ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к вычислительным системам, а точнее к системам и способам распознавания текста на изображении с использованием иерархической классификации.
УРОВЕНЬ ТЕХНИКИ
[0002] Распознавание текста на изображении - это одна из важных операций в автоматической обработке изображений, содержащих тексты на естественном языке. Определение графем на изображении может выполняться с помощью глубоких нейронных сетей. Однако распознавание символов для языков с большими алфавитами может быть непростой задачей. Например, некоторые языки (такие как японский, китайский и т.д.) могут иметь алфавит из более 20000 различных графем. Нейронная сеть, способная распознавать более 20000 графем, может быть большой и иметь очень сложную архитектуру. Использование одной нейронной сети для распознавания этих графем может занимать много времени и давать результаты низкого качества. Также может быть сложно обучить нейронную сеть распознавать все графемы языка с большим алфавитом.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0003] Вариант реализации настоящего изобретения описывает распознавание символов с использованием нейронных сетей. Способ по раскрываемому изобретению включает отнесение, с помощью классификатора первого уровня классификатора графем, входного изображения графемы к первому кластеру графем из множества кластеров графем, где первый кластер графем содержит первое множество графем; выбор обрабатывающим устройством классификатора из множества классификаторов второго уровня классификатора графем исходя из первого кластера графем, такого, что выбранный классификатор был обучен распознавать первое множество графем; и обработку входного изображения графемы с помощью выбранного классификатора для распознавания как минимум одного символа на входном изображении графемы.
[0004] Система по настоящему изобретению включает память; и обрабатывающее устройство, оперативно соединенное с памятью, обрабатывающее устройство выполняет следующие операции: отнесение, с помощью классификатора первого уровня классификатора графем, входного изображения графемы к первому кластеру графем из множества кластеров графем, где первый кластер графем содержит первое множество графем; выбор обрабатывающим устройством классификатора из множества классификаторов второго уровня классификатора графем исходя из первого кластера графем, такого, что выбранный классификатор был обучен распознавать первое множество графем; и обработка входного изображения графемы с помощью выбранного классификатора для распознавания как минимум одного символа на входном изображении графемы.
[0005] Постоянный машиночитаемый носитель данных по настоящему изобретению содержит инструкции, которые при обращении к ним обрабатывающего устройства приводят к выполнению обрабатывающим устройством следующих операций: отнесение, с помощью классификатора первого уровня классификатора графем, входного изображения графемы к первому кластеру графем из множества кластеров графем, где первый кластер графем содержит первое множество графем; выбор обрабатывающим устройством классификатора из множества классификаторов второго уровня классификатора графем исходя из первого кластера графем, такого, что выбранный классификатор был обучен распознавать первое множество графем; и обработка входного изображения графемы с помощью выбранного классификатора для распознавания как минимум одного символа на входном изображении графемы.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0006] Изложение сущности изобретения будет лучше понятно из приведенного ниже подробного описания и приложенных чертежей различных вариантов осуществления изобретения. Однако не следует считать, что чертежи ограничивают сущность изобретения конкретными вариантами осуществления; они предназначены только для пояснения и улучшения понимания сущности изобретения.
[0007] Фиг. 1 представляет пример вычислительной системы, в которой может выполняться реализация данного изобретения.
[0008] Фиг. 2 представляет схему, иллюстрирующую пример сверточной нейронной сети (CNN, convolutional neural networks) в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0009] Фиг. 3 представляет блок-схему, иллюстрирующую способ обучения первого уровня классификатора графем в соответствии с одной из реализаций настоящего изобретения.
[0010] Фиг. 4 представляет блок-схему, иллюстрирующую способ обучения второго уровня классификатора графем в соответствии с одной из реализаций настоящего изобретения.
[0011] Фиг. 5 представляет блок-схему, иллюстрирующую способ распознавания символов с помощью классификатора графем в соответствии с некоторыми вариантами реализации настоящего изобретения.
[0012] На Фиг. 6А схематически изображен пример классификатора графем в соответствии с одним из вариантов реализации настоящего изобретения.
[0013] На Фиг. 6B схематически изображен пример классификатора графем в соответствии с другим вариантом реализации настоящего изобретения.
[0014] Фиг. 7 иллюстрирует примеры исходных кластеров графем и расширенных кластеров графем в соответствии с одним из вариантов реализации настоящего изобретения.
[0015] Фиг. 8 иллюстрирует блок-схему вычислительной системы в соответствии с некоторыми реализациями настоящего изобретения.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0016] Распознавание символов может включать распознавание текста на изображении с использованием классификаторов. Традиционные механизмы распознавания символов не в состоянии предоставить классификаторы, подходящие для распознавания текста на языках с большими алфавитами. Например, японский алфавит может содержать более 20000 графем. Для выполнения распознавания символов в тексте на японском языке традиционные механизмы распознавания текстов могут сконструировать нейронную сеть, способную распознавать все эти графемы. Эта нейронная сеть может быть большой и иметь очень сложную архитектуру. Традиционные механизмы распознавания текстов также не в состоянии предоставить классификаторы, подходящие для распознавания мультиязычных текстов. Например, для распознавания мультиязычных текстов на изображении традиционные механизмы распознавания текстов могут обучать соответствующий классификатор для каждого из множества языков. Таким образом, использование традиционных механизмов распознавания текстов может требовать много времени и давать результаты низкого качества.
[0017] Аспекты настоящего раскрытия устраняют отмеченные выше и другие недостатки путем предоставления механизмов для распознавания символов с использованием иерархической классификации. Эти механизмы могут автоматически подразделять графемы одного или более языков на множество кластеров (также называемых «кластерами графем»). Как указано в этом документе, графема может представлять наименьшую распознаваемую единицу системы письменности данного языка (или набора схожих языков). Графема может содержать буквы алфавита, типографские лигатуры, символы китайского языка, цифры, знаки препинания и другие отдельные символы или знаки. В некоторых вариантах реализации изобретения механизмы могут подразделять графемы, кластеризуя обучающие изображения, содержащие графемы, по кластерам графем, используя нейронную сеть. Автоматическое подразделение графем делает механизмы, описанные в этом документе, применимыми к любым языкам, а также к мультиязычному распознаванию.
[0018] Эти механизмы могут обучать классификатор графем распознавать графемы, используя кластеры графем. Классификатор графем может содержать множество уровней. Каждый уровень классификатора графем может включать нейронную сеть. В некоторых вариантах реализации изобретения классификатор графем может содержать сеть-выборщик, обученную распознавать кластеры графем. Сеть-выборщик может выступать в качестве классификатора первого уровня для классификатора графем. Классификатор графем может также включать множество классификаторов второго уровня, обученных распознавать графемы в кластере графем. Например, соответствующий дифференциальный классификатор может быть обучен распознавать графемы из соответствующего кластера графем из кластеров графем. Комбинация классификатора первого уровня и классификаторов второго уровня может работать в качестве классификатора графем в соответствии с настоящим изобретением. После получения входного изображения графемы для распознавания содержимого (то есть распознавания графемы) классификатор графем может отнести входное изображение графемы к одному из кластеров графем, используя классификатор первого уровня (также называемый «первым кластером графем»). Затем для дальнейшей обработки входного изображения может быть выбран классификатор второго уровня, обученный распознавать графемы в отдельном кластере графем. Выбранный классификатор второго уровня может распознать на входном изображении графемы одну или более графем. Как указано в настоящем документе, изображение графемы может быть любым изображением, содержащим одну или более графем.
[0019] Таким образом, механизмы, раскрываемые в данном документе, предоставляют классификатор графем, который может выполнять распознавание символов, используя иерархическую классификацию. Каждый уровень описываемого в настоящем документе классификатора графем может содержать нейронную сеть с относительно простой архитектурой. По сравнению с традиционными механизмами распознавания символов, которые используют одну большую нейронную сеть для распознавания всех графем алфавита языка, механизм, описываемый в настоящем документе, использует несколько простых нейронных сетей для распознавания графем одного или более языков, обеспечивая эффективное и точное распознавание символов для языков с большим алфавитом и мультиязычных текстов.
[0020] Фиг. 1 представляет блок-схему примера вычислительной системы 100, в которой может выполняться реализация данного изобретения. Как показано на изображении, система 100 включает вычислительное устройство 110, хранилище 120 и сервер 150, подключенный к сети 130. Сеть 130 может быть общественной сетью (например, Интернет), частной сетью (например, локальная сеть (LAN) или распределенной сетью (WAN)), а также их комбинацией.
[0021] Вычислительное устройство 110 может быть настольным компьютером, портативным компьютером, смартфоном, планшетным компьютером, сервером, сканером или любым подходящим вычислительным устройством, которое в состоянии использовать технологии, описанные в этом изобретении. В некоторых вариантах реализации изобретения вычислительное устройство 110 может быть и (или) включать одну или более вычислительных систем 800 с Фиг. 8.
[0022] В одном из вариантов реализации изобретения вычислительное устройство 110 может содержать ядро системы распознавания символов 111. Ядро системы распознавания символов 111 может содержать инструкции, сохраненные на одном или более физических машиночитаемых носителях данных вычислительного устройства 110 и выполняемые на одном или более обрабатывающих устройств вычислительного устройства 110. В одном из вариантов реализации изобретения ядро системы распознавания символов 111 может использовать для распознавания символов классификатор графем 114. Классификатор графем 114 обучен и используется для выявления графем на входном изображении. Ядро системы распознавания символов 111 также может предварительно обрабатывать некоторые полученные изображения, используя эти изображения для обучения классификатора графем 114 и (или) применяя классификатор графем 114 к изображениям. В некоторых вариантах реализации классификатор графем 114 может быть частью ядра системы распознавания символов 111 или может быть доступен с другой машины (например, сервера 150) для ядра системы распознавания символов 111.
[0023] Ядро системы распознавания символов 111 может представлять собой клиентское приложение или же сочетание компонентов, базирующихся на рабочей станции клиента и на сервере. В некоторых вариантах реализации изобретения ядро системы распознавания символов 111 может быть полностью реализовано на вычислительном устройстве клиента, например это могут быть планшетный компьютер, смартфон, ноутбук, фотокамера, видеокамера и т.д. В альтернативном варианте реализации клиентский компонент ядра системы распознавания символов 111, исполняемый на клиентском вычислительном устройстве, может получать документ и передавать его на серверный компонент ядра системы распознавания символов 111, исполняемый на серверном устройстве, который выполняет классификацию графем. Серверная часть ядра системы распознавания символов 111 может после этого возвращать результаты распознавания (то есть один или более распознанных символов и (или) графем) клиентской части ядра системы распознавания символов 111, выполняющейся на вычислительном устройстве клиента для сохранения или передачи в другое приложение. В других вариантах реализации изобретения ядро системы распознавания символов 111 может быть запущено на исполнение на серверном устройстве в качестве интернет-приложения, доступ к которому обеспечивается через интерфейс браузера. Серверное устройство может быть представлено в виде одной или более вычислительных систем, например одним или более серверов, рабочих станций, больших ЭВМ (мейнфреймов), персональных компьютеров (ПК) и т.д.
[0024] Сервер 150 может быть и (или) включать стоечный сервер, маршрутизатор, персональный компьютер, карманный персональный компьютер, мобильный телефон, портативный компьютер, планшетный компьютер, фотокамеру, видеокамеру, нетбук, настольный компьютер, медиацентр или их сочетание. Сервер 150 может содержать систему обучения 151. Система обучения 151 может конструировать классификатор графем 114 для распознавания символов. Классификатор графем 114, приведенный на Фиг. 1, может ссылаться на артефакты модели, созданные обучающей системой 151 с использованием обучающих данных, которые содержат обучающие входные данные и соответствующие целевые выходные данные (правильные ответы на соответствующие обучающие входные данные). Признаки обучающих данных, которые могут использоваться для отображения обучающих входных данных на целевые выходные данные (правильный ответ), могут быть найдены и могут быть затем использованы классификатором графем 114 для будущих предсказаний. Классификатор графем 114 может быть иерархическим классификатором, содержащим множество нейронных сетей. Каждая нейронная сеть из этого множества может рассматриваться в качестве уровня классификатора графем. В некоторых вариантах реализации изобретения классификатор графем 114 может содержать классификатор первого уровня, один или более классификаторов второго уровня, один или более классификаторов дополнительных уровней (то есть классификаторов третьего уровня и т.д.).
