ОБЛАСТЬ ТЕХНИКИ
[1] Изобретение относится к алгоритмам машинного обучения и, конкретнее, к способам и системам выбора потенциально ошибочно ранжированных документов алгоритмом машинного обучения.
УРОВЕНЬ ТЕХНИКИ
[2] Развитие вычислительной техники в купе с увеличением числа соответствующих мобильных электронных устройств, повышают интерес к развитию искусственного интеллекта и решению задач автоматизации, прогнозирования результатов, классификации информации и обучения на основе опыта, что относится к области машинного обучения. Машинное обучение, связанное со сбором данных (датамайнинг), вычислительной статистикой и оптимизацией, охватывает процесс обучения и создания алгоритмов, которые могут обучаться и делать прогнозы на основе данных.
[3] Область машинного обучения динамично развивается в последнее десятилетие, что приводит к появлению таких технологий как машины без водителя, распознавание голоса, распознавание изображений, эффективный веб-поиск, персонализация, расшифровка человеческого генома и так далее.
[4] Алгоритмы машинного обучения могут в общем случае быть разделены на такие большие категории как обучение с учителем, обучение без учителя и обучение с подкреплением. Обучение с учителем включает в себя алгоритм машинного обучения с помощью обучающих данных, состоящих из вводов и выводов, размеченных ассесорами, задача которых состоит в том, чтобы обучить алгоритм машинного обучения таким образом, чтобы алгоритм выучил общее правило для установления соответствия между вводом и выводом. Обучение без учителя включает в себя алгоритм машинного обучения с неразмеченными данными, и целью алгоритма машинного обучения является поиск структуры или неявного паттерна в данных. Обучение с подкреплением включает в себя алгоритм развития в динамической среде без алгоритма с размеченными данными или исправлений.
[5] Последние разработки в данной области техники также предусматривают активное обучение, частичное обучение с учителем, что полезно в ситуациях, когда неразмеченных данных очень много, и разметка данных может быть слишком дорогой. В подобных ситуациях, алгоритмы обучения могут при необходимости запрашивать разметку ассесорами и, с помощью итераций, улучшать свою модель таким образом, чтобы требовалось меньше данных.
[6] Обучение ранжированию (LTR) или машинно-обученное ранжирование (MLR) является способом применения машинного обучения при создании моделей ранжирования для извлечения информации, обработки естественного языка и сбора данных. В общем случае, система может содержать коллекцию документов, в которой модель ранжирования может ранжировать документы в ответ на запрос и выдавать наиболее релевантные документы. Модель ранжирования может быть заранее обучена на образцах документов. Тем не менее, большое число документов, которое доступно в Интернете и продолжает расти, не только сложно размечать, это также требует больших вычислительных мощностей и материальных вложений, поскольку это часто осуществляется людьми-ассесорами.
[7] Американская патентная заявка No. 8,713,023, выданная 29 апреля 2014 автору Кормаку и др., описывает системы и способы классификации электронной информации или документов на несколько классов и подклассов с помощью активного алгоритма обучения. Подобные системы классификации документов можно легко экстраполировать на большие коллекции документов, что потребует меньших человеческих усилий и может выполняться на одном компьютере, что потребует меньше ресурсов. Кроме того, описанные системы и способы классификации могут быть использованы для любых целей распознавания или классификации в широком диапазоне применения, включая электронные поиски в судебных разбирательствах.
[8] Американская патентная заявка No. 7,844,567, выданная 30 ноября 2010 года автору Хи и др., описывает систему и способ выбора обучающей выборки из набора примеров. Способ включает в себя определение близости между всеми выборками данных в наборе выборок данных, формирование границ между выборками данных в виде функции близости, вычисление весовых коэффициентов для границ в виде функции близости, выбор множества выборок данных в виде функции весовых коэффициентов для формирования подмножества выборок данных, и сохранение подмножества выборок данных.
[9] Американская патентная заявка No. 2012/0109860 А1 авторства Kсy и др. описывает, что обучающие данные используются алгоритмом обучения ранжированию для формулирования алгоритмов ранжирования. Обучающие данные могут быть изначально предоставлены оценивающими людьми, и далее смоделированы с учетом данных о кликах для определения вероятных ошибок ранжирования. Вероятные ошибки ранжирования предоставляются оценивающим людям, которые могут уточнить обучающие данные с учетом этой информации.
[10] По нижеследующим причинам, существует необходимость в способах и системах для выбора потенциально ошибочно ранжированных документов с помощью алгоритма машинного обучения.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[11] Варианты осуществления настоящего технического решения были разработаны с учетом определения разработчиками по меньшей мере одного технического недостатка, связанного с известным уровнем техники.
[12] Варианты осуществления настоящей технологии были разработаны на основе предположений разработчиков о том, что, несмотря на различные разработанные способы машинно-обученного ранжирования, часто сложно определить ошибки в ранжировании.
[13] Настоящая технология основана на наблюдениях разработчиков о том, что определение ошибок в ранжировании может не только улучшить точность алгоритмов машинного обучения, используемых для ранжирования, но и улучшить качество обучающих данных путем использования ошибочно ранжированных документов, что требует меньшего числа обучающих данных и приводит к экономии вычислительных мощностей, времени и денег.
[14] Следовательно, изобретатели разработали способ и системы выбора потенциально ошибочно ранжированных документов с помощью алгоритма машинного обучения.
[15] Первым объектом настоящей технологии является способ выбора потенциально ошибочно ранжированного документа в наборе поисковых результатов, набор поисковых результатов был создан сервером поисковой системы, который выполняет алгоритм машинного обучения в ответ на запрос, способ выполняется на электронном устройстве, электронное устройство соединено с сервером поисковой системы, способ включает в себя: получение электронным устройством набора поисковых результатов от сервера поисковой системы, каждый документ из набора поисковых результатов обладает оценкой релевантности, созданной алгоритмом машинного обучения и вектором свойств, созданным алгоритмом машинного обучения, оценка релевантности была создана, по меньшей мере частично, на основе вектора свойств, вычисление электронным устройством для каждой возможной пары документов из набора поисковых результатов, пары документов, содержащих первый документ и второй документ: первый параметр, полученный путем первой бинарной операции над оценками релевантности первого документа и второго документа, первый параметр указывает на уровень разницы в оценках релевантности первого документа и второго документа, и второй параметр, полученный путем второй бинарной операции над векторами свойств первого документа и второго документа, второй параметр указывает на уровень разницы в векторах свойств первого документа и второго документа, вычисление электронным устройством результата проверки для каждой возможной пары документов документов из набора поисковых результатов, результат проверки основан на первом параметре и втором параметре, результат проверки указывает на уровень рассогласования между оценками релевантности первого документа и второго документа и векторами свойств первого документа и второго документа из пары документов, выбор электронным устройством по меньшей мере одной пары документов, связанных с экстремальным результатом проверки, экстремальный результат проверки указывает на высокий уровень рассогласования между оценками релевантности первого документа и второго документа и векторов свойств первого документа и второго документа из пары документов, высокий уровень рассогласования указывает на потенциально ошибочно ранжированный документ в паре документов, и разметку электронным устройством по меньшей мере одной выбранной пары документов, связанных с экстремальным результатом проверки для проверки сервером поисковой системы.
[16] В некоторых вариантах осуществления технологии, экстремальный результат проверки далее указывает на неспособность алгоритма машинного обучения с сервера поисковой системы адекватно различать первый документ и второй документ из пары документов.
[17] В некоторых вариантах осуществления технологии, результат проверки возрастает для пар документов, обладающих высоким первым параметром и низким вторым параметром, и в котором результат проверки снижается для пар документов, обладающих низким первым параметром и высоким вторым параметром.
[18] В некоторых вариантах осуществления технологии, высокий первый параметр указывает на высокий уровень разницы между оценками релевантности первого документа и второго документа, и в котором низкий первый параметр указывает на низкий уровень разницы в оценках релевантности первого документа и второго документа.
[19] В некоторых вариантах осуществления технологии, высокий второй параметр указывает на высокий уровень разницы между векторами свойств первого документа и второго документа, и в котором низкий второй параметр указывает на низкий уровень разницы в векторах свойств первого документа и второго документа.
[20] В некоторых вариантах осуществления технологии, каждый документ из набора поисковых результатов обладает позицией на странице результатов поиска (SERP), позиция была определена по меньшей мере частично на основе оценки релевантности, и в котором результат проверки далее основан на третьем параметре, третий параметр основан на позициях на SERP первого документа и второго документа из пары документов.
[21] В некоторых вариантах осуществления технологии, первая бинарная операция является вычитанием и вторая бинарная операция является вычитанием.
[22] В некоторых вариантах осуществления технологии, третий параметр является низшей позицией между позицией первого документа из пары и второго документа из пары.
[23] В некоторых вариантах осуществления технологии, экстремальный результат проверки является самым низким результатом проверки.
[24] В некоторых вариантах осуществления технологии, выбор по меньшей мере одной пары, связанной с низшим результатом проверки включат в себя: ранжирование результатов проверки в порядке убывания, и выбор подмножества результатов проверки, каждый результат проверки подмножества результатов проверки ниже заранее определенного порога, заранее определенный порог указывает на ошибочно ранжированный документ.
[25] В некоторых вариантах осуществления технологии, первый параметр оценивается первым коэффициентом, второй параметр оценивается вторым коэффициентом, третий параметр оценивается третьим коэффициентом, первый коэффициент, второй коэффициент и третий коэффициент позволяют отражать степень влияния первого параметра, второго параметра и третьего параметра на результат проверки для выбора по меньшей мере одного возможно ошибочно ранжированного документа.
[26] В некоторых вариантах осуществления технологии, первый коэффициент, второй коэффициент и третий коэффициент определяются эвристическим путем.
[27] В некоторых вариантах осуществления технологии, вычисление для каждой пары соседних документов выполняется для подмножества из набора поисковых результатов.
[28] В некоторых вариантах осуществления технологии, способ далее включает в себя передачу по меньшей мере одной пары документов серверу поисковой системы и повтор этапов: получения набора поисковых результатов, вычисления первого параметра, второго параметра и третьего параметра, вычисления результата проверки, выбора по меньшей мере одной пары, связанной с низшим результатом проверки, и разметки по меньшей мере одной пары после заранее определенного периода времени.
[29] В некоторых вариантах осуществления технологии, результат проверки вычисляется на основе:
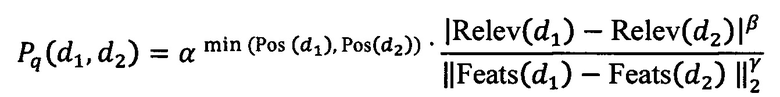
где
Pq(d1, d2) - результат проверки для пары документов;
d1 - первый документ из пары документов;
d2 - второй документ из пары документов;
Relev(d1) - Relev(d2) - первый параметр;
Feats(d1) - Feats(d2) - второй параметр;
min(Pos(d1)(d2)) - третий параметр;
β - первый коэффициент;
γ - второй коэффициент; и
α - третий коэффициент.
[30] Вторым объектом настоящей технологии является система для выбора потенциально ошибочно ранжированного документа в наборе поисковых результатов, набор поисковых результатов был создан сервером поисковой системы, который выполняет алгоритм машинного обучения в ответ на запрос, система соединена с сервером поисковой системы, система включает в себя: процессор, постоянный машиночитаемый носитель, содержащий инструкции, процессор, при выполнении инструкций выполнен с возможностью осуществлять: получение набора поисковых результатов от сервера поисковой системы, каждый документ из набора поисковых результатов обладает оценкой релевантности, созданной алгоритмом машинного обучения и вектором свойств, созданным алгоритмом машинного обучения, оценка релевантности была создана, по меньшей мере частично, на основе вектора свойств, вычисление для каждой возможной пары документов из набора поисковых результатов, пары документов, содержащих первый документ и второй документ: первый параметр, полученный путем первой бинарной операции над оценками релевантности первого документа и второго документа, первый параметр указывает на уровень разницы в оценках релевантности первого документа и второго документа, и второй параметр, полученный путем второй бинарной операции над векторами свойств первого документа и второго документа, второй параметр указывает на уровень разницы в векторах свойств первого документа и второго документа, вычисление результата проверки для каждой возможной пары документов документов из набора поисковых результатов, результат проверки основан на первом параметре и втором параметре, результат проверки указывает на уровень рассогласования между оценками релевантности первого документа и второго документа и векторами свойств первого документа и второго документа из пары документов, выбор по меньшей мере одной пары документов, связанных с экстремальным результатов проверки, экстремальный результат проверки указывает на высокий уровень рассогласования между оценками релевантности первого документа и второго документа и векторов свойств первого документа и второго документа из пары документов, высокий уровень рассогласования указывает на потенциально ошибочно ранжированный документ в паре документов, и разметку по меньшей мере одной выбранной пары документов, связанных с экстремальным результатом проверки для проверки сервером поисковой системы.
