ПРЕДПОСЫЛКИ СОЗДАНИЯ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к машинному переводу. В частности, настоящее изобретение относится к средствам для систематического совершенствования применяемой пользователем автоматической системы машинного перевода в обычном рабочем процессе получения откорректированных переводов из надежного источника.
В результате роста международного общения, обусловленного появлением таких технологий, как Интернет, в последние годы стал более широко использоваться машинный перевод и, в частности, получила большее распространение компьютерная система перевода текстов на естественных языках. В некоторых случаях машинный перевод может выполняться автоматически. Однако иногда в процесс создания качественного перевода необходимо вмешательство человека. Если говорить в общем, переводы, основанные на использовании человеческих ресурсов, являются более точными, но менее эффективными с точки зрения времени и стоимости по сравнению с полностью автоматизированными системами. В некоторых системах перевода к взаимодействию с человеком прибегают только в том случае, когда точность перевода имеет решающее значение. В общем случае время и стоимость, связанные с вмешательством человека, приходится затрачивать каждый раз, когда требуется особенно точный перевод.
Качество переводов, созданных с использованием полностью автоматизированной системы машинного перевода, с ростом потребности в подобных системах, в общем, не повышается. Общепризнанным фактом является то, что для получения автоматического перевода более высокого качества в конкретной области (или по конкретной тематике) должна быть произведена существенная настройка системы машинного перевода. В типичном случае настройка включает добавление специализированной терминологии и правил перевода текстов в требуемой области. Такая настройка в обычном случае выполняется квалифицированными специалистами по вычислительной лингвистике, использующими полуавтоматизированные средства для добавления терминов в онлайновые словари и пишущими лингвистически ориентированные правила, в типичном случае на специальных языках правил. Этот тип настройки является относительно дорогостоящим.
Кроме всего прочего, переводческие сервисы, доступные потребителям из множества источников, не могут обеспечить экономически эффективные, высококачественные, адаптированные переводы. Например, в настоящее время широкому кругу пользователей доступны архивированные и находящиеся во всемирной паутине системы перевода. Однако эти системы перевода трудно или невозможно настроить для специальной области или тематики. Кроме того, существуют коммерческие системы перевода. Эти системы могут быть настроены для конкретных областей, однако процесс настройки является утомительным и в типичном случае достаточно дорогостоящим. Также предлагаются услуги перевода, основанные на непосредственном участии человека (то есть услуги переводчиков, предлагаемые во всемирной паутине либо основанные на почтовых заказах). Однако использование услуг переводчиков в типичном случае требует выплаты гонорара за каждый переводимый документ, и это расходы, которые никогда не прекращаются.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Варианты осуществления настоящего изобретения относятся к реализуемому при помощи компьютера способу предоставления информации автоматической системе машинного перевода для повышения точности перевода. Данный способ включает прием исходного текста. От автоматической системы машинного перевода принимается пробный перевод, соответствующий исходному тексту. Также принимается коррекционная информация, сконфигурированная таким образом, чтобы осуществить коррекцию, по меньшей мере, одной ошибки в пробном переводе. На конечном этапе автоматической системе машинного перевода предоставляется информация для снижения вероятности того, что упомянутая ошибка будет повторяться в последующих переводах, созданных этой системой.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
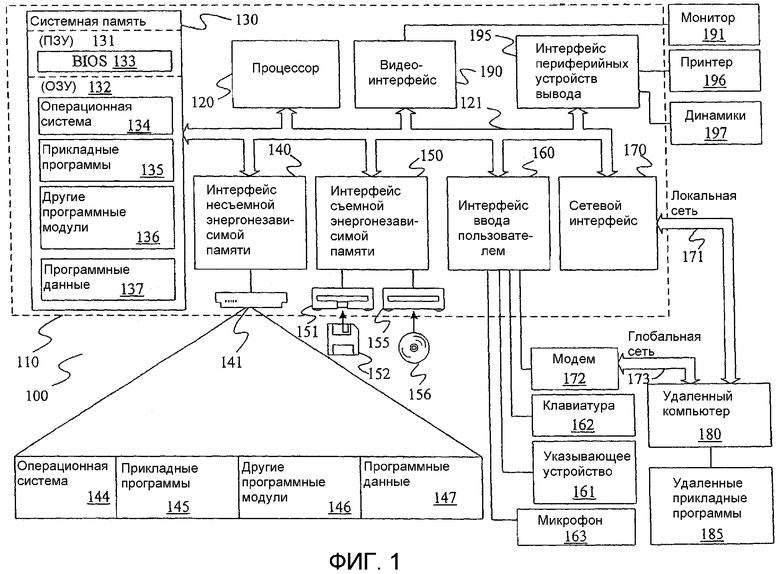
Фиг.1 - структурная схема одной примерной конфигурации, с использованием которой может быть реализовано настоящее изобретение.
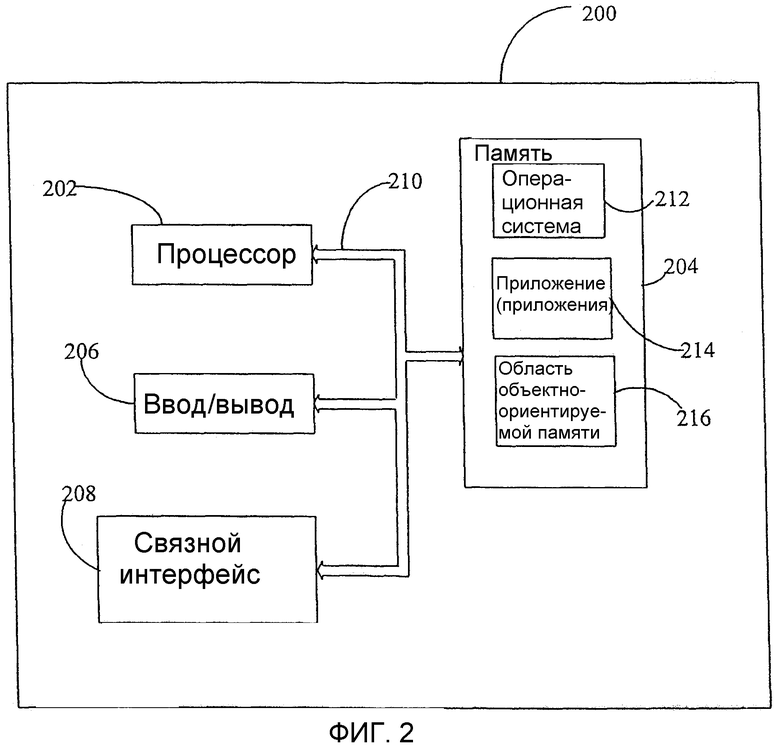
Фиг.2 - структурная схема другой примерной конфигурации, с использованием которой может быть реализовано настоящее изобретение.
Фиг.3 - структурная схема, иллюстрирующая сервис адаптивного машинного перевода, соответствующий настоящему изобретению.
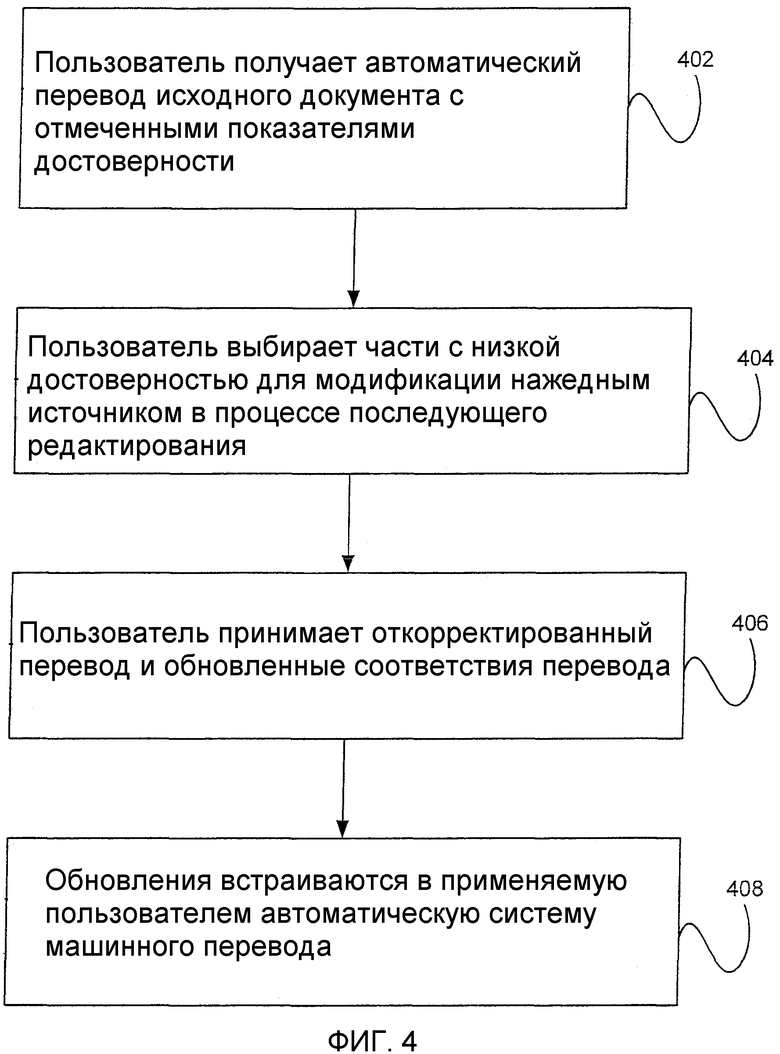
Фиг.4 - блок-схема, иллюстрирующая использование показателя достоверности в контексте сервиса адаптивного машинного перевода.
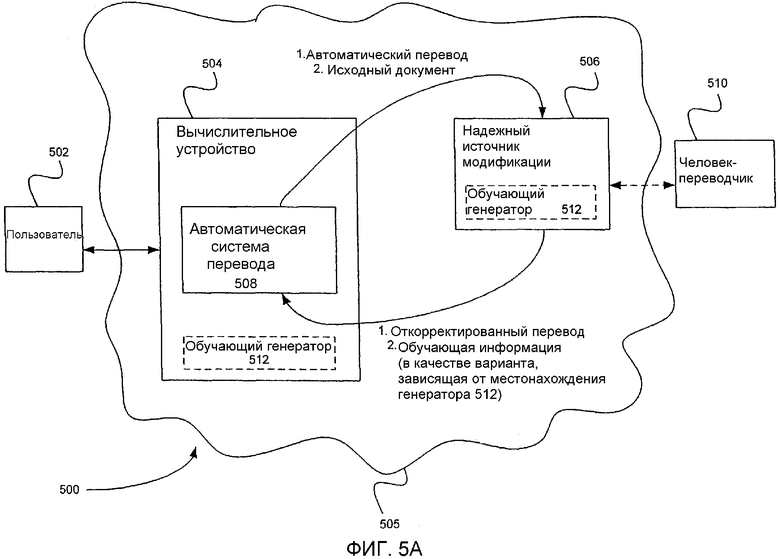
Фиг.5А - структурная схема одного конкретного применения вариантов осуществления настоящего изобретения.