[0025] Для построения классификатора графем 114 обучающая система 151 может обучить исходный классификатор, который в состоянии распознавать множество графем. В некоторых вариантах реализации изобретения исходный классификатор не является частью классификатора графем 114. В одном из вариантов реализации изобретения множество графем может представлять собой алфавит определенного языка (то есть все графемы алфавита). В другом варианте реализации изобретения множество графем может представлять собой несколько алфавитов нескольких языков. Каждая из графем также может быть упомянута как класс графем и может быть связана с идентификатором графемы. Идентификатор графемы может содержать любую подходящую информацию, которая может использоваться для установления класса графемы и (или) графемы, например описание класса графем и (или) графемы. Обученный исходный классификатор может определять идентификатор графемы для входного изображения графемы и может классифицировать входное изображение графемы как принадлежащее к классу графемы, который соответствует установленному идентификатору графемы.
[0026] Система обучения 151 может генерировать первые обучающие данные для обучения исходного классификатора. Первые обучающие данные могут содержать одни или более обучающих входных данных и одни или более целевых выходных данных. Первые обучающие данные могут также содержать данные об отображении обучающих входных данных на целевые выходные данные. Обучающие входные данные могут содержать первую обучающую выборку изображений графем. Каждое изображение графем в первой обучающей выборке может быть изображением, содержащим известную графему. Выходные данные обучения могут быть идентификаторами графем, описывающими известные графемы, включенные в первую обучающую выборку изображений графем. Например, первое обучающее изображение графемы в первой обучающей выборке может содержать первую известную графему (например, «Н»). Первое обучающее изображение графемы может быть первыми обучающими входными данными, которые можно использовать для обучения исходного классификатора. Первый идентификатор графемы, представляющий первую известную графему, может быть целевым результатом, который соответствует первым обучающим входным данным. В ходе обучения исходного классификатора система обучения 151 может определять признаки первых обучающих данных, которые можно использовать для отображения обучающих входных данных на целевые выходные данные (то есть предполагаемый идентификатор графемы). Затем исходный классификатор может использовать эти признаки для дальнейшего предсказания. Например, после получения входного изображения неизвестной графемы обученный исходный классификатор может предсказать графему, которая находится на входном изображении и вернуть предполагаемый идентификатор графемы, который определяет предсказанную графему.
[0027] В некоторых вариантах реализации изобретения обучающая система 151 может обучить исходный классификатор как одну или более сверточных нейронных сетей. Сверточные нейронные сети включают архитектуры, которые могут обеспечить эффективное распознавание образов. Сверточные нейронные сети могут включать несколько сверточных слоев и субдискретизирующих слоев, которые применяют фильтры к частям изображения текста для обнаружения определенных признаков. Сверточная нейронная сеть может выполнять операцию свертки, которая поэлементно умножает каждый фрагмент изображения на фильтры (например, матрицы) и суммирует результаты в аналогичной позиции выходного массива.
[0028] Исходный классификатор может содержать несколько слоев. Изображение графемы может поступать на первый слой исходного классификатора в качестве входного изображения. Входное изображение может обрабатываться слоями исходного классификатора. Предпоследний слой исходного классификатора может содержать несколько вершин. Каждая из вершин предпоследнего слоя может соответствовать одному из признаков, которые исходный классификатор использует для распознавания графемы. Количество вершин предпоследнего слоя может быть равно количеству признаков. Выход предпоследнего слоя может быть вектором признаков, соответствующих признакам входного изображения. Последний слой исходного классификатора (например, полносвязанного слоя) может содержать множество вершин. Каждая из вершин последнего слоя может соответствовать ответу сети для известной графемы. Выход исходного классификатора может быть классом или вероятностями классов, наилучшим образом описывающих входное изображение. Обученный исходный классификатор может выявлять признаки для каждого изображения графемы (вычисляемые нейронной сетью), которые позднее могут использоваться для возможного отбора классов с близкими значениями признаков в один кластер. Обучение исходного классификатора более подробно обсуждается ниже с отсылкой к Фиг. 2.
[0029] Согласно Фиг. 1 обучающая система 151 может создавать экстрактор признаков на основе исходного классификатора. Например, обучающая система 151 может убрать последний слой исходного классификатора (то есть выходной слой CNN 220, как показано на Фиг. 2) из исходного классификатора и использовать получившуюся нейронную сеть в качестве экстрактора признаков. Предпоследний слой исходного классификатора может быть выходным слоем экстрактора признаков, который создает выходной результат (то есть вектор признаков) экстрактора признаков. Затем обучающая система 151 может генерировать множество векторов признаков, используя экстрактор признаков. Каждый из векторов признаков может представлять один или более признаков графемы, которая будет распознаваться классификатором графем 114. В некоторых вариантах реализации изобретения соответствующий вектор признаков может быть создан для каждого класса графем, используя экстрактор признаков. Например, обучающая система 151 может выбирать обучающее изображение графемы, отнесенной к определенному классу графем, в качестве представителя изображения графемы для этого класса графем. Обучающая система 151 может обрабатывать это изображение графемы, используя экстрактор признаков. Экстрактор признаков при этом порождает вектор признаков для данного представителя изображения графемы. В другом примере обучающая система 151 может получать множество обучающих изображений графем, приписанных к определенному классу графем. В частности, например, обучающая система 151 может выявлять множество обучающих изображений графем, связанных с идентификатором графемы, который идентифицирует определенный класс графем. Обучающая система 151 может затем использовать экстрактор признаков для обработки множества обучающих изображений графем с созданием множества исходных векторов признаков. Затем обрабатывающее устройство может создавать вектор признаков для соответствующего класса графем (например, определяя среднее значение исходных векторов признаков). Это может давать более обобщенный результат, который учитывает различные вариаций в обучающих изображениях графем, отражающих представление графем. В еще одном примере обучающая система 151 может использовать в качестве векторов признаков направления векторов признаков с последнего слоя исходного классификатора.
[0030] Обучающая система 151 может кластеризовать векторы признаков, создавая первое множество наборов графем (также упоминаемое как «первое множество кластеров графем»). Кластеризация может выполняться с помощью любого подходящего алгоритма кластеризации, например метода k-средних. Каждый кластер из первого множества кластеров графем может содержать множество графем, которые были признаны похожими друг на друга (то есть графически подобны друг другу). В некоторых вариантах реализации изобретения векторы признаков, кластеризованные в определенный кластер графем, могут быть признаны более похожими друг на друга, чем на векторы из других кластеров графем. Обучающая система 151 может кластеризовать графемы, имеющие векторы признаков, направленные в одном направлении или приблизительно в одном направлении, в один кластер графем.
[0031] Обучающая система 151 может отнести каждое из обучающих изображений графем из первой обучающей выборки к одному из кластеров графем (например, связывая идентификатор кластера с каждым из изображений графем). Сеть-выборщик можно обучать на архитектуре более простой, чем архитектура, используемая для обучения исходного классификатора, таким образом можно добиться высокой производительности распознавания.
[0032] Обучающая система 151 может обучать сеть-выборщик распознавать первое множество кластеров графем. Сеть-выборщик может обучаться как нейронная сеть. Система обучения 151 может генерировать вторые обучающие данные для обучения сети-выборщика. Вторые обучающие данные могут содержать одни или более обучающих входных данных и одни или более целевых выходных данных. Вторые обучающие данные могут также содержать данные об отображении обучающих входных данных на целевые выходные данные. Обучающие входные данные могут содержать первую обучающую выборку изображений графем. Обучающие выходные данные могут быть первым множеством кластеров графем. Например, первое обучающее изображение графемы в первой обучающей выборки может включать первую известную графему (например, «Н»), помещенную в первый кластер графем первого множества кластеров графем. Первое обучающее изображение графемы может быть первыми обучающими входными данными, которые можно использовать для обучения сети-выборщика. Первый кластер графем может быть целевым выходом, соответствующим первым обучающим входным данным. В ходе обучения сети-выборщика обучающая система 151 может определять признаки вторых обучающих данных, которые можно использовать для отображения обучающих входных данных на целевые выходные данные (то есть предполагаемые кластеры графем). Затем сеть-выборщик может использовать эти признаки для дальнейшего предсказания. Например, после получения входного изображения неизвестной графемы обученная сеть-выборщик может, основываясь на признаках, предсказать кластер графем, к которому относится входное изображение, и вернуть в качестве результата предполагаемый кластер графем.
[0033] Обучающая система 151 может обрабатывать вторую обучающую выборку изображений графем, используя обученную сеть-выборщик. Например, сеть-выборщик может классифицировать вторую обучающую выборку изображений графем на один или более кластеров графем из первого множества кластеров графем. Вторая обучающая выборка изображений графем может содержать одно или более обучающих изображений графем. Каждое из обучающих изображений графем во второй обучающей выборке может содержать одну или более известных графем. В некоторых вариантах реализации изобретения вторая обучающая выборка изображений графем может отличаться от первой обучающей выборки изображений графем.
[0034] Обучающая система 151 может также собирать статистические данные об обработке второй обучающей выборки изображений графем сетью-выборщиком. Эти статистические данные могут включать любые соответствующие данные об обработке второй обучающей выборки изображений графем сетью-выборщиком. Например, эти статистические данные могут включать данные о неправильном назначении определенного обучающего изображения графемы из второй обучающей выборки (то есть второго обучающего изображения графемы) определенному кластеру графем из первого множества кластеров графем. Второе обучающее изображение графемы может считаться неправильно отнесенным к определенному кластеру графем, если этот определенный кластер графем содержит множество графем, которое не включает известную графему, из второго обучающего изображения графемы. Эти статистические данные могут включать количество ошибочных назначений обучающих изображений графем, относящихся к определенной графеме, к определенному кластеру графем, долю ошибок неправильного назначения (то есть отношение числа неправильных назначений к общему количеству обучающих изображений графем, содержащих определенную графему) и т.д.
[0035] На основе первого множества наборов графем и статистических данных обучающая система 151 может генерировать второе множество наборов графем. Например, обучающая система 151 может расширить первое множество графем из первого множества наборов графем, добавив в него одну или более дополнительных графем исходя из статистических данных. В одном из вариантов осуществления изобретения обучающая система 151 может определить долю изображений определенной графемы, ошибочно отнесенный к первому множеству графем, исходя из статистических данных (например, определив для данной графемы процент обучающих изображений графемы, ошибочно отнесенных к первому множеству графем сетью-выборщиком). Далее обучающая система 151 может определить, что этот процент превышает предельное значение. После этого обучающая система 151 может добавить указанную графему в первое множество графем для создания расширенного множества графем. Это расширенное множество графем может рассматриваться как кластер графем. Исходя из первого множества наборов графем и статистических данных можно создавать множество расширенных наборов графем. Например, как показано на Фиг 7, кластеры графем 711А, 711В и 711X можно расширить до расширенных кластеров графем 712А, 712B и 712Х соответственно. Обучающая система 151 может определять расширенные наборы графем в качестве второго множества кластеров графем. Расширяя первое множество наборов графем до второго множества наборов графем, обучающая система 151 создает пересекающиеся кластеры графем (второе множество кластеров графем), которые могут использоваться для обучения следующего уровня классификатора графем 114 (например, второго уровня классификатора графем 114). Это может значительно повысить итоговое качество результатов распознавания, производимого классификатором графем 114.
