Настоящее изобретение относится к обработке аудиоданных и, в частности, к обработке аудиоданных в контексте предварительной обработки аудиоданных и постобработки аудиоданных.
Опережающее эхо: проблема временного маскирования
Классический набор фильтров, основанных на перцепционных кодерах, таких как MP3 или AAC, в первую очередь разработан для того, чтобы воспользоваться перцепционным эффектом одновременного маскирования, но также должен иметь дело с временным аспектом явления маскирования: шум маскируется на короткое время до и после представления маскирующего сигнала (явление предшествующего маскирования и последующего маскирования). Последующее маскирование наблюдается в течение намного более длительного периода времени, чем предшествующее маскирование (порядка 10,0-50,0 мс вместо 0,5-2,0 мс, в зависимости от уровня и продолжительности маскера).
Таким образом, временной аспект маскирования приводит к дополнительному требованию для схемы перцепционного кодирования: чтобы достигнуть перцепционного прозрачного качества кодирования, шум квантования также не должен превышать зависящего от времени маскированного порога.
На практике перцепционным кодерам не легко достигнуть этого требования, поскольку использование спектрального разложения сигнала для квантования и кодирования подразумевает, что ошибка квантования, введенная в этой области, будет распространена во времени после воссоздания посредством наборов фильтров синтеза (принцип погрешности времени/частоты). Для обычно используемых структур наборов фильтров (например, MDST c 1024 линиями) это означает, что шум квантования может быть распространен на период более 40 миллисекунд при частоте дискретизации компакт дисков (CD). Это приведет к проблемам, когда сигнал, который должен быть закодирован, будет содержать компоненты сильного сигнала только в частях окна анализа набора фильтров, т.е. для транзиентных сигналов. В частности, шум квантования распространяется перед вступлениями сигнала и в крайних случаях даже может превысить первоначальные компоненты сигнала по уровню в течение некоторых временных интервалов. Известный пример критического сигнала ударных представляет собой запись кастаньет, когда после декодирования компоненты шума квантования распространяются на некоторое время перед "атакой" первоначального сигнала. Такая комбинация традиционно известна как ʺявление опережающего эхоʺ [Joh92b].
Вследствие свойств человеческой слуховой системы такое "опережающее эхо" маскируется, только если существенное количество шума кодирования не присутствует дольше, чем приблизительно 2,0 мс перед вступлением сигнала. Иначе шум кодирования будет воспринят как артефакт опережающего эха, т.е. короткое подобное шуму событие, предшествующее вступлению сигнала. Чтобы избежать таких артефактов, нужно позаботиться о том, чтобы поддерживать подходящие временные характеристики шума квантования, чтобы по-прежнему удовлетворять условиям для временного маскирования. Эта проблема формирования временного шума традиционно мешала достигать хорошего перцепционного качества сигнала на низких битовых скоростях для транзиентных сигналов, таких как кастаньеты, колокольчик, треугольник и т.д.
Подобные аплодисментам сигналы: чрезвычайно критический класс сигналов
Хотя ранее упомянутые транзиентные сигналы могут вызвать опережающее эхо в перцепционных аудиокодеках, они демонстрируют одиночные изолированные атаки, т.е., существует некоторое минимальное время, пока не появляется следующая атака. Таким образом, у перцепционного кодера есть некоторое время, чтобы восстановиться после обработки последней атаки, и он может, например, снова собрать запасные биты, чтобы справиться со следующей атакой (см. 'резервуар битов', как описано ниже). В отличие от этого звук аплодирующей аудитории состоит из непрекращающегося потока плотно расположенных хлопков, каждый из которых сам по себе является транзиентным событием. Фиг. 11 показывает иллюстрацию высокочастотной временной огибающей стереосигнала аплодисментов. Как видно, среднее время между последовательными событиями хлопков значительно меньше 10 мс.
Поэтому аплодисменты и подобные аплодисментам сигналы (такие как капли дождя или взрывы фейерверков) составляют класс чрезвычайно трудных для кодирования сигналов, при этом они часто встречаются во многих живых записях. Это также относится к случаю, когда используются параметрические методы для совместного кодирования двух или больше каналов [Hot08].
Традиционные подходы к кодированию транзиентных сигналов
Был предложен ряд методик, чтобы избежать артефактов опережающего эхо в закодированном/декодированном сигнале.
Управление опережающим эхом и резервуар битов
Один путь состоит в том, чтобы увеличить точность кодирования для спектральных коэффициентов окна набора фильтров, которое охватывает участок транзиентного сигнала (так называемое ʺуправление опережающим эхоʺ, [MPEG1]). Поскольку это значительно увеличивает количество необходимых битов для кодирования таких кадров, этот способ не может быть применен в кодере с постоянной битовой скоростью. До некоторой степени локальные вариации потребности битовой скорости могут учитываться при помощи резервуара битов ([Bra87], [MPEG1]). Эта методика позволяет справляться с пиковыми потребностями битовой скорости с использованием битов, которые были зарезервированы во время кодирования более ранних кадров, в то время как средняя битовая скорость еще остается постоянной.
Адаптивное переключение окна
Другая стратегия, используемая во многих перцепционных аудиокодерах, представляет собой адаптивное переключение окна, внедренное Эдлером [Edl89]. Эта методика адаптирует размер окон наборов фильтров к характеристикам входного сигнала. В то время как стационарные части сигнала будут кодироваться с использованием большой длины окна, короткие окна используются для кодирования транизиентных частей сигнала. Таким образом, пиковая потребность битов может быть значительно сокращена, поскольку область, для которой требуется высокая точность кодирования, ограничена во времени. Опережающее эхо неявно ограничивается по продолжительности посредством более короткого размера преобразования.
Придание формы шуму во временной области (TNS)
Придание формы шуму во временной области (TNS) было введено в [Her96] и достигает придания формы шуму квантования во временной области посредством применения прогнозирующего кодирования без обратной связи вдоль направления частоты на блоках времени в спектральной области.
Модификация усиления (управление усилением),
Другой способ избежать временного распространения шума квантования состоит в том, чтобы применить динамическую модификацию усиления (процесс управления усилением) к сигналу до вычисления его спектрального разложения и кодирования.
Принцип этого подхода проиллюстрирован на фиг. 12. Динамика входного сигнала сокращается посредством модификации усиления (мультипликативная предварительная обработка) до его кодирования. Таким образом, "пики" в сигнале ослабляются до кодирования. Параметры модификации усиления передаются в битовом потоке. С использованием этой информации процесс выполняется в обратном порядке на стороне декодера, т.е., после декодирования другая модификация усиления восстанавливает первоначальную динамику сигнала.
[Lin93] предлагает управление усилением как дополнение к перцепционному аудиокодеру, когда модификация усиления выполняется на сигнале во временной области (и, таким образом, ко всему спектру сигнала).
Модификация/управление усилением в зависимости от частоты использовалась раньше во многих случаях.
Основанное на фильтрации управление усилением : в своей диссертации [Vau91] Вопель замечает, что управление усилением на полном диапазоне не применимо. Чтобы достигнуть управления усилением в зависимости от частоты, он предлагает пару фильтров сжатия и расширения, характеристиками усиления которых можно управлять. Эта схема показана на фиг. 13a и 13b.
Вариация частотной характеристики фильтра показана на фиг. 13b.
Управление усилением с гибридным набором фильтров (проиллюстрировано на фиг. 14): в профиле SSR схемы MPEG-2 Advanced Audio Coding [Bos96] управление усилением используется в структуре гибридного набора фильтров. Первый модуль набора фильтров (PQF) разбивает входной сигнал на четыре полосы равной ширины. Затем датчик усиления и модификатор усиления выполняют обработку кодера управления усилением. Наконец, в качестве второй стадии, четыре отдельных набора фильтров MDCT с сокращенным размером (256 вместо 1024) дополнительно разбивают полученный в результате сигнал и производят спектральные компоненты, которые используются для последующего кодирования.
Управляемое придание формы огибающей (GES) представляет собой инструмент, содержащийся в MPEG Surround, который передает индивидуальные по каналам временные параметры огибающей и восстанавливает временные огибающие на стороне декодера. Следует отметить, что в отличие от обработки HREP на стороне кодера нет какого-либо сглаживания огибающей, чтобы поддержать обратную совместимость на понижающем микшировании. Другой инструмент в MPEG Surround, который функционирует для выполнения придания формы огибающей, представляет собой обработку подполос во временной области (STP). Здесь, LPC-фильтры низкого порядка применяются в представлении набора фильтров QMF аудиосигналов.
Соответствующий предшествующий уровень техники изложен в патентных публикациях WO 2006/045373 A1, WO 2006/045371 A1, WO2007/042108 A1, WO 2006/108543 A1 или WO 2007/110101 A1.
Литература
[Bos96] M. Bosi, K. Brandenburg, S. Quackenbush, L. Fielder, K. Akagiri, H. Fuchs, M. Dietz, J. Herre, G. Davidson, Oikawa: "MPEG-2 Advanced Audio Coding", 101st AES Convention, Los Angeles 1996
[Bra87] K. Brandenburg: "OCF - A New Coding Algorithm for High Quality Sound Signals", Proc. IEEE ICASSP, 1987
[Joh92b] J. D. Johnston, K. Brandenburg: "Wideband Coding Perceptual Considerations for Speech and Music", in S. Furui and M. M. Sondhi, editors: "Advances in Speech Signal Processing", Marcel Dekker, New York, 1992
[Edl89] B. Edler: "Codierung von Audiosignalen mit überlappender Transformation und adaptiven Fensterfunktionen", Frequenz, Vol. 43, pp. 252-256, 1989
[Her96] J. Herre, J. D. Johnston: "Enhancing the Performance of Perceptual Audio Coders by Using Temporal Noise Shaping (TNS)", 101st AES Convention, Los Angeles 1996, Preprint 4384
[Hot08] Gerard Hotho, Steven van de Par, and Jeroen Breebaart: "Multichannel coding of applause signals", EURASIP Journal of Advances in Signal Processing, Hindawi, January 2008, doi: 10.1155/2008/531693
[Lin93] M. Link: "An Attack Processing of Audio Signals for Optimizing the Temporal Characteristics of a Low Bit-Rate Audio Coding System", 95th AES convention, New York 1993, Preprint 3696
[MPEG1] ISO/IEC JTC1/SC29/WG11 MPEG, International Standard ISO 11172-3 "Coding of moving pictures and associated audio for digital storage media at up to about 1.5 Mbit/s"
[Vau91] T. Vaupel: "Ein Beitrag zur Transformationscodierung von Audiosignalen unter Verwendung der Methode der 'Time Domain Aliasing Cancellation (TDAC)' und einer Signalkompandierung im Zeitbereich", PhD Thesis, Universität-Gesamthochschule Duisburg, Germany, 1991
Резервуар битов может помочь справляться с пиковыми потребностями битовой скорости в перцепционном кодере и тем самым улучшить перцепционное качество транзиентных сигналов. Однако на практике размер резервуара битов должен быть нереалистично большим, чтобы избежать артефактов при кодировании входные сигналы с очень транзиентной природой без дополнительных предупредительных мер.
Адаптивное переключение окна ограничивает потребность битов транзиентных частей сигнала и сокращенного опережающего эха посредством ограничения транзиентов (переходов) в короткие блоки преобразования. Ограничение адаптивного переключения окна задается посредством его времени ожидания и времени повторения: самый быстрый оборотный цикл между двумя последовательностями короткого блока требует по меньшей мере трех блоков ("короткий" → "стоп" → "начало" → "короткий", приблизительно 30,0-60,0 мс для типичных размеров блока 512-1024 отсчетов), что является слишком долгим для определенных типов входных сигналов, включающих в себя аплодисменты. Следовательно, распространения шума квантования во времени для подобных аплодисментам сигналов можно было бы избежать, только постоянно выбирая короткий размер окна, что обычно приводит к уменьшению эффективности разработки кодера.
TNS выполняет сглаживание во времени в кодере и придание формы во времени в декодере. Теоретически возможно произвольно мелкое временное разрешение. Однако на практике функционирование ограничено временным искажением набора фильтров кодера (как правило, MDCT, т.е. преобразование накладывающихся блоков с 50% наложением). Таким образом, также появляется сформированный шум кодирования зеркальным образом на выходе набора фильтров синтеза.
Широкополосные методики управления усилением страдают от отсутствия спектрального разрешения. Однако для хорошего выполнения для многих сигналов важно, чтобы обработка модификации усиления могла быть применена независимо в разных частях аудио спектра, поскольку транзиентные события часто преобладают только в частях спектра (на практике события, которые трудно закодировать, присутствуют почти всегда в высокочастотной части спектра). Эффективно применение динамической мультипликативной модификации входного сигнала до его спектрального разложения в кодере эквивалентно динамической модификации окна анализа набора фильтров. В зависимости от формы функции модификации усиления частотная характеристика аналитических фильтров изменяется в соответствии с составной функцией окна. Однако нежелательно расширять частотную характеристику низкочастотных каналов фильтров из набора фильтров, поскольку это увеличивает несоответствие до критического масштаба ширины диапазона.
Управление усилением, использующее гибридный набор фильтров, имеет недостаток увеличенной вычислительной сложности, поскольку набор фильтров первой стадии должен достигнуть значительной селективности, чтобы избежать искажений от наложения спектров после последнего разделения второй стадией набора фильтров. Кроме того, пересекающиеся частоты между полосами управления усилением фиксированы одной четвертью частоты Найквиста, т.е., равны 6, 12 и 18 кГц для частоты дискретизации 48 кГц. Для большинства сигналов первый переход на уровне 6 кГц является слишком высоким для хорошего функционирования.
Методики придания формы огибающей, содержащиеся в решениях полупараметрического многоканального кодирования, такие как MPEG Surround (STP, GES), как известно, улучшают перцепционное качество транзиентов посредством временного изменения выходного сигнала или его частей в декодере. Однако эти методики не выполняют сглаживания во времени перед кодером. Следовательно, транзиентный сигнал по-прежнему входит в кодер со своей первоначальной кратковременной динамикой и налагает высокое требование битовой скорости к бюджету битов кодера.
Задача настоящего изобретения состоит в том, чтобы обеспечить улучшенную концепцию предварительной обработки аудиоданных, постобработки аудиоданных, или аудиокодирования, или аудиодекодирования, с другой стороны.
Эта задача достигается посредством постпроцессора аудиоданных по п. 1, препроцессора аудиоданных по п. 32, устройства аудиокодирования по п. 53, устройства аудиодекодирования по п. 55, способа постобработки по п. 57, способа предварительной обработки по п. 58, способа кодирования по п. 59, способа аудиодекодирования по п. 60 или компьютерной программы по п. 61 формулы изобретения.
Первым аспектом настоящего изобретения является постпроцессор аудиоданных для постобработки аудиосигнала, имеющего переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации, содержащий модуль извлечения полос для извлечения высокочастотной полосы аудиосигнала и низкочастотной полосы аудиосигнала; процессор высокочастотных полос для выполнения переменной во времени модификации высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах для получения обработанной высокочастотной полосы; и модуль объединения для объединения обработанной высокочастотной полосы и низкочастотной полосы.
Вторым аспектом настоящего изобретения является препроцессор аудиоданных для предварительной обработки аудиосигнала, содержащий анализатор сигнала для анализа аудиосигнала для определения переменной во времени информации усиления на высоких частотах; модуль извлечения полос для извлечения высокочастотной полосы аудиосигнала и низкочастотной полосы аудиосигнала; процессор высокочастотных полос для выполнения переменной во времени модификации высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах для получения обработанной высокочастотной полосы; модуль объединения для объединения обработанной высокочастотной полосы и низкочастотной полосы для получения предварительно обработанного аудиосигнала; и выходной интерфейс для формирования выходного сигнала, содержащего предварительно обработанный аудиосигнал и переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации.
Третьим аспектом настоящего изобретения является устройство аудиокодирования для кодирования аудиосигнала, содержащее препроцессор аудиоданных первого аспекта, выполненный с возможностью формировать выходной сигнал, имеющий переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации; базовый кодер для формирования базового закодированного сигнала и базовой вспомогательной информации; и выходной интерфейс для формирования закодированного сигнала, содержащего базовый закодированный сигнал, базовую вспомогательную информацию и переменную во времени информацию усиления на высоких частотах в качестве дополнительной вспомогательной информации.
Четвертым аспектом настоящего изобретения является устройство аудиодекодирования, содержащее входной интерфейс для приема закодированного аудиосигнала, содержащего базовый закодированный сигнал, базовую вспомогательную информацию и переменную во времени информацию усиления на высоких частотах в качестве дополнительной вспомогательной информации; базовый декодер для декодирования базового закодированного сигнала с использованием базовой вспомогательной информации для получения декодированного базового сигнала; и постпроцессор для постобработки декодированного базового сигнала с использованием переменной во времени информации усиления на высоких частотах в соответствии с описанным выше вторым аспектом.
Пятым аспектом настоящего изобретения является способ постобработки аудиосигнала, имеющего переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации, содержащий извлечение высокочастотной полосы аудиосигнала и низкочастотной полосы аудиосигнала; выполнение переменной во времени модификации высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах для получения обработанной высокочастотной полосы; и объединение обработанной высокочастотной полосы и низкочастотной полосы.
Шестым аспектом настоящего изобретения является способ предварительной обработки аудиосигнала, содержащий анализ аудиосигнала для определения переменной во времени информации усиления на высоких частотах; извлечение высокочастотной полосы аудиосигнала и низкочастотной полосы аудиосигнала; выполнение переменной во времени модификации высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах для получения обработанной высокочастотной полосы; объединение обработанной высокочастотной полосы и низкочастотной полосы для получения предварительно обработанного аудиосигнала; и формирование выходного сигнала, содержащего предварительно обработанный аудиосигнал и переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации.
Седьмым аспектом настоящего изобретения является способ кодирования аудиосигнала, содержащий способ предварительной обработки аудиоданных шестого аспекта, выполненный с возможностью формировать выходной сигнал, имеющий переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации; формирование базового закодированного сигнала и базовой вспомогательной информации; и формирование закодированного сигнала, содержащего базовый закодированный сигнал, базовую вспомогательную информацию и переменную во времени информацию усиления на высоких частотах в качестве дополнительной вспомогательной информации.
Восьмым аспектом настоящего изобретения является способ аудиодекодирования, содержащий прием закодированного аудиосигнала, содержащего базовый закодированный сигнал, базовую вспомогательную информацию и переменную во времени информацию усиления на высоких частотах в качестве дополнительной вспомогательной информации; декодирование базового закодированного сигнала с использованием базовой вспомогательной информации для получения декодированного базового сигнала; и постобработку декодированного базового сигнала с использованием переменной во времени информации усиления на высоких частотах в соответствии с пятым аспектом.
Девятый аспект настоящего изобретения относится к компьютерной программе или энергонезависимому запоминающему носителю, имеющему сохраненную на нем компьютерную программу для выполнения при ее исполнении на компьютере или процессоре любого из способов в соответствии с приведенными выше пятым, шестым, седьмым или восьмым аспектами.
Настоящее изобретение обеспечивает выборочную по полосам обработку высоких частот, такую как выборочное ослабление в препроцессоре или выборочное усиление в постпроцессоре, чтобы выборочно закодировать некоторый класс сигналов, таких как транзиентные сигналы, с переменной во времени информацией усиления на высоких частотах для высокочастотной полосы. Таким образом, предварительно обработанный сигнал является сигналом, имеющим дополнительную вспомогательную информацию в форме прямой переменной во времени информации усиления на высоких частотах и самого сигнала, чтобы некоторый класс сигналов, таких как транзиентные сигналы, больше не возникал в предварительно обработанном сигнале или возникал лишь в меньшей степени. В постобработке аудиоданных первоначальная форма сигнала восстанавливается посредством выполнения переменного во времени умножение высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах, связанной с аудиосигналом в качестве вспомогательной информации, чтобы в конце, т.е., после цепи, состоящей из предварительной обработки, кодирования, декодирования и постобработки, слушатель не чувствовал существенных различий для первоначального сигнала и, в частности, не чувствовал сигнал, имеющий сокращенный транзиентный характер, хотя внутренний базовый кодер/базовый декодер блокирует в нем позицию для обработки менее транзиентного сигнала, что привело для обработки кодера к сокращенному количеству необходимых битов, с одной стороны, и увеличению качества звука, с другой стороны, поскольку класс трудно кодируемых сигналов был удален из сигнала, прежде чем кодер фактически начал свою задачу. Однако это удаление трудно кодируемых участков сигнала не приводит к сокращению качеству звука, поскольку эти участки сигнала воссоздаются посредством постобработки аудиоданных вслед за операцией декодера.
В предпочтительных вариантах осуществления препроцессор также усиливает части, немного более тихие, чем средний уровень фона, и постпроцессор ослабляет их. Эта дополнительная обработка потенциально полезна и для индивидуальных сильных атак, и для частей между последовательными транзиентными событиями.
Далее обозначены преимущества предпочтительных вариантов осуществления.
Технология HREP (обработка огибающей высокого разрешения) является инструментом для улучшенного кодирования сигналов, которые преимущественно состоят из многих плотных транзиентных событий, таких как аплодисменты, звуки капель дождя и т.д. На стороне кодера инструмент работает как препроцессор с высоким временным разрешением перед фактическим перцепционным аудиокодеком посредством анализа входного сигнала, ослабления и тем самым сглаживания во времени высокочастотной части транзиентных событий и формирования небольшого количества вспомогательной информации (1-4 кбит/с для стереосигналов). На стороне декодера инструмент работает как постпроцессор после аудиокодека посредством повышения и тем самым придания формы во времени высокочастотной части транзиентных событий с использованием вспомогательной информации, которая была сформирована во время кодирования. Выгода применения технологии HREP является двойной: технология HREP ослабляет требование битовой скорости, накладываемое на кодер, посредством сокращения кратковременной динамики входного сигнала; дополнительно технология HREP гарантирует надлежащую реконструкцию огибающей на стадии (повышающего) микширования декодера, что является тем более важным, если в кодеке были применены методики параметрического многоканального кодирования.
Кроме того, настоящее изобретение имеет преимущество в том, что оно улучшает работу по кодированию для подобных аплодисментам сигналов посредством использования подходящих способов обработки сигналов, например, в предварительной обработке, с одной стороны, или в постобработке, с другой стороны.
Дополнительное преимущество настоящего изобретения состоит в том, что обработка огибающей с высоким разрешением (HREP) изобретения, т.е., предварительная обработка аудиоданных или постобработка аудиоданных решает проблемы предшествующего уровня техники посредством выполнения предварительного сглаживания перед кодером или соответствующего обратного сглаживания после декодера.
Далее обобщенно представлены характерные и новые признаки вариантов осуществления настоящего изобретения, направленного на обработку сигналов HREP и описаны уникальные преимущества.
HREP обрабатывает аудиосигналы только в двух частотных полосах, которые разбиты с помощью фильтров. Это делает обработку простой и имеющей низкую вычислительную и структурную сложность. Обрабатывается только высокочастотная полоса, низкочастотная полоса проходит без модификации
Эти частотные полосы выводятся посредством низкочастотной фильтрации входного сигнала для вычисления первой полосы. Высокочастотная (вторая) полоса выводится простым вычитанием низкочастотного компонента из входного сигнала. Таким образом, только один фильтр должен быть вычислен явным образом, а не два, что сокращает сложность. В качестве альтернативы, высокочастотный фильтрованный сигнал может быть вычислен явно, и низкочастотный компонент может быть выведен как разность между входным сигналом и высокочастотным сигналом.
Для поддержки реализаций постпроцессора с низкой сложностью возможны следующие ограничения.
- Ограничение активных каналов/объектов HREP
- Ограничение максимальных переданных коэффициентов усиления g(k), которые являются нетривиальными (тривиальные коэффициенты усиления 0 дБ уменьшают необходимость соответствующей пары DFT/IDFT),
- Вычисление DFT/IDFT в эффективной топологии разбиения по основанию 2 с прореживанием.
В варианте осуществления кодер или препроцессор аудиоданных, связанный с базовым кодером, выполнен с возможностью ограничивать максимальное количество каналов или объектов, в которых HREP является активным в то же время, или декодер или постпроцессор аудиоданных, связанный с базовым декодером, выполнен с возможностью выполнять постобработку только с максимальным количеством каналов или объектов, в которых HREP является активным в то же время. Предпочтительное количество для ограничения активных каналов или объектов равно 16, и еще более предпочтительно равно 8.
В дополнительном варианте осуществления кодер HREP или препроцессор аудиоданных, связанный с базовым кодером, выполнен с возможностью ограничивать вывод максимумом нетривиальных коэффициентов усиления или декодера, или постпроцессор аудиоданных, связанный с базовым декодером, выполнен таким образом, что тривиальные коэффициенты усиления со значением "1" не вычисляют пару DFT/IDFT, а проходят через не измененный (обработанный с помощью оконной функции) сигнал во временной области. Предпочтительное количество для ограничения нетривиальных коэффициентов усиления равно 24, и еще более предпочтительно 16 на кадр и канал или объект.
В дополнительном варианте осуществления кодер HREP или препроцессор аудиоданных, связанный с базовым кодером, выполнен с возможностью вычислять преобразование DFT/IDFT в эффективной топологии разбиения по основанию 2 с прореживанием, или декодер или постпроцессор аудиоданных, связанный с базовым декодером, выполнен с возможностью также вычислять преобразование DFT/IDFT в эффективной топологии разбиения по основанию 2 с прореживанием.
Низкочастотный фильтр HREP может быть эффективно реализован посредством использования алгоритма FFT с прореживанием. Здесь дан пример, начиная с топологии 8-точечного (N=8) FFT по основанию 2 с прореживанием во времени, где только X(0) и X(1) необходимы для постобработки; следовательно, E(2) и E(3), и O(2) и O(3) не являются необходимыми. Затем, представим, что оба N/2-точечных преобразования DFT подразделяются далее на два N/4-точечных преобразования DFT с последующим применением графа "бабочка". Теперь можно аналогичным образом повторить описанные выше опущения и т.д., как проиллюстрировано на фиг. 15.
В отличие от схемы управления усилением на основе гибридных наборов фильтров (где обработка пересекающихся частот полос продиктована первой стадией набора фильтров и практически привязана к дробям со степенью числа 2 частоты Найквиста), частота разделения HREP может быть свободно скорректирована посредством адаптации фильтра. Это дает возможность оптимальной адаптации к характеристикам сигнала и психоакустическим требованиям.
В отличие от схемы управления усилением на основе гибридных наборов фильтров нет какой-либо необходимости в длинных фильтрах для разделения обрабатываемых полос, чтобы избежать проблем искажения после второй стадии набора фильтров. Это возможно, поскольку HREP является автономным препроцессором/постпроцессором, который не обязательно должен работать с критически дискретизированным набором фильтров.
В отличие от других схем управления усилением, HREP динамически адаптируется к локальной статистике сигнала (вычисление двухстороннего скользящего среднего огибающей входной высокочастотной фоновой энергии). Это сокращает динамику входного сигнала до некоторой части его первоначального размера (так называемый коэффициент альфа). Это дает возможность "мягкой" работы схемы без внесения артефактов посредством нежелательного взаимодействия с аудиокодеком.
В отличие от других схем управления усилением, HREP может компенсировать дополнительную потерю в динамике посредством аудиокодека с низкой битовой скоростью посредством моделирования ее как ʺпотери некоторой части энергетической динамикиʺ (так называемый коэффициент бета) и возвращения этой потери.
Пара препроцессора/постпроцессора является (почти) совершенным восстановлением в отсутствие квантования (т.е. без кодека).
Для достижения этого постпроцессор использует адаптивный наклон для разделительного фильтра в зависимости от весового коэффициента амплитуды на высоких частотах и корректирует ошибку интерполяции, которая возникает при восстановлении переменных во времени спектральных весов, примененных к накладывающимся преобразованиям T/F посредством применения коэффициента коррекции во временной области.
Реализации HREP могут содержать так называемое мета-управление усилением (MGC), которое мягко управляет силой перцепционного эффекта, обеспеченного посредством обработки HREP, и может избежать артефактов при обработке сигналов без аплодисментов. Таким образом, это ослабляет требования точности внешней входной классификации сигналов для управления применением HREP.
Сопоставление результата классификации аплодисментов с настройками MGC и HREP.
HREP представляет собой автономный препроцессор/постпроцессор, который охватывает все другие компоненты кодера, в том числе инструменты расширения полосы частот и параметрического пространственного кодирования.
HREP ослабляет требования к аудиокодеру с низкой битовой скоростью посредством предварительного сглаживания высокочастотной временной огибающей. Эффективно меньше коротких блоков будет инициировано в кодере, и потребуется меньше активных фильтров TNS.
HREP также улучшает параметрическое многоканальное кодирование посредством сокращения взаимных искажений между обработанными каналами, которое обычно происходит вследствие ограниченного пространственно-временного разрешения.
Топология кодека: взаимодействие с TNS/TTS, IGF и заполнением стерео
Формат битового потока: сигнализация HREP
Предпочтительные варианты осуществления настоящего изобретения далее описаны в контексте следующих приложенных чертежей.
