ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к интеллектуальным системам - компьютерным (как к цифровым, так и аналоговым моделям искусственной интуиции и предназначено для автоматизированного создания модели объектов не по подобию свойств, а по отклику на внешние воздействия. При этом для решения конкретных узкоспециализированных или работающих в режиме реального времени задач (например распознавания образов в условиях выполнения боевой задачи) может применяться сборка из простейших однотипных электронных схем. (Для распознавания летящей пули или снаряда их должно быть не меньше 1000000).
УРОВЕНЬ ТЕХНИКИ
Заявленное изобретение на сегодняшний момент не имеет аналогов, раскрывающих основные особенности, применяемого подхода.
Заявленное изобретение относится к классу интуитивных систем и является, по сути, единственным в своем роде техническим воплощением искусственной интуиции.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Задачей настоящего изобретения является создание принципиально нового способа создания информационных моделей, представляющего по своей природе искусственную интуицию.
Техническим результатом изобретения является повышение точности решения проблем, связанных с чувственной оценкой и других интуитивных задач с помощью заявленной технологии построения компьютерной интеллектуальной модели. При этом полученные модели могут быть специализированными под конкретную задачу, но в любом случае модель используется для решения задачи, а не является ее решением. А так как вариантов построения даже специализированных моделей может быть сколь угодно много, то критерии выбора из них приводятся в соответствие с требованиями задачи, это могут быть, например, такие, что допускают однозначную визуализацию, либо позволяют пройти последующую обработку в гибридной интеллектуальной системе (нейронная сеть + экспертная система) при наименьших затратах на вычислительные операции, либо те, что обеспечивают наибольшую точность вычислений или дают наилучший прогноз. То есть, мы имеем связку искусственная интуиция + интеллект (естественный или искусственный). При этом интуиция служит для того, чтобы выделить критические объекты путем отслеживания закономерностей между различными вариантами обработки связей между ними, а интеллект - предсказать их развитие и поведение при изменении условий. При этом эффективность интеллектуальной составляющей достигается не путем ее усложнения и специализации, а тем, что интуитивная часть системы обладает высокой степенью свободы (точность, количество, релевантность) в плане представления выходных данных.
Заявленный технический результат достигается за счет выполнения способа компьютерного создания модели объекта, содержащего этапы, на которых:
1) осуществляют деление упомянутого объекта на части, которыми являются понятия, характеризующиеся идентичными наборами данных, описывающих их характеристики, причем понятия формируются на основании заданных правил разгруппировки и при необходимости понятия, содержащие одинаковые или близкие значения свойств, сокращаются;
2) получают первичные данные, представляющие собой все существующие пары упомянутых частей объекта в количестве (n*n)/2-n, где n количество частей;
3) осуществляют оценку и оптимизацию количества свойств между описывающих упомянутые части объекта;
4) осуществляют функциональную обработку полученных рядов, причем используется стандартный набор функций, в частности корреляция или среднеквадратичная разница, либо используются специализированные функции, вытекающие из логики постановки задачи;
5) осуществляют сортировку и группировку полученных результатов, после чего осуществляют проверку сгруппированных данных на избыточность, после чего выполняют процедуру нормализации сгруппированных данных, при которой избыточные данные отфильтровываются;
6) осуществляют построение функциональных связей между нормализованными сгруппированными данными полученными разными способами с помощью интеллектуальной обработки с использованием работы экспертной системы (ЭС);
7) пары данных, которые при обработке различными функциями дают близкий либо предсказуемый результат определяются как связанные и в дальнейшем используются для построения модели объекта;
8) определяют следующую информацию: какие функции применялись для анализа связей между частями моделируемого объекта, какие связи между его частями наиболее сильные, какие связи образуются наибольшим количеством наиболее отличных друг от друга функций, какое понятие чаще всего присутствует в верхних и нижних позициях отсортированного по значениям различных функций списка пар, характер функции распределения для различных понятий; и выявляют коррелирующие и незначащие свойства;
9) определяют, если полученная модель дает предсказуемый результат, то она считается созданной, если полученный результат не удовлетворяет предъявляемым требованиям, то он считается предварительным и используется для изменения правил разгруппировки, оценки свойств, выбора функций для обработки, и критериев фильтрации, если результат отсутствует, то анализируют количество свойств и точность их оценки и осуществляют замену специализированных функций обработки пар данных на стандартные.
