Область техники
Изобретение относится к способу анализа пакетов данных в коммуникационных сетях пакетной передачи данных, причем указанные пакеты данных содержат метаданные и полезные данные и их предпочтительно передают в потоке данных как часть сетевой сессии.
Уровень техники
Анализ пакетов данных в потоке данных выполняют во многих областях, например, с целью фильтрации или классификации данных по их содержанию. Анализировать содержание индивидуальных пакетов данных и сетевых сессий требуется, в частности, при контроле потоков данных. В известных способах создают копии пакетов данных, передаваемых по линии передачи данных, сохраняя их для обработки в будущем или же анализируя пакеты данных в режиме реального времени.
Однако хранение всех имеющихся в потоке данных пакетов данных требует очень емкой и мощной памяти для данных. Кроме того, для последующего анализа сохраненных данных требуется большая вычислительная мощность. Тем не менее, системы такого рода обычно неприменимы для непрерывного контроля, потому что на больших периодах времени на хранении в памяти для данных обычно оказывается такое большое количество данных, что становится невозможным обеспечение своевременного анализа этих данных. Также может происходить переполнение памяти.
Системы, обладающие способностью анализа в реальном времени, обеспечивают безотлагательный анализ данных, передаваемых по линии передачи данных, и принципиально подходят для непрерывного контроля трафика данных, хотя при использовании этих систем обычно не имеется возможности реконструкции всей полноты содержания сетевой сессии, так как пакеты данных по сети зачастую передаются дважды или не в хронологическом порядке. Это происходит, в частности, в сетях с балансировкой нагрузки и резервированием. Следовательно, системы такого типа, имеющие способность анализа в реальном времени, не способны гарантировать полностью надежного контроля, так как, например, ключевые слова, поиск которых обычно осуществляют в сообщении или в сетевой сессии, могут быть распределены среди разных пакетов данных, что делает их неотслеживаемыми.
Раскрытие изобретения
Целью настоящего изобретения является обеспечение способа и устройства для анализа пакетов данных и/или содержания полезных данных и метаданных в пакетах данных, делающего возможным осуществление непрерывного контроля трафика данных и надежного обнаружения подлежащего контролю содержания.
Эта цель достигается с помощью способа и устройства, имеющих отличительные признаки, указанные в независимых пунктах формулы изобретения. В зависимых пунктах формулы изобретения описаны признаки дополнительных вариантов осуществления и другие полезные разработки.
Сначала, в терминах настоящего изобретения, из потока данных извлекают пакеты данных, подлежащие анализу. Для этого, предпочтительно создают копию каждого из этих пакетов данных. Затем для каждого извлеченного пакета данных генерируют сигнатуру. В качестве сигнатуры предпочтительно используют хеш-функцию, определенную хеш-кодом, причем идентичные пакеты данных имеют одинаковый хеш-код. Затем пакет данных сохраняют в буфере, причем метаданные сохраняют в первой области памяти, а полезные данные сохраняют во второй области памяти так, чтобы и в буферном накопителе поддерживалась ассоциация между полезными данными и метаданными пакета данных. Это может быть реализовано, например, с помощью так называемых указателей. В соответствии с предпочтительным вариантом осуществления, в котором первая область памяти и вторая область памяти буферного накопителя разделены на сегменты, полезные данные присваиваются соответствующим метаданным посредством того, что полезные данные и метаданные пакета данных сохраняются в соответствующим образом соотнесенных друг другу сегментах первой и второй областей данных. Например, может быть обеспечено, чтобы номер сегмента, относящегося к первой области памяти, в которой сохраняют метаданные, соответствовал бы номеру сегмента второй области памяти, в которой сохраняют полезные данные этого пакета данных. Несомненно, также возможно с использованием заданного правила вычисления можно также по номерам сегментов одной области памяти рассчитать номера сегментов другой области памяти для того, чтобы таким образом создать четкую взаимосвязь между метаданными и полезными данными.
Когда имеется множество известных элементов памяти, которые, в случае их присутствия, могут быть использованы как основа для буферного накопителя по настоящему изобретению, для доступа к памяти в процессе сохранения можно использовать так называемый номер транзакции. В случае буферного накопителя такого вида целесообразным будет в качестве номера транзакции использовать сигнатуру пакета данных. В частности, когда имеется множество обрабатывающих модулей, выполняющих извлечение пакетов данных из потока данных, наличие уникального номера транзакции гарантирует, что каждый пакет данных будет сохранен в буфере только один раз. Попытка повторной записи пакета данных с уже имеющимся номером транзакции может быть отклонена, например, логикой элемента памяти. При этом достигается особенно экономичное использование емкости памяти, так как каждый извлеченный пакет данных может быть сохранен только один раз. Такое свойство также делает возможным особенно просто реализовывать масштабируемость устройства по настоящему изобретению, что будет раскрыто далее по тексту.
Для того, чтобы сделать возможным анализ содержимого извлеченных пакетов данных, изобретение предусматривает, чтобы перед сохранением или после сохранения метаданных и полезных данных пакета данных в полезных данных выполнялся поиск по меньшей мере одного предмета поиска. Для этого полезно выполнить по меньшей мере одну частичную реконструкцию сетевой сессии, чтобы также можно было использовать предметы поиска за пределами пакета. Для этого пакеты одной сетевой сессии предпочтительно сортируют в хронологическом порядке их поступления или по порядковым номерам, и данные уровней 5-7 записывают в кольцевой буфер в соответствии с так называемой моделью OSI (Open Systems Interconnection), после чего выполняют поиск уже в этом кольцевом буфере. Например, при максимальном размере пакета в сетевой сессии, равном 1500 байт, размер кольцевого буфера может составлять 1600 байт на одну сетевую сессию. Фактический поиск может быть задан, в частности, с помощью так называемых регулярных выражений. Положительный результат поиска в метаданных предпочтительно отмечают, например, установкой идентификатора, так называемого флага. Таким образом, уже по метаданным пакетов данных сетевой сессии можно выяснить, имеется ли предмет поиска в полезных данных. Ввиду того, что, как правило, метаданные занимают меньше памяти, в буферном накопителе к этим данным возможен более быстрый доступ. Полезные данные предпочтительно сохраняют также и тогда, когда поиск в этих полезных данных не дал положительного результата. Ввиду того, что предмет поиска может оказаться также и в другом пакете данных сетевой сессии, тем самым обеспечивают, чтобы для реконструкции сетевой сессии имелись в наличии все пакеты данных, и чтобы сетевая сессия могла быть реконструирована полностью.