Фиг. 1 иллюстрирует постпроцессор аудиоданных в соответствии с вариантом осуществления;
Фиг. 2 иллюстрирует предпочтительную реализацию модуля извлечения полос, показанного на фиг. 1;
Фиг. 3a - схематическое представление аудиосигнала, имеющего переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации;
Фиг. 3b - схематическое представление обработки модулем извлечения полос, процессором высокочастотных полос или модулем объединения накладывающихся блоков, имеющих область наложения;
Фиг. 3c иллюстрирует постпроцессор аудиоданных, имеющий блок сложения наложения;
Фиг. 4 иллюстрирует предпочтительную реализацию модуля извлечения полос, показанного на фиг. 1;
Фиг. 5a иллюстрирует дополнительную предпочтительную реализацию постпроцессора аудиоданных;
Фиг. 5b иллюстрирует предпочтительное встраивание постпроцессора аудиоданных (HREP) в структуре аудиодекодера MPEG-H 3D;
Фиг. 5c иллюстрирует дополнительное предпочтительное встраивание постпроцессора аудиоданных (HREP) в структуре аудиодекодера MPEG-H 3D;
Фиг. 6a иллюстрирует предпочтительный вариант осуществления вспомогательной информации, содержащей соответствующую информацию позиции;
Фиг. 6b иллюстрирует модуль извлечения вспомогательной информации, объединенный с декодером вспомогательной информации, для постпроцессора аудиоданных;
Фиг. 7 иллюстрирует препроцессор аудиоданных в соответствии с предпочтительным вариантом осуществления;
Фиг. 8a иллюстрирует блок-схему последовательности этапов, выполняемых препроцессором аудиоданных;
Фиг. 8b иллюстрирует блок-схему последовательности этапов, выполняемых анализатором сигналов препроцессора аудиоданных;
Фиг. 8c иллюстрирует блок-схему последовательности этапов процедур, выполняемых анализатором сигналов, процессором высокочастотных полос и выходным интерфейсом препроцессора аудиоданных;
Фиг. 8d иллюстрирует процедуру, выполняемую препроцессором аудиоданных, показанным на фиг. 7;
Фиг. 9a иллюстрирует устройство аудиокодирования с препроцессором аудиоданных в соответствии с вариантом осуществления;
Фиг. 9b иллюстрирует устройство аудиодекодирования, содержащее постпроцессор аудиоданных;
Фиг. 9c иллюстрирует предпочтительную реализацию препроцессора аудиоданных;
Фиг. 10a иллюстрирует устройство аудиокодирования с многоканальной функциональностью/функциональностью с несколькими объектами;
Фиг. 10b иллюстрирует устройство аудиодекодирования с многоканальной функциональностью/функциональностью с несколькими объектами;
Фиг. 10c иллюстрирует дополнительную реализацию встраивания препроцессора и постпроцессора в цепь кодирования/декодирования;
Фиг. 11 иллюстрирует высокочастотную временную огибающую стереосигнала с аплодисментами;
Фиг. 12 иллюстрирует функциональность обработки модификации усиления;
Фиг. 13a иллюстрирует основанную на фильтре обработку управления усилением;
Фиг. 13b иллюстрирует различные функциональности фильтра для соответствующего фильтра на фиг. 13a;
Фиг. 14 иллюстрирует управление усилением с гибридным набором фильтров;
Фиг. 15 иллюстрирует реализацию цифрового преобразования Фурье с прореживанием;
Фиг. 16 иллюстрирует обзор теста на прослушивание;
Фиг. 17a иллюстрирует абсолютные оценки MUSHRA для теста в конфигурации 5.1 каналов 128 кбит/с;
Фиг. 17b иллюстрирует разностные оценки MUSHRA для теста в конфигурации 5.1 каналов 128 кбит/с;
Фиг. 17c иллюстрирует абсолютные оценки MUSHRA для теста сигналов с аплодисментами в конфигурации 5.1 каналов 128 кбит/с;
Фиг. 17d иллюстрирует разностные оценки MUSHRA для теста сигналов с аплодисментами в конфигурации 5.1 каналов 128 кбит/с;
Фиг. 17e иллюстрирует абсолютные оценки MUSHRA для теста в конфигурации стерео 48 кбит/с;
Фиг. 17f иллюстрирует разностные оценки MUSHRA для теста в конфигурации стерео 48 кбит/с;
Фиг. 17g иллюстрирует абсолютные оценки MUSHRA для теста в конфигурации стерео 128 кбит/с; и
Фиг. 17h иллюстрирует разностные оценки MUSHRA для теста в конфигурации стерео 128 кбит/с.
Фиг. 1 иллюстрирует предпочтительный вариант осуществления постпроцессора 100 аудиоданных для постобработки аудиосигнала 102, имеющего переменную во времени информацию 104 усиления на высоких частотах в качестве вспомогательной информации 106, проиллюстрированную на фиг. 3a. Постпроцессор аудиоданных содержит модуль 110 извлечения полос для извлечения высокочастотной полосы 112 из аудиосигнала 102 и низкочастотной полосы 114 из аудиосигнала 102. Кроме того, постпроцессор аудиоданных в соответствии с этим вариантом осуществления содержит процессор 120 высокочастотных полос для выполнения переменной во времени модификации высокочастотной полосы 112 в соответствии с переменной во времени информацией 104 усиления на высоких частотах для получения обработанной высокочастотной полосы 122. Кроме того, постпроцессор аудиоданных содержит модуль 130 объединения для объединения обработанной высокочастотной полосы 122 и низкочастотной полосы 114.
Предпочтительно процессор 120 высокочастотных полос выполняет выборочное усиление высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах для этой заданной полосы. Это делается, чтобы отменить или воссоздать первоначальную высокочастотную полосу, поскольку соответствующая высокочастотная полоса была ослаблена ранее в препроцессоре аудиоданных, таком как препроцессор аудиоданных на фиг. 7, который будет описан позже.
В частности, в варианте осуществления на входе модуля 110 извлечения полос обеспечивается аудиосигнал 102 как извлеченный из аудиосигнала, связанного со вспомогательной информацией. Кроме того, выход модуля извлечения полос соединен со входом модуля объединения. Кроме того, второй вход модуля объединения соединен с выходом процессора 120 высокочастотных полос для подачи обработанной высокочастотной полосы 122 в модуль 130 объединения. Кроме того, дополнительный выход модуля 110 извлечения полос соединен со входом процессора 120 высокочастотных полос. Кроме того, процессор высокочастотных полос дополнительно имеет управляющий вход для приема переменной во времени информации усиления на высоких частотах, как проиллюстрировано на фиг. 1.
Фиг. 2 иллюстрирует предпочтительную реализацию модуля 110 извлечения полос. В частности, модуль 110 извлечения полос содержит низкочастотный фильтр 111, который на своем выходе предоставляет низкочастотную полосу 114. Кроме того, высокочастотная полоса 112 формируется посредством вычитания низкочастотной полосы 114 из аудиосигнала 102, т.е., аудиосигнала, который был введен в низкочастотный фильтр 111. Однако модуль 113 вычитания может выполнить некоторую предварительную обработку перед фактическим вычитанием типично для каждого отсчета, как будет показано относительно модуля 121 оконной обработки аудиосигнала на фиг. 4 или соответствующего модуля 121 на фиг. 5a. Таким образом, модуль 110 извлечения полос, как проиллюстрировано на фиг. 2, может содержать низкочастотный фильтр 111 и присоединенный далее модуль 113 вычитания, т.е., модуль 113 вычитания, имеющий вход, соединенный с выходом низкочастотного фильтра 111, и имеющий дополнительный вход, соединенный со входом низкочастотного фильтра 111.
Однако, в качестве альтернативы, модуль 110 извлечения полос также может быть реализован посредством фактического использования высокочастотного фильтра и вычитания высокочастотного выходного сигнала или высокочастотной полосы из аудиосигнала для получения низкочастотной полосы. Или, в качестве альтернативы, модуль извлечения полос может быть реализован без какого-либо модуля вычитания, т.е., посредством комбинации низкочастотного фильтра и высокочастотного фильтра, например, в виде набора фильтров с двумя каналами. Предпочтительно модуль 110 извлечения полос на фиг. 1 (или фиг. 2) реализован для извлечения только двух полос, т.е., одной низкочастотной полосы и одной высокочастотной полосы, в то время как эти полосы вместе охватывают полный диапазон частот аудиосигнала.
Предпочтительно граничная или пороговая частота низкочастотной полосы, извлеченной модулем 110 извлечения полос, находится между 1/8 и 1/3 максимальной частоты аудиосигнала, и предпочтительно равна 1/6 максимальной частоты аудиосигнала.
Фиг. 3a иллюстрирует схематическое представление аудиосигнала 102, имеющего полезную информацию в последовательности блоков 300, 301, 302, 303, где для иллюстрации блок 301 рассматривается как первый блок значений отсчетов, и блок 302 рассматривается как второй более поздний блок значений отсчетов аудиосигнала. Блок 300 предшествует первому блоку 301 во времени, и блок 303 следует за блоком 302 во времени, и первый блок 301 и второй блок 302 являются смежными во времени друг с другом. Кроме того, как проиллюстрировано номером 106 на фиг. 3a, каждый блок имеет привязанную к нему вспомогательную информацию 106, содержащую для первого блока 301 первую информацию 311 усиления, и содержащую для второго блока вторую информацию 312 усиления.
Фиг. 3b иллюстрирует обработку модуля 110 извлечения полос (и процессора 120 высокочастотных полос и модуля 130 объединения) в накладывающихся блоках. Таким образом, окно 313, используемое для вычисления первого блока 301, накладывается на окно 314, используемое для извлечения второго блока 302, и оба окна 313 и 314 накладываются в пределах диапазона 321 наложения.
Хотя масштаб на фиг. 3a и 3b обозначает, что длина каждого блока составляет половину размера длины окна, ситуация также может быть другой, т.е., длина каждого блока является такой же, как размер окна, используемого для оконной обработки соответствующего блока. Фактически это предпочтительная реализация для этих последующих предпочтительных вариантов осуществления, проиллюстрированных на фиг. 4 или, в частности, на фиг. 5a для постпроцессора или на фиг. 9c для препроцессора.
Таким образом, длина диапазона 321 наложения составляет половину размера окна, соответствующего половине размера или длину блока значений отсчетов.
В частности, переменная во времени информация усиления на высоких частотах обеспечена для последовательности 300-303 блоков значений отсчетов аудиосигнала 102, таким образом, что первый блок 301 значений отсчетов имеет привязанную к нему первую информацию 311 усиления, и второй более поздний блок 302 значений отсчетов аудиосигнала имеет другую вторую информацию 312 усиления, причем блок 110 извлечения полос выполнен с возможностью извлекать из первого блока 301 значений отсчетов первую низкочастотную полосу и первую высокочастотную полосу и извлекать из второго блока 302 значений отсчетов вторую низкочастотную полосу и вторую высокочастотную полосу. Кроме того, процессор 120 высокочастотных полос выполнен с возможностью модифицировать первую высокочастотную полосу с использованием первой информации 311 усиления для получения первой обработанной высокочастотной полосы и модифицировать вторую высокочастотную полосу с использованием второй информации 312 усиления для получения второй обработанной высокочастотной полосы. Кроме того, модуль 130 объединения выполнен с возможностью объединять первую низкочастотную полосу и первую обработанную высокочастотную полосу для получения первого объединенного блока и объединять вторую низкочастотную полосу и вторую обработанную высокочастотную полосу для получения второго объединенного блока.
Как проиллюстрировано на фиг. 3c, модуль 110 извлечения полос, процессор 120 высокочастотных полос и модуль 130 объединения выполнены с возможностью обрабатывать накладывающиеся блоки, проиллюстрированные на фиг. 3b. Кроме того, постпроцессор 100 аудиоданных содержит модуль 140 сложения наложения для вычисления подвергнутого постобработке участка посредством сложения отсчетов аудиоданных первого блока 301 и отсчетов аудиоданных второго блока 302 в диапазоне 321 наложения блоков. Предпочтительно модуль 140 сложения наложения выполнен с возможностью применять весовой коэффициент для отсчетов аудиоданных второй половины первого блока с использованием функции уменьшения или постепенного затухания и применять весовой коэффициент к первой половине второго блока, следующего за первым блоком, с использованием функции постепенного нарастания или увеличения. Функция постепенного затухания и функция постепенного нарастания быть линейными или нелинейными функциями, и функция постепенного нарастания монотонно увеличивается, а функция постепенного затухания монотонно уменьшается.
На выходе модуля 140 сложения наложения имеется последовательность образцов подвергнутого постобработке аудиосигнала как, например, проиллюстрировано на фиг. 3a, но теперь без какой-либо вспомогательной информации, поскольку вспомогательная информация была "употреблена" постпроцессором 100 аудиоданных.
Фиг. 4 иллюстрирует предпочтительную реализацию блока 110 извлечения полос постпроцессора аудиоданных, проиллюстрированного на фиг. 1, или, в качестве альтернативы, блока 210 извлечения полос препроцессора аудиоданных 200, представленного на фиг. 7. Оба из них - блок 110 извлечения полос на фиг. 1 или блок 210 извлечения полос на фиг. 7 - могут быть реализованы таким же образом, как проиллюстрировано на фиг. 4 или как проиллюстрировано на фиг. 5a для постпроцессора или фиг. 9c для препроцессора. В варианте осуществления постпроцессор аудиоданных содержит модуль извлечения полос, который имеет в качестве некоторых признаков модуль 115 оконной обработки анализа для формирования последовательности блоков значений отсчетов аудиосигнала с использованием окна анализа, в котором блоки являются накладывающимися во времени, как проиллюстрировано на фиг. 3b посредством диапазона 321 наложения. Кроме того, модуль 110 извлечения полос содержит процессор 116 DFT для выполнения дискретного преобразования Фурье для формирования последовательности блоков спектральных значений. Таким образом, каждый индивидуальный блок значений отсчетов преобразовывается в спектральное представление, которое является блоком спектральных значений. Таким образом, формируется такое же количество блоков спектральных значений, как если бы они являлись блоками значений отсчетов.
Процессор 116 DFT имеет выход, соединенный со входом низкочастотного формирователя 117. Низкочастотный формирователь 117 фактически выполняет действие низкочастотной фильтрации, и выход низкочастотного формирователя 117 соединен с процессором 118 обратного DFT для формирования последовательности блоков низкочастотных значений отсчетов во временной области. Наконец, модуль 119 оконной обработки синтеза обеспечен на выходе процессора обратного DFT для оконной обработки последовательности блоков низкочастотных значений отсчетов во временной области с использованием окна синтеза. Выводом модуля 119 оконной обработки синтеза является низкочастотный сигнал во временной области. Таким образом, модули 115-119 соответствуют модулю 111 "низкочастотного фильтра" на фиг. 2, и модули 121 и 113 соответствуют "модулю 113 вычитания" 113 на фиг. 2. Таким образом, в варианте осуществления, проиллюстрированном на фиг. 4, модуль извлечения полос дополнительно содержит модуль 121 оконной обработки аудиосигнала для оконной обработки аудиосигнала 102 с использованием окна анализа и окна синтеза для получения последовательности обработанных с помощью оконной функции блоков значений аудиосигнала. В частности, модуль 121 оконной обработки аудиосигнала синхронизирован с модулем 115 оконной обработки анализа и/или модулем 119 оконной обработки синтеза, чтобы последовательность блоков низкочастотных значений отсчетов во временной области, выдаваемая модулем 119 оконной обработки синтеза, была синхронна во времени с последовательностью обработанных с помощью оконной функции блоков значений аудиосигнала, выдаваемых блоком 121, который является сигналом полного диапазона.
Однако сигнал полного диапазона теперь обработан с помощью оконной функции с использованием модуля 121 оконной обработки аудиосигнала, и, таким образом, вычитание для каждого отсчета выполняется модулем 113 вычитания для каждого отсчета на фиг. 4, чтобы, наконец, получить высокочастотный сигнал. Таким образом, высокочастотный сигнал дополнительно доступен в последовательности блоков, поскольку вычитание 113 для каждого отсчета было выполнено для каждого блока.
Кроме того, процессор высокочастотных полос 120 выполнен с возможностью применять модификацию к каждому отсчету каждого блока последовательности блоков высокочастотных значений отсчетов во временной области, сформированной модулем 110 на фиг. 3c. Предпочтительно модификация для отсчета блока зависит вновь от информации предыдущего блока и вновь от информации текущего блока или, в качестве альтернативы или дополнительно, вновь от информации текущего блока и вновь от информации следующего блока. В частности, и предпочтительно, модификация выполняется посредством модуля 125 умножения на фиг. 5a, и модификации предшествует модуль 124 коррекции интерполяции. Как проиллюстрировано на фиг. 5a, коррекция интерполяции выполняется между предыдущими значениями усиления g[k-1], g[k] и коэффициентом усиления g[k+1] следующего блока после текущего блока.
Кроме того, как указано, модулем 125 умножения управляет модуль 126 компенсации усиления, управляемый, с одной стороны, посредством коэффициента 500 beta_factor и, с другой стороны, посредством коэффициента 104 усиления g[k] для текущего блока. В частности, коэффициент beta_factor используется для вычисления фактической модификации, применяемой посредством модуля 125 умножения, обозначенной как 1/gc[k], из коэффициента усиления g[k], связанного с текущим блоком.
Таким образом коэффициент beta_factor учитывает дополнительное ослабление транзиентов, которое приблизительно моделируется этим коэффициентом beta_factor, причем это дополнительное ослабление транзиентных событий является побочным эффектом либо кодера, либо декодера, который работает перед постпроцессором, проиллюстрированным на фиг. 5a.
Предварительная обработка и постобработка применяются посредством разбиения входного сигнала на низкочастотную (LP) часть и высокочастотную (HP) часть. Это может быть достигнуто: a) посредством преобразования FFT для вычисления LP-части или HP-части, b) посредством использования КИХ-фильтра (FIR-фильтра) нулевой фазы для вычисления LP-части или HP-части, или c) посредством БИХ-фильтра (IIR-фильтра), применяемого в обоих направлениях, с достижением нулевой фазы для вычисления LP-части или HP-части. Если получена LP-часть или HP-часть, другая часть может быть получена простым вычитанием во временной области. Зависящее от времени скалярное усиление применяется к HP-части, которая обратно добавляется к LP-части для создания предварительно обработанного или подвергнутого постобработке вывода.
Разбиение сигнала в LP-часть и HP-часть с использованием преобразования FFT (фиг. 5a, 9c)
В предложенной реализации преобразование FFT используется для вычисления LP-части. Пусть размер преобразования FFT составляет 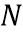 , в частности,
, в частности, 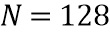 . Входной сигнал
. Входной сигнал 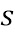 разбивается на блоки с размером , которые наполовину накладываются, производя входные блоки
разбивается на блоки с размером , которые наполовину накладываются, производя входные блоки 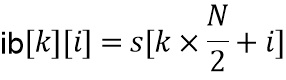 , где
, где 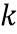 - индекс блока, и
- индекс блока, и 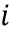 - позиция отсчета в блоке . Окно
- позиция отсчета в блоке . Окно 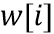 применяется (115, 215) к
применяется (115, 215) к 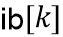 , в частности, синусное окно, определенное как
, в частности, синусное окно, определенное как
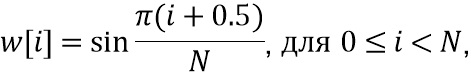
и после применения также преобразования FFT (116, 216) получаются комплексные коэффициенты 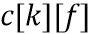 как
как
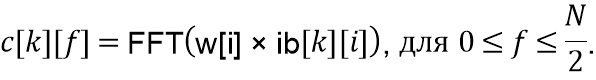
На стороне кодера (фиг. 9c) (217a), чтобы получить LP-часть, применяется поэлементное умножение (217a) 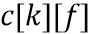 на форму обработки
на форму обработки 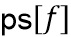 , которое состоит в следующем:
, которое состоит в следующем:
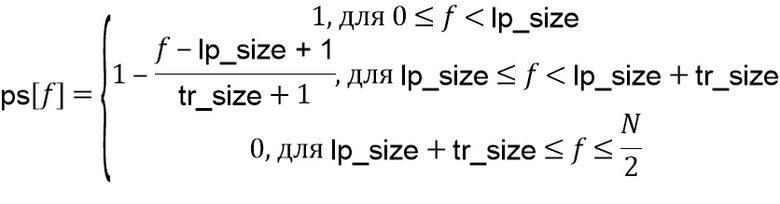
Параметр 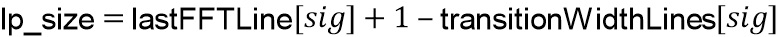 представляет ширину в линиях FFT низкочастотной области, и параметр
представляет ширину в линиях FFT низкочастотной области, и параметр  представляет ширину в линиях FFT области транзиента. Форма предложенной формы обработки является линейной, однако может использоваться любая произвольная форма.
представляет ширину в линиях FFT области транзиента. Форма предложенной формы обработки является линейной, однако может использоваться любая произвольная форма.
LP-блок 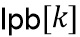 получается посредством применения преобразования IFFT (218) и оконной обработки (219) снова как
получается посредством применения преобразования IFFT (218) и оконной обработки (219) снова как
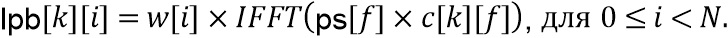
Приведенное выше уравнение пригодно для кодера/препроцессора на фиг. 9c. Для декодера или постпроцессора вместо ps[f] используется адаптивная форма обработки rs[f].
Затем HP-блок 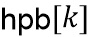 получается простым вычитанием (113, 213) во временной области как
получается простым вычитанием (113, 213) во временной области как
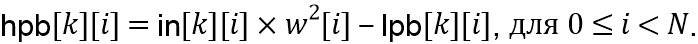
Выходной блок  получается посредством применения скалярного усиления
получается посредством применения скалярного усиления 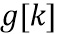 к HP-блоку как (225) (230)
к HP-блоку как (225) (230)
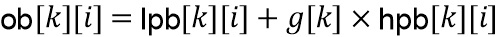
Выходной блок , наконец объединяется с использованием сложения наложения с предыдущим выходным блоком 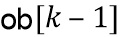 , чтобы создать
, чтобы создать  дополнительных окончательных отсчетов для предварительно обработанного выходного сигнала
дополнительных окончательных отсчетов для предварительно обработанного выходного сигнала 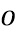 как
как
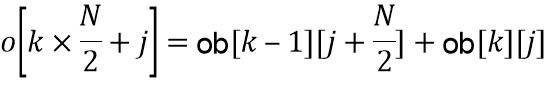 , где
, где 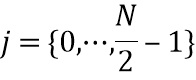 .
.
Вся обработка выполняется отдельно для каждого входного канала, который индексирован посредством  .
.
Адаптивная форма реконструкции на стороне постобработки (фиг. 5a)
На стороне декодера, чтобы получить совершенное воссоздание в области транзиента, должна использоваться адаптивная форма воссоздания 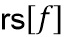 (117b) в области транзиента вместо формы обработки (217b), используемой на стороне кодера, в зависимости от формы обработки и как
(117b) в области транзиента вместо формы обработки (217b), используемой на стороне кодера, в зависимости от формы обработки и как
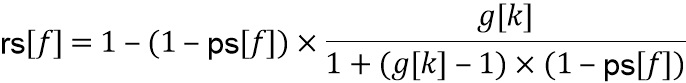
В LP-области и , и равны единице в HP-области и , и равны нулю, они отличаются только в области транзиента. Кроме того, когда 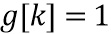 , тогда имеем
, тогда имеем 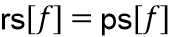 .
.
Форма адаптивного воссоздания может быть вычтена посредством гарантии того, что магнитуда линии FFT в области транзиента восстановлена после постобработки, что дает отношение
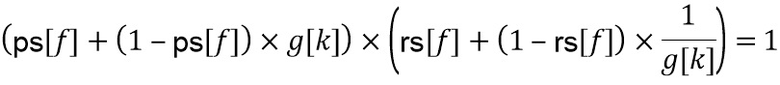 .
.
Обработка аналогична стороне предварительной обработки, за исключение того, что используется вместо как
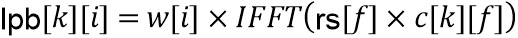 , где
, где 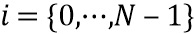
и выходной блок 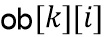 вычисляется с использованием инверсии скалярного усиления как (125)
вычисляется с использованием инверсии скалярного усиления как (125)
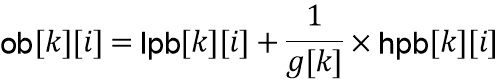 .
.
Коррекция интерполяции (124) на стороне постобработки (фиг. 5a)
Первая половина вклада выходного блока в окончательный предварительно обработанный выход задается посредством 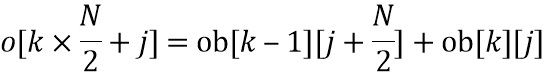 , где
, где 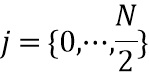 . Таким образом, усиления
. Таким образом, усиления 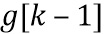 и , примененные на стороне предварительной обработки, неявным образом интерполируются вследствие оконной обработки и операции сложения наложения. Магнитуда каждой линии FFT в HP-области фактически умножается во временной области на скалярный коэффициент
и , примененные на стороне предварительной обработки, неявным образом интерполируются вследствие оконной обработки и операции сложения наложения. Магнитуда каждой линии FFT в HP-области фактически умножается во временной области на скалярный коэффициент 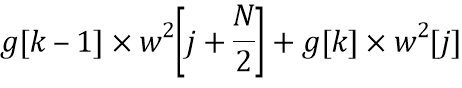 .
.
Аналогичным образом, на стороне постобработки магнитуда каждой линии FFT в HP-области фактически умножается во временной области на коэффициент
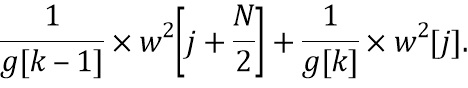
Чтобы достигнуть совершенного воссоздания, произведение двух предыдущих членов,
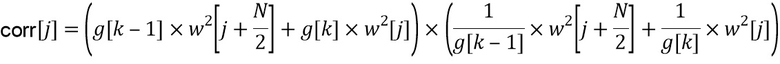 ,
,
которое представляет полное усиление во временной области в позиции  для каждой линии FFT в HP-области, должно быть нормализовано в первой половине выходного блока как
для каждой линии FFT в HP-области, должно быть нормализовано в первой половине выходного блока как
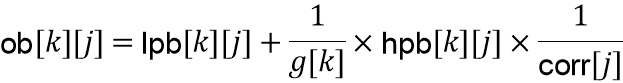 .
.
Значение  может быть упрощено и переписано как
может быть упрощено и переписано как
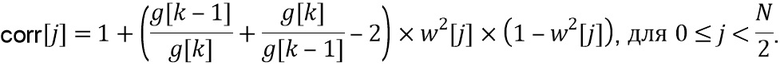
Вторая половина вклада выходного блока в окончательный предварительно обработанный вывод задается посредством 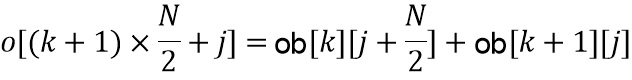 , и коррекция интерполяции может быть записана на основе усилений и
, и коррекция интерполяции может быть записана на основе усилений и 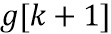 как
как
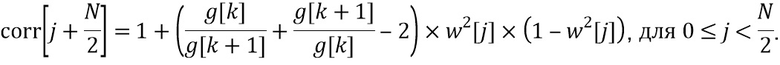
Обновленное значение для второй половины выходного блока задается посредством
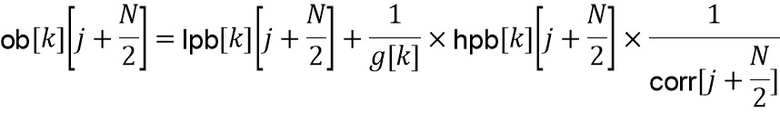 .
.
Вычисление усиления на стороне предварительной обработки (фиг. 9c)
На стороне предварительной обработки HP-часть блока , которая, как предполагается, содержит транзиентное событие, корректируется с использованием скалярного усиления , чтобы сделать его более подобным фону в его окружении. Энергия HP-части блока будет обозначена 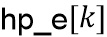 , и средняя энергия HP-фона в окружении блока будет обозначена
, и средняя энергия HP-фона в окружении блока будет обозначена 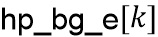 .
.
Параметр 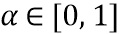 , который управляет величиной корректировки, определен как
, который управляет величиной корректировки, определен как
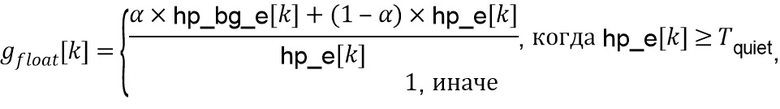
Значение 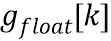 квантуется и обрезается до разрешенного диапазона посредством выбранного значения параметра конфигурации extendedGainRange для получения индекса усиления
квантуется и обрезается до разрешенного диапазона посредством выбранного значения параметра конфигурации extendedGainRange для получения индекса усиления 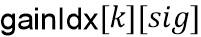 как
как
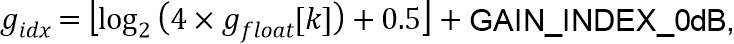
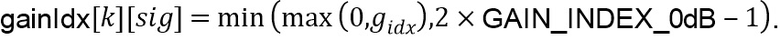
Значение , используемое для обработки, является квантованным значением, определенным на стороне декодера как
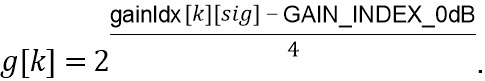
Когда 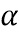 равно 0, усиление имеет значение
равно 0, усиление имеет значение 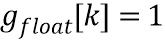 , таким образом, корректировка не выполняется, и когда равно 1, усиление имеет значение
, таким образом, корректировка не выполняется, и когда равно 1, усиление имеет значение 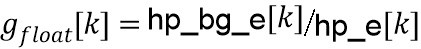 , и тем самым делается, что скорректированная энергия совпадает со средней энергией фона. Приведенное выше отношение может быть переписано как
, и тем самым делается, что скорректированная энергия совпадает со средней энергией фона. Приведенное выше отношение может быть переписано как
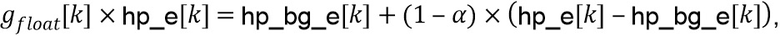
указывая, что вариация скорректированной энергии 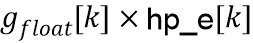 вокруг соответствующей средней энергии фона сокращается с коэффициентом
вокруг соответствующей средней энергии фона сокращается с коэффициентом 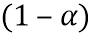 . В предложенной системе используется
. В предложенной системе используется 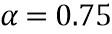 , таким образом, вариация HP-энергии каждого блока вокруг соответствующей средней энергии фона сокращается до 25% от первоначальной.
, таким образом, вариация HP-энергии каждого блока вокруг соответствующей средней энергии фона сокращается до 25% от первоначальной.
