Родственная заявка
По данной заявке испрашивается приоритет Предварительной заявки на патент США, серийный номер 60/549,371, поданной 2 марта 2004 года и озаглавленной "PRINCIPLES AND METHODS FOR PERSONALIZING NEWSFEEDS VIA AN ANALYSIS OF INFORMATION DYNAMICS", которая полностью включена в данное описание посредством ссылки.
Область техники, к которой относится изобретение
Настоящее изобретение относится, в общем, к компьютерным системам и, более конкретно, к системам и способам, которые персонализируют временные потоки информации, например новости, посредством автоматизированного анализа динамики информации.
Предшествующий уровень техники
Всего десятилетие назад крупномасштабные потоки информации, такие как потоки новостей, принадлежали, отслеживались и фильтровались организациями, специализирующимися в подготовке новостей. Web-технологии стали причиной сложностей и широких возможностей управления и принятия потоков новостей всеми заинтересованными пользователями. Определение "важной" информации было важнейшим аспектом исследований по web-поиску и резюмированию текста. Способы поиска ориентированы на определение набора документов, который максимально удовлетворяет острым информационным потребностям пользователя. Резюмирование направлено на сжатие больших объемов текста в более краткую формулировку. При отсутствии автоматизированных способов определения глубокой семантики, ассоциированной с текстом, прежняя работа по резюмированию в типичном варианте проводилась на уровне законченных предложений, соединяя наиболее представительные предложения для того, чтобы создать резюме по документу. Исследования в области поиска и резюмирования обычно игнорировали динамику информационного содержимого, непрерывно прибывающего со временем.
Сущность изобретения
Далее представлено упрощенное изложение сущности изобретения для того, чтобы предоставить базовое понимание некоторых аспектов изобретения. Эта сущность не является всесторонним обзором изобретения. Она не предназначена для того, чтобы определять ключевые/важнейшие элементы изобретения или обрисовывать объем изобретения. Ее единственная цель - представить некоторые концепции изобретения в упрощенной форме в качестве вступления в более подробное описание, которое представлено далее.
Настоящее изобретение предоставляет системы и способы определения новизны информации и посвящено тому, как эти способы могут быть применены так, чтобы управлять информационным содержимым, которое развивается во времени. Представлена общая инфраструктура для сравнения совокупностей документов, в соответствии с чем документы могут быть предположительно организованы в группы по своему содержимому или источнику и проанализированы на предмет межгрупповых и внутригрупповых различий и общностей. Например, сопоставление двух групп документов, посвященных одной теме, но полученных из двух различных источников, к примеру, информационного обзора происшествия в различных частях мира, может показать интересные различия мнений и общих истолкований ситуаций. За счет перемещения содержимого из статичных совокупностей в наборы статей, генерируемых во времени, может быть рассмотрено его развитие. Например, поток новостных статей по общему описанию может быть рассмотрен во времени с целью выделения действительно информативных свежих новостей и фильтрования множества статей, которые в значительной степени передают "практически то же самое".
Может быть собрана подробная статистика по вхождению слова в наборы документов, чтобы охарактеризовать различия и сходства в этих наборах. Различные модели слова могут быть расширены за счет выделения именованных объектных сущностей, которые обозначают, например, имена людей, названия организаций и географических местоположений. В отличие от фраз и словосочетаний, чьи отличительные семантические свойства обычно компенсируются отсутствием достаточной статистики, именованные объектные сущности определяют относительно стабильные речевые обороты, которые используются одинаково многими авторами в данной теме и, таким образом, их использование приносит значительный объем информации. Например, один тип подготовленного анализа представляет статьи, использующие найденные в них именованные объектные сущности. Анализ может быть ориентирован на прямые потоки новостей или другие темы. Прямые потоки новостей представляют значительные сложности и широкие возможности для исследований. Потоки новостей охватывают огромные объемы данных, представляют изобилие мнений и взглядов и включают в себя широкий спектр форматов и содержимого от коротких свежих новостей до крупных резюме по описанным событиям и простых повторов "тех же устаревших фактов", передаваемых снова и снова.
Могут быть разработаны алгоритмы, которые определяют важные свежие новости по отслеживаемым описаниям, освобождая пользователей от необходимости тщательно анализировать длинные списки похожих статей, приходящих из разных источников. Способы, предоставленные в соответствии с настоящим изобретением, обеспечивают основу для персонализированного портала новостей и служб оповещения о новости, которые позволяют минимизировать время и потери для пользователей, которые хотят следить за развитием новостных описаний.
Настоящее изобретение предоставляет различные архитектурные компоненты для анализа информации и фильтрации содержимого для пользователей. Во-первых, представлена инфраструктура для определения различий в наборах документов посредством анализа распределений слов и распознанных именованных сущностей. Эта инфраструктура может быть применена для того, чтобы сравнивать отдельные документы, наборы документов или документ и набор (например, новую статью с сочетанием ранее просмотренных новостных статей по теме). Во-вторых, совокупность алгоритмов, которые оперируют прямыми потоками новостей (или другими развивающимися во времени потоками), предоставляет пользователям возможность персонализованной работы с новостями. Эти алгоритмы были реализованы в иллюстративной системе, названной News Junkie, которая представляет пользователям максимально информативные свежие новости. Пользователи могут запрашивать свежие новости через заданные пользователем периоды или по каждому всплеску сообщений по описанию. Пользователи также могут настраивать требуемую степень значимости этих свежих новостей по основному описанию, разрешая доставку смежных статей, которые описывают связанные или похожие описания. Кроме того, предусмотрен способ оценки, который представляет пользователям единое исходное описание и набор статей, ранжированных в соответствии с показателями оценки новизны, и позволяет понять, каким образом участники осознают новизну этих наборов в контексте исходного описания.
Для осуществления вышеупомянутых и связанных целей определенные иллюстрационные аспекты изобретения описаны в данном документе в связи со следующим описанием и прилагаемыми чертежами. Эти аспекты указывают на различные способы, которыми изобретение может быть использовано на практике; при этом подразумевается, что все они охвачены настоящим изобретением. Другие преимущества и новые признаки изобретения могут стать явными из следующего подробного описания изобретения, если рассматривать их вместе с чертежами.
Перечень чертежей
Фиг.1 - блок-схема, иллюстрирующая систему динамики информации в соответствии с аспектом настоящего изобретения.
Фиг.2 - блок-схема, иллюстрирующая инфраструктуру для сравнения совокупностей текста в соответствии с аспектом настоящего изобретения.
Фиг.3 - схема потока данных, иллюстрирующая процесс новизны информации в соответствии с аспектом настоящего изобретения.
Фиг.4 - схема, иллюстрирующая ранжирование результатов в соответствии с аспектом настоящего изобретения.
Фиг.5 - иллюстрация персонализированного процесса обновления новостей в соответствии с аспектом настоящего изобретения.
Фиг.6 - иллюстрация сигналов новизны в соответствии с аспектом настоящего изобретения.
Фиг.7 - иллюстрация примерных взаимоотношений статей в соответствии с аспектом настоящего изобретения.
Фиг.8-11 - иллюстрации примерных пользовательских интерфейсов в соответствии с аспектом настоящего изобретения.
Фиг.12 - блок-схема, иллюстрирующая подходящую рабочую среду в соответствии с аспектом настоящего изобретения.
Фиг.13 - блок-схема примера вычислительной среды, с которой может взаимодействовать настоящее изобретение.
Подробное описание изобретения
Настоящее изобретение относится к системе и способу для идентификации новизны информации и управления информационным содержимым по мере того, как оно развивается во времени. Согласно одному аспекту, предоставляется система распространения персонализированной информации. Система включает в себя компонент, который определяет различия между двумя или более единицами информации. Анализатор автоматически определяет подмножество единиц информации частично на основе определенных различий и того, как данные, относящиеся к единицам информации, развиваются во времени. Кроме того, предоставляются различные способы. С одной стороны, способ создания персонализированной информации включает в себя автоматический анализ документов из различных информационных источников и автоматическое определение новизны документов. Персонализированный поток информации затем предоставляется пользователю на основе новизны документов.
Системы и способы настоящего изобретения могут быть применены к множеству различных вариантов применения. Они могут включать в себя варианты применения, которые помогают в разработке идеальных последовательностей чтения или путей через не прочитанные на данный момент новостные описания по теме с различными промежутками новизны от настоящего времени. Для разработки последовательностей отслеживания развития новостей варианты применения рассматривают самые последние новости, а также всплески новостей во времени, для того, чтобы помочь людям понять развитие новостного описания и перемещаться по истории описаний по основным происшествиям/свежим новостям. Другие варианты применения включают в себя разработку различных типов образцов отображения и модельных представлений, например, использование представления во времени или других аспектов, например, представление кластеров во времени. Что касается идеального оповещения на рабочем столе и мобильных настроек самых последних новостных описаний по теме, один из вариантов применения предоставляет пользователям возможность задавать темы или ключевые слова, но оповещать только когда достаточно новизны при известности того, что пользователь прочел. В способах на основе ключевого слова оповещения могут быть предусмотрены, когда новостное описание выходит с ключевыми словами, если новизна информации достаточна, что более практично, чем схемы простого оповещения на основе ключевого слова.
При использовании в данной заявке термины "компонент", "анализатор", "система" и т.п. означают связанную с компьютером объектную сущность: либо аппаратные средства, сочетание аппаратных средств и программного обеспечения, программное обеспечение, либо программное обеспечение в ходе исполнения. Например, компонент может быть, но не только, процессом, запущенным на процессоре, процессором, объектом, исполняемым файлом, потоком исполнения, программой и/или компьютером. В качестве иллюстрации, и приложение, запущенное на сервере, и сервер могут быть компонентом. Один или более компонентов могут постоянно находиться внутри процесса и/или потока исполнения, и компонент может быть локализован на компьютере и/или распределен между двумя и более компьютерами. Кроме того, эти компоненты могут исполняться с различных машиночитаемых носителей, на которых хранятся различные структуры данных. Компоненты могут обмениваться данными посредством локальных и/или удаленных процессов, например, в соответствии с сигналом, имеющим один или более пакетов данных (к примеру, данных из компонента, взаимодействующего с другим компонентом в локальной системе, распределенной системе и/или по сети, например, по Интернету, с другими системами посредством сигнала).
