ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[1] Это описание относится к верификации говорящего.
УРОВЕНЬ ТЕХНИКИ
[2] Голосовая аутентификация предоставляет пользователю пользовательского устройства легкий способ получения доступа к пользовательскому устройству. Голосовая аутентификация обеспечивает пользователю возможность разблокировки, и осуществления доступа к, устройства пользователя без запоминания или ввода пароля. Однако, существование многочисленных разных языков, диалектов, акцентов и подобного представляет некоторые проблемы в области голосовой аутентификации.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[3] В одной реализации, модель верификации говорящего улучшается на обыкновенных системах посредством способствования верификации говорящего независимо от языка, диалекта или акцента говорящего. Модель верификации говорящего может быть основана на нейронной сети. Нейронная сеть может быть обучена с использованием вводов, которые включают в себя фрагмент речи и идентификатор языка. Однажды обученные, активации, выводимые скрытым слоем нейронной сети, могут быть использованы как отпечаток голоса, который можно сравнить с опорным представлением на устройстве пользователя. Говорящий может быть аутентифицирован, если отпечаток голоса и опорное представление удовлетворяют предварительно определенному порогу сходства.
[4] Согласно одной реализации, изобретение согласно этому описанию может быть осуществлено в способе способствования независимой от языка верификации говорящего. Способ может включать в себя действия по: приему, пользовательским устройством, аудиоданных, представляющих фрагмент речи пользователя; определению идентификатора языка, ассоциированного с пользовательским устройством; предоставлению, нейронной сети, хранящейся на пользовательском устройстве, набора входных данных, полученных из аудиоданных и определенного идентификатора языка, причем нейронная сеть имеет параметры, обученные с использованием речевых данных, представляющих речь на разных языках и разных диалектах; генерированию, на основе вывода нейронной сети, произведенного в ответ на прием набора входных данных, представления говорящего, указывающего характеристики голоса пользователя; определению, на основе представления говорящего и второго представления, что фрагмент речи является фрагментом речи пользователя; и предоставлению пользователю доступа к пользовательскому устройству на основе определения того, что фрагмент речи является фрагментом речи пользователя.
[5] Другие версии включают в себя соответствующие системы, устройства и компьютерные программы для выполнения действий способов, кодированные на компьютерных устройствах хранения.
[6] Эти и другие версии могут опционально включать в себя один или более из нижеследующих признаков. Например, в некоторых реализациях, набор входных данных, полученных из аудиоданных и определенного идентификатора языка, включает в себя первый вектор, который получен из аудиоданных, и второй вектор, который получен из определенного идентификатора языка.
[7] В некоторых реализациях, способ может включать в себя генерирование входного вектора посредством объединения первого вектора и второго вектора в единый объединенный вектор, предоставление, нейронной сети, сгенерированного входного вектора и генерирование, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представления говорящего, указывающего характеристики голоса пользователя.
[8] В некоторых реализациях, способ может включать в себя генерирование входного вектора посредством объединения выводов по меньшей мере двух других нейронных сетей, которые соответственно генерируют выводы на основе (i) первого вектора, (ii) второго вектора или (iii) и первого вектора, и второго вектора, предоставление, нейронной сети, сгенерированного входного вектора и генерирование, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представления говорящего, указывающего характеристики голоса пользователя.
[9] В некоторых реализациях, способ может включать в себя генерирование входного вектора на основе первого вектора и взвешенной суммы второго вектора, предоставление, нейронной сети, сгенерированного входного вектора и генерирование, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представления говорящего, указывающего характеристики голоса пользователя.
[10] В некоторых реализациях, вывод нейронной сети, произведенный в ответ на прием набора входных данных, включает в себя набор активаций, сгенерированных скрытым слоем нейронной сети.
[11] В некоторых реализациях, определение, на основе представления говорящего и второго представления, что фрагмент речи является фрагментом речи пользователя, может включать в себя определение расстояния между первым представлением и вторым представлением.
[12] В некоторых реализациях, способ может включать в себя предоставление пользователю доступа к пользовательскому устройству на основе определения того, что фрагмент речи является фрагментом речи пользователя, включая разблокировку пользовательского устройства.
[13] Другие реализации изобретения, описанного этим описанием, включают в себя способ независимой от языка верификации говорящего, который включает в себя прием, мобильным устройством, которое реализует независимую от языка модель верификации говорящего, выполненную с возможностью определения того, включают ли вероятно в себя принятые аудиоданные фрагмент речи с одним из многочисленных характерных для языка ключевых слов, (i) конкретных аудиоданных, соответствующих конкретному фрагменту речи пользователя, и (ii) данных, указывающих конкретный язык, на котором говорит пользователь, и в ответ на прием (i) конкретных аудиоданных, соответствующих конкретному фрагменту речи пользователя, и (ii) данных, указывающих конкретный язык, на котором говорит пользователь, предоставление, для вывода, указания, что независимая от языка модель верификации говорящего определила, что конкретные аудиоданные вероятно включают в себя фрагмент речи с ключевым словом, предназначенным для конкретного языка, на котором говорит пользователь.
[14] Эти и другие версии могут опционально включать в себя один или более из нижеследующих признаков. Например, в одной реализации, предоставление, для вывода, указания может включать в себя предоставление доступа к ресурсу мобильного устройства. В качестве альтернативы, или в дополнение, предоставление, для вывода, указания может включать в себя разблокировку мобильного устройства. В качестве альтернативы, или в дополнение, предоставление, для вывода, указания может включать в себя выведение мобильного устройства из состояния с пониженным энергопотреблением. В качестве альтернативы, или в дополнение, предоставление, для вывода, указания содержит предоставление указания, что независимая от языка модель верификации говорящего определила, что конкретные аудиоданные включают в себя фрагмент речи конкретного пользователя, ассоциированного с мобильным устройством.
[15] В некоторых реализациях, независимая от языка модель верификации говорящего может включать в себя нейронную сеть, обученную без использования фрагментов речи пользователя.
[16] Изобретение согласно этому описанию предоставляет многочисленные преимущества над обыкновенными способами. Например, изобретение по настоящей заявке предусматривает модель верификации говорящего, которая может быть легко распространена. Так как модель верификации говорящего является независимой от языка, диалекта и акцента, одна и та же модель верификации говорящего может быть широко распространена на пользовательские устройства. Это гораздо более эффективно, чем предоставление разных моделей верификации говорящего разным устройствам на основе языка пользователя устройства. В качестве альтернативы, это предотвращает необходимость развертывания многочисленных моделей верификации говорящего на одном и том же устройстве, из которых пользователь может выбрать одну.
[17] Модель верификации говорящего, предусматриваемая настоящей заявкой, демонстрирует улучшенную точность при использовании одной и той же модели для выполнения верификации говорящего независимо от языка, диалекта или акцента говорящего. Например, вариации в языке, диалекте или акценте могут привести к тому, что конкретный пользователь произносит предварительно определенное ключевое слово иным образом, чем другие пользователи. В обыкновенных системах эта разница в произношении может вызвать проблемы с точностью. Модель верификации говорящего по настоящему раскрытию улучшает эту слабость обыкновенных систем.
[18] Модель верификации говорящего, предусматриваемая настоящей заявкой, также обеспечивает легкое обновление. Например, вновь обученная модель может легко быть развернута как часть обновления стандартного программного обеспечения для операционной системы пользовательского устройства. Такие обновленные модели верификации говорящего могут легко обучаться, чтобы учитывать новые языки, диалекты и/или акценты по мере их появления. В качестве альтернативы, обновления могут быть созданы для существующей версии модели верификации говорящего на основе известных языков, диалектов и/или акцентов. Такие обновленные модели верификации говорящего могут быть универсальным образом развернуты, без необходимости предоставления конкретных моделей верификации говорящего конкретным устройствам в конкретных географических регионах.
[19] Подробности одного или более вариантов осуществления изобретения, описанного в этом описании, изложены на прилагаемых чертежах и в описании ниже. Другие признаки, аспекты и преимущества изобретения станут очевидны из описания, чертежей и формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[20] Фиг. 1 показывает контекстную схему примера системы для использования независимой от языка модели верификации говорящего для выполнения верификации говорящего.
[21] Фиг. 2 является примером системы для обучения независимой от языка модели верификации говорящего.
[22] Фиг. 3 является примером концептуального представления множества соответствующих векторов идентификации языка.
[23] Фиг. 4 является примером системы, которая выполняет независимую от языка верификацию говорящего.
[24] Фиг. 5 является схемой последовательности операций процесса для выполнения независимой от языка верификации говорящего.