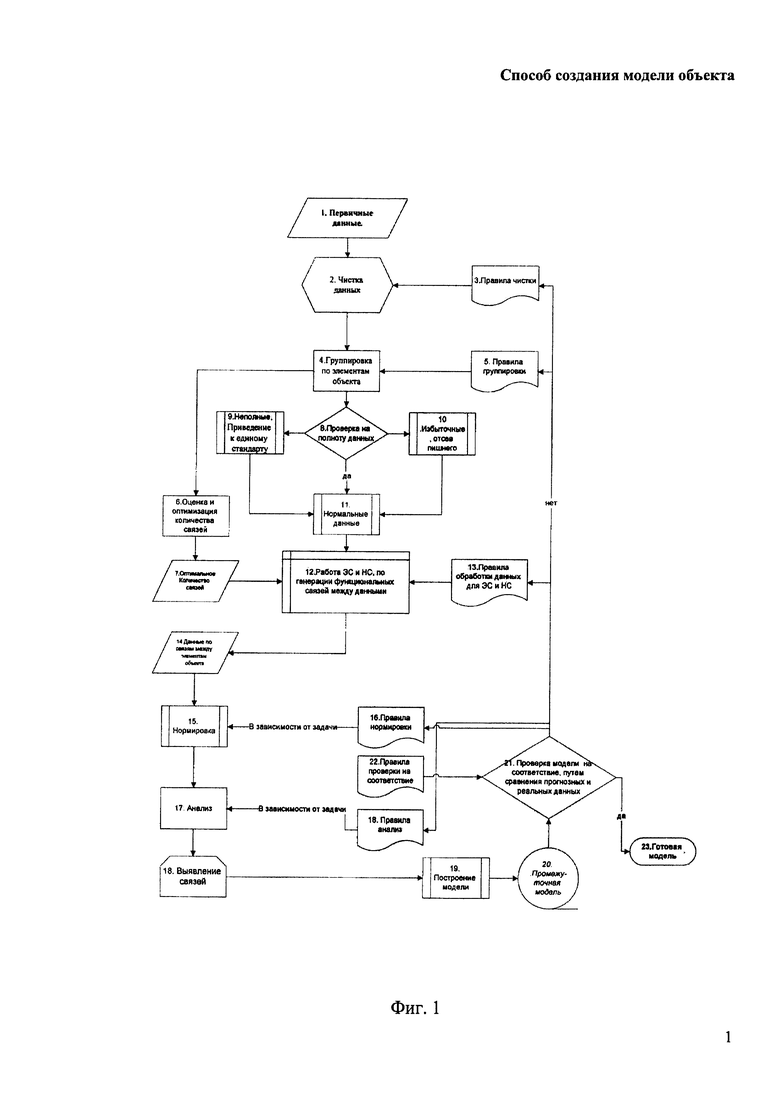
На Фиг. 1 показана блок-схема работы компьютерной модели искусственной интуиции, заявляемой в изобретении.
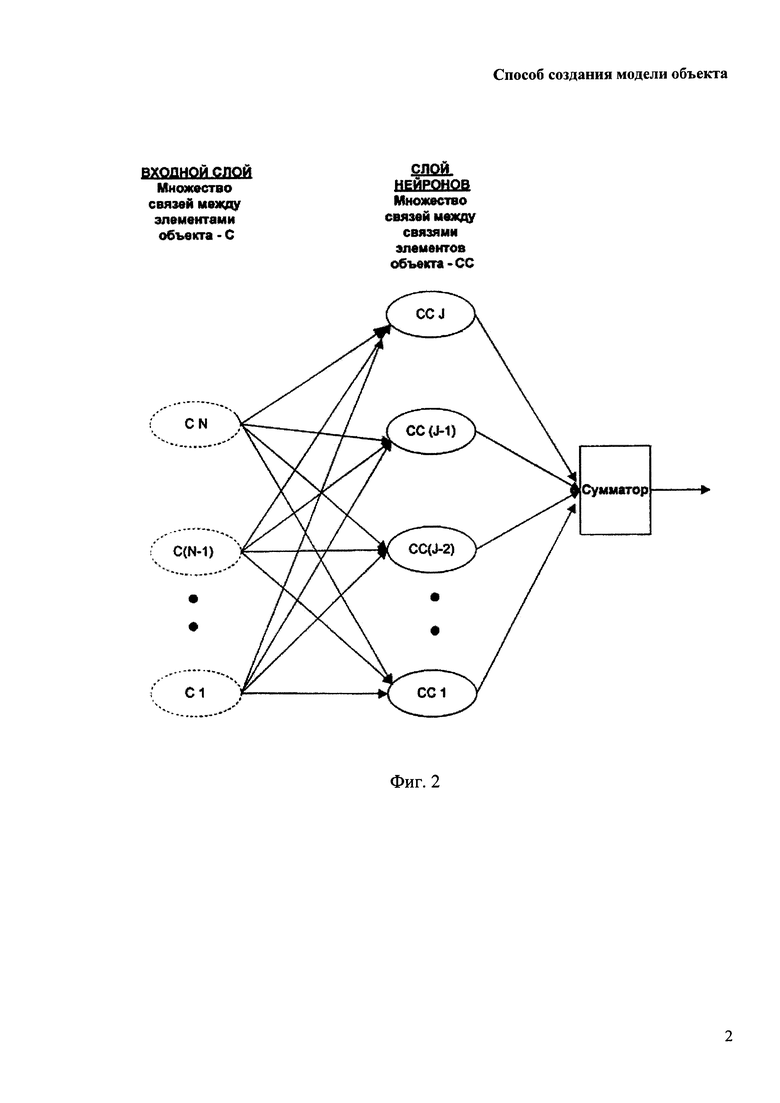
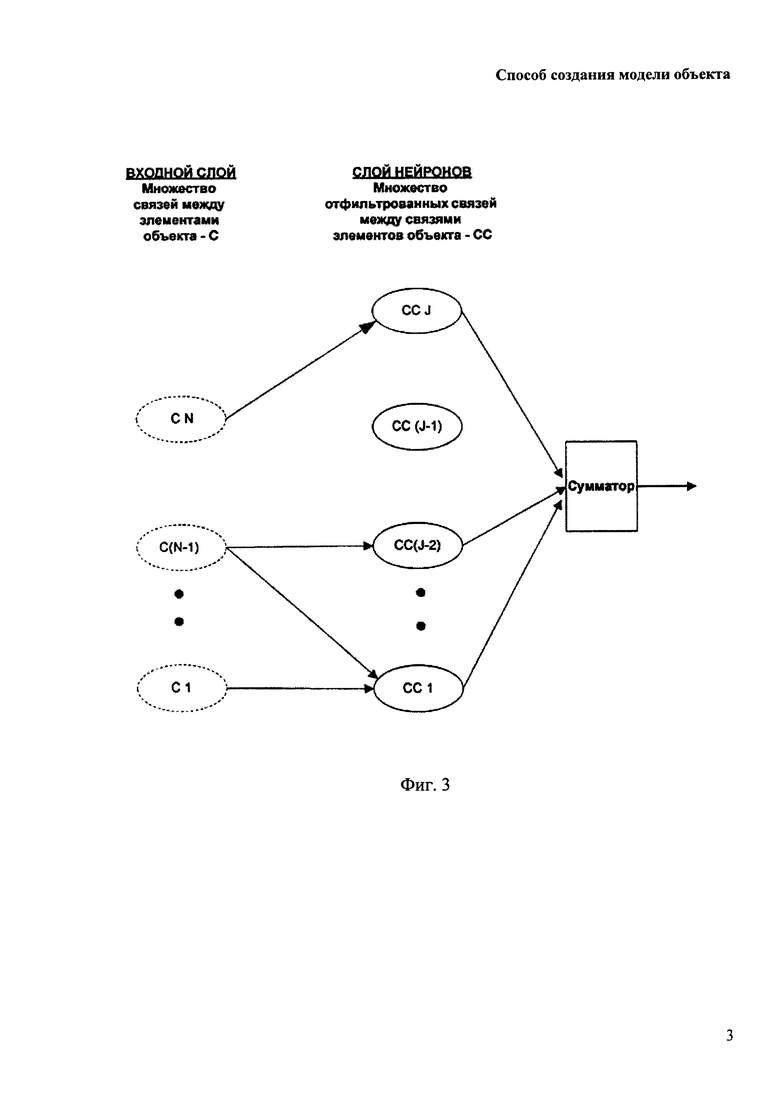
На Фиг. 2 - 3 показана геометрия однослойного персептрона компьютерной модели искусственной интуиции, заявляемой в изобретении, до и после обучения.
Изобретение относится к интеллектуальным системам - компьютерным моделям искусственной интуиции и предназначено для автоматизированного создания модели объектов не по подобию свойств, а по отклику на внешние воздействия, при этом в качестве входных данных используются не свойства данного объекта, а различные характеристики связей между его частями (элементами объекта) с помощью выявления закономерностей между ними с целью поиска релевантных знаний или, другими словами, восстановление фрагмента знания (образа) по его неполному или зашумленному образцу (см. источник 1).
Как указывалось выше, в заявленном решении воплощается связка - искусственная интуиция + интеллект (естественный или искусственный). При этом интуиция служит для того, чтобы выделить критические объекты путем отслеживания закономерностей между различными вариантами обработки связей между ними, а интеллект - предсказать их развитие и поведение при изменении условий, при этом эффективность интеллектуальной составляющей достигается не путем ее усложнения и специализации, а тем, что интуитивная часть системы обладает высокой степенью свободы (точность, количество, релевантность) в плане представления выходных данных. Связей между частями объекта заведомо больше, чем самих частей, например, при обработке только парных связей эта величина будет (N*N-N)*К, где N - количество связей, а К - количество вариантов обработки