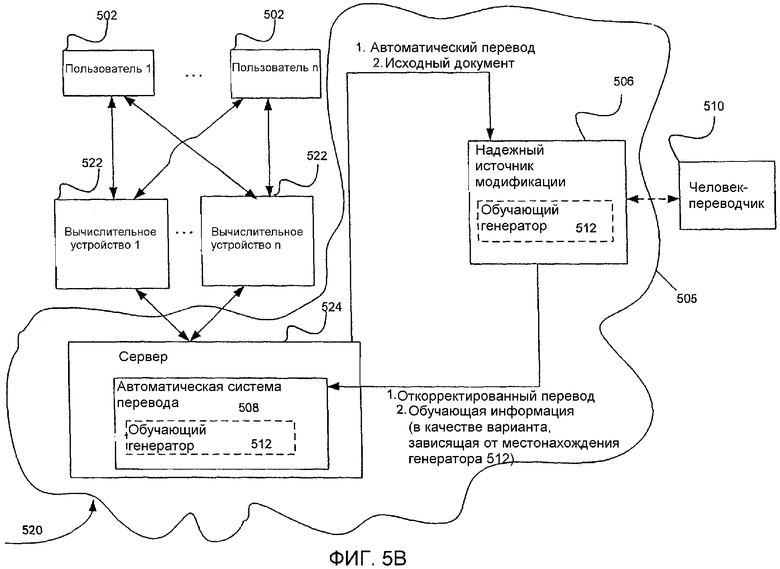
Фиг.5В - структурная схема другого конкретного применения вариантов осуществления настоящего изобретения.
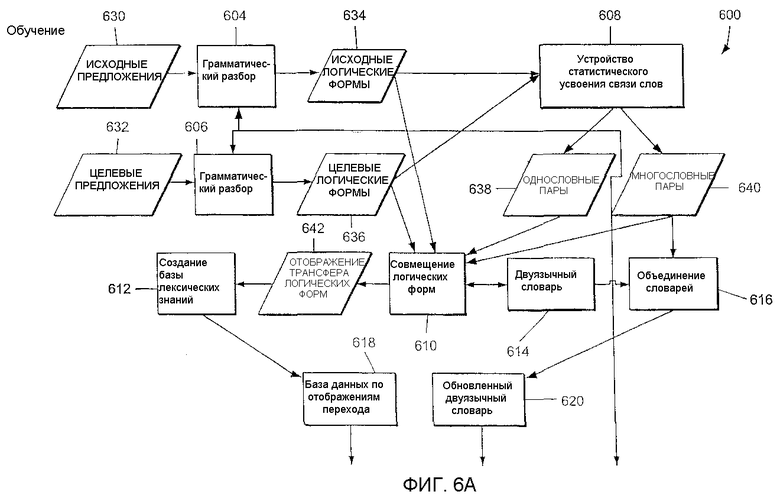
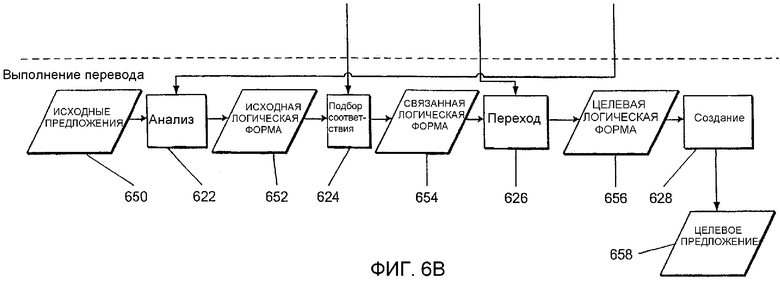
Фиг.6 - структурная схема системы машинного перевода, с использованием которой может быть реализовано настоящее изобретение.
Фиг.7 - блок-схема, иллюстрирующая вариант осуществления настоящего изобретения, в котором применяемая пользователем система перевода обновляется дистанционно.
Фиг.8 - блок-схема, иллюстрирующая вариант осуществления настоящего изобретения, в котором применяемая пользователем система перевода обновляется локально.
Фиг.9 - структурная схема еще одного конкретного применения вариантов осуществления настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ПРИМЕРНЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
I. ПРИМЕРЫ ОПЕРАЦИОННОЙ СРЕДЫ
Различные аспекты настоящего изобретения относятся к включению адаптивного машинного перевода в обычный рабочий процесс получения откорректированных переводов из надежного источника. Однако перед более подробным рассмотрением данного изобретения будут описаны варианты примерной среды, в которой оно может быть реализовано.
На Фиг.1 изображен пример подходящей конфигурации вычислительной системы 100, с использованием которой может быть реализовано данное изобретение. Конфигурация вычислительной системы 100 является всего лишь одним из примеров подходящей вычислительной среды и не подразумевает какого-либо ограничения объема использования или функциональных возможностей данного изобретения. Кроме того, конфигурация вычислительной системы 100 не должна восприниматься как зависящая от какого-либо одного из изображенных ее компонентов или их комбинации либо как требующая их наличия.
Данное изобретение можно использовать с множеством других вычислительных систем, сред или конфигураций вычислительной системы общего или специального назначения. Примеры хорошо известных вычислительных систем, сред и/или конфигураций, пригодных для использования с настоящим изобретением, включают персональные компьютеры, серверы, карманные или портативные устройства, мультипроцессорные системы, системы на основе микропроцессоров, приставки, программируемую бытовую электронику, сетевые ПК, мини-компьютеры, универсальные ЭВМ, телефонные системы, распределенные вычислительные среды, содержащие любые из перечисленных систем или устройств и т.п., но не ограничиваются упомянутым.
Настоящее изобретение может быть описано в общем контексте исполняемых компьютером команд, например программных модулей, выполняемых компьютером. В основном программные модули включают процедуры, программы, объекты, компоненты, структуры данных и т.д., выполняющие конкретные задачи или использующие конкретные абстрактные типы данных. Настоящее изобретение создано с учетом его реализации в распределенных вычислительных средах, где задачи выполняются устройствами удаленной обработки, которые соединены посредством сети связи. В распределенной вычислительной среде программные модули находятся в компьютерных средствах хранения как локального, так и удаленного компьютера, включающих запоминающие устройства. Задачи, выполняемые программами и модулями, описаны ниже с помощью чертежей. Специалисты в данной области техники могут реализовать приведенные описания и чертежи в виде исполняемых процессором команд, которые могут быть записаны на машиночитаемом носителе любого типа.
Как показано на Фиг.1, примерная система, реализующая данное изобретение на практике, включает вычислительное устройство общего назначения в виде компьютера 110. Компоненты компьютера 110 могут включать процессор 120, системную память 130 и системную шину 121, соединяющую различные компоненты системы, включая системную память, с процессором 120, но не ограничиваются упомянутым. Системная шина 121 может относиться к любому из нескольких типов шинных архитектур, включая шину памяти или контроллер памяти, шину периферийных устройств и локальную шину на основе любой из множества шинных архитектур. В качестве примера, не подразумевающего ограничение, подобные архитектуры включают шину ISA (архитектура промышленного стандарта), шину MCA (микроканальная архитектура), шины EISA (расширенная архитектура промышленного стандарта), локальную шину VESA (стандарт высокоскоростной локальной видеошины) и шину PCI (локальная шина для системных плат), также известную как Mezzanine bus.
Компьютер 110 в типичном случае содержит множество машиночитаемых носителей информации. Машиночитаемые носители могут представлять собой любые существующие носители, к которым может обращаться компьютер 110, и включают как энергозависимые, так и энергонезависимые носители, съемные и несъемные носители. В качестве примера, не подразумевающего ограничение, машиночитаемые носители могут включать компьютерные средства хранения и коммуникационные среды. Компьютерные средства хранения включают как энергозависимые, так и энергонезависимые, съемные и несъемные носители, использующие любой способ или технологию хранения такой информации, как машиночитаемые команды, структуры данных, программные модули или другие данные. Компьютерные средства хранения включают оперативное запоминающее устройство (ОЗУ, RAM), постоянное запоминающее устройство (ПЗУ, ROM), электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ, EEPROM), флэш-память или другие виды памяти, ПЗУ на компакт-дисках (CD-ROM), цифровые универсальные диски (DVD) или другие оптические диски, кассеты с магнитной лентой, магнитную ленту, магнитные диски, или другие магнитные носители, или любой другой носитель, который может использоваться для хранения требуемой информации и к которому может обращаться компьютер 110.
Коммуникационные среды в типичном случае воплощают машиночитаемые команды, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, например несущей волны или другого механизма передачи, и включают любую среду доставки информации. Термин "модулированный сигнал данных" означает сигнал, одна или более характеристик которого заданы или изменяются таким образом, чтобы закодировать информацию в данном сигнале. В качестве примера, не подразумевающего ограничение, коммуникационная среда включает проводную среду, например проводную сеть или прямое соединение, и беспроводную среду, например акустическую, радиочастотную, инфракрасную и другую беспроводную среду. Комбинации любого из вышеупомянутого также представляют собой машиночитаемую среду.
Системная память 130 содержит компьютерное средство хранения в виде энергозависимой и/или энергонезависимой памяти, например ПЗУ 131 и ОЗУ 132. Базовая система ввода/вывода 133 (BIOS), содержащая основные процедуры, помогающие элементам компьютера 110 обмениваться информацией, например, во время запуска, в типичном случае хранится в ПЗУ 131. ОЗУ 132 в типичном случае содержит данные и/или программные модули, которые непосредственно доступны процессору 120 и/или используются им в текущий момент. В качестве примера, не подразумевающего ограничение, на Фиг.1 изображена операционная система 134, прикладные программы 135, другие программные модули 136 и программные данные 137.
