ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящая технология относится к сервисами агрегации новостей и, конкретнее, к системе и способу компьютерной обработки цитат в цифровых текстах для определения их автора.
УРОВЕНЬ ТЕХНИКИ
[0002] С ростом числа пользователей, имеющим доступ к сети Интернет, приобрело популярность большое количество Интернет-сервисов. Подобные сервисы включают в себя, например, сервисы поисковой системы (например, Yandex™ Google™ и так далее), сервисы социальной сети (например, Facebook™), сервисы мультимедиа (например, Instagram™ и YouTube™), и сервисы агрегации новостей (например, Яндекс.Новости™). Последний сервис является особенно полезным для простого просмотра пользователями новостных статей на одной платформе.
[0003] Агрегация цифровых новостей является технологической областью, интерес к которой возрастает. В самом деле, новости являются очень важной частью повседневной жизни, как для биржевого брокера, так и для юриста. Сервис агрегации новостей позволяет пользователю просматривать наиболее актуальные новости без необходимости частого посещения отдельных веб-сайтов (например, связанных с индивидуальными новостными агентствами или индивидуальными газетами) для проверки того, есть ли обновления содержимого.
[0004] В общем случае, новости представляют собой редакционное содержимое и различные цитаты людей (например, политиков, звезд, частных лиц с конкретным знанием, релевантным для статьи, и так далее). Эти цитаты могут повторяться различными новостными агентствами, которые могут содержать ошибки авторства или могут обладать неясными ссылками на автора цитаты. Таким образом, в некоторых случаях, сервису агрегации новостей предоставляются различные новостные статьи, в которых авторство той же самой цитаты не совпадает с другими новостными статьями.
[0005] Излишне говорить, что пользователю не только приходится просматривать различные новостные статьи, где одни и те же цитаты приписываются разным авторам, но пользователю также приходится производить дополнительные поиски в интернете для определения правильного автора, что может потребовать значительного количества вычислительной мощи и ресурсов.
[0006] Кроме того, широко известно, что пользователи сервисов агрегации новостей, в попытке передать суть происходящего события, часто фокусируются больше на цитатах, чем на содержимом новостной статьи. Таким образом, некоторые сервисы агрегации новостей предоставляют цитату отдельно от содержимого новостной статьи. Другими словами, может быть желательно, чтобы новостной агрегатор показывал только цитату и автора цитаты вместо всей новостной статьи. Например, данный новостной агрегатор может предоставлять множество различных цитат (с соответствующими авторами) в новостную ленту важных цитат.
[0007] При обычном подходе к отображению одной или нескольких цитат в сервисе агрегации новостей требуется, чтобы один или несколько человек, связанные с этим сервисом агрегации новостей, заранее выбрали цитату и вручную определили его автора. Излишне говорить, что этот подход не только требует большого, количества человеческих и вычислительных ресурсов, но также приводит к задержкам в "публикации" новостных статей на сервисе агрегации новостей.
[0008] Заявка US 8,805,781 В2 (опубликованная 21 декабря 2006 года) описывает компьютеризированную систему и способ для анализа цитат в цитируемом текстовом документе, которые первоначально находятся в исходном документе. Настоящее изобретение анализирует цитируемый документ для цитируемого текста, ищет исходный документ для этого текста и сохраняет факт наличия цитаты в связи с исходным документом. При отображении исходного документа, список текстовых элементов, которые были процитированы другим документом, представлен с ранжированием по частоте цитирования. Цитируемый текст также подсвечивается, когда отображается оригинальный текст исходного документа. Разрешены гиперссылки между элементами цитируемого пользователем текста и списком документов, которые цитируют этот текст. Из этого списка может отображать полный текст цитируемого документа. Частота цитирования исходного документа может также использоваться для ранжирования документов в поисковых результатах.
[0009] Заявка US 2017/220677 А1 (опубликованная 3 августа 2017 года) описывает в одном варианте осуществления технологии, способ, который включает в себя получение доступа ко множеству сообщений, причем каждое сообщение связано с конкретным элементом содержимого и включает в себя текст сообщения; извлечение, для каждого из сообщений, цитат из текста сообщения; определение, для каждой извлеченной цитаты, частей цитаты; группирование извлеченных цитат на кластеры на основе соответствующей степени сходства среди соответствующих частей; вычисление кластерной оценки для каждого кластера на основе частоты вхождений частей цитат в кластере в сообщения; и создание модулей цитат, содержащих соответствующие цитаты, причем представление цитаты представляет собой цитату из кластера, обладающую кластерной оценкой выше, чем порог кластерной оценки.
[00010] Заявка US 9,223,881 В1 (опубликована 30 июня, 2016) описывает системы и способы управления цитатами. Система может упрощать пользователю поиск, связанный с одной или несколькими конкретными цитатами, авторами, категориями цитат, конкретными тегами цитаты и так далее. На основе пользовательского поиска может предоставляться набор результатов. Могут быть созданы профиль цитаты и автор профиля, что предоставляет информацию о цитате и ее авторе соответственно. Страница профиля пользователя может отображать информацию, включающую в себя любимые цитаты пользователя.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[00011] Целью настоящей технологии является предоставление улучшенного способа и систем для компьютерной обработки одной или нескольких цитат в цифровых текстах для определения связанного с ними автора.
[00012] Без ограничения какой-либо конкретной теорией, варианты осуществления настоящей технологии были разработаны на основе предположения о том, что путем анализа набора новостных статей на одну и ту же тематику, возможно более точно идентифицировать цитаты и их "правильных" авторов. Тем самым, становится возможным отображать одну или несколько цитат на сервисе агрегации новостей с "правильным" автором с меньшей вычислительной нагрузкой.
[00013] Объектом настоящей технологии является предоставление исполняемого на компьютере способа и для обработки одной или нескольких цитат в цифровых текстах для определения связанного с ними автора. Способ выполняется на сервере, выполненном с возможностью выполнять сервис агрегации новостей, который также соединен со множеством цифровых сервисов новостей с помощью сети передачи данных. Способ включает в себя: получение множества цифровых текстов из базы данных; парсинг каждого из множества цифровых текстов для извлечения одной или нескольких цитат, причем парсинг выполняется путем применения одного или нескольких правил парсинга; определение по меньшей мере одного связанного кандидата-автора для каждой из одной или нескольких цитат, причем определение выполняется путем применения одного или нескольких правил идентификации; назначение первым классификатором величины сходства цитаты для данной цитаты в отношении каждой одной или нескольких остальных цитат, причем величина сходства цитаты представляет собой вероятность того, что данная цитата происходит из той же цитаты, что и каждая из одной или нескольких остальных цитат; создание кластера цитат, который включает в себя: одну или несколько цитат, которые включают в себя данную цитату и подмножество из одной или нескольких остальных цитат, каждая из которых обладает величиной сходства выше порога; набор кандидатов-авторов, который включает в себя по меньшей мере одного кандидата-автора, связанного с каждой одной или несколькими аналогичными цитатами; анализ набора кандидатов-авторов для определения данного кандидата-автора, который удовлетворяет условию; и сохранение кандидата-автора, который удовлетворяет условию, как автора одной или нескольких сходных цитат.
[00014] В некоторых вариантах осуществления технологии, цифровые тексты соответствуют новостным статьям, представляющим одну и ту же тему, причем множество новостных статей получено из множества цифровых новостных сервисов.
[00015] В некоторых вариантах осуществления технологии, одно или несколько правил парсинга включают в себя извлечение одной или нескольких частей цифровых текстов, вставленных между данным набором кавычек.
[00016] В некоторых вариантах осуществления технологии, одно или несколько правил идентификации включают в себя определение по меньшей мере одного слова с прописной буквы на заранее определенном расстоянии от данного набора кавычек.
[00017] В некоторых вариантах осуществления настоящей технологии, данная цитата является первой цитатой; порог является первым порогом; и назначение величины сходства цитаты первой цитате в отношении второй цитаты включает в себя: определение кратчайшей общей последовательной строки слов между первой цитатой и второй цитатой; и определение того, находится ли кратчайшая общая последовательная строка слов выше второго порога.
[00018] В некоторых вариантах осуществления настоящей технологии, величина сходства цитат является бинарной величиной.
[00019] В некоторых вариантах осуществления настоящей технологии, анализ набора кандидатов-авторов для определения данного кандидата-автора, удовлетворяющего условию, включает в себя: определение частоты вхождений данного кандидата-автора в набор кандидатов-авторов; и определение того, что частота вхождений данного кандидата-автора является наибольшей частотой в наборе кандидатов-авторов.
[00020] В некоторых вариантах осуществления настоящей технологии, в ответ на то, что клиентское устройство получает доступ к сервису агрегации новостей, передача клиентскому устройству пакета данных, который включает в себя: лучшую цитату, соответствующую одной или нескольким сходным цитатам; и автора лучшей цитаты.
[00021] В некоторых вариантах осуществления настоящей технологии, лучшая цитата соответствует одной или нескольким сходным цитатам, которые обладают наибольшей строкой последовательных слов.
[00022] В некоторых вариантах осуществления настоящей технологии, сервер далее соединен с базой данных изображений, которая включает в себя множество изображений, связанных по меньшей мере с одним или несколькими кандидатами-авторами; и способ дополнительно включает в себя: до передачи пакета данных, извлечение изображения, связанного с автором; и причем пакет данных дополнительно включает в себя изображение.
[00023] Другим объектом настоящей технологии является сервер для обработки одной или нескольких цитат в цифровых текстах для определения связанного с ними автора. Сервер соединен со множеством цифровых новостных сервисов с помощью сети передачи данных. Сервер содержит процессор, выполненный с возможностью осуществлять: получение множества цифровых текстов из базы данных; парсинг каждого из множества цифровых текстов для извлечения одной или нескольких цитат, причем парсинг выполняется путем применения одного или нескольких правил парсинга; определение по меньшей мере одного связанного кандидата-автора для каждой из одной или нескольких цитат, причем определение выполняется путем применения одного или нескольких правил идентификации; назначение первым классификатором величины сходства цитаты для данной цитаты в отношении каждой из одной или нескольких остальных цитат, причем величина сходства цитаты представляет собой вероятность того, что данная цитата происходит из той же цитаты, что и каждая из одной или нескольких остальных цитат; создание кластера цитат, который включает в себя: одну или несколько цитат, которые включают в себя данную цитату и подмножество из одной или нескольких остальных цитат, каждая из которых обладает величиной сходства выше порога; набор кандидатов-авторов, который включает в себя по меньшей мере одного кандидата-автора, связанного с каждой одной или несколькими аналогичными цитатами; анализ набора кандидатов-авторов для определения данного кандидата-автора, который удовлетворяет условию; и сохранение кандидата-автора, который удовлетворяет упомянутому условию, как автора одной или нескольких сходных цитат.
[00024] В некоторых вариантах осуществления технологии, цифровые тексты соответствуют новостным статьям, представляющим одну и ту же тему, причем множество новостных статей получено из множества цифровых новостных сервисов.
[00025] В некоторых вариантах осуществления технологии, одно или несколько правил парсинга включают в себя извлечение одной или нескольких частей цифровых текстов, вставленных между данным набором кавычек.
[00026] В некоторых вариантах осуществления технологии, одно или несколько правил идентификации включают в себя определение по меньшей мере одного слова с прописной буквы на заранее определенном расстоянии от данного набора кавычек.
[00027] В некоторых вариантах осуществления настоящей технологии, данная цитата является первой цитатой; порог является первым порогом; и для назначения величины сходства цитаты первой цитате в отношении второй цитаты, процессор выполнен с возможностью осуществлять: определение кратчайшей общей последовательной строки слов между первой цитатой и второй цитатой; и определение того, находится ли кратчайшая общая последовательная строка слов выше второго порога.
[00028] В некоторых вариантах осуществления настоящей технологии, величина сходства цитат является бинарной величиной.
