Изобретение относится к области лингвистики, психолингвистики и социолингвистики и может быть использовано при составлении речей различного характера, в т.ч. рассчитанных на массового адресата, при формировании паттернов, концептов и др. ментальных образований мышления, пропаганде, рекламе, средствах массовой информации, дипломатическом общении, бизнес-коммуникации и др.
Определения ключевых понятий.
Дискурс - сложно-структурированная динамичная коммуникативно-знаковая система, взаимодействующая с объективной реальностью по диалектическому принципу; обладающая шестью основными планами: интенциональным, актуальным, виртуальным, контекстуальным, психологическим и «осадочным».
Отрезок дискурса - часть дискурса объемом не менее 30000-40000 слов
Фрагмент дискурса - совокупность нескольких сегментов дискурса, границами которых могут выступать союзы, пунктуационные знаки или атрибутивные предложения.
Контрольный фрагмент - фрагмент дискурса, ответ респондента на который исследователем предполагается как очевидный; используется для того, чтобы фильтровать выборку респондентов по определенному критерию.
Экстралингвистический фактор (ЭЛФ) - свойство или характеристика внеязыковой социальной действительности, обусловливающее изменения в языке как глобального, так и частного характера.
Эффективность речевого воздействия (ЭРВ) - результативное достижение регуляции поведения реципиента, осуществляемой с помощью обращенной к нему речи (устной, письменной, через средства массовой информации и др.) и с минимально возможными издержками.
Потенциал речевого воздействия (РВ) - возможности лингвистических средств оказывать речевое воздействие.
Эталон нормы речевого воздействия - мера-ориентир, служащая для определения отклонения определенной величины РВ от исходной величины РВ, вычисляемой для фрагмента, обладаемого наименьшим РВ.
Адресант - отправитель; который в процессах социальной коммуникации при помощи передачи сообщения стремится вызвать определенное поведение у реципиента.
Реципиент - субъект социальной коммуникации, воспринимающий адресованное ему сообщение.
Риторический прием - мотивированное условиями речевого общения отклонение от языковой нормы.
Плотность риторических приемов - величина, описывающая наличие определенного количества риторических приемов в определенном объеме дискурса.
Непараметр - характеристика лингвистического объекта, представляющая собой отсутствие в нем параметров, предусмотренных гипотезой исследования.
Когнитивный подход - подход, основанный на положениях когнитивной психологии и предусматривающий опору на принцип сознательности, учет различных когнитивных стилей и стратегий, связанных с познанием и мышлением.
Семиотика - наука о знаках и знаковых системах, знаковом (использующем знаки) поведении и знаковой - лингвистической и нелингвистической - коммуникации.
Фиктивная переменная - качественная переменная, принимающая значения 0 и 1 (бинарная), и большее количество значений (многозначная), включаемая в эконометрическую модель для учета влияния качественных признаков и событий на объясняемую переменную.
Коэффициент Пирсона - мера тесноты связи двух признаков при наличии линейной зависимости между ними.
Уравнение множественной линейной регрессии - математическое уравнение, устанавливающее линейную зависимость между результирующим признаком и рядом независимых параметров.
Приблизительное уравнение регрессии - математическое уравнение, устанавливающее линейную зависимость между результирующим признаком и рядом независимых параметров; при этом коэффициенты уравнения могут варьироваться в ограниченном диапазоне в зависимости от репрезентативности и объема выборки.
Проблема поиска оптимальных, максимально эффективных форм выражения мысли, форм внедрения определенной концепции мироустройства в сознание человека и форм воздействия на последнего - одна из наиболее актуальных на сегодняшний день. Существует множество лингвистических и психолингвистических работ по описанию и оценке ЭРВ, как отечественных (О.С. Иссерс, В.Е. Чернявская, К.В. Никитина, Ю.И. Плахотная, С.А. Виноградова, М.Р. Желтухина, И.А. Скрипак и др.), так и зарубежных (Т.А. van Dijk, W. Ladov, D. Franchel, G. Kress, T. Zheng, P. DiMaggio, P. Catellani, M. Dertolotti et al.), однако во всех работах дискурс и, в частности, ЭРВ его фрагментов изучаются с помощью собственно филологических методов (контент-анализ, когнитивный анализ, сравнительный, сопоставительный анализ, ранжирование и др.) или психолингивстических (дискурс-анализ и др.).
Основные направления в области изучения речевого воздействия (РВ) включают в себя исследования РВ как психологического, когнитивного и коммуникативного феномена.
Психологический подход рассматривает РВ как определенные манипуляции, целью которых является изменение поведения и мышления человека путем мотивации или демотивации, путем удовлетворения основных потребностей: физиологических, потребностей в самосохранении, любви, уважении, самоутверждении. Этот подход оценивает ЭРВ через изменения в мышлении и поведении человека, абстрактные критерии.
Недостатками подхода являются субъективность оценки ЭРВ вследствие разного оценивания изменений в мышлении и поведении человека; несистемность набора критериев оценки ЭРВ, их неконкретность, неточность и зависимость от различных субъектных и несубъектных ЭЛФ; невозможность какой-либо количественной оценки ЭРВ; невозможность сравнения различных отрезков дискурса, если неизвестно, насколько и как изменилось мышление или поведение человека после восприятия фрагмента дискурса (прослушивания, просматривания, чтения и др.)
Когнитивный подход рассматривает РВ как модификацию когнитивной модели мира реципиента, воспринимающего фрагмент дискурса. Модификация происходит в результате интенсификации (например, преувеличения положительных характеристик) или преуменьшения (умолчания, сокрытия негативных характеристик). Эти две стратегии РВ осуществляются с помощью различных преобразований: аннулирующего (например, полуправды), фингирующего (например, «заговаривания зубов»), индефинитизирующего (например, изменения уровня абстракции явлений или объектов). Все стратегии основаны на введении новых знаний в когнитивную модель мира реципиента или индуцирования представления уже имеющихся знаний в искаженном виде.
Недостатками подхода являются невозможность определения степени достоверности или искаженности когнитивной модели мира реципиента до и после восприятия последним фрагмента дискурса; невозможность определения или точного определения того, сколько реципиент приобрел знаний и сколько утратил; субъективность оценивания того или иного фрагмента дискурса как, например, полуправды или изменения уровня абстракции: один исследователь считает, что уровень абстракции изменился, другой считает, что нет, т.е. отсутствуют критерии однозначной детерминации параметров, приводящих к изменению когнитивной модели мира реципиента.
Коммуникативный подход к РВ связан с семиотикой и моделью коммуникативного акта, предопределяющими потенциал РВ и условия его эффективной реализации. Согласно подходу ЭРВ увеличивается при изменении ментального образа адресанта, образа реципиента, при выборе кода сообщения, канала связи и при наличии обратной связи. Основу ЭРВ коммуникативный подход видит в асимметрии языкового знака.
Однако недостатками этого подхода является невозможность объективной и точной диагностики каких-либо изменений в ментальном образе адресанта, образе реципиента: для
этого не разработано специальное техническое оборудование. О выборе коде сообщения и канале связи имеется только общая информация: определенный код сообщения или канал связи обладает наибольшей ЭРВ (по мнению большинства ученых). Соответственно, оценить, сравнить ЭРВ различных фрагментов дискурса, а тем более, в точных величинах в рамках данного подхода невозможно. Кроме того, в класс определенного кода сообщения и канала связи, даже при определенном ментальном образе адресанта и реципиента, попадают тысячи фрагментов дискурса - в связи с чем, исследователь вынужден считать их ЭРВ одинаковыми. В свою очередь, для того, чтобы выделить такие классы исследователю необходимо учесть все комбинации типичных образов адресанта и реципиента, кодов сообщения, каналов связи и видов обратной связи, что является трудоемкой работой, на которую могут уйти десятилетия.
Ни в одном из известных исследований РВ не делается попытки объективно оценить его эффективность, тем более, ее измерить. Все труды находят косвенные доказательства (например, из импликаций текстов, опираясь на здравый смысл и логику) наличия или отсутствия РВ. Если это и возможно сделать более-менее объективно - хотя опосредованные методы изучения РВ через исключительно содержание дискурса не учитывают большое количество привходящих факторов, которые могут повлиять на результаты исследования - то сравнение фрагментов дискурса и других лингвистических данных между собой, т.е. оценка их ЭРВ относительно друг друга в подобных работах субъективна, поскольку невозможно только филологическими методами и подсчетом частотности и процентных значений оценить разницу между ЭРВ одного фрагмента и другого. Кроме того, если нет точных величин, у каждого исследователя может быть свое мнение насчет того, насколько сильно воздействует тот или иной фрагмент; мнение исследователя может зависеть от его принадлежности к какой-либо лингвистической школе, направлению, культуре (славянской, западной, восточной и др.) и т.д., тем более, если исследование осуществляется на материале языков из разных языковых групп. Следовательно, такое исследование в большой степени будет субъективным.
Основной путь повышения объективности и точности исследования ЭРВ лежит через непосредственное получение данных от большого количества потенциальных реципиентов, на которых может быть направлено РВ, с помощью онлайн-анкетирования, преобразования качественных параметров и показателей в количественные и статистической обработки. Реципиентами являются носители языка, поскольку именно на них направлено РВ.
Технической задачей изобретения является точное измерение, сравнение и прогнозирование ЭРВ фрагмента дискурса на любом языке за счет преобразования качественных параметров в количественные, в т.ч. путем приписывания значений фиктивным переменным согласно поставленным гипотезам и введения количественной оценки степени убедительности фрагмента; возможность проведения одним человеком недорогостоящего
исследования на основе ответов неограниченного количества респондентов (онлайн-анкетирование) в короткие сроки и автоматической статистической обработки.
