УРОВЕНЬ ТЕХНИКИ
[0001] Системы считывания (ввода) данных применяются для извлечения информации из бумажных документов или изображений, полученных на их основе. Как правило, система состоит из считывающего устройства, которое получает изображения документов, и установленного на компьютере ПО, обрабатывающего полученное изображение.
[0002] Данные бумажного документа считываются и передаются в компьютерную систему посредством системы ввода данных, преобразующей бумажные документы в электронный вид (сканирование, фотографирование), а затем извлекающего данные из различных частей документа для последующего хранения, анализа и обработки. Бумажные документы могут иметь различную структуру.
[0003] Структурированный документ может включать в себя жесткие или гибкие формы на одной или нескольких страницах, которые заполняются вручную или с помощью устройства печати. Как правило, форма содержит поля данных для заполнения, каждое из полей формы сопровождается описанием информации, которая должна быть внесена.
[0004] В жестких формах расположение и число полей данных остается неизменным на всех копиях (вариантах) документа. Зачастую формы сопровождаются опорными элементами, например, черными квадратами (реперами) или разделителями. Гибкие или слабоструктурированные формы могут иметь переменное число полей, расположение которых в документе меняется от копии к копии.
[0005] Примерами гибких форм являются заявления, счета-фактуры, страховые формы и формы для денежных переводов, квитанции, деловые письма, формы возврата налогов и т.п. Например, счета-фактуры, полученные от разных компаний, могут иметь различное число полей в разных частях документа. Однако все счета-фактуры имеют такие поля, как номер счета или общая сумма, хотя их расположение внутри документа может различаться.
[0006] Для обработки структурированных документов системе считывания (ввода) данных требуется дополнительная информация о таких полях, например, об их расположении относительно границ страницы и других объектов, свойства данных, правила верификации и т.д. Системы автоматического считывания данных особенно эффективны при высоких объемах документов, подлежащих обработке.
[0007] Для точного считывания данных из гибких форм система ввода данных должна быть предварительно обучена находить нужные поля данных на различных типах документов, которые предстоит обрабатывать системе. После обучения система сможет находить заданные поля и автоматически извлекать информацию из них. Для обучения системы обрабатывать определенные типы документов и находить нужные поля необходимо участие высококвалифицированного специалиста. Обучение системы ведется в специальном редакторском приложении и является очень трудоемким.
[0008] Такие документы, как телефонные счета, счета-фактуры, анкеты и регистрационные формы, могут состоят из нескольких страниц. Информация в одностраничных или многостраничных документах может быть представлена в форме повторяющихся структур (например, одинаковые поля или группы полей). Другими словами, документы могут содержать несколько групп данных с аналогичной структурой. Например, в каждой группе полей могут содержаться подзаголовок, фрагмент таблицы, промежуточная сумма или подпись к фрагменту таблицы. Число и размер таких групп могут изменяться между экземплярами документов одного типа, следовательно, будет меняться и число страниц.
[0009] Таблицы в многостраничных документах могут иметь сложную и нерегулярную структуру, которую невозможно распознать при помощи обычных методов определения рядов, столбцов или ячеек таблицы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0010] В настоящем документе описаны системы, машиночитаемые носители и методы создания гибких структурных описаний. Для создания гибких структурных описаний используется изображение документа конкретного типа, содержащего таблицу. Используется отмеченная позиция, описывающая одну запись в таблице. На основе этой позиции производится поиск элементов заголовка внутри документа. Для отмеченной позиции определяются поля с данными и опорные элементы. Создается гибкое структурное описание документа, включающее ряд элементов поиска для каждого из полей данных на изображении документа, а также элементы заголовка. Гибкое структурное описание накладывается на изображение документа. Данные извлекаются из изображения в соответствии с результатом наложения гибкого структурного описания на это изображение. В других реализациях описанный подход может подразумевать использование соответствующих систем, аппаратных устройств и цифровых носителей, настроенных для выполнения этапов изложенного метода.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0011] Вышеизложенные и другие особенности настоящего изобретения станут в более полной мере понятны из последующего описания и прилагаемой формулы изобретения, рассматриваемых совместно с прилагаемыми чертежами. Представленные иллюстрации показывают лишь несколько вариантов осуществления в соответствии с раскрытием изобретения и, следовательно, не должны рассматриваться как ограничивающие его область применения. Изобретение будет раскрыто с дополнительной детализацией и подробностями при помощи прилагаемых чертежей.
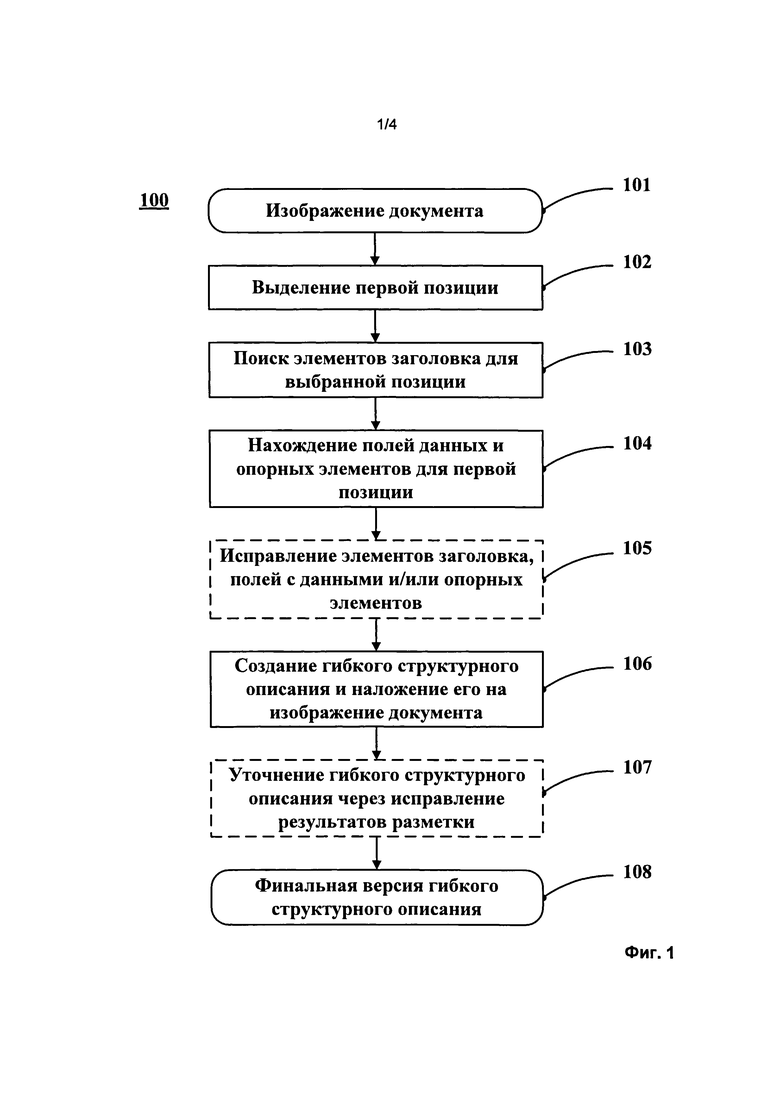
[0012] Фиг. 1 - Блок-схема действий для формирования гибкого структурного описания согласно одному из вариантов осуществления изобретения.