связей. Естественно, при необходимости могут рассматриваться не только парные связи, но и варианты связи между различными способами группировки частей объекта. Поэтому, имея высокую избыточность данных для расчета, мы, применяя различные варианты выбора алгоритма группировки и последующей фильтрации, можем легко адаптировать их как под конкретную интеллектуальную составляющую, так и имеющиеся аппаратные ограничения, так как для решения задачи могут быть использованы различные варианты разделения полномочий между системой компьютер - человек. И, кроме того, для решения одной задачи могут использоваться как компьютерные программы, так и специализированные процессоры или аналоговые системы обработки данных.
Под задачами интеллектуальной обработки понимаются, например, аппроксимации и интерполяции, распознавание и классификация образов, сжатие данных, прогнозирование, идентификация, управление, ассоциация и т.п.
Задача создания модели изучаемого объекта, описываемой наборами связей между элементами объекта, в общем случае весьма сложна. Удовлетворительное построение модели во многих случаях не может быть осуществлено без участия человека, который при построении использует неформализованные признаки, накопленные опытом.
Интеллектуальная обработка информации с помощью вычислительной техники может облегчить человеку создание модели изучаемого объекта. Особенно эффективна такая обработка при большом количестве элементов изучаемого объекта, когда получают большое количество данных об объекте. Полную информацию об объекте необходимо свести к виду, позволяющему оптимально интерпретировать полученные данные. При подготовке информации об объекте для облегчения понимания сущности объекта человеком применяются различные методы, в том числе - теории распознавания.
