Уровень техники
Твердотельный диск (SSD) представляет собой устройство хранения данных высокой производительности, который не содержит движущихся частей. SSD имеют значительно высокое быстродействие, чем обычные накопители на жестких дисках (HDD) с обычными вращающимися магнитными носителями и, как правило, включают в себя контроллер для управления хранением данных. Контроллер управляет операциями SSD, включающие в себя хранение и доступа к данным, а также обеспечивает связь между SSD и хост-устройством. Алгоритм дедупликации данных является механизмом, в котором идентифицируется дублирование любого заданного набора данных и осуществляется перекрестные ссылки, и только уникальные шаблоны данных записываются на носитель информации и все дубликаты будут захвачены как указатели на уникальные наборы данных, как правило, блоки. Если есть дублирование в потоке данных, то этот способ позволяет системе существенно сократить объем данных, записанных на диск.
Краткое описание чертежей
Вышеизложенное описание и другие задачи, признаки и преимущества настоящего изобретения будут очевидны из следующего описания конкретных вариантов осуществления изобретения, как показано на прилагаемых чертежах, на которых одинаковые ссылочные позиции используются для обозначения тех же самых частей на различных видах. Чертежи не обязательно выполнены в масштабе, вместо этого, внимание сфокусировано на иллюстрировании принципов изобретения.
Фиг. 1а-1с показывают контекст вариантов реализации для вычисления дайджеста сообщения;
Фиг. 2 показывает блок-схему алгоритма вычисления дайджеста сообщения, как описано здесь;
Фиг. 3 показывает блок-схему устройства для вычисления дайджеста сообщения, как показано на фиг. 2;
Фиг. 4 показывает блок-схему алгоритма хост-интерфейса для вычисления дайджеста сообщения; и
Фиг. 5 показывает блок-схему алгоритма интерфейса устройства для вычисления дайджеста сообщения.
Описание вариантов осуществления
Подход дедупликации данных использует аппаратное ускорение в массовых запоминающих устройствах, таких как HDDs и SSD для выполнения операций дедублирования и поддержки присоединенного хоста, тем самым избавляя хоста от вычислительной нагрузки вычисления хэша для обработки дедублирования (дедубликация). Обработка дедублирования обычно включают в себя вычисление и сравнение дайджестов сообщений (MD) и/или хэш-функций. Функции MD применяются к оригинальному элементу данных, чтобы генерировать меньший, но уникальный идентификатор, такой, что любое изменение данных изменит значение дайджеста, и часто используется также для криптографических операций, таких как шифрование и аутентификация. Часто SSD включают в себя встроенные аппаратные ускорители для функций MD, ассоциированных с признаками безопасности SSD. Тем не менее, аппаратные ускорители также могут использоваться для вычисления результата дайджеста (MD) и возврата результата в хост, эффективно разгружая нагрузку MD вычислений с хоста, аналогично на внешний аппаратный ускоритель, но без перенаправления данных, так как вычисление выполняется на потоке данных, проходящих через SSD для хранения.
Конфигурации здесь основаны, в частности, на наблюдении, что дайджест сообщения и хэш-операции, как правило, имеют тенденцию к интенсификации вычислений, что может потребовать значительных CPU циклов для больших объемов данных. К сожалению, традиционные подходы к операциям дедубликации имеют недостаток, который заключается в том, что требуются дополнительные накладные расходы для вычислений MD на хосте или требуется наличие и использование дорогостоящих аппаратных систем, которые перенаправляют данные, дополнительно препятствуя повышению производительности и увеличению стоимости. Тем не менее, встроенные аппаратные ускорители, расположенные в современных SSDs, не могут быть полностью использованы собственными операциями по обеспечению безопасности в SSD, и возможности SSD аппаратных ускорителей могут быть использованы хостом для MD вычислений. Соответственно, конфигурации, описанные здесь, по существу, преодолевают описанные выше недостатки, посредством использования встроенных аппаратных ускорителей SSD для приема запросов на дайджест сообщения из хоста и возвращает результаты хеш/дайджеста в хост.
Описанный подход предлагает способ ускорения процесса дедубликации данных (форма сжатия данных) за счет ускорения выполнения операции вычисления хэш-дайджеста на самом SSD. Архитектура и структура SSD предлагает уникальную возможность для ускорения вычисления дайджеста в аппаратных средствах посредством сквозной распределенной архитектуры вычислений хэш-дайджеста. В предлагаемом подходе, поскольку потоки данных проходят через SSD, SSD вычисляет дайджесты и отправляет их обратно на хост для сопоставления с дайджестом дедупликации, обеспечивая низкую стоимость, высокую производительность и эффективное энергопотребление посредством поддержки дедупликации. В рамках всей системы шифрования диска, SSD уже имеет собственные доступные HW компоненты, например, усовершенствованный стандарт шифрования (AES)/дешифрования и SHA-256 вычислений дайджеста. SSD уже выполняет преобразование данных, такое как AES шифрование/дешифрование, так как потоки данных проходят через него. Добавление потока, подвергнутого вычислению SHA дайджеста, следовательно, вызывает лишь незначительные дополнительные затраты, так как в большинстве конструкций HW аппаратные ускорители для вычисления уже доступны в контроллере SSD. Описываются две различные конфигурации реализации вычисления дайджеста, включающие в себя в способ линейного вычисления и автономный способ вычисления. Они могут быть использованы по отдельности или в сочетании друг с другом.
Конфигурации, описанные здесь, позволяют вычислить дайджесты в SSD. Этот подход снижает латентность, так как данные подаются параллельно выделенному HW аппаратному ускорителю. Такой подход также энергоэффективен, так как данные не передаются в систему динамической памяти с произвольным доступом (DRAM) или к выделенному HW аппаратному ускорителю, которые оба потребляют больше энергии для выполнения той же операции. Подход разгружает центральный процессор (CPU) для вычисления дайджестов и позволяет распределить процесс вычисления между несколькими драйверами в подсистеме хранения данных.
