ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Данное изобретение относится к способу и аппаратуре для генерации сигнала речи, в частности к генерации сигнала речи из множества сигналов микрофонов, таких как, например, микрофоны в разных устройствах.
УРОВЕНЬ ТЕХНИКИ
Традиционно, речевая связь между удаленными пользователями обеспечивалась посредством прямой двусторонней связи с использованием специальных устройств на каждом конце. Конкретно, традиционная связь между двумя пользователями обеспечивалась через проводную телефонную связь или беспроводную радиосвязь между двумя приемопередатчиками радиосвязи. Однако, в последние десятилетия, существенно увеличилось разнообразие возможностей для захвата и передачи речи, и был разработан целый ряд новых услуг и речевых применений, включая более гибкие применения для речевой связи.
Например, широкое распространение возможности подключения широкополосного Интернета привело к новым способам связи. Интернет-телефония существенно снизила стоимость связи. Это, в сочетании с тенденцией перемещения семей и друзей по всему миру, привело к большой продолжительности телефонных разговоров. Вызовы с использованием VoIP (Voice over Internet Protocol - передача голоса с помощью протокола сети Интернет), длящиеся больше часа, не являются редкостью, и пользовательский комфорт во время таких продолжительных вызовов является теперь более важным, чем когда-либо.
Дополнительно, диапазон устройств, которыми владеет или которые использует пользователь, существенно вырос. Конкретно, устройства, снабженные захватом звука (звукозаписью) и, обычно, беспроводной передачей данных, становятся все более распространенными, как, например, мобильные телефоны, планшетные компьютеры, портативные компьютеры, и т.д.
Качество большинства речевых применений сильно зависит от качества захваченной речи. Следовательно, большинство практических применений основано на расположении микрофона близко ко рту говорящего. Например, мобильные телефоны включают в себя микрофон, который при использовании пользователи располагают близко к своему рту. Однако такой метод может быть невыполнимым во многих сценариях и может обеспечить взаимодействие с пользователем, которое не является оптимальным. Например, для пользователя может быть невыполнимой необходимость удерживания планшетного компьютера близко к голове.
Для обеспечения более свободного и более гибкого взаимодействия с пользователем были предложены различные решения громкой связи. Эти решения включают в себя беспроводные микрофоны, которые содержатся в очень маленьких корпусах, которые могут быть надеты и, например, прикреплены к одежде пользователя. Однако это все же воспринимается как неудобство во многих сценариях. Фактически, обеспечение громкой связи со свободой перемещения и многозадачностью во время вызова, но без необходимости нахождения близко к устройству или надевания телефонной гарнитуры, является важным шагом в направлении улучшения взаимодействия с пользователем.
Другим методом является использование громкой связи на основе микрофона, расположенного дальше от пользователя. Например, были разработаны системы конференц-связи, которые, при расположении, например, на столе, обеспечивают захват речи говорящих, находящихся в помещении. Однако такие системы, как правило, не всегда обеспечивают оптимальное качество речи, и, в частности, речь более удаленных пользователей, как правило, является слабо слышимой и имеет шумы. Также, в таких сценариях, захваченная речь, как правило, имеет высокую степень реверберации, которая может существенно снизить разборчивость речи.
Было предложено использовать более одного микрофона, например, для таких систем конференц-связи. Однако проблема в таких случаях заключается в том, как объединить множество сигналов микрофонов. Общепринятым методом является простое суммирование этих сигналов вместе. Однако это, как правило, не обеспечивает оптимальное качество речи. Были предложены различные более сложные методы, такие как выполнение взвешенного суммирования на основе относительных уровней сигналов микрофонов. Однако эти методы не обеспечивают, как правило, оптимальную производительность во многих сценариях, например, они все же включают в себя высокую степень реверберации, восприимчивость к абсолютным уровням, сложность, необходимость централизованного доступа ко всем сигналам микрофонов, относительную непрактичность, необходимость специальных устройств, и т.д.
Следовательно, был бы предпочтительным улучшенный метод для захвата сигналов речи, и, в частности, был бы предпочтительным метод, обеспечивающий возможность увеличения гибкости, улучшения качества речи, уменьшения реверберации, уменьшения сложности, уменьшения требований по связи, увеличения приспособленности для разных устройств (включая многофункциональные устройства), уменьшения потребности в ресурсах и/или улучшения производительности.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Таким образом, задачей данного изобретения является, предпочтительно, ослабить, смягчить или устранить один или несколько вышеупомянутых недостатков, отдельно или в любой комбинации.
Согласно аспекту данного изобретения, обеспечена аппаратура по п. 1 формулы изобретения.
Данное изобретение может обеспечить возможность генерации улучшенного сигнала речи во многих вариантах осуществления. В частности, оно может во многих вариантах осуществления обеспечить возможность генерации сигнала речи с меньшей реверберацией и/или, часто, меньшим шумом. Этот метод может обеспечить улучшенную производительность речевых применений, и может, в частности, во многих сценариях и вариантах осуществления, обеспечить улучшенную речевую связь.
Сравнение по меньшей мере одной характеристики, получаемой из сигналов микрофонов, со справочной характеристикой для нереверберирующей речи, обеспечивает конкретный эффективный и точный способ идентификации относительной важности отдельных сигналов микрофонов для сигнала речи и может, в частности, обеспечить лучшую оценку, чем методы на основе, например, меры уровня сигнала или меры отношения сигнал-шум. Фактически, соотношение захваченного звукового сигнала и сигналов нереверберирующей речи может обеспечить ясное указание на то, какая доля речи достигает микрофона по прямому пути, и какая доля достигает микрофона по реверберирующим путям.
По меньшей мере одна справочная характеристика может быть одной или несколькими характеристиками/ значениями, которые связаны с нереверберирующей речью. В некоторых вариантах осуществления, по меньшей мере одна справочная характеристика может быть набором характеристик, соответствующих разным сэмплам (выборкам, фрагментам) нереверберирующей речи. Может быть определено, что указание сходства отражает различие между значением по меньшей мере одной характеристики, получаемой из сигнала микрофона, и значением по меньшей мере одной справочной характеристики для нереверберирующей речи, и, конкретно, по меньшей мере одной справочной характеристики одного сэмпла нереверберирующей речи. В некоторых вариантах осуществления, по меньшей мере одна характеристика, получаемая из сигнала микрофона, может быть самим сигналом микрофона. В некоторых вариантах осуществления, по меньшей мере одна справочная характеристика для нереверберирующей речи может быть сигналом нереверберирующей речи. Альтернативно, эта характеристика может быть подходящим признаком, таким как огибающие спектра, нормированные по коэффициенту усиления.
Микрофоны, обеспечивающие сигналы микрофонов, могут быть, во многих вариантах осуществления, микрофонами, распределенными в некоторой области, и могут быть удаленными друг от друга. Метод может, в частности, обеспечить улучшенное использование звукового сигнала, захваченного в разных положениях, без необходимости знания или предположения этих положений пользователем или аппаратурой/ системой. Например, микрофоны могут быть случайно распределены произвольным образом в помещении, и система может автоматически приспособиться к обеспечению улучшенного сигнала речи для конкретного расположения.
Сэмплы нереверберирующей речи могут быть, конкретно, сэмплами, по существу, «сухой», или безэховой речи.
Указание сходства речи может быть любым указанием степени различия или сходства между отдельным сигналом микрофона (или его частью) и нереверберирующей речью, как, например, сэмплом нереверберирующей речи. Указание сходства речи может быть указанием сходства по восприятию.
Согласно необязательному признаку данного изобретения, аппаратура содержит множество отдельных устройств, причем каждое устройство содержит микрофонный приемник для приема по меньшей мере одного сигнала микрофона из множества сигналов микрофонов.
Это может обеспечить конкретный эффективный метод для генерации сигнала речи. Во многих вариантах осуществления, каждое устройство может содержать микрофон, обеспечивающий сигнал микрофона. Данное изобретение может обеспечить улучшенные и/или новые взаимодействия с пользователем с улучшенной производительностью.
Например, некоторое количество возможных различных устройств может быть расположено в помещении. При выполнении речевого применения, такого как речевая связь, каждое из отдельных устройств может обеспечить сигнал микрофона, и эти устройства могут быть оценены для нахождения наиболее подходящих устройств/ микрофонов для использования для генерации сигнала речи.
Согласно необязательному признаку данного изобретения, по меньшей мере первое устройство из множества отдельных устройств содержит локальный блок сравнения для определения первого указания сходства речи по меньшей мере для одного сигнала микрофона первого устройства.
Это может обеспечить улучшенное функционирование во многих сценариях и может, в частности, обеспечить распределенную обработку, которая может уменьшить, например, потребности в ресурсах связи и/или в распределенных вычислительных ресурсах.
Конкретно, во многих вариантах осуществления, отдельные устройства могут определить указание сходства локально и могут передать сигнал микрофона, только если критерий сходства соответствует критерию.
Согласно необязательному признаку данного изобретения, генератор реализован в генерирующем устройстве, отдельном по меньшей мере от первого устройства; и причем первое устройство содержит передатчик для передачи первого указания сходства речи к генерирующему устройству.
Это может обеспечить предпочтительные реализацию и функционирование во многих вариантах осуществления. В частности, это может обеспечить во многих вариантах осуществления одно устройство для оценки качества речи на всех других устройствах без необходимости передачи какого-либо звукового сигнала или сигнала речи. Передатчик может быть выполнен с возможностью передачи первого указания сходства речи через беспроводной канал связи, такой как канал связи стандарта Bluetooth™ или стандарта Wi-Fi.
Согласно необязательному признаку данного изобретения, генерирующее устройство выполнено с возможностью приема указаний сходства речи от каждого из множества отдельных устройств, и причем генератор выполнен с возможностью генерации сигнала речи с использованием поднабора сигналов микрофонов от множества отдельных устройств, причем этот поднабор определяют в ответ на указания сходства речи, принимаемые от множества отдельных устройств.
Это может обеспечить высокоэффективную систему во многих сценариях, где сигнал речи может быть сгенерирован из сигналов микрофонов, захватываемых посредством разных устройств, с использованием только наилучшего поднабора устройств для генерации сигнала речи. Таким образом, ресурсы связи существенно уменьшаются, обычно без значительного влияния на результирующее качество сигнала речи.
Во многих вариантах осуществления, этот поднабор может включать в себя только единственный микрофон. В некоторых вариантах осуществления, генератор может быть выполнен с возможностью генерации сигнала речи от единственного сигнала микрофона, выбираемого из множества сигналов микрофонов на основе указаний сходства.
Согласно необязательному признаку данного изобретения, по меньшей мере одно устройство из множества отдельных устройств выполнено с возможностью передачи по меньшей мере одного сигнала микрофона по меньшей мере одного устройства к генерирующему устройству, только если по меньшей мере один сигнал микрофона по меньшей мере одного устройства содержится в поднаборе сигналов микрофонов.
