ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области вычислительной техники и может быть использовано при создании сверхбольших интегральных схем (СБИС) для высокопроизводительного решения вычислительно трудоемких задач, с использованием распараллеливания и конвейеризации вычислительных процессов.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Для решения подобных задач используются графические микропроцессоры (GPU) фирм NVIDIA (http://www.nvidia.ru/object/tesla-server-gpus-ru.html) и AMD Radeon (http://www.amd.com/ru-ru/products/graphics/desktop/r9#), которые позволяют быстро реализовать алгоритмы решения и обеспечивают требуемую на практике производительность. Недостатками применения таких графических процессоров являются низкие показатели по удельной производительности на единицу площади кристалла и единицу мощности потребления. Второй показатель наиболее критичен на практике и определяет энергоэффективность устройства.
Известен вычислительный модуль (RU №139326, МПК G06F 15/16, заявлено 10.12.2013, опубликовано 10.04.2014, БИ №10) со СБИС с прямой реализацией заданного прикладного алгоритма, который содержит вычислительное поле из L вычислительных элементов, соответствующих количеству каналов распараллеливания и каждый вычислительный элемент содержит S ступеней конвейера, блок памяти FIFO, блок генератора переменной X, входной и выходной буферы, группу из L классификаторов, элемент ИЛИ, четыре внешних входа и четыре внешних выхода. Структура данного вычислительного модуля представляет собой множество специализированных каналов обработки (вычислительных элементов).
Недостатком данного решения является узкая специализация вычислительных элементов на заданный прикладной алгоритм, а также специализация блока генератора и классификаторов на использующую эти алгоритмы задачу.
Для повышения показателей по удельной производительности применяются специализированные вычислительные устройства с прямой реализацией алгоритмов. Известны устройства (Apparatus and method for a hash processing system using integrated message digest and secure hash architectures, US 7,213,148 B2, Date of patent May 1, 2007; Fast SHA1 implementation 2007; US 7,229,355 B2, Date of Patent Nov.20, 2007), в которых также описаны варианты реализации специализированных каналов обработки под конкретные прикладные алгоритмы.
Преимущества этих решений состоят в достижении высокой производительности и энергоэффективности, при создании специализированных функциональных устройств для проблемно-ориентированных аппаратных СБИС. Недостатком данных устройств также является узкая специализация вычислительных элементов под заданные прикладные алгоритмы
Наиболее близким к заявленному изобретению устройством того же назначения по совокупности признаков является принятый за прототип микропроцессор Cryptoraptor (Cryptoraptor: High Throughput Reconfigurable Cryptographic Processor. ICC AD 2014, 8 pp. http://users.ece.utexas.edu/~derek/Papers/ICCAD2014_Cryptoraptor.pdf). содержащий решающее поле в виде 20 ступенчатого конвейера, каждая ступень которого соединяется со следующей ступенью через коммутатор, содержащий кроме мультиплексоров конвейерные регистры для фиксации результатов вычислений в ступенях, кроме того, каждая ступень содержит четыре процессорных элемента РЕ, состоящие из пяти независимо реконфигурируемых специализированных функциональных устройств, и общий для решающего поля 256-входовой регистровый файл, имеющий 80 портов на чтение и 8 портов на запись. Особенностью архитектуры Cryptoraptor является то, что : возможна статическая реконфигурация как функциональных устройств, так и коммутаторов; кроме последовательной регулярной передачи данных между ступенями конвейера в ней реализована возможность нерегулярных передач данных между ступенями через общий регистровый файл.
Недостатками данного устройства являются отсутствие возможности повторения действий в ступенях необходимое количество раз, что ограничивает глубину реализуемых конвейерных алгоритмов, применение коммутаторов для передачи данных между ступенями с большим количеством входов и выходов и организация нерегулярных передач между ступенями через общий регистровый файл с большим количеством портов чтения - записи.
ЗАДАЧА ИЗОБРЕТЕНИЯ
Задача, на решение которой направлено предлагаемое изобретение, состоит в создании реконфигурируемого вычислительного модуля с программируемыми узлами и динамически реконфигурируемыми связями между ними для построения проблемно-ориентированной СБИС, для высокопроизводительного решения вычислительно трудоемких задач, с использованием распараллеливания и конвейеризации вычислительных процессов.
Техническим результатом предлагаемого изобретения является повышение удельных производительностей на единицу мощности потребления и на единицу площади.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Для решения поставленной задачи, реконфигурируемый вычислительный модуль, подключаемый к внутрикристальной кольцевой сети 5, содержит макроблок контроллера 1, макроблок динамически реконфигурируемого процессора 13,
причем макроблок контроллера 1 содержит процессорное ядро 2 соединенное с блоком статической памяти 3, образующие функциональный блок 17, адаптер 4, который соединен с внутрикристальной кольцевой сетью 5, а также с процессорным ядром 2 по последовательному интерфейсу UART 15,
макроблок динамически реконфигурируемого процессора 13 содержит конвейерный ускоритель 11 и последовательно соединенные двунаправленными шинами переключатель каналов сервисных и информационных команд 6, блок приема и дешифрации команд 7, драйвер 36, включающий блок сегментов входной и выходной очереди 8 и дуплексный канал с изменяемой маршрутизацией информационных пакетов 9, второй выход и второй вход которого соединены соответственно с входом и выходом конвейерного ускорителя 11, которые соединены друг с другом через дуплексный канал 9 напрямую, при этом конвейерный ускоритель 11 содержит N динамически реконфигурируемых ступеней 12, соединенных между собой связями 24-27, а также переключатель каналов 6, блок приема и дешифрации команд 7, блок сегментов входной и выходной очереди 8 и N динамически реконфигурируемых ступеней 12 объединены сервисной сетью 10,
