ОБЛАСТЬ ТЕХНИКИ
Объекты предлагаемого изобретения, в целом, относятся к генной инженерии и, в частности, к способу обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, и используемому с этой целью устройству.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ
Делеция - это частичная потеря хромосомы или молекул ДНК в геноме, которая является одной из важнейших причин, приводящих к генетической мутации.
В настоящее время для обнаружения микроделеций в ДНК-маркирующем участке обычно используют метод ПЦР (полимеразной цепной реакции). Метод ПЦР позволяет выборочно амплифицировать определенный участок ДНК in vitro, воспроизводя сценарий репликации ДНК in vivo. Преимущества использования метода ПЦР включают быстроту и удобство при детекции небольшого числа участков. Кроме того, для конструирования зонда требуется заранее знать последовательности на обоих концах определенной области ДНК, и с этой целью необходимо, чтобы эти микроделеций в ДНК-маркирующем сайте хромосомы были заранее известны.
Но детекция методом ПЦР при наличии большого числа образцов или неизвестных микроделеций может иметь серьезные ограничения. Так, при необходимости обнаружения области с ДНК-маркирующим участком, включающей относительно большое число участков, или, в частности, в процессе поиска, традиционный метод ПЦР не отвечает поставленным требованиям, в связи с чем существует потребность в новом методе исследования.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Основная техническая проблема, которую решает предложенное изобретение, заключается в создании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком и используемого с этой целью аппарата, которые позволят обнаруживать микроделеций в области хромосомы с ДНК-маркирующим участком при работе с большим количеством образцов и ограниченности ресурсов, и также позволят обнаруживать неизвестные микроделеций в области хромосомы с ДНК-маркирующим участком.
Для решения вышеуказанной технической проблемы в предложенном изобретении используется техническое решение, относящееся к способу обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, который включает:
получение зонда захвата, соответствующего последовательности ДНК в области с ДНК-маркирующим участком;
гибридизацию зонда захвата со смешанной библиотекой из множества образцов ДНК для связывания с последовательностью ДНК из области с ДНК-маркирующим участком, из множества образцов ДНК;
секвенирование захваченной последовательности ДНК из области с ДНК-маркирующим участком, для получения данных секвенирования, и
анализ результатов секвенирования с использованием метода математической статистики с получением результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
В предпочтительном варианте этап анализа полученных при секвенировании данных с использованием статистических критериев включает:
нормализацию значения глубины секвенирования области с ДНК-маркирующим участком с целью получения нормализованного значения глубины секвенирования; и
поиск резко отклоняющихся («выбрасывающихся») значений глубины секвенирования области с ДНК-маркирующим участком, основанный на нормализованном значении глубины секвенирования, с использованием метода математической статистики, для получения результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
В предпочтительном варианте, этап нормализации значения глубины секвенирования ДНК-маркирующего участка включает:
деление всех значений глубины секвенирования одной и той же области в каждом из множества образцов ДНК на среднее значение глубины каждого из множества образцов ДНК, с целью получения нормализованных значений глубины секвенирования одной и той же области для множества образцов ДНК.
Предпочтительный вариант этапа поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включает:
расчет среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования одной и той же области во множестве образцов ДНК;
построение графика нормального распределения по всем «невыбрасывающимся» значениям для одной и той же области, на основании рассчитанного среднего значения и дисперсии всех нормализованных значений глубины в одной и той же области для каждого из множества образцов ДНК;
расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
определение первого критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования; и
получение результата R1, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше первого критического значения вероятности.
В предпочтительном варианте после этапа получения результата R1 способ включает:
экспериментальную проверку результата R1 для получения результата проверки;
определение второго критического значения вероятности на основании результата проверки, в котором второе критическое значение вероятности меньше первого критического значения вероятности; и
получение результата R2, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше второго критического значения вероятности.
Предпочтительный вариант этапа поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включает:
расчет первого отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК; и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
расчет первого отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК; и медианой значений глубины секвенирования, полученных для всех областей, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
обучение критического значения первого отношения первому отношению D/S с использованием алгоритма ID3 и обучение критического значения второго отношения первому отношению D/R с использованием алгоритма ID3;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S больше критического значения первого отношения;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R больше критического значения второго отношения; и
получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R меньше критического значения второго отношения.
В предпочтительном варианте этап поиска резко отклоняющегося значения глубины секвенирования области с ДНК-маркирующим участком включает:
расчет среднего значения и дисперсии на основании всех нормализованных значений глубины одной и той же области для каждого из множества образцов ДНК;
построение графика нормального распределения по всем «невыбрасьшающимся» значениям для одной и той же области, на основании рассчитанного среднего значения и дисперсии всех нормализованных значений глубины в одной и той же области для каждого из множества образцов ДНК;
расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
определение третьего критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования;
получение результата R3, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше третьего критического значения вероятности;
расчет второго отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК; и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК в результате R3;
расчет второго отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК; и медианой значений глубины секвенирования, полученных для всех областей, в результате R3;
обучение критического значения третьего отношения второму отношению D/S при использовании алгоритма ID3 и обучение критического значения четвертого отношения второму отношению D/R при использовании алгоритма ID3;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S больше критического значения третьего отношения;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R больше критического значения четвертого отношения; и
получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R меньше критического значения четвертого отношения.
Предпочтительно этап получения зонда захвата включает:
нахождение последовательности ДНК в области с ДНК-маркирующим участком в геномной базе данных;
выбор квалифицированной последовательности ДНК в области с ДНК-маркирующим участком, соответствующей требованиям к конструированию зонда захвата; и
проектирование и синтез зонда захвата на основании квалифицированной последовательности ДНК.
В предпочтительном варианте создание смешанной библиотеки из множества образцов ДНК включает следующие этапы:
создание множества библиотек ДНК для множества отдельных образцов ДНК, таким образом, чтобы каждая из множества библиотек ДНК имела адаптор, отличающийся от адаптора других библиотек ДНК;
смешивание множества библиотек ДНК в заданном соотношении; и
определение полученной смеси как смешанной библиотеки, если полученная смесь соответствует требованиям контроля качества.
В предпочтительном варианте на этапе создания множества библиотек ДНК из множества отдельных образцов ДНК конструирование библиотеки ДНК для каждого из множества отдельных образцов ДНК включает следующие подэтапы:
фрагментацию геномной ДНК на фрагменты ДНК заданного размера с использованием для этого физических или химических методов;
концевую репарацию фрагментов ДНК с получением фрагментов ДНК с репарированными - фосфорилированными концами;
добавление основания "А" к фрагментам ДНК с репарированными концами с 3'-конца, для того чтобы получить фрагменты ДНК с основанием "А" на 3'-конце;
лигирование Индекс-адаптора с фрагментами ДНК, имеющими основание «А» на 3'-конце, для получения фрагментов ДНК, лигированных с Индекс-адаптором;
амплификацию фрагментов ДНК, лигированных с Индекс-адаптором, при использовании праймера, включающего последовательность, специфичную к Индекс-адаптору, для получения продукта амплификации; и
определение продукта амплификации как библиотеки ДНК, если продукта амплификации соответствует требованиям контроля качества.
В предпочтительном варианте, после этапа секвенирования захваченной последовательности ДНК и до этапа анализа результатов секвенирования способ включает контроль качества результатов секвенирования.
Предпочтительно, этап контроля качества результатов секвенирования включает:
фильтрование первых неквалифицированных данных, содержащихся в результате секвенирования, для получения первых квалифицированных данных секвенирования;
картирование первых квалифицированных данных секвенирования к эталонной геномной последовательности посредством использования программного обеспечения для картирования коротких последовательностей, и расчет первого параметра корреляции для значения глубины секвенирования для каждого из множества образцов ДНК и второго параметра корреляции для значения глубины секвенирования для области с ДНК-маркирующим участком, содержащей заданную последовательность среди множества образцов ДНК;
фильтрование вторых неквалифицированных данных, содержащихся в результате секвенирования, на основании первого рассчитанного параметра корреляции, для получения вторых квалифицированных данных секвенирования; и
фильтрование третьих неквалифицированных данных, содержащихся в результате секвенирования, на основании второго рассчитанного параметра корреляции, для получения третьих квалифицированных данных секвенирования области с ДНК-маркирующим участком, содержащей заданную последовательность.
В предпочтительном варианте, этап фильтрования первых неквалифицированных данных, содержащихся в результате секвенирования, для получения первых квалифицированных данных секвенирования, включает:
получение первого набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих больше заданного процента низкокачественных оснований, из данных секвенирования;
получение второго набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих более 10% неопределенных оснований, из первого набора секвенированных данных;
получение третьего набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих последовательность сиквенс-адаптора, из второго набора секвенированных данных после картирования к библиотеке последовательностей сиквенс-адаптеров; и
получение первых квалифицированных данных секвенирования посредством фильтрования неквалифицированных данных, содержащих экзогенную последовательность, из третьего набора секвенированных данных после картирования ко всем внесенным экзогенным последовательностям.
В предпочтительном варианте, этап фильтрования вторых неквалифицированных данных, содержащихся в результате секвенирования, включает:
получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования для множества образцов ДНК в первых квалифицированных данных секвенирования в возрастающем порядке; и
фильтрование неквалифицированных данных секвенирования со значениями глубины секвенирования вне интервала от Q1-1,5 МКР до Q3+l,5 МКР, для получения вторых квалифицированных данных секвениирования.
В предпочтительном варианте, этап фильтрования третьих неквалифицированных данных, содержащихся в результате секвенирования, включает:
получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования в заданной области для различных образцов ДНК во вторых квалифицированных данных секвенирования в возрастающем порядке; и
фильтрование неквалифицированных данных, у которых медиана значений глубины секвенирования в заданной области в различных образцах ДНК равна нулю или больше чем Q3+1,5 МКР, с получением третьих квалифицированных данных секвенирования.
Для решения вышеуказанной технической проблемы служит другой объект предлагаемого изобретения - аппарат для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, который может включать:
устройство для получения зонда захвата, соответствующего последовательности ДНК в области с ДНК-маркирующим участком;
устройство для гибридизации зонда захвата со смешанной библиотекой образцов ДНК, для связывания последовательности ДНК в области с ДНК-маркирующим участком из множества образцов ДНК;
устройство для получения данных секвенирования захваченной последовательности ДНК из области с ДНК-маркирующим участком; и
устройство для получения результата при выявлении микроделеций, выполняющее анализ данных секвенирования посредством использования метода математической статистики с получением результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
Предпочтительно устройство для получения результата при выявлении микроделеций включает:
блок для нормализации значения глубины секвенирования области с ДНК-маркирующим участком с получением нормализованного значения глубины секвенирования; и
блок выявления микроделеций для обнаружения резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком на основании нормализированного значения глубины секвенирования при использовании метода математической статистики с получением результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
В предпочтительном варианте, блок для нормализации значений глубины секвенирования используют для деления всех значений глубины секвенирования одной и той же области в каждом из множества образцов ДНК на среднее значение глубины каждого из множества образцов ДНК, чтобы получить нормализованные значения глубины в одной и той же области для множества образцов ДНК.
В предпочтительном варианте, блок выявления микроделеций включает:
модуль для получения среднего значения и дисперсии для расчета среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования в одной и той же области каждого из множества образцов ДНК;
модуль построения графика нормального распределения по всем «невыбрасывающимся» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
модуль расчета вероятности, для расчета вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения; и
первый модуль определения, для определения первого критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования, и для получения результата R1, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше первого критического значения вероятности.
Предпочтительно, блок выявления микроделеций, кроме того, включает:
модуль определения критического значения вероятности, для экспериментальной проверки результата R1 с получением результата проверки, и для определения второго критического значения вероятности, основанного на результате проверки, в котором второе критическое значение вероятности меньше первого критического значения вероятности; и
второй модуль определения, для получения результата R2, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины, меньше второго критического значения вероятности.
В предпочтительном варианте, блок выявления микроделеций также включает:
модуль получения первого отношения D/S, для расчета первого отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
модуль получения первого отношения D/R, для расчета первого отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
модуль получения критического значения первого отношения, для обучения критического значения первого отношения первому отношению D/S при использовании алгоритма ID3, и обучения критического значения второго отношения первому отношению D/R при использовании алгоритма ID3;
третий модуль определения, для получения результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S больше критического значения первого отношения;
четвертый модуль определения, для получения результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения, и первое отношение D/R больше критического значения второго отношения; и
пятый модуль определения, для получения результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения, и первое отношение D/R меньше критического значения второго отношения.
Предпочтительно, блок для выявления микроделеций, кроме того, включает:
модуль получения среднего значения и дисперсии, для расчета среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования в одной и той же области каждого из множества образцов ДНК;
модуль построения графика нормального распределения, для построения графика нормального распределения по всем «невыбрасывающимся» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
модуль расчета вероятности, для расчета вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
шестой модуль определения, для определения третьего критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования, и для получения результата R3, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше третьего критического значения вероятности;
модуль получения второго отношения D/S для расчета второго отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования полученных для каждого из множества образцов ДНК в результате R3;
модуль получения второго отношения D/R для расчета второго отношения между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей в результате R3;
модуль определения критического значения второго отношения, для обучения критического значения третьего отношения второму отношению D/S при использовании алгоритма ID3, и обучения критического значения четвертого отношения второму отношению D/R при использовании алгоритма ID3;
седьмой модуль определения, для получения результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S больше критического значения третьего отношения;
восьмой модуль определения, для получения результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R больше критического значения четвертого отношения; и
девятый модель определения, для получения результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R в результате R3 меньше критического значения четвертого отношения.
В предпочтительном варианте, устройство для получения зонда захвата включает:
блок нахождения области, для нахождения в геномной базе данных последовательности ДНК, соответствующей области с ДНК-маркирующим участком,
блок выбора последовательности, для выбора квалифицированной последовательности ДНК в области с ДНК-маркирующим участком, соответствующей требованиям к конструированию зонда захвата; и
блок получения зонда захвата, для проектирования и синтеза зонда захвата на основании квалифицированной последовательности ДНК.
В предпочтительном варианте аппарат согласно изобретению может включать устройство для создания смешанной библиотеки, которое содержит:
блок создания множества библиотек ДНК для множества отдельных образцов ДНК, таким образом, чтобы каждая из множества библиотек ДНК имела адаптор, отличающийся от адаптора других библиотек ДНК;
блок смешивания, для смешивания множества библиотек ДНК в заданном соотношении; и
блок создания смешанной библиотеки, для определения полученной смеси, как смешанной библиотеки, если полученная смесь соответствует требованиям контроля качества.
