Настоящее изобретение относится к обработке звука, и конкретнее, к устройству и способу геометрического кодирования пространственного звука.
Обработка звука, и в особенности, кодирование пространственного звука, становится все более и более важным. Традиционная запись пространственного звука ставит своей задачей захват звукового поля, такого, как в репродуцируемой стороне, слушатель воспринимает звуковое изображение так, как если бы он находился в месте записи. На современном уровне развития техники известны разные подходы к способам записи и воспроизведения пространственного звука, которые бывают основаны на канальных, объектных или параметрических представлениях.
Представления, основанные на каналах, представляют звуковую сцену средствами N дискретных звуковых сигналов, предназначенных для проигрывания на N громкоговорителях, расставленных в известной компоновке, например, компоновке 5.1 surround sound («звук вокруг»). В этом подходе для записи пространственного звука обычно применяют установленные на расстоянии всенаправленные микрофоны, например, в AB стереофонии, или совмещенные направленные микрофоны, например, в интенсивностной стереофонии. В ином случае, можно применять более сложные микрофоны, такие как микрофоны B-формата, например, в амбиофонии, см.:
[1] Michael A. Gerzon. Ambisonics in multichannel broadcasting and video. J. Audio Eng. Soc, 33(11):859-871, 1985.
Требуемые сигналы громкоговорителей для известной компоновки можно извлекать напрямую из записанных сигналов микрофонов и затем передавать или хранить в дискретном виде. Более эффективное представление достигается путем применения к дискретным сигналам кодирования звука, которое, в отдельных случаях, кодирует информацию различных каналов совместно, для повышения эффективности, например, в MPEG-Surrond для 5.1, см.:
[21] J. Herre, K. Kjorling, J. Breebaart, С Faller, S. Disch, H. Pumhagen, J. Koppens, J. Hilpert, J. Roden, W. Oomen, K. Linzmeier, K.S. Chong: "MPEG Surround - The ISO/MPEG Standard for Efficient and Compatible Multichannel Audio Coding", 122nd AES Convention, Vienna, Austria, 2007, Preprint 7084.
Большим недостатком этих способов является невозможность модификации звуковой сцены после завершения вычисления сигналов громкоговорителей.
Объектные представления, например, используют в кодировании пространственных звуковых объектов (SAOC), см.:
[25] Jeroen Breebaart, Jonas Engdegard, Cornelia Falch, Oliver Hellmuth, Johannes Hiipert, Andreas Hoelzer, Jeroens Koppens, Werner Oomen, Barbara Resch, Erik Schuijers, and Leonid Terentiev. Spatial audio object coding (saoc) - the upcoming mpeg standard on parametric object based audio coding. In Audio Engineering Society Convention 124, 5 2008.
Объектные представления представляют звуковую сцену с N дискретными звуковыми объектами. Это представление дает высокую гибкость на стороне воспроизведения, поскольку звуковой сценой можно манипулировать, изменяя, например, позицию и громкость для каждого объекта. Несмотря на то, что такое представление может быть доступно в настоящий момент с, например, многодорожечной записи, его очень сложно получить из сложной звуковой сцены, записанной с нескольких микрофонов (см., например, [21]). Фактически, говорящие стороны (или другие испускающие звук объекты) необходимо сначала локализовать и затем извлечь из смеси, что может вызвать артефакты.
Параметрические представления, для определения одного или более малоканальных сигналов вместе с пространственной информацией стороны, описывающей пространственный звук, часто применяют пространственные микрофоны. Примером является направленное кодирование звука (DirAC), как описано в
[22] Vilie Pulkki. Spatial sound reproduction with directional audio coding. J. Audio Eng. Soc, 55(6):503-516, June 2007.
Термин "пространственный микрофон" относится к любому устройству для получения пространственного звука, способному извлекать направление прихода звука (например, комбинация направленных микрофонов, массив микрофонов, и т.п.).
Термин "непространственный микрофон" относится к любому устройству, которое не адаптировано для извлечения направления прихода звука, такому как один всенаправленный или направленный микрофон.
Другой пример предложен в:
[23] C. Fallen Microphone front-ends for spatial audio coders. In Proc. of the AES 125 International Convention, San Francisco, Oct. 2008.
В DirAC, информация пространственного сигнала включает в себя направления прихода (DOA) звука и диффузность звукового поля, вычисленную в частотно-временной области. Для воспроизведения звука сигналы проигрывания звука можно извлечь на основании параметрического описания. Эти способы предлагают очень большую гибкость в стороне воспроизведения, поскольку можно использовать произвольную компоновку громкоговорителей, поскольку представление особенно гибко и компактно, так как оно включает в себя малоканальный монозвуковой сигнал и информацию о стороне, и поскольку оно позволяет легко осуществлять модификации звуковой сцены, например, акустическое масштабирование, направленную фильтрацию, объединение сцены и т.п.
Однако, эти способы по-прежнему ограничены в том, что пространственное изображение всегда записано относительно использованного пространственного микрофона. Таким образом, акустическую точку обзора нельзя сменить, и позицию слушателя в звуковой сцене нельзя изменить.
Подход с виртуальным микрофоном, изложенный в
[20] Giovanni Del Galdo, Oliver Thiergart, Tobias Weller, and E.A.P. Habets. Generating virtual microphone signals using geometrical information gathered by distributed arrays. In Third Joint Workshop on Hands-free Speech Communication and Microphone Arrays (HSCMA '11), Edinburgh, United Kingdom, May 2011,
который позволяет вычислять выходные сигналы произвольного пространственного микрофона, виртуально размещенного в окружающем пространстве произвольным образом (т.е., с произвольным местоположением и направленностью). Гибкость, характеризующая подход с виртуальным микрофоном (VM), позволяет произвольный виртуальный захват звуковой сцены на этапе постобработки, но не делает доступным представление звукового поля, которое можно использовать для эффективных передачи, и/или хранения, и/или модификации звуковой сцены. Более того, предполагается активным только один источник на каждый частотно-временной элемент выборки, и, таким образом, он не может корректно описать звуковую сцену, если в одном и том же частотно-временном элементе выборки активно два или более источников. Дополнительно, если виртуальный микрофон (VM) применяют на стороне приемника, все сигналы микрофона необходимо посылать по каналу, что делает представление неэффективным, в то же время при применении микрофона на стороне передатчика, звуковой сценой нельзя дополнительно манипулировать, и модель теряет гибкость и становится ограниченной определенной компоновкой громкоговорителей. Более того, она не позволяет манипулировать звуковой сценой на основании параметрической информации.
В
[24] Emmanuel Gallo and Nicolas Tsingos. Extracting and re-rendering structured auditory scenes from field recordings. In AES 30th International Conference on Intelligent Audio Environments, 2007,
оценку позиции звукового источника основывают на попарной разнице во времени поступления, измеренного при помощи распределенных микрофонов. Дополнительно, приемник зависим от записи и требует для синтеза все сигналы микрофонов (например, генерирования сигналов громкоговорителей).
Способ, представленный в
[28] Svein Berge. Device and method for converting spatial audio signal. US patent application, Appl. No. 10/547,151,
использует, аналогично DirAC, направление прихода как параметр, таким образом, ограничивая представление определенной точкой зрения звуковой сцены. Более того, он не предлагает возможности передавать/хранить представление звуковой сцены, поскольку и анализ, и синтез необходимо применять на одной и той же стороне системы связи.
Задачей настоящего изобретения является предоставление улучшенных концепций по захвату пространственного звука и описание путем извлечения геометрической информации. Задача настоящего изобретения достигается устройством для генерации, по меньшей мере, одного выходного звукового сигнала, основанного на потоке звуковых данных по п.1 формулы изобретения, устройством для генерации потока звуковых данных по п.10 формулы изобретения, системой по п.19 формулы изобретения, потоком звуковых данных по п.20 формулы изобретения, способом генерации, по меньшей мере, одного выходного звукового сигнала по п.23 формулы изобретения, способом генерации потока звуковых данных по п.24 формулы изобретения и компьютерной программой по п.25 формулы изобретения.
Предоставлено устройство для генерирования, по меньшей мере, одного выходного звукового сигнала, основанного на потоке звуковых данных, включающего в себя звуковые данные, относящиеся к одному или более источникам звука. Устройство включает в себя приемник для приема потока звуковых данных, включающего в себя звуковые данные. Звуковые данные включают в себя одно или более значений давления для каждого из источников звука. Дополнительно, звуковые данные включают в себя одно или более значений расположения, указывающих расположение одного из источников звука для каждого из источников звука. Более того, устройство включает в себя модуль синтеза, для генерирования, по меньшей мере, одного выходного звукового сигнала, основанного на, по меньшей мере, одном из одного или более значений расположения звуковых данных из потока звуковых данных. В варианте осуществления, каждый из одного или более значений местоположения может включать в себя, по меньшей мере, два значения координат.
Звуковые данные можно определить для частотно-временного элемента выборки из множества частотно-временных элементов выборки. Иначе, звуковые данные можно определить для момента времени из множества моментов времени. В некоторых вариантах осуществления, одно или более значений давления из звуковых данных можно определить для момента времени из множества моментов времени, в то время как соответствующие параметры (например, значения местоположения) можно определить в частотно-временной области. Этого можно легко добиться путем преобразования обратно во временную область значений давления, иначе определенных в частотно-временном. Для каждого из источников звука, по меньшей мере одно значение давления включают в звуковые данные, причем, по меньшей мере, одно значение давления может представлять собой значение давления, относящееся к испущенной звуковой волне, например, исходящей из источника звука. Значение давления может представлять собой значение звукового сигнала, например, значение давления выходного звукового сигнала, сгенерированного устройством для генерирования выходного звукового сигнала виртуального микрофона, причем этот виртуальный микрофон размещен в местоположении источника звука.
Вышеописанный вариант осуществления позволяет рассчитать представление звукового поля, которое в действительности не зависит от местоположения записи и предоставляет возможность эффективной передачи и хранения сложной звуковой сцены, а также возможность простых модификаций и повышенную гибкость в системе воспроизведения.
Наряду с прочим, важными преимуществами этого способа является то, что на стороне воспроизведения слушатель может свободно выбирать свое положение в записанной звуковой сцене, использовать любую компоновку громкоговорителей и дополнительно манипулировать звуковой сценой на основании геометрической информации, например, осуществлять позиционную фильтрацию. Другими словами, в предлагаемом способе акустическую точку зрения можно менять, и местоположения прослушивания в звуковой сцене можно изменять.
В соответствии с вышеописанным вариантом осуществления, звуковые данные, включенные в поток звуковых данных, включают в себя одно или более значений давления для каждого из источников звука. Таким образом, значения давления указывают звуковой сигнал относительно одного из источников звука, например, звуковой сигнал, исходящий из источника звука, и безотносительно местоположения записывающих микрофонов. Аналогично, одно или более значений местоположения, которые включены в поток звуковых данных, указывают местоположения источников звука, а не микрофонов.
Таким образом, осуществляют множество преимуществ: например, достигнутое представление звуковой сцены можно кодировать, используя немного бит. Если звуковая сцена включает в себя только единственный источник звука в определенном частотно-временном элементе выборки, вместе со значением местоположения, указывающим местоположение источника звука, необходимо кодировать значения давления единственного звукового сигнала, относящегося к единственному источнику звука. В отличии, в обычных способах может оказаться необходимым кодировать множество значений давления из множества записанных сигналов микрофона, для реконструкции звуковой сцены на приемнике. Более того, вышеописанный вариант осуществления позволяет легко модифицировать звуковую сцену на передатчике, а также на стороне приемника, как будет описано ниже. Таким образом, композиция сцены (например, определение местоположения прослушивания в звуковой сцене), также можно выполнять и на стороне приемника.
В вариантах осуществления применяют принцип моделирования сложной звуковой сцены посредством источников звука, например, точечных источников звука (PLS = точечный источник звука), например, изотропных точечных источников звука (IPLS), которые активны в определенных ячейках частотно-временного представления, такого как то, которое предоставлено оконным преобразованием Фурье (STFT).
В соответствии с вариантом осуществления, приемник может быть выполнен с возможностью приема потока звуковых данных, включающего в себя звуковые данные, причем звуковые данные, в свою очередь, включают в себя одно или более значений диффузности для каждого из источников звука. Модуль синтеза может быть выполнен с возможностью генерации, по меньшей мере, одного выходного звукового сигнала, основанного на, по меньшей мере, одном или более значениях диффузности.
В другом варианте осуществления, приемник может дополнительно включать в себя модуль модификации для модификации звуковых данных принятого потока звуковых данных путем модификации, по меньшей мере, одного из, одного или более значений давления из звуковых данных, путем модификации, по меньшей мере, одного из, одного или более значений местоположения из звуковых данных или путем модификации, по меньшей мере, одного из значений диффузности из звуковых данных. Модуль синтеза может быть выполнен с возможностью генерирования, по меньшей мере, одного выходного звукового сигнала, на основании, по меньшей мере, одного модифицированного значения давления, на основании, по меньшей мере, одного модифицированного значения местоположения или на основании, по меньшей мере, одного модифицированного значения диффузности.
В последующем варианте осуществления, каждое из значений местоположения каждого из источников звука может включать в себя, по меньшей мере, два значения координат. Дополнительно, модуль модификации может быть выполнен с возможностью модификации значений координат путем добавления, по меньшей мере, одного случайного числа к значениям координат, когда значения координат указывают, что источник звука расположен в местоположении, находящемся в предварительно определенной области окружающего пространства.
В соответствии с другим вариантом осуществления, каждое из значений местоположения каждого из источников звука может включать в себя, по меньшей мере, два значения координат. Более того, модуль модификации выполнен с возможностью модификации значений координат путем применения для значений координат детерминированной функции, когда значения координат указывают, что источник звука расположен в местоположении, находящемся в предварительно определенной области окружающего пространства.
В дополнительном варианте осуществления, каждое из значений местоположения каждого из источников звука может включать в себя, по меньшей мере, два значения координат. Более того, модуль модификации может быть выполнен с возможностью модификации выбранного значения давления из одного или более значений давления из звуковых данных, относящегося к тому же источнику звука, что и значения координат, когда значения координат указывают, что источник звука расположен в местоположении, находящемся в предварительно определенной области окружающего пространства.
В соответствии с вариантом осуществления, модуль синтеза может включать в себя блок первого этапа синтеза и блок второго этапа синтеза. Блок первого этапа синтеза может быть выполнен с возможностью генерирования сигнала прямого давления, включающего в себя прямой звук, сигнала диффузного давления, включающего в себя диффузный звук и информацию о направлении прихода, на основании, по меньшей мере, одного из одного или более значений давления из звуковых данных из потока звуковых данных, на основании, по меньшей мере, одного из одного или более значений местоположения из звуковых данных из потока звуковых данных и на основании, по меньшей мере, одного из одного или более значений диффузности из звуковых данных из потока звуковых данных. Блок второго этапа синтеза может быть выполнен с возможностью генерирования, по меньшей мере, одного выходного звукового сигнала на основании сигнала прямого давления, сигнала диффузного давления и информации о направлении прихода.
В соответствии с вариантом осуществления, предоставляют устройство для генерирования потоках звуковых данных, включающего данные источника звука, относящиеся к одному или более источникам звука. Устройство для генерирования потока звуковых данных включает в себя определитель для определения данных источника звука на основании, по меньшей мере, одного входного звукового сигнала, записанного при помощи, по меньшей мере, одного микрофона и основанного на информации звуковой стороны, предоставленной, по меньшей мере, двумя пространственными микрофонами. Дополнительно, устройство включает в себя генератор потока данных, для генерирования потока звуковых данных, так, чтобы поток звуковых данных включал в себя данные источника звука. Данные источника звука включают в себя одно или более значений давления для каждого из источников звука. Более того, данные источника звука дополнительно включают в себя одно или более значений местоположения, указывающих на местоположение источника звука для каждого из источников звука. Дополнительно, данные источника звука определены для частотно-временного элемента выборки из множества частотно-временных элементов выборки.
В дополнительном варианте осуществления, определитель может быть выполнен с возможностью определения данных источника звука на основании информации диффузности, по меньшей мере, с одного пространственного микрофона. Генератор потока данных может быть выполнен с возможностью генерирования потока звуковых данных так, чтобы поток звуковых данных включал в себя данные источника звука. В свою очередь, данные источника звука включают в себя одно или более значений диффузности для каждого из источников звука.
В другом варианте осуществления, устройство для генерирования потока звуковых данных может дополнительно включать в себя модуль модификации для модификации потока звуковых данных, сгенерированного генератором потока данных, путем модификации, по меньшей мере, одного из значений давления звуковых данных, по меньшей мере, одного из значений местоположения из звуковых данных или, по меньшей мере, одного из значений диффузности из звуковых данных, относящихся к, по меньшей мере, одному из источников звука.
В соответствии с другим вариантом осуществления, каждое из значений местоположения каждого из источников звука может включать в себя, по меньшей мере, два значения координат (например, две координаты декартовой системы координат или азимут и расстояние в полярной системе координат). Модуль модификации может быть выполнен с возможностью модификации значений координат путем добавления, по меньшей мере, одного случайного числа к значениям координат или путем применения к значениям координат детерминированной функции, когда значения координат указывают, что источник звука расположен в местоположении, находящемся в предварительно определенной области окружающего пространства.
В соответствии со следующим вариантом осуществления, предоставляют поток звуковых данных. Поток звуковых данных может включать в себя звуковые данные, относящиеся к одному или более источникам звука, причем звуковые данные включают в себя одно или более значений давления для каждого из источников звука. Звуковые данные могут дополнительно включать в себя, по меньшей мере, одно значение местоположения, указывающее местоположение источника звука для каждого из источников звука. В варианте осуществления, каждое из, по меньшей мере, одного значения местоположения может включать в себя, по меньшей мере, два значения координат. Звуковые данные можно определить для частотно-временного элемента выборки из множества частотно-временных элементов выборки.
В другом варианте осуществления, звуковые данные дополнительно включают в себя одно или более значений диффузности для каждого из источников звука.
Ниже будут описаны предпочтительные варианты осуществления изобретения, в которых:
на фиг.1 проиллюстрировано устройство для генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных, включающего в себя звуковые данные, относящиеся к одному или более источникам звука в соответствии с вариантом осуществления,
на фиг.2 проиллюстрировано устройство для генерации потока звуковых данных, включающего в себя данные источников звука, относящихся к одному или более источникам звука в соответствии с вариантом осуществления,
на фиг.3a-3c проиллюстрированы потоки звуковых данных в соответствии с разными вариантами осуществления,
на фиг.4 проиллюстрировано устройство для генерации потока звуковых данных, включающего в себя данные источников звука, относящиеся к одному или более источникам звука в соответствии с другим вариантом осуществления,
на фиг.5 проиллюстрирована звуковая сцена, состоящая из двух источников звука и двух равномерных линейных массивов микрофонов,
на фиг.6a проиллюстрировано устройство 600 для генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных в соответствии с вариантом осуществления,
на фиг.6b проиллюстрировано устройство 660 для генерации потока звуковых данных, включающего в себя данные источников звука, относящихся к одному или более источникам звука в соответствии с вариантом осуществления,
на фиг.7 изображен модуль модификации в соответствии с вариантом осуществления,
на фиг.8 изображен модуль модификации в соответствии с другим вариантом осуществления,
на фиг.9 проиллюстрированы блоки передатчика/анализатора и блоки приемника/синтезатора в соответствии с вариантом осуществления,
на фиг.10a изображен модуль синтеза в соответствии с вариантом осуществления,
на фиг.10b изображен блок первого этапа синтеза в соответствии с вариантом осуществления,
на фиг.10c изображен блок второго этапа синтеза в соответствии с вариантом осуществления,
на фиг.11 изображен модуль синтеза в соответствии с другим вариантом осуществления,
на фиг.12 проиллюстрировано устройство для генерации выходного звукового сигнала виртуального микрофона в соответствии с вариантом осуществления,
на фиг.13 проиллюстрированы входы и выходы устройства и способ для генерации выходного звукового сигнала виртуального микрофона в соответствии с вариантом осуществления,
на фиг.14 проиллюстрирована основная структура устройства для генерации выходного звукового сигнала виртуального микрофона в соответствии с вариантом осуществления, которое включает в себя оценщик местоположения звукового события и модуль вычисления информации,
на фиг.15 показан примерный сценарий, в котором реальные пространственные микрофоны изображены как равномерные линейные массивы из 3 микрофонов каждый,
на фиг.16 показаны два пространственных микрофона в 3D, для оценки направления прихода в 3D пространстве,
на фиг.17 проиллюстрирована геометрия, в которой изотропный точечный источник звука текущего частотно-временного элемента выборки (k, n) расположен в местоположении PIPLS(k, n),
на фиг.18 показан модуль вычисления информации в соответствии с вариантом осуществления,
на фиг.19 показан модуль вычисления информации в соответствии с другим вариантом осуществления,
на фиг 20 показаны два реальных пространственных микрофона, локализованное звуковое событие и местоположение виртуального пространственного микрофона,
на фиг.21 проиллюстрировано, как получить направление прихода по отношению к виртуальному микрофону в соответствии с вариантом осуществления,
на фиг.22 показан возможный путь вывода DOA звука с точки зрения виртуального микрофона в соответствии с вариантом осуществления,
на фиг.23 проиллюстрирован блок вычисления информации, включающий в себя блок вычисления диффузности в соответствии с вариантом осуществления,
на фиг.24 показан блок вычисления диффузности в соответствии с вариантом осуществления,
на фиг.25 проиллюстрирован сценарий, при котором невозможна оценка местоположения звукового события,
на фиг.26 проиллюстрировано устройство для генерации потока данных виртуального микрофона в соответствии с вариантом осуществления,
на фиг.27 проиллюстрировано устройство для генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных в соответствии с другим вариантом осуществления, и
на фиг.28a-28c проиллюстрированы сценарии, в которых два массива микрофонов принимают прямой звук, звук, отраженный от стены, и диффузный звук.