[0013] Фиг. 2А - Первая страница многостраничного документа с нерегулярной структурой согласно одному из вариантов осуществления изобретения. (Приведенная страница инвойса носит иллюстративный характер и переводу не подлежит.)
[0014] Фиг. 2Б - Вторая страница многостраничного документа с нерегулярной структурой согласно одному из вариантов осуществления изобретения. (Приведенная страница инвойса носит иллюстративный характер и переводу не подлежит.)
[0015] Фиг. 3 - Аппаратное обеспечение (300), которое может быть использовано для реализации методов, описанных в настоящем изобретении.
[0016] Нижеследующее детальное описание содержит ссылки на прилагаемые чертежи. На чертежах одинаковые символы обычно используются для обозначения одинаковых компонентов, если только контекст не предполагает иное. Варианты реализации, представленные в подробном описании, чертежах и формуле изобретения, служат лишь для иллюстрации, но не для ограничения изобретения. Можно использовать другие варианты реализации и осуществлять прочие изменения, без отступления от сущности и объема представленного объекта изобретения. Легко становится понятным, что аспекты раскрываемого изобретения, представленные в настоящем документе и проиллюстрированные чертежами, можно перераспределять, заменять, комбинировать и моделировать, создавая широкий спектр различных конфигураций, и все эти конфигурации явным образом предусмотрены настоящим описанием и являются его частью.
ПОДРОБНОЕ ОПИСАНИЕ
[0017] Различные варианты реализации раскрываемого изобретения относятся к сбору данных средствами оптического распознавания символов, а также автоматического создания и обучения структурного описания, используемого для извлечения данных из изображения документа.
[0018] В изложенных вариантах осуществления описывается считывание (извлечение) данных из изображения одно- или многостраничного документа. Гибкое структурное описание для слабоструктурированного документа создается и обучается автоматически во время считывания данных, без предварительной настройки алгоритма нахождения полей. Одностраничный или многостраничный документ, на основе которого получено изображение документа (например, путем сканирования), может содержать множество повторяющихся структур. «Повторяющиеся» в данном контексте означает, что похожие или одинаковые структуры встречаются в документе (а следовательно, и на его изображении) по крайней мере дважды.
[0019] Под термином «документ» подразумевается широкий спектр гибких форм или документов с нефиксированным или нерегулярным форматом и т.п.
[0020] Также описаны системы считывания данных, позволяющие реализовать метод, предложенный данным изобретением. В одном из вариантов осуществления система считывания данных из изображения документа содержит устройство, формирующее изображения, соединенное с компьютером посредством специально разработанного приложения для ввода данных на основе оптического и интеллектуального распознавания символов (OCR/ICR). В некоторых вариантах осуществления система считывания данных может быть внедрена с помощью аппаратной платформы, описанной на Фиг. 3.
[0021] Специально подготовленные гибкие структурные описания могут быть использованы для считывания информации с бумажных документов. Гибкое структурное описания состоят из полей, элементов и связей (отношений) между последними. Поле (или поле данных) задает область на изображении, из которой производится извлечение данных, а также определяет тип данных, которые могут находиться в этой области. Расположение полей обычно определяется с помощью опорных элементов, т.н. «якорей». Якорь может соответствовать одному или нескольким предопределенным элементам изображения (например, разделительные линии, неизменяемый текст, картинки и пр.), по отношению к которым задается расположение других элементов. Например, текст «Счет-фактура №» или «Всего, руб.» может быть использован в качестве якоря, относительно которого определяется расположение соответствующих полей.
[0022] Гибкие структурные описания также наделены алгоритмом определения полей в гибких (слабоструктурированных) документах. Эти описания создаются специалистами и могут быть загружены в систему считывания данных с целью выполнения автоматического наложения на поступающие документы.
[0023] Предложенный метод позволяет проводить автоматическое обучение и «дополнительное обучение» гибких структурных описаний, чтобы обеспечить обработку новых типов документов, не прибегая к помощи специалиста, а также чтобы облегчить специалистам создание гибких структурных описаний, в случае если полностью автоматическое создание гибкого структурного описания невозможно (например, при обработке изображений очень плохого качества).
[0024] В одном из вариантов осуществления данный метод может быть использован для создания гибких структурных описаний. В случае когда новый слабоструктурированный одно- или многостраничный документ неизвестен системе, то в первую очередь на всем изображении документа выбираются графические объекты предопределенных типов (разделительные линии, штрих-коды, флажки (чек-марки), картинки, слова-разделители, строки текста, параграфы и т.п.). Для того чтобы произвести выбор таких объектов, системе предоставляется информация о полях данных, из которых предстоит извлекать информацию в базу данных, и об опорных элементах, помогающих обнаружить эти поля. Информация о полях данных может быть введена оператором (пользователем). Ниже описано, как опорный элемент позволяет обнаружить поле данных на основе его расположения относительно данного опорного элемента.
[0025] Область поля может содержать один или несколько графических объектов предварительно выбранных типов (флажков, штрих-кодов, текста). Как только содержимое поля задано, система автоматически распознает текстовые объекты или штрих-коды внутри этого поля. Кроме того, система распознает строки текста рядом с полем, которое могут содержать название поля или дополнительную информацию о нем. В случае если поле содержит текст, система автоматически определяет тип данных, соответствующий этому тексту, на основе предопределенных типов данных. В одном из вариантов осуществления могут быть предопределены следующие типы данных: дата, время, число, валюта, номер телефона, строка текста из заранее заданных символов, регулярное выражение или строка из нескольких определенных комбинаций.
