Данное изобретение относится к способу и системе обработки графов данных.
Любые типы данных могут быть представлены в виде троек. В отношении настоящего изобретения, данные о которых идет речь, включают пользовательские данные и онтологии. Данные могут быть представлены, например, в виде RDF-графа.
Ниже приведены два примера представления RDF-графов в XML-формате (который зачастую наиболее удобен для компьютерной обработки) и в виде N-троек или N3 (которые используются в настоящем подходе и которые наиболее удобны для понимания человеком).
XML-синтаксис:

Таким образом, XML-синтаксис намного подробней N3-синтаксиса, однако он легче обрабатывается компьютерами.
Тройка является основной единицей Среды Описания Ресурса RDF (RDF) и состоит из Субъекта, Предиката и Объекта. Набор троек обычно называют RDF-графом, пример которого представлен на ФИГ. 1. Направление стрелки (например, (110а, 110б) в любой взятой тройке (например, 120) указывает от Субъекта (130) к Объекту (140). Модель RDF-данных похожа на классические концептуальные подходы моделирования, такие как сущность-связь или диаграммы классов, так как в ее основе лежит идея создания утверждений о ресурсах (в частности, веб-ресурсов) в виде выражений Субъект-Предикат-Объект.
Данные выражения рассматриваются как тройки в RDF-терминологии. Субъект обозначает ресурс, а Предикат обозначает особенности или аспекты ресурса и выражает отношение между Субъектом и Объектом. Набор RDF-утверждений представляет собой помеченный, ориентированный мульти-граф. Таким образом, модель данных на основе RDF естественней подходит для представления определенных видов знаний, чем реляционная модель и другие онтологические модели.
Как было сказано выше, RDF-данные часто хранятся в реляционных базах данных или в нативных хранилищах Троек, или хранилищах Четверок, если контекст (т.е. именованный граф) также хранится для каждой RDF-тройки. Именованные графы являются ключевой концепцией архитектуры Семантической Сети, в которой набор утверждений Среды Описания Ресурса (граф) идентифицируется с использованием URI, позволяя создавать описания этого набора утверждений, таких как контекст, информации о происхождении или других метаданных.
Именованные графы являются простым расширением RDF-модели данных посредством которой могут быть созданы графы, однако такая модель лишена эффективных средств различения между ними после появления в Вебе целиком. В то время как именованные графы могут отображаться в Вебе в виде простых связанных документов (т.е. Связанных Данных), они также крайне полезны для управления наборами RDF-данных внутри RDF-хранилища.
Как традиционно известного на ФИГ. 1 объект "Человек", "Менеджер" 140 и субъекты "Джон" 130, "Майкл", "Морган", "Мона", "Алекс" RDF-утверждений являются Унифицированными Идентификаторами Ресурса (URI), определяющими ресурсы. Ресурсы также могут быть показаны пустыми узлами. Пустые узлы не являются непосредственно идентифицированными из RDF-утверждений. В RDF-графе пустой узел является узлом, представляющим ресурс, для которого не задан URI или литерал. Ресурс, представленный пустым узлом, также называется анонимным ресурсом. Согласно RDF-стандарту, пустой узел может быть использован только в качестве Субъекта или Объекта RDF-тройки. Пустые узлы могут быть обозначены посредством идентификаторов пустых узлов в следующих форматах, RDF/XML, Turtle, N3 и N-тройках. Следующий пример показывает, как это работает в RDF/XML:

Идентификаторы пустых узлов ограничены лишь в области сериализации определенного RDF-графа, т.е. узел "_:b" в последующем примере представляют не один и тот же узел, как узел с именем "_:b" в другом графе. Пустые узлы рассматриваются в качестве простых указателей на существование вещи без использования URI (Унифицированного Идентификатора Ресурса) для определения какой-то конкретной вещи. Это не то же самое, как если предположить, что пустой узел указывает на "неизвестный" URI.
Предикат ("это" 110а, "должность" 1106) являются URI, которые также указывают на ресурс, представляя собой связи. Объект ("Менеджер", "Разработчик", "Генеральный директор" и, в частных случаях, "Джон", "Майкл", "Морган", "Мона", "Алекс") являются URI, пустыми узлами или строковым литералов в Юникоде. В данном изобретении для обработки информации из различных источников используется троечный подход.
На чертежах:
ФИГ. 1 иллюстрирует пример системы графов в соответствии с примерным вариантом;
ФИГ. 2 иллюстрирует часть семантической сети в соответствии с примерным вариантом;
ФИГ. 3 иллюстрирует традиционное получение данных (систему обработки запроса клиента) с использованием существующих технологий;
ФИГ. 4 иллюстрирует реализацию интерфейса матчера модуля получения данных;
ФИГ. 5 иллюстрирует алгоритм обработки запроса на примере точного матчинга;
ФИГ. 6 иллюстрирует алгоритм обработки запроса на примере матчинга данных по шаблону;
ФИГ. 7 иллюстрирует пример различных бизнес-приложений, используемых в различных отделах компании, и обработку данных в них.
ФИГ. 8 иллюстрирует систему для примерного варианта.
ФИГ. 9 иллюстрирует базу данных со структурой В-дерева для хранения троек.
ФИГ. 10 иллюстрирует пример хранения предикатов и их атрибутов в В-дереве.
ФИГ. 11 иллюстрирует примерную систему для реализации изобретения.
ФИГ. 12 иллюстрирует обработку запроса клиента после того, как будет найдено соответствующее правило.
ФИГ. 13А, 13Б иллюстрирует пример комбинирования моделей (объединения моделей).
ДЕТАЛЬНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ
Обозначенные выше материалы будут описаны детально применимо к предпочтительным вариантам текущего изобретения, примеры которых проиллюстрированы на соответствующих чертежах.
На ФИГ. 2 показан семантический стек в соответствии с примерным вариантом изобретения. Семантический стек, используемый в примерном варианте, включает в себя Унифицированный Идентификатор Ресурса (URI) 201. Стоит отметить, что описано может быть все, что может быть идентифицировано при помощи URI, так что семантическая сеть может относиться к животным, людям местам, идеям и т.д. Семантическая разметка часто генерируется автоматически, чем вручную. URI могут быть классифицированы в качестве указателей (URL), имен (URN) или тех и других.
Единообразное имя ресурса (URN) является как именем для человека, в то время, как Универсальный Указатель Ресурса (URL) напоминает адрес проживания человека. URN определяет индивидуальность элемента, в то время как URL предоставляет способ его поиска. CmwL (Язык Comindware) 211 описывает функцию и отношения всех этих компонентов семантического веб-стека; XML 203 обеспечивает элементарным синтаксисом структуру содержимого в документах, поскольку ассоциации не имеют семантики для значения контента, содержащегося в них; RDF 205 является простым языком для представления модели данных, который относится к объектам ("ресурсам") и их связям. Модель на основе RDF может быть представлена в XML-синтаксисе. RDF-схема 207 расширяет RDF и является словарем для описания свойств и классов основанных на RDF ресурсов и семантики для обобщенных иерархий таких свойств и классов.
Онтология 215 формально представляет собой знания в виде набора понятий в домене, используя общий словарь для определения типов, свойств и взаимосвязей данных понятий. Онтологии представляют собой структурные каркасы для организации информации. Онтологии описываются посредством (Языка Описания Онтологий) OWL или посредством CmwL, который позволяет описать Классы и их связи друг с другом и другими сущностями (см. ниже). Онтологии могут расширять предопределенный словарь (например, RDF-словари или OWL-словари). Словарь представляет собой набор данных информации определенных терминов, которые имеют одинаковый смысл во всех контекстах.
Онтологии используют предварительно определенный зарезервированный словарь/глоссарий терминов для понятий и отношений, определенный для конкретного домена/предметной области. Онтологии могут быть использованы для выражения семантики терминов словаря, их связей и контекстов использования. Таки образом RDF-схема является словарем для RDF. OWL или CmwL могут быть использованы для записи семантики предметных областей в онтологии. По существу, любые данные, например, онтологии или таксономии, могут быть выражены в тройках. Тройка - это факт.
Таксономия 209 является иерархическим способом классифицировать все объекты в данном мире: книги, продукты, виды, концепции и др. В семантической сети таксономия является словарем терминов и их точных определений. Когда словарь логически упорядочен в иерархии, он называется таксономией. Он является общим ресурсом для всех в информационной экосистеме, использующимся для синхронизации значения терминов.
В одном варианте осуществления, язык Comindware 211 используется вместо Языка описания Онтологий (OWL) в семантическом стеке. Comindware-язык представляет собой ограниченную версию OWL с целью повышения производительности и избавления от функциональности и операций, которые не являются необходимыми для целей бизнес-приложений и/или для использования с онтологиями (но с использованием OWL-словаря и некоторых его правил 213).
Как было сказано выше, данные состоят из пользовательских данных и онтологий. Пользовательские данные хранятся в базе данных (например, на жестком диске) в виде аксиом. Аксиома, или постулат, является исходной или стартовой точкой рассуждений. Как классически задумывалось, аксиома является настолько очевидным предположением, что без споров принимается за истину.
Как было сказано выше, N3 основан на RDF-стандартах и эквивалентен синтаксису RDF/XML, однако обладает дополнительными особенностями, такими как правила и формула. Правила могут быть написаны на N3, OWL, XNL и др.
Простое правило (N3-правило) может сказать что-то вроде: если X является частью Y и если Y является частью Z, то X является частью Z, или "{?x rdfs:частьОТ ?y. ?ty rdfs:частьОТ ?z} => {?x rdfs:частьОТ ?z}."
Комбинация скобок "{"и"}" и "=>" является правилом. Фигурные скобки здесь заключают в себе набор утверждений и представляют собой формулу. Все формулы заключены в фигурные скобки. Не считая того, что Субъект и Объект тройки (Субъект формулы представлен двумя утверждениями, а Объект формулы представлен одним утверждением) является формулой, показанный выше пример является простым утверждением. Формула является частью правила и может быть представлена набором утверждений (по крайней мере, одним утверждением), где правило также является утверждением, и где утверждение является тройкой.
В приведенном выше примере утверждения «?x» является переменной (или неизвестной величиной, искомой величиной). Стоит отметить, что «?x» не всегда представлен искомой величиной, вместо этого известная часть утверждения (в виде URI) «?x» может быть использована для проверки подлинности факта. Как было сказано выше, любые данные, такие как сущность, событие и другие могут быть описаны тройкой. Тройка может описывать факт, например, "Билл - это Человек", "Джон - это Человек", "Джона должность - менеджер".
Если тройка выглядит следующим образом: "?x это Человек", то будут найдены все вещи (которые удовлетворяют утверждению). Но если часть утверждения, такая как "Билл" и "Джон" будут использоваться в качестве входных данных для «?x», то данное утверждение может быть проверено на "истину" или "ложь", т.е. хранился ли данная тройка (тройки) среди троек. Для данного примера после подстановки "Билл" и "Джон" в «?x» следующие утверждения: "Билл - это Человек" и "Джон - это Человек" будут истинны, поскольку эти тройки хранятся в базе данных. Если используется утверждение "?x должность менеджер", и "Джон" и "Билл" используются в качестве входных параметров для «?x», то только одно утверждение " Джона должность - менеджер" интерпретируется, как истина, а утверждение "Билла должность - менеджер" является ложью, поскольку такой тройки не хранится в базе данных (и она не выводится из тройки (троек)). Если переменная «?x» не связана со значением из тройки "?x это Человек", то данная тройка используется для поиска всего, что удовлетворяет данной тройки, т.е. будут найдены "Билл" и "Джон".
В описанном выше примере "=>" используется в качестве специального предиката, означающего "следует". Он используется для связи формул. На самом деле, это - сокращение от URI log:implies, или: http://www.w3.org/2000/10/swap/log#implies. Когда две формулы связаны при помощи "log:implies", это - правило, и, как было сказано выше, все правила являются просто различными видами утверждений. Формула содержит вещи, которые могут быть представлены с использованием текущих RDF/XML; эти правила не являются частью стандартного RDF-синтаксиса.
Стоит отметить, что значение выражений, написанных на N3 при помощи фактов и правил, легко могут быть поняты без знания языка программирования. В данном описании изобретения части утверждений поименованы в виде описательных имен. Так "Ошибка" является ошибкой; "Джона должность менеджер" означает, что Джона занимает должность менеджера (например, в компании); "Билл - это человек" означает, что Билл является человеком; "задача1 статус закрыта" означает, что статус "задачи1" - закрыта и т.д. таким образом код, описанный в данном изобретении, может быть использован в качестве описания особенностей изобретения.
Например, часть утверждения "продуктДляОшибкиТег" может быть интерпретирована как "Тег для продукта для ошибки" или как "Тег с именем "Продукт для ошибки". Другими словами, "Тег, который ассоциирует Продукт с Ошибкой". Другим примером является "cmw/:атрибутыСвойства", который может быть интерпретирован как атрибуты свойства или свойственные атрибуты. Еще один пример: часть утверждения "создательТег" может быть интерпретирована как Тег, имя которого "Создатель" или автор, т.е. человек, который что-то создает, например, задачу или ошибку.
Упомянутые выше значения переменных могут быть предопределены перед тем, как будет обрабатываться/вычисляться правило с этими переменными.
Следующая запись используется для определения "?тег" и "?значения" в качестве входных данных (стоит отметить, что Входные данные могут быть связаны/зарегистрированы на данные переменные, как обсуждается в данном изобретении:
-вх ?тег, ?значения.
Данная запись маркирует переменные "?тег", "?значения" как переменные, которые должны содержать значения, и определяет невозможность использование данных переменных без значений, т.е. значения данных переменных не должны быть не определены. Такие переменные также называются Входами, а значения переменных входными значениями, например, для правил, методов/функций/встроенных функций/функторов и т.д., которые описаны ниже.
Следующий пример демонстрирует использование Входов для вычисления правил.

В данном примере переменные "?тег" и "?значения" определены в утверждениях "(пример:продуктДляОшибкиТег (продукты:Продукт1 продукты:Продукт2)) запрос:тегЗапрос ?х." и "(пример:важностьОшибкиТег (важностьОшибки:высокая)) запрос: тегЗапрос ?x", где "пример:продуктДляОшибкиТег" и "пример:важностьОшибкиТег" являются значениями для "?тег"; и "важностьОшибки:высокая", а список из "продукты:Продукт1" и "продукты:Продукт2" является значениями для "?значения".
Данные, получаемые и обрабатываемые в процессе работы, используют приведенные выше правила в зависимости от того, как эти правила будут вызваны и с какими параметрами, т.е. с неизвестными или с определенными данными.
В одном варианте осуществления настоящего изобретения, если "- вх ?тег, ?значения." не добавлена в исходный код, то приведенные выше два правила все еще остаются вычисляемыми, однако все, что будет найдено в базе данных и/или в Хранилищах Модуля Получения Данных будут использованы вместо Входов.