До предоставления подробного описания вариантов осуществления настоящего изобретения описывают устройство для генерации выходного звукового сигнала виртуального микрофона, для предоставления уровня техники, относящегося к идеям настоящего изобретения.
На фиг.12 проиллюстрировано устройство для генерации выходного звукового сигнала для эмуляции записи микрофона в настраиваемом виртуальном местоположении posVmic в окружающем пространстве. Устройство включает в себя оценщик 110 местоположения звуковых событий и модуль 120 вычисления информации. Оценщик 110 местоположения звуковых событий принимает первую информацию о направлении di1 с первого реального пространственного микрофона и вторую информацию о направлении di2 со второго реального пространственного микрофона. Оценщик 110 местоположения звуковых событий выполнен с возможностью оценки местоположения источника звука ssp, указывающего местоположение источника звука в окружающем пространстве, источник звука испускает звуковую волну, причем оценщик 110 местоположения звуковых событий выполнен с возможностью оценки местоположения ssp источника звука на основании первой информации о направлении di1, предоставленной первым реальным пространственным микрофоном, расположенным в окружающем пространстве в месторасположении pos1mic первого реального пространственного микрофона, и на основании второй информации о направлении di2, предоставленной вторым реальным пространственным микрофоном, расположенным в окружающем пространстве в месторасположении второго реального пространственного микрофона. Модуль 120 вычисления информации выполнен с возможностью генерации выходного звукового сигнала на основании первого записанного входного звукового сигнала is1, записанного первым реальным пространственным микрофоном, на основании местоположения pos1mic первого реального пространственного микрофона и на основании виртуального местоположения posVmic виртуального микрофона. Модуль 120 вычисления информации включает в себя компенсатор распространения, выполненный с возможностью генерации первого модифицированного звукового сигнала, путем модификации первого записанного входного звукового сигнала is1, путем компенсации первой задержки или затухания амплитуды между приходом звуковой волны, испущенной источником звука на первый реальный пространственный микрофон и приходом звуковой волны на виртуальный микрофон, путем поправки значения амплитуды, значения магнитуды или значения фазы первого записанного звукового сигнала is1, для получения выходного звукового сигнала.
На фиг.13 проиллюстрированы входы и выходы устройства и способ, в соответствии с вариантом осуществления. Информацию с двух или более реальных пространственных микрофонов 111, 112, …, 11N направляют в устройство/обрабатывают в соответствии со способом. Эта информация включает звуковые сигналы, принятые реальными пространственными микрофонами, а также информацию о направлении с реальных пространственных микрофонов, например, оценки направления прихода (DOA). Звуковые сигналы и информация о направлении, такие как оценки направления прихода, можно выражать в частотно-временной области. Если, например, требуема реконструкция 2D геометрии и для представления сигналов выбрана традиционная область STFT (кратковременное преобразование Фурье), DOA можно выразить как углы азимута, зависимые от k и n, а именно частотного и временного индексов.
В вариантах осуществления, локализацию звукового события в пространстве, а также описание местоположения виртуального микрофона, можно проводить на основании местоположений и ориентации реальных и виртуальных пространственных микрофонов в общей системе координат. Эту информацию можно представить входными сигналами 121…12N и входным сигналом 104 на фиг.13. Входной сигнал 104 может дополнительно указывать характеристику виртуального пространственного микрофона, например, его местоположение и диаграмму направленности приема, как будет описано ниже. Если виртуальный пространственный микрофон включает в себя многочисленные виртуальные датчики, можно учитывать их местоположения и соответствующие разные диаграммы направленности приема.
Выходным сигналом устройства или соответствующего способа могут являться, если желательно, один или более звуковых сигналов 105, которые можно было принять пространственным микрофоном, определенным и расположенным, как указано 104. Более того, устройство (или, скорее, способ) может, в качестве выхода, предоставлять соответствующую пространственную информацию 106 стороны, которую можно оценить с применением виртуального пространственного микрофона.
На фиг.14 проиллюстрировано устройство в соответствии с вариантом осуществления, которое включает в себя два главных блока обработки, оценщик 201 местоположения звуковых событий и модуль 202 вычисления информации. Оценщик 201 местоположения звуковых событий может выполнять геометрическую реконструкцию на основании DOA, включенных в входы 111…11N, и на основании знания местоположения и ориентации реальных пространственных микрофонов, где DOA были вычислены. Выходной сигнал оценщика 205 местоположения звуковых событий включает в себя оценку местоположения (либо в 2D, либо в 3D) источников звука, причем для каждого частотно-временного элемента выборки происходят звуковые события. Второй блок 202 обработки представляет собой модуль вычисления информации. В соответствии с вариантом осуществления с фиг.14, второй блок 202 обработки вычисляет сигнал виртуального микрофона и информацию о пространственной стороне. Таким образом, еще его обозначают как блок 202 вычисления сигнала виртуального микрофона и информации стороны. Блок 202 вычисления сигнала виртуального микрофона и информации стороны, для обработки звуковых сигналов, включенных в 111…11N, использует местоположения 205 звуковых событий, для выходного сигнала звукового сигнала 105 виртуального микрофона. Блок 202, если требуется, также может вычислять информацию 106 пространственной стороны, соответствующую виртуальному пространственному микрофону. Варианты осуществления ниже иллюстрируют возможные варианты функционирования блоков 201 и 202.
В нижеследующем, оценка местоположения звуковых событий, в соответствии с вариантом осуществления, описана более детально.
На основании размерности задачи (2D или 3D) и количества пространственных микрофонов возможны несколько решений по оценке местоположения.
Если в 2D существуют два пространственных микрофона, (самый простой из возможных случай) возможна простая триангуляция. На фиг.15 показан примерный сценарий, в котором реальные пространственные микрофоны изображены как равномерные линейные массивы (ULA) из трех микрофонов каждый. DOA, выраженная как углы азимута a1(k, n) и a2(k, n), рассчитывают для частотно-временного элемента выборки (k, n). Этого достигают, применяя подходящий оценщик DOA, такой как ESPRIT,
[13] R. Roy, A. Paulraj, and T, Kailath, "DIrection-of-arrival estimation by subspace rotation methods - ESPRIT," in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Stanford, CA, USA, April 1986,
или (корневой) MUSIC, см.
[14] R. Schmidt, "Multiple emitter location and signal parameter estimation," IEEE Transactions on Antennas and Propagation, vol. 34, no. 3, pp. 276-280, 1986
к сигналам давления, преобразованным в частотно-временную область.
На фиг.15 проиллюстрированы два реальных пространственных микрофона, здесь, два реальных пространственных массива микрофонов 410, 420. Два оцениваемых DOA a1(k, n) и a2(k, n) представлены двумя линиями, первой линией 430, представляющей DOA a1(k, n), и второй линией 440, представляющей DOA a2(k, n). Зная местоположение и ориентацию каждого массива, при помощи простых геометрических принципов возможна триангуляция.
Триангуляция невозможна, когда две линии, 430, 440, в точности параллельны. Однако, в реальном применении это крайне маловероятно. Однако, не все результаты триангуляции соответствуют физическому или реалистическому местоположению звукового события в рассматриваемом пространстве. Например, оцененное местоположение звукового события может быть слишком удаленно или даже вне предполагаемого пространства, указывая на то, что возможно DOA не соответствуют никакому звуковому событию, которое можно физически интерпретировать в используемой модели. Такие результаты могут быть вызваны шумом датчиков или слишком сильной реверберацией комнаты. Таким образом, в соответствии с вариантом осуществления, такие нежелательные результаты помечают так, чтобы модуль 202 вычисления информации мог обработать их соответствующим образом.
На фиг.16 изображен сценарий, в котором местоположения звукового события оценивают в 3D пространстве. Применяют подходящие пространственные микрофоны, например, планарный или 3D массив микрофонов. На фиг.16, первый пространственный микрофон 510, например, является первым 3D массивом микрофонов, и второй пространственный микрофон 520, например, является вторым 3D массивом микрофонов, как проиллюстрировано. DOA в 3D пространстве можно, например, выразить как азимут и высоту. Для выражения DOA можно применить блочные векторы 530, 540. Две линии, 550, 560 проецируют в соответствии с DOA. В 3D, даже при очень достоверных оценках, две линии, 550, 560, спроецированные в соответствии с DOA, могут не пересечься. Однако, триангуляцию все равно можно выполнить, например, путем выбора средней точки наименьшего сегмента, соединяющего две линии.
Аналогично со случаем 2D, триангуляция может закончиться неудачей, либо предоставить неправдоподобные результаты для определенной комбинации направлений, которые, затем, также можно пометить, например, для блока 202 вычисления информации с фиг.14.
Если существует более двух пространственных микрофонов, возможны несколько решений. Например, триангуляцию, описанную выше, можно выполнить для всех пар реальных пространственных микрофонов (если N=3, 1 со 2, 1 с 3 и 2 с 3). Затем, результирующие местоположения можно усреднить (вдоль x и y, и, если рассматривается 3D, z).
Иначе, можно использовать более сложные принципы. Например, как описано в
[15] J. Michael Steele, "Optimal Triangulation of Random Samples in the Plane", The Annals of Probability, Vol. 10, No.3 (Aug., 1982), pp. 548-553.
можно применять вероятностные подходы.
В соответствии с вариантом осуществления, звуковое поле можно анализировать в частотно-временной области, например, полученной при помощи оконного преобразования Фурье (STFT), в котором k и n обозначают частотный индекс k и временной индекс n, соответственно. Сложное давление Pv(k, n) в произвольном местоположении Pv для определенных k и n моделируют, как одиночную сферическую волну, испущенную узкополосным изотропным точечным источником, например, применяя формулу
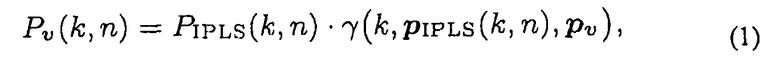
где PIPLS(k, n) представляет собой сигнал, испущенный IPLS в его местоположении PIPLS(k, n). Сложный коэффициент γ(k, PIPLS, Pv) выражает распространение от PIPLS(k, n) к Pv, например, представляет подходящие модификации фазы и магнитуды. Здесь, можно применить предположение, что в каждом частотно-временном элементе выборки активен только один IPLS. Тем не менее, множественные узкополосные IPLS, расположенные в разных местоположениях, также могут быть активны в единственный момент времени.
Каждый IPLS либо моделирует прямой звук, или четкое отражение комнаты. Его местоположение PIPLS(k, n) может идеально соответствовать фактическому источнику звука, находящемуся в комнате, или отраженному изображению источника, находящегося снаружи, соответственно. Таким образом, местоположение PIPLS(k, n) может также указывать местоположение звукового события.
Необходимо отметить, что термин "реальный источник звука" обозначает фактические источники звука, физически существующие в окружающей среде записи, такие, как собеседники или музыкальные инструменты. Напротив, с "источниками звука", или "звуковыми событиями", или "IPLS" обозначают эффективные источники звука, которые активны в определенные моменты времени или в определенных частотно-временных элементах выборки, причем источники звука могут, например, представлять реальные источники звука или отраженные изображения источников.
На фиг.28a-28b проиллюстрированы массивы микрофонов, локализующие источники звука. Локализованные источники звука могут обладать разными физическими интерпретациями, в зависимости от их природы. Когда массив микрофонов принимает прямой звук, то она может оказаться способна локализовать местоположение настоящего источника звука (например, собеседников). Когда массивы микрофонов принимают отражения, они могут локализовать местоположение отраженного изображения источника. Отраженные изображения источников также являются источниками звука.
На фиг.28a проиллюстрирован сценарий, в котором два массива 151 и 152 микрофонов принимают прямой звук из фактического источника звука (физически существующего источника звука) 153.
На фиг.28b проиллюстрирован сценарий, в котором два массива микрофонов 161, 162, принимают отраженный звук, причем звук был отражен от стены. Из-за отражения, массивы микрофонов 161, 162 локализуют местоположение, из которого, по видимости, идет звук, в местоположении отраженного изображения источника 165, которое отличается от местоположения громкоговорителя 163.
И фактический источник 153 звука с фиг.28a, а также отраженное изображение источника 165 представляют собой источники звука.
На фиг 28c проиллюстрирован сценарий, в котором два массива микрофонов 171, 172 принимают диффузный звук и не могут локализовать источник звука.
Хотя эта одноволновая модель точна только для слабо реверберантных окружающих сред, при условии, что исходные сигналы удовлетворяют условию W-дизъюнктивной ортогональности (WDO), т.е. частотно-временное перекрытие достаточно мало. Обычно, это так для речевых сигналов, см., например,
[12] S. Rickard and Z. Yilmaz, "On the approximate W-disjoint orthogonality of speech," in Acoustics, Speech and Signal Processing, 2002. ICASSP 2002. IEEE International Conference on, April 2002, vol. 1.
Однако, эта модель также предоставляет хорошую оценку для других окружающих сред и, таким образом, применима для этих сред.
В нижеследующем объясняют оценку местоположений PIPLS(k, n) в соответствии с вариантом осуществления. Местоположение PIPLS(k, n) активного IPLS в определенном частотно-временном элементе выборки, и, таким образом, оценки звукового события в частотно-временном элементе выборки, оценивают при помощи триангуляции, на основании направления прихода (DOA) звука, измеренного в, по меньшей мере, двух разных точках наблюдения.
На фиг.17 проиллюстрирована геометрия, в которой IPLS текущего частотно-временного слота (k, n) расположен в неизвестном местоположении PIPLS(k, n). Для того, чтобы определить требуемую информацию DOA, применяют два реальных пространственных микрофона, здесь, обладающие известной геометрией, местоположением и ориентацией два массива микрофонов, которые размещают в местоположениях 610 и 620, соответственно. Векторы p1 и p2 указывают на местоположения 610, 620, соответственно. Ориентации массивов определены блочными векторами c1 и c2. DOA звука определяют в местоположениях 610 и 620 для каждого (k, n), используя алгоритм оценки DOA, например, как предоставленный анализом DirAC (см. [2], [3]). Так, первый блочный вектор точки зрения, e1 POV(k, n), и второй блочный вектор точки зрения, e2 POV(k, n), с учетом точки зрения массивов микрофонов (обе не показаны на фиг.17), можно предоставить как выходной сигнал анализа DirAC. Например, при работе в 2D, первый блочный вектор точки зрения результирует в:
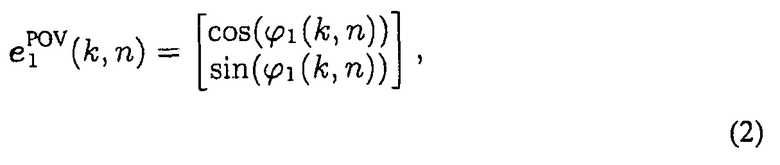
Здесь, φ1(k, n) представляет азимут DOA, оцененный на первом массиве микрофонов, как изображено на фиг.17. Соответствующие блочные векторы DOA e1(k, n) и e2(k, n), относительно глобальной координатной системы в исходной точке, можно вычислить, применяя формулу:
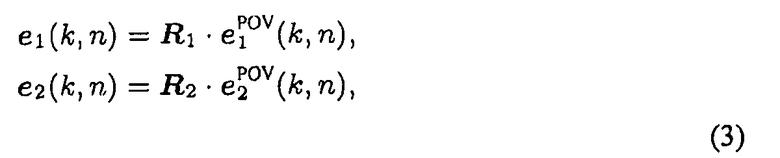
где R представляют собой массивы преобразования координат, например,

при функционировании в 2D, и c1=[c1,x, c1,y]T. Для выполнения триангуляции, векторы направленности d1(k, n) и d2(k, n) можно рассчитать как:
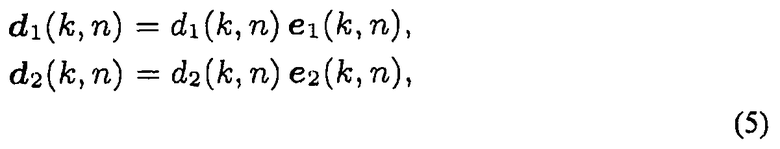
где d1(k, n)=||d1(k, n)|| и d2(k, n)=||d2(k, n)|| являются неизвестными расстояниями между IPLS и двумя массивами микрофонов. Следующее уравнение
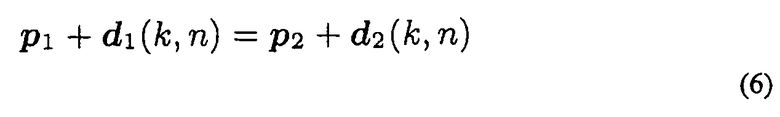
можно решить для d1(k, n). Наконец, местоположение PIPLS(k, n) IPLS дается в
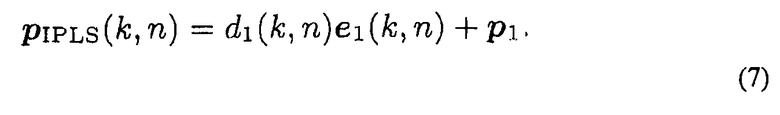
В другом варианте осуществления, уравнение (6) можно решить для d2(k, n), и PIPLS(k, n) вычисляют аналогично, применяя d2(k, n).
Уравнение (6) всегда предоставляет решение при функционировании в 2D, если только e1(k, n) и e2(k, n) не параллельны. Однако, при использовании более чем двух массивов микрофонов, или при функционировании в 3D, решение нельзя найти, когда векторы направленности d не пересекаются. В соответствии с вариантом осуществления, в этом случае, должна быть вычислена точка, наиболее близкая ко всем векторам направленности d, и результат можно использовать как местоположение IPLS.
В варианте осуществления, все точки обзора p1, p2, … должны располагаться так, чтобы звук, испускаемый IPLS, попадал в один и тот же временной блок n. Это требование просто выполнить, когда расстояние Δ между любыми двумя точками обзора меньше, чем
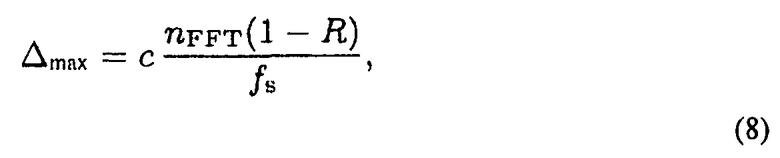
где nFFT представляет собой длину окна STFT, 0≤R<1 указывает перекрытие между последовательными временными кадрами, и fs представляет собой частоту сэмплирования. Например, для 1024-точечного STFT при 48 КГц с 50% перекрытием (R=0,5), максимальное расстояние между массивами, удовлетворяющее вышеприведенному требованию составит Δ=3,65 м.
В нижеследующем, в соответствии с вариантом осуществления, будет более подробно описан модуль 202 вычисления информации, например, модуль вычисления сигнала виртуального микрофона и информации стороны.
На фиг.18 проиллюстрирован схематичный вид модуля 202 вычисления информации, в соответствии с вариантом осуществления. Блок вычисления информации включает в себя компенсатор 500 распространения, объединитель 510 и блок 520 спектрального взвешивания. Модуль 202 вычисления информации принимает оценки местоположения источника звука ssp, оцененного оценщиком местоположения звуковых событий, один или более входных звуковых сигналов записывают при помощи одного или более реальных пространственных микрофонов, местоположения posRealMic одного или более реальных пространственных микрофонов и виртуальное местоположение posVmic виртуального микрофона. Он выводит выходной звуковой сигнал os, представляющий звуковой сигнал виртуального микрофона.
На фиг.19 проиллюстрирован модуль вычисления информации в соответствии с другим вариантом осуществления. Модуль вычисления информации с фиг.19 включает в себя компенсатор 500 распространения, объединитель 510 и блок 520 спектрального взвешивания. Компенсатор 500 распространения включает в себя модуль 501 вычисления параметров распространения и модуль 504 компенсации распространения. Объединитель включает в себя модуль 502 вычисления коэффициентов объединения и модуль 505 объединения. Блок 520 спектрального взвешивания включает в себя блок 503 вычисления спектральных весов, модуль 506 применения спектральных весов и модуль 507 вычисления пространственной информации стороны.