[0026] Система автоматически создает новое гибкое структурное описание (структурное описание), которое соответствует определенному типу документа с заданными полями. Для каждого поля в структурном описании создается один или множество элементов поиска, предназначенных для описания алгоритма поиска данного поля. Элементы поиска используются поисковым алгоритмом для обнаружения полей и включают в себя опорные элементы и идентификаторы типов. Идентификатор типа добавляется к множеству поисковых элементов, тип которого совпадает с типом поля данных. Идентификатор типа может использоваться с целью корректного обнаружения полей. Также в это множество могут быть добавлены дополнительные опорные элементы различных типов. Система устанавливает местонахождения полей данных относительно этих элементов.
[0027] В случае если поблизости с полем данных система обнаруживает строку, расположение и содержание которой указывает на то, что в строке может содержаться название поля или дополнительная информация о нем, система добавляет к набору элемент типа «Статический текст» (Static Text), устанавливающий критерии поиска для строки текста. Гипотеза будет проверена позднее, когда системе будет предоставлено еще несколько документов того же типа. В случае если строка будет надежно обнаружена рядом с одним и тем же полем в большинстве других изображений, гипотеза будет считаться подтвержденной. Также гипотеза может быть подтверждена или отвергнута оператором системы сбора данных, а элемент статического текста - удален из множества элементов, описывающих поле.
[0028] Созданное описание структуры может быть обучено путем наложения на несколько других изображений документов и исправления ошибок и несоответствий пользователем. Система корректирует набор поисковых ограничений в структурном описании таким образом, чтобы они не конфликтовали с полями (105), обозначенными пользователем. В то же время к элементу могут быть добавлены альтернативные области поиска, величина отступа для связей «сверху», «снизу», «справа» и «слева» может быть скорректирована, ненадежные опорные элементы могут быть удалены и добавлены новые. Помимо этого для поля могут быть созданы дополнительные альтернативные элементы поиска, которые впоследствии будут использованы системой.
[0029] Сделанные корректировки применяется для обучения структурного описания. В процессе обучения система оценивает, насколько надежно определены элементы идентифицирующие тип, и вносит изменения в их состав и критерии поиска. Исправленное структурное описание сопоставляется как с проблемными страницами (для подтверждения того, что ошибка исправлена), так и с остальными страницами документов (чтобы убедиться, что исправления не затронули качество обнаружения элементов где-либо еще).
[0030] Система позволяет задавать неограниченное количество дополнительных опорных элементов в любом множестве элементов, описывающих поле. Примеры предопределенных элементов, которые могут быть включены в набор: статический текст, разделитель, пропуск, штрих-код, строка текста, параграф, изображение, номер телефона, дата, время, валюта, логотип, группа, таблица, повторяющийся элемент и другие. Системе может быть предоставлена информация о расположении дополнительных графических объектов, в этом случае система автоматически создает элементы соответствующих типов и задает их критерии поиска. В гибком (слабоструктурированном) документе некоторые или даже все поля могут не сопровождаться названиями, в этом случае такие поля определяются с помощью других опорных элементов.
[0031] К критериям поиска элементов относятся тип искомого объекта, его физические характеристики, его область поиска и пространственные взаимоотношения с другими, уже описанными элементами. Например, для того чтобы найти сумму счета на изображении счета-фактуры, пользователь может создать элемент типа «Валюта» со следующими параметрами: возможные названия валют ($, USD, EUR, GBP, RUB и т.д.), десятичные разделители («,» или «.»), расположение названия валюты относительно суммы (перед суммой, за суммой) и т.д. Важной характеристикой метода является возможность задавать физические свойства элементов любого типа через установку допустимых диапазонов значений. Например, могут быть заданы минимальная/максимальная длина и ширина разделителя, возможные буквенные комбинации ключевых слов, алфавит символов для строки текста и т.д. Таким образом, для одного элемента или поля может быть задан широкий перечень альтернативных способов для его определения, что отражает вариативность, свойственную слабоструктурированным документам.
[0032] Кроме того, свойства элементов могут включать параметры для обработки возможных искажений изображения, которые могут возникнуть в процессе преобразования документа в электронный формат (например, в процессе сканирования или фотографирования документа). Например, пользователь может установить допустимое процентное содержание ошибок OCR (оптического распознавания) в ключевых словах (или в элементах статического текста); допустимые разрывы в разделительных линиях могут быть заданы абсолютной или относительной величиной длины, а пробелы (элементы типа «просвет») могут содержать некоторое количество шумов, которые могут возникать в процессе сканирования. Описанные параметры устанавливаются системой автоматически и могут, в случае необходимости, быть подобраны оператором.
[0033] Область поиска любого элемента в структурном описании может быть создана при помощи любого из следующих методов и их комбинаций: путем установки абсолютных ограничений поиска с помощью прямоугольников с заданными координатами; путем установки ограничения поиска относительно краев изображения; и путем установки ограничений относительно предварительно описанных элементов.
[0034] Примеры абсолютных ограничений с использованием прямоугольников с координатами, заданными пользователем: поиск в пределах прямоугольников [0 дюймов, 1,2 дюйма, 5 дюймов, 3 дюйма], [2 дюйма, 0,5 дюйма, 6 дюймов, 5,3 дюйма]. Примеры ограничений относительно краев изображения: искать ниже 1/3 высоты изображения, справа от центра изображения. Пример границ относительно других предварительно описанных элементов: искать под нижним краем RefElement1, начиная на уровне 5 точек ниже края (т.е. с отступом в 5 точек); искать слева от центра прямоугольника, ограничивающего элемент RefElement2, начиная с 1 см слева от центра (т.е. с отступом в 1 см). При комбинировании нескольких методов установки области поиска результирующая область будет вычисляться как пересечение всех областей, описанных каждым из этих методов.
[0035] Система автоматически генерирует поисковые ограничения для элемента, которые задаются относительно других элементов. Для автоматического создания поисковых ограничений система последовательно исследует несколько изображений документов одного типа и выбирает ограничения, внутри которых соблюдены все заданные отступы и условия «сверху», «снизу», «слева» и «справа» на всех изображениях. Значения отступов также выбираются автоматически таким образом, чтобы критерии поиска удовлетворяли всем перечисленным условиям. Если расположение опорных элементов относительно полей меняется от документа к документу, то ограничение поиска задается следующим образом: например, «на 3 дюйма выше RefElement1 или на 5 дюймов ниже RefElement1». Таким образом, условия задают альтернативные области поиска для одного и того же элемента.
[0036] Абсолютные ограничения области поиска элемента и ограничения относительно краев изображения не являются обязательными: они могут быть заданы оператором в случае отсутствия надежного опорного элемента на изображении. Надежным считается опорный элемент, который встречается на большинстве документов заданного типа.
