Ссылка на родственные заявки
По настоящей заявке испрашивается приоритет в соответствии с предварительной заявкой на патент США №61/869020. Содержание указанной выше заявки включено в настоящий документ для всех целей посредством ссылки.
Перечень последовательностей
Настоящая заявка содержит перечень последовательностей, который был подан в электронном виде в формате ASCII и полностью включен в настоящий документ посредством ссылки. Указанная копия ASCII, созданная 22 ноября 2013 г., названа 24731PCT_CRF_sequencelisting.txt и ее размер составляет 5749 байт.
Область техники
Настоящее изобретение относится к областям диагностики и теории передачи информации, и, в частности, относится к способам цифрового анализа молекулярных анализируемых веществ.
Уровень техники
Множественные молекулярные и биохимические подходы доступны для идентификации и количественного определения молекулярных анализируемых веществ. Примеры включают в себя широко используемые основанные на нуклеиновых кислотах анализы, например, количественную ПЦР (количественную полимеразную цепную реакцию) и ДНК-микрочип, и основанные на белке подходы, таких как иммуноанализ и масс-спектрометрию. Тем не менее, существуют различные ограничения в современных технологиях анализа исследуемых вещества. Например, в настоящее время способы характеризуются ограничениями чувствительности, особенно там, где анализируемые вещества присутствуют в биологических образцах в низком количестве копий или в низких концентрациях. Большинство технологий количественного определения нуклеиновых кислот включают в себя амплификацию образца для более высокой чувствительности. Однако, техники амплификации вводят стандартные ошибки и неточности в количественную оценку. Кроме того, амплификация не возможна для белков и пептидов. Из-за отсутствия чувствительности, подходы для обнаружения и количественного определения часто требуют относительно больших объемов образцов. Современные способы также ограничены в их способности к идентификации и количественной оценке большого числа анализируемых веществ. Количественное определение всех мРНК и белков в образце требует высокой мультиплексности и большого динамического диапазона. Кроме того, современным технологиям не хватает возможности для обнаружения и количественного определения нуклеиновых кислот и белков одновременно.
Современные способы часто генерируют ошибки во время обнаружения и количественного определения анализируемого вещества из-за таких условий, как слабое обнаружения сигнала, ложноположительные срабатывания и другие ошибки. Эти ошибки могут привести к ошибочной идентификации и неточному количественному определению анализируемых веществ.
Таким образом, необходимы способы и системы для исследования анализируемого вещества, которые позволяют высокую чувствительность с малым объемом образца, высокой мультиплексностью, большим динамическим диапазоном й возможностью обнаружения молекул белков и нуклеиновых кислот в одном анализе. Что еще более важно, необходимы способы коррекции ошибок для коррекции ошибок обнаружения анализируемых веществ. Настоящее изобретение решает эти и другие ограничения предшествующей области техники путем введения чувствительной одномолекулярной идентификации и количественного определения биологических анализируемых веществ со считыванием цифровой информации.
Краткое описание чертежей
Раскрытые варианты осуществлений характеризуются другими преимуществами и особенностями, которые будут более очевидны из следующего подробного описания настоящего изобретения и прилагаемой формулы изобретения при рассмотрении вместе с прилагаемыми графическими материалами, на которых:
Фигура (или "фиг.") 1 представляет собой блок-схему высокого уровня, иллюстрирующую пример компьютера в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 2А показан пример зонда, содержащего антитело и обнаруживаемую метку, причем зонд связывается с белком-мишенью в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 2В показан пример зонда, содержащего первичное антитело и вторичное антитело, конъюгированное с обнаруживаемой меткой, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 3 показано анализируемое вещество-мишень, связанное с зондом, содержащим аптамер и хвостовую область, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 4 показан флуоресцентный тег, прикрепленный к зонду, содержащему аптамер и хвостовую область, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 5 показан пример зонда, содержащего антитело, связанное с областью, которая может гибридизоваться с хвостовой областью, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 6 показан пример зонда, содержащего первичное антитело и вторичное антитело, конъюгированное с хвостовой областью, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 7 показан пример твердой подложки, связанной с образцом, содержащим анализируемое вещество (например, белки, ДНК и/или РНК), в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 8 показан пример подложки (матрица 10x10) для связывания анализируемых веществ, в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 9 представляет собой вид сверху на твердую подложку с анализируемыми веществами, случайным образом связанными с подложкой, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 10A-10D показан пример шестнадцати белков-мишеней, расположенных на подложке. На фиг. 10В и 10С показаны примеры изображений подложки после контакта с различными пулами зонда, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 11 показана иллюстративная структура коррекции ошибок Рида-Соломона, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 12А показана иллюстративная подложка, разделенная на три области, изображающие концентрационные уровни анализируемого вещества-мишени, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 12В-12С показаны графики диапазонов относительного содержания анализируемых веществ-мишеней, в соответствии с одним из вариантов осуществления изобретения.
На фиг. 13 показан иллюстративный анализ обнаружения с использованием подложки и четырех анализируемых веществ с использованием одноцветной флуоресцентной метки, одного прохода, учета темного цикла и 1 бита на цикл, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 14 показан иллюстративный анализ обнаружения с использованием подложки и четырех анализируемых веществ с использованием одноцветной флуоресцентной метки, четырех проходов за цикл, без учета темного цикла и 1 битом на цикл, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 15 показаны цветные последовательности и идентификаторы для анализируемых веществ-мишеней и показаны результаты сканирования анализируемых веществ-мишеней для циклов зондирования, связывания и стрипирования, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 16А показаны количества специфических анализируемых веществ-мишеней, идентифицированных на различных участках подложки, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 16В показаны цветные последовательности и идентификаторы для анализируемых веществ-мишеней, в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 17 представляет собой изображение отдельных флуоресцентных зондов, гибридизированных с анализируемыми веществами-мишенями, связанными с подложкой, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 18 показаны примеры идентификации различных анализируемых веществ-мишеней с использованием обнаружения отдельного флуоресцентных молекул, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 19 показаны цветные последовательности и идентификаторы для двух анализируемых веществ-мишеней и показаны результаты сканирования анализируемых веществ-мишеней для циклов зондирования, связывания и стрипирования, в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг.20 представляет собой изображение одномолекулярных пептидов, связанных с подложкой, гибридизованной с конъюгированными антителами, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 21 показан вероятностный график расчетных концентраций белков из базы данных UniProt, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 22 показан перечень предполагаемых значений для различных областей относительного содержания подложки, в соответствии с одним вариантом осуществления настоящего изобретения.
Фиг. 23 представляет собой имитирующее изображение идентификации белков через любой диапазон относительного содержания, в соответствии с одним вариантом осуществления настоящего изобретения.
На фиг. 24 показан график частоты системных ошибок против частоты грубых ошибок для идентификации анализируемых веществ-мишеней, в соответствии с одним вариантом осуществления настоящего изобретения.
Сущность изобретения
В настоящем изобретении предусмотрены системы и способы для обнаружения множества анализируемых веществ, включающие: получение множества упорядоченных наборов реагентов-зондов, каждый из упорядоченных наборов реагентов-зондов, содержащий один или несколько зондов, направленных на определенное подмножество N различных анализируемых веществ-мишеней, причем N различных анализируемых веществ-мишеней иммобилизовано на пространственно разделенных областях подложки и каждый из зондов помечен обнаруживаемой меткой. Способ также включает стадии для выполнения по меньшей мере M циклов связывания зонда и обнаружения сигнала, каждый цикл, включающий один или несколько проходов, причем проход включает использование по меньшей мере одного из упорядоченных наборов реагентов-зондов. Способ включает обнаружение из по меньшей мере M циклов наличия или отсутствия множества сигналов от пространственно разделенных областей подложки.
Способ включает определение из множества сигналов по меньшей мере К битов информации за один цикл на одного или нескольких из N различных анализируемых веществ-мишеней, причем по меньшей мере К битов информации используются для определения L общих битов информации, причем К×M=L битов информации и L>log2 (Ν), и причем L битов информации используются для определения наличия или отсутствия одного или нескольких из N различных анализируемых веществ-мишеней.
Согласно некоторым вариантам осуществления L>log2 (Ν) и L содержит биты информации для идентификации мишеней. Согласно другим вариантам осуществления L>log2 (Ν) и L содержит биты информации, которые упорядочены в заранее заданном порядке.
Согласно одному варианту осуществления заранее заданный порядок представляет собой случайный порядок. Согласно другому варианту осуществления L>log2 (Ν) и L содержит биты информации, содержащие ключ для декодирования порядка множества упорядоченных наборов реагентов-зондов.
Способ также включает оцифровку множества сигналов, чтобы расширить динамический диапазон обнаружения множества сигналов. Согласно некоторым вариантам осуществления по меньшей мере К битов информации содержат информацию о количестве проходов в цикле. Согласно другому варианту осуществления по меньшей мере К битов информации содержат информацию об отсутствии сигнала для одного из N различных анализируемых веществ-мишеней.
Согласно одному варианту осуществления обнаруживаемая метка представляет собой флуоресцентную метку. Согласно другому варианту осуществления зонд содержит антитело. Согласно одному варианту осуществления антитело конъюгируют непосредственно с меткой. Антитело может быть также связано со вторичным антителом, конъюгированным с меткой. Согласно другим вариантам осуществления зонд содержит аптамер. Согласно одному варианту осуществления аптамер содержит гомополимерную область оснований. Согласно другим вариантам осуществления множество анализируемых веществ содержит белок, пептидный аптамер или молекулу нуклеиновой кислоты.
Способ может включать обнаружение из по меньшей мере M циклов наличия или отсутствия множества оптических сигналов. Способ также может включать обнаружение из по меньшей мере M циклов наличия или отсутствия множества электрических сигналов.
Согласно одному варианту осуществления способ реализован с помощью компьютера. Согласно другому варианту осуществления К представляет собой один бит информации за один цикл. Согласно другим вариантам осуществления К представляет собой два бита информации за один цикл. К также может представлять собой три или более битов информации за один цикл.
Согласно другому варианту осуществления способ включает определение из L битов информации коррекции ошибок для множества выходных сигналов. Способ коррекции ошибок может представлять собой код Рида-Соломона.
Согласно одному варианту осуществления способ включает определение количества упорядоченных наборов реагентов-зондов, основанных на количестве N различных анализируемых веществ-мишеней. Способ может также включать определение типа наборов реагентов-зондов на основе типа N различных анализируемых веществ-мишеней.
Согласно одному варианту осуществления N различных анализируемых веществ-мишеней присутствуют в образце, который разделен на множество аликвот, разбавленных до множества различных конечных разведений, и каждую из множества аликвот иммобилизуют на отдельной секции подложки. Согласно другому варианту осуществления одно из различных конечных разведений определяется на основании возможной встречающейся в природе концентрации по меньшей мере одного из N различных анализируемых веществ-мишеней. Согласно другому варианту осуществления концентрация одного из N различных анализируемых веществ-мишеней определяется путем подсчета распространения анализируемого вещества-мишени в одной из отдельных секций и корректировки количества в соответствии с разведением соответствующей аликвоты.
В настоящем изобретении предусмотрен набор для обнаружения множества анализируемых веществ, содержащий: множество упорядоченных наборов реагентов-зондов, каждый из упорядоченных наборов реагентов-зондов, содержащих один или несколько зондов, направленных на определенное подмножество из N различных анализируемых веществ-мишеней, причем N различных анализируемых веществ-мишеней иммобилизуют на пространственно разделенных областях подложки, и каждый из зондов метят обнаруживаемой меткой. Набор включает в себя инструкции для обнаружения указанных N различных анализируемых веществ на основании множества обнаруживаемых сигналов. Набор включает в себя инструкции для выполнения по меньшей мере M циклов связывания зондов и обнаружения сигналов, каждый цикл, включающий один или несколько проходов, причем проход включает использование по меньшей мере одного из упорядоченных наборов реагентов-зондов. Набор включает в себя инструкции для обнаружения из по меньшей мере M циклов наличия или отсутствия множества сигналов от пространственно разделенных областей указанной подложки. Набор также включает в себя инструкции для определения из множества сигналов по меньшей мере К битов информации на цикл для одного или нескольких из указанных N различных анализируемых веществ, причем по меньшей мере К битов информации используются для определения L общих битов информации, причем К×M=L битов информации и L>log2 (Ν) и причем указанные L битов информации используются для определения наличия или отсутствия одного или нескольких из N различных анализируемых веществ.
Согласно некоторым вариантам осуществления набор включает в себя один или несколько зондов, которые содержат антитело. Согласно другим вариантам осуществления метка представляет собой флуоресцентную метку. Согласно другому варианту осуществления зонд представляет собой антитело. Согласно одному варианту осуществления антитело конъюгируют непосредственно к метке. Согласно еще одному варианту осуществления антитело связывается со вторичным антителом, конъюгированным с меткой. Согласно другим вариантам осуществления зонд содержит аптамер. Аптамер может содержать гомополимерную базовую область. Согласно некоторым вариантам осуществления множество анализируемых веществ содержит белок, пептидный аптамер или молекулу нуклеиновой кислоты.
Согласно другим вариантам осуществления L>log2 (Ν). Согласно другому варианту осуществления M≤N. Набор также может включать в себя инструкции для определения идентификации каждого из N различных анализируемых веществ-мишеней с использованием L битов информации, причем L содержит биты информации для идентификации мишеней.
Набор может включать в себя инструкции для определения порядка указанного множества упорядоченных наборов реагентов-зондов с использованием L битов информации, причем L содержит биты информации, которые упорядочены в заранее определенном порядке. Заранее определенный порядок может представлять собой случайный порядок. Набор может также включать в себя инструкции по использованию ключа для декодирования порядка множества упорядоченных наборов реагентов-зондов.
Подробное описание изобретения
Фигуры и последующее описание относятся к различным вариантам осуществления настоящего изобретения только в качестве иллюстрации. Следует отметить, что из приведенного ниже обсуждения, альтернативные варианты осуществления описанных в настоящем документе структур и способов будут легко определены как жизнеспособные альтернативы, которые могут быть использованы без отступления от принципов формулы изобретения.
Далее будет сделана подробная ссылка на несколько вариантов осуществления, примеры которых проиллюстрированы на прилагаемых фигурах. Следует отметить, что там, где это практически возможно, аналогичные или подобные номера ссылок могут быть использованы в фигурах и могут указывать на сходную или подобную функциональность. На фигурах показаны варианты осуществления раскрытой системы (или способа) только для целей иллюстрации. Специалисту в настоящей области техники будет понятно из нижеследующего описания, что альтернативные варианты осуществления показанных в настоящем документе структур и способов могут быть использованы без отступления от описанных в настоящем документе принципов.
Определения
"Анализируемое вещество-мишень" или "анализируемое вещество" относится к молекуле, соединению, веществу или компоненту, который должен быть идентифицирован, количественно определен и иначе охарактеризован. Анализируемое вещество-мишень может содержать в качестве примера без ограничения атом, соединение, молекулу (любого молекулярного размера), полипептид, белок (сложенный или развернутый), олигонуклеотидную молекулу (РНК, кДНК или ДНК), ее фрагмент, ее модифицированную молекулу, такую как модифицированную нуклеиновую кислоту, или их комбинацию. Согласно одному варианту осуществления анализируемое вещество-мишень полипептид или белок составляет приблизительно девять аминокислот в длину. Как правило, анализируемое вещество-мишень может быть в любой из широкого диапазона концентраций (например, в диапазоне от мг/мл до аг/мл) в любом объеме раствора (например, в таком низком, как диапазон пиколитра). Например, образцы крови, сыворотки, фиксированной в формалине заключенной в парафин (FFPE) ткани, слюны или мочи могут содержать различные анализируемые вещества-мишени. Анализируемые вещества-мишени распознаются зондами, которые используются для идентификации и количественной оценки анализируемых веществ-мишеней с использованием электрических или оптических методов обнаружения.
Модификация белка-мишени, например, может включать в себя посттрансляционные модификации, такие как присоединение к белку других биохимических функциональных групп (таких как ацетат, фосфат, различные липидм и углеводы), изменяя химическую природу аминокислоты (например; цитруллинирование), или производя структурные изменения (например, образование дисульфидных мостиков). Примеры посттрансляционных модификаций также включают в себя без ограничения добавление гидрофобных групп для локализации мембраны (например, миристоилирование, пальмитоилирование), добавление кофакторов для усиленной ферментативной активности (например, липоилирование), модификации трансляционных факторов (например, образование дифтамида), добавление химических групп (например, ацилирование, алкилирование, образование амидной связи, гликозилирование, окисление), модифицирование сахара (гликирование), добавление других белков или пептидов (убиквитинилирование) или изменения в химической природе аминокислот (например, деамидирование, карбамилирование).
Согласно другим вариантам осуществления анализируемые вещества-мишени представляют собой олигонуклеотиды, которые были модифицированы. Примеры модификаций ДНК включают в себя метилирование ДНК и модификацию гистонов.
Используемый в настоящем документе "зонд" относится к молекуле, которая способна связываться с другими молекулами (например, олигонуклеотидами, содержащими ДНК или РНК, полипептидами или полноразмерными белками и т.д.), клеточными компонентами или структурами (липидами, клеточными стенками и т.д.) или клетками для обнаружения или оценки свойств молекул, клеточных компонентов или структур, или клеток. Зонд содержит структуру или компонент, который связывается с анализируемым веществом-мишенью. Согласно некоторым вариантам осуществления множество зондов может распознавать различные части одного и того же анализируемого вещества-мишени. Примеры зондов включают в себя без ограничения аптамер, антитело, полипептид, олигонуклеотид (ДНК, РНК) или любую их комбинацию. Антитела, аптамеры, олигонуклеотидные последовательности и их комбинации в качестве зондов также подробно описаны ниже.
Зонд может содержать тег, который используется для обнаружения наличия анализируемого вещества-мишени. Тег может быть прямо или опосредованно связан с, гибридизирован с, конъюгирован с или ковалентно связан со связывающим анализируемое вещество-мишень компонентом. Согласно некоторым вариантам осуществления тег представляет собой обнаруживаемую метку, такую как флуоресцентная молекула или хемилюминесцентная молекула. Согласно другим вариантам осуществления тег содержит олигонуклеотидную последовательность, которая содержит гомополимерную базовую область (например, поли-А хвост). Зонд может быть обнаружен электрически, оптически или химически с помощью тега.
Используемый в настоящем документе термин "тег" относится к молекуле, способной обнаруживать анализируемое вещество-мишень. Тег может представлять собой олигонуклеотидную последовательность, которая содержит гомополимерную область оснований (например, поли-А хвост). Согласно другим вариантам осуществления тег представляет собой метку, например, флуоресцентную метку. Тег может содержать без ограничения флуоресцентную молекулу, хемилюминесцентную молекулу, хромофор, фермент, субстрат фермента, кофактор фермента, ингибитор фермента, краситель, ион металла, золь металла, лиганд (например, биотин, авидин, стрептавидин или гаптены), радиоактивный изотоп и тому подобное. Тег может быть прямо или опосредованно связан с, гибридизирован с, конъюгирован с или ковалентно связан с зондом.
"Белок" или "полипептид" или "пептид" относится к молекуле из двух или более аминокислот, аминокислотных аналогов или других пептидомиметиков. Белок может быть упакованным или развернутым (денатурированным). Полипептид или пептид может характеризоваться вторичной структурой, такой как α-спираль, β-лист или другая конформация. Используемый в настоящем документе термин "аминокислота" относится либо к природным и/или неприродным, либо синтетическим аминокислотам, включающим в себя глицин и как D, так и L оптические изомеры и аналоги аминокислот и пептидомиметики. Пептид может составлять две или более аминокислоты в длину. Более длинные пептиды часто относятся к полипептидам. Белок может относиться к полноразмерным белкам, аналогам и их фрагментам, которые охватываются определением. Термины также включают в себя пост-экспрессионные модификации белка или полипептида, например, гликозилированйе, ацетилирование, фосфорилирование и т.п.Кроме того, поскольку в молекуле присутствуют способные к ионизации амино- и карбоксильные группы, определенный полипептид может быть получен в виде кислой или основной соли или в нейтральной форме. Белок или полипептид может быть получен непосредственно из исходного организма или может быть произведен рекомбинантно или синтетически.
Белки могут быть идентифицированы и охарактеризованы с помощью пептидной последовательности, модификаций боковой цепи и/или третичной структуры. Модификации боковой цепи включают в себя фосфорилирование, ацетилирование, сахара и т.д. Фосфорилирования гидроксильных групп из аминокислот серии, треонин и тирозин представляют собой особенно важные представляющие интерес модификации.
Термин "in vivo" относится к процессам, которые происходят в живом организме.
Используемый в настоящем документе термин "млекопитающее" включает в себя как людей, так и отличных от людей животных, и включает в себя без ограничения людей, нечеловекообразных приматов, собак, кошачьих, мышиных, крупный рогатый скот, лошадей и свиней.
Используемый в настоящем документе "образец" включает в себя экземпляр, культуру или коллекцию из биологического материала. Образцы могут быть получены из или взяты от млекопитающих, включающих в себя без ограничения человека, обезьяну, крысу или мышь. Образцы могут включать в себя такие материалы, как, без ограничения, культуру, кровь, ткань, фиксированную в формалине заключенную в парафин (FFPE) ткань, слюну, волосы, фекалии, мочу и тому подобное. Эти примеры не должны быть истолкованы как ограничивающие типы образцов, применимые к настоящему изобретению.
Используемый в настоящем документе "бит" относится к основной единице информации в компьютерных и цифровых коммуникациях. Бит может характеризоваться только одним из двух значений. Наиболее распространенные представления этих значений: 0 и 1. Термин бит представляет собой сокращение двоичной единицы информации. В одном примере система, которая использует 4 бита информации, может создать 16 различных значений (как показано в таблице 1А). Все одноразрядные шестнадцатеричные числа можно записать 4 битами. Двоично-десятичное кодирование представляет собой цифровой способ кодирования для чисел с использованием десятичного обозначения, с каждой десятичной цифрой, представленной четырьмя битами. В другом примере, расчет с использованием 8 битов представляет собой 28 (или 256) возможных значений.