кроме того, переключатель каналов 6 соединен с адаптером 4 по первому двунаправленному параллельному интерфейсу 16 и по второму двунаправленному параллельному интерфейсу 18 с процессорным ядром 2, которое также имеет порт подключения по интерфейсу JTAG 14 к хост-процессору,
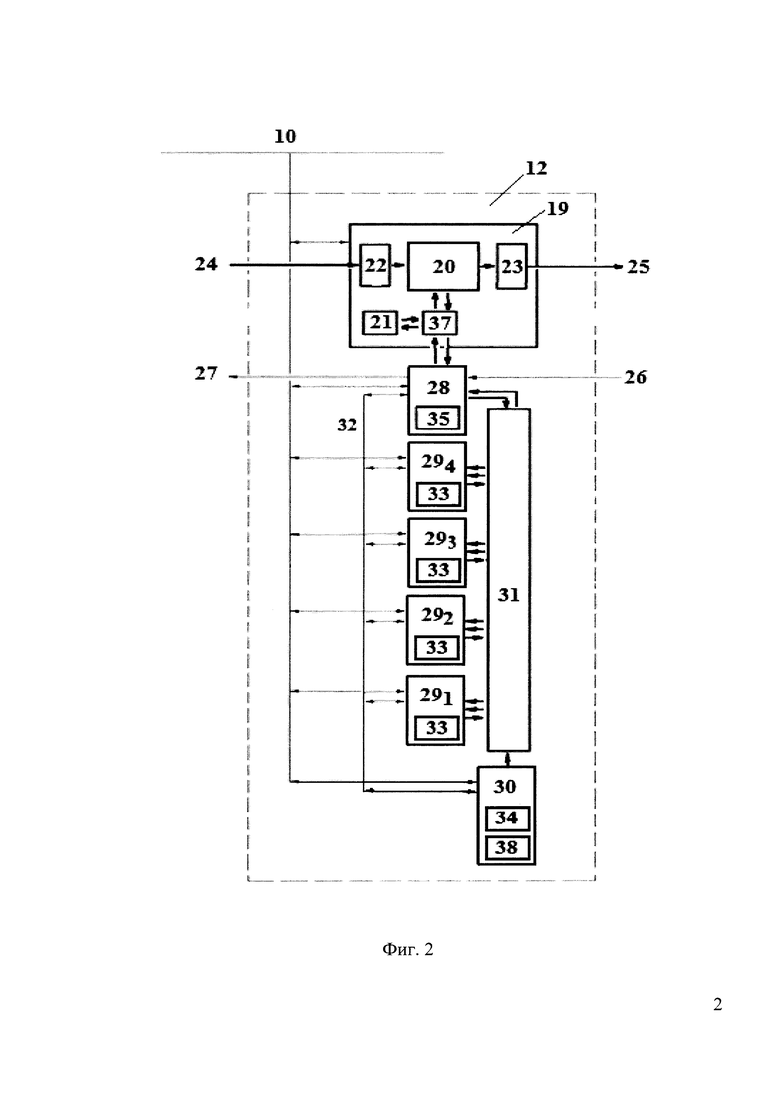
при этом каждая из N динамически реконфигурируемых ступеней 12 содержит модуль памяти 19, мастер-узел управления и работы с памятью 28, четыре подчиненных вычислительных узла 29 с первой локальной памятью команд 33 у каждого, подчиненный узел динамического управления реконфигурацией соединений 30, со второй локальной памятью команд 34 и памятью кодов множественных коммутаций 38, которые объединены сервисной сетью 10 и коммутатор конвейерной ступени 31,
причем модуль памяти 19, состоит из четырехпортовой двухбанковой регистровой памяти с расслоением четырехбайтовых слов 20, регистровой однопортовой памяти байтов 21 и блока дешифрации и управления выполнением операций 37, и имеет входное устройство прямого доступа на запись 22 и выходное устройство прямого доступа на чтение 23, вход которого соединен с первым выходом чтения регистровой памяти четырехбайтовых слов 20, а выход устройства 23 является первым выходом данных 25 ступени 12, вход устройства 22 является первым входом 24 ступени 12, а выход устройства 22 соединен с первым входом записи регистровой памяти четырехбайтовых слов 20, второй выход чтения и второй вход записи регистровой памяти четырехбайтовых слов 20 соединены с блоком дешифрации и управления выполнением операций 37, который также соединен с регистровой памятью байтов 21 и первым входом и первым выходом мастер-узла управления 28, который содержит третью локальную память команд 35,
второй вход мастер-узла управления 28 является вторым входом сигнала готовности 26 ступени 12, а второй выход мастер-узла управления 28 является вторым выходом сигнала готовности 27 ступени 12,
мастер-узел управления 28 двунаправленной шиной соединен с коммутатором 31 и двунаправленной сигнальной шиной 32 соединен с подчиненными вычислительными узлами 29 и подчиненным узлом динамического управления реконфигурацией соединений 30, выход которого соединен с коммутатором 31, который двунаправленными шинами соединен с подчиненными вычислительными узлами 29.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг. 1 приведена структура предлагаемого реконфигурируемого вычислительного модуля. На фиг. 2 приведена структура одной ступени 12 конвейерного ускорителя 11. На фиг. 3 приведен пример временной диаграммы работы ступени 12, в составе одного подчиненного вычислительного узла 29 (slave-узла) и мастер-узла 28 (master-узла). На фиг. 4 приведена схема алгоритм MD5. На фиг.5 приведена программа реализации параллельной обработки двух информационных блоков по алгоритму MD5.
На фиг. 1 и фиг. 2 приняты следующие обозначения:
1 - макроблок контроллера;
2 - процессорное ядро;
3 - блок статической памяти;
4 -адаптер внутрикристальной сети 5;
5 - внутрикристальная кольцевая сеть с выходом на хост-процессор;
6 - переключатель каналов сервисных и информационных команд;
7 - блок приема и дешифрации информационных и сервисных команд;
8 - блок сегментов входной и выходной очереди, интерфейсов с конвейерным ускорителем 11 для выполнения информационных команд;
9 - дуплексный канал с изменяемой маршрутизацией информационных пакетов;
10 - сервисная сеть для передачи сервисных команд;
11 - конвейерный ускоритель;
12 - ступень конвейерного ускорителя с программируемыми узлами и их динамически реконфигурируемыми связями;
13 - макроблок динамически реконфигурируемого процессора;
14 - интерфейс JTAG для подключения к хост-процессору;
15 - последовательный интерфейс UART для передачи вычислительных заданий;
16 - первый двунаправленный параллельный интерфейс для прямой передачи информационных и сервисных команд;
17 - функциональный блок с процессорным ядром 2 и блоком памяти 3;
18 - второй двунаправленный параллельный интерфейс передачи информационных и сервисных команд;
19 - модуль памяти, содержащий четырехбайтовую и байтовую памяти и устройства прямого доступа для пересылок между ступенями 12;
20 - регистровая память четырехбайтовых слов с расслоением на два блока и двумя портами на запись, двумя портами на считывание;
21 - регистровая память байтов, без расслоения, содержащая один порт на запись и считывание;
22 - входное устройство прямого доступа к памяти 20 на запись;
23 - выходное устройство прямого доступа к памяти 20 на чтение;
24 - первый вход ступени 12 по данным;
25 - первый выход ступени 12 по данным;
26 - второй вход приема сигнала готовности и завершения пересылки;
27 - второй выход выдачи сигнала готовности и завершения пересылки;
28 - мастер-узел (master) управления и работы с памятью конвейерной ступени 12;
29 - подчиненные (slave) вычислительные узлы выполнения арифметико-логических операций и операций сдвига;
30 - подчиненный (slave) узел динамического управления реконфигурацией соединений узлов конвейерной ступени 12 через коммутатор 31;
31 - коммутатор конвейерной ступени 12;
32 - двунаправленная сигнальная шина;
33 - первая локальная память команд программы управления подчиненным вычислительным узлом 29;
34 - вторая локальная память команд программы управления подчиненным узлом динамического управления реконфигурацией соединений 30;
35 - третья локальная память команд программы управления мастер-узлом 28;
36 - драйвер, включающий блок 8 сегментов входной и выходной очереди и дуплексный канал 9 с изменяемой маршрутизацией информационных пакетов.
37 - блок дешифрации и управления выполнением операций с регистровыми памятями 20, 21 и устройствами прямого доступа к памяти 22, 23.
38 - память кодов множественных коммутаций коммутатора конвейерной ступени 12.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Предлагаемый реконфигурируемый вычислительный модуль осуществляется следующим образом.
Внутрикристальная кольцевая сеть 5 посредством портов с адаптерами 4 соединяет множество реконфигурируемых вычислительных модулей на кристалле СБИС и имеет также порты подключения по входу и выходу внешнего управляющего этой СБИС хост-процессора.
