Изобретение относится к способам поиска информации, размещенной на локальных и удаленных устройствах хранения данных. В частности, изобретение относится к способам поиска на локальных и удаленных устройствах хранения данных файлов, похожих структурно на выбранный файл.
Известен способ поиска похожих электронных документов, размещенных на устройствах хранения данных, при помощи сравнения семантических сетей по патенту RU 2571539, кл. G06F 017/30. Известный способ включает следующую последовательность действий. Осуществляют загрузку двух электронных документов с устройств хранения данных, определяют параметры поиска путем задания правил формирования множества уникальных слов, формируют множество взвешенных уникальных слов и взвешенных связей между ними, строят семантическую сеть и производят поиск похожих по смыслу документов путем сравнения семантических сетей. При этом дополнительно задают правила формирования стилистических образов документов путем определения размера матриц частот переходов и выбора элементов матриц частот переходов. И, наконец, сравнивают матрицы частот переходов документов на схожесть путем вычисления коэффициента сходства.
Наиболее близким по технической сущности и выполняемым функциям аналогом (прототипом) к заявляемому изобретению является способ поиска похожих файлов с использованием гибкой свертки (патент RU №2580036, МПК G06 F 21/14). Он включает следующую последовательность действий. Выделяют множество признаков из файлов. Разделяют множество выделенных признаков файла, по меньшей мере, на два подмножества, в одном из которых есть как минимум один изменяемый признак, а в другом есть как минимум один неизменяемый признак. Получают свертку каждого из вышеописанных подмножеств признаков файла. Создают свертку файла как комбинацию сверток каждого из вышеописанных подмножеств признаков файла. Сравнивают свертку, по меньшей мере, одного файла с набором заранее созданных сверток файлов. Признают файл похожим на файлы из множества похожих файлов, имеющих одинаковую свертку, если при сравнении свертка указанного файла совпадает со сверткой файла из указанного множества.
В данной области техники существует техническая проблема, заключающаяся в том, что поиск похожих файлов осуществляют сравнением со всеми ранее обработанными файлами, что приводит к значительному снижению скорости поиска.
Техническая проблема решается разработкой способа поиска подобных файлов, размещенных на устройствах хранения данных, обеспечивающего при его реализации возможность повысить скорость поиска подобных файлов различных форматов путем сравнения загруженного файла не со всеми ранее обработанными файлами, а с подгруппой ранее обработанных файлов. Для этого представляют загруженный файл в виде случайного марковского процесса, для чего задают значение максимально возможного изменения вероятностного расстояния, а также задают связность используемой марковской цепи, которая показывает максимальный размер битовой последовательности, для которой учитывают корреляционные свойства. Далее рассчитывают вероятности появления последовательностей бит размером, меньшим и равным заданной связности, путем деления количества появлений последовательностей бит на размер файла в битах и определяют максимально возможное изменение размера файла, используя полученный ряд вероятностей и исходный размер файла. Производят сравнение только с теми файлами, у которых модуль разницы их размеров и размера проверяемого файла меньше рассчитанной границы максимально возможного изменения размера файла. И если вероятностное расстояние между загруженным файлом и каким-либо ранее обработанным файлом из полученной подгруппы меньше максимально возможного изменения вероятностного расстояния, то данные файлы признают подобными.
Перечисленная новая совокупность существенных признаков обеспечивает возможность повышения скорости поиска подобных файлов.
