ПЕРЕКРЕСТНАЯ ССЫЛКА
[001] По настоящей заявке испрашивается приоритет по российской патентной заявке №2016104133, поданной 9 февраля 2016, и озаглавленной "СПОСОБ И СИСТЕМА ОБРАБОТКИ ТЕКСТА", которая включена здесь полностью посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[002] Настоящая технология относится к системам и способам обработки исходного цифрового текста и целевого цифрового текста, целевой цифровой текст является переводом исходного цифрового текста. Конкретнее, системы и способы относятся к сопоставлению исходного лексического элемента исходного цифрового текста с целевым лексическим элементом целевого цифрового текста, второй лексический элемент является переводом цифрового лексического элемента.
УРОВЕНЬ ТЕХНИКИ
[003] С постоянно возрастающим проникновением сети Интернет в различные области земного шара, увеличивается количество веб-страниц в Интернете, написанных на различных языках. Увеличивается число пользователей, которые используют средства сетевого перевода, что отражает необходимость предоставлять пользователям адекватные и высококачественные переводы.
[004] Параллельный текст - это текст, расположенный напротив своего перевода. Параллельное выравнивание текста представляет собой идентификацию соответствующих фрагментов (например, предложения или его части) исходного текста в переведенном тексте.
[005] Один обычный способ выравнивания текстов заключается в применении эвристических правил, например, выравнивания предложений на основе знаков препинания и расположения предложений. Подобный способ может быть недостаточно точным, например, из-за того что оригинальное предложение переведено как два предложения и расположение оригинального предложения в оригинальном тексте не обязательно отражает расположение соответствующего переведенного предложения в переведенном тексте.
[006] Другой привычный способ заключается в использовании заранее составленного словаря для перевода. Тем не менее, составление словаря для перевода является дорогой процедурой, которая требует много времени и производственных ресурсов.
[007] Статья « ЧЕРНАЯ КОШКА В ТЕМНОЙ КОМНАТЕ ИЛИ МОЖНО ЛИ АВТОМАТИЗИРОВАТЬ ПОИСК ПЕРЕВОДНЫХ ЭКВИВАЛЕНТОВ В ПАРАЛЛЕЛЬНОМ КОРПУСЕ ТЕКСТОВ?" М.Н. Михайлов (в сб.: Алфавит: Филологический сборник. Смоленск, 2002. - С. 181188) (Перевод: Black Cat in а Dark Room or Can we Automate Search of Translation Equivalents in a Parallel Corpus of Texts, M.N. Mihaylov, Philological Compilation, Smolensk, 2002 c. 181-188) описывает способ нахождения эквивалентов слов в параллельных текстах с помощью совместного вхождения двух слов на первом языке и втором языке в известные эквивалентные фрагменты.
[008] Патентная заявка US 9,047,275 описывает исполняемые на компьютере системы и способы выравнивания фрагментов первого текста с соответствующими фрагментами второго текста, который является переводом первого текста. Один предпочитаемый вариант осуществления предварительно делит первый и второй тексты на фрагменты; создает гипотезу о соответствии между фрагментами первого и второго текста; выполняет лексико-морфологический анализ фрагментов с помощью лингвистических описаний; выполняет синтаксический анализ фрагментов с помощью лингвистических описаний и создает синтаксические структуры для фрагментов; создает семантические структуры для фрагментов; и оценивает степень соответствия между семантическими структурами.
[009] Патентная заявка US 2015/0278197 описывает системы и способ создания сравнительного корпуса путем получения набора исходных документов, содержащих текст, составления независимых от языка семантических структур по меньшей мере для одного предложения из каждого текста в исходных документах; определения универсальных оценок сходства для групп из исходных документов путем сравнения составленных независимых от языка семантических структур из текстов в исходных документов; идентификации наборов одинаковых документов на основе определенных универсальных оценок сходства для групп из исходных документов; и создания корпуса на основе идентифицированных наборов одинаковых документов.
РАСКРЫТИЕ
[0010] Настоящее техническое решение может уменьшить по меньшей мере некоторые недостатки, присущие текущему уровню техники, в отношении автоматического создания тезауруса.
[0011] Без ограничения какой-либо конкретной теорией, варианты осуществления настоящей технологии были разработаны на основе предположений разработчиков о том, что при анализе (i) отношений между данным исходным лексическим элементом и другими исходными лексическими элементами (исходного контекстного параметра) и (ii) отношений между данным целевым лексическим элементом, который является переводом данного исходного лексического элемента, и другими целевыми лексическими элементами (целевого контекстного параметра), можно автоматически идентифицировать, какой переведенный лексический элемент соответствует оригинальному лексическому элементу. Другими словами, автоматическое сопоставление данного исходного лексического элемента и данного целевого лексического элемента может осуществляться путем определения сходства между данным исходным контекстным параметром и данным целевым контекстным параметром, тем самым избегая использования каких-либо словарей для сопоставления исходных лексических элементов и переведенных лексических элементов.
[0012] Первым объектом настоящей технологии является исполняемый на компьютере способ сопоставления исходного лексического элемента из исходного цифрового текста на первом языке с целевым лексическим элементом целевого цифрового текста на втором языке, целевой цифровой текст является переводом исходного цифрового текста, способ выполняется на сервере, способ включает в себя: получение сервером указания на исходный цифровой текст, который будет обработан, исходный цифровой текст включает в себя множество исходных предложений; парсинг сервером по меньшей мере части из множества исходных предложений на одно или несколько исходных лексических элементов; создание для каждого из одного или нескольких исходных лексических элементов исходного контекстного параметра, исходный контекстный параметр включает в себя: первый набор исходных значений контекстно-зависимых отношений (CDR), каждое исходное значение CDR представляет собой отношение (i) числа исходных предложений, где совместно встречаются данный исходный лексический элемент и каждого из одного или нескольких исходных лексических элементов к (ii) общему числу исходных предложений, содержащих данный исходный лексический элемент; и указание на одно или несколько исходных предложений, в которые входит каждый из одного или нескольких исходных лексических элементов; получение сервером указания на целевой цифровой текст, который будет обработан, целевой цифровой текст включает в себя множество целевых предложений; парсинг сервером по меньшей мере части из множества целевых предложений на один или несколько целевых лексических элементов; создание для каждого из одного или нескольких целевых лексических элементов целевого контекстного параметра; целевой контекстный параметр включает в себя: первый набор целевых значений CDR, каждое целевое значение CDR представляет собой отношение (i) числа целевых предложений, где совместно встречаются данный исходный лексический элемент и каждый из одного или нескольких целевых лексических элементов к (ii) общему числу целевых предложений, содержащих данный целевой лексический элемент; указание на одно или несколько целевых предложений, в которые входит каждый из одного или нескольких целевых лексических элементов; выбор первого исходного лексического элемента, и первый исходный лексический элемент обладает первым исходным контекстным параметром; сравнение сервером первого исходного контекстного параметра со множеством целевых контекстных параметров для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы; и сопоставление первого исходного лексического элемента с первым целевым лексическим элементом, первый целевой лексический элемент связан с данным целевым контекстным параметром, который обладает наименьшим значением разницы.
[0013] В некоторых вариантах осуществления способа, парсинг каждого из множества исходных предложений и каждого из множества целевых предложений включает в себя назначение грамматического типа каждому слову как из исходного цифрового текста, так и из целевого цифрового текста; и лексический элемент представляет собой одно из: слово, слово было определено на основе его соответствующего грамматического типа; и фразу, которая является группой из дух или более слов, определенной на основе соответствующего грамматического типа одного из двух или более слов.
[0014] В некоторых вариантах осуществления способа, сравнение первого исходного контекстного параметра со множеством целевых контекстных параметров для сравнения данного целевого контекстного параметра, обладающего наименьшим значением разницы, включает в себя: выбор первого исходного предложения, включающего в себя первый исходный лексический элемент; для каждого целевого предложения из множества целевых предложений: сравнение первого исходного контекстного параметра с одним или несколькими целевыми контекстными параметрами, связанными с одним или несколькими целевыми лексическими элементами, которые содержат данное целевое предложение для определения локального минимального значения, локальное минимальное значение указывает на предварительное соответствие первого исходного контекстного параметра и данного целевого контекстного параметра в данном целевом предложении; и, на основе определенного набора локальных минимальных значений, выбор локального минимального значения, являющегося наименьшим значением разницы.
[0015] В некоторых вариантах осуществления способа, первый исходный лексический элемент и первый целевой лексический элемент, связанный с наименьшим значением разницы, является гипотезой эквивалентности перевода.
[0016] В некоторых вариантах осуществления способа, способ далее включает в себя проверку гипотезы эквивалентности перевода путем: создания для каждого из одного или нескольких исходных лексических элементов, второго набора исходных значений контекстно-независимых отношений (CIR), каждое исходное значение CIR представляет собой отношение (i) числа общих слов между данным исходным лексическим элементом и каждым из одного или нескольких исходных лексических элементов к (ii) числу слов данного исходного лексического элемента; создания для каждого из одного или нескольких целевых лексических элементов, второго набора целевых значений CIR, каждое целевое значение CIR представляет собой отношение (i) числа общих слов между данным целевым лексическим элементом и каждым из одного или нескольких целевых лексических элементов к (ii) числу слов данного целевого лексического элемента; и определения того, что сходство набора исходных значений CIR, связанных с первым исходным лексическим элементом, с набором целевых значений CIR, связанных с первым целевым лексическим элементом находится выше заранее определенного порога.
[0017] В некоторых вариантах осуществления способа, способ далее выполнен с возможностью сопоставлять каждый исходный лексический элемент с каждым целевым лексическим элементом и сохранять сопоставление в базе данных сопоставлений.
[0018] В некоторых вариантах осуществления способа, где после завершения сопоставления каждого исходного лексического элемента с каждым целевым лексическим элементом, способ далее включает в себя сопоставление первого исходного предложения с первым целевым предложением, первое целевое предложение является эквивалентом перевода первого исходного предложения, путем: идентификации набора исходных лексических элементов, включающих первое исходное предложение; получения из базы данных сопоставлений набора целевых лексических элементов, соответствующих набору исходных лексических элементов; и идентификации первого целевого предложения, включающего набор целевых лексических элементов.
[0019] В некоторых вариантах осуществления способа, где после определения того, что ни одно из целевых предложений не содержит набор целевых лексических элементов, определение набора целевых предложений, набор целевых предложений содержит два или более соседних целевых предложений, включающих в себя набор целевых лексических элементов.
[0020] В некоторых вариантах осуществления способа, получение указаний на исходный цифровой текст и целевой цифровой текст включает в себя получение указаний на исходный цифровой текст и целевой цифровой текст из соответствующего устройства памяти.
[0021] В некоторых вариантах осуществления способа, получение указаний на исходный цифровой текст и целевой цифровой текст включает в себя получение указаний на исходный цифровой текст и целевой цифровой текст из приложения по обработке текста, приложение по обработке текста обладает ранее созданным целевым цифровым текстом в ответ на получение исходного цифрового текста от электронного устройства.
[0022] В контексте настоящего описания, если четко не указано иное, "электронное устройство", "пользовательское устройство", "сервер", "удаленный сервер" и "компьютерная система" подразумевают под собой аппаратное и/или системное обеспечение, подходящее к решению соответствующей задачи. Таким образом, некоторые неограничивающие примеры аппаратного и/или программного обеспечения включают в себя компьютеры (серверы, настольные компьютеры, ноутбуки, нетбуки и так далее), смартфоны, планшеты, сетевое оборудование (маршрутизаторы, коммутаторы, шлюзы и так далее) и/или их комбинацию.
[0023] В контексте настоящего описания, если четко не указано иное, "машиночитаемый носитель" и "память" подразумевает под собой носитель абсолютно любого типа и характера, не ограничивающие примеры включают в себя ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB-ключи, флеш-карты, твердотельные накопители и накопители на магнитной ленте.
[0024] В контексте настоящего описания, если четко не указано иное, "указание" информационного элемента может представлять собой сам информационный элемент или указатель, отсылку, ссылку или другой косвенный способ, позволяющий получателю указания найти сеть, память, базу данных или другой машиночитаемый носитель, из которого может быть извлечен информационный элемент. Например, указание файла может включать в себя сам файл (т.е. его содержимое), или же оно может являться уникальным дескриптором файла, идентифицирующим файл по отношению к конкретной файловой системе, или какими-то другими средствами передавать получателю указание на сетевую папку, адрес памяти, таблицу в базе данных или другое место, в котором можно получить доступ к файлу. Как будет понятно специалистам в данной области техники, степень точности, необходимая для такого указания, зависит от степени первичного понимания того, как должна быть интерпретирована информация, которой обмениваются получатель и отправитель указателя. Например, если до установления связи между отправителем и получателем понятно, что признак информационного элемента принимает вид ключа базы данных для записи в конкретной таблице заранее установленной базы данных, содержащей информационный элемент, то передача ключа базы данных - это все, что необходимо для эффективной передачи информационного элемента получателю, несмотря на то, что сам по себе информационный элемент не передавался между отправителем и получателем указания.
[0025] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[0026] Каждый вариант осуществления настоящей технологии включает по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[0027] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0028] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[0029] На Фиг. 1 представлена система, которая подходит для реализации вариантов осуществления настоящей технологии и/или которая используется в сочетании с вариантами осуществления настоящей технологии.
[0030] На Фиг. 2 представлена схематическая иллюстрация приложения по сопоставлению, относящегося к серверу системы, которая показана на Фиг. 1.
[0031] На Фиг. 3 представлен снимок экрана, показывающий два цифровых текста, а именно - исходный цифровой текст и целевой цифровой текст, которые будут обработаны приложением по сопоставлению, показанным на Фиг. 2.
[0032] На Фиг. 4 представлен первый вариант осуществления процесса идентификации фразы в двух цифровых текстах, показанных на Фиг. 3.
[0033] На Фиг. 5 представлен второй вариант осуществления процесса идентификации фразы в двух цифровых текстах, показанных на Фиг. 3.
[0034] На Фиг. 6 представлена блок-схема процесса заполнения матрицы контекстно-зависимых отношений (CDR).
[0035] На Фиг. 7 представлена схематическая иллюстрация матрицы CDR, заполненной в ходе процесса, показанного на Фиг. 6.
[0036] На Фиг. 8 представлена блок-схема процесса заполнения матрицы контекстно-независимых отношений (CIR).
[0037] На Фиг. 9 представлен пример определения значения CIR в соответствии с процессом, показанном на Фиг. 8.
[0038] На Фиг. 10 представлена схематическая иллюстрация матрицы CDR, заполненной в ходе процесса, показанного на Фиг. 8.
[0039] На Фиг. 11 представлен первый вариант осуществления сопоставления исходного лексического элемента с целевым лексическим элементом с помощью приложения по сопоставлению, показанного на Фиг. 2.
[0040] На Фиг. 12 представлена схематическая иллюстрация процесса, показанная на Фиг. 11.
[0041] На Фиг. 13 представлена схематическая иллюстрация процессов, показанных на Фиг. 11 и 14.
[0042] На Фиг. 14 представлен второй вариант осуществления процесса сопоставления исходного лексического элемента с целевым лексическим элементом с помощью приложения по сопоставлению, показанного на Фиг. 2.
[0043] На Фиг. 15 представлена схематическая иллюстрация процесса, показанная на Фиг. 14.
[0044] На Фиг. 16 представлена схематическая иллюстрация процесса, показанная на Фиг. 14.
[0045] На Фиг. 17 представлена блок-схема процесса сопоставления исходного предложения с целевым предложением с помощью приложения по сопоставлению, показанного на Фиг. 2.
[0046] На Фиг 18 представлена схематическая иллюстрация снимка экрана, показывающего исходный цифровой текст, выровненный с целевым цифровым текстом с помощью приложения по переводу, относящегося к системе, которая показана на Фиг. 1.
[0047] На Фиг. 19 представлена блок-схема способа сопоставления исходного лексического элемента с целевым лексическим элементом, который выполняется сервером на Фиг. 1, способ выполняется в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем.
[0048] Также следует отметить, что чертежи выполнены не в масштабе, если не специально указано иное.
