УРОВЕНЬ ТЕХНИКИ
S-списки представляют собой структуры данных, которые являются безблокировочными реализациями списка LIFO (последним пришел - первым обслужен), сделанными доступными в операционных системах. S-списки, как правило, являются желаемым выбором структуры данных для хранения буферов фиксированного размера, которые могут быть выделены и освобождены без удерживания каких-либо спин-блокировок или других примитивов синхронизации. S-списки также могут использоваться для содержимого переменного размера в форме безблокировочного однонаправленного списка. Другие возможности предоставлены в среде операционной системы - такие как сохраняющие списки, которые построены на S-списках.
Однако в некоторых сценариях использование S-списков может быть нежелательным. В качестве одного из примеров, единственный заголовок S-списка может стать горячей точкой конкуренции строки кэша на серверах со многими процессорами, осуществляющими доступ к одному и тому же S-списку. Это может быть узким местом масштабируемости как в родном, так и в Hyper-V виртуализированных сценариях.
В другом сценарии S-списки могут быть в основном использованы как пакетные кэши или буферные хранилища фиксированного размера. Однако существуют сценарии, где более сложные структуры данных или ресурсы вероятно меняющихся размеров должны поддерживаться в таком безблокировочном списке. Может быть желательно иметь больше операций, чем просто 'Поместить' ('Push') и 'Извлечь' ('Pop') для таких целей, как балансировка нагрузки, занятие пакетов, осведомленность NUMA (архитектура неоднородного доступа к памяти) и других алгоритмических требований. Они часто удовлетворяются другой абстракцией структуры данных, чтобы управлять несколькими S-списками. Сохраняющие списки являются одним таким примером.
Сохраняющие списки поддерживают кэш буферов фиксированного размера для быстрого выделения и освобождения памяти. Для преимуществ привязки к процессору некоторые операционные системы также предоставляют сохраняющие списки из расчета на процессор. Эти сохраняющие списки из расчета на процессор, как правило (но не обязательно), поддерживаются глобальным списком, чтобы содержать резервные пакеты в случае, если список из расчета на процессор пустой. Может быть желательно иметь дополнительные выделения ресурсов, чтобы иметь довольно большой резервный список для предоставления абстракции единого пула ресурсов. Когда потребность падает, эти дополнительные выделения памяти могут быть освобождены, если есть потребность в памяти. Однако в определенных сценариях ресурсы не могут быть избыточно выделены. Это особенно верно для аппаратных драйверов, которые определяют пределы своих возможностей - подобно максимальному числу запросов I/O (ввода/вывода), которые может обработать RAID контроллер. Усовершенствованные алгоритмы связывают эти пределы с глубинами S-списков и избегают использования спин-блокировок. Также дополнительные издержки выделений и освобождений вызывают фрагментацию памяти и затраты в виде циклов ЦП (CPU, центрального процессора). Сохраняющие списки, которые выделяют больше, чем необходимое количество, могут не быть использованы по этим причинам.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Нижеследующее представляет упрощенное изложение сущности инновации, чтобы обеспечить базовое понимание некоторых аспектов, описанных в материалах настоящей заявки. Это краткое изложение сущности изобретения не является исчерпывающим обзором заявленного изобретения. Оно не предназначено ни для определения ключевых или критических элементов заявленного изобретения, ни для очерчивания объема изобретения. Его единственная цель состоит в том, чтобы представить некоторые принципы заявленного изобретения в упрощенной форме в качестве вводной части к более подробному описанию, которое представлено позже.
В одном из вариантов осуществления представлены системы и способы для управления выделением множества элементов памяти, хранимых во множестве безблокировочных списковых структур. Эти безблокировочные списковые структуры (такие как S-списки) могут быть сделаны доступными в среде операционной системы многоядерного процессора. В некоторых вариантах осуществления безблокировочные списковые структуры, S-списки или тому подобное могут быть встроены в другие общие структуры данных, такие как хэши, деревья и т.д., чтобы удовлетворить различным требованиям по выделению ресурсов и управлению.
Некоторые варианты осуществления могут разделять это множество безблокировочных списковых структур и изначально разделять элементы памяти среди этих безблокировочных списковых структур. Когда ядерный процессор (или другой обрабатывающий элемент) делает запрос на выделение себе элемента памяти, система и/или способ могут искать среди безблокировочных списковых структур доступный элемент памяти. Когда подходящий и/или доступный элемент памяти найден, система может выделить доступный элемент памяти запрашивающему ядерному процессору.
В некоторых вариантах осуществления система и/или способ могут затем динамически балансировать набор элементов памяти среди различных безблокировочных списковых структур в соответствии с подходящей метрикой балансировки. Такая возможная метрика может заключаться просто в поддержке, по существу, числового равенства элементов памяти среди безблокировочных списковых структур. Другие метрики могут включать в себя другие соображения балансировки нагрузки - возможно, основанные на типе выполняющегося процесса, возможных конкурентных ситуациях или тому подобном - например, такие как упомянутые выше, чтобы уменьшить конкуренцию ЦП или избежать избыточного выделения (over-allocation) ресурсов памяти.
