ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области вычислительной техники и может быть применено для высокопроизводительных вычислений при решении трудоемких вариативных задач дискретной математики, которые отличаются многократным повторением последовательностей целочисленных операций, производимых с независимыми блоками данных, размером до нескольких килобайт.
ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ
Известен ускоритель Nvidia GeForce GTX серии 10 (Danskin J.M. et al. Parallel array architecture for a graphics processor. Патент US 8730249 (B2). МПК G06F 12/02, G06F 15/80, G06T 1/20, G06T 15/00, G09G 5/36 опубликован 2014, http://international.download.nvidia.com/geforce-com/international/pdfs/GeForce_GTX_1080_-Whitepaper_FINAL.pdf). Ускоритель содержит 1152-3584 скалярных процессоров (ядер с архитектурой CUDA - Compute Unified Device Architecture), ориентированных на выполнение вычислений в задачах трехмерной графики. Ускоритель состоит из нескольких потоковых мультипроцессоров, каждый из которых содержит вычислительные устройства и суперфункциональные блоки. Также ускоритель содержит память, подразделяемую на глобальную, локальную, разделяемую и память констант.
Недостатком ускорителя Nvidia GeForce GTX является избыточность вычислительных ресурсов при решении вариативных задачах дискретной математики, так как вычислительные устройства ускорителя Nvidia GeForce GTX ориентированы на выполнение алгоритмов, характерных для задач трехмерной графики и обеспечивают поддержку операций с числами с плавающей запятой. Также недостатком данного ускорителя является большая задержка при доступе к памяти, не являющейся локальной по отношению к соответствующим скалярным процессорам.
Наиболее близким устройством того же назначения к заявленному изобретению по совокупности признаков является, принятый за прототип, высокопроизводительный криптографический процессор Cryptoraptor (Gokhan Sayilar, Derek Chiou. Cryptoraptor: High Throughput Reconfigurable Cryptographic Processor ISBN: 978-1-4799-6277-8), который содержит матрицу из 80 процессорных элементов, автомат управления, который имеет счетчик состояний и управляющую память, а также регистровый файл, состоящий из 256 32-разрядных слов. При этом матрица процессорных элементов состоит из 20 ступеней конвейера, каждая ступень которого содержит 4 параллельно работающих процессорных элемента. Также матрица процессорных элементов содержит 19 полных коммутаторов, которые имеют память конфигураций, для осуществления связей между выходами ступени i и входами ступени i+1. Процессорный элемент содержит целочисленные функциональные узлы, память управляющих сигналов, определяющую работу функциональных узлов, а также 3 блока локальной памяти по 1024 байт и 1 блок локальной памяти размером 4096 байт. Доступ к регистровому файлу с 80 портами считывания и 8 портами записи разделяется между всеми процессорными элементами.
Перед началом работы, с помощью автомата управления, в память управляющих сигналов процессорных элементов загружаются данные, задающие работу функциональных узлов внутри процессорных элементов, а также загружаются данные в память конфигураций полных коммутаторов, определяющие связи между процессорными элементами соседних слоев. В блоки локальной памяти загружаются табличные данные. В процессе вычислений автомат управления производит переконфигурацию процессорных элементов и связей между ними, если этого требует реализуемый алгоритм. Регистровый файл используется для хранения промежуточных и результирующих данных.
Недостатком криптографического процессора Cryptoraptor является малое число параллельных потоков вычислений (до 4 потоков). Кроме того, автомат управления процессора Cryptoraptor не поддерживает многократное повторение последовательностей операций. Процессор Cryptoraptor также отличается избыточностью аппаратных средств, к которым относятся блоки локальной памяти большого объема, соединенные с каждым процессорным элементом и общий регистровый файл, к которому подключены все процессорные элементы.
ЗАДАЧА ИЗОБРЕТЕНИЯ
Задача, на решение которой направлено предлагаемое изобретение, заключается в создании вычислительного модуля и способа обработки данных, предназначенных для ускорения расчетов при решении вариативных задач из области дискретной математики, которые отличаются многократным повторением последовательностей целочисленных операций, производимых с независимыми блоками данных, размером до нескольких килобайт. Данные задачи эффективно реализуются с помощью большого числа вычислительных потоков, функционирующих по одному алгоритму, с независимыми блоками данных.
Техническим результатом изобретения является повышение производительности многопотоковых вычислений в вариативных задачах дискретной математики за счет параллельной работы специализированных процессорных элементов по общей программе с независимыми блоками данных.
КРАТКОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
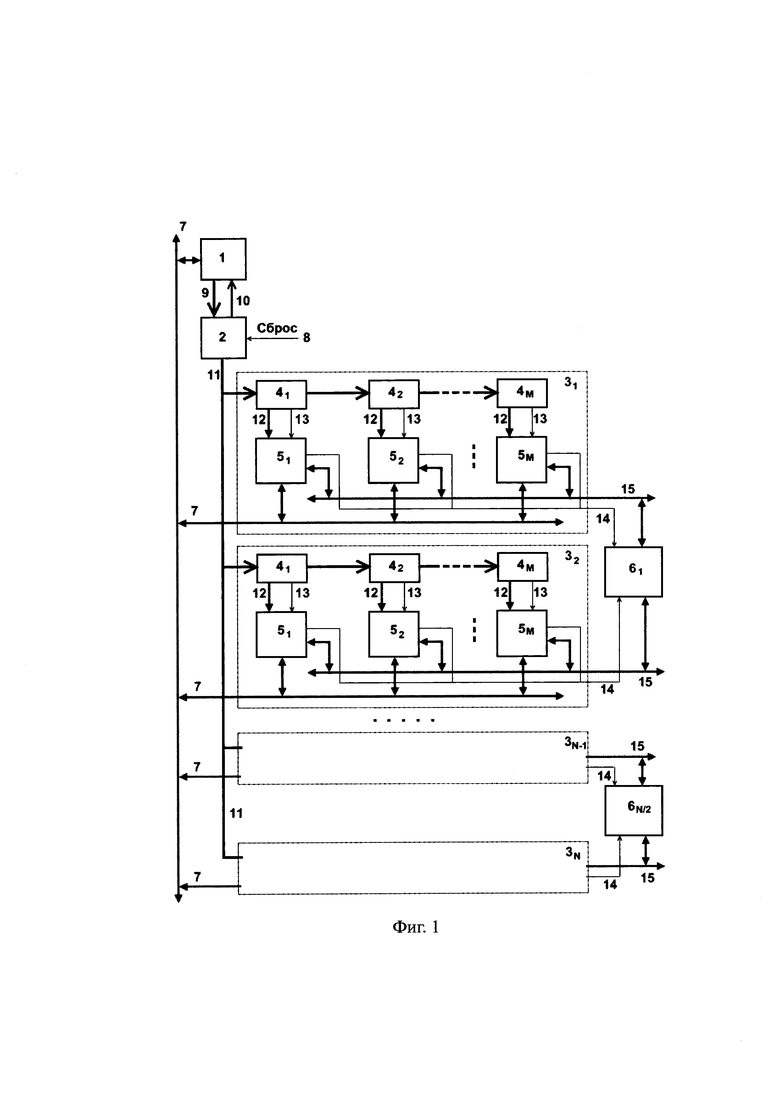
Указанный технический результат при осуществлении изобретения достигается тем, что в вычислительный модуль для многопотоковой обработки цифровых данных содержащий процессорные элементы 5,
дополнительно введены двухпортовая память команд 1, устройство управления 2, группа из N вычислительных блоков 31, 32, …, 3N, каждый из которых содержит группу из М регистров команды 41, 42, …, 4M и группу из М процессорных элементов 51, 52, …, 5M, группа из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2, двунаправленная шина обмена с внешним устройством 7, внешний вход сброса 8 и внешний вход синхронизации CLK,
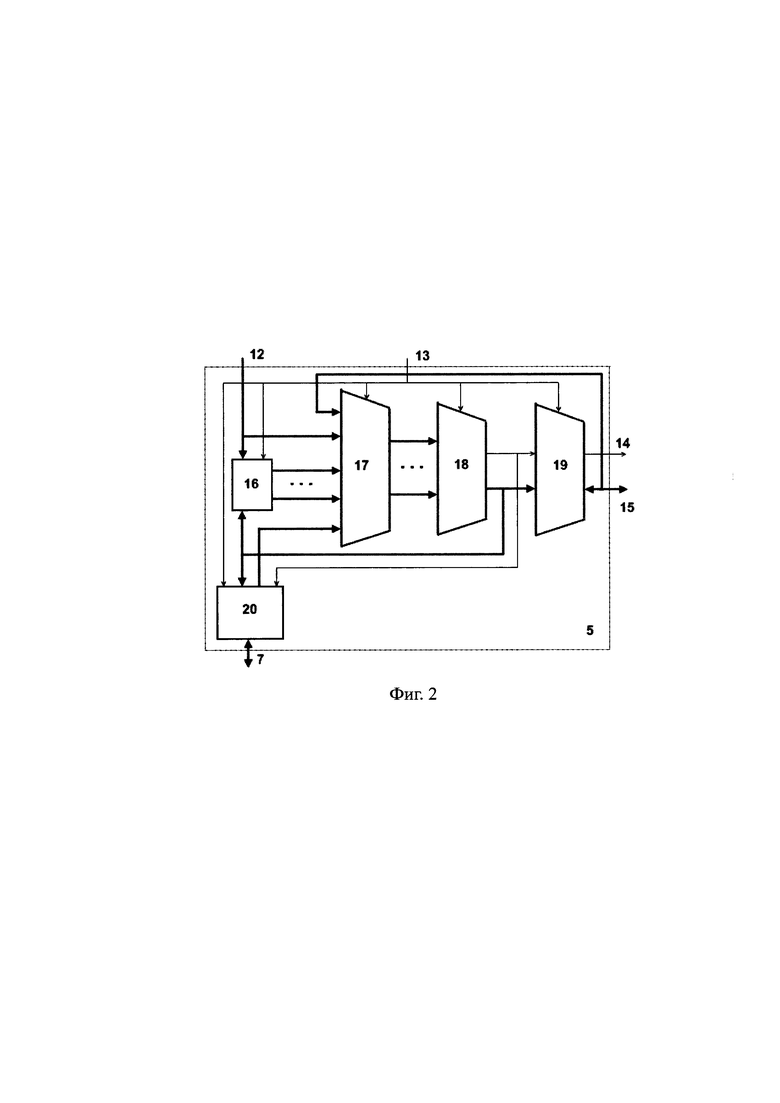
кроме того, в каждый процессорный элемент 5 введены R-портовая регистровая память 16, блок коммутаторов 17, многовходовое арифметико-логическое устройство 18, выходной буфер 19 и двухпортовая локальная память данных 20,
в состав устройства управления 2 включены регистр кода команды, счетчик команд, предназначенный для хранения адреса текущей команды, в котором в зависимости от кода операций инкрементируют адрес текущей команды или в зависимости от соответствующего счетчика итераций (циклов) записывают адрес перехода с регистров возврата,
причем внешний вход синхронизации CLK соединен с входами синхронизации памяти команд 1, устройства управления 2, всех групп из М регистров команды 41, 42, …, 4M, группы из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2, всех R-портовых регистровых памятей 16 и двухпортовых локальных памятей данных 20 всех процессорных элементов,
вход сброса 8 соединен с соответствующим входом начальной установки устройства управления 2, выход счетчика команд является первым выходом устройства управления и по шине 10 соединен с адресным входом первого порта двухпортовой памяти команд 1, а выход данных первого порта которой по шине 9 соединен с первым входом устройства управления, второй выход которого по шине кода команды 11 соединен с входами первых регистров команды 41 из всех групп регистров, в которых выходы предыдущих регистров команды соединены с входами последующих регистров команды,
кроме того, первая группа выходов каждого регистра команды 4 является шиной разрядов адресного поля команды 12, а вторая группа выходов каждого регистра команды 4 шиной разрядов операционного поля команды 13, причем шины 12 и 13 от каждого регистра команды 4 всех групп соединены также с первыми и вторыми группами входов одноименных процессорных элементов 5 в каждом вычислительном блоке 31, 32, …, 3N,
