Настоящее изобретение относится к обработке звукового сигнала, и в частности - к фильтру и способу для информированной пространственной фильтрации, используя многочисленные мгновенные оценки направления прибытия.
Выделение излучателей звука в условиях шума и реверберации обычно обеспечивается в современных системах связи. За последние четыре десятилетия было предложено большое разнообразие методов пространственной фильтрации для выполнения этой задачи. Существующие пространственные фильтры оптимальны, когда наблюдаемые сигналы соответствуют модели сигнала и когда информация, требуемая для вычисления фильтров, является точной. Практически, однако, модель сигнала часто нарушается, и основной сложной проблемой является оценка требуемой информации.
Существующие пространственные фильтры могут грубо классифицироваться на линейные пространственные фильтры (см., например, [1, 2, 3, 4]) и параметрические пространственные фильтры (см., например, [5, 6, 7, 8]). В общем случае линейные пространственные фильтры требуют оценки одного или более векторов распространения или статистических данных второго порядка (SOS) искомого одного или более излучателей плюс SOS помех. Некоторые пространственные фильтры разработаны для выделения сигнала одного излучателя, или реверберирующего, или с подавлением реверберации (см., например, [9, 10, 11, 12, 13, 14, 15, 16]), в то время как другие разработаны для выделения сигнала суммы двух или более реверберирующих излучателей (см., например, [17, 18]). Вышеупомянутые способы требуют предшествующего знания о направлении искомого одного или более излучателей или о периоде, в котором только искомые излучатели активны, или отдельно или одновременно.
Недостатком этих способов является невозможность адаптироваться достаточно быстро к новым ситуациям, например, к перемещениям излучателей или к конкурирующим динамикам, которые становятся активными, когда искомый излучатель активен.
Параметрические пространственные фильтры часто основаны на относительно простой модели сигнала, например, принятый сигнал в частотно-временной области состоит из одной плоской волны плюс рассеянный звук, и вычисляются, основываясь на мгновенных оценках параметров модели. Преимуществами параметрических пространственных фильтров являются очень гибкая диаграмма направленности, сравнительно сильное подавление рассеянного звука и источников помех, и возможность быстро адаптироваться к новым ситуациям. Однако, как показано в [19], базовая модель сигнала с одной плоской волной может легко нарушаться на практике, что сильно ухудшает эффективность параметрических пространственных фильтров. Следует заметить, что параметрические пространственные фильтры уровня техники используют все доступные сигналы микрофона для оценки параметров модели, хотя только один сигнал микрофона и действительное усиление используются для вычисления окончательного выходного сигнала. Расширение для объединения множества доступных сигналов микрофона для обнаружения усовершенствованного выходного сигнала не является прямым.
Поэтому было бы высоко оценено, если бы были обеспечены улучшенные концепции для получения искомой пространственной реакции на излучатели звука.
Поэтому задачей настоящего изобретения является обеспечение улучшенных концепций для выделения излучателей звука. Задача настоящего изобретения решается с помощью фильтра по п. 1, способа по п. 17 и компьютерной программы по п. 18.
Обеспечен фильтр для генерации выходного звукового сигнала, содержащего множество выборок выходного звукового сигнала, на основании двух или более входных сигналов микрофона. Выходной звуковой сигнал и два или более входных сигналов микрофона представлены в частотно-временной области, причем каждая из множества выборок выходного звукового сигнала назначена частотно-временному элементу из множества частотно-временных элементов.
Фильтр содержит генератор весов, адаптированный для приема для каждого из множества частотно-временных элементов информации направления прибытия одной или более компонент звука одного или более излучателей звука или информации расположения одного или более излучателей звука, и адаптированный для генерации информации взвешивания для каждого из множества частотно-временных элементов в зависимости от информации направления прибытия одной или более компонент звука одного или более излучателей звука указанного частотно-временного элемента или в зависимости от информации расположения одного или более излучателей звука указанного частотно-временного элемента.
Кроме того, фильтр содержит генератор выходного сигнала для генерации выходного звукового сигнала с помощью генерации для каждого из множества частотно-временных элементов одной из множества выборок выходного звукового сигнала, которая назначена указанному частотно-временному элементу, в зависимости от информации взвешивания указанного частотно-временного элемента и в зависимости от выборки входного звукового сигнала, назначенной указанному частотно-временному элементу, каждого из двух или более входных сигналов микрофона.
