ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение в целом относится к обработке пространственного аудиосигнала и конкретно - к устройству и способу для приспосабливания пространственного аудиосигнала, намеченного для исходной (базовой) установки громкоговорителя, к установке громкоговорителя для воспроизведения, которая отличается от исходной установки громкоговорителя. Дополнительные варианты осуществления настоящего изобретения относятся к гибкому преобразованию многоканальной звуковой сцены высокого качества.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
С годами требования к современной системе воспроизведения аудио изменились. От одноканальной (моно) к двухканальной (стерео) до многоканальных систем, подобных Surround-системам (объемного звука) конфигураций 5.1 и 7.1, или синтеза однородного волнового поля, число используемых каналов громкоговорителя увеличилось. Однородные системы с громкоговорителями верхнего расположения нужно видеть в современных кинотеатрах. Это способствует предоставлению слушателю аудиовпечатления о записанной или искусственно созданной аудиосцене, по отношению к восприятию реальности, погружения и окружения звуком, каковое становится насколько возможно близким к реальной аудиосцене или альтернативно наилучшим образом отражает намерения звукооператора (см. например, M. Morimoto, “The Role of Rear Loudspeakers in Spatial Impression”, в материалах 103-th Convention of the AES (Конгресс Общества инженеров-звукотехников), 1997; D. Griesinger, “Spaciousness and Envelopment in Musical Acoustics”, в материалах 101th Convention of the AES, 1996; K. Hamasaki, K. Hiyama и R. Okumura, “The 22.2 Multichannel Sound System and Its Application” в материалах 118th Convention of the AES, 2005). Однако имеются, по меньшей мере, два недостатка: из-за множества доступных акустических систем по отношению к числу используемых громкоговорителей и рекомендуемому их позиционированию отсутствует общая совместимость между всеми этими системами. Кроме того, любое отступление от рекомендуемого позиционирования громкоговорителя приведет к нарушенной аудиосцене и, следовательно, снизит пространственное аудиовпечатление слушателя, и, следовательно, качество пространственного звука.
В применении в реальных условиях многоканальные системы воспроизведения часто не являются сконфигурированными корректно по отношению к позиционированию громкоговорителя. Чтобы не искажать исходный пространственный образ аудиосцены, что возможно произойдет вследствие неправильного позиционирования, требуется гибкая система высокого качества, которая способна компенсировать эти несоответствия установок. Современные подходы часто испытывают недостаток способности описать сложную и возможно искусственно сформированную звуковую сцену, где, например, появляется более одного прямого источника на один частотный диапазон и момент времени.
Следовательно, задача настоящего изобретения состоит в обеспечении усовершенствованного принципа для приспосабливания пространственного аудиосигнала с тем результатом, что пространственный образ аудиосцены сохраняется по существу таким же, если установка громкоговорителя для воспроизведения отличается от исходной установки громкоговорителя, то есть, установки громкоговорителя, для которой аудиоконтент пространственного аудиосигнала первоначально создавался.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Эта задача изобретения решается посредством устройства по п. 1, способа по п. 14 или компьютерной программы по п. 15.
Согласно варианту осуществления настоящего изобретения обеспечивается устройство для адаптации пространственного аудиосигнала, предназначенного для исходной установки громкоговорителя, к установке громкоговорителя воспроизведения, которая отличается от исходной установки громкоговорителя. Пространственный аудиосигнал содержит множество канальных сигналов. Устройство содержит группирователь, выполненный с возможностью группирования, по меньшей мере, двух канальных сигналов в сегмент. Устройство также содержит блок декомпозиции на прямой звук и звук окружения (режим «прямой-окружение»), выполненный с возможностью декомпозиции, по меньшей мере, двух канальных сигналов в сегменте, по меньшей мере, на один компонент прямого звука и, по меньшей мере, один компонент окружения. Блок декомпозиции на прямой звук и звук окружения может быть дополнительно выполнен с возможностью определения направления прихода, по меньшей мере, для одного компонента прямого звука. Устройство также содержит блок представления (рендеринга) прямого звука, выполненный с возможностью приема информации установки громкоговорителя для воспроизведения для, по меньшей мере, одного сегмента воспроизведения, связанной с сегментом, и для настройки, по меньшей мере, одного компонента прямого звука с использованием информации установки громкоговорителя для воспроизведения для сегмента с тем, что воспринимаемое направление прихода, по меньшей мере, одного компонента прямого звука в установке громкоговорителя для воспроизведения является идентичным направлению прихода для сегмента или более близким к направлению прихода, по меньшей мере, одного компонента прямого звука по сравнению с ситуацией, в которой настройка не имела место. Кроме того, устройство содержит объединитель, выполненный с возможностью объединения настроенных компонентов прямого звука и компонентов окружения или модифицированных компонентов окружения, чтобы получать сигналы громкоговорителя для, по меньшей мере, двух громкоговорителей в установке громкоговорителя для воспроизведения.
Основная концепция, лежащая в основе настоящего изобретения, состоит в группировании соседних каналов громкоговорителя в сегменты (например, круговые секторы, цилиндрические секторы, или сферические секторы) и декомпозиции сигнала каждого сегмента на соответствующие части сигнала прямого звука и звука окружения. Прямые сигналы ведут к позиции фантомного источника (или нескольким позициям фантомных источников) в пределах каждого сегмента, тогда как сигналы окружения соответствуют диффузному звуку и отвечают за окружение звуком (envelopment) слушателя. В течение процесса представления прямые компоненты повторно отображаются (распределяются), взвешиваются и настраиваются при посредстве позиций фантомных источников, чтобы соответствовать фактической установке громкоговорителя для воспроизведения и сохранить исходную локализацию источников. Компоненты окружения повторно отображаются и взвешиваются, чтобы создать такую же величину окружения звуком в модифицированной установке прослушивания. По меньшей мере, часть обработки может выполняться на основе элемента разрешения по частоте-времени. С помощью этой методики можно обрабатывать даже повышенное или сниженное число громкоговорителей в выходной установке.
Сегмент в исходной установке громкоговорителя может также именоваться “исходный сегмент” для более легкой ссылки в последующем описании. Подобным образом, сегмент в установке громкоговорителя для воспроизведения может также именоваться “сегмент воспроизведения”. Сегмент обычно охвачен или ограничен двумя или большим числом громкоговорителей и позицией слушателя, то есть, сегмент обычно соответствует пространству, которое ограничивается двумя или большим числом громкоговорителей и слушателем. Данный громкоговоритель может быть назначен двум или большему числу сегментов. В двумерной установке громкоговорителей конкретный громкоговоритель обычно назначают "левому" сегменту и "правому" сегменту, то есть, громкоговоритель излучает звук прежде всего в левый и правый сегменты. Группирователь (или группирующий элемент) выполнен с возможностью сбора тех канальных сигналов, которые связаны с данным сегментом. Поскольку каждый канальный сигнал может быть назначен двум или большему числу каналов, его можно распределять этим двум или большему числу сегментов посредством группирователя или нескольких группирователей.
Блок декомпозиции на прямой звук и звук окружения может быть выполнен с возможностью определения компонентов прямого звука и компонентов окружения для каждого канала. Альтернативно, блок декомпозиции на прямой звук и звук окружения может быть выполнен с возможностью определять одиночный компонент прямого звука и одиночный компонент окружения на один сегмент. Направление(я) прихода можно определять путем анализа (например, кросскорреляции), по меньшей мере, двух канальных сигналов. В качестве альтернативы направление(я) прихода можно определять на основе информации, предоставленной на блок декомпозиции на прямой звук и звук окружения от дополнительного компонента устройства или от внешнего объекта.
Блок представления прямого звука может обычно рассматривать, каким образом различие между исходной установкой громкоговорителя и установкой громкоговорителя для воспроизведения влияет на текущий рассматриваемый сегмент исходной установки громкоговорителя, и какие меры должны быть предприняты, чтобы поддерживать восприятие компонентов прямого звука внутри упомянутого сегмента. Эти меры могут содержать (неисчерпывающий перечень):
- модифицирование амплитудного взвешивания для компонента прямого звука между громкоговорителями упомянутого сегмента;
- модифицирование фазового отношения и/или отношения задержки между специфическими для громкоговорителя компонентами прямого звука для громкоговорителей упомянутого сегмента;
- удаление компонента прямого звука для упомянутого сегмента из конкретного громкоговорителя благодаря доступности более подходящего громкоговорителя в установке громкоговорителя для воспроизведения;
- применение компонента прямого звука для соседнего сегмента в исходной установке громкоговорителя к громкоговорителю в текущем рассматриваемом сегменте, поскольку упомянутый громкоговоритель является более подходящим для воспроизведения упомянутого компонента прямого звука (например, из-за границы сегмента, пересекавшей направление прихода для фантомного источника при переходе от исходной установки громкоговорителя к установке громкоговорителя для воспроизведения);
- применение компонента прямого звука к добавленному громкоговорителю (дополнительный громкоговоритель), который является доступным в установке громкоговорителя для воспроизведения, но не в исходной установке громкоговорителя;
- возможные дополнительные меры, как описано ниже.
Блок представления прямого звука может содержать множество блоков представления сегмента, каждый блок представления сегмента выполняет обработку канальных сигналов одного сегмента.
Объединитель может объединять настроенные компоненты прямого звука, компоненты окружения и/или модифицированные компоненты окружения, которые были сгенерированы блоком представления прямого звука (или последующим блоком представления прямого звука) для одного или нескольких соседних сегментов относительно текущего рассматриваемого сегмента. Согласно некоторым вариантам осуществления компоненты окружения могут быть по существу идентичными, по меньшей мере, одному компоненту окружения, определенному посредством блока декомпозиции на прямой звук и звук окружения. Согласно альтернативным вариантам осуществления, модифицированные компоненты окружения могут быть определены на основе компонентов окружения, определенных посредством блока декомпозиции на прямой звук и звук окружения с учетом различия между исходным сегментом и сегментом воспроизведения.
Согласно дополнительному варианту осуществления установка громкоговорителя для воспроизведения может содержать дополнительный громкоговоритель внутри сегмента. Следовательно, сегмент исходной установки громкоговорителя соответствует двум или большему числу сегментов в сегменте громкоговорителя для воспроизведения, то есть, исходный сегмент в исходной установке громкоговорителя был разделен на два или большее число сегментов воспроизведения в установке громкоговорителя для воспроизведения. Блок представления прямого звука может быть выполнен с возможностью формирования настроенных компонентов прямого звука для этих, по меньшей мере, двух громкоговорителей и дополнительного громкоговорителя в установке громкоговорителя для воспроизведения.
Противоположный случай также является возможным: Согласно дополнительному варианту осуществления, в установке громкоговорителя для воспроизведения может отсутствовать громкоговоритель по сравнению с исходной установкой громкоговорителя, так что сегмент и соседний сегмент исходной установки громкоговорителя совмещают в один совмещенный сегмент установки громкоговорителя для воспроизведения. Блок представления прямого звука тогда может быть выполнен с возможностью распределения настроенных компонентов прямого звука для канального сигнала, соответствующего громкоговорителю, который отсутствует в установке громкоговорителя для воспроизведения, по меньшей мере, двум оставшимся громкоговорителям совмещенного сегмента в установке громкоговорителя для воспроизведения. Громкоговоритель, который присутствует в исходной установке громкоговорителя, но не в установке громкоговорителя для воспроизведения, может также именоваться “недостающий громкоговоритель”.
Согласно дополнительным вариантам осуществления, блок представления прямого звука может быть выполнен с возможностью перераспределения компонента прямого звука, имеющего определенное направление прихода, из сегмента в исходной установке громкоговорителя в соседний сегмент в установке громкоговорителя для воспроизведения, если граница между сегментом и соседним сегментом нарушает границу или пересекает определенное направление прихода при переходе от исходной установки громкоговорителя к установке громкоговорителя для воспроизведения.
Согласно дополнительным вариантам осуществления, блок представления прямого звука может быть дополнительно выполнен с возможностью перераспределения компонента прямого звука, имеющего определенное направление прихода, по меньшей мере, из одного первого громкоговорителя, по меньшей мере, в один второй громкоговоритель, по меньшей мере, один первый громкоговоритель, назначаемый сегменту в исходной установке громкоговорителя, но не соседнему сегменту в установке громкоговорителя для воспроизведения и, по меньшей мере, один второй громкоговоритель, назначаемый соседнему сегменту в установке громкоговорителя для воспроизведения.
Согласно дополнительным вариантам осуществления, блок представления прямого звука может быть выполнен с возможностью формирования "специфических для сегмента громкоговорителя" компонентов прямого звука для, по меньшей мере, двух действительных пар громкоговоритель-сегмент в установке громкоговорителя для воспроизведения, по меньшей мере, две действительные пары громкоговоритель-сегмент относятся к одному и тому же громкоговорителю и двум соседним сегментам в установке громкоговорителя для воспроизведения. Объединитель может быть выполнен с возможностью объединения специфических для сегмента громкоговорителя компонентов прямого звука для, по меньшей мере, двух действительных пар громкоговоритель-сегмент, относящихся к тому же громкоговорителю, чтобы получить один из сигналов громкоговорителя для, по меньшей мере, двух громкоговорителей в установке громкоговорителя для воспроизведения. Действительная пара сегмент-громкоговоритель относится к громкоговорителю и одному из сегментов, которому назначен этот громкоговоритель. Громкоговоритель может быть частью последующих действительных пар громкоговоритель-сегмент, если громкоговоритель назначают последующим сегментам (как обычно имеет место). Подобным образом, сегмент может быть (и обычно является) частью последующих действительных пар громкоговоритель-сегмент. Блок представления прямого звука может быть выполнен с возможностью рассматривать эту двойственность каждого громкоговорителя и обеспечивать специфические для сегмента компоненты прямого звука для громкоговорителя. Объединитель может быть выполнен с возможностью сбора различных специфических для сегмента компонентов прямого звука (и возможно, в зависимости от обстоятельств, специфических для сегмента компонентов окружения, также), намеченных для конкретного громкоговорителя в установке громкоговорителя для воспроизведения от различных сегментов, которым назначен этот конкретный громкоговоритель. Нужно отметить, что добавление или удаление громкоговорителя в установке громкоговорителя для воспроизведения может оказать влияние на действительные пары сегмент-громкоговоритель: добавление громкоговорителя обычно разделяет исходный сегмент, по меньшей мере, на два сегмента воспроизведения с тем, что подвергшиеся влиянию громкоговорители назначаются новым сегментам в установке громкоговорителя для воспроизведения. Удаление громкоговорителя может приводить к совмещению двух или большего числа исходных сегментов в один сегмент воспроизведения и соответствующему влиянию на действительные пары сегмент-громкоговоритель.