Компенсация усиления (126) на стороне постобработки (фиг. 5a)
Базовые кодер и декодер вносят дополнительное ослабление транзиентных событий, которое приблизительно моделируется посредством введения дополнительного этапа ослабления с использованием параметра 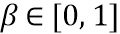 в зависимости от конфигурации базового кодера и характеристик сигнала кадра как
в зависимости от конфигурации базового кодера и характеристик сигнала кадра как
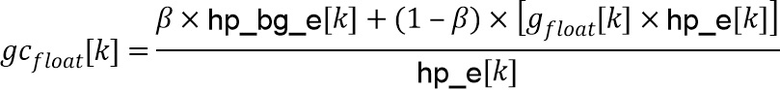
указывая, что, после прохождения через базовые кодер и декодер вариация декодированной энергии 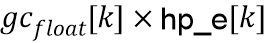 вокруг соответствующей средней энергии фона далее сокращается с дополнительным коэффициентом
вокруг соответствующей средней энергии фона далее сокращается с дополнительным коэффициентом 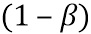 .
.
Просто используя , 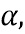 и
и 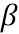 , возможно вычислить оценку
, возможно вычислить оценку 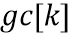 на стороне декодера как
на стороне декодера как
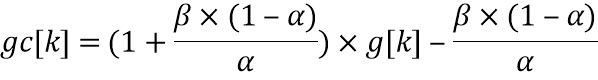
Параметр 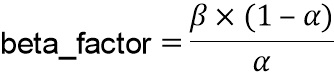 квантуется в betaFactorIdx[sig] и передается как вспомогательная информация для каждого кадра. Компенсированное усиление может быть вычислено c использованием
квантуется в betaFactorIdx[sig] и передается как вспомогательная информация для каждого кадра. Компенсированное усиление может быть вычислено c использованием 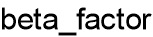 как
как

Мета-управление усилением (MGC)
Сигналы аплодисментов живых концертов и т.д. обычно содержат не только звук хлопков рук, но также и крик толпы, свист и топот ног зрителей. Часто исполнитель делает дает объявление во время аплодисментов, или звуки инструментов (управления инструментами), наложенные на звук продолжительных аплодисментов. Здесь существующие способы придания формы временной огибающей, такие как STP или GES, могут ослабить эти не относящиеся к аплодисментам компоненты, если они активируются в самый момент интерферирующих звуков. Таким образом, классификатор сигнала гарантирует деактивацию во время таких сигналов. Обработка HREP предлагает функциональность так называемого мета-управления усилением (MGC). MGC используется, чтобы мягко ослабить перцепционный эффект обработки HREP, избегая необходимости очень точной классификации входных сигналов. С помощью MGC аплодисменты, смешанные с окружающими и интерферирующими звуками всех видов, могут быть обработаны без внесения нежелательных артефактов.
Как обсуждалось ранее, предпочтительный вариант осуществления дополнительно имеет управляющий параметр 807 или, в качестве альтернативы, управляющий параметр beta_factor, обозначенный номером 500 на фиг. 5a. В качестве альтернативы или дополнительно, индивидуальные коэффициенты альфа или бета, как обсуждалось ранее, могут быть переданы в качестве дополнительной вспомогательной информации, но предпочтительно иметь единственный управляющий параметр beta_factor, который состоит из беты, с одной стороны, и альфы, с другой стороны, где бета представляет собой параметр между 0 и 1 и зависит от конфигурации базового кодера, а также факультативно от характеристик сигнала, и, дополнительно, коэффициент альфа определяет вариацию энергии высокочастотной части каждого блока вокруг соответствующей средней энергии фона, и альфа также представляет собой параметр между 0 и 1. Если количество транзиентов в одном кадре очень мало, например, 1-2, то TNS может потенциально обеспечить их сохранность лучше, и в результате дополнительное ослабление через кодер и декодер для кадра может быть уменьшено. Поэтому улучшенный кодер может соответствующим образом немного уменьшить beta_factor, чтобы предотвратить сверхусиление.
Другими словами, MGC в настоящее время модифицирует вычисленные усиления g (обозначенные здесь g_float [k]) с использованием подобного вероятности параметра p, как g'=g ^ p, который сжимает усиления к 1, прежде чем они будут квантованы. Параметр beta_factor представляет собой дополнительный механизм для управления расширением квантованных усилений, однако текущая реализация использует фиксированное значение на основе конфигурации базового кодера, такой как битовая скорость.
Параметр beta_factor определяется посредством β x (1-α)/α и предпочтительно вычисляется на стороне кодера и квантуется, и индекс betaFactorIdx квантованного параметра beta_factor передается как вспомогательная информация один раз в каждом кадре в дополнение к переменной во времени информации усиления на высоких частотах g[k].
В частности, дополнительный управляющий параметр 807, такой как бета или beta_factor 500 имеет временное разрешение, которое ниже, чем временное разрешение переменной во времени информации усиления на высоких частотах, или дополнительный управляющий параметр даже является стационарным для конкретной конфигурации базового кодера или фрагмента аудиоданных.
Предпочтительно процессор высокочастотных полос, модуль извлечения полос и модуль объединения обрабатывают накладывающиеся блоки, причем диапазоны наложения составляют между 40% и 60% длины блока, и предпочтительно используется 50% диапазон наложения.
В других вариантах осуществления или в тех же самых вариантах осуществления длина блока находится между 0,8 мс и 5,0 мс.
Кроме того, предпочтительно или дополнительно модификация, выполненная процессором 120 высокочастотных полос, представляет собой зависимый от времени мультипликативный коэффициент, применяемый к каждому отсчету блока во временной области в соответствии с g[k], дополнительно в соответствии с управляющим параметром 500 и дополнительно в соответствии с коррекцией интерполяции, как пояснено в контексте блока 124 на фиг. 5a.
Кроме того, граничная или пороговая частота низкочастотной полосы находится между 1/8 и 1/3 максимальной частоты аудиосигнала и предпочтительно равна 1/6 максимальной частоты аудиосигнала.
Кроме того, низкочастотный формирователь, состоящий из 117b и 117a на фиг. 5a в предпочтительном варианте осуществления, выполнен с возможностью применять функцию придания формы rs[f], которая зависит от переменной во времени информации усиления на высоких частотах для соответствующего блока. Предпочтительная реализация функции придания формы rs[f] была пояснена раньше, но также могут использоваться альтернативные функции.
Кроме того, предпочтительно функция придания формы rs[f] дополнительно зависит от функции придания формы ps[f], используемой в препроцессоре 200 аудиоданных для модификации или ослабления высокочастотной полосы аудиосигнала с использованием переменной во времени информации усиления на высоких частотах для соответствующего блока. Заданная зависимость rs[f] от ps[f] была пояснена раньше относительно фиг. 5a, но также могут использоваться другие зависимости.
Кроме того, как пояснено раньше относительно модуля 124 на фиг. 5a, модификация для отсчета блока дополнительно зависит от коэффициента оконной обработки, примененной к некоторому отсчету, как определено функцией окна анализа или функцией окна синтеза, как пояснено раньше, например, относительно коэффициента коррекции, который зависит от функции окна w[j], и еще более предпочтительно от квадрата оконного коэффициента w[j].
Как указано раньше, в частности, относительно фиг. 3b, обработка, выполняемая модулем извлечения полос, модулем объединения и процессором высокочастотных полос, выполняется на накладывающихся блоках, чтобы последний участок более раннего блока был выведен из тех же отсчетов аудиосигнала, как и более ранний участок более позднего блока, являющегося смежным во времени с более ранним блоком, т.е., обработка выполняется в диапазоне 321 наложения и с его использованием. Этот диапазон 321 наложения накладывающихся блоков 313 и 314 равен половине более раннего блока, и более поздний блок имеет такую же длину, что и более ранний блок, относительно количества значений отсчетов, и постпроцессор дополнительно содержит модуль 140 сложения наложения для выполнения операции сложения наложения, как проиллюстрировано на фиг. 3c.
В частности, модуль 110 извлечения полос выполнен с возможностью применять наклон разделительного фильтра 111 между диапазоном блокировки и диапазоном пропускания разделительного фильтра к блоку отсчетов аудиоданных, причем этот наклон зависит от переменной во времени информации усиления на высоких частотах для блока отсчетов. Предпочтительный наклон задан относительно наклона rs[f], который зависит от информации усиления g[k], как определено раньше и как пояснено в контексте фиг. 5a, но другие зависимости также могут быть полезными.
Обычно информация усиления на высоких частотах предпочтительно имеет значения усиления g[k] для текущего блока k, причем наклон увеличивается сильнее для более высокого значения усиления по сравнению с увеличением наклона для более низкого значения усиления.
Фиг. 6a иллюстрирует более подробное представление вспомогательной информации 106, представленной на фиг. 3. В частности, вспомогательная информация содержит последовательность индексов 601 усиления, информацию 602 точности усиления, информацию 603 компенсации усиления и информацию 604 точности компенсации.
Предпочтительно постпроцессор аудиоданных содержит модуль 610 извлечения вспомогательной информации для извлечения аудиосигнала 102 и вспомогательной информации 106 из аудиосигнала со вспомогательной информацией, и вспомогательная информация переадресуется декодеру 620 вспомогательной информации, который формирует и вычисляет декодированное усиление 621 и/или декодированное значение 622 компенсации усиления на основе соответствующей информации точности усиления и соответствующей информации точности компенсации.
В частности, информация точности определяет несколько разных значений, где информация высокой точности усиления определяет большее количество значений, которые может иметь индекс усиления, по сравнению с информацией более низкой точности усиления, указывающей меньшее количество значений, которые может иметь значение усиления.
Таким образом, информация усиления высокой точности может указывать большее количество битов, используемых для передачи индекса усиления, по сравнению с информацией более низкой точности усиления, указывающей меньшее количество битов, используемых для передачи информации усиления. Информация высокой точности может указывать 4 бита (16 значений для информации усиления), и информация более низкой точности может составлять только 3 бита (8 значений) для квантования усиления. Таким образом, информация точности усиления, например, может представлять собой простой флаг, обозначенный как "extendedGainRange". В последнем случае флаг конфигурации extendedGainRange указывает не информацию точности, а имеет ли усиление обычный диапазон или расширенный диапазон. Расширенный диапазон содержит все значения в обычном диапазоне и, кроме того, меньшие и большие значения, чем возможно с использованием обычного диапазона. Расширенный диапазон, которая может использоваться в некоторых вариантах осуществления, потенциально позволяет применять более интенсивный эффект предварительной обработки для сильных транзиентных событий, которые были бы в ином случае обрезаны до обычного диапазона.
Аналогичным образом, для точности коэффициента бета, т.е., для информации точности компенсации усиления, также может использоваться флаг, который обозначает, используют ли индексы параметра beta_factor 3 бита или 4 бита, и этот флаг может называться extendedBetaFactorPrecision.
Предпочтительно процессор 116 FFT выполнен с возможностью выполнять поблочное дискретное преобразование Фурье с длиной блока N значений отсчетов для получения некоторого количества спектральных значений, которое меньше, чем количество N/2 комплексных спектральных значений, посредством выполнения алгоритма разреженного дискретного преобразования Фурье, в котором пропускаются вычисления ветвей для спектральных значений выше максимальной частоты, и модуль извлечения полос выполнен с возможностью вычислять сигнал низкочастотной полосы посредством использования спектральных значений вплоть до частотного диапазона начала транзиента и посредством взвешивания спектральных значений в частотном диапазоне транзиента, причем частотный диапазон транзиента простирается только до максимальной частоты или частоты, меньшей максимальной частоты.
Эта процедура проиллюстрирована на фиг. 15, например, где проиллюстрированы некоторые операции с применением графа "бабочка". Пример дан, начиная с топологии 8-точечного (N=8) FFT по основанию 2 с прореживанием во времени, где только X(0) и X(1) необходимы для постобработки; следовательно, E(2) и E(3), и O(2) и O(3) не являются необходимыми. Затем, представим, что оба N/2-точечных преобразования DFT подразделяются далее на два N/4-точечных преобразования DFT с последующим применением графа "бабочка". Теперь можно аналогичным образом повторить описанные выше опущения, как проиллюстрировано на фиг. 15.
Далее более подробно разъясняется препроцессор аудиоданных 200 относительно фиг. 7.
Препроцессор 200 аудиоданных содержит анализатор 260 сигнала для анализа аудиосигнала 202, чтобы определить переменную во времени информацию 204 усиления на высоких частотах.
Кроме того, препроцессор 200 аудиоданных содержит модуль 210 извлечения полос для извлечения высокочастотной полосы 212 из аудиосигнала 202 и низкочастотной полосы 214 из аудиосигнала 202. Кроме того, процессор 220 высокочастотных полос обеспечен для выполнения переменной во времени модификации высокочастотной полосы 212 в соответствии с переменной во времени информацией 204 усиления на высоких частотах для получения обработанной высокочастотной полосы 222.
Препроцессор 200 аудиоданных дополнительно содержит модуль 230 объединения для объединения обработанной высокочастотной полосы 222 и низкочастотной полосы 214 для получения предварительно обработанного аудиосигнала 232. Кроме того, обеспечен выходной интерфейс 250 для формирования выходного сигнала 252, содержащего предварительно обработанный аудиосигнал 232 и переменную во времени информацию 204 усиления на высоких частотах в качестве вспомогательной информации 206, соответствующей вспомогательной информации 106, описанной в контексте фиг. 3.
Предпочтительно анализатор 260 сигнала выполнен с возможностью анализировать аудиосигнал для определения первой характеристики в первом временном блоке 301, как проиллюстрировано с помощью этапа 801 на фиг. 8a, и второй характеристики во втором временном блоке 302 аудиосигнала, вторая характеристика является более транзиентной, чем первая характеристика, как проиллюстрировано с помощью этапа 802 на фиг. 8a.
Кроме того, анализатор 260 выполнен с возможностью определять первую информацию 311 усиления для первой характеристики и вторую информацию 312 усиления для второй характеристики, как проиллюстрировано на этапе 803 на фиг. 8a. Затем процессор 220 высокочастотных полос выполнен с возможностью ослаблять участок высокочастотной полосы второго временного блока 302 в соответствии со второй информацией усиления сильнее, чем участок высокочастотной полосы первого временного блока 301 в соответствии с первой информацией усиления, как проиллюстрировано на этапе 804 на фиг. 8a.
Кроме того, анализатор 260 сигнала выполнен с возможностью вычислять показатель фона для энергии фона высокочастотной полосы для одного или более временных блоков, граничащих во времени, размещенных перед текущим временным блоком, или размещенных после текущего временного блока, или размещенных перед и после текущего временного блока, или включающих в себя текущий временной блок, или исключающих из себя текущий временной блок, как проиллюстрировано на этапе 805 на фиг. 8b. Кроме того, как проиллюстрировано на этапе 808, вычисляется энергетический показатель для высокочастотной полосы текущего блока и, как обозначено на этапе 809, коэффициент усиления вычисляется с использованием показателя фона, с одной стороны, и энергетического показателя, с другой стороны. Таким образом, результатом этапа 809 является коэффициент усиления, проиллюстрированный номером 810 на фиг. 8b.
Предпочтительно анализатор 260 сигнала выполнен с возможностью вычислять коэффициент 810 усиления на основе проиллюстрированного ранее уравнения g_float, но также могут быть выполнены другие методы вычисления.
Кроме того, параметр альфа влияет на коэффициент усиления таким образом, что вариация энергии каждого блока вокруг соответствующей средней энергии фона сокращается по меньшей мере на 50% и предпочтительно на 75%. Таким образом, вариация высокочастотной энергии каждого блока вокруг соответствующей средней энергии фона предпочтительно сокращается до 25% от первоначального посредством параметра альфа.
Кроме того, модуль/функциональность 806 мета-управления усилением выполнена с возможностью формировать управляющий коэффициент p. В варианте осуществления модуль 806 MGC использует способ статистического обнаружения для идентификации потенциальных транзиентов. Для каждого блока (например, 128 отсчетов), он производит подобный вероятности коэффициент "уверенности" p между 0 и 1. Окончательное усиление, которое должно быть применено к блоку, представляет собой g'=g ^ p, где g - первоначальное усиление. Когда p равен 0, g'=1, таким образом, обработка не применяется, и когда p равен 1, g'=g, обработка применяется в полную силу.
Модуль 806 MGC используется для сжатия усиления к 1 перед квантованием во время предварительной обработки, для управления силой обработки между отсутствием изменений и полным эффектом. Параметр beta_factor (который представляет собой улучшенную параметризацию параметра бета) используется для расширения усиления после обратного квантования во время постобработки, и одна возможность состоит в том, чтобы использовать фиксированное значение для каждой конфигурации кодера, определенной битовой скоростью.
В варианте осуществления параметр альфа фиксирован на значении 0,75. Следовательно, коэффициент α представляет собой сокращение вариации энергии вокруг среднего фона, и оно фиксировано в реализации MPEG-H на значении 75%. Управляющий коэффициент p на фиг. 8b служит в качестве подобного вероятности коэффициента "уверенности" p.
Как проиллюстрировано на фиг. 8c, анализатор сигнала выполнен с возможностью квантовать и обрезать не обработанную последовательность значений информации усиления для получения переменной во времени информации усиления на высоких частотах как последовательности квантованных значений, и процессор 220 высокочастотных полос выполнен с возможностью выполнять переменную во времени модификацию высокочастотной полосы в соответствии с последовательностью квантованных значений, а не не квантованных значений.
Кроме того, выходной интерфейс 250 выполнен с возможностью вносить последовательность квантованных значений во вспомогательную информацию 206 в качестве переменной во времени информации 204 усиления на высоких частотах, как проиллюстрировано на фиг. 8c на этапе 814.
Кроме того, препроцессор 200 аудиоданных выполнен с возможностью определять 815 дополнительное значение компенсации усиления, описывающее потерю вариации энергии, внесенную присоединенным далее кодером или декодером, и, дополнительно, препроцессор 200 аудиоданных квантует 816 эту дополнительную информацию компенсации усиления и вносит 817 эту квантованную дополнительную информацию компенсации во вспомогательную информацию, и, дополнительно, анализатор сигнала предпочтительно выполнен с возможностью применять мета-управление усилением при определении переменной во времени информации усиления на высоких частотах для постепенного сокращения или постепенного увеличения эффекта процессора высокочастотных полос на аудиосигнале в соответствии с дополнительными управляющими данными 807.
Предпочтительно, модуль 210 извлечения полос препроцессора 200 аудиоданных более подробно реализован, как проиллюстрировано на фиг. 4 или в фиг. 9c. Таким образом, модуль 210 извлечения полос выполнен с возможностью извлекать низкочастотную полосу с использованием устройства 111 низкочастотного фильтра и извлекать высокочастотную полосу посредством вычитания 113 низкочастотной полосы из аудиосигнала точно таким же образом, как было пояснено ранее относительно устройства постпроцессора.
Кроме того, модуль 210 извлечения полос, процессор 220 высокочастотных полос и модуль 230 объединения выполнены с возможностью обрабатывать накладывающиеся блоки. Модуль 230 объединения дополнительно содержит модуль сложения наложения для вычисления подвергнутого постобработке участка посредством сложения отсчетов аудиоданных первого блока и отсчетов аудиоданных второго блока в диапазоне наложения блоков. Таким образом, модуль сложения наложения, связанный с модулем 230 объединения на фиг. 7, может быть реализован таким же образом, как модуль сложения наложения для постпроцессора, проиллюстрированный на фиг. 3c под номером 130.
В варианте осуществления для препроцессора аудиоданных диапазон 320 наложения находится между 40% длины блока и 60% длины блока. В других вариантах осуществления длина блока находится между 0,8 мс и 5,0 мс, и/или модификация, выполняемая процессором 220 высокочастотных полос, представляет собой мультипликативный коэффициент, применяемый к каждому отсчету блока во временной области, чтобы результатом всей предварительной обработки был сигнал с сокращенным транзиентным характером.
В дополнительном варианте осуществления граничная или пороговая частота низкочастотной полосы находится между 1/8 и 1/3 максимального диапазона частот аудиосигнала 202 и предпочтительно равна 1/6 максимальной частоты аудиосигнала.
Как проиллюстрировано, например, на фиг. 9c, и как было также пояснено относительно постпроцессора на фиг. 4, модуль 210 извлечения полос содержит модуль 215 оконной обработки анализа для формирования последовательности блоков значений отсчетов аудиосигнала с использованием окна анализа, причем эти блоки являются накладывающимися во времени, как проиллюстрировано номером 321 на фиг. 3b. Кроме того, обеспечен процессор 216 дискретного преобразования Фурье для формирования последовательности блоков спектральных значений, а также обеспечен присоединенный далее низкочастотный формирователь 217a, 217b для придания формы каждому блоку спектральных значений для получения последовательности сформированных низкочастотных блоков спектральных значений. Кроме того, обеспечен процессор 218 обратного дискретного преобразования Фурье для формирования последовательности блоков значений отсчетов во временной области и, модуль 219 оконной обработки синтеза соединен с выходом процессора 218 обратного дискретного преобразования Фурье для оконной обработки последовательности блоков для низкочастотных значений отсчетов во временной области с использованием окна синтеза.
Предпочтительно низкочастотный формирователь, состоящий из блоков 217a, 217b, применяет низкочастотную форму ps[f] посредством умножения индивидуальных линий FFT, как проиллюстрировано посредством умножителя 217a. Низкочастотная форма ps[f] вычисляется, как указано ранее относительно фиг. 9c.
Кроме того, сам аудиосигнал, т.е., аудиосигнал полного диапазона также подвергается оконной обработке с использованием модуля 221 оконной обработки аудиосигнала для получения последовательности обработанных с помощью оконной функции блоков значений аудиосигнала, причем этот модуль 221 оконной обработки аудиосигнала синхронизирован с модулем 215 оконной обработки анализа и/или модулем 219 оконной обработки синтеза, чтобы последовательность блоков низкочастотных значений отсчетов во временной области была синхронна с последовательностью оконных блоков значений аудиосигнала.
Кроме того, анализатор 260 на фиг. 7 выполнен с возможностью дополнительно обеспечивать управляющий параметр 807, используемый для управления силой предварительной обработки между отсутствием и полным эффектом, и параметр 500 beta_factor как дополнительную вспомогательную информацию, причем процессор 220 высокочастотных полос выполнен с возможностью применять модификацию также с учетом дополнительного управляющего параметра 807, причем временное разрешение параметра beta_factor ниже, чем временное разрешение переменной во времени информации усиления на высоких частотах, или дополнительный управляющий параметр является стационарным для заданного фрагмента аудиоданных. Как упомянуто раньше, подобный вероятности управляющий параметр из MGC используется для сжатия усиления к 1 перед квантованием, и он явным образом не передается в качестве вспомогательной информации.
Кроме того, модуль 230 объединения выполнен с возможностью выполнять для каждого отсчета сложение соответствующих блоков последовательности блоков низкочастотных значений отсчетов во временной области и последовательности модифицированных, т.е., обработанных блоков высокочастотных значений отсчетов во временной области для получения последовательности блоков значений объединенного сигнала, как проиллюстрировано для стороны постпроцессора на фиг. 3c.
Фиг. 9a иллюстрирует устройство аудиокодирования для кодирования аудиосигнала, содержащее препроцессор 200 аудиоданных, описанный ранее, который выполнен с возможностью формировать выходной сигнал 252, имеющий переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации. Кроме того, обеспечен базовый кодер 900 для формирования базового закодированного сигнала 902 и базовой вспомогательной информации 904. Кроме того, устройство аудиокодирования содержит выходной интерфейс 910 для формирования закодированного сигнала 912, содержащего базовый закодированный сигнал 902, базовую вспомогательную информацию 904 и переменную во времени информацию усиления на высоких частотах в качестве дополнительной вспомогательной информации 106.
Предпочтительно препроцессор 200 аудиоданных выполняет предварительную обработку каждого канала или каждого объекта отдельно, как проиллюстрировано на фиг. 10a. В этом случае аудиосигнал является многоканальным сигналом или сигналом с множеством объектов. В дополнительном варианте осуществления, проиллюстрированном на фиг. 5c, препроцессор 200 аудиоданных выполняет предварительную обработку каждого транспортного канала SAOC или каждого транспортного канала стандарта High Order Ambisonics (HOA, звукозапись с эффектом присутствия высокого порядка) отдельно, как проиллюстрировано на фиг. 10a. В этом случае аудиосигнал является пространственным транспортным каналом аудиообъекта или транспортным каналом HOA.
В противоположность этому базовый кодер 900 выполнен с возможностью применять совместную многоканальную обработку кодера, или совместную обработку кодера для множества объектов, или заполнение промежутков кодера, или обработку расширения полосы частот кодера на предварительно обработанных каналах 232.
Таким образом, как правило, базовый закодированный сигнал 902 имеет меньше каналов, чем было введено в совместном многоканальном базовом кодере/базовом кодере 900 с несколькими объектами, поскольку базовый кодер 900, как правило, содержит некоторую операцию понижающего микширования.
Устройство аудиодекодирования проиллюстрировано на фиг. 9b. Устройство аудиодекодирования имеет входной интерфейс 920 аудиоданных для приема закодированного аудиосигнала 912, содержащего базовый закодированный сигнал 902, базовую вспомогательную информацию 904 и переменную во времени информацию 104 усиления на высоких частотах в качестве дополнительной вспомогательной информации 106. Кроме того, устройство аудиодекодирования содержит базовый декодер 930 для декодирования базового закодированного сигнала 902 с использованием базовой вспомогательной информации 904 для получения декодированного базового сигнала 102. Кроме того, устройство аудиодекодирования имеет постпроцессор 100 для постобработки декодированного базового сигнала 102 с использованием переменной во времени информации 104 усиления на высоких частотах.
Предпочтительно, и как проиллюстрировано на фиг. 10b, базовый декодер 930 выполнен с возможностью применять многоканальную обработку декодера, или обработку декодера для множества объектов, или обработку декодера расширения полосы частот, или обработку декодера с заполнением промежутков для формирования декодированных каналов многоканального сигнала 102 или декодированных объектов сигнала 102 с несколькими объектами. Таким образом, другими словами, процессор 930 совместного декодера, как правило, содержит некоторое повышающее микширование для формирования из меньшего количества каналов в закодированном аудиосигнале 902 большего количества индивидуальных объектов/каналов. Эти индивидуальные каналы/объекты вводятся в индивидуальную по каналам постобработку посредством постпроцессора 100 аудиоданных с использованием индивидуальной переменной во времени информации усиления на высоких частотах для каждого канала или каждого объекта, как проиллюстрировано номером 104 на фиг. 10b. Индивидуальный по каналам постпроцессор 100 выдает подвергнутые постобработке каналы, которые могут быть выданы на цифро-аналоговый конвертер и на присоединенные далее громкоговорители, или которые могут быть выданы на некоторую постобработку, или запоминающему устройству, или любой другой подходящей процедуре обработки аудиообъектов или аудиоканалов.
Фиг. 10c иллюстрирует ситуацию, подобную той, которая была проиллюстрирована на фиг. 9a или 9b, т.е., полную цепь, содержащую препроцессор 100 обработки огибающей высокого разрешения, присоединенный к кодеру 900 для формирования битового потока, и битовый поток декодируются декодером 930, и вывод декодера подвергается постобработке постпроцессором 100 процессора огибающей высокого разрешения для формирования окончательного выходного сигнала.
Фиг. 16 и фиг. 17a-17h иллюстрируют результаты теста на прослушивания для громкоговорителей в конфигурации 5.1 каналов (128 кбит/с). Кроме того, представлены результаты для прослушивания в стереонаушниках со средним (48 кбит/с) и высоким (128 кбит/с) качеством. Фиг. 16a обобщенно представляет установки теста на прослушивание. Результаты проиллюстрированы в фиг. 17a-17h.
На фиг. 17a перцепционное качество находится в диапазоне от "хорошего" до "отличного". Следует отметить, что подобные аплодисментам сигналы находятся среди позиций с наименьшей оценкой в "хорошем" диапазоне.
Фиг. 17b иллюстрирует, что все позиции с аплодисментами демонстрируют существенное улучшение, тогда как для позиций без аплодисментов не наблюдается существенного изменения перцепционного качества. Ни одна из позиций значительно не ухудшается.
Относительно фиг. 17c и 17d обозначено, что абсолютное перцепционное качество находится в "хорошем" диапазоне. В разностных оценках в целом имеется значительное усиление на семь пунктов. Индивидуальные усиления по качеству находятся в диапазоне между 4 и 9 пунктами, все из них являются значительными.
На фиг. 17e все сигналы из множества тестов являются сигналами с аплодисментами. Перцепционное качество находится в диапазоне от "удовлетворительного" до "хорошего". Всякий раз условия "HREP" имеют более высокую оценку, чем условие "NOHREP". На фиг. 17f можно видеть, что для всех позиций, кроме одной, "HREP" оценивается значительно лучше, чем "NOHREP". Наблюдаются улучшения в пределах от 3 до 17 пунктов. В целом имеется значительное среднее усиление в 12 пунктов. Ни одна из позиций значительно не ухудшается.
Относительно фиг. 17g и 17h можно видеть, что в абсолютных оценках все сигналы имеют оценку диапазоне "отлично". В разностных оценках можно заметить, что даже при том, что перцепционное качество является почти прозрачным, для шести из восьми сигналов имеется существенное улучшение в три-девять пунктов, что в целом дает среднее значение пять пунктов MUSHRA. Ни одна из позиций значительно не ухудшается.
Результаты ясно показывают, что технология HREP предпочтительных вариантов осуществления имеет значительное преимущество для кодирования подобных аплодисментам сигналов в широком диапазоне битовых скоростей и абсолютного качества. Кроме того, показано, что не имеется какого-либо ухудшения на сигналах без аплодисментов. Технология HREP является инструментом для улучшенного перцепционного кодирования сигналов, которые преимущественно состоят из многих плотных транзиентных событий, таких как аплодисменты, звуки дождя и т.д. Выгода применения технологии HREP является двойной: технология HREP ослабляет требование битовой скорости, накладываемое на кодер, посредством сокращения кратковременной динамики входного сигнала; дополнительно технология HREP гарантирует надлежащую реконструкцию огибающей на стадии (повышающего) микширования декодера, что является тем более важным, если в кодеке были применены методики параметрического многоканального кодирования. Субъективные тесты продемонстрировали улучшение приблизительно на 12 пунктов MUSHRA посредством обработки HREP в конфигурации стерео 48 кбит/с и на 7 пунктов MUSHRA в конфигурации 5.1 каналов 128 кбит/с.
