Уровень техники
[0001] Собрания, которые планируются заранее, могут использовать один или более инструментов для конференц-связи, которые устанавливаются перед собранием или в начале собрания, чтобы записывать беседу и формировать расшифровку стенограммы с атрибуцией говорящих. Такие существующие инструменты для конференц-связи могут включать в себя устройство, имеющее множество фиксированных динамиков на различных сторонах устройства, которое стоит на конференц-столе. Устройство может иметь башне- или конусообразную форму и может иметь или ассоциироваться с видеокамерой, которая может использоваться для того, чтобы идентифицировать и отслеживать людей на собрании. Алгоритмы преобразования речи в текст могут использоваться для того, чтобы создавать расшифровку стенограммы. Формирование аудиодиаграммы направленности может использоваться в связи с известными местоположениями фиксированных динамиков наряду с видео присутствующих, чтобы атрибутировать речь в расшифровке стенограммы.
Краткое описание чертежей
[0002] Фиг. 1 является видом в перспективе собрания между несколькими пользователями согласно примерному варианту осуществления.
[0003] Фиг. 2 является блок-схемой пользовательского устройства для использования на собраниях согласно примерному варианту осуществления.
[0004] Фиг. 3 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ инициирования интеллектуального собрания между двумя пользователями с ассоциированными распределенными устройствами согласно примерному варианту осуществления.
[0005] Фиг. 4 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ добавления распределенных устройств в интеллектуальное собрание посредством использования кода конференции согласно примерному варианту осуществления.
[0006] Фиг. 5 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ добавления дополнительных устройств в интеллектуальное собрание согласно примерному варианту осуществления.
[0007] Фиг. 6 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ обнаружения того, что происходит специальное собрание, согласно примерному варианту осуществления.
[0008] Фиг. 7 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ удаления аудиоканалов из пользовательских устройств и других устройств в ответ на выход пользователей из собрания согласно примерному варианту осуществления.
[0009] Фиг. 8 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ аутентификации устройства для добавления аудиопотока из устройства в аудиоканалы, обрабатываемые посредством экземпляра сервера собраний согласно примерному варианту осуществления.
[0010] Фиг. 9 является высокоуровневой блок-схемой системы для формирования расшифровки стенограммы для собрания между несколькими пользователями согласно примерному варианту осуществления.
[0011] Фиг. 10 является подробной блок-схемой последовательности операций способа, иллюстрирующей распределенную серверную обработку собраний на предмет информации, включающей в себя аудиопотоки из распределенных устройств согласно примерному варианту осуществления.
[0012] Фиг. 11 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ синхронизации нескольких аудиоканалов, принимаемых из нескольких распределенных устройств во время интеллектуального собрания согласно примерному варианту осуществления.
[0013] Фиг. 12 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ разделения перекрывающейся речи на интеллектуальном собрании распределенных устройств согласно примерному варианту осуществления.
[0014] Фиг. 13 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ слияния аудиопотоков в нескольких выбранных точках во время обработки согласно примерному варианту осуществления.
[0015] Фиг. 14A и 14B иллюстрируют примерное устройство захвата объемного окружения согласно примерному варианту осуществления.
[0016] Фиг. 15 иллюстрирует примерное размещение массива микрофонов согласно примерному варианту осуществления.
[0017] Фиг. 16 иллюстрирует систему искусственного интеллекта (AI) с устройством захвата объемного окружения согласно примерному варианту осуществления.
[0018] Фиг. 17 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ уменьшения числа аудиопотоков, отправленных по сети на сервер собраний для использования при формировании расшифровки стенограммы согласно примерному варианту осуществления.
[0019] Фиг. 18 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ для использования как видео, так и аудиоканалы, аудиовизуальные данные, из распределенных устройств, чтобы обеспечивать лучшую идентификацию говорящих согласно примерному варианту осуществления.
[0020] Фиг. 19 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ для индивидуальной настройки вывода на основе пользовательских предпочтений согласно примерному варианту осуществления.
[0021] Фиг. 20 является принципиальной блок-схемой компьютерной системы, чтобы реализовывать один или более примерных вариантов осуществления.
Подробное описание изобретения
[0022] В нижеприведенном описании, следует обратиться к прилагаемым чертежам, которые составляют часть описания и на которых показаны в качестве иллюстрации конкретные варианты осуществления, которые могут осуществляться на практике. Эти варианты осуществления описываются с достаточной степенью детализации, чтобы обеспечивать возможность специалистам в данной области техники осуществлять на практике изобретение, и следует понимать, что другие варианты осуществления могут использоваться и что структурные, логические и электрические изменения могут быть внесены без отступления от объема настоящего изобретения. Нижеприведенное описание примерных вариантов осуществления в силу этого не должно рассматриваться в ограниченном смысле, и объем настоящего изобретения задается посредством прилагаемой формулы изобретения.
[0023] Функции или алгоритмы, описанные в данном документе, могут реализовываться в программном обеспечении в одном варианте осуществления. Программное обеспечение может содержать машиноисполняемые инструкции, сохраненные на машиночитаемых носителях либо на машиночитаемом устройстве хранения данных, к примеру, на одном или более энергонезависимых запоминающих устройств или другой тип аппаратных устройств хранения данных, локальных или сетевых. Дополнительно, такие функции соответствуют модулям, которые могут представлять собой программное обеспечение, аппаратные средства, микропрограммное обеспечение либо любую комбинацию вышеозначенного. Несколько функций могут выполняться в одном или более модулей требуемым образом, и описанные варианты осуществления представляют собой просто примеры. Программное обеспечение может выполняться на процессоре цифровых сигналов, ASIC, микропроцессоре или другом типе процессора, работающем на компьютерной системе, такой как персональный компьютер, сервер или другая компьютерная система, превращая такую компьютерную систему в специально программируемую машину.
[0024] Функциональность может быть выполнена с возможностью выполнять этап с использованием, например, программного обеспечения, аппаратных средств, микропрограммного обеспечения и т.п. Например, фраза "выполненный с возможностью" может означать логическую схемную структуру аппаратного элемента, который должен реализовывать ассоциированную функциональность. Фраза "выполненный с возможностью" также может означать логическую схемную структуру аппаратного элемента, который должен реализовывать проектное решение на основе кодирования ассоциированной функциональности микропрограммного обеспечения или программного обеспечения. Термин "модуль" означает структурный элемент, который может реализовываться с использованием любых подходящих аппаратных средств (например, процессора, в числе других), программного обеспечения (например, приложения, в числе других), микропрограммного обеспечения либо любой комбинации аппаратных средств, программного обеспечения и микропрограммного обеспечения. Термин "логика" охватывает любую функциональность для выполнения задачи. Например, каждый этап, проиллюстрированный на блок-схемах последовательности операций способа, соответствует логике для выполнения этого этапа. Этапа может выполняться с использованием программного обеспечения, аппаратных средств, микропрограммного обеспечения и т.п. Термины "компонент", "система", и т.п. могут означать связанные с компьютером объекты, аппаратные средства и программное обеспечение при выполнении, микропрограммное обеспечение либо комбинацию вышеозначенного. Компонент может представлять собой процесс, выполняющийся на процессоре, объект, исполняемый фрагмент, программу, функцию, вложенную процедуру, компьютер либо комбинацию программного обеспечения и аппаратных средств. Термин "процессор" может означать аппаратный компонент, такой как блок обработки компьютерной системы.
[0025] Дополнительно, заявленное изобретение может быть реализовано в качестве способа, оборудования или промышленного изделия с использованием стандартных технологий программирования и/или проектирования, чтобы создавать программное обеспечение, микропрограммное обеспечение, аппаратные средства либо любую комбинацию означенного, чтобы управлять вычислительным устройством с возможностью реализовывать раскрытое изобретение. Термин "промышленное изделие" при использовании в данном документе подразумевается охватывающим компьютерную программу, доступную из любого машиночитаемого устройства или носителя данных.
[0026] Люди, называемые "пользователями", могут начинать беседу или собрание в любое время. Если собрание запланировано, организационные мероприятия могут проводиться для того, чтобы записывать беседу и создавать расшифровку стенограммы беседы для дальнейшего использования. Тем не менее специальные собрания, в общем, не предусматривают такую подготовку. Прекращение собрания или иное выделение времени на то, чтобы настраивать способ для того, чтобы записывать беседу и организовывать создание расшифровки стенограммы, может быть отвлекающим либо может не рассматриваться в ходе собрания. Помимо этого, специальные собрания зачастую осуществляются возле конференц-залов. В этих случаях, записывающие устройства, специально предназначенные для собраний, недоступны.
[0027] Во время беседы, аудио беседы может захватываться посредством устройств, которые носят пользователи, называемых "распределенными устройствами". В примерных вариантах осуществления, захваченные аудиосигналы передаются в систему проведения собраний по беспроводным каналам, чтобы распознавать то, что несколько пользователей ведут беседу, называемую "собранием", которое может быть запланированным или не запланированным. Если собрание не запланировано, оно называется "специальным собранием".
[0028] В ответ на обнаружение или иную организацию собрания, экземпляр собрания формируется на системе проведения собраний, чтобы распознавать речь от пользователей, которые говорят, и формировать расшифровку стенограммы собрания. Несколько сигналов речи из нескольких распределенных устройств принимаются как отдельные аудиоканалы и используются для того, чтобы формировать расшифровку стенограммы. Распределенные устройства могут включать в себя персональные пользовательские устройства (например, смартфон), а также другие устройства, включающие в себя цифровые помощники, камеры и любой тип устройства, которое допускает прием аудио и/или видео в пределах диапазона беседы.
[0029] В некоторых вариантах осуществления, собрание может создаваться с помощью одного нажатия кнопки на одном устройстве через приложение для проведения собраний. Другие устройства и пользователи с устройствами могут присоединяться к собранию либо через нажатие кнопки, представленной на пользовательском устройстве через приложение для проведения собраний, либо за счет набора в случае неиспользования (например, существующее устройство конференц-связи, которое присутствует в комнате). Участники собрания могут логически выводиться (например, идентифицироваться) посредством голосового цифрового отпечатка, владельцем участвующего устройства, посредством распознавания лиц или посредством добавления вручную пользователя через приложение для проведения собраний на устройстве в любой точке (например, для удаленных участников).
[0030] Предусмотрено множество способов, которым может устанавливаться собрание. В некоторых вариантах осуществления, распределенные устройства, такие как, смартфоны, ассоциированы с соответствующими пользователями и включают в себя приложение для проведения собраний, используемое для того, чтобы передавать в потоковом режиме аудио, принимаемое из микрофона на устройстве, в систему или сервер проведения собраний. Аудио, принимаемое из близлежащих устройств, должно иметь аудиоподпись на основе комбинации окружающего шума и/или любого звука, сформированного около устройства. В ответ на то, что два пользовательских устройства предоставляют аналогичную аудиоподпись через соответствующие аудиопотоки (аудиоканалы), система проведения собраний распознает то, что может происходить собрание, и создает экземпляр собрания, чтобы обрабатывать принимаемое аудио. Пользователям может предлагаться через их приложения для проведения собраний присоединяться к собранию. Альтернативно, другая информация, такая как информация местоположения, предшествующие взаимодействия, информация календаря или недавние взаимодействия по электронной почте, например, может использоваться для того, чтобы подтверждать, что оба пользователя или еще третий пользователь должны добавляться в экземпляр собрания.
[0031] В дополнительных вариантах осуществления, водяной аудиознак формируется посредством одного или более пользовательских устройств. Водяной аудиознак содержит аудиоподпись, или аудиоподпись может обнаруживаться отдельно. Водяной аудиознак может представлять собой звуковой шаблон, имеющий частоту выше нормального диапазона слуха пользователя, к примеру, 20 кГц или выше, или может представлять просто собой звук, который является незаметным для пользователей, с тем чтобы не создавать помехи беседе. В дополнительных вариантах осуществления, водяной знак может быть абсолютно слышимым и распознаваемым. Водяной знак может выбираться для отправки пользователем, желающим обеспечивать то, что экземпляр собрания создается во время беседы, в некоторых вариантах осуществления. Водяной знак принимается посредством распределенных устройств в пределах диапазона и автоматически или необязательно добавляется в экземпляр собрания. Устройства в пределах диапазона звука водяного знака также могут иметь добавленные аудиопотоки в экземпляр собрания в качестве дополнительных аудиоканалов.
[0032] В некоторых вариантах осуществления, код конференции формируется и отправляется другим пользователям, чтобы добавлять их в запланированные или специальное собрание. Код конференции также может выбираться перед запланированным собранием и использоваться в приглашении на собрание. Система проведения собраний, после приема кода конференции из пользовательского устройства, добавляет аудиопоток из такого пользовательского устройства в собрание после создания экземпляра.
[0033] Предусмотрены примерные варианты осуществления, которые представляют системы и способы для обеспечения индивидуально настроенного вывода на основе пользовательских предпочтений в распределенной системе. В примерных вариантах осуществления, сервер или система проведения собраний принимает аудиопотоки из множества распределенных устройств, предусмотренных на интеллектуальном собрании. Система проведения собраний идентифицирует пользователя, соответствующего распределенному устройству из множества распределенных устройств, и определяет предпочтительный язык пользователя. Расшифровка стенограммы из принимаемых аудиопотоков формируется по мере того, как происходит собрание. Система проведения собраний переводит расшифровку стенограммы на предпочтительный язык пользователя, чтобы формировать переведенную расшифровку стенограммы. Переведенная расшифровка стенограммы предоставляется в распределенное устройство пользователя. В примерных вариантах осуществления, переведенная расшифровка стенограммы предоставляется в реальном времени (или практически в реальном времени) по мере того, как происходит собрание. Переведенная расшифровка стенограммы может предоставляться с помощью текста (например, отображаться на устройстве пользователя) или выводиться в качестве аудио (например, через говорящего, слуховой аппарат, наушник). В некоторых вариантах осуществления, вместо или в дополнение к переводу, другие типы преобразования могут применяться к исходной расшифровке стенограммы, к переведенной расшифровке стенограммы или к переведенному речевому аудио.
[0034] Фиг. 1 является видом в перспективе собрания 100 между несколькими пользователями. Первый пользователь 110 имеет первое устройство 115, которое включает в себя микрофон, чтобы захватывать аудио, включающее в себя речь. Второй пользователь 120 имеет второе устройство 125, которое также допускает захват аудио, включающего в себя речь. Пользователи могут садиться за столом 130 на одном примерном собрании 100.
[0035] Первое и второе устройства 115 и 125 (также называемые "несколькими распределенными устройствами" или "множеством распределенных устройств") передают захваченное аудио на сервер 135 собраний для обработки и формирования расшифровки стенограммы. Собрание может быть специальным в том, что оно не запланировано. Например, пользователи могут встретиться с другом в перерыве или случайно встретиться в коридоре и решить поговорить касательно проекта, на которым они работают. Приложение для проведения собраний (также называемое "приложением для проведения собраний") может выполняться на первом и на втором устройствах 115 и 125. Приложение для проведения собраний может использоваться для того, чтобы предоставлять аудио на сервер 135 собраний.
[0036] Сервер 135 собраний обнаруживает то, что оба устройства отправляют: аудио с аналогичной аудиоподписью, аналогичным водяным аудиознаком, аналогичным кодом собрания, предоставленным посредством обоих устройств, либо с другой информацией, указывающей текущее обсуждение между пользователями. В ответ, сервер 135 собраний формирует экземпляр собрания, чтобы обрабатывать принимаемое аудио и формировать расшифровку стенограммы.
[0037] В различных вариантах осуществления, водяной знак может представлять собой любой тип звука, имеющего энергии только выше человеческого акустического диапазона, который составляет приблизительно 20 кГц, или является в других отношениях неслышимым, незаметным или неотвлекающим, который идентифицирует экземпляр собрания или код собрания, соответствующий собранию 100. Водяной знак может представлять собой кодирование звука код собрания или другую идентификацию экземпляра собрания в дополнительных вариантах осуществления.
[0038] Собрание 100 может предусматривать более двух человек, независимо от того, является оно запланированным или специальным. Третий пользователь 140 с третьим устройством 145 также может присоединяться к собранию 100. Третье устройство 145 также предоставляет аудио на распределенный сервер 135 собраний. Аудио распознается как предусмотренное как предусмотренное в собрании 100 посредством одного или более идентичных механизмов, описанных для распознавания того, что первые два пользователя/устройства предусмотрены в собрании 100.
[0039] Владелец/пользователь распределенного устройства может регистрировать себя с помощью приложения для распознавания посредством сервера 135 собраний. Пользователь может иметь или создавать голосовой профиль, называемый "голосовым цифровым следом" или "цифровым отпечатком", чтобы помогать серверу 135 собраний ассоциировать входящий речевой звук с пользователем. Если случайный человек присоединяется к собранию 100, сервер 135 собраний распознает то, что человек не известен, и предлагает одного или более пользователей уже на собрании на предмет имени человека. Альтернативно, сервер 135 собраний выполняет поиск в базе данных в организации, ассоциированной с известными пользователями на собрании, чтобы сопоставлять человека с профилем. Если человек не известен или не идентифицируется иным образом, человек идентифицируется с помощью метки или тега, к примеру, говорящий 1, говорящий 2 и т.д., в сформированной расшифровке стенограммы, помогая модифицировать расшифровку стенограммы, если человеку позднее присваивается имя. Любой из пользователей может назначать имя метке говорящего в любое время в ходе или после собрания. Известные или частые контакты этих, которые уже на собрании, могут использоваться для того, чтобы уменьшать пул/базу данных, используемый для того, чтобы первоначально проверять человека, чтобы оптимизировать процесс идентификации человека.
[0040] Могут быть предусмотрены дополнительные устройства, которые находятся в пределах аудио- или визуального диапазона собрания 100, такие как цифровой помощник 148 или специализированное устройство 150 для проведения собраний, оба из которых показаны на столе 130, но могут находиться в любом месте в пределах диапазона звуковых частот собрания 100. Такие дополнительные устройства могут соединяться с распределенным сервером 135 собраний и добавлять свои аудиопотоки в экземпляр собрания для обработки, чтобы дополнительно улучшать характеристики обработки аудио и преобразования речи в текст экземпляра собрания, выполняющегося на сервере 135 собраний. Такие дополнительные устройства могут обнаруживаться посредством сервера 135 собраний и добавляться в собрание, как описано выше, или могут представляться одному или более пользователей в качестве варианта для добавления в собрание.
[0041] Видеокамера 155 или другое устройство захвата изображений может иметь поле зрения, которое охватывает собрание 100 (или часть собрания 100). Сервер 135 собраний имеет сведения по нахождению камеры 155 около собрания 100, и может предоставлять индикатор одному или более пользователям, предоставляющий вариант получать информацию из камеры 155, и предоставлять информацию в экземпляр собрания, чтобы дополнительно улучшать обработку и предоставление расшифровки стенограммы. Например, камера 155 может использоваться для того, чтобы обнаруживать то, какой пользователь говорит, или, по меньшей мере, предоставлять информацию касательно того пользователь с большой вероятностью должен говорить в любой конкретный момент времени.
[0042] Фиг. 2 является блок-схемой пользовательского устройства 200 для использования на собраниях. Другие устройства, которые участвуют в собрании, могут иметь аналогичный набор компонентов. Устройство 200 включает в себя, по меньшей мере, один микрофон 210 и процессор 215 для выполнения приложения 220 для проведения собраний, которое сохраняется на запоминающем устройстве 225. Приемо-передающее устройство 230 используется для передачи в потоковом режиме аудио и/или видео из камеры 235 на распределенный сервер 135 собраний. Пользовательское устройство 200 также может иметь экран отображения, к примеру, сенсорный экран 240, часть которого показывается.
[0043] Устройства, которые могут участвовать в собрании, могут идентифицироваться через календарные записи, текущее местоположение, NFC (телефоны должны быть очень близко друг к другу), Bluetooth®-оповещение и прямое приглашение через код конференции или другой код, который может формироваться и ассоциироваться с собранием 100.