[0036] Обучающая система 151 также может обучать один или более дифференциальных классификаторов второго уровня классификатора графем. Каждый из дифференциальных классификаторов второго уровня может распознавать графемы внутри одного из вторых множеств кластеров графем. В некоторых вариантах осуществления изобретения классификаторы второго уровня могут быть обучены путем обучения соответствующего дифференциального классификатора для каждого набора из второго множества наборов графем. Например, обучающая система 151 может создавать третьи обучающие данные для обучения классификатора второго уровня распознаванию графем из данного кластера графем. Третьи обучающие данные могут содержать одни или более обучающих входных данных и одни или более целевых выходных данных. Третьи обучающие данные могут также содержать данные об отображении обучающих входных данных на целевые выходные данные. Обучающие входные данные могут быть обучающими изображениями графем из данного кластера графем. Целевые выходные данные могут быть графемами из данного кластера графем. Например, первое обучающее изображение графемы в первой обучающей выборке может включать первую известную графему (например, «Н»), помещенную в первый кластер графем. Первое обучающее изображение графемы может быть первыми обучающими входными данными, которые можно использовать для обучения классификатора второго уровня. Первая графема может быть целевым выходом, соответствующим первым обучающим входным данным. В ходе обучения классификатора второго уровня система обучения 151 может определять признаки обучающих данных, которые можно использовать для отображения учебных входных данных из третьих учебных данных на целевые выходные данные (то есть предполагаемую графему из данного кластера графем). Затем классификатор второго уровня может использовать эти признаки для дальнейшего предсказания. Например, после получения входного изображения неизвестной графемы обученный классификатор второго уровня может предсказать графему из данного кластера графем и предоставить предполагаемую графему в качестве выходных данных.
[0037] Таким образом, каждый уровень описываемого в настоящем документе классификатора графем 114 может содержать нейронную сеть с относительно простой архитектурой. По сравнению с традиционными механизмами распознавания символов, которые используют одну большую нейронную сеть для распознавания всех графем алфавита языка, классификатор графем 114 использует простые нейронные сети для распознавания графем одного или более языков, обеспечивая эффективное и точное распознавание символов для языков с большим алфавитом и мультиязычных текстов.
[0038] В некоторых вариантах реализации изобретения обучающая система 151 может обучать классификатор графем 114, выполняя одну или более операций, описанных применительно к Фиг. 3 и 4. Классификатор графем 114 может реализовывать двухуровневую модель классификации, описанную применительно к Фиг. 6А.
[0039] В некоторых вариантах реализации изобретения могут быть построены один или более дополнительных уровней классификатора графем 114. Например, обучающая система 151 может определить, что двухуровневый классификатор графем не обеспечивает требуемого качества распознавания или скорости обработки, обучающая система 151 может заменить один или более классификаторов второго уровня многоуровневым классификатором, который реализует схему классификации с вложенными уровнями (например, классификатор 700 на Фиг. 6B). В одном из вариантов осуществления обучающая система 151 может заменить классификатор второго уровня на такой многоуровневый классификатор, если обнаружит, что классификатор второго уровня обучен распознавать кластер графем с предельным количеством графем (например, с количеством графем больше предельного значения). В таком варианте осуществления изобретения можно использовать вторую обучающую выборку изображений графем для проверки качества распознавания автоматически построенного иерархического классификатора. Как будет описано подробнее применительно к Фиг. 6B, один или более классификаторов можно заменить на многоуровневый классификатор, итеративно выполняя описанный выше процесс. Таким образом, иерархический классификатор для распознавания символов может быть построен автоматически.
[0040] Ядро системы распознавания символов 111 может получать входное изображение графемы и распознать на этом изображении графемы одну или более графем. Входное изображение графемы может быть любым изображением, содержащим одну или более неизвестных графем (то есть графем, которые можно распознать с помощью классификатора графем, описанного в этом документе). Входное изображение графемы может быть получено ядром системы распознавания символов 111 в виде части изображения документа или в виде одиночного изображения графемы от клиентского устройства или от приложения, которое связано с вычислительным устройством 110. Ядро системы распознавания символов 111 может затем вызвать классификатор графем 114 для распознавания одной или более графем на изображении графемы. Классификатор первого уровня классификатора графем 114 может отнести входное изображение графемы к кластеру графем. Ядро системы распознавания символов 111 может выбрать из классификаторов второго уровня тот классификатор, который был обучен распознавать множество графем из этого кластера графем. Выбранный классификатор может обрабатывать входное изображение графемы и распознавать на этом изображении графемы одну или более графем.
[0041] В некоторых вариантах реализации изобретения ядро системы распознавания символов 111 может использовать классификатор графем 114 для прогнозирования различных результатов распознавания (то есть гипотез) для входного изображения графемы. Каждый из результатов распознавания может содержать один или более символов, распознанных ядром системы распознавания символов 111. В некоторых вариантах реализации ядро системы распознавания символов 111 может определить множество целевых символов, которые максимально похожи на входное изображение графемы. В одном из вариантов реализации изобретения ядро системы распознавания символов 111 может определить один или более целевых символов, которые имеют графические характеристики или признаки, сходные с входным изображением графемы, и назначить эти целевые символы множеству результатов распознавания.
[0042] В некоторых вариантах реализации классификатор графем 114 может определять степень уверенности для каждого из результатов распознавания. В одном из вариантов реализации изобретения степень уверенности для каждого из результатов распознавания может быть процентным значением вероятности для этой распознаваемой графемы. Например, если классификатор графем 114 анализирует графему из входного изображения графемы и определяет, что существует вероятность 70% того, что графема на входном изображении графемы является символом «С», то соответствующая степень уверенности может быть представлена значением 70%. В некоторых вариантах реализации изобретения классификатор графем 114 (или ядро системы распознавания символов 111 после получения результата от классификатора графем 114) может ранжировать результаты распознавания исходя из степени уверенности, связанной с результатами распознавания. Классификатор графем 114 ядра системы распознавания символов 111 также может генерировать список результатов распознавания, отсортированный по такому ранжированию (сортировка результатов распознавания по убыванию степени уверенности). В некоторых вариантах реализации изобретения результаты распознавания могут быть представлены (например, отображены) на дисплее.
[0043] Хранилище 120 представляет собой постоянную память, которая может хранить документы и (или) изображения 141, а также структуры данных для выполнения распознавания символов в соответствии с настоящим изобретением. Хранилище 120 может располагаться на одном или более запоминающих устройствах, таких как основная память, магнитные или оптические запоминающие устройства на основе дисков, лент или твердотельных накопителей, NAS, SAN и т.д. Несмотря на то что хранилище изображено отдельно от вычислительного устройства 110, в одной из реализаций изобретения хранилище 120 может быть частью вычислительного устройства 110. В некоторых вариантах реализации хранилище 120 может представлять собой подключенный к сети файловый сервер, в то время как в других вариантах реализации изобретения хранилище содержимого 120 может представлять собой какой-либо другой тип энергонезависимого запоминающего устройства, например объектно-ориентированной базы данных, реляционной базы данных и т.д., которая может находиться на сервере или одной или более различных машинах, подключенных к нему через сеть 130. Хранилище 120 может хранить обучающие данные в соответствии с настоящим изобретением.
[0044] Фиг. 2 представляет схему, иллюстрирующую пример 200 сверточной нейронной сети (CNN) в соответствии с некоторыми вариантами реализации настоящего изобретения. CNN 200 может быть использована для обучения исходного классификатора, сети-выборщика, классификаторов второго уровня и (или) классификаторов дополнительных уровней, как указано применительно к Фиг. 1.
[0045] Как было показано, CNN 200 может содержать одну или более сверточных нейронных сетей (CNN) (например, CNN 220А, 200 В, … и 220Х). Каждая из сетей с CNN 220А по 220Х может быть нейронной сетью специализированной архитектуры, направленной на эффективное распознавание изображений. Каждая CNN может содержать последовательность слоев, причем все слои будут разного типа. Эти слои могут включать, например, сверточные слои, субдискретизирующие слои, слои блока линейной ректификации (ReLU) и полносвязанные слои, каждый из которых выполняет отдельную операцию в процессе распознавания текста на изображении. В некоторых вариантах реализации изобретения каждый слой CNN может иметь тип, отличающийся от типа непосредственно предшествующего слоя и непосредственно последующего слоя. Результат одного слоя может быть исходными данными для следующего слоя.
[0046] В некоторых вариантах реализации изобретения каждая из сетей CNN с 220А по 220Х может быть и (или) включать CNN 200. Как было показано, CNN 220 может содержать входной слой 221, один или более сверточных слоев 223А-223B, слои ReLU 225А-225В, субдискретизирующие слои 227А-227В и выходной слой 229.
[0047] В некоторых вариантах реализации изобретения входное изображение может приниматься входным слоем 221 и передаваться через набор слоев CNN 220 для обработки. Например, каждый из сверточных слоев CNN 220 может выполнять операцию свертки, которая может включать поэлементное умножение каждого положения изображения из входного изображения на один или несколько фильтров (то есть матриц свертки) с суммированием результата и его записью в соответствующее положение выходного массива. Конкретнее, например, сверточные слои 223А могут умножать значение пикселя входного изображения на значения одного или более фильтров. Каждый из этих фильтров может иметь матрицу пикселей с определенными размерами и значениями. Каждый из фильтров может выявлять определенный признак. Фильтры применяются к позициям путем прохода по входному изображению. Например, первая позиция может быть выбрана, и фильтры могут применяться к верхнему левому углу. Значения каждого фильтра могут быть умножены на оригинальные значения пикселей входного изображения (поэлементное умножение), и эти произведения могут суммироваться, давая в результате одно число. Фильтры могут сдвигаться по входному изображению на следующую позицию в соответствии с операцией свертки, и процесс свертки может повторяться для следующей позиции входного изображения. Каждая уникальная позиция входного изображения при применении одного или более фильтров может производить число. После того как по каждой позиции пройдут один или более фильтров, будет получена матрица, которая называется картой признаков. Карта признаков может быть меньше входного изображения. В некоторых вариантах реализации изобретения каждый фильтр может создавать карту признаков. Например, если в слое используется 16 фильтров, будет создано 16 карт признаков.
[0048] Результат работы сверточного слоя (например, сверточного слоя 223А) может быть передан в слой ReLU (например, слой ReLU 225А) как входные данные для слоя ReLU. Слой ReLU может использовать нелинейную модель для обработки результата работы сверточного слоя. Например, ReLU может применить функцию активации, которая может заменить отрицательные числа на нули и оставить положительные числа неизменными.
[0049] Информация, полученная при операции свертки и при применении функции активации, может быть сохранена и передана на следующий слой CNN 220. Например, слой ReLU 225А может передать информацию в качестве входных данных субдискретизирующему слою 227А. Субдискретизирующий слой 227А может выполнять операцию по снижению дискретизации пространственных размеров (ширины и высоты), в результате размер карт признаков уменьшается.
[0050] Далее субдискретизирующий слой 227А может выполнять нелинейное уплотнение карт признаков. Например, если некоторые признаки уже были обнаружены в предыдущей операции свертки, то для дальнейшей обработки уже не нужно подробное изображение, и оно уплотняется до менее подробных картинок. В субдискретизирующем слое при применении фильтра к изображению умножение не производится. Вместо этого выполняется более простая математическая операция, например поиск наибольшего числа в позиции на оцениваемом входном изображении. Найденное наибольшее число заносится в карты признаков, и фильтр перемещается в следующую позицию, и операция повторяется до достижения конца входного изображения.
[0051] Результат субдискретизирующего слоя 227А используется в качестве входных данных для сверточного слоя 223B. Обработка входного изображения с использованием CNN 220 может продолжаться путем применения каждого последующего слоя, пока каждый слой не выполнит свою операцию. Как показано на Фиг. 2, CNN 220 может содержать чередующиеся сверточные слои и субдискретизирующие слои. Эти чередующиеся слои могут обеспечивать создание новых карт признаков уменьшенного размера. Например, новая карта признаков может создаваться на каждом следующем слое с уменьшенным размером и увеличенным числом каналов. В некоторых вариантах реализации изобретения предпоследний слой CNN 220 может создавать множество карт признаков выбранного размера (например, матрицы 1×1). Каждая карта признаков может соответствовать одному из множества признаков входного изображения, который можно использовать для распознавания графемы. Количество карт признаков может совпадать с количеством признаков. Результат предпоследнего слоя может быть вектором признаков, соответствующим признакам входного изображения. Например, в некоторых вариантах реализации изобретения, где для распознавания графемы используется 512 признаков, вектор признаков может быть 512-мерным вектором (массив 1×1×512 при условии, что все карты признаков являются матрицами 1×1). Этот вектор признаков можно рассматривать как представление графемы.
