Область техники, к которой относится изобретение
Варианты настоящего изобретения относятся в общем к области компьютерных систем. Более конкретно, варианты настоящего изобретения относятся к устройству и способу реверсирования и перестановки битов в регистре маски.
Уровень техники
Общая характеристика
Набор команд или архитектура набора команд (instruction set architecture (ISA)), является частью компьютерной архитектуры, относящейся к программированию, включая типы внутренних данных, команды, архитектуру регистров, режимы адресации, архитектуру памяти, обработку прерываний и исключений и внешний ввод/вывод (I/O). Следует отметить, что термин «команда» обычно обозначает макрокоманду - т.е. команду, передаваемую процессору для выполнения, в отличие от микрокоманды или микрооперации, являющейся результатом декодирования макрокоманды в декодере процессора.
Архитектура набора команд отличается от микроархитектуры, представляющей собой набор способов проектирования процессора, используемый для реализации этого набора команд. Процессоры с различными микроархитектурами могут использовать общий набор команд. Например, процессоры Intel® Pentium 4, Intel® Core™ и процессоры фирмы Advanced Micro Devices, Inc. из Sunnyvale С А реализуют почти идентичные версии набора команд х86 (с некоторыми расширениями, которые были добавлены в новых версиях), но имеют разные внутренние структуры. Например, одна и та же регистровая архитектура ISA может быть реализована различными способами в разных микроархитектурах с использованием хорошо известных способов, включая специализированные физические регистры, один или более динамически назначаемых физических регистров с использованием механизма переименования регистров (например, с использованием таблицы псевдонимов регистров (Register Alias Table (RAT)), буфера переупорядочения (Reorder Buffer (ROB)) и регистрового файла изъятия, как описано в патенте США No. 5,446,912; с использованием нескольких карт и пула регистров, как описано в патенте США No. 5,207,132) и т.п. Если не указано иначе, фразы «архитектура регистров», «регистровый файл» и «регистр», относятся к тому, что видимо для программного обеспечения/программиста, и к способу, которым команды специфицируют регистры. Когда требуется различать регистры, будут использованы прилагательные «логический», «архитектурный» или «видимый для программного обеспечения» для обозначения регистров/файлов в регистровой архитектуре, но для обозначения регистров в конкретной микроархитектуре будут использованы другие прилагательные (например, физический регистр, буфер переупорядочения, регистр изъятия, пул регистров).
Набор команд содержит один или более форматов. Конкретный формат команд определяет различные поля (число битов, расположение битов) для задания, помимо всего прочего, операции, которую нужно выполнить, и операнда(ов), над которым должна быть выполнена эта операция. Некоторые форматы команд дополнительно подразделены для определения шаблонов команд (подформатов). Например, шаблоны команд для конкретного формата команд могут быть определены с различными подмножествами полей формата команд (входящие в шаблон поля обычно располагаются в том же самом порядке, но по меньшей мере некоторые из этих полей занимают другие позиции битов, поскольку формат содержит меньшее число полей) и/или эти форматы могут быть определены таким образом, что какое-нибудь конкретное поле интерпретируется по-другому. Конкретная команда всегда выражена в каком-то конкретном формате команд (и, если так определено, согласно конкретному шаблону команд в рамках этого формата команд) и задает операцию и операнды. Поток команд представляет собой некую конкретную последовательность команд, где каждая команда в этой последовательности является событием команды в каком-либо формате команд (и, если определено, согласно конкретному шаблону команд в рамках этого формата команд).
Научные, финансовые приложения, автоматически векторизованные приложения общего назначения, приложения типа «распознавание, поиск («раскопки») и синтез» (RMS (recognition, mining, and synthesis)), а также визуальные и мультимедийные приложения (например, 2D/3D-графика, обработка изображения, видео сжатие/расширение, алгоритмы распознавания речи и манипуляции со звуком) часто требуют выполнения одной и той же операции над большим числом единиц данных (именуется «параллелизм данных»). Термин «операции в формате одна команда-множество данных» (Single Instruction Multiple Data (SIMD)) обозначает тип команд, в соответствии с которыми процессор выполняет операции над множеством единиц данных. Технология SIMD специально предназначена для процессоров, которые могут логически разбить биты в регистре на несколько элементов данных фиксированного размера, каждый из которых представляет отдельную величину. Например, биты в 64-разрядном регистре могут быть заданы в качестве исходного операнда, над которым нужно выполнить операцию, в виде четырех раздельных 16-битовых элементов данных, каждый из которых представляет отдельную 16-разрядную величину. Этот тип данных называется данными упакованного типа или данными векторного типа, а операнды этого типа данных называются операндами упакованных данных или векторными операндами. Иными словами, единица упакованных данных или вектор обозначает последовательность элементов упакованных данных; а операнд упакованных данных или векторный операнд является исходным операндом или операндом-адресатом в SIMD-команде (также известной, как команда упакованных данных или векторная команда).
В качестве примера, один тип SIMD-команды задает одну векторную операцию, которая должна быть выполнена над двумя исходными векторными операндами вертикальным образом для генерации векторного операнда-адресата (также называемого результирующим векторным операндом) такого же размера с таким же числом элементов данных и с таким же порядком следования этих элементов данных. Элементы данных из состава исходных векторных операндов называются исходными элементами данных, тогда как элементы данных в составе векторного операнда-адресата называются результирующими элементами данных или элементами-адресатами данных. Эти исходные векторные операнды имеют одинаковый размер и содержат элементы данных одинаковой ширины, так что они содержат одинаковое число элементов данных. Исходные элементы данных, находящиеся в одних и тех же битовых позиций в этих двух исходных векторных операндах образуют пары элементов данных (также именуемые соответствующими элементами данными). Операция, заданная этой SIMD-командой, выполняется отдельно над каждой парой исходных элементов данных для генерации такого же числа результирующих элементов данных, так что каждая пара исходных элементов данных имеет соответствующий результирующий элемент данных. Поскольку операция является вертикальной и поскольку результирующий векторный операнд имеет такой же размер и такое же число элементов данных, а также результирующие элементы данных сохраняются в том же самом порядке элементов данных, как исходные векторные операнды, эти результирующие элементы данных находятся в тех же самых битовых позициях в результирующем векторном операнде, как соответствующая пара исходных элементов данных в составе исходных векторных операндов. В дополнение к этому примеру SIMD-команд имеются разнообразные другие типы SIMD-команд (например, команды, имеющие только один или больше двух исходных операндов; команды, работающие горизонтальным образом; команды, генерирующие результирующий векторный операнд другого размера, имеющие элементы данных другого размера и/или имеющий другой порядок элементов данных). Должно быть понятно, что термин «векторный операнд-адресат» (или операнд-адресат) определен как прямой результат выполнения операции, заданной командой, включая сохранение операнда-адресата в позиции (будь-то регистр или адрес в памяти, заданный этой командой), где к ним может обратиться и получить доступ другая команда, как к исходному операнду (путем задания этой же позиции посредством этой другой команды).
Технология SIMD, такая как технология, используемая процессорами Intel® Core™, имеет набор команд, содержащий х86, ММХ™, потоковые расширения SIMD (Streaming SIMD Extensions (SSE)), SSE2, SSE3, SSE4.1 и SSE4.2, и позволила значительно улучшить работу приложений (Core™ и ММХ™ являются зарегистрированными торговыми марками или торговыми марками корпорации Интел из г. Санта Клара, Калифорния (Intel Corporation of Santa Clara, Calif.)). Был опубликован дополнительный набор будущих SIMD-расширений, называемый «Усовершенствованные векторные расширения» (Advanced Vector Extensions (AVX)) и использующий схему кодирования VEX.
