ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области вычислительной техники, в частности к вычислительным устройствам с многопотоковой архитектурой, и может быть использована в высокопроизводительных вычислительных системах, предназначенных для решения трудоемких задач из области криптографии, математической физики и информационного поиска, с использованием распараллеливания большого числа вычислительных потоков.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Известен ускоритель Nvidia GeForce GTX серии 10 (Danskin J. M. et al. Parallel array architecture for a graphics processor. Патент US 8730249 (B2). МПК G06F 12/02, G06F 15/80, G06T 1/20, G06T 15/00, G09G 5/36 опубликован 2014, htty://international.download.nvidia.com/international/pdfs/GeForce_GTX_1080_Whitepaper_FINAL.pdf). Ускоритель содержит 1152-3584 скалярных процессоров (ядер с архитектурой CUDA - Compute Unified Device Architecture), ориентированных на выполнение вычислений в задачах трехмерной графики. Ускоритель состоит из нескольких потоковых мультипроцессоров, каждый из которых содержит вычислительные устройства и суперфункциональные блоки. Также ускоритель содержит память, подразделяемую на глобальную, локальную, разделяемую и память констант.
Недостатком ускорителя Nvidia GeForce GTX является избыточность вычислительных ресурсов при реализации алгоритмов, не характерных для задач трехмерной графики. Также недостатком данного ускорителя является отсутствие аппаратной поддержки для мелкозернистой синхронизации работы потоков.
Известна вычислительная система Cray ХМТ (Designing Next-Generation Massively Multithreaded Architectures for Irregular Applications ISSN: 0018-9162), которая состоит из набора процессоров с архитектурой Threadstorm, поддерживающих выполнение с чередованием потоков, и коммуникационной сети, объединяющей процессоры с блоками разделяемой памяти. Синхронизация потоков обеспечивается за счет использования тегов, добавляемых к каждому слову памяти.
Недостатком вычислительной системы Cray ХМТ является отсутствие в процессоре Threadstorm поддержки одновременного выполнения потоков.
Наиболее близким устройством того же назначения к заявленному изобретению по совокупности признаков является, принятый за прототип, процессор для массово-параллельных вычислений Intel Xeon Phi Knights Landing (Sodani A. et al. Knights Landing: Second-Generation Intel Xeon Phi Product ISSN: 0272-1732), который содержит 8 контроллеров общей памяти и матрицу из ячеек, каждая их которых состоит из 2 процессорных ядер, 2 векторных ускорителей и единой для ячейки кэш-памяти второго уровня размером 1 Мбайт. Ячейки матрицы объединены коммуникационной сетью с поддержкой когерентности распределенной кэш-памяти и топологией решетки.
Недостатком процессора Knights Landing является число параллельных потоков вычислений, ограниченное требованиями поддержки когерентности распределенной кэшпамяти. Кроме того, в архитектуре процессора Knights Landing отсутствуют высокоуровневые механизмы для синхронизации работы потоков.
ЗАДАЧА ИЗОБРЕТЕНИЯ
Задачей, на решение которой направлено предлагаемое изобретение, является создание вычислительного модуля, предназначенного для ускорения расчетов при решении трудоемких вычислительных задач с использованием большого числа параллельно выполняемых вычислительных потоков.