Варианты осуществления обеспечивают пространственный фильтр для получения искомой реакции для самое большее L одновременно активных излучателей звука. Обеспеченный пространственный фильтр получается с помощью минимизации мощности рассеянного сигнала плюс шума на выходе фильтра при условии L линейных ограничений. В отличие от концепций уровня техники L ограничений основаны на мгновенных узкополосных оценках направления прибытия. Кроме того, обеспечиваются новые оценки для отношения рассеянного сигнала к шуму/мощности рассеянного сигнала, которые показывают достаточно высокое временное и спектральное разрешение для обеспечения и подавления реверберации, и снижения шума.
Согласно некоторым вариантам осуществления обеспечены концепции для получения искомой произвольной пространственной реакции для самое большее L излучателей звука, которые одновременно активны в частотно-временной момент. Для этой цели мгновенная параметрическая информация (IPI) об акустической сцене внедряется в разработку пространственного фильтра, что приводит к «информированному пространственному фильтру».
В некоторых вариантах осуществления такой информированный пространственный фильтр, например, объединяет все доступные сигналы микрофона, на основании комплексных весов, для обеспечения усовершенствованного выходного сигнала.
Согласно вариантам осуществления информированный пространственный фильтр может, например, реализовываться в качестве пространственного фильтра минимальной дисперсии с линейными ограничениями (LCMV) или в качестве параметрического многоканального Винеровского фильтра.
В некоторых вариантах осуществления обеспеченный информированный пространственный фильтр, например, получается с помощью минимизации мощности рассеянного сигнала плюс собственных шумов при условии L линейных ограничений.
В некоторых вариантах осуществления, в отличие от уровня техники, L ограничений основаны на мгновенных оценках направления прибытия (DOA) и результирующих реакциях на L DOA, соответствующих конкретной искомой направленности.
Кроме того, обеспечены новые средства оценки для статистических данных требуемого сигнала и шума, например, отношение рассеянного сигнала к шуму (DNR), которые показывают достаточно высокое временное и спектральное разрешение, например, для уменьшения и реверберации, и шума.
Более того, обеспечен способ для генерации выходного звукового сигнала, содержащего множество выборок выходного звукового сигнала, на основании двух или более входных сигналов микрофона. Выходной звуковой сигнал и два или более входных сигналов микрофона представлены в частотно-временной области, причем каждая из множества выборок выходного звукового сигнала назначена частотно-временному элементу из множества частотно-временных элементов. Способ содержит этапы, на которых:
- Принимают для каждого из множества частотно-временных элементов ((k, n)), информацию направления прибытия одной или более компонент звука одного или более излучателей звука или информацию расположения одного или более излучателей звука.
- Генерируют информацию взвешивания для каждого из множества частотно-временных элементов в зависимости от информации направления прибытия одной или более компонент звука одного или более излучателей звука указанного частотно-временного элемента или в зависимости от информации расположения одного или более излучателей звука указанного частотно-временного элемента. И:
- Генерируют выходной звуковой сигнал с помощью генерации для каждого из множества частотно-временных элементов ((k, n)) одной из множества выборок выходного звукового сигнала, которая назначена указанному частотно-временному элементу ((k, n)), в зависимости от информации взвешивания указанного частотно-временного элемента ((k, n)) и в зависимости от выборки входного звукового сигнала, которая назначена указанному частотно-временному элементу ((k, n)), каждого из двух или более входных сигналов микрофона.
Кроме того, обеспечена компьютерная программа для воплощения вышеописанного способа, когда она выполняется на компьютере или процессоре обработки сигнала.
В последующем варианты осуществления настоящего изобретения описаны более подробно со ссылкой на фигуры, на которых:
фиг. 1A показывает фильтр согласно варианту осуществления,
фиг. 1B показывает возможный сценарий применения фильтра согласно варианту осуществления,
фиг. 2 показывает фильтр согласно варианту осуществления и множество микрофонов,
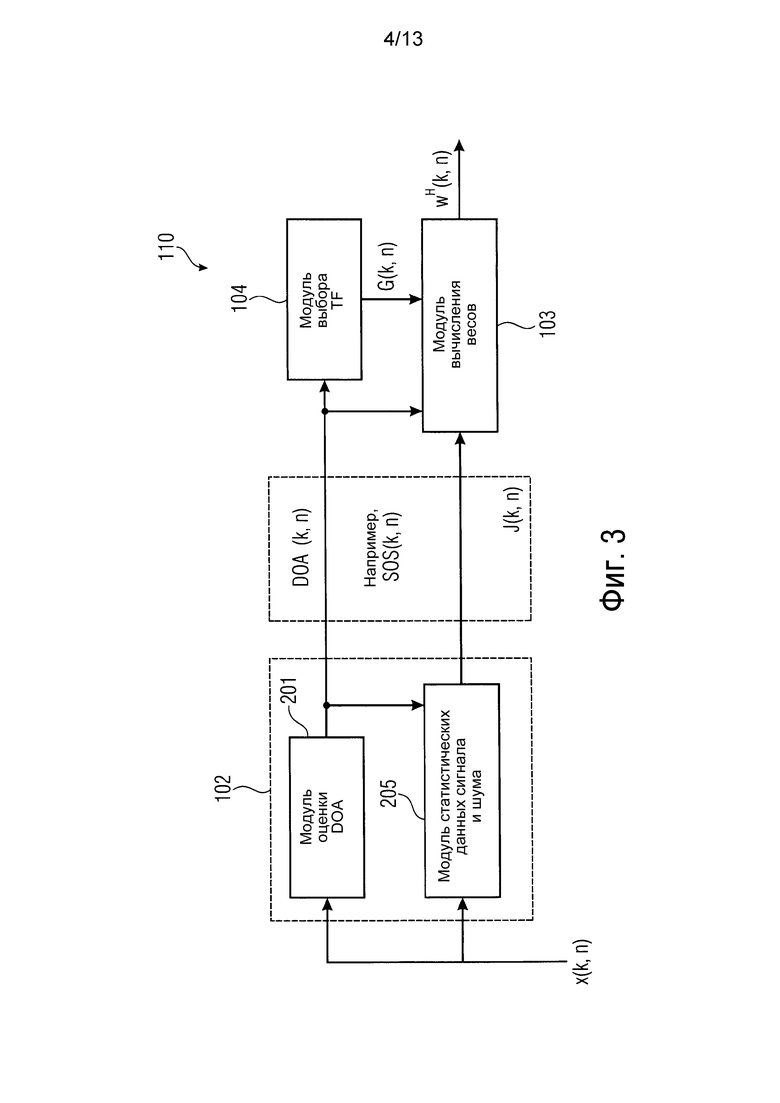
фиг. 3 показывает генератор весов согласно варианту осуществления,
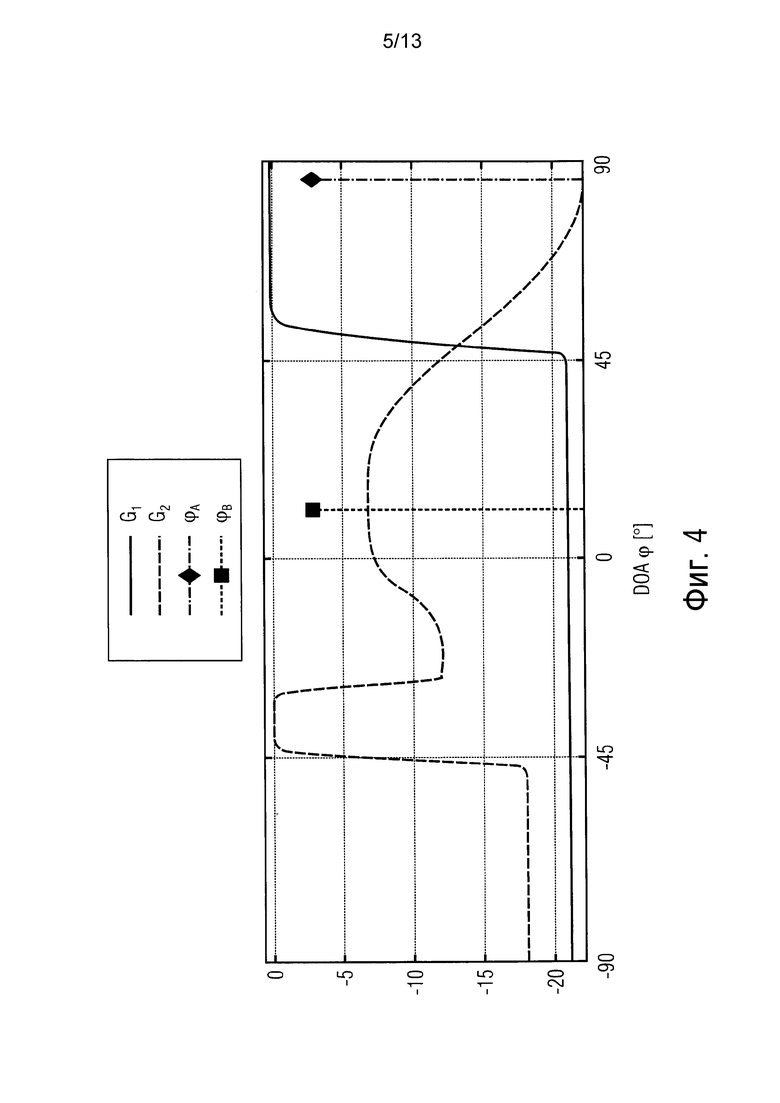
фиг. 4 показывает величину двух реакций в качестве примера согласно варианту осуществления,
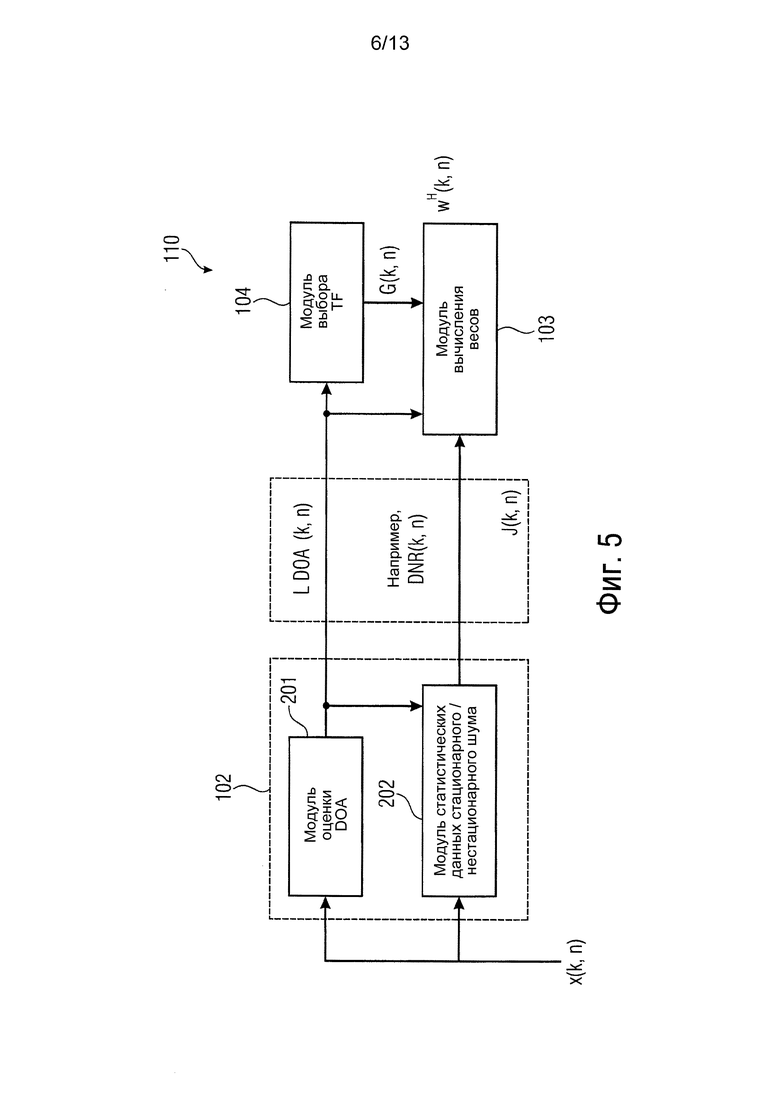
фиг. 5 показывает генератор весов согласно другому варианту осуществления, обеспечивающий подход минимальной дисперсии с линейными ограничениями,
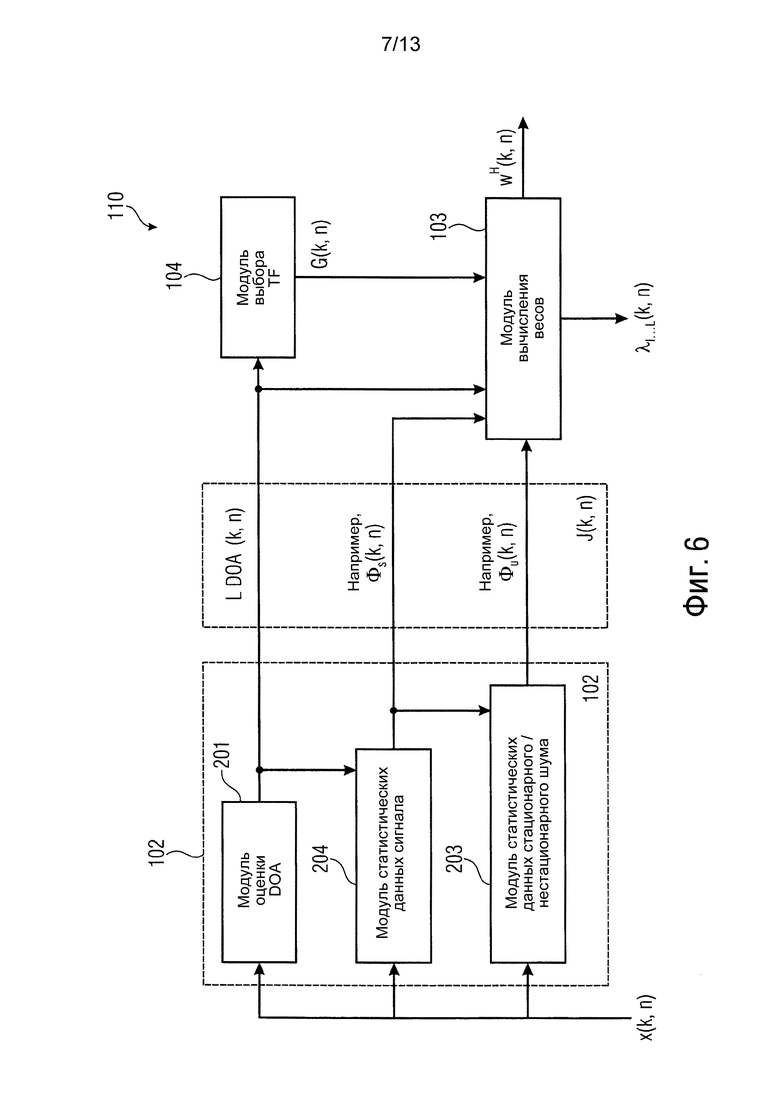
фиг. 6 показывает генератор весов согласно дополнительному варианту осуществления, обеспечивающий подход параметрического многоканального Винеровский фильтра,
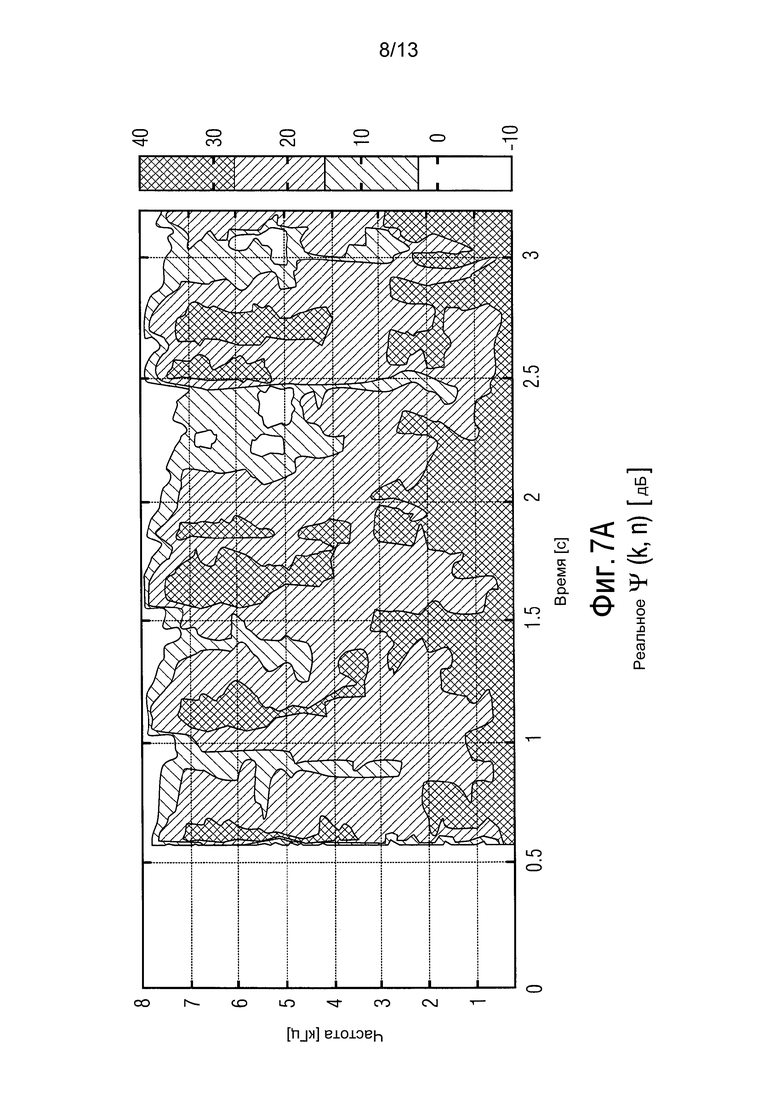
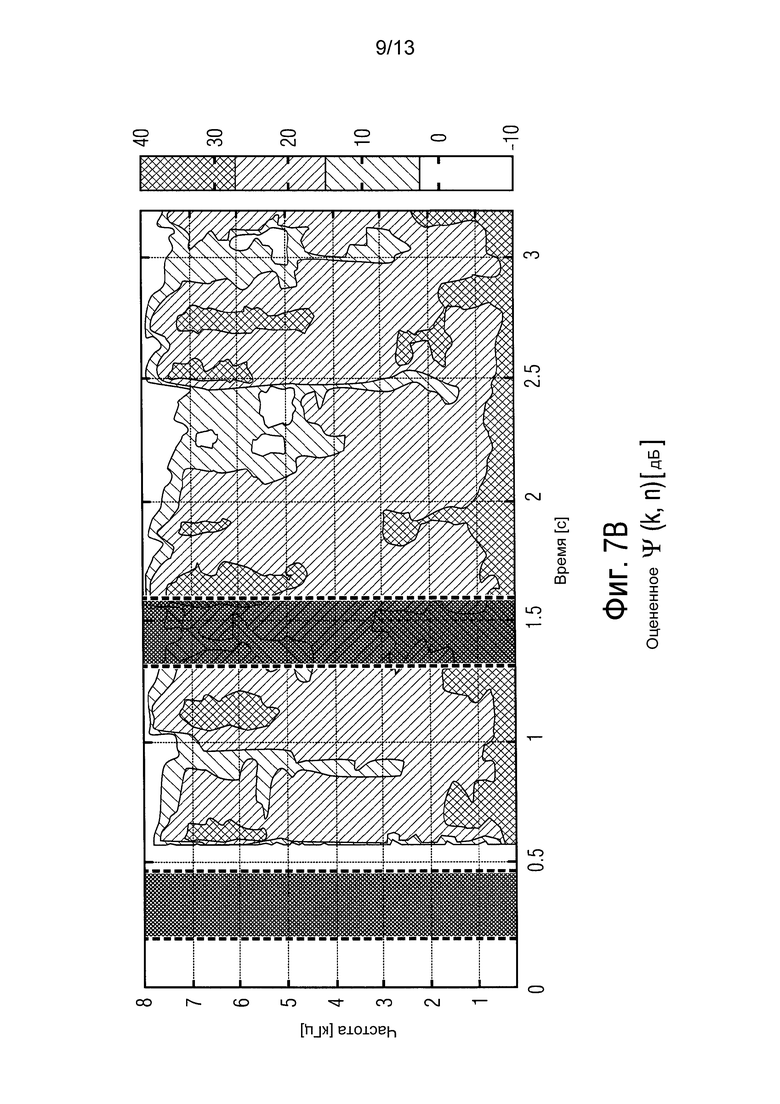
фиг. 7 показывает реальное и оцененное отношение рассеянного сигнала к шуму в качестве функции от времени и частоты,
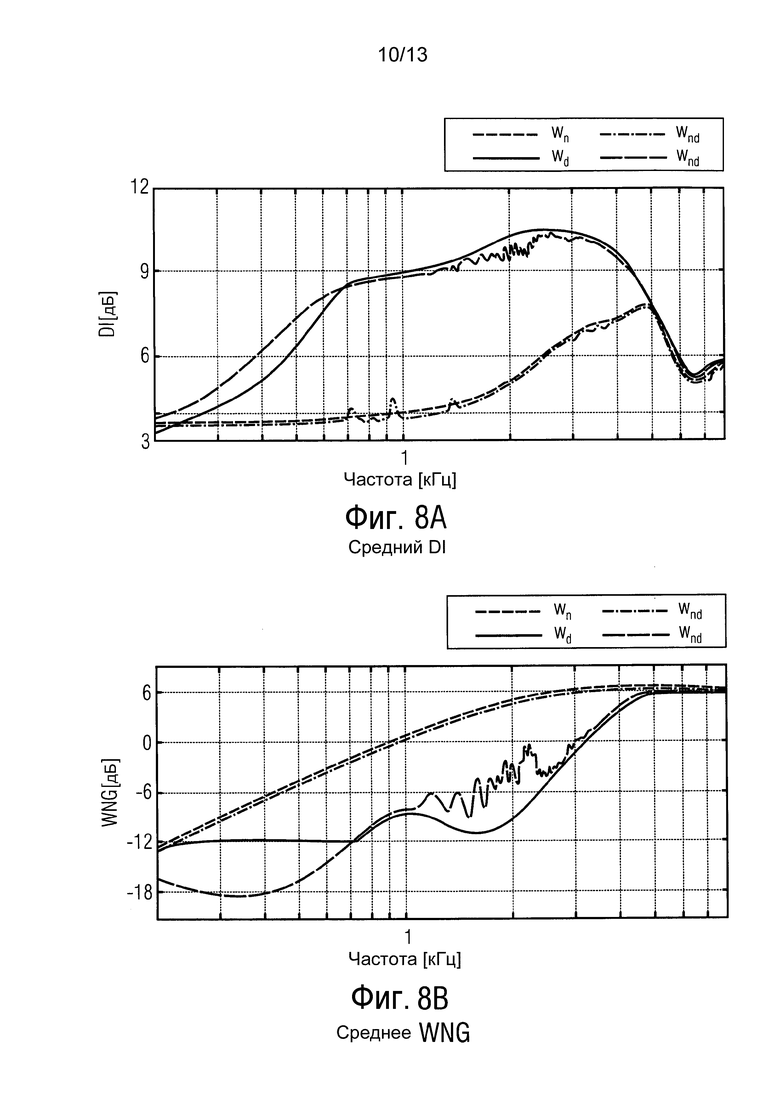
фиг. 8 показывает индекс направленности и усиление белого шума сравниваемых пространственных фильтров,
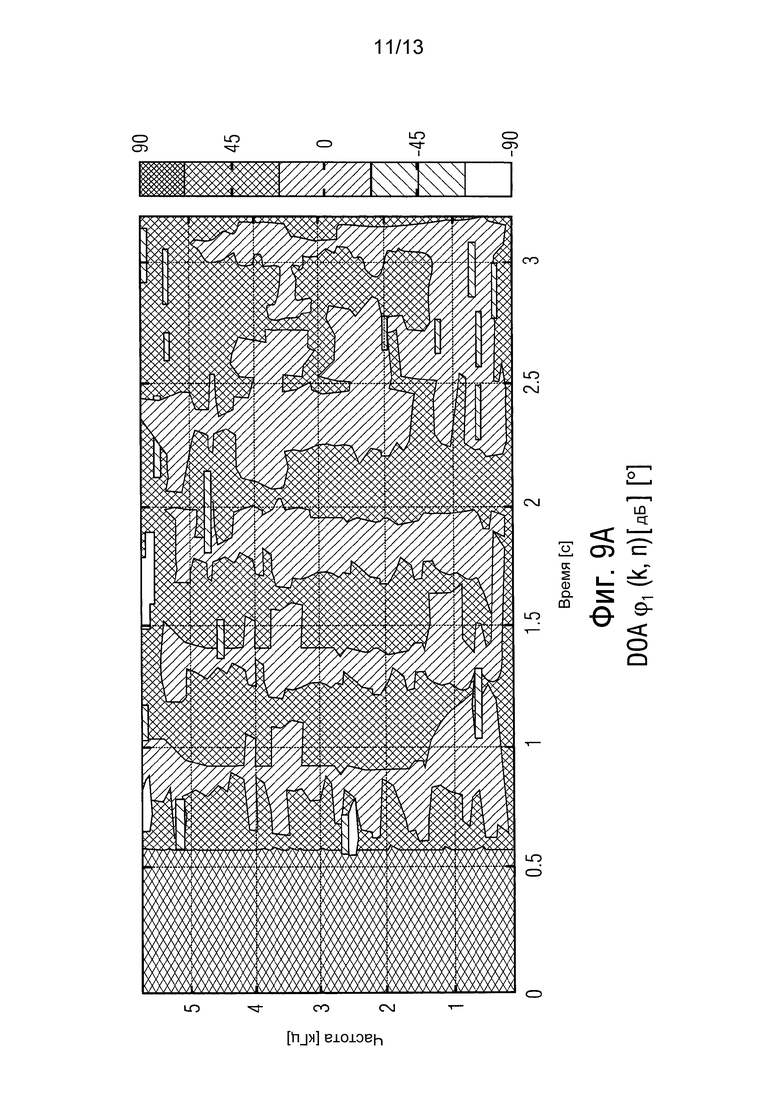
фиг. 9 показывает оцененное направление прибытия и результирующее усиление, и
фиг. 10 показывает пример для случая воспроизведения стереофонического громкоговорителя.