Наш анализ существующих методов распознавания при помощи искусственной нейронной сети (ИНС) выявил неучтенные возможности в интеллектуальной обработке информации, а именно в предварительной обработке (предпроцессинге) информации, подаваемой на нейроны ИНС.
Принципиальным отличием компьютерной модели искусственной интуиции в заявляемом изобретении является построение модели объекта путем использования выявленных закономерностей в связях между частями (элементами) объекта, что позволяет увеличить точность в решении задач по моделированию сложных объектов, в отличие от традиционного аналитического подхода, где основное внимание уделяется описанию элементов объекта. При этом сочетание различных способов обработки и отсечения незначащих значений позволяет выявить различные виды связей, что впоследствии можно применить для создания, построения или настройки геометрии экспертных систем и нейронных сетей, в которых информация о внутренних связях объекта явно присутствует в геометрии обученной ИНС типа однослойный персептрон (см. 2, стр. 194) в отличие от традиционных многослойных ИНС (см. 2, стр. 218), где информация о внутренних связях объекта хранится неформализованной в виде связей между нейронами разных слоев.
Заявленная в изобретении компьютерная модель искусственной интуиции ориентирована на решение различных задач интеллектуальной обработки информации, в том числе - аппроксимации и интерполяции, распознавания и классификации образов, сжатия данных, прогнозирования, идентификации, управления, ассоциации и т.п. и по сравнению с традиционными способами более эффективна в случае неполной и ошибочной исходной информации.
Сумма вышеизложенных признаков изобретения связана причинно-следственной связью с техническим результатом изобретения. Итоговая модель объекта получается в результате работы заявленной компьютерной модели искусственной интуиции из профильтрованной по заданным параметрам совокупности (синтеза) управляющих центральных, стабилизирующих и других связей между элементами объекта таким образом, что в результате построенная модель (образ) объекта обеспечивает отклик подобный эталону в пределах оптимума вычислительных возможностей пользователя.
На Фиг. 1 представлена последовательность действий, выполняемых при осуществлении заявленного способа. Ход решения задач заявленным методом искусственной интуиции разбивается на ряд шагов, объединенных в этапы.
На этапе 1) осуществляют деление упомянутого объекта на части (понятия), характеризующиеся идентичными наборами данных, описывающих их характеристики (разгруппировка), причем понятия формируются на основании заданных правил разгруппировки и при необходимости понятия, содержащие одинаковые или близкие значения свойств сокращаются (в некоторых случаях допустимо выполнить предварительный расчет, содержащий только несколько частей (понятий) объекта).
Затем на этапе 2) получают первичные данные (шаг 1), представляющие собой парные связи и/или связи об изучаемом объекте, причем объект может представлять из себя совокупность делимых или не делимых элементов, характеризующихся набором данных. Первичные данные представляют собой все существующие пары упомянутых частей объекта в количестве (n*n)/2-n, где n - количество частей. Упомянутые связи представляют числовые ряды, характеризующие свойства конкретного объекта. Далее выполняют фильтрацию первичных данных (шаг 2) на основании заданных правил чистки (шаг 3), в ходе которой исключаются несущественные данные, причем упомянутые правила чистки могут быть адаптивно изменены в ходе итерационного процесса построения модели изучаемого объекта. Правила чистки зависят от предметной области. Например, для формата геофизических данных (частотное распределение) рассматриваются только максимумы. Для анализа колебаний стоимости товара или валюты во времени - только максимумы и минимумы. Если работа осуществляется с экспериментальными данными, отслеживающими изменение каких-то величин в зависимости от воздействия на объект, то одинаковые строки исключаются из обработки. При распознавании фотоснимков зеленый канал рассматривается только в случае возникновения неоднозначности в красном канале, а синий не рассматривается вовсе. Чаще всего для выработки правила чистки достаточно реально существующего и широко известного состояния изучаемого объекта, но иногда имеет смысл и поэкспериментировать с различными вариантами наборов данных. И если меньшее количество данных дает более стабильный результат, то в дальнейшем применяется именно этот набор.
На этапе 3) осуществляют оценку и оптимизацию количества свойств, описывающих части объекта. Изучаемый объект делится на элементы (группы) (шаг 4), характеризующиеся идентичными наборами данных, группы формируются на основании правил группировки (шаг 5), которые могут быть адаптивно изменены в ходе итерационного процесса построения модели изучаемого объекта. Правила группировки используются для оценки (шаг 6) и оптимизации (шаг 7) количества связей между элементами (группами) объекта. Если количество генерируемых связей накладывает определенные ограничения, связанные с вычислительными возможностями, то либо изменяются правила группировки, либо применяются различные варианты их фильтрации.