Далее делается ссылка на фиг. 5b, иллюстрирующую реализацию постобработки, с одной стороны, или предварительную обработку, с другой стороны, в структуре аудиокодера/аудиодекодера MPEG-H 3D. Более конкретно, фиг. 5b иллюстрирует постпроцессор 100 HREP, реализованный в аудиодекодере MPEG-H 3D. Более конкретно, постпроцессор изобретения обозначен номером 100 на фиг. 5b.
Можно видеть, что декодер HREP соединен с выходом базового аудиодекодера 3D, проиллюстрированного номером 550. Кроме того, между элементом 550 и модулем 100 в верхней части проиллюстрирован элемент MPEG Surround, который, как правило, выполняет реализованное посредством MPEG Surround повышающее микширование из основных каналов на входе модуля 560 для получения большего количества каналов на выходе модуля 560.
Кроме того, фиг. 5b иллюстрирует другие элементы в дополнение к части базового аудио. В части рендеризации аудиоданных имеется drc_1 570 для каналов, с одной стороны, и объектов, с другой стороны. Кроме того, обеспечены модуль 580 преобразования формата, модуль 590 рендеризации объектов, декодер 592 метаданных объектов, декодер 594 SAOC 3D и декодер 596 HOA.
Все эти элементы подают данные на модуль 582 передискретизации, который выдает свои выходные данные в микшер 584. Микшер либо переадресовывает, свои выходные каналы в модуль 586 подачи громкоговорителей, либо в модуль 588 подачи наушников, которые представляют элементы в ʺконце цепиʺ, и которые представляют дополнительную постобработку, последующую за выводом микшера 584.
Фиг. 5c иллюстрирует дополнительное предпочтительное встраивание постпроцессора аудиоданных (HREP) в структуре аудиодекодера MPEG-H 3D. В отличие от фиг. 5b, обработка HREP также применяется к транспортным каналам SAOC и/или к транспортным каналам HOA. Другая функциональность на фиг. 5c аналогична фиг. 5b.
Следует отметить, что приложенная формула изобретения, относящаяся к модулю извлечения полос, также применяется к модулю извлечения полос в постпроцессоре аудиоданных и препроцессоре аудиоданных, даже когда пункт формулы изобретения обеспечен только для постпроцессора в одном из постпроцессора или препроцессора. То же самое относится к процессору высокочастотных полос и модулю объединения.
Конкретная ссылка сделана на дополнительные варианты осуществления, проиллюстрированные в приложении и в приложении A.
Хотя это изобретение было описано с точки зрения нескольких вариантов осуществления, имеются изменения, перестановки и эквиваленты, которые находятся в пределах объема этого изобретения. Также следует отметить, что существует много альтернативных методов реализации способов и композиций настоящего изобретения. Таким образом, предполагается, что последующая приложенная формула изобретения интерпретируется как включающая в себя все такие изменения, перестановки и эквиваленты, как находящиеся в пределах истинной сущности и объема настоящего изобретения.
Хотя некоторые аспекты были описаны в контексте устройства, ясно, что эти аспекты также представляют описание соответствующего способа, где модуль или устройство соответствуют этапу способа или признаку этапа способа. Аналогичным образом аспекты, описанные в контексте этапа способа, также представляют описание соответствующего модуля, или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут быть исполнены (или использовать) аппаратное устройство, как, например, микропроцессор, программируемый компьютер или электронная схема. В некоторых вариантах осуществления некоторые или более из самых важных этапов способа могут быть исполнены таким устройством.
Закодированный аудиосигнал изобретения может быть сохранен на цифровом запоминающем носителе или может быть передан на носителе передачи, таком как беспроводной носитель передачи или проводной носитель передачи, например, Интернет.
В зависимости от некоторых требований реализации варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может быть выполнена с использованием цифрового запоминающего носителя, например, гибкого диска, DVD, Blu-ray, CD, ПЗУ (ROM), ППЗУ (PROM), СППЗУ (EPROM), ЭСППЗУ (EEPROM) или флэш-памяти, имеющих сохраненные на них читаемые в электронном виде управляющие сигналы, которые взаимодействуют (или способны взаимодействовать) с программируемой компьютерной системой, в результате чего выполняется соответствующий способ. Таким образом, цифровой запоминающий носитель может являться машиночитаемым.
Некоторые варианты осуществления в соответствии с изобретением содержат носитель данных, имеющий в читаемые в электронном виде управляющие сигналы, которые способны взаимодействовать с программируемой компьютерной системой, в результате чего выполняется один из способов, описанных в настоящем документе.
Обычно варианты осуществления настоящего изобретения могут быть реализованы как компьютерный программный продукт с программным кодом, программный код выполнен с возможностью выполнения одного из способов, когда компьютерный программный продукт выполняется на компьютере. Программный код, например, может быть сохранен на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для выполнения одного из способов, описанных в настоящем документе, сохраненных на машиночитаемом носителе.
Другими словами, вариант осуществления способа изобретения, таким образом, представляет собой компьютерную программу, имеющую программный код для выполнения одного из способов, описанных в настоящем документе, когда компьютерная программа выполняется на компьютере.
Дополнительный вариант осуществления способов изобретения, таким образом, представляет собой носитель данных (или цифровой запоминающий носитель или машиночитаемый носитель), содержащий записанную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Носитель данных, цифровой запоминающий носитель или носитель с записанными данными обычно являются материальными и/или непереходными.
Дополнительный вариант осуществления способа изобретения, таким образом, представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для выполнения одного из способов, описанных в настоящем документе. Поток данных или последовательность сигналов, например, могут быть выполнены с возможностью быть перенесенными через соединение передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью или адаптированное для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную на нем компьютерную программу для выполнения одного из способов, описанных в настоящем документе.
Дополнительный вариант осуществления в соответствии с изобретением содержит устройство или систему, выполненную с возможностью переносить (например, в электронном или оптическом виде) компьютерную программу для выполнения одного из способов, описанных в настоящем документе, к приемнику. Приемник, например, может являться компьютером, мобильным устройством, запоминающим устройством и т.п. Устройство или система, например, могут содержать файловый сервер для переноса компьютерной программы к приемнику.
В некоторых вариантах осуществления программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения некоторой или всей функциональности способов, описанных в настоящем документе. В некоторых вариантах осуществления программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для выполнения одного из способов, описанных в настоящем документе. Обычно способы предпочтительно выполняются любым аппаратным устройством.
Устройство, описанное в настоящем документе, может быть реализовано с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в настоящем документе, могут быть выполнены с использованием аппаратного устройства, или с использованием компьютера, или с использованием комбинации аппаратного устройства и компьютера.
Описанные выше варианты осуществления являются лишь иллюстрацией принципов настоящего изобретения. Подразумевается, что модификации и вариации размещений и подробностей, описанных в настоящем документе, будут очевидны для других специалистов в области техники. Таким образом, подразумевается, что изобретение ограничено только объемом последующей патентной формулы изобретения, а не конкретными подробностями, представленными посредством описания и разъяснения представленных в настоящем документе вариантов осуществления.
Приложение
Описание дополнительного варианта осуществления технологии HREP в MPEG-H 3D Audio
Обработка огибающей высокого разрешения (HREP) является инструментом для улучшенного перцепционного кодирования сигналов, которые преимущественно состоят из многих плотных транзиентных событий, таких как аплодисменты, звуки капель дождя и т.д. Эти сигналы традиционно было очень трудно закодировать для аудиокодеков MPEG, в частности, на низких битовых скоростях. Субъективные тесты показали существенное улучшение приблизительно в 12 пунктов MUSHRA посредством обработки HREP в конфигурации стерео 48 кбит/с.
Выводы
Инструмент HREP обеспечивает улучшенную функциональность кодирования для сигналов, которые содержат плотно расположенные транзиентные события, такие как сигналы аплодисментов, поскольку они являются важной частью концертной записи. Аналогичным образом, звук капель дождя или другие звуки, такие как фейерверк, могут демонстрировать такие характеристики. К сожалению, этот класс звуков представляет трудности для существующих аудиокодеков, преимущественно при кодировании на низких битовых скоростях и/или с параметрическими инструментами кодирования.
Фиг. 10c изображает поток сигнала в кодеке, оборудованном технологией HREP. На стороне кодера инструмент работает как препроцессор, который сглаживает во временной области сигнал для высоких частот, формируя небольшое количество вспомогательной информации (1-4 кбит/с для стереосигналов). На стороне декодера инструмент работает как постпроцессор, который придает форму во временной области сигналу для высоких частот с использованием вспомогательной информации. Выгода применения технологии HREP является двойной: технология HREP ослабляет требование битовой скорости, накладываемое на кодер, посредством сокращения кратковременной динамики входного сигнала; дополнительно технология HREP гарантирует надлежащую реконструкцию огибающей на стадии (повышающего) микширования декодера, что является тем более важным, если в кодеке были применены методики параметрического многоканального кодирования.
Фиг. 10c: обзор потока сигнала в кодеке, оборудованном технологией HREP.
Инструмент HREP работает для всех конфигураций входных каналов (моно, стерео, многоканальная, в том числе 3D), а также для аудиообъектов.
В базовом эксперименте мы представляем результаты теста на прослушивание MUSHRA, которые показывают преимущество технологии HREP для кодирования сигналов с аплодисментами. Существенное улучшение перцепционного качества продемонстрировано для следующих тестовых сценариев
- среднее улучшение 7 пунктов MUSHRA для конфигурации 5.1 каналов 128 кбит/с
- среднее улучшение 12 пунктов MUSHRA для конфигурации стерео 48 кбит/с
- среднее улучшение 5 пунктов MUSHRA для конфигурации стерео 128 кбит/с
Иллюстративно, посредством оценки перцепционного качества для сигналов конфигурации 5.1 каналов с использованием полного известного набора тестов MPEG Surround, мы доказываем, что качество сигналов без аплодисментов не ухудшается посредством технологии HREP.
Подробное описание технологии HREP
Фиг. 10c изображает поток сигналов в кодеке, оборудованном HREP. На стороне кодера инструмент работает как препроцессор с высоким временным разрешением перед фактическим перцепционным аудиокодеком посредством анализа входного сигнала, ослабления и, таким образом, сглаживания во временной области высокочастотной части транзиентных событий и формирования небольшого количества вспомогательной информации (1-4 кбит/с для стереосигналов). Классификатор аплодисментов может направлять решение кодера, следует ли активировать HREP. На стороне декодера инструмент работает как постпроцессор после аудиокодека посредством повышения и, таким образом, придания формы во временной области высокочастотной части транзиентных событий с использованием вспомогательной информации, которая была сформирована во время кодирования.
Фи. 9c: подробный поток сигналов HREP в кодере.
Фиг. 9c отображает поток сигнала в процессоре HREP в кодере. Предварительная обработка применяется посредством разбиения входного сигнала на низкочастотную (LP) часть и высокочастотную (HP) часть. Это достигается посредством использования преобразования FFT для вычисления LP-части. С учетом LP-части HP-часть получается посредством вычитания во временной области. Скалярное усиление с временной зависимостью применяется к HP-части, которая добавляется обратно к LP-части, для создания предварительно обработанного вывода.
Вспомогательная информация содержит низкочастотную (LP) информацию о форме и скалярные усиления, которые оцениваются в модуле анализа HREP (не изображен). Модуль анализа HREP может содержать дополнительные механизмы, которые могут мягко уменьшить эффект обработки HREP содержания сигнала ("сигналов, не являющихся аплодисментами"), когда HREP не является полностью применимым. Таким образом, требования к точности обнаружения аплодисментов значительно ослабляются.
Фиг. 5a: подробный поток сигналов HREP в декодере.
Обработка на стороне декодера обозначена на фиг. 5a. Вспомогательная информация в информации о форме HP и скалярных усилениях выбирается из битового потока (не изображен) и применяется к сигналу, напоминающему постобработку декодера, обратную по отношению к предварительной обработке кодера. Постобработка применяется посредством разбиения сигнала на низкочастотную (LP) часть и высокочастотную (HP) часть. Это достигается посредством использования преобразования FFT для вычисления LP-части. С учетом LP-части HP-часть получается посредством вычитания во временной области. Скалярное усиление, зависящее от переданной вспомогательной информации, применяется к HP-части, которая добавляется обратно к LP-части для создания предварительно обработанного вывода.
Вся вспомогательная информация HREP сообщается в дополнительном полезном грузе и встраивается с обратной совместимостью в битовый поток MPEG-H 3D Audio.
Текст описания
Необходимые изменения WD, предложенный синтаксис битового потока, семантика и подробное описание процесса декодирования могут быть найдены в приложении A настоящего документа как текст различий.
Сложность
Вычислительная сложность обработки HREP задается посредством вычисления пар DFT/IDFT, которые реализуют разделение сигнала на LP/HP-части. Для каждого аудиокадра, содержащего 1024 значения во временной области, должны быть вычислены 16 пар действительных значений 128 точечного DFT/IDFT.
Для включения в профиль низкой сложности (LC) мы предлагаем следующие ограничения
- Ограничение активных каналов/объектов HREP
- Ограничение максимальных передаваемых коэффициентов усиления g(k), которые являются нетривиальными (тривиальные коэффициенты усиления 0 дБ уменьшают необходимость соответствующей пары DFT/IDFT),
- Вычисление DFT/IDFT в эффективной топологии разбиения по основанию 2 с прореживанием.
Доказательства преимущества
Тесты на прослушивание
В качестве доказательства преимущества будут представлены результаты теста на прослушивание для конфигурации громкоговорителей 5.1 каналов (128 кбит/с). Кроме того, представлены результаты для прослушивания в стереонаушниках со средним (48 кбит/с) и высоким (128 кбит/с) качеством. Фиг. 16 обобщенно представляет установки теста на прослушивание.
Фиг. 16 - обзор тестов на прослушивание.
Результаты
5.1 каналов 128 кбит/с
Фиг. 4 показывает абсолютные оценки MUSHRA для теста в конфигурации 5.1 каналов 128 кбит/с. Перцепционное качество находится в диапазоне от "хорошего" до "отличного". Следует отметить, что подобные аплодисментам сигналы находятся среди позиций с наименьшей оценкой в "хорошем" диапазоне.
Фиг. 17a: абсолютные оценки MUSHRA для теста в конфигурации 5.1 каналов 128 кбит/с.
Фиг. 17b изображает разностные оценки MUSHRA для теста в конфигурации 5.1 каналов 128 кбит/с. Все позиции с аплодисментами демонстрируют существенное улучшение, тогда как для позиций без аплодисментов не наблюдается существенного изменения перцепционного качества. Ни одна из позиций значительно не ухудшается.
Фиг. 17b: разностные оценки MUSHRA для теста в конфигурации 5.1 каналов 128 кбит/с.
Фиг. 17c изображает абсолютные оценки MUSHRA для всех позиций с аплодисментами, содержащихся в множестве тестов, и фиг. 17d изображает разностные оценки MUSHRA для всех позиций с аплодисментами, содержащихся в множестве тестов. Абсолютное перцепционное качество находится в "хорошем" диапазоне. В разностях в целом существует значительное усиление на 7 пунктов. Индивидуальные усиления по качеству находятся в диапазоне между 4 и 9 пунктами, все из них являются значительными.
Фиг. 17c: абсолютные оценки MUSHRA для тестовых сигналов с аплодисментами в конфигурации 5.1 каналов 128 кбит/с.
Фиг. 17d: разностные оценки MUSHRA для тестовых сигналов с аплодисментами в конфигурации 5.1 каналов 128 кбит/с.
Стерео 48 кбит/с
Фиг. 17e показывает абсолютные оценки MUSHRA для тестов в конфигурации стерео 48 кбит/с. Здесь все сигналы из множества тестов являются сигналами с аплодисментами. Перцепционное качество находится в диапазоне от "удовлетворительного" до "хорошего". Всякий раз условие "hrep" имеет более высокую оценку, чем условие "nohrep". Фиг. 17f изображает разностные оценки MUSHRA. Для всех позиций, кроме одной, "hrep" имеет значительно лучшую оценку, чем "nohrep". Наблюдаются улучшения в диапазоне от 3 до 17 пунктов. В целом имеется значительное среднее усиление на 12 пунктов. Ни одна из позиций значительно не ухудшается.
Фиг. 17e: абсолютные оценки MUSHRA для теста в конфигурации стерео 48 кбит/с.
Фиг. 17f: разностные оценки MUSHRA для теста в конфигурации стерео 48 кбит/с.
Стерео 128 кбит/с
Фиг. 17g и 17h изображают абсолютные и разностные оценки MUSHRA для теста в конфигурации стерео 128 кбит/с, соответственно. В абсолютных оценках все сигналы имеют оценку в диапазоне "отлично". В разностных оценках можно заметить, что даже при том, что перцепционное качество является почти прозрачным, для 6 из 8 сигналов имеется существенное улучшение на 3-9 пунктов, что в целом дает среднее значение 5 пунктов MUSHRA. Ни одна из позиций значительно не ухудшается.
Фиг. 17g: абсолютные оценки MUSHRA для теста в конфигурации стерео 128 кбит/с.
Фиг 17h: разностные оценки MUSHRA для теста в конфигурации стерео 128 кбит/с.
Результаты ясно показывают, что технология HREP предложения CE имеет значительное преимущество для кодирования подобных аплодисментам сигналов в широком диапазоне битовых скоростей и абсолютного качества. Кроме того, доказано, что не имеется какого-либо ухудшения для сигналов без аплодисментов.
Заключение
Технология HREP является инструментом для улучшенного перцепционного кодирования сигналов, которые преимущественно состоят из многих плотных транзиентных событий, таких как аплодисменты, звуки капель дождя и т.д. Выгода применения технологии HREP является двойной: технология HREP ослабляет требование битовой скорости, накладываемое на кодер, посредством сокращения кратковременной динамики входного сигнала; дополнительно технология HREP гарантирует надлежащую реконструкцию огибающей на стадии (повышающего) микширования декодера, что является тем более важным, если в кодеке были применены методики параметрического многоканального кодирования. Субъективные тесты продемонстрировали улучшение приблизительно на 12 пунктов MUSHRA посредством обработки HREP в конфигурации стерео 48 кбит/с и на 7 пунктов MUSHRA в конфигурации 5.1 каналов 128 кбит/с.
Приложение A
Предпочтительный вариант осуществления технологии HREP в MPEG-H 3D Audio
Далее даны модификации данных для изменений, требуемых для технологии HREP, относительно документов 23008-3:2015 ISO/IEC и ISO/IEC 23008-3:2015/EAM3.
Добавить следующую строку в Таблицу 1, ʺФункциональные блоки MPEG-H 3DA и внутренняя область обработки. fs,core обозначает выходную частоту дискретизации базового декодера, fs,out, обозначает выходную частоту дискретизации декодераʺ, в Разделе 10.2:
Таблица 1 - функциональные блоки MPEG-H 3DA и внутренняя область обработки. fs,core обозначает выходную частоту дискретизации базового декодера, fs,out обозначает выходную частоту дискретизации декодера.
[1/fs,core]
или
[1/fs,out]
Профиль высокого уровня
Отсчеты [1/fs,out]
Профиль низкой сложности
Отсчеты [1/fs,out]
Добавить следующий Случай к Таблице 13, ʺСинтаксис mpegh3daExtElementConfig()ʺ, в Разделе 5.2.2.3:
Таблица 13 - Синтаксис mpegh3daExtElementConfig()

Добавить следующее определение значения в Таблицу 50, ʺЗначение usacExtElementTypeʺ, в Разделе 5.3.4:
Таблица 50 - Значение usacExtElementType
Добавить следующую интерпретацию к Таблице 51, ʺИнтерпретация блоков данных для декодирования полезного груза расширенияʺ, в Разделе 5.3.4:
Таблица 51 - Интерпретация блоков данных для декодирования полезного груза расширения
Добавить новый подпункт в конце 5.2.2 и добавить следующую таблицу:
5.2.2.X Конфигурация элементов расширения
Таблица 2 - синтаксис HREPConfig()

В конце 5.2.2.3 добавить следующие таблицы:
Таблица 3 - синтаксис HREPFrame()

Вспомогательная функция HREP_decode_ac_data(gain_count, signal_count) описывает чтение значений усиления в массив gainIdx с использованием следующих функций арифметического кодирования низкого уровня USAC:
arith_decode(*ari_state, cum_freq, cfl),
arith_start_decoding(*ari_state),
arith_done_decoding(*ari_state).
Введены две дополнительные вспомогательные функции,
ari_decode_bit_with_prob(*ari_state, count_0, count_total),
которая декодирует один бит с  и
и 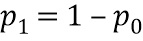 , и
, и
ari_decode_bit(*ari_state),
которая декодирует один бит без моделирования, с 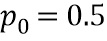 и
и 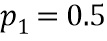 .
.




Добавить следующие новые подпункты ʺ5.5.X Инструменты обработки огибающей с высоким разрешением (HREP)ʺ в конце подпункта 5.5:
5.5.X Инструмент обработки огибающей с высоким разрешением (HREP)
5.5.X.1 Описание инструмента
Инструмент HREP обеспечивает улучшенную функциональность кодирования для сигналов, которые содержат плотно расположенные транзиентные события, такие как сигналы аплодисментов, поскольку они являются важной частью концертной записи. Аналогичным образом, звук капель дождя или другие звуки, такие как фейерверк, могут демонстрировать такие характеристики. К сожалению, этот класс звуков представляет трудности для существующих аудиокодеков, преимущественно при кодировании на низких битовых скоростях и/или с параметрическими инструментами кодирования.
Фиг. 5b или 5c изображает поток сигнала в кодеке, оборудованном HREP. На стороне кодера инструмент работает как препроцессор, который сглаживает во временной области сигнал для высоких частот посредством формирования небольшого количества вспомогательной информации (1-4 Кбит/с для стереосигналов). На стороне декодера инструмент работает как постпроцессор, который придает форму сигналу для высоких частот во временной области с использованием вспомогательной информации. Выгода от применения технологии HREP является двойной: технология HREP ослабляет требование битовой скорости, накладываемое на кодер, посредством сокращения кратковременной динамики входного сигнала; дополнительно технология HREP гарантирует надлежащую реконструкцию огибающей на стадии (повышающего) микширования декодера, что является тем более важным, если в кодеке были применены методики параметрического многоканального кодирования. Инструмент HREP работает для всех конфигураций входных каналов (моно, стерео, многоканальная, в том числе 3D), а также для аудиообъектов.
5.5.X.2 Элементы данных и вспомогательные элементы
current_signal_group Параметр current_signal_group основан на синтаксическом элементе Signals3d() и синтаксическом элементе mpegh3daDecoderConfig().
signal_type Тип группы текущего сигнала, используемый для различения между сигналами канала и объектом, HOA, и сигналами SAOC.
signal_count Количество сигналов в группе текущего сигнала.
extendedGainRange Указывает, используют ли индексы усиления 3 бита (8 значений) или 4 бита (16 значений), как вычислено посредством nBitsGain.
extendedBetaFactorPrecision Указывает, используют ли индексы коэффициента бета 3 бита или 4 бита, как вычислено посредством nBitsBeta.
isHREPActive[sig] Указывает, является ли активным инструмент для сигнала на индексе sig в группе текущего сигнала.
lastFFTLine[sig] Позиция последней не нулевой линии, используемой в низкочастотной процедуре, реализованной с использованием FFT.
transitionWidthLines[sig] Ширина в линиях области транзиента, используемая в низкочастотной процедуре, реализованной с использованием FFT.
defaultBetaFactorIdx[sig] Индекс коэффициента бета по умолчанию, используемый для модификации усилений в процедуре компенсации усиления.
outputFrameLength Эквивалентное количество отсчетов на кадр с использованием первоначальной частоты дискретизации, как определено в стандарте USAC.
gain_count Количество усилений на сигнал в одном кадре.
useRawCoding Указывает, закодированы ли индексы усиления без обработки с использованием nBitsGain каждый, или они закодированы с использованием арифметического кодирования.
gainIdx[pos][sig] Индекс усиления, соответствующий блоку в позиции pos сигнала в позиции sig в группе текущего сигнала. Если extendedGainRange=0, возможные значения находятся в диапазоне {0,..., 7}, и если extendedGainRange=1, возможные значения находятся в диапазоне {0,..., 15}.
GAIN_INDEX_0dB Смещение индекса усиления, соответствующее 0 дБ, со значением 4, используемым, если extendedGainRange=0, и со значением 8, используемым, если extendedGainRange=1. Индексы усиления передаются как значения без знака посредством добавления GAIN_INDEX_0dB к их первоначальным диапазонам данных со знаком.
all_zero Указывает, имеют ли все индексы усиления в одном кадре для текущего сигнала значение GAIN_INDEX_0dB.
useDefaultBetaFactorIdx Указывает, имеет ли индекс коэффициента бета для текущего сигнала значение по умолчанию defaultBetaFactor[sig].
betaFactorIdx [сигнал] индекс коэффициента бета, используемый для модификации усилений в процедуре компенсации усиления.
5.5.X.2.1 Ограничения для профиля низкой сложности
Если общее количество сигналов, подсчитанное по всем группам сигналов, равно по большей мере 6, никаких ограничений нет.
В ином случае, если общее количество сигналов, в которых HREP является активным, обозначенное посредством синтаксического элемента isHREPActive[sig] в HREPConfig(), и подсчитанное по всем группам сигналов, равно по большей мере 4, никаких дальнейших ограничений нет.
В ином случае общее количество сигналов, в которых HREP является активным, обозначенное синтаксическим элементом isHREPActive[sig] в HREPConfig(), и подсчитанное по всем группам сигналов, должно быть ограничено по большей мере как 8.
Кроме того, для каждого кадра, общее количество индексов усиления, которые отличаются от GAIN_INDEX_0dB, подсчитанное для сигналов, в которых HREP является активным, и по всем группам сигналов должен быть равен по большей мере  . Для блоков, которые имеют индекс усиления, равный GAIN_INDEX_0dB, должны быть пропущены преобразование FFT, коррекция интерполяции и преобразование IFFT. В этом случае входной блок должен быть умножен на квадрат синусного окна и использоваться непосредственно в процедуре сложения наложения.
. Для блоков, которые имеют индекс усиления, равный GAIN_INDEX_0dB, должны быть пропущены преобразование FFT, коррекция интерполяции и преобразование IFFT. В этом случае входной блок должен быть умножен на квадрат синусного окна и использоваться непосредственно в процедуре сложения наложения.
5.5.X.3 Процесс декодирования
5.5.X.3.1 Общая информация
В синтаксическом элементе mpegh3daExtElementConfig() поле usacExtElementPayloadFrag должно быть равно нулю в случае элемента ID_EXT_ELE_HREP. Инструмент HREP применим только для групп сигналов типа SignalGroupTypeChannels и SignalGroupTypeObject, как определено посредством синтаксического элемента SignalGroupType[grp] в Signals3d(). Таким образом, элементы ID_EXT_ELE_HREP должны присутствовать только для групп сигналов типа SignalGroupTypeChannels и SignalGroupTypeObject.
Размер блока и соответственно используемый размер FFT составляет .
Вся обработка выполняется независимо на каждом сигнале в группе текущего сигнала. Таким образом, чтобы упростить обозначение, процесс декодирования описан только для одного сигнала в позиции sig.
Фигура 5a: блок-схема инструмента обработки огибающей с высоким разрешением (HREP) на стороне декодирования
5.5.X.3.2 Декодирование квантованных бета-коэффициентов
Следующие таблицы поиска для преобразования индекса бета-коэффициента  в бета-коэффициент должны использоваться в зависимости от значения
в бета-коэффициент должны использоваться в зависимости от значения  .
.
tab_beta_factor_dequant_coarse[8]={
0.000f, 0.035f, 0.070f, 0.120f, 0.170f, 0.220f, 0.270f, 0.320f
}
tab_beta_factor_dequant_precise[16]={
0.000f, 0.035f, 0.070f, 0.095f, 0.120f, 0.145f, 0.170f, 0.195f,
0.220f, 0.245f, 0.270f, 0.295f, 0.320f, 0.345f, 0.370f, 0.395f
}
Если extendedBetaFactorPrecision=0, преобразование вычисляется как
beta_factor=tab_beta_factor_dequant_coarse[betaFactorIndex[sig]]
Если extendedBetaFactorPrecision=1, преобразование вычисляется как
beta_factor=tab_beta_factor_dequant_precise[betaFactorIndex[sig]]
5.5.X.3.3 Декодирование квантованных усилений
Один кадр обрабатывается как  блоков, каждый состоящих из отсчетов, которые наполовину накладываются. Скалярное усиление для каждого блока выводится на основе значения
блоков, каждый состоящих из отсчетов, которые наполовину накладываются. Скалярное усиление для каждого блока выводится на основе значения  .
.
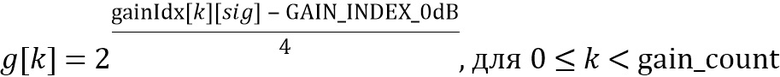
5.5.X.3.4 Вычисление LP-части и HP-части
Входной сигнал разбивается на блоки с размером , которые наполовину накладываются, и получаются входные блоки , где - индекс блока, и - позиция отсчета в блоке . Окно применяется к , в частности, синусное окно, определенное как
и после применения также преобразования FFT получаются комплексные коэффициенты как
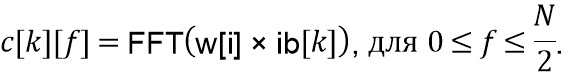
На стороне кодера, чтобы получить LP-часть, мы применяем поэлементное умножение 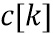 на форму обработки , которое состоит в следующем:
на форму обработки , которое состоит в следующем:
Параметр представляет ширину в линиях FFT низкочастотной области, и параметр представляет ширину в линиях FFT области транзиента.