причем в каждом процессорном элементе 5 первая группа входов с шины 12 соединена с группой адресных входов R-портовой регистровой памяти 16 и второй группой входов блока коммутаторов 17, группа выходов данных R-портовой регистровой памяти 16 соединена с соответствующими входами третьей группы входов блока коммутаторов 17, четвертая группа входов которого соединена с выходами данных первого порта двухпортовой локальной памяти данных 20,
кроме того, в каждом процессорном элементе 5 вторая группа входов с шины 13 соединена с группами входов задания операций многовходового арифметико-логического устройства 18, R-портовой регистровой памяти 16 и двухпортовой локальной памяти данных 20, а также с группой входов управления блока коммутаторов 17 и входом разрешения выдачи выходного буфера 19,
группа выходов блока коммутаторов 17 соединена с соответствующими входами операндов многовходового арифметико-логического устройства 18, первая группа выходов которого является адресной группой и соединена с первой группой входов выходного буфера 19 и второй адресной группой входов первого порта двухпортовой локальной памяти данных 20, а вторая группа выходов многовходового арифметико-логического устройства 18 является группой результата и соединена со второй группой входов выходного буфера 19, третьей группой входов записи данных первого порта двухпортовой локальной памяти данных 20 и группой входов записи данных R-портовой регистровой памяти 16,
причем в каждом вычислительном блоке 31, 32, …, 3N у всех М процессорных элементов 51, 52, …, 5M первые группы выходов выходных буферов 19 являются группой адресных выходов и соединены между собой адресно-управляющей шиной 14, вторые группы выходы выходных буферов 19 являются данными результата и соединены между собой двунаправленной шиной данных 15, которая также соединена с первой группой входов блока коммутаторов 17,
при этом адресно-управляющие шины 14 и двунаправленные шины данных 15 нечетных вычислительных блоков 3(2i-1) (где i=1, 2, …, N/2) и соответствующих им четных вычислительных блоков 3(2i) подключены к группам адресных входов и входов данных соответственно первого и второго портов соответствующей памяти 6i группы из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2,
кроме того, двунаправленная шина обмена с внешним устройством 7 подключена ко второму порту двухпортовой памяти команд 1 и вторым портам всех двухпортовых локальных памятей данных 20 всех процессорных элементов 5.
