ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Изобретение относится к области вычислительной техники и может быть применено для высокопроизводительных вычислений при решении трудоемких вариативных задач дискретной математики и цифровой обработки сигналов, которые отличаются многократным параллельным повторением последовательностей целочисленных операций, производимых с разделяемыми блоками данных, размером до нескольких килобайт.
УРОВЕНЬ ТЕХНИКИ
Известен высокопроизводительный криптографический процессор Cryptoraptor (Gokhan Sayilar, Derek Chiou. Cryptoraptor: High Throughput Reconfigurable Cryptographic Processor ISBN: 978-1-4799-6277-8), который содержит матрицу из 80 процессорных элементов, автомат управления, который имеет счетчик состояний и управляющую память, а также регистровый файл, состоящий из 256 32-разрядных слов. При этом матрица процессорных элементов состоит из 20 ступеней конвейера, каждая ступень которого содержит 4 параллельно работающих процессорных элемента. Также матрица процессорных элементов содержит 19 полных коммутаторов, которые имеют память конфигураций, для осуществления связей между выходами ступени i и входами ступени i+1. Процессорный элемент содержит целочисленные функциональные узлы, память управляющих сигналов, определяющую работу функциональных узлов, а также 3 блока локальной памяти по 1024 байт и 1 блок локальной памяти размером 4096 байт. Доступ к регистровому файлу с 80 портами считывания и 8 портами записи разделяется между всеми процессорными элементами.
Перед началом работы, с помощью автомата управления, в память управляющих сигналов процессорных элементов загружаются данные, задающие работу функциональных узлов внутри процессорных элементов, а также загружаются данные в память конфигураций полных коммутаторов, определяющие связи между процессорными элементами соседних слоев. В блоки локальной памяти загружаются табличные данные. В процессе вычислений автомат управления производит переконфигурацию процессорных элементов и связей между ними, если этого требует реализуемый алгоритм. Регистровый файл используется для хранения промежуточных и результирующих данных.
Недостатком криптографического процессора Cryptoraptor является малое число параллельных потоков вычислений (до 4 потоков). Кроме того, автомат управления процессора Cryptoraptor не поддерживает многократное повторение последовательностей операций. Процессор Cryptoraptor также отличается избыточностью аппаратных средств, к которым относятся блоки локальной памяти большого объема, соединенные с каждым процессорным элементом и общий регистровый файл, к которому подключены все процессорные элементы.
Наиболее близким устройством того же назначения к заявленному изобретению по совокупности признаков является, принятый за прототип, многоядерный вычислитель Kalray МРРА (Bostan). (Benoit Dupont de Dinechin. Kalray MPPA®: Massively parallel processor array: Revisiting DSP acceleration with the Kalray MPPA Manycore processor ISBN: 978-1-4673-8885-6). Вычислитель сделан по техпроцессу TSMC CMOS 28HP, имеет тактовую частоту до 800 МГц и суммарно содержит 288 процессорных ядра, организованных в виде матрицы из 16 вычислительных кластеров по 16 VLIW ядер плюс одно системное ядро в каждом, а также двух IO кластеров, в каждом из которых имеются два 4-ядерных IO сопроцессора, 8 PCIe Gen3, 4 Ethernet 10G и один DDR3 контроллер. Вычислительный кластер имеет в своем составе 16 VLIW ядер соединенных по SMP схеме, 2 МБ разделяемой памяти с общей пропускной способностью 77 Gb/s, два сетевых контроллера (Network-on-Chip) - один с большой пропускной способностью, другой с малой задержкой (для коротких сообщений), средства отладки (DSU unit) и одно вспомогательное системное ядро. Каждое VLIW ядро содержит регистровую память - 10 портовую на чтение и 5 портовую на запись, содержащую 64 32-битных ячейки с возможностью объединения в 64-битные пары, два целочисленных арифметико-логических устройства, один умножитель объединенный с вычислителем плавающей точки, устройство чтения/записи памяти, устройство ветвления, а также различные шины и коммутаторы. В отличие от вычислителя предыдущего поколения (Andey), в модели Bostan присутствуют 128 встроенных криптографических ускорителя, что позволяет значительно повысить быстродействие некоторого узкого класса алгоритмов.
Недостатком вычислителя Kalray MPPA является избыточность вычислительных ресурсов при решении вариативных задач дискретной математики, по причине того, что вычислительные устройства Kalray MPPA ориентированы на выполнение очень широкого спектра задач, в том числе вычислений с плавающей точкой, поддержку операционных систем и т.д. Также недостатком данного ускорителя является задержка при доступе к разделяемой памяти, относительно невысокая тактовая частота и наличие специализированных не конфигурируемых ускорителей, бесполезных на задачах отличных от криптографических, высокая сложность и избыточность организации регистровой памяти и доступа к ней. Также, вычислительное VLIW ядро является полициклическим, когда результаты некоторых исполнительных устройств готовы не строго в одинаковый момент времени - это сильно усложняет программирование, снижает производительность, и вынуждает использовать специальные средства для решения данной проблемы.
