ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к области формирования видеоизображения правдоподобного отображения течения времени (timelapse) из единственного изображения и, в частности, к способам, компьютерно-реализуемым системам, вычислительным устройствам, и компьютерно-читаемым носителям данных для формирования правдоподобного отображения течения времени суточного масштаба.
УРОВЕНЬ ТЕХНИКИ, К КОТОРОМУ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
[0002] В последние годы, проблема преобразования изображений на основе глубоких нейронных сетей эволюционировала от преобразования между двумя предопределенными спаренными доменами к разработке унифицированных моделей для преобразования между множественными доменами. Большинство классических подходов к преобразованию изображений нуждается в доменных метках. Современная FUNIT-модель ослабляет это ограничение: для получения стиля в момент времени вывода, она использует несколько изображений из целевого домена в качестве правила для преобразования (это известно, как установка по нескольким кадрам “few-shot setting”), но все же нуждается в доменных метках во время обучения. Решения предшествующего уровня техники всегда используют спаренные или доменно-помеченные обучающие изображения для решения проблемы преобразования изображений.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
[0003] Проблема преобразования изображений решается изобретением, раскрытым в данном документе, для практической задачи формирования видеоизображений отображения течения времени суточного масштаба из единственного изображения, которое может быть захвачено пользователем на пользовательском вычислительном устройстве. Поскольку получение набора данных высокоразрешенных различных изображений или видеоизображений отображения течения времени суточного масштаба является гораздо более трудным, чем получение набора данных высокоразрешенных различных изображений, изобретение, раскрытое в данном документе, основано на подходе преобразования изображений. Вместо сбора доменных аннотаций, которые трудно определять и трудно получать от пользователей, предлагается способ, который раскрывает неявную доменную структуру данных без явного доменного управления.
[0004] Система искусственного интеллекта (Artificial Intelligence - AI), используемая в изобретении, раскрытом в данном документе, обучается на большом наборе данных не совмещенных изображений без доменных меток. Единственным внешним (слабым) управлением, используемым в одном варианте осуществления предлагаемого изобретения, являются карты грубой сегментации, которые могут быть оценены с использованием готовой сети семантической сегментации.
[0005] Согласно первому аспекту настоящего раскрытия обеспечен способ формирования одного или нескольких изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе контентного изображения с использованием обученной генеративной нейронной сети и обученной объединяющей нейронной сети, причем способ содержит этапы, на которых: принимают контентное изображение и (а) один или несколько предопределенных стилей, соответственно, соответствующих одному или нескольким временам суток, подлежащих применению к контентному изображению, или (b) одно или несколько стилевых изображений, имеющих один или несколько стилей, подлежащих применению к контентному изображению; разделяют контентное изображение на n обрезанных изображений; применяют обученную генеративную нейронную сеть с каждым из одного или нескольких стилей к n обрезанным изображениям для получения n обрезанных изображений, рестилизованных согласно каждому из одного или нескольких стилей; и объединяют рестилизованные n обрезанных изображений для каждого из одного или нескольких стилей с помощью обученной объединяющей нейронной сети для получения одного или нескольких изображений последовательности правдоподобного отображения течения времени суточного масштаба для контентного изображения. Генеративная нейронная сеть, используемая в способе согласно первому аспекту настоящего раскрытия, обучается в одном из или в комбинации следующих режимов: режим перестановки, случайный режим, и режим автоэнкодера. Генеративная нейронная сеть содержит по меньшей мере контентный кодер, стилевой кодер, и декодер.
[0006] Согласно второму аспекту настоящего раскрытия обеспечено вычислительное устройство, содержащее процессор и память, хранящую исполняемые компьютером инструкции, которые, при исполнении процессором, побуждают процессор к выполнению способа согласно первому аспекту.
[0007] Согласно третьему аспекту настоящего раскрытия обеспечен способ формирования одного или нескольких изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе контентного изображения с использованием обученной генеративной нейронной сети, причем способ содержит этапы, на которых: принимают контентное изображение и (a) предопределенные один или несколько стилей, подлежащих применению к контентному изображению, или (b) одно или несколько стилевых изображений, имеющих один или несколько стилей, подлежащих применению к контентному изображению; уменьшают разрешение контентного изображения до низкого разрешения по меньшей стороне контентного изображения с сохранением соотношения сторон контентного изображения; применяют обученную генеративную нейронную сеть с каждым из одного или нескольких стилей к уменьшенному контентному изображению для получения одного или нескольких уменьшенных контентных изображений, рестилизованных согласно каждому из одного или нескольких стилей; и осуществляют разложение каждого из рестилизованных контентных изображений на высокочастотные составляющие и низкочастотную составляющую, имеющую низкое разрешение по меньшей стороне с сохранением соотношения сторон; фильтруют низкочастотную составляющую с учетом контента соответствующего рестилизованного контентного изображения; и формируют одно или несколько изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе отфильтрованной низкочастотной составляющей и высокочастотных составляющих каждого из соответствующих рестилизованных контентных изображений.
[0008] Согласно четвертому аспекту настоящего раскрытия обеспечено вычислительное устройство, содержащее процессор и память, хранящую исполняемые компьютером инструкции, которые, при исполнении процессором, побуждают процессор к выполнению способа согласно третьему аспекту.
ПРЕДПОЧТИТЕЛЬНЫЕ ЭФФЕКТЫ И ПРЕИМУЩЕСТВА ПЕРЕД ПРЕДШЕСТВУЮЩИМ УРОВНЕМ ТЕХНИКИ
[0009] Во-первых, предлагаемый способ позволяет выполнять сохраняющий-семантику перенос стилей между изображениями без знаний о доменах, представленных в наборе данных. Внутреннее смещение собранного набора данных, архитектурное смещение, и специально разработанная обучающая процедура позволяют обучаться преобразованиям стилей даже в этом режиме.
