1. Область техники, к которой относится изобретение
Вариант осуществления согласно изобретению относится к аудиодекодеру для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации.
Другой вариант осуществления согласно изобретению относится к способу для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации.
Другой вариант осуществления согласно изобретению относится к компьютерной программе для осуществления упомянутого способа.
В общем, варианты осуществления согласно изобретению относятся к обработке перехода от CELP-кодека к кодеку на основе MDCT при переключаемом кодировании аудио.
2. Уровень техники
В последние годы возрастает потребность в передаче и хранении кодированной аудиоинформации. Также возрастает потребность в кодировании аудио и декодировании аудио для аудиосигналов, содержащих как речь, так и общее аудио (такое как, например, музыка, фоновый шум и т.п.).
Для того, чтобы повышать качество кодирования, а также для того, чтобы повышать эффективность по скорости передачи битов, введены переключаемые (или переключающиеся) аудиокодеки, которые переключаются между различными схемами кодирования таким образом, что, например, первый кадр кодируется с использованием первого принципа кодирования (например, принципа кодирования на основе CELP), и таким образом, что последующий второй аудиокадр кодируется с использованием другого второго принципа кодирования (например, принципа кодирования на основе MDCT). Другими словами, может возникать переключение между кодированием в области линейного прогнозного кодирования (например, с использованием принципа кодирования на основе CELP) и кодированием в частотной области (например, кодированием, которое основано на преобразовании из временной области в частотную область или преобразовании из частотной области во временную область, таком как, например, FFT-преобразование, обратное FFT-преобразование, MDCT-преобразование или обратное MDCT-преобразование). Например, первый принцип кодирования может представлять собой принцип кодирования на основе CELP, принцип кодирования на основе ACELP, принцип кодирования в области линейного прогнозирования с возбуждением по кодированию с преобразованием и т.п. Второй принцип кодирования, например, может представлять собой принцип кодирования на основе FFT, принцип кодирования на основе MDCT, принцип кодирования на основе AAC или принцип кодирования, который может рассматриваться как принцип-последователь принципа кодирования на основе AAC.
Далее описываются некоторые примеры традиционных аудиокодеров (кодеров и/или декодеров).
Переключаемые аудиокодеки, такие как, например, MPEG USAC, основаны на двух основных схемах кодирования аудио. Одна схема кодирования представляет собой, например, CELP-кодек, предназначенный для речевых сигналов. Другая схема кодирования представляет собой, например, кодек на основе MDCT (в дальнейшем называемый просто MDCT), предназначенный для всех других аудиосигналов (например, музыки, фонового шума). В сведенных сигналах контента (например, речь поверх музыки), кодер (и в силу этого также декодер) зачастую переключается между двумя схемами кодирования. В таком случае необходимо исключать все артефакты (например, щелчки вследствие неоднородности) при переключении из одного режима (или схемы кодирования) на другой.
Переключаемые аудиокодеки, например, могут содержать проблемы, которые вызываются посредством переходов из CELP в MDCT.
Переходы из CELP в MDCT, в общем, вводят две проблемы. Наложение спектров может вводиться вследствие пропущенного предыдущего MDCT-кадра. Неоднородность может вводиться на границе между CELP-кадром и MDCT-кадром, вследствие неидеальной природы кодирования на основе формы сигналов двух схем кодирования, работающих на низких/средних скоростях передачи битов.
Уже существуют несколько подходов для того, чтобы разрешать проблемы, введенные посредством переходов из CELP в MDCT, и поясняются далее.
Возможный подход описывается в статье "Efficient cross-fade windows for transitions between LPC-based and non-LPC based audio coding" авторов Jeremie Lecomte, Philippe Gournay, Ralf Geiger, Bruno Bessette и Max Neuendorf (представлена на126-th AES Convention, май 2009 года, документ 771). Эта статья описывает подход в разделе 4.4.2 "ACELP to non-LPD mode". Также следует обратиться, например, к фиг. 8 упомянутой статьи. Проблема наложения спектров разрешается сначала посредством увеличения MDCT-длины (здесь с 1024 до 1152) таким образом, что левая MDCT-точка перегиба перемещается влево от границы между CELP- и MDCT-кадрами, затем посредством изменения левой части MDCT-окна таким образом, что уменьшается перекрытие, и в завершение посредством искусственного введения пропущенного наложения спектров с использованием CELP-сигнала и операции суммирования с перекрытием. Проблема неоднородности разрешается одновременно посредством операции суммирования с перекрытием.
Этот подход хорошо работает, но имеет недостаток в том, что он вводит задержку в CELP-декодере, причем задержка равна длине перекрытия (здесь: 128 выборок).
Другой подход описывается в US 8725503 B2, датированной 13 мая 2014 года и озаглавленной "Forward time domain aliasing cancellation with application in weighted or original signal domain" автора Bruno Bessette.
В этом подходе, MDCT-длина не изменяется (как и форма функции MDCT-окна). Проблема наложения спектров разрешается здесь посредством кодирования сигнала коррекции наложения спектров с помощью отдельного кодера на основе преобразования. Дополнительные вспомогательные информационные биты отправляются в поток битов. Декодер восстанавливает сигнал коррекции наложения спектров и добавляет его в декодированный MDCT-кадр. Дополнительно, характеристика при отсутствии входного сигнала (ZIR) синтезирующего CELP-фильтра используется для того, чтобы уменьшать амплитуду сигнала коррекции наложения спектров и повышать эффективность кодирования.
ZIR также помогает существенно снижать остроту проблемы неоднородности.
Этот подход также хорошо работает, но недостаток заключается в том, что он требует существенного объема дополнительной вспомогательной информации, и требуемое число битов, в общем, является переменным, что не является подходящим для кодека с постоянной скоростью передачи битов.
Другой подход описывается в заявке на патент (США) US 2013/0289981 A1, датированной 31 октября 2013 года и озаглавленной "Low-delay sound-encoding alternating between predictive encoding and transform encoding" авторов Stephane Ragot, Balazs Kovesi and Pierre Berthet. Согласно упомянутому подходу, MDCT не изменяется, но левая часть MDCT-окна изменяется, чтобы уменьшать длину перекрытия. Чтобы разрешать проблему наложения спектров, начало MDCT-кадра кодируется с использованием CELP-кодека, и затем CELP-сигнал используется для того, чтобы подавлять наложение спектров, либо посредством полной замены MDCT-сигнала, либо посредством искусственного введения компонента пропущенного наложения спектров (аналогично вышеуказанной статье авторов Jeremie Lecomte и др.). Проблема неоднородности разрешается посредством операции суммирования с перекрытием, если используется подход, аналогичный статье авторов Jeremie Lecomte и др., иначе она разрешается посредством простой операции перекрестного перехода между CELP-сигналом и MDCT-сигналом.
Аналогично US 8725503 B2, этот подход, в общем, хорошо работает, но недостаток заключается в том, что он требует существенного объема вспомогательной информации, введенного посредством дополнительного CELP.
С учетом вышеописанных традиционных решений, желательно иметь принцип, который содержит улучшенные характеристики (например, улучшенный компромисс между объемом служебной информации в скорости передачи битов, задержкой и сложностью) для переключения между различными режимами кодирования.
3. Раскрытие изобретения
Вариант осуществления согласно изобретению создает аудиодекодер для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации. Аудиодекодер содержит декодер в области линейного прогнозирования, сконфигурированный с возможностью предоставлять первую декодированную аудиоинформацию на основе аудиокадра, кодированного в области линейного прогнозирования, и декодер в частотной области, сконфигурированный с возможностью предоставлять вторую декодированную аудиоинформацию на основе аудиокадра, кодированного в частотной области. Аудиодекодер также содержит процессор переходов. Процессор переходов сконфигурирован с возможностью получать характеристику при отсутствии входного сигнала линейной прогнозирующей фильтрации, при этом начальное состояние линейной прогнозирующей фильтрации задается в зависимости от первой декодированной аудиоинформации и второй декодированной аудиоинформации. Процессор переходов также сконфигурирован с возможностью модифицировать вторую декодированную аудиоинформацию, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией.
Этот аудиодекодер основан на таких выявленных сведениях, что плавный переход между аудиокадром, кодированным в области линейного прогнозирования, и последующим аудиокадром, кодированным в частотной области, может достигаться посредством использования характеристики при отсутствии входного сигнала линейного прогнозирующего фильтра, чтобы модифицировать вторую декодированную аудиоинформацию, при условии, что начальное состояние линейной прогнозирующей фильтрации учитывает как первую декодированную аудиоинформацию, так и вторую декодированную аудиоинформацию. Соответственно, вторая декодированная аудиоинформация может быть адаптирована (модифицирована) таким образом, что начало модифицированной второй декодированной аудиоинформации является аналогичным окончанию первой декодированной аудиоинформации, что помогает уменьшать или даже исключать существенные неоднородности между первым аудиокадром и вторым аудиокадром. По сравнению с аудиодекодером, описанным выше, принцип, в общем, является применимым, даже если вторая декодированная аудиоинформация не содержит наложение спектров. Кроме того, следует отметить, что термин "линейная прогнозирующая фильтрация" может обозначать как одно применение линейного прогнозирующего фильтра, так и несколько применений линейных прогнозирующих фильтров, при этом следует отметить, что одно применение линейной прогнозирующей фильтрации типично является эквивалентным нескольким применениям идентичных линейных прогнозирующих фильтров, поскольку линейные прогнозирующие фильтры типично являются линейными.
В качестве вывода, вышеуказанный аудиодекодер обеспечивает возможность получать плавный переход между первым аудиокадром, кодированным в области линейного прогнозирования, и последующим вторым аудиокадром, кодированным в частотной области (или в области преобразования), при этом задержка не вводится, и при этом вычислительные затраты являются сравнительно небольшими.
Другой вариант осуществления согласно изобретению создает аудиодекодер для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации. Аудиодекодер содержит декодер в области линейного прогнозирования, сконфигурированный с возможностью предоставлять первую декодированную аудиоинформацию на основе аудиокадра, кодированного в области линейного прогнозирования (или, эквивалентно, в представлении в области линейного прогнозирования). Аудиодекодер также содержит декодер в частотной области, сконфигурированный с возможностью предоставлять вторую декодированную аудиоинформацию на основе аудиокадра, кодированного в частотной области (или, эквивалентно, в представлении в частотной области). Аудиодекодер также содержит процессор переходов. Процессор переходов сконфигурирован с возможностью получать первую характеристику при отсутствии входного сигнала линейного прогнозирующего фильтра в ответ на первое начальное состояние линейного прогнозирующего фильтра, заданное посредством первой декодированной аудиоинформации, и получать вторую характеристику при отсутствии входного сигнала линейного прогнозирующего фильтра в ответ на второе начальное состояние линейного прогнозирующего фильтра, заданное посредством модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации. Альтернативно, процессор переходов сконфигурирован с возможностью получать комбинированную характеристику при отсутствии входного сигнала линейного прогнозирующего фильтра в ответ на начальное состояние линейного прогнозирующего фильтра, заданное посредством комбинации первой декодированной аудиоинформации и модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации. Процессор переходов также сконфигурирован с возможностью модифицировать вторую декодированную аудиоинформацию, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо в зависимости от комбинированной характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией.
Этот вариант осуществления согласно изобретению основан на таких выявленных сведениях, что плавный переход между аудиокадром, кодированным в области линейного прогнозирования, и последующим аудиокадром, кодированным в частотной области (или, в общем, в области преобразования), может получаться посредством модификации второй декодированной аудиоинформации на основе сигнала, который является характеристикой при отсутствии входного сигнала линейного прогнозирующего фильтра, начальное состояние которого задается посредством как первой декодированной аудиоинформации, так и второй декодированной аудиоинформации. Выходной сигнал такого линейного прогнозирующего фильтра может использоваться для того, чтобы адаптировать вторую декодированную аудиоинформацию (например, начальную часть второй декодированной аудиоинформации, которая идет сразу после перехода между первым аудиокадром и вторым аудиокадром), так что существует плавный переход между первой декодированной аудиоинформацией (ассоциированной с аудиокадром, кодированным в области линейного прогнозирования) и модифицированной второй декодированной аудиоинформацией (ассоциированной с аудиокадром, кодированным в частотной области или в области преобразования) без необходимости изменять первую декодированную аудиоинформацию.