Это может уменьшить использование ресурсов связи и может уменьшить использование ресурсов связи для устройств, для которых сигнал микрофона не включен в этот поднабор. Передатчик может быть выполнен с возможностью передачи по меньшей мере одного сигнала микрофона через беспроводной канал связи, такой как канал связи стандарта Bluetooth™ или стандарта Wi-Fi.
Согласно необязательному признаку данного изобретения, генерирующее устройство содержит устройство выбора, выполненное с возможностью определения поднабора сигналов микрофонов, и передатчик для передачи указания на этот поднабор по меньшей мере для одного их множества отдельных устройств.
Это может обеспечить преимущества функционирования во многих сценариях.
В некоторых вариантах осуществления, генератор может определять этот поднабор и может быть выполнен с возможностью передачи указания на этот поднабор по меньшей мере для одного устройства из множества устройств. Например, для устройства или устройств сигналов микрофонов, содержащихся в поднаборе, генератор может передать указание на то, что устройство должно передать сигнал микрофона к генератору.
Передатчик может быть выполнен с возможностью передачи этого указания через беспроводной канал связи, такой как канал связи стандарта Bluetooth™ или стандарта Wi-Fi.
Согласно необязательному признаку данного изобретения, блок сравнения выполнен с возможностью определения указания сходства для первого сигнала микрофона в ответ на сравнение по меньшей мере одной характеристики, получаемой из сигнала микрофона, со справочными характеристиками для сэмплов речи из набора сэмплов нереверберирующей речи.
Сравнение сигналов микрофонов с большим набором сэмплов нереверберирующей речи (например, в подходящей области признака) обеспечивает конкретный эффективный и точный способ идентификации относительной важности отдельных сигналов микрофонов для сигнала речи и может, в частности, обеспечить лучшую оценку, чем методы на основе, например, меры уровня сигнала или меры отношения сигнал-шум. Фактически, соотношение захваченного звукового сигнала и сигнала нереверберирующей речи может обеспечить ясное указание на то, какая доля речи достигает микрофона по прямому пути и какая доля достигает микрофона по реверберирующим/ отраженным путям. Фактически, можно предположить, что сравнение с сэмплами нереверберирующей речи включает в себя рассмотрение формы импульсной переходной характеристики путей звука, а не только рассмотрение энергии или уровня.
Метод может быть независимым от говорящего, и, в некоторых вариантах осуществления, набор сэмплов нереверберирующей речи может включать в себя сэмплы, соответствующие разным характеристикам говорящего (таким как высокий или низкий голос). Во многих вариантах осуществления, обработка может быть сегментирована, и набор сэмплов нереверберирующей речи может, например, содержать сэмплы, соответствующие фонемам человеческой речи.
Блок сравнения может определить для каждого сигнала микрофона отдельное указание сходства для каждого сэмпла речи из набора сэмплов нереверберирующей речи. Указание сходства для сигнала микрофона может быть определено из отдельных указаний сходства, например, посредством выбора отдельного указания сходства, который указывает на наивысшую степень сходства. Во многих сценариях, может быть идентифицирован наилучшим образом согласующийся сэмпл речи, и указание сходства для сигнала микрофона может быть определено в отношении этого сэмпла речи. Указание сходства может обеспечить указание сходства сигнала микрофона (или его части) с сэмплом нереверберирующей речи из набора сэмплов нереверберирующей речи, для которого найдено наибольшее сходство.
Указание сходства для данного сэмпла сигнала речи может отражать правдоподобие того, что сигнал микрофона, получаемый из фрагмента речи, соответствует сэмплу речи.
Согласно необязательному признаку данного изобретения, сэмплы речи из набора сэмплов нереверберирующей речи представлены посредством параметров для модели нереверберирующей речи.
Это может обеспечить эффективное, надежное и/или точное функционирование. Метод может во многих вариантах осуществления уменьшить потребности в вычислительных ресурсах и/или ресурсах памяти.
Блок сравнения может в некоторых вариантах осуществления оценивать модель для различных наборов параметров и сравнивать результирующие сигналы с сигналом (сигналами) микрофона. Например, могут быть сравнены частотные представления сигналов микрофонов и сэмплов речи.
В некоторых вариантах осуществления, параметры модели для модели речи могут быть сгенерированы из сигнала микрофона, т.е. могут быть определены параметры модели, которые должны привести к согласованию сэмпла речи и сигнала микрофона. Эти параметры модели могут быть сравнены с параметрами набора сэмплов нереверберирующей речи.
Модель нереверберирующей речи может быть, конкретно, моделью линейного предсказания, такой как модель CELP (Code-Excited Linear Prediction - линейное предсказание с кодовым возбуждением).
Согласно необязательному признаку данного изобретения, блок сравнения выполнен с возможностью определения первой справочной характеристики для первого сэмпла речи из набора сэмплов нереверберирующей речи из сигнала сэмпла речи, генерируемого посредством оценки модели нереверберирующей речи, с использованием параметров для первого сэмпла речи, и определения указания сходства для первого сигнала микрофона из множества сигналов микрофонов, в ответ на сравнение характеристики, получаемой из первого сигнала микрофона, и первой справочной характеристики.
Это может обеспечить предпочтительное функционирование во многих сценариях. Указание сходства для первого сигнала микрофона может быть определено посредством сравнения характеристики, определяемой для первого сигнала микрофона, со справочными характеристиками, определяемыми для каждого из сэмплов нереверберирующей речи, причем справочные характеристики определяют из представления сигнала, генерируемого посредством оценки модели. Таким образом, блок сравнения может сравнить характеристику сигнала микрофона с характеристикой сэмплов сигналов, получаемой в результате оценки модели нереверберирующей речи, с использованием сохраненных параметров для сэмплов нереверберирующей речи.
Согласно необязательному признаку данного изобретения, блок сравнения выполнен с возможностью разложения первого сигнала микрофона из множества сигналов микрофонов в набор базисных сигнальных векторов; и определения указания сходства в ответ на характеристику из этого набора базисных сигнальных векторов.
Это может обеспечить предпочтительное функционирование во многих сценариях. Метод может обеспечить уменьшение сложности и/или использования ресурсов во многих сценариях. Справочная характеристика может относиться к набору базисных векторов в подходящей области признака, из которых может быть сгенерирован вектор нереверберирующего признака в виде взвешенной суммы базисных векторов. Этот набор может быть рассчитан таким образом, чтобы взвешенной суммы с использованием только немногих базисных векторов было достаточно для точного описания вектора нереверберирующего признака, т.е. набор базисных векторов обеспечивает разреженное представление для нереверберирующей речи. Справочная характеристика может быть количеством базисных векторов, которые появляются во взвешенной сумме. Использование набора базисных векторов, который рассчитан для нереверберирующей речи, для описания вектора признака реверберирующей речи, приведет к менее разреженному разложению. Эта характеристика может быть количеством базисных векторов, которые имеют ненулевой вес (или вес выше заданного порога), при использовании для описания вектора признака, извлекаемого из сигнала микрофона. Указание сходства может указывать на увеличение сходства с нереверберирующей речью при уменьшении количества базисных сигнальных векторов.
Согласно необязательному признаку данного изобретения, блок сравнения выполнен с возможностью определения указаний сходства речи для каждого сегмента из множества сегментов сигнала речи, а генератор выполнен с возможностью определения параметров объединения для объединения для каждого сегмента.
Аппаратура может использовать сегментированную обработку. Объединение может быть неизменным для каждого сегмента, но может быть изменено от одного сегмента к следующему. Например, сигнал речи может быть сгенерирован посредством выбора одного сигнала микрофона в каждом сегменте. Параметры объединения могут быть, например, весами объединений для сигнала микрофона или могут быть, например, выбором поднабора сигналов микрофонов для включения в объединение. Метод может обеспечить улучшенную производительность и/или облегченное функционирование.
Согласно необязательному признаку данного изобретения, генератор выполнен с возможностью определения параметров объединения для одного сегмента, в ответ на указания сходства по меньшей мере одного предыдущего сегмента.
Это может обеспечить улучшенную производительность во многих сценариях. Например, это может обеспечить лучшую приспособленность к медленным изменениям и может уменьшить разрывы в генерируемом сигнале речи.
В некоторых вариантах осуществления, параметры объединения могут быть определены только на основе сегментов, содержащих речь, а не на основе сегментов во время периодов молчания или пауз.
В некоторых вариантах осуществления, генератор выполнен с возможностью определения параметров объединения для первого сегмента в ответ на модель перемещения пользователя.
Согласно необязательному признаку данного изобретения, генератор выполнен с возможностью выбора поднабора сигналов микрофонов для объединения, в ответ на указания сходства.
Это может обеспечить улучшенное и/или облегченное функционирование во многих вариантах осуществления. Объединение может быть, конкретно, объединением с выбором. Генератор может, конкретно, выбрать только сигналы микрофонов, для которых указание сходства соответствует абсолютному или относительному критерию.
В некоторых вариантах осуществления, поднабор сигналов микрофонов содержит только один сигнал микрофона.
Согласно необязательному признаку данного изобретения, генератор выполнен с возможностью генерации сигнала речи в виде взвешенного объединения сигналов микрофонов, причем вес для первого из сигналов микрофонов зависит от указания сходства для сигнала микрофона.
Это может обеспечить улучшенное и/или облегченное функционирование во многих вариантах осуществления.
Согласно аспекту данного изобретения, обеспечен способ генерации сигнала речи, причем этот способ предусматривает: прием сигналов микрофонов от множества микрофонов; для каждого сигнала микрофона, определение указания сходства речи, указывающего на сходство между сигналом микрофона и нереверберирующей речью, причем указание сходства определяют в ответ на сравнение по меньшей мере одной характеристики, получаемой из сигнала микрофона, по меньшей мере с одной справочной характеристикой для нереверберирующей речи; и генерацию сигнала речи посредством объединения сигналов микрофонов в ответ на указания сходства.
Эти и другие аспекты, признаки и преимущества данного изобретения будут ясны из варианта (вариантов) осуществления, описанных ниже, и будут прояснены со ссылкой на него (них).