Возможным техническим результатом, достигаемым при работе предлагаемого вычислительного модуля, является повышение производительности его работы при многопотоковых вычислениях. Для этого используются сотни упрощенных процессорных ядер, которые снабжены локальными памятями, объединены коммуникационной сетью и имеют доступ к внешней общей памяти посредством контроллера общей памяти. Контроллер общей памяти обеспечивает синхронизацию работы вычислительных потоков, исполняемых на упрощенных процессорных ядрах, используя теги, добавляемые к каждому слову данных.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Указанный возможный технический результат, достигаемый при осуществлении изобретения, состоит в том, что
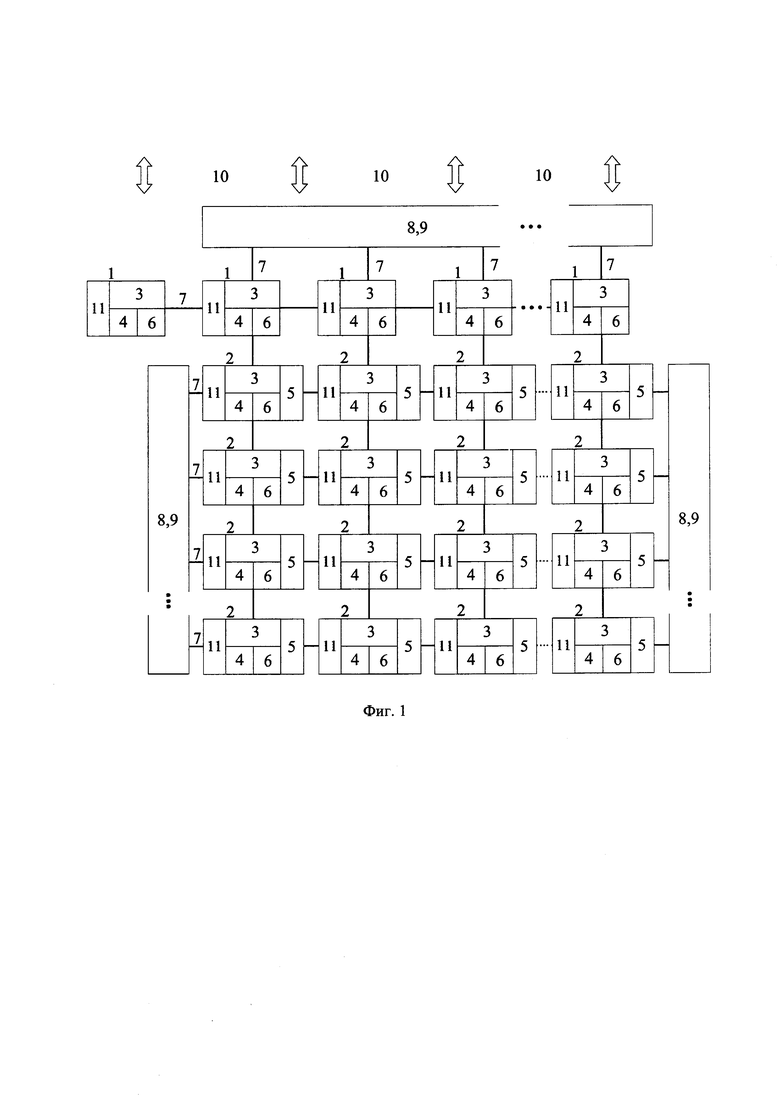
в вычислительный модуль, содержащий процессорные ядра 1 и 2 с упрощенной целочисленной RISC-архитектурой, группу из K коммуникационных подсетей 7, а также группу из Р контроллеров общей памяти 8, дополнительно введены специализированные для конкретной области задач сопроцессоры 5, которые подключены к группе вычислительных процессорных ядер 2,
в состав процессорного ядра, аппаратно реализующего поток вычислений, входит локальное ОЗУ 3, в котором содержится стек выполняемого потока вычислений и буфер сообщений коммуникационной сети, ПЗУ 6, АЛУ 11 и кэш-память команд 4, управляемая программно,
управляющие процессорные ядра 1, не задействованные в вычислительных задачах, выполнены с возможностью реализации задач по распределению потоков по процессорным ядрам и по программной маршрутизации сообщений между коммуникационными подсетями 7, внутри которых аппаратно реализуется передача данных между процессорными ядрами,
контроллеры общей памяти 8 подключены через коммуникационную сеть 7 к процессорным ядрам 1 и 2 и блокам внешней общей памяти 9, которая доступна процессорным ядрам как общий ресурс,
при этом контроллер общей памяти выполнен с возможностью синхронизации потоков вычислений на уровне обращений к внешней общей памяти с помощью тегов, добавляемых к каждому слову данных, а также с возможностью поддержки следующих операций: атомарный инкремент заданного слова данных, копирование областей памяти, перенос данных из внешней общей памяти в локальную память заданного процессорного ядра, заполнение заданного участка памяти заданным значением и команды векторной адресации.
