Настоящее изобретение относится к обработке аудиосигналов и, в частности, к аудиокодерам/декодерам, применяющим зависимое от сигнала управление точностью и числом.
Современные аудиокодеры на основе преобразования применяют последовательность психоакустически обусловленных обработок к спектральному представлению аудиосегмента (кадра) для получения остаточного спектра. Этот остаточный спектр квантуется, и коэффициенты кодируются с использованием энтропийного кодирования.
В этом процессе, размер шага квантования, который обычно регулируется через глобальное усиление, имеет прямое влияние на потребление битов энтропийного кодера и должен выбираться таким образом, чтобы соответствовать битовому бюджету, который обычно ограничен и зачастую является фиксированным. Поскольку потребление битов энтропийного кодера и, в частности, арифметического кодера точно не известно до кодирования, вычисление оптимального глобального усиления может выполняться только в итерации с замкнутым контуром квантования и кодирования. Тем не менее, это является нецелесообразным при определенных ограничениях по сложности, поскольку арифметическое кодирование влечет за собой существенную вычислительную сложность.
Кодеры из уровня техники, которые содержатся в кодеке EVS 3GPP, в силу этого содержат модуль оценки потребления битов для извлечения первой оценки глобального усиления, которая обычно работает в спектре мощности остаточного сигнала. В зависимости от ограничения по сложности, после него может содержаться контур скорости передачи для детализации первой оценки. Использование только такой оценки или в сочетании с очень ограниченной пропускной способностью коррекции уменьшает сложность, но также и уменьшает точность, что приводит к существенным недо- или переоценкам потребления битов.
Переоценка потребления битов приводит к избыточным битам после первого каскада кодирования. Кодеры из уровня техники используют их для детализации квантования кодированных коэффициентов во втором каскаде кодирования, называемом «остаточным кодированием». Остаточное кодирование фундаментально отличается от первого каскада кодирования, поскольку оно работает при степени детализации в бит и в силу этого не включает энтропийного кодирования. Кроме того, остаточное кодирование обычно применяется только на частотах с квантованными значениями, неравными нулю, оставляя мертвые зоны, которые дополнительно не улучшаются.
С другой стороны, недооценка потребления битов неизбежно приводит к частичным потерям спектральных коэффициентов, обычно наибольших частот. В кодерах из уровня техники, этот эффект уменьшается посредством применения замещения шума в декодере, которое основано на предположении, что высокочастотное содержимое обычно является шумным.
В этой конфигурации совершенно очевидно, что желательно кодировать максимально возможно большую часть сигнала возможного на первом этапе кодирования, который использует энтропийное кодирование, и в силу этого является более эффективным, чем этап остаточного кодирования. Следовательно, можно хотеть выбирать глобальное усиление с битовой оценкой, максимально возможно близкой к доступному битовому бюджету. Хотя модуль оценки на основе спектра мощности хорошо работает для большей части аудиосодержимого, он может вызывать проблемы для высокотональных сигналов, в которых оценка первого каскада главным образом основана на нерелевантных боковых лепестках частотного разложения гребенки фильтров, в то время как важные компоненты теряются вследствие недооценки потребления битов.
Задача настоящего изобретения состоит в создании усовершенствованной концепции для кодирования или декодирования аудио, которая, тем не менее, является эффективной и достигает хорошего качества звука.
Данная задача решается аудиокодером по пункту 1, способом кодирования входных аудиоданных по пункту 33 и аудиодекодером по пункту 35, способом декодирования кодированных аудиоданных по пункту 41 или компьютерной программой по пункту 42 формулы.
Настоящее изобретение основано на выводах о том, что для повышения эффективности, в частности, в отношении скорости передачи битов, с одной стороны, и качества звучания, с другой стороны, требуется зависимое от сигнала изменение относительно примерной ситуации, которая определяется рассматриваемыми психоакустическими факторами. Обычные психоакустические модели или рассматриваемые психоакустические факторы приводят к хорошему качеству звука при низкой скорости передачи битов для всех классов сигналов в среднем, т.е. для всех кадров аудиосигналов независимо от их характеристики сигналов, когда предусмотрен средний результат. Тем не менее обнаружено, что для определенных классов сигналов или для сигналов, имеющих определенные характеристики сигналов, например, для довольно тональных сигналов, простая психоакустическая модель или простое психоакустическое управление кодером приводит только к субоптимальным результатам относительно качества звучания (когда скорость передачи битов поддерживается постоянной) либо относительно скорости передачи битов (когда качество звучания поддерживается постоянным).
Следовательно, для устранения этого недостатка обычных рассматриваемых психоакустических факторов, настоящее изобретение предусматривает, в контексте аудиокодера с препроцессором для предварительной обработки входных аудиоданных для получения аудиоданных, которые должны кодироваться, и процессора кодера для кодирования аудиоданных, которые должны кодироваться, контроллер для управления процессором кодера таким образом, что в зависимости от определенной характеристики сигналов кадра, число элементов аудиоданных для аудиоданных, которые должны кодироваться посредством процессора кодера, уменьшается по сравнению с обычными простыми результатами, полученными посредством рассматриваемых психоакустических факторов из уровня техники. Кроме того, это уменьшение числа элементов аудиоданных выполняется зависимым от сигнала способом таким образом, что для кадра с определенной первой характеристикой сигналов, число более существенно уменьшается, чем для другого кадра с другой характеристикой сигналов, которая отличается от характеристики сигналов из первого кадра. Это уменьшение числа элементов аудиоданных может считаться уменьшением абсолютного числа или уменьшением относительного числа, хотя это не является решающим. Тем не менее, имеется такой признак, что информационные единицы, которые «экономятся» посредством намеренного уменьшения числа элементов аудиоданных, просто не теряются, но используются для более точного кодирования оставшегося числа элементов данных, т.е. элементы данных, которые не исключены посредством намеренного уменьшения числа элементов аудиоданных.
В соответствии с изобретением, контроллер для управления процессором кодера работает таким образом, что в зависимости от первой характеристики сигналов первого кадра аудиоданных, которые должны кодироваться, число элементов аудиоданных для аудиоданных, которые должны кодироваться посредством процессора кодера для первого кадра, уменьшается по сравнению со второй характеристикой сигналов второго кадра, и в то же время первое число информационных единиц, используемых для кодирования уменьшенного числа элементов аудиоданных для первого кадра, более существенно улучшается по сравнению со вторым числом информационных единиц для второго кадра.
В предпочтительном варианте осуществления, уменьшение выполняется таким образом, что для более тональных кадров сигнала, более существенное уменьшение выполняется, и в то же время число битов для отдельных линий более существенно улучшается по сравнению с кадром, который является менее тональным, т.е. который является более шумным. Здесь, число не уменьшается в такой высокой степени, и, соответственно, число информационных единиц, используемых для кодирования менее тональных элементов аудиоданных, не увеличивается настолько сильно.
Настоящее изобретение обеспечивает инфраструктуру, в которой, зависимым от сигнала способом, обычно предусмотренные рассматриваемые психоакустические факторы в той или иной степени нарушаются. Тем не менее, с другой стороны, это нарушение не трактуется так, как в нормальных кодерах, в которых нарушение рассматриваемых психоакустических факторов, например, осуществляется в чрезвычайной ситуации, например, в ситуации, когда для поддержания требуемой скорости передачи битов, более высокочастотные части задаются равными нулю. Вместо этого, в соответствии с настоящим изобретением, такое нарушение нормальных рассматриваемых психоакустических факторов осуществляется независимо от чрезвычайной ситуации, и «сэкономленные» информационные единицы применяются для дополнительной детализации «сохранившихся» элементов аудиоданных.
В предпочтительных вариантах осуществления, используется двухкаскадный процессор кодера, который имеет в качестве каскада начального кодирования, например, энтропийный кодер, такой как арифметический кодер, или кодер переменной длины, такой как кодер Хаффмана. Второй каскад кодирования служит в качестве каскада детализации, и этот второй кодер обычно реализован в предпочтительных вариантах осуществления в виде остаточного кодера или битового кодера, работающего со степенью детализации в бит, которая, например, может быть реализована посредством прибавления определенного заданного смещения в случае первого значения информационной единицы или вычитания смещения в случае противоположного значения информационной единицы. В варианте осуществления, этот детализирующий кодер предпочтительно реализован в виде остаточного кодера, прибавляющего смещение в случае значения первого бита и вычитающего смещение в случае значения второго бита. В предпочтительном варианте осуществления, уменьшение числа элементов аудиоданных приводит к ситуации, когда распределение доступных битов в обычном сценарии с фиксированной частотой кадров изменяется таким образом, что каскад начального кодирования принимает более низкий битовый бюджет, чем каскад детализирующего кодирования. К настоящему моменту, парадигма заключается в том, что каскад начального кодирования заключается в приёме битового бюджета, который является максимально возможно высоким независимо от характеристики сигналов, поскольку считается, что каскад начального кодирования, такой как каскад арифметического кодирования, имеет наибольшую эффективность и в силу этого кодирует гораздо лучше, чем каскад остаточного кодирования с энтропийной точки зрения. Тем не менее, в соответствии с настоящим изобретением, эта парадигма удаляется, поскольку обнаружено, что для определенных сигналов, таких как, например, сигналы с более высокой тональностью, эффективность энтропийного кодера, такого как арифметический кодер, не является настолько высокой, как эффективность, полученная посредством последующего соединенного остаточного кодера, такого как битовый кодер. Тем не менее, хотя следует признавать то, что каскад энтропийного кодирования является высокоэффективным для аудиосигналов в среднем, настоящее изобретение теперь разрешает эту проблему за счет исключения из рассмотрения среднего, но в силу уменьшения битового бюджета для каскада начального кодирования зависимым от сигнала способом и, предпочтительно, для тональных частей сигнала.
В предпочтительном варианте осуществления, сдвиг битового бюджета из каскада начального кодирования в каскад детализирующего кодирования на основе характеристики сигналов входных данных выполняется таким образом, что по меньшей мере две детализирующих информационных единицы доступны по меньшей мере для одного и предпочтительно 50% и еще более предпочтительно всех элементов аудиоданных, которые остаются в силе после уменьшения числа элементов данных. Кроме того, обнаружено, что очень эффективная процедура для вычисления этих детализирующих информационных единиц на стороне кодера и применения этих детализирующих информационных единиц на стороне декодера представляет собой итеративную процедуру, при которой, в определенном порядке, например, от низкой частоты к высокой частоте, оставшиеся биты из битового бюджета для каскада детализирующего кодирования потребляются один за другим. В зависимости от числа остающихся в силе элементов аудиоданных и в зависимости от числа информационных единиц для каскада детализирующего кодирования, число итераций может быть значительно больше двух, и обнаружено, что для сильно тональных кадров сигналов, число итераций может составлять четыре, пять или даже выше.
В предпочтительном варианте осуществления, определение управляющего значения посредством контроллера выполняется опосредованным способом, т.е. без явного определения характеристики сигналов. С этой целью управляющее значение вычисляется на основе манипулируемых входных данных, причем эти манипулируемые входные данные, например, представляют собой входные данные, которые должны квантоваться, или связанные с амплитудой данные, извлекаемые из данных, которые должны квантоваться. Хотя управляющее значение для процессора кодера определяется на основе манипулируемых данных, фактическое квантование/кодирование выполняется без этого манипулирования. Таким образом, зависимая от сигнала процедура получается посредством определения значения манипуляции для манипулирования зависимым от сигнала способом, причем это манипулирование в той или иной степени оказывает влияние на полученное уменьшение числа элементов аудиоданных без явно заданных знаний конкретной характеристики сигналов.
В другой реализации, может применяться прямой режим, в котором определенная характеристика сигналов непосредственно оценивается и зависит от результата этого анализа сигналов, определенное уменьшение числа элементов данных выполняется для того получения более высокой точности для остающихся в силе элементов данных.
В дополнительной реализации, разделенная процедура может применяться для целей уменьшения элементов аудиоданных. В разделенной процедуре, определенное число элементов данных уже получается посредством квантования, управляемого посредством обычно психоакустически обусловленного управления квантователем, и на основе входного аудиосигнала, квантованные элементы аудиоданных уменьшаются относительно своего числа, и, предпочтительно, это уменьшение выполняется посредством исключения наименьших элементов аудиоданных относительно их амплитуды, их энергии или их мощности. Управление для уменьшения, снова, может получаться посредством прямого/явного определения характеристик сигналов либо посредством опосредованного или неявного управления сигналами.
В дополнительном предпочтительном варианте осуществления, применяется интегрированная процедура, в которой переменный квантователь управляется таким образом, чтобы выполнять одно квантование, но на основе манипулируемых данных, при этом одновременно квантуются неманипулируемые данные. Управляющее значение квантователя, например, глобальное усиление вычисляется с использованием зависимых от сигнала манипулируемых данных, в то время как данные без этого манипулирования квантуются, и результат квантования кодируется с использованием всех доступных информационных единиц таким образом, что в случае двухкаскадного кодирования, обычно большое количество информационных единиц для каскада детализирующего кодирования остается.
Варианты осуществления обеспечивают решение проблемы потерь качества для высокотонального содержимого, который основан на модификации спектра мощности, который используется для оценки потребления битов энтропийного кодера. Эта модификация существует для сигнально-адаптивного сумматора минимального уровня шума, который поддерживает оценку для общего аудиосодержимого с плоским остаточным спектром на практике неизменной, в то время как он увеличивает оценку битового бюджета для высокотонального содержимого. Эффект от этой модификации является двойным. Во-первых, он вызывает шум гребенки фильтров и нерелевантные боковые лепестки гармонических компонентов, которые накладываются посредством минимального уровня шума, с возможностью квантования в ноль. Во-вторых, он сдвигает биты из первого каскада кодирования в каскад остаточного кодирования. Хотя такой сдвиг не требуется для большинства сигналов, он является полностью эффективным для высокотональных сигналов, поскольку биты используются для повышения точности квантования гармонических компонентов. Это означает, что они используются для кодирования битов с низкой значимостью, которые обычно придерживаются равномерного распределения и в силу этого полностью эффективно кодируются с помощью двоичного представления. Кроме того, процедура является вычислительно недорогой, что делает ее очень эффективным инструментальным средством для решения вышеуказанной проблемы.
Далее описаны предпочтительные варианты осуществления настоящего изобретения с обращением к сопровождающим чертежам, на которых:
Фиг. 1 является вариантом осуществления аудиокодера;
Фиг. 2 иллюстрирует предпочтительную реализацию процессора кодера по фиг. 1;
Фиг. 3 иллюстрирует предпочтительную реализацию каскада детализирующего кодирования;
Фиг. 4a иллюстрирует примерный синтаксис кадра для первого или второго кадра с итеративными детализирующими битами;
Фиг. 4b иллюстрирует предпочтительную реализацию модуля уменьшения числа элементов аудиоданных в качестве переменного квантователя;
Фиг. 5 иллюстрирует предпочтительную реализацию аудиокодера со спектральным препроцессором;
Фиг. 6 иллюстрирует предпочтительный вариант осуществления аудиодекодера с временным постпроцессором;
Фиг. 7 иллюстрирует реализацию процессора кодера для аудиодекодера по фиг. 6;
Фиг. 8 иллюстрирует предпочтительную реализацию каскада детализирующего декодирования по фиг. 7;
Фиг. 9 иллюстрирует реализацию опосредованного режима для вычисления управляющих значений;
Фиг. 10 иллюстрирует предпочтительную реализацию модуля вычисления значений манипуляции по фиг. 9;
Фиг. 11 иллюстрирует вычисление управляющих значений в прямом режиме;
Фиг. 12 иллюстрирует реализацию разделенного уменьшения числа элементов аудиоданных; и
Фиг. 13 иллюстрирует реализацию интегрированного уменьшения числа элементов аудиоданных.
Фиг. 1 иллюстрирует аудиокодер для кодирования входных аудиоданных 11. Аудиокодер содержит препроцессор 10, процессор 15 кодера и контроллер 20. Препроцессор 10 предварительно обрабатывает входные аудиоданные 11 для получения аудиоданных в расчете на кадр или аудиоданные, которые должны кодироваться, проиллюстрированные в элементе 12. Аудиоданные, которые должны кодироваться, вводятся в процессор 15 кодера для кодирования аудиоданных, которые должны кодироваться, и процессор кодера выводит кодированные аудиоданные. Контроллер 20 соединяется, относительно своего ввода, с аудиоданными в расчете на кадр препроцессора, но, в качестве альтернативы, контроллер также может быть соединён с возможностью приёма входных аудиоданных без предварительной обработки. Контроллер выполнен с возможностью уменьшения числа элементов аудиоданных в расчете на кадр в зависимости от сигнала в кадре, и в то же время контроллер увеличивает число информационных единиц или, предпочтительно, битов для уменьшенного числа элементов аудиоданных в зависимости от сигнала в кадре. Контроллер выполнен с возможностью управления процессором 15 кодера таким образом, что в зависимости от первой характеристики сигналов первого кадра аудиоданных, которые должны кодироваться, число элементов аудиоданных для аудиоданных, которые должны кодироваться посредством процессора кодера для первого кадра, уменьшается по сравнению со второй характеристикой сигналов второго кадра, и число информационных единиц, используемых для кодирования уменьшенного числа элементов аудиоданных для первого кадра, более существенно улучшается по сравнению со вторым числом информационных единиц для второго кадра.