Обратимся сначала к фиг.1, на которой проиллюстрирована система 100 динамики информации в соответствии с аспектом настоящего изобретения. Настоящее изобретение предоставляет системы и способы определения новизны информации и посвящено тому, как эти способы могут быть применены для того, чтобы управлять информационным содержимым, которое развивается во времени. Предусмотрена общая инфраструктура 100 для сравнения совокупностей документов 110 посредством блока 114 сравнения, в соответствии с которой документы могут быть организованы в группы по своему содержимому или источнику 120 и проанализированы анализатором 130 на предмет межгрупповых и внутригрупповых различий и общностей. Например, сопоставление двух групп документов или файлов, посвященных одной теме, но полученных из двух различных источников, к примеру, информационного обзора происшествия в различных частях мира может показать интересные различия мнений и истолкований ситуаций в целом. За счет перемещения содержимого из статичных совокупностей в наборы статей, генерируемых во времени, может быть рассмотрено его развитие. Например, поток новостных статей может быть рассмотрен по общему описанию во времени с целью выделения действительно информативных свежих новостей и отфильтровывания множества статей посредством фильтра 140, который взаимодействует с анализатором 140, чтобы доставлять персонализированную информацию на 150.
Может быть собрана подробная статистика по вхождению слова в наборы документов, чтобы охарактеризовать различия и сходства в этих наборах. Модель на основе слов может быть расширена за счет выделения именованных объектных сущностей, которые обозначают, например, имена людей, названия организаций и географических местоположений. В отличие от фраз и словосочетаний, чьи отличительные семантические свойства обычно компенсируются отсутствием достаточной статистики, именованные объектные сущности определяют относительно стабильные речевые обороты, которые используются одинаково многими авторами в данной теме, и, таким образом, их использование приносит значительный объем информации. Один тип подготовленного анализа представляет статьи, используя найденные в них именованные объектные сущности. Анализ может быть ориентирован на прямые потоки новостей или другие временные потоки данных. В одном примере потоки новостей охватывают огромные объемы данных, представляют изобилие мнений и взглядов и включают в себя широкий спектр форматов и содержимого от коротких свежих новостей до крупных резюме по описанным событиям и простых повторов устаревших фактов, передаваемых снова и снова.
Алгоритмы, которые описаны более подробно ниже, могут быть предусмотрены в блоке сравнения 114, анализаторе 130 и/или фильтре 140; они определяют свежие новости по отслеживаемым описаниям или потокам, освобождая пользователей от необходимости тщательно анализировать длинные списки похожих статей, поступающих из разных источников новостей. Различные способы обеспечивают основу для персонализированного портала новостей и служб оповещения о новостях (см. 150), которые позволяют минимизировать время и потери для пользователей, которые хотят следить за развитием описаний. Необходимо принимать во внимание, что хотя один иллюстративный аспект настоящего изобретения может быть применен к анализу и фильтрации такой информации, как новости, по существу любой развивающийся во времени поток информации может быть обработан в соответствии с настоящим изобретением. Кроме того, данные могут быть собраны из множества различных информационных источников, например, из портативного компьютера, мобильного устройства, настольного компьютера, причем такие данные могут быть кэшированы (к примеру, на централизованном сервере) и проанализированы в соответствии с тем, за какими данными пользователь следил ранее. Так можно принять во внимание, что информация может быть сгенерирована из множества источников, таких как Интернет, например, или в местных средах, таких как внутренняя сеть интранет компании.
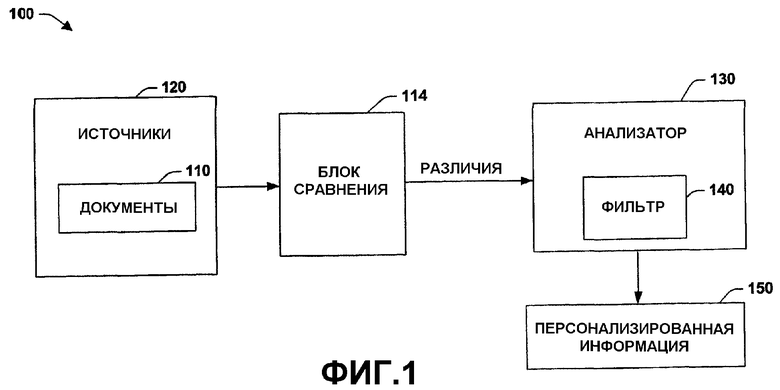
Обратимся теперь к фиг.2, на которой проиллюстрирована система 210 для сравнения совокупностей текста в соответствии с аспектом настоящего изобретения. Рассматривая два или более набора текстового содержимого, следует определить, каким образом характеризуются различия между наборами. Определение различий полезно во множестве вариантов применения, в том числе автоматическом профилировании и сравнении совокупностей текста, автоматическом определении различных взглядов, намерений и интересов, отражаемых в текстах, и автоматическом определении новой информации. Вообще, некоторые аспекты "различия" могут быть рассмотрены следующим образом:
На 220 различия в содержимом могут отражать различные способы, которыми конкретный человек или происшествие описано в наборах документов. Например, рассмотрим анализ различий в предопределенных разделах, к примеру, сравнение американских и европейских сообщений по различным политическим вопросам или сравнение освещения нарушения электроснабжения на Восточном побережье в новостях, создаваемых в источниках, базирующихся на Восточном и Западном побережье.
На 230 различия в структурной организации могут выйти далеко за рамки текста и также учитывать структуру ссылок web-узлов, к примеру, сравнение web-узла IBM и web-узла Intel.
На 240 различия во времени (т.е. временные аспекты различий в содержимом) могут показать интересные тематические изменения в последовательности документов. Такой тип анализа может быть использован для того, чтобы сравнивать сегодняшние новости с новостями, опубликованными месяц или год назад для того, чтобы отслеживать изменения во времени в журналах регистрации запросов поисковой машины или определять временные изменения в темах в личной электронной почте пользователя.
Временные различия включают в себя автоматическую оценку новизны во времени новостных статей (или другого типа информации), создаваемых в прямых потоках новостей. Конкретно, рассматриваются следующие стороны:
На 250 характеристика новизны новостных описаний предоставляет возможность упорядочивания новостных статей таким образом, чтобы каждая статья добавляла максимум информации в ранее прочитанные или представленные единицы (или их сочетание).
На 260 анализируется развитие темы во времени, что делает возможным измерение важности и релевантности свежих новостей, предоставление конечным пользователям контроля над этими параметрами и обеспечения им возможности персонализированной работы с новостями.
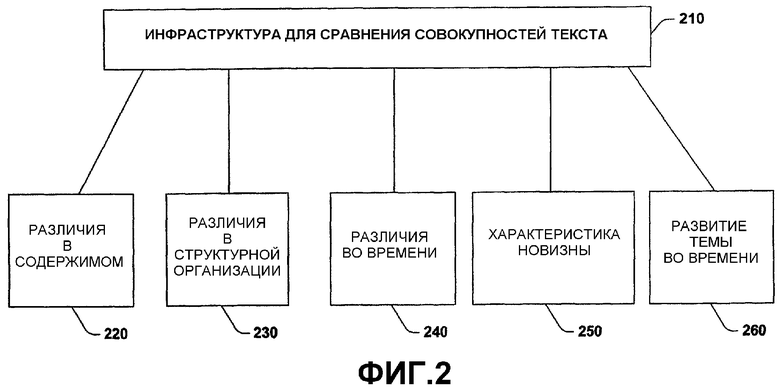
Фиг.3 - это методика 300, иллюстрирующая процесс характеризации новизны в соответствии с аспектом настоящего изобретения. Хотя в целях упрощения пояснения методика показана и описана как последовательность действий, необходимо понимать и принимать во внимание, что настоящее изобретение не ограничено порядком действий, поскольку некоторые действия могут, в соответствии с настоящим изобретением, осуществляться в различном порядке и/или параллельно с другими действиями, что показано и описано в данном документе. Например, специалисты в данной области техники поймут и примут во внимание, что методика может быть альтернативно представлена как последовательность взаимосвязанных состояний или событий, например, на диаграмме состояний. Более того, не все проиллюстрированные действия могут быть необходимы, чтобы реализовать методику в соответствии с настоящим изобретением.
Переходя к 310, разработаны различные инструментальные средства, чтобы реализовывать и тестировать рабочие характеристики алгоритма. Одни такой набор программных инструментальных средств, который реализует совокупность алгоритмов и ряд вариантов визуализации для сравнения совокупностей текста, назван "NewsJunkie". NewsJunkie представляет документы как набор слов, дополненный именованными объектными сущностями, извлеченными из текста. Для этой цели также были использованы стандартные средства извлечения, которыми определяют имена людей, названия организаций и географических местоположений.
На 320 определяются элементы, которые подлежат сравнению в рамках документов. Вообще, группы документов содержат документы с некоторым общим свойством и являются базовой единицей сравнения. Примерами таких общих свойств могут быть конкретная тема или источник новостей (к примеру, описания нарушения электроснабжения, исходящие из агентств новостей Восточного побережья). Умозаключения о различиях между группами документов выводятся посредством создания модели для каждой группы и последующего сравнения моделей с помощью показателя сходства, как описано ниже. Чтобы облегчить выявление множества моделей, NewsJunkie представляет документы либо как сглаженные распределения вероятностей по всем признакам (слова + именованные объектные сущности), либо как векторы взвешенных признаков (в том же пространстве признаков). Веса могут быть назначены с помощью популярного семейства функций TF.IDF, которые используют компоненты, представляющие частоту вхождения термина в документ и обратную частоту вхождения термина в документы. Также могут быть использованы функции вероятностного взвешивания. Также могут быть реализованы различные варианты сглаживания для того, чтобы уточнять предварительный расчет взвешивания термина. Например, закон следования Лапласа или линейное сглаживание с вероятностями слова во всей совокупности текста; последний вариант был использован в экспериментах, описанных ниже. Заметим, что более одного варианта сглаживания может быть реализовано в рамках системы.