ПОДРОБНОЕ ОПИСАНИЕ
[25] В некоторых реализациях, система предоставляет пользовательскому устройству независимую от языка модель верификации говорящего, которая может быть моделью на основе нейронной сети. Независимая от языка модель верификации говорящего обучается, до установки на пользовательское устройство, на основе обучающих данных, которые включают в себя (i) фрагменты речи от многочисленных разных пользователей и (ii) векторы, указывающие языки или местоположения, соответствующие соответственным фрагментам речи. После установки на пользовательское устройство, независимая от языка модель верификации говорящего может быть использована для верификации подлинности пользователя пользовательского устройства без последующего обучения независимой от языка модели верификации говорящего. Хотя пользовательское устройство может получить и использовать фрагменты речи пользователя для регистрации пользователя, сама модель не должна обучаться на основе каких-либо фрагментов речи пользователя пользовательского устройства.
[26] Как используется в настоящем документе, "независимая от языка" модель верификации говорящего относится к единой модели, которая может быть использована для точной верификации подлинности говорящих, которые говорят на разных языках или диалектах. То есть, модель не зависит, или не ограничивается, от речи, имеющей конкретный единственный язык. В результате, вместо использования разных моделей для разных языков, диалектов или акцентов, может быть использована единственная независимая от языка модель. В некоторых реализациях, зависимая от текста модель, обученная идентифицировать говорящего на основе фрагмента речи с конкретным словом или фразой, например, предварительно определенным ключевым словом или словом для привлечения внимания. Независимая от языка модель может быть обучена различать говорящих на разных языках на основе единого ключевого слова, либо на основе разных ключевых слов для разных языков или местоположений. Даже когда одно и то же ключевое слово используется в разных языках или местоположениях, пользователи, имеющие разные языки, диалекты, акценты или местоположения, могут произносить ключевое слово по-разному. Эти вариации снизили точность предшествующих моделей, которые часто неверно описывали вариативность из-за регионального языка или акцента как отличающую говорящего характеристику. Например, частота ложноположительного результата при верификации увеличивается, когда предшествующая модель интерпретирует основные признаки регионального акцента как главные отличительные элементы голоса конкретного говорящего, когда в действительности признаки являются фактически общими для многих других пользователей, которые имеют очень схожий акцент. В настоящей заявке получают информацию о языке или местоположении пользователя и предоставляют информацию модели, обеспечивая модели возможность создавать представления говорящего, например, отпечатки голоса, которые лучше отличают пользователя от других пользователей, имеющих тот же язык, диалект, акцент или местоположение.
[27] Фиг. 1 показывает контекстную схему примера системы для использования независимой от языка модели верификации говорящего для выполнения верификации подлинности. Система 100 включает в себя пользовательское устройство 110, пользовательское устройство 120, сеть 130, сервер 140, нейронную сеть 150 и модель 180 верификации говорящего.
[28] Система 100 включает в себя сервер 140, который хранит нейронную сеть 150. Нейронная сеть 150 была обучена с использованием речевых данных, представляющих образцы речи на разных языках, разных диалектах или и с тем, и другим. Сервер 140 генерирует модель 180 верификации говорящего на основе нейронной сети 150. Затем, сервер 150 передает копию модели 180 верификации говорящего через сеть 130 первому пользовательскому устройству 110 и второму пользовательскому устройству 120. Копия модели 180 верификации говорящего затем сохраняется на каждом соответствующем пользовательском устройстве 110, 120.
[29] Пользователь, например, "Joe" может попытаться получить доступ к пользовательскому устройству 110 с использованием голосовой аутентификации. Например, Joe может произнести предварительно определенное ключевое слово 105a, или фразу, такую как "Ok Google" на английском. Аудио 105b, соответствующее предварительно определенному фрагменту речи, может быть обнаружено микрофоном 111 пользовательского устройства 110. Пользовательское устройство 110 может сгенерировать первый ввод для сохраненной модели 180 верификации говорящего, который получен из аудио 105b, обнаруженного микрофоном 111. В дополнение, пользовательское устройство 110 может получить второй ввод для сохраненной модели 180 верификации говорящего на основе определения, что Joe произнес ключевое слово 105a, или фразу, на английском языке. Пользовательское устройство 110 может определить, что Joe произнес ключевое слово 105a, или фразу, на английском языке, посредством получения настройки языка устройства. Модель 180 верификации говорящего, хранящаяся на пользовательском устройстве 110 Joe, может затем сгенерировать отпечаток голоса для Joe, на основе обработки первого ввода, полученного из аудио 105b, и второго ввода, полученного исходя из использования Joe английского языка. На основе анализа сгенерированного отпечатка голоса, пользовательское устройство 110 может определить, что Joe аутентифицирован для осуществления доступа к устройству 110. В ответ на определение, что Joe аутентифицирован для осуществления доступа к пользовательскому устройству 110, пользовательское устройство 110 может инициировать обработку, которая разблокирует пользовательское устройство 110. В некоторых случаях, пользовательское устройство 110 может отобразить сообщение на графическом пользовательском интерфейсе 112, которое говорит, например, "Speaker Identity Verified" 113. В качестве альтернативы, или в дополнение, когда пользовательское устройство 110 разблокировано, динамик пользовательского устройства 110 может вывести аудиоприветствие 115, которое говорит "Welcome Joe".
[30] В примере по Фиг. 1, другой пользователь, например, "Wang", имеет пользовательское устройство 120, которое также хранит копию той же самой модели 180 верификации говорящего. Wang, имеющий беглую речь на китайском языке, может попытаться получить доступ к пользовательскому устройству 120 с использованием голосовой аутентификации. Например, Wang может произнести предварительно определенное ключевое слово 115a, или фразу, такую как "Nǐ hǎo Android" на китайском (грубо переводимую на английский как "Hello Android"). Аудио 115b, соответствующее предварительно определенному фрагменту речи, может быть обнаружено микрофоном 121 пользовательского устройства 120. В дополнение, пользовательское устройство 120 может получить второй ввод для сохраненной модели 180 верификации говорящего на основе определения, что Wang произнес ключевое слово 115a, или фразу, на китайском языке. Пользовательское устройство 120 может определить, что Wang произнес ключевое слово 115a, или фразу, на китайском языке, посредством получения настройки языка устройства. Модель 180 верификации говорящего, хранящаяся на пользовательском устройстве 120 Wang, может затем сгенерировать отпечаток голоса для Wang, на основе обработки первого ввода, полученного из аудио 115b, и второго ввода, полученного исходя из использования Wang китайского языка. На основе анализа сгенерированного отпечатка голоса, пользовательское устройство 120 может определить, что Wang аутентифицирован для осуществления доступа к устройству 120. В ответ на определение, что Wang аутентифицирован для осуществления доступа к пользовательскому устройству 120, пользовательское устройство 120 может инициировать обработку, которая разблокирует пользовательское устройство 120. В некоторых случаях, пользовательское устройство 120 может отобразить сообщение на графическом пользовательском интерфейсе 122, которое говорит, например, "Shuōhuàzhě de shēnfèn yànzhèng" 123 (грубо переводимое на английский как "Speaker Identity Verified"). В качестве альтернативы, или в дополнение, когда пользовательское устройство 120 разблокировано, динамик пользовательского устройства 120 может вывести аудиоприветствие 125, которое говорит "Huānyíng Wang" (грубо переводимое на английский как "Welcome Wang").
[31] Как показано в примере по Фиг. 1, единая зависимая от текста модель 180 распознавания говорящего может быть выполнена с возможностью использования разных предварительно определенных ключевых слов для разных языков или местоположений. В дополнение, или в качестве альтернативы, модель 180 может использовать одно и то же ключевое слово для многочисленных языков или местоположений, но модель 180 может генерировать представления говорящего относительно разных вариаций произношения ключевого слова, например, из-за разных языков или региональных акцентов. Как рассмотрено ниже, модель 180 может тонко настроить процесс верификации посредством ввода идентификатора для языка или местоположения в нейронную сеть модели 180 вместе с аудиоинформацией.
[32] Фиг. 2 является примером системы 200 для обучения независимой от языка модели 280 верификации говорящего. Система 200 включает в себя пользовательское устройство 210, сеть 230, сервер 240 и нейронную сеть 250. В общем, обучение независимой от языка модели 280 верификации говорящего происходит посредством обработки, которая происходит на сервере 240, до распределения модели 280 на пользовательское устройство 210 и использования для выполнения распознавания говорящего. Такое обучение не требует соединения пользовательского устройства 210 с сетью 230.
[33] Перед началом обучения, сервер 240 получает набор обучающих фрагментов речи 210a и 210b. Обучающие фрагменты речи могут включать в себя один или более образцов речи, каждый из который был соответственно произнесен многочисленными разными обучающими говорящими, записан и сохранен в репозитории обучающих фрагментов речи, сделанным доступным для сервера 240. Каждый обучающий фрагмент речи 210a, 210b может включать в себя по меньшей мере участок аудиосигнала, который возникает, когда пользователь произносит обучающий фрагмент речи.