[0052] Этот вектор признаков может быть предоставлен в качестве входных данных выходному слою 229. Выходной слой 229 может быть последним слоем CNN 220. В некоторых вариантах реализации изобретения выходной слой 229 может быть полносвязанным слоем. Выходной слой 229 может содержать множество вершин. Каждая из вершин выходного слоя 229 может соответствовать отклику одной или более графем, распознаваемых CNN 220. Выходной слой 229 может генерировать N-мерный вектор (где N - число классов графем), который можно использовать для причисления входного изображения к одному из классов графем. Например, в алфавите из 20000 графем (то есть 20000 классов графем) полносвязанный слой может перевести вектор признаков, предоставленный предыдущим слоем (например, вектор 1×1×512) в вектор 1×1×20000, где каждая размерность вектора соответствует классу графемы (то есть графеме). Выходной слой 229 может создавать выходной результат, указывающий на классификацию входного изображения, в идентификатор графемы (то есть графему). Результат работы итогового уровня может быть графемой, связанной с входным изображением, вероятностями графем, которые могут соответствовать входному изображению, и т.д.
[0053] Хотя на Фиг. 2 показано некоторое количество слоев CNN 220, она в основном имеет иллюстративную ценность. CNN 220 может содержать любое необходимое количество сверточных слоев, слоев ReLU, субдискретизирующих слоев и (или) любых других слоев. Порядок слоев, количество слоев, количество фильтров и (или) другие параметры CNN 220 могут регулироваться (например, на основе эмпирических данных).
[0054] Фиг. 3 и 4 представляют собой блок-схемы, иллюстрирующие способы 300 и 400 обучения классификатора графем распознаванию символов в соответствии с некоторыми вариантами реализации настоящего изобретения. Фиг. 5 представляет собой блок-схему, иллюстрирующую способ 500 для распознавания символов с использованием классификатора графем в соответствии с некоторыми вариантами реализации настоящего изобретения. Каждый из способов 300, 400 и 500 может выполняться логикой обработки, которая может включать аппаратные средства (электронные схемы, специализированную логику, программируемую логику, микрокоманды и т.д.), программное обеспечение (например, инструкции, выполняемые обрабатывающим устройством), встроенное программное обеспечение или комбинацию всех этих средств. В одном из вариантов реализации изобретения способы 300, 400 и 500 могут выполняться обрабатывающим устройством (например, обрабатывающим устройством 802 на Фиг. 8) вычислительного устройства 110 и (или) сервера 150, как показано применительно к Фиг. 1.
[0055] Как показано на Фиг. 3, способ 300 может начинаться с шага 310, в котором обрабатывающее устройство может обучить исходный классификатор, используя обучающие данные. Исходный классификатор обучается, чтобы иметь возможность распознавать множество графем. Каждая из графем может быть графемой из множества графем, распознаваемых классификатором графем. В некоторых вариантах осуществления изобретения графемы могут соответствовать графемам алфавита одного языка (то есть всем графемам алфавита). В другом варианте реализации изобретения графемы могут соответствовать нескольким алфавитам нескольких языков.
[0056] Обучающие данные для обучения исходного классификатора могут включать первую обучающую выборку изображений графем в качестве учебных входных данных и соответствующие идентификаторы графем (описывающие известные графемы) в качестве целевых результатов для учебных входных данных. Обучающие данные также могут включать связь между каждой единицей входных данных (изображением графемы) и одним или более соответствующими результатами (одним или более идентификаторами известных графем). В одном из вариантов реализации изобретения известные графемы могут быть графемами алфавита какого-либо языка. В другом варианте реализации известные графемы могут содержать графемы нескольких языков (например, китайского, японского, английского и т.д.). Исходный классификатор может быть, например, одноуровневым дифференциальным классификатором или нейронной сетью. Исходный классификатор может быть обучен на обучающих данных с использованием функций потерь качества для классификации. В некоторых вариантах осуществления изобретения целью этого обучения может быть не достижение высокой точности или высокой скорости распознавания графем, а обучение исходного классификатора возможности порождать признаки, типичные для каждого класса графем, которые впоследствии можно будет использовать для отбора классов с близкими значениями признаков в один кластер. В некоторых вариантах осуществления изобретения исходный классификатор может обучаться путем выполнения одной или более операций, описанных при рассмотрении Фиг. 2.
[0057] На шаге 320 обрабатывающее устройство может получить, на основе исходного классификатора, экстрактор признаков для извлечения признаков изображений графем. Например, обрабатывающее устройство может получать экстрактор признаков путем удаления последнего слоя исходного классификатора из исходного классификатора. Последний слой исходного классификатора может быть полносвязанным слоем. Последний слой исходного классификатора может быть выходным слоем, который настроен на генерацию выходного результата исходного классификатора (например, выходной слой 229 на Фиг. 2). Как описывалось в сочетании с Фиг. 1 и 2, первый уровень исходного классификатора может быть настроен на получение входного изображения, содержащего графему. Предпоследний слой исходного классификатора может содержать несколько вершин. Каждая из вершин предпоследнего слоя может соответствовать одному из признаков, которые исходный классификатор использует для распознавания графемы. Количество вершин предпоследнего слоя может быть равно количеству признаков. Выход предпоследнего слоя может быть вектором признаков, соответствующих признакам входного изображения. Последний слой исходного классификатора может содержать несколько вершин. Каждая из вершин последнего слоя может соответствовать отклику для одной или более графем, распознаваемых классификатором графем. Выход исходного классификатора может быть классом или вероятностями классов, наилучшим образом описывающих входное изображение. Таким образом, удаление последнего слоя исходного классификатора может создавать нейронную сеть, результатом работы которой будет вектор признаков, содержащий признаки графемы со входного изображения.
[0058] На шаге 330 обрабатывающее устройство может генерировать, используя экстрактор признаков, множество векторов признаков, соответствующих всем известным графемам, которые может распознавать классификатор графем. Соответствующий вектор признаков может быть создан для каждой из графем и (или) классов графем. Каждый из признаков может быть и (или) включать любой признак (то есть переменную), которую можно использовать для распознавания одной или более графем на изображениях графем (то есть признак, который можно использовать для отнесения изображения графемы к определенному классу). В некоторых вариантах реализации изобретения каждый из векторов признаков может быть использован для отнесения изображения графемы к классу и (или) выполнения распознавания символов в соответствии с настоящим изобретением.
[0059] Векторы признаков могут быть получены любым подходящим способом. Например, обрабатывающее устройство может выбирать обучающее изображение графемы, отнесенное к определенному классу графем, в качестве представителя изображения графемы для этого класса графем. Это обрабатывающее устройство может обрабатывать это изображение графемы, используя экстрактор признаков. Экстрактор признаков при этом порождает вектор признаков для данного представителя изображения графемы. В другом примере обрабатывающее устройство может выявлять, для соответствующего класса графем, множество обучающих изображений графем, отнесенных к определенному классу графем (например, получая изображения графем с определенным идентификатором графемы, который определяет соответствующий класс графем). Это обрабатывающее устройство может затем использовать экстрактор признаков для обработки множества обучающих изображений графем с созданием множества исходных векторов признаков. Затем обрабатывающее устройство может создавать вектор признаков для соответствующего класса графем (например, определяя среднее значение исходных векторов признаков). Это может давать более обобщенный результат, который учитывает различные вариации в обучающих изображениях графем, отражающих представление графем. В еще одном примере обрабатывающее устройство может использовать в качестве векторов признаков направления векторов признаков с последнего слоя исходного классификатора.
[0060] На шаге 340 обрабатывающее устройство может генерировать первое множество кластеров графем, кластеризуя векторы признаков. Каждый из кластеров графем может содержать множество графем, которые были признаны похожими друг на друга (то есть графически подобны друг другу). Первое множество кластеров графем может соответствовать первому множеству наборов графем (например, кластеры графем 711A, 711В и 711Х, как показано на Фиг. 7). В некоторых вариантах реализации изобретения векторы признаков, кластеризованные в определенный кластер графем, могут быть признаны более похожими друг на друга, чем на графемы в других кластерах графем. Векторы признаков для графем из одного кластера графем могут быть направлены в одном направлении или приблизительно в одном направлении. Графемы из одного кластера графем могут распознаваться классификатором на основе сверточной нейронной сети. В некоторых вариантах осуществления изобретения обрабатывающее устройство может определять, что графема была отнесена классификатором в несколько кластеров графем (например, определив, что обучающие изображения графем, содержащие эту графему, были отнесены к нескольким кластерам графем). Обрабатывающее устройство может приписывать графему (графемы) на обучающем изображении графемы в кластер, который содержит больше представителей (например, больше обучающих изображений графем). Кластеризация может выполняться с помощью любого подходящего механизма кластеризации, например метода k-средних.
[0061] На шаге 350 обрабатывающее устройство может обучать сеть-выборщик распознавать первое множество кластеров графем. Например, после получения входного изображения графемы, содержащего неизвестную графему (то есть графему, которую предстоит распознать), обученная сеть-выборщик может определить один из кластеров графем, к которому принадлежит неизвестная графема. Обрабатывающее устройство может обучить сеть-выборщик, используя одно или более обучающих изображений графем из первой обучающей выборки, как было описано выше в сочетании с Фиг. 1. Сеть-выборщик может выступать в качестве классификатора первого уровня классификатора графем в соответствии с различными вариантами осуществления настоящего изобретения.
[0062] В соответствии с Фиг. 4 способ 400 начинается на шаге 410, где обрабатывающее устройство может обрабатывать вторую обучающую выборку изображений графем, используя классификатор первого уровня классификатора графем. Классификатор первого уровня может содержать сеть-выборщик, например созданную на шаге 350 на Фиг. 3. Обрабатывающее устройство может классифицировать каждое обучающее изображение графемы из второй обучающей выборки по одному или более из второго множества кластеров графем. Вторая обучающая выборка изображений графем может содержать одно или более изображений графем. Каждое из изображений графем во второй обучающей выборке данных может содержать одну или более известных графем. В некоторых вариантах реализации изобретения вторая обучающая выборка изображений графем может отличаться от первой обучающей выборки изображений графем.
[0063] На шаге 420 обрабатывающее устройство может собирать статистические данные об обработке второй обучающей выборки изображений графем классификатором первого уровня. Эти статистические данные могут включать любые соответствующие данные об обработке второй обучающей выборки изображений графем сетью-выборщиком. Например, эти статистические данные могут включать данные о неправильном отнесении определенного обучающего изображения графемы из второй обучающей выборки (то есть второго обучающего изображения графемы) к определенному кластеру графем из первого множества кластеров графем. Определенное обучающее изображение графемы может считаться неправильно отнесенным к определенному кластеру графем, если этот определенный кластер графем содержит множество графем, которое не включает эту определенную графему. Эти статистические данные могут включать количество ошибочных назначений обучающих изображений графем, относящихся к определенной графеме, к определенному кластеру графем, долю ошибок неправильного назначения (то есть отношение числа неправильных назначений к общему количеству обучающих изображений графем, содержащих определенную графему) и т.д.
