ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение, в целом, относится к параметрической пространственной обработке звука, и, в частности, к устройству и способу формирования множества параметрических звуковых потоков, и устройству и способу для формирования множества сигналов акустической системы. Дополнительные варианты осуществления настоящего изобретения относятся к секторориентированной параметрической пространственной обработке звука.
УРОВЕНЬ ТЕХНИКИ
В многоканальном прослушивании слушатель окружен несколькими акустическими системами. Существуют множество известных способов улавливания звука для таких установок. Авторы изобретения предлагают сначала рассмотреть акустические системы и пространственное ощущение, которое может ими создаваться. Без специальных методов, обычные двухканальные стереофонические установки могут создавать акустические явления только на линии, соединяющей акустические системы. Звук, поступающий с других направлений не может воспроизводиться. Логически, путем использования большего количества акустических систем вокруг слушателя, можно охватить большее количество направлений и можно создать более естественное пространственное ощущение. Самой известной многоканальной акустической системой и схемой размещения является стандарт 5.1 ("ITU-R 775-1"), который включает в себя пять акустических систем на азимутальных углах 0°, 30° и 110° по отношению к месту прослушивания. Также известны другие системы с различным количеством акустических систем, расположенных по другим направлениям.
В данной области техники, были разработаны некоторые различные способы записи для вышеуказанных акустических систем, с целью воспроизведения пространственного ощущения в обстановке прослушивания, так же как это ощущалось в момент записи. Идеальный способ для записи пространственного звука, для выбранной многоканальной акустической системы, состоит в использовании того же количества микрофонов, как и акустических систем. В таком случае, диаграммы направленности микрофонов должны также соответствовать схеме размещения акустической системы так, чтобы звук от любого одиночного направления был записан только одним, двумя, или тремя микрофонами. Чем больше используется акустических систем, тем более узкие диаграммы направленностей, таким образом, будут необходимы. Однако, такие узконаправленные микрофоны являются относительно дорогими и обычно имеют неравномерную АХЧ, что не желательно. Кроме того, используя несколько микрофонов со слишком широкими диаграммами направленности в качестве входа для многоканального воспроизведения, ведет к окрашенности и смазанности восприятия слушателем, по причине того, что звук, исходящий от одиночного источника всегда воспроизводится на большем количестве акустических систем, чем необходимо. Следовательно, имеющиеся в настоящее время микрофоны лучше всего подходят для двухканальной записи и воспроизведения без цели пространственного ощущения окружающей обстановки.
Другой известный подход к пространственной записи звука состоит в записи с большого количества микрофонов, которые распределены по большой области пространства. Например, при записи оркестра на сцене, отдельные инструменты могут быть приняты так называемыми «высоконаправленными микрофонами», которые располагаются близко к источникам звука. Пространственное распределение фронтальной звуковой сцены, например, можно получить обычными стерео микрофонами. Составляющие звукового поля, соответствующие запаздывающей реверберации можно получить несколькими микрофонами, расположенными на относительно большой дистанции от сцены. Звукорежиссер может впоследствии смикшировать желаемый многоканальный выход путем использования комбинации всех имеющихся микрофонных каналов. Однако, такая техника записи подразумевает очень большую записывающую установку и очень большую ручную работу по микшированию записанных каналов, что не всегда практически осуществимо.
Традиционные системы для записи и воспроизведения пространственного звука на основе направленного звукового кодирования (DirAC), как описано в T. Lokki, J. Merimaa, V. Pulkki: Method for Reproducing Natural or Modified Spatial Impression in Multichannel Listening, U.S. Patent 7,787,638 B2, Aug. 31, 2010 и V. Pulkki: Spatial Sound Reproduction with Directional Audio Coding. J. Audio Eng. Soc, Vol. 55, No. 6, pp. 503-516, 2007, основаны на простой глобальной модели для звукового поля. Таким образом, они страдают от некоторых систематических недостатков, что ограничивает достижение высокого качества звучания и восприятия на практике.
Общей проблемой известных решений является то, что они относительно сложны и как правило связаны с ухудшением качества пространственного звука.
Таким образом, задачей настоящего изобретения является предоставление улучшенного метода для параметрической пространственной обработки звука, который позволяет достичь более высокого качества, большей реалистичности пространственной записи и воспроизведения звука с использованием относительно простых и компактных конструкций микрофона.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
Данная цель достигается с помощью устройства согласно пункту 1, устройства согласно пункту 13, способа согласно пункту 15, способа согласно пункту 16, компьютерной программы согласно пункту 17 или компьютерной программы согласно пункту 18. Согласно варианту осуществления настоящего изобретения, устройство для формирования множества параметрических звуковых потоков из входного пространственного сигнала, полученного из записи в пространстве звукозаписи, включает в себя устройство сегментации и формирователь. Устройство сегментации выполняется с возможностью предоставления по меньшей мере двух входных сегментированных звуковых сигналов из входного пространственного сигнала. В настоящем документе, по меньшей мере два входных сегментированных звуковых сигнала связаны с соответствующими сегментами пространства звукозаписи. Формирователь выполняется с возможностью формирования параметрического звукового потока для каждого из по меньшей мере двух входных сегментированных звуковых сигналов для получения множества параметрических звуковых потоков.
Основной идеей, лежащей в основе настоящего изобретения, является то, что улучшение параметрической пространственной обработки звука можно достичь, если по меньшей мере два входных сегментированных звуковых сигнала, предоставляются из входного пространственного сигнал, в котором по меньшей мере два входных сегментированных звуковых сигнала относятся к соответствующим сегментам пространства звукозаписи и, если параметрический звуковой поток формируется для каждого из по меньшей мере двух входных сегментированных звуковых сигналов для получения множества параметрических звуковых потоков. Это позволяет достичь более высокого качества, более реалистичной пространственной записи и воспроизведения звука с использованием относительно простых и компактных конструкций микрофона.
Согласно другому варианту осуществления, устройство сегментации выполняется с возможностью использования диаграммы направленности для каждого из сегментов пространства звукозаписи. В настоящем документе, диаграмма направленности показывает направленность по меньшей мере двух входных сегментированных звуковых сигналов. При использовании диаграмм направленности, возможно получение лучшего соответствия модели наблюдаемого звукового поля, особенно в сложных звуковых сценах.
Согласно другому варианту осуществления, формирователь выполняется с возможностью получения множества параметрических звуковых потоков, в которых каждый из множества параметрических звуковых потоков включает в себя составляющую по меньшей мере двух входных сегментированных звуковых сигналов и соответствующую параметрическую пространственную информацию. Например, параметрическая пространственная информация каждого из параметрических звуковых потоков включает в себя параметр направления прихода (DOA) и/или параметр рассеяния. Путем предоставления параметров DOA и/или параметров рассеяния, можно описать наблюдаемое звуковое поле в области представления параметрического сигнала. Согласно другому варианту осуществления, устройство для формирования множества сигналов акустической системы из множества параметрических звуковых потоков полученных из входного пространственного сигнала, записанного в пространстве звукозаписи, включает в себя устройство воспроизведения и устройство смешивания. Устройство воспроизведения выполняется с возможностью предоставления множества входных сегментированных сигналов акустической системы из множества параметрических звуковых потоков. В настоящем документе, входные сегментированные сигналы акустической системы относятся к соответствующим сегментам пространства звукозаписи. Устройство смешивания выполняется с возможностью смешивания входных сегментированных сигналов акустической системы для получения множества сигналов акустической системы. Другие варианты осуществления настоящего изобретения предоставляют способы для формирования множества параметрических звуковых потоков и для формирования множества сигналов акустической системы.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
В дальнейшем варианты осуществления настоящего изобретения объясняются со ссылкой на прилагаемые чертежи, на которых:
на ФИГ. 1 показана структурная схема варианта осуществления устройства для формирования множества параметрических звуковых потоков из входной пространственной звукозаписи в пространстве звукозаписи с устройством сегментации и формирователем;
на ФИГ. 2 показано схематическое изображение устройства сегментации варианта осуществления устройства в соответствии с ФИГ. 1 на основе микширования или операции матрицирования;
на ФИГ. 3 показано схематическое изображение устройства сегментации варианта осуществления устройства в соответствии с ФИГ. 1 с использованием диаграммы направленности;
на ФИГ. 4 показано схематическое изображение формирователя варианта осуществления устройства в соответствии с ФИГ. 1 на основе параметрического пространственного анализа;
на ФИГ. 5 показана структурная схема варианта осуществления устройства для формирования множества сигналов акустической системы из множества параметрических звуковых потоков с устройством воспроизведения и устройством смешивания;
на ФИГ. 6 показано схематическое изображение примера сегментов пространства звукозаписи, каждое из которых представляет подмножество направлений в пределах двумерной (2D) плоскости или в пределах трехмерного (3D) пространства;
на ФИГ. 7 показано схематическое изображение примера обработки сигнала акустической системы для двух сегментов или секторов пространства звукозаписи;
на ФИГ. 8 показано схематическое изображение примера обработки сигнала акустической системы для двух сегментов или секторов пространства звукозаписи с использованием входных сигналов второго порядка формата B;
на ФИГ. 9 показано схематическое изображение примера обработки сигнала акустической системы для двух сегментов или секторов пространства звукозаписи, включающего в себя преобразование сигнала в область представления параметрического сигнала;
на ФИГ. 10 показано схематическое изображение примера полярных диаграмм направленностей входных сегментированных звуковых сигналов, предоставляемых устройством сегментации варианта осуществления устройства в соответствии с ФИГ. 1;
на ФИГ. 11 показано схематическое изображение примера конструкции микрофона для выполнения записи звукового поля; и
на ФИГ. 12 показано схематическое изображение примера кругового расположения ненаправленных микрофонов для получения сигналов микрофона высокого порядка.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Прежде чем подробнее обсудить настоящее изобретение с использованием чертежей, следует указать, что на чертежах одинаковым элементам, элементам, имеющим одинаковую функцию или одинаковый результат, назначаются одинаковые ссылочные номера, так что описание данных элементов и иллюстрация выполняемой ими функции в настоящем документе в различных вариантах осуществления являются взаимозаменяемыми или могут быть применены друг к другу в различных вариантах осуществления.
На ФИГ. 1 показана структурная схема варианта осуществления устройства 100 для формирования множества параметрических звуковых потоков 125 (θi, Ψi, Wi) из входного пространственного сигнала 105, полученного из записи в пространстве звукозаписи с устройством 110 сегментации и формирователем 120. Например, входной пространственный сигнал 105 включает в себя ненаправленный сигнал W и множество сигналов различной направленности X, Y, Z, U, V (или X, Y, U, V). Как показано на ФИГ. 1, устройство 100 включает в себя устройство 110 сегментации и формирователь 120. Например, устройство 110 сегментации выполняется с возможностью обеспечения по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi) из ненаправленного сигнала W и множества различных направленных сигналов X, Y, Z, U, V входного пространственного сигнала 105, в котором по меньшей мере два входных сегментированных звуковых сигнала 115 (Wi, Xi, Yi, Zi) относятся к соответствующим сегментам Segi пространства звукозаписи. Кроме того, формирователь 120 может быть выполнен с возможностью формирования параметрического звукового потока для каждого из по меньшей мере двух входных звуковых сигналов устройства 115 сегментации (Wi, Xi, Yi, Zi) с целью получения множества параметрических звуковых потоков 125 (θi, Ψi, Wi).
С помощью устройства 100 можно избежать ухудшения качества пространственного звука и избежать относительно сложных конструкций микрофона для формирования множества параметрических звуковых потоков 125. Соответственно, вариант осуществления устройства 100, в соответствии с ФИГ. 1 делает возможным более высокое качество, более реалистичную пространственную запись звука с использованием относительно простых и компактных конструкций микрофона.
В вариантах осуществления, каждый из сегментов Segi пространства звукозаписи представляет собой подмножество направлений в пределах двумерной (2D) плоскости или в пределах трехмерного (3D) пространства.
В вариантах осуществления, каждый из сегментов Segi пространства звукозаписи является свойственным соответствующему направленному измерению.
Согласно вариантам осуществления, устройство 100 выполняется с возможностью выполнения записи звукового поля для получения входного пространственного сигнала 105. Например, устройство 110 сегментации выполняется с возможностью деления представляющего интерес полного углового диапазона на сегменты Segi пространства звукозаписи. Кроме того, каждый из сегментов Segi пространства звукозаписи может включать уменьшенный угловой диапазон по сравнению с представляющим интерес полным угловым диапазоном.
На ФИГ. 2 показано схематическое изображение устройства 110 сегментации варианта осуществления устройства 100 в соответствии с ФИГ. 1 на основе операции микширования (или матрицирования). Как, в качестве примера, показано на ФИГ. 2 устройство 110 сегментации выполняется с возможностью формирования по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi) из ненаправленного сигнала W и множества сигналов различной направленности X, Y, Z, U, V с использованием операции микширования или матрицирования, которая зависит от сегментов Segi пространства звукозаписи. С помощью устройства сегментации 110, в качестве примера, показанного на ФИГ. 2, можно связать ненаправленный сигнал W и множество сигналов различной направленности X, Y, Z, U, V, составляющих входной пространственный сигнал 105 с по меньшей мере двумя входными сегментированными звуковыми сигналами 115 (Wi, Xi, Yi, Zi) с использованием заранее заданной операции микширования или матрицирования. Данная заранее заданная операция микширования или матрицирования зависит от сегментов Segi пространства звукозаписи и может быть практически использована для разветвления по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi) из входного пространственного сигнала 105. Разветвление по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi) на сегменты 110, которое основано на операции микширования или матрицирования, практически делает возможными получение вышеуказанных преимуществ для звукового поля, в отличие от простой глобальной модели.
На ФИГ. 3 показано схематическое изображение устройства сегментации 110 варианта осуществления устройства 100 в соответствии с ФИГ. 1 с использованием (желаемой или заранее заданной) диаграммы направленности 305, 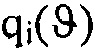 . Как, в качестве примера, показано на ФИГ. 3, устройство 110 сегментации, выполняется с возможностью использования диаграммы 305 направленности, для каждого из сегментов Segi пространства звукозаписи. Кроме того, диаграмма 305 направленности, , может показывать направленность по меньшей мере двух входных сегментированных звуковых сигнала 115 (Wi, Xi, Yi, Zi).
. Как, в качестве примера, показано на ФИГ. 3, устройство 110 сегментации, выполняется с возможностью использования диаграммы 305 направленности, для каждого из сегментов Segi пространства звукозаписи. Кроме того, диаграмма 305 направленности, , может показывать направленность по меньшей мере двух входных сегментированных звуковых сигнала 115 (Wi, Xi, Yi, Zi).
В вариантах осуществления, диаграмма 305 направленности, , имеет вид
 ,
,
где a и b обозначают множители, которые могут быть изменены для получения желаемых диаграмм направленностей и в котором 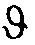 обозначает азимутальный угол и Θi показывает предпочтительное направление i-того сегмента пространства звукозаписи. Например, a находится в диапазоне от 0 до 1 и b находится в диапазоне от -1 до 1.
