ОБЛАСТЬ ТЕХНИКИ
[001] Настоящее изобретение в общем относится к вычислительным системам, а более конкретно - к системам и способам распознавания рукописного текста с помощью нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[002] Может быть трудно формализовать алгоритм распознавания почерков, так как форма, размер и согласованность рукописных символов могут отличаться, даже если человек пишет печатными буквами. Кроме того, одни и те же буквы, написанные разными людьми, и одни и те же буквы, написанные одним и тем же человеком в разное время или при разных обстоятельствах, могут показаться совершенно разными.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[003] В вариантах реализации настоящего изобретения описаны система и метод распознавания рукописного текста (в том числе иероглифических символов) с использованием моделей глубоких нейронных сетей. В одном из вариантов реализации изобретения система получает изображение, на котором представлена строка текста. Система сегментирует изображение на два или более фрагментов изображения. Для каждого из двух или более фрагментов изображений система определяет первую гипотезу для сегментации фрагмента изображения в первое множество изображений графемы и первую оценку уверенности фрагментации. Система определяет вторую гипотезу для сегментации фрагмента изображения на второе множество изображений графемы и вторую оценку уверенности фрагментации. Система определяет, что первая оценка уверенности выше, чем вторая оценка уверенности. Система переводит первое множество графем изображений, определенных первой гипотезой, в символы. Система собирает символы каждого фрагмента изображения для получения строки текста.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[004] Настоящее изобретение иллюстрируется на примере, без каких бы то ни было ограничений; его сущность становится понятной при рассмотрении приведенного ниже подробного описания изобретения в сочетании с чертежами, при этом:
[005] На Фиг. 1А-1В приведены схемы системы верхнего уровня для примера системы распознавания текста в соответствии с одним или более вариантами реализации настоящего изобретения.
[006] Фиг. 2 иллюстрирует пример изображения, фрагментов изображения и изображений графемы в соответствии с одним или более вариантами реализации настоящего изобретения.
[007] На Фиг. 3 приведена блок-схема модуля распознавателя графемы, работающего в соответствии с одним или более вариантами реализации настоящего изобретения.
[008] На Фиг. 4 приведена блок-схема нейронной сети первого уровня, работающей в соответствии с одним или более вариантами реализации настоящего изобретения.
[009] На Фиг. 5 приведена блок-схема нейронной сети второго уровня, работающей в соответствии с одним или более вариантами реализации настоящего изобретения.
[0010] На Фиг. 6 схематически изображен пример функции уверенности Q(d), реализованной в соответствии с одним или более вариантами настоящего изобретения.
[0011] На Фиг. 7 изображена блок-схема способа распознавания строки текста в соответствии с одним или более вариантами реализации настоящего изобретения.
[0012] На Фиг. 8 приведена блок-схема способа распознавания графемы в соответствии с одним или более вариантами реализации настоящего изобретения.
[0013] На Фиг. 9 приведена блок-схема иллюстративной вычислительной системы, работающей в соответствии с одним или более вариантами реализации настоящего изобретения.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[0014] Оптическое распознавание символов может включать сопоставление данного изображения графемы со списком потенциальных символов, за которым следует определение вероятности, соотнесенной с каждым потенциальным символом. Чем выше вероятность совпадения, тем выше вероятность того, что потенциальный символ является правильным символом. Однако в распознавании отдельного символа возникают две проблемы: неоднозначность в отдельном символе и неправильная сегментация изображения. Первая проблема возникает потому, что одно и то же изображение в разном контексте может соответствовать разным символам, например, символам для разных языков, номеру, имени, дате, электронной почте и т.п. Вторая проблема возникает, если изображение графемы не содержит допустимого символа, то есть изображение графемы не содержит целого символа или изображение графемы представляет собой два символа, склеенных вместе.
[0015] Здесь описаны способы и системы распознавания рукописного текста. Процесс распознавания текста позволяет извлекать машиночитаемую и текстовую информацию с возможностью поиска из изображений различной информационной среды, содержащей информационные признаки (например, рукописные бумажные документы, баннеры, объявления, вывески, рекламные щиты и (или) другие физические объекты, на которых содержатся видимые графемы на одной или более поверхностях). В этом документе «графема» означает элементарную единицу системы письма заданного языка. Графема может быть представлена, например, в виде логограммы, обозначающей слово или морфему, силлабического (слогового) символа, обозначающего слог, или алфавитный символ, обозначающий фонему. «Фрагмент» в настоящем документе означает абзац, предложение, заголовок, часть предложения, комбинацию слов, например, группу существительных и т.д. Под «рукописным текстом» или «рукописными символами» в широком смысле понимаются любые символы, включая скорописные и печатные символы, написанные вручную с использованием любого подходящего пишущего инструмента (например, карандаша, ручки и т.п.) на любой подходящей поверхности (например, бумаге), а также символы, сгенерированные компьютером в соответствии с входным сигналом пользовательского интерфейса, полученным от указательного устройства (например, стилуса). В иллюстративном примере строка рукописных символов может включать визуальные разрывы между отдельными символами (графемы), В другом иллюстративном примере строка рукописных символов может содержать один или более соединенных символов без визуальных разрывов между отдельными символами (графемы).
[0016] В соответствии с вариантами реализации настоящего изобретения, процесс распознавания текста включает в себя этап сегментации и этап распознавания отдельных символов. Сегментация включает в себя разделение изображения на фрагменты изображения, а затем на изображения графемы, которые содержат соответствующие отдельные символы. Различные варианты сегментации или гипотезы могут быть созданы и/или оценены, и наилучшая гипотеза может быть выбрана на основе некоторых предопределенных критериев.
[0017] Для распознавания отдельного символа существует проблема неоднозначности (например, одинаковое изображение в разных контекстах может соответствовать разным символам), а в качестве входных данных для распознавания отдельных символов могут использоваться неправильно сегментированные изображения. Проблемы неоднозначности и неправильной сегментации можно решить путем проверки символа (или изображения графемы) на более высоком уровне (например, фрагмент изображения). Кроме того, каждому отдельному символу может быть присвоена оценка уверенности классификации, а распознанный символ с оценкой уверенности классификации ниже заданного порогового значения может быть исключен из рассмотрения для улучшения распознавания символов. Оценка уверенности классификации может быть получена путем комбинации структурного классификатора и классификатора нейронных сетей, как описано ниже. Классификатор нейронной сети может обучаться по положительным и отрицательным (неправильным/поврежденным) образцам изображений с функцией потерь, которая представляет собой комбинацию потерь по центру, потерь перекрестной энтропии и штрафной функции близости к центру. Отрицательные образцы изображений могут использоваться в качестве дополнительного класса в классификаторе нейронных сетей.
[0018] Комбинированный подход, описанный в настоящем документе, представляет собой значительные улучшения по сравнению с различными распространенными методами, благодаря применению гипотез сегментации и составлению оценки уверенности для гипотез с использованием функций потерь. Функции потерь могут быть конкретно направлены на обучение нейронной сети распознаванию правильных и неправильных или поврежденных изображений графем, таким образом улучшая общее качество и эффективность оптического распознавания символов. Кроме того, способы оптического распознавания символов посредством специализированных функций уверенности, реализуемые на основе нейронной сети и описанные в данной заявке, позволяют внести существенные улучшения по сравнению с различными общепринятыми способами за счет применения функции уверенности, которая вычисляет расстояния в пространстве признаков изображения между вектором признаков, представляющим изображение, и векторами, представляющими центры классов из множества классов, и преобразует вычисленные расстояния в вектор оценки уверенности таким образом, что каждая оценка уверенности (например, значение в диапазоне 0-1) отображает степень уверенности для гипотезы изображения графемы, представляя экземпляр определенного класса из множества классов графем, как более подробно представлено в дальнейшем описании.
[0019] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в настоящем документе с помощью примеров, без каких бы то ни было ограничений.
[0020] На Фиг. 1А-1В приведены схемы системы верхнего уровня для примера систем распознавания текста в соответствии с одним или более вариантами реализации настоящего изобретения. Система распознавания текста 100 может включать компонент распознавания текста 110, который может выполнять оптическое распознавание символов для рукописного текста. Компонент распознавания текста 110 может представлять собой клиентское приложение или же сочетание компонентов, базирующихся на рабочей станции клиента и на сервере. В некоторых вариантах реализации изобретения компонент распознавания текста 110 может быть запущен на исполнение на вычислительном устройстве клиента, например, это могут быть планшетный компьютер, смартфон, ноутбук, фотокамера, видеокамера и т.д. В альтернативном варианте реализации клиентский компонент распознавания текста 110, исполняемый на клиентском вычислительном устройстве, может получать документ и передавать его на серверный компонент распознавания текста 110, исполняемый на серверном устройстве, который выполняет распознавание текста. Серверный компонент распознавания текста 110 затем может возвратить список символов на клиентский компонент распознавания текста 110, исполняемый на клиентском вычислительном устройстве для хранения или предоставления другому приложению. В других вариантах осуществления компонент распознавания текста 110 может исполняться на серверном устройстве в качестве интернет-приложения, доступ к которому обеспечивается через интерфейс браузера. Серверное устройство может быть представлено одной или более вычислительными системами, например одним или более серверами, рабочими станциями, большими ЭВМ (мейнфреймами), персональными компьютерами (ПК) и т.д.
[0021] Как показано на Фиг. 1А, компонент 110 распознавания текста может включать, помимо прочего, приемник 101 изображения, модуль 102 сегментатора изображений, модуль 103 гипотез, модуль 104 распознавателя графемы, модуль 105 оценки уверенности, модуль 106 интервала и перевода и модуль 107 исправления. Один или более компонентов 101-107 или их сочетание могут быть реализованы одним или несколькими программными модулями, работающими на одном или более аппаратных устройствах.
[0022] Приемник 101 изображения может получать изображение из различных источников, таких как камера, вычислительное устройство, сервер, карманное устройство. Изображение может быть файлом документа или файлом изображения с видимым текстом. Изображение может быть получено с различных носителей информации (например, рукописные бумажные документы, баннеры, объявления, вывески, рекламные щиты и (или) другие физические объекты, на которых содержатся видимые графемы на одной или более поверхностях). В одном из вариантов реализации изобретения изображение может быть предварительно обработано путем применения одного или более преобразований изображения к полученному изображению, например, бинаризации, масштабирования размера, обрезки, преобразования цветов и т.д., чтобы подготовить изображение к распознаванию текста.
[0023] Модуль 102 сегментатора изображений может сегментировать полученное изображение на фрагменты изображения, а затем на изображения графемы. Фрагменты изображения или изображения графемы могут быть сегментированы визуальными интервалами или пробелами в строке текста на изображении. Модуль гипотез 103 может генерировать различные варианты или гипотезы, чтобы разбить строку текста на составляющие фрагменты изображения, а фрагмент изображения на одну или более составляющих графемы. Модуль 104 распознавателя графемы может выполнять распознавание изображения графемы с использованием моделей 162 нейронной сети (в составе хранилища данных 160). Модуль 105 оценки уверенности может определить оценку уверенности для гипотезы на основе распознанной графемы. Оценка уверенности может быть оценкой уверенности фрагментации (уверенность для фрагмента/слова) или оценкой уверенности классификации (уверенность для символа/знака). Модуль 106 интервала и перевода может добавлять пробелы (при необходимости) к графеме и переводить графему в символы. После распознавания фрагментов в тексте модуль 107 исправления может исправить определенные части текста с учетом контекста. Исправление может быть выполнено путем проверки символов в соответствии со словарными/морфологическими/синтаксическими правилами 161. Хотя модули 101-107 показаны отдельно, некоторые модули 101-107 или их функциональные возможности могут быть объединены вместе.
[0024] На Фиг. 1 В показана высокоуровневая схема системы взаимодействий модулей 101-107 согласно одному варианту реализации изобретения. Например, приемник 101 изображений может получить изображение 109. Выходы приемника 101 изображения вводятся в последующие модули 102-107 для генерации символов 108. Обратите внимание, что модули 101-107 могут обрабатываться последовательно или параллельно. Например, один экземпляр модуля 102 сегментатора изображений может обрабатывать изображение 109, в то время как несколько экземпляров модуля 104 распознавателя графемы могут обрабатывать несколько графем параллельно, например, несколько гипотез для фрагментов и/или графем могут обрабатываться параллельно.
[0025] Фиг. 2 иллюстрирует пример изображения, фрагментов изображения и изображений графемы в соответствии с одним или более вариантами реализации настоящего изобретения. Как показано на Фиг. 1-2, изображение 109 может быть бинаризованным изображением со строкой текста «This sample» на английском языке. В одном из вариантов реализации изобретения модуль 102 сегментации на Фиг. 1А-1В разбивает изображение 109 на гипотезы (или варианты) 201 А-С с использованием графа линейного деления. Граф линейного деления представляет собой граф с разметкой всех точек деления. Т.е. если есть несколько способов разделить строку на слова, а слова - на буквы, все возможные точки деления отмечены, а часть изображения между двумя отмеченными точками считается потенциальной буквой (или словом). Каждая из гипотез 201 может быть вариацией того, сколько точек деления есть и/или где разместить эти точки деления, чтобы разбить строку текста на один или более фрагментов изображений. Здесь гипотеза 201А разбивает строку текста на два фрагмента изображения 203А-В, например, «This» и «sample». Сегментация может выполняться на основе видимых вертикальных интервалов/разрывов в строке текста.
[0026] Модуль 102 сегментации может дополнительно разбивать фрагменты изображения 203В на гипотезы (или варианты) 205А-С, где гипотеза 205А представляет собой один вариант, чтобы разбить фрагмент изображения 203В на множество изображений 207 графемы. Здесь точки сегментации (или точки деления) могут быть определены на основе разрывов во фрагменте изображения. В некоторых случаях пробелы представляют собой вертикальные разрывы или наклонные разрывы (наклонные под определенным углом почерка) на фрагменте изображения. Еще в одном варианте реализации изобретения точки деления могут определяться на основе областей с низким распределением пикселей вертикального (или наклонного) пиксельного профиля изображения фрагмента. В некоторых других вариантах реализации изобретения для сегментации может использоваться обучение машины.
[0027] Еще в одном варианте реализации изобретения может оцениваться гипотеза о делении графем для получения оценки уверенности фрагментации, а фрагмент, определяющий гипотезу с наивысшей оценкой уверенности фрагментации, выбирается в качестве окончательного фрагмента. В одном из вариантов реализации изобретения составляющие строки текста (например, фрагменты) или составляющие фрагменты изображения (например, графемы) могут храниться в структуре данных графа линейного деления. Затем для перечисления одной или более гипотез (или вариантов, или комбинаций) фрагментов/графем на основе точек сегментации/деления могут использоваться различные пути структуры данных графа линейного деления.
[0028] Как показано на Фиг. 2, в сценарии модуль 103 гипотезы может составить три гипотезы 201А-С для делений фрагментов. Для фрагмента 203В, например, «sample», модуль 103 гипотез генерирует гипотезы 205А-С, например, «s-a-m-p-1-е», «s-a-mp-1-е» и «s-a-m-p-le», где «-» представляет выявленные визуальные разрывы или потенциальные разделительные промежутки между одной или несколькими графемами. Как показано на Фиг. 2, в данном примере гипотезы 205В и 205С представляют варианты, в которых некоторые символы «склеиваются» вместе, то есть изображение графемы с двумя или более символами без заметных пробелов между ними. Следует учесть, что склеенные изображения графемы будут исключены из рассмотрения модулем 104 распознавания графемы, как описано ниже.
[0029] На Фиг. 3 приведена блок-схема модуля распознавателя графемы, работающего в соответствии с одним или более вариантами реализации настоящего изобретения. Модуль 104 распознавателя графемы может преобразовать входное изображение 301 графемы в выходной символ. В одном из вариантов реализации изобретения модуль 104 распознавателя графемы включает определитель 320 типа языка (например, модель (модели) нейронных сетей первого уровня), классификатор 330 глубоких нейронных сетей (DNN) (например, модель (модели) нейронных сетей второго уровня), структурные классификаторы 310, комбинатор 340 оценок уверенности и блок 350 оценки порогового значения. Один или более компонентов 320-350 или их сочетание могут быть реализованы одним или несколькими программными модулями, работающими на одном или более аппаратных устройствах.
[0030] Определитель 320 типа языка (например, модель (модели) нейронной сети первого уровня) может определять группу символов графемы (например, набор символов для конкретной группы языков или алфавитов) для поиска изображения 301 графемы. В одном из вариантов реализации изобретения модель нейронной сети первого уровня используется для классификации изображения 301 графемы на один или более языков в группе языков. Модель нейронной сети первого уровня может быть сверточной моделью нейронной сети, обученной классифицировать изображение графемы как одну из групп языков. В другом варианте реализации изобретения язык задается пользователем, управляющим системой 100 распознавания текста, например, языковой ввод 303. Еще в одном варианте реализации изобретения язык задается ранее определенным языком для соседней графемы и/или фрагмента. Классификатор глубоких нейронных сетей (DNN) (например, модель (модели) нейронных сетей второго уровня) 330 может классифицировать изображение графемы как символ выбранного алфавита и связать оценку уверенности классификации с гипотезой, связывающей графему с символом. Классификаторы 330 DNN могут использовать модель нейронной сети второго уровня, которая обучена для конкретного языка для классификации. Структурные классификаторы 310 могут классифицировать изображение графемы по символу с оценкой уверенности классификации, на основе системы классификации, основанной на правилах. Комбинатор 340 оценок уверенности может комбинировать оценки уверенности классификации (например, измененную оценку уверенности классификации) для изображения графемы на основе оценки уверенности классификации с целью классификации нейронной сети и оценки уверенности классификации для структурной классификации. В одном из вариантов реализации изобретения комбинированная оценка уверенности классификации представляет собой линейную комбинацию (например, в виде взвешенной суммы) оценок уверенности классификации из двух классификаций. Еще в одном варианте комбинированная оценка уверенности классификации представляет собой обобщенную функцию (например, минимальную, максимальную или среднюю) оценки уверенности классификации из двух классификаций. Блок 350 оценки порогового значения может определить комбинированную оценку уверенности классификации для конкретной графемы. Если комбинированная оценка уверенности классификации ниже заданного порогового значения (например, склеенные графемы, недопустимые графемы или графемы, относящиеся к другому языку, и т.д.). Графема может быть исключена из дальнейшего рассмотрения.
[0031] Как показано на Фиг. 3, в одном из вариантов реализации изобретения, классификаторы 330 DNN могут включать экстрактор 331 признаков, который генерирует вектор признаков, соответствующий входному изображению 301 графемы.
Классификаторы 330 DNN могут преобразовать вектор признаков в вектор весов класса таким образом, что каждый вес может характеризовать вероятность того, что введенное изображение 301 является классом графем из множества классов (например, множество алфавитных символов/знаков А, В, С и т.д.), где класс графем идентифицируется по индексу элемента вектора в пределах вектора весов класса. Классификаторы 330 DNN могут затем использовать нормализованную экспоненциальную функцию для преобразования вектора весов класса в вектор вероятностей таким образом, что каждая вероятность может характеризовать гипотезу для изображения 301 графемы, представляющую экземпляр конкретного класса графем из множества классов, где класс графем идентифицируется по индексу элемента вектора в пределах вектора вероятностей. В иллюстративном примере множество классов может быть представлено в виде множества алфавитных символов А, В, С и т.д. так, что каждая вероятность из множества вероятностей, сформированная классификаторами 330 DNN, может характеризовать гипотезу для изображения, представляющего соответствующий символ из множества алфавитных символов А, В, С и т.д.
[0032] Однако, как отмечалось выше, такие вероятности могут быть ненадежными, например, для склеенных графем, недействительных графем, графем, принадлежащих к другому языку, и т.д. Чтобы смягчить проблему такой ненадежности, классификаторы DNN 330 могут включать функцию 335 уверенности для расстояния, которая вычисляет расстояния в пространстве признаков изображения между векторами 333 центра класса (центры класса для конкретной модели нейронной сети второго уровня могут храниться в составе векторов 163 центра класса в хранилище 160 данных Фиг. 1А) и вектором признаков вводного изображения 301, и преобразует вычисленные расстояния в вектор оценок уверенности классификации, таким образом, чтобы каждая оценка уверенности классификации (например, выбранная из диапазона 0-1) отражала степень уверенности для гипотезы 301 вводного изображения графемы, представляющего экземпляр определенного класса из множества классов, где класс графемы определяется индексом элемента вектора в пределах вектора оценок уверенности классификации. В иллюстративном примере множество классов может соответствовать множеству алфавитных символов (например, А, В, С и т.д.), поэтому функция 335 уверенности может формировать множество оценок уверенности классификации таким образом, что каждая оценка уверенности классификации характеризует гипотезу для изображения, представляя соответствующий символ из множества алфавитных символов. В одном из вариантов реализации изобретения оценка уверенности классификации, вычисленная для каждого класса (например, алфавитный символ) функцией 335 уверенности, может быть представлена расстоянием между вектором признаков изображения 301 и центром соответствующего класса.
[0033] Как показано на Фиг. 3, структурные классификаторы 310 могут классифицировать изображение графемы по множеству символов и сформировать рейтинг уверенности классификации для соответствующего символа с использованием основанной на правилах системы классификации. Структурные классификаторы 310 могут включать структурный классификатор для соответствующего класса (символа) из множества классов (символов). Структурный классификатор может анализировать структуру изображения 301 графемы путем разложения изображения 301 графемы на составляющие компоненты (например, каллиграфические элементы: линии, дуги, окружности, точки и т.д.). Составные компоненты (или каллиграфические элементы) затем сравниваются с предопределенными составляющими компонентами (например, каллиграфическими элементами) для конкретного из набора классов/символов. При наличии определенного составляющего компонента, комбинация, например, взвешенная сумма, для составляющего компонента может быть использована для вычисления оценки уверенности для классификации. В одном из вариантов реализации изобретения структурный классификатор включает в себя линейный классификатор. Линейный классификатор классифицирует графему на основе линейной комбинации весов составляющих компонентов. Еще в одном варианте реализации изобретения структурный классификатор включает байесовский двоичный классификатор. Здесь каждый составляющий компонент соответствует двоичному значению (т.е. нулю или единице), которое способствует уверенности классификации. На основе структурной классификации для каждого класса (например, алфавитного символа) из множества классов генерируется оценка уверенности классификации.
[0034] Далее комбинатор 340 оценок уверенности может комбинировать оценки уверенности классификации для каждого класса из множества классов 344 для классификаторов DNN и структурный классификатор с целью составления (комбинированной) оценки 342 уверенности классификации для множества классов 344. В одном из вариантов реализации изобретения объединенная оценка уверенности классификации представляет собой взвешенную сумму оценок уверенности классификации классификаторов DNN и структурного классификатора. Еще в одном варианте реализации изобретения комбинированная оценка уверенности классификации представляет собой минимальную, максимальную или среднюю оценку уверенности классификации двух классификаторов. Класс с наивысшей комбинированной оценкой уверенности классификации и соответствующей комбинированной оценкой уверенности классификации может быть выбран в качестве выходных данных модуля распознавателя 104 графемы.
[0035] В одном из вариантов реализации изобретения блок 350 оценки порогового значения определяет, находится ли комбинированная оценка уверенности классификации ниже заданного порогового значения. При определении комбинированной оценки уверенности классификации ниже заданного порогового значения, модуль 104 распознавателя графемы может вернуть код ошибки (или аннулированную оценку уверенности классификации), указывающий на то, что на введенном изображении отсутствует допустимая графема (например, на изображении может присутствовать склеенная графема и/или графема из другого языка).
[0036] В иллюстративном примере нейронная сеть первого уровня определителя 320 типа языка может быть реализована в виде сверточной нейронной сети, имеющей структуру, схематически иллюстрированную на Фиг. 4. Пример сверточной нейронной сети 400 может содержать последовательность слоев различных типов, например сверточные слои, субдискретизирующие слои, слои блоков линейной ректификации (ReLU) и полносвязные слои, каждый из которых может выполнять определенную операцию по распознаванию строки текста в изображении. Выходные данные слоя могут поступать в качестве входных данных в один и более последующих слоев. Как показано, сверточная нейронная сеть 400 может содержать слой 411 входных данных, один или более сверточных слоев 413А-413В, ReLU-слой 415А-415В, субдискретизирующие слои 417А-417В и слой 419 выходных данных.
[0037] В некоторых вариантах входное изображение (например, изображение 301 графемы на Фиг. 3) может быть получено входным слоем 411 и впоследствии может быть обработано серией слоев 400 сверточной нейронной сети. Каждый из сверточных слоев может выполнять сверточную операцию, которая может заключаться в обработке каждого пикселя фрагмента изображения с помощью одного или более фильтров (сверточные матрицы) и записи результата в соответствующую позицию матрицы выходных данных. Один или более сверточных фильтров могут предназначаться для детектирования определенного признака изображения путем обработки изображения и формирования соответствующей карты признаков.
[0038] Выходные данные сверточного слоя (например, сверточного слоя 413А) могут поступать в ReLU-слой (например, ReLU-слой 415А), который может применить нелинейное преобразование (например, функцию активации) для обработки выходных данных сверточного слоя. Выходные данные ReLU-слоя 415А могут поступать в субдискретизирующий слой 417А, который может выполнять операцию подвыборки для уменьшения разрешения и размера карты признаков. Выходные данные субдискретизирующего слоя 417А могут поступать в сверточный слой 413В.
