Область техники, к которой относится изобретение
Настоящее изобретение относится, в общем, к архитектуре процессора компьютера и, более конкретно, к модулю сопроцессора кэша.
Уровень техники
Набор команд или структура набора команд (ISA) представляет собой часть архитектуры компьютера, относящуюся к программированию, и может содержать различные виды внутренних данных, команды, архитектуру регистров, режимы адресации, архитектуру памяти, обработку прерываний и особых ситуаций, а также внешний ввод и вывод (I/O). Следует отметить, что термин команда здесь обычно относится к макрокоманде, т.е. команде, направляемой в процессор для выполнения, в отличие от микрокоманды или микрооперации, являющихся результатом декодирования макрокоманд посредством декодера процессора.
Структура набора команд отличается от микроархитектуры, представляющей собой внутреннюю конструкцию процессора, реализующего структуру ISA. Процессоры с различными микроархитектурами могут использовать общий набор команд. Набор команд содержит один или более форматов команд. Конкретный набор команд определяет разнообразные поля (число битов, расположение битов) для спецификации, помимо всего прочего, операции, которую нужно выполнить, и операнд(ы), над которыми должна быть выполнена эта операция. Конкретную команду представляют с использованием конкретного формата команд, и эта команда определяет и операцию, и операнд(ы). Поток команд представляет собой определенную последовательность команд, где каждая команда в последовательности является событием команды в некоем формате команды.
Разного рода научные, финансовые приложения, автоматически векторизуемые приложения общего назначения, приложения RMS (распознавание, анализ и синтез)/визуальные и мультимедийные (например, 2D/3D графика, обработка изображения, сжатие/расширение видео, алгоритмы распознавания речи и манипуляции со звуком) приложения часто требуют, чтобы одна и та же операция была выполнена над большим числом элементов данных (именуется «параллелизмом данных»). Название «одна команда, множество данных» (SIMD) обозначает тип команд, в соответствии с которыми процессор выполняет одну и ту же операцию применительно к множеству объектов данных. Технология SIMD специально приспособлена для процессоров, способных разбивать биты в регистре на некоторое число элементов данных фиксированного размера, каждый из которых представляет отдельную величину. Например, биты в 64-битовом регистре могут быть определены как операнд-источник, работать с которым следует как с четырьмя отдельными 16-битовыми элементами данных, каждый из которых представляет отдельную 16-битовую величину. В качестве другого примера, биты в 256-битовом регистре могут быть определены как операнд-источник, работать с которым следует как с четырьмя отдельными 64-битовыми упакованными элементами данных (элементы данных размером со счетверенное слово (Q)), восемью отдельными 32-битовыми упакованными элементами данных (элементы данных размером со сдвоенное слово (D)), шестнадцатью отдельными 16-битовыми упакованными элементами данных (элементы данных размером в одно слово (W)) или тридцатью двумя отдельными 8-битовыми элементами данных (элементы данных размером в один байт (В)). Данные такого типа именуются данными упакованного типа (упакованными данными) или данными векторного типа (векторными данными), а операнды данных такого типа называются операндами упакованных данных или векторными операндами. Другими словами термином «объект упакованных данных» или «вектор» обозначают последовательность упакованных элементов, а операнды такого типа именуются операндами упакованных данных или векторными операндами. Другими словами, термин «упакованный объект данных» или «вектор» обозначает последовательность упакованных элементов данных; а операнд упакованных данных или векторный операнд является операндом-источником или операндом-адресатом для SIMD-команды (также называемой «команда для упакованных данных» или «векторная команда»).
Операция транспонирования является общеупотребительной элементарной операцией (примитивом) для векторного программного обеспечения. Хотя некоторые структуры наборов команд имеют команды для осуществления операции транспонирования, эти команды обычно производят перетасовку и перестановку, что требует дополнительных издержек, чтобы задать маски управления перетасовкой с использованием битов непосредственной адресации или с использованием отдельного векторного регистра, увеличивая тем самым нагрузку команд и увеличивая размеры. Кроме того, операции перетасовки в некоторых структурах наборов команд являются 128-битовыми операциями. В результате для осуществления операции полного транспонирования применительно к 256-битовому регистру или 512-битовому регистру (например) необходимо сочетание перетасовок и перестановок.
Программные приложения расходуют значительную долю времени на операции загрузки (LD) и сохранения (ST) в памяти, причем число операций загрузки обычно более чем вдвое превосходит число сохранений в памяти. Некоторые функции, требующие многочисленных операций загрузки и сохранения, почти не требуют вычислений - это, например, очистка памяти, копирование памяти, транспонирование; а другие используют незначительный объем вычислений - это например, вычисление скалярного произведения матриц, суммирование массивов и т.п. Каждая операция загрузки или операция сохранения требует использования ресурсов ядра (например, станций резервации (RS), буфера переупорядочения (ROB), буферов заполнения и т.п.).
Краткое описание чертежей
Настоящее изобретение иллюстрируется примером и не ограничивается прилагаемыми чертежами, на которых подобные позиционные обозначения присвоены аналогичным элементам и на которых:
фиг. 1 иллюстрирует пример выполнения команды транспонирования согласно одному из вариантов;
фиг. 2 иллюстрирует другой пример выполнения команды транспонирования согласно одному из вариантов;
фиг. 3 представляет логическую схему, иллюстрирующую пример операций транспонирования элементов данных в векторном регистре или в позиции памяти путем выполнения одной команды транспонирования согласно одному из вариантов;
фиг. 4 представляет блок-схему, иллюстрирующую пример варианта ядра с архитектурой выполнения команд по порядку и пример ядра архитектуры с выдачей/выполнением команд не по порядку и переименованием регистров, содержащего пример модуля сопроцессора кэша, выполняющего команды, которые были выгружены, чтобы их не выполнял исполнительный кластер процессорного ядра, согласно одному из вариантов;
фиг. 5 представляет блок-схему, иллюстрирующую пример операций для выполнения выгруженной команды согласно одному из вариантов;
фиг. 6А иллюстрирует пример формата команды AVX, содержащего префикс VEX, поле кода операции реального режима, байт Mod R/M, байт SIB, поле смещения и IMM8 согласно одному из вариантов;
фиг. 6В показывает, какие поля из представленных на фиг. 6А составляют поле полного кода операции и поле базовой операции согласно одному из вариантов;
фиг. 6С показывает, какие поля из представленных на фиг. 6А составляют поле индекса регистра согласно одному из вариантов;
фиг. 7А представляет блок-схему, иллюстрирующую обобщенный удобный для работы с векторами формат команд и шаблон команд класса А в этом формате согласно вариантам настоящего изобретения;
фиг. 7В представляет блок-схему, иллюстрирующую обобщенный удобный для работы с векторами формат команд и шаблон команд класса В в этом формате согласно вариантам настоящего изобретения;
фиг. 8А представляет блок-схему, иллюстрирующую пример специального удобного для работы с векторами формата команд согласно вариантам настоящего изобретения;
фиг. 8В представляет блок-схему, иллюстрирующую поля показанного на фиг. 8А конкретного удобного для работы с векторами формата команд, составляющие поле полного кода операции согласно одному из вариантов настоящего изобретения;
фиг. 8С представляет блок-схему, иллюстрирующую поля конкретного удобного для работы с векторами формата команд, составляющие поле индекса регистра согласно одному из вариантов настоящего изобретения;
фиг. 8D представляет блок-схему, иллюстрирующую поля конкретного удобного для работы с векторами формата команд, составляющие поле дополнительной операции согласно одному из вариантов настоящего изобретения;
фиг. 9 представляет блок-схему регистровой архитектуры согласно одному из вариантов настоящего изобретения;
фиг. 10А представляет блок-схему, иллюстрирующую пример конвейера, выполняющего команды по порядку, и пример конвейера с выдачей данных/выполнением команд не по порядку и переименованием регистров согласно вариантам настоящего изобретения;
фиг. 10В представляет блок-схему, иллюстрирующую пример варианта ядра с архитектурой выполнения команд по порядку и пример ядра архитектуры с выдачей данных/выполнением команд не по порядку и переименованием регистров для включения в состав процессора согласно вариантам настоящего изобретения;
фиг. 11А представляет блок-схему одного ядра процессора вместе с его соединением с выполненной на кристалле соединительной схемой и с его локальным подмножеством кэша Уровня 2 (L2) согласно вариантам настоящего изобретения;
фиг. 11В представляет расширенное изображение части ядра процессора, показанного на фиг. 11А, согласно вариантам настоящего изобретения;
фиг. 12 представляет блок-схему процессора, который может иметь больше одного ядра, может иметь встроенный контроллер памяти и может иметь встроенную графику согласно вариантам настоящего изобретения;
фиг. 13 представляет блок-схему системы согласно одному из вариантов настоящего изобретения;
фиг. 14 представляет блок-схему первого более конкретного примера системы согласно одному из вариантов настоящего изобретения;
фиг. 15 представляет блок-схему второго более конкретного примера системы согласно одному из вариантов настоящего изобретения;
фиг. 16 представляет блок-схему «системы на кристалле» (SoC) согласно одному из вариантов настоящего изобретения; и
фиг. 17 представляет блок-схему сравнения использования программного преобразователя команд с целью преобразования двоичных команд из состава исходного набора команд в двоичные команды из состава целевого набора команд согласно вариантам настоящего изобретения.
Осуществление
В последующем описании приведены многочисленные конкретные детали. Однако понятно, что варианты настоящего изобретения могут быть практически реализованы и без этих конкретных деталей. В других случаях хорошо известные схемы, структуры и способы не были показаны подробно, чтобы не затруднять понимание настоящего описания.
Ссылки в настоящем описании на «один вариант», «некоторый вариант», «пример варианта» и т.п. означают, что описываемый вариант может иметь конкретный признак, структуру или характеристику, но каждый вариант совсем не обязательно содержит этот конкретный признак, структуру или характеристику. Более того, такая фраза совсем не обязательно относится к тому же самому варианту. Далее, когда конкретный признак, структура или характеристика описывается в связи с каким-либо вариантом, предполагается, что у специалиста в рассматриваемой области достаточно знаний, чтобы применить их в других вариантах, независимо от того, описано такое применение в явном виде или нет.
Команда транспонирования
Как подробно описано ранее, операцию транспонирования элементов традиционно выполняли в виде сочетания операций перетасовки и перестановки, что требует дополнительных издержек задания масок управления перетасовкой с использованием самих ближайших битов или с использованием отдельного векторного регистра, что увеличивает нагрузку и размер команд.
Варианты команды транспонирования (Transpose) подробно рассмотрены ниже, равно как и варианты, систем, архитектур, форматов команд и т.п., которые могут быть использованы для выполнения такой команды. Команда транспонирования содержит операнд, определяющий векторный регистр или позицию в памяти. При выполнении команды транспонирования процессор сохраняет элементы данных, записанные в определенном векторном регистре или позиции памяти, в порядке, обратном первоначальному порядку. Например, наиболее значимый («самый старший») элемент данных становится наименее значимым («самым младшим») элементом данных, наименее значимый элемент данных становится наиболее значимым элементом данных и т.д.
В некоторых вариантах, если команда определяет позицию в памяти, эта команда дополнительно содержит операнд, указывающий число элементов.
В некоторых вариантах, как будет подробно описано позднее, команду транспонирования выгружают для выполнения в модуле сопроцессора кэша.
Один из примеров этой команды выглядит так "Transpose [PS/PD/B/W/D/Q] Vector_Register/Memory", где параметр Vector_Register указывает векторный регистр (такой как 128, 256 или 512-битовый регистр), а параметр Memory указывает позиции в памяти. Участок "PS" команды обозначает скалярную плавающую запятую (4 байта). Участок "PD" команды указывает плавающую запятую для двойного формата (8 байт). Участок "В" обозначает байт, независимо от атрибута размера операнда. Участок "W" команды обозначает слово, независимо от атрибута размера операнда. Участок "D" команды обозначает сдвоенное слово, независимо от атрибута размера операнда. Участок "Q" команды обозначает счетверенное слово, независимо от атрибута размера операнда.
Определенный векторный регистр или позиция памяти является и источником, и адресатом операции. В результате выполнения команды транспонирования элементы данных, находящиеся в определенном векторном регистре или позиции памяти, сохраняют в порядке, обратном первоначальному порядку, в этом же определенном векторном регистре или позиции памяти.
Другой пример этой команды выглядит так "Transpose [PS/PD/B/W/D/Q] Memory, Num_Elements", где параметр Memory обозначает позиции в памяти, а параметр Num_Elements обозначает число элементов. В одном из вариантов команду такого вида выгружают и выполняют в модуле сопроцессора кэша.
Фиг. 1 иллюстрирует пример выполнения команды транспонирования согласно одному из вариантов. Команда 100 транспонирования содержит операнд 105. Эта команда 100 транспонирования принадлежит к структуре набора команд, и каждое «появление» такой команды 100 в потоке команд должно содержать величины в операнде 105. В этом примере операнд 105 определяет векторный регистр (такой как 128-, 256- или 512-битовый регистр). В качестве такого векторного регистра показан регистр zmm с 16 32-битовыми элементами данных; однако здесь могут быть использованы и другие размеры элементов данных и регистров, например, регистры xmm или ymm с 16-битовыми или 64-битовыми элементами данных.
Содержимое регистра, определенное операндом 105 (zmml), представлено, как показано на чертеже, 16 элементами данных. Фиг. 1 иллюстрирует регистр zmml до выполнения команды 100 транспонирования и после выполнения этой команды 100. Перед выполнением команды 100 транспонирования элемент данных с индексом 0 в регистре zmml сохраняет величину А, элемент данных с индексом 1 в регистре zmml сохраняет величину В, и т.д., так что последний элемент данных с индексом 15 в регистре zmml сохраняет величину Р. Выполнение команды 100 транспонирования вызывает пересохранение элементов данных, находившихся в регистре zmml, в этом же регистре, но в обратном порядке. Таким образом, элемент данных с индексом 0 в регистре zmml сохраняет величину Ρ (которая раньше находилась под индексом 15 в регистре zmml), элемент данных с индексом 1 сохраняет величину О (которая раньше находилась под индексом 14), и т.д., так что элемент данных с индексом 15 сохраняет величину А (которая раньше находилась под индексом 0).
Фиг. 2 иллюстрирует другой пример выполнения команды транспонирования. Команда 200 транспонирования содержит операнд 205 и операнд 210. Операнд 205 определяет позицию в памяти (в которой в этом примере хранится массив данных), а операнд 210 указывает число элементов (которое в этом примере равно 16). Перед выполнением команды 200 транспонирования элемент данных с индексом 0 в массиве сохраняет величину А, элемент данных с индексом 1 в массиве сохраняет величину В и т.д., а последний элемент данных с индексом 15 в массиве сохраняет величину Р. Выполнение команды 200 транспонирования вызывает пересохранение элементов данных, находившихся в массиве, в этом же массиве, но в обратном порядке относительно первоначального порядка. Таким образом, элемент данных с индексом 0 в массиве сохраняет величину Ρ (которая раньше находилась в массиве под индексом 15), элемент данных с индексом 1 сохраняет величину О (которая раньше находилась под индексом 14), и т.д., так что элемент данных с индексом 15 сохраняет величину А (которая раньше находилась под индексом 0).
Фиг. 3 представляет логическую схему, иллюстрирующую пример операций для транспонирования элементов данных в векторном регистре или в позиции памяти при выполнении одной команды транспонирования согласно одному из вариантов. На операции 310 процессор выбирает команду транспонирования (например, посредством модуля выборки в составе процессора). Эта команда транспонирования содержит операнд, определяющий векторный регистр или позицию в памяти. Специфицированный векторный регистр или позиция в памяти содержит несколько элементов данных, которые нужно транспонировать. Векторный регистр может, например, представлять собой регистр zmm, имеющий 16 32-битовых элементов данных; однако здесь могут быть использованы и другие размеры элементов данных и регистров, например, регистры xmm или ymm с 16-битовыми или 64-битовыми элементами данных.
Процесс переходит от операции 310 к операции 315, где процессор декодирует команду транспонирования. Например, в некоторых вариантах, процессор содержит аппаратный декодирующий модуль, куда поступает команда (например, от модуля выборки в составе процессор). В качестве декодирующего модуля могут быть использованы самые разнообразные и хорошо известные декодирующие модули. Например, такой декодирующий модуль может декодировать команду транспонирования и превратить ее в одну широкую микрокоманду. В качестве другого примера декодирующий модуль может декодировать команду транспонирования и превратить ее в несколько широких микрокоманд. Еще в одном примере, особенно хорошо подходящем для конвейерных систем, выполняющих команды не по порядку, декодирующий модуль может декодировать команду транспонирования и превратить ее в одну или несколько микроопераций, где каждая такая микрооперация может быть выдана и выполнена не по порядку (с изменением очередности). Кроме того, декодирующий модуль может быть реализован в составе одного или нескольких декодеров, причем каждый декодер может быть выполнен в виде программируемой логической матрицы (PLA), как это хорошо известно в технике. В качестве примера, конкретный декодирующий модуль может содержать: 1) управляющую логическую схему, направляющую различные макрокоманды в разные декодеры; 2) первый декодер, который может декодировать подмножество набора команд (но больше, чем это может делать каждый из второго, третьего и четвертого декодеров) и генерировать две микрооперации за один раз; 3) второй, третий и четвертый декодеры, каждый из которых может декодировать только подмножество всего набора команд и генерировать только одну микрооперацию за один раз; 4) ROM коммутатора микрокоманд, которое может декодировать только подмножество всего набора команд и генерировать четыре микрооперации за один раз; и 5) мультиплексорную логическую схему, получающую на входы микрокоманды от декодеров и от ROM коммутатора микрокоманд и определяющую, выходную команду какого из этих модулей поставить в очередь микроопераций. Другие варианты декодирующего модуля могут содержать больше или меньше декодеров, способных декодировать больше или меньше команд и подмножеств команд. Например, один вариант может содержать второй, третий и четвертый декодеры, каждый из которых может генерировать по две микрооперации за один раз; и может содержать ROM коммутатора микрокоманд, которое генерирует по восемь микроопераций за один раз.
Далее процедура переходит к операции 320, в ходе которой процессор выполняет команду транспонирования, вызывающую сохранение элементов данных, находящихся в некотором порядке в определенном векторном регистре или позиции памяти, в этом же определенном регистре или позиции памяти, но в порядке, обратном первоначальному порядку.
Команду транспонирования может автоматически генерировать компилятор, либо ее может закодировать вручную разработчик программного обеспечения. Выполнение описанной здесь команды транспонирования улучшает программируемость структуры набора команд и уменьшает число команд, снижая тем самым потребление энергии в ядре. Кроме того, выполнение команды транспонирования происходит, не требуя создания временного буфера для сохранения транспонированных элементов в памяти, в отличие от традиционных способов выполнения операции транспонирования, что уменьшает требования к размеру памяти. Кроме того, выполнение одной команды транспонирования проще, чем выполнение сложного набора перетасовок и перестановок, который раньше требовался для осуществления операций транспонирования.