ОСУЩЕСТВЛЕНИЕ
[0049] На Фиг. 1 представлена принципиальная схема системы 100, выполненной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание показательных вариантов осуществления настоящей технологии. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[0050] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящей технологии, а не для установления границ ее объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящей технологии и находятся в границах ее объема. Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящей технологии. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[0051] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящей технологии, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ, вне зависимости от того, известны ли они на данный момент или будут разработаны в будущем. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящей технологии. Аналогично, любые блок-схемы, диаграммы переходного состояния, псевдокоды и т.п.представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор или нет.
[0052] Функции различных элементов, показанных на фигурах, включая функциональный блок, обозначенный как «процессор», могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящей технологии, процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина "процессор" или "контроллер" не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральная схема специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[0053] С учетом этих примечаний, далее будут рассмотрены некоторые не ограничивающие варианты осуществления аспектов настоящей технологии.
[0054] Система 100 включает в себя электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и, таким образом, иногда может упоминаться как «клиентское устройство». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[0055] В контексте настоящего описания, если конкретно не указано иное, «электронное устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как электронное устройство в настоящем контексте, может вести себя как сервер по отношению к другим электронным устройствам. Использование выражения «электронное устройство» не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[0056] Электронное устройство 102 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, для использования поискового приложения 104. В общем случае, задачей приложения 104 по переводу является позволить пользователю, связанному с электронным устройством 102, выполнить перевод исходного цифрового текста 302 (показано на Фиг. 3), написанного на первом языке, в целевой цифровой текст 318 (показано на Фиг. 3), написанный на втором языке. Реализация приложения 104 по переводу никак конкретно не ограничена. Одним из примеров приложения 104 по переводу может быть встроен в доступный пользователям веб-сайт, связанный с услугами перевода. Например, приложение 104 по переводу может быть вызвано путем ввода URL, связанного с сервисом Yandex.Translate™ по адресу translate.yandex.com. Важно иметь в виду, что приложение 104 по переводу может быть доступно с помощью любых других коммерчески доступных или собственных сервисов перевода. Альтернативно, приложение 104 по переводу может быть приложением, которое сохраняется и используется локально.
[0057] В общем случае, приложение 104 по переводу содержит часть 106 для ввода текста, выполненную для получения исходного цифрового текста 302 и часть 108 для вывода текста, выполненную для вывода целевого цифрового текста 318, который является переводом исходного цифрового текста 302. То, как именно выводится целевой цифровой текст 318, более подробно описано далее.
[0058] Электронное устройство 102 соединено с сетью связи 112 через линию связи ПО. В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 112 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящей технологии, сеть связи 112 может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п.
[0059] Реализация линии связи 110 не ограничена, и будет зависеть от того, какое электронное устройство 102 используется. В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии, когда электронное устройство 102 представляет собой беспроводное устройство связи (например, смартфон), линия 110 передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных сети 3G, линия передачи данных сети 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.).
[0060] Важно иметь в виду, что варианты осуществления электронного устройства 102, линии 110 передачи данных и сети 112 передачи данных даны исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления электронного устройства 102, линии 110 передачи данных и сети 112 передачи данных. Таким образом, представленные здесь примеры не ограничивают объем настоящей технологии.
[0061] Система далее включает в себя сервер 114, соединенный с сетью 112 передачи данных. Сервер 114 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения сервер 114 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 114 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящей технологии, не ограничивающем ее объем, сервер 114 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 114 может быть разделена, и может выполняться с помощью нескольких серверов.
[0062] Вариант осуществления сервера 114 хорошо известен. Тем не менее, сервер 114 содержит интерфейс передачи данных (не показан), который настроен и выполнен с возможностью обмениваться данными с различными элементам (например, электронным устройством 102) через сеть 112 передачи данных. Сервер 113 далее включает в себя по меньшей мере один компьютерный процессор (не показан), функционально соединенный с интерфейсом передачи данных, который структурирован и выполнен с возможностью выполнять заранее определенный набор исполняемых на компьютере операций в ответ на получение соответствующего машиночитаемого кода, выбранного из заранее определенного родного набора кодов, который хранится в памяти (не показано) - для выполнения различных описанных здесь процессов. В некоторых вариантах осуществления настоящей технологии, сервер 114 находится под контролем и/или управлением сервиса по переводу, например, Yandex.Translate™ компании ООО «Яндекс», расположенной по адресу: 119021, Москва, ул. Льва Толстого, дом 16.
[0063] В общем случае, сервер 114 выполнен с возможностью получать первый пакет 120 данных от приложения 104 по переводу, первый пакет 120 данных содержит указание на исходный цифровой текст 302, введенный в часть 106 для ввода текста. При получении первого пакета 120 данных, приложение 116 по обработке текста, относящееся к серверу 114, выполнено с возможностью создавать целевой цифровой текст 318, который является переводом исходного цифрового текста 302. После создания перевода исходного цифрового текста 302 (т.е. целевого цифрового текста 318), сервер 114 далее выполнен с возможностью передавать второй пакет 122 данных приложению 104 по переводу, второй пакет 122 данных содержит указание на целевой цифровой текст 318, который будет выведен в части 108 для вывода текста (и, опционально, указание на исходный цифровой текст 302). Способ, в соответствии с которым приложение 104 по переводу создает целевой цифровой текст 318, хорошо известен в данной области техники и не будет описан здесь.
[0064] На Фиг. 3 представлен обычный снимок экрана с приложением 104 по переводу после получения второго пакета 122 данных.
[0065] Часть 106 для ввода текста включает в себя исходный цифровой текст 302. Исходный цифровой текст 302 создан из множества исходных предложений 304,0 множество исходных предложений 304 включает в себя ряд индивидуальных исходных предложений 306, например, первое исходное предложение 306, второе исходное предложение 308 и третье исходное предложение 310. Несмотря на то что в представленной иллюстрации множество исходных предложений 304 полностью разделены (т.е. разделены точкой), специалисты в данной области техники поймут, что это не является обязательным, и разделять множество исходных предложений 304 могут и другие знаки препинания, например, вопросительный знак, восклицательный знак и др. Первое исходное предложение 306 включает в себя первый исходный лексический элемент 312, второе исходное предложение 308 включает в себя второй исходный лексический элемент 314, и третье исходное предложение 310 включает в себя третий исходный лексический элемент 316. Во избежание сомнений, следует отметить, что исходный цифровой текст 302 (и, конкретнее, каждая буква лексических элементов) представлена буквой «X», тем не менее, в реальности лексические элементы созданы из букв первого языка. Например, если первым языком является английский, первое исходное предложение 306 может представлять собой: "Although not an athlete, the lawyer was having a leg day, as he was running away from all the deadlines" ("Даже не будучи спортсменом, адвокат накачал отличные мышцы на ногах, убегая от дедлайнов").
[0066] Часть 108 для вывода текста включает в себя целевой цифровой текст 318, который создан приложением 116 по обработке текста. Целевой цифровой текст 318 создан из множества целевых предложений 320, множество целевых предложений 320 включает в себя ряд индивидуальных целевых предложений 322, например, первое целевое предложение 306, второе целевое предложение 324 и третье целевое предложение 326. Несмотря на то что в представленном примере осуществления технологии множество целевых предложений 320 полностью разделены (т.е. разделены точкой), специалисты в данной области техники поймут, что это не является обязательным, и разделять множество целевых предложений 320 могут и другие знаки препинания, например, вопросительный знак, восклицательный знак и др. Первое целевое предложение 322 содержит первый целевой лексический элемент 328, второй целевой лексический элемент 330 и третий целевой лексический элемент 332. Во избежание сомнений, следует отметить, что целевой цифровой текст 318 (и, конкретнее, каждая буква лексических элементов) представлена буквой «Y», тем не менее, в реальности целевые лексические элементы созданы из букв второго языка. Например, если вторым языком является французский, первое целевое предложение 322 может представлять собой: "Sans être un athlète, ľavocat travaillait ses jambes, alors qưil fuyait toutes les échéances".
[0067] В некоторых вариантах осуществления настоящей технологии, данный один из лексических элементов (первый исходный лексический элемент 312, второй исходный лексический элемент 314, третий исходный лексический элемент 316, первый целевой лексический элемент 328, второй целевой лексический элемент 330, третий целевой лексический элемент 332) может представлять собой: (i) слово, которое является наименьшим самостоятельным элементом речи, или (ii) фразу, которая является смысловой единицей, содержащей группу из двух или более слов (например, "современные компьютерные системы", "способы получения информации", "деревянный стул" и так далее) или комбинацию из слов и фраз.
[0068] Возвращаясь к Фиг. 1, сервер 114 далее включает в себя приложение 118 по сопоставлению. Как будет более подробно описано далее, приложение 118 по сопоставлению содержит набор машиночитаемых кодов (как описано выше), выполняемых процессором (не показано) сервера 114 для выполнения различных процессов, описанных далее. Несмотря на то, что приложение 118 по сопоставлению описано как отдельное от приложения 116 по обработке текста, это не является ограничением, и приложение 118 по сопоставлению может быть частью приложения 116 по обработке текста.
[0069] В некоторых вариантах осуществления настоящей технологии, приложение 118 по сопоставлению выполнено с возможностью получать, до передачи второго пакета 112 данных приложения 104 по переводу, исходный цифровой текст 302 и целевой цифровой текст 318. Приложение 118 по сопоставлению далее выполнено с возможностью сопоставлять каждый исходный лексический элемент (т.е. первый исходный лексический элемент 312, второй исходный лексический элемент 314, третий исходный лексический элемент 316) с его соответствующим эквивалентом перевода из целевых лексических элементов (т.е. первый целевой лексический элемент 328, второй целевой лексический элемент 330, третий целевой лексический элемент 332). В еще одном другом варианте осуществления технологии, приложение 118 сопоставления выполнено с возможностью выравнивать множество исходных предложений 304 с множеством целевых предложений 320.
[0070] Приложение по сопоставлению
[0071] Функции и операции различных компонентов приложения 118 по сопоставлению будут далее описаны более подробно. Со ссылкой на Фиг. 2, представлена схематическая иллюстрация приложения 118 по сопоставлению для автоматического сопоставления исходных лексических элементов исходного цифрового текста 302 и целевых лексических элементов целевого цифрового текста 318. Приложение 118 по сопоставлению выполняет (или иначе имеет доступ к): процедуру 202 получения текста, процедуру 204 парсинга, процедуру 206 создания контекстного параметра, процедуру 208 сопоставления и процедуру 210 выравнивания предложений.
[0072] В контексте настоящего описания термин термин "процедура" относится к подмножеству машиночитаемых кодов приложения 118 по сопоставлению, которое выполняется процессором (не показано) сервера 114 для выполнения функций, которые описаны далее. Во избежание каких-либо сомнений, следует иметь в виду, что процедура 202 получения текста, процедура 204 парсинга, процедура 206 создания контекстного параметра, процедура 208 сопоставления и процедура 210 выравнивания предложений представлены здесь схематично в распределенном и разделенном виде для простоты понимания процессов, выполняемых приложением 118 по сопоставлению. Считается, что некоторые или все из процедуры 202 получения текста, процедуры 204 парсинга, процедуры 206 создания контекстного параметра, процедуры 208 сопоставления и процедуры 210 выравнивания предложений могут быть выполнены как одна или несколько объединенных процедур.
[0073] Функции каждой из процедуры 202 получения текста, процедуры 204 парсинга, процедуры 206 создания контекстного параметра, процедуры 208 сопоставления и процедуры 210 выравнивания предложений, а также данных и/или обработанной или сохраненной информации будут описаны далее.
[0074] Процедура получения текста
[0075] В соответствии с вариантами осуществления настоящего технического решения, процедура 202 получения текста выполнена с возможностью получать пакет 212 данных, включающий в себя указание на исходный цифровой текст 302 и целевой цифровой текст 318.
[0076] То, как именно процедура 202 получения текста получает пакет 212 данных, никак не ограничена, и он может быть получен напрямую от приложения 116 по обработке текста или от цифрового устройства памяти (не показано), связанного с сервером 114, который хранит указания на исходный цифровой текст 302, а также целевой цифровой текст 318, созданный приложением 116 по обработке текста.
[0077] Процедура парсинга
[0078] С учетом примера с исходным цифровым текстом 302, процедура 204 парсинга выполнена с возможностью парсить множество исходных предложений 304 на одно или несколько отдельных исходных предложений, например, первое исходное предложение 306, второе исходное предложение 308 и третье исходное предложение 310. Способ, которым выполняется парсинг, хорошо известен в данной области техники и не ограничен каким-либо конкретным алгоритмом, и может выполняться путем анализа знаков препинания и/или применения правил грамматики.
[0079] В некоторых вариантах осуществления настоящей технологии, процедура 204 парсинга выполнена с возможностью относить каждое слово исходного цифрового текста 302 к соответствующему грамматическому типу (например, существительное, глагол и т.д.). Способ, которым выполняется такая отметка, хорошо известен в данной области техники, никак не ограничен каким-либо конкретным алгоритмом, и может быть выполнен путем анализа окончания соседних слов или окончания данного слова.
[0080] В некоторых вариантах осуществления настоящей технологии, процедура 204 парсинга далее выполнена с возможностью выбирать первый исходный лексический элемент 312, второй исходный лексический элемент 314, и третий исходный лексический элемент 316.
[0081] Как указано выше, каждый исходный лексический элемент может быть словом или фразой. Способ идентификации данной фразы с помощью двух неограничивающих способов будет описан далее.
[0082] На Фиг. 4 представлен вариант осуществления первого процесса идентификации данной фразы. На этапе 402, процедура 204 парсинга выполнена с возможностью анализировать множество исходных предложений 304 и идентифицировать по меньшей мере одну группу слов, каждая группа слов включает в себя по меньшей два слова, которые повторяются вместе в исходном цифровом тексте 302.
[0083] На этапе 404, для каждой идентифицированной группы слов, процедура 204 парсинга выполнена с возможностью определять, обладает ли логическим значением по меньшей мере одно слово из группы слов. В контексте настоящей технологии, термины "логическое значение" относится к семантике, содержащейся в лексической морфеме. В некоторых вариантах осуществления настоящей технологии, процедура 204 парсинга выполнена с возможностью определить, обладает ли данное слово из группы слов логическим значением на основе грамматического типа данного слова. Например, процедура 204 парсинга выполнена с возможностью идентифицировать лексические морфемы, такие как глаголы, прилагательные и наречия, как обладающие логическим значением. С другой стороны, слова, которые являются грамматическими морфемами (которые указывают на отношения между другими морфемами, например, предлогами, артиклями, союзами и так далее), считаются не обладающими логическим значением при процедуре 204 парсинга. В некоторых вариантах осуществления настоящей технологии, даже если данное слово из группы слов определено как обладающее логическим значением, процедура 204 парсинга также выполнена, на основе эмпирического анализа, с возможностью считать данное слово не обладающим логическим значением, если определено, что данное слово является бессмысленным, неважным и/или создающим шум, например, частое повторение таких глаголов как, "to be" и "to have" ("быть" и "иметь").
[0084] Далее на этапе 404, если есть по меньшей мере одно слово, обладающее логическим значением в рамках группы слов, способ переходит к этапу 412, где процедура 204 парсинга выполнена с возможностью идентифицировать группу слов как фразу. С другой стороны, если идентифицированная группа слов не обладает по меньшей мере одним словом с логическим значением, группа слов игнорируется на этапе 406.
[0085] Опционально, далее на этапе 404 и до перехода напрямую к этапу 412, процедура 204 парсинга выполнена с возможностью вычислять частоту записей данной группы слов в исходном цифровом тексте 302 на этапе 408. Если частота находится ниже заранее определенного порога (который может быть определен эмпирически), данная группа слов игнорируется на этапе 410. Если группа слов обладает частотой записей, находящейся выше заранее определенного порога, процесс переходит к этапу 412, где процедура 204 парсинга выполнена с возможностью идентифицировать группу слов как фразу.