Обнаружено, что характеристика при отсутствии входного сигнала линейного прогнозирующего фильтра оптимально подходит для предоставления плавного перехода, поскольку начальное состояние линейного прогнозирующего фильтра основано как на первой декодированной аудиоинформации, так и на второй декодированной аудиоинформации, при этом наложение спектров, включенное во вторую декодированную аудиоинформацию, компенсируется посредством искусственного наложения спектров, которое вводится в модифицированную версию первой декодированной аудиоинформации.
Кроме того, обнаружено, что задержка декодирования не требуется посредством модификации второй декодированной аудиоинформации на основе первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо в зависимости от комбинированной характеристики при отсутствии входного сигнала при оставлении первой декодированной аудиоинформации без изменений, поскольку первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала очень хорошо адаптированы для того, чтобы сглаживать переход между аудиокадром, кодированным в области линейного прогнозирования, и последующим аудиокадром, кодированным в частотной области (или в области преобразования), без изменения первой декодированной аудиоинформации, поскольку первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала модифицируют вторую декодированную аудиоинформацию таким образом, что вторая декодированная аудиоинформация практически является аналогичной первой декодированной аудиоинформации, по меньшей мере, при переходе между аудиокадром, кодированным в области линейного прогнозирования, и последующим аудиокадром, кодированным в частотной области.
В качестве вывода, вышеописанный вариант осуществления согласно настоящему изобретению обеспечивает возможность предоставлять плавный переход между аудиокадром, кодированным в области линейного прогнозного кодирования, и последующим аудиокадром, кодированным в частотной области (или в области преобразования), при этом введение дополнительной задержки исключается, поскольку модифицируется только вторая декодированная аудиоинформация (ассоциированная с последующим аудиокадром, кодированным в частотной области), и при этом хорошее качество перехода (без существенных артефактов) может достигаться посредством использования первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо комбинированной характеристики при отсутствии входного сигнала, которая получается в результате с учетом как первой декодированной аудиоинформации, так и второй аудиоинформации.
В предпочтительном варианте осуществления, декодер в частотной области сконфигурирован с возможностью осуществлять обратное перекрывающееся преобразование таким образом, что вторая декодированная аудиоинформация содержит наложение спектров. Обнаружено, что вышеуказанные идеи изобретения работают очень хорошо даже в случае, если декодер в частотной области (или декодер в области преобразования) вводит наложение спектров. Обнаружено, что упомянутое наложение спектров может подавляться при небольших усилиях и с хорошими результатами посредством предоставления искусственного наложения спектров в модифицированной версии первой декодированной аудиоинформации.
В предпочтительном варианте осуществления, декодер в частотной области сконфигурирован с возможностью осуществлять обратное перекрывающееся преобразование таким образом, что вторая декодированная аудиоинформация содержит наложение спектров во временной части, которая временно перекрывается с временной частью, для которой декодер в области линейного прогнозирования предоставляет первую декодированную аудиоинформацию, и таким образом, что вторая декодированная аудиоинформация не имеет наложения спектров для временной части после временной части, для которой декодер в области линейного прогнозирования предоставляет первую декодированную аудиоинформацию. Этот вариант осуществления согласно изобретению основан на такой идее, что преимущественно использовать перекрывающееся преобразование (или обратное перекрывающееся преобразование) и оконное преобразование, которое поддерживает временную часть, для которой первая декодированная аудиоинформация не предоставляется, без наложения спектров. Обнаружено, что первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала могут предоставляться с небольшими вычислительными затратами, если необязательно предоставлять информацию о подавлении наложения спектров в течение времени, когда отсутствует предоставляемая первая декодированная аудиоинформация. Другими словами, предпочтительно предоставлять первую характеристику при отсутствии входного сигнала и вторую характеристику при отсутствии входного сигнала либо комбинированную характеристику при отсутствии входного сигнала на основе начального состояния, причем в этом начальном состоянии наложение спектров практически подавляется (например, с использованием искусственного наложения спектров). Следовательно, первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала практически не имеют наложение спектров, так что желательно не иметь наложения спектров во второй декодированной аудиоинформации в течение периода времени после периода времени, в течение которого декодер в области линейного прогнозирования предоставляет первую декодированную аудиоинформацию. Относительно этой проблемы, следует отметить, что первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала типично предоставляются в течение упомянутого периода времени после периода времени, в течение которого декодер в области линейного прогнозирования предоставляет первую декодированную аудиоинформацию (поскольку первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала фактически представляют собой затухающее продолжение первой декодированной аудиоинформации, с учетом второй декодированной аудиоинформации и, типично, искусственного наложения спектров, которое компенсирует наложение спектров, включенное во вторую декодированную аудиоинформацию для "перекрывающегося" периода времени.
В предпочтительном варианте осуществления, часть второй декодированной аудиоинформации, которая используется для того, чтобы получать модифицированную версию первой декодированной аудиоинформации, содержит наложение спектров. Посредством предоставления возможности некоторого наложения спектров во второй декодированной аудиоинформации, оконное преобразование может поддерживаться простым, и может исключаться чрезмерное увеличение информации, требуемой для того, чтобы кодировать аудиокадр, кодированный в частотной области. Наложение спектров, которое включено в часть второй декодированной аудиоинформации, которая используется для того, чтобы получать модифицированную версию первой декодированной аудиоинформации, может компенсироваться посредством вышеупомянутого искусственного наложения спектров, так что не возникает серьезного ухудшения качества звука.
В предпочтительном варианте осуществления, искусственное наложение спектров, которое используется для того, чтобы получать модифицированную версию первой декодированной аудиоинформации, по меньшей мере, частично компенсирует наложение спектров, которое включено в часть второй декодированной аудиоинформации, которая используется для того, чтобы получать модифицированную версию первой декодированной аудиоинформации. Соответственно, может получаться высокое качество звука.
В предпочтительном варианте осуществления, процессор переходов сконфигурирован с возможностью применять первое оконное преобразование к первой декодированной аудиоинформации, чтобы получать полученную с помощью оконного преобразования версию первой декодированной аудиоинформации, и применять второе оконное преобразование к версии с временным зеркалированием первой декодированной аудиоинформации, чтобы получать полученную с помощью оконного преобразования версию версии с временным зеркалированием первой декодированной аудиоинформации. В этом случае, процессор переходов может быть сконфигурирован с возможностью комбинировать полученную с помощью оконного преобразования версию первой декодированной аудиоинформации и полученную с помощью оконного преобразования версию версии с временным зеркалированием первой декодированной аудиоинформации, чтобы получать модифицированную версию первой декодированной аудиоинформации. Этот вариант осуществления согласно изобретению основан на такой идее, что некоторое оконное преобразование должно применяться для того, чтобы получать надлежащее подавление наложения спектров в модифицированной версии первой декодированной аудиоинформации, которая используется в качестве ввода для предоставления характеристики при отсутствии входного сигнала. Соответственно, может достигаться то, что характеристика при отсутствии входного сигнала (например, вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала) является очень подходящей для сглаживания перехода между аудиоинформацией, кодированной в области линейного прогнозного кодирования, и последующим аудиокадром, кодированным в частотной области.
В предпочтительном варианте осуществления, процессор переходов сконфигурирован с возможностью линейно комбинировать вторую декодированную аудиоинформацию с первой характеристикой при отсутствии входного сигнала и второй характеристикой при отсутствии входного сигнала либо с комбинированной характеристикой при отсутствии входного сигнала для временной части, для которой первая декодированная аудиоинформация не предоставляется посредством декодера в области линейного прогнозирования, чтобы получать модифицированную вторую декодированную аудиоинформацию. Обнаружено, что простое линейное комбинирование (например, простое суммирование и/или вычитание или линейное комбинирование со взвешиванием, или линейное комбинирование с перекрестным переходом) оптимально подходит для предоставления плавного перехода.
В предпочтительном варианте осуществления, процессор переходов сконфигурирован с возможностью оставлять первую декодированную аудиоинформацию без изменений посредством второй декодированной аудиоинформации при предоставлении декодированной аудиоинформации для аудиокадра, кодированного в области линейного прогнозирования, так что декодированная аудиоинформация, предоставленная для аудиокадра, кодированного в области линейного прогнозирования, предоставляется независимо от декодированной аудиоинформации, предоставленной для последующего аудиокадра, кодированного в частотной области. Обнаружено, что принцип согласно настоящему изобретению не требует изменять первую декодированную аудиоинформацию на основе второй декодированной аудиоинформации, чтобы получать достаточно плавный переход. Таким образом, посредством оставления первой декодированной аудиоинформации без изменений посредством второй декодированной аудиоинформации, задержка может исключаться, поскольку первая декодированная аудиоинформация в силу этого может предоставляться для рендеринга (например, слушателю) даже до того, как завершается декодирование второй декодированной аудиоинформации (ассоциированной с последующим аудиокадром, кодированным в частотной области). Напротив, характеристика при отсутствии входного сигнала (первая и вторая характеристика при отсутствии входного сигнала либо комбинированная характеристика при отсутствии входного сигнала) может вычисляться, как только вторая декодированная аудиоинформация доступна. Таким образом, задержка может исключаться.
В предпочтительном варианте осуществления, аудиодекодер сконфигурирован с возможностью предоставлять полностью декодированную аудиоинформацию для аудиокадра, кодированного в области линейного прогнозирования, после которого идет аудиокадр, кодированный в частотной области, до декодирования (или до завершения декодирования) аудиокадра, кодированного в частотной области. Этот принцип является возможным вследствие того факта, что первая декодированная аудиоинформация не модифицируется на основе второй декодированной аудиоинформации, и помогает исключать задержку.
В предпочтительном варианте осуществления, процессор переходов сконфигурирован с возможностью выполнять оконное преобразование первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо комбинированной характеристики при отсутствии входного сигнала, до модификации второй декодированной аудиоинформации в зависимости от полученной с помощью оконного преобразования первой характеристики при отсутствии входного сигнала и полученной с помощью оконного преобразования второй характеристики при отсутствии входного сигнала либо в зависимости от полученной с помощью оконного преобразования комбинированной характеристики при отсутствии входного сигнала. Соответственно, переход может задаваться очень плавным. Кроме того, могут исключаться все проблемы, которые возникают в результате очень длительной характеристики при отсутствии входного сигнала.
В предпочтительном варианте осуществления, процессор переходов сконфигурирован с возможностью выполнять оконное преобразование первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо комбинированной характеристики при отсутствии входного сигнала, с использованием линейного окна. Обнаружено, что использование линейного окна является простым принципом, который, тем не менее, способствует хорошему впечатлению от прослушивания.
Вариант осуществления согласно изобретению создает способ для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации. Способ содержит выполнение декодирования в области линейного прогнозирования, чтобы предоставлять первую декодированную аудиоинформацию на основе аудиокадра, кодированного в области линейного прогнозирования. Способ также содержит выполнение декодирования в частотной области, чтобы предоставлять вторую декодированную аудиоинформацию на основе аудиокадра, кодированного в частотной области. Способ также содержит получение первой характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации в ответ на первое начальное состояние линейной прогнозирующей фильтрации, заданное посредством первой декодированной аудиоинформации, и получение второй характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации в ответ на второе начальное состояние линейной прогнозирующей фильтрации, заданное посредством модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации. Альтернативно, способ содержит получение комбинированной характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации в ответ на начальное состояние линейной прогнозирующей фильтрации, заданное посредством комбинации первой декодированной аудиоинформации и модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации. Способ дополнительно содержит модификацию второй декодированной аудиоинформации, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо в зависимости от комбинированной характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией. Этот способ основан на соображениях, аналогичных соображениям для вышеописанного аудиодекодера, и способствует идентичным преимуществам.
Другой вариант осуществления согласно изобретению создает компьютерную программу для осуществления упомянутого способа, когда компьютерная программа работает на компьютере.
Другой вариант осуществления согласно изобретению создает способ для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации. Способ содержит предоставление первой декодированной аудиоинформации на основе аудиокадра, кодированного в области линейного прогнозирования. Способ также содержит предоставление второй декодированной аудиоинформации на основе аудиокадра, кодированного в частотной области. Способ также содержит получение характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации, при этом начальное состояние линейной прогнозирующей фильтрации задается в зависимости от первой декодированной аудиоинформации и второй декодированной аудиоинформации. Способ также содержит модификацию второй декодированной аудиоинформации, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией.
Этот способ основан на соображениях, идентичных соображениям для вышеописанного аудиодекодера.