[0064] На шаге 430 обрабатывающее устройство может генерировать второе множество кластеров графем исходя из статистических данных. Каждый кластер из второго множества кластеров графем может содержать множество графем, которые были признаны похожими друг на друга. Второе множество кластеров графем может соответствовать второму множеству наборов графем. Второе множество наборов графем может представлять собой расширенные наборы из первого множества наборов графем. Например, обрабатывающее устройство может расширить первое множество графем из первого множества наборов графем, добавив в него одну или более дополнительных графем исходя из статистических данных. В одном из вариантов осуществления изобретения обрабатывающее устройство может определить долю изображений определенной графемы, ошибочно назначенных первому множеству графем, исходя из статистических данных (например, определив для данной графемы процент обучающих изображений графемы, ошибочно отнесенных к первому множеству графем классификатором первого уровня). Далее обрабатывающее устройство может определить, что этот процент превышает предельное значение. После этого обрабатывающее устройство может добавить указанную графему в первое множество графем для создания расширенного множества графем. В качестве примера кластеры графем 711A, 711В и 711Х, приведенные на Фиг. 7, могут быть расширены до расширенных кластеров графем 712А, 712B и 712Х соответственно.
[0065] На шаге 440 обрабатывающее устройство может обучать соответствующий классификатор распознавать каждый кластер из второго множества кластеров графем. Множество дифференциальных классификаторов можно обучить для второго множества кластеров графем, и они могут работать как классификаторы второго уровня классификатора графем. Множество классификаторов второго уровня может быть обучено, например, с использованием первой обучающей выборки изображений графем, как описано выше в связи с Фиг. 1. Комбинация обученного классификатора первого уровня и обученных классификаторов второго уровня может использоваться в качестве классификатора графем, подходящего для распознавания символов на изображениях, содержащих текст на любом языке, и может обучаться автоматически.
[0066] В соответствии с Фиг. 5 способ 500 может начинаться с шага 510, в котором обрабатывающее устройство может получать входное изображение графемы. Входное изображение графемы может быть изображением, которое содержит одну или более неизвестных графем, для распознавания. На шаге 520 обрабатывающее устройство может идентифицировать кластер графем для входного изображения графемы, используя классификатор первого уровня классификатора графем. Например, классификатор первого уровня может обрабатывать входное изображение графемы, чтобы классифицировать входное изображение графемы как принадлежащее одному из множества кластеров графем (например, второму множеству кластеров графем, как было описано выше).
[0067] На шаге 530 обрабатывающее устройство может выбирать классификатор из множества классификаторов второго уровня классификатора графем исходя из выявленного кластера графем. Каждый из классификаторов второго уровня может быть настроен на распознавание графем из соответствующего кластера графем. Обрабатывающее устройство может выбирать из классификаторов второго уровня классификатор, который был выполнен с возможностью распознавания графем из кластера графем, идентифицированного на шаге 520.
[0068] На шаге 540 обрабатывающее устройство может обрабатывать входное изображение графемы, используя выбранный классификатор. Например, выбранный классификатор может распознать на входном изображении графемы одну или более графем. Выбранный классификатор также может генерировать один или более результатов распознавания как результаты распознавания входного изображения графемы. Каждый из результатов распознавания может включать одну или более распознанных графем.
[0069] На Фиг. 6А схематически изображен пример 600 классификатора графем в соответствии с одним из вариантов реализации настоящего изобретения. Классификатор графем 600 может выполнять двухуровневую классификацию для распознавания текста (то есть символов) на изображении.
[0070] Как было показано, классификатор графем 600 может содержать классификатор первого уровня 604 и множество классификаторов второго уровня 606 (то есть классификаторов 606а, 606b, 606с, 606d, …, 606х). Исходный классификатор 602 может быть обучен, как описано выше в соответствии с Фиг. 1-3. Исходный классификатор 602 может использоваться для обучения классификатора первого уровня 604. Например, исходный классификатор 602 может разделять множество графем на множество кластеров графем (например, кластеризуя векторы признаков, представляющие признаки обучающих изображений, содержащих графемы). Каждый из кластеров графем может содержать множество графем, которые были признаны похожими друг на друга. Кластеры графем могут соответствовать первому множеству наборов графем. Классификатор первого уровня 604 может быть обучен распознавать первое множество наборов графем. Например, классификатор первого уровня 604 может быть обучен с использованием первой обучающей выборки изображений графем и может относить изображения всех известных графем к одному из кластеров графем (то есть одному из множеств графем из первого множества наборов графем). Обученный классификатор первого уровня 604 может обрабатывать вторую обучающую выборку изображений графем. Кластеры графем могут быть расширены так, чтобы включать второе множество наборов графем исходя из статистических данных об обработке второй обучающей выборки графем (то есть путем выполнения шага 430 на Фиг. 4). Затем дифференциальный классификатор может быть обучен распознаванию одного из наборов графем из второго множества наборов графем (то есть графем из одного из расширенных кластеров графем). Например, могут быть созданы классификаторы с 606а по 606х. Комбинация классификаторов с 606а по 606х может представлять второй уровень классификации 606 классификатора графем.
[0071] В некоторых вариантах осуществления изобретения один или более кластеров из второго множества кластеров графем могут рассматриваться как весьма большие (например, содержащие предельное количество элементов, значительно большие, чем другие кластеры графем и т.д.). Это может уменьшить скорость обработки классификации второго уровня 606. В некоторых вариантах осуществления изобретения некоторые из классификаторов второго уровня могут не обеспечивать требуемого качества распознавания символов. В некоторых вариантах осуществления изобретения могут быть созданы один или более дополнительных уровней классификаторов графем для выделения подкластеров. Например, может быть создан классификатор третьего уровня для обеспечения классификации третьего уровня. В этом случае итоговый результат распознавания классификатора графем может создаваться третьим уровнем классификатора графем. Графемы из других наборов по-прежнему будут распознаваться на втором уровне. Таким образом, дополнительный уровень может добавляться в модель локально. Дополнительные уровни могут добавляться в классификатор графем путем итеративной реализации описанного выше процесса. Это может обеспечить локальное замещение классификатора графем на втором уровне и позволит настраивать скорость и качество распознавания и создавать оптимальный иерархический классификатор для распознавания символов.
[0072] На Фиг. 6B схематично показана модель иерархического классификатора в соответствии с некоторыми вариантами осуществления настоящего изобретения. Как было показано, классификатор второго уровня 606с, описанный в связи с Фиг. 6А, может быть заменен классификатором 700. Классификатор 606 с может использоваться в качестве исходного классификатора, обученного распознавать графемы в кластере графем, на котором классификатор 606с был обучен (также упоминается как «первый расширенный кластер графем»). Этот исходный классификатор может использоваться для создания экстрактора признаков, как описано на шаге 320 Фиг. 3. Затем могут быть выполнены операции, описанные в связи с Фиг. 3-4, с целью построения двухуровневого классификатора 700 на основе исходного классификатора 606с. Двухуровневый классификатор 700 может включать классификатор первого уровня 704, который обучен распознавать множество подкластеров первого расширенного кластера графем. Каждый из подкластеров может включать подмножество графем из первого расширенного кластера графем. Классификатор второго уровня 700 может также содержать множество классификаторов дополнительных уровней 706, которые могут быть обучены на основе классификатора первого уровня 704 выполнению одной или более операций, описанных в связи с Фиг. 4. Каждый из классификаторов дополнительных уровней 706 может быть обучен распознаванию графем в соответствующем подкластере этих подкластеров.
[0073] Классификатор 606 с может быть затем заменен двухуровневым классификатором 700 для создания классификатора графем в соответствии с настоящим изобретением. После получения входного изображения графемы для распознавания символов классификатор первого уровня 604 может выявить кластер графем для входного изображения графемы, как описано выше. В некоторых вариантах осуществления изобретения, в которых выявленный кластер графем является первым расширенным кластером графем, который классификатор 606 с обучен распознавать, классификатор 704 может обработать входное изображение графемы для выявления подкластера первого расширенного кластера графем для входного изображения графемы. Для распознавания графем на входном изображении графемы может быть запущен один из классификаторов 706, обученных распознавать графемы в определенном подкластере. В некоторых вариантах осуществления один или более классификаторов 604 и 606 могут быть заменены двухуровневым классификатором (классификатор 700), как описано выше. Таким образом, иерархический классификатор для распознавания символов может быть построен автоматически.
[0074] На Фиг. 8 приведен пример вычислительной системы 800, которая может выполнять один или более описанных здесь способов. Эта вычислительная система может быть подключена (например, по сети) к другим вычислительным системам в локальной сети, сети интранет, сети экстранет или сети Интернет. Данная вычислительная система может выступать в качестве сервера в сетевой среде клиент-сервер. Эта вычислительная система может представлять собой персональный компьютер (ПК), планшетный компьютер, телевизионную приставку (STB), карманный персональный компьютер (PDA), мобильный телефон, фотоаппарат, видеокамеру или любое устройство, способное выполнять набор команд (последовательно или иным способом), который определяется действиями этого устройства. Кроме того, несмотря на то что показана система только с одним компьютером, термин «компьютер» также включает любой набор компьютеров, которые по отдельности или совместно выполняют набор команд (или несколько наборов команд) для реализации любого из описанных здесь способов или нескольких таких способов.
[0075] Пример вычислительной системы 800 включает устройство обработки 802, основную память 804 (например, постоянное запоминающее устройство (ПЗУ), флэш-память, динамическое ОЗУ (DRAM), например синхронное DRAM (SDRAM)), статическую память 806 (например, флэш-память, статическое оперативное запоминающее устройство (ОЗУ)) и устройство хранения данных 816, которые взаимодействуют друг с другом по шине 808.
[0076] Обрабатывающее устройство 802 представляет собой одно или более устройств обработки общего назначения, например микропроцессоров, центральных процессоров или аналогичных устройств. В частности, обрабатывающее устройство 802 может представлять собой микропроцессор с полным набором команд (CISC), микропроцессор с сокращенным набором команд (RISC), микропроцессор со сверхдлинным командным словом (VLIW), процессор, в котором реализованы другие наборы команд, или процессоры, в которых реализована комбинация наборов команд. Обрабатывающее устройство 802 также может представлять собой одно или более устройств обработки специального назначения, такое как специализированная интегральная схема (ASIC), программируемая пользователем вентильная матрица (FPGA), процессор цифровых сигналов (DSP), сетевой процессор и т.п. Обрабатывающее устройство 802 реализовано с возможностью выполнения инструкций 826 для реализации ядра системы распознавания символов 111 и (или) обучающей системы 151 на Фиг. 1, а также выполнения операций и шагов, описанных в этом документе (то есть способов 300-500 на Фиг. 3-5).
[0077] Вычислительная система 800 может дополнительно включать устройство сопряжения с сетью 822. Вычислительная система 800 может также включать видеомонитор 810 (например, жидкокристаллический дисплей (LCD) или электроннолучевую трубку (ЭЛТ)), устройство буквенно-цифрового ввода 812 (например, клавиатуру), устройство управления курсором 814 (например, мышь) и устройство для формирования сигналов 820 (например, динамик). В одном из иллюстративных примеров видеодисплей 810, устройство буквенно-цифрового ввода 812 и устройство управления курсором 814 могут быть объединены в один компонент или устройство (например, сенсорный жидкокристаллический дисплей).
[0078] Устройство хранения данных 816 может содержать машиночитаемый носитель данных 824, в котором хранятся инструкции 826, реализующие одну или более из методик или функций, описанных в настоящем документе. Инструкции 826 могут также находиться полностью или по меньшей мере частично в основном запоминающем устройстве 804 и (или) в обрабатывающем устройстве 802 во время их выполнения вычислительной системой 800, основным запоминающим устройством 804 и обрабатывающим устройством 802, также содержащим машиночитаемый носитель информации. В некоторых вариантах осуществления изобретения инструкции 826 могут дополнительно передаваться или приниматься по сети через устройство сетевого интерфейса 822.
