Область техники, к которой относится изобретение
Данное изобретение относится к методам и системам автоматизации обучения лексике (расширения словарного запаса) при помощи учебного контекстного словаря и системы автоматического перевода.
Уровень техники
В настоящее время существует некоторое количество общедоступных он-лайновых словарей и систем обучения лексике иностранных языков. Как правило, в таких системах пользователь может ввести слово или фразу на одном языке и получить их перевод на интересующий пользователя язык. Такие системы могут быть использованы при изучении иностранных языков, но они должны быть созданы заблаговременно и не могут отражать интересов и потребностей пользователя. Создание подобных систем и адаптация их к запросам каждого конкретного пользователя может быть долгим, сложным и дорогим процессом. Предлагаемое изобретение призвано решить проблему автоматического создания систем персонализированного изучения лексики (расширения словарного запаса) на основе анализа статистических характеристик собранных пользователями (крауд-сорсных) материалов.
Раскрытие изобретения
Данное изобретение относится к системам и методам автоматического создания списков слов (словарей, вокабуляров), используемым для обучения иностранным языкам, решающее названные выше проблемы персонализации такого обучения.
Данное изобретение представляет собой способ и систему, включающую компьютерную программу, создающие индивидуализированные списки слов и фраз (словари, вокабуляры), встреченных пользователями, с точными контекстно-обусловленными переводами таковых.
Технический результат, достигаемый заявленными решениями, заключается в обеспечении возможности просматривать, выбирать и сохранять переводы слов и фраз в определенном контексте. Словарь-переводчик отражает частотность определенного перевода данного слова или фразы в данном контексте данного языка.
Результат, достигаемый заявленными решениями, заключается в ускорении и улучшении запоминания лексики изучаемого языка пользователем при помощи персонализации слов и фраз, которая состоит в изучении лексических единиц в контекстах и в значениях, релевантных пользователю. Указанный результат достигается при помощи крауд-сорсного способа обучения лексике при помощи компьютера, в которой все лексические единицы получают контекстно-обусловленные переводы, качество которых основано на рейтингах, которые присваивают пользователи. Лексические единицы, их контексты, а также прочие метаданные (присвоенные им рейтинги, показатели освоенности, транскрипции, звучание и пр.) могут быть обработаны статистическими алгоритмами и хранятся в базе данных.
