Эта заявка испрашивает приоритет на основании предварительной заявки 61/221804, которая была подана в Патентное ведомство США 30 июня 2009 года, полное раскрытие которой настоящим включено в состав посредством ссылки.
ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Раскрытие относится к использованию одного или более алгоритмов извлечения правил ассоциации для извлечения наборов данных, содержащих признаки, созданные из, по меньшей мере, одного основанного на растениях или животных молекулярного генетического маркера, нахождения правил ассоциации и использования признаков, созданных по этим правилам ассоциации, для классификации или прогнозирования.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ РАЗВИТИЯ ТЕХНИКИ
Одна из основных целей улучшения растений и животных состоит в том, чтобы получать новые культурные сорта, которые превосходны в показателях желательных целевых признаков, таких как урожайность, содержание масла в зерне, устойчивость к болезням и устойчивость к абиотическим нагрузкам.
Традиционный подход к улучшению растений и животных состоит в том, чтобы отбирать отдельные растения или животные на основе их фенотипов или фенотипов их потомков. Отобранные особи могут затем, например, подвергаться дополнительному испытанию или становиться родителями будущих поколений. Полезно, чтобы некоторые программы разведения имели прогнозирования продуктивности до того, как формируются фенотипы для определенной особи, или когда только несколько записей фенотипа было получено для такой особи.
Некоторыми ключевыми ограничениями для улучшения растений и животных, которые основываются только на фенотипическом отборе, являются себестоимость и скорость формирования таких данных, и что есть сильное влияние окружающей среды (например, температуры, организации работ, грунтовые условия, дневной свет, ирригационные условия) на выражение целевых признаков.
В последнее время, развитие молекулярных генетических маркеров открыло возможность использования основанных на ДНК признаков растений или животных в дополнение к их фенотипам, информации об окружающей среде и другим типам признаков, для выполнения многих задач, в том числе, задач, описанных выше.
Некоторыми важными соображениями касательно способа анализа данных для этого типа наборов данных, являются способность извлекать исторические данные, быть стойким к мультиколлинеарности и учитывать взаимодействия между признаками, включенными в эти наборы данных (например, эпистатические эффекты и генотип от взаимодействий с окружающей средой). Способность извлекать исторические данные избегает потребности в хорошо структурированных данных для анализа данных. Способы, которые требуют хорошо структурированных данных, из планируемых экспериментов, обычно являются ресурсоемкими в показателях человеческих ресурсов, денег и времени. Сильное воздействие окружающей среды на выражение многих из наиболее важных особенностей в экономически важных растениях и животных, требует, чтобы такие эксперименты были большими, тщательно разработанными и тщательно контролируемыми. Ограничение мультиколлинеарности указывает на ситуацию, в которой два или более признака (или поднабора признаков) линейно коррелированы в отношении друг друга. Мультиколлинеарность может приводить к менее точной оценке влияния признака (или поднабора признаков) на целевой признак и, следовательно, на смещенные прогнозы.
Основные принципы, основанные на извлечении правил ассоциации и использовании признаков, созданных по этим правилам, для улучшения прогнозирования или классификации, пригодны для принятия мер в ответ на три соображения, упомянутые выше. Предпочтительные способы для классификации или прогнозирования являются способами машинного обучения. Правила ассоциации, поэтому, могут использоваться для классификации или прогнозирования касательно одного или более целевых признаков.
Подход, описанный в настоящем раскрытии, основывается на реализации одного или более основанных на машинном обучении алгоритмов извлечения правил ассоциации для извлечения наборов данных, содержащих в себе, по меньшей мере, один растительный или животный молекулярный генетический маркер, создает признаки на основании найденных правил ассоциации и использует эти признаки для классификации и прогнозирования целевых признаков.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
В варианте осуществления раскрыты способы для извлечения наборов данных, содержащих в себе признаки, созданные из, по меньшей мере, одного основанного на растениях молекулярного генетического маркера для нахождения, по меньшей мере, одного правила ассоциации, а затем, для использования признаков, созданных по этим правилам ассоциации для классификации или прогнозирования. Некоторые из этих способов пригодны для классификации или прогнозирования по наборам данных, содержащим в себе признаки растений и животных.
В варианте осуществления этапы для извлечения набора данных с, по меньшей мере, одним признаком, созданным из, по меньшей мере, одного основанного на растениях молекулярного генетического маркера, для нахождения, по меньшей мере, одного правила ассоциации, и использования признаков, созданных по этим правилам ассоциации для классификации или прогнозирования касательно одного или более целевых признаков, включают в себя:
(a) выявление правил ассоциации;
(b) создание новых признаков на основании выводов этапа (a), и добавление этих признаков в набор данных;
(c) разработку модели для прогнозирования или классификации касательно одного или более целевых признаков с, по меньшей мере, одним признаком, созданным с использованием признаков, созданных на этапе (b);
(d) отбора поднабора признаков из признаков в наборе данных; и
(e) выявление правил ассоциации из пространственных и временных ассоциаций с использованием самоорганизующихся карт (смотрите Teuvo Kohonen (2000), Self-Organizing Map, Springer, 3rd edition (Теуво Кохонен (2000), Самоорганизующаяся карта, Спрингер, 3-е издание)).
В варианте осуществления раскрыт способ извлечения набора данных с одним или более признаков, при этом, способ включает в себя использование, по меньшей мере, одного основанного на растениях молекулярного маркера для нахождения, по меньшей мере, одного правила ассоциации и использование признаков, созданных по этим правилам ассоциации, для классификации или прогнозирования, причем способ содержит этапы: (a) выявления правил ассоциации; (b) создания новых признаков на основании выводов этапа (a), и добавления этих признаков в набор данных; (c) отбора поднабора признаков из признаков в наборе данных.
В варианте осуществления, алгоритмы извлечения правил ассоциации используются для классификации или прогнозирования одним или более алгоритмами машинного обучения, выбранными из: алгоритмов оценки признаков, алгоритмов отбора поднабора признаков, байесовых сетей (смотрите Cheng and Greiner (1999), Comparing Bayesian network classifiers. Proceedings UAI, pp. 101-107 (Ченг и Грейнер (1999), Сравнение классификаторов байесовских сетей. Труды UAI, стр. 101-107)), алгоритмов, основанных на примерах, машин опорных векторов (например, смотрите Shevade et al., (1999), Improvements to SMO Algorithm for SVM Regression. Technical Report CD-99-16, Control Division Dept of Mechanical and Production Engineering, National University of Singapore (Шивади и другие, (1999), Усовершенствования в алгоритм SMO для регрессии SVM. Технический отчет CD-99-16, Департамент отдела управления механической и технологической подготовки производства, Государственный университет Сингапура); Smola et al., (1998). A Tutorial on Support Vector Regression. NeuroCOLT2 Technical Report Series - NC2-TR-1998-030 (Смола и другие, (1998). Пособие по регрессии опорных векторов. Серия технических отчетов NeuroCOLT2 - NC2-TR-1998-030); Scholkopf, (1998). SVMs - a practical consequence of learning theory. IEEE Intelligent Systems. IEEE Intelligent Systems 13.4: 18-21 (Шолкоф, (1998). SVM - практические следствия теории обучения. Интеллектуальные системы IEEE. Интеллектуальные системы 13.4 IEEE: 18-21); Boser et al., (1992), A Training Algorithm for Optimal Margin Classifiers V 144-52 (Бозер и другие, (1992), Алгоритм обучения для классификаторов с оптимальным допуском, V 144-52); и Burges (1998), A tutorial on support vector machines for pattern recognition. Data Mining and Knowledge Discovery 2 (1998): 121-67 (Бурже (1998), Пособие по машинам опорных векторов для распознавания шаблона. Извлечение данных и обнаружение знаний, 2 (1998): 121-67)), алгоритма голосований, чувствительного к стоимости классификатора, алгоритма укладки, правил классификации и алгоритмов дерева решений (смотрите Witten and Frank (2005), Data Mining: Practical machine learning Tools and Techniques. Morgan Kaufmann, San Francisco, Second Edition. (Виттен и Франк (2005), Извлечение данных: практические инструменты и технологии машинного обучения. Морган Кауфман, Сан-Франциско, второе издание).
Подходящие алгоритмы извлечения правил ассоциации включают в себя, но не в качестве ограничения, априорный алгоритм (смотрите Witten and Frank (2005), Data Mining: Practical machine learning Tools and Techniques. Morgan Kaufmann, San Francisco, Second Edition (Виттен и Франк (2005), Извлечение данных: Практические инструменты и техники машинного обучения. Морган Кауфман, Сан-Франциско, Второе издание), алгоритм FP-growth, алгоритмы извлечения правил ассоциации, которые могут обрабатывать большое количество признаков, алгоритмы извлечения огромных шаблонов, алгоритм извлечения прямых различительных шаблонов, деревья решений, неточные множества (смотрите Zdzislaw Pawlak (1992), Rough Sets: Theoretical Aspects of Reasoning About Data. Kluwer Academic Print on Demand (Ждзислав Павак (1992), Неточные множества: теоретические аспекты осмысления данных. Академическая печать Клювера по требованию)) и алгоритм самоорганизующихся карт (SOM).
В варианте осуществления, пригодный алгоритм извлечения правил ассоциации для обработки больших количеств признаков включает в себя, но не в качестве ограничения, CLOSET+ (see Wang et. al (2003), CLOSET+: Searching for best strategies for mining frequent closed itemsets, ACM SIGKDD 2003, pp. 236-245 (смотрите Ванг и другие (2003), CLOSET+: Поиск наилучших стратегий для извлечения часто встречающихся близких наборов элементов, ACM SIGKDD 2003, стр. 236-245), CHARM (смотрите Zaki et. al (2002), CHARM: An efficient algorithm for closed itemset mining, SIAM 2002, pp. 457-473 (Заки и другие (2002), CHARM: Эффективный алгоритм для извлечения близких наборов элементов)), CARPENTER (see Pan et. al (2003), CARPENTER: Finding Closed Patterns in Long Biological Datasets, ACM SIGKDD 2003, pp. 637-642 (Пан и другие, (2003), CARPENTER: Обнаружение близких шаблонов в длинных биологических наборах данных, ACM SIGKDD 2003, стр. 637-642 )), и COBBLER (смотрите Pan et al (2004), COBBLER: Combining Column and Row Enumeration for Closed Pattern Discovery, SSDBM 2004, pp. 21 (Пан и другие (2004) COBBLER: Объединение нумерации столбцов и строк для обнаружения близких шаблонов, SSDBM 2004, стр. 21)).
В варианте осуществления, подходящий алгоритм для обнаружения прямых различительных шаблонов включает в себя, но не в качестве ограничения, DDPM (смотрите Cheng et. al (2008), Direct Discriminative Pattern Mining for Effective Classification, ICDE 2008, pp. 169- 178 (Ченг и другие (2008), Извлечение прямых различительных шаблонов для эффективной классификации, ICDE 2008, стр. 169-178)), HARMONY (смотрите Jiyong et. al (2005), HARMONY: Efficiently Mining the Best Rules for Classification, SIAM 2005, pp. 205-216 (Джиенг и другие (2005) HARMONY: Эффективное извлечение наилучших правил для классификации, SIAM 2005, стр. 205-216)), RCBT (смотрите Cong et. al (2005), Mining top-K covering rule groups for gene expression data, ACM SIGMOD 2005, pp. 670-681 (Конг и другие (2005), Извлечение верхних K покрывающих групп правил для данных экспрессии генов, ACM SIGMOD 2005, стр. 670-681 )), CAR (смотрите Kianmehr et al (2008), CARSVM: A class association rule-based classification framework and its application in gene expression data, Artificial Intelligence in Medicine 2008, pp. 7-25 (Кианмер и другие (2008), CARSVM: Основанная на правилах ассоциации классов инфраструктура классификации и ее применение в данных экспрессии генов, Искусственный интеллект в медицине, 2008, стр. 7-25)), и PATCLASS (смотрите Cheng et. al (2007), Discriminative Frequent Pattern Analysis for Effective Classification, ICDE 2007, pp. 716-725 (Ченг и другие (2007), Анализ часто встречающихся различительных шаблонов для эффективной классификации, ICDE 2007, стр. 716-725)).
В варианте осуществления, пригодный алгоритм для нахождения огромных шаблонов включает в себя, но не в качестве ограничения, алгоритм слияния шаблонов (смотрите Zhu et. al (2007), Mining Colossal Frequent Patterns by Core Pattern Fusion, ICDE 2007, pp. 706-715 (Жу и другие, (2007), Извлечения часто встречающихся огромных шаблонов посредством слияния основных шаблонов, ICDE 2007, стр. 706-715)).
В варианте осуществления, подходящий алгоритм оценки признака выбирается из группы алгоритма прироста информации, алгоритма Relief (например, смотрите Robnik-Sikonja and Kononenko (2003), Theoretical and empirical analysis of Relief and ReliefF. Machine learning, 53:23-69 (Робник-Зиконжа и Кононенко (2003), Теоретический и эмпирический анализ Relief и ReliefF, Машинное обучение, 53:23-69); и Kononenko (1995). On biases in estimating multi-valued attributes. In IJCAI95, pages 1034-1040 (Кононенко (1995). О смещениях при оценке многозначных атрибутов. В IJCAI95, страницы 1034-1040)), алгоритма ReliefF (например, смотрите Kononenko, (1994), Estimating attributes: analysis and extensions of Relief. In: L. De Raedt and F. Bergadano (eds.): Machine learning: ECML-94. 171-182, Springer Verlag. (Кононенко, (1994), Оценка атрибутов: анализ и расширения Relief. В: Л. де-Раедт и Ф. Бергано (и др.): Машинное обучение: ECML-94. 171-182, Спрингер Верлаг)), алгоритма RReliefF, алгоритма симметричных неопределенностей, алгоритма отношений прироста и алгоритма ранжировщика.
В варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм отбора поднабора признаков, выбранный из группы алгоритма основанного на корреляции отбора признаков (CFS) (смотрите Hall, M. A. 1999. Correlation-based feature selection for Machine Learning. Ph.D. thesis. Department of Computer Science - The University of Waikato, New Zealand (Холл, M. A. 1999. Основанный на корреляции отбор признаков для машинного обучения. Ph.D. диссертация. Департамент вычислительной техники - университет Уайкато, Новая Зеландия)), и алгоритма упаковки в ассоциации с любым другим алгоритмом машинного обучения. Эти алгоритмы отбора поднабора признаков могут быть ассоциативно связаны с методом поиска, выбранным из группы жадного алгоритма многошагового поиска, алгоритма поиска наилучшего первого, алгоритма исчерпывающего поиска, алгоритма поиска с состязаниями, и алгоритма рангового поиска.
В варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм байесовской сети, включающий в себя наивный алгоритм Байеса.
В варианте осуществления, подходящим алгоритмом машинного обучения является основанный на примерах алгоритм, выбранный из группы, состоящей из основанного на примерах алгоритма 1 (IB1), основанного на примерах алгоритма k ближайших соседей (IBK), KStar, алгоритма облегченных правил Байеса (LBR) и алгоритма локально взвешенного обучения (LWL).
В варианте осуществления, подходящим алгоритмом машинного обучения является для классификации или прогнозирования алгоритм машины опорных векторов. В предпочтительном варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм машины опорных векторов, который использует алгоритм последовательной минимальной оптимизации (SMO). В предпочтительном варианте осуществления, алгоритм машинного обучения является алгоритмом машины опорных векторов, который использует алгоритм последовательной минимальной оптимизации для регрессии (SMOReg) (например, смотрите Shevade et al., (1999), Improvements to SMO Algorithm for SVM Regression. Technical Report CD-99-16, Control Division Dept of Mechanical and Production Engineering, National University of Singapore (Шивади и другие, (1999), Усовершенствования в алгоритм SMO для регрессии SVM. Технический отчет CD-99-16, Департамент отдела управления механической и технологической подготовки производства, Государственный университет Сингапура); Smola & Scholkopf (1998), A Tutorial on Support Vector Regression. NeuroCOLT2 Technical Report Series - NC2-TR-1998-030 (Смола и Чолкопф (1998), Пособие по регрессии опорных векторов. Серия технических отчетов NeuroCOLT2 - NC2-TR-1998-030)).
В варианте осуществления, подходящим алгоритмом машинного обучения является самоорганизующаяся карта (Самоорганизующиеся карты, Теуво Кохонен, Спрингер).
В варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм дерева решений, выбранный из группы алгоритма дерева логистической модели (LMT), алгоритма дерева переменных решений (ADTree) (Смотрите Freund and Mason (1999), The alternating decision tree learning algorithm. Proc. Sixteenth International Conference on machine learning, Bled, Slovenia, pp. 124-133 (Фреунд и Мейсон (1999), Алгоритм дерева переменных решений. Ученые записки, Шестнадцатая международная конференция по машинному обучению, Блед, Словения, стр. 124-133)), алгоритма M5P (смотрите Quinlan (1992), Learning with continuous classes, in Proceedings AI'92, Adams & Sterling (Eds.), World Scientific, pp. 343-348 (Куинлан (1992), Обучение с непрерывными классами, в трудах AI'92, Адамс & Стерлинг (и другие), Научный мир, стр. 343-348); Wang and Witten (1997), Inducing Model Trees for Continuous Classes. 9th European Conference on machine learning, pp. 128-137 (Ванг и Виттен (1997), Деревья индукционной модели для непрерывных классов. 9-ая европейская конференция по машинному обучению, стр. 128-137)), и алгоритма REPTree (Виттен и Франк, 2005).
В варианте осуществления, целевой признак выбирается из группы непрерывного целевого признака и дискретного целевого признака. Дискретный целевой признак может быть двоичным целевым признаком.