[0079] Несмотря на то что машиночитаемый носитель данных 824 показан в иллюстративных примерах как единичный носитель, термин «машиночитаемый носитель данных» следует понимать и как единичный носитель, и как несколько таких носителей (например, централизованная или распределенная база данных и (или) связанные кэши и серверы), на которых хранится один или более наборов команд. Термин «машиночитаемый носитель данных» также следует рассматривать как термин, включающий любой носитель, который способен хранить, кодировать или переносить набор команд для выполнения машиной, который заставляет эту машину выполнять одну или более методик, описанных в настоящем описании изобретения. Соответственно, термин «машиночитаемый носитель данных» следует понимать как содержащий, среди прочего, устройства твердотельной памяти, оптические и магнитные носители.
[0080] Несмотря на то что операции способов показаны и описаны в настоящем документе в определенном порядке, порядок выполнения операций каждого способа может быть изменен таким образом, чтобы некоторые операции могли выполняться в обратном порядке или чтобы некоторые операции могли выполняться, по крайней мере частично, одновременно с другими операциями. В некоторых вариантах реализации изобретения команды или подоперации различных операций могут выполняться с перерывами и (или) попеременно.
[0081] Следует понимать, что приведенное выше описание носит иллюстративный, а не ограничительный характер. Различные другие варианты реализации станут очевидны специалистам в данной области техники после прочтения и понимания приведенного выше описания. Поэтому область применения изобретения должна определяться с учетом прилагаемой формулы изобретения, а также всех областей применения эквивалентных способов, которые покрывает формула изобретения.
[0082] В приведенном выше описании изложены многочисленные детали. Однако специалистам в данной области техники должно быть очевидно, что варианты реализации изобретения могут быть реализованы на практике и без этих конкретных деталей. В некоторых случаях хорошо известные структуры и устройства показаны в виде блок-схем, а не подробно, чтобы не усложнять описание настоящего изобретения.
[0083] Некоторые части описания предпочтительных вариантов реализации выше представлены в виде алгоритмов и символического изображения операций с битами данных в компьютерной памяти. Такие описания и представления алгоритмов являются средством, используемым специалистами в области обработки данных, чтобы наиболее эффективно передавать сущность своей работы другим специалистам в данной области. Приведенный здесь (и в целом) алгоритм сформулирован как непротиворечивая последовательность шагов, ведущих к нужному результату. Эти шаги требуют физических манипуляций с физическими величинами. Обычно, хотя и не обязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и выполнять другие манипуляции. Иногда удобно, прежде всего для обычного использования, описывать эти сигналы в виде битов, значений, элементов, символов, терминов, цифр и т.д.
[0084] Однако следует иметь в виду, что все эти и подобные термины должны быть связаны с соответствующими физическими величинами и что они являются лишь удобными обозначениями, применяемыми к этим величинам. Если прямо не указано иное, как видно из последующего обсуждения, следует понимать, что во всем описании такие термины, как «прием» или «получение», «определение» или «обнаружение», «выбор», «хранение», «анализ» и т.п., относятся к действиям вычислительной системы или подобного электронного вычислительного устройства или к процессам в нем, причем такая система или устройство манипулирует данными и преобразует данные, представленные в виде физических (электронных) величин, в регистрах и памяти вычислительной системы в другие данные, также представленные в виде физических величин в памяти или регистрах компьютерной системы или в других подобных устройствах хранения, передачи или отображения информации.
[0085] Настоящее изобретение также относится к устройству для выполнения операций, описанных в настоящем документе. Такое устройство может быть специально сконструировано для требуемых целей, или оно может содержать универсальный компьютер, который избирательно активируется или дополнительно настраивается с помощью компьютерной программы, хранящейся в компьютере. Такая вычислительная программа может храниться на машиночитаемом носителе данных, включая, среди прочего, диски любого типа, в том числе гибкие диски, оптические диски, CD-ROM и магнитно-оптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), программируемые ПЗУ (EPROM), электрически стираемые ППЗУ (EEPROM), магнитные или оптические карты или любой тип носителя, пригодный для хранения электронных команд, каждый из которых соединен с шиной вычислительной системы.
[0086] Алгоритмы и изображения, приведенные в этом документе, не обязательно связаны с конкретными компьютерами или другими устройствами. Различные системы общего назначения могут использоваться с программами в соответствии с изложенной здесь информацией, возможно также признание целесообразным сконструировать более специализированные устройства для выполнения шагов способа. Структура разнообразных систем такого рода определяется в порядке, предусмотренном в описании. Кроме того, изложение вариантов реализации изобретения не предполагает ссылок на какие-либо конкретные языки программирования. Следует принимать во внимание, что для реализации принципов настоящего изобретения могут быть использованы различные языки программирования.