Дополнительные варианты осуществления настоящего изобретения обеспечивают способ для приспосабливания пространственного аудиосигнала, намеченного для исходной установки громкоговорителя, к установке громкоговорителя для воспроизведения, которая отличается от исходной установки громкоговорителя. Пространственный аудиосигнал содержит множество каналов. Способ содержит группирование, по меньшей мере, двух канальных сигналов в сегмент и декомпозицию, по меньшей мере, двух канальных сигналов в сегменте, по меньшей мере, на один компонент прямого звука и, по меньшей мере, один компонент окружения. Способ дополнительно содержит определение направления прихода для, по меньшей мере, одного компонента прямого звука. Способ также содержит настройку, по меньшей мере, одного компонента прямого звука с использованием информации установки громкоговорителя для воспроизведения для сегмента с тем, что воспринимаемое направление прихода для компонента прямого звука в установке громкоговорителя для воспроизведения является по существу идентичным направлению прихода для сегмента. По меньшей мере, воспринимаемое направление прихода для, по меньшей мере, одного компонента прямого звука является более близким к направлению прихода для сегмента по сравнению с ситуацией, в которой настройка не имела место. Способ дополнительно содержит объединение настроенных компонентов прямого звука и компонентов окружения или модифицированных компонентов окружения, чтобы получать сигналы громкоговорителя для, по меньшей мере, двух громкоговорителей в установке громкоговорителя для воспроизведения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
В последующем варианты осуществления настоящего изобретения будут пояснены со ссылкой на сопроводительные чертежи, на которых:
Фиг. 1 показывает структурную схему возможного сценария применения.
Фиг. 2 показывает структурную схему общего представления системы для устройства и способа настройки пространственного аудиосигнала.
Фиг. 3 показывает схематичную иллюстрацию примера для модифицированной установки громкоговорителя с одним громкоговорителем, который был перемещен/смещен.
Фиг. 4 показывает схематичную иллюстрацию примера для другой модифицированной установки громкоговорителя с увеличенным числом громкоговорителей.
Фиг. 5 показывает схематичную иллюстрацию примера для другой модифицированной установки громкоговорителя с уменьшенным числом громкоговорителей.
Фиг. 6A и 6B показывают схематичные иллюстрации примеров для дополнительных модифицированных установок громкоговорителя со смещенными громкоговорителями.
Фиг. 7 показывает структурную схему устройства для настройки пространственного аудиосигнала.
Фиг. 8 показывает структурную схему способа для настройки пространственного аудиосигнала.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Прежде описания настоящего изобретения с дополнительными подробностями с использованием чертежей, отмечается, что на фигурах чертежей идентичным элементам, элементам с такой же функцией или таким же действием, даются одинаковые или сходные ссылочные позиции с тем, что описание этих элементов и их функциональность, иллюстрируемая в различных вариантах осуществления, являются взаимно заменяемыми или могут применяться одно к другому в различных вариантах осуществления.
Некоторые способы для настройки пространственного аудиосигнала не являются достаточно гибкими, чтобы обрабатывать сложную звуковую сцену, особенно те, которые основываются на глобальных физических допущениях (см. например, V. Pulkki, “Spatial Sound Reproduction with Directional Audio Coding”, J. Audio Eng. Soc, vol. 55, no. 6, pp. 503-516, 2007 и V. Pulkki и J. Herre, “Method and Apparatus for Conversion Between Multi-Channel Audio Formats”, публикация заявки на патент США №2008/0232616 A1) или которые ограничены одним локализуемым (прямым) компонентом на один частотный диапазон в полной аудиосцене (см. например, M. Goodwin и J.-M. Jot, “Spatial Audio Scene Coding”, в материалах 125-th Convention of the AES, 2008 и J. Thompson, B. Smith, A. Warner, and J.-M. Jot, “Direct-Diffuse Decomposition of Multichannel Signals Using a System of Pairwise Correlations”, в материалах 133rd Convention of the AES 2012, October 2012). Допущение одной плоской волны или прямой составляющей могут быть достаточными в некоторых специальных сценариях, но, в общем, не способны получить сложную аудиосцену с несколькими активными источниками за один раз. Это приводит к пространственному искажению и непостоянным или даже «прыгающим» источникам в течение воспроизведения.
Имеются системы, моделирующие громкоговорители входной установки, которые не соответствуют выходной установке, в виде виртуального громкоговорителя (полный сигнал громкоговорителя панорамируется соседними громкоговорителями к намеченной позиции громкоговорителя) (A. Ando, “Conversion of Multichannel Sound Signal Maintaining Physical Properties of Sound in Reproduced Sound Field”, IEEE Transactions on Audio, Speech and Language Processing, vol. 19, no. 6, pp. 1467-1475, 2011). Это также может приводить к пространственному искажению фантомных источников, в которые вносят вклад эти каналы громкоговорителя. Подход, приведенный A. Laborie, R. Bruno и S. Montoya А. в “Reproducing Multichannel Sound on any Speaker Layout”, 118th Convention of the AES, 2005, требует от пользователя сначала калибровать свои громкоговорители и впоследствии осуществлять представление сигнала для этой установки из вычислительно интенсивного преобразования сигналов.
Кроме того, система высокого качества должна быть сохраняющей форму волны. Когда входные каналы представляются на установку громкоговорителя, которая идентична входной установке, форма волны не должна изменяться значительно, иначе информация теряется, что может приводить к слышимым артефактам и снижению пространственного и аудиокачества. Основанные на объектах способы могут испытывать здесь дополнительное перекрестное искажение, которое вносится в течение извлечения объекта (F. Melchior, “Vorrichtung zum Verändern einer Audio-Szene und Vorrichtung zum Erzeugen einer Richtungsfunktion”, заявка на патент Германии № DE 10 2010 030534 A1, 2011). Глобальные физические допущения также приводят к различным формам волны (см. например, M. Goodwin и J.-M.Jot, “Spatial Audio Scene Coding”, в материалах 125-th Convention of the AES, 2008; V. Pulkki, “Spatial Sound Reproduction with Directional Audio Coding”, J. Audio Eng. Soc, vol. 55, no. 6, pp. 503-516, 2007; и V. Pulkki и J. Herre, “Method and Apparatus for Conversion Between Multi-Channel Audio Formats”, в публикации заявки на патент США № 2008/0232616 A1).
Многоканальный панорамировщик (блок панорамирования, Panner) может использоваться, чтобы помещать фантомный источник где-либо в аудиосцене. Алгоритмы, приведенные Eppolito, Pulkki и Blauert, основываются на относительно простых допущениях, которые могут вызвать серьезные неточности в пространственном расположении, к которому источник был панорамирован, и в котором источник воспринимается (A. Eppolito, “Multi-Channel Sound Panner”, публикация заявки на патент США № 2012/0170758 A1; V. Pulkki, “Virtual Sound Source Positioning Using Vector Base Amplitude Panning”, J. Audio Eng. Soc, vol. 45, no. 6, pp. 456-466, 1997; и J. Blauert, “Spatial hearing: The psychophysics of human sound localization”, 3rd ed. Cambridge and Mass: MIT Press, 2001, section 2.2.2).
Использующие повышающее микширование способы извлечения пространственной характеристики окружения (ambience) разработаны с возможностью извлекать части внешнего сигнала и распределять их среди дополнительных громкоговорителей, чтобы сформировать некоторый объем окружения звуком (J. S. Usher и J. Benesty, “Enhancement of Spatial Sound Quality: A New Reverberation-Extraction Audio Upmixer”, IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, no. 7, pp. 2141-2150, 2007; C. Faller, “Multiple-Loudspeaker Playback of Stereo Signals”, J. Audio Eng. Soc, vol. 54, no. 11, pp. 1051-1064, 2006; C. Avendano и J.-M. Jot, “Ambience extraction and synthesis from stereo signals for multi-channel audio up-mix”, в материалах Международной конференция по акустике и обработке речи и сигналов (ICASSP), 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, vol. 2, 2002, pp. II-1957 - II-1960; и R. Irwan и R. M. Aarts, “Two-to-Five Channel Sound Processing”, J. Audio Eng. Soc, vol. 50, no. 11, № 11, pp. 914-926, 2002). Извлечение основывается только на одном или двух каналах, вот почему результирующая аудиосцена более не является точным образом исходной сцены, и почему они не являются полезными подходами для целей изобретения. Это также справедливо для подходов с матрицированием, как описал Dressler в “Dolby Surround Pro Logic II Decoder Principles of Operation” (доступно в режиме онлайн, адрес указан ниже). Подход с повышающим микшированием два к трем, упомянутый Vickers в публикации заявки на патент США № 2010/0296672 A1 “Two-to-Three Channel Upmix for Center Channel Derivation”, использует некоторые предварительные сведения о позиции третьего громкоговорителя и результирующем распределении сигналов среди других двух громкоговорителей и, следовательно, не имеет способности генерировать точные сигналы для произвольной позиции введенного громкоговорителя.
Варианты осуществления настоящего изобретения направлены на обеспечение системы, которая способна сохранять исходную аудиосцену в среде воспроизведения, где установка громкоговорителя отличается от исходной, путем группирования подходящих громкоговорителей в сегменты и применения обработки повышающего микширования, понижающего микширования и/или настроечного смещения. Каскад пост-обработки к обычному аудиокодеку может быть возможным сценарием применения. Такой случай изображен на Фиг. 1, где N, ρs, ϑs, 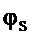
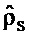
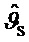
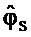
Каждый сегмент может быть охарактеризован связанной мерой направления, которая может использоваться, чтобы указывать или обращаться к соответствующему сегменту. Мера направленности может, например, быть вектором, указывающим на центр сегмента, или азимутальным углом в случае 2D, или набором из азимута и угла возвышения в случае 3D. Сегмент может именоваться вместе подмножеством направлений в пределах плоскости 2D или в пределах пространства 3D. Для представляемой простоты последующие примеры являются примерами, описанными для случая 2D; однако расширение к конфигурациям 3D является несложным.
Фиг. 1 показывает структурную схему вышеуказанного возможного сценария применения для устройства и/или способа для настройки пространственного аудиосигнала. Пространственный аудиосигнал 1 стороны кодера кодируется кодером 10. Пространственный аудиосигнал стороны кодера имеет N каналов и был создан для исходной установки громкоговорителя, например, установки громкоговорителя конфигурации 5.0 или установки громкоговорителя конфигурации 5.1 с позициями громкоговорителей в 0 градусов, +/-30 градусов и +/-110 градусов относительно ориентации слушателя. Кодер 10 создает кодированный аудиосигнал, который может быть передан или сохранен. Обычно, кодированный аудиосигнал подвергался компрессии по сравнению с пространственным аудиосигналом 1 стороны кодера, чтобы ослабить требования к хранению и/или передаче. Декодер 20 обеспечивается для декодирования и конкретно осуществляет декомпрессию кодированного пространственного аудиосигнала. Декодер 20 создает декодированный пространственный аудиосигнал 2, который является весьма сходным или даже идентичным пространственному аудиосигналу 1 стороны кодера. В этот момент в обработке пространственного аудиосигнала могут использоваться способ или устройство 100 для настройки пространственного аудиосигнала. Назначение способа или устройства 100 состоит в том, чтобы настраивать пространственный аудиосигнал 2 к установке громкоговорителя для воспроизведения, которая отличается от исходной установки громкоговорителя. Способ или устройство обеспечивают настроенный пространственный аудиосигнал 3 или 4, который приспособлен к имеющейся установке громкоговорителя для воспроизведения.
Общее представление системы для предложенного способа изображено на Фиг. 2. Краткосрочные представления в частотной области для входных каналов группируются в K сегментов группирователем 110 (группирующий элемент) и подаются в блок 130 декомпозиции на прямой звук и звук окружения (Direct/Ambience-Decomposition), и каскад 140 оценки DOA, где A - пространственная характеристика окружения и D - прямые сигналы на один громкоговоритель и сегмент, и ϑ, ϕ являются оцененными DOA на сегмент. Эти сигналы подают в блок 170 представления окружения или блок 150 представления прямого звука соответственно, имея в результате заново представленные сигналы Â и 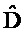
На первом этапе способ или устройство группирует сигналы подходящего соседнего громкоговорителя в K сегментов, тогда как каждый сигнал громкоговорителя может вносить вклад в несколько сегментов, и каждый сегмент состоит из, по меньшей мере, двух сигналов громкоговорителя. В установке громкоговорителя, подобной изображенной на Фиг. 3, сегменты входной установки, например, будут сформированы парами громкоговорителей Segin=[{L1,L2}, {L2,L3}, {L3,L4}, {L4,L5}, {L5,L1}], и выходными сегментами будут Segout=[{L1,L'2}, {L'2,L3}, {L3,L4}, {L4,L5}, {L5,L1}]. Громкоговоритель L2 в исходной установке громкоговорителя (громкоговоритель, вычерченный пунктирной линией), был модифицирован в перемещенный или смещенный громкоговоритель L'2 в установке громкоговорителя для воспроизведения.
В течение анализа выполняется нормированная, основанная на кросс-корреляции декомпозиция на прямой звук и звук окружения на каждый сегмент, имея результатом компоненты D прямого сигнала и компоненты A сигнала окружения для каждого громкоговорителя (для каждого канала) относительно каждого рассматриваемого сегмента. Это означает, предложенный способ/устройство способно оценивать сигналы прямого звука и окружения для другого источника внутри каждого сегмента. Декомпозиция на прямой звук и звук окружения не ограничивается упомянутым подходом на основе нормированной кросс-орреляции, и может выполняться с помощью любого подходящего алгоритма декомпозиции. Число созданных сигналов прямых и окружения на один сегмент имеет значение от, по меньшей мере, одного до числа вносящих вклад в рассматриваемый сегмент громкоговорителей. Например, для входной установки, данной на Фиг. 3, имеются, по меньшей мере, один прямой и один сигнал окружения или максимально два прямых и два сигнала окружения на один сегмент.
Кроме того, поскольку один конкретный сигнал громкоговорителя вносит вклад в несколько сегментов в течение декомпозиции на прямой звук и звук окружения, сигналы могут уменьшаться в масштабе или разделяться до входа в декомпозицию на прямой звук и звук окружения. Легчайшим способом выполнения этого, будем уменьшение в масштабе каждого сигнала громкоговорителя в пределах каждого сегмента согласно числу сегментов, в которые вносит вклад этот конкретный громкоговоритель. Например, для случая на Фиг. 3 каждый канал громкоговорителя вносит вклад в два сегментам, так что коэффициентом уменьшения в масштабе будет 1/2 для каналов каждого громкоговорителя. Но в общем, более сложное и несбалансированное разделение также является возможным.
Каскад оценки направления прихода (каскад оценки DOA) 140 может быть подключен к декомпозиции 130 на прямой звук и звук окружения. Оценки DOA, состоящие из азимутального угла ϑ и возможно угла ϕ возвышения, оцениваются на один сегмент и частотный диапазон и в соответствии с выбранным способом декомпозиции на прямой звук и звук окружения. Например, если используется способ декомпозиции с нормированной кросс-корреляцией, каскад оценки DOA применяет для оценки рассмотрение энергии для входных и извлеченных сигналов прямого звука. В общем, однако, можно выбирать между несколькими алгоритмами декомпозиции на прямой звук и звук окружения и обнаружения позиции.