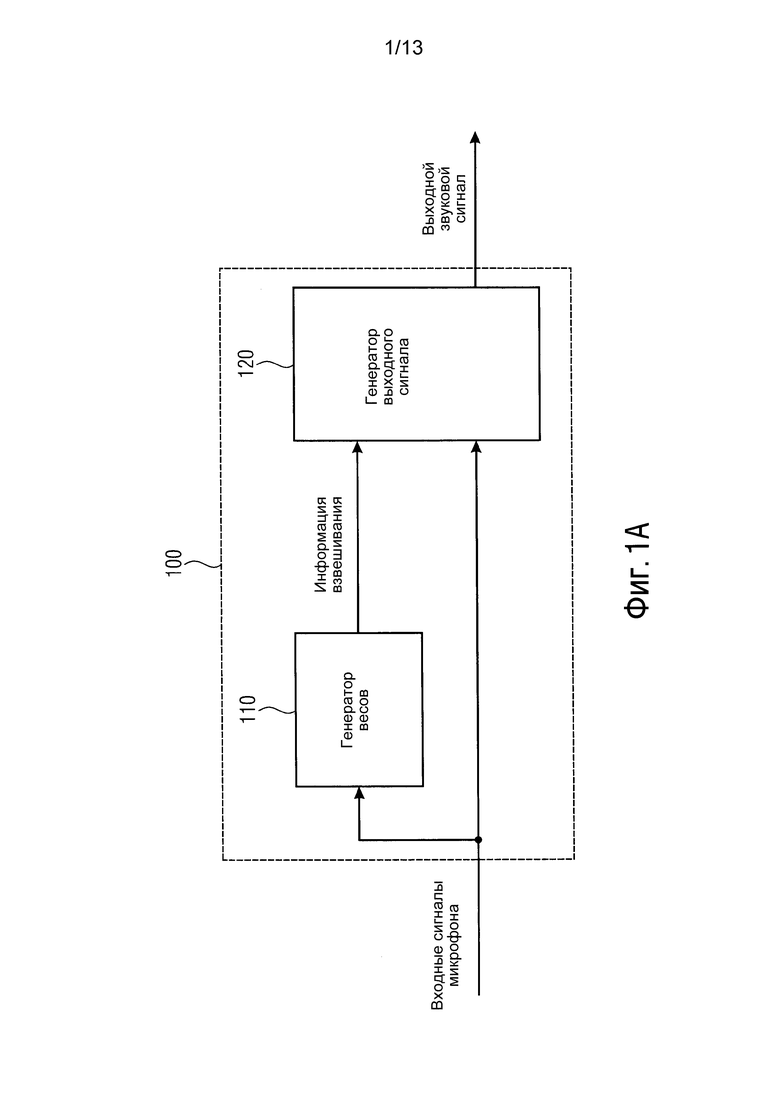
Фиг. 1A показывает фильтр 100 для генерации выходного звукового сигнала, содержащего множество выборок выходного звукового сигнала, обеспеченных, на основании двух или более входных сигналов микрофона. Выходной звуковой сигнал и два или более входных сигналов микрофона представлены в частотно-временной области, причем каждая из множества выборок выходного звукового сигнала назначена частотно-временному элементу (k, n) из множества частотно-временных элементов (k, n).
Фильтр 100 содержит генератор 110 весов, адаптированный для приема для каждого из множества частотно-временных элементов (k, n) информации направления прибытия одной или более компонент звука одного или более излучателей звука или информации расположения одного или более излучателей звука, и адаптированный для генерации информации взвешивания для каждого из множества частотно-временных элементов (k, n) в зависимости от информации направления прибытия одной или более компонент звука одного или более излучателей звука указанного частотно-временного элемента (k, n) или в зависимости от информации расположения одного или более излучателей звука указанного частотно-временного элемента (k, n).
Кроме того, фильтр содержит генератор 120 выходного сигнала для генерации выходного звукового сигнала с помощью генерации для каждого из множества частотно-временных элементов (k, n) одной из множества выборок выходного звукового сигнала, которая назначена указанному частотно-временному элементу (k, n), в зависимости от информации взвешивания указанного частотно-временного элемента (k, n) и в зависимости от выборки входного звукового сигнала, которая назначена указанному частотно-временному элементу (k, n), каждого из двух или более входных сигналов микрофона.
Например, каждый из двух или более входных сигналов микрофона содержит множество выборок входного звукового сигнала, причем каждая из выборок входного звукового сигнала назначена одному из частотно-временных элементов (k, n), и генератор 120 звукового сигнала может адаптироваться для генерации одной из множества выборок выходного звукового сигнала, которая назначена указанному частотно-временному элементу (k, n), в зависимости от информации взвешивания указанного частотно-временного элемента (k, n) и в зависимости от одной из выборок входного звукового сигнала каждого из двух или более входных сигналов микрофона, а именно, например, в зависимости от одной из выборок входного звукового сигнала каждого из двух или более входных сигналов микрофона, которая назначена указанному частотно-временному элементу (k, n).
Для каждой выборки выходного звукового сигнала, которая будет генерироваться для каждого частотно-временного элемента (k, n), генератор 110 весов вновь генерирует отдельную информацию взвешивания. Генератор 120 выходного сигнала затем генерирует выборку выходного звукового сигнала рассматриваемого частотно-временного элемента (k, n), на основании информации взвешивания, сгенерированной для этого частотно-временного элемента. Другими словами, новая информация взвешивания вычисляется с помощью генератора 110 весов для каждого частотно-временного элемента, для которого должна генерироваться выборка выходного звукового сигнала.
Когда генерируют информацию взвешивания, генератор 110 весов адаптирован для учета информации одного или более излучателей звука.
Например, генератор 110 весов может учитывать позицию первого излучателя звука. В варианте осуществления генератор весов может также учитывать позицию второго излучателя звука.
Или, например, первый излучателей звука может испускать первую звуковую волну с первой компонентой звука. Первая звуковая волна с первой компонентой звука достигает микрофона, и генератор 110 весов может учитывать направление прибытия первой компоненты звука/звуковой волны. С помощью этого генератор 110 весов учитывает информацию о первом излучателе звука. Кроме того, второй излучатель звука может испускать вторую звуковую волну со второй компонентой звука. Вторая звуковая волна со второй компонентой звука достигает микрофона, и генератор 110 весов может учитывать направление прибытия второй компоненты звука/второй звуковой волны. С помощью этого генератор 110 весов учитывает также информацию о втором излучателе звука.
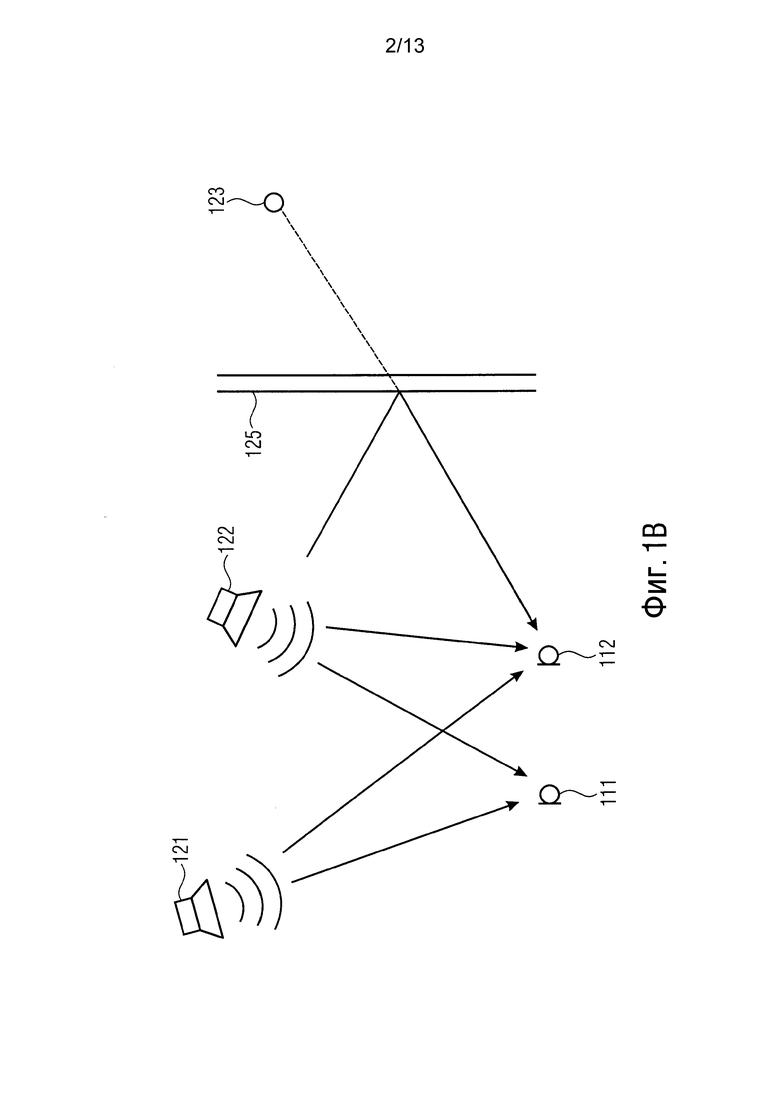
Фиг. 1B показывает возможный сценарий применения фильтра 100 согласно варианту осуществления. Первая звуковая волна с первой компонентой звука испускается первым громкоговорителем 121 (первым излучателем звука) и достигает первого микрофона 111. Направление прибытия первой компоненты звука (=направление прибытия первой звуковой волны) учитывается в первом микрофоне 111. Кроме того, вторая звуковая волна со второй компонентой звука испускается вторым громкоговорителем 122 (вторым излучателем звука) и достигает первого микрофона 111. Генератор 110 весов имеет возможность также учитывать направление прибытия второй компоненты звука в первом микрофоне 111 для определения информации взвешивания. Кроме того, направления прибытия компонент звука (=направления прибытия звуковых волн) в других микрофонах, таких как микрофон 112, могут также учитываться с помощью генератора весов для определения информации взвешивания.
Следует заметить, что излучатели звука могут, например, быть материальными излучателями звука, которые физически существуют в среде, например, громкоговорителями, музыкальными инструментами или говорящим человеком.
Однако, следует заметить, что излучатели зеркального отображения также являются излучателями звука. Например, звуковая волна, испускаемая динамиком 122, может отражаться стенкой 125, и тогда кажется, что звуковая волна испускается из расположения 123, отличающегося от расположения динамика, который фактически испускает звуковую волну. Такой излучатель 123 зеркального отображения также рассматривают в качестве излучателя звука. Генератор 110 весов может адаптироваться для генерации информации взвешивания в зависимости от информации направления прибытия, относящейся к излучателю зеркального отображения, или в зависимости от информации расположения, относящейся к одному, двум или более излучателей зеркального отображения.
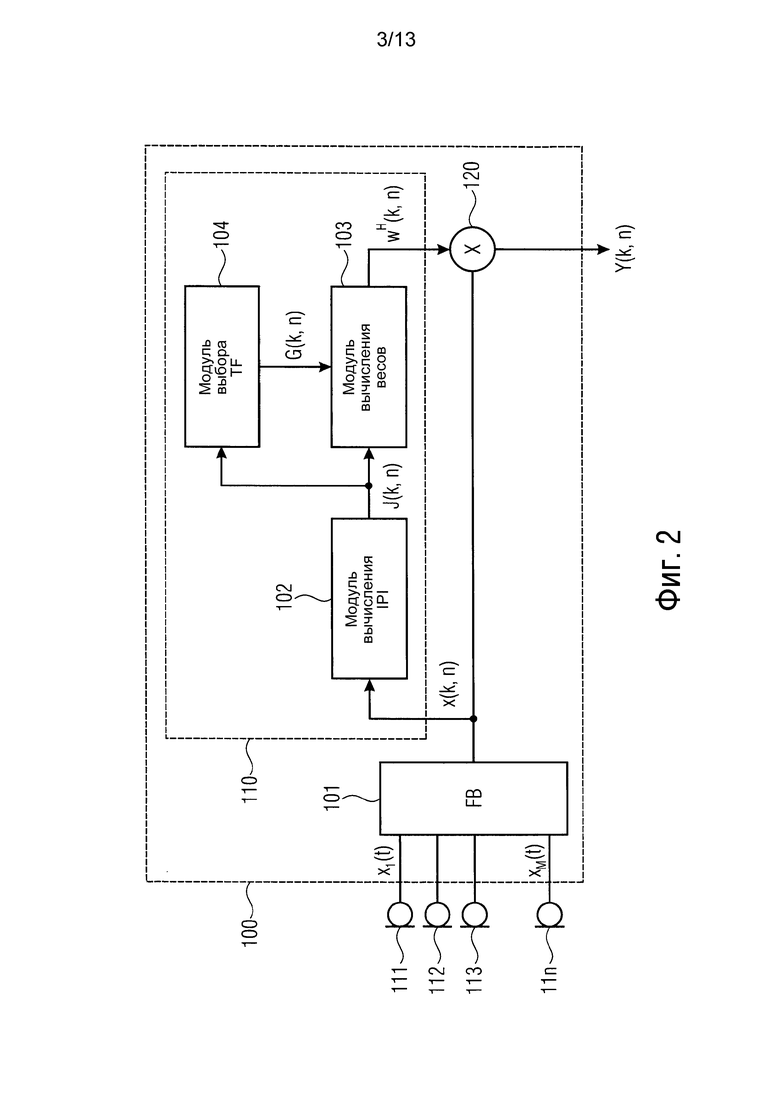
Фиг. 2 показывает фильтр 100 согласно варианту осуществления и множество микрофонов 111, 112, 113, ..., 11n. В варианте осуществления на фиг. 2 фильтр 100 кроме того содержит набор 101 фильтров. Кроме того, в варианте осуществления на фиг. 2 генератор 110 весов содержит модуль 102 вычисления информации, модуль 103 вычисления весов и модуль 104 выбора передаточной функции.
Обработка выполняется в частотно-временной области, причем k обозначает частотный показатель, и n обозначает показатель времени, соответственно. Входом на устройство (фильтр 100) являются M сигналов x1...M(t) микрофона во временной области от микрофонов 111, 112, 113, ..., 11n, которые преобразовываются в частотно-временную область с помощью набора 101 фильтров. Преобразованные сигналы микрофона задаются с помощью вектора
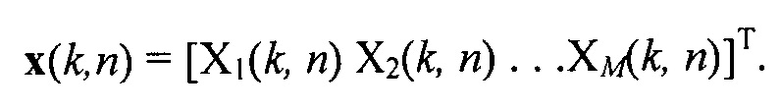
Фильтр 100 выводит искомый сигнал Y(k, n) (выходной звуковой сигнал). Выходной звуковой сигнал (искомый сигнал) Y(k, n) может, например, представлять усовершенствованный сигнал для монофонического воспроизведения, сигнал наушников для воспроизведения звука с бинауральным эффектом или сигнал громкоговорителя для воспроизведения пространственного звука с произвольной установкой громкоговорителя.
Искомый сигнал Y (k, n) генерируется с помощью генератора 120 выходного сигнала, например, с помощью выполнения линейной комбинации М сигналов x(k, n) микрофона, основываясь на мгновенных комплексных весах w(k, n)=[W1(k, n) W2 (k, n) ... WM(k, n)]T, например, используя формулу
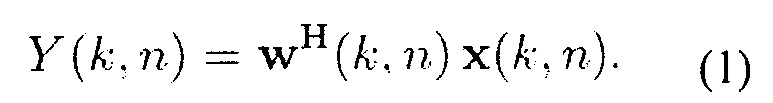
Веса w(k, n) определяются с помощью модуля 103 вычисления весов. Для каждого k и каждого n вновь определяются веса w(k, n). Другими словами, для каждого частотно-временного элемента (k, n) выполняется определение весов w(k, n). Более конкретно, веса w(k, n), например, вычисляются, основываясь на мгновенной параметрической информации (IPI) J(k, n) и основываясь на соответствующей искомой передаточной функции G(k, n).
Модуль 102 вычисления информации конфигурируется для вычисления IPI J(k, n) из сигналов x(k, n) микрофона. IPI описывает пространственные характеристики сигнала и шумовых компонент, содержащихся в сигналах x(k, n) микрофона, в течение заданного частотно-временного момента (k, n).
Фиг. 3 показывает генератор 110 весов согласно варианту осуществления. Генератор 110 весов содержит модуль 102 вычисления информации, модуль 103 вычисления весов и модуль 104 выбора передаточной функции.
Как показано в примере на фиг. 3, IPI прежде всего содержит мгновенное направление прибытия (DOA) одной или более компонент направленного звука (например, плоских волн), например, вычисленное с помощью модуля 201 оценки DOA.