обозначает азимутальный угол и Θi показывает предпочтительное направление i-того сегмента пространства звукозаписи. Например, a находится в диапазоне от 0 до 1 и b находится в диапазоне от -1 до 1.
Один возможный вариант множителей a, b может быть a=0,5 и b=0,5, имея результатом следующую диаграмму направленности:
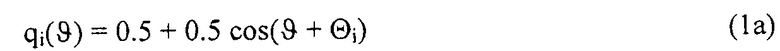
С помощью устройства 110 сегментации, в качестве примера показанного на ФИГ. 3, можно получить по меньшей мере два входных сегментированных звуковых сигнала 115 (Wi, Xi, Yi, Zi), ассоциированных с соответствующими сегментами Segi пространства звукозаписи, имеющих заранее заданную диаграмму направленности 305 , соответственно. Следует указать, что здесь использование диаграммы 305 направленности , для каждого из сегментов Segi пространства звукозаписи, позволяет повысить качество пространственного звука, полученного устройством 100.
На ФИГ. 4 показано схематическое изображение формирователя 120 варианта осуществления устройства 100 в соответствии с ФИГ. 1 на основе параметрического пространственного анализа. Как, в качестве примера, описано на ФИГ. 4, формирователь 120 выполняется с возможностью получения множества параметрических звуковых потоков 125 (θi, Ψi, Wi). Кроме того, каждый из множества параметрических звуковых потоков 125 (θi, Ψi, Wi) может включать в себя составляющую Wi из по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi) и соответствующую параметрическую пространственную информацию θi, Ψi.
В вариантах осуществления, формирователь 120 может быть исполнен с возможностью выполнения параметрического пространственного анализа для каждого из по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi) для получения соответствующей параметрической пространственной информации θi, Ψi.
В вариантах осуществления, параметрическая пространственная информация θi, Ψi, каждого из параметрических звуковых потоков 125 (θi, Ψi, Wi) включает в себя параметр θi направления прихода (DOA) и/или параметр рассеяния Ψi.
В вариантах осуществления, параметр θi направления прихода (DOA) и параметр рассеяния Ψi предоставляется формирователем 120, в качестве примера показанного на ФИГ. 4, могут составлять параметры DirAC для параметрической пространственной обработки звукового сигнала. Например, формирователь 120 выполняется с возможностью формирования параметров DirAC (например, параметр θi DOA и параметр рассеяния Ψi) с использованием частотно-временного представления по меньшей мере двух входных сегментированных звуковых сигналов 115.
На ФИГ. 5 показана структурная схема варианта осуществления устройства 500 для формирования множества сигналов акустической системы 525 (L1, L2, …) из множества параметрических звуковых потоков 125 (θi, Ψi, Wi) устройством 510 воспроизведения и устройством 520 смешивания. В варианте осуществления на ФИГ. 5 множество параметрических звуковых потоков 125 (θi, Ψi, Wi) может быть получены из входного пространственного сигнала (например, входной пространственный сигнал 105, в качестве примера, показанного в варианте осуществления на ФИГ. 1), записанного в пространстве звукозаписи. Как показано на ФИГ. 5, устройство 500 включает в себя устройство 510 воспроизведения и устройство 520 смешивания. Например, устройство 510 воспроизведения выполняется с возможностью предоставления множества входных сегментированных сигналов акустической системы 515 из множества параметрических звуковых потоков 125 (θi, Ψi, Wi), в которых входные сегментированные сигналы акустической системы 515 относятся к соответствующим сегментам (Segi) пространства звукозаписи. Кроме того, устройство 520 смешивания может быть выполнено с возможностью смешивания входных сегментированных сигналов акустической системы 515 для получения множества сигналов акустической системы 525 (L1, L2, …).
Предоставляя устройство 500 на ФИГ. 5, можно формировать множество сигналов акустической системы 525 (L1, L2, …) из множества параметрических звуковых потоков 125 (θi, Ψi, Wi), в которых параметрические звуковые потоки 125 (θi, Ψi, Wi) могут быть переданы из устройства 100 на ФИГ. 1. Кроме того, устройство 500 на ФИГ. 5 позволяет достичь более высокого качества, более реалистичного пространственного воспроизведения звука с использованием параметрических звуковых потоков, полученных в результате использования относительно простых и компактных конструкций микрофона. В вариантах осуществления, устройство 510 воспроизведения выполняется с возможностью получения множества параметрических звуковых потоков 125 (θi, Ψi, Wi). Например, каждый из множества параметрических звуковых потоков 125 (θi, Ψi, Wi) включает в себя сегментированную звуковую составляющую Wi и соответствующую параметрическую пространственную информацию θi, Ψi. Кроме того, устройство 510 воспроизведения может быть выполнено с возможностью воспроизведения каждого из сегментированных звуковых составляющих Wi, с использованием соответствующей параметрической пространственной информации 505 (θi, Ψi) для получения множества входных сегментированных сигналов акустической системы 515.
На ФИГ. 6 показано схематическое изображение 600 примера сегментов Segi (i=1, 2, 3, 4) 610, 620, 630, 640 пространства звукозаписи. На схематическом изображении 600 на ФИГ. 6, примеры каждого из сегментов 610, 620, 630, 640 пространства звукозаписи представляют собой подмножество направлений в пределах двумерной (2D) плоскости. Кроме того, каждый из сегментов Segi пространства звукозаписи могут представлять собой подмножество направлений в пределах трехмерного (3D) пространства. Например, сегменты Segi, представляющие собой подмножества направлений в пределах трехмерного (3D) пространства, могут быть сходны с сегментами 610, 620, 630, 640, в качестве примера показанных на ФИГ. 6. Согласно схематическому изображению 600 на ФИГ. 6, четыре примера сегментов 610, 620, 630, 640 устройства 100 на ФИГ. 1 показаны в качестве образца. Однако, также можно использовать другие номера сегментов Segi (i=1, 2, n, в котором i является целочисленным индексом и n обозначает номера сегментов). Каждый пример сегментов 610, 620, 630, 640 может быть представлен в полярной системе координат (см., например, ФИГ. 6). Для трехмерного (3D) пространства, сегменты Segi могут быть представлены подобным образом в сферической системе координат.
В вариантах осуществления, устройство сегментации 110 в качестве примера показанное на ФИГ. 1, может быть выполнено с возможностью использования сегментов Segi (например, приведенные в качестве примера сегменты 610, 620, 630, 640 на ФИГ. 6) для предоставления по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi). Путем использования сегментов (или секторов), можно реализовать сегментоориентированную параметрическую модель звукового поля (или секторориентированную). Данный подход позволяет достичь более высокого качества записи и воспроизведения пространственного звука с относительно компактной конструкцией микрофона.
На ФИГ. 7 показано схематическое изображение 700 примера расчета сигнала акустической системы для двух сегментов или секторов пространства звукозаписи. На схематическом изображении 700 на ФИГ. 7, вариант осуществления устройства 100 для формирования множества параметрических звуковых потоков 125 (θi, Ψi, Wi) и вариант осуществления устройства 500 для формирования множества сигналов акустической системы 525 (L1, L2, …) показаны в качестве примера. Как показано на схематическом изображении 700 на ФИГ. 7 устройство 110 сегментации может быть выполнено с возможностью приема входного пространственного сигнала 105 (например, сигнала микрофона). Кроме того, устройство 110 сегментации может быть выполнено с возможностью предоставления по меньшей мере двух входных сегментированных звуковых сигналов 115 (например, сегментированные сигналы микрофона 715-1 первого сегмента и сегментированные сигналы микрофона 715-2 второго сегмента). Формирователь 120 может включать в себя первый параметрический пространственный блок 720-1 анализа и второй параметрический пространственный блок 720-2 анализа. Кроме того, формирователь 120 может быть выполнен с возможностью для формирования параметрического звукового потока для каждого из по меньшей мере двух входных сегментированных звуковых сигналов 115. На выходе варианта осуществления устройства 100, будет получено множество параметрических звуковых потоков 125. Например, первый параметрический пространственный блок 720-1 анализа будет выводить первый параметрический звуковой поток 725-1 первого сегмента, вместе с тем второй параметрический пространственный блок 720-2 анализа будет выводить второй параметрический звуковой поток 725-2 второго сегмента. Кроме того, первый параметрический звуковой поток 725-1, предоставленный первым параметрическим пространственным блоком 720-1 анализа, может включать в себя параметрическую пространственную информацию (например, θ1, Ψ1) первого сегмента и один или несколько сегментированных звуковых сигналов (например, W1) первого сегмента, вместе с тем второй параметрический звуковой поток 725-2, предоставленный вторым параметрическим пространственным блоком 720-2 анализа, может включать в себя параметрическую пространственную информацию (например, θ2, Ψ2) второго сегмента и один или несколько сегментированных звуковых сигнала (например, W2) второго сегмента. Вариант осуществления устройства 100 может быть выполнен с возможностью передачи множества параметрических звуковых потоков 125. А также, показанный на схематическом изображении 700 на ФИГ. 7 вариант осуществления устройства 500, может быть выполнен с возможностью приема множеств параметрических звуковых потоков 125 из варианта осуществления устройства 100. Устройство 510 воспроизведения может включать в себя первое устройство 730-1 воспроизведения и второе устройство 730-2 воспроизведения. Кроме того, устройство 510 воспроизведения может быть выполнено с возможностью предоставления множества входных сегментированных сигналов акустической системы 515 из полученного множества параметрических звуковых потоков 125. Например, первое устройство 730-1 воспроизведения может быть выполнено с возможностью предоставления входных сегментированных сигналов акустической системы 735-1 первого сегмента из первого параметрического звукового потока 725-1 первого сегмента, вместе с тем второе устройство 730-2 воспроизведения может быть выполнено с возможностью предоставления входных сегментированных сигналов акустической системы 735-2 второго сегмента из второго параметрического звукового потока 725-2 второго сегмента. Кроме того, устройство 520 смешивания может быть выполнено с возможностью смешивания входных сегментированных сигналов акустической системы 515 для получения множества сигналов акустической системы 525 (например, L1, L2, …).
Вариант осуществления на ФИГ. 7 по существу представляет собой метод пространственной звукозаписи и воспроизведения более высокого качества с использованием сегменториентированной параметрической модели звукового поля (или секторориентированной), который также позволяет записывать сложные пространственные звуковые сцены с помощью относительно компактной конструкции микрофона.
На ФИГ. 8 показано схематическое изображение 800 примера обработки сигнала акустической системы для двух сегментов или секторов пространства звукозаписи с использованием входных сигналов 105 второго порядка формата B. Пример обработки сигнала акустической системы, схематически показанный на ФИГ. 8, по существу, соответствует примеру обработки сигнала акустической системы, схематически показанной на ФИГ. 7. На схематическом изображении на ФИГ. 8, в качестве примера, показан вариант осуществления устройства 100 для формирования множества параметрических звуковых потоков 125 и вариант осуществления устройства 500 для формирования множества сигналов акустической системы 525. Как показано на ФИГ. 8, вариант осуществления устройства 100 может быть выполнен с возможностью приема входного пространственного сигнала 105 (например, каналы микрофона формата B, такие как [W, X, Y, U, V]). В настоящем документе, констатируется, что сигналы U, V на ФИГ. 8 являются составляющими второго порядка формата B. Устройство сегментации 110, в качестве примера показанное с помощью "микширования", может быть выполнено с возможностью формирования по меньшей мере двух входных сегментированных звуковых сигналов 115 из ненаправленного сигнала и множества сигналов различной направленности с использованием операции микширования или матрицирования, которая зависит от сегментов Segi пространства звукозаписи. Например, по меньшей мере два входных сегментированные звуковые сигнала 115 могут включать в себя сегментированный сигнал микрофона 715-1 первого сегмента (например, [W1, X1, Y1]) и сегментированных сигналов микрофона 715-2 второго сегмента (например, [W2, X2, Y2]). Кроме того, формирователь 120 может включать в себя первый блок 720-1 анализа направления и рассеяния и второй блок 720-2 анализа направления и рассеяния. Первый и второй блоки 720-1, 720-2 анализа направления и рассеяния в качестве примера, показанные на ФИГ. 8, по существу представляют собой первый и второй параметрические пространственные блоки 720-1, 720-2 анализа, в качестве примера показанные на ФИГ. 7. Формирователь 120 может быть выполнен с возможностью формирования параметрического звукового потока для каждого из по меньшей мере двух входных сегментированных звуковых сигналов 115 с целью получения множества параметрических звуковых потоков 125. Например, формирователь 120 может быть выполнен с возможностью выполнения пространственного анализа сегментированных сигналов микрофона 715-1 первого сегмента с использованием первого блока 720-1 анализа направления и рассеяния и для извлечения первого элемента (например, сегментированного звукового сигнала W1) из сегментированных сигналов микрофона 715-1 первого сегмента для получения первого параметрического звукового потока 725-1 первого сегмента. Кроме того, формирователь 120 может быть выполнен с возможностью выполнения пространственного анализа сегментированных сигналов микрофона 715-2 второго сегмента и для извлечения второй составляющей (например, сегментированный звуковой сигнал W2) из сегментированных сигналов микрофона 715-2 второго сегмента с использованием второго блока 720-2 анализа направления и рассеяния для получения второго параметрического звукового потока 725-2 второго сегмента. Например, первый параметрический звуковой поток 725-1 первого сегмента может включать в себя параметрическую пространственную информацию первого сегмента, включающего в себя первый параметр θ1 направления прихода (DOA) и первый параметр рассеяния Ψ1 так же, как первую извлеченную составляющую W1, вместе с тем второй параметрический звуковой поток 725-2 второго сегмента может включать в себя параметрическую пространственную информацию второго сегмента, включая в себя второй параметр θ2 направления прихода (DOA) и второй параметр рассеяния Ψ2, так же как вторую извлеченную составляющую W2. Вариант осуществления устройства 100 может быть выполнен с возможностью передачи множества параметрических звуковых потоков 125.