В каскаде 170, 150 представления (блок представления окружения и прямого звука) имеет место фактическое преобразование между входной и выходной установкой громкоговорителя, причем сигналы прямые и окружения обрабатываются отдельно и различно. Любая модификация к входной установке может быть описана в виде комбинации трех основных случаев: вставка, удаление и смещение громкоговорителей. По причинам простоты эти случаи описываются индивидуально, но в реальной обстановке они происходят одновременно и, следовательно, обрабатываются также одновременно. Это выполняют суперпозицией основных случаев. Вставка и удаление громкоговорителей влияет только на рассматриваемые сегменты и должны появляться в виде основанного на сегменте способа повышающего и понижающего микширования. В течение представления прямые сигналы могут подаваться в функцию повторного панорамирования, которая гарантирует корректную локализацию фантомных источников в выходной установке. Чтобы сделать это, сигналы могут быть “панорамированными с инверсией” по отношению к входной установке и панорамированными снова относительно выходной установки. Этого можно добиться путем применения коэффициентов повторного панорамирования к прямым сигналам внутри сегмента. Возможное исполнение, например, для случая смещения, для коэффициента 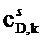
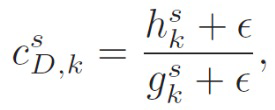 (1)
(1)
где 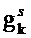
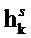
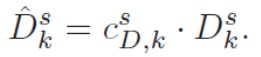 (2)
(2)
В любом сегменте, в котором вносящие вклад громкоговорители совпадают во входной и выходной установке, это приводит к умножению на 1 и оставляет извлеченные прямые компоненты неизменными.
Поправочный коэффициент также применяется к сигналам окружения, который в общем зависит от того, насколько изменились размеры сегмента. Поправочный коэффициент может быть реализован, как изложено ниже:
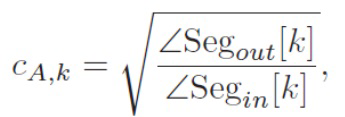 (3)
(3)
где 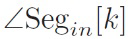 и
и 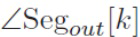 обозначают угол между позициями громкоговорителя внутри сегмента k во входной установке (исходная установка громкоговорителя) или выходной установке (установка громкоговорителя для воспроизведения), соответственно. Это дает для скорректированных сигналов окружения:
обозначают угол между позициями громкоговорителя внутри сегмента k во входной установке (исходная установка громкоговорителя) или выходной установке (установка громкоговорителя для воспроизведения), соответственно. Это дает для скорректированных сигналов окружения:
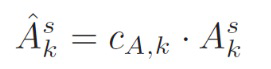 (4)
(4)
Подобно прямым сигналам, в любом сегменте, в котором вносящие вклад громкоговорители совпадают во входной и выходной установке, сигналы окружения умножают на единицу и оставляют неизменными. Это поведение представления прямого и окружения гарантирует сохраняющую форму волны обработку конкретного канала громкоговорителя, если ни один из сегментов, в который вносит вклад канал громкоговорителя, не пострадает от изменений. Кроме того, обработка сходится гладко к решению сохранения формы волны, если позиции громкоговорителя в сегментах постепенно перемещают к позициям входной установки.
Фиг. 4 визуализирует сценарий, где громкоговоритель (L6) был добавлен к стандартной конфигурации громкоговорителя, то есть, увеличенное число громкоговорителей. Добавление громкоговорителя может приводить к одному или большему числу следующих эффектов: стабильность вне зоны наилучшего восприятия для аудиосцены может быть улучшена, то есть, повышенная стабильность воспринимаемой пространственной аудиосцены, если слушатель перемещается из идеальной точки прослушивания (так называемой зоны наилучшего восприятия). Окружение звуком для слушателя может быть улучшено, и/или может быть улучшена пространственная локализация, например, если фантомный источник заменяется реальным громкоговорителем. На Фиг. 4, S обозначает оцененную позицию фантомного источника в сегменте, образованном громкоговорителями L2 и L3. Оценка позиции фантомного источника может быть определена на основе декомпозиции на прямой звук и звук окружения, выполненной блоком 130 декомпозиции на прямой звук и звук окружения, и оценки направления прихода для одного или нескольких фантомных источников внутри сегмента. Для добавленного громкоговорителя должен создаваться соответствующий сигнал прямого звука и окружения, и сигналы прямые и окружения для соседних громкоговорителей должны быть настроены. Это приводит практически к повышающему микшированию для текущего сегмента с помощью обработки сигнала, как изложено ниже:
Прямые сигналы: В установке громкоговорителя для воспроизведения (выходная установка) с дополнительным громкоговорителем L6, фантомный источник S назначен сегменту {L2, L6} в установке громкоговорителя для воспроизведения. Следовательно, части прямого сигнала, соответствующие S в исходном громкоговорителе или канале L3, должны быть повторно назначены и перераспределены дополнительному громкоговорителю L6 и обработаны функцией повторного панорамирования, которая гарантирует, что воспринимаемая позиция S остается такой же в установке громкоговорителя для воспроизведения. Перераспределение включает в себя удаление перераспределяемых сигналов из L3. «Прямые» части S в L2 также должны обрабатываться повторным панорамированием.
Сигналы окружения: сигнал окружения для L6 формируется из частей сигнала окружения в L2 и L3 и передается на декоррелятор, чтобы обеспечить восприятие окружения для сформированных сигналов. Энергии сигналов окружения в L2, L6 и L3 (каждый громкоговоритель вновь сформированных сегментов {L2, L6} и {L6, L3} выходной установки) настраиваются в соответствии с выбираемой Схемой модификации отображения энергии окружения (Ambience Energy Remapping Scheme), которая в последующем именуется AERS. Частью этих схем является схема Постоянной энергии окружения (Constant Ambience Energy, CAE), где полная энергия окружения сохраняется постоянной, и схема Постоянной плотности окружения (Constant Ambience Density, CAD), где плотность энергии окружения внутри сегмента сохраняется постоянной (например, плотность энергии окружения внутри новых сегментов {L2, L6} и {L6, L3} должна быть такой же, как в исходном сегменте {L2, L3}). Эти схемы в последующем сокращенно именуются CAE и CAD соответственно.
Если S позиционируется в сегменте воспроизведения {L6, L3}, обработка сигналов прямого и окружения следует тем же правилам и выполняется аналогично.
Как проиллюстрировано на Фиг. 4, установка громкоговорителя для воспроизведения содержит дополнительный громкоговоритель L6 внутри исходного сегмента {L2, L3} с тем, что исходный сегмент исходной установки громкоговорителя соответствует двум сегментам {L2, L6} и {L6, L3} установки громкоговорителя для воспроизведения. В общем, исходный сегмент может соответствовать двум или большему числу сегментов для сегментов воспроизведения, то есть, дополнительный громкоговоритель подразделяет исходный сегмент на два или большее число сегментов. Блок 150 представления прямого звука в этом сценарии выполнен с возможностью формирования настроенных компонентов прямого звука для, по меньшей мере, двух громкоговорителей L2, L3 и для дополнительного громкоговорителя L6 установки громкоговорителя для воспроизведения.
На Фиг. 5 схематично иллюстрируется ситуация уменьшенного числа громкоговорителей в установке громкоговорителя для воспроизведения по сравнению с исходной установкой громкоговорителя. На Фиг. 5 изображен сценарий, где громкоговоритель (L2) был удален из стандартной установки громкоговорителя конфигурации 5.1. S1 и S2 представляют оценки позиций фантомных источников на один частотный диапазон в сегментах {L1, L2} и {L2, L3} входной установки соответственно. Обработка сигнала, описанная ниже, практически приводит к низведению (понижающему микшированию) этих двух сегментов {L1, L2} и {L2, L3} к новому сегменту {L1, L3}.
Прямые сигналы: Части прямого сигнала в L2 должны быть перераспределены в L1 и L3 и совмещены, так что позиции S1 и S2 воспринимаемых фантомных источников не изменяются. Это делается путем перераспределения прямых частей S1 из L2 в L3 и прямых частей S2 из L2 в L1. Соответствующие сигналы S1 и S2 в L1 и L3 обрабатываются функцией повторного панорамирования, каковое гарантирует корректное восприятие позиций фантомных источников в установке громкоговорителя для воспроизведения. Совмещение выполняют суперпозицией соответствующих сигналов.
Сигналы окружения: сигналы окружения, соответствующие сегментам {L1, L2} и {L2, L3}, расположенным оба в L2, перераспределяются в L1 и L3 соответственно. Снова, перераспределенные сигналы масштабируются согласно одной из введенных Схем модификации отображения энергии окружения (AERS) и совмещаются с исходными сигналами окружения в L1 и L3.
Как проиллюстрировано на Фиг. 5, в установке громкоговорителя для воспроизведения отсутствует громкоговоритель L2 по сравнению с исходной установкой громкоговорителя, так что сегмент {L1, L2} и соседний сегмент {L2, L3} объединяются в один совмещенный сегмент в установке громкоговорителя для воспроизведения. В общем и в частности в трехмерной установке громкоговорителя удаление громкоговорителя может привести к совмещаемым нескольким исходным сегментам в один сегмент воспроизведения.
На Фиг. 6A и 6B схематично иллюстрируются две ситуации смещенных громкоговорителей. В частности громкоговоритель L2 в исходной установке громкоговорителя был перемещен в новую позицию и именуется громкоговорителем L'2 в установке громкоговорителя для воспроизведения. Предложенная обработка для случая смещенного громкоговорителя является следующей.
Два примера возможных сценариев смещения громкоговорителя изображены на Фиг. 6A и 6B, где на Фиг. 6A происходит только изменение размеров сегмента и перемещение фантомного источника становится ненужным, тогда как на Фиг. 6B смещенный громкоговоритель L'2 смещен выше оцененной позиции (направления) фантомного источника S2 и, следовательно, источник должен быть перемещен и совмещен с выходным сегментом {L1,L'2}. Исходный громкоговоритель L2 и его направление в перспективе слушателя вычерчены пунктиром на Фиг. 6A и 6B.
В случае, схематично иллюстрируемом на Фиг. 6A, прямые сигналы обрабатываются, как изложено ниже. Как указано ранее, перераспределение не является необходимым. Таким образом, обработка ограничивается пропусканием компонента прямого сигнала для S1 и S2 в громкоговорителях L1, L2 и L3, соответственно, на функцию повторного панорамирования, которая корректирует сигналы с тем, что фантомные источники воспринимаются в своей исходной позиции со смещенным громкоговорителем L'2.
Сигналы окружения в случае, показанном на Фиг. 6A, обрабатываются, как изложено ниже. Поскольку также нет необходимости перераспределений сигнала, сигналы окружения в соответствующих сегментах и громкоговорителях просто настраиваются согласно одной из схем AERS.
Что касается Фиг. 6B, теперь описывается обработка прямых сигналов. Если громкоговоритель смещен выше позиции фантомного источника, становится необходимым переместить этот источник в другой выходной сегменту. Здесь, согласно сигналу источника S2 должен быть перераспределен в выходной сегмент {L1, L'2} и обработан функцией повторного панорамирования, чтобы обеспечить эквивалентное восприятие позиции источника. Дополнительно, соответствующие сигналы источника S2 в {L1, L2} должны быть повторно панорамированы, чтобы соответствовать новому выходному сегменту {L1, L'2} и обе новые части сигнала источника в каждом громкоговорителе L1 и L'2 должны быть совмещены.
Следовательно, блок представления прямого звука выполнен с возможностью перераспределения компонента прямого звука, имеющего определенное направление прихода S2, из сегмента {L2, L3} в исходной установке громкоговорителя к соседнему сегменту {L1, L'2} в установке громкоговорителя для воспроизведения, если граница между сегментом и соседним сегментом нарушает границу определенного направления прихода S2, при переходе от исходной установки громкоговорителя к установке громкоговорителя для воспроизведения. Кроме того, блок представления прямого звука может быть выполнен с возможностью перераспределения компонента прямого звука, имеющего определенное направление прихода, от по меньшей мере одного громкоговорителя исходного сегмента {L2, L3}, по меньшей мере, одному громкоговорителю в соседнем сегменте в выходной установке {L1, L'2}. В частности блок представления прямого звука может быть выполнен с возможностью перераспределения прямого компонента для S2 в L3, назначенном сегменту {L2, L3} во входной установке, в смещенный громкоговоритель L'2, назначенный сегменту {L1, L'2} в установке громкоговорителя для воспроизведения, и для перераспределения прямого компонента для S2 в L2, назначенном сегменту {L2, L3} во входной установке, в L1, назначенный сегменту {L1, L'2} в установке громкоговорителя для воспроизведения. Нужно отметить, что действие перераспределения может также включать в себя настройку компонента прямого звука, например, путем выполнения повторного панорамирования по отношению к относительной амплитуде и/или относительной задержке сигналов громкоговорителя.
Для сигналов окружения на Фиг. 6B может выполняться аналогичная обработка: сигналы окружения в сегменте {L2, L3} настраиваются с использованием одной из схем AERS. Для больших смещений, кроме того, часть этих сигналов окружения может добавляться к сегменту {L1, L'2} и настраиваться согласно AERS.
Внутри каскада 180 объединения (Фиг. 2), формируются фактические сигналы громкоговорителя для установки громкоговорителя для воспроизведения (выходная установка). Это делается суммированием соответствующих перераспределенных и повторно представленных сигналов прямых и окружения, соответствующих левому и правому сегменту относительно громкоговорителя между ними (термины "левый" и "правый" громкоговоритель поддерживаются для двумерного случая, то есть, все громкоговорители находятся в той же плоскости, обычно горизонтальной плоскости). На выходе каскада 180 объединения, излучаются сигналы для исходной аудиосцены, но теперь представленные для новой установки громкоговорителя (установка громкоговорителя для воспроизведения) с М громкоговорителями в позициях 
На этой стадии, то есть, на выходе объединителя или каскада 180 объединения, новая система обеспечивает сигналы громкоговорителя, где все модификации относительно азимутального угла и угла возвышения для громкоговорителей в выходной установке были скорректированы. Если громкоговоритель в выходной установке был перемещен так, что его расстояние до точки прослушивания изменилось на новое расстояние 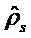
Другой вариант осуществления может использовать изобретение, чтобы осуществить перемещающуюся зону наилучшего восприятия для установки громкоговорителя для воспроизведения. Для этого, на первом этапе, алгоритм или устройство должны определить позицию слушателя. Это можно легко сделать с использованием способа/устройства отслеживания, чтобы определять текущую позицию слушателя. Затем, устройство повторно вычисляет позиции громкоговорителей относительно позиции слушателя, что означает новую систему координат со слушателем в начале координат. Это является эквивалентным наличию неподвижного слушателя и перемещающихся громкоговорителей. Алгоритм затем вычисляет сигналы оптимально для этой новой установки.