Макроблок контроллера 1 предназначен для приема вычислительных заданий и выдачи результатов через интерфейс UART 15, адаптер 4 и вычислительную сеть 5; выполнения вычислительных заданий по генерации исходных данных и анализу результатов вычислений в макроблоке динамически реконфигурируемого процессора 13; формирования и выдачи информационных команд через интерфейс 18 для реализации вычислений в макроблоке 13 в соответствии с вычислительными заданиями; передачу информационных и сервисных команд по параллельному интерфейсу 16 напрямую из сети 5 и адаптер 4 и возвращения результатов их выполнения.
Сервисные команды (S-команды), служат для сброса, начального пуска, останова, пуска с точки останова макроблока реконфигурируемого процессора 13, записи и считывания содержимого регистров и памяти, отображенных на глобальное виртуальное адресное пространство ресурсов макроблока 13.
Информационные команды (I-команды), служат для передачи и приема данных через драйвер 36, а также для управления дуплексным каналом 9 для соединения портов блока 8 с первой и последней ступенью 12 конвейерного ускорителя 11, либо отключения блока 8 и замыкания последней ступени 12 конвейерного ускорителя 11 на его первую ступень 12.
Функциональный блок 17 содержит процессорное ядро 2 и блок статической памяти 3. Процессорное ядро 2 предназначено для выполнения действий по принимаемым через интерфейс UART 15 вычислительным заданиям посредством передаваемых в макроблок 13 информационных и сервисных команд по двунаправленному параллельному интерфейсу 18. Блок памяти 3 содержит оперативную память произвольного доступа для хранения выполняемой программы, констант и данных и постоянную программируемую память для записи начальной программы загрузчика. Запись в постоянную программируемую память производится при начальной загрузке через интерфейс JTAG 14.
Блок приема и дешифрации информационных и сервисных команд 7 после получения команды от переключателя каналов 6 и ее дешифрации реализует выполнение сервисных команд через сервисную сеть 10, а информационных команд - через драйвер 36. Блок 7 также формирует пакеты с результатами выполнения команд и производит их выдачу через переключатель каналов 6.
Драйвер 36, включающий блок 8 сегментов входной и выходной очереди, интерфейсы с конвейерным ускорителем 11, а также дуплексный канал 9 с изменяемой маршрутизацией информационных пакетов, является блоком сопряжения ядра 2 и конвейерного ускорителя 11. При этом протоколы взаимодействия интерфейсов блока 36 с конвейерным ускорителем 11 такие же, как и в интерфейсах ступеней 12 этого конвейерного ускорителя 11. Сегменты входной и выходной очереди - это участки памяти в 128 32-х разрядных слов, доступ к которым со стороны ядра 2 осуществляется через информационные команды операциями считывания/записи слов, а со стороны конвейерного ускорителя 11 реализующими интерфейс устройствами прямого доступа к памяти. Каждый сегмент входной и выходной очереди является критическими ресурсом, т.е. с ним может работать либо ядро 2, либо интерфейс с конвейерным ускорителем 11. Одновременная работа исключена.
Интерфейс драйвера 36 с конвейерным ускорителем 11 может быть отключен информационной командой, а затем включен также информационной командой. Это используется в случаях, когда при решении задачи необходима независимая работа драйвера 36 по загрузке и выгрузке данных и конвейерного ускорителя 11 по обработке информационных пакетов, которые в этом варианте использования многократно проходят через конвейерный ускоритель благодаря включенной маршрутизации в блоке 9 с выхода конвейерного ускорителя на его вход.
Сервисная сеть 10, представляет собой иерархическую сеть дешифраторов адресной части сервисных команд с виртуальными адресами ресурсов, что позволяет осуществить доставку сервисных операций к адресуемому ресурсу макроблока 13, с дешифраторами операций сервисных команд на терминальных вершинах этой сети, блоками непосредственного доступа к ресурсам и формирования результатов выполнения сервисных команд.
Конвейерный ускоритель 11 макроблока динамически реконфигурируемого процессора 13 содержит N программно настраиваемых и динамически реконфигурируемых ступеней 121, 122, …, 12n., каждая из которых содержит: модуль 19 четырехбайтовой и байтовой памяти с устройствами прямого доступа для обмена данными между реконфигурируемыми ступенями 12; мастер-узел 28; подчиненные вычислительные узлы 29; подчиненный узел управления реконфигурации соединений 30; главный коммутатор 31 конвейерной ступени 12.
При выполнении программ в макроблоке контроллера 1 и макроблоке 13 в конвейерном ускорителе 11, в зависимости от характера решаемой задачи, производится обработка потока информационных пакетов, которые порождаются в макроблоке контроллера 1, а после обработки поступают обратно в макроблок контроллера 1 для анализа результата обработки. Одновременно в конвейерном ускорителе 11 макроблока 13 могут обрабатываться "n" таких пакетов, по количеству конвейерных ступеней 12. Причем возможно зацикливание обработки пакетов, когда с выхода конвейерного ускорителя 11 они поступают на его вход. Этот режим реализуется блоком 9 дуплексного канала с изменяемой маршрутизацией. При этом обработка пакета в некоторой конвейерной ступени 12 "i" обычно совмещена с приемом нового пакета из ступени "i-1" и выдачей независимой от вычислений в ступени "i" части обрабатываемого пакета в ступень "i+1". Для совмещения вычислений с передачей пакетов используются имеющиеся в каждой ступени 12 устройства прямого доступа к памяти 22 и 23.
Модуль 19 содержит четырехбайтовую память 20 с входным 22 и выходным 23 устройствами прямого доступа, а также однобайтовую память 21. Операции обращения к памятям и выдачи через блок 23 поступают от узла 28 через блок дешифрации и управления их выполнением 37. Входной блок прямого доступа 22 выполняет операции пересылки от предыдущей ступени 12.
Четырехбайтовая память 20 расслоена по четным и нечетным адресам четырехбайтовых слов на два физических блока. Каждый блок имеет порт на чтение и порт на запись. Блоки памяти реализуются на регистрах с логическим управлением сигналами синхронизации (режим clock-gating), что резко сокращает энергетические затраты на обращения к ней. Объем этой памяти 128×32 разрядных слов. Входное устройство 22 прямого доступа к памяти 20 на запись соединено с первым входом 24 ступени 12 по данным и предназначено для приема данных от предыдущей ступени 12 конвейерного устройства 11 или от интерфейса драйвера 36. Выходное устройство 23 прямого доступа к памяти 20 на чтение соединено с первым выходом 25 ступени 12 по данным и предназначено для выдачи данных в следующую ступень 12 или в интерфейс драйвера 36.
Однобайтовая память 21 реализуется одним блоком с одним портом на считывание и запись. Объем этой памяти 128x8 разрядов, также реализуется на регистрах с логическим управлением сигналами синхронизации.
Блок 28 является мастер-узлом в конвейерной ступени 12 и обеспечивает управление началом/окончанием счета в подчиненных slave-узлах 291, 292, 293, 294 и 30 конвейерной ступени 12, а также выполняет операции с модулем памяти 19 и взаимодействие по данным с подчиненными узлами через коммутатор 31. Блок мастер-узла 28 может работать в асинхронном режиме, когда подчиненные slave-узлы 29 и 30 ступени 12 остановлены, а также совместно с подчиненными slave-узлами, синхронно с ними выполняя команды каждый своей программы - синхронный режим.