[0086] На Фиг. 5 представлен вариант осуществления второго процесса для идентификации данной фразы для первого исходного предложения 306, которое выглядит как "Не sat on the wooden chair of the captain" ("Он сидел на деревянном стуле капитана"). На этапе 502, процедура 204 парсинга выполнена с возможностью анализировать предложение и идентифицировать слова, ранее отмеченные как относящиеся к конкретному грамматическому типу, например, как существительные (т.е. "chair" ("стул") и "captain" ("капитан")). На этапе 504, процедура 204 парсинга выполнена с возможностью анализировать слова, идентифицированные как существительные, и определять, является ли данное слово, определенное как существительное, "кодовым словом", т.е. главным словом во фразе.
[0087] Конкретные эвристические правила определения инициирующего слова могут изменяться (т.е. конкретные правила могут зависеть от языка). В русском языке, главное слово обычно является существительным, которое находится левее всего во фразе. В английском языке, это может быть существительное, которое стоит во фразе правее всего, если отсутствуют такие предлоги как «of», или ж существительное, которое стоит во фразе левее всего до предлога. Таким образом, в представленном примере, слово "chair" ("стул") считается кодовым словом в результате процедуры 204 парсинга. На этапе 506, процедура 204 парсинга далее выполнена с возможностью анализировать соседние с кодовым словом слова, и определять, формируют ли одно или несколько соседних слов логическую запись с кодовым словом. Например, процедура 204 парсинга может быть выполнена с возможностью считать слова конкретного типа, например, прилагательные, существительные и так далее, расположенные рядом с кодовым словом, формирующими логическую запись с кодовым словом (например, "wooden chair"("деревянный стул")).
[0088] В некоторых вариантах осуществления настоящей технологии, как часть идентификации фраз в качестве лексических элементов, процедура 204 парсинга выполнена с возможностью лемматизации каждого слова каждой идентифицированной фразы.
[0089] Способ, в соответствии с которым лемматизируется слово, хорошо известен в данной области техники, достаточно будет упомянуть, что лемматизация может быть выполнена путем стемминга и анализа данного слова для создания леммы упомянутого слова, как известно в данной области техники. Излишне говорить, что при лемматизации может дополнительно или опционально использоваться словарь для улучшения качества лемматизации.
[0090] В некоторых вариантах осуществления настоящей технологии, процедура 204 парсинга далее выполнена с возможностью реорганизовывать слова в идентифицированной фразе таким образом, чтобы реорганизованная версия фразы состояла из слов в алфавитном порядке. Естественно, процедура 204 парсинга может реорганизовывать слова с помощью различных подходов (например, после первого слова, которое является словом, обладающим логическим значением, идут остальные лемматизированные слова, расположенные в алфавитном порядке).
[0091] Исключительно в виде примера, первая идентифицированная фраза может представлять собой "information search systems" («системы информационного поиска»), а вторая идентифицированная фраза может представлять собой "system for information searching"(«система для информационного поиска»). Используя различные техники, описанные выше, процедура 204 парсинга лемматизирует первую идентифицированную фразу до "system information search" и вторую идентифицированную фразу до "system information search". Конкретный технический эффект от процедуры 204, которая лемматизирует и/или реорганизует одну или несколько идентифицированных фраз 310, заключается в возможности более эффективно определять сходство между различными из одной или нескольких идентифицированных фраз (процесс будет описан далее).
[0092] Излишне говорить, что другие средства идентификации фразы в исходном цифровом тексте 302 известны в данной области техники, и представленные выше примеры не являются ограничивающими.
[0093] После того как одна или несколько фраз были идентифицированы в исходном цифровом тексте 302, процедура 204 парсинга выполнена с возможностью выбирать одну или несколько идентифицированных фраз в качестве лексических элементов. Например, если процедура 204 парсинга идентифицирует в исходном цифровом тексте 302 две фразы, процедура 204 парсинга будет выбирать две фразы в качестве первого исходного лексического элемента 312 и второго исходного лексического элемента 314.
[0094] После того как в процедуре 204 парсинга выбраны одна или несколько фраз в качестве исходных лексических элементов, в качестве лексических элементов будут выбраны одно или несколько слов. Способ выбора слова в качестве данного исходного лексического элемента будет описан далее.
[0095] В некоторых вариантах осуществления настоящей технологии, процедура 204 парсинга выполнена с возможностью исключать заранее идентифицированные фразы из исходного цифрового текста 302 и идентифицировать отметку оставшихся слов исходного цифрового текста 302 и выбирать слово, которое относится к одному конкретному грамматическому типу. В некоторых вариантах осуществления настоящей технологии, процедура 204 парсинга выполнена с возможностью выбирать слова, обладающие логическим смыслом, как было описано выше.
[0096] Несмотря на то, что функции процедуры 204 парсинга были описаны в отношении исходного цифрового текста 302 и без ссылок на целевой цифровой текст 318, это сделано только для избежания повторов. Излишне упоминать, что процедура 204 парсинга также выполнена с возможностью выполнять различные функции, представленные выше, в отношении целевого цифрового текста 318 для идентификации и выбора целевых лексических элементов (первого целевого лексического элемента 320, второго целевого лексического элемента 330 и третьего целевого лексического элемента 332).
[0097] Процедура создания контекстного параметра
[0098] После того как в процедуре 204 парсинга были выбраны исходные лексические элементы, процедура 206 создания контекстного параметра выполнена с возможностью анализировать первую связь для каждого исходного лексического элемента в отношении каждого оставшегося лексического элемента.
[0099] На Фиг. 6 представлена блок-схема анализа первой связи между каждым исходным лексическим элементом в соответствии с некоторыми вариантами осуществления настоящей технологии при выполнении процедуры 206 создания контекстного параметра. Чтобы избежать повторов, описание процесса представлено с помощью исходного цифрового текста 302, однако описанный ниже процесс также применим и к целевому цифровому тексту 318.
[00100] На этапе 602, процедура 206 создания контекстного параметра выполнена с возможностью идентифицировать, для каждого исходного лексического элемента (например, первого исходного лексического элемента 312, второго исходного лексического элемента 314 и третьего исходного лексического элемента 316), одно или несколько исходных предложений, в которых они появляются. Например, процедура 206 создания контекстного параметра может определять, что первый исходный лексический элемент 312 является записью в исходных предложениях #1, #4, #5 и #7 исходного цифрового текста 302, второй исходный лексический элемент 314 является записью в исходных предложениях #1, #4, #7 и #8 исходного цифрового текста 302, и третий исходный лексический элемент 316 является записью в исходных предложениях #2, #3, #8 и #9 исходного цифрового текста 302.
[00101] На этапе 604, процедура 206 создания контекстного параметра выполнена с возможностью выбирать данный исходный лексический элемент, например первый исходный лексический элемент 312.
[00102] На этапе 606, процедура 206 создания контекстного параметра выполняет первый анализ для создания исходного значения контекстно-зависимых отношений (CDR) для первого исходного лексического элемента 312 в отношении каждого оставшегося исходного лексического элемента (т.е. второго исходного лексического элемента 314, третьего исходного лексического элемента 316). В общем случае, исходное значение CDR представляет первое соотношение: (i) числа исходных предложений, где первый исходный лексический элемент 312 совместно встречается с другим исходным лексическим элементом (т.е. вторым исходным лексическим элементом 314, третьим исходным лексическим элементом 316) и (ii) общего числа исходных предложений, которые обладают первым исходным лексическим элементом 312 в качестве записи в исходном цифровом тексте 302.
[00103] На этапе 608, процедура 206 создания контекстного параметра заполняет полученными значениями первую исходную матрицу 700 (показано на Фиг. 7 и описано далее).
[00104] На этапе 610, процедура 206 создания контекстного параметра итерационно выполняет тот же процесс в отношении оставшихся исходных лексических элементов (т.е. второго исходного лексического элемента 314 и третьего исходного лексического элемента 316).
[00105] На Фиг. 7 показан пример первой исходной матрицы 700. Как показано в первой исходной матрице 700, каждая запись в первом столбце 702 и первом ряду 704 включает в себя указание на данный исходный лексический элемент (например, первый исходный лексический элемент 312, второй исходный лексический элемент 314 и третий исходный лексический элемент 316). Первая исходная матрица 700 включает в себя множество ячеек (например, первую ячейку 706, вторую ячейку 708 и третью ячейку 710).
[00106] В некоторых вариантах осуществления настоящей технологии, каждая ячейка включает в себя указание на один или несколько исходных предложений, в которых встречается каждый из исходных лексических элементов в исходном цифровом тексте 302, как определено на этапе 602.
[00107] В дополнении к указанию на одно или несколько исходных предложений, каждая ячейка дополнительно содержит указание на исходное значение CDR среди каждого из исходных лексических элементов, как было определено на этапе 606. Учитывая первый исходный лексический элемент 312 в качестве примера, исходное значение CDR первого исходного лексического элемента 312 в отношении первого исходного лексического элемента равно 1 (как показано в первой ячейке 706); исходное значение CDR первого исходного лексического элемента 312 в отношении второго исходного лексического элемента 314 равно 0,7 (как показано во второй ячейке 708); и исходное значение CDR первого исходного лексического элемента 312 в отношении третьего исходного лексического элемента 316 равно 0 (как показано в третьей ячейке 710).
[00108] После заполнения первой исходной матрицы 700, процедура 206 создания контекстного параметра выполняется для извлечения первого исходного контекстного параметра 712 для первого исходного лексического элемента 312, второго исходного контекстного параметра 714 для второго исходного лексического элемента 314, и третьего исходного контекстного параметра 716 для третьего исходного лексического элемента 316.
[00109] В контексте настоящей технологии, термин "контекстный параметр" относится к указанию на набор исходных значений CDR, связанных с данным лексическим элементом, а также указание на предложения, в которых встречается каждый лексический элемент.
[00110] Например, первый исходный контекстный параметр 712 соответствует строке, связанной с первым исходным лексическим элементом 312 в первой исходной матрице 700, и включает в себя набор исходных значений CDR, связанных с первым исходным лексическим элементом 312 (т.е. исходные значения CDR, хранящиеся в первой ячейке 706, второй ячейке 708 и третьей ячейке 710), и указания на предложения, в которых встречается каждый лексический элемент (т.е. указания на предложения, хранящиеся в первой ячейке 706, второй ячейке 708 и третьей ячейке 710).
[00111] В некоторых вариантах осуществления настоящей технологии, процедура 206 создания контекстного параметра далее выполнена с возможностью анализировать вторую связь для каждого исходного лексического элемента в отношении каждого оставшегося лексического элемента.
[00112] На Фиг. 8 представлена блок-схема анализа второй связи между каждым лексическим элементом в соответствии с некоторыми вариантами осуществления настоящей технологии при выполнении процедуры 206 создания контекстного параметра. Во избежание повторений, описание процесса осуществлено с помощью исходного цифрового текста 302.
[00113] На этапе 802, процедура 206 создания контекстного параметра выполнена с возможностью идентифицировать, для каждого исходного лексического элемента (например, первого исходного лексического элемента 312, второго исходного лексического элемента 314 и третьего исходного лексического элемента 316), одно или несколько исходных предложений, в которых они появляются. Например, процедура 206 создания контекстного параметра может определять, что первый исходный лексический элемент 312 является записью в исходных предложениях #1, #4, #5 и #7 исходного цифрового текста 302, второй исходный лексический элемент 314 является записью в исходных предложениях #1, #4, #7 и #8 исходного цифрового текста 302, и третий исходный лексический элемент 316 является записью в исходных предложениях #2, #3, #8 и #9 исходного цифрового текста 302.
[00114] На этапе 804, процедура 206 выбирает данный исходный лексический элемент, например первый исходный лексический элемент 312.
[00115] На этапе 806, процедура 206 создания контекстного параметра выполнена с возможностью осуществлять второй анализ для создания исходного значения контекстно-независимых отношений (CIR) для первого исходного лексического элемента 312 в отношении каждого оставшегося исходного лексического элемента (т.е. второго исходного лексического элемента 314, третьего исходного лексического элемента 316). В общем случае, исходное значение CIR первого исходного лексического элемента 312 в отношении данного другого исходного лексического элемента представляет собой второе отношение: (i) числа слов первого исходного лексического элемента 312, встречающегося с данном другом исходном лексическом элементе и (ii) общего числа слов первого исходного лексического элемента 312.
[00116] На Фиг. 9 показан пример определения исходного значения CIR между первым исходным лексическим элементом 312 и вторым исходным лексическим элементом 314. В представленном примере, первый исходный лексический элемент 312 является фразой "modern computer system" ("современная компьютерная система), которая содержит первое слово 902 ("modern"), второе слово 904 ("computer") и третье слово 906 ("system"). Второй исходный лексический элемент 314 является фразой "modern mainframe computer system" ("современная мейнфреймовая компьютерная система), которая содержит четвертая слово 908 ("modern"), пятое слово 910 ("mainframe"), шестое слово 912 ("computer") и седьмое слово 914 ("system").
[00117] Процедура 206 создания контекстного параметра высчитывает исходное значение CIR первого исходного лексического элемента 312 в отношении второго исходного лексического элемента 314, равное 1, поскольку все слова первого исходного лексического элемента 312 (т.е. первое слово 902, второе слово 904 и третье слово 906) содержатся во втором исходном лексическом элементе 314. Аналогичным образом, исходное значение CIR второго исходного лексического элемента 314 в отношении первого исходного лексического элемента 312 будет равно 0,75, поскольку только 3 слова (т.е. четвертое слово 908, шестое слово 912 и седьмое слово 914) из 4 слов, которые составляют второй исходный лексический элемент 314, содержатся в первом исходном лексическом элементе 312.
[00118] Возвращаясь к Фиг. 8, после того как исходные значения CIR первого исходного лексического элемента 312 в отношении каждого из оставшихся исходных лексических элементов были подсчитаны, процедура 206 создания контекстного параметра заполняет полученными значениями вторую исходную матрицу 1000 (описано ниже) на этапе 808.
[00119] На этапе 810, процедура 206 создания контекстного параметра итерационно выполняет тот же процесс в отношении оставшихся исходных лексических элементов (т.е. второго исходного лексического элемента 314 и третьего исходного лексического элемента 316).
[00120] На Фиг. 10 показан пример второй исходной матрицы 1000. Как показано во второй исходной матрице 1000, каждая запись в первом столбце 1002 и первом ряду 1004 включает в себя указание на данный исходный лексический элемент (например, первая ячейка 706, вторая ячейка 708 и третья ячейка 710). Вторая исходная матрица 1000 далее включает в себя множество ячеек (например, первую ячейку 1006, вторую ячейку 1008 и третью ячейку 1010).
[00121] В некоторых вариантах осуществления настоящей технологии, каждая ячейка включает в себя указание на один или несколько исходных предложений, в которых встречается каждый из исходных лексических элементов в исходном цифровом тексте 302, как определено на этапе 802. Например, первая ячейка 1006 указывает на то, что первый исходный лексический элемент 312 встречается в исходных предложениях, идентифицированных как #1, #4, #5 и #7.
[00122] В дополнении к указанию на одно или несколько исходных предложений, каждая ячейка дополнительно содержит указание на исходное значение CIR среди каждого из исходных лексических элементов, как было определено на этапе 806. Учитывая первый исходный лексический элемент 312 в качестве примера, исходное значение CIR первого исходного лексического элемента 312 в отношении первого исходного лексического элемента равно 1 (как показано в первой ячейке 1006); исходное значение CIR первого исходного лексического элемента 312 в отношении второго исходного лексического элемента 314 равно 0,5 (как показано во второй ячейке 1008); и исходное значение CIR первого исходного лексического элемента 312 в отношении третьего исходного лексического элемента 316 равно 1 (как показано в третьей ячейке 1010).
[00123] После заполнения второй исходной матрицы 1000, процедура 206 создания контекстного параметра выполняется для извлечения первого исходного альтернативного контекстного параметра 1012 для первого исходного лексического элемента 312, второго исходного альтернативного контекстного параметра 1014 для второго исходного лексического элемента 314, и третьего исходного альтернативного контекстного параметра 1016 для третьего исходного лексического элемента 316.
[00124] В контексте настоящей технологии, термин "альтернативный контекстный параметр" относится к указанию на набор значений CDR, связанных с данным лексическим элементом, а также указание на предложения, в которых встречается каждый лексический элемент.