Другие признаки и аспекты настоящей системы представлены ниже в Подробном Описании при прочтении в связи с чертежами, представленными в этой заявке.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Примерные варианты осуществления проиллюстрированы на чертежах, на которые даны ссылки. Предполагается, что варианты осуществления и чертежи, раскрытые в материалах настоящей заявки, следует рассматривать как иллюстративные, а не ограничительные.
Фиг. 1 иллюстрирует примерную компьютерную систему, в которой системы и методики настоящей заявки могут располагаться и работать.
Фиг. 2A представляет собой один из вариантов осуществления адаптивной системы структуры хэш и способа для управления S-списками.
Фиг. 2B представляет собой один из вариантов осуществления системы динамической перестановки списков и способа для управления S-списками.
Фиг. 3 иллюстрирует логическую блок-схему в одном из вариантов осуществления адаптивной хэш-системы, как могло быть реализовано на фиг. 2A.
ПОДРОБНОЕ ОПИСАНИЕ
Как использовано в материалах настоящей заявки, термины "компонент", "система", "интерфейс" и т.п. предназначены для обозначения связанной с компьютером сущности, т.е. аппаратных средств, программных средств (например, в ходе исполнения) и/или программно-аппаратных средств (firmware). Например, компонент может быть процессом, запущенным на процессоре, процессором, объектом, исполняемым файлом, программой и/или компьютером. В качестве иллюстрации, как приложение, работающее на сервере, так и сервер могут быть компонентом. Один или более компонентов могут находиться внутри процесса, и компонент может быть локализован на одном компьютере и/или распределен между двумя и более компьютерами.
Заявленное изобретение описано со ссылкой на чертежи, на всем протяжении которых одинаковые номера ссылок используются для указания идентичных элементов. В последующем описании, в целях пояснения, многочисленные характерные детали изложены для того, чтобы обеспечить исчерпывающее понимание предмета инновации. Однако может быть очевидно, что заявленное изобретение может быть реализовано на практике без этих характерных деталей. В других случаях широко известные структуры и устройства показаны в форме структурной схемы, чтобы облегчить описание предмета инновации. Чтобы удовлетворить потенциальную нехватку ресурсов, настоящая заявка раскрывает ряд вариантов осуществления, которые допускают действенное и эффективное использование S-списков. В одном из вариантов осуществления S-списки могут быть разделены эффективным способом, который решает многие из вышеупомянутых ограничений, при этом все еще поддерживая безблокировочную природу ресурсных S-списков, уменьшая конкуренцию, связанную со строками кэша, выделение фиксированного количества и совместное использование/занятие ресурсов между списками. В других вариантах осуществления эти методики могут использовать привязку к процессору и осведомленность NUMA (архитектура неоднородного доступа к памяти) для оптимальной производительности.
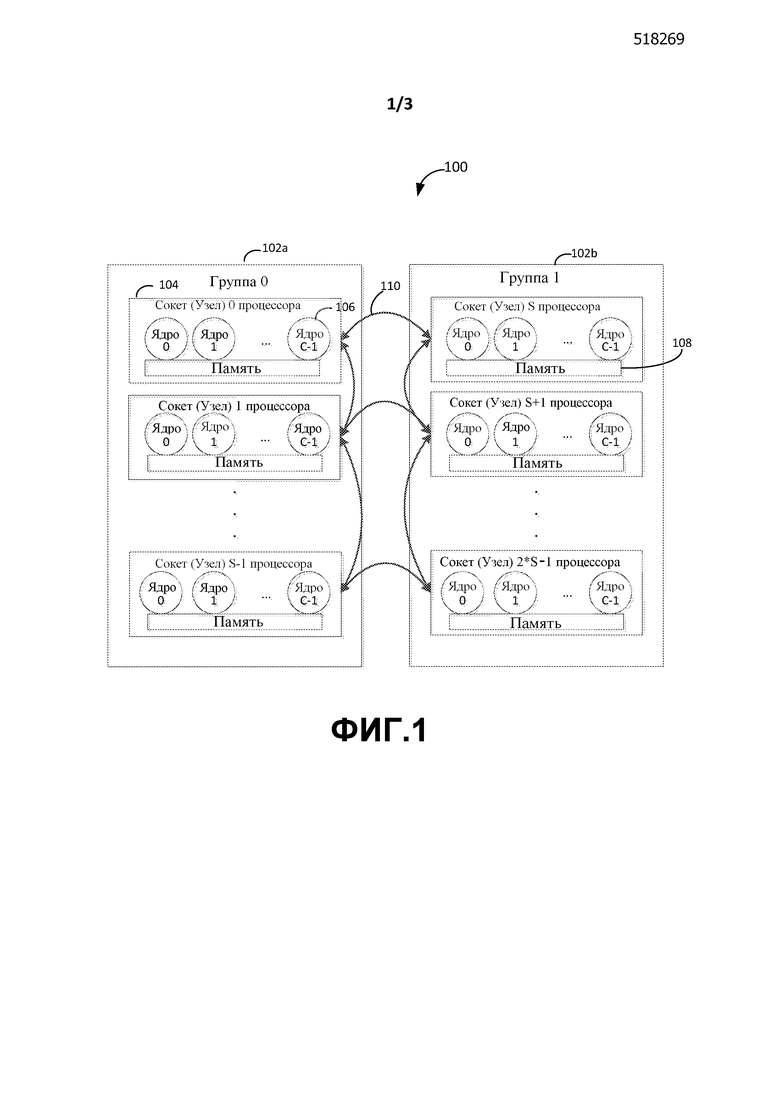
Фиг. 1 изображает схему компьютерной системы, показывающую состоящую из нескольких групп многоядерную систему 100 с узлами NUMA (т.е., сокетами процессора). Система 100, как показано, содержит 2 группы - например, Группу 0 (102a) и Группу 1 (102b). В одном из вариантов осуществления каждая группа может содержать до 64 (например, маркированных от 0 до 63) Логических Процессоров (LP).