Поставленная задача достигается тем, что способ прогнозирования эффективности речевого воздействия (ЭРВ) фрагмента включает в себя отбор параметров ЭРВ в исследуемых языках, отбор фрагментов дискурса с данными параметрами, определение ЭЛФ, влияющих на ЭРВ, нивелирование влияния этих ЭЛФ в отобранных фрагментах, составление онлайн-анкеты и проведение онлайн-анкетирования на исследуемых языках (перевод осуществляется с сохранением потенциала РВ), проведение корреляционного и сравнительного анализа результатов онлайн-анкетирования с составлением уравнения регрессии, позволяющего прогнозировать ЭРВ в зависимости от наличия и количества параметров ЭРВ, ранжирование данных параметров согласно значениям стандартизированных Beta-коэффициентов.
Категоричный вывод о том, насколько эффективен тот или иной фрагмент с точки зрения речевого воздействия, формулируют в соответствии с составленным уравнением регрессии, если коэффициент Пирсона для данной модели не менее 0,1, что говорит о наличие связи включенных в модель параметров и ЭРВ.
Способ позволяет объективно оценить и точно измерить ЭРВ фрагмента дискурса за счет непосредственного оценивания убедительности фрагмента носителями языка по 5-балльной шкале путем онлайн-анкетирования и за счет преобразования качественных параметров в количественные, в т.ч. приписывания значений фиктивным переменным.
В качестве параметров ЭРВ рассматриваем все возможные в дискурсе риторические приемы, которые способны влиять на ЭРВ фрагмента: метафора, сравнение, повтор, стилистический контраст, нестилистический контраст, эпитет, ирония/сатира, риторический вопрос, преувеличение/преуменьшение, каламбур (игра слов), неологизм, аллюзия, перестановка частей слова/предложения, замена слова/структуры другим словом/структурой, олицетворение, зевгма, градация, плотность риторических приемов (18 параметров).
При этом из массива параметров исключаются те, которые являются видом или подвидом выделенных выше параметров. Так, метонимию и синекдоху относят к параметру «метафора», поскольку все три риторических приема основаны на сходстве признака(-ов) двух объектов действительности и переносе этого признака на другой объект.
Дополнительно в анализ могут быть включены и другие параметры, специфичные для определенных языков. При этом все остальные процедуры способа измерения ЭРВ остаются теми же.
Из массива полученных онлайн-анкет исключаются незаполненные анкеты, т.к. не дают общей картины ответов, а также те онлайн-анкеты, которые заполнялись в течение периода не менее 1,5 минут и не более 10 минут. Поскольку задаче соответствует измерение только ЭРВ, то автоматическое или бездумное заполнение онлайн-анкет (как в случае, если те заполнялись
в течение периода менее 1,5 минут) или, наоборот, слишком глубокое вникание в суть фрагмента (как в случае, если те заполнялись в течение периода более 10 мин.), а не быстрая реакция респондента с последующим кликом на одну из категорий 5-балльной шкалы ответов, могут в сумме дать необъективную картину результатов, особенно если количество таких онлайн-анкет превышает 5% от общего количества. Среднее время заполнения онлайн анкет равняется 4-6 мин. и рассчитывается исходя из количества фрагментов в онлайн-анкете и их длины. Наиболее оптимальное количество фрагментов для лингвистических Интернет-опросов - 8, а длина каждого фрагмента - 300 печатных знаков.
Для увеличения точности и объективности заявленного способа косвенным подтверждением правильности составленных уравнений регрессии для ЭРВ является дополнительный анализ среднеарифметических значений ЭРВ, а проверкой уравнения служит анализ пропорций значений ЭРВ, вычисленных с помощью уравнения и с помощью анализа среднеарифметических значений реальных ответов респондентов на определенные фрагменты, выбираемые случайно. Если разница между значениями, полученных делением значений, полученных с помощью уравнения, на значения, полученные с помощью анализа среднеарифметических значений, не превышает 0,1, то уравнение регрессии для данного языка считается точным; если эта разница находится в диапазоне 0,1-0,3 - то приблизительным; если разница составляет более 0,3 - то неточным. Получение приблизительного уравнения может быть вызвано влиянием факторов, которые не были учтены на предыдущих этапах способа измерения.
Однако признание уравнения приблизительным не означает неуспех в плане общей оценки ЭРВ и сравнения параметров ЭРВ. Надежные коэффициенты корреляции, вычисленные для проверки выдвинутых гипотез, - достаточное основание для выводов о частичном подтверждении гипотез и наличии тенденций в исследуемых языках. Также данные коэффициенты для разных языков могут сравниваться между собой.
Сущность изобретения заключается в способе измерения, сравнения и прогнозирования ЭРВ фрагмента дискурса в разных языках путем онлайн-анкетирования и корреляционного и сравнительного анализа его результатов; для проведения онлайн-анкетирования разрабатывается специальное программное обеспечение, в т.ч. автоматическая запись ответов респондентов в специализированную базу данных, пригодную для последующей фильтрации на выделенные параметры ЭРВ, а также социологические параметры: пол, возраст, образование, и для последующей автоматической статистической обработки в специализированных программных пакетах Microsoft Excel, STATISTICA, UNISTAT 6.5, MedCalc, SPSS 20, SAS и др.; при этом статистическая обработка предоставляет данные, пригодные для сравнительного анализа значений ЭРВ и ее параметров в исследуемых языках, а именно: вычисляются коэффициенты корреляции Пирсона и стандартизированные коэффициенты Beta, составляются
уравнения регрессии для измерения и прогнозирования ЭРВ фрагмента в определенном языке, проверяются уравнения регрессии пропорциональным анализом значений ЭРВ, полученных с помощью уравнения и с помощью неопосредованного анализа среднеарифметических значений ответов респондентов, сравниваются значения ЭРВ одних и тех же фрагментов на разных языках, подтверждаются или опровергаются выдвинутые гипотезы исследования, ранжируются параметры ЭРВ согласно значениям стандартизированных Beta-коэффициентов (см. Таблица Coefficients » ниже).
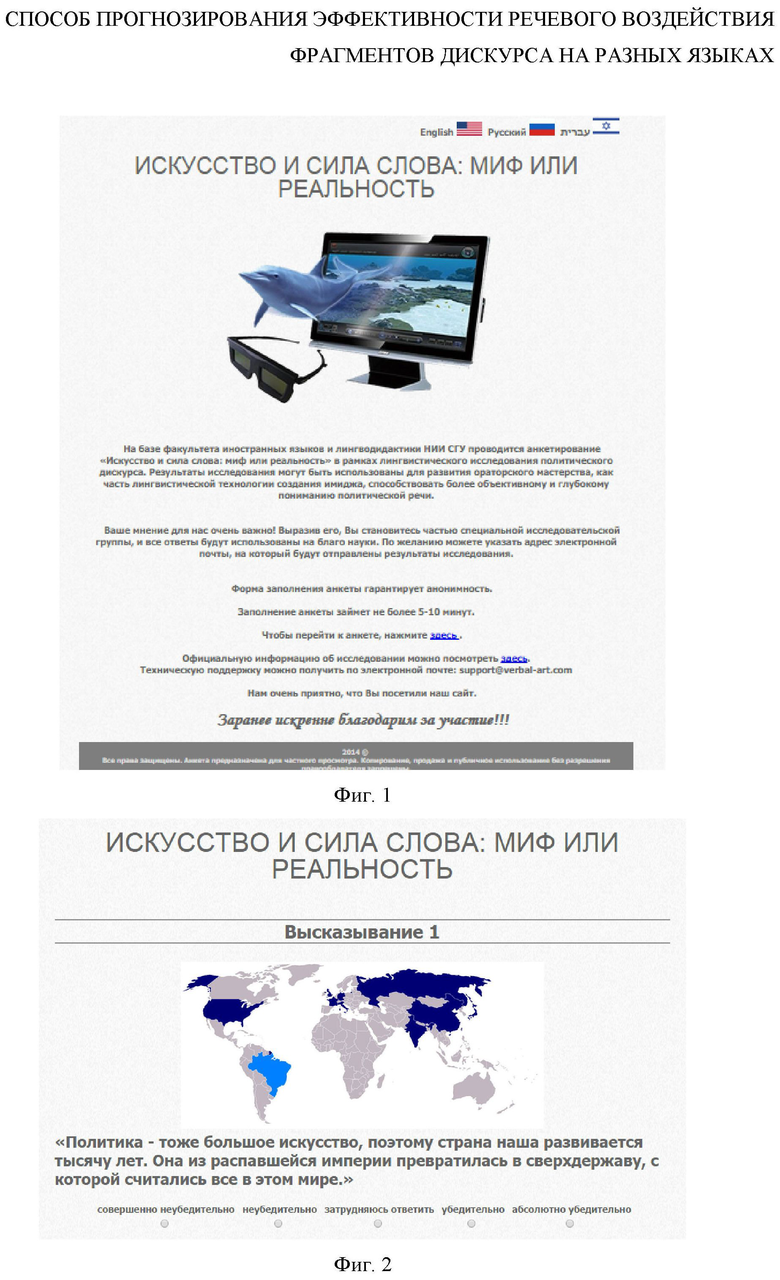
Предлагаемый способ поясняется скриншотами с сайта, где находится онлайн-анкета:
Фиг. 1 Главная веб-страница онлайн-анкеты;
Фиг. 2 Веб-страница онлайн-анкеты с одним из фрагментов;
Фиг. 3 Скриншот фрагмента онлайн-анкеты на иврите;
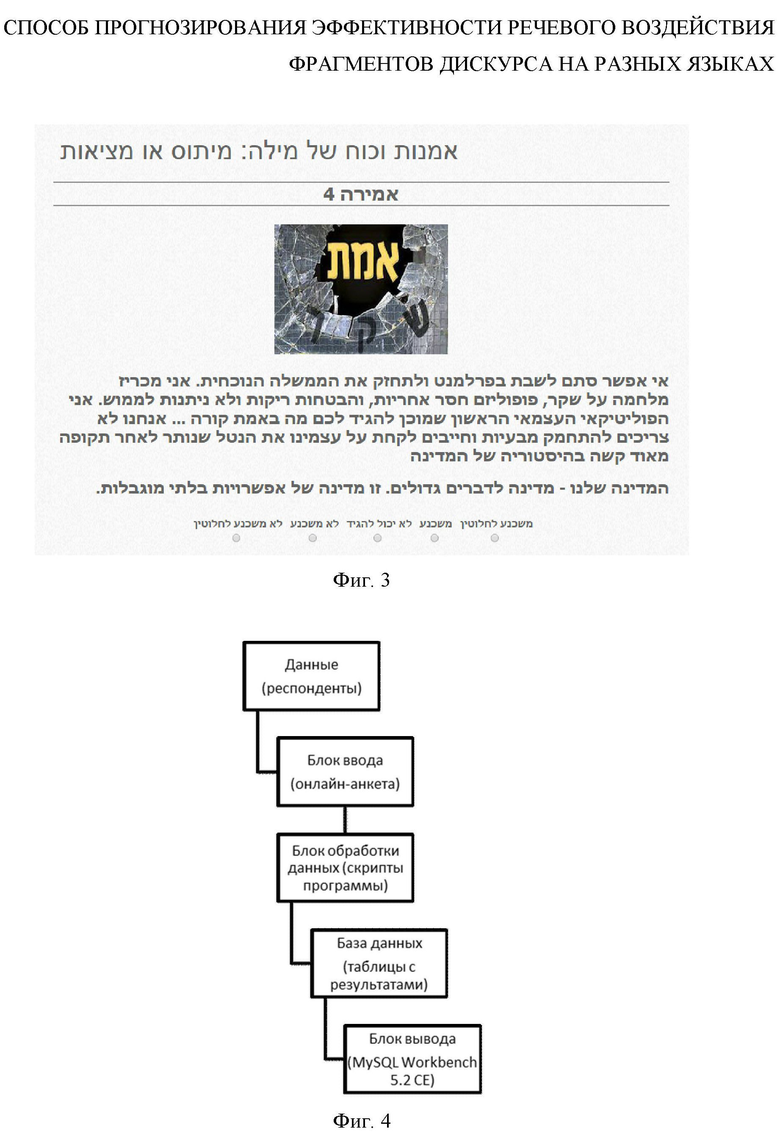
Фиг. 4 Блок схема устройства для реализации способа.