В соответствии с изобретением, для дальнейшего анализа данных пакеты данных одной сетевой сессии реконструируют полностью, чтобы снова иметь в наличии полностью всю оригинальную информацию, например, содержание электронного письма, пересылаемого документа или видео. Для этого с помощью модуля реконструкции сначала считывают из буферного накопителя метаданные. После считывания метаданных сначала выполняют проверку с целью определения того, был ли в метаданных установлен идентификатор, указывающий на то, что в настоящее время метаданные находятся в обработке. Если такой идентификатор уже был установлен, то обработку метаданных прерывают. Если нет, то обработку продолжают и устанавливают этот идентификатор. Тем самым гарантируется то, что в случае присутствия множества модулей реконструкции, этим множеством будут сгенерированы различные сетевые сессии в обработке с резервированием. Идентификатор, следовательно, указывает на то, задействован ли в настоящий момент времени модуль реконструкции в реконструкции сетевой сессии, включающей в себя этот пакет данных, и тем самым снова делает возможным масштабирование всей системы, что может быть реализовано особенно просто.
Если были считаны все метаданные и полезные данные сетевой сессии, и если поиск предмета поиска дал положительный результат в по меньшей мере одном элементе полезных данных, что может быть определено, например, по вышеописанному идентификатору в метаданных, который демонстрирует результат поиска, то полезные данные будут возвращены к своей изначальной последовательности; таким образом сетевая сессия будет реконструирована. Предпочтительно, после считывания последнего пакета данных сетевой сессии, в принадлежащие этой сетевой сессии и сохраненные в буфере метаданные вносят отметку о том, что эта сетевая сессия была реконструирована и/или что пакеты данных этой сетевой сессии были считаны из буферного накопителя. Соответствующие позиции памяти тогда будут снова доступны и смогут быть использованы для сохранения новых пакетов данных. Кроме того, такая отметка позволит определить степень полноты реконструкции или, с другой стороны, выявить выход из строя модуля реконструкции. Это может быть реализовано тем, что отметку удаляют в случае успешной реконструкции сетевой сессии. С другой стороны, если отметка будет оставаться на месте дольше заданного периода времени, то будет сделан вывод о том, что модуль реконструкции работал неправильно, например, из-за системного выхода из строя этого модуля реконструкции. Тогда для этого модуля реконструкции может быть вынесено решение о его проверке и/или о реконструкции рассматриваемой сетевой сессии другим модулем реконструкции.
Используя способ и устройство по изобретению, можно анализировать пакеты данных одной сетевой сессии фактически в режиме реального времени, и если будет обнаружено, что определенный предмет поиска встречается в пакете данных, то вся сетевая сессия будет сделана доступной для последующей обработки или сохранения. Дополнительным преимуществом является возможность особо простого масштабирования всей системы. При этом отдельные модули можно подключать или изымать даже в ходе работы устройства по изобретению или, в некоторых случаях, в ходе осуществления способа по изобретению. Например, можно добавлять или изымать модули извлечения, выполняющие извлечение пакетов данных из потока данных. При соответствующем управлении памятью можно также увеличивать или уменьшать емкость памяти, а также можно добавлять модули реконструкции, выполняющие реконструкцию сетевых сессий, и для этого не надо будет прерывать анализ потока данных.
В соответствии с еще одной полезной разработкой изобретения анализ полезных данных сетевой сессии выполняют для того, чтобы идентифицировать по меньшей мере один тип файла для передаваемого в сетевой сессии файла. Это можно сделать, например, путем поиска, ориентированного на так называемый тип MIME. Идентифицированный таким способом файл затем может быть извлечен из сетевой сессии и сделан доступным для дальнейшей обработки. Здесь особенно полезно вместе с извлеченными данными сохранять дополнительные данные, делающие возможной идентификацию отправителя или получателя. В частности, может быть предусмотрено выполнение анализа присутствующей в полезных данных метаинформации соответствующей сетевой сессии, например, для идентификации коммуникационных шаблонов. Это может быть сделано на основе эвристического анализа независимо от используемого коммуникационного протокола. Например, этот тип анализа может обеспечивать информацию об используемой отправителем операционной системе и о любых присутствующих маршрутизаторах или брандмауэрах, которые могут быть установлены у отправителя.
Особо полезно, если после реконструкции сетевой сессии будет выполнена оценка переданных в сетевой сессии полезных данных с учетом сетевых протоколов уровня приложений (так называемые уровни с 5 по 7 модели OSI).
В соответствии с предпочтительным вариантом осуществления первую область памяти и вторую область памяти буферного накопителя выполняют в виде кольцевого буфера. С одной стороны, это делает возможным быстрый доступ к отдельным сегментам памяти и обеспечивает адекватную многократность использования отдельных сегментов, а с другой стороны, предотвращает переполнение памяти.
Предпочтительно, чтобы сохраненные в буфере метаданные присваивались сохраненным полезным данным посредством уникального номера сегмента соответствующей области памяти. Кроме того, буферный накопитель предпочтительно конфигурируют таким образом, чтобы разрешение на сохранение данных зависело от результата проверки используемого номера транзакции. Этим предотвращается сохранение в буфере дубликатов данных, например, когда получатель пакета данных запросил пакет повторно, или в результате присутствия нескольких моделей извлечения, которые считали один и тот же пакет данных и теперь хотят записать его в буферный накопитель.