Следует иметь в виду, что подходящая система может иметь 1 группу, если в ней меньше чем 64 логических процессора. Подобным образом, система может иметь больше чем 2 группы. Узлы NUMA полностью содержатся в группе, поэтому может быть возможно, что группа может иметь меньше чем 64 логических процессора. Система может иметь несколько (больше чем 2 группы) в зависимости от количества логических процессоров, содержащихся в системе.
Как показано, каждая группа может дополнительно содержать узлы 104 (т.е., сокеты для установки процессора). Узлы на схеме могут также относиться к Узлам NUMA (Неоднородный Доступ к Памяти). Во многих современных системах узлы NUMA пронумерованы от 0 до 63 в рамках всей системы, охватывающей все группы; однако будущие системы могут иметь другое количество узлов, и настоящая заявка не ограничена такими современными спецификациями. Каждый такой узел может дополнительно содержать ядра 106. В настоящем варианте осуществления каждый LP может быть ядром или аппаратным потоком. Логические Процессоры уникальным образом пронумерованы от 0 до 63 в каждой группе.
В некоторой вычислительной среде системы с более чем одним физическим процессором - или системы с физическими процессорами, которые имеют несколько ядер - могут предоставить операционной системе несколько логических процессоров. Логический Процессор представляет собой одну логическую вычислительную машину с точки зрения операционной системы, приложения или драйвера. "Ядро" (или "ядерный процессор") представляет собой процессор, который может состоять из одного или более логических процессоров. Физический процессор может состоять из одного или более ядер. Физический процессор может быть истолкован так же, как корпус процессора, сокет или ЦП.
Кроме того, Ядра с 0 по C-1 могут совместно использовать ресурс 108 памяти. Время доступа к локальной памяти между ядрами и памятью на заданном узле может быть быстрее, чем время доступа к памяти к другим узлам. Соединения 110 между узлами могут быть такими, что все узлы могут осуществлять доступ к памяти во всех других узлах, но время доступа к памяти может быть медленнее, чем доступ к локальной памяти.
Следует иметь в виду, что все узлы могут не обязательно быть полностью соединены, и, кроме того, доступ к памяти от одного узла к другому, возможно, должен пройти дополнительный узел, чтобы получить доступ к памяти на 3-м узле.
Управление S-списком
Настоящая заявка раскрывает много вариантов осуществления для эффективного управления безблокировочными списковыми структурами, S-списками или тому подобным. Фиг. 2A и 2B изображают два таких варианта осуществления - адаптивная хэш функция (Фиг. 2A) и динамическая структура Помещения и Извлечения (Фиг. 2B) для управления S-списком. В этих вариантах осуществления может быть желательно предоставить управление ресурсами или пакетами в безблокировочных списках (таких как S-списки), для того чтобы:
i) уменьшить конкуренцию строки кэша ЦП;
ii) избежать избыточного выделения ресурсов;
iii) предусмотреть совместное использование и занятие ресурсов между списками, чтобы приспособиться к требованиям ресурсов с максимальным лимитом;
iv) предоставить дополнительную логику для осведомленности топологии NUMA, привязки к процессору и т.д. и/или
v) предоставить определенные требования к выделению памяти, такие как программы распределения, например, в границах 4Гб и другие такие ограничения. Могут быть нежелательными дополнительные выделения и освобождения памяти, которые могут привести к фрагментации, которая может быть проблемой - например, особенно с пределами 4 Гб.
В целом, для методик и вариантов осуществления настоящей заявки характерно встраивать безблокировочные списковые структуры, S-списки или тому подобное в другие общие структуры данных, такие как хэши, деревья и т.д., чтобы удовлетворить различным требованиям по выделению ресурсов и управлению.
Во многих из настоящих вариантов осуществления представлены системы и способы для управления выделением множества элементов памяти, хранимых во множестве безблокировочных списковых структур. Эти безблокировочные списковые структуры (такие как S-списки) могут быть сделаны доступными в среде операционной системы многоядерного процессора.
Эти варианты осуществления могут разделять данное множество безблокировочных списковых структур и изначально разделять элементы памяти среди этих безблокировочных списковых структур. Когда ядерный процессор (или другой обрабатывающий элемент) делает запрос на выделение себе элемента памяти, система и/или способ могут искать среди безблокировочных списковых структур доступный элемент памяти. Когда подходящий и/или доступный элемент памяти найден, система может выделить доступный элемент памяти запрашивающему ядерному процессору. Таким разделением безблокировочных списковых структур может обеспечиваться уменьшение конкуренции ЦП.