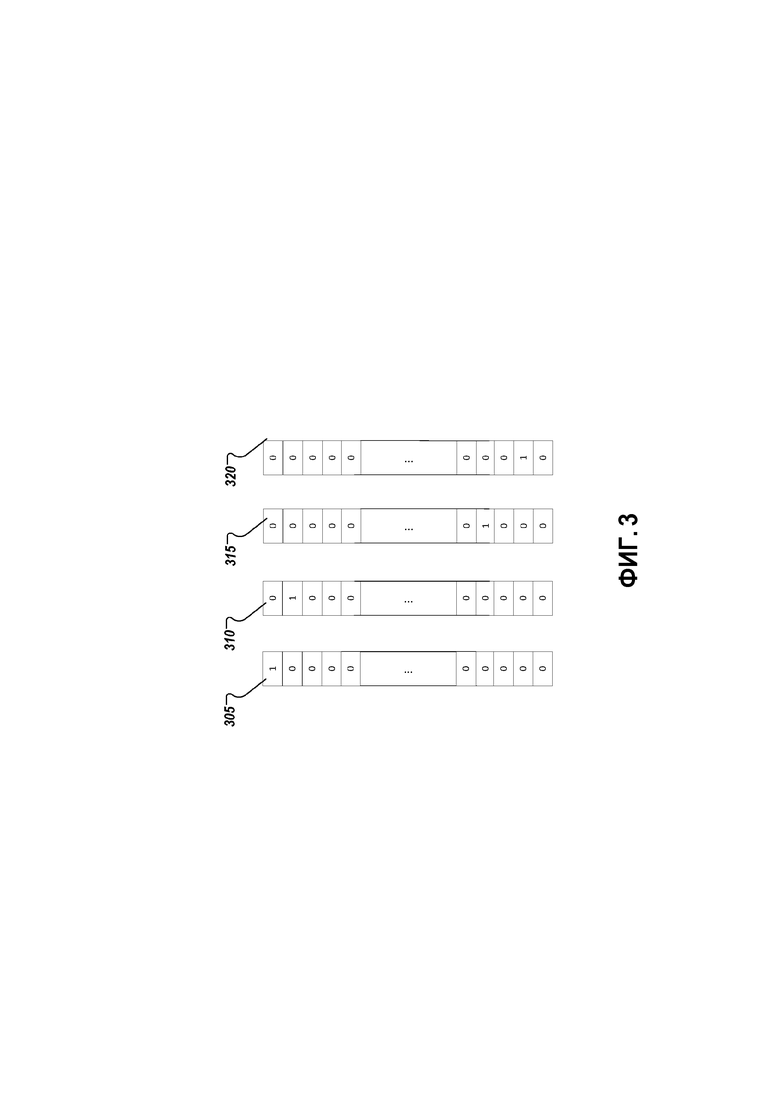
[34] Чтобы способствовать голосовой аутентификации, нейронная сеть 250 может быть обучена с использованием обучающих фрагментов речи, которые соответствуют предварительно определенному ключевому слову, которое может быть произнесено пользователем пользовательского устройства 210 во время голосовой аутентификации. Обучающие фрагменты речи могут включать в себя фрагменты речи от многочисленных разных пользователей, каждый из которых произносит одно и то же ключевое слово на разном языке, разном диалекте, с разным акцентом или подобным. В одной реализации, многочисленные наборы обучающих данных могут быть использованы для обучения нейронной сети 250, причем каждый набор обучающих данных, соответствующий произнесению конкретного ключевого слова на конкретном языке, диалекте, с акцентом или подобным. Например, единая нейронная сеть 250 может быть обучена с помощью набора обучающих фрагментов речи от многочисленных разных пользователей, произносящих "Ok Google" на американском английском, и другого набора обучающих данных, где многочисленные разные пользователи произносят "Ok Google" на британском английском. В одной реализации, единая нейронная сеть 250 может быть аналогичным образом обучена с помощью других наборов обучающих данных, которые включают в себя ключевое слово "Ok Google", произнесенное на разных языках, с разными диалектами, разными акцентами или подобным, пока нейронная сеть 250 не будет обучена для всех известных языков, диалектов, акцентов или подобного. В качестве альтернативы, единая нейронная сеть 250 может быть аналогичным образом обучена с помощью других наборов обучающих данных, которые включают в себя ключевое слово "Ok Google", произнесенное на разных языках, с разными диалектами, разными акцентами или подобным, пока нейронная сеть 250 не будет обучена для всех языков, диалектов, акцентов или подобного в регионах, где будет развернута модель верификации говорящего на основе нейронной сети 250. Как использовано в настоящем документе, ключевое слово может быть одиночным словом или фразой, которая включает в себя многочисленные слова. В некоторых реализациях, ключевое слово для каждого языка является фиксированным во время обучения модели, так что каждый пользователь с использованием модели в конкретном местоположении использует то же самое ключевое слово.
[35] Аудиосигналы, соответствующие произнесенным обучающим фразам, могут быть захвачены и записаны. Хотя предоставленные здесь примеры обучающих фрагментов речи, соответствующих предварительно определенному ключевому слову, включают в себя "Ok Google" и "Nǐ hǎo Android", настоящее раскрытие не должно ограничиваться таким образом. Вместо этого, обучающие фрагменты речи, соответствующие любому предварительно определенному ключевому слову, на любом языке или любом диалекте могут быть использованы для обучения нейронной сети 250. В дополнение, предполагается, что нейронная сеть 250 может быть легко обучена для вмещения всех известных языков, диалектов, акцентов или подобного.
[36] В некоторых случаях, обучающего говорящего могут попросить произнести, и записать, одну и ту же обучающую фразу множество раз для того, чтобы сгенерировать многочисленные разные обучающие фрагменты речи для одного и того же обучающего слова или фразы. Таким образом, обучающие фрагменты речи могут быть получены с использованием многочисленных разных говорящих, произносящих обучающее слово или фразу на многочисленных разных языках, многочисленных разных диалектах или подобном. Как только обучающие фрагменты речи 210a, 210b получены, система 200 может получить 212a, 212b соответствующий вектор признаков для каждого обучающего фрагмента речи, который соответствует акустическим признакам соответствующего обучающего фрагмента речи. Соответствующий вектор признаков для каждого обучающего фрагмента речи может включать в себя, например, вектор N на 1, который получен из обучающего фрагмента речи и соответствует акустическим признакам фрагмента речи. Вектор N на 1 может быть концептуально смоделирован с использованием одиночной колонны из N значений. В одной реализации, каждое из N значений в векторе N на 1 может включать в себя значение либо "0", либо "1".
[37] Система 200 может также получить многочисленные разные ID 215a, 215b языков. ID языка может включать в себя данные, которые идентифицируют конкретный язык. В одной реализации, ID языка может включать в себя вектор языка с одним активным состоянием. Такие векторы языка с одним активным состоянием могут включать в себя вектор N на 1, где активирован только один признак вектора языка. Конкретный признак вектора языка может быть активирован, например, посредством задания признака в значение "1". Аналогично, для любого заданного вектора языка с одним активным состоянием, все остальные признаки вектора языка с одним активным состоянием будут деактивированы. Признак вектора языка может быть деактивирован, например, посредством задания признака в значение "0".
[38] Фиг. 3 является примером концептуального представления множества векторов 305, 310, 315, 320 языка с одним активным состоянием. В каждом векторе 305, 310, 315, 320 языка с одним активным состоянием был активирован только один признак, тогда как все остальные признаки деактивированы. Система 200 может ассоциировать каждый вектор 305, 310, 315, 320 языка с одним активным состоянием с конкретным языком. Например, система 200 может определить, что вектор языка с одним активным состоянием с активированным первым признаком вектора языка, таким как в случае в отношении вектора 305 идентификации языка, может быть ассоциирован с "английским" языком. Аналогично, система 200 может определить, что вектор языка с одним активным состоянием с активированным вторым признаком вектора, таким как в случае в отношении вектора 310 идентификации языка, может быть ассоциирован с "китайским" языком. Аналогичные ассоциации языка могут быть сделаны между векторами идентификации языков 315 и 320 и другими языками.