По сравнению с традиционными способами и системами изобретение имеет то преимущество, что пакеты данных сетевой сессии анализируют фактически в режиме реального времени и что, по меньшей мере, в случае положительного результата поиска сетевая сессия делается доступной полностью.
Изначально указанная цель также достигается, в частности, с помощью компьютерной программы, исполняемой на устройстве для анализа содержания пакетов данных потока данных, например, на сетевом узле, и составлена для осуществления способа по изобретению. Таким образом, компьютерная программа, посредством отдельных этапов обработки, составляет изобретение в той же мере, что и сам способ.
Другие полезные отличительные признаки изобретения могут быть обнаружены в осуществлениях, представленных и раскрытых со ссылкой на нижеследующие фигуры чертежей.
Краткое описание чертежей
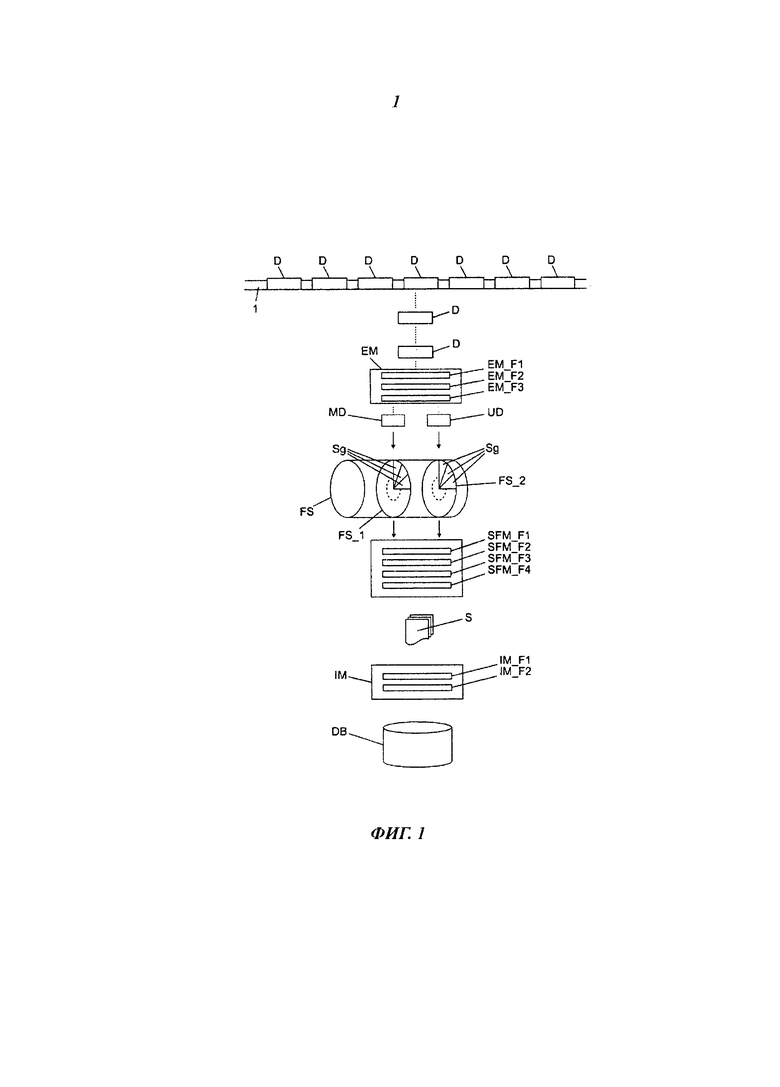
Фиг.1 является блок-схемой устройства, пригодного для реализации способа по изобретению в соответствии с первым вариантом осуществления.
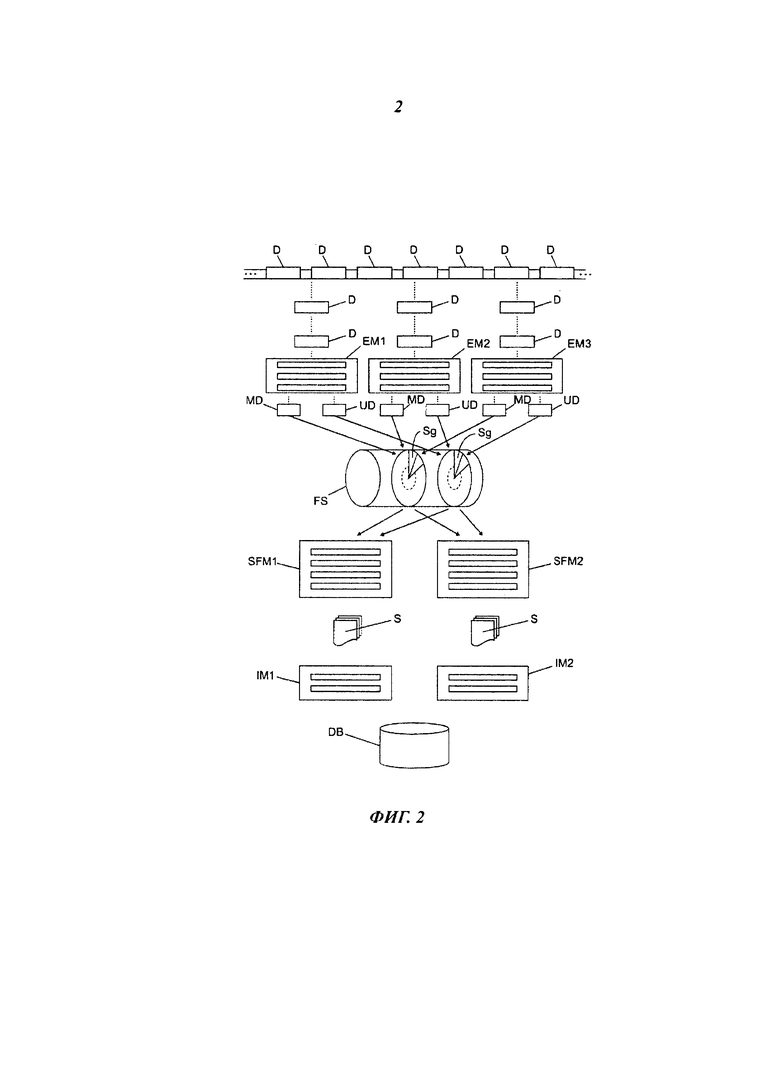
Фиг.2 является блок-схемой устройства, пригодного для реализации способа по изобретению в соответствии со вторым вариантом осуществления.