Способ заключается в следующем.
Для повышения объективности случайной выборки выбирают вид дискурса для анализа и на одном из исследуемых языков подбирают материал (книги, речи, выступления и т.д.) объемом не менее 40000 слов в рамках этого вида дискурса. Методом случайной выборки отбирают фрагменты дискурса, поскольку любой из них оказывает какое-либо РВ. РВ равняться нулю не может, может только стремиться к нулю. Из каждого фрагмента выделяют параметры, связанные с РВ. Из всех параметров отбирают те, которые способны воздействовать на реципиента. Это те параметры, благодаря которым элементы фрагмента дискурса (слова, словосочетания и т.д.) переходят из нейтрального стиля в другой (официально-деловой, разговорный, жаргон и т.п.), а именно: метафора, сравнение, повтор, стилистический контраст, нестилистический контраст, эпитет, ирония/сатира, риторический вопрос, преувеличение/преуменьшение, каламбур (игра слов), неологизм, аллюзия, перестановка частей слова/предложения, замена слова/структуры другим словом/структурой, олицетворение, зевгма, градация. Это т.н. риторические приемы, цель которых является повысить ЭРВ фрагмента. Отдельно выделяют параметр плотности риторических приемов.
После отбора параметров выделяют большие отрезки дискурса из подобранного материала на одном из исследуемых языков.
Составляют стандартный список ЭЛФ, выделенных из больших отрезков дискурса: ЭЛФ пространства, времени, социальные ЭЛФ (принадлежность к социальному классу, социальные потребности, количество адресатов речи, социальные задачи исторического периода, активность общественной жизни и степень участия в ней), собственно политические ЭЛФ (интенсивность связи с историей общества, политические цели и задачи исторического периода), психологические ЭЛФ (личные отношений между субъектами дискурса, психического состояния).
На основании стандартного списка ЭЛФ выделяют ЭЛФ, влияющие именно на ЭРВ в исследуемых языках путем пропорционального анализа параметров в фрагментах дискурса; получают специализированный список ЭЛФ.
Составляют таблицу, где указывают пропорции одного параметра к общему числу параметров в конкретном фрагменте дискурса:
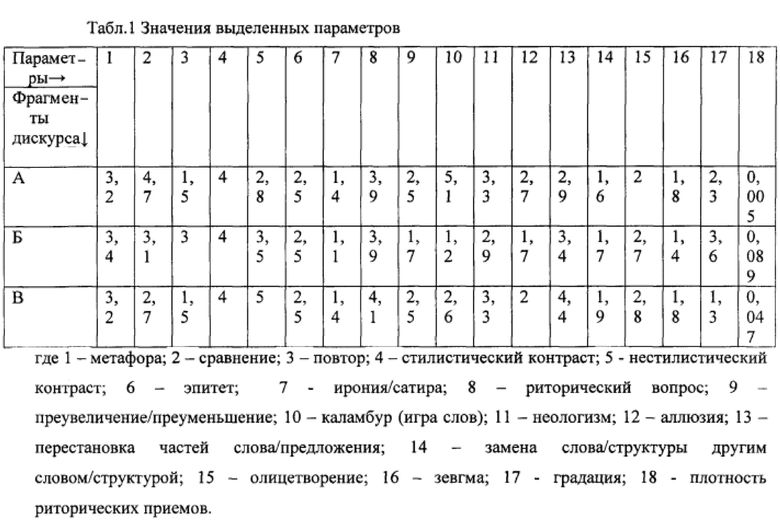
Так может быть определена относительная величина присутствия параметра в фрагменте дискурса. Соотнесение выделенных параметров с фрагментами дискурса позволяет ранжировать последние согласно любому из этих параметров. Подобное ранжирование при распределении каждого ЭЛФ, например, по убыванию позволяет при сопоставительном анализе ранжирования фрагментов дискурса и распределения ЭЛФ выделить между ними зависимости.
Пример: согласно Табл. 1 распределяют фрагменты дискурса по убыванию ЭЛФ пространства, т.е. по уменьшению объема пространства (стадион (фрагмент А) - площадь (фрагмент Б) - официальная трибуна (фрагмент В). Добавляют столбец с указанным ЭЛФ и сопоставляют значения на предмет устойчивой зависимости (корреляции) между указанным ЭЛФ и параметрами:
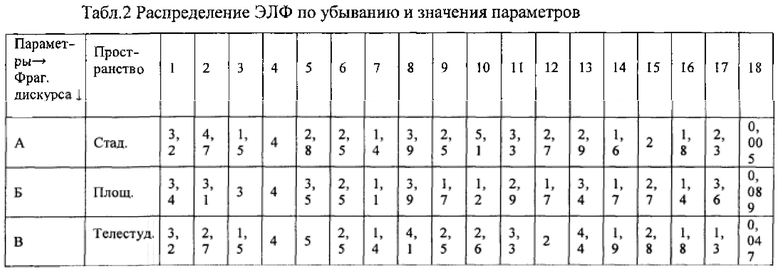
Под устойчивой зависимостью понимается такое ранжирование фрагментов дискурса по одному из параметров, которое полностью коррелирует с распределением ЭЛФ, и ни одно из значений параметра или распределения ЭЛФ не нарушает общую тенденцию.
Получают устойчивые зависимости между ЭЛФ и параметрами. Если устанавливают устойчивые зависимости между определенным ЭЛФ и хотя бы одним из параметров, то данные ЭЛФ относят к ЭЛФ, влияющим на ЭРВ. В случае с Табл.2 существуют устойчивые зависимости между объемом пространства дискурса и параметрами 2, 14, 15 (прямо пропорциональные); 5, 13 (обратно пропорциональные).
С помощью подобной процедуры проверяются все ЭЛФ из стандартного списка и все параметры на наличие устойчивых зависимостей между ними. Составляют специализированный список ЭЛФ (тех, которые влияют на ЭРВ).
В целях проведения психолингвистического исследования ЭРВ, максимально свободного от вмешательства привходящих факторов экстралингвистического характера, нивелируют влияние ЭЛФ из специализированного списка. Другими словами, при проведении исследования оставляют фрагменты с одинаковыми ЭЛФ из специализированного списка. Например, все фрагменты дискурса произносились в телестудии.
Исследователем могут вводиться дополнительные экстралингвистические критерии отбора, если их влияние на ЭРВ очевидно. К таким критериям относится, например, авторство.
Таким образом получают набор фрагментов дискурса с одинаковыми ЭЛФ: все фрагменты находятся в равных экстралингвистических условиях.
Далее из этого набора фрагментов отбирают фрагменты с выделенными 18 параметрами в соответствии с количеством параметров - 18 фрагментов, добавляют 2 фрагмента, необходимых для сравнения плотностей риторических приемов, 2 фрагмента, в которых риторические приемы отсутствуют, и 1 контрольный фрагмент. Итого 23 фрагмента. Контрольный фрагмент подбирают так, чтобы он содержал 100%-но логичную, энциклопедическую и доступную всем информацию. Контрольный фрагмент выявляет тех респондентов, которые посчитали его нелогичным и неубедительным, что означает, что они не вдавались в суть фрагмента, а оценивали свои мнения и ощущения, насколько убедительно этот фрагмент звучит. Это и является одной из задач исследования - собрать ответы респондентов, которые не вдавались в суть фрагмента и при ответе руководствовались не логикой, своими
знаниями, а ощущениями, психологической реакцией и быстро сформированным мнением о содержимом фрагмента.