[0010] Во-вторых, для обеспечения сохранения мелких деталей, раскрытая архитектура преобразования изображений объединяет две технологии: обходные связи и адаптивная раздельная нормализация (adaptive instance normalization - AdaIN). Такое объединение является возможным и приводит к архитектуре, которая сохраняет детали гораздо лучше, чем преобладающие в настоящее время AdaIN-архитектуры без обходных связей. Кроме главной цели настоящей заявки, предлагаемое изобретение может быть использовано для обучения многодоменной стилизации/перекраски изображений и обеспечивает качество, не уступающее текущему состоянию данной области техники.
[0011] Наконец, поскольку прямое обучение высокопроизводительной сети преобразования изображений с высоким разрешением не является оправданным с точки зрения вычислительной сложности, новая схема улучшения (с использованием объединяющей сети) позволяет применять сеть преобразования изображений, обученную с низким разрешением, для создания правдоподобных изображений высокого разрешения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0012] Вышеупомянутые и другие аспекты, признаки, и преимущества настоящего изобретения станут более понятны из нижеследующего подробного описания, используемого вместе с сопутствующими чертежами, в которых:
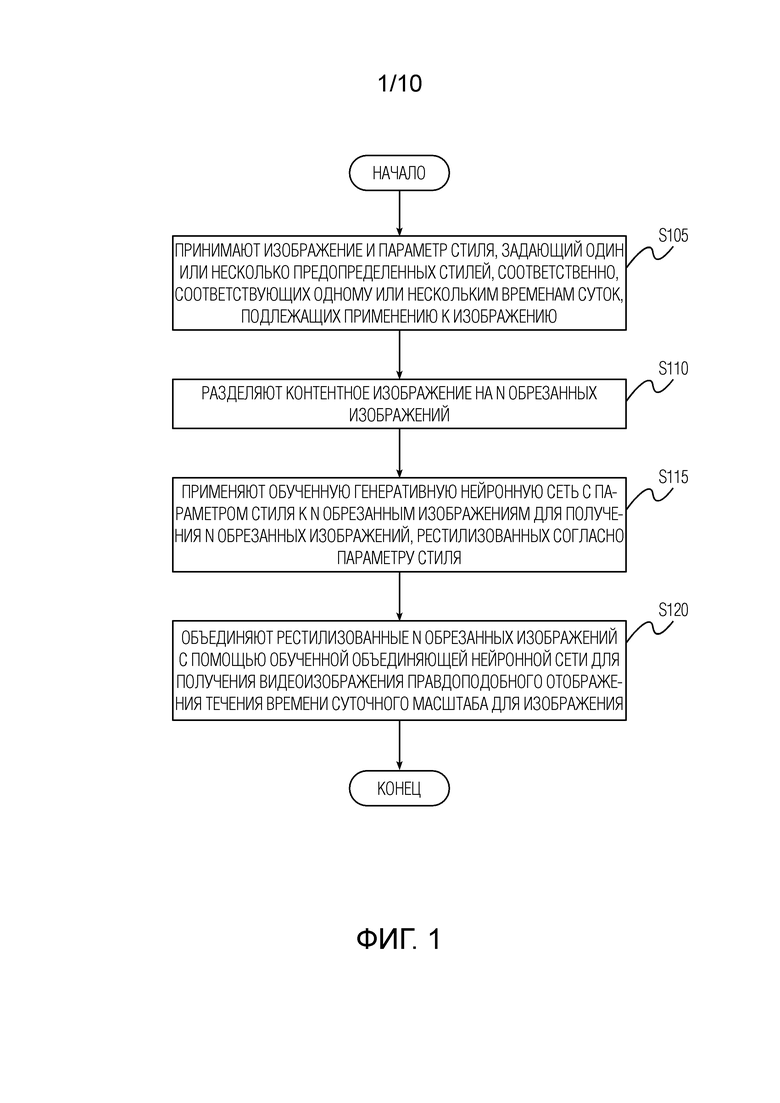
[Фиг. 1] Фиг. 1 показывает блок-схему последовательности операций способа формирования правдоподобного отображения течения времени суточного масштаба из изображения с использованием обученной генеративной нейронной сети и обученной объединяющей нейронной сети согласно одному варианту осуществления изобретения, раскрытого в данном документе.