На этапе 4) осуществляют функциональную обработку полученных рядов, причем используется стандартный набор функций, в частности корреляция или среднеквадратичная разница, либо используются специализированные функции, вытекающие из логики постановки задачи. Например, при очистке матрицы фотоаппарата от шума наиболее естественный метод группировки (строки-столбцы) дает недопустимо огромное количество вычислений. Поэтому, если имеются сведения об архитектуре матрицы, можно осуществить группировку элементов в соответствии с правилами, характеризующими выбор пикселей в соответствии с ее структурой. В реальности для достижения требуемого эффекта осуществляется несколько раз фотографирование в условиях слабой освещенности при большой чувствительности серого листа бумаги, и затем сбор статистики о наиболее часто шумящих пикселях и при очистке фотоснимка впоследствии используются данные только с этих мест.
На этапе 5) осуществляют сортировку и группировку полученных результатов, после чего осуществляют проверку сгруппированных данных на избыточность, после чего выполняют процедуру нормализации сгруппированных данных, при которой избыточные данные отфильтровываются. Для этого осуществляется проверка полученных сгруппированных данных на полноту и избыточность (шаг 8), причем при установлении факта неполноты (шаг 9) данных упомянутые данные дополняются интерполированными данными в зависимости от модели изучаемого объекта, а при факте избыточности данных (шаг 10) - выполняют процедуру нормализации сгруппированных данных, при которой избыточные данные отфильтровываются. Данные являются избыточными, если они не содержат критичной информации. Например, необходимо измерить пульс-давление-температуру тела и как эти показатели реагируют на прием лекарственного препарата. Предположим, что измерения делаются с интервалом в 10 минут. Если все три показателя на какой-то период не вышли за пределы нормы, то они не рассматриваются. Если же все показатели не вышли за пределы нормы, то они считаются неполными и необходимо добавить критерии для анализа. Например, измерить частоту и глубину дыхания или померить температуру в различных точках тела. В некоторых же случаях, иногда, наоборот, имеет смысл сократить какие-то данные, как незначащие или связанные друг с другом (например, частота и глубина дыхания). При обработке анализов больных конкретным заболеванием целесообразно сравнивать полученные анализы с анализами здоровых людей, чтобы впоследствии исключить из обработки те показатели, на которые данная болезнь не влияет или влияет очень слабо. Это избыточные данные.
На этапе 6) осуществляют построение функциональных связей между нормализованными сгруппированными данными с помощью интеллектуальной обработки компьютерной моделью искусственной интуиции с использованием работы экспертной системы (ЭС), в ходе которой выполняется, по меньшей мере, попарная обработка функциями однородных данных согласно правилам совместной обработки данных для ЭС. Для обработки дополнительно может использоваться искусственная нейронная сеть (ИНС), в этом случае будут применяться правила совместной обработки данных для ЭС и ИНС. Если функция обработки связей одна - то ограничиваются работой ЭС по сортировке. А если функций несколько - то к работе подключается ИНС, архитектура которой оптимизирована под накопление результатов обработки с целью установления зависимостей и закономерностей между распределением значений результатов разных функций при разных параметрах и фиксированных данных. Упомянутые правила могут адаптивно изменятся в ходе итерационного процесса построения модели изучаемого объекта. Допустим, нам необходимо выявить деструктивную деятельность постороннего агента в информационной сети (например, при анализе сообщений с форума). Поскольку семантический анализ программными средствами далек от человеческих возможностей, то ставим задачу - собрать статистику по пользователям, по доступным программой критериям (длина сообщений, количество служебных слов, употребление эмоционально значимых слов, а также выражений оценки, коэффициент встречаемости в сообщениях слов, указанных в заголовке и вступительной статье темы, количество общих слов с предыдущим постом, а также с последним наиболее длинным постом в теме и т.п.). После чего каждый логин (ряд чисел) попарно сравнивается с предыдущим. Например, считается корреляция. После чего те же данные проверяются на разброс (среднеквадратичное расстояние между рядами). Далее экспертная система получает задание - выявить тех пользователей, которые в наименьшей степени коррелируют с остальными, но пары данных с их участием обеспечивают максимальный разброс. При этом суммируются все полученные значения по данному пользователю (результаты всех пар, в которых данный пользователь присутствует), т.е. сам пользователь никого не слушает и при этом нарушает стабильность. После чего для анализа берутся не все его сообщения, а разбиваются на минимально возможные для съема данных блоки и выбирается тот из них, который в максимальной степени дестабилизирует систему и в наименьшей степени коррелирует с основными. Это сообщение представляется для анализа оператору-человеку, взаимодействующему с ЭС. Но задача, поставленная перед экспертной системой, может быть другой, например выявление лиц, имеющих несколько логинов. В этом случае данные могут быть дополнены, а если и это не поможет, то будут дополнены новыми функциями или старыми функциями с дополнительными параметрами (например, можно рассматривать количество сходных значений одних элементов в разных рядах). И естественно, изменится алгоритм действия экспертной системы. В этом случае ей необходимо выявить те пары, в которых наибольшее количество одинаковых элементов и одновременно высокий коэффициент корреляции между ними. При этом, в отличие от предыдущего примера, просто рассматриваются значения пар и выбираются наибольшие. Основная проблема в подобных случаях заключается в том, что некоторые категории понятий (пользователей) или связей между ними, несмотря на свою определенность, значимость и сильное влияние на ситуацию, не имеют общепринятого обозначения.
