Область техники, к которой относится изобретение
Предлагаемое изобретение относится к области информационной безопасности, обработки и анализа многомерных данных, машинного обучения.
Уровень техники
Задача по обнаружению аномального (подозрительного) сетевого трафика может решаться различными способами. При этом, большую часть способов можно разделить на две категории: способы по обнаружению злоупотреблений и способы по обнаружению аномалий. К первой категории относятся способы, которые подразумевают обнаружение конкретный действий атакующего. Например, способы на основе сигнатур детектируют атаки путем обнаружения определенных шаблонов. Такие способы показывают высокую точность обнаружения известных техник, для обнаружения которых эти способы и разрабатывались. Однако способы первой категории уязвимы к атакам нулевого дня, а также уязвимы при использовании злоумышленниками определенных легитимных в системе инструментов.
Способы относящиеся ко второй категории обычно являются менее точными в плане обнаружения подозрительной активности, но при этом такие способы могут быть более точными в плане уменьшения количества ложных срабатываний. Также такие способы могут обнаружить атаки нулевого дня. Обычно для реализации таких способов не нужна информация о известных атаках, так как задача по обнаружению аномалий обычно подразумевает построение модели нормального поведения системы. Известны способы обнаружения аномалий в сетевом трафике.
Известен способ обнаружения подозрительного трафика (заявка США №2017/0230392, опубл. 10.08.2017 г.), согласно которому для обнаружения подозрительного трафика совместно используются статистические методы и математические модели с обучением без учителя. Способ получает на вход метаданные пакетов сетевого трафика. На основе таких данных создаются метрики двух типов. Метрики первого типа создаются с помощью применения математический функций, например, скользящего среднего, экспоненциально взвешенные среднего, квадратного корня, логарифма и других. Метрики второго типа вычисляются на основе метрик первого типа с помощью математических моделей неконтролируемого обучения. К таким моделям, например, относятся: метод опорных векторов с одним классом (One-class SVM), метод локального фактора выброса (LOF) или вероятностное моделирования выбросов.
Используя метрики первого и второго типа, строится модель нормального поведения для каждого устройства в сети по каждой из метрик. После чего, вычисляется общий показатель аномального поведения каждого устройства.
Способ предполагает вычислять вероятность аномального поведения устройства на основе определенной статистики. Если вероятность аномального поведения будет превышать установленный порог, поведение устройства будет считается аномальным.
Описанный способ имеет следующие недостатки:
• не используется информацию об используемых приложениях, протоколах и сервисах, которая может иметь высокую значимость при обнаружении определенных сетевых атак, что может привести к большому количеству ошибок первого (false positive) и второго рода (false negative);
• при использовании статистических методов предполагается, что параметры сетевого трафика являются независимыми случайными величинами, однако компоненты реальной сети зачастую влияют друг на друга, также, как и отдельные параметры сетевого трафика могут иметь определенные зависимости.
Известен способ обнаружения аномалий в многомерных данных (патент РФ №2773010, приоритет от 08.09.2021), согласно которому для обнаружения аномалий в многомерных данных используется архитектура нейронной сети типа автокодировщик. Такая архитектура позволяет построить модель нормального поведения для последующего обнаружения аномальный строк входной выборки.
Способ предполагает двойное обучение модели нейронной сети. После первого обучения автокодировщика, вычисляется мгновенная ошибка реконструкции (Immediate Reconstruction Error, IRE) для обучающего набора данных. Вычисляется порог IRE и из обучающей выборки удаляются все строки, IRE которых превышает заданный порог.
После удаления аномалий из обучающей выборки автокодировщик обучается повторно. Порог IRE устанавливается равным максимальному значению IRE обучающего набора. Вычисляется ошибка реконструкции для тестового набора данных. Аномальными строками тестового набора будут являться строки IRE которых превосходит заданный порог.
Этот способ принимается в качестве прототипа. Однако, известный способ имеет следующие недостатки:
• при работе с многомерными временными рядами, способ не предполагает использование информации о временных зависимостях элементов временного ряда, а исследует аномальное поведение каждого элемента временного ряда независимо, поэтому при обнаружении распределенных во времени аномалий точность способа значительно уменьшается и увеличивается количество ошибок первого и второго рода;
• в способе реализуется формирование и обучение двух нейронных сетей;
• в способе не уделено внимание проблеме переобучения нейронных сетей, что, в случае переобучения, может привести к понижению порога аномалии и к повышению количества ошибок первого рода на тестовом наборе данных;
• в способе не предполагается использование дополнительных слоев для обработки символьных параметров в нейронной сети, поэтому при наличии в данных таких признаков эффективность обучения нейронной сети ухудшается.
Раскрытие изобретения
Техническим результатом является:
1) уменьшение количества ошибок первого и второго рода при обнаружении распределенных во времени аномалий;
2) обучение единственной нейронной сети;
3) уменьшение количества ошибок первого рода за счет устранения переобучения нейронной сети;
4) повышение эффективности процесса обучения нейронной сети при наличии в данных символьных параметров.
Для этого предлагается способ обнаружения аномального трафика в сети с использованием вычислительной системы, включающей, по крайней мере, один компьютер, имеющий установленную операционную систему и прикладные программы, подключенный к сети и выполненный с возможностью:
 получать, обрабатывать и хранить, многомерные данные сессий сетевого трафика;
получать, обрабатывать и хранить, многомерные данные сессий сетевого трафика;
обеспечивать формирование, функционирование и обучение нейронной сети типа автокодировщик; заключающийся в том, что:
запускают компьютер в режиме контролируемой нормальной работы; о задают значимые параметры сетевых сессий;
сохраняют сетевой трафик за выбранный промежуток времени в режиме нормальной работы системы; о записывают параметры сетевых сессий из сохраненного сетевого трафика в таблицу параметров сессий в хронологическом порядке их появления; о разделяют таблицу параметров сессий на таблицу для обучения и таблицу валидации;
осуществляют оцифровку значений символьных параметров в таблице для обучения, выполняя следующие действия:
• находят для каждого символьного параметра все уникальные значения в таблице для обучения;
• присваивают каждому уникальному найденному значению символьного параметра уникальный порядковый номер, начиная с единицы;
• присваивают номер 0 неопределенному значению в каждом из параметров;
• записывают все найденные уникальные значения каждого символьного параметра и присвоенные уникальные порядковые номера в таблицу соответствия;
• заменяют в таблице для обучения символьные значения на присвоенные им порядковые номера согласно таблице соответствия;
осуществляют в таблице для обучения нормализацию значений всех параметров, кроме оцифрованных, выполняя следующие действия:
• находят первый порог выбросов B1, i для каждого i-ого параметра по формуле
B1, i=qv3, i+3(qv3, i - qv1, i),
где qv3, i - третий квартиль массива всех значений i-ого параметра;
qv1, i - первый квартиль массива всех значений i-ого параметра;
• получают массив промежуточных значений Di путем деления всех значений i-ого параметра на соответствующий первый порог выбросов
Di=Vi/B1, i;
• получают промежуточный массив Fi, выбирая значения Di большие единицы;
• получают промежуточный массив Gi, вычитая единицу из каждого значения массива промежуточных значений Fi
Gi=Fi-1;
• находят второй порог выбросов В2, i для каждого промежуточного массива Gi по формуле
В2, i=qe3, i+3(qe3, i - qe1, i),
где qe3, i - третий квартиль массива Gi i-ого параметра;
qe1, i - первый квартиль массива Gi i-ого параметра;
• получают массив промежуточных значений Hi путем деления всех значений промежуточного массива Gi на соответственное значение второго порога выбросов В2, i
Hi=Gi/B2, i;
• получают массив промежуточных значений Ri путем прибавления единицы к каждому значению массива промежуточных значений Hi
Ri=Hi+1;
• сохраняют значения 1-го и 2-го порога выбросов для каждого i-ого параметра;
• получают массив Li путем замены значений больших единицы в промежуточном массиве Di на соответственные значения Ri;
• получают нормализованную таблицу для обучения, заменяя исходные значения каждого i-ого параметра в таблице для обучения на значения Li;
полученную нормализованную таблицу для обучения разбивают на последовательности сессий, выполняя следующие действия:
• выбирают ширину окна WS - целочисленное значение, равное числу сессий в одной последовательности сессий;
• выбирают сдвиг окна ST - целочисленное значение, на которое окно будет сдвигаться по таблице сессий, причем ST<WS;
• выбирают в качестве первой последовательности сессий параметры первых WS сессий нормализованной таблицы для обучения;
• сдвигают окно по таблице на значение ST и формируют следующую последовательность сессий;
• формируют последовательности сессий до тех пор, пока окно не дойдет до конца нормализованной таблицы для обучения;
формируют обучающую выборку из полученных последовательностей сессий;
осуществляют оцифровку символьных значений параметров в таблице валидации, выполняя следующие действия:
• находят для каждого символьного параметра все уникальные значения в таблице валидации;
• проводят поиск и сравнение для каждого уникального значения символьного параметра в таблице соответствия;
• если уникальное значение символьного параметра отсутствует в таблице соответствия, дополняют таблицу соответствия парами новых уникальных значений и их уникальных порядковых номеров;
• заменяют в таблице валидации символьные значения на присвоенные им порядковые номера согласно таблице соответствия;
осуществляют в таблице валидации нормализацию значений всех параметров, кроме оцифрованных, выполняя следующие действия:
• получают массив промежуточных значений VDi путем деления всех значения i-ого параметра на значение первого порога выбросов
VDi=VVi/B1, i;
• получают промежуточный массив VFi, выбирая значения VDi большие единицы;
• получают промежуточный массив VGi, вычитая единицу из каждого значения массива промежуточных значений VFi
VGi=VFi-1;