В предпочтительном варианте, аппарат в соответствии с предложенным изобретением может включать устройство контроля качества, которое содержит:
первый блок фильтрования, для фильтрования первых неквалифицированных данных, содержащихся в результате секвенирования, и получения первых квалифицированных данных секвенирования;
блок расчета значения глубины секвенирования, для картирования первых квалифицированных данных секвенирования к эталонной геномной последовательности посредством использования программного обеспечения для картирования коротких последовательностей, и расчета первого параметра корреляции для значения глубины секвенирования для каждого из множества образцов ДНК и второго параметра корреляции для значения глубины секвенирования для области с ДНК-маркирующим участком, содержащей заданную последовательность, среди множества образцов ДНК;
второй блок фильтрования, для фильтрования вторых неквалифицированных данных, содержащихся в результате секвенирования, на основании первого рассчитанного параметра корреляции, и получения вторых квалифицированных данных секвенирования; и
третий блок фильтрования, для фильтрования третьих неквалифицированных данных, содержащихся в результате секвенирования, на основании второго рассчитанного параметра корреляции, и получения третьих квалифицированных данных секвенирования области с ДНК-маркирующим участком, содержащей заданную последовательность.
Предложенное изобретение включает отличающиеся от предшествующего уровня техники способ обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, и используемый с этой целью аппарат, посредством которых получают зонд захвата, перекрывающий полную область хромосомы с ДНК-маркирующим участком, связывают последовательность ДНК, в области с ДНК-маркирующим участком из множества образцов ДНК, и после гибридизации со смешанной библиотекой, включающей множество образцов ДНК, эффективно и точно детектируют известные и неизвестные микроделеций в области хромосомы с ДНК-маркирующим участком при обработке большого количества образцов ДНК. Процесс анализа секвенированных данных с помощью метода математической статистики является научно-обоснованным, стабильным, высокочувствительным, обеспечивает низкую частоту ложноположительных результатов, что позволяет использовать его для эффективного анализа микроделеций. В предложенном изобретении также используется машиночитаемый носитель, включающий команды с настройками для осуществления процессором описанного выше способа.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На Фиг. 1 - Фиг. 7, Фиг. 10, Фиг. 12 - Фиг. 15 и Фиг. 19 представлены согласно предложенному изобретению блок-схемы, показывающие этапы способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком;
Фиг. 8 - гистограмма, показывающая отсеянный/забракованный образец с резко отклоняющимся значением глубины секвенирования, определенный при использовании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 9 - гистограмма, показывающая образец с нормальным значением глубины секвенирования, определенный при использовании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 11 - гистограмма, показывающая образец с нормальным значением глубины секвенирования, определенный при использовании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 16 - диаграмма, на которой показан иллюстративный пример дерева решений, полученный при использовании алгоритма ID3, включенного в способ обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 17 - часть блок-схемы, на которой показан анализ с использованием дерева решений, включенный в способ обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 18 - блок-схема, на которой показан анализ с использованием дерева решений, включенный в способ обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с другим вариантом данного изобретения;
Фиг. 20 - гистограмма и коробчатая диаграмма, показывающая медиану значения глубины секвенирования образца, полученные при использовании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг.21 - гистограмма и коробчатая диаграмма, показывающая значение глубины секвенирования области, полученные при использовании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 22 - диаграмма, показывающая вероятность при определенном значении глубины секвенирования согласно способу обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 23 - диаграмма, показывающая порог вероятности и взаимосвязь между ожиданием порога вероятности и наблюдаемым порогом вероятности, полученная при использовании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 24 - диаграмма, показывающая отношение частоты истинно положительных значений к частоте ложноположительных значений при использовании способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 25 - схема аппарата для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с вариантом данного изобретения;
Фиг. 26 - схема аппарата для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с другим вариантом данного изобретения;
Фиг. 27 - схема аппарата для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с иным вариантом данного изобретения;
Фиг. 28 - схемы аппарата для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с еще одним вариантом данного изобретения;
Фиг. 29 - диаграмма, показывающая схему аппарата для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком в соответствии с еще одним вариантом данного изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Далее приводятся подробные ссылки на чертежи и варианты предлагаемого изобретения. Термины «первый» и «второй» используются в настоящем документе с описательной целью и не указывают и не подразумевают относительную важность или значение признаков.
Фиг. 1 - блок-схема способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, в соответствии с вариантом предложенного изобретения. Как показано на Фиг. 1, способ включает:
этап 101: Получение зонда захвата соответствующего последовательности ДНК в области с ДНК-маркирующим участком.
ДНК-маркирующий участок (STS) - это короткая однокопийная последовательность ДНК с известной локализацией, служащая маркером, которая может быть уникально картирована при амплификации методом ПЦР, с целью получения участка для картирования, а именно, детекция с использованием серии STS позволяет картировать область генома. Зонд - это короткий фрагмент одноцепочечной ДНК или РНК (состоящий приблизительно из 20-500 п.н.), используемый для детекции комплементарной ему последовательности нуклеиновой кислоты.
этап 102: Гибридизация зонда захвата с множеством образцов ДНК из смешанной библиотеки (сложной смеси), для связывания/захвата последовательности ДНК в области с ДНК-маркирующим участком, во множестве образцов ДНК.
В данном описании выражение «смешанные библиотеки» относится ко всем последовательностям ДНК, используемым для секвенирования и полученным посредством смешивания библиотек ДНК, которые были созданы для множества отдельных образцов ДНК. Этапы создания смешанной библиотеки подробно описаны ниже.
этап 103: секвенирование захваченной последовательности ДНК, из соответствующей области с ДНК-маркирующим участком, для получения данных секвенирования.
этап 104: анализ результатов секвенирования с использованием метода математической статистики с получением результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
Математическая статистика - одно из направлений математики, которая развивается вместе с разработкой теории вероятности, изучает эффективную оптимизацию, систематизацию и анализ данных, зависимых от случайных факторов, создающих основу для принятия определенных решений или выполнения определенных действий, на основании которых можно делать логические выводы или прогнозировать исходы рассматриваемых ситуаций.
В соответствии с одним из вариантов изобретения, показанным на Фиг. 2, этап получения зонда захвата включает:
этап 201: нахождение последовательности ДНК в области с ДНК-маркирующим участком в геномной базе данных.
Основываясь на координатах, последовательность ДНК, локализованная в области Y-хромосомы с ДНК-маркирующим участком, может быть найдена в базе данных UCSC с координатами, соответствующими референсной последовательности генома человека Hg19 (http://genome.ucsc.edu/).
этап 202: выбор квалифицированной последовательности ДНК в области с ДНК-маркирующим участком, соответствующей требованиям к конструированию зонда захвата.
На эффективность связывания чипа могут влиять количество повторов и содержание пар ГЦ в последовательности ДНК, которые могут приводить к ошибкам при захвате. Поэтому очень важно выбрать квалифицированную последовательность ДНК, соответствующую требованиям к конструированию зонда захвата.
этап 203: проектирование и синтез зонда захвата на основании квалифицированной последовательности ДНК.
Длина зонда захвата, предназначенного для захвата фрагмента ДНК, как правило, составляет от 60 до 150 п.н. при содержании пар ГЦ от 40% до 70%. При проектировании зонда для последовательности ДНК, расположенной в одной и той же области, требуется множество зондов, чтобы полностью покрыть последовательность ДНК. Кроме того, два зонда захвата частично перекрываются обычно на длину 20 п.н.
В одном из вариантов предлагаемого изобретения в геномной базе данных находят координаты последовательности ДНК в области хромосомы с ДНК-маркирующим участком. После этого данные о координатах предоставляют фирмы, осуществляющей услуги по захвату ДНК; и такая фирма выполняет проектирование и синтез зонда захвата.
В предпочтительном варианте, как показано на Фиг. 3, создание смешанной библиотеки из множества образцов ДНК включает следующие этапы:
этап 301: создание множества библиотек ДНК для множества отдельных образцов ДНК, таким образом, чтобы каждая из множества библиотек ДНК имела адаптер, отличающийся от адаптера других библиотек ДНК, соответственно;
каждая из множества библиотек ДНК имеет адаптер, отличающийся от адаптера других библиотек ДНК, для различения библиотек, созданных из разных образцов ДНК, на этапе секвенирования. Каждая из множества библиотек ДНК имеет собственную индексную нуклеотидную последовательность длиной от 6 п.н. до 8 п.н. на конце последовательности, отличающуюся от индексной нуклеотидной последовательности других библиотек ДНК.
этап 302:смешивание множества библиотек ДНК в заданном соотношении. Множество библиотек ДНК могут быть смешаны в равных или заданных отношениях.
этап 303: определение полученной смеси как смешанной библиотеки, если полученная смесь соответствует требованиям контроля качества.
Смешанные библиотеки из множества образцов ДНК подвергают количественному определению и контролю качества для удаления экзогенных примесей.
В предпочтительном варианте, как показано на Фиг. 4, отражающем этап создания множества библиотек ДНК для множества отдельных образцов ДНК, создание библиотеки ДНК включает следующие этапы:
этап 401: фрагментацию генома ДНК на фрагменты ДНК заданного размера с использованием для этого физических или химических методов.
В целом, длина полученных фрагментов ДНК составляет 200-300 п.н., длина зонда - приблизительно 80 п.н., При длине фрагментов ДНК 200-300 п.н. относительная эффективность захвата может быть выше. Значение глубины секвенирования, как правило, составляет 200-300 п.н. при парном секвенировании (секвенировании с концов ДНК) после связывания зонда.
этап 402: выполнение концевой репарации фрагментов ДНК с получением фрагментов ДНК с репарированными - фосфорилированными концами;
этап 403: добавление основания "А" к фрагментам ДНК с репарированными концами с 3'-конца, для того чтобы получить фрагменты ДНК с основанием "А" на 3'-конце;
этап 404: лигирование Индекс-адаптора с фрагментами ДНК, имеющими основание «А» на 3'-конце, для получения фрагментов ДНК, дотированных с Индекс-адаптором;
этап 405: амплификация фрагментов ДНК, лигированных с Индекс-адаптором, при использовании праймера, включающего последовательность, специфичную к Индекс-адаптору, для получения продукта амплификации; и
этап 406: определение продукта амплификации как библиотеки ДНК, если продукт амплификации соответствует требованиям контроля качества.
В предпочтительном варианте, после этапа секвенирования захваченной последовательности ДНК и до этапа анализа результатов секвенирования способ включает: контроль качества полученных при секвенировании данных. Как показано на Фиг. 5, этап контроля качества результатов секвенирования включает:
этап 501: фильтрование первых неквалифицированных данных, содержащихся в результате секвенирования, для получения первых квалифицированных данных секвенирования. В предпочтительном варианте для высокоскоростного секвенирования может применяться методика Illumina Hiseq 2000 или другая известная высокопроизводительная методика секвенирования.
этап 502: картирование первых квалифицированных данных секвенирования к эталонной геномной последовательности посредством использования программного обеспечения для картирования коротких последовательностей, и расчет первого параметра корреляции для значения глубины секвенирования для каждого из множества образцов ДНК и второго параметра корреляции для значения глубины секвенирования для области с ДНК-маркирующим участком, содержащей заданную последовательность среди множества образцов ДНК;
этап 503: фильтрование вторых неквалифицированных данных, содержащихся в результате секвенирования, на основании первого рассчитанного параметра корреляции, для получения вторых квалифицированных данных секвенирования; и
этап 504: фильтрование третьих неквалифицированных данных, содержащихся в результате секвенирования, на основании второго рассчитанного параметра корреляции, для получения третьих квалифицированных данных секвенирования области с ДНК-маркирующим участком, содержащей заданную последовательность.
В предпочтительном варианте, показанном на Фиг. 6 (этап 501), этап фильтрования первых неквалифицированных данных, содержащихся в результате секвенирования, для получения первых квалифицированных данных секвенирования включает:
этап 601: получение первого набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих больше заданного процента низкокачественных оснований из данных секвенирования. Различные секвенаторы используют разные методы расчета показателя качества. По поводу стандарта последовательности с низким показателем качества можно проконсультироваться с фирмой-производителем оборудования для секвенирования или руководствоваться общими стандартами в данной области техники. В рассматриваемом примере для расчета показателя качества секвенато-ром HiSeq2000 фирмы Illumina используется формула Q=А-64, где Q - показатель качества секвенирования определенного основания, А в соответствии со стандартом ASCII соответствует показателю качества секвенирования определенного основания в выходном файле FQ секвенатора HiSeq2000. В рассматриваемом примере основания с показателем качества ниже 5 определяют как основания с низким показателем качества. Если последовательность содержит более 50% оснований с низким показателем качества, такую последовательность определяют как «первые неквалифицированные данные секвенирования», которые должны быть отфильтрованы для получения первых квалифицированных данных секвенирования.
этап 602: получение второго набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих более 10% неопределенных оснований, из первого набора секвенированных данных;
этап 603: получение третьего набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих последовательность сиквенс-адаптора, из второго набора секвенированных данных после картирования к библиотеке последовательностей сиквенс-адапторов; и
этап 604: получение первых квалифицированных данных секвенирования посредством фильтрования неквалифицированных данных, содержащих экзогенную последовательность, из третьего набора секвенированных данных после картирования ко всем внесенным экзогенным последовательностям.
При практическом применении для высокоскоростного секвенирования может применяться методика Illumina Hiseq 2000 или другая известная высокопроизводительная методика секвенирования. Различные секвенаторы и различные условия могут предусматривать разные стандарты фильтрования неквалифированных данных секвенирования. Например, при секвенировании на оборудовании Illumina Hiseq 2000 может применяться известный стандарт: последовательность, содержащая более 50% оснований с показателем качества ниже установленного порога, рассматривается как неквалифицированная последовательность, при этом пороговый показатель низкого качества зависит от конкретной методики секвенирования. Последовательность, содержащая более 10% неопределенных оснований (основание N в результате секвенирования, полученном при использовании Illumina Hiseq 2000), рассматривается как неквалифицированная последовательность; за исключением последовательности адаптера образца. Эти квалифицированные данные секвенирования картируют к другим экзогенным последовательностям, внесенным при проведении эксперимента, например, различным адапторным последовательностям. Если присутствует экзогенная последовательность, то всю последовательность, содержащую экзогенную последовательность признают неквалифицированной.
В предпочтительном варианте, показанном на Фиг. 7, этап фильтрования вторых неквалифицированных данных секвенирования включает:
этап 701: получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования множества образцов ДНК в первых квалифицированных данных секвенирования в возрастающем порядке.