На этапе 7) определяются пары данных, которые при обработке различными функциями дают близкий либо предсказуемый результат определяются как связанные и в дальнейшем используются для построения модели объекта. Полученные на этапе 6) значения (шаг 14) по связям между элементами изучаемого объекта подвергают нормализации (шаг 15) согласно правилам нормировки связей (шаг 16). На этапе 8) определяют следующую информацию: какие функции применялись для анализа связей между частями моделируемого объекта, какие связи между его частями наиболее сильные, какие связи образуются наибольшим количеством наиболее отличных друг от друга функций, какое понятие чаще всего присутствует в верхних и нижних позициях отсортированного по значениям различных функций списка пар, характер функции распределения для различных понятий; и выявляют коррелирующие и незначащие свойства. Нормализованные значения по связям между элементами изучаемого объекта проходят процедуру анализа (шаг 17) с помощью применения заданных правил анализа (шаг 18), которые могут быть адаптивно изменены в ходе итерационного процесса построения модели изучаемого объекта. Целью анализа является выявление связей (шаг 18) между элементами объекта, например «управляющих связей», «стабилизирующих связей», «центральных связей», то есть связей, значение которых является критичным в полученной модели (шаг 19) изучаемого объекта, причем в окончательной модели изучаемого объекта не "работающие" связи могут быть отброшены как несущественные, что выражается в их «отключении» у соответствующих нейронов ИНС. Несущественность связей для модели объекта определяется характером обрабатываемых функций, а также поставленной задачей. Критичными считаются те данные, которые прошли процедуру фильтрации и присутствуют в результатах обработки различными функциями, либо группами функций, например группа функций, определяющих связь близости типов данных, включает в себя корреляцию, отношение, среднеквадратичное расстояние, интервал, и если хотя бы в двух из этих функций находятся совпадающие пары данных, прошедших фильтрацию по верхнему порогу, то эти данные считаются критическими для данного типа связей. Для построения модели объекта наиболее значимыми являются «крайние показатели» (например, самый высокий и самый низкий коэффициент корреляции) и именно они характеризуют связь объекта с другими. Но если мы рассматриваем несколько разных способов обработки данных, то мы в зависимости от поставленной задачи можем изменить правила нормировки. При этом возможно получения такого результата, при котором критерии оценки могут быть настолько строгими, что в них, вообще, ничего не попадет или, наоборот, попадет половина данных. Поэтому фильтр сделан динамическим и диапазон значений изменяется до тех пор, пока не будет оставлено примерно заданное количество объектов. Основная задача упомянутого фильтра - это выявление групп понятий с наименьшим среднеквадратичным расстоянием между ними. То есть, данные выводятся в n-мерное пространство (где n - количество функций) и рассматриваются «области скопления». Фильтр же задает критерий границы областей, которые обычно бывают размыты.
Далее осуществляют построение промежуточной модели (шаг 20) изучаемого объекта и ее проверку (шаг 21) на соответствие с помощью сравнения прогнозных и реальных данных объекта согласно правилам проверки на соответствие (шаг 22), которые могут быть адаптивно изменены в итерационном процессе построения модели изучаемого объекта. Чаще всего проверка на соответствие делается сравнением результатов, полученных разными методами. На этапе 9) определяют, если полученная модель дает предсказуемый результат, то она считается созданной, если полученный результат не удовлетворяет предъявляемым требованиям, то он считается предварительным и используется для изменения правил разгруппировки, оценки свойств, выбора функций для обработки и критериев фильтрации, если результат отсутствует, то анализируют количество свойств и точность их оценки и осуществляют замену специализированных функций обработки пар данных на стандартные. Промежуточная модель изучаемого объекта проверяется на соответствие критериям проверки, и если промежуточная модель ее проходит, то такая модель становится окончательной моделью изучаемого объекта, если полученная промежуточная модель не удовлетворяет критериям проверки, то вносятся изменения в упомянутые правила. Существует не так много причин, которые не позволяют методом искусственной интуиции построить корректную модель объекта или явления. И если это произошло, то проверяются следующие варианты: а) недостаточность данных, б) неточность данных, в) применения функций обработки, не соответствующих заявленной цели, г) неверные критерии фильтрации данных, д) неправильная установка для экспертной системы, устанавливающая критерии выборки критичных связей. После внесенных изменений в наборы правил процесс получения модели объекта запускается вновь до получения окончательной (готовой) модели изучаемого объекта.