В варианте осуществления, по меньшей мере, один основанный на растениях молекулярный генетический маркер происходит из популяции растений, а популяция растений может быть неструктурированной популяцией растений. Популяция растений может включать в себя инбредные растения или гибридные растения или их комбинацию. В варианте осуществления, пригодная популяция растений выбирается из группы кукурузы, сои, сахарного тростника, сорго, пшеницы, подсолнечника, риса, канола, хлопка и просо. В варианте осуществления, популяция растений может включать в себя от приблизительно 2 до приблизительно 100000 членов.
В варианте осуществления, количество молекулярных генетических маркеров может находиться в диапазоне от приблизительно 1 до приблизительно 1000000 маркеров. Признаки могут включать в себя данные молекулярных генетических маркеров, которые включают в себя, но не в качестве ограничения, один или более из простой повторяющейся последовательности (SSR), расщепленных амплифицированных полиморфных последовательностей (CAPS), полиморфизма длин простой последовательности (SSLP), полиморфизма длин рестрикционных фрагментов (RFLP), маркера произвольной амплифицированной полиморфной ДНК (RAPD), полиморфизма одиночных нуклеотидов (SNP), полиморфизма длины произвольного фрагмента (AFLP), вставки, удаления или любого другого типа молекулярного генетического маркера, выведенного из ДНК, РНК, белка или метаболита, гаплотипа, созданного из двух или более из описанных выше молекулярных генетических маркеров, выведенных из ДНК, и их комбинации.
В варианте осуществления, признаки также могут включать в себя один или более из простой повторяющейся последовательности (SSR), расщепленных амплифицированных полиморфных последовательностей (CAPS), полиморфизма длин простой последовательности (SSLP), полиморфизма длин рестрикционных фрагментов (RFLP), маркера произвольной амплифицированной полиморфной ДНК (RAPD), полиморфизма одиночных нуклеотидов (SNP), полиморфизма длины произвольного фрагмента (AFLP), вставки, удаления или любого другого типа молекулярного генетического маркера, выведенного из ДНК, РНК, белка или метаболита, гаплотипа, созданного из двух или более из описанных выше молекулярных генетических маркеров, выведенных из ДНК, и их комбинацию в соединении с одним или более измерений фенотипа, данных микроматрицы уровней экспрессии РНК, включающих в себя m-РНК, микро-РНК (mi-РНК), некодирующую РНК (nc-РНК), аналитических измерений, биохимических измерений или относящихся к окружающей среде измерений, либо их комбинации, в качестве признаков.
Подходящий целевой признак в популяции растений включает в себя одну или более численно представимых и/или количественно выражаемых особенностей фенотипа, включающих в себя устойчивость к болезням, урожайность, зерновой выход, прочность пряжи, белковый состав, содержание белка, устойчивость к насекомым, влагосодержание зерна, содержание масла в зерне, качество зерновых масел, засухоустойчивость, устойчивость к корневому полеганию, высота растения, высота колоса, содержание белка в зерне, содержание аминокислот в зерне, цвет зерна и устойчивость к стеблевому полеганию.
В варианте осуществления, генотип выборочной популяции растений для одного или более молекулярных генетических маркеров определяется экспериментально прямым секвенированием ДНК.
В варианте осуществления, способ извлечения набора данных с, по меньшей мере, одним основанным на растениях молекулярным генетическим маркером для нахождения правила ассоциации и использования признаков, созданных по этим правилам ассоциации, для классификации или прогнозирования касательно одного или более целевых признаков, при этом, способ включает в себя этапы:
(a) выявления правил ассоциации;
(b) создания новых признаков на основании выводов этапа (a), и добавление этих признаков в набор данных;
(c) оценки признаков;
(d) отбора поднабора признаков из признаков в наборе данных; и
(e) разработки модели для прогнозирования или классификации касательно одного или более целевых признаков с, по меньшей мере, одним признаком, созданным на этапе (b).
В варианте осуществления, способ для отбора инбредных линий, отбора гибридов, ранжирования гибридов, ранжирования гибридов для определенной географии, отбора родителей новых инбредных популяций, нахождения участков для интрогрессии в элитные инбредные линии, или любой их комбинации выполняется с использованием комбинации этапов (a)-(e), приведенных выше.
В варианте осуществления, выявление правил ассоциации включает в себя пространственные и временные ассоциации с использованием самоорганизующихся карт.
В варианте осуществления, по меньшей мере, один признак модели для прогнозирования или классификации является поднабором признаков, выбранных ранее с использованием алгоритма оценки признаков.
В варианте осуществления перекрестная проверка используется для сравнения алгоритмов и наборов значений параметров. В варианте осуществления, кривые рабочих характеристик приемника (ROC) используются для сравнения алгоритмов и наборов значений параметров.
В варианте осуществления, один или более признаков выводятся математически или вычислительным образом из других признаков.
В варианте осуществления, раскрыт способ извлечения набора данных, который включает в себя, по меньшей мере, один основанный на растениях молекулярный генетический маркер для нахождения, по меньшей мере, одного правила ассоциации и использования признаков по этим правилам ассоциации для классификации или прогнозирования касательно одного или более целевых признаков, при этом, способ включает в себя этапы:
(a) выявления правил ассоциации;
(i) при этом, правила ассоциации, пространственные и временные ассоциации выявляются с использованием самоорганизующихся карт;
(b) создания новых признаков на основании выводов этапа (a), и добавление этих признаков в набор данных;
(c) разработки модели для прогнозирования или классификации касательно одного или более целевых признаков с, по меньшей мере, одним признаком, созданным на этапе (b);
при этом этапы (a), (b) и (c) могут предваряться этапом отбора поднабора признаков из признаков в наборе данных.
В варианте осуществления, раскрыт способ извлечения набора данных, который включает в себя, по меньшей мере, один основанный на растениях молекулярный генетический маркер для нахождения, по меньшей мере, одного правила ассоциации и использования признаков, созданных по этим правилам ассоциации, для классификации или прогнозирования, при этом, способ включает в себя этапы:
(a) выявления правил ассоциации;
(b) создания новых признаков на основании выводов, основанных на выводах этапа (a), и добавления этих признаков в набор данных;
(c) отбора поднабора признаков из признаков в наборе данных.
В варианте осуществления при этом результаты этих способов содержат набор данных с, по меньшей мере, одним основанным на растениях молекулярным генетическим маркером, используемым для нахождения, по меньшей мере, одного правила ассоциации, и с использованием признаков, созданных из этих правил ассоциации для классификации или прогнозирования, применяются для:
(a) прогнозирования продуктивности гибрида,
(b) прогнозирования продуктивности гибрида по различным географическим местоположениям;
(c) отбора инбредных линий;
(d) отбора гибридов;
(e) ранжирования гибридов для определенных географий;
(f) отбора родителей новых инбредных популяций;
(g) нахождения участков ДНК для интрогрессии в элитные инбредные линии;
(h) или любой их комбинации (a)-(g).
В варианте осуществления набор данных с, по меньшей мере, одним основанным на растениях молекулярным генетическим маркером используется для нахождения, по меньшей мере, одного правила ассоциации, и признаки, созданные из этих правил ассоциации, используются для классификации или прогнозирования и отбора, по меньшей мере, одного растения из популяции растений для одного или более интересующих целевых признаков.
В варианте осуществления, учитываются априорные знания, состоящие из предварительного исследования, количественных исследований генетики растения, генных сетей, анализов последовательностей или любой их комбинации.
В варианте осуществления, способы, описанные выше, модифицированы, чтобы включать в себя следующие этапы:
(a) понижения размерности заменой исходных признаков комбинацией одного или более признаков, включенных в одно или более из правил ассоциации;
(b) извлечения различительных и присущих часто встречающихся шаблонов посредством основанного на модели дерева поиска.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1: площадь под кривой ROC до и после добавления новых признаков с этапа (b).
ПОДРОБНОЕ ОПИСАНИЕ
Алгоритмы извлечения правил ассоциации предоставляют инфраструктуру и масштабируемость, необходимую для нахождения значимых взаимодействий на очень больших наборах данных.
Способы, раскрытые в материалах настоящей заявки, полезны для идентификации многолокусных взаимодействий, оказывающих влияние на фенотипы. Способы, раскрытые в материалах настоящей заявки, полезны для идентификации взаимодействий между молекулярными генетическими маркерами, гаплотипами и факторами влияния окружающей среды. Новые признаки, созданные на основании этих взаимодействий, полезны для классификации или прогнозирования.
Устойчивость некоторых из этих способов по отношению к проблемам мультиколлинеарности и отсутствующих значений для признаков, а также пропускная способность этих способов для описания сложных зависимостей между признаками, делают такие способы пригодными для анализа больших сложных наборов данных, которые включают в себя признаки, основанные на молекулярных генетических маркерах.
WEKA (Среда Уайкато для анализа знаний, разработанная в Университете Уайкато, Новая Зеландия) является комплектом программного обеспечения машинного обучения, написанным с использованием языка программирования Java, который реализует многочисленные алгоритмы машинного обучения из различных парадигм обучения. Эти инструментальные средства программного обеспечения машинного обучения содействуют реализации алгоритмов машинного обучения и поддерживают разработку алгоритма или адаптацию способов извлечения данных и вычислительных способов. WEKA также предоставляет инструмент для надлежащего испытания качества функционирования каждого алгоритма и наборов значений параметров посредством способов, таких как перекрестная проверка и кривые ROC (рабочих характеристик приемника). WEKA использовался для реализации алгоритмов машинного обучения для моделирования. Однако, специалист в данной области техники принял бы во внимание, что другое программное обеспечение машинного обучения может использоваться для осуществления на практике настоящего изобретения.
Более того, извлечение данных с использованием подходов, описанных в материалах настоящей заявки, дает гибкую масштабируемую инфраструктуру для моделирования с наборами данных, которые включают в себя признаки, основанные на молекулярных генетических маркерах. Эта инфраструктура гибка, так как она включает в себя встроенные средства испытания (то есть, перекрестную проверку и кривые ROC) для определения, какой алгоритм и конкретные настройки параметров должны использоваться для анализа набора данных. Эта инфраструктура является масштабируемой, так как она пригодна для очень больших наборов данных.
В варианте осуществления раскрыты способы для извлечения наборов данных, содержащих в себе признаки, созданные из, по меньшей мере, одного основанного на растениях молекулярного генетического маркера для нахождения, по меньшей мере, одного правила ассоциации, а затем, для использования признаков, созданных по этим правилам ассоциации для классификации или прогнозирования. Некоторые из этих способов пригодны для классификации или прогнозирования по наборам данных, содержащим в себе признаки растений и животных.
В варианте осуществления этапы для извлечения набора данных с, по меньшей мере, одним признаком, созданным из, по меньшей мере, одного основанного на растениях молекулярного генетического маркера, для нахождения, по меньшей мере, одного правила ассоциации, и использования признаков, созданных по этим правилам ассоциации для классификации или прогнозирования касательно одного или более целевых признаков, включают в себя:
(a) выявления правил ассоциации;
(b) создание новых признаков на основании выводов этапа (a), и добавление этих признаков в набор данных;
(c) разработку модели для одного или более целевых признаков с, по меньшей мере, одним признаком, созданным с использованием признаков, созданных на этапе (b);
(d) отбора поднабора признаков из признаков в наборе данных; и
(e) выявления правил ассоциации из пространственных и временных ассоциаций с использованием самоорганизующихся карт.
В варианте осуществления раскрыт способ извлечения набора данных с, одним или более, признаками, при этом, способ включает в себя использование, по меньшей мере, одного основанного на растениях молекулярного маркера для нахождения, по меньшей мере, одного правила ассоциации и использование признаков, созданных по этим правилам ассоциации, для классификации или прогнозирования, способ содержит этапы: (a) выявления правил ассоциации; (b) создания новых признаков на основании выводов этапа (a), и добавления этих признаков в набор данных; (c) отбора поднабора признаков из признаков в наборе данных.
В варианте осуществления, алгоритмы извлечения правил ассоциации используются для классификации или прогнозирования одним или более алгоритмами машинного обучения, выбранными из: алгоритмов оценки признаков, алгоритмов отбора поднабора признаков, байесовых сетей, основанных на примерах алгоритмов, машин опорных векторов, алгоритма голосований, чувствительного к стоимости классификатора, алгоритма укладки, правил классификации и алгоритмов дерева решений.
Подходящие алгоритмы извлечения правил ассоциации включают в себя, но не в качестве ограничения, априорный алгоритм, алгоритм FP-growth, алгоритмы извлечения правил ассоциации, которые могут обрабатывать большое количество признаков, алгоритмы извлечения огромных шаблонов, алгоритм извлечения прямого различительного шаблона, деревья решений, неточные множества и алгоритм самоорганизующейся карты (SOM).
В варианте осуществления, подходящий алгоритм извлечения правил ассоциации для обработки больших количеств признаков включает в себя, но не в качестве ограничения, CLOSET+, CHARM, CARPENTER и COBBLER.
В варианте осуществления, подходящий алгоритм для нахождения прямых различительных шаблонов, включает в себя, но не в качестве ограничения, DDPM, HARMONY, RCBT, CAR и PATCLASS.
В варианте осуществления, подходящий алгоритм для нахождения огромных шаблонов, включает в себя, но не в качестве ограничения, алгоритм слияния шаблонов.
В варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм отбора поднабора признаков, выбранный из группы алгоритма основанного на корреляции отбора признаков (CFS) и алгоритма упаковки в ассоциации с любым другим алгоритмом машинного обучения. Алгоритмы отбора поднабора признаков могут быть ассоциативно связаны методом поиска, выбранным из группы жадного алгоритма многошагового поиска, алгоритма поиска наилучшего первого, алгоритма исчерпывающего поиска, алгоритма поиска с состязаниями и алгоритма рангового поиска.
В варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм байесовской сети, включающий в себя наивный алгоритм Байеса.
В варианте осуществления, подходящий алгоритм машинного обучения является основанным на примерах алгоритмом, выбранным из группы, состоящей из основанного на примерах алгоритма 1 (IB1), основанного на примерах алгоритма k ближайших соседей (IBK), KStar, алгоритма облегченных правил Байеса (LBR) и алгоритма локально взвешенного обучения (LWL).
В варианте осуществления, подходящим алгоритмом машинного обучения является для классификации или прогнозирования алгоритм машины опорных векторов. В предпочтительном варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм машины опорных векторов, который использует алгоритм последовательной минимальной оптимизации (SMO). В предпочтительном варианте осуществления, алгоритм машинного обучения является алгоритмом машины опорных векторов, который использует алгоритм последовательной минимальной оптимизации для регрессии (SMOReg).
В варианте осуществления, подходящим алгоритмом машинного обучения является самоорганизующаяся карта.
В варианте осуществления, подходящим алгоритмом машинного обучения является алгоритм дерева решений, выбранный из группы алгоритма дерева логистической модели (LMT), алгоритма дерева переменных решений (ADTree), алгоритма M5P и алгоритма REPTree.
В варианте осуществления, целевой признак выбирается из группы непрерывного целевого признака и дискретного целевого признака. Дискретный целевой признак может быть двоичным целевым признаком.
В варианте осуществления, по меньшей мере один основанный на растениях молекулярный генетический маркер происходит из популяции растений, а популяция растений может быть неструктурированной популяцией растений. Популяция растений может включать в себя инбредные растения или гибридные растения, или их комбинацию. В варианте осуществления, пригодная популяция растений выбирается из группы кукурузы, сои, сахарного тростника, сорго, пшеницы, подсолнечника, риса, канола, хлопка и просо. В варианте осуществления, популяция растений может включать в себя приблизительно 2 и приблизительно 100000 членов.
В варианте осуществления, количество молекулярных генетических маркеров может находиться в диапазоне от приблизительно 1 до приблизительно 1000000 маркеров. Признаки могут включать в себя данные молекулярных генетических маркеров, которые включают в себя, но не в качестве ограничения, один или более из простой повторяющейся последовательности (SSR), расщепленных амплифицированных полиморфных последовательностей (CAPS), полиморфизма длин простой последовательности (SSLP), полиморфизма длин рестрикционных фрагментов (RFLP), маркера произвольной амплифицированной полиморфной ДНК (RAPD), полиморфизма одиночных нуклеотидов (SNP), полиморфизма длины случайного фрагмента (AFLP), вставки, удаления или любого другого типа молекулярного генетического маркера, выведенного из ДНК, РНК, белка или метаболита, гаплотипа, созданного из двух или более из описанных выше молекулярных генетических маркеров, выведенных из ДНК, и их комбинации.
В варианте осуществления, признаки также могут включать в себя один или более из простой повторяющейся последовательности (SSR), расщепленных амплифицированных полиморфных последовательностей (CAPS), полиморфизма длин простой последовательности (SSLP), полиморфизма длин рестрикционных фрагментов (RFLP), маркера произвольной амплифицированной полиморфной ДНК (RAPD), полиморфизма одиночных нуклеотидов (SNP), полиморфизма длины случайного фрагмента (AFLP), вставки, удаления или любого другого типа молекулярного генетического маркера, выведенного из ДНК, РНК, белка или метаболита, гаплотипа, созданного из двух или более из описанных выше молекулярных генетических маркеров, выведенных из ДНК, и их комбинацию в соединении с одним или более измерений фенотипа, данных микроматрицы, аналитических измерений, биохимических измерений или относящихся к окружающей среде измерений, либо их комбинации, в качестве признаков.