В описательной статистике квартилями в упорядоченном наборе данных, расположенных в порядке возрастания, являются три точки, которые делят набор данных на четыре равные группы, где каждая группа включает четверть данных. Первый квартиль (обозначаемый Q1), который также называют «меньшим квартилем», а именно нижний квартиль, равен 25%-му значению в упорядоченном множестве всех данных. Второй квартиль (обозначаемый Q2), также называемый медианой, равен 50%-му значению в упорядоченном множестве всех данных. Третий квартиль (обозначаемый Q3), также называют «большим квартилем» - это верхний квартиль, равный 75%-му значению в упорядоченном множестве всех данных. Межквартильный размах (обозначаемый МКР) - это разность между верхним квартилем и нижним квартилем. Каждое из значений Q1 Q2 и Q3 рассматривается в качестве демаркационной точки, независимо от значений дисперсии этих точек, которые делят все данные на 4 равные части. Сравнивая Q1 и Q3 можно проанализировать тренд дисперсий данных. Кроме того, квартили широко применяются в статистике при построении коробчатых диаграмм. Коробчатая диаграмма состоит из прямоугольника и двух сегментов построенных на основании множества данных и представляет пять статистических величин (характеристик); коробчатая диаграмма не только отражает распределение в наборе данных, но также позволяет проанализировать множество данных. Эти пять статистических величин включают максимальное значение, минимальное значение, медиану и два квартиля.
этап 702: фильтрование неквалифицированных данных секвенирования со значениями глубины секвенирования вне интервала от Q1-1,5 МКР до Q3+1,5 МКР, для получения вторых квалифицированных данных секвениирования.
Согласно варианту предлагаемого изобретения, показанному на Фиг. 8 и Фиг. 9, координата по оси X показывает распределение глубины по областям; координата по оси Y показывает на частоту областей с одинаковыми значениями глубины. Фиг. 8 - это гистограмма, показывающая отфильтрованный образец, в котором имеются резко отклоняющиеся значения глубины секвенирования. Фиг. 9 - гистограмма образца с нормальным распределением значений глубины секвенирования.
В предпочтительном варианте, показанном на Фиг. 10, этап фильтрования третьих неквалифицированных данных секвенирования включает:
этап 1001: получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования в заданной области для различных образцов ДНК во вторых квалифицированных данных секвенирования в возрастающем порядке; и
этап 1002: фильтрование неквалифицированных данных, у которых медиана значений глубины секвенирования в заданной области в различных образцах ДНК равна нулю или больше чем Q3+1,5 МКР, с получением третьих квалифицированных данных секвенирования.
В другом варианте предлагаемого изобретения, показанном на Фиг. 11, координата по оси X показывает глубину распределения множества образцов в одной и той же области, координата по оси Y показывает частоту областей с одинаковым значением глубины секвенирования. Фиг. 11 - это гистограмма, показывающая отфильтрованную область, в которой имеются резко отклоняющиеся значения глубины секвенирования.
В предпочтительном варианте, показанном на Фиг. 12, этап анализа данные секвенирования с использованием статистического критерия включает:
этап 1201: нормализацию значения глубины секвенирования области с ДНК-маркирующим участком для получения нормализованного значения глубины секвенирования. В предпочтительном варианте, этап нормализации значения глубины секвенирования области с ДНК-маркирующим участком включает: деление всех значений глубины секвенирования одной и той же области в каждом из множества образцов ДНК на среднее значение глубины каждого из множества образцов ДНК, с целью получения нормализованных значений глубины в одной и той же области для множества образцов ДНК.
этап 1202: поиск резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком, на основании нормализированного значения глубины секвенирования при использовании метода математической статистики, чтобы получить результат, показывающий наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
В предпочтительном варианте, показанном на Фиг. 13, этап 1202 кроме того включает:
этап 1301: расчет среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования одной и той же области каждого из множества образцов ДНК;
этап 1302: построение графика нормального распределения по всем «невыброшенным» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
этап 1303: расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
этап 1304: определение первого критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования, и для получения результата R1, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования меньше первого критического значения вероятности.
Согласно другом предпочтительному варианту предлагаемого изобретения, показанному на Фиг. 14, после этапа 1304 способ включает:
этап 1401: экспериментальную проверку результата R1, с целью получения результата проверки, и для определения второго критического значения вероятности основанного на результате проверки, в котором второе критическое значение вероятности меньше первого критического значения вероятности; и
этап 1402: получение результата R2, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины, меньше второго критического значения вероятности.
При практическом применении в случае, когда в большинстве образцов и в определенной области микроделеций отсутствуют, значение глубины секвенирования образца с микроделециями должно резко отклоняться от нормального распределения, полученного для образцов, в которых отсутствуют микроделеций. Для детекции резко отклоняющегося значения глубины секвенирования используется надлежащий статистический метод, в соответствии с которым область с резко отклоняющимися значениями глубины секвенирования определяют как область, в которой имеются микроделеция.
Метод, позволяющий определить, является ли значение глубины секвенирования в данной области резко отклоняющимся значением, включает: построение графика нормального распределения по всем «невыброшенным» значениям для одной и той же области, на основании рассчитанного среднего значения и дисперсии всех нормализованных значений глубины в одной и той же области для каждого из множества образцов ДНК после исключения («фильтрования») резко отклоняющихся значений глубины секвенирования; расчет вероятности (значения p) для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения; определение первого критического значения вероятности (критического значения для p) для этих вероятностей; и получение результата R1, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше первого критического значения вероятности.
Метод определения критического значения вероятности может включать: расчет вероятности (значения p) для каждого из множества образцов ДНК в каждой области, для которой имеется значение глубины секвенирования, на графике нормального распределения, в соответствии с описанным выше методом; определение наличия или отсутствия микроделеций в дополнительных областях образца при более мягком критическом значении; и экспериментальную проверку эти областей образца для определения наличия или отсутствия микроделеций. Метод экспериментальной проверки может включать: конструирование соответствующего зонда; проведение ПЦР ДНК из таких областей образца; проверку соответствия норме продукта амплификации, полученного при ПЦР, с целью установления наличия или отсутствия микроделеций. После получения информации, показывающей наличие/отсутствие микроделеций в таких областях образца может быть выбрано надлежащее критическое значение вероятности, для того чтобы частота ложноположительных и ложноотрицательных данных была как можно более низкой.
В другом предпочтительном варианте предлагаемого изобретения, показанном Фиг. 15, этап поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включает:
этап 1501: расчет первого отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
этап 1502: расчет первого отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
этап 1503: обучение критического значения первого отношения при использовании первого отношения D/S и алгоритма ID3, и обучения критического значения второго отношения при использовании первого отношения D/R и алгоритма ID3;
этап 1504: получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S больше критического значения первого отношения;
этап 1505: получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R больше критического значения второго отношения; и
этап 1506: получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R меньше критического значения второго отношения.
На практике, когда требуется проверить множество образцов и областей, а процент областей, несущих микроделеций, в образцах относительно невелик, отношение между значением глубины секвенирования области, содержащей микроделецию, и медианой, рассчитанной для всех значений глубины секвенирования во множестве образцов ДНК обычно меньше, и отношение между значением глубины секвенирования области, содержащей микроделеций, и медианой значений глубины секвенирования, рассчитанной для всех областей, также обычно меньше. Таким образом, для проверки резко отклоняющихся значений глубины секвенирования может применяться метод, основанный на использовании дерева решений.
Конкретные этапы метода, основанного на применении дерева решений, могут включать: расчет первого отношения между значением глубины секвенирования исследуемой области образца и медианой всех значений глубины секвенирования, рассчитанной для множества образцов ДНК; получение результата, показывающего отсутствие микроделеций, если первое отношение больше, чем первое определенное критическое значение; расчет второго отношения между значением глубины секвенирования исследуемой области образца и медианой значений глубины секвенирования, полученных для всех областей, если первое отношение меньше, чем первое определенное критическое значение; получение результата, показывающего отсутствие микроделеций, если второе отношение больше, чем второе определенное критическое значение, и получение результата, показывающего наличие микроделеций, если второе отношение меньше, чем второе определенное критическое значение.
Для расчета критического значения методом дерева решений используют итерационный дихотомический алгоритм 3 (ID3) построения дерева решений (Mitchell, Tom М. Machine Learning. McGraw-Hill, 1997). Ядро алгоритма ID3 включает: во время выбора признака среди междоузлий дерева решений в качестве стандарта для выбора признака используют прирост информации, таким образом, что при проверке каждого из неконцевых узлов может быть получена максимальная информация о классе, касающаяся исследуемой записи.
Основные идеи алгоритма построения дерева решений ID3:
этап 1, выбор одного признака в качестве корневого узла дерева решений и создание ветвей со всеми значениями признака;
этап 2: классификация сформированных данных при использовании созданного дерева, в котором
если все примеры одного концевого узла принадлежат к одному и тому же классу, такой концевой узел относят к этому же классу; затем, если все концевые узлы классифицированы, то выполнение алгоритма закончено;
этап 3: если все еще остается не классифицированный концевой узел, для его маркировки используют признак, который отсутствовал на пути от концевого узла до корневого узла; и непрерывно создают ветви со всеми значениями такого признака; затем повторяется 2-й этап алгоритма.
На 1-м этапе выбор различных признаков может приводить к разным деревьям решений, таким образом, выбор надлежащего признака позволяет создать простое дерево решений. В алгоритме ID3 для выбора признака обычно используют метод, основанный на эвристической информации. Признак, выбранный с помощью эвристического метода, может содержать наибольшее количество информации, в результате у дерева решений будет минимальное число ветвей. В предлагаемом изобретении следует выбрать два распределения, а именно, отношение T1 (D/S) между значением глубины секвенирования и медианой глубины секвенирования области образца, и отношение Т2 (D/R) между значением глубины секвенирования и медианой глубины секвенирования, рассчитанной для одной области множества образцов ДНК.
Признаки с максимальной информацией определяют по приросту информации.
Метод расчета прироста информации может включать:
Предполагается, что D - подразделение обучающего множества на классы, и энтропия D представлена формулой 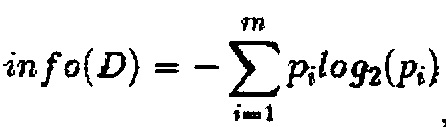 , где pi представляет вероятность присутствия i-го класса в обучающем множестве, которую можно оценить, разделив количество обучающих наборов данных, принадлежащих к такому классу, на общее количество всех обучающих наборов данных. Практическое значение энтропии относится к среднему количеству информации, требуемому для отнесения обучающего набора данных к определенному классу в D.
, где pi представляет вероятность присутствия i-го класса в обучающем множестве, которую можно оценить, разделив количество обучающих наборов данных, принадлежащих к такому классу, на общее количество всех обучающих наборов данных. Практическое значение энтропии относится к среднему количеству информации, требуемому для отнесения обучающего набора данных к определенному классу в D.
Предположим, что обучающий набор данных в D делят на признак А, тогда ожидаемая информация о делении D на А составит 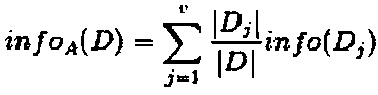 , при этом прирост информации
, при этом прирост информации 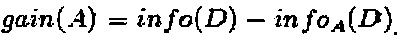
Алгоритм ID3 применяется для расчета скорости прироста каждого признака при каждом требуемом делении и выполняет деление, основываясь на признаке с максимальной скоростью прироста.
Ниже на примере выявления нереального клиента в сообществе проиллюстрировано создание дерева решений при использовании алгоритма ID3. Для простоты предполагали, что обучающий набор данных включает 10 элементов, показанных в Таблице 1
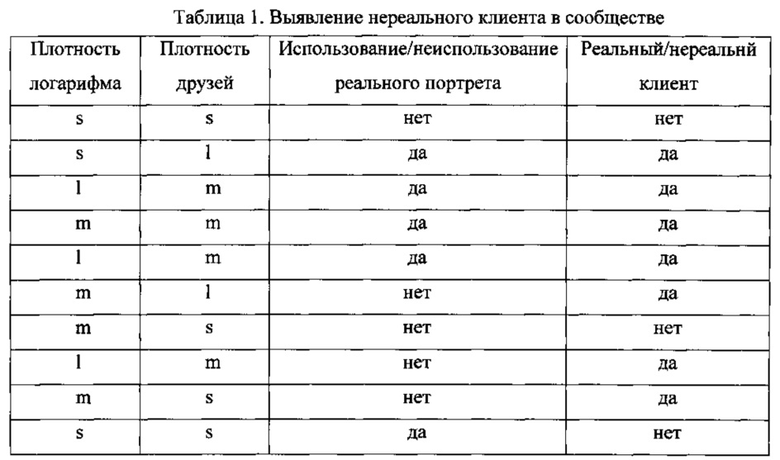
Буквами обозначено s - «малый», m - «средний» и l - «большой». Предположим, что буквами L, F, Н и R обозначены соответственно плотность логарифма, плотность друзей, использование/неиспользование реального портрета.
Ниже рассчитан прирост информации по каждому признаку.
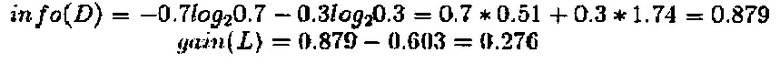
Таким образом, прирост информации по признаку «плотность логарифма» составила 0,276. При расчете с помощью этого метода прирост информации по признакам Н и F составило 0,033 и 0,553, соответственно. Максимальный прирост информации отмечен для признака F, и признак F был выбран в качестве признака для первого деления. Результат, полученный после первого деления, показан на Фиг. 16.
Для того чтобы обработать данные, содержащие последовательные признаки, такие как Т1 и Т2, вначале выполняли дискретизацию данных. Для решения этой задачи применяли простой метод деления значений признака А на две части: одна часть Ai содержит значения признака А меньше N, и вторая часть Ai содержит значения признака А больше N. Для любого из этих признаков все значения в одном наборе данных ограниченны. Предположим, что значения признака были равны (vl1, v2, …, vn). Тогда в таком наборе данных полностью присутствовали п-1 частей делителя, на основании которых было построено дерево решений.
Отдельные этапы дискретизации могут включать:
1) нахождение минимального значения (MIN) последовательного признака, нахождение максимального значения МАХ последовательного признака;
2) определение N точек Ai, с одинаковым расстоянием между точками, в интервале (MIN, МАХ), которые составили, соответственно, Ai=MIN+((MAX-MrN)/N)*i, где i=1. 2, 3 ……;
3) расчет прироста при рассмотрении (MIN, Ai) и (Ai, МАХ) в качестве крайних точек интервала, соответственно, и сравнение рассчитанных значений прироста;
4) выбор Ak, имеющего максимальное значение прироста в качестве точки разрыва для последовательного признака, и определение двух интервалов признака как (MIN, Ak) и (Ak, МАХ).
В примере, рассмотренном в предлагаемом изобретении, отдельные этапы определения критического значения при использовании дерева решений, включали:
Во-первых, проведение проверки области во множестве образцов методом ПЦР для получения результата, показывающего наличие микроделеций, где "+" соответствует положительному результату, показывающему наличие микроделеций; и "-" соответствует отрицательному результату, показывающему отсутствие микроделеций.