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты осуществления данного изобретения будут описаны, только в качестве примера, со ссылкой на чертежи, в которых
Фиг. 1 является иллюстрацией аппаратуры захвата речи согласно некоторым вариантам осуществления данного изобретения;
Фиг. 2 является иллюстрацией системы захвата речи согласно некоторым вариантам осуществления данного изобретения;
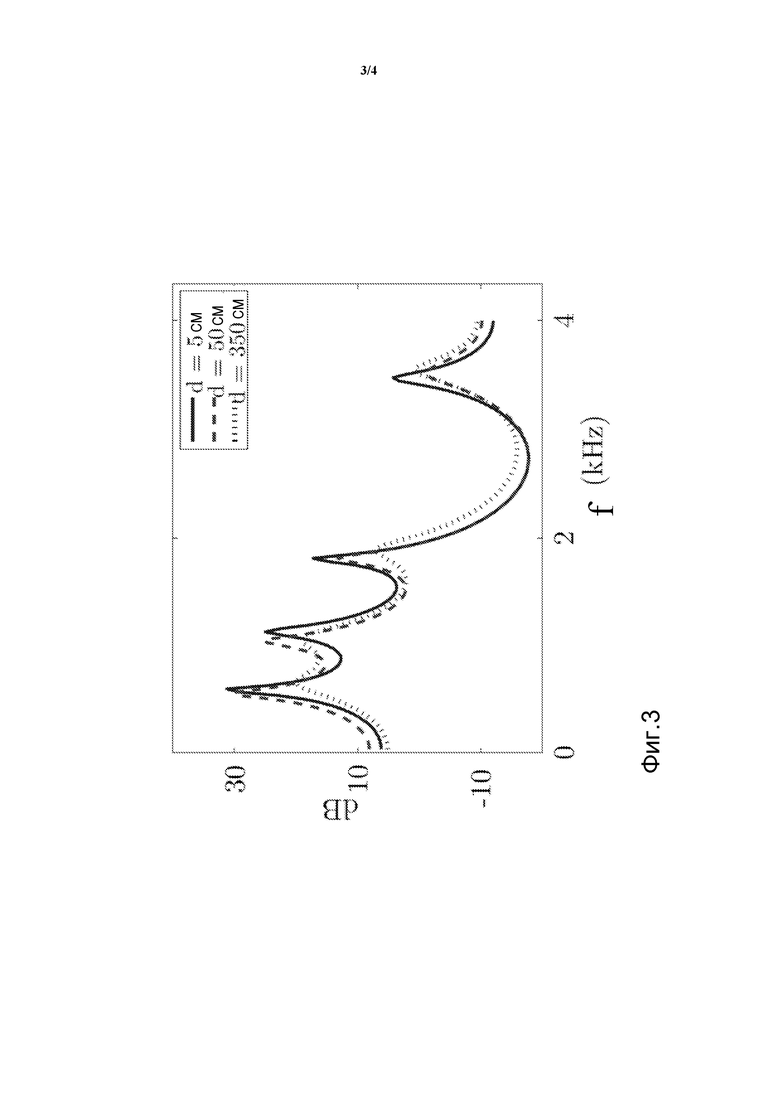
Фиг. 3 иллюстрирует пример огибающих спектра, соответствующих сегменту речи, записанному на трех разных расстояниях в реверберирующем помещении; и
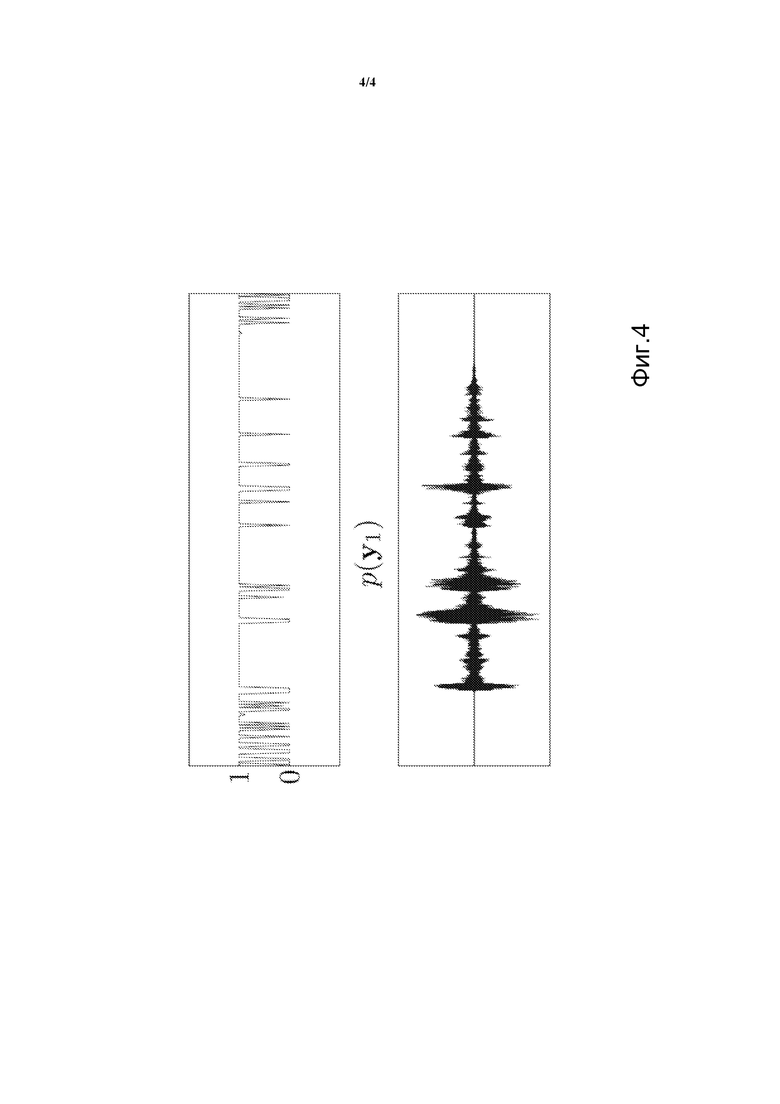
Фиг. 4 иллюстрирует пример правдоподобия микрофона, являющегося ближайшим микрофоном к говорящему, определяемого согласно вариантам осуществления данного изобретения.
ПОДРОБНОЕ ОПИСАНИЕ НЕКОТОРЫХ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Последующее описание сфокусировано на вариантах осуществления данного изобретения, применимых к захвату речи для генерации сигнала речи для дистанционной связи. Однако следует понимать, что данное изобретение не ограничено этим применением и может быть применено ко многим другим услугам и применениям.
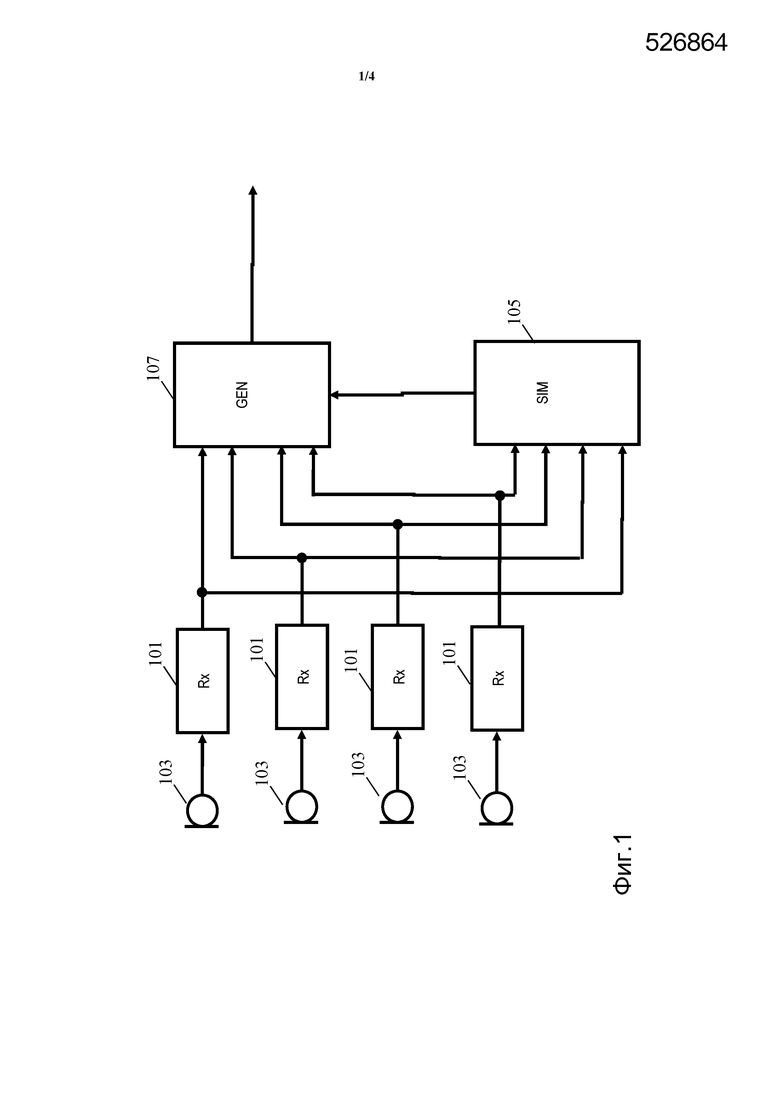
Фиг. 1 иллюстрирует пример элементов аппаратуры захвата речи согласно некоторым вариантам осуществления данного изобретения.
В этом примере, аппаратура захвата речи содержит множество микрофонных приемников 101, которые соединены с множеством микрофонов 103 (которые могут быть частью аппаратуры или могут быть внешними по отношению к аппаратуре).
Набор микрофонных приемников 101, таким образом, принимает набор сигналов микрофонов от микрофонов 103. В этом примере, микрофоны 103 распределены в помещении в различных и неизвестных положениях. Таким образом, разные микрофоны могут захватить звук из разных областей, могут захватить один и тот же звук с разными характеристиками или могут, фактически, захватить один и тот же звук с похожими характеристиками, если они находятся близко друг к другу. Отношения между микрофонами 103 и между микрофонами 103 и разными источниками звука являются, обычно, неизвестными системе.
Аппаратура захвата речи выполнена с возможностью генерации сигнала речи из сигналов микрофонов. Конкретно, эта система выполнена с возможностью обработки сигналов микрофонов для извлечения сигнала речи из звукового сигнала, захваченного микрофонами 103. Система выполнена с возможностью объединения сигналов микрофонов в зависимости от того, насколько точно каждый из них соответствует сигналу нереверберирующей речи, обеспечивая, таким образом, объединенный сигнал, который, наиболее вероятно, соответствует такому сигналу. Объединение может быть, конкретно, объединением с выбором, в котором аппаратура выбирает сигнал микрофона, наиболее сходный с сигналом нереверберирующей речи. Генерация сигнала речи может быть независимой от конкретного положения отдельных микрофонов и не полагается на какое-либо знание положения микрофонов 103 или положения кого-либо из говорящих. Напротив, микрофоны 103 могут быть, например, случайно распределены в помещении, и система может автоматически приспособиться, например, к преимущественному использованию сигнала от микрофона, ближайшего к любому заданному говорящему. Это приспособление может происходить автоматически, и конкретный метод для идентификации такого ближайшего микрофона 103 (как будет описано ниже) приведет к обеспечению особенно подходящего сигнала речи в большинстве сценариев.
В аппаратуре захвата речи фиг. 1 микрофонные приемники 103 соединены с блоком сравнения или процессором 105 сходства, на который подают сигналы микрофонов.