Подходящий целевой признак в популяции растений включает в себя одну или более численно представимых особенностей фенотипа, включающих в себя устойчивость к болезням, урожайность, зерновой выход, прочность пряжи, белковый состав, содержание белка, устойчивость к насекомым, влагосодержание зерна, содержание масла в зерне, качество зерновых масел, засухоустойчивость, устойчивость к корневому полеганию, высота растения, высота колоса, содержание белка в зерне, содержание аминокислот в зерне, цвет зерна и устойчивость к стеблевому полеганию.
В варианте осуществления, генотип выборочной популяции растений для одного или более молекулярных генетических маркеров определяется экспериментально прямым секвенированием ДНК.
В варианте осуществления, способ извлечения набора данных с, по меньшей мере, одним основанным на растениях молекулярным генетическим маркером для нахождения правила ассоциации и использования признаков, созданных по этим правилам ассоциации, для классификации или прогнозирования касательно одного или более целевых признаков, при этом, способ включает в себя этапы:
(a) выявления правил ассоциации;
(b) создания новых признаков на основании выводов этапа (a), и добавление этих признаков в набор данных;
(c) оценки признаков;
(d) отбора поднабора признаков из признаков в наборе данных; и
(e) разработки модели для прогнозирования или классификации касательно одного или более целевых признаков с, по меньшей мере, одним признаком, созданным на этапе (b).
В варианте осуществления, способ для отбора инбредных линий, отбора гибридов, ранжирования гибридов, ранжирования гибридов для определенной географии, отбора родителей новых инбредных популяций, нахождения участков для интрогрессии в элитные инбредные линии, или любой их комбинации выполняется с использованием комбинации этапов (a)-(e), приведенных выше.
В варианте осуществления, где выявление правил ассоциации включает в себя пространственные и временные ассоциации с использованием самоорганизующихся карт.
В варианте осуществления, по меньшей мере, один признак модели для прогнозирования или классификации является поднабором признаков, выбранных ранее с использованием алгоритма оценки признаков.
В варианте осуществления перекрестная проверка используется для сравнения алгоритмов и наборов значений параметров. В варианте осуществления, кривые рабочих характеристик приемника (ROC) используются для сравнения алгоритмов и наборов значений параметров.
В варианте осуществления, один или более признаков выводятся математически или вычислительным образом из других признаков.
В варианте осуществления, раскрыт способ извлечения набора данных, который включает в себя, по меньшей мере, один основанный на растениях молекулярный генетический маркер для нахождения, по меньшей мере, одного правила ассоциации и использования признаков по этим правилам ассоциации для классификации или прогнозирования касательно одного или более целевых признаков, при этом, способ включает в себя этапы:
(a) выявления правил ассоциации;
(i) при этом, правила ассоциации, пространственные и временные ассоциации выявляются с использованием самоорганизующейся карты;
(b) создание новых признаков на основании выводов этапа (a), и добавление этих признаков в набор данных;
(c) разработки модели для прогнозирования или классификации касательно одного или более целевых признаков с, по меньшей мере, одним признаком, созданным на этапе (b);
при этом этапы (a), (b) и (c), приведенные выше, могут быть предварены этапом отбора поднабора признаков из признаков в наборе данных.
В варианте осуществления, раскрыт способ извлечения набора данных, который включает в себя, по меньшей мере, один основанный на растениях молекулярный генетический маркер для нахождения, по меньшей мере, одного правила ассоциации и использования признаков, созданных по этим правилам ассоциации, для классификации или прогнозирования, при этом, способ включает в себя этапы:
(a) выявления правил ассоциации;
(b) создания новых признаков на основании выводов, основанных на выводах этапа (a), и добавления этих признаков в набор данных;
(c) отбора поднабора признаков из признаков в наборе данных.
В варианте осуществления, при этом, результаты этих способов содержат набор данных с, по меньшей мере, одним основанным на растениях молекулярным генетическим маркером, используемым для нахождения, по меньшей мере, одного правила ассоциации, и с использованием признаков, созданных из этих правил ассоциации для классификации или прогнозирования, применяются для:
(a) прогнозирования продуктивности гибрида,
(b) прогнозирования продуктивности гибрида по различным географическим местоположениям;
(c) отбора инбредных линий;
(d) отбора гибридов;
(e) ранжирования гибридов для определенных географий;
(f) отбора родителей новых инбредных популяций;
(g) нахождения участков ДНК для интрогрессии в элитные инбредные линии;
(h) или любой их комбинации (a)-(g).
В варианте осуществления, при этом, набор данных с, по меньшей мере, одним основанным на растениях молекулярным генетическим маркером используется для нахождения, по меньшей мере, одного правила ассоциации, и признаки, созданные из этих правил ассоциации, используются для классификации или прогнозирования и отбора, по меньшей мере, одного растения из популяции растений ради одного или более интересующих целевых признаков.
В варианте осуществления, учитываются априорные знания, состоящие из предварительного исследования, количественных исследований генетики растения, генных сетей, секвенирования или любой их комбинации.
В варианте осуществления, способы, описанные выше, модифицированы, чтобы включать в себя следующие этапы:
(a) понижения размерности заменой исходных признаков комбинацией одного или более признаков, включенных в одно или более из правил ассоциации;
(b) извлечения различительных и присущих часто встречающихся шаблонов посредством основанного на модели дерева поиска.
В варианте осуществления, алгоритмы оценки признаков, такие как прирост информации, симметричных неопределенностей и семейство алгоритмов Relief являются пригодными алгоритмами. Эти алгоритмы способны к оценке всех признаков вместе вместо одного признака за раз. Некоторые из этих алгоритмов устойчивы к проблемам смещения, отсутствующих значений или коллинеарности. Семейство алгоритмов Relief предусматривает инструментальные средства, способные к учету взаимодействий глубокого уровня, но требует пониженной коллинеарности между признаками в наборе данных.
В варианте осуществления, технологии отбора поднаборов применяются посредством алгоритмов, таких как оценщик поднаборов CFS. Технологии отбора поднаборов могут использоваться для снижения сложности посредством устранения избыточных отвлекающих признаков и сохранения поднабора, способного к надлежащему выражению целевого признака. Устранение этих отвлекающих признаков обычно повышает качество функционирования алгоритмов моделирования, когда оцениваются с использованием способов, таких как перекрестная проверка и кривые ROC. Известно, что некоторые классы алгоритмов, таких как основанные на примерах алгоритмы, должны быть очень чувствительными к отклоняющим признакам, а другие, такие как машины опорных векторов в средней степени подвержены влиянию отвлекающих признаков. Понижение сложности посредством формирования новых признаков на основании существующих признаков также часто ведет к повышенным прогнозирующим характеристикам алгоритмов машинного обучения.
В варианте осуществления, фильтровые и алгоритмы упаковки могут использоваться для отбора поднабора признаков. Для выполнения отбора поднабора признаков с использованием фильтров, является обычным ассоциативно связывать эффективный метод поиска (например, жадного многошагового, наилучшего первого и поиска с состязаниями) для нахождения наилучшего поднабора признаков (то есть, исчерпывающий поиск может не всегда быть осуществимым с вычислительной точки зрения) с формулой полезных качеств (например, оценщиком поднабора CFS). Оценщик поднабора CFS надлежащим образом учитывает уровень избыточности в пределах поднабора наряду с отсутствием игнорирования локально прогнозирующих признаков. Кроме снижения сложности для поддержки моделирования, основанные на машинном обучении технологии отбора поднаборов, также могут использоваться для отбора поднабора признаков, которые надлежащим образом выражают целевой признак наряду с обладанием низким уровнем избыточности между признаками, включенными в поднабор. Одной из целей подходов отбора поднабора является снижение потерь во время сбора данных о признаках, усилий по обращению и сохранению, фокусируясь только на поднаборе, найденном для надлежащего выражения целевого признака. Технологии машинного обучения, используемые для снижения сложности, описанного в материалах настоящей заявки, могут сравниваться, например, с использованием перекрестной проверки и кривых ROC. Алгоритм отбора поднабора признаков с наилучшим качеством функционирования, в таком случае, может выбираться для заключительного анализа. Это сравнение обычно выполняется посредством перекрестной проверки и кривых ROC, применяемых к разным комбинациям алгоритмов отбора поднабора и алгоритмов моделирования. Чтобы прогонять перекрестную проверку во время этапов отбора признаков и моделирования, могут использоваться многочисленные компьютеры, выполняющие распараллеленный вариант программного обеспечения машинного обучения (например, WEKA). Технологии, описанные в материалах настоящей заявки, для отбора поднаборов признаков используют эффективные методы поиска для обнаружения наилучшего поднабора признаков (то есть, исчерпывающий поиск не всегда возможен).
Аспект способов моделирования, раскрытый в материалах настоящей заявки, состоит в том, что, так как одиночный алгоритм может не всегда быть наилучшим вариантом отбора для моделирования каждого набора данных, инфраструктура, представленная в материалах настоящей заявки, использует технологии перекрестной проверки, кривые ROC, а также точность и отмену для отбора наилучшего алгоритма для каждого набора данных из различных вариантов в пределах области машинного обучения. В варианте осуществления, несколько алгоритмов и настроек параметров могут сравниваться с использованием перекрестной проверки, кривых ROC, а также точности и повторного вызова, во время разработки модели. Некоторые алгоритмы машинного обучения устойчивы к проблемам мультиколлинеарности (предоставляя возможность моделирования с большим количеством признаков), устойчивы к отсутствующим значениям и способны к учету взаимодействий глубокого уровня между признаками без избыточной подгонки данных.
В варианте осуществления, алгоритмами машинного обучения для моделирования являются машины опорных векторов, такие как SMOReg, деревья решений, такие как M5P, RepTree и ADTree, в дополнение к байесовым сетям и основанным на примерах алгоритмам. Деревья, сформированные алгоритмом M5P, REPTree и ADTree растут, сосредотачиваясь на снижении отклонения целевого признака в поднаборе выборок, назначенных каждому вновь созданному узлу. M5P обычно используется для обработки непрерывных целевых признаков, ADTree обычно используется для обработки двоичных (или приведенных к двоичным) целевых признаков, а REPTree может использоваться для обработки как непрерывных, так и дискретных целевых признаков.
Аспект способов машинного обучения, раскрытых в материалах настоящей заявки, состоит в том, что алгоритмы, используемые в материалах настоящей заявки, могут не требовать хорошо структурированных наборов данных, в отличие от некоторых способов, основанных строго на статистических техниках, которые часто полагаются на хорошо структурированные наборы данных. Структурированные эксперименты часто являются ресурсозатратными в показателях рабочей силы, затрат и времени, так как сильное воздействие окружающей среды на выражение многих из наиболее важных количественно унаследованных особенностей в экономически важных растениях и животных, требует, чтобы такие эксперименты были большими, тщательно разработанными и тщательно контролируемыми. Извлечение данных с использованием алгоритмов машинного обучения, однако, может эффективно использовать существующие данные, которые не были сформированы специально для этой цели извлечения данных.
В варианте осуществления, способы, раскрытые в материалах настоящей заявки, могут использоваться для прогнозирования значения целевого признака у одного или более членов второй целевой популяции растений на основании их генотипа для одного или более молекулярных генетических маркеров или гаплотипов, ассоциативно связанных с особенностью. Значения могут прогнозироваться заранее или вместо определения экспериментально.
В варианте осуществления, способы, раскрытые в материалах настоящей заявки, имеют некоторое количество применений в прикладных программах разведения по растениям (например, гибридным зерновым растениям) в ассоциации с или без других статистических способов, таких как BLUP (наилучшее линейное несмещенное прогнозирование). Например, способы могут использоваться для прогнозирования характеристик фенотипа гибридного потомства, например, гибрида простого скрещивания, порожденного (либо фактически либо в умозрительной ситуации) скрещиванием заданной пары инбредных линий генотипа с известным молекулярным генетическим маркером. Способы также полезны при селекции растений (например, инбредных растений, гибридных растений, и т. д.) для использования в качестве родителей в одном или более скрещиваниях; способы дают возможность отбора родительских растений, чей потомок имеет наивысшую вероятность обладания требуемым фенотипом.
В варианте осуществления, изучаются ассоциации между, по меньшей мере, одним признаком и целевым признаком. Ассоциации могут оцениваться в выборочной популяции растений (например, воспроизводящейся популяции). Ассоциации оцениваются в первой популяции растений посредством тренировки алгоритма машинного обучения с использованием набора данных с признаками, которые включают в себя генотипы для, по меньшей мере, одного молекулярного генетического маркера и значения для целевого признака у, по меньшей мере, одного члена популяции растений. Значения целевого признака, в таком случае, могут прогнозироваться на второй популяции с использованием алгоритма машинного обучения и значений для, по меньшей мере, одного признака. Значения могут прогнозироваться заранее или вместо этого определяться экспериментально.
В варианте осуществления, целевой признак может быть количественной особенностью, например, для которой предусмотрено количественное значение. В еще одном варианте осуществления, целевой признак может быть качественной особенностью, например, для которой предусмотрено качественное значение. Особенности фенотипа, которые могут быть включены в некоторые признаки, могут определяться одиночным геном или множеством генов.
В вариантах осуществления, способы также могут включать в себя отбор, по меньшей мере, одного из членов целевой популяции растений, имеющего требуемое прогнозируемое значение целевого признака, и включать в себя размножение, по меньшей мере, одного выбранного члена целевой популяции растений с, по меньшей мере, одним другим растением (или самоопыление, по меньшей мере, одного выбранного члена, например, для создания инбредной линии).
В варианте осуществления, выборочная популяция растений может включать в себя множество инбредов, гибридов простого скрещивания F1 или их комбинацию. Инбреды могут происходить из инбредных линий, которые родственны и/или неродственны друг другу, а гибриды простого скрещивания могут порождаться из простых скрещиваний инбредных линий и/или одной или более дополнительных инбредных линий.
В варианте осуществления, члены выборочной популяции растений включают в себя членов из существующей устоявшейся, воспроизводящейся популяции (например, промышленной воспроизводящейся популяции). Члены устоявшейся, воспроизводящейся популяции обычно являются потомками относительно небольшого количества основателей и обычно наделены внутренним родством. Достаточная по количеству для дальнейшего размножения популяция может покрывать большее количество поколений и циклов размножения. Например, устоявшаяся, достаточная по количеству для дальнейшего размножения популяция может охватывать три, четыре, пять, шесть, семь, восемь, девять или более циклов размножения.
В варианте осуществления, выборочной популяции растений не нужно быть воспроизводящейся популяцией. Выборочная популяция может быть подпопуляцией какой-нибудь существующей популяции растений, для которой, полностью или частично, имеются в распоряжении генотипические и данные о фенотипе. Выборочная популяция растений может включать в себя любое количество членов. Например, выборочная популяция растений включает в себя от приблизительно 2 до приблизительно 100000 членов. Выборочная популяция растений может содержать, по меньшей мере, около 50, 100, 200, 500, 1000, 2000, 3000, 4000, 5000 или даже 6000, либо 10000, или большее количество членов. Выборочная популяция растений обычно демонстрирует изменчивость в отношении интересующего целевого признака (например, количественную изменчивость для качественного целевого признака). Выборочная популяция растений может извлекаться из одной или более растительных клеточных культур.
В варианте осуществления значение целевого признака в выборочной популяции растений получается посредством оценки целевого признака среди членов выборочной популяции растений (например, количественного определения количественного целевого признака среди членов популяции). Фенотип может оцениваться среди членов (например, инбредов и/или гибридов простого скрещивания F1), составляющих первую популяцию растений. Целевой признак может включать в себя любой количественный или качественный признак, например, один из агрономической или экономической значимости. Например, целевой признак может выбираться из урожайности, влагосодержания зерна, содержания масла в зерне, прочности пряжи, высоты растения, высоты колоса, устойчивости к болезням, устойчивости к насекомым, засухоустойчивости, содержания белка в зерне, натуральной массы, визуальной или эстетической наружности и цвета початка. Эти особенности и техники для их оценки (например, количественного определения) широко известны в данной области техники.
В варианте осуществления, генотип выборочной популяции растений для набора молекулярных генетических маркеров может определяться экспериментально, прогнозироваться или определяться по их комбинации. Например, в одном из классов вариантов осуществления, генотип каждого инбреда, присутствующего в популяции растений, определяется экспериментально, и прогнозируется генотип каждого гибрида простого скрещивания F1, присутствующего в первой популяции растений (например, экспериментально определенные генотипы двух инбредных родителей каждого гибрида простого скрещивания). Генотипы растений могут определяться экспериментально посредством любой подходящей техники. В варианте осуществления, множество участков ДНК из каждого инбреда секвенируются для экспериментального определения генотипа каждого инбреда. В варианте осуществления, генеологические деревья и вероятностный подход могут использоваться для расчета вероятностей генотипа в разных локусах маркера для двух инбредных родителей гибридов простого скрещивания.
В варианте осуществления, способы, раскрытые в материалах настоящей заявки, могут использоваться для отбора растений для выбранного генотипа, включающего в себя, по меньшей мере, один молекулярный генетический маркер, ассоциативно связанный с целевым признаком.
«Аллель» или «тип аллели» относится к альтернативной форме генетического локуса. Одиночная аллель для каждого локуса наследуется отдельно от каждого родителя. Диплоидная особь является гомозиготной, если одна и та же аллель присутствует дважды (то есть, один раз в каждой гомологичной хромосоме), или гетерозиготной, если присутствуют две разные аллели.