• получают массив промежуточных значений VHi путем деления всех значений промежуточного массива VGi на значение второго порога выбросов В2, i
VHi=VGi/B2, i;
• получают массив промежуточных значений VRi путем прибавления единицы к каждому значению массива промежуточных значений VHi
VRi=VHi+1;
• получают массив VLi путем замены значений больших единицы в промежуточном массиве VDi на соответственные значения VRi;
• получают нормализованную таблицу валидации, заменяя исходные значения каждого i-ого параметра в таблице валидации на значения VLi;
полученную нормализованную таблицу валидации разбивают на последовательности сессий, выполняя следующие действия:
• в качестве первой последовательности сессий выбирают параметры первых WS сессий нормализованной таблицы валидации;
• сдвигают окно по таблице на значение ST и формируют следующую последовательность сессий;
• формируют последовательности сессий до тех пор, пока окно не дойдет до конца нормализованной таблицы валидации;
формируют валидационную выборку из полученных последовательностей сессий;
формируют нейронную сеть с архитектурой автокодировщика, выполняя следующие действия:
• формируют слой встраивания для каждого символьного параметра, выполняя следующие действия:
 выбирают размер словаря слоя встраивания i-ого символьного параметра EDi, причем
выбирают размер словаря слоя встраивания i-ого символьного параметра EDi, причем
- если для i-ого символьного параметра известно максимальное количество уникальных значений, то EDi выбирают равным такой максимальной величине;
- если для i-ого символьного параметра неизвестно максимальное количество уникальных значений, то EDi выбирают, по крайней мере, в 2 раза большим количества уникальных значений такого символьного параметра в таблице соответствия;
получают промежуточное значение EMi по формуле
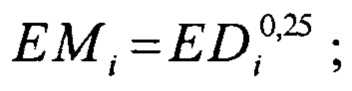
выбирают размер результирующего массива слоя встраивания i-ого символьного параметра равным целой частью числа EMi;
• создают одномерные сверточные слои с архитектурой TCN, выполняя следующие действия:
задают одинаковую ширину фильтров всех сверточных слоев, равную KS;
задают коэффициент расширения на первом сверточном слое равным единице;
на каждом новом сверточном слое увеличивают коэффициент расширения;
если коэффициент расширения получается больше, чем 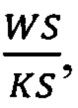 задают коэффициент расширения сверточного слоя равным единице;
задают коэффициент расширения сверточного слоя равным единице;
количество каналов входных данных ICH на первом сверточном слое вычисляют по формуле
ICH=FC-ELC+EFC,
где FC - количество параметров сессий в таблице параметров сессий;
ELC - количество слоев встраивания;
EFC - сумма размеров выходных массивов всех слоев встраивания;
задают минимальное количество каналов в скрытых слоях меньше количества параметров сессий в таблице параметров сессий;
задают количество каналов последнего слоя равным количеству параметров в таблице параметров сессий;
обучают нейронную сеть с использованием обучающей выборки, причем минимизируют при обучении ошибку реконструкции RE, которая вычисляется по формуле
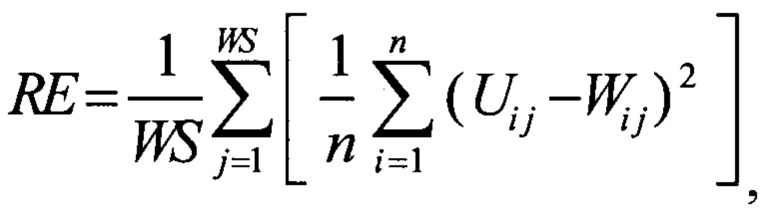
где WS - ширина окна;
n - количество параметров в таблице параметров сессий;
Uij - значение i-ого параметра j-той сессии, полученной на входе нейронной сети;
W ij - значение i-ого параметра j-той сессии, реконструированной на выходе нейронной сети; о после обучения вычисляют ошибку реконструкции для каждой j-ой сессии в каждой k-ой последовательности валидационной выборки REkj
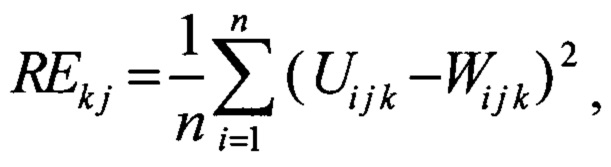
где Ui j k - значение i-ого параметра j-той сессии в k-той последовательности, полученной на входе нейронной сети;
Wi j k - значение i-ого параметра j-той сессии в k-той последовательности, реконструированной на выходе нейронной сети;
вычисляют значение ошибки реконструкции для каждой сессии как среднее значение ошибок реконструкции этой сессии в разных последовательностях;
получают одномерный временной ряд средних значений итоговых ошибок реконструкций RETS для каждой сессии;
вычисляют порог аномалии В по формуле:
B=q3+1.5 (q3-q1),
где q1 и q3 - соответственно первый и третий квартиль массива RETS;
сохраняют тестовый сетевой трафик за выбранный промежуток времени в режиме нормальной работы системы;
извлекают из тестового трафика параметры сетевых сессий;
записывают параметры сетевых сессий из сохраненного сетевого трафика в тестовую таблицу параметров сессий;
осуществляют оцифровку значений символьных параметров в тестовой таблице параметров сессий, выполняя следующие действия:
• находят для каждого символьного параметра все уникальные значения в тестовой таблице параметров сессий;
• проводят поиск и сравнение для каждого уникального значения символьного параметра в таблице соответствия;
• если уникальное значение символьного параметра отсутствует в таблице соответствия, дополняют таблицу соответствия парами новых уникальных значений и их уникальных порядковых номеров;
• заменяют в тестовой таблице параметров сессий символьные значения на присвоенные им порядковые номера согласно таблице соответствия;
осуществляют в тестовой таблице параметров сессий нормализацию значений всех параметров, кроме оцифрованных, выполняя следующие действия:
• получают массив промежуточных значений PDi путем деления всех значения i-ого параметра на соответствующий порог выбросов;
PDi=PVi/B1, i;
• получают промежуточный массив PFi, выбирая значения PDi большие единицы;
• получают промежуточный массив PGi, вычитая единицу из каждого значения массива промежуточных значений PFi
PGi=PFi-1;
• получают массив промежуточных значений PHi путем деления всех значений промежуточного массива PGi на значение второго порога выбросов В2, i
PHi=PGi/B2, i;
• получают массив промежуточных значений PRi путем прибавления единицы к каждому значению массива промежуточных значений PHi
PRi=PHi+1;
• получают массив PLi путем замены значений больших единицы в промежуточном массиве PDi на соответственные значения PRi;
• получают нормализованную тестовую таблицу, заменяя исходные значения каждого i-ого параметра в тестовой таблице параметров сессий на значения PLi;
полученную нормализованную тестовую таблицу разбивают на последовательности сессий, выполняя следующие действия:
• в качестве первой последовательности сессий выбирают параметры первых WS сессий нормализованной тестовой таблицы;
• сдвигают окно по таблице на значение ST и формируют следующую последовательность сессий;
• формируют последовательности сессий до тех пор, пока окно не дойдет до конца нормализованной тестовой таблицы;
формируют тестовую выборку из полученных последовательностей сессий;
подают тестовую выборку на вход нейронной сети;
вычисляют ошибку реконструкции REPk j для каждой j-той сессии в каждой k-той последовательности тестовой выборки по формуле
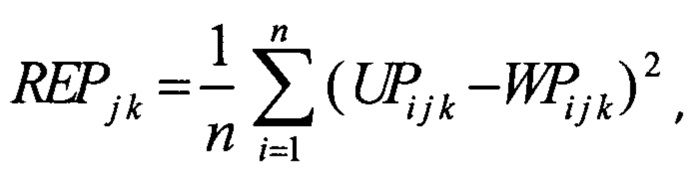
где UPi j k - значение i-ого параметра j-той сессии в k-той последовательности, полученной на входе нейронной сети;
WPi j k - значение i-ого параметра j-той сессии в k-той последовательности, реконструированной на выходе нейронной сети;
вычисляют значение ошибки реконструкции для каждой сессии как среднее значение ошибок реконструкции этой сессии в разных последовательностях;
получают временной ряд TRETS средних значений итоговых ошибок реконструкций для каждой сессии;
сопоставляют каждой ошибке реконструкции во временном ряду TRETS временную метку соответственной сессии;
выбирают значение временного окна Т;
разбивают временной ряд TRETS на m последовательных непересекающихся временных сегментов по длительности равные Т;
находят среднее значение ошибки реконструкции Pm на каждом m-ом временном сегменте;
отмечают в качестве аномальных временные сегменты, значение Pm которых больше, чем порог аномалии В;
при необходимости, формируют отчет об обнаруженных в тестовой выборке аномалиях.
В предложенном способе в качестве входных данных используются многомерные временные ряды.
Временной ряд - это упорядоченный набор значений, имеющих временные метки. Во временном ряду все значения отсортированы по значениям их временных меток. При детектировании аномалий во временных рядах, можно столкнуться с ошибками двух видов. Ошибками первого рода называют такие ошибки, при которых элемент временного ряда, фиксируют как аномальный, тогда как на самом деле элемент является нормальным. Ошибками второго рода называют такие ошибки, при которых элемент временного ряда фиксируют как нормальный, тогда как на самом деле элемент является аномальным.
Многомерные временные ряды - это совокупность нескольких временных рядов соответственные элементы которых имеют одинаковые значения временных меток. Такие ряды можно получить, например, с помощью одновременной записи значений различных сенсоров через определенные промежутки времени. Элементом многомерного временного ряда будем называть набор значений, соответствующих одной временной метке.
Обычно многомерные временные ряды имеют определенные временные зависимости. Такие зависимости могут иметь высокую значимость при создании модели нормального поведения системы. Поэтому при исследовании многомерного временного ряда параметров сессий способ предлагает использовать архитектуру Temporary Convolution Network (TCN). Сессия (сетевая сессия) - это набор сетевых пакетов, которыми обмениваются по сети два устройства (хоста), имеющие адреса сетевого уровня. Сессия характеризуется транспортным протоколом (TCP, UDP и др.) и двумя транспортными портами, каждый из которых выделяется на одном из хостов и не меняется в течение всей сессии.
Архитектура TCN изначально создавалась для работы с временными рядами, поэтому в таких нейронных сетях используются различные механизмы для исследования информации о временных зависимостях. Используя информацию о временных зависимостях элементов временного ряда можно повысить точность определения аномалии в сетевом трафике, используя в качестве элемента временного ряда параметры одной сессии. На вход такая нейронная сеть получает многомерный временной ряд или его сегмент. На выходе такая нейронная сеть получает одно или несколько значений для каждого элемента входного временного ряда.
Нейронная сеть типа TCN состоит из одномерных сверточных слоев. Каждый одномерный сверточный слой имеет один или несколько фильтров, каждый фильтр это - двумерный массив значений с глубиной равной количеству каналов входного временного ряда и определенной заданной шириной.
При использовании сверточных сетей для анализа временных рядов, каналом называют одномерные временные ряды, из которых состоит входной многомерный временной ряд.
Тогда глубина всех фильтров сверточного слоя нейронной сети должна равняться количеству временных рядов во входном многомерном временном ряду. С помощью операции одномерной свертки получают одно или несколько значений для каждого элемента входного временного ряда.