Как объясняется ниже, информация DOA может быть представлена как угол (например, с помощью [азимутальный угол ϕ(k, n), угол места 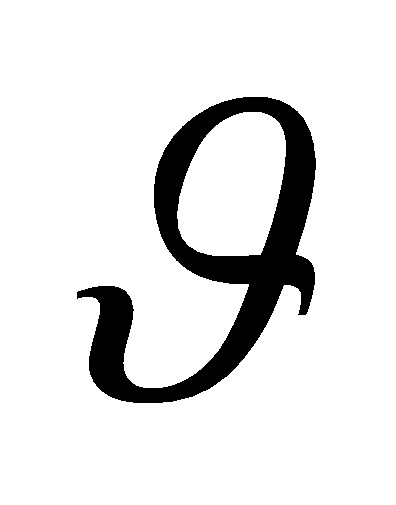 (k, n)]), с помощью пространственной частоты (например, μ[k | ϕ(k, n)]), с помощью сдвига фаз (например, a[k | ϕ(k, n)]), с помощью временной задержки между микрофонами, с помощью вектора распространения (например, с помощью a[k | ϕ(k, n)]), или с помощью интерауральной разницы по уровню (ILD) или интерауральной разницы по времени (ITD).
(k, n)]), с помощью пространственной частоты (например, μ[k | ϕ(k, n)]), с помощью сдвига фаз (например, a[k | ϕ(k, n)]), с помощью временной задержки между микрофонами, с помощью вектора распространения (например, с помощью a[k | ϕ(k, n)]), или с помощью интерауральной разницы по уровню (ILD) или интерауральной разницы по времени (ITD).
Кроме того, IPI J(k, n) может, например, содержать дополнительную информацию, например, статистические данные второго порядка (SOS) сигнальной или шумовой компоненты.
В варианте осуществления генератор 110 весов адаптирован для генерации информации взвешивания для каждого из множества частотно-временных элементов (k, n) в зависимости от статистической информации о сигнальной компоненте или шумовой компоненте двух или более входных сигналов микрофона. Такой статистической информацией, например, являются статистические данные второго порядка, упомянутые в данной работе. Статистическая информация может, например, быть мощностью шумовой компоненты, информацией отношения сигнала к рассеянному сигналу, информацией отношения сигнала к шуму, информацией отношения рассеянного сигнала к шуму, информацией отношения рассеянного сигнала к шуму, мощностью сигнальной компоненты, мощностью рассеянной сигнальной компоненты или мощностью спектральной матрицы плотности сигнальной компоненты или шумовой компоненты двух или более входных сигналов микрофона.
Статистические данные второго порядка могут вычисляться с помощью модуля 205 вычисления статистических данных. Эта статистическая информация второго порядка может, например, содержать мощность стационарной шумовой компоненты (например, собственных шумов), мощность нестационарной шумовой компоненты (например, рассеянного звука), отношение сигнала к рассеянному сигналу (SDR), отношение сигнала к шуму (SNR) или отношение рассеянного сигнала к шуму (DNR). Эта информация предоставляет возможность вычислять оптимальные веса w(k, n) в зависимости от критериев пространственной оптимизации.
«Стационарная шумовая компонента»/«медленно изменяющаяся шумовая компонента» является, например, шумовой компонентой со статистическими данными, которые не изменяются или медленно изменяются относительно времени.
«Нестационарная шумовая компонента» является, например, шумовой компонентой со статистическими данными, которые быстро изменяются со временем.
В варианте осуществления генератор 110 весов адаптирован для генерации информации взвешивания для каждого из множества частотно-временных элементов (k, n) в зависимости от первой шумовой информации, указывающей информацию о первых шумовых компонентах двух или более входных сигналов микрофона, и в зависимости от второй шумовой информации, указывающей информацию о вторых шумовых компонентах двух или более входных сигналов микрофона.
Например, первые шумовые компоненты могут быть нестационарными шумовыми компонентами, и первая шумовая информация может быть информацией о нестационарных шумовых компонентах.
Вторые шумовые компоненты могут, например, быть стационарными шумовыми компонентами/медленно изменяющимися шумовыми компонентами, и вторая шумовая информация может быть информацией о стационарных/медленно изменяющихся шумовых компонентах.
В варианте осуществления генератор 110 весов конфигурируется для генерации первой шумовой информации (например, информации о нестационарных/не являющихся медленно изменяющимися шумовых компонентах), используя, например, предварительно определенную статистическую информацию (например, информацию о пространственной когерентности между двумя или большим количеством входных сигналов микрофона, которая является результатом нестационарных шумовых компонент), и причем генератор 110 весов конфигурируется для генерации второй шумовой информации (например, информации о стационарных/медленно изменяющихся шумовых компонентах), не используя статистическую информацию.
По отношению к шумовым компонентам, которые изменяются быстро, одни только входные сигналы микрофона не предоставляют достаточную информацию для определения информации о таких шумовых компонентах. Статистическая информация, например, дополнительно должна определять информацию, относящуюся к быстро изменяющимся шумовым компонентам.
Однако, по отношению к шумовым компонентам, которые не изменяются или медленно изменяются, статистическая информация не является необходимой для определения информации об этих шумовых компонентах. Вместо этого достаточно оценивать сигналы микрофона.
Следует заметить, что статистическая информация может вычисляться, используя оцененную информацию DOA, как показано на фиг. 3. Дополнительно следует заметить, что IPI может также обеспечиваться внешним образом. Например, DOA звука (расположение излучателей звука, соответственно) может определяться с помощью видео камеры вместе с алгоритмом распознания лиц, предполагая, что говорящие люди формируют звуковую сцену.
Модуль 104 выбора передаточной функции конфигурируется для обеспечения передаточной функции G(k, n). (Потенциально комплексная) передаточная функция G(k, n) на фиг. 2 и фиг. 3 описывает искомую реакцию системы при условии (например, текущей параметрической) IPI J(k, n). Например, G(k, n) может описывать произвольный шаблон захвата искомого пространственного микрофона для улучшения сигнала при монофоническом воспроизведении, DOA-зависимое усиление громкоговорителя при воспроизведении громкоговорителя, или передаточную функцию слухового аппарата человека (HRTF) для воспроизведения с бинауральным эффектом.
Следует заметить, что обычно статистические данные записываемой звуковой сцены изменяются быстро по времени и частоте. Следовательно, IPI J(k, n) и соответствующие оптимальные веса w(k, n) действительны только для конкретного частотно-временного показателя и таким образом повторно вычисляются для каждого k и n. Поэтому, система может адаптироваться мгновенно к текущей ситуации записи.
Дополнительно следует заметить, что М входных микрофонов могут или формировать один массив микрофонов, или они могут быть распределяться для формирования множества массивов в различных расположениях. Кроме того, IPI J(k, n) может содержать информацию расположения вместо информации DOA, например, расположения излучателей звука в трехмерной комнате. С помощью этого могут определяться пространственные фильтры, которые не только фильтруют конкретные направления, которые необходимы, но и трехмерные пространственные области записываемой сцены.
Все объяснения, обеспеченные относительно DOA, одинаково применимы, когда доступна информация о расположении излучателя звука. Например, информация о расположении может быть представлена с помощью DOA (угла) и расстояния. Когда используется такое представление расположения, DOA может сразу получаться из информации расположения. Или информация расположения может, например, описываться с помощью координат x, y, z. Тогда DOA может легко вычисляться, основываясь на информации расположения излучателя звука и основываясь на расположении микрофона, который записывает соответствующий входной сигнал микрофона.
В последующем описаны дополнительные варианты осуществления.
Некоторые варианты осуществления предоставляют возможность пространственно выборочную запись звука с подавлением реверберации и уменьшением шума, в данном контексте обеспечены варианты осуществления для применения пространственной фильтрации для улучшения сигнала на основе выделения излучателя, подавления реверберации и уменьшения шума. Целью таких вариантов осуществления является вычисление сигнала Y(k, n), который соответствует выходу направленного микрофона с произвольным шаблоном захвата. Это подразумевает, что направленный звук (например, одна плоская волна) ослабляется или сохраняется в качестве искомого в зависимости от его DOA, в то время как рассеянный звук или собственные шумы микрофона устраняются. Согласно вариантам осуществления обеспеченный пространственный фильтр объединяет преимущества пространственных фильтров уровня техники, среди прочего обеспечивая высокий индекс направленности (DI) в ситуациях с высоким DNR и высокое усиление белого шума (WNG) в иных случаях. Согласно некоторым вариантам осуществления пространственный фильтр может только линейно ограничиваться, что предоставляет возможность быстрого вычисления весов. Например, передаточная функция G(k, n) на фиг. 2 и фиг. 3 может, например, представлять искомый шаблон захвата направленного микрофона.
В последующем обеспечивается формулировка задачи. Затем обеспечиваются варианты осуществления модуля 103 вычисления весов и модуля 102 вычисления IPI для пространственно выборочной записи звука с подавлением реверберации и уменьшением шума. Кроме того, описываются варианты осуществления соответствующего модуля 104 выбора TF.
Сначала обеспечена формулировка задачи. Рассматривают массив из М всенаправленных микрофонов, расположенных в местоположениях d1…M. Для каждого (k, n) предполагается, что звуковое поле состоит из L<М плоских волн (направленный звук), распространяющихся в изотропном и пространственно однородном поле рассеянного звука. Сигналы х(k, n) микрофона могут записываться как
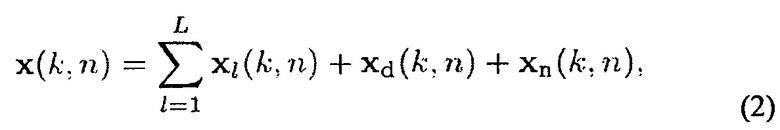
где xl(k, n)=[Xl(k, n, dl)…Xl(k, n, dM)]T содержит сигналы микрофона, которые пропорциональны звуковому давлению 1-й плоской волны, xd(k, n) является взвешенным нестационарным шумом (например, рассеянным звуком), и xn(k, n) является стационарным шумом/медленно изменяющимся шумом (например, собственными шумами микрофона).
Предполагая, что три компоненты в формуле (2) взаимно некоррелированы, матрица спектральной плотности мощности (PSD) сигналов микрофона может описываться с помощью
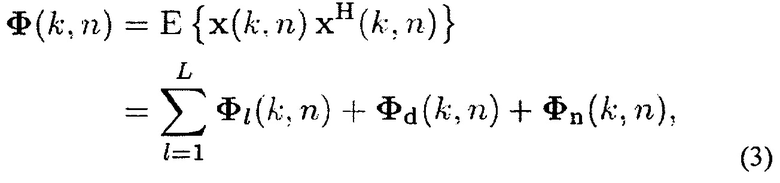
При
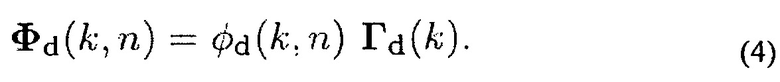
Где Е - обозначает функцию математического ожидания (Expectation).
В данном случае Фn(k, n) является матрицей PSD стационарного шума/медленно изменяющегося шума, и ϕd(k, n) является ожидаемой мощностью нестационарного шума, который может изменяться быстро по времени и частоте, ij-й элемент матрицы Гd(k) когерентности, обозначенный с помощью yij(k), является когерентностью между микрофонами i и j, которая является результатом нестационарного шума. Например, для сферически изотропного рассеянного поля yij(k)=sinc (к rij) [20] с номером волны к и rij=||dj-di|||, где rij равен расстоянию между j-м и i-м микрофонами, ij-й элемент матрицы Гn(k) когерентности является когерентностью между микрофонами i и j, которая является результатом стационарного шума/медленно изменяющегося шума. Для собственных шумов микрофона Фn(k, n)=ϕn (k, n) I, где I - единичная матрица, и ϕn(k, n) является ожидаемой мощностью собственных шумов.
Направленный звук xl(k, n) в (2) может записываться как
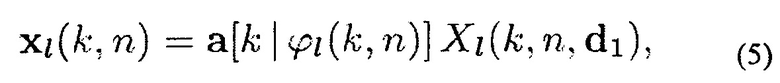
где ϕl(k, n) является азимутом DOA l-й плоской волны (ϕ=0 обозначает направление, перпендикулярное плоскости массива антенн) и a[k|ϕl(k, n)]=[a1[kϕl(k, n)]…[аM[kϕl(k, n)]]T является вектором распространения, i-й элемент a[kIϕl(k, n)]
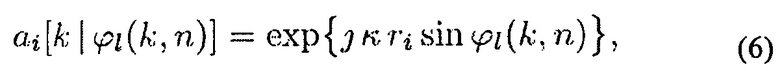
описывает сдвиг фаз i-й плоской волны между первым и i-м микрофонами. Следует заметить, что ri=||di-d1|| равен расстоянию между первым и i-м микрофонами.
Угол ∠ai[k|ϕl(k, n)]=μi[k|ϕl(k, n)] часто упоминается как пространственная частота. DOA l-й волны может быть представлен с помощью ϕl (k, n), аi[k|ϕl (k, n))], а[k|ϕl (k, n))] или с помощью μi[k|ϕl(k, n)].
Как объяснено выше, целью варианта осуществления является фильтрация сигналов х(k, n) микрофона таким образом, чтобы направленные звуки, прибывающие из конкретных пространственных областей, ослаблялись или усиливались, как необходимо, в то время как стационарный и нестационарный шум устранялся. Искомый сигнал может поэтому выражаться как
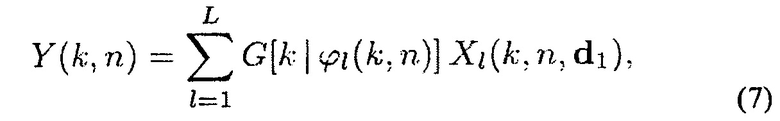
в которой G[k|ϕ(k, n)] является действительной или комплексной произвольной, например, предварительно определенной функцией направленности, которая может зависеть от частоты.
Фиг. 4 относится к сценарию с двумя произвольными функциями направленности и расположениями излучателя согласно варианту осуществления. В частности, фиг. 4 показывает амплитуду двух примерных направленностей G1[k|ϕ(k, n)] и G2[k|ϕ(k, n)]. Когда используют G1[k|ϕ(k, n)] (см. сплошную линию на фиг. 4), направленный звук, прибывающий от ϕ<45°, ослабляется на 21 дБ, в то время как направленный звук от других направлений не ослабляется. В принципе, могут разрабатываться произвольные направленности, даже функции, такие как G2[k|ϕ(k, n)] (см. пунктирную линию на фиг. 4). Кроме того, G[kIϕ(k, n)] может разрабатываться как величина, зависящая от времени, например, для выделения перемещающихся или внезапно появляющихся излучателей звука, как только их расположение определено.
Оценка сигнала Y(k, n) получается с помощью линейной комбинации сигналов х(k, n) микрофона, например, с помощью
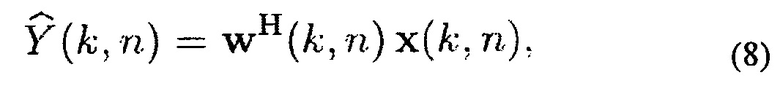
где w(k, n) является комплексным вектором веса с длиной М. Соответствующий оптимальный вектор веса w(k, n) выводится в последующем. В последующем зависимость весов w(k, n) от k и n опущена для краткости.
Далее описываются два варианта осуществления модуля 103 вычисления весов на фиг. 2 и фиг. 3.
Из (5) и (7) следует, что w(k, n) должны соответствовать линейным ограничениям
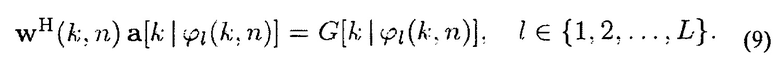
Кроме того, мощность нестационарного и стационарного/медленно изменяющегося шума на выходе фильтра должна минимизироваться.
Фиг. 5 изображает вариант осуществления изобретения для применения пространственной фильтрации. В частности, фиг. 5 показывает генератор 110 весов согласно другому варианту осуществления. Снова, генератор 110 весов содержит модуль 102 вычисления информации, модуль 103 вычисления весов и модуль 104 выбора передаточной функции.