Для оценки параметра «плотность риторических приемов» необходимо ввести 3 фрагмента с наиболее разными плотностями: низкой, средней и высокой: 0,005; 0,01; 0,02. Указанные плотности могут варьироваться от языка к языку от одного массива фрагментов к другому. Таким образом, получают набор оригинальных фрагментов дискурса, в которых перемешаны выделенные параметры и последние содержатся в различном количестве. Для повышения объективности исследования уравнивают объемы фрагментов и количество параметров. Объем фрагмента, равный 400 печатным знакам - достаточное количество для реализации любого риторического приема. Количество параметров уравнивают путем оставления в каждом фрагменте по 1 параметру. В итоге, получают набор из 18 модифицированных фрагментов, содержащих 18 выделенных параметров, а также 2 дополнительных фрагмента для сравнения плотностей контраста при корреляционном анализе, 2 фрагмента без параметров в качестве эталона нормы РВ и 1 контрольный фрагмент. Фрагменты с эталоном нормы РВ вводятся, во-первых, для того, чтобы полностью убедиться, что наличие параметров РВ приводит к отклонению от нормы и последующему повышению ЭРВ, а во-вторых, чтобы определить насколько ЭРВ фрагментов без выделенных параметров отличается от фрагментов с ними.
Затем из полученных фрагментов составляют онлайн-анкету. Данный процесс включает в себя как составление анкеты, так и разработку специального программного обеспечения для ее вывешивания в сети Интернет. Для получения хорошего процента заполненных анкет делят набор фрагментов на 3 примерно равные части и получают по 7+7+6 (20) фрагментов в онлайн-анкетах и добавляют в каждую из них 2 фрагмента без риторических приемов (т.е. без параметров) и 1 контрольный фрагмент. Соответственно, приходят к следующему: 10+10+9 фрагментов в 3 онлайн-анкетах.
Все фрагменты в онлайн-анкетах организованы по следующим двум принципам. В основной части (т.е. в середине анкеты с 3-го по 7-й фрагменты) располагают самые трудные для восприятия фрагменты. Трудные для восприятия фрагменты чередуют с более простыми.
Устанавливают период проведения онлайн-анкетирования в пределах максимально сжатых сроков - 3 месяца, поскольку в течение более длинных периодов могут появиться ЭЛФ, не зависящие ни от исследователя, ни от условий в которых проводится исследование.
Устанавливают диапазон времени, в течение которого онлайн-анкета должна быть заполнена: максимальный диапазон от -60% (в мин.) до +50% (в мин.) от общего количества фрагментов в этой онлайн-анкете. Соответственно, для онлайн-анкеты в 9-10 фрагментов, этот диапазон равняется 4-15 минут. Ограничение диапазона времени вводится как во избежание быстрого автоматического заполнения онлайн-анкеты, так и во избежание анкет, где
респонденты слишком глубоко пытались вникнуть в суть фрагмента, что не соответствует задачам исследования и инструкции к онлайн-анкете, которую респонденты читают перед ее заполнением. Онлайн-анкета проверяет и регистрирует убедительность фрагментов - их ЭРВ - а не их логичность, моральность и т.п.
В фрагментах используются грамматические конструкции не выше средней сложности, может использоваться небольшое количество специфической терминологии изучаемого вида дискурса. Для снижения сложности восприятия в фрагментах избегаются пассивные конструкции, жаргон, аббревиатуры и сложные/редкие слова.
Каждая онлайн-анкета состоит из вводной, реквизитной классификационной и информационной частей и повторной благодарности.
- Вводная часть содержит общую информацию об исследовательском институте, о цели исследовании, практическом применении результатов исследования, а также информацию о полезности данной анкеты, что повышает мотивацию респондентов.
- В реквизитной части даются данные об учреждении, проводящем анкетирование, названии анкеты, времени проведения, теме.
- Классификационная часть (паспортичка) запрашивает данные о респонденте: пол, возраст, образование и электронный адрес (опционально для тех, кто хотел бы получить результаты исследования на свой адрес электронной почты)
- Информационная часть содержит вводные инструкции по заполнению, 6 основных вопросов-фрагментов (4 с параметрами, 2 без и 1 контрольный фрагмент)
- Повторная благодарность за прохождение анкеты находится в ее конце.
Любые элементы в фрагментах, способные склонить респондента к тому или иному варианту ответа были максимально элиминированы. Такие элементы широко известны под названием эффектов (в зарубежной литературе - biases). Ниже представлена таблица со всеми возможными в онлайн-анкете эффектами и способами их нейтрализации, которые применяют при составлении онлайн-анкеты для точного измерения ЭРВ:
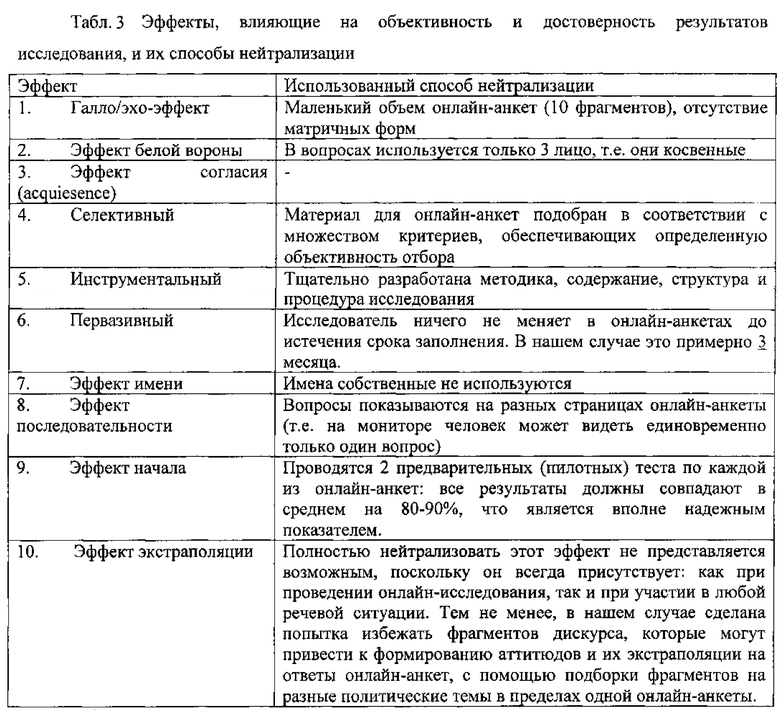
В качестве вариантов ответа применяют сбалансированную 5-балльную шкалу: 2 позитивных ответа («убедительно» и «абсолютно убедительно»), 2 негативных («неубедительно», «совершенно неубедительно») и 1 нейтральный («затрудняюсь ответить»). Наличие в фрагментах дискуссионных тем сделало все варианты ответа равновозможными, что крайне важно для получения объективных результатов.
Кроме того, фрагменты в каждой из 3-х онлайн-анкет не взаимосвязаны ни тематически, ни логически. В анкетах учитывают специфику культуры и используют реалии, понятные большинству респондентов, говорящих на том или ином языке. В онлайн-анкете повсеместно используются иллюстрации. При заполнении онлайн-анкеты предусмотрена полная анонимность. Программа ЭВМ для онлайн-анкет разработана под цель и задачи исследования.
Она написана на языках HTML и Javascript с применением РНР для обработки данных на сервере. Также используется библиотека jQuery для динамического отображения контента: загрузка новых фрагментов анкеты без перезагрузки страницы. Данные об ответах респондентов записываются в базу данных MySQL для дальнейшей работы с полученным набором данных.
Новые технические решения, предпринятые при разработке программного обеспечения для онлайн-анкеты.
1. Анкеты чередуются с каждым новым посещением сайта с цикличностью: анкета №1, 2, 3. В итоге, количество респондентов, ответивших на каждую из 3 онлайн-анкет будет, примерно одинаковым.
Для этого в таблице choose_tbl в базе данных SQL есть столбец с названием ′number′, который принимает значения 1-3. После того как респондент нажимает «Перейти к анкете», программа обращается к базе данных, чтобы выбрать следующую по счету анкету.
После этого программа обновляет значение в столбце ′number′, чтобы следующему опрашиваемому была показана другая анкета. Всего имеется 3 онлайн-анкеты.
Код программы выглядит так:

2. Найдено решение для отображения текста на языках, графически сильно отличающихся от европейских: иврит, китайский, японский и др.
Представим простую запись части программы на русском языке:
 «Нельзя просто сидеть в парламентах и обслуживать нынешнюю власть. Я объявляю войну вранью, безответственному популизму и пустым, невыполнимым обязательствам. Я первый независимый политик, и могу говорить о том, что происходит на самом деле...Нам необходимо смотреть проблемам в лицо и взять на себя груз, оставшийся после очень трудного периода истории страны.
«Нельзя просто сидеть в парламентах и обслуживать нынешнюю власть. Я объявляю войну вранью, безответственному популизму и пустым, невыполнимым обязательствам. Я первый независимый политик, и могу говорить о том, что происходит на самом деле...Нам необходимо смотреть проблемам в лицо и взять на себя груз, оставшийся после очень трудного периода истории страны.
Наша страна - это страна для великих дел. Это страна неограниченных возможностей.»
В иврите в отличие от русского языка направление текста обратное, т.е. справа налево. Большинство браузеров, отображающих веб-страницы и доступных обычным пользователям, разработаны в Америке или Европе: Internet Explorer (США), Google Chrome (США), Safari (США), Opera (Норвегия) - следовательно преимущественно рассчитаны на европейские языки. Поэтому при попытке простой записи в HTML документе абзаца на иврите слова в предложениях переставлены местами:

Любой символ - в нашем случае буква языка - может быть закодирован, и если закодировать каждую букву цифрой, цепочка цифр записывается в HTML документе в корректно читаемом браузером направлении, т.е. слева направо. Поэтому запись была представлена в кодировке Unicode:

Полученный результат демонстрирует Фиг. 3.