Также, как показано, на схематическом изображении 800 на ФИГ. 8, вариант осуществления устройства 500 для формирования множества сигналов акустической системы 525, может быть выполнен с возможностью приема множества параметрических звуковых потоков 125, передающихся из варианта осуществления устройства 100. На схематическом изображении 800 на ФИГ. 8, устройство 510 воспроизведения включает в себя первое устройство 730-1 воспроизведения и второе устройство 730-2 воспроизведения. Например, первое устройство 730-1 воспроизведения включает в себя первый умножитель 802 и второй умножитель 804. Первый умножитель 802 первого устройства 730-1 воспроизведения может быть выполнен с возможностью применения первого весового коэффициента 803 (например, 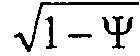 ) к сегментированному звуковому сигналу W1 первого параметрического звукового потока 725-1 первого сегмента для получения прямого звукового подпотока 810 с помощью первого устройства 730-1 воспроизведения, вместе с тем второй умножитель 804 первого устройства 730-1 воспроизведения может быть выполнен с возможностью применения второго весового коэффициента 805 (например,
) к сегментированному звуковому сигналу W1 первого параметрического звукового потока 725-1 первого сегмента для получения прямого звукового подпотока 810 с помощью первого устройства 730-1 воспроизведения, вместе с тем второй умножитель 804 первого устройства 730-1 воспроизведения может быть выполнен с возможностью применения второго весового коэффициента 805 (например, 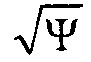 ) к сегментированному звуковому сигналу W1 первого параметрического звукового потока 725-1 первого сегмента для получения рассеянного подпотока 812 с помощью первого устройства 730-1 воспроизведения. Кроме того, второе устройство 730-2 воспроизведения может включать в себя первый умножитель 806 и второй умножитель 808. Например, первый умножитель 806 второго устройства 730-2 воспроизведения может быть выполнен с возможностью применения первого весового коэффициента 807 (например, ) к сегментированному звуковому сигналу W2 второго параметрического звукового потока 725-2 второго сегмента для получения прямого звукового потока 814 с помощью второго устройства 730-2 воспроизведения, вместе с тем второй умножитель 808 второго устройства 730-2 воспроизведения может быть выполнен с возможностью применения второго весового коэффициента 809 (например, ) к сегментированному звуковому сигналу W2 второго параметрического звукового потока 725-2 второго сегмента для получения рассеянного подпотока 816 с помощью второго устройства 730-2 воспроизведения. В вариантах осуществления, первый и второй весовые коэффициенты 803, 805, 807, 809 первого и второго устройств 730-1, 730-2 воспроизведения получены из соответствующих параметров рассеяния Ψi. Согласно вариантам осуществления, первое устройство 730-1 воспроизведения может включать в себя умножители 811 коэффициентов усиления, блоки 813 обработки декорреляции и устройства 832 смешивания, вместе с тем второе устройство 730-2 воспроизведения может включать в себя умножители 815 коэффициента усиления, блоки 817 обработки декорреляции и устройства 834 смешивания. Например, умножители 811 коэффициента усиления первого устройства 730-1 воспроизведения могут быть выполнены с возможностью применения коэффициентов усиления, полученных в результате операции векторного амплитудного панорамирования (VBAP) с помощью блоков 822, к выводу прямого звукового подпотока 810 первого умножителя 802 первого устройства 730-1 воспроизведения. Кроме того, блоки 813 обработки декорреляции первого устройства 730-1 воспроизведения, могут быть выполнены с возможностью применения операции декорреляции/усиления к рассеянному подпотоку 812 на выходе второго умножителя 804 первого устройства 730-1 воспроизведения. Кроме того, устройства смешивания 832 первого устройства 730-1 воспроизведения, могут быть выполнены с возможностью суммирования сигналов, полученных из умножителей 811 коэффициента усиления и блоков 813 обработки декорреляции для получения сегментированных сигналов акустической системы 735-1 первого сегмента. Например, умножители 815 коэффициента усиления второго устройства 730-2 воспроизведения могут быть выполнены с возможностью применения коэффициентов усиления, полученных в результате операции векторного амплитудного панорамирования (VBAP) с помощью блоков 824, к выходу прямого звукового подпотока 814 первого умножителя 806 второго устройства 730-2 воспроизведения. Кроме того, блоки 817 обработки декорреляции второго устройства 730-2 воспроизведения могут быть выполнены с возможностью применения операции декорреляции/усиления к рассеянному подпотоку 816 на выходе второго умножителя 808 второго устройства 730-2 воспроизведения. Кроме того, устройства 834 смешивания второго устройства 730-2 воспроизведения могут быть выполнены с возможностью суммирования сигналов, полученных из умножителей коэффициента усиления 815 и блоков 817 обработки декорреляции для получения сегментированных сигналов акустической системы 735-2 второго сегмента.
) к сегментированному звуковому сигналу W1 первого параметрического звукового потока 725-1 первого сегмента для получения рассеянного подпотока 812 с помощью первого устройства 730-1 воспроизведения. Кроме того, второе устройство 730-2 воспроизведения может включать в себя первый умножитель 806 и второй умножитель 808. Например, первый умножитель 806 второго устройства 730-2 воспроизведения может быть выполнен с возможностью применения первого весового коэффициента 807 (например, ) к сегментированному звуковому сигналу W2 второго параметрического звукового потока 725-2 второго сегмента для получения прямого звукового потока 814 с помощью второго устройства 730-2 воспроизведения, вместе с тем второй умножитель 808 второго устройства 730-2 воспроизведения может быть выполнен с возможностью применения второго весового коэффициента 809 (например, ) к сегментированному звуковому сигналу W2 второго параметрического звукового потока 725-2 второго сегмента для получения рассеянного подпотока 816 с помощью второго устройства 730-2 воспроизведения. В вариантах осуществления, первый и второй весовые коэффициенты 803, 805, 807, 809 первого и второго устройств 730-1, 730-2 воспроизведения получены из соответствующих параметров рассеяния Ψi. Согласно вариантам осуществления, первое устройство 730-1 воспроизведения может включать в себя умножители 811 коэффициентов усиления, блоки 813 обработки декорреляции и устройства 832 смешивания, вместе с тем второе устройство 730-2 воспроизведения может включать в себя умножители 815 коэффициента усиления, блоки 817 обработки декорреляции и устройства 834 смешивания. Например, умножители 811 коэффициента усиления первого устройства 730-1 воспроизведения могут быть выполнены с возможностью применения коэффициентов усиления, полученных в результате операции векторного амплитудного панорамирования (VBAP) с помощью блоков 822, к выводу прямого звукового подпотока 810 первого умножителя 802 первого устройства 730-1 воспроизведения. Кроме того, блоки 813 обработки декорреляции первого устройства 730-1 воспроизведения, могут быть выполнены с возможностью применения операции декорреляции/усиления к рассеянному подпотоку 812 на выходе второго умножителя 804 первого устройства 730-1 воспроизведения. Кроме того, устройства смешивания 832 первого устройства 730-1 воспроизведения, могут быть выполнены с возможностью суммирования сигналов, полученных из умножителей 811 коэффициента усиления и блоков 813 обработки декорреляции для получения сегментированных сигналов акустической системы 735-1 первого сегмента. Например, умножители 815 коэффициента усиления второго устройства 730-2 воспроизведения могут быть выполнены с возможностью применения коэффициентов усиления, полученных в результате операции векторного амплитудного панорамирования (VBAP) с помощью блоков 824, к выходу прямого звукового подпотока 814 первого умножителя 806 второго устройства 730-2 воспроизведения. Кроме того, блоки 817 обработки декорреляции второго устройства 730-2 воспроизведения могут быть выполнены с возможностью применения операции декорреляции/усиления к рассеянному подпотоку 816 на выходе второго умножителя 808 второго устройства 730-2 воспроизведения. Кроме того, устройства 834 смешивания второго устройства 730-2 воспроизведения могут быть выполнены с возможностью суммирования сигналов, полученных из умножителей коэффициента усиления 815 и блоков 817 обработки декорреляции для получения сегментированных сигналов акустической системы 735-2 второго сегмента.
В вариантах осуществления, операция векторного амплитудного панорамирования (VBAP) с помощью блоков 822, 824 первого и второго устройств 730-1, 730-2 воспроизведения зависит от соответствующих параметров θi направления прихода (DOA). Как, в качестве примера, показано на ФИГ. 8, устройство 520 смешивания может быть выполнено с возможностью смешивания входных сегментированных сигналов акустической системы 515 для получения множества сигналов акустической системы 525 (например, L1, L2, …). Как, в качестве примера, показано на ФИГ. 8, устройство 520 смешивания может включать в себя первое устройство 842 суммирования и второе устройство 844 суммирования. Например, первое устройство 842 суммирования выполняется с возможностью суммирования первых сегментированных сигналов акустической системы 735-1 первого сегмента и первых сегментированных сигналов акустической системы 735-2 второго сегмента для получения первого сигнала 843 акустической системы. Кроме того, второе устройство 844 суммирования может быть выполнено с возможностью суммирования вторых сегментированных сигналов акустической системы 735-1 первого сегмента и вторых сегментированных сигналов акустической системы 735-2 второго сегмента для получения второго сигнала 845 акустической системы. Первый и второй сигналы 843, 845 акустической системы могут составлять множество сигналов 525 акустической системы. Относительно варианта осуществления на ФИГ. 8, следует отметить, что для каждого сегмента, потенциально могут быть сформированы сигналы акустической системы для всех акустических систем воспроизведения.
На ФИГ. 9 показано схематическое изображение 900 примера обработки сигнала акустической системы для двух сегментов или секторов пространства звукозаписи, включающей в себя преобразование сигнала в области представления параметрического сигнала. Пример обработки сигнала акустической системы на схематическом изображении 900 на ФИГ. 9 по существу соответствует примеру обработки сигнала акустической системы на схематическом изображении 700 на ФИГ. 7. Однако, пример обработки сигнала акустической системы на схематическом изображении 900 на ФИГ. 9 включает в себя дополнительное преобразование сигнала. На схематическом изображении 900 на ФИГ. 9, устройство 100 включает в себя устройств 110 сегментации и формирователь 120 для получения множества параметрических звуковых потоков 125 (θi, Ψi, Wi). Кроме того, устройство 500 включает в себя устройство 510 воспроизведения и устройство 520 смешивания для получения множества сигналов 525 акустической системы.
Например, устройство 100 может дополнительно включать в себя преобразователь 910 для преобразования множества параметрических звуковых потоков 125 (θi, Ψi, Wi) в области представления параметрического сигнала. Кроме того, преобразователь 910 может быть выполнен с возможностью преобразования по меньшей мере одного из параметрических звуковых потоков 125 (θi, Ψi, Wi) с использованием соответствующего параметра управления преобразованием 905. Таким образом, могут быть получены первый преобразованный параметрический звуковой поток 916 первого сегмента и второй преобразованный параметрический звуковой поток 918 второго сегмента. Первый и второй преобразованные параметрические звуковые потоки 916, 918 могут составлять множество преобразованных параметрических звуковых потоков 915. В вариантах осуществления, устройство 100 может быть выполнено с возможностью усиления множества преобразованных параметрических звуковых потоков 915. Кроме того, устройство 500 может быть выполнено с возможностью приема множества преобразованных параметрических звуковых потоков 915, передающихся из устройства 100.
Путем предоставления типовой обработки сигнала акустической системы согласно ФИГ. 9, можно достичь более гибкой схемы пространственной звукозаписи и воспроизведения. В частности, можно получить выходные сигналы более высокого качества, при применении преобразований в области параметра. С помощью сегментирования входных сигналов перед формированием множества параметрических звуковых представлений (потоков), получается более высокая пространственная избирательность, которая позволяет лучше анализировать различные составляющие охватывающего звукового поля.
На ФИГ. 10 показано схематическое изображение 1000 примера полярной диаграммы направленности входных сегментированных звуковых сигналов 115 (например, Wi, Xi, Yi), предоставляемых устройством 110 сегментации варианта осуществления устройства 100, для формирования множества параметрических звуковых потоков 125 (θi, Ψi, Wi) в соответствии с ФИГ. 1. На схематическом изображении 1000 на ФИГ. 10, пример входных сегментированных звуковых сигналов 115 наглядно представляется в соответствующей полярной системе координат для двумерной (2D) плоскости. Подобным образом, пример входных сегментированных звуковых сигналов 115 может быть наглядно представлен в соответствующей сферической системе координат для трехмерного (3D) пространства. Схематическое изображение 1000 на ФИГ. 10 в качестве примера показывает первую диаграмму 1010 направленности для первого входного сегментированного звукового сигнала (например, ненаправленный сигнал Wi), вторую диаграмму 1020 направленности второго входного сегментированного звукового сигнала (например, первый направленный сигнал Xi) и третью диаграмму 1030 направленности третьего входного сегментированного звукового сигнала (например, второй направленный сигнал Yi). Кроме того, четвертая диаграмма 1022 направленности с обратным знаком в сравнении со второй диаграммой 1020 направленности и пятой диаграммой 1032 направленности с обратным знаком в сравнении с третьей диаграммой 1030 направленности показываются в качестве примера на схематическом изображении 1000 на ФИГ. 10. Таким образом, различные диаграммы 1010, 1020, 1030, 1022, 1032 направленности (полярные диаграммы направленности) могут использоваться для входных сегментированных звуковых сигналов 115 устройством сегментации 110. Следует указать, что в настоящем документе входные сегментированные звуковые сигналы 115 могут зависеть от времени и частоты, то есть Wi=Wi(m, k), Xi=Xi(m, k) и Yi=Yi(m, k), где (m, k) являются индексами, показывающими частотно-временную ячейку в представлении пространственного звукового сигнала.
В данном контексте, следует отметить, что ФИГ. 10 в качестве примера показывает полярные диаграммы для единичного набора входных сигналов, то есть сигналы 115 для единичного сектора i (например, [Wi, Xi, Yi]). Кроме того, положительные и отрицательные части полярной диаграммы выводят вместе представляя полярную диаграмму сигнала, соответственно (например, части 1020 и 1022 вместе показывают полярную диаграмму сигнала Xi, в то время как части 1030 и 1032 вместе показывают полярную диаграмму сигнала Yi).
На ФИГ. 11 показано схематическое изображение 1100 примера конструкции микрофона 1110 для выполнения записи звукового поля. На схематическом изображении 1100 на ФИГ. 11, конструкция микрофона 1110 может включать в себя множественные, расположенных по линейной схеме, направленные микрофоны 1112, 1114, 1116. Схематическое изображение 1100 на ФИГ. 11 в качестве примера показывает как двумерное (2D) наблюдаемое пространство можно разделить на различные сегменты или сектора 1101, 1102, 1103 (например, Segi, i=1, 2, 3) пространства звукозаписи. В настоящем документе, сегменты 1101, 1102, 1103 на ФИГ. 11 могут соответствовать сегментам Segi в качестве примера, показанным на ФИГ. 6. Подобным образом, пример конструкции микрофона 1110 также можно использовать в трехмерном (3D) наблюдаемом пространстве, в котором трехмерное (3D) наблюдаемое пространство можно разделить на сегменты или сектора для данной конструкции микрофона. В вариантах осуществления, пример конструкции микрофона 1110 на схематическом изображении 1100 на ФИГ. 11 можно использовать для предоставления входного пространственного сигнала 105 для варианта осуществления устройства 100 в соответствии с ФИГ. 1 . Например, множественные, расположенные по линейной схеме, направленные микрофоны 1112, 1114, 1116 конструкции микрофона 1110 можно выполнить с возможностью предоставления сигнала различной направленности для входного пространственного сигнала 105. С помощью использования примера конструкции микрофон 1110 на ФИГ. 11, можно оптимизировать качество пространственной звукозаписи с использованием параметрической модели звукового поля на основе сегментов (или на основе секторов).
В предшествующих вариантах осуществления устройство 100 и устройство 500 можно выполнить с возможностью работать в частотно-временной области.