Более конкретно, фиг. 5 показывает подход минимальной дисперсии с линейными ограничениями (LCMV). В данном варианте осуществления (см. фиг. 5) веса w(k, n) вычисляются, основываясь на IPI l(k, n), содержащей DOA L плоских волн, и на статистических данных стационарного и нестационарного шума. Последняя информация может содержать DNR, отдельные мощности ϕn (k, n) и ϕd (k, n) двух шумовых компонент или матрицы PSD Фn и Фd двух шумовых компонент.
Например, Фd может рассматриваться в качестве первой шумовой информации о первой шумовой компоненте из двух шумовых компонент, и Фn может рассматриваться в качестве второй шумовой информации о второй шумовой компоненте из двух шумовых компонент.
Например, генератор 110 весов может конфигурироваться для определения первой шумовой информации Фd, зависящей от одной или более когерентностей между по меньшей мере некоторыми из первых шумовых компонент одного или более входных сигналов микрофона. Например, генератор 110 весов может конфигурироваться для определения первой шумовой информации в зависимости от матрицы Гd(k) когерентности, указывающей когерентности, являющиеся результатом первых шумовых компонент двух или более входных сигналов микрофона, например, с помощью применения формулы
Фd(k,n)=φd(k,n)Гd(k).
Одна или более когерентностей определяются предварительно.
Веса w(k, n) для решения задачи в (8) находят с помощью минимизации суммы мощностей собственных шумов (стационарного шума/медленно изменяющегося шума) и мощности рассеянного звука (нестационарного шума) на выходе фильтра, то есть
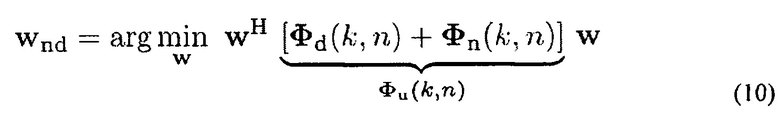
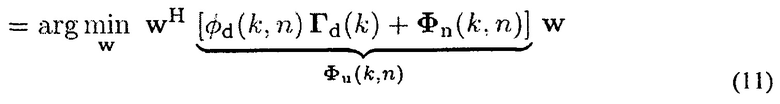
Фu=Фd+Фn
Используя (4) и принимая Фn(k, n)=ϕn (k, n) I, задача оптимизации может быть выражена как
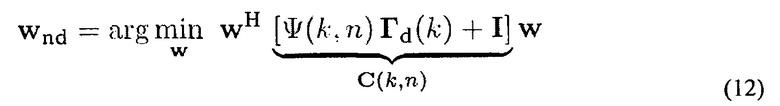
Где
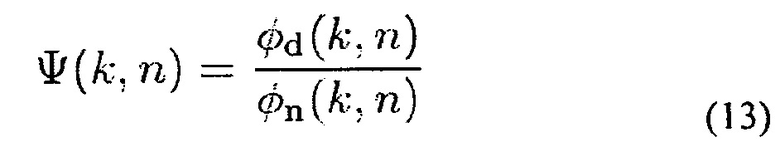
является изменяющимся во времени входным DNR в микрофонах. Решением (10) и (12), учитывая ограничения (9), является [21]
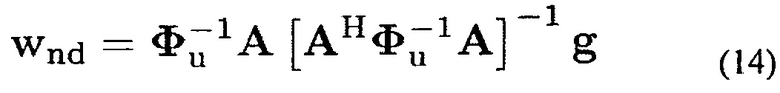
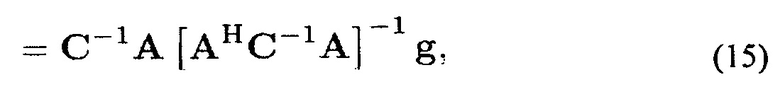
где А(k, n)=[а[k|ϕ1(k, n)]…а[k|ϕl(k, n)]] содержит информацию DOA для L плоских волн на основе векторов распространения. Соответствующие искомые усиления задаются с помощью
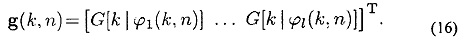
Варианты осуществления оценки Ψ(k, n) и другой требуемой IPI описываются ниже.
Другие варианты осуществления основаны на параметрическом многоканальном Винеровском фильтре. В таких вариантах осуществления, которые показаны на фиг. 6, IPI дополнительно содержит информацию о статистических данных сигнала, например, матрицу Фs(k, n) PSD сигнала, содержащую энергии L плоских волн (направленного звука). Кроме того, дополнительные параметры λ1…L(k, n) управления, как полагают, управляют величиной искажения сигнала для каждой из L плоских волн.
Фиг. 6 показывает вариант осуществления для применения пространственной фильтрации, воплощающий генератор 110 весов, используя параметрический многоканальный Винеровский фильтр. Снова, генератор 110 весов содержит модуль 102 вычисления информации, модуль 103 вычисления весов и модуль 104 выбора передаточной функции.
Веса w(k, n) вычисляются через подход многоканального Винеровского фильтра. Винеровский фильтр минимизирует мощность разностного сигнала на выходе, то есть
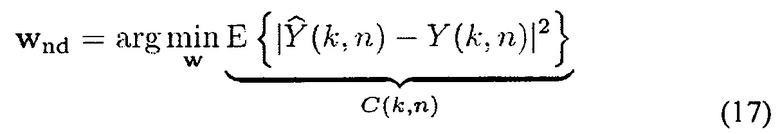
Функция C(k, n) стоимости для минимизации может записываться как
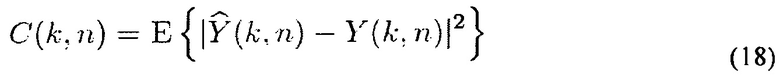
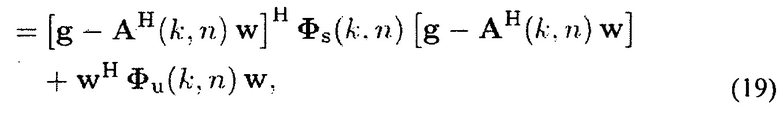
где w указывает вторую информацию взвешивания, Фs(k, n)=E{xs(k, n)xs(k, n)H} содержит PSD направленного звука, и xs(k, n)=[X1(k, n, d1)Х2(k, n, d1)…XL(k, n, d1)] содержит сигналы, пропорциональные звуковым давлениям L плоских волн в эталонном микрофоне. Следует заметить, что Фs(k, n) является диагональной матрицей, где диагональные элементы diag{Фs(k, n)}=[ϕ1(k, n)…ϕL(k, n)]T являются мощностями прибывающих плоских волн. Для управления представленными искажениями сигнала, она может включать в себя диагональную матрицу Λ (k, n), содержащую зависящие от времени и частоты управляющие параметры diag{Λ}=[λ1(k, n)λ2(k, n)…λL(k, n)}T, то есть функция стоимости мощности
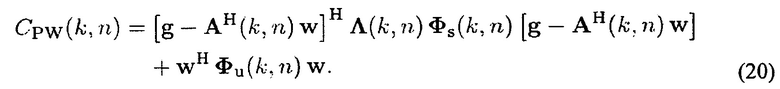
Решением задачи минимизации в (17) при условии CPW(k, n) является
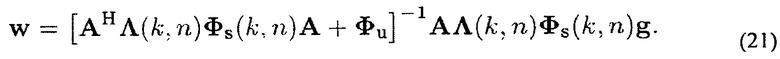
Это идентично
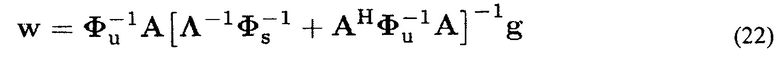
Следует заметить, что для Λ-1=0 получается решение LCMV в (14). Для Λ-1=I получается многоканальный Винеровский фильтр. Для других значений λ1…L(k, n) величина искажений соответствующего сигнала излучателя и значение подавления остаточного шума, могут управляться, соответственно. Поэтому, обычно определяют λ1-1(k, n) в зависимости от доступной параметрической информации, то есть
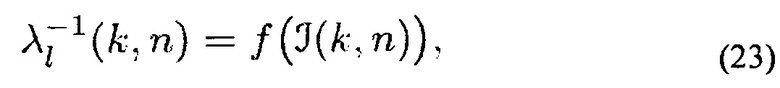
где f(⋅) - произвольная определяемая пользователем функция. Например, можно выбирать λ1…L(k, n) согласно
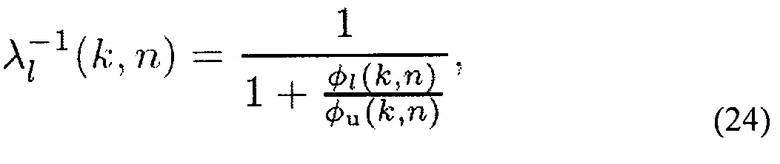
где ϕl(k, n) – мощность l-го сигнала (l-й плоской волны) и ϕu(k, n)=ϕn(k, n)+ϕd(k, n) является мощностью нежелательного сигнала (стационарного шума/медленно изменяющегося шума плюс нестационарного шума). С помощью этого параметрический Винеровский фильтр зависит от статистической информации о сигнальной компоненте двух или более входных сигналов микрофона, и таким образом параметрический Винеровский фильтр дополнительно зависит от статистической информации о шумовой компоненте двух или более входных сигналов микрофона.
Если излучатель l является сильным по сравнению с шумом, то λl-1(k, n) получается близким к нолю, означая, что решение LCMV получено (нет искажения сигнала излучателя). Если шум является сильным по сравнению с мощностью излучателя, то λl-1(k, n) получается близким к единице, означая, что получается многоканальный Винеровский фильтр (сильное подавление шума).
Оценка Φs(k, n) и Фu(k, n) описывается ниже.
В последующем описываются варианты осуществления модуля 102 мгновенной оценки параметра.
Различная IPI должна оцениваться до того, как могут вычисляться веса. DOA L плоских волн, вычисленные в модуле 201, могут получаться с помощью известных узкополосных средств оценки DOA, таких как ESPRIT [22] или root MUSIC [23], или других средств оценки уровня техники. Эти алгоритмы могут обеспечивать, например, азимутальный угол ϕ(k, n), пространственную частоту μ[k | ϕ(k, n)], сдвиг фаз a[k | ϕ(k, n)], или вектор распространения a[k I ϕ(k, n)] для одной или более волн, прибывающих в массив. Оценка DOA не будет дополнительно обсуждаться, поскольку сама оценка DOA известна из уровня техники.
В последующем описывается оценка отношения рассеянного сигнала к шуму (DNR). В частности, обсуждается оценка входного DNR Ψ(k, n), то есть реализация модуля 202 на фиг. 5. Оценка DNR использует информацию DOA, полученную в модуле 201. Для оценки Ψ(k, n) может использоваться дополнительный пространственный фильтр, который гасит L плоских волн, так что только рассеянный звук фиксируется. Веса этого пространственного фильтра находят, например, с помощью максимизации массива WNG, то есть
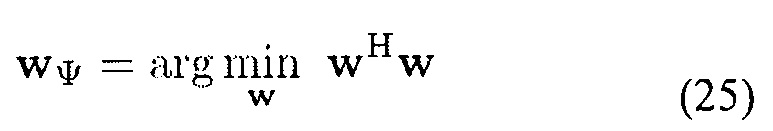
при условии
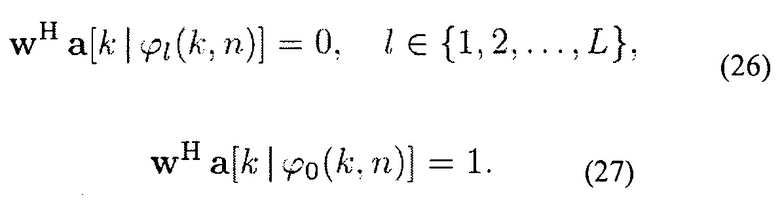
Ограничение (27) обеспечивает ненулевые веса WΨ. Вектор распространения a[k | ϕ (k, n)] соответствует пространственному направлению ϕ0(k, n), которое отличается от DOA ϕl(k, n) L плоских волн. В последующем для ϕ0(k, n) выбирается направление, которое имеет наибольшее расстояние ко всем ϕl(k, n), то есть
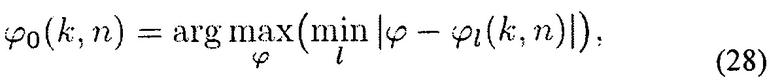
где ϕ 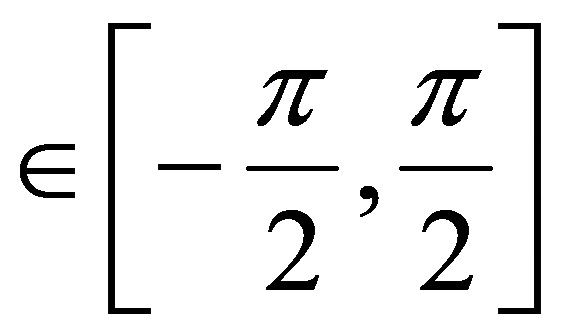 . Учитывая веса WΨ, выходная мощность дополнительного пространственного фильтра задается с помощью
. Учитывая веса WΨ, выходная мощность дополнительного пространственного фильтра задается с помощью
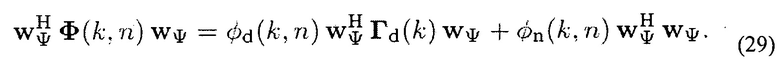
Вход DNR может теперь вычисляться с помощью (13) и (29), то есть
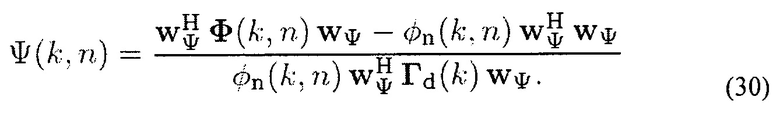
Требуемая ожидаемая мощность собственных шумов микрофона ϕn (k, n) может, например, оцениваться во время тишины, предполагая, что мощность является постоянной или медленно изменяющейся с течением времени. Следует заметить, что предложенное средство оценки DNR не обязательно обеспечивает самую низкую дисперсию оценок на практике из-за выбранных критериев оптимизации (45), но обеспечивает неискаженные результаты.
В последующем обсуждается оценка нестационарной PSD ϕd(k, n), то есть другая реализация модуля (202) на фиг. 5. Мощность (PSD) нестационарного шума может оцениваться с помощью
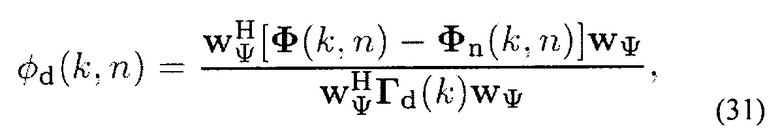
где WΨ определен в предыдущем абзаце. Следует заметить, что матрица PSD стационарного/медленно изменяющегося шума Φn(k, n) может оцениваться во время тишины (то есть во время отсутствия сигнала и нестационарного шума), то есть
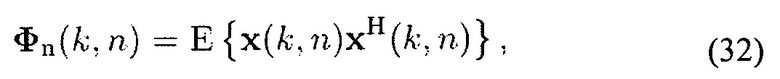
где ожидание аппроксимируется с помощью усреднения по n кадрам тишины. Кадры тишины могут обнаруживаться с помощью способов уровня техники.
В последующем обсуждается оценка матрицы PSD нежелательного сигнала (см. модуль 203).