расчет энтропии по формуле Info(D)=-(P+)log2 (P+)-(P-)log2(P-), в которой p+(Р-) -вероятность присутствия (отсутствия) микроделеций во всей использованной для обучения группе данных, для оценки которой количество элементов, принадлежащего к данному классу, делили на общее количество элементов во всех обучающих наборах данных. Фактическое значение энтропии относится к среднему количеству информации, требуемому для классификации обучающих наборов данных в D.
Во-вторых, расчет отношения Т1 между нормализованным значением глубины секвенирования области образца и медианой всех значений глубины секвенирования, полученных для множества образцов ДНК;
упорядочивание полученного отношения Т1 в порядке возрастания, с получением значений V1, V2, V3, …, Vn;
расчет среднего значения для пары последовательных упорядоченных значений, в качестве критического значения a1'=(V1+V2)/2, a2'=(V2+V3)/2, (n-1)'=(Vn-1+Vn)/2;
получение минимального критического значения a1' и максимального критического значения а(n-1)'.
В-третьих, расчет отношения Т2 между нормализованным значением глубины секвенирования области образца и медианой значений глубины секвенирования, рассчитанной для всех областей;
упорядочивание полученного отношения Т2 в порядке возрастания, с получением значений U1, U2, U3, …, Un;
расчет среднего значения для пары последовательных упорядоченных значений, в качестве критического значения b1'=(U1+U2)/2, b2'=(U2+U3)/2, …, b(n-l)'=(Un-1+Un)/2;
получение минимального критического значения b1' и максимального критического значения b(n-1)'.
В-четвертых, расчет энтропий различных разделенных значений, а1', а2', полученных при циклической обработке данных по формуле:
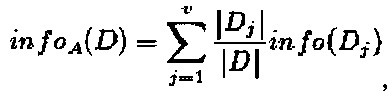
где прирост информации составил:
gain(A)=info(D) - infoA(D).
В-пятых, расчет энтропий различных разделенных значений, b1', b2', …, полученных при циклической обработке данных по формуле:
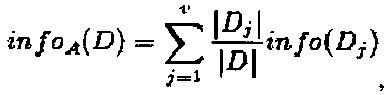
где прирост информации составил:
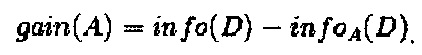
В-шестых, сравнение групп с максимальным приростом информации, в которых в качестве корня рассматривали признак (а), имевший большее значение;
классификация информации на основании критического значения, имеющего максимальное критическое значение прироста, как показано на Фиг. 17.
В-седьмых, расчет максимального прироста посредством деления значений глубины секвенирования, полученных для двух наборов данных, на медиану значений глубины секвенирования области, соответственно, согласно вышеописанным этапам;
Классификация информации на основании критического значения, имеющего максимальное критическое значение прироста, как показано на Фиг. 18, т.е. последнее определение с использованием дерева решений, описанного в предлагаемом изобретении.
Согласно другому предпочтительному варианту предлагаемого изобретения, показанному на Фиг. 19, этап поиска резко отклоняющихся значений глубины секвенирования в области с ДНК-маркирующим участком включает:
этап 1901: расчет среднего значения и дисперсии на основании всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
этап 1902: построение графика нормального распределения по всем «невыброшенным» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
этап 1903: расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
этап 1904: определение критического значения третьей вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования, и для получения результата R3, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше третьего критического значения вероятности;
этап 1905: расчет второго отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования полученных для каждого из множества образцов ДНК в результате R3;
этап 1906: расчет второго отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей в результате R3;
этап 1907: обучение критического значения третьего отношения второму отношению D/S при использовании алгоритма ID3, и обучение критического значения четвертого отношения второму отношению D/R при использовании алгоритма ID3;
этап 1908: получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S больше критического значения третьего отношения;
этап 1909: получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R больше критического значения четвертого отношения; и
этап 1910: получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R в результате R3 меньше критического значения четвертого отношения.
На практике для более точного определения области с микроделецией, может быть использована стратегия, объединяющая два описанных выше метода и включающая предварительное определение более мягкого значения p - критического значения и фильтрование полученных данных на основании дерева решения, для того чтобы получить результат, показывающий наличие микроделеций в области хромосомы с ДНК-маркирующим участком.
Способ и аппарат для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, при использовании которых получают зонд захвата, перекрывающий полную область хромосомы с ДНК-маркирующим участком, и связывают последовательность ДНК в области с ДНК-маркирующим участком, из множества образцов ДНК, после гибридизации со смешанной библиотекой, полученной из множества образцов ДНК, позволяют эффективно и точно детектировать известные и неизвестные микроделеций в области хромосомы с ДНК-маркирующим участком при обработке большого количества образцов ДНК. Процесс анализа с использованием метода математической статистики, согласно предлагаемому изобретению, может быть основан на нормальном распределении, или на анализе методом дерева решений, или на комбинации этих математических методов с последующей экспериментальной проверкой. Такой процесс анализа информации является научно-обоснованным, стабильным, высокочувствительным, обеспечивающим низкую частоту ложноположительных результатов, что позволяет использовать его для эффективного анализа микроделеций.
Будет приведена подробная ссылка на примеры предлагаемого изобретения. Специалистам следует принять во внимание, что описанные ниже примеры представлены с разъяснительной целью и не должны ограничивать объем предлагаемого изобретения. В тех случаях, когда в примерах отсутствует указание на конкретную технологию или условия, при воспроизведении такого примера следует использовать технологии и условия, описанные в литературе или известные из уровня техники (например, в публикации J. Sambrook, et al. (в переводе Huang РТ), Молекулярное клонирование: Руководство по лабораторным исследованиям, 3-е издание, Science Press), либо технологии и условия, описанные в инструкциях на продукт. При отсутствии указаний на производителей реактивов или оборудования, могут быть использованы коммерческие реактивы и оборудование, например, фирмы Illumina.
В рассматриваемом примере описано обнаружение микроделеций в области Y-хромосомы с ДНК-маркирующим участком, однако пример не ограничен Y-хромосомой. В описанном примере были использованы 11 образцов, включая 10 образцов пациентов с бесплодием и 1 образец здорового пациента; образцы подвергали гибридизации с чипом Nimblegen (Roche) после создания библиотеки. В рассматриваемом примере использовали количество образцов, необходимое для иллюстрации предлагаемого изобретения, но количество образцов не ограничивается использованным в одном эксперименте.
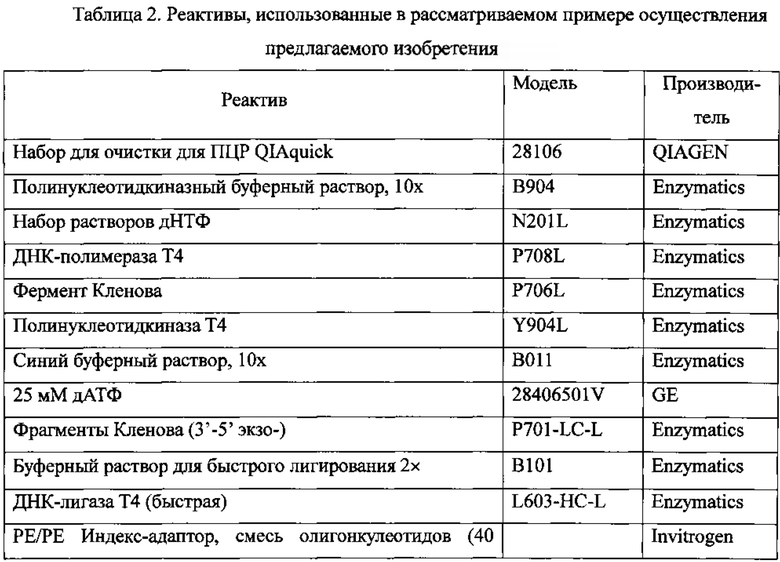
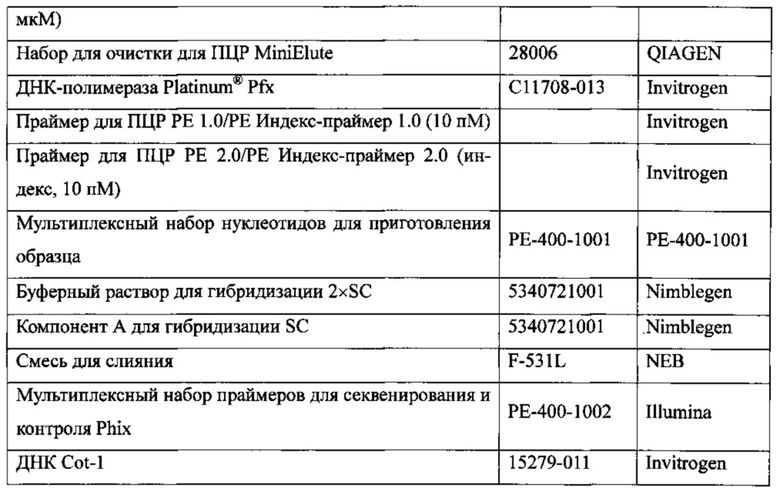
В Таблице 2 показаны реактивы, которые были использованы при проведении рассматриваемого эксперимента..
I. Фрагментация ДНК-генома
Этап создания множества библиотек ДНК для множества отдельных образцов ДНК включал: фрагментацию ДНК-генома на фрагменты ДНК заданного размера с помощью физического или химического метода.
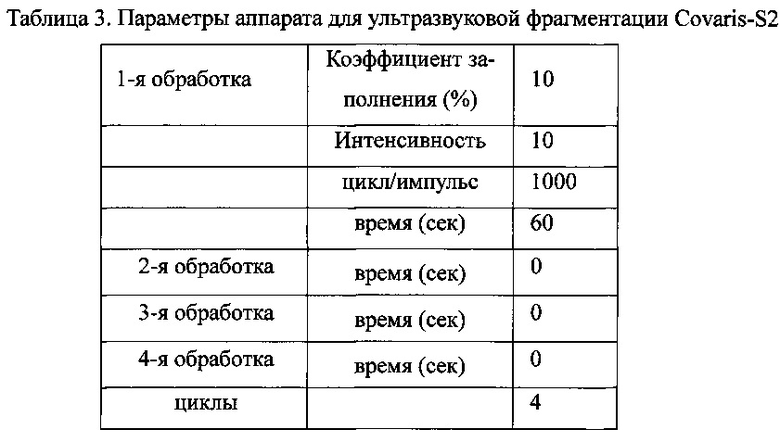
В качестве исходного материала использовали геномную ДНК (http://yh.genomics.org.cn) массой 3 мкг, не загрязненную белком или РНК, или продуктами разложения; для разбиения ДНК использовали оборудование для ультразвуковой фрагментации Covaris-S2 (Covaris, США. Параметры, использованные для фрагментации, показаны в Таблице 3 3.
Выполняли проверку качества фрагментированного образца методом электрофореза, затем выполняли очистку квалифицированного образца с использованием набора для очистки QIAquick, предназначенного для ПЦР, с последующим растворением очищенного образца в 32 мкл элюирующего буферного раствора. Большие полосы квалифицированной ДНК занимали центральное положение между 200 п.н. и 300 п.н.
II. Концевая репарация фрагментов ДНК
Этап создания множества библиотек ДНК для множества отдельных образцов ДНК включал: концевую репарацию фрагментов с получением фрагментов ДНК с репарированными - фосфорилированными концами.
ДНК, полученную на предыдущем этапе, помещали для концевой реапарации в центрифужную пробирку вместимостью 1,5 мл, содержащую реакционную систему, состав которой показан в Таблице 4.

После осторожного перемешивания пробирку, содержащую 100 мкл описанной выше реакционной смеси, помещали в термостат (Thermomixter, Eppendorf) при 20°С, и проводили реакцию в течение 30 мин. После завершения реакции полученный образец очищали с использованием набора для очистки, предназначенного для ПЦР QIAquick (Qiagen). Затем очищенный образец растворяли в 32 мкл бидистилированной Н2О до полного растворения.
III. Добавление основания "А" к фрагментам ДНК с репарированными концами Этап создания множества библиотек ДНК для множества отдельных образцов ДНК включал:
добавление основания "А" к фрагментам ДНК с репарированными концами с 3'-конца для получения фрагментов ДНК с основанием "А" на 3'-конце.
ДНК, полученную на предыдущем этапе, помещали для добавления основания "А" в центрифужную пробирку вместимостью 1,5 мл, содержащую реакционную систему, состав которой показан в Таблице 5.

После осторожного перемешивания пробирку, содержащую 50 мкл указанной реакционной смеси, помещали в термостат (Thermomixter, Eppendorf) при 37°С, и проводили реакцию в течение 30 мин. После окончания реакции полученный образец очищали с помощью набора для очистки, предназначенного для ПЦР QIAquick (Qiagen). Затем очищенный образец растворяли в 15 мкл бидистилированной Н2О до полного растворения.
IV. Лигирование Индекс-адаптора
Этап создания множества библиотек ДНК для множества отдельных образцов ДНК включал:
лигирование Индекс-адаптора с фрагментами ДНК, имеющими основание «А» на 3'-конце, для получения фрагментов ДНК, лигированных с Индекс- адаптером.
ДНК, полученную на предыдущем этапе, для лигирования Индекс-адаптора помещали в центрифужную пробирку вместимостью 1,5 мл, содержащую реакционную систему, состав которой показан в Таблице 6.

После осторожного перемешивания пробирку, содержащую 50 мкл описанной выше реакционной смеси, помещали в термостат (Thermomixter, Eppendorf) при 20°С, и проводили реакцию в течение 15 мин. После завершения реакции полученный образец очищали с использованием набора для очистки, предназначенного для ПЦР MiniElute (Qiagen). Затем очищенный образец растворяли в 25 мкл элюирующего буферного раствора.
V. ПЦР, предшествующая гибридизации
Этап создания множества библиотек ДНК для множества отдельных образцов ДНК включал:
амплификацию фрагментов ДНК, литерованных с Индекс-адаптором, при использовании праймера, включающего последовательность, специфичную к Индекс-адаптору, для получения продукта амплификации
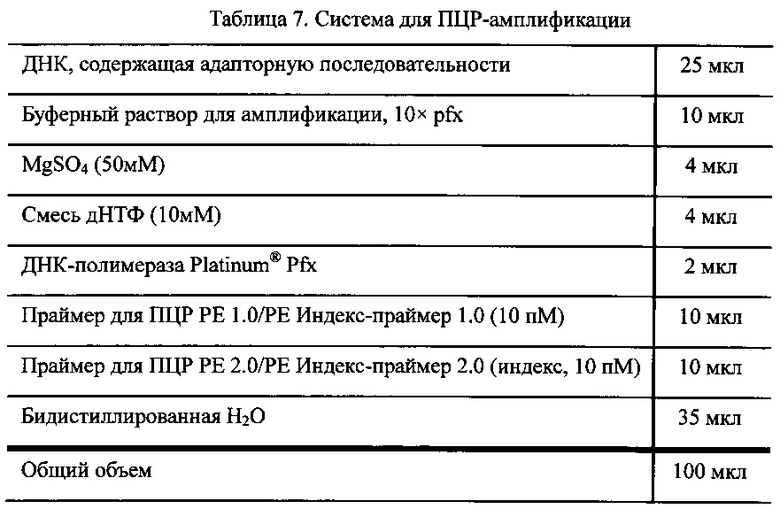
Выполняли ПЦР-амплификацию при использовании в качестве матрицы образца ДНК, полученного на этапе IV, и в качестве праймера - последовательности, содержащей адаптор. Система для амплификации показана в Таблице 7.