В качестве используемого в материалах настоящей заявки, термин «животное» подразумевается охватывающим нечеловеческие организмы, отличающиеся от растений, в том числе, но не в качестве ограничения, одомашненных животные (то есть, домашние животные), мясомолочный скот, рабочие животные или животные зоопарков. Предпочтительные животные включают в себя, но не в качестве ограничения, рыбу, кошек, собак, лошадей, хорьков и других куньих, крупный рогатый скот, овец и свиней. Более предпочтительные животные включают в себя кошек, собак, лошадей и других одомашненных животных, причем, кошки, собаки и лошади являются даже еще более предпочтительными. В качестве используемого в материалах настоящей заявки, термин «одомашненное животное» относится к любому животному, которое человек рассматривает в качестве домашнего животного. В качестве используемого в материалах настоящей заявки, кошка относится к любому члену семейства кошачьих (то есть, кошачьи), в том числе, к одомашненным кошкам, диким кошкам и кошкам зоопарков. Примеры кошек включают в себя, но не в качестве ограничения, одомашненных кошек, львов, тигров, леопардов, пантер, когуаров, рыжих рысей, рысей, ягуаров, гепардов и сервалов. Предпочтительной кошкой является одомашненная кошка. В качестве используемой в материалах настоящей заявки, собака относится к любому члену семейства собачьих, в том числе, но не в качестве ограничения, к одомашненным собакам, диким собакам, лисицам, волкам, шакалам и койотам, и другим членам семейства собачьих. Предпочтительной собакой является одомашненная собака. В качестве используемой в материалах настоящей заявки, лошадь относится к любому члену семейства лошадиных. Непарнокопытное является копытным и включает в себя, но не в качестве ограничения, одомашненных лошадей и диких лошадей, таких как лошади, ишаки, ослы и зебры. Предпочтительные лошади включают в себя одомашненных лошадей, в том числе, скаковых лошадей.
Термин «ассоциация», в контексте машинного обучения, относится к любой взаимосвязи между признаками, но не только теми, которые прогнозируют конкретный класс или числовое значение. Ассоциация включает в себя, но не в качестве ограничения, нахождение правил ассоциации, обнаружение шаблонов, выполнение оценки признаков, выполнение отбора поднаборов признаков, разработку прогнозирующих моделей и осмысление взаимодействий между признаками.
Термин «правила ассоциации», в контексте этого изобретения, относится к элементам, которые часто появляются вместе в пределах набора данных. Он включает в себя, но не в качестве ограничения, ассоциативные шаблоны, различительные шаблоны, частные шаблоны, близкие шаблоны и огромные шаблоны.
Термин «преобразованный в двоичную форму», в контексте машинного обучения, относится к непрерывному или безусловному признаку, который был преобразован в двоичный признак.
«Воспроизводящаяся популяция» в целом указывает на совокупность растений, используемых в качестве родителей в программе разведения. Обычно, отдельные растения в воспроизводящейся популяции характеризуются как по генотипу, так и по фенотипу.
Термин «извлечение данных» относится к идентификации или извлечению зависимостей и шаблонов из данных с использованием вычислительных алгоритмов для сокращения, моделирования, осмысления или анализа данных.
Термин «деревья решений» относится к любому типу основанных на деревьях алгоритмов обучения, в том числе, но не в качестве ограничения, деревья моделей, деревья классификаций и деревья регрессий.
Термин «признак» или «атрибут» в контексте машинного обучения относится к одной или более необработанных входных переменных, на одну или более обработанных переменных или на одно или более математических сочетаний других переменных, в том числе, необработанных переменных и обработанных переменных. Признаки могут быть непрерывными или дискретными. Признаки могут формироваться благодаря обработке любым фильтровым алгоритмом или любым статистически методом. Признаки могут включать в себя, но не в качестве ограничения, данные маркера ДНК, данные гаплотипа, данные о фенотипе, биохимические данные, данные микроматрицы, относящиеся к окружающей среде данные, белковые данные и метаболические данные.
Термин «оценка признака» в контексте этого изобретения относится к ранжированию признаков или к ранжированию, сопровождаемому отбором признаков на основании их влияния на целевой признак.
Фраза «поднабор признаков» относится к группе одного или более признаков.
«Генотип» относится к генетическому строению клетки или отдельного растения или организма относительно одного или более молекулярных генетических маркеров или аллелей.
«Гаплотип» относится к набору аллелей, которые особь наследует от одного родителя. Термин гаплотип также может относиться к физически связанным и/или несвязанным молекулярным генетическим маркерам (например, полиморфным последовательностям), ассоциированным с целевым признаком. Гаплотип также может указывать ссылкой на группу из двух или более молекулярных генетических маркеров, которые физически связаны в хромосоме.
Термин «пример» в контексте машинного обучения относится к образцу из набора данных.
Термин «взаимодействие» в контексте этого изобретения относится к ассоциативной связи между признаками и целевыми признаками в виде зависимости одного признака от другого признака.
Термин «обучение» в контексте машинного обучения относится к идентификации и обучению подходящих алгоритмов для выполнения интересующих задач. Термин «обучение» включает в себя, но не в качестве ограничения, обучение ассоциаций, обучение классификации, кластеризацию и числовое прогнозирование.
Термин «машинное обучение» указывает ссылкой на область вычислительной техники, которая изучает проектирование компьютерных программ, способных выводить шаблоны, закономерности или правила из прошлого опыта для совершенствования надлежащей реакции на будущие данные или описания данных некоторым содержательным образом. Под алгоритмами «машинного обучения», в контексте этого изобретения, подразумеваются алгоритмы правил ассоциации (например, априорные, извлечения различительных шаблонов, извлечения часто встречающихся шаблонов, извлечения близких шаблонов, извлечения огромных шаблонов и самоорганизующихся карт), алгоритмы оценки признаков (например, прироста информации, Relief, ReliefF, RReliefF, симметричных неопределенностей, алгоритма отношений прироста и ранжировщика), алгоритмы отбора поднаборов (например, упаковки, непротиворечивости, классификатора, основанного на корреляции отбора признаков (CFS)), машины опорных векторов, байесовы сети, правила классификации, деревья решений, нейронные сети, основанные на примерах алгоритмы, другие алгоритмы, которые используют перечисленные в материалах настоящей заявки алгоритмы (например, голосования, укладки, чувствительного к стоимости классификатора) и любой другой алгоритм в области вычислительной техники, который относится к выведению шаблонов, закономерностей или правил из прошлого опыта для совершенствования надлежащей реакции на будущие данные или описания данных некоторым содержательным образом.
Термин «разработка модели» относится к процессу построения одной или более моделей для извлечения данных.
Термин «молекулярный генетический маркер» относится к одному из простой повторяющейся последовательности (SSR), расщепленных амплифицированных полиморфных последовательностей (CAPS), полиморфизма длин простой последовательности (SSLP), полиморфизма длин рестрикционных фрагментов (RFLP), маркера произвольной амплифицированной полиморфной ДНК (RAPD), полиморфизма одиночных нуклеотидов (SNP), полиморфизма длины случайного фрагмента (AFLP), вставки, удаления или любого другого типа молекулярного маркера, выведенного из ДНК, РНК, белка или метаболита и их комбинации. Молекулярный генетический маркер также относится к полинуклеотидным последовательностям, используемым в качестве проб.
Термин «особенность фенотипа» или «фенотип» относится к наблюдаемым физическим или биохимическим характеристикам организма, которые определены как генетической конструкцией, так и влияниями окружающей среды. Фенотип указывает ссылкой на наблюдаемое выражение (экспрессию) конкретного генотипа.
Термин «растение» включает в себя класс высших или низших растений, в том числе, покрытосеменные (однодольные и двудольные растения), голосеменные, папоротники и многоклеточные водоросли. Он включает в себя растения в многообразии уровней плоидности, в том числе, анэуплоидные, полиплоидные, диплоидные, гаплоидные и гемизиготные.
Термин «основанный на растениях молекулярный генетический маркер» относится к одному из простой повторяющейся последовательности (SSR), расщепленных амплифицированных полиморфных последовательностей (CAPS), полиморфизма длин простой последовательности (SSLP), полиморфизма длин рестрикционных фрагментов (RFLP), маркера произвольной амплифицированной полиморфной ДНК (RAPD), полиморфизма одиночных нуклеотидов (SNP), полиморфизма длины случайного фрагмента (AFLP), вставки, удаления или любого другого типа молекулярного маркера, выведенного из ДНК, РНК, белка или метаболита и их комбинации. Молекулярный генетический маркер также относится к полинуклеотидной последовательности, используемой в качестве проб.
Термин «априорные знания», в контексте этого изобретения относится к любой форме информации, которая может использоваться для модификации качества функционирования алгоритма машинного обучения. Матрица зависимостей, указывающая родственность между особями, является примером априорных знаний.
«Качественная особенность» обычно относится к признаку, который управляется одним или несколькими генами и является дискретным по природе. Примеры качественных особенностей включают цвет цветка, цвет початка и устойчивость к болезням.
«Количественная особенность» обычно относится к признаку, который может быть определен количественно. Количественная особенность типично показывает непрерывное изменение между особями популяции. Количественная особенность часто является результатом взаимодействия генетического локуса с окружающей средой, или взаимодействия многочисленных генетических локусов друг с другом и/или с окружающей средой. Примеры количественных особенностей включают в себя зерновой выход, содержание белка и прочность пряжи.
Термин «ранжирование» в отношении признаков относится к упорядоченной компоновке признаков, например, молекулярные генетические маркеры могут быть ранжированы по их прогнозирующей способности в отношении особенности.
Термин «самоорганизующаяся карта» относится к технике обучения без учителя, часто используемую для визуализации и анализа высокоразмерных данных.
Термин «с учителем», в контексте машинного обучения, относится к способам, которые работают под контролем, с предоставлением фактического результата для каждого из обучающих примеров.
Термин «машина опорных векторов», в контексте машинного обучения, включает в себя, но не в качестве ограничения, классификатор опорных векторов, используемый для целей классификации, и регрессию опорных векторов, используемую для числового прогнозирования. Другие алгоритмы (например, последовательная минимальная оптимизация (SMO)) могут быть реализованы для обучения машины опорных векторов.
Термин «целевой признак» в контексте этого изобретения относится к, но не в качестве ограничения, признаку, который представляет интерес для прогнозирования или объяснения, или с которым интересно развивать ассоциацию. Усилия по извлечению данных могут включать в себя один целевой признак или более чем один целевой признак, и термин «целевой признак» может относиться к одному или более чем одному признаку. «Целевой признак» может включать в себя, но не в качестве ограничения, данные маркера ДНК, данные о фенотипе, биохимические данные, данные микроматрицы, относящиеся к окружающей среде данные, белковые данные и метаболические данные. В области техники машинного обучения, когда «целевой признак» является дискретным, его часто называют «классом». Зерновой выход является примером целевого признака.
Термин «без учителя», в контексте машинного обучения, относится к способам, которые работают без контроля без предоставления фактического результата для каждого из обучающих примеров.
Обзор теоретических и практических аспектов некоторых применимых способов
Извлечение правил ассоциации
Извлечение правил ассоциации (ARM) - техника для извлечения содержательных шаблонов ассоциаций между признаками. Одним из алгоритмов машинного обучения, пригодных для обучения правилам ассоциации, является априорный алгоритм.
Обычный основной этап алгоритмов ARM состоит в том, чтобы находить набор элементов или признаков, которые наиболее часто встречаются среди всех наблюдений. Таковые известны как часто встречающиеся наборы элементов. Их частота также известна как опора (пользователь может идентифицировать минимальное опорное пороговое значение для набора элементов, которые должны считаться часто встречающимися). Как только получены часто встречающиеся наборы элементов, правила извлекаются из них (например, с предписанной пользователем минимальной степенью доверия). Последняя часть не настолько напряженна по вычислениям, как первая. Отсюда, цель алгоритмов ARM фокусируется на нахождении часто встречающихся множеств элементов.
Не всегда является определенным, что часто встречающиеся наборы элементов являются базовыми (наиболее применимыми) информационными шаблонами набора данных, так как часто есть много избыточности среди шаблонов. Как результат, многие приложения полагаются на получение часто встречающихся близких шаблонов. Часто встречающийся близкий шаблон является шаблоном, который удовлетворяет требованию минимальной опоры, заданному пользователем, и не имеет такой же опоры, как его непосредственные надмножества. Часто встречающийся шаблон не является близким, если, по меньшей мере, одно из его непосредственных надмножеств имеет такой же счет опоры, как у него. Обнаружение часто встречающихся близких шаблонов предоставляет нам возможность находить поднабор значимых взаимодействий среди признаков.
Априорный алгоритм работает итерационно, комбинируя повторяющиеся наборы элементов с n-1 признаками для формирования повторяющегося набора элементов с признаками. Эта процедура является экспоненциальной по времени выполнения с ростом количества признаков. Отсюда, извлечение повторяющихся наборов элементов априорным алгоритмом становится затратным по вычислениям для наборов данных с очень большим количеством признаков.
С проблемой масштабируемости для нахождения часто встречающихся близких наборов элементов могут хорошо справляться некоторые существующие алгоритмы. CARPENTER, алгоритм нумерации строк первой глубины, способен к обнаружению часто встречающихся близких шаблонов из больших биологических наборов данных с большим количеством признаков. CARPENTER не осуществляет хорошее масштабирование с ростом количества выборок.
Другими алгоритмами извлечения часто встречающихся шаблонов являются CHARM, CLOSET. Оба из них являются эффективными алгоритмами нумерации столбцов первой глубины.
COBBLER - алгоритм нумерации столбцов и строк, который осуществляет хорошее масштабирование с ростом количества признаков и выборок.
Для многих разных целей, обнаружение различительных часто встречающихся шаблонов полезно даже больше, чем нахождение часто встречающихся близких шаблонов ассоциаций. Некоторые алгоритмы эффективно извлекают только различительные шаблоны из наборов данных. Большинство существующих алгоритмов осуществляют двухэтапный подход для обнаружения различительных шаблонов: (a) найти часто встречающиеся шаблоны, (b) из часто встречающихся шаблонов, получить различительные шаблоны. Этап (a) является очень времязатратным процессом и имеет результатом много избыточных часто встречающихся шаблонов.
DDPMine (извлечение прямого различительного шаблона), алгоритм извлечения различительного шаблона не придерживается описанного выше двухэтапного подхода. Вместо извлечения часто встречающихся шаблонов, он формирует сокращенное представление дерева FP данных. Эта процедура не только уменьшает размер проблемы, но также ускоряет процесс извлечения. Она использует прирост информации в качестве меры для извлечения различительных шаблонов.
Другими алгоритмами извлечения различительных шаблонов являются HARMONY, RCBT и PatClass. HARMONY - центрирующийся на примере основанный на правилах классификатор. Он непосредственно извлекает окончательный набор правил классификации. Классификатор RCBT действует сначала посредством идентификации верхних k групп правил покрытия для каждой строки и их использования для инфраструктуры классификации. PatClass предпринимает двухэтапную процедуру сначала посредством извлечения набора повторяющихся наборов элементов, сопровождаемого этапом выбора признаков.
Большинство существующих алгоритмов извлечения правил ассоциации возвращают малоразмерные часто встречающиеся или близкие шаблоны. С ростом количества признаков, количество крупноразмерных часто встречающихся или близких шаблонов также возрастает. Является слишком напряженным по вычислениям, скорее даже невозможным, выводить все часто встречающиеся шаблоны всех длин для наборов данных с большим количеством признаков. Алгоритм слияния шаблонов пытается принять меры в ответ на эту проблему, объединяя небольшие часто встречающиеся шаблоны в огромные шаблоны, предпринимая скачки в пространстве поиска шаблонов.
Самоорганизующиеся карты
Самоорганизующаяся карта (SOM), также известная как сохраняющая карта сети Кохонена, является техникой обучения без учителя, часто используемой для визуализации и анализа данных высокой размерности. Типичные применения фокусируются на визуализации центральных зависимостей в пределах данных на карте. Некоторые области, где они использовались, включают в себя автоматическое распознавание речи, клинический анализ голоса, классификация спутниковых снимков, анализ электрических сигналов из мозга и организация и поиск данных из больших массивов документов.
Карта, формируемая посредством SOM, использовалась для ускорения идентификации правил ассоциации способами, подобными априорному, посредством использования кластеров SOM (визуальные кластеры, идентифицированные во время обучения SOM).
Карта SOM состоит из сетки блоков обработки, «нейронов». Каждый нейрон ассоциативно связан с вектором признаков (наблюдением). Карта пытается представить все имеющиеся в распоряжении наблюдения с оптимальной точностью с использованием ограниченного набора моделей. Одновременно, модели становятся упорядоченными в сетке, так что подобные модели близки друг к другу, а несходные модели отдалены друг от друга. Эта процедура дает возможность идентификации, а также визуализации зависимостей или ассоциаций между признаками в данных.
В течение фазы обучения SOM, алгоритм соревновательного обучения используется для подгонки векторов модели к сетке нейронов. Это процесс последовательной регрессии, где t=1, 2,... - индекс этапа: Для каждой выборки x(t), первый победивший индекс c (нейрон наибольшего совпадения) идентифицируется условием
∀i, ||x(t)-mc (t)||≤||x(t)-mi(t)||
После того, все векторы модели или их поднабор, которые принадлежат узлам, центрированным вокруг узла c=c(x), обновляются как
mi(t+1)=mi(t)+hc(x),i(x(t)-mi(t))
где:
mc - вектор средних весов сого узла (то есть, победителя).
mi - вектор средних весов iого узла.
hc(x),i - «функция соседства», убывающая функция расстояния между iым и cым узлами в сетке карты.
mi(t+1) - обновленный вектор весов после tого этапа.
Эта регрессия обычно многократно повторяется на имеющихся в распоряжении наблюдениях.