При анализе временных рядов используется проверка прогноза при помощи ретроспективного анализа. Для исследования применимости конкретных функций сравнения и технологии очистки данных обычно проверяются те процессы, которые можно перепроверить при помощи стандартных технологий, например, экспериментальным путем. При построении модели объекта делаются прогнозы ее развития, а также вычисляются связи между другими объектами. Часть прогнозов может быть отфильтрована как общеизвестных и очевидно предопределенных. Однако некоторые состояния модели становятся известны лишь спустя некоторое время ввиду отсутствия необходимых данных. Некоторые же данные можно перепроверить, создав определенные условия. Все эти возможности используются для проверки соответствия модели явления и реального процесса. Если соответствие ниже заданной величины, то новая модель строится на основании новых функций обработки и/или применения новых механизмов фильтрации. Но чаще всего достаточно изменить значимость и надежность некоторых оценок. Сами же вводимые данные изменяются только в том случае, если приведенные операции результата не дали. Иногда возникает необходимость уточнения и дополнения, но «старые» данные из обработки не исключаются, т.к. «неработающие» данные отфильтровываются автоматически и сам факт, что какие-то данные являются «некритичными» иногда имеет очень большую значимость для выяснения распространенных и общепринятых заблуждений по логике процесса или наличие декларируемой логики, что является важным фактором, для решения ряда задач. Общим же критерием проверки является «предсказуемость», то есть степень соответствия поведения модели и объекта, а вовсе не совпадения (то есть наличия сходных частей и степени их взаимодействия) модели и объекта. Такого рода задачи обычно решаются средствами искусственного (и естественного) интеллекта. Искусственная интуиция внутреннюю логику процесса не рассматривает, хотя с помощью такого подхода можно определить, какая из логических схем наиболее эффективна, т.к. они обычно дают меньший разброс между различными функциями.
Вышеуказанный способ реализуется с помощью его воплощения в машиночитаемой среде, с помощью системы построения модули объекта. Данная система может быть выполнена на базе широко известных ЭВМ, например IBM PC. Система включает один или процессоров и одно или более устройств памяти. В качестве указанных устройств памяти может использоваться, но не ограничиваться: ОЗУ, ПЗУ, устройства флеш-памяти, HDD диск, SSD диск, USB накопители, оптические диски и т.п. Заявленный способ может быть реализован в качестве машиночитаемых инструкций, хранимых в памяти ЭВМ и выполняться с помощью одного или более процессоров данной ЭВМ.
Основным критерием преимущества данного способа является не объем извлекаемой информации, а ее качество. Способ позволяет упростить и ускорить создание синтезированной модели объекта для интерпретации (в том числе - визуальной) и при этом позволяет сконцентрировать внимание на интересующих наблюдателя скрытых закономерностях объектах. Синтезированная заявленным способом модель объекта существенно менее чувствительна к исходным данным объекта, поэтому при ее осуществлении снижаются требования к условиям получения данных. Важным является то, что синтезированная компьютерной моделью искусственной интуиции модель объекта в большинстве случаев является компактной, что дает возможность по ее применению в широком спектре устройств, имеющих ограничения по вычислительным возможностям.
Источники информации
1. А.В. Гаврилов. Гибридные интеллектуальные системы: Монография - Новосибирск: Изд-во НГТУ, 2002. - 142 с.
2. Хайкин, Саймон. Нейронные сети: полный курс, 2-е издание.: Пер. с англ. - М.: Издательский дом "Вильямс", 2006. - 1104 с.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИНТЕЛЛЕКТУАЛЬНАЯ ОБУЧАЮЩАЯ СИСТЕМА | 2006 |
|
RU2310237C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ ИНФОРМАЦИОННО-ПРЕОБРАЗУЮЩИХ ЭЛЕМЕНТОВ БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНОГО СУДНА НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ | 2022 |
|
RU2802976C1 |
| СИСТЕМА ИНТЕГРИРОВАННОГО КОНТРОЛЯ РАБОТЫ БОРТОВОГО ОБОРУДОВАНИЯ ЛЕТАТЕЛЬНОГО АППАРАТА | 2010 |
|
RU2431175C1 |
| СПОСОБ ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ БЕЗ УЧИТЕЛЯ С АВТОМАТИЧЕСКИМ ОПРЕДЕЛЕНИЕМ ПАРАМЕТРОВ ОБУЧЕНИЯ МОДЕЛЕЙ | 2023 |
|
RU2818858C1 |
| ИНТЕЛЛЕКТУАЛЬНАЯ ГРИД-СИСТЕМА ДЛЯ ВЫСОКОПРОИЗВОДИТЕЛЬНОЙ ОБРАБОТКИ ДАННЫХ | 2009 |
|
RU2411574C2 |
| СУПЕРКОМПЬЮТЕРНЫЙ КОМПЛЕКС ДЛЯ РАЗРАБОТКИ НАНОСИСТЕМ | 2009 |
|
RU2432606C2 |
| Интеллектуальная космическая система для управления проектами | 2018 |
|
RU2679541C1 |
| УСТРОЙСТВО ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ КОМПЛЕКСА БОРТОВОГО ОБОРУДОВАНИЯ ВОЗДУШНЫХ СУДОВ НА ОСНОВЕ МАШИННОГО ОБУЧЕНИЯ | 2024 |
|
RU2831917C1 |
| Способ интеллектуальной поддержки экипажа | 2020 |
|
RU2767406C1 |
| Алгоритм комплексного дистанционного бесконтактного мультиканального анализа психоэмоционального и физиологического состояния объекта по аудио- и видеоконтенту | 2017 |
|
RU2708807C2 |
Изобретение относится к компьютерно-реализуемому способу и системе создания модели объекта. Технический результат заключается в обеспечении автоматизированного создания модели объекта. В способе принимают входные данные, описывающие моделируемый объект, содержащие набор характеристик связей между его частями, осуществляют деление набора данных для выявления понятий, получают первичные данные, представленные в виде числовых рядов, характеризующих свойства моделируемого объекта, осуществляют оценку и оптимизацию количества свойств, описывающих части объекта, функциональную обработку полученных рядов, сортировку, группировку полученных результатов, проверку сгруппированных данных на избыточность и процедуру их нормализации, осуществляют построение функциональных связей между нормализованными сгруппированными данными, определяют функции, примененные для анализа связей между частями моделируемого объекта, выявляют коррелирующие и незначащие свойства, получают нормализованные значения по связям между группами изучаемого объекта, выполняют определение критичных и не критичных связей, выполняют построение модели объекта, которая считается созданной, если она дает предсказуемый результат, иначе этот результат используется для итеративного повторения предыдущих шагов. 2 н. и 4 з.п. ф-лы, 3 ил.