Компьютер 110 может также содержать другие съемные/несъемные энергозависимые/энергонезависимые компьютерные средства хранения. Только в качестве примера на Фиг.1 изображены накопитель 141 на жестких дисках, считывающий информацию с несъемного, энергонезависимого магнитного носителя или записывающий информацию на него, накопитель 151 на магнитных дисках, считывающий информацию со съемного, энергонезависимого магнитного диска 152 или записывающий информацию на него, и накопитель 155 на оптических дисках, считывающий информацию со съемного, энергонезависимого оптического диска 156, например диска CD-ROM или другого оптического носителя, и записывающий информацию на него. Другие съемные/несъемные, энергозависимые/энергонезависимые компьютерные средства хранения, которые могут использоваться в примерной операционной среде, включают кассеты с магнитной лентой, карты флэш-памяти, цифровые универсальные диски, кассеты для цифрового видео, твердотельное ОЗУ, твердотельное ПЗУ и т.п., но не ограничиваются упомянутым. Накопитель 141 на жестких дисках в типичном случае соединен с системной шиной 121 посредством интерфейса несъемных запоминающих устройств, например интерфейса 140, а накопитель 151 на магнитных дисках и накопитель 155 на оптических дисках в типичном случае соединены с системной шиной 121 при помощи интерфейса съемных запоминающих устройств, например, интерфейса 150.
Рассмотренные выше и изображенные на Фиг.1 накопители и соответствующие им компьютерные средства хранения обеспечивают хранение машиночитаемых команд, структур данных, программных модулей и других данных для компьютера 110. Например, на Фиг.1 накопитель 141 на жестких дисках изображен как средство хранения операционной системы 144, прикладных программ 145, других программных модулей 146 и программных данных 147. Отметим, что эти компоненты могут быть идентичны или отличаться от операционной системы 134, прикладных программ 135, других программных модулей 136 и программных данных 137. Операционная система 144, прикладные программы 145, другие программные модули 146 и программные данные 147 обозначены здесь отличающимися номерами, чтобы проиллюстрировать то, что они представляют собой, как минимум, другие копии.
Пользователь может вводить команды и информацию в компьютер 110 при помощи устройств ввода, например клавиатуры 162, микрофона 163, и координатно-указательного устройства 161, например мыши, трекбола или сенсорной панели. Другие устройства ввода (не показаны) могут включать джойстик, игровую панель, спутниковую параболическую систему, сканер или т.п. Эти и другие устройства ввода часто соединяют с процессором 120 через интерфейс 160 ввода пользователем, соединенный с системной шиной, но могут быть соединены при помощи других интерфейсов и шин другой архитектуры, таких как параллельный порт, игровой порт или универсальная последовательная шина (USB). С системной шиной 121 через интерфейс, например видеоинтерфейс 190, также соединен монитор 191 или другое устройство отображения информации. Кроме монитора компьютеры могут также содержать другие периферийные устройства вывода, например динамики 197 и принтер 196, которые могут быть соединены через интерфейс 195 периферийных устройств вывода.
Компьютер 110 работает в сетевой среде, используя логические соединения с одним или более удаленными компьютерами, например удаленным компьютером 180. Удаленный компьютер 180 может представлять собой персональный компьютер, карманное устройство, сервер, маршрутизатор, сетевой ПК, устройство, соединенное через одноранговую сеть, или другой общий сетевой узел, и в типичном случае содержит многие или все элементы, описанные выше применительно к компьютеру 110. Логические соединения, изображенные на Фиг.1, включают локальную вычислительную сеть (ЛВС) 171 и глобальную вычислительную сеть (ГВС) 173, но могут также включать и другие сети. Такие сетевые среды представляют собой офисные серверы, компьютерные сети предприятий, сети интранет и Интернет.
При использовании в сетевой среде ЛВС компьютер 110 соединен с ЛВС 171 посредством сетевого интерфейса или адаптера 170. При использовании в сетевой среде ГВС компьютер 110 в типичном случае включает модем 172 или другие средства для установления связи в ГВС 173, например Интернет. Модем 172, который может быть внутренним или внешним, может быть соединен с системной шиной 121 посредством интерфейса 160 ввода пользователем или другого подходящего устройства. В сетевой среде программные модули, описанные применительно к компьютеру 110, или их части могут храниться в удаленном запоминающем устройстве. В качестве примера, не подразумевающего ограничение, на Фиг.1 удаленные прикладные программы 185 изображены как находящиеся на удаленном компьютере 180. Понятно, что показанные сетевые соединения являются примерными и могут быть использованы другие средства установления канала связи между компьютерами.
Необходимо отметить, что настоящее изобретение может быть реализовано с использованием компьютерной системы, подобной описанной с использованием Фиг.1. Однако настоящее изобретение может быть реализовано с использованием сервера, компьютера, выделенного для обработки сообщений, или распределенной системы, в которой различные части настоящего изобретения могут быть реализованы с использованием различных частей этой распределенной вычислительной системы.
Фиг.2 представляет собой структурную схему мобильного устройства 200, являющегося другим примером подходящей вычислительной системы, в которой может быть реализовано настоящее изобретение. Конфигурация вычислительной системы 200 является всего лишь еще одним примером подходящей вычислительной системы и не предполагает какого-либо ограничения объема использования или функциональных возможностей данного изобретения. Также вычислительная система 200 не должна восприниматься как зависящая от какого-либо из изображенных ее компонентов или их комбинации либо как требующая их наличия.
Мобильное устройство 200 включает микропроцессор 202, память 204, компоненты 206 ввода/вывода и связной интерфейс 208 для связи с удаленными компьютерами или другими мобильными устройствами. В одном из вариантов для связи друг с другом данные компоненты соединены при помощи соответствующей шины 210.
Память 204 реализована как энергонезависимая электронная память, например ОЗУ с резервным аккумуляторным модулем (не показан), в результате чего информация, хранящаяся в памяти 204, не теряется при отключении основного питания мобильного устройства 200. Часть памяти 204 предпочтительно выделена как адресуемая память для исполнения программ, в то время как другая часть памяти 204 предпочтительно применяется для хранения, например, имитирующего хранение с использованием дискового накопителя.
Память 204 содержит операционную систему 212, прикладные программы 214, а также область 216 объектно-ориентированной памяти. Во время работы операционная система 212 предпочтительно исполняется процессором 202 из памяти 204. Операционная система 212 в одном из предпочтительных вариантов представляет собой операционную систему WINDOWS® CE, предлагаемую на рынке Microsoft Corporation. Операционная система 212 предпочтительно разработана для мобильных устройств и реализует средства управления базами данных, которые могут использоваться приложениями 214 при помощи набора открытых интерфейсов и способов прикладного программирования. Объекты, находящиеся в области 216 объектно-ориентируемой памяти, используются приложениями 214 и операционной системой 212, по меньшей мере, отчасти в ответ на обращения к упомянутым открытым интерфейсам и способам прикладного программирования.
Связной интерфейс 208 представляет собой различные устройства и технологии, позволяющие мобильному устройству 200 передавать и принимать информацию. Упомянутые устройства включают в качестве всего лишь нескольких примеров проводные и беспроводные модемы, спутниковые приемники и телевизионные тюнеры. Мобильное устройство 200 может также непосредственно устанавливать соединение с компьютером для обмена данными. В таких случаях связной интерфейс 208 может представлять собой инфракрасный приемопередатчик либо последовательное или параллельное соединение, при этом все из перечисленного способно передавать потоковую информацию.
Компоненты 206 ввода/вывода включают множество устройств ввода, например сенсорный экран, клавиши, ролики и микрофон, а также множество устройств вывода, включая звуковой генератор, виброустройство и дисплей. Перечисленные выше устройства приведены в качестве примера и не обязательно все присутствуют в мобильном устройстве 200. Кроме того, в пределах объема настоящего изобретения к мобильному устройству 200 могут быть присоединены или использоваться вместе с ним и другие устройства ввода/вывода.
II. КРАТКОЕ ОПИСАНИЕ СЕРВИСА АДАПТИВНОГО МАШИННОГО ПЕРЕВОДА
Фиг.3 представляет собой структурную схему, иллюстрирующую адаптивный машинный перевод в обычном рабочем процессе получения откорректированных переводов из надежного источника.
Было проведено исследование, целью которого являлась автоматизация настройки автоматических систем машинного перевода с использованием различных методов обучения машины, включая статистический и основанный на примерах методы. При помощи таких методов система машинного перевода способна усваивать соответствие перевода из уже переведенных материалов (часто называемые битекстами или двуязычными массивами), которые содержат предложения на одном (исходном) языке и соответствующие переведенные (целевые) предложения на другом языке. Кроме того, такие системы машинного перевода могут усваивать дополнительные соответствия из "сравнимых" массивов или тексты, которые не являются точными переводами друг друга, но которые оба описывают похожие понятия и события как на исходном, так и на целевом языках. Они могут далее использовать одноязычные массивы для усвоения гибких конструкций на целевом языке. Согласно одному из основных аспектов настоящего изобретения эти технологии настройки применяются в традиционной среде управления документооборотом и используют его преимущества. А именно, данные для обучения автоматической системы перевода создаются в ходе обычного процесса создания документов, получения соответствующих переводов и их коррекции пользователем системы. Обучающие данные делают возможной систематическую настройку применяемой пользователем автоматической системы машинного перевода.
Как показано на Фиг.3, варианты реализации настоящего изобретения относятся к включению адаптивной системы машинного перевода в среду управления документооборотом или рабочую среду, где пользователи передают исходный документ 302 автоматическому переводчику, находящемуся на компьютере пользователя (или на сервере, связанном с пользователем) для перевода. Это действие представлено блоком 330. Исходный документ 302 и автоматически созданный перевод 304 передаются надежному источнику модификации (т.е. человеку-переводчику) для просмотра и коррекции. Это действие представлено блоком 332.
Откорректированный перевод 306 и оригинал исходного документа 302 обрабатываются для создания совокупности обновленных и предположительно точных соответствий 308 перевода. Это действие представлено блоком 334. Согласно одному из вариантов реализации настоящего изобретения соответствия 308 создаются самонастраивающейся системой машинного перевода, которая работает параллельно самонастраивающейся системе машинного перевода, используемой пользователем. Согласно одному из вариантов реализации настоящего изобретения обновленные соответствия 308 перевода помещаются в обновленную базу данных (или, если используется статистическая система машинного перевода, они отражаются в обновленной таблице статистических параметров), которая посылается обратно пользователю вместе с откорректированным переведенным документом. Эти обновления встраиваются в применяемую пользователем автоматическую систему машинного перевода. Когда в следующий раз пользователь пытается перевести похожий текстовый материал 310, система автоматически создает перевод 312 более высокого качества на основе обновлений, возвращенных с ранее откорректированными документами. Это действие представлено блоком 336. Необходимо отметить, что данный процесс обучения, а также все описанные здесь сходные процессы обучения в качестве примера помогают при последующих переводах, осуществляемых в обоих направлениях языковой пары (т.е. испанский - английский и английский - испанский).