Для вычисления звукового сигнала виртуального микрофона, геометрическую информацию, например, местоположение и ориентацию реальных пространственных микрофонов 121…12N, местоположение, ориентацию и характеристики виртуального пространственного микрофона 104, и оценки местоположения звуковых событий 205 направляют на блок 202 вычисления информации, а точнее, в модуль 501 вычисления параметров распространения компенсатора 500 распространения, в модуль 502 вычисления коэффициентов объединения объединителя 510 и в блок 503 вычисления спектральных весов блока 520 спектрального взвешивания. Модуль 501 вычисления параметров распространения, модуль 502 вычисления коэффициентов объединения и блок 503 вычисления спектральных весов вычисляют параметры, используемые в модификации звуковых сигналов 111…11N в модуле 504 компенсации распространения, модуле 505 объединения и модуле 506 применения спектрального взвешивания.
В модуле 202 вычисления информации, звуковые сигналы 111…11N можно сначала модифицировать для компенсации эффектов, внесенных различными расстояниями распространения между местоположениями звуковых событий и реальными пространственными микрофонами. Затем, сигналы можно объединить для улучшения, например, отношения сигнал-шум (SNR). Наконец, результирующий сигнал можно подвергнуть спектральному взвешиванию, для принятия во внимание диаграммы направленности приема виртуального микрофона, а также любые зависящие от расстояния функции усиления. Эти три этапа описаны ниже более подробно.
Теперь опишем более подробно компенсацию распространения. В верхней части фиг.20 проиллюстрированы два реальных пространственных микрофона (первый массив микрофонов 910 и второй массив микрофонов 920), местоположение локализованного звукового события 930 для частотно-временного элемента выборки (k, n) и местоположение виртуального пространственного микрофона 940.
В нижней части фиг.20 изображена ось времени. Предполагается, что звуковое событие испущено во время t0 и затем распространяется к реальным и виртуальному пространственным микрофонам. Временные задержки прихода, а также амплитуды, изменяются с расстоянием так, что чем больше длина распространения, тем слабее амплитуда и длительнее временная задержка.
Сигналы на двух реальных массивах можно сравнивать только в том случае, если относительная временная задержка Dt12 между ними мала. Иначе, один из двух сигналов необходимо временно пересинхронизировать для компенсации относительной задержки Dt12 и, возможно, смасштабировать для компенсации различных затуханий.
Компенсация задержки между приходом на виртуальный микрофон и приходом на реальные массивы микрофонов (на одном из реальных пространственных микрофонов) изменяет задержку независимо от локализации звукового события, что делает ее, для большинства применений, избыточной.
Возвращаясь к фиг.19, модуль 501 вычисления параметров распространения выполнен с возможностью вычисления задержек, подлежащих коррекции для каждого реального пространственного микрофона и для каждого звукового события. Если желательно, он также вычисляет коэффициенты усиления, подлежащие рассмотрению для компенсации разных затуханий амплитуды.
Модуль 504 компенсации распространения сконфигурирован для использования этой информации для соответствующей модификации звуковых сигналов. Если сигналы необходимо сдвинуть на небольшой промежуток времени (по сравнению с временным окном банка фильтров), то достаточна простая фазовая ротация. Если задержки больше, необходимы более сложные реализации.
Выходной сигнал модуля 504 компенсации распространения представляет собой модифицированные звуковые сигналы, выраженные в исходном частотно-временной области.
В нижеследующем, со ссылкой на фиг.17, на которой, в том числе, проиллюстрировано местоположение 610 первого реального пространственного микрофона и местоположение 620 второго реального пространственного микрофона, будет описана конкретная оценка компенсации распространения для виртуального микрофона, в соответствии с вариантом осуществления.
В описываемом в настоящий момент варианте осуществления, предполагают, что доступен, по меньшей мере, первый входной записанный звуковой сигнал, например, сигнал давления с, по меньшей мере, одного из реальных пространственных микрофонов (например, массивов микрофонов), например, сигнал давления с первого реального пространственного микрофона. Рассматриваемый микрофон будет обозначен как эталонный микрофон, его местоположение как эталонное местоположение Pref и его сигнал давления как эталонный сигнал давления Pref(k, n). Однако, компенсацию распространения нельзя проводить по отношению к только одному сигналу давления, но также и по отношению к сигналам давления с множества или со всех реальных пространственных микрофонов.
Отношение между сигналом давления PIPLS(k, n), испущенного IPLS, и эталонным сигналом давления Pref(k, n) эталонного микрофона, расположенного в Pref, можно выразить формулой (9):
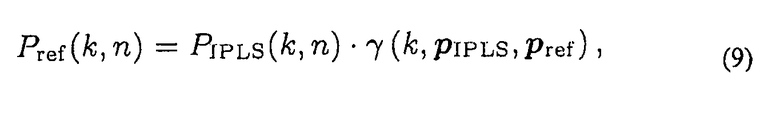
В общем, комплексный коэффициент γ(k, pa, pb) выражает фазовую ротацию и затухание амплитуды, внесенные распространением сферической волны из ее источника в pa к pb. Однако, практическое тестирование показало, что рассмотрение в γ только затухания амплитуды ведет к приемлемым впечатлениям от сигнала виртуального микрофона, с существенно меньшими артефактами, по сравнению с рассмотрением вместе с фазовой ротацией.
Звуковая энергия, которую можно измерить в определенной точке в пространстве, сильно зависит от расстояния r от источника звука, на фиг.6, с местоположения PIPLS источника звука. Во многих ситуациях, эту зависимость можно, с достаточной точностью, смоделировать, используя хорошо известные физические принципы, например, затухание 1/r звукового давления на удалении от точечного источника. Когда известно расстояние эталонного микрофона, например, первого реального микрофона, от источника звука, и когда также известно расстояние виртуального микрофона от источника звука, то, из сигнала и энергии с эталонного микрофона, например, первого реального пространственного микрофона, можно оценить звуковую энергию в местоположении виртуального микрофона. Это значит, что выходной сигнал виртуального микрофона можно получить путем применения подходящих усилений к эталонному сигналу давления.
Предполагая, что первый реальный пространственный микрофон является эталонным микрофоном, то Pref=p1. На фиг.17, виртуальный микрофон расположен в Pv. поскольку геометрия на фиг.17 известна подробно, расстояние d1(k, n)=||d1(k, n)|| между эталонным микрофоном (на фиг.17: первый реальный пространственный микрофон) и IPLS можно легко определить, а также расстояние s(k, n)=||s(k, n)|| между виртуальным микрофоном и IPLS, а конкретно
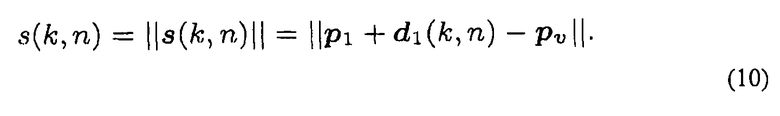
Звуковое давление Pv(k, n)в местоположении виртуального микрофона вычисляют при помощи комбинирования формул (1) и (9), что приводит к
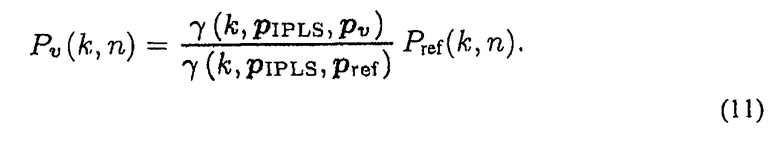
Как упомянуто выше, в некоторых вариантах осуществления, коэффициенты γ могут рассматривать только затухание амплитуды при распространении. Предполагая, для примера, что звуковое давление уменьшается с 1/r, то
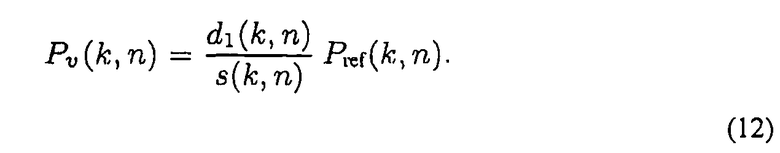
Когда модель из формулы (1) подходит, например, когда присутствует только прямой звук, то формула (12) может точно реконструировать информацию магнитуды. Однако, в случае чистых диффузных звуковых полей, например, когда допущения модели не выполняются, представленный способ дает явную дереверберацию сигнала при перемещении виртуального микрофона вдаль от местоположения массивов датчиков. Фактически, как описано выше, в диффузных звуковых полях, ожидается, что большая часть IPLS локализована рядом с двумя массивами датчиков. Таким образом, при перемещении виртуального микрофона вдаль от этих местоположений, скорее всего, увеличивается расстояние s=||s|| с фиг.17. Таким образом, магнитуда эталонного давления уменьшается при применении взвешивания в соответствии с формулой (11). Соответственно, при перемещении виртуального микрофона вблизь от фактического источника звука, частотно-временные элементы выборки, соответствующие прямому звуку, будут усилены, таким образом, что весь звуковой сигнал будет восприниматься как менее диффузный. Путем поправки правила в формуле (12), можно управлять усилением прямого звука и подавлением диффузного звука произвольным образом.
Путем выполнения компенсации распространения на записанный входной звуковой сигнал (например, сигнал давления) первого реального пространственного микрофона, получают первый модифицированный звуковой сигнал.
В вариантах осуществления, второй модифицированный звуковой сигнал можно получить путем проведения компенсации распространения на дополнительно записанные входные звуковые сигналы (дополнительные сигналы давления) дополнительных реальных пространственных микрофонов.
Теперь, более подробно описывают объединение в блоках 502 и 505 с фиг.19, в соответствии с вариантом осуществления. Предполагают, что модифицировали два или более звуковых сигналов с множества разных реальных пространственных микрофонов, для компенсации различных путей распространения для получения двух или более модифицированных звуковых сигналов. После того, как звуковые сигналы с разных реальных пространственных микрофонов модифицировали для компенсации различных путей распространения, их можно объединить для повышения качества звука. Таким образом можно, например, увеличить SNR или уменьшить реверберацию.
Возможные решения для объединения включают в себя:
- Взвешенное усреднение, например, рассматривая SNR, или расстояние до виртуального микрофона, или диффузность, оцененная реальными пространственными микрофонами. Можно применять традиционные решения, например, объединение максимального отношения (MRC), или объединение равного усиления (EQC), или
- Линейное объединение нескольких или всех модифицированных звуковых сигналов для получения объединенного сигнала. Модифицированные звуковые сигналы можно взвешивать в линейном объединении для получения объединенного сигнала, или
- Выбор, например, использование только одного сигнала, например, в зависимости от SNR, или расстояния, или диффузности.
Задачей модуля 502, если применимо, является вычисление параметров для объединения, которое выполняют в модуле 505.
Теперь, описывается более подробно спектральное взвешивание, в соответствии с вариантами осуществления. Для этого делаются ссылки на блоки 503 и 506 с фиг.19. На этом последнем этапе, звуковой сигнал, получившийся из объединения или из компенсации распространения входных звуковых сигналов, взвешивают в частотно-временной области в соответствии с пространственными характеристиками виртуального пространственного микрофона, как указано входным сигналом 104, и/или в соответствии с реконструированной геометрией (данной в 205).
Для каждого частотно-временного элемента выборки геометрическое реконструирование позволяет легко получить DOA относительно виртуального микрофона, как показано на фиг.21. Более того, расстояние между виртуальным микрофоном и местоположение звукового события также легко вычисляется.
Затем вычисляют вес для частотно-временного элемента выборки, с учетом желательного типа виртуального микрофона.
В случае направленных микрофонов, спектральные веса можно вычислить в соответствии с предварительно определенной диаграммой направленности приема. Например, в соответствии с вариантом осуществления, кардиоидный микрофон может обладать диаграммой направленности приема, определенной функцией g(theta),
g(theta)=0,5+0,5cos(theta),
где theta - это угол между направлением взгляда виртуального пространственного микрофона и DOA звука с точки зрения виртуального микрофона.
Другой возможностью являются художественные (не физические) функции затухания. В определенных применениях, может быть желательно подавлять звуковые события, сильно удаленные от виртуального микрофона, с коэффициентом, большим, чем обусловлено распространением сквозь свободную область. Для этой цели некоторые варианты осуществления вносят дополнительную взвешивающую функцию, которая зависит от расстояния между виртуальным микрофоном и звуковым событием. В варианте осуществления, нужно принять только звуковые события в пределах определенного расстояния (например, в метрах) от виртуального микрофона.
С учетом направленности виртуального микрофона для виртуального микрофона можно применять произвольные диаграммы направленности. Этим способом можно, например, выделить источник из сложной звуковой сцены.
Поскольку DOA звука можно вычислить в местоположении pv виртуального микрофона, а именно
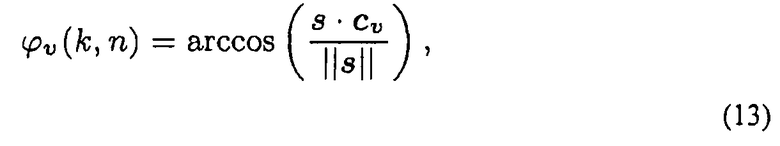
где cv представляет собой блочный вектор, описывающий ориентацию виртуального микрофона, для виртуального микрофона можно реализовывать произвольные направленности. Например, предполагая, что Pv(k, n) указывает объединенный сигнал или скомпенсированный по распространению модифицированный звуковой сигнал, то формула:
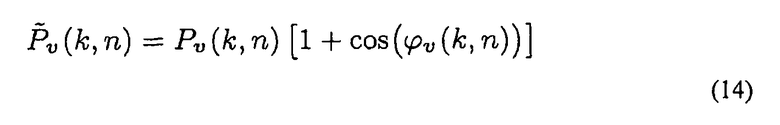
вычисляет выходной сигнал виртуального микрофона с кардиоидной направленностью. Диаграммы направленности, которые потенциально можно генерировать таким образом, зависят от точности оценки местоположения.
В вариантах осуществления, один или более реальных, не пространственных микрофонов, например, всенаправленный микрофон или направленный микрофон, такой как кардиоиддный, размещают в звуковой сцене в дополнение к реальным пространственным микрофонам для дополнительного улучшения качества звука сигналов 105 виртуального микрофона с фиг.8. Эти микрофоны не используют для сбора какой-либо геометрической информации, но, напротив, только для предоставления более чистого звукового сигнала. Эти микрофоны можно размещать ближе к источникам звука, чем пространственные микрофоны. В этом случае, в соответствии с вариантом осуществления, звуковые сигналы реальных, не пространственных микрофонов и их местоположения просто направляют для обработки в модуль 504 компенсации распространения с фиг.19, вместо звуковых сигналов с реальных пространственных микрофонов. Затем проводят компенсацию распространения, для одного или более записанных звуковых сигналов не пространственных микрофонов, относительно местоположения одного или более не пространственных микрофонов. Таким образом, вариант осуществления реализуют с использованием дополнительных не пространственных микрофонов.
В дополнительном варианте осуществления реализуют вычисление пространственной информации стороны виртуального микрофона. Для вычисления пространственной информации 106 стороны для микрофона, модуль 202 вычисления информации с фиг.19 включает в себя модуль 507 вычисления пространственной информации стороны, который выполнен с возможностью приема, в качестве входного сигнала, местоположений 205 источников звука, и местоположения, ориентации и характеристик 104 виртуального микрофона. В некоторых вариантах осуществления, в соответствии с информацией 106 стороны, которую необходимо вычислить, звуковой сигнал виртуального микрофона 105 также можно принять в расчет, как входной сигнал в модуль 507 вычисления пространственной информации стороны.
Выходной сигнал из модуля 507 вычисления пространственной информации стороны представляет собой информацию стороны виртуального микрофона 106. Этой информацией стороны может являться, например, DOA или диффузность звука для каждого частотно-временного элемента выборки (k, n) с точки зрения виртуального микрофона. Другой возможной информацией стороны может, например, являться активный вектор звуковой интенсивности Ia(k, n), который был бы измерен в местоположении виртуального микрофона. Теперь описывается, как можно вывести эти параметры.
В соответствии с вариантом осуществления, реализуют оценку DOA для виртуального пространственного микрофона. Модуль 120 вычисления информации выполнен с возможностью оценки направления прихода на виртуальный микрофон как пространственную информацию стороны, на основании вектора местоположения виртуального микрофона и на основании вектора местоположения звукового события, как проиллюстрировано на фиг.22.
На фиг.22 изображен возможный путь по выводу DOA звука с точки зрения виртуального микрофона. Местоположение звукового события, предоставленное блоком 205 с фиг.19, можно описать для каждого частотно-временного элемента выборки (k, n) при помощи вектора местоположения r(k, n), вектора местоположения звукового события. Аналогично, местоположение виртуального микрофона, предоставленное как входной сигнал 109 с фиг.19, можно описать при помощи вектора местоположения s(k, n), вектора местоположения виртуального микрофона. Направление взгляда виртуального микрофона можно описать вектором v(k, n). DOA относительно виртуального микрофона задается вектором a(k, n). Он представляет угол между v и путем распространения звука h(k, n). h(k, n) можно вычислить, применив формулу:
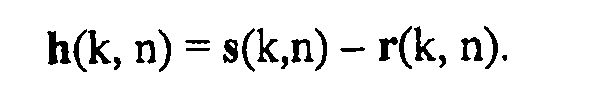
Теперь можно вычислить требуемый DOA a(k, n) для каждой (k, n), например, при помощи определения точечного продукта h(k, n) и v(k, n), а именно
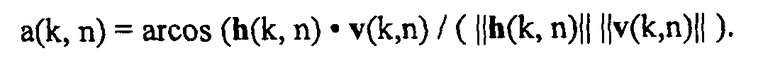
В другом варианте осуществления, модуль 120 вычисления информации может быть выполнен с возможностью оценки интенсивности активного звука на виртуальном микрофоне, как пространственную информацию стороны, на основании вектора местоположения виртуального микрофона и на основании вектора местоположения звукового события, как проиллюстрировано на фиг.22.
Из DOA a(k, n), определенного выше, можно вывести интенсивность активного звука Ia(k, n), в местоположении виртуального микрофона. Для этого предполагают, что звуковой сигнал 105 виртуального микрофона с фиг.19 соответствует выходному сигналу всенаправленного микрофона, например, предполагают, что виртуальный микрофон является всенаправленным микрофоном. Кроме того, направление взгляда v с фиг.22 предполагают параллельным оси x системы координат. Поскольку требуемый вектор интенсивности активного звука Ia(k, n) описывает чистый поток энергии через местоположение виртуального микрофона, можно вычислить Ia(k, n), например, вычисляя в соответствии с формулой:
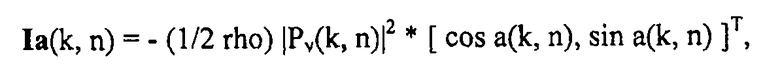
где []T обозначает транспонированный вектор, rho представляет собой плотность воздуха, и Pv(k, n) представляет собой звуковое давление, измеренное виртуальным пространственным микрофоном, например, выходной сигнал 105 блока 506 с фиг.19.
Если активный вектор интенсивности необходимо вычислить выраженным в общей системе координат, но по-прежнему в местоположении виртуального микрофона, можно применять следующую формулу:
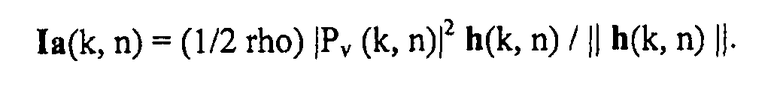
Диффузность звука выражает, насколько диффузным является звуковое поле в данной частотно-временной ячейке (см., например, [2]). Диффузность выражается значением Ψ, где 0≤Ψ≤1. Диффузность в 1 указывает, что вся энергия звукового поля полностью диффузная. Эта информация важна, например, при воспроизведении пространственного звука. Обычно, диффузность вычисляют в определенной точке в пространстве, где размещен массив микрофонов.
В соответствии с вариантом осуществления, диффузность можно вычислить как дополнительный параметр к информации стороны, сгенерированной для виртуального микрофона (VM), который можно разместить в звуковой сцене в произвольном местоположении. Так, устройство, которое вычисляет, в виртуальном местоположении виртуального микрофона, помимо звукового сигнала, также и диффузность, можно рассматривать как внешний интерфейс виртуального DirAC, поскольку возможно создание потока DirAC, а именно звукового сигнала, направления прихода, и диффузности, для произвольной точки в звуковой сцене. Кроме того, поток DirAC можно обрабатывать, сохранять, передавать и проигрывать на наборе громкоговорителей произвольной компоновки. В этом случае, слушатель испытывает звуковую сцену так, как будто бы он или она находились в местоположении, указанном виртуальным микрофоном, и смотрели бы в направлении, определенным его ориентацией.
