ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области обработки информационных материалов, использующих тексты, представленные на естественных языках, и может быть использовано для повышения качества оформления и представления инструкций, учебных пособий, рекламных материалов и других информационных средств, при изучении которых от пользователя требуется понимание представляемой информации.
УРОВЕНЬ ТЕХНИКИ
В настоящее время в уровне техники существует потребность в повышении информативности текстовых материалов и ускорении верного восприятия пользователями содержания текстовых документов. Например, в патентной заявке WO2013016707, опубликованной 31.01.2013 описан способ представления текстовых инструкций в интерактивном виде с использованием поясняющих изображений. Несмотря на то, что данный способ следует признать эффективным, отсутствуют объективные средства определения эффективности технологии, используемые для представления текста.
Предложенное изобретение решает актуальную задачу уровня техники и дает возможность объективно оценить эффективность представления текстовых материалов. Прямых аналогов предложенного изобретения в уровне техники не выявлено, в связи с чем в качестве наиболее близкого аналога изобретения выбрано решение, раскрытое в патенте RU2571373, опубликованном 20.12.2015, где информационные тексты на естественном языке подвергаются лексическому анализу, по результатам которого можно сделать выводы о воздействии текста на пользователей, например, определить психологический климат в сообществе пользователей, формирующих текстовые сообщения.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Технический результат, достигаемый при использовании изобретения, заключается в возможности генерации оптимальной структуры для представления информационных текстов, которые должны побуждать пользователей к определенным действиям, а также в обеспечении возможности реструктуризации текстов, для обеспечения повышения их информативности.
Согласно одному из вариантов реализации, предлагается способ определения эффективности представления заданных текстовых материалов, заключающийся в том, что: измеряют объем и определяют лингвистическую сложность нескольких текстовых материалов; для каждой из заданных форм представления текстовых материалов определяют когнитивную трудность восприятия; формируют базу данных соответствия когнитивной трудности восприятия объему и лингвистической сложности для различных текстовых материалов; для заданных текстовых материалов, имеющих заданную форму представления, определяют лингвистическую сложность и определяют когнитивную трудность восприятия заданной формы представления заданных текстовых материалов; выбирают из базы данных текстовые материалы, имеющие ближайший к заданным текстовым материалам объем и лингвистическую сложность, сравнивают когнитивную трудность восприятия заданных и выбранных текстовых материалов и определяют эффективность представления заданных текстовых материалов по разнице в когнитивной трудности восприятия выбранных и заданных тестовых материалов, где повышенная когнитивная трудность восприятия заданных текстовых материалов соответствует относительно низкой эффективности представления заданных текстовых материалов, а пониженная когнитивная трудность восприятия заданных текстовых материалов соответствует относительно высокой эффективности представления заданных текстовых материалов.
В одном из частных вариантов реализации при низкой эффективности представления заданных текстовых материалов изменяют форму представления текстовых материалов до приведения когнитивной трудности восприятия заданных текстовых материалов в соответствие с когнитивной трудностью восприятия выбранных текстовых материалов.
В одном из частных вариантов реализации при существенной высокой относительной эффективности заданных текстовых материалов изменяют лексическую структуру заданных текстовых материалов в соответствии с заданной формой представления заданных текстовых материалов.
В одном из частных вариантов реализации лингвистическую сложность текстового материала определяют следующими адаптированными для русского языка способами в отдельности или в их комбинации: способ вычисления сложности с использованием теста Флэша-Кинкайда, как суммы произведения средней длины предложения на коэффициент, равный 0.318, и произведения среднего количества слогов в слове на коэффициент, равный 14.2, и из этой суммы вычитается коэффициент, равный 30.5; способ вычисления сложности с использованием теста Колман-Лиау, как разности произведения среднего количества букв на сто слов на коэффициент, равный 0.055, и произведения среднего количества предложений на сто слов на коэффициент, равный 0.35 и из этой разности вычитается коэффициент, равный 20.33; способ вычисления сложности по формуле SMOG, как суммы коэффициента, равного 0.05, и результата умножения коэффициента, равного 1.1, на корень квадратный из результата умножения количества многосложных слов на результат деления коэффициента, равного 64.6, на количество предложений, где многосложные слова состоят из трех и более слогов; способ вычисления сложности по формуле Дэйла-Чалла, как суммы результата умножения коэффициента, равного 0.552, на результат деления количества многосложных слов на общее количество слов и результата произведения коэффициента, равного 0.273 на результат деления общего количества слов на общее количество предложений; способ вычисления сложности с использованием вычисления автоматизированного индекса удобочитаемости, как суммы результата деления количества букв и цифр в тексте на количество слов в тексте, умноженного на коэффициент, равный 6.26, и результата деления количества слов в тексте на количество предложений в тексте, умноженного на коэффициент, равный 0.28.
В одном из частных вариантов реализации лингвистическая сложность текстового материала вычисляется, как среднее арифметическое от индекса, вычисленного по Флэшу-Кинкайду, индекса, вычисленного по Колман-Лиау, индекса, вычисленного по SMOG (Simple Measure of Gobbledygook), индекса, вычисленного по Дейлу-Чаллу и автоматизированного индекса удобочитаемости.
В одном из частных вариантов реализации для определения значения когнитивной трудности восприятия обеспечивают определение направления взгляда пользователя относительно последовательно расположенных участков текста, а значение когнитивной трудности восприятия определяют как количество возвратных перемещений взгляда пользователя от позднее расположенных участков к ранее расположенным участкам за время от начала до окончания чтения текста пользователем.
В одном из частных вариантов реализации уточняют значение когнитивной трудности восприятия, путем деления количества возвратных перемещений на количество фиксаций, где фиксацией является сосредоточение взгляда пользователем на участках текстовых материалов.
В одном из частных вариантов реализации дополняют базу данных свойствами пользователей, имеющими отношение к уровню когнитивной трудности восприятия.
В одном из частных вариантов реализации свойствами пользователей, имеющими отношение к уровню когнитивной трудности восприятия, является уровень образования или специализация по образованию.
В одном из частных вариантов реализации дополнительно выбирают из базы данных текстовые материалы, имеющие ближайший к заданным текстовым материалам объем и иную лингвистическую сложность и проверяют правильность определения эффективности представления заданных текстовых материалов путем сравнения когнитивной трудности восприятия заданных текстовых материалов и когнитивной трудности восприятия дополнительно выбранных текстовых материалов, где соответствие направление изменения когнитивной трудности восприятия и лингвистической сложности свидетельствует о правильности определения эффективности представления.
В одном из частных вариантов реализации текстовыми материалами являются рекламные текстовые материалы.