Алгоритмы SOM также часто использовались для исследования пространственных и временных зависимостей между сущностями. Зависимости и ассоциации между наблюдениями выводятся на основании пространственной кластеризации этих наблюдений в карте. Если нейроны представляют разные временные состояния, то карта визуализирует временные шаблоны между наблюдениями.
Оценка признаков
Одно из основных назначений алгоритмов оценки признаков состоит в том, чтобы понять лежащий в основе процесс, который формирует данные. Эти способы также часто применяются для уменьшения количества «отвлекающих» признаков с целью улучшения качества функционирования алгоритмов классификации (смотрите Guyon and Elisseeff (2003). An Introduction to Variable and Feature Selection. Journal of Machine learning Research 3, 1157-1182 (Гийон и Елисеев (2003). Введение в отбор переменных и признаков. Журнал исследований по машинному обучению, 3, 1157-1182)). Термин «переменная» иногда используется вместо более широких терминов «признак» или «атрибут». Отбор признаков (или атрибутов) относится к выбору переменных, обрабатываемых посредством методов, таких как ядерные методы, но иногда относится к выбору необработанных входных переменных. Требуемыми выходными данными этих алгоритмов оценки признаков обычно является ранжирование признаков на основании их влияния на целевой признак, или ранжирование, сопровождаемое отбором признаков. Это влияние может быть измерено разными путями.
Прирост информации является одним из способов машинного обучения, пригодных для оценки признаков. Определение прироста информации требует определения энтропии, которая является мерой инородности в совокупности обучающих примеров. Снижение энтропии целевого признака, которое происходит посредством узнавания значений определенного признака, называется приростом информации. Прирост информации может использоваться в качестве параметра для определения эффективности признака в объяснении целевого признака.
Симметричная неопределенность, используемая алгоритмом основанного на корреляции отбора признаков (CFS), описанным в материалах настоящей заявки, компенсирует смещение прироста информации по направлению к признакам с большими значениями посредством нормировки признаков диапазоном [0,1]. Симметричная неопределенность всегда находится между 0 и 1. Она является одним из способов для измерения корреляции между двумя номинальными признаками.
Алгоритм ранжировщика также может использоваться для ранжирования признаков по их индивидуальным оценкам на каждом проходе перекрестной проверки и выдачи среднего достоинства и ранга для каждого признака.
Relief является классом алгоритмов оценщика атрибутов, который может использоваться для этапа оценки признаков, раскрытого в материалах настоящей заявки. Этот класс содержит в себе алгоритмы, которые способны иметь дело с безусловными или непрерывными целевыми признаками. Этот широкий диапазон делает их полезными для некоторых приложений извлечения данных.
Исходный алгоритм Relief имеет несколько версий и расширений. Например, ReliefF, расширение исходного алгоритма Relief, не ограничен задачей двух классов и может обрабатывать неполные наборы данных. ReliefF также более устойчив, чем Releif, и может иметь дело с зашумленными данными.
Обычно, в Relief и ReliefF, оцененная значимость признака определяется суммой балльных оценок, назначенных ему для каждого из примеров. Каждая балльная оценка зависит от того, насколько важен признак при определении класса примера. Признак получает максимальное значение, если он имеет решающее значение в определении класса. Когда значительное количество неинформативных признаков добавляется в анализ, много примеров требуется для этих алгоритмов для схождения к правильным оценкам ценности каждого признака. Если имеют дело с несколькими соседними промахами, важными признаками являются те, для которых минимальное изменение их значения приводит к изменению в классе оцениваемого примера. В ReliefF, когда количество примеров огромно, ближние попадания играют минимальную роль, а ближние промахи играют огромную роль, но, с проблемами практического размера, ближние попадания играют большую роль.
RReliefF является расширением ReliefF, которое имеет дело с непрерывными целевыми признаками. Положительные обновления формируют вероятности, что признак проводит различение между примерами с разными значениями класса. С другой стороны, отрицательные обновления формируют вероятности, что признак проводит различение между примерами с одинаковыми значениями класса. Из задачи регрессии, часто трудно сделать вывод, относятся или нет два примера к одному и тому же классу, поэтому, алгоритм вводит значение вероятности, которое прогнозирует, различны ли значения двух примеров. Поэтому, алгоритмы RReliefF отдают должное признакам для неразделения подобных прогнозных значений и накладывают взыскание на признаки для неразделения разных прогнозных значений. RReliefF, в отличие от Relief и ReliefF, не использует знаки, таким образом, концепция попадания и промаха не применяется. RReliefF считает хорошими признаками те, которые разделяют примеры с разными прогнозными значениями и не разделяют примеры с близкими прогнозными значениями.
Оценки, сформированные алгоритмами из класса алгоритмов Relief, зависимы от количества используемых соседей. Если ограничение на количество соседей не используют, каждый признак будет испытывать влияние всех выборок в наборе данных. Используемое ограничение на количество выборок предоставляет оценки посредством алгоритмов Relief, которые являются средними значениями на локальных оценках в меньших частях пространства примеров. Эти локальные прогнозы позволяют алгоритмам Relief принимать во внимание другие признаки при обновлении веса каждого признака, в то время как наиболее близкие соседи определяются мерой расстояния, которая учитывает все из признаков. Поэтому, алгоритмы Relief чувствительны к количеству и полезности признаков, включенных в набор данных. Другие признаки рассматриваются по их условным зависимостям по отношению к обновляемому признаку при данных прогнозируемых значениях, которые могут выявляться в локальном окружении. Расстояние между примерами определяется суммой разниц в значениях «существенных» и «несущественных» признаков. Как и другие алгоритмы k ближайших соседей, эти алгоритмы не устойчивы к несущественным признакам. Поэтому, в присутствие большого количества несущественных признаков, рекомендовано использовать большое значение k (то есть, увеличивать количество ближайших соседей). Поступая так, лучшие условия предоставляются для существенных признаков для «навязывания» «правильного» обновления для каждого признака. Однако, известно, что алгоритмы Relief могут утрачивать функциональность, когда количество ближайших соседей, используемых в весовой формуле, слишком велико, зачастую со смешением информативных признаков. Это особенно справедливо, когда учитываются все из выборок, в то время как будет всего лишь небольшая асимметрия между попаданиями и промахами, и эта асимметрия гораздо более заметна, когда учитывается только несколько ближайших соседей. Мощь алгоритмов Relief проистекает из способности использовать локальное окружение наряду с обеспечением глобального видения.
Алгоритм RReliefF может иметь тенденцию к недооценке важных численных признаков по сравнению с номинальными признаками при расчете евклидова или манхэттенского расстояния между примерами для определения ближайших соседей. RReliefF также переоценивает случайные (неважные) численные признаки, потенциально снижая разделяемость двух групп признаков. Линейно нарастающая функция (смотрите Hong (1994) Use of contextual information for feature ranking and discretization. Technical Report RC19664, IBM (Хонг (1994) Использование контекстной информации для ранжирования и дискретизации признаков. Технический отчет RC19664, IBM); и Hong (1997) IEEE transactions on knowledge and data engineering, 9(5) 718-730 (Хонг (1997) Труды IEEE по технологиям знаний и данных, 9(5) 718-730)) может использоваться для преодоления этой проблемы RReliefF.
При оценке веса, который должен быть назначен каждому признаку из данного набора признаков, является общепринятой практикой придавать особое значение более близким примерам по сравнению с более отдаленными примерами. Однако, часто является опасным использовать слишком малое количество соседей с зашумленными или сложными целевыми признаками, поскольку это может привести к потере устойчивости оценки. Использование большего количества ближайших соседей устраняет снижение значимости некоторых признаков, для которых верхние 10 (например) ближайших соседей временно подобны. Такие признаки теряют значимость по мере того, как снижается количество соседей. Если влияние всех соседей обрабатывается как равное (пренебрегая их расстоянием до точки запроса), то предложенным значением для количества ближайших соседей обычно является 10. Если расстояние принимается во внимание, предложенным значением обычно является 70 ближайших соседей с экспоненциально нарастающим влиянием.
ReliefF и RReliefF являются чувствительными к окружению, а потому, более чувствительны к количеству случайных (не важных) признаков при анализе, чем ограниченные меры (например, коэффициент прироста и MSE). Алгоритмы Relief оценивают каждый признак в окружении других признаков, и лучшие признаки получают более высокие балльные оценки. Алгоритмы Relief имеют тенденцию недооценивать менее значимые признаки, когда есть сотни значимых признаков в наборе данных, кроме того, дублированные или высоко избыточные признаки будут разделять доверие и выглядеть более важными, чем они являются на самом деле. Это может происходить, так как дополнительные копии признака изменяют область решения проблемы, в которой наблюдаются ближайшие соседи. С использованием ближайших соседей, обновления будут происходить, только когда есть различия между значениями признаков для двух соседних примеров. Поэтому, никакие обновления для данного признака в данном наборе соседей происходить не будут, если различие между двумя соседями нулевое. Высоко избыточные признаки будут иметь эти различия всегда равными нулю, снижая благоприятную возможность для обновления по всем соседним примерам и признакам. Близорукие оценщики, такие как коэффициент прироста и MSE не чувствительны к дублированным признакам. Однако, алгоритмы Relief будут работать лучше, чем близорукие алгоритмы, если есть взаимодействия между признаками.
Отбор поднаборов
Алгоритмы отбора поднаборов полагаются на комбинацию метода оценки (например, симметричных неопределенностей и прироста информации) и метода поиска (например, ранжировщика, исчерпывающего поиска, первого наилучшего и жадного поиска экстремума).
Алгоритмы отбора поднаборов, подобно алгоритмам оценки признаков, ранжируют поднаборы признаков. В противоположность алгоритмам оценки признаков, однако, алгоритмы отбора поднаборов нацеливаются на поднабор признаков с наивысшим влиянием на целевой признак наряду с учетом степени избыточности между признаками, включенными в поднабор. Алгоритмы отбора поднаборов проектируются, чтобы быть устойчивыми к мультиколлинеарности и отсутствующим значениям, и, таким образом, предоставляют возможность для выбора из исходной совокупности сотен или даже тысяч признаков. Выгоды от отбора поднаборов признаков включают в себя облегчение визуализации и осмысления данных, снижение требований к измерению и хранению, сокращение времени обучения и использования, и устранение отвлекающих признаков для улучшения классификации. Например, результаты из способов отбора поднаборов признаков полезны для генетики растений и животных, так как они могут использоваться для предварительного выбора молекулярных генетических маркеров, которые должны анализироваться во время проекта выполняемого с помощью маркеров отбора, с особенностью фенотипа в качестве целевого признака. Это может значительно сокращать количество молекулярных генетических маркеров, которые должны анализироваться и, таким образом, снижает затраты, ассоциативно связаны с объемом работ.
Алгоритмы отбора поднаборов могут применяться к широкому диапазону наборов данных. Важным соображением при выборе подходящего алгоритма поиска является количество признаков в наборе данных. По мере того, как количество признаков увеличивается, количество возможных поднаборов признаков возрастает экспоненциально. По этой причине, алгоритм исчерпывающего поиска подходит, только когда количество признаков относительно невелико. При соответствующей вычислительной мощности, однако, можно использовать исчерпывающий поиск для определения наиболее существенного поднабора признаков.
Существует несколько алгоритмов, пригодных для наборов данных с набором признаков, который слишком велик (или недостаточно велика имеющаяся в распоряжении вычислительная мощность) для исчерпывающего поиска. Два базовых подхода к алгоритмам отбора поднабора являются процессом добавления признаков в рабочий поднабор (прямой отбор) и удаления из текущего множества признаков (обратное удаление). В машинном обучении, прямой отбор делается по-иному, нежели статистическая процедура с тем же самым названием. Здесь признак, который должен быть добавлен в текущий поднабор, обнаруживается посредством оценки текущего поднабора, расширенного одним новым признаком, с использованием перекрестной проверки. При прямом выборе поднабора надстраиваются добавлением каждого оставшегося признака в свою очередь в текущий поднабор наряду с оценкой ожидаемых характеристик каждого нового поднабора с использованием перекрестной проверки. Признак, который приводит к наилучшим характеристикам, когда добавлен в текущий поднабор, сохраняется, и процесс продолжается. Поиск заканчивается, когда ни один из оставшихся имеющихся в распоряжении признаков не улучшает прогнозирующую способность текущего поднабора. Этот процесс находит локальный (то есть, не обязательно глобальный) оптимальный набор признаков.
Обратное удаление реализуется подобным образом. При обратном удалении, поиск заканчивается, когда дальнейшее сокращение набора признаков не улучшает прогнозирующей способности поднабора. Для введения смещения по отношению к меньшим поднаборам, может требоваться улучшать способность прогнозировать на определенную величину для признака, который должен быть добавлен (во время прямого отбора) или удален (во время обратного удаления).
В аспекте, алгоритм первого наилучшего может осуществлять прямой поиск, обратный поиск или в обоих направлениях (учитывая все возможные добавления или удаления одиночного признака в заданной точке) благодаря применению жадного поиска экстремума, усиленного возможностью перебора с возвратами (смотрите Pearl, J. (1984), Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison-Wesley, p. 48 (Пеарл, Дж. (1984), Эвристика: Стратегии интеллектуального поиска для решения вычислительных задач. Эддисон-Весли, стр. 48); и Russell, S.J., & Norvig, P. Artificial Intelligence: A Modern Approach, 2nd edition. Pearson Education, Inc., 2003, pp. 94 and 95 (Рассел, С. Дж. и Норвиг, П. Искусственный интеллект: Современный подход, 2-е издание. Pearson Education, Inc., 2003, стр. 94 и 95)). Этот способ поддерживает список со всеми из поднаборов, посещенных ранее, и повторно посещает их всякий раз, когда прогнозирующая способность прекращает улучшаться для определенного поднабора. Он может осуществлять поиск в полном пространстве (то есть, исчерпывающий поиск), если предоставлено время, и не накладывает никакого критерия останова, причем имеет значительно меньшую вероятность нахождения локального максимума, по сравнению с прямым отбором и обратным удалением. Первый наилучший результат, как ожидается, очень похож на результаты, полученные исчерпывающим поиском. В аспекте, метод лучевого поиска работает подобно наилучшему первому, но сокращает список поднаборов признаков на каждой стадии, таким образом, он ограничен фиксированным числом, названным шириной луча.
В аспекте, генетический алгоритм является методом поиска, который использует случайные нарушения текущего списка предполагаемых для выбора поднаборов для формирования новых хороших поднаборов (смотрите Schmitt, Lothar M (2001), Theory of Genetic Algorithms, Theoretical Computer Science (259), pp. 1-61 (Шмит, Лотар M (2001), Теория генетических алгоритмов, Теоретические основы вычислительной техники (259), стр. 1-61)). Они являются адаптивными и используют техники поиска, основанные на принципах естественного отбора в биологии. Состязающиеся решения настраиваются и выявляются со временем, с параллельным поиском в пространстве решений (что помогает избегать локального максимума). Скрещивания и мутации применяются к членам текущего поколения для создания следующего поколения. Случайное добавление или удаление признаков из поднабора на понятийном уровне аналогично роли мутации в природной системе. Подобным образом, скрещивания комбинируют признаки из пары поднаборов, чтобы сформировать новый поднабор. Концепция приспособленности вступает в действие по той причине, что самый приспособленный (наилучший) поднабор в данном поколении имеет больший шанс отбора для формирования нового поднабора благодаря скрещиванию и мутации. Поэтому, хорошие поднаборы развиваются со временем.
В аспекте, специфичный схеме (упаковщик) (Kohavi and John (1997), Wrappers for feature selection. Artificial Intelligence, 97(1-2):273-324, December 1997. (Кохави и Джон (1997), Упаковщики для выбора признаков. Искусственный интеллект, 97(1-2):273-324, декабрь 1997 г.)) является подходящим методом поиска. Здесь, идея состоит в том, чтобы отбирать поднабор признаков, которые будут иметь наилучшие характеристики классификации, которые используются для построения модели с конкретным алгоритмом. Точность оценивается посредством перекрестной проверки, набора уклонений или оценщика самонастройки. Модель и набор проходов перекрестной проверки должны выполняться для каждого поднабора признаков, являющихся оцениваемыми. Например, прямой отбор или обратное удаление с k признаками и 10-кратная перекрестная проверка будет занимать приблизительно k2 раз по 10 процедур обучения. Алгоритмы исчерпывающего поиска иногда будут занимать порядка 2k раз по 10 процедур обучения. Хорошие результаты были показаны для поиска по специфике схемы, причем, обратное удаление приводило к более точным моделям, чем прямой отбор, а также большим поднаборам. Более сложные техники обычно не оправданны, но могут приводить к лучшим результатам в некоторых случаях. Статистические критерии значимости могут использоваться для определения времени для останова поиска на основании шансов, что поднабор, являющийся оцениваемым, приведет к улучшению по отношению к текущему наилучшему поднабору.
В аспекте, подходит поиск с состязаниями, который использует t-тест для определения вероятности поднабора, являющегося лучшим, чем наилучший поднабор, на, по меньшей мере, небольшое предписанное пользователем пороговое значение. Если, во время процесса перекрестной проверки с исключением по одному, вероятность становится небольшой, поднабор может быть отброшен, так как совершенно невероятно, что добавление или удаление признаков в отношении этого поднабора приведет к улучшению сверх текущего наилучшего поднабора. При прямом отборе, например, все из добавлений признака в поднабор оцениваются одновременно и те, которые не работают достаточно хорошо, отбрасываются. Поэтому, не все примеры используются (при перекрестной проверке с исключением по одному) для оценки всех поднаборов. Алгоритм поиска с состязаниями также блокирует все почти идентичные поднаборы признаков и использует байесову статистику для сохранения распределения вероятностей на оценке средней погрешности перекрестной проверки с исключением по одному для каждого конкурирующего поднабора. Используется прямой отбор, но, вместо испытания одного за другим всех возможных изменений в отношении наилучшего поднабора, эти изменения подвергаются состязанию, состязание заканчивается, когда заканчивается перекрестная проверка, или остается единственный поднабор.