Поставленная задача решается тем, что предлагаемый способ с использованием вычислительного модуля для многопотоковой обработки цифровых данных, содержит следующие этапы, на которых:
записывают программу в память команд и данные в локальную память данных со стороны внешнего устройства через шину обмена,
формируют сигнал на вход сброса, по которому начинают обработку данных,
в устройстве управления в соответствии с выполняемым алгоритмом формируют исполнительные адреса команд, по которым из памяти команд считывают коды команд и дешифрируют соответствующие разряды коды операций,
в устройстве управления, которое хранит адрес текущей команды, формируют адрес следующей команды, в зависимости от разрядов кода команды, инкрементируют адрес текущей команды или формируют адрес перехода в зависимости от значений счетчиков итераций (циклов) или регистров адресов возврата,
передают соответствующие разряды кода команды на входы всех первых регистров команд в группы вычислительных блоков и коды команд синхронно записывают в регистры команд, а затем синхронно эти коды команд последовательно передают в группах между регистрами команд,
при этом во всех процессорных элементах, соответствующих данным регистрам команд, параллельно считывают требуемые операнды из R-портовой регистровой памяти, или локальной памяти или разделенной памяти, передают операнды на соответствующие группы входов многовходовых арифметико-логических устройств,
при этом во всех арифметико-логических устройствах вычислительного модуля параллельно одновременно выполняют соответствующие цепочки операций, в результате выполнения обработки операндов формируют результаты и формируют адреса для обращений к памяти,
синхронно записывают результаты в соответствии с кодом операции в R-портовую регистровую память или локальную память, или разделенную память.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
На фиг. 1 представлена схема предлагаемого вычислительного модуля. На фиг. 2 представлена схема процессорного элемента.
На фиг. 1 и фиг. 2 приняты следующие обозначения:
1 - двухпортовая память команд,
2 - устройство управления,
31, 32, …, 3N - группа из N вычислительных блоков,
41, 42, …, 4M - группы из М регистров команды,
51, 52, …, 5M - группы из М процессорных элементов,
61, 62, …, 6N/2 - группа из N/2 двухпортовых разделяемых памятей данных,
7 - двунаправленная шина обмена с внешним устройством,
8 - внешний вход сброса,
9 - шина данных памяти команд 1,
10 - адресная шина памяти команд 1,
11 - шина кода команды,
12 - шина разрядов адресного поля команды,
13 - шина разрядов операционного поля команды,
14 - адресно-управляющая шина разделяемых памятей данных 6,
15 - двунаправленная шина данных разделяемых памятей данных 6,
16 - R-портовая регистровая память,
17 - блок коммутаторов,
18 - многовходовое арифметико-логическое устройство,
19 - выходной буфер,
20 - двухпортовая локальная память данных.
Внешний вход синхронизации CLK и входы синхронизации устройства управления, всех памятей и регистров на фиг. 1 и фиг. 2 не показаны.
Предлагаемый вычислительный модуль осуществляется следующим образом.
Вычислительный модуль содержит двухпортовую память команд 1, устройство управления 2, группу из N вычислительных блоков 31 32, …, 3N, каждый из которых содержит группу из М регистров команды 41, 42, …, 4M и группу из М процессорных элементов 51, 52, …, 5M, группу из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2, двунаправленную шина связи с внешним устройством 7, внешний вход сброса 8 и вход синхронизации CLK.
Каждый процессорный элемент 5 содержит R-портовую регистровую память 16, блок коммутаторов 17, многовходовое арифметико-логическое устройство 18, выходной буфер 19 и двухпортовую локальную память данных 20.
В состав устройства управления 2 включены регистр кода команды, счетчик команд, предназначенный для хранения адреса текущей команды, в котором в зависимости от кода операций инкрементируют адрес текущей команды или в зависимости от соответствующего счетчика итераций (циклов) записывают адрес перехода с регистров возврата.
Внешний вход синхронизации CLK соединен с входами синхронизации памяти команд 1, устройства управления 2, всех групп из М регистров команды 41, 42, …, 4M, группы из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2, всех R-портовых регистровых памятей 16 и двухпортовых локальных памятей данных 20 всех процессорных элементов. Внешний вход сброса 8 соединен с соответствующим входом начальной установки устройства управления 2.
Устройство управления 2 соединено с первым портом двухпортовой памяти команд 1 с помощью шины данных памяти команд 9 и адресной шины памяти команд 10. Устройство управления, имеющее внешний вход сброса 8, по шине кода команды 11 соединено с входами первых регистров команд 41 из всех групп регистров, в которых выходы предыдущих регистров команд соединены с входами последующих регистров команд.
Каждый процессорный элемент 5 связан с соответствующим одноименным регистром команды 4 с помощью шины разрядов адресного поля команды 12 и шины разрядов операционного поля команды 13.
Каждый процессорный элемент 5 в каждом вычислительном блоке 3 подключен к двунаправленной шине данных разделяемых памятей данных 15 и к адресно-управляющей шине разделяемых памятей данных 14. При этом адресно-управляющие шины 14 и двунаправленные шины данных 15 нечетных вычислительных блоков 3(2i-1) (где i=1, 2, …, N/2) и соответствующих им четных вычислительных блоков 3(2i) подключены к группам адресных входов и входов данных соответственно первого и второго портов соответствующей памяти 6, группы из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2.