Фиг. 2 иллюстрирует предпочтительную реализацию процессора кодера. Процессор кодера содержит каскад 151 начального кодирования и каскад 152 детализирующего кодирования. В реализации, каскад начального кодирования содержит энтропийный кодер, такой как арифметический кодер или кодер Хаффмана. В другом варианте осуществления, каскад 152 детализирующего кодирования содержит битовый кодер или остаточный кодер, работающий со степенью детализации в бит или информационную единицу. Кроме того, функциональность относительно уменьшения числа элементов аудиоданных осуществляется на фиг. 2 посредством модуля 150 уменьшения числа элементов аудиоданных, который, например, может быть реализован как переменный квантователь в режиме интегрированного уменьшения, проиллюстрированном на фиг. 13, или в качестве альтернативы, как отдельный элемент, уже работающий с квантованными элементами аудиоданных, как проиллюстрировано в режиме 902 разделенного уменьшения, и в дополнительном непроиллюстрированном варианте осуществления, модуль уменьшения числа элементов аудиоданных также может работать с неквантованными элементами посредством задания равными нулю таких неквантованных элементов или посредством взвешивания, с тем чтобы исключать элементы данных с определенным весовым числом таким образом, что такие элементы аудиоданных квантуются до нуля и в силу этого исключаются в последующем соединенном квантователе. Модуль 150 уменьшения числа элементов аудиоданных по фиг. 2 может работать с элементами неквантованных или квантованных данных в процедуре разделенного уменьшения или может быть реализован посредством переменного квантователя, конкретно управляемого посредством зависимого от сигнала управляющего значения, как проиллюстрировано в режиме интегрированного уменьшения по фиг. 13.
Контроллер 20 по фиг. 1 выполнен с возможностью уменьшения числа элементов аудиоданных, кодированных посредством каскада 151 начального кодирования для первого кадра, и каскад 151 начального кодирования выполнен с возможностью кодирования уменьшенного числа элементов аудиоданных для первого кадра с использованием начального числа информационных единиц первого кадра, и вычисленные биты/единицы из начального числа информационных единиц выводятся посредством блока 151, как проиллюстрировано на фиг. 2, элемент 151.
Кроме того, каскад 152 детализирующего кодирования выполнен с возможностью использования оставшегося числа информационных единиц первого кадра для детализирующего кодирования для уменьшенного числа элементов аудиоданных для первого кадра, и начальное число информационных единиц первого кадра, сложенное с оставшимся числом информационных единиц первого кадра, приводит к заданному числу информационных единиц для первого кадра. В частности, каскад 152 детализирующего кодирования выводит оставшееся число битов первого кадра и оставшееся число битов второго кадра, и существуют по меньшей мере два детализирующих бита по меньшей мере для одного или предпочтительно по меньшей мере для 50% или еще более предпочтительно для всех ненулевых элементов аудиоданных, т.е. для элементов аудиоданных, которые остаются в силе после уменьшения элементов аудиоданных и которые начально кодируются посредством каскада 151 начального кодирования.
Предпочтительно, заданное число информационных единиц для первого кадра равно заданному числу информационных единиц для второго кадра либо находится достаточно близко к заданному числу информационных единиц для второго кадра таким образом, что получается работа с постоянной или с практически постоянной скоростью передачи битов для аудиокодера.
Как проиллюстрировано на фиг. 2, модуль 150 уменьшения числа элементов аудиоданных уменьшает число элементов аудиоданных за рамками психоакустически обусловленного числа зависимым от сигнала способом. Таким образом, для первой характеристики сигналов, число уменьшается незначительно на психоакустически обусловленное число, и в кадре со второй характеристикой сигналов, например, число существенно улучшается за рамками психоакустически обусловленного числа. Так же, предпочтительно модуль уменьшения числа элементов аудиоданных исключает элементы данных с наименьшими амплитудами/мощностями/энергиями, и эта операция предпочтительно выполняется через косвенный выбор, полученный в интегрированном режиме, при этом уменьшение числа элементов аудиоданных осуществляется посредством квантования до нуля определенных элементов аудиоданных. В варианте осуществления, каскад начального кодирования кодирует только элементы аудиоданных, которые не квантованы до нуля, и каскад 152 детализирующего кодирования детализирует только элементы аудиоданных, уже обработанные посредством каскада начального кодирования, т.е. элементы аудиоданных, которые не квантованы до нуля посредством модуля 150 уменьшения числа элементов аудиоданных по фиг. 2.
В предпочтительном варианте осуществления, каскад детализирующего кодирования выполнен с возможностью итеративного назначения оставшегося числа информационных единиц первого кадра уменьшенному числу элементов аудиоданных первого кадра по меньшей мере на двух последовательно выполняемых итерациях. В частности, значения назначенных информационных единиц по меньшей мере для двух последовательно выполняемых итераций вычисляются, и вычисленные значения информационной единицы по меньшей мере для двух последовательно выполняемых итераций вводятся в кодированный выходной кадр в заданном порядке. В частности, каскад детализирующего кодирования выполнен с возможностью последовательного назначения информационной единицы для каждого элемента аудиоданных из уменьшенного числа элементов аудиоданных для первого кадра в порядке от низкочастотной информации для элемента аудиоданных к высокочастотной информации для элемента аудиоданных на первой итерации. В частности, элементы аудиоданных могут представлять собой отдельные спектральные значения, полученные посредством временно-спектрального преобразования. В качестве альтернативы, элементы аудиоданных могут представлять собой кортежи из двух или более спектральных линий, обычно смежных друг с другом в спектре. Вычисление битовых значений осуществляется от определенного начального значения с низкочастотной информацией к определенному конечному значению с наиболее высокочастотной информацией, и в дополнительной итерации, выполняется та же процедура, т.е. снова обработка от низких спектральных информационных значений/кортежей к высоким спектральным информационным значениям/кортежам. В частности, каскад 152 детализирующего кодирования выполнен с возможностью проверки, является ли число уже назначенных информационных единиц меньшим, чем заданное число информационных единиц для первого кадра, меньшее, чем начальное число информационных единиц первого кадра, и каскад детализирующего кодирования также выполнен с возможностью прекращения второй итерации в случае отрицательного результата проверки, или выполнения в случае положительного результата проверки определенного числа дополнительных итераций до тех пор, пока не будет получен отрицательный результат проверки, причём число дополнительных итераций равно 1, 2, ...,. Предпочтительно, максимальное число итераций ограничено двухразрядным числом, например, значениями от 10 до 30, и предпочтительно 20 итерациями. В альтернативном варианте осуществления, проверка на предмет максимального числа итераций может быть исключена, если сначала подсчитываются ненулевые спектральные линии, и число остаточных битов регулируется соответствующим образом для каждой итерации или для целой процедуры. Следовательно, когда предусмотрено, например, 20 остающихся в силе спектральных кортежей и 50 остаточных битов, можно, без проверки во время процедуры в кодере или декодере, определять то, что число итераций составляет три, и в третьей итерации, детализирующий бит должен вычисляться или быть доступным в потоке битов для первых десяти спектральных линий/кортежей. Таким образом, эта альтернатива не требует проверки во время итеративной обработки, поскольку информация относительно числа ненулевых или остающихся в силе аудиоэлементов известна после обработки начального каскада в кодере или декодере.
Фиг. 3 иллюстрирует предпочтительную реализацию итеративной процедуры, выполняемой посредством каскада 152 детализирующего кодирования по фиг. 2, которая становится возможной вследствие того факта, что, в отличие от других процедур, число детализирующих битов для кадра значительно увеличено для определенных кадров вследствие соответствующего уменьшения элементов аудиоданных для таких определенных кадров.
На этапе 300, остающиеся в силе элементы аудиоданных определяются. Это определение может автоматически выполняться посредством управления элементами аудиоданных, которые уже обработаны посредством каскада 151 начального кодирования по фиг. 2. На этапе 302, начало процедуры осуществляется в заранее заданном элементе аудиоданных, таком как элемент аудиоданных с наиболее низкой спектральной информацией. На этапе 304, битовые значения для каждого элемента аудиоданных в заранее заданной последовательности вычисляются, причем эта заранее заданная последовательность, например, представляет собой последовательность от низких спектральных значений/кортежей к высоким спектральным значениям/кортежам. Вычисление на этапе 304 выполняется с использованием начального смещения 305 и согласно такому управлению 314, что детализирующие биты по-прежнему доступны. В элементе 316, выводятся первые итеративные детализирующие информационные единицы, т.е. битовая комбинация, указывающая один бит для каждого остающегося в силе элемента аудиоданных, причем бит указывает, должно ли смещение, т.е. начальное смещение 305, прибавляться или вычитаться, либо, в качестве альтернативы, должно ли начальное смещение прибавляться или не прибавляться.
На этапе 306, смещение уменьшается с использованием заданного правила. Это заданное правило, например, может заключаться в том, что смещение делится на два, т.е. что новое смещение составляет половину от исходного смещения. Тем не менее, также могут применяться другие правила уменьшения смещения, которые отличаются от взвешивания в 0,5.
На этапе 308, битовые значения для каждого элемента в заранее заданной последовательности снова вычисляются, но теперь на второй итерации. В качестве ввода во вторую итерацию, детализированные элементы после первой итерации, проиллюстрированной на 307, вводятся. Таким образом, для вычисления на этапе 314, детализация, представленная посредством первых итеративных детализирующих информационных единиц, уже применяется, и согласно такой необходимой предпосылке, что детализирующие биты по-прежнему доступны, как указано на этапе 314, вторые итеративные детализирующие информационные единицы вычисляются и выводятся на 318.
На этапе 310, смещение снова уменьшается с использованием заданного правила для готовности к третьей итерации, и третья итерация снова основывается на детализированных элементах после второй итерации, проиллюстрированной на 309, и снова согласно такой необходимой предпосылке, что детализирующие биты по-прежнему доступны, как указано на 314, третьи итеративные детализирующие информационные единицы вычисляются и выводятся на 320.
Фиг. 4a иллюстрирует примерный синтаксис кадра с информационными единицами или битами для первого кадра или второго кадра. Часть битовых данных для кадра состоит из начального числа битов, т.е. элемента 400. Кроме того, первые итеративные детализирующие биты 316, вторые итеративные детализирующие биты 318 и третьи итеративные детализирующие биты 320 также включаются в кадр. В частности, в соответствии с синтаксисом кадра, декодер в состоянии идентификации того, какие биты кадра представляют собой начальное число битов, того, какие биты представляют собой первый, второй или третий итеративные детализирующие биты 316, 318, 320, и того, какие биты в кадре представляют собой любые другие биты 402, такая вспомогательная информация, которая, например, может также включать в себя кодированное представление глобального усиления (gg), например, которое, например, может вычисляться посредством контроллера 200 непосредственно или которое, например, может затрагиваться посредством контроллера посредством выходной информации контроллера 21. В секции 316, 318, 320, придается определенная последовательность отдельных информационных единиц. Эта последовательность предпочтительно является такой, что биты в битовой последовательности применяются к начально декодированным элементам аудиоданных, которые должны декодироваться. Поскольку нецелесообразно, относительно требований по скорости передачи битов, явно передавать в служебных сигналах что-либо относительно первого, второго и третьего итеративных детализирующих битов, порядок отдельных битов в блоках 316, 318, 320 должен быть тем же, что и соответствующий порядок остающихся в силе элементов аудиоданных. С учетом этого, предпочтительно использовать одинаковую итеративную процедуру на стороне кодера, как проиллюстрировано на фиг. 3, и на стороне декодера, как проиллюстрировано на фиг. 8. Не обязательно передавать в служебных сигналах конкретное выделение битов или битовое ассоциирование по меньшей мере в блоках 316-320.
Кроме того, числа для начального числа битов, с одной стороны, и оставшегося числа битов, с другой стороны, являются лишь примерными. Обычно начальное число битов, которые обычно кодируют старшую битовую часть элемента аудиоданных, такую как спектральные значения или кортежи спектральных значений, превышает итеративные детализирующие биты, которые представляют младшую часть «сохранившихся» элементов аудиоданных. Кроме того, начальное число 400 битов обычно определяется посредством энтропийного кодера или арифметического кодера, но итеративные детализирующие биты определяются с использованием остаточного или битового кодера, работающего со степенью детализации в информационную единицу. Хотя каскад детализирующего кодирования не выполняет энтропийное кодирование и т.п., кодирование младшей битовой части элементов аудиоданных, тем не менее, более эффективно выполняется посредством каскада детализирующего кодирования, поскольку можно предполагать, что младшая битовая часть элементов аудиоданных, таких как спектральные значения, одинаково распределяется, и в силу этого энтропийное кодирование с кодом переменной длины или арифметическим кодом вместе с определенным контекстом не вводит дополнительного преимущества, а вместо этого даже вводит дополнительный объем служебной информации.
Другими словами, для младшей битовой части элементов аудиоданных, использование арифметического кодера должно быть менее эффективным, чем использование битового кодера, поскольку битовый кодер вообще не требует скорости передачи битов для определенного контекста. Намеренное уменьшение числа элементов аудиоданных, вызываемое посредством контроллера, не только повышает точность доминирующих спектральных линий или кортежей линий, но и, кроме того, обеспечивает высокоэффективную операцию кодирования для целей детализации частей MSB этих элементов аудиоданных, представленных посредством арифметического кода или кода переменной длины.
С учетом этого, несколько и, например, следующие преимущества получаются посредством реализации процессора 15 кодера по фиг. 1, как проиллюстрировано на фиг. 2, с каскадом 151 начального кодирования, с одной стороны, и с каскадом 152 детализирующего кодирования, с другой стороны.
Предлагается эффективная схема двухкаскадного кодирования, содержащая первый каскад энтропийного кодирования и второй каскад остаточного кодирования на основе однобитового (неэнтропийного) кодирования.
Схема использует модуль оценки глобального усиления с низкой сложностью, который включает модуль оценки потребления битов на основе энергии для первого каскада кодирования, содержащего сигнально-адаптивный сумматор минимального уровня шума.
Сумматор минимального уровня шума эффективно передает биты из первого каскада кодирования во второй каскад кодирования для высокотональных сигналов при оставлении оценки для других типов сигналов неизменной. Этот сдвиг битов из каскада энтропийного кодирования в каскад неэнтропийного кодирования является полностью эффективным для высокотональных сигналов.
Фиг. 4b иллюстрирует предпочтительную реализацию переменного квантователя, который, например, может быть реализован с возможностью выполнения уменьшения числа элементов аудиоданных управляемым способом предпочтительно в режиме интегрированного уменьшения, проиллюстрированном относительно фиг. 13. С этой целью, переменный квантователь содержит модуль 155 взвешивания, который принимает (неманипулируемые) аудиоданные, которые должны кодироваться, проиллюстрированные в линии 12. Эти данные также вводятся в контроллер 20, и контроллер выполнен с возможностью вычисления глобального усиления 21, но на основе неманипулируемых данных, вводимых в модуль 155 взвешивания, и с использованием зависимого от сигнала манипулирования. Глобальное усиление 21 применяется в модуле 155 взвешивания, и вывод модуля взвешивания вводится в ядро 157 квантователя, которое основывается на фиксированном размере шага квантования. Переменный квантователь 150 реализован в виде управляемого модуля взвешивания, в котором управление выполняется с использованием глобального усиления 21 (gg) и последующего соединенного ядра 157 квантователя с фиксированным размером шага квантования. Тем не менее, также могут выполняться другие реализации, такие как ядро квантователя, имеющее переменный размер шага квантования, который управляется посредством выходного значения контроллера 20.
Фиг. 5 иллюстрирует предпочтительную реализацию аудиокодера и, в частности, определенную реализацию препроцессора 10 по фиг. 1. Предпочтительно, препроцессор содержит модуль 13 кодирования со взвешиванием, который формирует, из входных аудиоданных 11, кадр аудиоданных временной области, кодированных со взвешиванием с использованием определенной функции аналитического кодирования со взвешиванием, которая, например, может представлять собой косинусоидальную функцию кодирования со взвешиванием. Кадр аудиоданных временной области вводится в спектральный преобразователь 14, который может быть реализован с возможностью выполнения модифицированного дискретного косинусного преобразования (MDCT) или любого другого преобразования, такого как FFT или MDST, либо любого другого временно-спектрального преобразования. Предпочтительно, модуль кодирования со взвешиванием работает с определенным опережающим управлением таким образом, что формирование перекрывающихся кадров выполняется. В случае 50%-ного перекрытия, опережающее значение модуля кодирования со взвешиванием составляет половину от размера функции аналитического кодирования со взвешиванием, применяемой посредством модуля 13 кодирования со взвешиванием. (Неквантованный) кадр спектральных значений, выводимых посредством спектрального преобразователя, вводится в спектральный процессор 15, который реализован для выполнения некоторой спектральной обработки, такой как выполнение операции формирования временного шума, операции формирования спектрального шума или любой другой операции, такой как операция спектрального отбеливания, посредством которой модифицированные спектральные значения, сформированные посредством спектрального процессора, имеют спектральную огибающую, более плоскую, чем спектральная огибающая спектральных значений перед обработкой посредством спектрального процессора 15. Аудиоданные, которые должны кодироваться (в расчете на кадр), перенаправляются через линию 12 в процессор 15 кодера и в контроллер 20, при этом контроллер 20 передаёт управляющую информацию через линию 21 в процессор 15 кодера. Процессор кодера выводит свои данные в модуль 30 записи потоков битов, реализованный, например, в виде мультиплексора потоков битов, и кодированные кадры выводятся в линии 35.