В другом варианте осуществления настоящего изобретения, если во втором правиле вместо "-(пример:продуктДляОшибкиТег (продукты:Продукт1 продукты:Продукт2)) запрос:тегЗапрос ?х." написать "- ?некаяПеременная запрос:тегЗапрос ?х.", другими словами, если список значений заменить на неизвестную переменную, то результатом обработки утверждения является все, что ему соответствует. Стоит отметить, что в данном варианте "?тег" и "?значения" не определены в качестве Входов, как в предыдущем варианте.
В другом варианте осуществления изобретения, если "?тег" и "?значения" не определены в качестве Входов и вместо них в предыдущем описанном примере, вместо неизвестных переменных, используются известные значения, то обработкой утверждения будет являться проверка наличия данной конкретной тройки.
Возвращаясь к обсуждению обработки правил с Входами "?тег" и "?значения", в условиях приведенного выше исходного кода утверждения первой формулы используются для поиска данных, где найденные данные (например, Объекты/Элементы, которые являются экземплярами Классов и о которых будет сказано ниже), сохраняются в «?x»; а значения "?значения" и "?тег" из второго правила используются в качестве входных параметров (Входов) для первого правила (для вычисления правила). На самом деле, первое правило вызывается из второго правила с заданными параметрами - значениями "?тег" и "?значения".
В левой части первого правила ищутся пары с общим предикатом "тег:предикат". Части утверждений ("пример:продуктДляОшибкиТег" и "пример:важностьОшибкиТег") являются значениями для ?тег. В связи с тем, что приведенный выше исходный код содержит тройку "пример:важностьОшибкиТег тег:предикат пример:важностьОшибки;", то одной из искомых пар может быть пара "пример:важностьОшибкиТег + пример:важностьОшибки", а пара "пример:продуктДляОшибкиТег + пример:продукт" может быть второй искомой парой, как видно из исходного кода.
В правой части первого правила содержимое скобок (?тег ?значения) представляет собой массив/список из двух элементов/переменных. Стоит отметить, что список или последовательность является абстрактным типом данных, который реализует законченную упорядоченную коллекцию значений, где одно и то же значение может встречаться более чем один раз. Экземпляр списка представляет собой компьютерное представление математической концепции конечной последовательности; (потенциально) бесконечным аналогом списка является поток. Все найденные вещи/значения (и сохраненные в переменную «?x») в левой части второго правила являются результатом запроса на поиск "запрос:42", например, системе поиска данных Объектов в базах данных.
Стоит отметить, что первое утверждение в левой части второго правила "(пример:продуктДляОшибкиТег (продукты:Продукт1 продукты:Продукт2))" является списком из двух элементов, где первым элементом является "пример:продуктДляОшибкиТег", а вторым элементом - список/массив, содержащий элементы "продукты:Продукт1", "продукты:Продукт2".
Пользовательские данные и онтологии используются для описания Объектов/Элементов и связей Объектов/Элементов с другими объектами/Элементами, а также системы или ее части, которой принадлежат Объекты/Элементов, их взаимодействия с системой и т.д.
Объект/Элемент является сущностью, например, бизнес-сущностью: задача "Добавить описание для фото животного" является Объектом/Item, сотрудник "Билл" - Объект/, как и запрос на "Строительство моста", запись о пользователе в базе данных, IT-отдел, HR-отдел или любая другая сущность. Такие сущности в области программирования называются экземплярами класса. Таким образом, пользователь "Билл" является экземпляром Класса "Пользователь"; IT-отдел, HR-отдел являются экземплярами Класса "департамент" и т.д. Такие Объекты/Элементы являются искомыми данными, которые интересны пользователю и/или системе, и которые необходимо найти в базе данных.
В другом варианте осуществления изобретения встроенные функции (билт-ины) могут быть связаны/зарегистрированы на предикаты, которые (билт-ины) представляют программный (исходный) код, который позволяет выполнять определенные операции/действия. Такие действия не могут быть выполнены в тройках, поскольку тройки по своей природе носят описательный характер и не могут быть обработаны без специального внутреннего или внешнего кода.
Примерами источников данных в данном изобретении являются данные (например, в форме троек) из баз данных троек и из хранилищ троек, хранящих тройки, которые являются результатом обработки правил. Данные (например, в форме троек), которые были получены в процессе или после выполнения кодов билт-инов (которые связаны с определенными предикатами) являются другим источником данных в данном изобретении. Например, билт-ин может быть связан с ":отправитьВ" из тройки/утверждения "?имя:отправитьВ:ComindwareProjectМодуль.". Связанный с предикатом билт-ин вызывает выполнение кода билт-ина, когда обрабатывается/считается правило с таким предикатом. Код билт-ина будет выполнен вместо обычной обработки правила, описанной выше. Обычная обработка правила (если ни один билт-ин не связан с предикатом ":отправитьВ"), например, означает выполнение поиска всех троек с предикатом "отправитьВ" и Объектом ":ComindwareProjectМодуль ", где найденные Субъекты данных найденных троек будут сохранены в переменную "?имя". Если билт-ин (который описывает систему/набор шагов для управления утверждениями/правилами и предикатом в частности) связан с предикатом "?отправитьВ", то правило с упомянутым утверждением "?имя:отправитьВ:ComindwareProjectМодуль." Не будет обработано, как описано выше в данном параграфе (процесс поиска значений для переменной "?имя" не будет запущен), а будет выполнен код билт-ина. Например, билт-ин, связанный с предикатом "sотправитьВ", может включать код, который отвечает за передачу/отправку данных из системы (из модуля получения данных) во внешние программные или аппаратные модули, принтер, экран и т.д., где данные, которые необходимо передать, являются значениями переменной "?имя", а ":ComindwareProjectМодуль" является Объектом, который идентифицирует внешний модуль (идентификатор внешнего модуля).
Стоит отметить, что билт-ины обычно связываются с предикатами при старте системы или при создании Модуля Получения Данных, однако также возможно создавать и связывать новые билт-ины во время работы системы (например, во время обработки правил Модулем Получения Данных). Билт-ины могут быть сохранены во внешнем модуле. Также стоит отметить, что билт-ины могут быть отвязаны или заменены другим билт-ином.
Билт-ины, сохраненные во внешних модулях, могут быть скомпилированы, например, в исполняемый код, такой как ".exe" файл, библиотеку, в частности, в динамическую библиотеку (.dII). Билт-ин по сути является функцией (Классом, Подклассом, методом и т.д.) или их набором, написанном на любом языке программирования, таком как C#, C++, Java, java script, Язык Comindware, и т.д. Когда система "видит" упомянутый выше предикат (например, ":отправитьВ"), она ищет связанный с этим предикатом билт-ин, и после этого она вызывает/активирует соответствующий билт-ин. Билт-ин может иметь несколько входных параметров, например, ":CominwareProjectMoдyль", также как и все данные, найденные и сохраненные в переменной "?имя" в виде списка или массива (см. пример выше).
Эти параметры отправляются в билт-ин и обрабатываются в соответствие с функциональностью, прописанной в билт-ине. Билт-ин способен возвращать значения по их типу (целое, список, массив, строковый, символ и т.д.), а также то, был ли вызов успешно обработан или нет (если что-то может быть возвращено) в виде "истина" или "ложь". "Истина" означает, что вызов билт-ина был успешно обработан, и, например, правило может обрабатываться дальше (т.е. будет обработано следующее утверждение). "Ложь" означает, что система прекращает обрабатывать правило, содержащее предикат, используемый для вызова текущего билт-ина. Другими словами, "истина" и "ложь" указывают на наличие решения/результата согласно входу билт-ина.
Также стоит отметить, что функциональность билт-ина может включать математические операции, передачу/вывод данных на внешние устройства, модули и приложения, операции с данными (например, массивами, списками и т.д.), вычисление номера элемента, поиск начального элемента и т.д., т.е. любые операции, действие, методы с данными (с тройками и частями троек/утверждениями).
Другой пример изобретения может включать специализированные ключевые слова/зарезервированные слова. Как было сказано выше, тройку, упомянутые в данном изобретении, являются описательными, и необходимо связывать билт-ины с предикатами, которые описывают операции. Упомянутые здесь ключевые слова ("if", "else", "then" в данном примере) используются в качестве примера таких типов билт-инов (так называемые билт-ин-доказательства):


Упомянутые билт-ины-доказательства могут быть вызваны также, как и билт-ины, и способны выполнять те же функции, что и билт-ин, и даже некоторые дополнительные, однако принцип их работы отличается. Билт-ин-доказательство является способом предоставления интерфейса для использования данных из модуля получения данных (таких как компоненты, функции, факты, аксиомы, константы модуля получения данных, части системы (проиллюстрированной на ФИГ. 8) и их комбинации) для вычисления правил. Другими словами, билт-ин-доказательство может получить доступ и использовать внутренние данные/компоненты внешних и внутренних модулей системы, включая модуль получения данных (и имеет разрешение на использование кода модуля получения данных), поскольку билт-ины-доказательства имеют интерфейс вызова билт-ина (или подобный билт-инам).
Рассмотрим "If" в качестве примера билт-ин-доказательства. "If является понятным (для разработчиков программного обеспечения) сокращением (короткой записью) для операций/действий с утверждениями или частями утверждений. Парсер ассоциирует имена билт-инов-доказательств для перевода части исходного кода с определенным билт-ином-доказательством (билт-ином-доказательством "если" в данном случае) в тройки, чтобы эти тройки могли быть обработаны системой. Стоит отметить, что билт-ин-доказательства могут быть связаны не только с "if", но и с программными методами/функциями и, например, с такими операторами, как "then", "else", "foreach", "next", "break", "switch", "continue" и любыми другими операторами и функциями/методами, например, тригонометрическими, логарифмическими и другими общими (и специальными) функциями/методами/действиями/операциями.
В другом варианте билт-ин-доказательство является частью модуля получения данных, и его вызывающий метод является единственным видимым аспектом. Это является унифицированным способом доступа к данным модуля получения данных. Стоит отметить, что билт-ин-доказательство может использовать ту же самую часть кода, что и модуль получения данных.
Другой пример изобретения включает функторы, которые способны работать, как минимум, как билт-ины, однако функторы написаны на тройках. Другими словами, функтор является определенным видом билт-ина, который использует тройки и может быть сохранен в хранилище модуля получения троек, в базу данных, т.е. в любое хранилище данных. Таким образом, функтор способен выполнять те же функции, что и билт-ин, но с использованием троек и без использования внешних модулей.
Стоит отметить, что билт-ины, билт-ин-доказательства, функторы могут быть расширены/дополнены после запуска модуля получения данных, во время выполнения приложения. Билт-ин может быть расширен путем добавления в него новых билт-инов, или путем создания новых билт-инов и связывания с существующими. Билт-ины могут храниться в файлах, внешних по отношению модулям системы, показанным на ФИГ. 4, ФИГ. 8 (таких как модули получения данных), которые (файлы) с билт-инами могут быть связаны, объединены/соединены. Также билт-ины могут быть сохранены в хранилища данных, таких как хранилища троек; в ОЗУ, базах данных, хранилища модулей получения данных, и т.д. Кпак было сказано выше, к модулям получения данных могут быть присоединены дополнительные файлы с билт-инами, например, для хранения билт-инов могут быть использованы dII-файлы, которые (файлы) могут быть написаны специально для приложения, или они могут быть общими системными файлами ОС, такими как компоненты MICROSOFT WINDOWS, компоненты LINUX или как файлы баз данных и т.д. Также стоит отметить, что вместо присоединения файла может быть использован любой источник данных, например, стрим данных, html, т.е. источник данных с интерфейсом передачи данных. Также стоит отметить, что билт-ин может быть не только внешним модулем для данного изобретения, но и являться частью модуля в составе компонента изобретения, таким как семантический процессор 840 (см. ФИГ. 8), или может быть присоединен к нему. Стоит отметить, что билт-ины могут сохранены в нескольких файлах или хранилищах данных.
ФИГ. 3 иллюстрирует традиционную системы получения данных (систему обработки клиентских запросов) с использованием существующих технологий.
Одной из функций любого приложения является получение данных во время работы, например, для отображения их на экране или для дальнейшей обработки. В контексте данного обсуждения такой запрос данных/запрос называется 'событием'. События могут быть вызваны действиями пользователя, оператора программного обеспечения или разработчика, и т.д. Например, данные могут быть запрошены из базы данных с использованием ГИП-функции. События также могут быть вызваны внешними модулями или приложениями, в частности операциями сервисов программы или действиями сервиса внешнего модуля. В примерном варианте сервис представляет собой автоматизированного пользователя, т.е. действия пользователя, которые могут быть запрограммированы в приложение, также являются частным случаем сервиса. Процесс формирования клиентского запроса к данным, используемым приложением, является примером того, как обрабатываются такие события. Такими запросами могут быть либо внутренними (адресованными модулям приложения), либо внешними (адресованными внешним модулям приложения, баз данных и т.д.). Такие запросы обеспечивают приложение определенными данными в соответствии с запросом. Запросы могут быть представлены в виде вызова функций/методов приложения, запросов к базе данных и т.д.
Клиент 310 может выступать в роли примера приложения, отправляющего данные типы запросов. Клиент 310 может быть представлен приложением 801-806 (см. ФИГ. 8), модулем приложения 807, семантическим процессором 840 (включая Слой Бизнес-Логики Приложения 820), модуль ГИПов (например, которые отвечают за поиск данных), модулями получения данных, моделями, упомянутыми ниже, частями модулей получения данных и т.д.
Следующий пример клиентского запроса к совокупности хранимых данных работает, как при традиционном подходе, так и в настоящем изобретении. В данном случае, совокупностью данных являются данные, сохраненные а базе данных 340 в хранилище данных 320. Формат сохраненных данных определяется внутренней структурой базы данных, т.е. если база данных используется Б-деревья, то сохраненные данные также будут представлены в виде Б-деревьев (см. ФИГ. 9 и ФИГ. 10).
В одном примерном варианте данного изобретения данные хранятся в базе данных, ОЗУ, хранилищах (например, хранилище модуля получения данных) и т.д. и могут быть представлены в виде набора аксиом, фактов и правил. Факты представляют собой данные, выведенные из аксиом с использованием, как минимум, одного правила и попутно записаны, например, в тройках. Стоит отметить, что факты также могут быть выведены из других фактов или аксиом в сочетании с правилами.
Например, правило, из которого может быть выведен факт: "{?x статус закрыт} => {?x видим ложь}". Данное правило может быть применимо к аксиомам или фактам "Ошибка номер 345 статус закрыта", "Ошибка номер 235 статус закрыта " и так далее. В приведенном выше примере все тройки, выведенные из правила "{?x статус закрыт} => {?x видим ложь}", являются фактами. Данное правило может быть применимо к любому факту или аксиоме, таким как "Что-то статус закрыт ". После применения правило будут выведены следующие факты: "Ошибка номер 345 видим ложь" и "Ошибка номер 235 видим ложь", которые могут быть интерпретированы системой или приложением (таким как Comindware Task Manager (R), Comindware Tracker (R) и т.д.) в качестве инструкция для остановки показа ошибок Ошибка номер 345 и Ошибка номер 235.
После формирования запроса, в данном случае к базе данных, клиент 310 будет ждать ответа.
