ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к вычислительным системам, а более конкретно к системам и способам обучения нейронной сети посредством специализированных функций потерь.
УРОВЕНЬ ТЕХНИКИ
[0002] Сверточная нейронная сеть может быть реализована в виде искусственной нейронной сети с обратной связью, в которой схема соединений между нейронами подобна тому, как организована зрительная зона коры мозга животных. Отдельные нейроны коры откликаются на раздражение в ограниченной области пространства, известной под названием рецептивного поля. Рецептивные поля различных нейронов частично перекрываются, образуя поле зрения. Отклик отдельного нейрона на раздражение в границах его рецептивного поля может быть аппроксимирован математически с помощью операции свертки. Нейроны соседних слоев соединены взвешенными ребрами. Веса ребер и (или) другие параметры сети определяются на стадии обучения сети на основе обучающей выборки данных.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] В соответствии с одним или более вариантами настоящего изобретения пример реализации способа обучения нейронной сети посредством специализированных функций потерь может содержать: получение набора обучающих данных, содержащего несколько изображений, где каждое изображение из набора обучающих данных ассоциируется с идентификатором класса из набора классов; вычисление с помощью нейронной сети множества векторов признаков, где каждый вектор признаков из множества векторов признаков представляет изображение из набора обучающих данных в пространстве признаков изображений; вычисление для набора обучающих данных значения функции потерь, отображающей множество вероятностей, где каждая вероятность из множества вероятностей характеризует гипотезу, ассоциирующую изображение из набора обучающих данных с классом, ассоциируемым с этим изображением в соответствии с набором обучающих данных, при этом функция потерь дополнительно отображает множество расстояний, где каждое расстояние из множества расстояний вычисляется в пространстве признаков изображений между вектором признаков, представляющим изображение из набора обучающих данных, и центром класса, ассоциируемого с этим изображением в соответствии с набором обучающих данных; и настройку параметра нейронной сети на основе значения функции потерь.
[0004] В соответствии с одним или более вариантами настоящего изобретения пример системы для обучения нейронной сети посредством специализированных функций потерь может содержать запоминающее устройство и процессор, соединенный с указанным запоминающим устройством. Процессор может быть выполнен с возможностью: получать набор обучающих данных, содержащий несколько изображений, где каждое изображение из набора обучающих данных ассоциируется с идентификатором класса из набора классов; вычислять с помощью нейронной сети множество векторов признаков, при этом каждый вектор признаков из множества векторов признаков представляет изображение набора обучающих данных в пространстве признаков изображений; вычислять для набора обучающих данных значение функции потерь, отображающей множество вероятностей, где каждая вероятность из множества вероятностей характеризует гипотезу, ассоциирующую изображение из набора обучающих данных с классом, ассоциируемым с этим изображением в соответствии с набором обучающих данных, при этом функция потерь дополнительно отображает множество расстояний, где каждое расстояние из множества расстояний вычисляется в пространстве признаков изображений между вектором признаков, представляющим изображение из набора обучающих данных, и центром класса, ассоциируемого с этим изображением в соответствии с набором обучающих данных; и настраивать параметр нейронной сети на основе значения функции потерь.
[0005] В соответствии с одним или более вариантами настоящего изобретения пример машиночитаемого постоянного носителя данных может содержать исполняемые команды, которые при выполнении их вычислительной системой заставляют вычислительную систему: получать набор обучающих данных, содержащий несколько изображений, где каждое изображение из набора обучающих данных ассоциируется с идентификатором класса из набора классов; вычислять с помощью нейронной сети множество векторов признаков, при этом каждый вектор признаков из множества векторов признаков представляет изображение из набора обучающих данных в пространстве признаков изображений; вычислять для набора обучающих данных значение функции потерь, отображающей множество вероятностей, где каждая вероятность из множества вероятностей характеризует гипотезу, ассоциирующую изображение из набора обучающих данных с классом, ассоциируемым с этим изображением в соответствии с набором обучающих данных, при этом функция потерь дополнительно отображает множество расстояний, где каждое расстояние из множества расстояний вычисляется в пространстве признаков изображений между вектором признаков, представляющим изображение из набора обучающих данных, и центром класса, ассоциируемого с этим изображением в соответствии с набором обучающих данных; и настраивать параметр нейронной сети на основе значения функции потерь.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Настоящее изобретение иллюстрируется с помощью примеров, а не способом ограничения, и может быть лучше понято при рассмотрении приведенного ниже описания предпочтительных вариантов реализации в сочетании с чертежами, на которых:
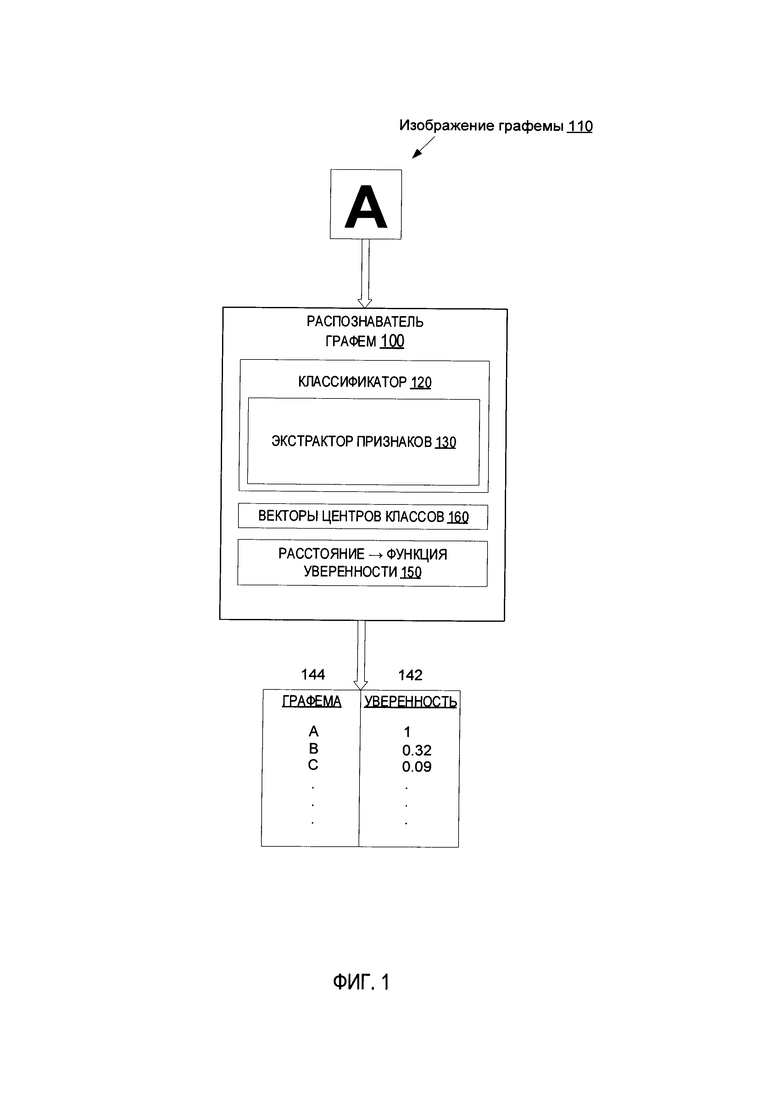
[0007] На Фиг. 1 схематически изображена функциональная структура примера распознавателя графем, исполненного в соответствии с одним или более вариантами настоящего изобретения.
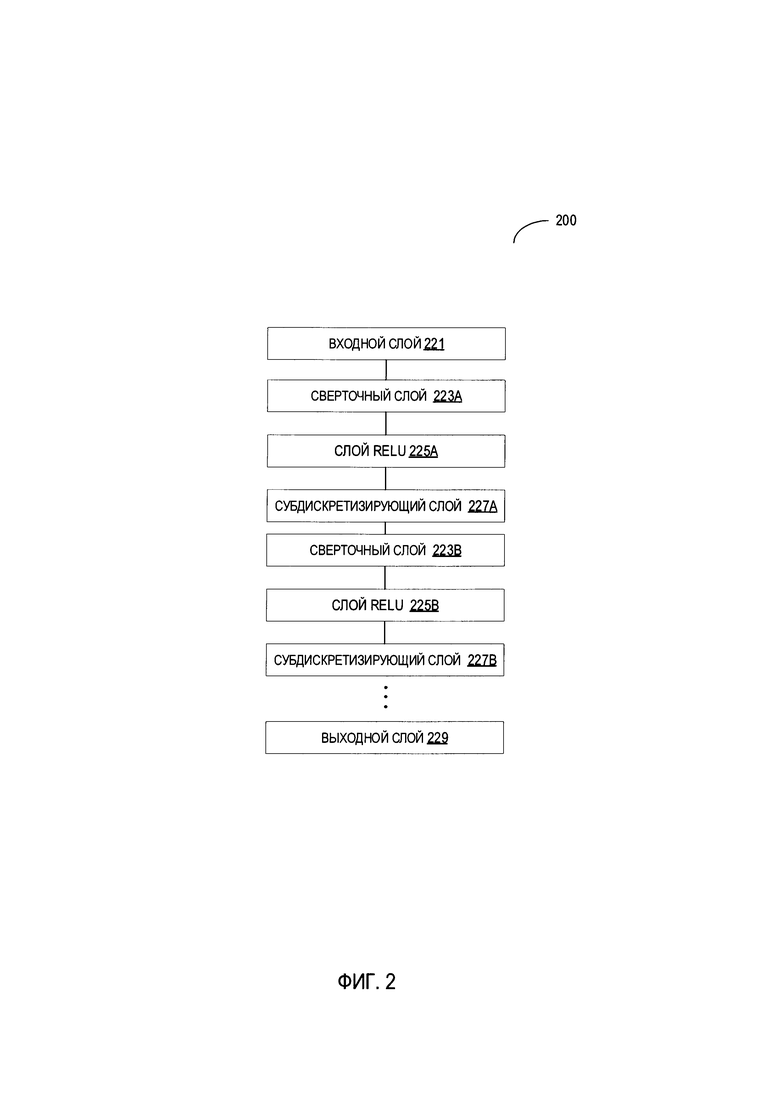
[0008] На Фиг. 2 схематически изображена функциональная структура примера сверточной нейронной сети, исполненной в соответствии с одним или более вариантами настоящего изобретения.