[00125] Например, первый исходный альтернативный контекстный параметр 1012 соответствует строке, связанной с первым исходным лексическим элементом 312 во второй исходной матрице 1000, и включает в себя набор исходных значений CIR, связанных с первым исходным лексическим элементом 312 (т.е. исходные значения CIR, содержащиеся в первой ячейке 1006, второй ячейке 1008 и третьей ячейке 1010), и указания на предложения, в которых встречается каждый лексический элемент, как указано в в первой ячейке 1006, второй ячейке 1008 и третьей ячейке 1010.
[00126] Несмотря на то, что функции процедуры 206 создания контекстного параметра были описаны в отношении исходного цифрового текста 302 и без ссылок на целевой цифровой текст 318, это сделано только для избежания повторов. Излишне упоминать, что процедура 206 создания контекстного параметра далее выполнена с возможностью выполнять различные функции, описанные выше в отношении целевого цифрового текста 318 для создания первой целевой матрицы, второй целевой матрицы, целевого контекстного параметра и целевого альтернативного контекстного параметра для каждого из целевых лексических элементов (первого целевого лексического элемента 328, второго целевого лексического элемента 330 и третьего целевого лексического элемента 332).
[00127] Процедура сопоставления
[00128] Варианты осуществления настоящей технологии основаны на предположении разработчиков о том, что данный исходный контекстуальный параметр относится к данному целевому контекстному параметра тем же образом, которым данный исходный лексический элемент относится к данному целевому лексическому элементу, и, тем самым, сопоставление данного исходного лексического элемента с данным целевым лексическим элементом может быть выполнено путем определения сходства между данным исходным контекстным параметром и данным целевым контекстным параметром.
[00129] Далее описано сопоставление данного исходного лексического элемента с данным целевым лексическим элементом с помощью двух неограничивающих процессов.
[00130] На Фиг. 11 представлен неограничивающий вариант осуществления первого процесса 1100 сопоставления данного исходного лексического элемента с данным целевым лексическим элементом.
[00131] На этапе 1102, процедура 208 сопоставления выполнена с возможностью выбирать один исходный лексический элемент, например первый исходный лексический элемент 312.
[00132] На этапе 1104, процедура 208 сопоставления выполнена с возможностью сравнивать первый исходный контекстный параметр 712 (который связан с первым исходным лексическим элементом 312) с набором целевых контекстных параметров.
[00133] На Фиг. 12 представлен неограничивающий пример сравнения первого исходного контекстного параметра 712 с набором целевых контекстных параметров в соответствии с этапом 1104.
[00134] В представленном примере, первый исходный контекстный параметр 712 сравнивается с каждым целевым контекстным параметром из множества целевых контекстных параметров 1202. Множество целевых контекстных параметров 1202 включает в себя пять целевых контекстных параметров, а именно - первый целевой контекстный параметр 1204 (который может быть связан с первым целевым лексическим элементом 328), второй целевой контекстный параметр 1206 (который может быть связан со вторым целевым лексическим элементом 330), третий целевой контекстный параметр 1208 (который может быть связан с третьим целевым лексическим элементом 332), четвертый целевой контекстный параметр 1210 и пятый целевой контекстный параметр 1212 (который может быть соответственно связан с четвертым и пятым целевым лексическим элементом (не показано), потенциально присутствующим в целевом цифровом тексте 318).
[00135] В некоторых вариантах осуществления настоящей технологии, для первого контекстного параметра 712, процедура 208 сопоставления выполнена с возможностью вычислять набор параметров 1226 сходства, который включает в себя первый параметр 1214 сходства, второй параметр 1216 сходства, третий параметр 1218 сходства, четвертый параметр 1220 сходства и пятый параметр 1222 сходства.
[00136] В контексте настоящего описания, термин "параметр сходства" относится к оценке (например, в процентах), обладающей значением разницы, которое представляет степень отличия между данным исходным контекстным параметром и целевым контекстным параметром (или, наоборот, чем ниже оценка, тем выше степень сходства между данным исходным контекстным параметром и целевым контекстным параметром). Например, первый параметр 1214 сходства представляет собой сходство между первым исходным контекстным параметром 712 и первым целевым контекстным параметром 1204. Способ определения первого параметра 1214 сходства, второго параметра 1216 сходства, третьего параметра 1218 сходства, четвертого параметра 1220 сходства и пятого параметра 1222 сходства описан далее со ссылкой на Фиг. 13.
[00137] Возвращаясь к Фиг. 11, после того как набор параметров 1226 сходства был рассчитан, процесс переходит к этапу 1106. На этапе 1106, процедура 208 сопоставления выполнена с возможностью анализировать набор параметров 1226 сходства и идентифицировать параметр сходства, который представляет оценку наименьшего значения разницы (т.е. указывает на наибольшее сходство между первым исходным контекстным параметром 712 и целевым контекстным параметром из множества целевых контекстных параметров 1202).
[00138] Например, может быть определено, что в наборе параметров 1226 сходства второй параметр 1216 сходства указывает на то, что первый исходный контекстный параметр 712 и второй целевой контекстный параметр 1206 обладают наименьшей разницей между собой.
[00139] После того, как было идентифицировано наименьшее значение разницы, процедура 208 сопоставления переходит к этапу 1106, где она может идентифицировать целевой лексический элемент, который связан с параметром сходства, обладающим наименьшим значением разницы (в вышепредставленном примере это второй целевой лексический элемент 330), и сопоставлять первый исходный лексический элемент 312 с идентифицированным целевым лексическим элементом для формирования сопоставленной пары.
[00140] В некоторых вариантах осуществления настоящей технологии, процедура 208 сопоставления выполнена с возможностью итерационно сопоставлять оставшиеся исходные лексические элементы (например, второй исходный лексический элемент 314 и третий исходный лексический элемент 316) для формирования множества сопоставленных пар. Другими словами, после того как этап 1108 выполнен для первого исходного лексического элемента 312, процедура 208 сопоставления выполнена с возможностью возвращаться к этапу 1102 для идентификации данного целевого лексического элемента, который будет сопоставлен с оставшимися исходными лексическими элементами.
[00141] На Фиг. 14 представлен другой неограничивающий вариант осуществления второго процесса 1400 сопоставления данного целевого лексического элемента с данным целевым лексическим элементом.
[00142] На этапе 1402, процедура 208 сопоставления выбирает исходное предложение (например, первое исходное предложение 306, второе исходное предложение 308 или третье исходное предложение 310), которое содержит первый исходный лексический элемент 312.
[00143] На этапе 1404 процедура 208 сопоставления выбирает целевое предложение (например, первое целевое предложение 322, второе целевое предложение 324 и третье целевое предложении), которое содержит по меньшей мере один целевой лексический элемент (например, первый целевой лексический элемент 328, второй целевой лексический элемент 330 и третий целевой лексический элемент 332).
[00144] На этапе 1406 процедура 208 сопоставления выполнена с возможностью сравнивать первый исходный контекстный параметр 712 с каждым из целевых контекстных параметров, связанных с выбранным целевым предложением (подробнее описано далее).
[00145] Этап 1406 описан с помощью Фиг. 15, которая является неограничивающим примером. Как показано на Фиг. 15, представлено первое исходное предложение 306, которое включает в себя первый исходный лексический элемент 312, второй исходный лексический элемент 314, и третий исходный лексический элемент 316. Первое целевое предложение 322 содержит первый целевой лексический элемент 328, второй целевой лексический элемент 330, третий целевой лексический элемент 332 и четвертый целевой лексический элемент (не пронумеровано).
[00146] В некоторых вариантах осуществления настоящей технологии, процедура 208 выполнена с возможностью сравнивать (описано далее) первый исходный контекстный параметр 712 с каждым целевым контекстным параметром, связанным с целевыми лексическими элементами, которые содержат первое целевое предложение 322 (т.е. первый целевой контекстный параметр 1204, второй целевой контекстный параметр 1206, третий целевой контекстный параметр 1208 и четвертый целевой контекстный параметр 1210) с целью создать первый параметр 1214 сходства, второй параметр 1216 сходства, третий параметр 1218 сходства и четвертый параметр 1220 сходства.
[00147] После завершения сравнения первого исходного контекстного параметра 712 с каждым целевым контекстным параметром, процесс переходит к этапу 1408, где процедура 208 сопоставления идентифицирует параметр сходства, представляющий собой оценку, которая обладает локальным минимальным значением в данном целевом предложении (т.е. указывает на наивысшее сходство между первым исходным контекстным параметром 712 и данным целевым контекстным параметром в данном целевом предложении).
[00148] Например, может быть определено, что в первом целевом предложении 322, первый параметр 1214 сходства указывает на то, что первый исходный контекстный параметр 712 и первый целевой контекстный параметр 1204 обладают наименьшей разницей между собой.
[00149] Возвращаясь к Фиг. 14, на этапе 1414 процедура 208 сопоставления итерационно выполняет тот же процесс в отношении к оставшимся целевым предложениям для вычисления множества локальных минимальных значений.
[00150] На Фиг. 16 представлен пример табличного списка 1600, содержащего набор локальных минимальных значений 1602, идентифицированных за время выполнения этапа 1408 для первого исходного контекстного параметра 712. Например, может быть определено, что локальное минимальное значение в первом целевом предложении 322 является первым параметром 1214 сходства (который связан с первым целевым лексическим элементом 328), третьим параметром 1218 сходства (который связан с третьим целевым лексическим элементом 332) для второго целевого предложения и четвертым параметром 1220 сходства (который связан с четвертым целевым лексическим элементом (не показано)) для третьего целевого предложения 326.
[00151] Возвращаясь к Фиг. 14, после того как табличный список 1600 был заполнен по меньшей мере подмножеством из набора локальных минимальных значений 1602, процедура 208 сопоставления выполнена с возможностью идентифицировать на этапе 1410 параметр сходства, который представляет оценку наименьшего значения разницы (т.е. указывает на наивысшее сходства между первым исходным контекстным параметрам 712 и данным целевым контекстным параметром, выбранным из целого набора локальных минимальных значений 1602). Например, может быть определено, что в наборе локальных минимальных значений 1602, первый параметр 1214 сходства обладает наименьшим значением разницы.
[00152] После того как наименьшее значение разницы было определено, процедура 208 сопоставления выполнена с возможностью, на этапе 1412, сопоставлять первый исходный лексический элемент 312 с целевым лексическим элементом, который связан с наименьшим значением разницы, а именно, первый целевой лексический элемент 328 в вышеприведенном примере, для формирования сопоставленной пары.
[00153] В некоторых вариантах осуществления настоящей технологии, процедура 208 итерационно выполняет тот же процесс на этапе 1416 в отношении оставшихся исходных лексических элементов (т.е. второго исходного лексического элемента 314 и третьего исходного лексического элемента 316) для сопоставления каждого из оставшихся исходных лексических элементов с данным целевым лексическим элементом, тем самым создавая множество сопоставленных пар.
[00154] Вычисление параметров сходства
[00155] На Фиг. 13 представлен неограничивающий пример вычисления первого параметра 1214 сходства между первым исходным контекстным параметром 712 и первым целевым контекстным параметром 1204 в соответствии с первым процессом 1100 и вторым процессом 1400. Несмотря на то, что последующее описание представлено только со ссылкой на первый параметр 1214 сходства, вычисление оставшихся параметров сходства может быть выполнено путем осуществления описанного далее способа.
[00156] Как было упомянуто ранее, первый исходный контекстный параметр 712 включает (i) первый набор исходных значений CDR, связанных с первым исходным лексическим элементом 312, и (ii) указание на один или несколько исходных предложений, в которых встречается каждый исходный лексический элемент.
[00157] Аналогично первому исходному контекстному параметру 712, первый целевой контекстный параметр 1204 включает в себя первую ячейку 1302, вторую ячейку 1304 и третью ячейку 1306. Каждая из первой ячейки 1302, второй ячейки 1304 и третьей ячейки 1306 включает в себя (i) первый набор исходных значений CDR, связанных с первым целевым лексическим элементом 328, и (ii) указание на одно или несколько целевых предложений, в которых встречается каждый целевой лексический элемент.
[00158] В некоторых вариантах осуществления настоящей технологии, первый параметр 1214 сходства является набором параметров сходства ячеек, который включает в себя первый параметр 1316 сходства ячеек, второй параметр 1318 сходства ячеек и третий параметр 1320 сходства ячеек.
[00159] Каждый параметр сходства ячеек (т.е. первый параметр 1316 сходства ячеек, второй параметр 1318 сходства ячеек и третий параметр 1320 сходства ячеек) указывает на сходство между данной ячейкой из первого исходного контекстного параметра 712 (т.е. первой ячейкой 706, второй ячейкой 708 и третьей ячейкой 710) и данной ячейкой из первой целевой контекстный параметр 1204 (т.е. первая ячейка 1302, вторая ячейка 1304 и третья ячейка 1306).
[00160] Используя вторую ячейку 708 в качестве примера, процедура 208 сопоставления выполнена с возможностью вычислять второй параметр 1318 сходства ячеек как описано далее. Излишне говорить, что, несмотря на то что последующее описание представлено только со ссылкой на второй параметр 1316 сходства ячеек, вычисление оставшихся параметров сходства ячеек может быть выполнено путем осуществления описанного далее способа.
[00161] Вторая ячейка 708 включает в себя исходное значение 1308 CDR и указание 1310 на исходные предложения (которое является указанием на один или несколько исходных предложений, в которых второй исходный лексический элемент 314 является записью).
[00162] Процедура 208 сопоставления выполнена с возможностью анализировать каждую ячейку из первого целевого контекстного параметра 1204 для идентификации ячейки, содержащей указание на целевые предложения аналогичное указаниям на исходные предложения.
[00163] Например, может быть определено, что вторая ячейка 1304 включает в себя указание 1314 (которое включает в себя указание на одно или несколько целевых предложении, в которых второй целевой лексический элемент 330 является записью), которое наиболее похоже на указание 1310 на исходные предложения.
[00164] После идентификации того, что второй исходный лексический элемент 314 и второй целевой лексический элемент 330 обладают наибольшим сходством по встречающимся предложениям, процедура 208 сопоставления выполнена с возможностью вычислять второй параметр 1318 сходства ячеек путем сравнения исходного значения 1308 CDR (второй ячейки 708) с целевым значением 1312 CDR (второй ячейки 1304).
[00165] Проверка сопоставленных пар
[00166] В некоторых вариантах осуществления настоящей технологии, каждая сопоставленная пара является гипотезой эквивалента перевода между целевым лексическим элементом и исходным лексическим элементом, связанным с сопоставленной парой. Таким образом, в некоторых вариантах осуществления настоящей технологии, процедура 208 сопоставления может быть выполнена с возможностью, как часть этапа 1108 и этапа 1412, проверять гипотезу для данной сопоставленной пары путем сравнения альтернативных контекстных параметров лексических элементов, связанных с данной сопоставленной парой.
[00167] Например, в случае, когда процедура 208 сопоставления сопоставила первый исходный лексический элемент 312 с первым целевым лексическим элементом 328, процедура 208 может быть выполнена с возможностью сравнивать альтернативный параметр сходства (не показан) путем сравнения первого исходного альтернативного контекстного параметра 1012 и первого целевого альтернативного контекстного параметра (не показано) с помощью аналогичного способа, представленного выше в отношении Фиг. 13.
[00168] Возвращаясь к Фиг. 2, если определено, что альтернативный параметр сходства выше, чем эмпирически определенный порог, процедура 208 сопоставления подтверждает гипотезу и сохраняет сопоставленную пару как пакет 214 данных, который может быть базой данных сопоставлений для выделенного пространства памяти на сервере 114. Если, наоборот, альтернативный параметр сходства ниже порога, процедура 208 сопоставления опровергает гипотезу и не сохраняет сопоставленную пару как пакет 214 данных.
[00169] В последнем случае, процедура 208 сопоставления выполнена с возможностью идентифицировать второй по величине параметр сходства из набора параметров 1226 или набора локальных минимальных значений 1602. Процедура 208 сопоставления далее выполнена с возможностью учитывать целевой лексический элемент, связанный со вторым по величине параметром, как альтернативную гипотезу эквивалента перевода для первого исходного лексического элемента 312. Процедура 208 сопоставления далее повторно выполняет упомянутый процесс для подтверждения (или опровержения) альтернативных гипотез.