Краткое описание чертежей
Фиг. 1А представляет блок-схему, иллюстрирующую как пример конвейера с выполнением команд по порядку, так и пример конвейера с переименованием регистров и внеочередной (не по порядку) выдачей/выполнением команд согласно вариантам настоящего изобретения;
фиг. 1В представляет блок-схему, иллюстрирующую как пример варианта ядра с архитектурой для выполнения команд по порядку, так и пример ядра с архитектурой с переименованием регистров и внеочередной (не по порядку) выдачей/выполнением команд для включения в процессор согласно вариантам настоящего изобретения;
фиг. 2 представляет собой блок-схему одноядерного процессора и многоядерного процессора с интегральным контроллером памяти и графическим контроллером согласно вариантам настоящего изобретения;
фиг. 3 иллюстрирует блок-схему системы согласно одному из вариантов настоящего изобретения;
фиг. 4 иллюстрирует блок-схему второй системы согласно вариантам настоящего изобретения;
фиг. 5 иллюстрирует блок-схему третьей системы согласно вариантам настоящего изобретения;
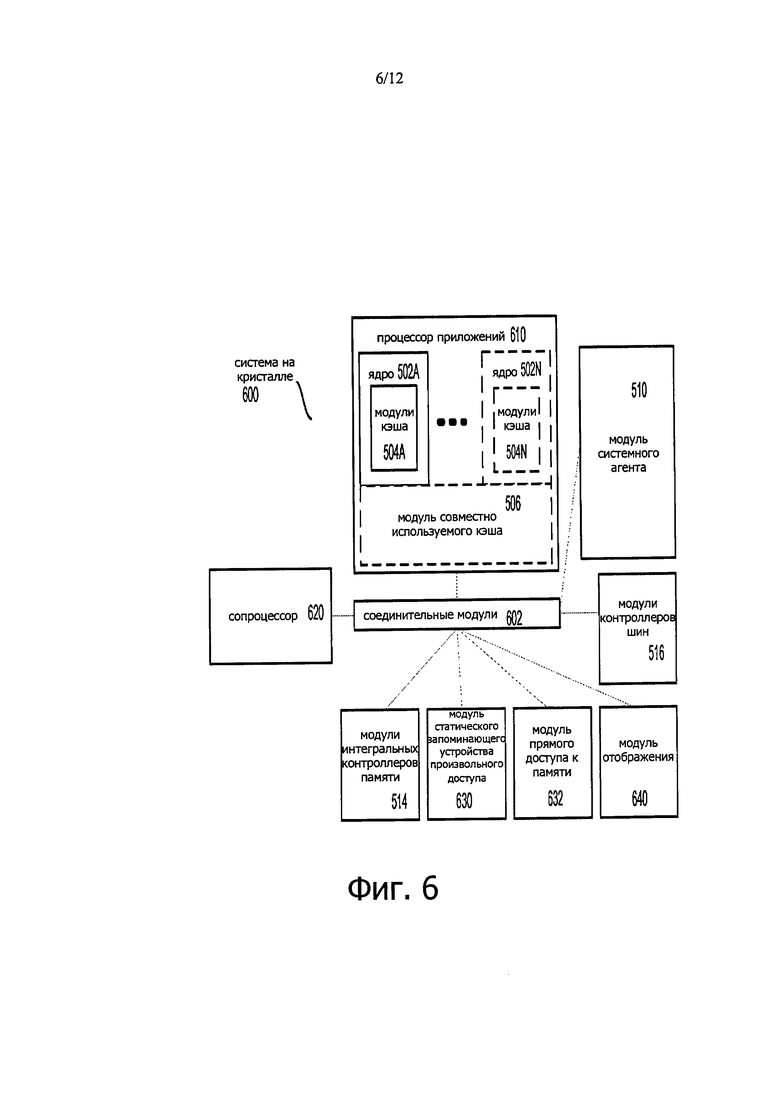
фиг. 6 иллюстрирует блок-схему системы на кристалле (system on a chip (SoC)) согласно вариантам настоящего изобретения;
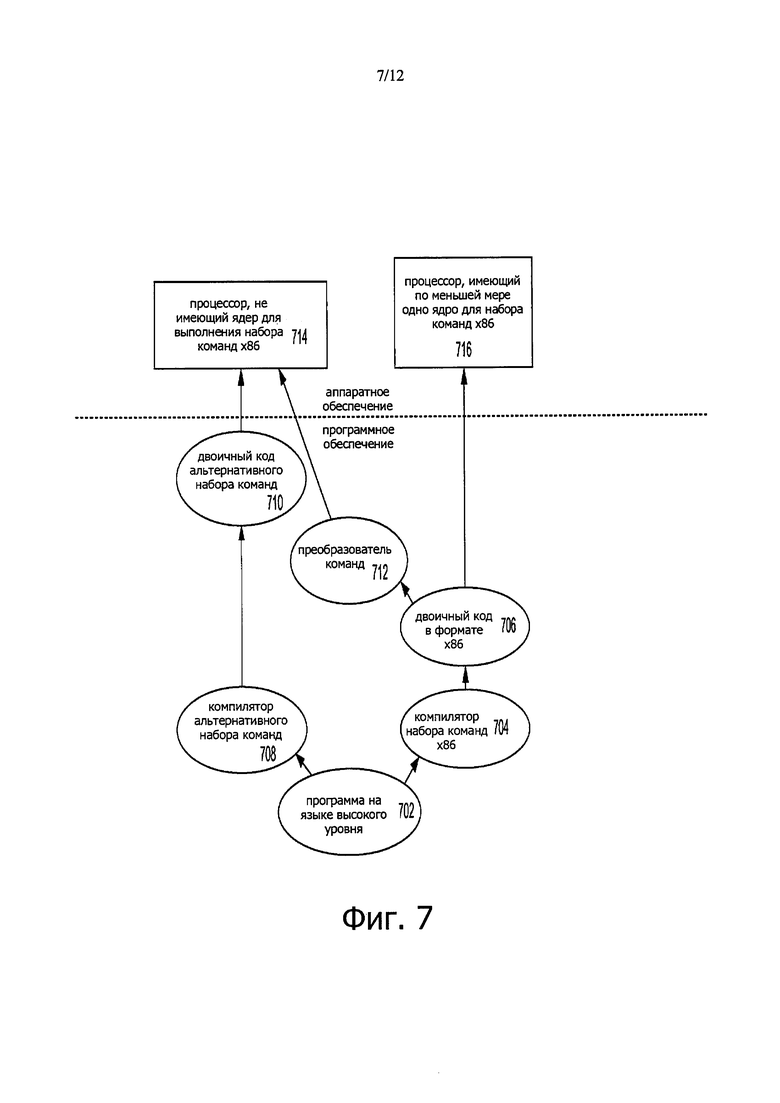
фиг. 7 иллюстрирует блок-схему, показывающую использование преобразователя программных команд для преобразования двоичных команд из состава исходного набора команд в двоичные команды в составе целевого набора команд согласно вариантам настоящего изобретения;
фиг. 8 иллюстрирует устройство выполнения операции инверсии порядка битов маски согласно одному из вариантов настоящего изобретения;
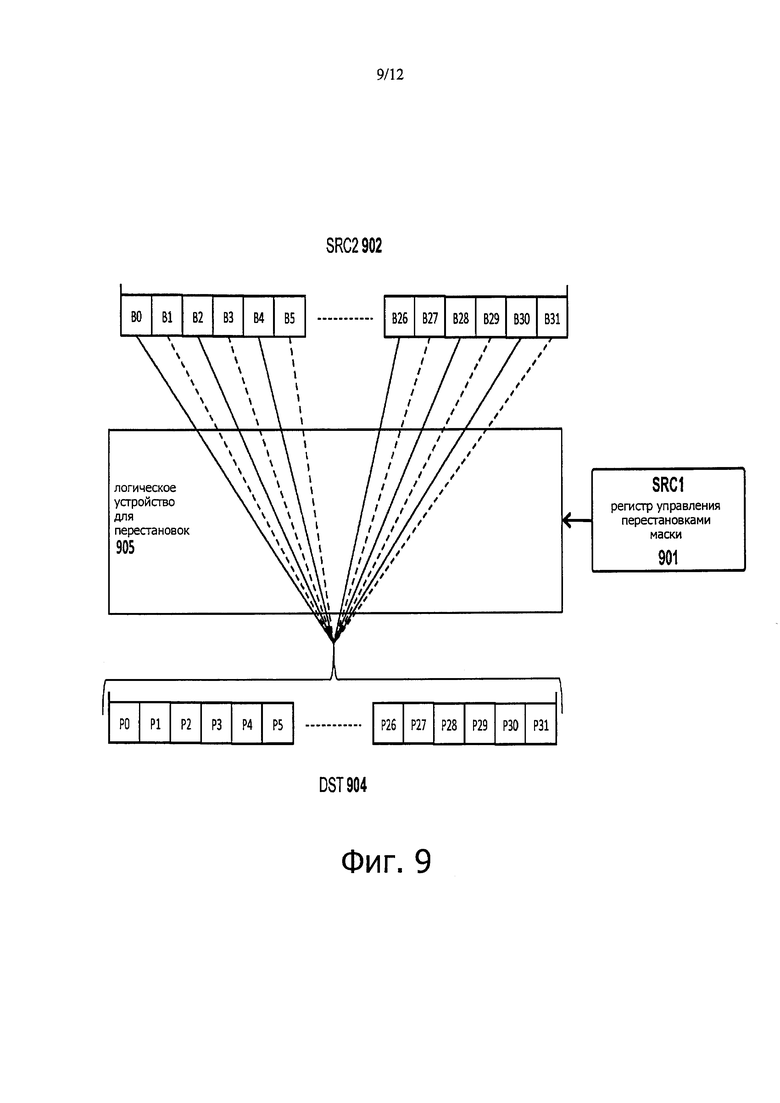
фиг. 9 иллюстрирует устройство выполнения операции перестановки битов маски согласно другому варианту настоящего изобретения;
фиг. 10 иллюстрирует архитектуру процессора, содержащего регистр упакованных данных и регистры масок операций с упакованными данными;
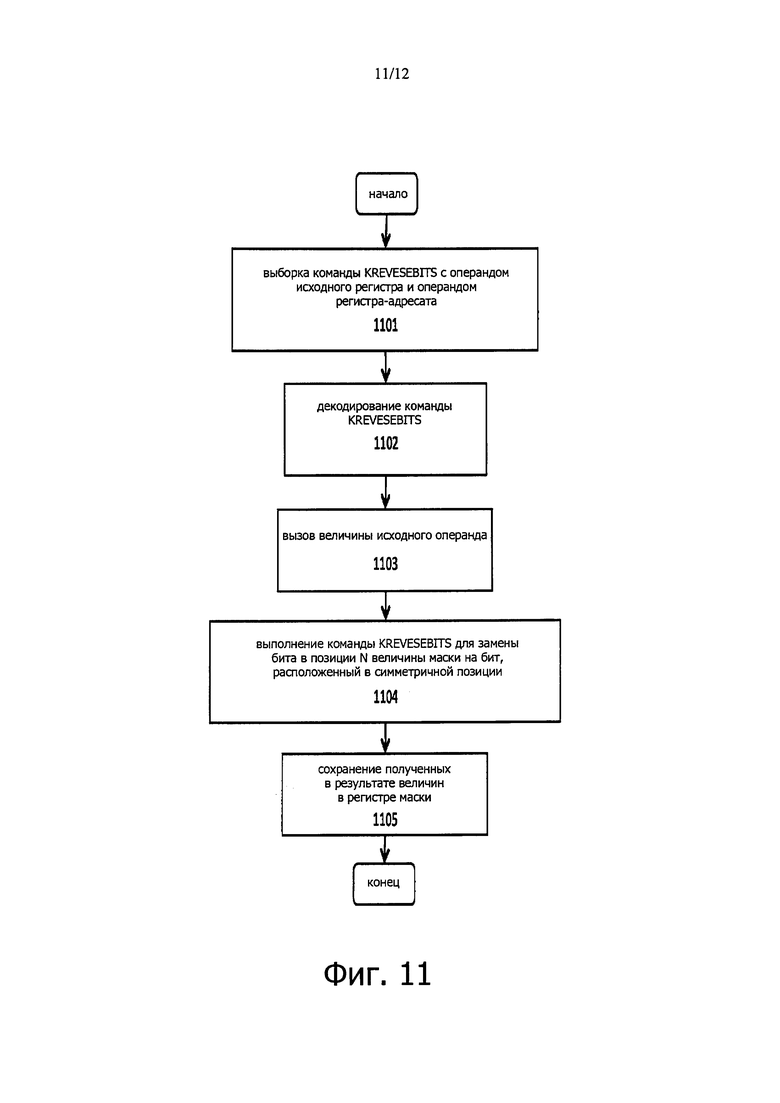
фиг. 11 иллюстрирует способ выполнения операции инверсии порядка битов маски согласно одному из вариантов настоящего изобретения;
фиг. 12 иллюстрирует способ выполнения операции перестановки битов маски согласно другому из вариантов настоящего изобретения.
Осуществление изобретения
Пример архитектур процессоров и типов данных
Фиг. 1А представляет блок-схему, иллюстрирующую как пример конвейера с выполнением команд по порядку, так и пример конвейера с переименованием регистров и внеочередной (не по порядку) выдачей/выполнением команд согласно вариантам настоящего изобретения. Фиг. 1В представляет блок-схему, иллюстрирующую как пример варианта ядра с архитектурой для выполнения команд по порядку, так и пример ядра с архитектурой с переименованием регистров и внеочередной (не по порядку) выдачей/выполнением команд для включения в процессор согласно вариантам настоящего изобретения. Прямоугольники из сплошных линий на фиг. 1А-В иллюстрируют конвейер с выполнением операций по порядку и ядро с выполнением операций по порядку, тогда как добавление в качестве опций прямоугольников из штриховых линий иллюстрирует конвейер и ядро с переименованием регистров и внеочередной (не по порядку) выдачей/выполнением команд. В предположении, что аспект с выполнением команд по порядку является подмножеством аспекта с внеочередным выполнением команд, будет рассмотрен аспект с внеочередным выполнением команд.
Как показано на фиг. 1А, процессорный конвейер 100 содержит ступень 102 выборки, ступень 104 декодирования длины, ступень 106 декодирования, ступень 108 распределения, ступень 110 переименования, ступень 112 планирования (также известную как ступень диспетчирования и выдачи), ступень 114 чтения регистров/чтения памяти, ступень 116 выполнения, ступень 118 обратной записи/записи в память, ступень 122 обработки исключений и ступень 124 завершения.
На фиг. 1 В показано процессорное ядро 190, содержащее входной блок 130, соединенный с модулем 150 механизма выполнения, причем и входной блок, и модуль механизма исполнения связаны с модулем 170 памяти. Ядро 190 может представлять собой ядро процессора с сокращенным набором команд (RISC), ядро процессора с полным набором команд (CISC), ядро процессора с очень длинным командным словом (VLIW), либо ядро гибридного или альтернативного типа. В качестве еще одной опции ядро 190 может представлять ядро специального назначения, такое как сетевое ядро или ядро связи, механизм сжатия данных, сопроцессорное ядро, ядро графического процессора общего назначения (general purpose computing graphics processing unit (GPGPU)), графическое ядро или другое подобное ядро.