ЗАДАЧА ИЗОБРЕТЕНИЯ
Задачей, на решение которой направлено предлагаемое изобретение, заключается в создании вычислительного модуля, процессорного элемента и способа обработки данных, предназначенных для ускорения расчетов при решении трудоемких вариативных задач дискретной математики и цифровой обработки сигналов, которые отличаются многократным параллельным повторением последовательностей целочисленных операций, производимых с разделяемыми блоками данных, размером до нескольких килобайт. Данные задачи эффективно реализуются с помощью большого числа многостадийных вычислительных потоков, функционирующих по одному алгоритму, с разделяемыми блоками данных. Техническим результатом предлагаемого изобретения является повышение производительности и энергетической эффективности многостадийных многопоточных вычислений в вариативных задачах дискретной математики и цифровой обработки сигналов за счет параллельной работы высокопроизводительных процессорных элементов по общим программам с разделяемыми блоками данных.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
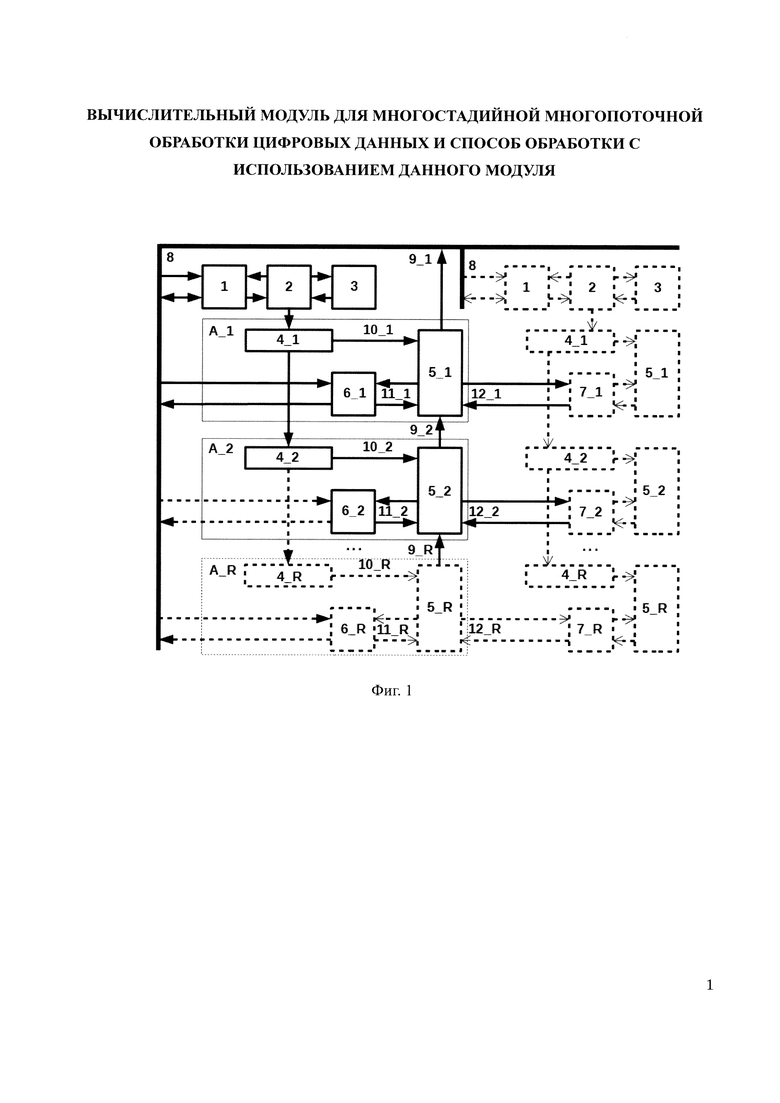
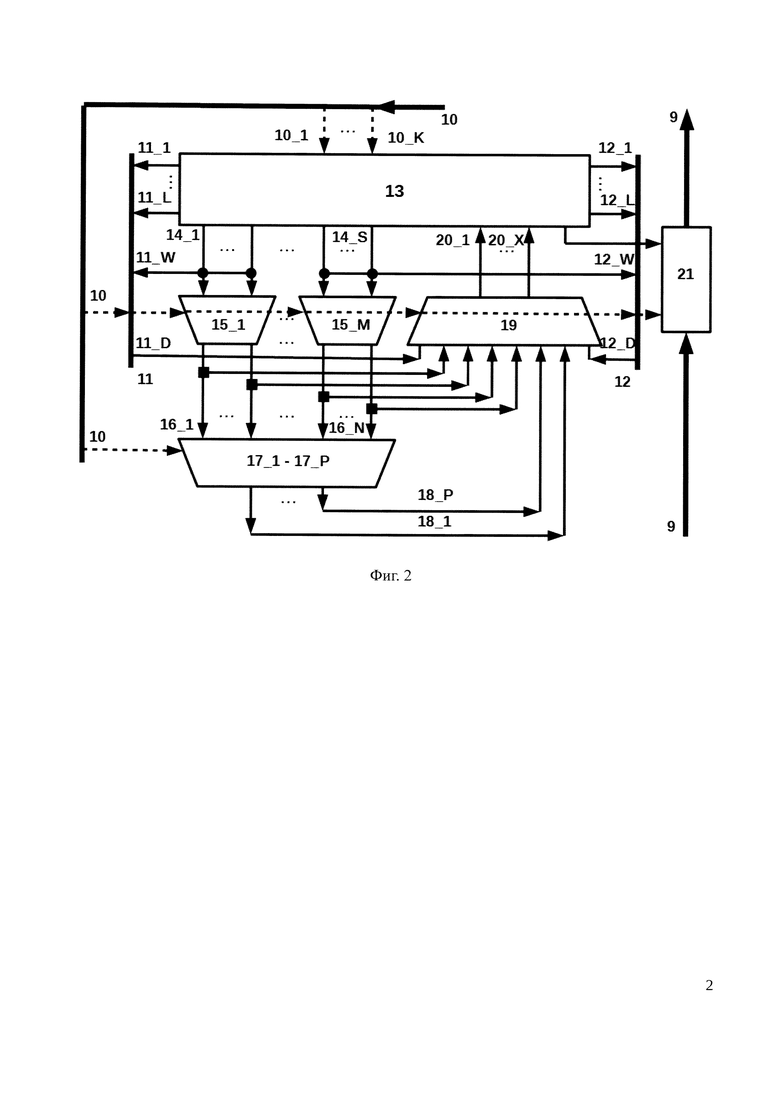
Указанный технический результат достигается тем, что в вычислительный модуль для многопоточной обработки цифровых данных содержащий процессорные элементы 5, дополнительно введены двухпортовая память команд 1, устройство управления потоком команд 2, стек циклов и подпрограмм 3, двунаправленная шина обмена с внешним устройством 8, группа из R вычислительных блоков А_1, А_2…A_R, каждый из которых содержит регистр команды 4, шину управления 10, процессорный элемент 5, разделяемую память 6 и 7, канал доступа к разделяемой памяти 11 и 12, шину коротких сообщений 9, кроме того в каждый процессорный элемент 5 введены регистровая память 13, имеющая S портов для чтения операндов и L портов для формирования адресов, группа из М многовходовых арифметико-логических устройств 15 первого уровня, группа из Р многовходовых арифметико-логических устройств 17 второго уровня, селектор промежуточных результатов из арифметико-логических устройств и данных из памяти 19, группа из X портов записи в регистровый файл 20, где устройство управления потоком команд 2 подключено ко второму порту памяти команд 1 и содержит регистр адреса текущей операции, который, в зависимости от ее типа, может инкрементироваться в каждом такте, принимая значение адреса вызываемой подпрограммы, адреса следующей инструкции за вызывающей инструкцией программы при возврате