В процессорном элементе 5 шина разрядов адресного поля команды 12 соединена с R-портовой регистровой памятью 16 и блоком коммутаторов 17. Шина разрядов операционного поля команды 13 соединена с блоком коммутаторов 17 локальной памятью данных 20, многовходовым арифметико-логическим устройством 18 и выходным буфером 19. Выходы регистровой памяти 6, локальной памяти данных 20 и шины данных разделяемой памяти 15 соединены со входами блока коммутаторов 17. Выходы блока коммутаторов 17 соединены со входами многовходового арифметико-логического устройства 18. Выходы многовходового арифметико-логического устройства 18 соединены со входами выходного буфера 19, локальной памяти данных 20 и регистровой памяти 16. Выходной буфер 19 соединен с адресно-управляющей шиной 14 и двунаправленной шиной данных 15.
Двунаправленная шина обмена с внешним устройством соединена с памятью команд 1 и вторым портом локальной памяти данных 20 каждого процессорного элемента 5.
ПОДРОБНОЕ ОПИСАНИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
Принцип работы устройства состоит в следующем.
Вариативные задачи дискретной математики, на решение которых ориентирован предлагаемый вычислительный модуль, отличаются многократным повторением последовательностей целочисленных операций и обладают высокой степенью распараллеливания по данным, то есть позволяют разбить входные данные на множество блоков, вычисления над которыми производятся параллельно и независимо от вычислений с другими блоками.
Реализация вариативных задач дискретной математики на предлагаемом вычислительном модуле предусматривает предварительное разбиение входных данных на блоки, размер которых не превышает размер локальной памяти данных 20. Эти блоки загружаются внешним устройством в локальные памяти данных 20 процессорных элементов 5 с помощью шины обмена с внешним устройством 7.
Программа для реализации задачи состоит из последовательности команд, загружаемой внешним устройством в память команд 1 с помощью шины обмена с внешним устройством 7. Формат кода команды содержит поля, предназначенные для выполнения операций с помощью процессорного элемента 5, разряды полей определяют целочисленные операции, непосредственные значения операндов и режимы обращения к регистровой, локальной и разделяемой памяти, а также поля, предназначенные для выполнения в устройстве управления 2 и которые не зависят от результатов вычислений, проводимых процессорными элементами. Поля, предназначенные для выполнения в устройстве управления 2, связаны с формированием исполнительных адресов следующей команды, организацией ветвлений, в том числе вложенных циклов, для организации которых устройство управления 2 имеет набор счетчиков итераций (циклов) и регистров адресов возврата.
Табличные данные, не требующие модификации в процессе решения, а также данные, размер которых превышает размер локальной памяти, помещаются в разделяемые памяти данных 6, доступные для обращений со стороны вычислительных блоков 3. Доступ со стороны внешнего устройства к разделяемой памяти данных 6 осуществляется с помощью предварительной загрузки данных в локальную память 20 и программы-загрузчика, которая помещается в память команд 1 и обеспечивает перезапись информации из локальной памяти данных 20 в разделяемую память данных 6.
Контроль процесса вычислений, осуществляемых вычислительным модулем, а также получение результатов осуществляются внешним устройством с помощью обращений через шину обмена 7 к локальной памяти данных 20.
Предлагаемый вычислительный модуль работает следующим образом.
Перед началом работы внешнее устройство осуществляет через шину обмена с внешним устройством 7 запись программы в память команд 1 и запись локальных данных в локальную память данных 20.
Внешнее устройство подает сигнал на вход сброса 8 устройства управления 2 и вычислительный модуль начинает выполнение загруженной программы. Выполнение операций в блоках вычислительного модуля проводится за один такт по синхросигналам CLK (на схеме не показаны). Внешнее устройство контролирует ход выполнения вычислений вычислительного модуля с помощью обращений через шину обмена 7 к локальной памяти данных 20. Очередная команда по адресу, указанному в счетчике команд, поступает из памяти команд 1 в устройство управления 2.
Устройство управления 2 передает код команды в каждый из N вычислительных блоков 31, 32, …, 3N, в которых по первому синхросигналу CLK код одной и той же команды записывается в первые регистры команд 41. На последующих синхросигналах CLK эта же команда в каждой группе будет перемещаться между регистрами команд 4, при этом на вход первых регистров команд 41 на каждом такте будет записываться код следующей команды, который также будет перемещаться по группам. При этом исполнительные адреса следующих команд формируются в устройстве управления 2 на основании кода операции, условий ветвлений и повторений циклов.
Процессорные элементы 5 выполняют команды, записанные в связанные с ними регистры команды 4. Для этого в каждом процессорном элементе 5 блок коммутаторов 17, управляемый разрядами адресного поля команды 12, осуществляет выборку заданного в команде количества входных операндов из следующих источников: R-портовой регистровой памяти 16, локальной памяти 20, разделяемой памяти 6 или с шины 12 константы заданной в коде команды. Операнды с выходов блока коммутаторов 17 поступают на входы многовходового арифметико-логического устройство 18, которое в соответствии командой, указанной в разрядах операционного поля команды 13, выполняет цепочки операций, вычисляет результаты и формирует адреса для записи в локальную память 20 или разделяемую память 6.