На фиг.23 проиллюстрирован блок вычисления информации в соответствии с вариантом осуществления, включающий в себя блок 801 вычисления диффузности для вычисления диффузности на виртуальном микрофоне. Блок 202 вычисления информации выполнен с возможностью приема входных сигналов со 111 по 11N, включая, дополнительно ко входным сигналам с фиг.14, диффузность на реальных пространственных микрофонах. Пусть эти значения обозначают c Ψ(SM1) по Ψ(SMN). Эти дополнительные входные сигналы направляют в модуль 202 вычисления информации. Выходной сигнал 103 блока 801 вычисления диффузности представляет собой параметр диффузности, вычисленный в местоположении виртуального микрофона.
Блок 801 вычисления диффузности, по варианту осуществления, проиллюстрированному на фиг.24, изображен более подробно. В соответствии с вариантом осуществления, оценивают энергию прямого и диффузного звука на каждом из N пространственных микрофонов. Затем, используя информацию о местоположениях IPLS, и информацию о местоположениях пространственных и виртуального микрофонов, получают N оценок этих энергий в местоположении виртуального микрофона. Наконец, оценки можно объединить для улучшения точности оценки и легко вычислить параметр диффузности на виртуальном микрофоне.
Пусть с Edir (SM1) по Edir (SMN) и с Ediff (SM1) по Ediff (SMN) обозначают оценки энергий прямого и диффузного звука для N пространственных микрофонов, вычисленных блоком 810 анализа энергии. Если Pi представляет собой сложный сигнал давления, и Ψi представляет собой диффузность для i-того пространственного микрофона, то энергии можно, например, вычислить в соответствии с формулами:
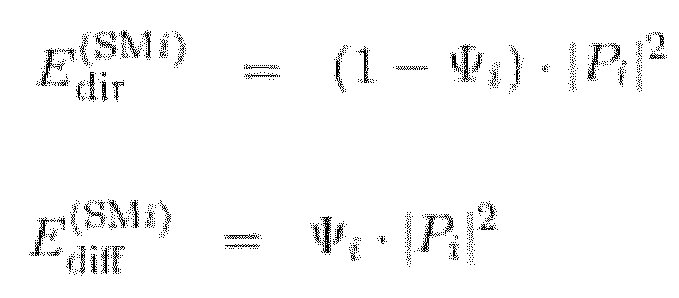
Энергия диффузного звука должна быть равна во всех местоположениях, следовательно, оценка энергии диффузного звука Ediff (VM) на виртуальном микрофоне можно вычислить просто усреднением с Ediff (SM1) по Ediff (SMN), например, в блоке 820 объединения диффузности, например, согласно формуле:
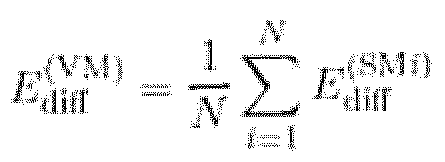
Можно выполнить более эффективное объединение с Ediff (SM1) по Ediff (SMN), путем рассмотрения дисперсии оценщиков, например, рассматривая SNR.
Из-за распространения, энергия прямого звука зависит от расстояния до источника. Таким образом, для того чтобы принять это в расчет, с Edir (SM1) по Edir (SMN) можно модифицировать. Это можно выполнять, например, блоком 830 поправки распространения прямого звука. Например, если предполагают, что энергия прямого звукового поля затухает с 1 через квадрат расстояния, то оценку для прямого звука на виртуальном микрофоне для i-того пространственного микрофона можно вычислить в соответствии с формулой:
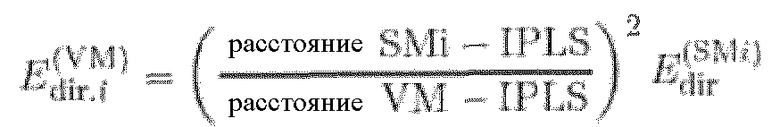
Аналогично блоку 820 объединения диффузности, оценки энергии прямого звука, полученные на разных пространственных микрофонах, можно объединять, например, при помощи блока 840 объединения прямого звука. Результатом является Edir (VM), например, оценка для энергии прямого звука на виртуальном микрофоне. Диффузность на виртуальном микрофоне Ψ(VM) можно вычислить, например, вспомогательным вычислителем 850 диффузности, например, в соответствии с формулой:

Как упомянуто выше, в некоторых случаях, оценка местоположения звуковых событий, выполняемая оценщиком местоположения звуковых событий не удается, например, в случае неправильной оценки направления прихода. На фиг.25 проиллюстрирован такой сценарий. В этих случаях, вне зависимости от параметров диффузности, оцененных на разных пространственных микрофонах и принятых как входные сигналы со 111 по 11N, диффузность для виртуального микрофона 103 можно установить в 1 (т.е. полностью диффузный), поскольку невозможно адекватное пространственное воспроизведение.
Дополнительно, можно рассмотреть надежность оценок DOA на N пространственных микрофонах. Это можно выразить, например, в терминах дисперсии в оценщике DOA или SNR. Такую информацию можно принять в расчет во вспомогательном вычислителе 850 диффузности, так, что диффузность 103 VM можно искусственно увеличить, в том случае, если оценки DOA ненадежны. Фактически, как последствия, оценки местоположения 205 также будут ненадежны.
На фиг.1 проиллюстрировано устройство 150 для генерации, по меньшей мере, одного выходного звукового сигнала, на основании потока звуковых данных, включающего в себя звуковые данные, относящиеся к одному или более источникам звука, в соответствии с вариантом осуществления.
Устройство 150 включает в себя приемник 160 для приема потока звуковых данных, включающего в себя звуковые данные. Звуковые данные включают в себя одно или более значений давления для каждого из одного или более источников звука. Кроме того, звуковые данные включают в себя одно или более значений местоположения, указывающих местоположение одного из источников звука для каждого из источников звука. Более того, устройство включает в себя модуль 170 синтеза для генерации, по меньшей мере, одного выходного звукового сигнала, на основании, по меньшей мере, одного из одного или более значений давления из звуковых данных из потока звуковых данных и на основании, по меньшей мере, одного из одного или более значений местоположения из звуковых данных из потока звуковых данных. Звуковые данные определены для частотно-временного элемента выборки из множества частотно-временных элементов выборки. Для каждого из источников звука, по меньшей мере, одно значение давления включено в звуковые данные, причем, по меньшей мере, одно значение давления может представлять собой значение давления, относящееся к испущенной звуковой волне, например, начавшейся из источника звука. Значение давления может представлять собой значение звукового сигнала, например, значение давления выходного звукового сигнала, сгенерированного устройством для генерации выходного звукового сигнала виртуального микрофона, причем этот виртуальный микрофон размещают в местоположении источника звука.
Таким образом, на фиг.1 проиллюстрировано устройство 150, которое можно применять для приема или обработки упомянутого потока звуковых данных, т.е., устройство 150 можно применять на стороне приемника/синтеза. Поток звуковых данных включает в себя звуковые данные, которые включают в себя одно или более значений давления и одно или более значений местоположения для каждого из множества источников звука, т.е., каждое из значений давления и значений местоположения относится к конкретному источнику звука из одного или более источников звука в записанной звуковой сцене. Это означает, что значения местоположения указывают местоположения источников звука, вместо местоположения записывающих микрофонов. По отношению к значениям давления это означает, что поток звуковых данных включает в себя одно или более значений давления для каждого из источников звука, т.е. значения давления указывают звуковой сигнал, который относится к источнику звука, вместо того, чтобы относиться к записи реального пространственного микрофона.
В соответствии с вариантом осуществления, приемник 160 может быть выполнен с возможностью приема потока звуковых данных, включающего в себя звуковые данные, причем звуковые данные, дополнительно включают в себя одно или более значений диффузности для каждого из источников звука. Модуль 170 синтеза может быть выполнен с возможностью генерации, по меньшей мере, одного выходного звукового сигнала, на основании, по меньшей мере, одного или более значений диффузности.
На фиг.2 проиллюстрировано устройство 200 для генерации потока звуковых данных, включающего в себя данные звуковых источников, относящихся к одному или более источникам звука, в соответствии с вариантом осуществления. Устройство 200 для генерации потока звуковых данных включает в себя определитель 210 для определения данных источника звука, на основании, по меньшей мере, одного входного звукового сигнала, записанного, по меньшей мере, одним пространственным микрофоном, и на основании, информации звуковой стороны, предоставленной на, по меньшей мере, двух пространственных микрофонах. Дополнительно, устройство 200 включает в себя генератор 220 потока данных, для генерации потока звуковых данных так, что поток звуковых данных включает в себя данные источников звука. Данные источников звука включают в себя одно или более значений давления для каждого из источников звука. Кроме того, данные источника звука дополнительно включают в себя одно или более значений местоположения, указывающих местоположение источника звука для каждого из источников звука. Дополнительно, данные источника звука определены для частотно-временного элемента выборки из множества частотно-временных элементов выборки.
Затем, поток звуковых данных, сгенерированный устройством 200, можно передать. Таким образом, устройство 200 можно применять на стороне анализа/передатчика. Поток звуковых данных включает в себя звуковые данные, которые включают в себя одно или более значений давления и одно или более значений местоположения для каждого из множества источников звука, т.е., каждое из значений давления и значений местоположения относится к конкретному источнику звука из одного или более источников звука записанной звуковой сцены. Это означает, что, по отношению к значениям местоположения, значения местоположения указывают местоположения источников звука, вместо записывающих микрофонов.
В дополнительном варианте осуществления, определитель 210 может быть выполнен с возможностью определения данных источника звука, на основании информации диффузности на, по меньшей мере, одном пространственном микрофоне. Генератор 220 потока данных может быть выполнен с возможностью генерации потока звуковых данных так, чтобы поток звуковых данных включал бы в себя данные источника звука. Данные источника звука дополнительно включают в себя, для каждого из источников звука, одно или более значений диффузности.
На фиг.3a проиллюстрирован поток звуковых данных в соответствии с вариантом осуществления. Поток звуковых данных включает в себя звуковые данные, относящиеся к двум источникам звука, активным в одном частотно-временном элементе выборки. В частности, на фиг.3 проиллюстрированы звуковые данные, которые передают для частотно-временного элемента выборки (k, n), где k обозначает частотный индекс, и n обозначает временной индекс. Звуковые данные включают в себя значение давления P1, значение местоположения Q1, и значение диффузности Ψ1 первого источника звука. Значение местоположения Q1 включает в себя три значения координат X1, Y1 и Z1, указывающих положение первого источника звука. Дополнительно, звуковые данные включают в себя значение давления P2, значение местоположения Q2 и значение диффузности Ψ2 второго источника звука. Значение местоположения Q2 включает в себя три значения координат X2, Y2 и Z2, указывающих положение второго источника звука.
На фиг.3b проиллюстрирован поток звуковых данных в соответствии с другим вариантом осуществления. Опять, звуковые данные включают в себя значение давления P1, значение местоположения Q1 и значение диффузности Ψ1 первого источника звука. Значение местоположения Q1 включает в себя три значения координат X1, Y1 и Z1, указывающих положение первого источника звука. Дополнительно, звуковые данные включают в себя значение давления P2, значение местоположения Q2 и значение диффузности Ψ2 второго источника звука. Значение местоположения Q2 включает в себя три значения координат X2, Y2 и Z2, указывающих положение второго источника звука.
На фиг.3c предоставлена еще одна иллюстрация потока звуковых данных. Поскольку поток звуковых данных предоставляет информацию геометрического пространственного звукового кодирования (GAC), его также обозначают как "поток геометрического пространственного звукового кодирования" или "поток GAC". Поток звуковых данных включает в себя информацию, которая относится к одному или более источникам звука, например, одному или более изотропным точечным источникам (IPLS). Как уже описано выше, поток GAC может включать в себя следующие сигналы, где k и n обозначают частотный индекс и временной индекс рассматриваемого частотно-временного элемента выборки:
P(k, n): Сложное давление на источнике звука, например, на IPLS. Возможно, этот сигнал включает в себя прямой звук (звук, исходящий из самого IPLS) и диффузный звук.
Q(k, n): Местоположение (например, декартовы координаты в 3D) источника звука, например, IPLS: Местоположение может, например, включать в себя декартовы координаты X(k, n), Y(k, n), Z(k, n).
Диффузность на IPLS: Ψ(k, n). Этот параметр относится к соотношению мощности прямого к диффузному звуку, включенному в P(k, n). Если P(k, n)=Pdir(k, n)+Pdiff(k, n), то одна из возможностей выразить диффузность - это Ψ(k, n)=|Pdiff(k, n)|2/|P(k, n)|2. Если |P(k, n)|2 известно, то возможны другие эквивалентные представления, например, отношение прямого к диффузному (DDR) Г=|Pdir(k, n)|2/|Pdiff(k ,n)|2.
Как уже отмечено, k и n обозначают частотный и временной индексы, соответственно. Если желательно, и если анализ это позволяет, в данной частотно-временной ячейка можно представить более чем один IPLS. Это изображено на фиг.3c как M несколько уровней, так что сигнал давления для i-того уровня (т.е., для i-того IPLS) обозначают с Pi(k, n). Для удобства, местоположение IPLS можно выразить как вектор Qi(k ,n)=[Xi(k, n), Yi(k, n), Zi(k, n)]T. В отличии от принятого в данной области техники, все параметры в потоке GAC выражены по отношению к одному или более источникам звука, например, по отношению к IPLS, таким образом, достигая независимости от местоположения записи. На фиг.3c, как и на фиг.3a и 3b, все количества на чертеже рассматривают в частотно-временной области; обозначение (k, n) опустили по причинам простоты, например, Pi обозначает Pi(k, n), например, Pi=Pi(k, n).
В нижеследующем, устройство для генерации потока звуковых данных, в соответствии с вариантом осуществления, описывают более подробно. Как и устройство с фиг.2, устройство с фиг.4 включает в себя определитель 210 и генератор потока данных 220, который может быть аналогичен определителю 210. По мере того как определитель анализирует входные звуковые данные для определения данных источника звука, на основании которых генератор потока данных генерирует поток данных, определитель и генератор потока данных можно совместно обозначать как "модуль анализа" (см. модуль 410 анализа на фиг.4).
Модуль 410 анализа вычисляет поток GAC из записей N пространственных микрофонов. в зависимости от требуемого количества M уровней (например, количества источников звука, для которых в определенный частотно-временной элемент выборки потока звуковых данных необходимо включать информацию), типа и количества N пространственных микрофонов, возможны разные способы анализа. В нижеследующем приведено несколько примеров.
В качестве первого примера рассматривают, оценку параметров для одного источника звука, например, одного IPLS, для каждой частотно-временной ячейки. В случае M=1, поток GAC можно легко получить при помощи идей, изложенных выше, для устройства для генерации выходного звукового сигнала виртуального микрофона, в котором виртуальный пространственный микрофон можно разместить в местоположении источника звука, например, в местоположении IPLS. Это позволяет вычислять сигналы давления в местоположении IPLS, вместе с соответствующими оценками местоположения и, возможно, диффузности. Эти три параметра группируют вместе в потоке GAC и далее, ими может манипулировать модуль 102 с фиг.8, перед передачей или сохранением.
Например, определитель может определить местоположение источника звука путем применения идей, предложенных для оценки местоположения звуковых событий устройства для генерирования выходного звукового сигнала виртуального микрофона. Кроме того, определитель может включать в себя устройство для генерирования выходного звукового сигнала и может использовать определенное местоположения источника звука как местоположение виртуального микрофона для вычисления значений давления (например, значений выходного звукового сигнала, подлежащего генерированию) и диффузности в местоположении источника звука.
В частности, определитель 210, например, с фиг.4), конфигурируют для определения сигналов давления, соответствующих оценок местоположения, и соответствующей диффузности, в то время как генератор 220 потока данных конфигурируют для генерирования потока звуковых данных на основании вычисленных сигналов давления, оценок местоположения и диффузности.
В качестве другого примера рассматриваем, оценку параметра для 2 источников звука, например, 2 IPLS, для каждой частотно-временной ячейки. Если модуль 410 анализа должен оценивать два источника звука для каждого частотно-временного элемента выборки, то можно использовать нижеприведенный принцип, основанный на оценщиках, известных в данной области техники.
На фиг.5 проиллюстрирована звуковая сцена, созданная из двух источников звука и двух равномерных линейных массивов микрофонов. Со ссылкой на ESPRIT, смотреть
[26] R. Roy and T. Kailath. ESPRIT-estimation of signal parameters via rotational invariance techniques. Acoustics, Speech and Signal Processing, IEEE Transactions on, 37(7):984-995, My 1989.
ESPRIT ([26]) можно применять раздельно на каждом массиве, для получения двух оценок DOA для каждого частотно-временного элемента выборки на каждом массиве. Из-за неопределенности парности, это приводит к двум возможным решениям по местоположению источников. Как можно видеть на фиг.5, два возможных решения даны как (1, 2) и (1', 2'). Для решения этой неопределенности можно применять следующее решение. Сигнал, испущенный на каждом источнике, оценивают при помощи формирователя пучка, ориентированного в направлении оцененных местоположений источников, и применения подходящего коэффициента для компенсации распространения (например, умножая на обратное затухание, испытанное волной). Это можно выполнять для каждого источника на каждом массиве для каждого из возможных решений. Затем, можно определить ошибку оценки для каждой пары источников (i, j) так:
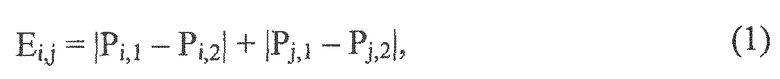
где (i, j) ∈ {(1, 2), (1', 2')} (см. фиг.5) и Pi,1 обозначает компенсированную мощность сигнала, видимую массивом r из источнику звука i. Для настоящей пары источников звука ошибка будет минимальной. После решения проблемы парности и вычисления корректных оценок DOA, их группируют, вместе с соответствующими сигналами давления и оценками диффузности, в потом GAC. Сигналы давления и оценки диффузности можно получать, используя такой же способ, как уже описан для оценки параметров для одного источника звука.
На фиг.6a проиллюстрировано устройство 600 для генерирования, по меньшей мере, одного выходного звукового сигнала, на основании потока звуковых данных, в соответствии с вариантом осуществления. Устройство 600 включает в себя приемник 610 и модуль 620 синтеза. Приемник 610 включает в себя модуль 630 модификации для модификации звуковых данных из принятого потока звуковых данных, путем модификации, по меньшей мере, одного из значений давления из звуковых данных, по меньшей мере, одного из значений местоположения из звуковых данных или, по меньшей мере, одного из значений диффузности из звуковых данных, относящихся к, по меньшей мере, одному из источников звука.
На фиг.6b проиллюстрировано устройство 660 для генерирования потока звуковых данных, относящихся к одному или более источникам звука, в соответствии с вариантом осуществления. Устройство для генерирования потока звуковых данных включает в себя определитель 670, генератор 680 потока данных и, дополнительно, модуль 690 модификации, для модификации потока звуковых данных, сгенерированного генератором потока звуковых данных, путем модификации, по меньшей мере, одного из значений давления из звуковых данных, по меньшей мере, одного из значений местоположения из звуковых данных или, по меньшей мере, одного из значений диффузности из звуковых данных, относящихся к, по меньшей мере, одному из источников звука.
В то время как модуль 610 модификации с фиг.6a применяют на стороне приемника/синтеза, модуль 660 с фиг.6b применяют на стороне передатчика/анализатора.
Модификации потока звуковых данных, проводимые модулями 610, 660 модификации, также можно рассматривать как модификации звуковой сцены. Таким образом, модуль 610, 660 модификации также можно обозначать как модули манипулирования звуковой сценой.
Представление звукового поля, предоставляемое потоком GAC, позволяет разные виды модификаций потока звуковых данных, т.е., как следствие, манипуляции звуковой сценой. Вот некоторые примеры в этом контексте:
1. Расширение произвольных секций пространства/объемов в звуковой сцене (например, расширение точечного источника звука для того, чтобы слушателю он представлялся более широким);
2. Преобразование выбранной секции пространства/объема в любую другую произвольную секцию пространства/объема в звуковой сцене (преобразованное пространство/объем может, например, содержать источник, который необходимо перенести в новое местоположение);
3. Фильтрация на основании местоположения, в которой выбранные области звуковой сцены усиливают или частично/полностью подавляют.
В нижеследующем допускается, что уровень потока звуковых данных, например, потока GAC, включает в себя все звуковые данные одного из источников звука, по отношению к конкретному частотно-временному элементу выборки.
На фиг.7 изображен модуль модификации в соответствии с вариантом осуществления. Блок модификации с фиг.7 включает в себя демультиплексор 401, процессор 420 манипуляции и мультиплексор 405.