Другой вариант осуществления согласно изобретению содержит компьютерную программу для осуществления упомянутого способа.
4. Краткое описание чертежей
Далее описываются варианты осуществления согласно настоящему изобретению со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает принципиальную блок-схему аудиодекодера, согласно варианту осуществления настоящего изобретения;
Фиг. 2 показывает принципиальную блок-схему аудиодекодера, согласно другому варианту осуществления настоящего изобретения;
Фиг. 3 показывает принципиальную блок-схему аудиокодера, согласно другому варианту осуществления настоящего изобретения;
Фиг. 4a показывает схематичное представление окон при переходе от MDCT-кодированного аудиокадра к другому MDCT-кодированному аудиокадру;
Фиг. 4b показывает схематичное представление окна, используемого для перехода от CELP-кодированного аудиокадра к MDCT-кодированному аудиокадру;
Фиг. 5a, 5b и 5c показывают графическое представление аудиосигналов в традиционном аудиодекодере;
Фиг. 6a, 6b, 6c и 6d показывают графическое представление аудиосигналов в традиционном аудиодекодере;
Фиг. 7a показывает графическое представление аудиосигнала, полученного на основе предыдущего CELP-кадра, и первой характеристики при отсутствии входного сигнала;
Фиг. 7b показывает графическое представление аудиосигнала, который является второй версией предыдущего CELP-кадра, и второй характеристики при отсутствии входного сигнала;
Фиг. 7c показывает графическое представление аудиосигнала, который получается, если вторая характеристика при отсутствии входного сигнала вычитается из аудиосигнала текущего MDCT-кадра;
Фиг. 8a показывает графическое представление аудиосигнала, полученного на основе предыдущего CELP-кадра;
Фиг. 8b показывает графическое представление аудиосигнала, который получается в качестве второй версии текущего MDCT-кадра; и
Фиг. 8c показывает графическое представление аудиосигнала, который является комбинацией аудиосигнала, полученного на основе предыдущего CELP-кадра, и аудиосигнала, который является второй версией MDCT-кадра;
Фиг. 9 показывает блок-схему последовательности операций способа для предоставления декодированной аудиоинформации, согласно варианту осуществления настоящего изобретения; и
Фиг. 10 показывает блок-схему последовательности операций способа для предоставления декодированной аудиоинформации, согласно другому варианту осуществления настоящего изобретения.
5. Осуществление изобретения
5.1. Аудиодекодер согласно фиг. 1
Фиг. 1 показывает принципиальную блок-схему аудиодекодера 100, согласно варианту осуществления настоящего изобретения. Аудиокодер 100 сконфигурирован с возможностью принимать кодированную аудиоинформацию 110, которая, например, может содержать первый кадр, кодированный в области линейного прогнозирования, и последующий второй кадр, кодированный в частотной области. Аудиодекодер 100 также сконфигурирован с возможностью предоставлять декодированную аудиоинформацию 112 на основе кодированной аудиоинформации 110.
Аудиодекодер 100 содержит декодер 120 в области линейного прогнозирования, который сконфигурирован с возможностью предоставлять первую декодированную аудиоинформацию 122 на основе аудиокадра, кодированного в области линейного прогнозирования. Аудиодекодер 100 также содержит декодер в частотной области (или декодер 130 в области преобразования), который сконфигурирован с возможностью предоставлять вторую декодированную аудиоинформацию 132 на основе аудиокадра, кодированного в частотной области (или в области преобразования). Например, декодер 120 в области линейного прогнозирования может представлять собой CELP-декодер, ACELP-декодер или аналогичный декодер, который выполняет линейную прогнозирующую фильтрацию на основе сигнала возбуждения и на основе кодированного представления характеристик линейного прогнозирующего фильтра (или коэффициентов фильтрации).
Декодер 130 в частотной области, например, может представлять собой AAC-декодер или любой декодер, который основан на AAC-декодировании. Например, декодер в частотной области (или декодер в области преобразования) может принимать кодированное представление параметров частотной области (или параметров области преобразования) и предоставлять, на их основе, вторую декодированную аудиоинформацию. Например, декодер 130 в частотной области может декодировать коэффициенты частотной области (или коэффициенты области преобразования), масштабировать коэффициенты частотной области (или коэффициенты области преобразования) в зависимости от коэффициентов масштабирования (при этом коэффициенты масштабирования могут предоставляться для различных полос частот и могут быть представлены в различных формах) и выполнять преобразование из частотной области во временную область (или преобразование из области преобразования во временную область), такое как, например, обратное быстрое преобразование Фурье или обратное модифицированное дискретное косинусное преобразование (обратное MDCT).
Аудиодекодер 100 также содержит процессор 140 переходов. Процессор 140 переходов сконфигурирован с возможностью получать характеристику при отсутствии входного сигнала линейной прогнозирующей фильтрации, при этом начальное состояние линейной прогнозирующей фильтрации задается в зависимости от первой декодированной аудиоинформации и второй декодированной аудиоинформации. Кроме того, процессор 140 переходов сконфигурирован с возможностью модифицировать вторую декодированную аудиоинформацию 132, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией.
Например, процессор 140 переходов может содержать определение 144 начального состояния, которое принимает первую декодированную аудиоинформацию 122 и вторую декодированную аудиоинформацию 132 и которое предоставляет, на их основе, информацию 146 начального состояния. Процессор 140 переходов также содержит линейную прогнозирующую фильтрацию 148, которая принимает информацию 146 начального состояния и которая предоставляет, на ее основе, характеристику 150 при отсутствии входного сигнала. Например, линейная прогнозирующая фильтрация может выполняться посредством линейного прогнозирующего фильтра, который инициализируется на основе информации 146 начального состояния и предоставляется с отсутствием входного сигнала. Соответственно, линейная прогнозирующая фильтрация предоставляет характеристику 150 при отсутствии входного сигнала. Процессор 140 переходов также содержит модификацию 152, которая модифицирует вторую декодированную аудиоинформацию 132 в зависимости от характеристики 150 при отсутствии входного сигнала, чтобы за счет этого получать модифицированную вторую декодированную аудиоинформацию 142, которая составляет выходную информацию процессора 140 переходов. Модифицированная вторая декодированная аудиоинформация 142 типично конкатенируется с первой декодированной аудиоинформацией 122, чтобы получать декодированную аудиоинформацию 112.
Относительно функциональности аудиодекодера 100, должен рассматриваться случай, в котором после аудиокадра, кодированного в области линейного прогнозирования (первого аудиокадра), идет аудиокадр, кодированный в частотной области (второй аудиокадр). Первый аудиокадр, кодированный в области линейного прогнозирования, декодируется посредством декодера 120 в области линейного прогнозирования. Соответственно, получается первая декодированная аудиоинформация 122, которая ассоциирована с первым аудиокадром. Тем не менее, декодированная аудиоинформация 122, ассоциированная с первым аудиокадром, типично остается незатронутой посредством аудиоинформации, декодированной на основе второго аудиокадра, который кодируется в частотной области. Тем не менее, вторая декодированная аудиоинформация 132 предоставляется посредством декодера 130 в частотной области на основе второго аудиокадра, который кодируется в частотной области.
К сожалению, вторая декодированная аудиоинформация 132, которая ассоциирована со вторым аудиокадром, типично не содержит плавный переход с первой декодированной аудиоинформацией 122, которая ассоциирована с первой декодированной аудиоинформацией.
Тем не менее, следует отметить, что вторая декодированная аудиоинформация предоставляется в течение определенного периода времени, который также перекрывается с периодом времени, ассоциированным с первым аудиокадром. Часть второй декодированной аудиоинформации, которая предоставляется в течение времени первого аудиокадра (т.е. начальная часть второй декодированной аудиоинформации 132) оценивается посредством определения 144 начального состояния. Кроме того, определение 144 начального состояния также оценивает, по меньшей мере, часть первой декодированной аудиоинформации. Соответственно, определение 144 начального состояния получает информацию 146 начального состояния на основе части первой декодированной аудиоинформации (причем эта часть ассоциирована со временем первого аудиокадра) и на основе части второй декодированной аудиоинформации (причем эта часть второй декодированной аудиоинформации 130 также ассоциирована со временем первого аудиокадра). Соответственно, информация 146 начального состояния предоставляется в зависимости от первой декодированной информации 132, а также в зависимости от второй декодированной аудиоинформации.
Следует отметить, что информация 146 начального состояния может предоставляться, как только вторая декодированная аудиоинформация 132 (или, по меньшей мере, ее начальная часть, требуемая посредством определения 144 начального состояния) доступна. Линейная прогнозирующая фильтрация 148 также может выполняться, как только информация 146 начального состояния доступна, поскольку линейная прогнозирующая фильтрация использует коэффициенты фильтрации, которые уже известны из декодирования первого аудиокадра. Соответственно, характеристика 150 при отсутствии входного сигнала может предоставляться, как только вторая декодированная аудиоинформация 132 (или, по меньшей мере, ее начальная часть, требуемая посредством определения 144 начального состояния) доступна. Кроме того, характеристика 150 при отсутствии входного сигнала может использоваться для того, чтобы модифицировать эту часть второй декодированной аудиоинформации 132, которая ассоциирована со временем второго аудиокадра (а не со временем первого аудиокадра). Соответственно, часть второй декодированной аудиоинформации, которая типично находится в начале времени, ассоциированного со вторым аудиокадром, модифицируется. Следовательно, достигается плавный переход между первой декодированной аудиоинформацией 122 (которая типично завершается в конце времени, ассоциированного с первым аудиокадром) и модифицированной второй декодированной аудиоинформацией 142 (при этом временная часть второй декодированной аудиоинформации 132, имеющая времена, которые ассоциированы с первым аудиокадром, предпочтительно отбрасывается и в силу этого предпочтительно используется только для предоставления информации начального состояния для линейной прогнозирующей фильтрации). Соответственно, полная декодированная аудиоинформация 112 может предоставляться без задержки, поскольку предоставление первой декодированной аудиоинформации 122 не задерживается (поскольку первая декодированная аудиоинформация 122 является независимой от второй декодированной аудиоинформации 132), и поскольку модифицированная вторая декодированная аудиоинформация 142 может предоставляться, как только вторая декодированная аудиоинформация 132 доступна. Соответственно, плавные переходы между различными аудиокадрами могут достигаться в декодированной аудиоинформации 112, даже если происходит переключение с аудиокадра, кодированного в области линейного прогнозирования (первого аудиокадра), на аудиокадр, кодированный в частотной области (второй аудиокадр).
Тем не менее, следует отметить, что аудиодекодер 100 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе.
5.2. Аудиодекодер согласно фиг. 2
Фиг. 2 показывает принципиальную блок-схему аудиодекодера, согласно другому варианту осуществления настоящего изобретения. Аудиодекодер 200 сконфигурирован с возможностью принимать кодированную аудиоинформацию 210, которая, например, может содержать один или более кадров, кодированных в области линейного прогнозирования (или эквивалентно в представлении в области линейного прогнозирования), и один или более аудиокадров, кодированных в частотной области (или эквивалентно в области преобразования, или эквивалентно в представлении в частотной области, или эквивалентно в представлении в области преобразования). Аудиодекодер 200 сконфигурирован с возможностью предоставлять декодированную аудиоинформацию 212 на основе кодированной аудиоинформации 210, при этом декодированная аудиоинформация 212, например, может содержаться в представлении во временной области.
Аудиодекодер 200 содержит декодер 220 в области линейного прогнозирования, который является практически идентичным декодеру 120 в области линейного прогнозирования, так что вышеприведенные пояснения применяются. Таким образом, декодер 210 в области линейного прогнозирования принимает аудиокадры, кодированные в представлении в области линейного прогнозирования, которые включены в кодированную аудиоинформацию 210, и предоставляет, на основе аудиокадра, кодированного в представлении в области линейного прогнозирования, первую декодированную аудиоинформацию 222, которая типично имеет форму аудиопредставления во временной области (и которая типично соответствует первой декодированной аудиоинформации 122). Аудиодекодер 200 также содержит декодер 230 в частотной области, который является практически идентичным частотному декодеру 130, так что вышеприведенные пояснения применяются. Соответственно, декодер 230 в частотной области принимает аудиокадр, кодированный в представлении в частотной области (или в представлении в области преобразования), и предоставляет, на его основе, вторую декодированную аудиоинформацию 232, которая типично имеет форму представления во временной области.