По следующему синхросигналу результаты записываются в R-портовую регистровую память 16, локальную память 20 или разделяемую память 6. Одновременно из этих памятей начинается считывание соответствующих операндов для следующей команды, принятой на соответствующий регистр команд 4.
При этом каждый процессорный элемент 5 в каждой группе из М процессорных элементов в каждом вычислительном блоке 31, 32, …, 3N обращается к соответствующему порту двухпортовой разделяемой памяти 6 не чаще, чем один раз за М тактов, что обеспечивается в реализуемых программах.
ОПИСАНИЕ ПРИМЕРОВ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
Предлагаемый вычислительный модуль может быть выполнен на базе ПЛИС Xilinx XC7V585. В состав реализованного вычислительного модуля входит 64 процессорных элемента, организованные в виде 16 вычислительных блоков по 4 процессорных элемента в каждом. Используется двухпортовая разделяемая память, к портам которой подключено 2 группы по 4 процессорных элемента в каждой. Шина связи с внешним устройством предоставляет возможность чтения-записи локальной памяти, разделяемой памяти и памяти команд. Шина связи с внешним устройством состоит из шины адреса, которая имеет разрядность 15 бит, и шины данных, которая имеет разрядность 32 бита. Процессорный элемент содержит 32 32-разрядных регистра и 256 32-разрядных слов локальной памяти. В качестве разделяемой памяти используется 8 блоков двухпортовой памяти ПЛИС по 4096 32-разрядных слов с разделяемым доступом со стороны группы процессорных элементов. Память команд может содержать до 1024 команд, разрядность каждой команды составляет 96 бит.
Оценим производительность предлагаемого вычислительного модуля и устройства-прототипа при решении вариативной задачи из области дискретной математики.
В качестве тестового примера оценим вычисление результатов криптографической хеш-функции MD5 (Rivest R. RFC 1321: The MD5 Message-Digest Algorithm // Request for Comments - 1992. - ISSN 2070-1721) для множества независимых 512-разрядных блоков данных. Предлагаемый вычислительный модуль, реализованный на базе ПЛИС Xilinx XC7V585, позволяет произвести в параллельном режиме вычисление 64 результатов хеш-функции MD5 с независимыми блоками данных, используя локальную память данных процессорных элементов. На каждом такте в многовходовом арифметико-логическом устройстве каждого процессорного элемента выполняются цепочки из нескольких операций битовой логики, простых и циклических сдвигов, сложения по модулю, арифметических операций, реализующие части вычислений хеш-функции MD5. Рассматриваемый вариант реализации вычислительного модуля вычисляет результаты хеш-функции MD5 для 64 512-разрядных блоков данных за 428 тактов.
Устройство-прототип процессор Cryptoraptor, который содержит 80 процессорных элементов, позволяет произвести в параллельном режиме вычисления только 2 результатов хеш-функции MD5 с независимыми блоками данных (см. таблицу 8 в Gokhan Sayilar, Derek Chiou. Cryptoraptor: High Throughput Reconfigurable Cryptographic Processor ISBN: 978-1-4799-6277-8). Процессор Cryptoraptor вычисляет результаты хеш-функции MD5 для двух 512-разрядных блоков данных за 254 такта, а для вычисления 64 результатов хеш-функции MD5 необходимо 8128 тактов.
Таким образом, в предлагаемом вычислительном модуле, содержащем 64 процессорных элемента, в сравнении с устройством-прототипом процессором Cryptoraptor, содержащем 80 процессорных элементов, при работе на одной тактовой частоте, достигается повышение производительности при многопотоковой обработке независимых блоков данных. Повышение производительности в предлагаемом вычислительном модуле достигается за счет высокого параллелизма реализации алгоритма и использования процессорных элементов всех вычислительных блоков, при этом, устройство-прототип отличает избыточность операций и связей, поэтому при вычислениях в ступенях конвейере невозможно использование всех процессорных элементов.