[0044] Сервер 135 собраний может обрабатывать несколько собраний одновременно через несколько экземпляров собраний. Каждый экземпляр собрания может включать в себя идентификатор собрания, к примеру, код собрания, идентификации устройств, которые передают в потоковом режиме аудио, идентификации пользователей, которые участвуют в собрании (либо через ассоциированное с пользователем устройство), или иным способом распознаваться посредством сервера 135 собраний посредством распознавания лиц, распознавания голоса или другого средства распознавания пользователей.
[0045] Фиг. 3 является блок-схемой последовательности операций, иллюстрирующей способ 300 инициирования интеллектуального собрания между двумя пользователями с ассоциированными распределенными устройствами. На этапе 310, водяной аудиознак принимается в первом распределенном устройстве через микрофон, ассоциированный с первым распределенным устройством. В одном варианте осуществления, водяной аудиознак передается посредством говорящего, ассоциированного со вторым распределенным устройством в ходе собрания.
[0046] Данные, соответствующие принимаемому водяному аудиознаку, передаются через первое распределенное устройство на сервер собрания с распределенными устройствами на этапе 320. В некоторых вариантах осуществления, принимаемый водяной аудиознак сначала преобразуется в цифровую форму, которая может представлять собой просто прямое преобразование водяного аудиознака в цифровое представление звука, либо может включать в себя декодирование водяного аудиознака, чтобы получать данные, идентифицирующие собрание или второе распределенное устройство, которое испускает водяной аудиознак.
[0047] На этапе 330 из распределенного сервера собраний принимается индикатор того, что первое распределенное устройство подтверждено для экземпляра собрания на сервере собрания с распределенными устройствами.
[0048] Первое распределенное устройство, на этапе 340, передает в потоковом режиме аудио собрания в экземпляр собрания на сервере собрания с распределенными устройствами в ответ на принимаемый индикатор. Принимаемый индикатор может включать в себя информацию, идентифицирующую канал связи, который следует использовать, либо аудиопоток может просто идентифицировать устройство потоковой передачи, который сервер собраний использует для того, чтобы направлять аудиопоток в корректный экземпляр собрания.
[0049] Фиг. 4 является блок-схемой последовательности операций, иллюстрирующей способ 400 добавления распределенных устройств в интеллектуальное собрание посредством использования кода конференции. В некоторых вариантах осуществления, код конференции кодируется в водяном знаке, как пояснено в способе 300. На этапе 410, код конференции принимается или формируется для собрания между пользователями посредством первого распределенного пользовательского устройства. Первое распределенное пользовательское устройство может принимать код из сервера собраний, выполняющего экземпляр собрания, либо первое распределенное пользовательское устройство формирует код собрания через приложение для проведения собраний, выполняющееся на первом распределенном пользовательском устройстве.
[0050] Код отправляется во второе распределенное пользовательское устройство на этапе 420. Код может отправляться по электронной почте, через текст или другое средство отправки данных электронно либо может кодироваться как слышимый сигнал (водяной аудиознак) и передаваться акустически в остальную часть участвующих устройств, к примеру, через говорящего одного из пользовательских устройств, к примеру, через первое распределенное пользовательское устройство.
[0051] Второй распределенный пользователь предоставляет код конференции в экземпляр собрания на сервере собраний, за счет чего код собрания используется, на этапе 430, для того, чтобы идентифицировать, по меньшей мере, одно второе распределенное пользовательское устройство. Второе распределенное пользовательское устройство передает в потоковом режиме аудио на этапе 440 в экземпляр собрания на сервере собраний из первого и второго распределенных пользовательских устройств.
[0052] Собрание может представлять собой специальное собрание между несколькими пользователями или несколькими пользовательскими устройствами, и код конференции формируется после того, как специальное собрание начато. Следует отметить, что также могут быть предусмотрены пользователи без ассоциированного пользовательского устройства, которые участвуют в собрании. Другие пользовательские устройства и устройства, не ассоциированные с пользователем, могут идентифицироваться на основе обнаруженного местоположения устройств. Данные из таких устройств могут иметь добавленные потоки данных в экземпляр собрания посредством предоставления списка других близлежащих устройств пользователю(ям) и обеспечивать возможность выбора таких устройств через пользовательский интерфейс приложения, чтобы добавлять в экземпляр собрания. Устройства, которые могут участвовать в собрании, могут идентифицироваться через календарные записи, текущее местоположение, NFC (телефоны должны быть очень близко друг к другу), Bluetooth-оповещение и прямое приглашение.
[0053] В дополнительных вариантах осуществления, собрание представляет собой запланированное собрание между несколькими пользователями или несколькими пользовательскими устройствами, и код конференции формируется до того, как запланированное собрание начинается. Код конференции может отправляться в каждое из пользовательских устройств и использоваться посредством соответствующих приложений, чтобы идентифицировать устройства для экземпляра собрания на сервере собраний для добавления потоков данных из таких устройств в ходе собрания.
[0054] Фиг. 5 является машинореализуемым способом 500 добавления дополнительных устройств в интеллектуальное собрание. На этапе 510, сервер собраний принимает аудиопотоки из группы распределенных устройств, при этом аудиопотоки содержат речь, обнаруженную посредством такой группы распределенных устройств в ходе собрания двух или более пользователей.
[0055] Сервер собраний на этапе 520 принимает информацию собрания, соответствующую собранию, из дополнительного или нового распределенного устройства. Новое устройство может представлять собой пользовательское устройство пользователя, который только что присоединен к собранию, либо новое устройство может представлять собой устройство, которое находится в комнате или иным образом находится в пределах диапазона интеллектуального собрания.
[0056] На этапе 530, дополнительное распределенное устройство добавляется в экземпляр собрания на сервере собраний. Поток информации из дополнительного распределенного устройства принимается на этапе 540 в ответ на добавление дополнительного распределенного устройства.
[0057] Фиг. 6 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ 600 обнаружения того, что происходит специальное собрание. На этапе 610 аудиопотоки принимаются на сервере собраний, по меньшей мере, из двух распределенных устройств, которые передают в потоковом режиме аудио, обнаруженное во время специального собрания между двумя пользователями.
[0058] Аудиопотоки сравниваются на этапе 620, чтобы определять то, что аудиопотоки представляют звук из специального собрания. Аудиопотоки могут сравниваться, например, посредством вычисления коэффициентов нормализованной взаимной корреляции между двумя сигналами. Если результаты выше предварительно определенного порогового значения, аудиопотоки наиболее вероятно исходят из идентичного специального собрания. Выбранное пороговое значение может быть числом между 0 и 1 и может выбираться эмпирически на основе тестов, осуществляемых в ходе ряда сценариев проведения собраний в различных окружениях. Выбор может выполняться, чтобы получать требуемый баланс ложноотрицательных суждений и ложноположительных суждений. Другие индикаторы того, что потоки исходят из идентичного собрания, включают в себя идентичное местоположение устройств. Дополнительные индикаторы включают в себя то, что пользователи, которые имеют несколько взаимодействий в прошлом, находятся в идентичной организации, и другие индикаторы того, что пользователи с большой вероятностью должны участвовать в собрании. Дополнительная верификация может получаться посредством сравнения текста, сформированного из аудиопотоков.
[0059] После того как потоки успешно сравниваются, идентификатор/код собрания может формироваться и использоваться для того, чтобы добавлять дополнительных участников. Другие участники могут добавляться в ответ на передачу, посредством дополнительных устройств, потокового аудио, которое успешно сравнивается с аудиопотоками уже на собрании. После того как устройство добавляется, устройство может формировать сигнал, указывающий присоединение к собранию, такой как проверка досягаемости.
[0060] Сервер собраний формирует экземпляр собрания на этапе 630, чтобы обрабатывать аудиопотоки в ответ на определение того, что аудиопотоки представляют звук из специального собрания. В некоторых вариантах осуществления, пользователи аутентифицируются до добавления аудиопотоков из их соответствующих устройств в экземпляр собрания. Аутентификация может быть основана на пользовательском подтверждении из приложения для проведения собраний, информации календаря, организационной схемы, использовании кода собрания, степени контакта/взаимосвязи с пользователями уже на собрании и на другом средстве аутентификации.
[0061] На этапе 640, аудиопотоки обрабатываются, чтобы формировать расшифровку стенограммы специального собрания. В одном варианте осуществления, сервер 135 собраний обнаруживает, когда устройство и/или ассоциированный пользователь вышло из собрания, и удаляет аудиопоток/канал из этого устройства из экземпляра собрания. Когда участник, ассоциированный с устройством, выходит из собрания, сервер 135 собраний обнаруживает отсутствие аудиосигнала, ассоциированного с устройством на собрании, и удаляет устройство из собрания. Альтернативы включают в себя то, что пользователь сигнализирует о выходе через приложение для проведения собраний, закрывает приложение для проведения собраний, обнаруживает то, что местоположение устройства более не находится около местоположения собрания, обнаруживает отсутствие соответствующего водяного аудиознака в видеопотоке из устройства, обнаруживает то, что аудиоподпись, принимаемая посредством устройства, более не совпадает с аудиоподписью других аудиопотоков устройства, или выполняет распознавание изображений на изображениях из видеосигналов, чтобы обнаруживать то, что пользователь выходит или вышел из конференц-зала или области, в которой проводится собрание. Аналогично, экземпляр собрания может в итоге выводиться в ответ на то, что остается один пользователь, или то, что остается одно пользовательское устройство.
[0062] Фиг. 7 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ 700 удаления аудиоканала пользовательского устройства и другого устройства в ответ на выход соответствующего пользователя из собрания. На этапе 710, несколько аудиосигналов в соответствующих нескольких аудиоканалах, принимаемые из группы распределенных устройств, принимающих аудио из собрания с распределенными устройствами, обрабатываются посредством экземпляра сервера собраний. Экземпляр сервера собраний используется на этапе 720 для того, чтобы обнаруживать то, что первый пользователь, ассоциированный с первым устройством группы распределенных устройств, вышел из собрания с распределенными устройствами, как пояснено выше. На этапе 730, аудиоканал первого распределенного устройства удаляется из нескольких аудиоканалов, обрабатывающихся посредством экземпляра сервера собраний, в ответ.
[0063] Фиг. 8 является блок-схемой последовательности операций, иллюстрирующей машинореализуемый способ 800 аутентификации устройства и добавления аудиопотока из устройства в аудиоканалы, обрабатываемые посредством экземпляра сервера собраний. Способ 800 начинается на этапе 810 посредством приема аудиопотоков на сервере собраний из нескольких распределенных устройств, принимающих речь от нескольких пользователей в ходе собрания. Принимаемые аудиопотоки обрабатываются на этапе 820 через экземпляр собрания, выполняющийся на сервере собраний, чтобы формировать расшифровку стенограммы на основе речи, включенной в себя в аудиопотоки.
[0064] На этапе 830 информация принимается на сервере собраний из первого дополнительного распределенного устройства, ассоциированного с первым дополнительным пользователем, причем информация соответствует собранию между пользователями. Информация может соответствовать запросу, чтобы добавлять устройство пользователя, либо может представлять собой подразумеваемый запрос с учетом того факта, что аудиопоток из такого устройства включает в себя водяной знак или аудиоподпись.
[0065] На этапе 840, первое дополнительное распределенное устройство или ассоциированный пользователь аутентифицируется или иным образом авторизуется на то, чтобы присоединяться к собранию. Участник может быть авторизован на то, чтобы присоединяться к собранию, на основе голосового цифрового отпечатка, подтверждения организатора собрания, использования кода собрания и/или нового кода, обнаруженного местоположения устройства участника, сравнения идентификатора устройства и/или ассоциированного идентификатора пользователя с авторизованным списком, проверки членов организации, использования флага закрытого собрания, чтобы требовать подтверждения посредством организатора, либо комбинаций одного или более из вышеуказанного. Следует отметить, что способ 800 также может применяться к первым двум устройствам, которые должны присоединяться к собранию, и также может применяться к устройствам, которые непосредственно не ассоциированы с пользователем, таким как тип устройства в виде помощника для проведения собраний в конференц-зале или видеокамера, имеющая поле зрения собрания.
[0066] В ответ на аутентификацию дополнительного распределенного устройства или ассоциированного пользователя, первое дополнительное распределенное устройство имеет добавленный аудиопоток в экземпляр собрания на этапе 850.
[0067] В некоторых вариантах осуществления, удаленные участники могут соединяться с собранием через платформу связи, к примеру, Microsoft Skype или Teams, телефонный коммутируемый доступ либо любое другое приложение для проведения телеконференций. Если используется платформа для удаленной конференц-связи, такая как Skype, к собранию можно присоединяться посредством перехода по ссылке, отправленной заранее. Для коммутируемого доступа, может совместно использоваться уникальный телефонный номер или код доступа, к примеру, код собрания. После того как удаленный аудиоканал соединяется с сервером для собрания, он обрабатывается способом, аналогичном аудиопотокам из области собрания. Идентификатор говорящего известен на основе процесса входа в систему. Аудиопоток может быть предназначен для одного пользователя/говорящего, что означает то, что разделение речи не требуется, если спикерфон не используется с несколькими удаленными пользователями. Аудио, воспроизводимое посредством спикерфона и обнаруживаемое посредством близлежащих распределенных устройств на собрании, может подавляться из аудиопотоков таких близлежащих распределенных устройств.
[0068] Фиг. 9 является высокоуровневой блок-схемой системы 900 для формирования расшифровки стенограммы для собрания с несколькими пользователями. Пользователи могут иметь быть ассоциированное (распределенное) устройство 910, 912, 914, которое оснащается микрофонами, чтобы захватывать аудио, включающее в себя речь различных пользователей на собрании, и предоставлять захваченное аудио в качестве аудиосигналов на сервер собраний, который включает в себя, по меньшей мере, транскрайбер 925 собраний, через аудиоканалы 916, 918 и 920, соответственно. Различные устройства могут иметь немного отличающиеся тактовые циклы и различные величины задержки при обработке. Помимо этого, каждый канал для соединения между устройством и сервером может иметь различное время задержки. Таким образом, аудиосигналы из аудиоканалов 916, 918 и 920 не обязательно синхронизируются.
[0069] Транскрайбер 925 собраний включает в себя модуль или функцию синхронизации в дополнение к модулю или функции распознавания речи. Аудиосигналы из аудиоканалов 916, 918 и 920 сначала синхронизируются и затем распознаются, приводя к текстам, ассоциированным с каждым из каналов согласно одному варианту осуществления. Выводы распознавания затем сливаются (посредством слияния 930) или иным образом обрабатываются, чтобы формировать расшифровку 940 стенограммы. Расшифровка 940 стенограммы затем может предоставляться обратно пользователям. В других вариантах осуществления, аудиосигналы из аудиоканалов 916, 918 и 920 сливаются перед распознаванием речи. Аудиосигнал, полученный после слияния, распознается, приводя к одной версии текста. В некоторых вариантах осуществления, расшифровка стенограммы может содержать очень незначительную задержку.
[0070] В различных вариантах осуществления, преобразование аудиосигналов в текст, которое используется в сочетании с идентификацией говорящих и формированием расшифровки стенограммы, которая диаризуется, чтобы идентифицировать говорящих, обеспечивается посредством сервера 135 собраний. Функции, выполняемые посредством сервера 135 собраний, включают в себя функции синхронизации, распознавания, слияния и диаризации. Хотя такие функции показаны в конкретном порядке на фиг. 9, в различных вариантах осуществления, функции могут выполняться в варьирующихся порядках. Например, слияние может выполняться до распознавания и также может выполняться в различных других точках, как описано ниже.
[0071] Фиг. 10 является подробной блок-схемой последовательности операций способа, иллюстрирующей серверную обработку собраний на предмет информации, в общем, в способе 1000, включающей в себя аудиопотоки из распределенных устройств. Несколько потоков 1005 аудиоданных принимаются из нескольких распределенных устройств. Потоки включают в себя M независимых последовательностей пакетов данных. Каждый пакет m-ой последовательности содержит сегмент оцифрованного аудиосигнала, захваченного посредством m-ого устройства. Принимаемые пакеты распаковываются, и данные из пакетов переформируются, чтобы создавать многоканальный сигнал. Многоканальный сигнал может представляться как: {[x0(t)..., xM-1(t)]; t=0, 1, ...,}.
[0072] Оцифрованные сигналы различных каналов в многоканальном сигнале, вероятно, не синхронизируются, поскольку многие распределенные устройства подвергаются разностям обработки цифровых сигналов согласно реализованным на устройстве разностям времени задержки программного обеспечения и подвергаются разностям скорости передачи сигналов. Все эти разности могут складываться, затрудняя консолидацию информации из различных устройств, чтобы создавать точную расшифровку стенограммы. Модуль 1015 синхронизации потоков принимает многоканальный сигнал и выбирает один из каналов в качестве опорного канала. Без потери общности, первый канал может использоваться в качестве опорного канала. Для опорного канала вывод является идентичным вводу (т.е. y0(t)=x0(t)). Для m-ого канала (0<m<M), величина неправильного совмещения между xm(t) и x0(t) оценивается и корректируется, чтобы формировать ym(t).
[0073] Степень неправильного совмещения может оцениваться посредством вычисления коэффициентов нормализованной взаимной корреляции между двумя сигналами с использованием скользящего окна для неопорного канального сигнала и отбора запаздывания, которое предоставляет максимальное значение коэффициента. Это может быть реализовано посредством использования буфера, чтобы временно сохранять сегменты акустического сигнала, в которых анализ взаимной корреляции выполняется отдельно между опорным каналом и каждым из других каналов. Вместо нормализованной взаимной корреляции, может использоваться любая функция количественных показателей, которая измеряет степень совмещения между двумя сигналами.
[0074] В одном варианте осуществления, взаимосвязь между смежными циклами синхронизации принимается во внимание. Неправильное совмещение вызывается посредством двух факторов: зависимое от устройств/каналов смещение и зависимый от устройств уход синхросигнала. Даже когда два устройства захватывают акустическое событие одновременно, сигналы, захваченные посредством отдельных устройств, могут поступать на сервер собраний в различные моменты времени вследствие разностей обработки цифровых сигналов, реализованных на устройстве разностей времени задержки программного обеспечения, разностей скорости передачи сигналов и т.д. Он представляет собой зависимое от устройств/каналов смещение. Кроме того, различные устройства неизбежно имеют немного отличающиеся синхросигналы вследствие изменчивости производственного процесса. Следовательно, даже если два устройства заявляют поддержку, например, частоты дискретизации в 16 кГц, сигналы, записываемые посредством этих устройств, не совмещаются на 100%, и величина рассогласования линейно растет с течением времени. Означенное представляет собой зависимый от устройств уход синхросигнала. Зависимое от устройств/каналов смещение и зависимый от устройств уход синхросигнала обозначаются как S и D. Разность времен в k-ом цикле синхронизации представляется как S+kD. Таким образом, оценки S и D обеспечивают надежную оценку степени неправильного совмещения, S+kD.
[0075] Величина неправильного совмещения может корректироваться посредством периодического обнаружения неправильного совмещения с использованием вышеописанной взаимной корреляции и коррекции такого обнаруженного неправильного совмещения. Помимо этого, чтобы уменьшать величину измеренного неправильного совмещения, (зависимое от устройств/каналов) глобальное смещение и зависимый от устройств уход синхросигнала вычисляется, чтобы оценивать степень неправильного совмещения. Глобальное смещение может использоваться для того, чтобы корректировать глобальное неправильное совмещение до измерения и коррекции неправильного совмещения посредством взаимной корреляции. Глобальное смещение может определяться в качестве среднего измеренного неправильного совмещения во времени и вероятно результата ухода синхросигнала в устройстве. Степень неправильного совмещения в силу этого оценивается и корректируется посредством простого учета разности из опорного канала в соответствии с одним вариантом осуществления. Синхронизация потоков может выполняться с варьирующимися интервалами, к примеру, каждые 30 секунд. Другие интервалы меньше или больше 30 секунд могут использоваться в дополнительных вариантах осуществления, поскольку сетевые задержки могут изменяться.