[0039] При обработке оригинального (исходного) изображения с помощью сверточной нейронной сети 400 может итеративно использоваться каждый соответствующий слой до тех пор, пока каждый слой не выполнит свою соответствующую операцию. Как схематически изображено на Фиг. 4, сверточная нейронная сеть 400 может содержать чередующиеся сверточные и субдискретизирующие слои. Такие чередующиеся слои могут позволять создавать несколько карт признаков различных размеров. Каждая из карт признаков может соответствовать одному из нескольких признаков изображения и может использоваться для распознавания графем.
[0040] В некоторых вариантах реализации изобретения предпоследний слой (например, субдискретизирующий слой 417В (полносвязный слой)) сверточной нейронной сети 400 может формировать вектор признаков, представляющий признаки исходного изображения, что можно принять за представление исходного изображения в многомерном пространстве признаков изображения.
[0041] Вектор признаков может поступать в полносвязный слой 419 выходных данных, который может формировать вектор весов класса таким образом, что каждый вес может характеризовать степень связанности изображения с классом графем из множества классов (например, множество языков). Затем вектор весов класса можно преобразовать, например, с помощью нормализованной экспоненциальной функции в вектор вероятностей таким образом, что каждая вероятность может характеризовать гипотезу для изображения графемы, представляя пример определенного класса графем из множества классов (например, английский язык).
[0042] Несмотря на то что на Фиг. 4 показано определенное количество слоев сверточной нейронной сети 400, сверточные нейронные сети, используемые в различных альтернативных вариантах изобретения, могут содержать любые соответствующие количества сверточных слоев, ReLU-слоев, субдискретизирующих слоев, пакетной нормализации, прореживающих и (или) других слоев. Сверточная нейронная сеть 400 может быть обучена прямым и обратным распространением с помощью изображений из обучающего набора данных, который включает изображения графем и соответствующие идентификаторы классов (например, символы конкретных языков), отражающие правильную классификацию изображений.
[0043] На Фиг. 5 приведена блок-схема нейронной сети второго уровня, работающей в соответствии с одним или более вариантами реализации настоящего изобретения. Нейронная сеть второго уровня (в составе классификаторов 330 DNN на Фиг. 3) может быть реализована в виде модифицированной сверточной нейронной сети 500. Пример измененной сверточной нейронной сети 500 может быть похожа на сверточную нейронную сеть 400 и содержать последовательность слоев различных типов, например сверточные слои, субдискретизирующие слои, слои блоков линейной ректификации (ReLU) и полносвязные слои, каждый из которых может выполнять определенную операцию по распознаванию текста в изображении.
[0044] Как показано на Фиг. 5, выход предпоследнего (или полносвязного) субдискретизирующего слоя 417В можно рассматривать как выполняющий функции экстрактора признаков, например, экстрактор 331 признаков на Фиг. 3. В одном из вариантов реализации изобретения сеть 500 включает конкатенирующий слой 518, который объединяет геометрические признаки 510 входных данных входного изображения 301 с выходными признаками субдискретизирующего слоя 417В. В одном из вариантов реализации изобретения геометрические признаки входного изображения 301 могут включать геометрические признаки графемы в изображении графемы. К таким геометрическим признакам могут относиться: соотношение пикселей ширины изображения графемы и высоты изображения графемы, отношение базовой линии (нижней) символа в изображении графемы к высоте изображения графемы и отношение высоты (верхушки) символа в изображении графемы к высоте изображения графемы. Здесь геометрические признаки могут использоваться для различения запятых и апострофов. Выходные данные для конкатенирующего слоя 518 затем подаются через один или более полносвязных слоев 519А-В, за которыми следует выходной слой 520.
[0045] Выходной слой 520 может соответствовать вектору весов класса, где каждый вес будет характеризовать степень ассоциации входного изображения с классом графемы набора классов (например, набор символов алфавита А, В, С и т.д.). Затем вектор весов класса можно преобразовать, например, с помощью нормализованной экспоненциальной функции в вектор вероятностей таким образом, что каждая вероятность может характеризовать гипотезу для изображения графемы, представляя пример определенного класса графем из множества классов.
[0046] В некоторых вариантах реализации изобретения векторы весов класса и/или вероятностей, создаваемых полносвязным выходным слоем 520, могут использоваться в обучении сети или в процессе логического вывода. Например, во время работы вектор признаков, создаваемый предпоследним слоем (например, субдискретизирующим слоем 417В) сверточной нейронной сети 500, может поступать в вышеописанную функцию 335 уверенности, которая производит вектор оценок уверенности классификации таким образом, что каждая оценка уверенности классификации (например, выбранная из диапазона 0-1) отражает степень уверенности для гипотезы входного изображения графемы, представляющего экземпляр определенного класса из множества классов. В некоторых вариантах реализации изобретения оценка уверенности классификации, вычисленная для каждого класса из множества классов с помощью функции уверенности, может быть представлена по расстоянию между вектором признаков изображения и центром соответствующего класса.
[0047] Сверточная нейронная сеть 500 может быть обучена прямым и обратным распространением на основе функции потерь и изображений из обучающего набора данных, который включает изображения графем и соответствующие идентификаторы классов (например, алфавитные символы, А, В, С, …), отражающие правильную классификацию изображений. Например, значение функции потерь может вычисляться (распространение вперед) на основе наблюдаемых выходных данных сверточной нейронной сети (то есть вектора вероятностей) и требуемого выходного значения, заданного массивом обучающих данных (например, графемой, которая фактически представлена на изображении, или, другими словами, правильным идентификатором классов). Разница между двумя значениями распространяется назад для регулировки весов в слоях сверточной нейронной сети 500.
[0048] В одном из вариантов реализации изобретения функция потерь может быть выражена посредством функции потерь с перекрестной энтропией (Cross Entropy Loss, CEL) в следующем виде:
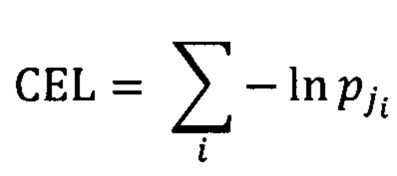
[0049] где i - номер изображения в пакете изображений;
[0050] ji - правильный идентификатор класса (например, идентификатор графемы) для изображения i;
[0051]  - вероятность, полученная с помощью нейронной сети для i-го изображения, представляющего j-й класс (то есть для правильной классификации изображения i).
- вероятность, полученная с помощью нейронной сети для i-го изображения, представляющего j-й класс (то есть для правильной классификации изображения i).
[0052] Суммирование выполняется по всем изображениям в текущем пакете изображений. Идентифицированная ошибка классификации подвергается обратному распространению в предыдущие слои сверточной нейронной сети, в которой соответствующим образом выполняется настройка параметров сети. Данный процесс можно повторять до тех пор, пока значение функции потерь не стабилизируется при приближении к конкретному значению или не опустится ниже предварительно заданного порогового значения. Нейронная сеть, обученная с использованием функции CEL, может размещать примеры одного и того же класса по определенному вектору в пространстве признаков, обеспечивая эффективное разделение примеров из различных классов.
[0053] Хотя функция CEL может быть приемлемым решением для различения изображений различных графем, она не всегда выдает удовлетворительные результаты при отфильтровывании неправильных графем. В соответствии с этим и в дополнение к функции CEL можно использовать и функцию потерь по центру (Center Loss function, CL), тем самым уменьшая представление каждого класса в пространстве признаков таким образом, что все примеры заданного класса можно расположить в пределах относительно небольшой близости от определенной точки, которая может стать центром класса, в то время как любое представление признаков в неправильном изображении графем можно расположить относительно дальше (например, на расстоянии, превышающем предварительно заданное или динамически формируемое пороговое значение) от любого центра класса.
[0054] В одном из вариантов реализации изобретения функция потерь по центру может быть выражена в следующем виде:
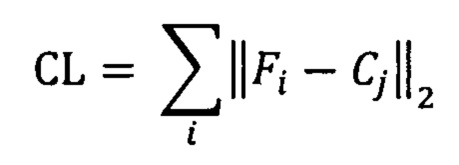
[0055] где i - номер изображения в пакете изображений;
[0056] Fi - вектор признаков i-го изображения;
[0057] j - правильный идентификатор класса (например, идентификатор графемы) для i изображения;
[0058] Cj - вектор центра j-го класса.
[0059] Суммирование выполняется по всем изображениям в текущем пакете изображений.