[31] В некоторых вариантах осуществления технологии, экстремальный результат проверки далее указывает на неспособность алгоритма машинного обучения с сервера поисковой системы различать первый документ и второй документ из пары документов.
[32] В некоторых вариантах осуществления технологии, результат проверки возрастает для пар документов, обладающих высоким первым параметром и низким вторым параметром, и в котором результат проверки снижается для пар документов, обладающих низким первым параметром и высоким вторым параметром.
[33] В некоторых вариантах осуществления технологии, высокий первый параметр указывает на высокий уровень разницы между оценками релевантности первого документа и второго документа, и в котором низкий первый параметр указывает на низкий уровень разницы в оценках релевантности первого документа и второго документа.
[34] В некоторых вариантах осуществления технологии, высокий второй параметр указывает на высокий уровень разницы между векторами свойств первого документа и второго документа, и в котором низкий второй параметр указывает на низкий уровень разницы в векторах свойств первого документа и второго документа.
[35] В некоторых вариантах осуществления технологии, каждый документ из набора поисковых результатов обладает позицией на странице результатов поиска (SERP), позиция была определена по меньшей мере частично на основе оценки релевантности, и в котором результат проверки далее основан на третьем параметре, третий параметр основан на позициях на SERP первого документа и второго документа из пары документов.
[36] В некоторых вариантах осуществления технологии, первая бинарная операция является вычитанием и вторая бинарная операция является вычитанием.
[37] В некоторых вариантах осуществления технологии, третий параметр является низшей позицией между позицией первого документа из пары и второго документа из пары.
[38] В некоторых вариантах осуществления технологии, экстремальный результат проверки является самым низким результатом проверки.
[39] В некоторых вариантах осуществления технологии, выбор по меньшей мере одной пары, связанной с низшим результатом проверки включат в себя выбор подмножества результатов проверки, каждый результат проверки подмножества результатов проверки ниже заранее определенного порога, заранее определенный порог указывает на ошибочно ранжированный документ.
[40] В некоторых вариантах осуществления технологии, первый параметр оценивается первым коэффициентом, второй параметр оценивается вторым коэффициентом, третий параметр оценивается третьим коэффициентом, первый коэффициент, второй коэффициент и третий коэффициент позволяют отражать степень влияния первого параметра, второго параметра и третьего параметра на результат проверки для выбора по меньшей мере одного возможно ошибочно ранжированного документа.
[41] В некоторых вариантах осуществления технологии, первый коэффициент, второй коэффициент и третий коэффициент определяются эвристическим путем.
[42] В некоторых вариантах осуществления технологии, вычисление для каждой пары соседних документов выполняется для подмножества из набора поисковых результатов.
[43] В некоторых вариантах осуществления технологии, способ далее включает в себя передачу по меньшей мере одной пары документов серверу поисковой системы и повтор этапов: получения набора поисковых результатов, вычисления первого параметра, второго параметра и третьего параметра, вычисления результата проверки, выбора по меньшей мере одной пары, связанной с низшим результатом проверки, и разметки по меньшей мере одной пары после заранее определенного периода времени.
[44] В некоторых вариантах осуществления технологии, результат проверки вычисляется на основе:
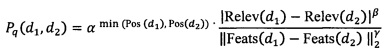
где
Pq(d1, d2) - результат проверки для пары документов;
d1 - первый документ из пары документов;
d2 - второй документ из пары документов;
Relev(d1) - Relev(d2) - первый параметр;
Feats(d1) - Feats(d2) - второй параметр;
min(Pos(d1), Pos(d2)) - третий параметр;
β - первый коэффициент;
γ - второй коэффициент; и
α - третий коэффициент.
[45] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один компьютер или одну компьютерную систему, однако ни одно, ни другое не является обязательным в отношении предлагаемой технологии. В контексте настоящего технического решения использование выражения «сервер» не означает, что каждая задача (например,полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[46] В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. В контексте настоящего описания, термин "электронное устройство" указывает на то, что устройство может функционировать как сервер для других электронным устройств и электронных устройство, хотя это не является необходимым для настоящей технологии. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Важно иметь в виду, что в контексте настоящего описания факт того, что устройство функционирует как электронное устройство не означает того, что оно не может функционировать как сервер для других электронных устройств. Использование выражения «электронное устройство» не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[47] В контексте настоящего описания «информация» включает в себя информацию любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
[48] В контексте настоящего описания «программный компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[49] В контексте настоящего описания, термин "документ" может широко интерпретироваться как включающий в себя любой машиночитаемый продукт или продукт, который может храниться на машине. Документ может включать в себя электронное сообщение, веб-сайт, файл, комбинацию файлов, один или несколько файлов со встроенными ссылками на другие файлы, групповое размещение новостей, блог, веб-рекламу и т.д. В контексте Интернета, обычный документ представляет собой веб-страницу. Веб-страницы часто включают в себя текстовую информацию и могут включать в себя встроенную информацию (например, мета-информацию, изображения, гиперссылки и т.д.) и/или встроенные инструкции (например, Javascript и т.д.). Страница может соответствовать документу или части документа. Следовательно, слова "страница" и "документа" могут быть взаимозаменяемы в некоторых случаях. В других случаях, термин "страница" может относиться к части документа, например, субдокументу. Также возможно, что страница будет соответствовать более чем одному документу.
[50] В контексте настоящего описания «носитель компьютерной информации» (также упоминаемый как носитель информации) подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д. Множество компонентов может быть объединено в носитель компьютерной информации, включая два или более мультимедийных компонента одного типа и/или два или более компонента разных типов.
[51] В контексте настоящего описания «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, на котором хранится или используется информация, хранящаяся в базе данных, или же база данных может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
[52] В контексте настоящего описания слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первая база данных" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, «первый» сервер и «второй» сервер могут являться одним и тем же программным и/или компонентами аппаратного обеспечения, а в других случаях они могут являться разными компонентами программного и/или аппаратного обеспечения.
[53] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[54] Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления настоящего технического решения станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[55] Эти и другие аспекты, свойства и преимущества настоящей технологии будут лучше понятны с учетом следующего описания, прилагаемой формулы изобретения и чертежей, где
[56] на Фиг. 1 представлены компоненты и свойства электронного устройств, выполненного в соответствии с вариантом осуществления настоящей технологии;
[57] на Фиг. 2 представлена система, которая включает в себя электронное устройство, показанное на Фиг. 1, реализованное в соответствии с вариантом осуществления настоящей технологии;
[58] на Фиг. 3 представлена структура машинно-обученного ранжирования, реализованная в соответствии с вариантом осуществления настоящей технологии;
[59] на Фиг. 4 представлена структура результата проверки, выполненная в соответствии с вариантом осуществления настоящей технологии;
[60] на Фиг. 5 представлена блок-схема способа, выполняемого электронным устройством, для выбора потенциально ошибочно ранжированных документов, реализованного в соответствии с неограничивающими вариантами осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ
[61] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящей технологии, а не для установления границ ее объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящей технологии и находятся в границах ее объема.
[62] Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящей технологии. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[63] Некоторые полезные примеры модификаций настоящей технологии также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающего списка, и специалисты в данной области техники могут создавать другие модификации, остающиеся в границах объема настоящей технологии. Кроме того, те случаи, где не были представлены примеры модификаций, не должны интерпретироваться как то, что никакие модификации невозможны, и/или что то, что было описано, является единственным вариантом осуществления этого элемента настоящей технологии.
[64] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящей технологии, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ, вне зависимости от того, известны ли они на данный момент или будут разработаны в будущем. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящей технологии. Аналогично, любые блок-схемы, диаграммы, псевдокоды и т.п. представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор, или нет.
[65] Функции различных элементов, показанных на фигурах, включая функциональный блок, обозначенный как «процессор» или «графический процессор», могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящей технологии, процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина «процессор» или «контроллер» не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также в это может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[66] Программные модули или простые модули, представляющие собой программное обеспечение, могут быть использованы здесь в комбинации с элементами блок-схемы или другими элементами, которые указывают на выполнение этапов процесса и/или текстовое описание. Подобные модели могут быть выполнены на аппаратном обеспечении, показанном напрямую или косвенно.
[67] С учетом этих примечаний, далее будут рассмотрены некоторые не ограничивающие варианты осуществления аспектов настоящей технологии.
[68] На Фиг. 1 представлена схема электронного устройства 100, которое подходит для некоторых вариантов осуществления настоящей технологии, причем электронное устройство 100 включает в себя различные аппаратные компоненты, включая один или несколько одно- или многоядерных процессоров, которые представлены процессором 110, графический процессор (GPU) 111, твердотельный накопитель 120, ОЗУ 130, интерфейс 140 монитора, и интерфейс 150 ввода/вывода.
[69] Связь между различными компонентами электронного устройства 100 может осуществляться с помощью одной или нескольких внутренних и/или внешних шин 160 (например, шины PCI, универсальной последовательной шины, высокоскоростной шины IEEE 1394, шины SCSI, шины Serial ATA и так далее), с которыми электронными средствами соединены различные аппаратные компоненты.
[70] Интерфейс 150 ввода/вывода может быть соединен с сенсорным экраном 190 и/или одной или несколькими внутренними и/или внешними шинами 160. Сенсорный экран 190 может быть частью экрана. В некоторых вариантах осуществления настоящей технологии сенсорный экран 190 является монитором. Сенсорный экран 190 может также упоминаться как экран 190. В вариантах осуществления технологии, изображенных на Фиг. 1 сенсорный экран 190 включает в себя сенсорное устройство 194 (например, чувствительные к давлению ячейки, встроенные в слой монитора, что позволяет обнаруживать физическое взаимодействие между пользователем и монитором) и сенсорный контроллер 192 ввода/вывода, позволяющий взаимодействовать интерфейсу 140 монитора и/или одной или нескольким внешним и/или внутренним шинам 160. В некоторых вариантах осуществления настоящей технологии, интерфейс 150 ввода/вывода может быть связан с клавиатурой (не показано), мышью (не показано) или трекпадом (не показано), что позволяет пользователю взаимодействовать с электронным устройством 100 дополнительно к сенсорному экрану 190 или вместо него.
[71] В соответствии с вариантами осуществления настоящей технологии твердотельный накопитель 120 хранит программные команды, подходящие для загрузки в ОЗУ 130, и использующиеся процессором 110 и/или графическим процессором GPU 111. Например, программные команды могут представлять собой часть библиотеки или приложение.
[72] Электронное устройство 100 может быть сервером, настольным компьютером, ноутбуком, планшетом, смартфоном, персональным цифровым органайзером (PDA) или другим устройством, которое может быть выполнено с возможностью реализовать настоящую технологию, как должно быть понятно специалисту в данной области техники. Электронное устройство 100 может осуществлять производственную фазу настоящей технологии.
[73] Возвращаясь к Фиг. 2, электронное устройство 100 соединено с сетью 210 передачи данных через линию 205 передачи данных. В некоторых вариантах осуществления настоящей технологии, не ограничивающих ее объем, сеть 210 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящей технологии сеть 210 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[74] Реализация линии 205 передачи данных никак конкретно не ограничена, и будет зависеть от того, какое электронное устройство 100 используется. В качестве примера, но не ограничения, в данных вариантах осуществления настоящего технического решения, когда электронное устройство 100 представляет собой беспроводное устройство связи (например, смартфон), линия связи 205 представляет собой беспроводную сеть связи (например, среди прочего, линия связи сети 3G, линия связи сети 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 100 представляет собой портативный компьютер, линия 205 передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
[75] Важно иметь в виду, что варианты осуществления электронного устройства 100, линии 205 передачи данных и сети 210 передачи данных даны исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления электронного устройства 100, линии 205 передачи данных и сети 210 передачи данных. Таким образом, представленные здесь примеры не ограничивают объем настоящей технологии.