[0076] Модуль 1015 синхронизации потоков предоставляет многоканальный синхронизированный сигнал {[y0(t)..., yM-1(t)]; t=0, 1, ...,} в модуль 1020 формирования диаграммы направленности. Модуль 1020 формирования диаграммы направленности функционирует с возможностью разделять перекрывающуюся речь. Перекрывающаяся речь возникает, когда два человека на собрании говорят одновременно. До распознавания речи и преобразования речи в текст, речь сначала разделяется на отдельные каналы. Таким образом, с M-канальным вводом, вывод составляет N каналов и называется "N-канальным сигналом со сформированной диаграммой направленности", {[z0(t)..., zN-1(t)]; t=0, 1, ...,}. Модуль 1015 синхронизации потоков выступает в качестве первой точки слияния, в которой несколько выводов формируются, чтобы сохранять разнесение входной информации. Если речь не перекрывается, такое слияние является необязательным.
[0077] Фиг. 11 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ 1100 синхронизации нескольких аудиоканалов, принимаемых из нескольких распределенных устройств во время интеллектуального собрания. На этапе 1110, аудиосигналы, представляющие передаваемую в потоковом режиме речь, принимаются из нескольких распределенных устройств, чтобы формировать несколько аудиоканалов. Выбранный один из аудиоканалов обозначается на этапе 1120 в качестве опорного канала.
[0078] После того как опорный канал обозначается, следующие этапы выполняются для каждого из оставшихся аудиоканалов. На этапе 1130, определяется разница во времени от опорного канала. Время каждого оставшегося аудиоканала корректируется посредством совмещения оставшихся аудиоканалов с опорным каналом в качестве функции соответствующей разницы во времени на этапе 1140. Это может осуществляться посредством простого отбрасывания излишних выборок, добавления в конец нулей или с использованием технологий повторной дискретизации.
[0079] Способ 1100 может осуществляться периодически, чтобы корректировать синхронизацию оставшихся аудиоканалов, к примеру, каждые 30 секунд. В одном варианте осуществления, способ 1100 включает в себя дополнительные этапы, чтобы корректировать глобальное смещение, вызываемое, по меньшей мере, посредством различных синхросигналов в распределенных устройствах. На этапе 1150, глобальное смещение определяется для каждого из оставшихся аудиоканалов. Оставшиеся аудиоканалы затем корректируются на этапе 1160 посредством глобального смещения каждого соответствующего оставшегося аудиоканала до коррекции каждого оставшегося аудиоканала для определенной разницы во времени.
[0080] Акустическое формирование диаграммы направленности или просто формирование диаграммы направленности представляет собой технологию, чтобы улучшать целевую речь посредством уменьшения нежелательных звуков, таких как фоновый шум из многоканальных аудиосигналов. Формирование диаграммы направленности может повышать точность последующей обработки речи, такой как распознавание речи и диаризация говорящих.
[0081] Для интеллектуального собрания с аудио, передаваемым в потоковом режиме из нескольких распределенных устройств, точные позиции которых относительно друг друга неизвестны, традиционные алгоритмы формирования диаграммы направленности, такие как формирование диаграммы направленности на основе задержки и суммирования, супернаправляющее формирование диаграммы направленности и дифференциальное формирование диаграммы направленности, не работают. Такие алгоритмы основываются на априорных знаниях относительно компоновки микрофонных устройств, которая не доступна для распределенных устройств.
[0082] В одном варианте осуществления, подход, называемый "агностическим к геометрии формированием диаграммы направленности" или "формированием диаграммы направленности вслепую", используется для того, чтобы выполнять формирование диаграммы направленности для распределенных записывающих устройств. Учитывая M микрофонных устройств, соответствующих M аудиоканалов, M-мерные пространственные ковариационные матрицы речи и фонового шума непосредственно оцениваются. Матрицы захватывают пространственную статистику речи и шума, соответственно. Чтобы формировать акустический луч, M-мерные пространственные ковариационные матрицы инвертируются.
[0083] Недостаток подхода к формированию диаграммы направленности, будь это традиционное формирование диаграммы направленности на основе геометрии или формирование диаграммы направленности вслепую, состоит в том, что он типично сокращает число информационных потоков от M до одного, что означает то, что последующие модули не могут использовать преимущество акустического разнесения, обеспеченного посредством пространственно распределенных устройств. Чтобы формировать M сигналов со сформированной диаграммой направленности и поддерживать акустическое разнесение, может предприниматься подход с исключением по одному. При этом подходе, первый выходной сигнал формируется посредством выполнения формирования диаграммы направленности с помощью микрофона 2-M. Второй выходной сигнал формируется с помощью микрофона 1-M и 3-M. Это может повторяться M раз таким образом, что M различных выходных сигналов получаются. Для каждого формирования диаграммы направленности, (M-1)-мерные пространственные ковариационные матрицы вычисляются и инвертируются, что требует большого объема вычислений. К счастью, вычислительные затраты могут значительно уменьшаться посредством извлечения всех (M-1)-мерных обратных матриц из исходных M-мерных обратных матриц.
[0084] В некоторых вариантах осуществления, модуль 1020 формирования диаграммы направленности может быть выполнен с возможностью разделять перекрывающиеся речевые сигнал различных пользователей. Это может приводить к повышению точности распознавания речи и атрибуции говорящих. В одном варианте осуществления, разделение слитной речи для распределенной микрофонной записывающей системы выполняется через нейронную сеть, которая обучается с использованием инвариантного к перестановкам обучения или его разновидности, такой как глубокая кластеризация или аттракторная сеть. Чтобы потенциально экономить на вычислении, обнаружение перекрытия может использоваться для того, чтобы определять то, должна или нет нейронная сеть для разделения речи выполняться для каждого периода времени. Если перекрывающаяся речь не обнаруживается в течение выбранного периода времени, нейронная сеть не выполняется, что экономит ресурсов обработки и обеспечивает более быстрое формирование расшифровки стенограммы в реальном времени.
[0085] Нейронная сетевая модель для разделения речи выполняется для того, чтобы выполнять разделение слитной речи для распределенной микрофонной записывающей системы, в которой число входных микрофонов может быть произвольным и варьироваться в течение времени. Модель выводит два непрерывных потока речи. Когда имеется один активный говорящий, один из выводимых потоков должен находиться в режиме молчания, тогда как, когда имеется перекрывающаяся речь между двумя говорящими, каждый говорящий должен занимать разный выходной поток.
[0086] В примерных вариантах осуществления, нейронная сетевая модель для разделения речи содержит три субмодуля: локальный модуль наблюдения, глобальный модуль реферирования и модуль восстановления масок. Многоканальный ввод обрабатывается посредством этих трех субмодулей последовательно. Во-первых, идентичный локальный модуль наблюдения применяется к каждому входному микрофону. Локальный модуль наблюдения содержит набор многоярусных слоев привлечения внимания, который преобразует каждый микрофонный ввод в высокомерное представление, в котором каждый канал должен перекрестно сравнивать и извлекать информацию из всех других каналов. Реализуются два различных типа внимания, которые представляют собой самовнимание и внимание с прямой связью.
[0087] Затем, глобальный модуль реферирования применяется, чтобы реферировать информацию из каждого модуля наблюдения, чтобы формировать глобальное представление через другой входной канал. Предусмотрено два варианта для глобального модуля реферирования: объединение в пул по среднему и инвариантный к перестановкам алгоритм сортировки, в которых представление каждого канала сравнивается с инвариантными к перестановкам потерями, чтобы совмещать их локальную перестановку и глобальную перестановку. Когда отсутствует слой реферирования, сеть уменьшается с сетью для поканального разделения речи, при котором каждый канал имеет собственное разделение (т.е. отсутствует глобальное согласование разделения между каналами).
[0088] В завершение, модуль восстановления масок сортирует два вывода маски одновременно в течение любого произвольного момента времени. Модуль восстановления масок содержит стек сети долгого кратковременного запоминающего устройства и формирует конечный двухканальный вывод из реферирования в каждый момент времени.
[0089] После получения двухканального вывода из модуля восстановления масок, целевая функция инвариантного к перестановкам обучения применяется между восстановленной маской и чистой ссылкой, при этом евклидово расстояние каждой пары перестановки вывода и чистой ссылки измеряется сначала, и затем минимальное расстояние и соответствующая перестановка выбираются, чтобы обновлять нейронную сеть.
[0090] Сеть обучается с моделированными многоканальными данными, причем число входных каналов случайно выбирается для каждой выборки (например, из 2 до 10 каналов). Набор речевых данных Libri применяется в качестве исходных данных на моделировании. В каждом моделированном предложении сначала выбираются два речевых фрагмента от двух случайных пользователей/говорящих. Затем каждый речевой фрагмент обрабатывается с моделированием акустики помещений с импульсными откликами в помещении из способа на основе формирования изображений со случайным помещением и окружающим местоположением.
[0091] Одно варьирование разделения речи представляет собой обнаружение перекрытия речи, при котором задача уменьшается, чтобы просто обнаруживать область перекрытия в записанной речи. Алгоритм работает аналогично, когда сеть принимает N каналов в качестве ввода и непрерывно выводит два канала в качестве вывода. В детекторе перекрытия сеть не выводит маски. Вместо этого, сеть выводит две одномерные индикаторные функции, при этом 1 означает, что имеется один активный говорящий в этом канале, и 0 означает молчание. Следовательно, когда имеется два активных говорящих, два потока вывода должны иметь 1 в качестве вывода. Когда имеется один активный говорящий, один произвольный канал должен иметь 1 в качестве вывода, а другой должен иметь 0. Сеть также обучается с целью инвариантного к перестановкам обучения, между выводом сети (т.е. индикаторной функцией) и опорным индикатором.
[0092] Фиг. 12 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ разделения перекрывающейся речи на интеллектуальном собрании распределенных устройств. На этапе 1210, аудиосигналы, представляющие речь, принимаются через несколько аудиоканалов, соответствующих потоковому аудио, передаваемому из соответствия несколько распределенных устройств.
[0093] Разделение слитной речи выполняется на этапе 1220 для принимаемых аудиосигналов, чтобы разделять речь от различных говорящих, говорящих одновременно, на отдельные аудиоканалы. В одном варианте осуществления, разделение речи на этапе 1220 выполняется посредством модели обученной нейронной сети. Нейронная сетевая модель обучается с использованием инвариантного к перестановкам обучения или его разновидности.
[0094] На этапе 1230, разделенные аудиоканалы предоставляются для распознавания речи и формирования расшифровки стенограммы. Этап 1230, в одном варианте осуществления, предусматривает фиксированное число отдельных выходных каналов. Поскольку может быть варьирующееся число микрофонных вводов, и число выводов является фиксированным заранее, могут возникать случаи, в которых ограниченное число аудиоканалов может размещаться, поскольку для каждого аудиоканала с несколькими перекрывающимися говорящими, каждый говорящий приводит к отдельному аудиоканалу. Таким образом, если число выходных аудиоканалов ограничено, не все каналы могут иметь разделенных говорящих.
[0095] Различные выводы N модуля 1020 формирования диаграммы направленности на фиг. 10 предоставляются в N акустических моделей 1025 и 1030, которые формируют последовательность вероятностей постериорных вариантов сенонов. Такие модели известны и типично основаны на нейронных сетях. Использование акустической модели для каждого из нескольких аудиоканалов из распределенных устройств и/или выводов модуля формирования диаграммы направленности обеспечивает N количественных показателей для каждого сенона.
[0096] Количественные показатели, включающие в себя количественные показатели для сенонов, предоставляются в модуль 1035 слияния количественных показателей акустических моделей. Аудио отдельных входных каналов может обрабатываться традиционно, чтобы обеспечивать последовательность сенонов и их вероятностей постериорных вариантов. Результаты комбинируются с использованием модуля 1035 слияния количественных показателей моделей, до того, как применять результат в несколько декодеров 1040, 1045 для распознавания речи (SR). Модуль 1035 слияния количественных показателей работает в качестве второй точки слияния, которая комбинирует несколько источников информации и в то же время формирует несколько выводов, чтобы сохранять разнесение входной информации. Двухэтапный процесс предусматривает две различных нейронных сети (или классификатора): ванильная акустическая модель и новая, более целевая акустическая модель. Вывод представляет собой последовательность 1x число сенонов. Следует отметить, что модуль 1035 слияния количественных показателей использует вывод последнего слоя акустической модели (нейронной сети) в качестве ввода. В дополнительных вариантах осуществления, модуль 1035 слияния количественных показателей может использовать вывод любого слоя перед последним. Размер ввода может отличаться от размера вывода.
[0097] Последовательности сенонов из модуля 1035 слияния количественных показателей акустических моделей предоставляются в SR-декодеры 1040 и 1045, каждый из которых использует стандартную обработку распознавания речи, чтобы предоставлять список из n лучших вариантов слов для каждого сегмента сенонов. Начальное время и длительность предоставляются для каждого слова. Сегментация может выполняться на основе обнаружения голосовой активности, обнаружения изменения говорящего, фиксированного интервала или некоторого другого подходящего способа. Повторная количественная оценка может выполняться посредством использования нейронной сетевой языковой модели (NNLM) для вывода декодера, чтобы формировать лучшие списки из n лучших вариантов гипотез относительно слов.
[0098] Несколько модулей 1050, 1055 диаризации говорящих принимают выводы модулей 1040, 1045 SR-декодера в качестве списка из N лучших вариантов для каждого сегмента. В одной реализации, только главная гипотеза относительно последовательности слов используется. Первый этап извлекает встраивание говорящего, к примеру, d-векторы (активации скрытых слоев глубокой нейронной сети для верификации говорящих), с фиксированными интервалами. Второй этап факторизует последовательность слов на гомогенные относительно говорящих субсегменты. Это может выполняться с разновидностями агломерационной кластеризации, BIC (байесовского информационного критерия) или других способов посредством использования признаков встраивания. Третий этап назначает идентификатор говорящего каждому из субсегментов, полученных выше, посредством сравнения близости (например, близости косинусов, отрицательного евклидова расстояния) встраиваний говорящего субсегмента и указанных элементов каждого возможного варианта говорящего. Результирующий вывод является назначением метки говорящего каждому распознанному слову главной SR-гипотезы.
[0099] Модуль 1060 комбинирования гипотез принимает в качестве ввода, списки из n лучших вариантов из N модулей 1040, 1045 SR-декодера (например, аудиоканалы со сформированной диаграммой направленности), и вывод с распознаванием говорящих из N источников, к примеру, разделенные аудиоканалы со сформированной диаграммой направленности. Модуль 1060 комбинирования гипотез обрабатывает количественные показатели из n лучших вариантов из каждого канала путем их масштабирования и нормализации и вычисления за счет этого вероятностей постериорных вариантов на уровне речевых фрагментов. Гипотезы из n лучших вариантов совмещаются в сети путаницы слов. Посредством добавления постериорных вариантов на уровне речевых фрагментов, связанных с гипотезой данного слова, получаются вероятности постериорных вариантов на уровне слов. Выводы с распознаванием говорящих из каждого канала форматируются в качестве сетей путаницы с переменными метками говорящих и слов. Метки слов исходят из гипотез распознавания из 1 наилучшего варианта, тогда как метки говорящих представляют модель говорящих из 1 наилучшего варианта или из n лучших вариантов, совпадающую в речевые сегменты. Вероятности постериорных вариантов для гипотез относительно говорящих представляют нормализованные вероятности модели говорящих. Последующее поколение на гипотезах относительно слов масштабируется вниз на два порядка величины, с тем чтобы не затрагивать конечное распознавание слов, в силу этого затрагивая только надлежащее совмещение меток слов и говорящих. Сети путаницы, такие полученные из каждого канала, усекаются и/или конкатенируются, при необходимости, с тем чтобы охватывать идентичное временное окно, как предписывается посредством ограничений онлайн-обработки. Вывод содержит кодирование сети путаницы (CN) обеих гипотез относительно слов и говорящих и их вероятности постериорных вариантов.
[00100] Сети путаницы слов и говорящих совмещаются согласно критерию минимального редакционного расстояния, а также штрафу за временные расхождения между совмещенными узлами. Это эффективно объединяет гипотезы относительно говорящих и слов в единую сеть, суммируя постериорные варианты согласования с метками. При желании главные гипотезы относительно говорящих и слов прочитываются из комбинированной CN посредством выбора метки с наивысшим постериорным вариантом в каждой позиции. Сети путаницы слов могут компоноваться из решеток слова вместо списков из n лучших вариантов, в зависимости от того, что выводит речевой декодер.
[00101] Вывод из модуля 1060 комбинирования представляет собой результат третьего слияния, называемого "поздним слиянием", чтобы формировать текст и идентификацию говорящих для формирования расшифровки стенограммы с атрибуцией говорящих собрания. Следует отметить, что первые два этапа слияния в модуле 1020 формирования диаграммы направленности и модуле 1035 слияния количественных показателей акустических моделей, соответственно, являются необязательными в различных вариантах осуществления. В некоторых вариантах осуществления, один или более аудиоканалов могут предоставляться непосредственно в модуль 1065 количественной оценки акустических моделей, без формирования диаграммы направленности или разделения речи. Распознавание речи затем выполняется для одного или более аудиоканалов через SR-декодер 1070, с последующим модулем 1075 диаризации говорящих, с выводом, предоставленным непосредственно в модуль 1060 комбинирования.
[00102] Аудиопотоки могут сливаться рано, после синхронизации цифровых аудиопотоков, посредством агностического к геометрии формирования диаграммы направленности или разделения слитной речи. Несколько выводов могут формироваться, чтобы сохранять разнесение входной информации. Позднее слияние может выполняться на уровне количественных показателей акустической модели и/или на уровне текста/уровне диаризации, чтобы использовать информацию говорящих и разнообразные модельные гипотезы. В одном варианте осуществления, позднее слияние по слову или двум выполняется посредством использования фиксированного временного окна. Временное окно, в одном варианте осуществления, соответствует явновыраженным аудиособытиям, и может быть фиксированным, например, как две секунды. Такое временное окно выбирается довольно коротким, с тем чтобы обеспечивать предоставление расшифровок стенограммы в реальном времени (или почти в реальном времени) с низкой задержкой.
[00103] В одном варианте осуществления, расшифровки стенограммы в реальном времени формируются на основе коротких последовательностей слов. Позднее слияние данных выполняется посредством распознавания речи для нескольких аудиоканалов, обрабатывающихся параллельно, чтобы формировать фразы. Фразы, извлекаемые из нескольких аудиоканалов, комбинируются в реальном времени. В одном варианте осуществления, приблизительно две секунды речи комбинируются в модуле 1060 комбинирования гипотез. Таким образом, аудиопотоки обрабатываются в качестве, они принимаются. Неперекрывающееся скользящее окно двух секунд используется для того, чтобы обрабатывать аудиопотоки, снижая время задержки системы проведения собраний 135 формирования расшифровки стенограммы почти до нуля.
[00104] Отдельные декодеры для распознавания речи непрерывно выводят некоторые результаты, и на основе модуля 1060 комбинирования гипотез, результаты сразу обрабатываются. Специальное условие указывается для совмещения отдельных систем в модуле 1015 синхронизации потоков, иначе конечные результаты могут содержать несколько экземпляров идентичных событий (вследствие неправильного совмещения). Этап постобработки удаляет любые копии, которые могут существовать независимо от совмещения вывода сигналов и/или распознавания речи. Совмещение может выполняться на уровне слов или на уровне выборок сигналов. Также следует отметить, что различные версии аудио принимаются посредством декодеров для распознавания речи. Каждый SR-декодер может прослушивать что-либо свое. Посредством комбинирования SR-результатов (позднее слияние) с низкой задержкой формируется высокоточная расшифровка стенограммы. Каждый SR выводит слово или два с доверительным уровнем. Время, к примеру, две секунды, является достаточно большим для того, чтобы получать некоторый явновыраженный вывод: другими словами, вывод, имеющий слово или два, который может распознаваться с некоторой уверенностью. Обнаружено, что фиксированное окно времени, к примеру, две секунды, работает лучше. Если время является слишком коротким, отсутствует явновыраженное событие, и если время является слишком большим, время задержки становится слишком большим, и расшифровка стенограммы задерживается, что уменьшает полезность расшифровки стенограммы в ходе собрания.