Блок 28 мастер-узла для начала синхронного режима выдает сигналы Restart по двунаправленной сигнальной шине 32, а завершение синхронного режима происходит в результате барьерной синхронизации подчиненных slave-узлов и мастер-узла. В подчиненных slave-узлах сигнал барьерной синхронизации возникает автоматически при достижении последней команды выполняемой в узле программы. В мастер-узле 28 выход в барьерную синхронизацию происходит в результате непосредственного выполнения команды барьерной синхронизации - команды Barrier. После такой синхронизации подчиненные узлы останавливаются, а мастер-узел 28 переходит в асинхронный режим работы.
Блок 28 мастер-узла имеет второй вход готовности 26, который служит для приема от следующей ступени 12 или интерфейса драйвера 36 сигнала готовности к приему очередного информационного пакета или сигнала об окончании пересылки через устройство 23. Второй выход готовности 27 ступени 12 предназначен для выдачи сигнала готовности к приему или окончания приема получаемых данных в эту ступень 12.
Команды программы управления блоком 28 мастер-узла загружаются в память команд 35 сервисными командами. Память команд 35 также выполнена на регистрах с режимом clock-gating и, что принципиально, имеет небольшой объем в 128 16-разрядных слов. Данная реализация управления значительно снижает накладные расходы на выполнение команд в блоке 28. Команды имеют 8-ми и 16-разрядный формат, работают с четырьмя адресными регистрами и четырьмя регистрами общего назначения, включают команды работы с памятью, синхронизации, команды условной и безусловной передачи управления, организации циклов, простейшие логические команды обработки данных и команды сравнения.
Все команды блока 28 являются двухтактовыми.
Подчиненные вычислительные slave-узлы 29 являются 32-х разрядными арифметико-логическими устройствами, которые выполняют целочисленное арифметическое сложение, логические операции, операции логического и циклического сдвига над операндами из регистровой памяти. Регистровая память иерархическая, первый уровень - регистры группы А непосредственно приближены к арифметико-логическому устройству и имеют жестко закрепленную функциональность - регистр первого операнда, регистр второго операнда, регистр результата. Команды выполняют операции только над регистрами группы А, что значительно снижает энергопотребление при выполнении команд, поскольку исключает работу с обычно требуемым многопортовым регистровым файлом. Регистры группы А служат и портами приема-выдачи данных через коммутатор 31 конвейерной ступени 12.
Микроархитектура узла 29 и временные соотношения выполнения операций узлов 29, коммутатора 31 и узла 30 управления коммутатором реализованы так, что за один машинный такт в узле 29 успевает выполниться операция, а результат не только записывается в регистр результата этого узла, но и, если необходимо, по сконфигурированному в этом же такте командой из узла 30 коммутатору 31, этот результат одновременно в конце такта фиксируется на входных портах - регистрах-операндах группы А другого вычислительного узла 29 этой конвейерной ступени 12.
Регистры второго уровня, регистры группы В реализованы как ячейки прямо адресуемой сверхбыстрой блокнотной памяти. Регистры группы В служат для сохранения промежуточных результатов и для них разрешены только операции пересылок с регистрами группы А.
Каждая команда подчиненного вычислительного slave-узла 29 имеет 18-разрядный формат и содержит одну арифметико-логическую операцию и до двух операций регистровых пересылок между регистрами разных групп. Команды обращения к памяти и передач управления отсутствуют. Регистровая память команд 33 вычислительных slave-узлов 29 также реализована на регистрах с режимом clock-gating и принципиально имеет небольшой размер в 32 команды, что обеспечивает низкие накладные расходы на выборку команд.
Исполнение команд в вычислительных slave-узлах 29 двухтактное: первый такт - выборка команды и дешифрация; второй такт - выполнение команды, что может включать, как описано ранее, дополнительно передачу результата через коммутатор 31 и фиксацию его на входных регистрах других slave-узлов 29 конвейерной ступени 12.
Коммутатор 31 имеет 5 входов (четыре входа от подчиненных вычислительных узлов 29 и один вход от мастер-узла 28) и 9 выходов (2×4 выходов на подчиненные вычислительные slave-узлы 29 и один выход на мастер-узел 28). Все входы и выходы 32-разрядные. Коммутатор 31 построен на 9-ти мультиплексорах 5:1 и управляется 20-ти разрядным кодом установки коммутации из подчиненного узла управления коммутацией 30. Микроархитектура коммутатора 31 позволяет за один такт установить коммутацию (соединения) и за этот же такт по установленным соединениям произвести до 9-ти пересылок 32-х разрядных слов. Такая работа коммутатора 31 обеспечивает динамическую реконфигурируемость в каждой конвейерной ступени 12 конвейерного ускорителя 11.
Подчиненный slave-узел динамического управления реконфигурацией 30 выдает 20-разрядные коды управления коммутацией в коммутатор 31. Узел 30 управляется программой управления, находящейся в его регистровой памяти команд 34. Объем этой памяти - 32 команды 8-разрядного формата. Одна команда может непосредственно задать одну коммутацию, т.е. по ее операндам формируется 20-разрядный код управления коммутатором 31. Если требуется множественная коммутация на такте, то 20-разрядный код множественной коммутации выбирается из подготовленной таблицы кодов множественных коммутаций 38. Эта таблица 38 может содержать до 8 кодов множественных коммутаций.
Команды программы узла динамического управления реконфигурацией 30 выполняются, как и для всех остальных узлов, по дваухтактовой временной диаграмме. Таким образом, новая коммутация главного коммутатора 31 может производиться на каждом такте.
Предлагаемый реконфигурируемый вычислительный модуль работает следующим образом.
После включения питания переключатель каналов 6 установлен на соединение по параллельному интерфейсу 16, поэтому макроблок динамически реконфигурируемого процессора 13 может принимать информационные и сервисные команды напрямую через адаптер 4 внутрикристальной сети 5. Эти команды могут выдаваться хост-процессором через внутрикристальную сеть 5. В этом режиме возможна полнофункциональная работа макроблока 13, однако он используется только для отладки и диагностики.
Если в вычислительном процессе решения задачи пользователя должен участвовать макроблок контроллера 1 посредством выполняемых в функциональном блоке 17 программ, то сначала в статическую память 3 по JTAG 14 хост-процессором загружается эта программа управления блоком 17 и также по JTAG 14 устанавливается начальное состояние ядра 2.
Программы для макроблока 13, таблицы констант и исходные данные для вычислений далее загружаются из хост-процессора через сеть 5, адаптер 4 и интерфейс UART 15 функциональным блоком 17 в память 3.
После этого по внутрикристальной сети 5 от хост-процессора выдается в блок переключения каналов 6 команда перехода на управление от функционального блока 17 через двунаправленную шину 18. После этого загрузка программ и констант в макроблоке 13, управление вычислениями в макроблоке 13 производится только блоком 17 посредством информационных и сервисных команд, поступающих в блок приема и дешифрации этих команд 7. Общее управление автономной работой функционального блока 17 при этом осуществляется через интерфейс JTAG 14 от хост-процессора.
Перед загрузкой программ и констант в макроблок 13 в него выдается сервисная команда сброса Reset.
Далее выполняются сервисные команды загрузки программ в памяти команд 35, 33, 34 узлов 28, 29 и 30 конвейерных ступеней 12, а также необходимых констант в памяти 20 и 21. Данные могут загружаться в сегменты памяти входных очередей блока 8 драйвера 36. В процессе такой загрузки макроблок 13 находится в неработающем состоянии.