Фиг. 7 изображает структурную схему устройства 100 для настройки пространственного аудиосигнала 2 к установке громкоговорителя для воспроизведения согласно, по меньшей мере, одному варианту осуществления. Устройство 100 содержит группирователь 110, выполненный с возможностью группирования, по меньшей мере, двух канальных сигналов 702 в сегмент. Устройство 100 дополнительно содержит блок 130 декомпозиции на прямой звук и звук окружения, выполненный с возможностью декомпозиции, по меньшей мере, двух канальных сигналов 702 в сегменте, по меньшей мере, на один компонент 732 прямого звука и, по меньшей мере, один компонент 734 окружения. Блок 130 декомпозиции на прямой звук и звук окружения может необязательно содержать блок 140 оценки направления прихода, выполненный с возможностью оценивать значение(я) DOA, для по меньшей мере, одного компонента 732 прямого звука. В качестве альтернативы, значение(я) DOA может обеспечиваться из внешней оценки DOA или в виде метаинформации/дополнительной информации, сопутствующей пространственному аудиосигналу 2.
Блок 150 представления прямого звука выполнен с возможностью приема информации установки громкоговорителя для воспроизведения для, по меньшей мере, одного сегмента воспроизведения, связанного с сегментом, и для настройки, по меньшей мере, одного компонента 732 прямого звука с использованием информации установки громкоговорителя для воспроизведения для сегмента с тем, что воспринимаемое направление прихода, по меньшей мере, одного компонента прямого звука в установке громкоговорителя для воспроизведения является по существу идентичным направлению прихода для сегмента. По меньшей мере, представление, выполняемое блоком 150 представления прямого звука, приводит к тому, что воспринимаемое направление прихода является более близким к направлению прихода, по меньшей мере, одного компонента прямого звука по сравнению с ситуацией, в которой настройка не имела место. Во вставке на Фиг. 7 схематично проиллюстрированы исходный сегмент исходной установки громкоговорителя и соответствующий сегмент громкоговорителя для воспроизведения для установки громкоговорителя для воспроизведения. Обычно, исходная установка громкоговорителя является известной или стандартизированной с тем, что информация об исходной установке громкоговорителя не обязательно должна предоставляться на блок 150 представления прямого звука, но блок представления прямого звука уже имеет эту информация доступной. Однако блок представления прямого звука может быть выполнен с возможностью приема исходной информации об установке громкоговорителя. Таким образом, блок 150 представления прямого звука может быть выполнен с возможностью поддержки пространственных аудиосигналов в качестве входных, которые были записаны или созданы для других исходных установок громкоговорителя, таких как конфигурации 5.1, 7.1, 10.2 или даже установок конфигурации 22.2.
Устройство 100 дополнительно содержит объединитель 180, выполненный с возможностью объединения настроенных компонентов 752 прямого звука и компонентов 734 окружения или модифицированных компонентов окружения, чтобы получать сигналы громкоговорителя для, по меньшей мере, двух громкоговорителей в установке громкоговорителя для воспроизведения. Сигналы громкоговорителя для, по меньшей мере, двух громкоговорителей в установке громкоговорителя для воспроизведения являются частью настроенного пространственного аудиосигнала 3, который может выводиться устройством 100. Как упомянуто выше, настройка расстояния может выполняться на настроенном по DOA пространственном аудиосигнале, чтобы получить пространственный аудиосигнал 4, настроенный по DOA и расстоянию (см. Фиг. 2). Объединитель 180 также может быть выполнен с возможностью объединения настроенных компонентов 752 прямого звука и компонента 734 окружения с компонентами прямого звука и/или окружения из одного или нескольких соседних сегментов(а), которые используют громкоговоритель совместно с рассмотренным сегментом.
Фиг. 8 изображает структурную схему способа для настройки пространственного аудиосигнала к установке громкоговорителя для воспроизведения, которая отличается от исходной установки громкоговорителя, намеченной для представления аудио контента, передаваемого пространственным аудиосигналом. Способ содержит этап 802 группирования, по меньшей мере, двух канальных сигналов в сегмент. Сегмент обычно является одним из сегментов исходной установки громкоговорителя. По меньшей мере, два канальных сигнала в сегменте подвергаются декомпозиции на компоненты прямого звука и компоненты окружения в течение этапа 804. Способ дополнительно содержит этап 806 для определения направления прихода для компонентов прямого звука. Компоненты прямого звука настраиваются на этапе 808 с использованием информации установки громкоговорителя для воспроизведения для сегмента с тем, что воспринимаемое направление прихода для компонентов прямого звука в установке громкоговорителя для воспроизведения является идентичным направлению прихода для сегмента или более близким к направлению прихода для сегмента по сравнению с ситуацией, в которой настройка не имела место. Способ также содержит этап 809 для объединения настроенных компонентов прямого звука и компонентов окружения или модифицированных компонентов окружения, чтобы получать сигналы громкоговорителя для, по меньшей мере, двух громкоговорителей в установке громкоговорителя для воспроизведения.
Предложенная настройка пространственного аудиосигнала к встретившейся установке громкоговорителя для воспроизведения может относиться к одному или нескольким из следующих аспектов:
- Группировка соседних каналов громкоговорителя исходной установки на сегменты
- Декомпозиция на прямой звук и звук окружения на основе сегментов
- Несколько выбираемых различных алгоритмов декомпозиции на прямой звук и звук окружения и извлечения позиции
- Модификация отображения прямых компонентов с тем, что воспринимаемое направление по существу остается таким же
- Модификация отображения компонентов окружения с тем результатом, что воспринимаемое окружение звуком по существу остается таким же
- Коррекция расстояния громкоговорителя путем применения масштабного коэффициента и/или задержки
- Несколько выбираемых алгоритмов панорамирования
- Независимая модификация отображения компонентов прямого и окружения
- Частотно-временная избирательная обработка
- Общая сохраняющая форму волны обработка для всех каналов громкоговорителя, если выходная установка соответствует входной установке
- По-канальное сохранение формы волны для каждого громкоговорителя, где сегменты, в которые вносит вклад громкоговоритель, не модифицируются относительно входной и выходной установки
Особые случаи:
- ”Инверсное панорамирование” и панорамирование данной входной сцены с помощью другого алгоритма панорамирования
- На один сегмент, по меньшей мере, один прямой сигнал и сигнал окружения.
В сегментах, состоящих из двух громкоговорителей: максимально два прямых и два сигнала окружения. Число используемых сигналов прямых и окружения не зависят друг от друга, но зависит от намеченного качества пространственного целевого объекта для подвергаемых представлению сигналов прямых и окружения.
- Понижающее/повышающее микширование на основе сегментов
- Модификация отображения окружения выполняется согласно схемам модификации отображения энергии окружения (схем AERS), состоящим из:
- Постоянной энергии окружения
- Постоянной (угловой) плотности окружения
По меньшей мере, некоторые варианты осуществления настоящего изобретения выполнены с возможностью выполнения по-канального гибкого преобразования звуковой сцены, которое содержит декомпозицию исходных каналов громкоговорителя на части прямого сигнала и сигнала окружения для (фантомного) источника внутри и согласно каждому ранее построенному сегменту. Направления прихода (DOA) для каждого прямого источника оцениваются и подаются, вместе с сигналами прямыми и окружения, в блок представления и корректор по расстоянию, где - согласно установке громкоговорителя для воспроизведения и значениям DOA - сигналы источника громкоговорителя модифицируются, чтобы сохранять фактическую аудиосцену. Предложенный способ и устройство функционируют с сохранением формы волны и даже могут обработать выходные установки с числом каналов громкоговорителя, увеличенным или уменьшенным, чем доступно во входной установке.
Хотя настоящее изобретение было описано в контексте блок-схем, где блоки представляют фактические или логические аппаратные компоненты, настоящее изобретение также может быть осуществлено реализуемым с помощью компьютера способом. В последнем случае блоки представляют соответствующие этапы способа, где эти этапы обозначают функциональности, выполняемые соответствующими логическими или физическими блоками аппаратных средств.
Описанные варианты осуществления являются лишь иллюстративными для принципов настоящего изобретения. Подразумевается, что модификации и изменения компоновок и подробностей, описанных в документе, будут очевидными специалистам в данной области техники. Намерение, следовательно, состоит в ограничении только объемом прилагаемой формулы изобретения, а не конкретными подробностями, представленными в документе в качестве описания и пояснения вариантов осуществления.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или признака соответствующего устройства. Некоторые или все этапы способа могут исполняться посредством (или с использованием) аппаратно реализованного устройства подобного, например, микропроцессору, программируемому компьютеру или электронной схеме. В некоторых вариантах осуществления некоторый один или большее число наиболее важных этапов способа могут исполняться таким устройством.
В зависимости от некоторых требований к исполнению варианты осуществления изобретения могут быть осуществлены аппаратными средствами или программными средствами. Реализация может выполняться с использованием носителя цифровых данных, например, гибкого диска, DVD, Blu-Ray, компакт-диска, ROM, EPROM, EEPROM или флэш-памяти, с наличием считываемого с помощью электроники управляющего сигнала, хранимого на нем, которые действуют совместно (или способны к совместному действию) с программируемой компьютерной системой с тем, что выполняется соответствующий способ. Следовательно, носитель цифровых данных может быть читаемым компьютером.
Некоторые варианты осуществления согласно изобретению содержат носитель данных с наличием читаемых с помощью электроники управляющих сигналов, которые способны совместно действовать с программируемой компьютерной системой с тем, что выполняется один из способов, описанных в документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с кодом программы, код программы может использоваться для выполнения одного из способов, когда компьютерный программный продукт работает на компьютере. Код программы может, например, сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из описанных в документе способов, сохраняемую на машиночитаемом носителе.
Другими словами, вариант осуществления способа по изобретению является, следовательно, компьютерной программой с наличием кода программы для выполнения одного из способов, описанных в документе, когда компьютерная программа работает на компьютере.
Дополнительным вариантом осуществления способа по изобретению является, следовательно, носитель данных (либо носитель цифровых данных, либо читаемый компьютером носитель) содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в документе. Носитель данных, носитель цифровых данных или носитель с записью являются обычно материальными и/или долговременными.
Дополнительным вариантом осуществления способа по изобретению является, следовательно, поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в документе. Поток данных или последовательность сигналов могут, например, быть выполнены с возможностью подлежать передаче через соединение для передачи данных, например, через межсетевую связь.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное или приспособленное для выполнения одного из способов, описанных в документе.
Дополнительный вариант осуществления содержит компьютер с наличием установленной на нем компьютерной программы для выполнения одного из способов, описанных в документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненные с возможностью передачи (например, с помощью электроники или оптически) компьютерной программы для выполнения одного из способов, описанных в документе, получателю. Получатель может, например, быть компьютером, мобильным устройством, запоминающим устройством и т.п. Устройство или система могут, например, содержать файловый сервер для осуществления передачи компьютерной программы получателю.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая вентильная матрица) может использоваться, чтобы выполнять некоторую или всю функциональность для способов, описанных в документе. В некоторых вариантах осуществления программируемая вентильная матрица может работать с микропроцессором, чтобы выполнять один из способов, описанных в документе. В общем, способы предпочтительно выполняются посредством любого аппаратно реализованного устройства.
Варианты осуществления настоящего изобретения могут быть основаны на способах для декомпозиции на прямой звук и звук окружения. Декомпозиция на прямой звук и звук окружения может выполняться либо основываться на модели сигнала, либо на физической модели.
Скрытая концепция декомпозиции на прямой звук и звук окружения на основании модели сигнала, состоит в допущении, что непосредственно воспринимаемый и локализуемый звук состоит либо из одного одиночного или из нескольких когерентных или коррелированных сигналов. Тогда как звук окружения, таким образом, нелокализуемый звук соответствует некоррелированным частям сигнала. Переход между «прямым звуком» и «звуком окружения» является бесшовным и зависит от корреляции между сигналами. Дополнительную информацию о декомпозиции на прямой звук и звук окружения можно найти: в материалах C. Faller, “Multiple-Loudspeaker Playback of Stereo Signals,” J. Audio Eng. Soc, vol. 54, no. 11, pp. 1051-1064, 2006; в материалах J. S. Usher и J. Benesty, “Enhancement of Spatial Sound Quality: A New Reverberation-Extraction Audio Upmixer,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, no. 7, pp. 2141-2150, 2007; и в материалах M. Goodwin и J.-M. Jot, “Primary-Ambient Signal Decomposition and Vector-Based Localization for Spatial Audio Coding and Enhancement”, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), vol. 1, 2007, pp. I-9 -I-12М.
Направленное кодирование аудио (DirAC) является одним возможным способом для декомпозиции сигналов на энергии прямого и диффузного сигнала на основании физической модели. Здесь, характеристики звукового поля для звукового давления и скорости звука (частицы) в точке прослушивания захватывают посредством записи либо фактического, либо виртуального формата B. Впоследствии, при допущении, что звуковое поле состоит только из одной одиночной плоской волны, а остальное является диффузной энергией, сигнал можно декомпозировать на части прямого и диффузного сигнала. Из частей прямого может быть вычислено так называемое «Направление приходов» (DOA). С наличием сведений о фактических позициях громкоговорителей части прямого сигнала могут быть повторно панорамированы с использованием специальных законов панорамирования (см. например, V. Pulkki, “Virtual Sound Source Positioning Using Vector Base Amplitude Panning,” J. Audio Eng. Soc, vol. 45, no. 6, pp. 456-466, 1997), чтобы сохранить их глобальную позицию в каскаде представления. В заключение, части декоррелированного сигнала окружения и панорамированного прямого объединяются снова, получая в результате сигналы громкоговорителя (как описано, например, в V. Pulkki, “Spatial Sound Reproduction with Directional Audio Coding,” J. Audio Eng. Soc, vol. 55, no. 6, pp. 503-516, 2007; или V. Pulkki и J. Herre “Method and Apparatus for Conversion Between Multi-Channel Audio Formats”, публикация заявки на патент США 2008/0232616 A1, 2008).
Другой подход описан авторами J. Thompson, B. Smith, A. Warner и J.-M. Jot в “Direct-Diffuse Decomposition of Multichannel Signals Using a System of Pairwise Correlations” (представлено на 133-ьем Конгрессе AES, октябрь 2012), где прямая и диффузная энергии для многоканального сигнала оцениваются согласно системе парных корреляций. Модель сигнала, используемая здесь, позволяет обнаруживать один прямой и диффузный сигнал внутри каждого канала, включая сдвиг фазы прямого сигнала по всем каналам. Одно допущение этого подхода состоит в том, что прямые сигналы по всем каналам являются коррелированными, то есть, они все представляют тот же сигнал источника. Обработка выполняется в частотной области и для каждого частотного диапазона.