[00105] Другая версия этого подхода состоит в том, чтобы ожидать моментов времени в аудиопотоке, в которые все потоки (1) либо не содержат речь с высоким доверием, либо (2) имеют одну гипотезу относительно слова с высоким доверием. В этих местах, пространство гипотез может сжиматься до одной гипотезы, что позволяет выполнять комбинацию без потерь точности как результат некорректной сегментации на слова.
[00106] Расшифровка стенограммы предоставляется для одного или более участников собрания на основе вывода, указываемого в 1080. Одна расшифровка стенограммы собрания предоставляется на основе вывода системы проведения собраний. Расшифровка стенограммы состоит из отдельных речевых фрагментов и ассоциированного мультимедиа, к примеру, слайды или фотографии чертежей. Каждому речевому фрагменту назначается универсальная временная метка, атрибутированный говорящий, ассоциированный текст и/или ассоциированный аудиосегмент, при этом аудио извлекается из синхронизированных входных потоков из всех участвующих клиентов.
[00107] Дополнительное мультимедиа или контент, такой как изображения, заметки и другие абстрактные объекты, может быть ассоциирован с расшифровкой стенограммы, встроенной через временную метку (например, кинокадр электронной доски захватывается и выгружается во время t), либо со всем собранием без конкретной временной метки (например, файл выгружен после собрания и ассоциирован с этим экземпляром собрания). Все присутствующие могут иметь доступ к собранию и ассоциированным данным. Специальные собрания могут просматриваться и модифицироваться владельцем собрания, всеми присутствующими либо любым человеком в зависимости от разрешений, заданных посредством объекта, который создает собрание. Дополнительные услуги, к примеру, реферирование собрания, идентификация намеченных мероприятий и тематическое моделирование, могут предоставляться с использованием расшифровки стенограммы и других ассоциированных данных собрания.
[00108] Фиг. 13 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ 1300 слияния аудиопотоков в нескольких выбранных точках во время обработки. Аудиопотоки записываются в ходе собрания посредством множества распределенных устройств. Способ 1300 осуществляется посредством одного или более процессоров, выполняющих этапы. Этап 1310 выполняет распознавание речи для каждого аудиопотока посредством соответствующей системы распознавания речи, выполняющейся на одном или более процессоров с возможностью формировать вероятности постериорных вариантов на уровне речевых фрагментов в качестве гипотез для каждого аудиопотока. Гипотезы совмещаются и форматируются на этапе 1320 в качестве сетей путаницы слов с ассоциированными вероятностями постериорных вариантов на уровне слов. Этап 1330 выполняет распознавание говорящих для каждого аудиопотока посредством выполнения алгоритма идентификации говорящих, который формирует поток гипотез относительно слов с атрибуцией говорящих. Гипотезы относительно говорящих форматируются с ассоциированными постериорными вероятностями постериорных вариантов меток говорящих и гипотезами с атрибуцией говорящих для каждого аудиопотока в качестве сети путаницы на этапе 1340. Этап 1350 совмещает сети путаницы слов и говорящих из всех аудиопотоков между собой, чтобы объединять вероятности постериорных вариантов и совмещать метки слов и говорящих. Наилучшая расшифровка стенограммы по словам с атрибуцией говорящих создается на этапе 1360 посредством прочитывания последовательности меток слов и говорящих с наибольшими вероятностями постериорных вариантов.
[00109] В одном варианте осуществления, специальная аппроксимированная версия получается, когда только одна гипотеза относительно слова из каждого потока формируется, возможно даже без вероятностей постериорных вариантов, и при этом используется простое голосование для всех потоков.
[00110] Этапы способа 1300 могут выполняться для последовательных временных окон, применяемых к аудиопотокам таким образом, что обработка выполняется инкрементно, с тем чтобы предоставлять формирование гипотез относительно распознавания слов с атрибуцией говорящих в реальном времени. Входные гипотезы усекаются во времени до общего временного окна, применяемого ко всем аудиопотокам на основе меток времени, ассоциированных с гипотезами относительно слов, сформированными для каждого аудиопотока.
[00111] Входные потоки гипотез относительно говорящих и/или слов могут исходить из множественной частичной комбинации входных аудиопотоков через слияние K из N, где K<N, аудиопотоков. Альтернативно, входные потоки гипотез относительно говорящих и/или слов исходят не из различных аудиопотоков, а из множественной частичной комбинации акустических моделей, применяемых к K из N аудиопотоков, которые в свою очередь могут получаться в результате необработанных аудиосигналов или слияния аудиосигналов.
[00112] В еще одном дополнительном варианте осуществления, входные гипотезы усекаются во времени до общего временного окна, применяемого ко всем аудиопотокам на основе меток времени, ассоциированных с гипотезами относительно слов, сформированными для каждого аудиопотока. Комбинация K из необработанных аудиосигналов N или слияния аудиосигналов может быть основана на критериях качества звучания и/или на основе относительной позиции говорящих относительно распределенных устройств.
[00113] В одном варианте осуществления, входные потоки гипотез относительно говорящих и/или слов исходят из множественной частичной комбинации входных аудиопотоков через слияние K из N аудиопотоков, где K<N. Комбинация K из N выводов акустической модели может быть основана на критериях качества звучания входных сигналов и/или на основе относительной позиции говорящих относительно распределенных устройств. Альтернативно, входные потоки гипотез относительно говорящих и/или слов могут исходить из множественных частичных комбинаций акустических моделей, применяемых к K из N аудиопотоков, где K<N, что в свою очередь получается в результате необработанных аудиопотоков или слияния аудиопотоков. В еще одном дополнительном варианте осуществления, вывод нескольких акустических моделей может применяться к K из N аудиопотоков, где K<N, что в свою очередь получается в результате необработанных аудиопотоков или слияния аудиопотоков, которые комбинируются в качестве ввода в M декодеров для распознавания речи.
[00114] Фиг. 14A и 14B иллюстрируют примерное устройство 1410 захвата объемного окружения. В одном варианте осуществления, устройство 1410 захвата объемного окружения имеет цилиндрическую фору с камерой 1411 типа "рыбий глаз" наверху и лицевой стороной вверх относительно устройства 1410. Массив 1413 микрофонов соединяется с устройством 1410 ниже камеры 1411 и размещается вокруг цилиндра, чтобы захватывать аудио на 360°. Следует отметить, что устройство на фиг. 14A не может чертиться в масштабе. Чтобы захватывать оптимальный обзор на 360° (например, видео или неподвижные изображения), может быть желательным, если камера типа "рыбий глаз" находится близко к поверхности 1450 пола или стола. В варианте осуществления, устройство может быть коротким и компактным, чтобы исключать мертвые зоны ниже камеры 1411. В варианте осуществления, камера типа "рыбий глаз" может быть размещена в непосредственной близости к массиву 1413 микрофонов.
[00115] Устройство 1410 захвата может использоваться с распределенными устройствами при захвате аудио и видео из собрания с распределенными устройствами. Устройство 1410 может непосредственно представлять собой одно из распределенных устройств. Идентификация пользователей, ассоциированных с речью, может выполняться только посредством устройства 1410 захвата в одном варианте осуществления, или информационные потоки, собранные из устройства 1410 захвата, могут использоваться вместе с информационными потоками, собранными из других распределенных устройств, чтобы формировать расшифровки стенограммы с атрибуцией говорящих в различных вариантах осуществления.
[00116] В примере, проиллюстрированном на фиг. 14B, семь микрофонов 1423A-G включаются в массив 1413 микрофонов. Как показано, шесть 1423A-F микрофонов размещаются вокруг устройства в плоскости и являются в той или иной степени равноотстоящим от центра устройства, и седьмой микрофон 1423G размещается в центре. Следует понимать, что устройство может быть изготовлено из аудиопроницаемого материала, такого как светлая ткань, решетчатый или сетчатый материал и что микрофоны 1423 не блокируются посредством камеры 1421 типа "рыбий глаз" или других конструктивных частей устройства 1420, так что звук не загораживается.
[00117] В одном варианте осуществления, камера типа "рыбий глаз" может находиться приблизительно в 30 см от основания устройства 1420, и массив 1413 микрофонов может прикрепляться приблизительно в 15 см над основанием 1430. При работе, устройство 1420 может стоять на или прикрепляться к полу или к столу 1450 в окружении. В качестве устройства 1420 размещается ближе к столу, горизонтальное поле зрения (HFOV) на 360° может включать в себя более окружения. Камера 1421 типа "рыбий глаз" типично прикрепляется к устройству 1420 лицевой стороной вверх, так что потолок может находиться в поле зрения. Следует понимать, что другие формы, размеры или конфигурации устройства 1420 и размещение камеры 1421 типа "рыбий глаз" и массива микрофонов 1423 могут реализовываться с некоторой адаптацией, чтобы предоставлять и аналогичные и варьирующиеся результаты.
[00118] В одном варианте осуществления, акустические параметры для аудиозахвата варьируются в зависимости от технических требований микрофонов. Пример акустических технических требований для варианта осуществления показывается ниже в таблице 1. В варианте осуществления, акустические параметры применяются ко всем аудиоподсистеме (например, к захваченным данным импульсно-кодовой модуляции (PCM)), а не только к микрофонам. Захваченное аудио может формировать соответствующую точность распознавания речи для использования в AI-приложении. Специалисты в данной области техники, с преимуществом настоящего раскрытия сущности, должны принимать во внимание, что различные акустические параметры могут использоваться для того, чтобы достигать точности распознавания речи, и что примерные параметры в таблице 1 приводятся в качестве иллюстрации.
≤5% (SPL на 115 дБ)
Максимальный SPL≥160 дБ
Максимальный шок≥10,000 г
Диапазон температур: от -40°C до +80°C
Таблица 1. Примерные акустические параметры
[00119] Фиг. 15 иллюстрирует примерное размещение массива 1523 микрофонов, согласно одному варианту осуществления. В варианте осуществления, устройство включает в себя семь микрофонов, размещенных в идентичную плоскость. Шесть 1523A-F микрофонов размещаются в круговом или шестиугольном шаблоне в плоскости, приблизительно в 4,25 см от центральной точки. Седьмой микрофон 1523G размещается в центральной точке. В варианте осуществления, конфигурация из семи микрофонов содержит микрофоны аналогичной спецификации. Следует понимать, что дополнительная обработка аудиоданных, принимаемых из массива микрофонов, может быть необходимой для того, чтобы нормализовать или регулировать аудио, когда микрофоны отличаются. В примерной реализации, массив 1523 микрофонов может содержать семь цифровых микрофонов на основе микроэлектромеханических систем (MEMS) с портами лицевой стороной вверх. Следует понимать, что лучшая производительность может получаться в результате, когда микрофоны не загораживаются посредством поглощающих или блокирующих звук компонентов, таких как схемная плата или корпус устройства.
[00120] В одном варианте осуществления, аналогичные микрофоны синхронизируются с использованием идентичного источника синхросигналов в устройстве (не показано). Тактирование или снабжение временной меткой аудио может помогать с синхронизацией и слиянием аудиовизуальных данных.
[00121] Устройство захвата объемного окружения может прореживать все сигналы микрофонов в 16-битовые PCM-данные на 16 кГц. В этом контексте, прореживание представляет собой процесс уменьшения частоты дискретизации сигнала. Для автоматического распознавания речи, полосы частот выше 8 кГц могут быть необязательными. Следовательно, частота дискретизации 16 кГц может быть адекватной. Прореживание уменьшает скорость передачи битов без нарушения требуемой точности. В варианте осуществления, устройство захвата может поддерживать дополнительные битовые глубины и частоты дискретизации. В варианте осуществления, устройство захвата может не обеспечивать возможность изменения ширины данных и частоты дискретизации, чтобы уменьшать сложность драйверов и повышать стабильность. Микрофоны могут монтироваться с использованием любого соответствующего механического демпфирующего механизма, например, резиновых прокладок, чтобы уменьшать колебания и шум.
[00122] Следует понимать, что большее или меньшее число микрофонов может присутствовать в массиве микрофонов. Тем не менее, меньшее число микрофонов может вводить некоторую неопределенность в местоположении динамика. Дополнительные микрофоны могут обеспечивать увеличенную достоверность или разрешение аудио, но за счет большего количества аппаратных средств и дополнительной сложности вычисления.
[00123] В одном варианте осуществления, аудиодинамик расположен в нижней части или в основании устройства для обратной аудиосвязи пользователю. Аудиодинамик может использоваться для уведомлений с обратной связью или составлять неотъемлемую часть AI-приложения. Например, в AI-приложении для управления конференциями, пользователь может запрашивать протокол собрания для прочтения присутствующим. Интегрированный динамик в устройстве предоставляет обратную связь или запрашивает инструкции или команды для этапов. Если произносимая команда не понимается, запрос на то, чтобы повторять команду, может воспроизводиться через аудиодинамик. Чтобы уменьшать акустическую обратную связь, аудиодинамик может быть обращен в противоположном направлении относительно массива микрофонов. Аудио, воспроизведенное через аудиодинамик, может контурно возвращаться назад в качестве дополнительного синхронизированного канала микрофона.
[00124] Возвращаясь к фиг. 14B, в варианте осуществления, камера 1421 типа "рыбий глаз" принимает HFOV на 360° и, по меньшей мере, вертикальное поле зрения (VFOV) на 95° выше и VFOV на 95° ниже горизонтальной оси, приводя к VFOV на 190° или диагональному полю зрения (DFOV) приблизительно на 200°. На практике, устройство 1410 захвата может быть размещено на столе или полу, так что вертикальный вид ниже поверхности не нужен. Таким образом, в пояснении в данном документе, VFOV идентифицируется как приблизительно 95°, чтобы указывать вид выше горизонтальной базовой плоскости устройства.
[00125] В одном варианте осуществления, камера 1421 типа "рыбий глаз" включает в себя один датчик типа "рыбий глаз" с разрешением в 12 мегапикселей (MP) (например, обеспечивающий 4K-разрешение). Линза камеры может монтироваться относительно датчика изображений, так что оптический центр совмещается с центром датчика изображений, и оптическая ось является перпендикулярной датчику изображений. Относительная позиция линзы камеры в массив микрофонов может быть фиксированной и известной. В частности, оптический центр может совмещаться с центром массива микрофонов с оптической осью, перпендикулярной массиву микрофонов.
[00126] Фиг. 16 иллюстрирует AI-систему 1600 с устройством 1610 захвата объемного окружения, как описано выше, и сервером собраний, называемым "облачным сервером 1620". В примере, пользователь 1630 взаимодействует с AI-приложением 1623. Следует понимать, что AI-приложение 1623 может постоянно размещаться на облачном сервере 1620 или на локальном устройстве (не показано). Аудиовизуальные данные могут захватываться на 360° посредством устройства 1610 AI-захвата. Как пояснено выше, устройство 1610 захвата может включать в себя камеру 1611 типа "рыбий глаз", предоставляющую HFOV на 360° и VFOV приблизительно на 95°. Устройство 1610 захвата также может включать в себя массив 1613 микрофонов, чтобы захватывать аудио на 360°.
[00127] Сжатие видео изображений и видеопотока, принимаемого посредством камеры 1611, может выполняться посредством процессора 1615 для устройства. Видеорежимы и протоколы сжатия и критерии могут управляться посредством выбираемого пользователем программного управления. В дополнение к сжатию, аудиовизуальные данные могут защищаться посредством шифрования, чтобы предотвращать получение данных неавторизованными людьми. В варианте осуществления, сжатие 1618 может выполняться посредством схемы для устройства и управляться посредством программных переключателей.
[00128] Предварительная обработка 1617 (например, обрезка изображений на основе контента изображений или уменьшения уровня шума) может выполняться посредством логики, выполняемой посредством процессора перед сжатием 1618. В варианте осуществления, предварительная обработка может включать в себя подавление асинхронных помех (AEC), чтобы уменьшать обратную связь, шум и эхо-сигнал, вызываемый посредством динамика 1612, соединенного с устройством.
[00129] В варианте осуществления, локальный процесс для опознавания по ключевым словам (KWS) может включаться в порядок прослушивать команды устройства для устройства захвата объемного окружения, к примеру, проснуться или выключать устройство. Локальное KWS может предпочесть повторный вызов по сравнению с точностью, и это может быть основано на уменьшенном массиве микрофонов (например, два микрофона вместо полного массива).
[00130] Когда AEC выполняется на устройстве 1610, акустический канал, включающий в себя аудио говорящего, возможно, не должен отправляться в модели, чтобы выполнять слияние 1621 данных датчиков. Сжатые аудиовизуальные данные могут отправляться на облачный сервер 1620 посредством передающего блока 1619. Передающий блок 1619 может включать в себя одно или более из следующего: сетевая интерфейсная плата для проводной связи, к примеру, Ethernet-соединение; беспроводное приемо-передающее устройство с использованием беспроводного протокола, к примеру, для WiFi®, Bluetooth®, NFC; или другое средство связи. В варианте осуществления, обратная аудиосвязь может отправляться в устройство через один из беспроводных каналов. Облачный сервер 1620 может выполнять слияние 1621 данных датчиков для AI-приложения 1623. Следовательно, сжатие может выполняться, чтобы уменьшать полосу пропускания передачи в облако через передающий блок 1619.
[00131] Фиг. 17 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ 1700 уменьшения числа аудиопотоков, отправленных по сети на сервер собраний для использования при формировании расшифровки стенограммы. Способ 1700 начинается посредством приема нескольких каналов аудио на этапе 1710 из множества (например, трех или более) микрофонов, обнаруживающих речь из собрания нескольких пользователей. На этапе 1720, оцениваются направления активных говорящих. Модель обратного сведения речи используется для того, чтобы выбирать два канала, соответствующие основному устройству и вторичному микрофону на этапе 1730, или может соответствовать сливаемому аудиоканалу. Два выбранных канала отправляются на этапе 1740 на сервер собраний для формирования расшифровки стенограммы интеллектуального собрания. Посредством уменьшения объема данных, отправленных на сервер собраний, экономится полоса пропускания. Поскольку выбранные данные являются возможно наилучшими данными, точность фактически не теряется.
[00132] В одном варианте осуществления, микрофоны поддерживаются посредством устройства в фиксированной конфигурации. Фиксированная конфигурация может включать в себя камеру, конфигурирующую поле зрения с возможностью включать в себя нескольких пользователей. Локализация источников звука может выполняться посредством выполнения модели, обученной на каналах аудио и видео из камеры. Например, если один пользователь использует переносной компьютер с камерой, переносной компьютер может обеспечивать аудио- и видеоканал. Аудиоканал может синхронизироваться относительно опорного аудиоканала, и идентичная разность времен может использоваться для того, чтобы синхронизировать видеоканал. Распознавание изображений может использоваться в видеоканале, чтобы идентифицировать пользователя в качестве говорящего для диаризации при формировании расшифровки стенограммы. В дополнительном варианте осуществления, переносной компьютер выполняет обработку изображений, чтобы определять то, что пользователь говорит, и предоставлять тег в аудиоканале, идентифицирующий пользователя в качестве говорящего. Тег затем может использоваться для диаризации без необходимости передавать видеоканал из переносного компьютера.
[00133] В дополнительном варианте осуществления, микрофоны ассоциированы с несколькими распределенными устройствами. Распределенные устройства могут включать в себя беспроводные устройства, соответственно, ассоциированные с несколькими пользователями. По меньшей мере, одно из распределенных устройств может включать в себя камеру, предоставляющую видео, по меньшей мере, одного из пользователей.
[00134] В еще одном дополнительном варианте осуществления, микрофоны включают в себя микрофоны, поддерживаемые в фиксированную конфигурацию, и микрофоны, ассоциированные с распределенными устройствами, ассоциированными с пользователями. Способ может осуществляться посредством одного или более из устройства, поддерживающего микрофоны в фиксированной позиции, или краевого устройства, принимающего несколько каналов аудио. Модель обратного сведения речи может выполняться на краевом устройстве.