В аспекте, схемный поиск является более сложным способом, предназначенным для состязания, прогона итерационных последовательностей состязаний, каждая из которых определяет, должен или нет признак быть включен в состав (смотрите Moore, A. W., and Lee, M. S. (1994). Efficient algorithms for minimizing cross-validation error. In Cohen, W. W., and Hirsh, H., eds., Machine learning: Proceedings of the Eleventh International Conference. Morgan Kaufmann (Моор, А. В. и Ли М. С. (1994). Эффективные алгоритмы для минимизации ошибки перекрестной проверки. В Коген В. В. и Хирш, Х., и другие, Машинное обучение: протоколы одиннадцатой международной конференции. Морган Кауфман)). Поиск начинается со всех признаков, маркированных как неизвестные, также как пустого или полного набора признаков. Все комбинации неизвестных признаков используются с равной вероятностью. На каждом обходе, выбирается признак, и поднаборы с и без выбранного признака подвергаются состязанию. Другие признаки, которые составляют поднабор, включаются в состав или исключаются случайным образом в каждой точке при оценке. Победитель состязания используется в качестве начальной точки для следующего повтора состязаний. При условии вероятностной инфраструктуры, хороший признак будет включен в окончательный поднабор, даже если он зависит от другого признака. Схемный поиск принимает во внимание взаимодействующие признаки наряду с ускорением процесса поиска и был показан более эффективным и более быстрым, чем поиск с состязаниями (который использует прямой или обратный отбор).
В аспекте, ранговый поиск с состязаниями упорядочивает признаки, например, на основании их прироста информации, а затем, осуществляет состязание с использованием поднаборов, которые основаны на ранжированиях признаков. Состязание начинается без признаков, продолжается с наделенным признанным лучшим признаком, лучшими двумя признаками, лучшими тремя признаками, и так далее. Перекрестная проверка может использоваться для определения наилучшего метода поиска для конкретного набора данных.
В аспекте, избирательный наивный алгоритм Байеса использует алгоритм поиска, такой как прямой отбор для избежания включения в состав избыточных признаков и признаков, которые зависимы друг от друга (например, смотрите Domingos, Pedro & Michael Pazzani (1997) "On the optimality of the simple Bayesian classifier under zero-one loss". Machine learning, 29:103-137 (Домингос, Педро и Майкл Паззани (1997) «Об оптимальности выборочного байесовского классификатора при десятипроцентных потерях». Машинное обучение, 29:103-137)). Наилучший поднабор обнаруживается простым испытанием характеристик поднаборов с использованием обучающего набора.
Фильтровые способы работают независимо от любого алгоритма обучения, тогда как способы упаковки полагаются на специфичный алгоритм обучения и используют способы, такие как перекрестная проверка для оценки точности поднаборов признаков. Упаковщики часто работают лучше, чем фильтры, но гораздо медленнее, и должны повторно прогоняться каждый раз, когда используется другой алгоритм обучения, или даже когда используется другой набор настроек параметров. Качество функционирования способов упаковки зависит от того, какой алгоритм обучения используется, процедуры, используемой для оценки вневыборочной точности алгоритма обучения, и организации поиска.
Фильтры (например, алгоритм CFS) гораздо быстрее, чем упаковщики для отбора поднаборов (вследствие причин, указанных выше), таким образом, могут использоваться с большими наборами данных. Фильтры также улучшают точность определенного алгоритма предоставлением начального поднабора признаков для алгоритмов упаковки. Этот процесс, поэтому, позволил бы ускорить анализ упаковки.
Исходный вариант алгоритма CFS измерял корреляцию только между дискретными признаками, поэтому сначала дискретизировал бы все непрерывные признаки. Самые последние варианты обрабатывают непрерывные признаки без необходимости в дискретизации.
CFS предполагает, что признаки независимо задаются целевым признаком. Если существует сильная зависимость признаков, качество функционирования CFS может пострадать, и он мог бы претерпеть неудачу в отборе всех из существенных признаков. CFS эффективен при устранении избыточных и несущественных признаков и будет обнаруживать все из существенных признаков в отсутствие сильной зависимости между признаками. CFS будет принимать признаки, способные к прогнозированию отклика переменного в областях пространства примеров, еще не прогнозируемых другими признаками.
Существуют варианты CFS, способные к улучшению обнаружения локально прогнозирующих признаков, очень важных в случаях, где мощные глобально прогнозирующие признаки затеняют локально прогнозирующие. Было показано, что CFS многократно превосходит упаковщик (Hall, M. A. 1999. Correlation-based feature selection for Machine Learning. Ph.D. thesis. Department of Computer Science - The University of Waikato, New Zealand (Холл, M. A. 1999. Основанный на корреляции отбор признаков для машинного обучения. Тезисы кандидатской диссертации. Департамент вычислительной техники - университет Уайкато, Новая Зеландия)), особенно с небольшими наборами данных и в случаях, где есть небольшие зависимости признаков.
В случае алгоритма CFS, числитель оценочной функции указывает, насколько прогнозирующим целевой признак является поднабор, а знаменатель указывает, насколько избыточны признаки в поднаборе. В исходном алгоритме CFS, целевой признак сначала делается дискретным с использованием способа Файяда и Ирани (Fayyad, U. M. and Irani, K. B.. 1993. Multi-interval discretisation of continuous-valued attributes for classification learning. In Proceedings of the Thirteenth International Join Conference on Artificial Intelligence. Morgan Kaufmann, 1993 (Файяд, У. М. и Ирани, К. Б., 1993. Многоинтервальная дискретизация атрибутов с непрерывными значениями для обучения классификации. В протоколах тринадцатой международной совместной конференции по искусственному интеллекту. Морган Кауфман, 1993)). Алгоритм, в таком случае, рассчитывает все корреляции признак - целевой признак (которые будут использоваться в числителе оценочной функции) и все корреляции признак - признак (которые будут использоваться в знаменателе оценочной функции). После того, алгоритм обыскивает пространство поднаборов признаков (с использованием определенного пользователем метода поиска), осуществляя поиск наилучшего поднабора. В модификации алгоритма CFS, симметричная неопределенность используется для расчета корреляций.
Наиболее крупное допущение CFS состоит в том, что признаки независимо задаются данным целевым признаком (то есть, что нет взаимодействий). Поэтому, если присутствуют сильные взаимодействия, CFS может претерпевать неудачу в обнаружении существенных признаков. Ожидается, что CFS должен хорошо работать при средних уровнях взаимодействия. CFS имеет тенденцию ставить в невыгодное положение зашумленные признаки. CFS сильно смещен в направлении небольших поднаборов признаков, приводя к пониженной точности в некоторых случаях. CFS не является сильно зависимым от используемого метода поиска. CFS может быть задано устанавливать большее значения на локально прогнозирующие признаки, даже если эти признаки не показывают выдающейся глобальной прогнозирующей способности. Если не задано учитывать локально прогнозирующие признаки, смещение CFS по направлению к небольшим поднаборам может исключать эти признаки. CFS имеет тенденцию действовать лучше, чем упаковщики на небольших наборах данных также потому, что ему не нужно сохранять часть набора данных для испытания. Упаковщики работают лучше, чем CFS, когда присутствуют взаимодействия. Упаковщик с прямым отбором может использоваться для выявления попарных взаимодействий, но обратное удаление необходимо для обнаружения более высокоуровневых взаимодействий. Обратные поиски, однако, делают упаковщики еще более медленными. Двунаправленный поиск может использоваться для упаковщиков, начиная с поднабора, выбранного алгоритмом CFS. Этот разумный подход может значительно сокращать объем времени, требуемого упаковщиком для выполнения поиска.
Разработка модели
Для моделирования больших наборов данных, могут использоваться несколько алгоритмов, в зависимости от природы данных. Например, в аспекте, способы байесовской сети дают полезный и гибкий вероятностный подход к логическому выводу.
В аспекте, алгоритм оптимального классификатора Байеса делает больше, чем применяет максимальную апостериорную гипотезу к новой записи, для того чтобы прогнозировать вероятность ее классификации (Friedman et al., (1997), Bayesian network classifiers. Machine learning, 29:131-163 (Фридман и другие, (1997), Классификаторы байесовской сети. Машинное обучение, 29:131-163)). Он также рассматривает вероятности по каждой из других гипотез, полученных из обучающего набора (не только максимальной апостериорной гипотезы), и использует эти вероятности в качестве весовых коэффициентов для будущих прогнозов. Поэтому, будущие прогнозы выполняются с использованием всех из гипотез (то есть, всех из возможных моделей), взвешенных своими апостериорными вероятностями.
В аспекте, наивный байесовский классификатор назначает наиболее вероятную классификацию записи, при условии суммарной вероятности признаков. Расчет суммарной вероятности требует большого набора данных и является напряженным по вычислительным затратам. Наивный байесовский классификатор является частью большего класса алгоритмов, называемых байесовыми сетями. Некоторые из этих байесовых сетей могут ослаблять сильное предположение, сделанное наивным алгоритмом Байеса о независимости между признаками. Байесовская сеть является ориентированным ациклическим графом (DAG) с условным распределением вероятностей для каждого узла. Она полагается на предположение, что признаки условно независимы при заданном целевом признаке (наивный алгоритм Байеса), или его родителях, которые могут требовать (расширенная байесовская сеть) или не требовать (обычная байесовская сеть) включения целевого признака. Предположение об условной независимости ограничено поднаборами признаков, и это приводит к набору предположений условной независимости вместе с набором условных вероятностей. Выходные данные отражают описание суммарной вероятности для набора признаков.
В аспекте, разные алгоритмы поиска могут быть реализованы с использованием пакета WEKA в каждой из этих зон, и таблицы вероятности могут рассчитываться простым оценщиком или усреднением байесовской модели (BMA).
Что касается способов для поиска наилучшей сетевой структуры, один из вариантов выбора состоит в том, чтобы использовать основанные на метрике глобальной балльной оценки алгоритмы. Эти алгоритмы полагаются на перекрестную проверку, выполняемую с помощью перекрестной проверки с исключением по одному, k-кратной или накопленной. Способ исключения по одному изолирует одну запись, обучается по оставшейся части набора данных, и оценивает, такую изолированную запись (повторно, для каждой из записей). k-кратный способ разбивает данные на k частей, изолирует одну из этих частей, обучается остатком набора данных и оценивает изолированный набор записей. Алгоритм накопленной перекрестной проверки начинается с пустого набора данных и добавляет запись за записью, обновляя состояние сети после каждой дополнительной записи, и оценивая следующую запись, которая должна быть добавлена согласно текущему состоянию сети.
В аспекте, надлежащая сетевая структура, найденная одним из этих процессов, рассматривается в качестве структуры, которая наиболее точно подогнана к данным, как определяется глобальной или локальной балльной оценкой. Она также может рассматриваться в качестве структуры, которая наилучшим образом кодирует условные независимости между признаками; эти независимости могут быть измерены критериями Хи-квадрат или испытаниями на полное количество информации. Условные независимости между признаками используются для построения сети. Когда вычислительная сложность высока, классификация может выполняться по поднабору признаков, определенному любым способом отбора поднабора.
В альтернативном подходе к построению сети, целевой признак может использоваться в качестве любого другого узла (обычная байесовская сеть) при обнаружении зависимостей после того, как он изолирован от других признаков посредством своего марковского ограждения. Марковское ограждение изолирует узел от нахождения под влиянием любого узла вне его границы, которая составлена из родителей узла, его потомков и родителей его потомков. Когда применяется, марковское ограждение целевого признака часто достаточно для выполнения классификации без потерь точности, и могут быть удалены все из других узлов. Этот способ отбирает признаки (то есть, включенные в марковское ограждение), которые должны использоваться в классификации, и снижает риск избыточной подгонки данных удалением всех узлов, которые находятся вне марковского ограждения целевого признака.
В аспекте, основанные на примерах алгоритмы также пригодны для разработки модели. Основанные на примерах алгоритмы, также указываемые ссылкой как «облегченные» алгоритмы, характеризуются формированием новой модели для каждого примера вместо смещения прогноза по деревьям или сетям, сформированным (однажды) из обучающего набора. Другими словами, они не предусматривают общей функции, которая может пояснять целевой признак. Эти алгоритмы сохраняют полный испытательный набор в памяти и строят модель из набора записей, подобных испытанным. Это подобие оценивается благодаря локально взвешенным способам или способам ближайших соседей, использующим евклидовы расстояния. Как только отобран набор записей, окончательная модель может быть построена с использованием нескольких разных алгоритмов, таких как наивный алгоритм Байеса. Получающаяся в результате модель обычно не проектируется, чтобы хорошо работать, когда применяется к другим записям. Так как наблюдения испытаний сохраняются явным образом, а не в виде дерева или сети, информация никогда не тратится попусту при обучении основанных на примерах алгоритмов.
В аспекте, основанные на примерах алгоритмы полезны для сложных многомерных задач, для которых вычислительные потребности деревьев и сетей превышают имеющуюся в распоряжении память. Этот подход избегает проблемы попытки выполнять понижение сложности посредством отбора признаков для соответствия требованиям деревьев или сетей. Однако, этот процесс может плохо работать при классификации нового примера, так как все вычисления происходят во время классификации. Это обычно не является проблемой во время применений, в которых один или несколько примеров должны классифицироваться одновременно. Обычно, эти алгоритмы дают сходную важность всем из признаков, не устанавливая больший вес на тех, которые лучше поясняют целевой признак. Это может приводить к отбору примеров, которые не являются фактически самыми близкими к оцениваемому примеру в показателях своего отношения к целевому признаку. Основанные на примерах алгоритмы устойчивы к шумам в совокупности данных, так как примеры получают наиболее общее назначение среди всех соседей или среднее значение (непрерывный случай) этих соседей, и эти алгоритмы обычно хорошо работают с очень большими обучающими наборами.
В аспекте, машины опорных векторов (SVM) используются для моделирования наборов данных в целях извлечения данных. Машины опорных векторов являются отростком теории статистического обучения и впервые были описаны в 1992 году. Важный аспект SVM состоит в том, что как только были идентифицированы опорные векторы, остальные наблюдения могут быть удалены из расчетов, таким образом, значительно снижая вычислительную сложность задачи.
В аспекте, алгоритмы обучения дерева решений являются подходящими способами машинного обучения для моделирования. Эти алгоритмы дерева решений включают в себя ID3, Assistant и C4.5. Эти алгоритмы имеют преимущество поиска по большому пространству гипотез без многих ограничений. Они часто смещены к построению небольших деревьев, свойству, которое иногда бывает желательным.
Получающиеся в результате деревья обычно могут быть представлены набором правил «если - то»; это свойство, которое не применяется к другим классам алгоритмов, таким как основанные на примерах алгоритмы, может улучшать удобочитаемость для человека. Классификация примеров происходит посредством сканирования дерева сверху вниз и оценки некоторого признака в каждом узле дерева. Разные алгоритмы обучения дерева решений меняются в показателях своих возможностей и требований; некоторые работают только с дискретными признаками. Большинство алгоритмов дерева решений также требуют, чтобы целевой признак был двоичным, тогда как другие могут обрабатывать непрерывные целевые признаки. Эти алгоритмы обычно устойчивы к ошибкам при определении классов (кодировании) для каждого признака. Другой существенный признак состоит в том, что некоторые из этих алгоритмов могут эффективно справляться с отсутствующими значениями.
В аспекте, алгоритм итерационного дихотомического преобразователя 3 (ID3) является подходящим алгоритмом дерева решений. Этот алгоритм использует «прирост информации», чтобы решать, какой признак наилучшим образом самостоятельно раскрывает цель, и он помещает этот признак на вершину дерева (то есть, в корневой узел). Затем, потомок назначается для каждого класса корневого узла посредством сортировки обучающих записей согласно классам корневого узла и нахождения признака с наибольшим приростом информации в каждом из этих классов. Этот цикл повторяется для каждого вновь добавленного признака, и так далее. Этот алгоритм не может осуществлять «перебор с возвратами» для повторного рассмотрения своих предыдущих решений, и это может приводить к схождению к локальному максимуму. Есть несколько расширений алгоритма ID3, которые выполняют «последующее обрезание» дерева решений, которое является формой перебора с возвратами.
Алгоритм ID3 выполняет «поиск экстремума» по пространству дерева решений, начиная с простой гипотезы и продвигаясь через более сложные гипотезы. Так как он выполняет полный поиск по пространству гипотез, он избегает проблемы выбора пространства гипотез, которое не содержит целевого признака. Алгоритм ID3 выдает только одно дерево, а не все корректные деревья.
Индуктивное смещение может возникать при алгоритме ID3, так как он является алгоритмом первого охвата сверху вниз. Другими словами, он рассматривает все возможные деревья на определенной глубине, выбирает одно наилучшее, а затем, перемещается на следующую глубину. Он отдает предпочтение коротким деревьям над длинными деревьями, и посредством выбора короткого дерева на определенной глубине, он помещает признаки с наивысшим приростом информации ближе всего к корню.
В аспекте дерева решений, вариантом алгоритма ID3 является дерево логистической модели (Landwehr et al., (2003), Logistic Model Trees. Proceedings of the 14th European Conference on machine learning. Cavtat-Dubrovnik, Croatia. Springer-Verlag (Ландвер и другие, (2003), Деревья логистической модели. Протоколы 14-ой европейской конференции по машинному. Кавтат-Дубровник, Хорватия. Спрингер-Верлаг)). Этот классификатор реализует функцию логистической регрессии на листьях. Этот алгоритм имеет дело с дискретными целевыми признаками и может справляться с отсутствующими значениями.