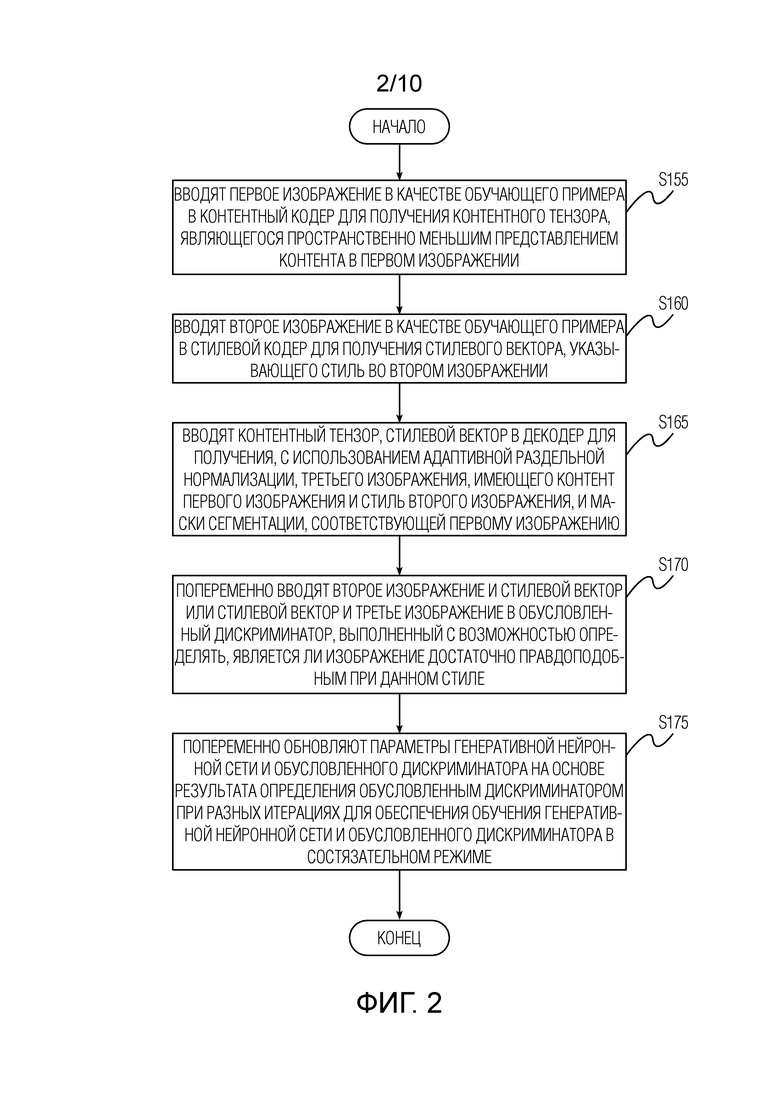
[Фиг. 2] Фиг. 2 показывает блок-схему последовательности операций способа обучения генеративной нейронной сети в режиме перестановки согласно одному варианту осуществления изобретения, раскрытого в данном документе.
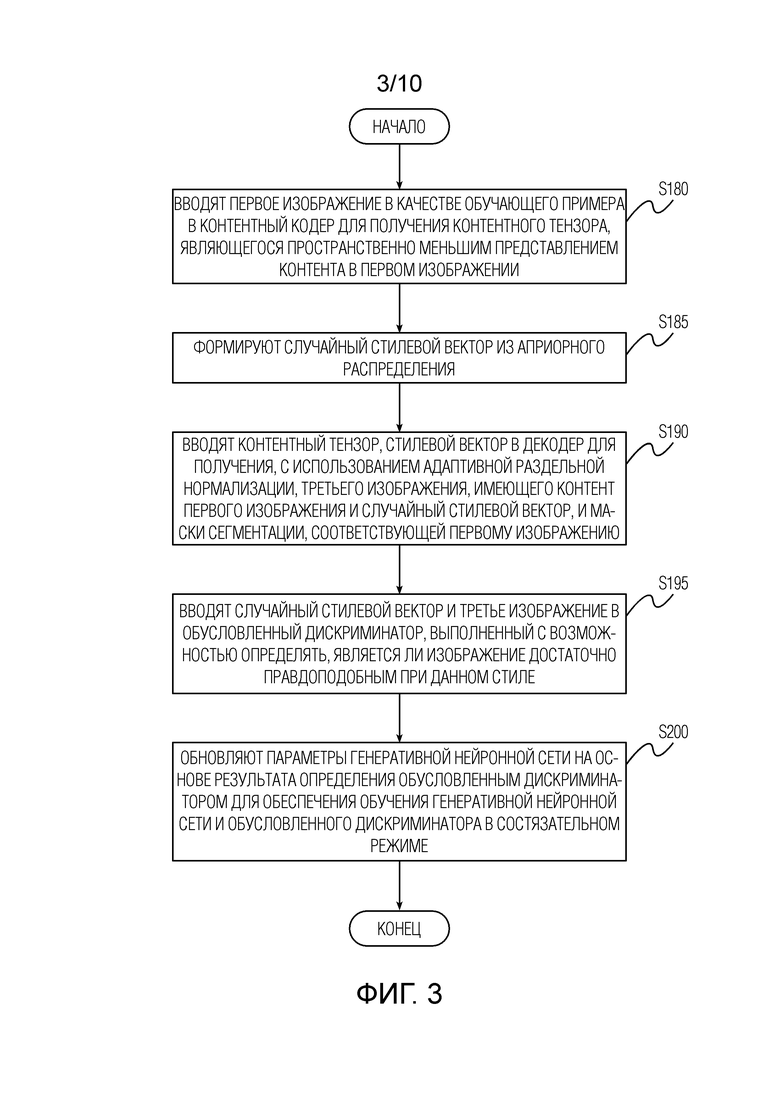
[Фиг. 3] Фиг. 3 показывает блок-схему последовательности операций способа обучения генеративной нейронной сети в случайном режиме согласно одному варианту осуществления изобретения, раскрытого в данном документе.