На стороне декодера, чтобы получить совершенное воссоздание в области транзиента, должна использоваться адаптивная форма воссоздания в области транзиента вместо формы обработки , используемой на стороне кодера, в зависимости от формы обработки и как
LP-блок получается посредством применения преобразования IFFT и оконной обработки снова как
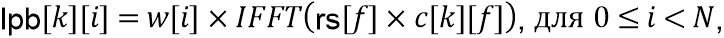
HP-блок затем получается посредством простого вычитания во временной области как
5.5.X.3.5 Вычисление коррекции интерполяции
Усиления и , примененные на стороне кодера к блокам на позициях  и , неявно интерполируются вследствие операций оконной обработки и сложения наложения. Чтобы достигнуть совершенного воссоздания в HP-части над областью транзиента, необходим коэффициент коррекции интерполяции, как
и , неявно интерполируются вследствие операций оконной обработки и сложения наложения. Чтобы достигнуть совершенного воссоздания в HP-части над областью транзиента, необходим коэффициент коррекции интерполяции, как
5.5.X.3.6 Вычисление компенсированных усилений
Базовые кодер и декодер вносят дополнительное ослабление транзиентных событий, которое компенсируется посредством корректировки усилений с использованием ранее вычисленного как

5.5.X.3.7 Вычисление выходного сигнала
На основе и  , значение выходного блока вычисляется как
, значение выходного блока вычисляется как
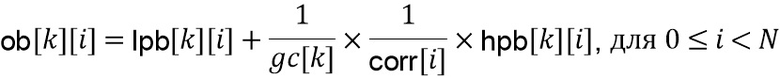
Наконец, выходной сигнал вычисляется с использованием выходных блоков с использованием сложения наложения как
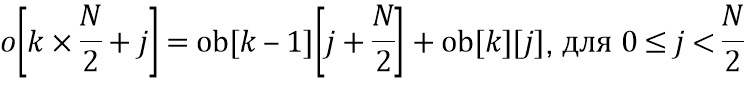
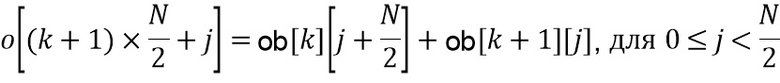
5.5.X.4 Описание кодера (информативное)
Фиг.9c: блок-схема инструмента обработки огибающей с высоким разрешением (HREP) на стороне кодирования
5.5.X.4.1 Вычисление усилений и бета-коэффициента
На стороне предварительной обработки HP-часть блока , которая, как предполагается, содержит транзиентное событие, корректируется с использованием скалярного усиления , чтобы сделать его более подобным фону в его окружении. Энергия HP-части блока будет обозначена , и средняя энергия HP-фона в окружении блока будет обозначена .
Мы определяем параметр , который управляет величиной корректировки? как
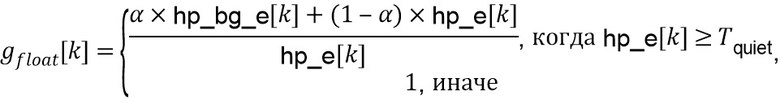
Значение квантуется и обрезается до разрешенного диапазона посредством выбранного значения параметра конфигурации extendedGainRange для получения индекса усиления как
Значение , используемое для обработки, является квантованным значением, определенным на стороне декодера как
Когда равно 0, усиление имеет значение , таким образом, корректировка не вносится, и когда равно 1, усиление имеет значение , и тем самым делается, что скорректированная энергия совпадает со средней энергией фона. Мы можем переписать приведенное выше отношение как
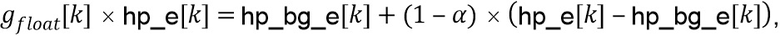
указывая, что вариация скорректированной энергии вокруг соответствующей средней энергии фона сокращается с коэффициентом . В предложенной системе используется , таким образом, вариация HP-энергии каждого блока вокруг соответствующей средней энергии фона сокращается до 25% от первоначальной.
Базовые кодер и декодер вносят дополнительное ослабление транзиентных событий, которое приблизительно моделируется посредством введения дополнительного этапа ослабления с использованием параметра в зависимости от конфигурации базового кодера и характеристик сигнала кадра как
после прохождения через базовые кодер и декодер вариация декодированной энергии вокруг соответствующей средней энергии фона далее сокращается с дополнительным коэффициентом .
Просто используя , и , возможно вычислить оценку на стороне декодера как
Параметр квантуется в betaFactorIdx[sig] и передается как вспомогательная информация для каждого кадра. Компенсированное усиление может быть вычислено c использованием как
5.5.X.4.2 Вычисление LP-части и HP-части
Обработка идентична соответствующей обработке на стороне декодера, определенной ранее, за исключением того, что форма обработки используется вместо адаптивной формы воссоздания при вычислении LP-блока , который получен посредством применения преобразования IFFT и оконной обработки снова как
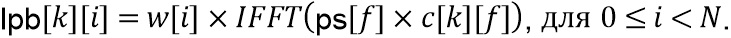
5.5.X.4.3 Вычисление выходного сигнала
На основе значение выходного блока вычисляется как
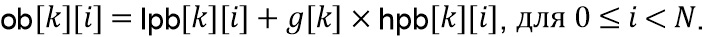
Идентичным образом относительно стороны декодера выходной сигнал вычисляется с использованием выходных блоков с использованием сложения наложения как
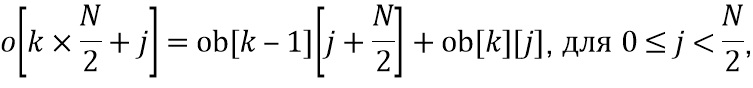
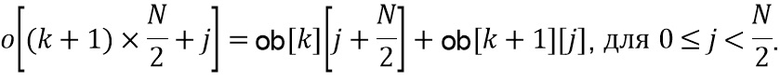
5.5.X.4.4 Кодирование усилений с использованием арифметического кодирования