Более того, такая форма записи решает проблему разнонаправленного текста: например, когда одна часть предложения записывается на языке, где направление текста справа налево
(семито-хамитская языковая семья), а другая часть - на языке, где направление текста слева направо (славянская, романо-германская группа), или сверху вниз (алтайская языковая семья (японский, корейский и др.) и сино-тибетскаясемья (китайский и др.).
3. Для исключения незаполненных анкет (тем самым повышается качество всех полученных данных), а также тех онлайн-анкет, которые заполнялись в течение периода не менее 4 минут и не более 15 минут, в программу введен таймер входа и выхода респондента с сайта. Запись времени входа на сайт производится в момент нажатия кнопки «Перейти к анкете». Программа вставляет в таблицу базы данных соответствующую данной анкете (survey_1, survey_2, survey_3) новую строку с выбранными параметрами (дата и время начала прохождения и завершения онлайн-анкеты, язык).
В базу данных SQL записывается новый порядковый номер респондента (его уникальный идентификационный номер), время и дата начала заполнения анкеты и язык, на котором заполнялась анкета. Далее, после ответа на последний вопрос, записывается время и дата завершения заполнения анкеты. Тем самым исследователь получает набор респондентов, заполнивших анкету полностью.
Дату начала заполнения мы получаем с помощью встроенной функции MySQL ′NOW()′.
Код программы приведен ниже:

4. Каждый фрагмент респонденту показывается на как будто отдельной вебстранице. «Как будто», поскольку смена фрагментов производится при помощи JavaScript (библиотека jQuery) без перезагрузки новой веб-страницы. Т.е. в реальности в коде программы
записаны все фрагменты в одном файле, но при отображении в браузере часть скрыта для респондента, поэтому он видит веб-страницу частично - единовременно для него показывается только один фрагмент. Соответственно, браузер загружает на веб-страницу все 8-9 фрагментов одновременно, но фрагменты показываются по очереди, и только при ответе на текущий фрагмент следующий будет показан, а текущий скрыт. Код программы выглядит так:

Для получения объективных результатов и точной статистики необходимо, по крайней мере, 200-300 ответов по каждому из параметров и на каждом изучаемом языке. В нашем примере с 18 различными параметрами и 2 дополнительными фрагментами это 900 (300*3) заполненных онлайн-анкет на каждом изучаемом языке.
Итак, составлены 3 онлайн-анкеты для оценки, измерения, сравнения и прогнозирования ЭРВ. Пример фрагментов из одной онлайн-анкеты:
1. (без параметра): «Хотелось бы сказать, что выборы - одно из проявлений демократии, и личное участие в них может решить, каким будет новый парламент. Примите взвешенное решение и приходите на выборы».
2. (повтор): «Когда вы сегодня говорите, что вы построили заводы. Их строили заключенные и солдаты Советской армии. 75%! А Беломорканал - только заключенные. Давайте посадим два миллиона в тюрьмы и бросим на строительство заводов, они нам построят тысячи заводов, тысячи заводов!»
3. (сравнение): «Наша страна должна конкурировать не за государственный бюджет, который ограничен и мал, а за те средства, которые есть у частного и международного бизнеса. Поэтому мы в дальнейшем будем рассматривать эти вопросы: судебная система, конкурентная среда и частный бизнес как двигатель перемен»;
4. (риторический вопрос): «Если исходить из того, что сказал предыдущий оратор, то сто лет назад также было: все выступали. Хорошо, мы пошли по левому пути. Ночью в
октябре 17-го левые взяли власть. Шли 75 лет. Ну и где результат? При этом у этой власти было все в руках»;
5. (стилистический контраст): «Я участвовал в президентских выборах и писал не раз. И вот новый президент, перезагрузилась вся страна, и все думали, каким будет новый президент, он такой у него Iphone есть, он сейчас твиттернет куда-нибудь, погуглит, все решит. И ничего не изменилось»;
6. (контрольный фрагмент): «Нужно усилить роль институтов государства в жизни общества. Устойчивое развитие общества невозможно без дееспособного государства. Сильное государство - государство, цель которого - создание лучших, наиболее комфортных условий для жизни, творчества и предпринимательства»;
7. (метафора): «Я - доктор наук, и понимаю что-нибудь в науке! Сейчас нахожусь во главе партии, и не нужно меня учить. Вот вы на наследстве Маркса едете. Вам должно быть стыдно: вы проедаете наследство партии, которой уже нет. Вот та была партия!»;
8. (нестилистический контраст): «Мы понимаем, что есть люди, у которых имеются интересы в том, чтобы какая-то часть территории нашей страны отделилась. Мы хотели бы объединять вокруг себя, в том числе других людей, для которых целостность страны является действительно безусловным приоритетом»;
9. (без параметра): «Что касается базовых специальностей: учитель, врач, инженер, ученый и военный и другие, зарплата должна быть удвоена. Я сделаю все необходимое для того, чтобы восстановить отношения с соседними государствами. Для молодежи гарантирую бесплатное образование вплоть до высшего.»;
10. (эпитет): «Нельзя просто обсуждать в парламентах. Я объявляю войну вранью, популизму и пустым обязательствам. Я независимый политик, и могу говорить о том, что происходит на самом деле… Нам нужно решать проблемы, оставшиеся после трудного периода истории страны.»
Все 3 онлайн-анкеты переводят на исследуемые языки с сохранением потенциала РВ. Чтобы потенциал РВ был одинаковым в фрагментах на разных языках сохраняют количественные и качественные характеристики дискурса. К количественным характеристикам относятся: частотность употребления слова, их совместная встречаемость и распределение в дискурсе, объем фрагмента. К качественным характеристикам относится наличие риторических приемов. Для сохранения качественных характеристик фрагмента исключают и/или добавляют, или заменяют риторические приемы с одинаковыми ЭРВ. Например:
«Столыпин выступал здесь, центристы и правые поддерживали, левые не поддерживали»;
«Stolypin spoke here, the centrists and the rightists supported him, the leftists did not.» (лексический повтор заменяют на эллипсис);
Как известно, нарушение принятой в языке конструкции используется как стилистический прием, поэтому при переводе предложения с русского языка, где использован один прием, в нашем случае лексический повтор, на английский язык оказывается, что в тексте перевода указанного предложения два приема: лексический повтор и нарушение принятой в языке конструкции.
Поэтому вместо лексического повтора используем эллипсис. В этом случае количество употреблений эллипсиса возрастает, компенсируя снижение количества лексического повтора. Эллипсис относится к риторическому приему замены структуры другой структурой.
Таким образом, при переводе максимально сохраняют потенциал РВ фрагмента, чтобы процесс перевода с одного языка на другой имел наименьшее влияние на результаты исследования.
После перевода онлайн-анкеты на исследуемые языки проводят онлайн-анкетирование носителей языка. Все ответы автоматически регистрируются в специализированной базе данных:

Итак, каждому параметру соответствует 1 фрагмент, а на каждый этот фрагмент есть, допустим, 300 ответов респондентов, оценивших его ЭРВ от 1 до 5; причем 300 ответов на каждом из исследуемых языков. Также есть 300 ответов на 2 фрагмента, в которых выделенные параметры отсутствуют.
С помощью оператора [select * from survey_1 (2, 3) timediff (end_date, start_date) > 240 and timediff (end_date, start_date) < 900] исключают из базы данных онлайн-анкеты, заполненные менее, чем за 4 минуты и более, чем за 15 минут. С помощью дополнительного фильтра [where lang = ru (eng, hebr и т.д.)] отбирают онлайн-анкеты на одном из исследуемых языков.
Затем выбирают совокупность всех полученных в результате фильтрации ответов на 3 онлайн-анкеты (на которые ранее поделили изначальные 20 фрагментов) с помощью оператора [union all]. Экспортируют базу данных в формате Microsoft Excel. Соединяют 3 таблицы, полученные в соответствии с ответами на 3 онлайн-анкеты, в одну, где оказываются 18 столбцов с ответов, соответствующими 18 выделенным параметрам, 2 столбца - с дополнительными плотностями риторических приемов (средней и высокой), 2 столбца с ответами респондентов на фрагмент, в котором выделенные параметры отсутствуют (непараметры) и 1 столбец с ответами на контрольный фрагмент - см. Табл. 5.
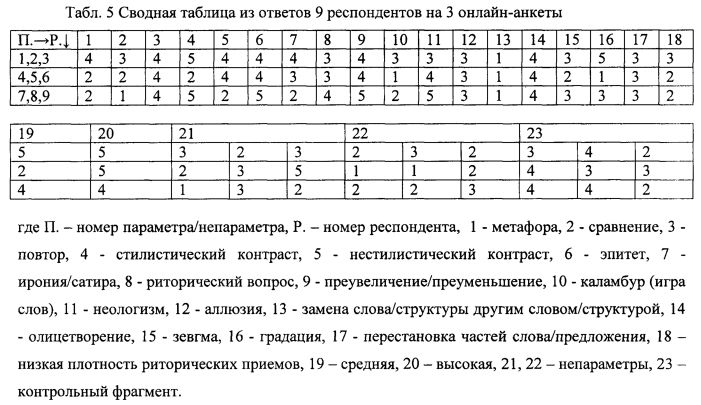 Оставляем один из столбцов с непараметрами вне выборки для проверки уравнения регрессии в дальнейшем. Вычисляем среднеарифметические значения (САЗ) ЭРВ каждого параметра и непараметра. Этот предварительный анализ показывает общую картину и тенденции, позволяющие выделить параметры, имеющие наибольшие ЭРВ.
