Изобретение относится к области сжатия данных и может использоваться при хранении больших объемов данных с избыточностью.
Из существующего уровня техники известны методы дедупликации данных, осуществляющие по крайней мере первичный поиск идентичных блоков данных по значению их хеш-сумм, описанные в публикации Александра Щербинина Решения по дедупликации данных // Storage News. 2008. №2 (35) (http://old.i-teco.ru/article198.html). Недостатками существующих технических решений являются необходимость накладных вычислительных расходов на вычисление результата хеш-функции для каждого блока данных, необходимость применения методов разрешения хеш-коллизий, большой объем метаданных, прямо пропорциональный объему уникальных блоков данных и зависящий от размера результата применяемой хеш-функции.
Наиболее близким к заявленному техническому решению является метод оптимизации блочной дедупликации данных (US 8108353 В2, опубл. 31.01.2012), осуществляющий разбиение цифровых данных на блоки данных равной длины и размещение метаданных этих блоков данных, представляющих значения их хеш-функций, в префиксном дереве. Недостатками данного технического решения является выбор в качестве метаданных результатов хеш-функций для каждого блока обрабатываемых данных, что требует дополнительных вычислительных расходов на вычисление результата хеш-функции для каждого блока обрабатываемых данных, и необходимость хранения больших объемов полученных метаданных.
Задачей, на решение которой направлено заявленное изобретение, является снижение объема метаданных, сокращение вычислительных накладных расходов и времени процесса.
Данная задача решается за счет того, что в способе префиксной дедупликации цифровых данных, согласно которому цифровые данные разбивают на блоки данных равной длины и последовательно обрабатывают, помещая метаданные этих блоков поразрядно в префиксное дерево, новым является то, что выбор метаданных осуществляется по сегментам также равной длины непосредственно из блоков данных, определение наличия идентичного обрабатываемому блоку среди уже обработанных осуществляется путем обхода префиксного дерева по заранее определенному порядку обхода сегментов, при отсутствии на очередном уровне префиксного дерева ссылки по значению соответствующего порядку обхода сегмента обрабатываемый блок признают уникальным и добавляют ссылку на этот блок на этом уровне префиксного дерева по соответствующему значению сегмента. В