Выгрузка команд для выполнения модулем сопроцессора кэша
Как подробно описано ранее, программные приложения могут содержать функции, обычно требующие выполнения некоторого числа операций загрузки и/или сохранения между исполнительным кластером процессорного ядра и модулем памяти (кэшем и памятью) компьютерной системы. Некоторые из этих функций почти не требуют вычислений, но могут потребовать большого числа операций загрузки и/или сохранения, таких как очистка памяти, копирование памяти и транспонирование. Другие функции, такие как вычисление скалярного произведения матриц и суммирование массивов требуют небольшого объема вычислений, но также могут потребовать большого числа операций загрузки и/или сохранения. Например, для выполнения операции транспонирования массива памяти этот массив памяти следует загрузить в регистр, ядро обратит порядок следования величин, после чего эти величины снова сохраняют в массиве памяти (эти этапы может потребоваться повторить несколько раз прежде, чем будет транспонирован весь массив памяти).
Варианты настоящего изобретения описывают модуль процессора кэша, выполняющий команды, выгруженные, чтобы не выполнять их посредством исполнительного кластера компьютерной системы. Например, некоторые функции управления памятью (такие как очистка памяти, копирование памяти, транспонирование и т.п.) выгружают, чтобы их не выполнял исполнительный кластер компьютерной системы, и выполняют непосредственно в модуле сопроцессора кэша (который может содержать данные, над которыми производятся операции). В качестве другого примера, команды, которые требуют проведения постоянной вычислительной операции в непрерывной области массива кэша в модуле сопроцессора кэша, могут быть выгружены в этот модуль сопроцессора кэша и выполнены им (например, скалярное произведение матриц, суммирование массивов и т.п.). Выгрузка этих команд в модуль сопроцессора кэша уменьшает число операций загрузки и сохранения между модулем процессора кэша и исполнительным кластером компьютерной системы, что уменьшает число команд, освобождает ресурсы исполнительного кластера (например, станций резервации (RS), буфера переупорядочения (ROB), буферов заполнения и т.п.), и тем самым позволяет исполнительному кластеру использовать эти ресурсы для выполнения других команд.
Фиг. 4 представляет блок-схему, иллюстрирующую пример варианта ядра с архитектурой выполнения команд по порядку и пример ядра архитектуры с выдачей/выполнением команд не по порядку и переименованием регистров, содержащего пример модуля сопроцессора кэша, выполняющего команды, которые были выгружены, чтобы их не выполнял исполнительный кластер процессорного ядра, согласно одному из вариантов. Прямоугольниками из сплошных линий на фиг. 4 обозначены компоненты конвейера с выполнением команд по порядку и ядра с выполнением команд по порядку, тогда как добавленные в качестве компоненты в прямоугольниках из штриховых линий обозначают компоненты конвейера и ядра архитектуры с выдачей/выполнением команд не по порядку и переименованием регистров. Поскольку аспект выполнения команд по порядку являются частью аспекта с выполнением команд не по порядку, далее будет описан аспект с выполнением команд не по порядку.
Как показано на фиг. 4, процессорное ядро 400 содержит модуль 410 ввода, соединенный с исполнительным модулем 415, который соединен с модулем 470 сопроцессора кэша. Процессорное ядро 400 может представлять собой компьютерное ядро с уменьшенным набором команд (RISC), ядро со сложным набором команд (CISC), ядро с очень длинным командным словом (VLIW), либо ядро гибридного или альтернативного типа. Еще в одном варианте ядро 400 может представлять собой ядро специального назначения, такое как, например, сетевое ядро или ядро связи, автомат сжатия, сопроцессорное ядро, ядро графического процессора общего назначения (GPGPU), графическое ядро или другое подобное ядро.
Входной модуль 410 содержит модуль 420 выборки команд, соединенный с декодирующим модулем 425. Этот декодирующий модуль 425 (или декодер) конфигурирован для декодирования команд и генерации на выходе одной или нескольких микроопераций, точек ввода микрокодов, микрокоманд, других команд или других сигналов управления, которые декодированы на основе, или как-то иначе отражают или выведены из исходных команд. Такой декодирующий модуль 425 может быть реализован с использованием разнообразных механизмов. К примерам подходящих механизмов относятся, не ограничиваясь этим, просмотровые таблицы, аппаратные реализации, программируемые логические матрицы (PLA), ROM микрокодов и т.п. В одном из вариантов, ядро 400 содержит ROM микрокодов или другой носитель, сохраняющий микрокоды для определенных макрокоманд (например, в декодирующем модуле 425 или, в ином случае, в модуле 410 ввода). Указанный декодирующий модуль 425 соединен с модулем 435 переименования/назначения в составе исполнительного модуля 415. Хотя на фиг. 1 это не показано, модуль 410 ввода может также содержать модуль прогнозирования ветвления, соединенный с модулем кэша команд, который в свою очередь соединен с буфером ассоциативной трансляции (TLB), связанным с модулем выборки команд 420.
Декодирующий модуль 425 также конфигурирован для определения, следует ли выгрузить какую-либо команду в модуль 470 сопроцессора кэша. В одном из вариантов, решение о выгрузке команды в модуль 470 сопроцессора кэша принимается динамически (во время выполнения программы) и зависит от архитектуры. Например, в одном из вариантов команда может быть выгружена, если ее длина в памяти больше длины кэш-линии (например, 64 байта) и если она кратна длине кэш-линии. В другом варианте решение о выгрузке команды в модуль 470 сопроцессора кэша может быть принято независимо от длины этой команды в памяти, а в зависимости от эффективности модуля 470 сопроцессора кэша.
В другом варианте при принятии решения о выгрузке команды в модуль 470 сопроцессора кэша может также учитываться сама команда. Иными словами, некоторые команды могут быть специально предназначены для выгрузки в модуль 470 сопроцессора кэша или по меньшей мере могут быть (допускают) выгружены в этот модуль 470 сопроцессора кэша. В качестве примера, такая команда может быть сформирована компьютером или написана разработчиком программного обеспечения на основе того, что такую команду было бы более эффективно выгрузить в модуль сопроцессора кэша.
Указанный исполнительный модуль 415 содержит модуль 435 переименования/назначения, соединенный с модулем 450 выбытия и группой из одного или более модулей планировщиков 440. Модули 440 планировщики представляют собой любое число различных планировщиков, включая станции резервации, центральное командное окно и т.п. Модули 440 планировщиков соединены с модулями 445 физических регистровых файлов. Каждый из этих модулей 445 физических регистровых файлов представляет один или более физических регистровых файлов, так что разные файлы сохраняют один или более различных типов данных, такие как скалярные целочисленные данные, скалярные данные с плавающей запятой, упакованные целочисленные данные, упакованные данные с плавающей запятой, векторные целочисленные данные, векторные данные с плавающей запятой, данные состояния (например, указатель команды, представляющий собой адрес следующей команды, которую нужно выполнить) и т.п. В одном из вариантов, модуль 445 физических регистровых файлов содержит модуль векторных регистров, модуль регистров масок записи и модуль скалярных регистров. Эти регистровые модули могут предоставлять архитектурные векторные регистры, регистры векторных масок и регистры общего назначения. На модули 445 физических регистровых файлов наложен модуль 450 выбытия для иллюстрации различных способов, которыми может быть реализовано переименование регистров и выполнение команд не по порядку (например, с использованием буфера(ов) переупорядочения и регистровых файлов выбытия; с использованием будущих файлов, буфера(ов) предыстории и регистровых файлов выбытия; с использованием карт регистров и пула регистров; и т.п.). Указанные модуль 450 выбытия и модули 445 физических регистровых файлов соединены с исполнительным кластером(ами) 455.
Исполнительный кластер(ы) 455 содержит группу из одного или более исполнительных модулей 460 и группу модулей 465 доступа к памяти. Исполнительные модули 455 могут осуществлять различные вычислительные операции (например, сдвиги, суммирование, вычитание, умножение) и над различными типами данных (например, скалярными данными с плавающей запятой, упакованными целочисленными данными, упакованными данными с плавающей запятой, векторными целочисленными данными, векторными данными с плавающей запятой). Модули 440 планировщиков, модули 445 физических регистровых файлов и исполнительные кластеры 455 показаны как, возможно, по несколько штук, поскольку в некоторых вариантах создают отдельные конвейеры для некоторых типов данных/операций (например, конвейер для скалярных целочисленных данных, конвейер для скалярных данных с плавающей запятой/упакованных целочисленных данных/упакованных данных с плавающей запятой/векторных целочисленных данных/векторных данных с плавающей запятой и/или конвейер доступа к памяти, так что каждый конвейер имеет свой собственный модуль планировщика, модуль физических регистровых файлов и/или исполнительный кластер - и в случае отдельного конвейера доступа к памяти реализованы некоторые варианты, в которых только исполнительный кластер этого конвейера имеет модули 465 доступа к памяти). Следует понимать, что при использовании раздельных конвейеров один или более из этих конвейеров могут использовать выдачу/выполнение не по порядку очередности, а остальные - в порядке очередности.
Группа модулей 465 доступа к памяти соединена с модулем 470 сопроцессора кэша. В одном из вариантов модуль 465 доступа к памяти содержит модуль 484 загрузки, модуль 486 адресов сохранения, модуль 488 сохранения данных и группу из одного или более модулей 490 выгрузки команд, осуществляющих выгрузку команд в модуль 470 сопроцессора кэша. Указанный модуль 484 загрузки выдает операции доступа для загрузки (которые могут иметь форму микроопераций загрузки) в модуль процессора кэша 470. Например, модуль 484 загрузки указывает адрес данных, которые нужно загрузить. Для выполнения операций сохранения используют модуль 486 адресов сохранения и модуль 488 сохранения данных. Здесь модуль 486 адресов сохранения задает адрес, а модуль 488 сохранения данных указывает данные, которые нужно записать в память. В некоторых вариантах, модули загрузки и модули адресов сохранения могут быть использованы либо в качестве модулей загрузки, либо в качестве модулей адресов сохранения.
Как описано ранее, программные приложения могут тратить значительное количество времени и ресурсов на выполнение операций загрузки и сохранения. Например, многие команды, такие как очистка памяти, копирование памяти и транспонирование, обычно требуют выполнения множества команд загрузки, вычисления и сохранения в исполнительных модулях исполнительного кластера ядра. Например, команду загрузки выдают для загрузки данных в регистр(ы), осуществляют вычисление и выдают команду сохранения, чтобы записать полученные в результате данные. Для полного выполнения команды могут потребоваться несколько итеративных циклов этих операций. Операции загрузки и сохранения также используют ширину полосы кэша и памяти, равно как и другие ресурсы ядра (например, станций RS, буфера ROB, буферов заполнения и т.п.).
Модуль(и) 490 выгрузки команд выдает команду(ы) в модуль 470 сопроцессора кэша с целью перенести («выгрузить») выполнение некоторых команд в модуль 470 сопроцессора кэша. Например, выполнение команд, которые обычно требуют значительного числа операций загрузки и/или сохранения, но при этом требуют незначительного (или вообще нулевого) объема вычислений, могут быть выгружены для выполнения прямо в модуль 470 сопроцессора кэша, чтобы уменьшить число операций загрузки и сохранения, которые в противном случае пришлось бы осуществить. Например, функция очистки памяти, функция копирования памяти и функция транспонирования обычно требуют выполнения большого числа операций загрузки и сохранения, но при этом связаны с незначительным (или даже нулевым) объемом вычислений. В одном из вариантов, выполнение этих функций может быть выгружено в модуль 470 сопроцессора кэша. В качестве другого примера в модуль 470 сопроцессора кэша могут быть для выполнения выгружены команды, для которых требуется постоянно выполнять одну и ту же операцию вычисления в непрерывной области данных. Примерами таких команд являются осуществление функций, таких как вычисление скалярного произведения матриц, вычисление суммы массивов и т.п.
Рассматриваемый модуль 470 сопроцессора кэша осуществляет операции с кэшем (например, кэш L1, кэш L2) для ядра 400 и обрабатывает выгруженные команды. Таким образом, модуль 470 сопроцессора кэша обрабатывает обращения для загрузки и обращения для сохранения аналогично тому, как это делает обычный модуль кэша, а также обрабатывает выгруженные команды. Декодирующий модуль 474 в составе модуля 470 сопроцессора кэша содержит логическую схему для декодирования выгруженных команд, а также запросов загрузки, адресов сохранения и запросов на сохранение данных. В одном из вариантов для декодирования каждого запроса используется отдельная управляющая проводная линия между каждым из модулей доступа к памяти и модулем 470 сопроцессора кэша. В другом варианте для уменьшения числа проводных линий используют группу из одного или более управляющих проводов между модулями 465 доступа к памяти и декодирующим модулем 474, управляемым одним или более мультиплексорами.
После декодирования запрошенной операции(й) операционные модули 472 из состава модуля 470 сопроцессора кэша выполняют эти операции. Например, операционный модуль(и) 472 содержит логическую схему для записи данных в массив 482 кэша (для операций сохранения) и считывания данных из массива 482 кэша (для операций загрузки), равно как из любых требуемых буферов. Например, если принят запрос загрузки, операционный модуль(и) 472 обращается в массив кэша по запрошенному адресу и выдает данные (в предположении, что эти данные находились в массиве 482 кэша). В качестве другого примера, если принят запрос сохранения, операционный модуль(и) 472 записывает запрошенные данные по запрашиваемому адресу.
Декодирующий модуль 474 определяет, какие операции должны быть произведены для выполнения выгруженной команды. В качестве примера, в варианте, где выгруженная команда является по существу невычислительной (например, очистка памяти, копирование памяти, транспонирование или другая функция, трансформирующая данные, не требуя вычислений), этот декодирующий модуль 474 определяет число операций загрузки и/или сохранения, которые должны осуществить операционные модули 472 для выполнения команды. Например, если принята команда очистки памяти, декодирующий модуль 474 может управлять операционными модулями 472 для осуществления некоторого числа операций сохранения (в зависимости от длины области памяти, которую нужно очистить) в массиве 482 кэша с целью приравнять запрошенные данные нулю (или другой величине). Таким образом, например, в модуль 470 сопроцессора кэша может быть выгружена только одна команда для осуществления этим модулем функции очистки памяти, не требуя, чтобы модули 465 доступа к памяти (модуль 486 адресов сохранения и модуль 488 сохранения данных) выдали множество запросов сохранения для завершения функции очистки памяти.
Операционные модули 472 при выполнении этих операций используют модуль 473 управления. Например, модуль 476 управления циклами в составе модуля 473 управления осуществляет управление циклами в массиве 482 кэша для выполнения операций, требующих циклов. В качестве примера, если декодирована команда очистки памяти, модуль 476 управления циклами осуществляет циклические проходы через массив 482 кэша несколько раз (в зависимости от размеров области памяти, которую нужно очистить), а операционные модули 472 очищают массив 482 соответственно. В одном из вариантов работа операционных модулей 472 ограничена обработкой в пределах размера кэш-линии и границы.
Модуль 473 управления содержит также модуль 478 блокирования кэша, осуществляющий блокирование области массива 482 кэша, обрабатываемой в текущий момент операционными модулями 472. Попадание в заблокированную область массива 482 кэша вызывает остановку попавшего в кэш процесса.
Модуль 473 управления содержит также модуль 480 контроля ошибок, предназначенный для сообщения об ошибках. Например, об ошибке, относящейся к обработке выгруженной команды, сообщают назад, в модуль 490 выгрузки команд, выдавший команду, которая привела либо к сбою выполнения команды, либо к записи кода ошибки в управляющем регистре. В одном из вариантов модуль 480 контроля ошибок сообщает об ошибке в модуль 490 выгрузки команд, выдавший выгруженную команду, когда в массиве 482 кэша нет данных. В одном из вариантов модуль 480 контроля ошибок сообщает об ошибке в модуль 490 выгрузки команд, выдавший выгруженную команду, когда имеет место состояние переполнения или недостаточного заполнения.
Хотя на фиг. 4 это не показано, модуль 470 сопроцессора кэша может быть также соединен с буфером ассоциативной трансляции (буфером преобразования адресов). Кроме того, модуль 470 сопроцессора кэша может быть соединен с кэшем уровня 2 и/или с основной памятью. Далее, модуль 473 управления может также содержать логическую схему слежения, контролирующую адресные шины для доступа к позициям памяти, которые были кэширование в массиве 482 кэша.
В некоторых вариантах выгруженные команды требуют вычислений (например, сдвига, суммирования, вычитания, умножения, деления). Например, вычислений требуют такие функции, как определение скалярного произведения матриц или суммирование массивов. В вариантах, где выгружаемые команды требуют вычислений, в одном из вариантов среди операционных модулей 472 присутствуют исполнительные модули (например, арифметическо-логические модули, модули для осуществления операций с плавающей запятой) для выполнения этих операций.
На фиг. 4 показано, что модуль 470 сопроцессора кэша реализован в кэше уровня 1. Однако в других вариантах этот модуль сопроцессора кэша может быть реализован в кэше другого уровня (например, в кэше уровня 2 или во внешнем кэше).
В одном из вариантов модуль 470 сопроцессора кэша реализован в виде дублирующей копии кэша уровня 1, где контент считывают из кэша уровня 1, блокируют, и вносят изменения в дублирующую копию. После завершения операций кэш-линии в кэше уровня 1 делают недействительными и разблокируют, а дублирующая копия имеет действительные данные.
В одном из вариантов выгруженная команда будет выдана, только если данные для этой команды уже находятся в кэше. В таком варианте приложение, генерирующее команду, обеспечивает наличие данных в кэше. В одном из вариантов ошибки кэш обрабатывают аналогично обычным, регулярным ошибки кэш. Например, после ошибки кэш обращаются в кэш следующего уровня или в основную память для доступа к нужным данным.
На фиг. 5 представлена логическая схема, иллюстрирующая пример операций для выполнения выгруженной команды согласно одному из вариантов. Схема на фиг. 5 будет рассмотрена со ссылками на пример архитектуры, показанный на фиг. 4. Однако следует понимать, что операции, представленные на фиг. 5, могут быть выполнены в вариантах, отличных от варианта, рассмотренного в связи с фиг. 4, а варианты, обсуждавшиеся в связи с фиг. 4, могут выполнять операции, отличные от операций, обсуждаемых со ссылками на фиг. 5.
На операции 510 происходит выборка команды. Эту выборку команды осуществляет, например, модуль 420 выборки команд. Затем процедура переходит к операции 515, на которой декодирующий модуль 425 из состава модуля 410 ввода декодирует команду и принимает решение, что ее следует выгрузить для выполнения в модуль 470 сопроцессора кэша. Например, команда может быть такого типа, какой специально предназначен для выгрузки в модуль 470 сопроцессора кэша. В качестве другого примера, рассматриваемая команда может допускать выгрузку, а ее длина в памяти может быть больше размера кэш-линии.