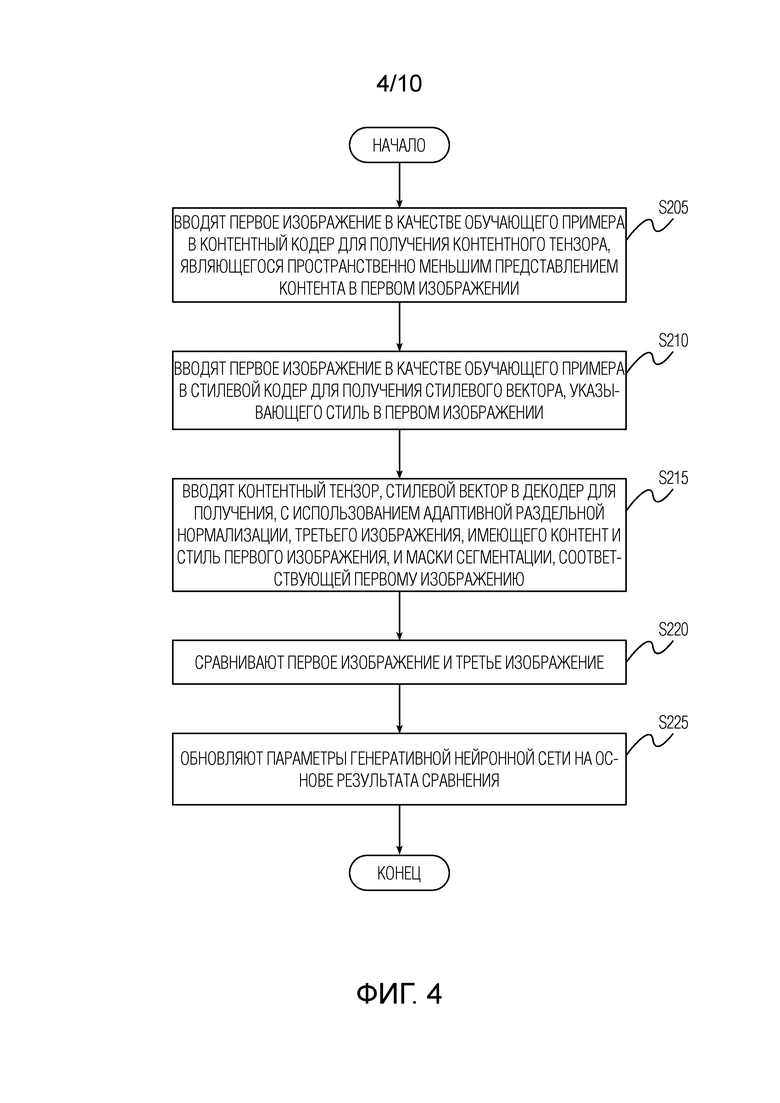
[Фиг. 4] Фиг. 4 показывает блок-схему последовательности операций способа обучения генеративной нейронной сети в режиме автоэнкодера согласно одному варианту осуществления изобретения, раскрытого в данном документе.
[Фиг. 5] Фиг. 5 показывает блок-схему последовательности операций способа обучения объединяющей нейронной сети согласно одному варианту осуществления изобретения, раскрытого в данном документе.
[Фиг. 6] Фиг. 6 показывает блок-схему вычислительного устройства, выполненного с возможностью выполнять способ согласно одному варианту осуществления изобретения, раскрытого в данном документе.
[Фиг. 7] Фиг. 7 показывает поток данных в возможной реализации генеративной нейронной сети согласно одному варианту осуществления изобретения, раскрытого в данном документе.
[Фиг. 8] Фиг. 8 показывает диаграмму адаптивной архитектуры U-Net согласно одному варианту осуществления изобретения, раскрытого в данном документе.
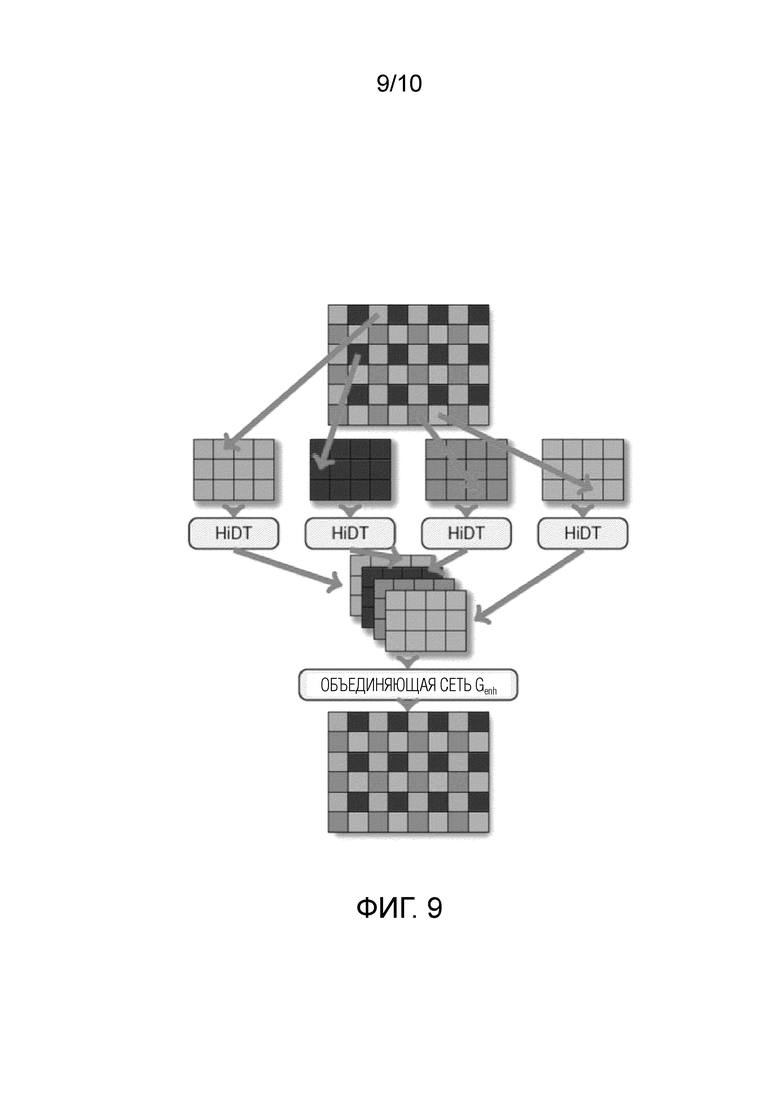
[Фиг. 9] Фиг. 9 показывает диаграмму схемы улучшения согласно одному варианту осуществления изобретения, раскрытого в данном документе.
[Фиг. 10] Фиг. 10 показывает иллюстративные изображения из правдоподобного отображения течения времени суточного масштаба, сформированные посредством способа согласно одному варианту осуществления изобретения, раскрытого в данном документе.