В приведенном выше традиционном примере запрос клиента обрабатывается базой данных с использованием интерфейса матчера. Стоит отметить, что интерфейс матчера может быть реализован в виде общего интерфейса, т.е. один общий интерфейс матчера может быть использован для связи между внешним/внутренним модулем (модулями) (инициатором запроса, клиентом и т.д.), базой данных (базами данных), модулем (модулями) получения данных, новыми моделями и объединенными моделями, описанными ниже.
Интерфейс представляет собой общую границу между двумя отдельными компонентами обмена информацией компьютерной системы (в данном случае такими компонентами являются База данных и Клиент). В данном случае обмен реализуется между программными модуля ми. Программный интерфейс может относиться широкому диапазону различных типов интерфейса на различных "уровнях": в данной реализации изобретения объекты/модули внутри приложения должны взаимодействовать посредством методов.
RDFLib является одной из программ, использующих технологию матчинга RDFLib графов, поддерживающую основные шаблоны матчинга троек с функцией "triples()". Данная функция является генератором троек, соответствующих шаблону, заданному с помощью аргументов. Этими аргументами являются RDF-условия, которые ограничивают возвращаемые тройки. Условия с отсутствием условия рассматриваются как поиск со звездочкой.
База данных способна ответить на запрос клиента посредством интерфейса матчера. Интерфейс матчера дает знать клиенту о том, что база данных понимает его запросы и способна обработать их, т.е. способна своими силами провести поиск данных, связанных с запросом клиента. Интерфейс матчера определяет формат данного взаимодействия, т.е. декларирует возможности матчера.
Особенности реализации системы (см. ФИГ. 3) позволяют базе данных обмениваться данными строго согласно запросу клиента (в частности, аксиом, хранимых в базе данных) без дополнительного анализа хранимых данных. Примером запроса может являться "Верни 'a b c' тройку". В соответствии с данным запросом система (или программный модуль) либо вернет данную тройку (если она существует) из набора данных (например, данных, хранимых в базе данных), либо вернет факт ее отсутствия. Такой клиентский запрос может быть представлен в виде вызова функции/метода интерфейса матчера: "ЕстьТройкаВСистеме (a b с);". Вызов методов интерфейса матчера позволяет получить ответы на запрос клиента.
В отличие от традиционных систем настоящее изобретение в одном из реализаций использует интерфейс матчера, способный отвечать на запросы двух типов:
Первым методом интерфейса матчера является запрос на точное совпадение (матчинг). Отвечая на данный запрос, система говорит, существуют ли тройки Субъект-Предикат-Объект в запрашиваемом объекте (например, базе данных) или нет. Например, база данных получает запрос от клиента "Существует тройка" "задача1 есть закрыта" в база данных?" Матчер вернет соответствующий ответ - "Да" или "нет".
Второй метод интерфейса матчера. Вторым типом запроса является запрос с переменными или неизвестными. В ответ на такой запрос система вернет набор (коллекцию, список, массив...) найденных данных. Например, клиент может отправить запрос к базе данных, вида "?x Предикат Объект", "Субъект Предикат ?x", "Субъект ?x Объект", "Субъект?x ?у", "?x ?у Объект", "?x Предикат ?y" и так далее. Затем клиент должен дождаться возврата системой соответствующих найденных данных. Другим примером типа запроса, о котором было сказано выше, является "?x ?y ?z", который просит систему вернуть все данных, хранящиеся в базе данных.
Имплементация интерфейса матчера. Первый метод интерфейса матчера использует запросы на точное совпадение от клиента к базе данных. Все последующие примеры, которые следуют далее, подразумевают, что данные хранятся в базе данных. Рассмотрим, например, что в клиенте 310 существует ГИП, который может быть использован, например, для просмотра информации о персонале компании. Должности сотрудников представлены в виде троек в форме групп (см. ФИГ. 1). Пользователь генеральный директор Алекс хочет посмотреть информацию о своих сотрудниках, выведенную на экран. Клиент подготавливает запрос данных, касающихся связей сотрудника с именем Морган и другими сохраненными данными. В данном случае запрос может относиться к таким категориям, как "разработчик", "человек", "создатель", "Корректор ошибок" и т.д. Для того, что выяснить, какие данные должны быть показаны, клиент подготавливает запрос. Могут быть отображены следующие данные: личная информация сотрудника, его/ее подчиненные и руководители, его/ее проекты, связанные с ним/с ней ошибки и т.д. Таким образом запрос на данные может затрагивать любое предполагаемое событие, например, отправку данных на экран, принтер, внешний или внутренний модуль или приложение; анализ данных (например, в соответствие с внешними правилами, не содержащимися в системе/приложении).
Другой тип клиентского запроса (например, посредством ГИПа или клиентской консоли) может запросить поиск сотрудников. Например, если задачей является поиск всех менеджером компании, запрос к сохраненным данным может выглядеть как тройка "?x это менеджер".
Запрос к базе данных (например, посредством интерфейса) может быть представлен в виде тройки (или вызова метода/функции интерфейса матчера с аргументом в виде тройки, например, вызова метода Match (a, b, с)), которую требуется найти в базе данных инструментами базы данных. Если в базе данных содержится такая тройка, то система вернет "да/истина", в противном случае ответом будет - "нет/ложь".
Второй метод интерфейса матчера оперирует по крайней мере одной переменной, например, трока "?x b с". При получении такого запроса база данных ничего не вернет, либо вернет набор соответствующих троек посредством итератора (например, в форме коллекции или набора). Коллекция также является итератором. Она не содержит все найденные элементы, напротив каждый последующий элемент будет получен посредством следующего запроса. Таким образом, система реализует отложенный возврат элементов: например, когда отправлен запрос типа "дай мне следующий элемент", итератор возвращает следующий найденный элемент. Т.е. каждый следующий элемент (тройка) становится доступным, когда это необходимо.
Итератор (IEnumerator в .NET) представляет собой объект, который позволяет обойти контейнер, в частности списки. Итератор выполняет обход и также получает доступ к элементам данных в контейнере. Итератор можно рассматривать как тип указателя, который обладает такими основными операциями, как ссылка на один конкретный элемент в коллекции объектов (так называемый "доступ к элементу") и изменение самого себя, чтобы указывать на следующий элемент (так называемый, "обход элементов "). Итератор проводит последовательный поиск троек, соответствующих запросу клиента 310.
ФИГ. 4 иллюстрирует реализацию интерфейса матчера модуля получения данных. Как было описано выше, когда база данных реализует интерфейс матчера, она способна отвечать на запросы клиентов, информируя о том, что запрошенная тройка наличествует или возвращая все найденные тройки в базе данных, которые соответствуют запросу клиента. Из-за своей структуры база данных может оперировать лишь с аксиомами, хранимыми в ней, (правила, хранимые в базе данных, также называются аксиомами в своем контексте). Если запрос клиента содержит факты, то база данных не способна сказать, что их нет, поскольку факты не хранятся базе данных. Как было сказано выше, факты выводятся из аксиом и/или других фактов с применением правил посредством модуля 410, после чего они сохраняются в хранилище 430.
Помимо фактов модуль 410 хранит информацию, используемую для получения этих данных, например, комбинацию фактов и правил (или их Идентификаторов), из которых они были выведены. Пример записи факта в хранилище 430 с Идентификатором правила из которого он был выведен: "m с b Правило номер 1234". Правило, используемое для вывода факта, может быть идентифицировано по его левой и правой части. Правило также может быть определено по совокупности обеих частей. Кроме того, левая часть правила может быть проиндексирована отдельно от правой части, так же как и совокупность проиндексированных/захэшированных частей может быть использована для идентификации посредством общего идентификатора, полученного из идентификаторов левой и правой частей правила. Левая часть правила или его правая часть, или факт и/или правило целиком могут быть обработаны модулем 410 (например, закешированы, захэшированы, проиндексированы, идентифицированы и т.д.) для того, чтобы сократить время, необходимое для доступа к фактам и правилам, хранимым в хранилище 430.
Для того чтобы ответить на запрос клиента, связанный с фактами, необходимо использовать модуль получения данных 430. Модуль 410 принадлежит движку/семантическому процессору 840 (см. ФИГ. 8) и не оперирует пользовательскими данными и онтологиями. Одной из особенностей модуля получения данных является его способность обрабатывать правила для вывода новых фактов, а также поиска данных в хранилище 430.
Модуль получения данных, как и база данных, реализует интерфейс матчера 440. Поскольку факты выводятся с использованием правил не только из других фактов, но и из аксиом, то модуль получения данных имеет доступ к базе данных для выяснения наличия там требуемых аксиом. ФИГ. 4 иллюстрирует случай, когда база данных также реализует интерфейс матчера 450 (только в случае, когда нет модуля получения данных, как показано на ФИГ. 3) для понимания запросов от модуля получения данных и ответа на них соответствующим образом.
Модуль получения данных может быть создан после возникновения события (см. выше), что также приводит к созданию снепшота базы данных 460. Стоит отметить, что обычно снепшоты создаются при запросе от клиента или нескольких таких запросах. Опционально, вместо создания снепшота система может остановить запись в базу данных. Также при создании модуля получения данных создается хранилище модуля получения данных 430, которое используется для хранения правил, взятых из базы данных. Стоит отметить, что взятые из базы данных правила могут быть сохранены в хранилище 430 не только в явном виде, а могут быть разобраны, что облегчает их обработку модулем получения данных. Например, хранилище 430 может хранить правые части правил, взятых из базы данных, вместе с Идентификаторами правил, по которым они вычисляются. Данные (правила), взятые из базы данных (также как и данные/факты, полученные в результате действий модуля 410) могут быть закешированы модулем 410 для более быстрого к ним доступа.
Стоит отметить, что вместо хранения данных (правил), полученных из базы данных, в хранилище 430, в хранилище 410 могут быть помещены ссылки на данные, сохраненные в базе данных.
В качестве примера рассмотрим запрос клиента к модулю получения данных, сформулированный в виде тройки "a b с" (точный матчинг). В отличие от случая, показанного на ФИГ. 3 (без модуля получения данных), в данном случае модуль получения данных будет иметь доступ к базе данных. Для того чтобы скоординировать запросы между модулем получения данных и базой данных, используются методы интерфейса матчера. Если запрошенные данные модулем получения данных не находятся в базе данных, то модуль 410 будет искать данную тройку в хранилище 430. Стоит отметить, что если запрошенной тройки нет в базе данных, то это означает не только то, что она отсутствует, но и то что она не является аксиомой. Если тройка найдена в хранилище 430 при запросе модулем 410, то модуль получения данных 410 продолжит поиск правила, используемое для вычисления этой тройки (поскольку тройка является фактом, как было сказано выше).
Также стоит отметить, что правые части правил, используемых для вычисления запрошенной тройки, не обязательно должны содержать указанную тройку. Если запрошенная тройка сформулирована как "a b с", то правая часть правила, содержащаяся в хранилище, может содержать "a b c", "?x b ?z", "?x ?y z", "a ?y ?z", "a ?y z" или другие тройки, и даже "?x ?y ?z", т.е. любые тройки, который потенциально могут соответствовать запрошенной. То есть может существовать несколько правил, которые могут быть использованы для вычисления тройки из запроса клиента. Правила анализируются с использованием IEnumerator, т.е. одновременно анализируется одно правило, и после этого анализа берется следующее правило, если таковое существует. Тройки разбиваются на составные части, где тройка является минимально частью для IEnumerator'a.
После того как модуль получения данных находит запрошенную тройку, будет проанализировано правило, в частности его левая часть, чтобы выяснить, существуют ли тройки, которые необходимо обработать модулем 410, как рассматривавшийся ранее запрос от клиента, т.е. посредством точного матчинга или матчинга с переменной (в зависимости от типа троек, найденных в левой части правила, т.е. являются ли они фактами или аксиомами, и содержат ли они переменные или нет).
Если используется точный матчинг, то после того, как будет найдено хотя бы одно правило, то это правило проверяется на истинность путем подстановки запрошенной тройки в правую и левую части правила. Например, правило "{?x d е. m ?y d} => {?x b с}", так что проверяется следующая тройка "{a d е. m ?y d} => {a b с}". Если правая часть может быть выведена из левой части, то ответ на запрос клиента будет положительным ("Истина"), в противном случае клиентское выражение маркируется как "Ложь".
Если в запросе клиента существует хотя бы одна переменная, то модуль 410 запускает поиск в хранилище и базе данных с использованием матчинга с переменной.
Если модуль получения данных не может найти правила, из которых может быть выведен данный факт, то ответ на запрос, отправленный в модуль получения данных, будет отрицательным: запрошенный факт/тройка отсутствует.
После того, как модуль получения данных 410 отвечает на запрос клиента, модуль 410 может быть удален или деактивирован. Однако стоит отметить, что модуль получения данных может быть создан не только на каждое событие, описанное выше. Один созданный модуль получения данных может отвечать на любое количество клиентских запросов. Процесс создания/удаления модуля получения данных управляется типом события, количеством запросов в событии и т.д. Например, запрос на отображение данных от пользователя Алекс в приведенном выше примере является событием. Клиент 310 может сформулировать, по крайней мере, один запрос, относящийся к данному событию. При обнаружении системой произошедшего события, вовлекающее обращение к хранимым данным, создается модуль 410 для обработки всех связанных с событием запросов. Также стоит отметить, что для каждого такого запроса или для группы запросов, связанных с одним и тем же событием, может быть создан отдельный модуль 410. Запросы могут быть сгруппированы, например, в соответствии с типами запрошенных данных или данных, к которым осуществляется доступ, (пользовательские данные, системные данные, аксиомы, онтологии), с их размером, их принадлежностью приложению (компании, отделу и т.д.) или они могут храниться в разных базах данных.
После того как модуль 410 обработает все запросы, относящиеся к одному событию, модуль может быть уничтожен. Модули 410, созданные для запросов или сгруппированным запросом, связанных с индивидуальным событием, могут быть уничтожены, как только будет готов ответ на запрос. Стоит отметить, что система может создавать один модуль 410 для группы событий, вместо создания модулей для каждого отдельного события. События могут быть сгруппированы, например, по времени их появления (т.е. они случились в определенный период времени, например, в нескольких миллисекундах или минутах друг от друга). В данном случае модуль 410 будет удален после того, как он ответит на все запросы, относящиеся к такой группе событий.
При создании модуля получения данных 410 в это же время может быть создан снепшот базы данных. В случае если существует несколько баз данных, то снепшот может быть создан не для каждой базы данных, а только для тех, к которым осуществляется доступ настоящим запросом (может включать только части баз данных, например, некоторые таблицы). Снепшоты также могут быть заменены другими средствами согласования записи данных, встроенными в базы данных. То есть, слияние данных из различных источников реализуется средствами баз данных. При использовании встроенных в базы данных/хранилища или внешних средств хранения и согласования записи данных, основанных на снепшотах базы данных и/или хранилища, данные могут временно храниться в промежуточных хранилищах.