Затем процедура переходит к операции 520, на которой декодированную команду выдают в модуль 470 сопроцессора кэша. Например, команду в модуль 470 сопроцессора кэша выдают модули 490 выгрузки команд. Далее процедура переходит к операции 525, на которой декодирующий модуль 474 из состава модуля 470 сопроцессора кэша декодирует выгруженную команду. После этого процедура переходит к операции 530, и операционные модули 472 выполняют эту команду, как было описано раньше.
В одном из вариантов команду для каждой функции, которая должна быть выгружена, формулируют таким образом, чтобы она могла быть выдана в модуль 470 сопроцессора кэша для обработки. В качестве конкретного примера, команда транспонирования может быть выгружена и выполнена модулем 470 сопроцессора кэша. Например, команда транспонирования может иметь вид "TransposeO [PS/PD/B/W/D/Q] Memory, Num_Elements", где параметр Memory обозначает позицию в памяти, а параметр Num_Elements обозначает число элементов в этой позиции памяти. Эта команда транспонирования аналогична команде транспонирования, описанной ранее; однако код операции для этой команды "TransposeO" обозначает, что эта команда транспонирования подлежит выгрузке.
После обнаружения этой команды декодирующий модуль 425 определяет, что она должна быть выгружена в модуль 470 сопроцессора кэша, как было описано ранее. Соответственно, модуль 490 выгрузки команд выдает команду в модуль 470 процессора кэша вместе с передаваемыми в модуль 470 сопроцессора кэша начальным адресом в памяти и длиной команды (в одном из вариантов модуль адресов сохранения передает начальный адрес в памяти и длину в виде, упакованном в полезную нагрузку, от модуля 470 сопроцессора кэша).
Декодирующий модуль 474 декодирует команду и инициирует выполнение соответствующих операций посредством операционных модулей 472. Например, операционные модули 472 начинают с загрузки первой и последней кэш-линий из позиции памяти, указанной начальным адресом в памяти, в массив 482 кэша, осуществляют свопинг этих двух кэш-линий и затем переходят в направлении внутрь, пока не выберут всю длину из памяти. Таким образом, единственная команда транспонирования, выполняемая сразу модулем 470 сопроцессора кэша, уменьшает число команд загрузки и сохранения между исполнительным кластером и модулем сопроцессора кэша, равно как и сберегает ресурсы исполнительного модуля 415, которые могут быть использованы для выполнения других команд.
Выгрузка команд для выполнения их посредством модуля сопроцессора кэша позволяет более не выполнять относительно простые задания, связанные с памятью, (например) посредством исполнительных модулей процессорного ядра, тем самым уменьшая число команд и сберегая затраты энергии в ядре, уменьшая степень использования буферов и улучшая характеристики за счет уменьшения размеров кода и упрощения программирования. Таким образом, с точки зрения модуля 410 ввода и исполнительного модуля 415 можно выгрузить и выполнить посредством модуля 470 сопроцессора кэша единственную команду вместо выполнения длинной цепочки команд. Это позволяет исполнительному модулю 415 использовать свои ресурсы для решения более сложных вычислительных задач, сберегая тем самым ресурсы ядра, затраты энергии в ядре и улучшая характеристики.
Примеры форматов команд
Описанные здесь варианты команд могут быть реализованы в различных форматах. Примеры систем, архитектур и конвейеров будут подробно рассмотрены ниже. Различные варианты команд можно выполнять в системах, архитектурах и конвейерах подобного типа, не ограничиваясь только теми, которые будут подробно описаны здесь. В одном из вариантов такие примеры систем, архитектур и конвейеров, подробно обсуждаемые ниже, можно использовать для выполнения команд, которые не выгружены в модуль сопроцессора кэша, описанный выше.
Формат VEX команды
Кодирование в формате VEX дает возможность командам иметь больше двух операндов и позволяет векторным регистрам SIMD быть длиннее 128 бит. Использование префикса VEX дает синтаксис с тремя операндами (или более). Например, предшествующие команды с двумя операндами позволяли осуществлять операции типа А = А + В, где результат записывают на место операнда источника. Использование префикса VEX позволяет операндам выполнять неразрушающие операции, такие как А = В + С.
Фиг. 6А иллюстрирует пример формата AVX команды, содержащего поле 602 префикса VEX, поле 630 действительного кода операции, байт 640 Mod R/M, байт 650 SIB 650, поле 662 смещения и параметр 672 IMM8. Фиг. 6В иллюстрирует, какие поля из изображенных на фиг. 6А, составляют поле 664 полного кода операции и поле 642 базовой операции. Фиг. 6С иллюстрирует, какие поля из изображенных на фиг. 6А, составляют поле 644 индекса регистра.
Префикс 602 VEX (байты 0-2) кодирован в виде трех байтов. Первый байт является полем 640 формата (VEX байт 0, биты [7:0]), содержащим величину явного байта С4 (уникальная величина, используемая, чтобы отличать формат С4 команд). Второй и третий байты (VEX байты 1-2) содержат ряд битовых полей, предоставляющих специальные возможности. В частности, поле 605 REX (VEX байт 1, биты [7-5]) содержит битовое поле VEX.R (VEX байт 1, бит [7] - R), битовое поле VEX.X (VEX байт 1, бит [6] - X) и битовое поле VEX.B (VEX байт 1, бит [5] - В). Другие поля команд кодируют три младших бита регистровых индексов, как это известно в технике (rrr, ххх и bbb), так что Rrrr, Хххх и Bbbb могут быть получены путем добавления VEX.R, VEX.X и VEX.B. Поле 615 отображения кода операции (VEX байт 1, биты [4:0] - mmmmm) содержит контент для кодирования первого байта операционного кода в неявном виде. Поле 664 W (VEX байт 2, бит [7] - W) - представлено обозначением VEX.vvvv и описывает различные функции, зависящие от команды. Роль поля 620 VEX.vvvv (VEX байт 2, биты [6:3]-vvvv) может быть следующей: 1) VEX.vvvv кодирует первый регистровый операнд-источник, заданный в инвертированной (1s дополнение или дополнение до 1) форме и действительный для команд с 2 или более операндами-источниками; 2) VEX.vvvv кодирует регистровый операнд-адресат, определенный в форме дополнения до 1 для некоторых векторных сдвигов; или 3) VEX.vvvv не кодирует ни один операнд, поле зарезервировано и должно содержать 1111b. Если поле 668 размера VEX.L (VEX байт 2, бит [2]-L) = 0, это означает 128-битовый вектор; если VEX.L = 1, это означает 256-битовый вектор. Поле 625 кодирования префикса (VEX байт 2, бит [1:0]-рр) предоставляет дополнительные биты для поля базовой операции.
Поле 630 действительного кода операции (байт 3) известно также под названием байта кода операции. В этом поле определена часть кода операции.
Поле 640 MOD R/M (байт 4) содержит поле 642 MOD (биты [7-6]), поле 644 Reg (биты [5-3]) и поле 646 R/M (биты [2-0]). Роль поля 644 Reg может состоять в следующем: кодирование либо регистрового операнда-адресата, либо регистрового операнда-источника (rrr или Rrrr), или это поле нужно рассматривать как расширение кода операции и не следует использовать для кодирования какого-либо операнда команды. Роль поля 646 R/M может состоять в следующем: кодирование операнда команды, указывающего адрес в памяти, или кодирование либо регистрового операнда-адресата, либо регистрового операнда-источника.
Масштаб, Индекс, База (Scale, Index, Base (SIB)) - Поле 650 Масштаб Scale (байт 5) содержит параметр SS652 (биты [7-6]), который используется для генерирования адресов памяти. Содержание полей 654 SIB.xxx (биты [5-3]) и 656 SIB.bbb (биты [2-0]) было предварительно соотнесено с регистровыми индексами Хххх и Bbbb.
Поле 662 смещения 662 и поле 672 непосредственной адресации (IMM8) содержат адресные данные.
Пример кодирования в VEX
Обобщенный удобный для работы с векторами формат команд
Удобный для работы с векторами формат команд представляет собой формат команд, приспособленный для векторных команд (например, имеются определенные поля, определенные для векторных операций). Хотя в описанных здесь вариантах и векторные операции, и скалярные операции поддерживаются посредством указанного удобного для работы с векторами формата команд, альтернативные варианты используют только векторные операции этого удобного для работы с векторами формата команд.
Фиг. 7А-7В представляют блок-схемы, иллюстрирующие обобщенный удобный для работы с векторами формат команд шаблоны команд в этом формате согласно вариантам настоящего изобретения. Фиг. 7А представляет блок-схему, иллюстрирующую обобщенный удобный для работы с векторами формат команд и шаблоны команд класса А в этом формате согласно вариантам настоящего изобретения; тогда как фиг. 7В показывает блок-схему, иллюстрирующую обобщенный удобный для работы с векторами формат команд и шаблоны команд класса В в этом формате согласно вариантам настоящего изобретения. В частности, показан обобщенный удобный для работы с векторами формат 700 команд, для которого определены шаблоны команд класса А и класса В, так что обе группы шаблонов содержат шаблоны 705 команд без доступа к памяти и шаблоны 720 команд с доступом к памяти. Термин «обобщенный» в контексте рассматриваемого удобного для работы с векторами формата команд означает, что этот формат команд не привязан к какому-либо конкретному формату команд.
Тогда как здесь будут описаны варианты настоящего изобретения, в которых упомянутый удобный для работы с векторами формат команд поддерживает следующее: длину (или размер) векторного операнда 64 байт с шириной (или размером) элемента данных 32 бит (4 байта) или 64 бит (8 байт) (и, таким образом, вектор размером 64 байт содержит либо 16 элементов в размере двойного слова, либо, в качестве альтернативы, 8 элементов в размере учетверенного слова); длину (или размер) векторного операнда 64 байт с шириной (или размером) элемента данных 16 бит (2 байт) или 8 бит (1 байт); длину (или размер) векторного операнда 32 байт с шириной (или размером) элемента данных 32 бит (4 байт), 64 бит (8 байт), 16 бит (2 байт) или 8 бит (1 байт); и длину (или размер) векторного операнда 16 байт с шириной (или размером) элемента данных 32 бит (4 байт), 64 бит (8 байт), 16 бит (2 байт) или 8 бит (1 байт); альтернативные варианты могут поддерживать больше, меньше или другие размеры векторных операндов (например, векторные операнды размером 256 байт) с большей, меньшей или другой шириной элементов данных (например, ширина элемента данных 128 бит (16 байт)).
Шаблоны команд класса А, показанные на фиг. 7А, содержат: 1) в совокупность шаблонов 705 команд без доступа к памяти входят шаблоны 710 команд для операций управления с полным округлением и без доступа к памяти и шаблоны 715 команд для преобразования данных без доступа к памяти; и 2) в совокупность шаблонов 720 команд с доступом к памяти входят шаблоны 725 временных команд с доступом к памяти и шаблоны 730 не временных команд с доступом к памяти. Шаблоны команд класса В, показанные на фиг. 7 В, содержат: 1) в совокупность шаблонов 705 команд без доступа к памяти входят шаблоны 712 команд для операций управления с частичным округлением, управлением маской записи и без доступа к памяти и шаблоны 717 команд для операций vsize-типа (с переменным размером), управлением маской записи и без доступа к памяти; и 2) в совокупность шаблонов 720 команд с доступом к памяти входят шаблоны 727 команд управления маской записи и с доступом к памяти.
Обобщенный удобный для работы с векторами формат 700 команд содержит следующие поля, перечисленные ниже в порядке, показанном на фиг. 7А-7В.
Поле 740 формата - конкретная величина (величина идентификатора формата команды) в этом поле однозначно идентифицирует удобный для работы с векторами формат команд, и, таким образом, появление команд, имеющих этот в удобный для работы с векторами формат команд, в потоке команд. Поэтому указанное поле является опцией в том смысле, что оно не требуется при работе с наборами команд, имеющими только рассматриваемый обобщенный удобный для работы с векторами формат команд.
Поле 742 базовой операции - его содержание различает различные базовые операции.
Поле 744 индекса регистра - его содержание, непосредственно, или через генерирование адреса определяет местонахождение операнда-источника и операнда-адресата, будь они в регистрах или в памяти. Это поле содержит достаточное число битов, чтобы выбрать N регистров из регистрового файла размером P×Q (например, 32×512, 16×128, 32×1024, 64×1024). Хотя в одном из вариантов в эти N регистров могут входить до трех регистров-источников и один регистр-адресат, альтернативные варианты могут поддерживать большее или меньшее число регистров-источников и регистров-адресатов (например, могут поддерживать до двух источников, причем один из этих источников служит также адресатом, могут поддерживать до трех источников, причем один из этих источников служит также адресатом, могут поддерживать до двух источников и одного адресата).
Поле 746 модификатора - его содержание отличает появление команд в обобщенном формате векторных команд, определяющих доступ к памяти, от команд, которые этого не делают; иными словами, отличает шаблоны 705 команд без доступа к памяти от шаблонов 720 команд с доступом к памяти. Операции доступа к памяти осуществляют чтение и/или запись в иерархическую структуру памяти (в некоторых случаях указывают адреса источника и/или адресата с использованием величин, находящихся в регистрах), тогда как операции без доступа к памяти этого не делают (например, источник и адресаты являются регистрами). Тогда как в одном из вариантов это поле также выбирает между тремя разными способами вычислений адресов в памяти, альтернативные варианты могут поддерживать больше, меньше или другие способы вычисления адресов в памяти.
Поле 750 дополнительной операции - его содержание указывает, какую из множества разных операций следует выполнить в дополнение к базовой операции. Это поле зависит от контекста. В одном из вариантов настоящего изобретения это поле разделено на поле 768 класса, поле 752 альфа и поле 754 бета. Это поле 750 дополнительной операции позволяет выполнять общую группу операций в одной команде, а не в 2, 3 или 4 командах.
Поле 760 масштаба - его содержание позволяет масштабировать содержание поля индекса для генерирования адреса в памяти (например, для генерирования адреса по формуле 2масштаб · индекс + база (2scale · index + base)).
Поле 762А смещения - его содержание используется как часть генерирования адреса в памяти (например, для генерации адреса в памяти с использованием формулы 2масштаб · индекс + база + смещение (2scale · index + base + displacement)).
Поле 762В фактора смещения (отметим, что наложение поля 762А смещения непосредственно на поле 762В фактора смещения указывает, что используется одно или другое из этих полей) - его содержание используется как часть процедуры генерирования адреса; это поле задает фактор смещения, который должен быть масштабирован по размеру единицы доступа к памяти (N) - где N обозначает число байтов в единице данных при доступе к памяти (например, для генерирования адреса в памяти с использованием формулы 2масштаб · индекс + база + масштабированное смещение (2scale · index + base + scaled displacement)). Избыточные младшие биты игнорируются, так что содержание поля фактора смещения умножают на полный размер (N) операндов в памяти для генерирования окончательного смещения, которое должно быть использовано при вычислении эффективного адреса. Величину N определяет аппаратура процессора во время выполнения программы на основе поля 774 полного кода операции (будет здесь описано позднее) и поля 754С манипуляции данными. Поле 762А смещения и поле 762В фактора смещения являются опциями в том смысле, что эти поля не используются в шаблонах 705 команд без доступа к памяти и/или в других вариантах могут применяться только одно из этих двух полей или ни одного.
Поле 764 ширины элемента данных - его содержание указывает, какое из множества возможных значений ширины элементов данных следует использовать (в некоторых вариантах - для всех команд; в других вариантах - только для некоторых команд). Это поле является опцией в том смысле, что оно не требуется, если поддерживается только одно значение ширины элементов данных, и/или если поддержка различных значений ширины элементов данных осуществляется с использованием некоторых аспектов кодов операций.
Поле 770 маски записи - его содержание управляет, на основе позиций элементов данных, отражает ли позиция элемента данных в векторном операнде-адресате результат базовой операции и дополнительной операции. Шаблоны команд класса А поддерживают объединяющее маскирование при записи (merging-writemasking), а шаблоны команд класса В поддерживают и объединяющее, и обнуляющее маскирование при записи. В случае объединения векторные маски позволяют любую группу элементов в адресате защитить от обновления при выполнении любой операции (заданной посредством базовой операции и дополнительной операции); в другом варианте - сохраняет старую величину каждого элемента в адресате, когда соответствующий бит маски равен 0. Напротив, при обнулении векторные маски позволяют любую группу элементов адресата обнулить во время выполнения какой-либо операции (заданной посредством базовой операции и дополнительной операции); в одном из вариантов элемент адреса делают равным 0, когда соответствующий бит маски имеет значение 0. Подмножеством этой функции является способность управлять длиной вектора выполняемой операции (иными словами, модифицируется размер совокупности элементов от первого элемента до последнего); однако нет необходимости, чтобы модифицируемые элементы располагались последовательно один за другим. Таким образом, поле 770 маски записи позволяет выполнять частичные векторные операции, включая загрузки, сохранения, арифметические операции, логические операции и т.п. Хотя в описанных здесь вариантах настоящего изобретения содержание поля 770 маски записи выбирает из ряда регистров масок записи один регистр, содержащий маску записи, которую нужно использовать (и, таким образом, содержание поля маски записи косвенно указывает, что должно быть применено маскирование), альтернативные варианты вместо этого или в дополнение к этому допускают, чтобы содержание поля 770 маски записи прямо определяло маскирование, которое должно быть произведено.
Поле 772 непосредственной адресации - его содержание позволяет определить непосредственную адресацию. Это поле является опцией в том смысле, что его нет в реализации обобщенного удобного для работы с векторами формата, не поддерживающего непосредственную адресацию, и этого поля нет в командах, не использующих непосредственную адресацию.
Поле 768 класса - его содержание позволяет отличать различные классы команд. Применительно к фиг. 7А-В содержание этого поля осуществляет выбор между командами класса А и командами класса В. На фиг. 7А-В квадраты со скругленными углами использованы для индикации, что в этом поле присутствует конкретная величина (например, класс А 768А и класс В 768 В для поля класса 768 на фиг. 7А-В, соответственно).
Шаблоны команд класса А
В случае шаблонов 705 команд класса А без доступа к памяти поле 752 альфа интерпретируют как поле RS 752А, содержание которого различает, какой из разных типов дополнительных операций нужно выполнить (например, округление 752А.1 и преобразование данных 752А.2 определены, соответственно, для шаблонов команд 710 для операции типа округления и без доступа к памяти и для операции типа преобразования данных и без доступа к памяти), тогда как поле 754 бета различает, какую операцию определенного типа следует выполнить. В шаблонах 705 команд без доступа к памяти отсутствуют поле 760 масштаба, поле 762А смещение и поле 762В фактора смещения.