"Проход" в реакции обнаружения относится к процессу, в котором множество зондов вводят к связанным анализируемым веществам, избирательное связывание происходит между зондами и различными анализируемыми веществами-мишенями и от зондов обнаруживают множество сигналов. Проход включает в себя введение набора антител, которые специфически связываются с анализируемым веществом-мишенью. Может быть несколько проходов различных наборов зондов, прежде чем от подложки стрипируют все зонды.
"Цикл" определяют путем завершения одного или нескольких проходов и стрипирование зондов от подложки. Могут быть выполнены последующие циклы одного или нескольких проходов за один цикл. Могут быть выполнены множественные циклы на одной подложке или образце. Для белков множественные циклы будут требовать того, чтобы условия удаления зонда (стрипирования) либо сохраняли белки сложенными в их надлежащей конфигурации, либо чтобы используемые зонды выбирали для связывания с пептидными последовательностями так, чтобы эффективность связывания не зависела от конфигурации упаковки белка.
Следует отметить, что, как использовано в описании и прилагаемой формуле изобретения, формы единственного числа неопределенного и определенного артикля включают в себя ссылки на множественное число, если из контекста явно не следует иное.
Обзор
Раскрыты техники обнаружения для высоко мультепликсированной одномолекулярной идентификации и количественного определения анализируемых веществ с использованием как оптических, так и электрических систем. Анализируемые вещества могут включать в себя без ограничения молекулы белка, пептида, ДНК и РНК, с модификациями и без. Электрическое обнаружение осуществляется с использованием ионно-чувствительных полевых транзисторов (ISFET), интегрированных со структурами MEMS (микро-электрические механические системы) для усиления чувствительности. Техники включают в себя поли-А теги с и без дифференциальных остановок, комплементарно специфические и неспецифические зонды для детальной характеристики анализируемых веществ, высоко мультепликсированную одномолекулярную идентификацию и количественное определение с использованием зондов-антител. Оптическое обнаружение осуществляют путем обнаружения флуоресцентных или люминесцентных тегов.
1. Компьютерная система
Фиг. 1 представляет собой блок-схему высокого уровня, иллюстрирующую пример компьютера 100 для использования в анализе молекулярных анализируемых веществ, в соответствии с одним вариантом осуществления. Изображен по меньшей мере один процессор 102, соединенный с чипсетом 104. Чипсет 104 включает в себя контроллер-концентратор памяти 120 и контроллер-концентратор ввода/вывода (I/O) 122. Память 106 и графический адаптер 112 соединены с контроллером-концентратором памяти 122, и устройство отображения 118 соединено с графическим адаптером 112. Устройство хранения 108, клавиатура 110, указательное устройство 114 и сетевой адаптер 116 соединены с контроллером-концентратором I/O 122. Другие варианты осуществления компьютера 100 характеризуются различными архитектурами. Например, память 106 непосредственно соединена с процессором 102 согласно некоторым вариантам осуществления.
Устройство хранения данных 108 представляет собой непреходящий машиночитаемый информационный носитель, такой как жесткий диск, компакт-диск только для чтения (CD-ROM), DVD или устройство твердотельной памяти. Память 106 удерживает инструкции и данные, используемые процессором 102. Указывающее устройство 114 используется в сочетании с клавиатурой ПО для ввода данных В компьютерную систему 100. Графический адаптер 112 отображает изображения и другую информацию на устройстве отображения 118. Согласно некоторым вариантам осуществления устройство отображения 118 включает в себя сенсорный экран с возможностью приема и выбора вводимой пользователем информации. Сетевой адаптер 116 соединяет компьютерную систему 100 с сетью. Некоторые варианты осуществления компьютера 100 содержат отличные и/или другие компоненты, чем показаны на фиг. 1. Например, сервер может быть образован из нескольких многодисковых серверов и не содержать устройство отображения, клавиатуру и другие компоненты.
Компьютер 100 выполняют с возможностью выполнения компьютером программных модулей для обеспечения описанных в настоящем документе функциональных возможностей. Используемый в настоящем документе термин "модуль" относится к инструкциям и другой логике компьютерной программы, используемой, чтобы обеспечить заданную функциональность. Таким образом, модуль может быть реализован в аппаратных средствах, микропрограммном обеспечении и/или программном обеспечении. Согласно одному варианту осуществления программные модули, образованные исполняемыми инструкциями компьютерной программы хранятся на запоминающем устройстве 108, загружаются в память 106 и выполняются процессором 102.
2. Композиции
Предусмотрены композиции, которые связывают и метят анализируемые вещества, такие как ДНК, РНК, белок, пептиды специфическим образом, например, так что отдельные молекулы могут быть обнаружены и подсчитаны.
Антитела в качестве зондов
Согласно некоторым вариантам осуществления зонд содержит антитела, которые могут быть использованы в качестве зондов для обнаружения анализируемых веществ-мишеней в образце. Как описано ниже, антитела представляют собой иммуноглобулины, которые специфически связываются с белками-мишенями или полипептидами-мишенями. Согласно предпочтительному варианту осуществления используемые в настоящем изобретении антитела представляют собой моноклональные и могут специфически связываться со сложенными или развернутыми белками.
Термин "антитело" относится к иммуноглобулину, который специфически связывается с и, таким образом, определяется как комплементарный другой молекуле. Антитело представляет собой гликопротеин, продуцируемый В-клетками, которые используются иммунной системой для идентификации и нейтрализации чужеродных объектов, таких как бактерии и вирусы. Антитело распознает уникальную часть чужеродной мишени, называемой антигеном. Антитела, как правило, состоят из основных структурных единиц: двух больших тяжелых цепей и двух маленьких легких цепей. Антитело может быть моноклональным или поликлональным и может быть встречающимся в природе, модифицированным или рекомбинантным. Антитела могут быть получены хорошо известными в настоящей области техники способами, такими как иммунизация хозяина и сбор сыворотки (поликлональной) или путем получения непрерывных гибридных клеточных линий и сбора секретируемого белка (моноклонального), или путем клонирования и экспрессии нуклеотидных последовательностей или содержащих мутации их версий кодирования по меньшей мере для аминокислотных последовательностей, необходимых для специфического связывания природных антител. Антитела могут включать в себя полный иммуноглобулин или его фрагмент, причем иммуноглобулины включают в себя различные классы и изотипы, такие как IgA, IgD, IgE, IgG1, IgG2a, IgG2b и IgG3, IgM и т.д. Их фрагменты могут включать в себя Fab, Fv и F(ab')2, Fab' и тому подобное.
"Моноклональное антитело" (mAB) представляет собой иммуноглобулин, произведенный одним клоном лимфоцитов, т.е. потомством одной В-клетки, которое распознает только один эпитоп на антигене. Кроме того, агрегаты, полимеры и конъюгаты иммуноглобулинов или их фрагменты могут быть использованы в случае необходимости до тех пор, пока поддерживается аффинность связывания к конкретной мишени. Антитело (первичное антитело) может быть ковалентно связано с обнаруживаемой меткой (например, флуоресцентной меткой). Согласно другим вариантам осуществления первичное антитело связывается со вторичным антителом; которое ковалентно связано с обнаруживаемой меткой. Согласно некоторым вариантам осуществления первичное антитело конъюгируют с меченой олигонуклеотидной молекулой, как описано в патенте США №7122319 Liu et al., поданном 5 ноября 2003 г., который полностью включен посредством ссылки.
На фиг. 2А показан пример зонда, содержащего антитело 132 и обнаруживаемый тег 134, и зонд связывается с анализируемым веществом-мишенью 130. На фиг. 2В показан пример зонда, содержащего первичное антитело 132 и вторичное антитело 210. Вторичное антитело 210 конъюгировано с обнаруживаемой меткой 134.
Аптамеры
Используемый в настоящем документе "аптамер" относится к молекуле нуклеиновой кислоты или пептидной молекуле, которая связывается с анализируемым веществом-мишенью. Аптамер может представлять собой компонент зонда. Согласно некоторым вариантам осуществления аптамеры нуклеиновых кислот представляют собой молекулы нуклеиновых кислот, которые были разработаны с помощью повторных циклов отбора in vitro или эквивалентно, SELEX (систематическая эволюция лигандов экспоненциальным обогащением) для связывания с различными молекулярными мишенями, такими как небольшие молекулы, белки, нуклеиновые кислоты и даже клетки, ткани и организмы. Смотрите Tuerk С & Gold L (1990). Другие способы получения аптамеров включают в себя SAAB (выбранный и амплифицированный сайт связывания) и CAST (циклическая амплификация и отбор мишеней). Систематическая эволюция лигандов экспоненциальным обогащением РНК лигандов к ДНК-полимеразе бактериофага Т4. Science. 249:505-510; M. Svobodová, A. Pinto, Р. Nadal and С.К. О' Sullivan. (2012). Сравнение различных способов получения одноцепочечной ДНК для процессов SELEX. "Anal Bioanal Chem " (2012) 404:835-842. Аптамеры могут связываться с уникальной последовательностью n-mer, найденной в белке (например, денатурированном или уложенном белке) или полипептиде. Согласно одному варианту осуществления аптамер связывается с уникальной последовательностью 9-mer. Согласно некоторым вариантам осуществления аптамер может связываться с тегом, таким как олигонуклеотидная нить, содержащая гомополимерную базовую область (например, поли-А хвост).
Согласно некоторым вариантам осуществления зонд содержит аптамер и хвостовую область. Аптамер представляет собой олигонуклеотидную или пептидную молекулу, которая связывается с конкретным анализируемым веществом-мишенью. На фиг. 3 показано анализируемое вещество-мишень 130, которое связано с аптамером 300. Аптамер 300 включает в себя область зонда 320, которая выполнена с возможностью специфически связываться с анализируемым веществом-мишенью 130; Область зонда 320 может содержать белок, пептид или нуклеиновую кислоту, и область зонда 320 распознает и связывается с анализируемым веществом-мишенью. Каждая область зонда 320 может быть соединена с тегом. Согласно некоторым вариантам осуществления тег представляет собой хвостовую область 310. Хвостовая область 310 представляет собой олигонуклеотидную молекулу, составляющую по меньшей мере 25 нуклеотидов и служащую в качестве матрицы для синтеза полинуклеотидов. Хвостовая область 310 представляет собой, как правило, одноцепочечную молекулу ДНК, но также может представлять собой молекулу РНК. Согласно одному варианту осуществления хвостовая область 310 ковалентно связана с областью зонда 330 через остов нуклеиновой кислоты.
Согласно другому варианту осуществления часть хвостовой области 310 специфически связывается с линкерной областью 330. Линкерная область 330 ковалентно связана с областью зонда 320 через остов нуклеиновой кислоты. Линкерная область 330 может быть сконфигурирована для специфического связывания с частью одной хвостовой области 310 или частями нескольких хвостовых областей 310. Согласно одному варианту осуществления линкерная область 330 содержит по меньшей мере 10 нуклеотидов. Согласно другому варианту осуществления линкерная область 330 содержит 20-25 нуклеотидов. Область зонда 320 может быть ковалентно связана с одной линкерной областью 330 или может быть ковалентно связана с несколькими различными линкерными областями 330, каждая из которых специфически связывается с частью отдельной хвостовой области 310.
Хвостовая область 310 обеспечивает шаблон для синтеза полинуклеотидов. Во время синтеза полинуклеотидов один ион водорода высвобождается для каждого нуклеотида, включенного по шаблону хвостовой области. Множество этих ионов водорода может быть обнаружено в виде электрического выходного сигнала транзистором. Минимальное пороговое число ионов водорода должно быть высвобождено для транзистора, чтобы обнаружить электрический выходной сигнал. Например, минимальное пороговое число может составлять 25, в зависимости от особенностей конфигурации детектора. В этом случае, хвостовая область 310 должна составлять не менее 25 нуклеотидов в длину. Согласно некоторым вариантам осуществления хвостовая область 310 составляет по меньшей мере 25, 100, 200, 1000 или 10000 нуклеотидов в длину. Хвостовая область 310 может включать в себя одну или несколько гомополимерных областей оснований. Например, хвостовая область 310 может представлять собой поли-А, поли-С, поли-G или поли-Т хвост. Согласно другому варианту осуществления хвостовая область 310 содержит гомополимерную область оснований, за которой следует другая гомополимерная область оснований, например, поли-А хвост с последующим поли-G хвостом. Согласно одному варианту осуществления хвостовая область 310 представляет собой основанный на ДНК поли-А хвост, который составляет 100 нуклеотидов в длину (SEQ ID NO: 1). Нуклеотиды (dTTP) добавляют в условиях, которые обеспечивают полинуклеотидный синтез, и нуклеотиды включают, чтобы расшифровать хвостовую область, тем самым высвобождая ионы водорода. Если минимальное пороговое число ионов водорода для транзистора для обнаружения электрического выходного сигнала составляет 100 нуклеотидов или менее, транзистор будет обнаруживать электрический выходной сигнал. Этот сигнал используется для идентификации анализируемого вещества-мишени, связанного с хвостовой областью поли-А и, возможно, определения концентрации анализируемого вещества-мишени в растворе.
Согласно некоторым вариантам осуществления хвостовая область 310 содержит гомополимерную область оснований, которая включает в себя одно или несколько стоп-оснований. На фиг. 3 показано одно стоп-основание 330, которое фланкировано двумя гомополимерными областями оснований. Стоп-основание 330 представляет собой часть хвостовой области 310, содержащей по меньшей мере один нуклеотид, смежный с гомополимерной областью оснований, таким образом, что по меньшей мере один нуклеотид состоит из основания, которое отличается от оснований внутри гомополимерной области оснований. Согласно одному варианту осуществления стоп-основание 330 представляет собой один нуклеотид. Согласно другим вариантам осуществления стоп-основание 330 содержит множество нуклеотидов. Как правило, стоп-основание 330 фланкировано двумя гомополимерными областями оснований. Согласно одному варианту осуществления две гомополимерные области оснований, фланкирующие стоп-основание 330, состоят из того же основания. Согласно другому варианту осуществления две гомополимерные области оснований состоят из двух различных оснований. Согласно другому варианту осуществления хвостовая область 310 содержит более чем одно стоп-основание 330.
Более подробная информация об аптамерах и хвостовых областях в качестве зондов для дифференциального обнаружения малых молекул описана в предварительной заявке на патент США №61/868988.
Молекулярные теги
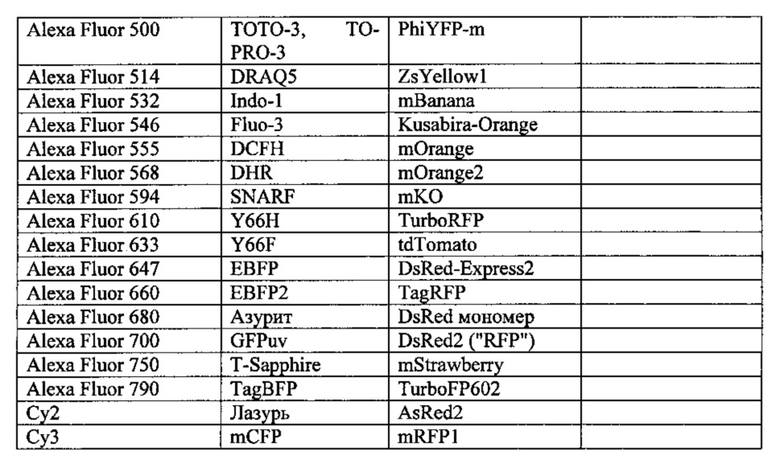
Согласно некоторым вариантам осуществления зонд содержит молекулярный тег для обнаружения анализируемого вещества-мишени. Теги могут быть присоединены химическим или ковалентно к другим областям зонда. Согласно некоторым вариантам осуществления теги представляют собой флуоресцентные молекулы. Флуоресцентные молекулы могут представлять собой флуоресцентные белки или могут представлять собой реакционноспособные производные флуоресцентной молекулы, известной как флуорофор. На фиг. 4 показан флуоресцентный тег 402, прикрепленный к зонду 320. Флуорофоры представляют собой флуоресцентные химические соединения, которые излучают свет при возбуждении светом. Согласно некоторым вариантам осуществления флуорофор избирательно связывается с конкретной областью или функциональной группой молекулы-мишени и может быть прикреплен химически или биологически. Примеры флуоресцентных тегов включают в себя без ограничения зеленый флуоресцентный белок (GFP), желтый флуоресцентный белок (YFP), красный флуоресцентный белок (RFP), голубой флуоресцентный белок (CFP), флуоресцеин, флуоресцеинизотиоцианат (FITC), тетраметилродаминизотиоцианат (TRITC), цианин (Су3), фикоэритрин (R-PE), 5,6-карбоксиметил флуоресцеин, (5-карбоксифлуоресцеин-N-гидроксисукцинимид эфир), техасский красный, нитробенз-2-окса-3-тиадиазол-4-ил (NBD), кумарин, дансилхлорид и родамин (5,6-тетраметилродамин).
Другие иллюстративные флуоресцентные теги перечислены ниже в таблице 1В.