Проведенный анализ уровня техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обусловливающих тот же технический результат, который достигнут в заявляемом способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Заявленный способ поясняется чертежами, на которых показаны:
фиг. 1 - древовидная структура взаимосвязей вероятностей двоичных векторов различной длины;
фиг. 2 - блок-схема реализации способа поиска подобных файлов, размещенных на устройствах хранения данных;
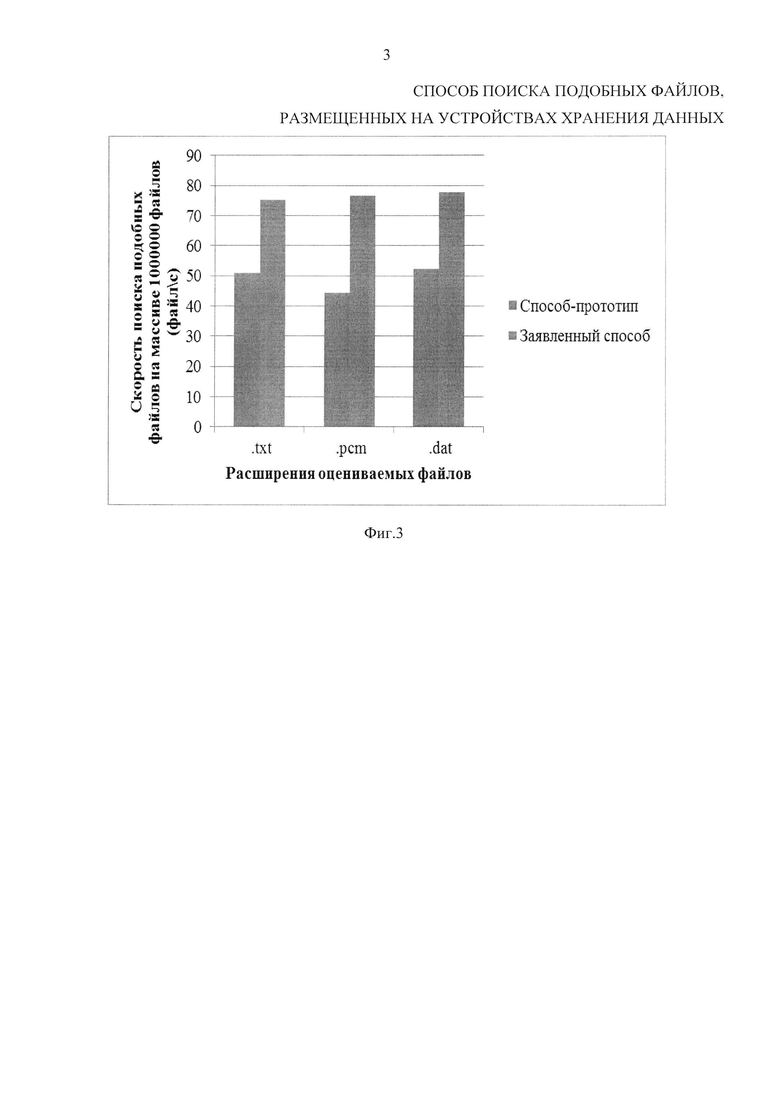
фиг. 3 - сравнение результатов имитационного моделирования для способа-прототипа и заявленного способа.
Реализация заявленного способа поиска подобных файлов, размещенных на устройствах хранения данных, поясняется на фиг. 2:
Блок №1 - осуществляют загрузку файла с устройства хранения данных.
Блок №2 - задают связность используемой марковской цепи, которая показывает максимальный размер битовой последовательности, для которой учитываются корреляционные свойства. Иными словами, задают количество уровней в древовидной структуре взаимосвязей вероятностей, представленной на фиг. 1. Чем больше количество используемых уровней, тем больше точность оценки статистических свойств, но и тем выше требования к ресурсоемкости. Также задают параметр Мкр - максимально возможное изменение вероятностного расстояния.
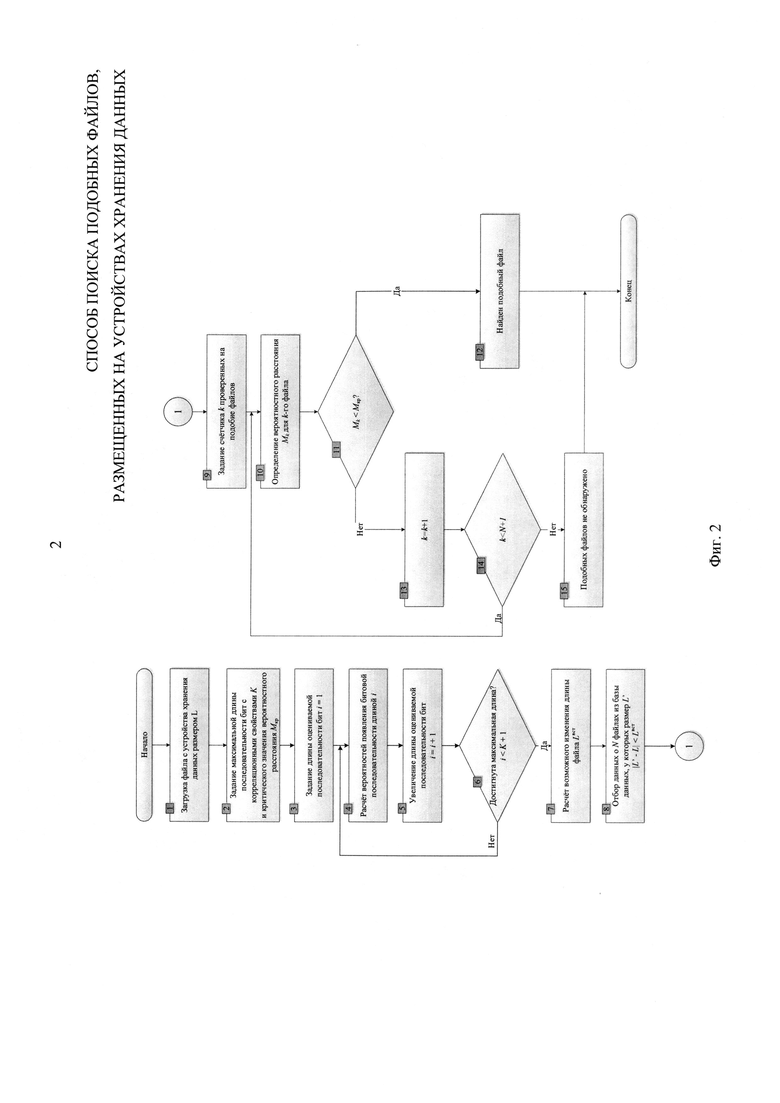
Блоки №3, 4, 5, 6 - определяют значения вероятностей для каждого уровня в древовидной структуре взаимосвязей вероятностей, представленной на фиг. 3, меньше или равного заданной связности используемой марковской цепи. Например, для связности марковской цепи, равной двум, определяют вероятности на первом уровне: р(0), и вероятности на втором уровне: р(00), р(01), р(10), р(11). Определение каждой вероятности происходит следующим образом: количество появлений каждой комбинации последовательности бит в файле делится на длину файла в битах.