[39] Обучение модели 280 верификации говорящего может начаться посредством предоставления обучающих данных нейронной сети 250. В одной реализации, нейронная сеть 250 может быть обучена с использованием метода попарного обучения. Например, первый набор обучающих данных 213a вводится в нейронную сеть 250, которая включает в себя вектор 214a обучающего фрагмента речи, и второй ввод, который включает в себя ID 215a языка. ID 215a языка может включать в себя, например, вектор языка с одним активным состоянием, который идентифицирует язык или диалект, используемый обучающим говорящим, который предоставляет обучающий фрагмент речи 210a, из которого был получен вектор 214a обучающего фрагмента речи. Нейронная сеть 250 обрабатывает первый набор обучающих данных 213a и генерирует вывод 260a. Впоследствии, второй набор обучающих данных 213b вводится в нейронную сеть 250. Нейронная сеть 250 обрабатывает второй набор обучающих данных 213b и генерирует вывод 260b. Выводы 260a, 260b затем сравниваются с использованием компаратора 270. Компаратор 270 анализирует выводы 260a, 260b для определения, были ли обучающие векторы 214a, 214b получены из обучающих фрагментов речи 210a, 210b, которые были произнесены одним и тем же говорящим. В одной реализации, модуль 440 сравнения может определить, были ли обучающие векторы 214a, 214b получены из обучающих фрагментов речи 210a, 210b, которые были произнесены одним и тем же говорящим, посредством вычисления расстояния между выводами 260a, 260b. Такое расстояние может быть вычислено, например, с использованием косинусного подобия.
[40] Вывод 272 модуля сравнения предоставляет указание, были ли обучающие фрагменты речи 210a, 210b произнесены одним говорящим. В одной реализации, например, выводом 272 может быть двоичное значение, которое содержит либо "0", либо "1". В такой реализации, "0" может указывать, что фрагменты речи были не от одного говорящего. С другой стороны, "1" может указывать, что фрагменты речи были от одного говорящего. В качестве альтернативы, выводом 272 может быть значение, которое может быть отображено в двоичное значение, такое как "0" или "1". Например, вывод 272 может включать в себя вероятность, которая указывает, были ли обучающие фрагменты речи 210a, 210b произнесены одним говорящим. Параметры нейронной сети 250 могут быть затем отрегулированы на основе вывода 272 модуля сравнения 270. В некоторых реализациях, параметры нейронной сети 250 могут быть отрегулированы автоматически на основе вывода 272. В качестве альтернативы, в некоторых реализациях, один или более параметров нейронной сети могут быть отрегулированы вручную на основе вывода 272. Многочисленные наборы обучающих данных могут обрабатываться таким образом, пока сравнение двух выводов 260a, 260b не будет неизменно указывать, была ли пара обучающих векторов, таких как 214a, 214b, получена из фрагментов речи 210a, 210b, которые были произнесены одним говорящим.
[41] Нейронная сеть 250 может включать в себя слой 252 ввода для ввода наборов обучающих данных, многочисленных скрытых слоев 254a, 254b, 254c для обработки наборов обучающих данных, и слой 256 вывода для предоставления вывода. Каждый скрытый слой 254a, 254b, 254c может включать в себя один или более весов или других параметров. Веса или другие параметры каждого соответствующего скрытого слоя 254a, 254b, 254c могут быть отрегулированы так, что обученная нейронная сеть производит желаемый целевой вектор, соответствующий каждому набору обучающих данных. Вывод каждого скрытого слоя 254a, 254b, 254c может сгенерировать вектор активации M на 1. Вывод последнего скрытого слоя, такого как 254c, может быть предоставлен слою 256 вывода, который выполняет дополнительные вычисления принятого вектора активации, для того, чтобы сгенерировать вывод нейронной сети. Как только нейронная сеть 250 достигает желаемого уровня производительности, нейронная сеть 250 может быть обозначена как обученная нейронная сеть. Например, нейронная сеть 250 может обучаться до тех пор, пока сеть 250 не сможет делать различие между речью разных говорящих, и идентифицировать совпадения между речью одного говорящего, с частотой ошибок, меньшей, чем максимальная частота ошибок.
[42] Набор обучающих данных, такой как 213a, который включает в себя вектор 214a обучающего фрагмента речи и ID 215a языка, может быть предварительно обработан до предоставления в качестве ввода в нейронную сеть 250 всевозможными способами. Например, вектор 214a обучающего фрагмента речи и ID 215a языка, такой как вектор языка с одним активным состоянием, могут быть объединены. В таких случаях, объединенный вектор может быть предоставлен как ввод в нейронную сеть 250 во время обучения. В качестве альтернативы, система 200 может сгенерировать ввод в нейронную сеть 250 посредством объединения выводов по меньшей мере двух других нейронных сетей, которые имеют соответствующим образом сгенерированные выводы на основе обработки каждой соответствующей нейронной сетью вектора 214a обучающего фрагмента речи, вектора языка с одним активным состоянием, или и вектора 214a обучающего фрагмента речи, и вектора языка с одним активным состоянием. В таких случаях, объединенный вывод двух или более других нейронных сетей может быть использован для обучения нейронной сети 250. В качестве альтернативы, система 200 может сгенерировать входной вектор на основе вектора 214a обучающего фрагмента речи и взвешенной суммы вектора языка с одним активным состоянием. Могут быть использованы другие способы генерирования набора обучающих данных на основе вектора 214a обучающего фрагмента речи и вектора языка с одним активным состоянием.
[43] Участок 258 нейронной сети 250 может быть получен, как только нейронная сеть 250 обозначена как обученная, и использован для генерирования модели 280 верификации говорящего. Полученный участок 258 нейронной сети 250 может включать в себя слой 252 ввода нейронной сети 250 и один или более скрытых слоев нейронной сети 254a. В некоторых реализациях, однако, полученный участок нейронной сети 250 не включает в себя слой 256 вывода. Как только обучена, нейронная сеть 250 способна произвести вектор активации как вывод последнего скрытого слоя полученного участка 258, который может быть использован как отпечаток голоса для говорящего. Отпечаток голоса может быть использован пользовательским устройством для верификации подлинности человека, который предоставляет фрагмент речи с ключевым словом пользовательскому устройству.
[44] Сервер 240 передает копию модели 280 верификации говорящего через сеть 230 одному или более соответствующим пользовательским устройствам, таким как пользовательское устройство 210. Копия модели 280 верификации говорящего затем сохраняется на каждом соответствующим пользовательском устройстве 110, и может быть использована для способствования независимой от языка верификации подлинности говорящего. В качестве другого примера, модель 280 верификации говорящего может быть предварительно установлена на пользовательское устройство 210, например, с помощью операционной системы пользовательского устройства 210.
[45] Фиг. 4 является примером системы 400, которая выполняет независимую от языка верификацию подлинности говорящего. Система 400 включает в себя пользовательское устройство 210, модель 280 верификации говорящего, модуль 440 сравнения и модуль 450 верификации.
[46] В примере, показанном на Фиг. 4, пользователь 402 пытается осуществить доступ к пользовательскому устройству 210 с использованием голосовой верификации. Пользовательское устройство 210, которое ранее приняло, и сохранило, модель 280 верификации говорящего, предоставленную сервером 240 через сеть 230. Для осуществления доступа к пользовательскому устройству 210 с использованием голосовой верификации, пользователь 402 произносит предварительно определенное ключевое слово 410a или фразу, такую как "Ok Google". Аудио 410b, соответствующее предварительно определенному ключевому слову 410a или фразе "Ok Google", обнаруживается микрофоном 211 пользовательского устройства 210. Пользовательское устройство 410b может получить 413 вектор акустических признаков из аудио 410b, которое представляет акустические признаки аудио 410b.
[47] В дополнение, система 400 может получить ID 415 языка, который сохранен в области хранения ID языков пользовательского устройства 210. ID языка может включать в себя данные, которые идентифицируют конкретный язык или диалект, ассоциированный с пользователем. В одной реализации, ID языка может включать в себя вектор языка с одним активным состоянием. ID 415 языка, который хранится на любом конкретном пользовательском устройстве 210, может быть задан в значение ID конкретного языка из набора ID многочисленных разных языков, соответствующих известным языкам и диалектам, любым числом разных способов. Например, пользователь может выбрать конкретный язык или диалект при включении питания, и конфигурировании, пользовательского устройства 210 в первый раз после приобретения пользовательского устройства 210. ID соответствующего языка может быть выбран, и сохранен в пользовательском устройстве 210, на основе конкретного языка или диалекта, выбранного пользователем.
[48] В качестве альтернативы, или в дополнение, ID конкретного языка может быть выбран, и сохранен в пользовательском устройстве 210, на основе местоположения устройства. Например, пользовательское устройство 210 может установить настройки по умолчанию для ID языка на основе местоположения, где устройство было впервые активировано, текущего местоположения устройства или подобного. В качестве альтернативы, или в дополнение, пользовательское устройство 210 может динамически обнаруживать конкретный язык или диалект, ассоциированный с пользователем, на основе образцов речи, полученных от пользователя. Динамическое обнаружение конкретного языка или диалекта, ассоциированного с пользователем, может быть определено, например, когда пользователь произносит предварительно определенное ключевое слово, во время аутентификации говорящего. В таких случаях, ID соответствующего языка может быть выбран, и сохранен на пользовательском устройстве 210, на основе языка или диалекта, обнаруженного из образцов речи пользователя. В качестве альтернативы, или в дополнение, пользователь может в любое время модифицировать настройки языка или диалекта, ассоциированные с пользовательским устройством 210, для того, чтобы выбрать конкретный язык или диалект. В таких случаях, ID соответствующего языка может быть выбран, и сохранен на пользовательском устройстве 210, на основе пользовательской модификации настроек языка или диалекта пользовательского устройства 210.