После создания несколькими пользователями личных словарей способ высчитывает количество раз использования различных переводов, выбранных пользователями. Когда пользователь работает с текстом, текст подвергается обработке, заключающейся в определении количества раз использования каждого слова в данном тексте. Информация о количестве раз использования слов сохраняется на сервере. Со временем на сервере накапливается большое количество статистики о количестве раз использования слов в разных текстах. База данных содержит информацию о дистрибутивных характеристиках слов и фраз (n-граммы, контекстное окружение второго порядка) в текстах.
Контекстный словарь позволяет пользователю добавлять аудио, видео и графические изображения и прочие метаданные (геолокацию, время и пр.), иллюстрирующие значение слова. Это позволяет увеличить релевантность нового слова к личному опыту пользователя, что позволяет лучше запомнить лексическую единицу. Добавление аудио-визуальных иллюстраций также помогает запоминать слова, используя слуховые и зрительные ассоциации (некоторые люди запоминают аудиоконтент лучше, другие - склонны лучше запоминать зрительные образы).
В дальнейшем создается личный словарь пользователя, основанный на этой статистике. Этот словарь позволяет пользователю увидеть различные варианты перевода слова в зависимости от конкретного контекста.
Краткое описание чертежей
Приложенные схемы и изображения призваны проиллюстрировать изобретение, принцип его работы и устройства. Схемы и изображения являются неотъемлемой частью данного документа.
Фиг. 1 иллюстрирует общую архитектуру, используемую для построения пользовательского словаря-переводчика на основе количества раз использования;
Фиг. 2 иллюстрирует метод подсчета количества раз использования слов, выбранных пользователем;
Фиг. 3 иллюстрирует метод тренировки новых слов из словаря пользователя;
Фиг. 4 иллюстрирует генерацию контекстных метаданных слова;
Фиг. 5 иллюстрирует использования количества раз использования перевода;
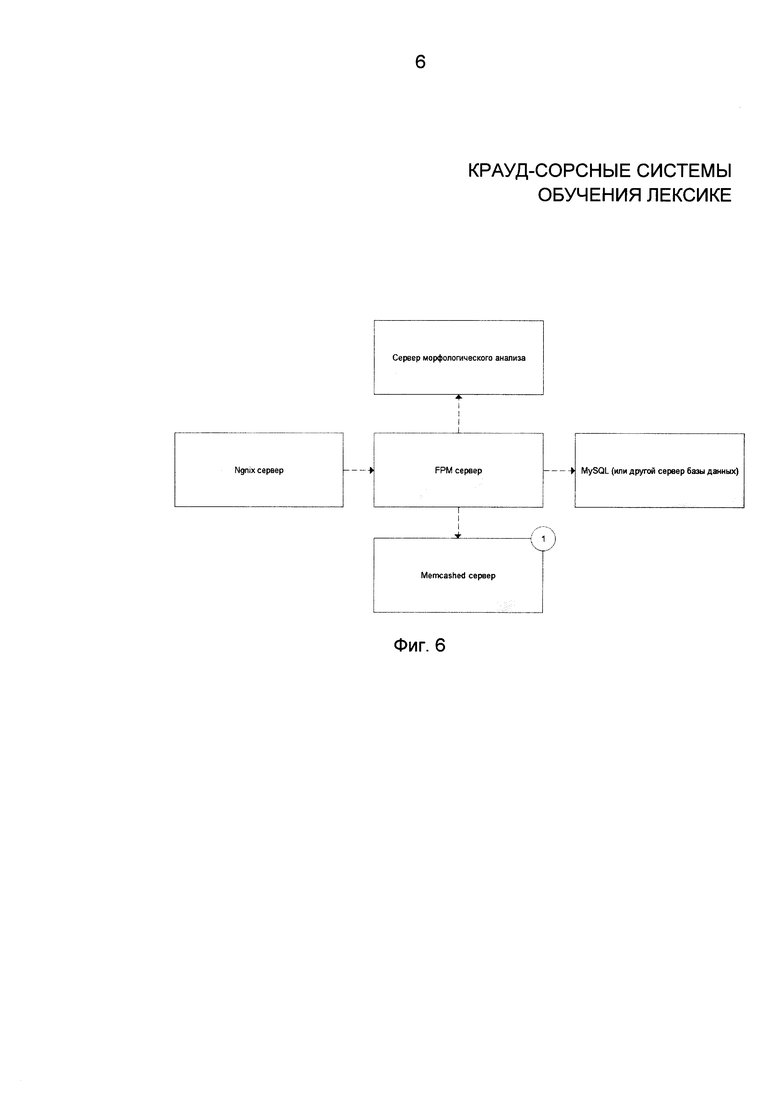
Фиг. 6 иллюстрирует взаимодействие серверов;
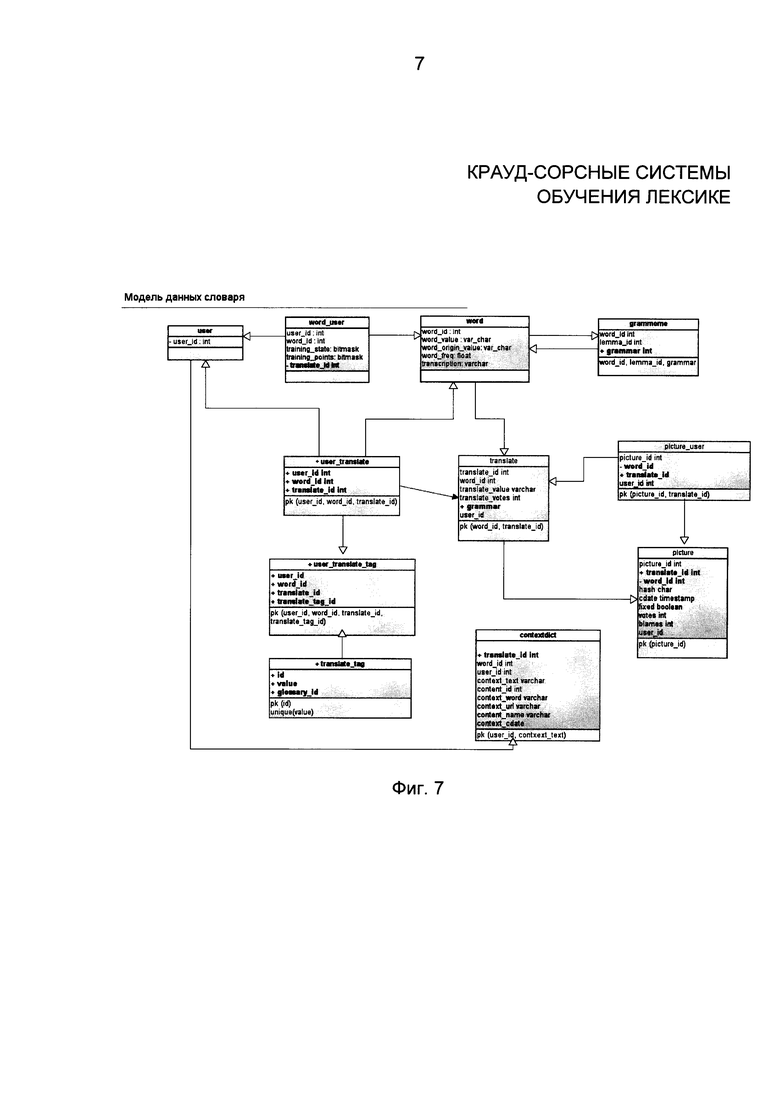
Фиг. 7 иллюстрирует структуру данных и взаимодействие отдельных компонентов способа;
Фиг. 8 - снимок экрана с примером, иллюстрирующим Фиг. 5, со словом «run»;
Фиг. 9 - снимок экрана с примером программного интерфейса словаря;
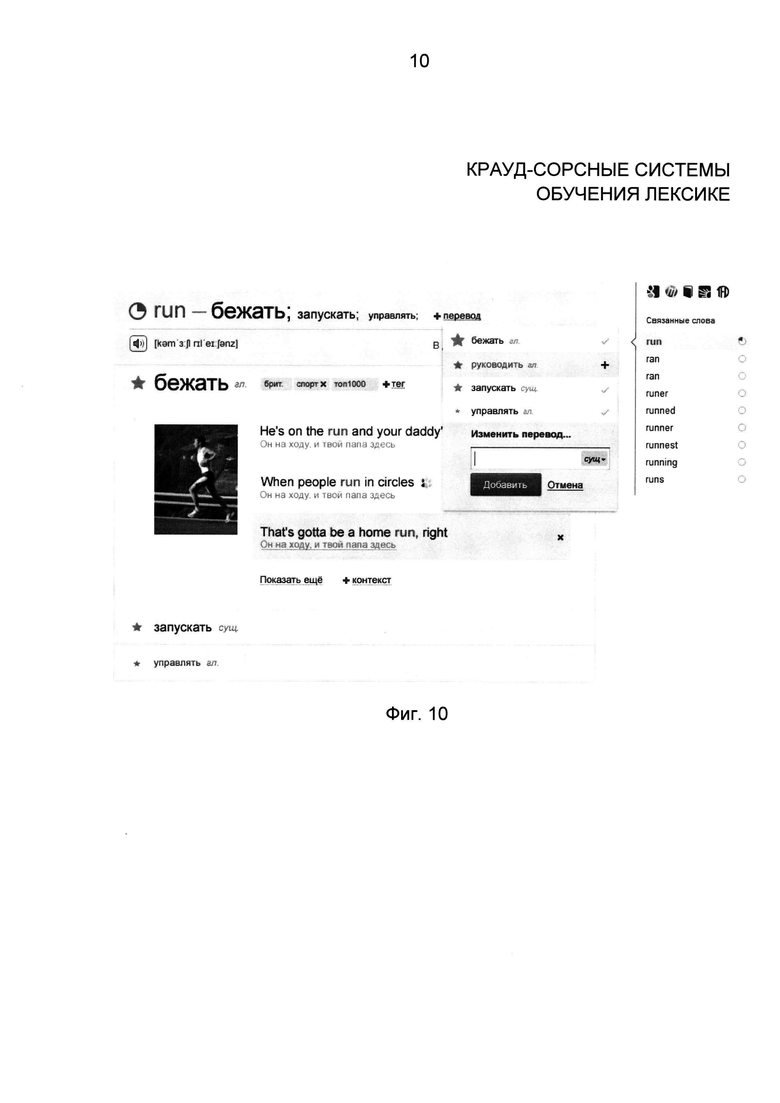
Фиг. 10 - снимок экрана с полем текстового ввода, куда пользователь может записать свой перевод;
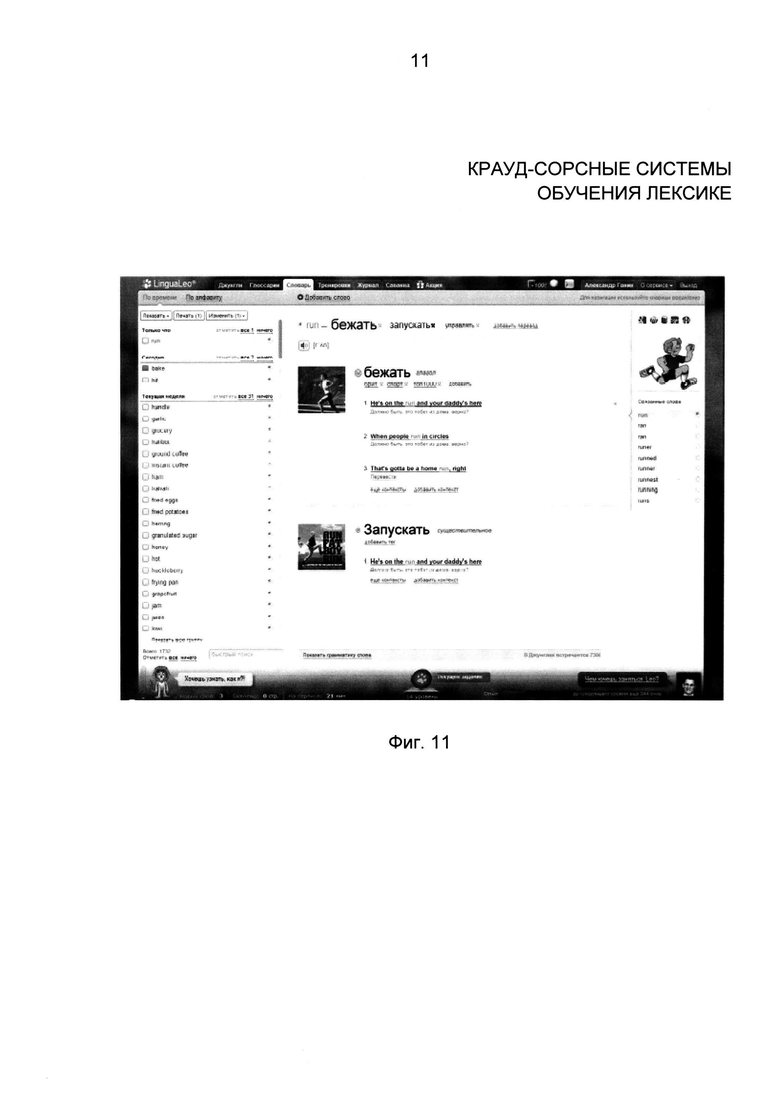
Фиг. 11 - пример интерфейса словаря для различных переводов слова «run»;
Фиг. 12 - пример аппаратно-программного комплекса, который может быть использован для реализации данного изобретения.
Осуществление изобретения
Изобретение представляет собой способ и систему, включающую компьютерную программу, для автоматического создания индивидуального учебного словаря, основанного на собранной контекстно-зависимой статистике и способного предоставлять точный, контекстно-обусловленный, перевод слов и фраз на основе собранной ранее статистики переводов другими пользователями.