Блок №7 - определяют максимально возможное изменение размера файла, используя полученный ряд вероятностей и исходный размер файла L:
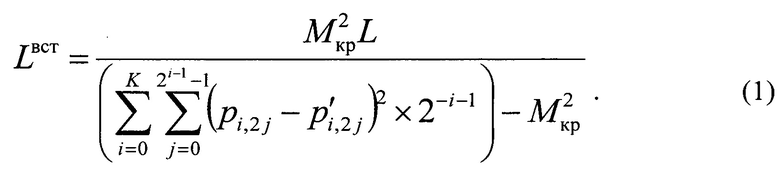
Блок №8 - выделяют подгруппу ранее обработанных файлов, у которых размер L' удовлетворяет условию:

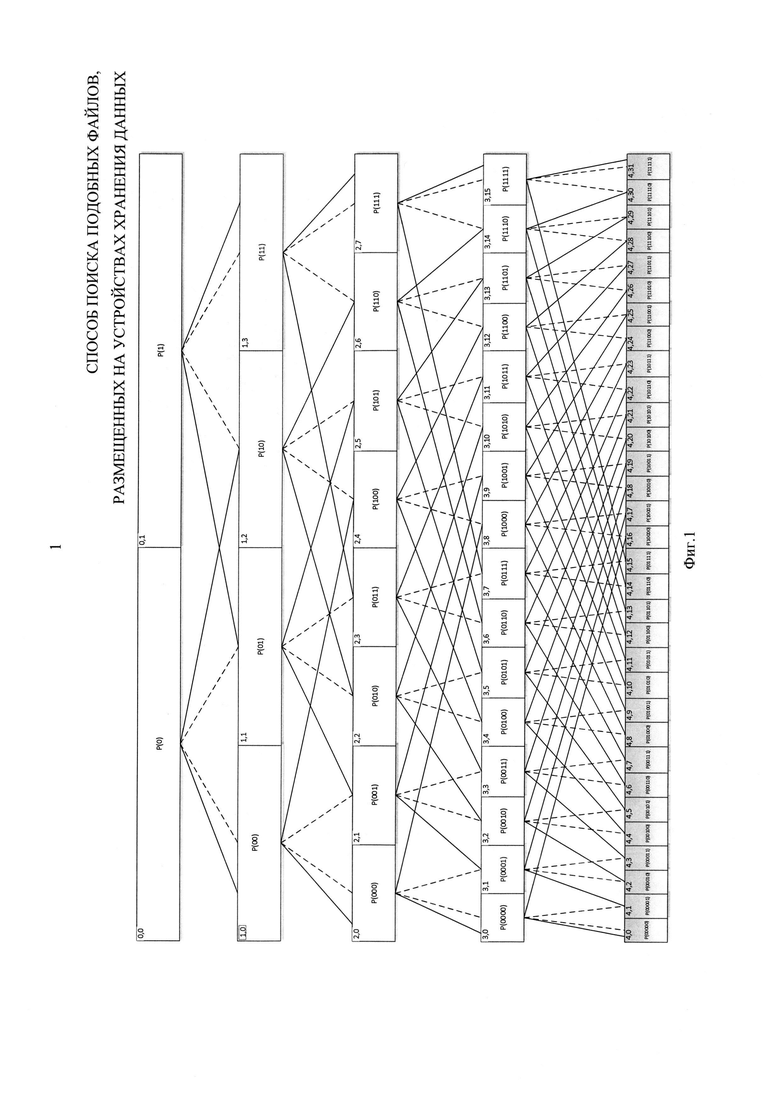
Блоки №9, 10, 11, 12, 13, 14, 15 - осуществляют расчет вероятностного расстояния между загруженным файлом и каждым файлом их выделенной подгруппы. Расчет производится с использованием модифицированной нормированной метрики Евклида:
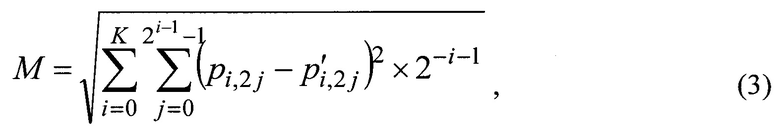
где K - связность используемой марковской цепи.
Сравнивают вероятностное расстояние между загруженным файлом и каждым файлом их выделенной подгруппы с максимально возможным изменением вероятностного расстояния Мкр, и если оно меньше максимально возможного, то принимают решение о подобности сравниваемых файлов.
Промышленная применимость изобретения обусловлена тем, что устройство, реализующее предложенный способ, может быть осуществлено с помощью современной элементной базы с достижением указанного в изобретении назначения.
Правомерность теоретических предпосылок проверялась с помощью машинного моделирования способа-прототипа и заявленного способа поиска подобных файлов, размещенных на устройствах хранения данных.
Показателем эффективности способа поиска подобных файлов, размещенных на устройствах хранения данных, является скорость поиска.
Для оценки качества функционирования разработанного способа были проведены эксперименты по поиску подобных файлов различных типов. С этой целью исследованы файлы с расширениями txt, pcm и dat, по которым затем осуществлялся поиск. Тестовый массив файлов составлял более 1000000 файлов. Результаты, представленные на фиг. 3, подтверждают существенное повышение скорости поиска при использовании разработанного способа.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ обнаружения вредоносных составных файлов | 2016 |