Оставляем один из столбцов с непараметрами вне выборки для проверки уравнения регрессии в дальнейшем. Вычисляем среднеарифметические значения (САЗ) ЭРВ каждого параметра и непараметра. Этот предварительный анализ показывает общую картину и тенденции, позволяющие выделить параметры, имеющие наибольшие ЭРВ.
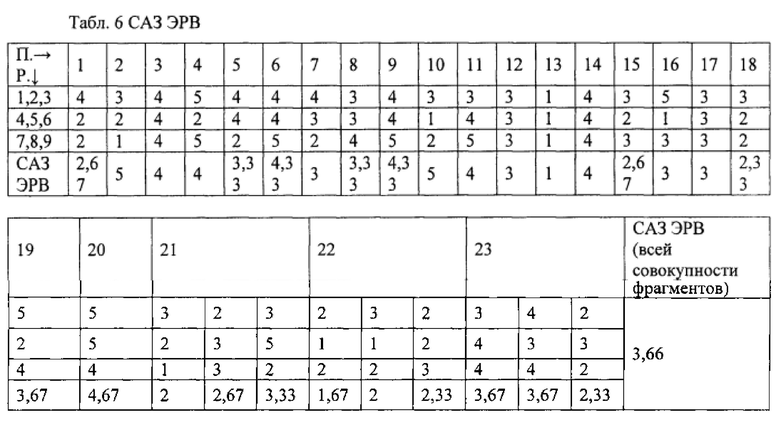
Однако анализ САЗ ЭРВ поверхностный, поскольку не учитывает т.н. «тяжелых хвостов», при наличии которых распределение значений ЭРВ не подчиняется нормальному закону. Поэтому результаты анализа САЗ ЭРВ подтверждаются, корректируются корреляционным анализом на коэффициент Пирсона, который представляет из себя множественную линейную регрессию. В соответствии с этим анализом находят корреляции между зависимой и независимыми переменными, где зависимой переменной выступает ЭРВ фрагмента, а независимыми - 23 параметра и непараметра. Значения зависимой переменной определяют респонденты; значения независимых переменных оценивает исследователь, преобразуя качественные параметры (метафора и др. риторические приемы) в количественные (0,1). По сути вводятся 20 двузначных фиктивных переменных со значениями 0 для непараметров и 1 для параметров. Фиктивная переменная, представляющая плотность риторических приемов, является многозначной и принимает следующие значения: 0 - если параметр плотности отсутствует в фрагменте, 1 - если плотность низкая (в нашем примере - 0,005), 2 - если плотность средняя (в примере - 0,01), 3 - если плотность высокая (в примере более - 0,02).
Все приведенные значения зависимой и независимой переменной записываются в таблице в виде пригодном для автоматического вычисления коэффициента корреляции Пирсона и составления уравнения множественной регрессии с данными переменными:
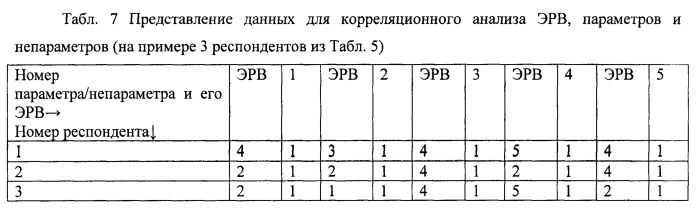
Номера параметров и непараметров см. Табл.5.

Все вычисления проводят с помощью программных пакетов Microsoft Excel, STATISTICA, UNISTAT 6.5, MedCalc, SPSS 20, SAS на уровне значимости p<0,05 (вероятность 95%). Другими словами, все полученные результаты с вероятностью 95% будут верны для других репрезентативных выборок в пределах исследуемых языков и видов дискурса (если изначально фрагменты отбирались только из одного вида дискурса).
С помощью корреляционного анализа получают следующие данные: коэффициент корреляции Пирсона для всей модели регрессии, для частных корреляций между ЭРВ и параметрами/непараметрами и для частных корреляций между параметрами/непараметрами; переменные, включенные в анализ (поскольку в анализ включают переменные, значения которых имеют нормальное распределение); коэффициент детерминации для всей модели (этот коэффициент определяет качество модели) и его изменение (определяет надежность результатов анализа); F change (также определяет надежность результатов анализа); F-отношение (показывает, насколько случайна связь между переменными); нестандартизированные коэффициенты В для уравнения регрессии; стандартизированные коэффициенты Beta (определяют вклад каждого параметра в величину ЭРВ); диагностики коллинеарности (проверка модели на коллинеарность осуществляется для выявления тесной корреляционной взаимосвязи между отбираемыми для анализа параметрами, совместно воздействующими на величину ЭРВ, которая затрудняет объективное оценивание каждого параметра в отдельности).
Для данных в Табл. 7 результаты корреляционного анализа выглядят следующим образом:
Descriptive Statistics
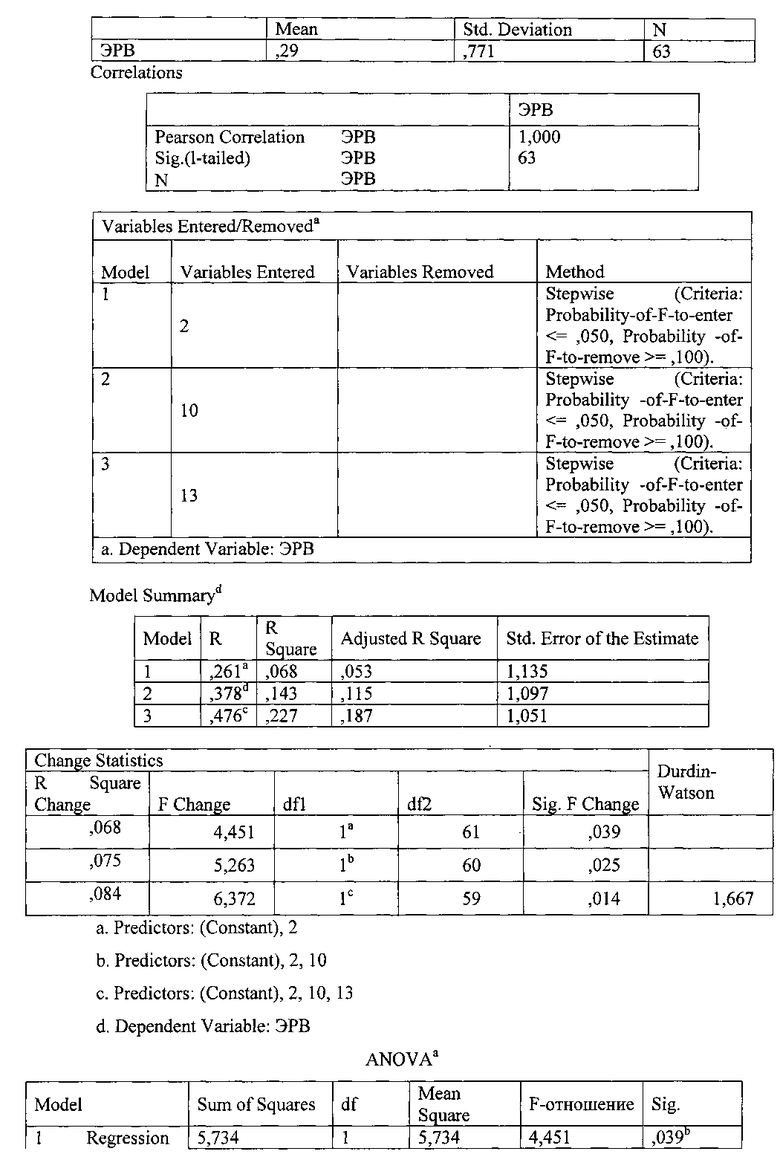


Анализируют полученные данные.
С помощью коэффициента корреляции R для всей модели определяют, существует ли связь между ЭРВ и параметрами и насколько она сильная. Так, в нашем примере самый высокий R в модели 3 - R=0,476, что констатирует существование слабой корреляции между ЭРВ и включенными в анализ переменными 2, 10, 13, а именно: риторическими приемами сравнения, каламбура и перестановки частей слова/предложения. В модель 3 входят данные три параметра.
Коэффициент Пирсона для частных корреляций между ЭРВ и конкретным параметром/непараметром позволяет определить, есть ли между ними связь, направление этой связи и силу. В нашем примере не выявлены такие корреляции.
Коэффициент детерминации R2 показывает качество всей модели регрессии: чем больше R2, тем качество модели выше. Так, в нашем примере модель 3 является наиболее качественной, поскольку R2=0,227.
Изменение R2 (R2 change) происходит в результате добавления/удаления из уравнения регрессии того или иного параметра. Соответственно, если величина изменения R2 достаточно большая, то эта модель - хороший предиктор. В нашем примере это модель 3, R2 change = 0,084.
F Change, т.е отношение доли вариации зависимой переменной (ЭРВ) к ее доли вариации, приходящейся на остатки, демонстрирует, что коэффициент Пирсона R для модели 3 с 3 параметрами надежнее, чем для модели 1 с параметром «сравнение», или модели 2 с параметрами «каламбур» и «перестановка частей слова/предложения».
С помощью F-отношения, или т.н. F-статистики, определяют носит ли установленная корреляционная связь между переменными случайный или неслучайный характер. F-отношение для всех 3 моделей незначительно, что не позволяет с уверенностью отвергнуть нулевую гипотезу о том, что связь параметров «сравнение», «каламбур» и «перестановка частей слова/предложения» с ЭРВ случайна. Соответственно, связь между данными параметрами и ЭРВ может быть случайной.