[76] К сети связи также присоединен обучающий сервер 220. Обучающий сервер 220 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения обучающий сервер 220 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что обучающий сервер 220 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, обучающий сервер 220 является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих его объем, функциональность обучающего сервера 220 может быть разделена и может выполняться с помощью нескольких серверов. В контексте настоящей технологии, обучающий сервер 220 может осуществлять часть описанных способов и систем. В некоторых вариантах осуществления настоящей технологии, обучающий сервер 220 находится под контролем и/или управлением оператора поисковой системы. Как вариант, обучающий сервер 220 может находиться под контролем и/или управлением другого поставщика сервиса. Обучающий сервер 220 может осуществлять обучающую фазу настоящей технологии.
[77] С сетью связи также соединен сервер 230 поисковой системы. Сервер 230 поисковой системы может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения, сервер 230 поисковой системы может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 230 поисковой системы может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленном варианте осуществления настоящего технического решения, не ограничивающем его объем, сервер 230 поисковой системы является одиночным сервером. В других вариантах осуществления настоящего технического решения, не ограничивающих ее объем, функциональность сервера 230 хостинга содержимого может быть разделена, и может выполняться с помощью нескольких серверов. В контексте настоящей технологии, сервер 230 поисковой системы может осуществлять часть описанных способов и систем. В некоторых вариантах осуществления настоящей технологии, сервер 230 поисковой системы находится под контролем и/или управлением поставщика поисковой систем, такого, например, как оператор поисковой системы Yandex. Как вариант, сервер 230 поисковой системы может находиться под контролем и/или управлением поставщика сервиса. Сервер 230 поисковой системы может осуществлять алгоритм машинного обучения для ранжирования поисковых результатов.
[78] Возвращаясь к Фиг. 3, компоненты структуры 300 машинно-обученного ранжирования представлены в соответствии с вариантом осуществления настоящей технологии. Структура 300 машинно-обученного ранжирования в общем случае включает в себя экстрактор 330 свойств, обучающую систему 350, модель 360 ранжирования и устройство 380 ранжирования поисковых результатов.
[79] Экстрактор 330 свойств, обучающая система 350, модель 360 ранжирования и устройство 380 ранжирования поисковых результатов структуры 300 машинно-обученного ранжирования могут вместе относиться к алгоритму машинного обучения обучающего сервера 220 и сервера 230 поисковой системы.
[80] Экстрактор 330 свойств, обучающая система 350, модель 360 ранжирования и устройство 380 ранжирования поисковых результатов структуры 300 машинно-обученного ранжирования могут быть реализованы и осуществлены на обучающем сервере 220 и сервера 230 поисковой системы. Специалисту в данной области техники будет понятно, что экстрактор 330 свойств, обучающая система 350, модель 360 ранжирования могут выполняться на обучающем сервере 220 во время фазы обучения, и модель 360 ранжирования может передаваться для встраивания в устройство 380 ранжирования поисковых результатов для фазы проверки и далее в фазу производства на сервере 230 поисковой системы. В неограничивающем примере, обучающий сервер 220 может представлять собой сервер, реализующий экстрактор 330 свойств, обучающую систему 350 и модель 360 ранжирования и сервер 230 поисковой системы может представлять собой сервер поисковой системы, реализующий устройство 380 ранжирования поисковой системы. В некоторых вариантах осуществления технологии, структура 300 машинно-обученного ранжирования может быть реализована только на обучающем сервере 220 или только на сервере 230 поисковой системы. В других вариантах осуществления технологии, экстрактор 330 свойств, обучающая система 350, модель 360 ранжирования структуры 300 машинно-обученного ранжирования может быть реализована на различных серверах (не показано).
[81] В общем случае, документы, использованные для обучения алгоритма машинного обучения, могут быть оценены или размечены одним или несколькими людьми-ассесорами. Для простоты понимания в данном примере представлен один ассесор 310, но специалисту в данной области техники будет очевидно, что число ассесоров никак не ограничено. Ассесор 310 может оценивать релевантность документов, связанных с одним или несколькими запросами, что в результате дает размеченные пары запрос-документ. Следует иметь в виду, что информация о релевантности или метка могут быть представлены несколькими способами. В качестве неограничивающего примера, ассесор 310 может использовать таблицу решений, предоставляемую поисковой системой с различными оценками рейтингов для разметки различных веб-сайтов, связанных с запросом, где веб-сайты или документы могут быть размечены оценками от 0 (не релевантно) до 4 (абсолютно релевантно). В некоторых вариантах осуществления технологии, ассесор 310 может представлять собой другую систему машинного обучения, если документы могут быть оценены алгоритмом машинного обучения в соответствии со свойствами предварительного впечатления и последующего впечатления, как описано в в находящейся на рассмотрении патентной заявке США 9,501,575, поданной 22 ноября 2016 года, которая в полном объеме включена в настоящую заявку посредством ссылки. Документы, размеченные ассесором 310, могут стать обучающими данными 320.
[82] Обучающие данные 320 далее могут поступать к экстрактор 330 свойств для вывода вектором 340 свойств, представляющих документы в обучающих данных 320. Каждый вектор свойств из векторов 340 свойств может быть связан с документом и запросом. Векторы свойств в общем случае представляют собой n-размерные векторы числовых функций, представляющих объект. Свойства, также известные как факторы или сигналы ранжирования, в общем случае используются для представления пар запрос-документ в системах извлечения информации. Векторы свойств могут в общем случае быть независимыми от запроса (т.е. статическими свойствами), зависимыми от запроса (т.е. динамическими свойствами) и свойствами уровня запроса. Примеры свойств включают в себя TF, TF-IDF, ВМ25, сумма IDF одного слова по разным зонам документа и длины этих зон, а также относящиеся к документу PageRank, HITS или другие алгоритмы ранжирования. В качестве неограничивающего примера, свойства векторов 340 свойств могут включать в себя: популярность документа, новизну документа, число исходящих ссылок, число входящих ссылок и длину документа. Каждый элемент вектора свойств может быть реальным значением, представляющим свойство. Следует иметь в виду, что размер вектора свойств никак не ограничен и может зависеть от того, как именно реализован сервер 230 поисковой системы. В качестве неограничивающего примера, вектор 340 свойств для каждого документа, связанного с запросом, может существовать 136-мерный вектор, включающий в себя, для каждого из тела, якоря, заголовка, URL и целого документа: количество слов (лемм) запроса, содержащихся в интересующем тексте, отношение слов из запроса, встреченных в тексте, к количеству слов в запросе, размер текста (потока данных), инвертированная частота встречаемости слова (леммы) по документам коллекции, сумма частот терминов, максимальная частота терминов, минимальная частоты терминов, средняя частота терминов и так далее. В некоторых вариантах осуществления технологии, векторы 340 свойств могут быть бинаризированы и принимать только бинарные значения (0 или 1). Векторы 340 свойств могут далее поступать в обучающую систему 350.
[83] Обучающая система 350 может в общем случае быть реализована как алгоритм машинного обучения с учетом того, что ввод в виде векторов 340 свойств, представляющих обучающие данные 320, в результате выводит модель 360 ранжирования. Реализация обучающей системы 350 никак не ограничена и хорошо известна в данной области техники. Целью обучающей системы 350 в обучающей фазе может в общем случае быть создание модели 360 ранжирования, которая является функцией, учитывающей в качестве ввода векторы 340 свойств обучающих данных 320, каждый вектор свойств из векторов 340 свойств связан с документом, и назначение оценки каждому вектору свойств из векторов 340 свойств, для как можно более близкого совпадения с отметками, данными ассесором 310. Примеры систем машинного обучения включают в себя LambdaMART от компании MICROSOFT™, RankBrain от компании GOOGLE™, и MatrixNET от компании YANDEX™, среди прочего. Обучающая система 350 и модель 360 ранжирования также могут упоминаться как алгоритм машинного обучения сервера 230 поисковой системы.
[84] В фазе проверки, модель 260 ранжирования устройства 380 ранжирования поисковых результатов сервера 230 поисковой системы может в качестве ввода обладать тестовыми данными 370 для вывода набора поисковых результатов 390. В фазе проверки, модель 260 ранжирования тестируются с вводными тестовыми данными 370, и корректируются и оптимизируются в зависимости от набора поисковых результатов 390, который был получен. Устройство 380 ранжирования результатов поиска может далее использовать модель 260 ранжирования для назначения оценок релевантности еще не оцененным документам. Работа модели 360 ранжирования также может быть оценена. Как известно специалистам в данной области техники, различные способы могут быть использованы для оценки работы модели ранжирования, например, без установки ограничений, нормализованный дисконтированный совокупный выигрыш (NDCG), дисконтированный совокупный выигрыш (DCG), усредненная точность (MAP), коэффициент ранговой корреляции Кэндалла (тау Кендалла) и метрика pfound.
[85] Устройство 380 ранжирования результатов поиска может постоянно обучаться заново проходя фазу обучения, фазу проверки и фазу производства после заранее определенного периода времени. Устройство 380 ранжирования поисковых результатов может постоянно обучаться путем мониторинга обратной связи от пользователей, учета личных предпочтений пользователей, выбора различных векторов свойств и т.д., как известно в данной области техники.
[86] Возвращаясь к Фиг. 4, структура 400 результата проверки представлена в соответствии с вариантом осуществления настоящей технологии.
[87] Структура 400 результата проверки включает в себя вычислитель 420 параметра пары, вычислитель 440 результата проверки и устройство 460 выбора результата проверки.
[88] Структура 400 результата проверки может быть реализована на электронном устройстве 100. В других вариантах осуществления технологии, структура 400 результата проверки, которая включает в себя вычислитель 420 параметров пары, вычислитель 440 результата проверки и устройство 460 выбора результата проверки, и может быть реализована, по меньшей мере частично, на обучающем сервере 200 и/или сервера 230 поисковой системы.
[89] Набор поисковых результатов 405 может быть набором поисковых результатов, предоставленных серверов 230 поисковой системы в ответ на запрос q. В некоторых вариантах осуществления технологии, набор поисковых результатов 405 может включать в себя несколько подмножеств поисковых результатов (не показано), каждое подмножество поисковых результатов предоставляется в ответ на различные запросы q1, q2, …, qn - В других вариантах осуществления технологии, набор поисковых результатов 405 может быть только подмножеством всех поисковых результатов в ответ на запрос, например, верхние 10, верхние 20, верхние 30, верхние 40 или верхние 50 результатов. Каждый документ 406 из набора поисковых результатов 405 может быть связан с или обладать набором параметров 410, набор параметров 410 включает в себя оценку 414 релевантности, связанную алгоритмом машинного обучения (MLА) сервера 230 поисковой системы, вектор 415 свойств, созданный MLА сервера 230 поисковой системы, и позицию 418 на странице результатов поиска (SERP), созданную сервером 230 поисковой системы. Следует иметь в виду, оценка 414 релевантности может быть создана алгоритмом машинного обучения сервера 230 поисковой системы на основе, по меньшей мере частично, вектора 416 свойств. Позиция 418 на SERP также может быть определена на основе, по меньшей мере частично, оценки 414 релевантности. Набор параметров 410, который связан с каждым документом 406 из набора поисковых результатов 405, может далее поступать на вычислитель 420 параметров пары.
[90] Вычислитель 420 параметра пары может получать в качестве ввода набор параметров 410, связанный с каждым документом 406 из набора поисковых результатов 405, и может выдавать в качестве вывода набора параметров 430 пары. Вычислитель 420 параметров пары может вычислять, для каждой возможной пары документов 431 из набора поисковых результатов 405, каждая возможная пара документов 431 обладает первым документов 432 и вторым документов 433: первый параметр 434, второй параметр 436 и третий параметр 438. Следовательно, число пар документов может быть выражено путем уравнения комбинирования:

где n - число документов в наборе поисковых результатов 405 и k - 2.
[91] В некоторых альтернативных вариантах осуществления технологии, первый параметр 434, второй параметр 436, третий параметр 438 могут быть вычислены только для соседних документов, т.е. документов, которые находятся на конкретном расстоянии друг от друга. В качестве примера, первый параметр 434, второй параметр 436, третий параметр 438 могут быть вычислены между первым расположенным документом и вторым расположенным документом, и между первым расположенным документом и третьим расположенным документом, но не между первым расположенным документом и сороковым расположенным документом. В других вариантах осуществления технологии, первый параметр 434, второй параметр 436, третий параметр 438 могут быть вычислены только для близких соседних документов, т.е. документов, которые находятся прямо возле друг друга. В других вариантах осуществления технологии, первый параметр 434, второй параметр 436, третий параметр 438 могут быть вычислены для трех или более документов вместо пары документов.