случае нахождения ссылки в префиксном дереве на обработанный блок данных выполняют полную сверку обоих блоков, в результате которой при обнаружении различия блоков осуществляют замену ссылки на обработанный блок ссылкой на новую ветвь дерева, содержащую последовательность узлов до первого различного сегмента, а в случае совпадения блоков принимают решение по определению обрабатываемого блока дубликатом.
Техническим результатом, обеспечиваемым приведенной совокупностью признаков, является устранение избыточности в обрабатываемых цифровых данных.
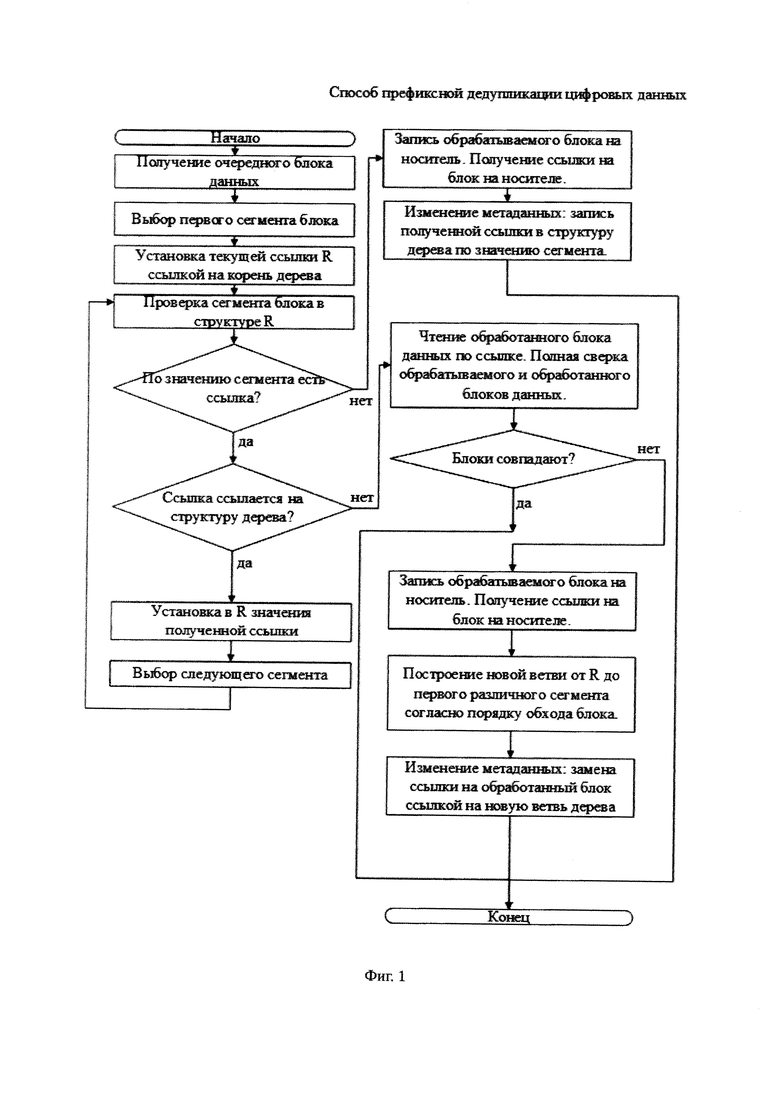
На фиг. 1 изображен алгоритм обработки блока данных способом префиксной дедупликации цифровых данных. Способ оперирует блоками данных равной длины, полученными из цифровых данных. Для очередного обрабатываемого блока данных определяется первый обрабатываемый сегмент согласно заранее выбранному порядку обхода блока данных, например прямому порядку обхода, подразумевающему последовательный обход блока данных от младшего сегмента к старшему. Обход префиксного дерева начинается с корневого узла префиксного дерева. Из цифровых данных выбирается блок данных и разбивается на сегменты равной длины. По значению первого сегмента этого блока, согласно выбранному порядку обхода, осуществляется переход из корневого узла в другой узел. Переход из текущего узла в следующий узел осуществляется по значению текущего сегмента блока данных в случае наличия ссылки на узел. В случае отсутствия ссылки по значению текущего сегмента обрабатываемого блока данных осуществляется его запись на носитель с последующем изменением метаданных путем записи ссылки на записанный блок в текущий узел префиксного дерева по значению текущего сегмента блока данных. При переходе в следующий узел префиксного дерева в качестве текущего сегмента выбирается следующий сегмент согласно выбранному порядку обхода блока данных. В случае наличия ссылки на блок данных на носителе информации по значению текущего сегмента блока данных осуществляется чтение блока данных с носителя и производится полная сверка с обрабатываемым блоком данных. При несовпадении блоков данных осуществляется запись обрабатываемого блока данных на носитель (блок признается уникальным), построение ветви префиксного дерева от текущего узла до первого отличного сегмента блоков данных согласно выбранному порядку обхода и запись ссылок на блоки данных в узел дерева по значениям отличных сегментов.