Аудиодекодер 200 также содержит процессор 240 переходов, который сконфигурирован с возможностью модифицировать вторую декодированную аудиоинформацию 232, чтобы за счет этого извлекать модифицированную вторую декодированную аудиоинформацию 242.
Процессор 240 переходов сконфигурирован с возможностью получать первую характеристику при отсутствии входного сигнала линейного прогнозирующего фильтра в ответ на начальное состояние линейного прогнозирующего фильтра, заданное посредством первой декодированной аудиоинформации 222. Процессор переходов также сконфигурирован с возможностью получать вторую характеристику при отсутствии входного сигнала линейного прогнозирующего фильтра в ответ на второе начальное состояние линейного прогнозирующего фильтра, заданное посредством модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации 232. Например, процессор 240 переходов содержит определение 242 начального состояния, которое принимает первую декодированную аудиоинформацию 222 и которое предоставляет информацию 244 первого начального состояния на ее основе. Например, информация 244 первого начального состояния может просто отражать часть первой декодированной аудиоинформации 222, например, часть, которая является смежной с концом временной части, ассоциированной с первым аудиокадром. Процессор 240 переходов также может содержать (первую) линейную прогнозирующую фильтрацию 246, которая сконфигурирована с возможностью принимать информацию 244 первого начального состояния в качестве начального состояния линейного прогнозирующего фильтра, и предоставлять, на основе информации 244 первого начального состояния, первую характеристику 248 при отсутствии входного сигнала. Процессор 240 переходов также содержит модификацию/добавление наложения спектров/комбинирование 250, которое сконфигурировано с возможностью принимать первую декодированную аудиоинформацию 222 или, по меньшей мере, ее часть (например, часть, которая является смежной с концом временной части, ассоциированной с первым аудиокадром), а также вторую декодированную информацию 232 или, по меньшей мере, ее часть (например, временную часть второй декодированной аудиоинформации 232, которая временно размещается в конце временной части, ассоциированной с первым аудиокадром, при этом вторая декодированная аудиоинформация предоставляется, например, в основном для временной части, ассоциированной со вторым аудиокадром, но также и, в некоторой степени, для конца временной части, ассоциированной с первым аудиокадром, который кодируется в представлении в области линейного прогнозирования). Модификация/добавление наложения спектров/комбинирование, например, может модифицировать временную часть первой декодированной аудиоинформации, добавлять искусственное наложение спектров на основе временной части первой декодированной аудиоинформации, а также добавлять временную часть второй декодированной аудиоинформации, чтобы за счет этого получать информацию 252 второго начального состояния. Другими словами, модификация/добавление наложения спектров/комбинирование может быть частью определения второго начального состояния. Информация второго начального состояния определяет начальное состояние второй линейной прогнозирующей фильтрации 254, которая сконфигурирована с возможностью предоставлять вторую характеристику 256 при отсутствии входного сигнала на основе информации второго начального состояния.
Например, первая линейная прогнозирующая фильтрация и вторая линейная прогнозирующая фильтрация могут использовать настройку фильтра (например, коэффициенты фильтрации), которая предоставляется посредством декодера 220 в области линейного прогнозирования для первого аудиокадра (который кодируется в линейном представлении в области линейного прогнозирования). Другими словами, первая и вторая линейная прогнозирующая фильтрация 246, 254 могут выполнять идентичную линейную прогнозирующую фильтрацию, которая также выполняется посредством декодера 220 в области линейного прогнозирования, чтобы получать первую декодированную аудиоинформацию 222, ассоциированную с первым аудиокадром. Тем не менее, начальные состояния первой и второй линейной прогнозирующей фильтрации 246, 254 могут задаваться равными значениям, определенным посредством определения 244 первого начального состояния и посредством определения 250 второго начального состояния (что содержит модификацию/добавление наложения спектров/комбинирование). Тем не менее, входной сигнал линейных прогнозирующих фильтров 246, 254 может задаваться равным нулю. Соответственно, первая характеристика 248 при отсутствии входного сигнала и вторая характеристика 256 при отсутствии входного сигнала получаются таким образом, что первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала основаны на первой декодированной аудиоинформации и второй декодированной аудиоинформации и формируются с использованием идентичного линейного прогнозирующего фильтра, который используется посредством декодера 220 в области линейного прогнозирования.
Процессор 240 переходов также содержит модификацию 258, которая принимает вторую кодированную аудиоинформацию 232 и модифицирует вторую декодированную аудиоинформацию 232 в зависимости от первой характеристики 248 при отсутствии входного сигнала и в зависимости от второй характеристики 256 при отсутствии входного сигнала, чтобы за счет этого получать модифицированную вторую декодированную аудиоинформацию 242. Например, модификация 258 может суммировать и/или вычитать первую характеристику 248 при отсутствии входного сигнала в/из второй декодированной аудиоинформации 232 и может суммировать или вычитать вторую характеристику 256 при отсутствии входного сигнала в/из второй декодированной аудиоинформации, чтобы получать модифицированную вторую декодированную аудиоинформацию 242.
Например, первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала могут предоставляться в течение периода времени, который ассоциирован со вторым аудиокадром, так что модифицируется только часть второй декодированной аудиоинформации, которая ассоциирована с периодом времени второго аудиокадра. Кроме того, значения второй декодированной аудиоинформации 232, которые ассоциированы с временной частью, которая ассоциирована с первым аудиокадром, могут отбрасываться в заключительном предоставлении модифицированной второй декодированной аудиоинформации (на основе характеристик при отсутствии входного сигнала).
Кроме того, аудиодекодер 200 предпочтительно сконфигурирован с возможностью конкатенировать первую декодированную аудиоинформацию 222 и модифицированную вторую декодированную аудиоинформацию 242, чтобы за счет этого получать полную декодированную аудиоинформацию 212.
Относительно функциональности аудиодекодера 200, следует обратиться к вышеприведенным пояснениям аудиодекодера 100. Кроме того, дополнительные подробности описываются ниже со ссылкой на другие чертежи.
5.3. Аудиодекодер согласно фиг. 3
Фиг. 3 показывает принципиальную блок-схему аудиодекодера 300, согласно варианту осуществления настоящего изобретения. Аудиодекодер 300 является аналогичным аудиодекодеру 200, так что подробно описываются только различия. В противном случае, следует обратиться к вышеприведенным пояснениям, изложенным относительно аудиодекодера 200.
Аудиодекодер 300 сконфигурирован с возможностью принимать кодированную аудиоинформацию 310, которая может соответствовать кодированной аудиоинформации 210. Кроме того, аудиодекодер 300 сконфигурирован с возможностью предоставлять декодированную аудиоинформацию 312, которая может соответствовать декодированной аудиоинформации 212.
Аудиодекодер 300 содержит декодер 320 в области линейного прогнозирования, который может соответствовать декодеру 220 в области линейного прогнозирования, и декодер 330 в частотной области, который соответствует декодеру 230 в частотной области. Декодер 320 в области линейного прогнозирования предоставляет первую декодированную аудиоинформацию 322, например, на основе первого аудиокадра, который кодируется в области линейного прогнозирования. Кроме того, аудиодекодер 330 в частотной области предоставляет вторую декодированную аудиоинформацию 332, например, на основе второго аудиокадра (который идет после первого аудиокадра), который кодируется в частотной области (или в области преобразования). Первая декодированная аудиоинформация 322 может соответствовать первой декодированной аудиоинформации 222, и вторая декодированная аудиоинформация 332 может соответствовать второй декодированной аудиоинформации 232.
Аудиодекодер 300 также содержит процессор 340 переходов, который может соответствовать, с точки зрения своей полной функциональности, процессору 340 переходов и который может предоставлять модифицированную вторую декодированную аудиоинформацию 342 на основе второй декодированной аудиоинформации 332.
Процессор 340 переходов сконфигурирован с возможностью получать комбинированную характеристику при отсутствии входного сигнала линейного прогнозирующего фильтра в ответ на (комбинированное) начальное состояние линейного прогнозирующего фильтра, заданное посредством комбинации первой декодированной аудиоинформации и модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации. Кроме того, процессор переходов сконфигурирован с возможностью модифицировать вторую декодированную аудиоинформацию, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от комбинированной характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией.
Например, процессор 340 переходов содержит модификацию/добавление наложения спектров/комбинирование 342, которое принимает первую декодированную аудиоинформацию 322 и вторую декодированную аудиоинформацию 332 и предоставляет, на их основе, информацию 344 комбинированного начального состояния. Например, модификация/добавление наложения спектров/комбинирование может рассматриваться как определение начального состояния. Также следует отметить, что модификация/добавление наложения спектров/комбинирование 342 может выполнять функциональность определения 242 начального состояния и определения 250 начального состояния. Информация 344 комбинированного начального состояния, например, может быть равна (или, по меньшей мере, соответствовать) сумме информации 244 первого начального состояния и информации 252 второго начального состояния. Соответственно, модификация/добавление наложения спектров/комбинирование 342, например, может комбинировать часть первой декодированной аудиоинформации 322 с искусственным наложением спектров, а также с частью второй декодированной аудиоинформации 332. Кроме того, модификация/добавление наложения спектров/комбинирование 342 также может модифицировать часть первой декодированной аудиоинформации и/или добавлять полученную с помощью оконного преобразования копию первой декодированной аудиоинформации 322, как подробнее описано ниже. Соответственно, информация 344 комбинированного начального состояния получается.
Процессор 340 переходов также содержит линейную прогнозирующую фильтрацию 346, которая принимает информацию 344 комбинированного начального состояния и предоставляет, на ее основе, комбинированную характеристику 348 при отсутствии входного сигнала в модификацию 350. Линейная прогнозирующая фильтрация 346, например, может выполнять линейную прогнозирующую фильтрацию, которая является практически идентичной линейной прогнозирующей фильтрации, которая выполняется посредством декодера линейного прогнозирования 320, чтобы получать первую декодированную аудиоинформацию 322. Тем не менее, начальное состояние линейной прогнозирующей фильтрации 346 может определяться посредством информации 344 комбинированного начального состояния. Кроме того, входной сигнал для предоставления комбинированной характеристики 348 при отсутствии входного сигнала может задаваться равным нулю, так что линейная прогнозирующая фильтрация 344 предоставляет характеристику при отсутствии входного сигнала на основе информации 344 комбинированного начального состояния (при этом параметры фильтрации или коэффициенты фильтрации, например, являются идентичными параметрам фильтрации или коэффициентам фильтрации, используемым посредством декодера 320 в области линейного прогнозирования для предоставления первой декодированной аудиоинформации 322, ассоциированной с первым аудиокадром). Кроме того, комбинированная характеристика 348 при отсутствии входного сигнала используется для того, чтобы модифицировать вторую декодированную аудиоинформацию 332, чтобы за счет этого извлекать модифицированную вторую декодированную аудиоинформацию 342. Например, модификация 350 может суммировать комбинированную характеристику 348 при отсутствии входного сигнала со второй декодированной аудиоинформации 332 или может вычитать комбинированную характеристику при отсутствии входного сигнала из второй декодированной аудиоинформации.
Тем не менее, для получения дальнейшей информации, следует обратиться к пояснениям аудиодекодеров 100, 200, а также к нижеприведенным подробным пояснениям.
5.4. Пояснение принципа перехода
Далее описываются некоторые подробности относительно перехода от CELP-кадра к MDCT-кадру, которые являются применимыми в аудиодекодерах 100, 200, 300.
Кроме того, описываются отличия по сравнению с традиционными принципами.
MDCT и оконное преобразование: общее представление
В вариантах осуществления согласно изобретению, проблема наложения спектров разрешается посредством увеличения MDCT-длины (например, для аудиокадра, кодированного в MDCT-области после аудиокадра, кодированного в области линейного прогнозирования) таким образом, что левая точка перегиба (например, аудиосигнала временной области, восстановленного на основе набора MDCT-коэффициентов с использованием обратного MDCT-преобразования) перемещается влево от границы между CELP- и MDCT-кадрами. Левая часть MDCT-окна (например, окна, которое применяется к аудиосигналу временной области, восстановленному на основе набора MDCT-коэффициентов с использованием обратного MDCT-преобразования) также изменяется (например, по сравнению с "нормальным" MDCT-окном), так что перекрытие уменьшается.