[92] Первый параметр 434 может быть получен с помощью первой бинарной операции над оценками 414 релевантности документов из пары документов 431, первый параметр 434 указывает на уровень разницы в оценках релевантности первого документа 432 и второго документа 433 из пары документов 431.
[93] Второй параметр 434 может быть получен с помощью второй бинарной операции над векторами 416 свойств документов из пары документов 431, второй параметр 434 указывает на уровень разницы в векторах свойств первого документа 432 и второго документа 433 из пары документов 431.
[94] Первая бинарная операция и вторая бинарная операция могут быть вычитаниями. В некоторых вариантах осуществления технологии, первая бинарная операция и вторая бинарная операция не обязательно являются одинаковыми операциями, и могут представлять собой сложение, умножение или деление. В других вариантах осуществления технологии, первый параметр 434 и второй параметр 436 могут быть получены с помощью математической операции другого типа.
[95] Первый параметр 434 и второй параметр 436 указывают соответственно на разницу в позициях и разницу в векторах свойств первого документа 432 и второго документа 433 из пары документов 431, и может быть использована любая математическая операция, которая позволяет представить подобную разницу.
[96] Третий параметр 438 может быть основан на позиции 418 первого документа 432 и второго документа 433 из пары документов 431 на SERP. Третий параметр 438 может представлять собой низшую позицию из позиций 418 первого документа 432 и второго документа 433 из пары документов 431. В других вариантах осуществления технологии, третий параметр 438 может быть средним из позиций 418 пары документов 431. В общем случае, третий параметр 438 может быть указанием на важность пары документов для выбора, т.е. документ, который отображается выше на SERP, обладает более низкой позицией 418 и, как правило, более высокой оценкой 414 релевантности для запроса, чем документы, которые обладают более высокими позициями 418 и, следовательно, ошибки в ранжировании документов, которые представлены на более низких позициях на первых нескольких страницах SERP, должны быть в приоритете, поскольку вероятность нажатия на них пользователем выше.
[97] То, как именно представлена каждая возможная пара документов 430, никак не ограничено, и каждая возможная пара документов 430 может быть, в качестве неограничивающего примера, реализована как массив ячеек, один или несколько векторов, матрица или набор матриц. Каждая возможная пара документов 430 может далее поступать на вычислитель 440 результата проверки.
[98] Вычислитель 440 результата проверки может и использовать каждую возможную пару документов 430 в качестве ввода и выводить набор результатов 450 проверки. Вычислитель 440 результатов проверки может вычислять результат 452 проверки на основе первого параметра 434, второго параметра 436 и третьего параметра 438 для каждой возможной пары документов 431 из набора поисковых результатов 405. В некоторых вариантах осуществления настоящей технологии, результат 452 проверки может быть основан только на первом параметре 434 и втором параметре 436.
[99] Первый параметр 434 может быть оценен первым коэффициентом (не показано), второй параметр 436 может быть оценен вторым коэффициентом (не показано) и третий параметр 438 может быть оценен третьим коэффициентом (не показано), первый коэффициент, второй коэффициент и третий коэффициент предоставляют более точное указание на результат проверки для выбора по меньшей мере одного возможного ошибочно ранжированного документа.
[100] Каждый из первого коэффициента, второго коэффициента и третьего коэффициента может соответственно определять степень влияния первого параметра 434, второго параметра 436 и третьего параметра 438 при вычислении результата 452 проверки. В некоторых вариантах осуществления технологии, первый коэффициент, второй коэффициент и третий коэффициент могут быть определены и настроены эвристически, причем изначальные величины могут быть присвоены каждому из первого коэффициента, второго коэффициента и третьего коэффициента, и величины могут быть настроены в зависимости от результатов, полученных экспериментально. В некоторых вариантах осуществления технологии, набор обучающих документов с ошибочно ранжированными документами может быть использован для обучения структуры 400 результата проверки, и могут быть найдены оптимальные величины для первого коэффициента, второго коэффициента и третьего коэффициента.
[101] Результат 452 проверки указывает на уровень рассогласования между первым документом 432 и вторым документом 433 из пары документов 431. Другими словами, результат 452 проверки дает указание на то, насколько отличным или различающимся кажутся первый документ 432 и второй документ 433 из пары документов 430 для MLА сервера 230 поисковой системы. В качестве примера, первый документ 432 и второй документ 433 из пары документов, которые далеко друг от друга в контексте векторов 416 свойств (указывает на то, насколько на самом деле различаются документы), но близки друг другу в контексте их оценок 414 релевантности (указывает на то, насколько близка релевантность документов для MLА сервера 230 поисковой системы), могут обладать результатом 452 релевантности, отражающим это рассогласование.
[102] Аналогично, первый документ 432 и второй документ 433 из пары документов, которые далеки друг от друга в контексте их оценок 414 релевантности (указывает на то, насколько далека релевантность документов для MLА сервера 230 поисковой системы), но близки в контексте их векторов 416 свойств (указывает на то, насколько на самом деле схожи документы), могут обладать результатом 452 проверки, отражающим это рассогласование.
[103] Следовательно, результат 452 проверки может позволить определить непостоянство и ошибки в ранжировании документов алгоритмом машинного обучения сервера 230, т.е. документы, которые были ранжированы как близкие друг другу, но были существенно различными, или документы, которые были существенно одинаковыми, но были ранжированы как далекие друг от друга в поисковых результатах.
[104] Подобные ситуации могут отражаться напрямую в оценке 452 релевантности, где первый параметр 434, который указывает на уровень разницы в оценках 414 релевантности первого документа 432 и второго документа 433 из пары документов 431, может быть высоким, и второй параметр 436, который указывает на уровень разницы в векторах свойств 404, может быть низким, что дает экстремальный результат 472 проверки. Аналогично, если первый параметр 434, который указывает на уровень разницы в оценках 414 релевантности первого документа 432 и второго документа 433 из пары документов 431, может быть низким, и второй параметр 436, который указывает на уровень разницы в векторах свойств 404, может быть высоким, что дает экстремальный результат 472 проверки. Высокий первый параметр, следовательно, может указывать на высокий уровень разницы между оценками релевантности первого документа и второго документа, и низкий первый параметр может указывать на низкий уровень разницы в оценках релевантности первого документа и второго документа. Высокий второй параметр может указывать на высокий уровень разницы между векторами свойств первого документа и второго документа, и низкий второй параметр указывает на низкий уровень разницы в векторах свойств первого документа и второго документа.
[105] Экстремальный результат 472 проверки, следовательно, может указывать на невозможность MLА сервера 230 поисковой системы различить первый документ 432 и второй документ 433 из пары документов 431 из-за их соответствующих векторов 404 свойств и их соответствующих оценок 414 релевантности.
[106] В некоторых вариантах осуществления технологии, каждый результат 452 проверки из набора результатов 450 проверки может быть вычислен на основе уравнения:
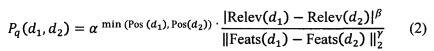
где:
Pq (d1,d2) - результат 452 проверки для пары документов 431;
d1 - первый документ из пары документов;
d2 - второй документ из пары документов;
Relev(d1) - Relev(d2) - первый параметр 434;
Feats (d1) - Feats(d2) - второй параметр 436;
min(Pos(d1), Pos(d2)) - третий параметр 438;
β- первый коэффициент;
γ - второй коэффициент; и
α - третий коэффициент.
[107] Как было указано ранее, величина коэффициентов α, β, и γ может быть определена эвристически. В общем случае, α>1, β>0 и γ>0. Экспериментально было определено, что оптимальные величины для каждого коэффициента представляют собой следующее: 1.56≤α≤1.58, β=0.55, γ=2.0. Тем не менее, другие величины также возможны, в зависимости от того, как реализован набор параметров 410.
[108] Набор результатов 450 проверки может далее поступать на устройство 460 выбора результата проверки.
[109] Устройство 460 выбора результата проверки может брать в качестве ввода набор результатов 450 проверки для вывода набора отмеченных результатов 470 проверки. В общем случае, целью устройства 460 выбора результатов проверки является выбор по меньшей мере одной пары документов 431, связанных с экстремальным результатом 472 проверки в наборе результатов 450 проверки. Как было описано ранее, пара документов 431, связанная с экстремальным результатом 472 проверки, может указывать на высокий уровень рассогласования между оценками релевантности пары документов 431 и векторами свойств пары документов 431, высокий уровень рассогласования указывает на возможное ошибочное ранжирование документа в паре документов 431.
[110] Реализация устройства 460 выбора результата проверки никак конкретно не ограничена. В некоторых вариантах осуществления технологии, устройство 460 выбора результата проверки может выбирать только один документ в наборе результатов 450 проверки, связанный с экстремальным (низшим или высшим) результатом проверки. В других вариантах осуществления технологии, устройство 460 выбора результата проверки может сначала ранжировать результаты 452 проверки из набора результатов 450 проверки в порядке убывания, и выбор подмножества результатов 452 проверки из набора результатов 450 проверки, которые находятся ниже заранее определенного порога.
[111] В некоторых вариантах осуществления технологии, устройство 460 выбора результата проверки может сравнивать каждый результат 452 проверки в наборе результатов 450 проверки с заранее определенным пороговым значением, и выбор результатов проверки, которые находятся ниже заранее определенного порога. Заранее определенный порог может быть определен экспериментально, т.е. может быть определено, что пара документов, которые, как правило, ошибочно ранжируются, находятся ниже конкретного значения результата проверки, и порог может быть определен на основе значения результата проверки.
[112] В других вариантах осуществления технологии, может быть два заранее определенных порога, первый заранее определенный порог для первого параметра 434 и второй заранее определенный порог для второго параметра 436, и комбинация первого и второго заранее определенных порогов может указывать на документы для выбора. Как может быть описано, то, как реализовано устройство 460 выбора результата проверки, зависит от того, как вычисляется результат 452 проверки.
[113] Выбранный документ, связанный с экстремальным результатом 472 проверки, может далее отмечен и передан для анализа серверу 230 поисковой системы. Документ в паре документов 431, связанный с экстремальным результатом 472 проверки, может быть ошибочно ранжирован алгоритмом машинного обучения сервера 230 поисковой системы по множеству причин: некоторые свойства не были представлены в документах, MLA может переоценивать некоторые свойства по сравнению с другими, может учитывать большее число свойств и т.д.
[114] Идентификация пары документов 431, обладающих экстремальным результатом 472 проверки может позволить анализировать документы из пары документов 431 для поиска ошибок в MLA алгоритма ранжирования и, следователь, может позволить настраивать и улучшать MLА сервера 230 поисковой системы путем вторичного обучения MLA без необходимости в большем количестве обучающих выборок. Документы из пары документов 431 могут быть заново оценены ассесорами и вторично используются для обучения MLA.
[115] Возвращаясь к Фиг. 5, способ 500 для выбора потенциально ошибочно ранжированных документов показан в форме блок-схеме в соответствии с вариантом осуществления настоящей технологии. Способ может начинаться на этапе 502. Выполнение способа 500 может быть осуществлено на электронном устройстве 100, реализованном как сервер проверки.
[116] ЭТАП 502: получение электронным устройством набора поисковых результатов от сервера поисковой системы, каждый документ из набора поисковых результатов обладает оценкой релевантности, созданной с помощью MLA, и вектором свойств, созданным с помощью MLA, оценка релевантности была создана по меньшей мере частично на основе вектора свойств
[117] На этапе 502 электронное устройство 100 может получать набор поисковых результатов 405 от сервера 230 поисковой системы, каждый документ 406 из набора поисковых результатов 405 связан с запросом, каждый документ 406 обладает оценкой 414 релевантности, созданной с помощью MLА сервера 230 поисковой системы, и вектором 416 свойств, созданным с помощью MLА сервера 230 поисковой системы, оценка 414 релевантности была создана, по меньшей мере частично, на основе вектора 416 свойств.