В одном из частных вариантов реализации формируют список вопросов, позволяющих определить степень усвоения текста испытуемым и при недостижении требуемой степени усвоения текста, исключают испытуемого из программы испытаний.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
ФИГ. 1 иллюстрирует примерный вариант осуществления настоящего изобретения;
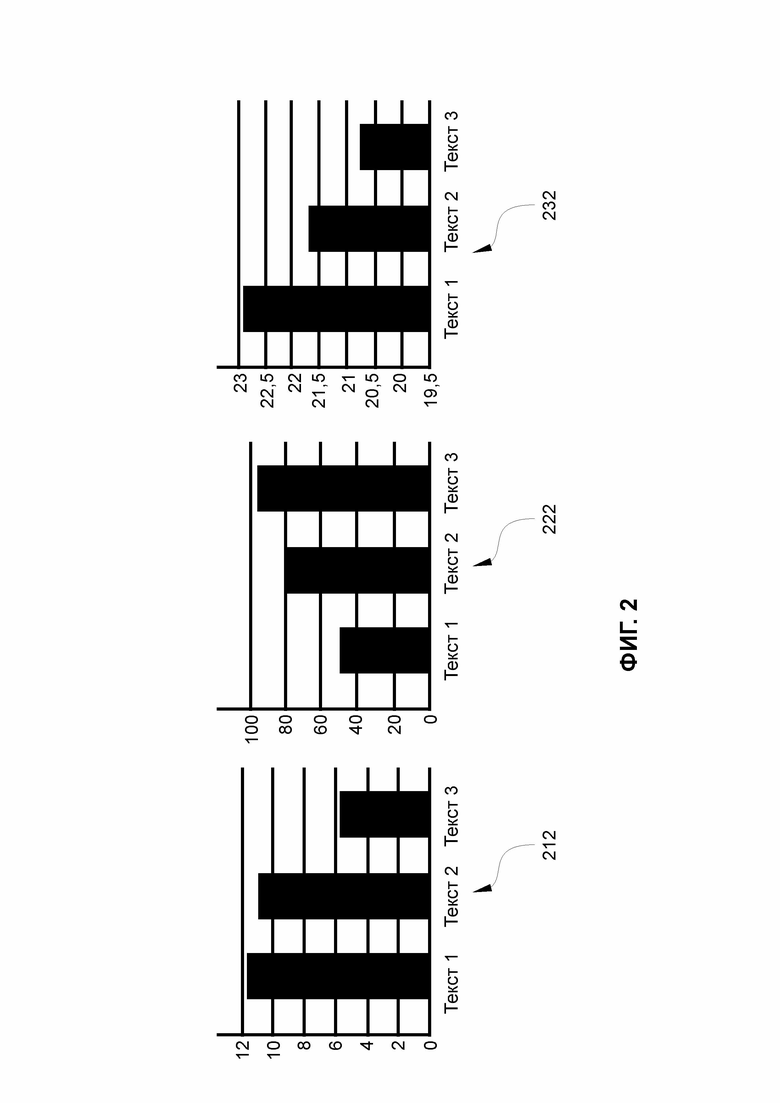
ФИГ. 2 иллюстрирует вариант диаграмм сравнения удобочитаемости, результатов контрольных вопросов и трудности чтения для тестов;
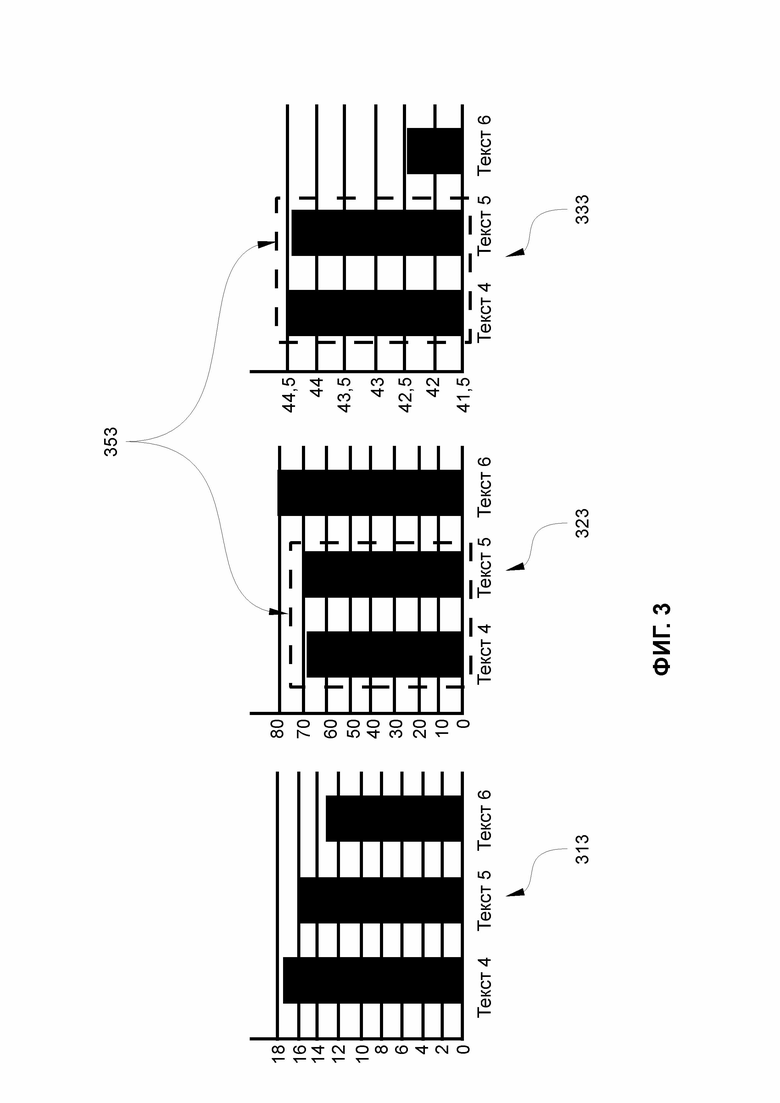
ФИГ. 3 иллюстрирует вариант диаграмм сравнения удобочитаемости, результатов контрольных вопросов и трудности чтения для тестов с рассогласованием;
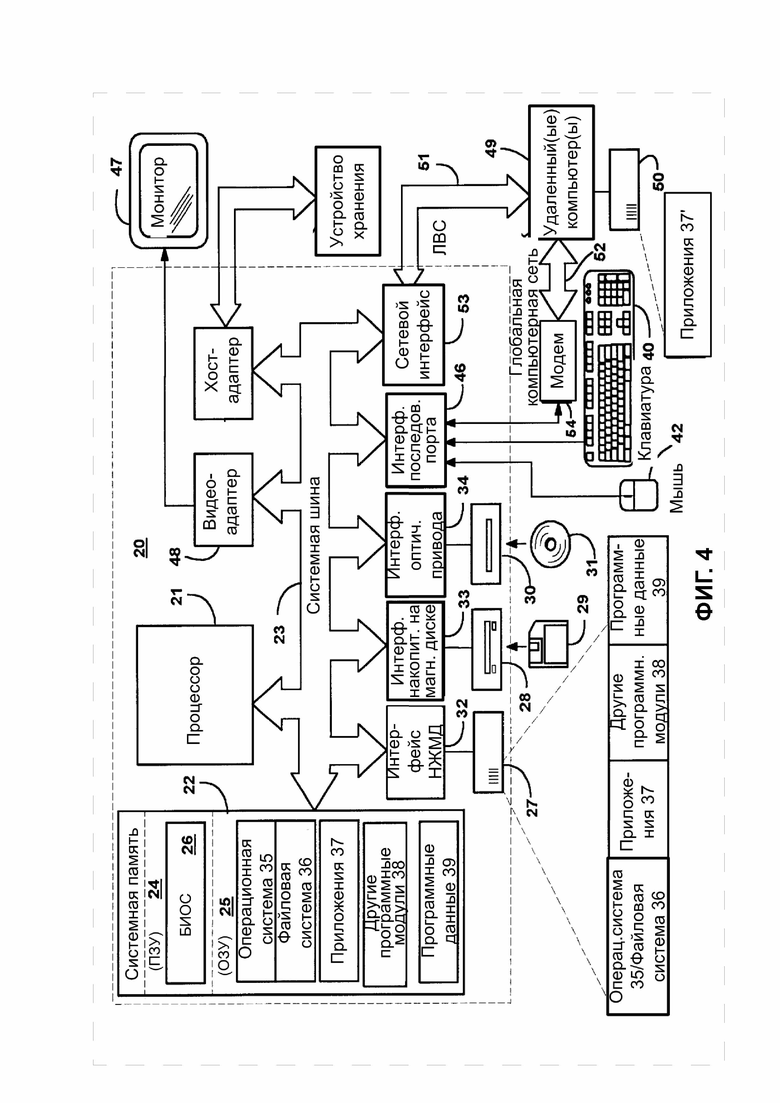
ФИГ. 4 иллюстрирует пример вычислительной системы, пригодной для реализации элементов предложенного изобретения;
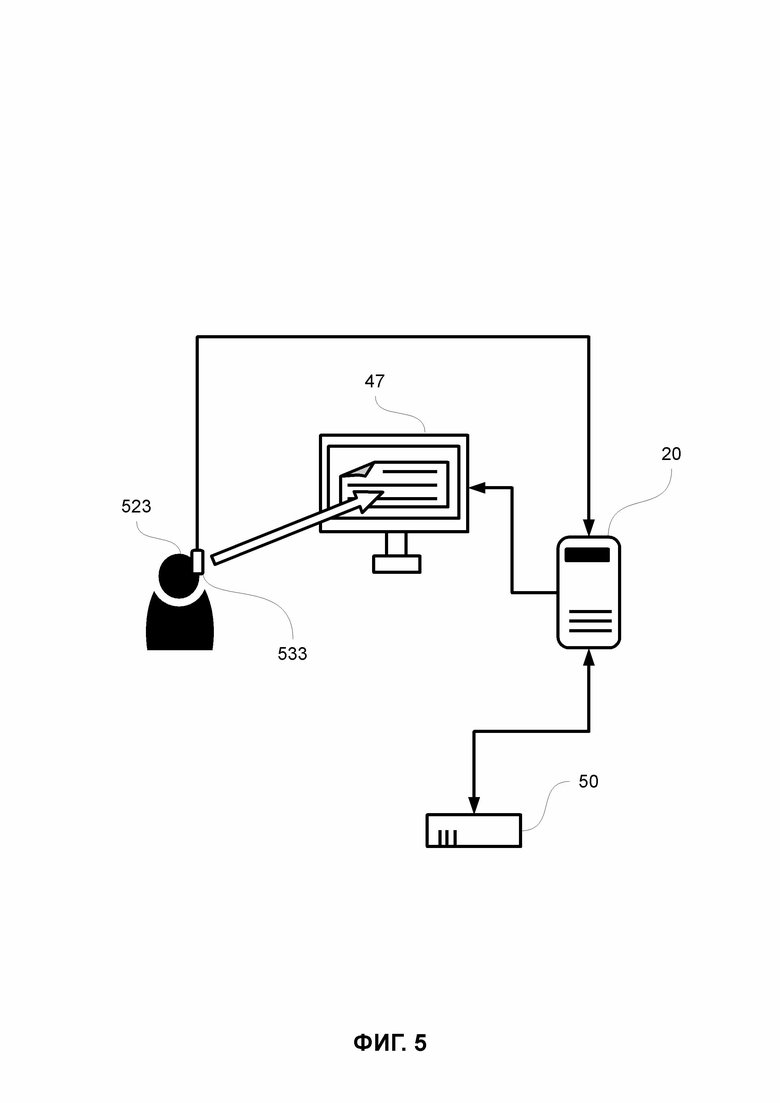
ФИГ. 5 иллюстрирует упрощенный пример аппаратной реализации предложенного изобретения.
ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется только в объеме приложенной формулы.
Используемые в настоящем описании изобретения термины «модуль», «компонент», «элемент», «часть», «составная часть» и подобные используются для обозначения компьютерных сущностей, которые могут являться аппаратным обеспечением, например, устройством или частью устройства, в частности, включающим, по крайней мере, один процессор, микроконтроллер и т.д., или программным обеспечением, например, компьютерной программой, «прошивкой» (от англ. firmware) и т.д., позволяющей аппаратному обеспечению вычислительной системы выполнять вычисления или функции управления, являющиеся комбинацией инструкций и данных.
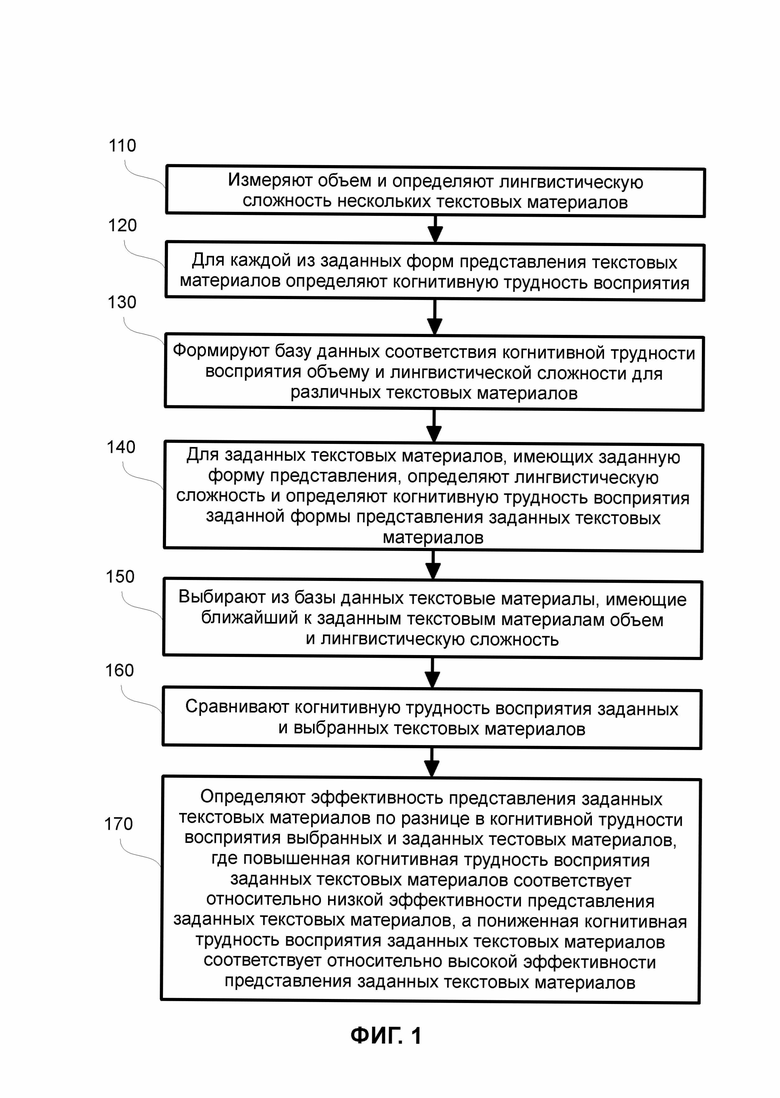
На ФИГ. 1 показан примерный вариант осуществления настоящего изобретения.
Для определения эффективности визуального представления текстовых материалов в настоящем изобретении вычисляется когнитивная трудность и лингвистическая сложность текстовых материалов.
Когнитивной трудностью является субъективное отношение пользователя 523 (ФИГ. 5) к тексту. Так, на восприятие текста пользователем 523 (ФИГ. 5) влияет ряд особенностей конкретных пользователей, например, уровень образования пользователя 523 (ФИГ. 5), его возраст, психологические показатели личности, функциональное состояние, показатели внимания, а также целый ряд других показателей. Такие особенности находят свое отражение в психофизиологических реакциях пользователя 523 (ФИГ. 5), которые регистрируются с использованием средств окулографии (айтрекинга, от англ. eye tracking), как описано в рамках настоящего изобретения.
Лингвистическая сложность текста является одной из характеристик, которая обуславливает когнитивную трудность и может быть вычислена независимо от когнитивной трудности.
В настоящее время известны методики, формулы и индексы, позволяющие вычислить коэффициент лингвистической сложности текста, в том числе для русского языка. В основном все они основаны на количественных показателях, связанных со средней длиной предложения, числом слогов в слове, процентом многосложности, и представляют собой линейную регрессионную модель.
Как показано на ФИГ. 1, в шаге 110 осуществляется измерение объема и определение лингвистической сложности нескольких текстовых материалов.
Лингвистическая сложность является объективным и независимым от особенностей конкретного пользователя 523 (ФИГ. 5), который читает предъявляемые ему текстовые материалы, параметром. Лингвистическая сложность относится исключительно к лингвистическим особенностям текстового материала и на современном уровне разработки автоматических методов вычисления этого показателя определяется без участия респондентов. Миком Я.А. еще несколько десятилетий назад была показана высокая корреляционная связь между уровнем усвоения материала и лингвистической сложностью текста для английского языка. С позиций механической оценки восприятия и понимания текста лингвистическая сложность является наиболее комплексным и информативным показателем, что было проверено в проведенных исследованиях на примере использования коммерческих текстов, встречающихся в актуальной на сегодняшний день рекламе, в частности, в предъявляемых пользователю 523 (ФИГ. 5) текстовых материалах, содержащих рекламу.
В частном случае лингвистическая сложность текстового материала, в том числе, по крайней мере, для одного заданного материала, например, рекламных материалов, может быть определена с использованием различных способов, например, приведенных ниже, в частности, адаптированных для русского языка.
Одним из упомянутых способов является способ вычисления сложности с использованием теста Флэша-Кинкайда (Flesch-Kinkaid Readability Test), который изначально был основан на тесте Рудольфа Флэша по оценке сложности английских текстов и был доработан Питером Кинкайдом. В данном тесте заложен тезис, что чем меньше слов в предложениях и чем короче слова, тем более простым является текст. Сложность, в частности, индекс удобочитаемости (индекс сложности) по Флэшу-Кинкайду вычисляется, как сумма произведения средней длины предложения на коэффициент, равный 0.39, и произведения среднего количества слогов в слове на коэффициент, равный 11.8, и из этой суммы вычитается коэффициент, равный 15.59. Приведенные коэффициенты используются для вычисления индекса для английского языка. Для русского языка индекс удобочитаемости по Флэшу-Кинкайду вычисляется, как сумма произведения средней длины предложения на коэффициент, равный 0.318, и произведения среднего количества слогов в слове на коэффициент, равный 14.2, и из этой суммы вычитается коэффициент, равный 30.5. Таким образом, индекс вычисляется по формуле:
0.318 * ASL + 14.2 * ASW - 30.5,
где
ASL - средняя длина предложения (число слов, деленное на число предложений);
ASW - среднее число слогов в слове (число слогов, деленное на число слов).
Коэффициенты подбираются эмпирически.
Следующим способом является способ вычисления сложности с использованием теста Колман-Лиау (Coleman-Lian Readability Test), который был разработан М. Колмен и Т.Л. Лиау для простой и механической оценки сложности текстов. Индекс по Колман-Лиау вычисляется, как разность произведения среднего количества букв на сто слов на коэффициент, равный 0.0588, и произведения среднего количества предложений на сто слов на коэффициент, равный 0.296 и из этой разности вычитается коэффициент, равный 15.8. Приведенные коэффициенты используются для вычисления индекса для английского языка. Для русского языка индекс по Колман-Лиау вычисляется, как разность произведения среднего количества букв на сто слов на коэффициент, равный 0.055, и произведения среднего количества предложений на сто слов на коэффициент, равный 0.35 и из этой разности вычитается коэффициент, равный 20.33, т.е. по формуле:
CLI=0.055*L-0.35*S-20.33,
где
L - среднее количество букв на 100 слов,
S - среднее количество предложений на 100 слов.