На 330 по фиг.3 определяются показатели сходства для определения различий между единицами информации, такими как документ или текст. Встречается стандартная ситуация, когда что-то интересное происходит в мире, и происшествие подхватывается новостными СМИ. Если происшествие представляет достаточный общественный интерес, его последующее развитие также отслеживается в новостях. Допустим, что первоначальный отчет прочтен и, позднее, пользователи интересуются развитием описания. При наличии Интернет-сайтов, которые собирают в единое целое тысячи источников новостей, острая необходимость пользователя в поиске информации может быть удовлетворена множеством способов и с гораздо большим числом свежих новостей, чем сможет просмотреть даже самый упорный новостной маньяк. Автоматизированные информационные средства для тщательного анализа большого количества документов по теме, которые работают так, чтобы определить элементы или абсолютно новую информацию, могут представлять достаточную ценность.
Следовательно, исключение излишков и совпадений может помочь минимизировать накладные расходы, связанные с отслеживанием новостных описаний. Обычно в новостных историях слишком много лишнего. Например, когда ожидаются новые события или результаты расследования, однако новая информация еще недоступна, агентства новостей часто заполняют пустоту резюме или более ранними выводами, пока не будет доступна новая информация. Ситуация дополнительно осложняется тем фактом, что многие агентства новостей получают часть своего содержимого от крупных транснациональных поставщиков содержимого, например, Reuters или Associated Press. Пользователи новых узлов не хотят читать каждое сообщение снова и снова. Пользователи в основном заинтересованы в сборе информации о том, что нового. Следовательно, упорядочивание новостных статей по новизне обещает быть полезным.
На 330 ряд показателей сходства документов может быть использован для того, чтобы определить документы, которые наиболее отличаются от данного набора документов (к примеру, сочетания ранее прочитанных), при этом задается показатель (метрика) расстояния термина, чтобы подчеркнуть тот факт, что осуществляется поиск документов, которые в целом являются наиболее несхожими с набором документов.
Могут быть реализованы следующие показатели расстояния:
- Отклонение Куллбэка-Лейблера (KL), классический асимметричный теоретико-информационный метод измерения. Допустим, вычисляется расстояние между документом 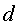 и набором документов
и набором документов 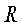 . Обозначим вероятностные распределения слов (и именованных объектных сущностей, если имеются) в (документе) и (наборе документов) как
. Обозначим вероятностные распределения слов (и именованных объектных сущностей, если имеются) в (документе) и (наборе документов) как 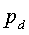 и
и 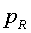 , соответственно. Тогда, расстояние
, соответственно. Тогда, расстояние 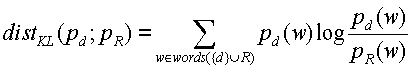 . Заметим, что вычисление
. Заметим, что вычисление 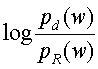 требует, чтобы оба распределения были сглажены так, чтобы подавить нулевые значения (соответствующие словам, которые встречаются в , но отсутствуют в , и наоборот).
требует, чтобы оба распределения были сглажены так, чтобы подавить нулевые значения (соответствующие словам, которые встречаются в , но отсутствуют в , и наоборот).
- Отклонение Йенсена-Шаннона (JS), симметричный вариант KL-отклонения. Используя определения предыдущего пункта, расстояние 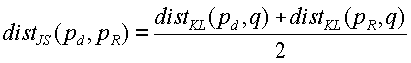 , где
, где 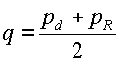 .
.
- Косинус векторов необработанных вероятностей (вычисление не требует сглаженных вероятностей).
- Косинус векторов весов признака TF.IDF.
- Собственный показатель, сформулированный так, чтобы измерять плотность ранее незамеченных именованных объектных сущностей в статье (называют NE). Интуиция для данного показателя основана на гипотезе, что новая информация часто передается посредством введения новых именованных объектных сущностей, таких как имена людей, названия организаций и мест. Показатель NE может быть задан следующим образом: Пусть 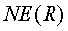 - это набор именованных объектных сущностей, имеющихся в наборе документов
- это набор именованных объектных сущностей, имеющихся в наборе документов 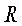 . Пусть
. Пусть 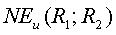 - это набор уникальных именованных объектных сущностей, имеющихся в наборе документов
- это набор уникальных именованных объектных сущностей, имеющихся в наборе документов 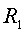 и отсутствующих в наборе
и отсутствующих в наборе 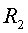 . То есть,
. То есть, 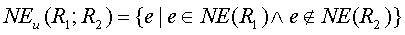 . Тогда, расстояние
. Тогда, расстояние 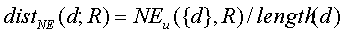 .
.
Нормализация по длине документа в типичном варианте необходима, поскольку без нормализации значение NE стремится к увеличению с увеличением длины из-за вероятностного влияния длины на видимые дополнительные именованные объектные сущности; чем длиннее документ, тем больше вероятность того, что он содержит больше именованных объектных сущностей.
На 340 по фиг.3 показатели расстояния могут быть укреплены, с тем чтобы определять новое информационное содержимое для представления пользователям. В приложении NewsJunkie алгоритм ранжирования по новизне применяется многократно, чтобы сгенерировать небольшой набор статей, которые могут заинтересовать читателя. Используется ресурсоемкий инкрементный анализ. Алгоритм первоначально сравнивает по существу все доступные свежие новости с исходным описанием, которое прочел пользователь, и выбирает статью, наименее схожую с ним. Затем эта статья добавляется в исходное описание (формируя группу из двух документов), и алгоритм ищет следующую свежую новость, наиболее несхожую с сочетанием этих статей, и т.д. Псевдокод алгоритма ранжирования приведен ниже в алгоритме RankNewsByNovelty (ранжирование новостей по новизне).
Алгоритм RankNewsByNovelty 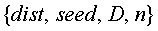
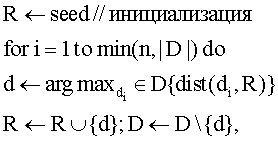
где dist - это показатель расстояния, seed - исходное описание, D - набор релевантных свежих новостей, n - требуемое число свежих новостей для выбора, R - список статей, упорядоченных по новизне.
Чтобы проверить правильность представленного выше алгоритма и показателей расстояния, был проведен эксперимент, в ходе которого просили субъектов оценить наборы новостных статей, упорядоченные по различным показателям расстояния.
Для описанных в данном документе экспериментов был использован прямой поток новостей, который собирает в единое целое новостные статьи из более чем 4000 Интернет-источников. Был использован поток новостей от Moreover Technologies, хотя могли быть использованы любые другие новости или поток RSS. Был использован алгоритм кластеризации для групповых описаний, обсуждающих одни и те же происшествия (в дальнейшем называемых темами). Было использовано двенадцать кластеров, которые соответствуют темам, передаваемым в новостях в середине сентября 2003 года. 12 тем охватили новостные отчеты в промежутке времени от 2 до 9 дней и представили от 36 до 328 статей. Темы включили в себя обзор новой вспышки SARS в Сингапуре, отзыв губернатора Калифорнии, визит Папы Римского в Словению и т.д.
Обычно оценка новизны - это субъективная задача. Один способ получить статистически осмысленные результаты - усреднить оценки набора пользователей. Чтобы сравнить различные показатели ранжирования по новизне, участникам было предложено прочесть несколько наборов статей, упорядоченных по альтернативным показателям, и решить, какие наборы заключали в себе самую новую информацию. Заметим, что этот сценарий обычно требует, чтобы оценивающие помнили все наборы статей, которые они прочли, до тех пор, пока они их не ранжируют. Поскольку трудно хранить несколько наборов статей по незнакомой теме в памяти, эксперимент был ограничен оценкой следующих трех показателей.
1. KL-отклонение было выбрано из-за его привлекательной теоретико-информационной основы (KL).
2. Показатель, подсчитывающий именованные объектные сущности, был выбран в качестве лингвистически оправданной альтернативы (NE).
3. Хронологическое упорядочивание статей было использовано в качестве базиса (ORG).
Для каждой из 12 тем первое описание было выбрано в качестве исходного описания, и использовались 3 описанных выше показателя для того, чтобы упорядочить остальные описания по новизне с помощью алгоритма RankNewsByNovelty. Алгоритм сначала выбирает самую новую статью относительно исходного описания. Эта статья затем добавляется в исходное описание, чтобы сформировать новую модель того, о чем пользователь знает, и выбирается следующая новая статья. Три статьи были выбраны таким способом для каждого из трех показателей и каждой из 12 тем. Для каждой темы субъектов сначала просили прочесть исходное описание, чтобы получить исходные данные о теме. Затем им были показаны три набора статей (каждый набор выбран по одному из показателей), и их попросили ранжировать наборы от самого нового до наименее нового набора. Им были даны указания представить себе задачу как определение набора статей, которые они бы выбрали для друга, который просмотрел исходное описание и теперь захотел узнать, что произошло нового. Порядок представления наборов, сгенерированных по трем показателям, был произвольно распределен между участниками.