Операция одномерной свертки представляет собой скалярное произведение фильтра и сегмента входного многомерного временного ряда, при этом ширина такого сегмента равна ширине фильтра сверточного слоя. Таким образом, для одного сегмента входного многомерного временного ряда, получают набор значений, количество которых равно количеству фильтров сверточного слоя.
В нейронных сетях типа TCN используется так называемся причинная свертка. При использовании такой свертки, сначала входной временной ряд дополняют нулевыми значениями слева (то есть с начала временного ряда), количество таких нулевых элементов временного ряда на единицу меньше чем ширина фильтра. После чего фильтр применяют к сегменту начала дополненного многомерного временного ряда. Тогда в операции свертки будет использоваться сегмент с нулевыми элементами дополненного временного ряда и первым элементом исходного временного ряда. Таким образом получают вещественное значение для первого элемента исходного временного ряда.
Последовательно сдвигая фильтр на один элемент входного временного ряда, получают вещественное значение для каждого элемента входного многомерного временного ряда. Если сверточный слой имеет несколько фильтров, тогда для каждого из них проводится аналогичная операция. Таким образом, результатом работы одномерного сверточного слоя с несколькими фильтрами будет многомерный временной ряд. Причем количество элементов такого результирующего временного ряда будет равно количеству элементов входного временного ряда, а количество каналов будет равно количеству фильтров сверточного слоя, так-как для каждого фильтра на выходе сверточного слоя получается одномерный временной ряд. Таким образом, устанавливая количество фильтров сверточных слоев, можно менять размерность данных от одного слоя к другому. Причем количество элементов результирующего временного ряда на каждом слое не меняется.
В нейронных сетях типа TCN используется механизм расширения. Принцип работы расширения заключается в том, что в операции причинной свертки, фильтр применяется не к соседним элементам, а к элементам с определенным пропуском. Таким образом, например, при коэффициенте расширения равном 2, для одной свертки выбирается каждый второй элемент входного временного ряда, пока количество элементов не станет равно ширине фильтров сверточного слоя. При использовании механизма расширения увеличивается количество дополняемых нулевых элементов, так, чтобы последним элементом в сегменте временного ряда для свертки был элемент, для которого данная операция свертки и получает значение. Увеличение коэффициента расширения от одного слоя к другому, позволяет увеличивать рецептивное поле нейронной сети.
В области сверточных нейронных сетей существует понятие, называемое рецептивным полем, которое используется для представления размера восприимчивого диапазона нейронов в разных положениях в сети к исходному изображению при использовании двумерной свертки или временному ряду при использовании одномерной свертки.
При увеличении коэффициента расширения, в тот момент когда оно становиться больше чем 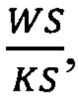 где WS - то есть количество элементов входного многомерного временного ряда, a KS - ширина фильтров сверточного слоя, коэффициент расширения устанавливают равным одному. Таким образом, нейронную сеть можно условно разделить на блоки сверточных слоев, в которых происходит последовательное увеличение коэффициента расширения. Обычно для эффективного увеличения рецептивного поля, коэффициент расширения удваивают на каждом новом слое, a KS выбирают равным двум.
где WS - то есть количество элементов входного многомерного временного ряда, a KS - ширина фильтров сверточного слоя, коэффициент расширения устанавливают равным одному. Таким образом, нейронную сеть можно условно разделить на блоки сверточных слоев, в которых происходит последовательное увеличение коэффициента расширения. Обычно для эффективного увеличения рецептивного поля, коэффициент расширения удваивают на каждом новом слое, a KS выбирают равным двум.
Тогда размер рецептивного поля R рассчитывается по формуле
R=BN*2L,
где BN - количество блоков с увеличением коэффициента расширения;
L - количество слоев в каждом блоке с увеличением коэффициента расширения.
В предложенном способе предлагается выбирать BN и L таким образом, чтобы R было больше либо равно WS, для того, чтобы максимально увеличить диапазон взаимодействия удаленных нейронов во входном временном ряду.
Также архитектура сверточных TCN слоев подразумевает использование и других механизмов, например, механизма остаточной связи, использование слоев активации, использование нормализации весов и другие.
Для обнаружения аномалий и построения модели нормального поведения системы, в предложенном способе используется архитектура автокодировщика.
Автокодировщик - это нейронная сеть, которая обучается восстанавливать входные данные из сжатого представления с минимальной ошибкой реконструкции.
Ошибка реконструкции - это метрика, характеризующая различие входного и выходного объекта автокодировщика.
Обычно автокодировщик состоит из входного слоя, слоя выхода и, по крайней мере, одного скрытого слоя. При этом размерность объектов на входе и на выходе автокодировщика должна совпадать, а в скрытых слоях информация о входном объекте должны сжиматься до меньшей размерности.
С помощью нейронных сетей типа TCN возможно реализовать архитектуру автокодировщика. Так как предполагается использование одномерных сверточных слоев с постоянным количеством элементов результирующих временных рядов на выходе таких слоев, уменьшение размерности входных данных производится за счет уменьшения числа каналов к середине нейронной сети и последующее увеличение числа каналов, до первоначальной размерности входных данных. Таким образом, создается архитектура Temporary Convolution AutoEncoder (ТСАЕ).
В качестве входных данных, предполагается использовать параметры сессий сетевого трафика. Для обучения нейронной сети требуется собирать трафик в течении некоторого периода времени. Предполагается, что трафик для обучения нейронной сети должен быть репрезентативным для данной сети. То есть, например, если нормальное поведение сети кардинально различается в различные дни недели, то период сбора трафика для обучения нейронной сети должен быть по крайней мере больше одной недели.
Из такого трафика необходимо извлечь информацию о параметрах сессий. В качестве таких параметров используются: IP адреса, сетевой порт, протокол транспортного уровня, mac адреса, информация о флагах, преданных в течении сессии и другие параметры. Также используются различные функции агрегации, например, среднее количество байт, переданных в течении сессии, среднее количество байт переданных от отправителя к получателю, среднее количество пакетов, переданных в течении сессии и другие.
Если из сессии возможно извлечь информацию с прикладного уровня стека TCP/IP, тогда также используются такие параметры, как: имя используемого приложения, класс используемого приложения, запрошенное имя сервера (SSL/TLS, DNS или HTTP) и другие. Пример таблицы параметров сессий приведен в табл. 1.
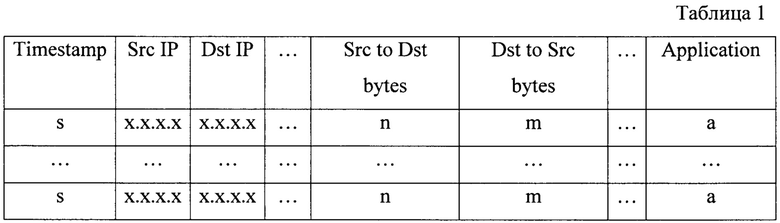
Такая таблица разбивается на таблицы для обучения и валидации. Обычно для обучающей таблицы выбирают 70-80% строк первоначальной таблицы, а для валидационной оставшиеся 20-30% строк. После чего происходит оцифровка таблицы для обучения.
Оцифровываются только символьные параметры, например, параметры принимающие строковые значения (IP и MAC адреса, протоколы или названия приложений) или целочисленные параметры, значения которых обусловлены нумерацией (например, номер сетевого порта). Для оцифровки одного такого параметра сначала находят все значения, которые встречаются в столбце такого параметра хотя бы один раз. Такие значения будем называть уникальными значениями этого параметра. То есть, например, для столбца со значениями: 100, 100, 50, 22, 22, 13, уникальными будут значения 100, 50, 22, 13. Каждому уникальному значению параметра задается порядковый номер, начинающийся с единицы. Для каждого параметра неопределенному значению задается номер равный нулю. Так как в исходной таблице есть парные параметры, например, два параметра IP адресов или два параметра MAC адресов, набор уникальных значений и нумерация таких параметров будут общими для обоих параметров. То есть, если в столбце IP отправителя (Src IP) присутствовал IP 10.0.115.8 и ему был присвоен номер 5, то и в столбце IP получателя (Dst IP), адресу 10.0.115.8 будет присвоен номер 5. Все уникальные значения для каждого символьного параметра и присвоенные им порядковые номера записываются в таблицу соответствия. После чего все значения символьных параметров в таблице заменяются их номерами согласно таблице соответствия.
Символьные параметры таблицы для валидации оцифровывается с помощью таблицы соответствия полученной на этапе оцифровки таблицы для обучения. Однако, так-как таблица соответствий создаются на основе таблицы для обучения, в валидационной таблице в столбцах символьных параметров могут присутствовать уникальные значения, которых не было в таблице для обучения. Таким значениям присваивают новые собственные порядковые номера, после чего таблица соответствий дополняется новой парой значений. Каждое уникальное значение в каждом из символьных параметров в валидационной таблице заменяется соответственным номером согласно таблице соответствий. Такая оцифровка необходима для последующего использования слоев встраивания (Embedding слоев).
Слой встраивания - это слой нейронной сети, получающий на входе оцифрованное символьное значение, а на выходе дающий массив вещественных чисел. Причем размер результирующего массива для каждого слоя встраивания является неизменным и задается при инициализации слоя. Предложенный способ предполагает реализацию слоев встраивания, при которой такие слои будут получают на вход целочисленный порядковый номер символьного значения. Каждый слой встраивания может принимать на вход ограниченное количество уникальных номеров символьных значений.
Набор значений, которые слой встраивания может принимать на вход называют словарем этого слоя встраивания. Размер словаря слоя встраивания равен максимальному количеству уникальных значений, которые этот слой может принимать на вход. Размер результирующего массива, как правило должен быть значительно меньше размера словаря, и подбирается на основе эмпирических наблюдений. Чтобы унифицировать выбор размера результирующего массива каждого слоя встраивания, сначала для слоя встраивания вычисляют промежуточное значение ЕМ по формуле
ЕМ=ED025,
где ED - размер словаря слоя встраивания
После чего задают размер результирующего массива слоя встраивания равным целой части числа ЕМ.
Использование слоев встраивания при наличии в данных символьных параметров повышает эффективность обучения нейронной сети. Предложенный способ предполагает применение таких слоев к символьным параметрам сессий. То есть для каждого такого параметра, будет создан собственный слой встраивания. На вход каждый слой встраивания будет получать оцифрованный столбец номеров, а на выходе слой встраивания будет давать несколько столбцов вещественных чисел.