Матрица PSD нежелательного сигнала (стационарного/медленно изменяющегося шума плюс нестационарного шума) Φu(k, n) может получаться с помощью
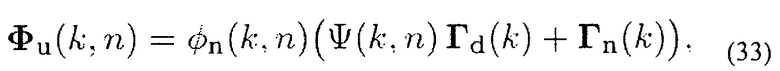
или более обобщенно с помощью
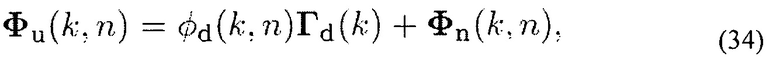
где Гd(k) и Гn(k) доступны в качестве априорной информации (см. выше). DNR Ψ(k, n), мощность стационарного/медленно изменяющегося шума ϕn(k, n) и другие требуемые количественные параметры могут вычисляться, как объяснено выше. Поэтому, оценка Φu(k, n) использует информацию DOA, полученную с помощью модуля 201.
В последующем описывается оценка матрицы PSD сигнала (см. модуль 204).
Мощность ϕ1...L(k, n) прибывающих плоских волн, требуемая для вычисления Фs(k, n), может вычисляться с помощью
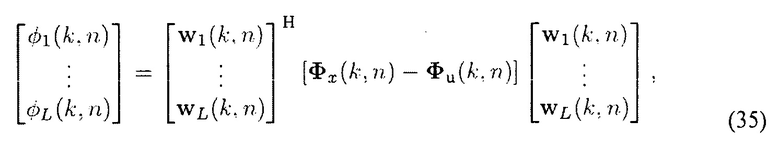
где веса wl подавляют все прибывающие плоские волны, кроме l-й волны, то есть
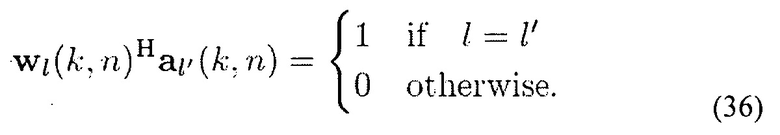
Например,
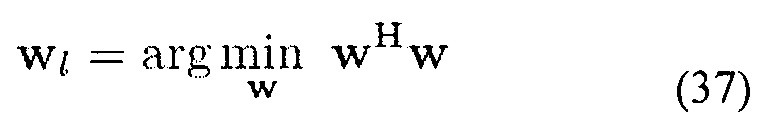
при условии (36). Оценка Φs(k, n) использует информацию DOA, полученную в модуле (201). Требуемая матрица PSD нежелательных сигналов Фu(k, n) может вычисляться, как объяснено в предыдущем абзаце.
Далее описывается модуль 104 выбора передаточной функции согласно варианту осуществления.
В данной заявке усиление G [k | ϕl(k, n)] может быть найдено для соответствующей плоской волны l в зависимости от информации DOA ϕl(k, n). Передаточная функция G[k | ϕ(k, n)] для различных DOA ϕ(k, n) доступна для системы, например, в качестве определяемой пользователем априорной информации. Усиление может также вычисляться, основываясь на анализе изображения, например, используя расположения обнаруженных лиц. Два примера изображены на фиг. 4. Эти передаточные функции соответствуют искомым шаблонам захвата направленного микрофона. Передаточная функция G[k | ϕl(k, n)] может обеспечиваться, например, в качестве таблицы поиска, то есть для оцениваемого ϕl(k, n) выбирают соответствующее усиление G[k | ϕl(k, n)] из таблицы поиска. Следует заметить, что передаточная функция может также определяться в качестве пространственной функции частоты μ[k | ϕ(k, n)] вместо азимута ϕl(k, n), то есть G(k, μ) вместо G[k | ϕ(k, n)]. Усиления могут также вычисляться, основываясь на информации расположения излучателя, вместо информации DOA.
Теперь обеспечены экспериментальные результаты. Следующие результаты моделирования демонстрируют практическую применимость вышеописанных вариантов осуществления. Предложенная система сравнивается с системами уровня техники, которые будут объяснены ниже. Затем обсуждается экспериментальная установка, и обеспечиваются результаты.
Сначала рассматривают существующие пространственные фильтры.
Хотя PSD ϕn(k, n) может оцениваться в течение периодов тишины, ϕd(k, n) обычно принимается неизвестным и ненаблюдаемым. Поэтому рассматривают два существующих пространственных фильтра, которые могут вычисляться без этого знания.
Первый пространственный фильтр известен как формирователь луча по принципу задержки и суммирования, и он минимизирует мощность собственных шумов на выходе фильтра [то есть, максимизирует WNG] [1]. Оптимальный вектор веса, который минимизирует среднеквадратическую погрешность (MSE) между (7) и (8) при условии (9), затем получается с помощью
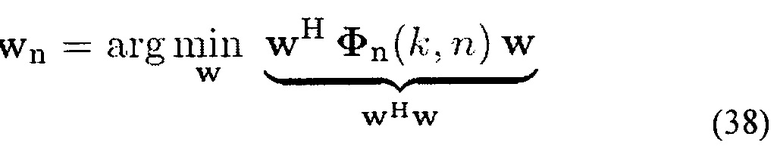
Существует аналитическое решение (38) [1], которое предоставляет возможность быстрого вычисления wn. Следует заметить, что этот фильтр не обязательно обеспечивает наибольший DI.
Второй пространственный фильтр известен как устойчивый сверхнаправленный (SD) формирователь луча, и он минимизирует мощность рассеянного звука на выходе фильтра [то есть максимизирует DI] с нижней границей на WNG [24]. Нижняя граница на WNG увеличивает устойчивость к погрешностям в векторе распространения и ограничивает усиление собственных шумов [24]. Оптимальный вектор веса, который минимизирует MSE между (7) и (8) при условии (9) и удовлетворяет нижней границе на WNG, затем получается с помощью
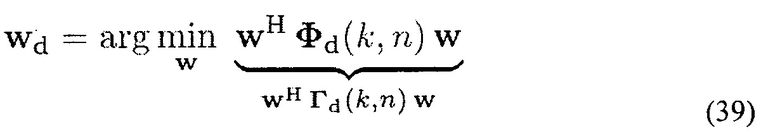
и при условии квадратичного ограничения wH w<β. Параметр β-1 определяет минимальное WNG и определяет доступный DI фильтра. Практически, часто трудно найти оптимальный компромисс между достаточным WNG в ситуациях низкого SNR и достаточно высоким DI в ситуациях высокого SNR. Кроме того, решение (39) приводит к задаче невыпуклой оптимизации из-за квадратичного ограничения, которая отнимает много времени для решения. Это особенно проблематично, так как комплексный вектор веса должен повторно вычисляться для каждого k и n из-за изменяющихся во времени ограничений (9).
Теперь рассматривают экспериментальную установку. Принимая L=2 плоские волны в модели в (2) и равномерную линейную матрицу (ULA) с М=4 микрофонами с расстоянием между микрофонами 3 см, крошечная комната (7,0×5,4×2,4 м3, RT60≈380 мс) моделировалась, используя способ изображения излучателя [25, 26] с двумя излучателями речи при ϕA=86° и ϕB=11°, соответственно (расстояние 1,75 м, сравни с фиг. 4). Сигналы состояли из 0,6 с тишины, за которой следовал одновременный разговор. Белый гауссов шум добавлялся к сигналам микрофона, что привело к сегментному отношению сигнала к шуму (SSNR), равному 26 дБ. Звук дискретизировался с частотой 16 кГц и преобразовывался в частотно-временную область, используя STFT с 512 точками с 50%-ым перекрытием.
Рассматривается функция G1(ϕ) направленности на фиг. 4, то есть излучатель A должен извлекаться без искажений, когда мощность излучателя B ослабляется на 21 дБ. Рассматриваются приведенные выше два пространственных фильтра и обеспеченный пространственный фильтр. Для устойчивого SD формирователя луча (39) минимальное WNG устанавливается в -12 дБ. Для обеспеченного пространственного фильтра (12) DNR Ψ(k, n) оценивается, как объяснено выше. Мощность собственных шумов ϕn(k, n) вначале вычисляется из тихой части сигнала. Ожидание в (3) аппроксимируется с помощью рекурсивного временного усреднения по τ=50 мс.
В последующем рассматриваются независимые от времени ограничения направлений.
Для этого моделирования предполагается априорное знание о расположениях двух излучателей ϕA и ϕB. На всех этапах обработки использовались ϕ1(k, n)=ϕΑ и ϕ2(k, n)=ϕB. Поэтому ограничения направления в (9) и (26) не изменяются по времени.
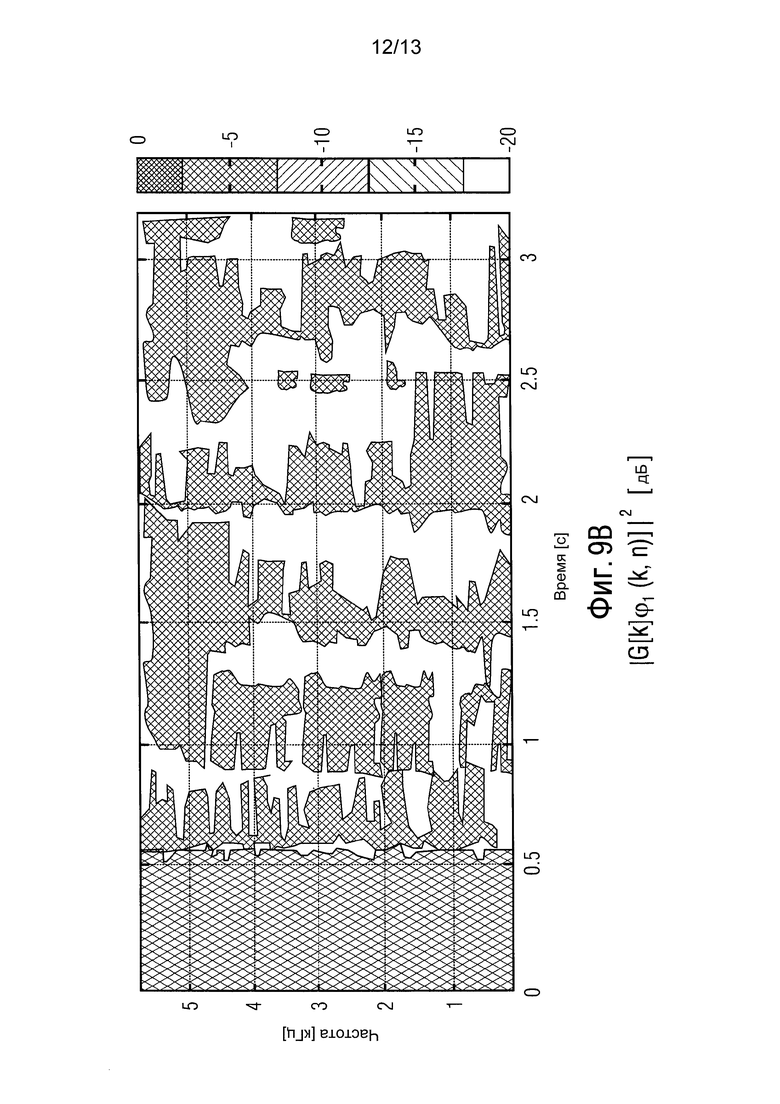
Фиг. 7 показывает реальное и оцененное DNR Ψ(k, n). Две отмеченные области указывают, соответственно, тихую и активную компоненты сигнала. В частности, фиг. 7 изображает реальное и оцененное DNR Ψ(k, n) в качестве функции от времени и частоты. Относительно высокое DNR во время речевой активности получают из-за реверберирующей среды. Оцененное DNR на фиг. 7B обладает ограниченным временным разрешением из-за внедренного процесса временного усреднения. Тем не менее, оценки Ψ(k, n) достаточно точны, как показано с помощью нижеперечисленных результатов.
Фиг. 8A изображает средний DI для wn и wd (которые оба не зависят от сигнала) и для предложенного пространственного фильтра wnd (который зависит от сигнала). Для предложенного пространственного фильтра показывают DI для тихой части сигнала и во время речевого действия [обе части сигнала обозначены на фиг. 7B]. Во время тишины предложенный пространственный фильтр (пунктирная линия wnd) обеспечивает такой же низкий DI, как wn. Во время речевого действия (сплошная линия wnd) полученный DI является таким же высоким, как для устойчивого формирователя луча (wd). Фиг. 8B показывает соответствующие WNG. Во время тишины предложенный пространственный фильтр (пунктирная линия wnd) достигает высокого WNG, в то время как во время действия сигнала WNG относительно низкое.
Фиг. 8: DI и WNG сравниваемых пространственных фильтров. Для wd минимальное WNG было установлено в -12 дБ чтобы сделать пространственный фильтр устойчивым по отношению к собственным шумам микрофона.
В общем случае фиг. 8 показывает, что предложенный пространственный фильтр объединяет преимущества обоих существующих пространственных фильтров: во время частей тишины обеспечивается максимальное WNG, что приводит к минимальному усилению собственных шумов, то есть к высокой устойчивости.
Во время действия сигнала и высокой реверберации, когда собственные шумы обычно маскируются, обеспечивается высокий DI (за счет низкого WNG), что приводит к оптимальному уменьшению рассеянного звука. В этом случае даже довольно небольшие WNG являются терпимыми.
Следует заметить, что для верхних частот (f5 кГц) все пространственные фильтры работают почти идентично, так как матрица когерентности Гd(k) в (39) и (12) приблизительно равна единичной матрице.
В последующем рассматриваются мгновенные направленные ограничения.
Для этого моделирования предполагается, что никакая априорная информация о ϕA и ϕB не доступна. DOA ϕ1(k, n) и ϕ2(k, n) оцениваются с помощью ESPRIT. Таким образом, ограничения (9) изменяются по времени. Только для устойчивого SD формирователя луча (wd) используется единственное и независимое от времени ограничение (9), соответствующее фиксированному направлению взгляда ϕA=86°. Этот формирователь луча служит в качестве эталонного.
Фиг. 9 изображает оцененное DOA ϕ1(k, n) и результирующие усиления G[k | ϕ1(k, n)]. В частности, фиг. 9 показывает оцененное DOA ϕ1(k, n) и результирующее усиление |G [k | ϕ1(k, n)]|2. Прибывающая плоская волна не ослабляется, если DOA находится в пространственном окне на фиг. 4 (сплошная линия). Иначе, мощность волны ослабляется на 21 дБ.
Таблица 1 иллюстрирует эффективность всех пространственных фильтров [* необработанных]. Значения в скобках относятся к независимым от времени направленным ограничениям, значения не в скобках относятся к мгновенным направленным ограничениям. Сигналы были взвешены по шкале A перед вычислением SIR, SRR и SSNR.
В частности, таблица 1 суммирует общую эффективность пространственных фильтров на основе отношения сигнала к помехе (SIR), отношения сигнала к реверберации (SRR) и SSNR на выходе фильтра. На основе SIR и SRR (разделение излучателей, подавление реверберации) предложенный подход (wnd) и устойчивый SD формирователь луча (wd) обеспечивает самую высокую эффективность. Однако, SSNR предложенного wnd на -6 дБ выше, чем SSNR wd, что представляет ясно слышимое преимущество. Наилучшая эффективность на основе SSNR получается, используя wn. На основе PESQ wnd и wd превосходят wn. Использование мгновенных направленных ограничений вместо независимых от времени ограничений (значения в скобках) главным образом уменьшает доступное SIR, но обеспечивает быструю адаптацию в случае изменения расположения излучателя. Следует заметить, что время вычисления всех требуемых комплексных весов за временной кадр было больше 80 с для wd (инструментальные средства CVX [27, 28]) и меньше 0,08 с для предложенного подхода (MATLAB R2012b, MacBook Pro 2008).
В последующем описываются варианты осуществления для воспроизведения пространственного звука. Целью вариантов осуществления является фиксация звуковой сцены, например, с помощью массива микрофонов, и воспроизведение пространственного звука с помощью произвольной системы воспроизведения звука (например, установки громкоговорителей 5,1, воспроизведения с помощью головного телефона) таким образом, чтобы повторно создавалось исходное пространственное впечатление. Предполагают, что система воспроизведения звука содержит N каналов, то есть вычисляют N выходных сигналов Y(k, n).