Зонды, включающие в себя антитела и олигонуклеотиды
Как показано на фиг. 5, зонд может содержать антитело 132, связанное с областью 410, которая может гибридизоваться с олигонуклеотидной хвостовой областью 310. Олигонуклеотидная хвостовая область 310 может быть связана с антителом 132 с помощью соединительной области 410, такой как цепь полиэтиленгликоля (ПЭГ), субъединицы этиленоксида или другие подобные цепи, которые могут связывать антитело 132 с олигонуклеотидным хвостом 310. Согласно некоторым вариантам осуществления связывающая область может включать в себя олигонуклеотид, который связан с пептидом антител с использованием стандартных химических способов, таких как, например, опосредованная NHS эфиром-малеимидом конъюгационная химия, где пептид с включенным N-терминальным Cys взаимодействует с малеимид активным олигонуклеотидом ted. Согласно другим вариантам осуществления связывание осуществляется через внутренний Cys с образованием оксима через реакцию пептида с модифицированным гидроксиламином с олигонуклеотидом с модифицированным альдегидом. Такие способы известны специалисту в настоящей области техники. Олигонуклеотидная последовательность в связывающей области 410 может гибридизоваться с частью олигонуклеотидной хвостовой области 310. Олигонуклеотидная хвостовая область 310 может содержать олигонуклеотидную последовательность, которая используется в качестве матрицы для полинуклеотидного синтеза и электрического обнаружения, как описано выше. В патенте США №7122319, поданном 5 ноября 2003 г., Liu et al., описаны различные варианты осуществления для связывающих анализируемые вещества средств (например, антител), связанных с олигонуклеотидными тегами, и он полностью включен в настоящий документ посредством ссылки.
Как показано на фиг. 6, зонд содержит первичное антитело 132 и вторичное антитело 210. Первичное антитело 132 связывается с анализируемым веществом-мишенью 130, и вторичное антитело 210 связывается с первичным антителом 132. Вторичное антитело 210 конъюгируют с линкерной областью 410, которая гибридизуется с олигонуклеотидной хвостовой областью 310. Хвостовая область 310 действует как обнаруживаемый тег в электрическом обнаружении анализируемого вещества-мишени 130.
3. СПОСОБЫ
I. Подготовка подложки и образцов
В настоящем изобретении предусмотрены способы идентификации и количественной оценки широкого спектра анализируемых веществ от одного анализируемого вещества до десятков тысяч анализируемых веществ одновременно свыше многих порядков величины динамического диапазона с учетом ошибок в анализе обнаружения.
Как показано на фиг. 7, образец, содержащий анализируемые вещества 610 (например, белки, пептиды, ДНК и/или РНК), связан с твердой подложкой 600. Подложка 600 может содержать предметное стекло, кремниевую поверхность, твердую мембрану, пластину или т.п., используемую в качестве поверхности для иммобилизации анализируемых веществ 610. Согласно одному варианту осуществления подложка 600 содержит покрытие, которое связывает анализируемое вещество 610 с поверхностью. Согласно другому варианту осуществления подложка 600 содержит антитела или гранулы захвата для связывания анализируемых веществ 610 с поверхностью. Анализируемые вещества 610 могут быть связаны случайным образом с подложкой 600 и могут быть пространственно разделены на подложке 600. Образец может быть в виде водного раствора и промываться на подложке, таким образом, что анализируемые вещества 610 связываются с подложкой 600. Согласно одному варианту осуществления белки в образце денатурируют и/или расщепляются с использованием ферментов перед связыванием с подложкой 600. Согласно некоторым вариантам осуществления анализируемые вещества 610 могут быть ковалентно присоединены к подложке. Согласно другому варианту осуществления выбранные меченые зонды случайным образом связываются с твердой подложкой 600, и анализируемые вещества 610 промывают через подложку.
На фиг. 8 показана иллюстративная подложка 600 (массив 10x10) для связывания анализируемых веществ 610, где каждый массив вставки 700 содержит 11×11 (110) массивов-мишеней.
Фиг. 9 представляет собой вид сверху на твердую подложку 600 с анализируемыми веществами, случайным образом связанные с подложкой 600. Различные анализируемые вещества помечены как А, В, С и D. Для оптического обнаружения анализируемых веществ система визуализации требует, чтобы анализируемые вещества были пространственно разделены на твердой подложке 600 таким образом, чтобы не было перекрытия флуоресцентных сигналов. Для случайного массива это означает, что необходимы будут несколько пикселей для каждого флуоресцентного пятна.
Количество пикселей может быть таким малым, как 1, и таким большим, как несколько сотен пикселей на пятно. Ожидается, что оптимальное количество пикселей на флуоресцентное пятно составляет от 5 до 20 пикселей. В одном примере система визуализации содержит 224 нм пикселей. Для системы с 10 пикселями на флуоресцентное пятно в среднем, существует поверхностная плотность 2 флуоресцентных пикселя/мкм2. Это не означает, что плотность поверхностного белка должна быть на таком низком уровне. Если зонды выбраны только для низкой насыщенности белков, то количество белка на поверхности может быть гораздо выше. Например, если существует в среднем 20000 белков в мкм2 на поверхности, и зонды выбраны только для самых редких 0,01% (как интегрированная сумма) белков, тогда плотность флуоресцентного поверхностного белка составляет 2 флуоресцентных пикселя/мкм2. Согласно другому варианту осуществления система визуализации содержит 163 нм пикселей. Согласно другому варианту осуществления система визуализации содержит 224 нм пикселей. Согласно предпочтительному варианту осуществления система визуализации содержит 325 нм пикселей. Согласно другим вариантам осуществления система визуализации содержит 500 нм пикселей.
II. Способы оптического обнаружения
Способы оптического обнаружения могут использоваться для количественного определения и идентификации большого числа анализируемых веществ одновременно в образце.
Согласно одному варианту осуществления оптическое обнаружение флуоресцентно-меченых отдельных молекул может быть достигнуто с помощью частотно-модулированной абсорбции и индуцированной лазером флуоресценции. Флуоресценция может быть более чувствительна, потому что она неразрывно усиливается, поскольку каждый флуорофор излучает от тысяч до, возможно, миллиона фотонов, прежде чем он затухнет. Эмиссия флуоресценции, как правило, происходит в виде четырехэтапного цикла: а) электронный переход от основного состояния электрона в возбужденное электронное состояние, скорость которого представляет собой линейную функцию от мощности возбуждения, b) внутренняя релаксация в возбужденном электронном состоянии, с) радиационное или нерадиационное затухание из возбужденного состояния в основное состояние, что определено продолжительностью возбужденного состояния, и d) внутренняя релаксация в основное состояние. Измерения одномолекулярной флуоресценции рассматриваются как цифровые, потому что измерение основывается на считывании сигнал/нет сигнала, не зависимо от интенсивности сигнала.
Оптическое обнаружение требует прибора или считывателя оптического обнаружения для обнаружения сигнала от меченых зондов. В патенте США №8428454 и патенте США №8175452, которые полностью включены посредством ссылки, описаны иллюстративные системы визуализации, которые могут быть использованы, и способы для улучшения системы для достижения субпиксельных допусков на совмещение. Согласно некоторым вариантам осуществления могут быть использованы способы основанной на аптамерах технологии микрочипов. Смотрите Optimization of Aptamer Microarray Technology for Multiple Protein Targets, Analytica Chimica Acta 564 (2006).
А. Оптическое обнаружение нескольких анализируемых веществ с использованием меченых антител
Способ включает оптическое обнаружение анализируемых веществ с использованием меченых антител в качестве зондов. Для известного анализируемого вещества-мишени (белка) в образце, антитело выбирают такое, которое специфически связывается с анализируемым веществом-мишенью. Выбранные антитела могут быть такими, которые разработаны для ELISA и сравниваемых систем в качестве одномолекулярных зондов. Существуют от сотен до тысяч квалифицированных первичных и вторичных антител, которые легко доступны. Согласно некоторым вариантам осуществления первичные антитела выбирают такие, которые конъюгированы с тегом, таким как флуорофор. Согласно другим вариантам осуществления выбирают такие первичные антитела, которые связываются со вторичными антителами, и вторичные антитела конъюгированы с флуоресцентной молекулой.
Согласно одному варианту осуществления способ включает выбор первичного антитела, которое характеризуется наличием известного, специфического белка-мишени в образце. Первичное антитело помечают обнаруживаемым тегом, таким как флуоресцентная молекула. Выбранные первичные антитела вводят и промывают через подложку. Первичные антитела связываются со своими анализируемыми веществами-мишенями, и сигналы от тегов обнаруживают.
Согласно другому варианту осуществления выбирают первичное антитело и вторичное антитело, конъюгированное с обнаруживаемой меткой. Выбранные первичные антитела вводят и промывают через подложку. Первичные антитела связываются с их анализируемыми веществами-мишенями. Далее, вторичные антитела промывают через подложку и связывают с первичными антителами. Теги производят обнаруживаемый сигнал, и сигналы обнаруживают и анализируют, предпочтительно с использованием компьютера, чтобы определить, обнаружен ли сигнал на определенном месте, а в некоторых вариантах осуществления дополнительную информацию о природе сигнала (например, цвет метки).
Проход включает стадию связывания и стадию обнаружения сигнала. Может быть несколько проходов за один цикл, где каждый проход включает связывание набора меченых антител с различными белками-мишенями и обнаружение и анализ сигналов от меченых антител. Может быть несколько проходов различных меченых антител, прежде чем от субстрата отделяться все меченые антитела. Цикл заключается, когда один или несколько проходов завершен, и меченые антитела отделяются от субстрата. Могут быть выполнены последующие циклы одного или нескольких проходов за один цикл на той же подложке и образце связанных анализируемых веществ.
Прибор или устройство считывания оптического обнаружения используется для оптического обнаружения каждого из сигналов от меченых антител. Количество сигналов, расположение сигнала и наличие или отсутствие сигнала может быть записано и сохранено. Подробности о количественном определении и идентификации анализируемых веществ на основании обнаруженных оптических сигналов описаны ниже.
1. Несколько тегов для нескольких анализируемых веществ
Согласно одному варианту осуществления множество антител, конъюгированных с флуоресцентными тегами, используется для обнаружения отдельных белков, связанных с подложкой. Каждый отдельный тип белка помечен ограниченным числом флуоресцентных меток. Например, за один проход вводят антитела, которые помечены красным флуоресцентным тегом и селективно связываются с белком А. Число красных флуоресцентных молекул на подложке подсчитывают после связывания. Количество рассчитанных тегов пропорционально концентрации белка А.
Каждый последующий проход вводит другой флуоресцентный тег (другого цвета) для обнаружения другого белка (например, синий флуоресцентный тег для белка В, желтый флуоресцентный тег для белка С и т.д.). Наличие каждого флуоресцентного тега подсчитывают в каждом проходе и записывают. На фиг. 9 показана твердая подложка, содержащая анализируемые вещества А, В, С и D. На каждом проходе может быть обнаружено другое анализируемое вещество с другим флуоресцентным тегом и подсчитано соответственно.
Согласно некоторым вариантам осуществления "темный уровень" используется для обнаружения и анализа анализируемого вещества. Темный уровень существует там, где тег не присутствует в проходе и не считывается позитивный сигнал, который называют "темный проход". Отсутствие любого сигнала рассматривается как уровень (т.е., подсчитанный темный цикл). Включение темного уровня позволяет уменьшить количество зондов за цикл до одного. Согласно некоторым вариантам осуществления предпочтительно получить положительный сигнал, а не использовать темный уровень, так как использование темных уровнях может быть более восприимчивым к ошибкам. Один иллюстративный вариант осуществления показан на фиг. 13. Согласно другим вариантам осуществления, где частота грубых системных ошибок низка и количество зондов за цикл низкое, использование темного уровня может значительно увеличить количество информации, передаваемой за один цикл.
Конкретный случай, в котором использование темного уровня полезно представляет собой тот, где зонд первичного антитела гибридизуется с анализируемым веществом, связанным с подложкой, и в котором флуоресцентно или электрически меченое вторичное антитело связывается с первым антителом. Вторичное антитело может связываться неспецифически со всеми антителами, так что только один уровень информации возможен за цикл для системы одного прохода. В этом случае, использование темного уровня (т.е., без учета первичного антитела в цикле) необходимо для достижения 1 бита информации за один цикл.
Для устранения использование темного уровня при использовании вторичных антител требуется либо использование двух или более типов вторичных антител, которые характеризуются высокими аффинностями к заранее определенному набору зондов первичных антител и характеризуются низкой аффинностью к другим заранее определенным наборам зондов первичных антител, либо по меньшей мере два прохода в цикле.
2. Единственный тег для нескольких анализируемых веществ
Согласно другому варианту осуществления множество антител, конъюгированных с флуоресцентными тегами, используют для обнаружения отдельных белков, связанных с подложкой. Каждый тип белка может быть помечен тем же флуоресцентным тегом (того же цвета). Например, за один проход антитела-зонды, помеченные красным флуоресцентным тегом, избирательно связываются с белком А, и подсчитывается количество красных флуоресцентных молекул на подложке. На втором проходе вводятся антитела-зонды, помеченные красной флуоресцентной молекулой, которая специфически связывается с белком В, и присутствие дополнительных красных флуоресцентных меток на дополнительных местах на подложке подсчитывается и записывается. Могут быть выполнены несколько проходов с использованием антител, меченных той же флуоресцентной меткой, которая специфически связывается с различными белками-мишенями. Наличие дополнительных красных флуоресцентных тегов, обнаруженных на подложке при каждом проходе, подсчитывается и записывается. Один иллюстративный вариант осуществления показан на фиг. 14.
В. Способы оптического обнаружения анализируемых веществ
Способы количественного определения анализируемых веществ в высоком динамическом диапазоне согласно настоящему изобретению позволяют измерять более 10000 анализируемых веществ из биологического образца. Способ может количественно определять анализируемые вещества с концентрацией приблизительно от 1 аг/мл до приблизительно 50 мг/мл и производить динамический диапазон более чем 1010. Оптические сигналы переводят в цифровую форму, и анализируемые вещества идентифицируют на основании кода (ID кода) цифровых сигналов1 для каждого анализируемого вещества.
Как описано выше, анализируемые вещества связываются с твердой подложкой, а зонды связываются с анализируемыми веществами. Каждый из зондов содержит теги и специфически связывается с анализируемым веществом-мишенью. Согласно некоторым вариантам осуществления теги представляют собой флуоресцентные молекулы, которые излучают тот же флуоресцентный цвет, а сигналы для дополнительных флуоресцентных молекул обнаруживают при каждом последующем проходе. Во время прохода набор содержащих метки зондов контактируют с подложкой, позволяя им связываться со своими мишенями. Изображение подложки захватывается, и анализируются обнаруживаемые сигналы от изображения, полученного после каждого прохода. Информация о наличии и/или отсутствии обнаруживаемых сигналов записывается для каждого обнаруженного положения (например, анализируемого вещества-мишени) на подложке.
Согласно некоторым вариантам осуществления в настоящем изобретении предусмотрены способы, которые включают стадии для обнаружения оптических сигналов, испускаемых зондами, содержащими теги, подсчет сигналов, испускаемых при многократных проходах и/или многократных циклах при различных положениях на подложке, и анализ сигналов в виде цифровой информации с использованием основанного на К-бит расчете для идентификации каждого анализируемого вещества-мишени на подложке. Может использоваться каждая коррекция для учета погрешностей оптически обнаруживаемых сигналов, как описано ниже.
Согласно некоторым вариантам осуществления субстрат связывается с анализируемыми веществами, содержащими N анализируемых веществ-мишеней. Для обнаружения N анализируемых веществ-мишеней выбираются M циклов связывания зонда и обнаружения сигнала. Каждый из M циклов включает в себя 1 или более проходов, и каждый проход состоит из N таких наборов зондов, что каждый набор зондов специфически связывается с одним из N анализируемых веществ-мишеней. Согласно некоторым вариантам осуществления существует N наборов зондов для N анализируемых веществ-мишеней.
В каждом цикле существует заранее заданный порядок для введения наборов зондов для каждого прохода. Согласно некоторым вариантам осуществления заранее заданный порядок для наборов зондов представляет собой случайный порядок. Согласно другим вариантам осуществления заранее заданный порядок для наборов зондов представляет собой неслучайный порядок. Согласно одному варианту осуществления неслучайный порядок может быть выбран с помощью компьютерного процессора. Заранее заданный порядок представлен в качестве ключа для каждого анализируемого вещества-мишени. Генерируется ключ, который включает в себя порядок наборов зондов, и порядок зондов переводится в цифровую форму в коде для идентификации каждого из анализируемых веществ-мишеней.
Согласно некоторым вариантам осуществления каждый набор упорядоченных зондов связан с отдельной меткой для обнаружения анализируемого вещества-мишени, и число отдельных меток меньше, чем число N анализируемых веществ-мишеней. В этом случае, каждое N анализируемое вещество-мишень соотносится с последовательностью M тегов для M циклов. Упорядоченная последовательность тегов ассоциируется с анализируемым веществом-мишенью в качестве идентифицирующего кода.
В одном примере существует 16 белков-мишеней и 16 различных зондов для каждого из белков-мишеней, но только четыре флуоресцентных тега (красный, синий, зеленый и желтый). На фиг. 10А показан пример 16 белков-мишеней (обозначены Р1, Р2, Р3 и т.д.), расположенных на подложке. Анализ может быть установлен с двумя циклами и одним проходом за цикл. Соответственно, создаются два упорядоченных набора пулов (один упорядоченный набор на цикл). Каждый пул зондов использует четыре тега для мечения 16 белков-мишеней в уникальной 2-цветной последовательности.
В таблице 2 ниже показаны 16 анализируемых веществ-мишеней и соответствующие номера зондов. В таблице 3 приведены четыре флуоресцентных тега (помеченные от 0 до 3). В таблицах 4 и 5 показаны два пула зондов, где каждый из 16 анализируемых веществ-мишеней помечен первым флуоресцентным тегом в пуле зондов 1 и вторым флуоресцентным тегом в пуле зондов 2. На фиг. 10В показана подложка фиг. 10А, которая контактировала с пулом зондов 1. На фиг. 10С представлена подложка фиг. 10А, которая контактировала с пулом зондов 2. Например, зонд А2 помечен синим флуоресцентным тегом в пуле зондов 1 и красным флуоресцентным тегом в пуле зондов 2. Соответственно, в цикле 1 зонд А2 (связанный с анализируемым веществом Р2) будет излучать синий цвет, а в цикле 2 зонд А2 будет излучать красный цвет. В другом примере, показанном на фиг. 10D, зонд А7 содержит зеленый (GRN) тег в пуле зондов 1 (или цикле номер 1). В пуле зондов 2 зонд А7 содержит синий (BLU) тег. В каждом пуле зондов несколько зондов характеризуются тем же цветом тега, но последовательность цветов в двух пулах уникальна для каждого анализируемого вещества. В пуле зондов #1, например, зонды A4 и А8 оба помечены желтым. Только зонд А9, однако, помечен красным в пуле зондов #1 и зеленым в пуле зондов #2.