из подпрограммы, и первой инструкции в цикле при его итерации, причем значения адресов возврата и первой инструкции цикла считываются из стека циклов и подпрограмм 3, который работает по кольцевому принципу и имеет конечную глубину, в то время как первый порт памяти команд 1 подключен к шине обмена с внешним устройством 8, в то время как устройство управления потоком команд 2 считывает из памяти команд 1 код новой инструкции и записывает его в регистр команды 4_1, откуда он в каждом такте поступает в следующий за ним регистр команд 4_2 и так далее по цепочке связанных вычислительных блоков А_1, А_2…A_R, в то время, как с каждого регистра команды 4 по шине управления 10 в вычислительный блок А поступает код текущей операции, где он декодируется в микроинструкции, задающие режимы работы арифметико-логических устройств 15 и 17, селектора результатов 19, регистровой памяти 13 и каналов доступа к разделяемой памяти 11 и 12, где сама разделяемая двухпортовая память 6 и 7 одним портом подключена к процессорному элементу 5 вычислительного модуля через каналы 11 и 12, а другим портом к соседнему процессорному элементу 5 соседнего вычислительного модуля через такие же каналы, таким образом, разделяя данные между соседними процессорными элементами 5 справа и слева, в которых арифметико-логические устройства 15 первого уровня считывают параллельно данные по портам 14_1,…14_S из регистровой памяти 13, формируя спектр результатов 16_1,…16_N, которые поступают на селектор результатов 19 и на арифметико-логические устройства 17_1,…17_Р второго уровня, которые формируют спектр результатов 18_1,…18_Р, которые также поступают на селектор результатов 19, с которого выборочные результаты согласно микрокоду с шины 10 поступают в регистровую память 13 через порты записи 20_1,…20_Х, также в каждом процессорном элементе 5_I контроллер коротких сообщений 21_I принимает данные из регистровой памяти 13_I и от аналогичного контроллера 21_I+1 процессорного элемента 5_I+1, а передает данные в контроллер 21_I-1 процессорного элемента 5_I-1, таким образом формируя единый поток сообщений от каждого процессорного элемента наружу, в то время как вычислительные модули, содержащие группу из R вычислительных блоков А_1, А_2…A_R, формируют вертикальный столбец, где вычислительные блоки связаны друг с другом по горизонтали через двухпортовую память 6 и 7 образуя строки, где разделяемая память 6 в крайнем слева столбце и разделяемая память 7 в крайнем справа столбце подключены к шине обмена 8.