Необходимо отметить, что на основе откорректированного перевода 306 и исходного документа 302 может быть создано множество различных типов обучающих данных. Эти различные типы обучающих данных могут быть использованы для адаптации применяемой пользователем автоматической системы перевода. Обновление соответствий перевода является всего лишь одним из примеров в пределах объема настоящего изобретения. В пределах данного объема находится также обновление любого источника знаний. Также в пределах этого объема находится любое обновление какого-либо статистического или основанного на примерах средства обучения. Конкретные примеры будут подробно описаны ниже.
По мере того как пользователь получает автоматический перевод различных документов и посылает из системы результаты для надежного последующего редактирования или постредактирования (т.е. коррекции и модификации), применяемая пользователем автоматическая система перевода постепенно самонастраивается, чтобы обеспечить более эффективный перевод похожих документов. Необходимость дорогостоящей настройки устраняется, и пользователь в последующем будет получать автоматические переводы более высокого качества. Адаптация и настройка применяемой пользователем автоматической системы перевода (в качестве примера) происходит "за сценой", пока пользователь занят в обычном процессе получения качественных переводов.
Согласно одному из вариантов реализации настоящего изобретения автоматически созданный перевод 304 содержит автоматически созданный показатель достоверности, указывающий качество всего перевода и/или его части. Показатель достоверности (в качестве примера) основан на предполагаемой удовлетворенности пользователя полученным результатом. Создание и использование такого показателя достоверности описано в заявке на патент США № 10/309,950 на "Систему и способ для усвоения машиной показателя достоверности машинного перевода" от 4 декабря 2002 года, переуступленной правообладателю настоящей заявки и включенной в настоящее описание посредством ссылки во всей своей полноте.
Фиг.4 представляет собой блок-схему последовательности операций, иллюстрирующую введение показателя достоверности в описанную самонастраивающуюся систему машинного перевода. На этапе 402 пользователь получает автоматический перевод исходного документа. Документ содержит отмеченную информацию о показателе достоверности, относящуюся ко всему документу и/или одной или более его отдельных частей. На этапе 404 пользователь выбирает для последующего редактирования одну или более частей, имеющих низкую оценку достоверности. Эти части передаются надежному источнику модификации (т.е. человеку-переводчику) для коррекции. Откорректированные части обрабатываются вместе с оригиналом исходного документа для создания совокупности обновленных и предположительно точных соответствий перевода. Согласно одному из вариантов реализации настоящего изобретения эта обработка выполняется самонастраивающейся системой машинного перевода, работающей параллельно с самонастраивающейся системой машинного перевода, применяемой пользователем.
На этапе 406 обновленные соответствия перевода посылаются обратно пользователю вместе с откорректированными переведенными частями (или полностью откорректированным переведенным документом). На этапе 408 обновления встраиваются в применяемую пользователем автоматическую систему машинного перевода. В следующий раз, когда пользователь пытается перевести похожий текстовой материал, применяемая им автоматическая система машинного перевода создаст перевод более высокого качества.
III. КОНКРЕТНЫЕ ВАРИАНТЫ ПРИМЕНЕНИЯ
Фиг.5А и 5В представляют собой структурные схемы конкретных применений описанных выше вариантов адаптивной системы машинного перевода. Конкретные применения являются всего лишь примерами и не предполагают какого-либо ограничения объема использования изобретения или его функциональных возможностей. Кроме того, конкретные варианты применения не должны восприниматься как зависящие от какого-либо из изображенных компонентов или их комбинации либо как требующие их наличия.
Фиг.5А представляет собой структурную схему вычислительной системы 500. Пользователь 502 использует вычислительное устройство 504, чтобы сделать возможным взаимодействие с надежным источником 506 модификации через компьютерную сеть 505 (т.е. Интернет). Источник 506 в качестве примера представляет собой переводческий сервис, реализованный в вычислительном устройстве и предоставляемый вычислительному устройству 504 и его пользователю 502 по сети 505.
Вычислительное устройство 504, так же как и вычислительное устройство, в котором реализован источник 506 модификации, могут представлять собой любые из множества известных вычислительных устройств, включая любое из описанных применительно к Фиг.1 и 2, но не ограничиваясь ими. Связь между вычислительным устройством 504 и источником 506 модификации в сети 505 может осуществляться с использованием любого из множества известных способов сетевой связи, включая любой из описанных применительно к Фиг.1 и 2, но не ограничиваясь ими. Согласно одному из вариантов реализации настоящего изобретения вычислительное устройство 504 представляет собой беспроводное мобильное устройство-клиент, конфигурация которого позволяет связываться с реализованным на сервере источником 506 модификации по беспроводной сети. Согласно другому варианту реализации настоящего изобретения вычислительное устройство 504 представляет собой персональный компьютер-клиент, конфигурация которого позволяет осуществлять связь с реализованным на сервере источником 506 модификации через Интернет. Это всего лишь два из множества конкретных вариантов реализации настоящего изобретения в пределах его объема.
Вычислительное устройство 504 содержит автоматическую систему 508 перевода. Пользователь 502 (в качестве примера) передает образец текста системе 508 для создания соответствующего автоматического перевода. Если пользователь 502 не удовлетворен одной или более частями перевода, созданного системой 508 перевода (т.е. пользователь не удовлетворен указанным низким показателем достоверности), то автоматический перевод передается источнику 506 модификации вместе с копией исходного документа. Источник 506 проводит коррекцию автоматического перевода. Согласно одному из вариантов реализации настоящего изобретения автоматический перевод корректирует человек-переводчик 510. Согласно другому варианту реализации настоящего изобретения коррекцию осуществляет надежная автоматизированная система. Откорректированный перевод возвращается в вычислительное устройство 504 для предоставления пользователю 502.
Обучающий генератор 512 используется для обработки автоматического перевода, откорректированного перевода и/или исходного документа с целью создания совокупности обучающих данных, которые могут быть использованы для адаптации автоматической системы 508 перевода. Обучающий генератор 512 представляет собой компонент, хранящийся в источнике 506 модификации, либо в вычислительном устройстве 504, либо в отдельном, но доступном независимом месте (т.е. хранящийся на независимом и доступном сервере). Если обучающий генератор 512 хранится вместе с источником 506 модификации, созданная обучающая информация передается (в качестве примера) автоматической системе 508 перевода вместе с соответствующим откорректированным переводом. Если обучающий генератор 512 хранится в вычислительном устройстве 504, то данная информация непосредственно реализуется в системе 508. Хранение обучающего генератора 512 вместе с источником 506 модификации снижает требования, касающиеся объема памяти и вычислительной мощности, предъявляемые к вычислительному устройству 504. Кроме того, такая конфигурация позволяет поддерживать и управлять обучающим генератором 512 из централизованного источника.
Согласно одному из вариантов реализации настоящего изобретения для облегчения адаптации автоматической системы 508 перевода обучающий генератор 512 находится как в надежном источнике 506 модификации, так и в вычислительном устройстве 504. Обучающие генераторы 512 из данной пары (в качестве примера) идентичны или существенно похожи. Эта пара обучающих генераторов 512 (в качестве примера) связана с самонастраивающимися системами машинного перевода (такая система будет подробно описана с использованием Фиг.6). После завершения последующего редактирования с использованием источника 506 модификации созданный откорректированный перевод вместе с оригиналом исходного текста (в качестве примера) обрабатывается посредством фазы обучения самонастраивающейся системы машинного перевода, реализованной на источнике 506 модификации. Во время фазы обучения усваиваются корректные соответствия перевода. Эти соответствия помещаются в обновленную базу данных (или, если используется статистическая система, они отражаются в обновленной таблице статистических параметров), посылаемую в версию системы машинного перевода, реализованной на вычислительном устройстве 504. Затем эти обновления автоматически встраиваются в версию самонастраивающейся системы на компьютере пользователя (или, как будет описано ниже, в версию, поддерживаемую на сервере). Когда в следующий раз пользователь будет пытаться перевести похожий текстовой материал, его/ее система перевода автоматически создаст перевод более высокого качества на основе обновлений, возвращенных с ранее откорректированными документами.
Согласно одному из вариантов реализации настоящего изобретения надежный источник 506 модификации связан с сервером, работающим в сети 505. Обучающий генератор 512 установлен и работает на том же сервере. Переводы и обучающая информация, предоставляемые пользователю 502 с использованием источника 506 модификации в качестве примера, но не обязательно, предоставляются на платной основе (т.е. оплачиваются на повременной основе или на основе подписки).
Фиг.5В представляет собой структурную схему вычислительной системы 520. Элементы, показанные на Фиг.5В, идентичные или сходные с элементами, показанными на Фиг.5А, обозначены теми же ссылочными номерами. Как показано на Фиг.5В, один или более пользователей 502 взаимодействуют с одним или более вычислительных устройств 522, которые могут устанавливать соединение с сервером 524. Автоматическая система 508 перевода, которая (в качестве примера) связана с пользователем 502, хранится и работает на сервере 524. Сервер 524 может устанавливать соединение с сетью 505. Пользователь 502 использует вычислительное устройство 522 для взаимодействия с надежным источником 506 модификации, который также может устанавливать соединение с сетью 505. Источник 506 модификации в качестве примера представляет собой переводческий сервис, предоставляемый в сети 505 пользователю 502 посредством вычислительного устройства 504.
Система 520 работает таким же образом, что и система 500, при этом к автоматической системе 508 перевода может потенциально обращаться множество вычислительных устройств с целью выполнения автоматического перевода для одного или более отдельных пользователей 502. Соответственно, система 508 перевода может адаптироваться и обновляться с использованием обучающей информации, связанной с документами, передаваемыми многочисленными пользователями. Точность переводов, выполняемых системой 508 перевода, будет совершенствоваться в соответствии с требованиями, предъявляемыми множеством пользователей 502. Это особенно желательно, если многочисленные пользователи связаны между собой определенным образом, что обуславливает создание и перевод документов этими пользователями в одной области или по одной тематике (т.е. они работают в одной отрасли промышленности, для одной компании и т.д.).
IV. КОНКРЕТНЫЙ ВАРИАНТ ПРИМЕНЕНИЯ СИСТЕМЫ МАШИННОГО ПЕРЕВОДА, ИСПОЛЬЗУЮЩЕЙ АВТОМАТИЧЕСКУЮ НАСТРОЙКУ
Автоматическая система 508 перевода выше описана в общем виде. Точные детали системы 508 не являются решающими для настоящего изобретения. Кроме того, не представлена точная схема того, как в систему 508 перевода встраиваются описанные обучающие данные. Настоящее изобретение не ограничивается каким-либо одним конкретным типом обучающих данных, а также каким-либо одним способом встраивания этих данных. Однако с использованием Фиг.6 ниже описаны конкретная автоматическая система перевода и соответствующая схема встраивания обучающих данных.