Способ многопотоковой обработки цифровых данных, реализуемый с помощью вычислительного модуля, учитывающий конструктивные особенности устройства, решается поэтапно:
загрузочное процессорное ядро, выделенное для выполнения управляющих функций и имеющее периферийный интерфейс 10 для осуществления загрузки программ из внешнего источника, загружает программу через коммуникационную сеть, с помощью которой фрагменты программы записываются в области кэш-памяти команд отдельных процессорных ядер, а также в блоки внешней общей памяти посредством контроллера общей памяти;
осуществляется запуск главного потока программы на загрузочном процессорном ядре и этот поток с помощью коммуникационной сети передает сообщения остальным управляющим процессорным ядрам, которые, в свою очередь, управляют запуском потоков вычислений на процессорных ядрах;
потоковые вычисления, выполняемые по программе в процессорных ядрах, производят обращения к локальным памятям или к внешней общей памяти, между процессорными ядрами осуществляются операции обмена, в том числе с использованием механизма синхронизации потоков, предоставляемого контроллером общей памяти. При этом управляющие процессорные ядра распределяют потоки по процессорным ядрам, а также занимаются маршрутизацией сообщений между коммуникационными подсетями;
контроль потоков вычислений, а также получение результатов выполняются загрузочным процессорным ядром.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг. 1 представлена схема предлагаемого вычислительного модуля, для которой приняты следующие обозначения:
1 - группа из М управляющих процессорных ядер,
2 - группа из N вычислительных процессорных ядер,
3 - группа из N+M локальных памятей данных,
4 - группа из N+M локальных кэш-памятей команд,
5 - группа из N специализированных сопроцессоров,
6 - группа из N+M локальных ПЗУ,
7 - группа из K коммуникационных подсетей,
8 - группа из Р контроллеров общей памяти,
9 - группа из Р блоков внешней общей памяти,
10 - группа из L периферийных интерфейсов,
11 - группа из N+M АЛУ.
Предлагаемый вычислительный модуль осуществляется следующим образом.
Вычислительный модуль содержит матрицу процессорных ядер, среди которых имеется N процессорных ядер, ориентированных на вычислительные задачи, и М управляющих процессорных ядер, запрограммированных на задачи управления.
Каждое из процессорных ядер содержит АЛУ, локальную память данных, локальную кэш-память команд и локальное ПЗУ. Процессорные ядра, ориентированные на вычислительные задачи, содержат специализированный сопроцессор. Процессорные ядра соединены между собой с помощью группы из К коммуникационных подсетей, а также соединены с блоками внешней общей памяти через контроллеры общей памяти.
Одно из управляющих процессорных ядер имеет периферийный интерфейс, который служит для загрузки программы в вычислительный модуль из внешнего источника.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Принцип работы устройства состоит в следующем.
Трудоемкие задачи из области криптографии, математической физики и информационного поиска, на решение которых ориентирован предлагаемый вычислительный модуль, отличаются высокой степенью параллелизма данных и параллелизма задач, что позволяет разбить процесс вычислений на множество взаимодействующих вычислительных потоков.
Реализация трудоемких вычислительных задач на предлагаемом вычислительном модуле предусматривает разбиение программы на управляющую часть, в которой осуществляется динамическое управление работой вычислительных потоков, и вычислительную часть, относящуюся к выполнению тел потоков на отдельных процессорных ядрах и специализированных сопроцессорах. При этом взаимодействие между потоками осуществляется с помощью сообщений, передаваемых по коммуникационной сети, а также с помощью обращений к общей памяти, ячейки которой снабжены тегами "занято"/"свободно".