Поставленная задача решается тем, что предлагаемый способ с использованием вычислительного модуля для многостадийной многопоточной обработки цифровых данных, содержит следующие этапы, на которых: внешнее устройство через шину обмена 8 записывает программу загрузчик в память команд 1 каждого вычислительного модуля, в разделяемую память 6_1, 6_2…6_R крайнего левого столбца и/или в разделяемую память 7_1, 7_2…7_R крайнего правого столбца записывается порция данных предназначенная для памяти внутренних столбцов, представляющая собой данные изолированной задачи выполняемой на столбце, либо данные для стадий задачи, выполняемой на группе столбцов, после чего программа загрузчик стартует, где устройство управления потоком команд 2 транслирует коды программы в регистр команды 4_1, откуда он поступает в следующий регистр команды 4_1, и так далее по столбцу до последнего регистра 4_R, тем самым во всем столбце на всех вычислительных блоках А_1, А_2…A_R, выполняется одинаковая программа, которая оперирует разными данными в блоках памяти 6_1, 6_2…6_R и 7_1, 7_2…7_R, которая переносит эти данные по направлению к внутренним столбцам на место их постоянного назначения, затем, по окончании работы загрузчика, в разделяемую память 6_1, 6_2...6_R и/или 7_1, 7_2... 7_R записывается новая порция данных, которая вместе с данными от предыдущей итерации переносится вновь запущенным загрузчиком вглубь к нужному столбцу до тех пор, пока вся память столбцов вычислительных модулей не будет заполнена верными данными, после чего в память команд 1 каждого вычислительного модуля загружается программа для изолированной задачи, либо группа программ для отдельных стадий задачи, выполняемой на группе столбцов, после чего все устройства управления потоком команд 2 на всех столбцах синхронно запускаются, что обеспечивает параллельную обработку задачи на группе вычислительных блоков А_1, А_2…A_R, либо параллельную обработку многостадийной задачи на группе вычислительных блоков А_1, А_2…A_R, сразу в нескольких столбцах, где в каждом из них выполняется отдельная стадия, причем, дянные являющиеся ее результатом, доступны через двухпортовую память программе следующей стадии в соседнем столбце, и так далее, до финальной стадии, данные которой появляются в разделяемой памяти крайнего столбца, откуда они через шину 8 могут быть прочитаны внешним устройством, в то время как по шине сообщений 9 внешнее устройство может получать от вычислительных блоков А_1, А_2…A_R каждого столбца короткие сообщения о промежуточных результатах вычислений.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг. 1 представлена схема предлагаемого вычислительного модуля.
На фиг. 2 представлена схема процессорного элемента.
На фиг. 1 и фиг. 2 приняты следующие обозначения:
1 - двухпортовая память команд,
2 - устройство управления потоком команд,
3 - стек циклов и подпрограмм,
А_1, А_2…A_R - группа из R вычислительных блоков,
4_1, 4_2…4_R - группа из R регистров команды,
51, 5_2…5_R - группа из R процессорных элементов,
61, 6_2…6_R - группа из R блоков разделяемой памяти данных процессорных элементов,
7_1, 7_2…7_R - группа из R блоков разделяемой памяти данных соседних процессорных элементов,
8 - двунаправленная шина обмена с внешним устройством,
9_1, 9_2…9_R - группа из R стадий шины коротких сообщений,
10_1, 10_2…10_R - группа из R шин управления,
11_1, 11_2…11_R - группа из R каналов доступа к разделяемой памяти данных процессорных элементов,
12_1, 12_2…12_R - группа из R каналов доступа к разделяемой памяти данных соседних процессорных элементов,
13 - регистровая память,
14_1, 14_2…14_S - группа из S портов доступа к регистровой памяти,
15_1, 15_2…15_М - группа из М арифметико-логических устройств первого уровня,
161, 16_2…16_N - группа из N результатов первого уровня,
17_1, 17_2…17_Р - группа из Р арифметико-логических устройств второго уровня,
18_1, 18_2…18_Р - группа из Р результатов второго уровня,
19 - селектор результатов,
20_1, 20_2…20_Х - группа из X портов записи в регистровую память,
21 - контроллер коротких сообщений
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Вариативные задачи дискретной математики и цифровой обработки сигналов, на решение которых ориентирован предлагаемый вычислительный модуль, отличаются многократным параллельным повторением последовательностей целочисленных операций и обладают высокой степенью распараллеливания по данным и алгоритмам их обработки, то есть позволяют разбить входные данные и алгоритмы на множество блоков и процессов, где вычисления внутри каждого процесса производятся одинаковым образом и параллельно над множеством блоков данных, в то время как сами процессы независимы друг от друга в плане алгоритмов, но могут обмениваться данными с соседними процессами через разделяемые блоки данных.
Реализация вариативных задач дискретной математики и цифровой обработки сигналов на предлагаемом вычислительном модуле предусматривает предварительное разбиение входных данных на блоки, размер которых не превышает размер локальной разделяемой памяти данных 6 процессорных элементов 5, в то время как способы обработки этих данных разбиваются на процессы производящие параллельные вычисления по независимым алгоритмам, программы которых записываются в память команд 1 каждого столбца. Таким образом, внутри каждого процесса происходит параллельная обработка отличающихся данных из множества локальных блоков памяти 6 по общему алгоритму и запись результатов обратно в те же блоки локальной памяти 6, данные из которых в свою очередь доступны для обработки соседним процессом, работающим аналогичным образом по своему отдельному и независимому алгоритму, результаты работы которого в свою очередь также доступны следующему за текущим соседнему процессу, и так далее.