В таблице 6 показан пример ключа, содержащий ID (идентификационный) код для каждого анализируемого вещества-мишени на основе цветовой последовательности. В таблице показаны N белковых мишеней по названию, соответствующему счислению с основанием 10 (от 1 до 10000), счислению с основанием М (например, основание 4 с 7 цифрами, показанными в настоящем документе) и цветовой последовательности. Цветовая последовательность представляет собой порядок и тип обнаруженного сигнала (красный, синий, зеленый, желтый), который испускался для конкретного анализируемого вещества. Ключ обеспечивает соответствующее счисление с основанием М (например, основание 4, 7 цифр) и идентичность анализируемого вещества-мишени, которое соответствует каждой последовательности цветов. Соответственно, расчет основание-4 позволяет упорядоченную цветовую последовательность 7 сигналов и идентификацию более 10000 различных анализируемых веществ-мишеней, каждое из которых характеризуется собственной идентифицирующей цветовой последовательностью.

Согласно одному варианту осуществления способ включает следующие стадии для мечения пулов зондов для расчета N различных видов анализируемых веществ-мишеней на подложке с использованием флуоресцентно помеченных зондов X различных цветов:
1. Пронумеровать перечень N мишеней (или их зондов) с использованием счисления с основанием X.
2. Связать флуоресцентные теги с основанными на X цифрами от 0 до X-1. (Например, 0, 1, 2, 3 соответствуют красному, синему, зеленому, желтому).
3. Найти такое С, что XC>N.
4. По меньшей мере С пулов зондов необходимо для идентификации N мишеней. Пометить С пулы зондов с помощью индекса k=1 до С.
5. В k-м пуле зондов пометить каждый зонд флуоресцентным тегом цвета, который соответствует k-ой основанной на X цифре счисления с основанием X, который идентифицирует мишень зонда в перечне, созданном на стадии 1.
Например, если существует N=10000 анализируемых веществ-мишеней и четыре флуоресцентных тега, может быть выбрано основание 4. 4 цвета флуоресцентных тегов обозначены числами 0, 1, 2 и 3, соответственно. Например, числа 0, 1, 2, 3 соответствуют красному, синему, зеленому и желтому.
Когда выбирается основание 4, каждый флуоресцентный цвет представлен 2 битами (0 и 1, где 0 = нет сигнала, 1 = сигнал присутствует), и есть 7 цветов, которые используются в качестве кода для идентификации анализируемого вещества-мишени. Например, белок А может быть идентифицирован с кодом "1221133", который представляет собой сочетание цвета и порядка "синий, зеленый, зеленый, синий, синий, желтый, желтый". Для 7 возможных цветов существует в общей сложности 14 битов информации для анализируемого вещества-мишени (7×2=14 бит).
Далее, С выбирают так, чтобы 4C>10000. В этом случае С может быть 7, таким образом, что существует 7 пулов зондов для идентификации 10000 мишеней (47=16384, что больше чем 10000). Цветовая последовательность длины С означает, что должны быть сконструированы С различных пулов зондов. 7 пулов зондов метят от k=1 до 7. Затем каждый зонд метят флуоресцентным тегом, который соответствует k-ому основанию и Х-цифре. Например, третий зонд в коде "1221133" будет 3 основанием и 4 цифрой и соответствовать зеленому цвету.
С. Количественное определение оптически обнаруженных зондов
После процесса обнаружения подсчитываются сигналы от каждого пула зондов, и наличие или отсутствие сигнала и цвета сигнала может быть записано для каждого положения на подложке.
Из обнаруживаемых сигналов К битов информации получают в каждом из M циклов для N различных анализируемых веществ-мишеней. К битов информации используются для определения L общих битов информации, так что К×M=L битов информации и L>log2 (Ν). L битов информации используют для установления идентичности (и наличия) N отдельных анализируемых веществ-мишеней. Если выполняется только один цикл (М=1), то К×1=L. Однако могут быть выполнены множественные циклы (Μ>1) для создания более общих битов информации L на анализируемое вещество. Каждый последующий цикл обеспечивает дополнительную информацию оптического сигнала, которая используется для идентификации анализируемого вещества-мишени.
На практике, возникают ошибки в сигналах, и это искажает достоверность идентификации анализируемых веществ-мишеней. Например, зонды могут связываться с неправильными мишенями (например, ложноположительные срабатывания) или не связываться с правильными мишенями (например, ложноотрицательные срабатывания). Предусмотрены описанные ниже способы для учета ошибок в оптическом и электрическом обнаружении сигнала.
III. Способы электрического обнаружения
Согласно другим вариантам осуществления способы электрического обнаружения используются для обнаружения наличия анализируемых веществ-мишеней на подложке. Анализируемые вещества-мишени метят олигонуклеотидными хвостовыми областями, и олигонуклеотидные теги обнаруживают с использованием ионно-чувствительного полевого транзистора (ISFET или датчика рН), который измеряет концентрации ионов водорода в растворе. ISFET описаны более подробно в патенте США 7948015, поданном 14 декабря 2007 г., Rothberg et al., и в публикации США №2010/0301398, поданной 29 мая 2009 г., Rothberg et al., которые оба полностью включены посредством ссылки.
ISFET представляют собой чувствительную и специфическую систему электрического обнаружения для идентификации и характеристики анализируемых веществ. Согласно одному варианту осуществления описанные в настоящем документе способы электрического обнаружения реализуются с помощью компьютера (например, процессора). Ионная концентрация раствора может быть преобразована в логарифмический электрический потенциал электродов в ISFET, и электрический выходной сигнал может быть обнаружен и измерен.
ISFET ранее использовались для облегчения секвенирования ДНК. Во время ферментативного превращения одноцепочечной ДНК в двухцепочечную ДНК, ионы водорода высвобождаются, когда каждый нуклеотид добавляется к молекуле ДНК; ISFET обнаруживает эти высвобожденные ионы водорода и может определить, когда нуклеотид был добавлен к молекуле ДНК. Благодаря синхронизации включения нуклеозидтрифосфатов (дАТФ, дЦТФ, дГТФ и дТТФ) последовательность ДНК также может быть определена. Например, если никакой выходной электрический сигнал не обнаружен, когда шаблон одноцепочечной ДНК подвергается воздействию дАТФ, но электрический выходной сигнал обнаружен в присутствии дГТФ, ДНК-последовательность состоит из комплементарного цитозинового основания в положении, о котором идет речь.
Согласно одному варианту осуществления ISFET используется для обнаружения хвостовой области зонда и последующей идентификации соответствующего анализируемого вещества-мишени. Например, анализируемое вещество-мишень может быть иммобилизовано на подложке, такой как чип с интегральными схемами, содержащей один или несколько ISFET. Когда добавляют соответствующий зонд (например, аптамер и хвостовую область) и он специфически связывается c анализируемым веществом-мишенью, нуклеотиды и ферменты (полимеразу) добавляют для транскрипции хвостовой области. ISFET обнаруживает высвобождение ионов водорода в виде электрических выходных сигналов и измеряет изменение концентрации ионов, когда дНТФ включается в хвостовую область. Количество высвобожденных ионов водорода соответствует длинам и останавливается в хвостовой области, и эта информация о хвостовых областях может быть использована, чтобы различать различные теги.
Простейший тип хвостовой области представляет собой область, которая полностью состоит из одной гомополимерной области оснований. В этом случае, существует четыре возможных хвостовых области: поли-А хвост, поли-С хвост, поли-G хвост и поли-Т хвост. Однако часто бывает желательно большое разнообразие хвостовых областей.
Один из способов получения разнообразия в хвостовых областях представляет собой обеспечение стоп-оснований в гомополимерной области оснований хвостовой области. Стоп-основание представляет собой часть хвостовой области, содержащей по меньшей мере один нуклеотид, смежный с гомополимерной областью оснований, таким образом, что по меньшей мере один нуклеотид состоит из основания, которое отличается от оснований внутри гомополимерной области оснований. Согласно одному варианту осуществления стоп-основание представляет собой один нуклеотид. Согласно другим вариантам осуществления стоп-основание содержит множество нуклеотидов. Как правило, стоп-основание окружено по бокам двумя гомополимерными областями оснований. Согласно одному варианту осуществления две гомополимерные области оснований, фланкирующие стоп-основание, состоят из того же основания. Согласно другому варианту осуществления две гомополимерные области оснований состоят из двух различных оснований. Согласно другому варианту осуществления хвостовая область содержит более чем одно стоп-основание.
В одном примере ISFET может обнаружить минимальное пороговое количество 100 ионов водорода. Анализируемое вещество-мишень 1 связывается с композицией с хвостовой областью, состоящей из 100-нуклеотидного поли-А хвоста с последующим одним цитозиновым основанием, за которым следует другой 100-нуклеотидной поли-А хвост, для общей длины хвостовой области 201 нуклеотидов (SEQ ID NO: 2). Анализируемое вещество-мишень 2 связывается с композицией с хвостовой областью, состоящей из 200-нуклеотидного поли-А хвоста (SEQ ID NO: 3). При добавлении дТТФ и в условиях, благоприятных для синтеза полинуклеотидов, синтез на хвостовой области, связанной с анализируемым веществом-мишенью 1, высвободит 100 ионов водорода, который можно отличить от синтеза полинуклеотидов на хвостовой области, связанного с анализируемым веществом-мишенью 2, который будет высвобождать 200 ионов водорода. ISFET будет обнаруживать другой электрический выходной сигнал для каждой хвостовой области. Кроме того, если добавляют дГТФ с последующими еще дТТФ, хвостовая область, связанная с анализируемым веществом-мишенью 1, будет затем высвобождать один, а затем еще 100 ионов водорода благодаря дальнейшем синтезу полинуклеотидов. Отличительные электрические выходные сигналы, полученные от добавления специфических нуклеозидтрифосфатов, основанных на композициях хвостовых областей, позволяют ISFET обнаруживать ионы водорода от каждой из хвостовых областей, и эта информация может быть использована для идентификации хвостовых областей и их соответствующих анализируемых веществ-мишеней.
Различные длины гомополимерных областей оснований, стоп-оснований и их комбинаций могут быть использованы, чтобы уникально пометить каждое анализируемое вещество в образце. Дополнительное описание электрического обнаружения аптамеров и хвостовых областей для идентификации анализируемых веществ-мишеней в подложке, описано в предварительной заявке на патент США №61/868988, который полностью включен посредством ссылки.
Согласно другим вариантам осуществления антитела используют в качестве зондов в описанном выше электрическом способе обнаружения. Антитела могут представлять собой первичные или вторичные антитела, которые связываются с помощью линкерной области с олигонуклеотидной хвостовой областью, которая действует в качестве тега. Примеры таких зондов показаны на фиг. 2, 5 и 6.
Эти способы электрического обнаружения могут быть использованы для одновременного обнаружения сотен (или даже тысяч) различных анализируемых веществ-мишеней. Каждое анализируемое вещество-мишень может быть связано с цифровым идентификатором, таким образом, что число различных цифровых идентификаторов пропорционально числу различных анализируемых веществ-мишеней в образце. Идентификатор может быть представлен числом битов цифровой информации и кодироваться упорядоченным набором хвостовых областей. Каждая хвостовая область в упорядоченном наборе хвостовых областей последовательно получена для специфического связывания с линкерной областью области зонда, которая специфически связывается с анализируемым веществом-мишенью. Кроме того, если хвостовые области ковалентно связаны с их соответствующими областями зондов, каждую хвостовую область в упорядоченном наборе хвостовых областей последовательно получают для специфического связывания с анализируемым веществом-мишенью.
Согласно одному варианту осуществления один цикл представлен связыванием и отделением хвостовой области от линкерной области, таким образом, что происходит синтез полинуклеотидов и высвобождение ионов водорода, которые обнаруживают в качестве электрического выходного сигнала. Таким образом, число циклов для идентификации анализируемого вещества-мишени равно количеству хвостовых областей в упорядоченном наборе хвостовых областей. Число хвостовых областей в упорядоченном наборе хвостовых областей зависит от количества идентифицируемых анализируемых веществ-мишеней, а также от общего количества создаваемых битов информации. Согласно другому варианту осуществления один цикл представляет собой хвостовую область, ковалентно связанную с областью зонда, специфически связывающуюся и отделяемую от анализируемого вещества-мишени.
Электрический выходной сигнал, обнаруженный от каждого цикла, оцифровывается в битах информации, так, что после того, как были выполнены все циклы для связывания каждой хвостовой области с соответствующей линкерной областью, общие биты полученной цифровой информации могут быть использованы для идентификации и характеристики исследуемого анализируемого вещества. Общее число битов зависит от количества идентификационных битов для идентификации анализируемого вещества-мишени, плюс число битов для коррекции ошибок. Количество битов для коррекции ошибок выбирается на основе требуемой надежности и точности электрического выходного сигнала. Как правило, количество битов коррекции ошибок будет в 2 или 3 раза превышать количество идентификационных битов.
IV. Расшифровка порядка и идентичности обнаруженных анализируемых веществ
Зонды, используемые для обнаружения анализируемых веществ, вводят на подложку упорядоченным образом в каждом цикле. Генерируется ключ, который кодирует информацию о порядке зондов для каждого анализируемого вещества-мишени. Сигналы, обнаруженные для каждого анализируемого вещества, могут быть оцифрованы в биты информации. Порядок сигналов обеспечивает код для идентификации каждого анализируемого вещества, который может быть закодирован в битах информации.
В одном примере для оптического обнаружения анализируемых веществ с использованием 1 бита информации каждое анализируемое вещество связано с упорядоченным набором зондов. Ниже в таблице 7 показано, что каждое анализируемое вещество-мишень связано с заранее заданным порядком набора зондов, введенных в течение 7 циклов, и порядок сигналов, испускаемых из упорядоченного набора зондов, используется в качестве кода для идентификации анализируемого вещества-мишени. Например, для альфа-1-кислого гликопротеина идентификационный код представляет собой упорядоченный набор зондов из шести красных (R) сигналов с последующим конечным синим (В) сигналом. Когда набор сигналов получают для анализируемого вещества-мишени, который считывает "RRRRRRB", ключ используется для поиска соответствия между идентификационным кодом порядка для зондов и полученными сигналами от анализируемого вещества. Соответственно, код используется для определения того, что анализируемое вещество-мишень представляет собой альфа-1-кислый гликопротеин.