Возможное выполнение декомпозиции на прямой звук и диффузный звук (или декомпозиции на прямой звук и звук окружения) теперь описывается в связи с стереофоническими сигналами в качестве примера. Другие способы для декомпозиции на прямой звук и диффузный звук также являются возможными, и кроме того сигналы, отличные от стереофонических сигналов, могут подвергаться декомпозиции на прямой звук и диффузный звук. Обычно, стереофонические сигналы записываются или микшируются таким образом, что для каждого источника сигнал идет когерентно в левый и правый канал сигнала с конкретными метками направленности (разность уровней, временная разность) и отраженных/реверберировавших независимых сигналов в каналах, определяющих значения акустической ширины объекта и метками окружения звуком слушателя. Стереофонические сигналы одиночного источника могут моделироваться сигналом s, который имитирует прямой звук из направления, определяемого коэффициентом a, и независимыми сигналами n1 и n2, соответствующими боковым отражениям. Пара x1, x2 стереофонического сигнала связана с этими сигналам s, n1, и n2 согласно следующим уравнениям:
x1(k)=s(k)+n1(k)
x2(k)=a⋅s(k)+n2(k),
причем k является индексом времени. Соответственно, сигнал s прямого звука появляется в обоих стереофонических сигналах x1 и x2, однако обычно с другой амплитудой. Описанная декомпозиция может выполняться во многих частотных диапазонах и адаптивно во времени, чтобы получить декомпозицию, которая является не только действительной в сценарии одного акустического объекта, но также и для нестационарных звуковых сцен с множественными одновременно активными источниками. Соответственно, вышеупомянутые уравнения могут быть записаны для конкретного временного индекса k и конкретного частотного поддиапазона m в виде:
x1,m(k)=sm(k)+n1,m(k)
x2,m(k)=Absm(k)+n2,m(k),
где m является индексом поддиапазона, k является индексом времени, Ab - коэффициент амплитуды для сигнала sm для некоторого параметрического диапазона b, который может содержать один или несколько поддиапазонов для сигналов поддиапазона. В каждом частотно-временном фрагменте с индексами m и k сигналы sm, n1,m, n2,m и коэффициент Ab оценивают независимо. Может использоваться перцепционно мотивированная декомпозиция поддиапазона. Это декомпозиция может основываться на быстром преобразовании Фурье, гребенке квадратурных зеркальных фильтров или другой гребенке фильтров. Для каждого параметрического диапазона b сигналы sm, n1,m, n2,m и Ab оценивают на основе сегментов с некоторой временной длительностью (например, приблизительно 20 миллисекунд). При заданной паре x1,m и x2,m стереофонического сигнала поддиапазона, задача состоит в том, чтобы оценить sm, n1,m, n2,m и Ab в каждом параметрическом диапазоне. Анализ энергий и кросс-корреляции для пары стереофонического сигнала могут выполняться с этой целью. Переменная px1,b обозначает краткосрочную оценку энергии x1,m в параметрическом диапазоне b. n1,m и n2,m можно полагать являющимися теми же, то есть, полагают, что величина бокового независимого звука является одинаковой для левого и правого сигналов: pn1,b=pn1,b=pn,b.
Энергия (px1,b, px2,b) и нормированная кросс-корреляция px1 x2,b для параметрического диапазона b может быть вычислена с использованием поддиапазонного представления для стереофонического сигнала. Переменные Ab, ps,b и pn,b затем оцениваются в виде функции оценок px1,b, px2,b и px1x2,b. Три уравнения, связывающие известные и неизвестные переменные:
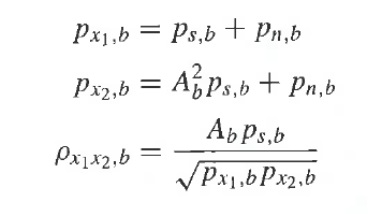
Эти уравнения, решенные относительно Ab, ps,b, и pn,b, дают:
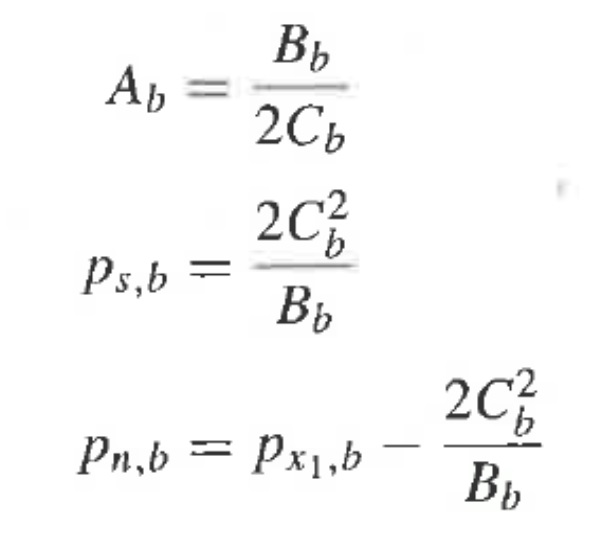
при
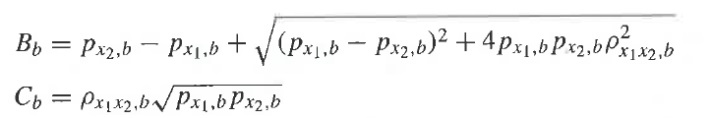
Затем, способом наименьших квадратов вычисляют оценки для sm, n1,m и n2,m в виде функции от Ab, ps,b, и pn,b. Для каждого параметрического диапазона b и каждого кадра независимого сигнала, сигнал sm оценивается в виде
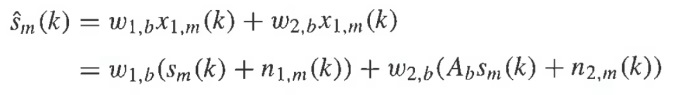
где w1,b и w2,b являются вещественнозначными весами. Веса b w1,b и w2,b являются оптимальными в смысле наименьшего среднеквадратического, когда сигнал E ошибки является ортогональным к x1,m и x2,m в параметрическом диапазоне b. Сигналы n1,m и n2,m могут быть оценены подобным образом. Например, n1,m может оцениваться в виде
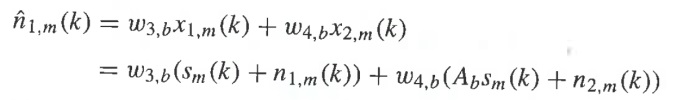
Пост-масштабирование может затем выполняться на начальных оценках 
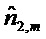
Варианты осуществления настоящего изобретения могут относиться к одному или нескольким или использовать один или несколько многоканальных панорамировщиков. Многоканальные панорамировщики являются инструментальными средствами, которые дают возможность звукооператору помещать виртуальный или фантомный источник внутри искусственной аудиосцены. Этого можно добиться несколькими способами. Следуя специализированной функции усиления или правилу панорамирования, фантомный источник может быть помещен внутри аудиосцены путем применения амплитудного взвешивания или задержки или обоего к сигналу источника. Дополнительную информацию о многоканальных панорамировщиках можно найти в материале A. Eppolito публикации заявки на патент США № 2012/0170758 A1 “Multi-Channel Sound Panner”, в материале V. Pulkki, “Virtual Sound Source Positioning Using Vector Base Amplitude Panning,” J. Audio Eng. Soc, vol. 45, no. 6, pp. 456-466, 1997; и в материале J. Blauert “Spatial hearing: The psychophysics of human sound localization”, section 2.2.2, 3rd ed. Cambridge and Mass: MIT Press, 2001. Например, может использоваться панорамировщик, который может поддерживать произвольное число входных каналов и изменения в конфигурациях по отношению к выходному звуковому пространству. Например, панорамировщик может бесшовно обрабатывать изменения числа входных каналов. Кроме того, панорамировщик может поддерживать изменения числа и позиций громкоговорителей в выходном пространстве. Панорамировщик может позволять непрерывный контроль затухания и ослабления. Панорамировщик может сохранять исходные каналы на периферии звукового пространства при ослаблении каналов. Панорамировщик может позволять контроль тракта, по которому источники слабеют. Эти аспекты можно достичь посредством способа, который содержит прием входного запроса повторной балансировки множества каналов исходного аудио в звуковом пространстве, имеющем множество громкоговорителей, причем множество каналов исходного аудио первоначально описывается начальной позицией в звуковом пространстве и начальной амплитудой, и при этом позиции и амплитуды каналов задают баланс каналов в звуковом пространстве. На основании ввода, новая позиция в звуковом пространстве определяется для, по меньшей мере, одного из исходных каналов. На основании ввода определяется модификация к амплитуде, по меньшей мере, одного из каналов источника, причем новая позиция и модификация к амплитуде обеспечивает повторную балансировку. В ответ на определение, что ввод указывает, что конкретный громкоговоритель из множества громкоговорителей должен быть отключен, звук, который должен исходить от конкретного громкоговорителя, может автоматически передаваться на другие громкоговорители, смежные с конкретным громкоговорителем. Способ выполняется посредством одного или нескольких вычислительных устройств. Один или большее число этих аспектов можно использовать в связи или в контексте предложенной настройки пространственного аудиосигнала.
Некоторые варианты осуществления настоящего изобретения могут относиться к принципам или использовать принципы для изменения существующей аудиосцены. Система для составления или даже изменения существующей аудиосцены была предложена IOSONO (как описано в заявке на патент Германии за номером № 10 2010 030534 A1, “Vorrichtung zum Verändern einer Аудио-Szene und Vorrichtung zum Erzeugen einer Richtungsfunktion”). В ней используется основанное на объектах представление источника плюс дополнительные метаданные, объединенные с функцией направленности для определения позиции источника в аудиосцене. Если уже существующая аудиосцена, без аудио объекта и метаданных, подается в эту систему, аудио объекты, направления и функции направленности должны быть сначала определены из этой аудиосцены. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
Некоторые варианты осуществления настоящего изобретения могут относиться к Преобразованию каналов или коррекции позиционирования или использовать таковое. Большинство систем, которые направлены на корректировку неправильного позиционирования громкоговорителя или отклонения в каналах воспроизведения, делают попытку сохранения физических характеристикк звукового поля. Для сценария понижающего микширования возможным подходом может быть моделирование опускаемых громкоговорителей как виртуальных громкоговорителей путем панорамирования и посредством этого сохранение звукового давления и акустической скорости частиц в точке прослушивания (как описано в работе A. Ando, “Conversion of Multichannel Sound Signal Maintaining Physical Properties of Sound in Reproduced Sound Field”, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 6, pp. 1467-1475, 2011). Другим способом являлось бы вычисление сигналов громкоговорителя в целевой установке, чтобы восстановить исходное звуковое поле. Это делается переводом сигналов источника громкоговорителя в представление звукового поля и представлением новых сигналов громкоговорителя из этого представления (как описано в материале A. Laborie, R. Bruno, and S. Montoya, “Reproducing Multichannel Sound on any Speaker Layout”, на 118-ом Конгрессе AES, 2005).