[49] Вектор 414 акустических признаков и ID 415 языка могут быть предоставлены в качестве ввода в модель 280 верификации речи, которая основана по меньшей мере на участке обученной нейронной сети 250. Например, модель 280 верификации речи может включать в себя один или более слоев обученной нейронной сети 250, таких как, например, слой 252 ввода и один или более скрытых слоев 254a, 254b, 254. В одной реализации, однако, модель 280 верификации речи не использует слой 256 вывода нейронной сети 250.
[50] Вектор 414 акустических признаков и ID 415 языка могут быть предоставлены как ввод в модель 280 верификации речи всевозможными способами. Например, вектор 414 акустических признаков и ID 415 языка, такой как вектор языка с одним активным состоянием, могут быть объединены. В таких случаях, объединенный вектор может быть предоставлен как ввод в модель верификации речи. В качестве альтернативы, система 400 может объединить выводы по меньшей мере двух других нейронных сетей, которые соответственно сгенерировали выводы на основе обработки каждой соответствующей нейронной сетью вектора 414 акустических признаков, ID 415 языка, такого как вектор языка с одним активным состоянием, или и вектора 414 акустических признаков, и ID 415 языка. В таких случаях, объединенный вывод двух или более других нейронных сетей может быть предоставлен модели 280 верификации речи. В качестве альтернативы, система 400 может сгенерировать входной вектор на основе вектора 414 акустических признаков и взвешенной суммы вектора языка с одним активным состоянием, используемого как ID 415 языка. Могут быть использованы другие способы генерирования входных данных для модели 280 верификации речи на основе вектора 414 акустических признаков и ID 415 языка.
[51] Обработка моделью 280 верификации речи предоставленных входных данных на основе вектора 414 акустических признаков и ID 415 языка может дать в результате генерирование набора активаций в одном или более скрытых слоях нейронной сети модели 280 верификации речи. Например, обработка моделью 280 верификации речи предоставленного ввода может дать в результате набор активаций, сгенерированных в первом скрытом слое 254a, втором скрытом слое 255b, третьем скрытом слое 254c или подобных. В одной реализации, система 400 может получить активации, выведенные последним скрытым слоем 254c нейронной сети модели 280 верификации речи. Активации, выведенные последним скрытым слоем 254c, могут быть использованы для генерирования вектора 420 говорящего. Этот вектор 420 говорящего предоставляет представление, которое указывает характеристики голоса пользователя. Этот вектор говорящего может называться отпечатком голоса. Отпечаток голоса может быть использован, чтобы уникальным образом верифицировать подлинность говорящего на основе характеристик голоса пользователя.
[52] Модуль 440 сравнения может быть выполнен с возможностью приема вектора 420 говорящего и опорного вектора 430. Опорный вектор 430 может быть вектором, который был получен из предыдущего фрагмента речи пользователя, захваченного устройством, например, фрагмента речи, предоставленного во время регистрации пользователя на устройстве. Например, в некоторый момент времени до использования пользователем 402 системы 400 для разблокирования пользовательского устройства 210 с использованием голосовой аутентификации, пользователь 402 может произнести фразу, такую как "Ok Google", один или несколько раз. Пользовательское устройство 210 может быть выполнено с возможностью использования микрофона 211 для захвата аудиосигналов, которые соответствуют фрагментам речи пользователя. Пользовательское устройство 210 может затем получить опорный вектор признаков 430 из аудиосигналов, которые соответствуют по меньшей мере одной из произнесенных фраз, захваченных в некоторый момент времени до использования пользователем 402 системы 400 для разблокировки пользовательского устройства 210 с использованием голосовой аутентификации. Опорный вектор 430 может предоставить базовое представление характеристик голоса пользователя 402, с которым можно сравнить сгенерированный отпечаток голоса. В одной реализации, опорный вектор 430 может быть сгенерирован на основе фрагмента речи пользователя 402 с предварительно определенным ключевым словом, которое может быть произнесено для разблокировки телефона во время голосовой авторизации.
[53] Модуль 440 сравнения может определить уровень сходства между вектором 420 говорящего и опорным вектором 430. В одной реализации, модуль 440 сравнения может вычислить показатель сходства между вектором 420 говорящего и опорным вектором 430. В некоторых случаях, модуль 440 сравнения может определить, превышает ли показатель сходства между вектором 420 говорящего и опорным вектором 430 предварительно определенный порог. В тех случаях, когда показатель сходства превышает предварительно определенный порог, модуль 440 сравнения может предоставить выходные данные в модуль 450 верификации, указывающие, что показатель сходства превышает предварительно определенный порог. В качестве альтернативы, модуль 440 сравнения может определить, что показатель сходства не превышает предварительно определенный порог. В таких случаях, модуль 440 сравнения может предоставить выходные данные в модуль 450 верификации, указывающие, что показатель сходства не превысил предварительно определенный порог.
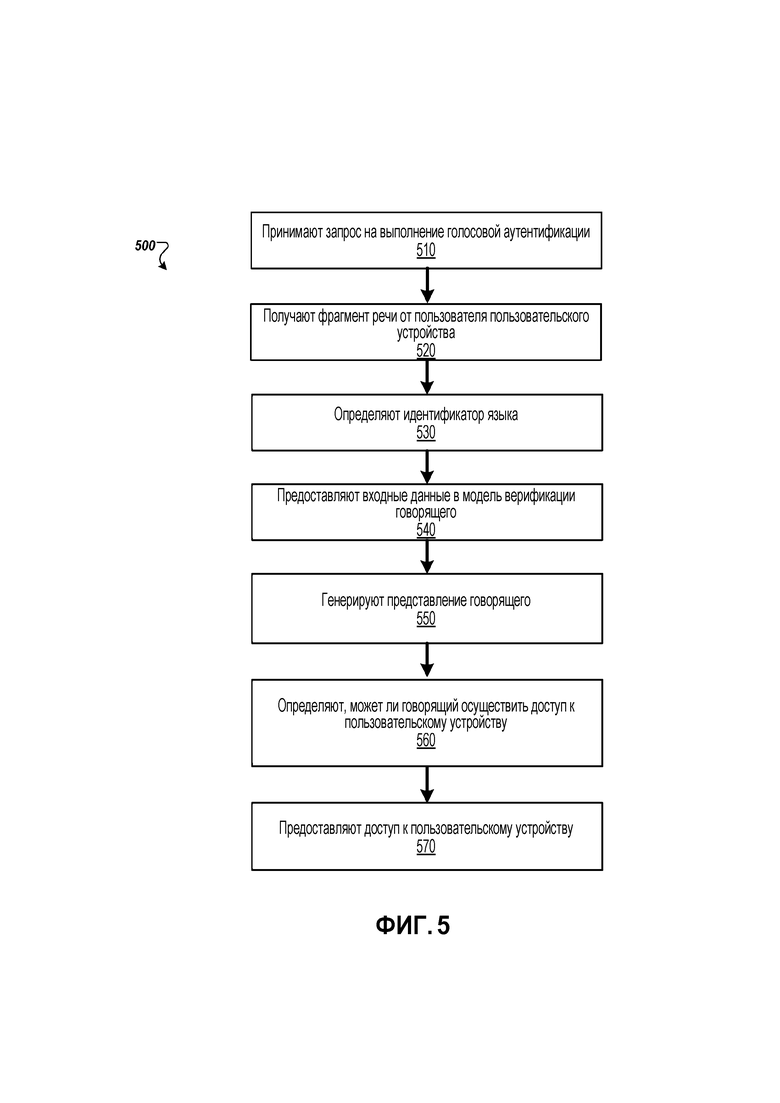
[54] В некоторых реализациях, показатель сходства между вектором 420 говорящего и опорным вектором 430 может быть вычислен на основе расстояния между вектором 420 говорящего и опорным вектором 430. Модуль 440 сравнения может быть выполнен с возможностью определения расстояния между вектором 420 говорящего и опорным вектором 430. В одной реализации, расстояние между вектором 420 говорящего и опорным вектором 430 может быть определено, например, с использованием функции косинуса. Функция косинуса может определить расстояние между вектором 420 говорящего и опорным вектором 430 посредством измерения угла между двумя векторами.