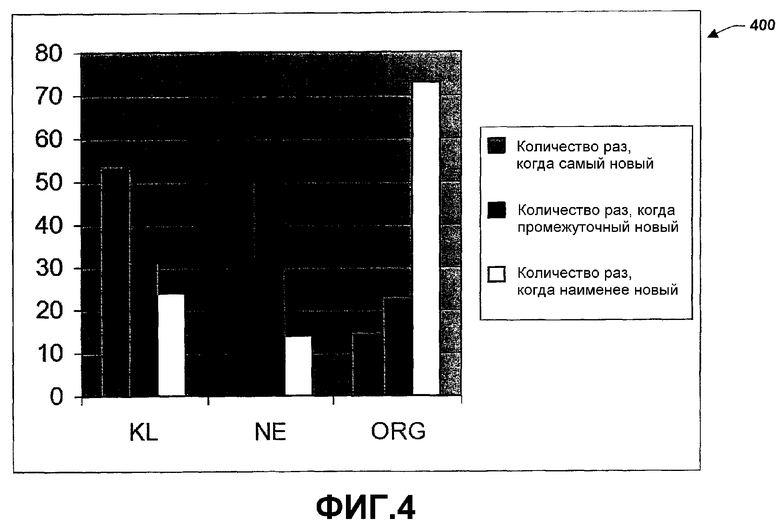
Фиг.4 - это график 400, иллюстрирующий ранжирование результатов в соответствии с аспектом настоящего изобретения. В общем, было получено 111 пользовательских оценок по 12 темам, в среднем 9-10 оценок на тему. Фиг.4 показывает количество раз, когда каждый показатель был ранжирован как самый новый, промежуточный и наименее новый. Как можно заметить из схемы 400, сгенерированные по показателям KL и NE наборы были ранжированы как более новые, чем сгенерированные по базисному показателю (ORG).
Результаты по темам
Таблица 1 представляет результаты по темам. Три предпоследних столбца показывают количество раз, когда каждый показатель был ранжирован как самый новый для каждой темы. Три последних столбца показывают средние ранги показателей при условии, что самому новому назначен ранг 1, промежуточному новому - 2, а наименее новому - 3. Был использован непараметрический тест знаков Вилкоксона (Wilcoxon), чтобы оценить статистическую значимость экспериментальных результатов. Сравнивая средние ранги показателей по всем темам (суммированные на фиг.4), и KL, и NE были признаны превосходящими по отношению к ORG при  <0,001. Рассматривая отдельные результаты по темам, показатель ORG достиг самого низкого (= наилучшего) ранга из всех трех показателей. В 6 случаях (темы 2, 4, 5, 6, 9, 12) разность в среднем ранге между ORG и показателем с самым низким значением была статистически значима при <0,05 и в одном дополнительном случае значимость была пограничной при =0,068 (тема 8). Сравнивая два лучших показателя (KL с NE), разность в пользу KL была статистически значимой при <0,05 для тем 4 и 6 и погранично значимой (=0,083) для темы 9. Разность в средних рангах в пользу NE была погранично значимой для тем 2 и 3 (=0,096 и =0,057, соответственно).
<0,001. Рассматривая отдельные результаты по темам, показатель ORG достиг самого низкого (= наилучшего) ранга из всех трех показателей. В 6 случаях (темы 2, 4, 5, 6, 9, 12) разность в среднем ранге между ORG и показателем с самым низким значением была статистически значима при <0,05 и в одном дополнительном случае значимость была пограничной при =0,068 (тема 8). Сравнивая два лучших показателя (KL с NE), разность в пользу KL была статистически значимой при <0,05 для тем 4 и 6 и погранично значимой (=0,083) для темы 9. Разность в средних рангах в пользу NE была погранично значимой для тем 2 и 3 (=0,096 и =0,057, соответственно).
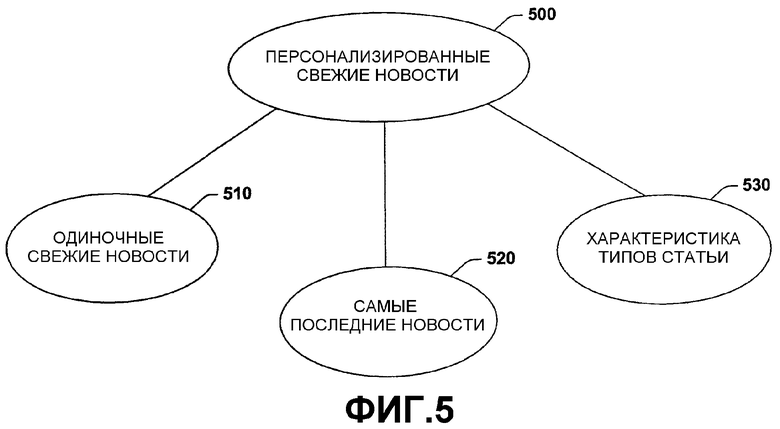
Фиг.5 иллюстрирует персонализированный процесс 500 обновления новостей в соответствии с аспектом настоящего изобретения. Алгоритм RankNewsByNovelty, представленный и оцененный в предыдущем разделе, работает исходя из предположения о том, что пользователь хочет отслеживать последнее развитие событий некоторое время после первого прочтения о них. В этом случае алгоритм упорядочивает последние статьи по новизне по сравнению с исходным описанием, и затем пользователь может прочесть ряд статей с самыми высокими значениями в зависимости от того, сколько свободного времени он может выделить для чтения.
Тем не менее, что, если пользователь хочет следить за свежими новостями по мере того, как фактически происходят новые события? Материально-техническое обеспечение, например, сервер сбора будет отслеживать статьи, которые читает пользователь, чтобы оценить новизну новых статей, идущих потоком в новостях или потоке информации. На основе личных предпочтений пользователя, например, насколько часто пользователь хочет получать свежие новости по описанию, сервер принимает решение о том, какие статьи отображать. Поэтому может быть предусмотрен механизм оперативного принятия решений, который определяет, содержит ли статья в достаточной мере новую информацию, чтобы служить основанием для ее доставки пользователю. В более общем анализе выгод в сравнении с затратами на оповещение есть возможности сбалансировать информационную ценность конкретных статей или групп статей с ценой прерывания пользователей на основе анализа их контекста.
В дальнейшем обсуждаются различные сценарии предоставления пользователям свежих новостей. В одном сценарии предоставления свежих новостей на 510 система полагает, что пользователь заинтересован в получении периодических свежих новостей, тогда как второй сценарий предоставляет пользователю свежие новости постоянно посредством мониторинга входящих новостей для всплесков новой информации на 520. Кроме того, может быть предусмотрен механизм, который предоставляет пользователям возможность контролировать тип новизны (описано ниже более подробно) статей, по которым они хотят получать свежие новости; он проиллюстрирован как характеристика статей по типу на 530.
Относительно одиночных свежих новостей на 510 рассмотрим случай, когда пользователь хочет отслеживать только периодические свежие новости по описанию. Один способ достичь этой цели - использовать алгоритм, аналогичный RankNewsByNovelty, т.е. собрать описания, принятые за все предыдущие дни, и оценить новизну каждого нового описания, которое поступило сегодня, посредством вычисления его расстояния от накопленного набора. Одна из проблем этого подхода состоит в том, что чем больше описаний объединены вместе, чем менее существенным становится интервал от любого нового описания до общего пула. Через несколько дней после того, как стоящие внимания статьи собраны, даже крупная свежая новость едва ли будет казаться новой.
Чтобы избежать этого подвоха, исходный алгоритм новизны модифицируется, как показано ниже относительно выбора периодической свежей новости. Как конкретный пример, был использован период в день, так чтобы алгоритм определял ежедневные свежие новости для пользователя. Рассматривая пользователя и его выбор темы для отслеживания, алгоритм PickDailyUpdate (выбора ежедневных свежих новостей) сравнивает статьи, принятые сегодня, с сочетанием всех статей, принятых накануне. Алгоритм пытается выбрать наиболее информативную свежую новость по сравнению с тем, что было известно вчера, и показывает ее пользователю при условии, что свежая новость заключает в себе достаточно новую информацию (к примеру, ее оценочная новизна выше персонализированного порога пользователя). Обеспечение таких условий наделяет систему возможностью передавать пользователю информативные свежие новости и отфильтровывать статьи, которые только резюмируют ранее известные подробности. Алгоритм может быть обобщен, чтобы определять n самых информативных обновлений в день.
Можно утверждать, что из-за игнорирования всех дней до непосредственно предшествующего, алгоритм PickDailyUpdate также может рассматривать как новые те статьи, которые резюмируют то, о чем было сообщено несколько дней назад. На практике такое происходит редко, поскольку большинство статей написаны так, что чередуют новую информацию с некоторым объемом исходных данных по предыдущим событиям. Так можно принять во внимание, что могут быть предоставлены более тщательно проработанные показатели расстояния, которые рассматривают все предыдущие статьи, относящиеся к теме, но снижают свой вес со временем.
Алгоритм PickDailyUpdate 
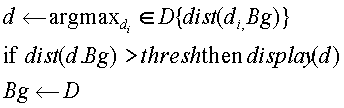
где dist - это показатель расстояния, Bg - набор стандартных исходных данных (сочетание значимых статей, принятых предыдущим днем), D - набор новых статей, принятых сегодня, thresh - заданный пользователем порог чувствительности.
Алгоритм, представленный выше на 510, может быть в значительной степени "автономной" процедурой, поскольку он предоставляет пользователям свежие новости с предопределенными промежутками времени. Упорные новостные маньяки могут счесть разочаровывающим фактом то, что нужно ожидать свежие новости ежедневно по расписанию. Для некоторых может быть предпочтительна более чувствительная форма анализа.
В экстремальной ситуации сравнение каждой статьи с предшествующей может быть не оптимальным вариантом, поскольку система потенциально может предположительно считать практически каждую статью новой. Вместо этого самые последние новостные происшествия могут быть обработаны на 520 по фиг.5, где используется скользящее окно, охватывающее ряд предшествующих статей, чтобы оценивать новизну текущей. Заметим, что оценка расстояний между статьями и предшествующим окном фиксированной длины облегчает сравнение значений, и были оценены окна различной длины в 20-60 статьях. Было установлено, что окна длиной примерно в 40 статей в типичном варианте на практике были оптимальным вариантом.