В соответствии с нестандартизированными коэффициентами составляют уравнение регрессии, которое при подстановке значений параметров/непараметров (а в нашем случае эти значения 0,1 или 0-4 (плотность риторических приемов)) позволяет измерить ЭРВ конкретного фрагмента, а также прогнозировать ЭРВ при, например, моделировании идеального с точки зрения ЭРВ фрагмента:
ЭРВ(фр.)=1,574а+1,574b+1,574с+3,426,
где а - значение параметра «сравнение», b - значение параметра «каламбур», с - значение параметра «перестановка частей слова/предложения».
При прогнозировании и моделировании важное значение имеет знание того, какие параметры являются основополагающими и оказывают наибольшее влияние на величину ЭРВ. Для этого вычисляют стандартизированные коэффициенты уравнения регрессии. Так, в нашем примере все 3 параметра осуществляют одинаковый вклад в величину ЭРВ (0,29).
Диагностики коллинеарности выявляют наличие взаимосвязей между переменными, т.е. параметрами/непараметрами. Такие связи могут влиять на результаты всего корреляционного анализа, поэтому важно диагностировать отсутствие мультиколлинеарности в модели регрессии. В нашем примере показатели коллинеарности имеют следующие значения: Eigenvalue (собственное значение коллинеарности) = 1,378; 1; 1; 0,622 (меньше критического значения 13) и Condition index (показатель обусловленности) = 1; 1,174; 1,174; 1,488 (меньше критического значения 15). Следовательно, констатируют отсутствие мультиколлинеарности в модели регрессии 3.
Проверка уравнения регрессии осуществляется с помощью реальных совокупностей ответов респондентов - пропорционального анализа, где сравниваются отношения среднеарифметических значений ЭРВ (в т.ч. фрагмента 22, не участвовавшего в
корреляционном анализе) и значений ЭРВ этих же фрагментов, полученных с помощью уравнения регрессии. Если разница между полученными значениями пропорций больше 0,2, то данное уравнение не считается точным. Согласно уравнению регрессии:
1. Фрагмент №1 анкеты 1 (1 параметр): ЭРВ=1,574*0+1,574*0+1,574*0+3,426=3,426
2. Фрагмент №4 анкеты 2 (10 параметр): ЭРВ=1,574*0+1,574*1+1,574*0+3,426=5
3. Фрагмент №3 анкеты 3 (15 параметр): ЭРВ=1,574*0+1,574*0+1,574*0+3,426=3,426
4. Фрагмент №10 анкеты 3 (22 параметр): 1,574*0+1,574*0+1,574*0+3,426=3,426
Согласно САЗ ЭРВ:
1. Фрагмент №1 анкеты 1: ЭРВ=8:3=2,667, где 8 - суммарное значение ЭРВ, 3 - количество онлайн-анкет
2. Фрагмент №4 анкеты 2: ЭРВ=15:3=5
3. Фрагмент №3 анкеты 3: ЭРВ=8:3=2,667
4. Фрагмент №10 анкеты 3: ЭРВ=9:3=3
Полученные пропорции:
1. 3,426:2,667=1,3
2. 5:5=1
3. 3,426:2,667=1,3
4. 3,426: 3=1,1
Таким образом, устанавливают, что связь между ЭРВ и параметрами «сравнение», «каламбур» и «перестановка частей слова/предложения» существует и является прямо пропорциональной, что подтверждает изначальную гипотезу о том, что фрагменты дискурса с риторическими приемами имеют более высокую ЭРВ, чем фрагменты без них, в отношении сравнения, каламбура и перестановки частей слова/предложения.
Однако большая разница между пропорциями значений ЭРВ, полученных с помощью корреляционного анализа и анкетирования, свидетельствует о приблизительности уравнения. Поэтому добавление остальных параметров в уравнение не считаем критическим, тем более, что в отношение некоторых из параметров поставленная гипотеза подтвердилась и менее вероятно, что фрагмент №10 анкеты 3 (22 параметр) имеет такую же ЭРВ, как фрагмент №1 анкеты 1 (1 параметр) и фрагмент №3 анкеты 3(15 параметр), хотя согласно уравнению это так.
В связи с этим вводят остальные параметры в уравнение регрессии с вычисленными для них нестандартизированными коэффициентами, которые были исключены ранее шаговым отбором, поскольку их распределение не соответствовало нормальному.
ЭРВ(фр.)=0,148а+1,574b+0,177с+0,112d+0,018е+0,177f+0,083g+0,018h+0,177i+1,574j+0,112k+0,083l+1,574m+0,112n+0,148o+0,083p+0,083q+0,171r+3,426, где буквы,
обозначают значение параметра, все буквы а-r соответствуют 1-18 параметрам в возрастающем порядке.
Итак, чтобы измерить ЭРВ фрагмента, необходимо подставить значения в фиктивные переменные уравнения. Если константа в уравнении намного больше, чем вся сумма переменных, то выделенные параметры - только небольшая часть тех факторов, которые влияют на ЭРВ фрагмента. Чем меньше константа в уравнении, тем больше объективность и точность самого уравнения, т.к. это означает, что все основные факторы влияния присутствуют в уравнении.
В нашем примере в полном уравнении регрессии константа равна 3,426, а максимальная сумма всех значений равна 6,406. Полагаем, что данная величина константы большая (составляет более 0,5 от максимальной величины совокупности всех параметров ЭРВ) и что в изначальной гипотезе остались некоторые существенные факторы влияния неучтенными.
При этом, в основном, можно констатировать большую надежность составленных уравнений регрессии, поскольку мультиколлинеарность в них отсутствует.
Сравнивают результаты анализа САЗ ЭРВ с результатами корреляционного анализа. Определяют наличие полностью и частично подтвержденных гипотез и тенденций. Под гипотезой в данном случае понимается предположение о том, что, например, фрагмент с риторическим приемом «метафора» имеет большую ЭРВ, чем без него. Отсюда значения фиктивной переменной (ЭРВ): с метафорой - 1, без - 0.
Градация гипотез на полностью и частично подтвержденные и тенденции осуществляется на основе совокупности данных анализа среднеарифметических значений и корреляционного анализа:
к полностью подтвержденным относим гипотезы, подтвердившиеся в ходе анализа среднеарифметических значений ЭРВ и имеющие коэффициент корреляции не меньше 0,1 при условии, что этот коэффициент надежен;
к частично подтвержденным - гипотезы, подтвердившиеся в ходе анализа среднеарифметических значений ЭРВ и имеющие коэффициент корреляции меньше 0,1, но больше 0,05 при условии, что этот коэффициент надежен; если коэффициент не надежен, то те гипотезы, которые имеют коэффициент корреляции не меньше 0,1;
к тенденциям - гипотезы, либо подтвердившиеся в ходе анализа среднеарифметических значений ЭРВ и имеющие коэффициент корреляции меньше 0,1, либо имеющие коэффициент корреляции не меньше 0,1.
Согласно указанной градации выявляем в примере:
- полностью подтвержденные гипотезы: фрагменты дискурса, содержащие риторические приемы сравнения, и/или каламбура, и/или перестановки частей слова/предложения, и/или со
средней или высокой плотностью риторических приемов имеют значительно большую ЭРВ, чем фрагменты, содержащие другие риторические приемы, а, тем более, без них;
- частично подтвержденные гипотезы (в соответствии с частичными корреляциями в таблице Excluded Variables, столбец Partial correlation): параметры 3, 4, 6, 9, 11, 14 имеют САЗ ЭРВ выше 3,0 и значение частичной корреляции выше 0,1, т.е. фрагменты дискурса, содержащие риторические приемы повтора, стилистического контраста, эпитета, преувеличения/преуменьшения, неологизма и замены слова/структуры другим словом/структурой, имеют большую ЭРВ, чем фрагменты, содержащие другие риторические приемы (кроме тех, указанных в полностью подтвердившихся гипотезах), а, тем более, без них;
- тенденции: в отношении параметров 5, 7, 8 была опровергнута изначальная гипотеза и выдвинута обратная ей, поскольку коэффициенты частичных корреляций имеют отрицательный знак, а значит, корреляция является обратной. Другими словами, в исследуемом языке существует тенденция снижения ЭРВ фрагментов в случае содержания в фрагменте параметров 5 (нестилистический контраст), 7 (ирония/сатира) и 8 (риторический вопрос).. Следует отметить, что весь анализ проводился на показательном примере из 3 респондентов, поэтому в полной статистически значимой выборке результаты исследования будут другими.
Достоверность частично подтвержденных гипотез и тенденций может быть проверена только дополнительным исследованием, учитывающим факторы, из-за которых происходит исключение переменных из уравнения регрессии.
После подтверждения/опровержения (в т.ч. частичного) поставленных гипотез сравнивают результаты анализа САЗ ЭРВ и корреляционного анализа для всех исследуемых языков и представляют это сравнение в табличной форме для удобства восприятия сжатой информации:


Составляют список общих и уникальных для исследуемых языков черт и закономерностей:
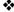 Общее (для 3 языков):
Общее (для 3 языков):
чем больше в фрагменте риторического приема «повтор» (параметр 3), тем выше ЭРВ фрагмента;
чем больше в фрагменте риторического приема «стилистический контраст» (параметр 4), тем выше ЭРВ фрагмента;
чем больше в фрагменте риторического приема «нестилистический контраст» (параметр 5), тем выше ЭРВ фрагмента;
чем больше в фрагменте риторического приема «неологизм» (параметр 11), тем выше ЭРВ фрагмента;
чем выше плотность риторических приемов (параметр 18) в фрагменте, тем выше его ЭРВ.
Общее (английский + русский): и т.д. Данный способ может быть реализован с помощью программно-аппаратного комплекса (ПАК), включающего в себя блок обработки данных, базу данных, блоки ввода и вывода (фиг. 4).
Блок ввода и блок вывода осуществляют взаимодействие ПАК с респондентами и оператором. Через блок ввода (онлайн-анкету) осуществляется ввод ответов респондентов. Блок вывода (программа MySQL Workbench 5.2 СЕ) осуществляет вывод данных в формате, удобном для последующей обработки оператором (в табличных форматах CSV, Excel Spreadsheet и др.).