Сначала обеспечивают формулировку задачи. Рассматривают модель сигнала (см. приведенную выше формулу (2)), и формулируют аналогичную задачу. Стационарный/медленно изменяющийся шум соответствует нежелательным собственным шумам микрофона, в то время как нестационарный шум соответствует искомому рассеянному звуку. Рассеянный звук является искомым в данной заявке, поскольку он имеет большое значение для воспроизведения исходного пространственного впечатления от сцены регистрации.
В последующем будет достигнуто воспроизведение направленного звука Xl(k, n, dl) без искажений от соответствующего DOA ϕl(k, n). Кроме того, рассеянный звук должен воспроизводиться с правильной энергией от всех направлений, в то время как устраняются собственные шумы микрофона. Поэтому, искомый сигнал Y(k, n) в (7) теперь выражается как
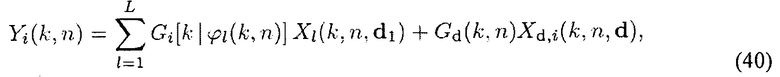
где Yi(k, n) является сигналом i-го канала системы воспроизведения звука (i={1,..., N}), Xd,i(k, n, d) является взвешенным рассеянным звуком в произвольной точке (например, в первом микрофоне d1), который воспроизводится от громкоговорителя i, и Gd(k, n) является функцией усиления для рассеянного звука для обеспечения правильной мощности рассеянного звука во время воспроизведения (обычно Gd(k, n)=1/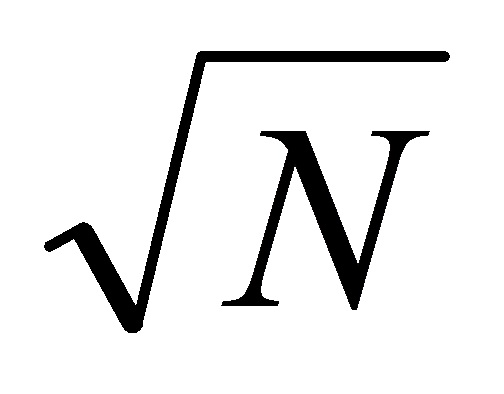 ). В идеале, сигналы Xd,i(k, n) имеют правильную мощность рассеянного звука и взаимно некоррелированы по каналам i, то есть
). В идеале, сигналы Xd,i(k, n) имеют правильную мощность рассеянного звука и взаимно некоррелированы по каналам i, то есть
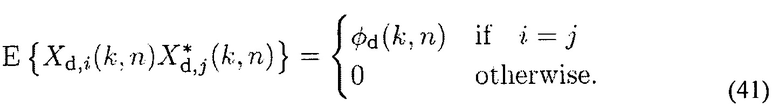
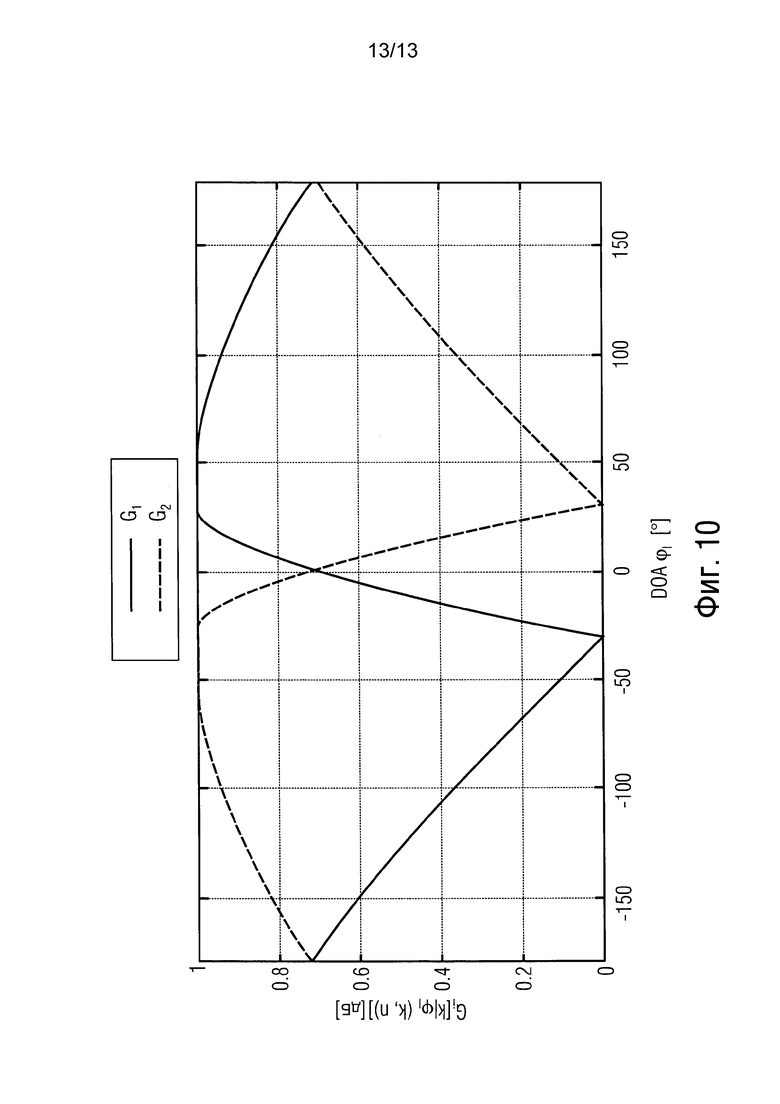
передаточная функция Gi[k | ϕl(k, n)] для направленных компонент звука соответствует DOA-зависимой функции усиления громкоговорителя. Пример для случая воспроизведения стереофонического громкоговорителя изображен на фиг. 10. Если волна I прибывает от ϕl(k, n)=30°, то G1 = 1 и G2=0.
Это означает, что направленный звук воспроизводится только от канала i=1 системы воспроизведения (левого канала). Для ϕl(k, n)=0°, имеется G1=G2=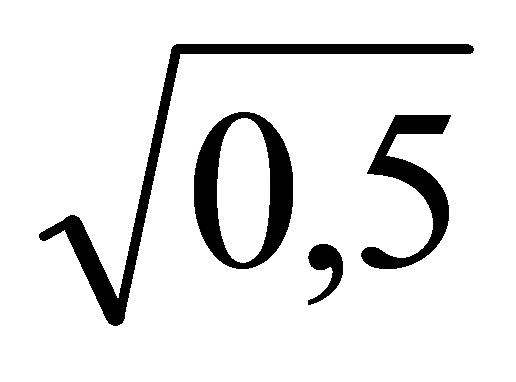 , то есть, направленный звук воспроизводится с равной мощностью от обоих громкоговорителей. Альтернативно, Gi[k I ϕl(k, n)] может соответствовать HRTF, если необходимо воспроизведение с бинауральным эффектом.
, то есть, направленный звук воспроизводится с равной мощностью от обоих громкоговорителей. Альтернативно, Gi[k I ϕl(k, n)] может соответствовать HRTF, если необходимо воспроизведение с бинауральным эффектом.
Сигналы Yi(k, n) оцениваются через линейную комбинацию сигналов микрофона, основываясь на комплексных весах w(k, n), как объяснено выше, то есть
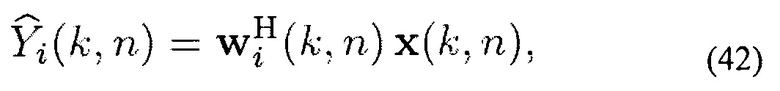
при условиях конкретных ограничений. Ограничения и вычисление весов wi(k, n) объясняются в следующем подразделе.
В последующем рассматривают модуль 103 вычисления весов согласно соответствующим вариантам осуществления, в данном контексте обеспечены два варианта осуществления модуля 103 вычисления весов на фиг. 2. Из формулы (5) и формулы (40) следует, что wi(k, n) должен соответствовать линейным ограничениям
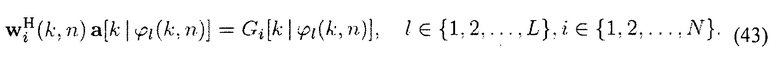
Кроме того, мощность рассеянного сигнала должна сохраняться. Поэтому, wi(k, n) может соответствовать квадратичному ограничению
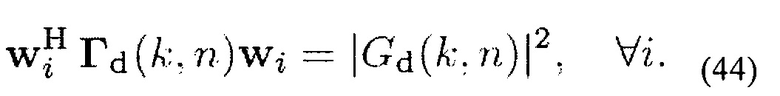
Кроме того, мощность собственных шумов на выходе фильтра должна быть минимизирована. Таким образом, оптимальные веса могут вычисляться как
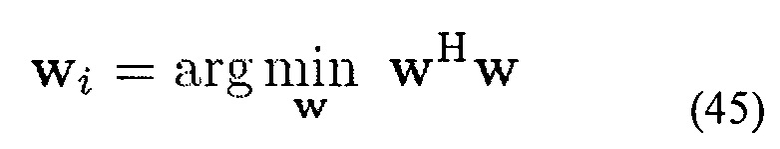
при условиях формулы (43) и формулы (44). Это приводит к задаче выпуклой оптимизации, которая может решаться, например, с помощью известных численных способов [29].
Что касается модуля 102 оценки мгновенного параметра, согласно соответствующим вариантам осуществления DOA ϕl(k, n) L плоских волн могут получаться с помощью известных узкополосных средств оценки DOA, таких как ESPRIT [22] или root MUSIC [23], или других средств оценки уровня техники.
Теперь рассматривается модуль 104 выбора передаточной функции согласно соответствующим вариантам осуществления. В данной заявке усиление Gi[k | ϕl(k, n)] для канала i находится для соответствующего направленного звука l в зависимости от информации DOA ϕl(k, n). Передаточная функция Gi[k | ϕ(k, n)] для различных DOA ϕ(k, n) и каналов i доступна для системы, например, в качестве определяемой пользователем априорной информации. Усиления могут также вычисляться, основываясь на анализе изображения, например, используя расположения обнаруженных лиц.
Передаточные функции Gi[k | ϕ(k, n)] обычно обеспечиваются в качестве таблицы поиска, то есть для оцененного ϕl(k, n) выбирают соответствующие усиления Gi[k | ϕl(k, n)] из таблицы поиска. Следует заметить, что передаточная функция может также определяться в качестве функции от пространственной частоты μ [k | ϕ(k, n)] вместо азимута ϕl(k, n), то есть Gi(k, μ) вместо Gi[k | ϕ(k, n)]. Следует дополнительно заметить, что передаточная функция может также соответствовать HRTF, что предоставляет возможность воспроизведения звука с бинауральным эффектом. В этом случае Gi[k | ϕ(k, n)] обычно является комплексным значением. Следует заметить, что усиления или передаточные функции могут также вычисляться, основываясь на информации расположения излучателя вместо информации DOA.
Пример для воспроизведения стереофонических громкоговорителей изображен на фиг. 10. В частности, фиг. 10 показывает функции усиления для стереофонического воспроизведения.
Хотя некоторые аспекты описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где блок или устройство соответствуют этапу способа или особенности этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента или особенности соответствующего устройства.
Изобретенный анализируемый сигнал может сохраняться на цифровом носителе данных или может передаваться по передающей среде, такой как беспроводная передающая среда или проводная передающая среда, такой как Интернет.
В зависимости от конкретных требований воплощения варианты осуществления изобретения могут воплощаться в оборудовании или в программном обеспечении. Воплощение может выполняться, используя носитель цифровых данных, например, гибкий диск, DVD (цифровой видеодиск), CD (компакт-диск), ПЗУ (постоянное запоминающее устройство), ППЗУ (программируемое постоянное запоминающее устройство), СППЗУ (стираемое программируемое постоянное запоминающее устройство), ЭСППЗУ (электрически стираемое программируемое постоянное запоминающее устройство) или флэш-память, имеющий сохраненные на нем считываемые с помощью электроники управляющие сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой вычислительной системой таким образом, чтобы выполнялся соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат не являющийся временным носитель информации, имеющий считываемые с помощью электроники управляющие сигналы, которые способны к взаимодействию с программируемой вычислительной системой, так, что выполняется один из способов, описанных в данной работе.
В общем случае варианты осуществления настоящего изобретения могут воплощаться как компьютерный программный продукт с кодом программы, код программы работает для выполнения одного из способов, когда компьютерный программный продукт работает на компьютере. Код программы может, например, сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в данной работе, сохраненную на машиночитаемом носителе.
Другими словами, вариантом осуществления изобретенного способа поэтому является компьютерная программа, имеющая код программы для выполнения одного из способов, описанных в данной работе, когда компьютерная программа работает на компьютере.
Дополнительным вариантом осуществления изобретенных способов поэтому является носитель информации (или цифровой носитель данных, или считываемый компьютером носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в данной работе.
Дополнительным вариантом осуществления изобретенного способа поэтому является поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в данной работе. Поток данных или последовательность сигналов могут, например, конфигурироваться для перемещения через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер, или программируемое логическое устройство, сконфигурированное или адаптированное для выполнения одного из способов, описанных в данной работе.
Дополнительный вариант осуществления содержит компьютер, установленную на нем компьютерную программу для выполнения одного из способов, описанных в данной работе.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторых или всех функциональных возможностей способов, описанных в данной работе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в данной работе. В общем случае способы предпочтительно выполняются с помощью любого аппаратного устройства.
Вышеописанные варианты осуществления являются просто иллюстративными для принципов настоящего изобретения. Подразумевается, что изменения и разновидности структур и деталей, описанных в данной работе, будут очевидны специалистам. Это намерение, поэтому, ограничивается только областью действия предстоящих пунктов формулы изобретения, а не конкретными подробностями, представленными посредством описания и объяснения вариантов осуществления в данной работе.
ССЫЛКИ
[1] J. Benesty, J. Chen and Y. Huang, Microphone Array Signal Processing. Berlin, Germany: Springer-Verlag. 2008,
[2] S. Doelo. S. Garmot, M. Moonen and A. Spriet, "Acoustic beamforming for hearing aid applications," in Handbook on Array Processing and Sensor Networks, S. Haykin and K. Ray Liu, Eds. Wiley, 2008, ch. 9.
[3] S. Garmot and I. Cohen, "Adaptive beamforming and postfiltering," in Springer Handbook of Speech Processing, J. Benesty, M. M. Sondhi, and Y. Huang, Eds. Springer- Verlag, 2008, ch. 47.
[4] J. Benesty, J. Chen and E. A. P. Habets, Speech Enhancement in the STFT Domain, ser. SpringerBriefs in Electrical and Computer Engineering. Springer-Verlag, 2011.
[5] I. Tashev, M. Seltzer and A. Acero, "Microphone array for headset with spatial noise suppressor," in Proc. Ninth International Workshop on Acoustic, Echo and Noise Control (IWAENC), Eindhoven, The Netherlands, 2005.
[6] M. Kallinger, G. Del Galdo, F. Kuech, D. Mahne and R. Schultz-Amling, "Spatial filtering using directional audio coding parameters," in Proc. IEEE Intl. Conf, on Acoustics, Speech and Signal Processing (ICASSP), Apr. 2009, pp. 217-220.
[7] M. Kallinger, G. D. Galdo, F. Kuech and O. Thiergart, "Dereverberation in the spatial audio coding domain," in Audio Engineering Society Convention 130, London UK, May 2011.
[8] G. Del Galdo, O. Thiergart, T. Weller and E. A. P. Habets, "Generating virtual microphone signals using geometrical information gathered by distributed arrays," in Proc. Hands-Free Speech Communication and Microphone Arrays (HSCMA), Edinburgh, United Kingdom, May 2011.
[9] S. Nordholm, I. Claesson and B. Bengtsson, "Adaptive array noise suppression of handsfree speaker input in cars," IEEE Trans. Veh. Technol, vol. 42, no. 4, pp. 51.4-518, Nov. 1993.