На примере параметра названия протокола, оцифрованный столбец номеров протоколов будет преобразован в несколько столбцов вещественных чисел, то есть протоколу каждой сессии будет сопоставлен массив вещественных чисел. Таким образом, на выходе каждый из слоев встраивания вернет двумерный массив вещественных чисел. Такой массив будет содержать количество сессий, равное количеству сессий во входной последовательности. Результирующие массивы каждого слоя встраивания конкатенируются по оси параметров сессий между собой и с массивом параметров сессий, не подлежащих оцифровке. Такой объединенный двумерный массив будет подаваться на вход сверточным TCN слоям. Тогда количество каналов в данных которые первый сверточной TCN слой будет получать на вход ICH рассчитывается по формуле
ICH=FC-ELC+EFC,
где FC - количество параметров сессий до прохождения через слои встраивания,
ELC - количество слоев встраивания,
EFC - сумма размеров выходных массивов всех слоев встраивания.
Так реализуется совместное обучение слоев встраивания и сверточных TCN слоев. Также при инициализации слоя встраивания необходимо указать ограничения вещественных значений на выходе таким образом, чтобы в результате работы, слои встраивания на выходе давали вещественные значения в интервале от 0 до 1.
Параметры, принимающие численные значения, за исключением параметров, которые подлежат оцифровке, нормализуются. Нормализация необходима так-как даже при нормальной работе сети значения некоторых параметров могут различаться на несколько порядков. Например, обычно количество пакетов в одной сессии достаточно мало, однако, некоторые длительные сессии могут содержать большое количество пакетов, при этом такие сессии также будут соответствовать нормальной работе сети.
Для нормализации каждого i-ого параметра, сначала вычисляется первый порог выбросов B1, i по формуле
B1, i=qv3, i+3(qv3, i- qv1, i),
где qv3, i - третий квартиль массива всех значений i-ого параметра;
qv1, i - первый квартиль массива всех значений i-ого параметра;
После чего получают массив промежуточных значений Di путем деления всех значений i-ого параметра на соответственный первый порог выбросов
Di=Vi/B1, i
Получают промежуточный массив Fi, выбирая значения Di большие единицы. Получают промежуточный массив Gi, вычитая единицу из каждого значения массива промежуточных значений Fi
Gi=Fi-1
Вычисляют второй порог выбросов В2, i для каждого промежуточного массива Gi по формуле
В2, i=qe3, i+3(qe3, i- qe1, i),
где qe3, i - третий квартиль массива Gi i-ого параметра;
qe1, i - первый квартиль массива Gi i-ого параметра;
Получают массив промежуточных значений Hi путем деления всех значений промежуточного массива Gi на соответственное значение второго порога выбросов B2, i
Hi=Gi/B2, i
Получают массив промежуточных значений Ri путем прибавления единицы к каждому значению массива промежуточных значений Hi
Ri=Hi+1
Получают массив Li путем замены значений больших единицы в промежуточном массиве Di на соответственные значения Ri. Получают нормализованную таблицу для обучения, заменяя исходные значения каждого i-ого параметра в таблице для обучения на значения Li. Сохраняют значения 1-го и 2-го порога выбросов для каждого i-ого параметра.
Таблица для валидации нормализуются на основе порогов статистических выбросов, полученных на этапе нормализации таблицы для обучения. Сначала получают массив промежуточных значений VDi путем деления всех значения i-ого параметра на соответствующий порог выбросов
VDi=VVi/B1, i
Получают промежуточный массив VFi, выбирая значения VDi большие единицы. Получают промежуточный массив VGi, вычитая единицу из каждого значения массива промежуточных значений VFi
VGi=VFi-1
Получают массив промежуточных значений VHi путем деления всех значений промежуточного массива VGi на значение второго порога выбросов В2, i
VHi=VGi/B2, i
Получают массив промежуточных значений VRi путем прибавления единицы к каждому значению массива промежуточных значений VHi
VRi=VHi+1
Получают массив VLi путем замены значений больших единицы в промежуточном массиве VDi на соответственные значения VRi. Нормализованную таблицу валидации получают, заменяя исходные значения каждого i-ого параметра в таблице валидации на значения VLi.
Нейронная сеть ТСАЕ получает на вход многомерный временной ряд, однако, использовать в качестве входного временного ряда полную таблицу для обучения нецелесообразно. Поскольку такая таблица может содержать большое количество сессий (элементов временного ряда), для того, чтобы исследовать временные зависимости любого масштаба для такого многомерного временного ряда необходимо использовать нейронную сеть с большим количество сверточных слоев. Однако, из-за использования архитектуры автокодировщика, максимальное количество слоев ограничено, так-как необходимо уменьшать число каналов к середине нейронной сети.
Также если использовать большое количество сверточных слоев нейронной сети при использовании временного ряда с большим числом элементов, эффективность обучения нейронной сети уменьшается, а длительность обучения увеличивается. При этом, если такая нейронная сеть будет обучена, то при получении на вход таблицы для валидации или новых данных в виде тестовой таблицы, размер которых отличен от размера таблицы для обучения, нейронная сеть может давать некорректный результат из-за переобучения к временным зависимостям определенного масштаба. Поэтому целесообразно разбивать таблицы для обучения и валидации на последовательности сессий одинаковой размерности. Соответственно, в качестве объекта, подаваемого на вход нейронной сети будет использоваться подтаблица, состоящая из нескольких последовательных строк исходной таблицы. Тогда обучающая и валидационная выборки будут представлять собой набор сегментов соответственных временных рядов.
Для создания обучающей выборки выполняют следующие действия:
• выбирается значение ширины окна WS - целочисленное значение, равное числу сессий в одной последовательности;
• выбирается значение сдвига окна ST - целочисленное значение на которое окно будет сдвигаться по строкам таблицы,
• в качестве первой последовательности сессий выбираются первые WS строк таблицы для обучения;
• после чего окно сдвигается на значение ST строк и формируется следующая последовательность сессий;
• аналогично формируются последовательности сессий до тех пор, пока окно не дойдет до конца таблицы для обучения.
Для увеличения репрезентативности обучающей выборки, при формировании последовательностей сессий параметры ST и WS выбирают так, что ST<WS. Тогда количество элементов в обучающей выборке будет значительно больше, при этом выборка становится более репрезентативной, так как в обучающей выборке одна и та же сессия может находиться на нескольких различных временных позициях в последовательностях сессий.
Для создания валидационной выборки выполняют следующие действия:
• выбираются WS и ST такие же, как и при создании обучающей выборки
• в качестве первой последовательности сессий выбираются первые WS строк таблицы для валидации;
• после чего окно сдвигается на значение ST строк и формируется следующая последовательность сессий;
• аналогично формируются последовательности сессий до тех пор, пока окно не дойдет до конца таблицы для валидации.
При обучении, оптимизируется ошибка реконструкции (reconstruction error, RE). То есть при обучении с использованием методом градиентного спуска минимизируется ошибка реконструкции. В качестве ошибки реконструкции используется среднеквадратичная ошибка, которая вычисляется по формуле;
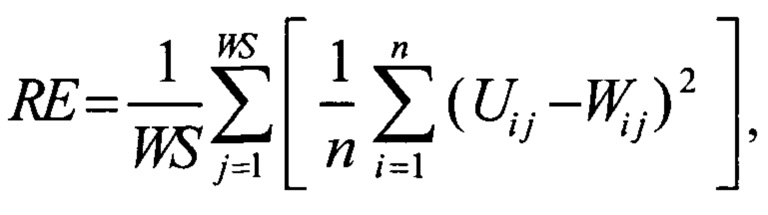
где WS - ширина окна;
n - количество параметров в таблице параметров сессий;
U i j - значение i-ого параметра j-той сессии, полученной на входе нейронной сети;
W i j - значение i-ого параметра j-той сессии, реконструированной на
выходе нейронной сети; После обучения нейронной сети на обучающей выборке, валидационная выборка используется для вычисления порога аномалии. Так как если вычислять порог аномалии на основе обучающей выборки, при переобучении нейронной сети порог будет занижен, так как в среднем ошибка реконструкции для обучающего набора при нормальном поведении может быть значительно меньше ошибки реконструкции нормального поведения новых данных. Из-за заниженного порога аномалии в следствии переобучения, есть риск появления большого количества ошибок первого рода.
Использование валидационной выборки для вычисления порога аномалии, способствует устранению последствий переобучения нейронной сети и уменьшению количества ошибок первого рода.
Для вычисления порога аномалии, сначала вычисляется ошибка реконструкции для каждой j-ой сессии в каждой k-ой последовательностей валидационного набора по формуле
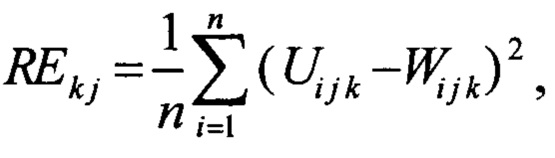
где Ui j k - значение i-ого параметра j-той сессии в k-той последовательности, полученной на входе нейронной сети;
Wi j k - значение i-ого параметра j-той сессии в k-той последовательности, реконструированной на выходе нейронной сети;
Таким образом, для каждой последовательности сессий будет получен массив ошибок реконструкции. При этом разные последовательности сессий могут содержать одни и те же сессии, так-как при формировании последовательностей сессий использовались такие ST и WS, что ST<WS. Поэтому каждой сессии, за исключением первых и последних ST сессий, будет соответствовать несколько ошибок реконструкции.
Итоговая ошибка реконструкции для каждой сессии вычисляется как среднее всех ошибок реконструкций соответствующих этой сессии в различных последовательностях. В качестве среднего используется среднее арифметическое. Итоговые ошибки реконструкции необходимо отсортировать по временной метке соответствующих им сессий, чтобы получить временной ряд итоговых ошибок реконструкции RETS (Reconstruction Error Time Series).
Существуют различные методы для вычисления порога аномалий. Однако, предложенный способ предполагает вычислять порог аномалий В по формуле вычисления верхнего порога статистических выбросов
B=q3+1.5(q3-q1),
где q1 и q3 - соответственно первый и третий квартиль массива RETS.
Обученная нейронная сеть может применяться для обнаружения аномалий в ранее собранном за определенное время трафике. Тогда такой трафик для тестирования нейронной сети необходимо обработать аналогично трафику для обучения и валидации. Поэтому сначала необходимо создать тестовую таблицу параметров сессий из тестового набора данных.
Символьные параметры таблицы для тестирования оцифровывается с помощью таблицы соответствия, полученной на этапах оцифровки таблиц для обучения и валидации. Однако, в тестовой таблице в столбцах символьных параметров могут присутствовать уникальные значения, которых не было в таблицах для обучения и валидации. Таким значениям присваивают новые собственные порядковые номера, после чего таблица соответствий дополняется новой парой значений. Каждое уникальное значение в каждом из символьных параметров в тестовой таблице заменяется соответственным номером согласно таблице соответствий.