[0060] Векторы Cj класса центра можно вычислить как среднее всех признаков изображений, принадлежащих j-му классу. Как схематически показано на Фиг. 3, вычисленные векторы 333 класса центра можно сохранить в запоминающем устройстве, доступ к которому обеспечивает модуль 104 распознавателя графемы.
[0061] В одном из вариантов реализации изобретения классификаторы 330 DNN могут быть обучены с помощью функции потерь, представленной в виде линейной комбинации функций CEL и CL, с учетом того, что исходные значения векторов класса центра принимаются равными нулю. Значения векторов класса центра можно вычислить повторно после обработки каждого массива обучающих данных (то есть каждого пакета изображений).
[0062] В другом варианте реализации изобретения классификаторы 330 DNN можно первоначально обучить с помощью функции CEL, а исходные значения векторов класса центра можно вычислить после выполнения первоначального этапа обучения. При последующем обучении может использоваться линейная комбинация функций CEL и CL, а значения векторов класса центра можно повторно вычислить после обработки каждого пакета обучающих данных.
[0063] Применение комбинации функций CEL и CL для обучения нейронной сети может обеспечить компактное представление каждого класса в пространстве признаков таким образом, что все примеры заданного класса можно расположить в пределах относительно небольшой близости от конкретной точки, которая может стать центром класса, при этом любое представление признака неправильного изображения графемы можно расположить относительно далеко (например, на расстоянии, превышающем предварительно заданное или динамически формируемое пороговое значение) от любого центра класса.
[0064] Еще в одном варианте реализации изобретения функцию потерь L можно выразить с помощью линейной комбинации функций CEL и CL в следующем виде:

[0065] где α - весовой коэффициент, позволяющий скорректировать влияние функции CL на значение результирующей функции потерь, что позволяет избежать чрезмерного сужения диапазона признаков для объектов одного класса.
[0066] Функция уверенности может быть направлена на обеспечение условия, при котором устройство распознавания графем могло бы назначать низкую оценку уверенности классификации для некорректных изображений графем. В соответствии с этим уверенность связанности заданного изображения с определенным классом (например, распознавание определенной графемы в изображении) может, таким образом, отображать расстояние между вектором признаков изображения и центром класса, которое можно выразить в следующем виде:

[0067] где dk - это расстояние между Ck центра k-го класса и вектора признаков F заданного изображения.
[0068] В одном из вариантов реализации изобретения функцию 335 уверенности можно представить с помощью монотонно убывающей функции расстояния между классом центра и вектором признаков изображения в пространстве признаков изображения. Таким образом, чем дальше вектор признаков расположен от центра класса, тем ниже будет уверенность классификации, назначенная для ассоциации изображения с данным классом.
[0069] В одном из вариантов реализации изобретения функцию 335 уверенности для расстояния можно сформировать с помощью кусочно-линейной функции от расстояния. Функцию 335 уверенности для расстояния можно построить путем выбора определенных оценок уверенности классификации qi и определения соответствующих значений расстояния di, которые смогут минимизировать количество ошибок классификации, допущенных классификатором, обрабатывающим выбранный набор контрольных данных, который может быть представлен, например, набором изображений документа (например, изображениями страниц документа) с ассоциируемыми метаданными, определяющими правильную классификацию графем в изображении). В некоторых вариантах реализации изобретения оценку уверенности классификации qi можно выбирать на равных интервалах в пределах действительного диапазона оценок уверенности классификации (например, 0-1). Кроме того, интервалы между оценками уверенности классификации qi можно выбирать таким образом, чтобы они увеличивались при перемещении в диапазоне оценок уверенности классификации к самым низким значениям оценок уверенности классификации так, что такие интервалы будут ниже в определенном диапазоне высоких оценок уверенности классификации и выше в определенном диапазоне низких оценок уверенности классификации.
[0070] На Фиг. 6 схематически изображен пример функции Q(d), реализованной в соответствии с одним или более вариантами настоящего изобретения. Как схематически изображено на Фиг. 6, оценки уверенности классификации qk можно выбирать в предварительно выбранных интервалах в пределах допустимого диапазона оценок уверенности классификации (например, 0-1), после чего можно определять соответствующие значения dk. Если требуется более высокая чувствительность функции к ее входным данным в более высоком диапазоне значений функции, то значения qk в пределах определенного диапазона высоких оценок уверенности классификации можно выбирать в относительно небольших интервалах (например, 1; 0,98; 0,95; 0,9; 0,85; 0,8; 0,7; 0,6;…). Затем расстояния Δk между соседними значениями dk (например, dk=dk-1+Δk) можно определить, применив методы оптимизации, такие как метод дифференциальной эволюции. Затем функцию уверенности Q(d) можно построить в виде кусочно-линейной функции, соединяющей вычисленные точки (dk, qk).
[0071] В некоторых вариантах реализации изобретения оценки уверенности классификации можно определять только для подмножества гипотез классификации, которые классификатор ассоциировал с высокими вероятностями (например, превышение определенного порогового значения).
[0072] Применение вышеописанных функций потерь и уверенности обеспечивает условие, при котором для большинства неправильных изображений графем низкие оценки уверенности классификации могут назначаться для гипотез, ассоциирующих изображения со всеми возможными графемами. Очевидное преимущество применения вышеописанных функций потерь и уверенности заключается в обучении классификатора без необходимости наличия отрицательных выборок в массиве обучающих данных, поскольку, как отмечено ранее, все возможные варианты неправильных изображений сложно сформировать, а число таких вариантов может существенно превышать число правильных графем.
[0073] В некоторых вариантах реализации изобретения классификаторы 330 DNN, обученные с помощью вышеописанных функций потерь и уверенности, могут тем не менее оказаться неспособными отфильтровывать небольшое количество неправильных изображений графем. Например, гипотеза, ассоциирующая неправильное изображение графемы с определенным классом (то есть ошибочно распознающая определенную графему в пределах изображения), будет принимать высокую оценку уверенности классификации, если вектор признаков неправильного изображения графемы расположен достаточно близко от центра класса. Так как число таких ошибок стремится к уменьшению, вышеописанная функция потерь может быть оптимизирована с целью обеспечения отфильтровывания таких неправильных изображений графем.
[0074] В одном из вариантов реализации изобретения вышеописанная функция потерь, представленная с помощью функции CEL и функции CL, может быть оптимизирована путем введения третьего члена, обозначенного в данном документе как штрафная функция приближения к центру (Close-to-Center Penalty Loss, CCPL), которая позволит удалить из центров всех классов векторы признаков известных типов в неправильных изображениях. В соответствии с этим функция потерь может быть выражена в виде:

[0075] Процесс обучения нейронной сети второго уровня с помощью функции потерь с функцией CCPL может заключаться в итеративной обработке пакетов изображений таким образом, что каждый пакет будет содержать положительные выборки (правильные изображения графем) и отрицательные выборки (неправильные изображения графем). В некоторых вариантах реализации изобретения выражение CEL  можно вычислить только для положительных выборок, при этом выражение
можно вычислить только для положительных выборок, при этом выражение  можно вычислить только для отрицательных выборок.
можно вычислить только для отрицательных выборок.
[0076] В иллюстративном примере массив обучающих данных может содержать отрицательные выборки, представленные реальными неправильными изображениями графем, которые были ошибочно классифицированы в качестве правильных изображений и в отношении которых были назначены оценки уверенности классификации, превышающие конкретное заданное пороговое значение. В другом иллюстративном примере массив обучающих данных может содержать отрицательные выборки, представленные в качестве искусственных неправильных изображений графем.
[0077] Функция CCPL, которая вычисляется для отрицательных выборок обучения, может быть выражена в виде:

[0078] где  - вектор признаков для j-й отрицательной выборки обучения;
- вектор признаков для j-й отрицательной выборки обучения;
[0079] Ci - центр i-го класса;
[0080] А - предварительно заданный и настраиваемый параметр, определяющий размер близости к центру класса (то есть расстояние до центра класса) в пространстве признаков изображения, так что векторы признаков, расположенные поблизости, штрафуются, при этом штраф не может применяться в отношении векторов признаков, расположенных за пределами такой близости.
[0081] Таким образом, если вектор признаков отрицательной выборки расположен в пределах расстояния, не превышающего значение параметра А от центра i-го класса, то значение функции CCPL инкрементно увеличивается на такое расстояние. Процесс обучения классификаторов DNN заключается в минимизации значения функции CCPL. И в случае неправильного изображения графемы обученные классификаторы DNN могут выдать вектор признаков, который расположен за пределами непосредственных близостей от центров действительных классов. Другими словами, классификатор обучается для того, чтобы различать изображения с действительными графемами и недействительными графемами.