[118] В некоторых вариантах осуществления технологии, каждый документ 406 из набора поисковых результатов 405 может далее позицией 418, позиция 418 была создана, по меньшей частично, на основе оценки 414 релевантности. В других вариантах осуществления технологии, набор поисковых результатов 405 может обладать множеством подмножеств поисковых результатов, каждое подмножество поисковых результатов реагирует на соответствующий запрос q. В неограничивающем представленном примере, набор поисковых результатов 405 может обладать только верхними 30 документами d1, d2, d3, d30, соответствующими запросу q, поскольку документы, отображающиеся на первых нескольких страницах SERP, с большей вероятностью будут выбраны пользователем, вводящим запрос. Способ 500 далее может перейти к выполнению этапа 504.
[119] ЭТАП 504: вычисление электронным устройством, для каждой возможной пары документов из набора поисковых результатов: первый параметр указывает на разницу в оценках релевантности; а второй параметр указывает на разницу в векторах свойств.
[120] На этапе 504, электронное устройство 100, исполняющее вычислитель 420 параметра пары, может вычислять, для каждой возможной пары документов 430 из набора поисковых результатов 405, первый параметр 434 указывает на разницу в оценках 414 релевантности первого документа 432 и второго документа 433, а второй параметр 436 указывает на разницу в векторах 340 свойств первого документа 432 и второго документа 433.
[121] В некоторых вариантах осуществления технологии, электронное устройство 100, исполняющее вычислитель 420 параметра пары может далее вычислять третий параметр 438, третий параметр 438 основан на позициях 418 первого документа 432 и второго документа 433 из пары документов 431. В представленном неограничивающем примере, где набор поисковых результатов 405 содержит верхние 30 документов, вычислитель 420 параметра пары должен вычислять первый параметр 434, второй параметр 436 и третий параметр 438 для каждой возможной пары документов в наборе из 30 документов, что в результате дает 435 возможных пар документов. Третий параметр 438 может представлять собой минимум между позициями 418 первого документа 432 и второго документа 433 из пары документов.
[122] В представленном неограничивающем примере, первый параметр 434 может быть вычислен путем вычитания значения оценки 414 релевантности первого документа 432 из пары документов 431 с оценкой 414 релевантности второго документа 433 из пары документов 431 и принимая абсолютное значение, которое может быть равно 17. Второй параметр 436 может далее быть вычислен путем вычитания значения вектора 416 свойств первого документа 432 из пары документов 431 с вектором 416 свойства второго документа 433 из пары документов 431 и принимая нормальную разницу, которая может быть равна 4,71. Третий параметр 438 может быть определен путем принятия минимальной позиции между первым документом 432 и вторым документом 433 из пары документов 431, обладающей позицией 3, и вторым документом из пары документов 431, обладающий позицией 7, минимальная позиция может быть равна 3. Способ 500 далее может перейти к выполнению этапа 506.
[123] ЭТАП 506: вычисление электронным устройством 100 результата проверки для каждой возможной пары документов из набора поисковых результатов, результат проверки основан на первом параметре и втором параметре.
[124] На этапе 506, электронное устройство 100, которое выполняет вычислитель 440 результата проверки, может вычислять результат 452 проверки для каждой возможной пары документов 430 из набора поисковых результатов 405, результат 452 проверки основан на первом параметре 434 и втором параметре 436. Результат 452 проверки может далее включать в себя третий параметр 438. Продолжая с предыдущим примером, обладающим минимальной позицией 3, разница в оценках релевантности 17 и норма разницы вектора свойств равна 4,71, результат проверки может быть вычислен с помощью уравнения (2), представленного раньше:
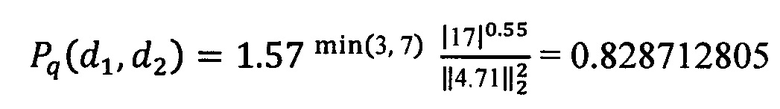
Способ 500 далее может перейти к выполнению этапа 508.
[125] ЭТАП 508: выбор, электронным устройством, по меньшей мере одной пары документов, связанных с экстремальным результатом проверки, экстремальный результат проверки указывает на возможность ошибочно ранжированного документа в паре соседних документов.
[126] На этапе 508, электронное устройство 100, выполняющее устройство 460 выбора результата проверки, может выбирать по меньшей мере одну пару документов 431, связанных с экстремальным результатом 472 проверки, экстремальный результат 472 проверки указывает на возможность ошибочно ранжированного документа в паре соседних документов 431. Электронное устройство 100, выполняющее устройство 460 выбора результата проверки, может выбирать низший результат проверки из результатов проверки для каждой возможной пары документов 430. Как было указано ранее, то, как устройство 460 выбора результатов проверки является выбор по меньшей мере одной пары документов 431, связанных с экстремальным результатом 472 проверки в наборе результатов 450 проверки. Способ 500 далее может перейти к выполнению этапа 510.
[127] ЭТАП 510: разметка электронным устройством по меньшей мере одной выбранной пары документов, связанных с экстремальным результатом проверки для проверки сервером поисковой системы.
[128] На этапе 510, электронное устройство 100, выполняющее устройство 460 выбора результата проверки, может маркировать по меньшей мере одну выбранную пару документов, связанных с экстремальным результатом 472 проверки для проверки с помощью сервера 230 поисковой системы. Первый документ и/или второй документ из помеченной пары документов мог быть ошибочно ранжирован по вышеуказанным причинам.
[129] Этапы 502-510 могут далее повторяться для множества набором поисковых результатов (не показано), каждый из наборов поисковых результатов, связанный с соответствующим запросом, где экстремальный результат 472 проверки для каждого запроса может быть ранжирован в порядке приоритета запроса для повторной оценки документов из пары документов 431 и/или для проверки ассесором или разработчиком. Пара документов 431, обладающих наивысшим или низшим значением экстремального результата 472 проверки, может быть выбрана для повторной оценки и обучения алгоритма машинного обучения сервера 230 поисковой системы.
[130] Затем способ 500 завершается.
[131] Варианты осуществления настоящей технологии могут быть кратко изложены в пронумерованных пунктах.
[132] ПУНКТ 1 Исполняемый на компьютере способ (500) выбора потенциально ошибочно ранжированного документа в наборе поисковых результатов (405), набор поисковых результатов (405) был создан сервером (230) поисковой системы, выполняющим алгоритм машинного обучения (MLA) в ответ на запрос, способ (500), выполняемый электронным устройством (100), электронное устройство (100) соединено с сервером (230) поисковой системы, способ (500) включает в себя: получение электронным устройством (100) набора поисковых результатов (405) от сервера (230) поисковой системы, каждый документ из набора поисковых результатов (405) обладает оценкой релевантности, созданной с помощью MLА, и вектором (416) свойств, созданным с помощью MLА, оценка релевантности была создана по меньшей мере частично на основе вектора (416) свойств;
вычисление электронным устройством (100), для каждой возможной пары документов (430) из набора поисковых результатов (405), пара документов (43) включает в себя первый документ (432) и второй документ (433):
первый параметр (434) получен с помощью первой бинарной операции над оценками (414) релевантности первого документа (432) и второго документа (433), первый параметр (434) указывает на уровень разницы в оценках (414) релевантности первого документа (432) и второго документа (433), и
второй параметр (436) получен с помощью второй бинарной операции над векторами (416) свойств первого документа (432) и второго документа (433), второй параметр (436) указывает на уровень разницы в векторах (416) свойств первого документа (432) и второго документа (433);
вычисление электронным устройством (100) результата (452) проверки для каждой возможной пары документов (430) из набора поисковых результатов (405), результат (452) проверки основан на первом параметре (434) и втором параметра (436), результат (452) проверки указывает на уровень рассогласования между оценками (414) релевантности первого документа (432) и второго документа (433) и векторами (416) свойств первого документа (432) и второго документа (433) из пары документов (430);
выбор электронным устройством (100) по меньшей мере одной пары документов (430), связанной с экстремальным результатом (472) (452) проверки, экстремальный результат (472) (452) проверки указывает на высокий уровень рассогласования между оценками (414) релевантности, высокий уровень рассогласования указывает на возможное ошибочное ранжирование документа в паре документов (430); и
разметка электронным устройством (100) по меньшей мере одной выбранной пары документов (430), связанных с экстремальным результатом (472) (452) проверки для проверки сервером (230) поисковой системы.
[133] ПУНКТ 2 Способ (500) по п. 1, в котором экстремальный результат (472) (452) проверки далее указывает на неспособность алгоритма машинного обучения с сервера (230) поисковой системы различать первый документ (432) и второй документ (433) из пары документов (430).
[134] ПУНКТ 3 Способ (500) по любому из пп. 1-2, в котором результат (452) проверки возрастает для пар документов, обладающих высоким первым параметром (434) и низким вторым параметром (436), и в котором результат (452) проверки снижается для пар документов, обладающих низким первым параметром (434) и высоким вторым параметром (436).
[135] ПУНКТ 4 Способ (500) по любому из пп. 1-3, в котором высокий первый параметр (434) указывает на высокий уровень разницы между оценками (414) релевантности первого документа (432) и второго документа (433), и в котором низкий первый параметр (434) указывает на низкий уровень разницы в оценках (414) релевантности первого документа (432) и второго документа (433).
[136] ПУНКТ 5 Способ (500) по любому из пп. 1-4, в котором высокий второй параметр (436) указывает на высокий уровень разницы между векторам (416) свойств первого документа (432) и второго документа (433), и в котором низкий второй параметр (436) указывает на низкий уровень разницы между векторами (416) свойств первого документа (432) и второго документа (433).
[137] ПУНКТ 6 Способ (500) по любому из пп. 1-5, в котором каждый документ из набора поисковых результатов (405) обладает позицией на странице результатов поиска (SERP), позиция была определена по меньшей мере частично на основе оценки релевантности, и в котором результат (452) проверки далее основан на третьем параметре (438), третий параметр (438) основан на позициях на SERP первого документа (432) и второго документа (433) из пары документов (430).
[138] ПУНКТ 7 Способ (500) по любому из пп. 1-6, в котором первая бинарная операция является вычитанием и вторая бинарная операция является вычитанием.
[139] ПУНКТ 8 Способ (500) по любому из пп. 1-7, в котором третий параметр (438) является низшей позицией между позицией первого документа (432) из пары и второго документа (433) из пары.
[140] ПУНКТ 9 Способ (500) по любому из пп. 1-8, в котором экстремальный результат (472) (452) проверки является низшим результатом (472) проверки.
[141] ПУНКТ 10 Способ (500) по любому из пп. 1-9, в котором выбор по меньшей мере одной пары, связанной с низшим результатом (472) проверки, включает в себя:
ранжирование результатов (452) проверки в порядке убывания; и
выбор результатов (452) проверки ниже заранее определенного порога.
[142] ПУНКТ 11 Способ (500) по любому из пп. 1-9, в котором первый параметр (434) оценивается первым коэффициентом, второй параметр (436) оценивается вторым коэффициентом, третий параметр (438) оценивается третьим коэффициентом, первый коэффициент, второй коэффициент и третий коэффициент позволяют отражать степень влияния первого параметра (434), второго параметра (436) и третьего параметра (438) на результат (452) проверки для выбора по меньшей мере одного возможно ошибочно ранжированного документа.
[143] ПУНКТ 12 Способ (500) по любому из пп. 1-11, в котором первый коэффициент, второй коэффициент и третий коэффициент определяются эвристическим путем.
[144] ПУНКТ 13 Способ (500) по любому из пп. 1-12, в котором вычисление для каждой пары соседних документов выполняется для подмножества из набора поисковых результатов (405).
[145] ПУНКТ 14 Способ (500) по любому из пп. 1-13, дополнительно включающий в себя:
передачу по меньшей мере одной пары документов (430) серверу (230) поисковой системы; и
повтор этапов: получения набора поисковых результатов (405), вычисления первого параметра (434), второго параметра (436) и третьего параметра (438), вычисления результата (452) проверки, выбора по меньшей мере одной пары, связанной с низшим результатом проверки (472), и разметки по меньшей мере одной пары после заранее определенного периода времени.
[146] ПУНКТ 15 Способ (500) по любому из пп. 1-14, в котором результат (452) проверки вычисляется на основе:
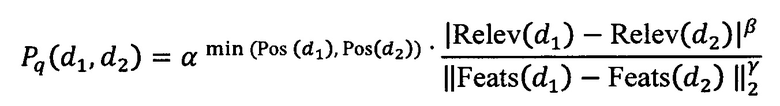
где
Pq(d1, d2) - результат (452) проверки для пары документов (430);
d1 - первый документ (432) из пары документов (430);
d2 - второй документ (433) из пары документов (430);
Relev(d1) - Relev(d2) - первый параметр (434);
Feats(d1) - Feats(d2) - второй параметр (436);
min(Pos(d1), Pos(d2)) - третий параметр (438);
β - первый коэффициент;
γ - второй коэффициент; и
α - третий коэффициент.