[00029] В некоторых вариантах осуществления настоящей технологии, для анализа набора кандидатов-авторов для определения данного кандидата-автора, удовлетворяющего условию, процессор выполнен с возможностью осуществлять: определение частоты вхождений данного кандидата-автора в наборе кандидатов-авторов; и определение того, что частота вхождений данного кандидата-автора является наибольшей частотой в наборе кандидатов-авторов.
[00030] В некоторых вариантах осуществления настоящей технологии, процессор выполнен с возможностью осуществлять: в ответ на то, что клиентское устройство получает доступ к сервису агрегации новостей, передачу клиентскому устройству пакета данных, который включает в себя: лучшую цитату, соответствующую одной или нескольким сходным цитатам; и автора лучшей цитаты.
[00031] В некоторых вариантах осуществления настоящей технологии, лучшая цитата соответствует одной или нескольким сходным цитатам, которые обладают наибольшей строкой последовательных слов.
[00032] В некоторых вариантах осуществления настоящей технологии, сервер далее соединен с базой данных изображений, которая включает в себя множество изображений, связанных по меньшей мере с одним или несколькими кандидатами-авторами; и процессор дополнительно выполнен с возможностью осуществлять: до передачи пакета данных, извлечение изображения, связанного с автором; и причем пакет данных дополнительно включает в себя изображение.
[00033] В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
[00034] В контексте настоящего описания, если конкретно не указано иное, слова «первый», «второй», «третий» и и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной передачи данных между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание «первого» элемента и «второго» элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[00035] В контексте настоящего описания, если конкретно не указано иное, термин «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, который сохраняет или использует информацию, хранящуюся в базе данных, или же она может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[00036] Для лучшего понимания настоящей технологии, а также других ее аспектов и характерных черт сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[00037] На Фиг. 1 представлена принципиальная схема системы, выполненной в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем.
[00038] На Фиг. 2 представлена схематическая иллюстрация новостной базы данных системы, показанной на Фиг. 1.
[00039] На Фиг. 3 представлен снимок экрана цифрового документа, отрисованного на электронном устройстве системы, показанной на Фиг. 1.
[00040] На Фиг. 4 представлен пример процесса компьютерной обработки одной или нескольких цитат в цифровых текстах для определения связанного автора.
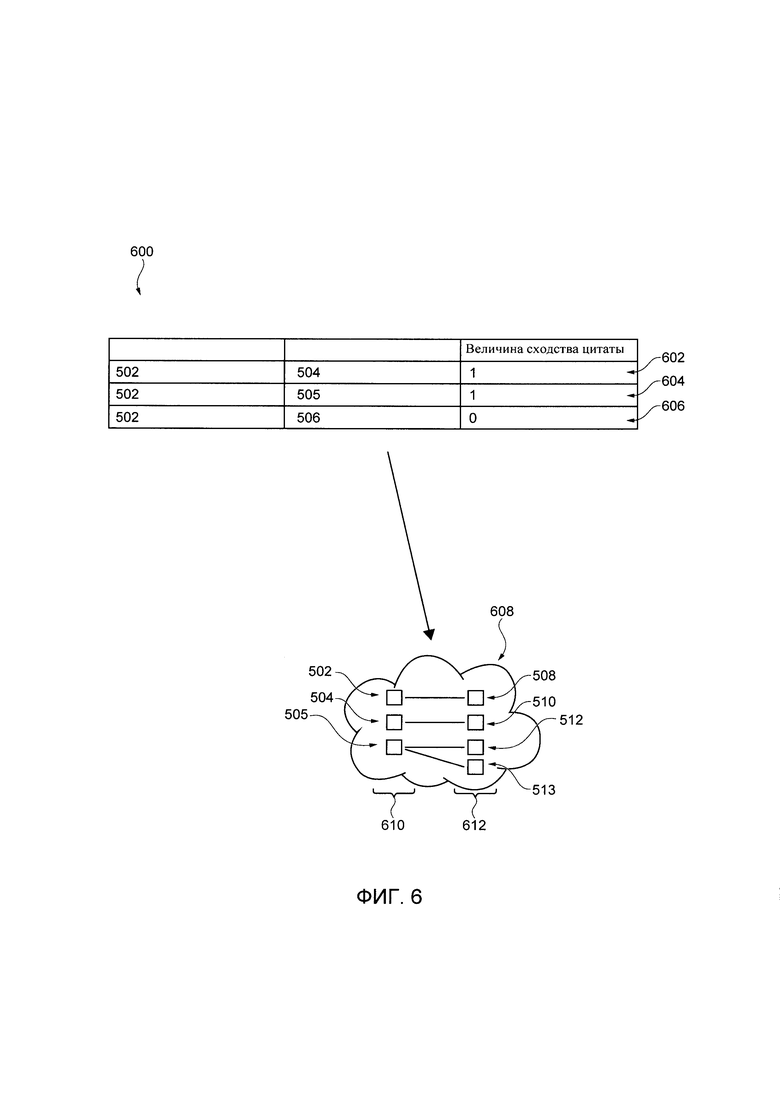
[00041] На Фиг. 5 представлен индекс, созданный процедурой парсинга цитаты, показанной на Фиг. 4.
[00042] На Фиг. 6 кластер цитат, созданный первой процедурой классифицирования, выполняемой как часть процесса, показанного на Фиг. 4.
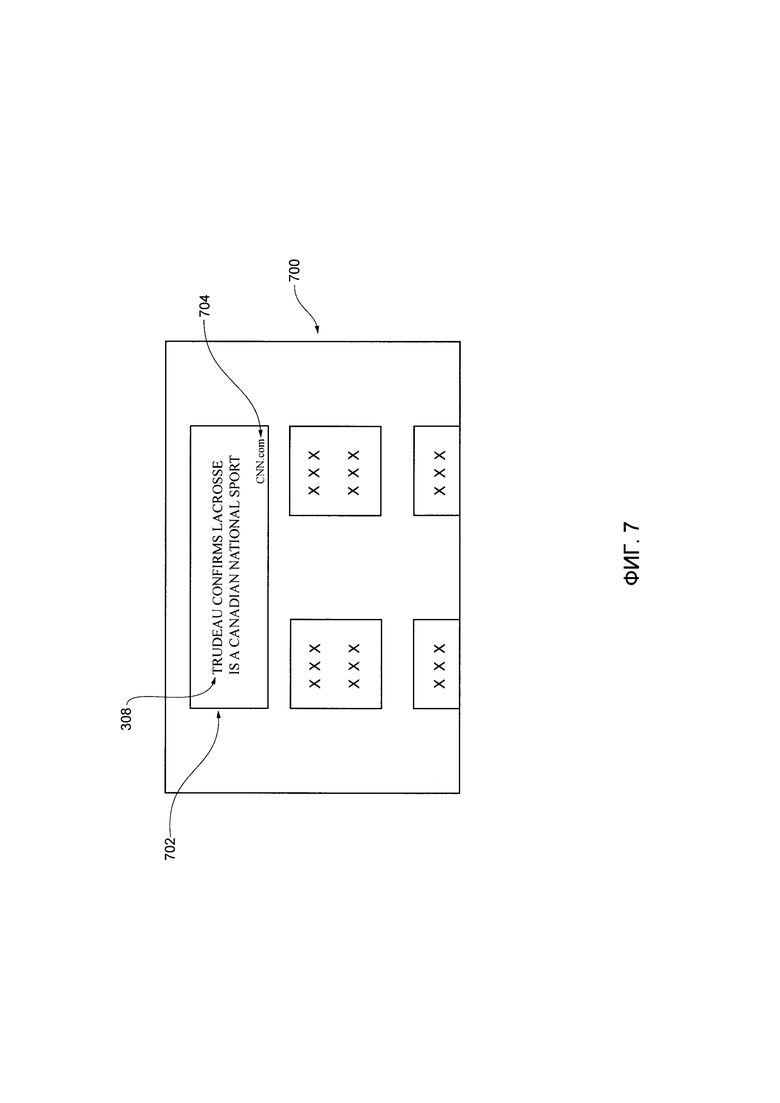
[00043] На Фиг. 7 представлен снимок экрана главной страницы сервиса новостного агрегатора, отрисованного на электронном устройстве системы, показанной на Фиг. 1.
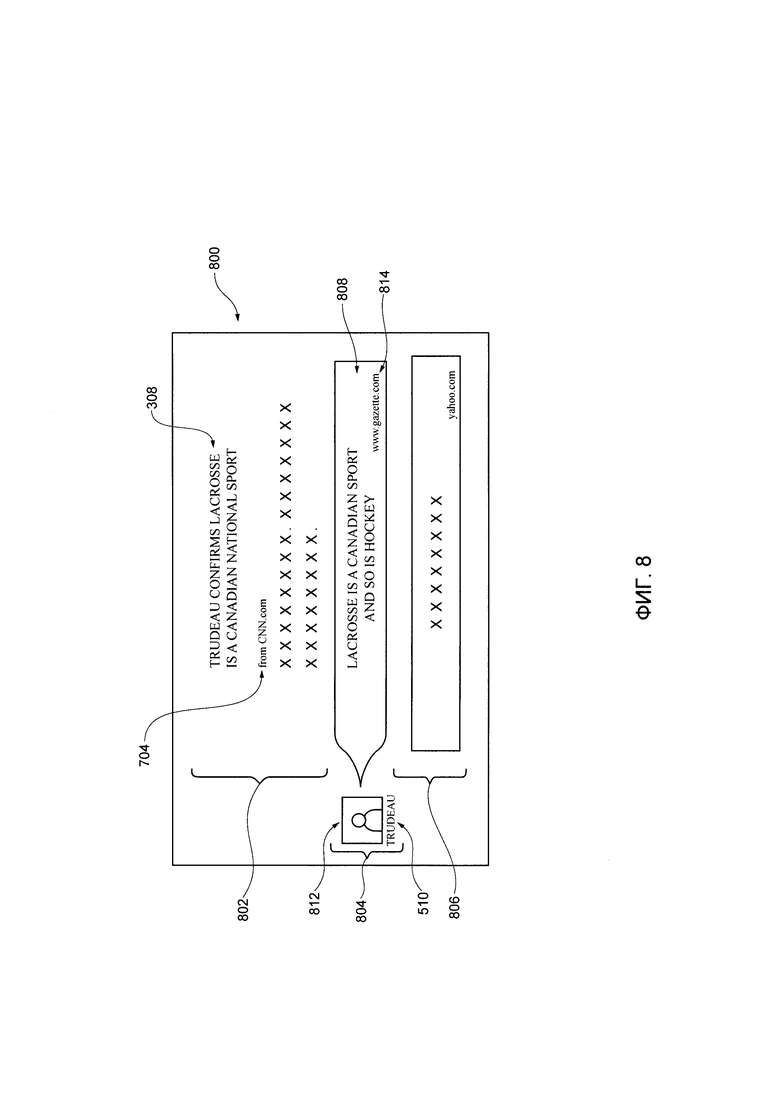
[00044] На Фиг. 8 представлен снимок экрана якорной страницы сервиса новостного агрегатора, отрисованного на электронном устройстве системы, показанной на Фиг. 1.
[00045] На Фиг. 9 представлена блок-схема способа компьютерной обработки одной или нескольких цитат в цифровых текстах для определения связанного автора.