Изначально пользователь располагает персональным словарем, содержащим слова и фразы, добавленные и переведенные пользователем самостоятельно. Контекстный словарь позволяет пользователю выбирать наиболее подходящее значение слова для перевода и сохранить его вместе с контекстом для дальнейшего использования.
После того, как большое количество пользователей создали свои личные словари на основе, например, 50 тыс. контекстов, подсчитывается количество раз использования контекстно-обусловленных переводов слов и фраз. Когда пользователь работает с текстом, текст подвергается лингвистической обработке, которая позволяет определить количество раз использования каждого слова или фразы в различных контекстах. Эта информация о количество раз использования слов сохраняется на сервере. Через некоторое время накапливается значительное количество статистических данных. Эти данные отражают статистическую дистрибуцию (например, n-граммы и/или контексты второго порядка) различных слов и фраз в текстах.
На основе собранной статистики создается словарь пользователя. Этот словарь позволяет пользователю видеть все возможные переводы данного слова в данном контексте. Осуществление изобретения предполагает наличие возможности просматривать, выбирать и сохранять переводы слов и фраз. Словарь-переводчик отражает количество раз использования определенного перевода данного слова или фразы в данном контексте данного языка.
Словарь-переводчик с течением времени совершенствуется (обучается) по мере добавления пользователями новых слов и фраз. Осуществление изобретения предполагает совершенствование словаря-переводчика при помощи «крауд-сорсинга» (от англ. crowd-sourcing, crowd - «толпа» и sourcing - «использование ресурсов»). «Обучение» словаря-переводчика может быть осуществлено при помощи различных алгоритмов машинного обучения (байесовский алгоритм, векторов поддержки и т.д. на основе различных типов данных: n-грамм, частеречной принадлежности слов, анализа контекста и пр.)
Иными словами, способ развивается большой группой заинтересованных пользователей, которые выбирают те переводы слов и фраз, которые они считают наиболее подходящими. Полученные таким образом данные могут быть в дальнейшем использованы для улучшения словаря при помощи алгоритмов машинного обучения, обработки естественного языка и прочих алгоритмов и техник.
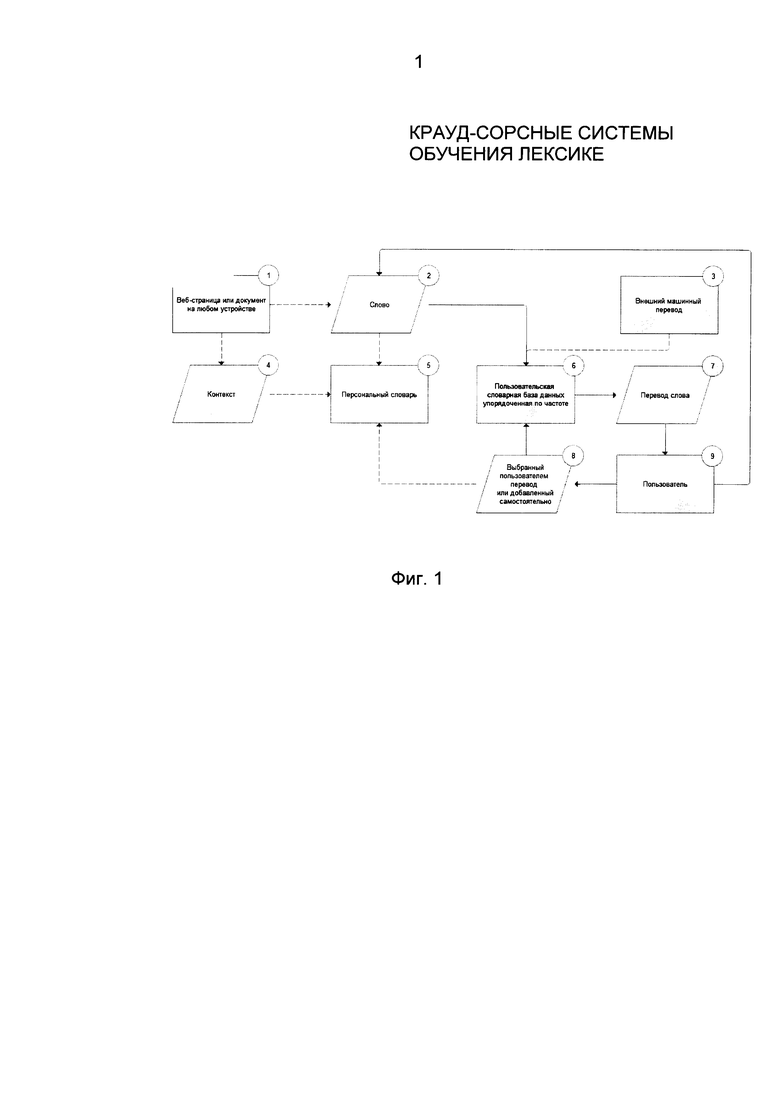
Фиг. 1 иллюстрирует общую архитектуру способа, используемую для создания частотного словаря-переводчика. Частотный словарь-переводчик 110 выполнен в виде базы данных 130, содержащей слова, переводы и метаданные. Источником пополнения частотного словаря-переводчика 110 являются слова 100, встреченные пользователем на веб-страницах 115, в документах и прочих текстовых файлах.