Демультиплексор 401 сконфигурирован для разделения различных уровней M-уровня потока GAC и формирования M одноуровневых потоков GAC. Кроме того, процессор 420 манипуляции включает в себя блоки 402, 403 и 404, которые применяют к каждому из потоков GAC отдельно. Кроме того, мультиплексор 405 сконфигурирован для формирования результирующего M-уровня потока GAC из сманипулированных одноуровневых потоков GAC.
На основании данных местоположения из потока GAC и знания о местоположении реальных источников (например, дикторов) энергию можно ассоциировать с определенным реальным источником для каждого частотно-временного элемента выборки. Затем, соответственно взвешивают значения давления P, для модификации громкости соответствующего реального источника (например, диктора). Это требует априорной информации или оценки местоположения реальных источников звука (например, дикторов).
В некоторых вариантах осуществления, если доступна информация о местоположении реальных источников, то, на основании местоположения из потока GAC, энергию можно ассоциировать с определенным реальным источником для каждого частотно-временного элемента выборки.
Манипуляция потоком звуковых данных, например, потоком GAC, может происходить в модуле 630 модификации устройства 600 для генерации, по меньшей мере, одного выходного звукового сигнала с фиг.6a, т.е. на стороне приемника/синтеза и/или в модуле 690 модификации устройства 660 для генерации потока звуковых данных с фиг.6b, т.е., на стороне передатчика/анализа.
Например, поток звуковых данных, т.е., поток GAC, можно модифицировать до передачи или перед синтезом после передачи.
В отличии от модуля 630 модификации с фиг.6a на стороне приемника/синтеза, модуль 690 модификации с фиг.6b на стороне передатчика/анализа может пользоваться дополнительной информацией с входных сигналов со 111 по 11N (записанными сигналами) и со 121 по 12N (относительным местоположением и ориентацией пространственных микрофонов), поскольку эта информация доступна на стороне передатчика. Используя эту информацию, можно реализовать блок модификации, в соответствии с альтернативным вариантом осуществления, который изображен на фиг.8.
На фиг.9 изображен вариант осуществления, путем иллюстрирования схематического общего плана системы, в которой поток GAC генерируют на стороне передатчика/анализа, причем, необязательно, поток GAC можно модифицировать модулем 102 модификации на стороне передатчика/анализа, причем поток GAC, необязательно, можно модифицировать на стороне приемника/синтеза модулем 103 модификации, и причем поток GAC используют для генерирования множества выходных звуковых сигналов 191…19L.
На стороне передатчика/анализа, представление звукового поля (например, поток GAC) вычисляют в блоке 101 из входных сигналов со 111 по 11N, т.е., сигналов, записанных с N≥2 пространственных микрофонов, и из входных сигналов со 121 по 12N, т.е., относительного местоположения и ориентации пространственных микрофонов.
Выходной сигнал блока 101 представляет собой ранее упомянутое представление звукового поля, каковое в нижеследующем обозначают как поток геометрического пространственного звукового кодирования. Аналогично предложению в
[20] Giovanni Del Galdo, Oliver Thiergart, Tobias Weller, and E.A.P. Habets. Generating virtual microphone signals using geometrical information gathered by distributed arrays. In Third Joint Workshop on Hands-free Speech Communication and Microphone Arrays (HSCMA '11), Edinburgh, United Kingdom, May 2011,
и, как описано для устройства для генерации выходного звукового сигнала виртуального микрофона в настраиваемом виртуальном местоположении, сложную звуковую схему моделируют средствами источников звука, например, изотропных точечных источников звука (IPLS), которые активны в конкретных ячейках в частотно-временном представлении, таком, как предоставляет оконное преобразование Фурье (STFT).
Далее поток GAC можно обрабатывать в необязательном модуле 102 модификации, который также можно обозначать как блок манипулирования. Модуль 102 модификации позволяет выполнять множество операций. Затем, поток GAC можно передать или сохранить. Параметрическая сущность потока GAC очень эффективна. На стороне синтеза/приемника можно применять еще один необязательный модуль 103 модификации. Результирующий поток GAC входит блок 104 синтеза, который генерирует сигналы громкоговорителей. С данной независимостью представления от записи, конечный пользователь на стороне воспроизведения может, потенциально, манипулировать звуковой сценой и свободно определять в звуковой сцене местоположение и ориентацию прослушивания.
Модификация/манипуляция потоком звуковых данных, например, потоком GAC, может иметь место в модулях 102 и/или 103 модификации, с фиг.9, путем модификации потока GAC, соответственно, либо до передачи в модуле 102 или после передачи до синтеза 103. В отличии от модуля модификации 103 на стороне приемника/синтеза, модуль 103 модификации на стороне передатчика/анализа может использовать дополнительную информацию с входных сигналов со 111 по 11N (звуковые данные, предоставленные пространственными микрофонами) и со 121 по 12N (относительное местоположение и ориентация пространственных микрофонов), поскольку на стороне передатчика эта информация доступна. На фиг.8 проиллюстрирован альтернативный вариант осуществления модуля модификации, который использует эту информацию.
Примеры различных идей по манипуляции потоком GAC описаны в нижеследующем, со ссылкой на фиг.7 и фиг.8. Блоки с одинаковыми обозначающими сигналами обладают одинаковыми функциями.
1. Расширение объема
Предполагают, что определенная энергия в сцене расположена внутри объема V. Объем V может указывать на предварительно определенную область окружающей среды. Θ обозначает набор частотно-временных элементов выборки (k, n), для которых соответствующие источники звука, например, IPLS, локализованы внутри объема V.
Если желательно расширение объема V до другого объема V', его можно достигнуть путем прибавления случайного условия к данным местоположения в потоке GAC, каждый раз, когда (k, n) ∈ Θ (вычисляется в блоках 403 решений), и подставляя Q(k, n)=[X(k, n), Y(k, n), Z(k, n)]T (уровень индексов опущен для упрощения) так, что выходные сигналы с 431 по 43M блоков 404 с фиг.7 и 8 становятся
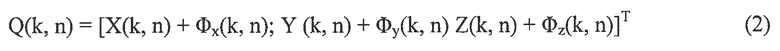
где Фх, Фy и Фz являются случайными переменными, чей диапазон зависит от геометрии нового объема V' по отношению к исходному объему V. Этот принцип можно, например, применять для уширения воспринимаемого источника звука. В этом примере, исходный объем V бесконечно мал, т.е., источник звука, например, IPLS, должен быть локализован в одной точке Q(k, n)=[X(k, n), Y(k, n), Z(k, n)]T для всех (k, n) ∈ Θ. Этот механизм можно рассматривать как форму дизеринга параметра местоположения Q(k, n).
В соответствии с вариантом осуществления, каждое из значений местоположения каждого из источников звука включает в себя, по меньшей мере, два значения координат, и модуль модификации выполнен с возможностью модификации значения координат путем добавления, по меньшей мере, одного случайного числа к значениям координат, когда значения координат указывают, что источник звука расположен в местоположении внутри предварительно определенной области окружающей среды.
2. Преобразование объема
В дополнение к расширению объема, данные местоположения из потока GAC можно модифицировать для переноса секций пространства/объемов внутри звукового поля. И в этом случае данные, подлежащие манипуляции, включают в себя пространственные координаты локализованной энергии.
V снова обозначает объем, подлежащий перемещению, и Θ обозначает набор всех частотно-временных элементов выборки (k, n) для которых энергия локализована в объеме V. Снова, объем V может указывать предварительно определенную область окружающей среды.
Переноса объема можно добиться путем модификации потока GAC, так, что для всех частотно-временных элементов выборки (k, n) ∈ Θ, Q(k ,n) заменяют на f(Q(k, n)) в выходных сигналах с 431 по 43M блоков 404, где f представляет собой функцию от пространственных координат (X, Y, Z), описывающую манипуляцию с объемом, подлежащую выполнению. Функция f может представлять простое линейное преобразование, такое как поворот, трансляцию, или любой другой сложный нелинейный перенос. Этот способ можно использовать, например, для перемещения источников звука из одного местоположения в звуковой сцене в другое, путем гарантии того, что Θ соответствует набору частотно-временных элементов выборки, в которых источники звука были локализованы в объеме V. Способ позволяет различные другие сложные манипуляции всей звуковой сценой, такие как отражение сцены, поворот сцены, увеличение сцены и/или сжатие, и т.п. Например, путем применения соответствующего линейного переноса на объем V, можно достигнуть эффекта, обратного расширению объема, т.е., уменьшения объема. Это можно выполнить путем переноса Q(k,n) для (k,n) ∈ Θ в f(Q(k,n)) ∈ V', где V' ⊂ V и V' составляет существенно меньший объем, чем V.
В соответствии с вариантом осуществления, модуль модификации выполнен с возможностью модификации значений координат, путем применения детерминированной функции на значения координат, когда значения координат указывают, что источник звука расположен в местоположении в рамках предварительно определенной области окружающей среды.
3. Фильтрация на основании местоположения
Идея фильтрации на основании геометрии (или фильтрации на основании местоположения), предлагает способ усилить или полностью/частично убрать секции пространства/объемов из звуковой сцены. По сравнению со способами расширения и трансформации объема, в этом случае, модифицируют только данные давления из потока GAC, путем применения соответствующих скалярных весов.
В фильтрации на основании геометрии, можно сделать различие между стороной передатчика 102 и стороной приемника модуля 103 модификации, в том, что предыдущий может использовать входные сигналы со 111 по 11N и со 121 по 12N, для содействия вычисления соответствующих весов фильтров, как показано на фиг.8. Предполагая, что стоит задача подавить/усилить энергию, возникающую из выбранной секции пространства/объема V, фильтрацию на основании геометрии можно применять следующим образом:
Для всех (k, n) ∈ Θ, сложное давление P(k, n) в потоке GAC модифицируют в ηP(k, n) в выходных сигналах 402, где η представляет собой реальный коэффициент взвешивания, например, вычисленный блоком 402. В некоторых вариантах осуществления, модуль 402 может быть выполнен с возможностью вычисления коэффициента взвешивания, также зависящего от диффузности.
Концепцию фильтрации на основании геометрии можно использовать во множестве применений, таких как улучшение сигнала и разделение источника. Некоторые из применений и требуемой априорной информации включают в себя:
- Дереверберацию. Зная геометрию комнаты, пространственный фильтр можно использовать для подавления энергии, локализованной за границами комнаты, которая может быть вызвана многолучевым распространением. Это применение может быть интересно, например, для громкой связи в конференц-залах и автомобилях. Необходимо отметить, что для подавления поздней реверберации, достаточно закрыть фильтр в случае высокого диффузности, в то время как для подавления ранних отражений фильтр, основанный на местоположении, более эффективен. В этом случае, как уже упоминалось, геометрия комнаты должна быть известна априори.
- Подавление фонового шума. Аналогичную концепцию также можно использовать для подавления фонового шума. Если потенциальные области, где можно обнаружить источники, (например, кресла участников в конференц-залах или места в машине) известны, то энергия, расположенная вне этих областей, связана с фоновым шумам и, следовательно, подавлена пространственным фильтром. Это применение требует априорную информацию или оценку, на основании доступных данных в потоках GAC, примерного местоположения источников.
- Подавление точечного источника помех. Если источник помех не является диффузным, а чисто локализован в пространстве, фильтрацию на основании местоположения можно применять для ослабления энергии, локализованной в местоположении источника помех. Это требует априорной информации или оценки местоположения источника помех.
- Управление эхом. В этом случае источники помех, которые нужно подавить, являются сигналами громкоговорителей. Для этой цели, аналогично случаю с точечными источниками помех, подавляют энергию, локализованную точно или в непосредственной близости от местоположений громкоговорителей. Это требует априорной информации или оценки местоположений громкоговорителей.
- Улучшенное определение голоса. Способы улучшения сигнала с изобретением геометрической фильтрации, можно реализовывать как этап предварительной обработки в обычной системе определения голосовой активности, например, в машинах. Для улучшения эффективности системы, в дополнение можно использовать дереверберацию или подавление шума.
- Наблюдение. Сохранение только энергии из определенных областей или подавление всех остальных представляет собой обычно используемый способ в применениях наблюдения. Это требует априорной информации о геометрии и местоположении интересующей области.
- Разделение источников. В окружающей среде с несколькими одновременно активными источниками, для разделения источников можно применять геометрическую пространственную фильтрацию. Размещение соответствующим образом разработанного пространственного фильтра, центрованного в местоположении источника, результирует в подавлении/ослаблении других одновременно активных источников. Эту инновацию можно использовать, например, как внешний интерфейс в SAOC. Это требует априорной информации или оценки местоположения источника.
- Зависимое от местоположения автоматическое управление усилением (AGC). Зависящие от местоположения веса можно использовать, например, для уравнивания громкости различных дикторов в применениях для конференц-связи.
В нижеследующем описывают модули синтеза в соответствии с вариантами осуществления. В соответствии с вариантом осуществления, модуль синтеза может быть выполнен с возможностью генерации, по меньшей мере, одного выходного звукового сигнала, на основании, по меньшей мере, одного значения давления из звуковых данных из потока звуковых данных и на основании, по меньшей мере, одного значения местоположения из звуковых данных из потока звуковых данных. По меньшей мере одно значение давления может представлять собой значения давления из сигнала давления, например, звукового сигнала.
Принципы работы за синтезом GAC мотивированы предположениями о восприятии пространственного звука, данными в
[27] WO 2004077884: Tapio Lokki, Juha Merimaa, and Ville Pulkki. Method for reproducing natural or modified spatial impression in multichannel listening, 2006.
В частности, пространственные направления, необходимые для правильного восприятия пространственного изображения звуковой сцены, можно получить путем правильного воспроизведения одного направления прихода недиффузного звука для каждого частотно-временного элемента выборки. Таким образом, синтез, изображенный на фиг.10a, разделен на два этапа.
На первом этапе рассматривают местоположение и ориентацию слушателя в звуковой сцене и определяют, какой из M IPLS доминирует в каждом частотно-временном элементе выборки. Следовательно, можно вычислить его сигнал давления Pdir и направление θ. Оставшиеся источники и диффузный звук собирают во второй сигнал давления Pdiff.
Второй этап идентичен второй половине синтеза DirAC, описанного в [27]. Недиффузный звук воспроизводят с механизмом переноса, который производит точечный источник, в то время как диффузный звук воспроизводят из всех громкоговорителей после декорреляции.
На фиг.10a изображен модуль синтеза в соответствии с вариантом осуществления, иллюстрирующий синтез потока GAC.
Блок 501 первого этапа синтеза вычисляет сигналы давления Pdir и Pdiff, которые необходимо проигрывать иначе. Фактически, в то время как Pdir включает в себя звук, который надо проигрывать в пространстве когерентно, Pdiff включает в себя диффузный звук. Третий выходной сигнал блока 501 первого этапа синтеза представляет собой направление прихода (DOA) θ 505, с точки зрения требуемого местоположения прослушивания, т.е. информация о направлении прихода. Необходимо отметить, что направление прихода (DOA) можно выразить как азимутальный угол в 2D пространстве или как пару азимутального и высотного угла в 3D. Эквивалентно, можно использовать блочный нормальный вектор, показывающий на DOA. DOA указывает, с какого направления (по отношению к требуемому местоположению прослушивания) должен приходит сигнал Pdir. Блок 501 первого этапа синтеза принимает как входной сигнал поток GAC, т.е., параметрическое представление звукового поля, и вычисляет упомянутые выше сигналы, на основании местоположения слушателя и ориентации, указанной входным сигналом 141. Фактически, конечным пользователь может свободно определять местоположение прослушивания и ориентацию в звуковой сцене, описанной потоком GAC.
Блок 502 второго этапа синтеза вычисляет L сигналов громкоговорителей с 511 по 51L, на основании знания компоновки 131 громкоговорителей. Необходимо помнить, что блок 502 идентичен второй половине синтеза DirAC, описанного в [27].
На фиг.10b изображен блок первого этапа синтеза в соответствии с вариантом осуществления. Входной сигнал, предоставляемый на блок, представляет собой поток GAC, составленный из M слоев. На первом этапе, блок 601 демультиплексирует M слоев в M параллельных потоков GAC из одного уровня каждый.
i-тый поток GAC включает в себя сигнал давления Pi, диффузность Ψi и вектор местоположения Qi=[Xi, Yi, Zi]T. Сигнал давления Pi включает в себя одно или более значений давления. Вектор местоположения представляет собой значение местоположения. Теперь, на основании этих значений, генерируют, по меньшей мере, один выходной звуковой сигнал.
Сигнал давления для прямого и диффузного звука Pdir и Pdiff,i, получают из Pi путем применения подходящего коэффициента, выведенного из диффузности Ψi. Сигналы давления, включающие в себя прямой звук, входят в блок 602 компенсации распространения, который вычисляет задержки, соответствующие распространению сигнала от местоположения источника звука, например, местоположения IPLS, к местоположения слушателя. В дополнение к этому, блок также вычисляет коэффициенты усиления, требуемые для компенсации разных угасаний магнитуды. В других вариантах осуществления, компенсируют только разные угасания магнитуды, в то время как задержки не компенсируют.
Скомпенсированные сигналы давления, обозначенные 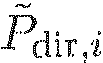 , входят в блок 603, который выводит индекс imax наиболее сильного входного сигнала
, входят в блок 603, который выводит индекс imax наиболее сильного входного сигнала
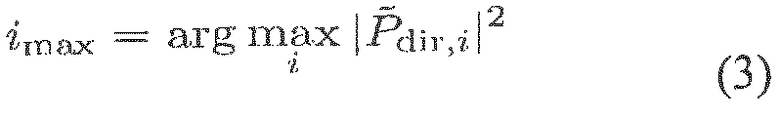
Основная идея за этим механизмом состоит в том, что M IPLS, активных в рассматриваемом частотно-временном элементе выборки, только наиболее сильный (по отношению к местоположению слушателя) будет проигран когерентно (т.е., как прямой звук). Блоки 604 и 605 выбирают из их входных сигналов тот, который определен imax. Блок 607 вычисляет направление прихода от imax-ного IPLS, по отношению к местоположению и ориентации слушателя (входной сигнал 141). Выходной сигнал блока 604 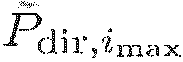 соответствует выходному сигналу блока 501, а именно звуковому сигналу Pdir, который будет проигран блоком 502 как прямой звук. Диффузный звук, а именно выходной сигнал 504 Pdiff, включает в себя сумму всего диффузного звука в M ветвях, а также все сигналы прямого звука
соответствует выходному сигналу блока 501, а именно звуковому сигналу Pdir, который будет проигран блоком 502 как прямой звук. Диффузный звук, а именно выходной сигнал 504 Pdiff, включает в себя сумму всего диффузного звука в M ветвях, а также все сигналы прямого звука 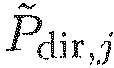 , кроме imax-того, а именно ∀j≠imax.
, кроме imax-того, а именно ∀j≠imax.
На фиг.10c проиллюстрирован блок 502 второго этапа синтеза. Как уже отмечено, этот этап идентичен второй половине модуля синтеза, предложенного в [27]. Недиффузный звук Pdir 503 воспроизводят как точечный источник при помощи, например, переноса, усиления которого вычисляют в блоке 701 на основании направления прихода (505). С другой стороны, диффузный звук, Pdiff, проходит через L четких декорреляторов (c 711 по 71L). Для каждого из L сигналов громкоговорителей, пути прямого и диффузного звука складывают, до прохождения через набор обратных фильтров (703).
На фиг.11 проиллюстрирован модуль синтеза в соответствии с альтернативным вариантом осуществления. Все количества на чертеже рассматривают в частотно-временной области, запись (k, n) пропущена по причине упрощения, например, Pi=Pi(k, n). Для повышения качества звука воспроизведения в случае особо сложных звуковых сцен, например, многочисленных активных в одно и то же время источниках, модуль синтеза, например, модуль 104 синтеза можно, например, реализовать так, как показано на фиг.11. Вместо выбора наиболее доминирующего IPLS для когерентного воспроизведения, синтез с фиг.11 выполняет полный синтез каждого из M уровней отдельно. L сигналов громкоговорителей из i-того уровня представляют собой выходной сигнал блока 502 и обозначены с 191i по 19Li. h-тый сигнал громкоговорителя 19h, на выходе блока 501 первого этапа синтеза представляет собой сумму с 19h1 по 19hM. Необходимо отметить, что, в отличии от фиг.10b, этап оценки DOA в блоке 607 необходимо выполнять для каждого из M уровней.
На фиг.26 проиллюстрировано устройство 950 для генерации потока данных виртуального микрофона в соответствии с вариантом осуществления. Устройство 950 для генерации потока данных виртуального микрофона включает в себя устройство 960 для генерации выходного звукового сигнала виртуального микрофона в соответствии с одним из вышеописанных вариантов осуществления, например, в соответствии с фиг.12, и устройство 970 для генерации потока звуковых данных в соответствии с одним из вышеописанных вариантов осуществления, например, в соответствии с фиг.2, где поток звуковых данных сгенерированный устройством 970 для генерации потока звуковых данных представляет собой поток данных виртуального микрофона.