Для очистки полученного продукта амплификации использовали набор для очистки для ПЦР QIAquick и 30 мкл элюирующего буферного раствора.
VII. Создание смешанной библиотеки
Создание смешанной библиотеки из множества образцов ДНК включало следующие этапы:
смешивание множества библиотек ДНК в заданном соотношении, например, в равных количествах. На практике соответствующее соотношение можно определить по требованию к созданию смешанной лаборатории.
VII. Гибридизация заданной области с зондом захвата
Способ обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, включал:
гибридизацию зонда захвата с множеством образцов ДНК из смешанной библиотеки, для связывания с последовательностью ДНК из области с ДНК-маркирующим участком, из множества образцов ДНК.
1) В центрифужную пробирку вместимостью 1,5 мл вносили 450 мкг ДНК СОТ-1 DNA, 3 мкг смешанной библиотеки, полученой на этапе VI, 1 нмоль Индекс-адаптер1-блока и Индекс-адаптор2-блока (Мультиплексный набор нуклеотидов для приготовления образца, Illumina). Пробирку с полученной смесью помещали в SpeedVac (Thermo) и поддерживали температуру 60°С.
2) В центрифужную пробирку с высушенной смесью добавляли 11,2 мкл очищенной воды для достаточного растворения ДНК с последующим добавлением 18,5 мкл буферного раствора для гибридизации и 7,3 мкл раствора SC Hybridiation. После смешивания полученную смесь помещали в гибридизатор (Nimblegen) при 95°С и оставляли для денатурации ДНК на 10 минут.
3) Образец, полученный на стадии 2), после встряхивания центрифугировали при максимальной скорости в течение 30 секунд и затем помещали в гибридизатор (Nimblegen) при 42°С для подготовки к гибридизации.
4) В качестве метода гибридизации может быть использована гибридизация на чипе фирмы NimbleGen Company (Руководство для пользователя по генетическим матрицам, NimbleGen, Версия 3.1, 7 июля 2009 г., Roche NimbleGen, Inc.). Объем исследуемого образца составлял 35 мкл, гибридизацию проводили при 42°С в течение 64-72 часов. Гибридизованный продукт элюировали 900 микролитрами 160 мМ NaOH и элюированный продукт очищали, используя набор для очистки ПЦР MiniElute. В конце очищенный продукт элюировали 80 микролитрами элюирующего буферного раствора.
VIII. ПЦР после захвата
Выполняли ПЦР-амплификацию захваченной библиотеки при использовании реакционной системы, содержавшей 150 мкл смеси для слияния; 4,2 мкл прямого праймера и 4,2 мкл обратного праймера (Мультиплексный набор праймеров для секвенирования и контроля Phix), 80 мкл очищенного продукта в элюирующем буферном растворе и 85 мкл бидистиллированной Н2О. После распределения по 6 пробиркам пробирки, содержащие смесь, подвергали ПЦР-амплификации в течение 16 циклов. После реакции ПЦР содержимое 6 пробирок с амплифицированными продуктом смешивали, и смешанный продукт амплификации очищали на гранулах, используя для этого набор для очистки для ПЦР QIAquick. Очищенный продукт с длиной от 300 до 450 п.н. элюировали 50 микролитрами элюирующего буферного раствора.
IX. Поиск в библиотеке
Для определения длины и содержания вставленных фрагментов в полученной библиотеке использовали систему для анализа Bioanalyzer analysis system (Agilent, Санта-Клара, США). Для определения концентрацию полученной библиотеки использовали количественную ПЦР
X. Секвенирование и анализ данных
Способ обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком включал:
секвенирование захваченной последовательности ДНК из области с ДНК-маркирующим участком для получения данных секвенирования; и
анализ результатов секвенирования с использованием метода математической статистики для получения результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
Секвенирование квалифицирвоанной библиотеки, полученной на этапе IX, выполняли на компьютере, см. Руководство для пользователя HiSeq 2000 User Guide. Номер по каталогу SY-940-1001, Часть 15011190, Версия В, Illumina.
Ниже представлен процесс информационного анализа применительно к рассматриваемому примеру осуществления предложенного изобретения:
1. получение данных секвенирования, полученных при использовании высокоскоростной методики, и контроль качества данных секвенирования:
этап контроля качества данных секвенирования включал:
фильтрование неквалифицированных данных, содержащихся в результате секвенирования, для получения квалифицированных данных секвенирования.
В рассматриваемом примере осуществления предлагаемого изобретения использовали высокоскоростную методику секвенирования Illumina Hiseq 2000. После получения результата секвенирования данные фильтровали для исключения неквалифицированных последовательностей. Неквалифицированная последовательность отвечала, по крайней мере, одному критерию:
содержала более 50% оснований, качество секвенирования которых было ниже 5;
содержала более 10% оснований, признанных N;
содержала сиквенс-адапотор после картирования к библиотеке сиквенс-адапторов.
2. Расчет значения глубину секвенирования области образца:
этап проверки качества данных секвенирования дополнительно включал:
картирование первых квалифицированных данных секвенирования к эталонной геномной последовательности посредством использования программного обеспечения для картирования коротких последовательностей, и расчет первого параметра корреляции для значения глубины секвенирования для каждого из множества образцов ДНК и второго параметра корреляции для значения глубины секвенирования для области с ДНК-маркирующим участком, содержащей заданную последовательность среди множества образцов ДНК;
В рассматриваемом примере данные секвенирования, полученные методом высокоскоростного секвенирования, картировали к референсной последовательности генома человека, используя программное обеспечение SOAPaligner. В качестве референсной ДНК генома человека использовали HG19 (http://genome.ucsc.edu/). Значения глубины секвенирования области образца подвергали статистической проверке.
3. Расчет значения глубины секвенирования для каждого образца
Этап контроля качества данных секвенирования включал:
фильтрование вторых неквалифицированных данных секвенирования на основании первого рассчитанного параметра корреляции для получения вторых квалифицированных данных секвенирования;
Этап фильтрования вторых неквалифицированных данных секвенирования включал:
получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования для множества образцов ДНК в первых квалифицированных данных секвенирования в возрастающем порядке; и
фильтрование неквалифицированных данных со значениями глубины секвенирования вне интервала от Q1-1,5 МКР до Q3+1,5 МКР, с получением вторых квалифицированных данных секвениирования.
Как показано на Фиг. 20, образец, содержавший данные секвенирования, признанные резко отклоняющимися, был отфильтрован. На Фиг. 20 левая панель - гистограмма медианы значения глубины секвенирования образца; правая панель - коробчатая диаграмма, показывающая медиану значения глубины секвенирования образца. Можно увидеть, что медиана значений глубины секвенирования, рассчитанная для множества образцов ДНК, сосредоточена, в основном на интервале 42Х-60Х.
4. Расчет значения глубины секвенирования для каждой области
Этап контроля качества данных секвенирования включал:
фильтрование третьих неквалифицированных данных секвенирования, на основании второго рассчитанного параметра корреляции, для получения третьих квалифицированных данных секвенирования области с ДНК-маркирующим участком, содержащей заданную последовательность
этап фильтрования третьих неквалицированных данных секвенирования включал:
получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования в заданной области для различных образцов ДНК во вторых квалифицированных данных секвенирования в возрастающем порядке;
фильтрование неквалифицированных данных, у которых медиана значений глубина секвенирования в заданной области в различных образцах ДНК равна нулю или больше чем Q3+1,5 МКР, с получением третьих квалифицированных данных секвенирования.
На левой панели Фиг. 21 представлена гистограмма, показывающая медиану значения глубины секвенирования области, на правой панели - коробчатая диаграмма, показывающая медиану значения глубины секвенирования области. Можно увидеть, что медиана значений глубины секвенирования, рассчитанная для области образца, сосредоточена, в основном на интервале 35Х-75Х.
5. после исключения области образца, имеющей резко отклоняющееся значение глубины секвенирования, полученные для каждого образца данные секвенирования были нормализованы, т.е. все значения глубины секвенирования одной и той ж области, полученные для каждого из множества образцов ДНК, были разделены на среднее значение глубины, полученное для каждого из множества образцов ДНК, чтобы получить нормализованные значения глубины одной и той же области для множества образцов ДНК. После этого нормализованные значения глубины были подвергнуты проверке на крайние значения с использованием графика нормального распределения, т.е. этап поиска резко отклоняющихся значений глубины секвенирования в области с ДНК-маркирующим участком, включал:
расчет среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования в одной и той же области каждого из множества образцов ДНК;
построение графика нормального распределения по всем «невыбрасывающимся» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
на основании графика нормального распределения расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования;
определение первого критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования; и
получение результата R1, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше первого критического значения вероятности;
экспериментальную проверку результата R1 для получения результата проверки;
определение второго критического значения вероятности на основании результата проверки, в котором второе критическое значение вероятности меньше первого критического значения вероятности; и
получение результата R2, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины, меньше второго критического значения вероятности.
Для каждой области после исключения резко отклоняющихся значений глубины секвенирования и выбора данных секвенирования множества образцов ДНК после исключения резко отклоняющихся значений глубины секвенирования был построен график нормального распределения по всем «невыбрасывающимся» значениям для одной и той же области на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК. Значение вероятности (p) для каждого из множества образцов ДНК в каждой области, для которой имелось конкретное значение глубины секвенирования было получено из графика нормального распределения. На Фиг. 22 по оси X отложены образцы, по оси Y - -log 10 (значение p). Диаграмма на Фиг. 23 показывает результат, иллюстрирующий ожидаемые и наблюдавшиеся значения p. При использовании этого метода была получена вероятность значений глубины секвенирования каждой области для каждого образца ДНК. 20 областей образца с низкими вероятностями были подвергнуты экспериментальной проверке, т.е. ПЦР Было определено критическое значение вероятности обнаружения микроделеций на основании подтвержденного результата, и выполнена оценка точности обнаружения микроделеций, включавшая следующие этапы:
выбор в некоторых образцах части области, которая включала наличие и отсутствие микроделеций, и также область с более широким диапазоном значения p;
создание праймеров для обоих концов различных областей, ПЦР-амплификация образцов ДНК с последующим проведением электрофореза амплифицированного продукта для получения результата, показывающего наличие микроделеций, и, в заключение, получение критического значения Р, являющегося статистически значимым. Как показано в Таблице 8, для того чтобы получить частоту истинно положительных результатов и частоту ложноположительных результатов, соответствующую различной глубине секвенирования, было получено значение площади под кривой (ППК), достигавшее 0.9968254, посредством проверки метода обнаружения микроделеций высокоскоростным секвенированием. Как показано на Фиг. 24, координате X соответствовала частота ложноположительных результатов, координате Y - частота истинно положительных результатов. Фиг. 24 показывает, что, основываясь на различных частотах истинно положительных результатов и ложноположительных результатов, могут быть выбраны различные критические значения вероятности.
6. Дополнительно наличие или отсутствие микроделеций в области образца определяли методом дерева решений, рассматривая значения глубины секвенирования области образца.
Этап поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включает:
расчет первого отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК, на основании рассчитанного для множества образцов ДНК нормализованного значения глубины области с ДНК-маркирующим участком;
расчет первого отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей, на основании рассчитанного для множества образцов ДНК нормализованного значения глубины области с ДНК-маркирующим участком;
обучение критического значения первого отношения при использовании первого отношения D/S и алгоритма ID3, и обучение критического значения второго отношения при использовании первого отношения D/R и алгоритма ID3;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S больше критического значения первого отношения;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R больше критического значения второго отношения; и
получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R меньше критического значения второго отношения.
В рассматриваемом примере было задано мягкое критическое значение р=10"6, и полученный положительный результат был классифицирован при использовании дерева решений, для того чтобы дополнительно снизить частоту ложно-положительных результатов, с последующим получением участка с микроделецией в области образца.
Этап поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включал:
расчет среднего значения и дисперсии на основании всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
построение графика нормального распределения по всем «невыбрасывающимся» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
определение третьего критического значения вероятности на основании вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования;
получение результата R3, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше третьего критического значения вероятности;
расчет второго отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования полученных для каждого из множества образцов ДНК в результате R3;
расчет второго отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей в результате R3;
обучение критического значения третьего отношения при использовании второго отношения D/S и алгоритма ID3 и обучение критического значения четвертого отношения при использовании второго отношения D/R и алгоритма ID3;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S больше критического значения третьего отношения;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R больше критического значения четвертого отношения; и
получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R в результате R3 меньше критического значения четвертого отношения.
В предлагаемом изобретении также раскрыта машиночитаемая среда, включающая команды с настройками для осуществления процессором описанного выше способа.
На Фиг. 25 показана блок-схема аппарата для обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком. Аппарат, являющийся предметом предлагаемого изобретения, может включать:
Устройство 2501 для получения зонда захвата, устройство 2502 для гибридизации, а устройство 2503 для получения данных секвенирования и устройство 2504 для получения результата при выявлении микроделеций.
Устройство 2501 предназначено для получения зонда захвата, соответствующего последовательности ДНК в области с ДНК-маркирующим участком.
ДНК-маркирующий участок (STS) - это короткая однокопийная последовательность ДНК с известной локализацией, служащая маркером, которая может быть уникально картирована при амплификации методом ПЦР, с целью получения участка для картирования, а именно, детекция с использованием серии STS позволяет картировать область генома. Зонд - это короткий фрагмент одноцепочечной ДНК или РНК (состоящий приблизительно из 20-500 п.н.), используемый для детекции комплементарной ему последовательности нуклеиновой кислоты.
Устройство 2502 для гибридизации предназначено для гибридизации зонда захвата со смешанной библиотекой, включающей множество образцов ДНК, для захвата последовательности ДНК в области с ДНК-маркирующим участком из множества образцов ДНК.
В данном описании выражение «смешанные библиотеки» относится ко всем последовательностям ДНК, используемым для секвенирования и полученным посредством смешивания библиотек ДНК, которые были созданы для множества отдельных образцов ДНК. Конкретные этапы создания смешанной библиотеки были подробно описаны выше.