Согласно Ando, преобразование многоканального звукового сигнала является возможным согласно преобразованию сигнала исходной многоканального акустической системы в таковой для альтернативной системы с другим числом каналов при поддержании при этом физических характеристик звука в точке прослушивания в воссозданном звуковом поле. Такая задача преобразования может быть описана неопределенным линейным уравнением. Чтобы получить аналитическое решение уравнения, способ разделяет звуковое поле альтернативной системы на основе позиций трех громкоговорителей и разрешает “локальное решение” в каждом подполе. В результате альтернативная система локализует каждый канальный сигнал исходной звуковой системы в соответствующей позиции громкоговорителя в качестве фантомного источника. Композиция локальных решений представляет “глобальное решение”, то есть, аналитическое решение задачи преобразования. Эксперименты были выполнены с 22-канальными сигналами для многоканальной акустической системы конфигурации 22.2 без двух каналов низкочастотного эффекта, преобразованных в 10- 8-, и 6-канальные сигналы согласно способу. Субъективные оценки показали, что предложенный способ может воспроизводить пространственное впечатление исходного 22-канального звука восемью громкоговорителями. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
Кодирование пространственной аудиосцены (SASC), является примером нефизической мотивированной системы (M. Goodwin и J.-M. Jot, “Spatial Audio Scene Coding,” в 125th Convention of the AES, 2008). Оно выполняет Анализ главных компонентов (PCA) для декомпозиции многоканальных входных сигналов на их первичные компоненты и компоненты окружения при некоторых ограничениях межканальной корреляции ((M. Goodwin and J.-M. Jot, “Primary-Ambient Signal Decomposition and Vector-Based Localization for Spatial Audio Coding and Enhancement”, в IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), vol. 1, 2007, pp. I-9 -I-12.). Первичный компонент идентифицируется здесь как собственный вектор корреляционной матрицы входного канала с наибольшим собственным значением. Впоследствии, выполняется анализ локализации (компонентов) первичного и окружения, где определяют вектор локализации «прямой и окружение). Представление выходных сигналов выполняют путем формирования матрицы форматов, которая содержит единичные векторы, указывающие на пространственные направления выходных каналов. На основании этой матрицы форматов получают множество нулевых весов, так что весовой вектор находится в нулевом пространстве матрицы форматов. Направленные компоненты формируют попарным панорамированием между этими векторами, и ненаправленные компоненты формируют с использованием всего множества векторов в матрице форматов. Окончательные выходные сигналы формируют интерполяцией между направленными и ненаправленными панорамированными частями сигнала. В этой структуре Кодирования пространственной аудиосцены (SASC), центральная идея состоит в том, чтобы представлять входную аудиосцену способом, который является независимым от любого рассматриваемого или намеченного формата воспроизведения. Эта инвариантная к формату параметризация дает возможность оптимального воспроизведения поверх любой заданной системы воспроизведения, а также гибкой модификации сцены. Инструментальные средства анализа и синтеза сигнала, необходимые для SASC, описаны, включая презентацию новых подходов для многоканальной декомпозиции первичный-окружение. Применения SASC к пространственному аудиокодированию, повышающему микшированию, декодированию фазово-амплитудной матрицы, многоканальному преобразованию формата, и бинауральному воспроизведению могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
Некоторые варианты осуществления настоящего изобретения могут относиться к способам повышающего микширования или использовать такоые. В общем, способы повышающего микширования можно классифицировать на две основные категории: вид способов, которые подают каналы звукового окружения с синтезированным или извлеченным окружением из существующих входных каналов (см. например, J. S. Usher and J. Benesty, “Enhancement of Spatial Sound Quality: A New Reverberation-Extraction Audio Upmixer”, IEEE Transactions on Audio, Speech, and Language Processing, vol. 15, no. 7, pp. 2141-2150, 2007; C. Faller, “Multiple-Loudspeaker Playback of Stereo Signals”, J. Audio Eng. Soc, vol. 54, no. 11, pp. 1051-1064, 2006 ; C. Avendano и J.-M. Jot, “Ambience extraction and synthesis from stereo signals for multi-channel audio up-mix”, в Acoustics, Speech, and Signal Processing (ICASSP), 2002 IEEE International Conference on, vol. 2, 2002, pp. II-1957 - II-1960 ; and R. Irwan and R. M. Aarts, “Two-to-Five Channel Sound Processing”, J. Audio Eng. Soc, vol. 50, no. 11, pp. 914-926, 2002), и те, которые создают управляющие сигналы для добавочных каналов кодированием существующих с помощью матричной схемы (см. например, R. Dressler. (05.08.2004) Dolby Surround Pro Logic II Decoder Principles of Operation. Доступно в режиме онлайн по адресу: http://www.dolby.com/uploadedFiles/Assets/US/Doc/Professional/ 209_Dolby_Surround_Pro_Logic_II_Decoder_Principles_of_Operation.pdf). Особый случай представляет способ, предложенный E. Vickers в публикации заявки на патент США № US2010/0296672 A1 “Two-to-Three Channel Upmix For Center Channel Derivation”, где вместо извлечения окружения выполняется пространственная декомпозиция. Среди прочих способы формирования окружения могут содержать применение искусственной реверберации, вычисление разности левого и правого сигналов, применение малых задержек для каналов окружающего звука и корреляцию на основе анализа сигнала. Примерами для способов кодирования с помощью матричной схемы являются линейные матричные конвертеры и способы матричного управления. Краткий обзор этих способов дается C. Avendano и J.-M. Jot в “Frequency Domain Techniques for Stereo to Multichannel Upmix”, в материалах 22nd International Conference of the AES on Virtual, Synthetic and Entertainment Audio, 2002 и теми же авторами в “Ambience extraction and synthesis from stereo signals for multi-channel audio up-mix”) в материалах 22nd International Conference of the AES on Acoustics, Speech and Signal Processing (ICASSP), 2002, vol. 2, 2002, pp. II-1957 - II-1960. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
Извлечение и синтез окружения из стереофонических сигналов для многоканального повышающего микширования аудио можно добиться способом частотной области для идентификации и извлечения информации окружения в стереофонических аудиосигналах. Способ основан на вычислении индекса межканальной когерентности и функции нелинейного отображения, которые позволяют определять частотно-временные области, состоящие в основном из компонентов окружения, в двухканальном сигнале. Сигналы окружения затем синтезируются и используются, чтобы подавать каналы окружения звуком многоканальной системы воспроизведения. Результаты моделирования демонстрируют эффективность способа в извлечении информации окружения, и тесты повышающего микширования на реальном аудио показывают различные преимущества и недостатки системы по сравнению с предыдущими стратегиями повышающего микширования. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
Способы частотной области для повышающего микширования стереофонического к многоканальному могут также использоваться в связи или в контексте настройки пространственного аудиосигнала к установке громкоговорителя для воспроизведения. Доступны несколько способов повышающего микширования для формирования многоканального аудио из стереофонических записей. Способы используют общую структуру анализа на основании сравнения между краткосрочными преобразованиями Фурье для левого и правого стереофонических сигналов. Мера межканальной когерентности используется, чтобы идентифицировать частотно-временные области, состоящие в основном из компонентов окружения, которые могут затем взвешиваться с помощью нелинейной функции отображения, и извлекаться, чтобы синтезировать сигналы окружения. Мера подобия используется, чтобы идентифицировать коэффициенты панорамирования различных источников в смешении в частотно-временной плоскости, и различные функции отображения применяются, чтобы выделить (извлечь) один или несколько источников, и/или повторно панорамировать сигналы в произвольное число каналов. Одно возможное применение различных способов относится к построению "двух к пяти" канальной системе повышающего микширования. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
Декодер многоканальной стереофонии может быть способным выявлять скрытые пространственные метки в обычных записях музыки естественным, убедительным образом. Слушатель вовлекается в трехмерное пространство вместо прослушивания плоского, двумерного представления. Это не только помогает разработать более вовлекающее звуковое поле, но также и решает узкую задачу "зоны наилучшего восприятия" обычного стереофонического воспроизведения. В некоторых логических декодерах схема управления проверяет относительный уровень и фазу между входными сигналами. Эта информация посылается на каскад переменной выходной матрицы, чтобы подстроить VCA, управляющие уровнем противофазных сигналов. Противофазные сигналы аннулируют нежелательные сигналы перекрестной помехи, приводя к улучшенному разделению канала. Это называют схемой с упреждением. Этот принцип может быть расширен рассмотрением тех же входных сигналов и выполнением управления по замкнутому контуру с тем, что они соответствуют своим уровням. Эти согласованные аудио сигналы посылают непосредственно на матричные каскады, чтобы получить различные выходные каналы. Поскольку те же аудио сигналы, которые подают на выходную матрицу, сами используются, чтобы управлять контуром следящей системы, это называют логической схемой с обратной связью. Принцип управления с обратной связью может повысить точность и оптимизировать динамические характеристики. Введение глобальной обратной связи вокруг процесса логического управления привносит подобные преимущества в точности управления и динамическом поведении. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
В связи с воспроизведением множественными громкоговорителями может использоваться перцепционно мотивированная пространственная декомпозиция для двухканальных стереофонических аудио сигналов, получая информацию о виртуальном павильоне звукозаписи. Пространственная декомпозиция позволяет повторно синтезировать аудио сигналы для воспроизведения через акустические системы, отличные от двухканальных стереофонических. С использованием большего количества фронтальных громкоговорителей ширина виртуального павильона звукозаписи может быть увеличена свыше ±30°, и область зоны наилучшего восприятия расширяется. Необязательно, боковые независимые звуковые компоненты могут воспроизводиться отдельно через громкоговорителям на сторонах слушателя, чтобы увеличить окружение звуком слушателя. Пространственная декомпозиция может использоваться с аудиосистемами на основе объемного звука и синтеза волнового поля. Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
Декомпозиция сигнала первичный-окружение и векторная локализация для пространственного аудиокодирования и улучшения направлены на растущую коммерческую потребность сохранять и распределять многоканальное аудио и предоставлять контент оптимально на произвольных системах воспроизведения. Схема пространственного анализа-синтеза может применять анализ главных компонентов к представлению в STFT-области (область краткосрочного преобразования частоты) исходного аудио, чтобы разделять его на компоненты первичный и окружения, которые затем соответственно анализируются относительно меток, которые описывают пространственный воспринимаемый образ аудиосцены на по-фрагментной основе; эти метки могут использоваться синтезом, чтобы осуществлять представление аудио соответственно на доступной системе воспроизведения. Эта структура может быть приспособлена для устойчивого пространственного аудиокодирования, или она может применяться непосредственно к сценариям расширения, где нет ограничений скорости на представление промежуточных пространственных данных и аудио.
Относительно объемности и окружения звуком в музыкальной акустике, общепринятая точка зрения признает, что объемность и окружение звуком обусловлены боковой звуковой энергией в помещениях, и в основном наиболее ответственным является ранний приход боковой энергии. Однако по определению небольшие помещения не являются вместительными, все же они могут быть загружены ранними боковыми отражениями. Следовательно, перцепционные механизмы для объемности и окружения звуком могут иметь влияние на настройку пространственного аудиосигнала. Признано, что восприятия чаще всего связаны с боковой (диффузной) энергией в залах на концах тонов(?) (фоновая реверберация) и менее часто, но существенно, с характеристиками звукового поля, если тоны удерживаются. Предлагается мера объемности, названная временем затухания ранних боковых отражений (LEDT). Один или большее число этих аспектов могут использоваться в связи или в контексте предложенной настройки пространственного аудиосигнала.
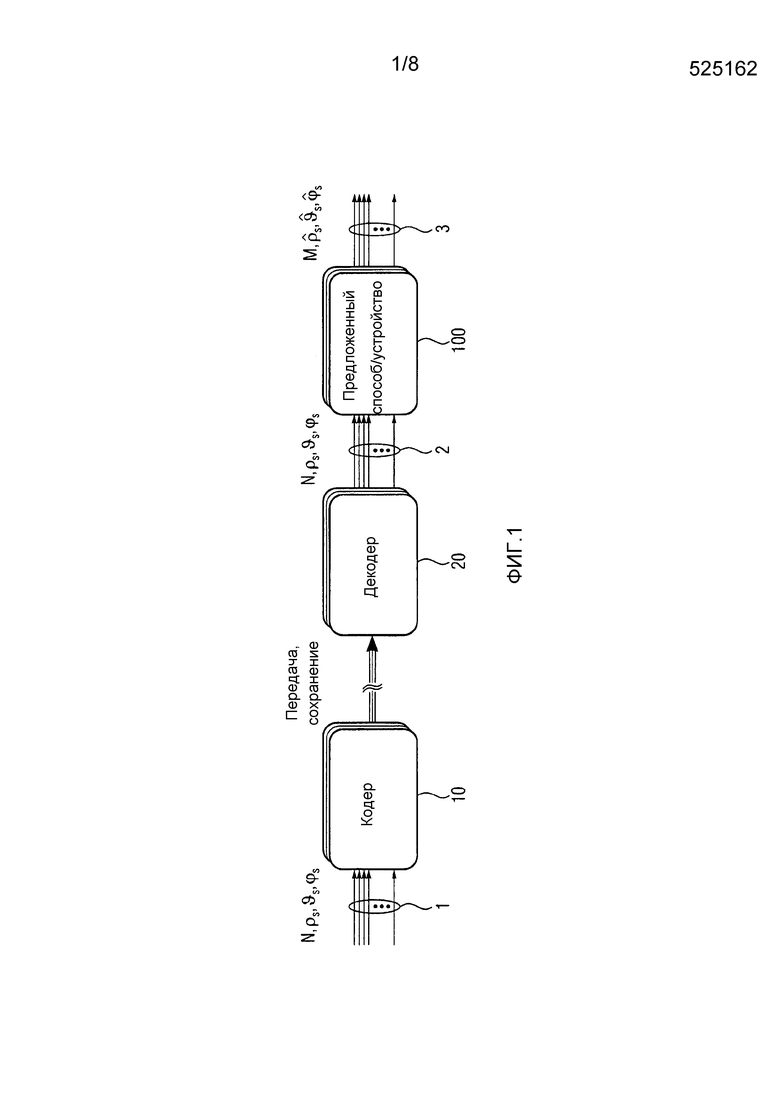
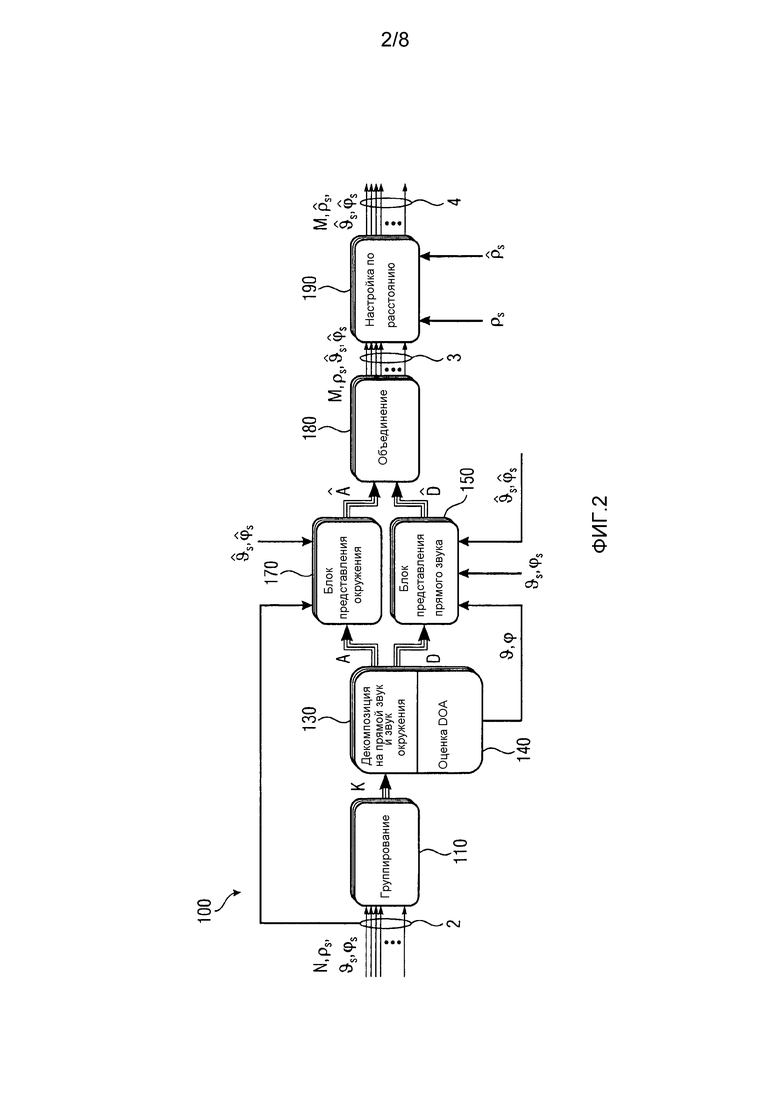
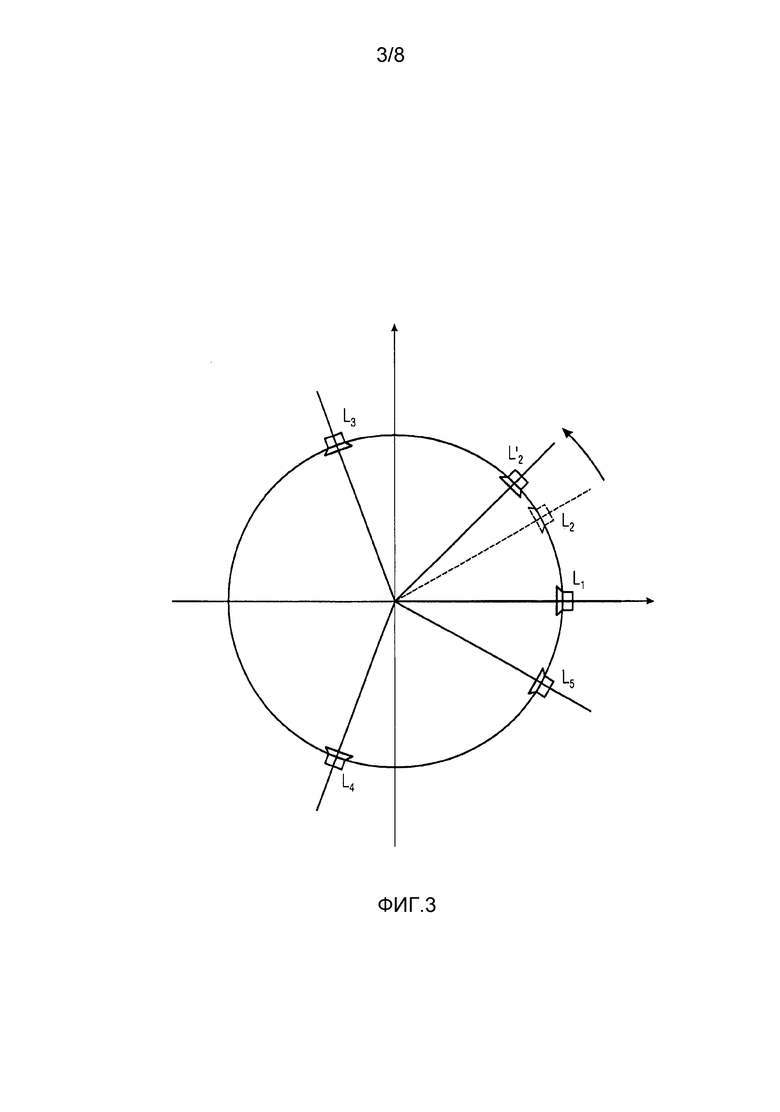
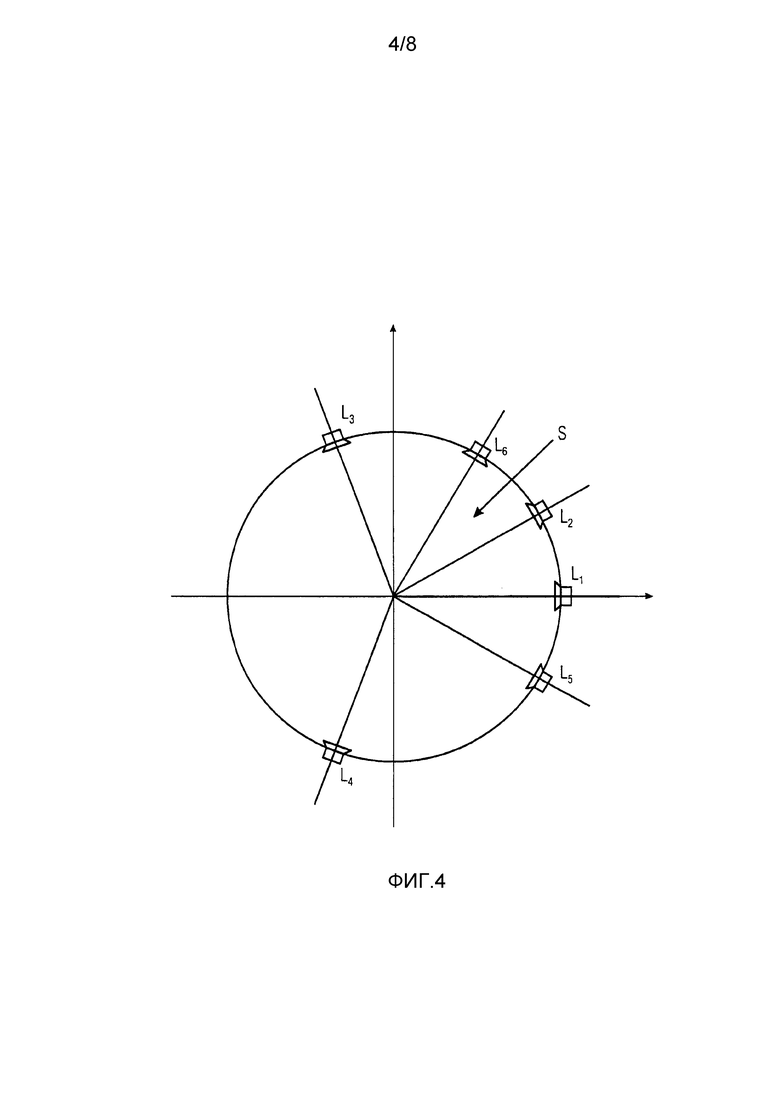
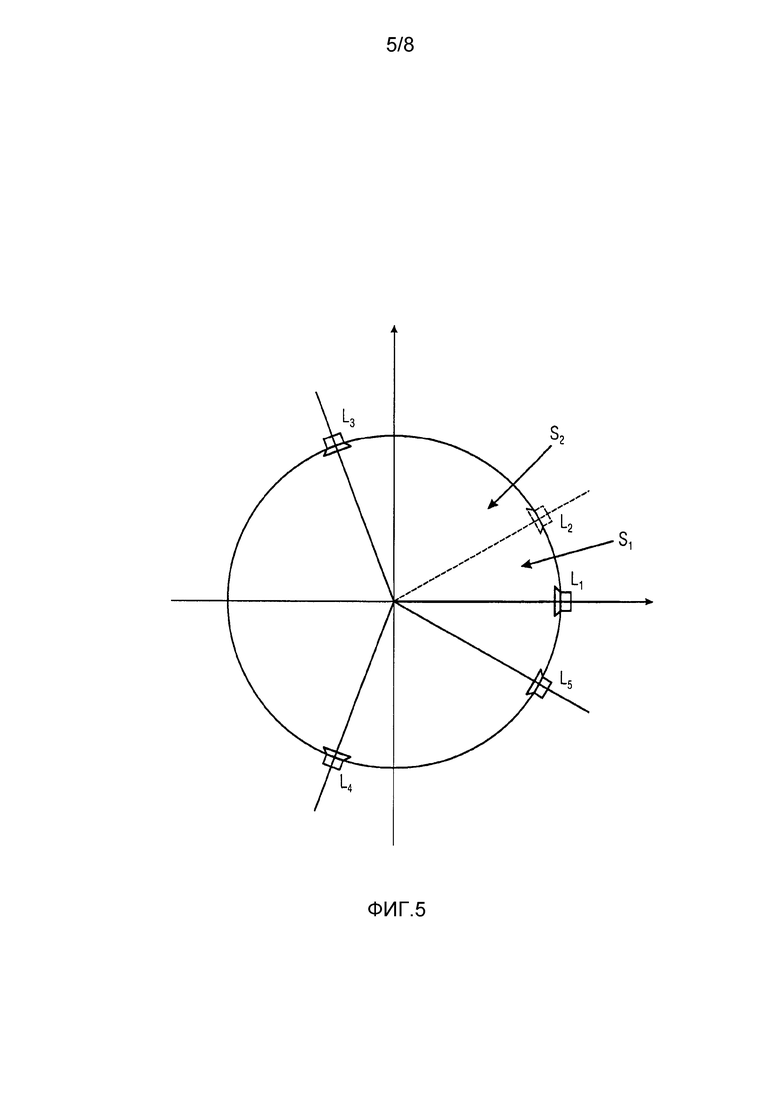
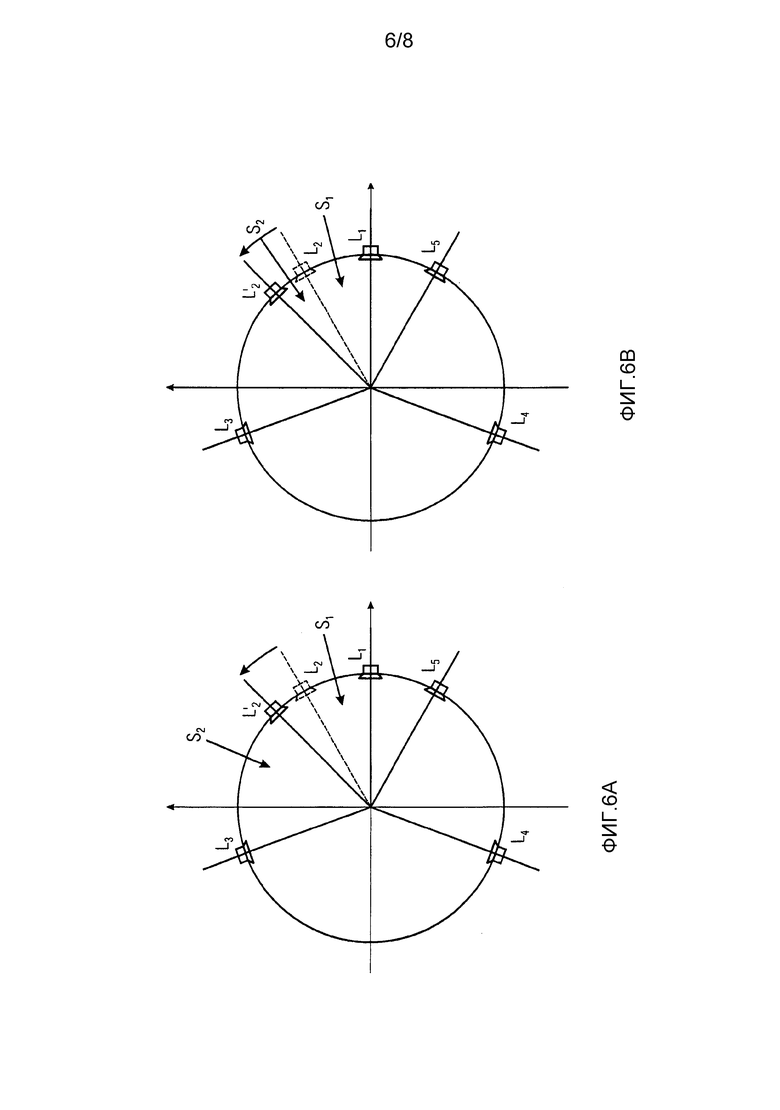
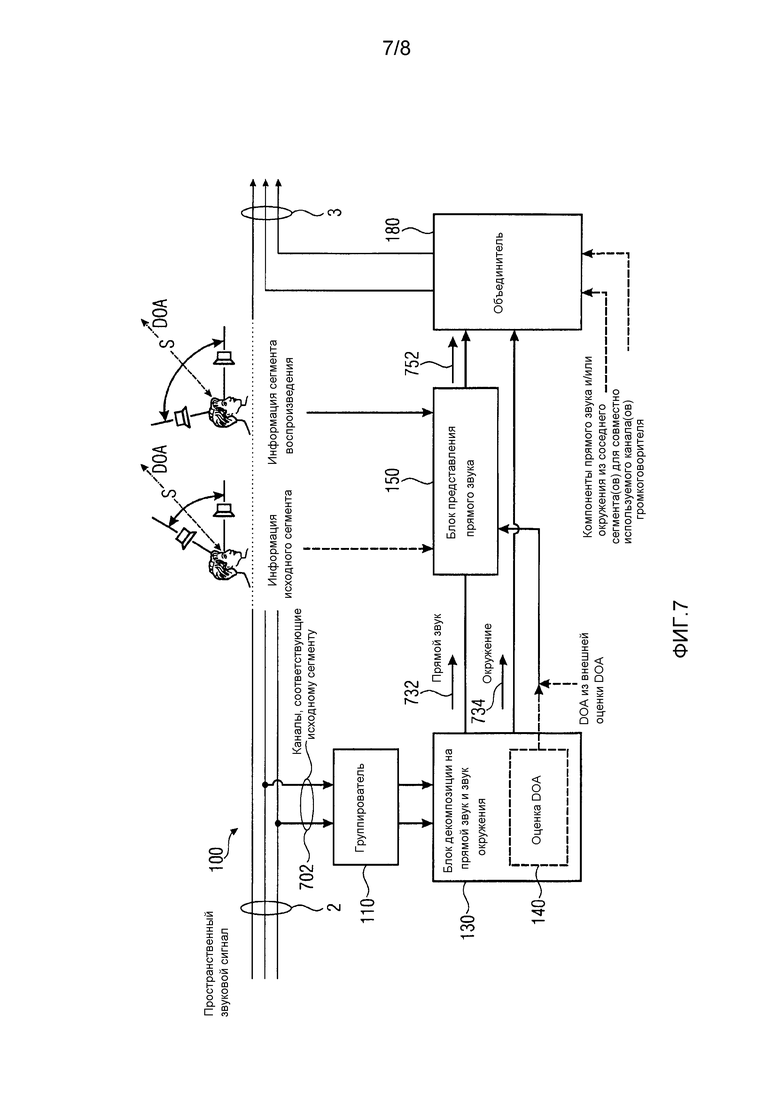
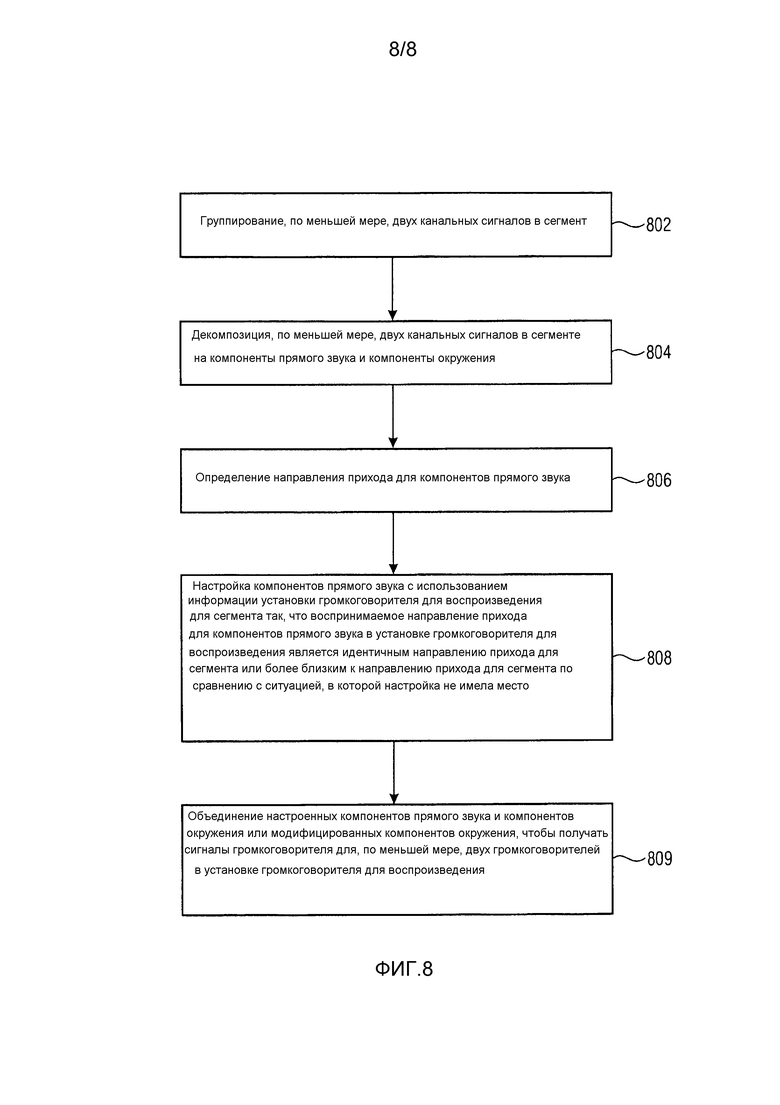
Изобретение относится к средствам посегментной настройки пространственного аудиосигнала к другой установке громкоговорителей для воспроизведения. Технический результат заключается в сохранении пространственного образа аудиосцены при перенастройке аудиосигнала к другой установке громкоговорителей. Предложено устройство для адаптации пространственного аудиосигнала, предназначенного для исходной установки громкоговорителя, к установке громкоговорителя для воспроизведения, которая отличается от исходной установки громкоговорителя. Устройство содержит блок декомпозиции на прямой звук и звук окружения, который выполнен с возможностью осуществления декомпозиции канальных сигналов в сегменте исходной установки громкоговорителя на компоненты прямого звука и окружения, и определения направления прихода для компонентов прямого звука. Блок представления прямого звука принимает информацию установки громкоговорителя для воспроизведения и настраивает компоненты прямого звука с использованием информации установки громкоговорителя для воспроизведения так, что воспринимаемое направление прихода для компонентов прямого звука в установке громкоговорителя для воспроизведения является идентичным направлению прихода для компонентов прямого звука. 3 н. и 13 з.п. ф-лы, 9 ил.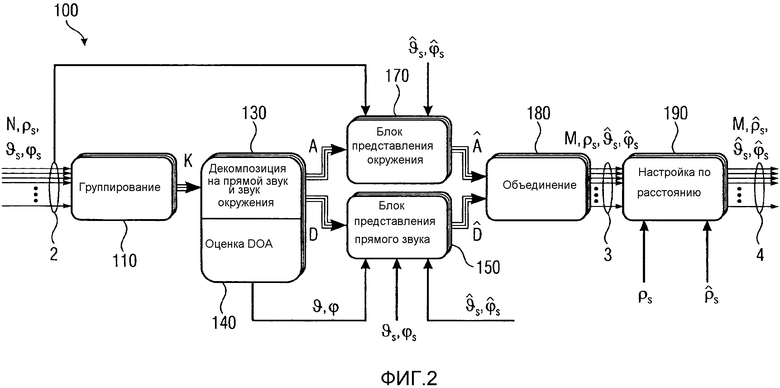
1. Устройство (100) для адаптации пространственного аудиосигнала (2), предназначенного для исходной установки громкоговорителей, к установке громкоговорителей для воспроизведения, которая отличается от исходной установки громкоговорителей, причем пространственный аудиосигнал (2) содержит множество канальных сигналов, причем каждый канальный сигнал является сигналом канала громкоговорителя, соответствующим громкоговорителю исходной установки громкоговорителей, причем устройство содержит:
группирователь (110), выполненный с возможностью группирования множества канальных сигналов в множество исходных сегментов, причем по меньшей мере два соседних канальных сигнала группируют в исходный сегмент и при этом громкоговоритель назначают первому исходному сегменту и второму исходному сегменту;
блок (130) декомпозиции на прямой звук и звук окружения, выполненный с возможностью декомпозиции по меньшей мере двух канальных сигналов в первом исходном сегменте на по меньшей мере один компонент (D; 732) прямого звука и по меньшей мере один компонент (А; 734) окружения, и определения направления прихода по меньшей мере одного компонента (S, S1, S2) прямого звука для первого исходного сегмента, и декомпозиции по меньшей мере двух канальных сигналов во втором исходном сегменте на по меньшей мере один компонент прямого звука и по меньшей мере один компонент окружения для второго исходного сегмента, и определения направления прихода по меньшей мере одного компонента прямого звука для второго исходного сегмента;
блок (150) представления прямого звука, выполненный с возможностью приема информации установки громкоговорителей для воспроизведения для первого сегмента воспроизведения, связанного с первым исходным сегментом, и настройки по меньшей мере одного компонента (D; 732) прямого звука первого исходного сегмента с использованием информации установки громкоговорителей для воспроизведения для первого сегмента воспроизведения для получения по меньшей мере одного настроенного компонента прямого звука так, что воспринимаемое направление прихода по меньшей мере одного компонента (S, S1, S2) прямого звука в установке громкоговорителей для воспроизведения является идентичным направлению прихода первого исходного сегмента или более близким к направлению прихода по меньшей мере одного компонента прямого звука первого исходного сегмента по сравнению с ситуацией, в которой настройка по меньшей мере одного компонента прямого звука не имела место, и выполненный с возможностью приема информации установки громкоговорителей для воспроизведения для второго сегмента воспроизведения, связанного со вторым исходным сегментом, и настройки по меньшей мере одного компонента прямого звука второго исходного сегмента с использованием информации установки громкоговорителей для воспроизведения для второго сегмента воспроизведения для получения по меньшей мере одного дополнительного настроенного компонента прямого звука так, что воспринимаемое направление прихода по меньшей мере одного компонента прямого звука в установке громкоговорителей для воспроизведения является идентичным направлению прихода второго исходного сегмента или более близким к направлению прихода по меньшей мере одного компонента прямого звука второго исходного сегмента по сравнению с ситуацией, в которой настройка по меньшей мере одного компонента прямого звука не имела место; и
объединитель (180), выполненный с возможностью объединения упомянутого по меньшей мере одного настроенного компонента (752) прямого звука и компонентов (734) окружения или модифицированных компонентов окружения первого сегмента воспроизведения и упомянутого по меньшей мере одного дополнительного настроенного компонента прямого звука и компонентов окружения или модифицированных компонентов окружения второго сегмента воспроизведения.
2. Устройство (100) по п. 1, в котором установка громкоговорителей для воспроизведения содержит дополнительный громкоговоритель (L6) внутри первого или второго исходного сегмента так, что первый или второй исходный сегмент соответствует двум или большему числу сегментов в сегменте громкоговорителя для воспроизведения;
причем блок (150) представления прямого звука выполнен с возможностью формирования настроенных компонентов (752) прямого звука для по меньшей мере двух громкоговорителей и дополнительного громкоговорителя в установке громкоговорителей для воспроизведения.
3. Устройство (100) по п. 1, в котором в установке громкоговорителей для воспроизведения отсутствует громкоговоритель по сравнению с исходной установкой громкоговорителей, так что левый или правый исходный сегмент и соседний левый или правый исходный сегмент совмещают в один совмещенный сегмент установки громкоговорителей для воспроизведения;
причем блок (150) представления прямого звука выполнен с возможностью распределения настроенных компонентов (752) прямого звука для канала, соответствующего громкоговорителю, который отсутствует в установке громкоговорителей для воспроизведения по меньшей мере двум оставшимся громкоговорителям (L1, L3) совмещенного сегмента в установке громкоговорителей для воспроизведения.