Программа, предназначенная для выполнения на вычислительном модуле, загружается из внешнего источника с помощью периферийного интерфейса, подключенного к одному из управляющих процессорных ядер. В процессе загрузки фрагменты программы с использованием коммуникационной сети записываются в кэш-памяти команд отдельных процессорных ядер, а также в блоки внешней общей памяти с использованием контроллера общей памяти. Далее происходит запуск управляющей части программы, выполняемой на группе управляющих процессорных ядер. В процессе работы управляющей части программы инициируется запуск отдельных потоков на вычислительных процессорных ядрах и специализированных сопроцессорах, осуществляется маршрутизация сообщений между коммуникационными подсетями, при необходимости осуществляется динамическое планирование распределения вычислительной нагрузки между вычислительными процессорными ядрами.
Контроль за выполнением вычислений, осуществляемый вычислительным модулем, а также получение результатов осуществляются внешним устройством с помощью обращений к периферийному интерфейсу загрузочного процессорного ядра.
Предлагаемый вычислительный модуль работает следующим образом.
Процесс загрузки программы осуществляется с помощью процедуры, записанной в локальном ПЗУ загрузочного процессорного ядра. При этом фрагменты программы с использованием коммуникационной сети записываются в кэш-памяти команд отдельных процессорных ядер.
В процессе работы программы процессорные ядра используют локальную память данных, в которой хранится стек потока и буфер сообщений, который связан с распределенным маршрутизатором коммуникационной сети, который подключен к каждому процессорному ядру.
Управляющие процессорные ядра осуществляют вызов готовых к исполнению потоков на вычислительных процессорных ядрах и осуществляют динамическое планирование распределения вычислительной нагрузки между вычислительными процессорными ядрами таким образом, что общее число используемых программой вычислительных потоков может превышать число параллельно исполняемых в данный момент потоков на вычислительных процессорных ядрах и специализированных сопроцессорах.
Управляющие процессорные ядра осуществляют программную маршрутизацию сообщений между коммуникационными подсетями, к которым подключены группы вычислительных процессорных ядер. Внутри отдельной коммуникационной подсети передача сообщений осуществляется аппаратным образом с коммутацией пакетов.
Контроллеры общей памяти подключены через коммуникационную сеть к процессорным ядрам и блокам внешней общей памяти, которая доступна процессорным ядрам как общий ресурс. Контроллер общей памяти реализует синхронизацию потоков вычислений на уровне обращений к внешней общей памяти с помощью тегов "занято"/"свободно", добавляемых к каждому слову данных, а также контроллер общей памяти поддерживает такие операции, как атомарный инкремент заданного слова данных, копирование областей памяти и перенос данных из внешней общей памяти в локальную память заданного процессорного ядра, заполнение заданного участка памяти заданным значением и команды векторной адресации.
ОПИСАНИЕ ПРИМЕРОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Предлагаемый вычислительный модуль может быть выполнен на базе ПЛИС Xilinx XC7V585. В состав реализованного вычислительного модуля входит 30 процессорных ядер, работающих на частоте 62,5 МГц, контроллер общей памяти и коммуникационная сеть, работающая на частоте 250 МГц. В качестве блоков внешней общей памяти, а также локальных памятей данных, локальных кэш-памятей команд и локальных ПЗУ процессорных ядер используется блочная память ПЛИС. Интерфейс связи с внешним устройством предоставляет возможность обращений к внешней общей памяти, а также загрузки программ.