В качестве примера, фиг. 4a и 4b показывают графическое представление различных окон, при этом фиг. 4a показывает окна для перехода от первого MDCT-кадра (т.е. первого аудиокадра, кодированного в частотной области) к другому MDCT-кадру (т.е. второму аудиокадру, кодированному в частотной области). Напротив, фиг. 4b показывает окно, которое используется для перехода от CELP-кадра (т.е. первого аудиокадра, кодированного в области линейного прогнозирования) к MDCT-кадру (т.е. следующему второму аудиокадру, кодированному в частотной области).
Другими словами, фиг. 4a показывает последовательность аудиокадров, которые могут рассматриваться как сравнительный пример. Напротив, фиг. 4b показывает последовательность, в которой первый аудиокадр кодируется в области линейного прогнозирования, и после него идет второй аудиокадр, кодированный в частотной области, при этом случай согласно фиг. 4b обрабатывается сверхпреимущественным способом посредством вариантов осуществления настоящего изобретения.
Со ссылкой теперь на фиг. 4a, следует отметить, что абсцисса 410 описывает время в миллисекундах, и что ордината 412 описывает амплитуду окна (например, нормализованную амплитуду окна) в произвольных единицах. Как можно видеть, длина кадра равна 20 мс, так что период времени, ассоциированный с первым аудиокадром, идет между t=-20 мс и t=0. Период времени, ассоциированный со вторым аудиокадром, идет от времени t=0 до t=20 мс. Тем не менее, можно видеть, что первое окно для оконного преобразования аудиовыборок временной области, предоставленных посредством обратного модифицированного дискретного косинусного преобразования на основе декодированных MDCT-коэффициентов, идет между временами t=-20 мс и t=8,75 мс. Таким образом, длина первого окна 420 превышает длину кадра (20 мс). Соответственно, даже если время между t=-20 мс и t=0 ассоциировано с первым аудиокадром, аудиовыборки временной области предоставляются на основе декодирования первого аудиокадра, для времен между t=-20 мс и t=8,75 мс. Таким образом, существует перекрытие приблизительно в 8,75 мс между аудиовыборками временной области, предоставленными на основе первого кодированного аудиокадра, и аудиовыборками временной области, предоставленными на основе второго декодированного аудиокадра. Следует отметить, что второе окно обозначено как 422 и идет между временем t=0 и t=28,75 мс.
Кроме того, следует отметить, что полученные с помощью оконного преобразования аудиосигналы временной области, предоставленные для первого аудиокадра и предоставленные для второго аудиокадра, имеют наложение спектров. Наоборот, полученная с помощью оконного преобразования (вторая) декодированная аудиоинформация, предоставленная для первого аудиокадра, содержит наложение спектров между временами t=-20 мс и t=-11,25 мс, а также между временами t=0 и t=8,75 мс. Аналогично, полученная с помощью оконного преобразования декодированная аудиоинформация, предоставленная для второго аудиокадра, содержит наложение спектров между временами t=0 и t=8,75 мс, а также между временами t=20 мс и t=28,75 мс. Тем не менее, например, наложение спектров, включенное в декодированную аудиоинформацию, предоставленную для первого аудиокадра, балансируется с наложением спектров, включенным в декодированную аудиоинформацию, предоставленную для последующего второго аудиокадра во временной части между временами t=0 и t=8,75 мс.
Кроме того, следует отметить, что для окон 420 и 422 временная длительность между MDCT-точками перегиба равна 20 мс, что равно длине кадра.
Со ссылкой теперь на фиг. 4b, описывается другой случай, а именно, окно для перехода от CELP-кадра к MDCT-кадру, которая может использоваться в аудиодекодерах 100, 200, 300 для предоставления второй декодированной аудиоинформации. На фиг. 4b, абсцисса 430 описывает время в миллисекундах, и ордината 432 описывает амплитуду окна в произвольных единицах.
Как можно видеть на фиг. 4b, первый кадр идет между временем t1=-20 мс и временем t2=0 мс. Таким образом, длина кадра первого аудиокадра, который представляет собой CELP-аудиокадр, составляет 20 мс. Кроме того, второй, последующий аудиокадр идет между временем t2 и t3=20 мс. Таким образом, длина второго аудиокадра, который представляет собой MDCT-аудиокадр, также составляет 20 мс.
Далее описываются некоторые подробности относительно окна 440.
Окно 440 содержит первый наклон 442 окна, который идет между временами t4=-1,25 мс и временем t2=0 мс. Второй наклон 444 окна идет между временами t3=20 мс и временем t5=28,75 мс. Следует отметить, что модифицированное дискретное косинусное преобразование, которое предоставляет (вторую) декодированную аудиоинформацию для (или ассоциирован с ним) второго аудиокадра, предоставляет выборки временной области между временами t4 и t5. Тем не менее, модифицированное дискретное косинусное преобразование (или, более точно, обратное модифицированное дискретное косинусное преобразование) (которое может использоваться в декодерах 130, 230, 330 в частотной области, если аудиокадр, кодированный в частотной области, например, в MDCT-области, идет после аудиокадра, кодированного в области линейного прогнозирования) предоставляет выборки временной области, содержащие наложение спектров, для времен между t4 и t2 и для времен между временем t3 и временем t5 на основе представления в частотной области второго аудиокадра. Напротив, обратное модифицированное дискретное косинусное преобразование предоставляет выборки временной области без наложения спектров в течение периода времени между временами t2 и t3 на основе представления в частотной области второго аудиокадра. Таким образом, первый наклон 442 окна ассоциирован с аудиовыборками временной области, содержащими некоторое наложение спектров, и второй наклон 444 окна также ассоциирован с аудиовыборками временной области, содержащими некоторое наложение спектров.
Кроме того, следует отметить, что время между MDCT-точками перегиба равно 25 мс для второго аудиокадра, что подразумевает то, что число кодированных MDCT-коэффициентов должно быть большим для ситуации, показанной на фиг. 4b, чем для ситуации, показанной на фиг. 4a.
В качестве вывода, аудиодекодеры 100, 200, 300 могут применять окна 420, 422 (например, для оконного преобразования вывода обратного модифицированного дискретного косинусного преобразования в декодере в частотной области) в случае, если как первый аудиокадр, так и второй аудиокадр после первого аудиокадра кодируются в частотной области (например, в MDCT-области). Напротив, аудиодекодеры 100, 200, 300 могут переключать работу декодера в частотной области в случае, если второй аудиокадр, который идет после первого аудиокадра, кодированного в области линейного прогнозирования, кодируется в частотной области (например, в MDCT-области). Например, если второй аудиокадр кодируется в MDCT-области и идет после предыдущего первого аудиокадра, который кодируется в CELP-области, может использоваться обратное модифицированное дискретное косинусное преобразование с использованием увеличенного числа MDCT-коэффициентов (что подразумевает то, что увеличенное число MDCT-коэффициентов включено, в кодированной форме, в представление в частотной области аудиокадра после предыдущего аудиокадра, кодированного в области линейного прогнозирования, по сравнению с представлением в частотной области кодированного аудиокадра после предыдущего аудиокадра, кодированного также в частотной области). Кроме того, другое окно, а именно, окно 440, применяется, чтобы выполнять оконное преобразование вывода обратного модифицированного дискретного косинусного преобразования (т.е. аудиопредставление во временной области, предоставленное посредством обратного модифицированного дискретного косинусного преобразования), чтобы получать вторую декодированную аудиоинформацию 132 в случае, если второй (текущий) аудиокадр, кодированный в частотной области, идет после аудиокадра, кодированного в области линейного прогнозирования (по сравнению со случаем, в котором второй (текущий) аудиокадр идет после предыдущего аудиокадра, также кодированного в частотной области).
В качестве еще одного вывода, обратное модифицированное дискретное косинусное преобразование, имеющее увеличенную длину (по сравнению с нормальным случаем), может применяться посредством декодера 130 в частотной области в случае, если аудиокадр, кодированный в частотной области, идет после аудиокадра, кодированного в области линейного прогнозирования. Кроме того, окно 440 может использоваться в этом случае (тогда как окна 420, 422 могут использоваться в "нормальном" случае, в котором аудиокадр, кодированный в частотной области, идет после предыдущей аудиообласти, кодированной в частотной области).
Относительно идеи изобретения, следует отметить, что CELP-сигнал не модифицируется, чтобы не вводить дополнительную задержку, как подробнее показано ниже. Вместо этого, варианты осуществления согласно изобретению создают механизм для того, чтобы удалять неоднородности, которые могут вводиться на границе между CELP- и MDCT-кадрами. Этот механизм сглаживает неоднородность с использованием характеристики при отсутствии входного сигнала синтезирующего CELP-фильтра (который используется, например, посредством декодера в области линейного прогнозирования). Ниже приводятся подробности.
Пошаговое описание: общее представление
Далее приводится короткое пошаговое описание. После этого предоставляются дополнительные сведения.
Сторона кодера
1. Когда предыдущий кадр (иногда также называемый "первым кадром") представляет собой CELP (или, в общем, кодированный в области линейного прогнозирования), текущий MDCT-кадр (также иногда называемый "вторым кадром") (который может рассматриваться как пример кадра, кодированного в частотной области, или в области преобразования) кодируется с другой MDCT-длиной и другим MDCT-окном. Например, в этом случае может использоваться окно 440 (а не "нормальное" окно 422).
2. MDCT-длина увеличивается (например, с 20 мс до 25 мс, см. фиг. 4a и 4b), так что левая точка перегиба перемещается влево от границы между CELP- и MDCT-кадрами. Например, MDCT-длина (которая может задаваться посредством числа MDCT-коэффициентов) может выбираться таким образом, что длина MDCT-точек перегиба (или между ними) равна 25 мс (как показано на фиг. 4b), по сравнению с "нормальной" длиной между MDCT-точками перегиба в 20 мс (как показано на фиг. 4a). Также можно видеть, что "левая" точка перегиба MDCT-преобразования находится между временами t4 и t2 (а не в середине между временами t=0 и t=8,75 мс), что можно видеть на фиг. 4b. Тем не менее, позиция правой MDCT-точки перегиба может оставаться неизменной (например, в середине между временами t3 и t5), что можно видеть из сравнения фиг. 4a и 4b (или, более точно, окон 422 и 440).
3. Левая часть MDCT-окна изменяется таким образом, что длина перекрытия уменьшается (например, с 8,75 мс до 1,25 мс). Например, часть, содержащая наложение спектров, находится между временами t4=-1,25 мс и t2=0 (т.е. перед периодом времени, ассоциированным со вторым аудиокадром, который начинается в t=0 и заканчивается в t=20 мс), в случае если предыдущий аудиокадр кодируется в области линейного прогнозирования. Напротив, часть сигнала, содержащая наложение спектров, находится между временами t=0 и t=8,75 мс в случае, если предыдущий аудиокадр кодируется в частотной области (например, в MDCT-области).
Сторона декодера
1. Когда предыдущий кадр (также называемый "первым аудиокадром") представляет собой CELP (или, в общем, кодированный в области линейного прогнозирования) текущий MDCT-кадр (также называемый "вторым аудиокадром") (который является примером для кадра, кодированного в частотной области, или область преобразования) декодируется с идентичными MDCT-длинами и идентичным MDCT-окном, которые используются на стороне кодера. Иными словами, оконное преобразование, показанное на фиг. 4b, применяется при предоставлении второй декодированной аудиоинформации, и также могут применяться вышеуказанные характеристики относительно обратного модифицированного дискретного косинусного преобразования (которые соответствуют характеристикам модифицированного дискретного косинусного преобразования, используемого со стороны кодера).
2. Чтобы удалять неоднородности, которые могут возникать на границе между CELP- и MDCT-кадрами (например, на границе между первым аудиокадром и упомянутым выше вторым аудиокадром), используется следующий механизм:
a) Первая часть сигнала составляется посредством искусственного введения пропущенного наложения спектров части перекрытия MDCT-сигнала (например, части сигнала между временами t4 и t2 аудиосигнала временной области, предоставленного посредством обратного модифицированного дискретного косинусного преобразования) с использованием CELP-сигнала (например, с использованием первой декодированной аудиоинформации) и операции суммирования с перекрытием. Длина первой части сигнала, например, равна длине перекрытия (например, 1,25 мс).
b) Вторая часть сигнала составляется посредством вычитания первой части сигнала из соответствующего CELP-сигнала (части, расположенной непосредственно перед границей кадра, например, между первым аудиокадром и вторым аудиокадром).
c) Характеристика при отсутствии входного сигнала синтезирующего CELP-фильтра формируется посредством фильтрации кадра из нулей и использования второй части сигнала в качестве состояний запоминающего устройства (или в качестве начального состояния).
d) Характеристика при отсутствии входного сигнала, например, подвергается оконному преобразованию таким образом, что она снижается до нулей после определенного числа выборок (например, 64).
e) Полученная с помощью оконного преобразования характеристика при отсутствии входного сигнала добавляется в начальную часть MDCT-сигнала (например, в аудиочасть, начинающуюся во время t2=0).