[0037] Важной характеристикой метода является использование ограничений поиска, которые заданы на основе взаимного расположения элементов (в том числе в случаях, когда некоторые из них не были обнаружены на изображении). Система может не обнаружить элемент либо по причине отсутствия соответствующего объекта на изображении (такое возможно в слабоструктурированных документах), или по причине того, что этот объект был утрачен либо искажен в процессе оцифровки. Если элемент не обнаружен, система использует область поиска, заданную для этого элемента, чтобы установить расположение других элементов относительно этого ненайденного элемента.
[0038] Таким образом, каждый раз, когда новый тип документа поступает в систему считывания данных, автоматически генерируется предварительное гибкое описание документа, которое уже содержит алгоритм поиска, который будет использоваться для обнаружения всех полей данных, указанных пользователем.
[0039] Кроме того, система может попытаться определить графические объекты (заголовки, логотипы), расположение и физические свойства которых могут быть применены, для того чтобы отличить этот тип документов от других типов. С этой целью система изучает объекты в верхней части документа и ищет строки текста, высота которых значительно больше, чем средняя высота символов в теле документа, а также строки, выделенные жирным шрифтом. Система также проводит поиск графических объектов (картинок) в верхней части документа, которые могут оказаться логотипом. Для каждой строки или картинки, обнаруженной таким способом, система создает элемент соответствующего типа («статический текст», «логотип»).
[0040] Гипотеза о том, что эти элементы, идентифицирующие тип документа, могут быть надежно обнаружены на других документах этого типа, тестируется в ходе дополнительного обучения, когда системе предоставляется еще несколько экземпляров документов. Когда элементы-идентификаторы, созданные системой, не могут быть обнаружены во всех документах, система задействует полный набор элементов структурного описания для распознавания типа документа.
[0041] Возможно использование двух систем координат: локальной системы координат (в пределах отдельной страницы) и глобальной системы (в пределах целого документа). Единственное различие между ними состоит в том, что в глобальной системе используется параллельное смещение, в то время как в локальной системе - отдельное смещение для каждой страницы. Глобальная система координат удобна для документов, где встречаются многостраничные экземпляры.
[0042] Если в документе содержится несколько страниц, то все страницы документа могут быть объединены в одно многостраничное полотно. Многостраничное полотно создается путем сливания или соединения страниц документа сверху-вниз, без обозначения границ или зазоров. При этом все страницы выравниваются по левому краю вдоль оси, проходящей через точку координат (0,0). Порядок страниц в полотне определяется порядком поступления страниц документа. Для описания расположения элементов относительно друг друга используется глобальная система координат, благодаря которой отношения, записанные, как НИЖЕ, верно интерпретируются, даже когда элементы расположены на разных страницах.
[0043] После того, как изображения страниц объединены в единое многостраничное полотно, гибкое структурное описание применяется сразу к целому полотну, аналогично тому, как оно применяется к отдельной странице. Далее система пытается определить поля данных и извлечь из них данные. Методы оптического распознавания символов (OCR) или интеллектуального распознавания символов (ICR) могут быть применены для распознавания данных, извлеченных из полей.
[0044] Документ, из которого было получено изображение документа (например, путем сканирования), может содержать множество повторяющихся структур. «Повторяющийся» здесь означает, что похожие или идентичные структуры встречаются в документе (а следовательно, и на его изображении) по меньшей мере дважды. Термин «повторяющаяся структура» может относится как к отдельному полю, так и к группе полей. Например, различные таблицы содержат повторяющуюся структуру.
[0045] Свойства повторяющейся структуры могут быть заданы и могут включать в себя правила постобработки данных, которые предположительно были внесены в отдельный тип структуры. К таким свойствам относятся процедуры подтверждения, верификации и экспорта, которые должны быть выполнены в процессе считывания данных из повторяющихся структур на изображении документа. К свойствам повторяющихся структур также относится обозначение, что некоторое поле внутри повторяющейся структуры является дополнительным, обозначения, что некоторая повторяющаяся структура охватывает несколько страниц документа, и прочие.
[0046] Независимо от свойств повторяющейся структуры метод, представленный в примере реализации, включает в себя обработку изображения документа, чтобы установить множество повторяющихся структур, и выполнение операций по извлечению данных, в том числе порождение множества примеров повторяющейся структуры на основе предварительно описанных свойств одной повторяющейся структуры в гибком описании, а также заполнение каждого из них соответствующими данными, извлеченными из изображения документа. Преимущество такого способа заключается в том, что описанные однажды свойства повторяющейся структуры могут быть применены одинаковым образом к каждой повторяющейся структуре, независимо от числа повторов. Число повторов даже не требуется знать заранее. В дальнейшем, в процессе создания гибкого структурного описания, даже не требуется повторно описывать или определять свойства структуры для того, чтобы применить их к множеству групп повторяющейся структуры (подробнее описано ниже).
[0047] В соответствии с примером осуществления изобретения, свойства повторяющихся структур в документе могут быть применены единожды для описания:
отдельного поля или групп полей, повторяющихся два или более раз по крайней мере в одном экземпляре документа рассматриваемого типа. Примеры: группа полей, которая может быть повторяющейся в одном документе, и при этом встречаются другие документы этого типа, где присутствует только одна подобная группа полей;
отдельная строка таблицы со сложной структурой. Примеры: строка таблицы может содержать объединенные ячейки или сама может занимать несколько строчек (обычно в больших таблицах, где все столбцы не помещаются в один ряд и переносятся на следующую строчку);
заголовок столбца многостраничной таблицы, повторяющийся более чем на одной странице;
повторяющиеся таблицы, данные в которых перетекают на следующую страницу.
[0048] Каждой повторяющейся структуре может быть присвоено множество структурных свойств. Конкретные структурные свойства зависят от характера самой структуры. В соответствии с примером реализации повторяющиеся структуры будут обладать одинаковыми структурными свойствами, которые могут быть единожды для нее описаны.
[0049] Различные таблицы или списки могут обрабатываться как элементы повторяющейся структуры. К свойствам повторяющейся структуры могут, в числе прочего, относиться:
типы данных внутри такой структуры - дата, время, название, номер телефона, валюта, адрес, число, статичный текст, строка символов, параграф, штрихкод и т.д.;
правила, устанавливающие связь между содержимым данной структуры и содержимым прочих структур и любых других доступных данных;
настройки для обработки данных, такие как параметры распознавания, информация о разметке структуры и т.п.
[0050] Обычно в случае многостраничных документов отдельная повторяющаяся структура может перетекать с одной страницы на другую (например, различные поля одной группы могут располагаться на разных страницах документа). Также внутри повторяющейся группы любое поле (или любое количество полей) могут быть необязательными. Это означает, например, что они могут присутствовать внутри одной группы и отсутствовать в другой группе.