[147] ПУНКТ 16 Система для выбора потенциально ошибочно ранжированного документа в наборе поисковых результатов (405), набор поисковых результатов (405) был создан сервером (230) поисковой системы, выполняющим алгоритм машинного обучения (MLA) в ответ на запрос, система соединена с сервером (230) поисковой системы, система включает в себя:
процессор;
постоянный машиночитаемый носитель компьютерной информации, содержащий инструкции;
процессор, при выполнении инструкций, настраиваемый на осуществление:
получения набора поисковых результатов (405) от сервера (230) поисковой системы, каждый документ из набора поисковых результатов (405) обладает оценкой релевантности, созданной с помощью MLА, и вектором (416) свойств, созданным с помощью MLA, оценка релевантности была создана по меньшей мере частично на основе вектора (416) свойств;
вычисления для каждой возможной пары документов (430) из набора поисковых результатов (405), пара документов (430) включает в себя первый документ (432) и второй документ (433):
первый параметр (434) получен с помощью первой бинарной операции над оценками (414) релевантности первого документа (432) и второго документа (433), первый параметр (434) указывает на уровень разницы в оценках (414) релевантности первого документа (432) и второго документа (433), и второй параметр (436) получен с помощью второй бинарной операции над векторами (416) свойств первого документа (432) и второго документа (433), второй параметр (436) указывает на уровень разницы в векторах (416) свойств первого документа (432) и второго документа (433);
вычисления результата (452) проверки для каждой возможной пары документов (430) из набора поисковых результатов (405), результат (452) проверки основан на первом параметре (434) и втором параметра (436), результат (452) проверки указывает на уровень рассогласования между оценками (414) релевантности первого документа (432) и второго документа (433) и векторами (416) свойств первого документа (432) и второго документа (433) из пары документов (430);
выбор по меньшей мере одной пары документов (430), связанной с экстремальным результатом (472) (452) проверки, экстремальный результат (472) (452) проверки указывает на высокий уровень рассогласования между оценками (414) релевантности первого документа (432) и второго документа (433) и векторам (416) свойств первого документа (432) и второго документа (432) из пары документов (430), высокий уровень рассогласования указывает на возможное ошибочное ранжирование документа в паре документов (430); и
разметка по меньшей мере одной выбранной пары документов (430), связанных с экстремальным результатом (472) (452) проверки для проверки сервером (230) поисковой системы.
[148] ПУНКТ 17 Система по п. 16, в которой экстремальный результат (472) (452) проверки далее указывает на неспособность алгоритма машинного обучения с сервера (230) поисковой системы различать первый документ (432) и второй документ (433) из пары документов (430).
[149] ПУНКТ 18 Система по любому из пп. 16-17, в которой результат (452) проверки возрастает для пар документов, обладающих высоким первым параметром (434) и низким вторым параметром (436), и в котором результат (452) проверки снижается для пар документов, обладающих низким первым параметром (434) и высоким вторым параметром (436).
[150]
[151]
[152] ПУНКТ 21 Система по любому из пп. 16-20, в которой каждый документ из набора поисковых результатов (405) обладает позицией на странице результатов поиска (SERP), позиция была определена по меньшей мере частично на основе оценки релевантности, и в котором результат (452) проверки далее основан на третьем параметре (438), третий параметр (438) основан на позициях на SERP первого документа (432) и второго документа (433) из пары документов (430).
[153] ПУНКТ 22 Система по любому из пп. 16-21, в которой первая бинарная операция является вычитанием и вторая бинарная операция является вычитанием.
[154] ПУНКТ 23 Система по любому из пп. 16-22, в которой третий параметр (438) является низшей позицией между позицией первого документа (432) из пары и второго документа (433) из пары.
[155] ПУНКТ 24 Система по любому из пп. 16-23, в котором экстремальный результат (472) (452) проверки является низшим результатом (472) проверки.
[156] ПУНКТ 25 Система по любому из пп. 16-24, в которой выбор по меньшей мере одной пары, связанной с низшим результатом (472) проверки, включает в себя:
ранжирование результатов (452) проверки в порядке убывания; и выбор результатов (452) проверки ниже заранее определенного порога.
[157] ПУНКТ 26 Система по любому из пп. 16-25, в которой первый параметр (434) оценивается первым коэффициентом, второй параметр (436) оценивается вторым коэффициентом, третий параметр (438) оценивается третьим коэффициентом, первый коэффициент, второй коэффициент и третий коэффициент позволяют отражать степень влияния первого параметра (434), второго параметра (436) и третьего параметра (438) на результат (452) проверки для выбора по меньшей мере одного возможно ошибочно ранжированного документа.
[158] ПУНКТ 27 Система по любому из пп. 16-26, в которой первый коэффициент, второй коэффициент и третий коэффициент определяются эвристическим путем.
[159] ПУНКТ 28 Система по любому из пп. 16-27, в котором вычисление для каждой пары соседних документов выполняется для подмножества из набора поисковых результатов (405).
[160] ПУНКТ 29 Система по по любому из пп. 16-28, дополнительно включающая в себя:
передачу по меньшей мере одной пары документов (430) серверу (230) поисковой системы; и
повтор этапов: получения набора поисковых результатов (405), вычисления первого параметра (434), второго параметра (436) и третьего параметра (438), вычисления результата (452) проверки, выбора по меньшей мере одной пары, связанной с низшим результатом проверки (472), и разметки по меньшей мере одной пары после заранее определенного периода времени.
[161] ПУНКТ 30 Система по любому из пп. 16-29, в которой результат (452) проверки вычисляется на основе:
[162] ПУНКТ 31 Система (500) по любому из пп. 16-30, в котором результат (452) проверки вычисляется на основе: 
где
Pq(d1, d2) - результат (452) проверки для пары документов (430);
d1 - первый документ (432) из пары документов (430);
d2 - второй документ (433) из пары документов (430);
Relev(d1) - Relev(d2) - первый параметр (434);
Feats(d1) - Feats(d2) - второй параметр (436);
min(Pos(d1), Pas(d2)) - третий параметр (438);
β - первый коэффициент;
γ - второй коэффициент; и
α - третий коэффициент.
[163] В рамках приведенного описания следует иметь в виду, что при упоминании любого случая, который включает в себя извлечение данных из любого клиентского устройства и/или из любого почтового сервера, может использоваться извлечение электронного или иного сигнала из соответствующего клиентского устройства (сервера, почтового сервера), а также отображение на экране устройства может быть реализовано как передача сигнала на экран, причем сигнал включает в себя конкретную информацию, которая далее может быть интерпретирована конкретным изображением и по меньшей мере частично отображена на экране клиентского устройства. Отправка и получение сигнала не упоминается в настоящем описании в некоторых случаях для упрощения описания и с целью облегчить понимание. Одной из возможных причин перекластеризации может быть то обстоятельство, что предыдущая кластеризация могла повлечь возникновение графических символов более крупных размеров, в результате чего новый графический символ кластера может коснуться графического символа метки точки интереса.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ВЫБОРА ДЛЯ РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2731658C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРИРОВАНИЯ ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТА | 2018 |
|
RU2733481C2 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСШИРЕНИЯ ПОИСКОВЫХ ЗАПРОСОВ С ЦЕЛЬЮ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2018 |
|
RU2720905C2 |
| СПОСОБ ОБУЧЕНИЯ МОДУЛЯ РАНЖИРОВАНИЯ С ИСПОЛЬЗОВАНИЕМ ОБУЧАЮЩЕЙ ВЫБОРКИ С ЗАШУМЛЕННЫМИ ЯРЛЫКАМИ | 2016 |
|
RU2632143C1 |
| СПОСОБ И СЕРВЕР ГЕНЕРИРОВАНИЯ МЕТА-ПРИЗНАКА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ | 2018 |
|
RU2721159C1 |
| СПОСОБ И СИСТЕМА СОЗДАНИЯ ВЕКТОРОВ АННОТАЦИИ ДЛЯ ДОКУМЕНТА | 2017 |
|
RU2720074C2 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| Система и способ формирования обучающего набора для алгоритма машинного обучения | 2018 |
|
RU2744029C1 |
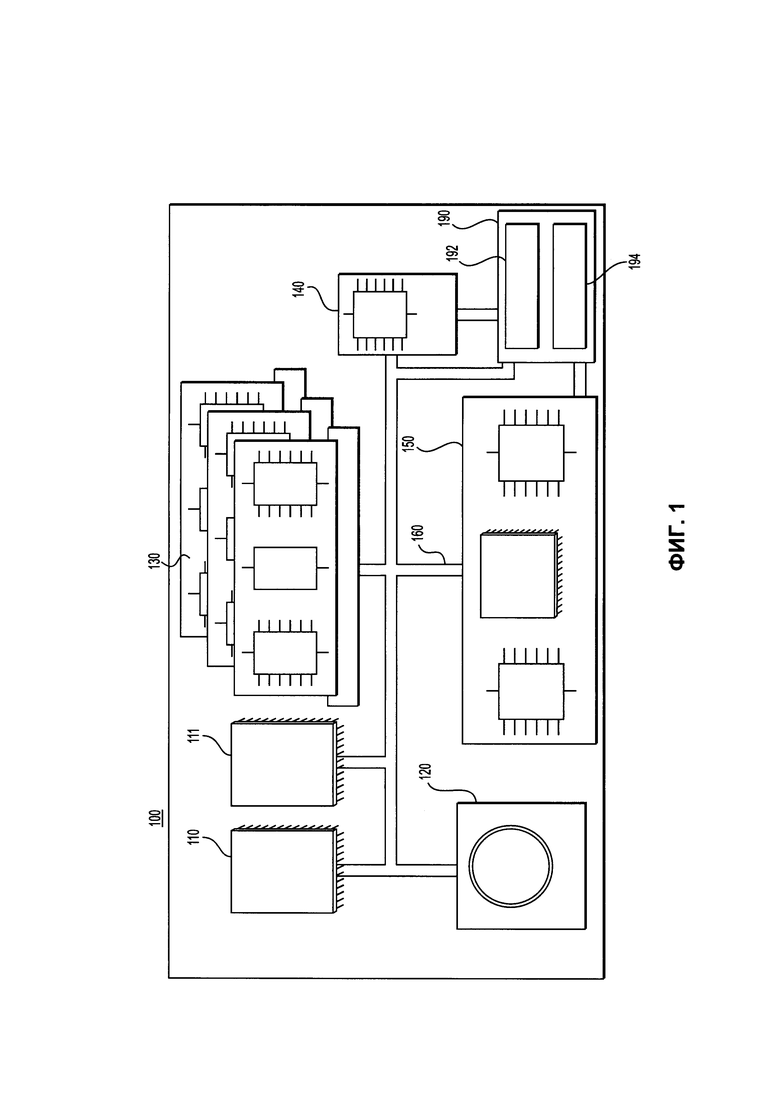
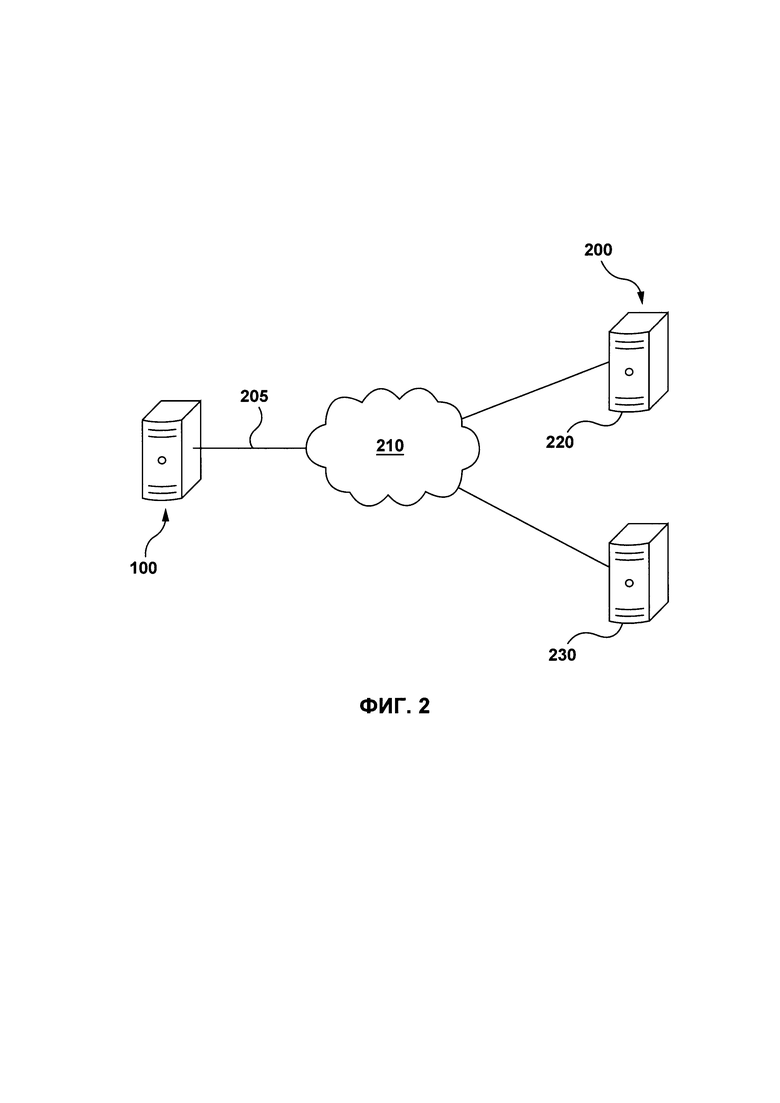
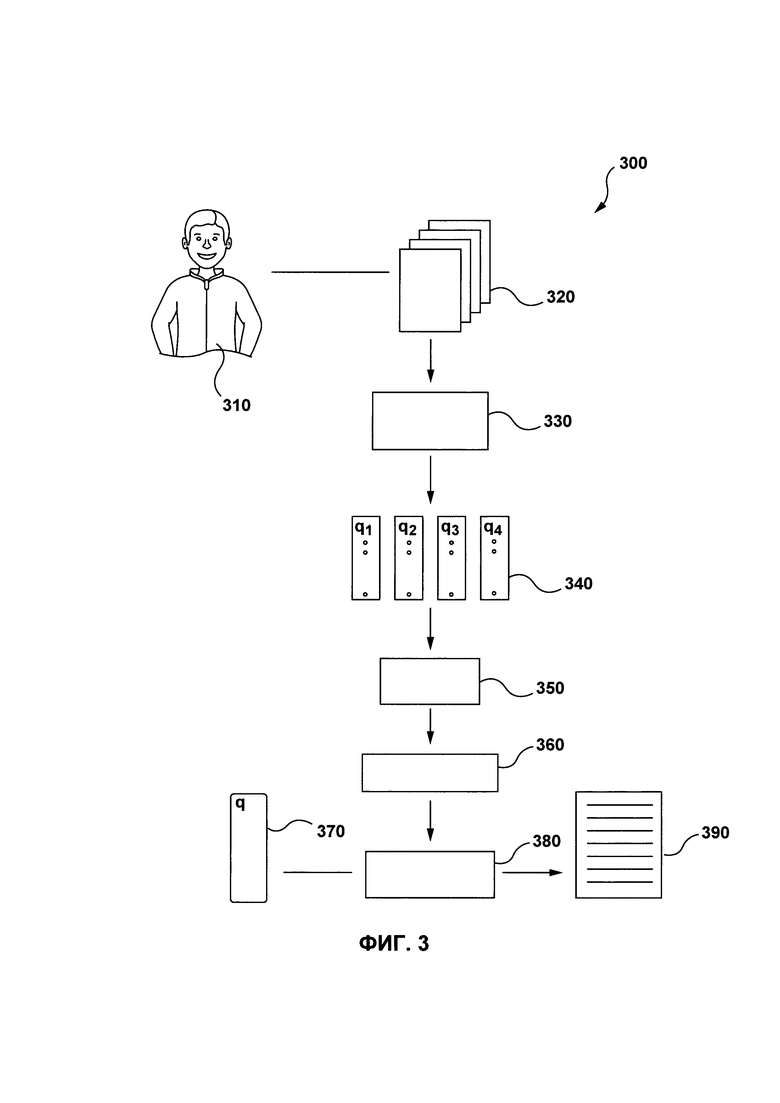
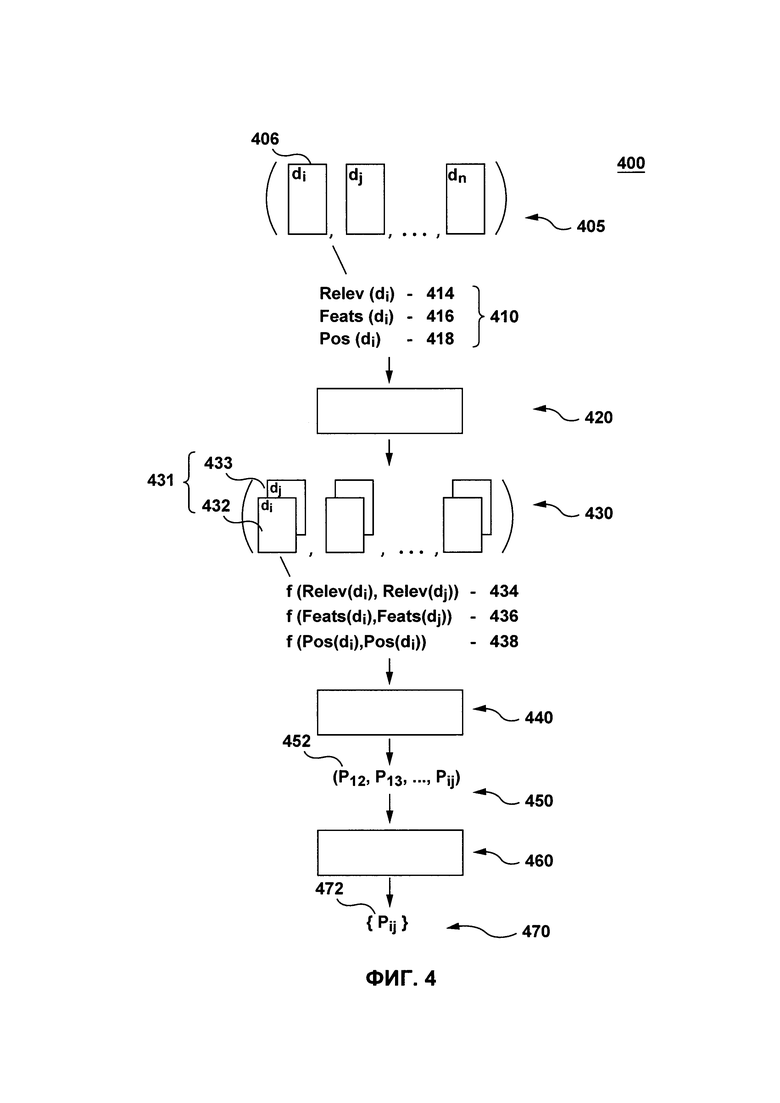
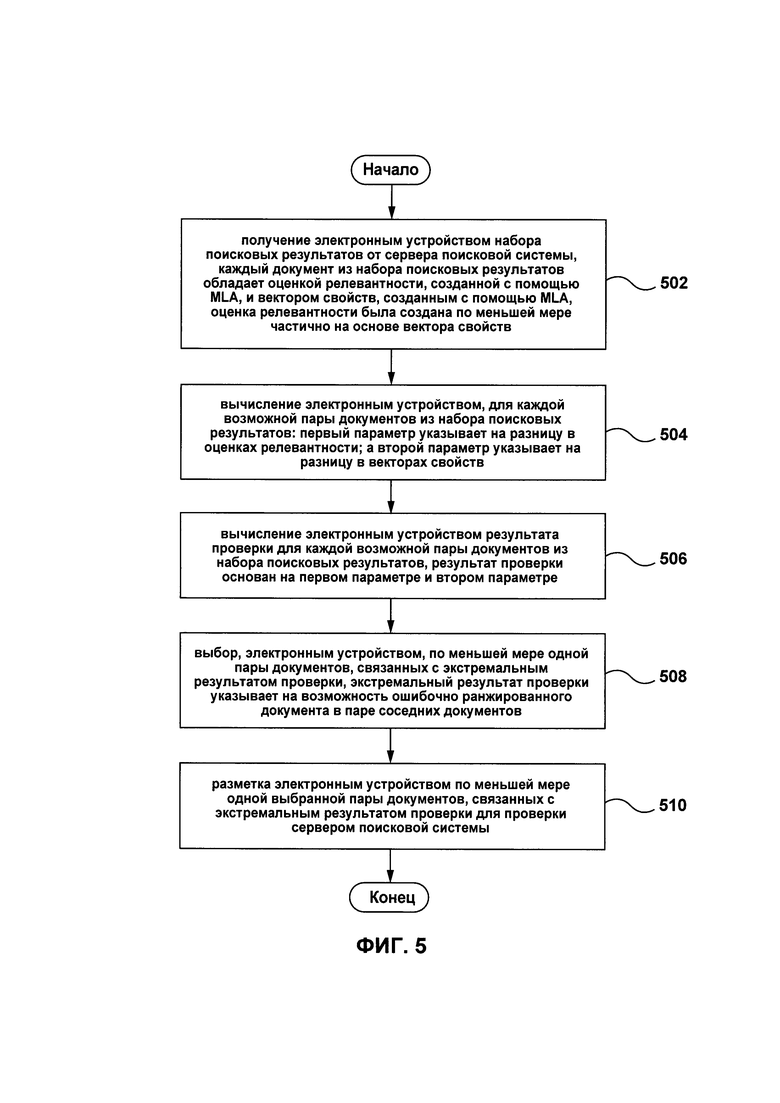
Изобретение относится к средствам для выбора потенциально ошибочно ранжированного документа в наборе поисковых результатов в ответ на запрос. Технический результат заключается в повышении точности машинного обучения. Получают набор поисковых результатов от сервера поисковой системы, причем каждый документ из набора поисковых результатов обладает оценкой релевантности и вектором свойств, созданным алгоритмом машинного обучение. Вычисляют для каждой возможной пары документов первый параметр, указывающий на уровень различия в оценке релевантности документов из пары документов, и второй параметр, указывающий на уровень разницы в векторах свойств документов из пары документов. Вычисляют результат проверки на основе первого параметра и второго параметра, причем результат проверки указывает на уровень несогласованности между оценками релевантности и векторами свойств. Выбирают и размечают пару документов, связанных с экстремальным результатом проверки для проверки. 2 н. и 28 з.п. ф-лы, 5 ил.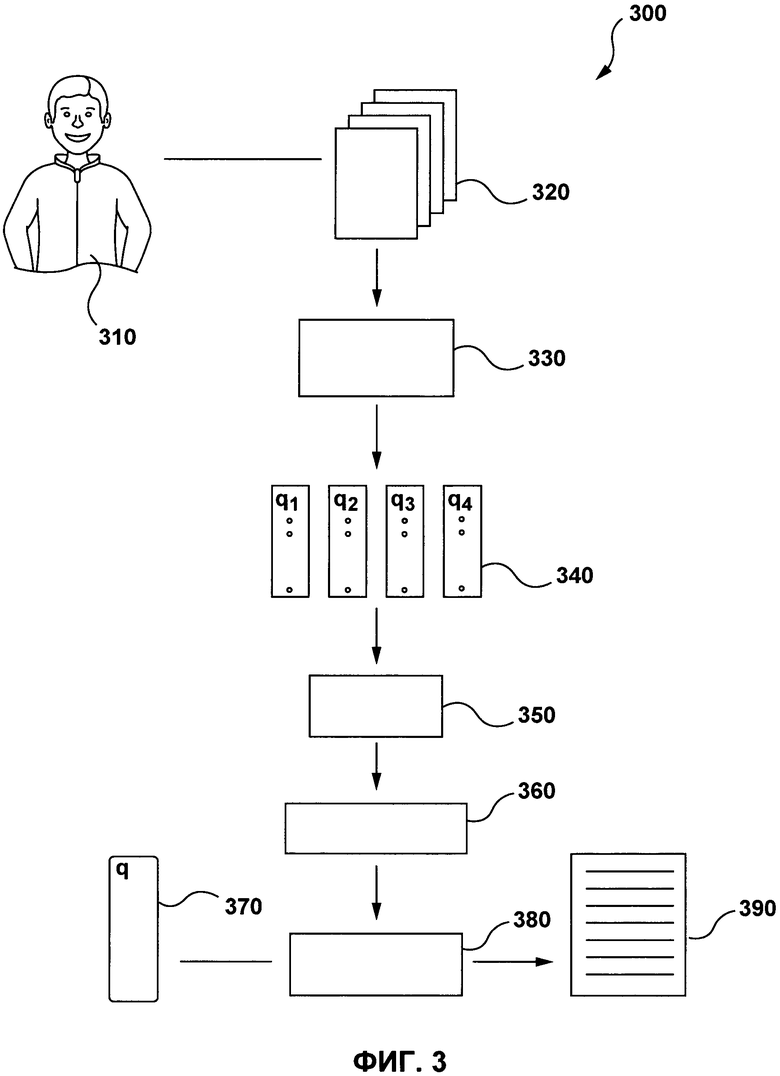
1. Исполняемый на компьютере способ выбора потенциально ошибочно ранжированного документа в наборе поисковых результатов, набор поисковых результатов был создан сервером поисковой системы, выполняющим алгоритм машинного обучения (MLA) в ответ на запрос, способ, выполняемый электронным устройством, электронное устройство соединено с сервером поисковой системы, способ включает в себя:
получение электронным устройством набора поисковых результатов от сервера поисковой системы, каждый документ из набора поисковых результатов обладает оценкой релевантности, созданной с помощью MLA, и вектором свойств, созданным с помощью MLA, оценка релевантности была создана по меньшей мере частично на основе вектора свойств;
вычисление электронным устройством, для каждой возможной пары документов из набора поисковых результатов, пара документов включает в себя первый документ и второй документ:
первый параметр получен с помощью первой бинарной операции над оценками релевантности первого документа и второго документа, первый параметр указывает на уровень разницы в оценках релевантности первого документа и второго документа, и
второй параметр получен с помощью второй бинарной операции над векторами свойств первого документа и второго документа, второй параметр указывает на уровень разницы в векторах свойств первого документа и второго документа;
вычисление электронным устройством результата проверки для каждой возможной пары документов из набора поисковых результатов, результат проверки основан на первом параметре и втором параметре, результат проверки указывает на уровень рассогласования между оценками релевантности первого документа и второго документа и векторами свойств первого документа и второго документа из пары документов;
выбор электронным устройством по меньшей мере одной пары документов, связанной с экстремальным результатом проверки, экстремальный результат проверки указывает на высокий уровень рассогласования между оценками релевантности первого документа и второго документа и вектором свойств первого документа и второго документа из пары документов, высокий уровень рассогласования указывает на возможное ошибочное ранжирование документа в паре документов; и
разметка электронным устройством по меньшей мере одной выбранной пары документов, связанных с экстремальным результатом проверки для проверки сервером поисковой системы.