Шаблоны команд без доступа к памяти - Операции типа управления полным округлением
В шаблоне 710 команды операции типа управления полным округлением и без доступа к памяти поле 754 бета интерпретируют, как поле 754А управления округлением, содержание которого обеспечивает статическое округление. Тогда как в описываемых вариантах настоящего изобретения поле 754А управления округлением содержит поле 756 подавления всех исключений с плавающей запятой (SAE) и поле 758 управления операцией округления, альтернативные варианты могут поддерживать кодирование обоих этих принципов в одном и том же поле, либо иметь только один из этих принципов/полей (например, могут иметь только поле 750 управления операцией округления).
Поле 756 SAE - его содержание определяет, отключать или нет сообщения об особых ситуациях (событиях исключений); когда содержание поля 756 SAE указывает, что подавление включено, конкретная команда не сообщает о каких либо флагах исключений с плавающей запятой и не запускает какую-либо программу обработки исключений с плавающей запятой.
Поле 758 управления операцией округления - его содержание определяет, какую из групп операций округления выполнить (например, округление вверх, округление вниз, округление по отношению к нулю и округление до ближайшего целого). Таким образом, поле 758 управления операцией округления позволяет изменять режим округления от команды к команде. В одном из вариантов настоящего изобретения, в котором процессор содержит регистр для определения режимов округления, содержание поля 758 управления операцией округления превалирует над величиной, записанной в регистре.
Шаблоны команд без доступа к памяти - операция типа преобразования данных
В шаблоне 715 команды для операции типа преобразования данных без доступа к памяти поле 754 бета интерпретировано как поле 754В преобразования данных, содержание которого указывает, какое именно из ряда преобразований данных следует выполнить (например, не преобразовывать данные, преобразовать ссылки, передать в режиме широкого вещания).
В случае шаблона 720 команды класса А с доступом к памяти поле 752 альфа интерпретируют как поле 752В рекомендации вытеснения, содержание которого указывает, какую именно рекомендацию вытеснения следует использовать (на фиг. 7А, временное 752В.1 и не временное 752В.2, соответственно, определены для доступа к памяти, шаблон 725 временной команды с доступом к памяти и шаблон 730 не временной команды с доступом к памяти), тогда как поле 754 бета интерпретируют как поле 754С манипуляции данными, содержание которого указывает, какой именно из ряда видов операций манипуляции данными (также именуемых примитивами) следует выполнить (например, не манипулировать данными, передавать в режиме вещания, преобразовать источник вверх и преобразовать адресат вниз). Шаблоны 720 команд с доступом к памяти содержат поле 760 масштаба и, в качестве опции, поле 762А смещения или поле 762В масштаба смещения.
Команды векторной памяти осуществляют загрузку векторов из памяти и сохранение векторов в памяти с поддержкой преобразования. Как и в случае обычных векторных команд, команды векторной памяти передают данные из/в память по элементам данных, причем, передача каких именно элементов происходит, реально обнаруживается содержание векторной маски, выбранной в качестве маски записи.
Шаблоны команд с доступом к памяти - временные
Под временными данными понимают данные, которые вероятно будут использованы повторно достаточно скоро, чтобы получить выигрыш от кэширования. Это, однако, всего лишь рекомендация, так что разные процессоры могут реализовать ее различными способами, включая полное игнорирование такой рекомендации.
Шаблоны команд с доступом к памяти - не временные
Под не временными данными понимают данные, которые вероятно не будут использованы повторно достаточно скоро, чтобы получить выигрыш от кэширования в кэше уровня 1, и которым следует отдать приоритет при вытеснении. Это, однако, всего лишь рекомендация, так что разные процессоры могут реализовать ее различными способами, включая полное игнорирование такой рекомендации.
Шаблоны команд класса В
В случае шаблонов команд класса В поле 752 альфа интерпретируют в качестве поля 752С управления маской записи (Z), содержание которого указывает, должно ли маскирование при записи, управляемое эти полем 770 маски записи, быть объединяющим или обнуляющим.
В случае шаблонов 705 команд класса В без доступа к памяти часть поля 754 бета интерпретируют как поле RL 757А, содержание которого указывает, какой из различных типов дополнительных операций следует выполнить (например, округление 757А.1 и длина вектора (VSIZE) 757А.2, соответственно, определены для шаблона 712 команды типа операции управления частичным округлением, с управлением маской записи и без доступа к памяти, и для шаблона 717 команды типа операции установления длины вектора VSIZE, с управлением маской записи и без доступа к памяти), тогда как остальная часть поля 754 бета указывает, какую именно операцию определенного первой частью типа следуют выполнить. В шаблонах 705 команд без доступа к памяти отсутствуют поле 760 масштаба, поле 762А смещения и поле 762В масштаба смещения.
В шаблоне 710 команды типа операции управления частичным округлением с управлением маской записи и без доступа к памяти остальную часть поля 754 бета интерпретируют как поле 759А операции округления при отключенном сообщении о событиях исключения (конкретная команда не сообщает о каких-либо флагах исключений с плавающей запятой и не запускает какую-либо программу обработки исключений с плавающей запятой).
Поле 759А управления операцией округления - точно так же, как для поля 758 управления операцией округления, его содержание указывает, какую из групп операций округления следует выполнить (например, округление вверх, округление вниз, округление по отношению к нулю и округление до ближайшего целого). Таким образом, поле 759А управления операцией округления позволяет изменять режим округления от команды к команде. В одном из вариантов настоящего изобретения, в котором процессор содержит регистр для определения режимов округления, содержание поля 750 управления операцией округления превалирует над величиной, записанной в регистре.
В шаблоне 717 команды типа операции установления длины VSIZE вектора, с управлением маской записи и без доступа к памяти остальную часть поля 754 бета интерпретируют как поле 759В длины вектора, содержание которого указывает, какую из ряда возможных длин вектора данных нужно применить (например, 128, 256 или 512 байт).
В случае шаблона 720 команд класса В с доступом к памяти часть поля 754 бета интерпретируют как поле 757 В вещания, содержание которого указывает, следует ли выполнять операцию манипуляции с данными типа широкого вещания, тогда как остальную часть поля 754 бета интерпретируют как поле 759В длины вектора. Шаблоны 720 команд с доступом к памяти содержат поле 760 масштаба и могут в качестве опций содержать поле 762А смещения или поле 762В масштаба смещения.
Применительно к обобщенному удобному для работы с векторами формату 700 команд поле 774 полного кода операции содержит поле 740 формата, поле 742 базовой операции и поле 764 ширины элемента данных. Хотя показан один из вариантов, в котором поле 774 полного кода операции содержит все эти поля, в вариантах, которые не поддерживают все перечисленные поля, это поле полного кода операции содержит меньшее число полей. Указанное поле 774 полного кода операции предоставляет код операции.
Перечисленные поле 750 дополнительной операции, поле 764 ширины элемента данных и поле 770 маски записи позволяют определить эти характеристики для каждой команды в обобщенном удобном для работы с векторами формате команд.
Сочетание поля маски записи и поля ширины элемента данных создает типовые команды в том смысле, что они позволяют применять маску на основе ширины элементов данных.
Разнообразные шаблоны команд, относящихся к классу А и классу В, обладают преимуществами в различных ситуациях. В некоторых вариантах настоящего изобретения различные процессоры или различные ядра процессоров могут поддерживать только класс А, только класс В или оба класса. Например, обладающее высокими характеристиками ядро для выполнения операций не по порядку, предназначенное для вычислений общего назначения, может поддерживать только класс В, ядро, предназначенное для графических и/или научных (скоростных) вычислений, может поддерживать только класс А, а ядро, предназначенное и для вычислений общего назначения, и для графических и/или научных вычислений, может поддерживать оба класса (безусловно, ядро, имеющее некоторую смесь шаблонов и команд из обоих классов, но не все шаблоны и команды из обоих классов, находится в сфере охвата настоящего изобретения). Кроме того, один процессор может иметь несколько ядер, причем все ядра могут поддерживать один и тот же класс, либо разные ядра могут поддерживать различные классы. Например, в процессоре с раздельными графическими ядрами и ядрами общего назначения одно из графических ядер, предназначенное главным образом для графических и/или научных вычислений, может поддерживать только класс А, тогда как одно или несколько ядер общего назначения могут быть обладающими высокими характеристиками ядрами с выполнением операций не по порядку и переименованием регистров, предназначенными для вычислений общего назначения, и поддерживать только класс В. Другой процессор, не имеющий графического ядра, может содержать одно или несколько ядер общего назначения с выполнением операций по порядку или не по порядку, поддерживающих оба класса - и класс А и класс В. Безусловно, в различных вариантах настоящего изобретения признаки из одного класса могут быть также реализованы в другом классе. Программы, записанные на языке высокого уровня, могут быть приведены (например, непосредственно во время компиляции или статической компиляции) к разнообразным исполняемым формам, и в том числе: 1) форма, содержащая только команды класса(ов), поддерживаемого целевым процессором, который, как предполагается, будет выполнять эту программу; или 2) форма, содержащая альтернативные процедуры, написанные с использованием различных сочетаний команд из всех классов, и имеющая управляющий код, выбирающий процедуры для исполнения на основе команд, поддерживаемых процессором, который выполняет программу в текущий момент.
Пример специального удобного для работы с векторами формата команд
Фиг. 8 представляет блок-схему, иллюстрирующую пример специального удобного для работы с векторами формата команд согласно вариантам настоящего изобретения. На фиг. 8 показан специальный удобный для работы с векторами формат 800 команд, являющийся определенным в том смысле, что он определяет позиции, размеры, интерпретацию и порядок полей, равно как и значения для некоторых из этих полей. Такой определенный удобный для работы с векторами формат 800 команд может быть использован для расширения набора команд х86, вследствие чего некоторые поля аналогичны или совпадают с полями, используемыми в существующем наборе команд х86 или его расширении (например, AVX). Этот формат остается совместим с полем кодирования префикса, полем байта действительного кода операции, полем MOD R/M, полем SIB, полем смещения и полями непосредственной адресации в существующем наборе команд х86 с расширениями. Показаны изображенные на фиг. 7 поля, на которые отображаются поля, представленные на фиг. 8.
Следует понимать, что хотя варианты настоящего изобретения описаны со ссылками на определенный удобный для работы с векторами формат 800 команд в контексте обобщенного удобного для работы с векторами формата 700 команд в целях иллюстрации, настоящее изобретение не ограничивается определенным удобным для работы с векторами форматом 800 команд, за исключением случаев, где это оговорено отдельно. Например, обобщенный удобный для работы с векторами формат 700 команд рассматривает разнообразные возможные размеры различных полей, тогда как определенный удобный для работы с векторами формат 800 команд показан как имеющий поля конкретных размеров. В качестве конкретного примера, тогда как поле 764 ширины элементов данных показано в определенном удобном для работы с векторами формате 800 команд в виде однобитового поля, настоящее изобретение этим не ограничивается (иными словами, обобщенный удобный для работы с векторами формат 700 команд может иметь дело и с другими размерами поля 764 ширины элементов данных).
Обобщенный удобный для работы с векторами формат 700 команд содержит следующие поля, перечисленные ниже в порядке, показанном на фиг. 8А.
Префикс EVEX Prefix (байты 0-3) 802 - кодирован в форме четырех байтов.
Поле 740 формата (EVEX байт 0, биты [7:0]) - первый байт (EVEX байт 0) является полем 740 формата и содержит 0×62 (уникальное значение, используемое для указания удобного для работы с векторами формата команд в одном из вариантов настоящего изобретения).
Байты со второго по четвертый (EVEX байты 1-3) содержат ряд битовых полей, предоставляющих специальные возможности.
Поле 805 REX (EVEX байт 1, биты [7-5]) - содержит битовое поле EVEX.R (EVEX байт 1, бит [7] - R), битовое поле EVEX.X (EVEX байт 1, бит [6] - X) и 757 ВЕХ байт 1, бит[5] - В). Битовые поля EVEX.R, EVEX.X и EVEX.B выполняют такие же функции, как соответствующие битовые поля VEX, и кодированы с использованием формы дополнения до 1, т.е. ZMM0 кодировано как 1111В, ZMM15 кодировано как 0000 В. Другие поля команды кодируют младшие три бита регистровых индексов, как это известно в технике (rrr, XXX и bbb), так что Rrrr, Хххх и Bbbb могут быть получены путем суммирования EVEX.R, EVEX.X и EVEX.B.
Поле 710 REX′ - это первая часть поля 710 REX′ и представляет собой битовое поле EVEX.R′ (EVEX байт 1, бит [4] - R′), используемое для кодирования либо верхних 16, либо нижних 16 из расширенной группы 32 регистров. В одном из вариантов настоящего изобретения этот бит, вместе с другими, как указано ниже, сохраняется в формате инвертированного бита, чтобы отличить (в хорошо известном 32-битовом режиме х86) от команды BOUND, действительный код операции для которой равен 62, но не приемлет в поле MOD R/M (описано ниже) величины 11 в поле MOD; альтернативные варианты настоящего изобретения не сохраняют этот и другие биты, указанные ниже, в инвертированном формате. Величина 1 используется для кодирования нижних 16 регистров. Другими словами, параметр R′Rrrr посредство сочетания EVEX.R′, EVEX.R и другого RRR из других полей.
Поле 815 отображения кода операции (EVEX байт 1, биты [3:0] - mmmm) - его содержание кодирует ведущий байт кода операции в неявном виде (OF, OF 38 или OF 3).
Поле 764 ширины элемента данных (EVEX байт 2, бит [7] - W) - представлено записью EVEX.W. Параметр EVEX.W используется для задания степени разбиения (размера) типа данных (либо 32-битовый элемент данных, либо 64-битовый элемент данных).
Поле 820 EVEX.vvvv (EVEX байт 2, биты [6:3] - ww) - роль параметра EVEX.ww может состоять в следующем: 1) EVEX.vvvv кодирует первый операнд-источник регистра, заданный в инвертированной (дополнение до 1) форме и действительный для команд с 2 или более операндами-источниками; 2) EVEX.vvvv кодирует операнд-адресат регистра, заданный в форме дополнения до 1 для некоторых сдвигов вектора; или 3) EVEX.vvvv не кодирует ни один операнд, поле зарезервировано и должно содержать 1111b. Таким образом, поле 820 EVEX.vvvv кодирует 4 младших бита определяется первого регистра-источника, сохраненного в инвертированной (дополнение до 1) форме. В зависимости от команды дополнительное другое битовое поле EVEX используется для увеличения размера определителя до 32 регистров.
Поле 768 класса EVEX.U (EVEX байт 2, бит [2]-U) - если EVEX.U = 0, это означает класс А или EVEX.U0; если EVEX.U = 1, это означает класс В или EVEX.U1.
Поле 825 кодирования префикса (EVEX байт 2, биты [1:0]-рр) - предоставляет дополнительные для поля базовой операции. В дополнение к поддержке существующих команд SSE в формате префикса EVEX это поле имеет также преимущество сжатия префикса SIMD (вместо того, чтобы требовать байт для выражения префикса SIMD, префикс EVEX требует только 2 бита). В одном из вариантов для поддержки существующих команд SSE, использующих префикс SIMD, (66Н, F2H, F3H) и в существующем формате, и в формате префикса EVEX, такие существующие префиксы SIMD кодируют в поле кодирования префикса SIMD; и во время работы расширяют до формата существующих префиксов SIMD перед тем, как передать в матрицу PLA декодера (так что эта матрица PLA может обрабатывать и существующий формат, и формат EVEX этих существующих команд без модификации). Хотя более новые команды могут использовать содержание поля кодирования префикса EVEX непосредственно в качестве расширения кода операции, некоторые варианты расширяют аналогичным образом для согласованности, но позволяют задавать различные значения с использованием этих существующих префиксов SIMD. Альтернативный вариант может изменить конфигурацию матрицы PLA для поддержки кодирования 2-битового префикса SIMD, и потому не требует расширения.
Поле 752 альфа (EVEX байт 3, бит [7] - ЕН; известно так же, как EVEX.EH, EVEX.rs, EVEX.RL, EVEX.write mask control и EVEX.N; и обозначено α) - как было описано ранее, это поле зависит от контекста.
Поле 754 бета (EVEX байт 3, биты [6:4] - SSS, известно так же, как EVEX.s2-0, EVEX.r2-0, EVEX.rrl, EVEX.LL0, EVEX.LLB; также иллюстрировано посредством βββ) - как было описано ранее, это поле зависит от контекста.
Поле 710 REX′ - это остальная часть поля REX′ и представляет собой битовое поле EVEX.V (EVEX байт 3, бит [3] - V), которое может быть использовано для кодирования либо верхних 16, либо нижних 16 регистров из расширенной группы 32 регистров. Этот бит сохраняют в инвертированном формате. Величину 1 используют для кодирования нижних 16 регистров. Другими словами, VVVVV образовано сочетанием EVEX.V, EVEX.vvvv.
Поле 770 маски записи (EVEX байт 3, биты [2:0]-kkk) - его содержание задает индекс регистра в группе регистров маски записи, как описано ранее. В одном из вариантов настоящего изобретения специальная величина EVEX.kkk = 000 имеет специальный характер, предполагая, что для конкретной команды никакая маска записи не используется (это может быть реализовано различными способами, включая использование маски записи, в которой аппаратно заданы все единицы, или аппаратуру, обходящую маскирующую аппаратуру).
Поле 830 действительного кода операции (байт 4) также известно как байт кода операции. В этом поле определена часть кода операции.
Поле 840 MOD R/M (байт 5) содержит поле 842 MOD, поле 844 Reg и поле 846 R/M. Как было описано ранее, содержание поля 842 MOD проводит различие между операциями с доступом к памяти и операциями без доступа к памяти. Роль поля 844 Reg можно, суммируя, свести к двум ситуациям: либо кодирование операнда регистра-адресата или операнда регистра-источника, либо интерпретация в качестве расширения кода операции и не использование для кодирования какого-либо операнда команды. Роль поля 846 R/M может быть следующей: кодирование операнда команды, связанного с адресом в памяти, либо кодирование операнда регистра-адресата или операнда регистра-источника.
Байт Масштаб, Индекс, База (SIB) (байт 6) - Как было описано ранее, содержание поля 750 масштаба используется для генерирования адреса в памяти. Поля 854 SIB.xxx и 856 SIB.bbb - содержание этих полей было ранее описано применительно к регистровым индексам Хххх и Bbbb.
Поле 762А смещения (байты 7-10) - когда поле 842 MOD содержит 10, байты 7-10 образуют поле 762А смещения и работают так же, как существующее 32-битовое смещение (disp32), и с разбиением по байтам.