Осуществление изобретения
В показанной на фиг.1 блок-схеме представлены пакеты D данных, которые передают по линии 1 данных. Пакеты данных передают по линии данных, например, по интернет-протоколу (IP). Показанные на фиг.1 пакеты D данных представляют собой только небольшую часть трафика данных, обычно осуществляемого по линии 1 данных.
Модуль ЕМ извлечения принимает пакеты данных, извлеченные из потока данных. Для дальнейшей обработки пакетов данных модуль ЕМ извлечения содержит множество функциональных блоков EM_F1, EM_F2, EM_F3. В первом функциональном блоке EM_F1 формируется сигнатура обрабатываемого пакета данных. Для этого, например, с помощью хеш-функции генерируют хеш-код, который присваивают пакету данных. Таким способом сигнатура позволяет - не принимая во внимание ограничений хеш-функции - четко идентифицировать пакет данных.
Во втором функциональном блоке EM_F2 реконструируют части сетевой сессии, и в их данных производится поиск одного или нескольких задаваемых символов или символьных строк, которые здесь и далее называются ключевыми словами. Для этого функциональный блок EM_F2 предпочтительно работает, основываясь на так называемых регулярных выражениях. Ключевые слова, поиск которых нужно осуществить, или которые в некоторых случаях могут быть регулярными выражениями, для модуля ЕМ извлечения задаются через подходящий пользовательский интерфейс. Результаты этого поиска сохраняют в метаданных. Например, каждому текущему предмету поиска, который в некоторых случаях может быть регулярным выражением, присваивают идентификатор. При положительном результате поиска предмета поиска идентификатор, присвоенный этому предмету поиска, будет сохранен в метаданных. Таким образом, по ходу анализа, с помощью метаданных пакета данных можно быстро определить присутствие определенных символьных строк в ассоциированных полезных данных.
В третьем функциональном модуле EM_F3 пакеты данных разделяют на метаданные MD и полезные данные DU соответственно, с последующим их сохранением в буферном накопителе FS, который, например, реализуют в виде кольцевого буфера. Здесь все метаданные пакетов данных сохраняют в первой области FS_1 памяти, а полезные данные сохраняют во второй области FS_2 памяти. В показанном на фиг.1 варианте осуществления сохранение метаданных и полезных данных выполнено в соответствующие сегменты Sg первой области памяти и второй области памяти, соответственно. Один сегмент первой области памяти для записи метаданных содержит, например, 32 байта, а один сегмент второй области памяти для записи полезных данных содержит, например, 64 килобайта. Предпочтительно размер сегментов выбирают в соответствии с используемым сетевым протоколом, чтобы для всех предполагаемых к использованию протоколов полезные данные и метаданные одного пакета данных можно было хранить, в каждом случае, в одном сегменте. В случае рассмотренного выше выбора размера, можно сохранять пакеты, например, протокола IPV4.
В соответствии с одним из вариантов осуществления устройства по изобретению, если размер сегмента выбирают как в вышеприведенном примере, то каждая из областей памяти будет содержать примерно 5 миллионов сегментов, что даст емкость буферного накопителя более 300 гигабайт. Помимо сетевых протоколов размер и количество сегментов зависят и от других факторов, например, от количества модулей извлечения в сети, контроль которой можно было бы выполнять.
Для сохранения в буфере метаданных и полезных данных предпочтительно использовать номер транзакции, соответствующий сигнатуре пакета данных, сгенерированной модулем ЕМ извлечения или, по меньшей мере, сформированный из сигнатуры. Например, для сохранения метаданных сигнатура используется в качестве номера транзакции неизменной, а для сохранения полезных данных значение сигнатуры увеличивается на величину 1.
Кроме того, на фиг.1 показан модуль SFM реконструкции сессии, также содержащий множество функциональных блоков. В первом функциональном блоке SFM_F1 выполняют считывание области метаданных из буфера. В рассматриваемом случае эти метаданные считывают только тогда, когда они принадлежат к обрабатываемой в настоящее время сетевой сессии. Это можно выяснить по присутствующему в метаданных идентификатору.
Во втором функциональном блоке SFM_F2 в соответствии с предпочтительным вариантом осуществления выполняют проверку с целью определения того, был ли установлен в метаданных идентификатор, указывающий на то, что эти данные в настоящее время находятся в обработке. Это особенно полезно в случае наличия множества модулей реконструкции сессии, как показано на фиг.2 ниже. В таком случае можно выяснить, был ли этот пакет данных уже обработан другим модулем реконструкции сессии. Если при этом считывавший пакет данных модуль реконструкции сессии выяснит, что эта сетевая сессия уже обрабатывается другим модулем реконструкции сессии, то он выберет для обработки другой пакет данных или, как возможно в некоторых случаях, другую сетевую сессию. Однако в случае, если такой идентификатор не был установлен, модуль реконструкции сессии установит соответствующий идентификатор и тем самым укажет, что этот пакет данных, или, как возможно в некоторых случаях, сетевая сессия, в настоящее время обрабатывается этим модулем.