База данных (БД) ПАК содержит информацию об отобранных параметрах и их значениях, информацию о респондентах и др. Блок обработки данных взаимодействует с БД программно-аппаратного комплекса, блоками ввода и вывода, производящих программную обработку информацию из БД и сохраняет в БД результаты обработки.
В качестве ПАК может быть использован персональный компьютер с оперативной системой Windows 7, содержащий центральный процессор, оперативное запоминающее устройство, накопитель на жестком диске, клавиатуру, монитор, сетевую карту, и/или модель для обеспечения работы с интернет-ресурсом. Алгоритм работы ПАК представлен на Фиг. 1. Респондент оценивает каждый из параметров по выделенному критерию - в соответствии с предложенной шкалой из 5 вариантов ответа. Данную оценку направляют в БД программно-аппаратного комплекса, имеющего массив информации для оценки параметра по выделенному критерию - эффективности речевого воздействия - в 5-балльной системе. При этом производится обработка массива информации в соответствии с видами загружаемой информации: информации о респонденте, онлайн-анкете и ответах респондента, - каждую из которых ПАК классифицирует на информационные элементы, записываемые в отдельных ячейках БД. К примеру, информация о респонденте включает в себя следующие информационные элементы: имя респондента, фамилия, электронный адрес, возраст, пол, образование. Каждому ответу респондента присваивается соответствующее значение по 5-балльной системе. Например, ответу «совершенно неубедительно» ПАК приписывает значение «1», «совершенно убедительно» - значение «5». Таким образом, получают значение эффективности речевого воздействия для каждого фрагмента в отдельности, а также для каждого параметра в целом после сортировки БД с помощью функции «select concat (наименование информационного элемента) from "наименование онлайн-анкеты" where lang = ′наименование языка онлайн-анкеты′» в блоке вывода (программа MySQL Workbench 5.2 СЕ).
На следующем этапе работы способа производится извлечение имеющейся в БД информации путем нажатия оператором ПАК кнопки «Export» и экспортирования данной информации в форматах CSV, Excel Spreadsheet, HTML, XML и др., пригодных для последующего составления уравнения регрессии и прогнозирования эффективности речевого воздействия (ЭРВ). Кроме того, ПАК может содержать дополнительные функции и информационные элементы, обеспечивающие ранжирование фрагментов дискурса по ЭРВ и прогнозирование ЭРВ этих фрагментов.
Заявленный способ был апробирован при оценке ЭРВ 19 фрагментов 450 респондентами. Каждый фрагмент оценивался по выделенным параметрам и критерию - ЭРВ (степени убедительности). Полученная совокупность количественных оценок по каждому параметру позволила ранжировать параметры и сами фрагменты по ЭРВ и составить уравнение регрессии, способное прогнозировать ЭРВ любого фрагмента подстановкой значений параметров в данное уравнение.
Преимуществами заявленного способа являются:
1. высокая степень точности и достоверности;
2. надежность и валидность;
3. возможность проверки главного результата, получаемого в ходе исследования - уравнения регрессии
4. возможность непосредственного изучения эффективности речевого воздействия в разных языках и на различных этапах их развития;
5. возможность измерения и моделирования идеального с точки зрения ЭРВ фрагмента дискурса для разных целей;
6. возможность автоматизировать процессы сбора, хранения и анализа результатов исследования;
7. заявленный способ является открытой системой, может сочетаться с другими способами (например, с обычным бумажным анкетированием) и формировать гибридный способ;
8. оперативность способа;
9. возможность дистанционного изучения ЭРВ и отсутствие контакта с анкетером-исследователем;
10. отсутствие сложного оборудования для получения необходимой информации;
11. невысокая стоимость (окупает себя, если выборка превышает 300 респондентов);
12. анонимность онлайн-анкет;
13. удобство респондента (заполнение в любом месте, где есть сеть интернет, в любое удобное время и т.п.);
14. возможность использования мультимедиа (повышает процент до конца заполненных анкет и мотивацию респондентов).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ПСИХОЛИНГВИСТИЧЕСКОЙ ДИАГНОСТИКИ НЕВРОТИЧЕСКИХ РАССТРОЙСТВ | 2003 |
|
RU2253365C1 |
| СПОСОБ И СИСТЕМА ОБЪЕКТИВНОЙ ОЦЕНКИ РЕАКЦИИ СЛУШАТЕЛЯ НА АУДИОКОНТЕНТ ПО СПЕКТРУ ПРОИЗВОЛЬНЫХ АФФЕКТИВНЫХ КАТЕГОРИЙ НА ОСНОВЕ ЭЛЕКТРОЭНЦЕФАЛОГРАММЫ | 2020 |
|
RU2747571C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО РАЗГОВОРНОГО РЕЧЕВОГО ФРАГМЕНТА | 2019 |
|
RU2757264C2 |
| СПОСОБ ПОВЫШЕНИЯ ПРИВЕРЖЕННОСТИ К ПРОТИВОТУБЕРКУЛЁЗНОЙ ТЕРАПИИ | 2023 |
|
RU2808910C1 |
| СПОСОБ ДИАГНОСТИКИ УРОВНЯ ТРЕВОЖНОСТИ | 2009 |
|
RU2402268C1 |
| СПОСОБ ОЦЕНКИ КАЧЕСТВА ЖИЗНИ У ПАЦИЕНТОВ С ДЕФЕКТАМИ ЗУБНЫХ РЯДОВ | 2009 |
|
RU2406440C1 |
| ИНДИВИДУАЛЬНО НАСТРОЕННЫЙ ВЫВОД, КОТОРЫЙ ОПТИМИЗИРУЕТСЯ ДЛЯ ПОЛЬЗОВАТЕЛЬСКИХ ПРЕДПОЧТЕНИЙ В РАСПРЕДЕЛЕННОЙ СИСТЕМЕ | 2020 |
|
RU2821283C2 |
| Способ определения эффективности визуального представления текстовых материалов | 2019 |
|
RU2722440C1 |
| СПОСОБ ЗНАКОМСТВА В СЕТИ ИНТЕРНЕТ ПОСРЕДСТВОМ ПСИХОЛОГИЧЕСКОГО ТЕСТА | 2008 |
|
RU2378987C1 |
| УСТРОЙСТВО ДЛЯ ВВОДА И ЭКСПРЕСС-АНАЛИЗА СОЦИОЛОГИЧЕСКОЙ ИНФОРМАЦИИ | 1991 |
|
RU2024921C1 |
Изобретение относится к средствам для прогнозирования эффективности речевого воздействия фрагментов дискурса на разных языках. Технический результат заключается в прогнозировании эффективности речевого воздействия (ЭРВ) фрагмента дискурса на разных языках. Отбирают параметры, которые могут воздействовать на реципиента; на одном из изучаемых языков отбирают фрагменты дискурса, содержащие отобранные параметры; выделяют экстралингвистические факторы (ЭЛФ), влияющие на ЭРВ фрагментов в исследуемых языках и нивелируют их влияние в отобранных фрагментах путем модификации этих фрагментов для проведения эксперимента, независимого от привходящих факторов; уравнивают объемы фрагментов, разрабатывают программное обеспечение и составляют онлайн-анкету, включающую модифицированные фрагменты с отобранными параметрами, добавляют контрольный фрагмент; переводят онлайн-анкету на исследуемые языки с сохранением потенциала речевого воздействия; проводят онлайн-анкетирование носителей языка; проводят корреляционный анализ на коэффициент Пирсона для каждого языка в отдельности и составляют уравнения регрессии; проводят сравнительный анализ ЭРВ фрагментов с различными параметрами на исследуемых языках; количественно определяют вклад параметров в величину ЭРВ и ранжируют их. 1 з.п. ф-лы, 4 ил., 7 табл.
1. Способ прогнозирования эффективности речевого воздействия (ЭВР) фрагментов дискурса на разных языках, характеризующийся тем, что выбирают параметры, воздействуют на реципиента на одном из изучаемых языков, в качестве которых используют риторические приемы; моделируют фрагменты дискурса, каждый из которых содержит один из выбранных параметров; выделяют экстралингвистические факторы, влияющие на эффективность речевого воздействия фрагментов в исследуемых языках и нивелируют их влияние в смоделированных фрагментах путем модификации этих фрагментов; уравнивают объемы фрагментов для каждого параметра, составляют онлайн-анкету, включающую модифицированные фрагменты с отобранными параметрами, добавляют контрольный фрагмент; переводят онлайн-анкету на исследуемые языки с сохранением потенциала речевого воздействия; проводят онлайн-анкетирование носителей языка; проводят корреляционный анализ на коэффициент Пирсона для каждого языка в отдельности для составления уравнения регрессии; проводят сравнительный анализ ЭРВ фрагментов с различными параметрами на исследуемых языках; количественно определяют вклад параметров в величину ЭРВ и ранжируют их согласно значениям стандартизированных Beta-коэффициентов, вывод об эффективности речевого воздействия фрагмента делают в соответствии со значением ЭРВ, полученным в результате вычисления уравнения регрессии.
2. Способ по п. 1, характеризующийся тем, что в качестве параметров выбирают риторические приемы, такие как: метафора, сравнение, повтор, стилистический контраст, нестилистический контраст, эпитет, ирония/сатира, риторический вопрос, преувеличение/преуменьшение, каламбур, неологизм, аллюзия, перестановка частей слова/предложения, замена слова/структуры другим словом/структурой, олицетворение, зевгма, градация, перестановка частей слова/предложения, плотность риторических приемов.
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| CN 102629156 A, 08.08.2012 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Топка с несколькими решетками для твердого топлива | 1918 |
|
SU8A1 |
| CN 102662776 A, 12.09.2012. | |||