Для каждого сигнала микрофона, процессор 105 сходства определяет указание сходства речи (далее называемое просто указанием сходства), которое указывает на сходство между сигналом микрофона и нереверберирующей речью. Процессор 105 сходства, конкретно, определяет указание сходства в ответ на сравнение по меньшей мере одной характеристики, получаемой из сигнала микрофона, по меньшей мере с одной справочной характеристикой для нереверберирующей речи. Справочная характеристика может быть, в некоторых вариантах осуществления, единственной скалярным значением, а в других вариантах осуществления, может быть сложным набором значений или функций. Справочная характеристика может быть, в некоторых вариантах осуществления, получена из конкретных сигналов нереверберирующей речи, и может быть, в других вариантах осуществления, типичной характеристикой, связанной с нереверберирующей речью. Справочная характеристика и/или характеристика, получаемая из сигнала микрофона, может быть, например, спектром, характеристикой спектральной плотности мощности, количеством ненулевых базисных векторов, и т.д. В некоторых вариантах осуществления, характеристики могут быть сигналами, и, конкретно, характеристика, получаемая из сигнала микрофона, может быть самим сигналом микрофона. Подобным образом, справочная характеристика может быть сигналом нереверберирующей речи.
Конкретно, процессор 105 сходства может быть выполнен с возможностью генерации указания сходства для каждого из сигналов микрофонов, причем указание сходства указывает на сходство сигнала микрофона с сэмплом речи из набора сэмплов нереверберирующей речи. Таким образом, процессор 105 сходства содержит запоминающее устройство, хранящее (обычно большое) количество сэмплов речи, причем каждый сэмпл речи соответствует речи в нереверберирующем, и, конкретно, по существу, безэховом, помещении. В качестве примера, процессор 105 сходства может сравнивать каждый сигнал микрофона с каждым из сэмплов речи и для каждого сэмпла речи определять меру различия между сохраненным сэмплом речи и сигналом микрофона. Меры различия для сэмплов речи могут быть затем сравнены, и мера, указывающая на наименьшее различие, может быть выбрана. Эта мера может быть затем использована для генерации (или в качестве) указания сходства для конкретного сигнала микрофона. Процесс повторяют для всех сигналов микрофонов, в результате чего получают набор указаний сходства. Таким образом, набор указаний сходства может указать, насколько каждый из сигналов микрофонов является сходным с нереверберирующей речью.
Во многих вариантах осуществления и сценариях, такое сравнение в области сэмплов сигналов может не быть достаточно надежным вследствие неопределенности в отношении изменений уровней микрофонов, шума и т.д. Следовательно, во многих вариантах осуществления, блок сравнения может быть выполнен с возможностью определения указания сходства в ответ на сравнение, выполняемое в области признака. Таким образом, во многих вариантах осуществления, блок сравнения может быть выполнен с возможностью определения некоторых признаков/ параметров из сигнала микрофона и сравнения их с сохраненными признаками/ параметрами для нереверберирующей речи. Например, как будет описано более подробно далее, сравнение может быть основано на параметрах для модели речи, таких как коэффициенты для модели линейного предсказания. Соответствующие параметры могут быть затем определены для сигнала микрофона и сравнены с сохраненными параметрами, соответствующими различным фрагментам речи в безэховой среде.
Нереверберирующую речь обычно получают, когда акустическая передаточная функция от говорящего преобладает на прямом пути, и причем, обеспечивают существенное ослабление отраженных и реверберирующих путей. Это также обычно соответствует ситуациям, в которых говорящий находится относительно близко к микрофону и может наиболее точно соответствовать традиционному расположению, в котором микрофон расположен близко ко рту говорящего. Также часто можно считать, что нереверберирующая речь является наиболее разборчивой речью и, фактически, речью, которая наиболее точно соответствует фактическому источнику речи.
Аппаратура фиг. 1 использует метод, который обеспечивает возможность оценки характеристики реверберации речи для отдельных микрофонов таким образом, чтобы она была принята во внимание. Фактически, автор изобретения реализовал не только то, что рассмотрение характеристик реверберации речи для отдельных сигналов микрофонов при генерации сигнала речи может существенно улучшить качество, но и то, насколько обоснованно это может быть достигнуто, без необходимости специальных тестовых сигналов и измерений. Фактически, автор изобретения реализовал то, что при сравнении характеристики отдельных сигналов микрофонов со справочной характеристикой, связанной с нереверберирующей речью, и, конкретно, с набором сэмплов нереверберирующей речи, можно определить подходящие параметры для объединения сигналов микрофонов для генерации улучшенного сигнала речи. В частности, метод обеспечивает возможность генерации сигнала речи без необходимости каких-либо специальных тестовых сигналов, тестовых измерений, или, фактически, априорного знания речи. Фактически, может быть разработана система для обработки любой речи, и она не потребует, например, проговаривания говорящим конкретных тестовых слов или предложений.
В системе фиг. 1, процессор 105 сходства соединен с генератором 107, на который подают указания сходства. Генератор 107 дополнительно соединен с микрофонными приемниками 101, от которых он принимает сигналы микрофонов. Генератор 107 выполнен с возможностью генерации выходного сигнала речи посредством объединения сигналов микрофонов, в ответ на указания сходства.
В качестве несложного примера, генератор 107 может реализовать объединитель с выбором, в котором, например, единственный сигнал микрофона выбирают из множества сигналов микрофонов. Конкретно, генератор 107 может выбрать сигнал микрофона, который наиболее точно согласуется с сэмплом нереверберирующей речи. Затем сигнал речи генерируют из этого сигнала микрофона, который является обычно, наиболее вероятно, самым чистым и отчетливым захватом речи. Конкретно, вероятно, он является захватом речи, который наиболее точно соответствует речи, произнесенной говорящим. Обычно, он будет также соответствовать микрофону, который является ближайшим к говорящему.
В некоторых вариантах осуществления, сигнал речи может быть передан к удаленному пользователю, например, через телефонную сеть, беспроводную связь, Интернет или другую сеть связи или канал связи. Передача сигнала речи может, обычно, включать в себя кодирование речи, а также, возможно, другую обработку.
Аппаратура фиг. 1 может, таким образом, автоматически приспосабливаться к положениям говорящего и микрофонов, а также к акустическим характеристикам среды, для генерации сигнала речи, который наиболее точно соответствует исходному сигналу речи. Конкретно, генерируемый сигнал речи будет, как правило, иметь уменьшенную реверберацию и шум и будет, таким образом, звучать менее искаженным, более чистым и более разборчивым.
Следует понимать, что обработка может включать в себя различную другую обработку, включающую в себя, обычно, усиление, фильтрацию, преобразование между временной областью и частотной областью, и т.д., выполняемые обычно в обработке звуковых сигналов и сигналов речи. Например, сигналы микрофонов могут быть, часто, усилены и отфильтрованы перед объединением и/или использованы для генерации указаний сходства. Подобным образом, генератор 107 может включать в себя фильтрацию, усиление, и т.д., в качестве части объединения и/или генерации сигнала речи.
Во многих вариантах осуществления, аппаратура захвата речи может использовать сегментированную обработку. Таким образом, обработка может быть выполнена в коротких временных интервалах, как, например, в сегментах продолжительностью менее 100 мс, и, часто, в сегментах продолжительностью около 20 мс.
Таким образом, в некоторых вариантах осуществления, указание сходства может быть сгенерировано для каждого сигнала микрофона в данном сегменте. Например, сегмент сигнала микрофона продолжительностью, например, 50 мс может быть сгенерирован для каждого из сигналов микрофонов. Сегмент может быть затем сравнен с набором сэмплов нереверберирующей речи, который сам по себе может состоять из сэмплов сегментов речи. Указания сходства могут быть определены для этого сегмента продолжительностью 50 мс, и генератор 107 может приступить к генерации сегмента сигнала речи для интервала 50 мс на основе сегментов сигналов микрофонов и указаний сходства для этого сегмента/ интервала. Таким образом, объединение может быть обновлено для каждого сегмента, например, посредством выбора в каждом сегменте сигнала микрофона, который имеет наибольшее сходство с сэмплом сегмента речи из сэмплов нереверберирующей речи. Это может обеспечить особенно эффективную обработку и функционирование и может обеспечить возможность непрерывного и динамического приспособления к конкретной среде. Фактически, приспособление к динамическому перемещению источника звука речи и/или положений микрофона может быть достигнуто с низкой сложностью. Например, если речь переключается между двумя источниками (говорящими), то система может приспособиться к соответствующему переключению между двумя микрофонами.
В некоторых вариантах осуществления, сэмплы сегментов нереверберирующей речи могут иметь продолжительность, которая согласуется с продолжительностью сегментов сигналов микрофонов. Однако, в некоторых вариантах осуществления, они могут быть продолжительнее. Например, каждый сэмпл сегмента нереверберирующей речи может соответствовать фонеме или конкретному звуку речи, который имеет большую продолжительность.
В таких вариантах осуществления, определение меры сходства для каждого сэмпла сегмента нереверберирующей речи может включать в себя выравнивание сегмента сигнала микрофона относительно сэмплов сегментов речи. Например, может быть определено значение корреляции для разных временных сдвигов, и наибольшее значение может быть выбрано в качестве указания сходства. Это может обеспечить уменьшение количества сэмплов сегментов речи, подлежащих сохранению.
В некоторых примерах, параметры объединения, такие как выбор поднабора сигналов микрофонов для использования, или веса для линейного суммирования, могут быть определены для временного интервала сигнала речи. Таким образом, сигнал речи может быть определен в сегментах из объединения, которое основано на параметрах, которые являются постоянными для сегмента, но которые могут изменяться между сегментами.
В некоторых вариантах осуществления, определение параметров объединения является независимым для каждого временного сегмента, т.е. параметры объединения для временного сегмента могут быть вычислены на основе только указаний сходства, которые определяют для каждого временного сегмента.
Однако, в других вариантах осуществления, параметры объединения могут быть, альтернативно или дополнительно, определены в ответ на указания сходства по меньшей мере одного предыдущего сегмента. Например, указания сходства могут быть отфильтрованы с использованием фильтра нижних частот, который продолжается на несколько сегментов. Это может обеспечить замедленное приспособление, которое может, например, уменьшить флуктуации и изменения в генерируемом сигнале речи. В качестве другого примера, может быть применен эффект гистерезиса, который предотвращает, например, быстрое попеременное переключение между двумя микрофонами, расположенными приближенно на одинаковом расстоянии от говорящего.
В некоторых вариантах осуществления, генератор 107 может быть выполнен с возможностью определения параметров объединения для первого сегмента в ответ на модель перемещения пользователя. Такой метод может быть использован для отслеживания относительного положения пользователя относительно микрофонных устройств 201, 203, 205. Эта пользовательская модель не нуждается в явном отслеживании положений пользователя или микрофонных устройств 201, 203, 205, но может напрямую отслеживать изменения указаний сходства. Например, представление в пространстве состояний может быть использовано для описания модели человеческого перемещения, и фильтр Калмана может быть применен к указаниям сходства отдельных сегментов одного сигнала микрофона для отслеживания изменений указаний сходства вследствие перемещения. Результирующие выходные данные фильтра Калмана могут быть затем использованы в качестве указания сходства для текущего сегмента.
Во многих вариантах осуществления, функциональность фиг. 1 может быть реализована распределенным образом, в частности система может быть распространена по множеству устройств. Конкретно, каждый из микрофонов 103 может быть частью другого устройства или может быть подключен к другому устройству, и, таким образом, микрофонные приемники 101 могут содержаться в разных устройствах.