Процесс дедупликации данных включает в себя идентификацию блоков данных, которые имеют идентичный контент. Традиционно, дайджесты сообщений вычисляются с использованием безопасных алгоритмов хэширования (SHA-256) или других алгоритмов вычислений дайджестов. Обычно 256 битовые или 32 байтовые или меньшего размера дайджесты вычисляются для каждого блока данных, которые могут изменяться по длине от 512 байт до 4096 байт или более. Путем сравнения дайджестов, можно легко определить, идентичен ли блок другому блоку или нет.
В традиционных подходах, как обсуждалось выше, системы дедупликации данных могут быть полностью основаны на SW, где вычисление дайджеста и сравнение с предшествующими дайджестами выполняется в SW, который имеет тенденцию нагружать процессор хоста. Есть также HW ускорители, которые могут быть присоединены к системам хранения данных в центре обработки данных, которые выполняют вычисление дайджеста и некоторую часть сравнения дайджестов в HW, однако такой подход, как правило, существенно увеличивает расходы.
Пример архитектуры системы, использующей предлагаемый подход вычислений дайджеста на самом SSD, показан ниже на фиг. 1с. Способ вычисления дайджеста представляет собой поточный, без сохранения состояний способ вычисления, который особенно хорошо подходит для использования на контроллере SSD. Контроллер SSD осуществляет мониторинг записанных данных и вычисляет дайджесты в HW для каждого блока, проходящего через него. Рассчитанные дайджесты возвращаются в хост при завершении команды. Эта архитектура показана более подробно на фиг. 3. Кроме того, обеспечивается минимальные дополнительные расходы для усовершенствования контроллера SSD, чтобы реализовать поточный способ вычисления дайджеста для поддержки раскрытого подхода.
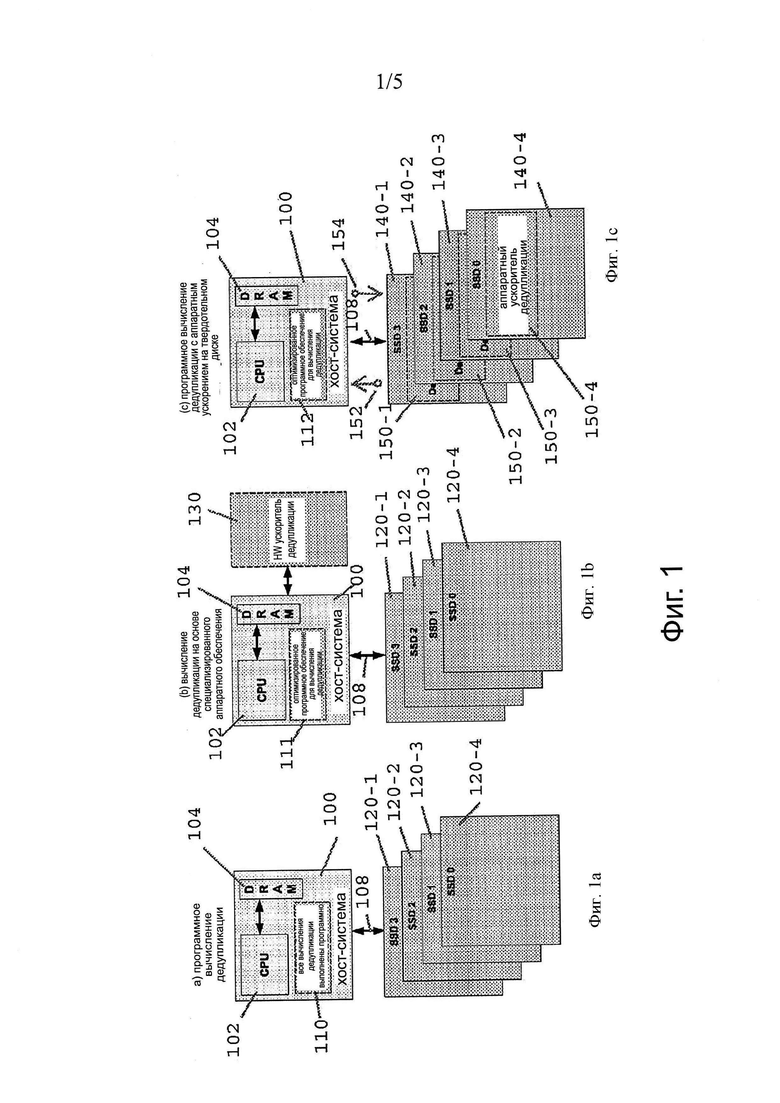
Фигуры 1а-1с показывают контекст вариантов реализации для вычисления дайджеста сообщения. Как показано на фигурах 1а-1с, фиг. 1а иллюстрирует традиционный подход к обнаружению дублирования (дедублирования), используя дайджесты сообщений. На фиг. 1а, хост-система 100 имеет CPU 102 и память (DRAM) 104 для выполнения приложения, и использует один или несколько SSDs 120-1…120-4 (120 в целом) для массового хранения. Хост-система 100 использует приложение дедубликации или утилиту 110 для выполнения вычислений дедубликации в программном обеспечении на хосте 100 и запрашивает 108 для хранения, рассматривая и сравнивая с выявлением дублирования (как правило, дублируются сектора, страницы или блоки). На фиг. 1а, обнаружение дедублирования снижает общую производительность CPU 102 за счет ресурсов, необходимых для выполнения вычисления дайджеста и сравнения. Программная реализация также обычно занимает больше времени для выполнения, чем подход, основанный на аппаратном или аппаратно-программном обеспечении.
Фиг. 1b показывает хост 100 с выделенными периферийными аппаратными средствами дедупликации или картой 130 примененные из оптимизированного кода 111 для перенаправления запросов 108 ввода/вывода в выделенные аппаратные средства 130 дедупликации. Подход, предусматривающий использование выделенных аппаратных средств, эффективен, но требует затрат на дополнительный аппаратный элемент и также требует запроса 108 на перенаправление ввода/вывода для выполнения процесса обработки посредством аппаратных средств 130.