Система и/или способ могут затем динамически балансировать набор элементов памяти среди различных безблокировочных списковых структур в соответствии с подходящей метрикой балансировки. Такая возможная метрика может заключаться просто в поддержке, по существу, числового равенства элементов памяти среди безблокировочных списковых структур. Другие метрики могут включать в себя другие соображения балансировки нагрузки - возможно, основанные на типе выполняющегося процесса, возможных конкурентных ситуациях или тому подобном - например, такие как упомянутое выше предотвращение избыточного выделения ресурсов памяти.
В другом варианте осуществления подходящий модуль выделения может быть реализован в компьютерной системе (такой как показанной на фиг. 1 - или в любой другой подходящей многоядерной обрабатывающей системе). В качестве лишь одного примера, модуль выделения может исполняться на одном из ядерных процессоров и выполнять динамическое выделение памяти оттуда. Как будет обсуждено более подробно ниже, модуль выделения может управлять динамическим разделением элементов памяти в различных структурах данных - например, динамических хэш структурах или структурах динамической перестановки списков или тому подобном.
Адаптивное Хэширование для Управления S-списком
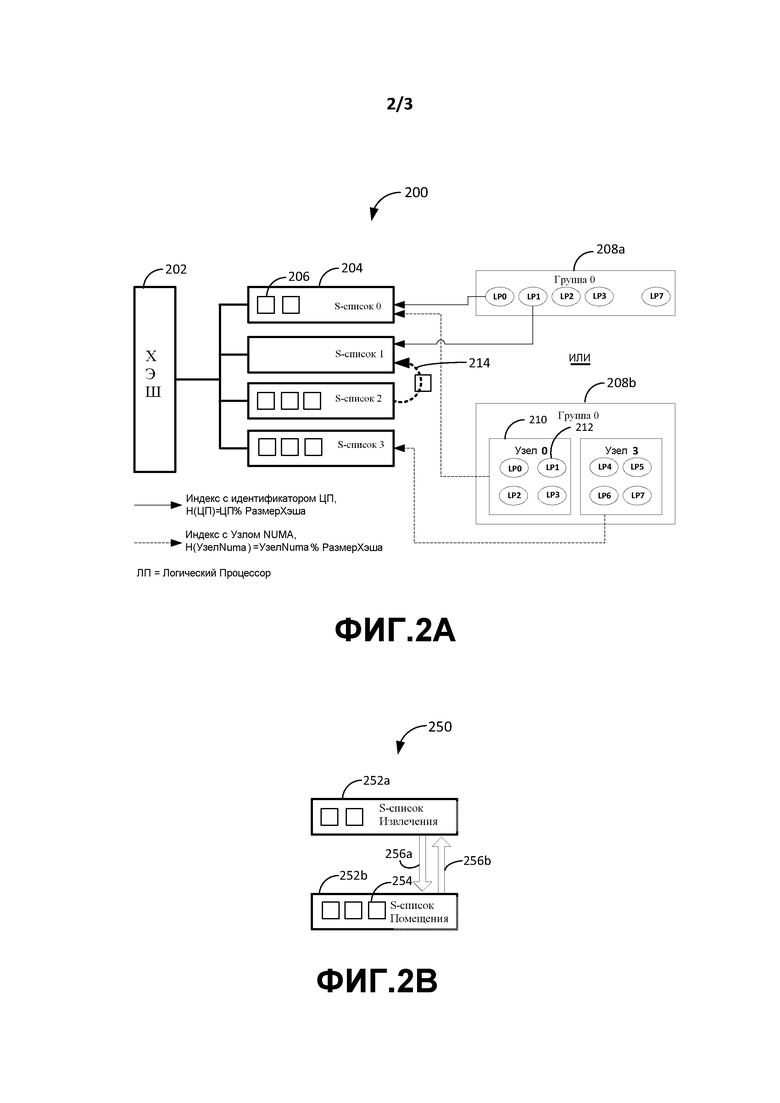
Фиг. 2A изображает адаптивную динамическую хэш систему и методики (200) для управления S-списками. Как показано, хэш модуль 202 соединен с одним или более S-списками 204 (например, от S-списка 0 до S-списка 3). Каждый S-список может дополнительно содержать ноль или более элементов 206 памяти. Каждый из этих элементов 206 памяти может быть либо буферами фиксированного размера, либо буферами переменного размера и/или структурами данных.
В этом варианте осуществления упомянутый хэш различных S-списков может поддерживаться использованием ключа таким способом, который связан с системой в целом таким образом, который относится к топологии вычислительной системы и/или архитектуре многоядерного процессора. Например, фиг. 2A изображает две такие топологии: (1) использование ключа в виде индекса процессора (как показано сплошной линией стрелки для Группы 0, маркированной 208a); (2) или использование ключа в виде номера узла NUMA (как показано пунктирными линиями стрелки для Группы 0, маркированной 208b, дополнительно содержащей узлы 210 и LP 212). В этих вариантах осуществления цель связывания индекса с топологией системы может заключаться в оптимизации времени доступа, чтобы уменьшить задержку и конкуренцию с другими процессорами в системе. Как может быть видно, элементы памяти могут быть отрегулированы и/или сбалансированы между S-списками (например, 214) в соответствии с подходящими метриками для балансировки нагрузки и/или выделений ресурсов памяти.