В некоторых вариантах осуществления, процессор 105 сходства и генератор 107 реализуют в единственном устройстве. Например, некоторое количество разных удаленных устройств может передавать сигнал микрофона к генерирующему устройству, которое выполнено с возможностью генерации сигнала речи от принимаемых сигналов микрофонов. Это генерирующее устройство может реализовать функциональность процессора 105 сходства и генератора 107, как описано выше.
Однако, во многих вариантах осуществления, функциональность процессора 105 сходства распределяют по множеству отдельных устройств. Конкретно, каждое их устройств может содержать процессор 105 (суб)сходства, который выполнен с возможностью определения указания сходства для сигнала микрофона этого устройства. Указания сходства могут быть затем переданы к генерирующему устройству, которое может определить параметры для объединения на основе принимаемых указаний сходства. Например, оно может просто выбрать сигнал микрофона/ устройство, который имеет указание наибольшего сходства. В некоторых вариантах осуществления, устройства могут не передавать сигналы микрофонов к генерирующему устройству, если генерирующее устройство не запрашивает этого. Таким образом, генерирующее устройство может передать запрос на сигнал микрофона к выбранному устройству, которое в ответ обеспечивает этот сигнал к генерирующему устройству. Генерирующее устройство затем приступает к генерации выходного сигнала на основе принимаемого сигнала микрофона. Фактически, в этом примере, может быть рассмотрено распределение генератора 107 по устройствам с использованием объединения, достигаемого посредством процесса выбора и селективной передачи сигнала микрофона. Преимущество такого метода состоит в том, что только один (или по меньшей мере один поднабор) из сигналов микрофонов должен быть передан к генерирующему устройству, и в том, что, таким образом, может быть достигнуто существенно уменьшенное использование ресурсов.
В качестве примера, метод может использовать микрофоны устройств, распределенных в интересующей области, для захвата речи пользователя. Обычная современная жилая комната обычно имеет некоторое количество устройств, снабженных одним или несколькими микрофонами и возможностями беспроводной передачи данных. Примеры включают в себя обычные радиотелефоны, мобильные телефоны, телевизионные приемники с поддержкой видеочата, планшетные персональные компьютеры, компактные портативные компьютеры и т.д. Эти устройства могут быть, в некоторых вариантах осуществления, использованы для генерации сигнала речи, например, посредством автоматического и адаптивного выбора речи, захватываемой посредством микрофона, ближайшего к говорящему. Это может обеспечить захваченную речь, которая, обычно, будет иметь высокое качество и будет свободна от реверберации.
Фактически, в общем, на сигнал, захватываемый посредством микрофона, как правило, влияет реверберация, шум окружающей среды и шум микрофона, причем влияние зависит от расположения микрофона относительно источника звука, например относительно рта пользователя. Система может стремиться выбрать микрофон, который принимает звуковой сигнал, который является наиболее близким к тому сигналу, который должен быть записан посредством микрофона, близкого ко рту пользователя. Генерируемый сигнал речи может быть применен там, где необходим захват речи по громкой связи, как, например, в домашней/ учрежденческой телефонии, системах телеконферец-связи, внешнем интерфейсе для систем с голосовым управлением и т.д.
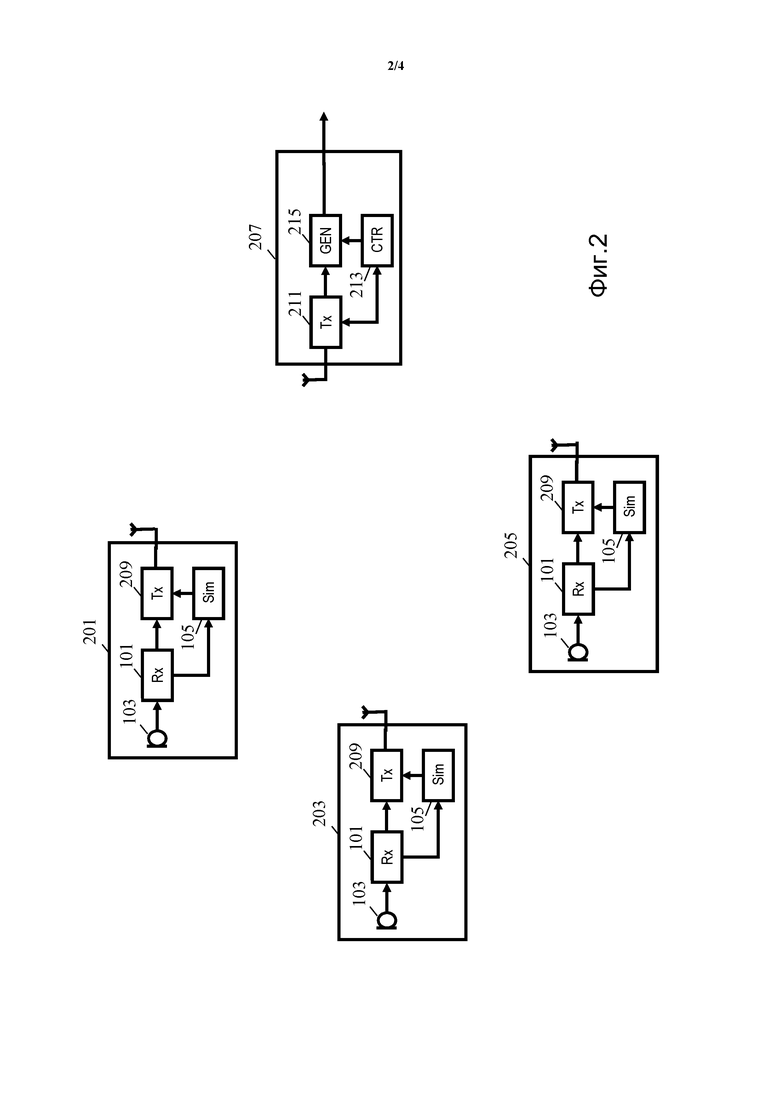
Фиг. 2 более подробно иллюстрирует пример распределенной аппаратуры/ системы генерации/ захвата речи. Этот пример включает в себя множество микрофонных устройств 201, 203, 205, а также генерирующее устройство 207.
Каждое из микрофонных устройств 201, 203, 205 содержит микрофонный приемник 101, который принимает сигнал микрофона от микрофона 103, который в этом примере является частью микрофонного устройства 201, 203, 205, но в других случаях может быть отдельным от них (например, одно или несколько микрофонных устройств 201, 203, 205 могут содержать микрофонный вход для присоединения внешнего микрофона). Микрофонный приемник 101 в каждом микрофонном устройстве 201, 203, 205 соединен с процессором 105 сходства, который определяет указание сходства для сигнала микрофона.
Процессор 105 сходства каждого микрофонного устройства 201, 203, 205, конкретно, выполняет функции процессора 105 сходства фиг. 1 для конкретного сигнала микрофона отдельного микрофонного устройства 201, 203, 205. Таким образом, процессор 105 сходства каждого из микрофонных устройств 201, 203, 205, конкретно, приступает к сравнению сигнала микрофона с набором сэмплов нереверберирующей речи, которые локально хранятся в каждом из этих устройств. Процессор 105 сходства может, конкретно, сравнить сигнал микрофона с каждым из сэмплов нереверберирующей речи и для каждого сэмпла речи определить указание на то, насколько похожими являются сигналы. Например, если процессор 105 сходства включает в себя запоминающее устройство для хранения локальной базы данных, содержащей представление каждой из фонем человеческой речи, то процессор 105 сходства может приступить к сравнению сигнала микрофона с каждой фонемой. Таким образом, определяют набор указаний, указывающих на то, насколько точно сигнал микрофона совпадает с каждой из фонем, которые не включают в себя никакой реверберации или шума. Указание, соответствующее наиболее точному согласованию, таким образом, вероятно, соответствует указанию на то, насколько точно захваченный звуковой сигнал соответствует звуку, генерируемому говорящим, произносящим эту фонему. Таким образом, указание наибольшего сходства выбирают в качестве указания сходства для сигнала микрофона. Это указание сходства, таким образом, отражает, насколько точно захваченный звуковой сигнал соответствует свободной от шума и реверберации речи. Для микрофона (и, таким образом, обычно, устройства), расположенного далеко от говорящего, захваченный звуковой сигнал, вероятно, включает в себя только низкие относительные уровни исходной испускаемой речи, сравнимые с вкладом от различных отражений, реверберации и шума. Однако для микрофона (и, таким образом, устройства), расположенного близко к говорящему, захваченный звук, вероятно, содержит существенно более высокий вклад от прямого пути звука и относительно более низкий вклад от отражений и шума. Таким образом, указание сходства обеспечивает хорошее указание на то, насколько чистой и разборчивой является речь из захваченного звукового сигнала отдельного устройства.
Каждое из микрофонных устройств 201, 203, 205 дополнительно содержит беспроводной приемопередатчик 209, который соединен с процессором 105 сходства и микрофонным приемником 101 каждого устройства. Беспроводной приемопередатчик 209, конкретно, выполнен с возможностью установления связи с генерирующим устройством 207 через беспроводное соединение.
Генерирующее устройство 207 также содержит беспроводной приемопередатчик 211, который может устанавливать связь с микрофонными устройствами 201, 203, 205 через беспроводное соединение.
Во многих вариантах осуществления, микрофонные устройства 201, 203, 205 и генерирующее устройство 207 могут быть выполнены с возможностью передачи данных в обоих направлениях. Однако следует понимать, что в некоторых вариантах осуществления, может быть применена только односторонняя передача данных от микрофонных устройств 201, 203, 205 к генерирующему устройству 207.
Во многих вариантах осуществления, устройства могут устанавливать связь через сеть беспроводной связи, такую как локальная сеть передачи данных стандарта Wi-Fi. Таким образом, беспроводной приемопередатчик 207 микрофонных устройств 201, 203, 205 может быть, конкретно, выполнен с возможностью установления связи с другими устройствами (и, конкретно, с генерирующим устройством 207) через средства связи стандарта Wi-Fi. Однако следует понимать, что в других вариантах осуществления, могут быть использованы другие способы связи, включая, например, связь через, например, проводную или беспроводную локальную сеть (Local Area Network), глобальную сеть (Wide Area Network), Интернет, каналы связи стандарта Bluetooth™, и т.д.
В некоторых вариантах осуществления, каждое их микрофонных устройств 201, 203, 205 может всегда передавать указания сходства и сигналы микрофонов к генерирующему устройству 207. Следует понимать, что специалист в данной области техники хорошо знает, как данные, такие как данные параметров и звуковые данные, могут быть переданы между устройствами. Конкретно, специалист в данной области техники хорошо знает, что передача звукового сигнала может включать в себя кодирование, сжатие, коррекцию ошибок и т.д.
В таких вариантах осуществления, генерирующее устройство 207 может принимать сигналы микрофонов и указания сходства от всех микрофонных устройств 201, 203, 205. Оно может затем приступить к объединению сигналов микрофонов на основе указаний сходства для генерации сигнала речи.