Для оценки производительности предлагаемого вычислительного модуля и устройства-прототипа при решении задачи, использующей множественные обращения процессорных ядер к внешней общей памяти в качестве тестового примера возьмем случайные обращения к внешней общей памяти с использованием программного теста Global RandomAccess, входящего в НРС Challenge Awards Competition (http://www.hpcchallenge.org/), в котором результаты измеряются в GUPS (giga-updates per second, гига-обновления в секунду).
Результаты работы предлагаемого вычислительного модуля с использованием данного теста показывают, что на одну итерацию теста у единственного процессорного ядра уходит 200 тактов. При этом 20 параллельно работающих процессорных ядер достаточно для достижения предела пропускной способности блочной памяти ПЛИС. Это соответствует производительности 6.25 MUPS (мега-обновлений в секунду).
Устройство-прототип процессор Xeon Phi Knighs Landing, который содержит 64 процессорных ядра с тактовой частотой 1.3 ГГц, в тесте Global RandomAccess имеет производительность до 1.1 GUPS (Peng I. В. et al. Exploring the performance benefit of hybrid memory system on HPC environments //Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2017 IEEE International. - IEEE, 2017. - C. 683-692, рис. 4 (с)).
Для сравнения производительности предлагаемого вычислительного модуля с устройством-прототипом процессором Xeon Phi Knighs Landing в тесте Global RandomAccess использовано моделирование характеристик коммуникационной сети и контроллеров общей памяти предлагаемого вычислительного модуля в гипотетической конфигурации с 250 процессорными ядрами, работающими на тактовой частоте 1 ГГц, без учета ограничений пропускной способности блоков внешней общей памяти. Результат моделирования производительности предлагаемого вычислительного модуля достигает 1.25 GUPS.
В отличие от устройства-прототипа, возможности масштабируемости архитектуры которого ограничены требованиями поддержки когерентности распределенной кэш-памяти, предлагаемый вычислительный модуль позволяет достичь большой производительности путем увеличения количества процессорных ядер.
Вышеизложенные сведения позволяют сделать вывод, что предлагаемый вычислительный модуль и способ многопотоковой обработки цифровых данных, реализуемый с помощью вычислительного модуля, решают поставленную задачу - создание устройства для решения трудоемких вычислительных задач из области криптографии, математической физики и информационного поиска, а также соответствует заявляемому техническому результату - повышение производительности многопотоковых вычислений.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОСТАДИЙНОЙ МНОГОПОТОЧНОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2681365C1 |
| МОДУЛЬ СОПРОЦЕССОРА КЭША | 2011 |
|
RU2586589C2 |
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ПРОГРАММНО-АППАРАТНОГО КОМПЛЕКСА | 2016 |
|
RU2618367C1 |
| Вычислительный модуль и способ обработки с использованием такого модуля | 2018 |
|
RU2689433C1 |
| Малогабаритный высокопроизводительный вычислительный модуль на базе многопроцессорной Системы-на-Кристалле | 2021 |
|
RU2778213C1 |
| НЕЧУВСТВИТЕЛЬНЫЙ К ЗАДЕРЖКЕ БУФЕР ТРАНЗАКЦИИ ДЛЯ СВЯЗИ С КВИТИРОВАНИЕМ | 2014 |
|
RU2598594C2 |
| Специализированная вычислительная система, предназначенная для вывода в глубоких нейронных сетях, основанная на потоковых процессорах | 2022 |
|
RU2793084C1 |
| Реконфигурируемый вычислительный модуль | 2018 |
|
RU2686017C1 |
| СПОСОБ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ИНФОРМАЦИИ В ГЕТЕРОГЕННОЙ МНОГОПРОЦЕССОРНОЙ СИСТЕМЕ НА КРИСТАЛЛЕ (СнК) | 2022 |
|
RU2790094C1 |
| СПОСОБ, УСТРОЙСТВО И СИСТЕМА ДЛЯ ПРЕДВАРИТЕЛЬНОЙ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ СЕНСОРНЫХ ДАННЫХ И УПРАВЛЕНИЯ ОБЛАСТЯМИ ИЗОБРАЖЕНИЯ | 2013 |
|
RU2595760C2 |
Изобретение относится к области вычислительной техники, в частности к вычислительным устройствам с многопотоковой архитектурой. Техническим результатом является повышение производительности вычислительного модуля за счет обеспечения синхронизации работы вычислительных потоков, исполняемых на процессорных ядрах. Вычислительный модуль содержит группу из N вычислительных процессорных ядер 1, группу из М управляющих процессорных ядер 2, группу из N локальных памятей данных 3, группу из N локальных кэш-памятей команд 4, группу из N специализированных сопроцессоров 5, группу из N локальных ПЗУ 6, группу из N коммуникационных подсетей 7, группу из N контроллеров общей памяти 8, группу из N блоков внешней общей памяти 9, группу из N периферийных интерфейсов 10. Способ обработки данных описывает работу вычислительного модуля. 2 н.п. ф-лы, 1 ил.