ОСУЩЕСТВЛЕНИЕ
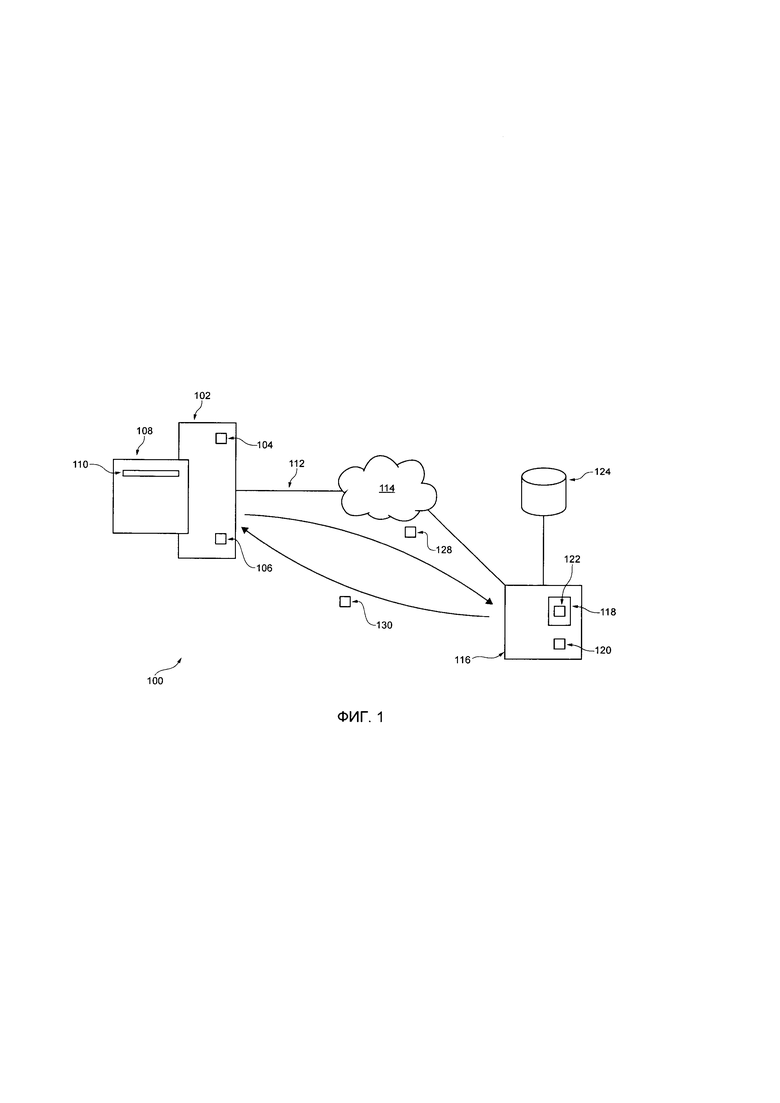
[00046] На Фиг. 1 представлена принципиальная схема системы 100, с возможностью реализации вариантом осуществления настоящей технологии, не ограничивающих ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание показательных вариантов осуществления настоящей технологии. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящей технологии. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[00047] Все примеры и используемые здесь условные конструкции предназначены, главным образом, для того, чтобы помочь читателю понять принципы настоящей технологии, а не для установления границ ее объема. Следует также отметить, что специалисты в данной области техники могут разработать различные схемы, отдельно не описанные и не показанные здесь, но которые, тем не менее, воплощают собой принципы настоящей технологии и находятся в границах ее объема. Кроме того, для ясности в понимании, следующее описание касается достаточно упрощенных вариантов осуществления настоящей технологии. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[00048] Более того, все заявленные здесь принципы, аспекты и варианты осуществления настоящей технологии, равно как и конкретные их примеры, предназначены для обозначения их структурных и функциональных основ, вне зависимости от того, известны ли они на данный момент или будут разработаны в будущем. Таким образом, например, специалистами в данной области техники будет очевидно, что представленные здесь блок-схемы представляют собой концептуальные иллюстративные схемы, отражающие принципы настоящей технологии. Аналогично, любые блок-схемы, диаграммы, псевдокоды и т.п.представляют собой различные процессы, которые могут быть представлены на машиночитаемом носителе и, таким образом, использоваться компьютером или процессором, вне зависимости от того, показан явно подобный компьютер или процессор, или нет.
[00049] Функции различных элементов, показанных на фигурах, включая функциональный блок, обозначенный как «процессор», могут быть обеспечены с помощью специализированного аппаратного обеспечения или же аппаратного обеспечения, способного использовать подходящее программное обеспечение. Когда речь идет о процессоре, функции могут обеспечиваться одним специализированным процессором, одним общим процессором или множеством индивидуальных процессоров, причем некоторые из них могут являться общими. В некоторых вариантах осуществления настоящей технологии, процессор может являться универсальным процессором, например, центральным процессором (CPU) или специализированным для конкретной цели процессором, например, графическим процессором (GPU). Более того, использование термина «процессор» или «контроллер» не должно подразумевать исключительно аппаратное обеспечение, способное поддерживать работу программного обеспечения, и может включать в себя, без установления ограничений, цифровой сигнальный процессор (DSP), сетевой процессор, интегральную схему специального назначения (ASIC), программируемую пользователем вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также в это может быть включено другое аппаратное обеспечение, обычное и/или специальное.
[00050] С учетом этих примечаний далее будут рассмотрены некоторые варианты осуществления аспектов настоящей технологии, не ограничивающие ее объем.
[00051] Система 100 включает в себя электронное устройство 102. Электронное устройство 102 обычно связано с пользователем (не показан) и, таким образом, иногда может упоминаться как «клиентское устройство». Следует отметить, что тот факт, что электронное устройство 102 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, быть зарегистрированным, или чего-либо подобного.
[00052] В контексте настоящего описания, если конкретно не указано иное, «электронное устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами электронных устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как электронное устройство в настоящем контексте, может вести себя как сервер по отношению к другим электронным устройствам. Использование выражения «электронное устройство» не исключает возможности использования множества электронных устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного метода.
[00053] Электронное устройство 102 включает в себя постоянное хранилище 104. Постоянное хранилище 104 памяти может охватывать один или несколько носителей и в общем случае предоставляет место для хранения исполняемых на компьютере инструкций, выполняемых компьютером 106. Например, постоянное хранилище 104 может быть реализовано как машиночитаемый носитель информации, включая ПЗУ (ROM), жесткие диски (HDD), твердотельные накопители (SSD) и флеш-карты памяти.
[00054] Электронное устройство 102 содержит аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в области техники, чтобы выполнять браузерное приложение 108. В общем случае, задачей браузерного приложения 108 является предоставление пользователю (не показан) доступа к одному или нескольким веб-ресурсам. Способ, в соответствии с которым реализовано браузерное приложение 108, хорошо известен в данной области техники и не будет описан здесь. Достаточно сказать, что браузерное приложение 108 может представлять собой любое из бразуерных приложений Google™ Chrome™, Ян деке. Браузер™ или любое другое коммерчески доступное или собственное браузерное приложение.
[00055] Вне зависимости от того, какое именно браузерное приложение 108 используется, оно обычно обладает командным интерфейсом 110. В общем случае, пользователь (не показано) может получить доступ к веб-ресурсу через сеть передачи данных двумя основными способами. Пользователь может получать доступ к конкретному веб-ресурсу напрямую, введя адрес веб-ресурса (обычно, URL или Единый указатель ресурса, например www.example.com) в командный интерфейс 110, или же нажав на ссылку в электронном сообщении или на другом веб-ресурсе (что, по сути, будет аналогом действия "копировать и вставить" соответствующий URL, связанный со ссылкой, в командный интерфейс 110).
[00056] В противном случае пользователь может выполнить поиск желаемого ресурса с помощью сервиса поисковой системы (не показано) на основе поискового намерения пользователя. Последнее особенно подходит для тех случаев, когда пользователю известна тема, в которой он заинтересован, но неизвестен конкретный URL интересующего веб-ресурса. Поисковая система обычно возвращает страницу результатов поиска (SERP), содержащую ссылки на один или несколько веб-ресурсов, которые отвечают на запрос пользователя. Опять же, путем нажатия на одну или несколько ссылок, представленных на SERP, пользователь может открыть необходимый веб-ресурс.
[00057] Электронное устройство 102 включает в себя интерфейс передачи данных (не показано) для двусторонней передачи данной через сеть 114 передачи данных через линию 112 передачи данных. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих ее объем, сеть 114 передачи данных может представлять собой Интернет. В других вариантах осуществления настоящей технологии сеть 114 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
[00058] Реализация линии 112 передачи данных никак конкретно не ограничена, и зависит от того, как именно реализовано электронное устройство 102. В качестве примера, но не ограничения, в данных вариантах осуществления настоящей технологии, когда электронное устройство 102 представляет собой беспроводное устройство связи (например, смартфон), линия 112 передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных сети 3G, линия передачи данных сети 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.).
[00059] Важно иметь в виду, что варианты осуществления электронного устройства 102, линии 112 передачи данных и сети 114 передачи данных даны исключительно в иллюстрационных целях. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления электронного устройства 102, линии 112 передачи данных и сети 114 передачи данных. Таким образом, представленные здесь примеры не ограничивают объем настоящей технологии.
[00060] Система 100 далее включает в себя сервер 116, соединенный с сетью 114 передачи данных. Сервер 116 может представлять собой обычный компьютерный сервер. В примере варианта осуществления настоящего технического решения сервер 116 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сервер 116 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленных неограничивающих вариантах осуществления настоящей технологии сервер 116 является одиночным сервером. В других вариантах осуществления настоящей технологии, не ограничивающих ее объем, функциональность сервера 116 может быть разделена, и может выполняться с помощью нескольких серверов.
[00061] Вариант осуществления сервера 116 хорошо известен. Тем не менее, вкратце, сервер 116 содержит интерфейс связи (не показан), который настроен и выполнен с возможностью устанавливать соединение с различными элементами (например, электронным устройством 102 и другими устройствами, потенциально присоединенными к сети 114 передачи данных) через сеть 114 передачи данных. Аналогично электронному устройству 102, сервер 116 включает в себя серверную память 118, которая включает в себя один или несколько носителей и в общем случае предоставляет место для хранения исполняемых на компьютере программных инструкций, выполняемых серверным процессором 120. В качестве примера, серверная память 118 может быть реализована как физический машиночитаемый носитель, включая постоянное запоминающее устройство - ПЗУ (ROM) и/или оперативное запоминающее устройство - ОЗУ (RAM). Серверная память 118 может также включать в себя одно или несколько физических устройств хранения в форме, например, жестких дисков (HDD), твердотельных накопителей (SSD) или флеш-карт памяти.
[00062] В некоторых вариантах осуществления технологии сервер 116 может управляться тем же лицом, которое предоставило вышеописанное браузерное приложение 108. Например, если браузерное приложение 108 представляет собой Яндекс.Бразуер™, сервер 116 может управляться ООО "Яндекс", расположенным по адресу 119021 ул. Льва Толстого, 16, Москва, Россия. В других вариантах осуществления технологии сервер 116 может управляться лицом, отличным от того, которое предоставило вышеописанное браузерное приложение 108.
[00063] В соответствии с настоящей технологией, сервер 116 выполнен с возможностью выполнять приложение 122 агрегации новостей, например, Яндекс.Новости™. Способ, в соответствии с которым выполняется приложение 122 агрегации новостей, описано более подробно далее. Достаточно сказать, что приложение 122 агрегации новостей выполнено с возможностью предоставлять сервис агрегации новостей, которому доступно электронное устройство 102 с помощью сети 114 передачи данных для предоставления новостного содержимого от множества источников (не показано).
[00064] С этой целью, сервер 116 коммуникативно соединен с новостной базой 124 данных через линию передачи данных (не пронумеровано). В альтернативных вариантах осуществления настоящей технологии, новостная база данных 124 может быть функционально соединена с сервером 116 через сеть 114 передачи данных, не выходя за границы настоящей технологии. Несмотря на то что новостная база 124 данных представлена здесь схематически как единый элемент, подразумевается, что новостная база данных 124 может быть выполнена в распределенном виде.
[00065] Новостная база 124 данных заполнена множеством цифровых документов (не показано). Природа каждого из множества цифровых документов никак конкретно не ограничена. В широком смысле, данный один из одного или нескольких цифровых документов содержит одно или несколько предложений, изображений, видео и т.д. Цифровой документ может представлять собой, например, новостную статью (например, статья CNN™ о текущей мировой политической ситуации).