Вспомогательная функция HREP_encode_ac_data(gain_count, signal_count) описывает запись значений усиления из массива gainIdx с использованием следующих функций арифметического кодирования низкого уровня USAC:
arith_encode(*ari_state, symbol, cum_freq),
arith_encoder_open(*ari_state),
arith_encoder_flush(*ari_state).
Введены две дополнительные вспомогательные функции,
ari_encode_bit_with_prob(*ari_state, bit_value, count_0, count_total),
которая кодирует один бит bit_value с и , и
ari_encode_bit(*ari_state, bit_value),
которая кодирует один бит bit_value без моделирования, с и .


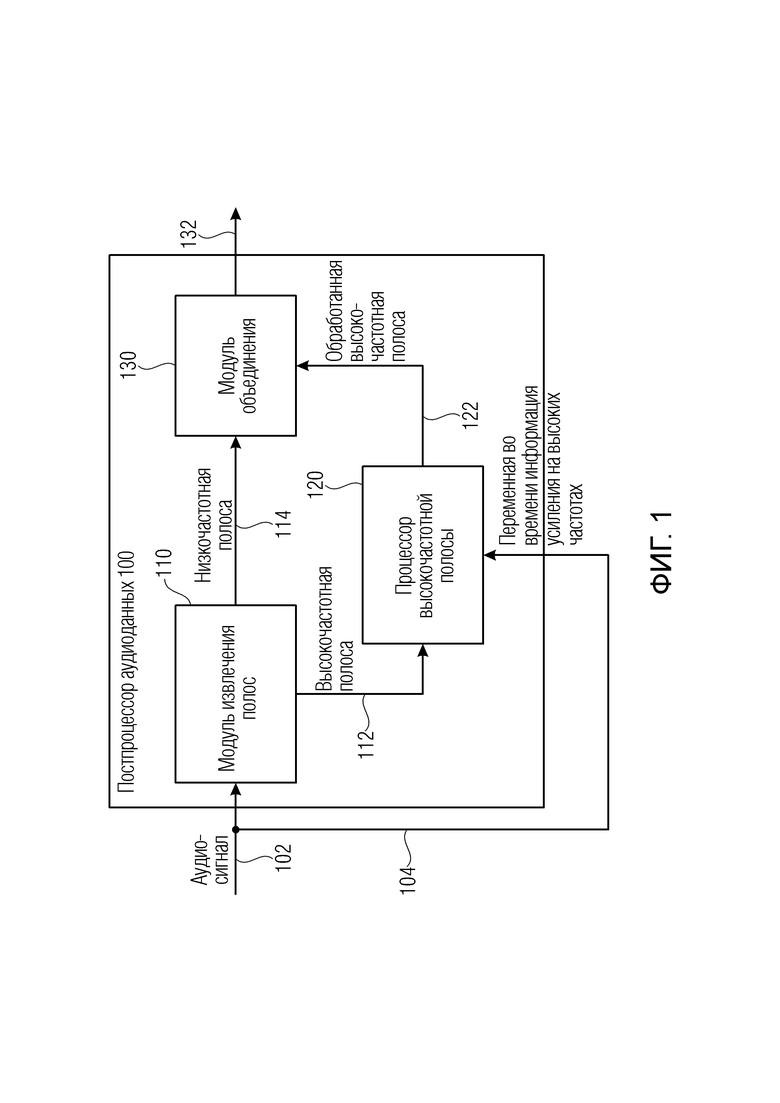
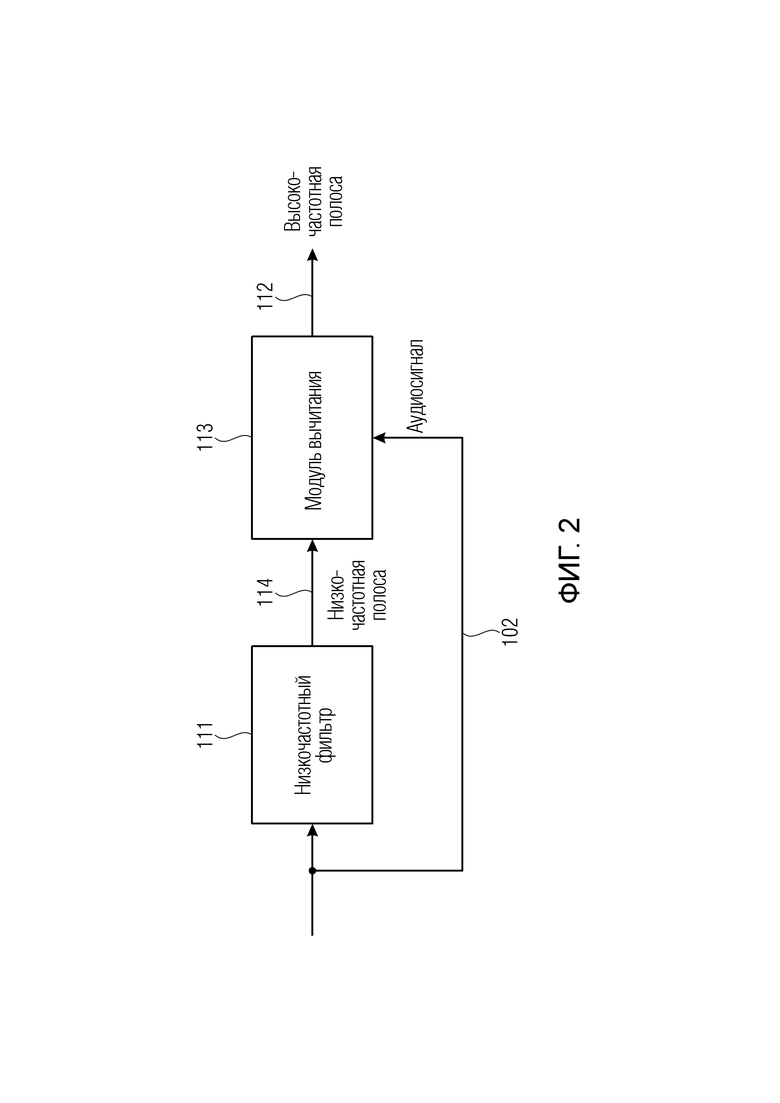
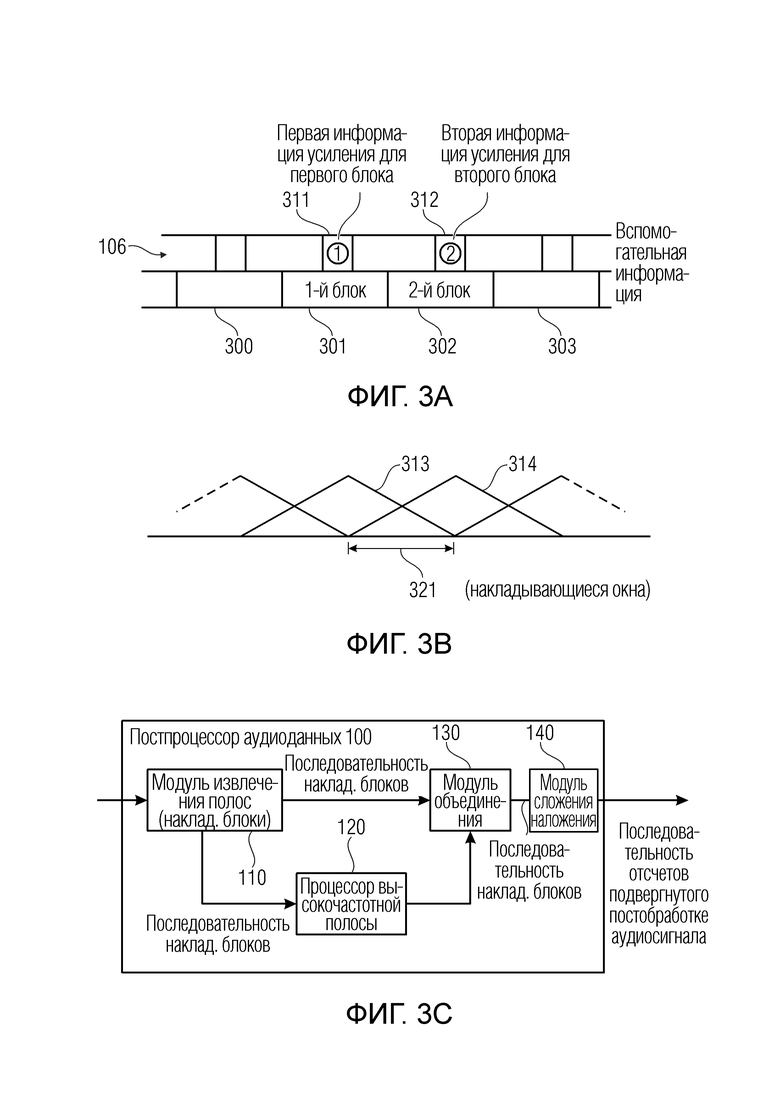
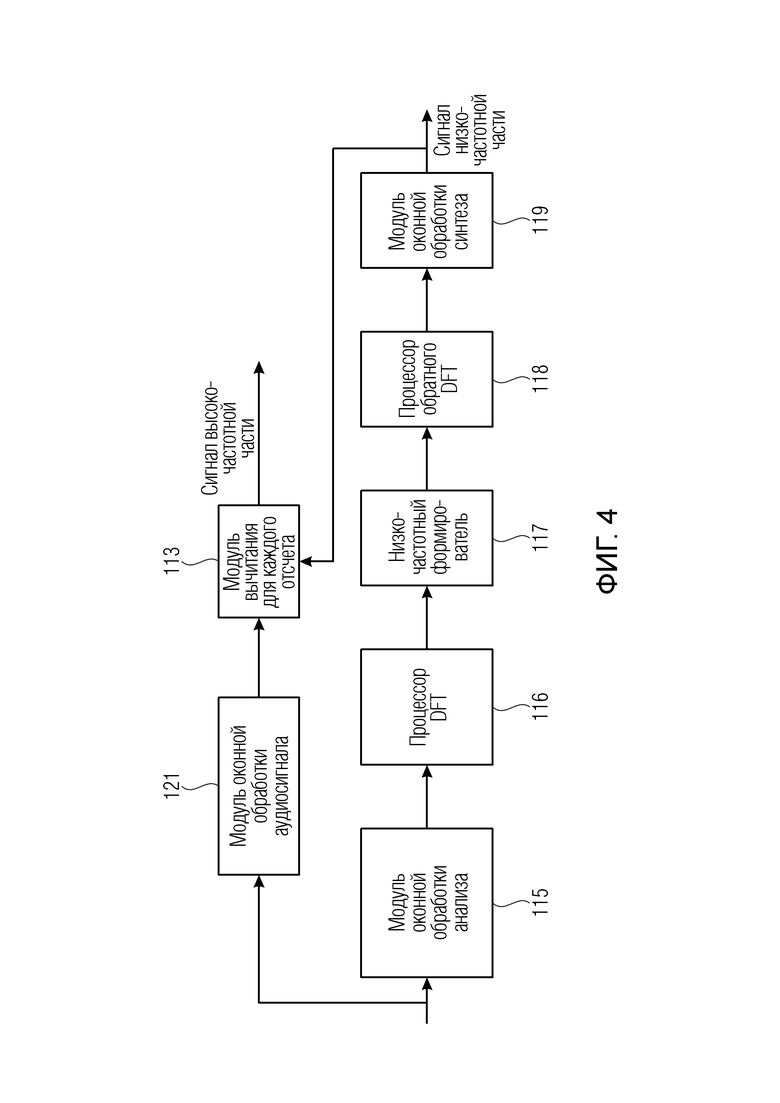
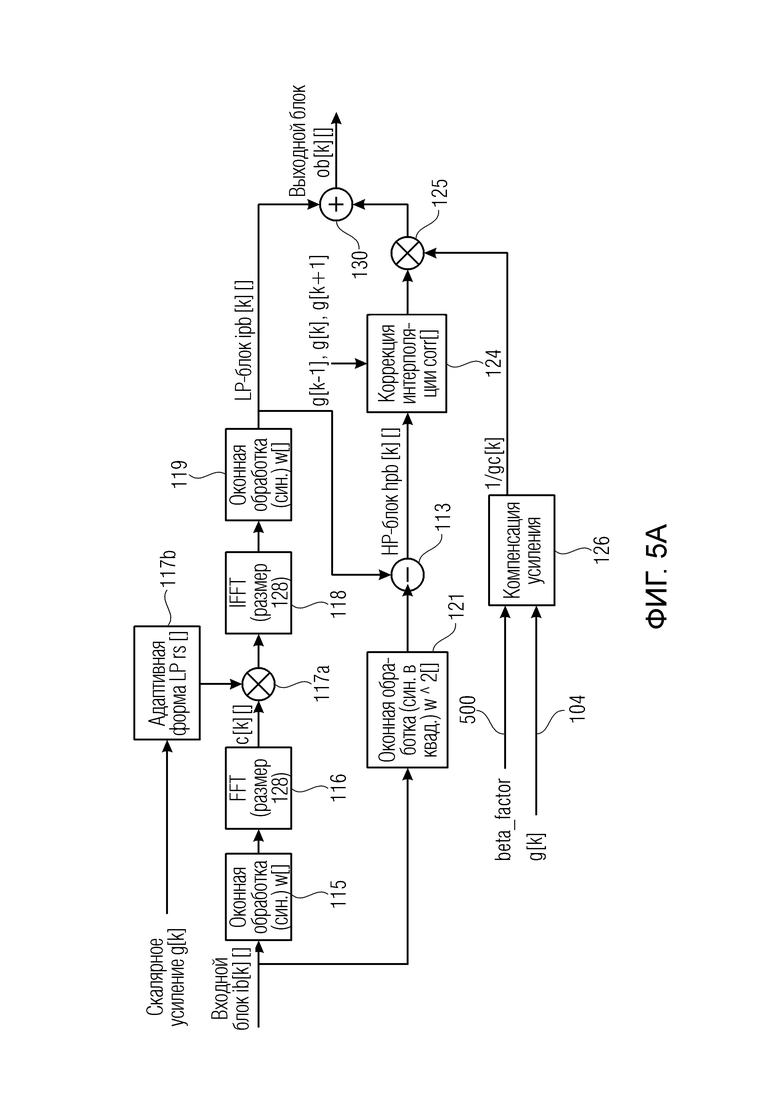
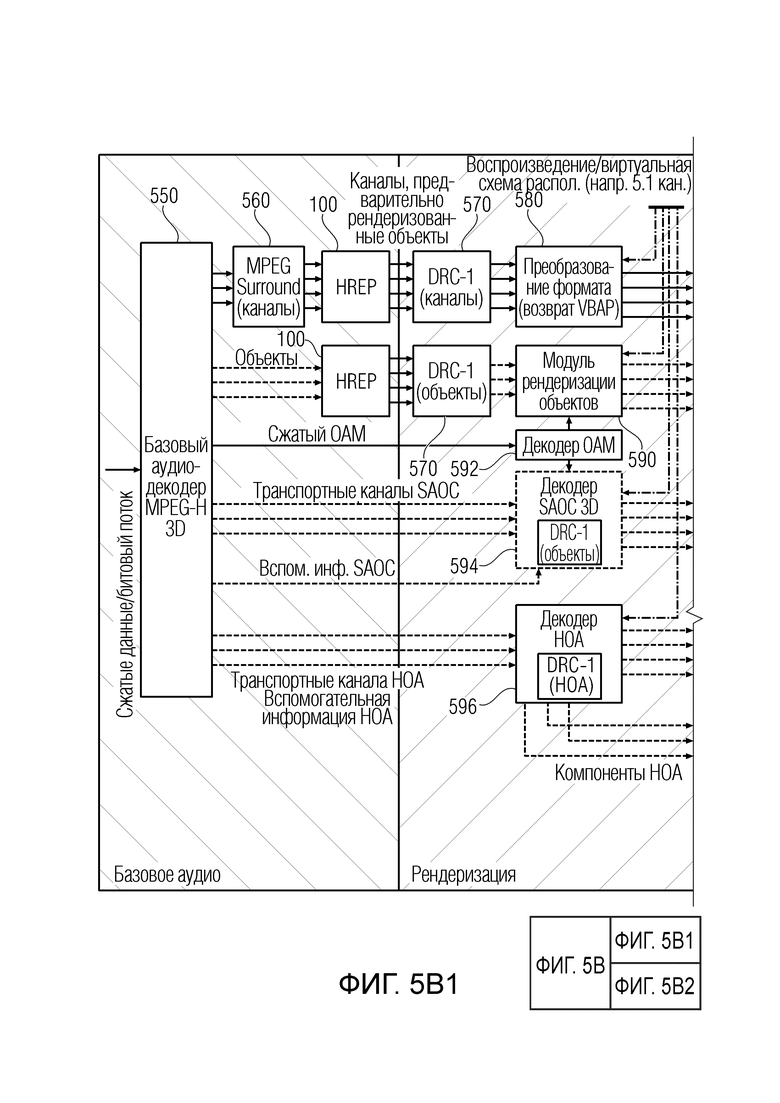
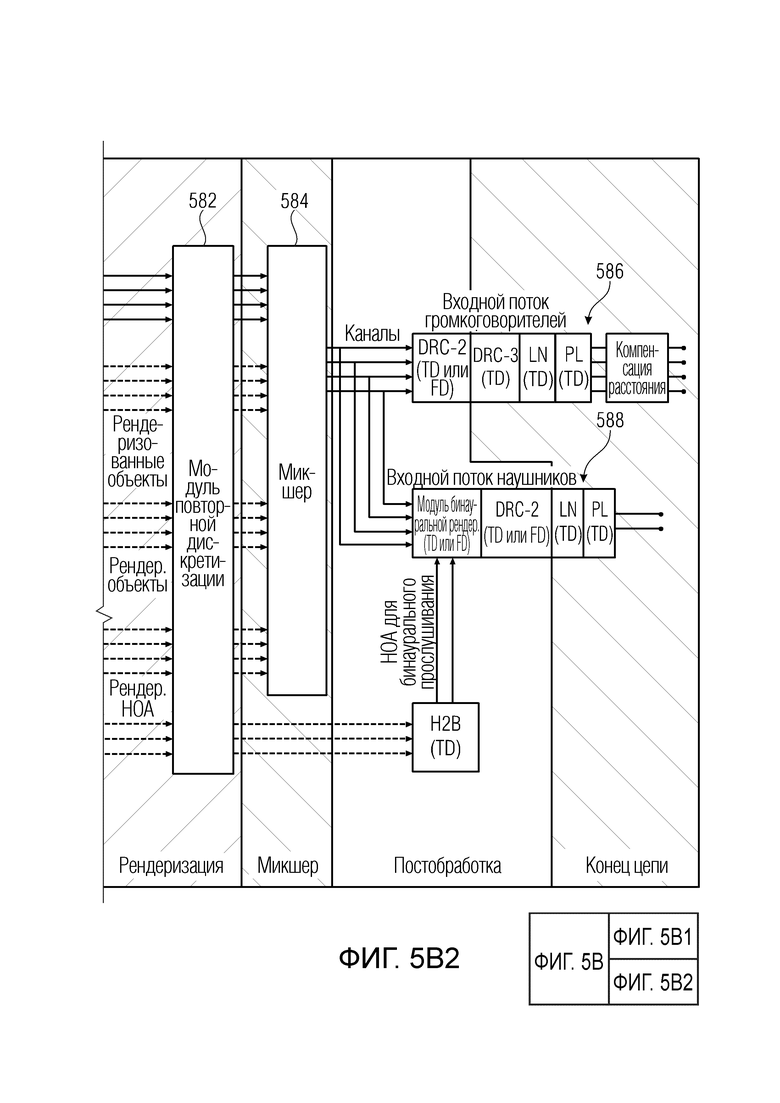
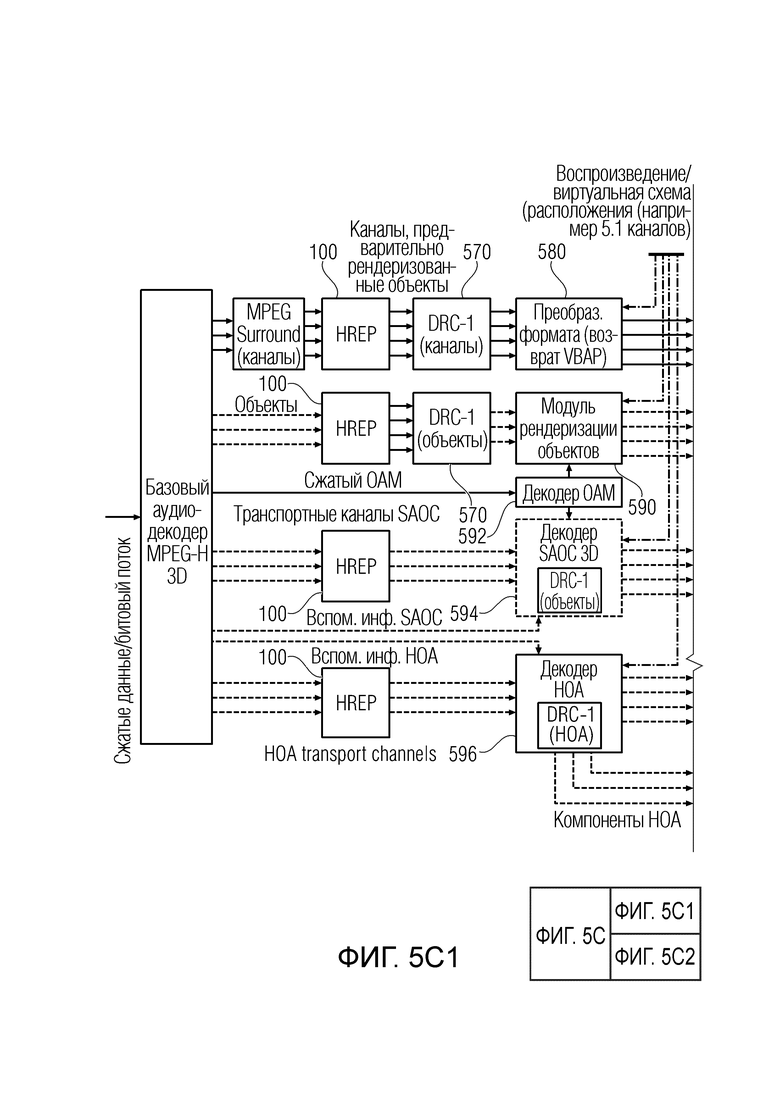
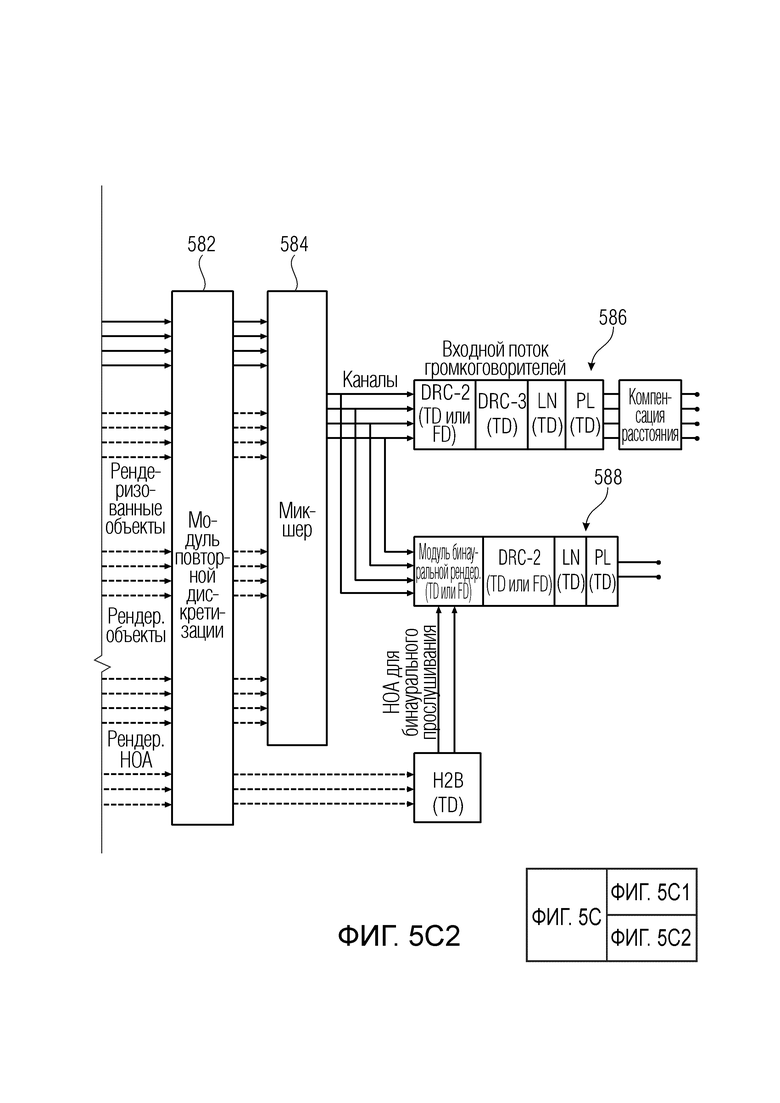
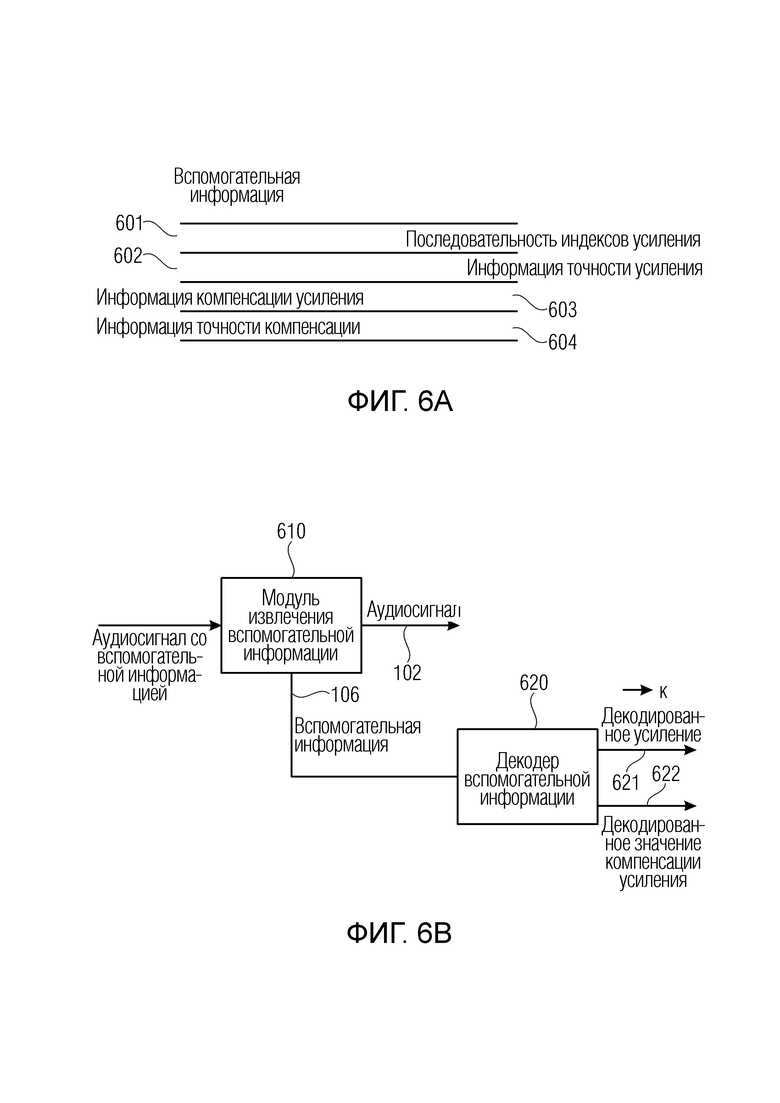
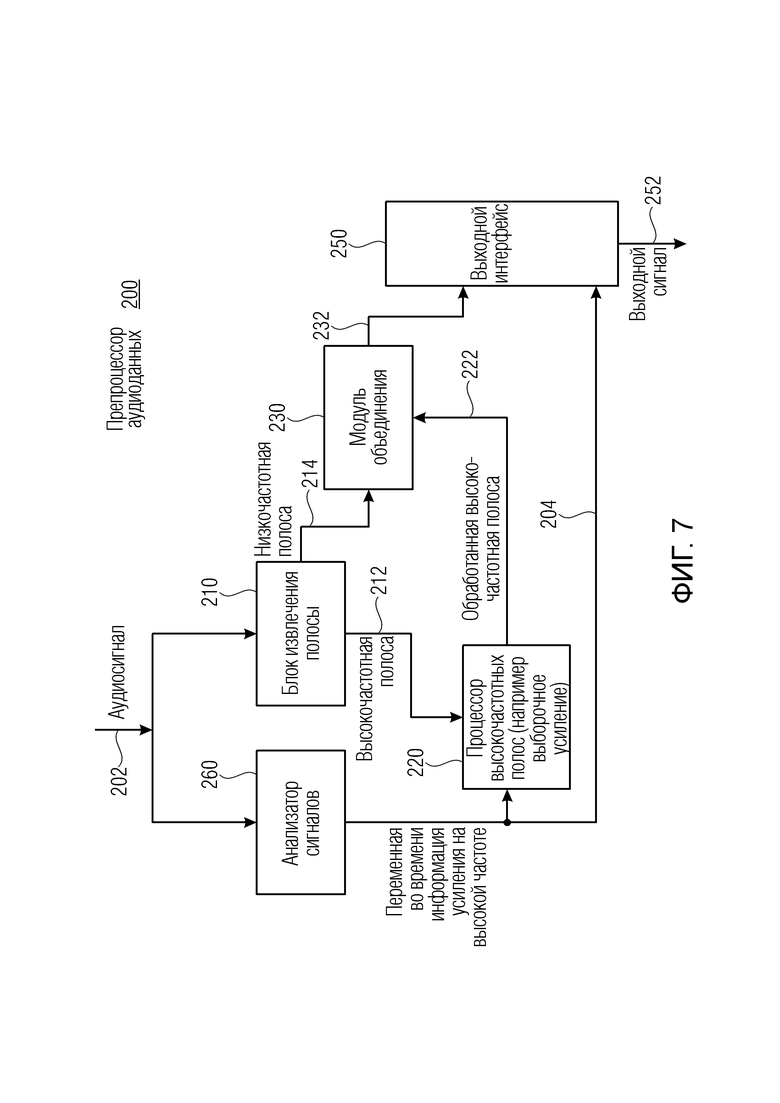
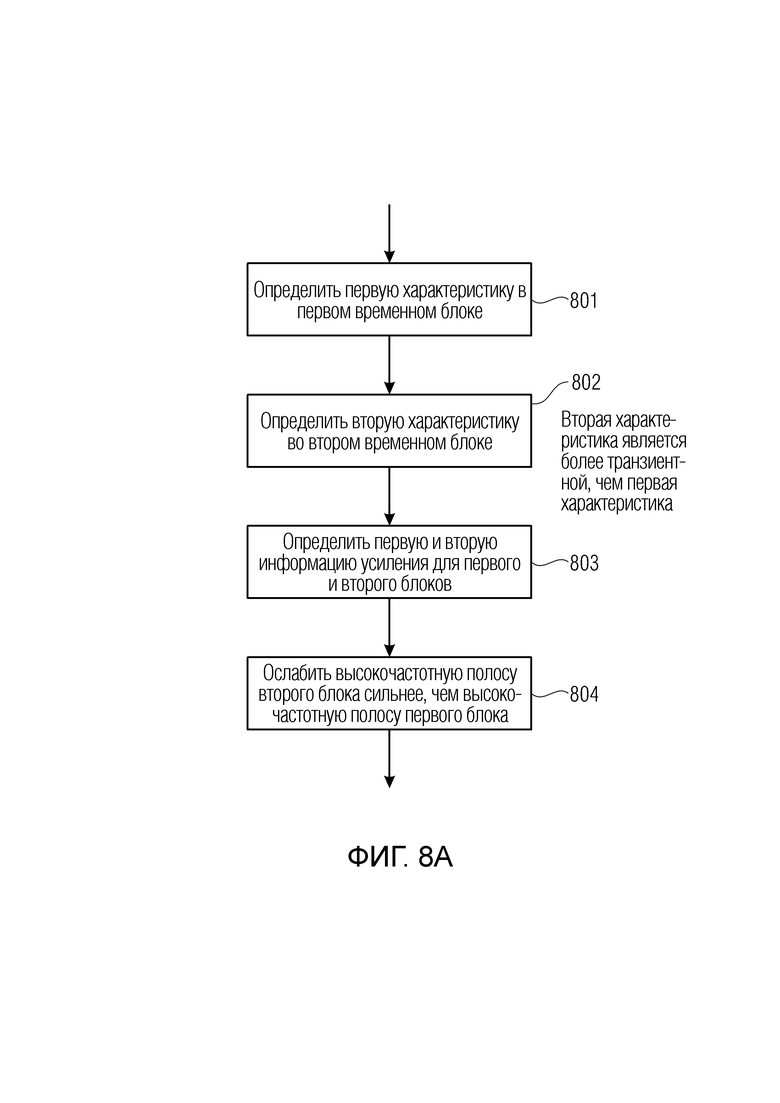
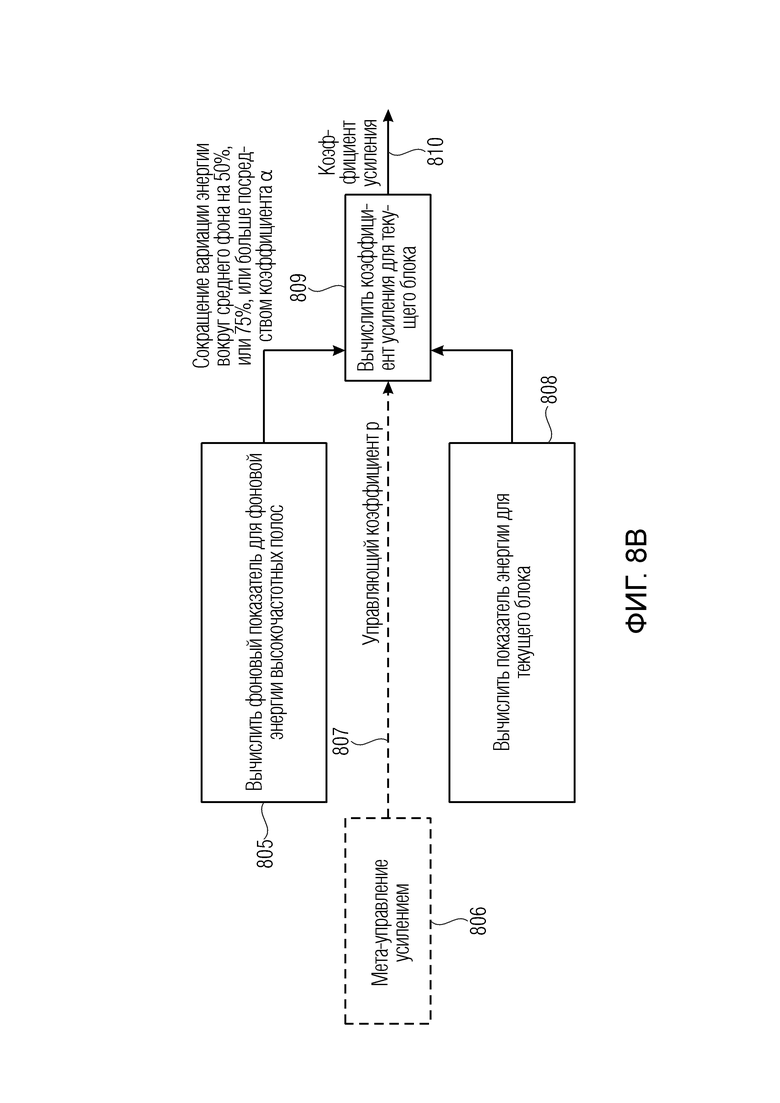
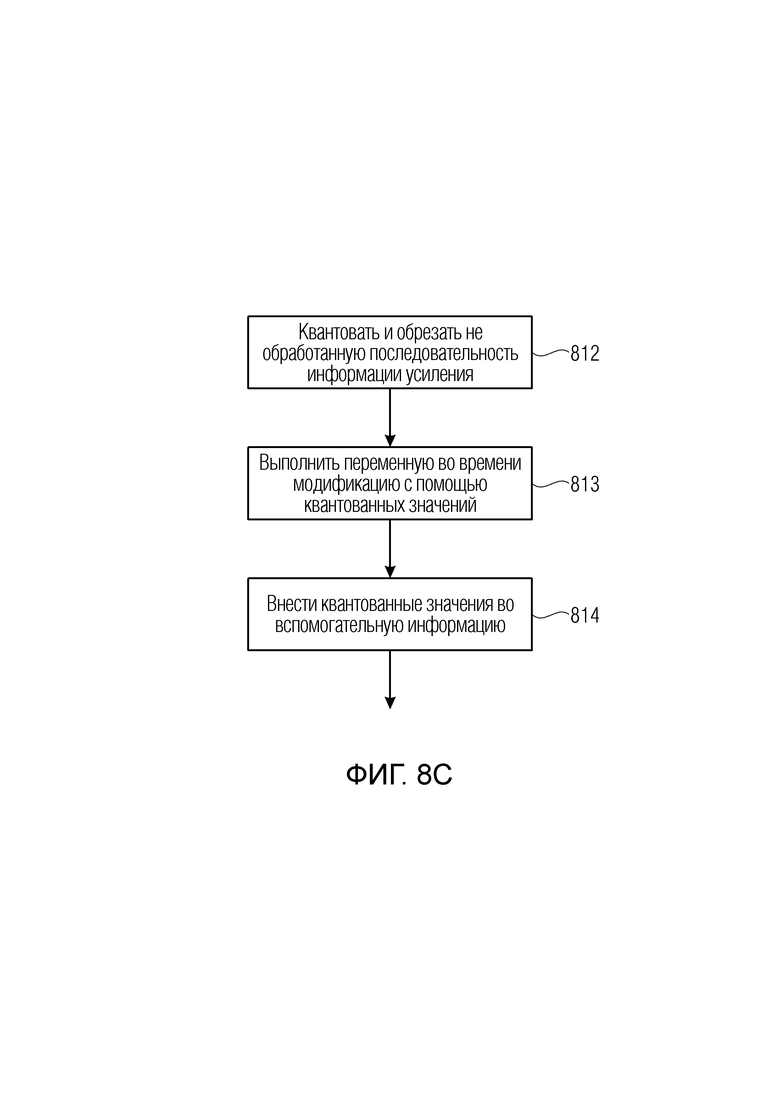
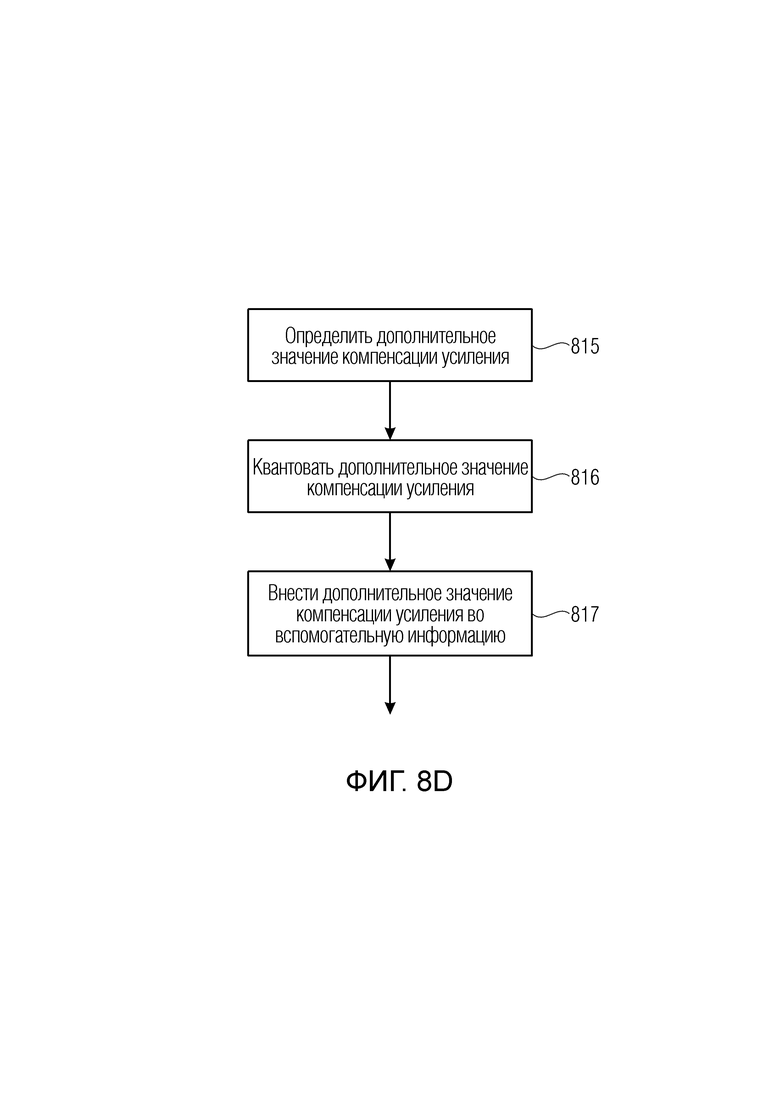
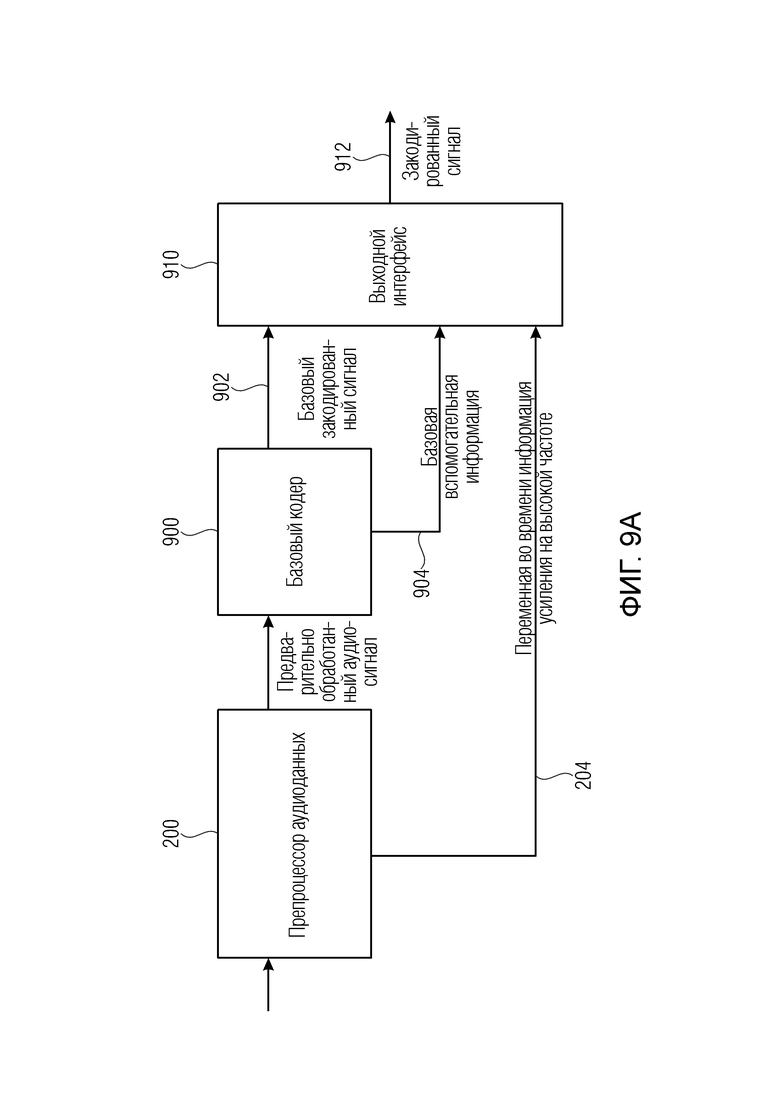
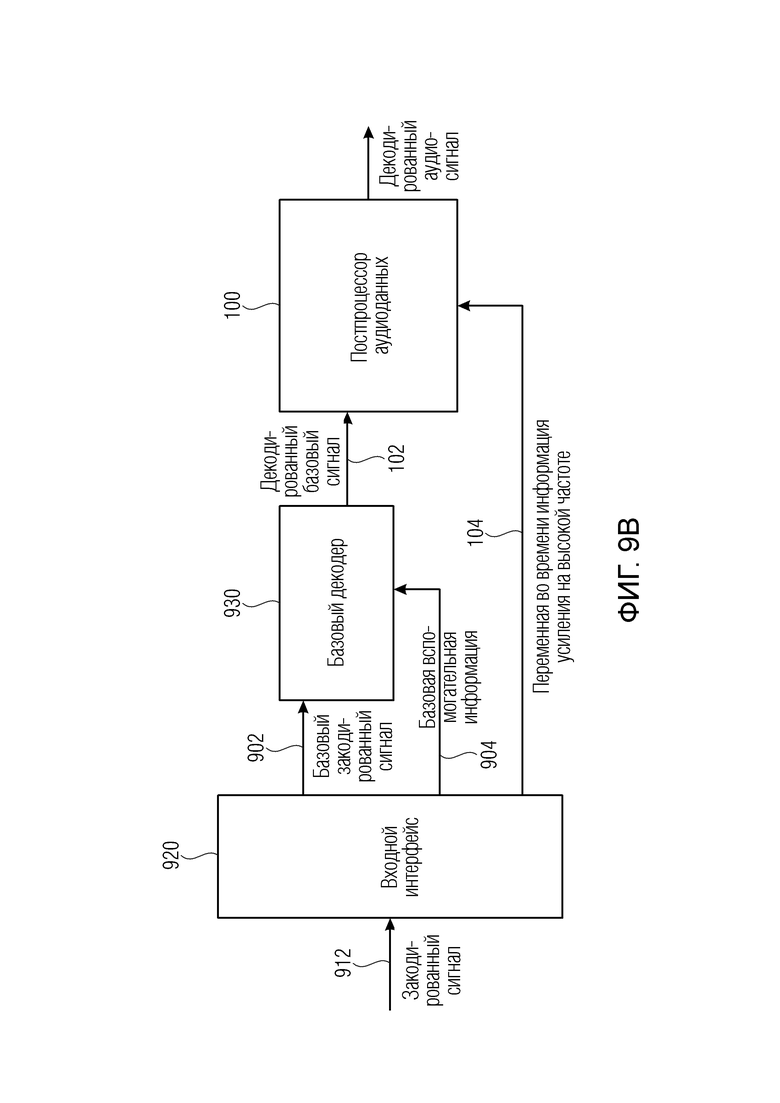
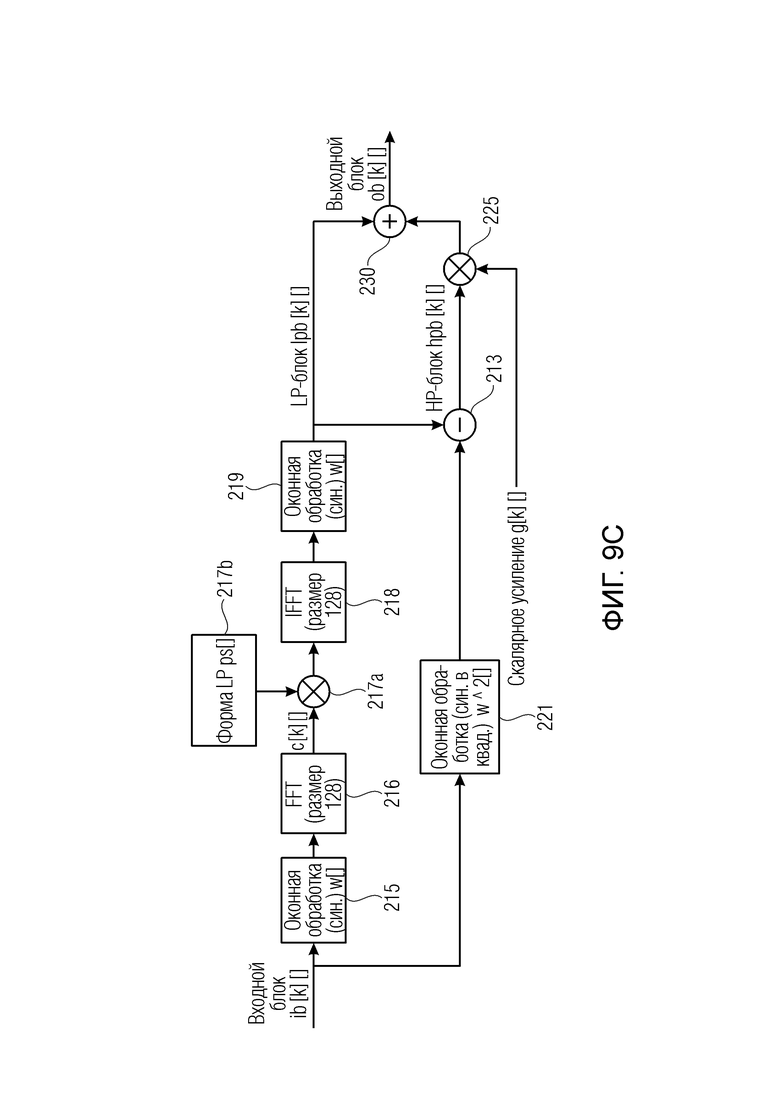
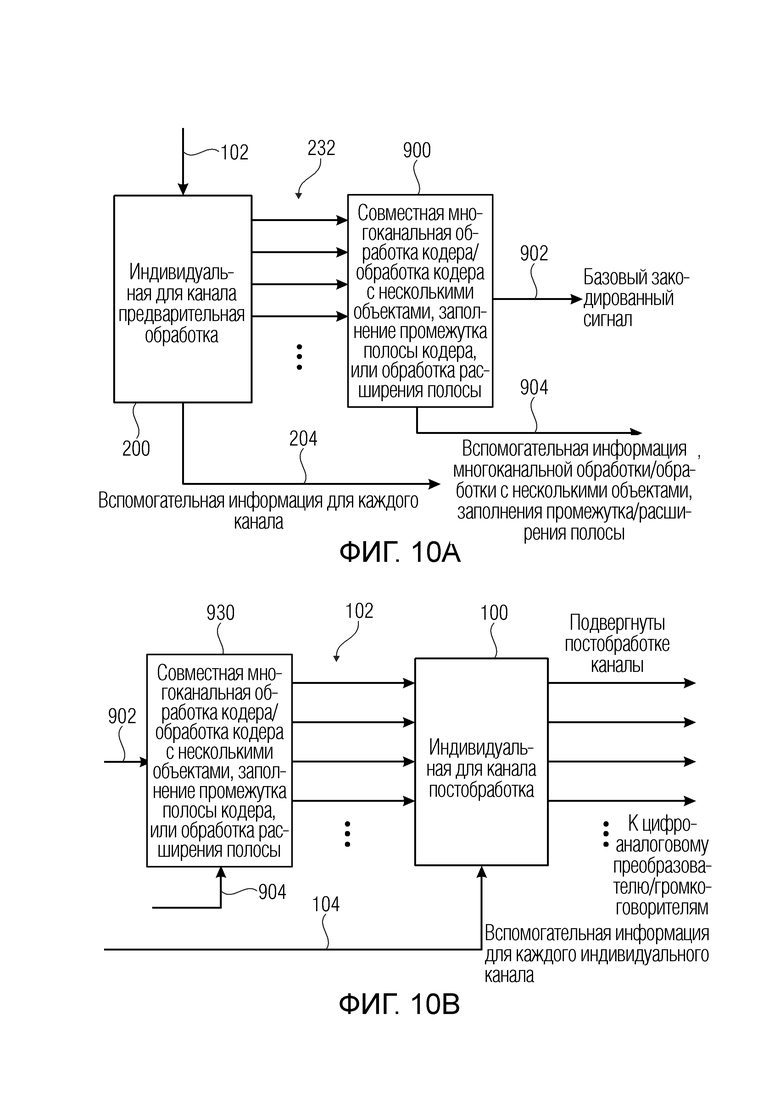
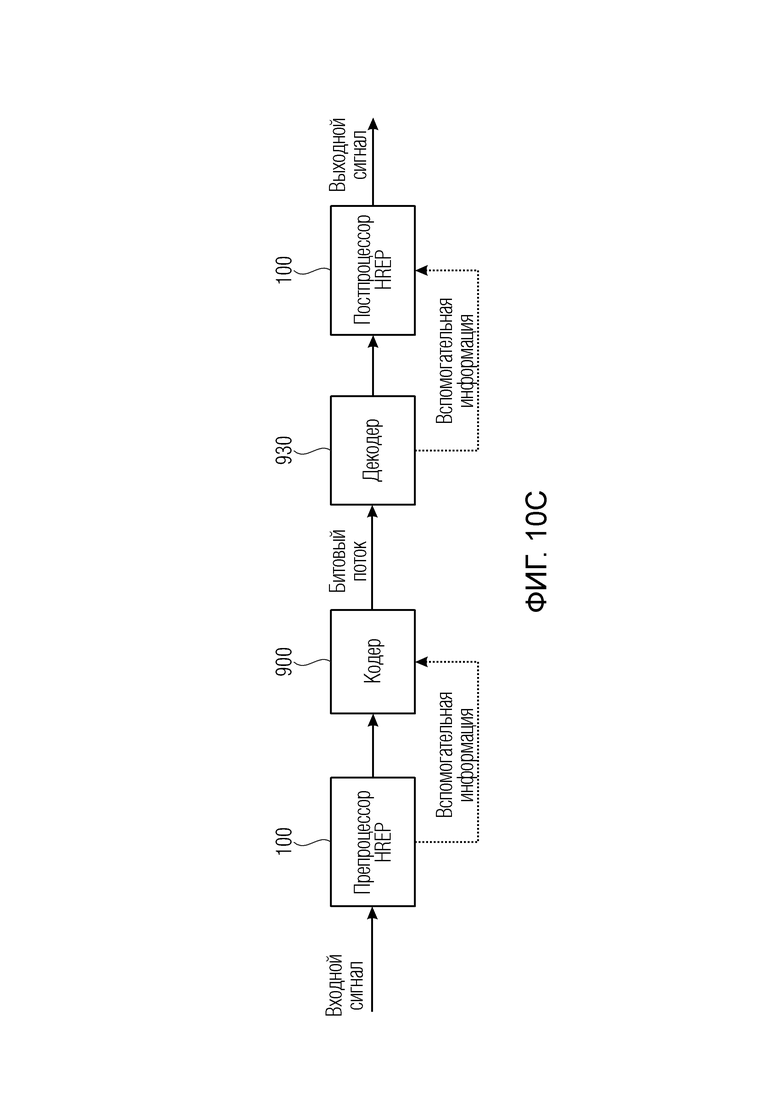
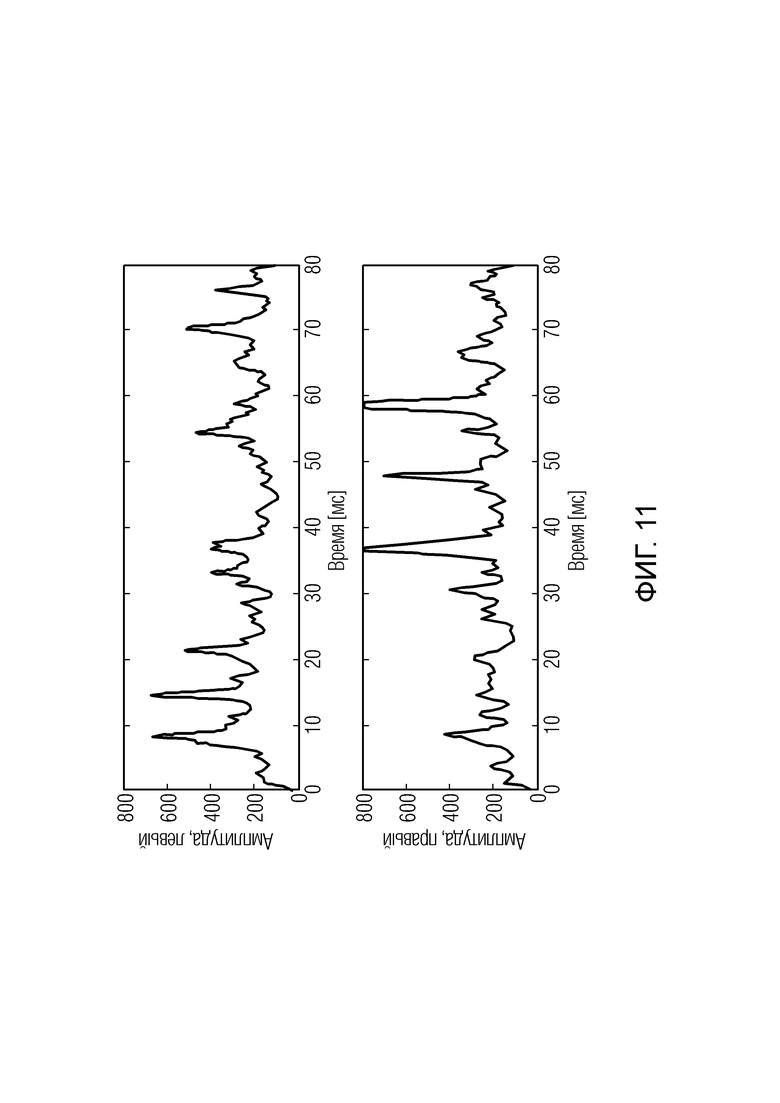
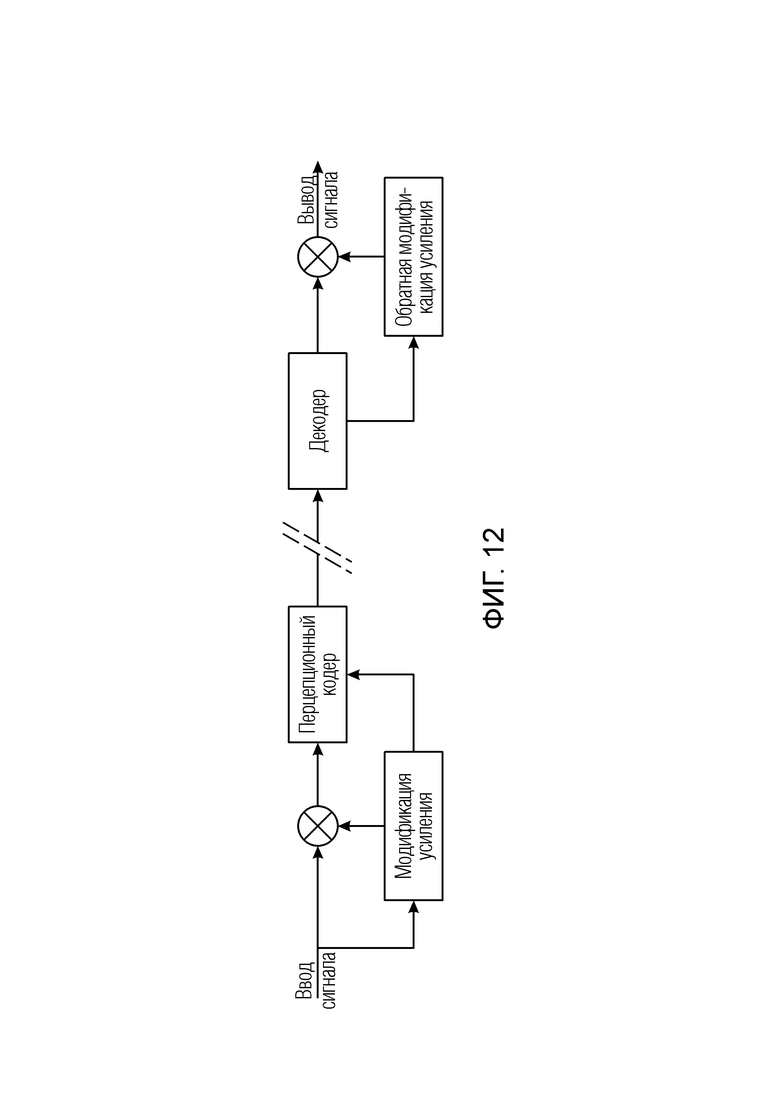
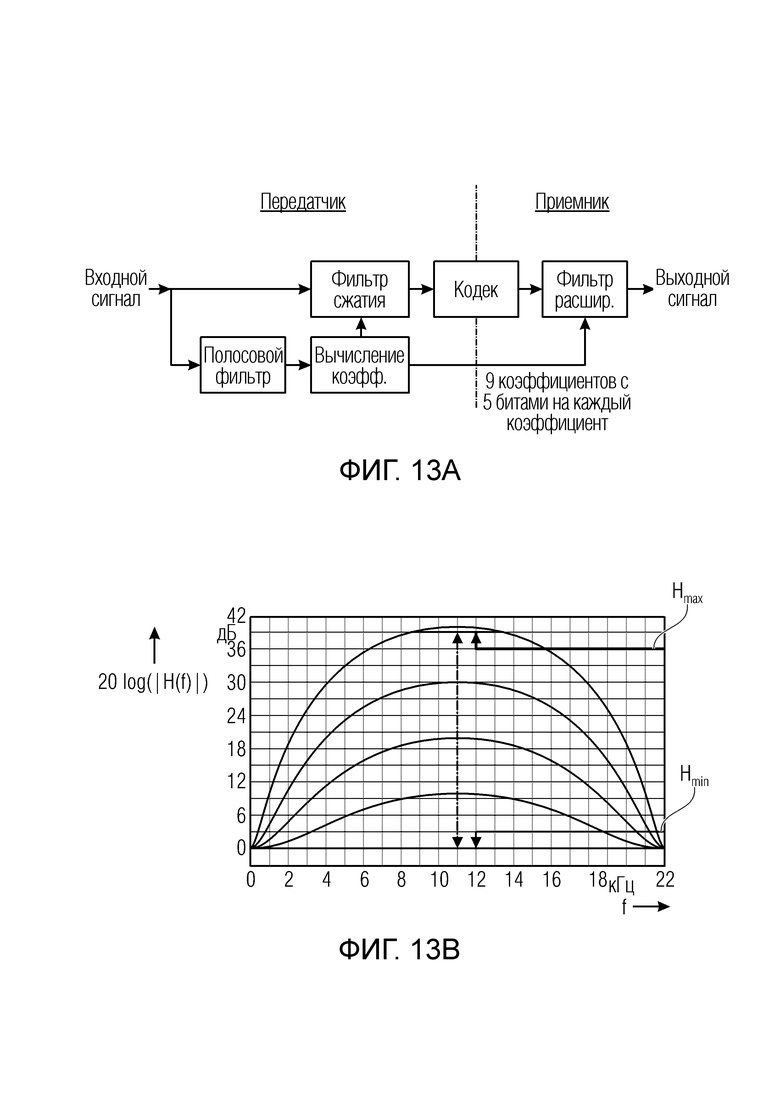
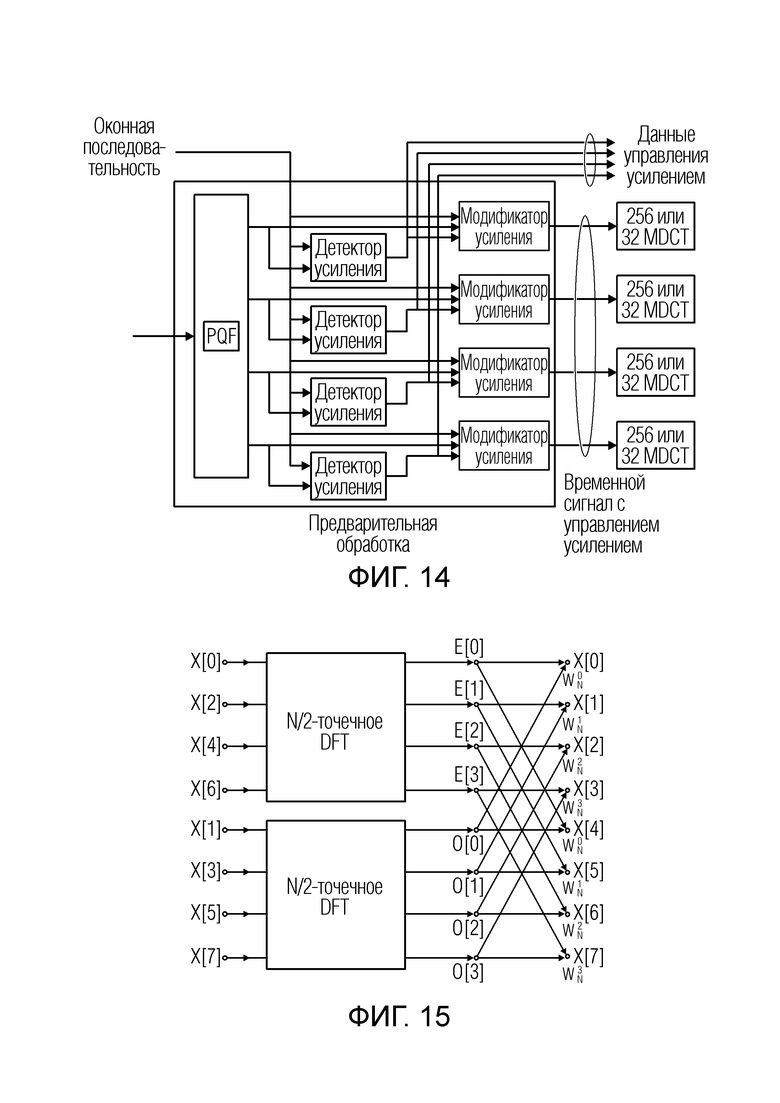


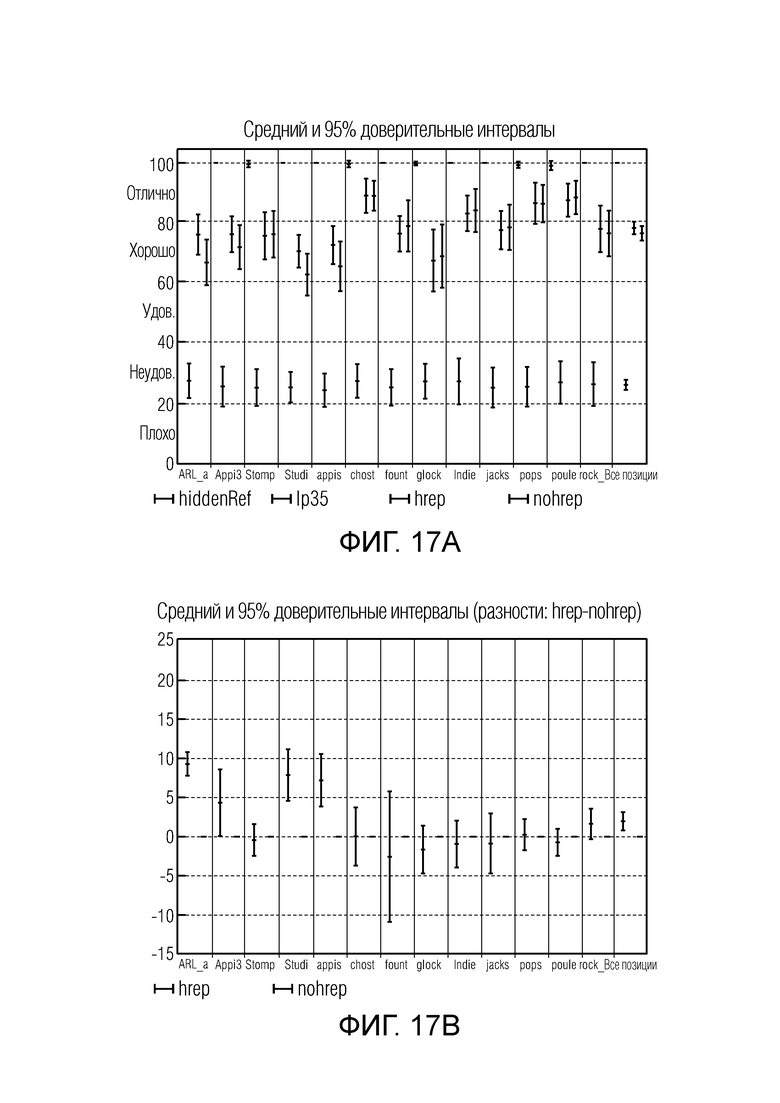
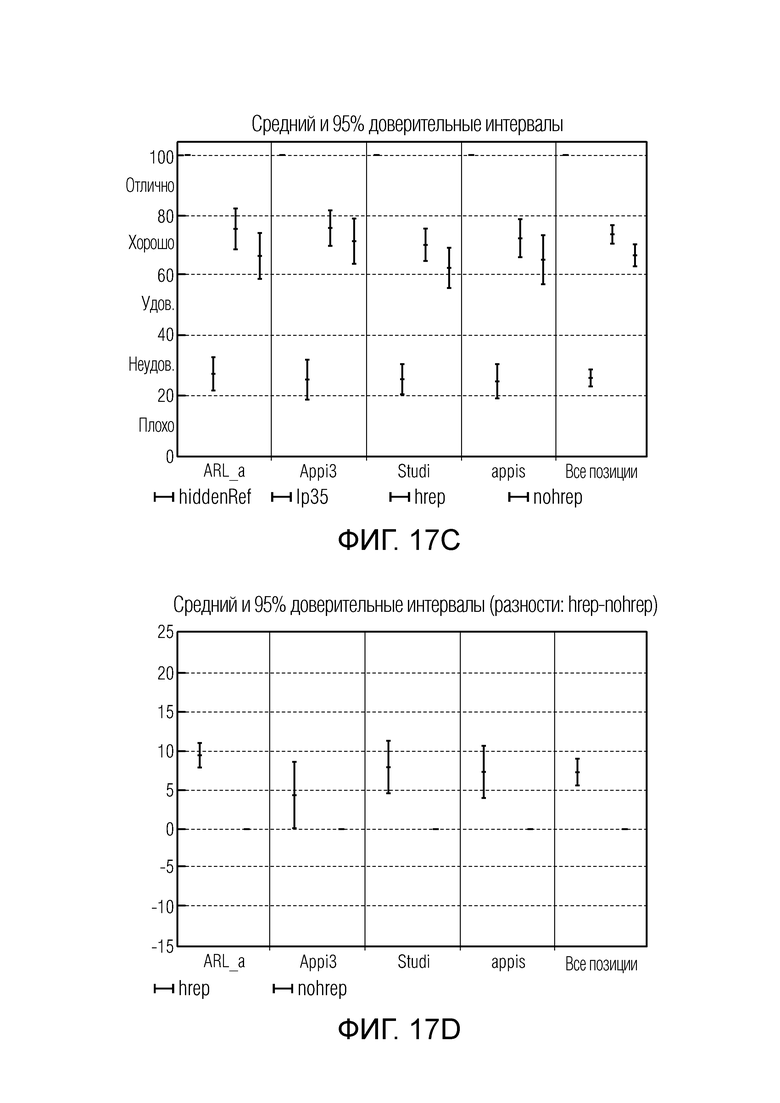
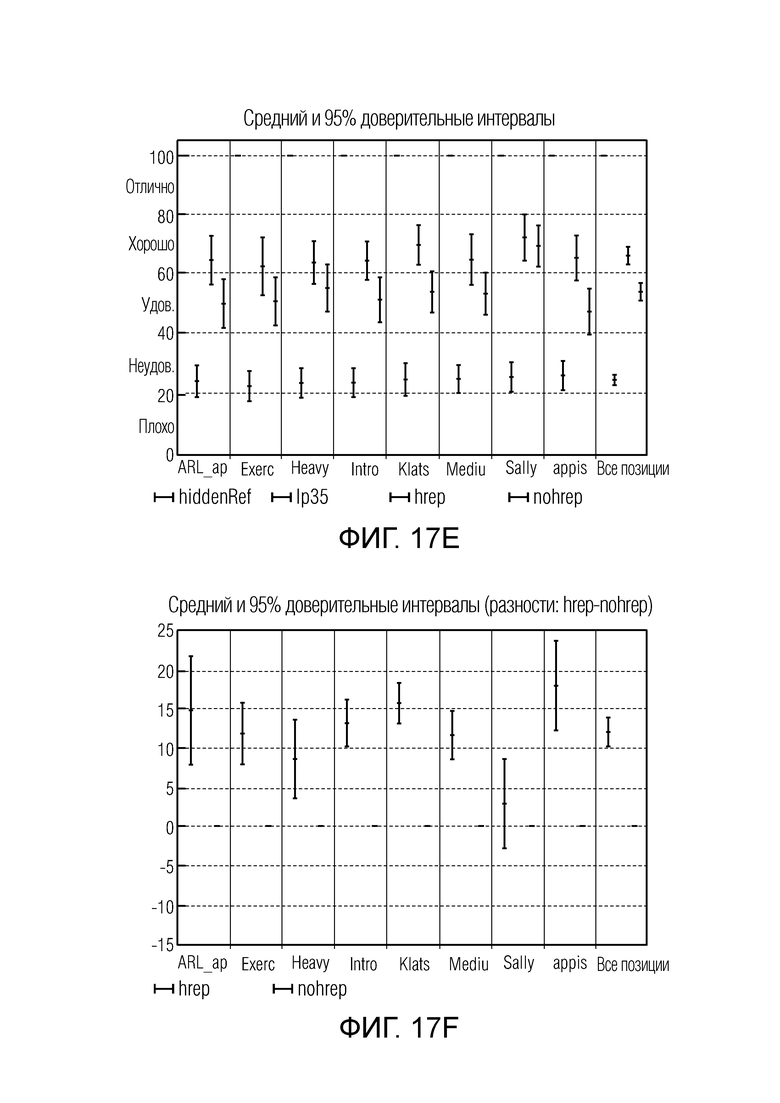
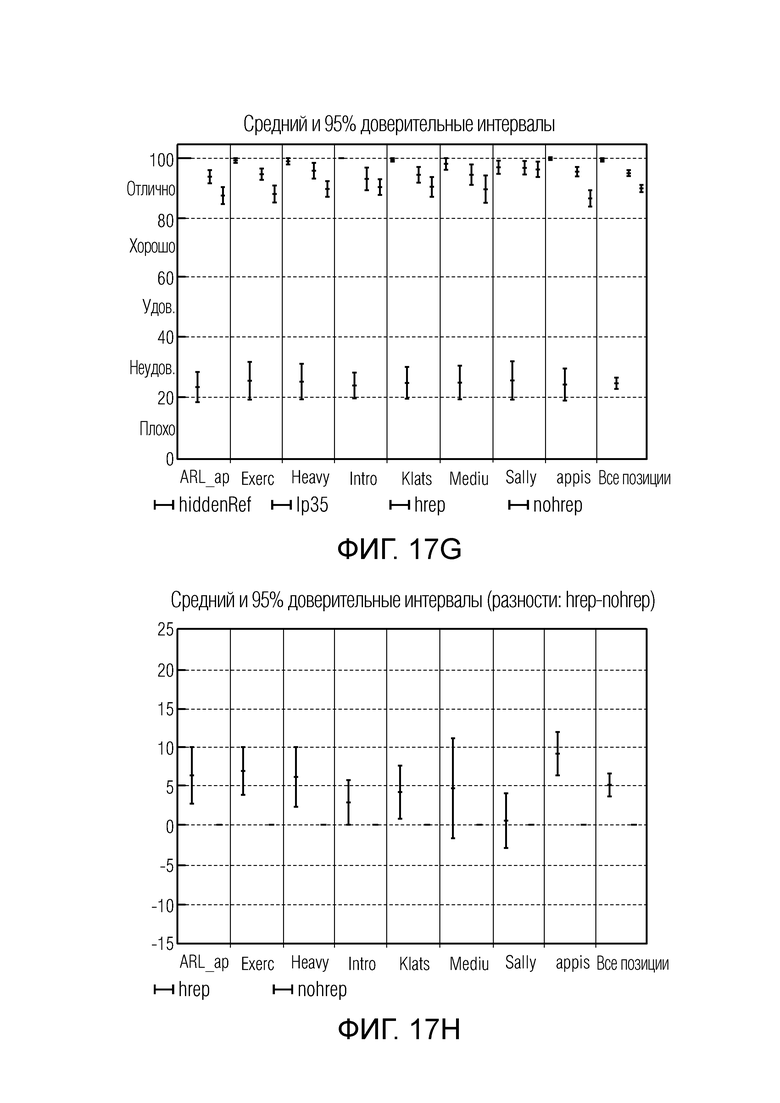
Изобретение относится к технологиям обработки аудиоданных. Технический результат заключается в повышении эффективности обработки аудиоданных. Постпроцессор аудиоданных для постобработки аудиосигнала, имеющего переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации, содержит модуль извлечения полос для извлечения высокочастотной полосы из аудиосигнала и низкочастотной полосы из аудиосигнала; процессор высокочастотных полос для выполнения переменного во времени усиления высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах для получения обработанной высокочастотной полосы; модуль объединения для объединения обработанной высокочастотной полосы и низкочастотной полосы. 12 н. и 52 з.п. ф-лы, 17 ил.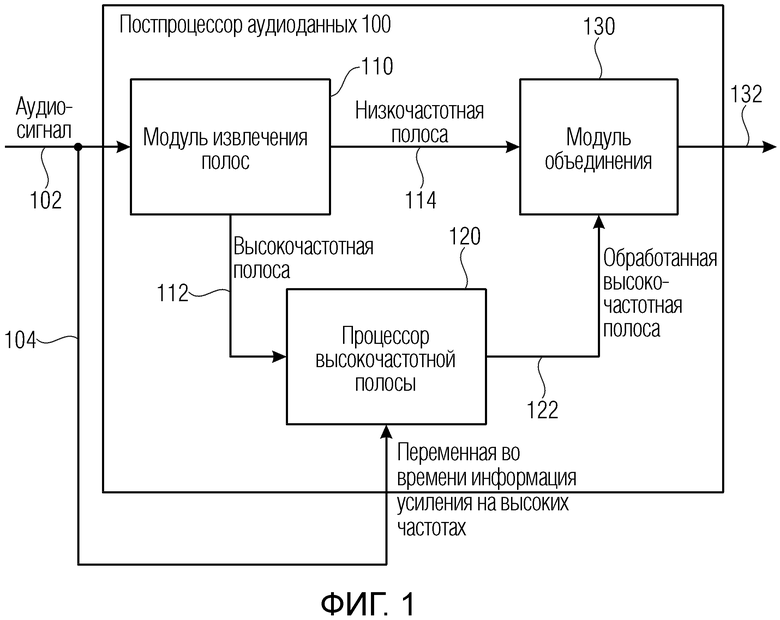
1. Постпроцессор (100) аудиоданных для постобработки аудиосигнала (102), имеющего переменную во времени информацию (104) усиления на высоких частотах в качестве вспомогательной информации (106), содержащий:
модуль (110) извлечения полос для извлечения высокочастотной полосы (112) из аудиосигнала (102) и низкочастотной полосы (114) из аудиосигнала (102);
процессор (120) высокочастотных полос для выполнения переменного во времени усиления высокочастотной полосы (112) в соответствии с переменной во времени информацией (104) усиления на высоких частотах для получения обработанной высокочастотной полосы (122);
модуль (130) объединения для объединения обработанной высокочастотной полосы (122) и низкочастотной полосы (114).
2. Постпроцессор аудиоданных по п. 1, в котором модуль (110) извлечения полос выполнен с возможностью извлекать низкочастотную полосу с использованием устройства (111) низкочастотного фильтра и извлекать высокочастотную полосу посредством вычитания (113) низкочастотной полосы из аудиосигнала.
3. Постпроцессор аудиоданных по п. 1, в котором переменная во времени информация (104) усиления на высоких частотах обеспечена для последовательности (300-303) блоков значений отсчетов аудиосигнала (102) таким образом, что первый блок (301) значений отсчетов имеет привязанную к нему первую информацию (311) усиления, и второй более поздний блок (302) значений отсчетов аудиосигнала имеет другую вторую информацию (312) усиления, причем модуль (110) извлечения полос выполнен с возможностью извлекать из первого блока (301) значений отсчетов первую низкочастотную полосу и первую высокочастотную полосу и извлекать из второго блока (302) значений отсчетов вторую низкочастотную полосу и вторую высокочастотную полосу, и
причем процессор (120) высокочастотных полос выполнен с возможностью модифицировать первую высокочастотную полосу с использованием первой информации (311) усиления для получения первой обработанной высокочастотной полосы и модифицировать вторую высокочастотную полосу с использованием второй информации (312) усиления для получения второй обработанной высокочастотной полосы, и