[0013] В нижеследующем описании, если не указано иное, одинаковые ссылочные позиции используются для одинаковых элементов, когда они показаны на разных чертежах, и их совпадающие описания будут опущены.
ПОДРОБНОЕ ОПИСАНИЕ ВАРИАНТОВ ОСУЩЕСТВЛЕНИЯ
[0014] Способы предшествующего уровня техники основаны на некоторой форме аннотаций доменов/атрибутов для обеспечения разложения изображения на «контент» и «стиль», которые могут независимо переставляться между изображениями. Такое разложение в настоящем изобретении полностью обеспечивается без учителя с использованием соответствующим образом выбранной архитектуры и обучающей процедуры, описанной ниже.
[0015] Фиг. 1 показывает блок-схему последовательности операций способа формирования правдоподобного отображения течения времени суточного масштаба из изображения с использованием обученной генеративной нейронной сети и обученной объединяющей нейронной сети согласно первому аспекту изобретения, раскрытого в данном документе. Способ содержит этап S105, на котором принимают изображение и параметр стиля, задающий один или несколько предопределенных стилей, соответственно, соответствующих одному или нескольким временам суток, подлежащих применению к изображению. В качестве альтернативы, одно или несколько стилевых изображений, имеющих один или несколько стилей, подлежащих применению к контентному изображению, могут быть приняты на этапе S105 вместо параметра стиля. Изображение может быть захвачено или загружено пользователем с использованием его/ее вычислительного устройства, такого как смартфон. Параметр стиля может быть задан пользователем с использованием его/ее вычислительного устройства. В качестве примера, пользователь может выбирать некоторый момент времени или временной интервал на временной шкале, и один или несколько предопределенных стилей могут быть, соответственно, определены на основе выбранного момента времени или временного интервала. Следует отметить, что если конкретный момент времени выбирается пользователем на временной шкале, способ обеспечит правдоподобное отображение течения времени суточного масштаба, содержащее только единственное изображение, сформированное для этого конкретного момента времени. Число предопределенных стилей не ограничено, но следует понимать, что для того, чтобы способ работал правильно для конкретного стиля, генеративная нейронная сеть должна быть предварительно обучена с использованием обучающего изображения, передающего такой стиль.
[0016] Затем, способ содержит этап S110, на котором разделяют изображение на n обрезанных изображений. n обрезанных изображений являются обрезанными изображениями, сильно перекрывающимися в предопределенном режиме, определяемом направлением смещения и шагом в k пикселов. Конкретные значения n и k не ограничены и могут быть любыми целыми. Затем, способ содержит этап S115, на котором применяют обученную генеративную нейронную сеть с параметром стиля к n обрезанным изображениям для получения n обрезанных изображений, рестилизованных согласно параметру стиля, и этап S120, на котором объединяют рестилизованные n обрезанных изображений с помощью обученной объединяющей нейронной сети для получения правдоподобного отображения течения времени суточного масштаба для изображения. Сформированное правдоподобное отображение течения времени суточного масштаба может содержать единственное изображение для конкретного стиля или последовательность изображений для выбранной последовательности стилей. Некоторые примеры изображений из сформированного правдоподобного отображения течения времени суточного масштаба показаны на фиг. 10.
[0017] Способ (не показан) согласно третьему аспекту настоящего раскрытия будет теперь описан относительно способа согласно первому аспекту в отношении их различий. Способ согласно третьему аспекту отличается от способа согласно первому аспекту тем, что он не использует объединяющую сеть и не использует этап разделения изображения на обрезанные изображения. Вместо этого, способ согласно третьему аспекту настоящего раскрытия содержит этапы, на которых уменьшают разрешение контентного изображения до низкого разрешения по меньшей стороне контентного изображения с сохранением соотношения сторон контентного изображения, осуществляют разложение каждого из рестилизованных контентных изображений на высокочастотные составляющие и низкочастотную составляющую, имеющую низкое разрешение по меньшей стороне с сохранением соотношения сторон, фильтруют низкочастотную составляющую с учетом контента соответствующего рестилизованного контентного изображения, и формируют одно или несколько изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе отфильтрованной низкочастотной составляющей и высокочастотных составляющих каждого из соответствующих рестилизованных контентных изображений. Пирамида Лапласа может быть использована в неограничивающем варианте осуществления для разложения. Направляемый фильтр (“guided filter”) может быть использован в неограничивающем варианте осуществления для фильтрации, и контент соответствующего рестилизованного контентного изображения используется в качестве направляющей для фильтрации. Низкое разрешение может быть равным 128 или может быть даже меньшим или большим 128. Обучение генеративной нейронной сети для способа согласно третьему аспекту отличается от обучения генеративной нейронной сети для способа согласно первому аспекту тем, что выходные данные генеративной нейронной сети не подаются в дискриминатор напрямую, а в него подается результат применения дифференцированного направляемого фильтра к исходному изображению и соответствующее синтезированное (сформированное) изображение.
[0018] Таким образом, генеративная нейронная сеть (также называемая моделью высокоразрешенного преобразования времени суток (high resolution daytime translation - HiDT) выполнена с возможностью получать независимые кодирования контента и стиля из входного изображения х с использованием его собственного архитектурного смещения в отсутствие явного контроля со стороны обучающего набора, и затем создавать изображения с новыми комбинациями контента и стилей. Таким образом, выходное изображение 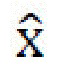 получает контент из х и изменяет свой стиль согласно выбранному параметру стиля. Таким образом, задача настоящей заявки определяется как перенос стиля из стилевого изображения x' в контентное изображение х, вместо использования общепринятых обусловленных GAN-архитектур с категориальными переменными в качестве условий.
получает контент из х и изменяет свой стиль согласно выбранному параметру стиля. Таким образом, задача настоящей заявки определяется как перенос стиля из стилевого изображения x' в контентное изображение х, вместо использования общепринятых обусловленных GAN-архитектур с категориальными переменными в качестве условий.