|
RU2634178C1 |
| Способ контроля доступа к составным файлам | 2017 |
|
RU2659739C1 |
| Способ определения похожести составных файлов | 2016 |
|
RU2628922C1 |
| Система и способ выбора средства обнаружения вредоносных файлов | 2019 |
|
RU2739830C1 |
| Система и способ определения похожих файлов | 2015 |
|
RU2614561C1 |
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |
| СПОСОБ ВНЕДРЕНИЯ СКРЫТОГО ЦИФРОВОГО СООБЩЕНИЯ В ПЕЧАТАЕМЫЕ ДОКУМЕНТЫ И ИЗВЛЕЧЕНИЯ СООБЩЕНИЯ | 2010 |
|
RU2431192C1 |
| Система и способ классификации объектов вычислительной системы | 2018 |
|
RU2724710C1 |
| Система и способ классификации объектов | 2017 |
|
RU2679785C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОГО ОБЪЕДИНЕНИЯ ДАННЫХ СО СДВИГОМ ВПРАВО | 2002 |
|
RU2273044C2 |
Изобретение относится к вычислительной технике для поиска информации. Технический результат заключается в повышении эффективности поиска подобных файлов. Технический результат достигается за счет сравнения, которое происходит с подгруппой ранее обработанных файлов, при этом для этого представляют загруженный файл в виде случайного марковского процесса, рассчитывают вероятности появления последовательностей бит размером, меньшим или равным заданной связности, путем деления количества появлений последовательностей бит на размер файла в битах, и производят сравнение только с теми файлами, у которых модуль разницы их размеров и размера проверяемого файла меньше рассчитанной границы максимально возможного изменения размера файла, и если вероятностное расстояние между загруженным файлом и каким-либо ранее обработанным файлом из полученной подгруппы меньше максимально возможного изменения вероятностного расстояния, то данные файлы признают подобными. 3 ил.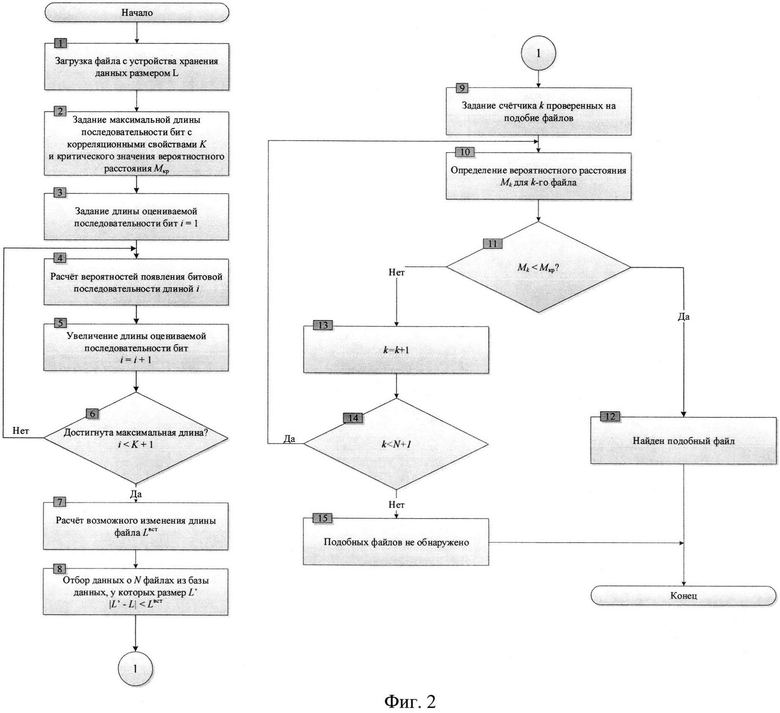