Пошаговое описание: подробное описание функциональности декодера
Далее подробнее описывается функциональность декодера.
Применяются следующие обозначения: длина кадра помечена как N, декодированный CELP-сигнал помечен как  , декодированный MDCT-сигнал (включающий в себя полученный с помощью оконного преобразования сигнал перекрытия) помечен как
, декодированный MDCT-сигнал (включающий в себя полученный с помощью оконного преобразования сигнал перекрытия) помечен как  , окно, используемое для оконного преобразования левой части MDCT-сигнала, является
, окно, используемое для оконного преобразования левой части MDCT-сигнала, является  , где L является длиной окна, и синтезирующий CELP-фильтр помечен как
, где L является длиной окна, и синтезирующий CELP-фильтр помечен как  с
с  , и M является порядком фильтра.
, и M является порядком фильтра.
Подробное описание этапа 1
После этапа 1 на стороне декодера (декодирования текущего MDCT-кадра с идентичной MDCT-длиной и идентичным MDCT-окном, которое используется на стороне кодера) получается текущий декодированный MDCT-кадр (например, представление во временной области "второго аудиокадра"), который составляет вышеупомянутую вторую декодированную аудиоинформацию. Этот кадр (например, второй кадр) не содержит наложение спектров, поскольку левая точка перегиба перемещена влево от границы между CELP- и MDCT-кадрами (например, с использованием принципа, как подробно описано со ссылкой на фиг. 4b). Это означает то, что можно получать идеальное восстановление в текущем кадре (например, между временами t2=0 и t3=20 мс) на достаточно высокой скорости передачи битов. Тем не менее, на низкой скорости передачи битов сигнал не обязательно совпадает с входным сигналом, и в силу этого неоднородность может вводиться на границе между CELP и MDCT (например, во время t=0, как показано на фиг. 4b).
Чтобы упрощать понимание, эта проблема проиллюстрирована со ссылкой на фиг. 5. Верхний график (фиг. 5a) показывает декодированный CELP-сигнал , средний график (фиг. 5b) показывает декодированный MDCT-сигнал (включающий в себя полученный с помощью оконного преобразования сигнал перекрытия), а нижний график (фиг. 5c) показывает выходной сигнал, полученный посредством отбрасывания полученного с помощью оконного преобразования сигнала перекрытия и конкатенации CELP-кадра и MDCT-кадра. Очевидно, существует неоднородность в выходном сигнале (показан на фиг. 5c) на границе между двумя кадрами (например, во время t=0 мс).
Сравнительный пример последующей обработки
Одно возможное решение этой проблемы представляет собой подход, предложенный в вышеуказанном ссылочном документе 1 ("Efficient cross-fade windows for transitions between LPC-based and non-LPC based audio coding" авторов J. Lecomte и др.), который описывает принцип, используемый в MPEG USAC. Далее предоставляется краткое описание упомянутого справочного подхода.
Вторая версия декодированного CELP-сигнала  сначала инициализируется как равная декодированному CELP-сигналу:
сначала инициализируется как равная декодированному CELP-сигналу:
 ,
,
затем пропущенное наложение спектров искусственно вводится в области перекрытия:

 ,
,
в завершение, вторая версия декодированного CELP-сигнала получается с использованием операции суммирования с перекрытием:
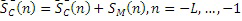
Как можно видеть на фиг. 6a-6d, этот подход на основе сравнения удаляет неоднородность (см., в частности, фиг. 6d). Проблема при этом подходе состоит в том, что он вводит дополнительную задержку (равную длине перекрытия), поскольку предыдущий кадр модифицируется после того, как текущий кадр декодирован. В некоторых вариантах применения, аналогично кодированию аудио с низкой задержкой, желательно (или даже необходимо) иметь задержку как можно меньше.
Подробное описание этапов обработки
В отличие от вышеуказанного традиционного подхода, подход, предложенный в данном документе для того, чтобы удалять неоднородность, не имеет дополнительной задержки. Он не модифицирует предыдущий CELP-кадр (также называемый "первым аудиокадром"), а вместо этого модифицирует текущий MDCT-кадр (также называемый "вторым аудиокадром", кодированным в частотной области после первого аудиокадра, кодированного в области линейного прогнозирования).
Этап a)
На первом этапе, "вторая версия" предыдущего ACELP-кадра 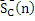 вычисляется так, как описано выше. Например, может использоваться следующее вычисление:
вычисляется так, как описано выше. Например, может использоваться следующее вычисление:
Вторая версия декодированного CELP-сигнала сначала инициализируется как равная декодированному CELP-сигналу:
,
затем пропущенное наложение спектров искусственно вводится в области перекрытия:
,
в завершение, вторая версия декодированного CELP-сигнала получается с использованием операции суммирования с перекрытием:
Тем не менее, в отличие от ссылочного документа 1 ("Efficient cross-fade windows for transitions between LPC-based and non-LPC-based audio coding" авторов J. Lecomte и др.), предыдущий декодированный ACELP-сигнал не заменяется посредством этой версии предыдущего ACELP-кадра, чтобы не вводить дополнительную задержку. Он используется просто в качестве промежуточного сигнала для модификации текущего MDCT-кадра, как описано на следующих этапах.
Иными словами, определение 144 начального состояния, модификация/добавление наложения спектров/комбинирование 250 или модификация/добавление наложения спектров/комбинирование 342, например, могут предоставлять сигнал  в качестве доли в информации 146 начального состояния или в информации 344 комбинированного начального состояния либо в качестве информации 252 второго начального состояния. Таким образом, определение 144 начального состояния, модификация/добавление наложения спектров/комбинирование 250 или модификация/добавление наложения спектров/комбинирование 342, например, могут применять оконное преобразование к декодированному CELP-сигналу
в качестве доли в информации 146 начального состояния или в информации 344 комбинированного начального состояния либо в качестве информации 252 второго начального состояния. Таким образом, определение 144 начального состояния, модификация/добавление наложения спектров/комбинирование 250 или модификация/добавление наложения спектров/комбинирование 342, например, могут применять оконное преобразование к декодированному CELP-сигналу  (умножение на значения
(умножение на значения  w
w  окон), добавлять версию с временным зеркалированием декодированного CELP-сигнала (
окон), добавлять версию с временным зеркалированием декодированного CELP-сигнала ( ), масштабированную с использованием оконного преобразования (
), масштабированную с использованием оконного преобразования ( ), и добавлять декодированный MDCT-сигнал , чтобы за счет этого получать долю в информации 146, 344 начального состояния или даже получать информацию 252 второго начального состояния.
), и добавлять декодированный MDCT-сигнал , чтобы за счет этого получать долю в информации 146, 344 начального состояния или даже получать информацию 252 второго начального состояния.
Этап b)
Принцип также содержит формирование двух сигналов посредством вычисления характеристики при отсутствии входного сигнала (ZIR) синтезирующего CELP-фильтра (который, в общем, может рассматриваться как линейный прогнозирующий фильтр) с использованием двух различных запоминающих устройств (также называемых "начальными состояниями") для синтезирующих CELP-фильтров.
Первая ZIR  формируется посредством использования предыдущего декодированного CELP-сигнала в качестве запоминающих устройств для синтезирующего CELP-фильтра.
формируется посредством использования предыдущего декодированного CELP-сигнала в качестве запоминающих устройств для синтезирующего CELP-фильтра.



Вторая ZIR  формируется посредством использования второй версии предыдущего декодированного CELP-сигнала в качестве запоминающих устройств для синтезирующего CELP-фильтра.
формируется посредством использования второй версии предыдущего декодированного CELP-сигнала в качестве запоминающих устройств для синтезирующего CELP-фильтра.


Следует отметить, что первая характеристика при отсутствии входного сигнала и вторая характеристика при отсутствии входного сигнала могут вычисляться отдельно, при этом первая характеристика при отсутствии входного сигнала может получаться на основе первой декодированной аудиоинформации (например, с использованием определения 242 начального состояния и линейной прогнозирующей фильтрации 246), и при этом вторая характеристика при отсутствии входного сигнала может вычисляться, например, с использованием модификации/добавления наложения спектров/комбинирования 250, которое может предоставлять "вторую версию предыдущего CELP-кадра " в зависимости от первой декодированной аудиоинформации 222 и второй декодированной аудиоинформации 232, а также с использованием второй линейной прогнозирующей фильтрации 254. Тем не менее, альтернативно, может применяться одна синтезирующая CELP-фильтрация. Например, может применяться линейная прогнозирующая фильтрация 148, 346, при которой сумма и используется в качестве ввода для упомянутой (комбинированной) линейной прогнозирующей фильтрации.
Это обусловлено тем фактом, что линейная прогнозирующая фильтрация является линейной операцией, так что комбинирование может выполняться либо перед фильтрацией, либо после фильтрации без изменения результата. Тем не менее, в зависимости от знаков, разность между и также может использоваться в качестве начального состояния (для n ) (комбинированной) линейной прогнозирующей фильтрации.
) (комбинированной) линейной прогнозирующей фильтрации.
В качестве вывода, информация ,  первого начального состояния и информация
первого начального состояния и информация  , второго начального состояния могут получаться либо отдельно, либо комбинированным способом. Кроме того, первая и вторая характеристики при отсутствии входного сигнала могут получаться либо посредством отдельной линейной прогнозирующей фильтрации отдельной информации начального состояния, либо с использованием (комбинированной) линейной прогнозирующей фильтрации на основе информации комбинированного начального состояния.
, второго начального состояния могут получаться либо отдельно, либо комбинированным способом. Кроме того, первая и вторая характеристики при отсутствии входного сигнала могут получаться либо посредством отдельной линейной прогнозирующей фильтрации отдельной информации начального состояния, либо с использованием (комбинированной) линейной прогнозирующей фильтрации на основе информации комбинированного начального состояния.
Как показано на графиках по фиг. 7, который подробнее поясняется далее, и являются непрерывными, и являются непрерывными. Кроме того, поскольку и также являются непрерывными,  представляет собой сигнал, который начинается со значения, очень близкого к 0.
представляет собой сигнал, который начинается со значения, очень близкого к 0.
Со ссылкой теперь на фиг. 7, поясняются некоторые подробности.
Фиг. 7a показывает графическое представление предыдущего CELP-кадра и первой характеристики при отсутствии входного сигнала. Абсцисса 710 описывает время в миллисекундах, а ордината 712 описывает амплитуду в произвольных единицах.
Например, аудиосигнал, предоставленный для предыдущего CELP-кадра (также называемого "первым аудиокадром") показан между временами t71 и t72. Например, сигнал для n<0 может быть показан между временами t71 и t72. Кроме того, первая характеристика при отсутствии входного сигнала может быть показана между временами t72 и t73. Например, первая характеристика при отсутствии входного сигнала может быть показана между временами t72 и t73.
Фиг. 7b показывает графическое представление второй версии предыдущего CELP-кадра и второй характеристики при отсутствии входного сигнала. Абсцисса обозначена как 720 и показывает время в миллисекундах. Ордината обозначена как 722 и показывает амплитуду в произвольных единицах. Вторая версия предыдущего CELP-кадра показана между временами t71 (-20 мс) и t72 (0 мс), и вторая характеристика при отсутствии входного сигнала показана между временами t72 и t73 (+20 мс). Например, сигнал , n<0, показан между временами t71 и t72. Кроме того, сигнал для n≥0 показан между временами t72 и t73.
Кроме того, разность между и показана на фиг. 7c, при этом абсцисса 730 обозначает время в миллисекундах, и при этом ордината 732 обозначает амплитуду в произвольных единицах.
Кроме того, следует отметить, что первая характеристика при отсутствии входного сигнала для n≥0 является (практически) установившимся продолжением сигнала для n<0. Аналогично, вторая характеристика при отсутствии входного сигнала для n≥0 является (практически) установившимся продолжением сигнала для n<0.
Этап c)
Текущий MDCT-сигнал (например, вторая декодированная аудиоинформация 132, 232, 332) заменен посредством второй версии 142, 242, 342 текущего MDCT (т.е. MDCT-сигнала, ассоциированного с текущим вторым аудиокадром).