Известным для некоторых автоматических систем перевода является использование автоматических технологий для настройки системы с целью ее адаптации к переводу ранее неизвестной терминологии (т.е. адаптации к переводу в специальной области). Варианты реализации настоящего изобретения удобно применять в контексте такой системы перевода. Такая система описана в заявке на патент США № 09/899,755 на "Совершенствуемую систему машинного перевода" от 5 июля 2001 года, переуступленной правообладателю настоящей заявки и включенной в данное описание посредством ссылки во всей своей полноте. Части системы, раскрытой в упомянутой заявке, описаны ниже со ссылкой на Фиг.6.
Перед рассмотрением автоматической системы перевода, показанной на Фиг.6, может оказаться полезным краткое обсуждение понятия логической формы. Полное и детальное описание логических форм, а также систем и способов для их создания содержится в патенте США № 5,966,686 на имя Heidorn и др., выданном 12 октября 1999 года на "Способ и систему вычисления семантических логических форм из синтаксических деревьев". Вкратце, логические формы создаются при выполнении морфологического и синтаксического анализа вводимого текста с целью обычного анализа построения фраз, дополненного грамматическими связями. Результат синтаксического анализа подвергается дальнейшей обработке для получения логических форм, являющихся структурами данных, описывающими отмеченные зависимости между словами со смысловой нагрузкой во вводимом тексте. Логические формы могут упорядочить некоторые синтаксические чередования (например, активный/пассивный) и определить как анафору внутри предложения, так и дистанционные зависимости. Логическая форма может быть представлена в виде графа, который помогает интуитивно понять элементы логических форм. Однако, как понятно специалистам в данной области техники, при хранении на машиночитаемом носителе логические формы с трудом воспринимаются в виде графа, а скорее воспринимаются как дерево (зависимостей).
Логическая связь состоит из двух слов, объединенных направленным типом связей, например:
ЛогическийСубъект, ЛогическийОбъект, КосвенныйОбъект;
ЛогическоеПодлежащее, ЛогическоеДополнение,
ЛогическийАгент;
СоАгент, Получатель;
Модификатор, Атрибут, МодификаторПредложения;
ПредложнаяСвязь;
Синоним, Эквивалент, Приложение;
Гиперним, Классификатор, ПодКласс;
Средство, Цель;
Оператор, ОбразДействия, Аспект, МодификаторСтепени, Усилитель;
Фокус, Тема;
Продолжительность, Время;
Место, Свойство, Материал, Способ, Мера, Цвет, Размер;
Характеристика, Часть;
Координата;
Пользователь, Обладатель;
Источник, Цель, Причина, Результат; и
Область.
Логическая форма является структурой данных на основе установленных логических связей, отражающих отдельный вводимый текст, например, предложение или его часть. Логическая форма как минимум состоит из одной логической связи и описывает структурные соотношения (т.е. синтаксические и семантические), в частности аргументное и/или обстоятельственное отношение (отношения) между важными словами во вводимой цепочке.
Конкретный код, который создает логические формы на основе синтаксического анализа, распределяется, например, по различным исходным и целевым языкам, с которыми работает система машинного перевода. Распределенная архитектура в значительной степени упрощает задачу совмещения сегментов логических форм от различных языков, так как внешне отличающиеся конструкции на двух языках часто сходятся в похожие или идентичные представления логических форм.
С учетом вышеупомянутого Фиг.6 представляет собой структурную схему системы 600 машинного перевода, соответствующей одному из аспектов настоящего изобретения. Система 600 представляет собой работающую под управлением данных систему машинного перевода, которая объединяет методы, основанные на правилах, и статистические методы с переходом на основе примеров. Система способна усваивать знания из дословных и идиоматических переводов непосредственно из данных. Главной особенностью режима обучения системы 600 является процедура автоматического совмещения логических форм, которая создает в системе базу примеров перевода из выровненных по предложениям двуязычных массивов.
Система 600 машинного перевода сконфигурирована таким образом, чтобы автоматически обучаться переводу на основе двуязычных соответствующих текстов. Система может быть настроена на конкретный текст путем обработки его предложений и соответствующих им переводов, сделанных человеком, что приводит к повышению качества последующих переводов для материала, похожего на данный текст. Система 600 машинного перевода также сконфигурирована таким образом, чтобы можно было удобно согласовывать встроенные балльные оценки достоверности, указывающие качество всего перевода и/или его части.
Система 600 содержит компоненты 604 и 606 грамматического разбора, компонент 608 статистического усвоения связи слов, компонент 610 совмещения логических форм, компонент 612 создания базы лексических знаний, двуязычный словарь 614, компонент 616 объединения словарей, базу данных 618 отображений перехода и обновленный двуязычный словарь 620. Во время обучения и выполнения перевода система 600 использует компонент 622 анализа, компонент 624 подбора соответствий, компонент 626 перехода и/или компонент 628 создания. Согласно одному из вариантов реализации настоящего изобретения компонент 604 грамматического разбора и компонент 622 анализа представляют собой один компонент или, по меньшей мере, идентичны друг другу.
Для обучения системы используется двуязычный массив. Двуязычный массив содержит совмещенные переведенные предложения (например, предложения на одном из двух языков, исходном или целевом, например английском, соответствующие один к одному их переводам, созданным человеком, на другом из двух языков, исходном или целевом, например испанском). Необходимо отметить, что "предложения" перевода в двуязычном массиве не ограничиваются реальными законченными предложениями и вместо этого могут представлять собой совокупность сегментов предложений. Во время обучения предложения поступают из выровненного двуязычного массива в систему 600 как исходные предложения 630 (предложения, которые нужно перевести) и целевые предложения 632 (перевод исходных предложений). Компоненты 604 и 606 грамматического разбора анализируют предложения из выровненного двуязычного массива для создания исходных логических форм 634 и целевых логических форм 636.
В ходе грамматического разбора слова в предложениях преобразуются в нормализованные словоформы (леммы) и могут поступать в компонент 608 статистического усвоения связи слов. Как однословные, так и многословные ассоциации итерационно сближаются и ранжируются компонентом 608 усвоения до тех пор, пока для каждой не будет получен надежный набор. Компонент 608 статистического усвоения связи слов создает на выходе усвоенные однословные пары 638 перевода, а также многословные пары 640.
Многословные пары 640 поступают в компонент 616 объединения словарей, которые используются для добавления дополнительных записей в двуязычный словарь 614 для создания обновленного двуязычного словаря. Новые записи отражают многословные пары 640.
Однословные пары 638 вместе с исходными логическими формами 634 и целевыми логическими формами 636 поступают в компонент 610 совмещения логических форм. Вкратце, компонент 610 сначала устанавливает пробные соответствия между узлами в исходной и целевой логических формах 630 и 636 соответственно. Это осуществляется с использованием пар перевода из двуязычного лексикона (например, двуязычного словаря) 614, которые могут дополняться однословными и многословными парами 638, 640 перевода из компонента 608 статистического усвоения связи слов. После установления возможных соответствий компонент 610 совмещения совмещает узлы логических форм в соответствии как с лексическими, так и со структурными соображениями и создает отображения 642 перехода слов и/или логических форм.
По существу, компонент 610 совмещения создает связи между логическими формами, используя информацию двуязычного словаря 614, а также однословные и многословные пары 638, 640. Отображения перехода могут фильтроваться на основе частоты, с которой они появляются в исходной и целевой логических формах 634 и 636, и поступают в компонент 612 создания базы лексических знаний.
Хотя фильтрация является необязательной, в одном из примеров, если отображение перехода не наблюдается, по меньшей мере, дважды в обучающих данных, оно не используется при создании базы данных 618 отображений перехода, хотя в качестве фильтра также может использоваться и любая другая требуемая частота. Кроме того, необходимо отметить, что могут быть использованы также и другие технологии фильтрации, отличающиеся от технологии на основе частоты появления. Например, отображения перехода могут фильтроваться, исходя из того, созданы ли они в результате полного грамматического разбора вводимых предложений, и исходя из того, полностью ли совмещены логические формы, используемые для создания этих отображений.
Компонент 612 создает базу данных 618 отображений перехода, содержащую отображения перехода, которые, по существу, связывают слова и/или логические формы на одном языке со словами и/или логическими формами на другом языке. После создания таким образом базы данных 618 отображений перехода система 600 считается сконфигурированной для выполнения переводов. При выполнении переводов в компонент 622 анализа поступает исходное предложение 650, которое должно быть переведено. Компонент 622 анализа принимает исходное предложение 650 и создает на основе введенного исходного предложения исходную логическую форму 652.
Исходная логическая форма 652 поступает в компонент 624 подбора соответствий. Компонент 624 подбора соответствий пытается найти соответствие исходной логической форме 652 в логических формах, находящихся в базе данных 618 отображений перехода, чтобы получить связанную логическую форму 654. Частям исходной логической формы 652 может соответствовать множество отображений перехода. Компонент 624 подбора соответствий ищет наилучший набор соответствующих отображений перехода в базе данных 618, которые содержат соответствующие леммы, части речи и другую характерную информацию. Набор наилучших соответствий находится на основе заранее определенного показателя. Например, отображения перехода, содержащие большие по размеру (более конкретные) логические формы, могут, например, оказаться предпочтительными по сравнению с отображениями перехода, содержащими меньшие по размеру (более общие) логические формы. Из отображений, содержащих логические формы равного размера, компонент 624 подбора соответствий может, например, предпочесть отображения с более высокой частотой. Отображения могут также соответствовать перекрывающимся частям исходной логической формы 652 при условии, что они не конфликтуют друг с другом каким бы то ни было образом. В качестве примера может оказаться предпочтительным весь набор отображений в совокупности, если эти отображения покрывают вводимое предложение в большей части, чем альтернативные наборы.
После нахождения набора подходящих отображений перехода компонент 624 подбора соответствий создает связи узлов исходной логической формы 652 с копиями соответствующих целевых слов или сегментов логической формы, принятых отображениями перехода, для создания связанной логической формы 654. Связи для многословных отображений представлены соединением корневых узлов соответствующих сегментов с последующим соединением звездочки с другими исходными узлами, участвующими в многословном отображении. В качестве примера могут также создаваться связи второго порядка между соответствующими отдельными исходными и целевыми узлами такого отображения для использования при переходе. Компонент 626 перехода принимает связанную логическую форму 654 от компонента 624 подбора соответствий и создает целевую логическую форму 656, которая создаст основу целевого перевода. Это осуществляется при выполнении прохода связанной логической формы 654 в направлении сверху вниз, при котором объединяются сегменты целевой логической формы, помеченные связями с узлами исходной логической формы 652. При объединении вместе сегментов логической формы для возможных комплексных многословных отображений связи второго порядка, установленные компонентом 624 подбора соответствий между отдельными узлами, используются для определения правильных точек присоединения для модификаторов и т.д. Если необходимо, могут использоваться точки присоединения по умолчанию.