Начальная загрузка всех данных локальных блоков памяти 6_1, 6_2…6_R происходит поэтапно следующим образом: - внешнее устройство через шину обмена 8 записывает программу загрузчик в память команд 1 каждого вычислительного модуля, в разделяемую память 6_1, 6_2…6_R крайнего левого столбца и/или в разделяемую память 7_1, 7_2…7_R крайнего правого столбца записывается порция данных предназначенная для памяти внутренних столбцов, представляющая собой данные изолированной задачи выполняемой на столбце, либо данные для стадий задачи, выполняемой на группе столбцов. После чего программа загрузчик стартует, а устройство управления потоком команд 2 транслирует коды программы в регистр команды 4_1, откуда он поступает в следующий регистр команды 4_1, и так далее по столбцу до последнего регистра 4_R. Тем самым во всем столбце на всех вычислительных блоках А_1, А_2…A_R, выполняется одинаковая программа, которая оперирует разными данными в блоках памяти 6_1, 6_2…6_R и 7_1, 7_2…7_R, которая переносит эти данные по направлению к внутренним столбцам на место их постоянного назначения. Затем, по окончании работы загрузчика, в разделяемую память 6_1, 6_2…6_R и/или 7_1, 7_2…7_R записывается новая порция данных, которая вместе с данными от предыдущей итерации переносится вновь запущенным загрузчиком вглубь к нужному столбцу до тех пор, пока вся память столбцов вычислительных модулей не будет заполнена верными данными. По окончанию процесса начальной загрузки в память команд 1 каждого вычислительного модуля загружается целевая программа изолированной задачи, либо группа программ для отдельных стадий задачи, выполняемой на группе столбцов.
Программа для реализации задачи состоит из последовательности команд, загружаемой внешним устройством в память команд 1 с помощью шины обмена 8. Формат кода команды процессорного элемента 5 имеет сложное кодирование с полями переменного назначения, где в зависимости от необходимости задаются режимы работы арифметико-логических устройств первого и второго уровня - 15 и 17 соответственно, адреса регистров, локальной памяти и прочие операнды-источники и приемники данных, а также поля, предназначенные для выполнения в устройстве управления потоком команд 2, которые не зависят от результатов вычислений, проводимых процессорными элементами 5. Поля, предназначенные для выполнения в устройстве управления потоком команд 2, связаны с формированием исполнительных адресов следующей команды, организацией ветвлений, в том числе вложенных циклов, для организации которых к устройству управления потоком команд 2 подключен стек циклов и подпрограмм 3, в котором хранятся адреса возврата и счетчики циклов.
Контроль процесса вычислений, осуществляемых вычислительным модулем, а также получение результатов осуществляются внешним устройством с помощью обращений через шину обмена 8 к разделяемой памяти данных 6 крайних процессорных элементов 5, или с помощью шины коротких сообщений 9 каждого столбца.
Предлагаемый вычислительный модуль работает следующим образом.
После этапа начальной загрузки данных разделяемой памяти 6, вычислительный модуль переводится в состояние сброса. Затем через шину обмена 8 в двухпортовую память команд 1 всех столбцов записываются программы процессов целевой задачи, после чего сигналы сброса всех столбцов деактивируются и на каждом столбце начинается выполнение процессов и алгоритмов предназначенных для данного столбца. Каждый процессорный элемент 5 внутри столбца выполняет одну и ту же программу, которая записана в память команд данного столбца 1. Все процессорные элементы внутри соседнего столбца выполняют другую программу, независимую от программ соседних столбцов, но связанную с ней по смыслу общей задачи. Все команды всех процессорных элементов выполняются за один такт синхронизации тактового синхроимпульса CLK (на схеме не показан). Устройство управления 2 считывает коды команд из памяти команд 1 и отсылает их в ближайший регистр команды 4_1, из которого эти коды далее по цепочке с каждым тактом синхроимпульса CLK поступают во все регистры команд 4_2…4_R столбца, а из них в процессорные элементы 5, после чего декодируются и появляются на шине управления 10. Исполнительные адреса следующих команд формируются в устройстве управления 2 на основании специального поля в коде операции вместе с условиями ветвлений и повторений циклов, а также из стека циклов и подпрограмм 3. Процессорные элементы 5 выполняют декодированные команды с шины управления 10. Для этого в каждом процессорном элементе 5 осуществляется выборка операндов из регистровой памяти 13 через порты доступа 14, после чего эти операнды поступают на арифметико-логические устройства первого уровня 15, формируя группу из N результатов первого уровня 16, далее, эти результаты поступают на арифметико-логические устройства второго уровня 17, формируя группу из Р результатов второго уровня 18, после чего результаты всех уровней поступают в селектор результатов 19, куда также поступают данные прочитанные из разделяемой памяти данных по каналам доступа 11 и 12. Затем, часть этих результатов через селектор результатов 19 поступает на группу X портов записи в регистровую память, в которой частично или полностью сохраняются. Параллельно этому по каналам доступа к разделяемой памяти данных 11 и 12 производятся операции чтения и/или записи, адреса для которых приходят из регистровой памяти 13 с одного из L портов 11_1…11_L и/или с одного из L портов 12_1…12_L, данные на запись поступают из регистровой памяти на порты 11_W и/или 12_W, а читаемые данные идут с портов чтения памяти 11_D и/или 12_D. Все операции выполняются и фиксируются по положительному перепаду тактового синхроимпульса CLK (на схеме не показан). В составе процессорного элемента 5 имеются команды условного выполнения, при помощи которых, в случае возникновения целевой ситуации, можно отправлять результаты вычислений через шину коротких сообщений 9 на шину обмена 8 во внешнее устройство. Частота отправки этих сообщений процессорными элементами не должна превышать 2*R тактов, где R - высота столбца (число вычислительных блоков А в нем).