После окончания загрузки программ и констант выдается сервисная команда Run, которая запускает макроблок динамически реконфигурируемого процессора 13 на счет, он переходит в режим выполнения вычислений. В этом режиме из макроблока контроллера 1 могут выдаваться информационные команд выдачи и приема данных от драйвера 36, а также, как исключение, единственная сервисная команда - команда Stop.
Выполнение программы в макроблоке 13 состоит в чередовании синхронных (работают все узлы ступени 12) и асинхронных (работает только мастер-узел 28) режимов работы ступени 12. Такое выполнение может завершиться либо по внутренней команде Stop, выполненной в одном из блоков управления и доступа к памяти 28 какой-либо ступени 12, либо по внешней сервисной команде Stop.В результате этого макроблок 13 переходит в состояние останова. При этом, если была работа в синхронном режиме, то сеанс такого режима дорабатывается, узлы останавливаются по барьерной синхронизации и это является точкой останова. В состоянии останова посредством сервисных команд может быть исследовано состояние макроблока 13 посредством считывания содержимого регистров любых узлов и участков в памяти модуля памяти 19. Далее выполнение программы может быть продолжено с точки останова посредством выдачи сервисной команды Run.
Ступень конвейерного ускорителя 12 в процессе вычислений функционирует следующим образом.
В состоянии останова команда Run может воздействовать только на блоки управления и доступа к памяти 28. Эти блоки могут работать в асинхронном и синхронном режимах. Синхронный режим начинается выдачей из мастер-узла 28 сигнала Restart в подчиненные узлы по шине 32. Синхронный режим заключается в совместной по тактовой работе всех блоков ступени 12. При этом доступ к памяти блока 19 имеет только мастер-узел 28, который снабжает данными вычислительные slave-узлы 29 и принимает от них результаты через коммутатор 31. Вычислительные slave-узлы 29, каждый управляемый небольшой программой из собственной памяти команд 33, могут обмениваться данными через коммутатор 31 непосредственно. Коммутатор 31 на каждом такте может менять конфигурацию соединений блоков ступени 12, что происходит под управлением блока 30, работающего по своей программе из памяти команд 34.
Выход из синхронного режима происходит по барьерной синхронизации всех блоков ступени 12.
Одновременно с вычислениями в синхронном режиме или выполнением программы мастер-узлом 28 управления и доступа к памяти в асинхронном режиме возможна асинхронная пересылка данных между блоками 19 соседних ступеней 12 конвейерного ускорителя 11. Это выполняется посредством блоков прямого доступа 22 и 23, запускаемых командами асинхронной пересылки из мастер-узлов управления и доступа к памяти 28. Готовность к приему и передаче данных отслеживается блоками 28 посредством анализа сигналов, передаваемых по линиям готовности 27 и 26.
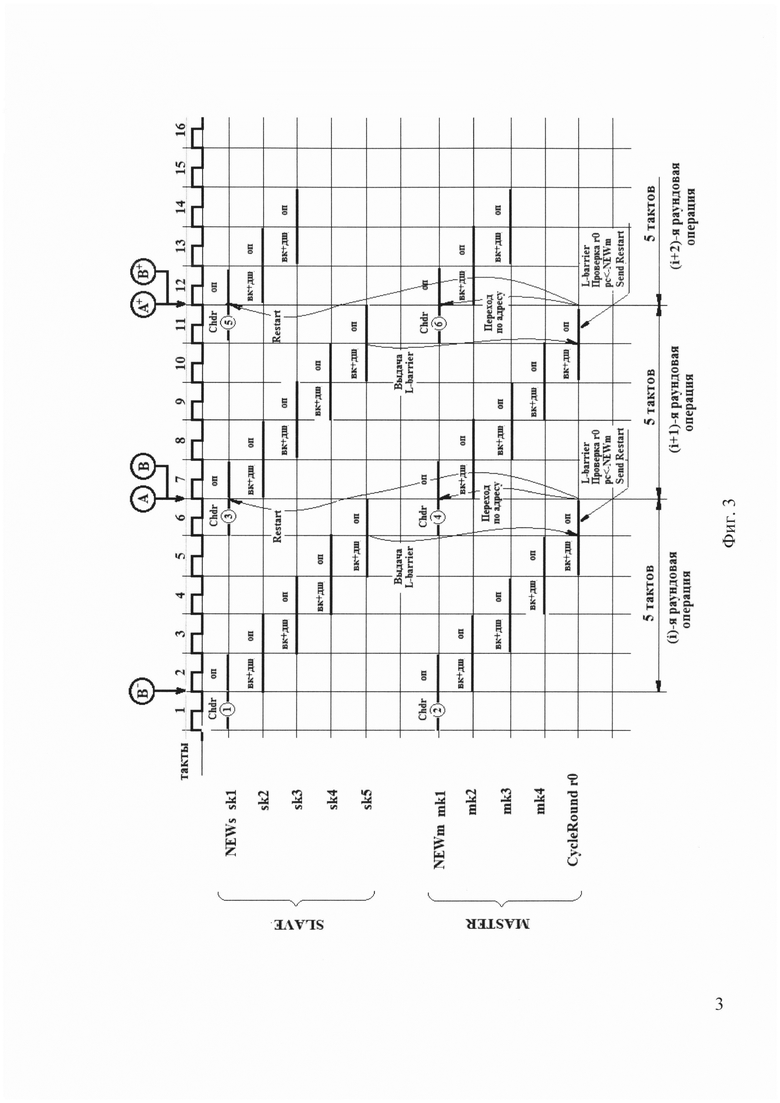
Пример работы одной ступени 12 приведен на фиг. 3 в виде временной диаграммы работы одного подчиненного вычислительного slave-узла 29 и master-узла 28. Выполняемые в этих узлах команды программ обозначены условно : для slave-узла - sk1,..sk5; для master-узла - mk1,…,mk4. В master-узле также выполняется команда CyclreRound r0, которая одновременно является командой проверки конца цикла по счетчику в регистре r0 и командой барьерной синхронизации slave- и master-узла.
Любая команда в slave- или master-узле выполняется за два такта: такт
1 - выборка команды и ее дешифрация (обозначается на фиг. 3 "вк+дш"); такт
2 - выполнение команды (обозначается "оп").
Программы в slave- и master-узлах начинаются синхронно и в одной фазе по такту выполнения команд - см. точки В-, А, В, А+, В+, фиг. 3. Первая команда каждой из этих программ хранится в соответствующем специальном регистре, они на фиг. 3 обозначены chdr. По этой причине эти команды выбираются не из памяти, а из этого специального регистра и экономится один такт, поэтому программа сразу начинается с выполнения такта 2 первой команды.
Программы узлов начинают выполняться строго по выдаче сигнала Restart из master-узла в slave-узлы. Завершается синхронное выполнение программ в узлах выдачей сигнала барьерной синхронизации из slave-узлов и какой-либо командой барьерной синхронизации в master-узле. В данном случае - это команда CycleRound r0. В приведенном примере, см. точку А, по этой команде происходит переход на метку NEWm, если счетчик циклов в r0 ненулевой, а также выдача сигнала Restart в slave-узел.
Обычно в одной ступени 12 выполняется несколько десятков циклов повторения таких программ в синхронном режиме, а команд в этих циклических программах также несколько десятков.