[00135] В дополнительных вариантах осуществления, клиентская обработка (обработка на одном или более распределенных устройств, на устройстве захвата объемного окружения и/или на краевом сервере) используется для того, чтобы уменьшать вычислительные ресурсы, требуемые посредством сервера собраний, а также уменьшать объем полосы пропускания сети, используемой для обработки распределенных информационных потоков собрания из распределенных устройств. В дополнение к уменьшению числа потоков, отправленных через сеть на сервер собраний, как описано выше, формирование диаграмму направленности, может выполняться на клиентское стороне, как и формирование водяных аудиознаков и кодов собраний. В дополнительных вариантах осуществления, размеры моделей могут уменьшаться и квантоваться, чтобы лучше выполняться на клиентской стороне. Целевая функция также может модифицироваться, чтобы лучше выполняться для размера клиента. Вместо вывода речевой маски, локализация источников звука может использоваться с соразмерным меньшим объемом вычислений.
[00136] Оба аудио- и видеоканала могут использоваться для того, чтобы атрибутировать выступление перед пользователями для создания диаризованной расшифровки стенограммы. Подход на основе аудиовизуальной диаризации обеспечивает возможность комбинирования голосовой идентификации, локализации источников звука, отслеживания/идентификации по лицу и визуального обнаружения активных говорящих из распределенных датчиков, чтобы достигать надежной диаризации.
[00137] Фиг. 18 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ 1800 для использования видео- и аудиоканалов, аудиовизуальных данных, из распределенных устройств, чтобы обеспечивать лучшую идентификацию говорящих. Способ 1800 начинается посредством приема, на этапе 1810, информационных потоков на сервере собраний из набора нескольких распределенных устройств, включенных в интеллектуальное собрание. На этапе 1820, принимаются аудиосигналы, представляющие речь, по меньшей мере, двух пользователей, по меньшей мере, в двух из информационных потоков. На этапе 1830, принимается, по меньшей мере, один видеосигнал, по меньшей мере, одного пользователя в информационных потоках. Принятые аудио- и видеосигналы используются для того, чтобы ассоциировать речь в принимаемых аудиосигналах с конкретным пользователем в качестве функции принимаемых аудио- и видеосигналов на этапе 1840. Расшифровка стенограммы интеллектуального собрания формируется на этапе 1850 с индикатором пользователя, ассоциированного с речью.
[00138] Несколько распределенных устройств, в одном варианте осуществления, представляют собой мобильные беспроводные устройства, ассоциированные с пользователями на интеллектуальном собрании. Мобильные беспроводные устройства могут включать в себя микрофон и камеру, которая предоставляет, по меньшей мере, один видеосигнал. В дополнительных вариантах осуществления, несколько распределенных устройств включают в себя устройство, имеющее несколько микрофонов, поддерживаемых в фиксированной конфигурации, причем каждый микрофон предоставляет один из принимаемых аудиосигналов. Устройство может включать в себя камеру, конфигурирующую поле зрения с возможностью включать нескольких пользователей в интеллектуальное собрание и предоставлять, по меньшей мере, один видеосигнал.
[00139] В одном варианте осуществления, модель слияния используется в принимаемых аудио- и видеосигналах, чтобы ассоциировать конкретного пользователя с речью. В варианте осуществления, аудиовизуальные данные могут анализироваться посредством сервера собраний. Аудиовизуальные данные могут сначала сжиматься до отправки на сервер собраний через сеть. В другом варианте осуществления, модель слияния соединяется с устройством захвата в качестве интегрированной системы. Пояснения в данном документе описывают сервер собраний в качестве иллюстрации, а не в качестве ограничения.
[00140] Распаковки сервера собраний, декодирует или дешифрует данные, при необходимости. Аудиовизуальные данные могут сливаться и анализироваться посредством AI-приложения, использующего LSTM-модель, например, чтобы идентифицировать или логически выводить признаки в аудиовизуальных данных, такие как, но не только: аудионаправление; местоположение динамика в изображении; перемещение говорящего; голосовая подпись; подпись лицом; жест; и/или объект. В примере, AI-приложение требует распознавания речи или распознавания лиц. LSTM-модель может обучаться с данными, конкретными для AI-приложения, с использованием данных датчиков. В варианте осуществления, может использоваться более одного механизма моделирования или анализа, как пояснено выше.
[00141] В варианте осуществления, речь может идентифицироваться, и распознавание жестов с использованием видеоданных может выполняться. LSTM-модель может использовать идентифицированную речь и распознанный жест, чтобы предоставлять вероятное слияние данных и отправлять вероятные результаты в AI-приложение. В примере, жест, комбинированный с голосовой командой, предоставляет конкретные управляющие команды в AI-приложение. В примере, анализ видеоданных указывает взгляд или отслеживает перемещение глаз, чтобы логически выводить то, куда смотрит пользователь. Анализ взгляда может приводить к управляющим командам для AI-приложения и может различаться на основе слияния с аудиоданными.
[00142] В варианте осуществления, LSTM-модель обучается для конкретного AI-приложения и предоставляет элемент управления или команды для этого приложения, на основе сливаемых данных. В другом варианте осуществления, LSTM-модель может быть более общей и предоставлять вероятные коррелированные данные, к примеру, аудиопотоки для каждого говорящего с идентификатором говорящего и местоположением в окружении и видеопотоке, в AI-приложение для последующей обработки и интерпретации вводов. В этом примере, AI-приложение использует ввод аудио- и видеопотоков, чтобы извлекать соответствующие команды или выполнять действия.
[00143] Один вариант осуществления использует камеру типа "рыбий глаз" с датчиком на 12MP. Другой вариант осуществления включает в себя инфракрасный (IR) или другой датчик глубины, чтобы обеспечивать трехмерную информацию или информацию глубины. Информация глубины может не быть доступной на 360°, если существует недостаточно датчиков глубины, чтобы покрывать все HFOV. Варьирования устройства захвата могут быть предусмотрены, чтобы адаптировать различные ценовые ориентиры, приемлемые для широкого диапазона пользователей или для различных приложений. Например, включение датчиков глубины или датчиков более высокого разрешения может увеличивать затраты или сложность устройства за рамками того, что требуется для выбранного AI-приложения.
[00144] Фиг. 19 является блок-схемой последовательности операций, иллюстрирующей машинореализованный способ 1900 для индивидуальной настройки вывода на основе пользовательских предпочтений согласно примерному варианту осуществления. Этапы в способе 1900 выполняются посредством сервера или системы проведения собраний (например, сервера 135 собраний), с использованием компонентов, описанных выше. Соответственно, способ 1900 описывается в качестве примера со ссылкой на сервер собраний. Тем не менее, следует принимать во внимание, что, по меньшей мере, некоторые этапы способа 1900 могут развертываться на различных других аппаратных конфигурациях или выполняться посредством аналогичных компонентов, постоянно размещающихся в другом месте в сетевом окружении. Следовательно, способ 1900 не имеет намерение быть ограниченным сервером собраний.
[00145] На этапе 1910, сервер собраний принимает аудиопотоки из множества распределенных устройств. В примерных вариантах осуществления, аудиопотоки содержат речь, обнаруженную посредством одного или более из множества распределенных устройств в ходе собрания двух или более пользователей. В некоторых вариантах осуществления, собрание представляет собой специальное собрание. В этих вариантах осуществления, сервер может выполнять формирование диаграммы направленности вслепую или разделение слитной речи для принимаемых аудиопотоков, чтобы разделять речь от фонового шума или различных говорящих, говорящих одновременно, на отдельные аудиоканалы. В некоторых случаях, аудиопотоки сравниваются, чтобы определять то, что аудиопотоки представляют звук из (идентичного) специального собрания. Экземпляр собрания затем формируется, чтобы обрабатывать аудиопотоки, идентифицированные как исходящие из специального собрания.
[00146] На этапе 1920, идентификационные данные пользователя одного из распределенных устройств идентифицируются посредством сервера собраний. В одном варианте осуществления, пользователь идентифицируется на основе видеосигнала, захваченного посредством камеры (например, камеры 155, камеры 1821), ассоциированной с собранием. Видеосигнал передается на сервер собраний. Сервер собраний сравнивает изображение пользователя из видеосигнала с сохраненными изображениями известных (например, зарегистрированных) пользователей, чтобы определять совпадение. Если сохраненное изображение совпадает с захваченным изображением пользователя в видеосигнале, то пользователь идентифицируется. В одном варианте осуществления, изображение пользователя сохраняется или ассоциируется с пользовательским профилем пользователя.
[00147] В альтернативном варианте осуществления, пользователь идентифицируется на основе голосовой подписи. В этом варианте осуществления, речь из аудиопотока синтаксически анализируется или диаризуется и сравнивается с сохраненными голосовыми подписями известных пользователей. Если сохраненная голосовая подпись совпадает с синтаксически проанализированной/диаризованной речью из аудиопотока, то пользователь идентифицируется. В одном варианте осуществления, голосовая подпись пользователя сохраняется или ассоциируется с пользовательским профилем пользователя.
[00148] На этапе 1930, предпочитаемый язык идентифицированного пользователя определяется. В некоторых вариантах осуществления, к пользовательскому профилю идентифицированного пользователя осуществляется доступ. Пользовательский профиль содержит, по меньшей мере, предварительно определенное предпочтение для языка пользователя. В некоторых случаях, предварительно определенное предпочтение устанавливается (например, явно указывается) пользователем. В других случаях, предварительно определенное предпочтение определяется на основе конфигурации устройства для устройства (например, распределенного устройства, такого как сотовый телефон или переносной компьютер), ассоциированного с пользователем. Например, устройство может быть выполнено с возможностью функционировать на английском или китайском языке.
[00149] На этапе 1940, сервер собраний формирует расшифровку стенограммы, как пояснено выше. В примерных вариантах осуществления, речь из аудиопотоков преобразуется в текст, чтобы формировать текстовую расшифровку стенограммы или цифровую расшифровку стенограммы. В одном варианте осуществления, как пояснено выше, расшифровка стенограммы в реальном времени формируется на основе коротких последовательностей слов. В некоторых вариантах осуществления, позднее слияние данных может выполняться посредством распознавания речи для нескольких аудиоканалов, обрабатывающихся параллельно, чтобы формировать фразы. Фразы, извлекаемые из нескольких аудиоканалов, комбинируются в реальном времени или практически в реальном времени. В одном варианте осуществления, приблизительно две секунды речи комбинируются. Как результат, аудиопотоки по существу обрабатываются по мере того, как они принимаются. Неперекрывающееся скользящее окно в несколько (например, в две) секунд используется для того, чтобы обрабатывать аудиопотоки, снижая время задержки для формирования расшифровки стенограммы.
[00150] На этапе 1950, сервер собраний переводит расшифровку стенограммы согласно предпочитаемому языку пользователя. В некоторых вариантах осуществления, сервер собраний принимает сформированную расшифровку стенограммы из этапа 1940 и переводит текст в сформированной расшифровке стенограммы в текст на предпочтительном языке. В других вариантах осуществления, сервер собраний принимает сформированную расшифровку стенограммы из этапа 1940 и преобразует сформированную расшифровку стенограммы в речь на предпочтительном языке. Также дополнительно, некоторые варианты осуществления могут выполнять как перевод текста, так и перевод речи. В примерных вариантах осуществления, идентификационные данные пользователя (например, говорящего) для каждого переведенного речевого фрагмента из расшифровки стенограммы содержат переведенную расшифровку стенограммы. В некоторых случаях, пользовательские идентификационные данные получаются из идентификатора пользователя, ассоциированного с распределенным устройством.
[00151] На этапе 1960, переведенная расшифровка стенограммы предоставляется в устройство (например, распределенное устройство) пользователя. В некоторых вариантах осуществления, устройство содержит идентичное устройство, которое используется для того, чтобы захватывать аудио от пользователя. Переведенная расшифровка стенограммы может предоставляться, например, в качестве текста, отображаемого на устройстве отображения (например, на экране) устройства, либо в качестве речевого аудио через устройства говорящего (например, наушники, слуховые аппараты или громкоговорители) посредством использования преобразования текста в речь. В некоторых вариантах осуществления, результаты диаризации также могут предоставляться.
[00152] Хотя способ 1900 по фиг. 19 описывается как имеющий этапы в конкретном порядке, альтернативные варианты осуществления могут осуществлять способ 1900 с этапами в другом порядке. Например, идентификация пользователя (этап 1920) и определение предпочитаемого языка (этап 1930) может осуществляться после или в то время, когда расшифровка стенограммы формируется (этап 1940), и до перевода расшифровки стенограммы (этап 1950).
[00153] Фиг. 20 является принципиальной блок-схемой компьютерной системы 2000 для того, чтобы реализовывать и управлять обработкой интеллектуальных собраний через несколько распределенных устройств, краевых устройств и облачных устройств, и для осуществления способов и алгоритмов согласно примерным вариантам осуществления. Все компоненты не должны обязательно использоваться в различных вариантах осуществления.
[00154] Одно примерное вычислительное устройство в форме компьютера 2000 включает в себя блок 2002 обработки, запоминающее устройство 2003, съемное устройство 2010 хранения данных и стационарное устройство 2012 хранения данных. Хотя примерное вычислительное устройство проиллюстрировано и описано в качестве компьютера 2000, вычислительное устройство может иметь различные формы в различных вариантах осуществления. Например, вычислительное устройство, вместо этого, может представлять собой смартфон, планшетный компьютер, интеллектуальные часы или другое вычислительное устройство, включающее в себя идентичные или аналогичные элементы, как проиллюстрировано и описано относительно фиг. 20. Устройства, такие как смартфоны, планшетные компьютеры и интеллектуальные часы, в общем, совместно называются "мобильными устройствами", "распределенными устройствами" или "абонентским устройством".
[00155] Хотя различные элементы хранения данных проиллюстрированы в качестве части компьютера 2000, устройство хранения данных также или альтернативно может включать в себя облачную систему хранения, доступную через сеть, к примеру, через Интернет, серверное устройство хранения данных или интеллектуальное устройство хранения данных (SSD). Также следует отметить, что SSD может включать в себя процессор, на котором синтаксический анализатор может выполняться, давая возможность передачи синтаксически проанализированных, фильтрованных данных через каналы ввода-вывода между SSD и основным запоминающим устройством.
[00156] Запоминающее устройство 2003 может включать в себя энергозависимое запоминающее устройство 2014 и энергонезависимое запоминающее устройство 2008. Компьютер 2000 может включать в себя (либо иметь доступ к вычислительному окружению, которое включает в себя) множество машиночитаемых носителей, таких как энергозависимое запоминающее устройство 2014 и энергонезависимое запоминающее устройство 2008, съемное устройство 2010 хранения данных и стационарное устройство 2012 хранения данных. Компьютерное устройство хранения данных включает в себя оперативное запоминающее устройство (RAM), постоянное запоминающее устройство (ROM), стираемое программируемое постоянное запоминающее устройство (EPROM) или электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), флэш-память или другие технологии запоминающих устройств, постоянное запоминающее устройство на компакт-дисках (CD-ROM), универсальные цифровые диски (DVD) или другое устройство хранения данных на оптических дисках, магнитные кассеты, магнитную ленту, устройство хранения данных на магнитных дисках или другие магнитные устройства хранения данных либо любой другой носитель, допускающий сохранение машиночитаемых инструкций.
[00157] Компьютер 2000 может включать в себя или иметь доступ к вычислительному окружению, которое включает в себя интерфейс 2006 ввода, интерфейс 2004 вывода и интерфейс 2016 связи. Интерфейс 2004 вывода может включать в себя устройство отображения, такое как сенсорный экран, который также может служить в качестве устройства ввода. Интерфейс 2006 ввода может включать в себя одно или более из сенсорного экрана, сенсорной панели, мыши, клавиатуры, камеры, одной или более конкретных для устройств кнопок, одного или более датчиков, интегрированных или соединенных через проводные или беспроводные соединения для передачи данных с компьютером 2000, и другие устройства ввода. Компьютер может работать в сетевом окружении с использованием соединения связи с возможностью соединяться с одним или более удаленных компьютеров, таких как серверы баз данных. Удаленный компьютер может включать в себя персональный компьютер (PC), сервер, маршрутизатор, сетевой PC, равноправное устройство или другие общие данные обеспечивают протекание сетевого коммутатора и т.п. Соединение связи может включать в себя локальную вычислительную сеть (LAN), глобальную вычислительную сеть (WAN), сотовую, Wi-Fi-, Bluetooth- или другие сети. Согласно одному варианту осуществления, различные компоненты компьютера 2000 соединяются с системной шиной 2020.
[00158] Машиночитаемые инструкции, сохраненные на машиночитаемом носителе, выполняются посредством блока 2002 обработки компьютера 2000, такого как программа 2018. Программа 2018 в некоторых вариантах осуществления содержит программное обеспечение, чтобы реализовывать один или более способов для реализации приложения для проведения собраний, и сервер собраний, а также модули, способы и алгоритмы, описанные в данном документе. Жесткий диск, CD-ROM и RAM представляют собой некоторые примеры изделий, включающих в себя энергонезависимое машиночитаемое устройство, такое как устройство хранения данных. Термин "машиночитаемое устройство хранения данных" не включает в себя несущие волны в той степени, в котором несущие волны считаются слишком энергозависимыми. Устройство хранения данных также может включать в себя сетевое устройство хранения данных, такое как сеть хранения данных (SAN). Компьютерная программа 2018 наряду с диспетчером 2022 рабочего пространства может использоваться для того, чтобы инструктировать блоку 2002 обработки осуществлять один или более способов или алгоритмов, описанных в данном документе.
Выполняемые инструкции и машинный носитель данных
[00159] При использовании в данном документе, термины "машинный носитель данных", "носитель данных устройства", "компьютерный носитель данных", "машиночитаемый носитель данных", "машиночитаемое устройство хранения данных" (совместно называются "машинным носителем данных") означают одно и то же и могут использоваться взаимозаменяемо в этом раскрытии сущности. Термины означают одно или более устройств и/или носителей данных (например, централизованную или распределенную базу данных и/или ассоциированные кэши и серверы), которые сохраняют выполняемые инструкции и/или данные, а также облачные системы хранения или сети хранения данных, которые включают в себя несколько экземпляров оборудования или устройства хранения данных. Термины, соответственно, должны считаться включающими в себя, но не только, полупроводниковые запоминающие устройства и оптические и магнитные носители, включающие в себя запоминающее устройство, внутреннее или внешнее по отношению к процессорам. Конкретные примеры машинных носителей данных, компьютерных носителей данных и/или носителей данных устройства включают в себя энергонезависимое запоминающее устройство, включающее в себя в качестве примера полупроводниковые запоминающие устройства, например, стираемое программируемое постоянное запоминающее устройство (EPROM), электрически стираемое программируемое постоянное запоминающее устройство (EEPROM), FPGA и устройства флэш-памяти; магнитные диски, такие как внутренние жесткие диски и съемные диски; магнитооптические диски; и CD-ROM- и DVD-ROM-диски. Термины "машинные носители данных", "компьютерные носители данных" и "носители данных устройства" конкретно исключают несущие волны, модулированные сигналы данных и другие такие среды в той степени, в которой такие среды считаются слишком энергозависимыми. Другие такие среды также охватываются термином "среда передачи сигналов", поясненным ниже. В этом контексте, машинный носитель данных является энергонезависимым.
Среда передачи сигналов
[00160] Термин "среда передачи сигналов" или "передающая среда" должен считаться включающим в себя любую форму модулированного сигнала данных, несущей волны и т.д. Термин "модулированный сигнал данных" означает сигнал, который имеет одну или более характеристик, заданных или измененных таким образом, чтобы кодировать информацию в сигнале.
Машиночитаемый носитель
[00161] Термины "машиночитаемый носитель", "машиночитаемый носитель" и "устройствочитаемый носитель" означают то же самое и могут использоваться взаимозаменяемо в этом раскрытии сущности. Термины задаются как включающие в себя как машинные носители, так данных и среды передачи сигналов. Таким образом, термины включают в себя как устройства хранения/носители данных, так и несущие волны/модулированные сигналы данных.