Таким образом, варианты осуществления настоящего изобретения относится к области техники высококачественной пространственной звукозаписи и воспроизведения. Использование параметрической модели звукового поля на основе сегментов или на основе секторов, также позволяют записывать сложные пространственные звуковые сцены относительно компактными конструкциями микрофона. В отличие от простой глобальной модели звукового поля, предполагаемым текущим уровнем способов данной области техники, параметрическая информация может определяться для ряда сегментов, в которых целостное наблюдаемое пространство разделяют. Таким образом, воспроизведение для почти произвольной конструкции акустической системы можно выполнить на основе параметрической информации с учетом записанных звуковых каналов. Согласно вариантам осуществления, для плоскостной двумерной (2D) записи звукового поля полный диапазон азимутальных углов, представляющий интерес, можно разделить на множественные сектора или сегменты, охватывающие уменьшенный диапазон азимутальных углов. Аналогично, в 3D-случае, полный диапазон пространственных углов (азимутальных углов и углов наклона) можно делить на сектора или сегменты, охватывающие меньший диапазон углов. Разные сектора или сегменты могут также частично перекрываться.
Согласно вариантам осуществления, каждый сектор или сегмент отличается соответствующим направлением измерения, которое можно использовать для определения или направления ссылаясь на соответствующий сектор или сегмент. Направленное измерение, например может быть вектором, направленным на (или от) центра сектора или сегмента, или углом направления в 2D-случае, или совокупностью азимутального угла и угла наклона в 3D-случае. Сегмент или сектор можно отнести к подмножеству направлений как в пределах 2D плоскости, так и в пределах 3D пространства. Для простоты восприятия, предшествующие примеры были, в качестве образца, описаны для 2D-случая; однако расширения для 3D-конструкций являются несложными. Со ссылкой на ФИГ. 6, направленное измерение может быть определено как вектор, который, для сегмента Seg3, указывает от источника, то есть центр с координатами (0, 0), направо, то есть по направления к координатам (1, 0) в полярной диаграмме или азимутальный угол 0°, если на ФИГ. 6 углы считаются от (или относятся к) оси x (горизонтальная ось).
Относительно варианта осуществления на ФИГ. 1, устройство 100 может быть выполнено с возможностью приема большого количества микрофонных сигналов в качестве входного (входной пространственный сигнал 105). Данные сигналы микрофона могут, например, или исходить от реальной записи или могут быть искусственно сформированными с помощью имитации записи в виртуальной среде. Из данных сигналов микрофона, можно определить соответствующие сегментированные сигналы микрофона (входные сегментированные звуковые сигналы 115), которые соотносятся с соответствующими сегментами (Segi). Сегментированные сигналы микрофона имеют специфические характеристики. Их диаграмма направления приема может показать значительно увеличенную чувствительность в пределах углового сектора в сравнении с чувствительностью вне данного сектора. Пример сегментации полного азимутального диапазона в 360° и диаграммы приема соответствующих сегментированных сигналов микрофона были показаны со ссылкой на ФИГ. 6. В примере на ФИГ. 6, направленность микрофонов связана с секторами, продемонстрированной кардиоидной диаграммой направленности, которая повернута в соответствии с угловым диапазоном, охватываченным соответствующим сектором. Например, направленность микрофона, связанная с сектором 3 (Seg3), указывающим в направлении 0°, также указывает в направлении 0°. В настоящем документе, следует отметить, что в полярных диаграммах на ФИГ. 6, направление максимальной чувствительности является направлением, в котором радиус, описанной кривой составляет максимальное значение. Таким образом, Seg3 имеет наивысшую чувствительность для звуковых составляющих, которые приходят справа. Другими словами, сегмент Seg3 имеет приоритетное направление на азимутальном угле 0° (предполагая, что углы отсчитываются от оси x).
Согласно вариантам осуществления, для каждого сектора, параметр (θi) DOA может быть определен с учетом секторориентированного параметра рассеяния (Ψi). В простой реализации, параметр рассеяния (Ψi) может быть одинаковым для всех секторов. В принципе, можно применить любой предпочтительный алгоритм оценки DOA (например, с помощью формирователя 120). Например, параметр (θi) DOA можно обработать, для отражения обратного направления, в котором большее количество звуковой энергии перемещается в пределах рассматриваемого сектора. Соответственно, секторориентированное рассеяние относится к соотношению энергии рассеянного звука и полной энергии звука в пределах рассматриваемого сектора. Следует отметить, что оценка параметра (такой, как выполненный формирователем 120) может быть выполнена переменным по времени и отдельно для каждого частотного диапазона.
Согласно вариантам осуществления, для каждого сектора, направленный звуковой поток (параметрический звуковой поток) может быть составлен включая в себя сегментированный сигнал микрофона (Wi) и секторориентированный DOA и параметры рассеяния (θi, Ψi), которые преимущественно описывают пространственные звуковые свойства звукового поля в пределах углового диапазона, представленного данным сектором. Например, сигналы 525 акустической системы для воспроизведения, могут быть определены с использованием параметрической информации направления (θi, Ψi) и одного или нескольких сегментированных сигналов микрофона 125 (например, Wi). Таким образом, в настоящем документе, набор сегментированных сигналов 515 акустической системы может быть определен для каждого сегмента, который может затем смешиваться так же, как устройством 520 смешивания (например, смешиваться или микшироваться), для построения окончательных сигналов 525 акустической системы для воспроизведения. Прямые звуковые элементы в пределах сектора, например, могут воспроизводиться как точечные источники путем применения примера векторного амплитудного панорамирования (как описано в V. Pulkki: Virtual sound source positioning using Vector Base Amplitude Panning. J. Audio Eng. Soc, Vol. 45, pp. 456- 466, 1997) тогда, как рассеянный звук может проигрываться на нескольких акустических системах в одно время.
Структурная схема на ФИГ. 7 показывает обработку сигналов 525 акустической системы, как описывалось выше, для случая с двумя секторами. На ФИГ. 7, толстые стрелки представляют собой звуковые сигналы тогда, как тонкие стрелки представляют собой параметрические сигналы или управляющие сигналы. На ФИГ. 7, схематически показано формирование сегментированных сигналов микрофона 115 устройством 110 сегментации, применение анализа параметрического пространственного сигнала (блоки 720-1, 720-1) для каждого сектора (например, формирователь 120), формирование сегментированных сигналов 515 акустической системы устройством 510 воспроизведения и смешивание сегментированных сигналов 515 акустической системы устройством смешивания 520. В вариантах осуществления, устройство 110 сегментации может быть исполнено с возможностью выполнения формирования сегментированных сигналов микрофона 115 из комбинации входных сигналов микрофона 105. Кроме того, формирователь 120 может быть выполнен с возможностью применения анализа параметрического пространственного сигнала для каждого сектора так, что будут получены параметрические звуковые потоки 725-1, 725-2 для каждого сектора. Например, каждый из параметрических звуковых потоков 725-1, 725-2 может состоять из по меньшей мере одного сегментированного звукового сигнала (например, W1, W2 соответственно) также, как соответствующая параметрическая информация (например, параметры θ1, θ2 DOA и параметры рассеяния Ψ1, Ψ2 соответственно). Устройство 510 воспроизведения может быть выполнено с возможностью выполнения формирования сегментированных сигналов 515 акустической системы для каждого сектора на основе параметрических звуковых потоков 725-1, 725-2, сформированных для конкретных секторов. Устройство 520 смешивания может быть выполнено с возможностью выполнения смешивания сегментированных сигналов 515 акустической системы для получения окончательных сигналов 525 акустической системы.
Структурная схема на ФИГ. 8 показывает пример обработки сигналов 525 акустической системы в случае двух секторов, показанных в качестве примера для применения микрофонного сигнала второго порядка формата B. Как показано в варианте осуществления на ФИГ. 8, два (набора) сегментированных сигнала микрофона 715-1 (например, [Wi, Xi, Yi]) и 715-2 (например, [W2, X2, Y2]) могут формироваться из комбинации входных сигналов микрофона 105 с помощью операции микширования или матрицирования (например, с помощью блока 110), как описывалось ранее. Для каждого из двух сегментированных сигналов микрофона, анализ направленного звука (например, с помощью блоков 720-1, 720-2) может выполняться, выдавая направленные звуковые потоки 725-1 (например, θ1, Ψ1, W1) и 725-2 (например, θ2, Ψ2, W2) для первого сектора и второго сектора соответственно.
На ФИГ. 8 сегментированные сигналы акустической системы 515 можно формировать отдельно для каждого сектора как указано далее. Сегментированные звуковые составляющие Wi, полученные из параметра рассеяния Ψi, можно разделять на два дополняющих друг друга подпотока 810, 812, 814, 816 путем "взвешивания" с умножителями 803, 805, 807, 809. Один подпоток может нести в основном прямые звуковые составляющие тогда, как другой подпоток может нести в основном рассеянные звуковые составляющие. Прямые звуковые подпотоки 810, 814 можно воспроизводить с использованием панорамирующих усилителей 811, 815, определенных с помощью параметра θi DOA тогда, как рассеянные подпотоки 812, 816 можно воспроизводить неоднородно с использованием блоков 813, 817 обработки декорреляции.
В качестве примера последней стадии, сегментированные сигналы 515 акустической системы можно смешивать (например, с помощью блока 520) для получения окончательных выходных сигналов 525 для воспроизведения акустической системой.
Ссылаясь на вариант осуществления на ФИГ. 9, следует отметить, что оцениваемые параметры (в пределах параметрических звуковых потоков 125) также могут быть преобразованы (например, преобразователем 910) для воспроизведения перед фактическим определением сигналов 525 акустической системы. Например, параметр θi DOA может быть переназначен с целью достижения управления звуковой сценой. В других случаях, звуковые сигналы (например, W1) некоторых секторов могут быть ослаблены перед обработкой сигналов 525 акустической системы, если звук приходящий от некоторых или всех направлений, включенных в указанные сектора не желателен. Аналогично, составляющие рассеянного звука можно ослабить, если основной или одиночный направленный звук должен воспроизводиться. Данная обработка, включающая в себя преобразование 910 параметрических звуковых потоков 125 в качестве образца показывается на ФИГ. 9 для примера сегментации на два сегмента.
Вариант осуществления оценки секторориентированного параметра в примере 2D-случая, выполненного с предшествующими вариантами осуществления, будет описываться далее. Предполагается, что сигналы микрофона, используемые для улавливания, можно преобразовать в, так называемые, сигналы второго порядка формата B. Сигналы второго порядка формата B можно описать с помощью формы диаграмм направленности соответствующих микрофонов:
 ,
,
где обозначает азимутальный угол. Соответствующие сигналы формата B (например, вход 105 на ФИГ. 8) обозначают через W(m, k), X(m, k), Y(m, k), U(m, k) и V(m, k), где m и k представляют собой временной показатель и показатель частоты соответственно. В настоящее время предполагается, что сегментированный сигнал микрофона, связанный с i-тым сектором, имеет диаграмму направленности . Затем авторы изобретения определяют (например, с помощью 110) дополнительные сигналы микрофона 115 Wi(m, k), Xi(m, k), Yi(m, k), имеющие диаграмму направленности, которая может быть выражена в соответствии с


Некоторые примеры для диаграмм направленности, описанных сигналов микрофона в случае примера кардиоидной диаграммы направленности =0,5 + 0,5 cos(+Θi), показаны на ФИГ. 10. Предпочтительное направление i-того сектора зависит от азимутального угла Θi. На ФИГ. 10 пунктирные линии показывают диаграммы 1022, 1032 направленности (полярные диаграммы направленности) с обратным знаком, в сравнении с диаграммами 1020, 1030 направленности, показанными сплошными линиями.
Необходимо отметить, что для примера случая с Θi=0, сигналы Wi(m, k), Xi(m, k), Yi(m, k) можно определить из сигналов второго порядка формата B с помощью микширования, составляющих на входе W, X, Y, U, V, согласно
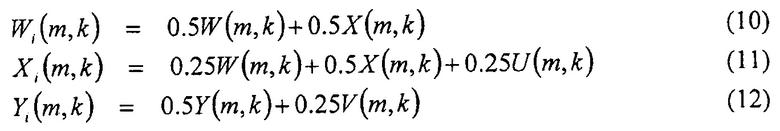
Данная операция микширования, выполняется например на ФИГ. 2 в структурном элементе 110. Необходимо отметить, что другой выбор приводит к другому правилу микширования для получения составляющих Wi, Xi, Yi из сигналов второго порядка формата B.
Из сегментированных сигналов микрофона 115 Wi(m, k), Xi(m, k), Yi(m, k) авторы изобретения затем определяют (например, с помощью блока 120) параметр θi DOA, связанный с i-тым сектором путем обработки секторориентированного активного вектора интенсивности
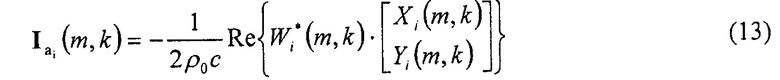 ,
,
где Re {A} обозначает действительную часть комплексного числа A и * обозначает комплексно сопряженную величину. Кроме того, ρ0 является плотностью воздуха и c является скоростью звука. Требуемая оценка DOA θi (m, k), например, представляемая единичным вектором ei(m, k), может быть получена в соответствии с

Авторы изобретения дополнительно определяют секторориентированную энергию звукового поля, относительно количества
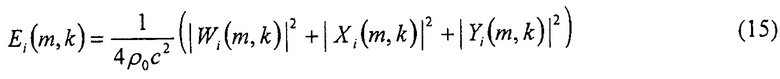
Требуемый параметр рассеяния Ψi (m, k) i-того сектора затем может быть определен в соответствии с
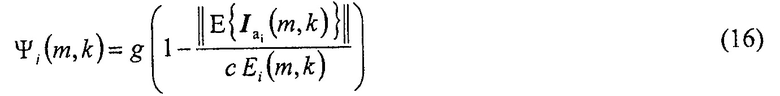 ,
,
где g обозначает подходящий коэффициент масштабирования, E{ } является оператором математического ожидания и  обозначает норму вектора. Можно показать, что параметр рассеяния Ψi (m, k) равен нулю, если присутствует плоская волна и принимает положительное значение меньшее или равное единице, в случае чисто диффузных звуковых полей. В общем случае, альтернативная функция отображения может определяться для рассеяния, которое демонстрирует подобное поведение, то есть равняется 0 только для прямого звука, и достигает 1 для полностью рассеянного звукового поля.
обозначает норму вектора. Можно показать, что параметр рассеяния Ψi (m, k) равен нулю, если присутствует плоская волна и принимает положительное значение меньшее или равное единице, в случае чисто диффузных звуковых полей. В общем случае, альтернативная функция отображения может определяться для рассеяния, которое демонстрирует подобное поведение, то есть равняется 0 только для прямого звука, и достигает 1 для полностью рассеянного звукового поля.
Ссылаясь на вариант осуществления на ФИГ. 11, альтернативная реализация для оценки параметра можно использовать для других конструкций микрофона. Как, в качестве примера, показано на ФИГ. 11, можно использовать множественные, линейно расположенные 1112, 1114, 1116, направленные микрофоны. На ФИГ. 11 также показывается пример того, как 2D наблюдаемое пространство разделяется на сектора 1101, 1102, 1103 для данной конструкции микрофона. Сегментированные сигналы микрофона 115 могут определяться с помощью техник формирования луча таких, как фильтр и формирование суммарного луча, приложенных к каждому из линейно расположенных микрофонов 1112, 1114, 1116. Формирование луча также можно исключить, то есть диаграммы направленности направленных микрофонов можно использовать в качестве единственного средства для получения сегментированных сигналов микрофона 115, которые показывают желаемую пространственную избирательность для каждого сектора (Segi). Параметр θi DOA в пределах каждого сектора можно оценивать с использованием общих методов оценки таких, как алгоритм "ESPRIT" (как описано в R. Roy и T. Kailath: ESPRIT-estimation of signal parameters via rotational invariance techniques. IEEE Transactions on Acoustics, Speech and Signal Processing, vol. 37, no. 7, pp. 984995, Jul 1989). Параметр рассеяния Ψi для каждого сектора можно, например, определять путем расчета временного колебания оценок DOA (как описывается в J. Ahonen, V. Pulkki: Diffuseness estimation using temporal variation of intensity vectors, IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, 2009. WAS-PAA '09. , pp. 285-288, 18-21 Oct. 2009). В качестве варианта, могут использоваться известные отношения связи между различными микрофонами и отношение прямого звука к рассеянному (как описывается в O. Thiergart, G. Del Galdo, E.A.P. Habets,: Signal-to-reverberant ratio estimation based on the complex spatial coherence between omnidirectional microphones, IEEE International Conference on Acoustics. Speech and Signal Processing (ICASSP), 2012. pp. 309-3 12. 25-30 March 2012).
На ФИГ. 12 показано схематическое изображение 1200 примера кругового расположения ненаправленных микрофонов 1210 для получения сигналов микрофона высокого порядка (например, входной пространственный сигнал 105). На схематическом изображении 1200 на ФИГ. 12 круговое расположение ненаправленных микрофонов 1210 включает в себя, например, 5 равноудаленных микрофонов расположенных по окружности (пунктирная линия) на полярной диаграмме. В вариантах осуществления, круговое расположение ненаправленных микрофонов 1210 можно использовать для получения сигналов микрофона высокого порядка (HO), как будет описано ниже. Для того, чтобы обработать пример сигналов микрофона второго порядка U и V из сигналов ненаправленного микрофона (предоставленных ненаправленными микрофонами 1210), следует использовать по меньшей мере 5 независимых сигналов микрофона. Указанной обработки можно элегантно достигнуть, например, с использованием равномерного кругового расположения (UCA) в качестве одного примера, показанного на ФИГ. 12. Вектор, полученный из сигналов микрофона в определенное время и с определенной частотой можно, например, преобразовать с помощью DFT (дискретное преобразование Фурье). Сигналы микрофона W, X, Y, U и V (то есть входной пространственный сигнал 105) можно затем получить с помощью линейной комбинации коэффициентов DFT. Необходимо отметить, что коэффициенты DFT представляют собой коэффициенты рядов Фурье, рассчитанных из вектора сигналов микрофона.
Пусть ϒm обозначает обобщенный m-ый порядок сигнала микрофона, определяемого с помощью диаграмм направленности
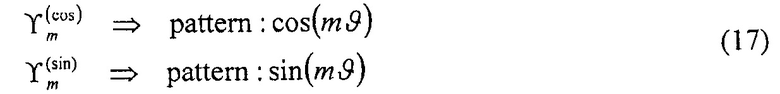 ,
,
где обозначает азимутальный угол такой, что

Затем показывается, что
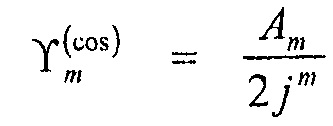
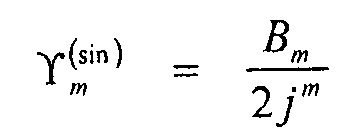 ,
,
где
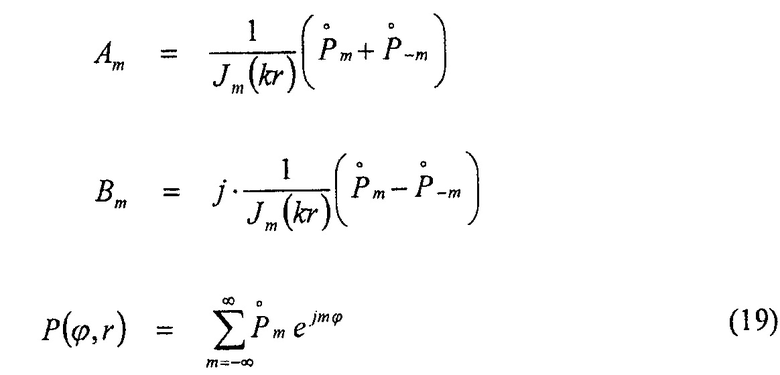 ,
,
где j является мнимой единицей, k является волновым числом, r и ϕ являются радиусом и азимутальным углом, определяющими полярную систему координат, 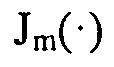 является m-порядком функции Бесселя первого рода и
является m-порядком функции Бесселя первого рода и 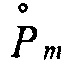 являются коэффициентами рядов Фурье давления сигнала, измеренного в полярных координатах (r, ϕ).
являются коэффициентами рядов Фурье давления сигнала, измеренного в полярных координатах (r, ϕ).
Необходимо отметить, что следует обратить внимание на разработку схемы расположения и реализацию расчета сигналов (высокого порядка) формата B, чтобы избежать чрезмерного усиления шума, по причине численных свойств функции Бесселя.
Математические обоснование и расчеты, относящиеся к описанию преобразования сигнала, могут быть найдены, например, в A. Kuntz. Wave field analysis using virtual circular microphone arrays, Dr. Hut, 2009. ISBN: 978-3-86853-006-3.
Другие варианты осуществления настоящего изобретения относятся к способу формирования множества параметрических звуковых потоков 125 (θi, Ψi, Wi) из входного пространственного сигнала 105, полученного из записи, сделанной в пространстве звукозаписи. Например, входной пространственный сигнал 105 включает в себя ненаправленный сигнал W и множество сигналов различной направленности X, Y, Z, U, V. Способ включает в себя предоставление по меньшей мере двух входных сегментированных звуковых сигнала 115 (Wi, Xi, Yi, Zi) из входного пространственного сигнала 105 (например, ненаправленного сигнала W и множества сигналов различной направленности X, Y, Z, U, V), в котором по меньшей мере два входных сегментированных звуковых сигнала 115 (Wi, Xi, Yi, Zi) относятся к соответствующим сегментам Segi пространства звукозаписи. Кроме того, способ включает в себя формирование параметрического звукового потока для каждого из по меньшей мере двух входных сегментированных звуковых сигналов 115 (Wi, Xi, Yi, Zi) для получения множества параметрических звуковых потоков 125 (θi, Ψi, Wi).
Другие варианты осуществления настоящего изобретения относятся к способу формирования множества сигналов 525 акустической системы (L1, L2, …) из множества параметрических звуковых потоков 125 (θi, Ψi, Wi), полученных из входного пространственного сигнала 105, записанного в пространстве звукозаписи. Способ включает в себя предоставление множества входных сегментированных сигналов 515 акустической системы из множества параметрических звуковых потоков 125 (θi, Ψi, Wi), в которых входные сегментированные сигналы 515 акустической системы относятся к соответствующим сегментам Segi пространства звукозаписи. Кроме того, способ включает в себя смешивание входных сегментированных сигналов 515 акустической системы для получения множества сигналов 525 акустической системы (L1, L2, …).
Хотя настоящее изобретение было описано в контексте структурных схем, где блоки представляют собой фактические и логические компоненты аппаратных средств, настоящее изобретение также может быть осуществлено реализуемым на основе компьютера способом. В последнем случае, блоки представляют собой соответствующие способу шаги, где данные шаги означают функциональность, выполненную с помощью соответствующих логических или физических аппаратных блоков.
Описанные варианты осуществления являются всего лишь иллюстрациями для принципов настоящего изобретения. Понятно, что преобразования и вариации устройств и деталей, описанные в настоящем документе будут очевидны для специалистов в данной области техники. Намерение, таким образом, должно быть ограничено только объемом прилагаемой формулы изобретения, а не конкретными деталями, представленными посредством описания и объяснения вариантов осуществления в настоящем документе.
Хотя некоторые аспекты были описаны в контексте устройства, становится ясно, что данные аспекты также представляют собой описание соответствующих способов, где блок или устройство соответствует шагу способа или характеристике шага способа. Аналогично, аспекты, описанные в контексте шага способа, также представляют собой описание соответствующего блока, или элемента, или характеристики соответствующего устройства. Некоторые или все из шагов способа могут быть выполнены с помощью (или с использованием) аппаратного устройства такого как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления, какой-нибудь один или несколько наиболее важных шагов способ могут быть исполнены таким устройством.
Параметрические звуковые потоки 125 (θi, Ψi, Wi) могут сохраняться на цифровом носителе информации или могут передаваться по среде передачи информации таким, как беспроводная среда передачи информации или проводная среда передачи информации такая, как Интернет.
В зависимости от некоторых требований реализации, варианты осуществления изобретения могут быть осуществлены в аппаратных средствах или с помощью программного обеспечения. Реализация может выполняться с использованием цифрового носителя информации, например, гибкого магнитного диска, DVD, Blu-Ray, CD, ПЗУ, ЭППЗУ, ЭСППЗУ или флэш-памяти, имеющего электронночитаемый управляющий сигнал, хранимый на нем, который взаимодействует (или способен взаимодействовать) с программируемой компьютерной системой так, что выполняется соответствующий способ. Таким образом, цифровой носитель информации может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению включают в себя носитель данных, имеющий электронночитаемые управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой так, что выполняется один из способов, описанных в настоящем документе.
Как правило, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, программным кодом, для оперативного выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код может, например, храниться на машиночитаемом носителе информации.
Другие варианты осуществления включают в себя компьютерную программу для выполнения одного из способов, описанных в настоящем документе, хранящуюся на машиночитаем носителе информации.
Другими словами, вариантом осуществления способа по изобретению является, таким образом, компьютерная программа, имеющая программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа, выполняется на компьютере.
Другим вариантом осуществления способа по изобретению является, таким образом, носитель данных (или цифровой носитель информации или машиночитаемый носитель информации), включающий в себя, записанную на нем, компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровой носитель информации или записанный носитель информации, как правило, является материальным носителем и/или энергонезависимым.
Другим вариантом осуществления способа по изобретению является, таким образом, поток данных или последовательность сигналов, представляющих компьютерную программу, выполняющую один из способов, описанных в настоящем документе. Поток данных или последовательность сигналов может, например, быть выполнена с возможностью передачи через подключение к информационной связи, например, через Интернет.
Другим вариантом осуществления, включающим в себя обрабатывающие устройства, например, компьютер или программируемое логическое устройство, выполненное с возможностью выполнять или адаптированной для выполнения одного из способов, описанных в настоящем документе. Другой вариант осуществления включает в себя компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Другой вариант осуществления согласно изобретению включает в себя устройство или систему выполнения с возможностью передачи (например, электронным способом или оптическим способом) компьютерной программы на приемник, для выполнения одного из способов, описанных в настоящем документе. Приемник может, например, быть компьютером, мобильным устройством, запоминающим устройством или т.п. Устройство или система может, например, включать в себя файловый сервер для передачи компьютерной программы приемнику.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторой или всей функциональности способов, описанных в настоящем документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может работать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Как правило, предпочтительно выполнять способы любым аппаратным устройством.
Варианты осуществления настоящего изобретения обеспечивают высокое качество, реалистичную пространственную запись и воспроизведение звука с использованием простых и компактных конструкций микрофона. Варианты осуществления настоящего изобретения основаны на направленном звуковом кодировании (DirAC) (как описано в T. Lokki, J. Merimaa, V. Pulkki: Method for Reproducing Natural or Modified Spatial Impression in Multichannel Listening, U.S. Patent 7,787,638 B2, Aug. 31, 2010 and V. Pulkki: Spatial Sound Reproduction with Directional Audio Coding. J. Audio Eng. Soc. Vol. 55, No. 6, pp. 503-516. 2007), которое можно использовать с различными системами микрофонов и с произвольными акустическими установками. Преимуществом DirAC является воспроизведение пространственного ощущения, имеющегося акустического пространства насколько можно более точно, с использованием многоканальной акустической системы. В пределах выбранного пространства, характеристики (непрерывный звук или импульсные характеристики) могут измеряться ненаправленным микрофоном (W) и набором микрофонов, что позволяет измерить направление на источник (DOA) звука и рассеяние звука. Возможный способ заключается в применении трех микрофонов в форме восьмерки (X, Y, Z), совпадающих с соответствующей декартовой осью координат. Способ сделать это заключается в применении микрофона "SoundField", который дает все необходимые характеристики. Стоит отметить, что сигнал ненаправленного микрофона представляет собой звуковое давление тогда, как дипольные сигналы пропорциональны соответствующим составляющим вектора скорости частицы.
Форма данных сигналов, параметры DirAC, то есть DOA звука и рассеяние, наблюдаемого звукового поля могут измеряться в подходящем временно-частотной сетке с разрешением, соответствующим слуховой системе человека. Фактические сигналы акустической системы затем можно определить из ненаправленного сигнала микрофона на основе параметров DirAC (как описано в V. Pulkki: Spatial Sound Reproduction with Directional Audio Coding. J. Audio Eng. Soc, Vol. 55, No. 6, pp. 503-516. 2007). Прямые звуковые составляющие могут воспроизводить только небольшое количество акустических систем (например, одна или две) с использованием техник панорамирования тогда, как составляющие рассеянного звука, в тоже самое время, можно воспроизводить через все акустические системы.
Варианты осуществления настоящего изобретения на основе DirAC представляют собой простой подход к пространственной записи звука с компактными конструкциями микрофона. В частности, настоящее изобретение избегает некоторых систематических недостатков, которые ограничивают достижимое качество звука и практический опыт на предшествующем уровне техники.
В отличие от обычного DirAC, варианты осуществления настоящего изобретения обеспечивают более высокое качество параметрической пространственной обработки звука. Обычный DirAC основан на простой глобальной модели для звукового поля, используя только один DOA и один параметр рассеяния для всего наблюдаемого пространства. Основываясь на предположении, что звуковое поле может быть представлено только одной одиночной составляющей прямого звука такой, как плоская волна и одним общим параметром рассеяния для каждой временной/частотной ячейки. На практике оказывается, однако, что часто упрощающее допущение о звуковом поле не верно. Это особенно верно в сложном, реальном мире акустики, например, в случае, если многочисленные источники звука такие, как говорящие люди или инструменты активны одновременно. С другой стороны, варианты осуществления настоящего изобретения не приводят к несовпадению модели наблюдаемого звукового поля и соответствующих оценок параметра более правильными. Также можно избежать результатов несовпадения модели, особенно в случаях, когда составляющие прямого звука воспроизводятся с рассеянием и направление невозможно различить при прослушивании выходных сигналов акустической системы. В вариантах осуществления, можно использовать декорреляторы для формирования некорректированного рассеянного звука воспроизведения из всех акустических систем (как описано в V. Pulkki: Spatial Sound Reproduction with Directional Audio Coding. J. Audio Eng. Soc, Vol. 55, No. 6, pp. 503-516. 2007). В отличие от предшествующего уровня техники, где декорреляторы часто вносят нежелательный дополнительный эффект комнаты, с настоящем изобретением можно более точно воспроизводить источники звука, которые имеют некоторый пространственный размер (в отличие от случая с использованием простой модели звукового поля DirAC, которая не способна точно улавливать такие источники звука). Варианты осуществления настоящего изобретения предоставляют большее количество степеней свободы предполагаемой модели сигнала, делают возможным лучшее соответствие модели в сложных звуковых сценах.
Кроме того, в случае с использованием направленных микрофонов для формирования секторов (или любых других независимых от времени линейных, например, физических устройств), можно получить увеличение характеристики направленности микрофонов. Таким образом, в меньшей степени требуется применение изменяющихся во времени усилений, чтобы избежать неопределенных направлений, взаимных помех и окрашивания звука. Данный подход приводит к меньшей нелинейной обработке на пути прохождения звукового сигнала, обуславливая более высокое качество.
В общем случае, большее количество составляющих прямого звука можно воспроизводить как прямые источники звука (точечные источники/источники плоской волны). Как следствие, встречается меньше артефактов декорреляции, различается больше (правильно) локализуемых событий и достигается более точное пространственное воспроизведение.
Варианты осуществления настоящего изобретения обеспечивают повышенную производительность управления областью параметра, например, направленная фильтрация (как описано в M. Kallinger, H. Ochsenfeld, G. Del Galdo, F. uech, D. Mahne, R. Schultz-Amling, and O. Thiergart: A Spatial Filtering Approach for Directional Audio Coding, 126th AES Convention, Paper 7653, Munich, Germany, 2009), по сравнению с простой глобальной моделью, поскольку большая доля полной энергии сигнала относится к прямым звуковым событиям с правильным DOA, относящимся к ним и доступно большое количество информации. Предоставление дополнительной (параметрической) информации позволяет, например, разделить множество прямых звуковых составляющих или также прямые звуковые составляющие из наложения первых отражений с различных направлений.
В частности, варианты осуществления обеспечивают следующие характеристики. В случае 2D, полный диапазон азимутальных углов можно разделить на секторы, охватывающие уменьшенные диапазоны азимутальных углов. В случае 3D, полный диапазон пространственного угла можно разделить на секторы, охватывающие уменьшенные диапазоны пространственного угла. Каждый сектор можно соотнести с предпочтительным диапазоном угла. Для каждого сектора, сегментированные сигналы микрофона можно определять из принятых сигналов микрофона, которые преимущественно состоят из звука, поступающего от направлений, которые поставлены в соответствие/охвачены определенным сектором. Данные сигналы микрофона могут также определяться искусственно моделированием виртуальных записей. Для каждого сектора, анализ параметрического звукового поля может выполняться для определения параметров направления таких, как DOA и рассеяние. Для каждого сектора, параметрическая информация о направлении (DOA и рассеяние) преимущественно описывает пространственные свойства углового диапазона звукового поля, который соответствует определенному сектору. В случае воспроизведения, для каждого сектора, сигналы акустической системы можно определять на основе параметров направленности и сегментированных сигналов микрофона. Общий выход затем получают смешиванием выходов всех секторов. В случае управления, перед обработкой сигналов акустической системы для воспроизведения, оцениваемые параметры и/или сегментированные звуковые сигналы также можно преобразовать с целью достижения управления звуковой сценой.
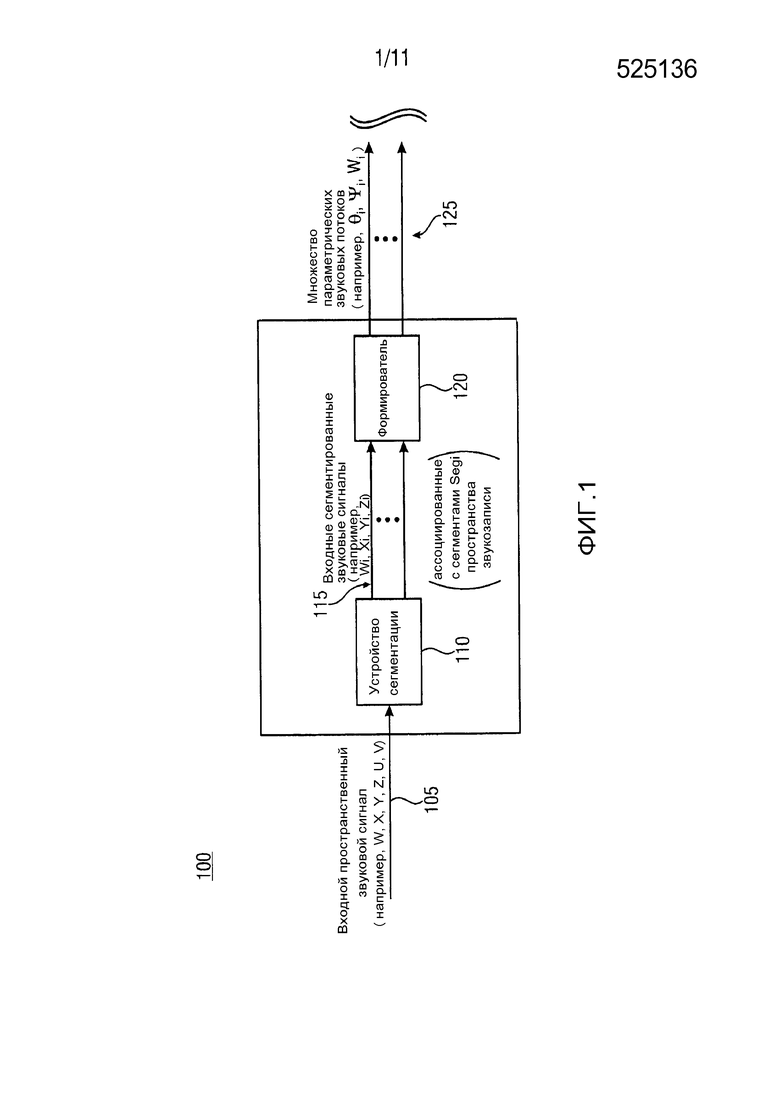
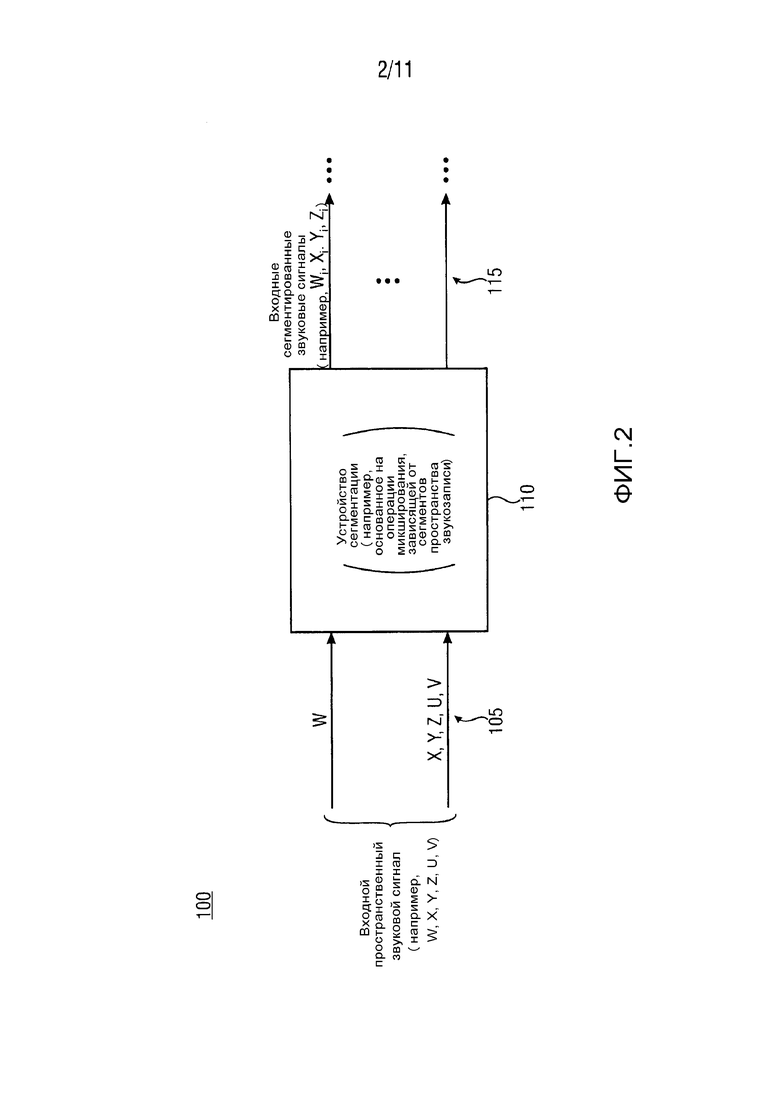
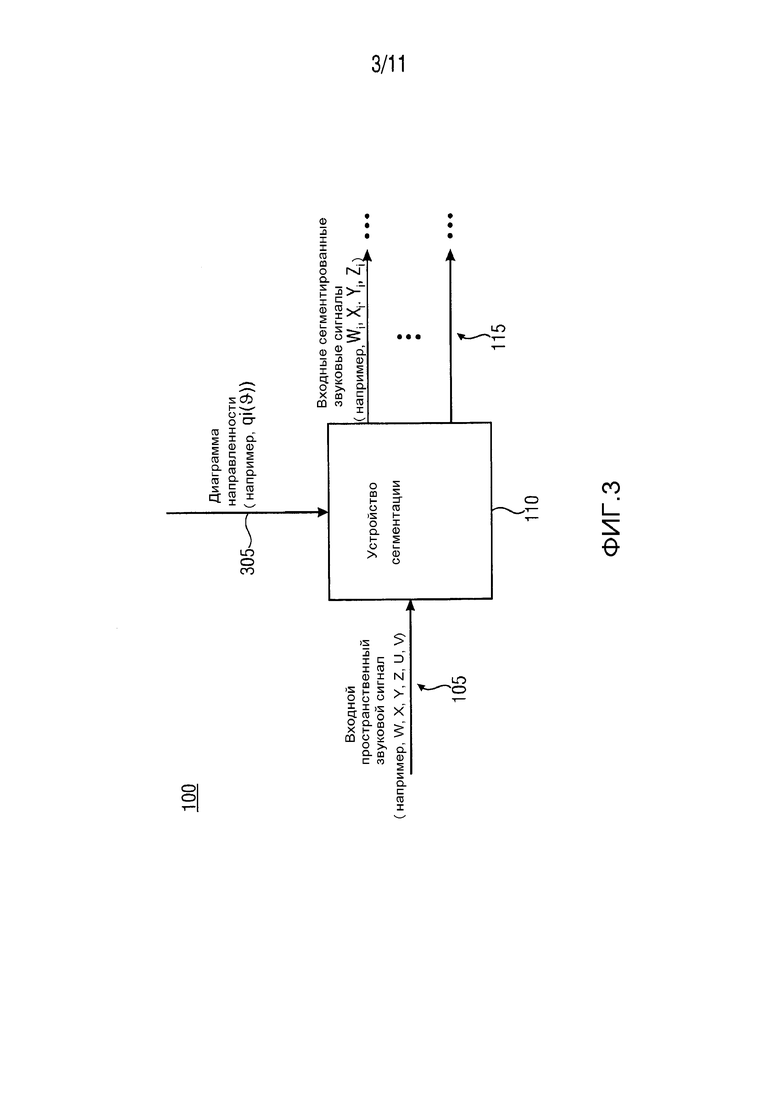
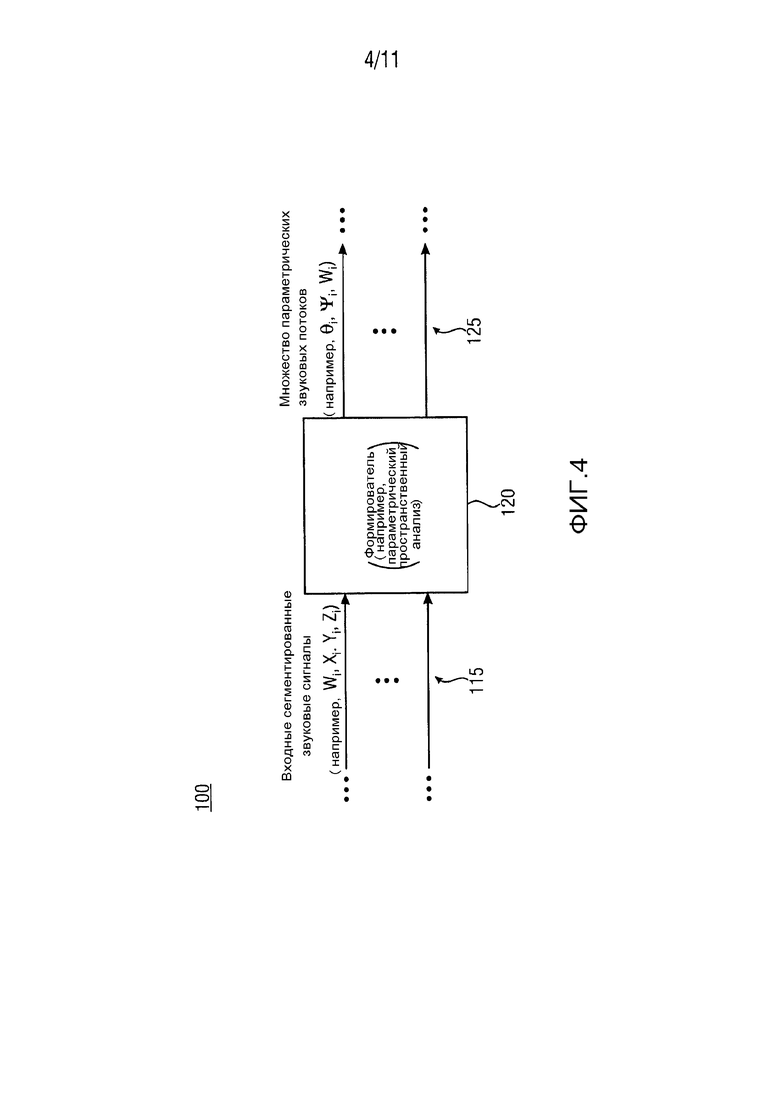
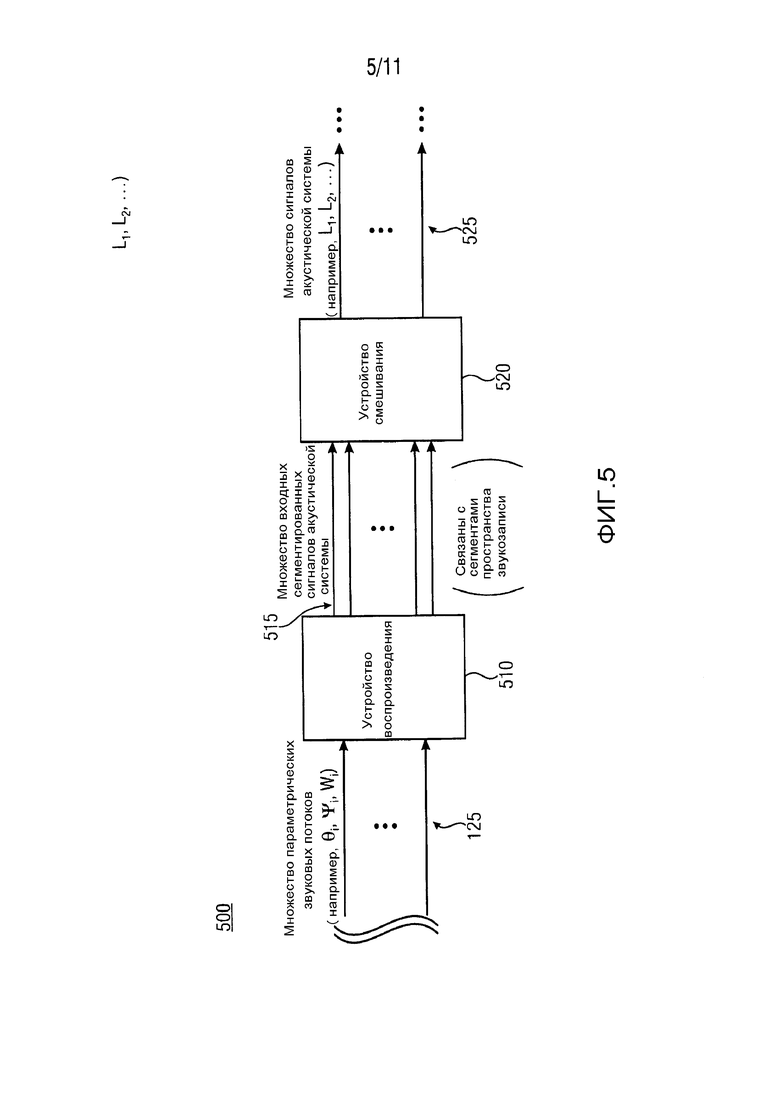
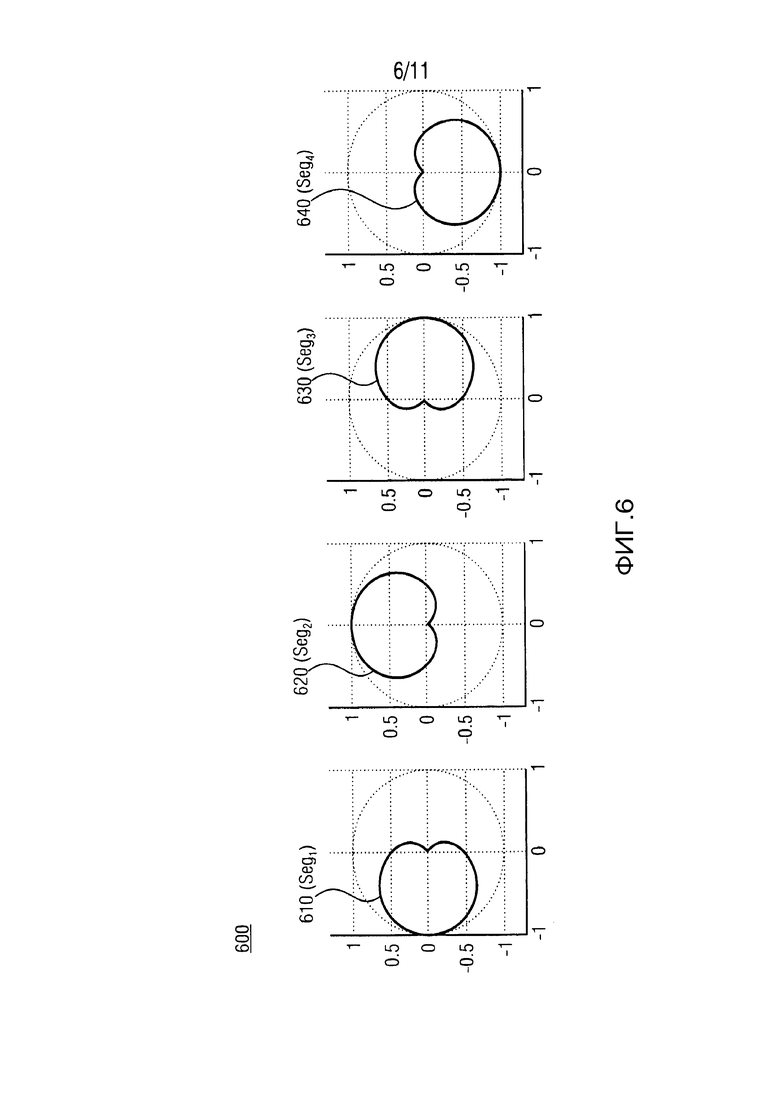
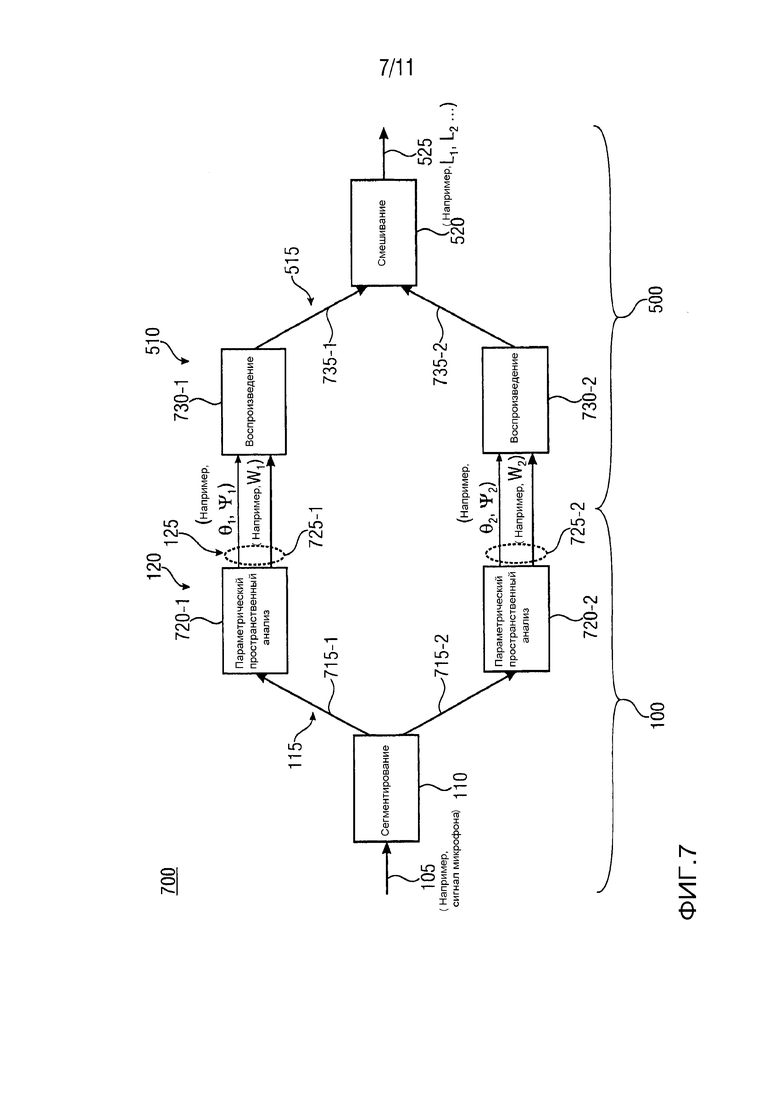