Поле 762В фактора смещения (байт 7) - когда поле 842 MOD содержит 01, байт 7 является полем 762В фактора смещения. Местонахождение этого поля такое же, как местонахождение существующего 8-битового смещения (disp8) в наборе команд х86, и работает это поле тоже с разбиением по байтам. Поскольку параметр disp8 расширен на знак, он может рассматривать сдвиги только между -128 и 127 байт; с точки зрения кэш-линий длиной 64 байт, параметр disp8 использует 8 бит, которые могут задать только четыре реально пригодных для использования величины -128, -64, 0 и 64; поскольку часто нужен более широкий диапазон, применяется параметр disp32; однако этот параметр disp32 требует 4 байт. В отличие от параметров disp8 и disp32, поле 762В является новой интерпретацией параметра disp8; при использовании поля 762В фактора смещения реальную величину смещения определяют посредством умножения содержания поля фактора смещения на размер единицы доступа к операндам в памяти (N). Смещение такого типа обозначается как disp8*N. Это уменьшает среднюю длину команды (для указания смещения используется только один байт, но обеспечивает гораздо более широкий диапазон). Такое сжатое представление смещения основано на предположении, что эффективная величина смещения кратна степени разбиения при доступе к памяти, и, следовательно, избыточные младшие биты в составе величины сдвига адреса кодировать не нужно. Другими словами, поле 762В фактора смещения заменяет существующий 8-битовый параметр смещения в наборе команд х86. Таким образом, поле 762В фактора смещения кодируют таким же образом, как 8-битовый параметр смещения в наборе команд х86 (так что нет никаких изменений в правилах кодирования Mod RM/SIB), за одним лишь исключением, что параметр disp8 заменяют параметром disp8*N. Другими словами, нет никаких изменений в правилах кодирования или длине кодирования, а единственное, что меняется, это интерпретация величины смещения аппаратурой (что требует масштабировать величину смещения с использованием размера операнда в памяти для получения побайтового сдвига адреса).
Поле 772 непосредственной адресации работает, как было описано раньше.
Поле полного кода операции
Фиг. 8В представляет блок-схему, иллюстрирующую поля определенного удобного для работы с векторами формата 800 команд" которые составляют поле 774 полного кода операции согласно одному из вариантов настоящего изобретения. В частности, поле 774 полного кода операции содержит поле 740 формата, поле 742 базовой операции и поле 764 ширины элемента данных (W). Поле 742 базовой операции содержит указанные поле 825 кодирования префикса, поле 815 отображения кода операции и поле 830 действительного кода операции.
Поле индекса регистра
Фиг. 8С представляет блок-схему, иллюстрирующую поля определенного удобного для работы с векторами формата 800 команд, составляющие поле 744 индекса регистра согласно одному из вариантов настоящего изобретения. В частности, это поле 744 индекса регистра 744 содержит поле 805 REX, поле 810 REX′, поле 844 MODR/M.reg, поле 846 MODR/M.r/m, поле 820 WW field 820, поле 854 ххх и поле 856 bbb.
Поле дополнительной операции
Фиг. 8D представляет блок-схему, иллюстрирующую поля определенного удобного для работы с векторами формата 800 команд, составляющие поле 750 дополнительной операции согласно одному из вариантов настоящего изобретения. Когда поле 768 класса (U) содержит 0, это означает EVEX.U0 (класс А 768А); когда это поле содержит 1, это означает EVEX.U1 (класс В 768 В). Когда U=0 и поле 842 MOD содержит 11 (означающее операцию без доступа к памяти), поле 752 альфа (EVEX байт 3, бит [7] - ЕН) интерпретируется как поле 752А rs. Когда это поле 752А rs содержит 1 (округление 752А.1), поле 754 бета (EVEX байт 3, биты [6:4]- SSS) интерпретируется, как поле 754А управления округлением. Это поле 754А управления округлением содержит однобитовое поле 756 SAE и двухбитовое поле 758 операции округления. Когда поле 752А rs содержит 0 (преобразование данных 752А.2), поле 754 бета (EVEX байт 3, биты [6:4] - SSS) интерпретируется как трехбитовое поле 754В преобразования данных. Когда U=0 и поле 842 MOD содержит 00, 01 или 10 (обозначает операцию доступа к памяти), поле 752 альфа (EVEX байт 3, бит [7] - ЕН) интерпретируют как поле 752В рекомендации вытеснения (ЕН) и поле 754 бета (EVEX байт 3, биты [6:4] - SSS) интерпретируют как трехбитовое поле 754С манипуляции данными.
Когда U=1, поле 752 альфа (ΕVEX байт 3, бит [7] - EH) интерпретируют как поле 752С управления маской записи (Z). Когда U=1 и поле 842 MOD содержит 11 (обозначая операцию без доступа к памяти), часть поля 754 бета (EVEX байт 3, бит [4] - S0) интерпретируют как поле 757А RL; когда это поле содержит 2 (округление 757А.1), остальную часть поля 754 бета (EVEX байт 3, бит [6-5] - S2-1) интерпретируют как поле 759А операции округления, тогда как если поле 757А RL содержит О (VSIZE 757.А2), остальную часть поля 754 бета (EVEX байт 3, бит [6-5] - S2-1) интерпретируют как поле 759В длины вектора (EVEX байт 3, бит [6-5] - L1-0). Когда U=1 и поле 842 MOD содержит 00, 01 или 10 (обозначая операцию с доступом к памяти), поле 754 бета (EVEX байт 3, биты [6:4] - SSS) интерпретируют как поле 759В длины вектора (EVEX байт 3, бит [6-5] - L1-0) и поле 757 В вещания (EVEX байт 3, бит [4] - В).
Пример кодирования в специальном удобном для работы с векторами формате команд
Пример регистровой архитектуры
Фиг. 9 представляет блок-схему регистровой архитектуры 900 согласно одному из вариантов настоящего изобретения. В иллюстрируемом варианте присутствуют 32 векторных регистра 910 шириной по 512 бит; эти регистры обозначены с zmm0 по zmm31. 256 младших битов нижних 16 регистров zmm наложены на регистры ymm0-16. 128 младших битов нижних 16 регистров zmm registers (младшие 128 бит регистров ymm) наложены на регистры xmm0-15. Специальный удобный для работы с векторами формат 800 команд оперирует с этими наложенными регистровыми файлами, как показано в таблице, приведенной ниже.
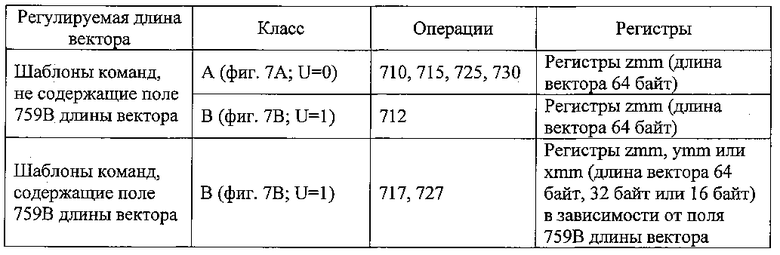
Другими словами, поле 759В длины вектора осуществляет выбор между максимальной длиной и одной или несколькими более короткими длинами, где каждая такая более короткая длина равна половине предыдущей длины; при этом шаблоны команд, не имеющие поля 759В длины вектора, оперируют с максимальной длиной вектора. Далее, в одном из вариантов шаблоны команд класса В в специальном удобном для работы с векторами формате 800 команд оперирует с упакованными или скалярными данными с плавающей запятой с одинарной/двойной точностью и упакованными или скалярными целочисленными данными. Скалярные операции представляют собой операции, выполняемые над позициями элементов данных самого низкого порядка в регистре zmm/ymm/xmm; позиции элементов данных более высокого порядка либо остаются теми же сами, какими они были до выполнения команды, либо обнуляются в зависимости от варианта.
Регистры 915 масок записи - в иллюстрируемом варианте имеются 8 регистров масок записи (с k0 по k7), каждый из которых имеет размер 64 байт. В альтернативном варианте регистры 915 масок записи имеют размер 16 бит каждый. Как было описано раньше, в одном из вариантов настоящего изобретения регистр k0 векторной маски не может быть использован в качестве маски записи; при кодировании, когда в нормальном режиме в качестве маски записи должен был бы указан регистр k0, система выбирает жестко заданную аппаратную маску записи 0xFFFF, эффективно отключая маскирование записи для этой команды.
Регистры 925 общего назначения - в иллюстрируемом варианте имеются шестнадцать 64-битовых регистров общего назначения, используемых в существующих режимах адресации х86 с целью обращения (адресации) к операндам в памяти. Эти регистры имеют названия RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP и R8-R15.
Стековый регистровый файл 945 (стек х87) для скалярных операций с плавающей запятой, на который наложен простой регистровый файл 950 ММХ для операций с упакованными целыми числами, - в иллюстрируемом варианте стек х87 представляет собой восьмиэлементный стек, используемый для выполнения скалярных операций с плавающей запятой над 32/64/80-битовыми данными с плавающей запятой с использованием расширения набора команд х87; при этом регистры ММХ используются для выполнения операций над 64-битовыми упакованными целочисленными данными, а также для хранения операндов для некоторых операций, осуществляемых между регистрами ММХ и ХММ.
Альтернативные варианты настоящего изобретения могут использовать более широкие или более узкие регистры. Кроме того, альтернативные варианты настоящего изобретения могут использовать больше, меньше или другие регистровые файлы и регистры.
Примеры архитектур ядер, процессоры и компьютерные архитектуры
Процессорные ядра могут быть реализованы различными способами для разных целей и в различных процессорах. Например, возможны следующие варианты реализации таких ядер: 1) ядро общего назначения с выполнением операций по порядку, предназначенное для вычислений общего назначения; 2) обладающее высокими характеристиками ядро общего назначения с выполнением операций не по порядку, предназначенное для вычислений общего назначения; 3) ядро специального назначения, предназначенное главным образом для графики и/или научных (скоростных) вычислений. Можно указать следующие реализации различных процессоров: 1) центральный процессор (CPU), содержащий одно или несколько ядер общего назначения с выполнением операций по порядку, предназначенных для вычислений общего назначения, и/или одно или несколько ядер общего назначения с выполнением операций не по порядку, предназначенных для вычислений общего назначения; и 2) сопроцессор, содержащий одно или несколько ядер специального назначения, предназначенных главным образом для графики и/или научных (скоростных) вычислений. Наличие таких различных процессоров ведет к разным архитектурам компьютерных систем, среди которых могут быть следующие: 1) сопроцессор на отдельном от центрального процессора CPU кристалле интегральной схемы; 2) сопроцессор на отдельном кристалле интегральной схемы, но в общем корпусе с центральным процессором CPU; 3) сопроцессор на одном кристалле интегральной схемы с центральным процессором CPU (в этом случае такой сопроцессор иногда называют логической схемой специального назначения, такой как интегральная графическая и/или научная (скоростная) логическая схема, или ядрами специального назначения); и 4) так называемая «система на кристалле», которая может содержать выполненные на одном и том же кристалле интегральной схемы описанный центральный процессор CPU (иногда именуемый ядром(ами) приложений или процессором(ами) приложений, описанный выше сопроцессор и дополнительные функциональные схемы. Далее описаны примеры архитектур ядер, после которых приведены описания примеров процессоров и компьютерных архитектур.
Примеры архитектур ядер
Блок-схемы ядер с выполнением операций по порядку и не по порядку
Фиг. 10А представляет блок-схему, иллюстрирующую пример конвейера, выполняющего команды не по порядку, и пример конвейера с выдачей данных/выполнением команд не по порядку и переименованием регистров согласно вариантам настоящего изобретения. Фиг. 10В представляет блок-схему, иллюстрирующую пример варианта ядра с архитектурой выполнения команд по порядку и пример ядра архитектуры с выдачей данных/выполнением команд не по порядку и переименованием регистров для включения в состав процессора согласно вариантам настоящего изобретения. Прямоугольники из сплошных линий на фиг. 10А-В иллюстрируют конвейер с выполнением операций по порядку и ядро с выполнением операций по порядку, тогда как добавленные в качестве опций прямоугольники из штриховых линий иллюстрируют конвейер и ядро с выдачей данных/выполнением команд не по порядку и переименованием регистров. Поскольку аспект выполнения операций по порядку представляет собой подмножество (частный случай) аспекта с выполнением операций не по порядку, далее будет описан аспект с выполнением операций не по порядку.
На фиг. 10А процессорный конвейер 1000 содержит ступень 1002 выборки, ступень 1004 декодирования длины, ступень 1006 декодирования, ступень 1008 назначения, ступень 1010 переименования, ступень 1012 планирования (также известная как ступень диспетчирования или выдачи), ступень 1014 чтения регистров/чтения памяти, исполнительную ступень 1016, ступень 1018 обратной записи/записи в память, ступень 1022 обработки особых ситуаций (исключений) и ступень 1024 фиксации.
На фиг. 10В показано ядро 1090 процессора, содержащее входной модуль 1030, соединенный с исполнительным модулем 1050, причем оба эти модуля соединены с модулем 1070 памяти. Ядро 1090 может представлять собой компьютерное ядро с уменьшенным набором команд (RISC), ядро со сложным набором команд (CISC), ядро с очень длинным командным словом (VLIW), либо ядро гибридного или альтернативного типа. В качестве еще одной опции ядро 1090 может представлять собой ядро специального назначения, такое как, например, сетевое ядро или ядро связи, автомат сжатия, сопроцессорное ядро, ядро графического процессора общего назначения (GPGPU), графическое ядро или другое подобное ядро.
Модуль 1030 ввода содержит модуль прогнозирования ветвления 1032, соединенный с модулем 1034 кэша команд, который соединен с буфером 1036 ассоциативной трансляции (TLB), который в свою очередь соединен с модулем 1036 выборки команд 1038, соединенным с декодирующим модулем 1040. Этот декодирующий модуль 1040 (или декодер) может декодировать команды и генерировать на выходе одну или более микроопераций, точек ввода микрокодов, микрокоманд, других команд или других сигналов управления, которые были декодированы из, или отражают как-то иначе или выведены из исходных команд. Указанный декодирующий модуль 1040 может быть реализован с использованием различных механизмов, К примерам подходящих механизмов относятся, не ограничиваясь, просмотровые таблицы, аппаратные варианты реализации, программируемые логические матрицы (PLA), ROM микрокодов и т.п. В одном из вариантов ядро 1090 содержит ROM микрокодов или другой носитель, сохраняющий микрокоды для определенных макрокоманд (например, в декодирующем модули 1040 или, иначе, во входном модуле 1030). Этот декодирующий модуль 1040 соединен с модулем 1052 переименования/назначения в составе исполнительного модуля 1050.
Указанный исполнительный модуль 1050 содержит модуль 1052 переименования/назначения, соединенный с модулем 1054 выбытия и группой из одного или более модулей 1056 планировщиков. Модули 1056 планировщиков представляют любое число различных планировщиков, включая станции резервации, центральное окно команд и т.п. Модули 1056 планировщиков соединены с модулями 1058 физических регистровых файлов. Каждый из этих модулей 1058 физических регистровых файлов представляет один или более физических регистровых файлов, так что разные файлы сохраняют один или более различных типов данных, такие как скалярные целочисленные данные, скалярные данные с плавающей запятой, упакованные целочисленные данные, упакованные данные с плавающей запятой, векторные целочисленные данные, векторные данные с плавающей запятой, данные состояния (например, указатель команды, представляющий собой адрес следующей команды, которую нужно выполнить) и т.п. В одном из вариантов, модуль 1058 физических регистровых файлов содержит модуль векторных регистров, модуль регистров масок записи и модуль скалярных регистров. Эти регистровые модули могут предоставлять архитектурные векторные регистры, регистры векторных масок и регистры общего назначения. На модули 1058 физических регистровых файлов наложен модуль 1054 выбытия для иллюстрации различных способов, которыми может быть реализовано переименование регистров и выполнение команд не по порядку (например, с использованием буфера(ов) переупорядочения и регистровых файлов выбытия; с использованием будущих файлов, буфера(ов) предыстории и регистровых файлов выбытия; с использованием карт регистров и пула регистров; и т.п.). Указанные модуль 1054 выбытия и модули 1058 физических регистровых файлов соединены с исполнительным кластером(ами) 1060. Исполнительный кластер(ы) 1060 содержит группу из одного или более исполнительных модулей 1062 и группу модулей 1064 доступа к памяти. Исполнительные модули 1062 могут осуществлять различные вычислительные операции (например, сдвиги, суммирование, вычитание, умножение) и над различными типами данных (например, скалярными данными с плавающей запятой, упакованными целочисленными данными, упакованными данными с плавающей запятой, векторными целочисленными данными, векторными данными с плавающей запятой). Тогда как некоторые варианты могут содержать ряд исполнительных модулей, специально предназначенных для выполнения конкретных функций или групп функций, другие варианты могут содержать только один исполнительный модуль или несколько исполнительных модулей, которые все выполняют все функции. Модули 1056 планировщиков, модули 1058 физических регистровых файлов и исполнительные кластеры 1060 показаны как, возможно, по несколько штук, поскольку в некоторых вариантах создают отдельные конвейеры для множества типов данных/операций (например, конвейер для скалярных целочисленных данных, конвейер для скалярных данных с плавающей запятой/упакованных целочисленных данных/упакованных данных с плавающей запятой/векторных целочисленных данных/векторных данных с плавающей запятой и/или конвейер доступа к памяти, так что каждый конвейер имеет свой собственный модуль планировщика, модуль физических регистровых файлов и/или исполнительный кластер - и в случае отдельного конвейера доступа к памяти реализованы некоторые варианты, в которых только исполнительный кластер этого конвейера имеет модули 1064 доступа к памяти). Следует понимать, что при использовании раздельных конвейеров один или множество из этих конвейеров могут использовать выдачу/выполнение не по порядку очередности, а остальные - в порядке очередности.
Группа модулей 1064 доступа к памяти соединена с модулем 1070 памяти, содержащим модуль 1072 буфера ассоциативной трансляции (TLB) для данных, соединенный с модулем 1074 кэша данных, который соединен с модулем 1076 кэша уровня 2 (L2). В одном из примеров вариантов модули 1064 доступа к памяти могут содержать модуль загрузки, модуль адресов сохранения и модуль сохранения данных, каждый из которых соединен с модулем 1072 буфера TLB для данных в составе модуля 1070 памяти. Модуль 1034 кэша команд соединен также с модулем 1076 кэша уровня 2 (L2) в составе модуля 1070 памяти. Этот модуль 1076 кэша L2 соединен с одним или более кэшами других уровней, а также по мере необходимости с главной памятью.
В качестве примера, архитектура с выдачей данных/выполнением команд не по порядку и переименованием регистров может реализовать конвейер 1000 следующим образом: 1) модуль 1038 выборки команд реализует ступени 1002 и 1004 выборки и декодирования длины; 2) декодирующий модуль 1040 реализует ступень 1006 декодирования; 3) модуль 1052 переименования/назначения реализует ступень 1008 назначения и ступень 1010 переименования 1010; 4) модули 1056 планировщиков реализуют ступень 1012 планирования; 5) модули 1058 физических регистровых файлов модуль 1070 памяти реализуют ступень 1014 чтения регистров/чтения памяти; исполнительный кластер 1060 реализует исполнительную ступень 1016; 6) модуль 1070 памяти и модули 1058 физических регистровых файлов реализуют ступень 1018 обратной записи/записи в память; 7) для реализации ступени 1022 обработки особых ситуаций (исключений) могут быть привлечены различные модули; и 8) модуль 1054 выбытия и модули 1058 физических регистровых файлов реализуют ступень 1024 фиксации.
