Изобретение относится к технологиям обработки информации, а более конкретно - к способам обеспечения доступа к информации, хранящейся в базах данных.
Данные и базы данных играют ключевую роль в современном мире. С развитием сетевых технологий появилась тенденция разделения сетевых ресурсов. Одна база данных обслуживает множество клиентов по сети. Таким образом, важнейшей характеристикой базы данных становится ее пропускная способность - количество запросов, которые она может обработать в единицу времени. Зачастую узким местом является вычислительная мощность машины. Для борьбы с этой проблемой были разработаны различные схемы параллельной обработки запросов.
Одна из попыток описана в [1]. Авторы этой работы предлагают метод декомпозиции SQL запроса, а также оптимальную стратегию параллельной обработки компонент запроса на нескольких процессорах. Недостаток описанного метода заключается в том, что потенциальная степень параллельности этого метода ограничена числом компонент запроса. Некоторые простейшие виды SQL запросов вообще не подлежат декомпозиции.
В [2] предлагается привязать каждый процессор в кластере к отдельной порции данных. Тогда SQL запрос будет применяться одновременно ко всем порциям, а результаты затем будут объединены. Теоретически степень параллельности этого подхода ограничена только количеством процессоров. На практике, однако, объединение результатов может занимать значительное время для большого числа порций. Узким местом может стать и канал передачи данных между процессорами в кластере. Кроме того, экономическая эффективность использования для этой задачи кластера с большим числом машин представляется сомнительной.
В настоящее время графические процессорные устройства ГПУ (GPU, Graphics Processing Unit) являются сравнительно недорогой альтернативой многоядерным процессорам и кластерам. В основе ГПУ лежит графический мультипроцессор. Он состоит из множества процессоров (streaming processor), которые логически объединяются в группы. На таком мультипроцессоре можно запускать сотни (по числу процессоров) параллельных потоков - копий одной и той же процедуры, называемой ядром (английский термин - kernel). Из уровня техники на данный момент для нескольких классов задач известны параллельные алгоритмы, позволяющие решать их па графических процессорах намного эффективнее, чем на многоядерном процессоре или в кластере.
Основная трудность, с которой сталкиваются при попытке использовать графический мультипроцессор для вычислений общего характера, заключается в том, что мощность одного процессора недостаточно велика, что компенсируется большим их числом. Также, устройство современных графических процессоров таково, что полная параллельность выполнения возможна лишь для простейших ядер. Наличие в коде ядра ветвлений и обращений к памяти может послужить причиной задержек и привести к сильному снижению степени параллелизма. Отсюда вытекает необходимость разделения любой задачи на как можно большее число очень простых независимых подзадач.
В [3] была предложена техника, в рамках которой ядро обработки запроса запускается одновременно для множества различных запросов. Чтобы использование ГПУ было оправдано, необходимо обрабатывать сотни запросов одновременно. Очевидно, что все данные, которые обрабатываются запросом в процессе поиска, должны находиться в памяти ГПУ (это может быть вся база данных или какой-то ее сегмент). Данные, обнаруженные в процессе поиска, также должны храниться в памяти ГПУ, прежде чем они будут переданы в основную память. Чтобы запустить сотни потоков одновременно, потребуется очень большой объем памяти ГПУ для хранения результатов. Кроме того, код ядра, которое обрабатывает целиком запрос типа SELECT, будет, очевидно, довольно сложным, и реальная степень параллелизма при его запуске будет далека от максимальной.
Особый интерес в связи с данной проблемой представляют семантические базы данных, в частности - представленные в виде RDF (Resource Description Framework). По сути, в такой базе хранятся тройки (s, p, о) - субъект, предикат и объект. Каждое поле представлено строкой, но довольно распространенной техникой является хранение троек целочисленных хэш-кодов, чего достаточно для идентификации. Запросы типа SELECT к RDF базе данных обычно формулируются на языке SPARQL (SPARQL Protocol and RDF Query Language).
Существенная простота структуры RDF баз данных позволяет надеяться, что для реализации запросов типа SELECT можно сконструировать весьма простые алгоритмы, допускающие параллельную реализацию. Основу SPARQL запроса составляет формула, оперирующая шаблонами троек, между которыми стоят логические операции «И» и «ИЛИ». Каждый шаблон содержит три поля, в которых находится либо конкретное значение, либо имя переменной.
Распространенная в настоящее время техника обработки SPARQL запроса заключается в том, что на основе данного набора шаблонов выводится формула, оперирующая другим типом шаблонов, также соединенных знаками «И» и «ИЛИ». При этом каждый шаблон в каждой позиции содержит либо набор допустимых значений, либо специальную маску, означающую, что в этой позиции допустимо любое значение. Каждый такой шаблон фактически является простейшим запросом на извлечение данных из базы (так называемый запрос на связывание). Результатом его выполнения является множество конкретных троек, извлеченных из базы. Над этими множествами затем производят вычисление вышеупомянутой формулы (операция «И» заменяется на пересечение множеств, а «ИЛИ» - на объединение) и получают результирующее множество троек.
В [4] описан метод обработки запросов типа SELECT к RDF базе данных, где всему вышеописанному процессу получения ответа на запрос предшествует его оптимизация - представление в виде другого, равносильного, набора шаблонов, который характеризуется меньшей длиной пути поиска данных в базе. Делается это на основе семантических правил, выведенных автоматически из текущего содержания базы на этапе предобработки. В принципе, эту оптимизацию можно применять независимо от того, как реализован сам процесс извлечения данных, но ее эффект может от этого зависеть.
Задача, на решение которой направлено заявляемое изобретение, заключается в увеличении пропускной способности сервера обработки запросов типа SELECT к RDF базе данных.