В отличие от алгоритма PickDailyUpdate, набор стандартных исходных данных теперь становится меньше, а именно, 40 статей вместо содержимого за весь день. Это повышает вероятность того, что окно недостаточно длинное, чтобы охватить задержанные отчеты и резюме, которые поступают через долгий промежуток времени после того, как описание было первоначально опубликовано. Чтобы отфильтровывать такие повторы, необходимо понимать природу новостных отчетов.
Когда важное происшествие или свежая новость о происшествии появляется, многие источники новостей добывают сведения о новом событии и сообщают о нем в течение довольно короткого промежутка времени. Если постепенно начертить схему расстояния между каждой статьей и предшествующим окном, подобное поступление новой информации приведет к максимумам на графике. Такие максимумы называют всплесками новизны. В начале каждого всплеска дополнительные статьи добавляют новые подробности, приводящие к росту на графике. По прошествии времени скользящее окно охватывает все большее и большее количество статей, передающих данное последнее событие, и последующие статьи не обладают той же новизной; в результате вычисленная новизна снижается, обозначая конец всплеска.
Наименее вероятно, что задержанные отчеты о происшествиях, а также резюме по описанию соотнесутся во времени между различными источниками. Такие отчеты могут казаться новыми по сравнению с предшествующим окном, но поскольку они обычно изолированы, то обычно вызывают узкие пики новизны. Чтобы не учитывать эти изолированные пики и не считать их настоящими свежими новостями, сигнал новизны должен быть отфильтрован соответствующим образом.
Медианный фильтр предусматривает эту функциональную возможность посредством снижения величины шума в сигнале. Фильтр последовательно рассматривает каждую точку в сигнале и адаптирует ее так, чтобы она больше походила на окружение, таким образом эффективно сглаживая исходный сигнал и удаляя выбросы значений. Конкретно, медианный фильтр ширины w сначала сортирует w точек данных в пределах окна, центрированного относительно текущей точки, и заменяет последнюю медианой этих точек.
После вычисления расстояния между статьями и скользящим окном, охватывающим предыдущие статьи, получившийся сигнал пропускается через медианный фильтр. Рассмотренные фильтры включают в себя фильтры ширины, например, 3-7; считается, что фильтр ширины 5 является оптимальным вариантом для большинства случаев.
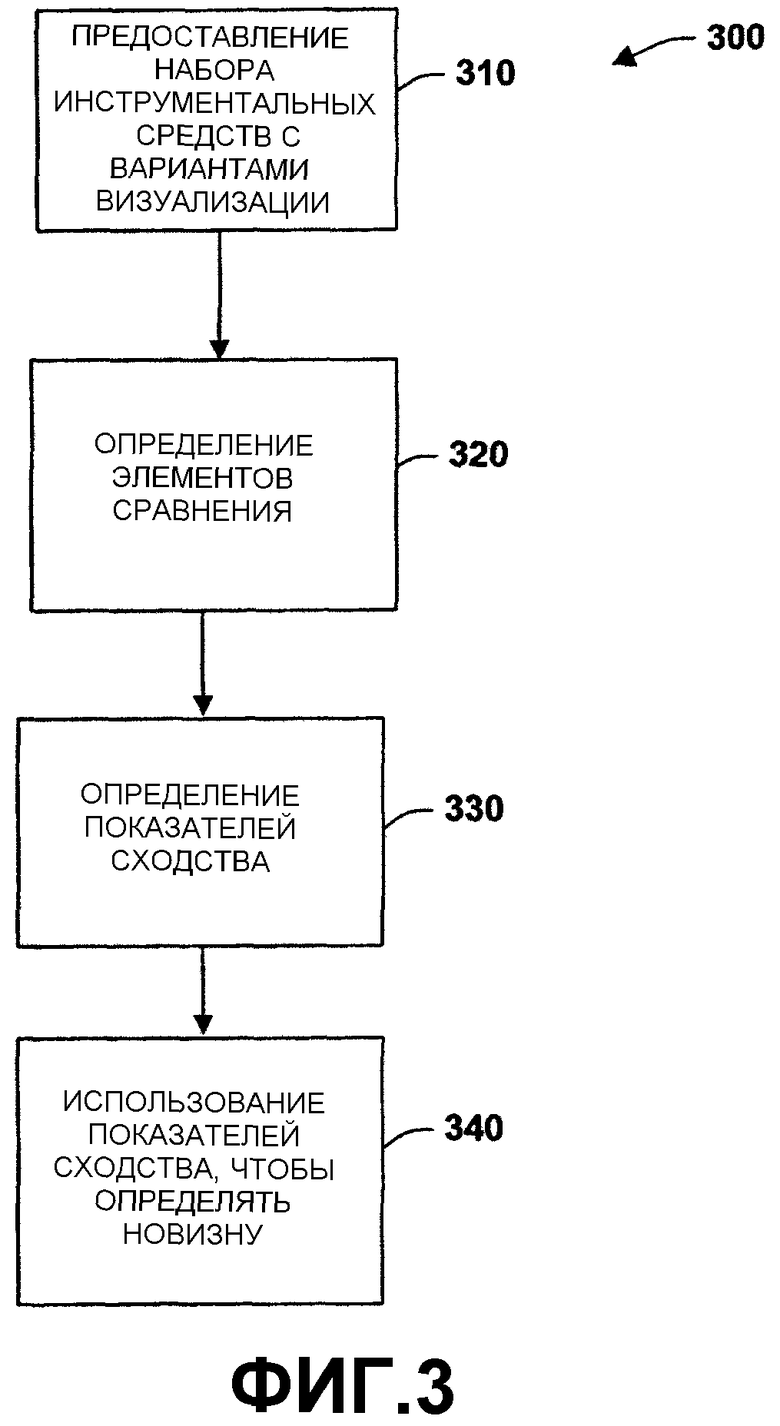
Алгоритм определения самых последних новостей IdentifyBreakingNews 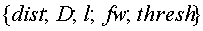

где dist - это показатель расстояния, D - последовательность релевантных статей, l - длина скользящего окна, fw - ширина медианного фильтра, thresh - заданный пользователем порог чувствительности.
Заметим, что использование медианного фильтра может задержать направление новых статей пользователям, поскольку, возможно, должны рассматриваться некоторые последующие статьи, чтобы надежно распознавать начало нового всплеска. Тем не менее, было установлено, что такие задержки достаточно малы (половина ширины используемого медианного фильтра), и полезность фильтра с лихвой компенсирует это неудобство. Если пользователи готовы допустить некоторую дополнительную задержку, алгоритм может просмотреть несколько десятков следующих статей от момента, когда всплеск был распознан, чтобы выбрать наиболее информативную свежую новость вместо простого выбора той, которая начинает всплеск. Также допустимы комбинированные подходы, например, представление предыдущей свежей новости и затем ожидание более существенного анализа всплеска для того, чтобы послать оптимальную статью по развитию. Вышеприведенный алгоритм показывает псевдокод для IdentifyBreakingNews, который реализует анализ всплеска для оповещения о новости.
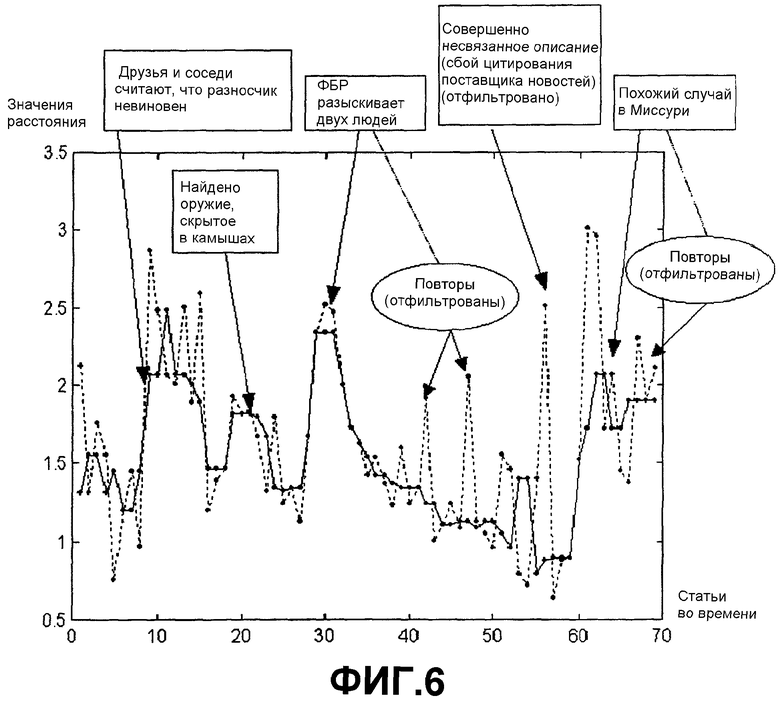
Фиг.6 показывает применение алгоритма IdentifyBreakingNews к примерной теме. Данная тема посвящена ограблению банка в Эри, штат Пенсильвания (США), где группа преступников, предположительно, захватила разносчика пиццы, прикрепила взрывное устройство на его шею и, согласно заявлениям разносчика, заставила его ограбить местный банк. Разносчик был сразу же задержан полицией, но вскоре после этого устройство сработало и убило его. Это странное исходное описание и последующее расследование отслеживалось многими источниками новостей в течение нескольких недель в сентябре 2003 года. Ось абсцисс на данной фигуре соответствует последовательности статей, как они поступали во времени, а ось ординат показывает (необработанные и медианно отфильтрованные) значения расстояния для каждой статьи при заданном предшествующем скользящем окне. Необработанные значения расстояния представлены пунктирной линией, а отфильтрованные значения показаны сплошной линией. Текстовые поля, сопровождающие фиг.6, содержат примечания по фактическим происшествиям, которые соответствуют определенным всплескам новизны, и показывают, какие потенциально ложные максимумы были отброшены фильтром. Сглаженное значение новизны, которое содержит в себе медианный фильтр, фиксирует основные события в описании (интервью с друзьями, подробности об оружии, сводка ФБР по двум подозреваемым и похожий случай), в то же время отфильтровывая ложные максимумы новизны.