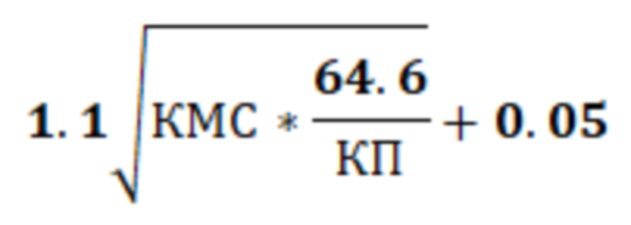
Другим способом является способ вычисления сложности по формуле SMOG (Simple Measure of Gobbledygook), которая была рассчитана Гарри МакЛауглином (Harry McLaughlin), как более точная и более легко вычисляемая замена индекса Тумана Ганнинга. В данном случае на вычисление сложности влияет количество слов с множеством слогов, то есть чем сложнее слово, тем больше слогов. Такой способ часто используется в медицинской сфере. В данном способе индекс вычисляется, как сумма коэффициента, равного 3,1291, и результата умножения коэффициента, равного 1,0430, на корень квадратный из результата умножения количества многосложных слов на результат деления коэффициента, равного 30, на количество предложений, где многосложные слова состоят из трех и более слогов. Приведенные коэффициенты используются для вычисления индекса для английского языка. Для русского языка индекс вычисляется, как сумма коэффициента, равного 0.05, и результата умножения коэффициента, равного 1.1, на корень квадратный из результата умножения количества многосложных слов на результат деления коэффициента, равного 64.6, на количество предложений, т.е. по формуле:
 ,
,
где
КМС - количество многосложных слов;
КП - количество предложений.
Еще одним из упомянутых способов является способ вычисления сложности по формуле Дэйла-Чалла (Dale-Chale readability formula), разработанной на основе списка из 763 слов, 80 процентов которых являются знакомыми для учеников четвертого класса, тем самым выявив сложные слова. Формула была обновлена с расширением списка слов до 3000 знакомых слов. Ввиду специфики оценки она в основном использовалась и используется для проверки текстов для школьников начиная с четвертого класса. В данном способе индекс вычисляется, как сумма результата умножения коэффициента, равного 1.1579, на результат деления количества многосложных слов (КМС) на общее количество слов (в частности, слов всего) и результата произведения коэффициента, равного 0.0496 на результат деления общего количества слов на общее количество предложений (в частности, предложений всего). Приведенные коэффициенты используются для вычисления индекса для английского языка. Для русского языка индекс вычисляется, как сумма результата умножения коэффициента, равного 0.552, на результат деления количества многосложных слов на общее количество слов и результата произведения коэффициента, равного 0.273 на результат деления общего количества слов на общее количество предложений, т.е. по формуле:
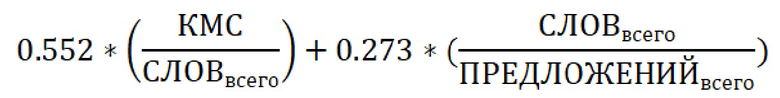 .
.
Также, одним из упомянутых способов является способ вычисления сложности с использованием вычисления автоматизированного индекса удобочитаемости (Automated Readability Index). Индекс предназначен для оценки понятности текста. В основе, как и в формуле Колеман-Лиау, лежит число букв, которое влияет на оценку сложности. В данном способе индекс вычисляется, как сумма результата деления количества букв и цифр в тексте на количество слов в тексте, умноженного на коэффициент, равный 4.71, и результата деления количества слов в тексте на количество предложений в тексте, умноженного на коэффициент, равный 0.5. Приведенные коэффициенты используются для вычисления индекса для английского языка. Для русского языка индекс вычисляется, как сумма результата деления количества букв и цифр в тексте на количество слов в тексте, умноженного на коэффициент, равный 6.26, и результата деления количества слов в тексте на количество предложений в тексте, умноженного на коэффициент, равный 0.28, т.е. по формуле:
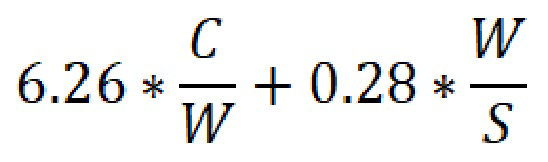 ,
,
где C - количество букв и цифр в тексте,
W - количество слов в тексте,
S - количество предложений в тексте.
В рамках осуществления настоящего изобретения из набора показателей, в частности индексов, формируется обобщенный индекс, который является сводной характеристикой, которая представляет собой одно значение, характеризующее то, насколько потенциально читаемый текст может быть сложен для потребителя. В частности, лингвистическая сложность проверяется посредством вычисления среднего значения для набора индексов, т.е. лингвистическая сложность вычисляется как сумма индекса по Флэшу-Кинкайду, индекса по Колман-Лиау, индекса по формуле SMOG, индекса по Дэйлу-Чаллу, автоматизированного индекса удобочитаемости, деленная на количество индексов, т.е. на пять.
Однако в ряде случаев поведенческие особенности (стратегии чтения, распределения внимания потребителя и ряд других субъективных характеристик) критично влияют на чтение и на восприятие просматриваемого (читаемого) пользователем 523 (ФИГ. 5) текста. Тогда показатель когнитивной трудности (в частности, доля возвратных движений глаз, регрессий, от общего количества фиксаций, совершенных на тексте) начинает расходиться с показателем лингвистической сложности.
В шаге 120 для каждой из заданных форм представления текстовых материалов осуществляется определение когнитивной трудности восприятия.
Когнитивная трудность (когнитивная трудность чтения, когнитивная трудность восприятия) определяет эффективность понимания пользователем 523 (ФИГ. 5) текста и его усвоение в реальных условиях его чтения.
В частном случае, для определения значения когнитивной трудности восприятия осуществляется определение направления взгляда пользователя 523 (ФИГ. 5) относительно последовательно расположенных участков текста. Значение когнитивной трудности восприятия определяется как количество возвратных перемещений взгляда пользователя 523 (ФИГ. 5) от позднее расположенных участков к ранее расположенным участкам за время от начала до окончания чтения текста пользователем 523 (ФИГ. 5).
В частном случае, осуществляется уточнение значения когнитивной трудности восприятия, путем деления количества возвратных перемещений на количество фиксаций, где фиксацией является сосредоточение взгляда пользователем на участках текстовых материалов, в частности, на частях текстовых материалов, например, на слове, частях слова, словосочетании, находящихся рядом словах и т.д. Данные фиксации (взгляда пользователя на части текстового материала) регистрируются и обрабатываются регистрирующим направление взгляда пользователя устройством 533 и компьютером 20 в частности, регистрируются и обрабатываются направление взгляда пользователя на части текстовых материалов и время, в течение которого на такие части текстового материала направлен взгляд пользователя. Так, если пользователь при прочтении текстовых материалов дольше смотрит на некоторые части текстовых материалов, то такая задержка взгляда пользователя на частях текстовых материалов регистрируется и обрабатывается с сохранением в компьютере 20 и/или в регистрирующем направление взгляда пользователя устройстве 533 таких частей текстовых материалов и/или координат (соответствующих расположению частей текстовых материалов), в которые направлен взгляд пользователя. Сохранение упомянутых данных может осуществляться, по крайней мере, на одном хранилище данных, по крайней мере, в одной базе данных, которое содержит или с которым связан компьютер 20 и/или регистрирующее направление взгляда пользователя устройство 533. Длительность задержки пользователя на частях текстовых материалов для установления фактов фиксации задается оператором на компьютере, например, в модуле задания длительности фиксации, в модуле обработки и анализа данных или в модуле обработки регистрируемых данных компьютера 20. В частности, для нормировки используется деление на количество фиксаций, что позволяет сравнивать тексты разного объема. Поскольку читатель не может не совершать фиксаций при чтении, то при чтении текстов большего объема совершается и больше фиксаций. В больших текстах, как правило, регистрируется больше и возвратных движений (перемещений), независимо от его сложности (не только из-за его сложности). Деление на количество фиксаций позволяет избежать этого ограничения. Кроме того, поскольку количество возвратных движений и фиксаций относятся к одному пользователю 523 (ФИГ. 5), это позволяет избежать влияния индивидуального фактора.
Для определения направления взгляда пользователя 523 (ФИГ. 5), в частности, координат взора пользователя 523 (ФИГ. 5), используются соответствующие регистрирующие направление взгляда пользователя устройства 533 (ФИГ. 5), связанные с вычислительным устройством, например, компьютером 20 (ФИГ. 4), осуществляющим обработку полученных данных. Использование таких регистрирующих направление взгляда пользователя устройств («видеоокулограф», «айтрекер», от англ. eye-tracker) 533 (ФИГ. 5) позволяет регистрировать точку или область, на которую в данный момент направлен взгляд пользователя 523 (ФИГ. 5), а также регистрировать предыдущие направления взгляда пользователя 523 (ФИГ. 5) при прочтении им предъявляемого текстового материала. Таким образом, такое устройство, по крайней мере, отслеживает траекторию движения взгляда при чтении пользователем 523 (ФИГ. 5) предъявляемых ему текстовых материалов. Также, такие устройства позволяют регистрировать фиксации взора пользователя 523 (ФИГ. 5) в определенных точках предъявляемого текстового материала, в частности, на участках предъявляемого текстового материала, например, словах, частях слов и т.д.