В таком случае проще всего показывать, что и  являются непрерывными: и являются непрерывными, начинается со значения, очень близкого к 0.
являются непрерывными: и являются непрерывными, начинается со значения, очень близкого к 0.
Например, может определяться посредством модификации 152, 258, 350 в зависимости от второй декодированной аудиоинформации 132, 232, 323 и в зависимости от первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала (например, как показано на фиг. 2) либо в зависимости от комбинированной характеристики при отсутствии входного сигнала (например, комбинированной характеристики  , 150, 348 при отсутствии входного сигнала). Как можно видеть на графиках по фиг. 8, предложенный подход удаляет неоднородность.
, 150, 348 при отсутствии входного сигнала). Как можно видеть на графиках по фиг. 8, предложенный подход удаляет неоднородность.
Например, фиг. 8a показывает графическое представление сигналов для предыдущего CELP-кадра (например, первой декодированной аудиоинформации), при этом абсцисса 810 описывает время в миллисекундах, и при этом ордината 812 описывает амплитуду в произвольных единицах. Как можно видеть, первая декодированная аудиоинформация предоставляется (например, посредством декодирования в области линейного прогнозирования) между временами t81 (-20 мс) и t82 (0 мс).
Кроме того, как можно видеть на фиг. 8b, вторая версия текущего MDCT-кадра (например, модифицированная вторая декодированная аудиоинформация 142, 242, 342) предоставляется с началом только со времени t82 (0 мс), даже если вторая декодированная аудиоинформация 132, 232, 332 типично предоставляется с началом со времени t4 (как показано на фиг. 4b). Следует отметить, что вторая декодированная аудиоинформация 132, 232, 332, предоставленная между временами t4 и t2 (как показано на фиг. 4b), не используется непосредственно для предоставления второй версии текущего MDCT-кадра (сигнала ), а используется просто для предоставления компонентов сигнала. Для понятности, следует отметить, что абсцисса 820 обозначает время в миллисекундах, и что ордината 822 обозначает амплитуду с точки зрения произвольных единиц.
Фиг. 8c показывает конкатенацию предыдущего CELP-кадра (как показано на фиг. 8a) и второй версии текущего MDCT-кадра (как показано на фиг. 8b). Абсцисса 830 описывает время в миллисекундах, а ордината 832 описывает амплитуду с точки зрения произвольных единиц. Как можно видеть, существует практически непрерывный переход между предыдущим CELP-кадром (между временами t81 и t82 и второй версией текущего MDCT-кадра (с началом во время t82 и окончанием, например, во время t5, показанное на фиг. 4b). Таким образом, исключаются слышимые искажения при переходе из первого кадра (который кодируется в области линейного прогнозирования) ко второму кадру (который кодируется в частотной области).
Также проще всего показывать, что идеальное восстановление достигается на высокой скорости: на высокой скорости,  и являются почти идентичными, и оба являются почти идентичными входному сигналу, далее две ZIR являются почти идентичными, в силу чего разность двух ZIR является очень близкой к 0, и наконец,
и являются почти идентичными, и оба являются почти идентичными входному сигналу, далее две ZIR являются почти идентичными, в силу чего разность двух ZIR является очень близкой к 0, и наконец,  является почти идентичным
является почти идентичным  , и оба являются почти идентичными входному сигналу.
, и оба являются почти идентичными входному сигналу.
Этап d)
Необязательно, окно может применяться к двум ZIR, чтобы не затрагивать весь текущий MDCT-кадр. Это является полезным, например, чтобы уменьшать сложность, либо если ZIR не близко к 0 в конце MDCT-кадра.
Один пример окна представляет собой простое линейное окно  с длиной P:
с длиной P:
 ,
,
где, например,  .
.
Например, окно может обрабатывать характеристику 150 при отсутствии входного сигнала, характеристики 248, 256 при отсутствии входного сигнала либо комбинированную характеристику 348 при отсутствии входного сигнала.
5.8. Способ согласно фиг. 9
Фиг. 9 показывает блок-схему последовательности операций способа для предоставления декодированной аудиоинформации на основе кодированной аудиоинформации. Способ 900 содержит предоставление 910 первой декодированной аудиоинформации на основе аудиокадра, кодированного в области линейного прогнозирования. Способ 900 также содержит предоставление 920 второй декодированной аудиоинформации на основе аудиокадра, кодированного в частотной области. Способ 900 также содержит получение 930 характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации, при этом начальное состояние линейной прогнозирующей фильтрации задается в зависимости от первой декодированной аудиоинформации и второй декодированной аудиоинформации.
Способ 900 также содержит модификацию 940 второй декодированной аудиоинформации, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией.
Способ 900 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе, также относительно аудиодекодеров.
5.10. Способ согласно фиг. 10
Фиг. 10 показывает блок-схему последовательности операций способа 1000 для предоставления кодированной аудиоинформации на основе входной аудиоинформации.
Способ 1000 содержит выполнение 1010 декодирования в области линейного прогнозирования, чтобы предоставлять первую декодированную аудиоинформацию на основе аудиокадра, кодированного в области линейного прогнозирования.
Способ 1000 также содержит выполнение 1020 декодирования в частотной области, чтобы предоставлять вторую декодированную аудиоинформацию на основе аудиокадра, кодированного в частотной области.
Способ 1000 также содержит получение 1030 первой характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации в ответ на первое начальное состояние линейной прогнозирующей фильтрации, заданное посредством первой декодированной аудиоинформации, и получение 1040 второй характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации в ответ на второе начальное состояние линейной прогнозирующей фильтрации, заданное посредством модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации.
Альтернативно, способ 1000 содержит получение 1050 комбинированной характеристики при отсутствии входного сигнала линейной прогнозирующей фильтрации в ответ на начальное состояние линейной прогнозирующей фильтрации, заданное посредством комбинации первой декодированной аудиоинформации и модифицированной версии первой декодированной аудиоинформации, которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации.
Способ 1000 также содержит модификацию 1060 второй декодированной аудиоинформации, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо в зависимости от комбинированной характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией.
Следует отметить, что способ 1000 может дополняться посредством любых из признаков и функциональностей, описанных в данном документе, также относительно аудиодекодеров.
6. Заключения
В качестве вывода, варианты осуществления согласно изобретению относятся к переходам из CELP в MDCT. Эти переходы, в общем, вводят две проблемы:
1. Наложение спектров вследствие пропущенного предыдущего MDCT-кадра; и
2. Неоднородность на границе между CELP-кадром и MDCT-кадром, вследствие неидеальной природы кодирования на основе формы сигналов двух схем кодирования, работающих на низких/средних скоростях передачи битов.
В вариантах осуществления согласно изобретению, проблема наложения спектров разрешается посредством увеличения MDCT-длины таким образом, что левая точка перегиба перемещается влево от границы между CELP- и MDCT-кадрами. Левая часть функции MDCT-окна также изменяется таким образом, что перекрытие уменьшается. В отличие от традиционных решений, CELP-сигнал не модифицируется, чтобы не вводить дополнительную задержку. Вместо этого, создается механизм для того, чтобы удалять неоднородности, которые могут вводиться на границе между CELP- и MDCT-кадрами. Этот механизм сглаживает неоднородность с использованием характеристики при отсутствии входного сигнала синтезирующих CELP-фильтров. Дополнительные подробности описываются в данном документе.
7. Альтернативы реализации
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть выполнены посредством (или с использованием) устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, некоторые из одного или более самых важных этапов способа могут выполняться посредством этого устройства.
Изобретаемый кодированный аудиосигнал может быть сохранен на цифровом носителе хранения данных или может быть передан по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой, так что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, при этом программный код сконфигурирован с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, следовательно, вариант осуществления изобретаемого способа представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть сконфигурирована с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, сконфигурированное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, сконфигурированную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может быть использовано для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого устройства.
Устройство, описанное в данном документе, может реализовываться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.









Изобретение относится к средствам для кодирования и декодирования аудио. Технический результат заключается в повышении эффективности кодирования при переключении между различными режимами. Предоставляют первую декодированную аудиоинформацию на основе аудиокадра, кодированного в области линейного прогнозирования. Предоставляют вторую декодированную аудиоинформацию на основе аудиокадра, кодированного в частотной области. Получают характеристику при отсутствии входного сигнала линейной прогнозирующей фильтрации. При этом начальное состояние линейной прогнозирующей фильтрации задается в зависимости от первой декодированной аудиоинформации и второй декодированной аудиоинформации. Модифицируют вторую декодированную аудиоинформацию, которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией и модифицированной второй декодированной аудиоинформацией. 3 н. и 15 з.п. ф-лы, 20 ил.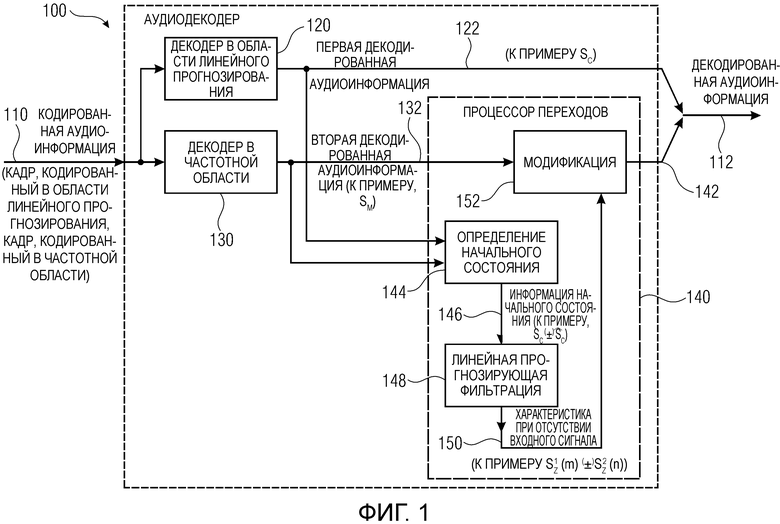
1. Аудиодекодер (100; 200; 300) для предоставления декодированной аудиоинформации (112; 212; 312) на основе кодированной аудиоинформации (110; 210; 310), причем аудиодекодер содержит:
- декодер (120; 220; 320) в области линейного прогнозирования, сконфигурированный с возможностью предоставлять первую декодированную аудиоинформацию (122; 222; 322; SC(n)) на основе аудиокадра, кодированного в области линейного прогнозирования;
- декодер (130; 230; 330) в частотной области, сконфигурированный с возможностью предоставлять вторую декодированную аудиоинформацию (132; 232; 332; SM(n)) на основе аудиокадра, кодированного в частотной области; и
- процессор (140; 240; 340) переходов,
- при этом процессор переходов сконфигурирован с возможностью получать характеристику (150; 256; 348) при отсутствии входного сигнала линейной прогнозирующей фильтрации (148; 254; 346), при этом начальное состояние (146; 252; 344) линейной прогнозирующей фильтрации задается в зависимости от первой декодированной аудиоинформации и второй декодированной аудиоинформации, и
- при этом процессор переходов сконфигурирован с возможностью модифицировать вторую декодированную аудиоинформацию (132; 232; 332; SM(n)), которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией (SC(n)) и модифицированной второй декодированной аудиоинформацией ( ).
).