Фиг. 1с показывает встроенные аппаратные ускорители 150-1…150-4 в SSD. Как показано на фиг. 1с, в отличие от традиционных подходов, описанных здесь конфигураций, используется аппаратный ускоритель, размещенный на SSD, который уже используется хостом 100 для запросов 108 ввода/вывода. SSDs часто используют специализированные аппаратные средства для обеспечения безопасности и/или операций шифрования для данных, хранящихся на нем. Вместо того чтобы занимать циклы процессора хоста или перенаправлять процесс обработки дорогостоящих аппаратных средств 130, применяются встроенные аппаратные ускорители 150-1…150-4 дедупликации на SSD 140-1…140-4. Инструкции 112 дедупликации хоста вызывают аппаратный ускоритель 150 для генерации дайджестов и принимают результаты 152 дедупликации дайджеста в ответ на запросы 154. Кроме того, ускоритель аппаратных средств 150 работает на потоке 108 данных, которые уже проходят через SSD для удовлетворения запросов I/O хоста, поэтому дополнительные выборки и записи для операций дедупликации исключаются. Таким образом, ускоритель аппаратных средств 150 дедупликации вызывается хостом 100 для выполнения операций дедупликации, которые в противном случае нагружают хост 100 вычислением (фиг. 1а) или перенаправляют (фиг. 1b) данные для операций дедупликации.
Фиг. 2 показывает блок-схему алгоритма процесса вычисления дайджеста сообщения, как описано здесь. Со ссылкой на фиг. 1с и фиг. 2, на этапе 200 способ хранения данных, как раскрыто в описании, включает в себя пополнение устройства хранения данных, такого как SSD 140, аппаратными ускорителями 150 для выполнения сжатия и функций безопасности на данных, посылаемых с хоста 100, чтобы храниться на устройстве хранения данных. В примере конфигурации, аппаратные ускорители 150 являются блоками шифрования, расположенными на устройстве хранения данных, и выполнены с возможностью шифровать, дешифровать и безопасно выполнять хэш-вычисления, как показано на этапе 201. Так как аппаратные ускорители 150 уже установлены на SSD 140 для поддержки выполнения безопасного шифрования и аутентификации, то не требуются какие-либо дополнительные производственные затраты для использования дедупликации.
Хост 100 вызывает аппаратные ускорители 150 на основе команды или запроса 154 из хоста 100, чтобы вычислить результат 152, как показано на этапе 202. SSD 140 возвращает результат 152 вычисленного дайджеста в хост 100, в котором вычисление дайджеста является поточным, без сохранения состояния вычислением, которое применяется к данным, проходящим из хоста 100 в запоминающее устройство для хранения на устройстве хранения данных, как показано на этапе 203. В примерной структуре, вычисленный результат 152 представляет собой дайджест сообщения, как описано на этапе 204, для сравнения с дайджестами других сохраненных блоков для поддержки операций дедупликации.
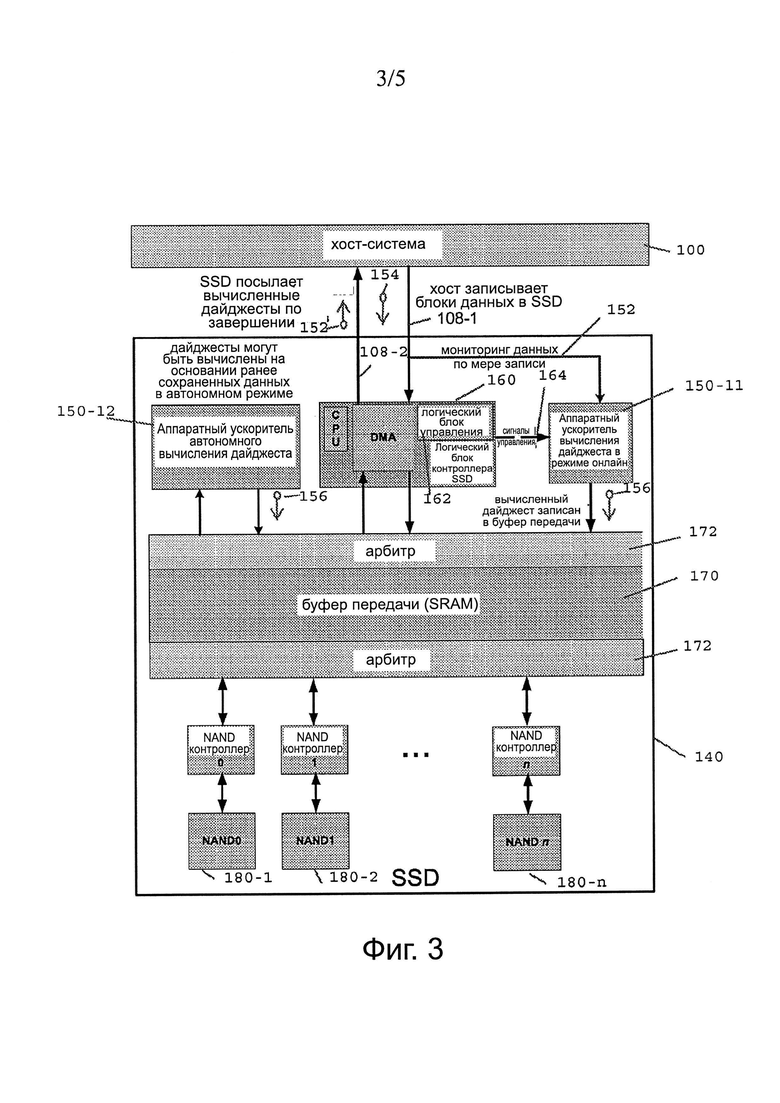