Анализ считанных метаданных выполняют в функциональном блоке SFM_F3. Здесь можно определить, например, был ли в метаданных установлен идентификатор, указывающий на положительный результат поиска. Если были считаны все метаданные сетевой сессии, а идентификатор в этих метаданных не был установлен, то можно остановить обработку на этом, так как можно предположить бесполезность дальнейшего анализа. Однако, если идентификатор был установлен по меньшей мере в одном экземпляре метаданных, то сетевая сессия будет реконструирована в функциональном блоке SFM_F4. Для этого полезные данные, например, с помощью их порядковых номеров, будут восстановлены в своей оригинальной последовательности. Если полезные данные еще не были считаны из буфера, это выполняют сейчас. Затем полезные данные сортируют и, таким образом, восстанавливают оригинальное содержание сетевой сессии. Как правило, оно будет полным, однако сетевую сессию, конечно же, нельзя будет реконструировать полностью в случае утери отдельных пакетов.
Сетевая сессия, состоящая, например, из множества документов и/или медиа-данных, таких как, например, видео- и музыкальные данные, или других данных одного типа, затем подается в модуль IM идентификации для анализа данных, которые теперь имеются в виде сетевой сессии. Модуль идентификации также может содержать множество функциональных блоков. Например, в первом функциональном блоке IM_F1 выполняют идентификацию или, как вариант, дешифрование и сохранение всей релевантной информации уровня приложений для уровней с 5 по 7 модели OSI. Предпочтительно, здесь дешифрование и/или идентификацию выполняют на нескольких уровнях. Например, на первом уровне будет выполнено извлечение данных на основе MIME. Это происходит на основе типов данных (например, PDF, JPEG, GIF, RTP…). Данное извлечение изначально не зависит от используемого сетевого протокола.
На следующем этапе может выполняться эвристическое извлечение данных. Здесь оценивают метаданные сетевой сессии (которые не следует путать с метаданными пакета данных) с целью идентификации коммуникационных шаблонов. Это тоже происходит независимо от используемого сетевого протокола. Следующим этапом может быть выполнена оценка данных сетевой сессии на основе протокола. Это может быть выполнено, например, согласно стандарту RFC.
В дополнительном функциональном модуле IM_F2 может быть обеспечена дополнительная или отдельная оценка дефектных или прерванных сетевых сессий.
Данные, сгенерированные в модуле SFM реконструкции сессии и модуле IM идентификации, сохраняют - по меньшей мере, частично - в дополнительной памяти DB хранения данных, которую создают, например, в форме так называемого хранилища данных на основе документоориентированной базы данных. Память хранения данных предпочтительно позволяет выполнять полнотекстовое индексирование на основе так называемых В*-деревьев. Дополнительные осуществления могут предусматривать полуструктурированное хранение данных и версионирование или, в некоторых случаях, проверку изменений всех томов данных.
В предпочтительных вариантах осуществления база DB данных имеет множество интерфейсов для доступа к базе данных. Такие интерфейсы включают в себя, например, JSON (Java Script Object Notation) для соединения с так называемыми серверами приложений. Дополнительные интерфейсы могут быть текстовыми или же могут размещаться непосредственно в базе данных, которая с этой целью предпочтительно должна иметь заданный интерфейс программирования. Кроме того, база DB данных может иметь подключение к дополнительным модулям оценки, осуществляющим расширенную оценку данных, например, на основе способа, относящегося к области интеллектуального сбора и анализа данных.
На фиг.2 представлено еще одно возможное осуществление изобретения, иллюстрирующее преимущества изобретения, касающиеся его масштабируемости. Показанное на фиг.2 осуществление содержит множество модулей ЕМ1, ЕМ2, ЕМ3 извлечения; множество модулей SFM1, SFM2 реконструкции сессии; и множество модулей IM1, IM2 идентификации. Показанные на фиг.2 модули следует рассматривать исключительно в качестве примеров. Естественно, что каждый модуль может быть представлен в любом количестве. Как было изначально раскрыто, изобретение делает возможным, например, добавлять отдельные модули даже в процессе работы устройства по изобретению, или, что может быть возможным при реализации способа по изобретению, без необходимости дополнительных изменений. Этого достигают, помимо всего прочего, использованием сигнатур пакетов данных, которые предпочтительно вычисляют с помощью хеш-функции, и использованием этих сигнатур в качестве номеров транзакции в процессе сохранения пакетов данных в буферном накопителе FS. В случае показанного на фиг.2 варианта осуществления возможно, что отдельные модули ЕМ1, ЕМ2, ЕМЗ извлечения извлекут из потока данных один и тот же пакет. При расчете сигнатуры все модули извлечения используют одну и ту же хеш-функцию, генерируя с ее помощью одну и ту же сигнатуру. Если модуль извлечения пытается сохранить в буфере пакет, или, как вариант, метаданные и полезные данные пакета, буфер позволит сделать это только в том случае, если номер транзакции еще не был использован в рамках заданного окна времени. То есть, именно в том случае, если данный пакет данных уже был зарегистрирован в буферном накопителе другим модулем извлечения. Наличие нескольких модулей извлечения гарантирует возможность фактической обработки каждого из пакетов данных. В частности, можно использовать модули извлечения с более низкими уровнями производительности, так как пакет данных, не извлеченный из-за низкой скорости обработки модуля извлечения, будет обработан следующим модулем или одним из следующих модулей извлечения. Таким образом, если в процессе работы устройства по изобретению окажется, что трафик данных увеличился, что требует подстройки производительности системы, это может быть выполнено простым добавлением дополнительного модуля извлечения или множества модулей извлечения.
Масштабируемость модуля реконструкции сессии может быть осуществлена столь же просто. Это достигается посредством механизма, изначально описанного выше, где модуль реконструкции сессии, считывая метаданные из буферного накопителя, начинает с проверки того, был ли там установлен идентификатор, указывающий на то, что сетевая сессия, к которой принадлежит этот пакет данных, уже была обработана другим модулем реконструкции сессии. Альтернативно и/или дополнительно к этому, идентификатор может быть сохранен в самих метаданных, показывая то, что этот пакет данных уже обрабатывается модулем реконструкции сессии. Обнаружив такой статус, модуль реконструкции сессии выберет другую сетевую сессию, а затем начнет считывать ассоциированные с ней пакеты данных из буферного накопителя. Если модуль реконструкции сессии считал все пакеты данных сетевой сессии, это также будет указано с помощью надлежащего идентификатора в буферном накопителе или с помощью надлежащих идентификаторов в метаданных этой сетевой сессии. Этим не допускается, чтобы одна и та же сетевая сессия обрабатывалась более или менее параллельно или последовательно множеством модулей реконструкции сессии. Этим также обеспечивается то, чтобы каждая сетевая сессия реконструировалась только один раз.
Предпочтительный вариант осуществления обеспечивает то, что идентификатор, указывающий, что сетевая сессия и/или элемент метаданных сетевой сессии в настоящее время находится в обработке, автоматически терял силу по истечении заданного времени. Этим гарантируется, что модуль реконструкции сессии не сможет блокировать реконструкцию сетевой сессии в случае выхода этого модуля из строя или изъятия его из системы. Этим гарантируется, что даже в течение работы устройства по настоящему изобретению модуль реконструкции сессии может быть изъят без причинения вреда работе системы в целом.
Количество отдельных обрабатывающих модулей определяется, с одной стороны, их доступностью и, с другой стороны, количеством подлежащих анализу пакетов данных и производительностью отдельного модуля. При использовании способа по изобретению в частности возможно, например, соединять между собой модули извлечения с различной производительностью в единую систему без дополнительной подготовки.
Изобретение также делает возможным активное вмешательство в трафик данных. Если, например, обнаруживают, что в сетевой сессии передаются нежелательные данные, или что нежелательные данные часто передаются от определенного отправителя, то модуль извлечения может быть выполнен таким образом, что данные не копируют незамедлительно в процессе извлечения, а фактически изымают их и возвращают обратно только после анализа. В соответствии с другим вариантом осуществления обеспечивается, что в случае обнаружения в сетевой сессии неразрешенного содержимого, эту сессию прерывают, или же полностью останавливают передачу данных от одного отправителя.
Буферный накопитель может быть реализован на базе разнообразных систем памяти, таких как NAS, SAN, локальные жесткие диски, виртуальные диски в оперативном запоминающем устройстве или другие известные системы памяти. Система также не зависит от используемого коммуникационного протокола. Здесь могут быть использованы, например, NFS, CIFS, FCP, SSP, SATA и т.п.
Для передачи данных на основе интернет-протокола, модуль реконструкции сессии может быть реализован для пассивного анализа данных на основе ТСР-стека, оптимизированного для этой цели. Модуль реконструкции сессии может предусматривать, чтобы извлечение и хранение всей информации выполнялось на уровнях с L2 по L4 модели OSI, например, IP, TCP, UDP, и добавлялось к эвристическому анализу. Этот анализ зависит от анализа информации уровня приложений (с L5 по L7 модели OSI).
Предложенное изобретение может быть реализовано, в частности, с использованием открытых стандартов, открытых интерфейсов и открытых архитектур, и может быть легко интегрировано в существующие системы посредством четко определенных интерфейсов. Что касается безопасности, то система по изобретению обладает тем преимуществом, что ее можно беспроблемно реализовать таким образом, чтобы эксплуатационная готовность системы в целом не зависела от эксплуатационной готовности отдельного модуля. Таким образом, в такой системе не будет существовать компонента, отказ которого приводил бы к отказу всей системы. Дополнительным преимуществом масштабирования является то, что в процессе работы системы отдельные модули могут быть обновлены безвредно для работы в целом.
При необходимости, в модуле идентификации может выполняться несколько процессов анализа. Кроме уже упомянутого анализа на основе MIME, с помощью которого могут быть распознаны практически все типы файлов, несомненно, что может быть обеспечено извлечение данных, передаваемых в сжатом виде. Будет особенно полезно, если идентификация HTML-данных будет включать в себя возможность автоматической повторной загрузки, например, из сети Интернет, статического содержания, которое, следовательно, не воспроизводится явно в сетевой сессии, с целью независимого завершения сетевой сессии таким способом.
Эвристический анализ может применяться к информации в пакетах данных и здесь может включать детектор для распознавания манипуляций с контрольными суммами TCP, идентификации операционной системы и анализа сетей, в которых используются маршрутизаторы и брандмауэры. Эвристический анализ полезных данных может охватывать адреса URL, адреса электронной почты, различную учетную информацию и пользовательские имена, распознавание SSL/TLS, распознавание Skype и/или DNS-запросы. Эвристический анализ, конечно же, можно адаптировать к типу сетевой сессии и, в зависимости от обнаруженного типа сетевой сессии, использовать дополнительные способы анализа. Например, можно распознавать тип чата. Из этого можно также вывести дополнительную информацию. В частности, можно определить, не выполняется ли процесс общения по неразрешенным протоколам или через неразрешенные серверы.
Показанные на фиг.1 и фиг.2 варианты осуществления должны рассматриваться исключительно как примеры, служащие для разъяснения изобретения. В другие вариантах осуществления, также иллюстрирующих настоящее изобретение, оно может быть реализовано в другой форме. Например, отдельные функциональные блоки внутри модулей должны рассматриваться только в качестве примеров. Каждый модуль может включать в себя дополнительные функциональные блоки, или же только часть функциональных блоков из показанных на фиг.1 и фиг.2. Кроме того, может быть предусмотрено, чтобы функциональные блоки не были в явном виде реализованы как таковые, но чтобы сам модуль имел одну или несколько соответствующих функциональных возможностей. Кроме того, показанное на фиг.1 и фиг.2 разделение общей функциональности приведено, прежде всего, с целью иллюстрирования. Конечно, также может быть предусмотрено дальнейшее подразделение модулей или же, по меньшей мере, частичное интегрирование функциональных возможностей нескольких модулей в другие модули.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ АВТОГЕНЕРАЦИИ РЕШАЮЩИХ ПРАВИЛ ДЛЯ СИСТЕМ ОБНАРУЖЕНИЯ ВТОРЖЕНИЙ С ОБРАТНОЙ СВЯЗЬЮ | 2016 |
|
RU2634209C1 |
| СПОСОБ И СИСТЕМА ОБМЕНА МЕДИЦИНСКИМИ ДАННЫМИ | 2021 |
|
RU2748052C1 |
| СПОСОБ И СИСТЕМА ДЕЦЕНТРАЛИЗОВАННОЙ ИДЕНТИФИКАЦИИ ВРЕДОНОСНЫХ ПРОГРАММ | 2018 |
|
RU2677361C1 |
| КАДРОВЫЙ ПРОТОКОЛ И СИСТЕМА ПЛАНИРОВАНИЯ | 2003 |
|
RU2323429C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ИДЕНТИФИКАЦИИ VoIP ТРАФИКА | 2010 |
|
RU2510916C2 |
| Способ обнаружения аномального трафика в сети | 2023 |
|
RU2811840C1 |
| ОБРАБОТКА ТРАНЗАКЦИЙ | 2002 |
|
RU2298225C2 |
| Способ проведения платежа онлайн-пользователем при наличии информации об идентификаторе пользователя | 2020 |
|
RU2743147C1 |
| РАСЩЕПЛЕННАЯ ЗАГРУЗКА ДЛЯ ЭЛЕКТРОННЫХ ЗАГРУЗОК ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ | 2006 |
|
RU2424552C2 |
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ ГРАФОВ | 2015 |
|
RU2708939C2 |
Изобретение относится к технологиям сетевой связи. Технический результат заключается в повышении безопасности передачи данных. Способ анализа пакета данных в потоке данных, причем пакету данных присваивают уникальную сигнатуру; пакет данных сохраняют в буферном накопителе, причем метаданные сохраняют в первой области памяти, а полезные данные сохраняют во второй области памяти так, чтобы поддерживать ассоциацию между полезными данными и соответствующими метаданными; причем номер транзакции, используемый для выполнения соответствующей операции сохранения, генерируют на основе сигнатуры пакета данных; перед сохранением пакета данных или после него выполняют поиск в полезных данных по меньшей мере одного предмета поиска, и по меньшей мере один положительный результат поиска в метаданных помечают путем установки идентификатора поиска; считывают метаданные из буферного накопителя, и, если проверка показывает, что данный пакет данных не находится в настоящее время в обработке, то ассоциированные полезные данные считывают из буферного накопителя, и в сохраненных в буферном накопителе метаданных устанавливают идентификатор. 3 н. и 9 з.п. ф-лы, 2 ил.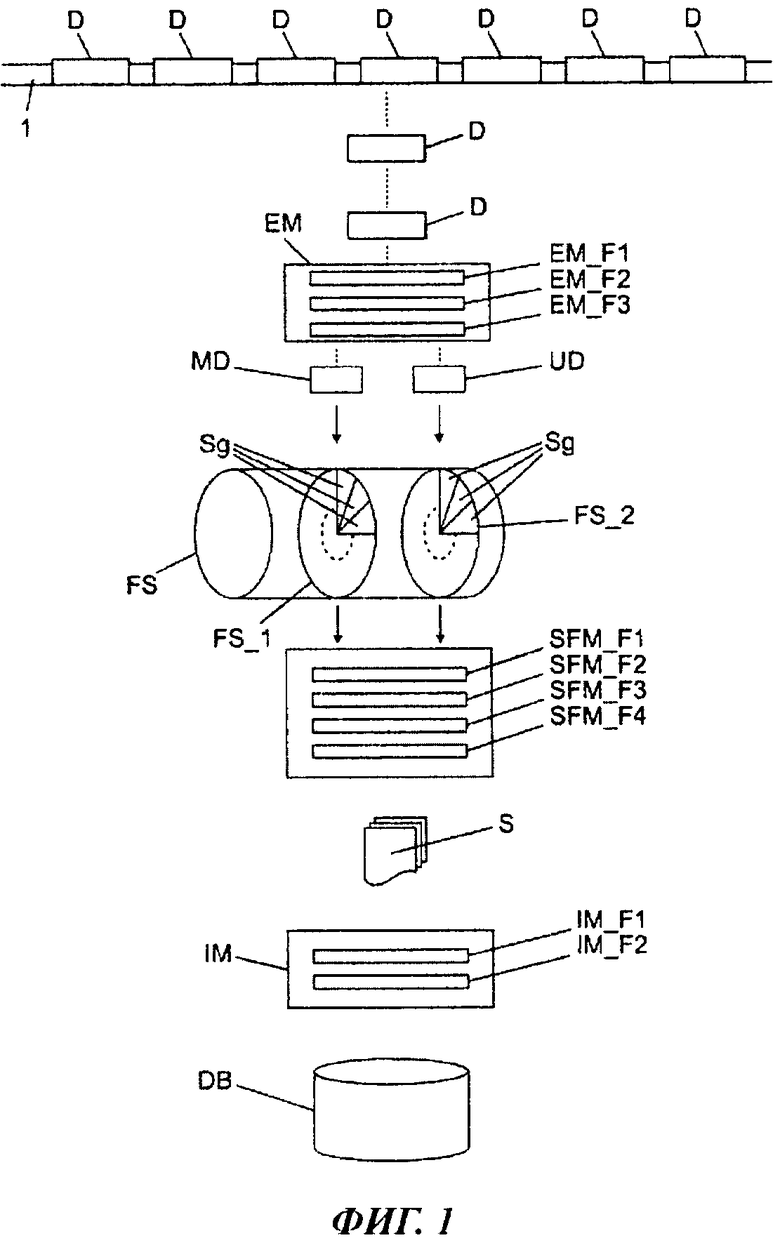
1. Способ анализа пакета (D) данных в потоке данных, причем пакет состоит из метаданных (MD) и полезных данных (UD), в котором пакет (D) данных извлекают/ из потока данных, отличающийся тем, что пакету (D) данных присваивают уникальную сигнатуру; пакет (D) данных сохраняют в буферном накопителе (FS), причем метаданные (MD) сохраняют в первой области (FS_1) памяти, а полезные данные (UD) сохраняют во второй области (FS_2) памяти так, чтобы поддерживать ассоциацию между полезными данными (UD) и соответствующими метаданными (MD); причем номер транзакции, используемый для выполнения соответствующей операции сохранения, генерируют на основе сигнатуры пакета (D) данных; перед сохранением пакета (D) данных или после него выполняют поиск в полезных данных (UD) по меньшей мере одного предмета поиска, и по меньшей мере один положительный результат поиска в метаданных (MD) помечают путем установки идентификатора поиска; считывают метаданные (MD) из буферного накопителя (FS), и, если проверка показывает, что данный пакет (D) данных не находится в настоящее время в обработке, то ассоциированные полезные данные (UD) считывают из буферного накопителя, и в сохраненных в буферном накопителе (FS) метаданных (MD) устанавливают идентификатор, указывающий на то, что данный пакет (D) данных находится в настоящее время в обработке; если были считаны все метаданные (MD) и полезные данные (UD) из сетевой сессии, и поиск предмета поиска дал положительный результат в по меньшей мере одном из элементов полезных данных (UD), то сетевую сессию реконструируют путем постановки полезных данных (UD) в их оригинальном порядке.