Примеры
[00162] Пример 1 представляет собой машинореализуемый способ для предоставления индивидуально настроенного вывода на основе пользовательских предпочтений в распределенной системе. Способ содержит прием аудиопотоков из множества распределенных устройств, предусмотренных на интеллектуальном собрании; идентификацию пользователя, соответствующего распределенному устройству из множества распределенных устройств; определение предпочтительного языка пользователя; формирование, посредством аппаратного процессора, расшифровки стенограммы из принимаемых аудиопотоков; перевод расшифровки стенограммы на предпочтительный язык пользователя, чтобы формировать переведенную расшифровку стенограммы; и предоставление переведенной расшифровки стенограммы в распределенное устройство.
[00163] В примере 2, изобретение по примеру 1 в необязательном порядке может включать в себя то, что предоставление переведенной расшифровки стенограммы содержит предоставление расшифровки стенограммы с переведенным текстом.
[00164] В примере 3, изобретение по примерам 1-2 в необязательном порядке может включать в себя то, что предоставление переведенной расшифровки стенограммы содержит преобразование текста переведенной расшифровки стенограммы в речь.
[00165] В примере 4, изобретение по примерам 1-3 в необязательном порядке может включать в себя то, что предоставление переведенной расшифровки стенограммы содержит предоставление идентификационных данных говорящего для каждого переведенного речевого фрагмента расшифровки стенограммы.
[00166] В примере 5 изобретение по примерам 1-4 в необязательном порядке может включать в себя то, что определение предпочтительного языка пользователя содержит осуществление доступа к пользовательским предпочтениям, ранее устанавливаемым для пользователя, указывающего предпочтительный язык.
[00167] В примере 6 изобретение по примерам 1-5 в необязательном порядке может включать в себя то, что интеллектуальное собрание представляет собой специальное собрание, причем способ дополнительно содержит сравнение аудиопотоков, чтобы определять то, что аудиопотоки представляют звук из специального собрания; и формирование экземпляра собрания, чтобы обрабатывать аудиопотоки, в ответ на сравнение, определяющее то, что аудиопотоки представляют звук из специального собрания.
[00168] В примере 7, изобретение по примерам 1-6 необязательно может включать в себя выполнение разделения слитной речи для принимаемых аудиопотоков, чтобы разделять речь от различных говорящих, говорящих одновременно, на отдельные аудиоканалы, причем формирование расшифровки стенограммы основано на разделенных аудиоканалах.
[00169] В примере 8, изобретение по примерам 1-7 в необязательном порядке может включать в себя то, что идентификация пользователя содержит прием видеосигнала, захватывающего пользователя; и сопоставление сохраненного изображения пользователя с видеосигналом, чтобы идентифицировать пользователя.
[00170] В примере 9, изобретение по примерам 1-8 в необязательном порядке может включать в себя то, что идентификация пользователя содержит согласование с сохраненной голосовой подписью пользователя с речью из аудиопотоков.
[00171] В примере 10, изобретение по примерам 1-9 в необязательном порядке может включать в себя то, что идентификация пользователя содержит получение идентификатора пользователя, ассоциированного с распределенным устройством.
[00172] Пример 11 представляет собой машинный носитель данных для предоставления индивидуально настроенного вывода на основе пользовательских предпочтений в распределенной системе. Машиночитаемое устройство хранения данных конфигурирует один или более процессоров с возможностью выполнять этапы, содержащие прием аудиопотоков из множества распределенных устройств, предусмотренных на интеллектуальном собрании; идентификацию пользователя, соответствующего распределенному устройству из множества распределенных устройств; определение предпочтительного языка пользователя; формирование расшифровки стенограммы из принимаемых аудиопотоков; перевод расшифровки стенограммы на предпочтительный язык пользователя, чтобы формировать переведенную расшифровку стенограммы; и предоставление переведенной расшифровки стенограммы в распределенное устройство
[00173] В примере 12, изобретение по примеру изобретения по примеру 11 в необязательном порядке может включать в себя то, что предоставление переведенной расшифровки стенограммы содержит предоставление расшифровки стенограммы с переведенным текстом.
[00174] В примере 13, изобретение по примерам 11-12 в необязательном порядке может включать в себя то, что предоставление переведенной расшифровки стенограммы содержит преобразование текста переведенной расшифровки стенограммы в речь.
[00175] В примере 14, изобретение по примерам 11-1 может необязательно включать в себя 3, в котором предоставление переведенной расшифровки стенограммы содержит предоставление идентификационных данных говорящего для каждого переведенного речевого фрагмента расшифровки стенограммы.
[00176] В примере 15, изобретение по примерам 11-14 в необязательном порядке может включать в себя то, что определение предпочтительного языка пользователя содержит осуществление доступа к пользовательским предпочтениям, ранее устанавливаемым для пользователя, указывающего предпочтительный язык.
[00177] В примере 16 изобретение по примерам 11-15 в необязательном порядке может включать в себя то, что интеллектуальное собрание представляет собой специальное собрание, причем способ дополнительно содержит сравнение аудиопотоков, чтобы определять то, что аудиопотоки представляют звук из специального собрания; и формирование экземпляра собрания, чтобы обрабатывать аудиопотоки в ответ на сравнение, определяющее то, что аудиопотоки представляют звук из специального собрания.
[00178] В примере 17 изобретение по примерам 11-16 в необязательном порядке может включать в себя то, что этапы дополнительно содержат выполнение разделения слитной речи для принимаемых аудиопотоков, чтобы разделять речь от различных говорящих, говорящих одновременно, на отдельные аудиоканалы, причем формирование расшифровки стенограммы основано на разделенных аудиоканалах.
[00179] В примере 18 изобретение по примерам 11-17 в необязательном порядке может включать в себя то, что идентификация пользователя содержит прием видеосигнала, захватывающего изображение пользователя; и сопоставление сохраненного изображения пользователя с видеосигналом, чтобы идентифицировать пользователя.