В соответствии с осуществлением изобретения, частотный словарь-переводчик 110 пополняется пользователями 140, которые встречают новые иностранные слова на веб-страницах и выбирают наиболее частотный перевод, обусловленный контекстом. Слова и фразы на веб-страницах обрабатываются в браузере при помощи специального приложения или дополнения к браузеру, поддерживаемому системным программным интерфейсом. В случае мобильных приложений (смартфоны, планшеты и пр.) словарная обработка производится специально разработанным программным обеспечением, позволяющим пользователю выбирать слова. Программа-клиент для персональных компьютеров позволяет пользователям работать со словами в документах, расположенных в памяти компьютера.
После того как пользователь 140 выбирает слово 100 в текстовом документе 115, слово 100 вместе с контекстом 100 сохраняется в личном словаре пользователя. Затем перевод слова 100 извлекается контекстной словарной базы 130. Если база данных 130 не содержит перевода для данного слова, перевод находится во внешних источниках (автоматических переводчиках) 125 и сохраняется в базу данных 130. Если пользователь 140 вводит свой собственный перевод 145, такой перевод добавляется в его личный словарь 110 и в базу данных для дальнейшего использования.
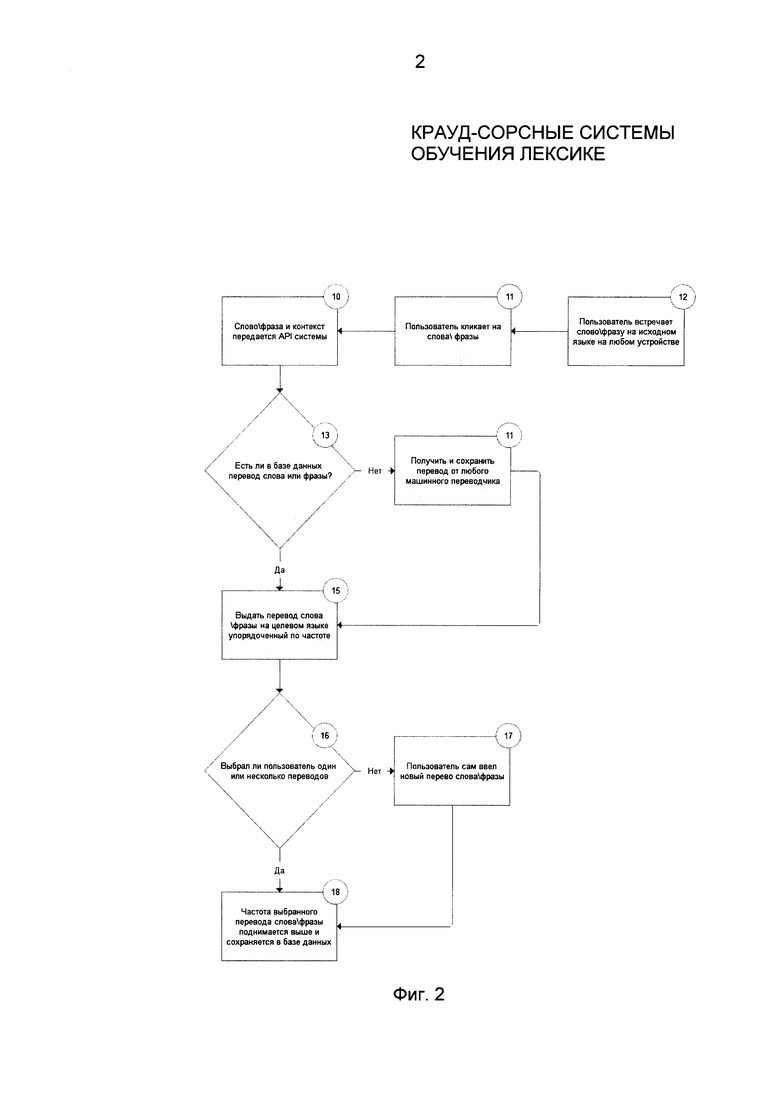
Фиг. 2 иллюстрирует метод расчета количества раз использования перевода для данного слова в соответствии с осуществлением изобретения. Пользователь встречает незнакомое слово в тексте (230) и выбирает слово (шаг 220). Выбранное слово (или фраза), а также его контекст передается по системному интерфейсу (шаг 210). Система проверяет наличие перевода в базе данных (шаг 240). Если переводы найдены в шаге 240, система показывает их в шаге 260 в виде списка различных вариантов перевода слова (фразы) на необходимый пользователю язык, отсортированных по их частотности (популярности) в данном контексте.
Если на шаге 240 не найдено ни одного перевода, система получает перевод из систем автоматизированного перевода на шаге 250 и показывает его пользователю на шаге 260. Если на шаге 270 пользователь выбирает один или несколько переводов, показатель количества раз использования для таких переводов увеличивается и сохраняется в базе данных на шаге 290. Если на шаге 270 пользователь не выбирает перевод, но добавляет свой собственный на шаге 280, то такой перевод также сохраняется в базе данных на шаге 270.
