов линейного предсказания по меньшей мере одного предыдущего кадра для получения информации об уровне шума; и
средство вставки шума, сконфигурированное добавлять шум к текущему кадру в зависимости от информации об уровне шума, предоставленной средством оценки уровня шума;
при этом аудиодекодер выполнен с возможностью декодировать сигнал возбуждения текущего кадра и вычислять его среднее квадратичное erms;
при этом аудиодекодер выполнен с возможностью вычисления пикового уровня p передаточной функции фильтра LPC текущего кадра;
при этом аудиодекодер выполнен с возможностью вычисления спектрального минимума mf текущего аудиокадра путем вычисления отношения среднего квадратичного erms и пикового уровня p для получения информации об уровне шума;
при этом средство оценки уровня шума выполнено с возможностью оценки уровня шума на основе двух или более отношений различных аудиокадров;
при этом аудиодекодер содержит ядро декодера, сконфигурированное для декодирования аудиоинформации текущего кадра с использованием коэффициентов линейного предсказания текущего кадра для получения декодированного выходного сигнала основного кодера, при этом средство вставки шума добавляет шум в зависимости от коэффициентов линейного предсказания, использованных при декодировании аудиоинформации текущего кадра и использованных при декодировании аудиоинформации одного или более предыдущих кадров.
5. Аудиодекодер по п.4, при этом аудиодекодер содержит средство определения типа кадра, которое определяет тип кадра текущего кадра, причем средство определения типа кадра выполнено с возможностью распознавать, является ли типом кадра текущего кадра речь или обычный звук, с тем чтобы оценка уровня шума могла быть выполнена в зависимости от типа кадра текущего кадра.
6. Аудиодекодер по п.4, при этом аудиодекодер выполнен с возможностью вычисления среднего квадратичного erms текущего кадра из представления временной области текущего кадра для получения информации об уровне шума, при условии, что текущий кадр относится к типу речи.
7. Аудиодекодер по п.4, при этом аудиодекодер выполнен с возможностью декодировать бесформенное MDCT-возбуждение текущего кадра и вычислять его среднее квадратичное erms из представления спектральной области текущего кадра для получения информации об уровне шума, если текущий кадр относится к типу обычного звука.
8. Аудиодекодер по п.4, при этом аудиодекодер выполнен с возможностью ставить в очередь отношение, полученное из текущего аудиокадра в средстве оценки уровня шума, независимо от типа кадра, причем средство оценки уровня шума содержит хранилище уровня шума для двух или более отношений, полученных из различных аудиокадров.
9. Аудиодекодер по п.4, в котором средство оценки уровня шума выполнено с возможностью оценки уровня шума на основе статистического анализа двух или более отношений различных аудиокадров.
10. Аудиодекодер по п.1 или 4, при этом аудиодекодер содержит фильтр компенсации предыскажений для компенсации предыскажений текущего кадра, причем аудиодекодер выполнен с возможностью применения фильтра компенсации предыскажений к текущему кадру после того, как средством вставки шума добавлен шум в текущий кадр.
11. Аудиодекодер по п.1 или 4, при этом аудиодекодер содержит генератор шума, причем генератор шума приспособлен для генерации шума, который добавляется к текущему кадру средством вставки шума.
12. Аудиодекодер по п.1 или 4, при этом аудиодекодер содержит генератор шума, сконфигурированный для генерации случайного белого шума.
13. Аудиодекодер по п.1 или 4, при этом аудиодекодер сконфигурирован для использования декодера, который основывается на одном или более из декодеров AMR-WB, G.718 или LD-USAC (EVS), чтобы декодировать закодированную аудиоинформацию.
14. Способ предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), содержащий этапы, на которых:
регулируют отклонение фонового шума с использованием информации об отклонении, при этом коэффициенты линейного предсказания текущего кадра используются для получения информации об отклонении; и
декодируют аудиоинформацию текущего кадра с использованием коэффициентов линейного предсказания текущего кадра для получения декодированного основного выходного сигнала кодера; и
добавляют отрегулированный фоновый шум к текущему кадру для выполнения наполнения шумом,
при этом результат анализа первого порядка линейных коэффициентов предсказания текущего кадра используют для получения информации об отклонении, и
при этом информацию об отклонении получают с помощью вычисления приращения g коэффициентов линейного предсказания текущего кадра в качестве упомянутого анализа первого порядка, причем
где ak - коэффициент линейного предсказания текущего кадра, находящийся по индексу k LPC.
15. Машиночитаемый носитель, на котором сохранена компьютерная программа для выполнения способа по п.14 при исполнении компьютерной программы на компьютере.
16. Способ предоставления декодированной аудиоинформации на основе закодированной аудиоинформации, содержащей коэффициенты линейного предсказания (LPC), содержащий этапы, на которых:
оценивают уровень шума для текущего кадра с использованием множества коэффициентов линейного предсказания по меньшей мере одного предыдущего кадра для получения информации об уровне шума; и
добавляют шум к текущему кадру в зависимости от информации об уровне шума, полученной путем оценки уровня шума;
при этом декодируется сигнал возбуждения текущего кадра, и при этом вычисляется среднее квадратичное erms;
при этом вычисляется пиковый уровень p передаточной функции фильтра LPC текущего кадра;
при этом вычисляется спектральный минимум mf текущего аудиокадра путем вычисления отношения среднего квадратичного erms и пикового уровня p для получения информации об уровне шума;
при этом уровень шума оценивается на основе двух или более отношений различных аудиокадров;
при этом способ содержит этап, на котором декодируют аудиоинформацию текущего кадра с использованием коэффициентов линейного предсказания текущего кадра для получения декодированного основного выходного сигнала кодера; и
при этом способ содержит этап, на котором добавляют шум в зависимости от коэффициентов линейного предсказания, использованных при декодировании аудиоинформации текущего кадра и использованных при декодировании аудиоинформации одного или более предыдущих кадров.
17. Машиночитаемый носитель, на котором сохранена компьютерная программа для выполнения способа по п.16 при исполнении компьютерной программы на компьютере.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| US 6691085 B1, 10.02.2004 | |||
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ АУДИОСИГНАЛА | 2009 |
|
RU2455709C2 |
| КОДИРОВАНИЕ РЕЧИ С ФУНКЦИЕЙ ИЗМЕНЕНИЯ КОМФОРТНОГО ШУМА ДЛЯ ПОВЫШЕНИЯ ТОЧНОСТИ ВОСПРОИЗВЕДЕНИЯ | 1999 |
|
RU2237296C2 |