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
Предлагаемый вычислительный модуль может быть выполнен на базе ПЛИС Xilinx XC7V585. В состав реализованного вычислительного модуля входит 64 процессорных элемента, организованные в виде матрицы из 8 столбцов и 8 строк. К каждому процессорному элементу подключена разделяемая двухпортовая локальная память данных объемом 1024 32-битных слов. Каждый столбец имеет в своем составе память команд объемом 1024 64-битных слов. Шина связи с внешним устройством предоставляет возможность чтения-записи локальной памяти крайних левого и правого столбцов, памяти команд столбцов и буфера коротких сообщений. Процессорный элемент содержит 32-битную регистровую память размером 32 слова.
Оценим производительность предлагаемого вычислительного модуля и устройства-прототипа при решении вариативной задачи из области дискретной математики. В качестве тестового примера оценим вычисление результатов криптографической хеш-функции MD5 (Rivest R. RFC 1321: The MD5 Message-Digest Algorithm // Request for Comments - 1992. - ISSN 2070-1721) для множества независимых 512-разрядных блоков данных. Предлагаемый вычислительный модуль, реализованный на базе ПЛИС Xilinx XC7V585, позволяет произвести в параллельном режиме вычисление 64 результатов хеш-функции MD5 с независимыми блоками данных, используя разделяемую память данных процессорных элементов. На каждом такте в многовходовых арифметико-логических устройствах первого и второго уровня каждого процессорного элемента выполняются цепочки из нескольких операций битовой логики, до двух простых и/или циклических сдвигов над 32-битными операндами или один над 64-битным операндом, сложения по модулю, до трех параллельных арифметических операций, до двух операций чтения и/или записи в память, реализующие части вычислений хеш-функции MD5. Рассматриваемый вариант реализации вычислительного модуля вычисляет результаты хеш-функции MD5 для 64 512-разрядных блоков данных за 203 такта. Устройство-прототип процессор Cryptoraptor, который содержит 80 процессорных элементов, позволяет произвести в параллельном режиме вычисления только 2 результатов хеш-функции MD5 с независимыми блоками данных (см. таблицу 8 в Gokhan Sayilar, Derek Chiou. Cryptoraptor: High Throughput Reconfigurable Cryptographic Processor ISBN: 978-1-4799-6277-8). Процессор Cryptoraptor вычисляет результаты хеш-функции MD5 для двух 512-разрядных блоков данных за 254 такта, а для вычисления 64 результатов хеш-функции MD5 необходимо 8128 тактов. Таким образом, в предлагаемом вычислительном модуле, содержащем 64 процессорных элемента, по сравнению с устройством-прототипом процессором Cryptoraptor, содержащем 80 процессорных элементов, при многопоточной обработке независимых блоков данных при работе на одной тактовой частоте достигается повышение производительности более чем в 40 раз. Повышение производительности в предлагаемом вычислительном модуле достигается за счет высокого параллелизма реализации алгоритма и использования процессорных элементов всех вычислительных блоков, вместе с высоким уровнем параллелизма выполнения самих операций в каждом процессорном элементе. Устройство-прототип отличает избыточность операций и связей, поэтому при вычислениях в ступенях конвейера невозможно использование всех процессорных элементов.
В качестве еще одного тестового примера оценим вычисление результатов криптографического преобразования AES128 (Federal Information Processing Standards Publication 197. United States National Institute of Standards and Technology (NIST). November 26, 2001.) для множества независимых 128-разрядных блоков данных. Взятый за прототип высокопроизводительный вычислитель Kalray MPPA Bostan, имеющий 256 VLIW + 128 специализированных криптографических ядер при тактовой частоте 800 МГц и энергопотреблении 10 Вт, показывает скорость преобразования 350 Gb/sec, тогда как предлагаемый вычислительный модуль спроектированный под техпроцесс TSMC CMOS 28НРСР имеющий в составе 480 универсальных ядер (без специальных криптоускорителей) на частоте 1000 МГц и том же энергопотреблении 10 Вт что и у прототипа, показывает скорость преобразования 550 Gb/sec, осуществляя в параллельном режиме вычисление 480 результатов преобразования за 111 тактов, включая затраты на загрузку и выгрузку результатов. Для примера, высокопроизводительный вычислитель Kalray MPPA Andey имеющий 256 VLIW ядер (без спец. криптоускорителей) на частоте 400 МГц показывает скорость обработки всего 45 Gb/sec.