Фиг. 3 показывает блок-схему устройства для вычисления дайджеста сообщения, как показано на фиг. 2. Со ссылкой на фиг. 1 и 3, SSD 140 включает в себя встроенные один или несколько аппаратных ускорителей 150-11, 150-12 (в общем, 150) в SSD и используемые для выполнения признаков безопасности в SSD. Тем не менее, в дополнение к этим встроенным функциям SSD, аппаратный ускоритель 150-11 для линейного вычисления дайджеста обеспечивает линейное вычисление дайджестов сообщений посредством анализа данных или мониторинга, как показано линией 152, что неразрушающее считывает поток 108-1 записи с хоста. Линейный неразрушающий способ позволяет избежать влияния на производительность, что будет влиять при использовании способа перенаправления и/или копирования данных в буфер для отдельных MD вычислений, как показано ранее на фиг. 1а и 1b. Автономное ускорение HW 150-12 вычисления дайджеста выполняется аналогично вычислению дайджеста в автономном режиме для запросов 154 из хоста, которые являются объемными или несрочными. В обоих случаях, MD результаты 152 возвращаются в хост 100 в ответ на запрос 154 хоста, позволяющий эффективно работать хосту 100 для реализации возможности SSD 140 вычисления дайджеста без перенаправления и/или без вовлечения отдельного выделенного аппаратного средства 130 для вычисления дайджеста, так как SSD ускорители 150 имеют поток 108-1 легкодоступных данных, и могут выполнять вычисление дайджеста с отсутствием или минимальным воздействием на нормальную SSD производительность
В SSD 140, SSD контроллер 160 включает в себя логику 162 управления SSD, которая направляет запрос 154 хоста для передачи управляющих сигналов 164 к аппаратному ускорителю 150-11. Вычисленные дайджесты 156 направляются в буфер 170 передачи, обычно представляющий собой SRAM, который буферизует данные, хранящиеся и извлекаемые из SSD 140. Арбитр 172 направляет проверенные данные на носитель 180-1…180-N (180 в общем) памяти, как правило, NAND память, для хранения в соответствии с исходным запросом на хранение из хоста 100, в то время как вычисленный дайджест 152 отправляется обратно на хост 100.
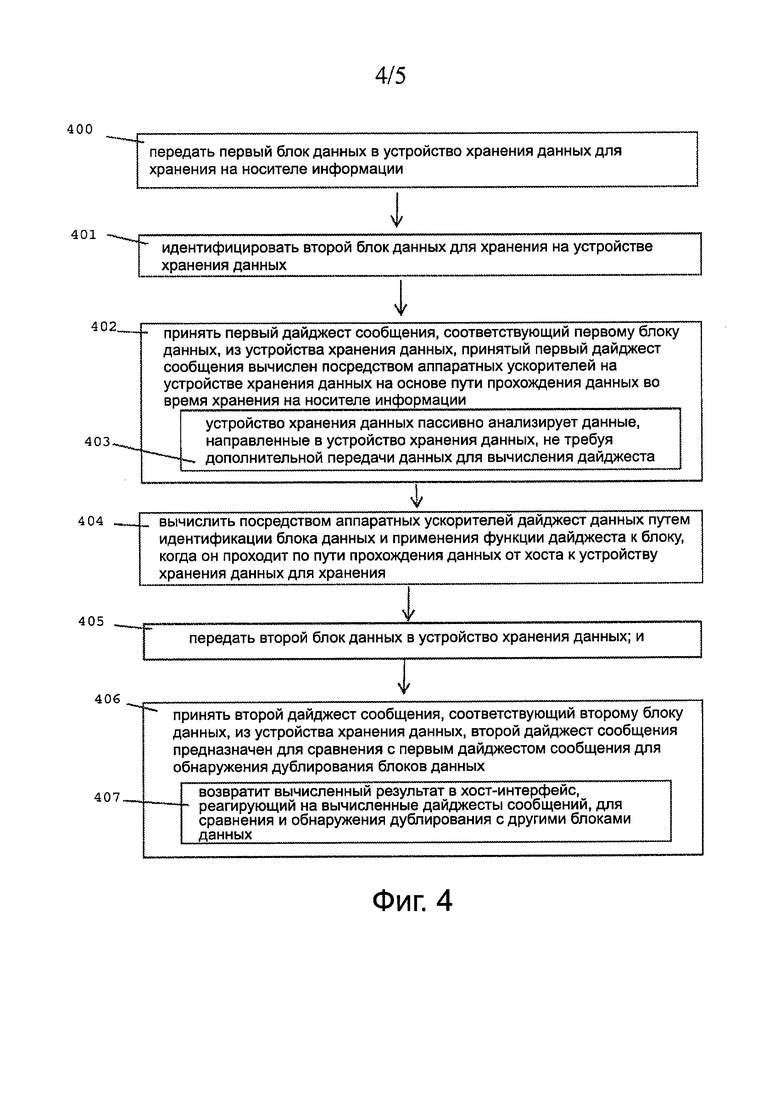
Фиг. 4 показывает блок-схему алгоритма работы хост-интерфейса для вычисления дайджеста сообщения. Как показано на фиг. 3 и 4, хост 100 вовлекает SSD 140 для выполнения вычисления дайджеста и принимает результат 152, основанный на вычисленном хэш (дайджест), так как хешированные данные проходят через SSD для хранения на носителе 180 в SSD 140. Хост 100 посылает первый блок данных в устройство 140 хранения для хранения на носителе 180 для хранения и идентифицирует второй блок данных для хранения на устройстве (SSD) 140 хранения данных, как показано на этапе 401. В ответ на это, хост 100 получит первый дайджест сообщения как ответ 152, соответствующий первому блоку данных, поступающий из устройства 140 хранения, таким образом, что принятый первый дайджест сообщения вычисляется с помощью аппаратных ускорителей 150 на устройстве 140 хранения из тракта 152 передачи данных, по которому проходят данные во время хранения на носителе 180 для хранения, как показано на этапе 402. Устройство 140 хранения пассивно анализирует данные, проходящие по тракту 152 данных, направленные на устройство хранения, не требуя дополнительной передачи данных для вычисления дайджеста, как показано на этапе 403.