Конкретно, беспроводной приемопередатчик 211 генерирующего устройства 207 соединен с контроллером 213 и генератором 215 сигнала речи. На контроллер 213 подают указания сходства от беспроводного приемопередатчика 211 и, в ответ на них, он определяет набор параметров объединения, который управляет генерацией сигнала речи из сигналов микрофонов. Контроллер 213 соединен с генератором 215 сигнала речи, на который подают параметры объединения. Дополнительно, на генератор 215 сигнала речи подают сигналы микрофонов от беспроводного приемопередатчика 211, и он может, таким образом, приступить к генерации сигнала речи на основе параметров объединения.
В качестве конкретного примера, контроллер 213 может сравнить принимаемые указания сходства и идентифицировать указание, указывающее на наибольшую степень сходства. Указание на соответствующее устройство/ сигнал микрофона может быть затем передано к генератору 215 сигнала речи, который может приступить к выбору сигнала микрофона от этого устройства. Затем генерируют сигнал речи из этого сигнала микрофона.
В качестве другого примера, в некоторых вариантах осуществления, генератор 215 сигнала речи может приступить к генерации выходного сигнала речи в виде взвешенного объединения принимаемых сигналов микрофонов. Например, может быть применено взвешенное суммирование принимаемых сигналов микрофонов, причем веса для каждого отдельного сигнала генерируют из указаний сходства. Например, указания сходства могут быть напрямую обеспечены в виде скалярного значения в пределах данного диапазона, и отдельные веса могут быть прямо пропорциональны скалярному значению (с использованием, например, коэффициента пропорциональности, обеспечивающего то, что уровень сигнала или общее значение веса является постоянным).
Такой метод может быть, в частности, перспективным в сценариях, где доступная полоса рабочих частот канала связи не является ограничением. Таким образом, вместо выбора устройства, ближайшего к говорящему, вес может быть назначен для каждого устройства/ сигнала микрофона, и сигналы микрофонов от различных микрофонов могут быть объединены в виде взвешенной суммы. Такой метод может обеспечить робастность и ослабить влияние ошибочного выбора в сильно реверберирующих или шумных средах.
Следует понимать, что методы объединения могут быть объединены. Например, вместо использования чистого объединения с выбором, контроллер 213 может выбрать поднабор сигналов микрофонов (таких как, например, сигналы микрофонов, для которых указание сходства превышает некоторый порог) и затем объединить сигналы микрофонов поднабора с использованием весов, которые зависят от указаний сходства.
Также следует понимать, что, в некоторых вариантах осуществления, объединение может включать в себя выравнивание разных сигналов. Например, могут быть введены временные задержки для обеспечения того, что принимаемые сигналы речи добавляются когерентно для данного говорящего.
Во многих вариантах осуществления, сигналы микрофонов передают к генерирующему устройству 207 не от всех микрофонных устройств 201, 203, 205, а только от микрофонных устройств 201, 203, 205, от которых будет сгенерирован сигнал речи.
Например, микрофонные устройства 201, 203, 205 могут сначала передать указания сходства к генерирующему устройству 207 с использованием оценки контроллером 213 указаний сходства для выбора поднабора сигналов микрофонов. Например, контроллер 213 может выбрать сигнал микрофона от микрофонного устройства 201, 203, 205, которое отправило указание сходства, которое указывает на наибольшее сходство. Контроллер 213 может затем передать сообщение запроса к выбранному микрофонному устройству 201, 203, 205 с использованием беспроводного приемопередатчика 211. Микрофонные устройства 201, 203, 205 могут быть выполнены с возможностью передачи данных к генерирующему устройству 207, только при приеме сообщения запроса, т.е. сигнал микрофона передают к генерирующему устройству 207, только когда он включен в выбранный поднабор. Таким образом, в примере, где выбран только единственный сигнал микрофона, только одно из микрофонных устройств 201, 203, 205 передает сигнал микрофона. Такой метод может существенно уменьшить использование ресурсов связи, а также уменьшить, например, энергопотребление отдельных устройств. Он может также существенно уменьшить сложность генерирующего устройства 207, поскольку оно должно иметь дело, например, только с одним сигналом микрофона одновременно. В этом примере, функциональность объединения с выбором, используемая для генерации сигнала речи, является, таким образом, распределенной по устройствам.
Разные методы для определения указаний сходства могут быть использованы в разных вариантах осуществления, и, конкретно, сохраненные представления сэмплов нереверберирующей речи могут быть разными в разных вариантах осуществления, и могут быть использованы различным образом в разных вариантах осуществления.
В некоторых вариантах осуществления, сохраненные сэмплы нереверберирующей речи представлены посредством параметров для модели нереверберирующей речи. Таким образом, вместо хранения, например, выборочного представления сигнала во временной или частотной области, набор сэмплов нереверберирующей речи может содержать набор параметров для каждого сэмпла, который может обеспечить генерацию этого сэмпла.
Например, модель нереверберирующей речи может быть моделью линейного предсказания, такой как, конкретно, модель CELP (Code-Excited Linear Prediction - линейное предсказание с кодовым возбуждением). В таком сценарии, каждый сэмпл речи из сэмплов нереверберирующей речи может быть представлен посредством элемента кодовой книги, который задает сигнал возбуждения, который может быть использован для возбуждения синтезирующего фильтра (который может быть также представлен посредством сохраненных параметров).
Такой метод может существенно уменьшить потребности в памяти для набора сэмплов нереверберирующей речи, и это может быть, в частности, важным для распределенных реализаций, где определение указаний сходства выполняют локально в отдельных устройствах. Кроме того, с использованием модели речи, которая напрямую синтезирует речь от источника речи (без рассмотрения акустической среды), достигается хорошее представление нереверберирующей, безэховой речи.
В некоторых вариантах осуществления, сравнение сигнала микрофона с конкретным сэмплом речи может быть выполнено посредством оценки модели речи для конкретного набора сохраненных параметров модели речи для этого сигнала. Таким образом, может быть получено представление сигнала речи, который будет синтезирован посредством модели речи для этого набора параметров. Результирующее представление может быть затем сравнено с сигналом микрофона, и может быть вычислена мера различия между ними. Сравнение может быть, например, выполнено во временной области или в частотной области и может быть стохастическим сравнением. Например, может быть определено указание сходства для одного сигнала микрофона и одного сэмпла речи для отражения правдоподобия того, что захваченный сигнал микрофона получен от источника звука, испускающего сигнал речи, получаемый из синтеза посредством модели речи. Затем может быть выбран сэмпл речи, получаемый с наибольшим правдоподобием, и указание сходства для этого сигнала микрофона может быть определено как наиболее правдоподобное.
Далее будет обеспечен подробный пример возможного метода для определения указаний сходства на основе LP-модели речи.
В этом примере K микрофонов могут быть распределены в некоторой области. Наблюдаемые сигналы микрофонов могут быть смоделированы как
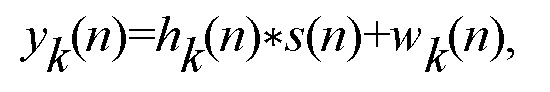
где s(n) является сигналом речи у рта пользователя, hk(n) является акустической передаточной функцией между местоположением, соответствующим рту пользователя, и местоположением k-го микрофона, и wk(n) является сигналом шума, включающим в себя как шум окружающей среды, так и собственный шум микрофона. Предполагая, что сигналы речи и шума являются независимыми, эквивалентное представление соответствующих сигналов в частотной области в терминах спектральных плотностей мощности (PSD) можно выразить следующим образом:
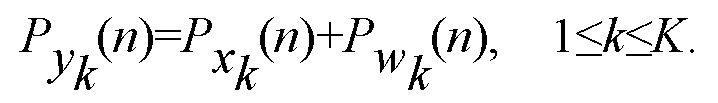
В безэховой среде, импульсная переходная характеристика hk(n) соответствует чистой задержке, соответствующей времени, требуемому для распространения сигнала от точки генерации к микрофону со скоростью звука. Следовательно, PSD сигнала xk(n) является идентичной PSD s(n). В реверберирующей среде, hk(n) моделирует не только прямой путь сигнала от источника звука к микрофону, но и сигналы, прибывающие к микрофону в результате отражения стенами, потолком, мебелью и т.д. Каждое отражение задерживает и ослабляет сигнал.
PSD xk(n) в этом случае может существенно отличаться от PSD s(n), в зависимости от уровня реверберации. Фиг. 3 иллюстрирует пример огибающих спектра, соответствующих сегменту речи продолжительностью 32 мс, записанному при трех разных расстояниях в реверберирующем помещении, с использованием T60, равного 0.8 секунды. Ясно, что огибающие спектра речи, записанной на расстоянии 5 см и 50 см от говорящего, являются относительно близкими, тогда как огибающая при 350 см является существенно отличающейся.
Когда интересующим сигналом является речь, как в применениях для громкой связи, PSD может быть смоделирована с использованием кодовой книги, подготовленной независимо с использованием большого набора данных. Например, кодовая книга может содержать коэффициенты линейного предсказания (linear prediction - LP), которые моделируют огибающую спектра.
Учебный набор обычно состоит из LP-векторов, извлекаемых из коротких сегментов (20-30 мс) из большого набора фонетически сбалансированных речевых данных. Такие кодовые книги успешно использовались в кодировании и улучшении речи. Кодовая книга, подготовленная на речи, записанной с использованием микрофона, расположенного близко ко рту пользователя, может быть затем использована в качестве справочной меры того, насколько реверберирующим является сигнал, принимаемый у конкретного микрофона.
Огибающая спектра, соответствующая кратковременному сегменту сигнала микрофона, захваченному у микрофона близко к говорящему, будет, обычно, находить лучшее согласование в кодовой книге, чем огибающая спектра, захваченная у микрофона, находящегося дальше (и, таким образом, подверженного относительно большему влиянию реверберации и шума). Это наблюдение может быть затем использовано, например, для выбора подходящего сигнала микрофона в данном сценарии.
Предполагая, что шум является гауссовым, и дан вектор а из коэффициентов LP, на k-м микрофоне мы имеем (со ссылкой, например, на S. Srinivasan, J. Samuelsson, and W.B. Kleijn, "Codebook driven short-term predictor parameter estimation for speech enhancement," IEEE Trans. Speech, Audio and Language Processing, vol. 14, no. 1, pp. 163-176, Jan. 2006):
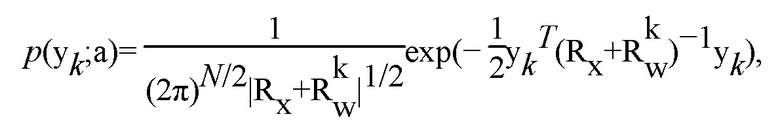
где 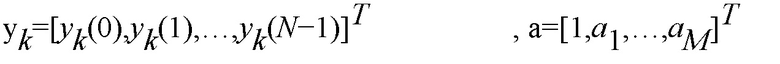 является данным вектором из коэффициентов LP, M является порядком модели LP, N является количеством сэмплов в кратковременном сегменте, Rkw является автокорреляционной матрицей сигнала шума у k-го микрофона, и Rx=g(ATA)-1, где A является NxN нижней треугольной матрицей Теплица с
является данным вектором из коэффициентов LP, M является порядком модели LP, N является количеством сэмплов в кратковременном сегменте, Rkw является автокорреляционной матрицей сигнала шума у k-го микрофона, и Rx=g(ATA)-1, где A является NxN нижней треугольной матрицей Теплица с 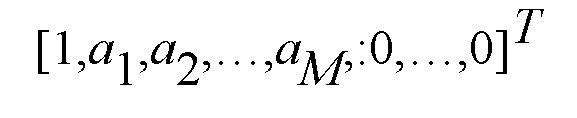 в качестве первого столбца, и g является членом коэффициента усиления для компенсации различия между нормированными спектрами кодовой книги и наблюдаемыми спектрами.