Устройство 2503 для получения данных секвенирования предназначено для секвенирования захваченной последовательности ДНК из области с ДНК-маркирующим участком.
Устройство 2504 для получения результата при выявлении микроделеций предназначено для анализа данных секвенирования посредством использования метода математической статистики, чтобы получить результат, показывающий наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
В предпочтительном варианте устройство 2501 для получения зонда захвата дополнительно включает:
блок нахождения области, для нахождения в геномной базе данных (ГБД) последовательности ДНК, соответствующей области с ДНК-маркирующим участком;
блок выбора последовательности, для выбора квалифицированной последовательности ДНК в области с ДНК-маркирующим участком, соответствующей требованиям к конструированию зонда захвата; и
блок получения зонда захвата, для проектирования и синтеза зонда захвата на основании квалифицированной последовательности ДНК.
Геномная база данных (ГБД; GDB, http://www.gdb.org/) - база данных для хранения и обработки геномной карты, созданная для проекта генома человека (HGP). Энциклопедия конструктов для генома человека, помимо конструирования геномной карты, также создает метод описания содержания последовательностей в геноме, включая варианты последовательностей и описание других функций и фенотипа. В базе данных GDB хранятся данные по объектным моделям, с предоставлением услуги поиска данных объекта на базе вэб-технологий. Пользователь может проводить поиск различных типов объектов и просматривать геномную карту в графическом режиме. Например, в базе данных UCSC по координате в референсной последовательности Hg19 (http://genome.ucsc.edu/) генома человека можно найти последовательность ДНК в области Y-хромосомы с ДНК-маркирующим участком.
В отдельных примерах в геномной базе данных была обнаружена координата последовательности ДНК в области хромосомы с ДНК-маркирующим участком, и эта информация была представлена фирме Roche-NimbleGen или другим фирмам, предоставляющим услуги по захвату ДНК. Маркировка и синтезы были выполнены этими компаниями.
В предпочтительном варианте, аппарат, являющийся предметом предлагаемого изобретения, включает устройство для создания смешанной библиотеки, которое содержит:
блок создания множества библиотек ДНК для множества отдельных образцов ДНК, таким образом, чтобы каждая из множества библиотек ДНК имела адаптор, отличающийся от адаптора других библиотек ДНК, соответственно;
блок смешивания, для смешивания множества библиотек ДНК в заданном соотношении; и
блок создания смешанной библиотеки, для определения полученной смеси, как смешанной библиотеки, если полученная смесь соответствует требованиям контроля качества.
В предпочтительном варианте, аппарат, согласно изобретению, включает: устройство контроля качества, которое содержит:
первый блок фильтрования, для фильтрования первых неквалифицированных данных секвенирования и получения первых квалифицированных данных секвенирования;
блок расчета значения глубины секвенирования, для картирования первых квалифицированных данных секвенирования к эталонной геномной последовательности посредством использования программного обеспечения для картирования коротких последовательностей, и расчета первого параметра корреляции для значения глубины секвенирования для каждого из множества образцов ДНК и второго параметра корреляции для значения глубины секвенирования для области с ДНК-маркирующим участком, содержащей заданную последовательность среди множества образцов ДНК;
второй блок фильтрования, для фильтрования вторых неквалифицированных данных, содержащихся в результате секвенирования, на основании первого рассчитанного параметра корреляции, для получения вторых квалифицированных данных секвенирования; и
третий блок фильтрования, для фильтрования третьих неквалифицированных данных, содержащихся в результате секвенирования, на основании второго рассчитанного параметра корреляции, для получения третьих квалифицированных данных секвенирования области с ДНК-маркирующим участком, содержащей заданную последовательность.
В предпочтительном варианте, устройство для получения результата при выявлении микроделеций включает:
блок нормализации глубины секвенирования для выполнения нормализации значения глубин секвенирования области с ДНК-маркирующим участком с получением нормализованного значения глубины секвенирования; и
блок выявления микроделеций для обнаружения резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком, на основании нормализированного значения глубины секвенирования при использовании метода математической статистики. Блок получает результат, показывающий наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
В предпочтительном варианте, блок нормализации глубины секвенирования, в частности, используют для деления всех значений глубины секвенирования одной и той же области в каждом из множества образцов ДНК на среднее значение глубины каждого из множества образцов ДНК, чтобы получить нормализованные значения глубины в одной и той же области для множества образцов ДНК.
В предпочтительном варианте, показанном на Фиг. 26, блок выявления микроделеций включает:
модуль 2601 получения среднего значения и дисперсии для расчета среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования в одной и той же области каждого из множества образцов ДНК;
модуль 2602 построения графика нормального распределения, для построения графика нормального распределения по всем «невыброшенным» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
модуль 2603 расчета вероятности, для расчета вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения; и
первый модуль 2604 определения, для определения первого критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования, и для получения результата R1, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше первого критического значения вероятности.
В предпочтительном варианте, показанном на Фиг. 27, блок выявления микроделеций кроме того включает:
модуль 2701 определения критического значения вероятности, для экспериментальной проверки результата R1, с целью получения результата проверки, и для определения второго критического значения вероятности основанного на результате проверки, в котором второе критическое значение вероятности меньше первого критического значения вероятности; и
второй модуль 2702 определения для получения результата R2, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины, меньше второго критического значения вероятности.
В другом предпочтительном варианте, показанном на Фиг. 28, блок для выявления микроделеций включает:
модуль 2801 получения первого отношения D/S, для расчета первого отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