Входной блок 130 содержит модуль 132 прогнозирования ветвления, соединенный с модулем 134 кэша команд, который связан с буфером 136 динамической трансляции (translation lookaside buffer (TLB)) команд. Этот буфер соединен с модулем 138 выборки команд, который соединен с модулем 140 декодера. Модуль 140 декодера или декодер может декодировать команды и генерировать на выходе одну или несколько микроопераций, входных точек микрокода, микрокоманд, других команд или других сигналов управления, декодированных из исходных команд, или отражающих исходные команды другим способом, или полученных из исходных команд. Декодер 140 может быть реализован с использованием разнообразных механизмов. К примерам таких разнообразных механизмов относятся, не ограничиваясь этим, преобразовательные таблицы, аппаратные схемы, программируемые логические матрицы (PLA), постоянные запоминающие устройства (ПЗУ (ROM)) микрокода и т.п. В одном из вариантов ядро 190 содержит ПЗУ микрокода или другой носитель, содержащий микрокод для некоторых макрокоманд (например, в модуле 140 декодера или где-либо еще во входном блоке 130). Модуль 140 декодера соединен с модулем 152 распределения/переименования в составе модуля 150 механизма выполнения.
Модуль 150 механизма выполнения содержит модуль 152 переименования/распределения, соединенный с модулем 154 изъятия и группой из одного или нескольких модулей 156 планировщиков. Эти модули 156 планировщиков представляют какое-то число различных планировщиков, включая станции резервирования, центральное окно команд и т.п. Модули 156 планировщиков соединены с модулями 158 физических регистровых файлов. Каждый из модулей 158 физических регистровых файлов представляет собой один или несколько физических регистровых файлов, каждый из которых сохраняет данные одного или нескольких различных типов, таких как скалярные целочисленные данные, скалярные данные с плавающей запятой, упакованные целочисленные данные, упакованные данные с плавающей 'запятой, векторные целочисленные данные, векторные данные с плавающей запятой и т.п., данные состояния (например, указатель команды, иными словами, адрес следующей команды, которую нужно выполнить) и т.д. В одном из вариантов модуль 158 физических регистровых файлов содержит модуль векторных регистров, модуль регистров масок записи и модуль скалярных регистров. Эти модули регистров могут представлять собой архитектурные векторные регистры, векторные регистры масок и регистры общего назначения. На модули 158 физических регистровых файлов наложен модуль 154 изъятия для иллюстрации различных способов, какими может осуществляться наложение регистров и внеочередное (не по порядку) выполнение (например, с использованием буферов переупорядочения и регистровых файлов изъятия; с использованием файлов будущего, файлов истории и регистровых файлов изъятия; с использованием карт регистров и пула регистров; и т.п.). Модуль 154 изъятия и модули 158 физических регистровых файлов соединены с исполнительными кластерами 160. Исполнительный кластер 160 содержит один или несколько исполнительных модулей 162 и группу из одного или нескольких модулей 164 доступа к памяти. Исполнительные модули 162 могут осуществлять разнообразные операции (например, сдвиги, суммирование, вычитание, умножение) и над различными типами данных (например, над скалярными данными с плавающей запятой, упакованными целочисленными данными, упакованными данными с плавающей запятой, векторными целочисленными данным, векторными данными с плавающей запятой). Тогда как некоторые варианты могут содержать ряд исполнительных модулей, выделенных для конкретных функций или групп функций, другие варианты могут содержать только один исполнительный модуль или несколько исполнительных модулей, где все модули выполняют все функции. Модули 156 планировщиков, модули 158 физических регистровых файлов и исполнительные кластеры 160, показаны для варианта с несколькими такими модулями, поскольку некоторые варианты создают раздельные конвейеры для некоторых типов данных/операций (например, конвейер для скалярных целочисленных данных, конвейер для скалярных данных с плавающей запятой/упакованных скалярных целочисленных данных/упакованных данных с плавающей запятой/векторных целочисленных данных/векторных данных с плавающей запятой и/или конвейер доступа к памяти, так что каждый из этих конвейеров имеет собственный модуль планировщика, модуль физических регистровых файлов и/или исполнительный кластер - и в случае отдельного конвейера для доступа к памяти реализуются некоторые варианты, в которых исполнительный кластер этого конвейера имеет модули 164 для доступа к памяти). Следует также понимать, что в случае использования раздельных конвейеров, один или несколько из этих конвейеров могут служить для внеочередного выпуска/выполнения, а остальные - для работы по порядку.
Набор модулей 164 доступа к памяти соединена с модулем памяти 170, содержащим модуль 172 буфера данных TLB, соединенный с модулем 174 кэша данных, связанным с модулем 176 кэша уровня 2 (L2). В примере одного из вариантов модули 164 доступа к памяти могут содержать модуль загрузки, модуль сохранения адреса и модуль сохранения данных, каждый из которых соединен с модулем 172 буфера данных TLB в составе модуля 170 памяти. Модуль 134 кэша команд дополнительно связан с модулем 176 кэша уровня 2 (L2) в составе модуля 170 памяти. Модуль 176 кэша L2 соединен с одним или несколькими другими уровнями кэша и в конечном итоге с главной памятью.
В качестве примера, архитектура с переименованием регистров и ядром для внеочередного выпуска/выполнения может реализовать конвейер 100 следующим образом: 1) модуль 138 выборки команд реализует ступени 102 и 104 выборки и декодирования длины; 2) модуль 140 декодера реализует ступень 106 декодирования; 3) модуль 152 переименования/распределения реализует ступень 108 распределения и ступень 110 переименования; 4) модули 156 планировщиков реализуют ступень 112 планирования; 5) модули 158 регистровых файлов и модуль 170 памяти реализуют ступень 114 чтения регистров/чтения памяти; исполнительный кластер 160 реализует ступень выполнения 116; 6) модуль 170 памяти и модули 158 физических регистровых файлов реализуют ступень 118 обратной записи/записи в память; 7) различные модули могут участвовать в реализации ступени 122 обработки исключений; а модуль 154 изъятия и модули 158 физических регистровых файлов реализуют ступень 124 завершения.
Ядро 190 может поддерживать один или более наборов команд (например, набор команд х86 (с некоторыми расширениями, которые были добавлены в более новых версиях); набор команд MIPS, разработанный компанией MIPS Technologies из Солнечной долины, Калифорния (MIPS Technologies, Sunnyvale, СА); набор команд ARM (с дополнительными расширениями, такими как NEON), разработанный компанией ARM Holdings of Sunnyvale, СА), включая описанные здесь команды. В одном из вариантов ядро 190 содержит логическое устройство для поддержки расширения набора команд для работы с упакованными данными (например, AVX1, AVX2, и/или некоторая форма обобщенного формата команд, дружественного для работы с векторами (U=0 и/или U=1), описанного ниже), что позволяет операции, применяемые многими мультимедийными приложениями, выполнять с использованием упакованных данных.
Следует понимать, что ядро может поддерживать многопоточность (выполнение двух или более параллельных наборов операций или потоков) и может делать это различными способами, включая многопоточность с разделением времени, одновременную многопоточность (где одно физическое ядро создает свое логическое ядро для каждого из потоков, которые должно выполнять это физическое ядро в многопоточном режиме), или их сочетание (например, выборка и декодирование в режиме разделения времени и затем одновременная многопоточность в соответствии с технологией Intel® Hyperthreading).
Хотя переименование регистров описано в контексте внеочередного выполнения, следует понимать, что переименование регистров может быть использовано также в архитектуре с выполнением команд по порядку. Тогда как иллюстрируемый вариант процессора также содержит раздельные модули 134/174 кэшей данных и совместно используемый модуль 176 кэша L2, альтернативные варианты могут иметь один внутренний кэш и для команд, и для данных, такой как, например, внутренний кэш Уровня 1 (L1), или многоуровневый внутренний кэш. В некоторых вариантах система может содержать сочетание внутреннего кэша и внешнего кэша, находящегося вне ядра и/или процессора. В качестве альтернативы весь кэш может быть внешним относительно ядра и/или процессора.
На фиг. 2 представлена блок-схема процессора 200, которая может иметь больше одного ядра, может содержать интегральный контроллер памяти и может иметь встроенную графику согласно вариантам настоящего изобретения. Прямоугольники из сплошных линий на фиг. 2 иллюстрируют процессор с одним ядром 202А, системным агентом 210, группой из одного или нескольких модулей 216 контроллеров шин, тогда как добавленные в качестве опции прямоугольники из штриховых линий иллюстрируют альтернативный процессор 200 с несколькими ядрами 202A-N, группой из одного или нескольких модулей 214 интегральных контроллеров памяти в составе модуля 210 системного агента и логическим устройством 208 специального назначения.
Таким образом, различные варианты процессора 200 могут содержать: 1) центральный процессор CPU с логическим устройством 208 специального назначения, представляющим собой встроенное графическое и/или научное логическое устройство (которое может содержать одно или несколько ядер), а ядра 202A-N представляют собой одно или более ядер общего назначения (например, ядра общего назначения с выполнением операций по порядку, ядра общего назначения с внеочередным выполнением операций или сочетание этих двух видов ядер); 2) сопроцессор с ядрами 202A-N, представляющими собой большое число ядер специального назначения, предназначенных главным образом для решения графических и/или научных задач; и 3) сопроцессор с ядрами 202A-N, представляющими собой большое число ядер общего назначения с выполнением операций по порядку. Таким образом, процессор 200 может представлять собой процессор общего назначения, сопроцессор или процессор специального назначения, такой как, например, сетевой процессор или процессор связи, механизм сжатия данных, графический процессор, процессор GPGPU (модуль графического процессора общего назначения), высокопроизводительный сопроцессор с множеством интегрированных ядер (many integrated core (MIC)) (содержащий 30 ядер или больше), встроенный процессор или другое подобное устройство. Процессор может быть реализован в виде одного или нескольких кристаллов. Процессор 200 может частью и/или целиком быть реализован на одной или нескольких подложек с использованием какого-либо числа процессорных технологий, таких как, например, BiCMOS, CMOS или NMOS.
Иерархия памяти содержит один или более уровней кэша внутри ядер, группу из одного или более модулей 206 совместно используемого кэша и внешнюю память (не показана), соединенную с одним или более модулями 214 интегральных контроллеров памяти. Группа модулей 206 совместно используемого кэша может содержать один или более кэшей средних уровней, таких как уровень 2 (L2), уровень 3 (L3), уровень 4 (L4) или другие уровни кэша, кэш последнего уровня (last level cache (LLC)) и/или их сочетания. Тогда как в одном из вариантов интегральное графическое логическое устройство 208, группа модулей 206 совместно используемого кэша и модуль 210 системного агента/модули 214 интегральных контроллеров памяти соединены один с другими посредством соединительного модуля 212 кольцевого типа, альтернативные варианты могут использовать любое количество хорошо известных способов для соединения таких модулей. В одном из вариантов между одним или более модулями 206 кэша и ядрами 202A-N поддерживается когерентность.
В некоторых вариантах одно или более из ядер 202A-N способны осуществлять многопоточность. Системный агент 210 содержит компоненты для координации и управления ядрами 202A-N. Модуль 210 системного агента может содержать, например, модуль управления питанием (power control unit (PCU)) и модуль отображения. Модуль PCU может представлять собой или содержать логические устройства и компоненты, необходимые для регулирования питания ядер 202A-N и интегрального графического логического устройства 208. Модуль отображения предназначен для управления одним или более присоединенными извне устройствами отображения.
Ядра 202A-N могут быть, с точки зрения набора команд архитектуры, однородными или неоднородными; иными словами два или более ядер 202A-N могут быть способны выполнять один и тот же набор команд, тогда как другие могут быть способны выполнять только подмножество этого набора команд или другой набор команд.
На фиг. 3-6 показаны блок-схемы примеров компьютерных архитектур. Подходят также другие структуры и конфигурации системы, известные в технике для портативных компьютеров, настольных компьютеров, ручных персональных компьютеров, персональных цифровых помощников, инженерных рабочих станций, серверов, сетевых устройств, сетевых концентраторов, коммутаторов, встроенных процессоров, цифровых процессоров сигнала (digital signal processors (DSP)), графических устройств, видео игровых устройств, приставок, микроконтроллеров, сотовых телефонов, портативных медиаплееров, ручных устройств и разнообразных других электронных устройств. В общем случае, может подходить колоссальное множество самых разнообразных систем или электронных устройств, которые могут содержать процессор и/или логическое устройство для выполнения команд, как это описано здесь.
На фиг. 3 представлена блок-схема системы 300 согласно одному из вариантов настоящего изобретения. Эта система 300 может содержать один или более процессоров 310, 315, соединенных с концентратором 320 контроллера. В одном из вариантов этот концентратор 320 контроллера содержит концентратор 390 контроллера графической памяти (graphics memory controller hub (GMCH)) и концентратор 350 ввода/вывода (Input/Output Hub IOH)) (которые могут быть выполнены на раздельных кристаллах); концентратор GMCH 390 содержит контроллеры памяти и графики, с которыми соединены запоминающее устройство 340 и сопроцессор 345; концентратор IOH 350 соединяет устройства 360 ввода/вывода с концентратором GMCH 390. В альтернативных вариантах один или оба контроллера памяти и графики интегрированы в процессор (как описано здесь), запоминающее устройство 340 и сопроцессор 345 соединены непосредственно с процессором 310, а концентратор 320 контроллеров выполнен в одном кристалле с концентратором IOH 350.
Тот факт, что дополнительные процессоры 315 могут присутствовать в качестве опции, показан на фиг. 3 штриховыми линиями. Каждый процессор 310, 315 может содержать одно или более процессорных ядер, как описано здесь, и может представлять собой некоторую версию процессора 200.
Запоминающее устройство 340 может представлять собой, например, динамическое запоминающее устройство с произвольной выборкой (dynamic random access memory (DRAM)), запоминающее устройство на фазовых переходах (phase change memory (PCM)) или сочетание этих двух типов запоминающих устройств. По меньшей мере в одном из вариантов концентратор 320 контроллеров сообщается с процессорами 310, 315 по многоотводной шине, такой как системная шина (frontside bus (FSB)), через двухпунктовый интерфейс, такой как QuickPath Interconnect (QPI), или через аналогичное соединение 395.
В одном из вариантов сопроцессор 345 представляет собой сопроцессор специального назначения, такой как, например, высокопроизводительный многоядерный процессор типа MIC, сетевой процессор или процессор связи, механизм сжатия данных, графический процессор, процессор GPGPU, встроенный процессор или другое подобное устройство. В некоторых вариантах концентратор 320 контроллеров может иметь в составе интегральный графический ускоритель.
Между физическими ресурсами 310, 315 могут быть множество различий с точки зрения спектра метрических показателей, включая архитектурные, микро архитектурные, тепловые характеристики, энергопотребление и другие подобные характеристики.
В одном из вариантов процессор 310 выполняет команды, управляющие операциями общего типа для обработки данных. Среди этих команд могут находиться команды для сопроцессора. Процессор 310 распознает эти команды для сопроцессора как тип команд, которые должен выполнять сопроцессор. Соответственно, процессор 310 выдает эти команды для сопроцессора (или сигналы управления, представляющие команды для сопроцессора) в шину сопроцессора или в другое соединение с сопроцессором 345. Сопроцессор(ы) 345 принимает и выполняет полученные им команды для сопроцессора.
На фиг. 4 показана блок-схема первого более конкретного примера системы 400 согласно одному из вариантов настоящего изобретения. Как показано на фиг. 4, многопроцессорная система 400 представляет собой систему с двухпунктовыми соединениями и содержит первый процессор 470 и второй процессор 480, связанные один с другим посредством двухпунктового соединения 450. Каждый из процессоров 470 и 460 может быть некой версией процессора 200. В одном из вариантов настоящего изобретения процессоры 470 и 480 - это соответственно процессоры 310 и 315, тогда как сопроцессор 438 представляет собой сопроцессор 345. В другом варианте процессоры 470 и 480 являются, соответственно, процессором 310 и сопроцессором 345.
Показано, что процессоры 470 и 480 содержат модули 472 и 482, соответственно, интегральных контроллеров памяти (integrated memory controller (IMC)). Процессор 470 содержит также, в качестве составной части своих модулей контроллеров шин, двухпунктовые (point-to-point (Р-Р)) интерфейсы 476 и 478; аналогично, второй процессор 480 содержит Р-Р интерфейсы 486 и 488. Процессоры 470, 480 могут обмениваться информацией через Р-Р интерфейс 450 с использованием интерфейсных Р-Р схем 478, 488. Как показано на фиг. 4, модули 472 и 482 контроллеров ГМС связывают процессоры с соответствующими запоминающими устройствами, а именно с запоминающим устройством 432 и запоминающим устройством 434, которые могут быть частями главного запоминающего устройства, локально присоединенными к соответствующим процессорам.
Процессоры 470, 480 могут обмениваться информацией с чипсетом 490 через индивидуальные Р-Р интерфейсы 452, 454 с использованием двухпунктовых интерфейсных схем 476, 494, 486, 498. Чипсет 490 может также, в качестве опции, обмениваться информацией с сопроцессором 438 через высокопроизводительный интерфейс 439. В одном из вариантов сопроцессор 438 представляет собой сопроцессор специального назначения, такой как, например, высокопроизводительный многоядерный процессор типа MIC, сетевой процессор или процессор связи, механизм сжатия данных, графический процессор, процессор GPGPU, встроенный процессор или другое подобное устройство.
Совместно используемый кэш (не показан) может входить в состав какого-либо из процессоров, либо располагаться вне обоих процессоров, будучи при этом связан с этими процессорами посредством Р-Р соединения, так что локальная кэшируемая информация какого-либо из процессоров или обоих процессоров может быть сохранена в этом совместно используемом кэше, если соответствующий процессор переведен в режим пониженного энергопотребления.
Чипсет 490 может быть соединен с первой шиной 416 через интерфейс 496. В одном из вариантов первая шина 416 может представлять собой шину соединения периферийных устройств (Peripheral Component Interconnect (PCI)) или быть такой шиной, как шина стандарта PCI Express, или какой-либо другой соединительной шиной ввода-вывода третьего поколения, хотя объем настоящего изобретения этим не ограничивается.
Как показано на фиг. 4, с первой шиной 416 могут быть соединены разнообразные устройства 414 ввода/вывода вместе с мостом 418, который соединяет первую шину 416 со второй шиной 420. В одном из вариантов с первой шиной 416 соединены один или несколько дополнительных процессоров 415, таких как сопроцессор специального назначения, такой как, например, высокопроизводительный многоядерный процессор типа MIC, процессор GPGPU, ускорители (например, графические ускорители или модули цифровых процессоров сигнала (DSP)), программируемые пользователем вентильные матрицы или какой-либо другой процессор. В одном из вариантов эта вторая шина 420 может представлять собой шину с небольшим числом контактов (low pin count (LPC)). В одном из вариантов со второй шиной 420 могут быть соединены разнообразные устройства, например, клавиатура и/или мышь 422, устройства 427 связи и модуль 428 запоминающего устройства, такого как дисковод или другое запоминающее устройство большой емкости, в котором могут храниться команды/код и данные 430. Кроме того, со второй шиной 420 может быть соединено аудио устройство 424 ввода/вывода. Отметим, что возможны и другие архитектуры. Например, вместо двухпунктовой архитектуры, показанной на фиг. 4, система может использовать многоотводную шину или другую подобную архитектуру.
На фиг. 5 показана блок-схема второго более конкретного примера системы 500 согласно одному из вариантов настоящего изобретения. Подобным элементам на фиг. 4 и 5 присвоены подобные цифровые позиционные обозначения, а некоторые аспекты, изображенные на фиг. 4, на фиг. 5 опущены, чтобы не затенять другие аспекты фиг. 5.
На фиг. 5 показано, что процессоры 470, 480 может содержать интегрированное логическое устройство 472 и 482, соответственно, для управления памятью и вводом/выводом ("CL"). Таким образом, устройство CL 472, 482 содержит модули интегральных контроллеров памяти и логическое устройство управления вводом/выводом. На фиг. 5 показаны не только запоминающие устройства 432, 434, связанные с устройством CL 472, 482, но и устройства 514 ввода/вывода, связанные с чипсетом 490.
На фиг. 6 представлена блок-схема системы 600 на кристалле (SoC) согласно одному или более аспектам настоящего изобретения. Элементы, подобные элементам, показанным на фиг. 2, имеют сходные цифровые позиционные обозначения. Кроме того, прямоугольники из штриховых линий обозначают функции, являющиеся опциями для более совершенных систем SoC. Как показано на фиг. 6, соединительные модули 602 могут быть связаны с: процессором 610 приложений, содержащим группу из одного или нескольких ядер 202A-N и совместно используемый кэш 206; модулем 210 системного агента; модулями 216 контроллеров шин; модулями 214 интегральных контроллеров памяти; группой из одного или более медиапроцессоров 620, которые могут содержать интегральное графическое логическое устройство, процессор изображений, аудио процессор и видео процессор; модулем 630 статического запоминающего устройства произвольного доступа (static random access memory (SRAM)); модулем 632 прямого доступа к памяти (DMA); и модулем 640 отображения для соединения с одним или более внешними устройствами отображения. В одном из вариантов сопроцессор 620 представляет собой процессор специального назначения, такой как, например, сетевой процессор или процессор связи, механизм сжатия данных, процессор GPGPU, высокопроизводительный многоядерный процессор типа MIC, встроенный процессор или другое подобное устройство.
Варианты механизмов, рассматриваемых здесь, могут быть реализованы посредством аппаратуры, загружаемого программного обеспечения, встроенного программного обеспечения или сочетания этих подходов. Варианты настоящего изобретения могут быть реализованы посредством компьютерных программ или программных кодов, выполняемых программируемыми системами, содержащими по меньшей мере один процессор, систему памяти (включая энергонезависимые и энергонезависимые запоминающие устройства и/или элементы памяти), по меньшей мере одно устройство ввода и по меньшей мере одно устройство вывода.
Программный код, такой как код 430, иллюстрируемый на фиг. 4, может быть применен к входным командам для выполнения описываемых здесь функций и генерации выходной информации. Эта выходная информация может быть применена известным образом к одному или нескольким устройствам вывода. Эта выходная информация может быть, известным образом, передана одному или нескольким устройствам вывода. Для целей настоящей заявки процессорная система представляет собой какую-либо систему, содержащую процессор, такой как, например, цифровой процессор сигнала (DSP), микроконтроллер, специализированная интегральная схема (application specific integrated circuit (ASIC)) или микропроцессор.
Программный код может быть на языке программирования высокого уровня, ориентированном на процедуры или объектно-ориентированном, для общения с процессорной системой. Программный код может быть также написан на ассемблере или на языке машинных команд, если нужно. На самом деле объем рассматриваемых здесь механизмов не ограничивается каким-либо конкретным языком программирования. В любом случае, язык может быть компилируемым или интерпретируемым языком.
Один или более аспектов по меньшей мере одного из вариантов могут быть реализованы в виде сохраняемых на машиночитаемом (компьютерном) носителе репрезентативных команд, представляющих разнообразные логические функции в процессоре, так что при считывании этих команд машиной эта машина создает логическое устройство для осуществления описываемых здесь способов. Такие представления, известные как ядра доверенных процессоров («TP-ядро»), могут быть записаны на материальном машиночитаемом носителе и переданы различным заказчикам или производственным предприятиям для загрузки в изготавливаемые машины, которые реально образуют логические устройства или процессоры.
Такой машиночитаемый носитель информации может представлять собой, без ограничений, энергонезависимые материальные структуры из различных деталей, изготовленных или образованных машиной или устройством, включая носители информации, такие как жесткие магнитные диски, диск какого-либо другого типа, включая дискеты, оптические диски, постоянные запоминающие устройства на компакт-дисках (CD-ROM), перезаписываемые компакт-диски (CD-RW) и магнитооптические диски, полупроводниковые приборы, такие как постоянные запоминающие устройства (ПЗУ (ROM)), запоминающие устройства с произвольной выборкой (ЗУПВ (RAM)), такие как динамические ЗУПВ (DRAM), статические ЗУПВ (SRAM), стираемые программируемые ПЗУ (СППЗУ (EPROM)), устройства флэш-памяти, электрически стираемые и программируемые ПЗУ (ЭСППЗУ (EEPROM)), запоминающее устройство на фазовых переходах (РСМ), магнитные или оптические карточки или какие-либо другие типы носителей, подходящие для хранения электронных команд.
Соответственно варианты настоящего изобретения содержат также энергонезависимые материальные машиночитаемые носители информации с записанными на них данными проектирования, такими как данные на языке описания аппаратных средств (Hardware Description Language (HDL)), которые определяют структуры, схемы, устройства, процессоры и/или системные функции, описываемые здесь. Такие варианты могут быть также названы программными продуктами.
В некоторых случаях может быть использован преобразователь команд для трансформации команд из исходного набора команд к целевому набору команд. Например, указанный преобразователь команд может транслировать (например, с использованием статической двоичной трансляции, динамической двоичной трансляции, включая динамическую компиляцию), осуществлять морфинг, эмуляцию или иное преобразование команды в одну или несколько других команд для обработки процессором. Преобразователь команд может быть реализован посредством загружаемого программного обеспечения, аппаратуры, встроенного программного обеспечения или сочетания этих компонентов. Преобразователь команд может представлять собой активный процессор, неактивный процессор или часть такого активного или неактивного процессора.
На фиг. 7 представлена блок-схема, иллюстрирующая использование программного преобразователя команд с целью преобразования двоичных команд из исходного набора команд в двоичные команды из целевого набора команд согласно вариантам настоящего изобретения. В иллюстрируемом варианте преобразователь команд является программным преобразователем команд, хотя в альтернативных вариантах преобразователь команд может быть реализован посредством загружаемого программного обеспечения, встроенного программного обеспечения, аппаратуры или сочетания этих компонентов. На фиг. 7 показано, что программа на языке 702 высокого уровня может быть компилирована с использованием компилятора 704 набора команд х86 с целью генерации двоичного кода 706 в формате х86, которые могут быть естественным образом выполнены процессором 716, имеющим по меньшей мере одно ядро для набора команд х86. Под процессором 716, имеющим по меньшей мере одно ядро с набором команд х86, понимают какой-либо процессор, который может выполнять по существу такие же функции, как процессор компании Интел по меньшей мере с одним ядром для выполнения набора команд х86, посредством совместимого выполнения или обработки иным способом (1) значительной части набора команд по меньшей мере одного ядра с набором команд Intel х86 или (2) версий объектного кода приложения или другого программного обеспечения, предназначенного для выполнения процессором компании Интел по меньшей мере с одним ядром для выполнения набора команд х86, с целью достижения по существу такого же результата, какой достигается процессором компании Интел по меньшей мере с одним ядром для выполнения набора команд х86. Компилятор 704 набора команд х86 представляет собой компилятор, генерирующий двоичный код 706 в формате х86 (например, объектный код), который может, с использованием дополнительной связующей обработки или без нее, быть выполнен процессором 716 по меньшей мере с одним ядром для выполнения набора команд х86. Аналогично, на фиг. 7 показано, что программа на языке 702 высокого уровня может быть компилирована посредством компилятора 708 альтернативного набора команд для генерации двоичного кода 710 альтернативного набора команд, который может быть естественным образом выполнен процессором 714, не имеющим по меньшей мере одного ядра для выполнения набора команд х86 (например, процессором с ядрами, выполняющими набор команд MIPS, разработанный компанией MIPS Technologies из Sunnyvale, СА, и/или с ядрами, выполняющими набор команд ARM, разработанный компанией ARM Holdings из Sunnyvale, СА). Преобразователь 712 команд используется для преобразования двоичного кода х86 706 в код, который может быть естественным образом выполнен процессором 714, не имеющим ядра для выполнения набора команд х86. Этот преобразованный код совсем не обязательно может быть таким же, как двоичный код 710 альтернативного набора команд, поскольку способный осуществить это преобразователь команд трудно сделать; однако преобразованный код будет осуществлять общие операции и при этом будет построен из команд, составляющий альтернативный набор команд. Таким образом, преобразователь 712 команд может быть реализован посредством загружаемого программного обеспечения, встроенного программного обеспечения, аппаратуры или их сочетания с использованием эмуляции, моделирования или какого-либо другого процесса, так что преобразователь команд позволяет процессору или другому электронному устройству, не имеющему процессора или ядра, способного выполнять набор команд х86, выполнять двоичный код х86 706.
Варианты реверсирования и перестановки битов в регистре маски
Регистры маски, используемые здесь, эффективно содержат биты, соответствующие элементам, находящимся в векторном регистре, и отслеживающие элементы, над которыми должны быть выполнены операции. По этой причине необходимо иметь общие операции, которые можно реплицировать аналогичным образом на этих битах маски как в векторных регистрах и которые позволят подстраивать эти биты маски в регистре маски.
Один из вариантов настоящего изобретения содержит команды, реверсирующие биты в регистре маски путем замены бита, находящегося в позиции n, на бит, находящийся в симметричной позиции, в зависимости от размера маски. Поскольку каждый бит маски соответствует одному элементу вектора, число активных битов в регистре маски зависит от размера векторного регистра (в битах) и от размеров элементов. Поэтому разные формы могут быть использованы для данных различных типов, включая, в качестве примера и без ограничений, с размерами Байт (8-бит), Слово (16-бит), Двойное слово (32-бит) и Учетверенное слово (64-бит). Один регистр маски могут быть использованы исходного регистра, а результаты при этом записывают во второй регистр маски.
Ниже приведен псевдокод для возможной реализации предполагаемой команды для двойных слов. Безусловно, эта команда может быть реализована для других типов данных (байт, слово и учетверенное слово).

Последняя строка, DEST[MAX_KL-1:32]←0, означает, что биты обнуляются, если нужно. Например, если регистр-адресат маски имеет размер больше 32 бит (например, 64 бит), тогда все биты сверх 32 бит обнуляются.
Фиг. 8 иллюстрирует архитектурные компоненты, используемые в одном из вариантов, так что совокупность этих компонентов содержит логическое устройство 805 для инверсии порядка битов, выполняющее команды инверсии порядка битов маски. После выполнения команд величины битов маски из регистра SRC2 802 передают в симметричные позиции в регистре-адресате 804. Например, логическое устройство 805 для инверсии порядка битов перемещает бит из позиции 0 в исходном регистре 802 в позицию 31 в регистре-адресате 804; бит из позиции 1 в исходном регистре 802 в позицию 30 в регистре-адресате 804, и т.д., пока все биты не будут переданы из исходного регистра в регистр-адресат, в результате чего происходит симметричное «зеркальное отображение» первоначального расположения битов. Полученная в результате маска, сохраняемая в регистре-адресате 804, может быть затем использована для последующих векторных операций.
Другой вариант настоящего изобретения содержит команды для перестановки величин из первого операнда маски (адресат) и третьего операнда (второй исходный операнд) и вставки их в операнд-адресат в позиции, указываемые индексы из второго операнда (первый исходный операнд). Отметим, что эти команды позволяют величину одного бита из исходного операнда скопировать более чем в одну позицию в операнде-адресате. Поскольку каждый бит маски соответствует одному векторному элементу, число активных битов в регистре маски зависит и от размера векторного регистра (в битах), и от размера элементов регистра. Таким образом, эта операция перестановки имеет свои формы для различных типов данных - с размерами Байт (8-бит), Слово (16-бит), Двойное слово (32-бит) и Учетверенное слово (64-бит).
В одном из вариантов команда имеет два источника: регистр маски, над которым нужно произвести перестановку, и векторный регистр, содержащий данные управления перестановками. Результат записывают во второй регистр маски.
Ниже приведен псевдокод для возможной реализации предполагаемой команды для двойных слов. Безусловно, эта команда может быть реализована для других типов данных (байт, слово и учетверенное слово).

В этом варианте на каждой итерации 6 битов из регистра SCR1 используют в качестве индекса для идентификации в позицию бита в регистре SRC2. Этот бит затем передают в регистр-адресат маски, DEST, в позицию j. Еще раз, в последней строке, DEST[MAX_KL-1:32]←0, означает, что биты обнуляются, если нужно. Например, если регистр-адресат маски имеет размер больше 32 бит (например, 64 бит), тогда все биты сверх 32 бит обнуляются.
Фиг. 9 иллюстрирует архитектурные компоненты, используемые в одном из вариантов, и в том числе логическое устройство 905 для перестановок, выполняющее команду перестановок маски. В соответствии с индексами, считываемыми из регистра 901 управления перестановками маски, (регистр SRC1 в этом примере) биты из обозначенных этими индексами позиций В0-В31 в регистре SRC2 902 переставляют в другие битовые позиции Р0-Р31 в регистре-адресате DST 904 (обозначены переменной j). Используя разные индексы в регистре управления перестановками, можно любой бит из регистра SRC2 902 скопировать в любую битовую позицию в регистре DST 904.
На фиг. 10 представлена блок-схема примера варианта процессора (процессорного ядра) 1000 для выполнения одной или более команд 1004А (например, KREVERSEBITSD) инверсии порядка битов маски и/или команд 1004 В (например, KPEMD) перестановок в маске. В некоторых вариантах процессор может представлять собой процессор общего назначения (например, процессор такого типа, какой используется в настольных компьютерах, портативных компьютерах, серверах и других подобных компьютерах). В качестве альтернативы процессор может представлять собой процессор специального назначения. Среди лишь нескольких примеров подходящих процессоров специального назначения процессоры связи, криптографические процессоры, графические процессоры, сопроцессоры, встроенные процессоры, цифровые процессоры сигналов (DSP) и контроллеры. Такой процессор может представлять собой какой-либо из различных вариантов процессоров компьютеров с полным набором команд (CISC), процессоров компьютеров с сокращенным набором команд (RISC), процессоров с очень длинным командным словом (VLIW), различных сочетаний таких процессоров или процессоров других типов.
Процессор 1000 содержит архитектурно видимые регистры (например, архитектурный регистровый файл) 1005. Архитектурные регистры могут здесь также называться просто регистрами. Если не указано или если не очевидно другое, фразы «архитектурный регистр», «регистровый файл» и «регистр» используются здесь для обозначения регистров, видимых для программного обеспечения и/или программиста, и/или регистров, специфицированных макрокомандами или командами языка ассемблер для идентификации операндов. Эти регистры отличаются от других неархитектурных или неархитектурно видимых регистров в какой-либо конкретной микро архитектуре (например, временных регистров, используемых командами, буферов переупорядочения, регистры изъятия и т.п.). Регистры в общем случае представляют собой расположенные на кристалле процессора области памяти.
Иллюстрируемые архитектурные регистры могут представлять собой регистры 1006 упакованных данных, способные сохранять упакованные или векторные данные. Иллюстрируемые архитектурные регистры могут также представлять собой регистры 1007 маски для операций с упакованными данными. Каждый из таких регистров маски для операций с упакованными данными может сохранять маску для операций с упакованными данными. Такие регистры могут в настоящем описании называться также регистрами маски записи. В регистрах 1007 для упакованных данных могут храниться операнды упакованных данных.
Процессор содержит также исполнительное логическое устройство 1008, способное выполнять или обрабатывать одну или более команд 1004А инверсии порядка битов маски и/или команд 1004В перестановок в маске. В некоторых вариантах исполнительное логическое устройство может представлять собой специализированное логическое устройство (например, специализированную схему или аппаратуру, потенциально сочетаемую с встроенным программным обеспечением) для выполнения этих команд.
Фиг. 11 иллюстрирует вариант выполнения команды KREVERSEBITS в процессоре. Выборка команды KREVESEBITS с операндом из первого исходного регистра и операндом из регистра-адресата, а также кода операции (opcode), осуществляется на этапе 1101.
На этапе 1102 декодируют команду KREVESEBITS посредством декодирующего логического устройства.
На этапе 1103 вызывают/считывают величины исходного операнда. Например, считывают данные из исходного регистра.
Декодированную команду KREVESEBITS (или операции, содержащие эту команду, такие как микрооперации) выполняют посредством исполнительных ресурсов, таких как один или более функциональных модулей, на этапе 1104 для замены каждого бита в одной из позиций n на бит, расположенный в симметричной позиции в исходном регистре маски. Вновь определенные величины маски сохраняют на этапе 1105 в операнде регистра-адресата. В некоторых вариантах вычисленные величины сохраняют в элементах данных в регистре упакованных данных. Хотя этапы 1104 и 1105 на чертеже показаны по отдельности, в некоторых вариантах эти этапы могут быть осуществлены совместно как часть выполнения команды.
Фиг. 12 иллюстрирует вариант выполнения команды KPERM в процессоре. Выборка команды KPERM с операндом из первого исходного регистра и операндом регистра-адресата, а также кода операции, осуществляется на этапе 1201.
На этапе 1202 декодируют команду KPERM посредством декодирующего логического устройства.
На этапе 1203 вызывают/считывают величины исходного операнда. Например, считывают биты управления из одного исходного регистра с целью определить, как переставлять биты, (например, из регистра SRC1 901 на фиг. 9) и считывают биты, которые нужно переставить, из другого исходного регистра (например, из регистра SCR2 902).
Декодированную команду KPERM (или операции, содержащие эту команду, такие как микрооперации) выполняют посредством исполнительных ресурсов, таких как один или более функциональных модулей, на этапе 1204 для перестановки битов из исходного регистра маски (SRC2) в регистр-адресат маски (DEST). Вновь определенные величины маски сохраняют на этапе 1205 в операнде регистра-адресата. В некоторых вариантах вычисленные величины сохраняют в элементах данных в регистре упакованных данных. Хотя этапы 1204 и 1205 на чертеже показаны по отдельности, в некоторых вариантах эти этапы могут быть осуществлены совместно как часть выполнения команды.
Варианты настоящего изобретения могут содержать различные этапы, описанные выше. Эти этапы могут быть реализованы посредством выполняемых машиной команд, которые могут быть использованы, чтобы процессор общего назначения или специализированный процессор осуществил эти этапы. В качестве альтернативы эти этапы могут быть осуществлены посредством специальных аппаратных компонентов, содержащих аппаратные логические устройства для выполнения этих этапов, или с использованием какого-либо сочетания программируемых компьютерных компонентов и специализированных аппаратных компонентов.
Как описано здесь, команды могут обращаться к специальным конфигурациям аппаратуры, таким как специализированные интегральные схемы (ASIC), конфигурированные для выполнения некоторых операций или имеющие заданные функции или программные команды, сохраненные в памяти, реализованной в виде энергонезависимого компьютерного носителя информации. Таким образом, способы, представленные на чертежах, могут быть реализованы с использованием кода и данных, сохраняемых и исполняемых в одном или нескольких электронных устройствах (таких как конечные станции, сетевые элементы и т.п.). Такие электронные устройства сохраняют и передают (внутри себя и/или обмениваются с другими электронными устройствами в сети) код и данные с использованием энергонезависимых компьютерных носителей информации (например, магнитных дисков; оптических дисков; запоминающих устройств с произвольной выборкой; постоянных запоминающих устройств; флэш-памяти; памяти на основе фазовых переходов) и энергозависимых компьютерных носителей для передачи информации (например, электрических, оптических, акустических или других форм распространяющихся сигналов, таких сигналы несущих, инфракрасные сигналы, цифровые сигналы и т.п.). Кроме того, такие электронные устройства обычно содержат группу из одного или нескольких процессоров, связанных с одним или несколькими другими компонентами, такими как одно или более запоминающих устройств (энергонезависимых компьютерных носителей информации), устройств ввода/вывода команд и данных пользователем (например, клавиатурой, сенсорным экраном и/или дисплеем) и сетевые соединения. Связь между группой процессоров и другими компонентами обычно осуществляется через одну или более шин и мосты (также именуемые контроллерами шин). Запоминающие устройства и сигналы, передаваемые в виде сетевого трафика, представляют собой, соответственно, один или несколько компьютерных (машиночитаемых) носителей для хранения информации и компьютерных носителей для передачи информации. Таким образом, запоминающее устройство в составе некоего конкретного электронного устройства обычно сохраняет коды и/или данные для выполнения посредством группы из одного или более процессоров в составе этого электронного устройства. Безусловно, одна или более частей какого-либо варианта настоящего изобретения может быть реализована с использованием различных сочетаний загружаемого программного обеспечения, встроенного программного обеспечения и/или аппаратуры. В пределах всего этого подробного описания, для целей пояснения, многочисленные конкретные подробности были приведены с целью обеспечения более полного понимания настоящего изобретения. Специалисту в рассматриваемой области должно быть, однако, очевидно, что настоящее изобретение может быть осуществлено на практике и без некоторых из числа этих конкретных подробностей. В некоторых случаях хорошо известные структуры и функции не были описаны подробно, чтобы не затемнять предмет настоящего изобретения. Соответственно, объем и смысл настоящего изобретения следует оценивать на основе прилагаемой ниже формулы изобретения.








Группа изобретений относится к компьютерным системам и может быть использована для переупорядочения битов маски. Техническим результатом является обеспечение реверсирования и перестановки битов маски. В одном из вариантов процессор выполнения команды осуществляет операции: чтения множества битов маски, хранящихся в исходном регистре маски, при этом указанные биты маски ассоциированы с элементами векторных данных в векторном регистре; и выполнения операции реверсирования битов для копирования каждого бита маски из исходного регистра маски в регистр-адресат маски, так что операция реверсирования битов вызывает инверсию порядка битов, имевшего место в исходном регистре маски, в регистре-адресате маски, что приводит в результате к симметричному зеркальному отображению первоначального расположения битов. 5 н. и 17 з.п. ф-лы, 13 ил.
1. Процессор исполнения команд для осуществления операций, содержащих этапы, на которых:
считывают множество битов маски, хранящихся в исходном регистре маски, при этом указанные биты маски ассоциированы с элементами векторных данных в векторном регистре; и
выполняют операцию реверсирования битов для копирования каждого бита маски из исходного регистра маски в регистр-адресат маски, при этом операция реверсирования битов вызывает реверсирование битов, имевших место в исходном регистре маски, в регистр-адресат маски так, что обеспечивается симметричное зеркальное отображение первоначального расположения битов.
2. Процессор по п. 1, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 32 бит данных маски.
3. Процессор по п. 1, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 64 бит данных маски.
4. Процессор по п. 1, в котором команда представляет собой макрокоманду, а совокупность операций содержит микрооперации.
5. Процессор выполнения команд для осуществления операций:
чтения множества битов маски, хранящихся в первом исходном регистре, и данных управления, хранящихся во втором исходном регистре, при этом указанные биты маски ассоциированы с элементами векторных данных в векторном регистре; и
выполнения операции перестановки битов маски для копирования каждого бита маски из исходного регистра маски в регистр-адресат маски, так что данные управления, хранящиеся во втором исходном регистре, указывают, какой бит из первого исходного регистра подлежит копированию в каждый бит в регистре-адресате так, что обеспечивается перестановка первоначального расположения битов.
6. Процессор по п. 5, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 32 бит данных маски.
7. Процессор по п. 5, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски хранят по 64 бит данных маски.
8. Процессор по п. 5, в котором команда представляет собой макрокоманду, а совокупность операций содержит микрооперации.
9. Способ переупорядочения битов маски, содержащий этапы, на которых:
считывают множество битов маски, хранящихся в исходном регистре маски, при этом указанные биты маски ассоциированы с элементами векторных данных в векторном регистре; и
выполняют операции реверсирования битов для копирования каждого бита маски из исходного регистра маски в регистр-адресат маски, так что операция реверсирования порядка битов вызывает реверсирование порядка битов, имевшего место в исходном регистре маски, в регистре-адресате маски так, что обеспечивается симметричное зеркальное отображение первоначального расположения битов.
10. Способ по п. 9, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 32 бит данных маски.
11. Способ по п. 9, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 64 бит данных маски.
12. Способ по п. 9, в котором команда представляет собой макрокоманду, а совокупность операций содержит микрооперации.
13. Способ переупорядочения битов маски, содержащий этапы, на которых:
считывают множество битов маски, хранящихся в первом исходном регистре, и данных управления, хранящихся во втором исходном регистре, при этом указанные биты маски ассоциированы с элементами векторных данных в векторном регистре; и
выполняют операции перестановки битов маски для копирования каждого бита маски из исходного регистра маски в регистр-адресат маски, при этом данные управления, хранящиеся во втором исходном регистре, указывают, какой бит из первого исходного регистра подлежит копированию в каждый бит в регистре-адресате, что приводит в результате к перестановке первоначального расположения битов.
14. Способ по п. 13, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 32 бит данных маски.
15. Способ по п. 13, в котором каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 64 бит данных маски.
16. Способ по п. 13, в котором команда представляет собой макрокоманду, а совокупность операций содержит микрооперации.
17. Компьютерная система переупорядочения битов маски, содержащая:
запоминающее устройство для хранения программного кода и данных;
интерфейс связи ввода/вывода (IO) для связи с одним или более периферийных устройств;
интерфейс связи с сетью для соединения с возможностью связи указанной системы с сетью; и
процессор выполнения команды для осуществления операций:
чтения множества битов маски, хранящихся в исходном регистре маски, при этом указанные биты маски ассоциированы с элементами векторных данных в векторном регистре; и
выполнения операции реверсирования битов для копирования каждого бита маски из исходного регистра маски в регистр-адресат маски, так что операция реверсирования порядка битов вызывает реверсирование порядка битов, имевшего место в исходном регистре маски, в регистре-адресате маски так, что обеспечивается симметричное зеркальное отображение первоначального расположения битов.
18. Система по п. 17, в которой каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 32 бит данных маски.
19. Система по п. 17, в которой каждый из регистров - исходный регистр маски и регистр-адресат маски - хранят по 64 бит данных маски.
20. Система по п. 17, в которой команда представляет собой макрокоманду, а совокупность операций содержит микрооперации.
21. Система по п. 20, дополнительно содержащая:
адаптер отображения для отображения графических изображений в ответ на выполнение программного кода процессором.
22. Система по п. 21, дополнительно содержащая:
пользовательский интерфейс ввода для приема сигналов управления от пользовательского устройства ввода, так что процессор выполнен с возможностью исполнения программного кода в ответ на указанные сигналы управления.
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| US 7062637 B2, 13.06.2006 | |||
| УСТРОЙСТВО УПРАВЛЯЕМОЙ ПЕРЕСТАНОВКИ БИТОВ БИНАРНОЙ СТРОКИ | 2009 |
|
RU2439662C2 |
| СИСТЕМА И СПОСОБ ПЕРЕМЕЖЕНИЯ | 2005 |
|
RU2376709C2 |