Относительно обработки на стороне декодера, следует обратиться к фиг. 6. Поток битов, выводимый посредством блока 30, например, может непосредственно вводиться в модуль 40 считывания потоков битов после некоторого хранения или передачи. Естественно, любая другая обработка может выполняться между кодером и декодером, например, обработка передачи в соответствии с протоколом беспроводной передачи, таким как протокол DECT или протокол Bluetooth либо любой другой протокол беспроводной передачи. Данные, вводимые в аудиодекодер, показанный на фиг. 6, вводятся в модуль 40 считывания потоков битов. Модуль 40 считывания потоков битов считывает данные и перенаправляет данные в процессор 50 кодера, который управляется посредством контроллера 60. В частности, модуль считывания потоков битов принимает кодированные данные, причем кодированные аудиоданные содержат, для кадра, начальное число информационных единиц кадра и оставшееся число информационных единиц кадра. Процессор 50 кодера обрабатывает кодированные аудиоданные, и процессор 50 кодера содержит каскад начального декодирования и каскад детализирующего декодирования, как проиллюстрировано на фиг. 7 в элементе 51 для каскада начального декодирования и в элементе 52 для каскада детализирующего декодирования, которые управляются посредством контроллера 60. Контроллер 60 выполнен с возможностью управления каскадом 52 детализирующего декодирования таким образом, чтобы использовать при детализации начально декодированных элементов данных, выводимых посредством каскада 51 начального декодирования по фиг. 7, по меньшей мере две информационных единицы из оставшегося числа информационных единиц для детализации одного и того же начально декодированного элемента данных. Кроме того, контроллер 60 выполнен с возможностью управления процессором кодера таким образом, чтобы каскад начального декодирования использовал начальное число информационных единиц кадра для получения начально декодированных элементов данных в линии, соединяющей блок 51 и 52 на фиг. 7, при этом, предпочтительно, контроллер 60 принимает индикатор начального числа информационных единиц кадра, с одной стороны, и начального оставшегося числа информационных единиц кадра из модуля 40 считывания потоков битов, как указано посредством входной линии в блок 60 по фиг. 6 или фиг. 7. Постпроцессор 70 обрабатывает детализированные элементы аудиоданных для получения декодированных аудиоданных 80 в выводе постпроцессора 70.
В предпочтительной реализации для аудиодекодера, который соответствует аудиокодеру по фиг. 5, постпроцессор 70 содержит, в качестве входного каскада, спектральный процессор 71, который выполняет операцию обратного формирования временного шума или операцию обратного формирования спектрального шума, или операцию обратного спектрального отбеливания, или любую другую операцию, которая уменьшает некоторую обработку, применяемую посредством спектрального процессора 15 по фиг. 5. Вывод спектрального процессора вводится во временной преобразователь 72, который работает с возможностью выполнения преобразования из спектральной области во временную область, и предпочтительно временной преобразователь 72 совпадает со спектральным преобразователем 14 по фиг. 5. Вывод временного преобразователя 72 вводится в каскад 73 суммирования с перекрытием, который выполняет операцию суммирования с перекрытием для определенного числа перекрывающихся кадров, например по меньшей мере для двух перекрывающихся кадров для получения декодированных аудиоданных 80. Предпочтительно, каскад 73 суммирования с перекрытием применяет функцию синтезирующего кодирования со взвешиванием к выводу временного преобразователя 72, причем эта функция синтезирующего кодирования со взвешиванием совпадает с функцией аналитического кодирования со взвешиванием, применяемой посредством модуля 13 аналитического кодирования со взвешиванием. Кроме того, операция перекрытия, выполняемая посредством блока 73, совпадает с опережающей операцией блока, выполняемой посредством модуля 13 кодирования со взвешиванием по фиг. 5.
Как проиллюстрировано на фиг. 4a, оставшееся число информационных единиц кадра содержит вычисленные значения информационных единиц 316, 318, 320 по меньшей мере для двух последовательных итераций в заданном порядке, при этом, в варианте осуществления 4a, проиллюстрированы даже три итерации. Кроме того, контроллер 60 выполнен с возможностью управления каскадом 52 детализирующего декодирования таким образом, чтобы использовать для первой итерации вычисленные значения, например, из блока 316 для первой итерации в соответствии с заданным порядком и использовать для второй итерации вычисленные значения из блока 318 для второй итерации в заданном порядке.
Затем, предпочтительная реализация каскада детализирующего декодирования под управлением контроллера 60 проиллюстрирована относительно фиг. 8. На этапе 800, контроллер или каскад 52 детализирующего декодирования по фиг. 7 определяет то, подлежащие детализации элементы аудиоданных. Эти элементы аудиоданных обычно представляют собой все элементы аудиоданных, которые выводятся посредством блока 51 по фиг. 7. Как указано на этапе 802, начало в заранее заданном элементе аудиоданных, таком как наиболее низкая спектральная информация, выполняется. С использованием начального смещения 805, первые итеративные детализирующие информационные единицы, принимаемые из потока битов или из контроллера 16, например, данные в блоке 316 по фиг. 4a, применяются 804 для каждого элемента в заранее заданной последовательности, причем заранее заданная последовательность протягивается от низкого к высокому спектральному значению/спектральному кортежу/спектральной информации. Результаты представляют собой детализированные элементы аудиоданных после первой итерации, как проиллюстрировано посредством линии 807. На этапе 808, битовые значения для каждого элемента в заранее заданной последовательности применяются, причем битовые значения исходят из вторых итеративных детализирующих информационных единиц, как проиллюстрировано на 818, и эти биты принимаются из модуля считывания потоков битов или контроллера 60 в зависимости от конкретной реализации. Результат этапа 808 представляет собой детализированные элементы после второй итерации. С другой стороны, на этапе 810, смещение уменьшается в соответствии с использованием заданного правила уменьшения смещения, которое уже применено в блоке 806. С уменьшенным смещением, битовые значения для каждого элемента в заранее заданной последовательности применяются, как проиллюстрировано на 812 с использованием принимаемых третьих итеративных детализирующих информационных единиц, например, из потока битов или из контроллера 60. Третьи итеративные детализирующие информационные единицы записываются в поток битов в элементе 320 по фиг. 4a. Результат процедуры в блоке 812 представляет собой детализированные элементы после третьей итерации, как указано на 821.
Эта процедура продолжается до тех пор, пока все итеративные детализирующие биты, включенные в поток битов для кадра, не обрабатываются. Это проверяется посредством контроллера 60 через управляющую линию 814, которая управляет оставшейся доступностью детализирующих битов предпочтительно для каждой итерации, но по меньшей мере для второй и третьей итераций, обработанных в блоках 808, 812. На каждой итерации, контроллер 60 управляет каскадом детализирующего декодирования таким образом, чтобы проверить, является ли число уже считанных информационных единиц меньшим, чем число информационных единиц в оставшихся информационных единицах кадра для кадра, для прекращения второй итерации в случае отрицательного результата проверки, либо, в случае положительного результата проверки, выполнения определенного числа дополнительных итераций до тех пор, пока не получается отрицательный результат проверки. Число дополнительных итераций составляет по меньшей мере одну. Вследствие применения аналогичных процедур на стороне кодера, поясненных в контексте по фиг. 3, и на стороне декодера, как указано на фиг. 8, конкретная передача служебных сигналов вообще не требуется. Вместо этого, множественная итеративная детализирующая обработка осуществляется высокоэффективным способом без конкретного объема служебной информации. В альтернативном варианте осуществления, проверка на предмет максимального числа итераций может быть исключена, если ненулевые спектральные линии подсчитываются сначала, и число остаточных битов регулируются соответствующим образом для каждой итерации.
В предпочтительной реализации, каскад 52 детализирующего декодирования выполнен с возможностью сложения смещения с начально декодированным элементом данных, когда считываемая информационная единица данных из оставшегося числа информационных единиц кадра имеет первое значение, и вычитания смещения из начально декодированного элемента, когда считываемая информационная единица данных из оставшегося числа информационных единиц кадра имеет второе значение. Это смещение, для первой итерации, представляет собой детализированные элементы по фиг. 8. На второй итерации, как проиллюстрировано на 808 на фиг. 8, уменьшенное смещение, сформированное посредством блока 806, используется для сложения уменьшенного или второго смещения с результатом первой итерации, когда считываемая информационная единица данных из оставшегося числа информационных единиц кадра имеет первое значение, и для вычитания второго смещения из результата первой итерации, когда считываемая информационная единица данных из оставшегося числа информационных единиц кадра имеет второе значение. Обычно, второе смещение ниже первого смещения, и предпочтительно, если второе смещение составляет 0,4-0,6 раз относительно первого смещения и наиболее предпочтительно 0,5 раз относительно первого смещения.
В предпочтительной реализации настоящего изобретения с использованием опосредованного режима, проиллюстрированного на фиг. 9, явное определение характеристик сигналов не требуется. Вместо этого, значение манипуляции вычисляется предпочтительно с использованием варианта осуществления, проиллюстрированного на фиг. 9. Для опосредованного режима, контроллер 20 реализован таким образом, как указано на фиг. 9. В частности, контроллер содержит управляющий препроцессор 22, модуль 23 вычисления значений манипуляции, модуль 24 комбинирования и модуль 25 вычисления глобальных усилений, который, в конечном счете, вычисляет глобальное усиление для модуля 150 уменьшения числа элементов аудиоданных по фиг. 2, который реализован в виде переменного квантователя, проиллюстрированного на фиг. 4b. В частности, контроллер 20 выполнен с возможностью анализа аудиоданных первого кадра для определения первого управляющего значения для переменного квантователя для первого кадра, и анализа аудиоданных второго кадра для определения второго управляющего значения для переменного квантователя для второго кадра, причем второе управляющее значение отличается от первого управляющего значения. Анализ аудиоданных кадра выполняется посредством модуля 23 вычисления значений манипуляции. Контроллер 20 выполнен с возможностью выполнения манипулирования аудиоданными первого кадра. В этой операции управляющий препроцессор 20, проиллюстрированный на фиг. 9, не присутствует, и в силу этого обходная линия для блока 22 является активной.
Тем не менее, когда манипулирование не выполняется для аудиоданных первого кадра или второго кадра, но применяется к связанным с амплитудой значениям, извлекаемым из аудиоданных первого кадра или второго кадра, управляющий препроцессор 22 присутствует, и обходная линия не существует. Фактическое манипулирование выполняется посредством модуля 24 комбинирования, который комбинирует значение манипуляции, выводимое из блока 23, со связанными с амплитудой значениями, извлекаемыми из аудиоданных определенного кадра. В выводе модуля 24 комбинирования, существуют манипулируемые (предпочтительно энергетические) данные, и на основе этих манипулируемых данных, модуль 25 вычисления глобальных усилений вычисляет глобальное усиление или по меньшей мере управляющее значение для глобального усиления, указываемого на 404. Модуль 25 вычисления глобальных усилений должен вводить ограничения относительно разрешенного битового бюджета для спектра таким образом, что получается определенная скорость передачи данных или определенное число информационных единиц, разрешенных для кадра.
В прямом режиме, проиллюстрированном на фиг. 11, контроллер 20 содержит анализатор 201 для определения характеристик сигналов в расчете на кадр, и анализатор 208 выводит, например, информацию количественных характеристик сигналов, например, информацию тональности, и управляет модулем 202 вычисления управляющих значений с использованием этих предпочтительно количественных данных. Одна процедура для вычисления тональности кадра заключается в вычислении показателя спектральной сглаженности (SFM) кадра. Любые другие процедуры определения тональности или любые другие процедуры определения характеристик сигналов могут выполняться посредством блока 201, и трансляция от определенного значения характеристик сигналов к определенному управляющему значению должна выполняться для получения намеченного уменьшения числа элементов аудиоданных для кадра. Вывод модуля 202 вычисления управляющих значений для прямого режима по фиг. 11 может представлять собой управляющее значение в процессор кодера, например, в переменный квантователь или, в качестве альтернативы, в каскад начального кодирования. Когда управляющее значение передаётся в переменный квантователь, выполняется режим интегрированного уменьшения, в то время как, когда управляющее значение обеспечивается для каскада начального кодирования, выполняется разделенное уменьшение. Другая реализация разделенного уменьшения заключается в удалении или оказании влияния на конкретно выбранные неквантованные элементы аудиоданных, присутствующие до фактического квантования, так что, посредством определенного квантователя, такие затрагиваемые элементы аудиоданных квантуются до нуля и в силу этого должны исключаться для целей энтропийного кодирования и последующего детализирующего кодирования.
Хотя опосредованный режим по фиг. 9 показан вместе с интегрированным уменьшением, т.е. что модуль 25 вычисления глобальных усилений выполнен с возможностью вычисления переменного глобального усиления, манипулируемые данные, выводимые посредством модуля 24 комбинирования, также могут использоваться для непосредственного управления каскадом начального кодирования для удаления любых определенных квантованных элементов аудиоданных, например, наименьших квантованных элементов данных, либо, в качестве альтернативы, управляющее значение также может отправляться в непроиллюстрированные аудиоданные, оказывающие влияние на каскад, который оказывает влияние на аудиоданные перед фактическим квантованием с использованием переменного управляющего значения квантования, которое определено без манипулирования данными и в силу этого обычно подчиняется психоакустическим правилам, которые, тем не менее, намеренно нарушаются процедурами по настоящему изобретению.
Как проиллюстрировано на фиг. 11 для прямого режима, контроллер выполнен с возможностью определения первой характеристики тональности в качестве первой характеристики сигналов и определения второй характеристики тональности в качестве второй характеристики сигналов таким образом, что битовый бюджет для каскада детализирующего кодирования увеличивается в случае первой характеристики тональности по сравнению с битовым бюджетом для каскада детализирующего кодирования в случае второй характеристики тональности, при этом первая характеристика тональности указывает большую тональность, чем вторая характеристика тональности.
Настоящее изобретение не приводит к более приблизительному квантованию, которое обычно получается посредством применения большего глобального усиления. Вместо этого, это вычисление глобального усиления на основе зависимых от сигнала манипулируемых данных приводит только к сдвигу битового бюджета из каскада начального кодирования, который принимает меньший битовый бюджет, в каскад детализирующего декодирования, который принимает более высокий битовый бюджет, но этот сдвиг битового бюджета выполняется зависимым от сигнала способом и составляет больше для части сигнала с более высокой тональностью.
Предпочтительно, управляющий препроцессор 22 по фиг. 9 вычисляет связанные с амплитудой значения в качестве множества значений мощности, извлекаемых из одного или более аудиозначений аудиоданных. В частности, именно эти значения мощности манипулируются с использованием прибавления одинакового значения манипуляции посредством модуля 24 комбинирования, и это одинаковое значение манипуляции, которое определено посредством модуля 23 вычисления значений манипуляции, комбинируется со всеми значениями мощности из множества значений мощности для кадра.
В качестве альтернативы, как указано посредством обходной линии, значения, полученные посредством одинаковой абсолютной величины значения манипуляции, вычисленного посредством блока 23, но предпочтительно с рандомизированными знаками, и/или значения, полученные посредством вычитания немного отличающихся членов из одинаковой абсолютной величины (но предпочтительно с рандомизированными знаками), или комплексное значение манипуляции, или, обобщённо, значения, полученные в качестве выборок из определенного нормализованного распределения вероятностей, масштабируемого с использованием вычисленной комплексной или действительной абсолютной величины значения манипуляции, складываются со всеми аудиозначениями из множества аудиозначений, включенных в кадр. Процедура, выполняемая посредством управляющего препроцессора 22, такая как вычисление спектра мощности и субдискретизация, может включаться в модуль 25 вычисления глобальных усилений. Следовательно, предпочтительно, минимальный уровень шума складывается либо непосредственно со спектральными аудиозначениями, либо, в качестве альтернативы, со связанными с амплитудой значениями, извлекаемыми из аудиоданных в расчете на кадр, т.е. с выводом управляющего препроцессора 22. Предпочтительно препроцессор контроллера вычисляет субдискретизированный спектр мощности, который соответствует использованию возведения в степень со значением экспоненты, равным 2. Тем не менее, в качестве альтернативы, может использоваться другое значение экспоненты, большее 1. В качестве примера, значение экспоненты, равное 3, должно представлять громкость, а не степень. Но также могут использоваться другие значения экспоненты, например, меньшие или большие значения экспоненты.