2. Способ по п. 1, в котором экстремальный результат проверки далее указывает на неспособность алгоритма машинного обучения с сервера поисковой системы различать первый документ и второй документ из пары документов.
3. Способ по п. 2, в котором результат проверки возрастает для пар документов, обладающих высоким первым параметром и низким вторым параметром, и в котором результат проверки снижается для пар документов, обладающих низким первым параметром и высоким вторым параметром.
4. Способ по п. 3, в котором высокий первый параметр указывает на высокий уровень разницы между оценками релевантности первого документа и второго документа и в котором низкий первый параметр указывает на низкий уровень разницы в оценках релевантности первого документа и второго документа.
5. Способ по п. 4, в котором высокий второй параметр указывает на высокий уровень разницы между векторами свойств первого документа и второго документа и в котором низкий второй параметр указывает на низкий уровень разницы между векторами свойств первого документа и второго документа.
6. Способ по п. 5, в котором каждый документ из набора поисковых результатов обладает позицией на странице результатов поиска (SERP), позиция была определена по меньшей мере частично на основе оценки релевантности, и в котором результат проверки далее основан на третьем параметре, третий параметр основан на позициях на SERP первого документа и второго документа из пары документов.
7. Способ по п. 6, в котором первая бинарная операция является вычитанием и вторая бинарная операция является вычитанием.
8. Способ по п. 7, в котором третий параметр является низшей позицией между позицией первого документа из пары и второго документа из пары.
9. Способ по п. 8, в котором экстремальный результат проверки представляет собой низший результат проверки.
10. Способ по п. 9, в котором выбор по меньшей мере одной пары, связанной с низшим результатом проверки включат в себя выбор подмножества результатов проверки, каждый результат проверки подмножества результатов проверки ниже заранее определенного порога, заранее определенный порог указывает на ошибочно ранжированный документ.
11. Способ по п. 10, в котором первый параметр оценивается первым коэффициентом, второй параметр оценивается вторым коэффициентом, третий параметр оценивается третьим коэффициентом, первый коэффициент, второй коэффициент и третий коэффициент позволяют отражать степень влияния первого параметра, второго параметра и третьего параметра на результат проверки для выбора по меньшей мере одного возможно ошибочно ранжированного документа.
12. Способ по п. 11, в котором первый коэффициент, второй коэффициент и третий коэффициент были определены эвристическим путем.
13. Способ по п. 12, в котором вычисление для каждой пары соседних документов выполняется для подмножества из набора поисковых результатов.
14. Способ по п. 13, дополнительно включающий в себя:
передачу по меньшей мере одной пары документов серверу поисковой системы; и
повтор этапов: получения набора поисковых результатов, вычисления первого параметра, второго параметра и третьего параметра, вычисления результата проверки, выбора по меньшей мере одной пары, связанной с низшим результатом проверки, и разметки по меньшей мере одной пары после заранее определенного периода времени.
15. Способ по п. 14, в котором результат проверки вычисляется на основе:
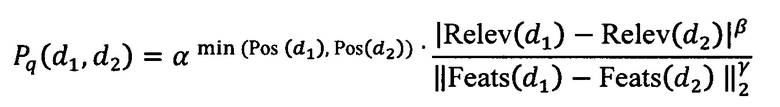
где
Pq (d1, d2) - результат проверки для пары документов;
d1 - первый документ из пары документов;
d2 - второй документ из пары документов;
Relev(d1)-Relev(d2) - первый параметр;
Feats(d1)-Feats(d2) - второй параметр;
min(Pos (d1), Pos(d2)) - третий параметр;
β - первый коэффициент;
γ - второй коэффициент; и
α - третий коэффициент.
16. Система для выбора потенциально ошибочно ранжированного документа в наборе поисковых результатов, набор поисковых результатов был создан сервером поисковой системы, выполняющим алгоритм машинного обучения (MLA) в ответ на запрос, система соединена с сервером поисковой системы, система включает в себя:
процессор;
постоянный машиночитаемый носитель компьютерной информации, содержащий инструкции;
процессор, при выполнении инструкций, настраиваемый на возможность осуществить:
получение набора поисковых результатов от сервера поисковой системы, каждый документ из набора поисковых результатов обладает оценкой релевантности, созданной с помощью MLA, и вектором свойств, созданным с помощью MLA, оценка релевантности была создана по меньшей мере частично на основе вектора свойств;
вычисление, для каждой возможной пары документов из набора поисковых результатов, пара документов включает в себя первый документ и второй документ:
первый параметр получен с помощью первой бинарной операции над оценками релевантности первого документа и второго документа, первый параметр указывает на уровень разницы в оценках релевантности первого документа и второго документа, и
второй параметр получен с помощью второй бинарной операции над векторами свойств первого документа и второго документа, второй параметр указывает на уровень разницы в векторах свойств первого документа и второго документа;
вычисление результата проверки для каждой возможной пары документов из набора поисковых результатов, результат проверки основан на первом параметре и втором параметре, результат проверки указывает на уровень рассогласования между оценками релевантности первого документа и второго документа и векторами свойств первого документа и второго документа из пары документов;
выбор по меньшей мере одной пары документов, связанной с экстремальным результатом проверки, экстремальный результат проверки указывает на высокий уровень рассогласования между оценками релевантности первого документа и второго документа и вектором свойств первого документа и второго документа из пары документов, высокий уровень рассогласования указывает на возможное ошибочное ранжирование документа в паре документов; и
разметка по меньшей мере одной выбранной пары документов, связанных с экстремальным результатом проверки для проверки сервером поисковой системы.
17. Система по п. 16, в которой экстремальный результат проверки далее указывает на неспособность алгоритма машинного обучения с сервера поисковой системы различать первый документ и второй документ из пары документов.
18. Система по п. 17, в которой результат проверки возрастает для пар документов, обладающих высоким первым параметром и низким вторым параметром, и в котором результат проверки снижается для пар документов, обладающих низким первым параметром и высоким вторым параметром.
19. Система по п. 18, в которой высокий первый параметр указывает на высокий уровень разницы между оценками релевантности первого документа и второго документа и в которой низкий первый параметр указывает на низкий уровень разницы в оценках релевантности первого документа и второго документа.
20. Система по п. 19, в которой высокий второй параметр указывает на высокий уровень разницы между векторами свойств первого документа и второго документа и в которой низкий второй параметр указывает на низкий уровень разницы между векторами свойств первого документа и второго документа.
21. Система по п. 20, в которой каждый документ из набора поисковых результатов обладает позицией на странице результатов поиска (SERP), позиция была определена по меньшей мере частично на основе оценки релевантности, и в которой результат проверки далее основан на третьем параметре, третий параметр основан на позициях на SERP первого документа и второго документа из пары документов.
22. Система по п. 21, в которой первая бинарная операция является вычитанием и вторая бинарная операция является вычитанием.
23. Система по п. 22, в которой третий параметр является низшей позицией между позицией первого документа из пары и второго документа из пары.
24. Система по п. 23, в которой третий параметр является низшей позицией между позицией первого документа из пары и второго документа из пары.
25. Система по п. 24, в которой выбор по меньшей мере одной пары, связанной с низшим результатом проверки, включает в себя выбор подмножества результатов проверки, каждый результат проверки подмножества результатов проверки ниже заранее определенного порога, заранее определенный порог указывает на ошибочно ранжированный документ.
26. Система по п. 25, в которой первый параметр оценивается первым коэффициентом, второй параметр оценивается вторым коэффициентом, третий параметр оценивается третьим коэффициентом, первый коэффициент, второй коэффициент и третий коэффициент позволяют отражать степень влияния первого параметра, второго параметра и третьего параметра на результат проверки для выбора по меньшей мере одного возможно ошибочно ранжированного документа.
27. Система по п. 26, в которой первый коэффициент, второй коэффициент и третий коэффициент определяются эвристическим путем.
28. Система по п. 27, в которой вычисление для каждой пары соседних документов выполняется для подмножества из набора поисковых результатов.
29. Система по п. 28, в которой процессор дополнительно выполнен с возможностью осуществлять:
передачу по меньшей мере одной пары документов серверу поисковой системы; и
повтор этапов: получения набора поисковых результатов, вычисления первого параметра, второго параметра и третьего параметра, вычисления результата проверки, выбора по меньшей мере одной пары, связанной с низшим результатом проверки, и разметки по меньшей мере одной пары после заранее определенного периода времени.
30. Система по п. 29, в которой результат проверки вычисляется на основе:
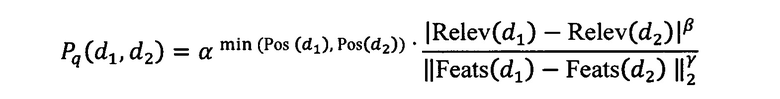
где
Pq (d1, d2) - результат проверки для пары документов;
d1 - первый документ из пары документов;
d2 - второй документ из пары документов;
Relev(d1)-Relev(d2) - первый параметр;
Feats(d1)-Feats(d2) - второй параметр;
min(Pos (d1), Pos(d2)) - третий параметр;
β - первый коэффициент;
γ - второй коэффициент; и
α - третий коэффициент.
| РАНЖИРАТОР РЕЗУЛЬТАТОВ ПОИСКА | 2014 |
|
RU2608886C2 |
| US 8713023 B1, 29.04.2014 | |||
| US 7844567 B2, 30.11.2010 | |||
| US 20120109860 A1, 03.05.2012. | |||