C4.5 является формирующим дерево решений алгоритмом, основанным на алгоритме ID3 (Quinlan (1993) C4.5: Programs for machine learning. Morgan Kaufmann Publishers (Куинлан (1993) C4.5: Программы для машинного обучения. Издатели Моргана Кауфмана)). Некоторые из улучшений, например, включают в себя выбор надлежащей меры оценки признака; обработку обучающих данных с отсутствующими значениями признака; обработку признаков с отличающимися стоимостями; и обработку непрерывных признаков.
Полезным инструментальным средством для оценки качества функционирования двоичных классификаторов является кривая рабочих характеристик приемника (ROC). Кривая ROC является графическим представлением зависимости чувствительности от (1 - специфичности) для системы двоичного классификатора, в то время как меняется ее порог различения (T. Fawcett (2003). ROC graphs: Notes and practical considerations for data mining researchers. Tech report HPL-2003-4. HP Laboratories, Palo Alto, CA, USA (Т. Фоусетт (2003). Графики ROC: Замечания и практические соображения для исследователей извлечения данных. Технический отчет HPL-2003-4. Лаборатории HP, Пало-Альто, Калифорния, США)). Кривые рабочих характеристик приемника (ROC), поэтому, строятся вычерчиванием 'чувствительности' по отношению к '1 - специфичности' для разных порогов. Эти пороги определяют, классифицируется ли запись в качестве положительной или отрицательной, и влияние чувствительности и '1 - специфичности'. В качестве примера, рассмотрим анализ, в котором ряд сортов растений оценивается на их реакцию на патоген, и желательно устанавливать порог, выше которого сорт будет рассматриваться в качестве восприимчивого. На нескольких таких порогах строится кривая ROC, которая помогает определению наилучшего порога для данной проблемы (того, которое дает наилучшее равновесие между частотой истинно положительных суждений и частотой ложноположительных суждений). Более низкие пороги приводят к более высоким частотам ложноположительных суждений вследствие повышенного отношения ложных положительных суждений и истинных отрицательных суждений (несколько отрицательных записей будут определены в качестве положительных). Площадь под кривой ROC является мерой общего качества функционирования классификатора, но выбор наилучшего классификатора может быть основан на конкретных отрезках такой кривой.
Техники перекрестной проверки являются способами, посредством которых конкретный набор алгоритмов выбирается для обеспечения оптимальной работы для данного набора данных. Техники перекрестной проверки используются в материалах настоящей заявки для выбора конкретного алгоритма машинного обучения, например, во время разработки модели. Когда несколько алгоритмов имеются в распоряжении для реализации, обычно интересно выбрать один, который ожидается, что должен иметь наилучшие рабочие характеристики в будущем. Перекрестная проверка обычно является методологией выбора для этой задачи.
Перекрестная проверка основана, в начале, на отделение части обучающих данных, затем обучении оставшимися данными, и, в заключение, на оценке рабочих характеристик алгоритма на отделенном наборе данных. Техники перекрестной проверки предпочтительны над оценкой остатка, так как оценка остатка не информативна в отношении того, как алгоритм будет работать, при применении к новому набору данных.
В аспекте, один из вариантов перекрестной проверки, способ уклонения, основан на разбиении данных надвое, обучение на первом поднаборе и испытание на втором поднаборе. Она занимает приблизительно такой же объем времени для вычисления, как остаточный способ, и она предпочтительна, когда набор данных достаточно велик. Рабочие характеристики этого способа могут меняться в зависимости от того, каким образом набор данных разбивается на поднаборы.
В аспекте перекрестной проверки, способ k-кратной перекрестной проверки является усовершенствованием способа уклонения. Набор данных делится на k поднаборов, и способ уклонения повторяется k раз. Затем вычисляется средняя ошибка по k испытаниям. Каждая запись является частью испытательного набора один раз, и является частью обучающего набора k-1 раз. Этот способ менее чувствителен к образу действий, которым делится набор данных, но вычислительные затраты в k раз больше, чем при способе уклонения.
В другом аспекте перекрестной проверки, способ перекрестной проверки с исключением по одному подобен k-кратной перекрестной проверке. Обучение выполняется с использованием N-1 записей (где N - суммарное количество записей), а испытание выполняется с использованием только одной записи за раз. Локально взвешенные обучающиеся снижают время прогона этих алгоритмов до уровней, аналогичных оценке остатка.
В аспекте перекрестной проверки, техника случайной выборки является еще одним вариантом выбора для испытания, в которой выборка умеренного размера из набора данных (например, большим, чем 30) используется для испытания, причем остаток набора данных используется для обучения. Преимущество использования случайных выборок состоит в том, что выборка может повторяться любое количество раз, что может давать в результате снижение доверительного интервала прогноза. Техники перекрестной проверки, однако, имеют преимущество, что записи в испытательных наборах независимы по всем испытательным наборам.
Некоторые из алгоритмов правил ассоциации, описанных в материалах настоящей заявки, могут использоваться для выявления взаимодействий между признаками в наборе данных, и также могут использоваться для разработки модели. Алгоритм M5P является алгоритмом дерева моделей, подходящим для непрерывных и дискретных целевых признаков. Он строит деревья решений с функциями регрессии вместо окончательных значений классов. Непрерывные признаки могут обрабатываться непосредственно, без преобразования в дискретные признаки. Он использует функцию условной вероятности класса, чтобы иметь дело с дискретными классами. Класс, чье дерево модели формирует наиболее близкое значение вероятности, выбирается в качестве прогнозируемого класса. Алгоритм M5P представляет любое кусочно-линейное приближение для неизвестной функции. M5P рассматривает все возможные испытания и выбирает то, которое доводит до максимума ожидаемое снижение ошибки. Затем, M5P отсекает это дерево в обратном направлении, заменяя поддеревья линейными регрессионными моделями в любом месте, где последняя имеет более низкую оценку ошибки. Оцененная ошибка является средней абсолютной разницей между прогнозируемыми и реальными значениями для всех примеров в узле.
Во время отсечения, недооценка ошибки для невидимых случаев компенсируется посредством (n+v)/(n-v), где n - количество примеров, достигающих узла, а v - количество параметров в линейной модели для такого узла (смотрите Виттен и Франк, 2005). Признаки, вовлеченные в каждую регрессию, являются признаками, которые испытаны в поддеревьях ниже этого узла (смотрите Ванг и Виттен, 1997). Процесс сглаживания в таком случае используется для избежания чрезмерных нарушений непрерывности между соседними линейными моделями на листьях дерева при прогнозировании непрерывных значений класса. Во время сглаживания, сначала выполняется прогнозирование листовой моделью и сглаживается комбинированием ее с прогнозируемыми значениями из линейных моделей в каждом промежуточном узле на пути обратно к корню.
В аспекте моделирования алгоритмами дерева решений, в материалах настоящей заявки используются деревья переменных решений (ADTrees). Этот алгоритм является обобщением деревьев решений, которое полагается на технику выделения, названную AdaBoost (смотрите Freund and Schapire (1996), Experiments with a new boosting algorithm. In L. Saitta, editor, Proceedings of the Thirteenth International Conference on machine learning, pages 148-156, San Mateo, CA, Morgan Kaufmann (Фреунд и Шапире (1996), Эксперименты с новым алгоритмом выделения. У Л. Саитта, редактора, Протоколы тринадцатой международной конференции по машинному обучению, страницы 148-156, Сан-Матео, Калифорния, Морган Кауфман)) для улучшения рабочих характеристик.
По сравнению с другими алгоритмами дерева решений, алгоритм дерева переменных решений имеет тенденцию строить меньшие деревья с более простыми правилами, а потому, будет легче интерпретируемым. Он также ассоциативно связывает реальные значения с каждым из узлов, что предоставляет каждому узлу возможность оцениваться независимо от других узлов. Меньший размер получающихся в результате деревьев и соответствующее снижение требуемому объему и конфигурации памяти делает алгоритм дерева переменных решений одним из немногих вариантов выбора для обработки очень больших и сложных наборов данных. Многочисленные пути, следуемые записью после узла прогнозирования, делают этот алгоритм более устойчивым к отсутствующим значениям, так как все из альтернативных путей отслеживаются, несмотря на один проигнорированный путь. Наконец, этот алгоритм предусматривает степень достоверности в каждой классификации, названную «допуском классификации», которая в некоторых применениях является настолько же важной, как и сама классификация. Как и с другими деревьями решений, этот алгоритм также весьма устойчив по отношению к мультиколлинеарности среди признаков.
Растения и животные часто разводятся на основе определенных желательных признаков, таких как зерновой выход, процентная жирность туши, масличный профиль и устойчивость к заболеваниям. Одна из целей программы улучшения растения или животного состоит в том, чтобы идентифицировать особи для разведения, из условия чтобы желательные признаки выражались чаще или заметнее в последующих поколениях. Обучение включает в себя, но не в качестве ограничения, изменение установленных порядков, действий или поведения, вовлеченных в идентификацию особей для разведения, из условия чтобы степень повышения выражения желательного признака была большей, или были ниже затраты на идентификацию особей для разведения. Посредством выполнения этапов, перечисленных в материалах настоящей заявки, можно разрабатывать модель для более эффективного отбора особей для разведения, чем другими способами, и для более точной классификации или прогнозирования продуктивности гипотетических особей на основании комбинации значений признаков.
В дополнение к желательным признакам, могут быть получены данные для одного или более дополнительных признаков, которые могут иметь или могут не иметь очевидного отношения к желательным признакам.
Все цитируемые источники, упомянутые в этом раскрытии, включены в материалы настоящей заявки посредством ссылки до степени, в которой они относятся к материалам и способам, используемым в этом раскрытии.
ПРИМЕР
Последующий пример предназначен только для иллюстративных целей и не подразумевается ограничивающим объем этого раскрытия.
Элитные линии кукурузы, содержащие высокий и низкий уровни устойчивости к патогену идентифицировались посредством сортировки в полевых и оранжерейных условиях. Линия, которая демонстрирует высокие уровни устойчивости к этому патогену использовалась в качестве донора и скрещивалась с восприимчивой элитной линией. Потоки затем подвергались обратному скрещиванию с той же самой восприимчивой линией. Получающаяся в результате популяция скрещивалась с запасом гаплоидных индукторов, и технология удвоения хромосом использовалась для развития 191 фиксированных инбредных линий. Уровень устойчивости к патогену оценивался для каждой линии в двух репликациях с использованием методологий сортировки в полевых условиях. Сорок четыре репликации восприимчивой элитной линии также оценивались с использованием методологий сортировки в полевых условиях. Данные генотипа формировались для всех 191 двойных гаплоидных линий, восприимчивой элитной линии и устойчивого донора с использованием 93 маркеров полиморфных SSR.
Заключительный набор данных содержал в себе 426 выборок, которые были поделены на две группы на основании результатов сортировки в полевых условиях. Растения с балльными оценками сортировки в полевых условиях, находящимися в диапазоне от 1 до 4 составляли восприимчивую группу, наряду с тем, что растения с балльными оценками сортировки в полевых условиях от 5 до 9 составляли устойчивую группу. Для нашего анализа, восприимчивая группа была помечена «0», а устойчивая группа была помечена «1».
Набор данных анализировался с использованием трехэтапного процесса, состоящего из: (a) выявления правил ассоциации; (b) создания новых признаков на основании выводов этапа (a), и добавления этих признаков в набор данных; (c) разработки модели классификации для целевого признака без признаков с этапа (b) и другой модели с признаками с этапа (b). Описание применения каждого из этих этапов к этим данным устанавливает следующее.
Этап (a): Выявление правил ассоциации: в этом примере, 426 выборок оценивалось с использованием DDPM (алгоритма извлечения различительного шаблона) и CARPENTER (алгоритма извлечения часто встречающихся шаблонов). Все 94 признака (с включенным в состав целевым признаком) использовались для оценки.
Правило ассоциации, выявленное алгоритмом DDPM, включало в себя следующие признаки:
1. Признак 48=5_103.776_umc2013, Признак 59=7_12.353_lgi2132 и Признак 89=10_43.909_phi050
Этот различительный шаблон имел наилучший прирост (0,068) информации из всех шаблонов с опорой (появлениями вне 426 выборок) ≥120.
Пять правил ассоциации, выявленных алгоритмом CARPENTER, включали в себя следующие признаки:
1. Признак 59=7_12.353_lgi2132, Признак 62=7_47.585_umcl036, и Реакция = 1
2. Признак 59=7_12.353_lgi2132, Признак 92=10_48.493_umcl648, и Реакция = 1
3. Признак 35=4_58.965_umcl964, Признак 59=7_12.353_lgi2132, и Реакция = 1
4. Признак 19=2_41.213_lgi2277, Признак 20=2_72.142_umcl285, и Реакция = 0
5. Признак 19=2_41.213_lgi2277, Признак 78=8_95.351_umc1384, и Реакция = 0
6. Признак 88=10_18.018_umc1576, Признак 89=10_43.909_phi050, и Реакция = 0
Правила ассоциации с реакцией = 1 имеют опору 180, а правила с реакцией =0 имеют опору 140.
Этап (b): Создание новых признаков на основании выводов этапа (a) и добавление этих признаков в набор данных: С использованием исходных признаков, включенных в 6 правил ассоциации, обнаруженных во время этапа (a), создавались новые признаки. Эти новые признаки создавались путем сцепления исходных признаков, как показано в таблице 1.