[0019] Генеративная нейронная сеть обучается в одном или в комбинации следующих режимов: режим перестановки, случайный режим, и режим автоэнкодера. В одном варианте осуществления, генеративная нейронная сеть обучается в каждом из указанных режимов. Ниже описаны стадии обучения для каждого из режимов и вводятся конкретные детали реализации, которые не следует толковать как ограничения.
[0020] Фиг. 2 показывает блок-схему последовательности операций способа обучения генеративной нейронной сети в режиме перестановки согласно одному варианту осуществления изобретения, раскрытого в данном документе. Генеративная нейронная сеть содержит по меньшей мере контентный кодер, стилевой кодер, и декодер. Обучение генеративной нейронной сети в режиме перестановки содержит следующие этапы, повторно выполняемые с некоторым количеством итераций: этап S115, на котором вводят первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении. Затем, обучение содержит этап S160, на котором вводят второе изображение в качестве обучающего примера в стилевой кодер для получения стилевого вектора, указывающего стиль во втором изображении. Первое изображение и второе изображение имеют первое разрешение, которое меньше разрешения правдоподобного отображения течения времени суточного масштаба, сформированного посредством способа, описанного выше со ссылкой на фиг. 1. Первое изображение (изображения) и второе изображение (изображения) могут быть случайно выбраны из обучающего набора данных изображений, например, ландшафтных изображений, в целях обучения генеративной нейронной сети.
[0021] Затем, обучение содержит этап S165, на котором вводят контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент первого изображения и стиль второго изображения, и маски сегментации, соответствующей первому изображению. Затем, обучение содержит этап S170, на котором попеременно вводят второе изображение и стилевой вектор или стилевой вектор и третье изображение в обусловленный дискриминатор, выполненный с возможностью определять, является ли изображение достаточно правдоподобным при данном стиле, и этап S175, на котором попеременно обновляют параметры генеративной нейронной сети и обусловленного дискриминатора на основе результата определения обусловленным дискриминатором при разных итерациях для обеспечения обучения генеративной нейронной сети и обусловленного дискриминатора в состязательном режиме. Маска сегментации дополнительно учитывается при обновлении параметров генеративной нейронной сети.
[0022] Фиг. 3 показывает блок-схему последовательности операций способа обучения генеративной нейронной сети в случайном режиме согласно одному варианту осуществления изобретения, раскрытого в данном документе. Обучение генеративной нейронной сети в случайном режиме содержит следующие этапы, повторно выполняемые с некоторым количеством итераций: этап S180, на котором вводят первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении. Затем, обучение содержит этап S185, на котором формируют случайный стилевой вектор из априорного распределения, и этап S190, на котором вводят контентный тензор, случайный стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент первого изображения, и стиль, определяемый случайным стилевым вектором, и маски сегментации, соответствующей первому изображению. Первое изображение и третье изображение имеют первое разрешение, которое меньше разрешения правдоподобного отображения течения времени суточного масштаба, сформированного посредством способа, описанного выше со ссылкой на фиг. 1. Затем, обучение содержит этап S195, на котором вводят случайный стилевой вектор и третье изображение в обусловленный дискриминатор, выполненный с возможностью определять, является ли изображение достаточно правдоподобным при данном стиле, и этап S200, на котором обновляют параметры генеративной нейронной сети на основе результата определения обусловленным дискриминатором для обеспечения обучения генеративной нейронной сети и обусловленного дискриминатора в состязательном режиме. Маска сегментации дополнительно учитывается при обновлении параметров генеративной нейронной сети.
[0023] Фиг. 4 показывает блок-схему последовательности операций способа обучения генеративной нейронной сети в режиме автоэнкодера согласно одному варианту осуществления изобретения, раскрытого в данном документе. Обучение генеративной нейронной сети в режиме автоэнкодера содержит следующие этапы, повторно выполняемые с некоторым количеством итераций: этап S205, на котором вводят первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении. Затем, обучение содержит этап S210, на котором вводят первое изображение в качестве обучающего примера в стилевой кодер для получения стилевого вектора, указывающего стиль в первом изображении, и этап S215, на котором вводят контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент и стиль первого изображения, и маски сегментации, соответствующей первому изображению. Первое изображение и третье изображение имеют первое разрешение, которое меньше разрешения правдоподобного отображения течения времени суточного масштаба, сформированного посредством способа, описанного выше со ссылкой на фиг. 1. Затем, обучение содержит этап S220, на котором сравнивают первое изображение и третье изображение, и этап S225, на котором обновляют параметры генеративной нейронной сети на основе результата сравнения. В неограничивающем варианте осуществления, сравнение может быть попиксельным сравнением. Маска сегментации дополнительно учитывается при обновлении генеративной нейронной сети.
[0024] Таким образом, во время обучения, декодер генеративной нейронной сети предсказывает не только входное изображение х, но и соответствующую маску сегментации, m (создаваемую внешней предварительно обученной сетью). Изобретение настоящего раскрытия не направлено на обеспечение сегментации, превосходящей предшествующий уровень техники, в качестве побочного продукта, но сегментация в генеративной нейронной сети помогает управлять переносом стилей и помогает лучше сохранять семантическую компоновку. Иначе, ничто не препятствует перерисовке генеративной нейронной сетью, например, травы в воду или наоборот. Следует отметить, что маски сегментации не задаются в виде входных данных для сетей, и, таким образом, они не нужны на стадии вывода (при использовании).