Так, пользователю 523 (ФИГ. 5) предъявляется текстовый материал, например, содержащий рекламные материалы, содержащие текст с рекламой того или иного продукта или услуги и т.д. Предъявление текстовых материалов может осуществляться пользователю 523 (ФИГ. 5) с использованием средств визуализации информации, например, монитора 47 (ФИГ. 4), связанного с компьютером 20 (ФИГ. 4), содержащим такие предъявляемые текстовые материалы. Также, предъявление текстовых материалов может осуществляться пользователю 523 (ФИГ. 5), посредством размещения перед ним таких текстовых материалов, например, напечатанных на листах бумаги, на экранах с использованием проекторов и т.д. или любым другим известным способом предъявления визуальной информации пользователю 523 (ФИГ. 5).
После предъявления пользователю 523 (ФИГ. 5) текстового материала и начала чтения пользователем 523 (ФИГ. 5) предъявляемых материалов осуществляется регистрация времени начала чтения и времени окончания чтения пользователем 523 (ФИГ. 5) предъявляемых материалов с использованием компьютера 20 (ФИГ. 4) и устройства для регистрации взгляда пользователя 523 (ФИГ. 5), в частности, регистрирующего направление взгляда пользователя устройства 533 (ФИГ. 5). Временем начала чтения может являться время начала предъявления пользователю 523 (ФИГ. 5) материалов, а временем окончания чтения может являться время, когда пользователю 523 (ФИГ. 5) перестали предъявлять материалы, т.е., например, убрали материалы из области видимости пользователя 523 (ФИГ. 5). Также, временем начала чтения может являться регистрируемый момент времени, когда пользователь 523 (ФИГ. 5) переместил взгляд на предъявляемый материал или начал перемещать взгляд от ранее расположенных участков материала к позднее расположенным участкам, например, от первого слова материала ко второму слову материала и т.д. Временем окончания чтения также может являться регистрируемый момент времени, когда пользователь 523 (ФИГ. 5) переместил взгляд за пределы предъявляемого материала, например, за пределы листа (или экрана монитора и т.д.), в том числе на заданный промежуток времени, например, на 2 секунды, 5 секунд и т.д.
Возвратные перемещения взгляда пользователя 523 (ФИГ. 5) от позднее расположенных участков к ранее расположенным участкам за время от начала до окончания чтения текста пользователем 523 (ФИГ. 5) регистрируются регистрирующим направление взгляда пользователя устройством 533 (ФИГ. 5) и передаются на компьютер 20 (ФИГ. 4), например, в формате координат. Регистрирующим направление взгляда пользователя устройством 533 (ФИГ. 5) определяются и сохраняются на устройство хранения информации (данных) 50 (ФИГ. 4) координаты направления взгляда пользователя 523 (ФИГ. 5) в каждый момент времени и соответствующее таким координатам время для последующей обработки. Зарегистрированные координаты направления взгляда пользователя 523 (ФИГ. 5) передаются на компьютер 20 для дальнейшей обработки, как описано в рамках настоящего изобретения.
В шаге 130 осуществляется формирование базы данных соответствия когнитивной трудности восприятия объему и лингвистической сложности для различных текстовых материалов. В частном случае, осуществляется дополнение базы данных свойствами пользователей, имеющими отношение к уровню когнитивной трудности восприятия, например, уровнем образования или специализацией по образованию. Упомянутая формируемая и дополняемая база данных хранится на устройстве хранения информации 50 (ФИГ. 4) компьютера 20 (ФИГ. 4), например, на накопителе на жестком диске 27 (ФИГ. 4). Упомянутое дополнение базы данных свойствами пользователей может осуществляться пользователями, например, респондентами, осуществляющими чтение предъявляемых материалов, или операторами, ответственными за предъявление текстовых материалов пользователю 523 (ФИГ. 5), обслуживание системы и т.д. Свойства пользователей 523 (ФИГ. 5) могут быть получены в процессе анкетирования пользователей с использованием компьютера 20 (ФИГ. 4), на мониторе 47 (ФИГ. 4) которого предъявляются пункты анкеты, которые заполняет пользователь 523 (ФИГ. 5) с использованием устройства ввода данных, связанного с компьютером 20 (ФИГ. 4). Упомянутая база данных хранится на устройстве хранения информации (данных) 50 (ФИГ. 4).
В частном случае перед началом предъявления пользователю текстовых материалов пользователь заполняет анкету, в которой пользователь указывает свои фамилию, имя и отчество, пол, ведущую руку, ведущий глаз, возраст, образование, сферу экономики, в которой работает пользователь (если работает), семейное положение, наличие и количество детей, материальное положение и т.д. Пользователь может заполнять анкету, например, на компьютере 20 (ФИГ. 4), или в письменном виде, причем анкета может обрабатываться с использованием компьютера 20 (ФИГ. 4), например, посредством сканирования заполненных анкет пользователей с добавлением результатов анкетирования в базу данных, в том числе оператором с использованием компьютера 20 (ФИГ. 4) и связанных с ним устройств.
В шаге 140 для заданных текстовых материалов, имеющих заданную форму представления, осуществляется определение лингвистической сложности и осуществляется определение когнитивной трудности восприятия заданной формы представления заданных текстовых материалов. Так, осуществляется предъявление пользователю (респонденту) 523 (ФИГ. 5) текстовых материалов с определением лингвистической сложности и определением когнитивной трудности, как описано в рамках настоящего изобретения, в том числе с использованием, по крайней мере, компьютера 20 (ФИГ. 4) и регистрирующего направление взгляда пользователя устройства 533 (ФИГ. 5). Так, в процессе чтения пользователем вычисляется показатель трудности на основе доли регрессий, а именно: осуществляется выделение из потока данных, полученных с использованием компьютера 20 (ФИГ. 4) и регистрирующего направление взгляда пользователя устройства 533 (ФИГ. 5) события - фиксации, их количество, автоматически определяются регрессии, т.е. возвратные движения глаз пользователем 523 (ФИГ. 5) и вычисляется отношение регрессий к общему количеству фиксаций во время чтения текстовых материалов. В частном случае, критерием регрессии является регистрируемое уменьшение координаты по горизонтальной оси внутри одной строки.
В шаге 150 осуществляется выбор из базы данных текстовых материалов, имеющих ближайший к заданным текстовым материалам объем и лингвистическую сложность. Так, оператор с использованием компьютера 20 (ФИГ. 4) или в автоматизированном режиме, в частности, компьютером 20 (ФИГ. 4), в том числе по заданным оператором параметрам, осуществляет поиск в базе данных указанных текстовых материалов, имеющих ближайший к заданным текстовым материалам объем и лингвистическую сложность.
В шаге 160 осуществляется сравнение когнитивной трудности восприятия заданных и выбранных текстовых материалов. Так, оператор с использованием компьютера 20 (ФИГ. 4) или компьютер 20 (ФИГ. 4) с установленным на нем программным обеспечением, в том числе по заданным оператором параметрам, осуществляет сравнение заданных текстовых материалов с ранее выбранными текстовыми материалами.
В шаге 170 осуществляется определение эффективности представления заданных текстовых материалов по разнице в когнитивной трудности восприятия выбранных и заданных тестовых материалов. Повышенная когнитивная трудность восприятия заданных текстовых материалов соответствует относительно низкой эффективности представления заданных текстовых материалов, а пониженная когнитивная трудность восприятия заданных текстовых материалов соответствует относительно высокой эффективности представления заданных текстовых материалов.
В частном случае, при низкой эффективности представления заданных текстовых материалов осуществляется изменение формы представления текстовых рекламных материалов до приведения когнитивной трудности восприятия заданных текстовых материалов в соответствие с когнитивной трудностью восприятия выбранных рекламных материалов.
В частном случае, при существенной высокой относительной эффективности заданных текстовых материалов осуществляется изменение лексической структуры заданных текстовых материалов в соответствии с заданной формой представления заданных текстовых материалов. Такой подход позволяет предотвратить злоупотребления, когда рекламное агентство формирует текст со сложными предложениями, а на рекламном плакате делит текст на простые фразы.
В частном случае, после определения эффективности представления из базы данных дополнительно осуществляется выбор текстовых материалов, имеющих ближайший к заданным текстовым материалам объем и лингвистическую сложность, и осуществляется проверка правильности определения эффективности представления заданных текстовых материалов путем сравнения когнитивной трудности восприятия заданных текстовых материалов и когнитивной трудности восприятия дополнительно выбранных текстовых материалов. Соответствие направление изменения когнитивной трудности восприятия и лингвистической сложности свидетельствует о правильности определения эффективности представления.
Также, в частном случае, осуществляется формирование списка вопросов, позволяющих определить степень усвоения текста пользователем (испытуемым) 523 (ФИГ. 5) и при недостижении требуемой степени усвоения текста, осуществляется исключение испытуемого из программы испытаний.
В частном случае осуществляется определение, соотносятся ли градации лингвистической сложности и когнитивной трудности для нескольких текстовых материалов, то есть является ли более сложный текст и более трудным. Если рассогласования нет, то динамика одного должна повторять динамику другого показателя, как показано на ФИГ. 2.
На ФИГ. 2 показан вариант диаграмм сравнения удобочитаемости 212, результатов контрольных вопросов 222 и трудности чтения (нейрометрики) 232 для трех тестов («Текст 1», «Текст 2» и «Текст 3»).
Как показано на ФИГ. 2, более сложные тексты являются и более трудными в описанной терминологии. Результаты контрольных вопросов 222 в частности, проверочные ответы по соцопросу, являются подтверждением того, что последовательность расставлена от сложного к простому.
На ФИГ. 3 показан вариант диаграмм сравнения удобочитаемости 313, результатов контрольных вопросов 323 и трудности чтения (нейрометрики) 333 для трех тестов («Текст 4», «Текст 5» и «Текст 6») с рассогласованием (353).
Как показано на ФИГ. 3, у сложности порядок выстраивается соответственно, а вот трудность (справа) уже не демонстрирует различий у текста «Текст 4» и текста «Текст 5». В этом случае это является поводом обратить внимание на особенности представления текста в данном конкретном текстовом материале, в частности, в конкретной рекламе, особенности его расположения, шрифта, фона, и внести корректировки в его представление, в частности, в форму его представления. Это может быть связано и с особенностями пользователя (пользователей), для которых получены данные (соответствие целевой группы и др.).
Поскольку для соотнесения показателей у разных пользователей необходима некоторая норма, в качестве контрольного показателя оценки когнитивной трудности (доли регрессий) может быть использован коридор нормы для среднестатистического пользователя (житель мегаполиса, средний трудоспособный возраст, стандартный уровень дохода), вычисляемый для (данных) базы данных, собранных по всем респондентам, читавшим предъявляемые им текстовые материалы. В этом случае может быть реализована возможность сравнения с определенным уровнем (baseline), характеризующим средний нормированный показатель доли регрессий. Границами коридора могут служить стандартные отклонения или верхний и нижний квартили распределения показателя.
На ФИГ. 4 показан пример вычислительной системы, пригодной для реализации элементов предложенного изобретения, которая включает в себя многоцелевое вычислительное устройство в виде компьютера 20 или сервера, или модуля описываемой в настоящем изобретении системы, включающего в себя процессор 21, системную память 22 и системную шину 23, которая связывает различные системные компоненты, включая системную память с процессором 21.
Системная шина 23 может быть любого из различных типов структур шин, включающих шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из множества архитектур шин. Системная память включает постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25. В ПЗУ 24 хранится базовая система ввода/вывода 26 (БИОС), состоящая из основных подпрограмм, которые помогают обмениваться информацией между элементами внутри компьютера 20, например, в момент запуска.
Компьютер 20 также может включать в себя накопитель 27 на жестком диске для чтения с и записи на жесткий диск, не показан, накопитель 28 на магнитных дисках для чтения с или записи на съемный магнитный диск 29, и накопитель 30 на оптическом диске для чтения с или записи на съемный оптический диск 31 такой, как компакт-диск, цифровой видео-диск и другие оптические средства. Накопитель 27 на жестком диске, накопитель 28 на магнитных дисках и накопитель 30 на оптических дисках соединены с системной шиной 23 посредством, соответственно, интерфейса 32 накопителя на жестком диске, интерфейса 33 накопителя на магнитных дисках и интерфейса 34 оптического накопителя. Накопители и их соответствующие читаемые компьютером средства обеспечивают энергонезависимое хранение читаемых компьютером инструкций, структур данных, программных модулей и других данных для компьютера 20.
Хотя описанная здесь типичная конфигурация использует жесткий диск, съемный магнитный диск 29 и съемный оптический диск 31, специалист примет во внимание, что в типичной операционной среде могут также быть использованы другие типы читаемых компьютером средств, которые могут хранить данные, которые доступны с помощью компьютера, такие как карты флеш-памяти, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Различные программные модули, включая операционную систему 35, могут быть сохранены на жестком диске, магнитном диске 29, оптическом диске 31, ПЗУ 24 или ОЗУ 25. Компьютер 20 включает в себя файловую систему 36, связанную с операционной системой 35 или включенную в нее, одно или более программное приложение 37, другие программные модули 38 и программные данные 39. Пользователь 523 (ФИГ. 5) может вводить команды и информацию в компьютер 20 при помощи устройств ввода, таких как клавиатура 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, геймпад, спутниковую антенну, сканер или любое другое.
Эти и другие устройства ввода соединены с процессором 21 часто посредством интерфейса 46 последовательного порта, который связан с системной шиной, но могут быть соединены посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (УПШ). Монитор 47 или другой тип устройства визуального отображения также соединен с системной шиной 23 посредством интерфейса, например, видеоадаптера 48. В дополнение к монитору 47, персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показано), такие как динамики и принтеры.
Компьютер 20 может работать в сетевом окружении посредством логических соединений к одному или нескольким удаленным компьютерам 49. Удаленный компьютер (или компьютеры) 49 может представлять собой другой компьютер, сервер, роутер, сетевой ПК, пиринговое устройство или другой узел единой сети, а также обычно включает в себя большинство или все элементы, описанные выше, в отношении компьютера 20, хотя показано только устройство хранения информации (данных) 50. Логические соединения включают в себя локальную сеть (ЛВС) 51 и глобальную компьютерную сеть (ГКC) 52. Такие сетевые окружения обычно распространены в учреждениях, корпоративных компьютерных сетях, Интернете.
Компьютер 20, используемый в сетевом окружении ЛВС, соединяется с локальной сетью 51 посредством сетевого интерфейса или адаптера 53. Компьютер 20, используемый в сетевом окружении ГКС, обычно использует модем 54 или другие средства для установления связи с глобальной компьютерной сетью 52, такой как Интернет.
Модем 54, который может быть внутренним или внешним, соединен с системной шиной 23 посредством интерфейса 46 последовательного порта. В сетевом окружении программные модули или их части, описанные применительно к компьютеру 20, могут храниться на удаленном устройстве хранения информации. Надо принять во внимание, что показанные сетевые соединения являются типичными, и для установления коммуникационной связи между компьютерами могут быть использованы другие средства.
На ФИГ. 5 показан упрощенный пример аппаратной реализации предложенного изобретения.
Показанное на ФИГ. 5 оборудование, в частном случае, относится к одному пользователю 523, компьютеру 20, регистрирующему направление взгляда пользователя устройству 533, монитору 47, хотя, стоит понимать, что оборудование или локальная часть системы может относиться, по крайней мере, к одному другому пользователю. Количество пользователей в описываемом изобретении, а также упомянутых компьютеров, средств, модулей, мониторов и т.д., в частном случае не ограничено, и может зависеть от скорости соединения компьютера, или любой другой части описываемой системы (например, при наличии в их составе, или связанных с ними вычислительных устройств, средств, модулей и т.д. с возможностью осуществления соединения между такими устройствами, средствами, модулями и т.д.), с сетью (системой) Интернет, скорости обработки данных описываемых устройств, средств, модулей и т.д. и других их характеристик.
Пользователю 523 текстовые материалы могут предъявляться с использованием вычислительного устройства, такого как компьютер 20, например, посредством их отображения на экране монитора 47, связанного с компьютером 20. Текстовые материалы могут предъявляться пользователю 523 посредством их визуализации с использованием, по крайней мере, устройства, позволяющего отображать информацию. Также, текстовые материалы могут предъявляться пользователю 523 с использованием известных носителей информации. Пользователю могут предъявляться текстовые материалы модулем предъявления текстовых материалов, являющимся частью компьютера 20. Характеристики текстовых материалов и их отображения, такие как, например, количество предъявляемых текстовых материалов, их объем, форма, время начала и окончания предъявления и т.д. задаются модулем предъявления текстовых материалов. В частном случае, ввод упомянутых характеристик текстовых материалов может осуществляться в модуле предъявления текстовых материалов оператором, например, с использованием модуля задания характеристик текстовых материалов, который может являться частью компьютера 20, подмодулем модуля предъявления текстовых материалов или может быть связан с ними любым известным способом. Модуль предъявления текстовых материалов также может осуществлять передачу данных в модуль обработки и анализа данных для дальнейшей обработки. Такими передаваемыми данными могут являться характеристики (параметры) текстовых материалов, которые могут использоваться модулем обработки и анализа данных, как описано в рамках настоящего изобретения.
При прочтении пользователем текстовых материалов, в частности, в процессе предъявления пользователю 523 текстовых материалов, осуществляется отслеживание положения глаз пользователя с использованием регистрирующего направление взгляда пользователя устройства 533. То, как пользователь 523 читает предъявляемые ему текстовые материалы, является окуломоторной активностью. Движения глаз пользователя 523 являются важным показателем особенностей когнитивной обработки информации пользователем 523, в частности, восприятия информации пользователем 523. В настоящем изобретении могут быть использованы различные типы регистрирующих направление взгляда пользователя устройства 533, в том числе устройства, с механическим контактом с глазом, например, контактные линзы с встроенными зеркалами и т.д.. Также, могут быть использованы бесконтактные способы (и, соответственно, устройства) отслеживания направления взгляда пользователя, например, с использованием инфракрасной подсветки, отражающейся глазным яблоком и регистрирующейся оптическим сенсором и т.д. Также могут использоваться способы с использованием измерения электрических потенциалов расположенными вокруг глаз пользователя 523 электродами. Регистрирующее направление взгляда пользователя устройство 533 может закрепляться на голове пользователя или может быть установлено в непосредственной близости от пользователя 523, или на требуемом для осуществления (максимально точной) регистрации взгляда пользователя расстоянии, в том числе на мониторе 47, компьютере 20, а также являться их частью, и т.д.
Полученные, в частности, регистрируемые или зарегистрированные данные регистрирующим направление взгляда пользователя устройством 533 могут быть обработаны (полностью или частично), как компьютером 20, в частности, по крайне мере, одним его модулем, например, модулем обработки и анализа данных, так и/или регистрирующим направление взгляда пользователя устройством 533, или, по крайне мере, одним его модулем, в случае, если такое регистрирующее направление взгляда пользователя устройство (модуль, средство и т.д.) 533 позволяет осуществлять такую обработку, например, с использованием, по крайней мере, одного процессора, микропроцессора, а также контроллера, микроконтроллера и т.д. Так, перед передачей в модуль обработки и анализа данных зарегистрированные данные регистрирующим направление взгляда пользователя устройством 533 могут быть предварительно обработаны регистрирующим направление взгляда пользователя устройством 533 или, по крайней мере, одной его частью, например, модулем предварительной обработки. В частном случае, такая предварительная обработка может осуществляться или компьютером 20, например, модулем обработки и анализа данных и/или другим модулем, например, модулем предварительной обработки данных, являющимся частью компьютера 20.
Регистрируемые регистрирующим направление взгляда пользователя устройством 533 данные передаются на компьютер 20, в том числе после предварительной обработки регистрирующим направление взгляда пользователя устройством 533. Регистрируемые регистрирующим направление взгляда пользователя устройством 533 данные обрабатываются компьютером 20, например, модулем обработки регистрируемых данных компьютера 20. Такая обработка может включать, по крайней мере, вычисление координат взгляда пользователя, сопоставление их с расположением частей предъявляемых текстовых материалов в предъявляемых текстовых материалах (в частности, с координатами частей предъявляемых текстовых материалов в предъявляемых текстовых материалах) и т.д.
Текстовые материалы могут храниться в базе данных компьютера 20, например, на устройстве хранения информации 50, которое может являться частью компьютера 20 или может быть связано с таким компьютером 20, например, посредством локальной вычислительной сети, сети Интернет и т.д.
Также, на устройстве хранения информации 50 может храниться база данных соответствия когнитивной трудности восприятия объему и лингвистической сложности для различных текстовых материалов.
Также, в базе данных могут храниться свойства пользователей, имеющие отношение к уровню когнитивной трудности восприятия, например, уровень образования или специализацию по образованию.
Упомянутая база данных может являться иерархической, объектной, объектно-ориентированной, документо-ориентированной, объектно-реляционной, реляционной, сетевой и/или функциональной базой данных, каждая из которых может быть централизованной, сосредоточенной, распределенной, неоднородной, однородной, фрагментированной (секционированной), тиражированной, пространственной, временной, пространственно-временной, циклической, сверх-большой базой данных и т.д., причем для управления, создания и использования баз данных могут использоваться различные системы управления базами данных (СУБД). В частном случае упомянутое хранилище данных может являться временным устройством хранения данных (например, Оперативным Запоминающим Устройством (ОЗУ)), постоянным хранилищем данных, например, (Программируемым) Постоянным Запоминающим Устройством (ПЗУ или ППЗУ), в том числе, реализуемым, по крайней мере, одной микросхемой или набором микросхем и т.д. Также, данные в хранилище данных могут храниться, по крайней мере, в одном файле, в частном случае, в виде текстового файла, либо данные могут храниться в любом, по крайней мере, одном другом известном в настоящее время формате хранения данных (информации) или в формате данных, изобретенном позднее.
Компьютер 20 также может включать связанный, по крайней мере, с модулем обработки регистрируемых данных модуль обработки и анализа данных, который осуществляет, по крайней мере, сравнение когнитивной трудности восприятия заданных и выбранных текстовых материалов и определение эффективности представления заданных текстовых материалов.
При помощи встроенных в регистрирующее направление взгляда пользователя устройство 533 и/или в компьютер 20 элементов обработки и анализа, например, реализующих структуры искусственного интеллекта, осуществляется возможность обрабатывать и интерпретировать регистрируемые данные, как описано в рамках настоящего изобретения.
Упомянутые элементы обработки и анализа, в том числе средства искусственного интеллекта, могут являться частью модуля обработки и анализа данных или являться модулем компьютера 20, связанным с регистрирующим направление взгляда пользователя устройством 533 или другим модулем, например, модулем компьютера 20. Модуль обработки и анализа данных или, по крайней мере, одна его часть, может являться частью регистрирующего направление взгляда пользователя устройства 533.
Также компьютер 20 может включать модуль выбора из базы данных текстовых материалов, имеющих ближайший к заданным текстовым материалам объем и лингвистическую сложность.
Также компьютер 20 может включать модуль измерения объема и определения лингвистической сложности текстовых материалов и модуль определения когнитивной трудности восприятия для заданных форм представления текстовых материалов.
Также компьютер 20 может включать модуль формирования списка вопросов, позволяющих определить степень усвоения текста пользователем.
В частном случае, модуль обработки регистрируемых данных, и/или модуль выбора из базы данных текстовых материалов, имеющих ближайший к заданным текстовым материалам объем и лингвистическую сложность и/или модуль измерения объема и определения лингвистической сложности текстовых материалов, и/или модуль определения когнитивной трудности восприятия для заданных форм представления текстовых материалов, и/или любой другой модуль и их совокупность могут являться частью модуля обработки и анализа данных.
Таким образом, в настоящем изобретении предлагается комплексный способ, который включает лингвистический и физиологический подходы, которые взаимо дополняют друг друга и позволяют не использовать классические опросные социологические методы.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой. Специалисту в данной области становится понятным, что могут существовать и другие варианты осуществления настоящего изобретения, согласующиеся с сущностью и объемом настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| Способ и система для определения потенциала развития высших психических функций и навыков человека посредством нейрометрии | 2017 |
|
RU2671869C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОГО ПОИСКА ЭЛЕКТРОННЫХ ДОКУМЕНТОВ | 2011 |
|
RU2473119C1 |
| РАЗРЕШЕНИЕ КОРЕФЕРЕНЦИИ В ЧУВСТВИТЕЛЬНОЙ К НЕОДНОЗНАЧНОСТИ СИСТЕМЕ ОБРАБОТКИ ЕСТЕСТВЕННОГО ЯЗЫКА | 2008 |
|
RU2480822C2 |
| СИСТЕМА КОМПЬЮТЕРНОЙ БЕЗОПАСНОСТИ, ОСНОВАННАЯ НА ИСКУССТВЕННОМ ИНТЕЛЛЕКТЕ | 2017 |
|
RU2750554C2 |
| СПОСОБ ОЦЕНКИ СПОСОБНОСТИ К ЗАПОМИНАНИЮ ИНОСТРАННЫХ СЛОВ С ИСПОЛЬЗОВАНИЕМ АНАЛИЗА ГЛАЗОДВИГАТЕЛЬНОЙ АКТИВНОСТИ | 2017 |
|
RU2659142C1 |
| СПОСОБ И СИСТЕМА СЕМАНТИЧЕСКОЙ ОБРАБОТКИ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2016 |
|
RU2630427C2 |
| Способ автоматизированного анализа текста и подбора релевантных рекомендаций по улучшению его читабельности | 2021 |
|
RU2769427C1 |
| СИСТЕМА ДЛЯ КОММУНИКАЦИИ ПОЛЬЗОВАТЕЛЕЙ БЕЗ ИСПОЛЬЗОВАНИЯ МЫШЕЧНЫХ ДВИЖЕНИЙ И РЕЧИ | 2018 |
|
RU2725782C2 |
| СПОСОБ ОБУЧЕНИЯ АССОЦИАТИВНО-ЭТИМОЛОГИЧЕСКОМУ АНАЛИЗУ ПИСЬМЕННЫХ ТЕКСТОВ НА ИНОСТРАННЫХ ЯЗЫКАХ | 2018 |
|
RU2702148C2 |
Изобретение относится к области вычислительной техники. Технический результат заключается в обеспечении возможности генерации оптимальной структуры для представления информационных текстов, которые должны побуждать пользователей к определенным действиям. Технический результат достигается за счет измерения объема и определения лингвистической сложности нескольких текстовых материалов; для каждой из заданных форм представления текстовых материалов определения когнитивной трудности восприятия; формирования базы данных соответствия когнитивной трудности восприятия объему и лингвистической сложности для различных текстовых материалов; для заданных текстовых материалов, имеющих заданную форму представления, определения лингвистической сложности и определения когнитивной трудности восприятия заданной формы представления заданных текстовых материалов; выбора из базы данных текстовых материалов, имеющих ближайший к заданным текстовым материалам объем и лингвистическую сложность, сравнения когнитивной трудности восприятия заданных и выбранных текстовых материалов и определения эффективности представления заданных текстовых материалов по разнице в когнитивной трудности восприятия выбранных и заданных тестовых материалов. 11 з.п. ф-лы, 5 ил.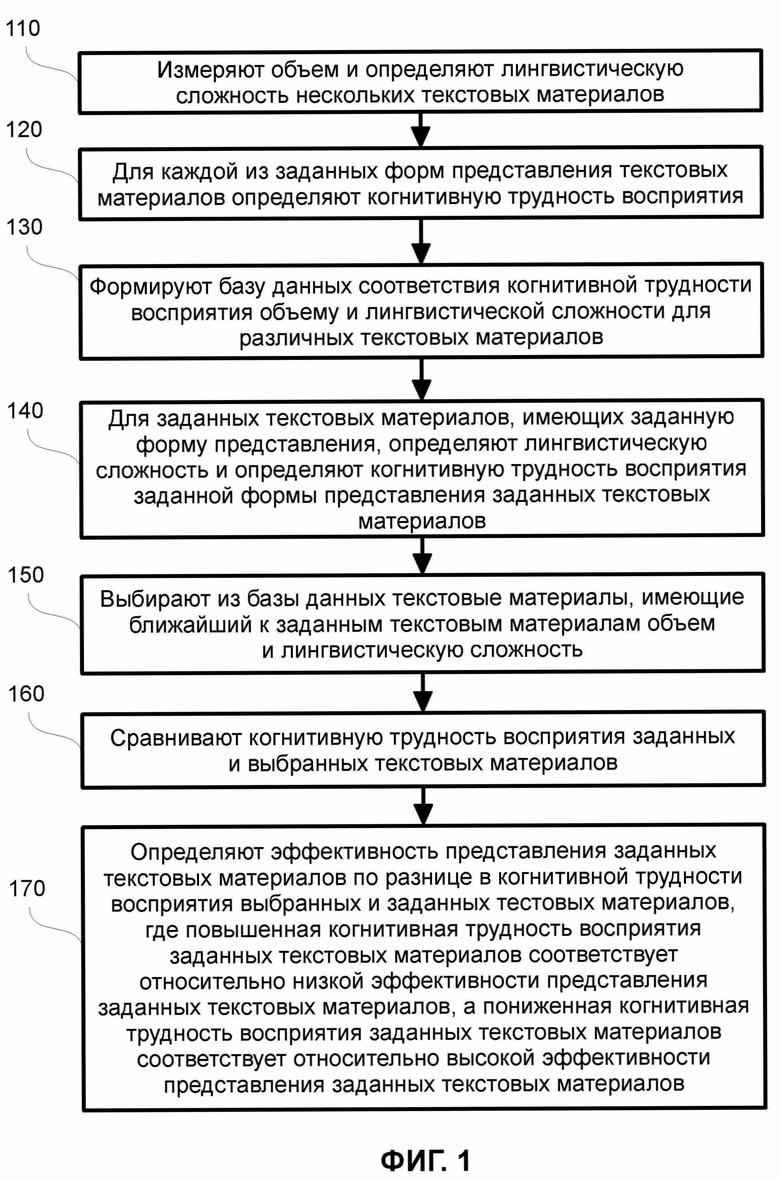
1. Способ определения эффективности представления заданных текстовых материалов, заключающийся в том, что:
измеряют объем и определяют лингвистическую сложность нескольких текстовых материалов;
для каждой из заданных форм представления текстовых материалов определяют когнитивную трудность восприятия;
формируют базу данных соответствия когнитивной трудности восприятия объему и лингвистической сложности для различных текстовых материалов;
для заданных текстовых материалов, имеющих заданную форму представления, определяют лингвистическую сложность и определяют когнитивную трудность восприятия заданной формы представления заданных текстовых материалов;
выбирают из базы данных текстовые материалы, имеющие ближайший к заданным текстовым материалам объем и лингвистическую сложность,
сравнивают когнитивную трудность восприятия заданных и выбранных текстовых материалов
и определяют эффективность представления заданных текстовых материалов по разнице в когнитивной трудности восприятия выбранных и заданных тестовых материалов, где повышенная когнитивная трудность восприятия заданных текстовых материалов соответствует относительно низкой эффективности представления заданных текстовых материалов, а пониженная когнитивная трудность восприятия заданных текстовых материалов соответствует относительно высокой эффективности представления заданных текстовых материалов.
2. Способ по п. 1, отличающийся тем, что при низкой эффективности представления заданных текстовых материалов изменяют форму представления текстовых материалов до приведения когнитивной трудности восприятия заданных текстовых материалов в соответствие с когнитивной трудностью восприятия выбранных текстовых материалов.
3. Способ по п. 1, отличающийся тем, что при существенной высокой относительной эффективности заданных текстовых материалов изменяют лексическую структуру заданных текстовых материалов в соответствии с заданной формой представления заданных текстовых материалов.
4. Способ по п. 1, отличающийся тем, что лингвистическую сложность текстового материала определяют следующими адаптированными для русского языка способами в отдельности или в их комбинации:
- способ вычисления сложности с использованием теста Флэша-Кинкайда как суммы произведения средней длины предложения на коэффициент, равный 0.318, и произведения среднего количества слогов в слове на коэффициент, равный 14.2, и из этой суммы вычитается коэффициент, равный 30.5;
- способ вычисления сложности с использованием теста Колман-Лиау как разности произведения среднего количества букв на сто слов на коэффициент, равный 0.055, и произведения среднего количества предложений на сто слов на коэффициент, равный 0.35, и из этой разности вычитается коэффициент, равный 20.33;
- способ вычисления сложности по формуле SMOG как суммы коэффициента, равного 0.05, и результата умножения коэффициента, равного 1.1, на корень квадратный из результата умножения количества многосложных слов на результат деления коэффициента, равного 64.6, на количество предложений, где многосложные слова состоят из трех и более слогов;
- способ вычисления сложности по формуле Дэйла-Чалла как суммы результата умножения коэффициента, равного 0.552, на результат деления количества многосложных слов на общее количество слов и результата произведения коэффициента, равного 0.273, на результат деления общего количества слов на общее количество предложений;
- способ вычисления сложности с использованием вычисления автоматизированного индекса удобочитаемости как суммы результата деления количества букв и цифр в тексте на количество слов в тексте, умноженного на коэффициент, равный 6.26, и результата деления количества слов в тексте на количество предложений в тексте, умноженного на коэффициент, равный 0.28.
5. Способ по п. 4, отличающийся тем, что лингвистическая сложность текстового материала вычисляется как среднее арифметическое от индекса, вычисленного по Флэшу-Кинкайду, индекса, вычисленного по Колман-Лиау, индекса, вычисленного по SMOG (Simple Measure of Gobbledygook), индекса, вычисленного по Дейлу-Чаллу, и автоматизированного индекса удобочитаемости.
6. Способ по п. 1, отличающийся тем, что для определения значения когнитивной трудности восприятия обеспечивают определение направления взгляда пользователя относительно последовательно расположенных участков текста, а значение когнитивной трудности восприятия определяют как количество возвратных перемещений взгляда пользователя от позднее расположенных участков к ранее расположенным участкам за время от начала до окончания чтения текста пользователем.
7. Способ по п. 6, отличающийся тем, что уточняют значение когнитивной трудности восприятия путем деления количества возвратных перемещений на количество фиксаций, где фиксацией является сосредоточение взгляда пользователем на участках текстовых материалов.
8. Способ по п. 1, отличающийся тем, что дополняют базу данных свойствами пользователей, имеющими отношение к уровню когнитивной трудности восприятия.
9. Способ по п. 8, отличающийся тем, что свойствами пользователей, имеющими отношение к уровню когнитивной трудности восприятия, является уровень образования или специализация по образованию.
10. Способ по п. 1, отличающийся тем, что дополнительно выбирают из базы данных текстовые материалы, имеющие ближайший к заданным текстовым материалам объем и иную лингвистическую сложность, и проверяют правильность определения эффективности представления заданных текстовых материалов путем сравнения когнитивной трудности восприятия заданных текстовых материалов и когнитивной трудности восприятия дополнительно выбранных текстовых материалов, где соответствие направления изменения когнитивной трудности восприятия и лингвистической сложности свидетельствует о правильности определения эффективности представления.
11. Способ по п. 1, отличающийся тем, что текстовыми материалами являются рекламные или информационные текстовые материалы.
12. Способ по любому из предыдущих пунктов, отличающийся тем, что формируют список вопросов, позволяющих определить степень усвоения текста испытуемым, и при недостижении требуемой степени усвоения текста исключают испытуемого из программы испытаний.
| МЕТОД АНАЛИЗА ТОНАЛЬНОСТИ ТЕКСТОВЫХ ДАННЫХ | 2014 |
|
RU2571373C2 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |