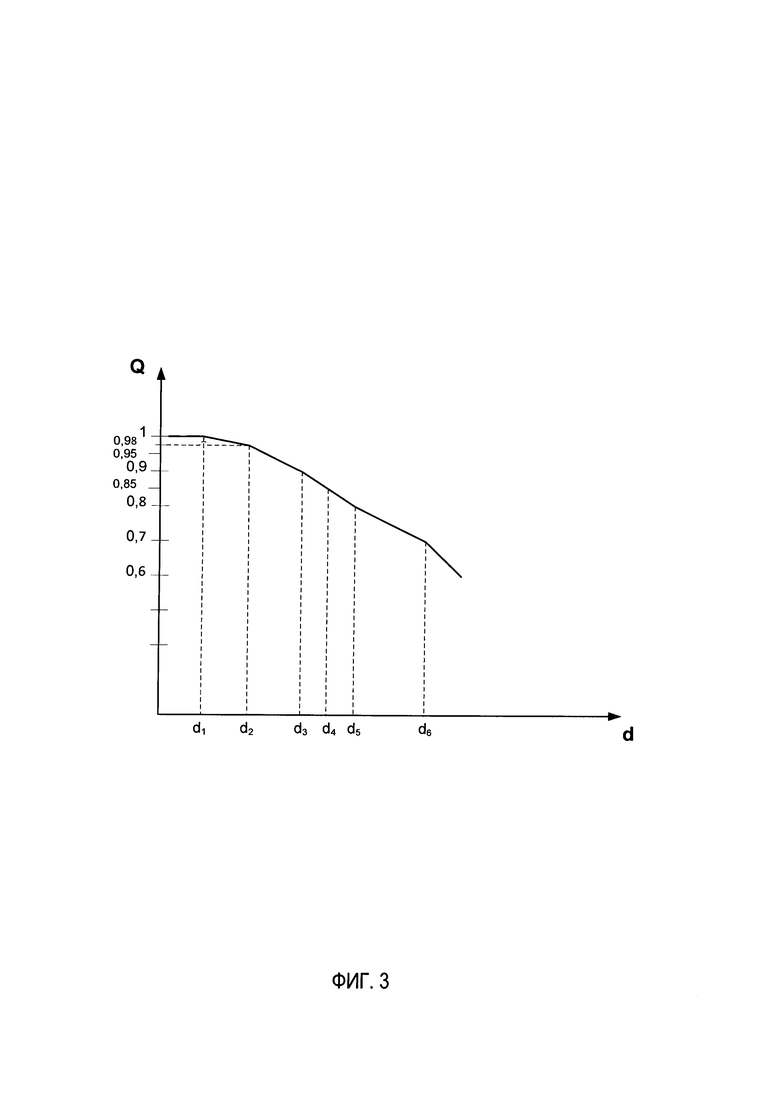
[0009] На Фиг. 3 схематически изображен пример функции уверенности Q(d), реализованной в соответствии с одним или более вариантами настоящего изобретения.
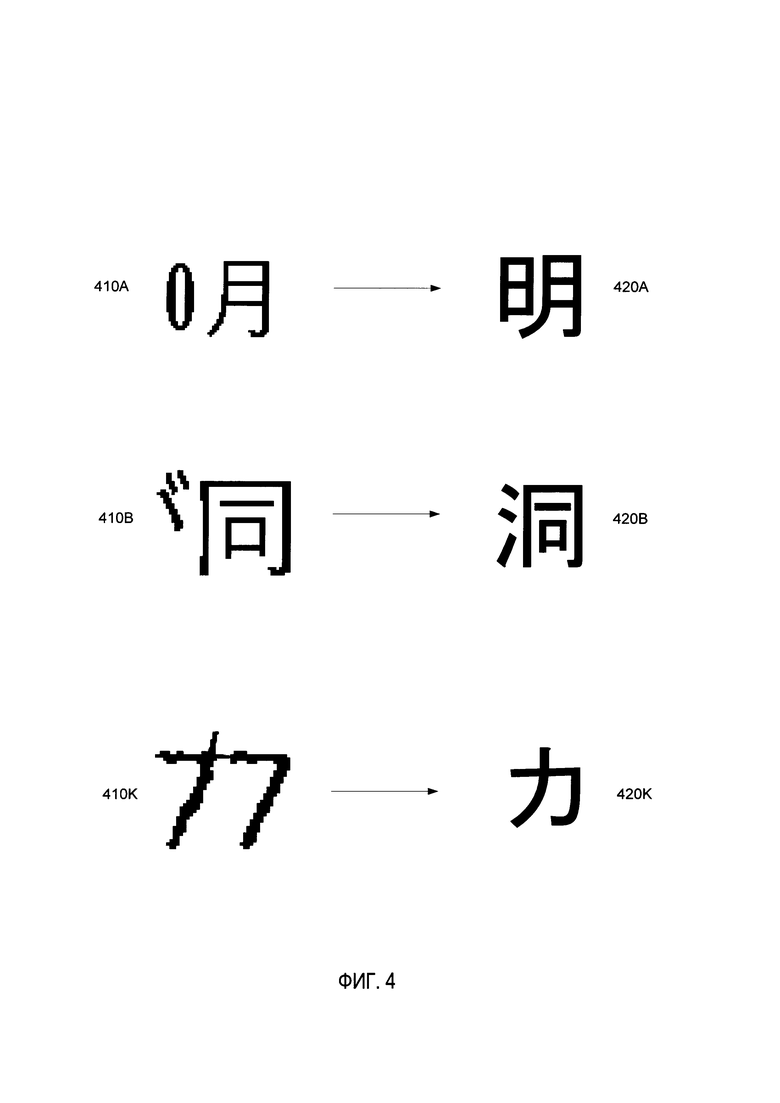
[00010] На Фиг. 4 схематически изображены примеры неправильных изображений графем и соответствующих правильных графем, имеющих визуальное сходство с соответствующими неправильными графемами, которые могут использоваться для обучения сверточных нейронных сетей, исполненных в соответствии с одним или более вариантами настоящего изобретения.
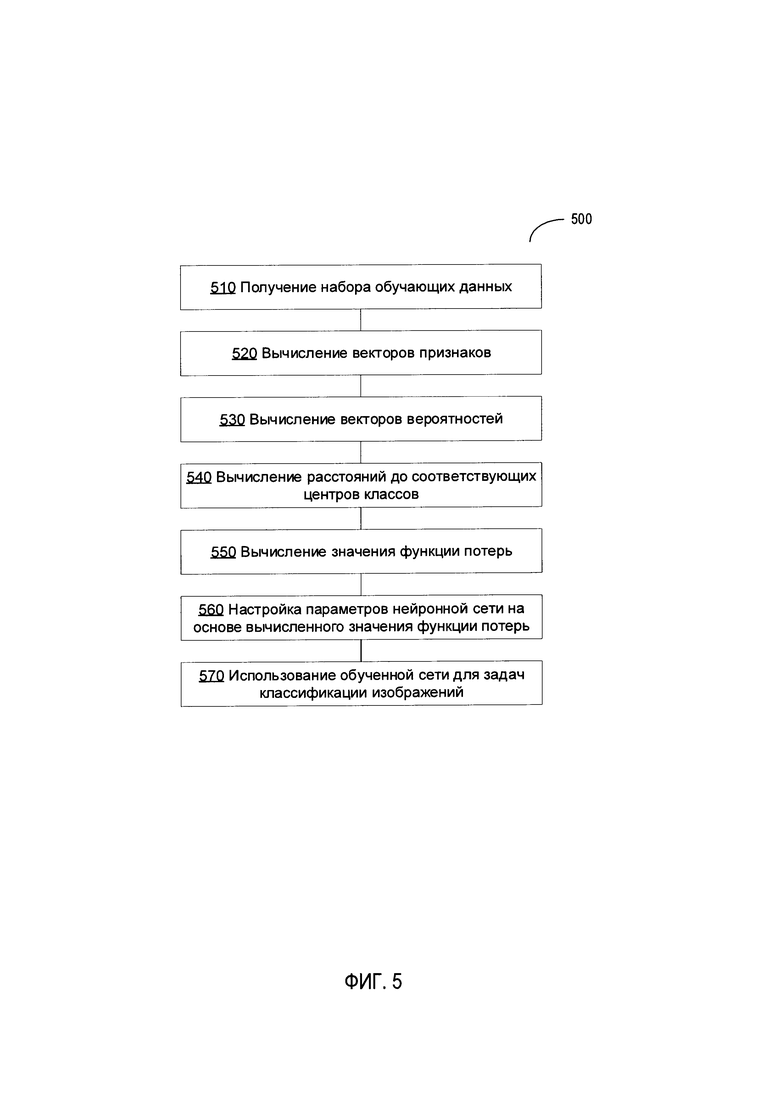
[00011] На Фиг. 5 изображена блок-схема примера способа обучения нейронной сети посредством специализированных функций потерь, в соответствии с одним или более вариантами настоящего изобретения.
