Изобретение относится к автоматизированным способам управления, а именно к автоматизированным способам управления требованиями, и может быть использовано, например, при управлении сложными проектами.
Известна система управления требованиями, описанная в заявке на выдачу патента США № 20130013613. При работе указанной системы реализуется следующий способ: каждому требованию ставят в соответствие один или несколько атрибутов. Каждый из атрибутов имеет уникальное значение и входит в группу атрибутов, соответствующих проекту. Когда формируется требование, значения атрибутов выбираются из группы атрибутов или задаются пользователем, при этом новое значение добавляется в группу. Значение каждого атрибута соответствует категории, к которой относится требование. Все требования разделены на категории.
Как и в заявляемом способе, в известном способе каждому требованию ставят в соответствие набор атрибутов, значения которых используется для сравнения и анализа требований, в том числе и для категоризации требований.
К недостатком упомянутого способа, реализованного в указанной системе, можно отнести, во-первых, отсутствие процедуры накопления знаний о предметной области (например, о «Процессе управлении требованиями»), что существенно сужает область применения способа, во-вторых, функциональные возможности способа ограничены сравнением требований по назначенным им значениям атрибутов, в-третьих, не предусмотрена возможность анализа различных версий требований, что существенно ограничивает применение указанного способа в реальных ситуациях, так как в любом проекте всегда происходят изменения.
Наиболее близким к заявляемому является известный способ управления требованиями, описанный в заявке на выдачу патента США № 20130205190. Способ включает создание онтологии, которая так же как и в заявляемом способе, состоит из предопределенных классов и связей между ними и используется для создания/формулирования требований и последующего их анализа.
К недостаткам упомянутого способа можно отнести следующие. Известный способ не позволяет накапливать знания о предметной области. Под предметной областью здесь и далее будет подразумеваться «Процесс управления требованиями», как он описан в стандартах ИСО 15504 и ИСО 15288. Это связано с тем, что в упомянутом способе онтология не подразумевает хранение и использование аксиом для классов, она состоит из наборов ключевых (для конкретного проекта) слов, используемых при формулировании требований. Способ не является универсальным по отношению к предметной области, т.к. онтология способа основана и содержит ключевые слова и понятия конкретного проекта. Т.е. при управлении требованиями в другом проекте потребуется заново переопределять все необходимые ключевые слова и понятия нового проекта. Способ не позволяет создавать новые данные на основе имеющихся.
Задача, на решение которой направлено заявляемое техническое решение, заключается в создании автоматизированного способа управления требованиями, универсального для указанной предметной области, позволяющего осуществлять накопление знаний о предметной области и не зависящего от данных конкретного проекта и компьютерных программ конкретного разработчика.
Предлагаемый способ позволяет автоматизировать процесс управления требованиями за счет накопления всех требований, учета их версионности, а также их отношений с другими объектами предметной области. По мере накопления данных способ позволяет выполнять различные виды анализа, например делать заключения о выполнении требований на основе выполнения подчиненных требований и множество других.
Технический результат от использования заявляемого способа заключается в повышении эффективности процессов управления требованиями в различных проектах за счет накопления знаний и сокращении времени настройки способа как по мере развития процесса, так и при переходе от проекта к проекту в пределах указанной предметной области. Эффективность способа определяется способностью к модернизации и масштабированию информационной системы, построенной на заявляемом способе. Т.е. возникающие новые или изменяемые текущие бизнес-задачи, связанные с управлением требованиями, могут быстро реализовываться в информационной системе, т.е. стать доступны для автоматизированного анализа и отчетности.
Указанные задача и технический результат достигаются за счет того, что в способе управления требованиями, включающем создание онтологии предметной области, состоящей из классов, их описания, и связей между классами, накопление требований и всей связанной с требованиями информации, и их анализ, в онтологию включают аннотации и определения, а также аксиомы, позволяющие делать логические выводы, а требования и связанную с ними информацию, представленную в виде файлов со структурированными данными, подготавливают для размещения в хранилище триплетов, при этом каждому файлу исходных данных ставят в соответствие свой алгоритм преобразования исходных данных к триплетам, основанный на соответствующей структуре данных (метаданных) исходного файла, для каждого элемента данных создают унифицированный по длине уникальный идентификатор, который создают с помощью алгоритма хеширования, далее исходные данные ставят в соответствие классам онтологии предметной области и результат размещают в хранилище триплетов, где всю информацию по предметной области представляют в виде единого связанного ориентированного графа, используемого для анализа.