Ядро 1090 может поддерживать один или более наборов команд (например, набор команд х86 (с некоторыми расширениями, которые были добавлены в более новые версии); набор команд MIPS, разработанный компанией MIPS Technologies из Sunnyvale, СА; набор команд ARM (с опциями дополнительных расширений, таких как NEON), разработанный компанией ARM Holdings из Sunnyvale, СА), включая команды, описанные здесь. В одном из вариантов ядро 1090 содержит логическую схему для поддержки расширения набора команд для обработки упакованных данных (например, AVX1, AVX2, и/или некоторая форма обобщенного удобного для работы с векторами формата команд (U=0 и/или U=1), описанного ранее), тем самым позволяя операции, применяемые многими приложениями мультимедиа, выполнять с использованием упакованных данных.
Следует понимать, что ядро может поддерживать многопоточность (выполнение двух или более параллельных наборов операций или потоков) и может делать это разнообразными способами, включая многопоточность с разбиением по временным интервалам, одновременную многопоточность (когда одно физическое ядро создает логическое ядро для каждого из потоков, выполняемых этим физическим ядром одновременно) или сочетание этих двух видов (например, выборка и декодирование по временным интервалам, а затем одновременная многопоточность, как это делается согласно технологии гиперпоточности (Intel® Hyperthreading technology)).
Хотя переименование регистров описано в контексте выполнения команд не по порядку, следует понимать, что переименование регистров может быть использовано в архитектуре с выполнением команд по порядку. Тогда как иллюстрируемый вариант процессора также содержит раздельные модули 1034/1074 кэшей команд и данных и совместно используемый модуль 1076 кэша L2, альтернативные варианты могут иметь один внутренний кэш и для команд, и для данных, такой как, например, внутренний кэш уровня 1 (L1) или множество уровней внутреннего кэша. В некоторых вариантах система может содержать сочетание внутреннего кэша и внешнего кэша, который является внешним для ядра и/или процессора. В качестве альтернативы весь кэш может быть внешним для ядра и/или процессора.
Конкретный пример архитектуры ядра с выполнением команд по порядку
Фиг. 11А-В иллюстрируют блок-схему более конкретного примера архитектуры ядра с выполнением команд по порядку, где это ядро будет одним из множества логических блоков (включая другие ядра того же типа и/или других типов) на кристалле интегральной схемы. Эти логические блоки сообщаются по соединительной сети с очень широкой полосой пропускания (например, кольцевой сети) с некоторыми логическими схемами, обладающими фиксированными функциями, интерфейсами ввода/вывода памяти и другими необходимыми логическими схемами ввода/вывода в зависимости от приложения.
Фиг. 11А представляет блок схему одного процессорного ядра вместе с его соединениями с выполненной на кристалле соединительной сетью 1102 и с его локальной областью кэша 1104 уровня 2 (L2) согласно вариантам настоящего изобретения. В одном из вариантов декодер 1100 команд поддерживает набор команд х86 с расширением набора команд для работы с упакованными данными. Кэш 1106 L1 обеспечивает доступ с очень малой задержкой к кэш-памяти скалярного и векторного модулей. Хотя в одном из вариантов (для упрощения конструкции) скалярный модуль 1108 и векторный модуль 1110 используют раздельные группы регистров (соответственно, скалярные регистры 1112 и векторные регистры 1114), и данные, передаваемые между ними, сначала записывают в память и затем считывают из кэша 1106 уровня 1 (L1), альтернативные варианты настоящего изобретения могут применять другой подход (например, использовать одну группу регистров или ввести тракт связи, позволяющий передавать данные между этими двумя регистровыми файлами без записи и считывания этих данных).
Локальная область 1104 кэша L2 является частью глобального кэша L2, разбитого на множество раздельных областей, по одной для каждого процессорного ядра. Каждое процессорное ядро имеет путь прямого доступа к своей собственной локальной области 1104 кэша L2. Данные, считываемые процессорным ядром, сохраняются в его области 1104 кэша L2, так что к ним возможен быстрый доступ параллельно с доступом других процессорных ядер к их собственным локальным областям кэша L2. Данные, записываемые процессорным ядром, сохраняются в его собственной области 1104 кэша L2 и удаляются из других таких локальных областей при необходимости. Кольцевая сеть обеспечивает когерентность для совместно используемых данных. Эта кольцевая сеть является двусторонней, чтобы позволить агентам, таким как процессорные ядра, кэши L2 и другие логические блоки, поддерживать связь одним с другими в пределах кристалла интегральной схемы. Каждый кольцевой тракт передачи данных имеет ширину 1012 бит в каждом направлении.
Фиг. 11В представляет расширенное изображение части процессорного ядра, изображенного на фиг. 11А, согласно вариантам настоящего изобретения. На фиг. 11В показана часть 1106А кэша L1 данных из состава области 1104 кэша Ll, а также приведены больше подробностей относительно векторного модуля 1110 и векторных регистров 1114. В частности, векторный модуль 1110 представляет собой 16-разрядный векторный процессор (vector processing unit (VPU)) (см. 16-разрядный арифметическо-логический модуль ALU 1128), который выполняет одну или более команд для работы с целыми числами, команд с плавающей запятой и с обычной, одинарной точностью и команд с плавающей запятой и с двойной точностью. Процессор VPU поддерживает преобразование ссылок входов регистров посредством модуля 1120 преобразования ссылок при перемещении данных, числовое преобразование с использованием модулей 1122А-В числовых преобразователей и копирование посредством модуля 1124 копирования на входе памяти. Регистры 1126 масок записи позволяют утверждать записи результирующих векторов.
Процессор с встроенными контроллером памяти и графикой
Фиг. 12 представляет блок-схему процессора 1200, который может иметь больше одного ядра, может иметь встроенный контроллер памяти и может иметь встроенную графику согласно вариантам настоящего изобретения. Прямоугольники из сплошных линий на фиг. 12 показывают процессор 1200, имеющий одно ядро 1202А, системного агента 1210 и группу из одного или более модулей 1216 контроллеров шин, тогда как добавляемые в качестве опций прямоугольники из штриховых линий показывают альтернативный процессор 1200, содержащий множество ядер 1202A-N, группу из одного или более встроенных модулей 1214 контроллеров памяти в составе модуля 1210 системного агента и логическую схему 1208 специального назначения.
Таким образом, различные варианты реализации процессора 1200 могут содержать: 1) центральный процессор CPU с логической схемой 1208 специального назначения, представляющей собой встроенные графические и/или научные (скоростные) схемы (которая может иметь одно или более ядер), и ядра 1202A-N, представляющие собой одно или более ядер общего назначения (например, ядра общего назначения с выполнением команд по порядку, ядра общего назначения с выполнением команд не по порядку или сочетание этих двух видов ядер); 2) сопроцессор, в котором ядра 1202A-N представляют собой большое число ядер специального назначения, предназначенных главным образом для графики и/или научных (скоростных) вычислений; и 3) сопроцессор, в котором ядра 1202A-N представляют собой большое число ядер общего назначения с выполнением операций по порядку. Таким образом, процессор 1200 может представлять собой процессор общего назначения, сопроцессор или процессор специального назначения, такой как, например, сеть процессоров связи, автомат сжатия, графический процессор, графический процессор общего назначения (GPGPU), высокопроизводительный сопроцессор с множеством встроенных ядер (MIC) (содержащий 30 или более ядер), встроенный процессор или другое подобное устройство. Процессор может быть выполнен на одном или более кристаллах интегральных схем. Этот процессор 1200 может занимать часть одной подложки и/или может быть реализован на одной или нескольких подложках с использованием какой-либо из ряда технологий, например, таких как BiCMOS, CMOS или NMOS.
Иерархическая структура памяти содержит один или более уровней кэша в составе ядер, группу из одного или более совместно используемых модулей 1206 кэшей и внешнюю память (не показана), соединенные с группой из одного или более встроенных модулей 1214 контроллеров памяти. Группа совместно используемых модулей 1206 может содержать один или более кэшей среднего уровня, таких как уровень 2 (L2), уровень 3 (L3), уровень 4 (L4) или другие уровни кэша, последний уровень кэша (LLC) и/или их сочетания. Хотя в одном из вариантов кольцевой соединительный модуль 1212 соединяет встроенную графическую логическую схему 1208, группу совместно используемых модулей 1206 кэшей и модуль 1210 системного агента/модули 1214 встроенных контроллеров памяти, альтернативные варианты могут использовать любое число хорошо известных способов соединения таких модулей. В одном из вариантов сохраняют когерентность между одним или более модулями 1206 кэшей и ядрами 1202-A-N.
В некоторых вариантах одно или более ядер 1202A-N способны обеспечивать многопоточность. Системный агент 1210 содержит компоненты, координирующие и управляющие работой ядер 1202A-N. Этот модуль 1210 системного агента может содержать, например, модуль управления питанием (PCU) и модуль отображения. Модуль PCU может представлять собой логическую схему или содержать логические схемы и компоненты, необходимые для регулировки состояния питания ядер 1202A-N и встроенной графической логической схемы 1208. Модуль отображения предназначен для управления одним или более присоединенными извне устройствами отображения.
Ядра 1202A-N могут быть гомогенными или гетерогенными с точки зрения структуры набора команд; иными словами два или более ядер 1202A-N могут быть способны выполнять один и тот же набор команд, тогда как другие могут быть способны выполнять только подмножество этого набора команд и/или другой набор команд.
Примеры компьютерных архитектур
Фиг. 13-16 представляют блок-схемы примеров компьютерных архитектур. Подходят также другие конструкции и конфигурации схемы, известные в технике, для портативных компьютеров, настольных компьютеров, ручных персональных компьютеров, персональных цифровых помощников, инженерных рабочих станций, серверов, сетевых устройств, сетевых концентраторов, коммутаторов, встроенных процессоров, цифровых процессоров сигналов (DSP), графических устройств, видео игровых устройств, приставок, микроконтроллеров, сотовых телефонов, портативных медиа плееров и разнообразных других электронных устройств. В общем случае подходят огромное разнообразие систем или электронных устройств, способных иметь процессор и/или другое исполнительное устройство, описанное здесь.
Обратимся к фиг. 13, где показана блок-схема системы 1300 согласно одному из вариантов настоящего изобретения. Эта система 1300 может содержать один или более процессоров 1310, 1315, соединенных с концентратором 1320 контроллера. В одном из вариантов концентратор 1320 контроллера содержит концентратор 1390 графического контроллера (GMCH) и концентратор 1350 ввода/вывода (IOH) (которые могут быть выполнены на раздельных кристаллах интегральных схем); концентратор GMCH 1390 содержит контроллеры памяти и графики, к которым присоединены память 1340 и сопроцессор 1345; концентратор IOH 1350 соединяет устройства 1360 ввода/вывода с концентратором GMCH 1390. В альтернативном варианте один или оба - контроллер памяти и графический контроллер, интегрированы в процессоре (как описано здесь), память 1340 и сопроцессор 1345 соединены непосредственно с процессором 1310, а концентратор 1320 контроллеров выполнен на одном кристалле интегральной схемы с концентратором IOH 1350.
Необязательная природа дополнительных процессоров 1315 обозначена на фиг. 13 штриховыми линиями. Каждый процессор 1310, 1315 может содержать одно или более описанных здесь процессорных ядер и может представлять собой некоторую версию процессора 1200.
Память 1340 может представлять собой, например, динамическое запоминающее устройство с произвольной выборкой (DRAM), запоминающее устройство с использованием фазовых переходов (РСМ) или их сочетание. По меньшей мере в одном из вариантов концентратор 1320 контроллера поддерживает связь с процессорами 1310, 1315 по имеющей множество отводов шине данных, такой как внешняя шина (frontside bus (FSB)), через двусторонний интерфейс, такой как QuickPath Interconnect (QPI), или через аналогичное соединение 1395.
В одном из вариантов сопроцессор 1345 представляет собой процессор специального назначения, такой как, например, высокопроизводительный MIC-процессор, сетевой процессор или процессор связи, автомат сжатия, графический процессор, процессор GPGPU, встроенный процессор или аналогичный процессор. В одном из вариантов концентратор 1320 контроллеров может иметь встроенный графический ускоритель.
Возможны самые разнообразные различия между физическими ресурсами 1310, 1315 с точки зрения целого спектра параметров, включая архитектурные, микроархитектурные, тепловые характеристики, энергопотребление и другие подобные характеристики.
В одном из вариантов процессор 1310 выполняет команды, управляющими операциями обработки данных общего типа. В совокупность команд могут быть встроены команды для сопроцессора. Процессор 1310 распознает эти сопроцессорные команды, как команды, подлежащие выполнению присоединенным сопроцессором 1345. Соответственно процессор 1310 выдает эти сопроцессорные команды (или сигналы управления, представляющие сопроцессорные команды) в шину сопроцессора или в другое соединение, чтобы передать сопроцессору 1345. Сопроцессор 1345 получает и выполняет принятые сопроцессорные команды.
Обратимся теперь к фиг. 14, где представлена блок-схема первого примера более конкретной системы 1400 согласно одному из вариантов настоящего изобретения. Как показано на фиг. 14, многопроцессорная система 1400 представляет собой систему с двусторонними соединениями, содержащую первый процессор 1470 и второй процессор 1480, связанные один с другим через двустороннее соединение 1450. Каждый из процессоров 1470 и 1480 может представлять собой некоторую версию процессора 1200. В одном из вариантов настоящего изобретения процессоры 1470 и 1480 представляют собой, соответственно, процессоры 1310 и 1315, тогда как сопроцессор 1438 представляет собой сопроцессор 1345. В другом варианте процессоры 1470 и 1480 представляют собой, соответственно, процессор 1310 и сопроцессор 1345.
Процессоры 1470 и 1480, как показано, содержат модули 1472 и 1482, соответственно, встроенных контроллеров памяти (IMC). Процессор 1470 содержит также, в качестве части группы своих модулей контроллеров шин, двусторонние (Р-Р) интерфейсы 1476 и 1478; аналогично, второй процессор 1480 содержит двусторонние (Р-Р) интерфейсы 1486 и 1488. Процессоры 1470 и 1480 могут обмениваться информацией через двусторонний (Р-Р) интерфейс 1450 с использованием двусторонних интерфейсных схем 1478, 1488. Как показано на фиг. 14, модули 1472 и 1482 контроллеров IMC соединяют процессоры с соответствующими запоминающими устройствами, а именно памятью 1432 и 1434, которые могут быть участками главной памяти, локально выделенными соответствующим процессорам.
Процессоры 1470, 1480 могут каждый обмениваться информацией с чипсетом 1490 через индивидуальные двусторонние (Р-Р) интерфейсы 1452, 1454 с использованием двусторонних интерфейсных схем 1476, 1494, 1486, 1498. Чипсет 1490 может в качестве опции обмениваться информацией с сопроцессором 1438 через высокопроизводительный интерфейс 1439. В одном из вариантов сопроцессор 1438 представляет собой процессор специального назначения, такой как, например, высокопроизводительный MIC-процессор, сетевой процессор или процессор связи, автомат сжатия, графический процессор, процессор GPGPU, встроенный процессор или другой аналогичный процессор.
Совместно используемый кэш (не показан), может быть введен в каждый процессор или располагаться снаружи обоих процессоров, будучи связан с процессорами посредством двустороннего (Р-Р) соединения, так что информацию локального кэша любого или обоих процессоров можно сохранять в этом совместно используемом кэше, если какой-либо процессор переведен в режим пониженного питания.
Чипсет 1490 может быть соединен с первой шиной 1416 через интерфейс 1496. В одном из вариантов первая шина 1416 может быть шиной для соединения периферийных устройств стандарта Peripheral Component Interconnect (PCI), или шиной типа PCI Express, или какой-либо другой соединительной шиной ввода/вывода третьего поколения, хотя объем настоящего изобретения этим не ограничивается.
Как показано на фиг. 14, различные устройства 1414 могут быть соединены с первой шиной 1416 вместе с мостом 1418 шины, который соединяет первую шину 1416 со второй шиной 1420. В одном из вариантов с первой шиной 1416 соединены один или более дополнительных процессоров 1415, таких как сопроцессоры, высокопроизводительные MIC-процессоры, процессоры GPGPU, ускорители, (такие как, например, графические ускорители или цифровые процессоры сигналов (DSP)), программируемые пользователем вентильные матрицы или какие-либо другие процессоры. В одном из вариантов вторая шина 1420 может быть шиной с небольшим числом выводов (LPC). Со второй шиной 1420 могут быть соединены различные устройства, включая, например, клавиатуру и/или мышь 1422, устройства 1427 связи и запоминающее устройство 1428, такое как дисковод или другое запоминающее устройство 1430 большой емкости, которое может содержать команды/код и данные, в одном из вариантов. Далее, со второй шиной 1420 может быть соединено звуковое устройство 1424 ввода/вывода. Отметим, что возможны и другие архитектуры. Например, вместо архитектуры с двусторонними связями, показанной на фиг. 14, система может использовать шину с множеством отводов или другую подобную архитектуру.
Обратимся сейчас к фиг. 15, где показана блок-схема второго примера более конкретной системы 1500 согласно одному из вариантов настоящего изобретения. Аналогичные элементы на фиг. 14 и 15 имеют одинаковые цифровые позиционные обозначения, а некоторые аспекты фиг. 14 будут в описании фиг. 15 опущены, чтобы не заслонять другие аспекты фиг. 15.
На фиг. 15 показано, что процессоры 1470, 1480 могут содержать встроенные, логические схемы 1472 и 1482, соответственно, управления ("CL") памятью и вводом/выводом. Таким образом, схемы CL 1472, 1482 содержат модули встроенных контроллеров памяти и логическую схему управления вводом/выводом. Фиг. 15 показывает, что со схемами CL 1472, 1482 соединены не только запоминающие устройства 1432, 1434, но и устройства 1514 ввода/вывода также соединены с этими логическими схемами 1472, 1482 управления. С чипсетом 1490 соединены существующие устройства 1515 ввода/вывода.
Обратимся сейчас к фиг. 16, где представлена блок-схема системы 1600 на кристалле (SoC) согласно одному из вариантов настоящего изобретения. Элементы, аналогичные элементам, показанным на фиг. 12, имеют такие же цифровые позиционные обозначения. Кроме того, прямоугольниками из штриховых линий обозначены признаки-опции, присущие более совершенным системам SoC. На фиг. 16 соединительные модули 1602 связаны с: процессором 1610 приложений, содержащим группу из одного или более ядер 1202A-N и совместно используемых модулей 1206 кэша; модулем 1210 системного агента; модулями 1216 контроллеров шин; модулями 1214 встроенных контроллеров памяти; группой из одного или более сопроцессоров 1620, которые могут содержать встроенную графическую логическую схему, процессор изображений, аудио процессор и видео процессор; модулем 1630 статического RAM (SRAM); модулем 1632 прямого доступа к памяти (DMA); и модулем 1640 отображения для соединения с одним или более внешними устройствами отображения. В одном из вариантов среди сопроцессоров 1620 могут быть один или более процессоров специального назначения, таких как, например, сетевой процессор или процессор связи, автомат сжатия, процессор GPGPU, высокопроизводительный MIC-процессор, встроенный процессор или другой подобный процессор.