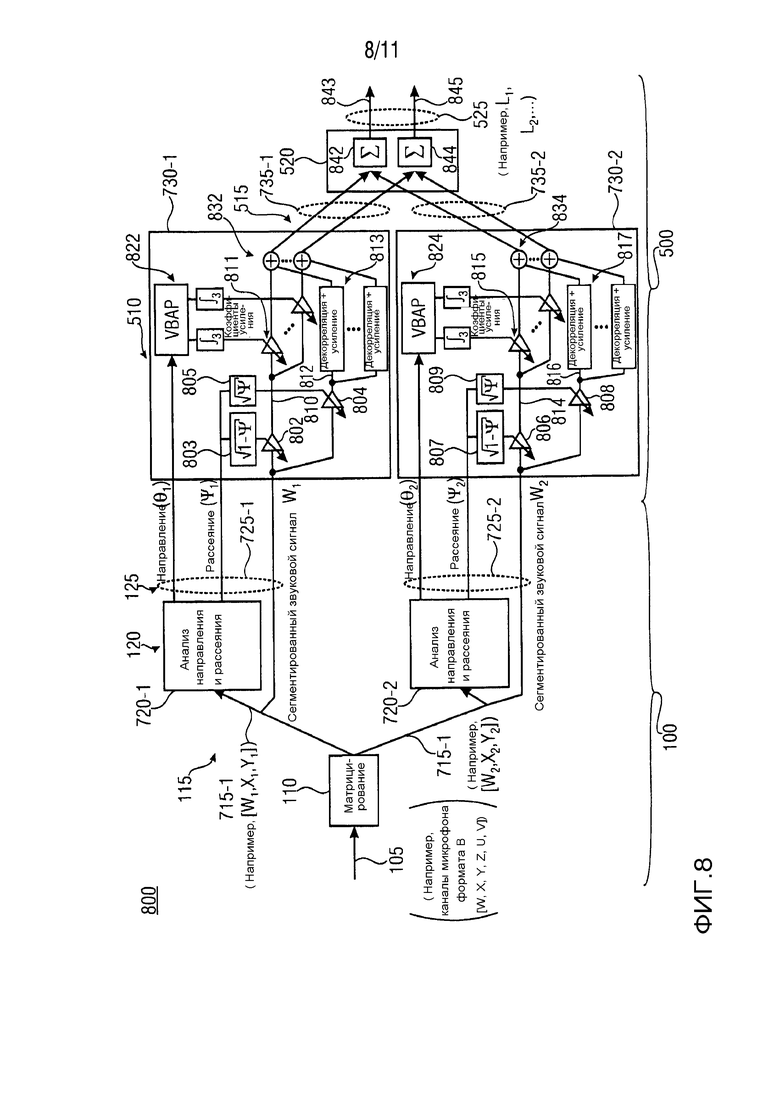
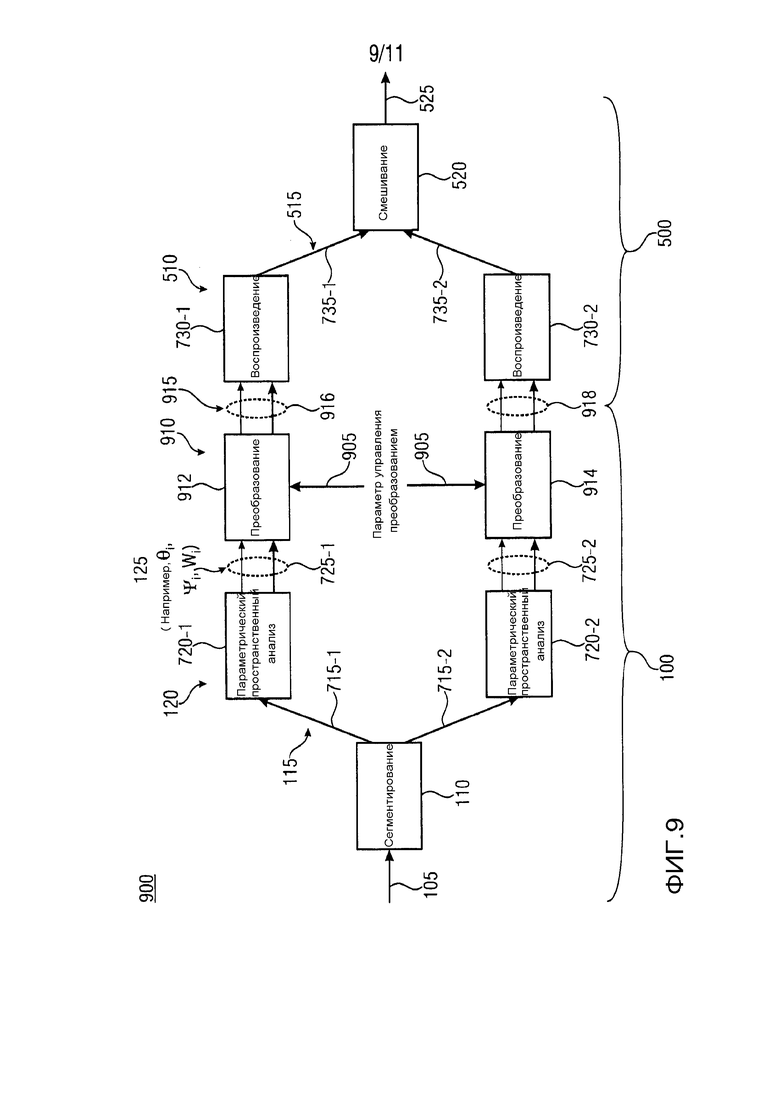
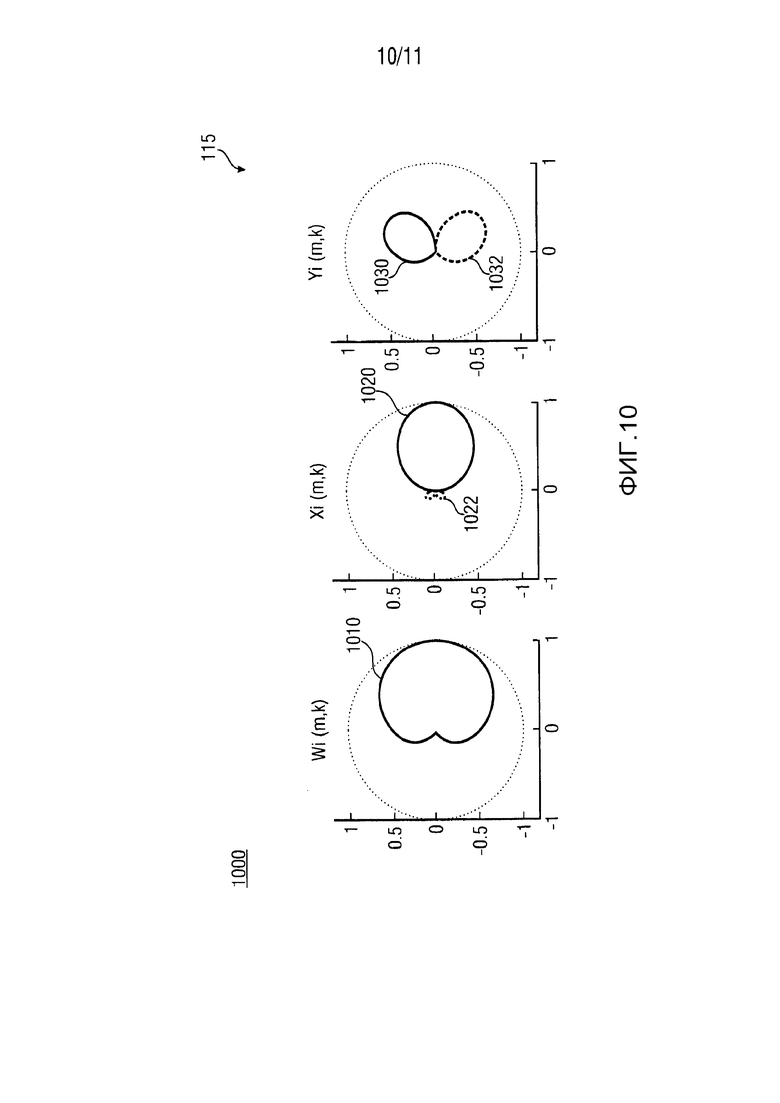
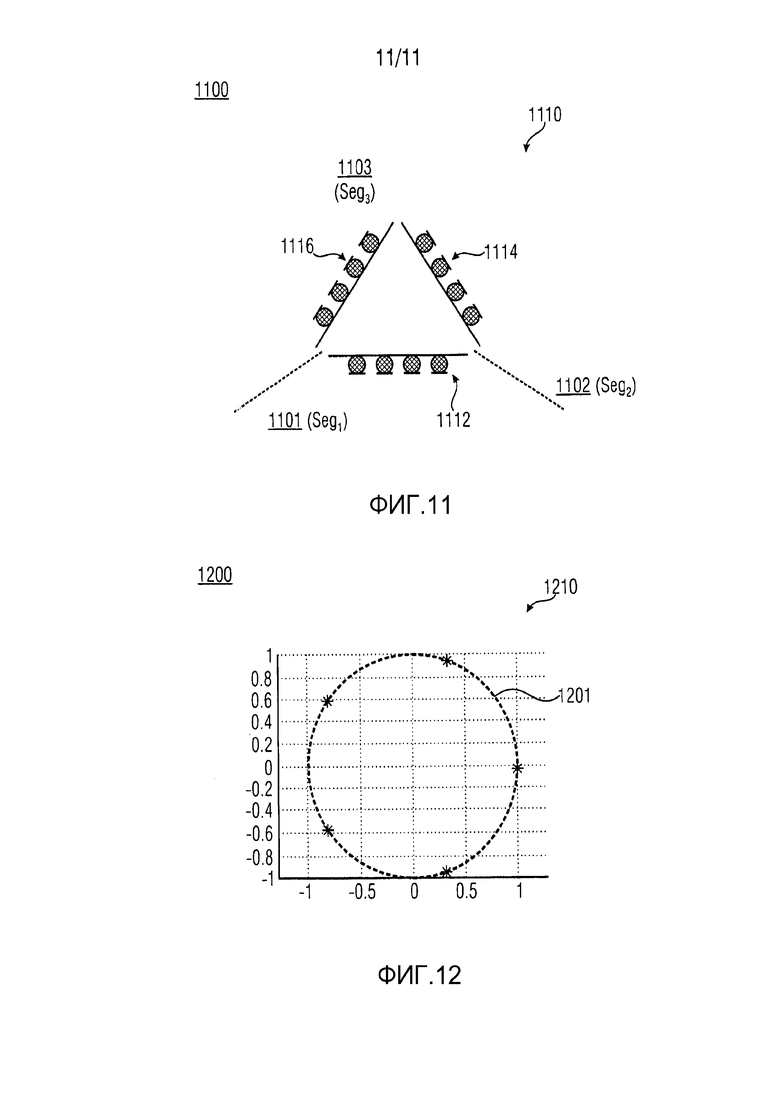
Изобретение относится к средствам для формирования множества параметрических звуковых потоков. Технический результат заключается в улучшении качества пространственного звука. Устройство для формирования множества параметрических звуковых потоков из входного пространственного звукового сигнала, полученного из записи пространства звукозаписи, содержит устройство сегментации и формирователь. Устройство сегментации выполнено с возможностью предоставления по меньшей мере двух входных сегментированных звуковых сигналов из входного пространственного звукового сигнала, причем по меньшей мере два входных сегментированных звуковых сигнала связаны с соответствующими сегментами пространства звукозаписи. Формирователь выполнен с возможностью формирования параметрического звукового потока для каждого из по меньшей мере двух входных сегментированных звуковых сигналов для получения множества параметрических звуковых потоков. 6 н. и 8 з.п. ф-лы, 12 ил.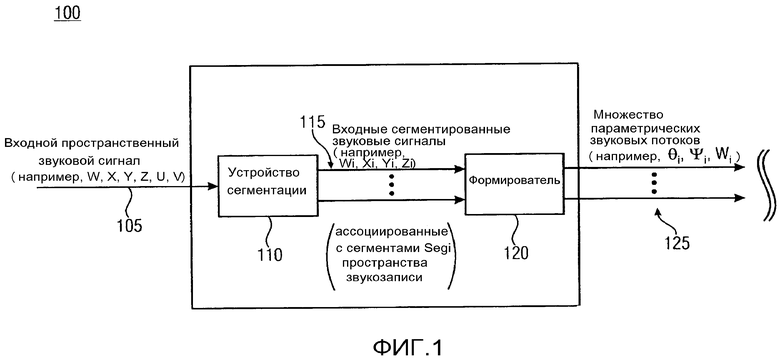
1. Устройство (100) для формирования множества параметрических звуковых потоков (125) (θi, Ψi, Wi) из входного пространственного звукового сигнала (105), полученного из записи в пространстве звукозаписи, причем устройство (100) содержит:
устройство (110) сегментации для формирования по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) из входного пространственного звукового сигнала (105); причем устройство (110) сегментации выполнено с возможностью формирования по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi), зависящих от соответствующих сегментов (Segi) пространства звукозаписи, при этом каждый из сегментов (Segi) пространства звукозаписи представляет собой подмножество направлений в пределах двухмерной (2D) плоскости или в пределах трехмерного (3D) пространства, и сегменты (Segi) отличаются друг от друга; и
формирователь (120) для формирования параметрического звукового потока для каждого из по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) для получения множества параметрических звуковых потоков (125) (θi, Ψi, Wi), так что каждый из множества параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит составляющую (Wi) по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) и соответствующую параметрическую пространственную информацию (θi, Ψi), причем параметрическая пространственная информация (θi, Ψi) каждого из параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит параметр (θi) направления прихода (DOA) и/или параметр (Ψi) рассеяния, при этом параметр (θi) направления прихода (DOA) указывает направление прихода (DOA) звука, а параметр (Ψi) рассеяния указывает рассеяние звука.
2. Устройство (100) по п. 1,
в котором каждый из сегментов (Segi) пространства звукозаписи характеризуется соответствующим направленным измерением.
3. Устройство (100) по п. 1,
при этом устройство (100) выполнено с возможностью осуществления записи звукового поля для получения входного пространственного звукового сигнала (105);
причем устройство (110) сегментации выполнено с возможностью деления представляющего интерес полного углового диапазона на сегменты (Segi) пространства звукозаписи;
причем каждый из сегментов (Segi) пространства звукозаписи перекрывает уменьшенный угловой диапазон по сравнению с представляющим интерес полным угловым диапазоном.
4. Устройство (100) по п. 1,
в котором входной пространственный звуковой сигнал (105) содержит ненаправленный сигнал (W) и множество сигналов различной направленности (X, Y, Z, U, V).
5. Устройство (100) по п. 1,
в котором устройство (110) сегментации выполнено с возможностью формирования по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) из ненаправленного сигнала (W) и множество сигналов различной направленности (X, Y, Z, U, V) с использованием операции микширования, которая зависит от сегментов (Segi) пространства звукозаписи.
6. Устройство (100) по п. 1,
в котором устройство (110) сегментации выполнено с возможностью использования диаграммы (305) направленности (qi(ϑ)) для каждого из сегментов (Segi) пространства звукозаписи;
причем диаграмма (305) направленности (qi(ϑ)) показывает направленность по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi).
7. Устройство (100) по п. 6,
в котором диаграмма (305) направленности (qi(ϑ)) имеет вид
qi(ϑ)=a+b cos(ϑ+Θi),
где а и b обозначают множители, которые изменяют для получения требуемой диаграммы (305) направленности (qi(ϑ));
при этом ϑ обозначает азимутальный угол и Θi указывает предпочтительное направление i-того сегмента пространства звукозаписи.
8. Устройство (100) по п. 1,
в котором формирователь (120) выполнен с возможностью осуществления параметрического пространственного анализа для каждого из по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) для получения соответствующей параметрической пространственной информации (θi, Ψi).
9. Устройство (100) по п. 1, дополнительно содержащее:
преобразователь (910) для преобразования множества параметрических звуковых потоков (125) (θi, Ψi, Wi) в области представления параметрического сигнала;
при этом преобразователь (910) выполнен с возможностью преобразования по меньшей мере одного из параметрических звуковых потоков (125) (θi, Ψi, Wi) с использованием соответствующего параметра (905) управления преобразованием.