Согласно некоторым вариантам осуществления пользователь набора, содержащего упорядоченный набор зондов и инструкции по использованию зонда, не имеет доступа к коду, например, чтобы он или она не могли соотнести упорядоченный набор сигналов с соответствующим анализируемым веществом-мишенью. Согласно одному варианту осуществления набор не включает в себя ключ для декодирования результатов, и пользователь отправляет данные третьей стороне для обработки данных с использованием кода. Согласно другому варианту осуществления ключ с идентификационными кодами предоставляется пользователю в наборе, и пользователь может расшифровать упорядоченный набор сигналов до анализируемого вещества-мишени.
Во втором примере каждый цвет (флуоресцентный сигнал) может быть представлен 2-битовой последовательностью, и 2-битовая последовательность может быть представлена 4-битовым символом данных. В таблице 8 приведен пример четырех цветов (красный, синий, зеленый и желтый) и их соответствующих битовых значений. Например, последовательность цветов "BGGBBYY" для конкретного анализируемого вещества может быть закодирована в 14 битах, как 01101001011111 в соответствии с битовой схемой, показанной в таблице 8.

Порядок зондов может быть различным для каждого анализируемого вещества для каждого нового цикла (когда цикл включает в себя несколько проходов) или для каждого набора циклов. Ключ, используемый для идентификации анализируемого вещества в одном наборе циклов, не должен быть снова использован во втором анализе. Коды для анализируемых веществ-мишеней могут быть изменены для каждого анализа.
Согласно некоторым вариантам осуществления заранее заданный порядок упорядоченного набора зондов выбирается случайным образом. Согласно другим вариантам осуществления заранее заданный порядок представляет собой неслучайный. Согласно одному варианту осуществления компьютерное программное обеспечение используется для установления порядка.
V. Способы коррекции ошибок
В описанных выше способах оптического и электрического обнаружения могут возникнуть ошибки в связывании и/или обнаружении сигналов. В некоторых случаях частота ошибок может быть такой высокой, как одна из пяти (например, один из пяти флуоресцентных сигналов представляет собой неверный). Это соответствует одной ошибке в каждой последовательности из пяти циклов. Фактические частоты ошибок не могут быть такими высокими, как 20%, но частоты ошибок в несколько процентов возможны. В общем, частота появления ошибок зависит от многих факторов, включающих в себя тип анализируемых веществ в образце и тип используемых зондов. В способе электрического обнаружения, например, хвостовая область может должным образом не связываться с соответствующей областью зондов на аптамере в течение цикла. В способе оптического обнаружения антитело-зонд может не связываться со своей мишенью или связываться с неправильной мишенью.
Создаются дополнительные циклы для учета ошибок в обнаруженных сигналах и получения дополнительных битов информации, таких как биты четности. Дополнительные биты информации используются для исправления ошибок с использованием кода коррекции ошибок. Согласно одному варианту осуществления код коррекции ошибок представляет собой код Рида-Соломона, который представляет собой не двоичный циклический код, используемый для обнаружения и исправления ошибок в системе. Согласно другим вариантам осуществления могут быть использованы различные другие коды коррекции ошибок. Другие коды коррекции ошибок включают в себя, например, блоковые коды, коды свертки, коды Голея, коды Хэмминга, коды БЧХ, коды AN, коды Рида-Мюллера, коды Гоппы, коды Адамара, коды Уолша, сверточные коды коррекции, полярные коды, коды с повторениями, накапливающие повторы коды, помехоустойчивые коды, онлайн коды, групповые коды, расширительные коды, равновесные коды, коды торнадо, коды малой плотности с контролем по четности, максимально разнесенные коды, коды пакетных ошибок, коды преобразования Люби, фонтанные коды и коды Raptor. Смотрите Error Control Coding, 2nd Ed., S. Lin and DJ Costello, Prentice Hall, New York, 2004. Ниже предусмотрены также примеры, которые демонстрируют способ для исправления ошибок путем добавления циклов и получения дополнительных битов информации.
Один пример кода Рида-Соломона включает в себя RS(15,9) код с 4-битовыми символами, где n=15, k=9, s=4 и t=3, и n=2s-1 и k=n-2t, "n" представляет собой число символов, "k" представляет собой число символов данных, "s" представляет собой размер каждого символа в битах и "t" представляет собой число ошибок, которые могут быть исправлены, и "2t" представляет собой количество символов четности. Существует девять символов данных (k=9) и шесть символов четности (2t=6). Если используется счисление с основанием X, а X=4, то каждый флуоресцентный цвет представлен двумя битами (0 и 1). Пара цветов может быть представлена в виде четырехбитового символа, который включает в себя два высоких бита и два низких бита.
На фиг. 11 показана иллюстративная структура RS(15,9). Поскольку было выбрано основание-4, семь пулов зондов или последовательность из семи цветов используются для идентификации каждого анализируемого вещества-мишени. Эта последовательность представлена 3 ½, 4-битовыми символами. Остальные 5 ½ символы данных устанавливаются в ноль. Устройство кодирования RS(15,9) Рида-Соломона затем генерирует шесть символов четности, представленных 12 дополнительными пулами зондов. Таким образом, в общей сложности 19 пулов зондов (7+12) необходимо для получения коррекции ошибок для t=3 символов.
Имитации Монте-Карло корректирующего ошибки выполнения кода были выполнены из расчета семи пулов зондов, чтобы идентифицировать до 16384 различных мишеней. С использованием этих имитаций максимально допустимую частоту грубых ошибок (связанных с идентификацией флуоресцентной метки) для достижения частоты исправленных ошибок 10-5 определяли для различных чисел битов четности. В таблица 10А ниже представлены эти выводы.

Согласно некоторым вариантам осуществления генерируется ключ, который включает в себя ожидаемые биты информации, связанные с анализируемым веществом (например, ожидаемый порядок зондов и типов сигналов анализируемого вещества). Эти ожидаемые биты информации для конкретного анализируемого вещества сравнивают с фактическими L битами информации, которые получают от анализируемого вещества-мишени. С использованием подход Рида-Соломона, допуск до t ошибок в сигналах может быть допустим, в сравнении с ожидаемыми битами информации и фактическими L битами информации.
Согласно некоторым вариантам осуществления декодер Рида-Соломона используется для сравнения ожидаемой сигнальной последовательности с наблюдаемой сигнальной последовательностью от конкретного зонда. Например, семь пулов зондов может быть использовано для идентификации анализируемого вещества-мишени, ожидаемая цветовая последовательность BGGBBYY, представленная 14 битами. Дополнительные пулы четности могут быть использованы для коррекции ошибок. Например, могут быть использованы шесть 4-битовых символов четности. Затем, как показано ниже в таблице 10В, ожидаемую сигнальную последовательность сравнивают с наблюдаемой сигнальной последовательностью, и декодированная сигнальная последовательность создается из сравнения.
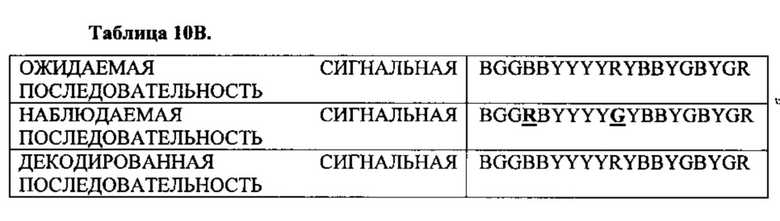
Наблюдаемая сигнальная последовательность содержит 2 ошибки в упорядоченной последовательности 19 сигналов. Когда полученная последовательность зонда декодируется декодером Рида-Соломона, оригинальная, переданная последовательность зонда восстанавливается. Ожидаемая сигнальная последовательность представляет собой последовательность, которая разработана для идентификации одного типа анализируемого вещества. Наблюдаемая сигнальная последовательность представляет собой последовательность флуоресцентных сигналов, полученных в конкретном положении на твердой подложке. Декодируемая последовательность представляет собой восстановленную после декодирования последовательность с помощью декодера кода коррекции ошибок.
Согласно другому варианту осуществления с использованием электрического обнаружения анализируемых веществ, зонды и выбранные биты информации, используемые в способе электрического обнаружения, следуют после расчетов коррекции ошибок, как показано в таблице 11 ниже. В примере 1 выбирают 3 бита идентификатора, что соответствует в общей сложности 8 анализируемым веществам-мишеням и 8 идентификационным номерам (23=8). Кроме того, коэффициент ошибок рассчитывается как количество битов ошибок, деленное на число битов идентификатора. В настоящем документе количество битов, используемых для коррекции ошибок в этом примере, составляет 9 (3×3=9), а коэффициент ошибок будет 3 (9/3=3). Общие биты на пробег составляют 12 (сумма 3 битов идентификатора и 9 битов коррекции ошибок). Количество битов за цикл может быть выбрано как 3 и число зондов за цикл определяется как 8 (23=8). Далее, число циклов рассчитывается как 4 на основании количества битов, коэффициента ошибок и битов за цикл. Используемое уравнение представляет собой ((биты × (1 + коэффициент ошибок)/биты за цикл). В настоящем документе, расчет представляет собой (3×(1+3))/3)=4 цикла. В этом примере, один стоп используется на электрический тег. Количество обнаруживаемых зондов может быть увеличено на основании выбора более высоких битов, как показано в примерах 2-5 в таблице 11.

Дополнительное описание способов электрического обнаружения можно найти в предварительной заявке на патент США №61/868988, которая полностью включена посредством ссылки.
VI. Динамический диапазон
Концентрации анализируемых веществ, таких как белки, в образцах, таких как сыворотка человека, могут варьировать в зависимости от факторов больше чем 1010. Динамические диапазоны возможных концентраций для конкретных белков, как правило, меньше. Например, ферритин обычно находится между 104-105 пг/мл в сыворотке человека. Большинство концентраций белка не изменяется более чем в 10 раз от одного образца сыворотки человека к другому.
Поскольку трудно обнаружить флуоресцентные метки, соответствующие анализируемым веществам-мишеням в большом динамическом диапазоне концентраций, подложка, содержащая анализируемые вещества-мишени, может быть разделена на концентрационные области. Например, на фиг. 12А показан пример подложки, которая была разделена на области "HIGH", "MED" и "LOW". Те же анализируемые вещества-мишени могут быть распределены по каждой из трех областей. Тем не менее, анализируемые вещества-мишени разбавляют до образцов различных концентраций перед распределением: по одному образцу с каждой концентрацией: высокой концентрацией (HIGH), средней концентрацией (MED) и низкой концентрацией (LOW). Согласно одному варианту осуществления анализируемые вещества-мишени в области "HIGH" подложки распределены в концентрации приблизительно 1 белок на квадратный микрон, анализируемые вещества-мишени в области "MED" распределены в концентрации приблизительно 102 белков на квадратный микрон и анализируемые вещества-мишени в области "LOW" области распределены в концентрации приблизительно 104 белков на квадратный микрон. Согласно другому варианту осуществления разведения регулируют таким образом, чтобы плотность флуоресцентных меток в каждой области концентраций составляла приблизительно один тег на 10-25 пикселей в изображении подложки.
Фиг. 12В представляет собой график, показывающий пример диапазонов относительного содержания анализируемых веществ-мишеней из образца, расположенных в различных областях концентрации (Low, Med и High) подложки. Фиг. 12С также представляет собой график, показывающий диапазоны относительного содержания анализируемых веществ-мишеней с четвертой областью концентрации: "Rare". Перекрывающиеся диапазоны относительного содержания демонстрируют, что определенные анализируемые вещества-мишени могут быть обнаружены в более чем одной области концентраций. Эти графики (фиг. 12В и 12С) были получены из моделирований, выполненных в примере 5 (ниже).
Согласно одному варианту осуществления конкретное анализируемое вещество-мишень в образце может быть отделено от образца, чтобы увеличить динамический диапазон еще больше. Например, в образце сыворотки крови человека может быть желательным удалить альбумин, находящийся в избытке белок. Может быть использована любая техника разделения, включающая в себя высокоэффективную жидкостную хроматографию.
Когда различные разведения образцов анализируемых веществ-мишеней были прикреплены к подложке, могут быть применены зонды, чтобы селективно связываться с анализируемыми веществами-мишенями. Согласно одному варианту осуществления зонды могут быть получены в различных концентрациях, чтобы они избирательно связывались с анализируемыми веществами-мишенями среднего относительного содержания в области подложки "MED".
ПРИМЕРЫ
Ниже приведены примеры конкретных вариантов осуществления настоящего изобретения. Примеры предлагаются только в иллюстративных целях и не предназначены для ограничения объема настоящего изобретения каким-либо образом. Были предприняты усилия, чтобы обеспечить точность в отношении используемых чисел (например, количеств, температуры и т.д.), но некоторые экспериментальные ошибки и отклонения должны, конечно, быть позволительны.
Для осуществления настоящего изобретения будут использованы, если не указано иное, обычные способы химии белка, биохимии, техник рекомбинантных ДНК и фармакологии, в пределах данной области техники. Такие техники подробно описаны в литературе. Смотрите, например, Т.Е. Creighton, Proteins: Structures and Molecular Properties (W.H. Freeman and Company, 1993); A.L. Lehninger, Biochemistry (Worth Publishers, Inc., current addition); Sambrook, et al., Molecular Cloning: A Laboratory Manual (2nd Edition, 1989); Methods In Enzymology (S. Colowick and N. Kaplan eds., Academic Press, Inc.); Remington's Pharmaceutical Sciences, 18th Edition (Easton, Pennsylvania: Mack Publishing Company, 1990); Carey and Sundberg Advanced Organic Chemistry 3rd Ed. (Plenum Press) Vols A and B (1992).
Пример 1: Анализ оптического обнаружения для нескольких анализируемых веществ с использованием одного флуоресцентного тега, одного прохода, с учетом темного цикла и 1 бита за цикл
В одном примере выполняется способ с использованием следующих параметров: единственный флуоресцентный тег (одноцветный), один проход, учтенный темный цикл и 1 бит за цикл. На фиг. 9 показан этот пример, где флуоресцентная поверхностная плотность ниже, чем поверхностная плотность осажденного белка. На фигуре показано четыре различных типа белков-мишеней в смеси с другими, белками-немишенями, случайным образом нанесенными на поверхность.
В таблице 12 ниже показано, как в общей сложности четыре бита информации могут быть получены с использованием четырех циклов гибридизации и стрипирования так, что существует один проход за цикл. Сигналы, полученные из четырех циклов, оцифровываются в биты информации.
Как показано на фиг. 13, зонды вводят для анализируемого вещества А в цикле 1, и присутствие анализируемого вещества обозначается с помощью "1". В цикле 2 зонды для анализируемого вещества А не добавляют, и анализируемое вещество не обнаруживают, обозначая с помощью "0". После четырех циклов анализируемое вещество может быть связано с двоичным кодом "1010". В системе счисления на основании 2 код представляется как "1010". В системе счисления на основании 10 тот же код представлен в виде "10" (например, (23×1)+(22×0)+(21×1)+(20×0)=10).
В первом цикле только антитела-зонды для мишеней А и В включены в пул зондов. Система визуализации измеряет одноцветное изображения для первого цикла, где флуоресцируют молекулы А и В, но С и D темные (отсутствуют зонды и отсутствует сигнал). Зонды для мишеней А и В стрипируют. Для второго цикла вводят антитела-зонды для мишеней С и D и визуализируют, а затем антитела-зонды для С и D стрипируют. Для третьего цикла вводят антитела-зонды, нацелено воздействующие на А и С, и визуализируют. Антитела-зонды для мишеней А и С затем стрипируют. Для четвертого цикла вводят антитела-зонды для мишеней В и D, и флуоресцентные молекулы визуализируют. После визуализации нескольких циклов определяют идентификатор (код флуоресцентных сигналов) для молекулы-мишени в каждом положении. Только 2 цикла необходимы для идентификации 4 молекул. Согласно некоторым вариантам осуществления дополнительные циклы могут быть использованы для информации коррекции ошибок, который описан ниже, или для выявления более 4 молекул.