модуль 2802 получения первого отношения D/R, для расчета первого отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
модуль 2803 получения критического значения первого отношения, для обучения критического значения первого отношения при использовании первого отношения D/S и алгоритма ID3, и обучения критического значения второго отношения при использовании первого отношения D/R и алгоритма ID3;
третий модуль 2804 определения для получения результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S больше критического значения первого отношения;
четвертый модуль определения 2805, для получения результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения, и первое отношение D/R больше критического значения второго отношения; и
пятый модуль 2806 определения, для получения результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения, и первое отношение D/R меньше критического значения второго отношения.
Как показано на Фиг. 29, еще в одном предпочтительном варианте изобретения, блок для выявления микроделеций включает:
модуль 2901 получения среднего значения и дисперсии, для расчета среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования в одной и той же области каждого из множества образцов ДНК;
модуль 2902 построения графика нормального распределения, для построения графика нормального распределения по всем «невыбрасывающимся» значениям для одной и той же области, на основании рассчитанных средних значений и дисперсии всех нормализованных значений глубины в одной и той же области каждого из множества образцов ДНК;
модуль 2903 расчета вероятности, для расчета вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
шестой модуль 2904 определения, для определения третьего критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области с конкретным значением глубины секвенирования, и для получения результата R3, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области с конкретным значением глубины секвенирования, меньше критического значения третьей вероятности;
модуль 2905 получения второго отношения D/S, для расчета второго отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования полученных для каждого из множества образцов ДНК в результате R3;
модуль 2906 получения второго отношения D/R, для расчета второго отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей в результате R3;
модуль 2907 определения критического значения второго отношения, для обучения критического значения третьего отношения второму отношению D/S при использовании алгоритма ID3, и обучения критического значения четвертого отношения второму отношения D/R при использовании алгоритма ID3;
седьмой модуль 2908 определения, для получения результата показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S больше критического значения третьего отношения;
восьмой модуль 2909 определения, для получения результата показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R больше критического значения четвертого отношения; и
девятый модуль 2910 определения, для получения результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R в результате R3 меньше критического значения четвертого отношения.
Способ и аппарат обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком при использовании которых получают зонд захвата, перекрывающий полную область хромосомы с ДНК-маркирующим участком, и связывают последовательность ДНК в области с ДНК-маркирующим участком, из множества образцов ДНК, после гибридизации со смешанной библиотекой, полученной из множества образцов ДНК, позволяют эффективно и точно детектировать известные и неизвестные микроделеций в области хромосомы с ДНК-маркирующим участком при обработке большого количества образцов ДНК. Анализ с использованием метода математической статистики, согласно предлагаемому изобретению, который может быть основан на нормальном распределении, или на анализе методом дерева решений, или на комбинации этих математических методов с последующей экспериментальной проверкой; является научно-обоснованным, стабильным, высокочувствительным, обеспечивающим низкую частоту ложноположительных результатов, что позволяет использовать его для эффективного анализа микроделеций.
Хотя были представлены и описаны поясняющие примеры, специалисту должно быть понятно, что приведенные варианты не ограничивают объем изобретения. Могут существовать изменения, варианты и модификации, не отклоняющиеся от духа и смысла изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ОПРЕДЕЛЕНИЯ ТОГО, ЯВЛЯЕТСЯ ЛИ ГЕНОМ АНОМАЛЬНЫМ | 2011 |
|
RU2599419C2 |
| СПОСОБ И СИСТЕМА ВЫЯВЛЕНИЯ ВАРИАЦИИ ЧИСЛА КОПИЙ В ГЕНОМЕ | 2012 |
|
RU2593708C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ НУКЛЕОТИДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ В ЗАДАННОЙ ОБЛАСТИ ГЕНОМА ПЛОДА | 2012 |
|
RU2597981C2 |
| НЕИНВАЗИВНОЕ ОБНАРУЖЕНИЕ ГЕНЕТИЧЕСКОЙ АНОМАЛИИ ПЛОДА | 2011 |
|
RU2589681C2 |
| СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ ВЫСОКОМУЛЬТИПЛЕКСНОЙ ПЦР | 2012 |
|
RU2650790C2 |
| Способ неинвазивного пренатального скрининга анеуплоидий плода | 2019 |
|
RU2712175C1 |
| СПОСОБЫ НЕИНВАЗИВНОГО ПРЕНАТАЛЬНОГО УСТАНОВЛЕНИЯ ПЛОИДНОСТИ | 2011 |
|
RU2671980C2 |
| СПОСОБ НЕИНВАЗИВНОЙ ДИАГНОСТИКИ АНЕУПЛОИДИЙ ПЛОДА МЕТОДОМ СЕКВЕНИРОВАНИЯ | 2014 |
|
RU2543155C1 |
| СПОСОБЫ СЕКВЕНИРОВАНИЯ ТРЕХМЕРНОЙ СТРУКТУРЫ ИССЛЕДУЕМОЙ ОБЛАСТИ ГЕНОМА | 2011 |
|
RU2603082C2 |
| ПОДАВЛЕНИЕ ОШИБОК В СЕКВЕНИРОВАННЫХ ФРАГМЕНТАХ ДНК ПОСРЕДСТВОМ ПРИМЕНЕНИЯ ИЗБЫТОЧНЫХ ПРОЧТЕНИЙ С УНИКАЛЬНЫМИ МОЛЕКУЛЯРНЫМИ ИНДЕКСАМИ (UMI) | 2016 |
|
RU2704286C2 |

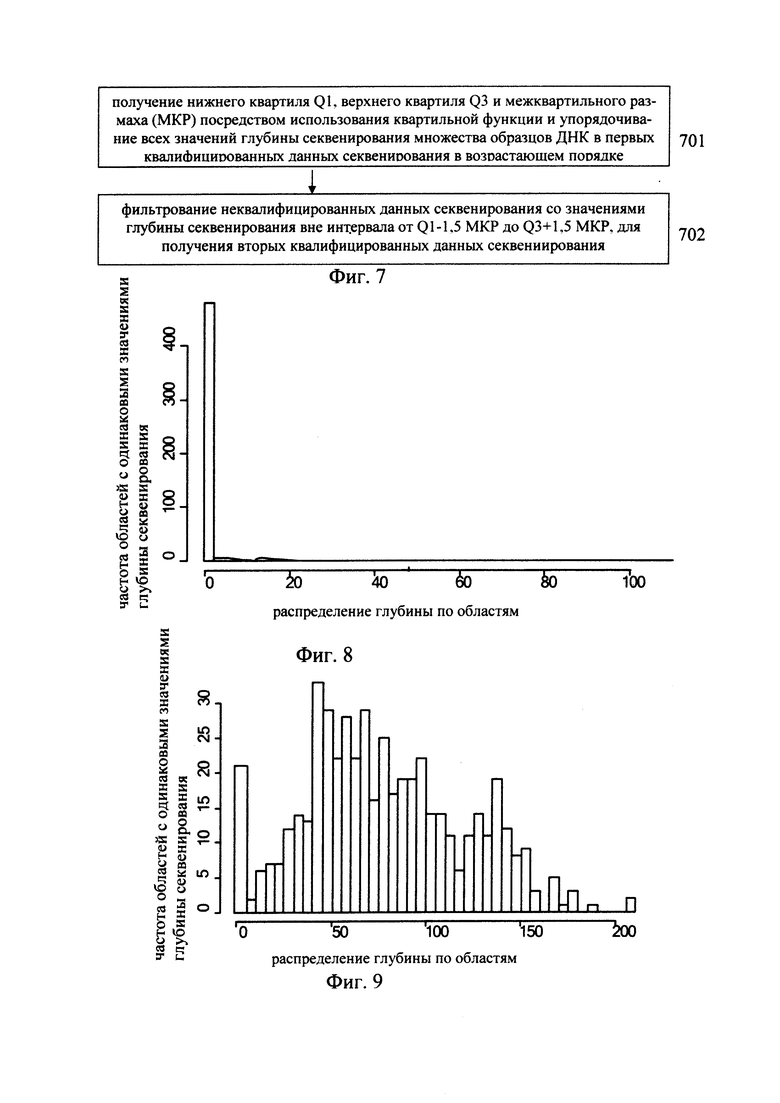
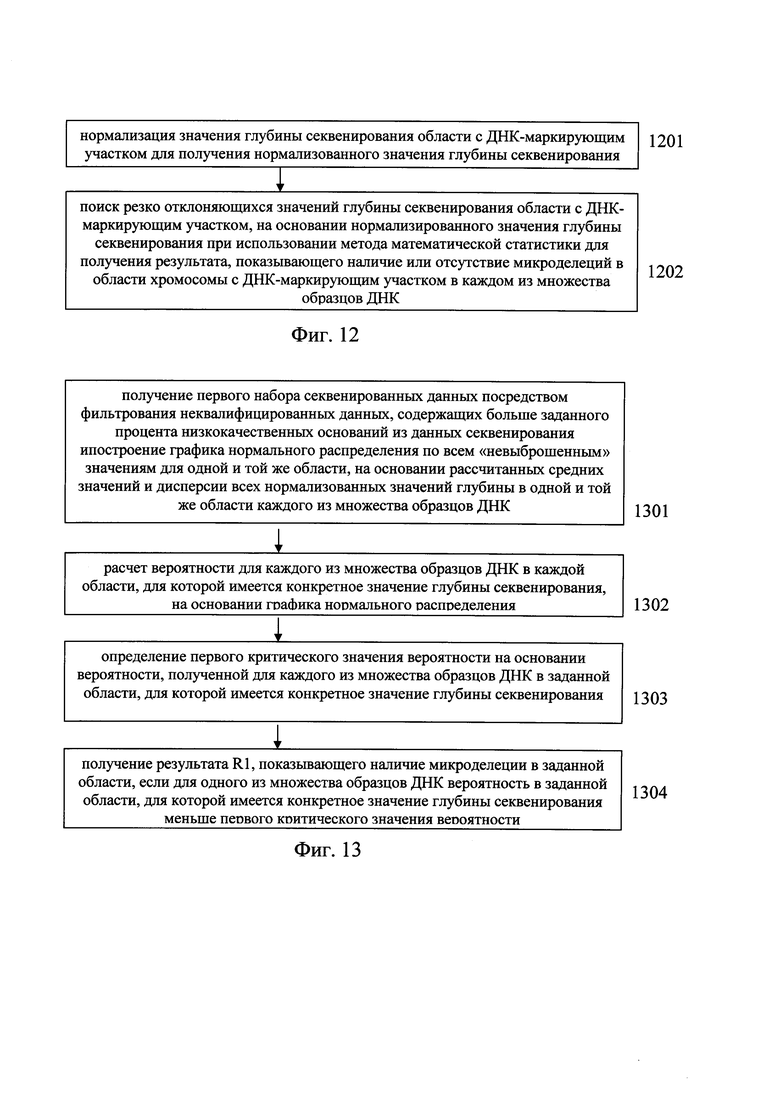
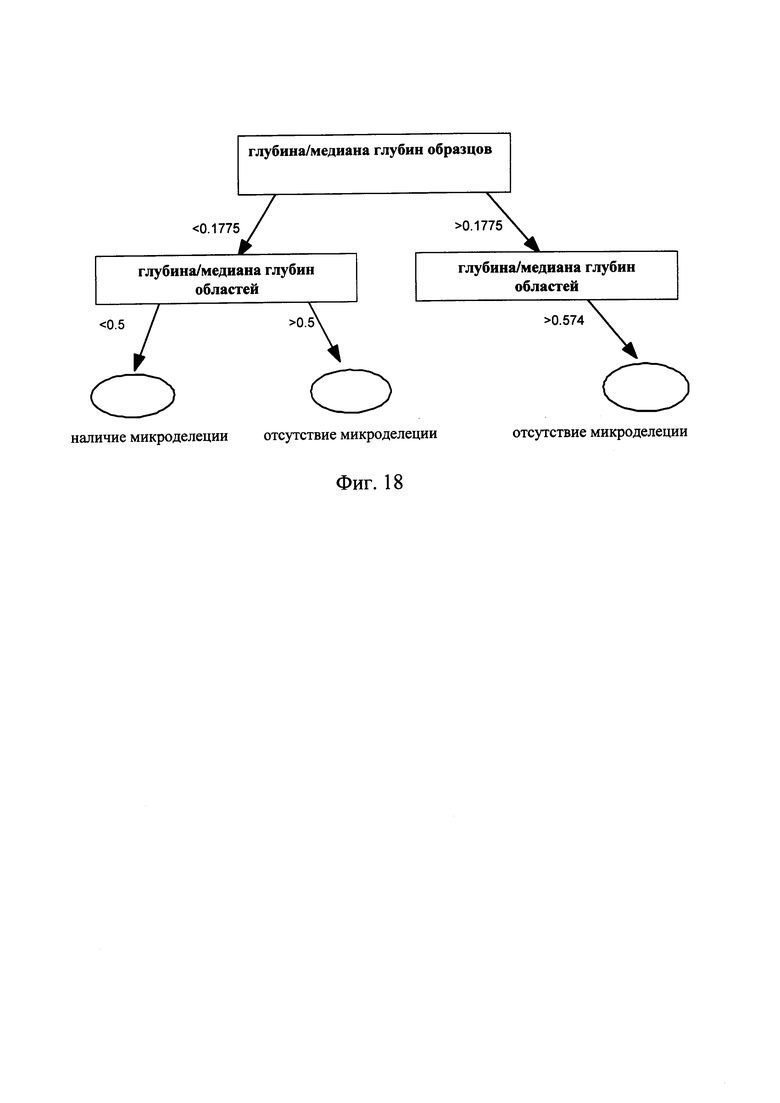

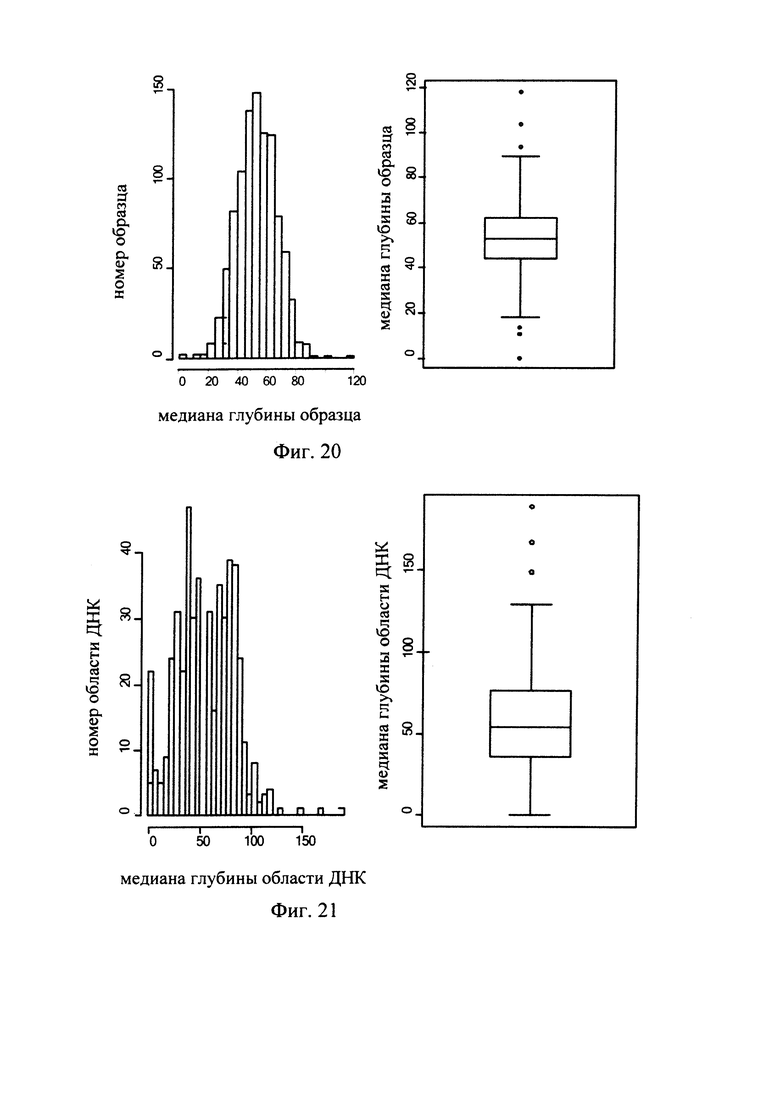
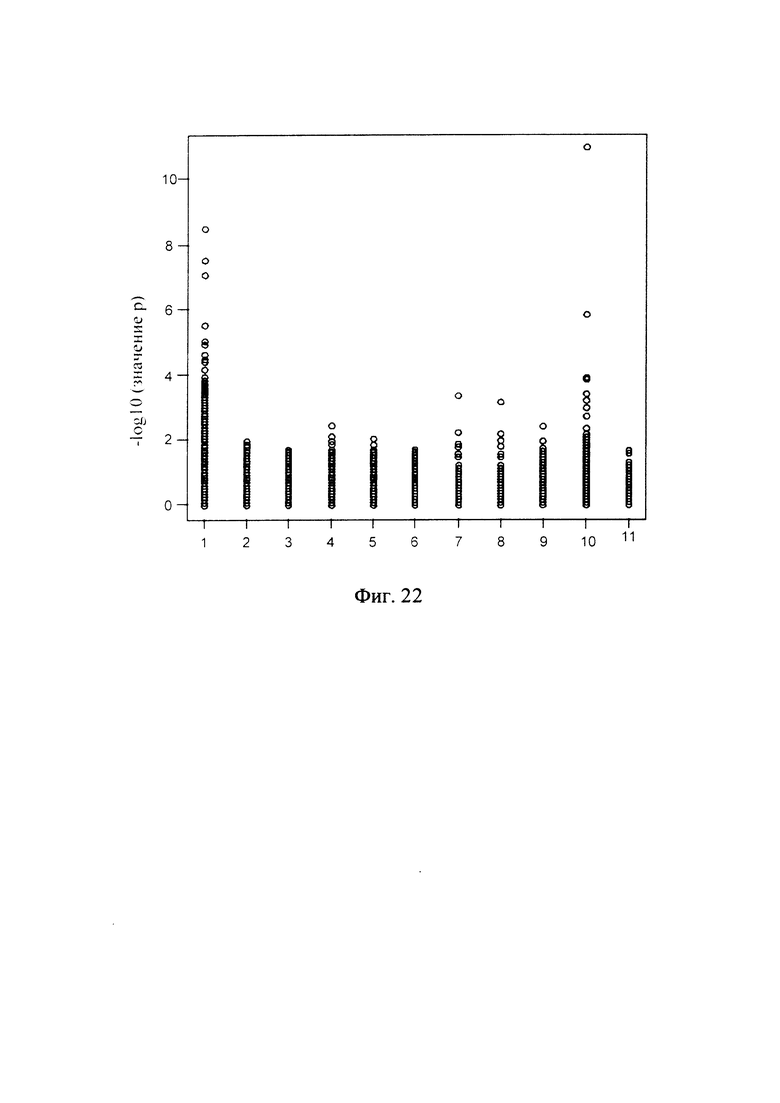
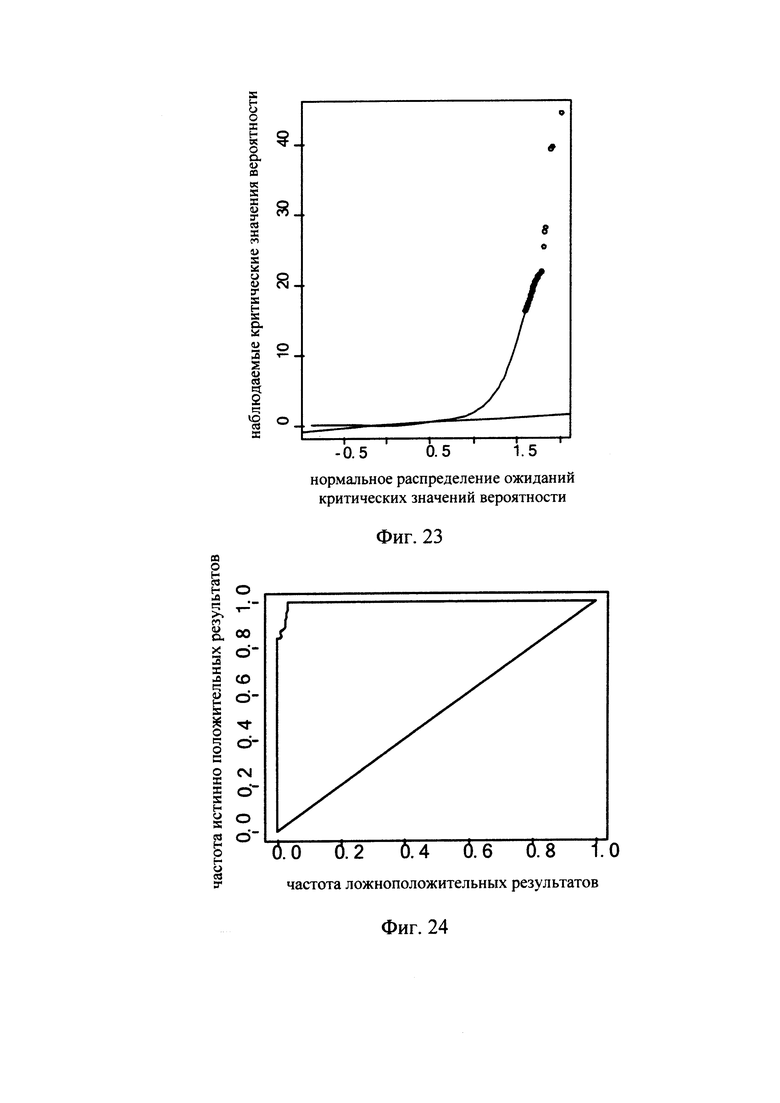
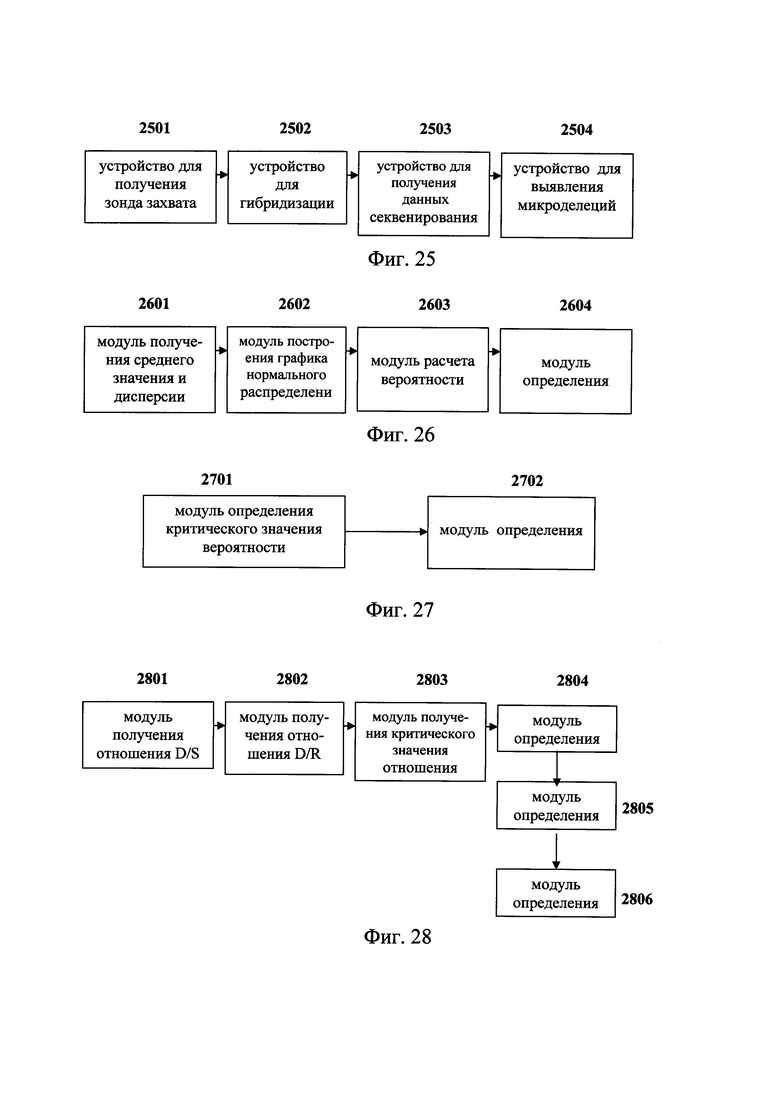
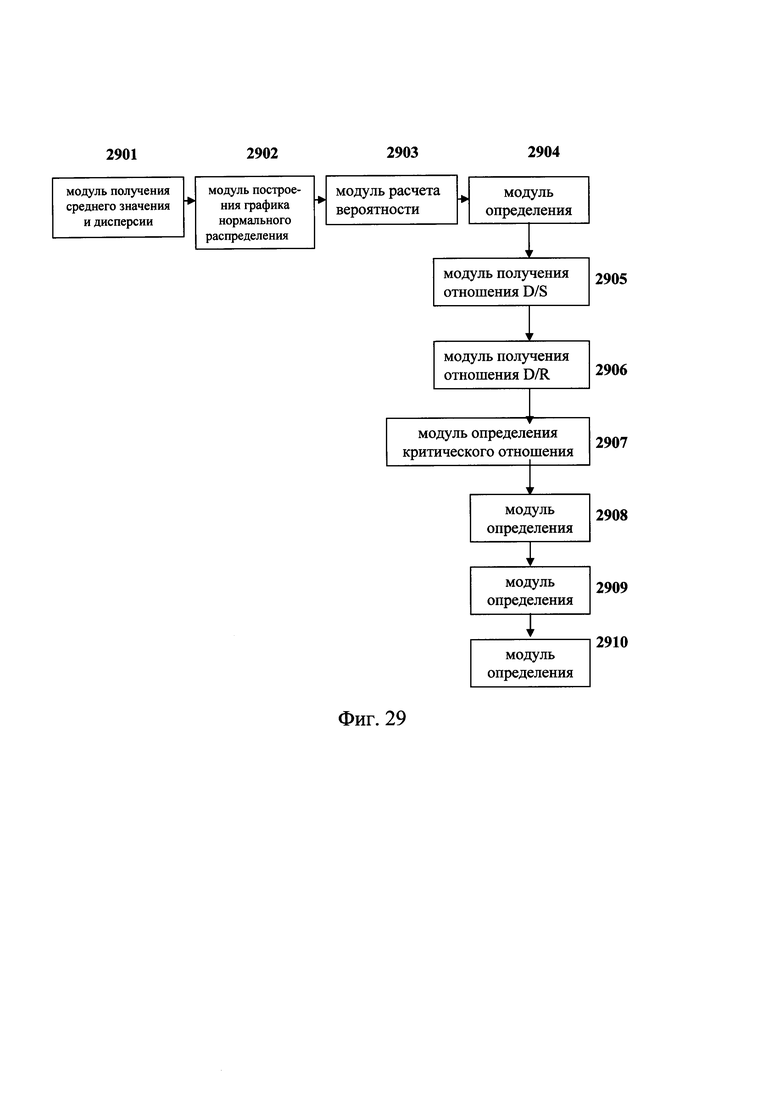
Изобретение касается способа обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком. Способ включает выбор области хромосомы с ДНК-маркирующим участком; получение зонда захвата, соответствующего последовательности ДНК в указанной области; гибридизацию зонда захвата со смешанной библиотекой для связывания с последовательностью из множества образцов ДНК из области с ДНК-маркирующим участком; секвенирование захваченной последовательности ДНК из области с ДНК-маркирующим участком для получения данных секвенирования и анализ результатов секвенирования с использованием метода математической статистики с получением результата, показывающего наличие или отсутствие микроделеции в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК. Изобретение позволяет эффективно и точно детектировать известные и неизвестные микроделеции в области хромосомы с ДНК-маркирующим участком при обработке большого количества образцов ДНК. 13 з.п. ф-лы, 29 ил., 8 табл.