Устройство 960, например, с фиг.26, для генерации выходного звукового сигнала виртуального микрофона включает в себя оценщик местоположения звукового события и модуль вычисления информации, как на фиг.12. Оценщик местоположения звукового события выполнен с возможностью оценки местоположения звукового события, указывая местоположение источника звука в окружающей среде, причем оценщик местоположения звукового события выполнен с возможностью оценки местоположения источника звука на основании информации первого направления, предоставленной первым реальным пространственным микрофоном, расположенным в местоположении первого реального микрофона в окружающей среде, и на основании информации второго направления, предоставленной вторым реальным пространственным микрофоном, расположенным в местоположении второго реального микрофона в окружающей среде. Модуль вычисления информации выполнен с возможностью генерации выходного звукового сигнала на основании записанного входного звукового сигнала, на основании местоположения первого реального микрофона, и на основании вычисленного местоположения микрофона.
Устройство 960 для генерации выходного звукового сигнала виртуального микрофона скомпоновано для предоставления выходного звукового сигнала на устройство 970 для генерации потока звуковых данных. Устройство 970 для генерации потока звуковых данных включает в себя определитель, например, определитель 210, описанный со ссылкой на фиг.2. Определитель устройства 970 для генерации потока звуковых данных определяет данные источника звука на основании выходного звукового сигнала, предоставленного устройством 960 для генерации выходного звукового сигнала виртуального микрофона.
На фиг.27 проиллюстрировано устройство 980 для генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных в соответствии с одним из вышеописанных вариантов осуществления, например, устройства по п.1, сконфигурированного для генерации выходного звукового сигнала на основании потока данных виртуального микрофона, как потока звуковых данных, предоставленного устройство 950 для генерации потока данных виртуального микрофона, например, устройством 950 с фиг.26.
Устройство 950 для генерации потока данных виртуального микрофона направляет сгенерированный сигнал виртуального микрофона в устройство 980 для генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных. Необходимо отметить, что поток данных виртуального микрофона представляет собой поток звуковых данных. Устройство 980 для генерации, по меньшей мере, одного выходного звукового сигнала, на основании потока звуковых данных, генерирует выходной звуковой сигнал на основании потока данных виртуального микрофона как потока звуковых данных, например, как описано со ссылкой на устройство с фиг.1.
Несмотря на то, что некоторые аспекты были описаны в контексте устройств, должно быть понятно, что эти аспекты также представляют описание соответствующего способа, причем блок или устройство соответствуют этапу способа или признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют собой описание соответствующего блока или предмета или признака соответствующего устройства.
Разложенный сигнал согласно изобретению можно сохранить на цифровом носителе хранения или можно передать на носителе передачи, таком как беспроводной носитель передачи или проводной носитель передачи, такой как Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения можно реализовывать в аппаратном обеспечении или в программном обеспечении. Реализацию можно исполнить, используя цифровой носитель хранения, например, гибкий диск, DVD, CD, ROM, PROM, EPROM, EEPROM или флеш-память, содержащую считываемые электронным образом управляющие сигналы, сохраненные на них, которые взаимодействуют (или способны к взаимодействию) с программируемой компьютерной системой так, что выполняется соответствующий способ.
Некоторые варианты осуществления в соответствии с изобретением включают в себя некратковременный носитель данных, содержащий считываемые электронным образом управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой так, что выполняют один из способов, описанных в настоящем документе.
Обычно, варианты осуществления настоящего изобретения можно реализовать как компьютерный программный продукт с программным кодом, причем программный код выполним для исполнения одного из способов, когда компьютерную программу исполняют на компьютере. Программный код, например, можно сохранить на машиночитаемом носителе.
Другие варианты осуществления включают в себя компьютерную программу для выполнения одного из способов, описанных в настоящем документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления способа согласно изобретению - это, следовательно, компьютерная программа, содержащая программный код для выполнения одного из способов, описанных в настоящем документе, при выполнении программы на компьютере.
Дополнительный вариант осуществления способов согласно изобретению - это, следовательно, носитель данных (или цифровой носитель хранения, или считываемый компьютером носитель), включающий в себя, на котором записана, компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Еще одним вариантом осуществления способа согласно изобретению, следовательно, является поток данных или последовательность сигналов, представляющая компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов можно, например, сконфигурировать для передачи по соединению связи данных, например, по Интернет.
Еще один вариант осуществления способа согласно изобретению включает в себя средство обработки, например, компьютер, или программируемое логическое устройство, сконфигурированное или выполненное с возможностью выполнения одного из способов, описанных в настоящем документе.
Еще один вариант осуществления включает в себя компьютер, содержащий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемую пользователем вентильную матрицу) можно использовать для выполнения некоторых или всех функционалов способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, с целью выполнения одного из способов, описанных в настоящем документе. Обычно, способы предпочтительно выполняют любым устройством аппаратного обеспечения.
Вышеописанные варианты осуществления лишь иллюстрируют идеи настоящего изобретения. Необходимо понимать, что изменения и модификации компоновок и подробностей, описанных в настоящем документе, будут очевидны другим специалистам в данной области техники. Таким образом, изобретение должно ограничиваться только объемом нижеследующей формулы изобретения, но не определенными подробностями, представленными путем описания и пояснения вариантов осуществления в настоящем документе.
Список литературы



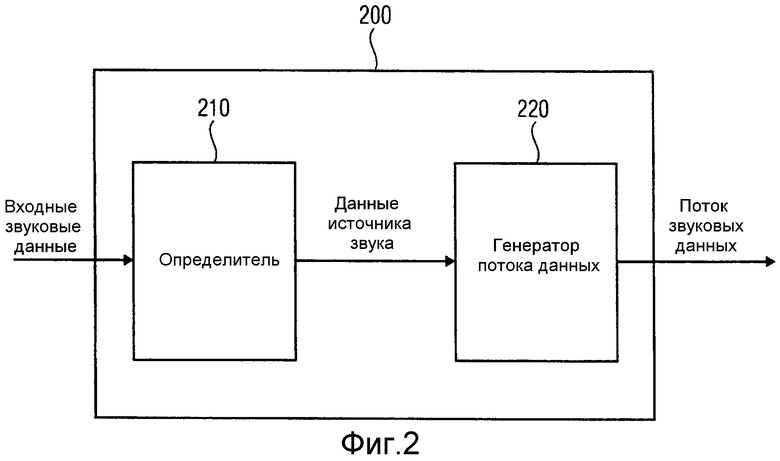
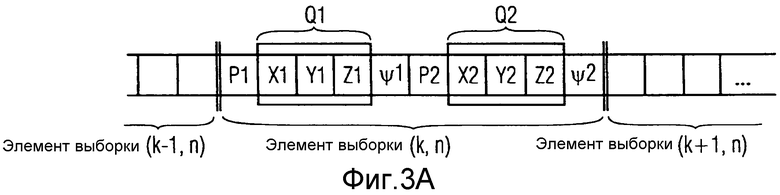
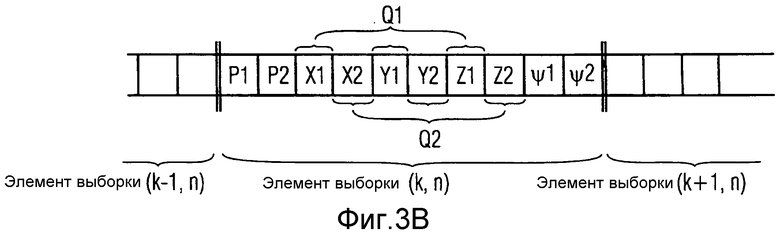
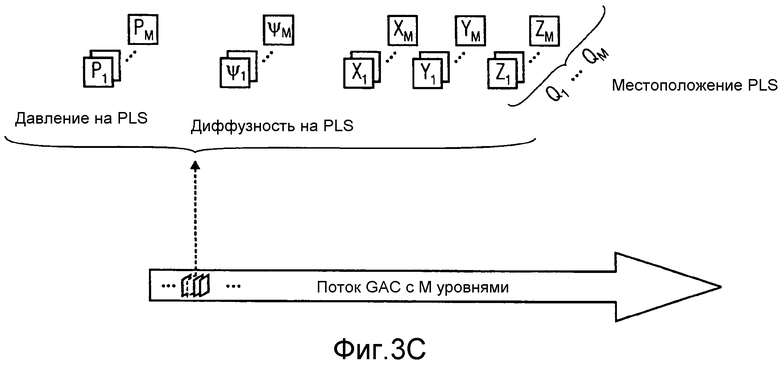
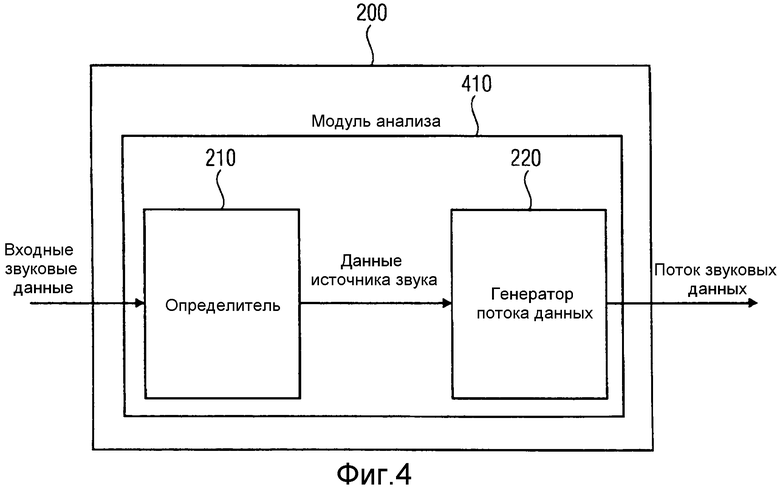
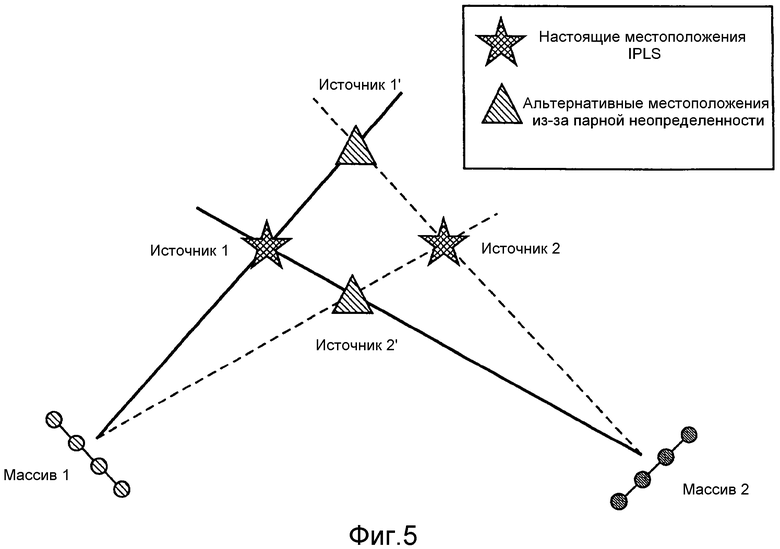
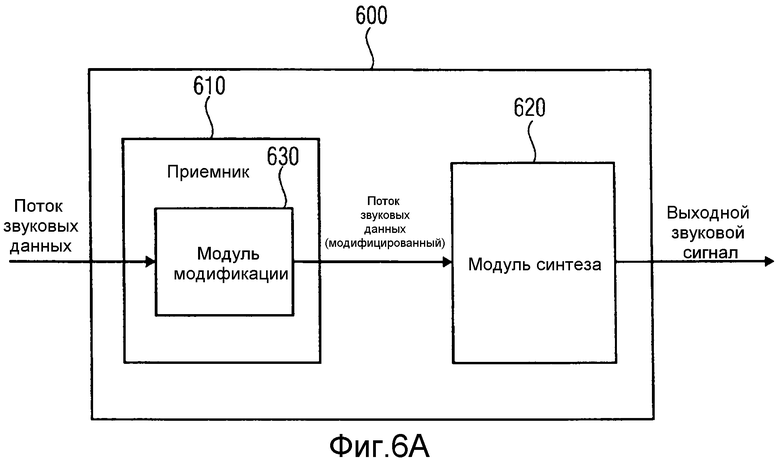
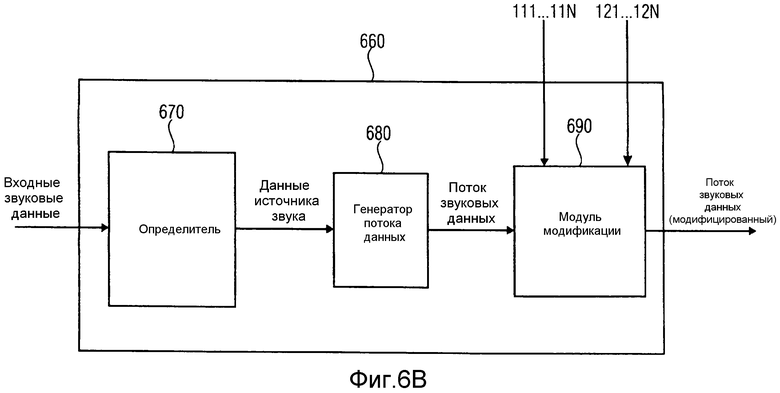
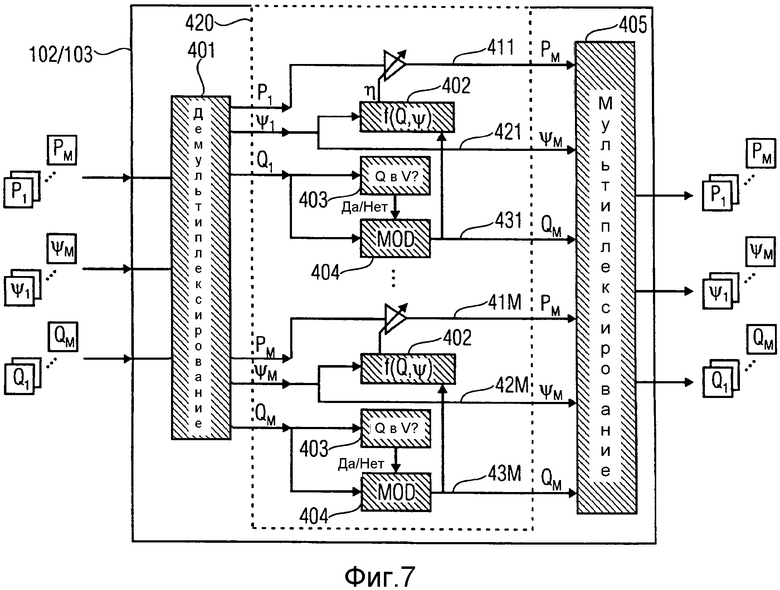
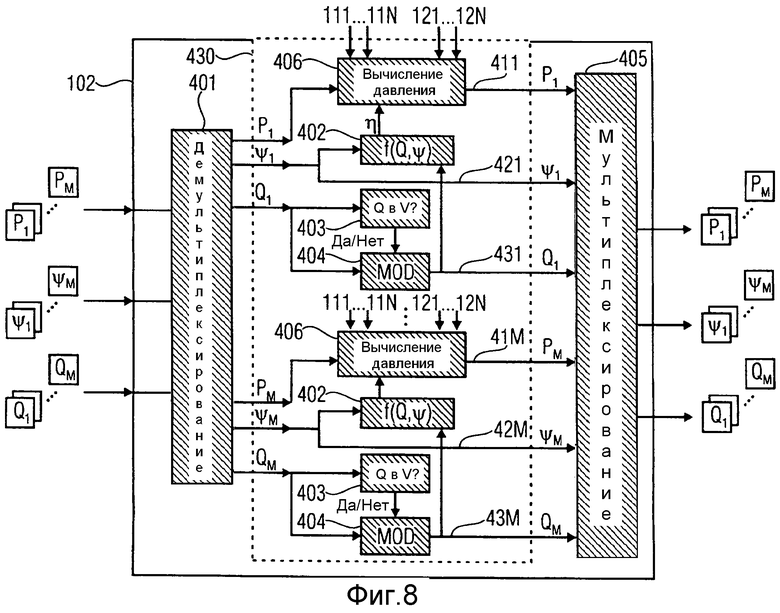
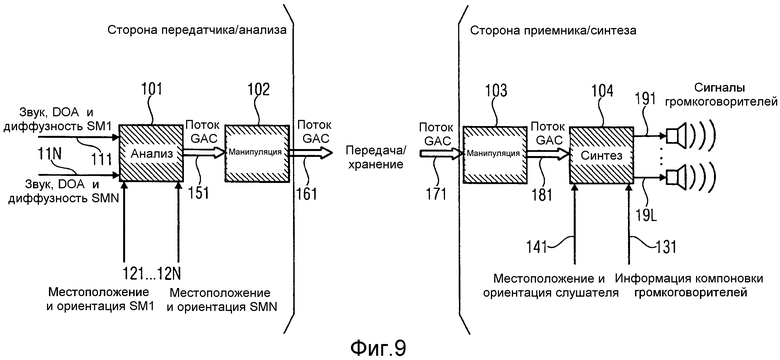
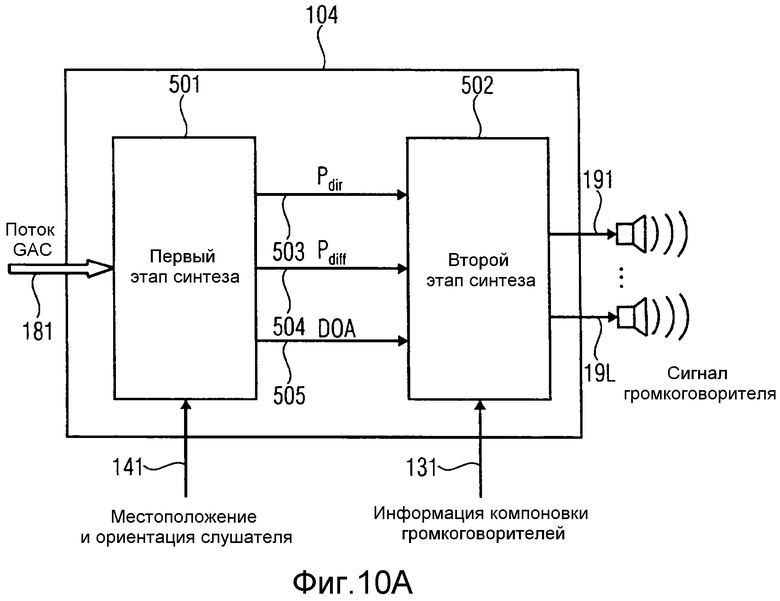
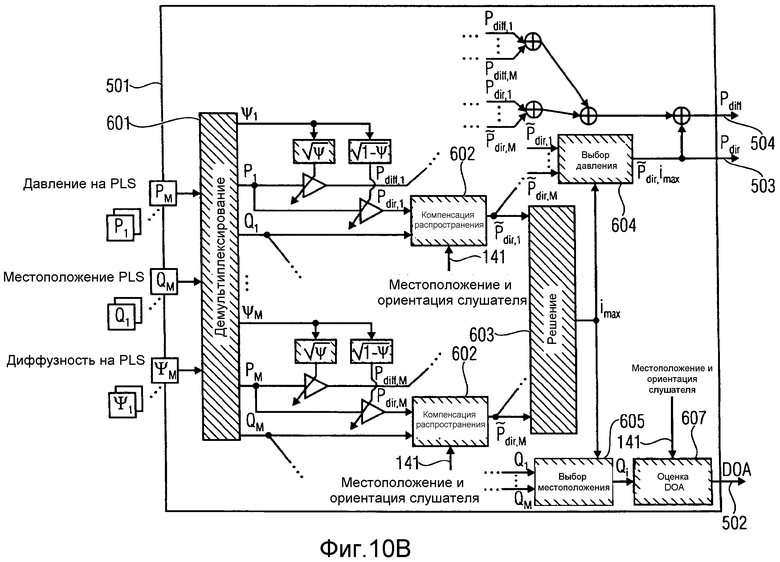
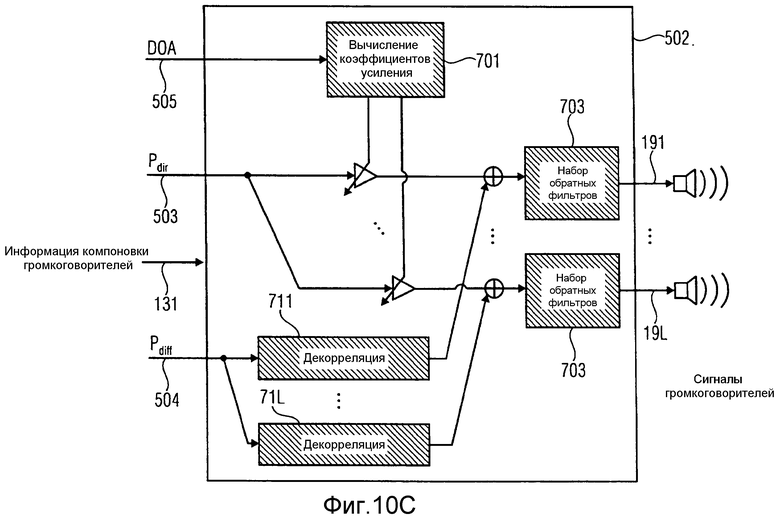
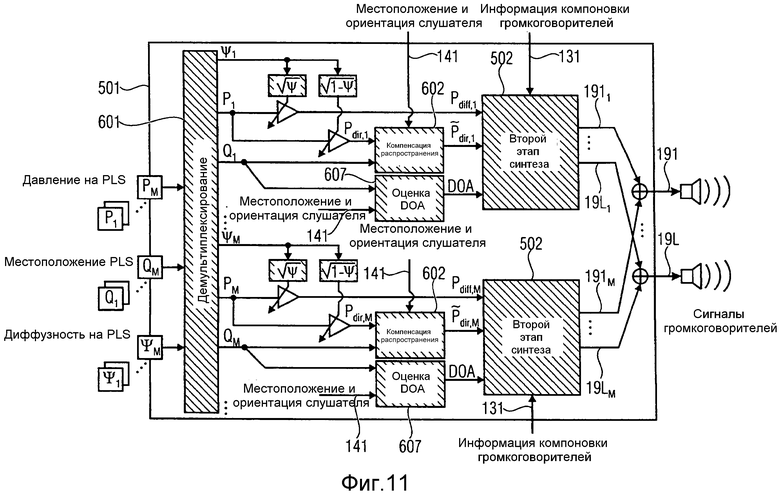
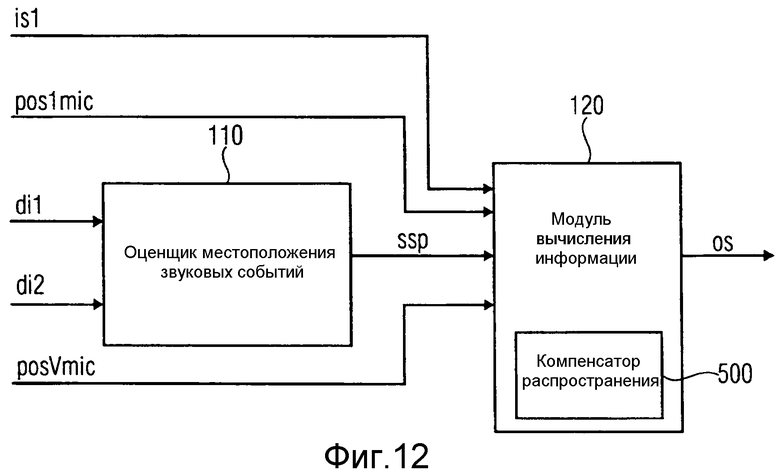
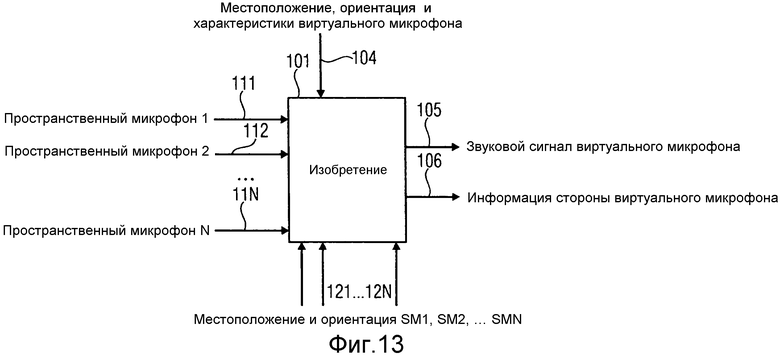
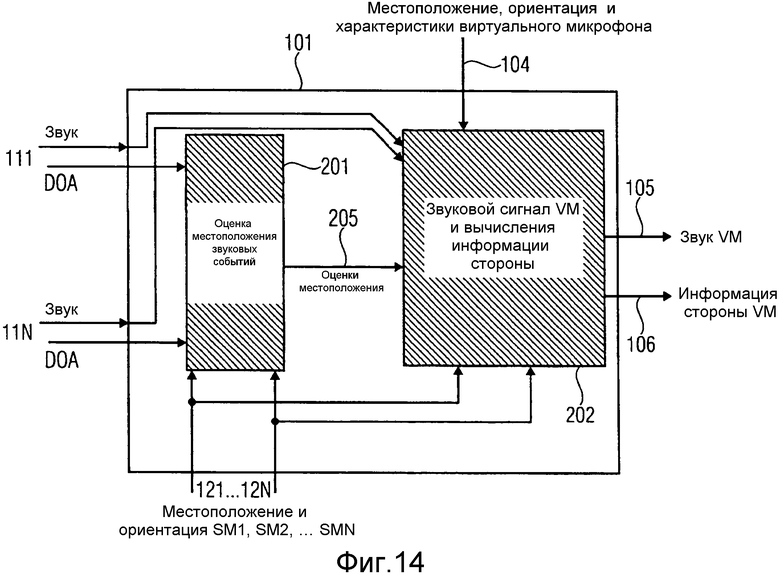
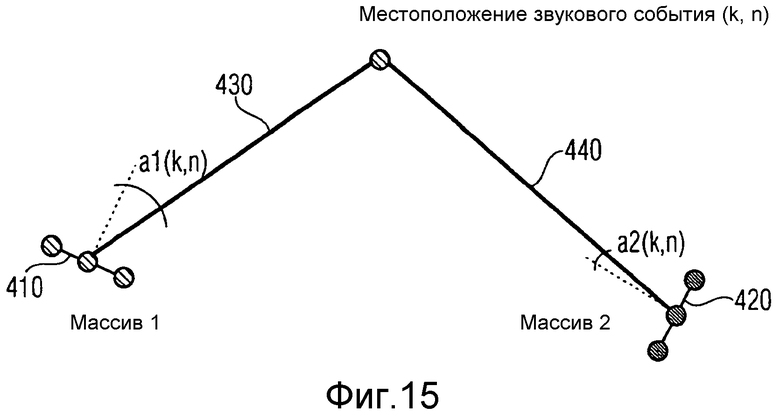
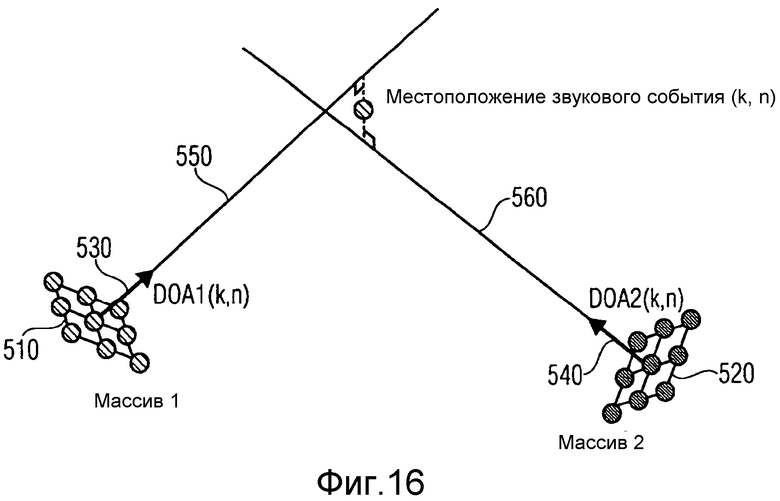
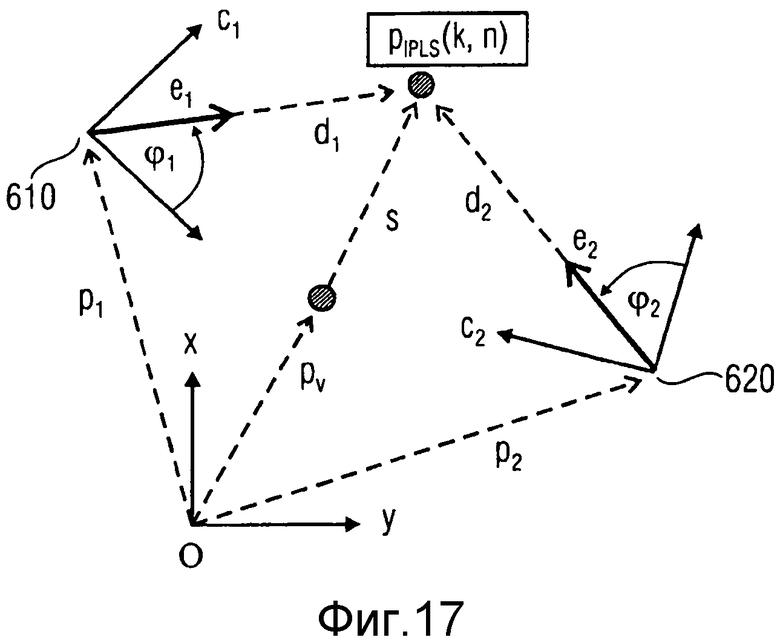
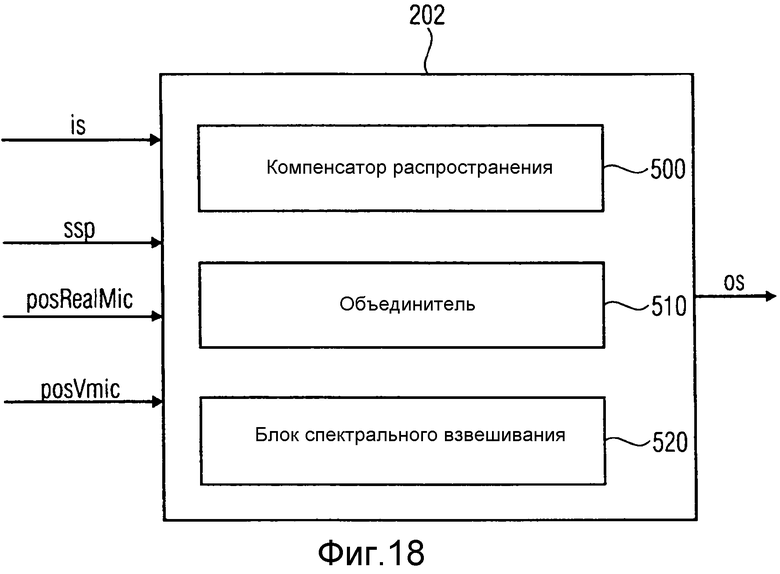
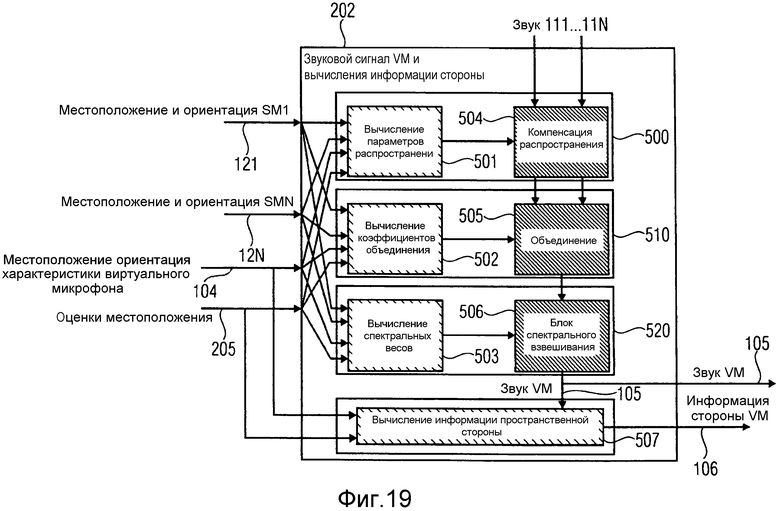
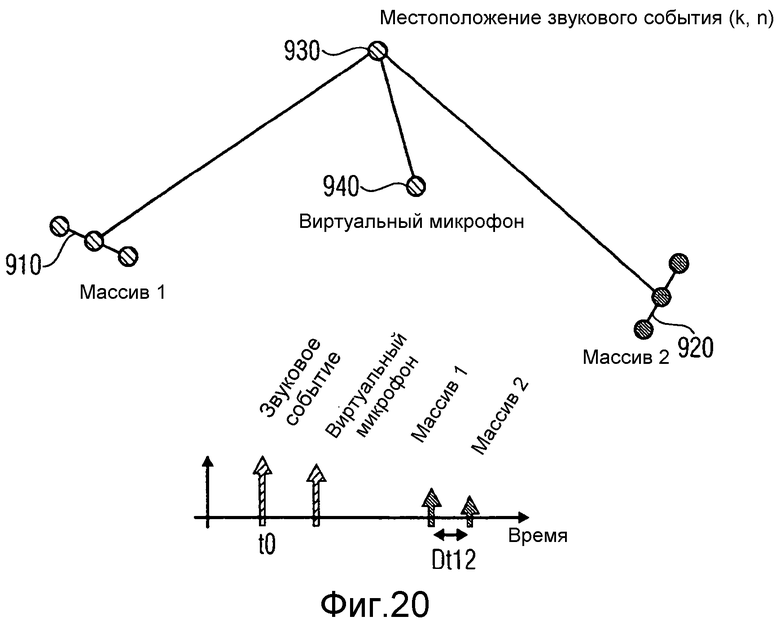
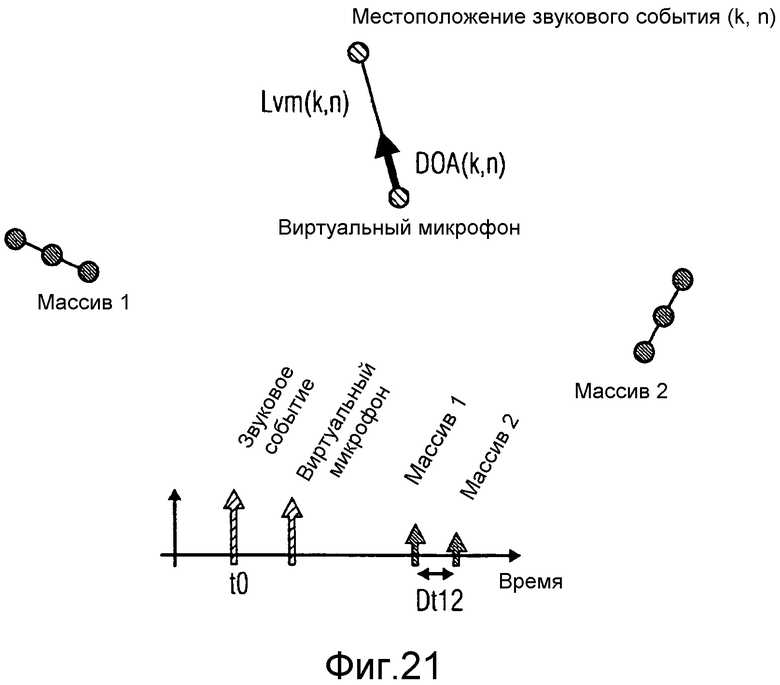
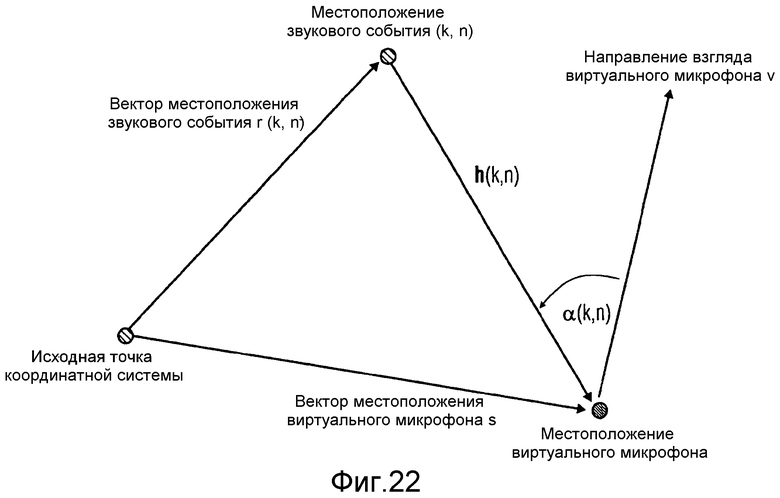
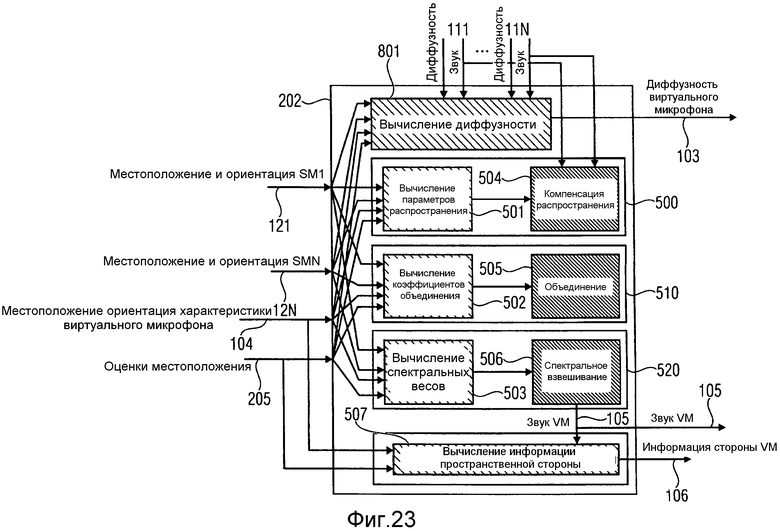
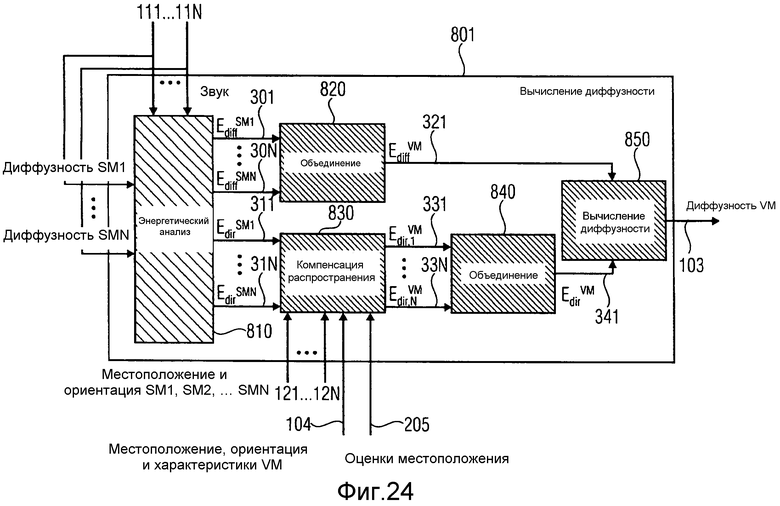
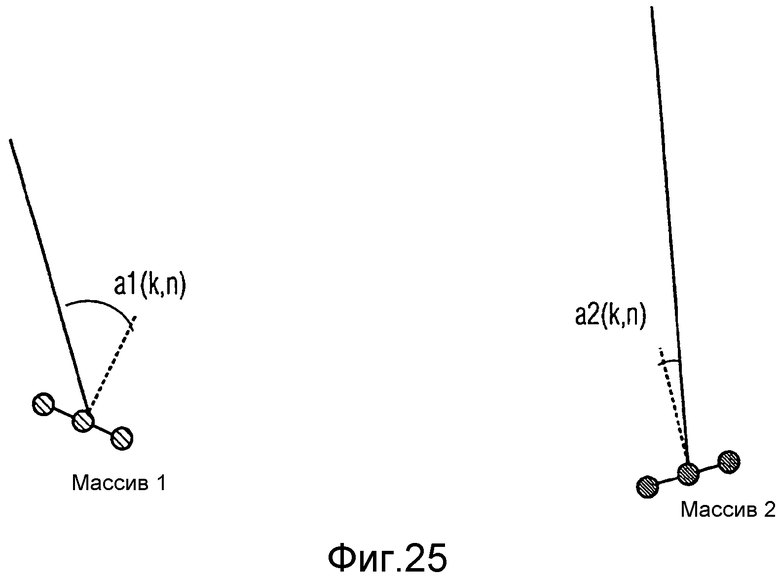
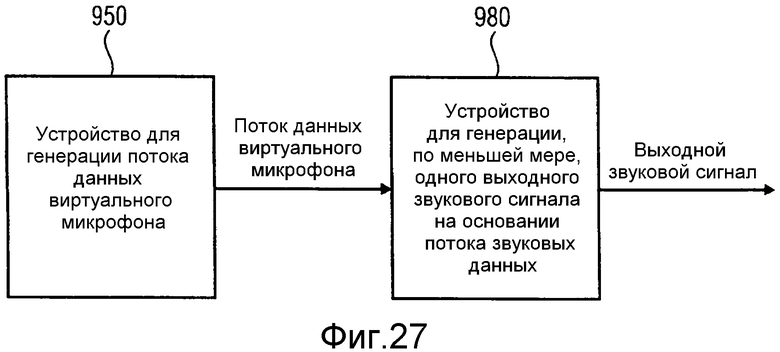
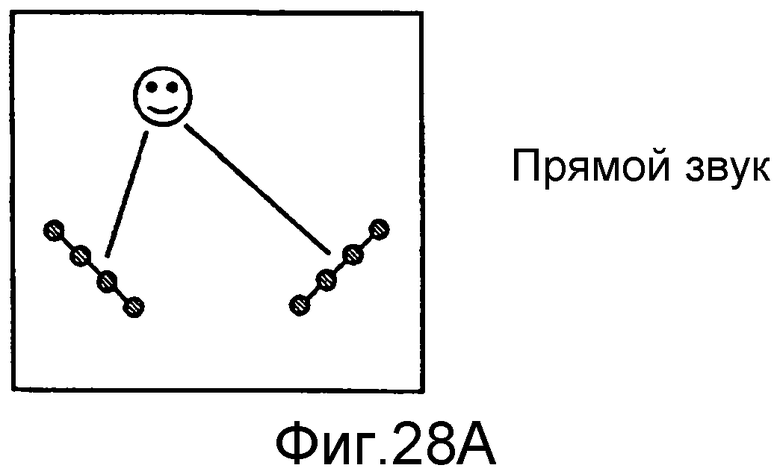
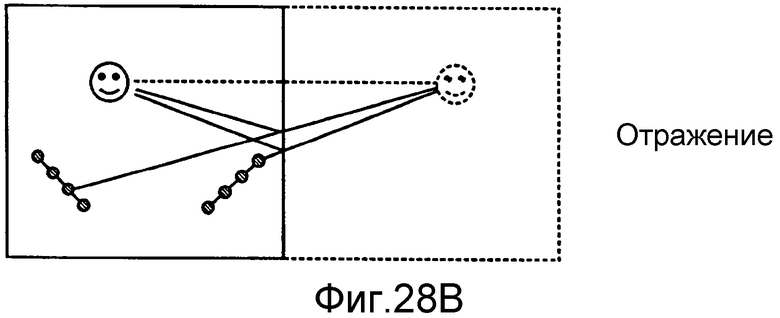
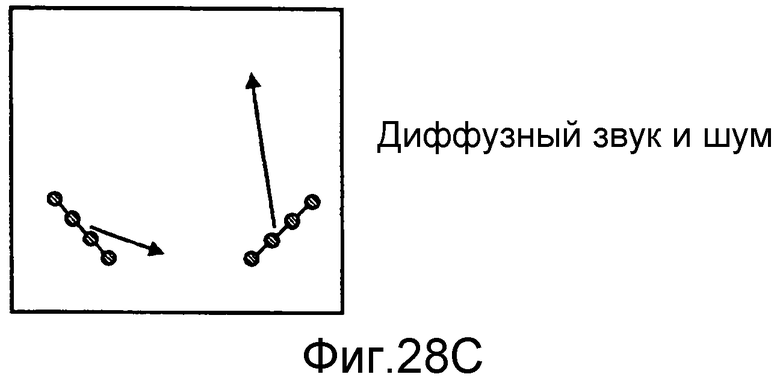
Изобретение относится к обработке звука. Технический результат - улучшенный захват пространственного звука. Предоставлено устройство для генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных, включающего в себя звуковые данные, относящиеся к одному или более источникам звука. Устройство включает в себя приемник для приема потока звуковых данных, включающего в себя звуковые данные. Звуковые данные включают в себя одно или более значений давления для каждого из источников звука. Дополнительно звуковые данные включают в себя одно или более значений местоположения, указывающих местоположение одного из источников звука для каждого из источников звука. Кроме того, устройство включает в себя модуль синтеза для генерации, по меньшей мере, одного выходного звукового сигнала на основании, по меньшей мере, одного из одного или более значений давления из звуковых данных из потока звуковых данных и на основании, по меньшей мере, одного из одного или более значений местоположения из звуковых данных из потока звуковых данных. 9 н. и 16 з.п. ф-лы, 34 ил.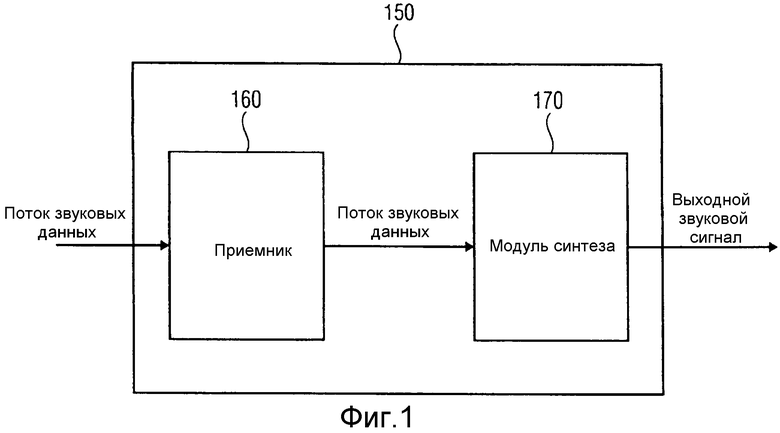