Основные особенности работы реконфигурируемого вычислительного модуля, определяющие его высокую производительность и энергоэффективность, определяются в отдельности и по совокупности архитектурными и микроархитектурными особенностями конвейерного ускорителя 11, состоящего из ступеней 12, а именно:
- конвейер 11 состоит из асинхронно работающих ступеней 12, содержащих узлы типа 28, 29, 30, параллельная работа каждого из которых, управляется программно командами из регистровых памятей малого объема, работающих в режиме clock-gating, применение таких памятей вносит существенный вклад в достижение высокой энергоэффективности, поскольку снижает накладные расходы на выборку команд;
- одна ступень 12 конвейера 11 может асинхронно от других ступеней выполнять многотактовый вычислительный процесс, реализуя некоторую сложную функцию, что позволяет реализовать в конвейере 11 алгоритмы с произвольным количеством вычислительных этапов и произвольной сбалансированности этапов по времени вычислений;
- функциональность узлов ступени 12 ограничена, специализирована и ортогональна по отношению друг к другу, что обеспечивает экономию оборудования, повышение производительности и энергоэффективности, большой запас модернизации узлов в отдельности из-за ортогональности их функций, особенности узлов:
- имеются несколько slave-узлов строго для вычислений над локализованными в них данными, причем, в отличие от обычных процессоров, регистровая память этих узлов иерерхическая, что обеспечивает экономию энергии при подготовке операндов команд к выполнению;
- имеется один master-узел, который кроме синхронизации работы узлов ступени 12 предназначен также для работы с модулем памяти 19 этой ступени, что позволяет разделить процессы с памятью 19 и вычислительные процессы в slave-узлах 29, таким образом, повышая производительность в сравнении с вариантом, когда оба процесса реализовались бы одной программой и вызывали бы взаимные блокировки выполнения команд друг у друга;
- имеется один slave-узел 30, предназначенный только для коммутации (динамической реконфигурации) входов/выходов узлов каждой ступени 12 через коммутатор 31 что позволяет без дополнительных затрат на реализацию протоколов взаимодействия реализовать передачу данных между узлами в ступени 12, а также усиливает свойства функциональной ортогональности узлов и возможности их модернизации в отдельности;
- основной режим работы узлов каждой ступени 12 синхронный, это упрощает планирование взаимодействий узлов через коммутатор 31 под управлением узла 30, однако для подготовки синхронного режима в ступени 12 и его завершения возможен асинхронный режим работы ступени 12, когда работает только мастер-узел 28.
ПРИМЕР ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Работу предлагаемого реконфигурируемого вычислительного модуля рассмотрим на примере реализации в ступени 12 конвейерного ускорителя 11 одной раундовой операции известного алгоритма обработки MD5. В этом алгоритме обработка информационного пакета (далее - М-блока) состоит из 4-х этапов, в каждом из которых выполняются 16 раундовых операций.
Для простоты будем считать, что реализуется зацикленная обработка М-блока в конвейерном устройстве 12, когда последняя ступень 12 соединена с первой ступенью 12 этого конвейера. В предлагаемом варианте реализации MD5 используются следующие три базовых решения.
Первое решение состоит в том, что на фоне вычисления в узлах 12 i-ой раундовой операции этапа, которое использует некоторое состояние регистров узлов ступени 12, производится подготовка состояния этих регистров для (i+1)-ой раундовой операции. Этот прием называется конвейеризацией циклов.
Второе решение состоит собственно в среднезернистом распараллеливании выполнения раундовой операции на узлах ступени 12. В вычислительном графе раунда, приведенном на фиг. 4, выделяются цепочки операций, которые отображаются в цепочки команд программ, выполняемых в синхронном режиме slave-узлами 29 и 30 (соответственно далее - FXU и SWC), а также master-узлом 28 (далее - mLWP). Начало такого режима инициируется из mLWP сигналом Restart в slave-узлы, а окончание режима происходит по барьерной синхронизации slave-узлов и master-узла. В master-узле mLWP выход в барьерную синхронизацию происходит по выполняемой в нем специальной команде CycleRound. В slave-узлах выход в барьерную синхронизацию производится автоматически по достижению конца программы.
Третье решение относится к распределению раундовых операций этапов MD5 по ступеням 12 конвейерного ускорителя 11. Последовательность раундовых операций разбивается на четыре группы в соответствии с количеством этапов MD5. Каждая из групп таких операций выполняется в одной ступени 12 последовательно. Для раундовых операций таких групп М-блок хранится в памяти MW-блока, именно оттуда выбираются 32-х разрядные фрагменты этого М-блока для вычислений в раундовых операциях. На фоне вычисления раундовых операций групп производится параллельная асинхронная передача обрабатываемого М-блока в следующую ступень 12, которая вычисляет раундовые операции следующей группы. Одновременно с этим в текущую ступень 12 принимается М-блок из предыдущей ступени 12 конвейера 11. Такие передачи производятся встроенными в MW-блок устройствами прямого доступа к памяти 22 и 23.
В данном варианте конвейерного ускорителя 11 имеются четыре ступени 12, поэтому для алгоритма MD5 одна группа раундовых операций -это один этап этого алгоритма, состоящий из 16-ти раундовых операций. За время их выполнения происходит передача М-блока из текущей ступени 12 в следующую ступень и прием в текущую ступень М-блока от предыдущей ступени конвейера.
Реализуемый в ступени 12 расширенный операциями подготовки данных вычислительный граф раундовой операции представлен на фиг. 4, в этом графе стрелками обозначены переходы между следующими операциями подготовки данных:
Ki+1 - выборка из К-таблицы констант 4-х байтовой памяти MW-блока константы для (i+1)-ой раундовой операции;
Si - выборка константы сдвига для i-й раундовой операции из S-таблицы, находящейся в байтовой памяти MW-блока;
J(i+1) - выборка индекса доступа к фрагменту М-блока для (i+1)-й раундовой операции;
MJ(i+1) - выборка фрагмента М-блока по индексу J(i+1) для (i+1)-й раундовой операции.
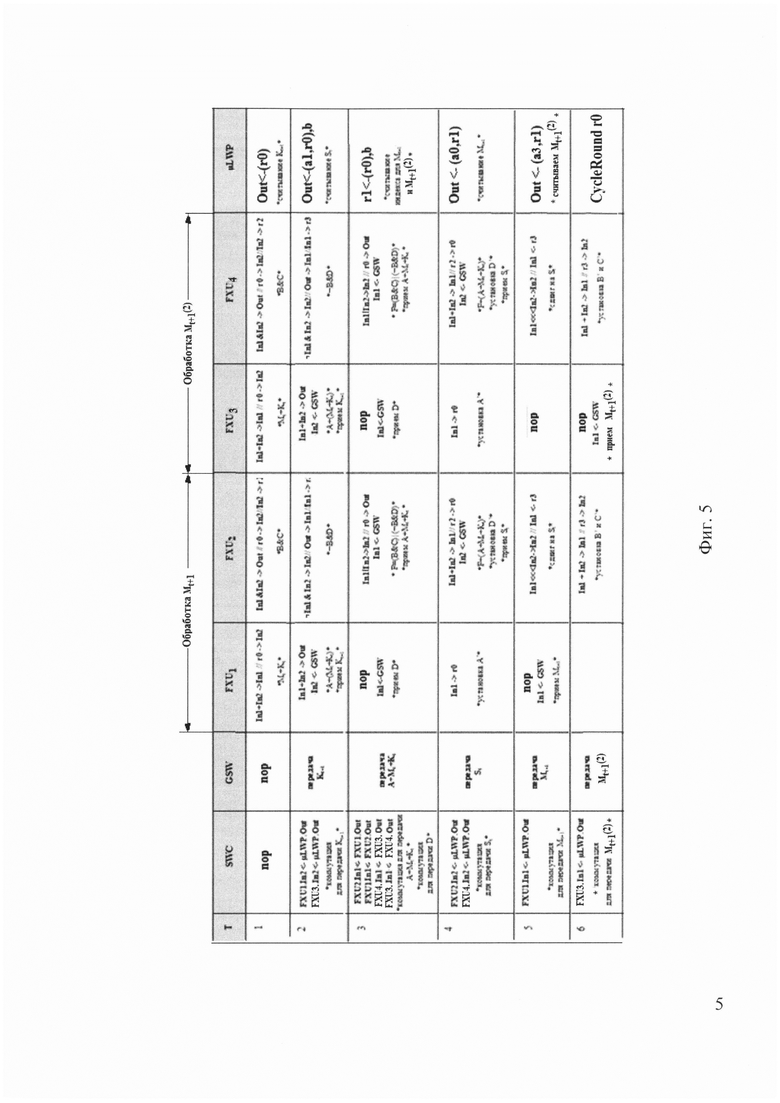
Приведенная на фиг. 6 программа обрабатывает одновременно два М-блока. Первый М-блок обрабатывается на подчиненных вычислительных узлах 29, называемых FXU1 и FXU2, а второй М-блок обрабатывается на узлах FXU3 и FXU4. Приведенные далее пояснения даны для узлов FXU1 и FXU2, для узлов FXU3 и FXU4 все аналогично. Программа для мастер-узла 28 (mLWP) для этих блоков общая.
Программа реализации алгоритма MD5 устроена так, что набор входных данных очередной раундовой операции всегда находится на регистрах. Эти входные данные обозначены в верхней части расширенного вычислительного графа, представленного на фиг. 4:
(i+1) - номер следующей раундовой операции, находится на регистре r0 master-узла mLWP, используется в качестве индекса при доступе к данным в памятях MW-блока;
MJ(i) - фрагмент М-блока, используемый в вычислении i-ой раундовой операции, он был взят по индексу J(i) и хранится на регистре In1 узла FXU1;
Ki - константа К, используемая в вычислении i-й раундовой операции, хранится на регистре In2 узла FXU1;
А - рабочая переменная, хранится на регистре r0 узла FXU1;
В - рабочая переменная, хранится на регистре In1 узла FXU2;
С - рабочая переменная, хранится на регистре In2 узла FXU2;
D - рабочая переменная, хранится на регистре r0 узла FXU2.
Программы реализации раундовой операции MD5, в соответствии с мелкозернистым распараллеливанием алгоритма ее выполнения представленном на фиг. 4, приведена на фиг. 5. Одна раундовая операция выполняется за 6 тактов, всего операций в раунде 16, поэтому выполнение одного этапа занимает 96 тактов. За это время получаются два результата обработки, по одному для каждого из одновременно обрабатываемых двух М-блоков. Таким образом на получение каждого результата приходится 48 тактов.
Выполнение раундовых операций конвейеризовано, поэтому время получения каждого результата обработки М-блока по алгоритму MD5 определяет темп получения этих результатов в конвейере, а, следовательно, производительность. Поскольку предлагаемый реконфигурируемый вычислительный модуль работает на частоте 1 ГГц, то производительность вычисляется как (1/48)×109=20.83 мрез/сек (миллионов результатов в секунду). В соответствии с протоколом синтеза САПР Cadence по RTL-модели на языке Verilog для предлагаемого вычислительного модуля и используемой технологии 40-45 нм TSMC были получены следующие оценки: мощность потребления 90 мВт при площади кристалла 0,6 мм2.
Проведем сравнение по энергоэффективности предлагаемого реконфигурируемого вычислительного модуля с устройствами аналогами и прототипом.
В таблице 1 приведены характеристики разных аппаратных платформ, а также развиваемая на них на алгоритме MD5 реальная производительность. Сведения по графическим процессорам GPU NVIDIA Titan X (GM100) приведены в работе (http://www.thg.ru/graphic/obzor_nvidia_titan_x_pascal), по AMD Radeon R9 Nano (Fiji XT) в (http://www.3dnews.ru/920417) и по реконфигурируемой СБИС Cryptoraptor в (Cryptoraptor : High Throughput Reconfigurable Cryptographic Processor. ICCAD 2014, 8 pp. http://users.ece.utexas.edu/~derek/Papers/ICCAD2014_Cryptoraptor.pdf). В таблице 1 приведены полученные оценки удельной производительности на единицу площади кристалла PF/S и удельная производительность на единицу потребляемой мощности PF/W.

Здесь PF - производительность,
S - занимаемая площадь кристалла,
Р - мощность потребления,
PF/S - удельная производительность на единицу площади кристалла,
PF/W - удельная производительность на единицу потребляемой мощности.
Из таблицы 1 следует, что предлагаемый реконфигурируемый вычислительный модуль имеет значительное увеличение приведенных удельных характеристик в сравнении с аналогами и прототипом.
Таким образом, вышеизложенные сведения позволяют сделать вывод, что предлагаемый реконфигурируемый вычислительный модуль решает поставленную задачу и соответствует заявляемому техническому результату - повышение энергоэффективности, за счет увеличения удельных производительностей на единицу мощности потребления и на единицу площади.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОСТАДИЙНОЙ МНОГОПОТОЧНОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2681365C1 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ ЯДРО | 2023 |
|
RU2819403C1 |
| МНОГОПРОЦЕССОРНАЯ ВЕКТОРНАЯ ЭВМ | 1995 |
|
RU2113010C1 |
| Вычислительный модуль и способ обработки с использованием такого модуля | 2018 |
|
RU2689433C1 |
| Способ распределения данных по многофункциональным блокам процессора со сверхдлинной командной строкой | 2024 |
|
RU2818498C1 |
| РЕКОНФИГУРИРУЕМАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2017 |
|
RU2677363C1 |
| Способ временной синхронизации работы вычислительной системы с реконфигурируемой архитектурой | 2023 |
|
RU2820034C1 |
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2618367C1 |
| Архитектура параллельной вычислительной системы | 2016 |
|
RU2644535C2 |
| МНОГОПРОЦЕССОРНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2012 |
|
RU2502126C1 |