Новостная база 124 данных
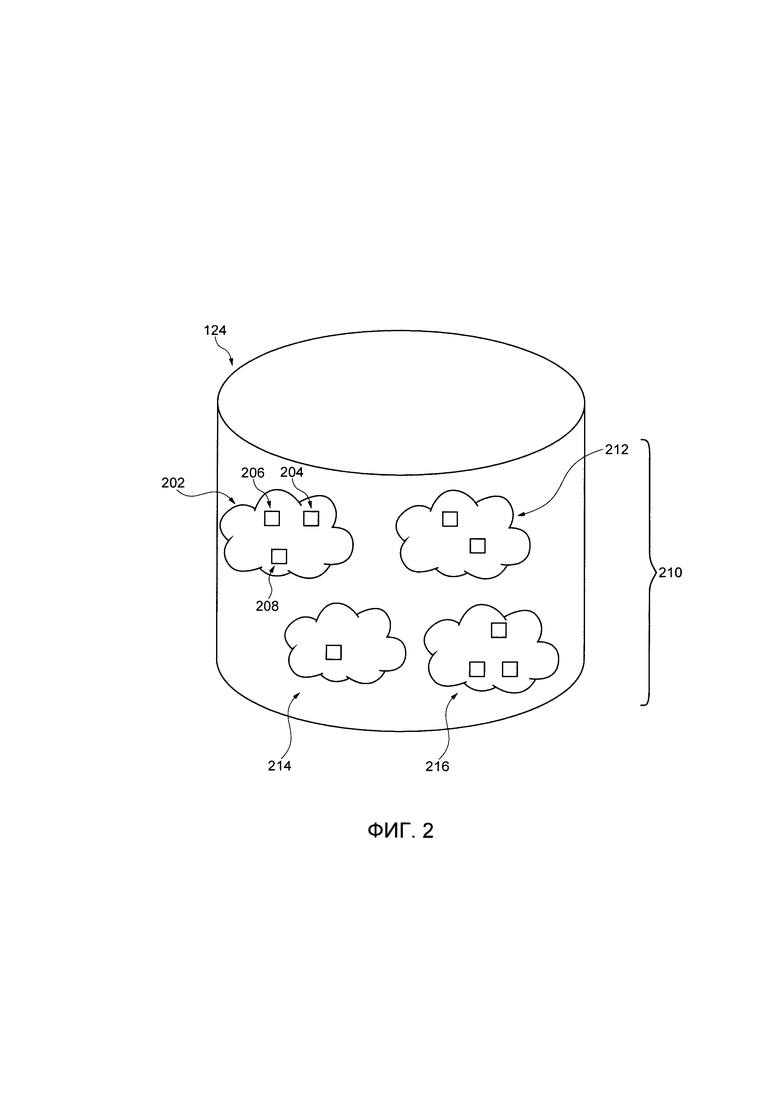
[00066] Со ссылкой на Фиг. 2, представлен неограничивающий вариант осуществления новостной базы 124 данных, заполненный множеством цифровых документов.
[00067] Способ, в соответствии с которым заполняется новостная база 124 данных, никак конкретно не ограничен. Исключительно в качестве примера, новостная база 124 данных может выполнять (или обладать доступом к) функции поискового робота, которая выполнена с возможностью собирать множество цифровых документов из выбранных новостных ресурсов, например, веб-сайтов газет, онлайн журналов, других электронных новостных ресурсов и т.д. Альтернативно, новостная база 124 данных может получать множество цифровых документов напрямую из различных ресурсов без использования функции поискового робота.
[00068] Новостная база 124 данных хранит множество цифровых документов, кластеризованных по одной или нескольким тематикам или событиям. Таким образом, новостная база 124 данных выполняет (или обладает доступом к) функции кластеризации тематик (не показано). Способ, в соответствии с которым кластеризовано множество цифровых документов, на одну или несколько тематик или событий, никак не ограничен, и может, например, выполняться с помощью обычных способов кластеризации, например, моделирования тематик или подходов на основе ключевых слов.
[00069] Множество цифровых документов кластеризовано на один или несколько тематических кластеров 210. Например, новостная база 124 данных включает в себя первый тематический кластер 202, второй тематический кластер 212, третий тематический кластер 214 и четвертый тематический кластер 216. Первый тематический кластер 202 включает в себя первый цифровой документ 204, второй цифровой документ 206 и третий цифровой документ 208. В представленном примере, первый тематический кластер 202 создан из новостных статей, в которых обсуждается заявление премьер-министра Канады Трюдо о том, что лакросс является национальным канадским видом спорта.
[00070] В некоторых вариантах осуществления технологии, новостная база 124 данных далее включает в себя указание на источник (например, URL) для каждого из множества хранящихся документов. Например, первый цифровой документ 204 связан с первым URL (не показано), связанным с CNN™, второй цифровой документ 206 связан со вторым URL (не показано), соответствующим Montreal Gazette™, а третий цифровой документ 208 связан с третьим URL (не показано), соответствующим Yahoo!™.
Цифровой документ
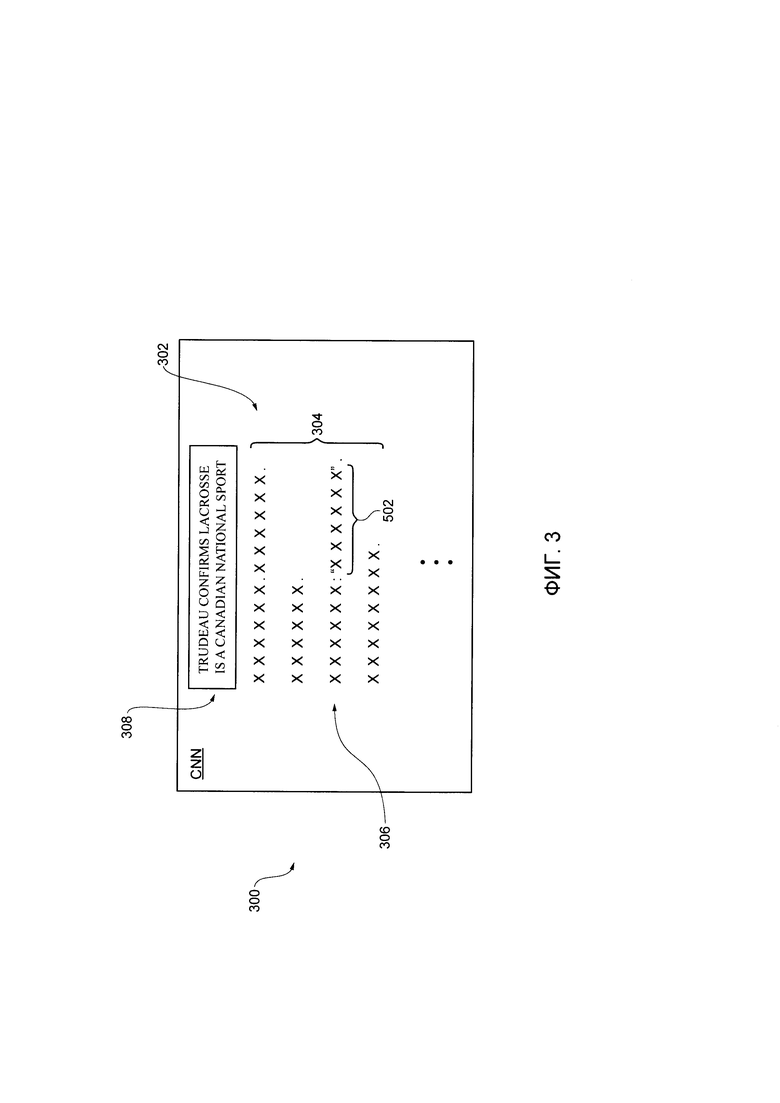
[00071] На Фиг. 3 представлен снимок 300 экрана первого цифрового документа 204, отображающего цифровой текст 302. Цифровой текст 302 может быть, например, версией первого цифрового документа 204, отрисованного на выводе электронного устройства 102 в ответ на то, что браузерное приложение 108, получающее доступ к первому URL (не показано), связанному с первым цифровым документом 204. Несмотря на то, что устройство вывода не показано, оно может быть реализовано как экран, монитор, сенсорный экран и так далее. В некоторых вариантах осуществления настоящей технологии, новостная статья представляет собой текст на естественном языке.
[00072] Цифровой текст 302 включает в себя название 308 и содержимое состоит из множества предложений 304. Множество предложений 304 включает в себя ряд индивидуальных предложений, например, предложение 306. Несмотря на то что множество предложений 304 полностью разделены (т.е. разделены точкой), специалисты в данной области техники поймут, что это не является обязательным, и разделять множество предложений 304 могут и другие знаки препинания, например, вопросительный знак, восклицательный знак и др. Во избежание сомнений, следует отметить, что цифровой текст 302 (и, конкретнее, каждая буква) представлен буквой «X», тем не менее, в реальности предложения состоят из букв конкретного языка (например, английского).
[00073] Несмотря на то, что представлен только снимок экрана первого цифрового документа 204, следует иметь в виду, что второй цифровой документ 206 и третий цифровой документ 208 также содержат соответствующие цифровые тексты.
Приложение новостного агрегатора
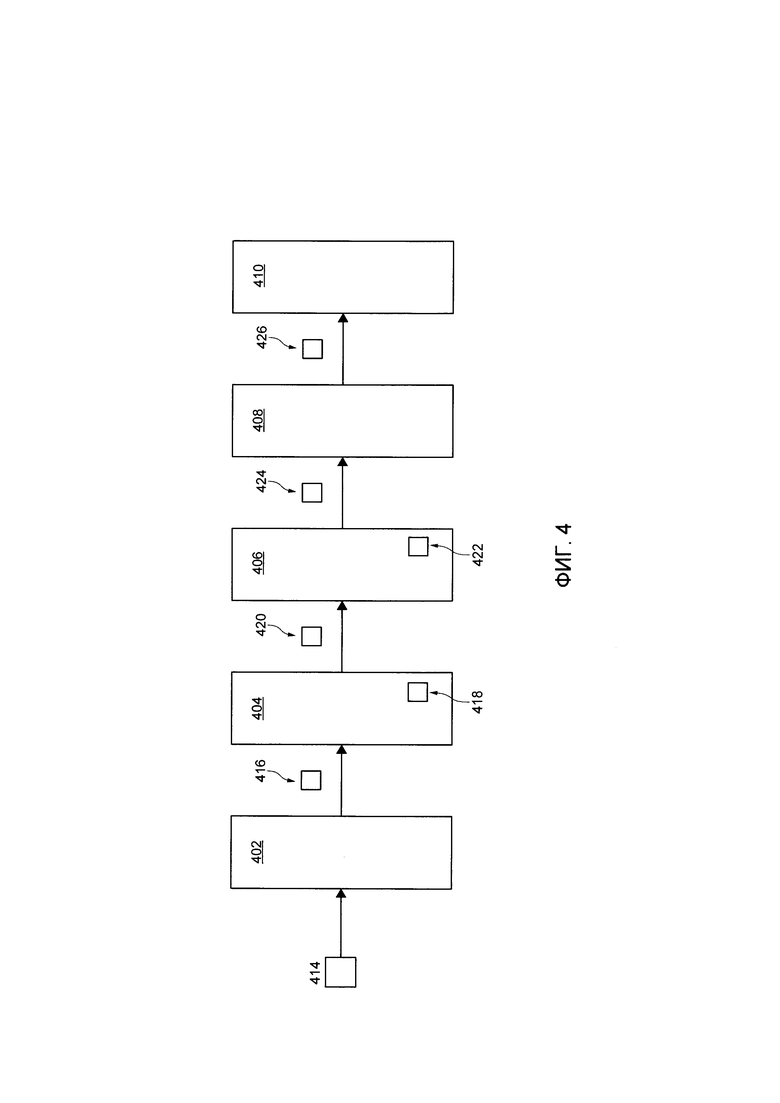
[00074] Функции и процедуры различных компонентов приложения 122 новостного агрегатора для связи автора с одной или несколькими цитатами будут более подробно описаны далее с использованием примера цифрового текста 302. На Фиг. 4 представлена схема приложения 122 новостного агрегатора, реализованного в соответствии с вариантами осуществления настоящей технологии, не ограничивающими ее объем. Приложение 122 новостного агрегатора выполняет (или иначе имеет доступ к): процедуру 402 парсинга цитаты, процедуру 404 первой классификации, процедуру 406 второй классификации, процедуру 408 выбора цитаты и процедуру 410 выбора статьи.
[00075] В контексте настоящей технологии, термин "процедура" относится к подмножеству исполняемых на компьютере инструкций приложения 122 новостного агрегатора, которые выполняются процессором 120 сервера для выполнения функций, которые будут объяснены ниже в связи с различными процедурами (процедура 402 парсинга цитаты, процедура 404 первой классификации, процедура 406 второй классификации, процедура 408 выбора цитаты и процедура 410 выбора статьи). Во избежание каких-либо сомнений, следует иметь в виду, что процедура 402 парсинга цитаты, процедура 404 первой классификации, процедура 406 второй классификации, процедура 408 выбора цитаты и процедура 410 выбора статьи представлены здесь схематично в распределенном и разделенном виде для простоты понимания процессов, выполняемых приложением 162 новостного агрегатора. Считается, что некоторые или все из процедуры 402 парсинга цитаты, процедуры 404 первой классификации, процедуры 406 второй классификации, процедуры 408 выбора цитаты и процедуры 410 выбора статьи могут быть выполнены как одна или несколько объединенных процедур.
[00076] Для простоты понимания, функции каждой из процедуры 402 парсинга цитаты, процедуры 404 первой классификации, процедуры 406 второй классификации, процедуры 408 выбора цитаты и процедуры 410 выбора статьи, а также данных и/или обработанной или сохраненной информации будут описаны далее.
Процедура парсинга цитаты
[00077] Процедура 402 парсинга цитаты выполнена с возможностью получать пакет 414 данных из новостной базы 124 данных. Пакет 414 данных включает в себя цифровые документы, которые ранее определены как относящиеся к одной и той же тематике. Например, пакет 414 данных включает в себя первый цифровой документ 204, второй цифровой документ 206 и третий цифровой документ 208, которые были ранее кластеризованы в первый тематический кластер 202.
[00078] Процедура 402 парсинга цитаты выполнена с возможностью выполнять следующие инструкции. Сначала, процедура 402 парсинга цитаты выполнена с возможностью анализировать содержимое каждого из первого цифрового документа 204, второго цифрового документа 206 и третьего цифрового документа 208 для идентификации наличия каких-либо цитат и их извлечения. В контексте настоящего описания, термин "цитата" относится к группе слов, выбранных из текста или речи, и повторенных кем-то кроме оригинального автора или спикера.
[00079] Процедура 402 парсинга цитаты далее выполнена с возможностью идентифицировать по меньшей мере одного связанного кандидата-автора для каждой из извлеченных цитат. В контексте настоящего описания, термин "кандидат-автор" относится к возможному автору или источнику идентифицированной цитаты.
[00080] Далее будет описано то, как выполняется процедура 402 парсинга цитаты, с использованием первого цифрового документа 204 в качестве примера. Излишне говорить, что процедура 402 парсинга цитаты с использованием второго цифрового документа 206 и третьего цифрового документа 208 выполняется по существу аналогично.
[00081] Процедура 402 парсинга цитаты выполняет парсинг путем применения одного или нескольких правил парсинга. Одно или несколько правил 214 парсинга могут быть основаны на одном или нескольких конкретных эвристических правилах. Одно или несколько эвристических правил могут представлять собой грамматические правила. В качестве примера, правило парсинга может заключаться в том, что часть текста, которая располагается внутри набора кавычек, является цитатой. В некоторых вариантах осуществления настоящей технологии, одно или несколько правил парсинга являются зависящими от языка правилами (т.е. правилами, которые специально выбираются для языка первого цифрового документа 204, второй цифрового документа 206 и третьего цифрового документа 208).
[00082] С учетом цифрового текста 302 в качестве примера, процедура 402 парсинга цитаты идентифицирует набор кавычек внутри предложения 306, и извлекает часть текста, включенного в первую цитату 502.
[00083] Излишне упоминать, что подразумевается, что процедура 402 парсинга цитаты может идентифицировать более одной цитаты в цифровом тексте 302.
[00084] После извлечения первой цитаты 502, процедура 402 парсинга цитаты далее идентифицирует кандидата-автора путем применения одного или нескольких правил идентификации. Один или несколько параметров 214 идентификации могут быть основаны на одном или нескольких конкретных эвристических правилах. Одно или несколько эвристических правил могут представлять собой грамматические правила. Например, правило идентификации может состоять в том, что одно или несколько последовательных слов с прописной буквы, находящихся в рамках заранее определенного расстояния (которое может быть определено эмпирически) от цитаты, является кандидатом-автором. В некоторых вариантах осуществления настоящей технологии, одно или несколько правил идентификации являются зависящими от языка правилами (т.е. правилами, которые специально выбираются для языка первого цифрового документа 204, второй цифрового документа 206 и третьего цифрового документа 208).
[00085] После цифрового текста 302 в качестве примера, процедура 402 парсинга цитаты анализирует и идентифицирует набор последовательных слов с прописной буквы в рамках предложения 306, и сохраняет набор последовательных слов с прописной буквы как первого кандидата-автора 508 первой цитаты 502 (показано на Фиг. 5).
[00086] Излишне упоминать, подразумевается, что процедура 402 парсинга цитаты может идентифицировать более одного кандидата-автора для данной цитаты (или даже не идентифицировать ни одного кандидата-автора), в зависимости от того, как был написан цифровой текст 302 (описано далее).
[00087] На основе извлеченных цитата и идентифицированных одного или нескольких кандидатов-авторов, процедура 302 парсинга цитаты выполнена с возможностью создавать индекс 500 (описано далее).
[00088] На Фиг. 5 представлен неограничивающий пример индекса 500, заполненного множеством цитат и кандидатов-авторов.
[00089] В представленном примере, процедура 402 парсинга цитаты определила первую цитату 502 в первом цифровом документе 204, который связан с первым кандидатом-автором 508.
[00090] Процедура 402 парсинга цитаты далее идентифицирует вторую цитату 504 во втором цифровом документе 206, который связан со вторым кандидатом-автором 510.
[00091] Процедура 402 парсинга цитаты идентифицирует две цитаты в третьем цифровом документе, а именно - третью цитату 505 и четвертую цитату 506.
[00092] Со ссылкой на третью цитату 505, процедура 402 парсинга цитаты идентифицирует двух кандидатов-авторов, а именно - третьего кандидата-автора 512 и четвертого кандидата-автора 513. Как было описано ранее, это возможно поскольку процедура 402 парсинга цитаты определяет, что и третий кандидат-автор 512 и четвертый кандидат-автор 513 соответствуют одному или нескольким правилам идентификации. Например, третий цифровой документ 208 мог быть написан, когда четвертый кандидат-автор 513 процитировал третьего кандидата-автора 512 и третью цитату 505 (например, "Katie Telford has confirmed that Justin Trudeau stated that: "[…]"(англ. "Кэти Телфорд подтвердила заявление Джастина Трюдо о том, что "[…]")), и как четвертый кандидат-автор 513, так и третий кандидат-автор 512 удовлетворяют одному или нескольким правилам идентификации.
[00093] Наконец, четвертая цитата 506 связана с пятым кандидатом-автором 514.
[00094] В некоторых вариантах осуществления технологии, процедура 402 парсинга цитаты обладает доступом к словарному приложению (не показано), и выполнена с возможностью определять, является ли одно или несколько слов с прописной буквы в данном кандидате-авторе именем собственным или нарицательным. Если определено, что кандидат-автор состоит как из имени собственного, так и из нарицательного, только имя собственное считается кандидатом-автором. Таким образом, используя в качестве примера первого кандидата-автора 508, процедура 402 парсинга цитаты удаляет термины "Prime Minister" ("премьер-министр"), что приводит к тому, что первый кандидат-автор 508 соответствует имени "Trudeau" ("Трюдо").
[00095] В другом варианте осуществления технологии, процедура 402 парсинга цитаты далее выполнена с возможностью стандартизировать каждую парсированную цитату (т.е. первую цитату 502, вторую цитату 504, третью цитату 505 и четвертую цитату 506). Например, процедура 402 парсинга цитаты выполнена с возможностью удалять какие-либо знаки пунктуации, например, многоточия (например, […]), изменять слова цитат на нижний регистр - и так далее.
Первая процедура классификации
[00096] После того как цитаты и их соответствующие кандидаты-авторы были идентифицированы, процедура 402 парсинга цитаты выполнена с возможностью передавать пакет 416 данных первой процедуре 404 классификации. Пакет 416 данных включает в себя индекс 500.
[00097] Первая процедура 404 классификации выполняет первый классификатор 418, который выполнен с возможностью выбирать одну цитату, включенную в индекс 500 (например, первую цитату 502) и назначать величину сходства цитаты каждой из оставшихся цитат. Величина сходства цитаты представляет собой вероятность того, что две цитаты происходят из одной и той же оригинальной цитаты.
[00098] То, как именно реализована величина сходства цитаты, никак не ограничено, и может, например, представлять собой бинарную величину, причем первая бинарная величина (например, 1) указывает на то, что первая цитата 502 с большой вероятностью происходит из той же самой оригинальной цитаты, что и вторая цитата 504 (или третья цитата 505, четвертая цитата 506), и вторая бинарная величина (например, 0) указывает на то, что первая цитата 502 маловероятно происходит из той же оригинальной цитаты, что и вторая цитата 504 (или третья цитата 505, четвертая цитата 506) (или наоборот).
[00099] Таким образом, используя в качестве примера первую цитату 502, способ, которым первый классификатор 418 вычисляет величину сходства цитаты с каждой из второй цитаты 504, третьей цитаты 505 и четвертой цитаты 506, будет описан далее.
[000100] Сначала, первый классификатор 418 выполнен с возможностью осуществлять определение кратчайшей общей последовательности слов между первой цитатой 502 и второй цитатой 504. Конкретнее, первая цитата 502 сравнивается со второй цитатой 504 для определения длины последовательности слов в первой цитате 502 также находится во второй цитате 504. Если определено, что длина наиболее короткой общей последовательности слов находится выше первого порога, первый классификатор 418 выполнен с возможностью назначать первую бинарную величину (например, 1) второй цитате 504. Способ, в соответствии с которым определяется первый порог, никак конкретно не ограничен, и может, например, быть определен эмпирически.
[000101] Это основано на предположении разработчиков о том, что новостные статьи могут обрезать некоторые части оригинальной цитаты, когда оригинальная цитата является длинной, или может только выбирать часть оригинальной цитаты для использования внутри новостной статьи. Таким образом, разработчики предполагают, что если определено то, что длина наиболее короткой общей последовательности слов между двумя цитатами (без каких-либо изменений друг относительно друга) находится выше первого порога, это указывает на то, что цитаты с большой вероятностью происходят из одной и той же цитаты.
[000102] Сначала, первый классификатор 418 выполнен с возможностью осуществлять определение кратчайшей общей последовательности слов между первой цитатой 502 и третьей цитатой 505. Если определено, что длина наиболее короткой общей последовательности слов находится выше первого порога, первый классификатор 418 выполнен с возможностью назначать первую бинарную величину (например, 1) третьей цитате 505.
[000103] Наконец, первый классификатор 418 выполнен с возможностью осуществлять определение кратчайшей общей последовательности слов между первой цитатой 502 и четвертой цитатой 506. Если определено, что длина наиболее короткой общей последовательности слов находится ниже первого порога, первый классификатор 418 выполнен с возможностью назначать вторую бинарную величину (например, 0) четвертой цитате 506.
[000104] Несмотря на то, что величина сходства цитаты была описана как реализованная с помощью бинарных величин, это не является ограничением. Величина сходства цитаты может быть реализована иначе, например, как процентная величина или любой другой масштаб.
[000105] На Фиг. 6 представлен неограничивающий пример списка 600, представляющий величины сходства цитаты первой цитаты 502 со ссылкой на каждую из второй цитаты 504, третьей цитаты 505 и четвертой цитаты 506.
[000106] В представленном примере, первый классификатор 418 был назначен первой величине 602 сходства цитаты (т.е. первой бинарной величине), указывающей на то, что первая цитата 502 и вторая цитата 504 вероятно происходят из одной и той же оригинальной цитаты.
[000107] Первый классификатор 418 был назначен второй величине 604 сходства цитаты (т.е. второй бинарной величине), указывающей на то, что первая цитата 502 и третья цитата 505 вероятно происходят из одной и той же оригинальной цитаты.
[000108] Наконец, первый классификатор 418 был назначен третьей величине 606 сходства цитаты (т.е. второй бинарной величине), указывающей на то, что первая цитата 502 и четвертая цитата 506, вероятно, не происходят из одной и той же оригинальной цитаты.
[000109] На основе списка 600, первый классификатор 418 далее выполнен с возможностью создавать кластер 608 цитат, который содержит набор сходных цитат 610. Набор сходных цитат 610 включает в себя цитаты, которым была назначена величина сходства цитаты выше второго порога. В некоторых вариантах осуществления технологии, цитаты, которым были назначены первое бинарное значение, находятся выше второго порога.
[000110] Таким образом, кластер 608 цитат содержит цитаты, которые были ранее определены как вероятно происходящие из одной и той же оригинальной цитаты (т.е. которым была ранее назначена первая бинарная величина). В представленном примере, набор сходных цитат 610 включает в себя первую цитату 502, вторую цитату 504 и третью цитату 505.
[000111] Кластер 608 цитат далее включает в себя набор кандидатов-авторов 612. Набор кандидатов-авторов 612 включает в себя одного или несколько кандидатов-авторов для каждой из первой цитаты 502 (т.е. первый кандидат-автор 508), второй цитаты 504 (т.е. второй кандидат-автор 510) и третьей цитаты 505 (т.е. третий кандидат-автор 512 и четвертый кандидат-автор 513).
Вторая процедура классификации
[000112] На Фиг. 4 первая процедура 404 классификации выполнена с возможностью передавать пакет 420 данных второй процедуре 406 классификации. Пакет 420 данных включает в себя кластер 608 цитат.
[000113] Вторая процедура 406 классификации выполнена с возможностью выполнять второй классификатор 422. Второй классификатор 422 выполнен с возможностью анализировать набор кандидатов-авторов 612 и определять, удовлетворяет ли данный кандидат-автор условию. Данный кандидат-автор, который удовлетворяет условию, считается правильным автором для каждой из цитат, включенных в кластер 608 цитат (первую цитату 502, вторую цитату 504 и третью цитату 505).
[000114] В некоторых вариантах осуществления технологии, данный кандидат-автор, который удовлетворяет условию, является кандидатом-автором, который обладает наибольшей частотой вхождений в набор кандидатов-авторов 612. Таким образом, определение того, когда данный кандидат-автор удовлетворяет условию, включает в себя (i) определение частоты вхождений данного кандидата-автора в набор кандидатов-авторов 612 (первый кандидат-автор 508, второй кандидат-автор 510, третий кандидат-автор 512 и четвертый кандидат-автор); и (ii) если данный кандидат-автор обладает наиболее высокой частотой вхождений, второй классификатор 422 определяет, что данный кандидат является правильным автором для каждой из цитат, включенных в кластер 608 цитат (первой цитаты 502, второй цитаты 504 и третьей цитаты 505).
[000115] Например, второй классификатор 422 выполнен с возможностью определять является ли частота вхождений второго кандидата-автора 510 ("Trudeau") [англ. "Трюдо"] в кластер 608 цитат наиболее высокой, поскольку каждый из первого кандидата-автора 508 и третьего кандидата-автора 512 включает в себя по меньшей мере слово "Trudeau". Соответственно, второй классификатор 422 выполнен с возможностью связывать второго кандидата-автора 510 как правильного автора для первой цитаты 502, второй цитаты 504 и третьей цитаты 505.
[000116] Второй классификатор 422 далее выполнен с возможностью сохранять второго кандидата-автора 510 как правильного автора (или спикера) для каждой из цитат, включенных в кластер 608 цитат (т.е. первую цитату 502, вторую цитату 504 и третью цитату 505).
[000117] В некоторых вариантах осуществления технического решения, второй классификатор 422 обладает доступом к базе данных изображений (не показано) для извлечения и сохранения одного или нескольких изображений, связанных с правильным автором.
[000118] В некоторых вариантах осуществления технологии, второй классификатор 422 обладает доступом к базе данных имен (не показано), которая хранит множество имен и их соответствующие названия. Например, база данных имен (не показано) может хранить указание на то, что имя "Trudeau" связано с названием "Prime Minister of Canada" (англ. "Премьер-министр Канады"). Например, второй классификатор 422 может быть выполнен с возможностью получать доступ к базе данных имен (не показано) для извлечения и сохранения соответствующего названия, связанного со вторым кандидатом-автором 510 и сохранять второго кандидата-автора 510 и соответствующее название как правильного автора (т.е. "Prime Minister of Canada Trudeau").
Процедура выбора цитаты
[000119] После установки правильного авторства для каждой цитаты, включенной в кластер 608 цитат, вторая процедура 406 классификации выполнена с возможностью передавать пакет 424 данных процедуре 408 выбора цитаты. Пакет 424 данных включает в себя набор сходных цитат 610, а также правильного автора, связанного с набором сходных цитат 610.
[000120] Процедура 408 выбора цитаты выполнена с возможностью определять лучшую цитату из набора сходных цитат 610. Лучшая цитата соответствует наиболее явно представимой цитате для новостей, изложенных в первом цифровом документе 204, втором цифровом документе 206 и третьем цифровом документе 208.
[000121] Способ, в соответствии с которым процедура 408 выбора цитаты выбирает лучшую цитату, никак не ограничен. Например, процедура 408 выбора цитаты может идентифицировать цитату, обладающую наибольшей длиной, в качестве лучшей цитаты. В некоторых вариантах осуществления технологии, процедура 408 выбора цитаты может быть выполнена с возможностью выбирать цитату, обладающую наибольшей длиной, которая находится ниже третьего порога. Способ, в соответствии с которым определяется третий порог, никак конкретно не ограничен, и может, например, быть определен эмпирически.
[000122] Например, процедура 408 выбора цитаты может определять, что третья цитата 505 является наиболее длинной цитатой в наборе сходных цитат 610, но длина третьей цитаты 505 выше третьего порога. В результате, процедура 408 выбора цитаты отбрасывает третью цитату 505 как лучшую цитату, и выбирает вторую цитату 504 (с учетом того, что вторая цитата 504 находится ниже третьего порога) как лучшую цитату.
[000123] После определения лучшей цитаты и ее правильного автора, процесс далее переходит к другому аспекту приложения 122 новостного агрегатора, которое направлено на идентификацию лучшей статьи (описано далее).
Процедура выбора статьи
[000124] Процедура 408 выбора цитаты выполнена с возможностью передавать пакет 426 процедуре 410 выбора статьи. Пакет 426 данных включает в себя первый тематический кластер 202 (который был ранее получен процедурой 402 парсинга цитаты).
[000125] Процедура 410 выбора статьи выполнен с возможностью выбирать лучшую статью из первого тематического кластера 202 (который включает в себя первый цифровой документ 204, второй цифровой документ 206 и третий цифровой документ 208). Лучшая статья соответствует цифровому документу, который выбран для отображения на главной странице приложения 122 новостного агрегатора при получении доступа со стороны электронного устройства 102 (описано далее).
[000126] Способ, в соответствии с которым процедура 410 выбора статьи выбирает лучшую статью хорошо известен в данной области техники, и, следовательно, не будет описан здесь. Исключительно в качестве примера, процедура 410 выбора статьи может быть выполнена с возможностью выбирать лучшую статью путем ранжирования первого цифрового документа 204, второго цифрового документа 206 и третьего цифрового документа 208 для определения "наиболее хорошо представляемого" цифрового документа в первом тематическом кластере 202.
[000127] Например, может быть определено, что первый цифровой документ 204 является лучшей статьей в первом тематическом кластере 202.
[000128] Несмотря на то, что первый цифровой документ 204 был определен как лучшая статья, лучшая цитата, которая была определена как вторая цитата 504, которая происходит из второго цифрового документа 206 (а не первого цифрового документа 204).
[000129] Это было основано на предположении разработчиков о том, что даже если конкретная новостная статья (например, первый цифровой документ 204) определена как лучшая статья, это необязательно означает, что данная новостная статья включает в себя лучшую цитату, представляющую описываемые новости.
[000130] Конкретный технический эффект настоящей технологии, таким образом, заключается в идентификации не только лучшей статьи из первого тематического кластера 202, а также в идентификации лучшей цитаты (и ее соответствующего автора), который находится в одном из цифровых документов первого тематического кластера 202, который не происходит из лучшей статьи.
[000131] С учетом описания определения первой цитаты, ее соответствующего автора и лучшей статьи, далее будет описано то, как используется приложением 122 новостного агрегатора лучшая цитата, ее соответствующий автор и лучшая статья.
Получение доступа к сервису новостного агрегатора
[000132] Снова обратимся к Фиг. 1. Как было упомянуто ранее, сервис новостного агрегатора, который выполняется приложением 122 новостного агрегатора, доступен с помощью браузерного приложения 108. Для получения доступа к сервису новостного агрегатора, браузерное приложение 108 передает пакет 128 данных (описанный ниже) серверу 116.
[000133] Пакет 128 данных содержит HTTP-запрос для доступа к главной странице (описано ниже) сервиса новостного агрегатора. При получении пакета 128 данных, сервер 116 выполнен с возможностью передавать запрошенное содержимое с помощью пакета 130 данных браузерному приложению 108 (описано далее).
Приложение новостного агрегатора
[000134] На Фиг. 7 представлен снимок 700 экрана главной страницы сервиса новостного агрегатора, отрисованного на электронном устройстве 102 в ответ на получение пакета 130 данных. На Фиг. 7 представлена главная страница с пятью новостными заголовками, которые включают в себя, среди прочего, первый заголовок 702.
[000135] С учетом того, что первый цифровой документ 204 был определен (процедурой 410 выбора статьи) как лучшая статья, название первого заголовка 702 соответствует названию 308 первого цифрового документа 204. В некоторых вариантах осуществления технологии, первый заголовок 702 далее включает в себя указание на первый URL 704 первого цифрового документа 204.
[000136] В ответ на то, что пользователь нажимает на первый заголовок 702, пользователь направляется на снимок 800 экрана (как показано на Фиг. 8), что иллюстрирует "якорную страницу", связанную с первым заголовком 702. Следует иметь в виду, что содержимое снимка 800 экрана может быть получено электронным устройством 102 через пакет 130 данных или отдельно от пакета данных (не показано).
[000137] В соответствии с вариантами осуществления настоящей технологии, якорная страница разделена на три части, а именно - первую часть 802, вторую часть 804 и третью часть 806.
[000138] Первая часть 802 включает в себя название 308 первого цифрового документа 204 (т.е. лучшая статья), выдержку из цифрового текста 302 и далее включает в себя первый URL 704, который при нажатии пользователем, позволяет браузерному приложению 108 получить доступ к новостному источнику первого цифрового документа 204. Таким образом, в ответ на то, что пользователь нажимает на первый URL 704, снимок 300 экрана (как показано на Фиг. 3), будет отрисован электронным устройством 102.
[000139] Вторая часть 804 содержит лучшую цитату 808, которая соответствует лучшей цитате, выбранной ранее с помощью процедуры 308 выбора цитаты. С учетом того, что процедура 408 выбора цитаты выбирает вторую цитату 504 как лучшую цитату, лучшая цитата 808 соответствует второй цитате 504.
[000140] Дополнительно, вторая часть 804 включает в себя указание на автора цитаты, которое соответствует второму кандидату-автору 510, как ранее было определено второй процедурой 406 классификации. В некоторых вариантах осуществления технологии, новостной агрегатор выполнен с возможностью отображать ранее сохраненное изображение 812, связанное с конкретным автором.
[000141] Вторая часть 804 далее содержит второй URL 814, связанный со вторым документом 206, который, при нажатии пользователем, позволяет браузерному приложению 108 получать доступ к новостному источнику второго цифрового документа 206.
[000142] Третья часть 806 включает в себя название третьего цифрового документа 208 и URL, связанный с третьим цифровым документом 208.
[000143] Подразумевается, что лучшая цитата 808 предоставляется на другой части снимка 800 экрана, как вышеупомянутое название 308.
[000144] Различные неограничивающие варианты осуществления настоящей технологии могут позволить определить корреляцию между одной или несколькими цитатами в цифровых текстах и правильным автором, с достаточно хорошим качеством, что требует меньше времени и действий от пользователя, и приводит к использованию меньшей вычислительной мощности.
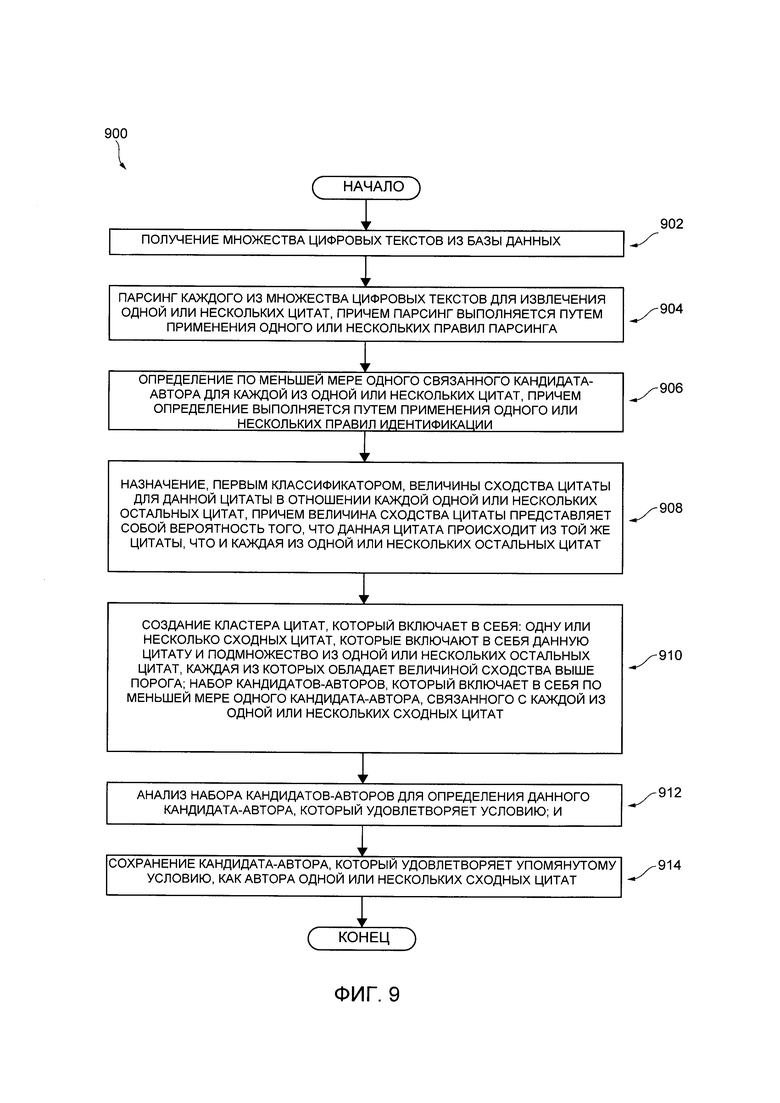
[000145] С учетом представленных выше архитектуры и примеров, возможно выполнить исполняемый на компьютере способ связывания правильного автора с цитатой. На Фиг. 9 представлена блок-схема способа 900 связывания автора с цитатой, причем способ 900 реализован в соответствии с неограничивающими вариантами осуществления настоящей технологии. Процесс 900 может выполняться сервером 116.
[000146] Этап 902 - получение множества цифровых текстов из базы данных
[000147] Способ 900 начинается на этапе 902, где процедура 402 парсинга цитаты требует пакет 414 данных, который содержит первый тематический кластер 202, включая первый цифровой документ 204, второй цифровой документ 206 и третий цифровой документ 208.
[000148] Этап 904 - парсинг каждого из множества цифровых текстов для извлечения одной или нескольких цитат, причем парсинг выполняется путем применения одного или нескольких правил парсинга
[000149] На этапе 904, процедура 402 парсинга цитаты подвергает парсингу содержимое каждого из первого цифрового документа 204, второго цифрового документа 206 и третьего цифрового документа 208 для извлечения одной или нескольких цитат. Этап парсинга 404 выполняется путем применения по меньшей мере одного правила парсинга, которое может зависеть от языка.
[000150] Этап 906 - определение по меньшей мере одного связанного кандидата-автора для каждой из одной или нескольких цитат, причем определение выполняется путем применения одного или нескольких правил идентификации
[000151] На этапе 906 процедура 902 парсинга цитаты анализирует содержимое каждого из первого цифрового документа, второго цифрового документа 206 и третьего цифрового документа для идентификации по меньшей мере одного кандидата-автора для каждой из первой цитаты 502, второй цитаты 504, третьей цитаты 505 и четвертой цитаты 506.
[000152] Этап идентификации кандидата-автора выполняется путем применения по меньшей мере одного правила идентификации, который может зависеть от языка.
[000153] После того как кандидаты-авторы были идентифицированы, процедура 402 парсинга цитаты выполнена с возможностью передавать пакет 416 данных первой процедуре 404 классификации. Пакет 416 данных включает в себя индекс 500, который включает в себя пары ранее парсированных цитат и их соответствующего по меньшей мере одного кандидата-автора.
[000154] Таким образом, первая цитата 502 связана с одним кандидатом-автором (первым кандидатом-автором 508). Вторая цитата 504 также связана с одним кандидатом-автором (вторым кандидатом-автором 510). Третья цитата 505 также связана с двумя кандидатами-авторами (третьим кандидатом-автором 512 и четвертым кандидатом-автором 513). Наконец, четвертая цитата 506 связана с единственным кандидатом-автором (пятым кандидатом-автором 514).
[000155] Этап 908 - назначение первым классификатором величины сходства цитаты для данной цитаты в отношении каждой одной или нескольких остальных цитат, причем величина сходства цитаты представляет собой вероятность того, что данная цитата происходит из того же текста в отношении каждой из одной или нескольких остальных цитат
[000156] На этапе 908, первая процедура 404 классификации получает пакет 416 данных. Первая процедура 404 классификации содержит первый классификатор 418, который выполнен с возможностью назначать величину сходства цитаты для данной цитаты (например, первой цитаты 502) в отношении каждой из остальных цитат (например, второй цитаты 504, третьей цитаты 505 и четвертой цитаты 506).
[000157] Величина сходства цитаты является величиной, представляющей вероятность того, что данная цитата (например, первая цитата 502) происходит из той же самой оригинальной цитаты, что и каждая из остальных цитат (например, вторая цитата 504, третья цитата 505 и четвертая цитата 506).
[000158] Этап 910 - создание кластера цитат, который включает в себя: одну или несколько сходных цитат, которые включают в себя данную цитату и подмножество из одной или нескольких остальных цитат, каждая из которых обладает величиной сходства выше порога; и набор кандидатов-авторов, который включает в себя по меньшей мере одного кандидата-автора, связанного с каждой из одной или нескольких сходных цитат
[000159] На этапе 910, в дополнение к назначению величин сходства цитат, первая процедура 404 классификации выполнена с возможностью создавать кластер 608 цитат, который содержит набор сходных цитат 610, состоящий из первой цитаты 502 и одной или нескольких из оставшихся цитат (т.е. второй цитаты 504, третьей цитаты 505 и четвертой цитаты 506), которым была назначена величина сходства цитат выше второго порога. В некоторых вариантах осуществления технологии, цитаты, которым были назначены первое бинарное значение, находятся выше второго порога.
[000160] Кластер 608 цитат далее включает в себя набор кандидатов-авторов 612, который включает в себя одного или нескольких кандидатов-авторов для соответствующих цитат, включенных в набор сходных цитат 610.
[000161] После создания кластера 608 цитат, первая процедура 404 классификации выполнена с возможностью передавать пакет 420 данных второй процедуре 406 классификации. Пакет 420 данных включает в себя кластер 608 цитат.
[000162] Этап 912 - анализ набора кандидатов-авторов для определения данного кандидата-автора, который удовлетворяет условию
[000163] На этапе 912, вторая процедура 406 классификации получает пакет 420 данных.
[000164] Вторая процедура 406 классификации выполнена с возможностью выполнять второй классификатор 422. Второй классификатор 422 выполнен с возможностью анализировать набор кандидатов-авторов 612 и определять, удовлетворяет ли данный кандидат-автор условию. Данный кандидат-автор, который удовлетворяет условию, считается правильным автором для каждой из цитат, включенных в кластер 608 цитат (первую цитату 502, вторую цитату 504 и третью цитату 505).
[000165] В некоторых вариантах осуществления технологии, данный кандидат-автор, который удовлетворяет условию, является кандидатом-автором, который обладает наибольшей частотой вхождений в набор кандидатов-авторов 612. Таким образом, определение того, когда данный кандидат-автор удовлетворяет условию, включает в себя (i) определение частоты вхождений данного кандидата-автора в набор кандидатов-авторов 612 (первый кандидат-автор 508, второй кандидат-автор 510, третий кандидат-автор 512 и четвертый кандидат-автор); и (ii) если данный кандидат-автор обладает наиболее высокой частотой вхождений, второй классификатор 422 определяет, что данный кандидат является правильным автором для каждой из цитат, включенных в кластер 608 цитат (первой цитаты 502, второй цитаты 504 и третьей цитаты 505).
[000166] Этап 914 - сохранение кандидата-автора, который удовлетворяет условию, как автора одной или нескольких сходных цитат
[000167] На этапе 914, вторая процедура 406 классификации выполнена с возможностью сохранять кандидата-автора, удовлетворяющего условию, как правильного автора для набора сходных цитат 610.
[000168] Специалистам в данной области техники будет понятно, что по меньшей мере некоторые варианты осуществления настоящей технологии нацелены на расширение диапазона технических решений, связанных с обычными сервисами новостной агрегации, а именно - связывание одной или нескольких цитат с автором.
[000169] Важно иметь в виду, что не все упомянутые здесь технические результаты могут проявляться в каждом из вариантов осуществления настоящей технологии. Например, варианты осуществления настоящей технологии, могут быть выполнены без проявления некоторых технических результатов, другие могут быть выполнены с проявлением других технических результатов или вовсе без них.
[000170] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
[000171] С учетом вышеописанных вариантов осуществления технологии, которые были описаны и показаны со ссылкой на конкретные этапы, выполненные в определенном порядке, следует иметь в виду, что эти этапы могут быть совмещены, разделены, обладать другим порядком выполнения - все это не выходит за границы настоящей технологии. Соответственно, порядок и группировка этапов не является ограничением для настоящей технологии.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| Способ и система для создания пуш-уведомлений, связанных с цифровыми новостями | 2018 |
|
RU2731654C1 |
| СПОСОБ И СИСТЕМА ПОИСКА РЕЛЕВАНТНЫХ НОВОСТЕЙ | 2019 |
|
RU2698916C1 |
| СПОСОБ И СИСТЕМА ДЛЯ КЛАСТЕРИЗАЦИИ ДОКУМЕНТОВ | 2019 |
|
RU2757592C1 |
| ПРИНЦИПЫ И СПОСОБЫ ПЕРСОНАЛИЗАЦИИ ПОТОКОВ НОВОСТЕЙ ПОСРЕДСТВОМ АНАЛИЗА НОВИЗНЫ И ДИНАМИКИ ИНФОРМАЦИИ | 2005 |
|
RU2382401C2 |
| Способ и система для рекомендации медиаобъектов | 2017 |
|
RU2666336C1 |
| СПОСОБ И СЕРВЕР ОПРЕДЕЛЕНИЯ ИСХОДНОЙ ССЫЛКИ НА ИСХОДНЫЙ ОБЪЕКТ | 2016 |
|
RU2660593C2 |
| Способ и система определения параметра релевантность для элементов содержимого | 2018 |
|
RU2714594C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ВЫБОРА ЭЛЕМЕНТОВ РЕКОМЕНДАЦИЙ ДЛЯ ПОЛЬЗОВАТЕЛЯ | 2017 |
|
RU2693323C2 |
| СПОСОБ И СИСТЕМА ДЛЯ СОПОСТАВЛЕНИЯ ИСХОДНОГО ЛЕКСИЧЕСКОГО ЭЛЕМЕНТА ПЕРВОГО ЯЗЫКА С ЦЕЛЕВЫМ ЛЕКСИЧЕСКИМ ЭЛЕМЕНТОМ ВТОРОГО ЯЗЫКА | 2016 |
|
RU2682002C2 |

Изобретение относится к средствам для компьютерной обработки цитат в цифровом тексте с целью определения автора, связанного с ними. Технический результат заключается в уменьшении скорости определения автора цитат в тексте. Получают множество цифровых текстов. Множество цифровых текстов подвергают парсингу для извлечения одной или нескольких цитат. Определяют по меньшей мере один кандидат-автор для каждого цифрового текста. Назначают величину сходства цитаты для данной цитаты в отношении каждой из одной или нескольких остальных цитат. Создают кластер цитат, который содержит одну или несколько сходных цитат и набора кандидатов-авторов. Набор кандидатов-авторов анализируют для определения данного кандидата-автора, который удовлетворяет условию. Кандидат-автор, который удовлетворяет условию, сохраняют как автор одной или нескольких сходных цитат. 2 н. и 18 з.п. ф-лы, 9 ил.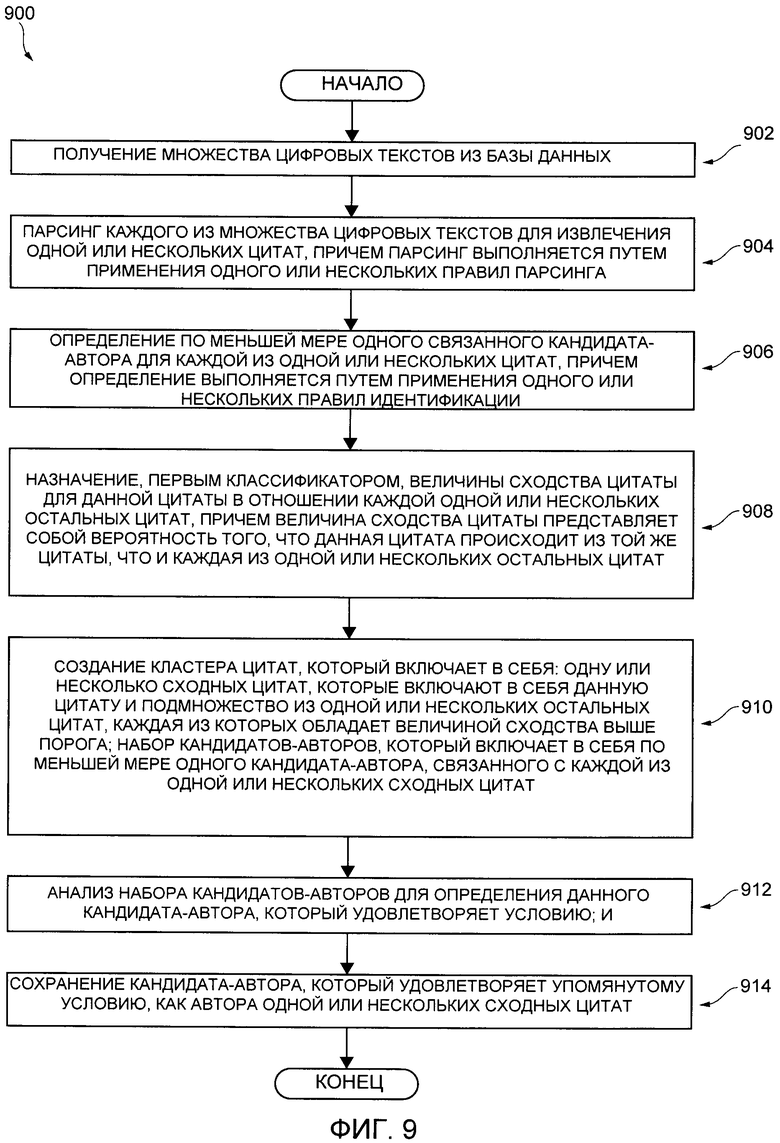
1. Исполняемый на компьютере способ обработки одной или нескольких цитат в цифровых текстах для определения связанного с ней или с ними автора, причем способ выполняется на сервере, который выполнен с возможностью исполнять сервис агрегации новостей, причем сервер связан со множеством цифровых новостных сервисов с помощью сети передачи данных, причем способ включает в себя:
получение множества цифровых текстов из базы данных;
парсинг каждого из множества цифровых текстов для извлечения одной или нескольких цитат, причем парсинг выполняется путем применения одного или нескольких правил парсинга;
определение по меньшей мере одного связанного кандидата-автора для каждой из одной или нескольких цитат, причем определение выполняется путем применения одного или нескольких правил идентификации;
назначение, первым классификатором, величины сходства цитаты для данной цитаты в отношении каждой одной или нескольких остальных цитат, причем величина сходства цитаты представляет собой вероятность того, что данная цитата происходит из той же цитаты, что и каждая из одной или нескольких остальных цитат;
создание кластера цитат, который включает в себя:
- одну или несколько сходных цитат, которые включают в себя данную цитату и подмножество из одной или нескольких остальных цитат, каждая из которых обладает величиной сходства выше порога;
- набор кандидатов-авторов, который включает в себя по меньшей мере одного кандидата-автора, связанного с каждой из одной или нескольких сходных цитат;
анализ набора кандидатов-авторов для определения данного кандидата-автора, который удовлетворяет условию; и
сохранение кандидата-автора, который удовлетворяет упомянутому условию, как автора одной или нескольких сходных цитат.
2. Способ по п. 1, в котором цифровые тексты соответствуют новостным статьям, представляющим одну и ту же тему, причем множество новостных статей получено из множества цифровых новостных сервисов.
3. Способ по п. 1, в котором одно или несколько правил парсинга включают в себя извлечение одной или нескольких частей цифровых текстов, вставленных между данным набором кавычек.
4. Способ по п. 3, в котором одно или несколько правил идентификации включают в себя определение по меньшей мере одного слова с прописной буквы на заранее определенном расстоянии от данного набора кавычек.
5. Способ по п. 1, в котором:
данная цитата является первой цитатой;
порог является первым порогом; и
назначение величины сходства цитаты первой цитате в отношении второй цитаты включает в себя:
определение кратчайшей общей последовательности слов между первой цитатой и второй цитатой; и
определение того, находится ли длина кратчайшей общей последовательности слов выше второго порога.
6. Способ по п. 5, в котором величина сходства цитаты является бинарной величиной.
7. Способ по п. 1, в котором анализ набора кандидатов-авторов для определения данного кандидата-автора, который удовлетворяет условию, включает в себя:
определение частоты вхождений данного кандидата-автора в набор кандидатов-авторов; и
определение того, что частота вхождений данного кандидата-автора является наибольшей частотой в наборе кандидатов-авторов.
8. Способ по п. 1, дополнительно включающий в себя:
в ответ на то, что клиентское устройство получает доступ к сервису агрегации новостей, передачу клиентскому устройству пакета данных, который включает в себя:
лучшую цитату, соответствующую одной или нескольким сходным цитатам; и
автора лучшей цитаты.
9. Способ по п. 8, в котором лучшая цитата соответствует одной или нескольким сходным цитатам, которые обладают наибольшей строкой последовательных слов.
10. Способ по п. 7, в котором:
сервер далее соединен с базой данных изображений, которая включает в себя множество изображений, связанных с по меньшей мере одним или несколькими кандидатами-авторами; и
способ дополнительно включает в себя:
до передачи пакета данных, извлечение изображения, связанного с автором; и
причем пакет данных дополнительно включает в себя изображение.
11. Сервер для обработки одной или нескольких цитат в цифровых текстах для определения связанного с ними автора, сервер выполнен с возможностью исполнять сервис агрегации новостей, причем сервер связан со множеством цифровых новостных сервисов с помощью сети передачи данных, причем сервер включает в себя процессор, выполненный с возможностью осуществлять:
получение множества цифровых текстов из базы данных;
парсинг каждого из множества цифровых текстов для извлечения одной или нескольких цитат, причем парсинг выполняется путем применения одного или нескольких правил парсинга;
определение по меньшей мере одного связанного кандидата-автора для каждой из одной или нескольких цитат, причем определение выполняется путем применения одного или нескольких правил идентификации;
назначение первым классификатором величины сходства цитаты для данной цитаты в отношении каждой одной или нескольких остальных цитат, причем величина сходства цитаты представляет собой вероятность того, что данная цитата происходит из той же цитаты, что и каждая из одной или нескольких остальных цитат;
создание кластера цитат, который включает в себя:
- одну или несколько сходных цитат, которые включают в себя данную цитату и подмножество из одной или нескольких остальных цитат, каждая из которых обладает величиной сходства выше порога;
- набор кандидатов-авторов, который включает в себя по меньшей мере одного кандидата-автора, связанного с каждой из одной или нескольких сходных цитат;
анализ набора кандидатов-авторов для определения данного кандидата-автора, который удовлетворяет условию; и
сохранение кандидата-автора, который удовлетворяет упомянутому условию, как автора одной или нескольких сходных цитат.
12. Сервер по п. 11, в котором цифровые тексты соответствуют новостным статьям, представляющим одну и ту же тему, причем множество новостных статей получено из множества цифровых новостных сервисов.
13. Сервер по п. 11, в котором одно или несколько правил парсинга включают в себя извлечение одной или нескольких частей цифровых текстов, вставленных между данным набором кавычек.
14. Сервер по п. 13, в котором одно или несколько правил идентификации включают в себя определение по меньшей мере одного слова с прописной буквы на заранее определенном расстоянии от данного набора кавычек.
15. Сервер по п. 11, в котором:
данная цитата является первой цитатой;
порог является первым порогом; и
для назначения величины сходства цитаты первой цитате в отношении второй цитаты, процессор выполнен с возможностью осуществлять:
определение кратчайшей общей последовательности слов между первой цитатой и второй цитатой; и
определение того, находится ли кратчайшая общая последовательность слов выше второго порога.
16. Сервер по п. 15, в котором величина сходства цитаты является бинарной величиной.
17. Сервер по п. 11, в котором анализ набора кандидатов-авторов для определения данного кандидата-автора, который удовлетворяет условию, процессор выполнен с возможностью осуществлять:
определение частоты вхождений данного кандидата-автора в наборе кандидатов-авторов; и
определение того, что частота вхождений данного кандидата-автора является наибольшей частотой в наборе кандидатов-авторов.
18. Сервер по п. 11, в котором процессор также выполнен с возможностью осуществлять:
в ответ на то, что клиентское устройство получает доступ к сервису агрегации новостей, передачу клиентскому устройству пакета данных, который включает в себя:
лучшую цитату, соответствующую одной или нескольким сходным цитатам; и
автора лучшей цитаты.
19. Сервер по п. 18, в котором лучшая цитата соответствует одной или нескольким сходным цитатам, которые обладают наибольшей строкой последовательных слов.
20. Сервер по п. 17, в котором:
сервер далее соединен с базой данных изображений, которая включает в себя множество изображений, связанных с по меньшей мере одним или несколькими кандидатами-авторами; и
процессор далее выполнен с возможностью осуществлять:
до передачи пакета данных, извлечение изображения, связанного с автором; и
причем пакет данных дополнительно включает в себя изображение.
| US 8805781 B2, 12.08.2014 | |||
| US 9223881 B1, 29.12.2015 | |||
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| RU 2014139482 A, 20.04.2016. | |||