в качестве первого столбца, и g является членом коэффициента усиления для компенсации различия между нормированными спектрами кодовой книги и наблюдаемыми спектрами.
При приближении длины цикла к бесконечности, ковариационные матрицы могут быть описаны как циркулянтные и являются диагонализируемыми посредством преобразования Фурье. Логарифм правдоподобия в приведенном выше уравнении, в соответствии с вектором ai i-го элемента речи в кодовой книге, может быть, тогда, записан в виде (со ссылкой, например, на U. Grenander and G. Szego, "Toeplitz forms and their applications", 2nd ed. New York: Chelsea, 1984):
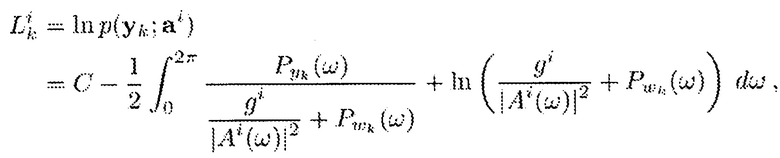
где C включает в себя постоянные члены, независящие от сигнала, и Ai(ω) является спектром i-го вектора из кодовой книги, заданным в виде
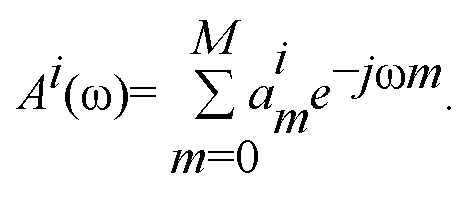
Для данного вектора ai из кодовой книги, член компенсации коэффициента усиления может быть получен в виде
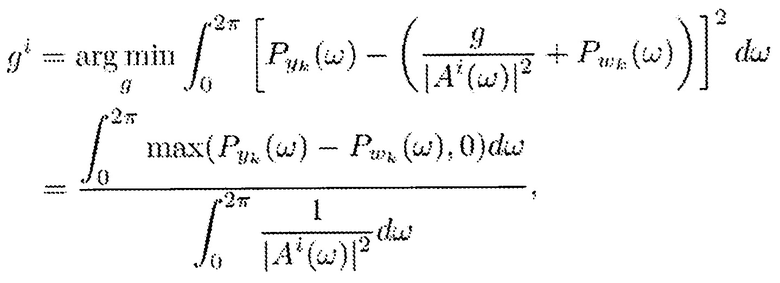
где отрицательные значения в числителе, которые могут возникнуть вследствие ошибочных оценок PSD шума Pwk(ω), устанавливают равными нулю. Следует отметить, что все величины в этом уравнении являются доступными. PSD с шумом Pyk(ω) и PSD шума Pwk(ω) могут быть оценены из сигнала микрофона, а Ai(ω) задают посредством i-го вектора из кодовой книги.
Для каждого датчика, значение максимального правдоподобия вычисляют по всем векторам их кодовой книги, т.е.
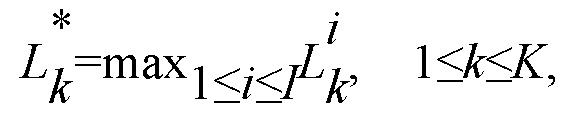
где I является количеством векторов в кодовой книге речи. Это значение максимального правдоподобия затем используют в качестве указания сходства для конкретного сигнала микрофона.
Наконец, микрофон с наибольшим значением t максимального правдоподобия определяют в качестве микрофона, ближайшего к говорящему, т.е. определяют сигнал микрофона, получаемый с наибольшим значением правдоподобия:
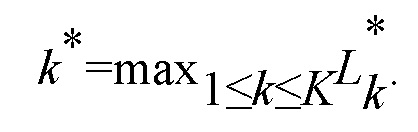
Были проведены эксперименты для этого конкретного примера. Кодовая книга коэффициентов LP речи генерировалась с использованием учебных данных из базы данных речи (CSR-II (WSJ1) Complete," Linguistic Data Consortium, Philadelphia, 1994) Wall Street Journal (WSJ). 180 отдельных учебных фрагментов речи продолжительностью около 5 сек каждый от 50 разных говорящих, 25 мужчин и 25 женщин, использовались в качестве учебных данных. С использованием учебных фрагментов речи, около 55000 коэффициентов LP было извлечено из сегментов с использованием окна Ханна из сэмплов размера 256, с перекрытием 50% при частоте выборки 8 кГц. Кодовая книга была подготовлена с использованием алгоритма LBG (Y. Linde, A. Buzo, and R.M. Gray, "An algorithm for vector quantizer design," IEEE Trans. Communications, vol. COM-28, no. 1, pp. 84-95, Jan. 1980.) с искажениями Итакуры-Саито (S.R. Quackenbush, T.P. Barnwell, and M.A. Clements, Objective "Measures of Speech Quality". New Jersey: Prentice-Hall, 1988.) в качестве критерия ошибок. Размер кодовой книги был зафиксирован на 256 элементах. Была рассмотрена аппаратура из трех микрофонов, и микрофоны располагались на расстоянии 50 см, 150 см и 350 см от говорящего в реверберирующем помещении (T60 = 800 мс). Импульсная переходная характеристика между местоположением говорящего и каждым из трех микрофонов записывалась и затем свертывалась с сухим сигналом речи для получения данных микрофона. Шум микрофона у каждого микрофона был на 40 дБ ниже уровня речи.
Фиг. 4 показывает правдоподобие p(y1) для микрофона, расположенного на расстоянии 50 см от говорящего. В области преобладания речи, этот микрофон (который расположен ближе всего к пользователю) принимает значение, близкое к единице, а значения правдоподобия у других двух микрофонов являются близкими к нулю. Ближайший микрофон, таким образом, идентифицирован правильно.
Конкретным преимуществом метода является то, что он, по существу, компенсирует для сигнала различия в уровнях между разными микрофонами.
Следует отметить, что метод выбирает подходящий микрофон во время речевой деятельности. Однако во время неречевых сегментов (таких как, например, паузы в речи или смены говорящего), метод не обеспечит определение такого выбора. Однако для этого можно просто обратиться к системе, включающей в себя детектор речевой деятельности (такой как простой детектор уровня) для идентификации неречевых периодов. Во время этих периодов, система может просто продолжить использование параметров объединения, определенных для последнего сегмента, который включал в себя компонент речи.
В предыдущих вариантах осуществления, указания сходства были сгенерированы посредством сравнения характеристик сигналов микрофонов с характеристиками сэмплов нереверберирующей речи, и, конкретно, сравнения характеристик сигналов микрофонов с характеристиками сигналов речи, которые получают из оценки модели речи с использованием сохраненных параметров.
Однако, в других вариантах осуществления, набор характеристик может быть получен посредством анализа сигналов микрофонов, и эти характеристики могут быть затем сравнены с ожидаемыми значениями для нереверберирующей речи. Таким образом, сравнение может быть выполнено в области параметра или характеристики без рассмотрения конкретных сэмплов нереверберирующей речи.
Конкретно, процессор 105 сходства может быть выполнен с возможностью разложения сигналов микрофонов с использованием набора базисных сигнальных векторов. Такое разложение может, конкретно, использовать разреженный полнокомплектный словарь, который содержит прототипы сигналов, также называемые элементарными единицами. Тогда, сигнал описывают в виде линейного объединения поднабора этого словаря. Таким образом, каждая элементарная единица может, в этом случае, соответствовать базисному сигнальному вектору.
В таких вариантах осуществления, характеристика, получаемая из сигналов микрофонов и используемая в сравнении, может быть количеством базисных сигнальных векторов, и, конкретно, количеством элементарных единиц из словаря, которые необходимы для представления сигнала в подходящей области признака.
Характеристика может быть затем сравнена с одной или несколькими ожидаемыми характеристиками для нереверберирующей речи. Например, во многих вариантах осуществления, значения для набора базисных векторов могут быть сравнены с сэмплами значений для наборов базисных векторов, соответствующих конкретным сэмплам нереверберирующей речи.
Однако, во многих вариантах осуществления, может быть использован более простой метод. Конкретно, если словарь подготовлен на нереверберирующей речи, то тогда сигнал микрофона, который содержит менее реверберирующую речь, может быть описан с использованием относительно малого количества элементарных единиц словаря. Когда сигнал все больше и больше подвергается воздействию реверберации и шума, потребуется большее количество элементарных единиц, т.е. энергия будет, как правило, распространена более равномерно по большему количеству базисных векторов.
Таким образом, во многих вариантах осуществления, распределение энергии по базисным векторам может быть оценено и использовано для определения указания сходства. Чем больше распределение распространено, тем меньшим является указание сходства.
В качестве конкретного примера, при сравнении сигналов от двух микрофонов, тот, который может быть описан с использованием меньшего количества элементарных единиц словаря, является более похожим на нереверберирующую речь (причем словарь подготовлен на нереверберирующей речи).
В качестве конкретного примера, количество базисных векторов, для которого это значение (конкретно, вес каждого базисного вектора в объединении базисных векторов, аппроксимирующем сигнал) превышает заданный порог, может быть использовано для определения указания сходства. Фактически, количество базисных векторов, которое превышает порог, может быть просто вычислено и напрямую использовано в качестве указания сходства для данного сигнала микрофона, причем увеличивающееся количество базисных векторов указывает на уменьшающееся сходство. Таким образом, характеристика, получаемая из сигнала микрофона, может быть количеством значений базисных векторов, которые превышают некоторый порог, и она может быть сравнена со справочной характеристикой для нереверберирующей речи из нулевых или единичных базисных векторов, имеющих значения выше порога. Таким образом, чем больше количество базисных векторов, тем меньше будет указание сходства.
Следует понимать, что приведенное выше описание для ясности описало варианты осуществления данного изобретения со ссылкой на разные функциональные схемы, блоки и процессоры. Однако должно быть ясно, что любое подходящее распределение функциональности между разными функциональными схемами, блоками и процессорами может быть использовано, не выходя за рамки данного изобретения. Например, функциональность, показанная подлежащей выполнению посредством отдельных процессоров или контроллеров, может быть выполнена посредством одного и того же процессора или контроллера. Следовательно, ссылки на конкретные функциональные блоки или схемы приведены для рассмотрения только в качестве ссылок на подходящие средства для обеспечения описываемой функциональности, а не указывают на определенную логическую или физическую структуру или организацию.