1. Способ обнаружения микроделеций в области хромосомы с ДНК-маркирующим участком, включающий:
получение зонда захвата, соответствующего последовательности ДНК в области с ДНК-маркирующим участком;
гибридизацию зонда захвата со смешанной библиотекой из множества образцов ДНК для связывания с последовательностью ДНК из области с ДНК-маркирующим участком, из множества образцов ДНК, при этом проводят концевую репарацию фрагментов с получением фрагментов ДНК с репарированными-фосфорилированными концами; добавление основания "А" к фрагментам ДНК с репарированными концами; лигирование Индекс-адаптора и амплификацию фрагментов ДНК, лигированных с Индекс-адаптором, при использовании праймера, включающего последовательность, специфичную к Индекс-адаптору, для получения продукта амплификации;
секвенирование захваченной последовательности ДНК из области с ДНК-маркирующим участком для получения данных секвенирования и
анализ результатов секвенирования с использованием метода математической статистики с получением результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК, при этом анализ включает:
нормализацию значения глубины секвенирования области с ДНК-маркирующим участком для получения нормализованного значения глубины секвенирования;
поиск резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком, основанный на нормализованном значении глубины секвенирования, с использованием метода математической статистики, для получения результата, показывающего наличие или отсутствие микроделеций в области хромосомы с ДНК-маркирующим участком в каждом из множества образцов ДНК.
2. Способ по п. 1, характеризующийся тем, что этап нормализации значения глубины секвенирования ДНК-маркирующего участка включает:
деление всех значений глубины секвенирования одной и той же области в каждом из множества образцов ДНК на среднее значение глубины каждого из множества образцов ДНК с целью получения нормализованных значений глубины секвенирования одной и той же области для множества образцов ДНК.
3. Способ по п. 1, характеризующийся тем, что этап поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включает:
расчет среднего значения и дисперсии на основании всех нормализованных значений глубины секвенирования одной и той же области во множестве образцов ДНК;
построение графика нормального распределения по всем невыбрасывающимся значениям для одной и той же области на основании рассчитанного среднего значения и дисперсии всех нормализованных значений глубины в одной и той же области для каждого из множества образцов ДНК;
расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
определение первого критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования; и
получение результата R1, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше первого критического значения вероятности.
4. Способ по п. 3, характеризующийся тем, что после этапа получения результата R1 способ включает:
экспериментальную проверку результата R1 и получение результата проверки;
определение второго критического значения вероятности на основании результата проверки, в котором второе критическое значение вероятности меньше первого критического значения вероятности; и
получение результата R2, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области с конкретным значением глубины секвенирования меньше второго критического значения вероятности.
5. Способ по п. 1, характеризующийся тем, что этап поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включает:
расчет первого отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
расчет первого отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК; и медианой значений глубины секвенирования, полученных для всех областей, на основании нормализованного значения глубины области с ДНК-маркирующим участком, рассчитанного для множества образцов ДНК;
обучение критического значения первого отношения первому отношению D/S с использованием алгоритма ID3 и обучение критического значения второго отношения первому отношению D/R с использованием алгоритма ID3;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S больше критического значения первого отношения;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R больше критического значения второго отношения; и
получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если первое отношение D/S меньше критического значения первого отношения и первое отношение D/R меньше критического значения второго отношения.
6. Способ по п. 1, характеризующийся тем, что этап поиска резко отклоняющихся значений глубины секвенирования области с ДНК-маркирующим участком включает:
расчет среднего значения и дисперсии на основании всех нормализованных значений глубины одной и той же области для каждого из множества образцов ДНК;
построение графика нормального распределения по всем невыбрасывающимся значениям для одной и той же области на основании рассчитанного среднего значения и дисперсии всех нормализованных значений глубины в одной и той же области для каждого из множества образцов ДНК;
расчет вероятности для каждого из множества образцов ДНК в каждой области, для которой имеется конкретное значение глубины секвенирования, на основании графика нормального распределения;
определение третьего критического значения вероятности на основании вероятности, полученной для каждого из множества образцов ДНК в заданной области, для которой имеется конкретное значение глубины секвенирования;
получение результата R3, показывающего наличие микроделеций в заданной области, если для одного из множества образцов ДНК вероятность в заданной области, для которой имеется конкретное значение глубины секвенирования, меньше третьего критического значения вероятности;
расчет второго отношения D/S между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК; и медианой всех значений глубины секвенирования, полученных для каждого из множества образцов ДНК в результате R3;
расчет второго отношения D/R между нормализованным значением глубины в заданной области, полученным для множества образцов ДНК, и медианой значений глубины секвенирования, полученных для всех областей, в результате R3;
обучение критического значения третьего отношения второму отношению D/S при использовании алгоритма ID3 и обучение критического значения четвертого отношения второму отношению D/R при использовании алгоритма ID3;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S больше критического значения третьего отношения;
получение результата, показывающего отсутствие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R больше критического значения четвертого отношения;
получение результата, показывающего наличие микроделеций в заданной области множества образцов ДНК, если второе отношение D/S меньше критического значения третьего отношения и второе отношение D/R меньше критического значения четвертого отношения.
7. Способ по п. 1, характеризующийся тем, что этап получения зонда захвата включает:
нахождение последовательности ДНК в области с ДНК-маркирующим участком в геномной базе данных;
выбор квалифицированной последовательности ДНК в области с ДНК-маркирующим участком, отвечающей требованиям к конструированию зонда захвата;
проектирование и синтез зонда захвата на основании квалифицированной последовательности ДНК.
8. Способ по п. 1, характеризующийся тем, что создание смешанной библиотеки из множества образцов ДНК включает следующие этапы:
создание множества библиотек ДНК для множества отдельных образцов ДНК, таким образом, чтобы каждая из множества библиотек ДНК имела адаптор, отличающийся от адаптера других библиотек ДНК;
смешивание множества библиотек ДНК в заданном соотношении;
определение полученной смеси как смешанной библиотеки, если полученная смесь соответствует требованиям контроля качества.
9. Способ по п. 7, характеризующийся тем, что на этапе создания множества библиотек ДНК из множества отдельных образцов ДНК конструирование библиотеки ДНК для каждого из множества отдельных образцов ДНК включает следующие подэтапы:
фрагментацию геномной ДНК на фрагменты ДНК заданного размера с использованием для этого физических или химических методов;
концевую репарацию фрагментов ДНК с получением фрагментов ДНК с репарированными-фосфорилированными концами;
добавление основания "А" к фрагментам ДНК с репарированными концами с 3'-конца, для того чтобы получить фрагменты ДНК с основанием "А" на 3'-конце;
лигирование Индекс-адаптера с фрагментами ДНК, имеющими основание «А» на 3'-конце, для получения фрагментов ДНК, лигированных с Индекс- адаптером;
амплификацию фрагментов ДНК, лигированных с Индекс-адаптером, при использовании праймера, включающего последовательность, специфичную к Индекс-адаптеру, для получения продукта амплификации; и
определение продукта амплификации как библиотеки ДНК, если продукт амплификации соответствует требованиям контроля качества.
10. Способ по п. 1, характеризующийся тем, что после этапа секвенирования захваченной последовательности ДНК и до этапа анализа результатов секвенирования производят контроль качества результатов секвенирования.
11. Способ по п. 9, характеризующийся тем, что этап контроля качества результатов секвенирования включает:
фильтрование первых неквалифицированных данных, содержащихся в результате секвенирования, для получения первых квалифицированных данных секвенирования;
картирование первых квалифицированных данных секвенирования к эталонной геномной последовательности посредством использования программного обеспечения для картирования коротких последовательностей и расчет первого параметра корреляции для значения глубины секвенирования для каждого из множества образцов ДНК и второго параметра корреляции для значения глубины секвенирования для области с ДНК-маркирующим участком, содержащей заданную последовательность среди множества образцов ДНК;
фильтрование вторых неквалифицированных данных, содержащихся в результате секвенирования, на основании первого рассчитанного параметра корреляции с получением вторых квалифицированных данных секвенирования; и
фильтрование третьих неквалифицированных данных, содержащихся в результате секвенирования, на основании второго рассчитанного параметра корреляции, для получения третьих квалифицированных данных секвенирования области с ДНК-маркирующим участком, содержащей заданную последовательность.
12. Способ по п. 10, характеризующийся тем, что этап фильтрования первых неквалифицированных данных, содержащихся в результате секвенирования, для получения первых квалифицированных данных секвенирования, включает:
получение первого набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих больше заданного процента низкокачественных оснований, из данных секвенирования;
получение второго набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих более 10% неопределенных оснований, из первого набора секвенированных данных;
получение третьего набора секвенированных данных посредством фильтрования неквалифицированных данных, содержащих последовательность сиквенс-адаптора, из второго набора секвенированных данных после картирования к библиотеке последовательностей сиквенс-адаптеров; и
получение первых квалифицированных данных секвенирования посредством фильтрования неквалифицированных данных, содержащих экзогенную последовательность, из третьего набора секвенированных данных после картирования ко всем внесенным экзогенным последовательностям.
13. Способ по п. 10, характеризующийся тем, что этап фильтрования вторых неквалифицированных данных, содержащихся в результате секвенирования, включает:
получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования для множества образцов ДНК в первых квалифицированных данных секвенирования в возрастающем порядке;
фильтрование неквалифицированных данных секвенирования со значениями глубины секвенирования вне интервала от Q1-1,5 МКР до Q3+1,5 МКР для получения вторых квалифицированных данных секвенирования.
14. Способ по п. 10, характеризующийся тем, что этап фильтрования третьих неквалифицированных данных, содержащихся в результате секвенирования, включает:
получение нижнего квартиля Q1, верхнего квартиля Q3 и межквартильного размаха (МКР) посредством использования квартальной функции и упорядочивание всех значений глубины секвенирования в заданной области для различных образцов ДНК во вторых квалифицированных данных секвенирования в возрастающем порядке; и
фильтрование неквалифицированных данных, у которых медиана значений глубины секвенирования в заданной области в различных образцах ДНК равна нулю или больше чем Q3+1,5 МКР для получения третьих квалифицированных данных секвенирования.
| US 20090176226 A1, 09.07.2009 | |||
| WO 2008030065 A1, 13.03.2008 | |||
| KR 2009112235 A, 28.10.2009 | |||
| GROSS S.J | |||
| ET AL., Rapid and novel prenatal molecular assay for detecting aneuploidies and microdeletion syndromes, Prenat Diagn., 2011, v | |||
| Способ очистки нефти и нефтяных продуктов и уничтожения их флюоресценции | 1921 |
|
SU31A1 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Арматура для железобетонных свай и стоек | 1916 |
|
SU259A1 |
| СПОСОБ СКРИНИНГА СЕРДЕЧНО-СОСУДИСТЫХ ЗАБОЛЕВАНИЙ И БИОЧИП ДЛЯ ОСУЩЕСТВЛЕНИЯ ЭТОГО СПОСОБА | 2008 |
|
RU2402771C2 |