Тестовая таблица нормализуется на основе порогов статистических выбросов, полученных на этапе нормализации таблицы для обучения. Для этого сначала получают массив промежуточных значений PDi путем деления всех значения i-ого параметра на соответствующий порог выбросов
PDi=PVi/B1, i
Получают промежуточный массив PFi, выбирая значения PDi большие единицы. Получают промежуточный массив PGi, вычитая единицу из каждого значения массива промежуточных значений PFi
PGi=PFi-1
Получают массив промежуточных значений PHi путем деления всех значений промежуточного массива PGi на значение второго порога выбросов В2, i
PHi=PGi/B2, i
Получают массив промежуточных значений PRi путем прибавления единицы к каждому значению массива промежуточных значений PHi
PRi=PHi+1
Получают массив PLi путем замены значений больших единицы в промежуточном массиве PDi на соответственные значения PRi. Получают нормализованную тестовую таблицу, заменяя исходные значения каждого i-ого параметра в тестовой таблице параметров сессий на значения PLi:
Если в таблице для тестирования количество сессий меньше либо равно WS, такая таблица целиком подается на вход обученной нейронной сети, после чего вычисляется ошибка реконструкции для каждой сессии. Если в такой таблице количество сессий больше чем WS, то таблица разбивают на последовательности сессий, выполняя следующие действия:
• выбираются WS и ST такие же, как и при создании обучающей выборки,
• в качестве первой последовательности сессий выбираются первые WS строк таблицы для тестирования;
• после чего окно сдвигается на значение ST строк и формируется следующая последовательность сессий;
• аналогично формируются последовательности сессий до тех пор, пока окно не дойдет до конца таблицы для тестирования.
Полученная тестовая выборка подается на вход обученной нейронной сети. После чего, вычисляется временной ряд итоговых ошибок реконструкции TRETS для тестового набора.
Результат работы нейронной сети (результирующий массив) для тестового набора вычисляется путем выполнения следующих действий:
• значениям TRETS присваиваются соответственные временные метки сессий из первоначального многомерного временного ряда;
• выбирается значение размера временного окна Т;
• одномерный временной ряд TRETS разбивается на последовательные непересекающиеся временные сегменты по длительности равные Т;
• на каждом временном сегменте находят среднее значение Pt;
• отмечают в качестве аномальных те временные сегменты, значения Pt которых больше, чем порог аномалии В.
Агрегирование ошибки реконструкции по времени позволяет уменьшить количество ошибок первого рода, за счет уменьшения влияния случайных статистических выбросов ошибки реконструкции. Значение размера временного окна Т выбирается на основе эмпирических наблюдений и плотности трафика в сети. Предложенный способ предполагает использование такого Т, при котором в среднем количество сессий во временных сегментах, по крайней мере, меньше, чем 1000 при нормальной работе сети.
Технический результат достигается за счет использования совокупности различных инструментов. Способ использует архитектуру ТСАЕ, благодаря которой возможно использовать информацию о временных зависимостях многомерных временных рядов. За счет этого достигается уменьшения количество ошибок первого и второго рода при обнаружении распределенных во времени аномалий.
Способ подразумевает обучение единственной нейронной сети.
Благодаря использованию валидационной выборки для вычисления порога аномалии, способ устраняет последствия переобучения нейронной сети. То есть даже в случае переобучения нейронной сети к обучающей выборке, при вычислении порога аномалий с использованием RETS валидационного набора, такой порог не будет заниженным относительно тестового набора, так как валидационный набор не принимал участия в обучении нейронной сети. За счет чего достигается уменьшение количества ошибок первого рода.
При использовании слоев встраивания для оцифровки символьных значений, нейронная сеть обучается эффективнее, чем при использовании унитарного кодирования (one-hot-encoding) и кодирования с помощью присваивания уникальных номеров без использования дополнительных обучаемых слоев нейронной сети.
Осуществление изобретения
Предложенный способ может быть реализован в следующей программно-аппаратной среде.
В качестве вычислительной системы выбирается компьютер со следующими аппаратными характеристиками:
процессор Intel Core i7-4770 3.40GHz;
оперативная память 16GB;
жесткий диск SSD 240GB, и установленным программным обеспечением:
операционная система Microsoft Windows 10;
Python 3.7.2;
модули Python: numpy 1.19.5, pandas 1.1.5, torch 1.10.2, nfstream 6.4.3.
Далее рассмотрим пример реализации способа, заключающийся в обнаружении аномальных сегментов сетевого трафика в корпоративной сети. Трафик корпоративной сети в режиме нормальной работы сохранялся в течении полутора часов. Для обучения и валидации нейронной сети использовался трафик за первый час, а для тестирования использовался трафик за последние полчаса.
Способ предполагает разбиение сетевого трафика на сессии. Для этого используется модуль nfstream. Используя этот модуль, преобразуем таблицу сетевых пакетов за первые полтора часа работы сети в таблицу параметров сессий. Строками такой таблицы являются сессии, а столбцами - параметры сессий. Всего используется 70 параметров сессий, извлеченных с помощью nfstream.
Среди параметров сессий 54 численных параметра:
1. src2dst_packets - количество переданных пакетов от отправителя к получателю,
2. src2dst_bytes - количество переданных байт от отправителя к получателю,
3. dst2src_packets - количество переданных пакетов от получателя к отправителю,
4. dst2src_bytes - количество переданных пакетов от получателя к отправителю,
5. bidirectional_min_ps - минимальный размер пакета в сессии,
6. bidirectional_mean_ps - средний размер пакетов в сессии,
7. bidirectional_stddev_ps - стандартное отклонение размера пакетов в сессии,
8. bidirectional_max_ps - максимальный размер пакета в сессии,
9. src2dst_min_ps - минимальный размер пакета передаваемого от отправителя к получателю в сессии,
10. src2dst_mean_ps - средний размер пакетов передаваемого от отправителя к получателю в сессии,
11. src2dst_stddev_ps - стандартное отклонение размера пакетов передаваемого от отправителя к получателю в сессии,
12. src2dst_max_ps - максимальный размер пакета передаваемого от отправителя к получателю в сессии,
13. dst2src_min_ps - минимальный размер пакета передаваемого от получателя к отправителю в сессии,
14. dst2src_mean_ps - средний размер пакетов передаваемых от получателя к отправителю в сессии,
15. dst2src_stddev_ps - стандартное отклонение размера пакетов передаваемых от получателя к отправителю в сессии,
16. dst2src_max_ps - максимальный размер пакета передаваемого от получателя к отправителю в сессии,
17. bidirectional_min_piat_ms - минимальный интервал между пакетами одной сессии в миллисекундах,
18. bidirectional_mean_piat_ms - средний интервал между пакетами одной сессии в миллисекундах,
19. bidirectional_stddev_piat_ms - стандартное отклонение интервалов между пакетами одной сессии в миллисекундах,
20. bidirectional_max_piat_ms - максимальный интервал между пакетами одной сессии в миллисекундах,
21. src2dst_min_piat_ms - минимальный интервал между пакетами передаваемыми от отправителя к получателю одной сессии в миллисекундах,
22. src2dst_mean_piat_ms - средний интервал между пакетами передаваемыми от отправителя к получателю одной сессии в миллисекундах,
23. src2dst_stddev_piat_ms - стандартное отклонение интервалов между пакетами передаваемыми от отправителя к получателю одной сессии в миллисекундах,
24. src2dst_max_piat_ms - максимальный интервал между пакетами передаваемыми от отправителя к получателю одной сессии в миллисекундах,
25. dst2src_min_piat_ms - минимальный интервал между пакетами передаваемыми от получателя к отправителю одной сессии в миллисекундах,
26. dst2src_mean_piat_ms - средний интервал между пакетами передаваемыми от получателя к отправителю одной сессии в миллисекундах,
27. dst2src_stddev_piat_ms - стандартное отклонение интервалов между пакетами передаваемыми от получателя к отправителю одной сессии в миллисекундах,
28. dst2src_max_piat_ms - максимальный интервал между пакетами передаваемыми от получателя к отправителю одной сессии в миллисекундах,
29. bidirectional_syn_packets - количество пакетов с флагом SYN,
30. bidirectional_cwr_packets - количество пакетов с флагом CWR,
31. bidirectional_ece_packets - количество пакетов с флагом ЕСЕ,
32. bidirectional_urg_packets - количество пакетов с флагом URG,
33. bidirectional_ack_packets - количество пакетов с флагом АСК,
34. bidirectional_psh_packets - количество пакетов с флагом PSH,
35. bidirectional_rst_packets - количество пакетов с флагом RST,
36. bidirectional_fin_packets - количество пакетов с флагом FIN,
37. src2dst_syn_packets - количество пакетов переданных от отправителя к получателю с флагом SYN,
38. src2dst_cwr_packets - количество пакетов переданных от отправителя к получателю с флагом CWR,
39. src2dst_ece_packets - количество пакетов переданных от отправителя к получателю с флагом ЕСЕ,
40. src2dst_urg_packets - количество пакетов переданных от отправителя к получателю с флагом URG,
41. src2dst_ack_packets - количество пакетов переданных от отправителя к получателю с флагом АСК,
42. src2dst_psh_packets - количество пакетов переданных от отправителя к получателю с флагом PSH,
43. src2dst_rst_packets - количество пакетов переданных от отправителя к получателю с флагом RST,
44. src2dst_fin_packets - количество пакетов переданных от отправителя к получателю с флагом FIN,
45. dst2src_syn_packets - количество пакетов переданных от получателя к отправителю с флагом SYN,
46. dst2src_cwr_packets - количество пакетов переданных от получателя к отправителю с флагом CWR,
47. dst2src_ece_packets - количество пакетов переданных от получателя к отправителю с флагом ЕСЕ,
48. dst2src_urg_packets - количество пакетов переданных от получателя к отправителю с флагом URG,
49. dst2src_ack_packets - количество пакетов переданных от получателя к отправителю с флагом АСК,
50. dst2src_psh_packets - количество пакетов переданных от получателя к отправителю с флагом PSH,
51. dst2src_rst_packets - количество пакетов переданных от получателя к отправителю с флагом RST,
52. dst2src_fin_packets - количество пакетов переданных от получателя к отправителю с флагом FIN,
53. bidirectional_packets - количество пакетов в сессии,
54. bidirectional_bytes - количество байт преданных за сессию. Коме того, имеется 15 символьных параметров:
1. src_ip - IP адрес отправителя,
2. dst_ip - IP адрес получателя,
3. src_mac - MAC адрес получателя,
4. dst_mac - MAC адрес отправителя,
5. src_oui - уникальный идентификатор организации отправителя,
6. dst_oui - уникальный идентификатор организации получателя,
7. application_name - название приложения полученного с помощью nDPI,
8. application_category_name - категория приложения полученного с помощью nDPI,
9. application_confidence - номер метода с помощью которого получены параметры прикладного уровня,
10. requested_server_name - запрошенное имя сервера (SSL/TLS, DNS, HTTP),
11. client_fingerprint - уникальный идентификатор пользователя (цифровой отпечаток DHCP для DHCP, JA3 для SSL/TLS и HASSH для SSH),
12. server_fingerprint - уникальный идентификатор сервера (JA3 для SSL/TLS и SSH для SSH),
13. protocol - протокол транспортного уровня,
14. src_port - порт отправителя,
15. dst_port - порт получателя.