[00170] Процедура выравнивания предложений
[00171] В некоторых вариантах осуществления настоящей технологии, процедура 210 выравнивания предложений выполнена с возможностью сопоставлять каждое исходное предложение исходного цифрового текста 302 с предложением-эквивалентом перевода целевого цифрового текста 318.
[00172] На Фиг. 17 представлен вариант осуществления процесса сопоставления данного исходного предложения с данным целевым предложением. Для простоты понимания Фиг. 17 будет описана со ссылкой на первое исходное предложение 306.
[00173] На этапе 1702, процедура 210 выравнивания предложения выполнена с возможностью выбирать исходное предложения из исходного цифрового текста 302, например, первого исходного предложения 306.
[00174] На этапе 1704, процедура 210 выравнивания предложения выполнена с возможностью идентифицировать один или несколько исходных лексических элементов, включающих в себя первое исходное предложение 306. Например, может быть определено, что первое исходное предложение 306 включает в себя первый исходный лексический элемент 312, второй исходный лексический элемент 314, и третий исходный лексический элемент 316.
[00175] На этапе 1706, процедура 210 выравнивания предложения выполнена с возможностью получать доступ к пакету 214 данных и определять набор целевых лексических элементов, включающий в себя целевые лексические элементы, которые были сопоставлены с первым исходным лексическим элементом 312, вторым исходным лексическим элементом 314 и третьим исходным лексическим элементом 316.
[00176] Например, может быть определено, что первый исходный лексический элемент 312 сопоставлен с первым целевым лексическим элементом 328, второй исходный лексический элемент 314 со вторым целевым лексическим элементом 330, а третий исходный лексический элемент 316 с третьим целевым лексическим элементом 332.
[00177] На этапе 1708, процедура 210 выравнивания предложений выполнена с возможностью определять, включает ли одно целевое предложение первый целевой лексический элемент 328, второй целевой лексический элемент 330 и третий целевой лексический элемент 332.
[00178] Например, с помощью указаний на одно или несколько целевых предложений, в которых встречается каждый из целевых лексических элементов (что содержится в первой целевой матрице (не показано)), процедура 210 выравнивания предложений выполнена с возможностью определять целевое предложение, в котором совместно встречаются первый целевой лексический элемент 328, второй целевой лексический элемент 330 и третий целевой лексический элемент 332, например, первое целевое предложение 322.
[00179] На этапе 1712, после идентификации первого целевого предложения 322 как содержащего все целевые лексические элементы, сопоставленные с исходными лексическими элементами первого исходного предложения 306, процедура 210 выравнивания предложения выполнена с возможностью сопоставлять первое исходное предложение 306 с первым целевым предложением 322 как эквивалент перевода для формирования пары предложений.
[00180] Специалисту в области машинного перевода будет понятно, что зачастую может не быть точного соответствия между предложениями в исходном цифровом тексте 302 и целевом цифровом тексте 318, следовательно, на этапе 1708 может быть определено, что нет ни одного целевого предложения, в котором первый целевой лексический элемент 328, второй целевой лексический элемент 330 и третий целевой лексический элемент 332 встречаются совместно. Таким образом, в случае, если процедура 210 выравнивания предложений не может определить ни одного целевого предложения, содержащего первый целевой лексический элемент 328, второй целевой лексический элемент 330 и третий целевой лексический элемент 332, процесс переходит к этапу 1710 после этапа 1708.
[00181] На этапе 1710, процедура 210 выравнивания предложений выполнена с возможностью идентифицировать данное целевое предложение, содержащее подмножество из набора целевых лексических элементом (например, первый целевой лексический элемент 328, второй целевой лексический элемент 330) и определять, содержат ли соседние предложения для данного целевого предложения оставшееся подмножество из набора лексических элементом (например, третий лексический элемент 332). После идентификации того, что набор целевых предложений (т.е. данное предложение и одно из соседних предложений) содержит набор целевых лексических элементов, процедура 210 выравнивания предложений выполнена с возможностью сопоставлять набор целевых предложении с первым исходным предложением 306 для формирования пары предложений на этапе 1712.
[00182] В некоторых вариантах осуществления настоящей технологии, после идентификации каждой пары предложений, процедура выравнивания предложений выполнена с возможностью передавать второй пакет 122 данных приложению 104 по переводу.
[00183] В некоторых вариантах осуществления настоящей технологии, второй пакет 122 данных включает в себя указания на (i) исходный цифровой текст 302 (ii) целевой цифровой текст 318 (iii) данные, указывающие на пары предложений, которые были созданы, и (iv) машиночитаемые инструкции для инициирования приложения 104 по переводу выравнять множество исходных предложений 304 со множеством целевых предложений 302 на основе пар предложений.
[00184] На Фиг. 18 показан снимок экрана с приложением 104 по переводу в фазе использования в соответствии с вариантами осуществления настоящей технологии. Приложение 104 по переводу включает в себя часть 106 для ввода текста для исходного цифрового текста 302 на первом языке, который разделен на одно или несколько исходных предложений с помощью горизонтальных линий, и часть 108 для вывода текста для целевого цифрового текста 318, отображающую выравненные одно или несколько целевых предложений в виде соответствующего предложения эквивалента перевода.
[00185] В представленном варианте осуществления технологии, первое исходное предложение 306 выравнено с первым целевым предложением 322. Второе исходное предложение 308 выравнено со вторым целевым предложением 324 и третьим целевым предложением 326.
[00186] В некоторых вариантах осуществления настоящей технологии, второй пакет 122 данных далее включает в себя (у) данные, указывающие на сопоставленные пары и (vi) машиночитаемые инструкции для инициирования приложения 104 по переводу для указания эквивалента перевода данного исходного лексического элемента исходного цифрового текста 302 для целевого цифрового текста 318 (и наоборот).
[00187] Например, когда курсор 1802, управляемый пользователем электронного устройства 102, наведен (или при нажатии курсором) на первый исходный лексический элемент 312, приложение 104 по переводу выполнено с возможностью визуально идентифицировать первый целевой лексический элемент 328 (который определен как эквивалент перевода первого исходного лексического элемента 312) путем выделения первого целевого лексического элемента 328 в первом целевом предложении 322.
[00188] Конкретный технический эффект от использования вариантов осуществления настоящей технологии проявляется в возможность сопоставлять лексический элемент на первом языке с лексическим элементом на втором языке как эквивалент перевода без использования словарей, только на основе исходного цифрового текста 302 и целевого цифрового текста 318 (таким образом, не требуется заполнение, обновление, поддержание и хранение словарей).
[00189] С учетом архитектуры и примеров, представленных выше, возможно осуществить исполняемый на компьютере способ сопоставления исходного исходного лексического элемента исходного цифрового текста с целевым лексическим элементом целевого цифрового текста, второй лексический элемент является эквивалентом перевода цифрового лексического элемента. На Фиг. 19 представлена блок-схема способа 1900, который выполняется в соответствии с не ограничивающими вариантами осуществления настоящей технологии. Процесс 1900 может выполняться сервером 114.
[00190] Этап 1902 - получение сервером указания на исходный цифровой текст, который будет обработан, исходный цифровой текст включает в себя множество исходных предложений %
[00191] Способ 1900 начинается на этапе 1902, где приложение 118 по сопоставлению, которое выполняется сервером 114, получает указание на исходный цифровой текст 302, содержащий множество исходных предложений 304, через процедуру 202 получения текста.
[00192] В некоторых вариантах осуществления настоящей технологии, исходный цифровой текст 302 получают напрямую от приложения 116 по обработке текста или из цифрового устройства памяти, относящегося к серверу 114 (не показано), который хранит исходный цифровой текст 302.
[00193] Этап 1904 - парсинг сервером по меньшей мере части множества исходных предложений на один или несколько исходных лексических элементов,
[00194] На этапе 1904, процедура 204 приложения 118 по сопоставлению
парсит по меньшей мере часть множества исходных предложений 304 для выбора первого исходного лексического элемента 312, второго исходного лексического элемента 314 и третьего исходного лексического элемента 316.
[00195] Этап 1906 - создание для каждого из одного или нескольких исходных лексических элементов исходного контекстного параметра, исходный контекстный параметр включает в себя: первый набор исходных значений контекстно-зависимых отношений (CDR), каждое исходное значение CDR представляет собой отношение (i) числа исходных предложений, где совместно встречаются данный исходный лексический элемент и каждый из одного или нескольких исходных лексических элементов к (ii) общему числу исходных предложений, содержащих данный исходный лексический элемент; и указание на одно или несколько исходных предложений, в которые входит каждый из одного или нескольких исходных лексических элементов,
[00196] На этапе 1906 процедура 206 создания контекстного параметра приложения 118 по сопоставлению выполнена с возможностью создавать исходный контекстный параметр для каждого из выбранных исходных лексических элементов.
[00197] Таким образом, с учетом примера первого исходного лексического элемента, для того чтобы создать первый исходный контекстный параметр 712, процедура 206 создания контекстного параметра выполнена с возможностью вычислять набор исходных значений CDR, которые представляют отношение числа исходных предложений, в которых совместно встречаются первый исходный лексический элемент 312 и каждый из одного или нескольких исходных лексических элементов (т.е. второй исходный лексический элемент 314 и третий исходный лексический элемент 316), к общему числу исходных предложений, содержащих первый исходный лексический элемент 312. Процедура 206 создания контекстного параметра далее выполнена с возможностью идентифицировать указание на одно или несколько исходных предложений, в которых встречаются каждый из одного или нескольких исходных лексических элементов (т.е. первый исходный лексический элемент 312, второй исходный лексический элемент 314 и третий исходный лексический элемент 316).
[00198] 1908 - получение сервером указания на целевой цифровой текст, который будет обработан, целевой цифровой текст включает в себя множество целевых предложений
[00199] На этапе 1908 процедура 202 получения текста приложения 118 по сопоставлению получает указание на целевой цифровой текст 318, который включает в себя множество целевых предложений 320.
[00200] В некоторых вариантах осуществления настоящей технологии, целевой цифровой текст 318 получают напрямую от приложения 116 по обработке текста или из цифрового устройства памяти, относящегося к серверу 114 (не показано), который хранит целевой цифровой текст 318, созданный приложением 116 по обработке текста.
[0201] Этап 1910 - парсинг сервером по меньшей мере части множества целевых предложений на один или несколько целевых лексических элементов,
[00202] На этапе 1910, процедура 204 приложения 118 по сопоставлению парсит по меньшей мере часть множества целевых предложений 320 для выбора первого целевого лексического элемента 328, второго целевого лексического элемента 330 и третьего целевого лексического элемента 332.
[00203] Этап 1912 - создание для каждого одного или нескольких целевых лексических элементов, целевого контекстного параметра, целевой контекстный параметр включает в себя: первый набор целевых значений CDR, каждое целевое значение CDR представляет собой отношение (Г) числа целевых предложений, где совместно встречаются данный исходный лексический элемент и каждый из одного или нескольких целевых лексических элементов к (ii) общему числу целевых предложений, содержащих данный целевой лексический элемент; и указание на одно или несколько целевых предложений, в которые входит каждый из одного или нескольких целевых лексических элементов.
[00204] На этапе 1912 процедура 206 создания контекстного параметра приложения 118 по сопоставлению выполнена с возможностью создавать целевой контекстный параметр для каждого из выбранных целевых лексических элементов.
[00205] Таким образом, с учетом примера первого целевого лексического элемента, для того чтобы создать первый целевой контекстный параметр 1204, процедура 206 создания контекстного параметра выполнена с возможностью вычислять набор целевых значений CDR, которые представляют отношение числа целевых предложений, в которых совместно встречаются первый целевой лексический элемент 328 и каждый из одного или нескольких целевых лексических элементов (т.е. второй целевой лексический элемент 330 и третий целевой лексический элемент 332), к общему числу исходных предложений, содержащих первый целевой лексический элемент 328. Процедура 206 создания контекстного параметра далее выполнена с возможностью идентифицировать указание на одно или несколько целевых предложений, в которых встречаются каждый из одного или нескольких целевых лексических элементов (т.е. первый целевой лексический элемент 328, второй целевой лексический элемент 330 и третий целевой лексический элемент 332).
[00206] Этап 1914 - выбор первого целевого лексического элемента, первый исходный лексический элемент, обладающий первым исходным контекстным параметром,
[00207] На этапе 1914, процедура 208 по сопоставлению приложения 118 по сопоставлению выполнена с возможностью выбора первого исходного лексического элемента 312, и первый исходный лексический элемент 312 обладает первым исходным контекстным параметром 712.
[00208] Этап 1916 - сравнение сервером первого исходного контекстного параметра со множеством целевых контекстных параметров для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы,
[00209] На этапе 1916, процедура 208 сопоставления выполнена с возможностью сравнивать первый исходный контекстный параметр 712 со множеством целевых контекстных параметров 1202 (например, первым целевым контекстным параметром 1204, вторым целевым контекстным параметром 1206 и третьим целевым контекстным параметром 1208) для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы.
[00210] Этап 1918 - сопоставление первого исходного лексического элемента с первым целевым лексическим элементом, первый целевой лексический элемент является связанным с данным целевым контекстным параметром, обладающим наименьшим значением разницы.
[00211] На этапе 1918, процедура 208 сопоставления выполнена с возможностью сопоставлять первый исходный лексический элемент 312 с первым целевым лексическим элементом 328, если определено, что первый целевой контекстный параметр 1204 обладают наименьшим значением разницы.
[00212] Некоторые из этих этапов, а также передача-получение сигнала хорошо известны в данной области техники и поэтому для упрощения были опущены в конкретных частях данного описания. Сигналы могут быть переданы/получены с помощью оптических средств (например, оптоволоконного соединения), электронных средств (например, проводного или беспроводного соединения) и механических средств (например, на основе давления, температуры или другого подходящего параметра).
[00213] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
[00214] С учетом вышеописанных вариантов осуществления технологии, которые были описаны и показаны со ссылкой на конкретные этапы, выполненные в определенном порядке, следует иметь в виду, что эти этапы могут быть совмещены, разделены, обладать другим порядком выполнения - все это не выходит за границы настоящей технологии. Соответственно, порядок и группировка этапов не является ограничением для настоящей технологии.
[00215] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом из вариантов осуществления настоящего технического решения. Например, варианты осуществления настоящего технического решения могут быть выполнены без проявления некоторых технических результатов, другие могут быть выполнены с проявлением других технических результатов или вовсе без них.
[00216] Таким образом, по меньшей мере некоторые неограничивающие варианты осуществления настоящей технологии, описанные выше, можно изложить следующим образом в виде пронумерованных пунктов.