Способ поиска подобных файлов, размещенных на устройствах хранения данных, заключающийся в том, что осуществляют загрузку файла с устройства хранения данных, создают его свертку и сравнивают полученную свертку со свертками ранее обработанных файлов для определения подобия файлов, отличающийся тем, что сравнение происходит не со всеми ранее обработанными файлами, а с подгруппой ранее обработанных файлов, для этого представляют загруженный файл в виде случайного марковского процесса, для чего задают значение максимально возможного изменения вероятностного расстояния, а также задают связность используемой марковской цепи, которая показывает максимальный размер битовой последовательности, для которой учитывают корреляционные свойства, после чего рассчитывают вероятности появления последовательностей бит размером, меньшим или равным заданной связности, путем деления количества появлений последовательностей бит на размер файла в битах, определяют максимально возможное изменение размера файла, используя полученный ряд вероятностей и исходный размер файла, и производят сравнение только с теми файлами, у которых модуль разницы их размеров и размера проверяемого файла меньше рассчитанной границы максимально возможного изменения размера файла, и если вероятностное расстояние между загруженным файлом и каким-либо ранее обработанным файлом из полученной подгруппы меньше максимально возможного изменения вероятностного расстояния, то данные файлы признают подобными.
| СИСТЕМА И СПОСОБ СОЗДАНИЯ ГИБКОЙ СВЕРТКИ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ПРОГРАММ | 2013 |
|
RU2580036C2 |
| ПЛАТФОРМА ДЛЯ СЛУЖБ ПЕРЕДАЧИ ДАННЫХ МЕЖДУ НЕСОПОСТАВИМЫМИ ОБЪЕКТНЫМИ СРУКТУРАМИ ПРИЛОЖЕНИЙ | 2006 |
|
RU2425417C2 |
| ПРИКЛАДНОЙ ПРОГРАММНЫЙ ИНТЕРФЕЙС ДЛЯ ИЗВЛЕЧЕНИЯ И ПОИСКА ТЕКСТА | 2005 |
|
RU2412476C2 |
| US 7502785 B2, 10.03.2009 | |||
| US 9158842 B1, 13.10.2015. | |||