2. Способ по п.1, отличающийся тем, что после считывания последнего пакета (D) данных в сетевой сессии в метаданные (MD), принадлежащие к данной сетевой сессии и сохраненные в буферном накопителе (FS), помещают пометку для указания на то, что эти метаданные (MD) находятся в обработке.
3. Способ по п.1 или 2, отличающийся тем, что выполняют анализ полезных данных (UD) реконструированной сетевой сессии с целью идентификации по меньшей мере одного типа файла для по меньшей мере одного переданного в ходе сетевой сессии файла.
4. Способ по п.1, отличающийся тем, что анализируют метаинформацию в полезных данных (UD) сетевой сессии.
5. Способ по п.1, отличающийся тем, что анализ переданных в ходе сетевой сессии полезных данных (UD) выполняют с учетом сетевых протоколов уровня приложений.
6. Способ по п.1, отличающийся тем, что сигнатуру пакета (D) данных определяют с помощью хеш-функции.
7. Способ по п.1, отличающийся тем, что первая область (FS_1) памяти и вторая область (FS_2) памяти буферного накопителя (FS) реализованы в виде кольцевого буфера.
8. Способ по п.1, отличающийся тем, что присвоение метаданных (MD), сохраненных в буферном накопителе (FS), сохраненным полезным данным (UD) производят с помощью уникального номера (Sg) сегмента соответствующей области памяти.
9. Способ по п.1, отличающийся тем, что буферный накопитель (FS) позволяет сохранять метаданные (MD) и полезные данные (UD) только в зависимости от результата проверки допустимости использованного номера транзакции.
10. Устройство для выполнения анализа пакета (D) данных в потоке данных, причем пакет состоит из метаданных (MD) и полезных данных (UD) и является частью сетевой сессии, содержащей по меньшей мере один данный пакет (D) данных, отличающееся тем, что устройство содержит по меньшей мере один функциональный блок (EM_F1) для создания уникальной сигнатуры пакета (D) данных; буферный накопитель (FS), содержащий первую область (FS_1) памяти и вторую область (FS_2) памяти, причем буферный накопитель обеспечивает возможность сохранения метаданных (MD) в первой области (FS_1) памяти и сохранения полезных данных (UD) во второй области (FS_2) памяти так, чтобы поддерживать ассоциацию между полезными данными (UD) и соответствующими метаданными (MD), а номер транзакции, используемый для выполнения соответствующего процесса сохранения, генерировался на основе сигнатуры пакета (D) данных; по меньшей мере один функциональный модуль (EM_F2), обеспечивающий возможность выполнения поиска в полезных данных (UD) по меньшей мере одного предмета поиска перед сохранением пакета (D) данных в буферном накопителе или после него и пометки по меньшей мере одного положительного результата поиска в метаданных (MD) путем установки идентификатора поиска; и по меньшей мере один модуль (SFM) реконструкции сессии, содержащий средства считывания метаданных (MD) из буферного накопителя (FS), функциональный блок (SFM_F1), реализующий проверку того, находятся ли считанные метаданные (MD) в настоящее время в обработке; средства установки идентификатора в сохраненных в буферном накопителе (FS) метаданных (MD) для указания того, что считанные метаданные (MD) находятся в настоящее время в обработке, и средства считывания всех сохраненных в буферном накопителе полезных данных (UD) сетевой сессии в случае, если в по меньшей мере одном пакете (D) данных данной сетевой сессии установлен идентификатор поиска, и средства реконструкции полезных данных (UD) в оригинальном порядке.
11. Устройство по п.10, отличающееся тем, что имеет средства для осуществления способа по одному из пп.1-9.
12. Сетевой узел с компьютерной программой, исполняемой на сетевом узле и составленной для осуществления способа по одному из пп.1-9.
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| ОБРАБОТКА ПАКЕТОВ, ПЕРЕДАВАЕМЫХ ПО СЕТЯМ ПЕРЕДАЧИ ДАННЫХ | 2005 |
|
RU2364040C2 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