Частотность переводов основана на количестве раз, когда пользователь выбирал этот перевод. Такая система подсчета может представлять собой простой инкрементальный счетчик. Осуществление изобретения предполагает постоянное сохранение контекста слова (фразы). Контекст сохраняется вместе со словом в личный словарь пользователя в общую (крауд-сорсную) базу данных. Когда пользователь запрашивает перевод, система сначала ищет перевод в словаре пользователя с таким же контекстом и метаданными. Если перевод не может быть найден в словаре пользователя, то поиск происходит по общей (крауд-сорсной) базе данных.
Контекст может быть определен как текст, окружающий слово, выбранное пользователем. Длина контекста может быть установлена как количество слов до и после данного слова или как лингвистическая единица (например, предложение, содержащее выбранное слово).
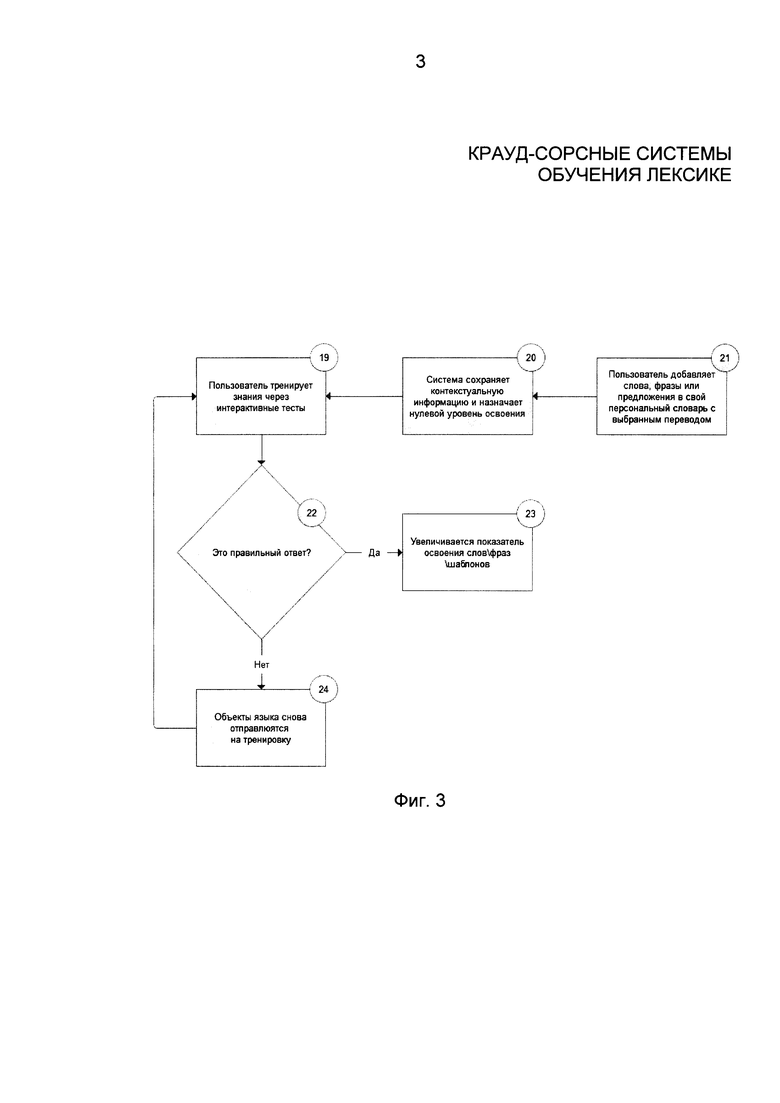
Фиг. 3 показывает метод тренировки слов из пользовательского личного словаря. Согласно осуществлению изобретения, все слова в пользовательском словаре имеют показатель состояния изученности, изначально равный нулю. Показатель состояния изученности увеличивается на единицу при каждой тренировке данного слова пользователем. Чем выше значение показателя, тем лучше знает пользователь слово. Слова периодически предлагаются пользователю для тренировки, а также тестируется уровень знания их. Если пользователь успешно проходит предложенные тренировки (тесты), то значение уровня изученности увеличивается на единицу. Слова, на которые пользователь совершает ошибки в ходе тренировок (или тестов), отправляются на повторные тренировки через некоторое время. Время, через которое слова предлагаются пользователю для повторной тренировки, может варьироваться и зависит от модели обучения.
На шаге 310 пользователь добавляет слово (или фразу) с выбранным переводом в свой словарь. Система также сохраняет информацию о контексте, метаданные для данного слова и присваивает нулевое значение состоянию изученности на шаге 320. Пользователю предлагается пройти интерактивные тесты для проверки знания и закрепления знаний о слове в шаге 330. Различные типы тестов могут быть использованы на данном этапе, в зависимости от целей и потребностей пользователя. Тестовые задания могут быть следующих типов:
- дать правильный перевод;
- написать слово под диктовку;
- услышав перевод слова, написать исходное слово.
Если пользователь дал правильные ответы на шаге 340, значение показателя изученности увеличивается на шаге 350. Иначе слово заново отправляется на изучение в шаге 360.
Фиг. 4 показывает, какие метаданные о слове используются в осуществлении изобретения. Слово 100 имеет несколько типов метаданных. Каждое слово 100 имеет один или несколько переводов. Каждый перевод может иметь визуальную иллюстрацию 413 (например, картинку, взятую из открытых источников или из базы данных системы). Каждый перевод 410 имеет частотность (популярность) 414.
Перевод 410 может принадлежать к определенной тематической группе 412. Каждый перевод имеет контекст (например, предложение или определенное количество окружающих его слов) 411, определяющий значение слова. Кроме того, слово 100 имеет транскрипцию 420 и звучание 430. Каждое слово 100 имеет значение степени изученности, которое отражает правильность выбора перевода в предложенных пользователю упражнениях (тренировках) и тестах. Каждое слово 100 может иметь связи с другими словами 450. Связанными словами называются слова, имеющие различные типы семантической связи с данным словом: синонимы, антонимы и пр., а также имеющие несемантические связи: близкое написание, схожее произношение и пр.
Как было отмечено выше, в случае, если система не имеет перевод и метаданных для слова, она может использовать доступные внешние ресурсы. Таким образом, даже в самом начале работы имеет некоторое минимально необходимое количество переводов и метаданных для исходного набора слов.
Осуществление изобретения совершенствует процесс обучения, позволяя пользователям самостоятельно определять содержание обучения. Например, пользователь по своему усмотрению может начать изучение с частых (высокочастотных) переводов слова, а продолжить - редкими, низкочастотными. Пользователь может изучать слова по темам, речевым шаблонам, типам семантической связи и пр. Иными словами, пользователь может изучать любые группы слов, выбранных по определенным метаданным.