[0025] На протяжении всего описания изобретения, пространство входных изображений обозначается 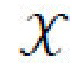 , их маски сегментации обозначаются
, их маски сегментации обозначаются 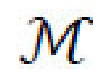 , и отдельные изображения с масками сегментации обозначаются х, m
, и отдельные изображения с масками сегментации обозначаются х, m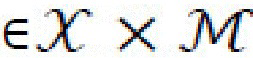 ; пространством скрытых контентных кодов с является с
; пространством скрытых контентных кодов с является с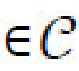 , и пространством скрытых стилевых кодов s является s
, и пространством скрытых стилевых кодов s является s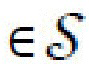 (
(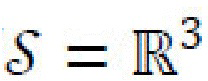 , в то время как
, в то время как 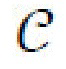 имеет более сложную структуру). Для получения с и s из изображения х, генеративная нейронная сеть использует два кодера:
имеет более сложную структуру). Для получения с и s из изображения х, генеративная нейронная сеть использует два кодера: 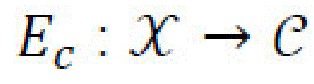 получает представление контента, с, входного изображения х, и
получает представление контента, с, входного изображения х, и 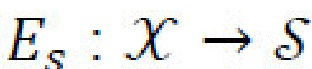 получает представление стиля, s, входного изображения х. Если дан скрытый контентный код с и скрытый стилевой код s, то декодер (генератор)
получает представление стиля, s, входного изображения х. Если дан скрытый контентный код с и скрытый стилевой код s, то декодер (генератор) 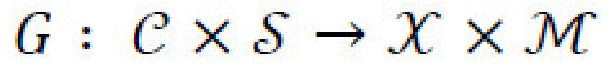 генеративной нейронной сети формирует новое изображение
генеративной нейронной сети формирует новое изображение  и соответствующую маску сегментации,
и соответствующую маску сегментации, 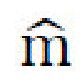 . Таким образом, генеративная нейронная сеть выполнена с возможностью объединять контент из х и стиль из x' в виде
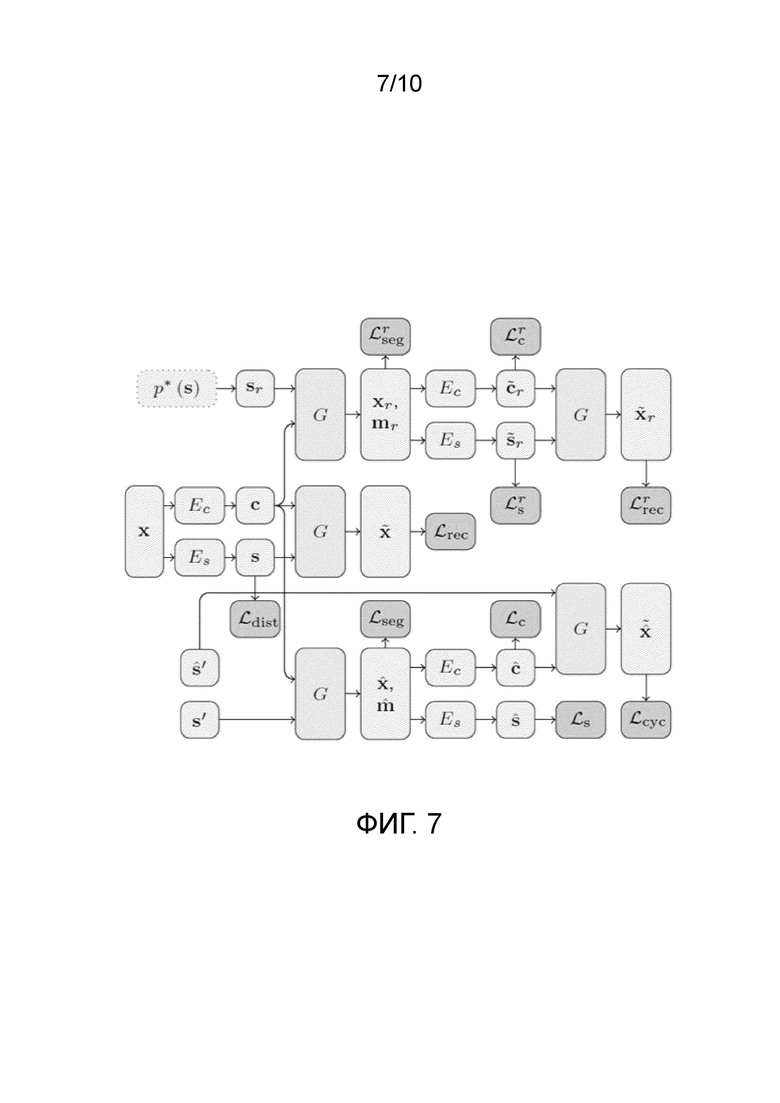
. Таким образом, генеративная нейронная сеть выполнена с возможностью объединять контент из х и стиль из x' в виде 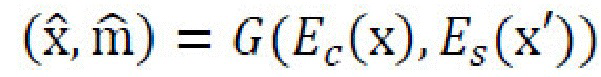 . Генеративная нейронная сеть, таким образом, объединяет по меньшей мере стилевой кодер Еs, контентный кодер Ec, и декодер G; входными рабочими данными являются (i) два входных изображения х и x', или (ii) входное изображение х и параметр стиля, задающий один или несколько предопределенных стилей, соответственно, соответствующих одному или нескольким временам суток, которые подлежат применению к изображению. Параметр стиля может быть получен из изображения x' или может быть прямо введен пользователем, например, как описано выше со ссылкой на «временную шкалу». Фиг. 7 показывает поток данных в возможной реализации генеративной нейронной сети согласно одному варианту осуществления изобретения, раскрытого в данном документе. Фиг. 7 показывает половину (симметричной) архитектуры.
