Уровень техники
С течением времени люди становятся все более зависимыми от компьютеров, которые как помогают им в работе, так и используются для развлечений. Однако компьютеры работают в цифровой области, что требует идентифицировать дискретные состояния при обработке информации. Это противно природе человека, который функционирует определенно аналоговым образом, и при этом происходящие события никогда не являются полностью черными или белыми, но представляют собой один из оттенков серого. Таким образом, основное различие между цифровым и аналоговым подходом состоит в том, что цифровой подход требует наличия дискретных состояний, которые разобщены по времени (например, представляют собой отчетливо выраженные уровни), в то время как аналоговый подход является непрерывным во времени. Поскольку человек естественно функционирует, используя аналоговый подход, компьютерные технологии развиваются таким образом, чтобы смягчить трудности при установлении связи людей с компьютерами (например, используя цифровые компьютерные интерфейсы), возникающие из-за указанных выше временных различий.
Технология вначале фокусировалась на попытке вводить существующую машинописную или печатную информацию в компьютеры. Сканеры или формирователи оптического изображения вначале использовались для преобразования в "цифровую" форму изображений (например, входных изображений в компьютерную систему). Поскольку изображения можно преобразовать в цифровую форму в компьютерной системе, следовательно, машинописный или печатный материал также должно быть возможно преобразовать в цифровую форму. Однако изображением сканированной страницы нельзя манипулировать как текстом или символами после ввода его в компьютерную систему, поскольку оно не "распознано" системой, то есть система не понимает страницу. Знаки и слова представляют собой "картинки", а не фактически пригодный для редактирования текст или символы. Для преодоления этого ограничения в отношении текста была разработана технология оптического распознавания символов (OCR, ОРС), которая предназначена для использования технологии сканирования для преобразования в цифровую форму текста с получением пригодной для редактирования страницы. Такая технология работала достаточно хорошо, если, в частности, использовался текстовый шрифт, который обеспечивал для программного обеспечения OCR возможность переводить сканированное изображение в пригодный для редактирования текст.
Даже когда текст был "распознан" компьютерной системой, важная дополнительная информация терялась в ходе процесса. Эта информация включает в себя такие аспекты, как форматирование текста, промежутки между знаками текста, ориентация текста и общая компоновка страницы и т.п. Таким образом, если бы страница имела две колонки с изображением в правом верхнем углу, сканированная страница после обработки в OCR могла представлять собой группы текста в текстовом редакторе без двойных колонок и изображения. Или, если изображение было включено, оно обычно внедрялось в некоторой случайной точке между частями текста. Еще одна большая проблема возникает, когда используются разные стандарты построения документа. Типичная технология OCR обычно не может "преобразовать" или правильно распознать структуру документа, сформированного в другом стандарте. Вместо этого она пытается распознать текст, ограничивая его или принудительно вписывая распознанные части в ассоциированный с нею стандарт. Когда такое происходит, процесс OCR обычно вводит маркеры "неизвестный", такие как вопросительные знаки, в распознанные участки для обозначения того, что он не может обработать эти компоненты документа.
Сущность изобретения
Ниже представлено упрощенное краткое описание предмета изобретения для обеспечения основного понимания некоторых аспектов вариантов воплощения предмета изобретения. Такое краткое описание изобретения не является подробным обзором предмета изобретения. При этом не предполагается идентифицировать ключевые/критические элементы вариантов воплощения для ограничения объема предмета изобретения. Единственное назначение состоит в представлении некоторых концепций предмета изобретения в упрощенной форме в качестве вводной части к более подробному описанию, которое представлено ниже.
Предложены системы и способы, в которых используется грамматический анализ (разбор) для упрощения распознавания структур документа. Двумерное представление документа используется для выделения иерархической структуры, которая способствует распознаванию документа. Визуальную структуру документа грамматически анализируют, используя двумерную адаптацию алгоритмов статистического анализа. Это также обеспечивает возможность распознавания компоновки (например, колонок, фамилий авторов, заголовков, сносок и т.д.) и т.п. таким образом, что можно точно интерпретировать структурные компоненты документа. Также можно использовать дополнительные методики для облегчения распознавания компоновки документа. Например, методики грамматического анализа (разбора), в которых используется обучение машины, оценка анализа на основе представлений изображения, методик усиления и/или "признаков быстрого распознавания" и т.п., можно использовать для упрощения распознавания документа. Это обеспечивает возможность эффективного распознавания документа с существенно улучшенной точностью.
Для достижения указанной выше и аналогичных целей некоторые иллюстративные аспекты вариантов выполнения представлены в следующем описании и на приложенных чертежах. Эти аспекты, однако, обозначают всего лишь несколько различных способов, с помощью которых могут быть воплощены принципы предмета изобретения, и предполагается, что предмет изобретения включает в себя все такие аспекты и их эквиваленты. Другие преимущества и новые признаки предмета изобретения будут понятны из следующего подробного описания, которое следует рассматривать совместно с чертежами.
Краткое описание чертежей
На фиг.1 показана блок-схема системы анализа визуальной структуры документа в соответствии с аспектом варианта воплощения.
На фиг.2 показана другая блок-схема системы анализа визуальной структуры документа в соответствии с аспектом варианта воплощения.
На фиг.3 показана еще одна блок-схема системы анализа визуальной структуры документа в соответствии с аспектом варианта воплощения.
На фиг.4 приведена иллюстрация примера страницы из базы данных UWIII в соответствии с аспектом варианта воплощения.
На фиг.5 приведена иллюстрация примерного уравнения, используемого для тренировки модуля распознавания математического выражения в соответствии с аспектом варианта воплощения.
На фиг.6 показана иллюстрация математического выражения в соответствии с аспектом варианта воплощения.
На фиг.7 показана блок-схема последовательности операций способа, способствующего анализу визуальной структуры документа в соответствии с аспектом варианта воплощения.
На фиг.8 показана другая блок-схема последовательности операций способа, способствующего анализу визуальной структуры документа в соответствии с аспектом варианта воплощения.
На фиг.9 иллюстрируется пример рабочей среды, в которой может функционировать вариант воплощения.
На фиг.10 иллюстрируется другая примерная операционная среда, в которой может функционировать вариант воплощения.
Подробное описание изобретения
Предмет изобретения описан ниже со ссылкой на чертежи, на которых одинаковые номера ссылочных позиций используются для обозначения одинаковых элементов на всех чертежах. В следующем описании, с целью пояснения, различные конкретные детали представлены для обеспечения полного понимания предмета изобретения. Однако следует понимать, что варианты воплощения предмета изобретения могут быть представлены на практике без этих конкретных деталей. В других случаях хорошо известные структуры и устройства показаны в форме блок-схемы для упрощения описания вариантов воплощения.
В данной заявке предполагается, что используемый здесь термин "компонент" обозначает объект, относящийся к компьютеру, представленный в виде либо аппаратного средства, комбинации аппаратных средств и программных средств, программного средства или в виде выполняемого программного средства. Например, компонент может представлять собой, но не ограничивается этим, процесс, работающий в процессоре, процессор, объект, выполняемую программу, поток управления, программу и/или компьютер. В качестве иллюстрации как приложения, работающие на сервере, так и сам сервер могут представлять собой компьютерный компонент. Один или больше компонентов могут находиться в процессе и/или в потоке управления, и компонент может быть локализован на одном компьютере и/или может быть распределен между двумя или больше компьютерами. "Поток" представляет собой объект процесса, выполнение которого планируется ядром операционной системы. Как хорошо известно в данной области техники, каждый поток имеет ассоциированный "контекст", который представляет собой энергозависимые данные, ассоциированные с выполнением потока. Контекст потока включает в себя содержание системных регистров и виртуального адреса, принадлежащих процессу потока. Таким образом, фактические данные, содержащие контекст потока, изменяются по мере его выполнения.
Предложены системы и способы, которые способствуют распознаванию документов путем использования визуальных структур. Неотъемлемую иерархическую структуру документа (например, документ -> страницы -> разделы -> колонки -> абзацы и т.д.) распознают, используя механизм двумерного анализа, в котором применяются методики на основе грамматики. Благодаря дальнейшему использованию процесса обучения машины с механизмами грамматического разбора эффективность распознавания документов может быть существенно улучшена при сохранении высокой точности. Также можно использовать технологии сохранения изображения, что способствует повышению скорости разбора и эффективности. Выбор быстрых особенностей (признаков) документа, а также методики усиления для обучения разбору также можно использовать для повышения производительности работы систем и способов.
Грамматический анализ (разбор) используется для обработки компьютерных языков и естественных языков. В случае компьютерных языков грамматика является однозначно выраженной, и при заданных входных данных существует один и только один достоверный результат анализа. В случае естественных языков грамматика является неоднозначной, и для одной входной последовательности существует большое количество потенциальных результатов анализа. Желательно при статистическом анализе естественного языка использовать обучение машины для получения функции оценки анализа, которая назначает наибольшую оценку для правильного результата анализа. В предложенных здесь системах и способах визуальную структуру моделируют как грамматику и глобальный поиск оптимального результата анализа выполняют на основе функции грамматической стоимости. Затем можно использовать обучение машины для дискриминационного выбора признаков и установки всех параметров в процессе грамматического анализа, адаптируя его к различным визуальным конструкциям.
На фиг.1 показана блок-схема системы 100 анализа визуальной структуры документа в соответствии с аспектом варианта воплощения. Система 100 анализа визуальной структуры документа состоит из компонента 102 анализа визуальной структуры документа, который принимает входные данные 104 и предоставляет выходные данные 106. Компонент 102 анализа визуальной структуры документа использует негенеративную грамматическую модель компоновки визуальной структуры документа для облегчения определения оптимального дерева анализа для компоновки визуальной структуры. Входные данные 104 включают в себя, например, визуальную компоновку страницы документа. Компонент 102 анализа визуальной структуры документа анализирует входные данные 104, используя процесс грамматического анализа (разбора) визуальной структуры документа, для получения выходных данных 106. Выходные данные 106 могут состоять, например, из оптимального дерева анализа для компоновки визуальной структуры документа. Глобально изученная "эталонная" грамматика также может быть установлена для получения решения анализа для разных задач, и при этом не требуются дополнительное изучение грамматики.
Рассмотрим фиг.2, на которой представлена другая блок-схема системы 200 анализа визуальной структуры документа в соответствии с аспектом варианта воплощения. Система 200 анализа визуальной структуры документа состоит из компонента 202 анализа визуальной структуры документа, который принимает входные данные 204 визуальной структуры и формирует оптимальное дерево 206 анализа. Компонент 202 анализа визуальной структуры документа использует дискриминативную грамматическую модель компоновки визуальной структуры документа. Компонент 202 анализа визуальной структуры документа состоит из приемного компонента 208 и грамматического компонента 210. Приемный компонент 208 принимает входные данные 204 визуальной структуры и передает их 204 в грамматический компонент 210. В других случаях функциональные возможности приемного компонента 208 могут быть включены в грамматический компонент 210, что обеспечивает для грамматического компонента 210 возможность непосредственного приема входных данных 204 визуальной структуры. Грамматический компонент 210 также принимает грамматику 212 компоновки основной структуры. Грамматика 212 компоновки основной структуры обеспечивает исходные рамки (инфраструктуру) грамматики визуальной структуры для компоновки документа. Грамматический компонент 210 анализирует входные данные 204 визуальной структуры для получения оптимального дерева 206 анализа. 210 выполняет это путем использования процесса грамматического анализа, который анализирует визуальную структуру документа. Грамматический компонент 210 использует процесс динамического программирования для определения глобально оптимального дерева анализа. Это предотвращает ограничение оптимального дерева 206 анализа локальными оценками и позволяет получить улучшенные глобальные результаты.
Рассмотрим фиг.3, на которой представлена еще одна блок-схема системы 300 анализа визуальной структуры документа в соответствии с аспектом варианта воплощения. Система 300 анализа визуальной структуры документа состоит из компонента 302 анализа визуальной структуры документа, который принимает входные данные 304 визуальной структуры и выдает дерево 306 оптимального анализа. Компонент 302 анализа визуальной структуры документа использует дискриминативную грамматическую модель компоновки визуальной структуры документа для анализа. Компонент 302 анализа визуальной структуры документа состоит из приемного компонента 308 и грамматического компонента 310. Грамматический компонент 310 состоит из компонента 312 анализа( разбора) и компонента 314 выделения структуры документа. Компонент 312 анализа состоит из грамматической модели 316 визуальной структуры с функцией 318 грамматической стоимости. Входные данные 304 визуальной структуры включают в себя, например, визуальную компоновку страницы документа. Приемный компонент 308 принимает входные данные 304 визуальной структуры и передает их 304 в компонент 312 анализа. В других случаях функциональные возможности приемного компонента 308 могут быть включены в компонент 312 анализа, что обеспечивает возможность для компонента 312 анализа непосредственно принимать входные данные 304 визуальной структуры. Компонент 312 анализа анализирует визуальную структуру документа по входным данным 304 визуальной структуры, которые основаны первоначально на грамматике 320 компоновки визуальной структуры. Компонент 312 анализа взаимодействует с компонентом 314 выделения структуры документа, чтобы, в частности, способствовать выделению информации визуальной структуры из входных данных 304 визуальной структуры.
Компонент 314 выделения структуры документа использует сложные локальные и/или глобальные признаки для того, чтобы способствовать анализу, выполняемому компонентом 312 анализа входных данных 304 визуальной структуры. Этот компонент 314 может использовать различные необязательные механизмы для улучшения анализа компоновки визуальной структуры, выполняемого компонентом 312 анализа, включая в себя, но без ограничений, обучение 322 машины, усиление 324 анализа, признаки 326 быстрого распознавания, оценку 328 анализа и/или другие подходы 330 и т.п. Другие подходы 330 представляют другие подходы повышения эффективности и/или механизмы, ориентированные на визуальное представление, которые способствуют быстрому выполнению и/или расширению возможностей компонента 312 анализа.
Например, обучение 322 машины может быть предусмотрено компонентом 314 выделения структуры документа, для того чтобы способствовать компоненту 312 анализа при генерировании диаграммы. Этот компонент 312 затем преобразует эту диаграмму в последующий набор примеров с метками, которые передаются на процесс классификации. В процессе классификации используется последующий набор примеров с метками вместе с обучением машины для тестирования набора классификаторов. Процесс классификации затем определяет признаки идентификации между положительными и отрицательными примерами. Свойства идентификации позволяют классификаторам назначать правильную стоимость для правильных и/или неправильных результатов анализа. Компонент 312 анализа затем использует набор классификаторов в функции 318 грамматической стоимости модели 316 грамматики визуальной структуры с тем, чтобы способствовать начислению очков вспомогательным элементам анализа в последующем наборе примеров с метками. Таким образом, процесс продолжается итерационно до тех пор, пока не будет получено оптимальное дерево 306 анализа (например, больше не будет получаться дерево анализа с большей оценкой или больше не будет получаться дерево анализа с меньшей стоимостью).
Аналогично, механизм 324 усиления анализа может быть предусмотрен для компонента 312 анализа, который способствует более эффективному обучению правильному анализу. Механизм 326 признаков быстрого распознавания может быть предусмотрен для вычисления изображений анализа путем вычисления интегральных изображений признаков документа и/или использования совокупностей интегральных изображений для повышения эффективности анализа. Механизм 328 оценки анализа изображения может способствовать анализу, предоставляя оценку анализируемых изображений для функции 318 грамматической стоимости. Эти механизмы 322-330 являются необязательными и не требуются для анализа входных данных 304 визуальной структуры.
При использовании совокупностей интегральных изображений, а не одного интегрального изображения для всей страницы документа интегральное изображение рассчитывают для каждого элемента страницы (например, символа, слова и/или строки соответственно и т.д.). Следует сфокусировать внимание на том, чтобы только один критический символ был включен в вычисление свойства. Описанные здесь системы и способы также могут использовать расчетные интегральные изображения свойств документов. Например, можно использовать такие свойства документов, как большие прямоугольники с незаполненным пространством, вертикальное выравнивание ограничивающих блоков и/или горизонтальное выравнивание строк текста и т.п.
Таким образом, при использовании интегрального изображения становится возможным быстро вычислить количество белых и/или черных пикселей в пределах прямоугольника изображения. Расчет интегрального изображения для изображения является дорогостоящим, но после его выполнения могут быть быстро рассчитаны прямоугольные суммы. Когда задан набор объектов, которые могут быть или могут не быть изображением, существует экспоненциальное количество изображений, которые могут быть получены из этого изображения (степенное множество P(N)). Получение этих изображений и вычисление прямоугольных сумм для каждого из полученных изображений является непомерно дорогостоящим. Поэтому вместо этого для каждого из объектов получают интегральное изображение и обозначают его "совокупностью интегральных изображений". Таким образом, прямоугольная сумма для каждого поднабора изображений представляет собой сумму прямоугольных сумм из совокупностей.
В еще одном конкретном варианте осуществления раскрыта система распознавания. Система распознавания использует упомянутую ранее систему анализа визуальной структуры документа для импорта и/или экспорта визуальных структур документа.
Двумерный анализ
Хотя существует ряд конкурирующих алгоритмов анализа, одна простая, но характерная для всего класса основа называется "анализом по диаграмме" (см. публикацию М. Kay "Algorithm schemata and data structures in syntactic processing," pp. 35-70, 1986). В ходе анализа по диаграмме делаются попытки заполнить элементы диаграммы C(A, R). В каждом элементе сохраняются наилучшие оценки неконечного элемента А как интерпретация вспомогательной последовательности конечных элементов R. Стоимость любого неконечного элемента может быть выражена как следующее рекуррентное соотношение:

где {BC} охватывает всю продуктивность для A, и R0 представляет собой подпоследовательность конечных элементов (обозначенную как "область"), и R1 и R2 представляют собой подпоследовательности, которые разделены и объединение которых представляет собой R0 (то есть они формируют "раздел"). По существу, рекуррентность указывает, что величину оценки анализа для A рассчитывают путем поиска декомпозиции с малой стоимостью конечных элементов в двух разъединенных наборах. Каждому порождению назначают стоимость (либо потери или отрицательную логарифмическую вероятность) в таблице l (А → BC). Элементы диаграммы (иногда называемые кромками) могут быть заполнены в любом порядке, как сверху вниз, так и снизу вверх. Сложность процесса анализа возникает из-за большого количества элементов диаграммы, которые следует заполнить, и объема работы, необходимой для заполнения каждого элемента. Диаграмма, построенная при анализе линейной последовательности N конечных элементов с использованием грамматики, включающих в себя P не конечных элементов, имеет O(PN
2) записей (существует 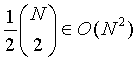 непрерывных подпоследовательностей {i, j}, так что 0 ≤ i < j и j < N). Поскольку работа, требуемая для заполнения каждой записи, представляет собой О(N), общая сложность представляет собой O(PN
3).
непрерывных подпоследовательностей {i, j}, так что 0 ≤ i < j и j < N). Поскольку работа, требуемая для заполнения каждой записи, представляет собой О(N), общая сложность представляет собой O(PN
3).
К сожалению, непосредственное применение анализа диаграммы для двумерных компоновок конечных элементов требует экспоненциального увеличения времени. Ключевая проблема состоит в том, что конечные элементы больше не имеют линейный порядок последовательности. Вернувшись к уравнению (1), можно видеть, что область R0 теперь представляет собой поднабор, и R1 и R2 представляют собой поднаборы, которые разъединены и объединение которых составляет R0 (то есть они формируют раздел). Размер диаграммы можно проанализировать, он составляет О(P|P(N)|), где P(N) представляет собой набор всех поднаборов N конечных элементов. Поскольку существует экспоненциальное количество поднаборов, алгоритм является экспоненциальным.
Hull ввел геометрический критерий, который сокращает поиск в случаях, когда геометрический компонент стоимости слишком велик (см., J. F. Hull, "Recognition of mathematics using a two-dimensional trainable context-free grammar," Master's thesis, MIT, June 1996). Miller и Viola ввели эвристический анализ на основе выпуклых оболочек, который отбрасывает области R1, R2, которые нарушают равенство chull(R1) ∩ R2 = Ш или chull(R2) ∩ R1 = Ш (см., E. G. Miller and P. A. Viola, "Ambiguity and constraint in mathematical expression recognition," in Proceedings of the National Conference of Artificial Intelligence, American Association of Artificial Intelligence, 1998). Теперь эти наборы можно соответственно назвать областями, поскольку каждый из этих наборов находится в пределах выпуклой области страницы. Следует отметить, что, если конечные элементы располагаются вдоль линии (и поэтому имеют строгую линейную упорядоченность), критерий выпуклой оболочки позволяет получить О(N 2) областей, и это эквивалентно линейной последовательности, используемой при обычном анализе.
Используя ограничения выпуклой оболочки, а также другие геометрические ограничения, набор рассматриваемых поднаборов во время анализа можно существенно уменьшить. Эти ограничения в комбинации позволяют получить сложность приблизительно О(N 2) для большинства типов печатных документов.
Анализ компоновки документа
Цель анализа компоновки документа состоит в определении информации, необходимой для преобразования сканированного документа в полностью редактируемый входной файл для программы подготовки документа, такой как, например, LaTeX и/или текстовый редактор и т.п. Хотя текст в виде сканированного файла можно легко извлечь, используя OCR, такая информация недостаточна для получения легко редактируемого файла. Также необходима дополнительная информация, такая как границы абзацев, колонки, выравнивание строк и, что еще более важно, поток считывания. Такая информация о структуре документа также часто отсутствует в файлах в формате переносимого документа (формат PDF, ФПД) и файлах на языке Postscript. Если к сканированным изображениям в виде файлов PDF и/или на языке Postscript добавить информацию о структуре документа, получается очень похожий на оригинал документ, в котором можно изменять количество страниц, форматирование и/или который можно редактировать и т.п. Таким образом, наличие такой возможности существенно повышает возможность использования документа.
Программы подготовки документов часто разделяют печатную страницу на секции. Каждая секция имеет некоторое количество колонок, и каждая колонка имеет некоторое количество параграфов. Такая рекурсивная структура выражена как грамматика в ТАБЛИЦЕ 1, приведенной ниже. Знание такой структуры достаточно для точного получения пригодного для редактирования файла из сканированного документа.
Пример грамматики, которую можно использовать для описания печатных страниц
(Word → terminal (конечный элемент)
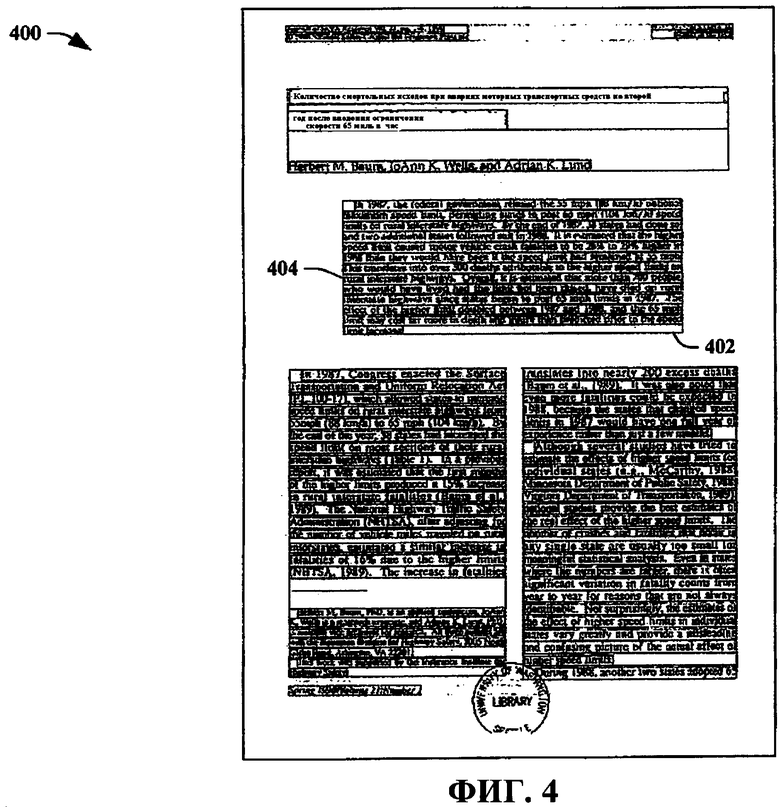
Были выполнены эксперименты с использованием базы данных UWIII изображений документов (см., I. Philips, S. Chen, and R. Haralick, "Cd-rom document database standard," in Proceedings of 2nd International Conference on Document Analysis and Recognition, 1993). База данных содержит сканированные документы, которые содержат контрольные данные в отношении строк, параграфов, областей и порядка считывания. На фиг.4 показана примерная страница 400 из базы данных UWIII. Входные данные для алгоритма анализа представляют собой ограничивающие прямоугольники (например, прямоугольник 402, ограничивающий параграф, и прямоугольник 404, ограничивающий строку) строк. Выходные данные представляют собой иерархическую декомпозицию на секции/колонки/параграфы. Для большинства документов метки контрольных данных легко преобразуются в упомянутую выше грамматику. Тренировку и оценку выполняли, используя набор из 60 документов, которые включают в себя страницы из научно-исследовательских публикаций, книг и журналов.
Интерпретация печатных математических текстов
В академическом исследовательском сообществе практически все новые публикации доступны либо в формате PDF или в формате Postscript. Хотя эти форматы удобны для печати, они не поддерживают простое повторное использование или изменение формата. Один из очевидных примеров представляет включенные в текст уравнения, которые легко выделить, редактировать или исследовать. Другие примеры включают в себя таблицы, сноски и библиографии и т.п. Фактически, стандарт научных публикаций представляет собой LaTeX, в частности, поскольку обеспечивает мощную и высококачественную компоновку математических текстов. Ни документы в формате PDF, ни документы на языке Postscript не обеспечивают информацию, требуемую для реконструкции уравнений LaTeX, используемых для генерирования оригинала.
Для заданного набора обучающих документов LaTeX можно использовать набор макросов LaTeX для "инструментального" исследования процесса получения документа. В результате получают набор файлов, содержащий инструменты, независимые от устройства (DVI, ИНУ), которые можно обрабатывать для выделения ограничивающих прямоугольников символов на странице и соответствующих выражений LaTeX. Эти макросы применяли для набора файлов LaTeX, которые были доступны на сервере предпечатных документов ArXiv (см., фиг.5 - примерное уравнение 500, используемое для обучения распознавателя математических выражений).
После последующей обработки обучающие данные представляли собой набор выражений, каждое из которых составляло хорошо сформированное синтаксическое дерево конечных элементов. Такие деревья обеспечивают возможность непосредственного ввода грамматики, поскольку порождения грамматики можно непосредственно наблюдать по входным деревьям (такая грамматика часто называется грамматикой "банка деревьев"). Индуцированная грамматика показана в приведенной ниже ТАБЛИЦЕ 2. Следует отметить, что конечные элементы грамматики не включены и обозначены неконечным элементом RawItem. Набор RawItem представляет собой знаки, цифры и символы, используемые для построения математических выражений. Конечные элементы грамматики представляют собой примитивно соединенные компоненты черных чернил.
Грамматика для математических выражений
В отличие от других работ математического разбора не предполагается, что конечные элементы были сегментированы и распознаны перед тем, как началась интерпретация. Распознавание конечных элементов представляет собой неотъемлемую часть процесса анализа. Каждый тип символа имеет ассоциированное грамматическое правило, которое описывает порождение конечных элементов. Например, (RawItem→ EQUALS (равняется)) и (EQUALS → CC1 CC2), что указывает, что "знак равенства" состоит из пар соединенных компонентов. Функцию стоимости, ассоциированную с порождением EQUALS, требуется определять для назначения малой стоимости для пар соединенных компонентов, которые выглядят как "=". Общая установка этой задачи является механически простой. Грамматику создают на примере файлов LaTeX, и свойства выбирают автоматически из большого набора, в общем, ценных признаков, которые определены ниже.
Признаки
Признаки, используемые для изучения функций оценки порождения, в общем случае, применяют и используют для широкого диапазона задач. Набор свойств геометрических ограничивающих прямоугольников доказал свою ценность при измерении степени выравнивания компонентов. Первый тип связан с ограничивающими прямоугольниками наборов R0, R1 и R2. Они измеряют положение углов, Xi, Yi и размер W, H прямоугольника в координатах страницы. Существует всего 360 признаков измерения, которые обозначаются как {mj (R)}. Второй набор признаков является комбинаторным и сопоставляет все пары признаков измерения прямоугольника: g(mj Rа), mj(Rb)), где a и b представляют собой {0,1,2} и функция g может представлять собой сложение, вычитание, умножение, деление, минимум или максимум. Третий набор признаков измеряет свойства ограничительных прямоугольников конечных элементов, включенных в области. Это включает в себя измерение минимума, максимума, среднего значения, среднеквадратичного отклонения и медиану некоторых признаков измерения, оцениваемых для конечных элементов во всей области.
Кроме того, существует большой набор признаков распознавания шаблонов, которые были разработаны для того, чтобы различать области на основе внешнего вида. Эти признаки работают с полученными изображениями конечных элементов в областях. На фиг.6 показана иллюстрация 600 математического выражения 602. Во время анализа встречается выражение Z0 604 и его требуется интерпретировать. Здесь представлены четыре изображения 606, используемые как входные данные для процесса оценки порождения. Визуальные признаки необходимы, когда сами конечные элементы требуется распознавать на основе внешнего вида. Применяют свойства прямоугольника, предложенные Viola и Jones (см., P. Viola and M. Jones, "Rapid object detection using a boosted cascade of simple features," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2001). Они являются эффективными для компьютерных вычислений и доказали свою эффективность для широкого диапазона задач. Каждое входное изображение представлено 121 признаком простого прямоугольника, выбранным однородно в соответствии с местоположением и масштабом. Намного больший набор использовали для более сложных задач распознавания изображения, но он оказался достаточным для этих задач.
Геометрическая нормализация представляет собой критический вопрос при построении функции классификации изображения. В этом случае выбирают эталонную рамку, которая нормализует размер и местоположение R0. Цель R0 состоит в том, чтобы заполнить 80% визуального изображения. Выполняют поиск конечных элементов R1 и R2 в этой рамке координат. Это обеспечивает признаки изображения со входным изображением, содержащим информацию об относительных положениях R1 и R2. Так, например, если R2 представляет собой подстрочный индекс, тогда положение его полученных компонентов будет направлено вниз эталонной рамки. Наконец, выполняют поиск конечных элементов всего документа в эталонной рамке R0, но в намного меньшем масштабе. Такое изображение кодирует "контекст" документа, и его можно использовать для разрешения местных неоднозначностей определенных типов.
Во время анализа каждую потенциальную область и подобласть кодируют как набор изображений. Когда существует множество областей, процесс кодирования изображения, который включает в себя изменение масштаба изображения, наивно привел бы к большему объему вычислений. Для исключения таких объемных вычислений используют представление интегрального изображения, введенное Viola и Jones, для расчета прямоугольных фильтров с любым масштабом без дополнительных затрат.
ПРИМЕРЫ
Два набора экспериментов были выполнены с использованием признаков, описанных выше. Общий процесс изучения грамматических параметров описан в приведенной ниже ТАБЛИЦЕ 3. В каждом раунде изучения AdaBoost используют конечные ветви по решениям. Это предусматривает очень простой механизм управления сложностью (ранние остановки). Такой подход также предусматривает механизм выбора признаков, поскольку каждый раунд усиления выбирает одиночную конечную ветвь, которая, в свою очередь, ассоциирована с одним признаком.
Псевдокод для алгоритма тренировки
Поскольку ранние раунды обучения, вероятно, встречаются с примерами, которые не являются репрезентативными для конечного распределения, AdaBoost работает по графику увеличения сложности. В первом раунде усиления выбирают 2 слабых классификатора. Во втором и третьем раундах выбирают 4 и 8 классификаторов соответственно. После этого 8 классификаторов (и, следовательно, 8 признаков) выбирают в каждом раунде анализа.
Оценка результатов анализа представляет собой своего рода искусство. Поскольку ни одна система не является совершенной, предпочтительно определить меру, которая определяет количественное значение качества анализа, который является самым правильным. Одна из схем состоит в измерении эффективности поиска и точности для каждого типа порождения. Контрольные данные содержат много примеров для каждого порождения. Процент правильной идентификации порождения представляет собой эффективность поиска. Изученная грамматика позволяет анализировать каждый входной пример. Процент соответствия этих порождений правильному анализу представляет собой точность.
База данных документов UWIII включает в себя 57 файлов, разделенных в соотношении 80-20 на три раунда перекрестной проверки результата (см. ТАБЛИЦУ 4, - среднее значение обозначает среднюю характеристику для всех порождений. Средневзвешенное значение назначает вес для средних значений, полученный на основе количества использованных примеров). Хотя характеристика для обучающего набора близка к идеальной, характеристика тестового набора является хорошей, но далеко не совершенной. Большое количество обучающих наборов и/или изменений в представлении признака может улучшить степень обобщения. Как для области документов, так и для области математических уравнений анализ типичного ввода с 80 конечными элементами занимает приблизительно 30 секунд для компьютера с процессором Pentium 4 1,7 ГГц и 1 Гб ОЗУ.
Результаты задачи по выделению структуры документа UWIII
База данных уравнения включает в себя 180 уравнений и грамматику с 51 разными математическими символами, такими как λ и δ. Результаты показаны в ТАБЛИЦЕ 5, приведенной ниже).
Результаты задачи распознавания математического уравнения
Примеры систем и способов обеспечивают основы для анализа, который может научиться одновременно сегментировать и распознавать компоненты печатных документов. Эта основа является весьма обобщенной в том, что все параметры процесса анализа установлены с использованием базы данных обучающих примеров. Эффективность и степень обобщения этой основы была продемонстрирована путем представления двух приложений: выделение структуры компоновки страницы и распознавание математического выражения. В первом случае входные данные в алгоритм представляют собой набор строк на странице, и выходные данные представляют собой структуру и секции колонок и параграфов. Во втором случае входные данные представляют собой набор соединенных компонентов на странице, и выход представляет собой набор распознанных математических символов и код LaTeX, необходимый для воспроизведения вводимых данных. Хотя конечные системы в достаточной степени отличаются друг от друга, очень мало модификаций для обучения и процесса анализа необходимо для формирования системы точного распознавания.
Учитывая примерные системы, представленные и описанные выше, методики, которые могут быть воплощены в соответствии с вариантами воплощения, будут более понятны со ссылкой на блок-схемы последовательности операций, показанные на фиг.7 и 8. Хотя с целью упрощения пояснений эти методики представлены и описаны как последовательность этапов, следует понимать и принимать во внимание, что варианты воплощения не ограничиваются порядком представленных этапов, поскольку некоторые этапы могут в соответствии с вариантом выполнения располагаться в другом порядке и/или одновременно с другими этапами по сравнению с тем, что здесь показано и описано. Кроме того, не все иллюстрируемые этапы могут потребоваться для воплощения методик в соответствии с вариантами воплощения.
Варианты воплощения могут быть описаны в общем контексте выполняемых компьютером инструкций, таких как программные модули, выполняемые одним или больше компонентами. В общем случае, программные модули включают в себя процедуры, программы, объекты, структуры данных и т.д., которые выполняют конкретные задачи или воплощают конкретные абстрактные типы данных. Как правило, функции программных модулей могут быть скомбинированы или распределены в соответствии с необходимостью в разных случаях вариантов воплощения.
На фиг.7 показана блок-схема способа 700, облегчающего анализ визуальной структуры документа в соответствии с аспектом варианта воплощения. Способ 700 начинается на этапе 702 с приема входных данных, ассоциированных с визуальной структурой документа 704. Процесс грамматического анализа затем применяют для того, чтобы сделать вывод о визуальной структуре 706 документа, завершая поток 708. Процесс грамматического анализа может включать в себя, но не ограничивается этим, процесс, в котором используется обучение машины и т.п. для построения классификаторов, которые способствуют получению грамматической функции стоимости. Обучение машины может включать в себя, но не ограничивается этим, обычные методики обучения машины, такие как, например, методики на основе перцептрона и т.п.
Рассмотрим фиг.8, на которой показана другая блок-схема последовательности операций способа 800, которая способствует анализу визуальной структуры документа в соответствии с аспектом варианта воплощения. Способ 800 начинается с этапа 802 с приема входных данных, ассоциированных с визуальной структурой документа 804. Затем выделяют визуальную структуру документа из входных данных, используя сложные локальные и/или глобальные признаки 806, заканчивая поток 808. Различные дополнительные механизмы можно использовать для расширения выделения визуальной структуры, которая включает в себя, но не ограничивается этим, обучение машины, усиление анализа, признаки быстрого распознавания и/или оценку анализа изображения и т.п. Например, обучение машины может способствовать анализу для генерирования диаграммы. Диаграмма может быть затем преобразована в последующий набор примеров с метками, которые передают в процесс классификации. Процесс классификации может использовать последующий набор примеров с метками вместе с обучением машины для обучения набора классификаторов. Процесс классификации затем может определить идентифицирующие свойства между положительными и отрицательными примерами. Идентифицирующие признака обеспечивают возможность для классификатора упростить назначение стоимостей для правильных и/или неправильных результатов анализа.
Аналогично усиление анализа может быть предусмотрено для процесса анализа, который способствует более эффективному поиску правильных результатов анализа. Процесс быстрого признака может быть представлен для расчета анализируемых изображений путем расчета интегральных изображений признаков документа и/или использования совокупностей интегральных изображений для повышения эффективности анализа. Процесс оценка анализа изображения может способствовать анализу благодаря тому, что предоставляются оценки анализируемых изображений для функции стоимости, используемой для анализа.
Для предоставления дополнительного контекста, для воплощения различных аспектов вариантов воплощения фиг.9 и следующее описание предназначены для представления краткого общего описания соответствующей вычислительной среды 900, в который могут быть воплощены различные аспекты вариантов воплощения. Хотя варианты воплощения были описаны выше в общем контексте исполняемых компьютером инструкций, компьютерной программы, которая работает в локальном компьютере и/или в удаленном компьютере, для специалиста в данной области техники будет понятно, что варианты воплощения также могут быть воплощены в комбинации с другими программными модулями. В общем случае программные модули включают в себя процедуры, программы, компоненты, структуры данных и т.д., которые выполняют определенные задачи и/или воплощают определенные типы абстрактных данных. Кроме того, для специалиста в данной области техники будет понятно, что способы в соответствии с изобретением могут выполняться на практике с другими конфигурациями компьютерной системы, включающими в себя однопроцессорные или многопроцессорные компьютерные системы, мини-компьютеры, большие электронно-вычислительные машины, а также персональные компьютеры, карманные вычислительные устройства и/или устройства, построенные на основе процессора, и/или программируемые электронные бытовые устройства и т.п., каждое из которых может оперативно связываться с одним или больше ассоциированными устройствами. Иллюстрируемые аспекты вариантов выполнения также могут быть выполнены на практике в распределенных компьютерных средах, когда конкретные задачи выполняют с использованием устройств удаленной обработки, которые подключены через сеть передачи данных. Однако некоторые, если не все, аспекты вариантов воплощения могут быть выполнены на практике на отдельных компьютерах. В распределенных вычислительных средах программные модули могут быть расположены в локальных и/или в удаленных запоминающих устройствах.
Используемый в этой заявке термин "компонент" предназначен для обозначения относящегося к компьютеру объекта, представленного как в виде аппаратных средств, так и в виде комбинации аппаратных и программных средств, программных средств или выполняемого программного обеспечения. Например, компонент может представлять собой, но не ограничивается этим, процесс, работающий в процессоре, процессор, объект, исполняемую программу, поток управления, программу и компьютер. В качестве иллюстрации приложение, работающее на сервере, и/или сервер могут представлять собой компонент. Кроме того, компонент может включать в себя один или больше подкомпонентов.
На фиг.9 показана примерная среда 900 системы, предназначенная для воплощения различных аспектов вариантов воплощения, которые включают в себя обычный компьютер 902, включающий в себя модуль 904 процессора, системную память 906 и системную шину 908, которая соединяет различные компоненты системы, включающие в себя системную память, с модулем 904 процессора. Модуль 904 процессора может представлять собой любой коммерчески доступный или разработанный внутри фирмы для собственных целей процессор. Кроме того, модуль процессора может быть воплощен как мультипроцессор, сформированный из нескольких процессоров, которые могут быть соединены параллельно.
Системная шина 908 может представлять собой любой из нескольких типов структуры шины, включая в себя шину памяти или контроллер памяти, периферийную шину и локальную шину, в которой используются любые из различных обычных архитектур шины, такие как PCI (МПК, межсоединение периферийных компонентов), VESA (АССЭ, Ассоциация по стандартам в области видеоэлектроники), Microchannel, ISA (АПС, архитектура шины промышленного стандарта) и EISA (РАПС, расширенная архитектура шины промышленного стандарта), помимо прочих. Системная память 906 включает в себя постоянное запоминающее устройство (ПЗУ) 910 и оперативное запоминающее устройство (ОЗУ) 912. Базовая система ввода/вывода (BIOS, БСВВ) 914, содержащая основные процедуры, которые помогают передавать информацию между элементами в компьютере 902, например, во время включения компьютера, сохранена в ПЗУ 910.
Компьютер 902 также может включать в себя, например, привод 916 жесткого диска, привод 918 магнитного диска, например, предназначенный для считывания данных со съемного диска 920 или записи на него, и привод 922 оптического диска, например, предназначенный для считывания данных с диска 924 или CD-ROM и записи на него или другой оптический носитель. Привод 916 жесткого диска, привод 918 магнитного диска и привод 922 оптического диска соединены с системной шиной 908 с помощью интерфейса 926 привода жесткого диска, интерфейса 928 привода магнитного диска и интерфейса 930 оптического привода соответственно. Приводы 916-922 и ассоциированные с ними считываемые компьютером носители информации обеспечивают энергонезависимый накопитель для данных, структур данных, исполняемых компьютером инструкций и т.д., для компьютера 902. Хотя описание считываемых компьютером носителей, приведенное выше, относится к жесткому диску, съемному магнитному диску и CD, для специалистов в данной области техники будет понятно, что другие типы носителей информации, считываемые компьютером, такие как магнитные кассеты, карты памяти типа флэш, цифровые видеодиски, картриджи Бернулли и т.п., также можно использовать в примерной оперативной среде 900, и, кроме того, что любой такой носитель может содержать выполняемые компьютером инструкции, предназначенные для выполнения способов вариантов воплощения.
Множество программных модулей могут быть сохранены в приводах 916-922 и в ОЗУ 912, которое включает в себя операционную систему 932, одну или больше прикладных программ 934, другие программные модули 936 и данные 938 программ. Операционная система 932 может представлять собой любую соответствующую операционную систему или комбинацию операционных систем. В качестве примера прикладные программы 934 и программные модули 936 могут включать в себя схему распознавания в соответствии с аспектом варианта воплощения.
Пользователь может вводить команды и информацию в компьютер 902 через одно или больше устройств ввода пользователя, таких как клавиатура 940 и устройство-указатель (например, мышь 942). Другие устройства ввода (не показаны) могут включать в себя микрофон, джойстик, игровую панель, спутниковую антенну, беспроводный пульт дистанционного управления, сканер или тому подобное. Эти и другие входные устройства часто подключают к модулю 904 обработки через интерфейс 944 последовательного порта, который подключен к системной шине 908, но может быть подключен с помощью других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB, УПШ). Монитор 946 или устройство дисплея другого типа также подключен к системной шине 908 через интерфейс, такой как видеоадаптер 948. Кроме монитора 946 компьютер 902 может включать в себя другие периферийные устройства вывода (не показаны), такие как громкоговорители, принтеры и т.д.
Следует понимать, что компьютер 902 может работать в сетевой среде, в которой используются логические соединения с одними или больше удаленными компьютерами 960. Удаленный компьютер 960 может представлять собой рабочую станцию, компьютер-сервер, маршрутизатор, устройство одноранговой сети или другой общий сетевой узел и обычно включают в себя множество или все элементы, описанные в отношении компьютера 902, хотя для краткости на фиг.9 показано только устройство 962 - накопитель. Логические соединения, представленные на фиг.9, могут включать в себя локальную вычислительную сеть (ЛВС) 964 и глобальную вычислительную сеть (ГВС) 966. Такие сетевые среды часто используют в офисах, в компьютерных сетях предприятий, Интранет и Интернет.
При использовании в сети ЛВС, например, компьютер 902 подключен к локальной сети 964 через сетевой интерфейс или адаптер 968. При использовании в сети ГВС компьютер 902 обычно включает в себя модем (например, телефон, DSL (ЦАЛ, цифровая абонентская линия), кабель, и т.д.) 970, или подключен к серверу передачи данных по сети ЛВС, или имеет другое средство установления связи через ГВС 966, такое как Интернет. Модем 970, который может быть внутренним или внешним относительно компьютера 902, подключен к системной шине 908 через интерфейс 944 последовательного порта. В сетевой среде программные модули (включающие в себя прикладные программы 934) и/или программные данные 938 могут быть сохранены в удаленном запоминающем устройстве 962. Следует понимать, что показанные сетевые соединения представляет примеры, и другие средства (например, кабельные или беспроводные) установления линии связи между компьютерами 902 и 960 можно использовать при воплощении аспектов варианта воплощения.
В соответствии с практикой специалистов в данной области техники в области компьютерного программирования варианты воплощения были описаны со ссылкой на действия и символьные представления операций, выполняемых компьютером, таким как компьютер 902 или удаленный компьютер 960, если только другое не будет указано. Такие действия и операции иногда называются выполняемыми компьютером. Следует понимать, что эти действия и символически представленные операции включают в себя манипуляции, выполняемые модулем 904 процессора над электрическими сигналами, представляющими биты данных, которые приводят к последующим преобразованиям или обработке и представлению электрического сигнала и сохранению битов данных в запоминающих устройствах, в системе памяти (включающей в себя системную память 906, привод 916 жесткого диска, гибкие диски 920, CD-ROM 924, и удаленное запоминающее устройство 962), чтобы, таким образом, реконфигурировать или другим образом изменить операции компьютерной системы, а также для другой обработки сигналов. Запоминающие устройства, в которых содержатся такие биты данных, представляют собой физические устройства, которые имеют определенные электрические, магнитные или оптические свойства, соответствующие битам данных.
На фиг.10 показана другая блок-схема примера вычислительной среды 1000, с которой могут взаимодействовать варианты воплощения изобретения. Система 1000 дополнительно иллюстрирует систему, которая включает в себя одно или больше устройство-клиент (клиенты) 1002. Клиент (клиенты) 1002 могут представлять собой аппаратные средства и/или могут представлять собой программное средство (например, представленное в виде потоков, процессов, вычислительных устройств). Система 1000 также включает в себя один или больше сервер (серверов) 1004. Сервер (серверы) 1004 также могут быть воплощены в виде аппаратных средств и/или программных средств (например, в виде потоков, процессов вычислительных устройств). Один из возможных вариантов обмена данными между устройством-клиентом 1002 и сервером 1004 может быть воплощен в форме пакетов данных, предназначенных для передачи двумя или больше вычислительными процессами. Система 1000 включает в себя структуру 1008 передачи данных, которая может быть воплощена таким образом, чтобы она способствовала передаче данных между устройством-клиентом (клиентами) 1002 и сервером (серверами) 1004. Устройство-клиент (клиенты) 1002 подключено к одному или больше накопителю (накопителям) 1010 данных клиента, которые могут использоваться для сохранения локальной информации для клиента (клиентов) 1002. Аналогично сервер (серверы) 1004 подключены к одному или больше накопителю (накопителям) 1006 данных сервера, которые могут использоваться для сохранения локальной информации для сервера (серверов) 1004.
Следует понимать, что системы и/или способы в соответствии с вариантами воплощения могут в равной мере использоваться как в компьютерных компонентах, так и в некомпьютерных компонентах, способствующих распознаванию. Кроме того, для специалиста в данной области техники будет понятно, что системы и/или способы в соответствии с вариантами выполнения можно применять в самых разных электронных технологиях, включающих в себя, но без ограничений, компьютеры, серверы и/или переносные электронные устройства и т.п.
Выше приведено описание, которое включает в себя примеры вариантов воплощения. Конечно, при этом невозможно описать каждую возможную комбинацию компонентов или методик с целью описания вариантов воплощения, но для специалистов в данной области техники будет понятно, что возможно множество дополнительных комбинаций и перестановок вариантов воплощения. В соответствии с этим предполагается, что предмет изобретения охватывает все такие изменения, модификации и вариации, которые находятся в пределах сущности и объема приложенной формулы изобретения. Кроме того, когда используется термин "включает в себя", либо в подробном описании, или в формуле изобретения, предполагается, что такой термин имеет включительный смысл аналогично термину "содержащий", как термин "содержащий" интерпретируется, когда его используют как переходное слово в пункте формулы изобретения.






Изобретение относится к методам распознавания и может быть использовано для распознавания текстовых документов. Техническим результатом является улучшение точности распознавания документа. Двумерное представление документа используется для выделения визуальной структуры, которая способствует распознаванию документа. Визуальную структуру подвергают грамматическому анализу посредством ассоциирования множества грамматических правил с множеством типов символов, идентифицированных в визуальной структуре документа. Это позволяет распознавать компоненты документа (например, колонки, фамилии авторов, заголовки, сноски и т.д.), в результате чего структурные компоненты документа можно точно интерпретировать. При этом грамматический анализ основан на функции грамматической стоимости, которую выводят посредством методики обучения машины. Причем грамматический анализ содержит представление анализа в виде изображения и оценку изображения для реализации функции грамматической стоимости при определении оптимального анализа. Для упрощения распознавания документа можно использовать методики грамматического анализа, в которых используются методики усиления и/или "признаки быстрого распознавания" и т.п. 6 н. и 13 з.п. ф-лы, 10 ил., 5 табл.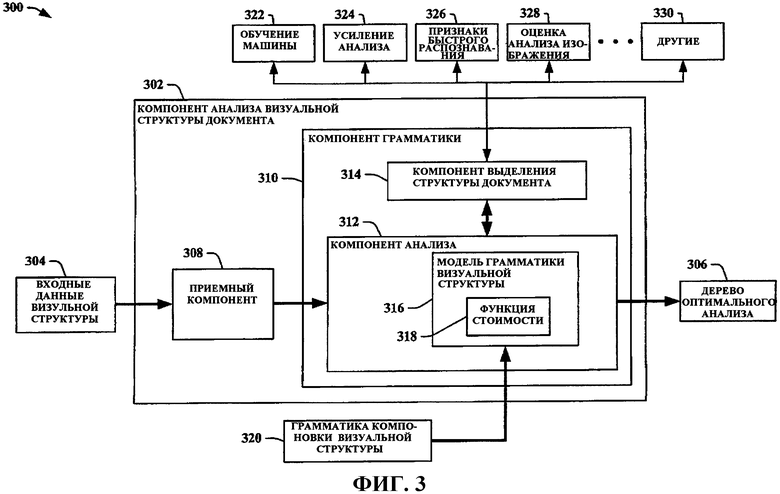
1. Система анализа визуальной структуры документа, содержащая
процессор, который выполняет следующие выполняемые компьютером компоненты:
приемный компонент, который принимает входные данные, ассоциированные с визуальной структурой документа; и
грамматический компонент, который использует, по меньшей мере частично, дискриминативную грамматическую модель визуальной структуры документа для грамматического анализа входных данных посредством ассоциирования множества грамматических правил с множеством типов символов, идентифицированных в визуальной структуре документа, причем грамматические правила содержат соотношения между абзацем естественного языка и подчастью этого абзаца и дополнительно содержат соотношения между математическим выражением и под-частью этого математического выражения, причем дискриминативная грамматическая модель включает в себя иерархическую информацию, ассоциированную с по меньшей мере одним из страниц, секций, колонок, абзацев, строк, авторов, заголовков, сносок или слов упомянутого документа, причем грамматический анализ входных данных основан, по меньшей мере частично, на функции грамматической стоимости, при этом функцию грамматической стоимости выводят, по меньшей мере частично, посредством методики обучения машины, которое позволяет определить оптимальный анализ документа из глобального поиска документа, и при этом грамматический анализ входных данных содержит
представление по меньшей мере одного анализа в виде изображения, и
оценку изображения для реализации функции грамматической стоимости при определении оптимального анализа.
2. Система по п.1, в которой грамматический компонент дополнительно содержит компонент выделения структуры документа, который выделяет структуру компоновки, ассоциированную с документом, с использованием по меньшей мере одного из локального или глобального признаков.
3. Система по п.2, в которой компонент выделения структуры документа использует по меньшей мере одно из: оценка анализа на основе представлений изображения, усиление обучения при анализе и/или признаки быстрого распознавания для упрощения выделения структуры компоновки документа.
4. Система по п.3, в которой грамматический компонент дополнительно содержит
компонент анализа, который использует по меньшей мере один классификатор для определения оптимального результата анализа по результатам глобального поиска.
5. Система по п.4, в которой компонент анализа использует упомянутый классификатор для определения функции грамматической стоимости.
6. Система по п.5, в которой классификатор является классификатором, обученным с использованием обычной методики обучения машины.
7. Система по п.6, в которой методика обучения машины содержит, по меньшей мере частично, методику на основе перцептрона.
8. Система по п.1, в которой грамматический компонент использует, по меньшей мере частично, динамическое программирование для определения оптимального дерева анализа для входных данных.
9. Система по п.2, в которой компонент выделения структуры документа использует обучение машины для выделения структуры компоновки документа.
10. Считываемый компьютером носитель, содержащий команды, которые при их выполнении компьютером выполняют способ анализа визуальной структуры документа, содержащий этапы: принимают входные данные, ассоциированные с визуальной структурой документа;
применяют процесс грамматического анализа к полученной визуальной структуре документа, причем полученная визуальная структура документа включает в себя по меньшей мере одно из: страницы, секции, колонки, абзацы, строки или слова упомянутого документа, причем процесс грамматического анализа основан на грамматических правилах, содержащих соотношения между абзацем естественного языка и подчастью этого абзаца, и дополнительно содержат соотношения между математическим выражением и подчастью этого математического выражения, при этом процесс грамматического анализа содержит
анализ входных данных на основании, по меньшей мере частично, функции грамматической стоимости, при этом функция грамматической стоимости выведена, по меньшей мере частично, посредством методики обучения машины, которое определяет оптимальный анализ документа из глобального поиска документа,
представление по меньшей мере одного анализа в качестве изображения, и оценку изображения для того, чтобы способствовать функции грамматической стоимости при определении оптимального анализа.
11. Носитель по п.10, дополнительно содержащий команды для реализации следующего этапа:
используют, по меньшей мере частично, грамматическую модель визуальной структуры документа для выполнения грамматического анализа входных данных визуальной структуры документа, причем грамматическая модель включает в себя иерархическую информацию, ассоциированную с по меньшей мере одним из: страницы, секции, колонки, абзацы, строки или слова документа.
12. Носитель по п.10, в котором процесс грамматического анализа основан на дискриминативной грамматической модели.
13. Носитель по п.10, дополнительно содержащий этапы:
вычисляют по меньшей мере одно из интегральных изображений по меньшей мере одного признака документа и/или по меньшей мере одной совокупности из множества интегральных изображений для проведения анализа входных данных.
14. Носитель по п.10, дополнительно содержащий этап:
используют AdaBoost для выполнения анализа входных данных.
15. Реализуемый компьютером способ анализа структуры компоновки документа, содержащий этапы:
принимают от входного устройства, подсоединенного к процессору и памяти, входные данные, ассоциированные с визуальной структурой документа, сохраненного в памяти; и
применяют, по меньшей мере частично, грамматическую модель визуальной структуры документа, сохраненного в памяти, чтобы выполнить грамматический анализ входных данных визуальной структуры, причем грамматическая модель включает в себя иерархическую информацию, ассоциированную с по меньшей мере одним из страниц, секций, колонок, абзацев, строк или слов упомянутого документа, причем грамматические правила содержат соотношения между абзацем естественного языка и подчастью этого абзаца и дополнительно содержат соотношения между математическим выражением и подчастью этого математического выражения, при этом грамматический анализ входных данных визуальной структуры документа основан, по меньшей мере частично, на функции грамматической стоимости, при этом функция грамматической стоимости выведена, по меньшей мере частично, посредством методики обучения машины, которая упрощает определение оптимального анализа документа из глобального поиска документа.
16. Способ по п.15, дополнительно содержащий анализ входных данных визуальной структуры, используя по меньшей мере один классификатор, тренированный с использованием методики обучения машины.
17. Вычислительное устройство, использующее считываемый компьютером носитель по п.10, представляющее собой по меньшей мере одно, выбранное из группы, состоящей из компьютера, сервера и переносного электронного устройства.
18. Система распознавания, использующая систему по п.1 для импорта и/или экспорта визуальных структур документа.
19. Система анализа структур компоновки документа, содержащая процессор, память, соединенную с возможностью связи с процессором, причем память хранит выполняемые компьютером команды, сконфигурированные реализовывать следующие компоненты:
приемный компонент, который принимает входные данные, ассоциированные с визуальной структурой документа, причем визуальная структура ассоциирована с по меньшей мере одним из форматирования, промежутками между знаками текста, ориентации текста, заголовками, авторами, математическими формулами, секциями, колонками, абзацами или картинками документа,
грамматический компонент, который использует, по меньшей мере частично, дискриминативную грамматическую модель визуальной структуры документа для выполнения грамматического анализа входных данных, посредством ассоциирования множества грамматических правил с множеством типов символов, идентифицированных в визуальной структуре документа, причем каждый тип символа имеет ассоциированное грамматическое правило, которое описывает конечный элемент, при этом конечный элемент содержит знак, цифру или символ текста, причем грамматические правила содержат соотношения между абзацем естественного языка и подчастью этого абзаца и дополнительно содержат соотношения между математическим выражением и подчастью этого математического выражения, причем дискриминативная грамматическая модель включает в себя иерархическую информацию, ассоциированную с по меньшей мере одним из страниц, секций, колонок, абзацев, строк, авторов, заголовков, сносок или слов упомянутого документа, причем грамматический анализ входных данных основан, по меньшей мере частично, на функции грамматической стоимости, при этом функция грамматической стоимости выводится, по меньшей мере частично, посредством методики обучения машины, которая позволяет определить оптимальный анализ документа из глобального поиска документа, и
компонент выделения структуры документа, который извлекает структуру компоновки, ассоциированную с документом, используя по меньшей мере один из локального или глобального признаков, при этом компонент выделения структуры документа использует обучение машины для выделения структуры компоновки документа.
| US 5987171 А, 16.11.1999 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА С ПРИМЕНЕНИЕМ НАСТРАИВАЕМОГО КЛАССИФИКАТОРА | 2002 |
|
RU2234126C2 |
| СПОСОБ МНОГОЭТАПНОГО АНАЛИЗА ИНФОРМАЦИИ РАСТРОВОГО ИЗОБРАЖЕНИЯ | 2002 |
|
RU2234734C1 |