Онтология в заявляемом способе выполняет роль метаданных, онтология содержит не только перечень классов и отношений между ними, но и аннотации и определения, сделанные на литературном языке специалистами предметной области. Аннотации и определения могут иметь и классы, и отношения между ними. Например, возьмем элемент данных <time0>, являющийся тегом XML файла или названием колонки в реляционной таблице. Из названия элемента не совсем ясно, что под ним подразумевается и как его интерпретировать. В онтологии же элемент <time0> должен содержать определение, например «Запланированное время старта задачи», и аннотацию, например «Плановые даты берутся из общего графика работ по проекту». В результате становится понятно, как интерпретировать этот элемент данных. Таким образом, как формальное описание предметной области, онтология сама по себе представляет базу знаний по этой области и может использоваться как для обучения, так и применения в других проектах.
Сокращение времени настройки заявляемого способа на конкретный проект достигается за счет того, что онтология является предметом, не зависимым от разработчика/поставщика информационных систем, так как хранится в виде триплетов и может быть отделена от триплетов с данными своим префиксом или одним из других способов описанных ниже. Т.е. по итогам одного проекта онтология может быть отделена от данных этого проекта и передана в новый проект для использования с новыми данными.
Преобразование предложенным способом файлов с исходными данными позволяет повысить эффективность способа за счет того, что большое разнообразие исходных форматов структурированных данных приводится к единому виду, которым выступает триплет. Триплет - это строка записи в хранилище, состоящая из трех элементов: субъект-предикат-объект.
Триплеты, к которым приводится результат сопоставления исходных данных классам онтологии предметной области, могут храниться не только в хранилищах триплетов, но и в виде файлов, формат которых определен в стандартах W3C (например, RDF/XML, TTL, NT и др). Такое хранение и передача данных позволяет легко мигрировать с информационных систем одного производителя на системы другого без потери какой-либо части данных и тем самым обеспечить независимость от поставщиков этих систем.
Создание для каждого элемента данных уникального идентификатора позволяет адресоваться, т.е. ссылаться на элемент данных и устанавливать связи с каждым конкретным элементом. Кроме того, если связи между некими элементами существуют, но не являются правилом, то предлагаемый способ позволяет хранить и обрабатывать такие исключения. Формально, предлагаемый способ может целиком содержать сплошные исключения, т.е. не иметь правил. И лишь потом, после размещения данных, позволяет искать и описывать необходимые правила через аксиомы онтологии. Для сравнения в реляционных базах данных для хранения исключительных ситуаций необходимо предварительно создавать отдельные таблицы для каждого отдельного типа исключительных ситуаций. Таким образом, в предложенном способе экономится время на обеспечение хранения и обработки данных.
Следующая особенность использования уникальных идентификаторов для каждого элемента данных заключается в том, что схожие по написанию, но разные по смыслу объекты будут иметь разный идентификатор. Например, город «Москва» в России и город с тем же названием, но находящийся в Америке, будут иметь разные идентификаторы и разные связи. С другой стороны, элемент данных, описывающий универсальные понятия, например цвет «Красный» и пр., будут иметь один-единственный уникальный идентификатор. И все объекты со свойством «Красный» будут связаны именно с одним этим элементом данных. И вместо поиска всех «Красных» объектов достаточно просто посмотреть текущие связи с узлом графа «Красный». А учитывая, что каждый отдельный объект предметной области с его свойствами представляют в виде связанного ориентированного графа, то в части совпадающих универсальных понятий разные объекты предметной области будут использовать одни и те же узлы графа. Это приводит к повышению эффективности хранения данных (дублирующиеся данные не хранятся) и к сокращению времени на модификацию/расширение системы. Для сравнения в реляционных системах для исключения дублирования данных используют правила нормализации. А выполнять нормализацию уже наполненной реляционной базы в связи с ее модификацией/расширением - очень трудный и ресурсоемкий процесс.
Еще одна особенность использования уникальных идентификаторов заключается в том, что они состоят из условно постоянной части, называемой «префикс», и уникальной части – «суффикс», генерируемой с помощью алгоритма хеширования. Префикс в предлагаемом способе используется как указатель на источник данных, либо на принадлежность к проекту, либо организации, либо чему-то еще по усмотрению пользователя.
Представление всех исходных данных в виде единого связанного ориентированного графа позволяет определить характер отношений между любыми имеющимися в распоряжении данными и проводить различные виды анализа с необходимой степенью детализации.
Разнообразие видов анализа и создание новых данные на основе имеющихся получаются в результате выполнения логических выводов, которые достигаются за счет использования языка запросов SPARQL и аксиом онтологии, сформулированных на языке OWL-2 и свойств отношений: транзитивность, симметрия, асимметрия, рефлексия, арефлексия, и тождественности – т.е. «sameAs».
Например, накапливают требования к оборудованию из разных нормативных документов с указанием названия документа и указанием страны его происхождения. В онтологию вносят аксиому: «Российский нормативный акт имеет приоритет над не российским». В результате логического вывода (ризонинга) будет получено две группы требований к оборудованию, где у российских требований будет более высокий приоритет над не российскими. Если требования касаются зарубежного объекта, то исходную аксиому следует поменять на противоположную, и тогда приоритеты изменятся. В результате без изменения исходных данных будет получен другой логический вывод, который полностью соответствует ситуации. Чем больше аксиом записано для предметной области управления требованиями, тем больше логических выводов можно получить и тем богаче онтология с точки зрения на нее как на базу знаний.
В ходе выполнения операций логического вывода с использованием аксиом или в результате SPARQL запросов создаются новые триплеты. Эти триплеты создают новые связи. Это могут быть связи, устанавливающие принадлежность данных к какому-либо классу. Тогда фактически речь идет о классификации. Это могут быть связи между объектами и тогда это расширяет свойства объектов.
Заявляемый способ позволяет добавлять новые элементы онтологии и аксиомы по мере необходимости, независимо от ранее загруженных данных. Такая возможность может достигаться несколькими способами. Первый способ основан на использовании префиксов у триплетов. Второй способ заключается в организации «федерации хранилищ». Т.е. когда для разделения информации используются несколько хранилищ триплетов, одно - с онтологией и другое - с данными, которые виртуально объединяются в одно общее хранилище. В третьем способе используются возможность указания для триплетов названия графа, которому они принадлежат. Таким образом, для удаления старой онтологии при любом из указанных способов достаточно удалить все триплеты, связанные с текущей версией онтологии, а потом добавить новые триплеты с новой версией онтологии. Такой подход не затрагивает сами данные.
Возможность масштабирования, т.е. накопления и наращивания разнообразия информации, связанной с требованиями, по мере развития организации и/или проекта, (например, источники требований, заинтересованные организации, эксперты, результаты верификаций и валидаций, ответственные за выполнение требований, тестовые программы и процедуры и т.д.) появляется за счет возможности расширения и развития онтологии, независимо от загрузки данных, как было показано выше. А также за счет того, что масштабирование не приводит к необходимости модернизации таблиц в хранилище, а лишь увеличивает количество триплетов, т.е. количество записей в хранилище. Совсем наоборот в реляционных СУБД. Там, по мере увеличения состава и содержания информации, необходимо не только добавлять новые таблицы и колонки в них, но и выполнять правила нормализации, которые приводят к изменению модели данных. Однако из-за уже созданных реляционных связей и содержащихся в таблицах данных выполнить модернизацию очень трудно и не всегда возможно.
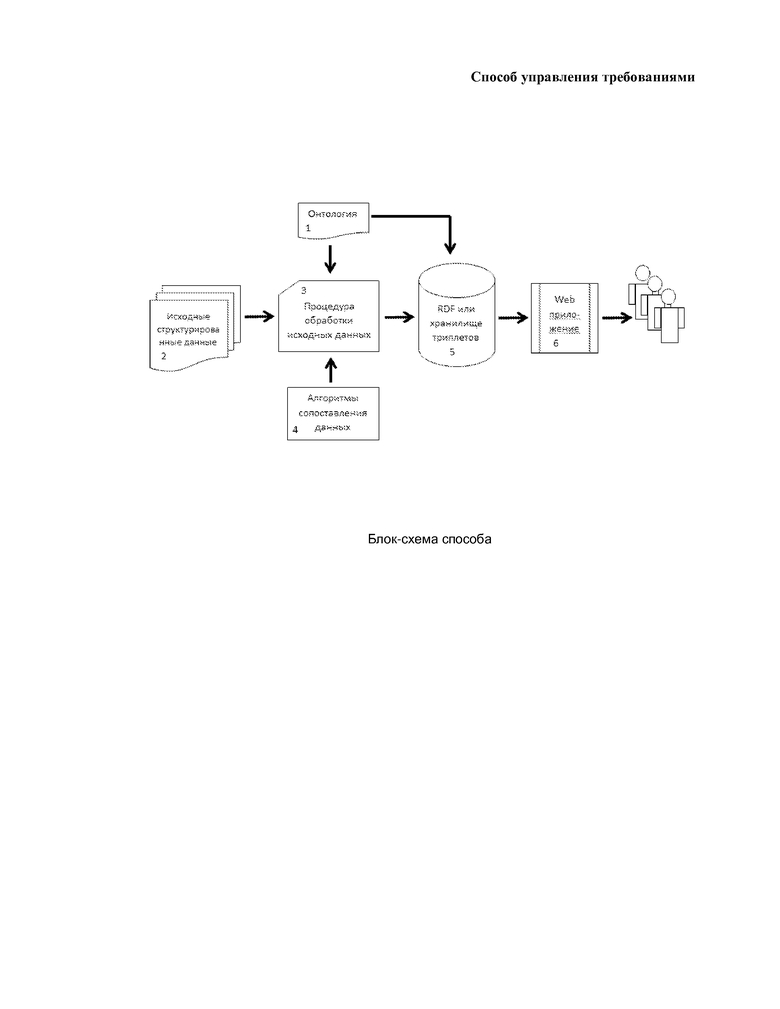
Заявляемое изобретение поясняется чертежом, на котором представлена блок-схема способа.