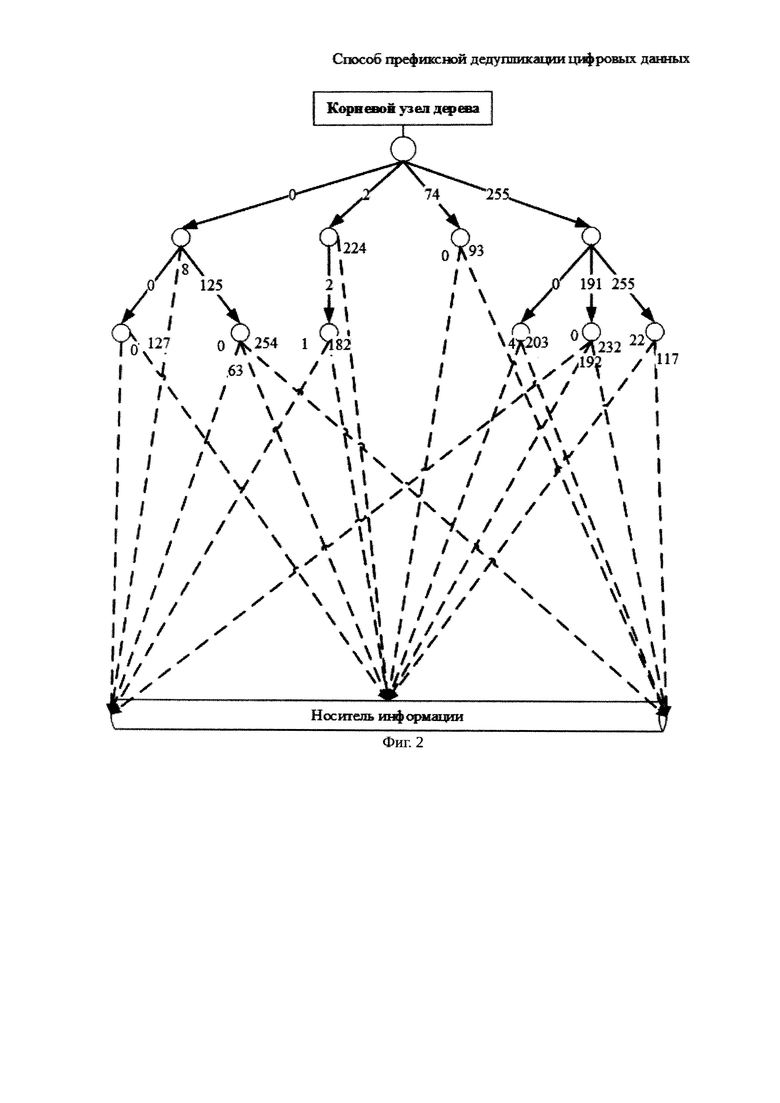
В соответствии с фиг. 1 на фиг. 2 изображено частично заполненное префиксное дерево, содержащее метаданные 18 обработанных блоков данных. На фиг. 2 ссылки на блоки данных на носителе изображены пунктиром. Размер сегмента в данном примере равен 1 байту, и максимальное количество ссылок в узле равно 256. По данному дереву можно найти блоки, расположенные на носителе, по первым трем сегментам согласно заранее выбранному порядку обхода блока данных. Значения сегментов в дереве изображены на ребрах дерева. В примере приведены блоки данных с начальными сегментами со значениями 0, 2, 74, 255. В частности метаданные содержат информацию о двух обработанных блоках со значением первого сегмента 74, отличных по значениям второго сегмента (0 и 93). По значениям отличных сегментов в узле содержатся ссылки на блоки данных, находящихся на носителе информации, а в узле по значению первого сегмента, равному 0, содержатся ссылки как на другие узлы по значениям отличных сегментов блоков данных (0 и 125), так и ссылки на блоки данных, находящиеся на носителе информации (8).
Предложенный способ может быть реализован 4 модулями:
1) модулем приема данных, отвечающим за получение данных и предоставление блока данных фиксированной длины;
2) модулем верификации данных, осуществляющим определение наличия подобного блока в хранилище;
3) модулем хранения метаданных, осуществляющим хранение, поиск и доступ метаданных;
4) модулем доступа к хранилищу, осуществляющим взаимодействие с носителем дедуплицированных данных.