Отметим, что, по умолчанию, модуль nfstream не располагает сессии в хронологическом порядке, поэтому также используется параметр src2dst_first_seen_ms - время появления первого пакета сессии. Отсортируем таблицу параметров сессий по этому параметру и удалим столбец src2dst_first_seen_ms.
После сбора трафика таблица параметров сессий содержит данные о 197107 сессиях. Пример таблицы параметров сессий приведен в табл. 2 (ip и mac адреса указаны условно).
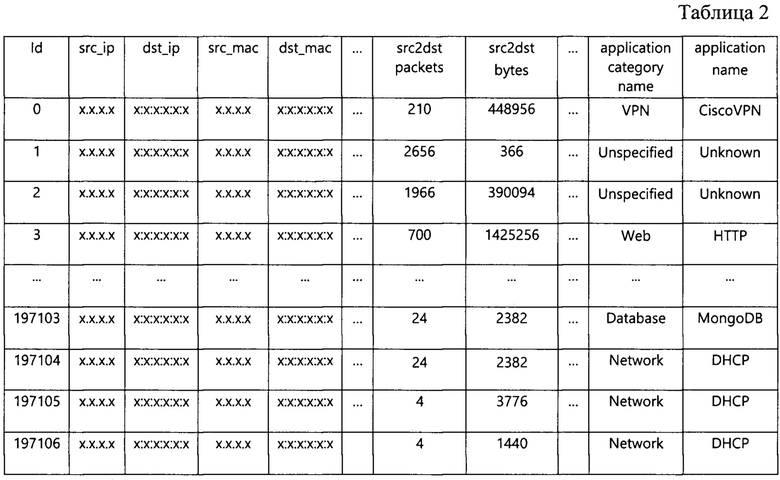
Если к извлекаемым параметрам сессии относятся параметры порта отправителя и порта получается, целесообразно из двух портов оставить только серверный порт, так-как второй порт является динамическим и случайным образом выбирается из диапазона от 49152 до 65535. Поэтому из двух параметров портов (столбцы src_port и dst_port) создают столбец port с сетевыми портами. Для этого необходимо создать массив со всеми существующими сетевыми портами. При совпадении одного из портов сессии с портом из такого массива, этот порт выбирается как сетевой. Если ни один их портов не был определен как сетевой, к сетевому будем относить порт с меньшим номером. После того, как определены сетевые порты, они записываются в столбец port, а столбцы src_port и dst_port удаляют.В результате, останется 14 символьных параметров.
Таблица параметров сессий разделяется на таблицы для обучения и валидации. При этом в качестве таблицы для обучения выберем первые 70% строк таблицы (получается 137975 строк). Оставшуюся часть таблицы выберем в качестве таблицы валидации (59132 строк).
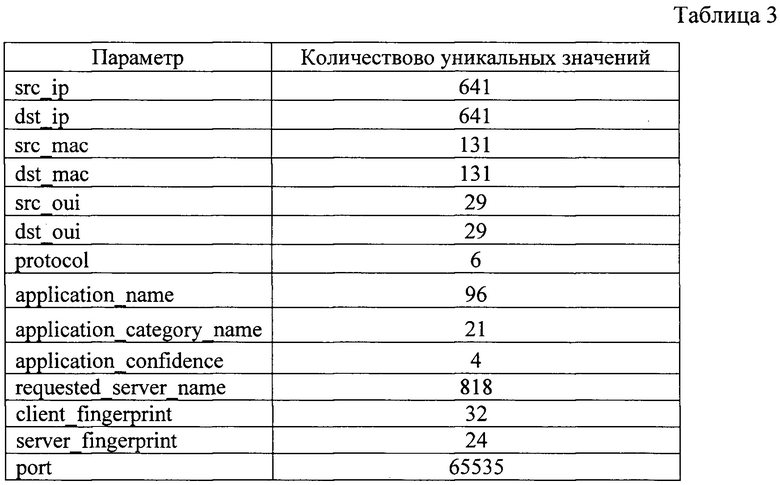
Символьные параметры таблицы для обучения необходимо оцифровать. Символьными параметрами в данном случае будем считать все параметры принимающие строковые значения, а также параметры принимающие численные значения, но характеризующие номера. Например, сетевой порт и протокол транспортного уровня (в столбце protocol, пакет nfstream возвращает численные значения, отображающие соответственные номера протоколов). Все символьные параметры в таблице для обучения оцифровываются согласно предложенному способу. При оцифровке получим таблицу соответствия номеров уникальных значений для каждого символьного параметра. В такой таблице будут содержаться соответствия названия символьного параметра, уникального значения этого параметра и его соответственного номера. В табл. 3 представлена сводная информация о количестве уникальных значений в каждом из параметров. Количество уникальный значений в парных параметрах одинаковое, так-как для таких параметров использовался общий уникальных символьных значений и их номеров. Максимальное количество возможных сетевых портов заранее известно и равно 65535.
Символьные параметры таблицы валидации оцифровываются с помощью таблицы соответствия согласно предложенному способу. Неоцифрованные параметры принимают только численные значения. При этом значения каждого из таких параметров могут различаться на несколько порядков. Поэтому для повышения скорости и эффективности обучения такие параметры необходимо нормализовать.
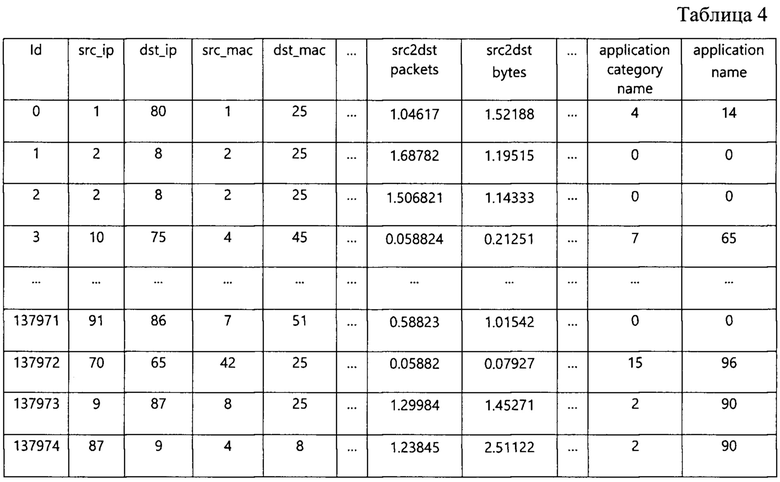
Нормализуем таблицу для обучения согласно действиям предложенного способа. В результате, получим нормализованную таблицу для обучения (табл. 4) и два массива статистических порогов выбросов.
Используем полученные пороги выбросов B1, i и В2, i для нормализации каждого i-ого параметра валидационной таблицы. В результате, получим нормализованную таблицу валидации.
Формируем последовательности сессий на основе таблицы для обучения и валидации с шириной окна WS равной 32 и сдвигом окна ST равным 2, согласно предложенному способу. Таким образом получаем обучающую и валидационную выборки.
С помощью модуля pytorch создаем нейронную сеть с архитектурой ТСАЕ. При этом перед одномерными сверточными слоями создаем слои встраивания через которые будут проходить только символьные параметры. Для каждого символьного параметра создаем отдельный слой встраивания. Количество слоев встраивания получилось 14.
Для создания слоев встраивания необходимо передать два значения: размер словаря слоя встраивания и размер выходного массива. Для каждого слоя встраивания задаем размер словаря в два раза больший, чем количество уникальных значений параметров, для которых создается слой встраивания. Причем для слоя встраивания параметра port задаем максимальное значение уникальных элементов равное 65535.
Для того, чтобы вычислить размер результирующего массива каждого слоя встраивания, сначала найдем промежуточное значение EMi по формуле
EMi=EDi025,
где EDi - размер словаря i-ого слоя встраивания
После чего размер результирующего массива i-ого слоя встраивания задаем равным целой частью числа EMi.
На выходе каждый из слоев встраивания вернет двумерный массив вещественных чисел. Такой массив будет содержать количество сессий, равное количеству сессий во входной последовательности. Результирующие массивы каждого слоя встраивания конкатенируются по оси параметров сессий между собой и с массивом, который не проходил через слои встраивания. Такой объединенный двумерный массив будет подаваться на вход сверточным слоям.
Создаются сверточные слои с архитектурой TCN. Количество каналов в данных которые первый сверточной слой будет получать ICH на вход рассчитывается по формуле
ICH=FC-ELC+EFC=68-14+54=108,
где FC - количество параметров сессий до прохождения через слои встраивания (равно 68, так как вместо двух параметров port используется один, а также не используется временная метка сессий), ELC - количество слоев встраивания,
EFC - сумма размеров выходных массивов всех слоев встраивания,
Минимальное количество каналов ТСАЕ выбираем равным 32. Количество каналов на выходе ТСАЕ выбираем равным FC=68. Ширину фильтров всех сверточных слоев (KS) устанавливаем равным двум. Коэффициент расширения будем увеличивать в два раза на каждом новом сверточном слое. Количество блоков с увеличением коэффициента расширения выбираем равным одному. Тогда количество слоев для ТСАЕ вычисляется в два этапа. Сначала вычисляется промежуточное значение BRF.