Способ требует наличия онтологии (1). Онтологии создают в специальной компьютерной программе – редактор онтологий. Существует большое количество редакторов онтологий, разработанных различными компаниями, например Protégé, Differential Ontology Editor, Onto.pro, OntoEdit, Ontolingua, WebOnto и др. Онтология содержит перечень классов и отношений между ними, а также аксиомы, аннотации и определения. Аннотации и определения делаются на литературном языке специалистами предметной области.
Исходные данные (2), соответствующие требованиям, вводят в компьютер. При этом исходные данные представляют в виде структурированных файлов, например в формате CSV, XML, XLS, DBF, ACCDB и пр. Поступившие в компьютер данные преобразуют в формат RDF (5), или размещают в хранилище триплетов (5), при этом каждому элементу структуры исходных данных соответствует свой алгоритм (4) его преобразования к формату триплетов, включая создание для этого элемента уникального идентификатора.
Преобразование к триплетам (3) осуществляют следующим образом: каждому элементу данных с помощью хеш-функции присваивается уникальный идентификатор, и каждый элемент данных соотносится к какому-то определенному классу онтологии. Далее все данные и отношения между ними записываются в виде триплета в файл или хранилище (5).
Для каждого структурированного файла исходных данных (2), обрабатываемого в первый раз, создают свой алгоритм (4) преобразования исходных данных к триплетам, основанный на соответствующей структуре данных (метаданных) исходного файла. Алгоритм представляет собой набор команд, записанный на машиночитаемом языке, например с помощью команд типа SELECT() осуществляется выборка однородного массива данных, далее с помощью соответствующих команд языка типа SUBSTRING(), CONCATENATE(), STR-TO-DATE() и т.д. происходит их изменение (например, при необходимости разбить данные на части или объединить с другими данными и т.д.), далее с помощью команд типа SHA1(), MD5() происходит создание уникальных идентификаторов для данных и далее с помощью команд типа UPDATE() происходит сохранение измененных данных в виде триплетов в хранилище триплетов (5). Алгоритм (4) сохраняют в виде файла на компьютере. Когда алгоритм запускают на исполнение, происходит преобразование данных и их сохранение в хранилище триплетов (5). Если структура изменена, то это требует создание нового или модификации предыдущего алгоритма.
Накопление всех требований, осуществляют путем импорта всех имеющихся в проекте структурированных данных. Учет версионности всех объектов осуществляют за счет того, что каждый отдельный объект предметной области с его свойствами представляют в виде связанного ориентированного ациклического графа.
Для визуализации хранящихся данных используется Web-приложение (6). Взаимодействие между Web-приложением (6) и хранилищем триплетов осуществляется любым стандартным способом, предусмотренным W3C.
Анализ требований осуществляется через интерфейс Web-приложения (6) и включает, но не ограничивается:
1) классификацию объектов предметной области по выбранному набору критериев;
2) получение заключения о выполнении требований на основе выполнения подчиненных требований;
3) анализ связей и свойств элементов предметной области. Для каждого узла графа принадлежность его к классу онтологии означает объект предметной области (например, требование, документ, организация или др.). Все исходящие связи характеризуют свойства этого объекта, а все входящие связи – ссылку на него со стороны других объектов предметной области. Таким образом, перемещаясь по графу, пользователь получает всю информацию по объекту, включая определение, аннотацию, характеристики и связи. При этом не требуется построения запросов или выполнения каких-либо вычислений.