[00180] В примере 19 изобретение по примерам 11-18 в необязательном порядке может включать в себя то, что идентификация пользователя содержит согласование с сохраненной голосовой подписью пользователя с речью из аудиопотоков.
[00181] Пример 20 представляет собой устройство для предоставления индивидуально настроенного вывода на основе пользовательских предпочтений в распределенной системе. Система включает в себя один или более процессоров и устройство хранения данных, сохраняющее инструкции, которые, при выполнении посредством одного или более аппаратных процессоров, инструктируют одному или более аппаратных процессоров выполнять этапы, содержащие прием аудиопотоков из множества распределенных устройств, предусмотренных на интеллектуальном собрании; идентификацию пользователя, соответствующего распределенному устройству из множества распределенных устройств; определение предпочтительного языка пользователя; формирование расшифровки стенограммы из принимаемых аудиопотоков; перевод расшифровки стенограммы на предпочтительный язык пользователя, чтобы формировать переведенную расшифровку стенограммы; и предоставление переведенной расшифровки стенограммы в распределенное устройство.
[00182] Хотя выше подробно описываются несколько вариантов осуществления, другие модификации являются возможными. Например, логические последовательности операций, проиллюстрированные на чертежах, не требуют показанного конкретного порядка или последовательного порядка для того, чтобы достигать требуемых результатов. Другие этапы могут быть предусмотрены, или этапы могут исключаться из описанных последовательностей операций, и другие компоненты могут добавляться или удаляться из описанных систем. Другие варианты осуществления могут находиться в пределах объема прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ИСПОЛЬЗОВАНИЯ В СОЗДАНИИ АУДИОСЦЕНЫ | 2007 |
|
RU2449496C2 |
| ИНТЕЛЛЕКТУАЛЬНЫЙ СПОСОБ, СИСТЕМА И УЗЕЛ ОГРАНИЧЕНИЯ АУДИО | 2007 |
|
RU2398361C2 |
| СОЕДИНЕНИЕ НЕЗАВИСИМЫХ МУЛЬТИМЕДИЙНЫХ ИСТОЧНИКОВ В КОНФЕРЕНЦ-СВЯЗЬ | 2007 |
|
RU2398362C2 |
| ВЕРИФИКАЦИЯ ГОВОРЯЩЕГО | 2017 |
|
RU2697736C1 |
| УСТРОЙСТВА И СПОСОБЫ ДЛЯ ИСПОЛЬЗОВАНИЯ В СОЗДАНИИ АУДИОСЦЕНЫ | 2007 |
|
RU2495538C2 |
| СОЗДАНИЕ ЗАМЕТОК С ИСПОЛЬЗОВАНИЕМ ГОЛОСОВОГО ПОТОКА | 2011 |
|
RU2571608C2 |
| УСТРОЙСТВО АУДИООБРАБОТКИ И СПОСОБ ДЛЯ ЭТОГО | 2014 |
|
RU2667630C2 |
| УПРАВЛЕНИЕ КОМПОНОВКОЙ КОНФЕРЕНЦИИ И ПРОТОКОЛ УПРАВЛЕНИЯ | 2007 |
|
RU2396730C2 |
| РАСПРЕДЕЛЯЕМАЯ, МАСШТАБИРУЕМАЯ, ПОДКЛЮЧАЕМАЯ АРХИТЕКТУРА КОНФЕРЕНЦСВЯЗИ | 2007 |
|
RU2459371C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОДИРОВАНИЯ И ОПТИМАЛЬНОЙ РЕКОНСТРУКЦИИ ТРЕХМЕРНОГО АКУСТИЧЕСКОГО ПОЛЯ | 2009 |
|
RU2533437C2 |
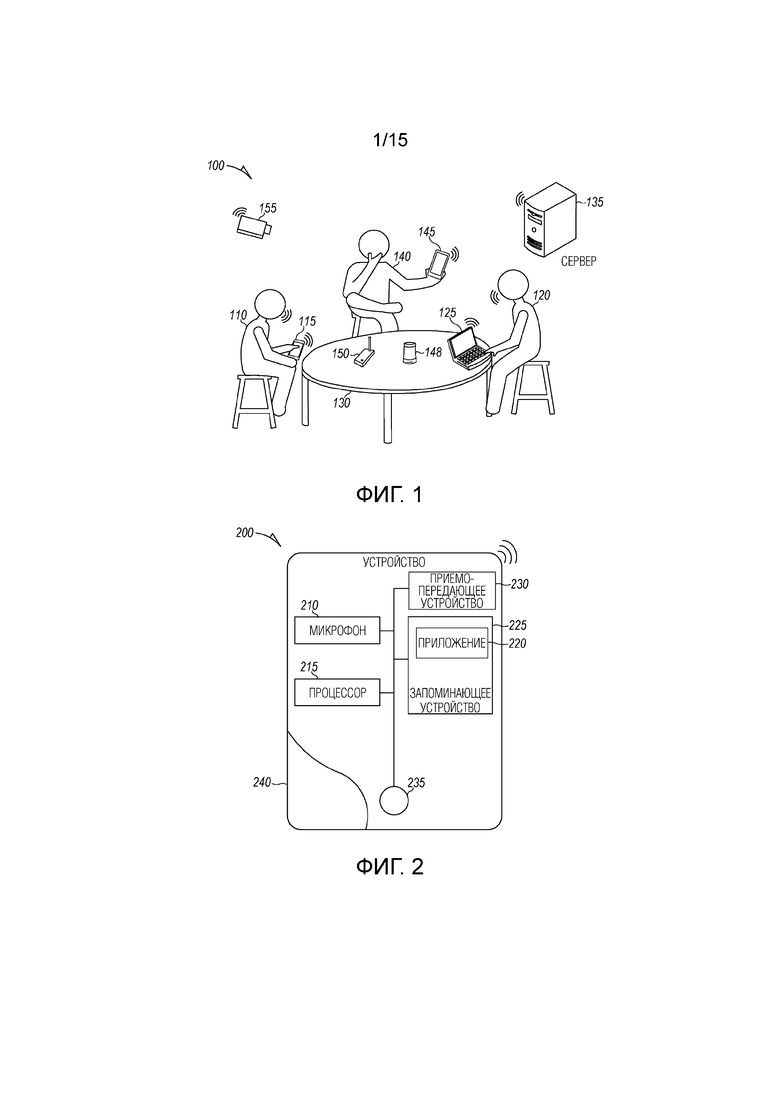
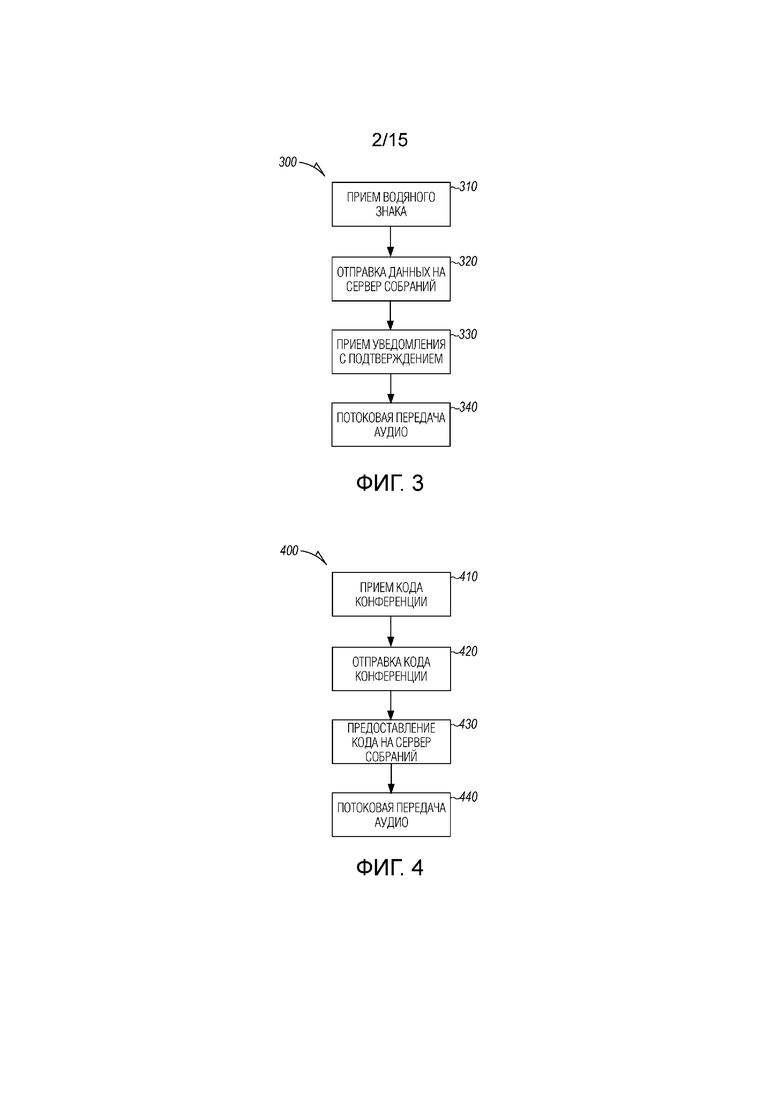
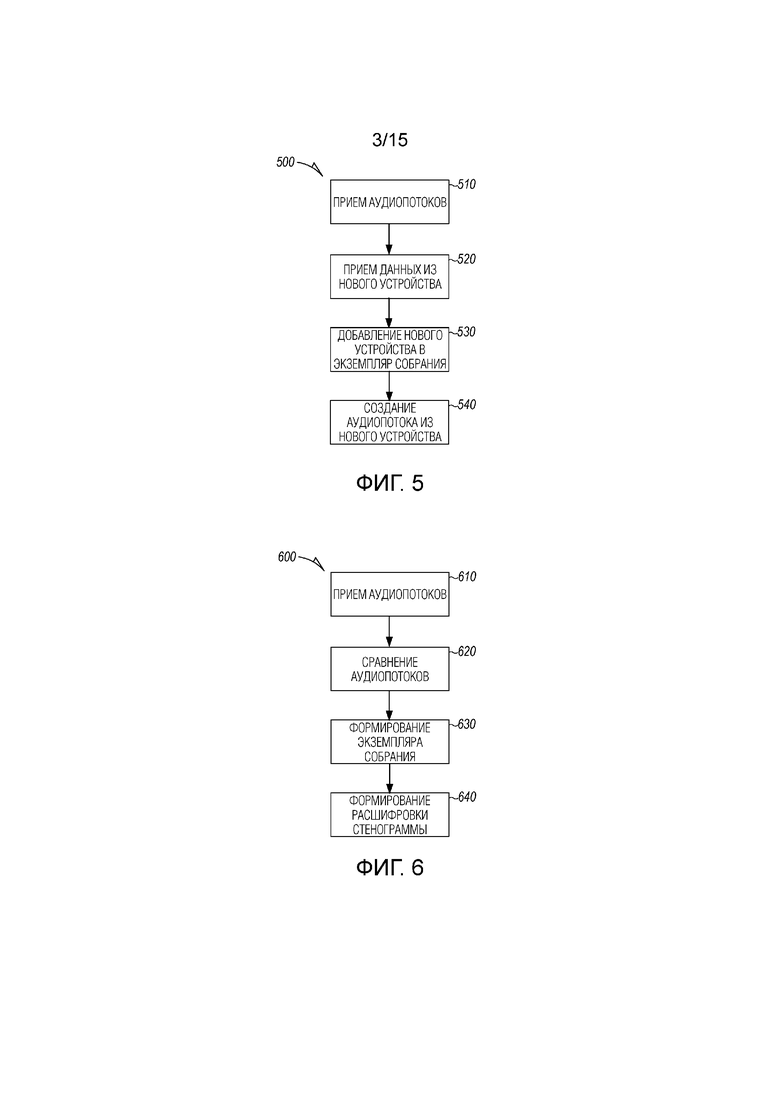
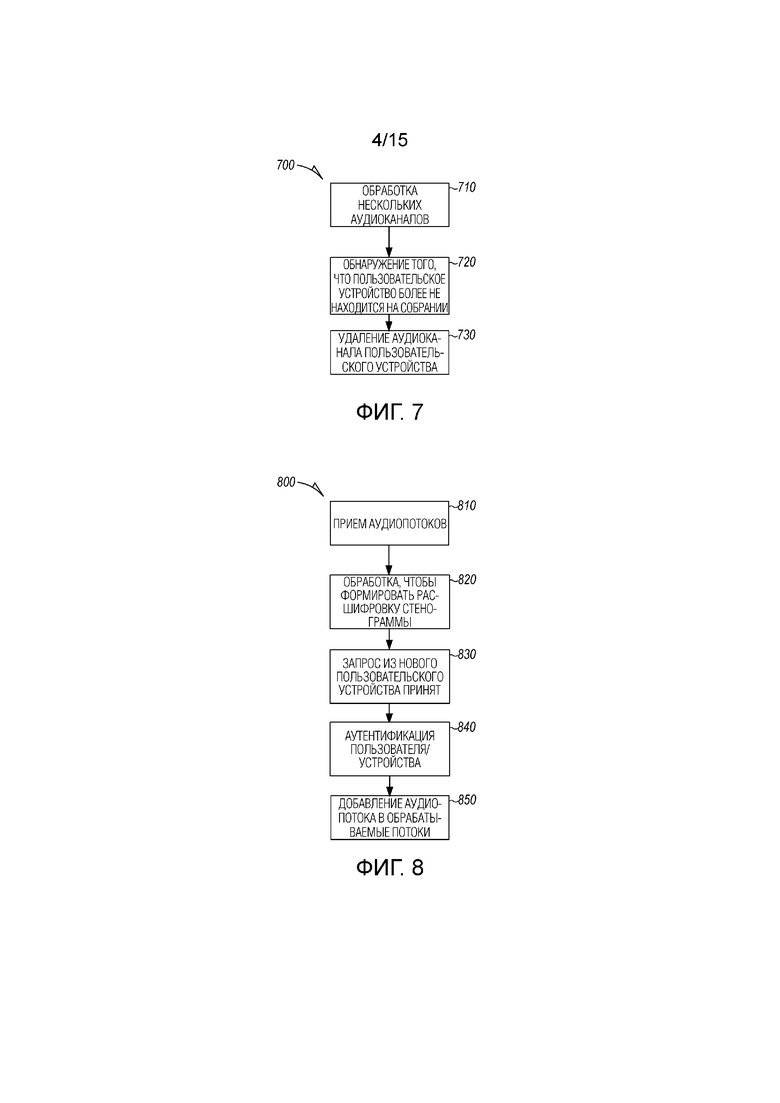
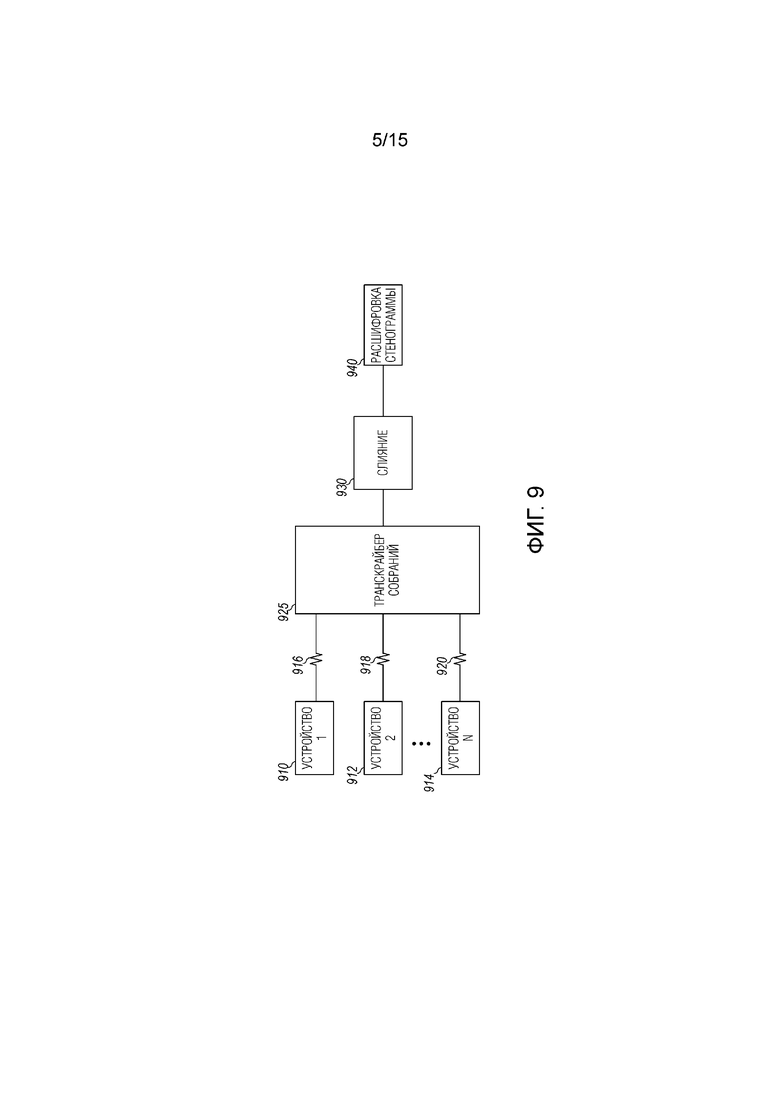
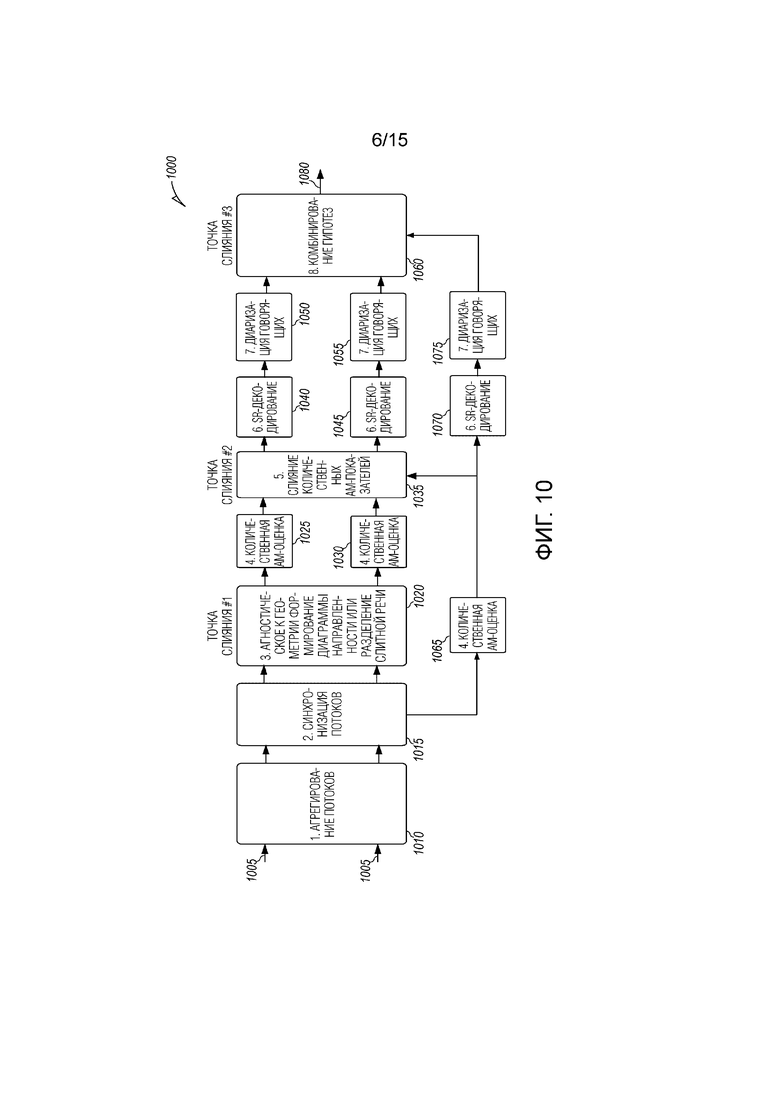
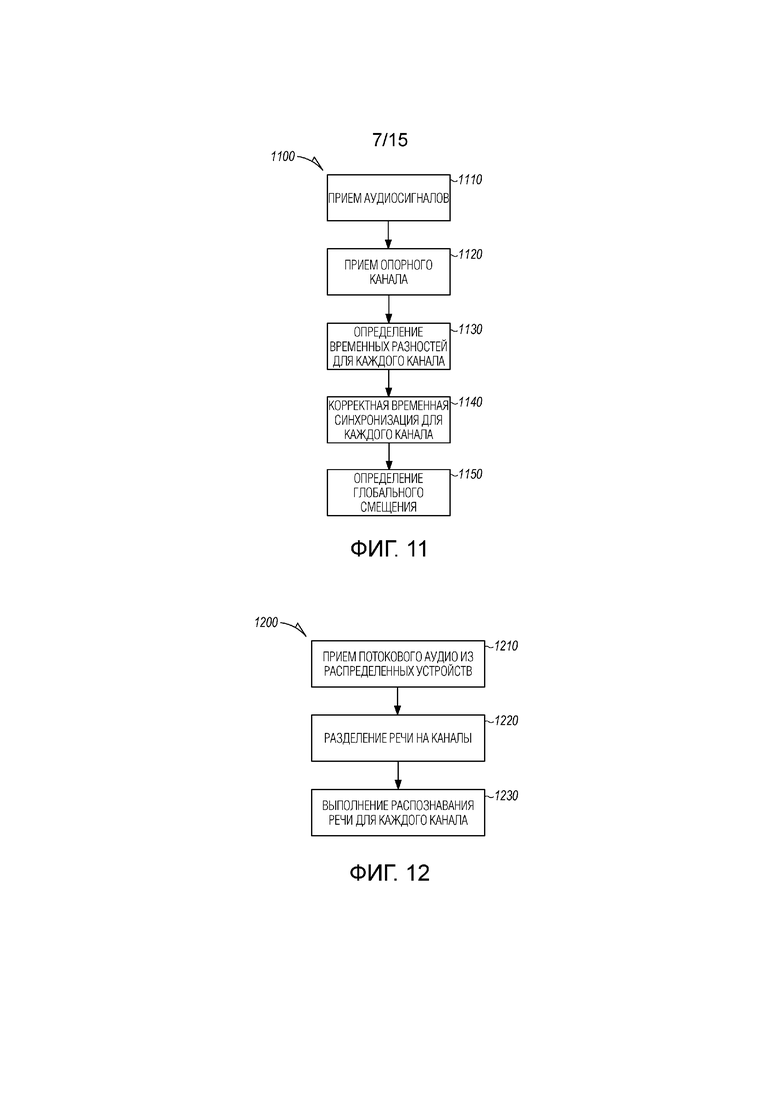
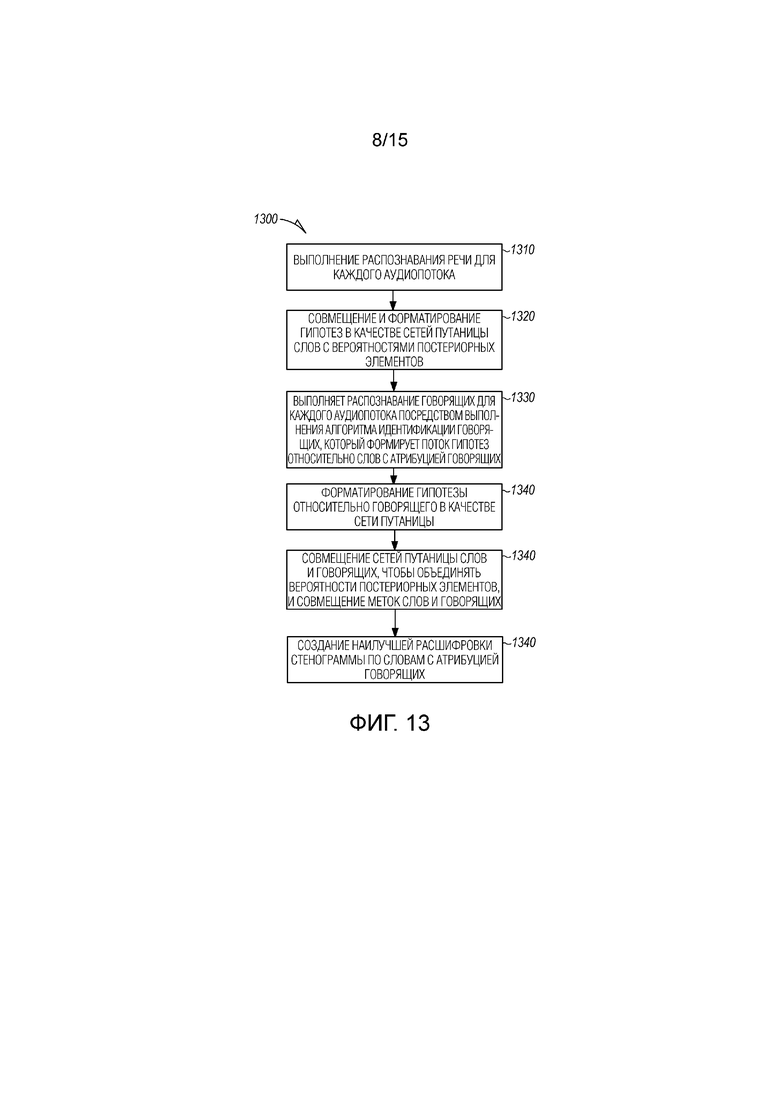
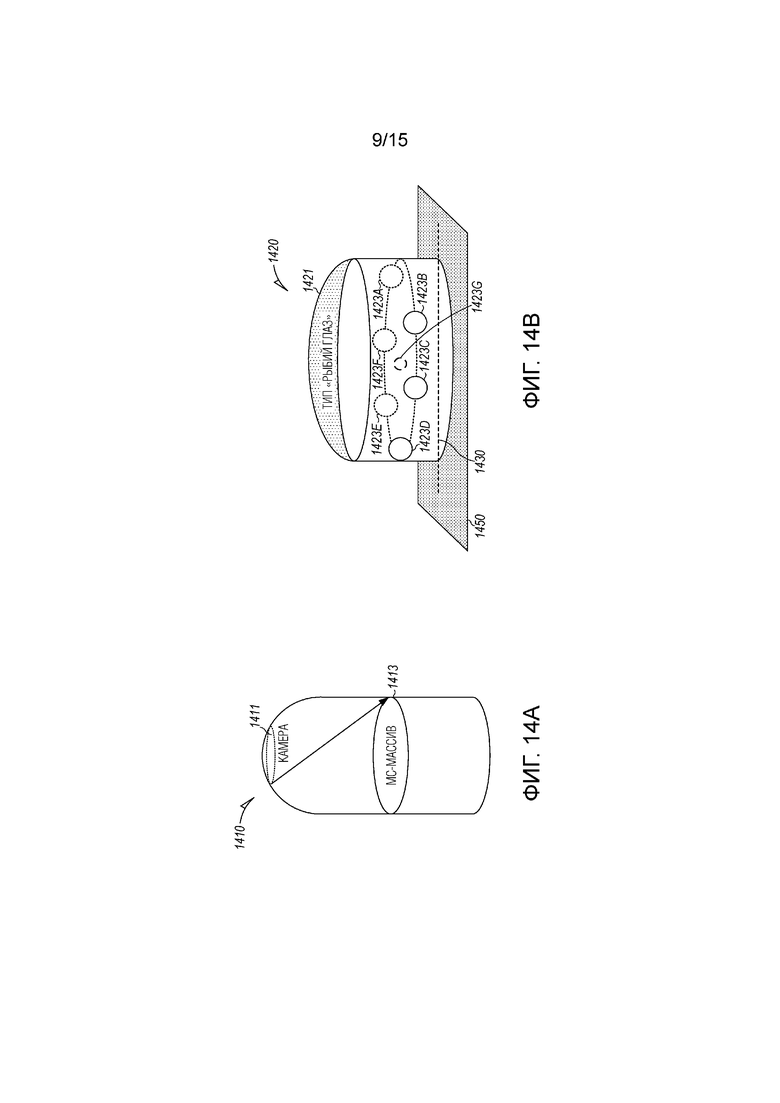
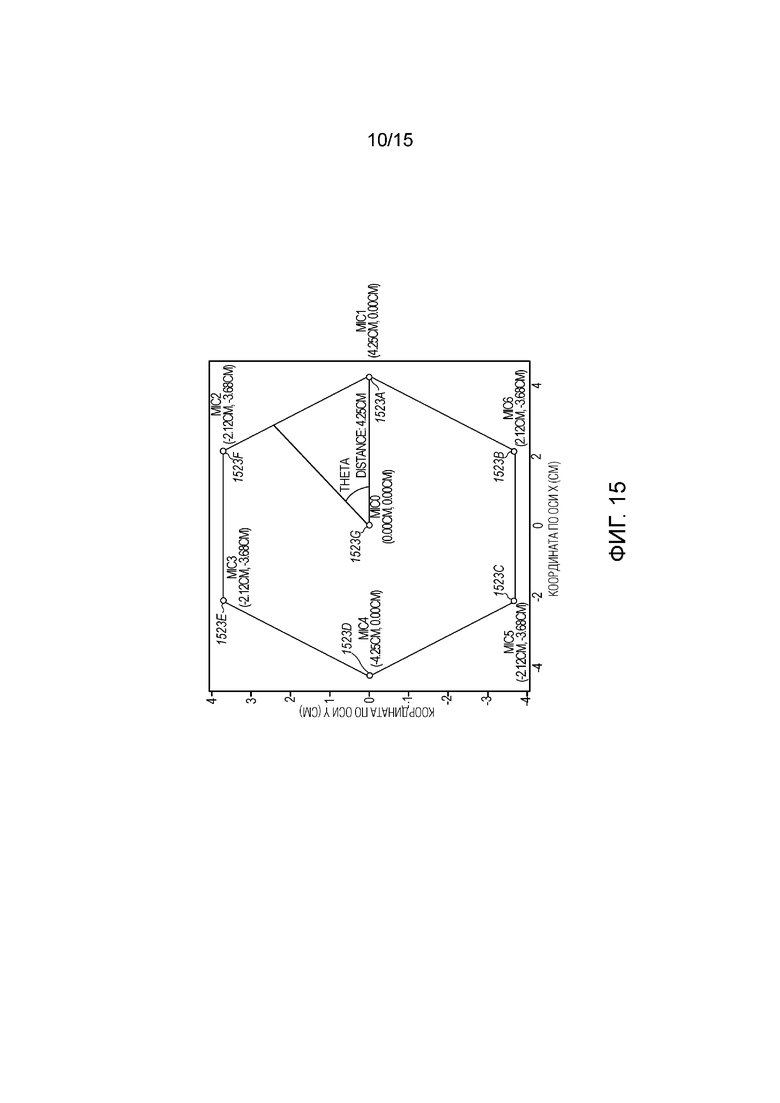
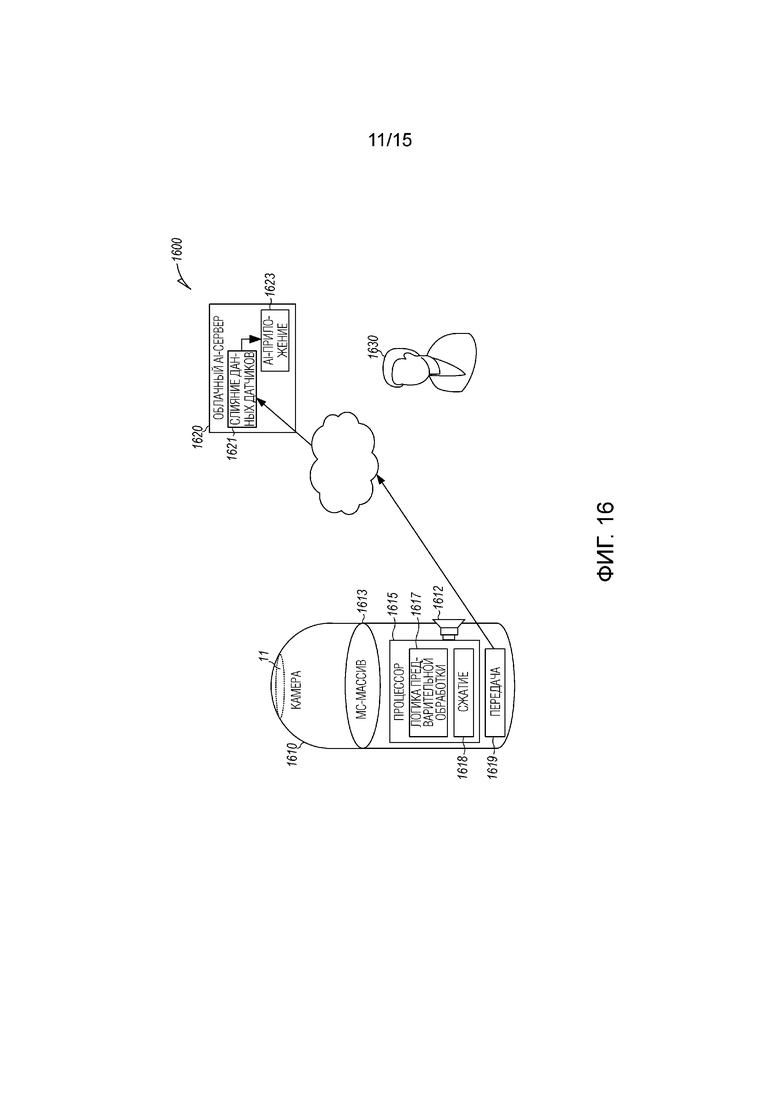
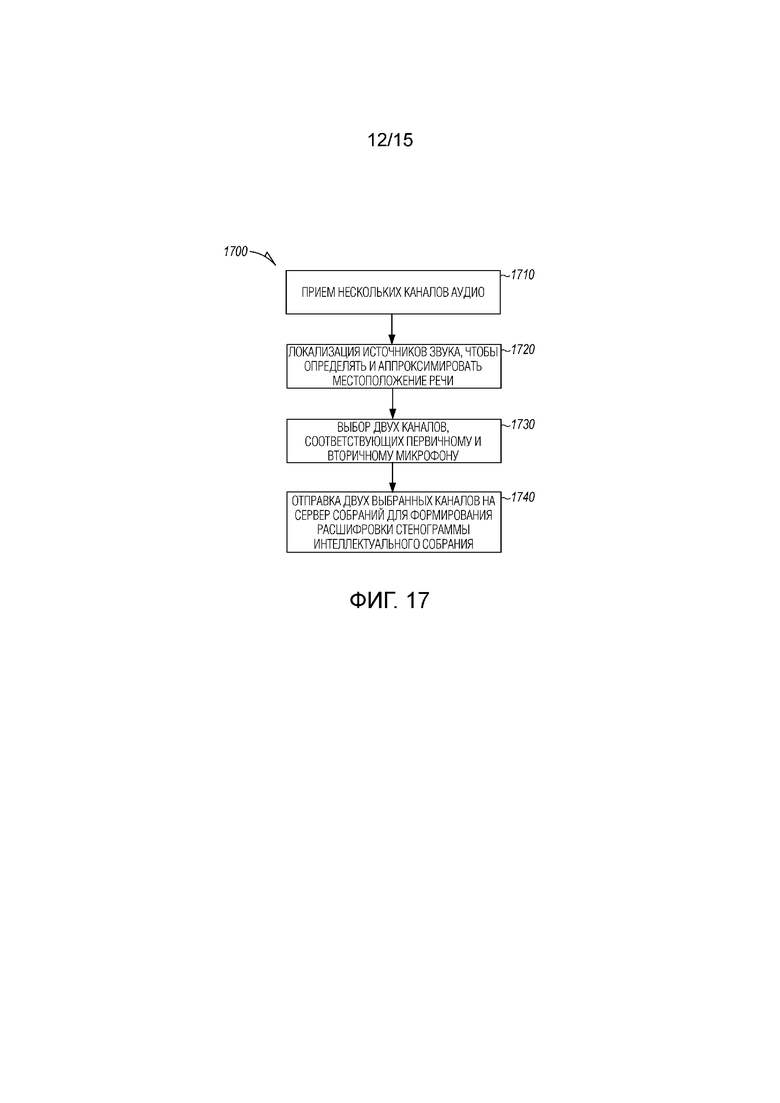
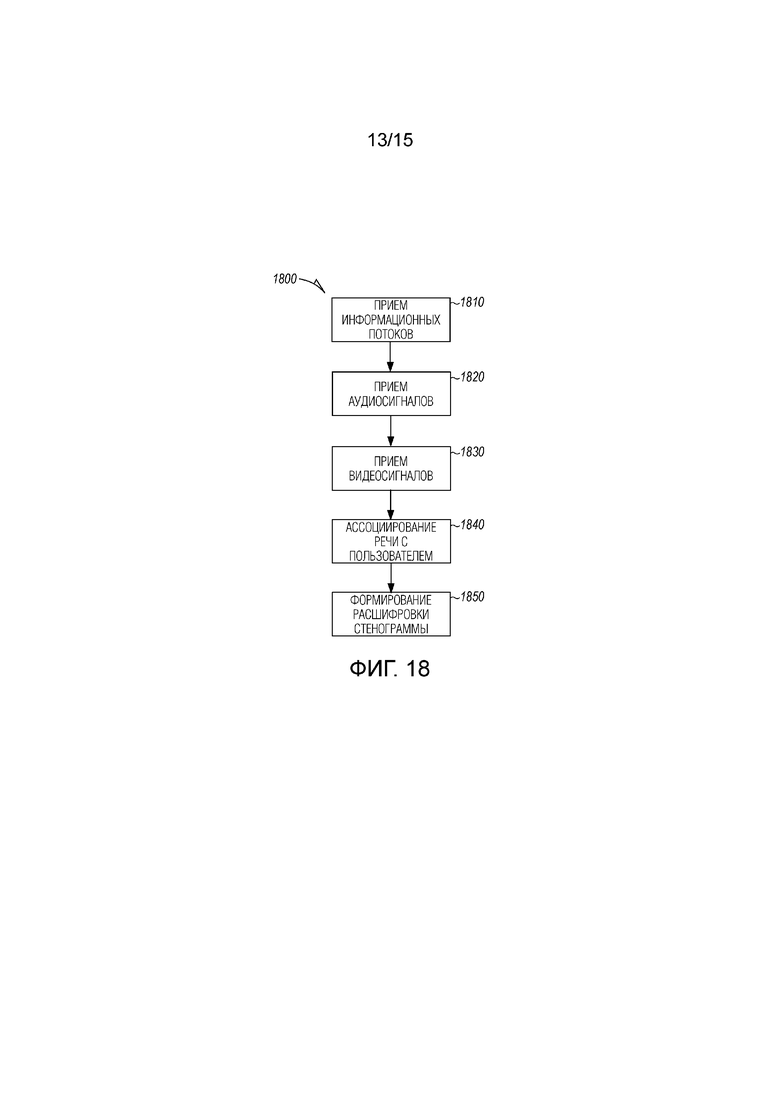
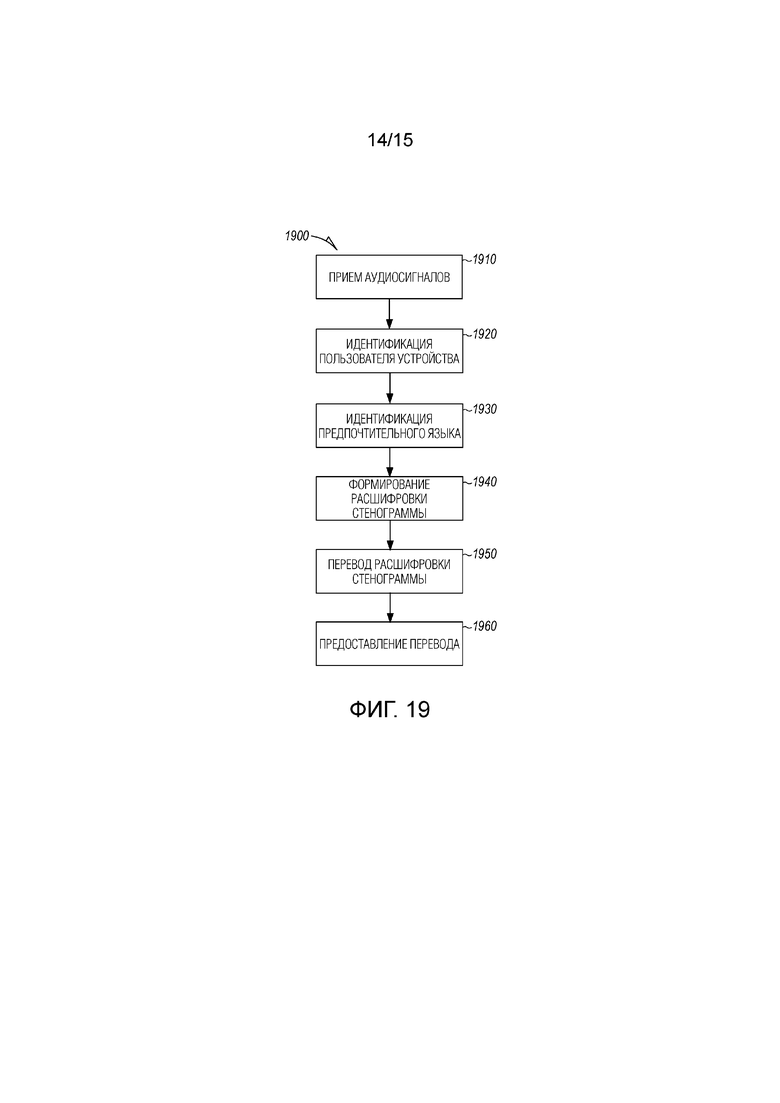
Изобретение относится к области инструментов для конференц-связи, которые устанавливаются перед собранием или в начале собрания, чтобы записывать беседу и формировать расшифровку стенограммы с атрибуцией говорящих. Предложены системы и способы для обеспечения индивидуально настроенного вывода на основе пользовательских предпочтений в распределенной системе. В примерных вариантах осуществления, сервер или система проведения собраний принимает аудиопотоки из множества распределенных устройств, предусмотренных на интеллектуальном собрании. Система проведения собраний идентифицирует пользователя, соответствующего распределенному устройству из множества распределенных устройств, и определяет предпочтительный язык пользователя. Формируется расшифровка стенограммы из принимаемых аудиопотоков. Система проведения собраний переводит расшифровку стенограммы на предпочтительный язык пользователя, чтобы формировать переведенную расшифровку стенограммы. Переведенная расшифровка стенограммы предоставляется в распределенное устройство пользователя. Технический результат – обеспечение возможности точной идентификации говорящих. 3 н. и 17 з.п. ф-лы, 21 ил., 1 табл.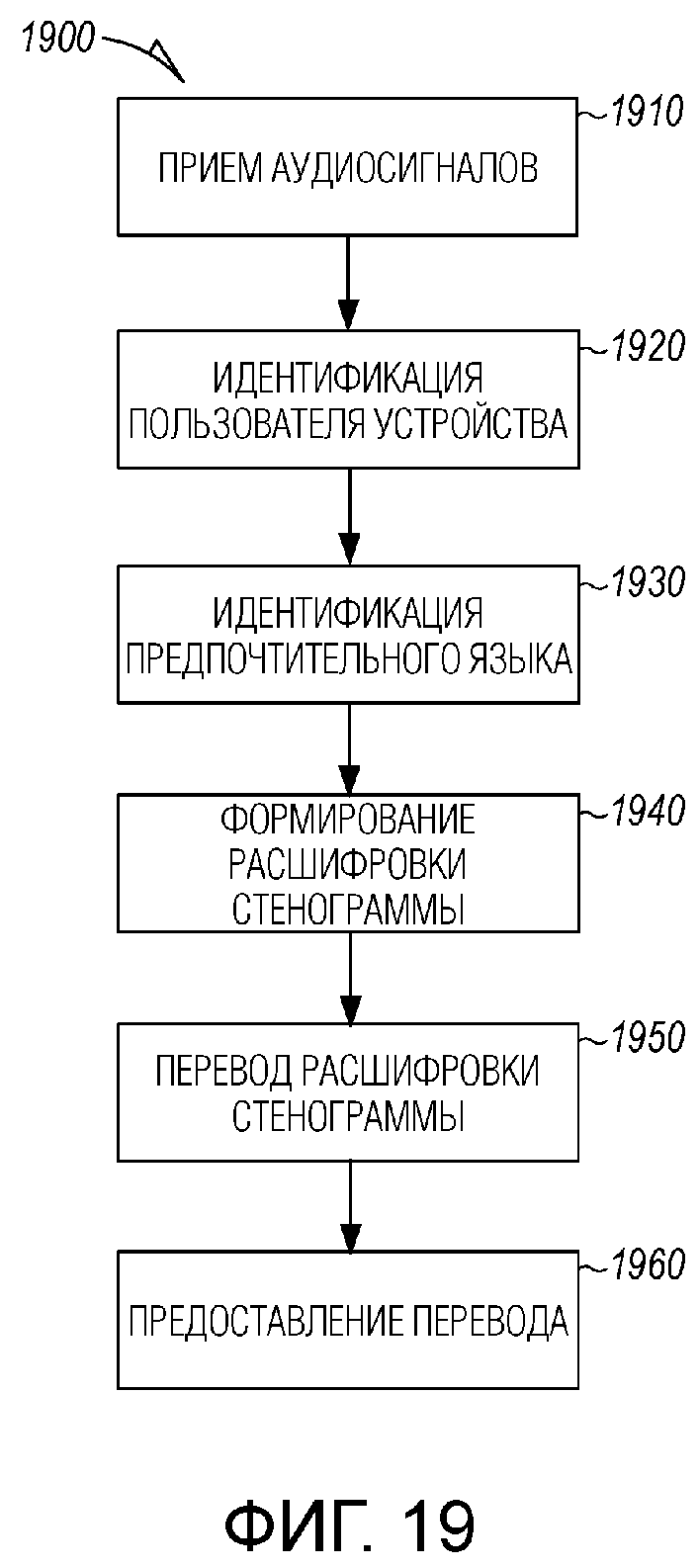
1. Машинореализуемый способ формирования расшифровки стенограммы из аудиопотоков, содержащий этапы, на которых:
принимают аудиопотоки, захваченные множеством распределенных устройств;
сравнивают эти аудиопотоки, захваченные множеством устройств, для определения того, представляют ли аудиопотоки звук с одного и того же собрания;
на основе того, что данное сравнение показывает, что аудиопотоки представляют звук с одного и того же собрания, создают экземпляр собрания для собрания;
идентифицируют пользователя, соответствующего распределенному устройству из множества распределенных устройств, на собрании;
определяют предпочтительный язык пользователя;
формируют, посредством аппаратного процессора, расшифровку стенограммы из принимаемых аудиопотоков по ходу собрания;
переводят расшифровку стенограммы на предпочтительный язык пользователя, чтобы сформировать переведенную расшифровку стенограммы по ходу собрания; и
предоставляют переведенную расшифровку стенограммы в распределенное устройство по ходу собрания.
2. Способ по п.1, в котором при упомянутом предоставлении переведенной расшифровки стенограммы предоставляют расшифровку стенограммы с переведенным текстом для отображения на распределенном устройстве по ходу собрания.
3. Способ по п.1, в котором упомянутое предоставление переведенной расшифровки стенограммы содержит этап, на котором преобразуют текст переведенной расшифровки стенограммы в речь для вывода пользователю распределенного устройства по ходу собрания.
4. Способ по п.1, в котором упомянутое предоставление переведенной расшифровки стенограммы содержит этап, на котором предоставляют идентификационные данные говорящего для каждого переведенного речевого фрагмента расшифровки стенограммы.
5. Способ по п.1, в котором упомянутое определение предпочтительного языка пользователя содержит этап, на котором осуществляют доступ к пользовательским предпочтениям, ранее установленным для пользователя, указывающего предпочтительный язык.