[00217] ПУНКТ 1 Исполняемый на компьютере способ (1900) сопоставления исходного лексического элемента (312) исходного цифрового текста (302) на первом языке с соответствующим целевым лексическим элементом (328) целевого цифрового текста (318) на втором языке, целевой цифровой текст (318) является переводом исходного цифрового текста (302), способ выполняется на сервере (114), способ включает в себя:
получение (1902) сервером (114) указания на исходный цифровой текст (302), который будет обработан, причем исходный цифровой текст (302) включает в себя множество исходных предложений (304);
парсинг (1904) сервером (114) по меньшей мере части множества исходных предложений (304) на один или несколько исходных лексических элементов (312,314,316);
создание (1906) для каждого из одного или нескольких исходных лексических элементов (312, 314, 316) исходного контекстного параметра (712, 714, 716), исходный контекстный параметр (712) включает в себя:
первый набор исходных значений контекстно-зависимых отношений (CDR), каждое исходное значение CDR представляет собой отношение (i) числа исходных предложений, в которых совместно встречаются данный исходный лексический элемент (312) и каждый из одного или нескольких исходных лексических элементов (314, 316) к (ii) общему числу исходных предложений, содержащих данный исходный лексический элемент (312); и
указание на одно или несколько исходных предложений, в которых встречается каждый из одного или нескольких исходных лексических элементов (312, 314, 316);
получение (1908) сервером (114) указания на целевой цифровой текст (318), который будет обработан, причем целевой цифровой текст (318) включает в себя множество целевых предложений (320);
парсинг (1910) сервером (114) по меньшей мере части множества целевых предложений (320) на один или несколько целевых лексических элементов (328, 330, 332);
создание (1912) для каждого из одного или нескольких целевых лексических элементов (328, 330, 332) целевого контекстного параметра (1204, 1206, 1208), целевой контекстный параметр (1204) включает в себя:
первый набор целевых значений CDR, каждое целевое значение CDR представляет собой отношение (i) числа целевых предложений, в которых совместно встречаются данный исходный лексический элемент (328) и каждый из одного или нескольких целевых лексических элементов (330, 332) к (ii) общему числу целевых предложений, содержащих данный целевой лексический элемент (330);
указание на одно или несколько целевых предложений, в которых встречается каждый из одного или нескольких целевых лексических элементов (328, 330, 332);
выбор первого целевого лексического элемента (312), первый исходный лексический элемент (312), обладающий первым исходным контекстным параметром (712);
сравнение (1916) сервером (114) первого исходного контекстного параметра (712) со множеством целевых контекстных параметров (1202) для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы;
сопоставление (1918) первого исходного лексического элемента (312) с первым целевым лексическим элементом (328), первый целевой лексический элемент является связанным с данным целевым контекстным параметром (1204), обладающим наименьшим значением разницы.
[00218] ПУНКТ 2 Исполняемый на компьютере способ по п. 1, в котором:
парсинг каждого из множества исходных предложений (304) и каждого из множества целевых предложений (320) включает в себя назначение грамматического типа каждому слову из исходного текста (302) и целевого цифрового текста (318); и
в котором лексический элемент представляет собой одно из следующего:
слово, которое было определено на основе соответствующего грамматического типа; и
фразу, которая является группой из двух или более слов, определенных на основе соответствующего грамматического типа одного из двух или более слов.
[00219] ПУНКТ 3 Исполняемый на компьютере способ по пп. 1-2, в котором сравнение первого исходного контекстного параметра (712) со множеством целевых контекстных параметров (1204, 1206, 1208) для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы, включает в себя:
выбор первого исходного предложения (306), включающего в себя первый исходный лексический элемент (312);
для каждого целевого предложения (322, 324, 326) из множества целевых предложений (320):
сравнение первого исходного контекстного параметра (712) с одним или несколькими целевыми контекстными параметрами (1204, 1206, 1208), связанными с одним или несколькими целевыми лексическими элементами, содержащими данное целевое предложение, для определения локального минимального значения, локальное минимальное значение указывает на предварительное соответствие первого исходного контекстного параметра (712) с данным целевым контекстным параметром в данном целевом предложении; и
на основе определенного набора локальных минимальных значений (1602), выбор локального минимального значения, которое является наименьшим значением разницы.
[00220] ПУНКТ 4 Исполняемый на компьютере способ по пп. 1-3, в котором первый исходный лексический элемент (312) и первый целевой лексический элемент (328), связанный с наименьшим значением разницы, является гипотезой эквивалентности перевода.
[00221] ПУНКТ 5 Исполняемый на компьютере способ по п. 4, способ далее включает в себя проверку гипотезы эквивалентности перевода путем:
создания для каждого из одного или нескольких исходных лексических элементов (312, 314, 316), второго набора исходных значений контекстно-независимых отношений (CIR), каждое исходное значение CIR представляет собой представляет собой отношение (i) числа общих слов между данным исходным лексическим элементом и каждым из одного или нескольких исходных лексических элементов к (ii) числу слов данного исходного лексического элемента;
создания для каждого из одного или нескольких целевых лексических элементов, второго набора целевых значений CIR, каждое целевое значение CIR представляет собой отношение (i) числа общих слов между данным целевым лексическим элементом и каждым из одного или нескольких целевых лексических элементов к (ii) числу слов данного целевого лексического элемента; и
определения того, что сходство набора исходных значений CIR, связанных с первым исходным лексическим элементом (312), с набором целевых значений CIR, связанных с первым целевым лексическим элементом (328) находится выше заранее определенного порога.
[00222] ПУНКТ 6 Исполняемый на компьютере способ по пп. 1-5, далее выполненный с возможностью сопоставлять каждый исходный лексический элемент (312, 314, 316) с каждым целевым элементом (328, 330, 332) и сохранять сопоставление в базе (214) данных сопоставлений.
[00223] ПУНКТ 7 Исполняемый на компьютере способ по пп. 1-6, в котором после завершения сопоставления каждого исходного лексического элемента (312, 314, 316) с каждым целевым лексическим элементом (328, 330, 332), способ далее включает в себя сопоставление первого исходного предложения (306) с первым целевым предложением (322), первое целевое предложение (322) является эквивалентом перевода первого исходного предложения (306), путем:
идентификации набора исходных лексических элементов, включающих первое исходное предложение (306);
получения из базы (214) данных сопоставлений набора целевых лексических элементов, соответствующих набору исходных лексических элементов; и
идентификации первого целевого предложения (322), включающего в себя набор целевых лексических элементов.
[00224] ПУНКТ 8 Исполняемый на компьютере способ по п. 7, в котором после определения того, что ни одно из целевых предложений не содержит набор целевых лексических элементов, определение набора целевых предложений, набор целевых предложений содержит два или более соседних целевых предложений, включающих в себя набор целевых лексических элементов.
[00225] ПУНКТ 9 Исполняемый на компьютере способ по пп. 1-8, в котором получение (1902) указаний на исходный цифровой текст (302) и целевой цифровой текст (318) включает в себя получение указаний на исходный цифровой текст (302) и целевой цифровой текст (318) от соответствующего устройства памяти.
[00226] ПУНКТ 10 Исполняемый на компьютере способ по пп. 1-8, в котором получение (1902) указаний на исходный цифровой текст (302) и целевой цифровой текст (318) включает в себя получение указаний на исходный цифровой текст (302) и целевой цифровой текст (318) из приложения (116) по обработке текста, приложение (116) по обработке текста обладает ранее созданным целевым цифровым текстом (318) в ответ на получение исходного цифрового текста (302) от электронного устройства (102).
[00227] ПУНКТ И Сервер (114) для сопоставления исходного лексического элемента (312) исходного цифрового текста (302) на первом языке с соответствующим целевым лексическим элементом (328) целевого цифрового текста (318) на втором языке, целевой цифровой текст (318) является переводом исходного цифрового текста (302), сервер (114) включает в себя:
сетевой интерфейс для коммуникативного соединения сети (112) передачи данных;
процессор соединен с сетевым интерфейсом, процессор выполнен с возможностью выполнять способ по любому из пп. 1-10.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и система автоматического создания тезауруса | 2016 |
|
RU2672393C2 |
| СПОСОБ (ВАРИАНТЫ) И СЕРВЕР ОБРАБОТКИ ТЕКСТА | 2016 |
|
RU2642413C2 |
| Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке | 2017 |
|
RU2692049C1 |
| СПОСОБ УПРАВЛЕНИЯ АВТОМАТИЗИРОВАННОЙ СИСТЕМОЙ ПРАВОВЫХ КОНСУЛЬТАЦИЙ | 2019 |
|
RU2718978C1 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕЗНАЧАЩИХ ЛЕКСИЧЕСКИХ ЕДИНИЦ В ТЕКСТОВОМ СООБЩЕНИИ И КОМПЬЮТЕР | 2014 |
|
RU2580424C1 |
| Способ и система для перевода исходной фразы на первом языке целевой фразой на втором языке | 2019 |
|
RU2767965C2 |
| СПОСОБ И СИСТЕМА КОМПЬЮТЕРНОЙ ОБРАБОТКИ ОДНОЙ ИЛИ НЕСКОЛЬКИХ ЦИТАТ В ЦИФРОВЫХ ТЕКСТАХ ДЛЯ ОПРЕДЕЛЕНИЯ ИХ АВТОРА | 2018 |
|
RU2711123C2 |
| Автоматическое построение семантического описания целевого языка | 2013 |
|
RU2642343C2 |
| КЛАССИФИКАЦИЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ НА ОСНОВЕ СЕМАНТИЧЕСКИХ ПРИЗНАКОВ | 2016 |
|
RU2628436C1 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
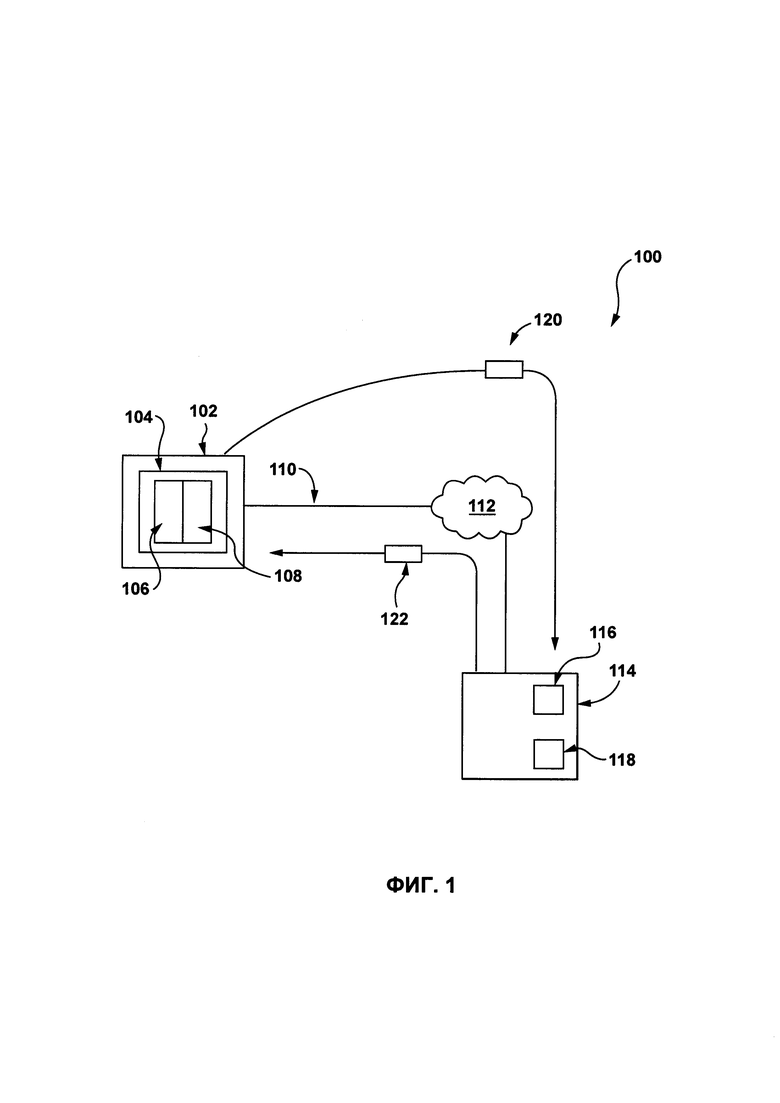
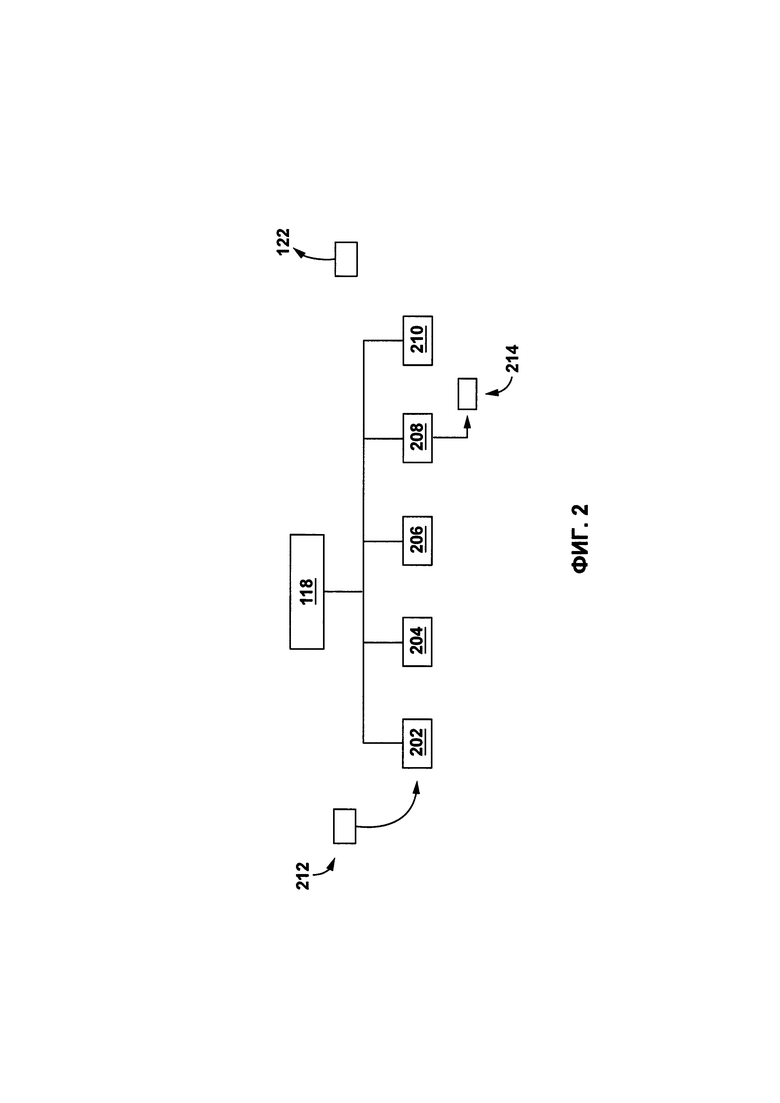
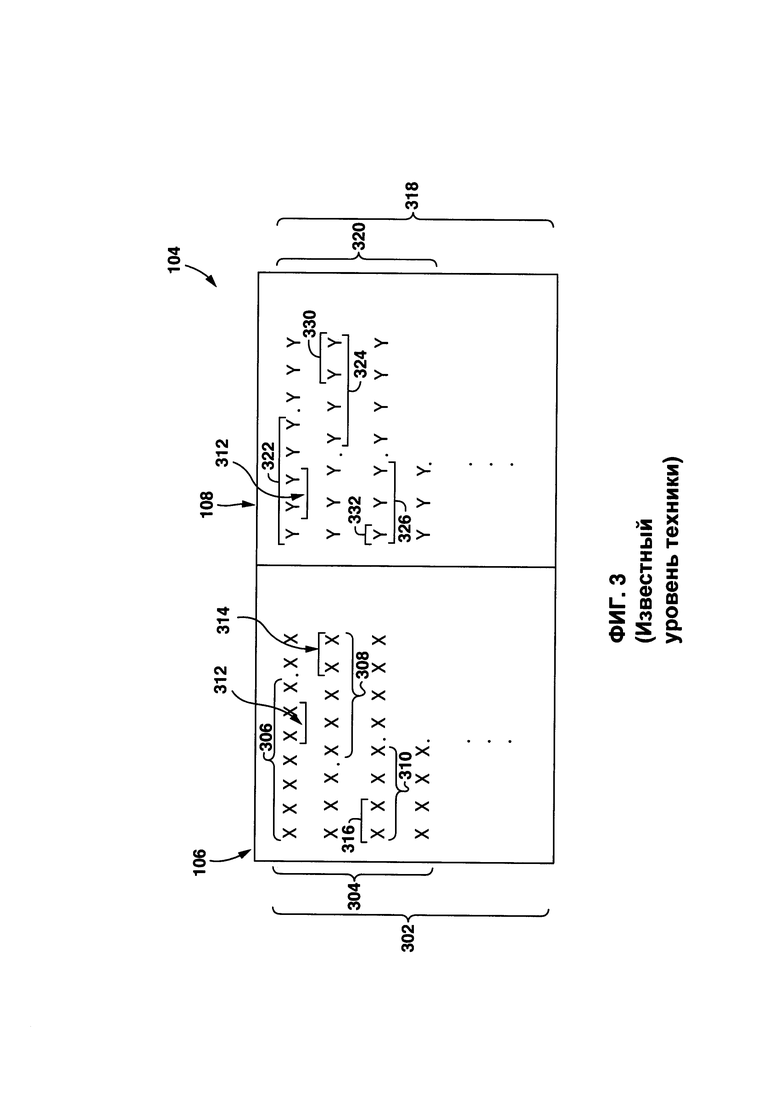


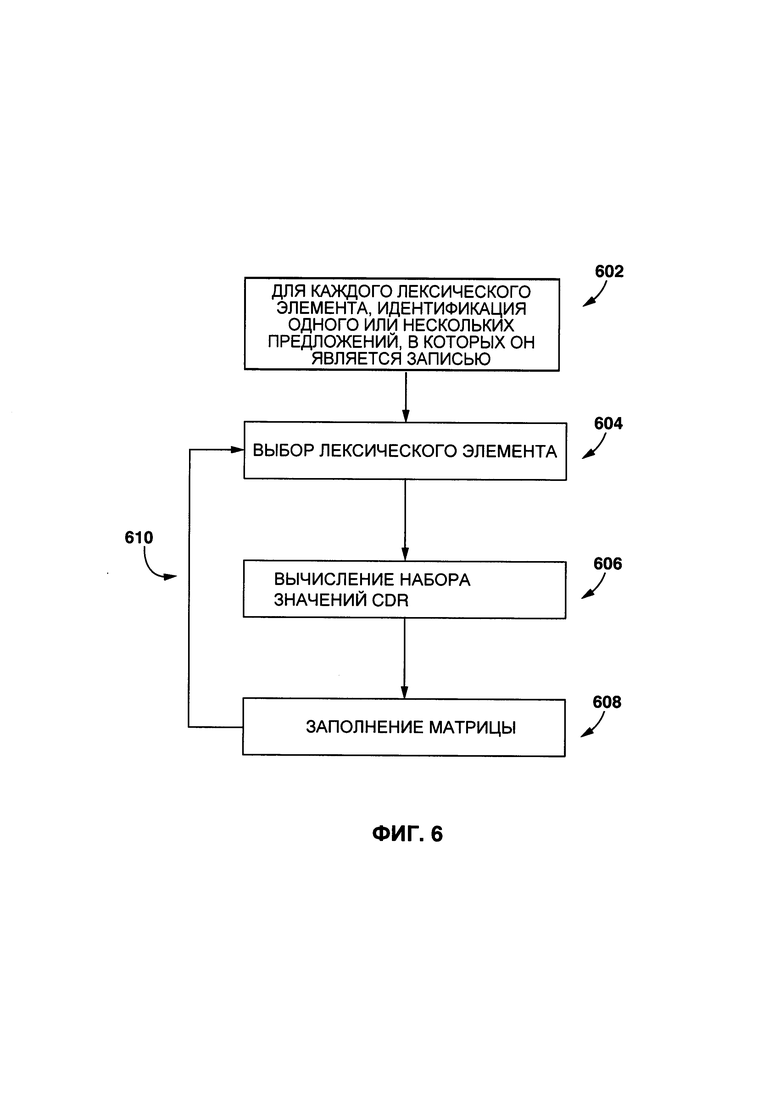
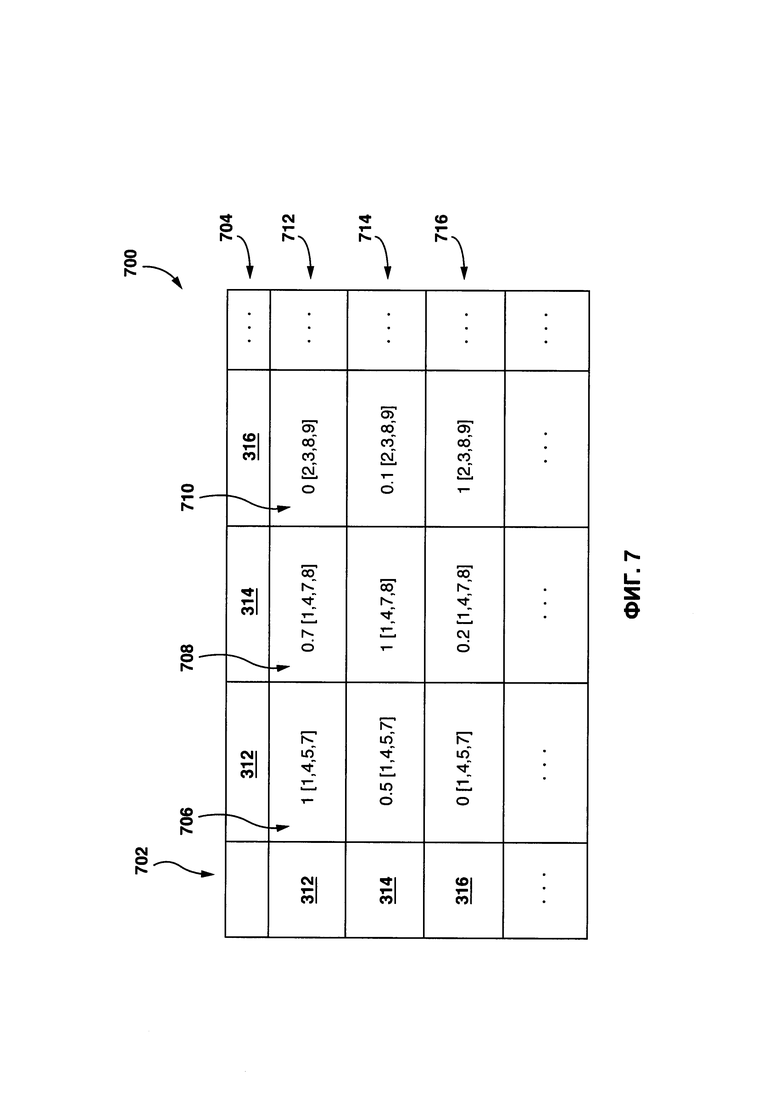



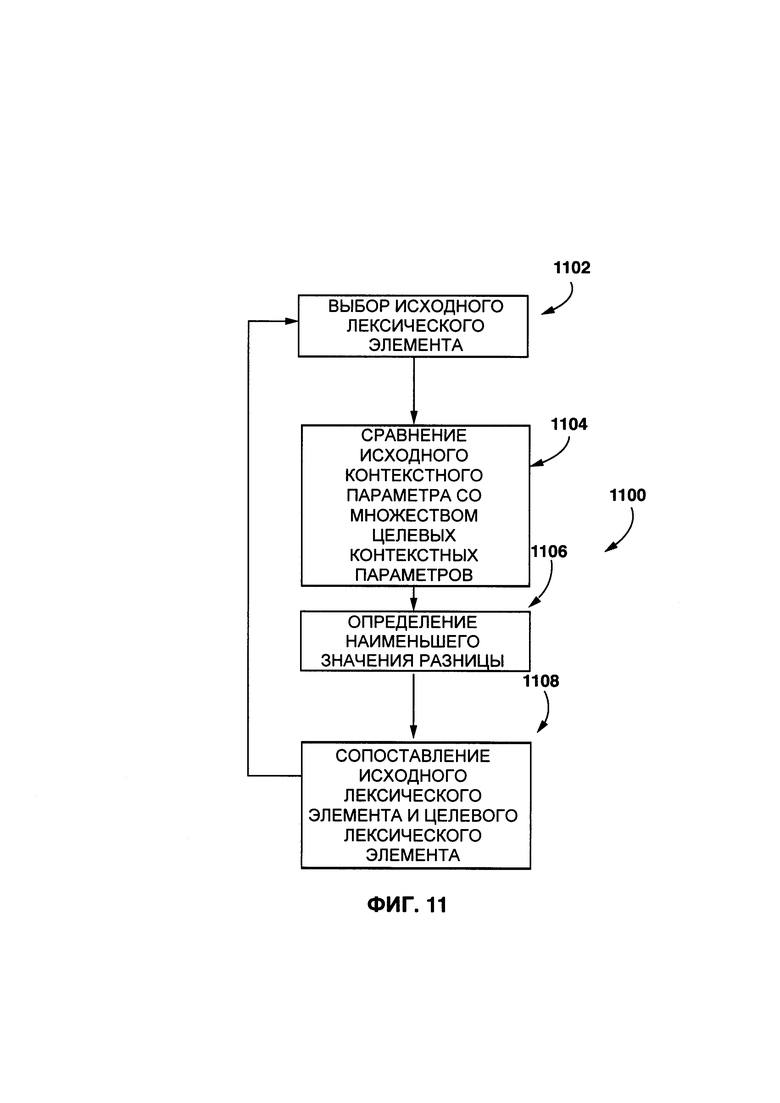
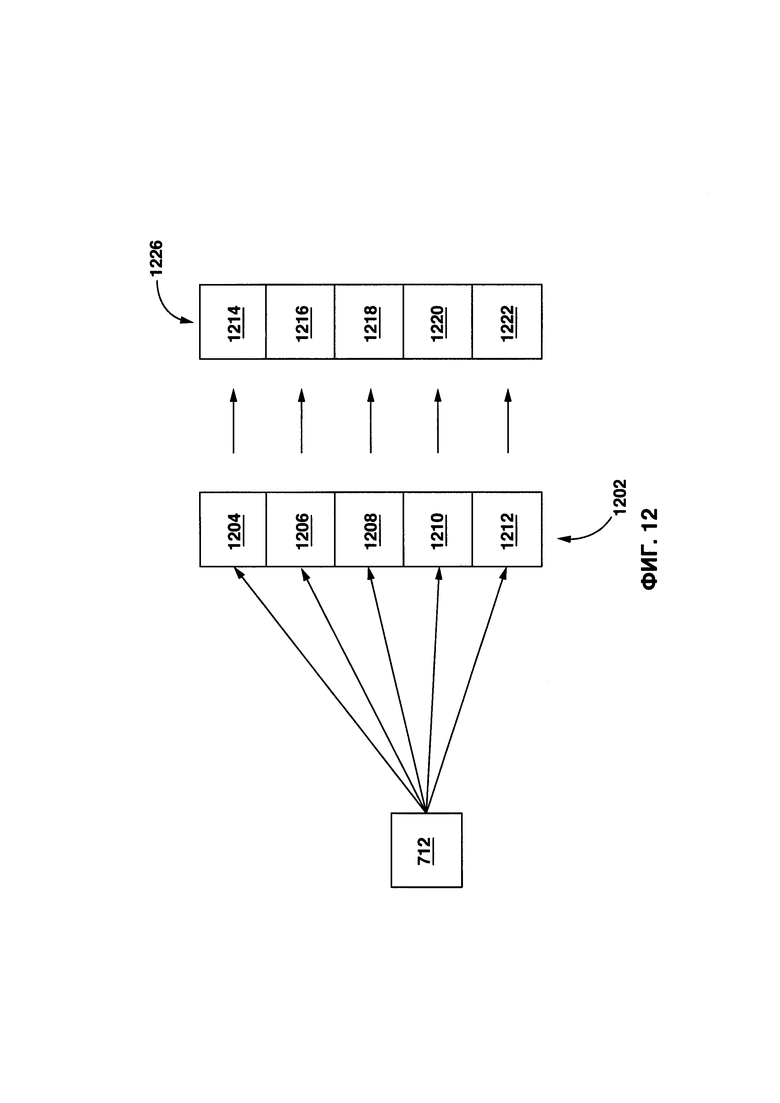

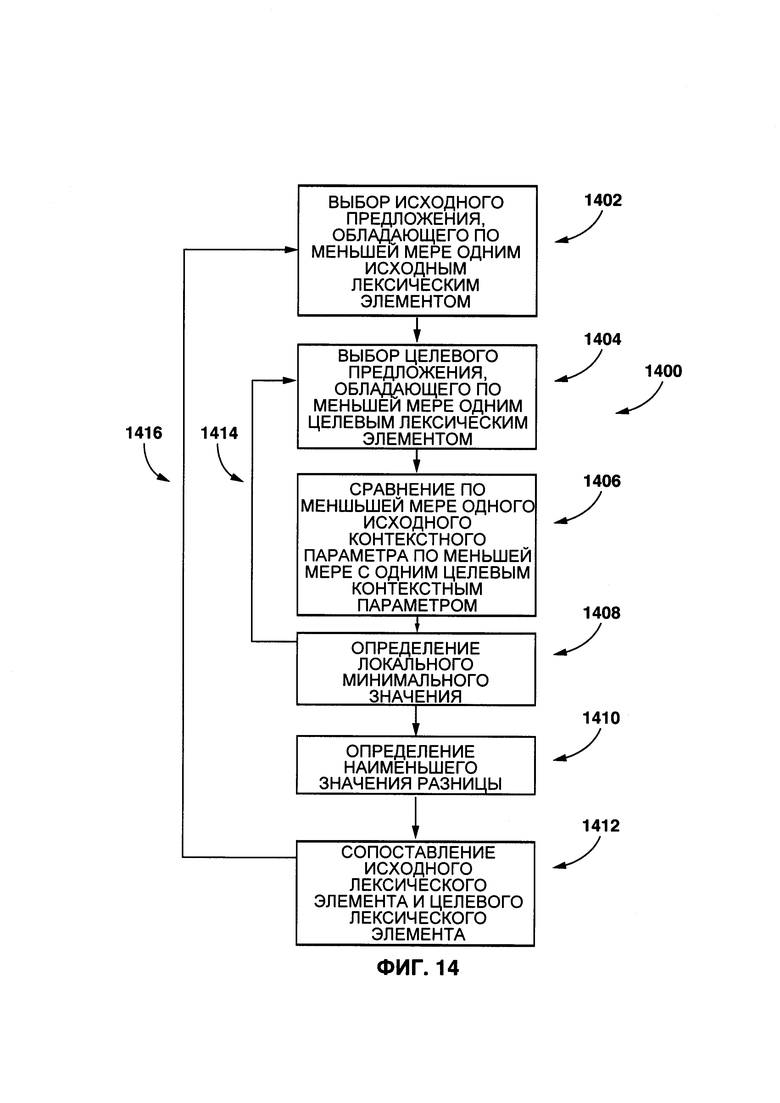



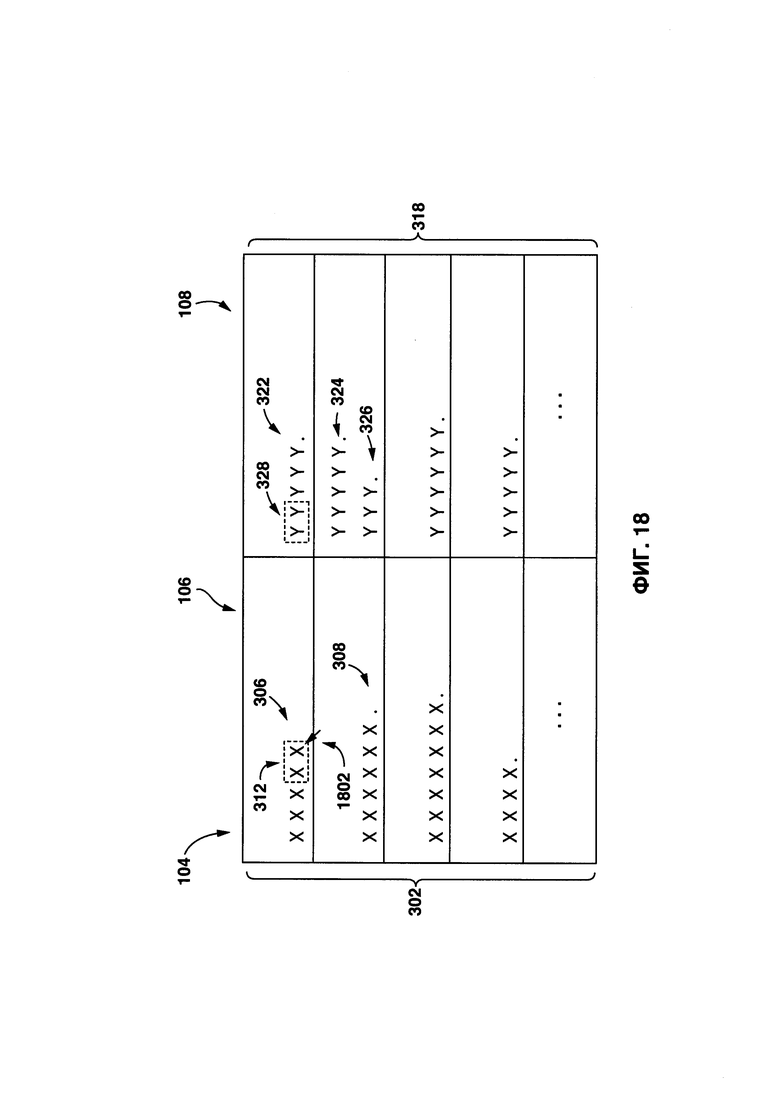

Изобретение относится к системам обработки исходного цифрового текста и целевого цифрового текста. Технический результат заключается в повышении скорости обработки данных. Способ содержит получение исходного цифрового текста, содержащего множество исходных предложений; парсинг множества исходных предложений на исходные лексические элементы; создание для каждого из одного или нескольких лексических элементов исходного контекстного параметра; получение целевого цифрового текста, содержащего множество целевых предложений; парсинг множества целевых предложений на целевые лексические элементы; создание для каждого одного или нескольких целевых лексических элементов целевого контекстного параметра; выбор первого исходного лексического элемента, обладающего первым исходным контекстным параметром; сравнение первого исходного контекстного параметра с множеством целевых контекстных параметров для определения целевого контекстного параметра, обладающего наименьшим значением разницы; сопоставление первого исходного лексического элемента с первым целевым лексическим элементом, который связан с данным целевым контекстным параметром. 2 н. и 18 з.п. ф-лы, 19 ил.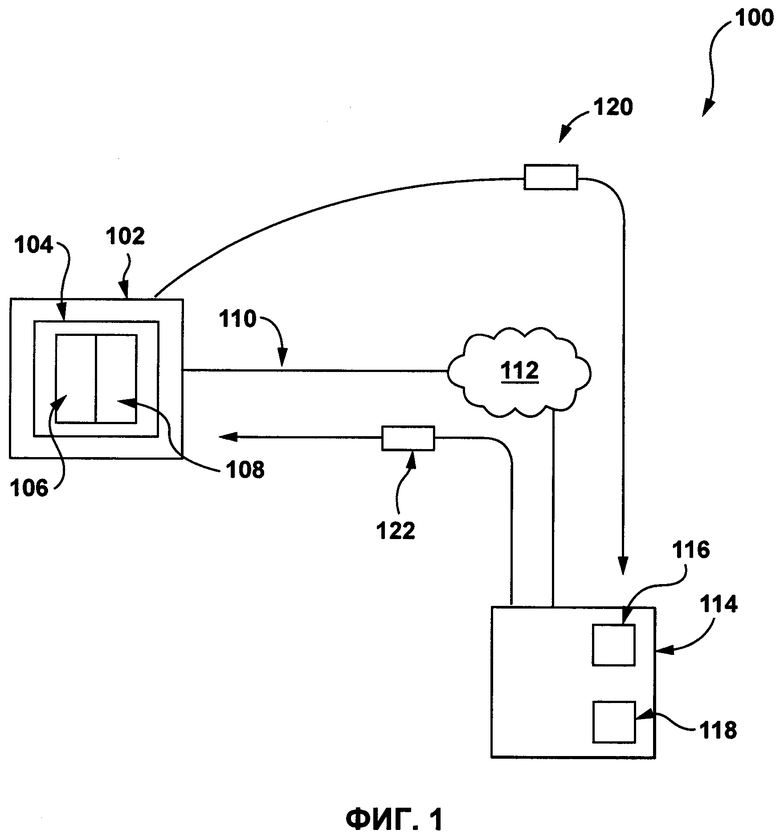
1. Исполняемый на компьютере способ сопоставления исходного лексического элемента исходного цифрового текста на первом языке с соответствующим целевым лексическим элементом целевого цифрового текста на втором языке, целевой цифровой текст является переводом исходного цифрового текста, способ выполняется на сервере, способ включает в себя:
получение сервером указания на исходный цифровой текст, который будет обработан, исходный цифровой текст включает в себя множество исходных предложений;
парсинг сервером по меньшей мере части множества исходных предложений на один или несколько исходных лексических элементов;
создание для каждого из одного или нескольких исходных лексических элементов исходного контекстного параметра, исходный контекстный параметр включает в себя:
первый набор исходных значений контекстно-зависимых отношений (CDR), каждое исходное значение CDR представляет собой отношение (i) числа исходных предложений, в которых совместно встречаются данный исходный лексический элемент и каждый из одного или нескольких исходных лексических элементов к (ii) общему числу исходных предложений, содержащих данный исходный лексический элемент; и
указание на одно или несколько исходных предложений, в которых встречается каждый из одного или нескольких исходных лексических элементов;
получение сервером указания на целевой цифровой текст, который будет обработан, целевой цифровой текст включает в себя множество целевых предложений;
парсинг сервером по меньшей мере части множества целевых предложений на один или несколько целевых лексических элементов;
создание для каждого из одного или нескольких целевых лексических элементов целевого контекстного параметра, целевой контекстный параметр включает в себя:
первый набор целевых значений CDR, каждое целевое значение CDR представляет собой отношение (i) числа целевых предложений, в которых совместно встречаются данный исходный лексический элемент и каждый из одного или нескольких целевых лексических элементов к (ii) общему числу целевых предложений, содержащих данный целевой лексический элемент;
указание на одно или несколько целевых предложений, в которых встречается каждый из одного или нескольких целевых лексических элементов;
выбор первого целевого лексического элемента, первый исходный лексический элемент, обладающий первым исходным контекстным параметром;
сравнение сервером первого исходного контекстного параметра с множеством целевых контекстных параметров для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы;
сопоставление первого исходного лексического элемента с первым целевым лексическим элементом, первый целевой лексический элемент является связанным с данным целевым контекстным параметром, обладающим наименьшим значением разницы.
2. Исполняемый на компьютере способ по п. 1, в котором
парсинг каждого из множества исходных предложений и каждого из множества целевых предложений включает в себя назначение грамматического типа каждому слову из исходного текста и целевого цифрового текста и
в котором лексический элемент представляет собой одно из следующего:
слово, которое было определено на основе соответствующего грамматического типа; и
фразу, которая является группой из двух или более слов, определенных на основе соответствующего грамматического типа одного из двух или более слов.
3. Исполняемый на компьютере способ по п. 1, в котором сравнение первого исходного контекстного параметра с множеством целевых контекстных параметров для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы, включает в себя:
выбор первого исходного предложения, включающего в себя первый исходный лексический элемент;
для каждого целевого предложения из множества целевых предложений:
сравнение первого исходного контекстного параметра с одним или несколькими целевыми контекстными параметрами, связанными с одним или несколькими целевыми лексическими элементами, содержащими данное целевое предложение, для определения локального минимального значения, локальное минимальное значение указывает на предварительное соответствие первого исходного контекстного параметра с данным целевым контекстным параметром в данном целевом предложении; и
на основе определенного набора локальных минимальных значений, выбор локального минимального значения, которое является наименьшим значением разницы.
4. Исполняемый на компьютере способ по п. 3, в котором первый исходный лексический элемент и первый целевой лексический элемент, связанный с наименьшим значением разницы, является гипотезой эквивалентности перевода.
5. Исполняемый на компьютере способ по п. 4, который далее включает в себя проверку гипотезы эквивалентности перевода путем:
создания для каждого из одного или нескольких исходных лексических элементов второго набора исходных значений контекстно-независимых отношений (CIR), каждое исходное значение CIR представляет собой отношение (i) числа общих слов между данным исходным лексическим элементом и каждым из одного или нескольких исходных лексических элементов к (ii) числу слов данного исходного лексического элемента;
создания для каждого из одного или нескольких целевых лексических элементов второго набора целевых значений CIR, каждое целевое значение CIR представляет собой отношение (i) числа общих слов между данным целевым лексическим элементом и каждым из одного или нескольких целевых лексических элементов к (ii) числу слов данного целевого лексического элемента; и
определения того, что сходство набора исходных значений CIR, связанных с первым исходным лексическим элементом, с набором целевых значений CIR, связанных с первым целевым лексическим элементом, находится выше заранее определенного порога.
6. Исполняемый на компьютере способ по п. 1, который далее выполнен с возможностью сопоставлять каждый исходный лексический элемент с каждым целевым лексическим элементом и сохранять сопоставление в базе данных сопоставлений.
7. Исполняемый на компьютере способ по п. 6, в котором после завершения сопоставления каждого исходного лексического элемента с каждым целевым лексическим элементом способ далее включает в себя сопоставление первого исходного предложения с первым целевым предложением, первое целевое предложение является эквивалентом перевода первого исходного предложения, путем:
идентификации набора исходных лексических элементов, включающих первое исходное предложение;
получения из базы данных сопоставлений набора целевых лексических элементов, соответствующих набору исходных лексических элементов; и
идентификации первого целевого предложения, включающего в себя набор целевых лексических элементов.
8. Исполняемый на компьютере способ по п. 7, в котором после определения того, что ни одно из целевых предложений не содержит набор целевых лексических элементов, определение набора целевых предложений, набор целевых предложений содержит два или более соседних целевых предложений, включающих в себя набор целевых лексических элементов.
9. Исполняемый на компьютере способ по п. 1, в котором получение указаний на исходный цифровой текст и целевой цифровой текст включает в себя получение указаний на исходный цифровой текст и целевой цифровой текст от соответствующего устройства памяти.
10. Исполняемый на компьютере способ по п. 1, в котором получение указаний на исходный цифровой текст и целевой цифровой текст включает в себя получение указаний на исходный цифровой текст и целевой цифровой текст из приложения по обработке текста, приложение по обработке текста обладает ранее созданным целевым цифровым текстом в ответ на получение исходного цифрового текста от электронного устройства.
11. Сервер для сопоставления исходного лексического элемента исходного цифрового текста на первом языке с соответствующим целевым лексическим элементом целевого цифрового текста на втором языке, целевой цифровой текст является переводом исходного цифрового текста, сервер включает в себя:
сетевой интерфейс для коммуникативного соединения сети передачи данных;
процессор, соединенный с сетевым интерфейсом и выполненный с возможностью осуществлять:
получение сервером указания на исходный цифровой текст, который будет обработан, исходный цифровой текст включает в себя множество исходных предложений;
парсинг сервером по меньшей мере части множества исходных предложений на один или несколько исходных лексических элементов;
создание для каждого из одного или нескольких исходных лексических элементов исходного контекстного параметра, исходный контекстный параметр включает в себя:
первый набор исходных значений контекстно-зависимых отношений (CDR), каждое исходное значение CDR представляет собой отношение (i) числа исходных предложений, в которых совместно встречаются данный исходный лексический элемент и каждый из одного или нескольких исходных лексических элементов к (ii) общему числу исходных предложений, содержащих данный исходный лексический элемент; и
указание на одно или несколько исходных предложений, в которых встречается каждый из одного или нескольких исходных лексических элементов;
получение сервером указания на целевой цифровой текст, который будет обработан, целевой цифровой текст включает в себя множество целевых предложений;
парсинг сервером по меньшей мере части множества целевых предложений на один или несколько целевых лексических элементов;
создание для каждого из одного или нескольких целевых лексических элементов целевого контекстного параметра, целевой контекстный параметр включает в себя:
первый набор целевых значений CDR, каждое целевое значение CDR представляет собой отношение (i) числа целевых предложений, в которых совместно встречаются данный исходный лексический элемент и каждый из одного или нескольких целевых лексических элементов к (ii) общему числу целевых предложений, содержащих данный целевой лексический элемент;
указание на одно или несколько целевых предложений, в которых встречается каждый из одного или нескольких целевых лексических элементов;
выбор первого целевого лексического элемента, первый исходный лексический элемент, обладающий первым исходным контекстным параметром;
сравнение сервером первого исходного контекстного параметра с множеством целевых контекстных параметров для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы;
сопоставление первого исходного лексического элемента с первым целевым лексическим элементом, первый целевой лексический элемент является связанным с данным целевым контекстным параметром, обладающим наименьшим значением разницы.
12. Сервер по п. 11, в котором
парсинг каждого из множества исходных предложений и каждого из множества целевых предложений включает в себя назначение грамматического типа каждому слову из исходного текста и целевого цифрового текста и
в котором лексический элемент представляет собой одно из следующего:
слово, которое было определено на основе соответствующего грамматического типа; и
фразу, которая является группой из двух или более слов, определенных на основе соответствующего грамматического типа одного из двух или более слов.
13. Сервер по п. 11, в котором сравнение первого исходного контекстного параметра с множеством целевых контекстных параметров для определения данного целевого контекстного параметра, обладающего наименьшим значением разницы, включает в себя:
выбор первого исходного предложения, включающего в себя первый исходный лексический элемент;
для каждого целевого предложения из множества целевых предложений:
сравнение первого исходного контекстного параметра с одним или несколькими целевыми контекстными параметрами, связанными с одним или несколькими целевыми лексическими элементами, содержащими данное целевое предложение, для определения локального минимального значения, локальное минимальное значение указывает на предварительное соответствие первого исходного контекстного параметра с данным целевым контекстным параметром в данном целевом предложении; и
на основе определенного набора локальных минимальных значений, выбор локального минимального значения, которое является наименьшим значением разницы.
14. Сервер по п. 13, в котором первый исходный лексический элемент и первый целевой лексический элемент, связанный с наименьшим значением разницы, является гипотезой эквивалентности перевода.
15. Сервер по п. 14, в котором процессор дополнительно выполнен с возможностью осуществлять проверку гипотезы перевода путем:
создания для каждого из одного или нескольких исходных лексических элементов второго набора исходных значений контекстно-независимых отношений (CIR), каждое исходное значение CIR представляет собой отношение (i) числа общих слов между данным исходным лексическим элементом и каждым из одного или нескольких исходных лексических элементов к (ii) числу слов данного исходного лексического элемента;
создания для каждого из одного или нескольких целевых лексических элементов второго набора целевых значений CIR, каждое целевое значение CIR представляет собой отношение (i) числа общих слов между данным целевым лексическим элементом и каждым из одного или нескольких целевых лексических элементов к (ii) числу слов данного целевого лексического элемента; и
определения того, что сходство набора исходных значений CIR, связанных с первым исходным лексическим элементом, с набором целевых значений CIR, связанных с первым целевым лексическим элементом, находится выше заранее определенного порога.
16. Сервер по п. 11, в котором процессор далее выполнен с возможностью сопоставлять каждый исходный лексический элемент с каждым целевым лексическим элементом и сохранять сопоставление в базе данных сопоставлений.
17. Сервер по п. 16, в котором после завершения сопоставления каждого исходного лексического элемента с каждым целевым лексическим элементом процессор выполнен с возможностью осуществлять сопоставление первого исходного предложения с первым целевым предложением, первое целевое предложение является эквивалентом перевода первого исходного предложения, путем:
идентификации набора исходных лексических элементов, включающих первое исходное предложение;
получения из базы данных сопоставлений набора целевых лексических элементов, соответствующих набору исходных лексических элементов; и
идентификации первого целевого предложения, включающего в себя набор целевых лексических элементов.
18. Сервер по п. 17, в котором после определения того, что ни одно из целевых предложений не содержит набор целевых лексических элементов, определение набора целевых предложений, набор целевых предложений содержит два или более соседних целевых предложений, включающих в себя набор целевых лексических элементов.
19. Сервер по п. 11, в котором указания на исходный цифровой текст и целевой цифровой текст получают из соответствующего устройства памяти.
20. Сервер по п. 11, в котором указания на исходный цифровой текст и целевой цифровой текст получают от приложения по обработке текста, приложение по обработке текста обладает ранее созданным целевым цифровым текстом в ответ на получение исходного цифрового текста от электронного устройства.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| US 9047275 B2, 02.06.2015 | |||
| US 7672830 B2, 02.03.2010 | |||
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 20120239378 A1, 20.09.2012 | |||
| US 5442782, 15.08.1995. | |||