Модуль приема данных выделяет из данных блок фиксированной длины и передает его в модуль верификации данных. Модуль верификации данных производит выявление блока данных путем обхода метаданных, взаимодействуя с модулем хранения метаданных. В случае наличия ссылки на блок данных модуль хранения метаданных возвращает ссылку на этот блок данных на носителе, и модуль верификации получает от модуля доступа к хранилищу блок данных и осуществляет полную сверку блоков данных. В случае совпадения блоков модуль верификации признает проверяемый блок дубликатом, иначе осуществляет запись проверяемого блока через модуль доступа к хранилищу и возвращает значение ссылки записанного блока в модуль хранения метаданных, который осуществляет построение ветви префиксного дерева от узла, содержащего ссылку считанного блока, согласно определенному порядку обхода блока данных до первого различного сегмента и запись ссылок блоков данных по значениям отличных сегментов. В случае отсутствия ссылки на блок данных модуль верификации инициирует запись блока данных в модуль доступа к хранилищу и, получив ссылку записанного блока данных, передает ссылку на него в модуль хранения метаданных, который осуществляет запись ссылки блока данных в узел префиксного дерева по значению последнего проверенного сегмента.
Результатом приведенного технического решения является получение данных с устраненной избыточностью на блочном уровне.
Изобретение относится к области сжатия данных и может использоваться при хранении больших объемов данных, содержащих избыточность. Технический результат заключается в устранении избыточности в обработанных цифровых данных. Указанный результат достигается за счет того, что цифровые данные разбивают на блоки данных равной длины, помещая метаданные этих блоков поразрядно в префиксное дерево. Осуществляют выбор метаданных по сегментам равной длины непосредственно из блоков данных, определяют наличие идентичного обрабатываемому блоку среди уже обработанных путем обхода префиксного дерева по заранее определенному порядку обхода сегментов, при отсутствии на очередном уровне префиксного дерева ссылки по значению соответствующего порядку обхода сегмента обрабатываемый блок признают уникальным и добавляют ссылку на этот блок на этом уровне префиксного дерева по соответствующему значению сегмента, в случае нахождения ссылки в префиксном дереве на обработанный блок данных выполняют полную сверку обоих блоков, в результате которой при обнаружении различия блоков осуществляют замену ссылки на обработанный блок ссылкой на новую ветвь дерева, содержащую последовательность узлов до первого различного сегмента, а в случае совпадения блоков принимают решение по определению обрабатываемого блока дубликатом. 2 ил.
Способ префиксной дедупликации цифровых данных, согласно которому цифровые данные разбивают на блоки данных равной длины и последовательно обрабатывают, помещая метаданные этих блоков поразрядно в префиксное дерево, отличающийся тем, что выбор метаданных осуществляется по сегментам также равной длины непосредственно из блоков данных, определение наличия идентичного обрабатываемому блоку среди уже обработанных осуществляется путем обхода префиксного дерева по заранее определенному порядку обхода сегментов, при отсутствии на очередном уровне префиксного дерева ссылки по значению соответствующего порядку обхода сегмента обрабатываемый блок признают уникальным и добавляют ссылку на этот блок на этом уровне префиксного дерева по соответствующему значению сегмента, в случае нахождения ссылки в префиксном дереве на обработанный блок данных выполняют полную сверку обоих блоков, в результате которой при обнаружении различия блоков осуществляют замену ссылки на обработанный блок ссылкой на новую ветвь дерева, содержащую последовательность узлов до первого различного сегмента, а в случае совпадения блоков принимают решение по определению обрабатываемого блока дубликатом.
| US 8751763 B1, 10.06.2014 | |||
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Ассоциативное оперативное запоминающее устройство | 1989 |
|
SU1714682A1 |
| СПОСОБ МАСШТАБИРУЕМОГО КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ВИДЕОСИГНАЛА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2004 |
|
RU2329615C2 |
| СПОСОБ СЖАТИЯ И ВОССТАНОВЛЕНИЯ ДАННЫХ БЕЗ ПОТЕРЬ | 2008 |
|
RU2382492C1 |
| RU 2011117578 A, 10.11.2012. | |||