6. Способ по п.1, в котором упомянутое сравнение аудиопотоков, захваченных множеством устройств, для определения того, что аудиопотоки представляют звук с одного и того же собрания, содержит этапы, на которых:
вычисляют коэффициенты нормализованной взаимной корреляции между сигналами аудиопотоков; и
определяют, превышено ли заранее определенное пороговое значение, причем превышение этого заранее определенного порогового значения указывает, что аудиопотоки представляют звук с одного и того же собрания.
7. Способ по п.1, дополнительно содержащий этап, на котором выполняют разделение слитной речи в отношении аудиопотоков, принимаемых от множества распределенных устройств, чтобы разделять речь от различных говорящих, которые говорят одновременно, на отдельные аудиоканалы, причем формирование расшифровки стенограммы основано на этих разделенных аудиоканалах.
8. Способ по п.1, в котором упомянутая идентификация пользователя содержит этапы, на которых:
принимают видеосигнал, захватывающий изображение пользователя; и
сопоставляют сохраненное изображение пользователя с видеосигналом, чтобы идентифицировать пользователя.
9. Способ по п.1, в котором упомянутая идентификация пользователя содержит этап, на котором сопоставляют сохраненную голосовую подпись пользователя с речью из аудиопотоков.
10. Способ по п.1, в котором упомянутая идентификация пользователя содержит этап, на котором получают идентификатор пользователя, ассоциированный с распределенным устройством.
11. Энергонезависимый машиночитаемый носитель, хранящий инструкции для исполнения процессором машины, чтобы предписывать процессору выполнять операции, содержащие:
прием аудиопотоков, захваченных множеством распределенных устройств;
сравнение этих аудиопотоков, захваченных множеством устройств, для определения того, представляют ли аудиопотоки звук с одного и того же собрания;
на основе того, что данное сравнение показывает, что аудиопотоки представляют звук с одного и того же собрания, создание экземпляра собрания для собрания;
идентификацию пользователя, соответствующего распределенному устройству из множества распределенных устройств, на собрании;
определение предпочтительного языка пользователя;
формирование расшифровки стенограммы из принимаемых аудиопотоков по ходу собрания;
перевод расшифровки стенограммы на предпочтительный язык пользователя, чтобы сформировать переведенную расшифровку стенограммы по ходу собрания; и
предоставление переведенной расшифровки стенограммы в распределенное устройство по ходу собрания.
12. Энергонезависимый машиночитаемый носитель по п.11, при этом при упомянутом предоставлении переведенной расшифровки стенограммы предоставляется расшифровка стенограммы с переведенным текстом для отображения на распределенном устройстве по ходу собрания.
13. Энергонезависимый машиночитаемый носитель по п.11, при этом упомянутое предоставление переведенной расшифровки стенограммы содержит преобразование текста переведенной расшифровки стенограммы в речь для вывода пользователю распределенного устройства по ходу собрания.
14. Энергонезависимый машиночитаемый носитель по п.11, при этом упомянутое предоставление переведенной расшифровки стенограммы содержит предоставление идентификационных данных говорящего для каждого переведенного речевого фрагмента расшифровки стенограммы.
15. Энергонезависимый машиночитаемый носитель по п.11, при этом упомянутое определение предпочтительного языка пользователя содержит осуществление доступа к пользовательским предпочтениям, ранее установленным для пользователя, указывающего предпочтительный язык.
16. Энергонезависимый машиночитаемый носитель по п.11, при этом упомянутое сравнение аудиопотоков, захваченных множеством устройств, для определения того, что аудиопотоки представляют звук с одного и того же собрания, содержит:
вычисление коэффициентов нормализованной взаимной корреляции между сигналами аудиопотоков; и
определение того, превышено ли заранее определенное пороговое значение, причем превышение этого заранее определенного порогового значения указывает, что аудиопотоки представляют звук с одного и того же собрания.
17. Энергонезависимый машиночитаемый носитель по п.11, при этом операции дополнительно содержат разделение слитной речи в отношении аудиопотоков, принимаемых от множества распределенных устройств, чтобы разделять речь от различных говорящих, которые говорят одновременно, на отдельные аудиоканалы, причем формирование расшифровки стенограммы основано на этих разделенных аудиоканалах.
18. Энергонезависимый машиночитаемый носитель по п.11, при этом упомянутая идентификация пользователя содержит:
прием видеосигнала, захватывающего изображение пользователя; и
сопоставление сохраненного изображения пользователя с видеосигналом, чтобы идентифицировать пользователя.
19. Энергонезависимый машиночитаемый носитель по п.11, при этом упомянутая идентификация пользователя содержит сопоставление сохраненной голосовой подписи пользователя с речью из аудиопотоков.
20. Вычислительное устройство, сконфигурированное для формирования расшифровки стенограммы из аудиопотоков, при этом вычислительное устройство содержит:
один или более аппаратных процессоров; и
запоминающее устройство, которое соединено с процессором и в котором сохранена программа, которая при её исполнении одним или более аппаратными процессорами инструктирует одному или более аппаратным процессорам выполнять операции, содержащие:
прием аудиопотоков, захваченных множеством распределенных устройств,
сравнение этих аудиопотоков, захваченных множеством устройств, для определения того, представляют ли аудиопотоки звук с одного и того же собрания,
на основе того, что данное сравнение показывает, что аудиопотоки представляют звук с одного и того же собрания, создание экземпляра собрания для собрания,
идентификацию пользователя, соответствующего распределенному устройству из множества распределенных устройств, на собрании,
определение предпочтительного языка пользователя,
формирование расшифровки стенограммы из принимаемых аудиопотоков по ходу собрания,
перевод расшифровки стенограммы на предпочтительный язык пользователя, чтобы сформировать переведенную расшифровку стенограммы по ходу собрания, и
предоставление переведенной расшифровки стенограммы в распределенное устройство по ходу собрания.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| ОБНАРУЖЕНИЕ РАЗГОВОРА | 2015 |
|
RU2685970C2 |