В предпочтительной реализации, проиллюстрированной на фиг. 10, модуль 23 вычисления значений манипуляциисодержит модуль 26 поиска для выполнения поиска максимального спектрального значения в кадре и по меньшей мере одно из вычисления не зависимой от сигнала доли, указываемого посредством элемента 27 по фиг. 10, или модуля вычисления для вычисления одного или более моментов в расчете на кадр, как проиллюстрировано посредством блока 28 по фиг. 10. По существу, блок 26 или блок 28 служит здесь для обеспечения зависимого от сигнала влияния на значение манипуляции для кадра. В частности, модуль 26 поиска выполнен с возможностью выполнения поиска максимального значения множества элементов аудиоданных или связанных с амплитудой значений или с возможностью выполнения поиска максимального значения множества субдискретизированных аудиоданных или множества субдискретизированных связанных с амплитудой значений для соответствующего кадра. Фактическое вычисление выполняется посредством блока 29 с использованием вывода блоков 26, 27 и 28, при этом блоки 26, 28 фактически представляют анализ сигналов.
Предпочтительно, не зависимая от сигнала доля определяется посредством скорости передачи битов для фактического сеанса работы кодера, длительности кадра или частоты дискретизации для фактического сеанса работы кодера. Кроме того, модуль 28 вычисления для вычисления одного или более моментов в расчете на кадр выполнен с возможностью вычисления зависимого от сигнала весового значения, извлекаемого по меньшей мере из первой суммы абсолютных величин аудиоданных или субдискретизированных аудиоданных в кадре, второй суммы абсолютных величин аудиоданных или субдискретизированных аудиоданных в кадре, умноженном на индекс, ассоциированный с каждой абсолютной величиной, и частного второй суммы и первой суммы.
В предпочтительной реализации, выполняемой посредством модуля 25 вычисления глобальных усилений по фиг. 9, требуемая битовая оценка вычисляется для каждого значения энергии в зависимости от значения энергии и возможного значения для значения фактического управления. Требуемые битовые оценки для значений энергии и возможного значения для управляющего значения накапливаются, и проверяется, соответствует ли накопленная битовая оценка для возможного значения для управляющего значения критерию разрешенного потребления битов, например, как проиллюстрировано на фиг. 9, в качестве битового бюджета для спектра, введенного в модуль 25 вычисления глобальных усилений. В случае если критерий разрешенного потребления битов не выполняется, возможное значение для управляющего значения модифицируется, и вычисление требуемой битовой оценки, накопление требуемой скорости передачи битов и проверка соответствия критерию разрешенного потребления битов для модифицированного возможного значения для управляющего значения повторяются. После того, как такое оптимальное управляющее значение обнаруживается, это значение выводится в линии 404 по фиг. 9.
Далее проиллюстрированы предпочтительные варианты осуществления.
Подробное описание кодера (например, фиг. 5)
Обозначение
Обозначим как f базовую частоту дискретизации в Гц, как Nms базовую длительность кадра в миллисекундах, и как br базовую скорость передачи битов в битах в секунду.
Извлечение остаточного спектра (например, препроцессор 10)
Вариант осуществления работает с действительным остаточным спектром 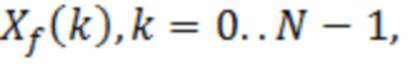 , который обычно извлекается посредством временно-частотного преобразования, такого как MDCT, с дальнейшими психоакустически обусловленными модификациями, такими как формирование временного шума (TNS) для удаления временной структуры, и формирование спектрального шума (SNS) для удаления спектральной структуры. Для аудиосодержимого с медленно варьирующейся спектральной огибающей, огибающая остаточного спектра Xf(k) в силу этого является плоской.
, который обычно извлекается посредством временно-частотного преобразования, такого как MDCT, с дальнейшими психоакустически обусловленными модификациями, такими как формирование временного шума (TNS) для удаления временной структуры, и формирование спектрального шума (SNS) для удаления спектральной структуры. Для аудиосодержимого с медленно варьирующейся спектральной огибающей, огибающая остаточного спектра Xf(k) в силу этого является плоской.
Оценка глобального усиления (например, фиг. 9)
Квантование спектра управляется посредством глобального усиления gglob через следующее:
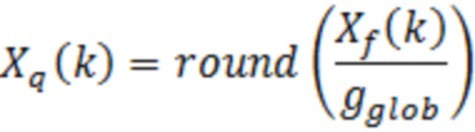
Начальная оценка глобального усиления (элемент 22 по фиг. 9) извлекается из спектра Xf(k)2 мощности после субдискретизации на коэффициент 4:
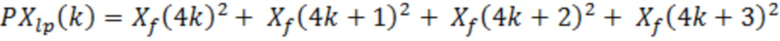
и сигнально-адаптивного минимального уровня N(Xf) шума, который задается следующим образом:
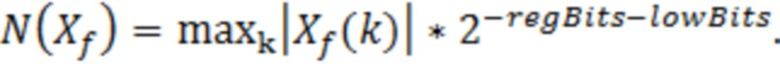 (например, элемент 23 по фиг. 9)
(например, элемент 23 по фиг. 9)
Параметр regBits зависит от скорости передачи битов, длительности кадра и частоты дискретизации и вычисляется следующим образом:
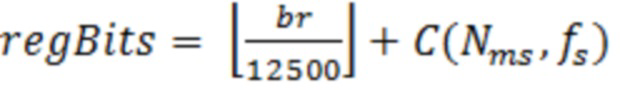 (например, элемент 27 по фиг. 10)
(например, элемент 27 по фиг. 10)
где C(Nms, fs) является таким, как указано в нижеприведенной таблице.
Параметр lowBits зависит от центра масс абсолютных значений остаточного спектра и вычисляется следующим образом:
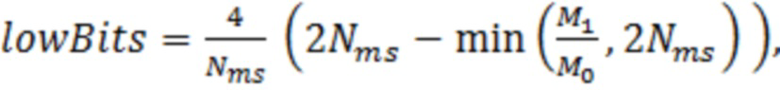 (например, элемент 28, фиг. 10)
(например, элемент 28, фиг. 10)
где:
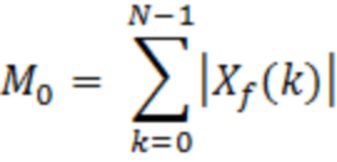
и:
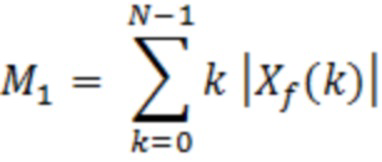
являются моментами абсолютного спектра.
Глобальное усиление оценивается в форме:
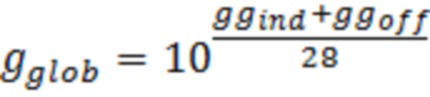
из значений:
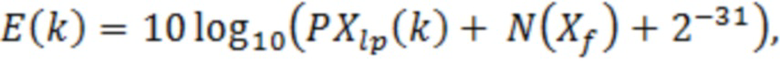 (например, вывода модуля 24 комбинирования по фиг. 9),
(например, вывода модуля 24 комбинирования по фиг. 9),
где ggoff является зависимым от скорости передачи битов и частоты дискретизации смещением.
Следует отметить, что сложение члена N(Xf) минимального уровня шума с PXlp(k) дает ожидаемый результат сложения соответствующего минимального уровня шума с остаточным спектром Xf(k), например, рандомизированного прибавления или вычитания члена 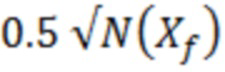 для каждой спектральной линии, перед вычислением спектра мощности.
для каждой спектральной линии, перед вычислением спектра мощности.
Чистые оценки на основе спектра мощности могут уже обнаруживаться, например, в кодеке EVS 3GPP (3GPP TS 26.445, раздел 5.3.3.2.8.1). В вариантах осуществления выполняется прибавление минимального уровня N(Xf) шума. Минимальный уровень шума является сигнально-адаптивным двумя способами.
Во-первых, он масштабируется с максимальной амплитудой Xf. Следовательно, влияние на энергию равномерного спектра, в котором все амплитуды находятся близко к максимальной амплитуде, является очень небольшим. Но для высокотональных сигналов, в которых спектр и, в расширении, также остаточный спектр демонстрируют определенное число сильных пиков, полная энергия значительно увеличивается, что увеличивает битовую оценку в вычислении глобального усиления, как указано ниже.
Во-вторых, минимальный уровень шума понижается через параметр lowBits, если спектр демонстрирует низкий центр масс. В этом случае, низкочастотное содержимое является доминирующим, в силу чего потери высокочастотных компонентов с большой вероятностью не должны быть настолько критическими, как для высокотонального содержимого.
Фактическая оценка глобального усиления выполняется (например, блок 25 по фиг. 9) посредством бисекционного поиска с низкой сложностью, как указано в нижеприведенном коде на языке C, где 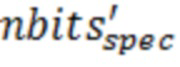 обозначает битовый бюджет для кодирования спектра. Оценка потребления битов (накопленная в переменной tmp) основана на значениях E(k) энергии с учетом контекстной зависимости в арифметическом кодере, используемом для кодирования в каскаде 1.
обозначает битовый бюджет для кодирования спектра. Оценка потребления битов (накопленная в переменной tmp) основана на значениях E(k) энергии с учетом контекстной зависимости в арифметическом кодере, используемом для кодирования в каскаде 1.
fac=0,3;
ggind=255;
for (iter=0; iter<8; iter++)
{
fac>>=1;
ggind-=fac;
tmp=0;
iszero=1;
for (i=N/4-1; i>=0; i--)
{
if (E[i]*28/20<(ggind+ggoff))
{
if (iszero==0)
{
tmp+=2,7*28/20;
}
}
else
{
if ((ggind+ggoff)<E[i]*28/20-43*28/20)
{
tmp+=2*E[i]*28/20-2*(ggind+ggoff)-36*28/20;
}
else
{
tmp+=E[i]*28/20-(ggind+ggoff)+7*28/20;
}
iszero=0;
}
}
if (tmp> 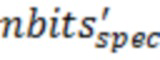 *1,4*28/20 andand iszero==0)
*1,4*28/20 andand iszero==0)
{
ggind+=fac;
}
}
Остаточное кодирование (например, фиг. 3)
Остаточное кодирование использует избыточные биты, которые доступны после арифметического кодирования квантованного спектра Xq(k). Пусть B обозначает число избыточных битов, и пусть K обозначает число кодированных ненулевых коэффициентов Xq(k). Кроме того, пусть ki, i=1, ... K, обозначает перечисление этих ненулевых коэффициентов от наименьшей к наибольшей частоте. Остаточные биты bi(j) (принимающие значения 0 и 1) для коэффициента ki вычисляются таким образом, чтобы минимизировать ошибку:
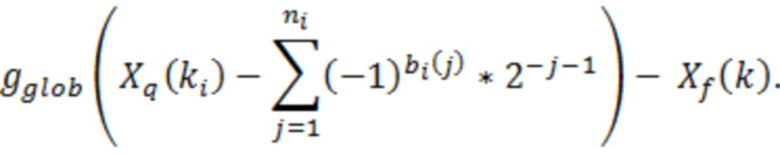
Это может осуществляться итеративным способом с проверкой того, выполняется ли следующее:
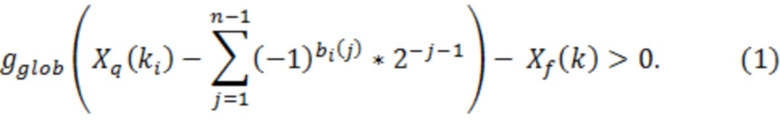
Если (1) является истинным, то n-й остаточный бит bi(n) для коэффициента ki задается равным 0, и иначе он задается равным 1. Вычисление остаточных битов выполняется посредством вычисления первого остаточного бита для каждого ki и затем второго бита и т.д. до тех пор, пока все остаточные биты не расходуются, или максимальное число nmax итераций не выполняется. Это оставляет:
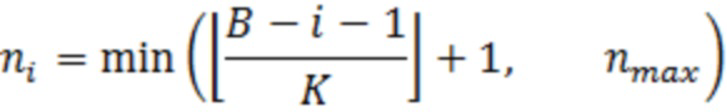
остаточных битов для коэффициента Xq(ki). Эта схема остаточного кодирования улучшает схему остаточного кодирования, которая применяется в 3GPP EVS-кодеке, который расходует самое большее один бит в расчете на ненулевой коэффициент.
Вычисление остаточных битов с nmax=20 проиллюстрировано посредством следующего псевдокода, при этом gg обозначает глобальное усиление:
iter=0;
nbits_residual=0;
offset=0,25;
while (nbits_residual<nbits_residual_max andand iter<20)
{
k=0;
while (k<NE andand nbits_residual<nbits_residual_max)
{
if (Xq[k] !=0)
{
if (Xf[k]>=Xq[k]*gg)
{
res_bits[nbits_residual]=1;
Xf[k] -=offset*gg;
}
else
{
res_bits[nbits_residual]=0;
Xf[k]+=offset*gg;
}
nbits_residual++;
}
k++;
}
iter++;
offset/=2;
}
Описание декодера (например, фиг. 6)
В декодере, энтропийно кодированный спектр 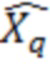 получается посредством энтропийного декодирования. Остаточные биты используются для детализации этого спектра, как продемонстрировано следующим псевдокодом (см. также, например, фиг. 8).
получается посредством энтропийного декодирования. Остаточные биты используются для детализации этого спектра, как продемонстрировано следующим псевдокодом (см. также, например, фиг. 8).
iter=n=0;
offset=0,25;
while (iter<20 andand n<nResBits)
{
k=0;
while (k<NE andand n<nResBits)
{
если ( 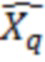 [k] !=0)
[k] !=0)
{
if (resBits[n++]==0)
{
[k] -=offset;
}
else
{
[k]+=offset;
}
}
k++;
}
iter++;
offset/=2;
}
Декодированный остаточный спектр задается следующим образом:
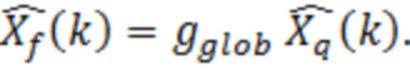
Заключения
Предлагается эффективная схема двухкаскадного кодирования, содержащая первый каскад энтропийного кодирования и второй каскад остаточного кодирования на основе однобитового (неэнтропийного) кодирования.
Схема использует модуль оценки глобального усиления с низкой сложностью, который включает модуль оценки потребления битов на основе энергии для первого каскада кодирования, содержащего сигнально-адаптивный сумматор минимального уровня шума.
Сумматор минимального уровня шума эффективно передает биты из первого каскада кодирования во второй каскад кодирования для высокотональных сигналов при оставлении оценки для других типов сигналов неизменной. Утверждается, что этот сдвиг битов из каскада энтропийного кодирования в каскад неэнтропийного кодирования является полностью эффективным для высокотональных сигналов.
Фиг. 12 иллюстрирует процедуру для уменьшения числа элементов аудиоданных зависимым от сигнала способом с использованием разделенного уменьшения. На этапе 901, квантование выполняется с использованием неманипулируемой информации, такой как глобальное усиление, вычисленное из сигнальных данных без манипулирования. С этой целью, (полный) битовый бюджет для элементов аудиоданных требуется, и в выводе блока 901, получаются квантованные элементы данных. В блоке 902, число элементов аудиоданных уменьшается посредством исключения (управляемого) количества предпочтительно наименьших элементов аудиоданных на основе зависимого от сигнала управляющего значения. В выводе блока 902, получается уменьшенное число элементов данных, и в блоке 903, применяется каскад начального кодирования, и с битовым бюджетом для остаточных битов, которые остаются вследствие управляемого уменьшения, применяется каскад детализирующего кодирования, как проиллюстрировано на 904.
Кроме того, в процедуру на фиг. 12, блок 902 уменьшения также может выполняться перед фактическим квантованием с использованием значения глобального усиления или, в общем, определенного размера шага квантователя, который определен с использованием неманипулируемых аудиоданных. Это уменьшение числа элементов аудиоданных может в силу этого также выполняться в неквантованной области посредством задания равными нулю определенных предпочтительно небольших значений или посредством взвешивания определенных значений с весовыми коэффициентами, что, в конечном счете, приводит к значениям, квантованным до нуля. В реализации для разделенного уменьшения, выполняются этап явного квантования, с одной стороны, и этап явного уменьшения, с другой стороны, при этом управление для конкретного квантования выполняется без манипулирования данных.
В отличие от этого, фиг. 13 иллюстрирует режим интегрированного уменьшения в соответствии с вариантом осуществления настоящего изобретения. В блоке 911, манипулируемая информация определяется посредством контроллера 20, такая как, например, глобальное усиление, проиллюстрированное в выводе блока 25 по фиг. 9. В блоке 912, квантование неманипулируемых аудиоданных выполняется с использованием манипулируемого глобального усиления, или в общем, манипулируемой информации, вычисленной в блоке 911. В выводе процедуры квантования блока 912, получается уменьшенное число элементов аудиоданных, которые начально кодируются в блоке 903, и детализация, кодированная в блоке 904. Вследствие зависимого от сигнала уменьшения элементов аудиоданных, остаточные биты по меньшей мере для одной полной итерации и по меньшей мере для части второй итерации и предпочтительно даже более чем для двух итераций остаются. Сдвиг битового бюджета из каскада начального кодирования в каскад детализирующего кодирования выполняется в соответствии с настоящим изобретением и зависимым от сигнала способом.
Настоящее изобретение может быть реализовано по меньшей мере в четырех различных режимах. Определение управляющего значения может выполняться в прямом режиме с явным определением характеристик сигналов или в опосредованном режиме без явного определения характеристик сигналов, но со сложением зависимого от сигнала минимального уровня шума с аудиоданными или с извлеченными аудиоданными в качестве примера для манипулирования. Одновременно, уменьшение числа элементов аудиоданных выполняется интегрированным способом или разделенным способом. Также могут выполняться опосредованное определение и интегрированное уменьшение или опосредованное формирование управляющего значения и разделенное уменьшение. Кроме того, также могут выполняться прямое определение вместе с интегрированным уменьшением и прямое определение управляющего значения вместе с разделенным уменьшением. Для целей низкой эффективности, предпочтительным является опосредованное определение управляющего значения вместе с интегрированным уменьшением элементов аудиоданных.
Здесь следует отметить, что все альтернативы или аспекты, поясненные выше, и все аспекты, определённые в независимых пунктах в нижеприведенной формуле изобретения, могут использоваться по отдельности, т.е. без альтернатив или задач, отличных от предполагаемой альтернативы, задачи или независимого пункта формулы изобретения. Тем не менее, в других вариантах осуществления, две или более из альтернатив или аспектов или независимых пунктов формулы изобретения могут комбинироваться друг с другом, и, в других вариантах осуществления, все аспекты или альтернативы и все независимые пункты формулы изобретения могут комбинироваться друг с другом.
Кодированный согласно изобретению аудиосигнал может сохраняться на цифровом носителе хранения данных или постоянном носителе хранения данных или может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, например, Интернет.
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогичным образом, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут быть реализованы в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные считываемые электронными средствами управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий считываемые электронными средствами управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут быть реализованы в виде компьютерного программного продукта с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе или на постоянном носителе хранения данных.
Другими словами, таким образом, вариант осуществления способа согласно изобретению представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления способов согласно изобретению представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Следовательно, дополнительный вариант осуществления способа согласно изобретению представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для выполнения части или всех из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором для осуществления одного из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Вышеописанные варианты осуществления являются лишь иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что специалистам в данной области техники должны быть очевидными модификации и изменения конфигураций и подробностей, описанных в данном документе. Следовательно, подразумевается ограничение лишь объемом нижеприведенной формулы изобретения, но не конкретными подробностями, представленными в данном документе в качестве описания и пояснения вариантов осуществления.
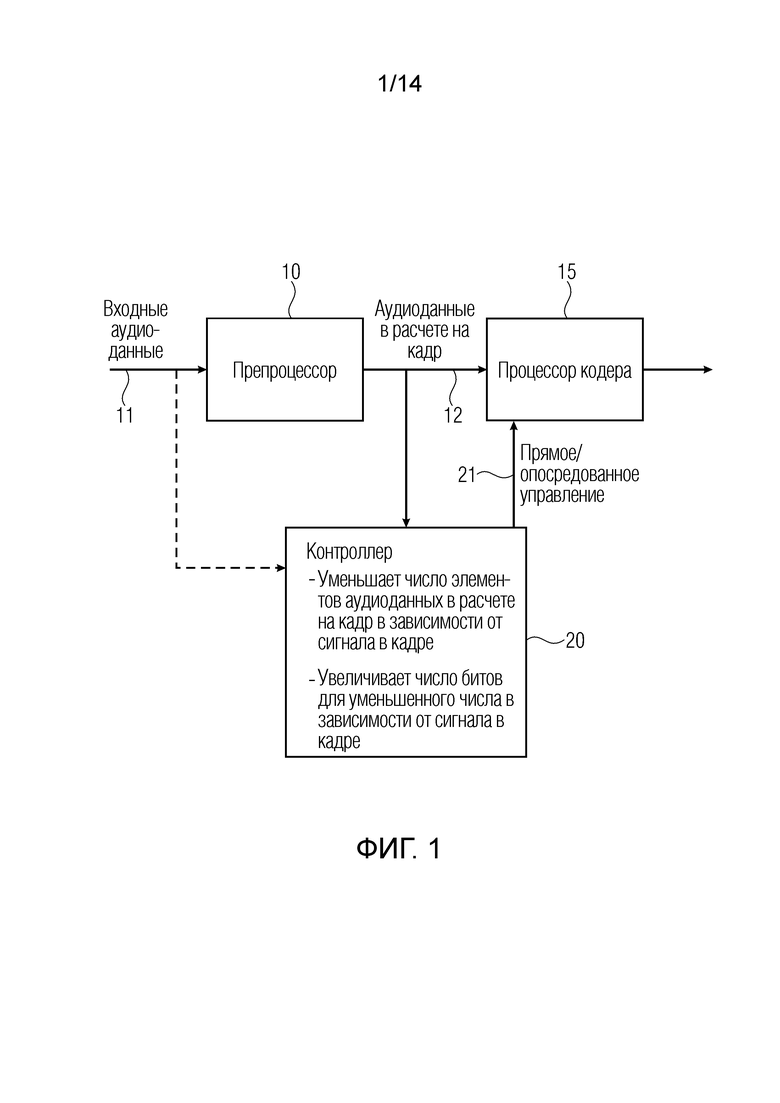
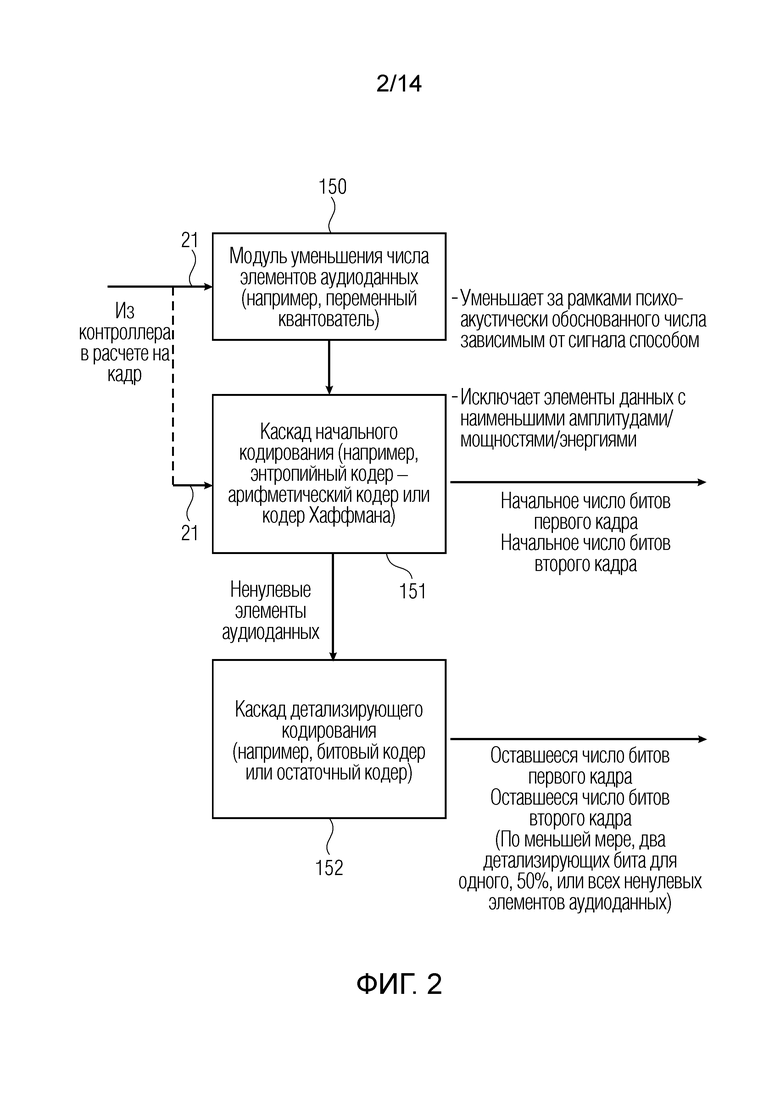
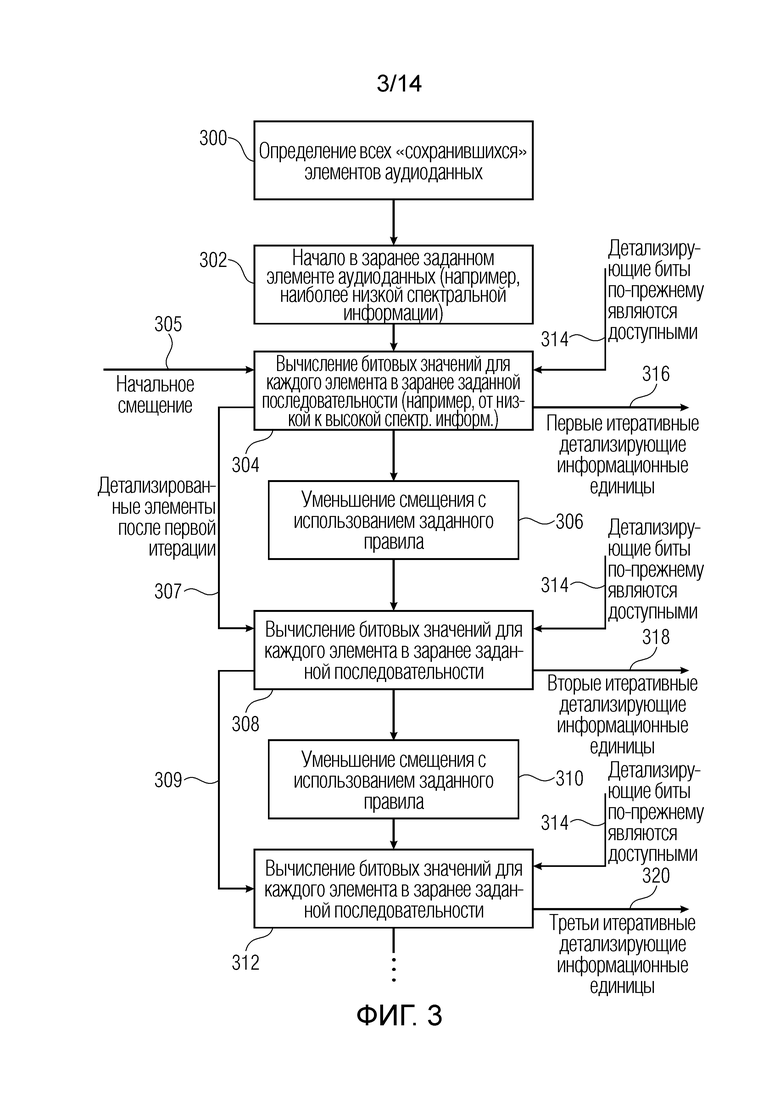
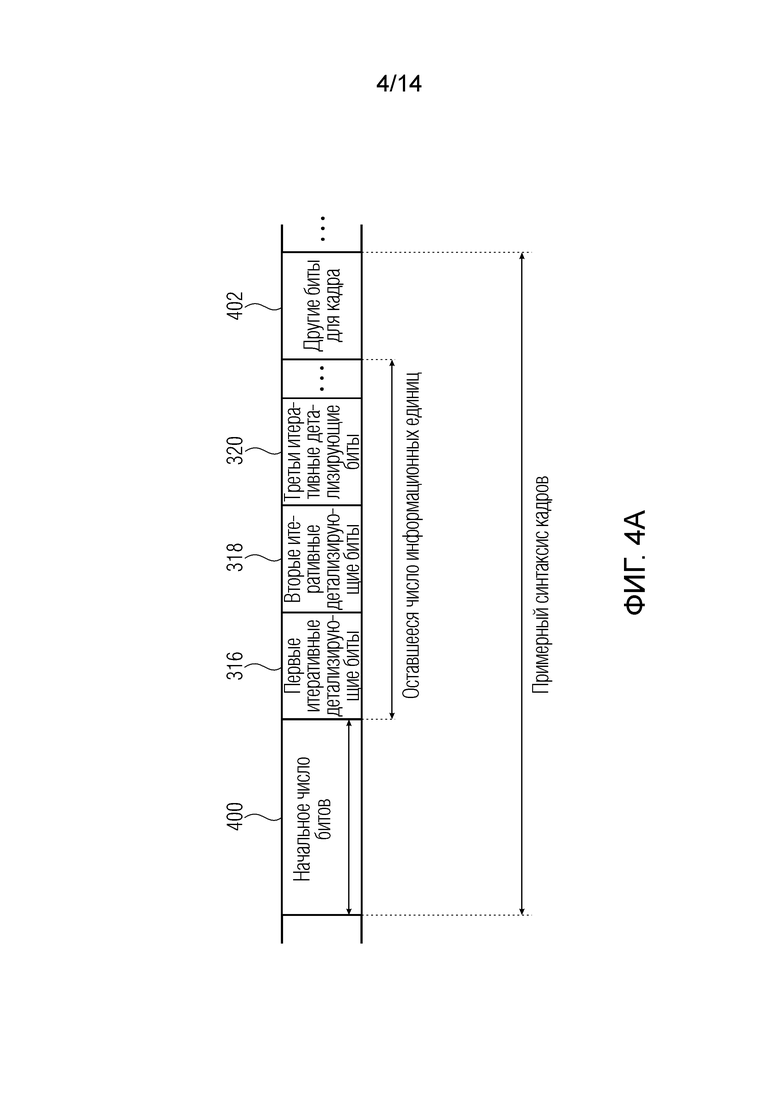
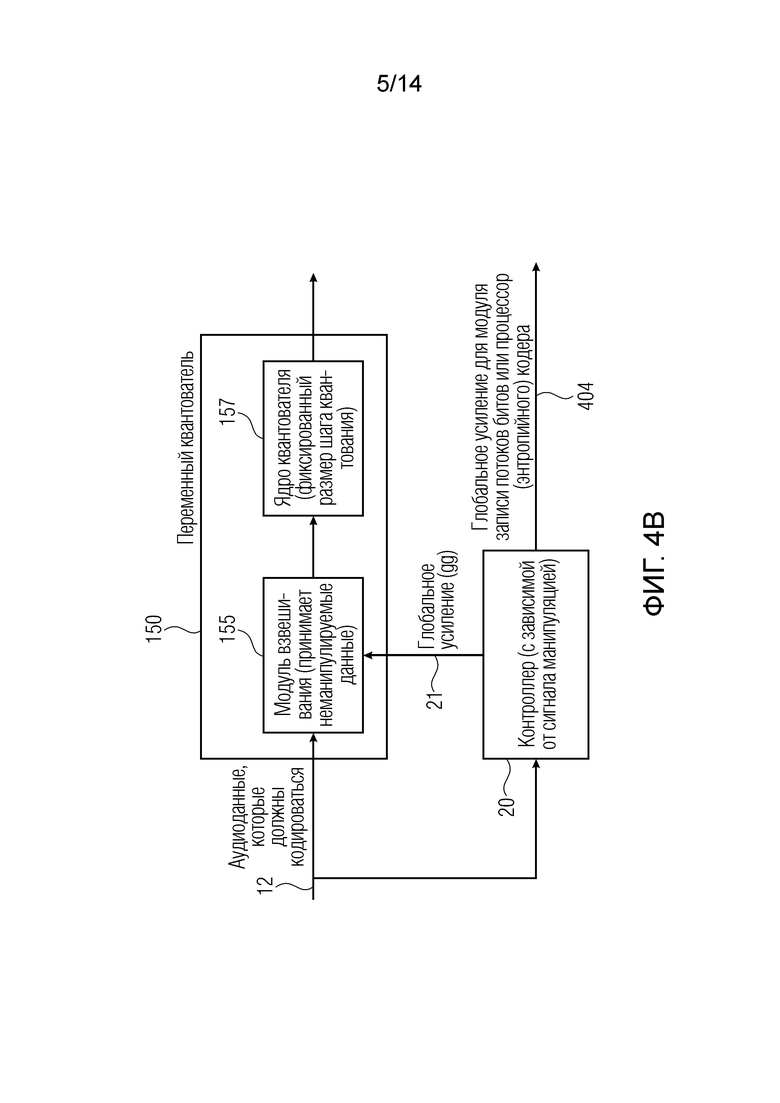
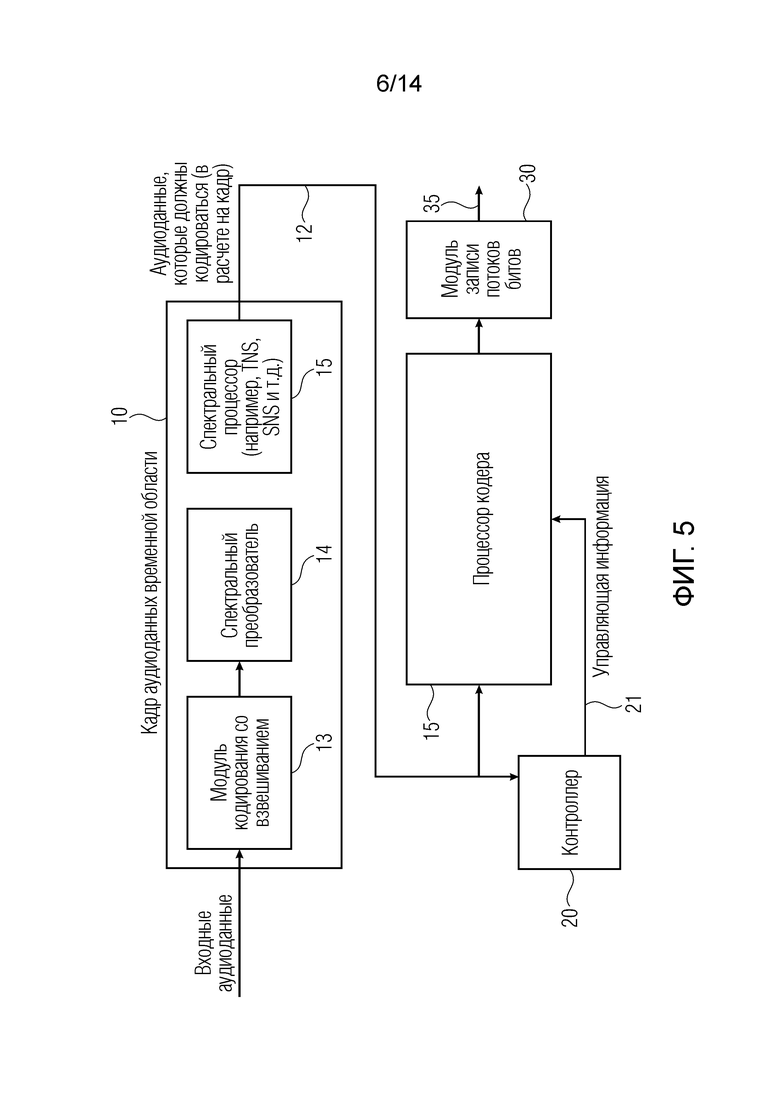
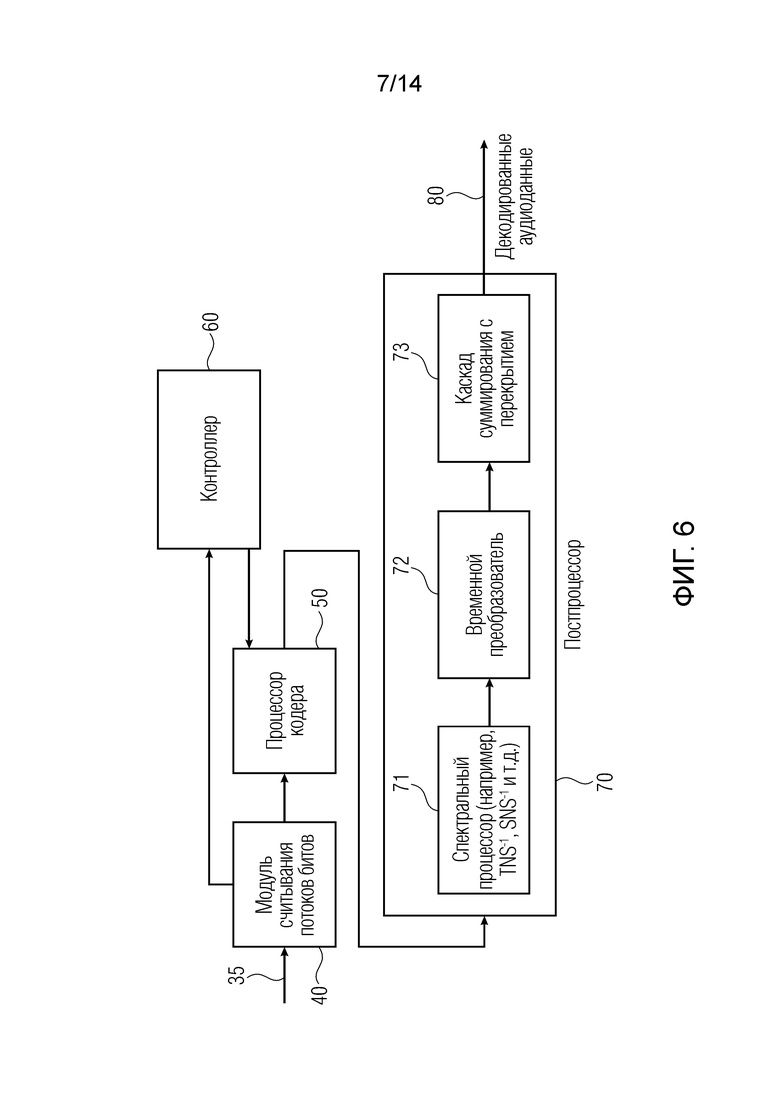
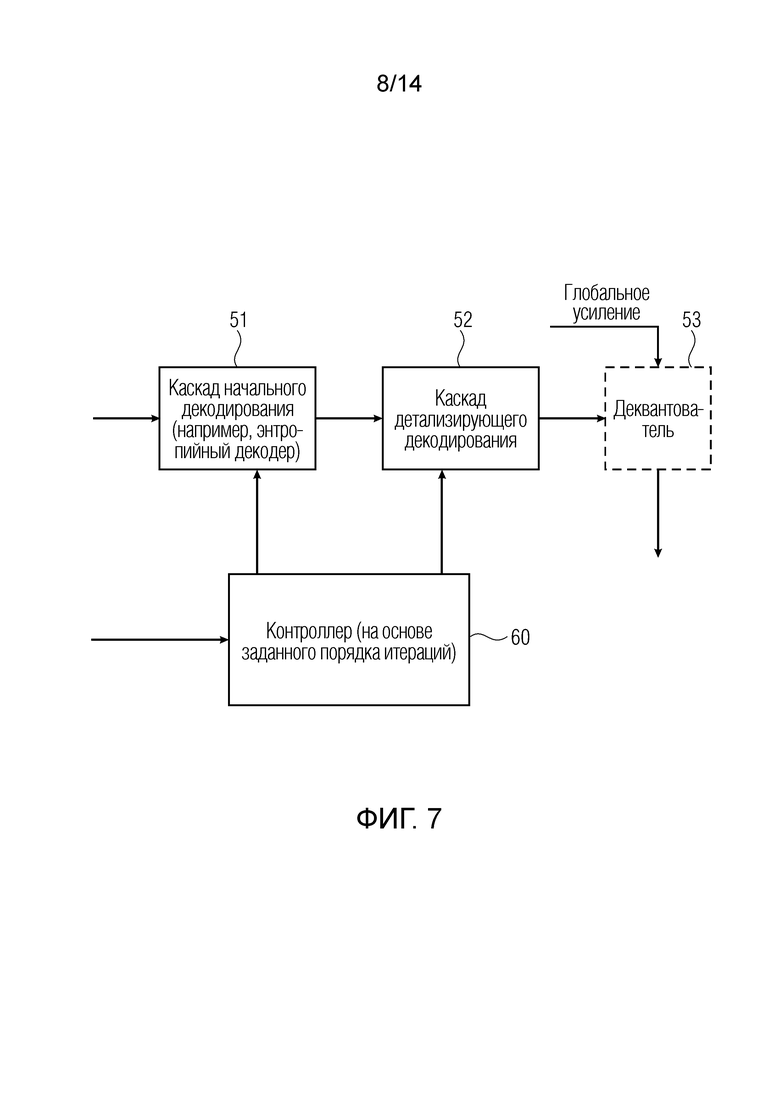
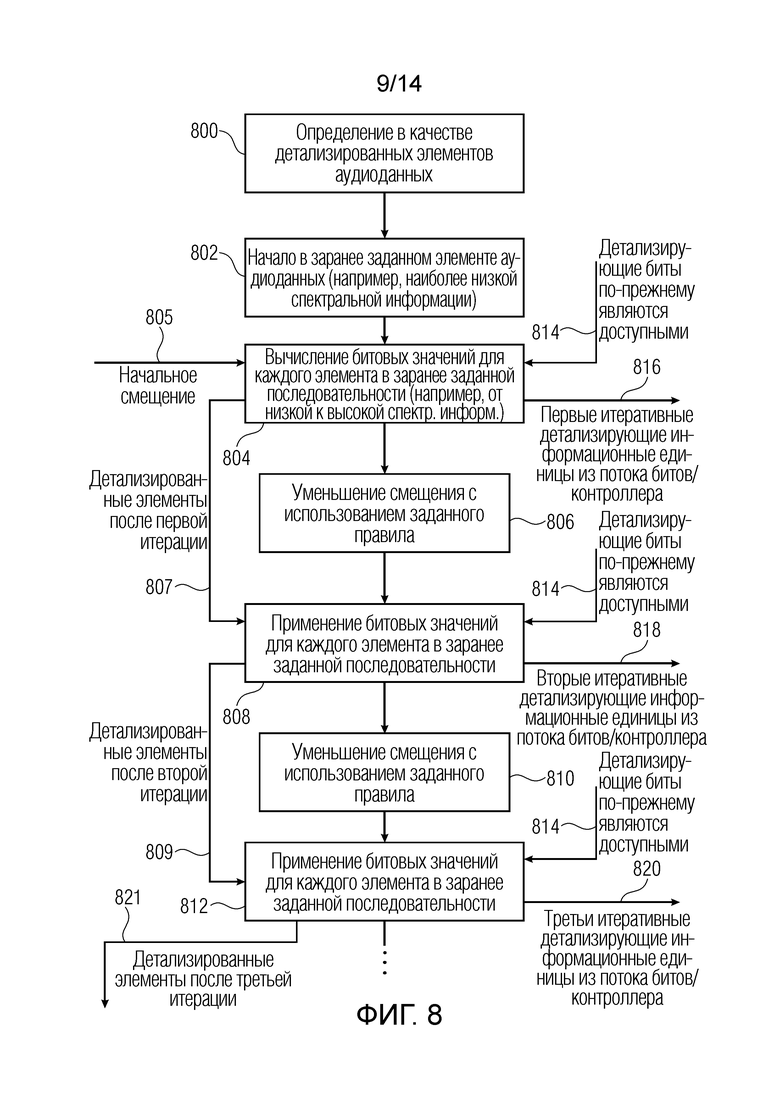
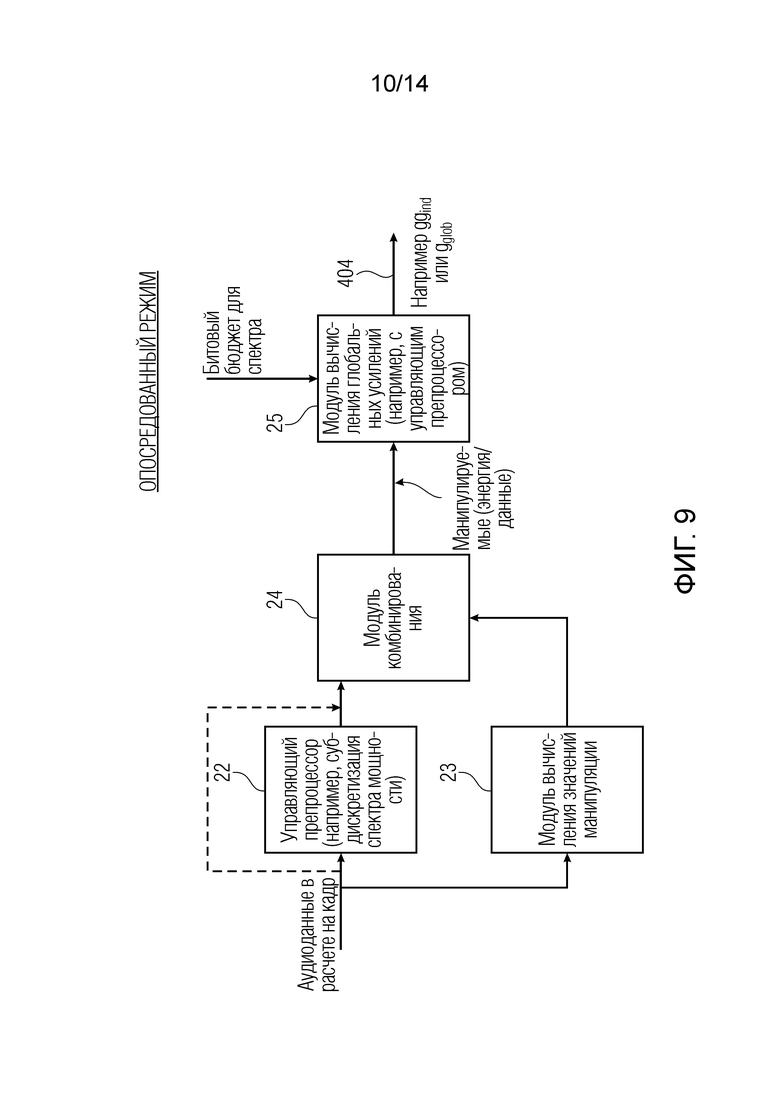
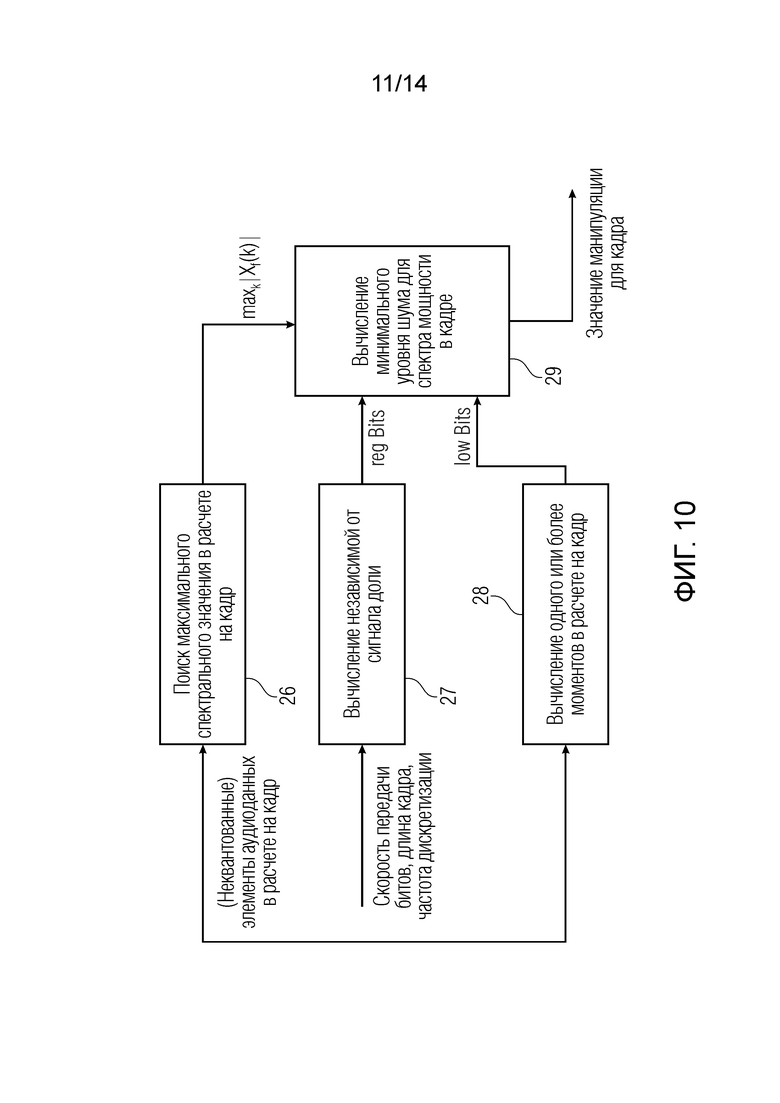
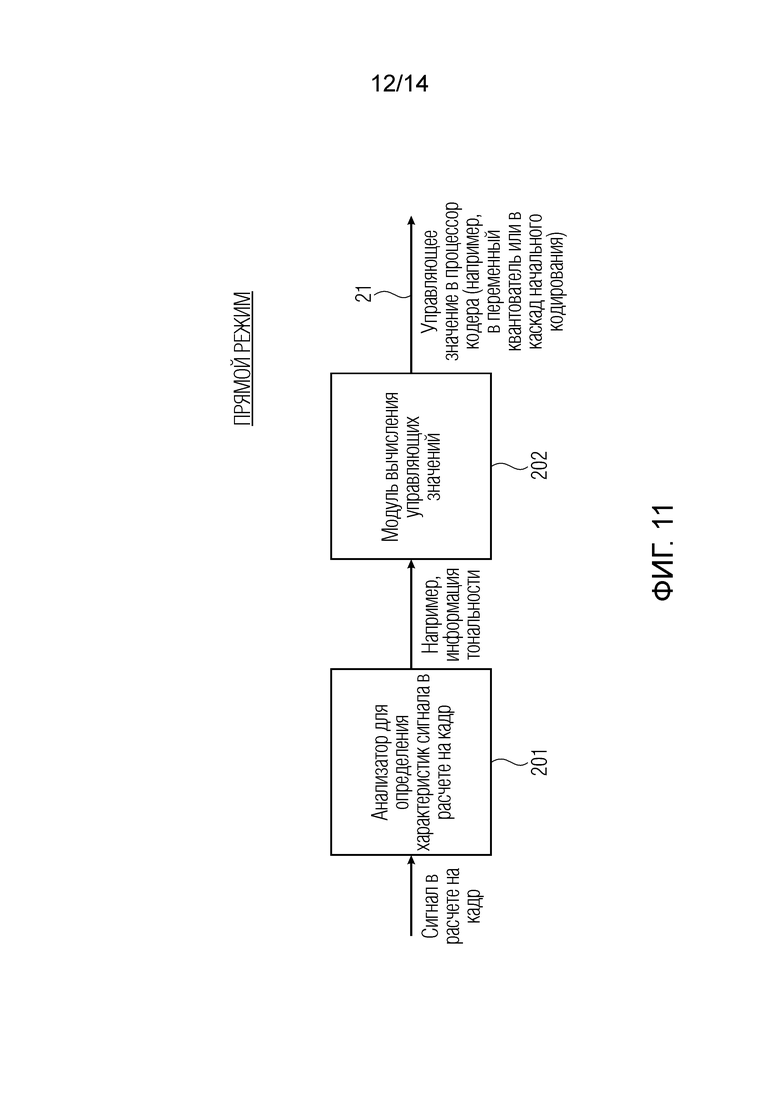
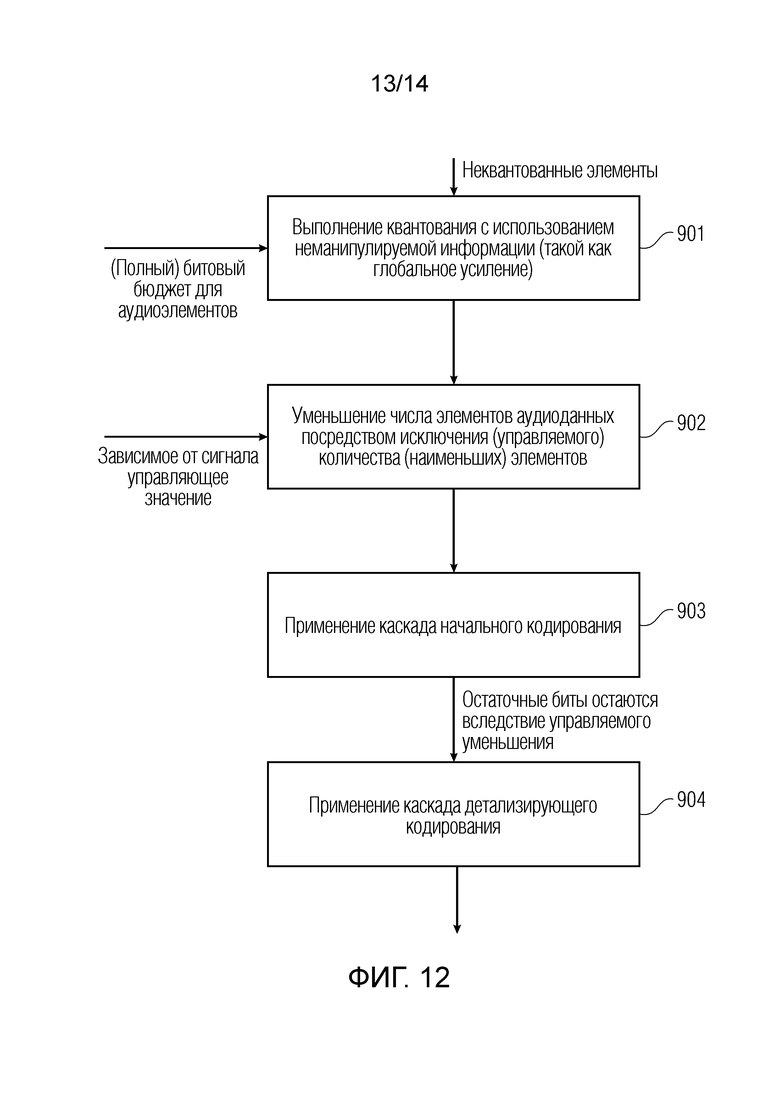
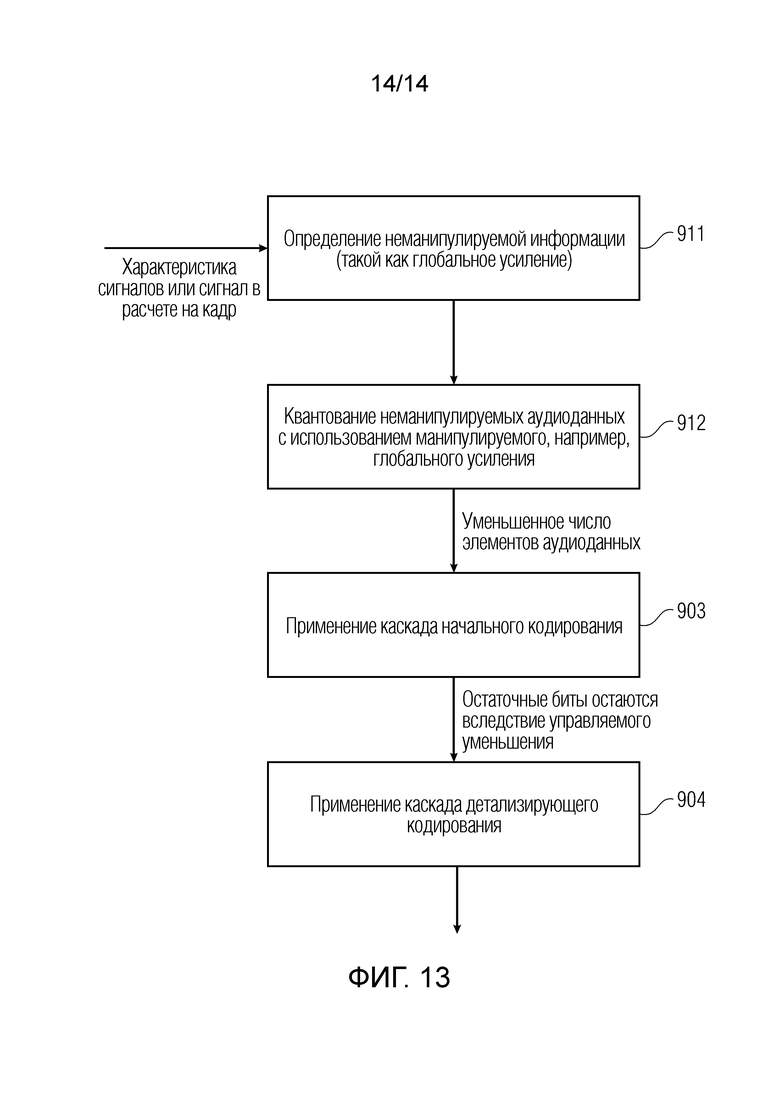
Изобретение относится к области вычислительной техники для кодирования аудио данных. Технический результат заключается в повышении скорости передачи битов и качества воспроизведения аудиоданных. Технический результат достигается за счет предварительной обработки входных аудиоданных для получения аудиоданных, которые должны кодироваться; кодирования аудиоданных, которые должны кодироваться; и управления кодированием таким образом, что, в зависимости от первой характеристики сигналов первого кадра аудиоданных, которые должны кодироваться, число элементов аудиоданных для аудиоданных, которые должны кодироваться для первого кадра, уменьшается по сравнению со второй характеристикой сигналов второго кадра, и первое число информационных единиц, используемых для кодирования уменьшенного числа элементов аудиоданных для первого кадра, более существенно улучшается по сравнению со вторым числом информационных единиц для второго кадра. 3 н. и 32 з.п. ф-лы, 14 ил., 1 табл. 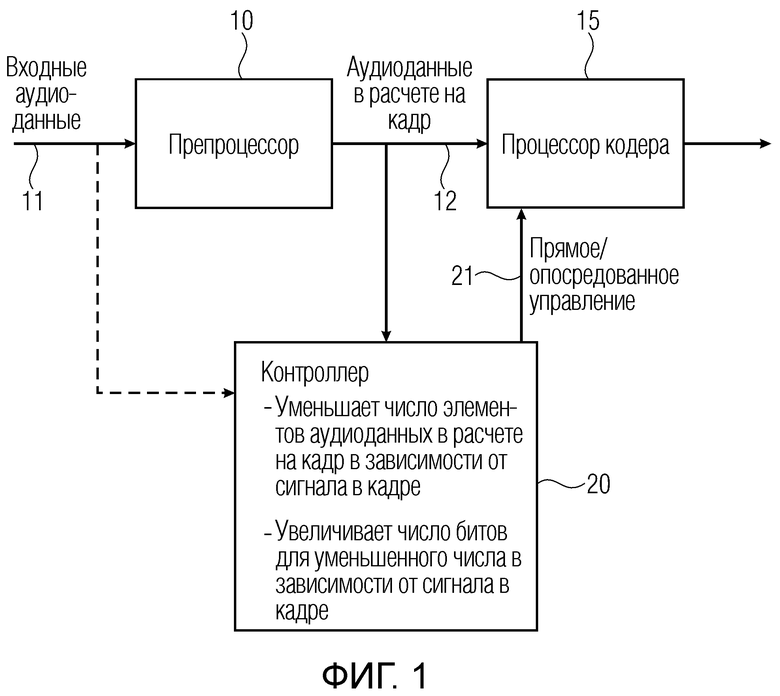
1. Аудиокодер для кодирования входных аудиоданных (11), содержащий:
- препроцессор (10) для предварительной обработки входных аудиоданных (11 для получения аудиоданных, которые должны кодироваться;
- процессор (15) кодера для кодирования аудиоданных, которые должны кодироваться; и
- контроллер (20) для управления процессором (15) кодера таким образом, что в зависимости от первой характеристики сигналов первого кадра аудиоданных, которые должны кодироваться, число элементов аудиоданных для аудиоданных, которые должны кодироваться процессором (15) кодера для первого кадра, уменьшается по сравнению со второй характеристикой сигналов второго кадра, и первое число информационных единиц, используемых для кодирования уменьшенного числа элементов аудиоданных для первого кадра, более существенно улучшается по сравнению со вторым числом информационных единиц для второго кадра.
2. Аудиокодер по п. 1,
- в котором процессор (15) кодера содержит каскад (151) начального кодирования и каскад (152) детализирующего кодирования,
- при этом контроллер (20) выполнен с возможностью уменьшения числа элементов аудиоданных, кодированных посредством каскада (151) начального кодирования для первого кадра,
- при этом каскад (151) начального кодирования выполнен с возможностью кодирования уменьшенного числа элементов аудиоданных для первого кадра с использованием начального числа информационных единиц первого кадра, и
- при этом каскад (152) детализирующего кодирования выполнен с возможностью использования оставшегося числа информационных единиц первого кадра для детализирующего кодирования для уменьшенного числа элементов аудиоданных для первого кадра, при этом результатом сложения начального числа информационных единиц первого кадра с оставшимся числом информационных единиц первого кадра является заданное число информационных единиц для первого кадра.
3. Аудиокодер по п. 2,
- в котором контроллер (20) выполнен с возможностью уменьшения числа элементов аудиоданных, кодируемых каскадом (151) начального кодирования для второго кадра, до более высокого числа элементов аудиоданных по сравнению с первым кадром,
- при этом каскад (151) начального кодирования выполнен с возможностью кодирования уменьшенного числа элементов аудиоданных для второго кадра с использованием начального числа информационных единиц второго кадра, причем начальное число информационных единиц второго кадра больше начального числа информационных единиц первого кадра, и
- при этом каскад (152) детализирующего кодирования выполнен с возможностью использования оставшегося числа информационных единиц второго кадра для детализирующего кодирования для уменьшенного числа элементов аудиоданных для второго кадра, при этом результатом сложения начального числа информационных единиц второго кадра с оставшимся числом информационных единиц второго кадра является заданное число информационных единиц для первого кадра.
4. Аудиокодер по любому из предшествующих пунктов,
- в котором процессор (15) кодера содержит каскад (151) начального кодирования и каскад (152) детализирующего кодирования,
- при этом каскад (151) начального кодирования выполнен с возможностью кодирования уменьшенного числа элементов аудиоданных для первого кадра с использованием начального числа информационных единиц первого кадра,
- при этом каскад (152) детализирующего кодирования выполнен с возможностью использования оставшегося числа информационных единиц первого кадра для детализирующего кодирования для уменьшенного числа элементов аудиоданных для первого кадра, при этом результатом сложения начального числа информационных единиц первого кадра с оставшимся числом информационных единиц первого кадра является заданное число информационных единиц для первого кадра, и
- при этом контроллер (20) выполнен с возможностью управления процессором (15) кодера таким образом, что каскад (152) детализирующего кодирования выполняет детализирующее кодирование по меньшей мере одного из уменьшенного числа элементов аудиоданных первого кадра с использованием по меньшей мере двух информационных единиц, либо таким образом, что каскад (152) детализирующего кодирования выполняет детализирующее кодирование более 50 процентов уменьшенного числа элементов аудиоданных с использованием по меньшей мере двух информационных единиц для каждого элемента аудиоданных, или
- при этом контроллер (20) выполнен с возможностью управления процессором (15) кодера таким образом, что каскад (152) детализирующего кодирования выполняет детализирующее кодирование всех элементов аудиоданных второго кадра с использованием менее двух информационных единиц, либо таким образом, что каскад детализирующего кодирования выполняет детализирующее кодирование менее 50 процентов уменьшенного числа элементов аудиоданных с использованием по меньшей мере двух информационных единиц для каждого элемента аудиоданных.
5. Аудиокодер по любому из предшествующих пунктов,
- в котором процессор (15) кодера содержит каскад (151) начального кодирования и каскад (152) детализирующего кодирования,
- при этом каскад (151) начального кодирования выполнен с возможностью кодирования уменьшенного числа элементов аудиоданных для первого кадра с использованием начального числа информационных единиц первого кадра,
- при этом каскад (152) детализирующего кодирования выполнен с возможностью использования оставшегося числа информационных единиц первого кадра для детализирующего кодирования для уменьшенного числа элементов аудиоданных для первого кадра,
- при этом каскад (152) детализирующего кодирования выполнен с возможностью итеративного назначения (300, 302) оставшегося числа информационных единиц первого кадра уменьшенному числу элементов аудиоданных по меньшей мере на двух последовательно выполняемых итерациях, вычисления (304, 308, 312) значения назначенных информационных единиц по меньшей мере для двух последовательно выполняемых итераций и ввода (316, 318, 320) вычисленных значений информационных единиц по меньшей мере для двух последовательно выполняемых итераций в кодированный выходной кадр в заданном порядке.
6. Аудиокодер по п. 5, в котором каскад (152) детализирующего кодирования выполнен с возможностью последовательного вычисления (304) информационной единицы для каждого элемента аудиоданных из уменьшенного числа элементов аудиоданных для первого кадра в порядке от низкочастотной информации для элемента аудиоданных к высокочастотной информации для элемента аудиоданных на первой итерации,
- при этом каскад (152) детализирующего кодирования выполнен с возможностью последовательного вычисления (308) информационной единицы для каждого элемента аудиоданных из уменьшенного числа элементов аудиоданных для первого кадра в порядке от низкочастотной информации для элемента аудиоданных к высокочастотной информации для элемента аудиоданных на второй итерации, и
- при этом каскад (152) детализирующего кодирования выполнен с возможностью проверки (314), является ли число уже назначенных информационных единиц меньшим, чем заданное число информационных единиц для первого кадра, меньшее, чем начальное число информационных единиц первого кадра, и прекращения второй итерации в случае отрицательного результата проверки, либо, в случае положительного результата проверки, выполнения (312) определенного числа дополнительных итераций до тех пор, пока не будет получен отрицательный результат проверки, причем число дополнительных итераций составляет по меньшей мере одну, или
- при этом каскад (152) детализирующего кодирования выполнен с возможностью подсчёта числа ненулевых аудиоэлементов и определения числа итераций из числа ненулевых аудиоэлементов и заданного числа информационных единиц для первого кадра, меньшего, чем начальное число информационных единиц первого кадра.
7. Аудиокодер по любому из предшествующих пунктов,
- в котором процессор (15) кодера содержит каскад (151) начального кодирования и каскад (152) детализирующего кодирования,
- при этом каскад (151) начального кодирования выполнен с возможностью кодирования числа старших информационных единиц для каждого элемента аудиоданных из уменьшенного числа элементов аудиоданных для первого кадра с использованием начального числа информационных единиц первого кадра, причем упомянутое число больше единицы, и
- при этом каскад (152) детализирующего кодирования выполнен с возможностью использования оставшегося числа информационных единиц первого кадра для кодирования числа младших информационных единиц для каждого элемента аудиоданных из уменьшенного числа элементов аудиоданных для первого кадра, причем упомянутое число больше единицы по меньшей мере для одного элемента аудиоданных из уменьшенного числа элементов аудиоданных для первого кадра.
8. Аудиокодер по любому из предшествующих пунктов,
- в котором первая характеристика сигналов составляет первое значение тональности, при этом вторая характеристика сигналов составляет второе значение тональности, и при этом первое значение тональности указывает более высокую тональность, чем второе значение тональности, и
- при этом контроллер (20) выполнен с возможностью уменьшения числа элементов аудиоданных для первого кадра до первого числа, меньшего, чем число элементов аудиоданных для второго кадра, и увеличения среднего числа информационных единиц, используемых для кодирования каждого элемента аудиоданных из уменьшенного числа элементов аудиоданных первого кадра, таким образом, чтобы оно превышало среднее число информационных единиц, используемых для кодирования каждого элемента аудиоданных из уменьшенного числа элементов аудиоданных второго кадра.
9. Аудиокодер по любому из предшествующих пунктов, в котором процессор (15) кодера содержит:
- переменный квантователь (150) для квантования аудиоданных первого кадра для получения квантованных аудиоданных для первого кадра, и для квантования аудиоданных второго кадра для получения квантованных аудиоданных для второго кадра;
- каскад (151) начального кодирования для кодирования квантованных аудиоданных первого кадра или второго кадра;
- каскад (152) детализирующего кодирования для кодирования остаточных данных первого кадра и второго кадра;
- при этом контроллер (20) выполнен с возможностью анализа (26, 28) аудиоданных первого кадра для определения первого управляющего значения (21) для переменного квантователя (150) для первого кадра, и анализа (26, 28) аудиоданных второго кадра для определения второго управляющего значения для переменного квантователя (150) для второго кадра, причем второе управляющее значение отлично от первого управляющего значения (21), и
- при этом контроллер (20) выполнен с возможностью выполнения (23, 24) манипулирования аудиоданными первого кадра или второго кадра или связанными с амплитудой значениями, извлекаемыми из аудиоданных первого кадра или второго кадра, в зависимости от аудиоданных для определения первого управляющего значения (21) или второго управляющего значения (21), и при этом переменный квантователь (150) выполнен с возможностью квантования аудиоданных первого кадра или второго кадра без упомянутого манипулирования.
10. Аудиокодер по любому из пп. 1-9, в котором процессор (15) кодера содержит:
- переменный квантователь (150) для квантования аудиоданных первого кадра для получения квантованных аудиоданных для первого кадра, и для квантования аудиоданных второго кадра для получения квантованных аудиоданных для второго кадра;
- каскад (151) начального кодирования для кодирования квантованных аудиоданных первого кадра или второго кадра;
- каскад (152) детализирующего кодирования для кодирования остаточных данных первого кадра и второго кадра;
- при этом контроллер (20) выполнен с возможностью анализа аудиоданных первого кадра для определения первого управляющего значения (21) для переменного квантователя (150), для каскада (151) начального кодирования или для модуля (150) уменьшения числа элементов аудиоданных для первого кадра, и с возможностью анализа аудиоданных второго кадра для определения второго управляющего значения для переменного квантователя (150), для каскада (151) начального кодирования или для модуля (150) уменьшения числа элементов аудиоданных для второго кадра, причем второе управляющее значение отлично от первого управляющего значения, и
- при этом контроллер (20) выполнен с возможностью (201) определения первой характеристики тональности в качестве первой характеристики сигналов для определения первого управляющего значения, и второй характеристики тональности в качестве второй характеристики сигналов для определения второго управляющего значения, таким образом, чтобы битовый бюджет для каскада (152) детализирующего кодирования увеличивался в случае первой характеристики тональности по сравнению с битовым бюджетом для каскада (152) детализирующего кодирования в случае второй характеристики тональности, при этом первая характеристика тональности указывает большую тональность, чем вторая характеристика тональности.
11. Аудиокодер по п. 9 или 10, в котором каскад (151) начального кодирования представляет собой каскад энтропийного кодирования для энтропийного кодирования, либо каскад (152) детализирующего кодирования представляет собой каскад остаточного или двоичного кодирования для кодирования остаточных данных первого кадра и второго кадра.
12. Аудиокодер по любому из пп. 9-11,
- в котором контроллер (20) выполнен с возможностью определения первого или второго управляющего значения таким образом, чтобы первый бюджет информационных единиц для каскада (151) начального кодирования был меньше или равен заранее заданному значению, и при этом контроллер (20) выполнен с возможностью извлечения второго бюджета информационных единиц для каскада (152) детализирующего кодирования с использованием первого бюджета информационных единиц и максимального числа информационных единиц для первого или второго кадра или заранее заданного значения.
13. Аудиокодер по любому из пп. 9-12, в котором контроллер (20) выполнен с возможностью вычисления (22) связанных с амплитудой значений в качестве множества значений мощности, извлекаемых из одного или более аудиозначений аудиоданных, и манипулирования (24) значениями мощности с использованием сложения одинакового значения манипуляции со всеми значениями мощности из множества значений мощности, или
- при этом контроллер (20) выполнен с возможностью:
- рандомизированного сложения или вычитания (24) одинакового значения манипуляции со всеми аудиозначениями из множества аудиозначений, включенных в кадр, или из них, или
- сложения или вычитания значений, полученных посредством одинаковой абсолютной величины значения манипуляции, но предпочтительно с рандомизированными знаками, или
- сложения или вычитания значений, полученных посредством вычитания немного отличающихся членов из одинаковой абсолютной величины,
- сложения или вычитания значений, полученных в качестве выборок из нормализованного распределения вероятностей, масштабированного с использованием вычисленной комплексной или действительной абсолютной величины значения манипуляции, или
- при этом контроллер (20) выполнен с возможностью вычисления (22) связанных с амплитудой значений с использованием возведения в степень аудиоданных первого или второго кадра или субдискретизированных аудиоданных первого или второго кадра со значением экспоненты, причем значение экспоненты больше 1.
14. Аудиокодер по любому из пп. 9-13, в котором контроллер (20) выполнен с возможностью вычисления (23) значения манипуляции для манипулирования с использованием максимального значения (26) множества аудиоданных или связанных с амплитудой значений либо с использованием максимального значения множества субдискретизированных аудиоданных или множества субдискретизированных связанных с амплитудой значений для первого или второго кадра.
15. Аудиокодер по любому из пп. 9-14, в котором контроллер (20) выполнен с возможностью вычисления (23) значения манипуляции для манипулирования дополнительно с использованием независимого от сигнала весового значения (27), причем не зависимое от сигнала весовое значение зависит по меньшей мере от одного из скорости передачи битов для первого или второго кадра, длительности кадра и частоты дискретизации.
16. Аудиокодер по любому из пп. 9-15, в котором контроллер (20) выполнен с возможностью вычисления (23, 29) значения манипуляции для манипулирования с использованием зависимого от сигнала весового значения, извлекаемого по меньшей мере из одного из первой суммы абсолютных величин аудиоданных или субдискретизированных аудиоданных в кадре, второй суммы абсолютных величин аудиоданных или субдискретизированных аудиоданных в кадре, умноженном на индекс, ассоциированный с каждой абсолютной величиной, и частного второй суммы и первой суммы.
17. Аудиокодер по любому из пп. 9-16,
- в котором контроллер (20) выполнен с возможностью вычисления (29) значения манипуляции для манипулирования на основе следующего уравнения:
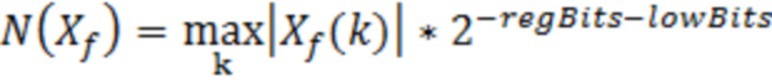 ,
,
- при этом k является частотным индексом, при этом Xf(k) является значением аудиоданных для частотного индекса k перед квантованием, при этом max является функцией максимума, при этом regBits является первым не зависимым от сигнала весовым значением, и при этом lowBits является вторым зависимым от сигнала весовым значением.
18. Аудиокодер по любому из предшествующих пунктов, в котором препроцессор (10) дополнительно содержит:
- частотно-временной преобразователь (14) для преобразования аудиоданных временной области в спектральные значения кадра; и
- спектральный процессор (15) для вычисления модифицированных спектральных значений, имеющих более плоскую спектральную огибающую, чем спектральная огибающая спектральных значений, при этом модифицированные спектральные значения представляют аудиоданные первого или второго кадра, который должен кодироваться процессором (15) кодера.
19. Аудиокодер по п. 18, в котором спектральный процессор (15) выполнен с возможностью выполнения по меньшей мере одного из операции формирования временного шума, операции формирования спектрального шума и операции спектрального отбеливания.
20. Аудиокодер по любому из пп. 9-19, в котором контроллер (20) выполнен с возможностью вычисления управляющего значения с использованием множества значений энергии в качестве связанных с амплитудой значений для кадра, при этом каждое значение энергии извлекается (22, 23, 24) из значения мощности в качестве связанного с амплитудой значения и значения зависимого от сигнала манипулирования для упомянутого манипулирования.
21. Аудиокодер по п. 20, в котором контроллер (20) выполнен с возможностью:
- вычисления требуемой битовой оценки каждого значения энергии в зависимости от значения энергии и возможного значения для управляющего значения,
- накопления требуемых битовых оценок для значений энергии и возможного значения для управляющего значения,
- проверки, соответствует ли накопленная битовая оценка для возможного значения для управляющего значения критерию разрешенного потребления битов, и
- модификации возможного значения для управляющего значения в случае, если критерий разрешенного потребления битов не выполнен, и повторения вычисления требуемой битовой оценки, накопления требуемой скорости передачи битов и проверки до тех пор, пока не будет обнаружено соответствие критерию разрешенного потребления битов для модифицированного возможного значения для управляющего значения.
22. Аудиокодер по п. 20 или 21,
- в котором контроллер (20) выполнен с возможностью вычисления множества значений энергии на основе следующего уравнения:
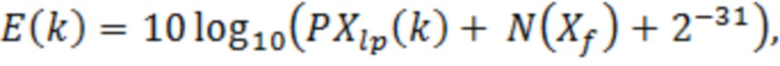
- при этом E(k) является значением энергии для индекса k, при этом PXlp(k) является значением мощности для индекса k в качестве связанного с амплитудой значения, и при этом N(Xf) представляет собой зависимое от сигнала значение манипуляции.
23. Аудиокодер по любому из пп. 9-22, в котором контроллер (20) выполнен с возможностью вычисления первого или второго управляющего значения на основе оценки накопленных информационных единиц, требуемых для каждого манипулируемого значения аудиоданных или манипулируемого связанного с амплитудой значения.
24. Аудиодекодер по любому из пп. 9-23,
- в котором контроллер (20) выполнен с возможностью манипулирования таким образом, что вследствие манипулирования увеличивается битовый бюджет для каскада (151) начального кодирования или уменьшается битовый бюджет для каскада (152) детализирующего кодирования.
25. Аудиодекодер по любому из пп. 9-24,
- в котором контроллер (20) выполнен с возможностью манипулирования таким образом, что манипулирование приводит к большему битовому бюджету каскада остаточного кодирования для сигнала с первой тональностью по сравнению с сигналом со второй тональностью, при этом вторая тональность ниже первой тональности.
26. Аудиодекодер по любому из пп. 9-25,
- в котором контроллер (20) выполнен с возможностью манипулирования таким образом, что энергия аудиоданных, из которых вычисляется битовый бюджет для каскада (151) начального кодирования, увеличивается относительно энергии аудиоданных, которые должны квантоваться посредством переменного квантователя (150).
27. Аудиокодер по любому из предшествующих пунктов, в котором процессор (15) кодера содержит переменный квантователь (150) для квантования аудиоданных первого кадра для получения квантованных аудиоданных для первого кадра и для квантования аудиоданных второго кадра для получения квантованных аудиоданных для второго кадра,
- при этом контроллер (20) выполнен с возможностью вычисления глобального усиления для первого или второго кадра, и
- при этом переменный квантователь (150) содержит: модуль (155) взвешивания для взвешивания с глобальным усилением; и ядро (157) квантователя, имеющее фиксированный размер шага квантования.
28. Аудиокодер по любому из предшествующих пунктов, в котором процессор (15) кодера содержит каскад (151) начального кодирования и каскад (152) детализирующего кодирования,
- при этом каскад (152) детализирующего кодирования выполнен с возможностью вычисления детализирующих битов для квантованных аудиозначений во множестве итераций, при этом на каждой итерации детализирующий бит указывает различное количество, или
- при этом детализирующий бит на более низкой итерации указывает большее количество, чем детализирующий бит на более высокой итерации, или
- при этом количество составляет дробное количество, составляющее часть размера шага квантователя, указываемого управляющим значением.
29. Аудиокодер по любому из предшествующих пунктов, в котором процессор (15) кодера содержит каскад (152) детализирующего кодирования, при этом каскад (152) детализирующего кодирования выполнен с возможностью (304, 308, 312):
- выполнения итеративной обработки, имеющей по меньшей мере две итерации,
- проверки, является ли квантованное аудиозначение или квантованное аудиозначение вместе с потенциальным первым количеством, ассоциированным с детализирующим битом для квантованного аудиозначения на первой итерации, складываемым со вторым количеством для второй итерации или вычитаемым из него, при взвешивании посредством глобального усиления, большим или меньшим, чем неквантованное аудиозначение, и
- задания детализирующего бита для второй итерации в зависимости от результата проверки.
30. Аудиокодер по любому из предшествующих пунктов, в котором процессор (15) кодера содержит переменный квантователь (150) и каскад (152) детализирующего кодирования, при этом каскад (152) детализирующего кодирования выполнен с возможностью вычисления детализирующего бита только для аудиозначений, которые не квантованы в ноль переменным квантователем (150).
31. Аудиокодер по любому из предшествующих пунктов,
- в котором контроллер (20) выполнен с возможностью уменьшения влияния манипулирования для аудиоданных, имеющих центр масс при более низкой частоте, и
- при этом каскад (151) начального кодирования процессора (15) кодера выполнен с возможностью удаления высокочастотных спектральных значений из аудиоданных в случае, если определено, что битовый бюджет для первого или второго кадра является недостаточным для кодирования квантованных аудиоданных кадра.
32. Аудиокодер по любому из предшествующих пунктов,
- в котором контроллер (20) выполнен с возможностью выполнения бисекционного поиска для каждого кадра по отдельности с использованием манипулируемых значений спектральной энергии для первого или второго кадра в качестве манипулируемых связанных с амплитудой значений для первого или второго кадра.
33. Способ кодирования входных аудиоданных, содержащий этапы, на которых:
- предварительно обрабатывают входные аудиоданные (11) для получения аудиоданных, которые должны кодироваться;
- кодируют аудиоданные, которые должны кодироваться; и
- управляют кодированием таким образом, что, в зависимости от первой характеристики сигналов первого кадра аудиоданных, которые должны кодироваться, число элементов аудиоданных для аудиоданных, которые должны кодироваться для первого кадра, уменьшается по сравнению со второй характеристикой сигналов второго кадра, и первое число информационных единиц, используемых для кодирования уменьшенного числа элементов аудиоданных для первого кадра, более существенно улучшается по сравнению со вторым числом информационных единиц для второго кадра.
34. Способ по п. 33, в котором кодирование содержит этапы, на которых:
- переменно квантуют аудиоданные кадра для получения квантованных аудиоданных;
- выполняют энтропийное кодирование квантованных аудиоданных кадра; и
- кодируют остаточные данные кадра;
- при этом управление содержит этап, на котором определяют управляющее значение для переменного квантования, причем определение содержит этапы, на которых: анализируют аудиоданные первого или второго кадра; и выполняют манипулирование аудиоданными первого или второго кадра или связанными с амплитудой значениями, извлекаемыми из аудиоданных первого или второго кадра в зависимости от аудиоданных для определения управляющего значения, при этом переменное квантование квантует аудиоданные кадра без манипулирования, или
- при этом управление содержит этап, на котором определяют первую или вторую характеристику тональности аудиоданных и определяют управляющее значение таким образом, чтобы битовый бюджет для остаточного кодирования увеличивался в случае первой характеристики тональности по сравнению с битовым бюджетом для каскада остаточного кодирования в случае второй характеристики тональности, при этом первая характеристика тональности указывает большую тональность, чем вторая характеристика тональности.
35. Физический носитель данных, на котором сохранена компьютерная программа для осуществления при выполнении на компьютере или в процессоре способа по п. 33 или 34.
| Пресс для выдавливания из деревянных дисков заготовок для ниточных катушек | 1923 |
|
SU2007A1 |
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ И СИСТЕМА КОДИРОВАНИЯ АУДИОДАННЫХ С АДАПТИВНОЙ НИЗКОЧАСТОТНОЙ КОРРЕКЦИЕЙ | 2012 |
|
RU2583717C1 |
| АУДИОКОДЕР ДЛЯ КОДИРОВАНИЯ МНОГОКАНАЛЬНОГО СИГНАЛА И АУДИОДЕКОДЕР ДЛЯ ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА | 2016 |
|
RU2679571C1 |