В одном из вариантов осуществления возможно абстрагировать единый логический S-список в несколько. В таком случае может быть возможно перемещать элементы списка между различными списками, так что выделения не оканчиваются неудачей, если один конкретный S-список пуст. Может быть осуществлен поиск по всем S-спискам в хэше, перед тем как выделение окончится неудачей. Следует иметь в виду, что различные алгоритмы хэширования могут также удовлетворять топологии системы и целям оптимизации, таким как расширения NUMA или привязки к процессору этих списков.
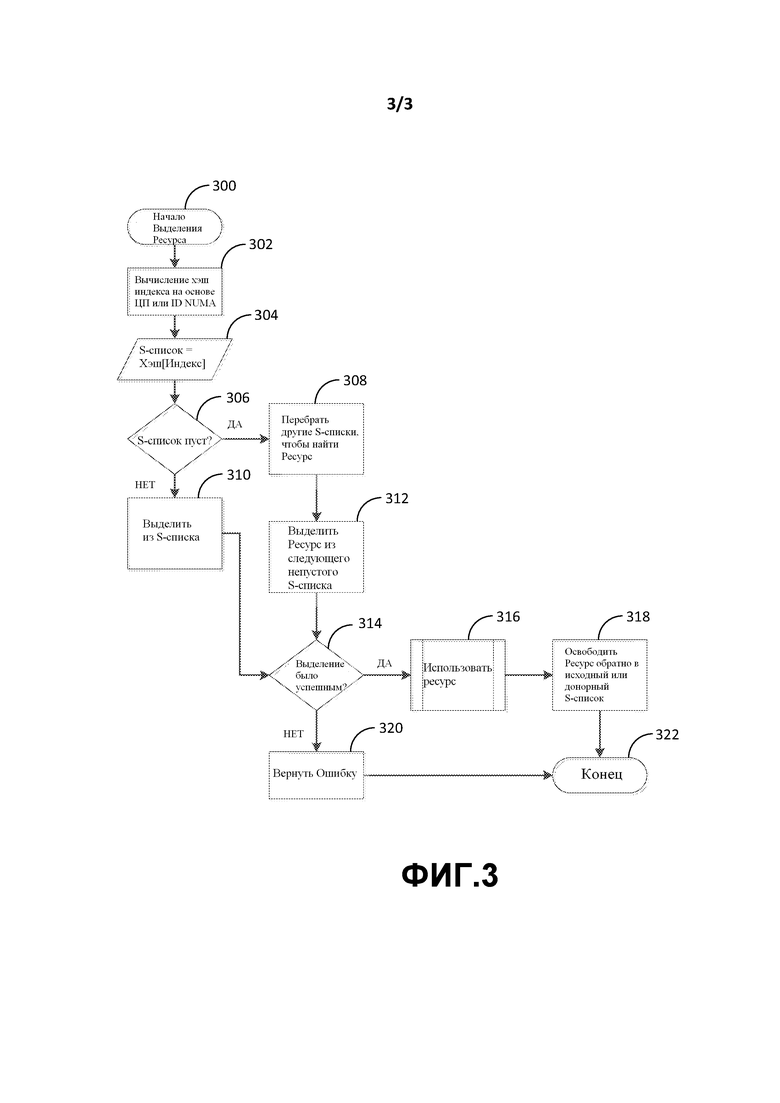
Фиг. 3 изображает одну возможную логическую блок-схему для обработки S-списка в хэш структуре. На этапе 300 система начинает выделять ресурс памяти, и на этапе 302 система может вычислить хэш индекс на основе желаемого ключа (такого как, например, номер ЦП или идентификатор NUMA, как указано на фиг. 2A). S-список может затем быть назначен хэшу(индексу), после того как вычислен.
Система может выполнить запрос на этапе 306 на предмет того, является ли S-список, в частности, пустым или лишенным элементов памяти - и если так, система может перебрать другие S-списки, чтобы найти подходящий ресурс. Как только найден, ресурс может быть выделен из, скажем, следующего непустого S-списка.
В случае, когда S-список не был пустым, ресурс может быть выделен из него на этапе 310. Независимо от того, было ли выделение сделано на этапе 310 или на этапе 312, система может запросить, было ли выделение успешным, на этапе 314. Если нет, система может в это время вернуть сообщение об ошибке на этапе 320 и завершить обработку на этапе 322.
Однако, если выделение было успешным, ресурс памяти может быть использован как выделенный, на этапе 316. Как только ресурс памяти больше не нужен, система может опционально освободить ресурс назад в исходный или донорный S-список и завершить процесс на этапе 322.
Динамическая Перестановка Списков
Фиг. 2B показывает еще один другой вариант осуществления использования структур (250) данных динамической перестановки списков для эффективного управления S-списками. Как можно увидеть, два отдельных S-списка - например, один для операций Извлечения (освобождения) 252a и один для операций Помещения (получения/выделения) 252b - могут поддерживаться, и каждый может иметь элементы 254 памяти для выделения. Два различных указателя (256a и 256b) могут использоваться для доступа к этим S-спискам. В процессе работы, если S-список Помещения пустой (или удовлетворена какая-либо другая подходящая метрика для балансировки ресурсов памяти) при попытке выделения, возможно поменять местами указатели, так что предыдущий S-список Извлечения теперь становится S-списком Помещения и наоборот. С этого момента возможно попытаться осуществить выделение из этого нового S-списка Помещения. Данная методика аналогична поддержке различных списков 'выделения' ('alloc') и 'освобождения' ('free') и переключению их, когда список 'выделения' пуст.