Пример 2: Анализ оптического обнаружения для нескольких анализируемых веществ с использованием одного цвета, четырех проходов за цикл, без учета темного прохода и 2 битов за цикл
В другом примере используются следующие параметры: один цвет, четыре прохода за цикл, не учтенный темный проход и 2 бита за цикл.
На фиг. 14 показаны четыре прохода для одного цикла. Первый проход включает в себя зонды для анализируемого вещества-мишени А. Зонды для мишени А гибридизуются и обнаруживаемый сигнал визуализируют. Например, зонды содержат зеленую флуоресцентную молекулу и излучают зеленый цвет. Зонды для мишени А не стрипируют от подложки в данном примере. В проходе 2 зонды для мишени В гибридизуют и зонды для мишени В характеризуются тем же флуоресцентным цветом, что и зонды для мишени А. Обнаруживают дополнительные сигналы для мишени В (зеленые флуоресцентные молекулы), и визуализируют оба сигнала для мишеней А и В. Зонды для А и В не стрипируют от подложки.
В проходе 3 вводят зонды для мишени С и гибридизуют с мишенью С. Зонды для мишени С излучают тот же флуоресцентный цвет, что и мишени А и В. Сигналы, испускаемые от зондов для мишеней А, В и С, визуализируют. В проходе 4 зонды для мишени D гибридизируют, и сигналы, излучаемые от мишеней А, В, С и D, визуализируют. Наконец, все зонды стрипируют, и первый цикл завершается.
Может быть выполнено множество циклов, чтобы увеличить число количественно проанализированных мишеней. Не обязательно наличие зондов для каждой мишени в каждом проходе и может быть на много больше, чем наблюдаемые четыре молекулы.
В таблице 13 ниже показано, как сигналы, полученные от одного цикла с четырьмя проходами, оцифровывают и представляют в виде двух битов информации за один цикл. За период из четырех циклов может быть получено в общей сложности 8 бит информации на анализируемое вещество. В таблице 14 приведен ключ для цифрового выхода для четырех проходов в цикле.




Можно использовать несколько флуоресцентных молекул на вторичных анализируемых веществах вместо выполнения последовательных гибридизаций для достижения больших битов информации за один цикл. Например, четыре цвета флуоресцентных тегов на вторичных антителах позволит за одну стадию гибридизации и одну стадию стрипирования в цикле достичь двух битов информации за один цикл.
Сочетание использования нескольких цветов, а также выполнения нескольких стадий гибридизации за цикл может увеличить количество измеряемых битов за один цикл. Например, с использованием четырехцветной системы визуализации и выполнения 4 стадий гибридизации за цикл позволит достичь до четырех битов информации за один цикл.
Пример 3: Анализ оптического обнаружения для нескольких анализируемых веществ с использованием пяти цветов, трех проходов за цикл, с учетом темного прохода, четырех битов за цикл
В другом примере используются следующие параметры: пять цветов, три прохода за цикл, учтенный темный проход, четыре бита за цикл.
В следующих таблицах показан анализ с системой пятью цветов с 3 проходами гибридизации за цикл. В общей сложности 16 уровней или эквивалентно четырем битам информации возможно за один цикл, если отсутствие какого-либо сигнала считается уровнем (то есть, подсчитывается темный цикл). В таблице 16 приведен ключ для идентификационного кода для каждого анализируемого вещества.

 1
1
В таблице 17 ниже показано количество битов за цикл для многоцветной, многопроходовой гибридизации для оптического обнаружения, с и без отсутствия сигнала, рассматриваемого как уровень (темный цикл учитывается/ темный цикл не учитывается).

Пример 4: Демонстрация зонда ДНК и гибридизации и стрипирования мишени на массовом уровне
Нуклеиновые кислоты использовали, чтобы продемонстрировать гибридизацию APTIQ зонда/мишени и циклы стрипирования на массовом уровне. Олигонуклеотиды (таблица 18) приобретали у IDT Integrated DNA Technologies (Coralville, Iowa). Олигонуклеотиды растворяли в воде молекулярного класса в конечной концентрации в 100 мкМ и хранили при -20°С.

Олигонуклеотиды с Сб-амино линкерами печатали на микрочипы в ArrayIt (Sunnyvale, California). Если не указано иное, все реагенты и оборудование, используемые в этих примерах, приобретали у ArrayIt. Олигонуклеотиды печатали в конечной концентрации 50 мкМ в 1-кратном MSP буфере (Cat ID: MSP) на подложку микрочипов SuperEpoxy 2 (Cat ID: SME2), на NanoPrint Microarrayer с использованием SMP3 Microarray Printing Pin. Напечатанные микрочипы сушили в течение ночи.
Перед использованием слайд подложки блокировали в течение 1,5 часов в блокирующем буфере BlockIt (Cat ID: ВКТ) при комнатной температуре с осторожным перемешиванием при 350 об/мин, с последующим промыванием 3 раза, по 1 минуте за раз, с однократными промывочными буферами 1, 2, 3 (Cat ID: WB1, WB2, WB3) в квадратной чашке Петри, объем 30 мл при 350 об/мин с орбитой 2 мм. Слайд затем! сушили в течение 10 секунд в центрифуге для микрочипов (Cat ID: МНС110).
Уплотнитель (Cat ID: GAHC4x24) блокировали в блокирующем буфере BlockIt в течение по меньшей мере 1 часа, промывали дистиллированной водой, сушили с использованием Microarray Cleanroom Wipe (Cat ID: MCW) и загружали в крышку кассеты (Cat ID: АНС4х24). Гибридизационный буфер Hybit (Cat ID: HHS2) использовали для гибридизации в виде однократного. Меченые Су3 или Су5 зонды (таблица 18) (соответствующие цветам R-красный или G-зеленый, соответственно) смешивали в пулах зондов в 1-кратном буфере для гибридизации. 75 мкл пулов зондов гибридизации загружали на микрочип и инкубировали в течение 15 минут при 37°С,; 350 об/мин на станции Arrayit Array Plate Hyb (Cat ID: MMHS110V).
100 мкл промывочного буфера 1 (при 37°С) добавляли в каждую лунку и затем инкубировали в течение 1 минуты при 350 об/мин. Промывочный буфер затем вьшимали, удаляя промывочный буфер в отходы. Промывочный буфер 1 использовали еще два раза, промывочный буфер 2 использовали три раза, а затем промывочный буфер 3 использовали три раза.
Слайд удаляли из уплотнителя, погруженного в промывочный буфер 3 в контейнере, и сушили в центрифуге для микрочипов. Слайд сканировали в сканере Axon 4200А с установкой РМТ250 для обоих лазеров 532 и 635. Слайд инкубировали с пятнами стороной вверх в квадратной чашке Петри, содержащей 30 мл буфера для стрипирования А при 350 об/мин в течение 10 минут.Буфер для стрипирования удаляли с немедленным последующим добавлением 30 мл буфера для стрипирования B. Процедуру повторяли с буфером для стрипирования В и буфером для стрипирования C. Слайд сушили в центрифуге микрочипов и подготавливали к следующему циклу гибридизации. Слайд сканировали после стрипирования, чтобы подтвердить эффективность стрипирования.
На фиг. 15 показаны результаты сканирования: три мишени олигонуклеотида (B1, В2, В3) идентифицировали путем зондирования связывания и стрипирования в течение 6 циклов. Цветовую последовательность каждой мишени-олигонуклеотида правильно идентифицировали.
Пример 5: Использование ДНК для демонстрации одномолекулярного подсчета
Авторы настоящего изобретения описывают способ идентификации и количественного определения отдельных молекул. Олигонуклеотиды (таблица 19) приобретали у IDT Integrated DNA Technologies. Олигонуклеотиды растворяли в воде молекулярного класса до конечной концентрации 100 мкМ и хранили при -20°С.