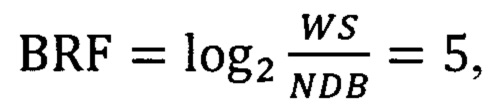
где NDB - количество блоков с увеличением расширения,
WS - ширина окна,
После чего вычисляем количество слоев NL, умножив NDB на целую часть от числа BRF
NL=NDB*[BRF]=1*5=5
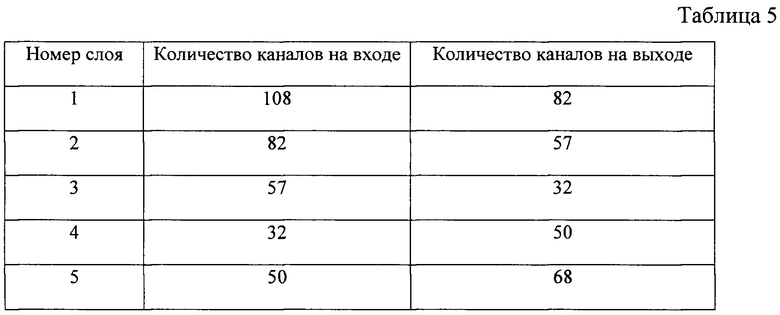
Массив значений количества каналов на каждом слое рассчитывается на основе значения ICH согласно эмпирическому правилу, по которому количество каналов к середине автокодировщика должно уменьшаться равномерно, при этом количество каналов от середины автокодировщика к его концу должно равномерно увеличиваться. Задаем количество каналов на каждом сверточном слове согласно табл. 5.
После чего происходит обучение нейронной сети. В течении процесса обучения следует уменьшать коэффициент скорости обучения (learning rate). Уменьшение коэффициента скорости обучения происходит тогда, когда ошибка реконструкции перестает стабильно убывать. При этом обучение завершается в том случае, если ошибка реконструкции обучающего набора перестает стабильно убывать даже при learning rate <10-4, либо если средняя ошибка реконструкции валидационного набора превосходит среднюю ошибку реконструкции обучающего набора более чем в два раза. После обучения рассчитывается RETS для валидационного набора данных. Рассчитывается порог аномалии по формуле
В=q3+1.5(q3-q1),
где q1 и q3 - соответственно первый и третий квартиль массива RETS.
После чего нейронная сеть и параметры ее инициализации сохраняются. Трафик для тестирования преобразуется в тестовую таблицу из 70 параметров сессий. Всего в тестовой таблице 126028 сессий. Отсортируем таблицу параметров сессий по временной метке первого пакета в сессии - src2dst_first_seen_ms, после чего сохраним такие временные метки каждой сессии в массиве, и удалим столбец src2dst_first_seen_ms. Тестовая таблица соответствует нормальной работе сети и не содержит подозрительного трафика. В такую тестовую таблицу интегрируем сессии эмулированной APT атаки (Advanced Persistent Threat, постоянная целевая угроза повышенной сложности), всего таких сессий 2834. Причем в качестве сегмента атаки выбирают сегмент тестовой таблицы, количество сессий в которой в 16 раз больше чем количество сессий принадлежащей APT атаке. Подозрительные сессии случайным образом распределяются в таком сегменте тестовой таблицы, причем хронологический порядок сессий, принадлежащих к атаке сохраняется. Таким образом тестовая таблица содержит всего 128862 сессии.
Из двух параметров портов создают столбец port с сетевыми портами на основе массива всех существующих сетевых портов. После того как определены сетевые порты, столбцы src_port и dst_port удаляют. Символьные параметры тестовой таблицы оцифровываются с помощью таблицы соответствия согласно предложенному способу. Используем полученные пороги выбросов B1, i и В2, i для нормализации каждого i-ого параметра тестовой таблицы. В результате, получим нормализованную тестовую таблицу.
Используя нормализованную тестовую таблицу формируются последовательности сессий с шириной окна WS равной 32 и сдвигом окна ST равным 2.
Нейронная сеть получает результат для тестовой выборки, после чего, вычисляется массив значений TRETS для тестового набора согласно предложенному способу. Массив TRETS содержит ошибку реконструкции для каждой сессии, причем порядок сессий, для которых найдены ошибки реконструкции соответствует порядку сессий в нормализованной тестовой таблице.
Результат работы нейронной сети (результирующий массив) для тестовой выборки вычисляется согласно следующим действиям:
• значениям TRETS присваиваются сохраненные временные метки соответственных сессий из тестовой таблицы
• выбирается значение временного окна Т равного пяти секундам;
• одномерный временной ряд TRETS разбивается на т непересекающихся временных сегмента по длительности равные Т;
• на каждом полученном временном сегменте находят среднее значение ошибки реконструкции Pm.
Если Pm превышает порог аномалий В, то m-ый временной сегмент отмечают как аномальный.
Отмечание сегментов можно сделать по-разному, например, записывая в отдельном месте номера m аномальных сегментов или подавая визуальный и звуковой сигналы или другим подходящим образом.
Сформируем отчет и получим результат тестирования. Таким образом, при тестировании получилось 360 сегментов тестового трафика по 5 секунд, из которых 130 сегментов содержали подозрительный трафик. По результатам работы нейронной сети, было отмечено 131 аномальный сегмент, из которых 128 сегментов действительно содержали подозрительный трафик (true positive=128), и 3 аномальных сегмента были отмечены неверно, так как эти сегменты не содержали подозрительного трафика (false positive=3).
Также из неотмеченных 229 сегментов, 227 действительно соответствовали нормальному поведению сети (true negative=227), при этом 2 неотмеченных сегмента содержали подозрительный трафик (false negative=2).
На основе сведений о сегментах можно, при необходимости, установить количество и распределение во времени аномальных сессий и поместить в отчет.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обнаружения и противодействия атакам типа отказ в обслуживании | 2024 |
|
RU2841028C1 |
| Способ выявления аномалий в работе высоконагруженной сети автоматизированной телекоммуникационной системы | 2021 |
|
RU2787078C1 |
| Способ выявления аномалий в работе сети автоматизированной системы | 2020 |
|
RU2738460C1 |
| КЛАССИФИКАЦИЯ САЙТОВ СПЛАЙСИНГА НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ | 2018 |
|
RU2780442C2 |
| Способ фильтрации части пакетов в сетевой сессии | 2022 |
|
RU2790635C1 |
| Способ выявления нормальных реакций узлов компьютерной сети на сетевые пакеты, относящиеся к неизвестному трафику | 2022 |
|
RU2802164C1 |
| Способ обнаружения аномалий в многомерных данных | 2021 |
|
RU2773010C1 |
| Способ динамической фильтрации сетевых пакетов по принадлежности к сессии | 2022 |
|
RU2779135C1 |
| Способ балансировки с сохранением целостности потоков данных | 2023 |
|
RU2807656C1 |
| Способ отслеживания сессий в сетевом трафике | 2022 |
|
RU2786178C1 |
Изобретение относится к области информационной безопасности. Техническим результатом является уменьшение количества ошибок первого и второго рода при обнаружении распределенных во времени аномалий трафика. Технический результат достигается за счет выполнения способа, который включает получение сетевого трафика за выбранный промежуток времени, запись параметров сетевых сессий в таблицу параметров сессий, оцифровку значений символьных параметров сессий, нормализацию значений параметров, формирование обучающей и валидационной выборки, формирование нейронной сети с архитектурой автокодировщика, обучение нейронной сети, вычисление порога аномалии, получение тестового трафика, получение тестовой выборки, подачу тестовой выборки на вход нейронной сети, вычисление ошибки реконструкции для каждой сессии, получение временного ряда средних значений итоговых ошибок реконструкций для каждой сессии; разделение временного ряда на множество временных сегментов равной длительности; нахождение среднего значения ошибки реконструкции для каждого сегмента; определение в качестве аномальных сегментов, в которых среднее значение ошибки реконструкции больше, чем порог аномалии, и, при необходимости, формирование отчета об обнаруженных в тестовой выборке аномалиях. 5 табл.