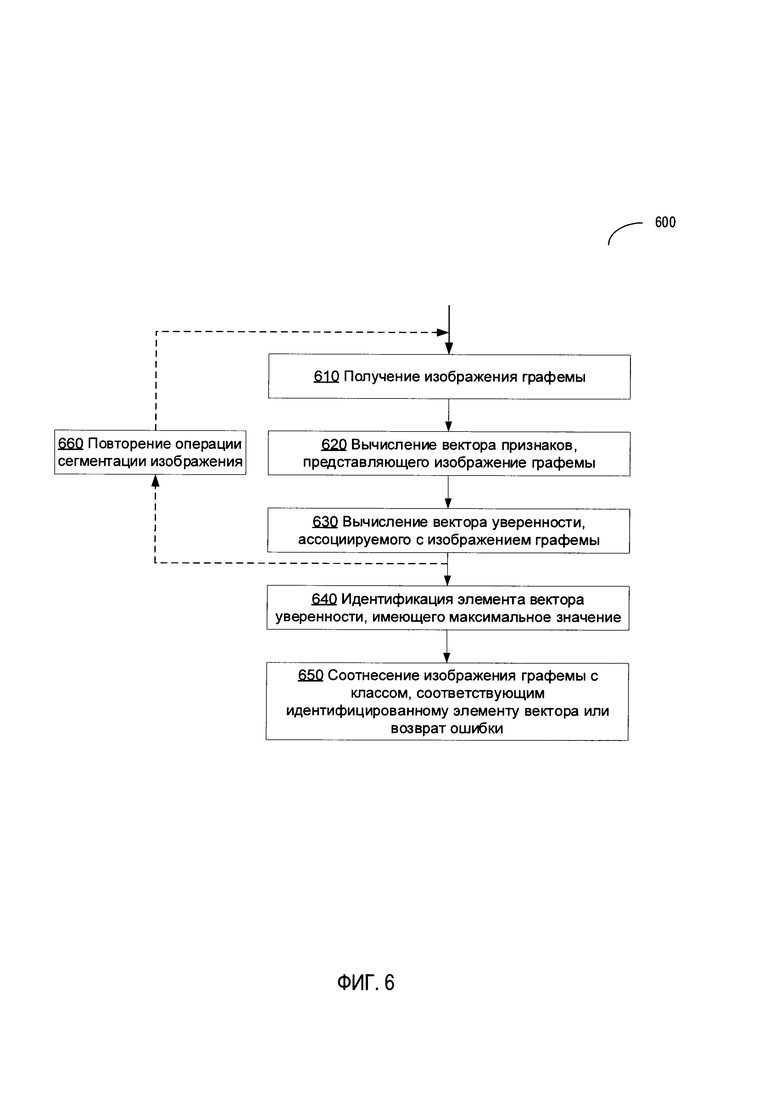
[00012] На Фиг. 6 изображена блок-схема примера способа оптического распознавания символов посредством специализированных функций уверенности, реализуемого на основе нейронной сети, в соответствии с одним или более вариантами настоящего изобретения.
[00013] На Фиг. 7 представлена схема компонентов примера вычислительной системы, которая может использоваться для реализации описанных в этом документе способов.
ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНЫХ ВАРИАНТОВ РЕАЛИЗАЦИИ
[00014] В этом разделе описаны способы и системы обучения нейронной сети посредством специализированных функций потерь. В некоторых вариантах реализации изобретения нейронные сети, обученные посредством способов, описанных в этом документе, могут использоваться для выполнения задач по классификации изображений (например, оптическое распознавание символов (OCR)). Процесс оптического распознавания символов позволяет извлекать машиночитаемую и текстовую информацию с возможностью поиска из изображений различной информационной среды, содержащих знаки (например, напечатанные или написанные от руки бумажные документы, баннеры, плакаты, вывески, рекламные щиты и (или) другие физические объекты, на которых содержатся видимые графемы на одной или более поверхностях). В этом документе «графема» означает элементарную единицу системы письма в заданном языке. Графема может быть представлена, например, в виде логограммы, обозначающей слово или морфему, силлабического (слогового) символа, обозначающего слог, или алфавитных символов, обозначающих фонему. В некоторых вариантах реализации изобретения процесс оптического распознавания символов может осуществляться с помощью обучаемых сверточных нейронных сетей.
[00015] Сверточная нейронная сеть может использовать множество функциональных преобразований в отношении множества входных данных (например, пиксели изображения), а затем использовать преобразованные данные с целью осуществления распознавания образа (например, распознавания графемы). Процесс обучения сети может приводить к активации сверточной нейронной сети для каждых входных данных из набора обучающих данных. Значение функции потерь можно вычислить на основе наблюдаемых выходных данных определенного слоя сверточной нейронной сети, а также требуемых выходных данных, заданных набором обучающих данных, а ошибка может быть обратно распространена к предыдущим слоям сверточной нейронной сети, в которой веса ребер и (или) другие сетевые параметры можно настроить соответствующим образом. Данный процесс можно повторять до тех пор, пока значение функции потерь не стабилизируется в окрестности определенного значения или не опустится ниже предварительно заданного порогового значения.
[00016] В отличие от различных способов оптического распознавания символов, в которых классификация графем основана на наборах признаков, подобранных человеком или определенных другими способами, сверточные нейронные сети могут автоматически определять наборы признаков, что является частью процесса обучения сети. Однако такие автоматически определенные наборы признаков могут быть недостаточно специфичными по меньшей мере для некоторых графем. Это может привести к неспособности нейронной сети, которая была обучена распознаванию графем определенного алфавита, отличать графему от других изображений содержащих знаки или изображений похожих на знаки, например изображения графем из другого алфавита, изображения части графы, группы «склеенных» графем и (или) различный графический шум. В иллюстративном примере изображения, полученные при неправильной сегментации строки, могут отображать значения признаков, которые не позволят их отличить от правильных графем; другими словами, нейронная сеть может стать неспособной определить, что такие изображения не являются правильными графемами, и поэтому классифицирует их в соответствии с классом правильной графемы.
[00017] Кроме того, эффективное обучение нейронных сетей, обрабатывающих изображения отличать неправильные графемы, может быть затруднено недостатком доступных отрицательных примеров, который возникает из-за сложности формирования всех возможных вариантов неправильных изображений графем, число которых может существенно превышать число правильных графем.
[00018] Способы обучения нейронной сети, описанные в заявке на изобретение, позволяют сделать существенные улучшения по сравнению с различными известными способами за счет применения функций потерь, которые конкретно направлены на обучение сети с целью распознавания неправильных или поврежденных изображений графем, что позволяет повысить качество и эффективность технологии оптического распознавания символов. Кроме того, способы оптического распознавания символов посредством специализированных функций уверенности, реализуемые на основе нейронной сети и описанные в данной заявке, позволяют сделать существенные улучшения по сравнению с различными известными способами за счет применения функции уверенности, которая вычисляет расстояния в пространстве признаков изображений между вектором признаков, представляющим полученное изображение, и векторами, представляющими центры классов из набора классов, и преобразует вычисленные расстояния в вектор значений уверенности таким образом, что каждое значение уверенности (например, значение в диапазоне 0-1) отображает степень уверенности гипотезы для полученного изображения графемы, представляющего пример определенного класса из набора классов графем, как более подробно представлено в дальнейшем описании.
[00019] Различные аспекты упомянутых выше способов и систем подробно описаны ниже в этом документе с помощью примеров, что не должно являться ограничивающим.
[00020] В общем процесс оптического распознавания символов может включать анализ и сегментацию изображения, содержащего знаки, определение алфавита и языка, распознавание графем, восстановление логической структуры изображенного документа и т.д. Ошибки сегментации изображения могут часто негативно влиять на последующие этапы процесса оптического распознавания символов, что приводит к появлению ошибок распознавания символов.