Аппаратные ускорители 150 вычисляют дайджест данных путем идентификации блока данных (или другого приращения) и, применяя функцию дайджеста к блоку, как он проходит по тракту 108 передачи данных от хоста 100 к устройству 140 хранения для хранения, как показано на этапе 404. Хост 100 передает второй блок данных на устройство 140 хранения, как показано на этапе 405. Первый и второй блоки данных могут не быть последовательными и могут быть разделены другими запросами на хранение. Далее, хост 100 принимает второй дайджест сообщения, соответствующий второму блоку данных из устройства 140 хранения, таким образом, что второй дайджест сообщения используется для сравнения с первым дайджестом сообщения для обнаружения дублирования блоков данных, как это представлено на этапе 406. Обнаружение дубликатов блоков данных (обработка дедупликации) может происходить в любом подходящем интервале, однако процесс оптимизации и настройки параметров будет определять диапазон предыдущих блоков, которые, вероятно, содержат дубликаты, например, в файле, на единицу времени (т.е. фиксированный интервал, такой как N минут) или другие критерии. Устройство 140 хранения возвращает вычисленный результат 152 в интерфейс хоста 100, реагирующий на вычисленные дайджесты сообщений для сравнения и обнаружения дублирования с другими блоками данных, как описано на этапе 407.
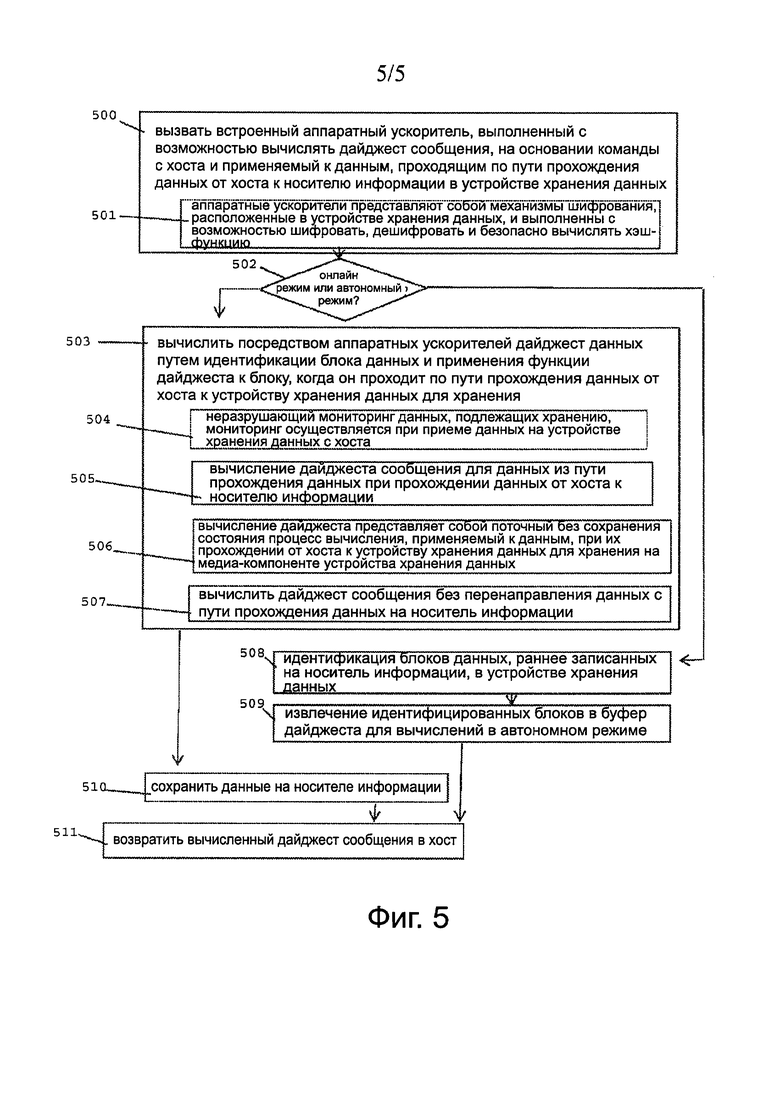
Фиг. 5 показывает блок-схему алгоритма работы интерфейса устройства для вычисления дайджеста сообщения. Как показано на фиг. 3 и 5, на этапе 500, способ обнаружения дублирования данных, как раскрыто в описании, включает в себя вызов встроенного аппаратного ускорителя 150, выполненного с возможностью вычислять дайджест сообщения на основании команды или запроса 154 от хоста 100 и применяемого к данным, передаваемым по тракту 108-1 передачи данных от хоста 100 на носитель 180 данных на устройстве 140 хранения. В примерной конфигурации, аппаратные ускорители 150 представляют собой блоки шифрования, расположенные на устройстве 140 хранения и выполнены с возможностью выполнять шифрование, дешифрование и безопасные хэш-вычисления, как показано на этапе 501. Решение принимается на этапе 502 на основании запроса 154 на выполнение вычислений в режиме онлайн или в автономном режиме. Если запрашивается онлайн режим вычисления, то аппаратные ускорители 140 вычисляют дайджест данных путем идентификации блока данных, и применяя функцию дайджеста к блоку, проходящему по тракту 152 передачи данных от хоста 100 на устройство 140 хранения для хранения на носителе 180 хранения, как показано на этапе 503. В примерной компоновке, это включает в себя осуществление неразрушительного мониторинга данных, которые должны быть сохранены, таким образом, чтобы мониторинг осуществлялся, так чтобы обеспечить данным, принятым на устройстве хранения данных от хоста по тракту 108-1 передачи данных и разветвленных или пассивно "проанализированных" по линии 152 данных, беспрепятственное дальнейшее хранение, как показано на этапе 504. Таким образом, аппаратные ускорители 140 вычисляют дайджест сообщения данных, переданных по тракту 108-1 передачи данных, как данных переданных от хоста 100 на носитель 180 хранения, как показано на этапе 505. Способ вычисления дайджеста является поточным без сохранения состояния способом вычисления, применяемым к данным, передаваемым от хоста 100 к устройству 140 хранения для хранения на компоненте носителе или носителе 180 данных устройства 140 хранения, как описано на этапе 506. Этот подход позволяет избежать задержки, так как данные подаются параллельно выделенному HW блоку ускорения. Такой подход также является энергоэффективным, так как данные не передаются в систему DRAM или выделенному внешнему HW блоку ускорения, которые оба потребляют больше энергии для выполнения той же операции. Подход разгружает CPU хоста от вычисления дайджестов и допускает распределенное вычисление среди большого количества дисков (запоминающих устройств 140) в подсистеме хранения. Аппаратные ускорители 150 поэтому вычисляют дайджест сообщения без перенаправления данных от тракта 108-1 передачи данных на носитель 180 хранения, а всего лишь анализируют или наблюдают за данными, как показано на этапе 507. Затем данные записываются (одновременно или в любом конкретном порядке) на носителе 180 хранения, как показано на этапе 510.