2. Аудиодекодер по п. 1,
- в котором процессор переходов сконфигурирован с возможностью получать первую характеристику (248;  ) при отсутствии входного сигнала линейного прогнозирующего фильтра (246) в ответ на первое начальное состояние (244; SC(n)) линейного прогнозирующего фильтра, заданное посредством первой декодированной аудиоинформации (222; SC(n)), и
) при отсутствии входного сигнала линейного прогнозирующего фильтра (246) в ответ на первое начальное состояние (244; SC(n)) линейного прогнозирующего фильтра, заданное посредством первой декодированной аудиоинформации (222; SC(n)), и
- при этом процессор переходов сконфигурирован с возможностью получать вторую характеристику (256;  ) при отсутствии входного сигнала линейного прогнозирующего фильтра (254) в ответ на второе начальное состояние (252) линейного прогнозирующего фильтра, заданное посредством модифицированной версии (
) при отсутствии входного сигнала линейного прогнозирующего фильтра (254) в ответ на второе начальное состояние (252) линейного прогнозирующего фильтра, заданное посредством модифицированной версии ( ) первой декодированной аудиоинформации (222, SC(n)), которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации (232, SM(n)), или
) первой декодированной аудиоинформации (222, SC(n)), которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации (232, SM(n)), или
- при этом процессор переходов сконфигурирован с возможностью получать комбинированную характеристику (150; 348) при отсутствии входного сигнала линейного прогнозирующего фильтра (148; 346) в ответ на начальное состояние (146; 344) линейного прогнозирующего фильтра, заданное посредством комбинации первой декодированной аудиоинформации (122; 322; SC(n)) и модифицированной версии () первой декодированной аудиоинформации (122; 322; SC(n)), которая предоставляется с искусственным наложением спектров и которая содержит долю части второй декодированной аудиоинформации (132; 332; SM(n));
- при этом процессор переходов сконфигурирован с возможностью модифицировать вторую декодированную аудиоинформацию (132; 232; 332; SM(n)), которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от первой характеристики (248; ) при отсутствии входного сигнала и второй характеристики (256; ) при отсутствии входного сигнала либо в зависимости от комбинированной характеристики (150;  ) при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией (122; 222; 322; SC(n)) и модифицированной второй декодированной аудиоинформацией (142; 242; 342;).
) при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией (122; 222; 322; SC(n)) и модифицированной второй декодированной аудиоинформацией (142; 242; 342;).
3. Аудиодекодер (100; 200; 300) по п. 1, в котором декодер (130; 230; 330) в частотной области сконфигурирован с возможностью осуществлять обратное перекрывающееся преобразование таким образом, что вторая декодированная аудиоинформация (132; 232; 332) содержит наложение спектров.
4. Аудиодекодер (100; 200; 300) по п. 1, в котором декодер (130; 230; 330) в частотной области сконфигурирован с возможностью осуществлять обратное перекрывающееся преобразование таким образом, что вторая декодированная аудиоинформация (132; 232; 332) содержит наложение спектров во временной части, которая временно перекрывается с временной частью, для которой декодер (120; 220; 320) в области линейного прогнозирования предоставляет первую декодированную аудиоинформацию (122; 222; 322), и таким образом, что вторая декодированная аудиоинформация не имеет наложения спектров для временной части после временной части, для которой декодер в области линейного прогнозирования предоставляет первую декодированную аудиоинформацию.
5. Аудиодекодер (100; 200; 300) по п. 1, в котором часть второй декодированной аудиоинформации (132; 232; 332), которая используется для того, чтобы получать модифицированную версию () первой декодированной аудиоинформации, содержит наложение спектров.
6. Аудиодекодер (100; 200; 300) по п. 5, в котором искусственное наложение спектров, которое используется для того, чтобы получать модифицированную версию () первой декодированной аудиоинформации, по меньшей мере частично компенсирует наложение спектров, которое включено в часть второй декодированной аудиоинформации (132; 232; 332), которая используется для того, чтобы получать модифицированную версию первой декодированной аудиоинформации.
7. Аудиодекодер (100; 200; 300) по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью получать первую характеристику  при отсутствии входного сигнала или первый компонент комбинированной характеристики при отсутствии входного сигнала согласно следующему выражению:
при отсутствии входного сигнала или первый компонент комбинированной характеристики при отсутствии входного сигнала согласно следующему выражению:
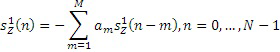
или согласно следующему выражению:

где


- при этом n обозначает временной индекс,
- при этом для n=0,..., N-1 обозначает первую характеристику (248) при отсутствии входного сигнала для временного индекса n или первый компонент комбинированной характеристики (150; 348) при отсутствии входного сигнала для временного индекса n;
- при этом для n=-L,..., -1 обозначает первое начальное состояние (244) для временного индекса n или первый компонент начального состояния (146; 344) для временного индекса n;
- при этом m обозначает скользящую переменную;
- при этом M обозначает длину фильтра для линейного прогнозирующего фильтра;
- при этом am обозначает коэффициенты фильтрации линейного прогнозирующего фильтра;
- при этом SC(n) обозначает ранее декодированное значение первой декодированной аудиоинформации (122; 222; 322) для временного индекса n;
- при этом N обозначает длину обработки.
8. Аудиодекодер (100; 200; 300) по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью применять первое оконное преобразование (w(-n-1)w(-n-1)) к первой декодированной аудиоинформации (122; 222; 322; SC(n)), чтобы получать полученную с помощью оконного преобразования версию первой декодированной аудиоинформации и применять второе оконное преобразование (w(n+L)w(-n-1)) к версии (SC(-n-L-1)) с временным зеркалированием первой декодированной аудиоинформации (122; 222; 322; SC(n)), чтобы получать полученную с помощью оконного преобразования версию версии с временным зеркалированием первой декодированной аудиоинформации, и
- при этом процессор переходов сконфигурирован с возможностью комбинировать полученную с помощью оконного преобразования версию первой декодированной аудиоинформации и полученную с помощью оконного преобразования версию версии с временным зеркалированием первой декодированной аудиоинформации, чтобы получать модифицированную версию () первой декодированной аудиоинформации.
9. Аудиодекодер по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью получать модифицированную версию первой декодированной аудиоинформации SC(n) согласно следующему выражению:

 ,
,
- при этом n обозначает временной индекс,
- при этом w(-n-1) обозначает значение оконной функции для временного индекса (-n-1);
- при этом w(n+L) обозначает значение оконной функции для временного индекса (n+L);
- при этом SC(n) обозначает ранее декодированное значение первой декодированной аудиоинформации (122; 222; 322) для временного индекса (n);
- при этом SC(-n-L-1) обозначает ранее декодированное значение первой декодированной аудиоинформации для временного индекса (-n-L-1);
- при этом SM(n) обозначает декодированное значение второй декодированной аудиоинформации (132; 232; 332) для временного индекса n; и
- при этом L описывает длину окна.
10. Аудиодекодер (100; 200; 300) по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью получать вторую характеристику (256;  ) при отсутствии входного сигнала или второй компонент комбинированной характеристики (150; 348) при отсутствии входного сигнала согласно следующему выражению:
) при отсутствии входного сигнала или второй компонент комбинированной характеристики (150; 348) при отсутствии входного сигнала согласно следующему выражению:

или согласно следующему выражению:

где

- при этом n обозначает временной индекс,
- при этом для n=0,..., N-1 обозначает вторую характеристику при отсутствии входного сигнала для временного индекса n или второй компонент комбинированной характеристики при отсутствии входного сигнала для временного индекса n;
- при этом для n=-L,..., -1 обозначает второе начальное состояние (252) для временного индекса n или второй компонент начального состояния (146; 344) для временного индекса n;
- при этом m обозначает скользящую переменную;
- при этом M обозначает длину фильтра для линейного прогнозирующего фильтра (148; 254; 346);
- при этом am обозначает коэффициенты фильтрации линейного прогнозирующего фильтра;
- при этом  обозначает значения модифицированной версии первой декодированной аудиоинформации для временного индекса n;
обозначает значения модифицированной версии первой декодированной аудиоинформации для временного индекса n;
- при этом N обозначает длину обработки.
11. Аудиодекодер (100; 200; 300) по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью линейно комбинировать вторую декодированную аудиоинформацию (132; 232; 332) с первой характеристикой (248) при отсутствии входного сигнала и второй характеристикой (256) при отсутствии входного сигнала либо с комбинированной характеристикой (150; 348) при отсутствии входного сигнала для временной части, для которой первая декодированная аудиоинформация (122; 222; 322) не предоставляется посредством декодера (120; 220; 320) в области линейного прогнозирования, чтобы получать модифицированную вторую декодированную аудиоинформацию.
12. Аудиодекодер (100; 200; 300) по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью получать модифицированную вторую декодированную аудиоинформацию  согласно следующему выражению:
согласно следующему выражению:
 , для n=0,..., N-1,
, для n=0,..., N-1,
или согласно следующему выражению:
 , для n=0,..., N-1,
, для n=0,..., N-1,
- при этом n обозначает временной индекс;
- при этом SM(n) обозначает значения второй декодированной аудиоинформации для временного индекса n;
- при этом для n=0,..., N-1 обозначает первую характеристику при отсутствии входного сигнала для временного индекса n или первый компонент комбинированной характеристики при отсутствии входного сигнала для временного индекса n; и
- при этом для n=0,..., N-1 обозначает вторую характеристику при отсутствии входного сигнала для временного индекса n или второй компонент комбинированной характеристики при отсутствии входного сигнала для временного индекса n;
- при этом v(n) обозначает значения оконной функции;
- при этом N обозначает длину обработки.
13. Аудиодекодер (100; 200; 300) по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью оставлять первую декодированную аудиоинформацию (122; 222; 322) неизменной посредством второй декодированной аудиоинформации (132; 232; 332) при предоставлении декодированной аудиоинформации для аудиокадра, кодированного в области линейного прогнозирования, так что декодированная аудиоинформация, предоставленная для аудиокадра, кодированного в области линейного прогнозирования, предоставляется независимо от декодированной аудиоинформации, предоставленной для последующего аудиокадра, кодированного в частотной области.
14. Аудиодекодер (100; 200; 300) по п. 1, при этом аудиодекодер сконфигурирован с возможностью предоставлять полностью декодированную аудиоинформацию (122; 222; 322) для аудиокадра, кодированного в области линейного прогнозирования, после которого идет аудиокадр, кодированный в частотной области, до декодирования аудиокадра, кодированного в частотной области.
15. Аудиодекодер (100; 200; 300) по п. 1, в котором процессор (140; 240; 340) переходов сконфигурирован с возможностью выполнять оконное преобразование первой характеристики (248) при отсутствии входного сигнала и второй характеристики (256) при отсутствии входного сигнала либо комбинированной характеристики (150; 348) при отсутствии входного сигнала до модификации второй декодированной аудиоинформации (132; 232; 332) в зависимости от полученной с помощью оконного преобразования первой характеристики при отсутствии входного сигнала и полученной с помощью оконного преобразования второй характеристики при отсутствии входного сигнала либо в зависимости от полученной с помощью оконного преобразования комбинированной характеристики при отсутствии входного сигнала.
16. Аудиодекодер (100; 200; 300) по п. 15, в котором процессор переходов сконфигурирован с возможностью выполнять оконное преобразование первой характеристики при отсутствии входного сигнала и второй характеристики при отсутствии входного сигнала либо комбинированной характеристики при отсутствии входного сигнала с использованием линейного окна.
17. Способ (900) предоставления декодированной аудиоинформации на основе кодированной аудиоинформации, при этом способ содержит этапы, на которых:
- предоставляют (910) первую декодированную аудиоинформацию (SC(n)) на основе аудиокадра, кодированного в области линейного прогнозирования;
- предоставляют (920) вторую декодированную аудиоинформацию (SM(n)) на основе аудиокадра, кодированного в частотной области; и
- получают (930) характеристику при отсутствии входного сигнала линейной прогнозирующей фильтрации, при этом начальное состояние линейной прогнозирующей фильтрации задается в зависимости от первой декодированной аудиоинформации и второй декодированной аудиоинформации; и
- модифицируют (940) вторую декодированную аудиоинформацию (SM(n)), которая предоставляется на основе аудиокадра, кодированного в частотной области после аудиокадра, кодированного в области линейного прогнозирования, в зависимости от характеристики при отсутствии входного сигнала, чтобы получать плавный переход между первой декодированной аудиоинформацией (SC(n)) и модифицированной второй декодированной аудиоинформацией ().
18. Машиночитаемый носитель, на котором сохранена компьютерная программа для осуществления способа по п. 17, когда компьютерная программа выполняется на компьютере.
| US 8725503 B2, 13.05.2014 | |||
| US 20120271644 A1, 25.10.2012 | |||
| НИЗКОСКОРОСТНАЯ АУДИОКОДИРУЮЩАЯ/ДЕКОДИРУЮЩАЯ СХЕМА С ОБЩЕЙ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКОЙ | 2009 |
|
RU2483365C2 |
| УСТРОЙСТВО И СПОСОБ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО ЗВУКОВОГО СИГНАЛА | 2009 |
|
RU2483366C2 |
| WO 2011048094 A1, 28.04.2011 | |||
| WO 2009059333 A1, 07.05.2009 | |||
| US 20080027717 A1, 31.01.2008 | |||
| WO 2011042464 A1, 14.04.2011. | |||