Ссылаясь снова на 530 по фиг.5, рассматривается характеристика типов статьи и средства управления для пользователя. В некоторых случаях нельзя полагаться только на значения новизны в качестве единственного критерия выбора; некоторые статьи определяются как новые на основании изменения в теме. Чтобы дополнительно детализировать анализ информационной новизны, сформулирована классификация типов новизны на основе различных взаимоотношений между статьей и исходным описанием или интересующей темой. Примеры таких классов взаимоотношений включают в себя:
1. Резюмирующие статьи - это статьи, которые релевантны, но обычно предлагают только обзоры того, о чем уже сообщалось, и заключают в себя мало новой информации.
2. Уточняющие статьи добавляют новую релевантную информацию по теме, изложенной в исходной статье.
3. Смежные статьи также значимы для основного направления обсуждения, но новая информация, которую они добавляют, в достаточной мере отличается от сообщенной в исходном описании, чтобы служить основанием для развития новой связанной темы.
4. Нерелевантные статьи - это статьи, которые далеки от интересующей темы. Они могут появляться из-за проблем кластеризации или синтаксического анализа. Заметим, что может быть задано и обработано более четырех категорий.
Из этих классов типы 2 и 3 взаимоотношения - вероятно, те, которые пользователи хотят видеть, когда они отслеживают тему. Чтобы достичь этой цели, может быть предусмотрен новый тип анализа документа, который тщательно рассматривает динамику внутри документа. В противоположность предыдущим типам анализа, которые сравнивали полные документы друг с другом, эта методика "укрупняет" документы, оценивая релевантность их частей.
В общем случае, модель создается для каждого документа, и используется фиксированный показатель расстояния, к примеру, KL-отклонение. Затем для каждого документа вычисляется значение расстояния скользящего окна слов в документе в сравнении с исходным описанием. Значение окна слов может быть истолковано как сумма поточечных значений каждого слова в окне в сравнении с исходным описанием, что обусловлено сравнением модели окна в документе с моделью окна в документе исходного описания с использованием выбранного показателя. Было рассмотрено несколько различных значений длины окна, и было установлено, что на практике значение 20 является оптимальным вариантом.
Полезное свойство данной методики заключается в том, что она выходит за рамки общеизвестного набора слов и рассматривает слова документа в их исходном контексте. Она была выбрана для использования скользящих контекстуальных окон, а не, несомненно, более привлекательных абзацных блоков, поскольку использование окна фиксированной длины делает значения расстояния непосредственно сопоставимыми. Еще одним очевидным вариантом единицы сравнения были бы отдельные предложения. Тем не менее, было решено, что выполнение этого анализа на уровне предложения будет принимать во внимание слишком мало информации, и диапазон возможных значений будет слишком велик, чтобы быть полезным.
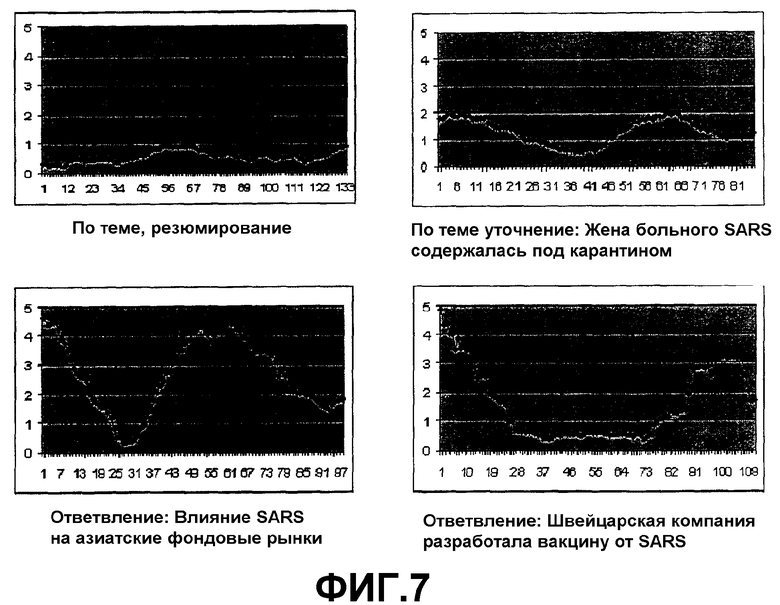
Фиг.7 показывает пример результатов анализа внутри документа. Исходным описанием для этого анализа был отчет по новому случаю SARS в Сингапуре. Статьи, которые в основном резюмируют то, о чем уже было сообщено, в типичном варианте имеют очень ограниченный диапазон динамики и низкие абсолютные значения. Уточняющие статьи обычно имеют более высокие абсолютные значения, которые отражают новую информацию, которую они заключают в себе. Одно уточнение по данному описанию сообщило, что жена больного содержалась под карантином. Дополнительно в соответствии с этим спектром, статьи, которые могут квалифицироваться как смежные, но по-прежнему закреплены за происшествиями, описанными в исходном описании, имеют гораздо более широкий диапазон динамики. Одним ответвлением было описание, которое касалось влияния SARS на азиатский фондовый рынок, а вторым - по успехам в разработке вакцины от SARS. Обе смежные статьи использовали недавний случай в качестве начальной точки, но на самом деле были о связанной теме. Было решено, что анализ динамики внутри документа, например, диапазона динамики и шаблонов значений новизны полезен при определении различных типов информации, за которой читатели хотят следить.
Web-технологии предоставили пользователям богатый набор источников новостей. Это является обманчиво легким для Интернет-серферов (людей, перемещающихся в Интернете с сайта на сайт по связанным гиперссылкам) просмотреть множество источников в погоне за свежими новостями; но несмотря на это тщательный анализ большого объема новостей может повлечь за собой прочтение большого объема лишнего материала. Была представлена совокупность алгоритмов, которая анализирует потоки новостей и определяет статьи, которые заключают в себе самую новую информацию, заданную моделью того, что пользователь прочел до этого. С этой целью представление на основе слова было дополнено именованными объектными сущностями, извлеченными из текста. С помощью данного представления используется множество показателей расстояния для того, чтобы оценивать несходство между каждой новостной статьей и совокупностью статей (к примеру, ранее прочтенных описаний). Методики, лежащие в основе алгоритмов, анализируют динамику между и внутри документов посредством изучения того, как подача информации развивается со временем от статьи к статье, а также внутри каждой отдельной статьи на уровне контекстуальных окон слов.
Средства обзора новостей или основанные на сервере службы, содержащие эти алгоритмы, могут предложить пользователям возможность персонализированной работы с новостями, давая возможность настраивать как требуемую частоту свежих новостей, так и степень, до которой эти свежие новости должны быть аналогичны исходному описанию, посредством осуществления контроля над ограничением новизны. Могут быть предусмотрены более сложные показатели расстояния, которые содержат некоторые из описанных в данном документе базовых показателей, а также более подробные профили шаблонов внутри документа.
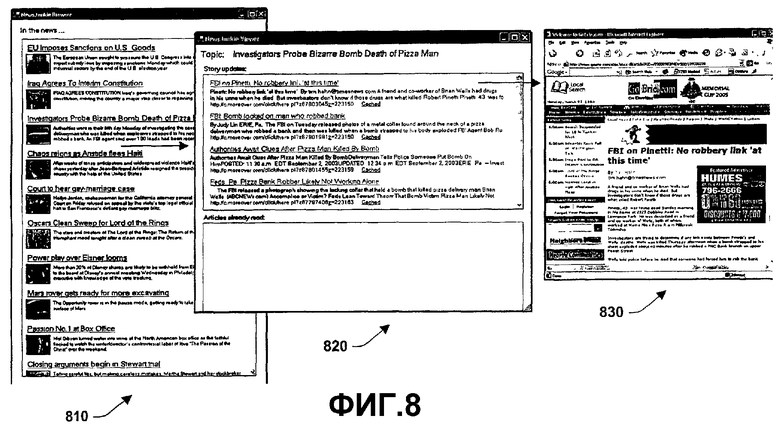
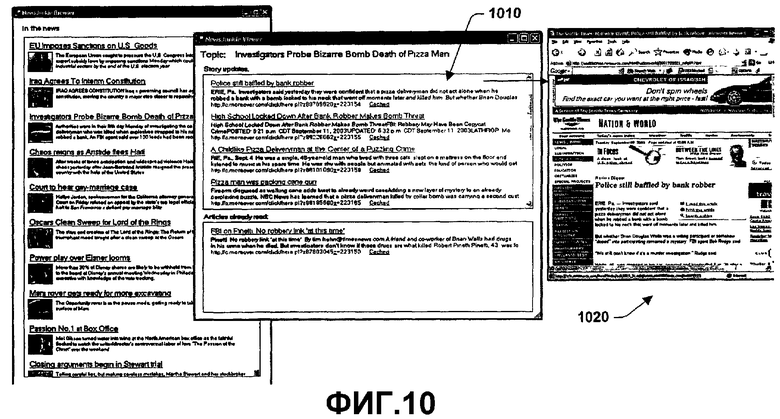
Фиг.8-11 иллюстрируют примерные пользовательские интерфейсы в соответствии с аспектом настоящего изобретения. Фиг.8 иллюстрирует список новостных описаний на 810, при этом конкретная тема выбирается из новостных описаний на 810 и отображается на 820 (к примеру, Исследовательское испытание...). Когда тема выбрана на 810, дисплей 820 отображает интересующие новостные элементы, относящиеся к выбранной теме. На 830 отображается конкретная новостная заметка, которая выбирается из списка на 820. Фиг.9 иллюстрирует, что после того, как выбрана тема, она может быть перечислена в разделе уже прочтенных на 910. Фиг.10 иллюстрирует, как следующая новая статья появляется на 1010, которая затем проверяется или прочитывается на 1020. Фиг.11 показывает, как прочитанная заметка из 1020 после этого помещается в местоположение уже прочтенных на 1110.