Снепшоты хранилища/базы данных обычно перекрываются, так как в этом случае данные записываются в базу данных асинхронно. Перекрытие снепшотов означает, что даже, если данные записаны в базу данных в последовательности снепшотов, то нет гарантии того, что они будут непрерывными, целостными и валидными. Для того чтобы сделать запись валидной, целостной и непрерывной, хранилище данных должно быть снабжено, по крайней мере, одним промежуточным контейнером данных для хранения данных, которые должны быть записаны в хранилище данных клиентом, модулем получения данных или базой данных. Обычно, данный контейнер представляет собой виртуальное хранилище, расположенное в памяти компьютера или в специально выделенном хранилище данных (например, хранилище с базой данных, хранилище с клиентом или сетевое/"облачное" хранилище). Стоит отметить, что описанное выше хранилище 320 может содержать клиента 310, по крайней мере одну базу данных и другие модули, используемые для обработки троек, такие как приложения 801-806, модули приложений 807, семантический процессор/движок 840. База данных 340, клиент 310 и другие модули могут располагаться на различных хранилищах и в различных комбинациях, например, клиент и база данных - на одном хранилище, остальные модули - на другом, или база данных - на одном хранилище, в клиент - на другом хранилище (хранилищах), и т.д. ФИГ. 5 иллюстрирует алгоритм обработки запроса, использующийся при точном матчинге.
Обработка запроса начинается в шаге 515. Фигура содержит запрос к интерфейсу матчера 440 модуля 410. После того, как интерфейс матчера модуля 410 получает 520 запрос, модулем 410 проверяется его соответствие данным, хранимым в базе данных. Если в базе данных содержатся данные для ответа на запрос, то далее система возвращает 540 факт того, что запрос "Истинен".
Если в шаге 520 система не может найти данных для ответа на запрос, то процесс переходит в шаг 530, где осуществляет попытку обнаружить данные для ответа на запрос, например, факты (тройки, выведенные модулем 410, как было описано выше). В том случае если модуль 410 находит данные, необходимые для ответа на запрос (530), то система возвращает "Истина" (540), подтверждая истинность запроса.
Если в шаге 530 модуль 410 не может найти данные для ответа на запрос, то процесс переходит к шагу 560, в котором пытается обнаружить правила, которые могут быть использованы для вывода данных для запроса. Если в данном шаге правила не были найдены, система возвращает факт, что запрос/утверждение "Ложно" (580).
Если в шаге 560 модуль 410 находит правило, которое может быть использовано для вывода данных для клиентского запроса, то процесс переходит к шагу 570, в котором пытается проанализировать правило (описанное выше), в зависимости от типа матчинга. Утверждения, получающиеся в результате анализа левой части правила, используются для создания запросов (входных данных для модуля 410), которые затем обрабатываются так же как и клиентские запросы. Другими словами, анализ существующего правила (правил) в шаге 570 приводит к формированию, по крайней мере, одного дополнительного запроса, например, запроса на прецизионный/точный матчинг или на матчинг на основе шаблона (основанный на паттерне матчинг). Таким образом процесс возвращается к шагу 510 и продолжает обрабатывать все запросы, сгенерированные в результате анализа правила.
В процессе анализа запроса модуль 410 вернет данные, которые найдет до тех пор, пока результатом не будет "Ложь". В случае, когда все данные, относящиеся к запросу "Истинны", модуль 410 вернет факт того, что весь запрос/утверждение "Истинно".
В отличие от точного матчинга, описанного выше, матчинг с переменной для троек вида "?x b с" вернет любые данные, соответствующие данной маске/паттерну, например, "a b с", "m b с", "o b с". Данные, которые возвращаются инициатору запроса (например, клиенту), могут быть взяты из базы данных или из хранилища 430.
Стоит отметить, что ФИГ. 5 применим не только к точному матчингу, но также и к матчингу данных на основе паттерна. В данном случае в шаге 520 процесс выполняет поиск всех троек, которые соответствуют указанному паттерну, например, "?x b c", каждая из которых может храниться в базе данных, в хранилище модуля получения данных 430, и могут быть выведены на основании правил. Таким образом, результатом первоначального запроса будут являться данные, отождествленные с запросом. IEnumerator является одним из способов возвращения данных инициатору запроса (например, клиенту/внешнему модулю и т.д.) в соответствие с шаблоном, упомянутым выше. IEnumerator позволяется возвращать найденные данные клиенту один за другим, пока клиент не скажет хватит. Это значит, что клиентский запрос "?x b с" возвращает IEnumerator.
Далее клиент (инициатор запроса, внешний/внутренний модуль, модуль получения данных и т.д.) должен решить, требуется ли ему следующий элемент (в частности, следующая тройка), включая первый, поскольку в какой-то момент времени во время обработки клиентского запроса клиент может получить результат, так что следующие элементы ему не понадобятся. Если система обнаружит, что клиенту достаточно данных, то IEnumerator будет остановлен. Стоит отметить, что IEnumerator является интерфейсом со своими методами, такими как Current_Element и Enum_Next. Enum_Next берет следующий элемент, в то время как Current_Element отражает текущий элемент. Если клиент не удовлетворен представленными данными, то для получения следующих данных (в частности, троек) будет вызван метод Enum_Next. Данный процесс продолжается до тех пор, пока клиент не будет удовлетворен, или до тех пор, пока не останется данных, соответствующих запросу.
Стоит отметить, что IEnumerator остается доступным (даже если он будет приостановлен), если он получит от клиента аналогичный запрос или относящийся к тому же первоначальному запросу, или любой другой запрос, или от модуля 410. В данном случае IEnumerator может продолжить работу, возвращая остальные данные.
Как было описано выше, хранилище 430 хранит не только правила, взятые из базы данных, но и факты, например, "m с b Правило Номер 1234", означающий, что факт "m c b" выведен согласно "Правилу Номер 1234". Стоит отметить, что хранилище 430 хранит данные в любом известном формате, например, в виде дерева (например, Б-дерева), таблиц, в xml-формате, текстовом формате (текстовом файле (текстовых файлах)). Также стоит отметить, что форматы хранимых данных могут поддерживать матчинг данных. Также, хранилище 430 хранит попытки вычислений с использованием, по крайней мере, одного правила, и хранит даже неудачные попытки этих вычислений, т.е. процессы вычисления были запущены, а результат этих вычислений - ложь, где желаемый результат не был достигнут, например, не были найдены тройки, не были найдены желаемые части троек и т.д.
Также стоит отметить, что перед сохранением в хранилище 430 правила могут быть разбиты на тройки, из которых они состоят. Таким образом, правило "Правило Номер 1234" может быть записано в виде, где: "m c b" - правая часть правила и "Правило Номер 1234" - идентификатор правила. Эта запись может быть расширена дополнительной информацией, например, о том, было ли это правило проанализировано или был ли данный факт обработан (например, как описано в шаге 570). Если правило или факт не были проанализированы, то запись может остаться неизмененной, или может быть расширена "НеСчиталось", например, как "гл с b Правило Номер 1234 НеСчиталось", означающее, что данное правило еще не было подсчитано. Если правило было подсчитано, но процесс был приостановлен, то добавляется следующее расширение: "m с b Правило Номер 1234 Приостановлено". Если правило считается/обрабатывается в настоящее время, то расширение будет следующим: "m с b Правило Номер 1234 Обрабатывается".
Дополнительная информация, хранимая вместе с фактами, может включать расширения "НеСчиталось" или "Правило", означающие, что данное правило еще не было подсчитано. Дополнение "Готово" означает, что правило полностью подсчитано, то есть правило было обработано согласно определенному запросу с определенными значениями. Дополнение "Выведено" означает подсчитанные и отданные факты. Расширение "Приостановлено" означает, что правило не было полностью обработано (такое происходит, например, когда, клиент удовлетворен выходными данными в какой-то момент времени). Дополнительная информация (дополнения) представлена в виде отметок, которые используются во время матчинга в хранилище 430, как было описано выше.
В случае если подсчитанный результат (факты) соответствуют определенному типу запросов (включая текущий запрос), факты будут переданы, например, клиенту. Факты будут передаваться до тех пор, пока не будет найдена определенная отметка. Таким образом, отметка "Готово" отменяет повторение вычисления текущего правила. Данная отметка также выступает в роли терминатора в Б-дереве (см. ниже).
Стоит отметить, что как только будет найдено правило, используемое для выведения факта, этот факт будет добавлен в хранилище 430. Для оптимизации работы с данными, хранящимися в хранилище 430, правило будет помещено в него в том же порядке, в котором было взято из базы данных. Также после окончания вышеупомянутого преобразования правила могут быть упорядочены по имени, идентификаторам и т.д. Факты, взятые из хранилища 430, в свою очередь, будут добавлены в конец списка правил, как только будут найдены соответствующие правила. В процессе обработки клиентских запросов факты берутся начиная с последней добавленной в хранилище записи.
В одном варианте изобретения обработка данных начинается с последних добавленных/сохраненных данных (т.е. сверху вниз, если хранимые данные представлены списком). Таким образом, недавно сохраненные данные будут найдены быстрее более старых данных. В связи с этим, полученные из базы данных правила помещаются в начало хранилища, в то время как тройки (факты) выведенные из них сохранены в конец хранилища.
Возвращаясь к ФИГ. 5, следует отметить, что алгоритм, продемонстрированный на данной фигуре, является универсальным алгоритмом возврата данных (применимым, как к точному матчингу, так и к матчингу по шаблону) инициатору запроса, и может быть представлен в виде внешнего (по отношению к модулю получения данных) инициатора запроса и в виде внутреннего инициатора запроса, где сам модуль получения данных выступает в роли инициатора запроса. Вариант, в котором модуль получения данных является инициатором запроса, показан на ФИГ. 5 и ФИГ. 6, см. переход от шага 570 в шаг 515 (и из шага 690 в шаг 620 на ФИГ. 6). На ФИГ. 6 переход из шага 690 в шаг 620 показан несколькими линиями, которые представляют собой специфический случай, когда во время анализа правил(а) основной запрос 510 в шаге 570 разбивается на несколько запросов (что также показано на ФИГ. 12 пунктирными линиями). Когда запрос разбивается на несколько запросов, это означает, что в ходе анализа правила, были выявлены ссылки на другие правила. Возвращаясь к обсуждению внешних и внутренних инициаторов запросов, следует отметить, что внешние инициаторы запросов являются типичными модулями или программными компонентами, которые не включают в себя модуль получения данных (например, полноценный программный продукт для управления персоналом, такой как Comindware Tracker, который включает получение данных и поиск данных объектов в качестве одной из своих функциональностей, или поиск задач сотрудника, поиск ответственных за проект сотрудников, компоненты или части, принадлежащие проекту, процессу, физическому объекту, например, автомобилю и так далее). Также следует отметить, что инициаторы запросов могут не являться частью такой компьютерной программы или компонента (например, модуль получения данных может быть отдельной программой и может выступать в роли интерфейса для программного обеспечения, в котором нет возможностей модуля получения данных и поиска, например, посредством ГИП, чтобы сделать возможным управление персоналом в данном примере, или, в более общем смысле, сделать возможным поиск данных, например, в базах данных, представленных в виде деревьев, Б-деревьев, таблиц, текстовых файлов и т.д., и которые могут быть сохранены в ОЗУ, на НЖМД, твердотельных накопителях, SAN, NAS, виртуальных хранилищах, виртуальной ОЗУ и т.д.).
На ФИГ. 6 проиллюстрирован пример обработки запроса от инициатора запроса 310 с использованием матчинга по шаблону.
В шаге 620 модуль получения данных 410 получает запрос. Далее, в шаге 640 система проводит поиск аксиом, которые соответствуют шаблону запроса, в базе данных 340. Здесь все найденные аксиомы отдаются инициатору запроса. Далее, в шаге 660 ищутся все факты в хранилище модуля получения данных 430, например, факты, найденные ранее с использованием других правил. Далее, в шаге 680 ищутся правила (которые необходимы для того, чтобы найти запрошенные инициатором запросов данные), и, если правило найдено для обрабатываемого запроса, то процесс переходит к шагу 690, в котором правила анализируются, как было описано выше, и в шаге 620 из первоначально полученного запроса (первоначального запроса) может быть сгенерирован, по крайней мере, один запрос на поиск данных. Данный запрос может быть как запросом на точный матчинг, так и запросом на матчинг по шаблону. Как правило, первоначальный запрос разбивается на несколько запросов, часть которых являются запросами на точный матчинг, а часть - на матчинг по шаблону. Этими запросами на точный матчинг являются запросы 510 на ФИГ. 5, а запросами на матчинг по шаблону - запросы 620 на ФИГ. 6, хотя алгоритмы, показанные на этих рисунках, применимы к обоим случаям.
Как только запросы были разделены (разбиты), процесс возвращается в шаг 620, что в данном случае обозначает рекурсию, делая тем самым алгоритм, показанный на ФИГ. 6, рекурсивным алгоритмом. Аналогично, ФИГ. 5 также может представлять собой рекурсивный алгоритм.
Стоит отметить, что шаги 640 и 660 могут быть выполнено как последовательно, так и асинхронно.
Результатом работы алгоритмов, проиллюстрированных на этих фигурах, является получение инициатором запроса данных по мере их нахождения.
ФИГ. 12 иллюстрирует обработку клиентского запроса после того, как будет найдено соответствующее правило. Правило 1220, найденное модулем 410, для клиентского запроса анализируется, то есть разбивается на составные части (утверждения/тройки), т.е. левые и правые части. Левая часть, в свою очередь, также разбивается на утверждения. Как было описано выше, правая часть правила 1210 являются фактом, выведенным при помощи левой части правила. Правило 1220 (в частности, части 1232, 1234, 1236) используют данные 1232а, 1234а. 1236а, сгенерированные правилами 1240, 1260, 1280, на которые и ссылается (показано пунктирными линиями), и использует данные (в частности, часть 1231), найденные в базе данных (базах данных) 340. В конкретном примере показаны данные (1232а, 1234а, 1236а), сгенерированные на основе обработки правил 1250, 1270, 1290 и на основе данных 1230 из базы данных (баз данных) 340. Все эти найденные данные используются в правиле 1220 и, в частности, в 1280. В данном варианте осуществления изобретения данные, которые используются в правилах, показанных на ФИГ. 12, могут ссылаться на другие правила или аксиомы. Правила, на которые они ссылаются, могут быть найдены модулем получения данных во время анализа правил, относящихся к первоначальным тройкам/фактам 1210. При поиске правил, относящихся к вычислению клиентской тройки, во время анализа троек, модуль получения троек сохраняет их данные.
Стоит отметить, что данные, которые были найдены во время обработки этих формул и правил, зависят от того, как правила вызываются и с какими параметрами. Другими словами, найдено может быть множество различных данных, удовлетворяющих формулам и их составным частям.