Способ обнаружения аномального трафика в сети с использованием вычислительной системы, включающей по крайней мере один компьютер, имеющий установленную операционную систему и прикладные программы, подключенный к сети и выполненный с возможностью:
получать, обрабатывать и хранить многомерные данные сессий сетевого трафика;
обеспечивать формирование, функционирование и обучение нейронной сети типа автокодировщик; заключающийся в том, что:
запускают компьютер в режиме контролируемой нормальной работы;
задают значимые параметры сетевых сессий;
сохраняют сетевой трафик за выбранный промежуток времени в режиме нормальной работы системы;
записывают параметры сетевых сессий из сохраненного сетевого трафика в таблицу параметров сессий в хронологическом порядке их появления;
разделяют таблицу параметров сессий на таблицу для обучения и таблицу валидации;
осуществляют оцифровку значений символьных параметров в таблице для обучения, выполняя следующие действия:
находят для каждого символьного параметра все уникальные значения в таблице для обучения;
присваивают каждому уникальному найденному значению символьного параметра уникальный порядковый номер, начиная с единицы;
присваивают номер 0 неопределенному значению в каждом из параметров;
записывают все найденные уникальные значения каждого символьного параметра и присвоенные уникальные порядковые номера в таблицу соответствия;
заменяют в таблице для обучения символьные значения на присвоенные им порядковые номера согласно таблице соответствия;
осуществляют в таблице для обучения нормализацию значений всех параметров, кроме оцифрованных, выполняя следующие действия:
находят первый порог выбросов B1, i для каждого i-го параметра по формуле
B1, i=qv3, i+3(qv3, i - qv1, i),
где qv3, i - третий квартиль массива всех значений i-го параметра;
qv1, i - первый квартиль массива всех значений i-го параметра;
получают массив промежуточных значений Di путем деления всех значений i-го параметра на соответствующий первый порог выбросов
Di=Vi/B1, i;
получают промежуточный массив Fi, выбирая значения Di большие единицы;
получают промежуточный массив Gi, вычитая единицу из каждого значения массива промежуточных значений Fi
Gi=Fi-1;
находят второй порог выбросов В2, i для каждого промежуточного массива Gi по формуле
В2, i=qe3, i+3(qe3,i - qe1, i),
где qe3, i - третий квартиль массива Gi i-го параметра;
qe1, i - первый квартиль массива Gi i-го параметра; получают массив промежуточных значений Hi путем деления всех значений промежуточного массива Gi на соответственное значение второго порога выбросов В2, i
Hi=Gi/B2, i;
получают массив промежуточных значений Ri путем прибавления единицы к каждому значению массива промежуточных значений Hi
Ri=Hi+1;
сохраняют значения 1-го и 2-го порога выбросов для каждого i-го параметра;
получают массив Li путем замены значений больших единицы в промежуточном массиве Di на соответственные значения Ri;
получают нормализованную таблицу для обучения, заменяя исходные значения каждого i-го параметра в таблице для обучения на значения Li;
полученную нормализованную таблицу для обучения разбивают на последовательности сессий, выполняя следующие действия:
выбирают ширину окна WS - целочисленное значение, равное числу сессий в одной последовательности сессий;
выбирают сдвиг окна ST - целочисленное значение, на которое окно будет сдвигаться по таблице сессий, причем ST<WS; выбирают в качестве первой последовательности сессий параметры первых WS сессий нормализованной таблицы для обучения;
сдвигают окно по таблице на значение ST и формируют следующую последовательность сессий;
формируют последовательности сессий до тех пор, пока окно не дойдет до конца нормализованной таблицы для обучения;
формируют обучающую выборку из полученных последовательностей сессий;
осуществляют оцифровку символьных значений параметров в таблице валидации, выполняя следующие действия:
находят для каждого символьного параметра все уникальные значения в таблице валидации;
проводят поиск и сравнение для каждого уникального значения символьного параметра в таблице соответствия;
если уникальное значение символьного параметра отсутствует в таблице соответствия, дополняют таблицу соответствия парами новых уникальных значений и их уникальных порядковых номеров;
заменяют в таблице валидации символьные значения на присвоенные им порядковые номера согласно таблице соответствия;
осуществляют в таблице валидации нормализацию значений всех параметров, кроме оцифрованных, выполняя следующие действия:
получают массив промежуточных значений VDi путем деления всех значений i-го параметра на значение первого порога выбросов;
VDi=VVi/B1, i;
получают промежуточный массив VFi, выбирая значения VDi большие единицы;
получают промежуточный массив VGi, вычитая единицу из каждого значения массива промежуточных значений VFi
VGi=VFi-1;
получают массив промежуточных значений VHi путем деления всех значений промежуточного массива VGi на значение второго порога выбросов В2, i
VHi=VGi/B2, i;
получают массив промежуточных значений VRi путем прибавления единицы к каждому значению массива промежуточных значений VHi
VRi=VHi+1;
получают массив VLi путем замены значений больших единицы в промежуточном массиве VDi на соответственные значения VRi;
получают нормализованную таблицу валидации, заменяя исходные значения каждого i-го параметра в таблице валидации на значения VLi;
полученную нормализованную таблицу валидации разбивают на последовательности сессий, выполняя следующие действия:
в качестве первой последовательности сессий выбирают параметры первых WS сессий нормализованной таблицы валидации;
сдвигают окно по таблице на значение ST и формируют следующую последовательность сессий;
формируют последовательности сессий до тех пор, пока окно не дойдет до конца нормализованной таблицы валидации;
формируют валидационную выборку из полученных последовательностей сессий;
формируют нейронную сеть с архитектурой автокодировщика, выполняя следующие действия:
формируют слой встраивания для каждого символьного параметра, выполняя следующие действия:
выбирают размер словаря слоя встраивания i-го символьного параметра EDi, причем
если для i-го символьного параметра известно максимальное количество уникальных значений, то EDi выбирают равным такой максимальной величине;
если для i-го символьного параметра неизвестно максимальное количество уникальных значений, то EDi выбирают по крайней мере в 2 раза большим количества уникальных значений такого символьного параметра в таблице соответствия;
получают промежуточное значение EMi по формуле
EMi=EDi0,25;
выбирают размер результирующего массива слоя встраивания i-го символьного параметра равным целой части числа EMi;
создают одномерные сверточные слои с архитектурой TCN, выполняя следующие действия:
задают одинаковую ширину фильтров всех сверточных слоев, равную KS;
задают коэффициент расширения на первом сверточном слое равным единице;
на каждом новом сверточном слое увеличивают коэффициент расширения;
если коэффициент расширения получается больше, чем 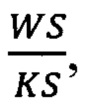 задают коэффициент расширения сверточного слоя равным единице;
задают коэффициент расширения сверточного слоя равным единице;
количество каналов входных данных ICH на первом сверточном слое вычисляют по формуле
ICH=FC-ELC+EFC,
где FC - количество параметров сессий в таблице параметров сессий;
ELC - количество слоев встраивания;
EFC - сумма размеров выходных массивов всех слоев встраивания;
задают минимальное количество каналов в скрытых слоях меньше количества параметров сессий в таблице параметров сессий;
задают количество каналов последнего слоя равным количеству параметров в таблице параметров сессий;
обучают нейронную сеть с использованием обучающей выборки, причем минимизируют при обучении ошибку реконструкции RE, которая вычисляется по формуле
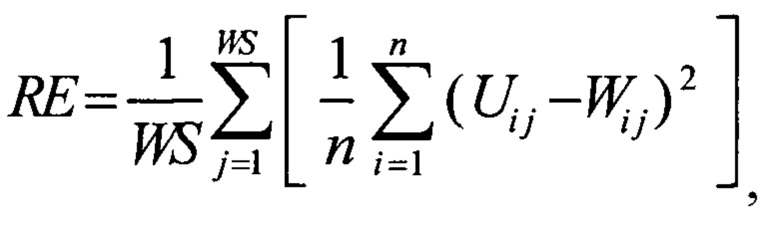
где WS - ширина окна;
n - количество параметров в таблице параметров сессий;
Ui j - значение i-го параметра j-той сессии, полученной на входе нейронной сети;
Wi j - значение i-го параметра j-той сессии, реконструированной на выходе нейронной сети; после обучения вычисляют ошибку реконструкции для каждой j-й сессии в каждой k-й последовательности валидационной выборки REk j
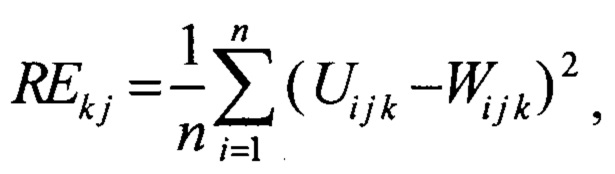
где Ui j k - значение i-го параметра j-той сессии в k-той последовательности, полученной на входе нейронной сети;
Wi j k - значение i-го параметра j-той сессии в k-той последовательности, реконструированной на выходе нейронной сети; вычисляют значение ошибки реконструкции для каждой сессии как среднее значение ошибок реконструкции этой сессии в разных последовательностях;
получают одномерный временной ряд средних значений итоговых ошибок реконструкций RETS для каждой сессии;
вычисляют порог аномалии В по формуле
B=q3+1.5(q3-q1),
где q1 и q3 - соответственно первый и третий квартиль массива RETS;
сохраняют тестовый сетевой трафик за выбранный промежуток времени в режиме нормальной работы системы;
извлекают из тестового трафика параметры сетевых сессий;
записывают параметры сетевых сессий из сохраненного сетевого трафика в тестовую таблицу параметров сессий;
осуществляют оцифровку значений символьных параметров в тестовой таблице параметров сессий, выполняя следующие действия:
находят для каждого символьного параметра все уникальные значения в тестовой таблице параметров сессий;
проводят поиск и сравнение для каждого уникального значения символьного параметра в таблице соответствия;
если уникальное значение символьного параметра отсутствует в таблице соответствия, дополняют таблицу соответствия парами новых уникальных значений и их уникальных порядковых номеров;
заменяют в тестовой таблице параметров сессий символьные значения на присвоенные им порядковые номера согласно таблице соответствия;
осуществляют в тестовой таблице параметров сессий нормализацию значений всех параметров, кроме оцифрованных, выполняя следующие действия:
получают массив промежуточных значений PDi путем деления всех значений i-го параметра на соответствующий порог выбросов
PDi=PVi/B1, i;
получают промежуточный массив PFi, выбирая значения PDi большие единицы;
получают промежуточный массив PGi, вычитая единицу из каждого значения массива промежуточных значений PFi
PGi=PFi-1;
получают массив промежуточных значений PHi путем деления всех значений промежуточного массива PGi на значение второго порога выбросов В2, i
PHi=PGi/B2, i;
получают массив промежуточных значений PRi путем прибавления единицы к каждому значению массива промежуточных значений PHi
PRi=PHi+1;
получают массив PLi путем замены значений больших единицы в промежуточном массиве PDi на соответственные значения PRi;
получают нормализованную тестовую таблицу, заменяя исходные значения каждого i-го параметра в тестовой таблице параметров сессий на значения PLi;
полученную нормализованную тестовую таблицу разбивают на последовательности сессий, выполняя следующие действия:
в качестве первой последовательности сессий выбирают параметры первых WS сессий нормализованной тестовой таблицы; сдвигают окно по таблице на значение ST и формируют следующую последовательность сессий;
формируют последовательности сессий до тех пор, пока окно не дойдет до конца нормализованной тестовой таблицы; формируют тестовую выборку из полученных последовательностей сессий;
подают тестовую выборку на вход нейронной сети;
вычисляют ошибку реконструкции REPk j для каждой j-той сессии в каждой k-той последовательности тестовой выборки по формуле
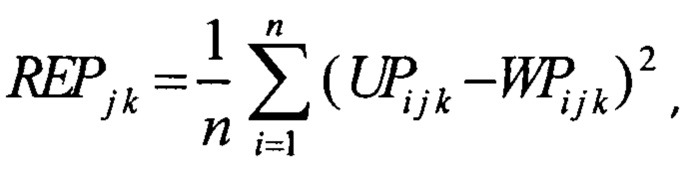
где UPi j k - значение i-го параметра j-той сессии в k-той последовательности, полученной на входе нейронной сети;
WPi j k - значение i-го параметра j-той сессии в k-той последовательности, реконструированной на выходе нейронной сети;
вычисляют значение ошибки реконструкции для каждой сессии как среднее значение ошибок реконструкции этой сессии в разных последовательностях;
получают временной ряд TRETS средних значений итоговых ошибок реконструкций для каждой сессии;
сопоставляют каждой ошибке реконструкции во временном ряду TRETS временную метку соответственной сессии;
выбирают значение временного окна Т;
разбивают временной ряд TRETS на m последовательных непересекающихся временных сегментов по длительности равных Т;
находят среднее значение ошибки реконструкции Pm на каждом m-м временном сегменте;
отмечают в качестве аномальных временные сегменты, значение Pm которых больше, чем порог аномалии В;
при необходимости, формируют отчет об обнаруженных в тестовой выборке аномалиях.
| CN 109639739 A, 16.04.2019 | |||
| Способ обнаружения сетевых атак на основе анализа фрактальных характеристик трафика в информационно-вычислительной сети | 2019 |
|
RU2713759C1 |
| US 20140380457 A1, 25.12.2014 | |||
| KR 101888683 B1, 14.08.2018 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ АНАЛИЗА ПАКЕТОВ ДАННЫХ | 2012 |
|
RU2601201C2 |