[00021] В иллюстративном примере операция сегментации изображения, которая должна разделить исходное изображение на текстовые строки и (или) отдельные графемы, может сформировать один или более фрагментов изображений, которые фактически не соответствуют правильным текстовым строкам или отдельным графемам (например, представляя собой изображение части графемы, группы «склеенных» графем или частей графем и т.д.). Как только выходные данные, полученные при сегментации изображения, поступают в модуль распознавания графем, большое число графем, распознанных с низкой уверенностью, может указывать на ошибочную сегментацию изображения, и в этом случае можно выбрать другой вариант сегментации либо операцию сегментации можно повторить с другим набором параметров. Однако в том случае, когда значение уверенности, полученное на этапе распознавания графем, превышает пороговое значение, ошибочная сегментация изображения может остаться не замеченной, что приведет к незамеченным ошибкам в процессе распознавания графем. Такие обстоятельства могут быть нивелированы посредством применения функций уверенности в соответствии с настоящим изобретением, что будет подробно описано далее.
[00022] На Фиг. 1 схематически изображена функциональная структура примера распознавателя графем 100, реализованного в соответствии с одним или более вариантами настоящего изобретения. Распознаватель графем 100 обрабатывает изображение графем 110 с помощью классификатора 120, который содержит экстрактор признаков 130, используемый для формирования вектора признаков, соответствующего изображению графем 110. Классификатор 120 преобразует вектор признаков в вектор весов классов таким образом, что каждый вес может характеризовать степень близости изображения 110 к классу графем из набора классов (например, множество алфавитных символов А, В, С и т.д.), где класс графем идентифицируется по индексу элемента вектора в пределах вектора весов классов. Классификатор 120 может затем использовать нормализованную экспоненциальную функцию для преобразования вектора весов классов в вектор вероятностей таким образом, что каждая вероятность может характеризовать гипотезу для изображения графемы 110, представляющую пример конкретного класса графем из набора классов, где класс графем идентифицируется по индексу элемента вектора в пределах вектора вероятностей. В иллюстративном примере набор классов может быть представлен в виде множества алфавитных символов А, В, С и т.д. так, что каждая вероятность из набора вероятностей, сформированная классификатором 120, может характеризовать гипотезу для входного изображения, представляющую соответствующий символ из множества алфавитных символов А, В, С и т.д.
[00023] Однако, как было отмечено ранее, такие вероятности могут быть ненадежными, например, в случае с неправильной сегментацией исходного изображения. Настоящее изобретение позволяет устранить этот и другие известные недостатки, присущие системам и способам, известным в данной области техники, с помощью применения функции уверенности 150, которая вычисляет расстояния, в пространстве признаков изображений, между центрами классов (которые могут сохраняться распознавателем графем 100 в запоминающем устройстве в качестве вектора центров классов 160) и вектором признаков изображения 110, и преобразует вычисленные расстояния в вектор значений уверенности 142 таким образом, что каждое значение уверенности (например, выбранное в диапазоне 0-1) отображает степень уверенности гипотезы для изображения графемы 110, представляющей пример определенного класса из набора классов 144, где класс графем идентифицируется по индексу элемента вектора в пределах вектора значений уверенности. В иллюстративном примере набор классов может соответствовать множеству алфавитных символов А, В, С и т.д., поэтому функция уверенности 150 может формировать набор значений уверенности таким образом, что каждое значение уверенности характеризует гипотезу для изображения, представляющую соответствующий символ из множества алфавитных символов А, В, С и т.д.
[00024] В некоторых вариантах реализации изобретения значение уверенности, вычисленное для каждого класса из набора классов с помощью функции уверенности 150, может быть отображено расстоянием между вектором признаков изображения 110 и центром соответствующего класса. Модуль распознавания графем 100 может выбирать класс графем, ассоциируемый с самым высоким значением уверенности, в качестве графемы, представленной на входном изображении. В некоторых вариантах реализации изобретения, если самое высокое значение уверенности ниже определенного порогового значения, то модуль распознавания графем может вернуть код ошибки, указывающий, что на входном изображении не представлена правильная графема (например, более одной графемы и (или) графема из другого алфавита может быть представлена на изображении).
[00025] В иллюстративном примере классификатор 120 может быть выполнен в виде сверточной нейронной сети со структурой, схематически изображенной на Фиг. 2. Пример сверточной нейронной сети 200 может содержать последовательность слоев различных типов, например, сверточные слои, субдискретизирующие слои, слои блоков линейной ректификации (ReLU) и полносвязные слои, каждый из которых может выполнять определенную операцию по распознаванию текста в изображении. Выходные данные слоя могут поступать в качестве входных данных в один и более последующих слоев. Как показано, сверточная нейронная сеть 200 может содержать слой входных данных 221, сверточные слои 223А-223 В, ReLU-слои 225А-225 В, субдискретизирующие слои 227А-227 В и слой выходных данных 229.
[00026] В некоторых вариантах изображение может быть получено слоем входных данных 221 и затем последовательно обработано несколькими слоями сверточной нейронной сети 200. Каждый из сверточных слоев может выполнять операцию свертки, которая может заключаться в обработке каждого пикселя фрагмента изображения с помощью одного или более фильтров (сверточные матрицы) и записи результата в соответствующую позицию матрицы выходных данных. Один или более сверточных фильтров могут предназначаться для детектирования определенного признака изображения путем обработки изображения и формирования соответствующей карты признаков.
[00027] Выходные данные сверточного слоя (например, сверточного слоя 223А) могут поступать в ReLU-слой (например, ReLU-слой 225А), который может применить нелинейное преобразование (например, функцию активации, которая заменяет отрицательные числа на ноль) для обработки выходных данных сверточного слоя. Выходные данные ReLU-слоя 225А могут поступать в субдискретизирующий слой 227А, который может выполнять операцию по снижению дискретизации для уменьшения разрешения и размера карты признаков. Выходные данные субдискретизирующего слоя 227А могут поступать в сверточный слой 223 В.
[00028] При обработке исходного изображения с помощью сверточной нейронной сети 200 может итеративно использоваться каждый соответствующий слой до тех пор, пока каждый слой не выполнит свою соответствующую операцию. Как схематически изображено на Фиг. 2, сверточная нейронная сеть 200 может содержать чередующиеся сверточные и субдискретизирующие слои. Такие чередующиеся слои могут позволять создавать разнообразные карты признаков различных размеров. Каждая из карт признаков может соответствовать одному из множества признаков изображения и может использоваться для распознавания графем.
[00029] В некоторых вариантах предпоследний слой (например, субдискретизирующий слой 227 В) сверточной нейронной сети 200 может формировать вектор признаков, представляющий признаки исходного изображения, что можно принять за представление исходного изображения в многомерном пространстве признаков изображений. Таким образом, сверточную нейронную сеть 200 без последнего полносвязного слоя 229 можно рассматривать в качестве сети, выполняющей функции экстрактора признаков 130.
[00030] Вектор признаков, сформированный с помощью экстрактора признаков, может поступать в полносвязный слой выходных данных 229, который может формировать вектор весов классов таким образом, что каждый вес может характеризовать степень близости изображения к классу графем из набора классов (например, множество алфавитных символов А, В, С и т.д.). Затем вектор весов классов можно преобразовать, например, с помощью нормализованной экспоненциальной функции в вектор вероятностей таким образом, что каждая вероятность может характеризовать гипотезу для входного изображения графемы, представляющую пример определенного класса графем из набора классов.
[00031] В некоторых вариантах реализации изобретения векторы весов классов и (или) вероятностей, сформированные с помощью полносвязного слоя 229 выходных данных, могут использоваться только для обучения сети, в то время как вектор признаков, сформированный с помощью предпоследнего слоя (например, субдискретизирующего слоя 227 В) сверточной нейронной сети 200, может поступать в вышеописанную функцию уверенности, которая формирует вектор значений уверенности таким образом, что каждое значение уверенности (например, выбранное в диапазоне 0-1) отображает степень уверенности гипотезы для изображения графемы, представляющей пример определенного класса из набора классов. В некоторых вариантах реализации изобретения значение уверенности, вычисленное для каждого класса из набора классов с помощью функции уверенности, может быть отображено расстоянием между вектором признаков изображения и центром соответствующего класса.
[00032] Однако, в некоторых вариантах реализации изобретения вычисления можно оптимизировать, использовав полносвязный слой 229 выходных данных для формирования вектора вероятностей, а затем вычислить значения уверенности для подмножества классов, состоящих из определенного числа классов, ассоциируемых с самыми высокими значениями вероятности или подмножества классов, ассоциируемых со значениями вероятности, превышающими пороговое значение вероятности.
[00033] Затем класс графем, ассоциируемый с самым высоким значением уверенности, можно выбрать в качестве графемы, представленной на входном изображении.
[00034] Несмотря на то что на Фиг. 2 показано определенное количество слоев сверточной нейронной сети 200, сверточные нейронные сети, используемые в различных альтернативных вариантах изобретения, могут содержать любое подходящее количество сверточных слоев, ReLU-слоев, субдискретизирующих слоев и (или) других слоев. Порядок слоев, количество слоев, количество фильтров и (или) другой параметр сверточной нейронной сети 200 можно настроить (например, на основе эмпирических данных).