1. Вычислительный модуль для многопотоковой обработки цифровых данных, содержащий процессорные ядра 1 и 2 с упрощенной целочисленной RISC-архитектурой, группу из K коммуникационных подсетей 7, а также группу из Р контроллеров общей памяти 8,
дополнительно введены специализированные для конкретной области задач сопроцессоры 5, которые подключены к группе вычислительных процессорных ядер 2,
в состав процессорного ядра, аппаратно реализующего поток вычислений, входит локальное ОЗУ 3, в котором содержится стек выполняемого потока вычислений и буфер сообщений коммуникационной сети, ПЗУ 6, АЛУ 11 и кэш-память команд 4, управляемая программно,
при этом управляющие процессорные ядра 1, не задействованные в вычислительных задачах, выполнены с возможностью реализации задач по распределению потоков по процессорным ядрам и по программной маршрутизации сообщений между коммуникационными подсетями 7, внутри которых аппаратно реализуется передача данных между процессорными ядрами,
контроллеры общей памяти 8 подключены через коммуникационную сеть 7 к процессорным ядрам 1 и 2 и блокам внешней общей памяти 9, которая доступна процессорным ядрам как общий ресурс,
при этом контроллер общей памяти выполнен с возможностью синхронизации потоков вычислений на уровне обращений к внешней общей памяти с помощью тегов, добавляемых к каждому слову данных, а также с возможностью поддержки следующих операций: атомарный инкремент заданного слова данных, копирование областей памяти, перенос данных из внешней общей памяти в локальную память заданного процессорного ядра, заполнение заданного участка памяти заданным значением и команды векторной адресации.
2. Способ многопотоковой обработки цифровых данных, реализуемый с помощью модуля по п. 1, содержащий этапы: загружают программу, предназначенную для выполнения на вычислительном модуле, из внешнего источника с помощью периферийного интерфейса, подключенного к одному из управляющих процессорных ядер;
записывают фрагменты программы через коммуникационную сеть в области кэш-памяти команд отдельных процессорных ядер, а также в блоки внешней общей памяти посредством контроллера общей памяти;
осуществляется запуск управляющей части программы, выполняемой на группе управляющих процессорных ядер, не задействованных в вычислительных процессах;
причем управляющие процессорные ядра выполнены с возможностью реализации задач по распределению вычислительных потоков по процессорным ядрам и по маршрутизации сообщений между коммуникационными подсетями, внутри которых аппаратно реализуется передача данных между процессорными ядрами;
в процессе работы процессорные ядра используют локальную память данных, в которой хранят стек потока и буфер сообщений;
контроль потоков вычислений, а также получение результатов выполняются загрузочным процессорным ядром.
| Высокопроизводительная вычислительная платформа на базе процессоров с разнородной архитектурой | 2016 |
|
RU2635896C1 |
| Архитектура параллельной вычислительной системы | 2016 |
|
RU2644535C2 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| US 6230252 B1, 08.05.2001. | |||