ФИГ. 12 демонстрирует, что факт 1210 вычисляется с использованием правила 1210 (шаг 560, см. ФИГ. 5). В процессе анализа правила (шаг 570, см. ФИГ. 5), его левая часть разделяется на составные утверждения 1232, 1234, 1236, данные для которых могут быть получены, например, из правил 1240, 1260, 1280 соответственно. Одно из утверждений в 1290, а именно 1234b, ссылается на данные, которые потенциально могут являться результатом обработки правила 1260. В зависимости от маркировки правила 1260, т.е. было ли начато его вычисление или нет, или оно было приостановлено и т.д., модуль 410 либо ожидает окончания вычисления, либо использует результаты вычислений, либо пересчитывает правило с другими входными данными/параметрами/экземплярами (например, для нового запроса, описанного выше) и т.д. Стоит отметить, что статус обработки правила (во время обработки запроса) сохраняется в хранилище модуля получения данных, так что система (в частности, модуль получения данных) знает, был ли запущен процесс обработки правила или оно было обработано, или обработка правила была приостановлена. Если обработка правила была приостановлена, обработка правила может быть продолжена после команды от модуля получения данных. Тип и параметры запроса сохраняются в хранилище модуля получения данных и статус обработки правила маркируется в соответствии с запросами, к которым они относятся. Таким образом, если запросы - одинаковые, но параметры запросов - разные, то правило может иметь несколько маркировок.
Как правило, полностью обработанное правило маркируется сразу, а если правило не было полностью обработано, то помечается точка, что была достигнута во время вычисления на тот момент, когда был найден ответ на запрос клиента. Например, маркировка может быть сделана для полностью подсчитанных, не подсчитанных и не полностью подсчитанных правил в соответствии с уровнем вложенности для троек. (Процедура представляет собой маркирование всех полностью подсчитанные/маркирование всех не полностью подсчитанные правила.)
Помимо запроса на предоставление данных клиент может запросить запись данных в базу данных. Например, директор Алекс (см. ФИГ. 1) решил сменить должность Моргана с Разработчика на Менеджера. В данном случае, Алекс, используя ГИП, может, например, заменить позицию сотрудника в соответствующем поле (или такой функционал может быть реализован посредством выпадающего списка). После того как изменение будет сделано, Алекс должен сохранить их, чтобы применить их. После сохранения изменений все данные в системе (например, базе данных) должны быть модифицированы соответствующим образом. После сохранения данных клиент генерирует запрос к данным, содержащим связи Моргана с другими данными. В этом случае запрос клиента может относиться ко всем данным, связанным с Морганом, а именно "разработчик", "человек" "создатель", "корректор ошибок " и т.д. Клиент также генерирует запрос для выяснения того, какие данные были модифицированы. Также стоит отметить, что сохранение и изменение данных приведены в качестве примера, поскольку даже для отображения в ГИП'е сохраненных данных, необходим запрос на чтение и запись данных ГИП'а.
Возвращаясь к обработке данных, в частности, к записи данных в базу данных, следует отметить, что для записи данных в базу данных используется компонент Builder. Как и матчер, Builder является интерфейсом.
Для упрощения обработки данных (чтения/записи) из базы данных или хранилищ(а) модуля получения данных, могут быть использованы модели. Модель может объединять матчер и Builder. В отличие от матчера 420 у модели нет своих методов.
Builder-модель обеспечивает добавление фактов в текущую модель. Если существует, по крайней мере, две модели, они могут быть объединены в одну. Модели, скомбинированные под одной общей моделью, называются подчиненными моделями. Стоит отметить, что каждая модель может быть подчиненной, по крайней мере, для одной общей/виртуальной модели.
Модели могут быть объединены в одну, например, по типу данных. Использование данного интерфейса, клиент/модуль получения данных может получать доступ ко всем подчиненным моделям. Подчиненные модели невидимы для пользователя, так что он/она работает только с общей моделью.
Отправленные в модуль получения данных 410 запросы направлены единой общей модели, которая, в свою очередь, перенаправляет их своим подчиненным. Комбинирование нескольких моделей в одну делает возможным получить доступ к данным, тип которых неизвестен или не важен. Также комбинирование моделей позволяет получить доступ сразу к нескольким моделям через одну, когда модель(и), связанная с запрашиваемыми данными, неизвестна или не важна.
Отдельные модели (системные или конфигурационные модели и т.д.) могут быть использованы независимо, т.е. они не обязательно должны быть объединены, если клиент 310 или модуль получения данных 410 знает наверняка, какая модель соответствует запрошенным данным. В данном случае нет необходимости обращаться к одной модели, а затем ко всем подчиненным ей для того, чтобы найти только системные или только пользовательские данные. В случае если тип данных неизвестен, существует возможность напрямую указать модель, в которой будет произведен поиск.
Некоторые модели, так называемые модели только для чтения, не могут быть модифицированы. Данные могут быть получены/прочитаны, но для записи данных, вычисленных модулем получения данных 410, использующим этот и/или другие модули, должна быть использована другая подходящая для записи модель (перезаписываемая модель).
Как было описано выше, каждая модель может иметь свой собственный тип: одна модель (например, для компании или отдела) может содержать аксиомы, другая - может содержать правила, еще одна может содержать данные о конфигурации или только системные правила, или все выведенные правила и так далее.
Модели могут быть не только объединены в зависимости от их типа, но они также могут быть сгруппированы для каких-либо определенных целей или операции. Объединенная модель может состоять из модели, хранящей операции с данными из базы данных; модели с правилами для операций с базами данных/таблицами; модели со служебными данными базы данных.
Объединенная пользовательская модель может включать: модель, хранящую важные данные (объекты, недавно адресованные пользователю), модель с пользовательскими установками, модель, хранящую связи с другими пользователями, модель с правилами выполнения операций пользователей с данными и т.д.
Комбинированные модели (объединенные модели посредством использования Модели Объединения, описанной здесь) могут быть в дальнейшем скомбинированы друг с другом, по меньшей мере, в одну виртуальную модель. Такое объединение моделей в одну или несколько виртуальных моделей позволяет при обращении к ним получить новые факты. Например, одна модель создана для работы с данными пользователей, другая создана для работы с правилами для данных пользователей. Если эти две модели разделены, то запрос к первой вернет пользовательские данные, соответствующие запросу, а запрос ко второй вернет правила, но новые факты получены не будут, поскольку запросы к данным моделям - раздельные. Если эти две модели объединить, то запрос к пользовательским данным будет учитывать правила, содержащиеся в модели с правилами.
Как было описано выше, объединенные модели подчинены модулю получения данных, так что модуль получения данных обрабатывает все необходимые знания о правилах, данных (соответствующих объединенным моделям), подсчитанным/выведенным фактам (общим для подчиненных моделей), а также знания о том, где искать правило, аксиому или выведенный факт, как к ним получить доступ и так далее.
ФИГ. 13А и ФИГ 13B иллюстрируют пример комбинирования моделей (объединение моделей). Вариант 1 (ФИГ. 13А): Хранилище Троек 11310, т.е. некоторые данные, прочитанные из базы данных и сохраненные в ОЗУ (или на НЖМД, SSD и т.д.), является моделью (Модель , 1305) и может быть объединена/связана с другой моделью (Модель В, 1315), которая может быть представлена Хранилищем Троек 2 1320 (например, хранящим другой набор данных из той же базы данных или из другой базы данных (других баз данных)). Такая комбинация может быть выполнена с использованием Модели объединения. Результатом объединения является созданная Объединенная модель 1 1330.
Объединенная модель 1 1330, в свою очередь, может быть подчинена Модулю получения данных 1 1340, тем самым создавая Новую Модель 1 1350, где Объединенная модель 1 1330 является обычным хранилищем модуля получения данных (модель, о которой сказано выше), описанной в данном изобретении.
Вариант 2 (ФИГ. 13B): Хранилище троек 1 1310 (Модель A, 1305) может быть подчинена Модулю получения данных 2 1360 с созданием Новой модели 2 1380 с использованием Модели объединения, в то время как Хранилище Троек 2 1320 (Модель B, 1315) может быть подчинено Модулю получения данных 3 1370, создавая Новую Модель 3 1390. Далее Новая модель 2 1380 может быть комбинирована/объединена с Новой Моделью 3 1390 в Новую Модель 4 1392 с использованием Модели объединения.
Принимая во внимание две результирующие/объединенные модели (Новая Модель 1 1350 и Объединенная Модель 4 1392), становится видно, что выдаваемые ими результаты будут различаться, т.е. результаты Новой Модели 1 не равны результатам Новой Модели 4. Также стоит отметить, что результирующие Новая Модель 1 и Новая Модель 4 также могут быть объединены друг с другом либо частично, либо в полном объеме. Например, Новая Модель 1 1350 может быть объединена с Новой моделью 2 1380 или Новой моделью 3 1390. Например, Новая Модель 1 1350 может быть объединена с Новой моделью 2 1380 и затем подчинена Модулю получения данных 4 (не показано), таким образом создавая Новую Модель 5 (не показано), которая в дальнейшем может быть объединена с Новой моделью 3 1390, создавая объединенную не показанную Новую Модель 6 (которая в дальнейшем также может быть подчинена другому модулю получения данных, создавая Новую Модель 7 и т.д.). Тройки, выведенные одним модулем получения данных, станут аксиомами для другого модуля получения данных или/и для других Новых Моделей. Тройки из объединенных моделей (объединенных модулей получения данных, объединенные хранилища троек) являются аксиомами для любого модуля получения данных, который используется с такой объединенной моделью (объединенными моделями). Например, тройки из Новой Модели 2 1380 являются аксиомами для Объединенной Модели 4 1392, а тройки Новой Модели 3 1390 являются аксиомами для Объединенной Модели 4 1392. Такие комбинации частей системы возможны между частями моделей, исключительно из-за того, что они сами являются моделями (интерфейсами моделей).
Далее будет описана обработка/компиляция правил. Как было сказано выше, правила являются конъюнкцией троек/фактов/утверждений. Утверждения предварительно обрабатываются, затем компилируются, что приводит к еще большей конъюнкции.
Правила могут быть скомпилированы в C# код. В данном варианте изобретения правила представлены в виде запроса, разбитого на тройки, которые затем преобразуются C#-код, использующийся для вычисления полученного запроса. Компиляция осуществляется только при получении запроса (процесс компиляции правил описан ниже). Стоит отметить, что тройки из базы данных могут быть представлены коллекциями, т.е. коллекциями, хранящими утверждения следующим способом: нулевой элемент - "Субъект1 Предикат1 Объект1", первый элемент - "Субъект2 Предикат2 Объект2". Формат элемента определяется шаблоном. Например, в данном случае шаблон для хранения троек выглядит как "Субъект, Предикат, Объект", и поэтому каждый элемент коллекции представлен массивом из трех компонент. Также, шаблон может выглядеть как строковая переменная, например "Субъект Предикат Объект ".
Также стоит отметить, что одна коллекция (массивы, списки и т.д.) может содержать только Субъекты, другая может содержать только Предикаты, а другая может содержать только Объекты. При добавлении в коллекцию эти элементы из каждой тройки поддерживают связи с другими коллекциями. Например, элементы из первой тройки записаны в качестве нулевых элементов в соответствующие коллекции: КолекцияСубъектов, КоллекцияПредикатов и КоллекцияОбъектов. Стоит отметить, что коллекции могут быть заполнены не одновременно, а последовательно, например, сначала добавляются Субъекты, затем идут Предикаты и последними - Объекты. Кроме того, порядок сам по себе не имеет значения и сначала может быть заполнена коллекция Объектов. Основным моментом в наполнении коллекции является то, что элементы из каждой последующей тройки должны занимать последующие позиции во всех коллекциях: элементы первой тройки должны занимать нулевые позиции, элементы второй тройки отправляются на первые позиции и так далее. Также стоит отметить, что нумерация в массивах, коллекциях и т.д. начинается с нуля.
Также стоит отметить, что вместо коллекций могут быть использованы массивы, ListArrays, списки, хеш-таблицы, Enumerators и т.д. При использовании хеш-таблиц порядок элементов не так важен, поскольку элементы тройки идентифицируются в соответствии с их хешом, который соотносит элемент со своей тройкой. Также стоит отметить, что для отдельного хранения элементов троек нет необходимости использовать несколько коллекций. Элементы или тройки целиком, как было описано выше, могут быть сохранены в единственной коллекции.
Что касается компиляции, стоит отметить, что запросы, включающие, по крайней мере, одну тройку и/или тройку из базы данных, компилируются в машиночитаемый код или в язык программирования, такой как C#, JavaScript, C++ и т.д., и далее компилируются в промежуточный язык (например, С Intermediate Language, Parrot intermediate representation, Microsoft's Common Intermediate Language и т.д.) и/или в машинный код, который должен быть выполнен для обработки запроса. Стоит отметить, что в упомянутые выше языки и код компилируются только необходимые тройки, например, скомпилированы могут быть только те тройки (правила, в данном варианте изобретения), которые были использованы по крайней мере один раз для ответа на описанные здесь запросы или части запросов (части утверждений). Как было сказано выше, запрос может быть разделен на несколько меньших элементов, например, составная тройка может быть разделена, по крайней мере, на две меньшие. Комплексные тройки (включая правила, представленные тройками) выглядят, как показано ниже:


Учитывая процесс компиляции правил, может существовать второе хранилище для хранения результатов вычислений, например, для правил (троек) согласно запросу клиента. Второе хранилище может быть как отдельным, так и может являться частью хранилища модуля получения данных, таким образом виртуально разбивая хранилище модуля получения данных на два виртуальных хранилища, оба из которых распознаются системой как единое хранилище модуля получения данных.
Как здесь описано, правила могут быть скопированы из базы данных в хранилище, например, в хранилище модуля получения данных, где они также заранее могут быть скомпилированы. В случае если правила, скопированные в хранилище модуля получения данных, не были скомпилированы, то далее, когда модуль получения данных обратится к такому правилу, оно будет скомпилировано в исполняемый код (например, с использованием C#), так что правило (вместе с другими правилами и утверждениями, связанными с ним) может быть выполнено. Скомпилированные правила вместе с вспомогательным кодом для их выполнения обычно хранятся в отдельном файле (например, в файле DLL) или в хранилище.
Как было сказано выше, некоторые языки программирования используют промежуточный язык, в который могут быть скомпилированы правила. Процесс работы с такими скомпилированными тройками, файлами и хранилищами (включая НЖМД и ОЗУ) для их хранения, напоминает процесс работы с билт-инами. Файл, содержащий скомпилированные правила, может быть расширен/увеличен (например при компилировании троек), могут быть добавлены другие файлы и т.д. В хранилище с не скомпилированным правилом (или не скомпилированными методами и функциями) появляется ссылка на хранилище со скомпилированной тройкой (или скомпилированным методом), как только она будет скомпилирована. Также стоит отметить, что скомпилированная тройка также может быть связана с не скомпилированным правилом, хранящимся в модуле получения данных.
Стоит также отметить, что не скомпилированные правила (также как и скомпилированные правила) копируются (или делаются общими) между модулями получения данных (например, среди новых созданных модулей получения данных). Кроме того, любые оставшиеся тройки из одного модуля получения данных могут быть скопированы (или быть сделаны общими) между другими, в то время как полученные данные - нет. Стоит также отметить, что ссылки на скомпилированные правила и сами правила могут быть скопированы (или сделаны общими) среди других модулей получения данных, тем самым избегая повторения компиляции правил, которые уже были скомпилированы, например, путем создания списка файлов всех скомпилированных правил, например, упомянутого выше DLL-файла, среди 'интеллектов' - созданными модулями получения данных, которыми (всем и из них) может быть использован DLL-файл). Другими словами, информация о правилах, которые были скомпилированы и которые - не были, могут быть скопированы из одного модуля получения данных в другие.