1. Способ автоматического компьютерно-реализуемого создания модели объекта, содержащий этапы, на которых:
1) принимают входные данные, описывающие моделируемый объект, содержащие набор характеристик связей между частями моделируемого объекта, и осуществляют деление упомянутого набора данных для выявления понятий, характеризуемых идентичными наборами данных, описывающих их характеристики, причем упомянутые понятия формируются на основании заданных правил разгруппировки, и если выявляются понятия, содержащие одинаковые или близкие значения свойств, то такие понятия сокращаются;
2) получают первичные данные, представляющие собой парные связи и/или связи об изучаемом объекте, представленные в виде числовых рядов, характеризующих свойства моделируемого объекта, причем упомянутые связи соответствуют частям объекта в количестве (n*n)/2-n, где n - количество частей;
3) осуществляют оценку и оптимизацию количества свойств между описывающих упомянутые части объекта, в ходе которой данные, описывающие изучаемый объект, делятся на группы, которые характеризуются идентичными наборами данных;
4) осуществляют функциональную обработку полученных рядов, причем используется стандартный набор функций, в частности корреляция или среднеквадратичная разница;
5) осуществляют сортировку и группировку полученных результатов, после чего осуществляют проверку сгруппированных данных на избыточность, после чего выполняют процедуру нормализации сгруппированных данных, при которой избыточные данные отфильтровываются;
6) осуществляют построение функциональных связей между нормализованными сгруппированными данными, полученными разными способами с помощью интеллектуальной обработки с использованием работы экспертной системы (ЭС), в ходе которой выполняется по меньшей мере попарная обработка однородных данных согласно заданным правилам совместной обработки данных для ЭС с помощью одной или более функций обработки, причем если необходимо применить более чем одну функцию обработки, то упомянутая обработка выполняется совместно с ИНС;
7) пары данных, которые при обработке различными функциями дают близкий либо предсказуемый результат, определяются как связанные и в дальнейшем используются для построения модели объекта;
8) определяют функции, которые применялись для анализа связей между частями моделируемого объекта, какие связи между его частями наиболее сильные, какие связи образуются наибольшим количеством наиболее отличных друг от друга функций, какое понятие чаще всего присутствует в верхних и нижних позициях отсортированного по значениям различных функций списка пар, характер функции распределения для различных понятий; и выявляют коррелирующие и незначащие свойства, получают нормализованные значения по связям между группами изучаемого объекта и выполняют определение критичных и не критичных связей с помощью выявления групп понятий с наименьшим среднеквадратичным расстоянием между ними;
9) выполняют построение промежуточной модели объекта и определяют, если полученная модель дает предсказуемый результат, то она считается созданной, если полученный результат не удовлетворяет предъявляемым требованиям системы, то он считается предварительным и используется для изменения правил разгруппировки, оценки свойств, выбора функций для обработки и критериев фильтрации и последующего выполнения итеративного повторения шагов 1-8; если результат отсутствует, то анализируют количество свойств и точность их оценки и осуществляют замену функций обработки пар данных на стандартные.
2. Способ по п. 1, отличающийся тем, что дополнительно на этапе 5) используют искусственную нейронную сеть (ИНС).
3. Способ по п. 2, отличающийся тем, что дополнительно применяют правила совместной обработки данных для ЭС и ИНС.
4. Способ по п. 2, отличающийся тем, что ИНС имеет оптимизированную архитектуру под накопление результатов обработки с целью установления зависимостей и закономерностей между распределением значений результатов разных функций при разных параметрах и фиксированных данных.
5. Способ по любому из пп. 1-4, отличающийся тем, что правила чистки, правила группировки, правила совместной обработки данных для ЭС, правила нормировки и правила анализа выполнены с возможностью адаптивного изменения в ходе итерационного процесса построения модели изучаемого объекта.
6. Система компьютерного создания модели объекта, содержащая по меньшей мере один или более процессоров и по меньшей мере одно устройство памяти, причем по меньшей мере одно устройство памяти хранит машиночитаемые инструкции, которые при их исполнении по меньшей мере одним процессором побуждают упомянутый по меньшей мере один процессор выполнять способ создания модели объекта по любому из пп. 1-5.
| US 5019961 A1, 28.05.1991 | |||
| US 7480640 B1, 20.01.2009 | |||
| US 8386499 B2, 26.02.2013 | |||
| МОДЕЛЬ ДАННЫХ ДЛЯ ОБЪЕКТНО-РЕЛЯЦИОННЫХ ДАННЫХ | 2006 |
|
RU2421798C2 |