То, что было описано выше, включает в себя примеры предмета инновации. Конечно, невозможно описать каждую мыслимую комбинацию компонентов или методологий в целях описания заявленного изобретения, но специалист в данной области техники может осознать, что возможны многочисленные дополнительные комбинации и перестановки предмета инновации. Соответственно, заявленное изобретение подразумевается охватывающим все такие изменения, модификации и варианты, которые подпадают под сущность и объем, определяемые прилагаемой формулой изобретения.
В частности и относительно различных функций, выполняемых вышеописанными компонентами, устройствами, схемами, системами и т.п., термины (включая ссылку на "средства"), используемые для описания таких компонентов, подразумеваются соответствующими, если не указано иное, любому компоненту, который выполняет указанную функцию описанного компонента (например, функциональный эквивалент), даже если он не эквивалентен структурно раскрытой структуре, которая выполняет функцию в проиллюстрированных в материалах настоящей заявки примерных аспектах заявленного изобретения. В связи с этим также будет признано, что инновация включает в себя систему, а также машинно-читаемый носитель, содержащий исполняемые компьютером инструкции для выполнения действий и/или событий различных способов заявленного изобретения.
Кроме того, хотя конкретный признак предмета инновации, возможно, был раскрыт относительно только одной из нескольких реализаций, этот признак может быть объединен с одним или более другими признаками других реализаций, что может быть желательно и предпочтительно для любого заданного или конкретного варианта применения. Более того, в тех рамках, в которых термины "включает в себя" и "включающий" и их варианты используются либо в подробном описании, либо в формуле изобретения, эти термины подразумеваются инклюзивными аналогично термину "содержащий".
| название | год | авторы | номер документа |
|---|---|---|---|
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2761066C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2804029C2 |
| ВЫПОЛНЕНИЕ ПАРАЛЛЕЛЬНОГО ПОВТОРНОГО ХЭШИРОВАНИЯ ХЕШ-ТАБЛИЦЫ ДЛЯ МНОГОПОТОЧНЫХ ПРИЛОЖЕНИЙ | 2009 |
|
RU2517238C2 |
| ЭФФЕКТИВНЫЙ АЛГОРИТМ И ПРОТОКОЛ ДЛЯ УДАЛЕННОГО ДИФФЕРЕНЦИАЛЬНОГО СЖАТИЯ | 2005 |
|
RU2382511C2 |
| МОДУЛЬ ВИЗУАЛЬНОГО ПРОСМОТРА ЦЕПОЧКИ БЛОКОВ | 2018 |
|
RU2746584C2 |
| СИСТЕМА УПРАВЛЕНИЯ И ДИСПЕТЧЕРИЗАЦИИ КОНТЕЙНЕРОВ | 2019 |
|
RU2751576C2 |
| ОСНОВАННЫЕ НА ХЕШАХ РЕШЕНИЯ КОДЕРА ДЛЯ КОДИРОВАНИЯ ВИДЕО | 2014 |
|
RU2679981C2 |
| Система и способ балансировки подключений между клиентами и серверами | 2021 |
|
RU2771444C1 |
| ВИРТУАЛЬНАЯ АРХИТЕКТУРА НЕОДНОРОДНОЙ ПАМЯТИ ДЛЯ ВИРТУАЛЬНЫХ МАШИН | 2010 |
|
RU2569805C2 |
| СИСТЕМА УПРАВЛЕНИЯ И ДИСПЕТЧЕРИЗАЦИИ КОНТЕЙНЕРОВ | 2015 |
|
RU2704734C2 |
Изобретение относится к средствам управления выделением множества элементов памяти, хранимых во множестве безблокировочных списковых структур. Технический результат заключается в расширении арсенала технических средств выделения памяти для памяти. Указанный результат достигается за счет применения способа выделения памяти для памяти, выполняемого в операционной системе многоядерного процессора. При этом способ предусматривает управление выделением памяти запрашивающим память частям многоядерного процессора посредством того, что: получают множество разделенных безблокировочных списковых структур; осуществляют поиск по упомянутому множеству разделенных безблокировочных списковых структур на предмет доступного элемента списка; по нахождении доступного элемента списка выделяют доступную секцию памяти процессору ядра для использования в качестве выделенной памяти; и динамически балансируют упомянутые доступные элементы списка. 3 н. и 17 з.п. ф-лы, 4 ил.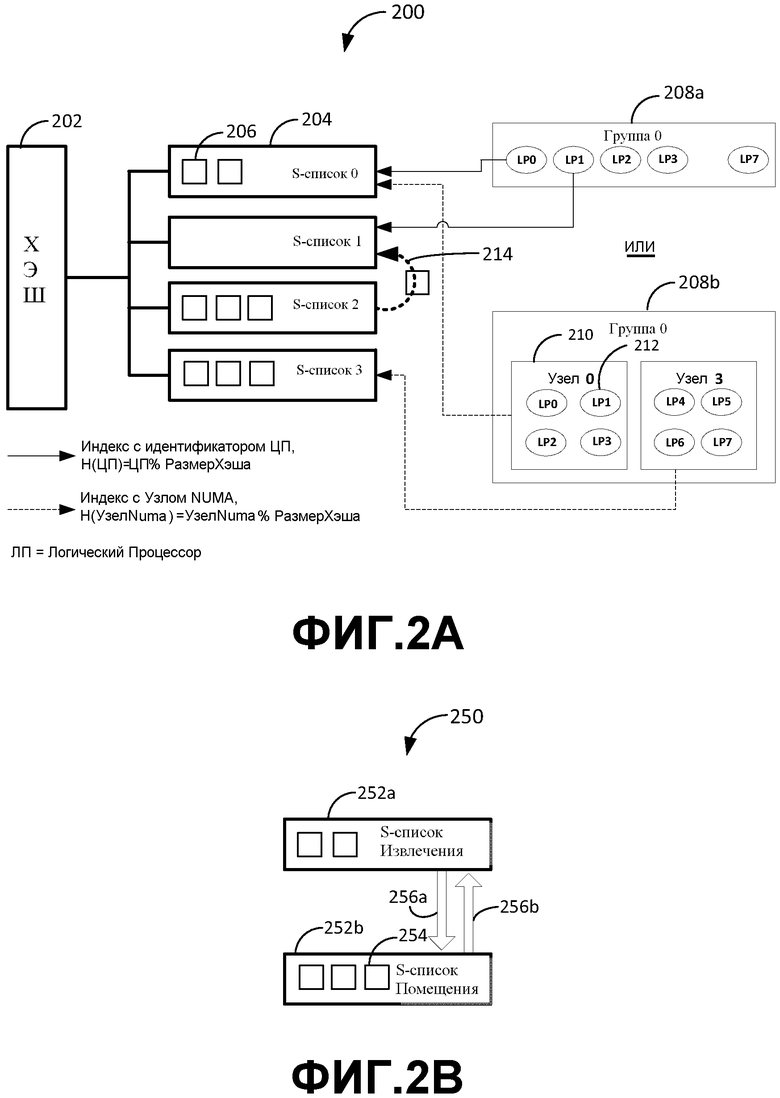