[0051] В некоторых случаях повторяющиеся группы могут встречаться в документе в любом порядке: слева направо, сверху вниз, снизу вверх или справа налево. Более того, точный порядок расположения может быть не указан вовсе. Прямоугольники, ограничивающие различные повторяющиеся группы, могут пересекаться. Однако предпочтительно, чтобы отдельные поля внутри повторяющейся группы не пересекались.
[0052] В процессе разработки следует учитывать, что одна повторяющаяся структура может быть вложенной в другую повторяющуюся структуру. Свойства каждой повторяющейся структуры описываются и вводятся лишь единожды независимо от предполагаемого числа повторов.
[0053] Повторяющиеся группы могут содержать произвольное число полей. В таких случаях другая повторяющаяся группа может выступать в качестве разделителя. При обнаружении повторяющейся группы-разделителя последняя считается границей для упомянутой выше повторяющейся группы с произвольным числом полей. Для вложенности повторяющихся групп не требуется устанавливать ограничения, поскольку в случае вложенных групп поиск ведется от самых внутренних групп к внешним, и на каждом этапе используется аналогичный подход для поиска повторяющихся групп, как и в случае одноуровневых, невложенных групп.
[0054] Настройки приложения по извлечению данных устанавливаются таким образом, чтобы при сканировании или фотографировании бумажного документа, в случае обнаружения повторяющихся структур в оцифрованном документе, это приложение выборочно обрабатывало данные в каждой повторяющейся структуре и применяло одни и те же единожды-заданные свойства структуры, включая методики подтверждения, верификации и экспорта для каждого примера таких данных в соответствующей повторяющейся структуре.
[0055] Некоторые слабоструктурированные документы могут содержать таблицы без линий-разделителей или иных разделителей строк и/или столбцов. Подобные таблицы могут иметь сложную и нерегулярную структуру. Пример многостраничного документа, содержащего таблицу без разделителей приведен на Фиг. 2А и 2Б. В некоторых случаях строка таблицы может содержать объединенные ячейки или занимать сразу несколько строчек. Например, содержимое ячейки 203 занимает две строчки. Столбцы, расположенные в две или более строчек, могут встречаться в больших таблицах, когда все столбцы могут не помещаться в одном ряду и поэтому переносятся на следующий. Столбцы могут даже переноситься на следующую страницу. Помимо этого содержимое отдельных ячеек может быть расположено слишком близко друг к другу настолько, что делает невозможным построение непересекающихся описывающих прямоугольников для этих ячеек. Например, содержимое ячейки 203 пересекается с содержимым ячейки 206. Пересекающиеся ячейки часто встречаются в счетах-фактурах, списках товаров и услуг, прайс-листах. В различных вариантах осуществления изобретения данные в нерегулярных структурированных таблицах могут быть найдены с помощью описания строки (записи, пункта или позиции) в качестве повторяющейся группы.
[0056] Для создания гибкого структурного описания документа с повторяющейся структурой пользователь может выделить первую позицию (запись или строку таблицы) (102) на изображении документа (101), Фиг. 1. В случае если одна повторяющаяся структура (позиция) вложена в другую повторяющуюся структуру, то повторяющаяся позиция верхнего уровня (201 на Фиг. 2А) и повторяющаяся позиция вложенного уровня (202) могут быть размечены с указанием их отношений.
[0057] Помимо выделения первой позиции пользователь может указывать свойства этой позиции или свойства структуры. В некоторых вариантах реализации свойства могут определяться или генерироваться автоматически или возможна частичная степень автоматизации. В свойства позиции или структуры могут быть включены одно или несколько правил подтверждения и верификации, способы экспорта, структурные атрибуты и прочее. Действия пользователя могут быть получены посредством пользовательского интерфейса, в том числе устройства ввода. В некоторых вариантах реализации пользователю могут быть подсказаны свойства, которые следует указать.
[0058] Документы могут иметь один или несколько заголовочных элементов, расположенных над позициями таблицы и описывающих содержимое этих позиций (например, заголовки столбцов в таблице, такие как код, наименование, артикул, цена, сумма и т.п.). Поэтому система считывания данных порождает гипотезу об элементах заголовка для отдельной выбранной позиции (строки или записи) (103). Поиск элементов заголовка может осуществляться выше отмеченной позиции. Например, на Фиг. 2А показаны элементы заголовка 204 над данными в таблице.
[0059] Заголовочные элементы столбцов таблицы могут повторяться на каждой из страниц, на которых присутствует таблица. Поэтому такие элементы заголовка также могут рассматриваться в качестве повторяющейся структуры, которая возникает один или более раз на странице. Например, эти элементы заголовка могут повторяться на протяжении многих страниц, где присутствует таблица. Например, элементы заголовка 204 повторяются на другой странице (221). Заголовочные элементы не обязательно должны располагаться в верхней части таблицы. Элементы заголовка для других повторяющихся групп могут быть найдены в любой части страницы (например, в нижней части таблицы). Например, заголовочный элемент 205 (Subtotal) присутствует в нижней части всех страниц, за исключением последней, а также повторяется в верхней части следующей страницы (222) счета-фактуры. В случае перетекающих элементов заголовка, возникновение этих элементов разрывает содержимое в таблице. Для лучшего подтверждения гипотезы об элементах заголовка наличие последних может быть подтверждено на других страницах документа (в случае многостраничного документа). Помимо этого поиск элементов заголовка может быть осуществлен в других документах того же типа. Например, поиск заголовочных элементов можно произвести во всех счетах-фактурах одной организации. В одном из вариантов реализации отдельное гибкое структурное описание создается для извлечения данных из документов (например, счетов) каждой компании. Иными словами, одно гибкое структурное описание для каждой компании (организации).
[0060] С помощью элементов заголовка отмеченная позиция разделяется на ячейки, в которых обнаружены по крайней мере одно поле данных и один опорный элемент (104). Пользователю предлагается гипотетическая разметка заголовков таблицы и выбранной позиции. Пользователь может исправить (105) найденные элементы заголовка, поля с данными и опорные элементы, а также запросить другую гипотетическую разметку. В некоторых вариантах осуществления изобретения пользователь может самостоятельно выделить область для поиска заголовочных элементов. В выделенной области может быть произведен поиск элементов заголовка, как описано выше. Выделенная позиция, поля данных и опорные элементы также могут быть определены или исправлены вручную.