Этап (c): Разработка модели классификации для целевого признака до добавления признаков с этапа (b) и еще одной модели после добавления признаков с этапа (b). Для разработки модели, алгоритм REPTree применялся к набору данных. Таблица 2 показывает, что после добавления новых признаков в набор данных, средняя абсолютная погрешность уменьшалась (то есть, новые признаки улучшали точность классификации). Таблица 3 показывает матрицу слияния, являющуюся результатом модели REPTree, использующей исходный набор данных без новых признаков с этапа (b). Таблица 4 показывает матрицу неточности, являющуюся результатом модели REPTree, использующей исходный набор данных и новые признаки с этапа (b). Добавление новых признаков с этапа (b) приводило к увеличению количества безошибочно классифицированных записей для обоих классов целевого признака. Для класса «0», количество безошибочно классифицированных записей увеличилось с 91 до 97. Для класса «1», количество безошибочно классифицированных записей увеличилось с 166 до 175. Фиг. 1 показывает увеличение площади под кривой ROC, полученной добавлением новых признаков с этапа (b). Это указывает, что добавление новых признаков с этапа (b) приводит к улучшенной модели. Эти результаты были получены с использованием 10-кратной перекрестной проверки.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ ВЫБОРА ПРИЗНАКОВ, ИСПОЛЬЗУЮЩИЕ ОСНОВАННЫЕ НА ГРУППЕ КЛАССИФИКАТОРОВ ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ | 2007 |
|
RU2477524C2 |
| СИСТЕМА АДМИНИСТРИРОВАНИЯ ТРАНЗАКЦИЙ С ИИ | 2020 |
|
RU2777958C2 |
| РАСТЕНИЕ АРБУЗА, ХАРАКТЕРИЗУЮЩЕЕСЯ ПРОДУКТИВНЫМ ЦВЕТЕНИЕМ | 2017 |
|
RU2792674C2 |
| КОМБИНИРОВАННОЕ ИСПОЛЬЗОВАНИЕ КЛИНИЧЕСКИХ ФАКТОРОВ РИСКА И МОЛЕКУЛЯРНЫХ МАРКЕРОВ ТРОМБОЗА ДЛЯ ПОДДЕРЖКИ ПРИНЯТИЯ КЛИНИЧЕСКИХ РЕШЕНИЙ | 2013 |
|
RU2682622C2 |
| Участки генов и гены, ассоциированные с повышенной урожайностью у растений | 2016 |
|
RU2758718C2 |
| ОСНОВАННОЕ НА СТРУКТУРЕ ПРОГНОЗНОЕ МОДЕЛИРОВАНИЕ | 2014 |
|
RU2694321C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ИНТЕГРИРОВАНИЯ СИСТЕМАТИЧЕСКОГО ПРОРЕЖИВАНИЯ ДАННЫХ В ОСНОВАННЫЙ НА ГЕНЕТИЧЕСКОМ АЛГОРИТМЕ ВЫБОР ПОДМНОЖЕСТВА ПРИЗНАКОВ | 2007 |
|
RU2449365C2 |
| МОЛЕКУЛЯРНЫЕ МАРКЕРЫ НИЗКОГО СОДЕРЖАНИЯ ПАЛЬМИТИНОВОЙ КИСЛОТЫ В ПОДСОЛНЕЧНИКЕ (HELIANTHUS ANNUS) И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2013 |
|
RU2670517C2 |
| МОЛЕКУЛЯРНЫЕ МАРКЕРЫ ГЕНА RLM2 РЕЗИСТЕНТНОСТИ К ЧЕРНОЙ НОЖКЕ BRASSICA NAPUS И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2014 |
|
RU2717017C2 |
| Способ диагностики онкологического заболевания крови | 2022 |
|
RU2803281C1 |
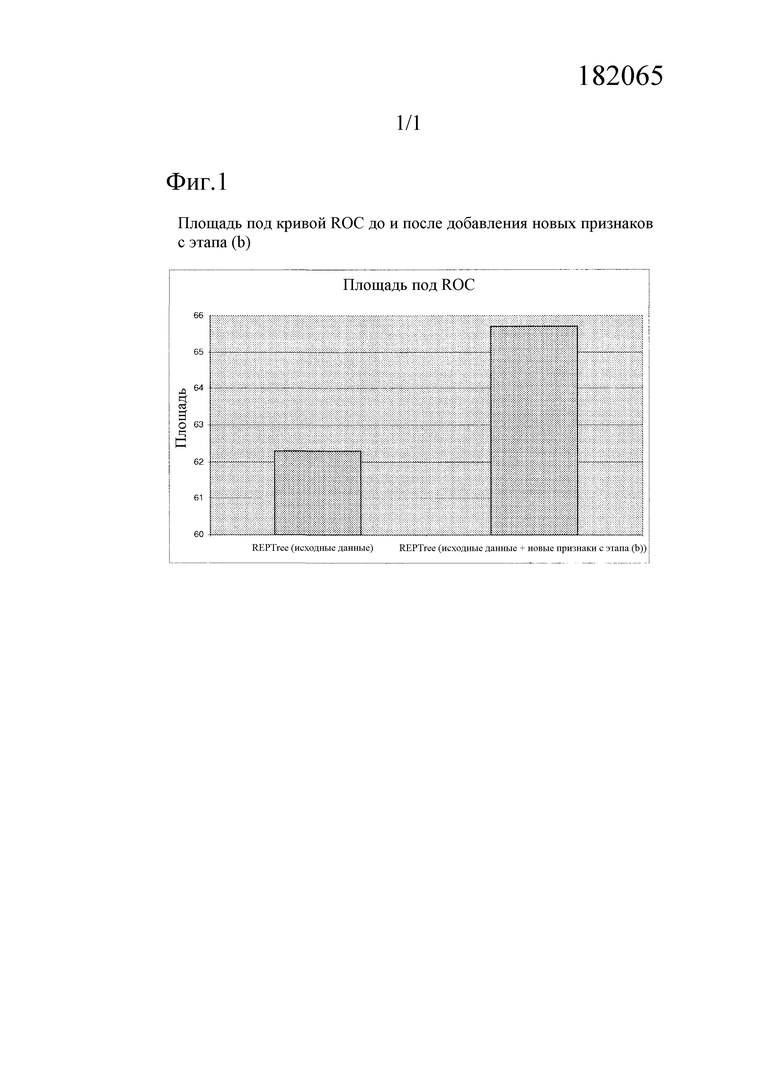
Изобретение относится к способу прогнозирования наличия по меньшей мере одного целевого признака в растении. Технический результат заключается в увеличении точности прогнозирования целевых признаков растений. Определяют посредством прямого секвенирования ДНК генотип растения для по меньшей мере одного молекулярного генетического маркера. Предоставляют набор данных, содержащий набор переменных, при этом по меньшей мере одна из переменных в наборе данных содержит значение, представляющее генотип растения для молекулярного(ых) генетического(их) маркера(ов). Определяют по меньшей мере одно правило ассоциации из набора данных, используя один или более алгоритмов извлечения правил ассоциации, причем правило ассоциации представляет собой правило, определяющее элементы, которые часто появляются вместе в пределах набора данных. Используют правило(а) ассоциации для создания одной или более новых переменных для набора данных. Добавляют новую(ые) переменную(ые) к набору данных и используют их для прогнозирования наличия целевых признаков в растении. 3 н. и 38 з.п. ф-лы, 4 табл., 1 ил.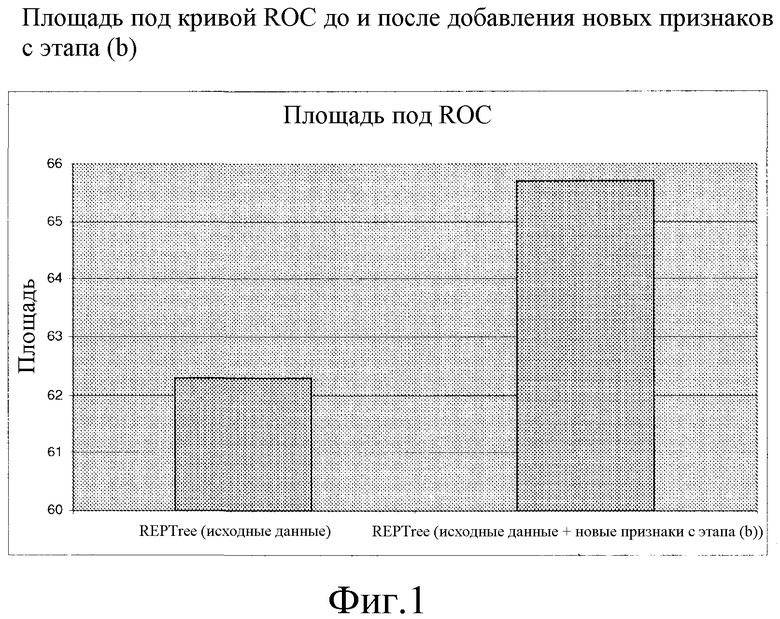
1. Способ прогнозирования наличия по меньшей мере одного целевого признака в растении, причем способ содержит этапы, на которых:
определяют посредством прямого секвенирования ДНК генотип растения для по меньшей мере одного молекулярного генетического маркера, выбираемого из группы, состоящей из молекулярного маркера ДНК и молекулярного маркера РНК;
предоставляют набор данных, содержащий набор переменных, при этом по меньшей мере одна из переменных в наборе данных содержит значение, представляющее генотип растения для молекулярного(ых) генетического(их) маркера(ов);
определяют по меньшей мере одно правило ассоциации из набора данных, используя компьютер и один или более алгоритмов извлечения правил ассоциации, причем правило ассоциации представляет собой правило, определяющее элементы, которые часто появляются вместе в пределах набора данных;
используют правило(а) ассоциации для создания одной или более новых переменных для набора данных;
добавляют новую(ые) переменную(ые) к набору данных;
используют новую(ые) переменную(ые) для прогнозирования наличия целевого(ых) признака(ов) в растении; и
используют спрогнозированное наличие непрерывного(ых) целевого(ых) признака(ов) в растении для отбора инбредных линий, отбора гибридов; ранжирования гибридов, ранжирования гибридов для определенной географии; отбора родителей новых инбредных популяций; или нахождения участков для интрогрессии в элитные инбредные линии.
2. Способ по п. 1, в котором правила ассоциации включают в себя пространственные и временные правила ассоциации, которые определяют самоорганизующимися картами.
3. Способ по п. 1, в котором набор данных содержит переменные, выбираемые из группы, состоящей из данных окружающей среды, данных о фенотипе, данных последовательности ДНК, данных микроматрицы, биохимических данных, метаболических данных или их комбинации.
4. Способ по п. 1, в котором использование новой(ых) переменной(ых) для прогнозирования наличия целевого(ых) признака(ов) в растении содержит использование одного или более алгоритмов машинного обучения, выбранных из группы, состоящей из алгоритмов оценки признаков, алгоритмов отбора поднабора признаков, байесовских сетей, алгоритмов, основанных на примерах, машин опорных векторов, алгоритма голосования, чувствительного к стоимости классификатора, алгоритма укладки, правил классификации и деревьев решений.
5. Способ по п. 1, в котором один или более алгоритмов извлечения правил ассоциации выбирают из группы, состоящей из алгоритма APriori, алгоритма FP-growth, алгоритмов извлечения правил ассоциации, которые могут обрабатывать большое количество признаков, алгоритмов извлечения огромных шаблонов, алгоритма извлечения прямых различительных шаблонов, деревьев решений, неточных множеств.
6. Способ по п. 1, в котором алгоритм извлечения правил ассоциации является алгоритмом самоорганизующейся карты (SOM).
7. Способ по п. 1, в котором один или более алгоритмов извлечения правил ассоциации являются алгоритмами извлечения правил ассоциации, которые могут обрабатывать большое количество признаков, включают в себя, но не в качестве ограничения, CLOSET+, CHARM, CARPENTER и COBBLER.
8. Способ по п. 1, в котором один или более алгоритмов извлечения правил ассоциации являются алгоритмами, которые могут находить прямые различительные шаблоны, включают в себя, но не в качестве ограничения, DDPM, HARMONY, RCBT, CAR и PATCLASS.
9. Способ по п. 1, в котором один или более алгоритмов извлечения правил ассоциации включают в себя алгоритм слияния шаблонов в качестве алгоритма, который может находить огромные шаблоны.
10. Способ по п. 1, в котором использование новой(ых) переменной(ых) для прогнозирования наличия целевого(ых) признака(ов) в растении включает в себя использование алгоритма оценки признаков, выбранного из группы, состоящей из алгоритма прироста информации, алгоритма Relief, алгоритма ReliefF, алгоритма RReliefF, алгоритма симметричной неопределенности, алгоритма отношений прироста и алгоритма ранжировщика.
11. Способ по п. 1, в котором использование новой(ых) переменной(ых) для прогнозирования наличия целевого(ых) признака(ов) в растении включает в себя использование алгоритма отбора поднабора признаков, выбираемого из группы, состоящей из алгоритма, основанного на корреляции отбора признаков (CFS), и алгоритма упаковки в ассоциации с любым другим алгоритмом машинного обучения.
12. Способ по п. 1, в котором использование новой(ых) переменной(ых) для прогнозирования наличия целевого(ых) признака(ов) в растении включает в себя использование алгоритма байесовской сети, включающего в себя наивный алгоритм Байеса.
13. Способ по п. 1, в котором использование новой(ых) переменной(ых) для прогнозирования наличия целевого(ых) признака(ов) в растении включает в себя использование основанного на примерах алгоритма, выбираемого из группы, состоящей из основанного на примерах алгоритма 1 (IB1), основанного на примерах алгоритма k ближайших соседей (IBK), KStar, алгоритма облегченных правил Байеса (LBR) и алгоритма локально взвешенного обучения (LWL).
14. Способ по п. 1, в котором использование новой(ых) переменной(ых) для прогнозирования наличия целевого(ых) признака(ов) в растении включает в себя использование алгоритма машины опорных векторов.
15. Способ по п. 14, в котором алгоритм машины опорных векторов является алгоритмом регрессии по методу опорных векторов (SVR).
16. Способ по п. 14, в котором алгоритм машины опорных векторов использует алгоритм последовательной минимальной оптимизации (SMO).
17. Способ по п. 14, в котором алгоритм машины опорных векторов использует алгоритм последовательной минимальной оптимизации для регрессии (SMOReg).
18. Способ по п. 1, в котором использование новой(ых) переменной(ых) для прогнозирования наличия целевого(ых) признака(ов) в растении включает в себя использование дерева решений, выбираемого из группы, состоящей из алгоритма дерева логистической модели (LMT), алгоритма дерева переменных решений (ADTree), алгоритма М5Р и алгоритма REPTree.
19. Способ по п. 1, в котором целевой(ые) признак(и) являе(ю)тся, каждый, непрерывным целевым признаком и дискретным целевым признаком.
20. Способ по п. 1, в котором целевой(ые) признак(и) включает(ют) в себя двоичный целевой признак.
21. Способ по п. 1, в котором набор данных содержит значение из каждого растения в популяции растений для по меньшей мере одной из переменных.
22. Способ по п. 21, в котором популяция растений является структурированной или неструктурированной популяцией растений.
23. Способ по п. 21, в котором популяция растений содержит инбредные растения.
24. Способ по п. 21, в котором популяция растений содержит гибридные растения.
25. Способ по п. 21, в котором растения популяции растений представляют собой кукурузу, сою, сахарный тростник, сорго, пшеницу, подсолнечник, рис, канолу, хлопок и просо.
26. Способ по п. 21, в котором популяция растений содержит от приблизительно 2 до приблизительно 1000000 членов.
27. Способ по п. 1, в котором набор данных содержит набор переменных, созданных из от приблизительно 1 до приблизительно 1000000 маркеров.
28. Способ по п. 1, в котором набор переменных включает в себя по меньшей мере одну переменную, созданную из молекулярного генетического маркера, выбранного из группы, состоящей из простой повторяющейся последовательности (SSR), расщепленной амплифицированной полиморфной последовательности (CAPS), полиморфизма длин простой последовательности (SSLP), полиморфизма длин рестрикционных фрагментов (RFLP), маркера произвольной амплифицированной полиморфной ДНК (RAPD), полиморфизма одиночных нуклеотидов (SNP), полиморфизма длины произвольного фрагмента (AFLP), вставки, удаления и гаплотипа, созданного из двух или более из описанных выше молекулярных генетических маркеров.
29. Способ по п. 1, в котором набор переменных включает в себя по меньшей мере одну переменную, созданную из молекулярного генетического маркера в соединении с одним или более измерений фенотипа, данных микроматрицы, аналитических измерений, биохимических измерений или относящихся к окружающей среде измерений в качестве признаков.
30. Способ по п. 1, в котором целевой(ые) признак(и) включает(ют) в себя по меньшей мере одну численно представимую особенность фенотипа, выбранную из группы, включающей: устойчивость к болезням, урожайность, зерновой выход, прочность пряжи, белковый состав, содержание белка, устойчивость к насекомым, влагосодержание зерна, содержание масла в зерне, качество зерновых масел, засухоустойчивость, устойчивость к корневому полеганию, высота растения, высота колоса, содержание белка в зерне, содержание аминокислот в зерне, цвет зерна и устойчивость к стеблевому полеганию.
31. Способ по п. 1, в котором целевой(ые) признак(и) включает(ют) в себя по меньшей мере одну численно представимую особенность фенотипа, которую устанавливают с использованием статистических способов, способов машинного обучения или любой их комбинации.
32. Способ по п. 21, в котором генотип каждого растения в популяции растений для по меньшей мере одного молекулярного генетического маркера определяют прямым секвенированием ДНК.
33. Способ прогнозирования наличия по меньшей мере одного целевого признака в растении посредством извлечения правил ассоциации из набора данных с по меньшей мере одной переменной, созданной из по меньшей мере одного основанного на растении молекулярного генетического маркера, выбранного из группы, состоящей из молекулярного маркера ДНК и молекулярного маркера РНК, согласно которому находят по меньшей мере одно правило ассоциации и используют переменные, созданные из этих правил ассоциации, для классификации или прогнозирования одного или более целевых признаков растения, причем способ содержит этапы, на которых:
определяют значения для переменных в большем наборе данных;
выбирают поднабор переменных из переменных в большем наборе данных;
разрабатывают модель для прогнозирования или классификации одного или более целевых признаков с по меньшей мере одной переменной, добавленной для создания большего набора данных;
используют модель для прогнозирования наличия целевого(ых) признака(ов) в растении; и
используют спрогнозированное наличие непрерывного(ых) целевого(ых) признака(ов) в растении для отбора инбредных линий, отбора гибридов, ранжирования гибридов, ранжирования гибридов для определенной географии, отбора родителей новых инбредных популяций, или нахождения участков для интрогрессии в элитные инбредные линии.
34. Способ по п. 33, в котором по меньшей мере один из перечисленных этапов выполняют с использованием алгоритма машинного обучения.
35. Способ по п. 33, в котором определение правил ассоциации включает в себя выявление пространственных и временных ассоциаций с использованием самоорганизующихся карт.
36. Способ по п. 33, в котором один или более целевых признаков представляет собой поднабор переменных, выбранных из переменных в большем наборе данных.
37. Способ по п. 33, дополнительно содержащий разработку по меньшей мере одной дополнительной модели для прогнозирования или классификации касательно одного или более целевых признаков с по меньшей мере одной новой переменной, добавленной для создания большего набора данных, при этом перекрестную проверку используют для сравнения алгоритмов и наборов значений параметров в моделях.
38. Способ по п. 33, дополнительно содержащий разработку по меньшей мере одной дополнительной модели для прогнозирования или классификации касательно одного или более целевых признаков с по меньшей мере одной новой переменной, добавленной для создания большего набора данных, при этом используют кривые рабочих характеристик приемника (ROC) для сравнения алгоритмов и наборов значений параметров в моделях.
39. Способ по п. 33, в котором одну или более переменных выводят математически или вычислительным образом из других переменных.
40. Способ селекционного разведения растений, содержащий этапы, на которых:
предоставляют набор данных, содержащий набор переменных, созданных из по меньшей мере одного молекулярного генетического маркера растения, причем набор данных содержит значение у каждого растения из популяции растений для по меньшей мере одной из переменных;
определяют по меньшей мере одно правило ассоциации из набора данных, используя компьютер и один или более алгоритмов извлечения правил ассоциации, причем правило ассоциации представляет собой правило, определяющее элементы, которые часто появляются вместе в пределах набора данных;
используют правило(а) ассоциации для создания одной или более новых переменных для набора данных;
добавляют новую(ые) переменную(ые) к набору данных;
используют новую(ые) переменную(ые) для прогнозирования характеристик гибрида в растениях популяции растений;
выбирают соответствующие родительские растения для создания гибридов, прогнозируемых как имеющие высокие характеристики; и
производят гибрид из выбранных растений.
41. Способ по п. 40, в котором новые переменные используют для прогнозирования характеристик гибрида в растениях популяции растений по различным географическим местоположениям.
| Jianming Yu et al, Genetic mapping and genome organization of maize, Current Opinion in Biotechnology, c | |||
| Канатное устройство для подъема и перемещения сыпучих и раздробленных тел | 1923 |
|
SU155A1 |
| Fadi A | |||
| Thabtah et al, MCAR: multi-class classification based on association rule, ACS/IEEE International Conference on Computer Systems and Applications 2005, 2005 г. | |||
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Jianyong Wang et al, HARMONY: Efficiently Mining the Best Rules for Classification, SIAM 2005, 2005 г., с | |||
| Автоматическая акустическая блокировка | 1921 |
|
SU205A1 |