Технический результат достигается благодаря разработке и применению оригинального алгоритма параллельной обработки множественных запросов на связывание, исполняемого на графическом процессорном устройстве (ГПУ), а также усовершенствованной системы RDF базы данных на основе устройства графического процессора (ГПУ).
Для решения поставленной задачи в заявляемом изобретении предлагается способ параллельной обработки множественных запросов к RDF базам данных при помощи графического процессора, отличающийся тем, что поступивший па сервер запрос на связывание предварительно разбивают на элементарные запросы, после чего указанные элементарные запросы передают в общую очередь на вход, откуда их блоками загружают в память графического процессорного устройства (ГПУ) и пропускают через ГПУ-конвейер, где для каждого элементарного запроса вычисляют набор элементарных ответов, и затем объединяют полученные ответы в список троек, являющийся ответом на запрос на связывание.
Согласно заявляемому изобретению указанное ГПУ устройство позволяет использовать его вычислительные мощности для вычислений общего назначения с помощью технологии OpenCL (Open Computing Language).
Согласно заявляемому изобретению указанный запрос на связывание представляет собой набор из трех списков, каждый из которых содержит набор допустимых значений для субъекта, предиката и объекта, соответственно, причем пустой список означает, что в соответствующей позиции допускается любое значение.
Согласно заявляемому изобретению указанный элементарный запрос представляет собой шаблон с тремя полями, в каждом из которых содержится либо конкретное значение для субъекта, предиката и объекта, либо маска, означающая, что в этой позиции допускается любое значение.
Согласно заявляемому изобретению указанное преобразование запроса па связывание в набор элементарных запросов заключается в том, что вычисляют декартово произведение множеств, заданных списками, составляющими запрос на связывание.
Согласно заявляемому изобретению каждый элементарный запрос содержит запись для идентификации с породившим его запросом на связывание.
Согласно заявляемому изобретению обработку элементарных запросов на ГПУ конвейере осуществляют в три стадии, на каждой из которых для каждого элементарного запроса, поступившего с предыдущей стадии, вычисляют набор элементарных запросов для следующей стадии и записывают в каждом из полученных запросов в поле, соответствующее текущей стадии, определенное значение, таким образом, что оно в комбинации со значениями полей, соответствующих предыдущим стадиям, образует допустимое сочетание.
Согласно заявляемому изобретению при обработке запросов на ГПУ конвейере последовательно осуществляют связывание по предикату, связывание по субъекту, связывание по объекту.
Согласно заявляемому изобретению на каждой стадии ГПУ конвейера сначала с помощью ГПУ процедуры расширения для каждого элементарного запроса из входного буфера вычисляют набор элементарных запросов для следующей стадии и записывают их в промежуточный буфер, где выделено место под максимально возможное количество запросов, проверяя при этом для каждого полученного запроса, содержит ли он допустимое сочетание полей, а затем с помощью ГПУ процедуры отбрасывания перемещают прошедшие проверку запросы в выходной буфер, который является одновременно входным буфером для следующей стадии.
Согласно заявляемому изобретению после окончания текущей стадии обработки данных ГПУ устройством следующую стадию для обработки выбирают с таким расчетом, чтобы она использовала максимальное количество ГПУ потоков.
Кроме того, для решения поставленной задачи в заявляемом изобретении также предлагается система RDF базы данных на основе устройства графического процессора (ГПУ) для параллельной обработки множественных запросов, включающая в себя:
- сервер для получения запросов на связывание к базе данных, где осуществляют преобразование запроса на связывание в набор элементарных запросов,
- базу данных,
- графическое процессорное устройство, выполненное с возможностью параллельной обработки запросов к базе данных, содержащее
- память и
- ГПУ конвейер, выполненный с возможностью вычисления набора элементарных ответов для каждого элементарного запроса, и последующего объединения полученных ответов в список троек, являющихся ответом на запрос на связывание к базе данных.
Согласно заявляемому изобретению конвейер устройства графического процессора состоит из трех последовательно выполняемых стадий обработки элементарных запросов.
Согласно заявляемому изобретению стадии обработки элементарных запросов на конвейере ГПУ представляют собой связывание по предикату, связывание по субъекту и связывание по объекту.
Согласно заявляемому изобретению на каждой стадии ГПУ конвейера элементарный запрос порождает ноль или более запросов для следующей стадии.
Согласно заявляемому изобретению часть памяти ГПУ предназначена для хранения базы данных, а другая часть отведена под буферы для хранения элементарных запросов, ожидающих обработки на одной из стадий ГПУ конвейера, и под промежуточные буферы.
Согласно заявляемому изобретению буферы для хранения элементарных запросов представляют собой кольцевую очередь.
Согласно заявляемому изобретению базу данных хранят в памяти в виде иерархии сбалансированных бинарных деревьев, в основе которой лежит дерево предикатов, каждый узел которого соответствует определенному предикату и ссылается на дерево субъектов, образующих с этим предикатом допустимую пару.
Согласно заявляемому изобретению при хранении базы данных в памяти используют сбалансированные бинарные деревья субъектов, каждый узел которых соответствует определенному субъекту и ссылается на дерево объектов, образующих допустимую тройку с этим субъектом и тем предикатом, которому подчинено дерево субъектов.
Для лучшего понимания заявленного изобретения далее приводится его детальное описание с привлечением графических материалов.
Фиг.1 - Схема обработки запроса на связывание.
Фиг.2 - Схема обработки SPARQL запроса.
Фиг.3 - Схема устройства стадии конвейера.
Фиг.4 - Блок-схема процедуры порождения.
Фиг.5 - Блок-схема процедуры отбрасывания.