[0087] Варианты реализации настоящего изобретения могут быть представлены в виде вычислительного программного продукта или программы, которая может содержать машиночитаемый носитель данных с сохраненными на нем инструкциями, которые могут использоваться для программирования вычислительной системы (или других электронных устройств) в целях выполнения процесса в соответствии с сущностью изобретения. Машиночитаемый носитель данных включает механизмы хранения или передачи информации в машиночитаемой форме (например, компьютером). Например, машиночитаемый (считываемый компьютером) носитель данных содержит машиночитаемый (например, компьютером) носитель данных (например, постоянное запоминающее устройство (ПЗУ), оперативное запоминающее устройство (ОЗУ), накопитель на магнитных дисках, накопитель на оптическом носителе, устройства флэш-памяти и т.д.) и т.п.
[0088] Слова «пример» или «примерный» используются здесь для обозначения использования в качестве примера, отдельного случая или иллюстрации. Любой вариант реализации или конструкция, описанные в настоящем документе как «пример», не должны обязательно рассматриваться как предпочтительные или преимущественные по сравнению с другими вариантами реализации или конструкциями. Слово «пример» лишь предполагает, что идея изобретения представляется конкретным образом. В этой заявке термин «или» предназначен для обозначения включающего «или», а не исключающего «или». Если не указано иное или не очевидно из контекста, то «X включает А или В» используется для обозначения любой из естественных включающих перестановок. То есть если X включает в себя А; X включает в себя В; или X включает А и В, то высказывание «X включает в себя А или В» является истинным в любом из указанных выше случаев. Кроме того, артикли «а» и «an», использованные в англоязычной версии этой заявки и в прилагаемой формуле изобретения, должны, как правило, означать «один или более», если иное не указано или из контекста не следует, что это относится к форме единственного числа. Использование терминов «вариант реализации» или «один вариант реализации» или «реализация» или «одна реализация» не означает одинаковый вариант реализации, если это не указано в явном виде. В описании термины «первый», «второй», «третий», «четвертый» и т.д. используются как метки для обозначения различных элементов и не обязательно имеют смысл порядка в соответствии с их числовым обозначением.
[0089] Принимая во внимание множество вариантов и модификаций раскрываемого изобретения, которые, без сомнения, будут очевидны лицу со средним опытом в профессии после прочтения изложенного выше описания, следует понимать, что любой частный вариант осуществления изобретения, приведенный и описанный для иллюстрации, ни в коем случае не должен рассматриваться как ограничение. Таким образом, ссылки на подробности не должны рассматриваться как ограничение объема притязания, который содержит только признаки, рассматриваемые в качестве сущности изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| ДИФФЕРЕНЦИАЛЬНАЯ КЛАССИФИКАЦИЯ С ИСПОЛЬЗОВАНИЕМ НЕСКОЛЬКИХ НЕЙРОННЫХ СЕТЕЙ | 2017 |
|
RU2652461C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| ОБУЧЕНИЕ НЕЙРОННОЙ СЕТИ ПОСРЕДСТВОМ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ ПОТЕРЬ | 2018 |
|
RU2707147C1 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ ПРИМЕНЕНИЯ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ УВЕРЕННОСТИ, РЕАЛИЗУЕМОЕ НА БАЗЕ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2703270C1 |
| СПОСОБ ВЫЯВЛЕНИЯ НЕОБХОДИМОСТИ ОБУЧЕНИЯ ЭТАЛОНА ПРИ ВЕРИФИКАЦИИ РАСПОЗНАННОГО ТЕКСТА | 2014 |
|
RU2641225C2 |
| АВТОМАТИЧЕСКОЕ ОПРЕДЕЛЕНИЕ НАБОРА КАТЕГОРИЙ ДЛЯ КЛАССИФИКАЦИИ ДОКУМЕНТА | 2018 |
|
RU2701995C2 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| ИДЕНТИФИКАЦИЯ ИСПОЛЬЗУЕМЫХ В ДОКУМЕНТАХ СИСТЕМ ПИСЬМА | 2021 |
|
RU2792743C1 |
| РАСПОЗНАВАНИЕ СОБЫТИЙ НА ФОТОГРАФИЯХ С АВТОМАТИЧЕСКИМ ВЫДЕЛЕНИЕМ АЛЬБОМОВ | 2020 |
|
RU2742602C1 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |


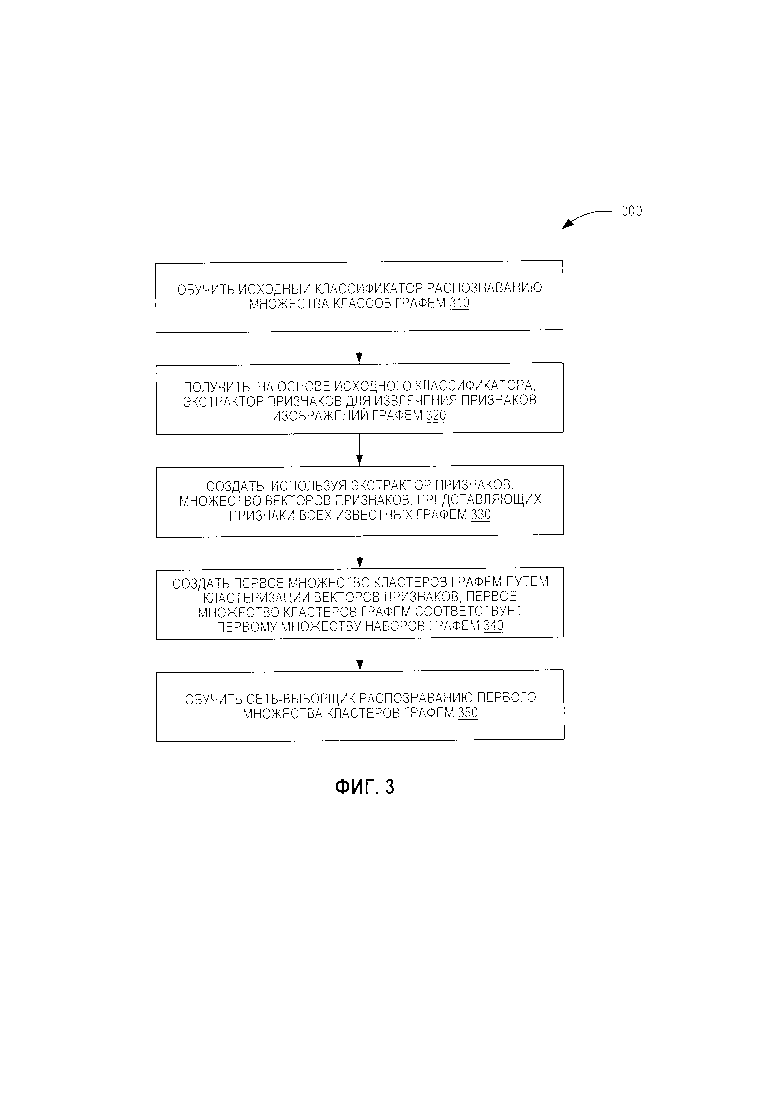

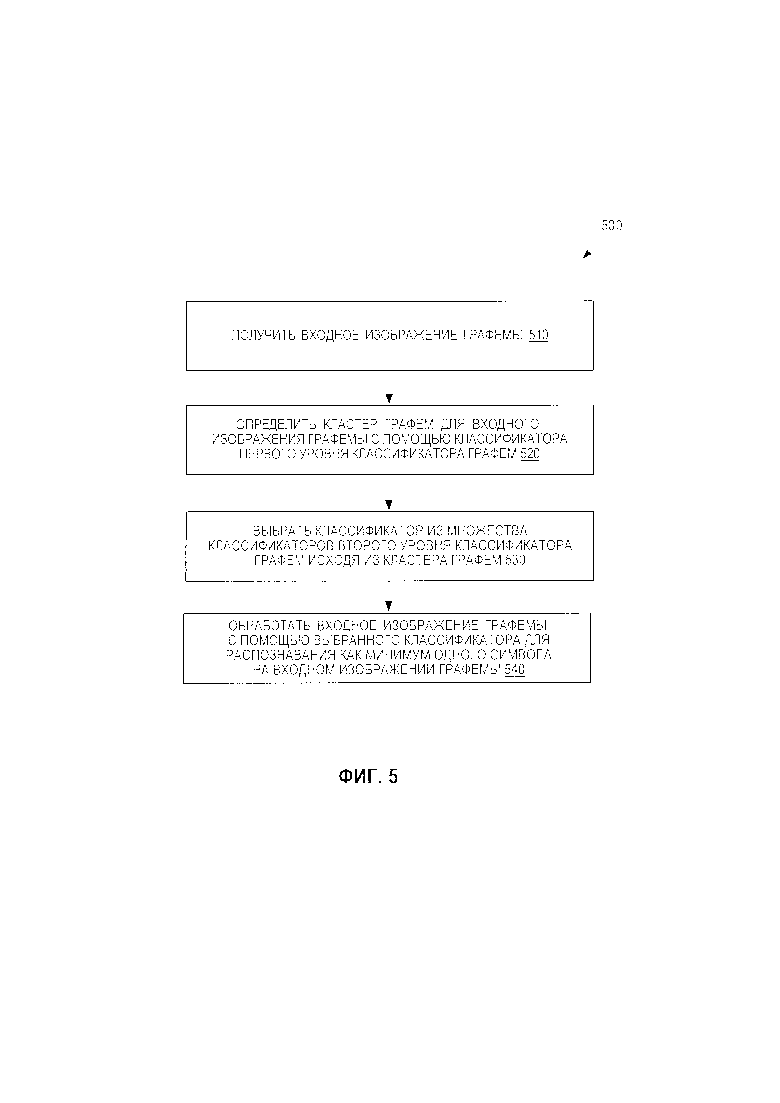
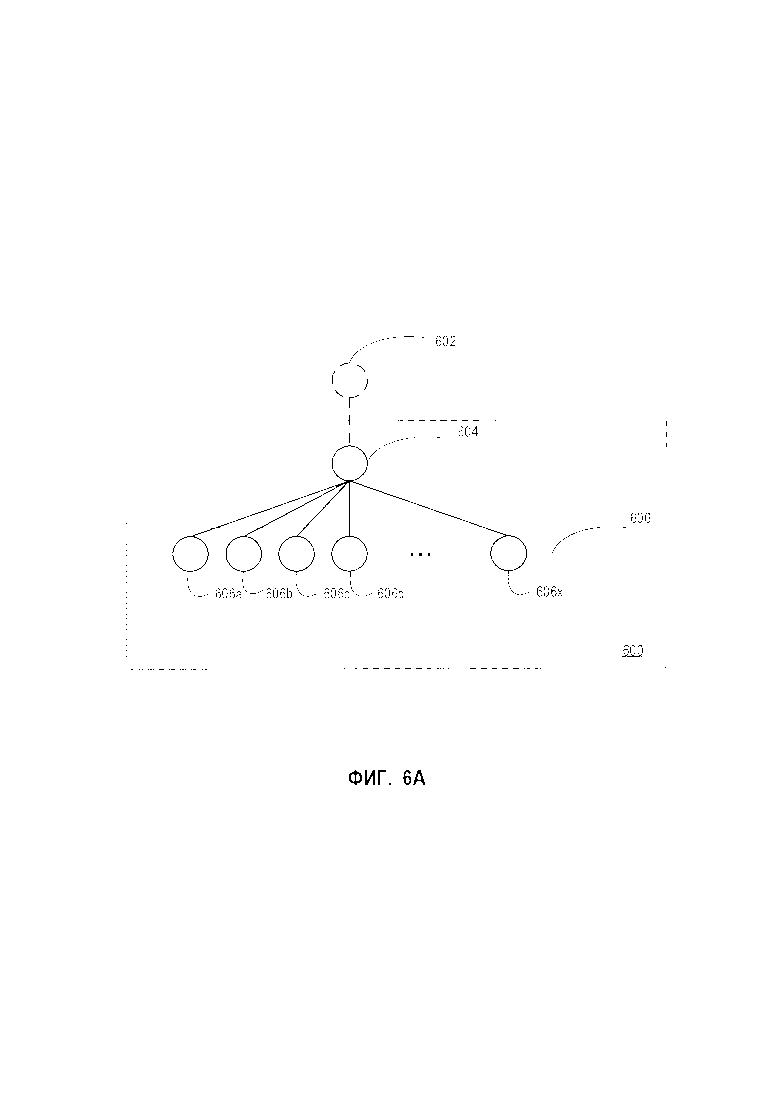
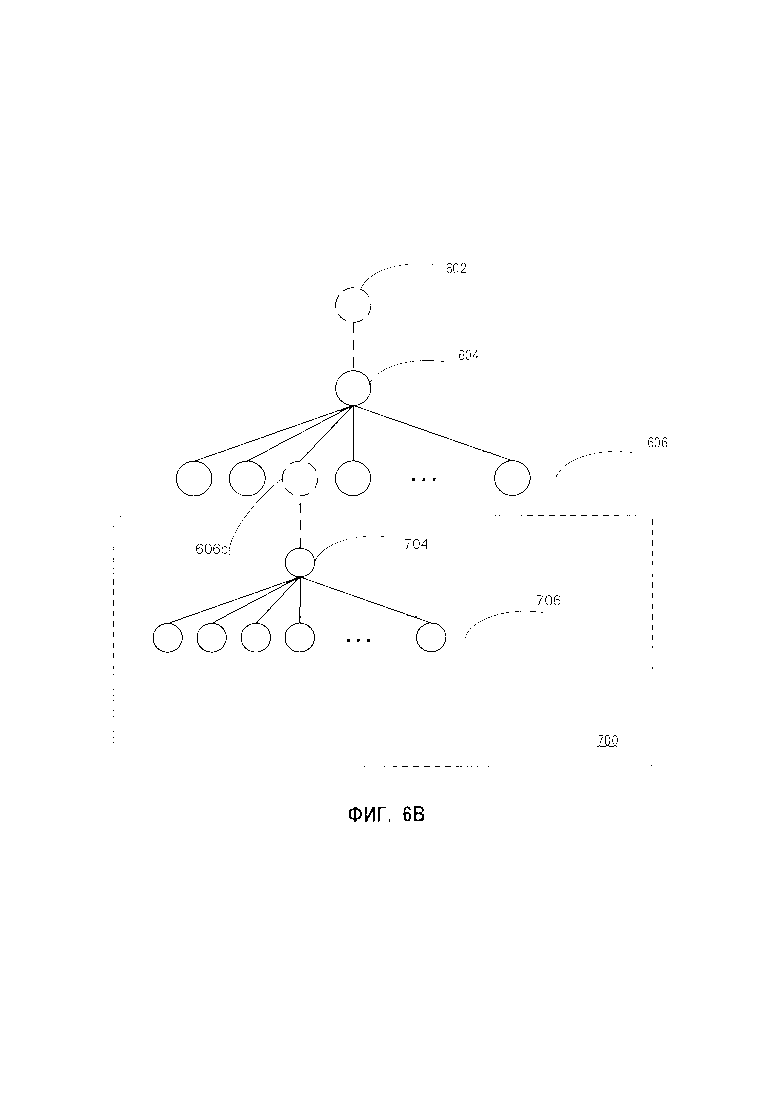
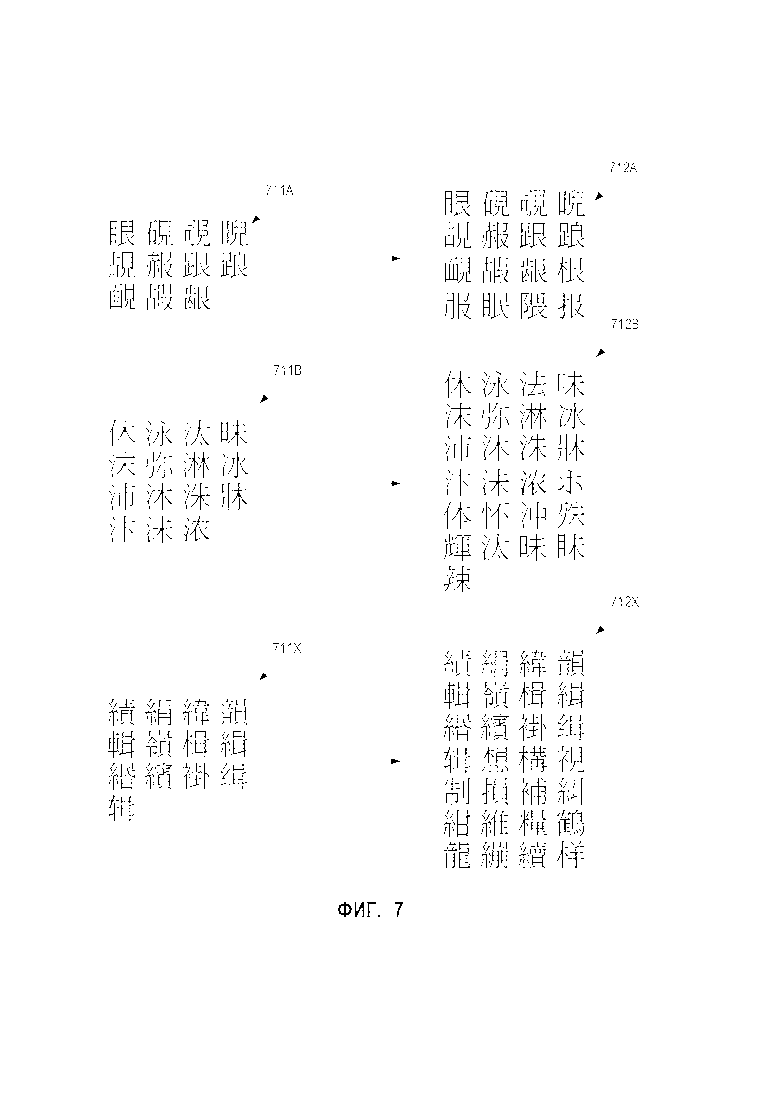
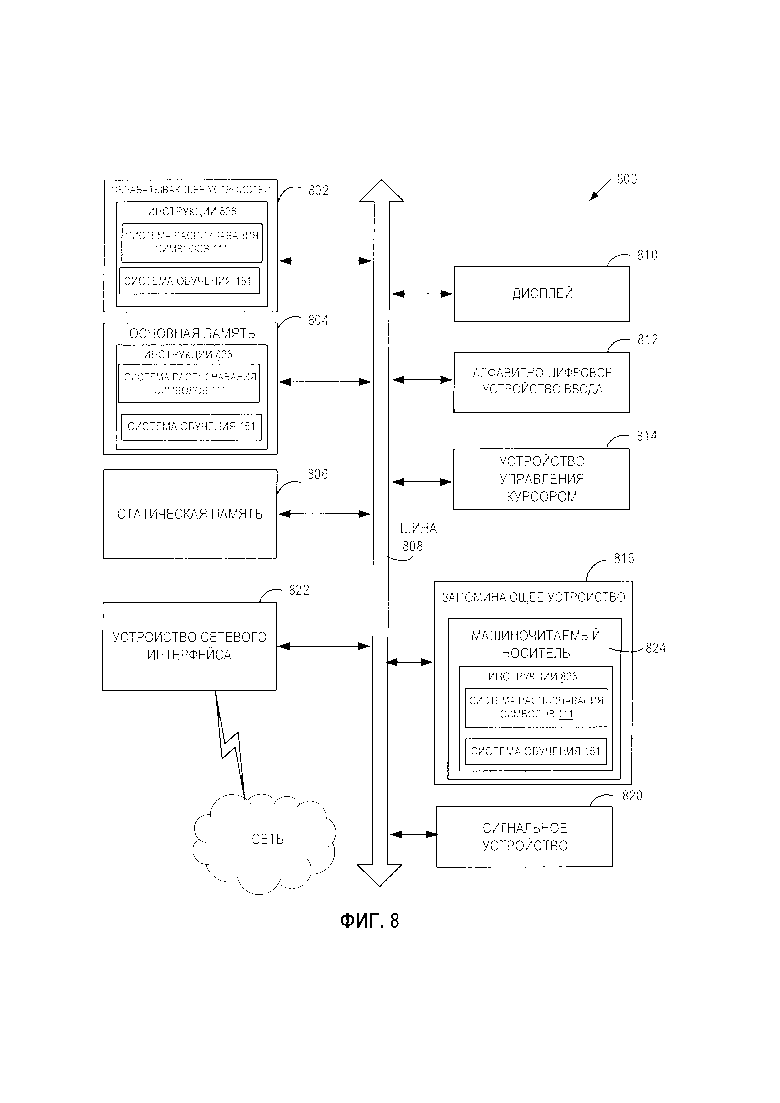
Изобретения относятся к средствам распознавания символов с использованием нейронных сетей. Техническим результатом является обеспечение эффективного и точного распознавания символов для языков с большим алфавитом и мультиязычных текстов. Способ содержит: отнесение входного изображения графемы к первому кластеру графем из множества кластеров графем, где первый кластер графем содержит первое множество графем, выбор обрабатывающим устройством классификатора из множества классификаторов второго уровня, классификатора графем исходя из первого кластера графем, такого что выбранный классификатор был обучен распознавать первое множество графем, и обработку входного изображения графемы с помощью выбранного классификатора для распознавания по меньшей мере одного символа на выходном изображении графемы. Системы обеспечивают работу способа. 3 н. и 17 з.п. ф-лы, 9 ил.