10. Устройство (500) для формирования множества сигналов (525) акустической системы (L1, L2, …) из множества параметрических звуковых потоков (125) (θi, ϑi, Wi); при этом каждый из множества параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит сегментированную звуковую составляющую (Wi) и соответствующую параметрическую пространственную информацию (θi, Ψi); причем параметрическая пространственная информация (θi, Ψi) каждого из параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит параметр (θi) направления прихода (DOA) и/или параметр (Ψi) рассеяния, при этом параметр (θi) направления прихода (DOA) указывает направление прихода (DOA) звука, а параметр (Ψi) рассеяния указывает рассеяние звука; при этом устройство (500) содержит:
устройство (510) воспроизведения для предоставления множества входных сегментированных сигналов (515) акустической системы из множества параметрических звуковых потоков (125) (θi, Ψi, Wi), так что входные сегментированные сигналы (515) акустической системы зависят от соответствующих сегментов (Segi) пространства звукозаписи, причем каждый из сегментов (Segi) пространства звукозаписи представляет собой подмножество направлений в пределах двухмерной (2D) плоскости или в пределах трехмерного (3D) пространства, и сегменты (Segi) отличаются друг от друга; при этом устройство (510) воспроизведения выполнено с возможностью воспроизведения каждой из сегментированных составляющих звука (Wi) с использованием соответствующей параметрической пространственной информации (505) (θi, Ψi) для получения множества входных сегментированных сигналов (515) акустической системы; и
устройство (520) смешивания для смешивания входных сегментированных сигналов (515) акустической системы для получения множества сигналов (525) акустической системы (L1, L2, …).
11. Способ формирования множества параметрических звуковых потоков (125) (θi, Ψi, Wi) из входного пространственного звукового сигнала (105), полученного из записи в пространстве звукозаписи, при этом способ содержит:
формирование по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) из входного пространственного звукового сигнала (105); причем формирование по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) проводится в зависимости от соответствующих сегментов (Segi) пространства звукозаписи, при этом каждый из сегментов (Segi) пространства звукозаписи представляет собой подмножество направлений в пределах двухмерной (2D) плоскости или в пределах трехмерного (3D) пространства, и сегменты (Segi) отличаются друг от друга;
формирование параметрического звукового потока для каждого из по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) для получения множества параметрических звуковых потоков (125) (θi, Ψi, Wi), так что каждый из множества параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит составляющую (Wi) из по меньшей мере двух входных сегментированных звуковых сигналов (115) (Wi, Xi, Yi, Zi) и соответствующую параметрическую пространственную информацию (θi, Ψi), причем параметрическая пространственная информация (θi, Ψi) каждого из параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит параметр (θi) направления прихода (DOA) и/или параметр (Ψi) рассеяния, при этом параметр (θi) направления прихода (DOA) указывает направление прихода (DOA) звука, а параметр (Ψi) рассеяния указывает рассеяние звука.
12. Способ формирования множества сигналов (525) акустической системы (L1, L2, …) из множества параметрических звуковых потоков (125) (θi, Ψi, Wi); при этом каждый из множества параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит сегментированную звуковую составляющую (Wi) и соответствующую параметрическую пространственную информацию (θi, Ψi); причем параметрическая пространственная информация (θi, Ψi) каждого из параметрических звуковых потоков (125) (θi, Ψi, Wi) содержит параметр (θi) направления прихода (DOA) и/или параметр (Ψi) рассеяния, при этом параметр (θi) направления прихода (DOA) указывает направление прихода (DOA) звука, а параметр (Ψi) рассеяния указывает рассеяние звука; при этом способ содержит:
предоставление множества входных сегментированных сигналов (515) акустической системы из множества параметрических звуковых потоков (125) (θi, Ψi, Wi), так что входные сегментированные сигналы (515) акустической системы зависят от соответствующих сегментов (Segi) пространства звукозаписи, причем каждый из сегментов (Segi) пространства звукозаписи представляет собой подмножество направлений в пределах двухмерной (2D) плоскости или в пределах трехмерного (3D) пространства, и сегменты (Segi) отличаются друг от друга; при этом предоставление множества входных сегментированных сигналов (515) акустической системы проводится путем воспроизведения каждой из сегментированных звуковых составляющих (Wi) с использованием соответствующей параметрической пространственной информации (505) (θi, Ψi) для получения множества входных сегментированных сигналов (515) акустической системы; и
смешивание входных сегментированных сигналов (515) акустической системы для получения множества сигналов (525) акустической системы (L1, L2, …).
13. Машиночитаемый носитель, содержащий компьютерную программу, содержащую программный код для выполнения способа по п. 11 при выполнении компьютерной программы на компьютере.
14. Машиночитаемый носитель, содержащий компьютерную программу, содержащую программный код для выполнения способа по п. 12 при выполнении компьютерной программы на компьютере.
| EP 1558061 A2, 27.07.2005 | |||
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| СПОСОБ ЗАЩИТЫ УГЛЕВОДОРОДНОГО ТОПЛИВА ОТ МИКРОБИОЛОГИЧЕСКОГО ПОРАЖЕНИЯ И БИОЦИДНАЯ ПРИСАДКА, ПРЕДНАЗНАЧЕННАЯ ДЛЯ ИСПОЛЬЗОВАНИЯ В ЭТОМ СПОСОБЕ | 2007 |
|
RU2346028C1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| МНОГОКАНАЛЬНЫЙ КОДЕР | 2005 |
|
RU2382419C2 |