В случаях, когда применимых отображений перехода не обнаружено, узлы исходной логической формы 652 и их взаимосвязи просто копируются в целевую логическую форму 656. Для этих узлов в базе данных 618 отображений перехода по-прежнему могут быть найдены переводы отдельных слов по умолчанию и вставлены в целевую логическую форму 656. Однако если ничего не обнаружено, переводы могут браться, например, из обновленного двуязычного словаря 620, который использовался во время совмещений.
Компонент 628 создания в качестве примера представляет собой компонент, основанный на использовании правил и не зависящий от области применения, который отображает целевую логическую форму 656 в целевую цепочку (или выводимое целевое предложение) 658. Компонент 628 создания может, например, не иметь информации, касающейся исходного языка вводимых логических форм, и работает исключительно с информацией, переданной ему компонентом 626 перехода. Кроме того, компонент 628 создания, например, использует эту информацию вместе с одноязычным словарем (например, для целевого языка) для создания целевого предложения 658. Таким образом, для каждого языка достаточно одного общего компонента 628 создания.
Таким образом, можно видеть, что система 600 при грамматическом разборе сортирует информацию из множества языков в распределенную общую логическую форму, в результате чего можно подобрать соответствующие логические формы из различных языков. Данная система при создании базы данных отображений перехода может также использовать простые технологии фильтрации, чтобы обрабатывать "зашумленные" вводимые данные. Следовательно, система 600 может автоматически обучаться, используя большое число пар предложений.
Если вернуться обратно к адаптивной автоматической системе перевода, рассмотренной с использованием Фиг.3, 4, 5А и 5В, описанная система 600 может (в качестве примера) быть использована как применяемая пользователем адаптивная автоматическая система перевода (т.е. система 508 перевода). Согласно одному из вариантов реализации настоящего изобретения, по меньшей мере, часть перевода, созданного системой 600, посылается, например, надежному источнику модификации (т.е. источнику 506) для коррекции (т.е. пользователь выбирает для модификации части с низким показателем достоверности). На основе проведенной коррекции генерируется обучающая информация (обучающая информация, созданная обучающим генератором 512). Система 600 принимает и обрабатывает эти обучающие данные. Согласно одному из вариантов настоящего изобретения система 600 обрабатывает двуязычный массив, соответствующий проведенной коррекции. Пользователи системы 600 перевода впоследствии будут получать переводы более высокого качества для похожих текстов.
Согласно одному из вариантов реализации настоящего изобретения, чтобы облегчить адаптацию применяемой пользователем автоматической системы перевода, система 600 находится как в надежном источнике модификации, так и в вычислительном устройстве пользователя (или на связанном с ним сервере). Пара систем 600, например, работает параллельно друг другу. После того как с использованием источника модификации завершено последующее редактирование, созданный откорректированный перевод вместе с оригиналом исходного текста, например, обрабатывается "обучающим" компонентом той версии системы 600, которая реализована в источнике модификации. Во время фазы обучения усваиваются корректные соответствия перевода. Эти соответствия затем помещаются в обновленную базу данных, которая посылается в версию системы 600, реализованную в вычислительном устройстве пользователя (или на связанном с ним сервере). Эти обновления могут пересылаться вместе с откорректированным переводом или независимо. Данные обновления автоматически встраиваются в пользовательскую версию системы 600. В следующий раз, когда пользователь пытается перевести похожий текстовый материал, пользовательская система 600 автоматически создает перевод более высокого качества на основе обновлений, возвращенных вместе с ранее откорректированными документами.
Обновление системы 600, основанное на обучающей информации, может выполняться любым из множества способов, и конкретный способ не является решающим для настоящего изобретения. Обучающие данные, предоставляемые системе 600, могут относиться к любому из множества различных типов, подходящих для осуществления адаптации. Как упомянуто выше, согласно одному из вариантов реализации настоящего изобретения обучающие данные представляют собой двуязычный массив (т.е. пары предложений 630 и 632, показанные на Фиг.6). Согласно другому варианту реализации настоящего изобретения обучающий генератор (т.е. генератор 512 на Фиг.5А и 5В) создает и поставляет в систему 600 обновление для средства 604 грамматического разбора и/или средства 606 грамматического разбора на основе проведенной коррекции (т.е. обновление обязывает, чтобы в будущем XY обрабатывалось как X и т.д.). Согласно другому варианту реализации настоящего изобретения обучающий генератор создает обновление на основе изменений, сделанных для однословных пар, используемых системой 600 перевода. Согласно еще одному варианту реализации настоящего изобретения обучающий генератор создает обновление для базы данных 618 отображений перехода на основе проведенной коррекции. Согласно следующему варианту реализации настоящего изобретения обучающий генератор непосредственно или опосредованно перестраивает базу данных 618 на основе проведенной коррекции. В пределах объема настоящего изобретения находится обновление любого источника знаний.
MindNet является общим термином, используемым в данной области техники для описания такой структуры, как база данных по лингвистическим конструкциям, состоящая из логических форм и связанная с системой 600 перевода (т.е. база данных 618 отображений перехода). Термин MindNet был предложен Microsoft Corporation, Редмонд, штат Вашингтон. Согласно одному из вариантов реализации настоящего изобретения применение обучающей информации для адаптации системы 600 на основе коррекции, проведенной надежным источником модификации, включает обработку (т.е. обновление) средства MindNet. Процесс обновления может проходить в системе, применяемой пользователем (или на сервере, связанном с пользователем), или в удаленном режиме в системе, связанной с источником модификации.
Фиг.7 представляет собой блок-схему последовательности операций в варианте реализации настоящего изобретения, в котором обновляется средство MindNet. На этапе 702 применяемое пользователем средство MindNet посылается (т.е. от машины-клиента) надежному источнику модификации (т.е. реализованному на сервере) вместе с переводом и оригиналом текста. После проведения необходимой коррекции перевода (этап 704) средство MindNet перестраивается для отражения данной коррекции (этап 706). После этого перестроенное средство MindNet посылается пользователю (т.е. возвращается на машину-клиент) вместе с откорректированным материалом перевода (этап 708). На этапе 710 перестроенное средство MindNet включается в состав применяемой пользователем автоматической системы перевода. Обновленное средство MindNet используется при осуществлении последующих переводов. Необходимо отметить, что описанное обновление применяемой пользователем системы перевода в удаленном режиме может выполняться с использованием структур данных, отличающихся от MindNet.
На фиг.8 представлена блок-схема последовательности операций, иллюстрирующая другой вариант реализации настоящего изобретения, в котором средство MindNet обновляется непосредственно на машине пользователя (или непосредственно на связанном с пользователем сервере). На этапе 802 надежный источник модификации принимает материал перевода и соответствующий оригинал текста от пользователя. Производится необходимая коррекция (этап 802) и составляется соответствующее дополнение к средству MindNet (этап 804). На этапе 806 вместе с откорректированным переводом клиент получает дополнение, которое должно быть загружено и вставлено в его средство MindNet (этап 808). Согласно варианту реализации настоящего изобретения, представленному этапом 810, средство MindNet пользователя не обновляется до тех пор, пока не наберется заранее определенное количество дополнений. Необходимо отметить, что описанное локальное обновление применяемой пользователем системы перевода может выполняться с использованием структур данных, отличающихся от MindNet.
Согласно одному из вариантов реализации настоящего изобретения несколько дополнений связываются вместе или собираются на сервере, а именно на сервере, где производится надежная коррекция. Когда собрано заранее определенное количество дополнений, пользователь посылает свое средство MindNet на сервер для перестройки и последующего возврата. В объем настоящего изобретения входят и другие схемы обновления пользовательского средства MindNet.
Согласно другому аспекту настоящего изобретения описанные процессы адаптивного машинного перевода могут быть реализованы в системе, где пользователь и надежный источник модификации являются одним лицом. Схема процесса, показанная на Фиг.3 совместима с таким вариантом. Другими словами, схема, показанная на Фиг.3, охватывает все варианты реализации настоящего изобретения, где адаптивная система машинного перевода включена в среду управления документооборотом или рабочую среду, в которой пользователь, являющийся (в качестве примера) надежным источником модификации, передает, по меньшей мере, часть исходного документа автоматическому переводчику, находящемуся на его собственном компьютере (или на связанном с пользователем сервере), для перевода. Далее такие варианты реализации настоящего изобретения будут описаны с использованием Фиг.3.
Передача, по меньшей мере, части исходного документа 302 представлена блоком 330. В качестве примера пользователь является надежным переводчиком с языков, относящихся к исходному документу 302. Информация, содержащаяся в исходном документе 302, а также соответствующий автоматически созданный перевод 304 предоставляются пользователю/корректору для просмотра и коррекции. Это действие представлено блоком 332.
Откорректированный перевод 306 и оригинал исходного документа 302 обрабатываются для создания совокупности обновленных и предположительно точных соответствий 308 перевода. Это действие представлено блоком 334. Согласно одному из вариантов реализации настоящего изобретения обновленные соответствия 308 перевода помещаются в обновленную базу данных (или, если используется статистическая система машинного перевода, они отражаются в обновленной таблице статистических параметров). Эти обновления встраиваются в применяемую пользователем автоматическую систему машинного перевода. В следующий раз, когда пользователь пытается перевести похожий текстовый материал 310, система автоматически создает перевод 312 более высокого качества исходя из обновлений, созданных на основе ранее откорректированных документов. Это действие представлено блоком 336. Необходимо отметить, что данный процесс обучения помогает при осуществлении последующих переводов в обоих направлениях языковой пары (т.е. испанский-английский и английский-испанский).
Необходимо подчеркнуть, что на основе откорректированного перевода 306 и исходного документа 302 может быть создано множество различных типов обучающих данных. Эти различные типы обучающих данных могут быть использованы для адаптации применяемой пользователем автоматической системы перевода. Обновление соответствий перевода является всего лишь одним примером в пределах объема настоящего изобретения. В пределах данного объема находится также обновление любого источника знаний. Также в пределах этого объема находится любое обновление какого-либо статистического или основанного на примерах средства обучения. Конкретные примеры описаны выше применительно к другим вариантам реализации настоящего изобретения.
Согласно другому аспекту настоящего изобретения описанные процессы адаптивного машинного перевода могут использоваться вместе со специализированным переводческим программным обеспечением, применяемым пользователем, являющимся надежным источником перевода. Известно, что люди-переводчики (т.е. профессиональные переводчики, переводчики-любители и т.д.) используют специализированное переводческое программное обеспечение для уменьшения объема требуемой работы по переводу. Общей характеристикой переводчиков, использующих это специализированное программное обеспечение, является то, что они обладают знаниями, необходимыми для выполнения точного перевода без этого программного обеспечения. Данное программное обеспечение используется просто для снижения объема набираемого текста при переводе определенного документа.