Система может предоставлять переводы текстов и веб-страниц, сделанные пользователями. Возможно производить анализ шаблонов предложений. Такие шаблоны являются результатом анализа контекстов, в которых слово употребляется чаще всего. Например, слово run («бежать») может встречаться в следующих контекстах: I run every day. She runs every morning. John runs in the park. Таким образом, шаблон будет PERSON run(s) TIME or PLACE.
Подобные шаблоны облегчают поиск общих контекстов в различных предложениях, что делает возможным использование переводов других пользователей в новых предложениях, встречаемых новым пользователем. База данных является динамической, постоянно пополняемой пользователями, и постоянно обучающейся на основе извлечения все новых шаблонов.
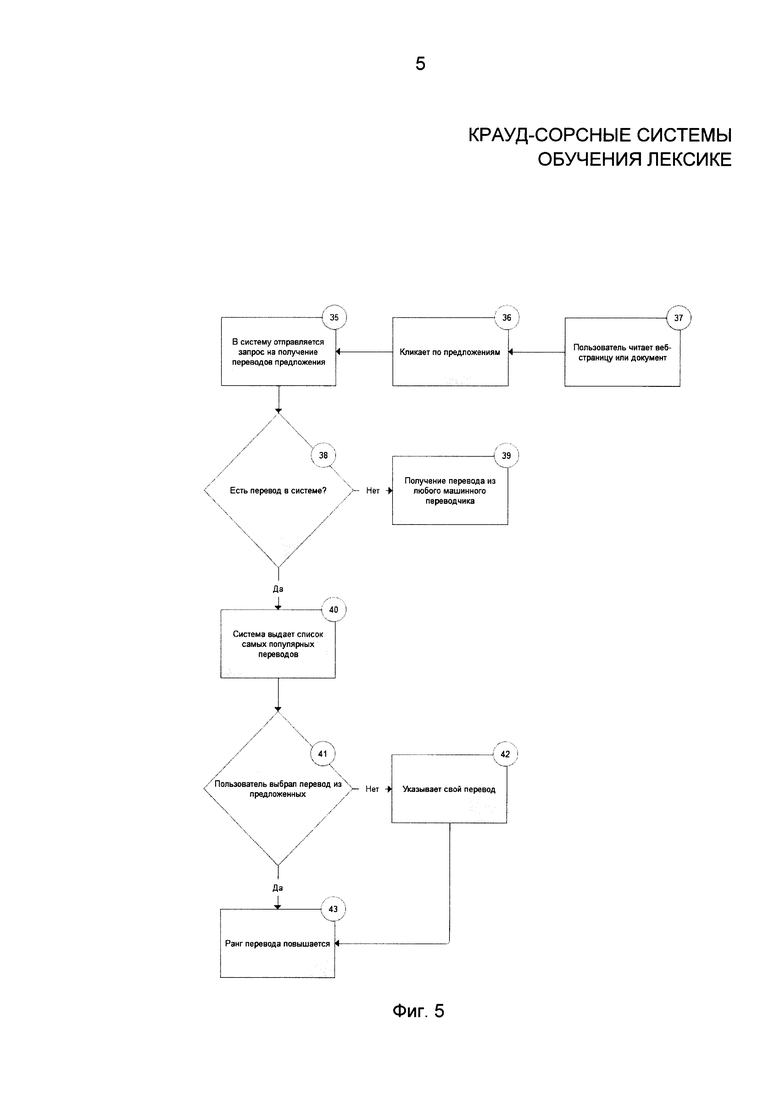
Фиг. 5 содержит пример использования параметра частоты перевода. Русскоязычный пользователь встретил незнакомое ему слово в предложении «Не runs the company very well». В данном примере слово «runs» является незнакомым, которое пользователь выбирает, чтобы выбрать наиболее подходящий перевод. У этого слова показатель количества раз использования равен 3454. Это значит, что у данного слова есть много переводов на русский язык. Первый перевод (на переднем плане) является наиболее очевидным и означает «бегать». Значение количества раз использования этого перевода равно 500. Пользователь выбирает более низкочастотный перевод «руководить» или «управлять», основываясь на значении слова в данном контексте. Таким образом значение количества раз использования данного перевода (напр. «руководить») увеличивается.
Фиг. 6 иллюстрирует аппаратную инфраструктуру изобретения. Веб-интрефейс основан на Nginx Server 640, который направляет данные серверу FastCGI Process Manager 620, который сохраняет информацию в кэширующем сервере 650 и отправляет текстовую информацию (слова и контексты) на сервер лингвистического анализа 610 для лингвистической обработки (лемматизации, определения частей речи, анализа контекста и т.д.). Результат лингвистической обработки сохраняется на сервере MySQL (или иной системе хранения данных) 630 в словаре пользователя или в глобальном словаре.
Фиг. 7 описывает структуру данных и схему работы отдельных элементов системы. Персональный словарь имеет три таблицы: UserDictionary, UserTranslations и ContextDictionary.
Пользователь добавляет новое слово в свой личный словарь путем добавления новой записи в UserDictionary. Слово записывается в поле word_value и ему присваивается идентификатор (word_id), слово связано с идентификатором пользователя user_id. Слово также имеет такие характеристики как язык (lang) и время добавления в словарь created_at. Сочетание user_id и word_id составляет уникальный первичный идентификатор.
Пользователь также добавляет перевод в свой личный словарь, который записывается в поле UserTranslation. Сам перевод хранится в поле trans_value. Каждый перевод связан с пользователем при помощи user_id, со словом при помощи word_id и имеет уникальный идентификатор (trans_id). Для обеспечения возможности работы системы с различными языковыми парами язык слова хранится в поле word_lang, а язык перевода - в поле trans_lang. Для увеличения скорости работы системы в UserTranslations можно кэшировать слова как значение word_value. Сочетание user_id и trans_id составляют уникальный первичный идентификатор.
ContextDictionary сохраняет контекст каждой пары слово-перевод. Каждая запись в этой таблице связана с пользователем при помощи user_id. Каждый контекст связан с парой слово-перевод при помощи word_id и trans_id, значения которых могут быть кэшированны в word_value и trans_value для увеличения скорости поиска.
Одновременно с добавлением слова в личный словарь оно также добавляется в таблицу Word общего словаря. Слово записывается в поле word_value, ему присваивается идентификатор (word_id), а также транскрипция. Слово также принадлежит какому-то языку (lang) и сохраняется время его добавления в поле created_at. Первичный уникальный ключ (pk) уникален для каждой записи и включает идентификатор слова (word_id).
Связь между словом и его переводом хранится в WordRank, где записаны word_id и trans_id, а также их рейтинг.
WordRings - специальная глобальная таблица, объединяющая слова на разных языках с одинаковым значением. Каждая запись в этой таблице имеет уникальный идентификатор ring_id. Идентификатор user_id указывает на пользователя, добавившего слово в глобальный словарь. Каждое слово с одинаковым значением имеет идентификатор word_id и язык lang. Первичный ключ (pk) является уникальным для каждой записи и состоит из ring_id и word_id.
Различные переводы ранжируются на основе метаданных и контекста. Пользователь может выбирать наиболее подходящее слово для встретившегося ему контекста и таким образом актуализировать информацию в своем личном словаре, а также и в глобальном.
Фиг. 8 является снимком экрана, на котором изображен пример из Фиг. 5 со словом «run» и его перевод на русский.
Фиг. 10 содержит снимок экрана с окном ввода, в котором пользователь может ввести свой перевод. Перевод, введенный пользователем, изменяет количество раз использования перевода слова.
Фиг. 11 показывает пример программного интерфейса с переводами слова «run».
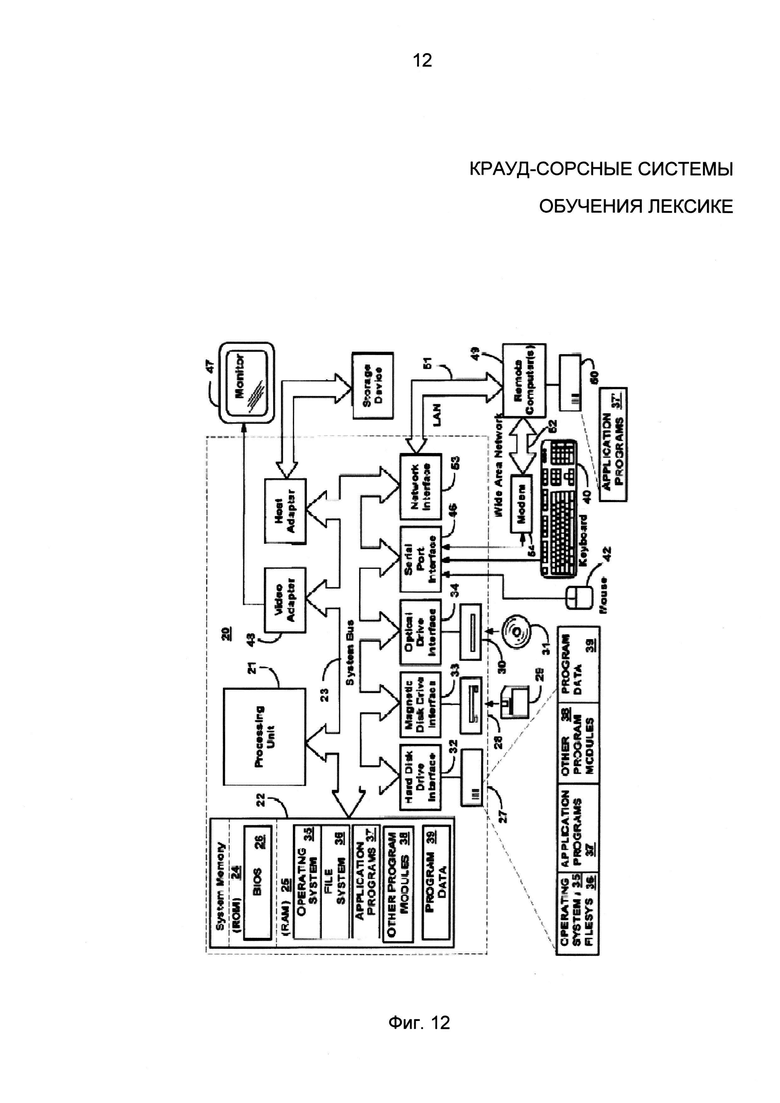
На фиг. 12 приведен пример компьютерной системы или сервера, который может использоваться в настоящем изобретении. Система для реализации изобретения включает в себя вычислительное устройство общего назначения в виде компьютера или сервера 20 или подобное устройство, в том числе блок обработки 21, системную память 22 и системную шину 23, которая соединяет различные системные компоненты, включая системную память, с блоком обработки 21.
Системная шина 23 может быть любой из нескольких типов шин, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из разнообразных архитектур подобных устройств. Системная память включает в себя постоянное запоминающее устройство (ПЗУ) 24 и оперативное запоминающее устройство (ОЗУ) 25. Базовая система ввода/вывода (BIOS) 26 содержит базовые процедуры, которые помогают передавать информацию между элементами в пределах компьютера 20, например, во время запуска. Базовая система ввода/вывода (BIOS) 26 хранится в ПЗУ 24.
Компьютер 20 может дополнительно включать в себя жесткий диск 27 для считывания и записи информации, который не показан, магнитный дисковод 28 для считывания или записи на съемный магнитный диск 29 и оптический дисковод 30 для считывания или записи на съемный оптический диск 31, такой как CD-ROM, DVD-ROM или другой оптический носитель.
Жесткий диск 27, магнитный дисковод 28 и оптический дисковод 30 подключены к системной шине 23 посредством интерфейса жесткого диска 32, интерфейса магнитного дисковода 33 и оптического интерфейса привода 34, соответственно. Накопители и дисководы и связанные с ними машиночитаемые носители обеспечивают энергонезависимое хранение машиночитаемых команд, структур данных, программных модулей и других данных для компьютера 20.
Хотя описанная здесь среда использует жесткий диск, сменный магнитный диск 29 и сменный оптический диск 31, также могут быть использованы и другие типы машиночитаемых носителей, которые могут хранить данные, доступные компьютеру, такие как магнитные кассеты, карты флэш-памяти, цифровые видеодиски, картриджи Бернулли, оперативные запоминающие устройства (ОЗУ), постоянные запоминающие устройства (ПЗУ) и т.п.
Ряд программных модулей может храниться на жестком диске, магнитном диске 29, оптическом диске 31, в ПЗУ 24 или ОЗУ 25, включая операционную систему 35. Компьютер 20 включает в себя файловую систему 36, связанную с или включенную в операционную систему 35 одной или несколькими прикладными программами 37, другими программными модулями 38 и программными данными 39. Пользователь может вводить команды и информацию в компьютер 20 через устройства ввода, такие как клавиатура 40 и указательное устройство 42. Другие устройства ввода (не показаны) могут включать микрофон, джойстик, игровую панель, спутниковую антенну, сканер или тому подобное.
Эти и другие устройства ввода часто подключены к процессору 21 через интерфейс 46 последовательного порта, который подсоединен к системной шине, но могут быть подключены посредством других интерфейсов, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). Монитор 47 или другой тип устройства отображения также связан с системной шиной 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47 персональные компьютеры обычно включают в себя другие периферийные устройства вывода (не показаны), такие как динамики и принтеры, и устройства хранения данных 57, подключенные к системной шине 23 через интерфейс 56 и хост-адаптер 55.