Вышеизложенные сведения позволяют сделать вывод, что предлагаемый вычислительный модуль и способ обработки решают поставленную задачу - создание высокопроизводительного устройства для решения вариативных задач из области дискретной математики и цифровой обработки сигналов и соответствует заявляемому техническому результату - повышение производительности для многопоточных вычислений.
| название | год | авторы | номер документа |
|---|---|---|---|
| Вычислительный модуль и способ обработки с использованием такого модуля | 2018 |
|
RU2689433C1 |
| Реконфигурируемый вычислительный модуль | 2018 |
|
RU2686017C1 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ ЯДРО | 2023 |
|
RU2819403C1 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОПОТОКОВОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2708794C2 |
| Способ работы электроприводного газоперекачивающего агрегата | 2023 |
|
RU2820147C1 |
| Процессорный модуль однородной вычислительной структуры | 1985 |
|
SU1345207A1 |
| ПАРАЛЛЕЛЬНАЯ ПРОЦЕССОРНАЯ СИСТЕМА | 1991 |
|
RU2084953C1 |
| АВТОНОМНЫЙ ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ С СУБМОДУЛЯМИ | 2020 |
|
RU2748299C1 |
| СПОСОБ, УСТРОЙСТВО И СИСТЕМА ДЛЯ ПРЕДВАРИТЕЛЬНОЙ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ СЕНСОРНЫХ ДАННЫХ И УПРАВЛЕНИЯ ОБЛАСТЯМИ ИЗОБРАЖЕНИЯ | 2013 |
|
RU2595760C2 |
| АВТОНОМНЫЙ ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ | 2019 |
|
RU2720556C1 |
Изобретение относится к области вычислительной техники. Техническим результатом изобретения является повышение производительности и энергетической эффективности многостадийных многопоточных вычислений в вариативных задачах дискретной математики и цифровой обработки. Указанный результат достигается за счет того, что вычислительный модуль содержит набор С блоков управления, содержащих двухпортовую память команд, устройство управления потоком команд, стек циклов и подпрограмм, также содержит матрицу, содержащую в качестве элементов разделяемую память, командный регистр, шину коротких сообщений, процессорные элементы, в свою очередь содержащие регистровую память, каналы доступа к разделяемой памяти, группу из S портов чтения операндов, группу из М многовходовых арифметико-логических устройств первого уровня, группу из Р многовходовых арифметико-логических устройств второго уровня, селектор результатов арифметико-логических устройств и данных из памяти, группу из X портов записи в регистровый файл, шину управления и контроллер шины коротких сообщений. 2 н.п. ф-лы, 2 ил.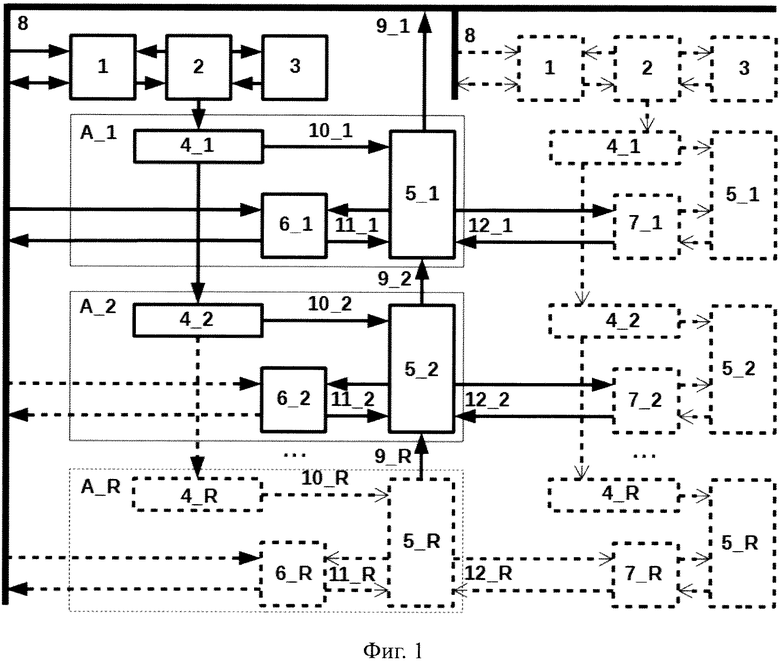
1. Вычислительный модуль для многопоточной обработки цифровых данных, содержащий процессорные элементы (5), отличающийся тем, что в него дополнительно введены двухпортовая память команд (1), устройство управления потоком команд (2), стек циклов и подпрограмм (3), двунаправленная шина обмена с внешним устройством (8), группа из R вычислительных блоков А_1, А_2…A_R, каждый из которых содержит регистр команды 4, шину управления (10), процессорный элемент (5), разделяемую память (6) и (7), канал доступа к разделяемой памяти (11) и (12), шину коротких сообщений (9), кроме того, в каждый процессорный элемент 5 введены регистровая память (13), имеющая S портов для чтения операндов и L портов для формирования адресов, группа из М многовходовых арифметико-логических устройств (15) первого уровня, группа из Р многовходовых арифметико-логических устройств (17) второго уровня, селектор промежуточных результатов из арифметико-логических устройств и данных из памяти (19), группа из X портов записи в регистровый файл (20), где устройство управления потоком команд (2) подключено ко второму порту памяти команд (1) и содержит регистр адреса текущей операции, который, в зависимости от ее типа, может инкрементироваться в каждом такте, принимая значение адреса вызываемой подпрограммы, адреса следующей инструкции за вызывающей инструкцией программы при возврате из подпрограммы, и первой инструкции в цикле при его итерации, причем значения адресов возврата и первой инструкции цикла считываются из стека циклов и подпрограмм (3), который работает по кольцевому принципу и имеет конечную глубину, в то время как первый порт памяти команд (1) подключен к шине обмена с внешним устройством (8), в то время как устройство управления потоком команд (2) считывает из памяти команд (1) код новой инструкции и записывает его в регистр команды 4_1, откуда он в каждом такте поступает в следующий за ним регистр команд 4_2 и так далее по цепочке связанных вычислительных блоков А_1, А_2…A_R, в то время, как с каждого регистра команды (4) по шине управления (10) в вычислительный блок А поступает код текущей операции, где он декодируется в микроинструкции, задающие