[0061] После того как разметка заголовков таблицы и выбранной позиции закончена, на ее основе может быть создано гибкое структурное описание. Система может самостоятельно определить опорные элементы или другие вспомогательные элементы для поиска полей данных и задать значения параметров поиска для каждого элемента и поля. Эта информация вносится в полученное гибкое описание. Гибкое описание накладывается на изображение всего документа с целью определения других позиций таблицы и разметки новых позиций (106). В многостраничных документах поиск заголовочных элементов проводится также и на остальных страницах документа. В одном из вариантов осуществления изобретения полученное гибкое структурное описание является предварительной версией. В этом случае результаты наложения предоставляются пользователю, который может исправить полученные наложения, при этом гибкое описание подстраивается соответственно (107). После того как желаемое качество наложения достигнуто, гибкое структурное описание сохраняется, а затем используется в системе считывания данных.
[0062] В процессе наложения повторяющихся позиций в многостраничном документе удобнее использовать представление документа в качестве многостраничного полотна. Система учитывает возможное нахождение искомых позиций как на отдельной странице, так и в документе в целом. В процессе поиска регионы, занимаемые уже обнаруженными группами, могут быть удалены из области поиска других представителей групп, что позволяет избежать перекрытия различных объектов. При этом описывающие прямоугольники различных объектов группы могут перекрываться. Процесс поиска новых повторяющихся позиций считается завершенным, когда система не может найти более ни одного элемента такой позиции в области поиска.
[0063] Использование многостраничного полотна (глобальная системы координат) совместно с изображениями отдельных страниц (локальная система координат) позволяет решать такие сложные задачи, как считывания данных из документов с многостраничными таблицами, имеющими нерегулярную структуру. Документ 200 - это пример документа с многостраничной таблицей, имеющей нерегулярную структуру. На Фиг. 2А показана первая страница документа 200, а на Фиг. 2Б - его последняя, пятнадцатая страница. Описание перетекающих заголовков (элементов заголовка) с помощью повторяющихся групп, которые возникают однократно на каждой странице, дает возможность обнаружить перетекающие заголовки и исключить заголовочные элементы из области поиска таблицы. Подобным образом может быть исключена из области поиска таблицы повторяющаяся группа (205), возникающая на всех страницах в нижней части таблицы. Информация о количестве, строении и порядке расположения столбцов в таблице используется при переходе от одной страницы к другой.
[0064] Необходимо принять во внимание, что в некоторых вариантах осуществления изобретения документ может содержать титульную страницу (например, первая страница или сопроводительный лист), а также последнюю страницу, в которых не будет таблиц. Или же таблица может быть занимать, например, 4 страницы в 7-страничном документе и т.п. В подобных случаях поиск позиций таблицы может вестись на страницах, где были найдены элементы заголовка. Как правило, окончание таблиц в таких документах, как счета-фактуры, списки заказов и т.п., сопровождается итоговой суммой. Эта информация, как правило, очень важна для пользователя и тоже может быть извлечена. На Фиг. 2Б показано поле данных для итоговой суммы в конце таблицы с опорным элементом "Total" (223).
[0065] Пользователь может исправить разметку таблицы, полученную на этапе 106, или выбрать область для поиска других позиций таблицы. Могут быть предложены различные решения для пользовательского интерфейса, позволяющие упростить взаимодействие с пользователем. Например, первая выделенная позиция может быть растянута вниз, как бы покрывая область для поиска других позиций таблицы. У пользователя есть возможность отмечать те поля, которые были определены некорректно или не были определены совсем. На основе полученной информации система может исправить (настроить) гибкое структурное описание (107). Исправленное гибкое описание затем можно использовать для дальнейшего считывания данных.
[0066] Гибкое структурное описание может быть наложено на множество других изображений документов (других экземпляров). Результаты наложения могут быть при необходимости исправлены. Гибкое структурное описание автоматически настраивается после каждого исправления пользователем любого из полей данных, заголовочных элементов и/или опорных элементов (107). Система может автоматически корректировать параметры поиска для всех элементов и полей, добавлять или удалять опорные элементы, а также другие дополнительные элементы для поиска полей с данными и т.п. Метод обучения гибкого структурного описания, упомянутый выше, был подробно описан в заявке США на патент №12/364,266. После достижения желаемого качества наложения структурное описание считается готовым (108). Готовое гибкое структурное описание (108) сохраняется в памяти системы для дальнейшего использования системой считывания данных. Например, гибкие структурные описания используются для автоматического извлечения данных из различных документов, содержащих таблицы, подобные тем, что описаны в гибком структурном описании.
[0067] На Фиг. 3 показан пример системы (300), служащей для реализации описанной в настоящем документе технологии. Система (300) включает в себя, по крайней мере, один процессор (302), связанный с памятью (304). Процессор (302) может представлять собой один или несколько процессоров (например, микропроцессоров), а память (304) может представлять собой оперативное запоминающее устройство (ОЗУ), содержащее основное хранилище системы (300), а также дополнительные уровни памяти, например, кэш-память, энергонезависимые или резервные запоминающие устройства (например, программируемая или флэш-память), ПЗУ и т.п. Кроме того, память (304) может подразумевать также и запоминающее устройство, которое физически расположено где-либо еще в составе системы (300) (например, любая кэш-память в процессоре (302), любая емкость запоминающего устройства, используемая в качестве виртуальной памяти, например, как хранимая на внешнем запоминающем устройстве (310).
[0068] Система (300) также, как правило, имеет ряд входов и выходов для обмена информацией с внешними устройствами. Для взаимодействия с пользователем или оператором система (300) может содержать одно или несколько устройств пользовательского ввода (306), таких как клавиатура, мышь, сканер и т.п., а также одно или более устройств вывода (308) (например, жидкокристаллический дисплей, устройство воспроизведения звука (динамик и т.п.)).
[0069] В качестве дополнительного устройства памяти система (300) также может включать в себя один или более накопителей данных (310), такие как дискеты, съемные диски, жесткие диски, ЗУ с прямым доступом (DASD), оптические приводы (например, приводы компакт-дисков (CD), DVD-приводы и т.п.) и/или магнитные ленточные накопители. Система (300) может также включать в себя интерфейс для взаимодействия с одной или более сетями (312) (например, это может быть локальная сеть (LAN), глобальная сеть (WAN), беспроводная сеть (Wi-Fi) и/или Интернет), для обмена информацией с другими компьютерами, подключенными к этим сетям. Следует принимать во внимание, что система (300), как правило, включает в себя различные аналоговые и/или цифровые интерфейсы между процессором (302) и каждым из компонентов системы (304, 306, 308 и 312), что хорошо известно в данной области.