Если аппаратные ускорители 150 используются для автономного вычисления, согласно проверке на этапе 502, то выполняются автономные вычисления. В способе онлайн дайджесты вычисляются как данные, проходящие через SSD для каждой выполняемой операции записи. Как правило, это наиболее эффективный способ вычисления дайджестов. Тем не менее, хост 100 может запросить дайджесты для других блоков, которые уже присутствуют на SSD, для которых запрос 154 инициирует автономный режим, когда данные считываются с носителя в буфер передачи, как правило, определенный посредством статической памятью с произвольным доступом (SRAM), и автономный блок 150-12 обрабатывает эти данные для вычисления дайджестов. После того как дайджесты будут вычислены, они направляются на хост 100 для проверки соответствия. Соответственно, автономное вычисление включает в себя идентификацию блоков данных, ранее записанных на носителе 180 данных на устройстве 140 хранения, как показано на этапе 508, и извлечение идентифицированных блоков в буфер дайджеста для автономного вычисления, как показано на этапе 509. В любом случае, устройство 140 хранения возвращает вычисленный дайджест сообщения в хост 100 в качестве ответа 152, как показано на этапе 511.
Специалистам в данной области техники должно быть понятно, что программы и способы, определенные в настоящем документе, являются компонентами обработки пользователя и устройства обработки в различных формах, включающие в себя, но не ограничиваясь этим, а) информацию, постоянно хранящуюся на неперезаписываемых носителях, таких как устройства ROM, b) изменяемую информацию, хранящуюся на перезаписываемых непреходящих носителях, таких как дискеты, диски, магнитные ленты, компакт-диски, устройства оперативной памяти и другие магнитные и оптические носители информации, или с) информацию, переданную на компьютер через средства коммуникации как по электронной сети, такой как интернет или телефонные линии модема. Операции и способы могут быть реализованы в программном обеспечении или как набор закодированных инструкций для исполнения процессором в ответ на инструкции. В качестве альтернативы операции и способы, раскрытые в данном документе, могут быть реализованы полностью или частично с использованием аппаратных компонентов, таких как специализированные интегральные схемы (ASIC), программируемые пользователем вентильные матрицы (FPGA), конечные автоматы, контроллеры или другие аппаратные компоненты или устройства или сочетание аппаратных средств, программного обеспечения и компонентов встроенного программного обеспечения.
В то время как система и способы, определенные в настоящем документе, были показаны и описаны со ссылками на варианты его осуществления, должно быть понятно специалистам в данной области техники, что различные изменения в форме и деталях могут быть сделаны без отступления от сущности и объема настоящего изобретения, охватываемого прилагаемой формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ДЛЯ УЛУЧШЕНИЯ БЕЗОПАСНОСТИ ПЕРЕДАЧИ ДАННЫХ | 2019 |
|
RU2746923C1 |
| СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2824327C1 |
| СПОСОБ И УСТРОЙСТВО ОБРАБОТКИ ОБЪЕКТА ДАННЫХ | 2013 |
|
RU2626334C2 |
| СПОСОБ КОДИРОВАНИЯ ДАННЫХ И СИСТЕМА ХРАНЕНИЯ ДАННЫХ | 2023 |
|
RU2819584C1 |
| ОБРАБОТКА КОМАНД ГЕНЕРАЦИИ ДАЙДЖЕСТОВ СООБЩЕНИЙ | 2004 |
|
RU2344467C2 |
| СПОСОБ И СИСТЕМА ИСПОЛЬЗОВАНИЯ ЛОКАЛЬНОГО ПОДДЕРЖИВАЕМОГО ХОСТ-УЗЛОМ КЭША И КРИПТОГРАФИЧЕСКИХ ХЭШ-ФУНКЦИЙ ДЛЯ ТОГО, ЧТОБЫ УМЕНЬШАТЬ СЕТЕВОЙ ТРАФИК | 2009 |
|
RU2475988C2 |
| ВЫПОЛНЕНИЕ ИЗМЕНЕНИЯ ПЕРВИЧНОГО УЗЛА В РАСПРЕДЕЛЕННОЙ СИСТЕМЕ | 2018 |
|
RU2716558C1 |
| СПОСОБЫ И СИСТЕМЫ ДЛЯ ОБОБЩЕННОЙ ПОДДЕРЖКИ МНОЖЕСТВА ТЕХНОЛОГИЙ РАДИОДОСТУПА | 2012 |
|
RU2594177C2 |
| ВЫПОЛНЕНИЕ ПРОЦЕССА ВОССТАНОВЛЕНИЯ ДЛЯ СЕТЕВОГО УЗЛА В РАСПРЕДЕЛЁННОЙ СИСТЕМЕ | 2018 |
|
RU2718411C1 |
| ЗАЩИТА ДАННЫХ В ПАМЯТИ ПОТРЕБЛЯЕМОГО ПРОДУКТА | 2013 |
|
RU2637429C2 |