Изобретение относится к области вычислительной техники. Технический результат заключается в повышении удельных производительностей на единицу мощности потребления и на единицу площади. Реконфигурируемый вычислительный модуль, подключаемый к внутрикристальной кольцевой сети, содержит макроблок контроллера , макроблок динамически реконфигурируемого процессора, причем макроблок контроллера содержит процессорное ядро соединенное с блоком памяти и адаптер подключения к внутрикристальной сети, макроблок динамически реконфигурируемого процессора содержит переключатель каналов, блок приема и дешифрации команд, драйвер, включающий блок сегментов входной и выходной очереди, дуплексный канал и конвейерный ускоритель, содержащий N динамически реконфигурируемых ступеней, каждая из которых содержит модуль памяти, мастер-узел (master) управления, подчиненные (slave) вычислительные узлы и узел динамического управления реконфигурацией соединений и коммутатор, объединенные сервисной сетью, три локальные памяти команд и память кодов множественных коммутаций. 1 табл., 5 ил.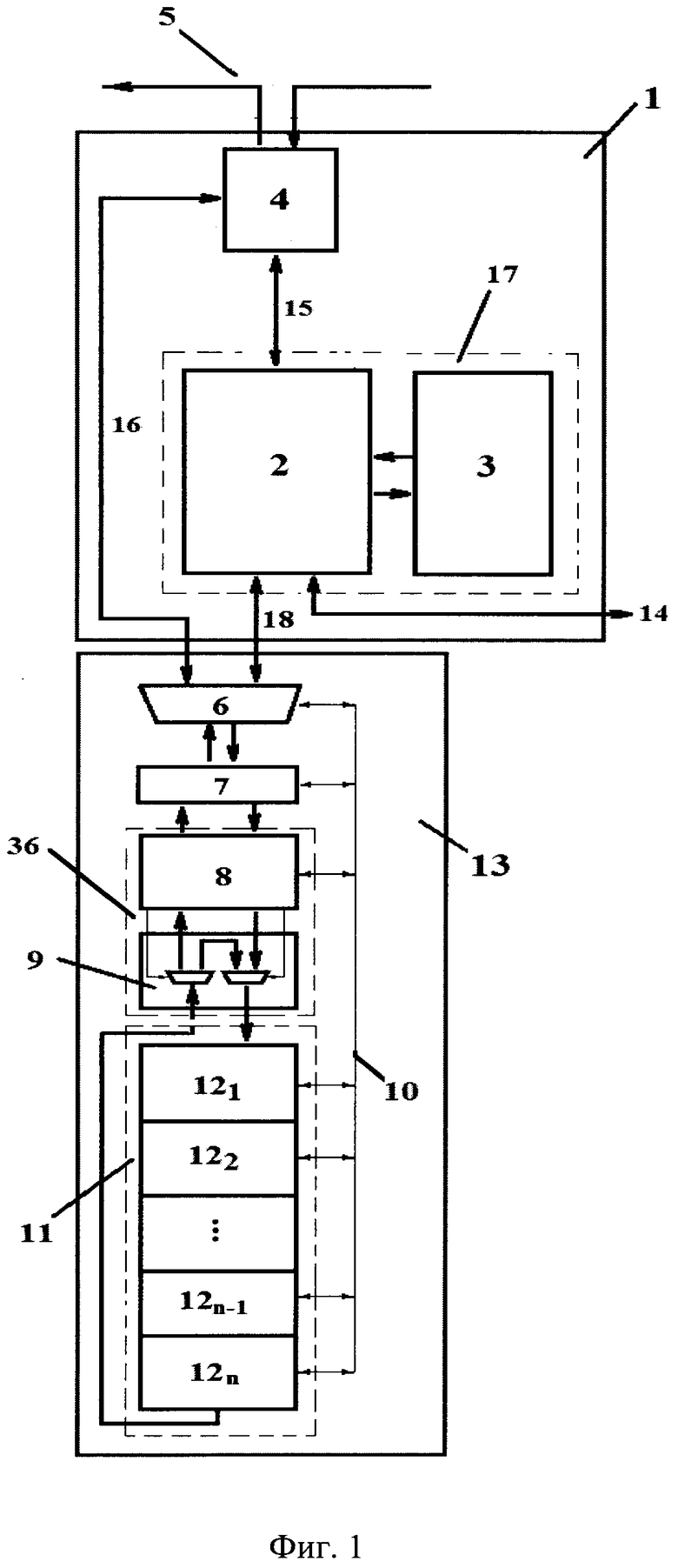
Реконфигурируемый вычислительный модуль, подключаемый к внутрикристальной кольцевой сети 5, содержащий макроблок контроллера 1, макроблок динамически реконфигурируемого процессора 13, причем макроблок контроллера 1 содержит процессорное ядро 2, соединенное с блоком статической памяти 3, образующие функциональный блок 17, адаптер 4, который соединен с внутрикристальной кольцевой сетью 5, а также с процессорным ядром 2 по последовательному интерфейсу UART 15, макроблок динамически реконфигурируемого процессора 13 содержит конвейерный ускоритель 11 и последовательно соединенные двунаправленными шинами переключатель каналов сервисных и информационных команд 6, блок приема и дешифрации команд 7, драйвер 36, включающий блок сегментов входной и выходной очереди 8 и дуплексный канал с изменяемой маршрутизацией информационных пакетов 9, второй выход и второй вход которого соединены соответственно с входом и выходом конвейерного ускорителя 11, которые соединены друг с другом через дуплексный канал 9 напрямую, при этом конвейерный ускоритель 11 содержит N динамически реконфигурируемых ступеней 12, соединенных между собой связями 24-27, а также переключатель каналов 6, блок приема и дешифрации команд 7, блок сегментов входной и выходной очереди 8 и N динамически реконфигурируемых ступеней 12 объединены сервисной сетью 10, кроме того, переключатель каналов 6 соединен с адаптером 4 по первому двунаправленному параллельному интерфейсу 16 и по второму двунаправленному параллельному интерфейсу 18 с процессорным ядром 2, которое также имеет порт подключения по интерфейсу JTAG 14 к хост-процессору, при этом каждая из N динамически реконфигурируемых ступеней 12 содержит модуль памяти 19, мастер-узел управления и работы с памятью 28, четыре подчиненных вычислительных узла 29 с первой локальной памятью команд 33 у каждого, подчиненный узел динамического управления реконфигурацией соединений 30, со второй локальной памятью команд 34 и памятью кодов множественных коммутаций 38, которые объединены сервисной сетью 10 и коммутатор конвейерной ступени 31, причем модуль памяти 19, состоит из четырехпортовой двухбанковой регистровой памяти с расслоением четырехбайтовых слов 20, регистровой однопортовой памяти байтов 21 и блока дешифрации и управления выполнением операций 37, и имеет входное устройство прямого доступа на запись 22 и выходное устройство прямого доступа на чтение 23, вход которого соединен с первым выходом чтения регистровой памяти четырехбайтовых слов 20, а выход устройства 23 является первым выходом данных 25 ступени 12, вход устройства 22 является первым входом 24 ступени 12, а выход устройства 22 соединен с первым входом записи регистровой памяти четырехбайтовых слов 20, второй выход чтения и второй вход записи регистровой памяти четырехбайтовых слов 20 соединены с блоком дешифрации и управления выполнением операций 37, который также соединен с регистровой памятью байтов 21 и первым входом и первым выходом мастер-узла управления 28, который содержит третью локальную память команд 35, второй вход мастер-узла управления 28 является вторым входом сигнала готовности 26 ступени 12, а второй выход мастер-узла управления 28 является вторым выходом сигнала готовности 27 ступени 12, мастер-узел управления 28 двунаправленной шиной соединен с коммутатором 31 и двунаправленной сигнальной шиной 32 соединен с подчиненными вычислительными узлами 29 и подчиненным узлом динамического управления реконфигурацией соединений 30, выход которого соединен с коммутатором 31, который двунаправленными шинами соединен с подчиненными вычислительными узлами 29.
| ИСПОЛНИТЕЛЬНЫЙ КЛАПАН С ПНЕВМАТИЧЕСКИМ ПРИНУДИТЕЛЬНЫМ ЗАПИРАНИЕМ | 0 |
|
SU168565A1 |
| Устройство для нанесения маркировочных красочных знаков, например, на эластичные трубки | 1960 |
|
SU139326A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| US 7213148 B2, 01.05.2007 | |||
| Бортовая литая алюминиевая шина для цинкоэлектролитных ванн | 1961 |
|
SU144357A1 |