Кремниевые стекла приобретали в University Wafer (Boston, MA), наносили сетку (American Precision Dicing Inc., San Jose, California) и покрывали подложкой SuperEpoxy (ArrayIt). Монокристаллические кремниевые чипы получали в виде слайдов подложки 25 мм × 75 мм. Толщина используемых кремниевых чипов составляла 500. мкм, 675 мкм и 1000 мкм. Термически образованный оксид выращивали на кремниевых чипах 100 нм, а затем наносили сетку на стекла.
Слайды инкубировали в растворе 4 олигонуклеотидов ДНК (таблица 19), каждый олигонуклеотид заканчивающийся молекулой Сб. Последовательности 4 олигонуклеотидов представляли собой А, В, С и D, соответствуя генам, кодирующим KRAS, EGFR, BRAF и Р53. 4 олигонуклеотида с С6-амино линкером смешивали в концентрации 100 нМ на олигонуклеотид в 1-кратном растворе для микропереноса (CAT ID: MSS, ArrayIt), а затем инкубировали на покрытом эпоксидом кремниевом стекле в контейнере при комнатной температуре в течение ночи. Во время инкубации реакция между эпоксидным покрытием и олигонуклеотидом С6 ковалентно связывала одноцепочечную ДНК с поверхностью. Стекло затем промывали водой молекулярного класса в течение 5 минут, 3 раза, с последующей инкубацией в блокирующем растворе ArrayIt BlockIt в течение 1 часа при комнатной температуре и осторожным-перемешиванием при 350 об/мин, с последующим промыванием 3 раза в течение 1 минуты каждый раз 1-кратным промывочным буфером 1, 2, 3 в квадратной чашке Петри, объем 30 мл при 350 об/мин на 2 мм орбите. Слайд сушили в течение 10 секунд центрифуге для микрочипов.
Чип изготовляли со связующим элементом в биочип, состоящим из 3-х частей, кремниевого чипа, считывающей рамки и покровного стекла толщиной 170 мкм. Покровное стекло (Nexterion, Tempe, AZ) прикрепляли на кремниевом стекле с помощью клея Bostik, смешанного с гранулами 50 мкм (Gelest, Morrisville, РА) на разработанном своими силами устройстве. Клей и гранулы упаковывали в шприц 3сс (Hamilton Company, Reno, NV) и центрифугировали в центрифуге EFD ProcessMate (Nordson, Westlake, ОН), а затем доставляли с помощью клеевого дозатора Nordson EFD Ultimus.
Меченые Су3 или Су5 зонды (таблица 19) смешивали в пулах зондов в 1-кратном буфере для гибридизации HybIt. Раствор для гибридизации из пула # 1 доставляли в биочип и инкубировали в течение 15 минут при комнатной температуре. Чип затем промывали промывочным буфером 1, 2 и 3 (ArrayIt), 8 раз с каждым буфером. 15% глицерина в 1-кратном SSPE (150 мМ NaCl, 10 мМ NaH2PO4, 1 мМ EDTA) добавляли в чип перед визуализацией. Последовательные пулы зондов 1, 2, 3, 4 гибридизовали и стрипировали. После каждой стадии гибридизации система визуализации отображала 12 областей слайда, каждая область составляла 100 мкм × 100 мкм. Используемая камера представляла собой Hamamatsu Orca 4.0 с 40-кратной системой увеличения с использованием части # UAPON40XW Olympus.
После визуализации чип промывали водой молекулярной класса, а затем стрипировали в буфере для стрипирования А, В, С (ArrayIt), 8 раз в каждом буфере. 15% глицерин в 1-кратном SSPE добавляли к чипу перед визуализацией. После цикла 1, который включает в себя гибридизацию пула зондов #1, визуализацию, стрипирование, визуализацию, цикл 2 начинается с гибридизации с пулом зондов #2.
Данные получали на двух слайдах (слайды #177 и #179, фиг. 16А), каждый слайд, содержащий двенадцать полей. Каждое поле составляло 100 мкм × 100 мкм. Двухцветную систему визуализации использовали с фильтрами Су3 и Су5. Для каждого слайда собирали по меньшей мере 12-14 циклов данных с анализом с использованием от 9 до 10 циклов данных. Картирование идентификации идентификаторов мишеней до цветовой последовательности представлено в таблице 19. На фиг. 16А каждый цвет соответствует последовательности таким образом, что зонд метят Су5 или Су3, соответствующим соответственно цвету R (красный) или G (зеленый), который отображает 1 или 0 с 1 битом информации, полученным за цикл (фиг. 16В). В этом случае, схема коррекции ошибок была консервативной и требовала нулевых ошибок на мишень, ошибка определяется как положительная идентификаций в последовательности, где она не ожидалась. Разрешалось до пяти отсутствующих последовательностей на молекулу. Отсутствующие последовательности представляли собой случаи, когда молекулу не идентифицировали в цикле. Они не классифицируется как ошибки.
Слайды #177 и #179 измеряли в аналогичных условиях. Измеряли небольшую часть каждого слайда (измерение всего слайда представляет собой реализацию шкалы и автоматизацию). На фиг. 16А показано число молекул в каждом поле с количеством каждого гена, который был идентифицирован. Проценты идентифицированных молекул составляли 12%-13%.
На фиг. 17 показано изображение, полученное с прототипным устройством формирования изображений одиночных флуоресцентных ДНК-зондов, которые были гибридизованы с ДНК олигонуклеотидами-мишенями, ковалентно связанными с поверхностью. От 10% до 15% идентифицированных молекул содержали несколько флуоресцентных молекул на пятно за счет агрегации, которая происходила во время прикрепления образца.
На фиг. 18 показаны репрезентативные примеры идентификации каждой из четырех мишеней из слайда #177 (фиг. 16А). Каждое пятно в кругу выравнивается по центру на мишени. Мишени идентифицируют с обнаружением одной флуоресцентной молекулы. Примерно 10%-15% мишеней на изображении представляло собой кластеризованные молекулярные виды, где было связано более одной флуоресцентной молекулы. Проверка данных показывает, что для обоих экспериментов наблюдались более высокие уровни Р53 и KRAS, чем BRAF и EGFR. Общее количество идентифицированных молекул составляло до 2000 в обоих случаях, демонстрируя потенциальную высокую чувствительность способа в обнаружении и идентификации низких количеств молекул.
Пример 6: Демонстрация пептидного зонда и гибридизации и стрипирования мишени на массовом уровне
Пептиды использовали для демонстрации циклов связывания APTIQ зонда/мишени и циклов стрипирования на массовом уровне. Пептид MUC1 (последовательность: APDTRPAPG (SEQ ID NO: 19)) приобретали у American Peptide (Sunnyvale, California). MUC1 растворяли в 1 мг/мл в 1-кратном буфере для печати пептидов 1 (Cat ID: PEP, ArrayIt). Пептид MUC16 в концентрации 0,2 мг/мл, моноклональные антитела против мышиного антитела к MUC1 С595 [Cat ID: NCRC48] и кроличьи антитела к MUC16 [Cat ID: EPSISR23] приобретали у Abeam (Cambridge, MA). Следующие вторичные антитела также приобретали в Abeam: козье антитело к мышиному IgG Су3 (Cat ID: ab97035), козье антитело к кроличьему IgG Су3 (Cat ID: ab6939), козье антитело к мышиному IgG Су5 (Cat ID: ab97037), козье антитело к кроличьему IgG Су5 (Cat ID: ab6564).
Пептиды печатали на микрочипы в ArrayIt (Sunnyvale, California). Пептид MUC1 печатали в конечной концентрации 0,5 мг/мл и MUC16 в концентрации 0,1 мг/мл в 1-кратном буфере для печати пептидов 2 (Cat ID: PEP, ArrayIt) на подложке для микрочипов SuperEpoxy 2 на NanoPrint Microarrayer с использованием SMP3 Microarray Printing Pin. Напечатанные микрочипы сушили в течение ночи.
Перед использованием слайд блокировали в течение 1,5 часов в блокирующем буфере BlockIt Plus (Cat ID: BKTP, ArrayIt) при комнатной температуре и осторожном перемешивании при 350 об/мин, с последующим промыванием 3 раза по 1 минуте каждый раз с 1-кратным PB S в квадратной чашке Петри, объем 30 мл при 350 об/мин на 2 мм орбите. Стекло сушили в течение 10 секунд в центрифуге для микрочипов ArrayIt.1,
Первичные антитела к MUC1 и к MUC 16 разводили в 250 раз в 1-кратном PBS буфере (137 мМ NaCl; 2,7 мМ KCl, 10 мМ Na2HPO4, 2 мМ KH2PO4, рН 7,4). Вторичные антитела разводили в 10000 раз в 1-кратном PBS. Меченые Су3 или Су5 антитела смешивали в 2 пулах в 1-кратном PBS: пул #1: антимышиный Су3 и антикроличий Су5; пул #2: антикроличий Су5 и антикроличий Су3.
5 мл смеси пулов первичных зондов добавляли к слайду и инкубировали в течение 1 часа при комнатной температуре в контейнере. Слайд затем промывали 1-кратным PBS 3 раза, по 5 минут каждый раз с легким перемешиванием при 450 об/мин.
Пул вторичных антител #1 добавляли к слайду и инкубировали в течение 1 часа при комнатной температуре. Слайд затем промывали 1-кратным PBS 3 раза, по 5 минут каждый раз с легким перемешиванием при 450 об/мин. Слайд удаляли из контейнера и высушивали в центрифуге для микрочипов. Слайд сканировали в Axon 4200A с настройками на РМТ250 для обоих лазеров 532 и 635.
Слайд инкубировали со стороной с пятнами вверх в квадратной чашке Петри, содержащей 5 мл отделяющего буфера (Cat ID: 21028, Fisher Scientific, Rockford, IL) при 300 об/мин в течение 1 часа. Слайд затем промывали дистиллированной водой 3 раза в течение 5 минут каждый раз. Слайд сушили в центрифуге для микрочипов, а затем подготавливали к следующему циклу связывания антител и стрипированию. Слайд сканировали после стрипирования, чтобы убедиться, что стрипирование было эффективным.
На фиг. 19 показаны результаты сканирования: два олигонуклеотида-мишени (MUC1 и MUC16) идентифицировали с помощью зондирования связывания и стрипирования в течение 4 циклов. Цветовую последовательность каждого олигонуклеотида-мишени правильно идентифицировали.
Пример 7: Использование пептидов для демонстрации одномолекулярмого подсчета
Приготовление пептидов проводили с использованием той же техники, что и в примере 4. Пептид MUC1 (20 нг/мл) и MUC 16 (4 нг/мл) разводили в 1-кратном буфере для печати пептидов 2 ArrayIt (ArrayIt, Sunnyvale, California), а затем инкубировали на кремниевом слайде в контейнере при комнатной температуре в течение ночи. Слайд затем промывали водой молекулярного класса в течение 5 минут, 3 раза, с последующей инкубацией в ArrayIt BlockIt плюс блокирующий раствор в течение 1 часа при комнатной температуре при осторожном перемешивании при 300 об/мин. Чип затем промывали водой молекулярного класса в течение 5 минут, 3 раза. Слайд сушили путем центрифугирования в высокоскоростной центрифуге для микрочипов. Слайд затем встраивали в биочип, следуя тем же процедурам, которые описаны выше.
Первичные антитела разбавляют в 250 раз в 1-кратном PBS. Вторичные антитела разбавляют в 10000 раз в 1-кратном PBS. Смесь первичных антител против MUC1 и MUC16 доставляли в биочип и инкубировали в течение 60 минут при комнатной температуре. Чип промывали 8 раз с 1-кратным PBS. Смесь вторичных антител (либо пула #1, содержащего антитела к мышиному Су3 и антитела к кроличьему Су5, либо пула #2, содержащего антитела к кроличьему Су5 и антитела к кроличьему Су3) доставляли в биочип и инкубировали в течение 60 минут при комнатной температуре. Чип затем промывали 8 раз 1-кратным PBS. 15% глицерин в 1-кратном SSPE добавляли к чипу перед визуализацией.
На фиг. 20 показано изображение отдельных молекул-пептидов, таких, что конъюгированные антитела (CY5 и СУ3) связывались с выделенными пептидами, которые, в свою очередь, были ковалентно связаны с поверхностью чипа. Несколько флуоресцентных молекул могут быть связаны с данным антителом, что создает усиление интенсивности каждой наблюдаемой молекулы. Эти молекулы измеряли как что-то более яркое, чем измерения одной молекулы ДНК, где одна из флуоресцентных молекул конъюгировала с каждым зондом ДНК. Проводили всего шесть циклов из двух белков в режиме одного молекулы. Молекулы были связаны и удалены с высоким выходом. Подобные техники могут быть использованы для расширения системы до многих других белков и ДНК/РНК-мишеней.
После визуализации биочип промывали водой молекулярной класса, а затем стрипировали в буфере для стрипирования (Cat ID: 21028, Fisher Scientific, Rockford, IL) в течение 1 часа с последующим 8-кратным промыванием с 1-кратным PBS. 15% глицерин в 1-кратном SSPE добавляли к биочипу перед визуализацией. После цикла 1, который включает в себя пул зондов гибридизации #1, визуализацию, стрипирование, визуализацию, цикл 2 начинался с гибридизации пула зондов #2.
Пример 8: Количественное определение протеома человеческой плазмы
Модель системы создавали для демонстрации возможности измерения концентрации ~ 10000 белков в протеоме человеческом плазмы по 12 логарифмам динамического диапазона с использованием идентификации одиночных молекул с кодированием с коррекцией ошибок Рида-Соломона. По этой модели белки в протеоме плазме разделяли на три области концентраций, как показано на фиг. 12В, называемые как области с низкой, средней и высокой концентрацией. Теоретически, общий диапазон концентраций белка в протеоме плазмы человека составляет более 10 логарифмов динамического диапазона, но концентрация каждого белка не изменяется более чем на несколько логарифмов. На фиг. 12В изображены пересекающиеся области концентраций. Для каждой из областей зонды выбирали для белков, которые, как ожидалось, упадут в пределах этой конкретной области, но не превышают максимальную концентрацию, допустимую для этой области. Большее перекрытие может быть достигнуто путем добавления другого диапазона концентраций, как показано на фиг. 12С, с компромиссом в том, что используется большая площадь микросхемы подложки.
Использованные в модели данные получены из базы данных UniProt (uniprot.org, файл FASTA для организма 9606), "Toward a Human Blood Serum Proteome," Joshua Adkins et al., "The Human Plasma Proteome, " N. Leigh Anderson et al. и "A High-Confidence Human Plasma Proteome Reference Set with Estimated Concentrations in PeptideAtlas, " T. Farrah et al. Поскольку не все белки в базе данных UniProt связаны с опубликованной концентрацией, случайные концентрации назначали без изменения известных высоких концентраций белка в изобилии или общую концентрацию. На фиг. 21 показан вероятностный график предполагаемых концентраций. Концентрации от 105 до 1011 мкг/мл используют опубликованные значения. Использовали все опубликованные значения, найденные в более низком диапазоне. Остальные концентрации белка оценивали с использованием приближения с логарифмически нормальным распределением, с оцененным гауссовым распределением по пространству, распределенному по логарифмически нормальному закону, 6 порядков от 10-1 пг/мл до 104 пг/мл.
На фиг. 22 перечислены конкретные расчетные значения для каждой из используемых областей относительного содержания. Для каждой области относительного содержания предполагалась плотность того же белка-мишени (dTP) 1,5 белка-мишени на мкм2. Тем не менее, в области низкого относительного содержания, количество белков области высокого относительного содержания на количество белков-мишеней (rHT) составляло 25000 к 1 и 250 к 1 в области среднего относительного содержания. Количество белков высокого относительного содержания на пиксель (rHP) колебалось от 1000 до 0,04. Количество пикселей на белок-мишень было постоянным для каждой из трех областей.
Для модели предполагается четырехцветная система визуализации, дающая 2 бита информации за цикл. На фиг. 23 показано, что можно было бы ожидать, что смоделированное изображение будет выглядеть подобно для любого из цветов через любой из диапазонов относительного содержания, за исключением альбумина в диапазоне высокого относительного содержания, когда в любой момент времени половина молекул-мишеней, как ожидается, будет того же цвета. Поле представляет собой область формирования изображения камеры для данного воздействия, в данном случае предполагается камера 2,000 на 2,000 пикселей с 40-кратным увеличением, дающая 163 нм пикселей. Необходимы всего 2500 полей (nF) для области низкого относительного содержания, но только 250 поля необходимы для каждой области высокого и среднего относительного содержания.
С оптимизированной системной моделью было установлено, что область с самым низким относительного содержания будет детально исследовать 9575 белков из 9719, или 98,5% протеома. На другом полюсе, область высокого относительного содержания детально исследует только максимум 2,9% протеома. Это потому, что существует только небольшой процент белков в протеоме плазме, который составляет область высокого относительного содержания. Измеряемые диапазоны концентрации варьируют в зависимости от области концентрации. Область концентрации низкого относительного содержания измеряет концентрации от 30 фг/мл до 300 нг/мл. Область концентрации среднего относительного содержания измеряет концентрации от 82 пг/мл до 85 мкг/мл. Область концентрации высокого относительного содержания измеряет концентрации от 20 нг/мл до 100 мг/мл. Общая площадь чипа, необходимая для этого измерения, составляет 320 мм2, или чип с размерами 18 мм × 18 мм.
Проводили анализ с целью определения эффективности коррекции ошибок Рида-Соломона в измерении протеома плазмы через 12 логарифмов динамического диапазона. Существует внутренняя частота ошибок для каждого цикла измерений для каждой рассчитанной молекулы. Поскольку каждая молекула распространена по стеклу (в частности, значительно для молекул низкого относительного содержания), будут и другие расположенные рядом молекулы, которые не должны перекрестно реагировать с зондами, но все еще реагируют. Надежная система позволит этому произойти и будет в состоянии исправить эти ошибки и дать правильную идентификацию молекулы. Скорость, с которой происходит неправильное связывание на одну молекулу за цикл, представляет собой частоту грубых ошибок. Частота системных ошибок представляет собой частоту ошибок идентификации на молекул после выполненной коррекции.
На фиг. 24 показана диаграмма ожидаемой частоты системных ошибок против частоты грубых ошибок для случаев варьирующих частот грубых ошибок и варьирующих количеств циклов визуализации. Данные для диаграммы получали с использованием моделирования способом Монте-Карло, в котором моделировалось большое количество системных конфигураций. Чтобы определить 16384 белков, необходимо в общей сложности 7 циклов данных для четырехцветной системы (47=16384). Максимальная допустимая частота ошибок рассчитывается путем деления допустимого количества системных ошибок на количество идентифицируемых молекул. В этом случае, для в среднем одной ошибки на белок допустимое количество ошибок составляет 16384. Количество идентифицируемых молекул составляет 4,0×108 (2500 полей × 1,6 × 105 молекул на поле) с рассчитанной допустимой частотой ошибок 4,1×10-5.
Кодирование Рида-Соломона требуется циклы четности для улучшения частоты грубых ошибок. Предполагая, что система Рида-Соломона над полем Галуа 4 (mm=4), каждый символ (или слово) представляет собой 4-битовый символ, который может быть представлен двумя 2-битовыми символами (например, 2 цикла 4-цветной системы, которая получает 2 бита за цикл). Для системы Рида-Соломона, длина символа (или кодового слова) составляет nn=2mm-1, или 15 4-битовых символов или эквивалентно 30 2-битовых символов. Это означает, что до 30 циклов может быть обработано с помощью четырехцветной системы флюидики/визуализации. Количество ошибок, которые могут быть исправлены, составляет 3, 4 или 5 на мишень, которая соответствует tt={3, 4 или 5} символов четности. Требуется четыре цикла визуализации за один цикл четности. Это дает в общей сложности 7 циклов данных для ID и 12, 16 или 20 циклов обработки изображений для исправления ошибок. Это означает, что общее число циклов, необходимых для идентификации 16384 одновременных белков, составляет 19, 23 и 27 циклов для 3, 4 и 5 допустимых ошибок на молекулу. Как ранее рассчитывалось, максимальная частота системных ошибок 4,1×10-5 позволяет одну ошибку на белок. Если разрешено больше ошибок в белке, то максимальная частота системных ошибок может упасть пропорционально.
На фиг. 24 показаны контуры частоты грубых ошибок по отношению к частоте системных ошибок. За 19 циклов визуализации максимальная допустимая частота грубых ошибок составляет 3%, для 23 циклов максимальная допустимая частота грубых ошибок составляет 6% и для 27 циклов максимальная допустимая частота грубых ошибок составляет 13%. Ожидается, что частот грубых ошибок будет меньше; чем 5%, хотя для всех, кроме редких белков частота грубых ошибок до 20%, по всей видимости, будет в пределах допустимого диапазона этой технологии.
Поскольку максимальное количество допустимых циклов составляет 30 циклов, может быть включено больше циклов данных. В частности, если были включены еще три цикла данных, количество идентифицируемых мишеней увеличится на 4^3, или 64 раза, приводя к максимально возможному количеству идентифицируемых мишеней 1048576, количеству выше, чем позволят реалистичные концентрации зонда. Тем не менее, это показывает, что способ представляет собой масштабируемый для сколь угодно большого числа молекул, ограниченных только биологией.
Сущность настоящего изобретения
Вышеприведенное описание вариантов осуществления настоящего изобретения было представлено с целью иллюстрации; оно не предназначено быть исчерпывающим или ограничивать настоящее изобретение точными раскрытыми формами. Специалисты в настоящей области техники могут оценить, что возможны многие модификации и вариации в свете приведенного выше описания.
Некоторые части настоящего описания описывают варианты осуществления настоящего изобретения в терминах алгоритмов и символических представлений операций над информацией. Эти алгоритмические описания и представления обычно используются специалистами в области обработки данных, чтобы эффективно передать сущность их работы другим специалистам в настоящей области техники. Эти операции, описанные функционально, вычислительно или логически, следует понимать как реализованные с помощью компьютерных программ или эквивалентных электрических цепей, микрокода или тому подобного. Кроме того, также оказывается порой удобным обратиться к этим соглашениям операций как модулям, без потери общности. Описанные операции и связанные с ними модули могут быть воплощены в программном обеспечении, встроенном программном обеспечении, аппаратных средствах или любых их сочетаниях.
Любая из описанных в настоящем документе стадий, операций или процессов может быть выполнена или реализована с одним или несколькими аппаратными или программными модулями, отдельно или в комбинации с другими устройствами. Согласно одному варианту осуществления программный модуль реализован с помощью продукта компьютерной программы, содержащего машиночитаемый носитель, содержащий компьютерный программный код, который может быть исполнен процессором компьютера для выполнения любого или всех описанных стадий, операций или процессов.
Варианты осуществления настоящего изобретения могут также относиться к устройству для выполнения операций в настоящем документе. Это устройство может быть специально построено для требуемых целей, и/или оно может содержать универсальное вычислительное устройство, избирательно активируемое или переконфигурируемое с помощью компьютерной программы, хранящейся в компьютере. Такая компьютерная программа может быть сохранена на энергонезависимом, значимом машиночитаемом носителе, или любом типе носителей, пригодных для хранения электронных инструкций, которые могут быть соединены с системной шиной компьютера. Кроме того, любые вычислительные системы, упомянутые в описании, могут включать в себя один процессор или могут представлять собой архитектуры, использующие несколько конструкций процессора для увеличения вычислительной способности.
Варианты осуществления настоящего изобретения могут также относиться к продукту, который получают посредством описанного в настоящем документе вычислительного процесса. Такой продукт может содержать информацию, полученную в результате вычислительного процесса, причем информация хранится на энергонезависимом, значимом машиночитаемом носителе и может включать в себя любой вариант осуществления компьютерного программного продукта или другие комбинации данных, описанные в настоящем документе.
Наконец, используемый в спецификации язык был выбран главным для удобства чтения и учебных целей, и он не был выбран, чтобы разграничить или ограничить предмет настоящего изобретения. Поэтому предполагается, что объем настоящего изобретения ограничивается не этим подробным описанием, а скорее формулой изобретения, которая вытекает из заявки. Соответственно, раскрытие вариантов осуществления настоящего изобретения предназначено для иллюстрации, но не ограничения объема настоящего изобретения, который изложен в следующей формуле изобретения.
Все ссылки, выданные патенты и патентные заявки, цитируемые в настоящем описании, полностью включены в настоящий документ посредством ссылки для всех целей.
| название | год | авторы | номер документа |
|---|---|---|---|
| МУЛЬТИПЛЕКСНЫЕ АНАЛИЗЫ НА ОСНОВЕ АПТАМЕРОВ | 2013 |
|
RU2666989C2 |
| УСОВЕРШЕНСТВОВАННЫЕ ПРОТЕОМНЫЕ МУЛЬТИПЛЕКСНЫЕ АНАЛИЗЫ | 2019 |
|
RU2792385C2 |
| СПОСОБ И АППАРАТ ДЛЯ ПРОЦЕССА ВОССТАНОВЛЕНИЯ АНТИГЕНА | 2010 |
|
RU2538022C2 |
| АНАЛИЗ СВЯЗЫВАНИЯ С ЛИГАНДОМ ДЛЯ ОБНАРУЖЕНИЯ ГИББЕРЕЛЛИНОВ | 2017 |
|
RU2748481C2 |
| ПРОГНОЗИРОВАНИЕ РИСКА СЕРДЕЧНО-СОСУДИСТОГО СОБЫТИЯ И ЕГО ПРИМЕНЕНИЕ | 2012 |
|
RU2651708C2 |
| Способ направленного истощения олигонуклеотидных библиотек для снижения неспецифической адсорбции при твердофазной селекции аптамеров на основе нуклеиновых кислот | 2015 |
|
RU2618872C1 |
| СВЯЗЫВАЮЩИЕ КОМПЛЕМЕНТ АПТАМЕРЫ И СРЕДСТВА ПРОТИВ С5, ПРИГОДНЫЕ ДЛЯ ЛЕЧЕНИЯ ГЛАЗНЫХ НАРУШЕНИЙ | 2007 |
|
RU2477137C2 |
| СПОСОБ ОБНАРУЖЕНИЯ ПРОСТРАНСТВЕННОЙ БЛИЗОСТИ ПЕРВОГО И ВТОРОГО ЭПИТОПОВ | 2015 |
|
RU2717956C2 |
| НАБОР ИЗ ДВУХ ПРАЙМЕРОВ ДЛЯ АМПЛИФИКАЦИИ НУКЛЕИНОВОЙ КИСЛОТЫ ВИРУСА ГЕПАТИТА А, СПОСОБ ОБНАРУЖЕНИЯ ВИРУСА ГЕПАТИТА А С ЕГО ИСПОЛЬЗОВАНИЕМ (ВАРИАНТЫ) И НАБОР ДЛЯ ОБНАРУЖЕНИЯ ВИРУСА ГЕПАТИТА А | 2003 |
|
RU2406762C2 |
| ФОТОАКТИВИРУЕМОЕ ХИМИЧЕСКОЕ ОБЕСЦВЕЧИВАНИЕ КРАСИТЕЛЕЙ | 2012 |
|
RU2623880C2 |