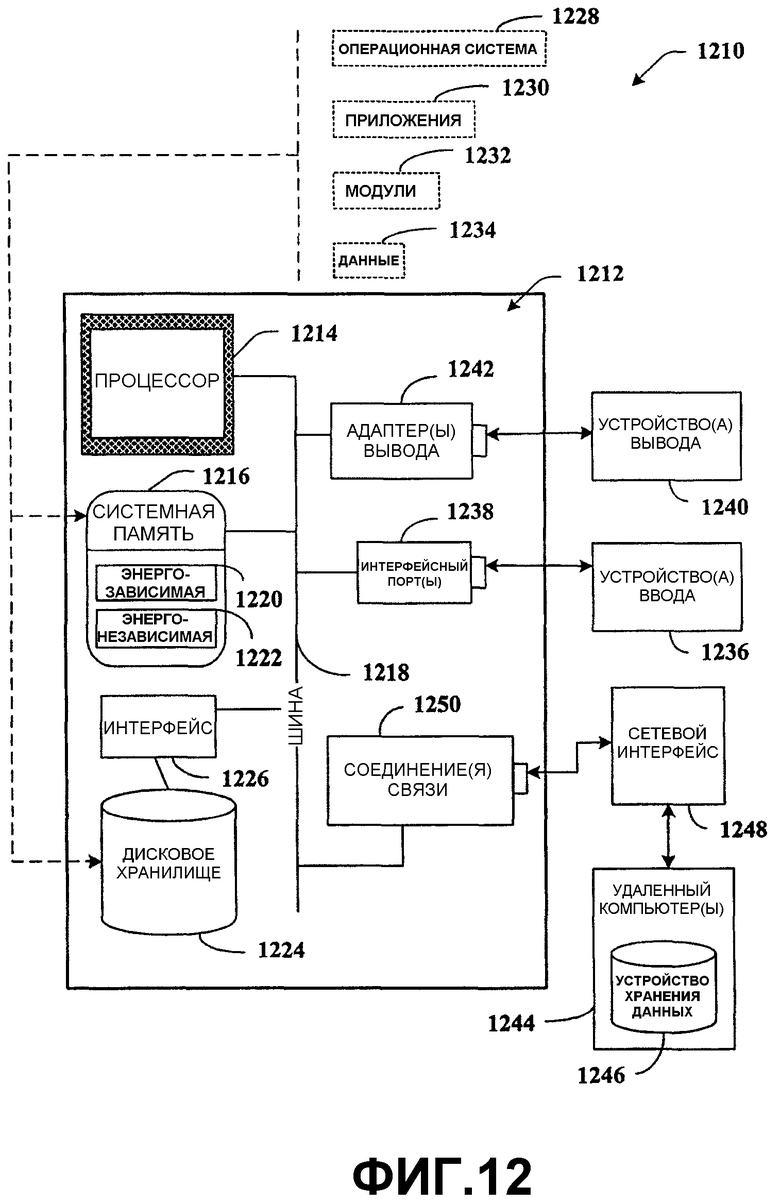
Что касается фиг.12, иллюстративная среда 1210 для реализации различных аспектов изобретения включает в себя компьютер 1212. Компьютер 1212 включает в себя процессор 1214, системную память 1216 и системную шину 1218. Системная шина 1218 соединяет компоненты системы, в том числе (но не только) системную память 1216, с процессором 1214. Процессор 1214 может быть любым из различных доступных процессоров. Архитектуры с двумя микропроцессорами и другие многопроцессорные архитектуры также могут быть использованы в качестве процессора 1214.
Системная шина 1218 может относиться к любому из нескольких типов структур(ы) шин, включая шину памяти или контроллер памяти, периферийную шину или внешнюю шину и/или локальную шину, используя любую из множества архитектур шин, в том числе, но не в ограничительном смысле, 16-битную шину архитектуры промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), расширенную шину ISA (EISA), встроенный интерфейс накопителей (IDE), логическую шину VESA (VLB), шину межсоединения периферийных компонентов (PCI), универсальную последовательную шину (USB), порт ускоренной графики (AGP), шину стандарта международной ассоциации карт памяти персонального компьютера (PCMCIA) и интерфейс малых компьютерных систем (SCSI).
Системная память 1216 включает в себя энергозависимую память 1220 и энергонезависимую память 1222. Базовая система ввода-вывода (BIOS), содержащая основные процедуры для того, чтобы передавать информацию между элементами в компьютере 1212, например, при загрузке, хранится в энергонезависимой памяти 1222. В качестве иллюстрации, но не ограничения, энергонезависимая память 1222 может включать в себя постоянное запоминающее устройство (ПЗУ, ROM), программируемое ПЗУ (PROM), электрически программируемое ПЗУ (EPROM), электрически стираемое программируемое ПЗУ (EEPROM) или флэш-память. Энергозависимая память 1220 включает в себя оперативное устройство (ОЗУ, RAM), которое действует как внешняя кэш-память. В качестве иллюстрации, но не ограничения, ОЗУ доступно во многих формах, например, синхронное ОЗУ (SRAM), динамическое ОЗУ (DRAM), синхронное DRAM (SDRAM), SDRAM с двойной скоростью передачи данных (DDR SDRAM), усовершенствованное SDRAM (ESDRAM), Synchlink DRAM (SLDRAM) и direct Rambus RAM (DRRAM).
Компьютер 1212 также включает в себя сменные/стационарные, энергозависимые/энергонезависимые компьютерные носители данных. Фиг.12 иллюстрирует, например, дисковое хранилище 1224. Дисковое хранилище 1224 включает в себя, но не в ограничительном смысле, такие устройства, как накопитель на магнитном диске, накопитель на гибком диске, ленточный накопитель, накопитель Jaz, накопитель Zip, накопитель LS-100, карту флэш-памяти или карту Memory Stick. Помимо этого, дисковое хранилище 1224 может включать в себя носители данных независимо или в сочетании с другими носителями данных, в том числе, но не в ограничительном смысле, накопитель на оптическом диске, например, компакт-диск (CD-ROM), накопитель на записываемом компакт-диске (CD-R), накопитель на перезаписываемом компакт-диске (CD-RW) или накопитель на универсальном цифровом диске (DVD-ROM). Чтобы обеспечить подключение дисковых устройств 1224 к системной шине 1218, в типичном варианте используется интерфейс сменных или стационарных устройств в качестве интерфейса 1226.
Необходимо принимать во внимание, что фиг.12 описывает программное обеспечение, которое выступает в качестве посредника между пользователями и базовыми ресурсами компьютера, описанными в подходящей рабочей среде 1210. Такое программное обеспечение включает в себя операционную систему 1228. Операционная система 1228, которая может храниться на диске 1224, служит для того, чтобы управлять ресурсами и распределять ресурсы компьютерной системы 1212. Системные приложения 1230 используют преимущества управления ресурсами операционной системой 1228 посредством программных модулей 1232 и данных 1234 программ, хранящихся либо в системной памяти 1216, либо в дисковом хранилище 1224. Необходимо принимать во внимание, что изобретение может быть реализовано с различными операционными системами или сочетаниями операционных систем.
Пользователь вводит команды или информацию в компьютер 1212 посредством устройств(а) 1236 ввода. Устройства 1236 ввода включают в себя, но не в ограничительном смысле, указательное устройство, такое как мышь, шаровой манипулятор, перо, сенсорную панель, клавиатуру, микрофон, джойстик, игровую панель, спутниковую антенну, сканер, плату ТВ-тюнера, цифровую камеру, цифровую видеокамеру, web-камеру и т.п. Эти и другие устройства ввода подключаются к процессору 1214 через системную шину 1218 посредством интерфейсного порта(ов) 1238. Интерфейсный порт(ы) 1238 включает в себя, например, последовательный порт, параллельный порт, игровой порт и универсальную последовательную шину (USB). Устройство(а) 1240 вывода использует те же типы портов, что и устройство(а) 1236 ввода. Таким образом, например, порт USB может быть использован для того, чтобы обеспечить ввод в компьютер 1212 и чтобы выводить информацию из компьютера 1212 на устройство 1240 вывода. Адаптер 1242 вывода предоставлен, чтобы проиллюстрировать, что существуют некоторые устройства 1240 вывода (такие как мониторы, динамики и принтеры) среди прочих устройств 1240 вывода, которые требуют специальных адаптеров. Адаптеры 1242 вывода включают в себя, в качестве иллюстрации, но не ограничения, видео- и звуковые платы, которые обеспечивают средство соединения между устройством 1240 вывода и системной шиной 1218. Следует заметить, что другие устройства и/или системы устройств предоставляют возможности как ввода, так и вывода, например, удаленный компьютер(ы) 1244.
Компьютер 1212 может работать в сетевом окружении, используя логические соединения с одним или более удаленными компьютерами, например, с удаленными компьютерами 1244. Удаленным компьютером(ами) 1244 может быть персональный компьютер, сервер, маршрутизатор, сетевой ПК, рабочая станция, устройство на базе микропроцессора, одноранговое устройство или другой стандартный сетевой узел и т.п., и в типичном варианте включает в себя большинство или все из элементов, описанных относительно компьютера 1212. В целях краткости, только устройство 1246 хранения данных проиллюстрировано с удаленным компьютером(ами) 1244. Удаленный компьютер(ы) 1244 логически соединены с компьютером 1212 посредством сетевого интерфейса 1248 и затем физически соединены через соединение 1250 связи. Сетевой интерфейс 1248 заключает в себе сети обмена данными, такие как локальные сети (LAN) и глобальные сети (WAN). Технологии LAN включают в себя распределенный интерфейс передачи данных по волоконно-оптическим каналам (FDDI), распределенный проводной интерфейс передачи данных (CDDI), Ethernet/IEEE 1102.3, Token Ring/IEEE 1102.5 и т.п. Технологии WAN включают в себя, но не только, двухточечные линии связи, сети с коммутацией каналов, такие как цифровые сети с комплексными услугами (ISDN) и их разновидности, сети с коммутацией пакетов и цифровые абонентские линии (DSL).
Соединение(я) 1250 связи означает аппаратные средства/программное обеспечение, используемое для соединения сетевого интерфейса 1248 к шине 1218. Хотя соединение 1250 связи показано в целях иллюстративной ясности внутри компьютера 1212, оно также может быть внешним по отношению к компьютеру 1212. Аппаратные средства/программное обеспечение, необходимое для подсоединения к сетевому интерфейсу 1248, включают в себя, только для примера, внутренние и внешние технологии, например, модемы, в том числе модемы на регулярных телефонных линиях, кабельные модемы и DSL-модемы, ISDN-адаптеры и платы Ethernet.
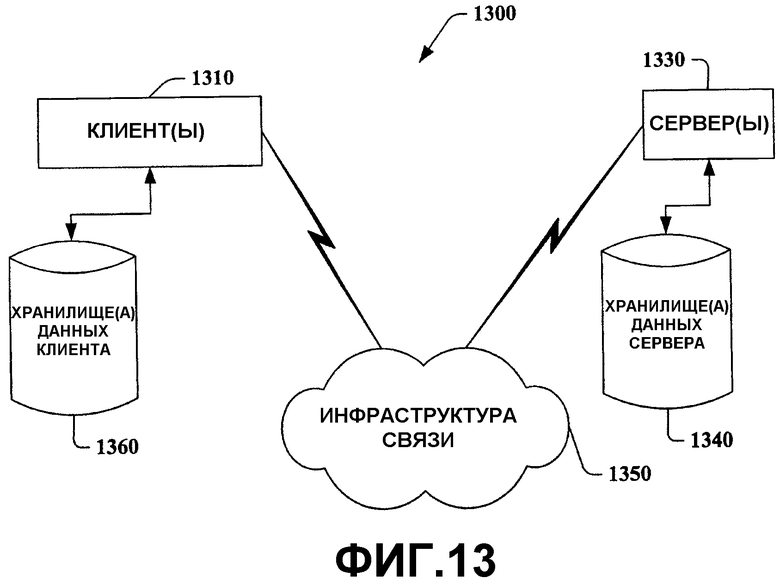
Фиг.13 - это схематическая блок-схема примера вычислительной среды 1300, с которой может взаимодействовать настоящее изобретение. Система 1300 включает в себя один или более клиентов 1310. Клиентом(ами) 1310 могут быть аппаратные средства и/или программное обеспечение (к примеру, потоки, процессы, вычислительные устройства). Система 1300 также включает в себя один или более серверов 1330. Сервером(ами) 1330 также могут быть аппаратные средства и/или программное обеспечение (к примеру, потоки, процессы, вычислительные устройства). Серверы 1330 могут размещать потоки так, чтобы выполнять преобразования, например, посредством использования настоящего изобретения. Одна возможная связь между клиентом 1310 и сервером 1330 может быть в форме пакета данных, приспособленного для передачи между двумя или более процессами компьютера. Система 1300 включает в себя инфраструктуру 1350 связи, которая может быть использована, чтобы обеспечить обмен данными между клиентом(ами) 1310 и сервером(ами) 1330. Клиент(ы) 1310 в рабочем состоянии подключены к одному или более хранилищам 1360 данных клиента, которые могут быть использованы для хранения информации, локальной для клиента(ов) 1310. Также сервер(ы) 1330 в рабочем состоянии подключены к одному или более хранилищам 1340 данных сервера, которые могут быть использованы для хранения информации, локальной для серверов 1330.
То, чтобы было описано выше, включает в себя примеры настоящего изобретения. Конечно, невозможно описать каждое вероятное сочетание компонентов или методик в целях описания настоящего изобретения, но специалист в данной области техники может признать, что многие дополнительные сочетания и перестановки настоящего изобретения допустимы. Следовательно, настоящее изобретение предназначено для того, чтобы охватывать все подобные преобразования, модификации и разновидности, которые попадают в рамки сущности и объема, определяемого прилагаемой формулой изобретения. Более того, в той мере, в какой термин "включает в себя" используется либо в подробном описании, либо в формуле изобретения, этот термин подразумевается обозначающим включение аналогично термину "содержит" в той мере, как "содержит" интерпретируется, когда он используется в качестве промежуточного слова в пункте формулы изобретения.


Представлена система и методика фильтрации временных потоков информации, таких как новостные описания, посредством статистических мер новизны информации. Различные методики могут быть применены к собственным разработанным потокам новостей или другим типам информации на основе информации, которую пользователь уже просмотрел. Предусмотрены способы анализа новизны информации наряду с системой, которая персонализирует и фильтрует информацию для пользователей посредством определения новизны описаний в контексте описаний, которые они уже просмотрели. Система использует алгоритмы анализа новизны, которые представляют статьи как набор слов и именованных объектных сущностей. Алгоритмы анализируют динамику между и внутри документов посредством рассмотрения того, как информация развивается со временем от статьи к статье, а также внутри отдельных статей. Технический результат - возможность упорядочивания новостных статей, чтобы каждая статья добавляла максимум информации по отношению к ранее представленным единицам информации. 3 н. и 11 з.п. ф-лы, 13 ил., 1 табл.
1. Машинно-реализованная система для распространения персонализированной информации, содержащая
блок сравнения, который определяет различия между двумя или более связанными единицами информации, и
анализатор, который автоматически определяет подмножество связанных единиц информации как персонализированную информацию частично на основе различий и того, как данные, относящиеся к единицам информации, развиваются во времени, и выполняет по меньшей мере одно из сохранения персонализированной информации на машиночитаемом носителе и отображения персонализированной информации на устройстве вывода, при этом анализатор использует следующий алгоритм:
алгоритм ранжирования новостей по новизне RankNewsByNovelty (dist, seed, D, n)
R ← seed // инициализация
for i=1 to min (n, |D|) do
d ← arg maxdi ∈ D {dist(di, R)}
R ← R∪{d}; D←D\{d},
где dist - показатель расстояния, seed - исходное описание, D - набор релевантных свежих новостей, d - документ, n - требуемое число свежих новостей для выбора, R - список статей, упорядоченных по новизне.
2. Система по п.1, дополнительно содержащая фильтр для отбрасывания ранее наблюдаемой информации.
3. Система по п.1, в которой единицы информации относятся к потоку новостей.
4. Система по п.1, дополнительно содержащая по меньшей мере один сервер для сбора единиц информации для последующей обработки анализатором.
5. Система по п.1, в которой блок сравнения обрабатывает подробную статистику, собранную в отношении вхождения слова в наборы документов, чтобы охарактеризовать различия и сходства между этими наборами.
6. Система по п.1, дополнительно содержащая модель слова, которая использует именованные объектные сущности, обозначающие людей, организации или географические местоположения.
7. Система по п.1, дополнительно содержащая персонализированный портал новостей или службу оповещения о новостях, которые позволяют минимизировать время и потери для пользователей.
8. Система по п.1, дополнительно содержащая инфраструктуру для определения различий во множестве вариантов применения, в том числе автоматическом профилировании и сравнении совокупностей текста, автоматическом определении различных взглядов, намерений и интересов, отражаемых в текстах, или автоматическом определении новой информации.
9. Система по п.1, в которой блок сравнения определяет по меньшей мере одно из различия в содержимом, различия в структурной организации и различия во времени.
10. Система по п.9, дополнительно содержащая компонент для характеризации новизны в новостных описаниях и обеспечения упорядочения новостных статей таким образом, чтобы каждая статья добавляла максимум информации к сочетанию ранее прочитанных статей.
11. Система по п.9, дополнительно содержащая компонент для анализа развития темы во времени для обеспечения возможности измерения важности и релевантности свежих новостей.
12. Система по п.11, дополнительно содержащая предоставление средств управления параметрами темы для пользователя с целью обеспечения возможности персонализированной работы с новостями.
13. Машиночитаемый носитель, на котором хранятся машиночитаемые команды для реализации компонентов системы по п.1.
14. Машинно-реализованная система для создания персонализированной информации, содержащая
средство для анализа множества документов из различных информационных источников,
средство для определения сходства документов и
средство для предоставления персонализированного потока новой информации на основе определенных различий в сходстве документов посредством реализации следующего алгоритма:
алгоритм ранжирования новостей по новизне RankNewsByNovelty [dist, seed, D, n)
R ← seed // инициализация
for i=1 to min (n, |D|) do
d ← arg maxdi ∈ D {dist (di, R)}
R ← R∪{d}; D←D\{d},
где dist - показатель расстояния, seed - исходное описание, D - набор релевантных свежих новостей, d - документ, n - требуемое число свежих новостей для выбора, R - список статей, упорядоченных по новизне, и средство для по меньшей мере одного из сохранения персонализированного потока новой информации на машиночитаемом носителе и отображения персонализированного потока новой информации на устройстве вывода.
| US 6167398 A, 26.12.2000 | |||
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ПОДГОТОВКИ И АТТЕСТАЦИИ ПО БЕЗОПАСНОСТИ ПРОИЗВОДСТВА | 1999 |
|
RU2166211C2 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| THORSTEN BRANTS, FRANCINE CHEN, AYMAN FARAHAT | |||
| A System for New Event Detection | |||
| Прибор для получения стереоскопических впечатлений от двух изображений различного масштаба | 1917 |
|
SU26A1 |