[00035] Как отмечено ранее, настоящее изобретение раскрывает способы обучения, которые гарантируют, что обученный классификатор 120 может не только эффективно различать правильные графемы, но и отфильтровывать входные данные, которые не представляют собой изображения правильных графем. Фильтрование входных данных, которые не представляют собой изображения правильных графем, может быть выполнено распознавателем графем, который использует обученный классификатор 120, основываясь на значениях уверенности, полученных с помощью вышеописанной функции уверенности, которая вычисляет расстояния в пространстве признаков изображений между вектором признаков, отображающим входное изображение, и векторами, отображающими центры классов из набора классов, и преобразует вычисленные расстояния в вектор значений уверенности таким образом, что каждое значение уверенности (например, выбранное в диапазоне 0-1) отражает степень уверенности гипотезы для изображения графемы, представляющей пример определенного класса из набора классов графем. В некоторых вариантах реализации изобретения, если самое высокое значение уверенности падает ниже определенного порогового значения, модуль распознавания графем может вернуть код ошибки, указывая на то, что изображение не показывает правильную графему (например, более одной графемы и (или) графема из другого алфавита может быть представлена на изображении).
[00036] Процесс обучения классификатора 120 может заключаться в обработке пакетов изображений из набора обучающих данных, который содержит изображения графем и соответствующих идентификаторов классов (например, символы алфавита или номера классов), отражающих правильную классификацию изображений. Для каждого входного изображения экстрактор признаков 130 может формировать вектор признаков, который может поступать в следующий слой сверточной нейронной сети, которая может формировать вектор вероятностей, соответствующий входному изображению таким образом, что каждый элемент вектора характеризует гипотезу для изображения, представляющую пример определенного класса графем из набора классов. Значение функции потерь вычисляется на основе наблюдаемых выходных данных сверточной нейронной сети (то есть вектора вероятностей) и требуемых выходных данных, заданных набором обучающих данных (например, графема, которая фактически представлена на изображении, или, другими словами, идентификатор правильного класса).
[00037] В иллюстрированном примере функция потерь может быть выражена посредством функции потерь с перекрестной энтропией (Cross Entropy Loss, CEL) в следующем виде:
CEL=∑i-lnpji
[00038] где i - номер изображения в пакете входных изображений;
[00039] ji -идентификатор правильного класса (например, идентификатор графемы) для i-го изображения; и
[00040] pji. вероятность, полученная с помощью нейронной сети для i-го изображения, представляющая j-й класс (то есть для правильной классификации i-го изображения).
[00041] Суммирование выполняется по всем изображениям из текущего пакета входных изображений. Идентифицированная ошибка классификации обратно распространяется в предыдущие слои сверточной нейронной сети, в которой соответствующим образом выполняется настройка параметров сети. Данный процесс можно повторять до тех пор, пока значение функции потерь не стабилизируется в окрестности определенного значения или не опустится ниже предварительно заданного порогового значения. Нейронная сеть, обученная с использованием функции CEL, может размещать примеры одного и того же класса вдоль определенного вектора в пространстве признаков, обеспечивая эффективное разделение примеров из различных классов.
[00042] Хотя функция CEL может быть приемлемым решением для различения изображений разных графем, она не всегда выдает удовлетворительные результаты при отфильтровывании неправильных графем. В соответствии с этим и в дополнение к функции CEL можно использовать и функцию центральных потерь (Center Loss function, CL), тем самым делая представление каждого класса более компактным в пространстве признаков таким образом, что все примеры заданного класса будут располагаться в пределах относительно небольшой окрестности определенной точки, которая может стать центром класса, в то время как любое признаковое представление неправильного изображения графемы будет расположено относительно далеко (например, на расстоянии, превышающем предварительно заданное или динамически формируемое пороговое значение) от любого центра класса.
[00043] В иллюстративном примере функция центральных потерь может быть выражена в следующем виде:
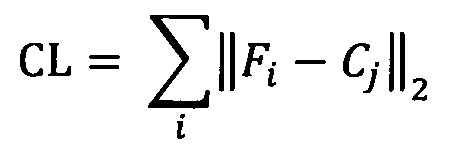
[00044] где i - номер изображения в пакете изображений;
[00045] Fi - вектор признаков i-го изображения;
[00046] j - идентификатор правильного класса (например, идентификатор графемы) для i-го изображения; и
[00047] Cj - вектор центра j-гo класса.
[00048] Суммирование выполняется по всем изображениям из текущего пакета входных изображений.
[00049] Векторы Cj центров классов можно вычислить как среднее всех признаков изображений, принадлежащих j-му классу. Как схематически показано на Фиг. 1, вычисленные векторы центров классов 160 можно сохранить в запоминающем устройстве, доступном для модуля распознавания графем 100.
[00050] В иллюстративном примере классификатор 120 может быть обучен с помощью функции потерь, представленной в виде линейной комбинации функций CEL и CL, при этом начальные значения векторов центров классов принимаются равными нулю. Значения векторов центров классов могут быть пересчитаны после обработки каждого набора обучающих данных (то есть каждого пакета входных изображений).
[00051] В другом иллюстративном примере классификатор 120 можно изначально обучить с помощью функции CEL, и исходные значения векторов центров классов можно вычислить после выполнения начального этапа обучения. При последующем обучении может использоваться линейная комбинация функций CEL и CL, а значения векторов центров классов могут быть пересчитаны после обработки каждого пакета обучающих данных (то есть каждого пакета входных изображений).
[00052] Применение комбинации функций CEL и CL для обучения нейронной сети может позволить обеспечить компактное представление каждого класса в пространстве признаков таким образом, что все примеры заданного класса будут располагаться в пределах относительно небольшой окрестности определенной точки, которая может стать центром класса, при этом любое признаковое представление неправильного изображения графемы будет располагаться относительно далеко (например, на расстоянии, превышающем предварительно заданное или динамически формируемое пороговое значение) от любого центра класса.
[00053] В иллюстративном примере функцию потерь L можно выразить с помощью линейной комбинации функций CEL и CL в следующем виде:
L=CEL+α*CL
[00054] где α - весовой коэффициент, значение которого можно настроить для снижения влияния функции CL на значение результирующей функции потерь, что позволяет избежать чрезмерного сужения диапазона признаков для примеров заданного класса.
[00055] Функция уверенности может быть представлена таким образом, чтобы распознаватель графем гарантированно назначал низкие значения уверенности для неправильных изображений графем. Соответственно уверенность назначения данного изображения определенному классу (например, распознавание определенной графемы на изображении) может, таким образом, отображать расстояние между вектором признаков изображения и центром класса, которое можно выразить в следующем виде:
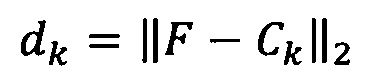
[00056] где dk - это расстояние между центром Ck k-го класса и вектором признаков F данного изображения.
[00057] Функцию уверенности можно представить с помощью монотонно убывающей функции расстояния между центром класса и вектором признаков изображения в пространстве признаков изображений. Таким образом, чем дальше вектор признаков расположен от центра класса, тем меньше будет значение уверенности, соответствующее назначению изображения данному классу.
[00058] В иллюстрированном примере функцию уверенности Q можно задать с помощью кусочно-линейной функции расстояния. Функцию уверенности Q можно построить путем выбора определенных значений уверенности qi и определения соответствующих значений расстояния di, которые позволят минимизировать количество ошибок классификации, полученных от классификатора, обрабатывающего выбранный контрольный набор данных (который может быть представлен, например, набором изображений документов (например, изображениями страниц документа) с метаданными, определяющими правильную классификацию графем на изображении). В некоторых вариантах реализации изобретения значения уверенности qt можно выбирать через равные интервалы в пределах применяемого диапазона значений уверенности (например, 0-1). Альтернативно, интервалы между значениями уверенности qi можно выбирать таким образом, чтобы они увеличивались при смещении в диапазоне значений уверенности к самым низким значениям уверенности так, что такие интервалы будут уже в некотором диапазоне высоких значений уверенности и будут шире в некотором диапазоне низких значений уверенности.
[00059] На Фиг. 3 схематически изображен пример функции Q(d), реализованной в соответствии с одним или более вариантами настоящего изобретения. Как схематически изображено на Фиг. 3, значения уверенности qk можно выбирать на предварительно заданных интервалах в пределах применяемого диапазона значений уверенности (например, 0-1), после чего можно определять соответствующие значения dk. Если требуется более высокая чувствительность функции к ее входным данным в более высоком диапазоне значений функции, то значения qk в пределах некоторого диапазона высоких значений уверенности можно выбирать на относительно небольших интервалах (например, 1; 0,98; 0,95; 0,9; 0,85; 0,8; 0,7; 0,6; …). Тогда расстояния Лк между соседними значениями dk (например, dk=dk-1+Δk) можно определить, применив методы оптимизации, такие как метод дифференциальной эволюции. Затем функцию уверенности Q(d) можно построить в виде кусочно-линейной функции, соединяющей вычисленные точки (dk, qk).
[00060] В некоторых вариантах реализации изобретения значения уверенности можно определять только для подмножества гипотез классификации, которые классификатор ассоциировал с высокими вероятностями (например, выше конкретного порогового значения).