Для каждой комплексной тройки (например, правила) существует машиночитаемый код. Соответственно, когда запрос касается одного правила "Правило_1", он разбивается на простые тройки, для которых скомпилирован машиночитаемый код. В следующий раз, когда будет запрошено то же самое правило, новый код не будет компилироваться, а вместо этого будет использоваться уже существующий код. Стоит отметить, что код компилируется в соответствии с запросом, т.е. вида и типа запрашиваемых данных. Например, для компиляции машиночитаемого кода из троек, необходимо знать содержание тройки, независимо от того, содержит ли она переменные и какое их количество, на каких позициях эти переменные стоят, или является ли запрос запросом на точный матчинг и поэтому не содержит переменных. В частности, запрос, где тройка либо "a b с" в базе данных, либо в выведенных тройках, которые были получены во время обработки предыдущих запросов и оставлены в ОЗУ, например. Для каждого конкретного типа запроса компилируется соответствующий код. При получении запроса модуль получения данных 410 производит вычисления: если таких запросов раньше не было, то - это новое вычисление; если такие запросы были ранее, то система возвращает полученный результат (кроме того, вычисление будет либо продолжено, либо начато с нуля). Как было описано выше, вычисление продолжается до тех пор, пока не будет получен удовлетворяющий результат (включая негативный результат, например, отсутствие удовлетворяющих параметрам запроса данных).
Как только результат будет получен (запрошенные данные будут найдены), обработка запроса будет приостановлена. Модуль получения данных сохранит позицию, которой он достиг во время обработки текущего запроса. После этого, когда Модуль получения данных получает запрос, похожий не приостановленный, и данные не будут найдены в массиве подсчитанных данных, то запрос будет "разморожен", и его обработка продолжится, пока не будут найдены соответствующие данные. Таким образом, вычисление/обработка может быть оставлена незаконченной, поскольку был найден удовлетворяющий результат. Процесс будет завершен позже, когда будет получен похожий запрос, или необходимо будет обсчитать запрос, подходящий к приостановленной тройке.
ФИГ. 7 иллюстрирует пример различных бизнес-приложений, используемых в различных отделах компании, и схему обработки данных в них. Данные из базы данных могут быть разделены на пользовательские данные в виде аксиом, фактов, правил и онтологий (представленных также в виде аксиом, но которые могут быть различимы по N3 синтаксису). Другими словами, онтологии содержат информацию о том, что за данные и как данные должны быть представлены конкретному пользователю в конкретном бизнес-приложении. Факты и онтологии обрабатываются Ядром, и результатом обработки являются данные в определенном контексте в соответствии с онтологиями.
Благодаря использованию RDF (Среды Описания Ресурса) можно работать с различными источниками данных (т.е. базами данных, локальными хранилищами данных, расположенными в корпоративной сети или расположенными в Интернете). Возможно использовать URI общего словаря, что позволяет интегрировать данные из различных серверов. Также, основываясь на данных и правилах, возможно обеспечить представление данных на лету (в отличие от статичных срезов (например, слепков), как это делается в OLAP кубах).
Пул информации (например, данные со всех департаментов: ИТ (705), Разработка (не показано), ЧР (701), Администрирование (не показано), Сбыт (не показано), Бухгалтерия (703) могут быть сохранены в различных базах данных или других хранилищах. Элемент 707 позволяет отображение контекстуализированной бизнес-информации для конкретного приложения. "Глобальная" является сущностью для представления данных в конкретном контексте бизнес-приложения.
Контекст может рассматриваться в качестве среды окружения конкретного события, объекта или индивида, который определяет интерпретацию данных и действий/операций над данными в конкретной ситуации. Опционально, контекст определяет метод обработки данных в конкретной ситуации. Например, чей-то адрес электронной почты может считаться информацией для входа в систему в одном контексте и в качестве контактной информации в профиле пользователя в другом контексте. Он может использоваться в качестве запрашивающей стороны в заявке в техническую поддержку в третьем контексте - все зависит от интерпретации данных.
Обмен информацией между серверами выполняется автоматически, поскольку все серверы используют общий словарь. Например:

Даже в случае, когда бухгалтерия при создании вручную записи о сотруднике использует свой собственный словарь, возможно написать правило {?x а Бухг:человек} => {?x а Глобально:сотрудник}, тем самым обеспечив механизм перевода между словарем бухгалтерии и глобальным словарем.
Из этого примера видно, что предлагаемая архитектура позволяет каждой отдельной группе или отделу в рамках бизнеса работать со своей собственной базой данных/хранилищем и своей собственной серверной системой, в то время как глобальный сервер с движком может представлять собой объединенное представление данных из всех отделов. Это осуществляется на лету и без дублирования данных, что особенно важно с точки зрения безопасности информации, а также сточки зрения поддержания актуальности информации (в данном случае, когда данные на одном хранилище меняются, то нет необходимости менять данные на других хранилищах).
Основанные на подсчитанных тегах результаты представления поиска, полученные на лету, могут быть проиллюстрированы следующем примером. Рассмотрим данные онтологий (т.е. данные, которые описывают управляемые сущности) в контексте бизнес-приложений, например, управления проектами, отслеживания проблем, отслеживания ошибок, CRM и т.д. Каждый из них хранится в своей собственной базе данных (или, альтернативно, в общей базе данных), и которые объединены на более высоком уровне. При помощи логического ядра можно комбинировать различные доступные данные в различные комбинации и наборы онтологий, например, используя специальные онтологии. Разработчик может видеть контекст представления ошибки, представленный Отделу качества в виде назначенной ему задачи. Другими словами, является возможным проследить, к какой задаче относится конкретная ошибка.
Различия между представлением на лету, доступным благодаря описанному здесь подходу, и статичным представлением, предоставляемым поиском данных с использованием OLAP кубов (сетевая аналитическая обработка в реальном времени) также заслуживают рассмотрения. OLAP является общепринятой техникой для генерирования отчетов и различных статистических документов. OLAP кубы часто используются аналитиками для быстрой обработки сложных запросов к базе данных, и они особенно часто встречаются в маркетинговых отчетах, отчетам по продажам, анализе данных и так далее.
Причина, по которой OLAP кубы настолько распространены, кроется в скорости, с которой может быть выполнена обработка. Реляционные базы данных хранят информацию о различных сущностях в отдельных таблицах, которые обычно хорошо нормализованы. Эта структура удобна для большинства операционных систем баз данных, однако сложные многотабличные запросы обычно сложно быстро выполнить. Хорошей моделью для таких запросов (в отличие от изменений) является таблица, построенная с использованием фактов из OLAP кубов.
Сложность использования OLAP в качестве методологии заключается в генерировании запросов, выборе базовых данных и генерировании соответствующей схемы, которая является причиной, по которой большинство современных OLAP продуктов обычно поставляются вместе с большим количеством предопределенных запросов.
Другая проблема заключается в базовых знаниях OLAP куба, которые должны быть завершенными и непротиворечивыми. Таким образом, основной проблемой с OLAP кубами является то, что процесс анализа обычно требует пересоздания самого куба или частого генерирования срезов. В отличие от OLAP кубов предложенный подход выигрышно позволяет перегенерацию представления данных (результатов поиска) на лету без сложностей предопределения и предварительного генерирования запросов. Вкратце, процесс обсуждаемого здесь подхода может быть описан следующим образом:
- бизнес-слой запрашивает данные из ядра;
- логическое ядро собирает данные из различных источников;
- логическое ядро распознает природу данных и делит данные на аксиомы и правила. Например, для баг-трекера аксиомой может быть "решение это "нужно больше информации"", и правилом может быть {?о операция:требуетсяБольшеДанных ?f. ?f bполе:пусто Истина.} => {?о операция:разрешить Ложь};
- система, необходимая для выполнения запроса бизнес слоя, собирает вместе скомпилированные правила (например, в C# коде, хотя изобретение не ограничено каким либо конкретным языком программирования). У системы могут наличествовать правила, которые были собраны и скомпилированы ранее, так же как и новые правила для правил, которые еще не были обработаны. Таким образом, компилирование должно быть выполнено только для новых правил. Поэтому ядру нет необходимости постоянно работать с данными, а только лишь адресовать данные в ответ на запросы из бизнес слоя;
- система обрабатывает аксиомы, и генерируются новые вытекающие из этого аксиомы;
- ядро возвращает запрошенные данные в бизнес слой.
Для обработки данных могут существовать несколько типов правил. Правило типа фильтр наиболее часто используется в трекер-кейсах, например, получение списка тикетов/ошибок/задач в службу поддержки от конкретного пользователя и конкретного проекта с определенными атрибутами. Кроме того, информация из общего пула задач/ошибок/тикетов должна быть отфильтрована для конкретного пользователя и проекта и представлена в виде отдельных аксиом.
Преобразовательные правила относятся к той же информации, что может быть представлена другим способом. Например, отдел Информационных Технологий рассматривает людей в качестве пользователей систем информационных технологий. С другой стороны, менеджер проекта может видеть тех же людей в виде ресурсов, работающих над конкретными задачами. В другом примере преобразовательные правила могут включать следующее: на входе получают данные (аксиомы), которые описывают определенный тикет (например, запрос от конкретного конечного пользователя) и представление его данных. Кроме того, система получит, в качестве выхода, аксиомы в виде определенного пользовательского интерфейса, наполненного данными.
Еще одним примером типа правил является генерирующее правило. Например, в определенном проекте, имеющем более 50% критических ошибок и более 50% критических задач, система автоматически генерирует факт о статусе проекта (например, статус проекта обозначен как "Критический").
Далее представлен пример применения правил. Информация преобразуется из баг-трекера и из задачи управления проектами в данные для проекта ABC. Далее фильтруются и оставляются только ошибки со статусом "критическая" и система подсчитывает общее количество ошибок, и далее, если количество "критических" ошибок больше половины от общего количества ошибок, генерируется критическое состояние ошибок проекта:

Те же самые операции выполняются для данных (задач) из систем управления проектами:

Далее выполняется автоматическое генерирование статуса "Критического" проекта, если в проекте есть задачи и ошибки со статусами "Критический":

То же самое происходит со статусом проекта, но с другим условием: автоматическим генерированием "Критического" статуса проекта, когда количество "критических" ошибок или задач станет больше половины.



Как могут увидеть специалисты в данной области, примеры из реальной жизни обычно гораздо сложнее, чем те, что описаны выше, и в большинстве реальных случаев может существовать гораздо больше типов правил, однако, принцип остается тем же самым.
Пример конъюнкции аксиом является одним из наиболее частым из тех, что легко понять. Например, при комбинировании информации, относящихся к требованиям проекта ("требования" аксиом представляют собой требования, определяемые аналитиками) и ошибкам из баг-трекера ("ошибки" аксиом представляют собой ошибки, обнаруженные тестировщиками, которые, как правило, являются специалистами по контролю качества, и заполняют формы отслеживания ошибок на основании определенных требований), результатом становится "результирующая аксиома", которая, по существу, является комбинацией количества ошибок, связанных с одним функциональным требованием.
ФИГ. 8 иллюстрирует систему в одном варианте реализации изобретения. JSON/Ajax API 822 является модулем для реализации протокола вызовов методов API (Интерфейса Программирования Приложений) с использованием формата сообщений JSON и передачей данных посредством HTTP с использованием запросов Ajax. WCF API 824 является модулем, который реализует протокол вызова методов API с использованием формата представления XML/SOAP и передачи данных посредством HTTP.
Модуль менеджера API 826:
- ищет требуемый метод API,
- реализует сериализацию аргументов в структуры данных, использующуюся в онтологиях бизнес-логики,
- реализует вызовы метода API,
- десериализует результаты, возвращенные методом.
Модуль менеджера API 826 использует N3-файлы 830 (которые содержат тройки в формате N3) для поиска реализации метода 828, где онтология "аркМетод" (например) содержит все методы, типы аргументов и возвращает значения. Реализация метода является программным кодом. Например, он может сохранять данные в базу данных или закрыть или открыть задачу, и другие операции.
Например, API метод "СоздатьЗадачу" используется для создания задачи. Метод принимает данные задачи в виде аргумента и возвращает идентификатор для созданной задачи. JSON-обработчик получает имя метода и аргументы (данные задачи) в JSON- формате, где метод вызывается посредством JSON-протокол. Далее аргументы преобразуются во внутреннее представление данных в памяти и передаются в API-менеджер. API-менеджер (у которого есть список методов) может найти требуемый метод "СоздатьЗадачу" по имени. Далее API-менеджер проверяет аргументы (количество и тип) и реализует метод "СоздатьЗадачу". После создания задачи методом "СоздатьЗадачу", API-менеджер возвращает результат JSON-обработчику. JSON-обработчик преобразует результат в JSON-формат и отправляет его обратно клиенту (например, в клиент MS Outlook или в приложение мобильного устройства).
API-менеджер загружает API-спецификацию и модули расширения из Базы данных во время запуска приложения (MS Outlook расширение 807). Данная спецификация может быть запрошена Outlook расширением/плагином 807 MS Outlook клиента 806 или посредством специального Ajax-запроса или в виде схемы в WSDL-формате с использованием SOAP-протокола.
Веб-клиент 802 (например, на базе JavaScript или на HTML5) или Клиент Командной Строки 804 могут быть использованы вместо MS Outlook. Консольный клиент является клиентским приложением, которое может вызывать методы API с использованием командной строки. Также может быть использовано мобильное приложение на мобильном устройстве 801.
Клиент JavaScript является клиентским приложением, которое исполняется в пользовательском веб-браузере и которое может вызывать методы API с использованием языка JavaScript.
Outlook расширение (Outlook-клиент) является клиентским приложением, которое исполняется в приложении MS-Outlook и которое может вызывать методы API с использованием WCF-протокола.
Язык Описания Веб-сервисов (WSDL) является основанным на XML языке описания интерфейсов, который используется для описания функциональности, предоставляемой веб-сервисом.
WSDL-описание веб-сервиса (также называемое WSDL-файлом) обеспечивает машиночитаемое описание того, как сервис может быть вызван, какие параметры он ожидает и какие структуры данных он ожидает. Таким образом, он служит той же цели, что, которая примерно соответствует цели сигнатуры метода в языке программирования.
Далее клиентские приложения могут осуществлять вызовы с использованием отчетности запросов Ajax в формате протокола JSON или SOAP.
Основными стадиями обработки запросов являются:
1. Входящий запрос обрабатывается HTTP-сервером (или Внешним сервером, или MS Exchange Сервером). Выполняется JSON сериализация или SOAP преобразование во внутренний формат.
2. API-менеджер 826 принимает входные данные и проверяет входные аргументы на соответствие описанию метода.
3. API-менеджер 826 загружает и подготавливает необходимую модель данных и создает снепшот модели для изоляции от других запросов и операций. Транзакция записи открыта, если операция меняет данные модели.
4. Вызывается программный код (или правила с онтологиями и Язык Comindware®), который выполняет метод.