4. Устройство (100) по п. 1, в котором блок (150) представления прямого звука выполнен с возможностью перераспределения компонента (S2) прямого звука, имеющего определенное направление прихода, из левого или правого исходного сегмента ({L2, L3}) в соседний исходный сегмент ({L1, L'2}), если граница между левым или правым исходным сегментом ({L2, L3}) и соседним сегментом ({L1, L'2}) переходит через определенное направление прихода, при переходе от исходной установки громкоговорителей к установке громкоговорителей для воспроизведения.
5. Устройство (100) по п. 4, в котором блок (150) представления прямого звука дополнительно выполнен с возможностью перераспределения компонента (S2) прямого звука, имеющего определенное направление прихода от по меньшей мере одного первого громкоговорителя (L3) по меньшей мере одному второму громкоговорителю (L'2), причем по меньшей мере один первый громкоговоритель (L3) назначается левому или правому исходному сегменту ({L2, L3}), а не соседнему сегменту ({L1, L'2}) в установке громкоговорителей для воспроизведения и по меньшей мере один второй громкоговоритель (L'2) назначается соседнему сегменту ({L1, L'2}) в установке громкоговорителей для воспроизведения.
6. Устройство (100) по п. 1, в котором блок (150) представления прямого звука выполнен с возможностью выполнения повторного панорамирования по меньшей мере одного компонента (S, S1, S2) прямого звука с использованием информации установки громкоговорителей для воспроизведения и направления прихода по меньшей мере одного компонента прямого звука.
7. Устройство (100) по п. 6, в котором блок (150) представления прямого звука дополнительно выполнен с возможностью выполнения повторного панорамирования по меньшей мере одного компонента прямого звука (S1), имеющего определенное направление прихода, путем настройки сигналов громкоговорителя для громкоговорителей (L1, L2) в левом или правом исходном сегменте ({L1, L2}), чтобы получать настроенные сигналы громкоговорителя для громкоговорителей (L1, L'2) в соответствующем модифицированном сегменте {L1, L'2} установки громкоговорителей для воспроизведения, если по меньшей мере один из громкоговорителей (L1, L2) в левом или правом исходном сегменте ({L1, L2}) смещается в соответствующем модифицированном сегменте {L1, L'2} установки громкоговорителей для воспроизведения без перехода через определенное направление прихода.
8. Устройство (100) по п. 1, в котором блок (150) представления прямого звука выполнен с возможностью формирования характерных для сегмента и громкоговорителя компонентов прямого звука для по меньшей мере двух пар громкоговоритель-сегмент в установке громкоговорителей для воспроизведения, причем по меньшей мере две пары громкоговоритель-сегмент относятся к одному и тому же громкоговорителю и двум соседним сегментам в установке громкоговорителей для воспроизведения; и
при этом объединитель (180) выполнен с возможностью объединения характерных для сегмента и громкоговорителя компонентов прямого звука для по меньшей мере двух пар громкоговоритель-сегмент, относящихся к одному и тому же громкоговорителю, чтобы получать один из сигналов громкоговорителя для по меньшей мере двух громкоговорителей в установке громкоговорителей для воспроизведения.
9. Устройство (100) по п. 1, в котором блок (150) представления прямого звука дополнительно выполнен с возможностью обработки по меньшей мере одного компонента (D; 732) прямого звука для заданного сегмента установки громкоговорителей для воспроизведения и посредством этого формирования настроенных компонентов прямого звука для каждого громкоговорителя, назначенного заданному сегменту.
10. Устройство (100) по п. 1, дополнительно содержащее блок (170) представления окружения, выполненный с возможностью приема информации установки громкоговорителей для воспроизведения для левого или правого сегмента воспроизведения и настройки по меньшей мере одного компонента окружения с использованием информации установки громкоговорителей для воспроизведения для левого или правого сегмента воспроизведения так, что воспринимаемое окружение звуком по меньшей мере одного компонента окружения в установке громкоговорителей для воспроизведения является идентичным окружению звуком по меньшей мере одного компонента окружения левого или правого исходного сегмента или более близким к окружению звуком по меньшей мере одного компонента окружения левого или правого исходного сегмента по сравнению с ситуацией, в которой настройка по меньшей мере одного компонента окружения не имела место.
11. Устройство (100) по п. 1, в котором группирователь (110) дополнительно выполнен с возможностью масштабирования по меньшей мере двух каналов в виде функции от количества исходных сегментов, которым назначен канал из по меньшей мере двух каналов.
12. Устройство (100) по п. 1, дополнительно содержащее блок (190) настройки по расстоянию, выполненный с возможностью настройки по меньшей мере одного из амплитуды и задержки для по меньшей мере одного из сигналов громкоговорителя для по меньшей мере двух громкоговорителей в установке громкоговорителей для воспроизведения с использованием информации расстояния относительно расстояния между слушателем и громкоговорителем в установке громкоговорителей для воспроизведения.
13. Устройство (100) по п. 1, дополнительно содержащее блок отслеживания слушателя, выполненный с возможностью определения текущей позиции слушателя относительно установки громкоговорителей для воспроизведения и определения информации установки громкоговорителей для воспроизведения с использованием текущей позиции слушателя.
14. Устройство (100) по п. 1, дополнительно содержащее частотно-временной преобразователь, выполненный с возможностью преобразования пространственного аудиосигнала из представления во временной области в представление в частотной области или в представление в частотно-временной области, причем блок декомпозиции на прямой звук и звук окружения и блок представления прямого звука выполнены с возможностью обработки представления в частотной области или представления в частотно-временной области.
15. Способ адаптации пространственного аудиосигнала (2), предназначенного для исходной установки громкоговорителей, к установке громкоговорителей для воспроизведения, которая отличается от исходной установки громкоговорителей, причем пространственный аудиосигнал (2) содержит множество канальных сигналов, причем каждый канальный сигнал является сигналом канала громкоговорителя, соответствующим громкоговорителю исходной установки громкоговорителей, причем способ содержит:
группирование (802) множества канальных сигналов в множество исходных сегментов, причем по меньшей мере два соседних канальных сигнала группируют в исходный сегмент и при этом громкоговоритель назначают первому исходному сегменту и второму исходному сегменту;
декомпозицию (804) по меньшей мере двух канальных сигналов в первом исходном сегменте на по меньшей мере один компонент (D; 732) прямого звука и по меньшей мере один компонент (А; 734) окружения, и определение направления прихода по меньшей мере одного компонента (S, S1, S2) прямого звука для первого исходного сегмента, и декомпозицию по меньшей мере двух канальных сигналов во втором исходном сегменте на по меньшей мере один компонент прямого звука и по меньшей мере один компонент окружения для второго исходного сегмента, и определение направления прихода по меньшей мере одного компонента прямого звука для второго исходного сегмента;
настройку (808) по меньшей мере одного компонента (D; 732) прямого звука первого исходного сегмента с использованием информации установки громкоговорителей для воспроизведения для первого сегмента воспроизведения для получения по меньшей мере одного настроенного компонента прямого звука так, что воспринимаемое направление прихода по меньшей мере одного компонента (S, S1, S2) прямого звука в установке громкоговорителей для воспроизведения является идентичным направлению прихода первого исходного сегмента или более близким к направлению прихода по меньшей мере одного компонента прямого звука первого исходного сегмента по сравнению с ситуацией, в которой настройка по меньшей мере одного компонента прямого звука не имела место, и настройку по меньшей мере одного компонента прямого звука второго исходного сегмента с использованием информации установки громкоговорителей для воспроизведения для второго сегмента воспроизведения для получения по меньшей мере одного дополнительного настроенного компонента прямого звука так, что воспринимаемое направление прихода по меньшей мере одного компонента прямого звука в установке громкоговорителей для воспроизведения является идентичным направлению прихода второго исходного сегмента или более близким к направлению прихода по меньшей мере одного компонента прямого звука второго исходного сегмента по сравнению с ситуацией, в которой настройка по меньшей мере одного компонента прямого звука не имела место; и
объединение (809) упомянутого по меньшей мере одного настроенного компонента (752) прямого звука и компонентов (734) окружения или модифицированных компонентов окружения первого сегмента воспроизведения и упомянутого по меньшей мере одного дополнительного настроенного компонента прямого звука и компонентов окружения или модифицированных компонентов окружения второго сегмента воспроизведения.
16. Физический носитель данных, содержащий сохраненную на нем компьютерную программу, имеющую код программы для выполнения способа по п. 15, когда компьютерная программа исполняется на компьютере.
| КАЛИБРОВКА ЗАПИСЕЙ ГРАДИЕНТА ДАВЛЕНИЯ | 2006 |
|
RU2457508C2 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ЗВУКОВОГО СИГНАЛА | 2008 |
|
RU2437247C1 |