Вышеизложенные сведения позволяют сделать вывод, что предлагаемый вычислительный модуль и способ обработки решают поставленную задачу -создание устройства для решения вариативных задач из области дискретной математики и соответствует заявляемому техническому результату - повышение производительности для многопотоковых вычислений.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОСТАДИЙНОЙ МНОГОПОТОЧНОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2681365C1 |
| Реконфигурируемый вычислительный модуль | 2018 |
|
RU2686017C1 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ ЯДРО | 2023 |
|
RU2819403C1 |
| Процессорный модуль однородной вычислительной структуры | 1985 |
|
SU1345207A1 |
| Центральный процессор | 1991 |
|
SU1804645A3 |
| Гибридный вычислительный комплекс | 2023 |
|
RU2830153C1 |
| Многопроцессорная система | 1987 |
|
SU1464168A1 |
| Архитектура параллельной вычислительной системы | 2016 |
|
RU2644535C2 |
| МОДУЛЬНОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО С РАЗДЕЛЬНЫМ МИКРОПРОГРАММНЫМ УПРАВЛЕНИЕМ АРИФМЕТИКО-ЛОГИЧЕСКИМИ СЕКЦИЯМИ | 1994 |
|
RU2079877C1 |
| ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА НА БАЗЕ МАТРИЦЫ ПРОЦЕССОРНЫХ ЭЛЕМЕНТОВ | 1998 |
|
RU2117326C1 |
Изобретение относится к области вычислительной техники. Технический результат изобретения заключается в повышении производительности многопотоковых вычислений в вариативных задачах дискретной математики за счет параллельной работы специализированных процессорных элементов по общей программе с независимыми блоками данных. Сущность изобретения в том, что вычислительный модуль содержит двухпортовую память команд, устройство управления, группу из N/2 двухпортовых разделяемых памятей и группу из N вычислительных блоков, каждый из которых содержит группу из М регистров команды и группу из М процессорных элементов, каждый из которых содержит R-портовую регистровую память 16, блок коммутаторов 17, многовходовое арифметико-логическое устройство 18, выходной буфер 19 и двухпортовую локальную память данных 20. Способ обработки данных содержит этапы извлечения и параллельного распространения команд по процессорным элементам, параллельного выполнения цепочек операций и синхронной записи результатов в группы памяти. 2 н.п. ф-лы, 2 ил.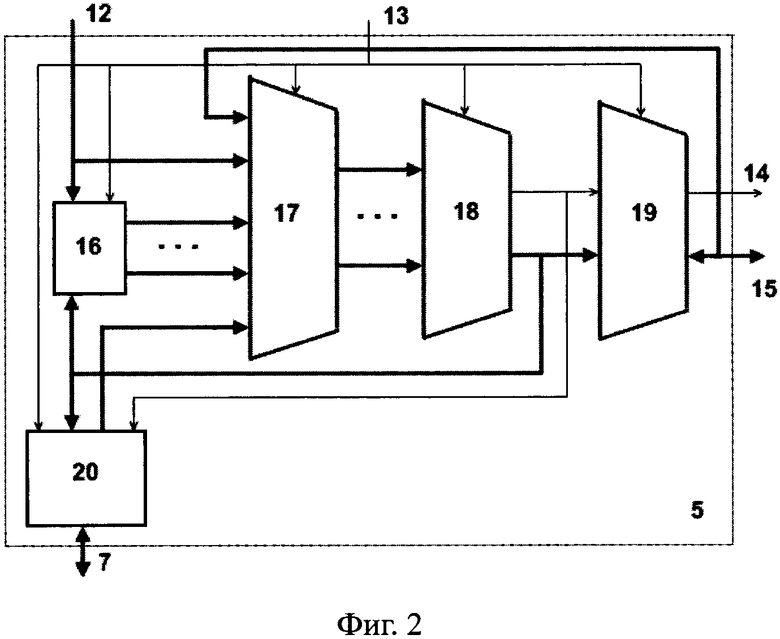
1. Вычислительный модуль для многопотоковой обработки цифровых данных, содержащий процессорные элементы 5,
отличающийся тем, что в него дополнительно введены двухпортовая память команд 1, устройство управления 2, группа из N вычислительных блоков 31, 32, …, 3N, каждый из которых содержит группу из М регистров команды 41, 42, …, 4М и группу из М процессорных элементов 51, 52, …, 5M, группа из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2, двунаправленная шина обмена с внешним устройством 7, внешний вход сброса 8 и внешний вход синхронизации CLK,
кроме того, в каждый процессорный элемент 5 введены R-портовая регистровая память 16, блок коммутаторов 17, многовходовое арифметико-логическое устройство 18, выходной буфер 19 и двухпортовая локальная память данных 20,
в состав устройства управления 2 включены регистр кода команды, счетчик команд, предназначенный для хранения адреса текущей команды, в котором в зависимости от кода операций инкрементируют адрес текущей команды или в зависимости от соответствующего счетчика итераций циклов записывают адрес перехода с регистров возврата,
причем внешний вход синхронизации CLK соединен с входами синхронизации памяти команд 1, устройства управления 2, всех групп из М регистров команды 41, 42, …, 4M, группы из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2, всех R-портовых регистровых памятей 16 и двухпортовых локальных памятей данных 20 всех процессорных элементов,
вход сброса 8 соединен с соответствующим входом начальной установки устройства управления 2, выход счетчика команд является первым выходом устройства управления и по шине 10 соединен с адресным входом первого порта двухпортовой памяти команд 1, а выход данных первого порта которой по шине 9 соединен с первым входом устройства управления, второй выход которого по шине кода команды 11 соединен с входами первых регистров команды 41 из всех групп регистров, в которых выходы предыдущих регистров команды соединены с входами последующих регистров команды,
кроме того, первая группа выходов каждого регистра команды 4 является шиной разрядов адресного поля команды 12, а вторая группа выходов каждого регистра команды 4 - шиной разрядов операционного поля команды 13, причем шины 12 и 13 от каждого регистра команды 4 всех групп соединены также с первыми и вторыми группами входов одноименных процессорных элементов 5 в каждом вычислительном блоке 31, 32, …, 3N,