[00061] Применение вышеописанных функций потерь и уверенности обеспечивает условие, при котором для большинства неправильных изображений графем низкие значения уверенности будут назначены гипотезам, ассоциирующим изображения со всеми возможными графемами. Очевидное преимущество применения вышеописанных функций потерь и уверенности заключается в обучении классификатора без необходимости предоставления отрицательных примеров в наборе обучающих данных, поскольку, как отмечено ранее, все возможные варианты неправильных изображений сложно сформировать, а число таких вариантов может существенно превышать число правильных графем.
[00062] В некоторых вариантах реализации изобретения классификатор, обученный с помощью вышеописанных функций потерь и уверенности, может тем не менее остаться неспособным отфильтровывать небольшое количество неправильных изображений графем. Например, гипотеза, ассоциирующая неправильное изображение графемы с определенным классом (то есть ошибочно распознающая определенную графему в пределах изображения), будет принимать высокое значение уверенности, если вектор признаков неправильного изображения графемы расположен достаточно близко от центра класса. Так как число таких ошибок мало, вышеописанная функция потерь может быть улучшена, чтобы отфильтровывать такие неправильные изображения графем.
[00063] В иллюстративном примере вышеописанная функция потерь, представленная с помощью функции CEL и функции CL, может быть улучшена путем введения третьего члена, обозначенного в данном документе как штрафная функция потерь приближения к центру (Close-to-Center Penalty Loss, CCPL), которая позволит отдалить векторы признаков известных типов неправильных изображений от центров всех классов. В соответствии с этим улучшенная функция потерь может быть выражена в виде:
L=CEL+α*CL+β*CCPL
[00064] Процесс обучения нейронной сети с помощью улучшенной функции потерь, которая отражает функцию CCPL, может заключаться в итеративной обработке пакетов изображений таких, что каждый пакет будет содержать положительные примеры (изображения правильных графем) и отрицательные примеры (неправильные изображения графем). В некоторых вариантах реализации изобретения член CEL+α*CL может быть посчитан только для положительных примеров, при этом член β*CCPL может быть посчитан только для отрицательных примеров.
[00065] В иллюстративном примере набор обучающих данных может содержать отрицательные примеры, представленные реальными неправильными изображениями графем, которые были ошибочно классифицированы в качестве правильных изображений и в отношении которых были получены значения уверенности, превышающие некоторое предварительно заданное пороговое значение. В другом иллюстративном примере набор обучающих данных может содержать отрицательные примеры, представленные синтетическими неправильными изображениями графем. На Фиг. 4 схематически изображены примеры неправильных изображений графем 410A-410К и соответствующие правильные графем 420А-420К, которые можно визуально соотнести с соответствующими неправильными изображениями.
[00066] Функция CCPL, которая вычисляется для отрицательных примеров обучения, может быть выражена в виде:
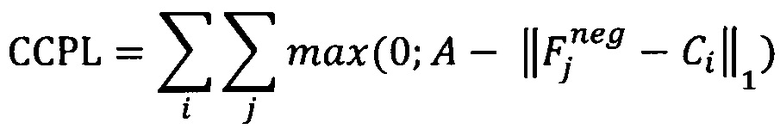
[00067] где  - вектор признаков для j-ro отрицательного примера обучения;
- вектор признаков для j-ro отрицательного примера обучения;
[00068] Сi - центр i-ro класса; и
[00069] А - предварительно заданный или настраиваемый параметр, определяющий размер окрестности центра класса (то есть расстояние до центра класса) в пространстве признаков изображений, такой что векторы признаков, расположенные в этой окрестности, штрафуются, при этом штраф не будет применяться в отношении векторов признаков, расположенных за пределами этой окрестности.
[00070] Таким образом, если вектор признаков отрицательного примера расположен в пределах расстояния, не превышающего значение параметра А от центра i-го класса, то значение функции CCPL увеличивается на такое расстояние. Процесс обучения классификатора заключается в минимизации значения функции CCPL. Таким образом для неправильного изображения графемы обученный классификатор будет выдать вектор признаков, который расположен за пределами непосредственных окрестностей центров имеющихся классов. Другими словами, классификатор обучается для того, чтобы отличать неправильные изображения графем от реальных графем.
[00071] Как отмечено ранее, нейронные сети, обученные с помощью способов, описанных в данном документе, можно использовать для выполнения различных задач по классификации изображений, включая, но без ограничения, оптическое распознавание символов.
[00072] На Фиг. 5 изображена блок-схема примера способа 500 обучения нейронной сети посредством специализированных функций потерь, реализованного на основе нейронной сети, в соответствии с одним или более вариантами настоящего изобретения. Способ 500 и (или) каждая из отдельных его функций, процедур, подпрограмм или операций может выполняться одним или более процессорами вычислительной системы (например, вычислительной системой 700, изображенной на Фиг. 7), реализующими этот способ. В некоторых вариантах реализации способ 500 может выполняться в одном потоке обработки. Альтернативно, способ 500 может выполняться в двух или более потоках обработки, при этом в каждом потоке будут выполняться одна или более отдельных функций, процедур, подпрограмм или операций способа. В одном из иллюстративных примеров потоки обработки, в которых реализован способ 500, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). Альтернативно, потоки обработки, реализующие способ 500, могут выполняться асинхронно друг относительно друга. Таким образом, несмотря на то что Фиг. 5 и соответствующее описание содержат список операций для способа 500 в определенном порядке, в различных вариантах осуществления способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке.
[00073] На шаге 510 вычислительная система, реализующая указанный способ, может принимать набор данных, содержащий множество изображений. Каждое изображение из набора обучающих данных может ассоциироваться с метаданными, определяющими правильную классификацию изображения, то есть идентификатором определенного класса из набора классов (например, символ алфавита).
[00074] На шаге 520 вычислительная система может вычислять для каждого изображения из набора обучающих данных вектор признаков, который может рассматриваться в качестве представления изображения в многомерном пространстве признаков изображения. В иллюстративном примере вектор признаков может формироваться с помощью предпоследнего слоя сверточной нейронной сети, которая была обучена, как было ранее описано в подробной форме.
[00075] На шаге 530 вычислительная система может использовать нейронную сеть, чтобы для каждого изображения из набора обучающих данных на основе вектора признаков, представляющего изображение, вычислить вектор вероятностей, каждый элемент которого отображает вероятность гипотезы, ассоциирующей это изображение с соответствующим классом из набора классов (то есть классом, идентифицированным по индексу элемента вектора). В иллюстративном примере такая классификация может быть выполнена с помощью полносвязного слоя сверточной нейронной сети, как было описано ранее в подробной форме.
[00076] На шаге 540 вычислительная система может вычислять для каждого изображения из набора обучающих данных расстояние в пространстве признаков изображений между вектором признаков, представляющим изображение, и центром класса, ассоциируемого с этим изображением в соответствии с набором обучающих данных.
[00077] На шаге 550 вычислительная система может вычислять для набора обучающих данных значение функции потерь. В иллюстративном примере функция потерь может быть представлена с помощью линейной комбинации функций CEL и CL. Значение функции CEL можно определить на основе вероятностей, вычисленных на шаге 530. Значение функции CL можно определить на основе расстояний, вычисленных на шаге 540, как было описано ранее в подробной форме.
[00078] В другом иллюстративном примере функция потерь представлена с помощью линейной комбинации функции потерь с перекрестной энтропией, функции центральных потерь и штрафной функции потерь приближения к центру. Последнюю можно определить на основе вычисленных расстояний между векторами признаков отрицательных примеров обучения и центрами классов, как было описано ранее в подробной форме.
[00079] На шаге 560 вычислительная система может настраивать на основе вычисленного значения функции потерь один или более параметров сверточной нейронной сети, которая обучается. В иллюстративном примере ошибка, отображаемая значением функции потерь, обратно распространению начиная с последнего слоя сверточной нейронной сети, а веса и (или) другие параметры сети настраиваются соответствующим образом. В некоторых вариантах реализации изобретения операции на шаге 560 могут содержать операции повторного вычисления значений центров классов в пространстве признаков изображений.
[00080] Данный процесс, описанный шагами 510-560, можно повторять до тех пор, пока значение функции потерь не стабилизируется в окрестности определенного значения или не опустится ниже предварительно заданного порогового значения.
[00081] На шаге 570 вычислительная система может использовать обученную сверточную нейронную сеть для выполнения задачи классификации изображений (например, оптического распознавания символов) одного или более входных изображений, а способ можно считать оконченным.
[00082] На Фиг. 6 изображена блок-схема примера способа 600 оптического распознавания символов с применением специализированных функций уверенности, реализуемого на основе нейронной сети в соответствии с одним или более вариантами настоящего изобретения. Способ 600 и (или) каждая из его отдельно взятых функций, процедур, подпрограмм или операций могут осуществляться с помощью одного или более процессоров вычислительной системы (например, вычислительной системы 700 на Фиг. 7), реализующей этот способ. В некоторых реализациях изобретения способ 600 может выполняться с помощью одного потока обработки. Альтернативно, способ 600 может выполняться в двух или более потоках обработки, при этом в каждом потоке будут выполняться одна или более отдельных функций, процедур, подпрограмм или операций способа. В одном из иллюстративных примеров потоки обработки, в которых реализован способ 600, могут быть синхронизированы (например, с использованием семафоров, критических секций и (или) других механизмов синхронизации потоков). Также потоки обработки, реализующие способ 600, могут выполняться асинхронно друг относительно друга. Таким образом, несмотря на то что Фиг. 6 и соответствующее описание содержат список операций для способа 600 в определенном порядке, в различных вариантах осуществления способа как минимум некоторые из описанных операций могут выполняться параллельно и (или) в случайно выбранном порядке.