1. Способ распознавания символов, включающий:
отнесение, с помощью классификатора первого уровня классификатора графем, входного изображения графемы к первому кластеру графем из множества кластеров графем, где первый кластер графем содержит первое множество графем и где множество кластеров графем является множеством пересекающихся кластеров графем, созданных на основании статистических данных классификатора первого уровня;
выбор обрабатывающим устройством классификатора из множества классификаторов второго уровня, для обучения которых используется множество пересекающихся кластеров графем, классификатора графем исходя из первого кластера графем, такого что выбранный классификатор был обучен распознавать первое множество графем; и
обработку входного изображения графемы с помощью выбранного классификатора для распознавания по меньшей мере одного символа на входном изображении графемы.
2. Способ по п. 1, дополнительно включающий:
замену выбранного классификатора иерархическим классификатором для построения классификатора графем, где первый уровень иерархического классификатора выполнен с возможностью распознавания множества подкластеров из первого кластера графем и где второй уровень иерархического классификатора содержит множество классификаторов дополнительного уровня, выполненных с возможностью распознавания графем из соответствующего подкластера в множестве подкластеров.
3. Способ по п. 2, дополнительно включающий:
выявление с помощью первого уровня иерархического классификатора первого подкластера из первого кластера графем для входного изображения графемы, где первый подкластер содержит первое подмножество первого множества графем; и
распознавание, с использованием одного из множества классификаторов дополнительного уровня, по меньшей мере одной графемы из первого подмножества первого множества графем на входном изображении графемы.
4. Способ по п. 1, дополнительно включающий построение обрабатывающим устройством классификатора графем, где построение классификатора графем дополнительно включает:
порождение обрабатывающим устройством множества векторов признаков, таких что каждый вектор признаков представляет признаки одной графемы из множества графем, распознаваемых классификатором графем; кластеризацию обрабатывающим устройством множества векторов признаков для создания первого множества кластеров графем; и
обучение, с использованием первой обучающей выборки изображений графем, классификатора первого уровня распознаванию первого множества кластеров графем.
5. Способ по п. 4, дополнительно включающий создание множества пересекающихся кластеров графем на основании статистических данных классификатора первого уровня, где создание множества пересекающихся кластеров графем дополнительно включает:
обработку второй обучающей выборки изображений графем с помощью классификатора первого уровня;
сбор статистических данных об обработке второй обучающей выборки изображений графем; и
создание множества пересекающихся кластеров графем на основе статистических данных и первого множества кластеров графем; и
обучение соответствующего дифференциального классификатора для каждого из множества пересекающихся кластеров графем для создания множества классификаторов второго уровня.
6. Способ по п. 5, отличающийся тем, что создание множества пересекающихся кластеров графем на основе статистических данных включает:
определение на основе статистических данных доли ошибок неправильного отнесения первой графемы к первому множеству графем из первого множества кластеров графем; и
в ответ на обнаружение того, что доля ошибок превышает предельное значение, добавление первой графемы в первое множество графем для создания первого кластера графем из множества пересекающихся кластеров графем.
7. Способ по п. 4, дополнительно включающий:
обучение, с использованием первой обучающей выборки изображений графем, исходного классификатора распознаванию множества классов графем, где каждый из множества классов графем соответствует одной графеме из множества графем, распознаваемых классификатором графем;
создание экстрактора признаков на основе исходного классификатора; и
создание, с использованием экстрактора признаков, множества векторов признаков.
8. Способ по п. 7, отличающийся тем, что создание экстрактора признаков на основе исходного классификатора включает удаление выбранного слоя из множества слоев исходного классификатора, где выбранный слой исходного классификатора настроен на создание выходного результата исходного классификатора.
9. Способ по п. 1, дополнительно включающий построение классификатора графем используя сверточные нейронные сети.
10. Система распознавания символов, включающая следующие компоненты:
память; и
обрабатывающее устройство, функционально связанное с памятью и предназначенное для:
отнесения, с помощью классификатора первого уровня классификатора графем, входного изображения графемы к первому кластеру графем из множества кластеров графем, где первый кластер графем содержит первое множество графем и где множество кластеров графем является множеством пересекающихся кластеров графем, созданное на основании статистических данных классификатора первого уровня;
выбора классификатора из множества классификаторов второго уровня, для обучения которых используется множество пересекающихся кластеров графем, классификатора графем исходя из первого кластера графем, такого что выбранный классификатор был обучен распознавать первое множество графем; и
обработки входного изображения графемы с помощью выбранного классификатора для распознавания по меньшей мере одного символа на входном изображении графемы.
11. Система по п. 10, отличающаяся тем, что обрабатывающее устройство дополнительно выполняет следующие действия:
замена выбранного классификатора иерархическим классификатором для построения классификатора графем, где первый уровень иерархического классификатора выполнен с возможностью распознавания множества подкластеров из первого кластера графем и где второй уровень иерархического классификатора содержит множество классификаторов дополнительного уровня, выполненных с возможностью распознавания графем из соответствующего подкластера во множестве подкластеров.
12. Система по п. 11, отличающаяся тем, что обрабатывающее устройство дополнительно выполняет следующие действия:
выявление, с помощью первого уровня иерархического классификатора, первого подкластера из первого кластера графем для входного изображения графемы, где первый подкластер содержит первое подмножество первого множества графем; и
распознавание, с использованием одного из множества классификаторов дополнительного уровня, по меньшей мере одной графемы из первого подмножества первого множества графем на входном изображении графемы.
13. Система по п. 10, отличающаяся тем, что для построения классификатора графем обрабатывающее устройство выполняет следующие действия:
порождение множества векторов признаков, таких что каждый вектор признаков представляет признаки одной графемы из множества графем, распознаваемых классификатором графем;
кластеризация обрабатывающим устройством множества векторов признаков для создания первого множества кластеров графем; и
обучение, с использованием первой обучающей выборки изображений графем, классификатора первого уровня распознаванию первого множества кластеров графем.
14. Система по п. 13, отличающаяся тем, что для создания множества пересекающихся кластеров графем на основании статистических данных классификатора первого уровня обрабатывающее устройство дополнительно выполняет следующие действия:
обработка второй обучающей выборки изображений графем с помощью классификатора первого уровня;
сбор статистических данных об обработке второй обучающей выборки изображений графем; и
создание множества пересекающихся кластеров графем на основе статистических данных и первого множества кластеров графем; и
обучение соответствующего дифференциального классификатора для каждого из множества пересекающихся кластеров графем для создания множества классификаторов второго уровня.
15. Система по п. 14, отличающаяся тем, что для создания множества пересекающихся кластеров графем на основе статистических данных обрабатывающее устройство дополнительно выполняет следующие действия:
определение, на основе статистических данных, доли ошибок неправильного отнесения первой графемы к первому множеству графем из первого множества кластеров графем; и
в ответ на обнаружение того, что доля ошибок превышает предельное значение, добавление первой графемы в первое множество графем для создания первого кластера графем из множества пересекающихся кластеров.
16. Система по п. 13, в которой обрабатывающее устройство дополнительно выполняет следующие действия:
обучение, с использованием первой обучающей выборки изображений графем, исходного классификатора распознаванию множества классов графем, где каждый из множества классов графем соответствует одной графеме из множества графем, распознаваемых классификатором графем;
создание экстрактора признаков на основе исходного классификатора; и
создание, с использованием экстрактора признаков, множества векторов признаков.
17. Система по п. 16, отличающаяся тем, что для создания экстрактора признаков на основе исходного классификатора система обработки дополнительно выполняет удаление выбранного слоя из множества слоев исходного классификатора, где выбранный слой исходного классификатора настроен на создание выходного результата исходного классификатора.
18. Система по п. 10, в которой обрабатывающее устройство дополнительно выполняет построение классификатора графем используя сверточные нейронные сети.
19. Постоянный машиночитаемый носитель данных, содержащий инструкции, которые при обращении к ним обрабатывающего устройства приводят к выполнению операций обрабатывающим устройством, включая:
отнесение, с помощью классификатора первого уровня классификатора графем, входного изображения графемы к первому кластеру графем из множества кластеров графем, где первый кластер графем содержит первое множество графем и где множество кластеров графем является множеством пересекающихся кластеров графем, созданных на основании статистических данных классификатора первого уровня;
выбор классификатора из множества классификаторов второго уровня, для обучения которых используется множество пересекающихся кластеров графем, классификатора графем исходя из первого кластера графем, такого что выбранный классификатор был обучен распознавать первое множество графем; и
обработку входного изображения графемы с помощью выбранного классификатора для распознавания по меньшей мере одного символа на входном изображении графемы.
20. Постоянный машиночитаемый носитель данных по п. 19, отличающийся тем, что дополнительно выполняет следующие действия:
замена выбранного классификатора иерархическим классификатором для построения классификатора графем, где первый уровень иерархического классификатора выполнен с возможностью распознавания множества подкластеров первого кластера графем и где второй уровень иерархического классификатора содержит множество классификаторов дополнительного уровня, выполненных с возможностью распознавания графем из соответствующего подкластера во множестве подкластеров;
выявление, с помощью первого уровня иерархического классификатора, первого подкластера из первого кластера графем для входного изображения графемы, где первый подкластер содержит первое подмножество первого множества графем; и
распознавание, с использованием одного из множества классификаторов дополнительного уровня, по меньшей мере одной графемы из первого подмножества первого множества графем на входном изображении графемы.
| US 5638491 A, 10.07.1997 | |||
| СПОСОБЫ И СИСТЕМЫ АВТОМАТИЧЕСКОГО РАСПОЗНАВАНИЯ СИМВОЛОВ С ИСПОЛЬЗОВАНИЕМ ДЕРЕВА РЕШЕНИЙ | 2015 |
|
RU2598300C2 |
| US 9613299 B2, 21.01.2014 | |||
| US 5835633 A, 20.11.1995 | |||
| JP 5577948 B2, 24.08.2010. | |||