1. Устройство (150) для генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных, включающего в себя звуковые данные, относящиеся к одному или более источникам звука, причем устройство (150) включает в себя:
приемник (160) для приема потока звуковых данных, включающего в себя звуковые данные, причем звуковые данные включают в себя, для каждого из одного или более источников звука, одно или более значений давления звука, причем звуковые данные дополнительно включают в себя, для каждого из одного или более источников звука, одно или более значений местоположения, указывающих местоположение одного из источников звука, причем каждое из одного или более значений местоположения включает в себя, по меньшей мере, два значения координат и причем звуковые данные дополнительно включают в себя одно или более значений диффузности звука для каждого из источников звука; и
модуль (170) синтеза для генерации, по меньшей мере, одного выходного звукового сигнала на основании, по меньшей мере, одного из одного или более значений давления звука из звуковых данных из потока звуковых данных, на основании, по меньшей мере, одного из одного или более значений местоположения из звуковых данных из потока звуковых данных и на основании, по меньшей мере, одного из одного или более значений диффузности звука из звуковых данных из потока звуковых данных.
2. Устройство (150) по п. 1, в котором звуковые данные определены в частотно-временной области.
3. Устройство (150) по п. 1,
в котором приемник (160; 610) дополнительно включает в себя модуль (630) модификации для модификации звуковых данных из принятого потока звуковых данных путем модификации, по меньшей мере, одного из одного или более значений давления звука из звуковых данных, путем модификации, по меньшей мере, одного из одного или более значений местоположения из звуковых данных или путем модификации, по меньшей мере, одного из одного или более значений диффузности звука из звуковых данных и
в котором модуль (170; 620) синтеза выполнен с возможностью генерации, по меньшей мере, одного выходного звукового сигнала на основании, по меньшей мере, одного значения давления звука, которое было модифицировано, на основании, по меньшей мере, одного значения местоположения, которое было модифицировано, или на основании, по меньшей мере, одного значения диффузности звука, которое было модифицировано.
4. Устройство (150) по п. 3, в котором каждое из значений местоположения каждого из источников звука включает в себя, по меньшей мере, два значения координат и в котором модуль (630) модификации выполнен с возможностью модификации значений координат путем добавления, по меньшей мере, одного случайного числа к значениям координат, когда значения координат указывают, что источник звука размещен в местоположении внутри предварительно определенной области окружающей среды.
5. Устройство (150) по п. 3, в котором каждое из значений местоположения каждого из источников звука включает в себя, по меньшей мере, два значения координат и в котором модуль (630) модификации выполнен с возможностью модификации значений координат путем применения к значениям координат детерминированной функции, когда значения координат указывают, что источник звука размещен в местоположении внутри предварительно определенной области окружающей среды.
6. Устройство (150) по п. 3, в котором каждое из значений местоположения каждого из источников звука включает в себя, по меньшей мере, два значения координат и в котором модуль (630) модификации выполнен с возможностью модификации выбранного значения давления звука из одного или более значений давления звука из звуковых данных, причем выбранное значение давления звука относится к тому же источнику звука, что и значения координат, когда значения координат указывают, что источник звука размещен в местоположении внутри предварительно определенной области окружающей среды.
7. Устройство (150) по п. 6, в котором модуль (630) модификации выполнен с возможностью модификации выбранного значения давления звука из одного или более значений давления звука из звуковых данных на основании одного из одного или более значений диффузности звука, когда значения координат указывают, что источник звука размещен в местоположении внутри предварительно определенной области окружающей среды.
8. Устройство (150) по п. 1, в котором модуль синтеза включает в себя
блок (501) первого этапа синтеза для генерации сигнала давления прямого звука, включающего в себя прямой звук, сигнала давления диффузного звука, включающего в себя диффузный звук, и информации о направлении прихода на основании, по меньшей мере, одного из одного или более значений давления звука из звуковых данных из потока звуковых данных, на основании, по меньшей мере, одного из одного или более значений местоположения из звуковых данных из потока звуковых данных и на основании, по меньшей мере, одного из одного или более значений диффузности звука из звуковых данных из потока звуковых данных; и
блок (502) второго этапа синтеза для генерации, по меньшей мере, одного выходного звукового сигнала на основании сигнала давления прямого звука, сигнала давления диффузного звука и информации о направлении прихода.
9. Устройство (200) для генерации потока звуковых данных, включающего в себя данные источника звука, относящиеся к одному или более источникам звука, причем устройство для генерации потока звуковых данных включает в себя:
определитель (210; 670) для определения данных источника звука на основании, по меньшей мере, одного входного звукового сигнала, записанного при помощи, по меньшей мере, одного микрофона, и на основании информации звуковой стороны, предоставленной, по меньшей мере, двумя пространственными микрофонами, причем информация звуковой стороны является информацией пространственной стороны, описывающей пространственный звук; и
генератор (220; 680) потока данных для генерации потока звуковых данных так, что поток звуковых данных включает в себя данные источника звука;
причем каждый из, по меньшей мере, двух пространственных микрофонов представляет собой устройство для получения пространственного звука, способное извлекать направление прихода звука, и
причем данные источника звука включают в себя одно или более значений давления звука для каждого из источников звука, причем данные источника звука дополнительно включают в себя одно или более значений местоположения, указывающих местоположение источника звука для каждого из источников звука.
10. Устройство (200) по п. 9, в котором данные источника звука определены в частотно-временной области.
11. Устройство (200) по п. 9, в котором данные источника звука дополнительно включают в себя одно или более значений диффузности звука для каждого из источников звука и
в котором определитель (210; 670) выполнен с возможностью определения одного или более значений диффузности звука из данных источника звука на основании информации диффузности звука, относящейся к, по меньшей мере, одному пространственному микрофону из, по меньшей мере, двух пространственных микрофонов, причем информация диффузности звука указывает диффузность звука на, по меньшей мере, одном из, по меньшей мере, двух пространственных микрофонов.
12. Устройство (200) по п. 11, причем устройство (200) дополнительно включает в себя модуль (690) модификации для модификации потока звуковых данных, сгенерированного генератором потока звуковых данных, путем модификации, по меньшей мере, одного из значений давления звука из звуковых данных, по меньшей мере, одного из значений местоположения из звуковых данных или, по меньшей мере, одного из значений диффузности звука из звуковых данных, относящихся к, по меньшей мере, одному из источников звука.
13. Устройство (200) по п. 12, в котором каждое из значений местоположения каждого из источников звука включает в себя, по меньшей мере, два значения координат и в котором модуль (690) модификации выполнен с возможностью модификации значений координат путем добавления, по меньшей мере, одного случайного числа к значениям координат или путем применения к значениям координат детерминированной функции, когда значения координат указывают, что источник звука расположен в местоположении внутри предварительно определенной области окружающей среды.
14. Устройство (200) по п. 12, в котором каждое из значений местоположения каждого из источников звука включает в себя, по меньшей мере, два значения координат, и, когда значения координат одного из источников звука указывают, что указанный источник звука расположен в местоположении внутри предварительно определенной области окружающего пространства, модуль (690) модификации выполнен с возможностью модификации выбранного значения давления звука указанного источника звука из звуковых данных.
15. Устройство (200) по п. 12, в котором модуль (690) модификации выполнен с возможностью модификации значений координат путем применения к значениям координат детерминированной функции, когда значения координат указывают, что источник звука расположен в местоположении внутри предварительно определенной области окружающего пространства.
16. Устройство (950) для генерации потока данных виртуального микрофона, включающее в себя:
устройство (960) для генерации выходного звукового сигнала виртуального микрофона и
устройство (970) по одному из пп. 9-12 для генерации потока звуковых данных как потока звуковых данных виртуального микрофона, причем поток звуковых данных включает в себя звуковые данные, причем звуковые данные включают в себя, для каждого из одного или более источников звука, одно или более значений местоположения, указывающих местоположение источника звука, причем каждое из одного или более значений местоположения включает в себя, по меньшей мере, два значения координат,
причем устройство (960) для генерации выходного звукового сигнала виртуального микрофона включает в себя:
оценщик (110) местоположения звуковых событий для оценки местоположения источника звука, указывающего местоположение источника звука в окружающей среде, причем оценщик (110) местоположения звуковых событий выполнен с возможностью оценки местоположения источника звука на основании первого направления прихода звука, испущенного первым реальным пространственным микрофоном, расположенным в окружающей среде в местоположении первого реального микрофона, и на основании второго направления прихода звука, испущенного вторым реальным пространственным микрофоном, расположенным в окружающей среде в местоположении второго реального микрофона; и
модуль (120) вычисления информации для генерации выходного звукового сигнала на основании записанного входного звукового сигнала, записываемого первым реальным пространственным микрофоном, на основании местоположения первого реального микрофона и на основании виртуального местоположения виртуального микрофона,
причем первый реальный пространственный микрофон и второй реальный пространственный микрофон представляют собой устройства для получения пространственного звука, способные извлекать направление прихода звука, и
причем устройство (960) для генерации выходного звукового сигнала виртуального микрофона скомпоновано для предоставления выходного звукового сигнала на устройство (970) для генерации потока звуковых данных,
и причем определитель устройства (970) для генерации потока звуковых данных определяет данные источника звука на основании выходного звукового сигнала, предоставленного устройством (960) для генерации выходного звукового сигнала виртуального микрофона, причем выходной звуковой сигнал представляет собой один из, по меньшей мере, одного входного звукового сигнала устройства (970) по одному из пп. 9-12 для генерации потока звуковых данных.
17. Устройство (980) по п. 1, сконфигурированное для генерации выходного звукового сигнала на основании потока данных виртуального микрофона как потока звуковых данных, предоставленного устройством (950) для генерации потока звуковых данных виртуального микрофона по п. 16.
18. Система для генерации потока звуковых данных, включающая в себя:
устройство по одному из пп. 1-8 или 17 и
устройство по одному из пп. 9-15.
19. Поток звуковых данных, включающий в себя звуковые данные, относящиеся к одному или более источникам звука, причем звуковые данные включают в себя, для каждого из одного или более источников звука, одно или более значений давления звука,
причем звуковые данные дополнительно включают в себя, для каждого из одного или более источников звука, одно или более значений местоположения, указывающих местоположения источника звука, причем каждое из одного или более значений местоположения включает в себя, по меньшей мере, два значения координат, и
причем звуковые данные дополнительно включают в себя одно или более значений диффузности звука для каждого из одного или более источников звука.
20. Поток звуковых данных по п. 19, в котором звуковые данные определены в частотно-временной области.
21. Способ генерации, по меньшей мере, одного выходного звукового сигнала на основании потока звуковых данных, включающего в себя звуковые данные, относящиеся к одному или более источникам звука, причем способ включает в себя этапы, на которых:
принимают поток звуковых данных, включающий в себя звуковые данные, причем звуковые данные включают в себя, для каждого из одного или более источников звука, одно или более значений давления звука, и причем звуковые данные дополнительно включают в себя, для каждого из одного или более источников звука, одно или более значений местоположения, указывающих местоположение одного из источников звука, причем каждое из одного или более значений местоположения включает в себя, по меньшей мере, два значения координат, и причем звуковые данные дополнительно включают в себя одно или более значений диффузности звука для каждого из источников звука; и
генерируют, по меньшей мере, один выходной звуковой сигнал на основании, по меньшей мере, одного из одного или более значений давления звука из звуковых данных из потока звуковых данных, на основании, по меньшей мере, одного из одного или более значений местоположения из звуковых данных из потока звуковых данных и на основании, по меньшей мере, одного из одного или более значений диффузности звука из звуковых данных из потока звуковых данных.
22. Способ по п. 21,
причем способ дополнительно включает в себя этап, на котором модифицируют звуковые данные из принятого потока звуковых данных путем модификации, по меньшей мере, одного из одного или более значений давления звука из звуковых данных, путем модификации, по меньшей мере, одного из одного или более значений местоположения из звуковых данных или путем модификации, по меньшей мере, одного из одного или более значений диффузности звука из звуковых данных,
причем этап, на котором определяют, по меньшей мере, один выходной звуковой сигнал, включает в себя этап, на котором генерируют, по меньшей мере, один выходной звуковой сигнал на основании, по меньшей мере, одного из одного или более значений диффузности звука из звуковых данных из потока звуковых данных, и причем этап, на котором определяют, по меньшей мере, один выходной звуковой сигнал, включает в себя этап, на котором генерируют, по меньшей мере, один выходной звуковой сигнал на основании, по меньшей мере, одного значения давления звука, которое было модифицировано, на основании, по меньшей мере, одного значения местоположения, которое было модифицировано, или на основании, по меньшей мере, одного значения диффузности звука, которое было модифицировано.
23. Способ генерации потока звуковых данных, включающего в себя данные источника звука, относящиеся к одному или более источникам звука, причем способ генерации потока звуковых данных включает в себя этапы, на которых:
определяют данные звукового источника на основании, по меньшей мере, одного входного звукового сигнала, записанного на, по меньшей мере, одном микрофоне, и на основании информации звуковой стороны, предоставленной, по меньшей мере, двумя пространственными микрофонами, причем информация звуковой стороны представляет собой информацию пространственной стороны, описывающую пространственный звук; и
генерируют поток звуковых данных так, что поток звуковых данных включает в себя данные источника звука;
причем каждый из, по меньшей мере, двух пространственных микрофонов представляет собой устройство для получения пространственного звука, способное извлекать направление прихода звука, и
причем данные источника звука включают в себя одно или более значений давления звука для каждого из источников звука, причем данные источника звука дополнительно включают в себя одно или более значений местоположения, указывающих местоположение источника звука для каждого из источников звука.
24. Способ генерации потока звуковых данных, включающего в себя звуковые данные, относящиеся к одному или более источникам звука, включающий в себя этапы, на которых:
принимают звуковые данные, включающие в себя, по меньшей мере, одно значение давления звука для каждого из источников звука, причем звуковые данные дополнительно включают в себя одно или более значений местоположения, указывающих местоположение источника звука для каждого из источников звука, и причем звуковые данные дополнительно включают в себя одно или более значений диффузности звука для каждого из источников звука;
генерируют поток звуковых данных так, что поток звуковых данных включает в себя, по меньшей мере, одно или более значений давления звука для каждого из источников звука, и так, что поток звуковых данных дополнительно включает в себя одно или более значений местоположения, указывающих местоположение источника звука для каждого из источников звука, и так, что поток звуковых данных дополнительно включает в себя одно или более значений диффузности звука для каждого из источников звука.
25. Считываемый компьютером носитель, содержащий компьютерную программу для реализации способа по пп. 21-24, при исполнении на компьютере или процессоре.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| СИСТЕМА АВТОМАТИЧЕСКОГО УПРАВЛЕНИЯ КОРОТКОВОЛНОВОЙ СВЯЗЬЮ | 1997 |
|
RU2154910C2 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| КОМПАКТНАЯ ДОПОЛНИТЕЛЬНАЯ ИНФОРМАЦИЯ ДЛЯ ПАРАМЕТРИЧЕСКОГО КОДИРОВАНИЯ ПРОСТРАНСТВЕННОГО ЗВУКА | 2005 |
|
RU2383939C2 |
| СПОСОБ, УСТРОЙСТВО, КОДИРУЮЩЕЕ УСТРОЙСТВО, ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО И АУДИОСИСТЕМА | 2005 |
|
RU2396608C2 |

