Область техники, к которой относится изобретение
Настоящая технология относится к машинному переводу и, в частности, к системе и способу перевода исходного предложения на первом языке целевым предложением на втором языке.
Уровень техники
С увеличением количества пользователей, имеющих доступ к сети Интернет, возникло огромное число интернет-служб. В качестве примера таких служб можно привести поисковую систему (например, Yandex™, Google™ и т.п.), социальную сеть (например, Facebook™), мультимедийную службу (например, Instagram™ и YouTube™) и службу перевода (например, Yandex.Translate™). Последняя служба особенно полезна для облегчения перевода текста (или даже устной речи) с одного естественного языка (обычно не полностью понятного данному пользователю) на другой (обычно понятный данному пользователю).
Интерес к автоматическому переводу текста с одного языка на другой постоянно растет, что, в частности, обусловлено развитием компьютерных технологий. Недавние успехи в обеспечении возможностей компьютеров по быстрой обработке разнообразной информации при использовании меньшего объема памяти способствовали значительному прогрессу в области машинного перевода.
Один из широко известных способов машинного перевода - это статистический машинный перевод (SMT). Технология SMT предусматривает выполнение статистического анализа для перевода текста с первого языка на второй язык. Достоинства SMT заключаются в доступности огромного количества корпусов двуязычных текстов для обучения SMT. Технология SMT способна обеспечить приемлемую точность перевода для текста, состоящего из коротких (или простых) предложений. В случае текста, состоящего из длинных (или сложных) предложений, точность SMT падает, поскольку этот способ не позволяет надлежащим образом переводить контекст текста.
Другой способ машинного перевода основывается на нейронном машинном переводе (NMT) с использованием большой нейронной сети. Технология NMT считается перспективным подходом к устранению недостатков SMT, поскольку NMT поддерживает возможность сквозного обучения преобразованию текста на входе в переведенный текст на выходе.
Несмотря на то, что NMT обеспечивает более высокую точность перевода по сравнению с STM, этот подход также обладает некоторыми недостатками. Например, в случае NMT возникают сложности с переводом редких слов с одного языка на другой, что часто приводит к бессмысленным переводам.
В документе US 9201871 В2 (опубликован 15 декабря 2011 г.) описана стратегия совместной оптимизации для объединения гипотез переводов из нескольких систем машинного перевода. Решения, касающиеся выравнивания (alignment) - соответствия слов, полученных по разным гипотезам, порядка слов и выбора объединенного выходного перевода, принимаются совместно и зависят от набора признаков. Также предложены и использованы дополнительные признаки, позволяющие моделировать подход к выравниванию и упорядочению.
В документе CN 105068998 А описан способ и устройство для перевода на основе модели нейронной сети. Основанный на модели нейронной сети способ перевода включает в себя: получение предложения на исходном языке; кодирование предложения на исходном языке для получения векторной последовательности; поочередное прогнозирование возможных слов перевода на целевом языке на основе векторной последовательности; и прогнозирование возможных слов перевода для формирования предложения на целевом языке.
Способ и устройство для перевода на основе модели нейронной сети в вариантах осуществления настоящего изобретения позволяют выполнять перевод в сочетании с различными инструментами перевода и повышать качество перевода, а также гладкость и удобочитаемость результата перевода.
Раскрытие изобретения
Целью настоящего изобретения является создание усовершенствованных способа и систем для перевода исходного предложения на первом языке целевым предложением на втором языке. Цель настоящего изобретения заключается в переводе исходного предложения целевым предложением таким образом, чтобы устранить недостатки традиционных технологий NMT и SMT.
При разработке данной технологии разработчики обратили внимание на возможность создания такой системы перевода, использующей технологии NMT и SMT, что их преимущества дополняют друг друга для получения более качественного перевода.
Безотносительно какой-либо конкретной теории, варианты осуществления данной технологии разработаны на основе предположения, что используя два обученных классификатора, возможно заменять перевод на основе NMT, определенный как семантически нелогичный или некачественный, на перевод на основе SMT для обеспечения общего приемлемого качества перевода текста.
Согласно общему широкому аспекту данной технологии обеспечен реализуемый на компьютере способ перевода исходного предложения на первом языке целевым предложением на втором языке. Выполняемый компьютерным устройством способ включает в себя: прием исходного предложения; формирование первой гипотезы перевода с использованием первой модели перевода; формирование второй гипотезы перевода с использованием второй модели перевода, отличной от первой модели перевода; назначение посредством первого классификатора первого значения оценки для первой гипотезы перевода, при этом первое значение оценки представляет собой вероятность того, что первая гипотеза перевода соответствует семантически нелогичному или семантически логичному переводу на второй язык, и первый классификатор обучен определять первое значение оценки на основе анализа триады данных, содержащей: исходное предложение, первую гипотезу перевода и вторую гипотезу перевода; назначение посредством второго классификатора второго значения оценки для первой гипотезы перевода, при этом второе значение оценки представляет собой предполагаемое различие качества перевода между первой гипотезой перевода и второй гипотезой перевода и второй классификатор обучен определять второе значение оценки на основе анализа триады данных. Способ также включает в себя формирование целевого предложения, соответствующего первой гипотезе перевода, если определено, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, или второй гипотезе перевода, если определено, что это условие не выполнено.
В некоторых вариантах осуществления первая модель перевода представляет собой модель машинного перевода на основе нейронной сети, а вторая модель перевода представляет собой модель статистического перевода на основе фраз.
В некоторых вариантах осуществления определение того, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, включает в себя определение того, что первое значение оценки меньше первого порога, и определение того, что второе значение оценки меньше второго порога.
В некоторых вариантах осуществления первый классификатор предварительно обучен на обучающих данных, содержащих по меньшей мере одно обучающее предложение, помеченное как семантически логичное или нелогичное, и способен определять, указывает триплет данных на более высокую вероятность семантической нелогичности первой гипотезы перевода или на более низкую вероятность семантической нелогичности первой гипотезы перевода на второй язык.
В некоторых вариантах осуществления обучающее предложение представляет собой первое обучающее предложение на втором языке, а обучающие данные дополнительно включают в себя обучающее исходное предложение на первом языке и второе обучающее предложение на втором языке; при этом первое обучающее предложение сформировано с использованием первой модели перевода на основе обучающего исходного предложения; второе обучающее предложение сформировано с использованием второй модели перевода на основе обучающего исходного предложения; а обучение первого классификатора дополнительно включает в себя: назначение экспертом для первого обучающего предложения двоичного значения метки, представляющего собой первое двоичное значение метки или второе двоичное значение метки, при этом первое двоичное значение метки указывает на то, что первое обучающее предложение семантически нелогично, а второе двоичное значение метки указывает на то, что первое обучающее предложение семантически логично; формирование прогнозной функции на основе обучающего исходного предложения, первого обучающего предложения, второго обучающего предложения и двоичного значения метки, назначенного для первого обучающего предложения, при этом прогнозная функция способна назначать первое значение оценки для первой гипотезы перевода на основе триады данных.
В некоторых вариантах осуществления назначение первого значения оценки для первой гипотезы перевода на основе триады данных включает в себя: определение связанного с триплетом данных набора признаков, содержащего по меньшей мере один из следующих признаков: признак выравнивания, указывающий на лексическое соответствие между словами, содержащимися в исходном предложении, первой гипотезе перевода и второй гипотезе перевода; признак оценки на основе языковой модели, связанный с оценкой на основе языковой модели, назначенной для каждой первой гипотезы перевода и каждой второй гипотезы перевода с использованием языковой модели; признак двуязычной таблицы словосочетаний, указывающий на соответствие друг другу словосочетаний, содержащихся в исходном предложении, первой гипотезе перевода и второй гипотезе перевода, при этом каждое соответствие словосочетаний дополнительно содержит вероятность их совместного появления в корпусе параллельных текстов; признак повторения, связанный с наличием повторения данного слова в первой гипотезе перевода; признак отношения длин, связанный с отношением длин последовательностей слов в исходном предложении и в первой и второй гипотезах перевода; и назначение первого значения оценки для первой гипотезы перевода на основе такого определенного набора признаков.
В некоторых вариантах осуществления первый порог задан заранее и способ дополнительно включает в себя корректировку этого порога путем выполнения следующих действий: прием набора исходных проверочных предложений на первом языке; формирование набора первых проверочных переводов с использованием первой модели перевода; формирование набора вторых проверочных переводов с использованием второй модели перевода; назначение экспертом двоичного значения метки для каждого первого проверочного перевода в наборе первых проверочных переводов; назначение первого значения оценки для каждого первого проверочного перевода посредством первого классификатора; определение количества ошибок проверки, соответствующего количеству первых проверочных переводов с первым значением метки, которым назначено первое значение оценки, меньшее заранее заданного первого порога; уменьшение первого порога, если определено, что количество ошибок проверки превышает заранее заданный проверочный порог.
В некоторых вариантах осуществления второй классификатор обучен на по меньшей мере одной тетраде данных, содержащей: обучающее исходное предложение на первом языке; первое обучающее предложение, сформированное с использованием первой модели перевода на основе обучающего исходного предложения; второе обучающее предложение, сформированное с использованием второй модели перевода на основе обучающего исходного предложения; переведенное человеком предложение, соответствующее обучающему исходному предложению, переведенному на второй язык экспертом; при этом обучение второго классификатора дополнительно включает в себя: расчет первой оценки качества перевода первого обучающего предложения на основе переведенного человеком предложения; расчет второй оценки качества перевода второго обучающего предложения на основе переведенного человеком предложения; формирование значения оценки различия качества, соответствующего разности второй оценки качества перевода и первой оценки качества перевода; формирование прогнозной функции, способной назначать второе значение оценки и формируемой на основе регрессионного анализа значения оценки различия качества, первого обучающего предложения, второго обучающего предложения и обучающего исходного предложения.
В некоторых вариантах осуществления первая оценка качества перевода и/или вторая оценка качества перевода представляет собой оценку методом двуязычного оценщика-дублера (BLEU).
В некоторых вариантах осуществления вычислительное устройство представляет собой сервер, связанный с клиентским устройством через сеть связи, при этом прием исходного предложения включает в себя прием исходного предложения от клиентского устройства, а способ дополнительно включает в себя передачу целевого предложения клиентскому устройству.
В соответствии с другим аспектом данной технологии разработан сервер, переводящий исходное предложение на первом языке целевым предложением на втором языке, содержащий процессор, способный выполнять следующие действия: прием исходного предложения; формирование первой гипотезы перевода с использованием первой модели перевода; формирование второй гипотезы перевода с использованием второй модели перевода, отличной от первой модели перевода; назначение первым классификатором первого значения оценки для первой гипотезы перевода, при этом первое значение оценки представляет собой вероятность того, что первая гипотеза перевода соответствует семантически логичному или семантически нелогичному переводу на второй язык, и первый классификатор обучен определять первое значение оценки на основе анализа триады данных, содержащей исходное предложение, первую гипотезу перевода и вторую гипотезу перевода; назначение вторым классификатором второго значения оценки для первой гипотезы перевода, при этом второе значение оценки представляет собой предполагаемое различие качества перевода между первой гипотезой перевода и второй гипотезой перевода, и второй классификатор обучен определять второе значение оценки на основе анализа триады данных; формирование целевого предложения, которое соответствует первой гипотезе перевода, если определено, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, или второй гипотезе перевода, если определено, что это условие не выполнено.
В некоторых вариантах осуществления первая модель перевода представляет собой модель машинного перевода на основе нейронной сети, а вторая модель перевода представляет собой модель статистического перевода на основе словосочетаний.
В некоторых вариантах осуществления для определения того, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, процессор способен определять, что первое значение оценки меньше первого порога, и определять, что второе значение оценки меньше второго порога.
В некоторых вариантах осуществления первый классификатор предварительно обучен на обучающих данных, содержащих по меньшей мере одно обучающее предложение, помеченное как семантически логичное или нелогичное, а процессор способен определять, указывает триплет данных на более высокую вероятность семантической нелогичности первой гипотезы перевода или на более низкую вероятность семантической нелогичности первой гипотезы перевода на второй язык.
В некоторых вариантах осуществления обучающее предложение представляет собой первое обучающее предложение на втором языке, а обучающие данные дополнительно включают в себя обучающее исходное предложение на первом языке и второе обучающее предложение на втором языке, при этом первое обучающее предложение формируется с использованием первой модели перевода на основе обучающего исходного предложения, а второе обучающее предложение формируется с использованием второй модели перевода на основе обучающего исходного предложения; для обучения первого классификатора процессор дополнительно способен выполнять следующие действия: назначение экспертом для первого обучающего предложения двоичного значения метки, которое представляет собой первое двоичное значение метки или второе двоичное значение метки, при этом первое двоичное значение метки указывает на то, что первое обучающее предложение семантически нелогично, а второе двоичное значение метки указывает на то, что первое обучающее предложение семантически логично; формирование прогнозной функции на основе обучающего исходного предложения, первого обучающего предложения, второго обучающего предложения и двоичного значения метки, назначенного для первого обучающего предложения, при этом прогнозная функция способна назначать первое значение оценки для первой гипотезы перевода на основе триады данных.
В некоторых вариантах осуществления для назначения первого значения оценки для первой гипотезы перевода на основе триады данных процессор способен выполнять следующие действия: определение связанного с триплетом данных набора признаков, содержащего по меньшей мере один из следующих признаков: признак выравнивания, указывающий на лексическое соответствие между словами, содержащимися в исходном предложении, первой гипотезе перевода и второй гипотезе перевода; признак оценки на основе языковой модели, связанный с оценкой на основе языковой модели, назначенной каждой первой гипотезе перевода и второй гипотезе перевода с использованием языковой модели; признак двуязычной таблицы словосочетаний, указывающий на соответствие друг другу словосочетаний, содержащихся в исходном предложении, первой гипотезе перевода и второй гипотезе перевода, при этом каждое соответствие словосочетаний дополнительно содержит вероятность их совместного появления в корпусе параллельных текстов; признак повторения, связанный с наличием повторения данного слова в первой гипотезе перевода; признак отношения длин, связанный с отношением длин последовательностей слов в исходном предложении и в первой и второй гипотезах перевода; и назначение первого значения оценки для первой гипотезы перевода на основе такого определенного набора признаков.
В некоторых вариантах осуществления такой порог задан заранее и процессор дополнительно способен корректировать этот порог путем выполнения следующих действий: прием набора исходных проверочных предложений на первом языке; формирование набора первых проверочных переводов с использованием первой модели перевода; формирование набора вторых проверочных переводов с использованием второй модели перевода; назначение экспертом двоичного значения метки для каждого первого проверочного перевода в наборе первых проверочных переводов; назначение первым классификатором первого значения оценки для каждого первого проверочного перевода; определение количества ошибок проверки, соответствующего количеству первых проверочных переводов с первым значением метки, которым назначено первое значение оценки, меньшее заранее заданного первого порога; уменьшение первого порога, если определено, что количество ошибок проверки превышает заранее заданный проверочный порог.
В некоторых вариантах осуществления второй классификатор обучен на по меньшей мере одной тетраде данных, содержащей: обучающее исходное предложение на первом языке; первое обучающее предложение, сформированное с использованием первой модели перевода на основе обучающего исходного предложения; второе обучающее предложение, сформированное с использованием второй модели перевода на основе обучающего исходного предложения; переведенное человеком предложение, соответствующее обучающему исходному предложению, переведенному на второй язык экспертом; при этом для обучения второго классификатора процессор способен выполнять следующие действия: расчет первой оценки качества перевода первого обучающего предложения на основе переведенного человеком предложения; расчет второй оценки качества перевода второго обучающего предложения на основе переведенного человеком предложения; формирование значения оценки различия качества, соответствующей разности второй оценки качества перевода и первой оценки качества перевода; формирование прогнозной функции, способной назначать второе значение оценки и формируемой на основе регрессионного анализа значения оценки различия качества, первого обучающего предложения, второго обучающего предложения и обучающего исходного предложения.
В некоторых вариантах осуществления первая оценка качества перевода и/или вторая оценка качества перевода представляет собой оценку BLEU.
В некоторых вариантах осуществления сервер соединен с клиентским устройством через сеть связи и содержит интерфейс связи для приема исходного предложения от клиентского устройства, а процессор дополнительно способен передавать целевое предложение клиентскому устройству.
В контексте данного описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от электронных устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Такие аппаратные средства могут представлять собой один физический компьютер или одну физическую компьютерную систему, но это не принципиально для данной технологии. В данном контексте выражение «по меньшей мере один сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая определенная задача принимается, выполняется или запускается на выполнение одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами); это выражение означает, что любое количество элементов программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов выполнения любых задач или запросов; все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, причем оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
В контексте данного описания, если специально не указано другое, числительные «первый», «второй», «третий» и т.д. используются только для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает обязательного наличия «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента могут быть одним и тем же реальным элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - разные программные и/или аппаратные средства.
В контексте данного описания, если специально не указано иное, термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их доступности иным способом. База данных может располагаться в тех же аппаратных средствах, что и процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
Краткое описание чертежей
Дальнейшее описание приведено для лучшего понимания данной технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
На фиг. 1 представлена схема системы, реализованной согласно вариантам осуществления данной технологии, не имеющим ограничительного характера.
На фиг. 2 приведен снимок экрана службы перевода, выполняемой электронным устройством в составе системы, представленной на фиг. 1.
На фиг. 3 представлен пример процесса перевода исходного предложения на первом языке целевым предложением на втором языке.
На фиг. 4 приведена схема обучения первого классификатора, представленного на фиг. 3.
На фиг. 5 приведена схема обучения второго классификатора, представленного на фиг. 3.
На фиг. 6 представлен пример двух способов определения первого порогового значения.
На фиг. 7 представлен пример способа определения второго порогового значения.
На фиг. 8 представлена блок-схема алгоритма перевода исходного предложения на первом языке целевым предложением на втором языке.
Осуществление изобретения
На фиг. 1 представлена схема системы 100, пригодной для реализации вариантов осуществления данной технологии, не имеющих ограничительного характера. Очевидно, что система 100 приведена только для демонстрации варианта практической реализации данной технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих настоящую технологию. Это описание не предназначено для определения объема или границ данной технологии. В некоторых случаях могут быть представлены полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объем или границы данной технологии. Эти модификации не составляют исчерпывающего списка. Специалисту в данной области очевидно, что возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственный вариант реализации того или иного элемента данной технологии. Специалисту в данной области очевидно, что это не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию данной технологии, и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Специалисту в данной области очевидно, что различные варианты реализации данной технологии могут быть значительно сложнее.
Представленные в данном описании примеры и условный язык предназначены для лучшего понимания принципов данной технологии, а не для ограничения ее объема до таких конкретных примеров и условий. Очевидно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но осуществляют принципы данной технологии в пределах ее существа и объема. Кроме того, чтобы способствовать лучшему пониманию, следующее описание может содержать упрощенные варианты реализации данной технологии. Специалисту в данной области очевидно, что различные варианты реализации данной технологии могут быть значительно сложнее.
Более того, описание принципов, аспектов и вариантов осуществления данной технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные структурные схемы соответствуют концептуальным представлениям иллюстративных схем, реализующих принципы данной технологии. Аналогично, должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п.соответствуют различным процессам, которые могут быть представлены на машиночитаемом носителе информации и могут выполняться компьютером или процессором, независимо от того, показан такой компьютер или процессор в явном виде или нет.
Функции различных элементов, показанных на фигурах, включая любой функциональный блок, обозначенный как «процессор», могут осуществляться путем использования специализированных аппаратных средств, а также аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, его функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления данной технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может подразумевать, помимо прочего, аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Кроме того, могут подразумеваться и другие аппаратные средства, общего назначения и/или заказные.
Учитывая вышеизложенные принципы, далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты осуществления аспектов данной технологии.
Система 100 содержит электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и иногда может называться «клиентским устройством». Следует отметить, что связь электронного устройства 102 с пользователем не означает указания или предположения какого-либо режима работы, например, необходимости входа в систему, необходимости регистрации и т.п.
В контексте данного описания, если специально не указано иное, термин «электронное устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения данной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры электронных устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, например, маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как электронное устройство, также может функционировать как сервер для других электронных устройств. Использование выражения «электронное устройство» не исключает использования нескольких электронных устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов выполнения любых задач или запросов, либо шагов любого описанного здесь способа.
Электронное устройство 102 содержит энергонезависимое ЗУ 104. Энергонезависимое ЗУ 104 может содержать один или несколько носителей информации и в общем случае обеспечивает пространство для хранения выполняемых на компьютере команд, которые выполняются процессором 106. Например, энергонезависимое ЗУ 104 может быть реализовано в виде машиночитаемого носителя, включая ПЗУ, жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
Электронное устройство 102 содержит известные в данной области техники аппаратные средства и/или программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для доступа к службе 108 перевода. Служба 108 перевода обеспечивает пользователю (не показан) возможность перевода текста с первого языка на второй язык (описано ниже). Для этого служба 108 перевода содержит входную область 110 перевода и выходную область 112 перевода.
На реализацию службы 108 перевода не накладывается каких-либо особых ограничений. В одном из примеров для доступа к службе 108 перевода пользователь (не показан) с использованием браузерного приложения (не показано) может осуществлять доступ к веб-сайту, связанному со службой перевода (такой как Yandex.Translate™). Например, доступ к службе 108 перевода может осуществляться путем ввода универсального указателя ресурсов (URL), связанного с Yandex.Translate™. Очевидно, что доступ к службе 108 перевода может осуществляться с использованием любой другой коммерчески доступной службы перевода или службы перевода для служебного пользования.
В других не имеющих ограничительного характера вариантах осуществления данной технологии служба 108 перевода может быть реализована как загружаемое приложение в электронном устройстве (таком как устройство беспроводной связи или стационарное электронное устройство). Например, если электронное устройство 102 реализовано как портативное устройство, такое как Samsung™ Galaxy™ S5, в электронном устройстве 102 может выполняться приложение Yandex.Translate™. Очевидно, что любое другое коммерчески доступное приложение для перевода или такое приложение для служебного пользования может использоваться для реализации не имеющих ограничительного характера вариантов осуществления данной технологии.
Электронное устройство 102 содержит пользовательский интерфейс ввода (не показан), такой как клавиатура, сенсорный экран, мышь и т.д., для приема вводимых пользователем данных, в частности, во входную область 110 перевода. На реализацию пользовательского интерфейса ввода не накладывается каких-либо особых ограничений, она зависит от реализации электронного устройства 102. Только в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления данной технологии, где электронное устройство 102 реализовано как устройство беспроводной связи (например, смартфон iPhone™), пользовательский интерфейс ввода может быть реализован как программируемая клавиатура (также называемая экранной или виртуальной клавиатурой). Если электронное устройство 102 реализовано как персональный компьютер, пользовательский интерфейс ввода может быть реализован как аппаратная клавиатура.
Электронное устройство 102 соединено с сетью 114 связи линией 116 связи. В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии в качестве сети 114 связи может использоваться сеть Интернет. В других вариантах осуществления данной технологии сеть 114 связи может быть реализована иначе, например, в виде произвольной глобальной сети связи, локальной сети связи, личной сети связи и т.д.
На реализацию линии 116 связи не накладывается каких-либо особых ограничений, она зависит от реализации электронного устройства 102. Только в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления данной технологии, где электронное устройство 102 реализовано как беспроводное устройство связи (например, смартфон), линия связи 116 может быть реализована как беспроводная линия связи (например, канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.). В тех примерах, где электронное устройство 102 реализовано как ноутбук, линия связи может быть беспроводной (например, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.д.) или проводной (например, соединение на основе Ethernet).
Очевидно, что варианты реализации электронного устройства 102, линии 116 связи и сети 114 связи приведены только для иллюстрации. Специалисту в данной области ясны и другие конкретные детали реализации электронного устройства 102, лини 116 связи и сети 114 связи. Представленные выше примеры никоим образом не ограничивают объем данной технологии.
Система 100 также содержит сервер 118, соединенный с сетью 114 связи. Сервер 118 может быть реализован как традиционный компьютерный сервер. В примере осуществления данной технологии сервер 118 может быть реализован как сервер Dell™ PowerEdge™, работающий под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 118 может быть реализован с использованием любых других подходящих аппаратных средств и/или программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления данной технологии сервер 118 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления данной технологии функции сервера 118 могут быть распределены между несколькими серверами.
Реализация сервера 118 хорошо известна. В целом, сервер 118 содержит интерфейс связи (не показан), структура и функции которого позволяют ему осуществлять связь с различными объектами (такими как электронное устройство 102 и другие устройства, которые могут быть связаны с сетью 114 связи) по сети 114 связи.
Сервер 118 содержит память 120 сервера, которая содержит один или несколько носителей информации и в общем случае обеспечивает пространство для хранения выполняемых на компьютере программных команд, которые выполняются процессором 122 сервера. Например, память 120 сервера может быть реализована как физический машиночитаемый носитель информации, включая ПЗУ и/или ОЗУ. Память 120 сервера также может включать в себя одно или несколько устройств постоянного хранения, например, жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии сервер 118 может управляться той же организацией, что предоставляет вышеописанную службу 108 электронного перевода. Например, сервер 118 может управляться компанией Yandex LLC (ул. Льва Толстого, 16, Москва, 119021, Россия). В других вариантах осуществления сервер 118 может управляться организацией, отличной от той, что предоставляет описанную службу 108 электронного перевода.
В некоторых вариантах осуществления данной технологии сервер 118 выполняет приложение 124 перевода. Реализация приложения 124 перевода подробно описана ниже. Здесь достаточно указать, что приложение 124 перевода способно принимать и переводить текст, введенный пользователем (не показан) во входную область 110 перевода, с первого языка на второй язык, выбранный пользователем. Приложение 124 перевода дополнительно способно передавать сформированный перевод электронному устройству 102 для его отображения пользователю электронного устройства 102 в выходной области 112 перевода.
На фиг. 2 представлен снимок экрана службы 108 перевода с входным текстом 202 во входной области ПО перевода. В некоторых вариантах осуществления входной текст 202 представляет собой текст на естественном языке, составленный на первом языке (в данном случае на английском). На способ ввода входного текста 202 во входную область 110 перевода не накладывается каких-либо ограничений. Например, текст может вводиться пользователем с использованием пользовательского интерфейса ввода (не показан) или путем вставки текста, скопированного, например, с сетевого ресурса, такого как веб-страница (не показана).
Входной текст 202 состоит из множества 204 предложений, включающего в себя несколько отдельных предложений, таких как первое предложение 206, второе предложение 208 и третье предложение 210. Несмотря на то, что на представленной иллюстрации множество 204 предложений разделено точками, специалисту в данной области очевидно, что множество 204 предложений может разделяться и другими знаками препинания, такими как вопросительный или восклицательный знак. Во избежание сомнений следует отметить, что входной текст 202 (точнее, каждая его буква) представлен символами «X». В действительности отдельные предложения состоят из слов на данном языке (в данном случае на английском). Например, первое предложение 206 может выглядеть следующим образом: «With the year coming to the end, the young lawyer was trying to attain his target billable hours».
В некоторых вариантах осуществления служба 108 перевода содержит приводимую в действие пользователем кнопку 212, предназначенную для выполнения перевода входного текста 202 на выбранный пользователем язык (в данном случае на французский), при этом перевод отображается в выходной области 112 перевода. Несмотря на то, что в данном примере служба 108 перевода осуществляет перевод текста с английского языка на французский, очевидно, что такой вариант не носит ограничительного характера и перевод может выполняться с любого языка на любой другой язык.
Далее более подробно описаны функции и действия различных компонентов приложения 124 перевода. На фиг. 3 представлена схема приложения 124 перевода входного текста 202, принятого электронным устройством 102, например, после использования приводимой в действие пользователем кнопки 212. Приложение 124 выполняет процедуру 302 разбора, процедуру 304 перевода, процедуру 306 классификации и процедуру 308 построения текста или осуществляет доступ к ним в ином виде.
В контексте данного описания термин «процедура» подразумевает подмножество выполняемых на компьютере программных команд приложения 124 перевода, выполняемых процессором 122 сервера для осуществления описанных ниже функций, связанных с различными процедурами (процедурой 302 разбора, процедурой 304 перевода, процедурой 306 классификации и процедурой 308 построения текста). Во избежание сомнений, должно быть однозначно понятно, что процедура 302 разбора, процедура 304 перевода, процедура 306 классификации и процедура 308 построения текста схематично показаны по отдельности и распределенным образом для удобства объяснения процесса, выполняемого приложением 124 перевода. Понятно, что некоторые или все процедуры из числа процедуры 302 разбора, процедуры 304 перевода, процедуры 306 классификации и процедуры 308 построения текста могут быть реализованы как одна или несколько комбинированных процедур.
Для лучшего понимания данной технологии ниже описаны функции и обрабатываемые или сохраняемые данные и/или информация процедуры 302 разбора, процедуры 304 перевода, процедуры 306 классификации и процедуры 308 построения текста.
Процедура разбора
Процедура 302 разбора способна принимать пакет 310 данных, содержащий входной текст 202, от электронного устройства 102.
Процедура 302 разбора способна разделять множество 204 предложений на одно или несколько отдельных предложений, таких как первое предложение 206, второе предложение 208 и третье предложение 210. Способ выполнения такого разбора хорошо известен в данной области техники и на него не накладывается каких-либо ограничений. Например, разбор может выполняться путем анализа знаков препинания и применения грамматических правил. В некоторых вариантах осуществления в процедуре 302 разбора используются правила для определенного языка (т.е. правила, специально выбранные для языка входного текста 202). Несмотря на то, что варианты осуществления данной технологии описаны с использованием процедуры 302 разбора для разделения множества 204 предложений на отдельные предложения, предполагается, что в других вариантах осуществления данной технологии процедура 302 разбора может разделять множество 204 предложений на части предложений (например, на фрагменты предложений). Предполагается, что процедура 302 разбора может дополнительно разбирать множество 204 предложений на группы слов, например, на словосочетания, в пределах каждого проанализированного предложения.
Процедура перевода
После разделения входного текста 202 на отдельные предложения процедура 302 разбора способна передавать пакет 312 данных процедуре 304 перевода. Пакет 312 данных содержит одно из отдельных предложений после разбора, например, первое предложение 206 (которое также может рассматриваться как исходное предложение).
Процедура 304 перевода способна применять две модели перевода: модель 314 перевода на основе нейронной сети (NN) (которая также может рассматриваться как первая модель перевода) и статистическая модель 318 перевода на основе фраз (PBS) (которая также может рассматриваться как вторая модель перевода).
Способы реализации модели 314 перевода NN и модели 318 перевода PBS известны в данной области техники и их подробное описание здесь опущено. Достаточно сказать, что после приема пакета 312 данных процедура 304 перевода способна формировать первую гипотезу 316 перевода с использованием модели 314 перевода NN и вторую гипотезу 320 перевода с использованием модели 318 перевода PBS. После формирования первой гипотезы 316 перевода и второй гипотезы 320 перевода процедура 304 перевода способна передавать пакет 322 данных процедуре 306 классификации. Пакет 322 данных содержит первое предложение 206, первую гипотезу 316 перевода и вторую гипотезу 320 перевода.
Процедура классификации
Процедура 306 классификации способна выполнять два алгоритма классификации: первый классификатор 324 и второй классификатор 326. Первый классификатор 324 обучен (описано ниже), чтобы назначать первое значение оценки для первой гипотезы 316 перевода. Первое значение оценки представляет собой вероятность того, что первая гипотеза 316 перевода соответствует семантически нелогичному или семантически логичному переводу на второй язык.
Точнее, первый классификатор 324 способен анализировать набор признаков (описано ниже), связанный с триплетом данных, содержащим первое предложение 206 (исходное предложение), первую гипотезу 316 перевода и вторую гипотезу 320 перевода, для определения вероятности того, что первая гипотеза 316 перевода бессмысленна на втором языке.
На способ реализации первого значения оценки не накладывается каких-либо ограничений, например, оно может быть реализовано в виде значения в диапазоне от 0 до 1. Например, первое значение оценки, близкое к 1, указывает на большую вероятность того, что первая гипотеза 316 перевода семантически нелогична, а первое значение оценки, более близкое к 0, указывает на меньшую вероятность того, что первая гипотеза 316 перевода семантически нелогична (или наоборот). Очевидно, что первое значение оценки может быть реализовано иначе, например, в виде процентного значения или с использованием любой другой шкалы.
Второй классификатор 326 обучен (описано ниже), чтобы назначать второе значение оценки для первой гипотезы 316 перевода. Второе значение оценки указывает на предполагаемое различие качества перевода между первой гипотезой 316 перевода и второй гипотезой 320 перевода. Другими словами, второй классификатор 326 обучен, чтобы прогнозировать различие качества перевода на основе контекста триады данных (т.е. первого предложения 206 (исходного предложения), первой гипотезы 316 перевода и второй гипотезы 320 перевода).
Точнее, второй классификатор 326 способен анализировать триплет данных (т.е. первое предложение 206 (исходное предложение), первую гипотезу 316 перевода и вторую гипотезу 320 перевода) для прогнозирования предполагаемого различия качества перевода между первой гипотезой 316 перевода и второй гипотезой 320 перевода. Этот подход основан на предположении разработчиков о том, что несмотря на обычно более высокое качество переводов, сформированных с использованием модели 324 перевода NN, по сравнению с переводами, сформированными с использованием модели 328 перевода PBS, существует вероятность того, что перевод, сформированный с использованием модели 324 перевода NN, может оказаться менее высокого качества, тогда как переводы, сформированные с использованием модели 328 перевода PBS, обладают стабильным качеством. Вторая гипотеза 320 перевода используется как основа для сравнения, а второе значение оценки указывает на предполагаемое различие качества перевода между первой гипотезой 316 перевода и второй гипотезой 320 перевода (описано ниже) на основе контекста анализируемой триады данных.
На способ реализации второго значения оценки не накладывается каких-либо ограничений, например, оно может быть реализовано в виде значения в диапазоне от -1 до 1. Если второе значение оценки близко к 1, то предполагается, что качество перевода согласно второй гипотезе 320 перевода выше, чем качество перевода согласно первой гипотезе 316 перевода, а если второе значение оценки близко к -1, то предполагается, что качество перевода согласно первой гипотезе 316 перевода выше, чем качество перевода согласно второй гипотезе 320 перевода (или наоборот). Очевидно, что второе значение оценки может быть реализовано иначе, например, в виде процентного значения, значения в диапазоне от 0 до 1 или с использованием любой другой шкалы.
После назначения первого значения оценки и второго значения оценки для первой гипотезы 316 перевода процедура 306 классификации способна определять, соответствует ли первое значение оценки и второе значение оценки по меньшей мере одному логическому условию 330. Например, определение соответствия первого значения оценки и второго значения оценки по меньшей мере одному логическому условию 330 может включать в себя определение того, что (а) первое значение оценки меньше первого порогового значения (описано ниже) и (б) второе значение оценки меньше второго порогового значения (описано ниже).
Если и первое, и второе значения оценки меньше, соответственно, первого и второго пороговых значений, то для передачи с использованием пакета 328 данных процедуре 308 построения текста выбирается первая гипотеза 316 перевода.
Если только первое или только второе значение оценки меньше, соответственно, первого или второго пороговых значений, то для передачи с использованием пакета 328 данных процедуре 328 построения текста выбирается вторая гипотеза 320 перевода.
Процедура построения текста
Процедура 308 построения текста способна принимать пакет 328 данных и извлекать из него гипотезу перевода (первую гипотезу 316 перевода или вторую гипотезу 320 перевода). Процедура 308 построения текста дополнительно способна рассматривать полученную гипотезу перевода в качестве перевода исходного предложения (т.е. первого предложения 206) целевым предложением на втором языке.
После завершения перевода (с использованием описанного выше способа) всех входящих в состав входного текста 202 предложений (т.е. первого предложения 206, второго предложения 208 и третьего предложения 210) процедура 308 построения текста способна объединять все выбранные гипотезы перевода и формировать переведенный текст (не показан). Затем процедура 308 построения текста способна отправлять выходной текст электронному устройству 102 для вывода в выходной области 112 перевода.
Должно быть понятно, что переведенный текст (не показан), формируемый с использованием описанного выше приложения 124 перевода из входного текста 202, содержащего три предложения (см. фиг. 2), также может содержать три целевых предложения (соответствующих первому предложению 206, второму предложению 208 и третьему предложению 210), формируемых раздельно с использованием модели 314 перевода NN или модели 318 перевода PBS. Например, переведенный текст может содержать первое и третье целевые предложения (которые соответствуют переводу первого предложения 206 и третьего предложения 210), сформированные с использованием модели 314 перевода NN, и второе целевое предложение (которое соответствует переводу второго предложения 208), сформированное с использованием модели 318 перевода PBS.
Выше описана фаза применения приложения 124 перевода. Далее описан способ обучения первого классификатора 324 и второго классификатора 326.
Обучение первого классификатора
На фиг. 4 представлена схема процесса обучения первого классификатора 324. Как указано выше, в фазе применения первый классификатор 324 обучается назначать первое значение оценки для гипотезы перевода, сформированной моделью 314 перевода NN, на основе набора признаков, связанных с исходным предложением (с первым предложением 206 в описанном выше примере), первой гипотезой 316 перевода и второй гипотезой 320 перевода.
Первый классификатор 324 обучается с использованием первых обучающих данных, содержащих следующую тетраду данных: обучающее исходное предложение 402, первое обучающее предложение 404, второе обучающее предложение 406 и метку 408, связанную с первым обучающим предложением 404.
Обучающее исходное предложение 402 соответствует предложению на первом языке. Первое обучающее предложение 404 представляет собой перевод (на второй язык) обучающего исходного предложения 402, сформированный с использованием модели 314 перевода NN. Второе обучающее предложение 406 представляет собой перевод (на второй язык) обучающего исходного предложения 402, сформированный с использованием модели 318 перевода PBS. Метка 408 назначается для первого обучающего предложения 404 экспертом (не показан) и указывает на то, что первое обучающее предложение 404 является семантически нелогичным или семантически логичным предложением на втором языке. В некоторых вариантах осуществления метка 408 представляет собой двоичное значение метки, при этом первое двоичное значение метки (например, 1) указывает на то, что первое обучающее предложение 404 семантически нелогично, а второе двоичное значение метки (например, 0) указывает на то, что первое обучающее предложение 404 семантически логично (или наоборот).
Первые обучающие данные вводятся в первый классификатор 324. Первый классификатор 324 содержит логику обучения для определения набора признаков, связанных с обучающим исходным предложением 402, первым обучающим предложением 404 и вторым обучающим предложением 406. В некоторых вариантах осуществления набор признаков указывает на различные свойства обучающего исходного предложения 402, первого обучающего предложения 404 и второго обучающего предложения 406.
Несмотря на то, что выше представлен только один экземпляр первых обучающих данных, очевидно, что это сделано для удобства иллюстрации. Также очевидно, что обучение первого классификатора 324 выполняется итеративно с использованием множества различных наборов первых обучающих данных.
В некоторых вариантах осуществления набор признаков, рассчитанный первым классификатором 324, может среди прочего включать в себя:
(i) признак выравнивания;
(ii) признак оценки на основе языковой модели;
(iii) признак двуязычной таблицы словосочетаний;
(iv) признак повторения;
(v) признак отношения длин.
Далее подробно рассмотрен каждый из вышеупомянутых признаков.
(i) Признак выравнивания
Первый классификатор 324 способен выполнять первое двухтекстовое выравнивание слов, содержащихся в обучающем исходном предложении 402 и в первом обучающем предложении 404, а также второе двухтекстовое выравнивание слов, содержащихся в обучающем исходном предложении 402 и во втором обучающем предложении 406, с использованием модели выравнивания.
Признак выравнивания указывает на лексическое соответствие между обучающим исходным предложением 402 с одной стороны и первым обучающим предложением 404 и вторым обучающим предложением 406 с другой стороны.
(ii) Признак оценки на основе языковой модели
Первый классификатор 324 способен назначать оценку языковой модели для каждого первого обучающего предложения 404 и второго обучающего предложения 406 с использованием языковой модели (не показана). Способ реализации языковой модели известен в данной области техники и его подробное описание здесь опущено.
Признак оценки на основе языковой модели указывает на вероятность того, что первое обучающее предложение 404 и второе обучающее предложение 406 являются допустимыми предложениями на втором языке, независимо от того, связаны ли они каким-либо образом с обучающим исходным предложением 402.
(iii) Признак двуязычной таблицы словосочетаний
Первый классификатор 324 способен разделять каждое обучающее исходное предложение 402, каждое первое обучающее предложение 404 и каждое второе обучающее предложение 406 на словосочетания, причем словосочетание является содержательным элементом, включающим в себя группу из двух или более слов (например, «современная компьютерная система», «способы извлечения информации», «деревянные стулья» и т.п.).
На возможности первого классификатора 324 по определению словосочетаний не накладывается каких-либо ограничений. Например, первый классификатор 324 может быть способен определять группы слов, имеющих логическое значение. В контексте данной технологии термин «логическое значение» относится к семантической связи с лексической морфемой. В некоторых вариантах осуществления первый классификатор 324 способен определять, имеет ли данная группа слов логическое значение, на основе типа слов, входящих в состав группы. Например, первый классификатор 324 способен определять лексические морфемы, такие как глаголы, прилагательные и наречия, как имеющие логическое значение. С другой стороны, слова, являющиеся грамматическими морфемами (т.е. определяющими связи между другими морфемами, например, предлогами, артиклями, союзами и т.п.), рассматриваются первым классификатором 324 как не имеющие логического значения. Первый классификатор 324 способен определять группу слов как словосочетание, если это группа слов содержит по меньшей мере одно слово с логическим значением.
После разделения на словосочетания обучающего исходного предложения 402, первого обучающего предложения 404 и второго обучающего предложения 406 первый классификатор 324 способен строить первую таблицу, содержащую пары словосочетаний из обучающего исходного предложения 402 и первого обучающего предложения 404, а также вторую таблицу, содержащую пары словосочетаний из обучающего исходного предложения 402 и второго обучающего предложения 406.
Первый классификатор 324 дополнительно способен назначать значение оценки совместного появления для каждой пары словосочетаний. В некоторых вариантах осуществления значение оценки совместного появления представляет собой вероятность совместного появления данной пары словосочетаний в предварительно просмотренном корпусе параллельных текстов.
Признак двуязычной таблицы словосочетаний указывает на соответствие друг другу словосочетаний и их совместное появление в обучающем исходном предложении 402 с одной стороны и в первом обучающем предложении 404 и во втором обучающем предложении 406 с другой стороны, соответственно.
(iv) Признак повторения
Первый классификатор 324 способен определять присутствие повторяющегося слова в первом обучающем предложении 404.
Признак повторения указывает на присутствие одного или нескольких повторяющихся слов в первом обучающем предложении 404.
(v) Признак отношения длин
Первый классификатор 324 способен определять первое отношение количества слов, содержащихся в обучающем исходном предложении 402, и количества слов, содержащихся в первом обучающем предложении 404, а также второго отношения количества слов, содержащихся в обучающем исходном предложении 402, и количества слов, содержащихся во втором обучающем предложении 406.
Другими словами, признак отношения длин указывает на количество слов, формируемых с использованием модели 314 перевода NN и модели 318 перевода PBS на основе обучающего исходного предложения 402.
После определения набора признаков для обучающего исходного предложения 402, первого обучающего предложения 404 и второго обучающего предложения 406 первый классификатор 324 способен анализировать этот набор признаков.
Точнее, с учетом того, что первые обучающие данные содержат метку 408, указывающую на то, что первое обучающее предложение 404 семантически логично или нелогично, первый классификатор 324 способен к обучению тому, какой набор признаков указывает на семантическую нелогичность первого обучающего предложения 404.
Соответственно, первый классификатор 324 способен формировать первую прогнозную функцию, которая в фазе применения способна назначать первое значение оценки для первой гипотезы 316 перевода на основе набора признаков, связанных с исходным предложением (с первым предложением 206), первой гипотезой 316 перевода и второй гипотезой 320 перевода.
Как показано на фиг. 3 (фаза применения), если определено, что первый набор признаков, связанный с исходным предложением (с первым предложением 206), первой гипотезой 316 перевода и второй гипотезой 320 перевода, указывает на высокую вероятность семантической нелогичности первой гипотезы 316 перевода, то первый классификатор 324 может назначать первое значение оценки соответственно (т.е. близкое к 1 значение). В качестве альтернативы, если определено, что набор признаков указывает на низкую вероятность семантической нелогичности первой гипотезы 316 перевода, то первый классификатор 324 может назначать первое значение оценки соответственно (т.е. близкое к 0 значение).
Выше описан способ обучения первого классификатора 324 перед фазой применения. Далее описан способ определения первого порогового значения.
Первое пороговое значение
Как описано выше, первое значение оценки, назначенное первым классификатором 324, сравнивается с первым пороговым значением. На фиг. 6 представлена схема двух способов определения первого порогового значения. В представленных вариантах осуществления первое пороговое значение определяется эмпирически.
Далее описан первый способ 602 определения первого порогового значения. Первый способ 602 начинается с шага 610, на котором первый классификатор 324 принимает первые проверочные данные. Первые проверочные данные включают в себя: (а) исходное проверочное предложение 604 на первом языке, (б) первый проверочный перевод 606 исходного проверочного предложения 604, сформированный с использованием модели 314 перевода NN, и (в) второй проверочный перевод 608 исходного проверочного предложения 604, сформированный с использованием модели 318 перевода PBS.
На шаге 612 первый классификатор 324 назначает первое значение оценки для первого проверочного перевода 606 на основе набора признаков, связанных с исходным проверочным предложением 604, первым проверочным переводом 606 и вторым проверочным переводом 608.
На шаге 614 эксперт (не показан) назначает значение обучающей метки для первого проверочного перевода 606. Как и в случае метки 408 (см. фиг. 4), значение обучающей метки может представлять собой двоичное значение метки, при этом первое значение метки (например, 1) указывает на то, что первый проверочный перевод 606 семантически нелогичен на втором языке, а второе значение метки (например, 0) указывает на то, что первый проверочный перевод 606 семантически логичен на втором языке.
На шаге 616 первое значение оценки, назначенное для первого проверочного перевода 606, сравнивается с первым заранее заданным пороговым значением. Например, с учетом того, что первое значение оценки представляет собой числовое значение в диапазоне от 0 до 1, первое заранее заданное пороговое значение может составлять 0,9.
На шаге 618 эксперт на основе первого значения оценки, назначенного для первого проверочного перевода 606, проверяет первое заранее заданное пороговое значение.
Точнее, эксперт на основе первого значения оценки, назначенного на шаге 616, и значения обучающей метки, назначенного на шаге 614, определяет, требуется ли корректировка первого заранее заданного порогового значения вследствие первой ошибки проверки (описано ниже) первого проверочного перевода 606.
Например, первая ошибка проверки может возникнуть, если для первого проверочного перевода 606 (а) первое значение оценки меньше первого заранее заданного порогового значения, но (б) назначенная обучающая метка равна 1. Это вызвано слишком низким первым заранее заданным пороговым значением, поэтому первое заранее заданное пороговое значение следует увеличить с получением первого порогового значения.
В другом случае первая ошибка проверки может возникнуть, если для первого проверочного перевода 606 (а) первое значение оценки больше первого заранее заданного порогового значения, но (б) назначенная обучающая метка равна 0. Это вызвано слишком высоким первым заранее заданным пороговым значением, поэтому первое заранее заданное пороговое значение следует уменьшить с получением первого порогового значения.
Далее описан второй способ 620 определения первого порогового значения.
Второй способ 620 начинается с шага 622, на котором первый классификатор 324 принимает первые проверочные данные.
На шаге 624 первое значение оценки BLEU назначается для первого проверочного перевода 606, а второе значение оценки BLEU назначается для второго проверочного перевода 608. Первое и второе значения оценки BLEU определяются с использованием переведенного человеком предложения (не показано), связанного с исходным проверочным предложением 604. На способ определения первого и второго значений оценки BLEU не накладывается каких-либо ограничений. Например, они могут определяться частью алгоритма первого классификатора 324.
На шаге 626 первый классификатор 324 назначает первое значение оценки для первого проверочного перевода 606 на основе набора признаков, связанных с исходным проверочным предложением 604, первым проверочным переводом 606 и вторым проверочным переводом 608.
На шаге 628 первое значение оценки, назначенное для первого проверочного перевода 606, сравнивается со вторым заранее заданным пороговым значением. В некоторых вариантах осуществления первое заранее заданное пороговое значение равно второму заранее заданному пороговому значению.
На шаге 630 эксперт на основе первого значения оценки, назначенного для первого проверочного перевода 606, проверяет второе заранее заданное пороговое значение.
Точнее, эксперт на основе первого значения оценки, назначенного на шаге 626, и первого и второго значений оценки BLEU, назначенных на шаге 624, определяет, требуется ли корректировка второго заранее заданного порогового значения вследствие наличия второй ошибки проверки.
Например, вторая ошибка проверки может возникнуть, если для первого проверочного перевода 606 (а) первое значение оценки меньше второго заранее заданного порогового значения, но (б) первое значение оценки BLEU меньше второго значения оценки BLEU. Это вызвано слишком высоким вторым заранее заданным пороговым значением, поэтому второе заранее заданное пороговое значение следует уменьшить с получением первого порогового значения.
В другом случае вторая ошибка проверки может возникнуть, если для первого проверочного переведенного предложения (а) первое значение оценки больше второго заранее заданного порогового значения, но (б) первое значение оценки BLEU больше второго значения оценки BLEU. Это вызвано слишком низким вторым заранее заданным пороговым значением, поэтому второе заранее заданное пороговое значение следует увеличить с получением первого порогового значения.
Очевидно, что первое пороговое значение может определяться с использованием только первого способа 602, или только второго способа 620, или сочетания первого способа 602 и второго способа 620.
Несмотря на то, что выше представлен только один экземпляр первых проверочных данных, это сделано для удобства иллюстрации. Очевидно, что определение первого порогового значения выполняется итеративно с использованием множества различных наборов первых проверочных данных и что корректировка первого и второго заранее заданных пороговых значений выполняется, например, путем задания проверочного порога, с которым сравнивается количество ошибок проверки (первой или второй ошибки проверки).
Выше описан способ обучения первого классификатора 324 и формирования (и корректировки) первого порогового значения перед фазой применения. Далее описан способ обучения второго классификатора 326 перед фазой применения.
Обучение второго классификатора
На фиг. 5 представлена схема процесса обучения второго классификатора 326.
Как указано выше, второй классификатор 326 обучается, чтобы в фазе применения назначать второе значение оценки для гипотезы перевода, сформированной с использованием модели 314 перевода NN. Второе значение оценки определяется на основе анализа исходного предложения (первого предложения 206 в представленном выше примере), первой гипотезы 316 перевода и второй гипотезы 320 перевода.
Второй классификатор 326 обучается с использованием вторых обучающих данных, содержащих следующую тетраду данных: обучающее исходное предложение 502, первое обучающее предложение 504, второе обучающее предложение 506 и переведенное человеком предложение 508.
Обучающее исходное предложение 502 соответствует предложению на первом языке. Первое обучающее предложение 504 представляет собой перевод (на второй язык) обучающего исходного предложения 502, сформированный с использованием модели 314 перевода NN. Второе обучающее предложение 506 представляет собой перевод (на второй язык) обучающего исходного предложения 502, сформированный с использованием модели 318 перевода PBS. Переведенное человеком предложение 508 представляет собой перевод (на второй язык) обучающего исходного предложения 502, выполненный экспертом (не показан). Предполагается, что переведенное человеком предложение 508 представляет собой эталонный перевод обучающего исходного предложения 502 на второй язык.
Вторые обучающие данные вводятся во второй классификатор 326 для его обучения. Очевидно, что несмотря на то, что выше представлен только один экземпляр вторых обучающих данных, это сделано для удобства иллюстрации. Очевидно, что обучение второго классификатора 326 выполняется итеративно с использованием множества различных наборов вторых обучающих данных.
После приема вторых обучающих данных второй классификатор 326 способен выполнять алгоритм 510 оценки качества для расчета первого значения оценки качества перевода, связанного с первым обучающим предложением 504 и второго значения оценки качества перевода, связанного со вторым обучающим предложением 506.
На способ реализации алгоритма 510 оценки качества не накладывается каких-либо ограничений. Например, он может быть реализован как алгоритм оценки BLEU, пригодный для расчета первой и второй оценки качества перевода (оценки BLEU) с использованием переведенного человеком предложения 508.
С использованием первой и второй оценок качества перевода второй классификатор 326 способен рассчитывать значение оценки различия качества, которое соответствует разнице первого значения оценки качества перевода и второго значения оценки качества перевода.
В некоторых вариантах осуществления значение оценки различия качества рассчитывается путем вычитания первого значения оценки качества перевода из второго значения оценки качества перевода. Например, если первое значение оценки качества перевода равно 0,8, а второе значение оценки качества перевода равно 0,3, то значение оценки различия качества составляет -0,5.
Другими словами, если значение оценки различия качества меньше 0, это указывает на то, что качество перевода первого обучающего предложения 504 выше, чем качество перевода второго обучающего предложения 506. С другой стороны, если значение оценки различия качества больше 0, это указывает на то, что качество перевода первого обучающего предложения 504 ниже, чем качество перевода второго обучающего предложения 506. Очевидно, что не имеющие ограничительного характера варианты осуществления данной технологии также могут быть реализованы путем вычитания второго значения оценки качества перевода из первого значения оценки качества перевода для определения значения оценки различия качества.
Как указано выше, второй классификатор 326 способен итеративно определять значение оценки различия качества для множества наборов вторых обучающих данных. После определения заранее заданного количества значений оценок различия качества второй классификатор 326 способен выполнять регрессионный анализ соответствующего обучающего исходного предложения 502, первого обучающего предложения 504, второго обучающего предложения 506 и соответствующего значения оценки различия качества для формирования второй прогнозной функции, способной назначать второе значение оценки (в фазе применения) на основе первого предложения 206 (исходного предложения), первой гипотезы 316 перевода и второй гипотезы 320 перевода.
Несмотря на то, что выше описано обучение второго классификатора 326, способного выполнять алгоритм 510 оценки качества, очевидно предполагается, что вторые обучающие данные могут уже включать в себя значение оценки различия качества, связанное с первым обучающим предложением 504 и вторым обучающим предложением 506. Другими словами, для целей обучения второго классификатора 326 вместо приема (а) обучающего исходного предложения 502, (б) первого обучающего предложения 504, (в) второго обучающего предложения 506 и (г) переведенного человеком предложения 508, как показано на фиг. 5, второй классификатор 326 может принимать (а) обучающее исходное предложение 502, (б) первое обучающее предложение 504, (в) второе обучающее предложение 506 и (г) значения оценки различия качества, заранее определенные с использованием алгоритма 510 оценки качества, выполненного другим объектом, отличным от второго классификатора 326.
Как показано на фиг. 3 (фаза применения), второй классификатор 326 способен назначать второе значение оценки, которое, как описано выше, соответствует предполагаемому различию качества между первой гипотезой 316 перевода и второй гипотезой 320 перевода. Если на основе анализа исходного предложения (первого предложения 206), первой гипотезы 316 перевода и второй гипотезы 320 перевода определено, что качество перевода для первой гипотезы 316 перевода ожидается более высоким, чем для второй гипотезы 320 перевода, то второй классификатор 326 способен назначать второе значение оценки соответственно (т.е. более близкое к -1 значение). В качестве альтернативы, если предполагаемое различие указывает на то, что качество перевода для второй гипотезы 320 перевода ожидается более высоким, чем для первой гипотезы 316 перевода, то второй классификатор 326 способен назначать второе значение оценки соответственно (т.е. более близкое к 1 значение).
Выше описан способ обучения второго классификатора 326. Далее описан способ определения второго порогового значения.
Второе пороговое значение
Как указано выше, второе значение оценки назначается для первой гипотезы 316 перевода вторым классификатором 326 и сравнивается со вторым пороговым значением. На фиг. 7 представлена схема способа 700 определения второго порогового значения. В представленном варианте осуществления второе пороговое значение определяется эмпирически.
Второй способ 700 начинается с шага 708, на котором второй классификатор 326 принимает вторые проверочные данные. Вторые проверочные данные включают в себя: (а) исходное проверочное предложение 702 на первом языке, (б) первый проверочный перевод 704, представляющий собой перевод исходного проверочного предложения 702, сформированный с использованием модели 314 перевода NN, и (в) второй проверочный перевод 706, представляющий собой перевод исходного проверочного предложения 702, сформированный с использованием модели 318 перевода PBS.
На шаге 710 второй классификатор 326 назначает второе значение оценки для первого проверочного перевода 704 на основе анализа исходного проверочного предложения 702, первого проверочного перевода 704 и второго проверочного перевода 706.
На шаге 712 значение оценки различия качества между первым проверочным переводом 704 и вторым проверочным переводом 706 определяется с использованием алгоритма 510 проверки качества (см. рис. 5).
На шаге 714 второе значение оценки, назначенное для первого проверочного перевода 704, сравнивается с третьим заранее заданным пороговым значением. Например, с учетом того, что второе значение оценки представляет собой числовое значение в диапазоне от -1 до 1, оно может быть равным 0.
На шаге 716 эксперт на основе второго значения оценки, назначенного для первого проверочного перевода 704, проверяет третье заранее заданное пороговое значение.
Точнее, эксперт на основе второго значения оценки, назначенного на шаге 710, и значения оценки различия качества, назначенного на шаге 712, определяет, требуется ли корректировка третьего заранее заданного порогового значения вследствие третьей ошибки проверки (описано ниже).
Например, третья ошибка проверки возникает, если для первого проверочного перевода 704 (а) второе значение оценки больше третьего заранее заданного порогового значения и (б) значение оценки различия качества меньше третьего заранее заданного порогового значения. Это является следствием слишком большого третьего заранее заданного порогового значения, поэтому третье заранее заданное пороговое значение следует уменьшить с получением второго порогового значения.
В другом случае третья ошибка проверки возникает, если для первого проверочного перевода 704 (а) второе значение оценки меньше третьего заранее заданного порогового значения и (б) значение оценки различия качества больше третьего заранее заданного порогового значения. Это является следствием слишком низкого третьего заранее заданного порогового значения, поэтому третье заранее заданное пороговое значение следует увеличить с получением второго порогового значения.
Несмотря на то, что выше представлен только один экземпляр вторых проверочных данных, очевидно, что это сделано для удобства иллюстрации. Также очевидно, что определение второго порогового значения выполняется итеративно с использованием множества различных наборов вторых проверочных данных и что корректировка третьего заранее заданного порога выполняется, например, путем задания проверочного порога, с которым сравнивается количество третьих ошибок проверки.
Различные не имеющие ограничительного характера варианты осуществления данной технологии способны обеспечивать перевод исходного предложения на первом языке целевым предложением на втором языке с лучшим итоговым качеством и при меньших затратах времени и усилий со стороны пользователя, приводя также к снижению потребления энергии для вычислений.
Несмотря на то, что этап использования приложения 124 перевода описан на примере сервера 118, объем изобретения этим не ограничивается. Очевидно, что приложение 124 перевода может быть реализовано с использованием различных устройств. В не имеющем ограничительного характера примере приложение 124 перевода может загружаться и сохраняться в электронном устройстве 102.
Описанные выше архитектура и примеры позволяют выполнять реализуемый на компьютере способ перевода исходного предложения на первом языке целевым предложением на втором языке. На фиг. 8 представлена блок-схема способа 800 перевода исходного предложения на первом языке целевым предложением на втором языке, реализованного согласно вариантам осуществления данной технологии, не имеющим ограничительного характера. Способ 800 может выполняться на сервере 118.
Шаг 802: прием исходного предложения.
Способ 800 начинается с шага 802, на котором процедура 302 разбора получает пакет 310 данных, содержащий входной текст 202, от электронного устройства 102.
Процедура 302 разбора способна разделять множество 204 предложений на одно или несколько отдельных предложений, таких как первое предложение 206, второе предложение 208 и третье предложение 210.
После разделения входного текста 202 на отдельные предложения процедура 302 разбора способна передавать пакет 312 данных процедуре 304 перевода. Пакет 312 данных содержит одно из разобранных отдельных предложений, например, первое предложение 206 (которое также может рассматриваться как исходное предложение).
Шаг 804: формирование первой гипотезы перевода с использованием первой модели перевода.
На шаге 804 процедура 304 перевода способна использовать модель 314 перевода NN для формирования первой гипотезы 316 перевода на втором языке, соответствующей первому предложению 206.
Шаг 806: формирование второй гипотезы перевода с использованием второй модели перевода, отличной от первой модели перевода.
На шаге 806 процедура 304 перевода способна использовать модель 318 перевода PBS для формирования второй гипотезы 320 перевода на втором языке, соответствующей первому предложению 206.
Шаг 808: назначение первым классификатором первого значения оценки для первой гипотезы перевода, при этом первое значение оценки представляет собой вероятность того, что первая гипотеза перевода соответствует семантически нелогичному или семантически логичному переводу на второй язык, и первый классификатор обучен определять первое значение оценки на основе анализа триады данных, содержащей исходное предложение, первую гипотезу перевода и вторую гипотезу перевода.
На шаге 808 процедура 306 классификации принимает пакет 322 данных, содержащий первое предложение 206, первую гипотезу 316 перевода и вторую гипотезу 320 перевода.
Процедура 306 классификации включает в себя первый классификатор 324, предварительно обученный для назначения первого значения оценки для первой гипотезы 316 перевода на основе набора признаков, связанных с первым предложением 206, первой гипотезой 316 перевода и второй гипотезой 320 перевода.
Первое значение оценки представляет собой вероятность того, что первая гипотеза 316 перевода соответствует семантически нелогичному или семантически логичному переводу на второй язык.
Шаг 810: назначение вторым классификатором второго значения оценки для первой гипотезы перевода, при этом второе значение оценки представляет собой предполагаемое различие качества перевода между первой гипотезой перевода и второй гипотезой перевода и второй классификатор обучен определять второе значение оценки на основе анализа триады данных.
На шаге 810, помимо выполнения алгоритма первого классификатора 324, процедура 306 классификации способна выполнять алгоритм второго классификатора 326, предварительно обученного для назначения второго значения оценки для первой гипотезы перевода на основе анализа первого предложения 206, первой гипотезы 316 перевода и второй гипотезы 320 перевода.
Второе значение оценки представляет собой предполагаемое различие качества перевода между первой гипотезой 316 перевода и второй гипотезой 320 перевода.
Шаг 812: формирование целевого предложения, соответствующего первой гипотезе перевода, если определено, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, или соответствующего второй гипотезе перевода, если определено, что это условие не выполнено.
На шаге 812 процедура 306 классификации способна определять, соответствует ли первое значение оценки и второе значение оценки по меньшей мере одному логическому условию 330. По меньшей мере одно логическое условие 330 выполняется, если первое значение оценки меньше первого порогового значения и второе значение оценки меньше второго порогового значения.
Другими словами, если первое значение оценки меньше первого порогового значения, но второе значение оценки больше второго порогового значения (или наоборот), то по меньшей мере одно логическое условие 330 не выполняется.
Если определено, что по меньшей мере одно логическое условие 330 выполнено, процедура 306 классификации способна отправлять пакет 328 данных, содержащий первую гипотезу 316 перевода, процедуре 308 построения текста. После завершения перевода входного текста 202 процедура 308 построения текста способна отправлять электронному устройству 102 первую гипотезу 316 перевода в качестве целевого предложения для первого предложения 206.
С другой стороны, если определено, что по меньшей мере одно логическое условие 330 не выполнено, процедура 306 классификации способна отправлять пакет 328 данных, содержащий вторую гипотезу 320 перевода, процедуре 308 построения текста. После завершения перевода входного текста 202 процедура 308 построения текста способна отправлять электронному устройству 102 вторую гипотезу 320 перевода в качестве целевого предложения для первого предложения 206.
Специалистам в данной области техники должно быть очевидно, что по меньшей некоторые варианты осуществления данной технологии преследуют цель расширения спектра технических решений определенной технической проблемы, присущей традиционным моделям перевода, а именно, проблемы перевода исходного предложения на первом языке целевым предложением на втором языке.
Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте реализации данной технологии. Например, возможны варианты реализации данной технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты реализации, когда пользователь получает другие технические эффекты либо технический эффект отсутствует.
Изменения и усовершенствования описанных выше вариантов реализации данной технологии очевидны для специалиста в данной области. Предшествующее описание приведено в качестве примера, а не для ограничения объема изобретения. Объем охраны данной технологии определяется исключительно объемом приложенной формулы изобретения.
Несмотря на то, что описанные выше варианты реализации приведены со ссылкой на конкретные шаги, выполняемые в определенном порядке, должно быть понятно, что эти шаги могут быть объединены, разделены или их порядок может быть изменен без отклонения от данной технологии. Соответственно, порядок и группировка шагов не носят ограничительного характера для данной технологии.
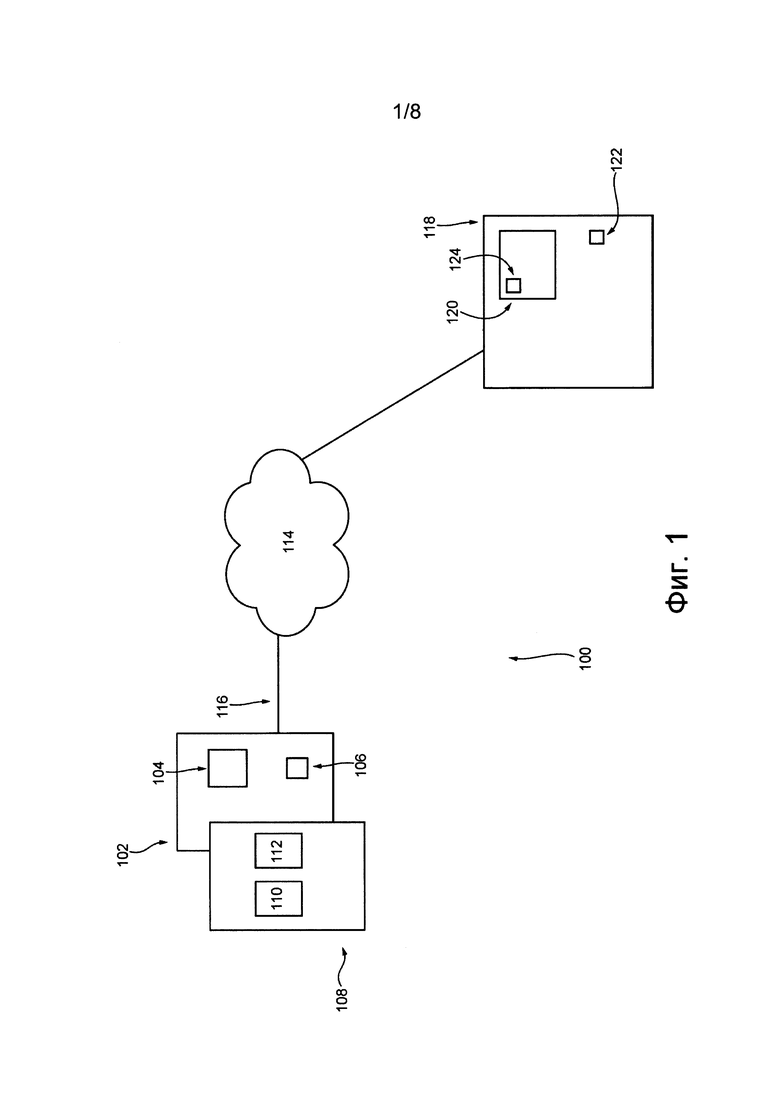
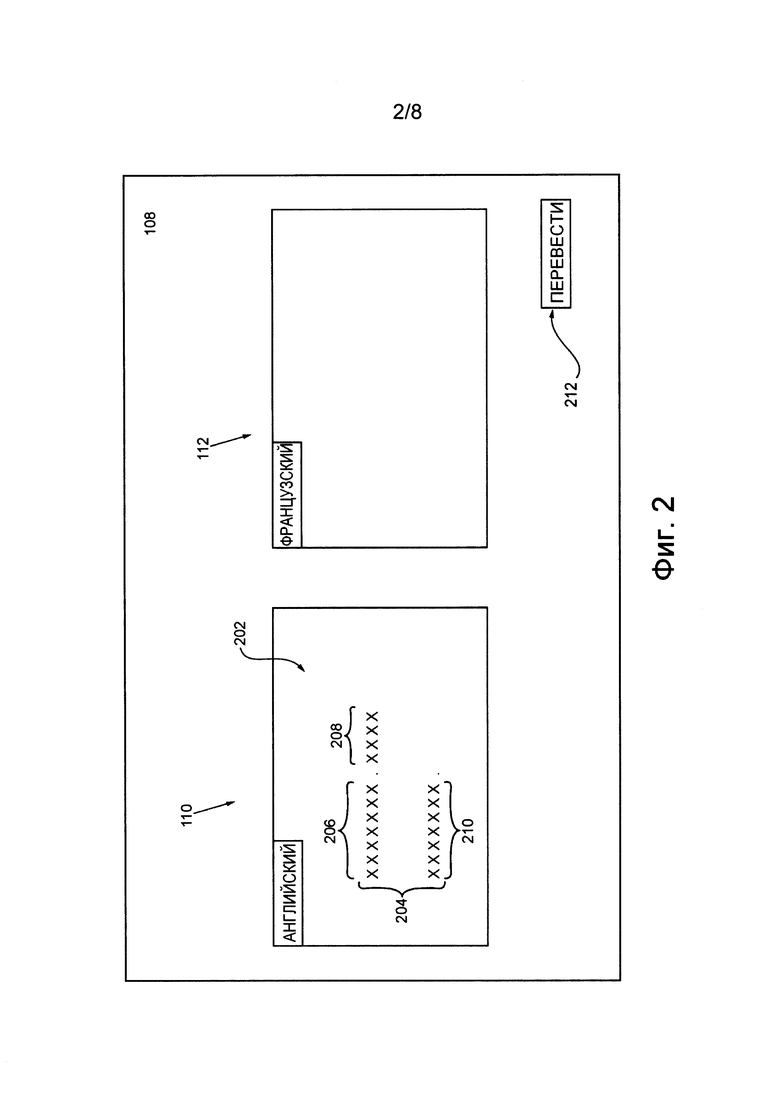
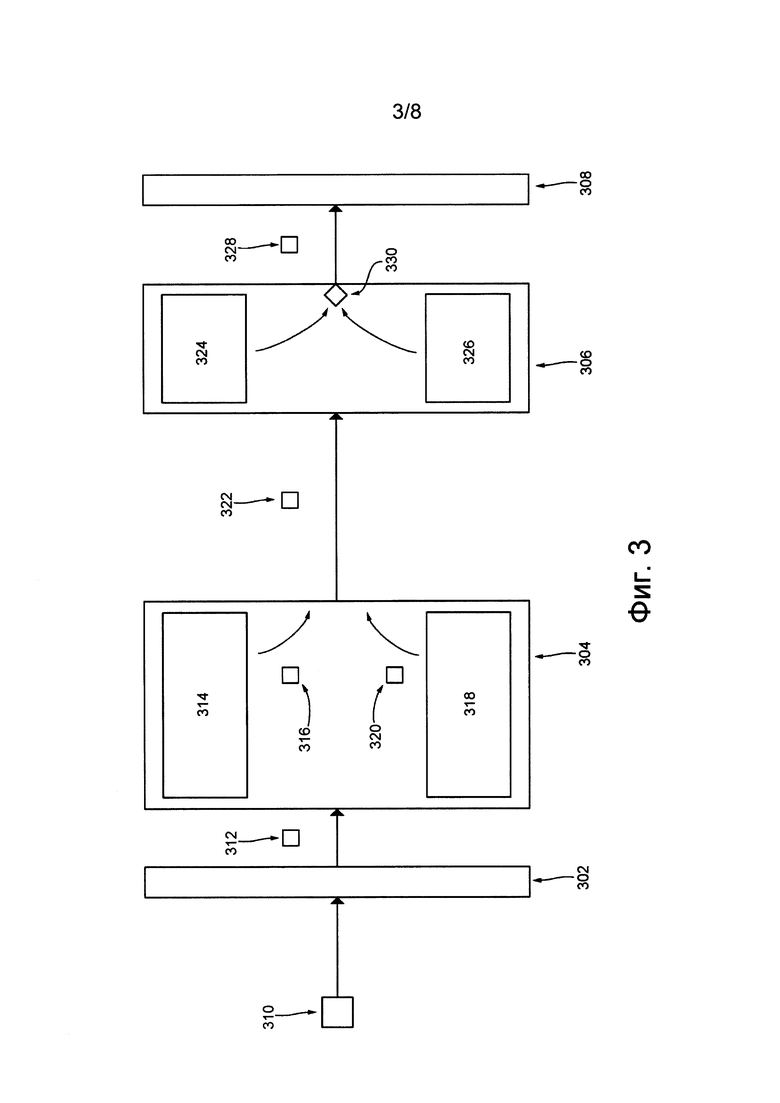

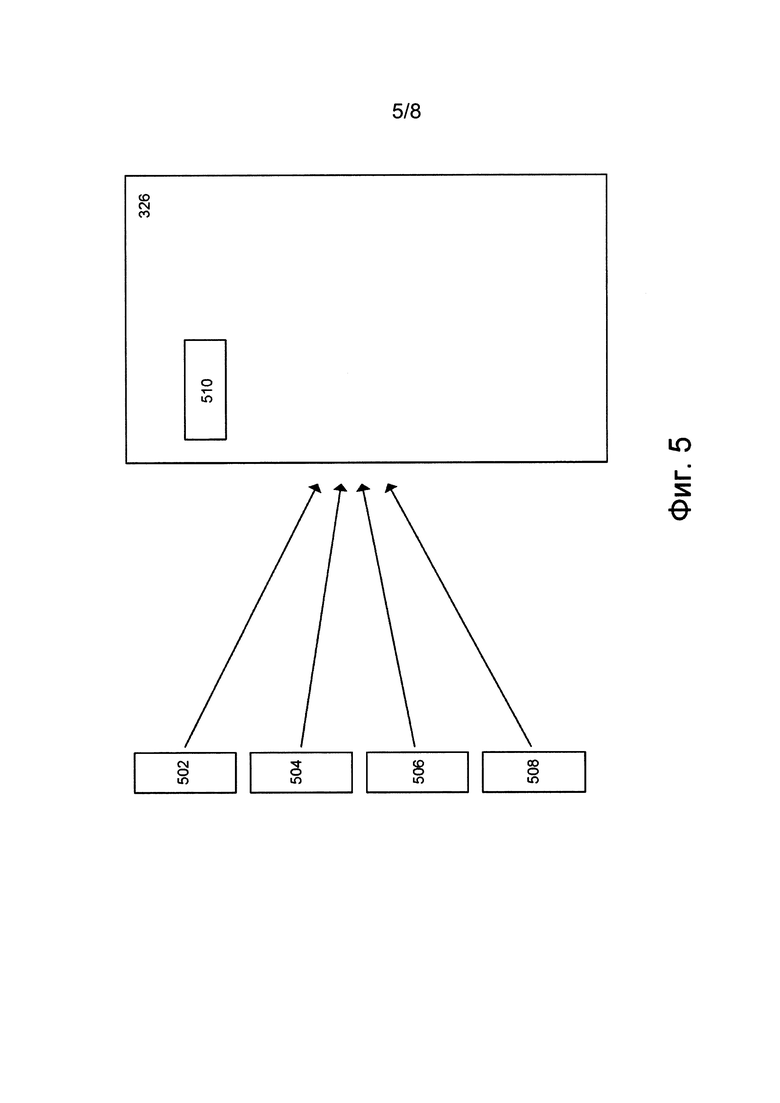

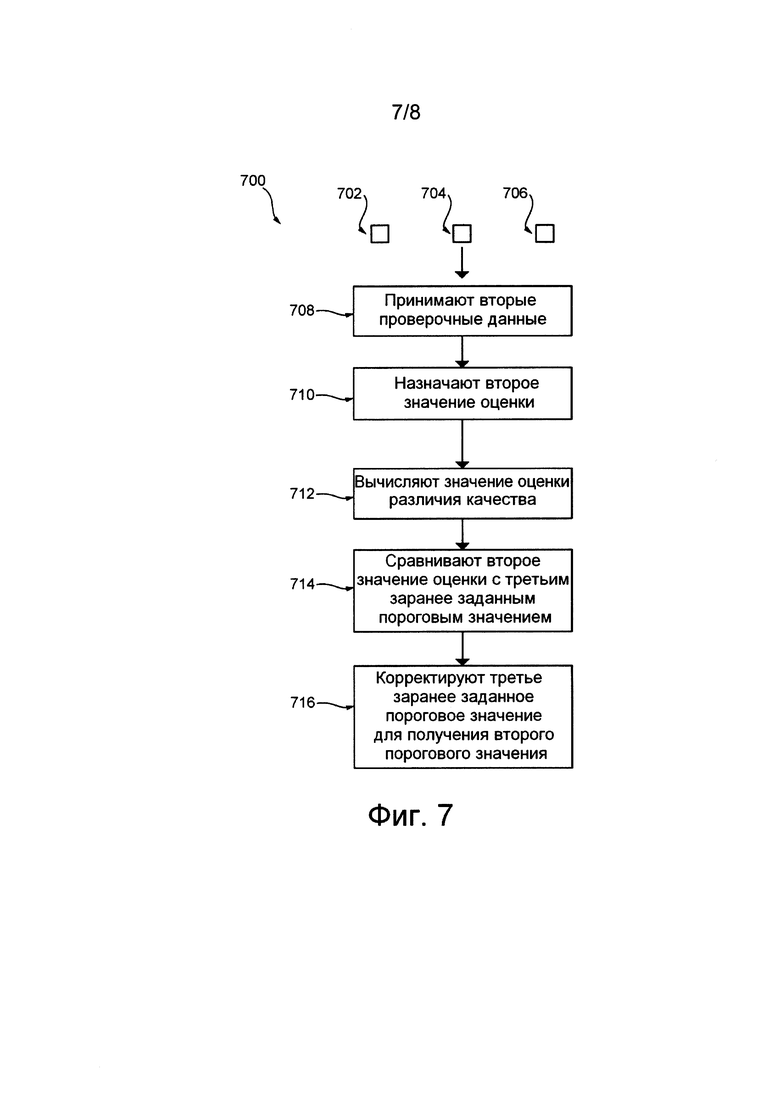

Изобретение относится к вычислительной технике. Технический результат – обеспечение перевода исходного предложения целевым предложением. Реализуемый на компьютере способ перевода исходного предложения на первом языке целевым предложением на втором языке включает: прием исходного предложения; формирование первой гипотезы перевода с использованием первой модели перевода; формирование второй гипотезы перевода с использованием второй модели перевода; назначение посредством первого классификатора первого значения оценки для первой гипотезы перевода, при этом первое значение оценки представляет собой вероятность того, что первая гипотеза перевода соответствует семантически нелогичному или логичному переводу на второй язык и первый классификатор обучен определять первое значение оценки на основе анализа триады данных: исходного предложения, первой гипотезы перевода; второй гипотезы перевода; назначение вторым классификатором второго значения оценки для первой гипотезы перевода, при этом второе значение оценки представляет собой различие качества перевода между первой гипотезой перевода и второй гипотезой перевода и второй классификатор обучен определять второе значение оценки на основе анализа триады данных; формирование целевого предложения. 2 н. и 18 з.п. ф-лы, 8 ил.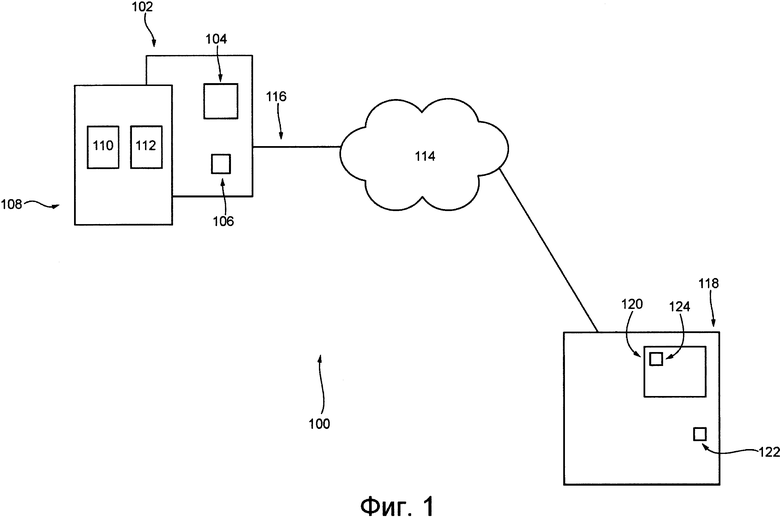
1. Реализуемый на компьютере способ перевода исходного предложения на первом языке целевым предложением на втором языке, выполняемый компьютерным устройством, включающий в себя:
прием исходного предложения;
формирование первой гипотезы перевода с использованием первой модели перевода;
формирование второй гипотезы перевода с использованием второй модели перевода, отличной от первой модели перевода;
назначение посредством первого классификатора первого значения оценки для первой гипотезы перевода, при этом первое значение оценки представляет собой вероятность того, что первая гипотеза перевода соответствует семантически нелогичному или семантически логичному переводу на второй язык и первый классификатор обучен определять первое значение оценки на основе анализа триады данных, содержащей исходное предложение, первую гипотезу перевода и вторую гипотезу перевода;
назначение посредством второго классификатора второго значения оценки для первой гипотезы перевода, при этом второе значение оценки представляет собой предполагаемое различие качества перевода между первой гипотезой перевода и второй гипотезой перевода и второй классификатор обучен определять второе значение оценки на основе анализа триады данных;
формирование целевого предложения, соответствующего первой гипотезе перевода, если определено, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, или соответствующего второй гипотезе перевода, если определено, что это условие не выполнено.
2. Способ по п. 1, отличающийся тем, что первая модель перевода представляет собой модель машинного перевода на основе нейронной сети, а вторая модель перевода представляет собой модель статистического перевода на основе фраз.
3. Способ по п. 1, отличающийся тем, что определение того, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, включает в себя определение того, что первое значение оценки меньше первого порога, и определение того, что второе значение оценки меньше второго порога.
4. Способ по п. 3, отличающийся тем, что первый классификатор предварительно обучен на обучающих данных, содержащих по меньшей мере одно обучающее предложение, помеченное как семантически логичное или нелогичное, и способен определять, указывает триплет данных на более высокую вероятность семантической нелогичности первой гипотезы перевода или на более низкую вероятность семантической нелогичности первой гипотезы перевода на второй язык.
5. Способ по п. 4, отличающийся тем, что обучающее предложение представляет собой первое обучающее предложение на втором языке, а обучающие данные дополнительно включают в себя обучающее исходное предложение на первом языке и второе обучающее предложение на втором языке; при этом первое обучающее предложение сформировано с использованием первой модели перевода на основе обучающего исходного предложения, второе обучающее предложение сформировано с использованием второй модели перевода на основе обучающего исходного предложения, и обучение первого классификатора дополнительно включает в себя:
назначение экспертом для первого обучающего предложения двоичного значения метки, представляющего собой первое двоичное значение метки или второе двоичное значение метки, при этом первое двоичное значение метки указывает на то, что первое обучающее предложение семантически нелогично, а второе двоичное значение метки указывает на то, что первое обучающее предложение семантически логично;
формирование прогнозной функции на основе обучающего исходного предложения, первого обучающего предложения, второго обучающего предложения и двоичного значения метки, назначенного для первого обучающего предложения, при этом прогнозная функция способна назначать первое значение оценки для первой гипотезы перевода на основе триады данных.
6. Способ по п. 5, отличающийся тем, что назначение первого значения оценки для первой гипотезы перевода на основе триады данных включает в себя:
определение связанного с триплетом данных набора признаков, содержащего по меньшей мере один из следующих признаков:
признак выравнивания, указывающий на лексическое соответствие между словами, содержащимися в исходном предложении, первой гипотезе перевода и второй гипотезе перевода;
признак оценки на основе языковой модели, связанный с оценкой на основе языковой модели, назначенной для каждой первой гипотезы перевода и каждой второй гипотезы перевода с использованием языковой модели;
признак двуязычной таблицы словосочетаний, указывающий на соответствие друг другу словосочетаний, содержащихся в исходном предложении, первой гипотезе перевода и второй гипотезе перевода, при этом каждое соответствие словосочетаний дополнительно содержит вероятность их совместного появления в корпусе параллельных текстов;
признак повторения, связанный с наличием повторения данного слова в первой гипотезе перевода;
признак отношения длин, связанный с отношением длин последовательностей слов в исходном предложении и в первой и второй гипотезах перевода; и
назначение первого значения оценки для первой гипотезы перевода на основе такого определенного набора признаков.
7. Способ по п. 5, отличающийся тем, что первый порог задан заранее и способ дополнительно включает в себя корректировку этого порога путем выполнения следующих действий:
прием набора исходных проверочных предложений на первом языке;
формирование набора первых проверочных переводов с использованием первой модели перевода;
формирование набора вторых проверочных переводов с использованием второй модели перевода;
назначение экспертом двоичного значения метки для каждого первого проверочного перевода в наборе первых проверочных переводов;
назначение посредством первого классификатора первого значения оценки для каждого первого проверочного перевода;
определение количества ошибок проверки, соответствующего количеству первых проверочных переводов с первым значением метки, которым назначено первое значение оценки, меньшее заранее заданного первого порога;
уменьшение первого порога, если определено, что количество ошибок проверки превышает заранее заданный проверочный порог.
8. Способ по п. 1, отличающийся тем, что второй классификатор обучен на по меньшей мере одной тетраде данных, содержащей:
обучающее исходное предложение на первом языке;
первое обучающее предложение, сформированное с использованием первой модели перевода на основе обучающего исходного предложения;
второе обучающее предложение, сформированное с использованием второй модели перевода на основе обучающего исходного предложения;
переведенное человеком предложение, соответствующее обучающему исходному предложению, переведенному на второй язык экспертом;
при этом обучение второго классификатора включает в себя:
расчет первой оценки качества перевода первого обучающего предложения на основе переведенного человеком предложения;
расчет второй оценки качества перевода второго обучающего предложения на основе переведенного человеком предложения;
формирование значения оценки различия качества, соответствующего разности второй оценки качества перевода и первой оценки качества перевода;
формирование прогнозной функции, способной назначать второе значение оценки и формируемой на основе регрессионного анализа значения оценки различия качества, первого обучающего предложения, второго обучающего предложения и обучающего исходного предложения.
9. Способ по п. 8, отличающийся тем, что первая оценка качества перевода и/или вторая оценка качества перевода представляет собой оценку BLEU.
10. Способ по п. 1, отличающийся тем, что:
вычислительное устройство представляет собой сервер, связанный с клиентским устройством через сеть связи;
прием исходного предложения включает в себя прием исходного предложения от этого клиентского устройства; и
способ дополнительно включает в себя передачу целевого предложения клиентскому устройству.
11. Сервер для перевода исходного предложения на первом языке целевым предложением на втором языке, содержащий процессор, выполненный с возможностью выполнения следующих действий:
прием исходного предложения;
формирование первой гипотезы перевода с использованием первой модели перевода;
формирование второй гипотезы перевода с использованием второй модели перевода, отличной от первой модели перевода;
назначение посредством первого классификатора первого значения оценки для первой гипотезы перевода, при этом первое значение оценки представляет собой вероятность того, что первая гипотеза перевода соответствует семантически нелогичному переводу или семантически логичному переводу на второй язык, и первый классификатор обучен определять первое значение оценки на основе анализа триады данных, содержащей исходное предложение, первую гипотезу перевода и вторую гипотезу перевода;
назначение посредством второго классификатора второго значения оценки для первой гипотезы перевода, при этом второе значение оценки представляет собой предполагаемое различие качества перевода между первой гипотезой перевода и второй гипотезой перевода и второй классификатор обучен определять второе значение оценки на основе анализа триады данных;
формирование целевого предложения, соответствующего первой гипотезе перевода, если определено, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, или соответствующего второй гипотезе перевода, если определено, что это условие не выполнено.
12. Сервер по п. 11, отличающийся тем, что первая модель перевода представляет собой модель машинного перевода на основе нейронной сети, а вторая модель перевода представляет собой модель статистического перевода на основе фраз.
13. Сервер по п. 11, отличающийся тем, что для определения того, что первое значение оценки и второе значение оценки удовлетворяют условию относительно первого порога и второго порога, соответственно, процессор выполнен с возможностью определения того, что первое значение оценки меньше первого порога, и определения того, что второе значение оценки меньше второго порога.
14. Сервер по п. 13, отличающийся тем, что первый классификатор предварительно обучен на обучающих данных, содержащих по меньшей мере одно обучающее предложение, помеченное как семантически логичное или нелогичное, а процессор выполнен с возможностью определять, указывает триплет данных на более высокую вероятность семантической нелогичности первой гипотезы перевода или на более низкую вероятность семантической нелогичности первой гипотезы перевода на второй язык.
15. Сервер по п. 14, отличающийся тем, что обучающее предложение представляет собой первое обучающее предложение на втором языке, а обучающие данные дополнительно содержат обучающее исходное предложение на первом языке и второе обучающее предложение на втором языке; при этом первое обучающее предложение сформировано с использованием первой модели перевода на основе обучающего исходного предложения, второе обучающее предложение сформировано с использованием второй модели перевода на основе обучающего исходного предложения и для обучения первого классификатора процессор дополнительно выполнен с возможностью выполнять следующие действия:
назначение экспертом для первого обучающего предложения двоичного значения метки, представляющего собой первое двоичное значение метки или второе двоичное значение метки, при этом первое двоичное значение метки указывает на то, что первое обучающее предложение семантически нелогично, а второе двоичное значение метки указывает на то, что первое обучающее предложение семантически логично;
формирование прогнозной функции на основе обучающего исходного предложения, первого обучающего предложения, второго обучающего предложения и двоичного значения метки, назначенного для первого обучающего предложения, при этом прогнозная функция способна назначать первое значение оценки для первой гипотезы перевода на основе триады данных.
16. Сервер по п. 15, отличающийся тем, что для назначения первого значения оценки для первой гипотезы перевода на основе триады данных процессор выполнен с возможностью выполнять следующие действия:
определение связанного с триплетом данных набора признаков, содержащего по меньшей мере один из следующих признаков:
признак выравнивания, указывающий на лексическое соответствие между словами, содержащимися в исходном предложении, первой гипотезе перевода и второй гипотезе перевода;
признак оценки на основе языковой модели, связанный с оценкой на основе языковой модели, назначенной для каждой первой гипотезы перевода и каждой второй гипотезы перевода с использованием языковой модели;
признак двуязычной таблицы словосочетаний, указывающий на соответствие друг другу словосочетаний, содержащихся в исходном предложении, первой гипотезе перевода и второй гипотезе перевода, при этом каждое соответствие словосочетаний дополнительно содержит вероятность их совместного появления в корпусе параллельных текстов;
признак повторения, связанный с наличием повторения данного слова в первой гипотезе перевода;
признак отношения длин, связанный с отношением длин последовательностей слов в исходном предложении и в первой и второй гипотезах перевода; и
назначение первого значения оценки для первой гипотезы перевода на основе такого определенного набора признаков.
17. Сервер по п. 16, отличающийся тем, что первый порог заранее задан и процессор выполнен с возможностью корректировать этот порог путем выполнения следующих действий:
прием набора исходных проверочных предложений на первом языке;
формирование набора первых проверочных переводов с использованием первой модели перевода;
формирование набора вторых проверочных переводов с использованием второй модели перевода;
назначение экспертом двоичного значения метки для каждого первого проверочного перевода в наборе первых проверочных переводов;
назначение посредством первого классификатора первого значения оценки для каждого первого проверочного перевода;
определение количества ошибок проверки, соответствующего количеству первых проверочных переводов с первым значением метки, которым назначено первое значение оценки, меньшее заранее заданного первого порога;
уменьшение первого порога, если определено, что количество ошибок проверки превышает заранее заданный проверочный порог.
18. Сервер по п. 11, отличающийся тем, что второй классификатор обучен на по меньшей мере одной тетраде данных, содержащей:
обучающее исходное предложение на первом языке;
первое обучающее предложение, сформированное с использованием первой модели перевода на основе обучающего исходного предложения;
второе обучающее предложение, сформированное с использованием второй модели перевода на основе обучающего исходного предложения;
переведенное человеком предложение, соответствующее обучающему исходному предложению, переведенному на второй язык экспертом;
при этом для обучения второго классификатора процессор выполнен с возможностью:
расчета первой оценки качества перевода первого обучающего предложения на основе переведенного человеком предложения;
расчета второй оценки качества перевода второго обучающего предложения на основе переведенного человеком предложения;
формирования значения оценки различия качества, соответствующего разности второй оценки качества перевода и первой оценки качества перевода;
формирования прогнозной функции, способной назначать второе значение оценки и формируемой на основе регрессионного анализа значения оценки различия качества, первого обучающего предложения, второго обучающего предложения и обучающего исходного предложения.
19. Сервер по п. 18, отличающийся тем, что первая оценка качества перевода и/или вторая оценка качества перевода представляет собой оценку BLEU.
20. Сервер по п. 19, отличающийся тем, что сервер соединен с клиентским устройством через сеть связи и дополнительно содержит интерфейс связи для приема исходного предложения от этого клиентского устройства через эту сеть связи, при этом процессор дополнительно выполнен с возможностью передавать целевое предложение клиентскому устройству.
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| CN 105068998 A, 18.11.2015 | |||
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 5805832 A, 08.09.1998 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| ВЫДЕЛЕНИЕ ВРЕМЕННЫХ ВЫРАЖЕНИЙ ДЛЯ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2014 |
|
RU2595489C2 |
| ИСПОЛЬЗОВАНИЕ ГЛУБИННОГО СЕМАНТИЧЕСКОГО АНАЛИЗА ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ ДЛЯ СОЗДАНИЯ ОБУЧАЮЩИХ ВЫБОРОК В МЕТОДАХ МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2636098C1 |