5. Транзакция закрывается, если операция является модифицирующей операцией, и выполняется проверка изменения в безопасности, определение конфликтов, обновление истории транзакций.
6. Результат сериализуется в формат, требуемый клиентом и передается в HTTP-запрос.
Бизнес логика приложения 820 реализует объектный слой поверх хранилища данных. Доступ к данным обеспечивается посредством клиентского API, который содержит методы для чтения/записи объектов (т.е. шаблоны объектов, бизнес-правила и т.д.) Вызовы клиентами методов API реализованы посредством сессий, которые создаются после авторизации клиента. Этот слой содержит несколько системных онтологий, таких как, например, "шаблон пользовательского объекта" или "бизнес-правило". Онтологии используются в API для сериализации и проверки данных.
Хранилище данных 842 обеспечивает физическое хранилище для модели данных на жестком диске. Данные оправляются в хранилище данных 842 и обратно в форме фактов (троек). Факт является тройкой, которая хранится в модели. Также, факт может быть получен путем применения правил или запросов. Хранилище данных состоит из:
- потокового хранилища троек 858 позволяет записывать и запрашивать тройки специального файлового формата. Потоковое хранение троек поддерживает несколько типов запросов по различным компонентам;
- менеджер транзакций и слепков 854 позволяет создавать:
а. транзакции. Транзакции являются объектами с интерфейсом для атомарной модификации троек хранилища. Изменение модели возможно только в рамках такой транзакции, гарантируя атомарную модификацию троек хранилища (подтверждение всех изменений, сделанных внутри транзакции, или ни одной из них);
б. слепки. Слепки представляют собой обладающие интерфейсом объекты для консистентного чтения из хранилища троек. Это гарантирует, что ни одна из транзакций (которые были подтверждены во время выполнения слепка) не повлияет на его содержимое.
- тройки, хранящиеся в репозитории, являются простыми, небольшими объектами (числами, строками, именами). Менеджер бинарных потоков 856 используется для сохранения больших значений (файлов, потоков данных) в хранилище. Поток хранится в отдельном файле, и хранится ссылка на поток сохраняется в этом файле;
- Модель хранилища данных 850 представляет набор интерфейсов для управления хранилищем данных 851. Такие интерфейсы могут включать транзакции, слепки, интерфейс для запроса фактов (троек) из слепка и интерфейс для записи фактов в транзакцию.
- Семантический процессор 840 содержит описание интерфейсов, таких как имя, факты (тройки) и правило модели.
N3-конвертер 849 позволяет генерировать модель данных на основе содержимого N3-файла 830. (Стоит отметить, что тройки могут быть сохранены в базе данных в любом формате, как говорилось выше). Объединение с хранилищем данных является еще одним методом формирования паттерна. Кроме того, могут быть сформированы объединенные модели, так что несколько моделей объединяются в одну. Запросы к таким моделям приводят к запросу фактов из каждой объединенной модели. Запись данных при этом продолжает производиться только в одну из моделей.
Обработчик бизнес-правил 844 является опциональным дополнением поверх модели данных. После подключения обработчика 844 к модели, он позволяет вычислять производные на основе существующих фактов и правил.
Интерфейс модели данных 846 является набором интерфейсов для запроса фактов из модели, для записи в модель, создания транзакция и слепков модели. Сериализатор онтологий 848 создает запросы на получение объектов из всей модели на основании онтологий (описание структуры объектов хранится в модели).
Транзакции и запросы изолированы с использованием транзакций. После открытия транзакции на запись или чтение, транзакция полностью изолирована от других транзакций. Любые изменения в модели данных, сделанные другими транзакциями, не отражаются в ней. Определение конфликтов и разрешение конфликтов выполняется при закрытии транзакции, которая была открыта на запись. Используется так называемая модель оптимистичного параллелизма. Определения конфликтов происходит на уровне отдельных семантических фактов. Конфликт возникает, когда факт был модифицирован двумя транзакциями после создания слепка модели и до закрытия транзакции. Во время определения конфликта будет сгенерировано исключение. В этом случае пользователь может попробовать обновить сохраненные изменения и попробовать еще раз подтвердить изменения.
Оптимистическое управление параллелизмом (ОСС) является методом управления параллелизмом для систем управления реляционными базами данных, который предполагает, что несколько транзакций могут быть завершены без влияния друг на друга и, следовательно, транзакции могут быть обработаны без блокировки ресурсов данных, которые они затрагивают. Перед подтверждением, каждая транзакция проверяет, что ни одна другая транзакция не изменила данные. Если проверка выявляет конфликтующие модификации, то подтверждающая транзакция откатывается.
ОСС, как правило, используется в средах с низкими конфликтами данных. Когда конфликты редки, транзакции могут быть завершены без затрат на управление блокировками и без необходимости транзакциям ожидать очистки других блокировок транзакций, что приводит к повышению пропускной способности по сравнению с другими методами управления параллелизмом. Однако, если конфликты происходят часто, то цена неоднократного перезапуска транзакций значительно влияет на производительность, и другие методы управления параллелизмом обладают большей производительностью при таких условиях.
Более конкретно, ОСС транзакции включают следующие фазы:
Начало: запись метки времени, отмечающей начало транзакции.
Модифицирование: чтение значений из базы данных и предварительная запись изменений.
Проверка: Проверка, модифицировали ли другие транзакции данные, которые используются текущей транзакцией (запись или чтение). Это включает транзакции, которые были завершены после даты начала текущей транзакции и опционально транзакции, которые еще активны на момент проверки.
Подтверждение/Откат: Если конфликта нет, сделать все изменения имеющими силу. Если конфликт существует, разрешить его, обычно путем отмены транзакции, хотя возможны другие схемы разрешения. Стоит позаботиться об избегании ошибки TOCTTOU (Time-Of-Check-To-Time-Of-Use), особенно если текущая фаза и предыдущая не выполнены в виде одной атомарной операции (см. также обсуждение механизмов разрешения конфликтов между транзакциями, т.е. транзакциями, не влияющими друг на друга, упомянутым выше.
Хранилище данных в форме В-дерева используется для того, чтобы сделать поиск более эффективным. В-дерево может быть реализовано в виде набора таблиц. На ФИГ. 9 показана база данных со структурой В-дерева для хранения троек. Согласно примерному варианту предикаты, дополнения и подлежащие хранятся в базе данных в хэшированием виде. Другими словами, значения задачи, статуса и владельца задачи могут быть захэшированы перед сохранением в таблицу. Хэширование позволяет ускорить процесс поиска путем сортировки значений хэшей в базе данных.
Для того чтобы найти связи между вершинами графов поиск в базе данных выполняется с помощью предикатов. Таким образом, таблица ключей в базе данных является таблицей, содержащей связи между предикатами, подлежащими и дополнениями. Подлежащие в таблице ключей отсортированы. Таблица предикатов 910 содержит предикаты P1…Pn, используемые для выбора подлежащих и дополнений.
Стоит отметить, что данный метод хранения данных не ограничен задачами в тройках. Данные четверок также могут храниться в таблице ключей. Ссылки N1S…NnS являются значениями в таблице предикатов и которые представляют собой ссылки на таблицы N1S…NnS (920 и 940 соответственно). Таблицы 920 и 940 представляют собой связи между подлежащим и дополнениями. Таблица предикатов 910 также содержит ссылки на таблицы N1O…NnO (930 и 950 соответственно), которые также представляют собой связи между подлежащим и дополнениями. Для некоторых предикатов (т.е. для предикатов одного типа), например, для предиката P1 = владелец, создается свой собственный набор таблиц N1S…NnS, а для других типов предикатов, например, для P2 = имя, создается другой набор таблиц N1O…NnO. Стоит отметить, что приведенный выше пример использует тройки, которые используют только два зависимых значения (атрибута). Любой узел графа может быть использован в качестве атрибута. В случаях, когда используется более двух связанных аргументов, например P1 (a1, a2, a3), то используется альтернативный метод для хранения. Также используется В-дерево. Примером предиката с тремя атрибутами может служить утверждение:
"кружки цвет красный вчера " или " цвет(чашка, красный, вчера). Другими словами, " цвет" - это предикат, а "чашка" - подлежащее, "красный" - дополнение и "вчера" - обстоятельство (атрибуты) данного предиката.
На ФИГ. 10 проиллюстрирован пример хранения предикатов с их атрибутами в В-дереве согласно примерному варианту. Таблица предикатов 1010 содержит предикаты, отсортированные в определенном порядке. Таблица предикатов 1010 также содержит ссылки на соответствующие сохраненные атрибуты для каждого из предикатов.
Запись предикатов и их соответствующих атрибутов в В-дерево 1000 реализуется следующим образом: первый набор предиката P1 имеет степень три (т.е. у предиката есть три атрибута). Следовательно, когда первый предикат записан в таблицу 1010, таблица 1010 содержит четыре ссылки на сохраненные атрибуты. Первая ссылка (Ссылка1) ссылается на таблицу 1020, содержащую все первые атрибуты (т.е. атрибуты, размещенные первыми во всех наборах). Вторая ссылка (Ссылка2) указывает на таблицу 1030, содержащую все вторые атрибуты всех наборов. Третья ссылка (Ссылка3) указывает на таблицу 1040, которая содержит все третьи атрибуты. Четвертая ссылка (Ссылка4) является дополнительной ссылкой, которая указывает на таблицу 1050, которая содержит терминатор.
Согласно примерному варианту терминатор является постоянной величиной (числовой или текстовой). Терминатор используется для получения троек из В-дерева 1000. Тройки идентифицируются внутри В-дерева посредством терминатора. Когда атрибуты считываются из В-дерева 1000, поиск тройки продолжается до тех пор, пока не будет найден терминатор, соответствующий конкретной тройке.
Каждому набору атрибутов, наряду с соответствующим предикатом, присваивается идентификационный номер при записи в В-дерево 1000. Следующий идентификационный номер увеличивается на единицу. Таким образом, наборы данных упорядочены согласно тому, когда они записаны в В-дерево 1000. Таким образом, каждый набор (предикат, атрибуты и терминатор) обладает соответствующим уникальным идентификатором, также сохраненным в В-дереве 1000.
Кроме того, каждый атрибут обладает идентификатором позиции, который идентифицирует позицию атрибута в наборе (т.е. первую, вторую, третью и т.д.). В примере на ФИГ. 3 первый набор содержит атрибут "a1" на первой позиции. Следовательно, атрибут "a1" записан в таблицу 1020 с идентификатором "1", указывающим на то, что атрибут принадлежит первому набору.
Атрибут "a2" - второй в первом наборе. Таким образом, он записан в таблицу 1030 с идентификатором "1." Атрибут "a3" - третий в первом наборе. Следовательно, он записан в таблицу 1040 с идентификатором "1." Терминатор с идентификатором "1" записан в таблицу 1050. Терминатор "1" указывает на то, что в первом наборе больше нет атрибутов.
Атрибут "a1" - первый во втором наборе. Следовательно, он записан в таблицу 1020 с идентификатором "2", который указывает на то, что атрибут "a1" принадлежит второму набору. Второй набор содержит только один атрибут. Таким образом, терминатор с идентификатором "2" записан в таблицу 1030.
Для всех остальных наборов предикаты, атрибуты и терминаторы сохранены таким же образом. Стоит отметить, что таблицы 1020-1050 могут содержать ссылки на другие таблицы вместо фактических идентификаторов. Данный пример изображен на ФИГ. 4. Таблица 1010 содержит ссылку (Таблица2Ссылка) на таблицу 1020. Таблица 1020 содержит ссылки (Таблица3Ссылка и Таблица4Ссылка), которые указывают на таблицы 1020 и 1030, содержащие идентификаторы.
Стоит отметить, что таблицы принадлежат В-дереву. Другими словами, таблицы служат ветвями В-дерева. Если необходимо получить определенный набор данных (предикат с атрибутами) из В-дерева, то предикат, атрибуты и терминатор ищутся на основе соответствующего идентификатора.
Со ссылкой на ФИГ. 11, типичная система для реализации изобретения включает в себя многоцелевое вычислительное устройство в виде компьютера 20 или сервера, включающего в себя процессор 21, системную память 22 и системную шину 23, которая связывает различные системные компоненты, включая системную память с процессором 21.
Системная шина 23 может быть любого из различных типов структур шин, включающих шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из множества архитектур шин. Системная память включает постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25. В ПЗУ 24 хранится базовая система ввода/вывода 26 (БИОС), состоящая из основных подпрограмм, которые помогают обмениваться информацией между элементами внутри компьютера 20, например, в момент запуска.
Компьютер 20 также может включать в себя накопитель 27 на жестком диске для чтения с и записи на жесткий диск, не показан, накопитель 28 на магнитных дисках для чтения с или записи на съемный магнитный диск 29, и накопитель 30 на оптическом диске для чтения с или записи на съемный оптический диск 31 такой, как компакт-диск, цифровой видео-диск и другие оптические средства. Накопитель 27 на жестком диске, накопитель 28 на магнитных дисках и накопитель 30 на оптических дисках соединены с системной шиной 23 посредством, соответственно, интерфейса 32 накопителя на жестком диске, интерфейса 33 накопителя на магнитных дисках и интерфейса 34 оптического накопителя. Накопители и их соответствующие читаемые компьютером средства обеспечивают энергонезависимое хранение читаемых компьютером инструкций, структур данных, программных модулей и других данных для компьютера 20.
Хотя описанная здесь типичная конфигурация использует жесткий диск, съемный магнитный диск 29 и съемный оптический диск 31, специалист примет во внимание, что в типичной операционной среде могут также быть использованы другие типы читаемых компьютером средств, которые могут хранить данные, которые доступны с помощью компьютера, такие как магнитные кассеты, карты флеш-памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Различные программные модули, включая операционную систему 35, могут быть сохранены на жестком диске, магнитном диске 29, оптическом диске 31, ПЗУ 24 или ОЗУ 25. Компьютер 20 включает в себя файловую систему 36, связанную с операционной системой 35 или включенную в нее, одно или более программное приложение 37, другие программные модули 38 и программные данные 39. Пользователь может вводить команды и информацию в компьютер 20 при помощи устройств ввода, таких как клавиатура 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, геймпад, спутниковую антенну, сканер или любое другое.
Эти и другие устройства ввода соединены с процессором 21 часто посредством интерфейса 46 последовательного порта, который связан с системной шиной, но могут быть соединены посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (УПШ). Монитор 47 или другой тип устройства визуального отображения также соединен с системной шиной 23 посредством интерфейса, например видеоадаптера 48. В дополнение к монитору 47, персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показано), такие как динамики и принтеры.
Компьютер 20 может работать в сетевом окружении посредством логических соединений к одному или нескольким удаленным компьютерам 49. Удаленный компьютер (или компьютеры) 49 может представлять собой другой компьютер, сервер, роутер, сетевой ПК, пиринговое устройство или другой узел единой сети, а также обычно включает в себя большинство или все элементы, описанные выше, в отношении компьютера 20, хотя показано только устройство хранения информации 50. Логические соединения включают в себя локальную сеть (ЛВС) 51 и глобальную компьютерную сеть (ГКС) 52. Такие сетевые окружения обычно распространены в учреждениях, корпоративных компьютерных сетях, Интранете и Интернете.
Компьютер 20, используемый в сетевом окружении ЛВС, соединяется с локальной сетью 51 посредством сетевого интерфейса или адаптера 53. Компьютер 20, используемый в сетевом окружении ГКС, обычно использует модем 54 или другие средства для установления связи с глобальной компьютерной сетью 52, такой как Интернет.
Модем 54, который может быть внутренним или внешним, соединен с системной шиной 23 посредством интерфейса 46 последовательного порта. В сетевом окружении программные модули или их части, описанные применительно к компьютеру 20, могут храниться на удаленном устройство хранения информации. Надо принять во внимание, что показанные сетевые соединения являются типичными, и для установления коммуникационной связи между компьютерами могут быть использованы другие средства.
Принимая во внимание описанный предпочтительный вариант, для специалиста в данной области очевидно, что были достигнуты определенные преимущества описанного способа и инструмента.
Также должно быть оценен тот факт, что различные модификации, адаптации и альтернативные реализации могут быть сделаны в пределах объема и духа настоящего изобретения. Изобретение далее определяется следующей формулой изобретения.
Принимая во внимание описанный предпочтительный вариант, для специалиста в данной области очевидно, что были достигнуты определенные преимущества описанного способа и инструмента.
Также должно быть оценен тот факт, что различные модификации, адаптации и альтернативные реализации могут быть сделаны в пределах объема и духа настоящего изобретения. Изобретение далее определяется следующей формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ ДАННЫХ ГРАФОВ | 2012 |
|
RU2605387C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ГЛОБАЛЬНОЙ ИДЕНТИФИКАЦИИ В КОЛЛЕКЦИИ ДОКУМЕНТОВ | 2015 |
|
RU2591175C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ, ИЗВЛЕКАЕМОЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2015 |
|
RU2605077C2 |
| СПОСОБ УСКОРЕНИЯ ОБРАБОТКИ МНОЖЕСТВЕННЫХ ЗАПРОСОВ ТИПА SELECT К RDF БАЗЕ ДАННЫХ С ПОМОЩЬЮ ГРАФИЧЕСКОГО ПРОЦЕССОРА | 2012 |
|
RU2490702C1 |
| Способ управления требованиями | 2016 |
|
RU2632121C1 |
| СПОСОБ ОБРАБОТКИ ПРОЦЕССОВ МАШИНОЙ СОСТОЯНИЙ | 2012 |
|
RU2630383C2 |
| СПОСОБ И СИСТЕМА ДЛЯ МАШИННОГО ИЗВЛЕЧЕНИЯ И ИНТЕРПРЕТАЦИИ ТЕКСТОВОЙ ИНФОРМАЦИИ | 2015 |
|
RU2592396C1 |
| СЕМАНТИЧЕСКАЯ НАВИГАЦИЯ ПО ВЕБ-КОНТЕНТУ И КОЛЛЕКЦИЯМ ДОКУМЕНТОВ | 2007 |
|
RU2442214C2 |
| СПОСОБ И СИСТЕМА СИНТЕЗА ТЕКСТА НА ОСНОВЕ ИЗВЛЕЧЕННОЙ ИНФОРМАЦИИ В ВИДЕ RDF-ГРАФА С ИСПОЛЬЗОВАНИЕМ ШАБЛОНОВ | 2015 |
|
RU2610241C2 |










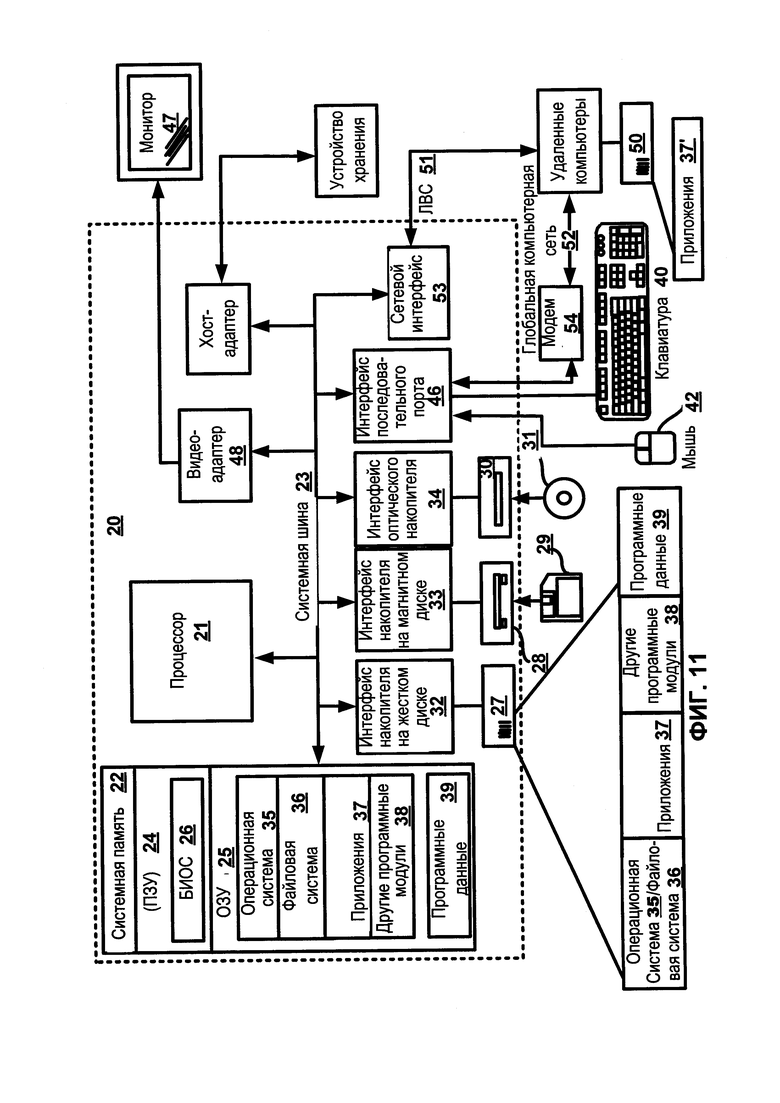


Изобретение относится к способу и системе поиска данных в хранилищах данных. Технический результат заключается в повышении эффективности поиска данных. В способе выполняют инициацию запроса данных от вычислительного устройства инициатором запроса, создание вычислительным устройством модуля получения данных, включающего хранилище данных модуля получения данных, копирование интерпретируемых структур и их метаданных, хранящихся во внешнем хранилище данных, данные которого хранятся в формате СПО-троек (субъект-предикат-объект), и в хранилище данных модуля получения данных хранятся интерпретируемые структуры, определяющие, как получить СПО-тройку из другой СПО-тройки, и определяющие способ выявления наличия представления СПО-троек, хранящихся в хранилище данных модуля получения данных и СПО-троек, обработку запроса посредством осуществления поиска в хранилище данных модуля получения троек для представления СПО-троек и метаданных, соответствующих запросу, и затем во внешнем хранилище данных, если данные не найдены, взаимодействие между инициатором запроса, модулем получения данных и внешним хранилищем данных через общий интерфейс матчера, который является общим для инициатора запроса, модуля получения данных и внешнего хранилища данных. 2 н. и 23 з.п. ф-лы, 14 ил.
1. Внедренный в вычислительное устройство способ поиска данных в хранилищах данных посредством обработки данных, представленных графами и хранящихся в хранилищах данных, с использованием интерпретируемых структур, в котором осуществляется:
инициация запроса данных от вычислительного устройства инициатором запроса, являющимся модулем, связанным с вычислительным устройством или модулем вычислительного устройства, причем модуль является программным модулем и/или аппаратным модулем;
создание вычислительным устройством модуля получения данных, включающего хранилище данных модуля получения данных;
копирование интерпретируемых структур и их метаданных, которые характеризуют данные, хранящиеся во внешнем хранилище данных, причем данные во внешнем хранилище данных хранятся в формате СПО-троек (субъект-предикат-объект) и в хранилище данных модуля получения данных хранятся интерпретируемые структуры, которые определяют, как получить с использованием процессора вычислительного устройства по крайней мере одну СПО-тройку из другой СПО-тройки, и которые определяют способ выявления с использованием процессора вычислительного устройства наличия представления СПО-троек, хранящихся в хранилище данных модуля получения данных, и СПО-троек, хранящихся во внешнем хранилище данных;
обработка запроса посредством осуществления сначала поиска в хранилище данных модуля получения троек для представления СПО-троек с использованием процессора вычислительного устройства и метаданных, соответствующих запросу;
обработка запроса посредством поиска данных, соответствующих запросу, во внешнем хранилище данных, если данные, соответствующие запросу, не найдены в хранилище данных модуля получения данных;
взаимодействие между инициатором запроса, модулем получения данных и внешним хранилищем данных через общий интерфейс матчера, который является общим для инициатора запроса, модуля получения данных и внешнего хранилища данных.
2. Способ по п. 1, отличающийся тем, что интерпретируемыми структурами являются:
- правила;
- встроенные функции (билт-ины); функторы;
билт-ины-доказательства;
и другие структуры, способные выводить по крайней мере одну СПО-тройку.
3. Способ по п. 1, отличающийся тем, что хранилище данных и модуль получения данных являются моделями.
4. Способ по п. 3, отличающийся тем, что модели объединены в любых вариациях по крайней мере в одну виртуальную модель.
5. Способ по п. 4, отличающийся тем, что виртуальные модели объединены по крайней мере в одну новую виртуальную модель.
6. Способ по п. 1, отличающийся тем, что данными являются аксиомы, факты, онтологии и интерпретируемые структуры.
7. Способ по п. 6, отличающийся тем, что факты выводятся модулем получения данных на основе интерпретируемых структур и аксиом.
8. Способ по п. 1, отличающийся тем, что интерпретируемые структуры компилируются один раз по запросу в исполняемый код при первом их вызове, чтобы избежать повторной компиляции интерпретируемых структур во время последующих обращений к ним.
9. Способ по п. 1, отличающийся тем, что встроенные функции используются во время обработки интерпретируемых структур, причем встроенные функции регистрируются на предикаты СПО-троек и отвечают за выполнение действий, которые не могут быть реализованы с использованием интерпретируемых структур.
10. Способ по п. 4, отличающийся тем, что модели, которые представляют данные, СПО-тройки и представление СПО-троек и которые используют общий интерфейс матчера для доступа к СПО-тройкам, объединены в одну виртуальную модель с общим интерфейсом матчера.
11. Способ по п. 3 или 4, отличающийся тем, что по крайней мере одна модель, которая была объединена в виртуальную модель, является подчиненной для такой объединенной модели, причем виртуальная модель получает доступ ко всем подчиненным моделям и виртуальная модель перенаправляет запросы подчиненным моделям для доступа к данным, тип которых неизвестен.
12. Способ по п. 1, отличающийся тем, что встроенные функции используются во время обработки интерпретируемых структур, причем встроенные функции записаны как билт-ины-доказательства и предварительно компилируются и отвечают за выполнение действий, которые не могут быть реализованы с использованием интерпретируемых структур.
13. Способ по п. 9, отличающийся тем, что функторы используются в процессе обработки интерпретируемых структур и записаны в СПО-формате.
14. Способ по п. 1, отличающийся тем, что обработка интерпретируемых структур включает точный матчинг и матчинг по паттерну.
15. Способ по п. 1, отличающийся тем, что запрос является:
- запросом от модуля получения данных;
- запросом от приложения с модулем получения данных;
- запросом от приложения, внешнего для модуля получения данных.
16. Способ по п. 1, отличающийся тем, что внешнее хранилище данных включает по крайней мере одну базу данных, хранящую СПО-тройки для модели.
17. Способ по п. 1, отличающийся тем, что запрос разбивается на несколько запросов.
18. Способ по п. 1, отличающийся тем, что интерпретируемые структуры маркируются в соответствии с запросом и параметрами запроса, и в соответствии со статусом обработки: обработка интерпретируемых структур началась, интерпретируемые структуры обработаны, обработка интерпретируемых структур приостановлена.
19. Способ по п. 1, отличающийся тем, что маркированные интерпретируемые структуры маркируются как «Вход», причем переменные для «Входа» предопределены.
20. Способ по п. 6, отличающийся тем, что интерпретируемые структуры, метаданные и факты хранятся в виде списка в хранилище данных модуля получения данных, и отличающийся тем, что новые факты, интерпретируемые структуры и метаданные добавляются в самый верх (в конец)списка.
21. Способ по п. 6, отличающийся тем, что обработка фактов и данных начинается с последних добавленных фактов и данных, если в ходе обработки интерпретируемых структур были выявлены ссылки на другие интерпретируемые структуры.
22. Способ по п. 1, отличающийся тем, что найденные данные возвращаются инициатору запроса по одной СПО-тройке за раз.
23. Система для поиска данных в базах данных посредством обработки данных, представленных графами и хранящихся в базах данных, с использованием интерпретируемых структур, включающая:
модуль инициирования запроса, инициирующий запрос данных от вычислительного устройства, причем инициатор запроса является модулем, связанным с вычислительным устройством или модулем вычислительного устройства, с которым связан модуль получения данных, причем модуль является программным модулем и/или аппаратным модулем;
внешнее хранилище данных, в котором хранятся данные, характеризуемые набором интерпретируемых структур и их метаданных и передаваемые в хранилище данных модуля получения данных, причем данные во внешнем хранилище данных хранятся в формате СПО-троек (субъект-предикат-объект);
хранилище данных модуля получения данных, в котором хранятся интерпретируемые структуры, которые определяют, как вывести с использованием процессора вычислительного устройства по крайней мере одну СПО-тройку из других СПО-троек, и которые определяют способ определения с использованием процессора вычислительного устройства наличия представления СПО-троек, хранящихся в хранилище данных модуля получения данных, и СПО-троек, хранящихся во внешнем хранилище данных;
модуль получения данных, который имеет доступ к хранилищу данных модуля получения данных, причем если данные, соответствующие запросу, не найдены в хранилище данных модуля получения данных модулем получения данных, то модуль получения данных осуществляет поиск данных, соответствующих запросу, во внешнем хранилище данных;
причем источник запроса, модуль получения данных и внешнее хранилище данных имеют общий интерфейс матчера, который используется для согласования взаимодействий между источником запроса, модулем получения данных и внешним хранилищем данных.
24. Система по п. 23, отличающаяся тем, что хранилище данных и модуль получения данных являются моделями.
25. Система по п. 24, отличающаяся тем, что модели объединены в любых вариациях по крайней мере в одну виртуальную модель.
| US 8244772 B2, 14.08.2012 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| US 7702636 B1, 20.04.2010 | |||
| US 7890518 B2, 15.02.2011 | |||
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| СПОСОБ УСКОРЕНИЯ ОБРАБОТКИ МНОЖЕСТВЕННЫХ ЗАПРОСОВ ТИПА SELECT К RDF БАЗЕ ДАННЫХ С ПОМОЩЬЮ ГРАФИЧЕСКОГО ПРОЦЕССОРА | 2012 |
|
RU2490702C1 |