Варианты описанных здесь механизмов могут быть реализованы посредством аппаратуры, загружаемого программного обеспечения, встроенного программного обеспечения (программно-аппаратных средств) или в виде сочетания таких подходов. Варианты настоящего изобретения могут быть реализованы в виде компьютерных программ или программного кода, исполняемого программируемыми системами, содержащими по меньшей мере один процессор, систему хранения информации (включая энергозависимую и энергонезависимую память и/или носители записи), по меньшей мере одно устройство ввода и по меньшей мере одно устройство вывода.
Программный код, такой как код 1430, показанный на фиг. 14, может быть применен к командам ввода для выполнения функций, описанных здесь, и генерирования выходной информации. Эта выходная информация может быть применена известным способом к одному или более устройствам вывода. Для целей настоящей заявки понятие процессорной системы охватывает любую систему, имеющую процессор, такой как, например, цифровой процессор сигнала (DSP), микроконтроллер, специализированная интегральная схема (ASIC) или микропроцессор.
Для связи с процессорной системой может быть написан программный код на процедурном или объектно-ориентированном языке программирования высокого уровня. Этот программный код может быть, если нужно, написан также на ассемблере или на языке машинных команд. На самом деле объем описанных здесь механизмов не ограничивается каким-либо конкретным языком программирования. В любом случае этот язык может быть компилируемым или интерпретируемым языком.
Один или более аспектов по меньшей мере одного из вариантов может быть реализован посредством записанных на компьютерном носителе записи репрезентативных команд, которые представляют разнообразные логические схемы в процессоре и которые при считывании их компьютером вызывают формирование в компьютере логических структур для реализации описанных здесь способов. Такие представления, именуемые "IP ядрами" могут быть сохранены на материальном компьютерном носителе записи и могут быть поставлены различным заказчикам или на промышленные предприятия для загрузки в изготавливаемые устройства, реально образующие логические схемы или процессоры.
Такими компьютерными носителями записи могут быть без ограничений энергонезависимые материальные конфигурации изделий, изготовленных или образованных посредством компьютеров или устройств, включая носители записи, такие как жесткие диски, диски любого другого типа, такие как дискеты, оптические диски, постоянные запоминающие устройства на компакт-дисках (CD-ROM), перезаписываемые компакт-диски (CD-RW) и магнитооптические диски, полупроводниковые приборы, такие как постоянные запоминающие устройства (ROM), запоминающие устройства с произвольной выборкой (RAM), такие как динамические RAM (DRAM), статические RAM (SRAM), стираемые программируемые ROM (EPROM), флэш-память, электрически стираемые программируемые ROM (EEPROM), запоминающие устройства с использованием фазовых переходов (РСМ), магнитные или оптические карточки или носители какого-либо другого типа, подходящие для хранения команд в электронной форме.
Соответственно варианты настоящего изобретения также содержат энергонезависимый материальный компьютерный носитель записи, содержащий команды или проектные данные, такие как на языке описания аппаратных средств (Hardware Description Language (HDL)), определяющие структуры, схемы, аппаратуру, процессоры и/или свойства системы, описываемые здесь. Такие варианты могут также именоваться программными продуктами.
Эмуляция (включая двоичную трансляцию, изменение формы кода и т.п.)
В некоторых случаях для преобразования команд от исходного набора команд к целевому набору команд может быть использован преобразователь команд. Например, этот преобразователь команд может транслировать (например, с использованием статической двоичной трансляции, динамической двоичной трансляции, включая динамическую компиляцию), изменение формы, эмуляцию или иное преобразование команды к одной или более другим командам для обработки ядром. Преобразователь команд может быть реализован посредством обычного загружаемого программного обеспечения, аппаратуры, встроенного программного обеспечения или их сочетания. Преобразователь команд может быть выполнен на процессоре, вне процессора или на компоненте на процессоре или компоненте вне процессора.
Фиг. 17 представляет блок-схему, показывающую сравнение использования программного преобразователя команд с целью преобразования двоичных команд из состава исходного набора команд в двоичные команды из состава целевого набора команд согласно вариантам настоящего изобретения. В иллюстрируемом варианте этот преобразователь команд представляет собой программный преобразователь команд, хотя в альтернативных вариантах преобразователь команд может быть реализован в форме загружаемого программного обеспечения, встроенного программного обеспечения, аппаратуры или различных сочетаний перечисленных компонентов. На фиг. 17 показана программа 1702 на языке высокого уровня, какую можно компилировать с использованием компилятора 1704 для стандарта х86 с целью получения двоичного кода 1706 в стандарте х86, который может быть естественным образом выполнен процессором 1716, имеющим по меньшей мере одно ядро для работы с набором команд х86. Процессор 1716 по меньшей мере с одним ядром для работы с набором команд х86 может быть любым процессором, который может выполнять по существу такие же функции, как процессор Intel по меньшей мере с одним ядром для работы с набором команд х86, путем совместимого выполнения или иной обработки (1) значительной части набора команд для ядра Intel с набором команд х86 или (2) версий объектного кода для приложений или другого программного обеспечения, предназначенного для выполнения процессором Intel по меньшей мере с одним ядром для работы с набором команд х86, с целью достижения по существу такого же результата, как в процессоре Intel по меньшей мере с одним ядром для работы с набором команд х86. Компилятор 1704 для стандарта х86 представляет собой компилятор, генерирующий двоичный код 1706 в стандарте х86 (например, двоичный код), который может, с дополнительной обработкой связей или без нее, быть выполнен в процессоре 1716, имеющем по меньшей мере одно ядро для работы с набором команд х86. Аналогично, на фиг. 17 показана программа 1702 на языке высокого уровня, какую можно компилировать с использованием компилятора 1708 для альтернативного набора команд с целью генерации двоичного кода 1710 для альтернативного набора команд, который может естественным образом выполнять процессор 1714, не имеющий по меньшей мере одного ядра для работы с набором команд х86 (например, процессор с ядрами, выполняющими набор команд MIPS, разработанный компанией MIPS Technologies of Sunnyvale, С А, и/или выполняющий набор команд ARM, разработанный компанией ARM Holdings of Sunnyvale, С А). Преобразователь 1712 команд используется для преобразования двоичного кода 1706 для стандарта х86 в код, который может быть естественным образом выполнен процессором 1714, не имеющим ядра для работы с набором команд х86. Этот преобразованный код, скорее всего, не будет таким же, как двоичный код 1710 для альтернативного набора команд, поскольку преобразователь команд, который мог бы выполнить это, трудно сделать; однако преобразованный код будет выполнять общую работу и будет построен из команд, принадлежащий указанному альтернативному набору команд. Таким образом, преобразователь 1712 команд представляет собой загружаемое программное обеспечение, аппаратуру, встроенное программное обеспечение или их сочетание, которое посредством эмуляции, моделирования или какого-либо другого процесса позволяет процессору или другому электронному устройству, не имеющему процессора или ядра для работы с набором команд х86, выполнить двоичный код 1706 для стандарта х86.
Хотя логические схемы на чертежах показывают конкретный порядок операций, выполняемых в некоторых вариантах настоящего изобретения, следует понимать, что такой порядок является всего лишь примером (например, альтернативные варианты могут выполнять эти операции в другом порядке, сочетать некоторые операции, накладывать некоторые операции одни на другие и т.д.).
В изложенном выше описании для целей пояснения были приведены многочисленные конкретные детали для обеспечения лучшего понимания вариантов настоящего изобретения. Однако специалистам в рассматриваемой области должно быть понятно, что один или несколько других вариантов могут быть практически реализованы и без некоторых из этих конкретных деталей. Конкретные варианты были здесь описаны не для ограничения объема настоящего изобретения, а только для иллюстрации вариантов этого изобретения. Объем изобретения определяется не описанными выше конкретными примерами, а только Формулой изобретения, приведенной ниже.


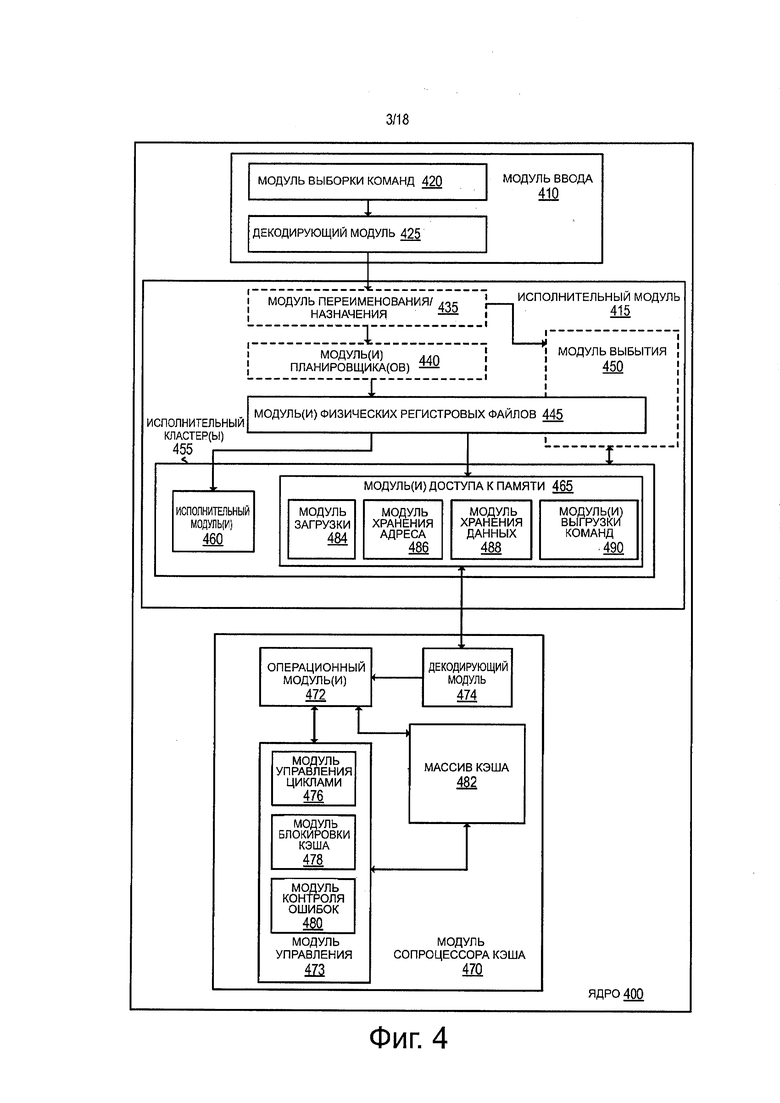

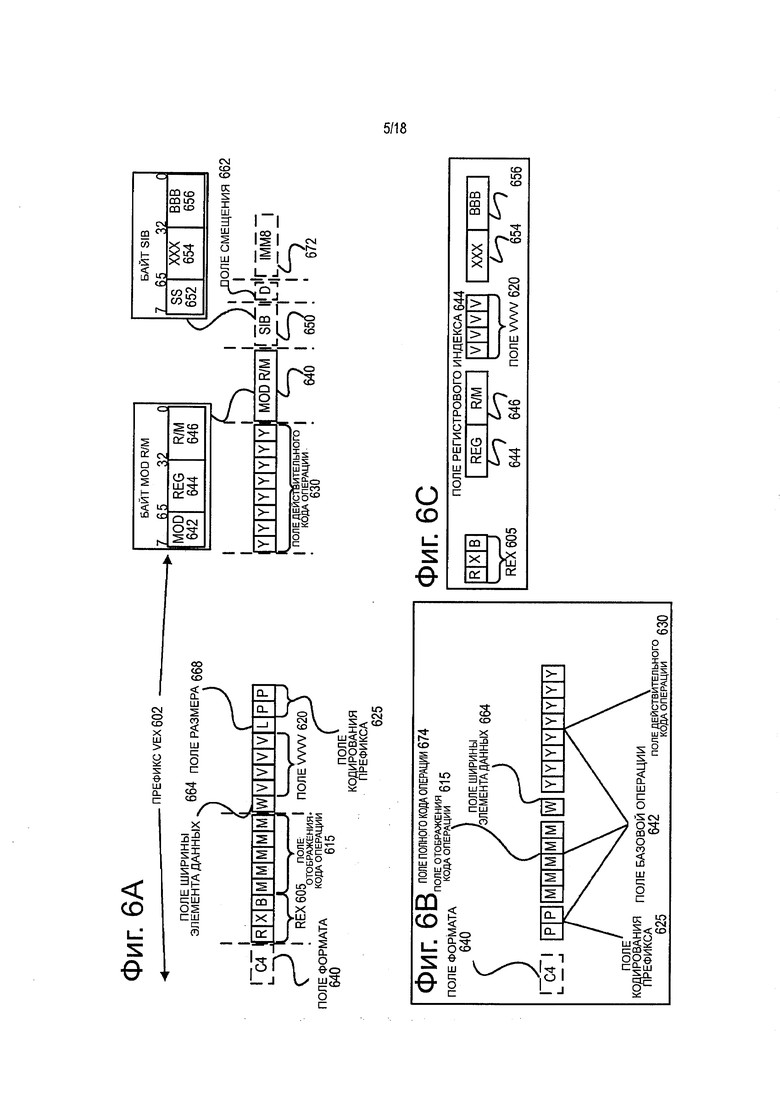


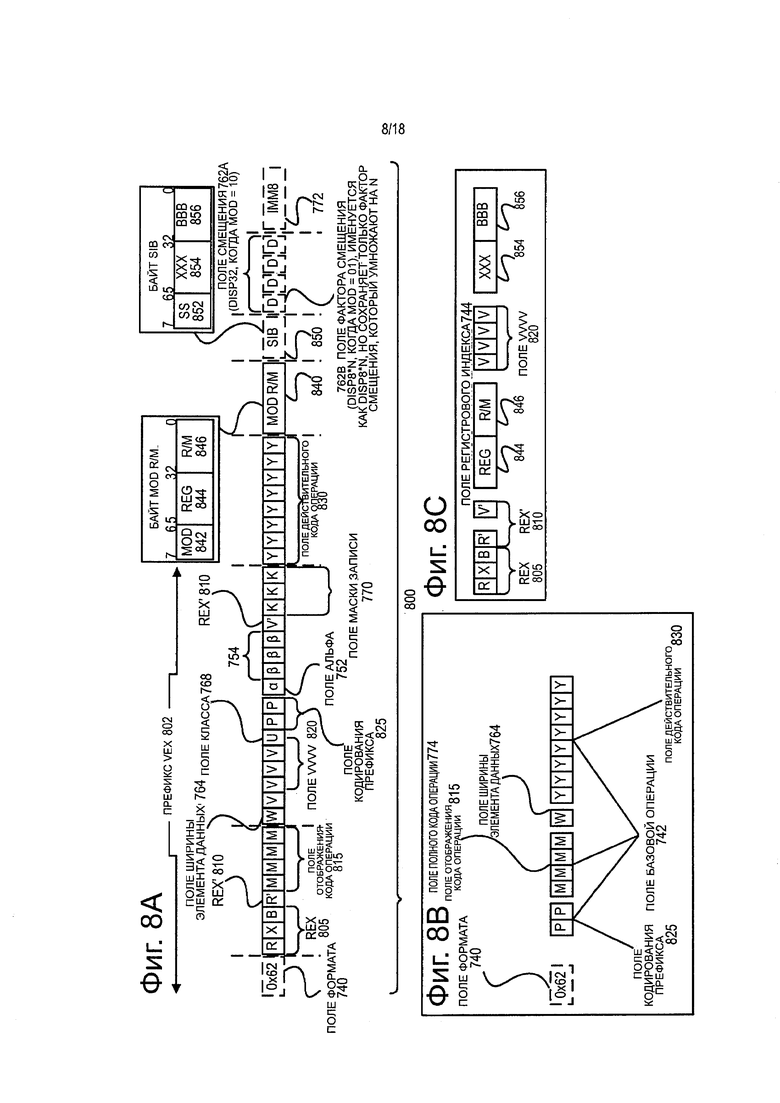

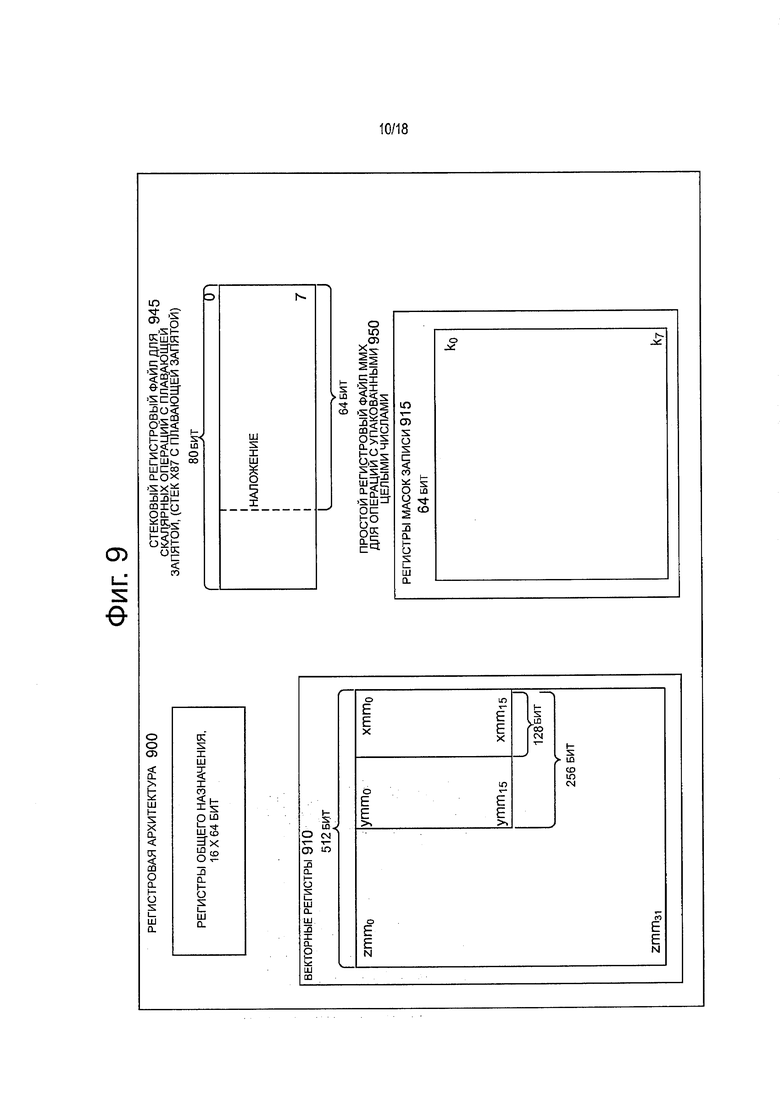



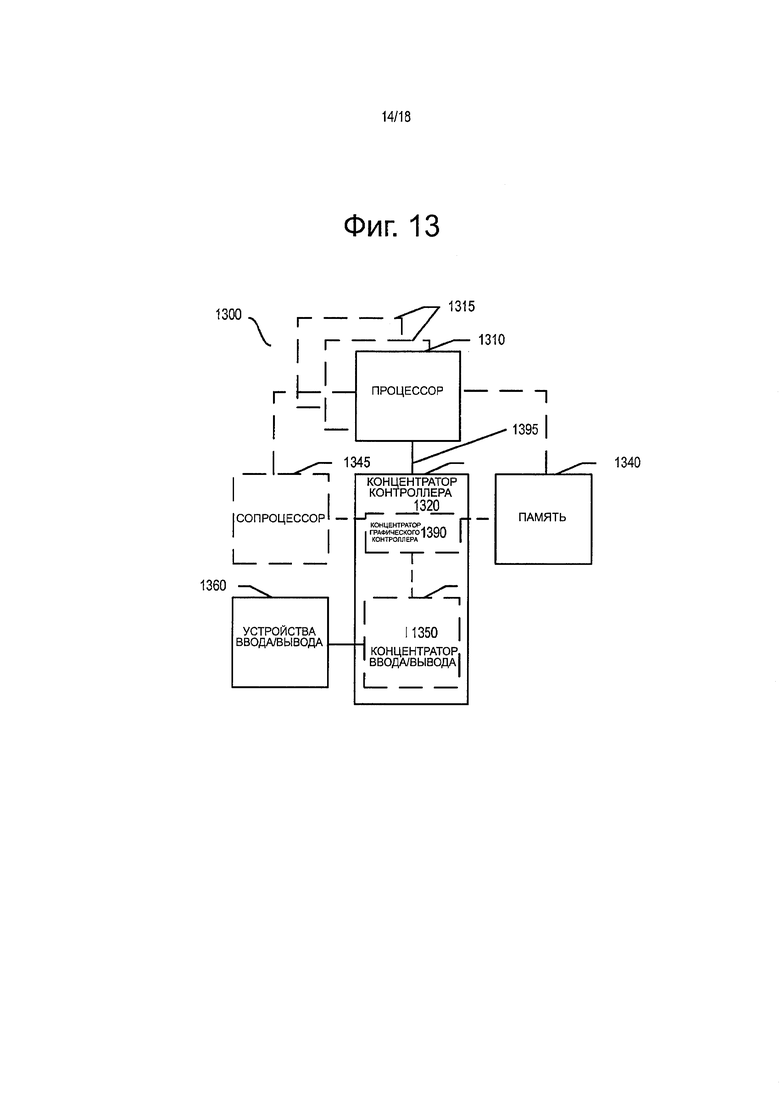

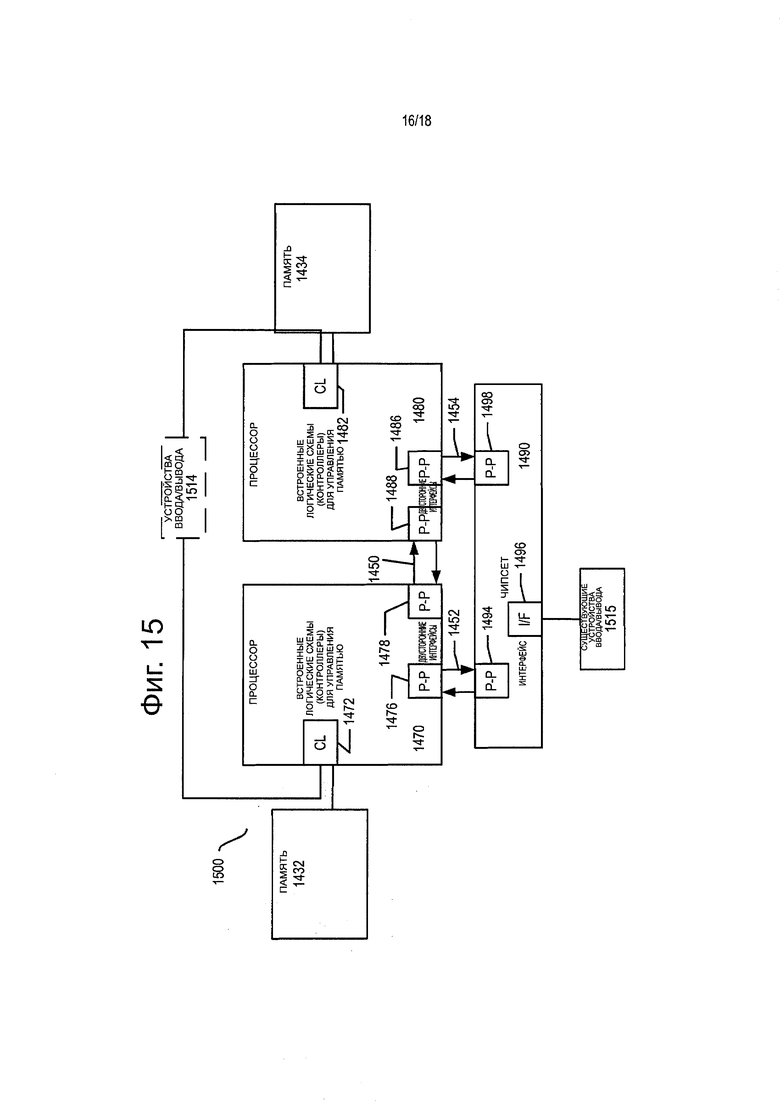

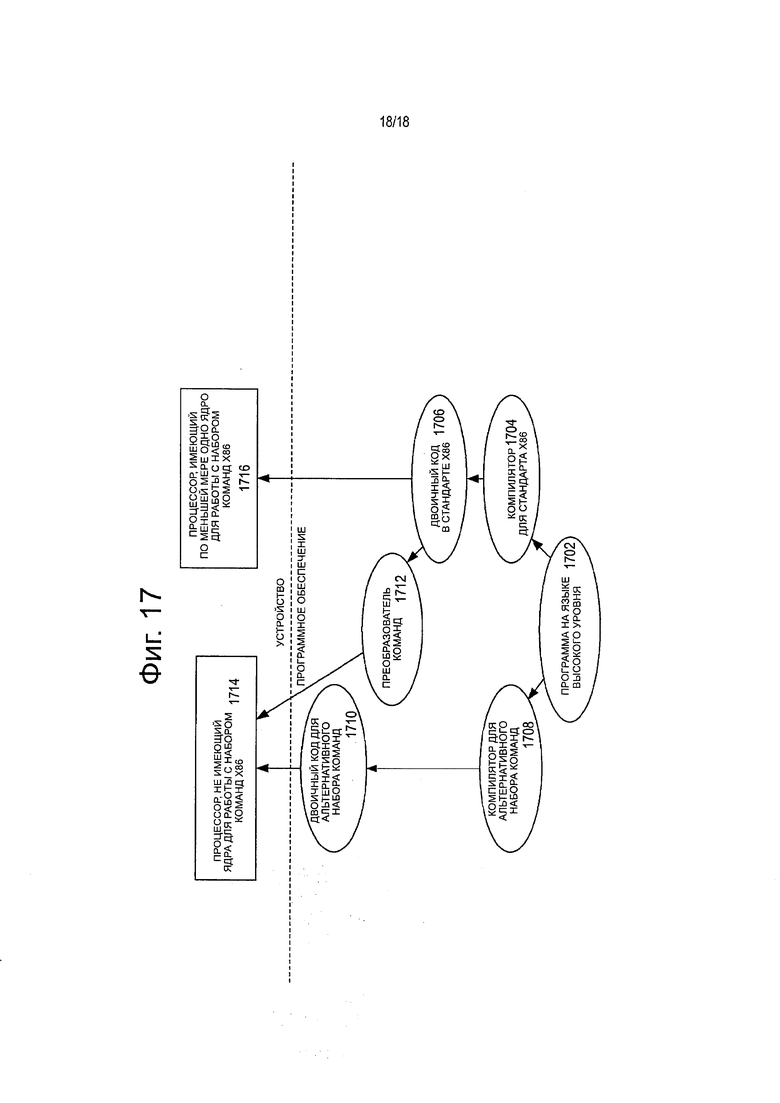
Изобретение относится к вычислительной технике. Технический результат заключается в уменьшении операций загрузки и сохранения, осуществляемых между исполнительным кластером и модулем сопроцессора кэша. Модуль сопроцессора кэша в компьютерной системе содержит массив кэша для хранения данных; аппаратный декодирующий модуль для декодирования команд, выгружаемых из потока выполнения исполнительным кластером компьютерной системы, для уменьшения операций загрузки и сохранения, осуществляемых между исполнительным кластером и модулем сопроцессора кэша; группу из одного или более операционных модулей для выполнения множества операций с массивом кэша в соответствии с декодированными командами; при этом модуль выгрузки команд выполнен с возможностью выдачи команд напрямую в модуль сопроцессора кэша для выгрузки выполнения указанных команд в модуль сопроцессора кэша. 3 н. и 18 з.п. ф-лы, 25 ил., 1 табл.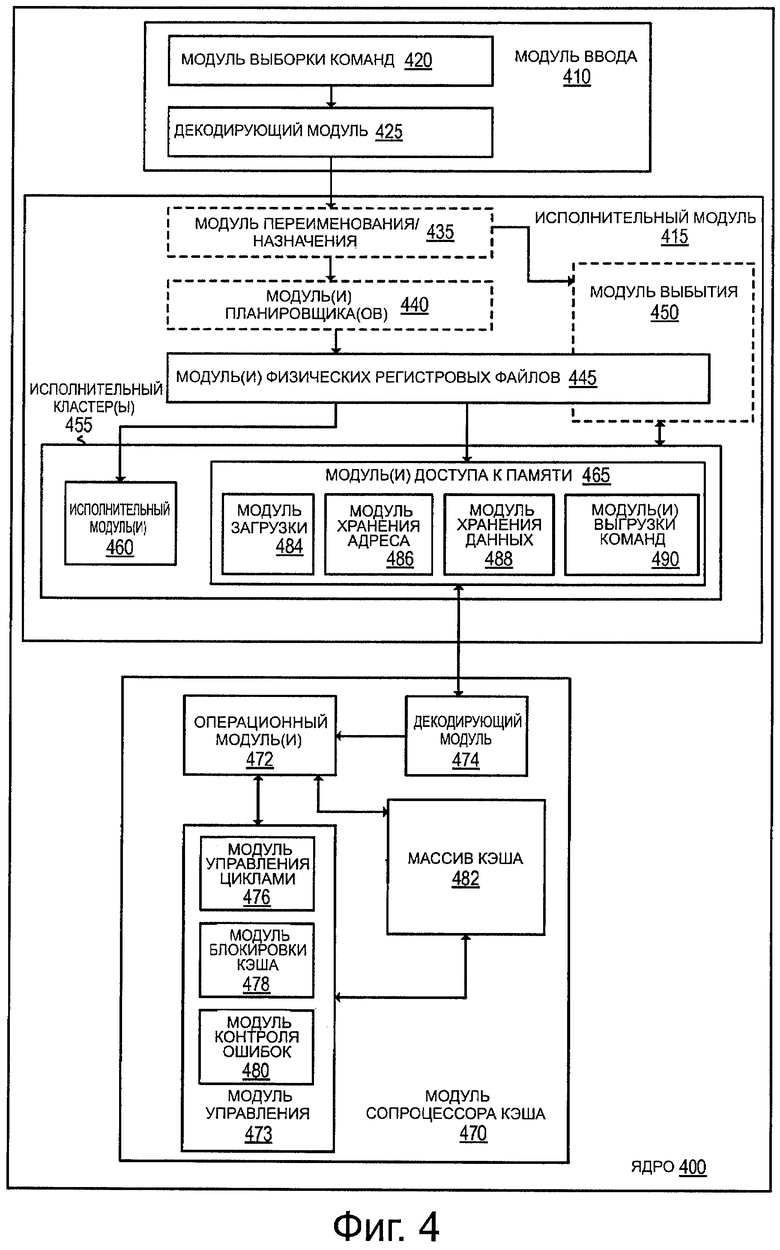
1. Модуль сопроцессора кэша в компьютерной системе, содержащий:
массив кэша для хранения данных;
аппаратный декодирующий модуль для декодирования команд, выгружаемых из потока выполнения исполнительным кластером компьютерной системы, для уменьшения операций загрузки и сохранения, осуществляемых между исполнительным кластером и модулем сопроцессора кэша;
группу из одного или более операционных модулей для выполнения множества операций с массивом кэша в соответствии с декодированными командами; при этом
модуль выгрузки команд выполнен с возможностью выдачи команд напрямую в модуль сопроцессора кэша для выгрузки выполнения указанных команд в модуль сопроцессора кэша.
2. Модуль сопроцессора кэша по п. 1, в котором группа операционных модулей дополнительно содержит группу из одного или более буферов для временного хранения данных, подлежащих обработке.
3. Модуль сопроцессора кэша по п. 1, дополнительно содержащий:
управляющий модуль, содержащий модуль блокировки кэша, выполненный с возможностью блокировки области в массиве кэша, данные которой обрабатывает группа операционных модулей.
4. Модуль сопроцессора кэша по п. 1, дополнительно содержащий модуль управления циклами, выполненный с возможностью управления циклическими проходами через массив кэша для декодированных команд.
5. Модуль сопроцессора кэша по п. 1, в котором группа операционных модулей содержит логические схемы для записи данных в массив кэша и логические схемы для чтения данных из массива кэша.
6. Модуль сопроцессора кэша по п. 1, в котором декодирующий модуль, дополнительно, выполнен с возможностью декодирования запросов загрузки и сохранения, принимаемых от исполнительного кластера компьютерной системы, при этом указанная группа операционных модулей выполнена с возможностью обработки указанных запросов загрузки и сохранения данных.
7. Модуль сопроцессора кэша по п. 1, в котором множество операций, подлежащих выполнению группой операционных модулей для декодированных команд, содержит операции сохранения и операции загрузки.
8. Модуль сопроцессора кэша по п. 1, в котором по меньшей мере одна из команд, выгружаемых из потока выполнения исполнительного кластера компьютерной системы, требует производства вычислений, при этом группа операционных модулей содержит группу из одного или более операционных модулей для выполнения вычислений в соответствии по меньшей мере с одной командой.
9. Реализуемый компьютером способ выполнения выгрузки команд, реализуемый компьютерной системой, содержащий этапы, на которых:
выполняют выборку команды;
выполняют декодирование выбранной команды;
принимают решение, что декодированная команда подлежит выполнению модулем сопроцессора кэша компьютерной системы;
выдают декодированную команду модулю сопроцессора кэша;
декодируют с помощью модуля сопроцессора кэша выданную команду; и
выполняют с помощью модуля сопроцессора кэша команду, декодированную указанным модулем сопроцессора кэша, при этом
модуль выгрузки команд выполнен с возможностью выдачи команд напрямую в модуль сопроцессора кэша для выгрузки выполнения указанных команд в модуль сопроцессора кэша.
10. Реализуемый компьютером способ по п. 9, в котором в соответствии с командой выполняют с помощью модуля сопроцессора кэша одну из операций: задание величины для по меньшей мере части массива кэша, копирование участка массива кэша в другой участок массива кэша и транспонирование элементов данных на участке массива кэша.
11. Реализуемый компьютером способ по п. 9, в котором указанная команда представляет собой постоянную вычислительную операцию, подлежащую выполнению в непрерывной области данных в массиве кэша в модуле сопроцессора кэша.
12. Реализуемый компьютером способ по п. 9, в котором этап выполнения команды, декодированной модулем сопроцессора кэша, содержит операции над группой из одной или более областей массива кэша в модуле сопроцессора кэша.
13. Реализуемый компьютером способ по п. 12, в котором этап выполнения команды, декодированной модулем сопроцессора кэша, дополнительно содержит подэтап, на котором задают блокировки кэша применительно к группе областей в массиве кэша, обрабатываемых в текущий момент.
14. Устройство выгрузки и выполнения команд, содержащее:
модуль сопроцессора кэша;
первый аппаратный декодирующий модуль для выполнения декодирования команды и принятия решения, что указанная команда подлежит выгрузке из потока выполнения исполнительных модулей исполнительного кластера для выполнения модулем сопроцессора кэша для уменьшения числа операций загрузки и сохранения между указанным исполнительным кластером и указанным модулем сопроцессора кэша;
модуль выгрузки команд для выдачи команды в модуль сопроцессора кэша; при этом
указанный модуль сопроцессора кэша содержит:
массив кэша для хранения данных, и
второй аппаратный декодирующий модуль для выполнения декодирования команды, выданной модулем выгрузки команд, и
группу из одного или более операционных модулей для выполнения множества операций с данными в массиве кэша в соответствии с декодированной командой, а
модуль выгрузки команд выполнен с возможностью выдачи команд напрямую в модуль сопроцессора кэша для выгрузки выполнения указанных команд в модуль сопроцессора кэша.
15. Устройство по п. 14, в котором группа операционных модулей дополнительно содержит группу из одного или более буферов для временного хранения данных, обрабатываемых операционными модулями.
16. Устройство по п. 14, в котором модуль сопроцессора кэша дополнительно содержит:
управляющий модуль, содержащий модуль блокировки кэша, выполненный с возможностью блокировки области в массиве кэша, обрабатываемой группой операционных модулей.
17. Устройство по п. 14, в котором управляющий модуль дополнительно содержит модуль управления циклами, выполненный с возможностью управления циклическими проходами через массив кэша для декодированных команд.
18. Устройство по п. 14, в котором группа операционных модулей содержит логические схемы для записи данных в массив кэша и логические схемы для чтения данных из массива кэша.
19. Устройство по п. 14, дополнительно содержащее:
модуль загрузки, выполненный с возможностью выдачи запросов загрузки в модуль сопроцессора кэша;
модуль адресов сохранения и модуль сохранения данных для выдачи запросов сохранения в модуль процессора кэша; при этом
второй аппаратный декодирующий модуль, дополнительно, выполнен с возможностью декодирования запросов загрузки и запросов сохранения данных, причем
группа операционных модулей выполнена с возможностью обработки запросов загрузки и сохранения данных.
20. Устройство по п. 14, в котором множество операций, подлежащих выполнению группой операционных модулей, содержит операции сохранения данных или операции загрузки данных.
21. Устройство по п. 14, в котором модуль сопроцессора кэша выполнен с возможностью функционирования в качестве кэша первого уровня.
| АДРЕСАЦИЯ РЕГИСТРОВ В УСТРОЙСТВЕ ОБРАБОТКИ ДАННЫХ | 1997 |
|
RU2193228C2 |
| US 6044478 A1, 28.03.2000 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