1. Способ выделения памяти для памяти, которая приспособлена для осуществления к ней доступа в среде операционной системы многоядерного процессора, при этом способ включает в себя управление выделением памяти запрашивающим память частям многоядерного процессора посредством того, что:
получают множество разделенных безблокировочных списковых структур, причем каждая из разделенных безблокировочных списковых структур включает в себя соответственное множество элементов списка, при этом каждый из соответственных элементов списка соответствует соответственной секции памяти, которая на текущий момент является пригодной для выделения, причем разделение упомянутого множества разделенных безблокировочных списковых структур реализуется посредством применения адаптивной хеш-функции к каждому из множества значений ключа, которые соответствуют элементам топологии архитектуры многоядерного процессора;
по запросу выделения одной или более из упомянутых соответственных секций памяти процессору ядра для использования в качестве выделенной памяти, осуществляют поиск по упомянутому множеству разделенных безблокировочных списковых структур на предмет доступного элемента списка, который соответствует доступной соответственной секции памяти, которая на текущий момент является пригодной для выделения для использования в качестве выделенной памяти, каковой поиск выполняют с использованием адаптивной хеш-функции, к которой обращаются по ключу для соответственного хеширования для доступа к каждой из упомянутого множества разделенных безблокировочных списковых структур;
по нахождении упомянутого доступного элемента списка выделяют упомянутую доступную секцию памяти процессору ядра для использования в качестве выделенной памяти; и
динамически балансируют упомянутые доступные элементы списка среди упомянутого множества безблокировочных списковых структур в соответствии с метрикой балансировки, которая приспособлена для оптимизации выделения памяти.
2. Способ по п. 1, в котором упомянутые соответственные секции памяти содержат одно или более из: буферов фиксированного размера и буферов переменного размера.
3. Способ по п. 2, в котором упомянутые разделенные безблокировочные списковые структуры представляют собой структуры S-списка.
4. Способ по п. 1, в котором упомянутое получение множества разделенных безблокировочных списковых структур включает в себя этапы, на которых:
получают исходную безблокировочную списковую структуру, которая включает в себя исходное множество элементов списка, причем каждый из исходных элементов списка соответствует исходной соответственной секции памяти, которая на текущий момент является пригодной для выделения; и
разделяют исходную безблокировочную списковую структуру на разделенные безблокировочные списковые структуры так, что каждой безблокировочной списковой структуре из множества разделенных безблокировочных списковых структур назначается хеш-индекс, вычисляемый применением адаптивной хеш-функции к соответственному значению ключа из упомянутого множества значений ключа.
5. Способ по п. 1, в котором в адаптивной хеш-функции используются ключи в соответствии с архитектурой многоядерного процессора.
6. Способ по п. 1, в котором в адаптивной хэш-функции используются ключи в соответствии с индексом процессора.
7. Способ по п. 1, в котором в адаптивной хеш-функции используются ключи в соответствии с номером узла архитектуры неоднородного доступа к памяти (NUMA).
8. Способ по п. 1, в котором метрика балансировки приспособлена для балансировки ресурсов памяти.
9. Способ по п. 1, в котором метрика балансировки приспособлена для поддержания, по существу, числового равенства элементов памяти среди безблокировочных списковых структур.
10. Способ по п. 1, в котором метрика балансировки приспособлена для избежания избыточного выделения ресурсов памяти.