[10] O. Hoshuyama. A. Sugiyama and A. Hirano, "A robust adaptive beam former for microphone arrays with a blocking matrix using constrained adaptive filters," IEEE Trans. Signal Process., vol. 47, no. 10, pp. 2677-2684, Oct. 1999.
[11] S. Gannot, D. Burshtein and E. Weinstein, "Signal enhancement using beam forming and nonstationarity with applications to speech," IEEE Trans. Signal Process., vol. 49, no. 8, pp. 1614-1626, Aug. 2001.
[12] W. Herbordt and W. Keliermann. "Adaptive beamforming for audio signal acquisition," in Adaptive Signal Processing: Applications to real-world problems, ser. Signals and Communication Technology, J. Benesty and Y. Huang, Eds. Berlin, Germany: Springer-Verlag, 2003, ch. 6, pp. 155-194.
[13] R. Talmon, I. Cohen and S. Gannot, "Convolutive transfer function generalized sideiobe canceler," IEEE Trans. Audio, Speech, Lang, Process. , vol. 17, no. 7, pp. 1420-1434, Sep. 2009.
[14] A. Krueger, E. Warsitz and R. Haeb-Umbach, "Speech enhancement with a GSC-like structure employing eigenvector-based transfer function ratios estimation," IEEE Trans. Audio, Speech, Lang. Process. , vol. 19, no. 1, pp. 206-219, Jan. 2011.
[15] E. A. P. Habets and J. Benesty, "Joint dereverberation and noise reduction using a two-stage beamforming approach," in Proc. Hands-Free Speech Communication and Microphone Arrays (HSCMA), 2011, pp. 191-195.
[16] M. Taseska and E. A. P. Habets, "MMSE-based blind source extraction in diffuse noise fields using a complex coherence-based a priori SAP estimator," in Proc. Intl. Workshop Acoust, Signal Enhancement (IWAENC), Sep. 2012.
[17] G. Rcuven, S. Gannot and I. Cohen, "Dual source transfer-function generalized sideiobe canceller," IEEE Trans. Speech Audio Process. , vol. 16, no. 4, pp. 711- 727, May 2008.
[18] S. Markovich, S. Gannot and I. Cohen, "Multichannel eigenspace beamforming in a reverberant noisy environment with multiple interfering speech signals," IEEE Trans. Audio, Speech, Lang. Process. , vol. 17, no. 6, pp. 1071 -1086, Aug. 2009.
[19] O. Thicrgart and E. A.P. Habets, "Sound field model violations in parametric spatial sound processing," in Proc, Intl. Workshop Acoust. Signal Enhancement (IWAENC), Sep. 2012.
[20] R. K. Cook, R. V. Waterhouse, R. D. Bcrendt, S. Edelman and M. C. Thompson Jr., "Measurement of correlation coefficients in reverberant sound fields," The Journal of the Acoustical Society of America, vol. 27, no. 6, pp. 1072-1077, 1955.
[21] O. L. Frost, III, "An algorithm for linearly constrained adaptive array processing," Proc. IEEE, vol. 60, no. 8, pp. 926-935, Aug. 1972.
[22] R. Roy and T. Kailath, "ESPRIT-estimation of signal parameters via rotational invariance techniques," Acoustics, Speech and Signal Processing, IEEE Transactions on, vol. 37, no. 7, pp. 984-995, My 1989.
[23] B. Rao and K. Hari, "Performance analysis of root-music*," in Signals, Systems and Computers, 1988. Twenty-Second Asilomar Conference on, vol. 2, 1988, pp. 578-582.
[24] H. Cox, R. M. Zeskind and M. M. Owen, "Robust adaptive beam forming," IEEE Tram. Acoust., Speech, Signal Process. , vol. 35, no. 10, pp. 1365-1376, Oct. 1987.
[25] J. B. Allen and D. A. Berkley, "Image method for efficiently simulating small-room acoustics," J. Acoust. Soc. Am. , vol. 65, no. 4, pp. 943-950, Apr. 1979.
[26] E. A. P. Habets. (2008, May) Room impulse response (RIR) generator. [Online], Available: http://home.tiscali.nl/ehabets/rirgenerator.html; see also: http://web. archive.org/web/20120730003147/http://home. tiscali.nl/ehabets/rir_generator.html
[27] I. CVX Research, "CVX: Matlab software for disciplined convex programming, version 2.0 beta," http://cvxr.com/cvx, September 2012.
[28] M. Grant and S. Boyd, "Graph implementations for nonsmooth convex programs," in Recent Advances in Learning and Control, ser. Lecture Notes in Control and Information Sciences, V. Blondel, S. Boyd, and H. Kimura, Eds. Springer-Verlag Limited, 2008, pp. 95-110.
[29] H. L. Van Trees, Detection, Estimation, and Modulation Theory: Part IV: Optimum Array Processing. John Wiley & Sons, April 2002, vol. 1.
Изобретение относится к акустике, в частности к устройствам обработки звуковой информации. Фильтр содержит генератор весовых коэффициентов, адаптированный для приема информации о направлении прибытия компонент звука от излучателей звука, информации о расположении излучателей звука, и адаптированный для генерации весовых коэффициентов для каждого из множества частотно-временных элементов в зависимости от информации направления прибытия звука и в зависимости от информации расположения одного или более излучателей звука указанного частотно-временного элемента. Причем генератор формирует весовые коэффициенты в зависимости от первой шумовой информации, описываемой первой матрицей когерентности шумовых компонент, и в зависимости от второй шумовой информации, описываемой второй матрицей когерентности. Генератор обеспечивает формирование для каждого из множества частотно-временных элементов одной из множества выборок выходного звукового сигнала, которая назначена указанному частотно-временному элементу в зависимости от информации взвешивания указанного частотно-временного элемента и в зависимости от выборки входного звукового сигнала, назначенной указанному частотно-временному элементу каждого из двух или более входных сигналов микрофона. Технический результат – улучшение алгоритмов обработки звука. 3 н. и 12 з.п. ф-лы, 14 ил., 1 табл. 
1. Фильтр (100) для генерации выходного звукового сигнала, содержащего множество выборок выходного звукового сигнала, на основании двух или более входных сигналов микрофона, в котором выходной звуковой сигнал и два или более входных сигналов микрофона представлены в частотно-временной области, причем каждая из множества выборок выходного звукового сигнала назначена частотно-временному элементу ((k, n)) из множества частотно-временных элементов ((k, n)) и причем фильтр (100) содержит:
генератор (110) весов, адаптированный для приема для каждого из множества частотно-временных элементов ((k, n)) информации направления прибытия одной или более компонент звука одного или более излучателей звука или информации расположения одного или более излучателей звука и адаптированный для генерации информации взвешивания для каждого из множества частотно-временных элементов ((k, n)) в зависимости от информации направления прибытия одной или более компонент звука одного или более излучателей звука указанного частотно-временного элемента ((k, n)) или в зависимости от информации расположения одного или более излучателей звука указанного частотно-временного элемента ((k, n)); причем генератор (110) весов адаптирован для генерации информации взвешивания для каждого из множества частотно-временных элементов ((k, n)) в зависимости от первой шумовой информации, указывающей информацию о первой матрице когерентности первых шумовых компонент двух или более входных сигналов микрофона, и в зависимости от второй шумовой информации, указывающей информацию о второй матрице когерентности вторых шумовых компонент двух или более входных сигналов микрофона; и
генератор (120) выходного сигнала для генерации выходного звукового сигнала с помощью генерации для каждого из множества частотно-временных элементов ((k, n)) одной из множества выборок выходного звукового сигнала, которая назначена указанному частотно-временному элементу ((k, n)), в зависимости от информации взвешивания указанного частотно-временного элемента ((k, n)) и в зависимости от выборки входного звукового сигнала, назначенной указанному частотно-временному элементу ((k, n)) каждого из двух или более входных сигналов микрофона.
2. Фильтр (100) по п. 1, в котором генератор (110) весов сконфигурирован для генерации первой шумовой информации с помощью использования статистической информации и в котором генератор (110) весов сконфигурирован для генерации второй шумовой информации без использования статистической информации, причем статистическая информация определяется предварительно.
3. Фильтр (100) по п. 1, в котором генератор (110) весов адаптирован для генерации информации взвешивания для каждого из множества частотно-временных элементов ((k, n)) в зависимости от формулы:
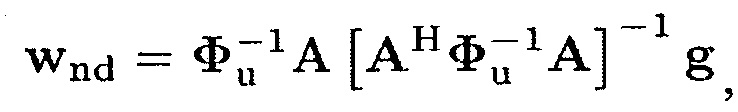
в которой Фu=Фd+Фn,
в которой Фd является первой матрицей спектральной плотности мощности первых шумовых компонент двух или более входных сигналов микрофона,
в которой Фn является второй матрицей спектральной плотности мощности вторых шумовых компонент двух или более входных сигналов микрофона,
в которой А указывает информацию направления прибытия,
в которой wnd является вектором, указывающим информацию взвешивания,
в которой 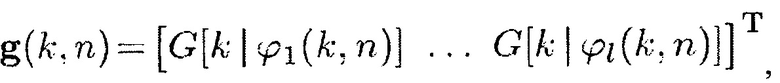
в которой G[k|ϕ1(k,n)] является первой действительной или комплексной предварительно определенной функцией направленности, зависящей от информации направления прибытия, и
в которой G[k|ϕl(k,n)] является дальнейшей действительной или комплексной предварительно определенной функцией направленности, зависящей от информации направления прибытия,
4. Фильтр (100) по п. 1, в котором генератор (110) весов сконфигурирован для определения первой шумовой информации в зависимости от одной или более когерентностей между по меньшей мере некоторыми из первых шумовых компонент двух или более входных сигналов микрофона, причем одна или более когерентностей определяются предварительно.
5. Фильтр (100) по п. 1, в котором генератор (110) весов сконфигурирован для определения первой шумовой информации в зависимости от матрицы Гd(k) когерентности, указывающей когерентности, являющиеся результатом первых шумовых компонент двух или более входных сигналов микрофона, причем матрица Гd(k) когерентности определяется предварительно.
6. Фильтр (100) по п. 5, в котором генератор (110) весов сконфигурирован для определения первой шумовой информации согласно формуле:
Фd(k,n)=φd(k,n)Гd(k),
в которой Гd(k) является матрицей когерентности, причем матрица когерентности определяется предварительно,
в которой Фd(k, n) является первой шумовой информацией, и
в которой ϕd(k, n) является ожидаемой мощностью первых шумовых компонент двух или более входных сигналов микрофона.
7. Фильтр (100) по п. 1, в котором генератор (110) весов сконфигурирован для определения первой шумовой информации в зависимости от второй шумовой информации и в зависимости от информации направления прибытия.
8. Фильтр (100) по п. 1,
в котором генератор (110) весов сконфигурирован для генерации информации взвешивания в качестве первой информации wΨ взвешивания, и
в котором генератор (110) весов сконфигурирован для генерации первой информации взвешивания с помощью определения второй информации взвешивания,
причем генератор (110) весов сконфигурирован для генерации первой информации wΨ взвешивания с помощью применения формулы:
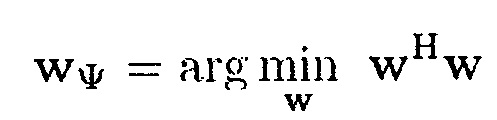
так что выполняется формула
wHa[k|ϕl(k,n)]=0.
в которой ϕl(k, n) указывает информацию направления прибытия,
в которой a[k|ϕl(k, n) указывает вектор распространения, и
в которой w указывает вторую информацию взвешивания.
9. Фильтр (100) по п. 8, в котором генератор (110) весов сконфигурирован для генерации информации отношения рассеянного сигнала к шуму или мощности рассеянной сигнальной компоненты в зависимости от второй информации взвешивания и в зависимости от двух или более входных сигналов микрофона для определения первой информации взвешивания.
10. Фильтр (100) по п. 1, в котором генератор (110) весов сконфигурирован для определения информации взвешивания с помощью применения параметрического винеровского фильтра, причем параметрический винеровский фильтр зависит от статистической информации о сигнальной компоненте двух или более входных сигналов микрофона и причем параметрический винеровский фильтр зависит от статистической информации о шумовой компоненте двух или более входных сигналов микрофона.
11. Фильтр (100) по п. 1, в котором генератор (110) весов сконфигурирован для определения информации взвешивания в зависимости от информации направления прибытия, указывающей направления прибытия одной или более плоских волн.
12. Фильтр (100) по п. 1,
в котором генератор (110) весов содержит модуль (104) выбора передаточной функции для обеспечения предварительно определенной передаточной функции, и
в котором генератор (110) весов сконфигурирован для генерации информации взвешивания в зависимости от информации направления прибытия и в зависимости от предварительно определенной передаточной функции.
13. Фильтр (100) по п. 12, в котором модуль (104) выбора передаточной функции сконфигурирован для обеспечения предварительно определенной передаточной функции так, чтобы предварительно определенная передаточная функция указывала произвольный шаблон захвата в зависимости от информации направления прибытия, так, чтобы предварительно определенная передаточная функция указывала усиление громкоговорителя в зависимости от информации направления прибытия, или так, чтобы предварительно определенная передаточная функция указывала передаточную функцию слухового аппарата человека в зависимости от информации направления прибытия.
14. Способ генерации выходного звукового сигнала, содержащего множество выборок выходного звукового сигнала, на основании двух или более входных сигналов микрофона, в котором выходной звуковой сигнал и два или более входных сигналов микрофона представлены в частотно-временной области, причем каждая из множества выборок выходного звукового сигнала назначена частотно-временному элементу ((k, n)) из множества частотно-временных элементов ((k, n)) и причем способ содержит этапы, на которых:
принимают для каждого из множества частотно-временных элементов ((k, n)) информацию направления прибытия одной или более компонент звука одного или более излучателей звука или информацию расположения одного или более излучателей звука,
генерируют информацию взвешивания для каждого из множества частотно-временных элементов ((k, n)) в зависимости от информации направления прибытия одной или более компонент звука одного или более излучателей звука указанного частотно-временного элемента ((k, n)) или в зависимости от информации расположения одного или более излучателей звука указанного частотно-временного элемента ((k, n)); причем генерация информации взвешивания для каждого из множества частотно-временных элементов ((k, n)) выполняется в зависимости от первой шумовой информации, указывающей информацию о первой матрице когерентности первых шумовых компонент двух или более входных сигналов микрофона и в зависимости от второй шумовой информации, указывающей информацию о второй матрице когерентности вторых шумовых компонент двух или более входных сигналов микрофона; и
генерируют выходной звуковой сигнал с помощью генерации для каждого из множества частотно-временных элементов ((k, n)) одной из множества выборок выходного звукового сигнала, которая назначена указанному частотно-временному элементу ((k, n)), в зависимости от информации взвешивания указанного частотно-временного элемента ((k, n)) и в зависимости от выборки входного звукового сигнала, которая назначена указанному частотно-временному элементу ((k, n)) каждого из двух или более входных сигналов микрофона.
15. Машиночитаемый носитель, содержащий коды компьютерной программы для реализации способа по п. 14 при исполнении на компьютере или процессоре обработки сигнала.
| WO 2005004532 A1, 13.01.2005 | |||
| WO 2011129725 A1, 20.10.2011 | |||
| US 20080310646 A1, 18.12.2008 | |||
| US 8098844 B2, 17.01.2012 | |||
| Устройство для измерения шага втулочно-роликовых цепей | 1979 |
|
SU1052838A1 |
| EP 1538867 B1, 18.07.2012 | |||
| JP 4184342 B2, 19.11.2008 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ ГЕНЕРАЦИИ БИНАУРАЛЬНОГО АУДИОСИГНАЛА | 2008 |
|
RU2443075C2 |
| EP 1879180 B1, 06.05.2009 | |||
| WO 2012158168 A1, 22.11.2012 | |||
| WO 2010048620 A1, 29.04.2010. | |||