Изобретение относится к обнаружению дублирования данных. Технический результат – сокращение записанного объема данных. Для этого предусмотрены этапы, на которых принимают первый запрос на сохранение первого блока данных в устройстве хранения данных, соединенном с хостом; вычисляют посредством использования аппаратного ускорителя в устройстве хранения данных первый дайджест сообщения для первого блока данных в ответ на прием первой команды на вычисление первого дайджеста сообщения в сочетании с выполнением первого запроса на сохранение, сохраняют первый блок данных на носителе информации устройства хранения данных; принимают второй запрос на сохранение второго блока данных в устройстве хранения данных; вычисляют посредством использования аппаратного ускорителя второй дайджест сообщения для второго блока данных в ответ на прием второй команды на вычисление второго дайджеста сообщения в сочетании с выполнением второго запроса на сохранение; сохраняют второй блок данных на носителе информации в устройстве хранения данных; и передают первый и второй дайджесты сообщения в хост для обеспечения сравнения хостом первого дайджеста сообщения и второго дайджеста сообщения для обнаружения дублирования блоков данных. 5 н. и 14 з.п. ф-лы, 7 ил.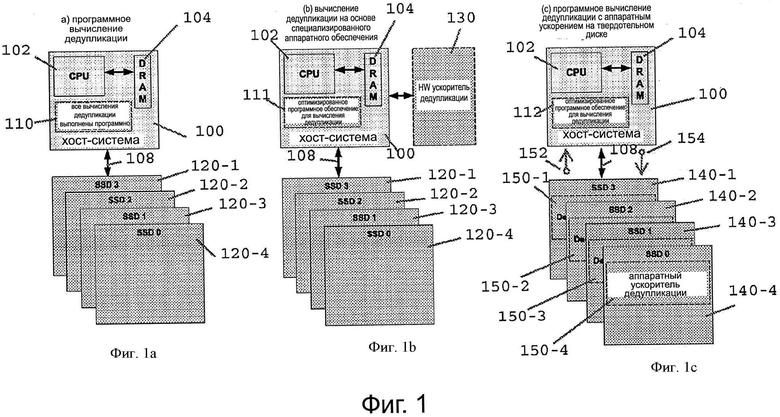
1. Способ обнаружения дублирования данных, содержащий этапы, на которых
принимают первый запрос на сохранение первого блока данных в устройстве хранения данных, соединенном с хостом;
вычисляют посредством использования аппаратного ускорителя в устройстве хранения данных первый дайджест сообщения для первого блока данных в ответ на прием первой команды на вычисление первого дайджеста сообщения в сочетании с выполнением первого запроса на сохранение,
сохраняют первый блок данных на носителе информации устройства хранения данных;
принимают второй запрос на сохранение второго блока данных в устройстве хранения данных;
вычисляют посредством использования аппаратного ускорителя второй дайджест сообщения для второго блока данных в ответ на прием второй команды на вычисление второго дайджеста сообщения в сочетании с выполнением второго запроса на сохранение;
сохраняют второй блок данных на носителе информации в устройстве хранения данных; и
передают первый и второй дайджесты сообщения в хост для обеспечения сравнения хостом первого дайджеста сообщения и второго дайджеста сообщения для обнаружения дублирования блоков данных.
2. Способ по п. 1, содержащий этап, на котором вычисляют первый и второй дайджесты сообщения без перенаправления соответствующих первого и второго блоков данных из тракта передачи данных к носителю информации.
3. Способ по п. 1 или 2, содержащий этап, на котором выполняют неинвазивный мониторинг первого и второго блоков данных, подлежащих сохранению в устройстве хранения данных, причем неинвазивный мониторинг выполняется при приеме соответствующих первого и второго блоков данных в устройстве хранения данных из хоста.
4. Способ по п. 1 или 2, в котором вычисление первого и второго дайджестов сообщения является поточным без сохранения состояния вычислением, применяемым к соответствующим первому и второму блокам данных, проходящим из хоста в устройство хранения данных.
5. Способ по п. 1 или 2, в котором на этапе вычисления первого и второго дайджестов данных отдельно применяют с помощью аппаратных ускорителей функцию дайджеста к первому и второму блокам данных, когда первый и второй блоки данных проходят по тракту передачи данных от хоста к устройству хранения данных.
6. Способ по п. 1 или 2, в котором аппаратные ускорители выполнены с возможностью выполнять сжатие и функции безопасности для данных, проходящих между хостом и устройством хранения данных, причем функции безопасности включаются в себя функции шифровать, дешифровать и безопасно вычислять хэш-функцию.
7. Способ по п. 1 или 2, дополнительно содержащий этапы, на которых
идентифицируют третьи блоки данных, ранее записанные на носитель информации;
извлекают третьи блоки в буфер дайджеста для вычисления дайджеста сообщения в автономном режиме;
вычисляют с помощью аппаратных ускорителей для вычисления третьего дайджеста сообщения для третьего блока данных, хранящегося в буфере; и
передают третий дайджест сообщения в хост для обеспечения сравнения хостом третьего дайджеста сообщения с одним и более другими дайджестами сообщения, ранее переданными из устройства хранения данных, для обнаружения дублирования блоков данных, хранящихся в устройстве хранения данных.