11. Способ по п. 1, в котором адаптивная хеш-функция приспособлена для размещения множества соответственных заголовков списков, каждый из которых ссылается на соответственные списковые структуры из разделенных безблокировочных списковых структур.
12. Система для управления выделением памяти для памяти, которая приспособлена для осуществления к ней доступа в среде операционной системы многоядерного процессора посредством управления выделением памяти запрашивающим память частям многоядерного процессора, каковая система содержит:
первый блок обработки, который изначально разделяет исходную безблокировочную списковую структуру на множество разделенных безблокировочных списковых структур с использованием адаптивной хеш-функции, к которой обращаются по ключу согласно архитектуре многоядерного процессора;
второй блок обработки, который изначально разделяет множество элементов списка среди упомянутого множества разделенных безблокировочных списковых структур, причем каждый из соответственных элементов списка соответствует соответственной секции памяти, которая на текущий момент является пригодной для выделения;
третий блок обработки, который, по запросу выделения памяти запрашивающему память процессору ядра осуществляет поиск по упомянутому множеству разделенных безблокировочных списковых структур на предмет доступного одного из упомянутых соответственных элементов списка и после нахождения доступного одного из соответственных элементов списка выделяет запрашивающему память процессору ядра упомянутую соответственную секцию памяти, которая на текущий момент является пригодной для выделения и которая соответствует найденному одному из соответственных элементов списка; и
четвертый блок обработки, который динамически балансирует упомянутые элементы списка среди упомянутого множества разделенных безблокировочных списковых структур в соответствии с метрикой балансировки, каковая метрика балансировки применяется для распределения элементов списка среди упомянутых разделенных безблокировочных списковых структур.
13. Система по п. 12, при этом упомянутые соответственные секции памяти содержат одно или более из: буферов фиксированного размера и буферов переменного размера, причем исходная безблокировочная списковая структура представляет собой структуру S-списка.
14. Система по п. 12, в которой при упомянутом разделении исходной безблокировочной списковой структуры на множество разделенных безблокировочных списковых структур исходная безблокировочная списковая структура разделяется на множество разделенных безблокировочных списковых структур с использованием адаптивной хеш-функции, к которой обращаются по ключу в соответствии с индексом процессора.
15. Система по п. 12, в которой при упомянутом разделении исходной безблокировочной списковой структуры на множество разделенных безблокировочных списковых структур исходная безблокировочная списковая структура разделяется на множество разделенных безблокировочных списковых структур с использованием адаптивной хеш-функции, к которой обращаются по ключу в соответствии с номером узла NUMA.
16. Способ управления выделением памяти запрашивающим память частям многоядерного процессора, содержащий этапы, на которых:
получают множество разделенных безблокировочных списковых структур, причем каждая из разделенных безблокировочных списковых структур включает в себя соответственное множество элементов списка, при этом каждый из соответственных элементов списка соответствует соответственной секции памяти, которая на текущий момент является пригодной для выделения, причем упомянутое множество разделенных безблокировочных списковых структур разделено с использованием адаптивной хеш-функции, к которой обращаются по ключу согласно архитектуре многоядерного процессора;
по запросу выделения одной или более из упомянутых соответственных секций памяти процессору ядра для использования в качестве выделенной памяти, осуществляют поиск по упомянутому множеству разделенных безблокировочных списковых структур на предмет доступного элемента списка, который соответствует доступной соответственной секции памяти, которая на текущий момент является пригодной для выделения для использования в качестве выделенной памяти, каковой поиск выполняют с использованием адаптивной хеш-функции;
по нахождении упомянутого доступного элемента списка выделяют упомянутую доступную секцию памяти процессору ядра для использования в качестве выделенной памяти; и
динамически балансируют упомянутые доступные элементы списка среди упомянутого множества безблокировочных списковых структур в соответствии с метрикой балансировки, которая приспособлена для оптимизации выделения памяти.
17. Способ по п. 16, в котором в адаптивной хэш-функции используются ключи в соответствии с индексом процессора.
18. Способ по п. 16, в котором в адаптивной хеш-функции используются ключи в соответствии с номером узла NUMA.
19. Способ по п. 16, в котором метрика балансировки приспособлена для балансировки ресурсов памяти.
20. Способ по п. 16, в котором адаптивная хеш-функция приспособлена для размещения множества соответственных заголовков списков, каждый из которых ссылается на соответственные списковые структуры из разделенных безблокировочных списковых структур.
| Колосоуборка | 1923 |
|
SU2009A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| ЦИФРОВОЙ ПРОЦЕССОР КУЩЕНКО В.А. | 2007 |
|
RU2406127C2 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| СПОСОБ, УСТРОЙСТВО И КОМПЬЮТЕРНЫЙ ПРОГРАММНЫЙ ПРОДУКТ, ОБЕСПЕЧИВАЮЩИЕ ПОИСКОВОЕ РЕШЕНИЕ ДЛЯ МОБИЛЬНОГО УСТРОЙСТВА, ИНТЕГРИРОВАННОЕ С ПРИЛОЖЕНИЯМИ И ИСПОЛЬЗУЮЩЕЕ КОНТЕКСТНУЮ ИНФОРМАЦИЮ | 2006 |
|
RU2390824C2 |