Компьютер 20 может работать в сетевой среде с использованием логических соединений с одним или более удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 может быть другой компьютер, сервер, маршрутизатор, сетевой ПК, одноранговое устройство или другой общий сетевой узел и обычно содержит многие или все из элементов, описанных выше применительно к компьютеру 20, хотя только запоминающее устройство 50 показано на рисунке. Логические соединения включают в себя локальную вычислительную сеть (LAN) 51 и глобальную сеть (WAN) 52. Такие сетевые среды часто используются в офисах, корпоративных вычислительных сетях, сетях интранет и Интернет.
При использовании в сетевой среде LAN компьютер 20 соединен с локальной сетью 51 через сетевой интерфейс или адаптер 53. При использовании в сетевой среде WAN компьютер 20 обычно включает в себя модем 54 или другое средство для установления связи через глобальную сеть 52, например, Интернет.
Модем 54, который может быть внутренним или внешним, подключен к системной шине 23 через интерфейс 46 последовательного порта. В сетевой среде программные модули, изображенные по отношению к компьютеру 20, или их части могут храниться в удаленном запоминающем устройстве. Следует иметь в виду, что указаны примерные сетевые соединения, и могут быть использованы другие средства установления линии связи между компьютерами.
Следует также понимать, что различные модификации, адаптации и альтернативные варианты его могут быть выполнены в пределах объема и сущности настоящего изобретения.



Изобретение относится к автоматизации обучения лексике при помощи учебного контекстного словаря и системы автоматического перевода. Техническим результатом является обеспечение возможности просматривать, выбирать и сохранять переводы слов и фраз в определенном контексте. В крауд-сорсном способе обучения лексике все лексические единицы получают контекстно-обусловленные переводы, качество которых основано на рейтингах, которые присваивают пользователи. Лексические единицы, их контексты, а также прочие метаданные хранятся в базе данных. Каждый пользователь имеет персональный словарь, содержащий слова и фразы, которые пользователь встретил и перевел ранее. Фразы и слова автоматически добавляются в личный словарь вместе с их контекстно-обусловленными переводами, выбранными пользователем. Контекстный словарь позволяет выбрать правильный перевод слова и сохранить его вместе с контекстом. После создания несколькими пользователями личных словарей определяют количество раз использования различных переводов, выбранных пользователями. Контекстный словарь позволяет пользователю добавлять аудио, видео и графические изображения и прочие метаданные, иллюстрирующие значение слова. 2 н. и 13 з.п. ф-лы, 12 ил.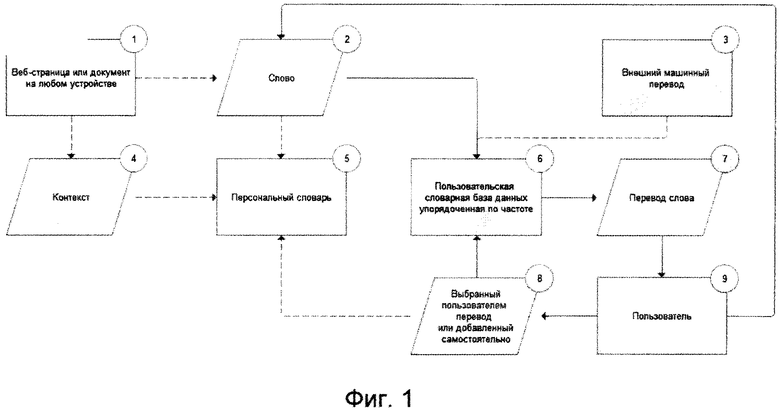
1. Крауд-сорсный способ обучения лексике при помощи компьютера, включающий в себя:
создание базы данных контекстно-обусловленных переводов на основе переводов слов с указанием количества раз, когда пользователь выбрал данный перевод, и пользовательских рейтингов;
получение слова для перевода;
определение контекста слова;
запросы к базе данных для переводов на основе контекста;
отображение переводов пользователю по количеству раз использования в случае существования перевода;
сохранение выбранного пользователем перевода в базу данных;
получение перевода от пользователя и сохранения его в базе данных, если перевод не найден в базе данных; и
повышение значения количества раз использования слова и сохранения его в базе данных, где слово отображается в последующем списке переводов в соответствии с его текущим показателем количества раз использования.
2. Способ по п. 1, дополнительно содержащий этап сохранения контекстно-связанных метаданных в базе данных.
3. Способ по п. 1, дополнительно содержащий этап сохранения перевода и соответствующих контекстно-связанных метаданных в пользовательский словарь.
4. Способ по п. 3, отличающийся тем, что слова в пользовательском персональном словаре имеют показатель освоения слова пользователем.
5. Способ по п. 4, в котором показатель освоения увеличивается после успешного тестирования слова.
6. Способ по п. 1, в котором этап определения метаданных контекста включает в себя определение контекста по некоторому количеству слов до и после слова.
7. Способ по п. 1, в котором этап определения метаданных контекста включает в себя определение языковых единиц, которые содержат выбранное слово.
8. Способ по п. 1, дополнительно содержащий получение перевода из внешнего источника, если перевод не найден в базе данных.
9. Способ по п. 1, дополнительно содержащий сохранение метаданных слова в базу данных.
10. Способ по п. 1, в котором метаданные слова включают:
a. транскрипцию;
b. звучание;
c. показатель точности;
d. контекст;
e. тематику;
f. связанное изображение;
g. связанные слова; и
h. частоту использования.
11. Способ по п. 1, дополнительно содержащий этап изучения контекстных метаданных слова с помощью:
a. правильного перевода слова;
b. написания слова по звучанию; и
c. написания слова по переводу.
12. Способ по п. 1, отличающийся тем, что словарь использует алгоритмы самообучения.
13. Способ по п. 12, в котором обучение словаря происходит при помощи следующих алгоритмов:
a. упрощенный алгоритм Байеса;
b. опорно-векторных алгоритмов; и
c. нейронных сетей.
14. Способ по п. 12, отличающийся тем, что самообучение словаря происходит при помощи следующих параметров:
a. n-грамм;
b. частей речи;
c. взаимной информации (PMI);
d. хи-квадрат;
e. лемматизации; и
f. контекстов второго порядка.
15. Крауд-сорсная система обучения лексике при помощи компьютера для выполнения способа по п. 1, отличающаяся тем, что состоит из:
a. процессора;
b. запоминающего устройства, соединенного с процессором;
c. компьютерной программы, хранящейся в памяти и выполняемой на процессоре.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СИСТЕМА ДЛЯ УПРАВЛЕНИЯ ЯЗЫКОВЫМ ПЕРЕВОДОМ | 2002 |
|
RU2285951C2 |