8. Устройство хранения данных, содержащее:
интерфейс, соединенный с хост-устройством;
носитель информации;
аппаратный ускоритель, выполненный с возможностью вычислять дайджесты сообщения для соответствующих блоков данных, принятых от хост-устройства, причем соответствующие блоки данных подлежат прохождению по тракту передачи данных от хоста к носителю информации, при этом аппаратный ускоритель выполнен с возможностью вычисления дайджестов сообщения в ответ на отдельные команды от хост-устройства для соответствующих запросов на сохранение соответствующих блоков данных на носителе информации, причем дайджесты сообщений вычисляются совместно с выполнением соответствующих запросов на сохранение, вычисленные дайджесты сообщения передаются в хост-устройство через интерфейс, а хост-устройство выполнено с возможностью использовать вычисленные дайджесты сообщения для обнаружения дублирования блоков данных, хранящихся на носителе информации.
9. Устройство хранения данных по п. 8, в котором аппаратный ускоритель выполнен с возможностью вычислять дайджесты сообщения без перенаправления соответствующих блоков данных из тракта передачи данных от хост-устройства на носитель информации.
10. Устройство хранения данных по п. 8 или 9, в котором аппаратный ускоритель выполнен с возможностью реализовать неинвазивный мониторинг данных, подлежащих сохранению, причем мониторинг осуществляется при приеме данных в устройстве хранения данных от хоста.
11. Устройство хранения данных по п. 8 или 9, в котором аппаратный ускоритель дополнительно выполнен с возможностью выполнять сжатие и функции безопасности для данных, проходящих между хост-устройством и устройством хранения данных, причем функции безопасности включают в себя функции шифровать, дешифровать и безопасно вычислять хэш-функцию.
12. Устройство хранения данных по п. 8 или 9, в котором вычисление вычисляемых дайджестов сообщения является поточным без сохранения состояния вычислением, применяемым к соответствующим блокам данных при прохождении соответствующих блоков данных от хост-устройства к устройству хранения данных.
13. Устройство хранения данных по п. 8 или 9, в котором аппаратный ускоритель дополнительно содержит автономные модули, причем автономные модули выполнены с возможностью
идентификации одного или более блоков данных, ранее записанных на носитель данных,
извлечения упомянутого одного или более блоков данных и сохранения упомянутого одного или более блоков данных в буфере для автономного вычисления дайджеста сообщения;
вычисления одного или более соответствующих дайджестов сообщения для указанного одного или более блоков данных, хранящихся в буфере; и
обеспечения передачи указанного одного или более соответствующих дайджестов сообщения в хост-устройство для обеспечения сравнения хост-устройством указанного одного или более соответствующих дайджестов сообщения с одним или более другими дайджестами сообщения, ранее переданными из устройства хранения данных, для обнаружения дублирования блоков данных, хранящихся на носителей информации.
14. Энергонезависимый машиночитаемый носитель информации, содержащий закодированные на нем команды, которые при выполнении процессором выполняют способ обнаружения дублирования данных, содержащий этапы, на которых:
передают первый запрос на сохранение первого блока данных на носителе информации в устройстве хранения данных, соединенном с хостом;
передают второй запрос на сохранение второго блока данных на носителе информации в устройстве хранения данных;
принимают первый и второй дайджесты сообщения, соответствующие первому и второму блокам данных, сохраненным на носителе информации в устройстве хранения данных, причем принимаемые первый и второй дайджесты сообщения вычислены с помощью аппаратного ускорителя в устройстве хранения данных в сочетании с выполнением устройством хранения данных соответствующих первого и второго запросов на сохранение; и
сравнивают второй дайджест сообщения с первым дайджестом сообщения для обнаружения дублирования блоков данных.
15. Энергонезависимый машиночитаемый носитель информации по п. 14, в котором устройство хранения данных выполнено с возможностью выполнять пассивный мониторинг данных, направленных в устройство хранения данных, не требуя дополнительной передачи данных для вычисления дайджеста сообщения.
16. Энергонезависимый машиночитаемый носитель информации по п. 14 или 15, в котором возвращают вычисленный результат в интерфейс хоста в ответ на вычисленные дайджесты сообщений для сравнения и обнаружения дублирования с другими блоками данных.
17. Энергонезависимый машиночитаемый носитель информации по п. 14 или 15, в котором на этапе вычисления первого и второго дайджестов сообщения отдельно применяют аппаратным ускорителем функцию дайджеста к первому и второму блокам данных при прохождении первым и вторым блоками данных по тракту передачи данных из хоста в устройство хранения данных.
18. Компьютерная система, содержащая:
хост-устройство; и
твердотельный диск, включающий в себя
интерфейс, соединенный с хост-устройством;
носитель информации; и
аппаратный ускоритель, выполненный с возможностью
вычислять дайджесты сообщения для соответствующих блоков данных, принимаемых от хост-устройства, причем соответствующие блоки данных подлежат прохождению по тракту передачи данных от хост-устройства к носителю информации, причем аппаратный ускоритель выполнен с возможностью вычисления дайджестов сообщения в ответ на отдельные команды от хост-устройства для соответствующих запросов на сохранение соответствующих блоков данных на носителе информации, причем дайджесты сообщения вычисляются в сочетании с выполнением соответствующих запросов на сохранение.
19. Компьютерная система, содержащая:
средство для передачи первого запроса на сохранение первого блока данных на носителе информации в устройстве хранения данных, соединенном с хостом;
средство для передачи второго запроса на сохранение второго блока данных на носителе информации в устройстве хранения данных;
средство для приема первого и второго дайджестов сообщения, соответствующих первому и второму блокам данных, сохраненным на носителе информации в устройстве хранения данных, причем принятые первый и второй дайджесты сообщения вычислены с помощью аппаратного ускорителя в устройстве хранения данных в сочетании с выполнением устройством хранения данных соответствующих первого и второго запросов на сохранение; и
средство для сравнения второго дайджеста сообщения с первым дайджестом сообщения для обнаружения дублирования блоков данных.
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Устройство для записывания игры на клавишных инструментах | 1927 |
|
SU10458A1 |
| US 7941459 B1, 10.05.2011 | |||
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