[0082] Как показано на Фиг. 3 и 5, в одном из вариантов реализации изобретения конкретная модель нейронной сети 500 второго уровня (в составе классификаторов 330 DNN) обучается для конкретной группы языков с целью создания модели нейронной сети второго уровня для этого конкретного языка (например, множество символов), где соответствующая нейронная сеть второго уровня выбирается в соответствии с конкретной обученной языковой моделью, когда указан язык. Как отмечено ранее, модели нейронных сетей второго уровня, обученные с помощью способов, описанных в данном документе, можно использовать для выполнения различных задач по классификации изображений, к числу которых, помимо прочего, относится распознавание текста.
[0083] Как показано на Фиг. 3, после обучения классификаторов 330 DNN, конкретная модель нейронной сети второго уровня (в составе классификаторов 330 DNN) может использоваться для классификации изображения графемы по множеству классов и для получения оценок уверенности классификации для множества классов. Комбинатор 340 может затем комбинировать оценки уверенности классификации с оценками уверенности классификации структурного классификатора. Блок 350 оценки порогового значения может оценивать (или исключать из рассмотрения) для лучшего класса графемы, используя комбинированную оценку уверенности классификации. Модуль распознавателя 104 графемы может перебирать изображения графемы гипотезы и генерировать (комбинированную) оценку уверенности классификации для каждого изображения графемы.
[0084] Возвратимся к Фиг. 1А-В. В одном из вариантов реализации изобретения, как только (комбинированные) оценки уверенности классификации определены для каждого изображения графемы в гипотезе, модуль 105 оценки уверенности может объединить оценки уверенности классификации всех изображений графемы в гипотезе для получения оценки уверенности фрагментации для конкретной гипотезы подразделений графем. Среди нескольких гипотез для делений графемы в качестве окончательной гипотезы выбирается гипотеза с наивысшей оценкой уверенности фрагментации (обозначается как оценка уверенности фрагментации для фрагмента). В одном из вариантов реализации изобретения оценки уверенности фрагментации для каждого фрагмента могут быть объединены для определения окончательной оценки уверенности для гипотезы, гипотезы о разбивке изображения со строкой текста на составляющие фрагменты изображения. Среди нескольких гипотез о разбивке фрагментов, в качестве окончательной гипотезы о разбивке фрагментов выбрана гипотеза с наивысшей оценкой уверенности. В одном из вариантов реализации изобретения модуль 106 интервала и перевода затем переводит окончательную гипотезу о разбивке фрагментов на выходные символы 108. В одном из вариантов реализации изобретения корректировка интервала/пунктуации может быть применена к выходным символам 108, при необходимости, с помощью алгоритма, основанного на правилах. Например, точка следует за концом предложения, двойной интервал применяется между предложениями и т.д.
[0085] Еще в одном варианте реализации изобретения модуль 107 исправления может дополнительно исправлять символы 108 с учетом контекста для выходных символов. Например, глубокая (сверточная) модель глубокой нейронной сети третьего уровня может классифицировать символы 108 на число, имя, адрес, адрес электронной почты, дату, язык и т.д., чтобы придать контекст символам 108. Еще в одном варианте реализации изобретения символы 108 (или слова внутри символов) с контекстом можно сравнить со словарем, морфологической моделью, синтаксической моделью и т.д. Например, неоднозначное слово (слова с оценкой уверенности ниже определенного порогового значения) можно сравнить со словарным определением соседних слов на совпадения, и неоднозначное слово может быть исправлено при обнаружении совпадения.
[0086] На Фиг. 7-8 представлены блок-схемы различных вариантов реализации способов, связанных с распознаванием текста. Эти способы могут осуществляться при помощи логической схемы обработки данных, которая может включать аппаратные средства (электронные схемы, специализированную логическую плату и т.д.), программное обеспечение (например, выполняться на универсальной ЭВМ или же на специализированной вычислительной машине) или комбинацию первого и второго. Представленные способы и (или) каждая из отдельно взятых функций, процедур, подпрограмм или операций могут быть реализованы с помощью одного или более процессоров вычислительного устройства {например, вычислительной системы 800 на Фиг. 9), в котором реализованы данные способы. В некоторых вариантах реализации изобретения представленные способы могут выполняться в одном потоке обработки. В альтернативных вариантах реализации изобретения представленные способы могут выполняться в двух и более потоках обработки в режиме обработки, при этом в каждом потоке реализована одна (или более) отдельно взятая функция, процедура, подпрограмма или операция, относящаяся к указанным способам. Способ 700 может быть выполнен системой 100 распознавания текста на Фиг. 1А, а способ 750 может быть выполнен модулем 104 распознавателя текста на Фиг. 1А.
[0087] Для простоты объяснения способы в настоящем описании изобретения изложены и наглядно представлены в виде последовательности действий. Однако действия в соответствии с настоящим описанием изобретения могут выполняться в различном порядке и (или) одновременно с другими действиями, не представленными и не описанными в настоящем документе. Кроме того, не все действия, приведенные для иллюстрации сущности изобретения, могут оказаться необходимыми для реализации способов в соответствии с настоящим описанием изобретения. Специалистам в данной области техники должно быть понятно, что эти способы могут быть представлены и иным образом - в виде последовательности взаимосвязанных состояний через диаграмму состояний или событий.
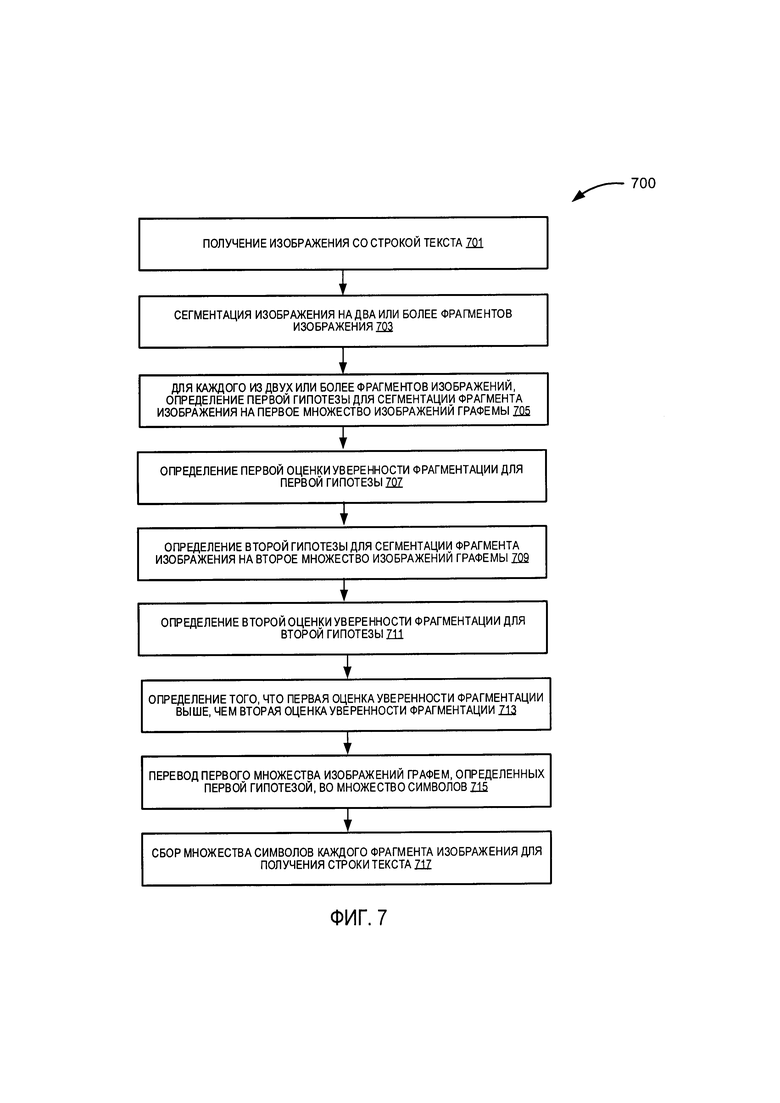
[0088] На Фиг. 7 изображена блок-схема способа распознавания строки текста в соответствии с одним или более вариантами реализации настоящего изобретения. На шаге 701 логика обработки получает изображение со строкой текста. На шаге 703 логика обработки разбивает изображение на два или более фрагментов изображений. На шаге 705 для каждого из двух или более фрагментов изображений логика обработки определяет первую гипотезу для сегментации фрагмента изображения на первое множество изображений графемы. На шаге 707 логика обработки определяет первую оценку уверенности фрагментации для первой гипотезы. На шаге 709 логика обработки определяет вторую гипотезу для сегментации фрагмента изображения на второе множество изображений графемы. На шаге 711 логика обработки определяет вторую оценку уверенности фрагментации для второй гипотезы. На шаге 713 логика обработки определяет, что первая оценка уверенности фрагментации выше, чем вторая оценка уверенности фрагментации. На шаге 715 логика обработки переводит первое множество изображений графемы, определенных первой гипотезой, во множество символов. На шаге 717 логика обработки собирает множество символов каждого фрагмента изображения для получения строки текста.