Некоторые специализированные программные продукты для перевода имеют конфигурацию, позволяющую сравнивать предложение (или группу предложений), которое должно быть переведено (т.е. предложение или группу предложений, взятые из переводимого документа) с базой данных, содержащей ранее переведенные предложения (или группы предложений). Если найдено совпадение, то соответствующий перевод может быть извлечен автоматически. В таких случаях пользователь будет избавлен от некоторой части бремени ручного перевода.
В тех случаях, когда для целевого предложения отсутствует точное соответствие, конфигурация некоторых специализированных программных продуктов для перевода позволяет извлекать "приближенное соответствие", которое представляет собой похожее, но не идентичное предложение. Пользователь может отказаться от использования приближенного соответствия и перевести предложение "с нуля" или может преобразовать приближенное соответствие в корректную форму. Во многих случаях преобразование приближенного соответствия будет менее трудоемким (т.е. на несколько нажатий клавиш меньше), чем перевод с нуля.
Некоторые специализированные программные продукты имеют конфигурацию, позволяющую их использовать вместе с автоматической системой перевода для получения автоматических машинных переводов для некоторых переводимых предложений, например предложений исходного текста, для которых отсутствует точный или приближенный перевод, но не ограничиваясь ими. Пользователь может отказаться от машинного перевода и переводить предложение с нуля либо может преобразовать машинный перевод в корректную форму. Во многих случаях преобразование машинного перевода будет менее трудоемким (т.е. на несколько нажатий клавиш меньше), чем перевод с нуля.
Согласно одному из аспектов настоящего изобретения пользователь, применяющий описанное специализированное переводческое программное обеспечение, в действительности представляет собой надежный источник перевода. Соответственно, когда пользователь корректирует приближенные или машинные переводы, информация, соответствующая этой коррекции, может быть использована для обучения или обновления системы машинного перевода, связанной с данным программным обеспечением. В этом случае эффективность и точность системы перевода будет повышаться при выполнении последующих переводов. Обучение или обновление системы машинного перевода может выполняться аналогично любому из описанных здесь способов или иным образом.
Фиг.9 представляет собой структурную схему конкретного применения вариантов реализации настоящего изобретения, включающих специализированное переводческое программное обеспечение. Изображенный вариант применения является всего лишь примером и не предполагает какого-либо ограничения объема использования или функциональных возможностей настоящего изобретения. Также данный конкретный вариант применения не должен восприниматься как зависящий от какого-либо одного из изображенных компонентов или их комбинации или как требующий их наличия.
Как показано на Фиг.9, пользователь/корректор 902 взаимодействует с вычислительным устройством 904, на котором установлены специализированная переводческая система 910 (т.е. специализированное переводческое программное обеспечение), автоматическая система 912 перевода и обучающий генератор 914 (т.е. идентичный или похожий на обучающий генератор 512, описанный выше). Вычислительное устройство 904 может представлять собой любое из множества известных вычислительных устройств, включая любое из описанных применительно к Фиг.1 и 2, но не ограничиваясь ими. Согласно одному из вариантов реализации настоящего изобретения вычислительное устройство 904 представляет собой персональный компьютер.
Пользователь 902 является переводчиком (профессиональным или любителем), который зависит от системы 910 в смысле уменьшения, по меньшей мере, частичного объема работы, связанного с переводом исходных документов. Специализированная переводческая система 910 имеет такую конфигурацию, чтобы помочь пользователю 902 в переводе исходных документов. В качестве примера пользователь 902 передает, по меньшей мере, часть исходного документа системе 910 для помощи в создании соответствующего перевода. Автоматическая система 912 перевода имеет такую конфигурацию, чтобы обеспечить автоматически получаемый машинный перевод предоставленного текста. Конфигурация специализированной переводческой системы 910 позволяет запрашивать и принимать от системы 912 перевода автоматический перевод анализируемого текста исходного документа (т.е. система 910 зависит от системы 912 в тех случаях, когда первая не способна создать точный или приближенный перевод).
Необходимо отметить, что на основе автоматических переводов, созданных системой 912, может быть обновлена любая база данных, состоящая из ранее переведенных предложений и связанная со специализированным переводческим программным обеспечением 910 (т.е. автоматические переводы становятся потенциальными точными или приближенными соответствиями). Необходимо также отметить, что машинный перевод может быть предоставлен "по требованию" (т.е. по запросу пользователя). В ином случае машинные переводы могут создаваться на этапе предварительной обработки и храниться с другими ранее переведенными предложениями (т.е. храниться с другими потенциальными точными и приближенными соответствиями). База данных, состоящая из ранее переведенных предложений, на этапе предварительной обработки может пополняться предложениями, для которых не существует точных или приближенных соответствий. Таким образом, машинные переводы могут создаваться "по требованию" или заблаговременно (а затем храниться в базе данных вместе с ранее переведенными предложениями).
Если пользователь 902 неудовлетворен одной или более частями перевода, созданного системой 912 перевода (т.е. пользователь неудовлетворен указанным низким показателем достоверности), то автоматический перевод, например, предоставляется пользователю 902 для коррекции (т.е. пользователь 902 предположительно является надежным источником модификации). В качестве примера в результате процесса коррекции получается откорректированный перевод 922. Обучающий генератор 914 применяется для обработки автоматического перевода, откорректированного перевода и/или исходного документа с целью создания совокупности обучающих данных, которые могут быть использованы для адаптации автоматической системы 912 перевода. Обучающий генератор 914 представляет собой компонент, хранящийся в вычислительном устройстве 904 или в отдельном, но доступном независимом месте проведения вычислений (т.е. хранится на независимом и доступном сервере). Если обучающий генератор 914 хранится в отдельном месте проведения вычислений, созданная обучающая информация, например, пересылается обратно автоматической системе 912 перевода. Если обучающий генератор 914 хранится в вычислительном устройстве 904, то информация предоставляется в систему 912 непосредственно. Хранение обучающего генератора 914 в вычислительном устройстве 904 снижает требования, предъявляемые к объему памяти и вычислительной мощности. Взаимоотношение между автоматической системой 912 перевода и обучающим генератором 914 в контексте обучения, например, аналогичны любому из вариантов, описанных выше применительно к автоматической системе 508 перевода и обучающему генератору 512.
Согласно одному из вариантов реализации настоящего изобретения с вычислительным устройством 904 и со специализированной переводческой системой 910 для совместного создания переводов более высокого качества может взаимодействовать более одного пользователя 902. Согласно другому варианту реализации настоящего изобретения пользователь 902 может обращаться к вычислительному устройству 904 непосредственно (как показано) или по компьютерной сети. Согласно еще одному варианту реализации настоящего изобретения обучающая информация или материал обновления, созданный генератором 914, в дополнение к используемым для обновления системы 912, также может передаваться по компьютерной сети для обновления, по меньшей мере, одной дополнительной автоматической системы машинного перевода. Например, обучающая информация или материал обновления может передаваться непосредственно в отдельную дополнительную автоматическую систему машинного перевода для встраивания. При этом в качестве альтернативы упомянутая информация может передаваться централизованному серверу и затем распределяться по нескольким системам машинного перевода для встраивания (т.е. на основе платной подписки). В другом случае упомянутая информация может передаваться централизованному серверу и затем распределяться для встраивания по нескольким системам машинного перевода, связанным с большой организацией (т.е. корпорацией).
Хотя настоящее изобретение описано со ссылкой на конкретные варианты его реализации, специалистам в данной области техники должно быть понятно, что в его форму и детали могут быть внесены изменения, не выходящие за пределы сущности и объема настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПЕРЕВОДЧЕСКИЙ СЕРВИС НА БАЗЕ ЭЛЕКТРОННОГО СООБЩЕСТВА | 2015 |
|
RU2604984C1 |
| СЕГМЕНТ ДАННЫХ О ПЕРЕВОДЕ | 2002 |
|
RU2295150C2 |
| КРАУД-СОРСНЫЕ СИСТЕМЫ ОБУЧЕНИЯ ЛЕКСИКЕ | 2014 |
|
RU2607416C2 |
| СИСТЕМА И МЕТОД УПРАВЛЕНИЯ ПРОЕКТАМИ ЯЗЫКОВОГО ПЕРЕВОДА | 2018 |
|
RU2696326C1 |
| Способ и система перевода исходного предложения на первом языке целевым предложением на втором языке | 2017 |
|
RU2692049C1 |
| Нейронная сеть для интерпретирования предложений на естественном языке | 2018 |
|
RU2699396C1 |
| СПОСОБ ДЛЯ ОТОБРАЖЕНИЯ СУБТИТРОВ В ПРОЦЕССЕ ВОСПРОИЗВЕДЕНИЯ МЕДИАКОНТЕНТА (ВАРИАНТЫ) | 2017 |
|
RU2668721C1 |
| ГИБКИЙ ПЕРЕВОД ОТОБРАЖЕНИЯ | 2006 |
|
RU2436146C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРЕВОДА | 2020 |
|
RU2790026C2 |
| СИСТЕМА И СПОСОБ ПЕРЕВОДА | 2016 |
|
RU2656697C2 |

Изобретение относится к машинному переводу. Изобретение позволяет повысить точность машинного перевода. Способ предоставления информации автоматической системе машинного перевода для повышения точности перевода включает прием исходного текста. От автоматической системы машинного перевода принимается пробный перевод, соответствующий исходному тексту. Кроме того, принимается коррекционная информация, сконфигурированная таким образом, чтобы осуществить коррекцию, по меньшей мере, одной ошибки в пробном переводе. На конечном этапе автоматической системе машинного перевода предоставляется информация для снижения вероятности того, что эта ошибка будет повторяться в последующих переводах, созданных этой системой, при этом указанная информация встраивается в автоматическую систему машинного перевода. 4 н. и 34 з.п. ф-лы; 11 ил.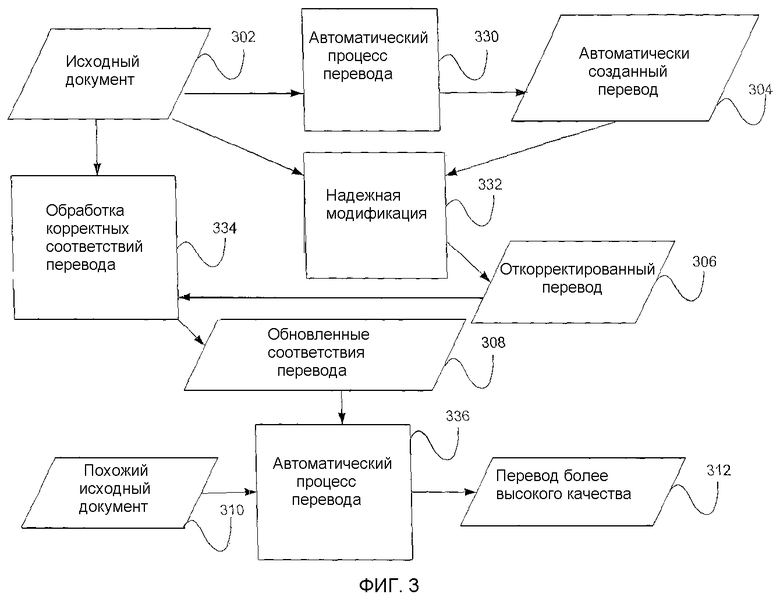
1. Реализуемый при помощи компьютера способ предоставления информации автоматической системе машинного перевода для повышения точности перевода, заключающийся в том, что
принимают исходный текст, который выражен на первом естественном языке;
принимают от автоматической системы машинного перевода пробный перевод, соответствующий исходному тексту, причем пробный перевод выражен на естественном языке, отличном от первого естественного языка;
обрабатывают пробный перевод и исходный текст для идентификации ошибки в пробном переводе; и
предоставляют информацию автоматической системе машинного перевода для снижения вероятности того, что упомянутая ошибка будет повторяться в последующих переводах с естественного языка, созданных автоматической системой машинного перевода,
при этом упомянутое предоставление информации включает в себя предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода.