Табл.1. Стадии GPU конвейера.
Табл.2. Результаты стадии 2 в зависимости от входных данных.
Схема способа обработки запроса на связывание, представлена на Фиг.1. Когда запрос 101 приходит на сервер базы данных, он преобразуется в набор элементарных запросов 102. Элементарный запрос по сути - это шаблон с тремя полями. Каждое поле либо задает конкретное значение субъекта (предиката, объекта), либо содержит маску, означающую, что в этой позиции может стоять любое значение. Процесс преобразования представляет собой не более, чем вычисление декартова произведения списков, составляющих запрос. Каждый элементарный запрос содержит запись для идентификации с породившим его запросом па связывание.
Элементарные запросы от разных запросов на связывание (и даже от разных клиентов) попадают в общую очередь па вход 103. Оттуда они блоками загружаются в память ГПУ и попадают на ГПУ конвейер 105. На выходе ГПУ конвейера 105 получают набор элементарных ответов. Каждый ответ представляет собой тот же самый шаблон с тремя полями, но на этот раз все поля в нем фиксированы (в них указаны конкретные значения). Присутствие такого ответа в выходной очереди 107 означает, что соответствующая тройка была обнаружена в базе, и что она удовлетворяет условиям запроса на связывание. Число элементарных ответов, таким образом, зависит от того, сколько таких троек было обнаружено.
Список троек 108, полученных из элементарных ответов, соответствующих одному и тому же запросу на связывание, является ответом на этот запрос.
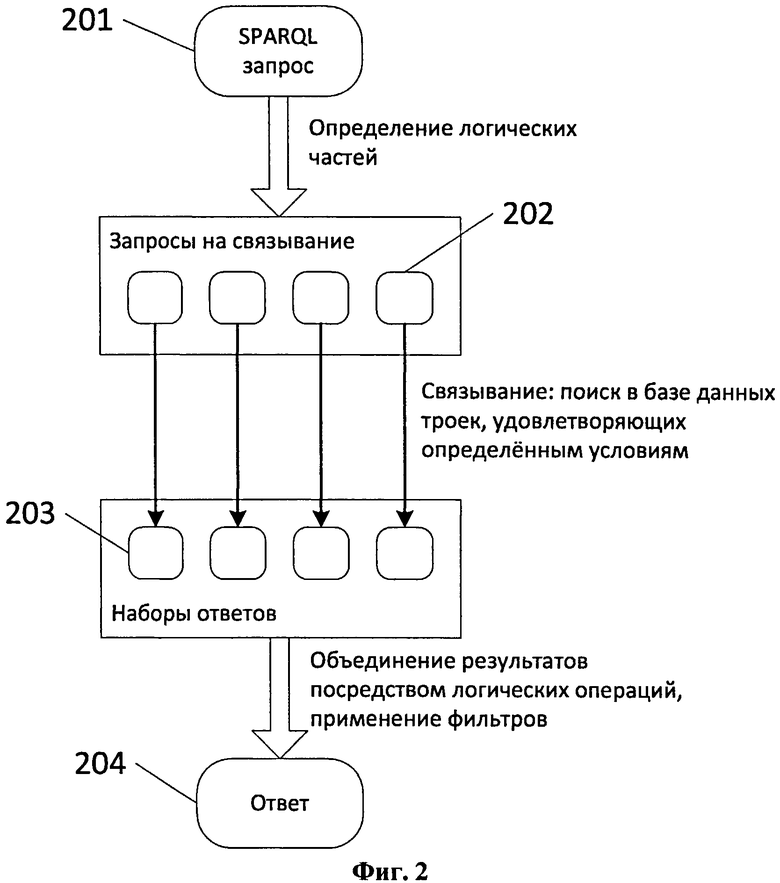
На Фиг.2 показана известная из уровня техники методика обработки SPARQL запроса 201. Процедура заключается в том, что на основе данного набора шаблонов выводится формула, оперирующая другим типом шаблонов, также соединенных знаками «И» и «ИЛИ». Здесь каждый шаблон в каждой позиции содержит либо набор допустимых значений, либо специальную маску, означающую, что в этой позиции допустимо любое значение. Каждый такой шаблон 202 фактически является простейшим запросом на извлечение данных из базы. Результатом его выполнения является множество конкретных троек 203, извлеченных из базы. Над этими множествами затем производят вычисление вышеупомянутой формулы (операция «И» заменяется на пересечение множеств, а «ИЛИ» - на объединение) и получают результирующее множество троек 204.
Что касается принципа работы ГПУ конвейера, то он поясняется па Фиг.3 и в Таблице 1.
В заявляемом изобретении ГПУ позволяет использовать его вычислительные мощности для вычислений общего назначения с помощью технологии OpenCL (Open Computing Language).
ГПУ конвейер состоит из трех стадий (см. Табл.1). В каждый конкретный момент времени графический процессор занят обработкой только одной стадии. При этом он обрабатывает несколько элементарных запросов сразу. В этот момент для процессора не играет никакой роли, каким запросом на связывание был порожден исходно тот или иной элементарный запрос. Множество запросов совершенно однородно.
На каждой стадии каждый элементарный запрос может породить ноль или более запросов для следующей стадии. В итоге на каждый элементарный запрос, попавший во входную очередь, конвейер выдает ноль или более элементарных ответов, которые записываются в выходную очередь.
Каждый раз, когда некоторая стадия заканчивает обработку, необходимо решить, какая стадия теперь загрузит графический процессор. Чтобы максимально эффективно использовать мощности графического процессора, выбирают стадию, которая обладает наибольшим потенциалом с точки зрения количества потоков. Это зависит как от числа запросов во входном буфере стадии, так и от количества свободного места в выходном буфере.
ГПУ состоит из графического мультипроцессора и некоторого объема памяти. Память эта делится па локальную (для отдельных процессоров и групп процессоров) и глобальную. Основной объем памяти приходится на глобальную память, где хранятся данные, доступ к которым может потребоваться любому процессору.
При использовании заявляемого способа часть глобальной памяти отводят под собственно базу данных (база может целиком находиться на одном ГПУ, а может быть разделена на сегменты, распределенные между несколькими устройствами), а другую часть - под буферы для хранения элементарных запросов, ожидающих обработки на одной из стадий конвейера. Важно отметить, что все данные, необходимые для ответа на любой запрос, постоянно находятся в памяти ГПУ, т.к. загрузка данных из основной памяти в память ГПУ требует весьма больших ресурсов.
Описанный конвейер последовательно проводит связывание сначала по предикату, затем по субъекту и, наконец, по объекту. Поэтому необходимо хранить базу данных в памяти таким образом, чтобы обеспечить быстрое выполнение следующих операций.
1) Проверить, является ли допустимым данный предикат р.
2) Получить список предикатов в базе.
3) Проверить, является ли допустимой данная пара предикат-субъект (р, s).
4) Получить список субъектов, образующих допустимую пару с предикатом р.
5) Проверить, является ли допустимой данная тройка (р, s, о).
6) Получить список объектов, образующих допустимую тройку с данной парой (р, s).
Эффективная реализация этих операций достигается при хранении данных в виде иерархии сбалансированных бинарных деревьев. В основе иерархии лежит дерево предикатов. Каждый узел дерева соответствует одному допустимому предикату и ссылается на дерево субъектов, образующих с этим предикатом допустимую пару. Каждый узел дерева субъектов, в свою очередь, ссылается на дерево объектов, образующих допустимую тройку с этим объектом и вышележащим предикатом. Бинарное дерево хранится в виде линейного массива узлов, где сыновья узла с номером n, имеют номера 2*n (левый) и 2*n+1 (правый). Поиск узла в таком дереве осуществляется за время O(log N), где N - число узлов в дереве.
Для работы конвейера требуется следующий набор буферов:
1) Элементарные запросы, ожидающие обработки на стадии 1 (в свободную часть этого же буфера загружаются новые элементарные запросы из основной памяти; на некоторых типах архитектур это может происходить параллельно с обработкой данных графическим процессором).
2) Элементарные запросы, ожидающие обработки на стадии 2 (в свободную часть этого же буфера попадают элементарные запросы на выходе со стадии 1).
3) Элементарные запросы, ожидающие обработки на стадии 3 (в свободную часть этого же буфера попадают элементарные запросы на выходе со стадии 2).
4) Элементарные ответы (сюда попадают элементарные запросы на выходе со стадии 3. Поскольку в них все поля уже зафиксированы, их можно назвать элементарными ответами. Отсюда же они выгружаются в основную память. На некоторых типах архитектур это может происходить параллельно с обработкой данных графическим процессором).
5) Промежуточный буфер (используется для временного хранения данных в процессе работы стадии).
Каждый из буферов, кроме промежуточного, представляет собой кольцевую очередь (очередь с ограничением на число элементов, одновременно находящихся в ней). Известно, где в данный момент находится «голова» очереди, и где - «хвост». При запуске очередной стадии конвейера выбирается максимально возможное число элементов, находящихся в «голове» входной очереди, а для результатов работы стадии выделяется место в «хвосте» выходной очереди.
Структура стадии.
Рассмотрим, для примера, стадию 2 (остальные работают похожим образом). Каждый элементарный запрос во входном буфере для этой стадии содержит шаблон, где указано конкретное значение предиката.
Будем говорить, что субъект s удовлетворяет предикату р (образует с ним допустимую пару), если в базе присутствует хотя бы одна тройка вида (р, s, о), т.е. имеется хотя бы один объект, дополняющий эту пару до полноценной тройки. Конкретное число дочерних запросов, порожденных одним элементарным запросом, зависит от того, сколько субъектов удовлетворяют указанному в нем предикату, а также от шаблона. Все возможные варианты приведены в Табл.2 (на этой стадии нас не интересует поле «объект», поэтому оно помечено знаком вопроса).
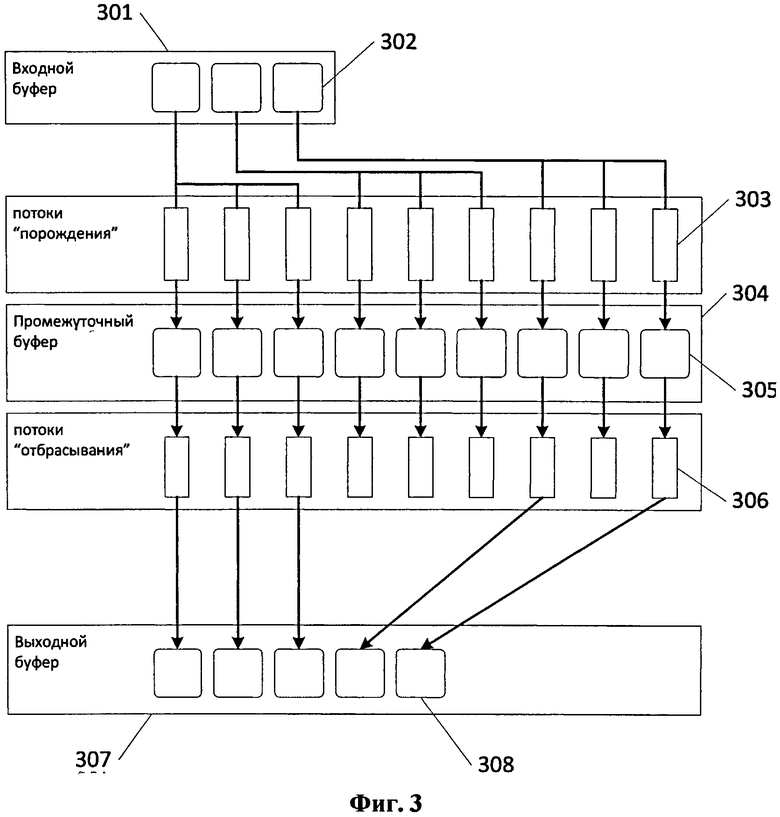
Устройство одной стадии конвейера представлено на Фиг.3. Обработка происходит в три шага:
1) Порождение.
2) Расчет смещений.
3) Отбрасывание.
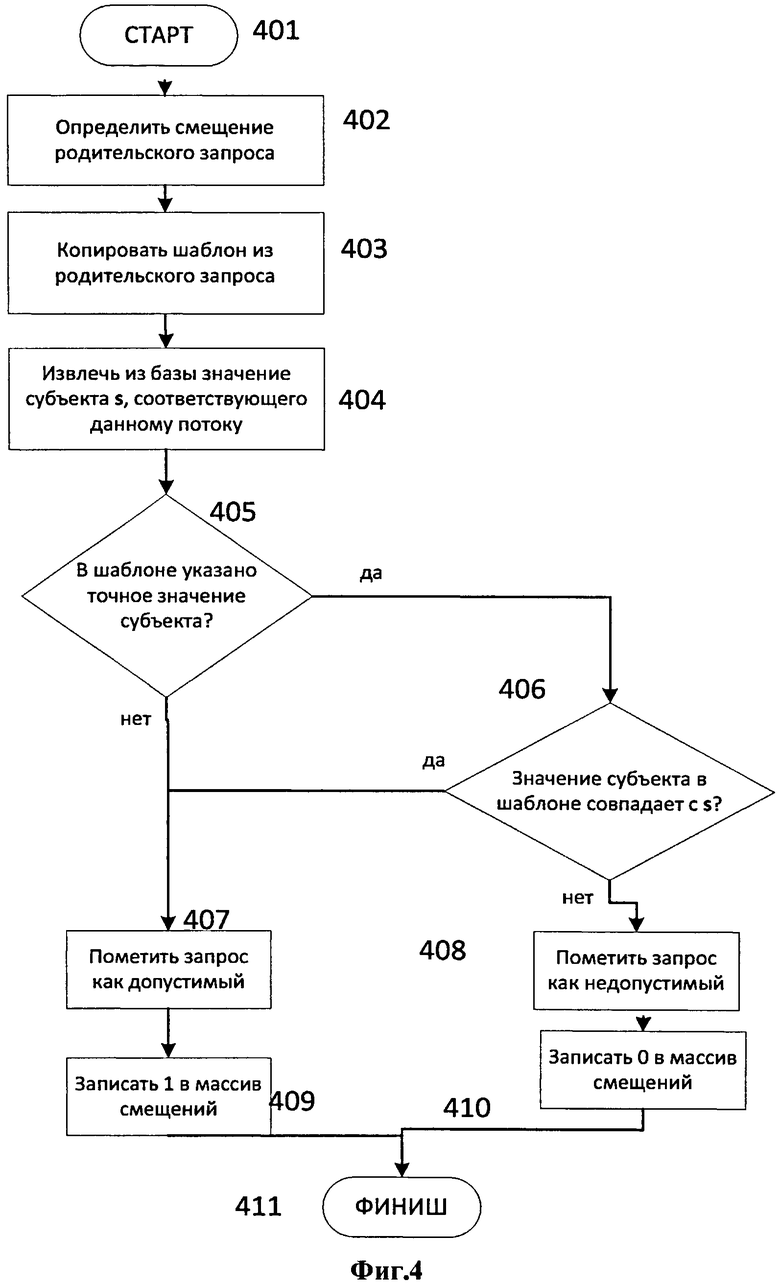
На первом шаге запускается ядро порождения. Число потоков при этом определяется тем, сколько свободного места имеется в выходном буфере 307. Блок-схема работы ядра порождения (для стадии 2) приведена на Фиг.4 (шаги 401-411). Каждый поток 303 порождает один элементарный запрос 305 и под него выделено место в промежуточном буфере 304. Изначально каждый поток 303 имеет лишь один параметр (число), отличающий его от других. Это - так называемый, глобальный ID. По нему вычисляется, какой запрос 302 из входного буфера 301 послужит родительским для данного, и шаблон из родительского запроса копируется в данный.
В этом шаблоне уже однозначно указан предикат (в случае стадии 2). Этому предикату в базе удовлетворяет некоторое число субъектов. По глобальному ID каждому потоку сопоставляется определенный субъект из этого списка. Формула определения родительского запроса такова, что число потоков 303, которые определили себя как дочерние для данного входного запроса 302, будет равно числу субъектов в этом списке.
Таким образом, каждый поток 303 создает в промежуточном буфере 304 дочерний запрос 305 с шаблоном, где фиксированы предикат и субъект. Осталось определить, имеет ли этот запрос 305 право на существование. Для этого мы должны убедиться, что либо в шаблоне в позиции «субъект» стоит маска, допускающая любые значения, либо, если там указано конкретное значение субъекта, что оно совпадает с выбранным для данного потока. Все прочие порожденные запросы помечаются как недопустимые.
Для уплотнения массива порожденных запросов используется широко известный алгоритм подсчета префиксной суммы. Для каждого допустимого запроса в соответствующую ячейку специального массива смещений заносится 1, а для недопустимого - 0. Затем запускается ядро подсчета префиксной суммы с числом потоков, равным числу порожденных запросов. В результате в каждой ячейке массива смещений оказывается сумма значений всех предыдущих ячеек. Это число можно использовать как смещение данного запроса в выходном буфере.
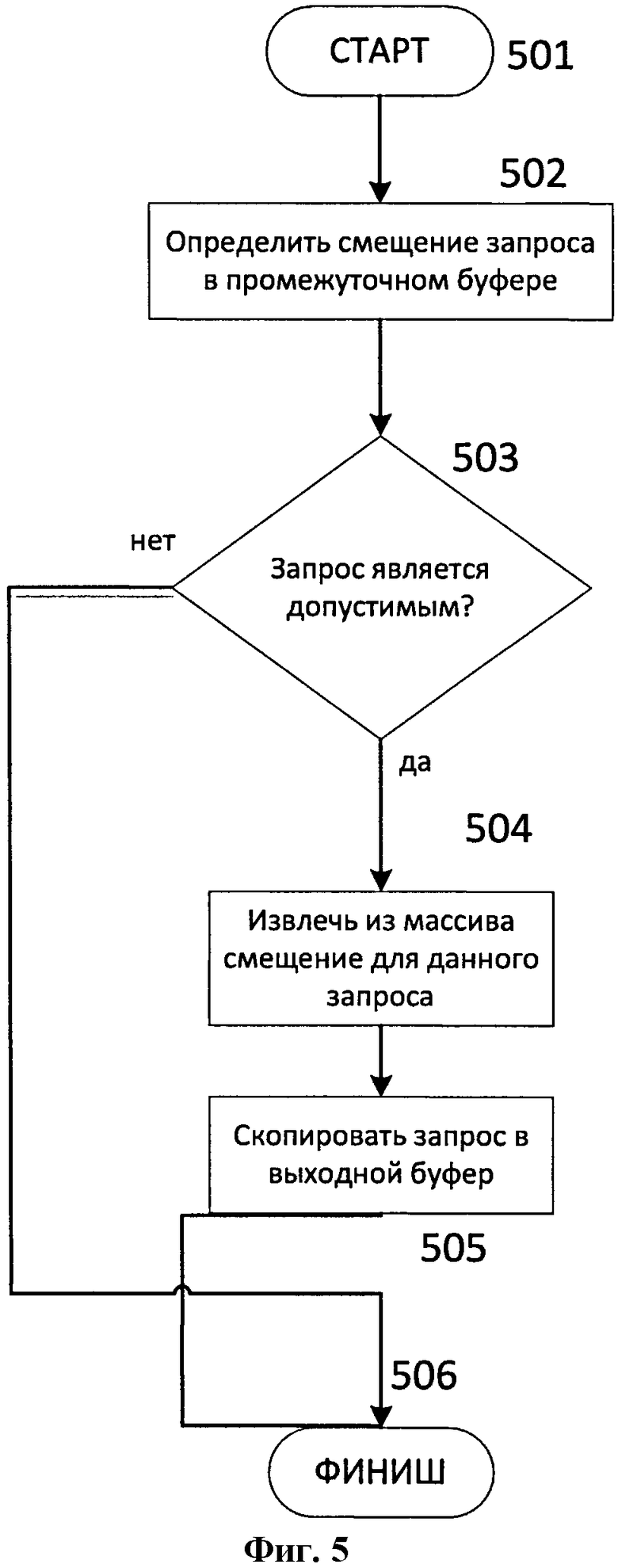
Наконец, на третьем шаге, запускается ядро отбрасывания с числом потоков 306, равным числу порожденных запросов 303. Блок-схема работы ядра отбрасывания приведена на Фиг.5 (шаги 501-506). Каждый поток по глобальному ID определяет смещение соответствующего запроса 305 в промежуточном буфере 304. В случае если запрос 305 оказывается допустимым, поток копирует его в выходной буфер 307 по смещению, извлеченному из массива смещений.
Легко видеть, что используемые ГПУ процедуры имеют достаточно простой вид с небольшим числом ветвлений. В то же время, число параллельно запускаемых потоков ограничено только числом поступивших в обработку запросов и размерами буферов. Ограничение на размер буфера не является существенным, так как объем памяти, необходимый для работы одного потока равен размеру структуры элементарного запроса, что составляет всего около 30 байт. Таким образом, используемый способ обеспечивает более высокую степень параллелизма и более высокий уровень загрузки графического процессора (при достаточном числе запросов на входе) по сравнению с способом, описанным в [3].
Ничто не препятствует применению совместно с заявляемым способом оптимизацию, предложенную в [4], но эффект ее в данном случае не может быть гарантирован, поскольку она рассчитана на определенный способ извлечения данных, скорость которого зависит от длины пути поиска, сокращение которого и является целью оптимизации.
Замеры производительности в описанном варианте реализации заявляемого способа показывают, что на некоторых видах запросов появляется возможность получения выигрыша в три раза по отношению к алгоритму обработки, исполнявшемуся на современном центральном процессоре. С увеличением числа процессоров в графическом мультипроцессоре и объема памяти на ГПУ устройстве способ будет давать все больший эффект.
Литература
1. - Program product for optimizing parallel processing of database queries (US 6009265, 12/28/1999)
2. - Database early parallelism method and system (US 20050131893, 06/16/2005)
3. - GPU ENABLED DATABASE SYSTEMS (US 20110264626, 10/27/2011)
4. - METHOD AND SERVER FOR HANDLING DATABASE QUERIES (WO 2011162645, 12/29/2011)
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ГЛОБАЛЬНОЙ ИДЕНТИФИКАЦИИ В КОЛЛЕКЦИИ ДОКУМЕНТОВ | 2015 |
|
RU2591175C1 |
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ ГРАФОВ | 2015 |
|
RU2708939C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ ДАННЫХ ГРАФОВ | 2012 |
|
RU2605387C2 |
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ХРАНЕНИЯ И ПОИСКА ИНФОРМАЦИИ, ИЗВЛЕКАЕМОЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ | 2015 |
|
RU2605077C2 |
| ГЕНЕРАЦИЯ СОБЫТИЙ С ИСПОЛЬЗОВАНИЕМ КОНТЕКСТНОЙ ИНФОРМАЦИИ НА ИНТЕЛЛЕКТУАЛЬНОМ ПРОГРАММИРУЕМОМ ЛОГИЧЕСКОМ КОНТРОЛЛЕРЕ | 2015 |
|
RU2683415C1 |
| КОНТЕКСТНЫЕ ЗАПРОСЫ | 2011 |
|
RU2573764C2 |
| Способ и система автоматизированного документирования угроз безопасности и уязвимостей, относящихся к информационному ресурсу | 2022 |
|
RU2789990C1 |
| СПОСОБ ЗАЩИТЫ ВЕБ-ПРИЛОЖЕНИЙ ПРИ ПОМОЩИ ИНТЕЛЛЕКТУАЛЬНОГО СЕТЕВОГО ЭКРАНА С ИСПОЛЬЗОВАНИЕМ АВТОМАТИЧЕСКОГО ПОСТРОЕНИЯ МОДЕЛЕЙ ПРИЛОЖЕНИЙ | 2017 |
|
RU2659482C1 |
| БИОИНФОРМАЦИОННЫЕ СИСТЕМЫ, УСТРОЙСТВА И СПОСОБЫ ДЛЯ ВЫПОЛНЕНИЯ ВТОРИЧНОЙ И/ИЛИ ТРЕТИЧНОЙ ОБРАБОТКИ | 2017 |
|
RU2799750C2 |
Изобретение относится к технологиям обработки информации, а более конкретно - к способам обеспечения доступа к информации, хранящейся в базах данных. Техническим результатом является увеличение пропускной способности сервера обработки запросов. Заявлен способ параллельной обработки множественных запросов к RDF базам данных при помощи графического процессора, отличающийся тем, что поступивший на сервер запрос на связывание предварительно разбивают на элементарные запросы, после чего указанные элементарные запросы помещают в общую очередь на вход, откуда их блоками загружают в память устройства графического процессора (ГПУ) и пропускают через ГПУ-конвейер, где для каждого элементарного запроса вычисляют набор элементарных ответов и затем объединяют полученные ответы в список троек, являющийся ответом на запрос на связывание. 2 н. и 16 з.п. ф-лы, 5 ил., 2 табл.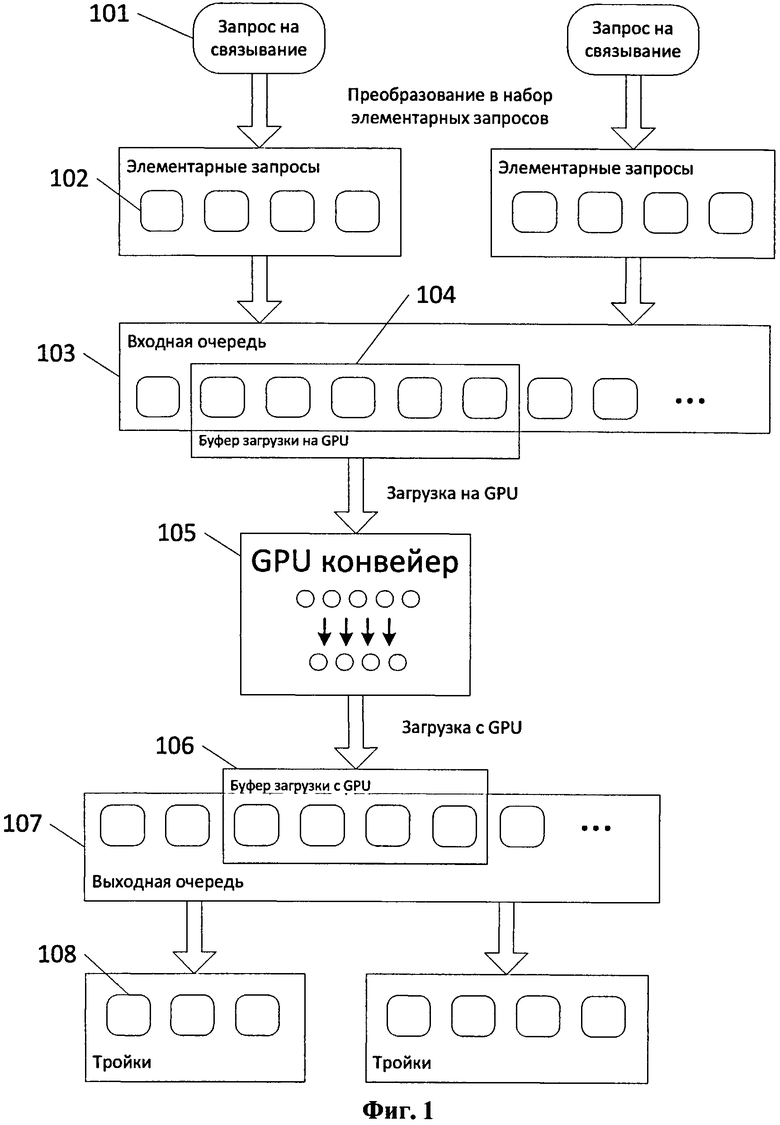
1. Способ параллельной обработки множественных запросов к RDF базам данных при помощи графического процессора, отличающийся тем, что поступивший на сервер запрос на связывание предварительно разбивают на элементарные запросы, после чего указанные элементарные запросы помещают в общую очередь на вход, откуда их блоками загружают в память устройства графического процессора (ГПУ) и пропускают через ГПУ-конвейер, где для каждого элементарного запроса вычисляют набор элементарных ответов, и затем объединяют полученные ответы в список троек, являющийся ответом на запрос на связывание.
2. Способ по п.1, отличающийся тем, что ГПУ устройство выполнено с возможностью использования его вычислительных мощностей для вычислений общего назначения с помощью технологии Open Computing Language.
3. Способ по п.1, отличающийся тем, что запрос на связывание представляют в виде набора из трех списков, каждый из которых содержит набор допустимых значений для субъекта, предиката и объекта соответственно, причем пустой список означает, что в соответствующей позиции допускается любое значение.
4. Способ по п.1, отличающийся тем, что элементарный запрос представляет собой шаблон с тремя полями, в каждом из которых содержится либо конкретное значение для субъекта, предиката и объекта, либо маска, означающая, что в этой позиции допускается любое значение.
5. Способ по п.1, отличающийся тем, что преобразование запроса на связывание в набор элементарных запросов выполняют посредством вычисления декартова произведения множеств, заданных списками, составляющими запрос на связывание.
6. Способ по п.1, отличающийся тем, что каждый элементарный запрос содержит запись для идентификации с породившим его запросом на связывание.
7. Способ по п.1, отличающийся тем, что обработку элементарных запросов на ГПУ конвейере осуществляют в три стадии, на каждой из которых для каждого элементарного запроса, поступившего с предыдущей стадии, вычисляют набор элементарных запросов для следующей стадии и записывают в каждом из полученных запросов в поле, соответствующем текущей стадии, определенное значение, таким образом, что оно в комбинации со значениями полей, соответствующих предыдущим стадиям, образует допустимое сочетание.
8. Способ по п.7, отличающийся тем, что при обработке запросов на ГПУ конвейере последовательно осуществляют связывание по предикату, связывание по субъекту, связывание по объекту.
9. Способ по п.7, отличающийся тем, что на каждой стадии ГПУ конвейера сначала с помощью ГПУ процедуры расширения для каждого элементарного запроса из входного буфера вычисляют набор элементарных запросов для следующей стадии и записывают их в промежуточный буфер, где выделено место под максимально возможное количество запросов, проверяя при этом для каждого полученного запроса, содержит ли он допустимое сочетание полей, а затем с помощью ГПУ процедуры отбрасывания перемещают прошедшие проверку запросы в выходной буфер, который является одновременно входным буфером для следующей стадии.
10. Способ по п.7, отличающийся тем, что после окончания текущей стадии обработки данных ГПУ устройством следующую стадию для обработки выбирают с таким расчетом, чтобы она использовала максимальное количество ГПУ потоков.
11. Система RDF базы данных на основе устройства графического процессора (ГПУ) для параллельной обработки множественных запросов, включающая сервер для получения запросов на связывание к базе данных, где осуществляют преобразование запроса на связывание в набор элементарных запросов, базу данных, устройство графического процессора, выполненное с возможностью параллельной обработки запросов к базе данных, содержащее память и ГПУ конвейер, выполненный с возможностью вычисления набора элементарных ответов для каждого элементарного запроса, и последующего объединения полученных ответов в список троек, являющихся ответом на запрос на связывание к базе данных.
12. Система по п.11, отличающаяся тем, что конвейер устройства графического процессора состоит из трех последовательно выполняемых стадий обработки элементарных запросов.
13. Система по п.12, отличающаяся тем, что стадии обработки элементарных запросов представляют собой связывание по предикату, связывание по субъекту и связывание по объекту.
14. Система по п.12, отличающаяся тем, что на каждой стадии ГПУ конвейера элементарный запрос порождает ноль или более запросов для следующей стадии.
15. Система по п.12, отличающаяся тем, часть памяти устройства графического процессора выполнена с возможностью хранения базы данных, а другая часть выполнена с возможностью использования под буферы для хранения элементарных запросов, ожидающих обработки на одной из стадий ГПУ конвейера, и под промежуточные буферы.
16. Система по п.15, отличающаяся тем, что база данных хранится в памяти в виде иерархии сбалансированных бинарных деревьев, в основе которой лежит дерево предикатов, каждый узел которого соответствует определенному предикату и ссылается на дерево субъектов, образующих с этим предикатом допустимую пару.
17. Система по п.15, отличающаяся тем, что при хранении базы данных в памяти используются сбалансированные бинарные деревья субъектов, каждый узел которых соответствует определенному субъекту и ссылается на дерево объектов, образующих допустимую тройку с этим субъектом и тем предикатом, которому подчинено дерево субъектов.
18. Система по п.12, отличающаяся тем, что буферы для хранения элементарных запросов представляют собой кольцевую очередь.
| ПЛАТФОРМА ДЛЯ СЛУЖБ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ НЕСОПОСТАВИМЫМИ ОБЪЕКТНЫМИ СРУКТУРАМИ ПРИЛОЖЕНИЙ | 2006 |
|
RU2425417C2 |
| Химический огнетушитель | 1927 |
|
SU8675A1 |
| СЕМАНТИЧЕСКАЯ НАВИГАЦИЯ ПО ВЕБ-КОНТЕНТУ И КОЛЛЕКЦИЯМ ДОКУМЕНТОВ | 2007 |
|
RU2442214C2 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| US 7987176 B2, 26.07.2011. | |||