[0089] В одном из вариантов реализации изобретения сегментация изображения на два или более фрагментов изображений выполняется на основе визуальных признаков (или разрывов), определенных в строке текста. В одном из вариантов реализации изобретения определение первой оценки уверенности фрагментации включает в себя: применение модели нейронной сети первого уровня к одному из первых множеств изображений графемы с целью определения группы языков для изображения графемы. Еще в одном варианте логика обработки далее выбирает модель нейронной сети второго уровня на основе группы языков, применяет модель нейронной сети второго уровня к изображению графемы для определения оценки уверенности классификации для изображения графемы и определения оценки уверенности первой фрагментации, основанной на оценках уверенности классификации для каждого из первых множеств изображений графемы.
[0090] В одном из вариантов реализации изобретения конкретная модель нейронной сети второго уровня соответствует конкретной группировке распознаваемых графем, в которой конкретная группа языков соответствует группе символов определенного языка.
[0091] В одном из вариантов реализации изобретения логика обработки дополнительно применяет структурный классификатор к изображению графемы, определяет измененную оценку уверенности классификации для изображения графемы на основе структурной классификации и определяет первую оценку уверенности фрагментации на основе измененной оценки уверенности классификации для каждого из первых множеств изображений графемы. В одном из вариантов реализации изобретения логика обработки дополнительно определяет, превышает ли первая оценка уверенности фрагментации заданное пороговое значение, и при обнаружении превышения заданного порогового значения первой оценкой уверенности фрагментации, логика обработки переводит первое множество изображений графемы первой гипотезы во множество символов.
[0092] В некоторых вариантах реализации изобретения модель нейронной сети второго уровня обучается с использованием функции потерь, в которой функция потерь представлена комбинацией функции потерь перекрестной энтропии, функции потерь по центру и/или штрафной функции близости к центру. В одном из вариантов реализации изобретения модель нейронной сети второго уровня включает первые входные данные для изображения графемы, вторые входные данные для геометрических признаков изображения графемы и конкатенирующий слой для объединения геометрических признаков изображения графемы во внутренний слой модели нейронной сети второго уровня. В одном из вариантов реализации изобретения логика обработки дополнительно проверяет множество символов в соответствии с морфологической, словарной или синтаксической моделью.
[0093] На Фиг. 8 приведена блок-схема способа распознавания графемы в соответствии с одним (или более) вариантом реализации настоящего изобретения. На шаге 751 логика обработки перебирает множество графических изображений гипотезы. На шаге 753 логика обработки распознает графему внутри изображения графемы и получает первую оценку уверенности классификации для изображения графемы. На шаге 755 логика обработки проверяет распознанную графему с помощью структурного классификатора и получает вторую оценку уверенности классификации. На шаге 757 логика обработки получает (комбинированную) оценку уверенности классификации для распознанных графем на основе первой и второй оценок уверенности классификации. На шаге 759 логика обработки определяет, превышает ли оценка уверенности классификации заданное пороговое значение. На шаге 761 логика обработки выводит распознанные графемы и оценки уверенности классификации для множества изображений графемы.
[0094] В одном из вариантов реализации изобретения распознавание графемы, включающей распознавание графемы с использованием модели сверточной нейронной сети второго уровня. В одном из вариантов реализации изобретения логика обработки собирает распознанные графемы для получения строки текста.
[0095] На Фиг. 9 приведен пример вычислительной системы 800, которая может выполнять любой описанный здесь способ или несколько таких способов. В одном из примеров вычислительная система 800 может соответствовать вычислительному устройству, способному выполнять компонент 110 распознавания текста, представленный на Фиг. 1А. Эта вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то, что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для реализации любого из описанных здесь способов или нескольких таких способов.
[0096] Пример вычислительной системы 800 включает устройство 802 обработки данных, основное запоминающее устройство 804 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например, синхронное DRAM (SDRAM)), статическое запоминающее устройство 806 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство 816 хранения данных, которые взаимодействуют друг с другом по шине 808.
[0097] Устройство 802 обработки данных представляет собой одно или более устройств обработки общего назначения, например, микропроцессоров, центральных процессоров или аналогичных устройств. В частности, устройство 802 обработки может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW), процессор, в котором реализованы другие наборы команд, или процессоры, в которых реализована комбинация наборов команд. Устройство 802 обработки также может представлять собой одно или более устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.д. Устройство обработки 802 реализовано с возможностью выполнения инструкций 826 в целях выполнения рассматриваемых в этом документе операций и шагов.
[0098] Вычислительная система 800 может дополнительно включать устройство 822 сетевого интерфейса. Вычислительная система 800 может также включать видеомонитор 810 (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (ЭЛТ)), устройство 812 буквенно-цифрового ввода (например, клавиатуру), устройство 814 управления курсором (например, мышь) и устройство 820 для формирования сигналов (например, громкоговоритель). В одном из иллюстративных примеров видеодисплей 810, устройство 812 буквенно-цифрового ввода и устройство 814 управления курсором могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0099] Запоминающее устройство 816 может включать машиночитаемый носитель 824, в котором хранятся инструкции 826 (например, соответствующие способам, показанным на Фиг. 7-8 и т.д.), отражающие одну или более методологий или функций, описанных в данном документе. Инструкции 826 могут также находиться полностью или по меньшей мере частично в основном запоминающем устройстве 804 и (или) в устройстве обработки 802 во время их выполнения вычислительной системой 800, основным запоминающим устройством 804 и устройством обработки 802, также содержащим машиночитаемый носитель информации. Инструкции 826 может дополнительно передаваться или приниматься по сети через устройство сопряжения с сетью 822.
[00100] Несмотря на то, что машиночитаемый носитель данных 824 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет данную машину выполнять одну или более методик, описанных в настоящем описании изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как включающий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[00101] Несмотря на то, что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться (по крайней мере частично) одновременно с другими операциями. В некоторых вариантах реализации операции или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[00102] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые охватывает формула изобретения.
[00103] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что аспекты настоящего изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, для того, чтобы не усложнять описание настоящего изобретения.