Заявляемый способ может быть реализован с использованием компьютера (например, Intel Core™ i3, оперативной памятью 8Гб, жестким диском от 100Гб, операционной системой Windows XP и старше, или OS X 10.7 и старше, или Linux с ядром 3.16 и старше).
Изобретение относится к способу управления требованиями. Технический результат заключается в обеспечении управления требованиями. В способе выполняют создание онтологии предметной области, состоящей из классов, их описания и связей между классами, накопление требований и всей связанной с требованиями информации и их анализ, при этом в онтологию включают аннотации и определения, а также аксиомы, позволяющие делать логические выводы, а требования и связанную с ними информацию, представленную в виде файлов, хранящихся на компьютере со структурированными данными, подготавливают для размещения в хранилище триплетов, при этом каждому файлу исходных данных ставят в соответствие свой алгоритм преобразования исходных данных к триплетам, основанный на соответствующей структуре данных (метаданных) исходного файла, алгоритм сохраняют в виде файла на компьютере, для каждого элемента структуры данных создают с помощью алгоритма хеширования унифицированный по длине уникальный идентификатор, далее исходные данные ставят в соответствие классам онтологии предметной области и результат размещают в хранилище триплетов, где всю информацию по предметной области представляют в виде единого связанного ориентированного графа, анализ которого осуществляется через интерфейс Web-браузера. 4 з.п. ф-лы, 1 ил.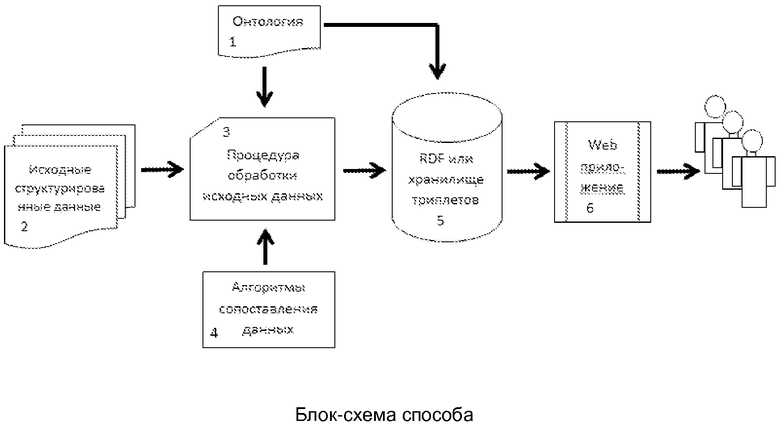
1. Способ управления требованиями, включающий создание онтологии предметной области, состоящей из классов, их описания и связей между классами, накопление требований и всей связанной с требованиями информации и их анализ, отличающийся тем, что в онтологию включают аннотации и определения, а также аксиомы, позволяющие делать логические выводы, а требования и связанную с ними информацию, представленную в виде файлов, хранящихся на компьютере со структурированными данными, подготавливают для размещения в хранилище триплетов, при этом каждому файлу исходных данных ставят в соответствие свой алгоритм преобразования исходных данных к триплетам, основанный на соответствующей структуре данных (метаданных) исходного файла, при этом алгоритм сохраняют в виде файла на компьютере, для каждого элемента структуры данных создают унифицированный по длине уникальный идентификатор, который создают с помощью алгоритма хеширования, далее исходные данные ставят в соответствие классам онтологии предметной области и результат размещают в хранилище триплетов, где всю информацию по предметной области представляют в виде единого связанного ориентированного графа, анализ которого осуществляется через интерфейс Web-браузера.
2. Способ по п. 1, отличающийся тем, что каждый отдельный объект предметной области с его свойствами представляют в виде связанного ориентированного ациклического графа.
3. Способ по п. 1, отличающийся тем, что в качестве алгоритма классификации объектов предметной области используют аксиомы существования, построенные на языке OWL-2.
4. Способ по п. 1, отличающийся тем, что алгоритмы логических выводов над объектами предметной области реализуют с использованием языка запросов SPARQL и аксиом онтологии, сформулированных на языке OWL-2 с использованием свойств отношений: транзитивность, симметрия, асимметрия, рефлексия, арефлексия, тождественности - «sameAs».
5. Способ по п. 1, отличающийся тем, что при создании уникальных идентификаторов используют разные префиксы.
| US 8429179 B1, 23.04.2013 | |||
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| EA 200400068 A1, 30.06.2005. | |||