[55] Модуль 450 верификации принимает и интерпретирует выходные данные, которые модуль 450 верификации принимает от модуля 440 сравнения. На основе выходных данных, принятых от модуля 440 сравнения, модуль верификации может определить, является ли пользователь 402, который произнес фразу 410a, из которой был получен вектор 420 говорящего, тем же пользователем, который ранее произнес фразу, из которой был получен опорный вектор 430. Если определено, что пользователь 402, который произнес фразу 410a, из которой был получен вектор 420 говорящего, является тем же пользователем, который ранее произнес фразу, из которой был получен опорный вектор 430, модуль 450 верификации может дать команду приложению, выполняющемуся на пользовательском устройстве 210, предоставить пользователю 402 доступ к устройству 420. В качестве альтернативы, или в дополнение, после определения, что пользователь 402, который произнес фразу 410a, из которой был получен вектор 420 говорящего, является тем же пользователем, который ранее произнес фразу, из которой был получен опорный вектор 420, модуль 450 верификации может предоставить доступ к конкретному ресурсу на устройстве, разблокировать устройство, вывести устройство из режима с пониженным энергопотреблением или подобное.
[56] Модуль 450 верификации может определить, на основе выходных данных от модуля 440 сравнения, что пользователь, который произнес фразу 410a, является тем же пользователем, который произнес фразу, из которой был получен опорный вектор 430, если выходные данные от модуля 440 сравнения, указывают, что показатель сходства превышает предварительно определенный порог. В таких случаях, модуль верификации может определить, что пользователь полностью аутентифицирован и авторизован для использования пользовательского устройства 210. В качестве альтернативы, модуль 450 верификации может определить, на основе выходных данных от модуля 440 сравнения, что модуль 450 верификации не может заключить, что пользователь 402, который произнес фразу 410a, является тем же пользователем, который произнес опорный вектор 430. В таких случаях, пользователь 402 не аутентифицируется, и ему не предоставляется доступ к устройству. Вместо этого, система 400, пользовательское устройство 210, одно или более других приложений, или их комбинация, могут предоставить альтернативные варианты для осуществления доступа к пользовательскому устройству 210. Например, пользовательское устройство 210 может предложить пользователю 402 ввести секретный пароль.
[57] Когда пользователь 402 был аутентифицирован, посредством определения того, что пользователь 402 который произнес фразу 410a, является тем же пользователем, который произнес фразу, из которой был получен опорный вектор 430, пользовательское устройство 210 разблокируется и может вывести сообщение 460 пользователю, указывающее, что "Speaker's Identity is Verified". Это сообщение может быть текстовым сообщением, отображаемым на графическом пользовательском интерфейсе пользовательского устройства 210, аудиосообщением, выведенным динамиком пользовательского устройства 210, видеосообщением, отображаемым на графическом пользовательском интерфейсе пользовательского устройства 210, или комбинацией одного или более из вышеупомянутых типов сообщений.
[58] Фиг. 5 является схемой последовательности операций процесса 500 для выполнения независимой от языка верификации подлинности говорящего. Для удобства, процесс 500 будет описан как выполняющийся системой. Например, система 400, рассмотренная выше, может выполнить процесс 500 для аутентификации пользователя, пытающегося осуществить доступ к пользовательскому устройству 210.
[59] Процесс 500 может начаться, когда пользовательское устройство 210 принимает 510 запрос на выполнение голосовой аутентификации от пользователя устройства. В некоторых реализациях, пользователь может быть должен выбрать кнопку на пользовательском устройстве, выполнить жест на пользовательском интерфейсе пользовательского устройства, выполнить жест в воздухе в области видимости камеры пользовательского устройства или подобное, для того, чтобы дать команду телефону инициировать голосовую аутентификацию пользователя. В таких случаях, после приема команды инициировать голосовую аутентификацию, пользователь может произнести предварительно определенное ключевое слово, на любом языке или диалекте, который может быть использован для верификации подлинности пользователя. В качестве альтернативы, или в дополнение, пользовательское устройство 210 может использовать микрофон, чтобы пассивно "прослушивать" на предмет обнаружения предварительно определенного произнесенного ключевого слова, на любом языке или диалекте, который может быть использован для инициирования голосовой аутентификации пользователя. Предварительно определенное ключевое слово, может включать в себя, например "Hello Phone", "Ok Google", "Nǐ hǎo Android" или подобное. В некоторых реализациях, есть единое ключевое слово для всех пользователей в конкретном местоположении или всех пользователей, которые говорят на конкретном языке.
[60] Процесс может продолжиться на этапе 520, когда система 400 получает фрагмент речи, введенный пользователем пользовательского устройства 210. Фрагмент речи может включать в себя, например, предварительно определенное ключевое слово, на любом языке или диалекте, который может быть использован для инициализации голосовой аутентификации пользователя. Система 400 может получить вектор акустических признаков из аудиосигналов, соответствующих полученному фрагменту речи.
[61] Система 400 может определить 530 идентификатор языка, ассоциированный с пользовательским устройством 210. Идентификатор языка может включать в себя данные, которые идентифицируют конкретный язык или диалект, ассоциированный с пользователем. В одной реализации, идентификатор языка может включать в себя вектор языка с одним активным состоянием. Идентификатор 415 языка, который храниться на любом конкретном пользовательском устройстве 210, может быть задан в значение идентификатора конкретного языка из пула идентификаторов многочисленных разных языков, соответствующих известным языкам и диалектам, любым числом разных способов, например, как описано выше. Однако, изобретение согласно настоящему описанию не ограничивается только известными в настоящее время языками или диалектами. Например, модель верификации говорящего может быть обучена для вмещения новых языков, диалектов или акцентов. Когда модель верификации говорящего обучается повторно, установление соответствий между языками или местоположениями и идентификаторами могут быть отрегулированы, например, чтобы добавить новые местоположения или языки.
[62] Система 400 может предоставить 540 входные данные в модель верификации говорящего на основе вектора акустических признаков и идентификатора языка. Ввод может быть предоставлен в модель верификации говорящего всевозможными способами. Например, вектор акустических признаков и идентификатор языка, такой как вектор языка с одним активным состоянием, могут быть объединены. В таких случаях, объединенный вектор может быть предоставлен как ввод в модель верификации речи. В качестве альтернативы, система 400 может объединить выводы по меньшей мере двух других нейронных сетей, которые соответственно сгенерировали выводы на основе обработки каждой соответствующей нейронной сетью вектора акустических признаков, идентификатора языка, такого как вектор языка с одним активным состоянием, или и вектора акустических признаков и идентификатора языка. В таких случаях, объединенный вывод двух или более других нейронных сетей может быть предоставлен модели верификации речи. В качестве альтернативы, система 400 может сгенерировать входной вектор на основе вектора акустических признаков и взвешенной суммы вектора языка с одним активным состоянием, используемого как идентификатор языка. Могут быть использованы другие способы генерирования входных данных для модели 280 верификации речи на основе вектора акустических признаков и идентификатора языка.
[63] Система 400 может сгенерировать представление говорящего на основе ввода, представленного на этапе 540. Например, модель верификации говорящего может включать в себя нейронную сеть, которая обрабатывает ввод, предоставленный на этапе 540, и генерирует набор активаций в одном или более скрытых слоях. Представление говорящего может быть затем получено из конкретного набора активаций, полученного по меньшей мере из одного скрытого слоя нейронной сети. В одной реализации, активации могут быть получены из последнего скрытого слоя нейронной сети. Представление говорящего может включать в себя вектор признаков, который указывает характеристики голоса пользователя.
[64] На этапе 560, система 400 может определить, может ли говорящий фрагмента речи, полученного на этапе 520, осуществить доступ к пользовательскому устройству 210. Это определение может быть основано, например, на сравнении представления говорящего с опорным представлением. Опорным может быть вектор признаков, который был получен из ввода пользовательского фрагмента речи в пользовательское устройство 210 в некоторый момент времени до осуществления пользователем запроса на доступ к пользовательскому устройству с использованием голосовой аутентификации. Сравнение представления говорящего с опорным представлением может привести к определению показателя сходства, который указывает сходство между представлением говорящего и опорным представлением. Показатель сходства может включать в себя расстояние между представлением говорящего и опорным представлением. В одной реализации, расстояние может быть вычислено с использованием функции косинуса. Если определено, что показатель сходства превышает предварительно определенный порог, система 400 может определить предоставить 570 пользователю доступ к пользовательскому устройству 210.