причем модуль (130) объединения выполнен с возможностью объединять первую низкочастотную полосу и первую обработанную высокочастотную полосу для получения первого объединенного блока и объединять вторую низкочастотную полосу и вторую обработанную высокочастотную полосу для получения второго объединенного блока.
4. Постпроцессор аудиоданных по п.1,
в котором модуль (110) извлечения полос, процессор (120) высокочастотных полос и модуль (130) объединения выполнены с возможностью обрабатывать накладывающиеся блоки, и
причем постпроцессор (100) аудиоданных дополнительно содержит модуль (140) сложения наложения для вычисления подвергнутого постобработке участка посредством сложения отсчетов аудиоданных первого блока (301) и отсчетов аудиоданных второго блока (302) в диапазоне наложения блоков.
5. Постпроцессор аудиоданных по п. 1, в котором модуль (110) извлечения полос содержит:
модуль (115) оконной обработки анализа для формирования последовательности блоков значений отсчетов аудиосигнала с использованием окна анализа, причем блоки являются накладывающимися во времени;
процессор (116) дискретного преобразования Фурье для формирования последовательности блоков спектральных значений;
низкочастотный формирователь (117) для придания формы каждому блоку спектральных значений для получения последовательности низкочастотных сформированных блоков спектральных значений;
процессор (118) обратного дискретного преобразования Фурье для формирования последовательности блоков низкочастотных значений отсчетов во временной области; и
модуль (119) оконной обработки синтеза для оконной обработки последовательности блоков низкочастотных значений отсчетов во временной области с использованием окна синтеза.
6. Постпроцессор аудиоданных по п. 5, в котором модуль (110) извлечения полос дополнительно содержит:
модуль (121) оконной обработки аудиосигнала для оконной обработки аудиосигнала (102) с использованием окна анализа и окна синтеза для получения последовательности обработанных с помощью оконной функции блоков значений аудиосигнала, причем модуль (121) оконной обработки аудиосигнала синхронизирован с модулем (115, 119) оконной обработки таким образом, чтобы последовательность блоков низкочастотных значений отсчетов во временной области была синхронна с последовательностью обработанных с помощью оконной функции блоков значений аудиосигнала.
7. Постпроцессор аудиоданных по п. 5,
в котором модуль (110) извлечения полос выполнен с возможностью выполнять вычитание (113) для каждого из отсчетов последовательности блоков низкочастотных значений во временной области из соответствующей последовательности блоков, выведенных из аудиосигнала, для получения последовательности блоков высокочастотных значений отсчетов во временной области.
8. Постпроцессор аудиоданных по п. 7,
в котором процессор (120) высокочастотных полос выполнен с возможностью применять модификацию к каждому отсчету каждого блока последовательности блоков высокочастотных значений отсчетов во временной области,
причем модификация для отсчета блока зависит от
информации усиления предыдущего блока и информации усиления текущего блока, или
информации усиления текущего блока и информации усиления следующего блока.
9. Постпроцессор аудиоданных по п.1, в котором аудиосигнал содержит дополнительный управляющий параметр (500) в качестве дополнительной вспомогательной информации, причем процессор (120) высокочастотных полос выполнен с возможностью применять модификацию также с учетом дополнительного управляющего параметра (500), причем временное разрешение дополнительного управляющего параметра (500) ниже, чем временное разрешение переменной во времени информации усиления на высоких частотах, или дополнительный управляющий параметр является стационарным для конкретного фрагмента аудиоданных.
10. Постпроцессор аудиоданных по п. 8,
в котором модуль (130) объединения выполнен с возможностью выполнять для каждого отсчета сложение соответствующих блоков последовательности блоков низкочастотных значений отсчетов во временной области и последовательности усиленных блоков высокочастотных значений отсчетов во временной области для получения последовательности блоков значений объединенного сигнала.
11. Постпроцессор аудиоданных по п. 10, дополнительно содержащий
процессор (140) сложения наложения для вычисления подвергнутого постобработке участка аудиосигнала посредством сложения отсчетов аудиоданных первого блока (301) из последовательности значений объединенного сигнала и отсчетов аудиоданных соседнего второго блока (302), смежного с первым блоком, в диапазоне (321) наложения блоков.