[0070] Система (300) работает под управлением операционной системы (314) и выполняет различные приложения, компоненты, программы, объекты, модули и т.п. с целью реализации описанных методов. Различные приложения, компоненты, программы, объекты и т.п., обобщенно обозначенные пунктом 316 на Фиг. 3, могут также выполняться на одном или более процессорах другого компьютера, соединенного с системой (300) по сети (312), например, в среде распределенных вычислений, причем вычисления, необходимые для реализации функций компьютерной программы, могут быть распределены по множеству компьютеров в сети. В состав прикладного ПО (316) может входить набор инструкций, выполняемых процессором (302), вследствие чего система (300) реализует методы, описанные в настоящем изобретении.
[0071] Несмотря на то, что настоящее описание было составлено на примере конкретных вариантов осуществления, следует понимать, что любые модификации и изменения последних могут быть добавлены без отступления от сущности представленного изобретения. Таким образом, описание и чертежи следует расценивать как иллюстрации, а не как ограничения.
[0072] В целом, процедуры, выполняемые в различных вариантах осуществления, могут быть реализованы как часть операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности команд, упомянутых как «компьютерные программы». Компьютерные программы, как правило, содержат один или более наборов инструкций, размещенных в разное время на различных запоминающих устройствах и системах хранения данных в компьютере, которые, будучи считанными и выполненными одним или более процессорами системы, инициируют выполнение компьютером операций, необходимых для выполнения элементов описанных вариантов осуществления. Более того, различные варианты реализации изобретения описаны в контексте полностью функциональных компьютеров и компьютерных систем, и специалистам в данной области будет понятно, что различные варианты реализации можно распространять в качестве программного продукта в различных формах и что распространение не зависит от конкретного типа машиночитаемого носителя, используемого для реализации распространения. Примеры машиночитаемых носителей включают в себя, без ограничений, носители с возможностью записи, такие как устройства оперативной и энергонезависимой памяти, гибкие магнитные и другие съемные диски, жесткие диски, оптические диски (например, ПЗУ на компакт-дисках (CD-ROM), компакт-диски в формате DVD, флэш-память и т.п.). Также могут быть использованы другие типы распространения, такие как загрузка из Интернета.
[0073] В приведенном выше описании многие подробности даны исключительно в целях пояснения. Однако специалисту в данной области очевидно, что эти конкретные детали являются лишь примерами. В других случаях структуры и устройства показаны только в виде блок-схемы во избежание затруднения процесса объяснения.
[0074] Приводимые в данном описании ссылки на «один из вариантов реализации» или «вариант осуществления» означают, что конкретный признак, структура или характеристика, описанные для варианта реализации, являются компонентом по меньшей мере одного варианта реализации. Фраза «в одном варианте реализации (осуществления)», встречающаяся в различных местах описания, не обязательно обозначает один и тот же вариант реализации изобретения или же отдельные или альтернативные варианты реализации, взаимоисключающие другие варианты реализации. Более того, некоторые описываемые особенности могут присутствовать в некоторых вариантах реализации, но не присутствовать в других вариантах реализации изобретения. Аналогично описания различных требований могут относиться к одним вариантам реализации и не относиться к другим вариантам реализации изобретения.
[0075] Примеры некоторых вариантов осуществления были описаны и проиллюстрированы в прилагаемых рисунках. Однако необходимо понимать, что эти варианты реализации приводятся исключительно в иллюстративных целях и не являются ограничениями описываемых вариантов реализации и что эти варианты реализации не ограничены конкретными показанными и описанными схемами и комбинациями, поскольку специалисты в данной области техники после изучения описания могут создавать другие модификации. В области технологии, к которой относится настоящее изобретение, где рост происходит быстро и дальнейшие достижения сложно прогнозировать, описанные варианты реализации можно легко подвергать изменениям в устройстве и деталях благодаря развитию технологии, не отклоняясь при этом от принципов представленного изобретения.


Изобретение раскрывает системы, машиночитаемые носители и методы создания гибких структурных описаний. Технический результат - автоматическое создание структурного описания, используемого для извлечения данных из изображения объекта. Для создания гибких структурных описаний используется изображение документа конкретного типа, содержащего таблицу. Отмечается позиция, описывающая одну запись в таблице. На основе отмеченной позиции производится поиск элементов заголовка внутри документа, определяются поля данных и опорные элементы. Для данного типа документов создается гибкое структурное описание документа, включающее набор элементов поиска для каждого из полей данных на изображении документа, а также элементы заголовка. Гибкое структурное описание накладывается на изображение. Данные извлекаются из изображения в соответствии с результатом наложения гибкого структурного описания на изображение документа. 3 н. и 15 з.п. ф-лы, 4 ил.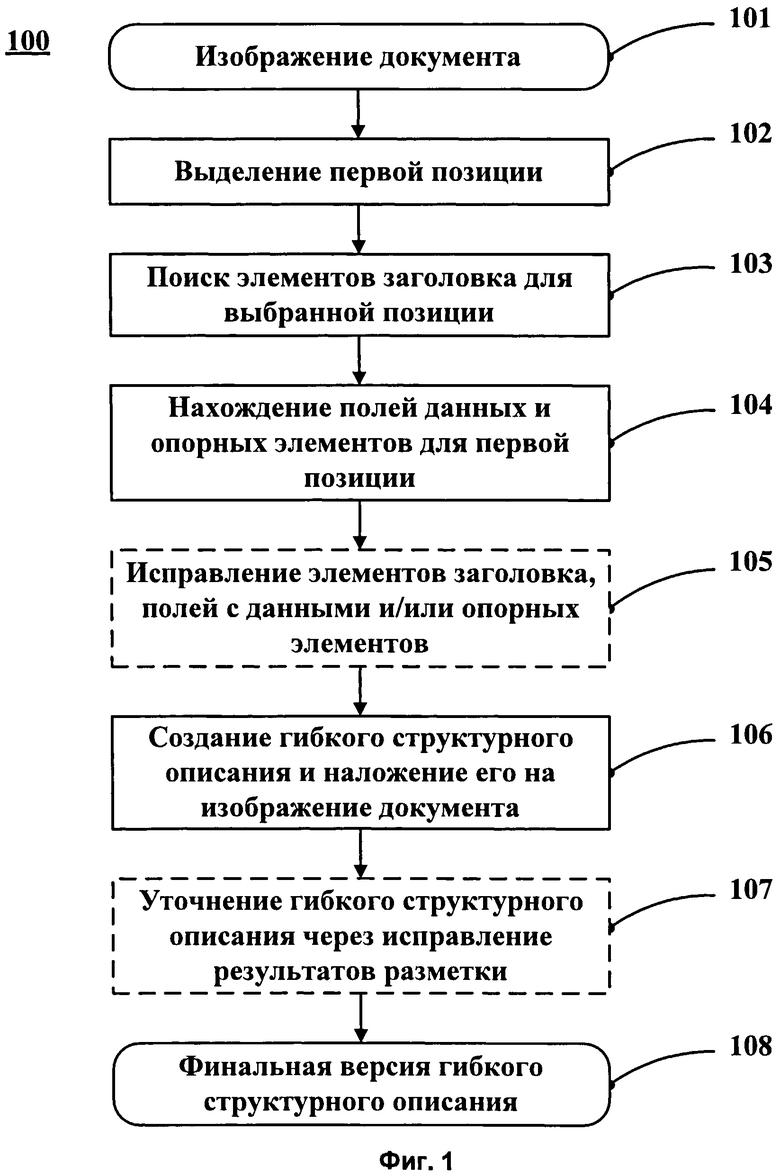
1. Способ создания гибкого структурного описания, содержащий:
получение изображения документа определенного типа, содержащего таблицу;
получение позиции, описывающей запись в таблице;
поиск элементов заголовка на основе позиции;
обнаружение полей данных и опорных элементов для позиции таблицы;
создание, используя процессор, гибкого структурного описания для документа определенного типа, включающего набор элементов поиска для каждого из полей данных на изображении документа, а также элементов заголовка;
наложение гибкого структурного описания на изображение, в котором наложение гибкого структурного описания на изображение включает
сопоставление элементов заголовка на каждой странице документа;
исключение сопоставленных элементов заголовка из области поиска документа; и
поиск полей данных по области с исключенными сопоставленными элементами заголовка; и
извлечение данных из изображения в соответствии с параметрами гибкого структурного описания наложением гибкого структурного описания на изображение.
2. Способ по п. 1, дополнительно включающий корректировку, используя процессор, гибкого структурного описания на основе пользовательских исправлений обнаруженных полей данных, элементов заголовка и/или опорных элементов.
3. Способ по п. 1, в котором таблица занимает несколько страниц документа, и в котором элементы заголовка повторяются на двух или более страницах многостраничного документа.
4. Способ по п. 1, в котором создание гибкого структурного описания включает определение опорных элементов для поиска полей данных.
5. Способ по п. 1, в котором создание гибкого структурного описания включает генерирование значений поисковых параметров для каждого отдельного элемента или поля.
6. Способ по п. 1, в котором позиция соответствует ячейке таблицы, охватывающей несколько строчек документа.
7. Способ по п. 1, дополнительно содержащий получение по крайней мере двух позиций таблицы, включающих множество ячеек, которые перекрываются.
8. Система создания гибкого структурного описания, содержащая:
один или несколько электронных процессоров, выполненных с возможностью:
получения изображения документа определенного типа, содержащего таблицу;
получения позиции, описывающей запись в таблице;
поиска элементов заголовка на основе позиции;
обнаружения полей данных и опорных элементов для позиции таблицы;
создания гибкого структурного описания для документа определенного типа, включающего набор элементов поиска для каждого из полей данных на изображении документа, а также элементов заголовка;
наложение гибкого структурного описания на изображение, в котором наложение гибкого структурного описания на изображение включает
сопоставление элементов заголовка на каждой странице документа;
исключение сопоставленных элементов заголовка из области поиска документа; и
поиск полей данных по области с исключенными сопоставленными элементами заголовка; и
извлечения данных из изображения в соответствии с наложением гибкого структурного описания на изображение.
9. Система по п. 8, где один или более электронных процессоров дополнительно выполнены с возможностью корректировать гибкое структурное описание на основе пользовательских исправлений обнаруженных полей данных, элементов заголовка и/или опорных элементов.
10. Система по п. 8, в которой таблица занимает несколько страниц документа и в которой элементы заголовка повторяются на двух или более страницах многостраничного документа.
11. Система по п. 8, в которой для создания гибкого структурного описания определенного типа документов один или более электронных процессоров выполнены с возможностью определения опорных элементов для поиска полей данных.
12. Система по п. 8, в которой для создания гибкого структурного описания определенного типа документов один или более электронных процессоров выполнены с возможностью генерировать значения поисковых параметров для каждого элемента или поля.
13. Система по п. 8, в которой позиция соответствует ячейке таблицы, охватывающей несколько строчек документа.
14. Система по п. 8, в которой один или несколько электронных процессоров дополнительно имеют возможность получения по крайней мере двух позиций таблицы, включающих множество ячеек, которые перекрываются.
15. Энергонезависимый машиночитаемый носитель информации, на котором хранятся инструкции по созданию гибкого структурного описания, содержащие:
инструкции по получению изображения документа определенного типа, содержащего таблицу;
инструкции по получению позиции, описывающей запись в таблице;
инструкции по поиску элементов заголовка на основе позиции;
инструкции по обнаружению полей данных и опорных элементов для позиции в таблице;
инструкции по созданию гибкого структурного описания для документа определенного типа, включающего набор элементов поиска для каждого из полей данных на изображении документа, а также элементов заголовка;
инструкции по наложению гибкого структурного описания на изображение, в котором наложение гибкого структурного описания на изображение включает
сопоставление элементов заголовка на каждой странице документа;
исключение сопоставленных элементов заголовка из области поиска документа; и
поиск полей данных по области с исключенными сопоставленными элементами заголовка; и
инструкции по извлечению данных из изображения в соответствии с наложением гибкого структурного описания на изображение.
16. Энергонезависимый машиночитаемый носитель информации по п. 15, дополнительно содержащий инструкции по корректировке гибкого структурного описания на основе пользовательских исправлений обнаруженных полей данных, элементов заголовка и/или опорных элементов.
17. Энергонезависимый машиночитаемый носитель информации по п. 15, в котором таблица занимает несколько страниц документа и в котором элементы заголовка повторяются на двух или более страницах многостраничного документа.
18. Энергонезависимый машиночитаемый носитель информации по п. 15, содержащий инструкции по созданию гибких структурных описаний для определенного типа документов, включая инструкции по определению опорных элементов для поиска полей данных.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Искроудержатель для паровозов | 1920 |
|
SU271A1 |
| БАЗА ЗНАНИЙ ПО ОБРАБОТКЕ, АНАЛИЗУ И РАСПОЗНАВАНИЮ ИЗОБРАЖЕНИЙ | 2003 |
|
RU2256224C1 |