[65] Варианты осуществления изобретения, функциональные операции и процессы, описанные в этом описании, могут быть реализованы в виде цифровой электронной схемы, в виде материально осуществленного компьютерного программного обеспечения или программно-аппаратных средств, в виде компьютерных аппаратных средств, включающих в себя структуры, раскрытые в этом описании, и их структурные эквиваленты, или в виде комбинаций одного или более из них. Варианты осуществления изобретения, описанного в этом описании, могут быть реализованы как одна или более компьютерных программ, т.е., один или более модулей инструкций компьютерной программы, закодированных на материальном энергонезависимом носителе программ для исполнения устройством обработки данных или управления его работой. В качестве альтернативы или в дополнение, программные инструкции могут быть кодированы в искусственно сгенерированном распространяемом сигнале, например, сгенерированном машиной электрическом, оптическом или электромагнитном сигнале, который сгенерирован для кодирования информации для передачи в подходящее устройство приемника для исполнения посредством устройства обработки данных. Компьютерный носитель информации может быть машиночитаемым устройством хранения, подложкой с машиночитаемым устройством хранения, устройством памяти с произвольным или последовательным доступом, или комбинацией одного или более из них.
[66] Термин "устройство обработки данных" охватывает все виды устройств и машин для обработки данных, включающих в себя в качестве примера программируемый процессор, компьютер, или несколько компьютеров или процессоров. Устройство может включать в себя логическую схему специального назначения, например, FPGA (программируемую пользователем вентильную матрицу) или ASIC (специализированную интегральную микросхему). Устройство может также включать в себя, в дополнение к аппаратным средствам, код, который создает исполнительная среда для компьютерной программы, например, код, который составляет программно-аппаратные средства процессора, стек протоколов, систему управления базой данных, операционную систему, или комбинацию одного или более из них.
[67] Компьютерная программа (которая может называться или описываться как программа, программное обеспечение, программное приложение, модуль, программный модуль, скрипт или код) может быть написана в любой форме языка программирования, включающей в себя компилируемые или интерпретируемые языки, декларативные или процедурные языки, и она может быть развернута в любой форме, включающей в себя в качестве самостоятельной программы или в качестве модуля, компонент, стандартную подпрограмму или другой блок, подходящий для использования в вычислительной среде. Компьютерная программа может, но не должна, соответствовать файлу в файловой системе. Программа может храниться в части файла, которая хранит другие программы или данные (например, один или более сценариев, хранящихся в документе языка разметки), в отдельном файле, выделенном программе, о которой идет речь, или в многочисленных согласованных файлах (например, файлах, которые хранят один или более модулей, подпрограмм, или частей кода). Компьютерная программа может быть развернута для исполнения на одном компьютере или многочисленных компьютерах, которые размещены на одном участке или распределены по многочисленным участкам и взаимно соединены посредством сети связи.
[68] Процессы и логические потоки, описанные в этом описании, могут выполняться одним или более программируемыми компьютерами, исполняющими одну или более компьютерных программ для выполнения функций посредством оперирования с входными данными и генерирования вывода. Процессы и логические потоки могут также выполняться, и устройство может быть также реализовано как, логической схемой специального назначения, например, FPGA (программируемой пользователем вентильной матрицей) или ASIC (специализированной интегральной микросхемой).
[69] Компьютеры, подходящие для выполнения компьютерной программы, включают в себя, в качестве примера, могут быть основаны на микропроцессорах общего или специального назначения, или обоих, или любом другом виде центрального процессора. В общем, центральный процессор будет принимать инструкции и данные из постоянной памяти или оперативной памяти, или обеих. Необходимыми элементами компьютера являются центральный процессор для выполнения или исполнения инструкций и одно или более запоминающих устройств для хранения инструкций и данных. В общем, компьютер будет также включать в себя одно или более устройств хранения большой емкости для хранения данных, например, магнитные, магнитно-оптические диски или оптические диски, или оперативно соединен для приема данных от них или передачи им данных, или того и другого. Однако, компьютеру не требуется иметь такие устройства. Более того, компьютер может быть встроен в другое устройство, например, мобильный телефон, персональный цифровой помощник (PDA), мобильный аудио или видеопроигрыватель, игровую консоль, приемник системы глобального позиционирования (GPS), или портативное устройство хранения (например, flash-накопитель с универсальной последовательной шиной (USB)), для примера.
[70] Компьютерно-читаемые носители, подходящие для хранения инструкций компьютерной программы и данных, включают в себя все виды энергонезависимой памяти, носителей и запоминающих устройств, например, EPROM, EEPROM и устройства flash-памяти; магнитные диски, например, внутренние жесткие диски или съемные диски; магнито-оптические диски; и диски CD-ROM и DVD-ROM. Процессор и память могут быть дополнены специальной логической схемой или соединены с ней.
[71] Для обеспечения взаимодействия с пользователем, варианты осуществления изобретения, описанного в это описании, могут быть реализованы на компьютере, имеющем устройство отображения, например, монитор с CRT (катодно-лучевой трубкой) или LCD (жидкокристаллическим дисплеем), для отображения информации пользователю, и клавиатуру и указывающее устройство, например, мышь или шаровый манипулятор, посредством которого пользователь может предоставить ввод компьютеру. Также могут быть использованы другие виды устройств для обеспечения взаимодействия с пользователем; например, обратная связь, предоставляемая пользователю, может быть любой формой сенсорной обратной связи, например, визуальной обратной связью, слышимой обратной связью или тактильной обратной связью; и ввод от пользователя может быть принят в любом виде, включая акустический, речевой или тактильный ввод. В дополнение, компьютер может взаимодействовать с пользователем посредством отправки документов на устройство, которое используется пользователем, и приема документов от него; например, посредством отправки веб-страницы в веб-браузер на пользовательском устройстве пользователя в ответ на запросы, принятые от веб-браузера.
[72] Варианты осуществления изобретения, описанного в этом описании, могут быть реализованы в вычислительной системе, которая включает в себя внутренний компонент, например, как сервер данных, или которая включает в себя промежуточный компонент, например, сервер приложений, или которая включает в себя внешний компонент, например, клиентский компьютер, имеющий графический пользовательский интерфейс или веб-браузер, посредством которого пользователь может взаимодействовать с изобретением, описанным в этом описании, или любую комбинацию таких внутреннего, промежуточного или внешнего компонентов. Компоненты системы могут быть взаимно соединены посредством любого вида или среды передачи цифровых данных, например, сети связи. Примеры сетей связи включают в себя локальную сеть ("LAN") и глобальную сеть ("WAN"), например, Интернет.
[73] Вычислительная система может включать в себя клиенты и серверы. Клиент и сервер обычно отдалены друг от друга и обычно взаимодействуют посредством сети связи. Взаимосвязь клиента и сервера возникает в силу выполнения компьютерных программ на соответствующих компьютерах и наличия взаимосвязи "клиент-сервер" друг с другом.
[74] Хотя это описание содержит много характерных для реализации сведений, они не должны трактоваться как ограничения на объем того, что может быть заявлено, но скорее как описания признаков, которые могут быть характерны для конкретных вариантов осуществления. Конкретные признаки, которые описаны в этом описании в контексте раздельных вариантов осуществления, могут быть также реализованы в комбинации с отдельным вариантом осуществления. И наоборот, различные признаки, которые описаны в контексте отдельного варианта осуществления, могут быть также реализованы в нескольких вариантах осуществления раздельно или в любой подходящей подкомбинации. Более того, хотя признаки могут быть описаны выше как действующие в определенных комбинациях и даже изначально заявленные как таковые, один или более признаков из заявленной комбинации могут в некоторых случаях удаляться из данной комбинации, и заявленная комбинация может быть направлена на подкомбинацию или вариацию подкомбинации.
[75] Аналогично, в то время как операции изображены на чертежах в конкретном порядке, это не должно пониматься как требование того, что такие операции должны выполняться в конкретном показанном порядке или в последовательном порядке, или что все проиллюстрированные операции должны выполняться, чтобы достигнуть желаемых результатов. В определенных обстоятельствах, многозадачная и параллельная обработка может быть полезной. Более того, разделение различных компонентов системы в вариантах осуществления, описанных выше, не следует понимать как требование такого разделения во всех вариантах осуществления, и следует понимать, что описанные программные компоненты и системы могут в основном быть интегрированы вместе в едином программном продукте или упакованы в многочисленные программные продукты.