2. Способ по п.1, в котором предоставление информации автоматической системе машинного перевода включает в себя коррекцию ошибки и предоставление скорректированного перевода.
3. Способ по п.1, в котором упомянутый прием от автоматической системы машинного перевода включает в себя прием от вычислительного устройства-клиента, на котором реализована автоматическая система машинного перевода.
4. Способ по п.3, в котором упомянутый прием от вычислительного устройства-клиента включает в себя прием посредством компьютерной сети.
5. Способ по п.4, в котором упомянутый прием посредством компьютерной сети включает в себя прием посредством сети Интернет.
6. Способ по п.1, в котором упомянутый прием от автоматической системы машинного перевода включает в себя прием от сервера, на котором реализована автоматическая система машинного перевода.
7. Способ по п.6, в котором упомянутый прием от сервера включает в себя прием посредством компьютерной сети.
8. Способ по п.1, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, включает в себя предоставление информации обновления, которая должна быть встроена в источник информации, связанный с автоматической системой машинного перевода.
9. Способ по п.1, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление информации обновления, которая должна быть встроена в, по меньшей мере, одно соответствие перевода, связанное с автоматической системой машинного перевода.
10. Способ по п.1, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление информации обновления, которая должна быть встроена в совокупность лингвистических конструкций, связанных с системой автоматического перевода.
11. Способ по п.10, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление информации обновления, которая должна быть встроена в базу данных соответствующих логических форм, связанную с автоматической системой машинного перевода.
12. Способ по п.1, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление информации обновления, которая должна быть встроена в совокупность статистических параметров, связанных с автоматической системой машинного перевода.
13. Способ по п.1, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление информации обновления, которая должна быть встроена в совокупность информации грамматического разбора, связанную с автоматической системой машинного перевода, причем упомянутая информация грамматического разбора представляет собой информацию, позволяющую средству грамматического разбора обеспечивать анализ совокупности сегментов.
14. Способ по п.1, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление информации обновления, которая должна быть встроена в совокупность ассоциаций соответствующих слов или фраз, связанную с автоматической системой машинного перевода.
15. Способ по п.1, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление двуязычных массивов.
16. Способ по п.8, в котором упомянутое предоставление информации, которая должна быть встроена в автоматическую систему машинного перевода, содержит предоставление двуязычного массива из одного или более пар предложений.
17. Способ обучения автоматической системы машинного перевода, заключающийся в том, что
используют автоматическую систему машинного перевода для создания перевода исходного текста, причем исходный текст выражен на первом естественном языке, а перевод выражен на естественном языке, отличном от первого естественного языка;
передают исходный текст и, по меньшей мере, часть упомянутого перевода надежному источнику модификации;
принимают от упомянутого надежного источника модификации указание ошибки в упомянутой, по меньшей мере, одной части перевода; и
осуществляют обучение автоматической системы машинного перевода таким образом, чтобы появление упомянутой ошибки стало менее вероятно в последующих переводах, созданных автоматической системой машинного перевода,
при этом обучение автоматической системы машинного перевода включает в себя обновление совокупности информации грамматического разбора, связанной с автоматической системой машинного перевода, причем упомянутая информация грамматического разбора представляет собой информацию, позволяющую средству грамматического разбора обеспечивать анализ совокупности сегментов.
18. Способ по п.17, в котором дополнительно формируют показатель достоверности, представляющий собой критерий качества перевода; и выбирают упомянутую часть перевода, передаваемую упомянутому надежному источнику модификации, основываясь, по меньшей мере, частично на упомянутом показателе достоверности.
19. Способ по п.17, в котором упомянутая передача содержит передачу с вычислительного устройства-клиента, на котором реализована автоматическая система машинного перевода, на вычислительное устройство-сервер, связанный с упомянутым надежным источником модификации.
20. Способ по п.17, в котором упомянутая передача содержит передачу с сервера, на котором реализована автоматическая система машинного перевода, на вычислительное устройство-сервер, связанное с упомянутым надежным источником модификации.
21. Способ по п.17, в котором при обучении автоматической системы машинного перевода осуществляют обновление источника знаний, связанного с автоматической системой машинного перевода.
22. Способ по п.17, в котором при обучении автоматической системы машинного перевода осуществляют обновление, по меньшей мере, одного соответствия перевода, связанного с автоматической системой машинного перевода.
23. Способ по п.17, в котором при обучении автоматической системы машинного перевода осуществляют обновление совокупности лингвистических конструкций, связанной с автоматической системой машинного перевода.
24. Способ по п.23, в котором при обучении автоматической системы машинного перевода осуществляют обновление базы данных соответствующих логических форм, связанной с автоматической системой машинного перевода.
25. Способ по п.17, в котором при обучении автоматической системы машинного перевода осуществляют обновление совокупности статистических параметров, связанной с автоматической системой машинного перевода.
26. Способ по п.17, в котором при обучении автоматической системы машинного перевода осуществляют обновление совокупности ассоциаций соответствующих слов или фраз, связанной с автоматической системой машинного перевода.
27. Способ по п.17, в котором при обучении автоматической системы машинного перевода предоставляют автоматической системе машинного перевода двуязычные массивы на основе упомянутой ошибки и обеспечивают ее самообучение на основе этих двуязычных массивов.
28. Способ по п.17, в котором при обучении автоматической системы машинного перевода предоставляют автоматической системе машинного перевода двуязычный массив из одной или более пар предложений.
29. Способ реализации автоматической системы машинного перевода, заключающийся в том, что
используют автоматическую систему машинного перевода для создания перевода исходного текста, при этом с частями упомянутого перевода связывают показатель достоверности, причем исходный текст выражен на первом естественном языке, а перевод выражен на естественном языке, отличном от первого естественного языка;
оценивают упомянутый показатель достоверности и выбирают часть перевода с низкой достоверностью;
передают упомянутую часть с низкой достоверностью по компьютерной сети надежному источнику модификации;
используют упомянутый надежный источник модификации для создания откорректированной версии упомянутой части с низкой достоверностью;
создают обновленную базу данных, содержащую переводческую информацию, на основе упомянутой откорректированной версии части с низкой достоверностью;
передают упомянутую обновленную базу данных переводческой информации по компьютерной сети автоматической системе машинного перевода; и
включают упомянутую обновленную базу данных переводческой информации в автоматическую систему машинного перевода для предоставления автоматической системе машинного перевода возможности в последующем переводить с более высокой точностью текст, похожий на упомянутую часть с низкой достоверностью,
при этом упомянутое включение обновленной базы данных переводческой информации содержит включение, по меньшей мере, одной обновленной лингвистической конструкции.
30. Способ по п.29, в котором упомянутое использование надежного источника модификации для создания откорректированной версии включает в себя использование человека-переводчика.
31. Способ по п.29, в котором передача по компьютерной сети включает в себя передачу через Интернет.
32. Способ по п.29, в котором автоматическая система машинного перевода реализована на вычислительном устройстве-клиенте.
33. Способ по п.29, в котором упомянутое включение базы данных переводческой информации содержит включение, по меньшей мере, одного обновленного соответствия перевода.
34. Способ по п.29, в котором упомянутое включение базы данных переводческой информации содержит включение, по меньшей мере, одного обновления в базу данных соответствующих логических форм.
35. Способ по п.29, в котором упомянутое включение базы данных переводческой информации содержит включение, по меньшей мере, одного обновления в совокупность статистических параметров.
36. Способ по п.29, в котором упомянутое включение базы данных переводческой информации содержит включение, по меньшей мере, одного обновления в совокупность информации грамматического разбора, которая позволяет средству грамматического разбора обеспечивать анализ совокупности сегментов.
37. Способ по п.29, в котором упомянутое включение базы данных переводческой информации содержит включение, по меньшей мере, одного обновления в совокупность ассоциаций соответствующих слов или фраз.
38. Способ реализации самонастраивающегося автоматического переводчика, заключающийся в том, что
реализуют первый самонастраивающийся автоматический переводчик на первом вычислительном устройстве;
реализуют второй самонастраивающийся автоматический переводчик на втором вычислительном устройстве;
обеспечивают надежный источник перевода;
устанавливают связь между первым и вторым вычислительными устройствами;
принимают исходный текст вторым вычислительным устройством;
снабжают второе вычислительное устройство откорректированной версией пробного перевода, созданного упомянутым надежным источником перевода, причем пробный перевод представляет собой пробный перевод исходного текста, при этом исходный текст выражен на первом естественном языке, а пробный перевод выражен на естественном языке, отличном от первого естественного языка;
используют второй самонастраивающийся автоматический переводчик для обработки упомянутых исходного текста и откорректированной версии пробного перевода, чтобы создать обучающую информацию для адаптации первого самонастраивающегося автоматического переводчика к последующему переводу текста, похожего на упомянутый исходный текст, с более высокой точностью;
передают упомянутую обучающую информацию от второго вычислительного устройства к первому вычислительному устройству; и
встраивают упомянутую обучающую информацию в первый самонастраивающийся автоматический переводчик для предоставления возможности первому самонастраивающемуся автоматическому переводчику в последующем переводить с более высокой точностью текст, похожий на упомянутый исходный текст.
| US 6278969 В1, 21.08.2001 | |||
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Походная разборная печь для варки пищи и печения хлеба | 1920 |
|
SU11A1 |