[00083] На шаге 610 вычислительная система, реализующая способ, может получать текст на естественном языке.
[00084] На шаге 620 вычислительная система может использовать нейронную сеть (например, нейронную сеть с архитектурой как у нейронной сети 200 на Фиг. 2) для вычисления вектора признаков, представляющего изображение графемы в пространстве признаков изображений, как было описано ранее в подробной форме.
[00085] На шаге 630 вычислительная система может вычислять вектор уверенности, ассоциируемый с изображением графемы. Каждый элемент вектора уверенности может отображать расстояние в пространстве признаков изображений между вектором признаков и центром класса из набора классов графем, при этом класс идентифицируется по индексу элемента вектора уверенности.
[00086] В некоторых вариантах реализации изобретения вычисления, выполняемые на шаге 630, можно оптимизировать посредством вычисления значений уверенности только для подмножества классов, состоящего из определенного числа классов, ассоциируемых со наивысшими значениями вероятности, выданными классификатором, или подмножеством классов, ассоциируемых со значениями вероятности, превышающими пороговое значение вероятности. Можно считать, что значения уверенности у оставшихся классов будут равны предварительно заданному небольшому значению (например, нулю).
[00087] На шаге 640 вычислительная система может идентифицировать элемент, имеющий максимальное значение среди элементов вектора уверенности.
[00088] На шаге 650 вычислительная система может установить, что изображение графемы представляет пример класса графем, соответствующий идентифицированному элементу вектора уверенности, как было описано ранее в подробной форме. Кроме того, если идентифицированное максимальное значение уверенности окажется ниже конкретного порогового значения, то описываемый способ может вернуть код ошибки, указывающий на то, что изображение не может быть распознано, поскольку не изображает правильную графему (например, на изображении входных данных отображается более одной графемы, часть по меньшей мере одной графемы и (или) графема из другого алфавита). После завершения операций способа 650 выполнение способа может быть завершено.
[00089] В некоторых вариантах реализации изобретения вместо выполнения операций 640-650 способ 600 может формировать на выходе вектор уверенности, который в дальнейшем обрабатывается с помощью системы оптического распознавания символов. В иллюстративном примере система оптического распознавания символов использует полученный вектор уверенности для идентификации оптимальной сегментации изображения (шаг 660), после чего осуществляется финальный этап операции распознавания символов (например, повторение операций 610-650 для нового изображения графем, сформированного с помощью сегментации идентифицированного оптического изображения), как схематически изображено на Фиг. 6 с помощью пунктирных стрелок.
[00090] На Фиг. 7 представлена схема компонентов примера вычислительной системы, которая может использоваться для реализации описанных в этом документе способов. Вычислительная система 700 может быть соединена с другой вычислительной системой по локальной сети, корпоративной сети, сети экстранет или сети Интернет. Вычислительная система 700 может работать в качестве сервера или клиента в сетевой среде «клиент / сервер» либо в качестве однорангового вычислительного устройства в одноранговой (или распределенной) сетевой среде. Вычислительная система 700 может быть представлена персональным компьютером (ПК), планшетным ПК, телевизионной приставкой (STB), карманным ПК (PDA), сотовым телефоном или любой вычислительной системой, способной выполнять набор команд (последовательно или иным образом), определяющих операции, которые должны быть выполнены этой вычислительной системой. Кроме того, несмотря на то что показана только одна вычислительная система, термин «вычислительная система» также может включать любую совокупность вычислительных систем, которые отдельно или совместно выполняют набор (или несколько наборов) команд для выполнения одной или более методик, обсуждаемых в настоящем документе.
[00091] Пример вычислительной системы 700 включает процессор 702, основное запоминающее устройство 704 (например, постоянное запоминающее устройство (ПЗУ) или динамическое оперативное запоминающее устройство (ДОЗУ)) и устройство хранения данных 718, которые взаимодействуют друг с другом по шине 730.
[00092] Процессор 702 может быть представлен одним или более универсальными вычислительными устройствами, такими как микропроцессор, центральный процессор и т.п. В частности, процессор 702 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW) или процессор, в котором реализованы другие наборы команд, или процессоры, в которых реализована комбинация наборов команд. Процессор 702 также может представлять собой одно или более вычислительных устройств специального назначения, например, заказную интегральную микросхему (ASIC), программируемую пользователем вентильную матрицу (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п.Процессор 702 реализован с возможностью выполнения команд 726 для осуществления рассмотренных в настоящем документе способов.
[00093] Вычислительная система 700 может дополнительно включать устройство сетевого интерфейса 722, устройство визуального отображения 710, устройство ввода символов 712 (например, клавиатуру) и устройство ввода в виде сенсорного экрана 714.
[00094] Устройство хранения данных 718 может включать машиночитаемый носитель данных 724, в котором хранится один или более наборов команд 726, в которых реализован один или более способов или функций, описанных в данном варианте реализации изобретения. Инструкции 726 во время выполнения их в вычислительной системе 700 также могут находиться полностью или по меньшей мере частично в основном запоминающем устройстве 704 и (или) в процессоре 702, при этом основное запоминающее устройство 704 и процессор 702 также представляют собой машиночитаемый носитель данных. Команды 726 также могут передаваться или приниматься по сети 716 через устройство сетевого интерфейса 722.
[00095] В иллюстративном примере инструкции 726 могут содержать инструкции способа 500 обучения нейронной сети с применением специализированных функций потерь, реализованного в соответствии с одним или более вариантами настоящего изобретения. В другом иллюстративном варианте инструкции 726 могут содержать инструкции способа 600 оптического распознавания символов с применением специализированных функций уверенности, реализуемого на основе нейронной сети, в соответствии с одним или более вариантами настоящего изобретения. Хотя машиночитаемый носитель данных 724, показанный в примере на Фиг. 7, является единым носителем, термин «машиночитаемый носитель» может включать один или более носителей (например, централизованную или распределенную базу данных и (или) соответствующие кэши и серверы), в которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует понимать как включающий любой носитель, который может хранить, кодировать или переносить набор команд для выполнения машиной и который обеспечивает выполнение машиной любой одной или более методик настоящего изобретения. Поэтому термин «машиночитаемый носитель данных» относится, помимо прочего, к твердотельным запоминающим устройствам, а также к оптическим и магнитным носителям.
[00096] Способы, компоненты и функции, описанные в этом документе, могут быть реализованы с помощью дискретных компонентов оборудования либо они могут быть встроены в функции других компонентов оборудования, например, ASICS (специализированная заказная интегральная схема), FPGA (программируемая логическая интегральная схема), DSP (цифровой сигнальный процессор) или аналогичных устройств. Кроме того, способы, компоненты и функции могут быть реализованы с помощью модулей встроенного программного обеспечения или функциональных схем аппаратного обеспечения. Способы, компоненты и функции также могут быть реализованы с помощью любой комбинации аппаратного обеспечения и программных компонентов либо исключительно с помощью программного обеспечения.
[00097] В приведенном выше описании изложены многочисленные детали. Однако любому специалисту в этой области техники, ознакомившемуся с этим описанием, должно быть очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем без детализации, чтобы не усложнять описание настоящего изобретения.
[00098] Некоторые части описания предпочтительных вариантов реализации изобретения представлены в виде алгоритмов и символического представления операций с битами данных в запоминающем устройстве компьютера. Такие описания и представления алгоритмов представляют собой средства, используемые специалистами в области обработки данных, что обеспечивает наиболее эффективную передачу сущности работы другим специалистам в данной области. В контексте настоящего описания, как это и принято, алгоритмом называется логически непротиворечивая последовательность операций, приводящих к желаемому результату. Операции подразумевают действия, требующие физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять с ними другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, графем, символов, терминов, цифр и т.д.
[00099] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано дополнительно, принимается, что в последующем описании термины «определение», «вычисление», «расчет», «получение», «установление», «изменение» и т.п.относятся к действиям и процессам вычислительной системы или аналогичной электронной вычислительной системы, которая использует и преобразует данные, представленные в виде физических (например, электронных) величин в реестрах и запоминающих устройствах вычислительной системы, в другие данные, аналогично представленные в виде физических величин в запоминающих устройствах или реестрах вычислительной системы или иных устройствах хранения, передачи или отображения такой информации.
[000100] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, либо оно может представлять собой универсальный компьютер, который избирательно приводится в действие или дополнительно настраивается с помощью программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на машиночитаемом носителе данных, например, помимо прочего, на диске любого типа, включая дискеты, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), СППЗУ, ЭППЗУ, магнитные или оптические карты и носители любого типа, подходящие для хранения электронной информации.