[76] Были описаны конкретные варианты осуществления изобретения. Другие варианты осуществления находятся в рамках объема нижеследующей формулы изобретения. Например, действия, изложенные в формуле изобретения, могут быть выполнены в другом порядке и все равно достигнут желаемых результатов. В качестве одного примера, процессы, изображенные на прилагающихся Фигурах не обязательно требуют конкретного показанного порядка, или последовательного порядка, для достижения желаемых результатов. В некоторых реализациях, многозадачная и параллельная обработка может быть полезной. Могут быть предусмотрены другие этапы или стадии, или этапы или стадии могут быть удалены из описанных процессов. Соответственно, другие реализации находятся в рамках объема нижеследующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ ГОВОРЯЩЕГО ПОЛЬЗОВАТЕЛЯ УПРАВЛЯЕМОГО ГОЛОСОМ УСТРОЙСТВА | 2018 |
|
RU2744063C1 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |
| ДИНАМИЧЕСКАЯ АКУСТИЧЕСКАЯ МОДЕЛЬ ДЛЯ ТРАНСПОРТНОГО СРЕДСТВА | 2015 |
|
RU2704746C2 |
| СПОСОБ И ОБОРУДОВАНИЕ РАСПОЗНАВАНИЯ ЭМОЦИЙ В РЕЧИ | 2019 |
|
RU2720359C1 |
| ИНДИВИДУАЛЬНО НАСТРОЕННЫЙ ВЫВОД, КОТОРЫЙ ОПТИМИЗИРУЕТСЯ ДЛЯ ПОЛЬЗОВАТЕЛЬСКИХ ПРЕДПОЧТЕНИЙ В РАСПРЕДЕЛЕННОЙ СИСТЕМЕ | 2020 |
|
RU2821283C2 |
| ПОИСК ИЗОБРАЖЕНИЙ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2688271C2 |
| СПОСОБ СОЗДАНИЯ МОДЕЛИ АНАЛИЗА ДИАЛОГОВ НА БАЗЕ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ОБРАБОТКИ ЗАПРОСОВ ПОЛЬЗОВАТЕЛЕЙ И СИСТЕМА, ИСПОЛЬЗУЮЩАЯ ТАКУЮ МОДЕЛЬ | 2019 |
|
RU2730449C2 |
| СПОСОБЫ И СЕРВЕРЫ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ ОБНАРУЖЕНИЮ СМЕНЫ ДИКТОРА | 2024 |
|
RU2841235C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ РЕЧЕВОГО ФРАГМЕНТА ПОЛЬЗОВАТЕЛЯ | 2021 |
|
RU2808582C2 |
| УПРАВЛЕНИЕ АКУСТИЧЕСКОЙ ЭХОКОМПЕНСАЦИЕЙ ДЛЯ РАСПРЕДЕЛЕННЫХ АУДИОУСТРОЙСТВ | 2020 |
|
RU2818982C2 |



Изобретение относится к верификации говорящего. Технический результат – обеспечение точной верификации подлинности говорящих, которые говорят на разных языках или диалектах. Предлагаются способы, системы, устройство, включающее в себя компьютерные программы, кодированные на компьютерном носителе информации, для способствования независимой от языка верификации говорящего. В одном аспекте, способ включает в себя действия по приему, пользовательским устройством, аудиоданных, представляющих фрагмент речи пользователя. Другие действия могут включать в себя предоставление в нейронную сеть, хранящуюся на пользовательском устройстве, входных данных, полученных из аудиоданных и идентификатора языка. Нейронная сеть может быть обучена с использованием речевых данных, представляющих речь на разных языках или диалектах. Способ может включать в себя дополнительные действия по генерированию, на основе вывода нейронной сети, представления говорящего и определению, на основе представления говорящего и второго представления, что фрагмент речи является фрагментом речи пользователя. Способ может предоставить пользователю доступ к пользовательскому устройству на основе определения, что фрагмент речи является фрагментом речи пользователя. 2 н. и 12 з.п. ф-лы, 5 ил.
1. Система для управления доступом пользователя к пользовательскому устройству с использованием голосовой аутентификации, содержащая:
один или более компьютеров и одно или более устройств хранения данных, хранящих инструкции, которые функционируют, при их исполнении одним или более компьютерами, для предписания одному или более компьютерам выполнять операции, содержащие:
прием, пользовательским устройством, аудиоданных (410b), представляющих фрагмент речи (410a) пользователя (402);
предоставление, в нейронную сеть (280), хранящуюся на пользовательском устройстве (211), набора входных данных (414), полученных из аудиоданных и идентификатора языка (415) или идентификатора местоположения, ассоциированного с пользовательским устройством, причем нейронная сеть имеет параметры, обученные с использованием речевых данных, представляющих речь на разных языках или разных диалектах;
генерирование, на основе вывода нейронной сети, произведенного в ответ на прием набора входных данных, представления (420) говорящего, которое указывает характеристики голоса пользователя;
определение, на основе представления говорящего и второго представления (430), что фрагмент речи является фрагментом речи пользователя; и
предоставление пользователю доступа к пользовательскому устройству на основе определения того, что фрагмент речи является фрагментом речи пользователя.
2. Система по п. 1, при этом набор входных данных, полученных из аудиоданных и идентификатора языка, включает в себя первый вектор, который получен из аудиоданных, и второй вектор, который получен из идентификатора языка, ассоциированного с пользовательским устройством.
3. Система по п. 2, в которой операции дополнительно содержат:
генерирование входного вектора посредством объединения первого вектора и второго вектора в единый объединенный вектор;
предоставление, в нейронную сеть, сгенерированного входного вектора; и
генерирование, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представления говорящего, указывающего характеристики голоса пользователя.
4. Система по п. 2, в которой операции дополнительно содержат:
генерирование входного вектора посредством объединения выводов по меньшей мере двух других нейронных сетей, которые соответственно генерируют выводы на основе (i) первого вектора, (ii) второго вектора или (iii) и первого вектора, и второго вектора;
предоставление, в нейронную сеть, сгенерированного входного вектора; и
генерирование, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представления говорящего, которое указывает характеристики голоса пользователя.
5. Система по п. 2, в которой операции дополнительно содержат:
генерирование входного вектора на основе взвешенной суммы первого вектора и второго вектора;
предоставление, в нейронную сеть, сгенерированного входного вектора; и
генерирование, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представления говорящего, указывающего характеристики голоса пользователя.
6. Система по любому из предыдущих пунктов, при этом вывод нейронной сети, произведенный в ответ на прием набора входных данных, включает в себя набор активаций, сгенерированных скрытым слоем нейронной сети.
7. Способ управления доступом пользователя к пользовательскому устройству с использованием голосовой аутентификации, содержащий этапы, на которых:
принимают, посредством пользовательского устройства, аудиоданные, представляющие фрагмент речи пользователя;
предоставляют, в нейронную сеть, хранящуюся на пользовательском устройстве, набор входных данных, полученных из аудиоданных и идентификатора языка или идентификатора местоположения, ассоциированного с пользовательским устройством, причем нейронная сеть имеет параметры, обученные с использованием речевых данных, представляющих речь на разных языках или разных диалектах;
генерируют, на основе вывода нейронной сети, произведенного в ответ на прием набора входных данных, представление говорящего, указывающее характеристики голоса пользователя;
определяют, на основе представления говорящего и второго представления, что фрагмент речи является фрагментом речи пользователя; и
предоставляют пользователю доступ к пользовательскому устройству на основе определения того, что фрагмент речи является фрагментом речи пользователя.
8. Способ по п. 7, в котором набор входных данных, полученный из аудиоданных и идентификатора языка, включает в себя первый вектор, который получен из аудиоданных, и второй вектор, который получен из идентификатора языка, ассоциированного с пользовательским устройством.
9. Способ по п. 8, дополнительно содержащий этапы, на которых:
генерируют входной вектор посредством объединения первого вектора и второго вектора в единый объединенный вектор;
предоставляют в нейронную сеть сгенерированный входной вектор; и
генерируют, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представление говорящего, указывающее характеристики голоса пользователя.
10. Способ по п. 8, дополнительно содержащий этапы, на которых:
генерируют входной вектор посредством объединения выводов по меньшей мере двух других нейронных сетей, которые соответственно генерируют выводы на основе (i) первого вектора, (ii) второго вектора или (iii) и первого вектора, и второго вектора;
предоставляют в нейронную сеть сгенерированный входной вектор; и
генерируют, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представление говорящего, указывающее характеристики голоса пользователя.
11. Способ по п. 8, дополнительно содержащий этапы, на которых:
генерируют входной вектор на основе взвешенной суммы первого вектора и второго вектора;
предоставляют в нейронную сеть сгенерированный входной вектор; и
генерируют, на основе вывода нейронной сети, произведенного в ответ на прием входного вектора, представление говорящего, указывающее характеристики голоса пользователя.
12. Способ по п. 7, в котором вывод нейронной сети, произведенный в ответ на прием набора входных данных, включает в себя набор активаций, сгенерированных скрытым слоем нейронной сети.
13. Способ по п. 7, в котором упомянутое определение, на основе представления говорящего и второго представления, что фрагмент речи является фрагментом речи пользователя, содержит этап, на котором определяют расстояние между первым представлением и вторым представлением.
14. Способ по п. 7, в котором упомянутое предоставление пользователю доступа к пользовательскому устройству на основе определения того, что фрагмент речи является фрагментом речи пользователя, включает в себя этап, на котором разблокируют пользовательское устройство.
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |
| Способ и аппарат для получения гидразобензола или его гомологов | 1922 |
|
SU1998A1 |
| US 9230550 B2, 05.01.2016 | |||
| US 6519561 B1, 11.02.2003 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |