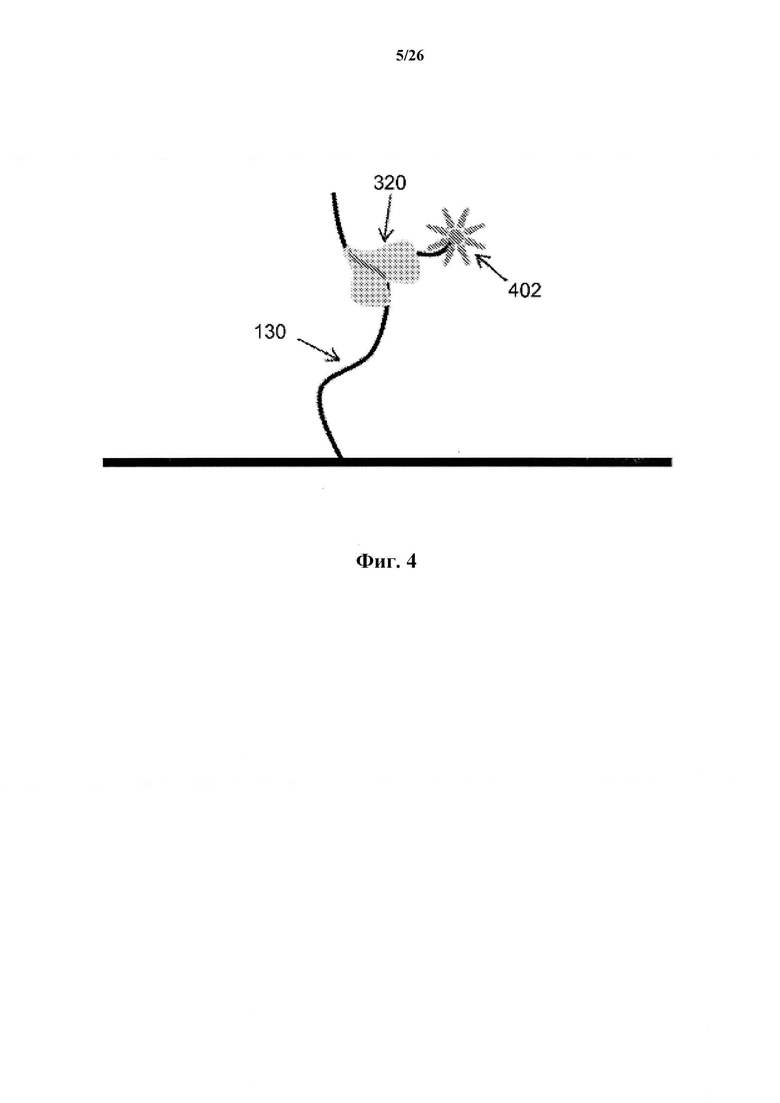


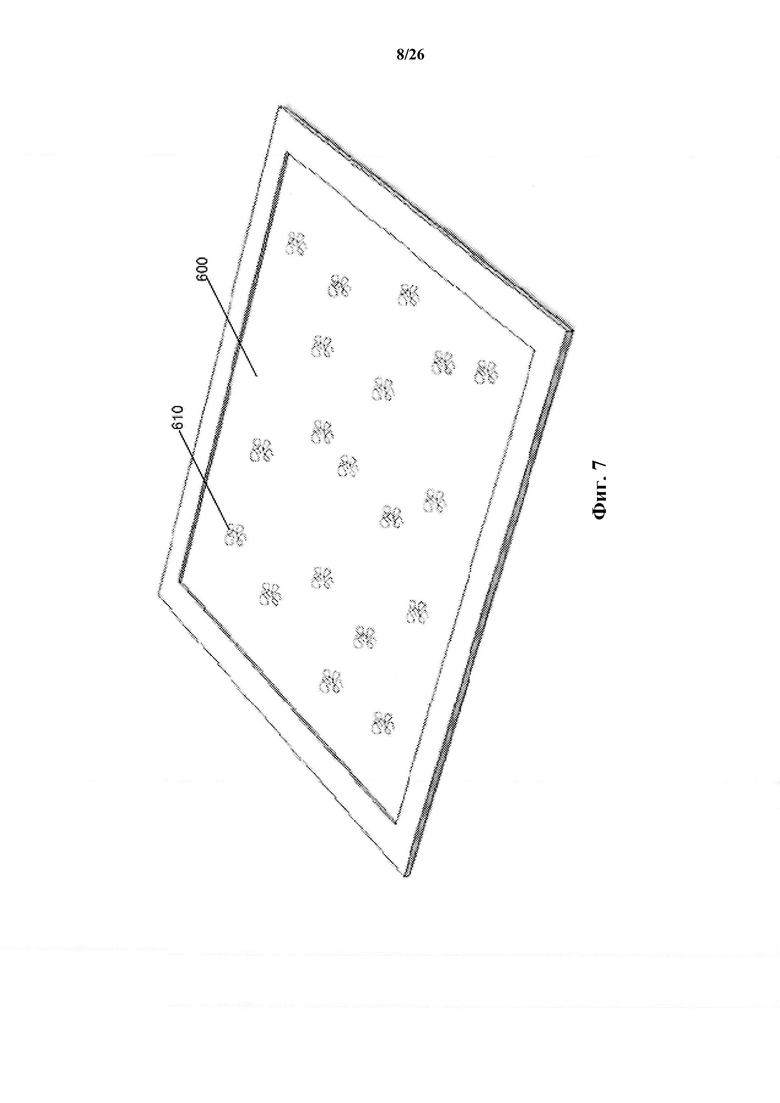
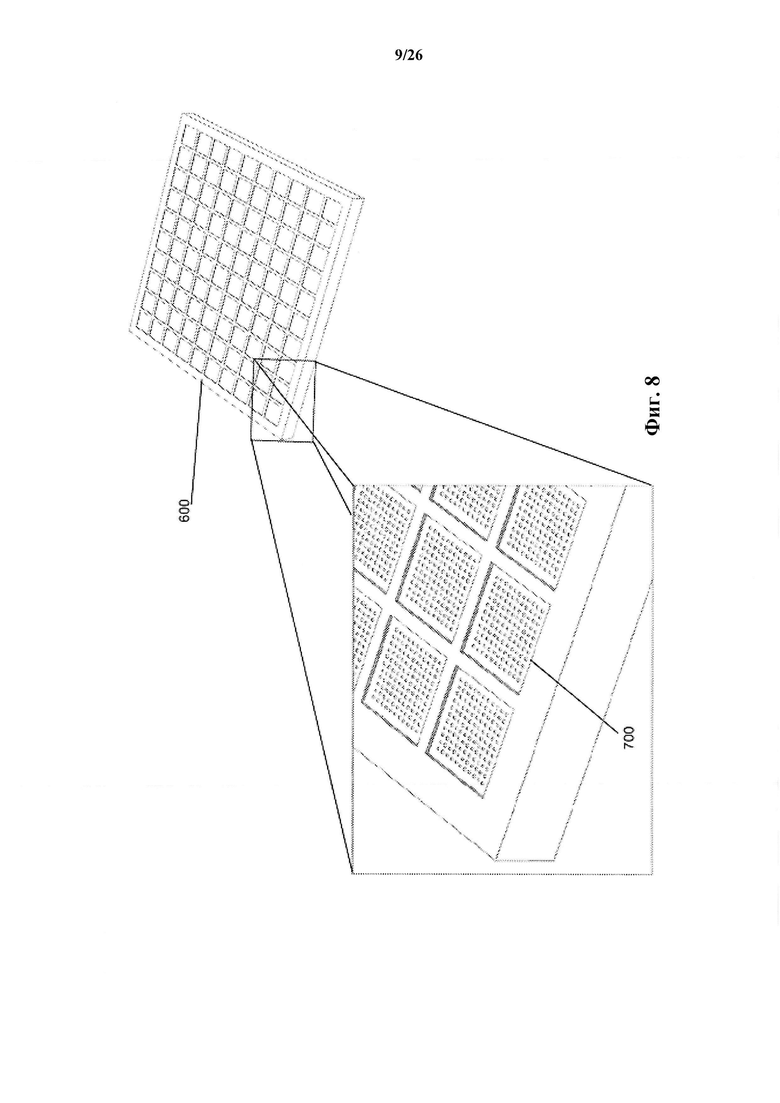











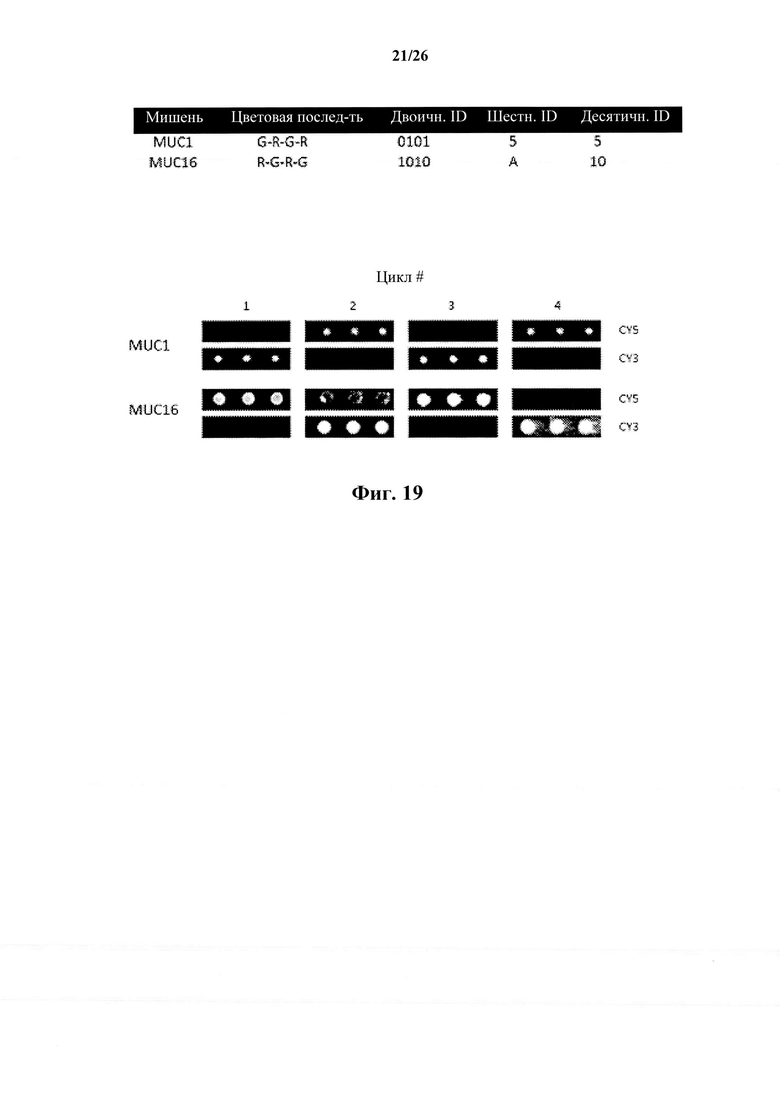





Изобретение относится к биотехнологии. Описан способ обнаружения множества одномолекулярных анализируемых веществ. Получают множество упорядоченных наборов реагентов-зондов, где каждый из указанных упорядоченных наборов реагентов-зондов содержит один или несколько зондов, направленных на определенное подмножество N различных одномолекулярных анализируемых веществ-мишеней. Каждое одномолекулярное анализируемое вещество-мишень представляет собой компонент физиологического образца. Каждое различное одномолекулярное анализируемое вещество-мишень N различных одномолекулярных анализируемых веществ-мишеней иммобилизуют на твердой подложке в положении, которое пространственно разделено от любого другого различного одномолекулярного анализируемого вещества-мишени N различных одномолекулярных анализируемых веществ-мишеней. Каждый из указанных зондов содержит обнаруживаемую метку так, что обнаруживаемый сигнал образуется благодаря связыванию одного зонда с одним различным одномолекулярным анализируемым веществом-мишенью. Выполняют по меньшей мере М циклов связывания зондов и обнаружения сигналов. Каждый цикл содержит один или несколько проходов, причем проход включает использование по меньшей мере одного из указанных упорядоченных наборов реагентов-зондов. Обнаруживают из по меньшей мере М циклов наличие или отсутствие множества сигналов от указанных пространственно разделенных положений указанной подложки и определяют из указанного множества сигналов по меньшей мере K битов информации за один цикл для одного или нескольких из указанных N различных одномолекулярных анализируемых веществ-мишеней. Указанные по меньшей мере K битов информации используют для определения L общих битов информации. Причем K×M=L битов информации и L>log2 (N). L битов информации используют для определения наличия или отсутствия одного или нескольких из указанных N различных одномолекулярных анализируемых веществ-мишеней. Также описан соответствующий набор для обнаружения множества одномолекулярных анализируемых веществ. 2 н. и 18 з.п. ф-лы, 24 ил., 19 табл., 8 пр.
1. Способ обнаружения множества одномолекулярных анализируемых веществ, включающий:
получение множества упорядоченных наборов реагентов-зондов, каждый из указанных упорядоченных наборов реагентов-зондов содержит один или несколько зондов, направленных на определенное подмножество N различных одномолекулярных анализируемых веществ-мишеней, причем каждое одномолекулярное анализируемое вещество-мишень представляет собой компонент физиологического образца, причем каждое различное одномолекулярное анализируемое вещество-мишень N различных одномолекулярных анализируемых веществ-мишеней иммобилизуют на твердой подложке в положении, которое пространственно отделено от любого другого различного одномолекулярного анализируемого вещества-мишени N различных одномолекулярных анализируемых веществ-мишеней, и причем каждый из указанных зондов содержит обнаруживаемую метку так, что обнаруживаемый сигнал образуется благодаря связыванию одного зонда с одним различным одномолекулярным анализируемым веществом-мишенью;
выполнение по меньшей мере М циклов связывания зондов и обнаружения сигналов, каждый цикл содержит один или несколько проходов, причем проход включает использование по меньшей мере одного из указанных упорядоченных наборов реагентов-зондов;
обнаружение из по меньшей мере М циклов наличия или отсутствия множества сигналов от указанных пространственно разделенных положений указанной подложки и
определение из указанного множества сигналов по меньшей мере K битов информации за один цикл для одного или нескольких из указанных N различных одномолекулярных анализируемых веществ-мишеней, причем указанные по меньшей мере K битов информации используют для определения L общих битов информации, причем K×M=L битов информации и L>log2 (N) и причем указанные L битов информации используют для определения наличия или отсутствия одного или нескольких из указанных N различных одномолекулярных анализируемых веществ-мишеней.
2. Способ по п. 1, при котором L>log2 (N) и при котором L содержит биты информации для идентификации мишеней.
3. Способ по п. 1, при котором L>log2 (N) и при котором L содержит биты информации, содержащие ключ для декодирования порядка указанного множества упорядоченных наборов реагентов-зондов.
4. Способ по п. 1, дополнительно включающий стадию оцифровки указанного множества сигналов для расширения динамического диапазона обнаружения указанного множества сигналов.
5. Способ по п. 1, при котором указанные по меньшей мере K битов информации содержат информацию о количестве проходов в цикле.
6. Способ по п. 1, при котором указанные по меньшей мере K битов информации содержат информацию об отсутствии сигнала для одного из указанных N различных одномолекулярных анализируемых веществ-мишеней.
7. Способ по п. 1, при котором указанная обнаруживаемая метка представляет собой флуоресцентную метку.
8. Способ по п. 1, при котором указанный зонд содержит антитело.
9. Способ по п. 1, при котором указанный зонд содержит аптамер.
10. Способ по п. 9, при котором указанный аптамер содержит гомополимерную область оснований.
11. Способ по п. 1, при котором указанное множество одномолекулярных анализируемых веществ содержит белок, пептидный аптамер или молекулу нуклеиновой кислоты.
12. Способ по п. 1, при котором указанное обнаружение из указанных по меньшей мере М циклов наличия или отсутствия множества сигналов включает оптическое обнаружение указанного множества сигналов.
13. Способ по п. 1, при котором указанное обнаружение из указанных по меньшей мере М циклов наличия или отсутствия множества сигналов включает электрическое обнаружение указанного множества сигналов.
14. Способ по п. 1, дополнительно включающий стадию определения из указанных L битов информации коррекции ошибок для указанного множества выходных сигналов.
15. Способ по п. 14, при котором указанная коррекция ошибок включает использование кода Рида-Соломона.
16. Способ по п. 1, при котором указанные N различных одномолекулярных анализируемых веществ-мишеней присутствуют в образце и при котором образец разделяют на множество аликвот, которые разбавляют до множества различных конечных разведений, каждую из указанного множества аликвот иммобилизуют на отдельной секции подложки.
17. Способ по п. 16, при котором концентрацию одного из N различных одномолекулярных анализируемых веществ-мишеней определяют путем подсчета встречаемости одномолекулярного анализируемого вещества-мишени в пределах одной из различных секций и корректировки количества в соответствии с разбавлением соответствующей аликвоты.
18. Набор для обнаружения множества одномолекулярных анализируемых веществ, содержащий:
множество упорядоченных наборов реагентов-зондов, каждый из указанных упорядоченных наборов реагентов-зондов содержит один или несколько зондов, направленных на определенное подмножество N различных одномолекулярных анализируемых веществ-мишеней, причем каждое одномолекулярное анализируемое вещество-мишень представляет собой компонент физиологического образца, причем каждое различное одномолекулярное анализируемое вещество-мишень иммобилизуют на твердой подложке в положении, которое пространственно отделено от любого другого N различного одномолекулярного анализируемого вещества-мишени N различных одномолекулярных анализируемых веществ-мишеней, и причем каждый из указанных зондов содержит обнаруживаемую метку так, что обнаруживаемый сигнал образуется благодаря связыванию одного зонда с одним различным одномолекулярным анализируемым веществом-мишенью;
инструкции для обнаружения указанных N различных одномолекулярных анализируемых веществ на основе множества обнаруживаемых сигналов, указанные инструкции содержат:
инструкции для выполнения по меньшей мере М циклов связывания зондов и обнаружения сигналов, каждый цикл содержит один или несколько проходов, причем проход включает использование по меньшей мере одного из указанных упорядоченных наборов реагентов-зондов;
инструкции для обнаружения из указанных по меньшей мере М циклов наличия или отсутствия множества сигналов от указанных пространственно разделенных положений указанной подложки и
инструкции для определения из указанного множества сигналов по меньшей мере K битов информации за один цикл для одного или нескольких из указанных N различных одномолекулярных анализируемых веществ-мишеней, причем указанные по меньшей мере K битов информации используются для определения L общих битов информации, причем K×М=L битов информации и L>log2 (N) и причем указанные L битов информации используются для определения наличия или отсутствия одного или нескольких из указанных N различных одномолекулярных анализируемых веществ-мишеней.
19. Набор по п. 18, в котором указанный один или несколько зондов содержит антитело.
20. Набор по п. 18, в котором указанная метка представляет собой флуоресцентную метку.
| GUNDERSON et al., "Decoding Randomly Ordered DNA Arrays", Genome Res., vol.14, no 5, p.870-877, 2004 | |||
| СПОСОБ И КЛАПАН ДЛЯ НЕПОСРЕДСТВЕННОГО ПОДОГРЕВА ВОДЫ ПАРОМ ДО НАПЕРЕД ЗАДАННОЙ ТЕМПЕРАТУРЫ | 1926 |
|
SU4655A1 |