причем в каждом процессорном элементе 5 первая группа входов с шины 12 соединена с группой адресных входов R-портовой регистровой памяти 16 и второй группой входов блока коммутаторов 17, группа выходов данных R-портовой регистровой памяти 16 соединена с соответствующими входами третьей группы входов блока коммутаторов 17, четвертая группа входов которого соединена с выходами данных первого порта двухпортовой локальной памяти данных 20,
кроме того, в каждом процессорном элементе 5 вторая группа входов с шины 13 соединена с группами входов задания операций многовходового арифметико-логического устройства 18, R-портовой регистровой памяти 16 и двухпортовой локальной памяти данных 20, а также с группой входов управления блока коммутаторов 17 и входом разрешения выдачи выходного буфера 19,
группа выходов блока коммутаторов 17 соединена с соответствующими входами операндов многовходового арифметико-логического устройства 18, первая группа выходов которого является адресной группой и соединена с первой группой входов выходного буфера 19 и второй адресной группой входов первого порта двухпортовой локальной памяти данных 20, а вторая группа выходов многовходового арифметико-логического устройства 18 является группой результата и соединена со второй группой входов выходного буфера 19, третьей группой входов записи данных первого порта двухпортовой локальной памяти данных 20 и группой входов записи данных R-портовой регистровой памяти 16,
причем в каждом вычислительном блоке 31, 32, …, 3N у всех М процессорных элементов 51, 52, …, 5M первые группы выходов выходных буферов 19 являются группой адресных выходов и соединены между собой адресно-управляющей шиной 14, вторые группы выходы выходных буферов 19 являются данными результата и соединены между собой двунаправленной шиной данных 15, которая также соединена с первой группой входов блока коммутаторов 17,
при этом адресно-управляющие шины 14 и двунаправленные шины данных 15 нечетных вычислительных блоков 3(2i-1) (где i=1, 2,…,N/2) и соответствующих им четных вычислительных блоков 3(2i) подключены к группам адресных входов и входов данных соответственно первого и второго портов соответствующей памяти 6i группы из N/2 двухпортовых разделяемых памятей данных 61, 62, …, 6N/2,
кроме того, двунаправленная шина обмена с внешним устройством 7 подключена ко второму порту двухпортовой памяти команд 1 и вторым портам всех двухпортовых локальных памятей данных 20 всех процессорных элементов 5.
2. Способ обработки с использованием вычислительного модуля для многопотоковой обработки цифровых данных по п. 1, содержащий следующие этапы, на которых:
записывают программу в память команд и данные в локальную память данных со стороны внешнего устройства через шину обмена,
формируют сигнал на вход сброса, по которому начинают обработку данных,
в устройстве управления в соответствии с выполняемым алгоритмом формируют исполнительные адреса команд, по которым из памяти команд считывают коды команд и дешифрируют соответствующие разряды кодов операций,
в устройстве управления, которое хранит адрес текущей команды, формируют адрес следующей команды, в зависимости от разрядов кода команды, инкрементируют адрес текущей команды или формируют адрес перехода в зависимости от значений счетчиков итераций (циклов) или регистров адресов возврата,
передают соответствующие разряды кода команды на входы всех первых регистров команд в группы вычислительных блоков и коды команд синхронно записывают в регистры команд, а затем синхронно эти коды команд последовательно передают в группах между регистрами команд,
при этом во всех процессорных элементах, соответствующих данным регистрам команд, параллельно считывают требуемые операнды из R-портовой регистровой памяти, или локальной памяти, или разделенной памяти, передают операнды на соответствующие группы входов многовходовых арифметико-логических устройств,
при этом во всех арифметико-логических устройствах вычислительного модуля параллельно одновременно выполняют соответствующие цепочки операций, в результате выполнения обработки операндов формируют результаты и формируют адреса для обращений к памяти,
синхронно записывают результаты в соответствии с кодом операции в R-портовую регистровую память, или локальную память, или разделенную память.
| МОДУЛЬ СОПРОЦЕССОРА КЭША | 2011 |
|
RU2586589C2 |
| Архитектура параллельной вычислительной системы | 2016 |
|
RU2644535C2 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ | 2017 |
|
RU2643622C1 |
| US 20150278742 A1, 01.10.2015 | |||
| WO 2012132692 A1, 04.10.2012 | |||
| МНОГОПРОЦЕССОРНАЯ ВЫЧИСЛИТЕЛЬНАЯ СИСТЕМА | 2012 |
|
RU2502126C1 |