12. Постпроцессор аудиоданных по п.1,
в котором модуль (110) извлечения полос, процессор (120) высокочастотных полос и модуль (130) объединения обрабатывают накладывающиеся блоки, причем диапазон (321) наложения находится между 40% длины блока и 60% длины блока, или
причем длина блока составляет от 0,8 до 5 мс, или
причем модификация, выполненная процессором (120) высокочастотных полос, представляет собой мультипликативный коэффициент, применяемый к каждому отсчету блока во временной области, или
причем граничная или пороговая частота низкочастотной полосы находится между 1/8 и 1/3 максимальной частоты аудиосигнала и предпочтительно равна 1/6 максимальной частоты аудиосигнала.
13. Постпроцессор аудиоданных по п. 5,
в котором низкочастотный формирователь (117) выполнен с возможностью применять функцию придания формы в зависимости от переменной во времени информации (104) усиления на высоких частотах для соответствующего блока.
14. Постпроцессор аудиоданных по п. 13,
в котором функция придания формы дополнительно зависит от функции придания формы, используемой в препроцессоре (200) аудиоданных для модификации или ослабления высокочастотной полосы аудиосигнала с использованием переменной во времени информации усиления на высоких частотах для соответствующего блока.
15. Постпроцессор аудиоданных по п. 8,
в котором модификация для отсчета блока дополнительно зависит от коэффициента оконной обработки, применяемого для некоторого отсчета, как определено функцией окна анализа или функцией окна синтеза.
16. Постпроцессор аудиоданных по п.1, в котором модуль (110) извлечения полос, процессор (120) высокочастотных полос и модуль (130) объединения выполнены с возможностью обрабатывать последовательности блоков (300-303), выведенных из аудиосигнала как накладывающиеся блоки таким образом, чтобы более поздний участок более раннего блока был выведен из тех же отсчетов аудиоданных аудиосигнала, что и более ранний участок более позднего блока, являющегося смежным во времени с более ранним блоком.
17. Постпроцессор аудиоданных по п. 16, в котором диапазон (321) наложения накладывающихся блоков равен одной половине более раннего блока, и в котором более поздний блок имеет такую же длину, что и более ранний блок относительно некоторого количества значений отсчетов, и причем постпроцессор дополнительно содержит модуль (140) сложения наложения для выполнения операции сложения наложения.
18. Постпроцессор аудиоданных по п. 16, в котором модуль (110) извлечения полос выполнен с возможностью применять наклон разделительного фильтра (111) между диапазоном блокировки и диапазоном пропускания разделительного фильтра к блоку отсчетов аудиоданных, причем наклон зависит от переменной во времени информации усиления на высоких частотах для блока отсчетов.
19. Постпроцессор аудиоданных по п. 18,
в котором информация усиления на высоких частотах содержит значения усиления, причем наклон увеличивается сильнее для более высокого значения усиления по сравнению с увеличением наклона для более низкого значения усиления.
20. Постпроцессор аудиоданных по п.17,
в котором наклон разделительного фильтра (111) определяется на основе следующего уравнения:
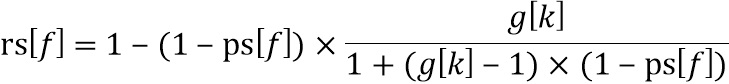 ,
,
где rs[f] - наклон разделительного фильтра (111), ps[f] - наклон разделительного фильтра, используемого для формирования аудиосигнала, g[k] - коэффициент усиления, выведенный из переменной во времени информации усиления на высоких частотах, f - индекс частоты и k - индекс блока.
21. Постпроцессор аудиоданных по п.16,
в котором информация усиления на высоких частотах содержит значения усиления для смежных блоков, причем процессор (120) высокочастотных полос выполнен с возможностью вычислять коэффициент коррекции для каждого отсчета в зависимости от значений усиления для смежных блоков и в зависимости от оконных коэффициентов для соответствующих отсчетов.
22. Постпроцессор аудиоданных по п. 21, в котором процессор (120) высокочастотных полос выполнен с возможностью работать на основе следующих уравнений:
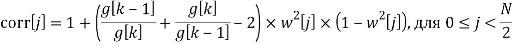 ,
,
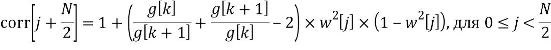 ,
,
где corr[j] - коэффициент коррекции для отсчета с индексом j, g[k-1] - коэффициент усиления для предыдущего блока, g[k] - коэффициент усиления для текущего блока, w[j] - коэффициент функции окна для отсчета с индексом j отсчета, N - длина блока в отсчетах и g[k+1] - коэффициент усиления для более позднего блока, причем k - индекс блока, и верхнее уравнение из приведенных выше уравнений предназначено для первой половины выходного блока k, и нижнее уравнение из приведенных выше уравнений предназначено для второй половины выходного блока k.
23. Постпроцессор аудиоданных по п.17,
в котором процессор (120) высокочастотных полос выполнен с возможностью дополнительно компенсировать ослабление транзиентных событий, внесенное в аудиосигнал посредством обработки, выполненной перед обработкой постпроцессором (100) аудиоданных.
24. Постпроцессор аудиоданных по п. 23,
в котором процессор высокочастотных полос выполнен с возможностью работать на основе следующего уравнения:
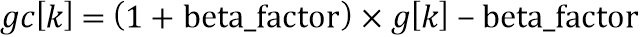 ,
,
где gc[k] - компенсированное усиление для блока с индексом k блока, g[k] - некомпенсированное усиление, как обозначено переменной во времени информацией усиления на высоких частотах, включенной в качестве вспомогательной информации, и beta_factor (500) - значение дополнительного управляющего параметра, включенное во вспомогательную информацию (106).
25. Постпроцессор аудиоданных по п. 22, в котором процессор (120) высокочастотных полос выполнен с возможностью вычислять обработанную высокочастотную полосу на основе следующего уравнения:
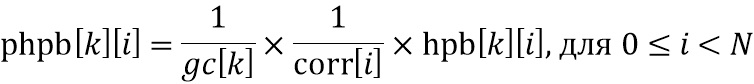 ,
,
где phpb[k][i] указывает обработанную высокочастотную полосу для блока k и значения i отсчета, gc[k] - компенсированное усиление, corr[i] - коэффициент коррекции, k - индекс блока, i - индекс значения отсчета, hpb[k][i] - высокочастотная полоса для блока и значения i отсчета и N - длина блока в отсчетах.
26. Постпроцессор аудиоданных по п. 25,
в котором модуль (130) объединения выполнен с возможностью вычислять объединенный блок как
ob[k][i]=lpb[k][i]+phpb[k][i],
где lpb[k][i] - низкочастотная полоса для блока k и индекса i отсчета.
27. Постпроцессор аудиоданных по п. 16, дополнительно содержащий модуль (140) сложения наложения, работающий на основе следующего уравнения:
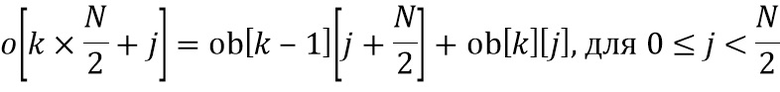 ,
,
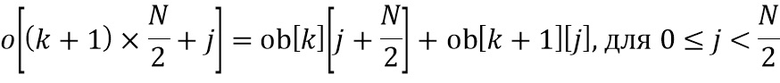 ,
,
где o[] - значение отсчета подвергнутого постобработке выходного аудиосигнала для индекса отсчета, выведенного из k и j, k - значение блока, N - длина блока в отсчетах, j - индекс дискретизации в блоке и ob указывает объединенный блок для индекса k-1 более раннего блока, индекса k текущего блока или индекса k+1 более позднего блока.
указывает объединенный блок для индекса k-1 более раннего блока, индекса k текущего блока или индекса k+1 более позднего блока.
28. Постпроцессор аудиоданных по п. 1, в котором переменная во времени информация усиления на высоких частотах содержит последовательность индексов (600) усиления и информацию (602) расширенного диапазона усиления, или в котором вспомогательная информация дополнительно содержит информацию (603) компенсации усиления и информацию (604) точности компенсации усиления,
причем постпроцессор аудиоданных содержит
декодер (620) для декодирования индексов (601) усиления в зависимости от информации (602) точности усиления для получения декодированного усиления (621) из первого количества разных значений для первой информации точности или декодированного усиления (621) из второго количества разных значений для второй информации точности, второе количество больше, чем первое количество, или
декодер (620) для декодирования индексов (603) компенсации усиления в зависимости от информации (604) точности компенсации для получения декодированного значения (622) компенсации усиления из первого количества разных значений для первой информации точности компенсации или декодированного значения (622) компенсации усиления из второго другого количества значений для второй другой информации точности компенсации, первое количество больше, чем второе количество.
29. Постпроцессор аудиоданных по п. 28,
в котором декодер (620) выполнен с возможностью вычислять коэффициент (621) усиления для блока:
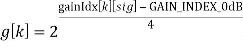 ,
,
где g[k] - коэффициент (621) усиления для блока (301) с индексом k блока, gainIdx[k][sig] - квантованное значение, включенное во вспомогательную информацию в качестве переменной во времени информации (104) усиления на высоких частотах, и GAIN_INDEX_0dB - смещение индекса усиления, соответствующее 0 дБ с первым значением, когда информация точности усиления имеет первый статус, и со вторым другим значением, когда информация точности усиления имеет второй статус.
30. Постпроцессор аудиоданных по п. 1,
в котором модуль (110) извлечения полос выполнен с возможностью выполнять поблочное дискретное преобразование (116) Фурье с длиной блока N значений отсчетов для получения некоторого количества спектральных значений, которое меньше, чем количество N/2 комплексных спектральных значений, посредством выполнения алгоритма разреженного дискретного преобразования Фурье, в котором пропускаются вычисления ветвей для спектральных значений выше максимальной частоты, и
в котором модуль (110) извлечения полос выполнен с возможностью вычислять сигнал низкочастотной полосы посредством использования спектральных значений до частотного диапазона начала транзиента и взвешивания (117a, 117b) спектральных значений в частотном диапазоне начала транзиента, причем частотный диапазон начала транзиента простирается только до максимальной частоты или частоты, меньшей максимальной частоты.
31. Постпроцессор аудиоданных по п. 1,
выполненный с возможностью выполнять только постобработку с максимальным количеством каналов или объектов, для которых вспомогательная информация (106) для переменного во времени усиления высокочастотной полосы является доступной, и не выполнять какую-либо постобработку с некоторым количеством каналов или объектов, для которых не доступна какая-либо вспомогательная информация для переменного во времени усиления высокочастотной полосы, или
причем модуль (110) извлечения полос выполнен с возможностью не выполнять какое-либо извлечение полосы или не вычислять пару дискретного преобразования Фурье и обратного дискретного преобразования Фурье для тривиальных коэффициентов усиления для переменного во времени усиления высокочастотной полосы и пропускать не измененный или обработанный с помощью оконной функции сигнал во временной области, связанный с такими тривиальными коэффициентами усиления.
32. Препроцессор (200) аудиоданных для предварительной обработки аудиосигнала (202), содержащий:
анализатор (260) сигнала для анализа аудиосигнала (202) для определения переменной во времени информации (204) усиления на высоких частотах;
модуль (210) извлечения полос для извлечения высокочастотной полосы (212) из аудиосигнала (202) и низкочастотной полосы (214) из аудиосигнала;
процессор (220) высокочастотных полос для выполнения переменной во времени модификации высокочастотной полосы (212) в соответствии с переменной во времени информацией усиления на высоких частотах для получения обработанной высокочастотной полосы (222);
модуль (230) объединения для объединения обработанной высокочастотной полосы (222) и низкочастотной полосы (214) для получения предварительно обработанного аудиосигнала (232); и
выходной интерфейс (250) для формирования выходного сигнала (252), содержащего предварительно обработанный аудиосигнал (232) и переменную во времени информацию (204) усиления на высоких частотах в качестве вспомогательной информации (206).
33. Препроцессор аудиоданных по п. 32,
в котором анализатор (260) сигнала выполнен с возможностью анализировать аудиосигнал для определения (801, 802) первой характеристики в первом временном блоке (301) аудиосигнала и второй характеристики во втором временном блоке (302) аудиосигнала, вторая характеристика является более транзиентной, чем первая характеристика, или является большим высокочастотным энергетическим уровнем, чем первая характеристика,
причем анализатор (260) сигнала выполнен с возможностью определять (803) первую информацию (311) усиления для первой характеристики и вторую информацию (312) усиления для второй характеристики, и
причем процессор (220) высокочастотных полос выполнен с возможностью применять более сильный мультипликативный коэффициент (804) к участку высокочастотной полосы второго временного блока (302) в соответствии со второй информацией усиления, чем применяется к участку высокочастотной полосы первого временного блока (301) в соответствии с первой информацией усиления.
34. Препроцессор аудиоданных по п. 32, в котором анализатор (260) сигнала выполнен с возможностью:
вычислять (805) показатель фона для энергии фона высокочастотной полосы для одного или более временных блоков, граничащих во времени, размещенных перед текущим временным блоком, или размещенных после текущего временного блока, или размещенных перед и после текущего временного блока, или включающих в себя текущий временной блок, или исключающих из себя текущий временной блок;
вычислять (808) энергетический показатель для высокочастотной полосы текущего блока; и
вычислять (809) коэффициент усиления с использованием показателя фона и энергетического показателя.
35. Препроцессор аудиоданных по п. 33, в котором анализатор (260) сигнала выполнен с возможностью вычислять коэффициент усиления на основе следующего уравнения:
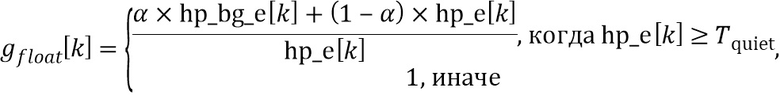
где gfloat - не квантованный коэффициент усиления, k - индекс блока, α - коэффициент влияния на вариацию, hp_bg_e[k] - высокочастотная фоновая энергия для блока k, hp_e[k] - энергия высокочастотного блока, Tquiet - порог тишины, и коэффициент α и порог тишины заранее определены или управляются посредством дополнительных управляющих параметров.
36. Препроцессор аудиоданных по п. 32, в котором анализатор (260) сигнала и процессор (120) высокочастотных полос выполнены с возможностью вычислять переменную во времени информацию усиления на высоких частотах и применять переменную во времени информацию усиления на высоких частотах таким образом, чтобы вариация энергии каждого блока вокруг соответствующей средней энергии фона была сокращена по меньшей мере на 50% и предпочтительно на 75%.
37. Препроцессор аудиоданных по п. 32,
в котором анализатор (260) сигнала выполнен с возможностью квантовать и обрезать (812) не обработанную последовательность значений информации усиления для получения переменной во времени информации усиления на высоких частотах в качестве последовательности квантованных значений,
причем процессор (220) высокочастотных полос выполнен с возможностью выполнять (813) переменную во времени модификацию высокочастотной полосы в соответствии с последовательностью квантованных значений, и
причем выходной интерфейс (250) выполнен с возможностью вносить (814) последовательность квантованных значений во вспомогательную информацию (206) как переменную во времени информацию (204) усиления на высоких частотах.
38. Препроцессор аудиоданных по п. 32, причем препроцессор (200) аудиоданных выполнен с возможностью
определять (815) дополнительное значение компенсации усиления, описывающее потерю энергетической вариации, внесенную посредством присоединенного далее кодера или декодера, и
квантовать (816) дополнительную информацию компенсации усиления, и
причем выходной интерфейс (250) выполнен с возможностью вносить (817) квантованную дополнительную информацию компенсации усиления во вспомогательную информацию.
39. Препроцессор аудиоданных по п. 32, в котором анализатор (260) сигнала выполнен с возможностью применять метауправление усилением (806), которое управляет дополнительной модификацией вычисленной переменной во времени информации усиления на высоких частотах, чтобы постепенно сократить или постепенно увеличить эффект процессора (220) высокочастотных полос на аудиосигнале в соответствии с дополнительными управляющими данными (807), дополнительно выведенными из аудиосигнала, или
в котором анализатор (260) сигнала выполнен с возможностью влиять на коэффициент альфа при вычислении информации усиления на основе следующего уравнения, причем увеличение коэффициента альфа приводит к более сильному влиянию, и уменьшение коэффициента альфа приводит к меньшему влиянию,
где gfloat - не квантованный коэффициент усиления, k - индекс блока, hp_bg_e[k] - высокочастотная фоновая энергия для блока k, hp_e[k] - энергия высокочастотного блока, Tquiet - порог тишины, и коэффициент α и порог тишины заранее определены или управляются посредством дополнительных управляющих параметров.
40. Препроцессор аудиоданных по п. 32, в котором модуль (210) извлечения полос выполнен с возможностью извлекать низкочастотную полосу с использованием устройства (111) низкочастотного фильтра и извлекать высокочастотную полосу посредством вычитания (113) низкочастотной полосы из аудиосигнала.
41. Препроцессор аудиоданных по п. 32,
в котором переменная во времени информация (204) усиления на высоких частотах обеспечена для последовательности (300-303) блоков значений отсчетов аудиосигнала таким образом, что первый блок (301) значений отсчетов имеет привязанную к нему первую информацию (311) усиления, и второй более поздний блок (302) значений отсчетов аудиосигнала имеет другую вторую информацию (312) усиления, причем модуль извлечения полос выполнен с возможностью извлекать из первого блока значений отсчетов первую низкочастотную полосу и первую высокочастотную полосу и извлекать из второго блока значений отсчетов вторую низкочастотную полосу и вторую высокочастотную полосу, и
причем процессор (220) высокочастотных полос выполнен с возможностью модифицировать первую высокочастотную полосу с использованием первой информации (311) усиления для получения первой обработанной высокочастотной полосы и модифицировать вторую высокочастотную полосу с использованием второй информации (312) усиления для получения второй обработанной высокочастотной полосы, и
причем модуль (230) объединения выполнен с возможностью объединять первую низкочастотную полосу и первую обработанную высокочастотную полосу для получения первого объединенного блока и объединять вторую низкочастотную полосу и вторую обработанную высокочастотную полосу для получения второго объединенного блока.
42. Препроцессор аудиоданных по п. 32,
в котором модуль (210) извлечения полос, процессор (220) высокочастотных полос и модуль (230) объединения выполнены с возможностью обрабатывать накладывающиеся блоки, и
причем модуль (230) объединения дополнительно содержит модуль сложения наложения для вычисления подвергнутого постобработке участка посредством сложения отсчетов аудиоданных первого блока и отсчетов аудиоданных второго блока в диапазоне (321) наложения блоков, или
причем модуль (210) извлечения полос, процессор (220) высокочастотных полос и модуль (230) объединения обрабатывают накладывающиеся блоки, причем диапазон (321) наложения находится между 40% длины блока и 60% длины блока, или
причем длина блока составляет от 0,8 до 5 мс, или
причем модификация, выполненная процессором (220) высокочастотных полос, представляет собой ослабление, применяемое к каждому отсчету блока во временной области, или
причем граничная или пороговая частота низкочастотной полосы находится между 1/8 и 1/3 максимальной частоты аудиосигнала (202) и предпочтительно равна 1/6 максимальной частоты аудиосигнала.
43. Препроцессор аудиоданных по п. 32, в котором модуль (210) извлечения полос содержит:
модуль (215) оконной обработки анализа для формирования последовательности блоков значений отсчетов аудиосигнала с использованием окна анализа, причем блоки являются накладывающимися во времени;
процессор (216) дискретного преобразования Фурье для формирования последовательности блоков спектральных значений;
низкочастотный формирователь (217a, 217b) для придания формы каждому блоку спектральных значений для получения последовательности низкочастотных сформированных блоков спектральных значений;
процессор (218) обратного дискретного преобразования Фурье для формирования последовательности блоков низкочастотных значений отсчетов во временной области; и
модуль (219) оконной обработки синтеза для оконной обработки последовательности блоков низкочастотных значений отсчетов во временной области с использованием окна синтеза.
44. Препроцессор аудиоданных по п. 43, в котором низкочастотный формирователь (217a, 217b) выполнен с возможностью работать на основе следующего уравнения:
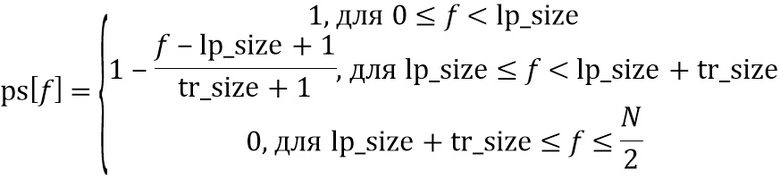 ,
,
где ps[f] указывает коэффициент придания формы для придания формы, которое должно быть применено низкочастотным формирователем для значения f частоты, f - значение частоты, tr_size - значение, определяющее ширину в спектральных линиях области транзиента, lp_size - указывает размер низкочастотного участка без области транзиента, N указывает количество значений отсчетов для блока.
45. Препроцессор аудиоданных по п. 43, в котором модуль извлечения блока дополнительно содержит:
модуль (221) оконной обработки аудиосигнала для оконной обработки аудиосигнала с использованием окна анализа и окна синтеза для получения последовательности обработанных с помощью оконной функции блоков значений аудиосигнала, причем модуль оконной обработки аудиосигнала синхронизирован с модулем (215, 219) оконной обработки таким образом, чтобы последовательность блоков низкочастотных значений отсчетов во временной области была синхронна с последовательностью обработанных с помощью оконной функции блоков значений аудиосигнала.
46. Препроцессор аудиоданных по п. 43,
причем модуль (210) извлечения полос выполнен с возможностью выполнять вычитание (113) для каждого из отсчетов последовательности блоков низкочастотных значений во временной области из соответствующей последовательности блоков, выведенных из аудиосигнала, для получения последовательности блоков высокочастотных значений отсчетов во временной области.
47. Препроцессор аудиоданных по п. 32, в котором анализатор (260) дополнительно обеспечивает управляющий параметр (807), вычисленный посредством метауправления усилением (806), причем процессор (220) высокочастотных полос выполнен с возможностью применять модификацию также с учетом этого управляющего параметра.
48. Препроцессор аудиоданных по п. 43,
в котором модуль (230) объединения выполнен с возможностью выполнять для каждого отсчета сложение соответствующих блоков последовательности блоков низкочастотных значений отсчетов во временной области и последовательности модифицированных блоков высокочастотных значений отсчетов во временной области для получения последовательности блоков значений объединенного сигнала.
49. Препроцессор аудиоданных по п. 48, дополнительно содержащий:
процессор сложения наложения для вычисления предварительно обработанного участка аудиосигнала посредством сложения отсчетов аудиоданных первого блока последовательности значений объединенного сигнала и отсчетов аудиоданных соседнего второго блока, смежного с первым блоком, в диапазоне наложения блоков.
50. Препроцессор аудиоданных по п. 32, в котором
в котором модуль (211) извлечения полос, процессор (720) высокочастотных полос и модуль (230) объединения обрабатывают накладывающиеся блоки, причем диапазон наложения находится между 40% длины блока и 60% длины блока, или
причем длина блока составляет от 0,8 до 5 мс, или
причем модификация, выполняемая процессором (220) высокочастотных полос, представляет собой мультипликативный коэффициент, применяемый к каждому отсчету блока во временной области.
51. Препроцессор аудиоданных по п. 32,
в котором диапазон (321) наложения накладывающихся блоков равен одной половине более раннего блока, и причем более поздний блок имеет такую же длину, что и более ранний блок относительно некоторого количества значений отсчетов, и причем модуль объединения содержит модуль сложения наложения для выполнения операции сложения наложения.
52. Постпроцессор аудиоданных по п. 32,
выполненный с возможностью выполнять только предварительную обработку с максимальным количеством каналов или объектов для формирования вспомогательной информации (206) для максимального количества каналов или объектов и не выполнять какую-либо предварительную обработку с некоторым количеством каналов или объектов, для которых вспомогательная информация (206) не сформирована, или
в котором модуль (210) извлечения полос выполнен с возможностью не выполнять какое-либо извлечение полосы или не вычислять пару дискретного преобразования Фурье и обратного дискретного преобразования Фурье для тривиальных коэффициентов усиления для переменной во времени информации (204) усиления на высоких частотах, определенной анализатором (260) сигнала, и пропускать не измененный или обработанный с помощью оконной функции сигнал во временной области, связанный с такими тривиальными коэффициентами усиления.
53. Устройство аудиокодирования для кодирования аудиосигнала, содержащее:
препроцессор аудиоданных по п. 32, выполненный с возможностью формировать выходной сигнал (252), имеющий переменную во времени информацию усиления на высоких частотах в качестве вспомогательной информации;
базовый кодер (900) для формирования базового закодированного сигнала (902) и базовой вспомогательной информации (904); и
выходной интерфейс (910) для формирования закодированного сигнала (912), содержащего базовый закодированный сигнал (902), базовую вспомогательную информацию (904) и переменную во времени информацию усиления на высоких частотах в качестве дополнительной вспомогательной информации (106).
54. Устройство аудиокодирования по п. 53, в котором аудиосигнал является многоканальным сигналом или сигналом с множеством объектов, причем препроцессор (200) аудиоданных выполнен с возможностью предварительно обрабатывать каждый канал или каждый объект отдельно, и причем базовый кодер (900) выполнен с возможностью применять совместную многоканальную обработку кодера, или совместную обработку кодера для множества объектов, или заполнение промежутка полосы кодера, или обработку расширения полосы частот кодера на предварительно обработанных каналах (232).
55. Устройство аудиодекодирования, содержащее:
входной интерфейс (920) для приема закодированного аудиосигнала (912), содержащего базовый закодированный сигнал (902), базовую вспомогательную информацию (904) и переменную во времени информацию (104) усиления на высоких частотах в качестве дополнительной вспомогательной информации;
базовый декодер (930) для декодирования базового закодированного сигнала (902) с использованием базовой вспомогательной информации (904) для получения декодированного базового сигнала; и
постпроцессор (100) для постобработки декодированного базового сигнала (102) с использованием переменной во времени информации (104) усиления на высоких частотах по п. 1.
56. Устройство аудиодекодера по п. 55,
в котором базовый декодер (930) выполнен с возможностью применять многоканальную обработку декодера, или обработку декодера для множества объектов, или обработку декодера расширения полосы частот, или обработку декодера заполнения промежутков для формирования декодированных каналов многоканального сигнала (102) или декодированных объектов для сигналов (102) с множеством объектов, и
в котором постпроцессор (100) выполнен с возможностью применять постобработку индивидуально для каждого канала или каждого объекта с использованием индивидуальной переменной во времени информации усиления на высоких частотах для каждого канала или каждого объекта.
57. Способ постобработки (100) аудиосигнала (102), имеющего переменную во времени информацию (104) усиления на высоких частотах в качестве вспомогательной информации (106), способ содержит этапы, на которых:
извлекают (110) высокочастотную полосу (112) из аудиосигнала и низкочастотную полосу (114) из аудиосигнала;
выполняют (120) переменную во времени модификацию высокочастотной полосы в соответствии с переменной во времени информацией (104) усиления на высоких частотах для получения обработанной высокочастотной полосы (122); и
объединяют (130) обработанную высокочастотную полосу (122) и низкочастотную полосу (114).
58. Способ предварительной обработки (200) аудиосигнала (202), способ содержит этапы, на которых:
анализируют (260) аудиосигнал (202) для определения переменной во времени информации (204) усиления на высоких частотах;
извлекают (210) высокочастотную полосу (212) из аудиосигнала и низкочастотную полосу (214) из аудиосигнала;
выполняют (220) переменную во времени модификацию высокочастотной полосы в соответствии с переменной во времени информацией усиления на высоких частотах для получения обработанной высокочастотной полосы;
объединяют (230) обработанную высокочастотную полосу (222) и низкочастотную полосу (214) для получения предварительно обработанного аудиосигнала; и
формируют (250) выходной сигнал (252), содержащий предварительно обработанный аудиосигнал (232) и переменную во времени информацию (204) усиления на высоких частотах в качестве вспомогательной информации (106).
59. Способ кодирования аудиосигнала, способ содержит этапы, на которых:
выполняют способ предварительной обработки (200) аудиоданных по п. 58, выполненный с возможностью формировать выходной сигнал, имеющий переменную во времени информацию (204) усиления на высоких частотах в качестве вспомогательной информации (106);
формируют базовый закодированный сигнал (902) и базовую вспомогательную информацию (904); и
формируют (910) закодированный сигнал (912), содержащий базовый закодированный сигнал (902), базовую вспомогательную информацию (904) и переменную во времени информацию (204) усиления на высоких частотах в качестве дополнительной вспомогательной информации (106).
60. Способ аудиодекодирования, способ содержит этапы, на которых:
принимают (920) закодированный аудиосигнал (912), содержащий базовый закодированный сигнал (902), базовую вспомогательную информацию (904) и переменную во времени информацию (204) усиления на высоких частотах в качестве дополнительной вспомогательной информации (106);
декодируют (930) базовый закодированный сигнал (902) с использованием базовой вспомогательной информации (904) для получения декодированного базового сигнала (102); и
выполняют постобработку (100) декодированного базового сигнала (102) с использованием переменной во времени информации (104) усиления на высоких частотах в соответствии со способом по п. 55.
61. Физический запоминающий носитель, на котором сохранена компьютерная программа для выполнения, при ее исполнении на компьютере или процессоре, способа по п. 57.
62. Физический запоминающий носитель, на котором сохранена компьютерная программа для выполнения, при ее исполнении на компьютере или процессоре, способа по п. 58.
63. Физический запоминающий носитель, на котором сохранена компьютерная программа для выполнения, при ее исполнении на компьютере или процессоре, способа по п. 59.
64. Физический запоминающий носитель, на котором сохранена компьютерная программа для выполнения, при ее исполнении на компьютере или процессоре, способа по п. 60.
| US 6014621, 11.01.2000 | |||
| СПОСОБ УПРАВЛЕНИЯ ПРОЦЕССОМ СИНТЕЗА ДИМЕТИЛДИОКСАНА | 1996 |
|
RU2116997C1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| СПОСОБ ПРОИЗВОДСТВА ВОССТАНОВЛЕННОГО ТАБАКА | 2008 |
|
RU2352225C1 |