режимы работы арифметико-логических устройств (15) и (17), селектора результатов (19), регистровой памяти (13) и каналов доступа к разделяемой памяти (11) и (12), где сама разделяемая двухпортовая память (6) и (7) одним портом подключена к процессорному элементу (5) вычислительного модуля через каналы (11) и (12), а другим портом - к соседнему процессорному элементу 5 соседнего вычислительного модуля через такие же каналы, таким образом разделяя данные между соседними процессорными элементами (5) справа и слева, в которых арифметико-логические устройства (15) первого уровня считывают параллельно данные по портам 14_1,…14_S из регистровой памяти (13), формируя спектр результатов 16_1,…16_N, которые поступают на селектор результатов (19) и на арифметико-логические устройства 17_1,…17_Р второго уровня, которые формируют спектр результатов 18_1,…18_Р, которые также поступают на селектор результатов (19), с которого выборочные результаты согласно микрокоду с шины (10) поступают в регистровую память (13) через порты записи 20_1,…20_Х, также в каждом процессорном элементе (5) контроллер коротких сообщений (21) принимает данные из регистровой памяти (13) и от аналогичного контроллера (21) соседнего снизу процессорного элемента (5) и передает данные в контроллер (21) соседнего сверху процессорного элемента (5), таким образом формируя единый поток сообщений от каждого процессорного элемента наружу, в то время как вычислительные модули, содержащие группу из R вычислительных блоков А__1, А_2…A_R, формируют вертикальный столбец, где вычислительные блоки связаны друг с другом по горизонтали через двухпортовую память (6) и (7), образуя строки, где разделяемая память (6) в крайнем слева столбце и разделяемая память 7 в крайнем справа столбце подключены к шине обмена (8).
2. Способ обработки с использованием вычислительного модуля для многостадийной многопоточной обработки цифровых данных содержит следующие этапы, на которых: внешнее устройство через шину обмена (8) записывает программу-загрузчик в память команд (1) каждого вычислительного модуля, в разделяемую память 6_1, 6_2…6_R крайнего левого столбца и/или в разделяемую память 7_1, 7_2…7_R крайнего правого столбца записывается порция данных, предназначенная для памяти внутренних столбцов, представляющая собой данные изолированной задачи, выполняемой на столбце, либо данные для стадий задачи, выполняемой на группе столбцов, после чего программа-загрузчик стартует, где устройство управления потоком команд (2) транслирует коды программы в регистр команды 4_1, откуда он поступает в следующий регистр команды 4_1,и так далее по столбцу до последнего регистра 4_R, тем самым во всем столбце на всех вычислительных блоках А_1, А_2…A_R выполняется одинаковая программа, которая оперирует разными данными в блоках памяти 6_1, 6_2…6_R и 7_1, 7_2…7_R, которая переносит эти данные по направлению к внутренним столбцам на место их постоянного назначения, затем, по окончании работы загрузчика, в разделяемую память 6_1, 6_2…6_R и/или 7_1, 7_2…7_R записывается новая порция данных, которая вместе с данными от предыдущей итерации переносится вновь запущенным загрузчиком вглубь к нужному столбцу до тех пор, пока вся память столбцов вычислительных модулей не будет заполнена верными данными, после чего в память команд (1) каждого вычислительного модуля загружается программа для изолированной задачи, либо группа программ для отдельных стадий задачи, выполняемой на группе столбцов, после чего устройства управления потоком команд (2) на всех столбцах синхронно запускаются, что обеспечивает параллельную обработку задачи на группе вычислительных блоков А_1, А_2…A_R, либо параллельную обработку многостадийной задачи на группе вычислительных блоков А_1, А_2…A_R, сразу в нескольких столбцах, где в каждом из них выполняется отдельная стадия, причем данные, являющиеся ее результатом, доступны через двухпортовую память программе следующей стадии в соседнем столбце, и так далее, до финальной стадии, данные которой появляются в разделяемой памяти крайнего столбца, откуда они через шину (8) могут быть прочитаны внешним устройством, в то время как по шине сообщений (9) внешнее устройство может получать короткие сообщения о промежуточных результатах вычислений с вычислительных блоков А_1, А_2…A_R каждого столбца.
| МНОГОПРОЦЕССОРНЫЙ МОДУЛЬ | 2008 |
|
RU2397538C1 |
| US 5581777 A, 03.12.1996 | |||
| МОДУЛЬНОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО С РАЗДЕЛЬНЫМ МИКРОПРОГРАММНЫМ УПРАВЛЕНИЕМ АРИФМЕТИКО-ЛОГИЧЕСКИМИ СЕКЦИЯМИ | 1994 |
|
RU2079877C1 |
| ГЕТЕРОГЕННЫЙ ПРОЦЕССОР | 2012 |
|
RU2513759C1 |
| Аппарат для постоянного воздействия на гнойные раны конечностей лекарственными растворами | 1947 |
|
SU72339A1 |