[000101] Следует понимать, что приведенное выше описание призвано иллюстрировать, а не ограничивать сущность изобретения. Специалистам в данной области техники после прочтения и уяснения приведенного выше описания станут очевидны и различные другие варианты реализации изобретения. Исходя из этого область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, на которые в равной степени распространяется формула изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ ПРИМЕНЕНИЯ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ УВЕРЕННОСТИ, РЕАЛИЗУЕМОЕ НА БАЗЕ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2703270C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| РАСПОЗНАВАНИЕ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ИЕРАРХИЧЕСКОЙ КЛАССИФИКАЦИИ | 2018 |
|
RU2693916C1 |
| ДИФФЕРЕНЦИАЛЬНАЯ КЛАССИФИКАЦИЯ С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ НЕЙРОННЫХ СЕТЕЙ | 2017 |
|
RU2652461C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ СВЕРТОЧНЫМИ НЕЙРОННЫМИ СЕТЯМИ | 2020 |
|
RU2771442C1 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| ИДЕНТИФИКАЦИЯ ИСПОЛЬЗУЕМЫХ В ДОКУМЕНТАХ СИСТЕМ ПИСЬМА | 2021 |
|
RU2792743C1 |
| РАСПОЗНАВАНИЕ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2661750C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ ОБУЧЕННЫМИ НЕЙРОННЫМИ СЕТЯМИ | 2021 |
|
RU2779281C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ НА ИЗОБРАЖЕНИИ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2018 |
|
RU2695489C1 |
Группа изобретений относится к области обучения нейронной сети посредством применения специализированных функций потерь. Техническим результатом является повышение качества и эффективности оптического распознавания символов. Способ содержит: получение вычислительной системой набора обучающих данных, содержащего множество изображений, где каждое изображение из набора обучающих данных ассоциируется с идентификатором класса из набора классов; вычисление с помощью нейронной сети множества векторов признаков, при этом каждый вектор признаков из множества векторов признаков представляет изображение из набора обучающих данных в пространстве признаков изображений; вычисление для набора обучающих данных значения функции потерь, отображающей множество вероятностей, где каждая вероятность из множества вероятностей представляет гипотезу, ассоциирующую изображение из набора обучающих данных с классом, ассоциируемым с этим изображением в соответствии с набором обучающих данных, при этом функция потерь дополнительно отображает множества расстояний, где каждое расстояние из множества расстояний вычисляется в пространстве признаков изображений между вектором признаков, представляющим изображение из набора обучающих данных, и центром класса, ассоциируемого с этим изображением в соответствии с набором обучающих данных; и настройку параметра нейронной сети на основе значения функции потерь. 3 н. и 17 з.п. ф-лы, 7 ил.
1. Способ обучения нейронной сети, содержащий:
получение вычислительной системой набора обучающих данных, содержащего несколько изображений, при этом каждое изображение из набора обучающих данных ассоциируется с идентификатором класса из набора классов;
вычисление с помощью нейронной сети множества векторов признаков, при этом каждый вектор признаков из множества векторов признаков представляет изображение из набора обучающих данных в пространстве признаков изображений;
вычисление для набора обучающих данных значения функции потерь, отображающей множество вероятностей, где каждая вероятность из множества вероятностей характеризует гипотезу, ассоциирующую изображение из набора обучающих данных с классом, ассоциируемым с этим изображением в соответствии с набором обучающих данных, при этом функция потерь дополнительно отображает множество расстояний, где каждое расстояние из множества расстояний вычисляется в пространстве признаков изображений между вектором признаков, представляющим изображение из набора обучающих данных, и центром класса, ассоциируемого с этим изображением в соответствии с набором обучающих данных; и
настройку одного или более параметров нейронной сети на основе значения функции потерь.
2. Способ по п. 1, отличающийся тем, что центр класса представлен как среднее значение признаков изображений, принадлежащих к этому классу.
3. Способ по п. 1, отличающийся тем, что вычисление значения функции потерь дополнительно включает:
настройку центра класса из набора классов.
4. Способ по п. 1, отличающийся тем, что функция потерь представлена с помощью линейной комбинации функции потерь с перекрестной энтропией и функции центральных потерь.
5. Способ по п. 1, дополнительно включающий:
выполнение с помощью нейронной сети оптического распознавания символов (OCR) изображения графемы.
6. Способ по п. 1, отличающийся тем, что каждый класс из набора классов соответствует символу алфавита.
7. Способ по п. 1, отличающийся тем, что функция потерь дополнительно отображает одно или более расстояний между вектором признаков отрицательного обучающего примера и центрами одного или более классов из набора классов.
8. Способ по п. 1, отличающийся тем, что функция потерь представлена с помощью линейной комбинации функции потерь с перекрестной энтропией, функции центральных потерь и штрафной функции потерь приближения к центру.
9. Способ по п. 8, отличающийся тем, что набор обучающих данных содержит первое множество правильных изображений графем и второе множество неправильных изображений графем.
10. Способ по п. 8, отличающийся тем, что набор обучающих данных содержит множество синтетических неправильных изображений графем.
11. Система для обучения нейронной сети, содержащая: запоминающее устройство;
процессор, соединенный с данным запоминающим устройством, выполненный с возможностью:
получать набор обучающих данных, содержащий несколько изображений, при этом каждое изображение из набора обучающих данных ассоциируется с идентификатором класса из набора классов;
вычислять с помощью нейронной сети множество векторов признаков, при этом каждый вектор признаков из множества векторов признаков представляет изображение из набора обучающих данных в пространстве признаков изображений;
вычислять для набора обучающих данных значение функции потерь, отображающей множество вероятностей, где каждая вероятность из множества вероятностей характеризует гипотезу, ассоциирующую изображение из набора обучающих данных с классом, ассоциируемым с этим изображением в соответствии с набором обучающих данных, при этом функция потерь дополнительно отображает множество расстояний, где каждое расстояние из множества расстояний вычисляется в пространстве признаков изображений между вектором признаков, представляющим изображение из набора обучающих данных, и центром класса, ассоциируемого с этим изображением в соответствии с набором обучающих данных; и
настраивать один или более параметров нейронной сети на основе значения функции потерь.
12. Система по п. 11, отличающаяся тем, что вычисление значения функции потерь дополнительно включает:
настройку центра класса из набора классов.
13. Система по п. 11, отличающаяся тем, что функция потерь представлена с помощью линейной комбинации функции потерь с перекрестной энтропией и функции центральных потерь.
14. Система по п. 11, отличающаяся тем, что процессор выполнен с возможностью: осуществления с помощью нейронной сети оптического распознавания символов (OCR) изображения графемы.
15. Система по п. 11, отличающаяся тем, что функция потерь дополнительно отображает одно или более расстояний между вектором признаков отрицательного обучающего примера и центрами одного или более классов из набора классов.
16. Постоянный машиночитаемый носитель данных, содержащий исполняемые команды, которые при исполнении вычислительной системой побуждают ее к тому, что вычислительная система:
получает набор обучающих данных, содержащий несколько изображений, при этом каждое изображение из набора обучающих данных ассоциируется с идентификатором класса из набора классов;
вычисляет с помощью нейронной сети множество векторов признаков, при этом каждый вектор признаков из множества векторов признаков представляет изображение из набора обучающих данных в пространстве признаков изображений;
вычисляет для набора обучающих данных значение функции потерь, отображающей множество вероятностей, где каждая вероятность из множества вероятностей характеризует гипотезу, ассоциирующую изображение из набора обучающих данных с классом, ассоциируемым с этим изображением в соответствии с набором обучающих данных, при этом функция потерь дополнительно отображает множество расстояний, где каждое расстояние из множества расстояний вычисляется в пространстве признаков изображений между вектором признаков, представляющим изображение из набора обучающих данных, и центром класса, ассоциируемого с изображением в соответствии с набором обучающих данных; и
настраивает один или более параметров нейронной сети на основе значения функции потерь.
17. Постоянный машиночитаемый носитель данных по п. 16, отличающийся тем, что вычисление значения функции потерь дополнительно включает:
настройку центра класса из набора классов.
18. Постоянный машиночитаемый носитель данных по п. 16, отличающийся тем, что функция потерь представлена с помощью линейной комбинации функции потерь с перекрестной энтропией и функции центральных потерь.
19. Постоянный машиночитаемый носитель данных по п. 16, дополнительно включающий:
выполнение с помощью нейронной сети оптического распознавания символов (OCR) изображения графемы.
20. Постоянный машиночитаемый носитель данных по п. 16, отличающийся тем, что функция потерь представлена с помощью линейной комбинации функции потерь с перекрестной энтропией, функции центральных потерь и штрафной функции потерь приближения к центру.
| US 10025950 B1, 17.07.2018 | |||
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| СПОСОБ ОБУЧЕНИЯ ГЛУБОКИХ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ РАСПРЕДЕЛЕНИЙ ПОПАРНЫХ МЕР СХОЖЕСТИ | 2016 |
|
RU2641447C1 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОЖНОГО ГРАФИЧЕСКОГО ОБЪЕКТА | 2006 |
|
RU2321058C1 |