[00104] Некоторые части подробных описаний выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь алгоритм в общем сконструирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Такие шаги требуют физических манипуляций с физическими величинами. Обычно, но не обязательно, такие величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать, а также выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать такие сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[00105] Однако следует иметь в виду, что все такие и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к таким величинам. Если прямо не указано иное, как видно из последующего обсуждения, то следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «анализ» и т.п., относятся к действиям и процессам вычислительной системы или подобного электронного вычислительного устройства, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин в регистрах и памяти вычислительной системы, в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[00106] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или дополнительно настраивается с помощью компьютерной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[00107] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной в настоящем документе информацией, возможно также признание целесообразности конструирования более специализированного устройства для выполнения необходимых шагов способа. Необходимая структура различных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов осуществления настоящего изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[00108] Варианты реализации настоящего изобретения могут быть представлены в виде компьютерного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования компьютерной системы (или других электронных устройств) в целях выполнения процесса в соответствии с настоящим изобретением. Машиночитаемый носитель данных включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[00109] Любой вариант реализации или конструкция, описанные в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представлена конкретным образом. В настоящей заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Это означает, если не указано иное или не очевидно из контекста, что «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X включает А, X включает В или X включает и А, и В, то высказывание «X включает А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «аn», использованные в англоязычной версии этой заявки и прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации» или «один вариант реализации» либо «реализация» или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБУЧЕНИЕ НЕЙРОННОЙ СЕТИ ПОСРЕДСТВОМ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ ПОТЕРЬ | 2018 |
|
RU2707147C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ ПРИМЕНЕНИЯ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ УВЕРЕННОСТИ, РЕАЛИЗУЕМОЕ НА БАЗЕ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2703270C1 |
| ДИФФЕРЕНЦИАЛЬНАЯ КЛАССИФИКАЦИЯ С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ НЕЙРОННЫХ СЕТЕЙ | 2017 |
|
RU2652461C1 |
| РАСПОЗНАВАНИЕ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ИЕРАРХИЧЕСКОЙ КЛАССИФИКАЦИИ | 2018 |
|
RU2693916C1 |
| ИДЕНТИФИКАЦИЯ ИСПОЛЬЗУЕМЫХ В ДОКУМЕНТАХ СИСТЕМ ПИСЬМА | 2021 |
|
RU2792743C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ НА ИЗОБРАЖЕНИИ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2018 |
|
RU2695489C1 |
| МЕТОД И СИСТЕМА ИЗВЛЕЧЕНИЯ ДАННЫХ ИЗ ИЗОБРАЖЕНИЙ СЛАБОСТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ | 2015 |
|
RU2613846C2 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| ОБНАРУЖЕНИЕ ТЕКСТОВЫХ ПОЛЕЙ С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2699687C1 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕОБХОДИМОСТИ ОБУЧЕНИЯ ЭТАЛОНА ПРИ ВЕРИФИКАЦИИ РАСПОЗНАННОГО ТЕКСТА | 2014 |
|
RU2641225C2 |









Изобретение относится к области вычислительной техники для распознавания рукописного текста. Технический результат заключается в улучшении распознавания символов. Технический результат достигается за счет способа распознавания текста, включающего: получение изображения со строкой текста; сегментацию изображения на два или более фрагментов изображения; для каждого из двух или более фрагментов изображения, определение первой гипотезы для сегментации фрагмента изображения на первое множество изображений графемы; определение первой оценки уверенности фрагментации для первой гипотезы; определение второй гипотезы для сегментации фрагмента изображения на второе множество изображений графемы; определение второй оценки уверенности фрагментации для второй гипотезы; определение того, что первая оценка уверенности фрагментации выше, чем вторая оценка уверенности фрагментации; и преобразование первого множества изображений графем, определенных первой гипотезой, во множество символов; и сбор множества символов каждого фрагмента изображения для получения строки текста. 3 н. и 17 з.п. ф-лы, 10 ил.
1. Способ распознавания текста, включающий:
получение изображения со строкой текста;
сегментацию изображения на два или более фрагментов изображения;
для каждого из двух или более фрагментов изображения,
определение первой гипотезы для сегментации фрагмента изображения на первое множество изображений графемы;
определение первой оценки уверенности фрагментации для первой гипотезы;
определение второй гипотезы для сегментации фрагмента изображения на второе множество изображений графемы;
определение второй оценки уверенности фрагментации для второй гипотезы;
определение того, что первая оценка уверенности фрагментации выше, чем вторая оценка уверенности фрагментации; и
преобразование первого множества изображений графем, определенных первой гипотезой, во множество символов; и
сбор множества символов каждого фрагмента изображения для получения строки текста.
2. Способ по п. 1, в котором сегментация изображения на два или более фрагментов изображений выполняется на основе визуальных признаков, определенных в строке текста.
3. Способ по п. 1, в котором определение первой оценки уверенности фрагментации дополнительно включает:
применение модели нейронной сети первого уровня к одному из первых множеств изображений графемы с целью определения группы языков для изображения графемы.
4. Способ по п. 3, дополнительно включающий:
выбор модели нейронной сети второго уровня на основе группы языков;
применение модели нейронной сети второго уровня к изображению графемы для определения оценки уверенности классификации для изображения графемы; и
определение первой оценки уверенности фрагментации на основе оценок уверенности классификации для каждого из первых множеств изображений графемы.
5. Способ по п. 4, дополнительно включающий:
применение структурной классификации к изображению графемы;
определение измененной оценки уверенности классификации для изображения графемы на основе структурной классификации; и
определение первой оценки уверенности фрагментации на основе измененных оценок уверенности классификации для каждого из первых множеств изображений графемы.
6. Способ по п. 3, дополнительно включающий:
определение того, превышает ли первая оценка уверенности фрагментации заданное пороговое значение; и
при обнаружении превышения заданного порогового значения первой оценкой уверенности фрагментации, перевод первого множества изображений графемы первой гипотезы во множество символов.
7. Способ по п. 4, в котором нейронная сеть второго уровня обучается с помощью функции потерь, причем функция потерь включает в себя функцию потерь перекрестной энтропии или функцию потерь по центру.
8. Способ по п. 7, в котором функция потерь включает в себя штрафную функцию потерь близости к центру.
9. Способ по п. 4, в котором нейронная сеть второго уровня включает первые входные данные для изображения графемы, вторые входные данные для геометрических признаков изображения графемы и конкатенирующий слой для объединения геометрических признаков изображения графемы во внутренний слой модели нейронной сети второго уровня.
10. Способ по п. 9, в котором геометрические признаки изображения графемы могут включать соотношение пикселей ширины изображения графемы и высоты изображения графемы, отношение базовой линии символа в изображении графемы к высоте изображения графемы и отношение высоты символа в изображении графемы к высоте изображения графемы.
11. Способ по п. 1, дополнительно включающий проверку множества символов в соответствии с морфологической, словарной или синтаксической моделью.
12. Система распознавания текста, включающая:
запоминающее устройство (ЗУ);
процессор, связанный с данным запоминающим устройством, выполненный с возможностью:
получать изображение со строкой текста;
сегментировать изображение на два или более фрагментов изображения;
для каждого из двух или более фрагментов изображения,
определять первую гипотезу для сегментации фрагмента изображения на первое множество изображений графемы;
определять первую оценку уверенности фрагментации для первой гипотезы;
определять вторую гипотезу для сегментации фрагмента изображения на второе множество изображений графемы;
определять вторую оценку уверенности фрагментации для первой гипотезы;
определять, что первая оценка уверенности фрагментации выше, чем вторая оценка уверенности фрагментации; и
преобразовывать первое множество изображений графем, определенных первой гипотезой, во множество символов; и
собирать множество символов каждого фрагмента изображения для получения строки текста.
13. Система по п. 12, в которой сегментация изображения на два или более фрагментов изображений выполняется на основе визуальных признаков, определенных в строке текста.
14. Система по п. 12, отличающаяся тем, что процессор также выполнен с возможностью:
применения модели нейронной сети первого уровня к одному из первых множеств изображений графемы с целью определения группы языков для изображения графемы.
15. Система по п. 12, отличающаяся тем, что процессор также выполнен с возможностью:
выбора модели нейронной сети второго уровня на основе группы языков;
применения модели нейронной сети второго уровня к изображению графемы для определения оценки уверенности классификации для изображения графемы; и
определения первой оценки уверенности фрагментации на основе оценок уверенности классификации для каждого из первых множеств изображений графемы.
16. Система по п. 15, отличающаяся тем, что процессор дополнительно выполнен с возможностью:
применения структурной классификации к изображению графемы;
определения измененной оценки уверенности классификации для изображения графемы на основе структурной классификации; и
определения первой оценки уверенности фрагментации на основе измененных оценок уверенности классификации для каждого из первых множеств изображений графемы.
17. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при их исполнении вычислительной системой побуждают ее:
получать изображение со строкой текста;
сегментировать изображение на два или более фрагментов изображения;
для каждого из двух или более фрагментов изображения,
определять первую гипотезу для сегментации фрагмента изображения на первое множество изображений графемы;
определять первую оценку уверенности фрагментации для первой гипотезы;
определять вторую гипотезу для сегментации фрагмента изображения на второе множество изображений графемы;
определять вторую оценку уверенности фрагментации для первой гипотезы;
определять, что первая оценка уверенности фрагментации выше, чем вторая оценка уверенности фрагментации; и
преобразовывать первое множество изображений графем, определенных первой гипотезой, во множество символов; и
собирать множество символов каждого фрагмента изображения для получения строки текста.
18. Носитель данных по п. 17, в котором сегментация изображения на два или более фрагментов изображений выполняется на основе визуальных признаков, определенных в строке текста.
19. Носитель данных по п. 17, дополнительно содержащий исполняемые вычислительной системой команды, которые побуждают ее:
применять модель нейронной сети первого уровня к одному из первых множеств изображений графемы с целью определения группы языков для изображения графемы.
20. Носитель данных по п. 19, дополнительно содержащий исполняемые вычислительной системой команды, которые побуждают ее:
выбирать модель нейронной сети второго уровня на основе группы языков;
применять модель нейронной сети второго уровня к изображению графемы для определения оценки уверенности классификации для изображения графемы; и
определять первую оценку уверенности фрагментации на основе оценок уверенности классификации для каждого из первых множеств изображений графемы.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| JP 2019506208 A, 07.03.2019 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| RU 2008147115 A, 10.06.2010. | |||