Данное изобретение может быть реализовано в любой подходящей форме, включая аппаратное обеспечение, программное обеспечение, аппаратно-программное обеспечение или любую их комбинацию. Данное изобретение может быть, необязательно, реализовано, по меньшей мере частично, в виде компьютерного программного обеспечения, выполняемого посредством одного или нескольких процессоров для обработки данных и/или цифровых сигнальных процессоров. Элементы и компоненты варианта осуществления данного изобретения могут быть физически, функционально и логически реализованы любым подходящим способом. Фактически, функциональность может быть реализована в единственном блоке, во множестве блоков или в виде части других функциональных блоков. Соответственно, данное изобретение может быть реализовано в единственном блоке или может быть физически и функционально распределено между разными блоками, схемами и процессорами.
Хотя данное изобретение описано в связи с некоторыми вариантами осуществления, оно не предназначено для ограничения конкретной формой, изложенной здесь. Напротив, объем данного изобретения ограничен только сопутствующей формулой изобретения. Дополнительно, хотя некоторый признак может появиться в описании в связи с конкретными вариантами осуществления, специалист в данной области техники должен понимать, что различные признаки описанных вариантов осуществления могут быть объединены согласно данному изобретению. В формуле изобретения, термин «содержащий» не исключает наличия других элементов или этапов.
Кроме того, несмотря на отдельное перечисление, множество средств, элементов или этапов способа может быть реализовано посредством, например, единственной схемы, блока или процессора.
Дополнительно, хотя отдельные признаки могут быть включены в разные пункты формулы изобретения, они могут быть объединены для получения выгоды, и включение в разные пункты формулы изобретения не означает, что объединение признаков не является возможным и/или выгодным. Также включение признака в одну категорию формулы изобретения не означает ограничение этой категорией, а, напротив, указывает на то, что признак равным образом применим к другим категориям формулы изобретения, при необходимости. Кроме того, порядок признаков в формуле изобретения не означает никакого конкретного порядка, в котором признаки должны работать, в частности порядок отдельных этапов в пунктах формулы изобретения на способ не означает, что этапы должны быть выполнены в этом порядке. Напротив, этапы могут быть выполнены в любом подходящем порядке. Дополнительно, ссылки в единственном числе не исключают множества. Таким образом, ссылки на «один», «некоторый», «первый», «второй» и т.д. не исключают множества. Ссылочные позиции в формуле изобретения обеспечены только в качестве разъясняющего примера и никоим образом не должны толковаться как ограничивающие объем формулы изобретения.
Изобретение относится к средствам для генерации сигнала речи. Технический результат заключается в повышении качества речи за счет уменьшения реверберации. Аппаратура содержит микрофонные приемники (101), которые принимают сигналы микрофонов от множества микрофонов (103). Блок (105) сравнения определяет указание сходства речи, указывающее на сходство между сигналом микрофона и нереверберирующей речью, для каждого сигнала микрофона. Определение происходит в ответ на сравнение характеристики, получаемой из сигнала микрофона, со справочной характеристикой для нереверберирующей речи. В некоторых вариантах осуществления, блок (105) сравнения определяет указание сходства речи посредством сравнения со справочными характеристиками для сэмплов речи из набора сэмплов нереверберирующей речи. Генератор (107) генерирует сигнал речи посредством объединения сигналов микрофонов в ответ на указания сходства. Аппаратура может быть распределена по множеству устройств, причем каждое устройство содержит микрофон, и данный метод может определить наиболее подходящий микрофон для генерации сигнала речи. 2 н. и 12 з.п. ф-лы, 4 ил.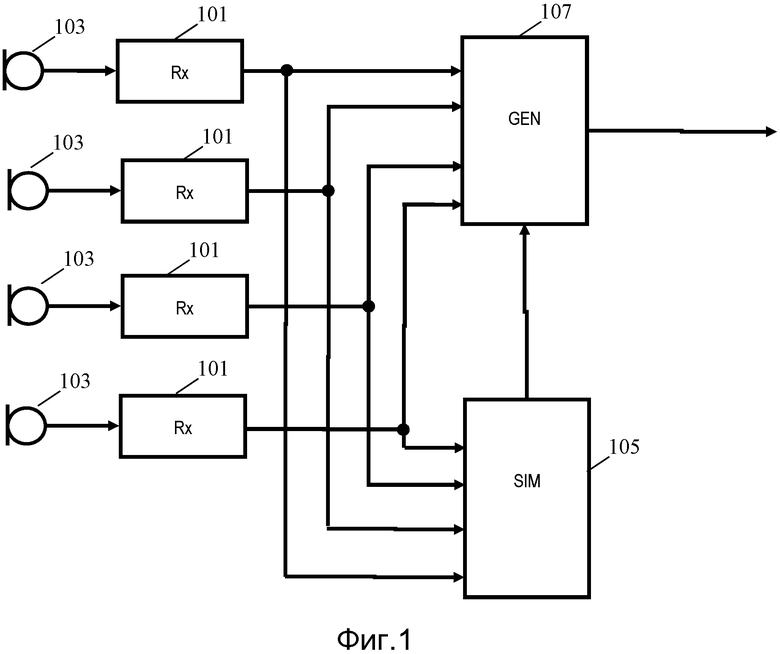
1. Аппаратура для генерации сигнала речи, причем аппаратура содержит:
микрофонные приемники (101) для приема сигналов микрофонов от множества микрофонов (103);
блок (105) сравнения, выполненный с возможностью, для каждого сигнала микрофона, определения указания сходства речи, указывающего на сходство между сигналом микрофона и нереверберирующей речью, причем блок (105) сравнения выполнен с возможностью определения указания сходства в ответ на сравнение по меньшей мере одной характеристики, получаемой из сигнала микрофона, по меньшей мере с одной справочной характеристикой для нереверберирующей речи; и
генератор (107) для генерации сигнала речи посредством объединения сигналов микрофонов в ответ на указания сходства,
причем блок (105) сравнения дополнительно выполнен с возможностью определения указания сходства для первого сигнала микрофона в ответ на сравнение по меньшей мере одной характеристики, получаемой из сигнала микрофона, со справочными характеристиками для сэмплов речи из набора сэмплов нереверберирующей речи.
2. Аппаратура по п. 1, содержащая множество отдельных устройств (201, 203, 205), причем каждое устройство содержит микрофонный приемник для приема по меньшей мере одного сигнала микрофона из упомянутого множества сигналов микрофонов.
3. Аппаратура по п. 2, в которой по меньшей мере первое устройство из упомянутого множества отдельных устройств (201, 203, 205) содержит локальный блок (105) сравнения для определения первого указания сходства речи для упомянутого по меньшей мере одного сигнала микрофона первого устройства.
4. Аппаратура по п. 3, в которой генератор (107) реализован в генерирующем устройстве (207) отдельно от по меньшей мере первого устройства; и в которой первое устройство содержит передатчик (209) для передачи первого указания сходства речи к генерирующему устройству (207).
5. Аппаратура по п. 4, в которой генерирующее устройство (207) выполнено с возможностью приема указаний сходства речи от каждого из упомянутого множества отдельных устройств (201, 203, 205) и в которой генератор (107, 207) выполнен с возможностью генерации сигнала речи с использованием поднабора сигналов микрофонов от упомянутого множества отдельных устройств (201, 203, 205), причем упомянутый поднабор определяют в ответ на указания сходства речи, принимаемые от упомянутого множества отдельных устройств (201, 203, 205).
6. Аппаратура по п. 5, в которой по меньшей мере одно устройство из упомянутого множества отдельных устройств (201, 203, 205) выполнено с возможностью передачи упомянутого по меньшей мере одного сигнала микрофона упомянутого по меньшей мере одного устройства к генерирующему устройству (207), только если упомянутый по меньшей мере один сигнал микрофона упомянутого по меньшей мере одного устройства содержится в упомянутом поднаборе сигналов микрофонов.
7. Аппаратура по п. 5, в которой генерирующее устройство (207) содержит устройство (213) выбора, выполненное с возможностью определения упомянутого поднабора сигналов микрофонов, и передатчик (211) для передачи указания на упомянутый поднабор по меньшей мере к одному из упомянутого множества отдельных устройств (201, 203, 205).
8. Аппаратура по п. 1, в которой сэмплы речи из набора сэмплов нереверберирующей речи представлены посредством параметров для модели нереверберирующей речи.
9. Аппаратура по п. 8, в которой блок (105) сравнения выполнен с возможностью определения первой справочной характеристики для первого сэмпла речи из набора сэмплов нереверберирующей речи из сигнала сэмпла речи, генерируемого посредством оценки модели нереверберирующей речи с использованием параметров для первого сэмпла речи, и определения указания сходства для первого сигнала микрофона из упомянутого множества сигналов микрофонов, в ответ на сравнение характеристики, получаемой из первого сигнала микрофона, и первой справочной характеристики.
10. Аппаратура по п. 1, в которой блок (105) сравнения выполнен с возможностью разложения первого сигнала микрофона из упомянутого множества сигналов микрофонов в набор базисных сигнальных векторов; и определения указания сходства в ответ на характеристику из упомянутого набора базисных сигнальных векторов.
11. Аппаратура по п. 1, в которой блок (105) сравнения выполнен с возможностью определения указаний сходства речи для каждого сегмента из множества сегментов сигнала речи и генератор выполнен с возможностью определения параметров объединения для объединения для каждого сегмента.
12. Аппаратура по п. 10, в которой генератор (107) выполнен с возможностью определения параметров объединения для одного сегмента в ответ на указания сходства по меньшей мере одного предыдущего сегмента.
13. Аппаратура по п. 1, в которой генератор (107) выполнен с возможностью выбора поднабора сигналов микрофонов для объединения в ответ на указания сходства.
14. Способ генерации сигнала речи, причем способ содержит:
прием сигналов микрофонов от множества микрофонов (103);
для каждого сигнала микрофона, определение указания сходства речи, указывающего на сходство между сигналом микрофона и нереверберирующей речью, причем указание сходства определяют в ответ на сравнение по меньшей мере одной характеристики, получаемой из сигнала микрофона, по меньшей мере с одной справочной характеристикой для нереверберирующей речи; и
генерацию сигнала речи посредством объединения сигналов микрофонов в ответ на указания сходства,
причем указание сходства дополнительно определяют для первого сигнала микрофона в ответ на сравнение по меньшей мере одной характеристики, получаемой из сигнала микрофона, со справочными характеристиками для сэмплов речи из набора сэмплов нереверберирующей речи.
| US 3814856 A1, 04.06.1974 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Устройство для слежения за краем материала | 1975 |
|
SU682436A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| КОДИРОВАНИЕ ОБОБЩЕННЫХ АУДИОСИГНАЛОВ НА НИЗКИХ СКОРОСТЯХ ПЕРЕДАЧИ БИТОВ И С НИЗКОЙ ЗАДЕРЖКОЙ | 2011 |
|
RU2596584C2 |