. Генеративная нейронная сеть, таким образом, объединяет по меньшей мере стилевой кодер Еs, контентный кодер Ec, и декодер G; входными рабочими данными являются (i) два входных изображения х и x', или (ii) входное изображение х и параметр стиля, задающий один или несколько предопределенных стилей, соответственно, соответствующих одному или нескольким временам суток, которые подлежат применению к изображению. Параметр стиля может быть получен из изображения x' или может быть прямо введен пользователем, например, как описано выше со ссылкой на «временную шкалу». Фиг. 7 показывает поток данных в возможной реализации генеративной нейронной сети согласно одному варианту осуществления изобретения, раскрытого в данном документе. Фиг. 7 показывает половину (симметричной) архитектуры. 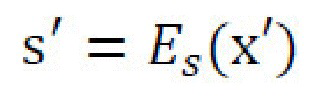 является стилем, полученным из другого изображения x', и
является стилем, полученным из другого изображения x', и 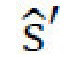 получают подобно s' перестановкой x и x'. Эта иллюстрация показывает элементы данных; функции потерь; функции (подсетей). Функции с идентичными метками имеют совместно используемые веса.
получают подобно s' перестановкой x и x'. Эта иллюстрация показывает элементы данных; функции потерь; функции (подсетей). Функции с идентичными метками имеют совместно используемые веса.
Функции потерь, применимые в генеративной нейронной сети
[0026] Состязательные потери. Генеративная нейронная сеть должна формировать правдоподобное и реалистичное изображение (изображения) отображения течения времени, определяемое в обычном состязательном режиме. Для учета стилей используются два дискриминатора, безусловный дискриминатор 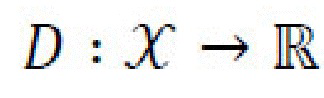 и обусловленный дискриминатор
и обусловленный дискриминатор 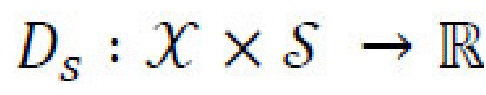 . Оба дискриминатора пытаются различить реальные и преобразованные изображения с использованием, например, GAN-подхода наименьших квадратов. «Фиктивное» изображение, создаваемое из реального контентного и стилевого изображений x, x'
. Оба дискриминатора пытаются различить реальные и преобразованные изображения с использованием, например, GAN-подхода наименьших квадратов. «Фиктивное» изображение, создаваемое из реального контентного и стилевого изображений x, x'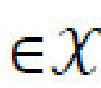 , s'=Es(x'), определяется в виде
, s'=Es(x'), определяется в виде 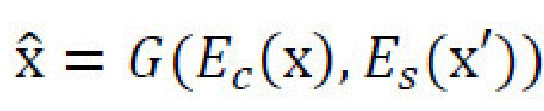 . Та же самая схема используется для изображений, создаваемых со случайным стилем sr~p*(s). Может быть использована схема согласования проекций, и стили могут быть отсоединены от вычислительного графа при подаче их в Ds во время этапа обновления параметров декодера. Реальные изображения используют извлекаемые из них стили, в то время как сгенерированные изображения связывают со стилями, в которые выполняют преобразование. Фиг. 7 не показывает состязательные потери.
. Та же самая схема используется для изображений, создаваемых со случайным стилем sr~p*(s). Может быть использована схема согласования проекций, и стили могут быть отсоединены от вычислительного графа при подаче их в Ds во время этапа обновления параметров декодера. Реальные изображения используют извлекаемые из них стили, в то время как сгенерированные изображения связывают со стилями, в которые выполняют преобразование. Фиг. 7 не показывает состязательные потери.
[0027] Потери восстановления изображений. Потери восстановления изображений, 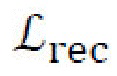 , определяются в виде L1-нормы разницы между исходным и восстановленным изображениями. Потери восстановления изображений применяются по меньшей мере три раза в архитектуре генеративной нейронной сети: для восстановления
, определяются в виде L1-нормы разницы между исходным и восстановленным изображениями. Потери восстановления изображений применяются по меньшей мере три раза в архитектуре генеративной нейронной сети: для восстановления 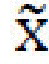 контентного изображения х,
контентного изображения х, 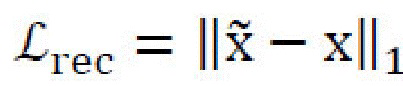 , для восстановления
, для восстановления 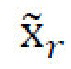 случайного стилевого изображения xr,
случайного стилевого изображения xr, 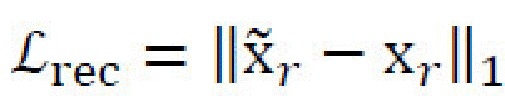 , и для восстановления
, и для восстановления  изображения х из контента стилизованного изображения
изображения х из контента стилизованного изображения  и стиля стилизованного изображения
и стиля стилизованного изображения  (перекрестная циклическая совместимость):
(перекрестная циклическая совместимость): 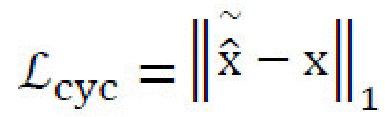 , где
, где 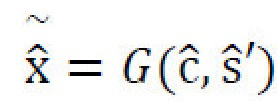 (см. фиг. 7).
(см. фиг. 7).
[0028] Потери сегментации. Потери сегментации, 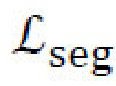 , используются вместе с потерями восстановления изображений и определяются в виде перекрестной энтропии
, используются вместе с потерями восстановления изображений и определяются в виде перекрестной энтропии 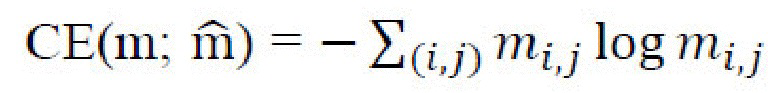 между исходной, m, и восстановленной,
между исходной, m, и восстановленной,  , масками сегментации. Потери сегментации применяются по меньшей мере дважды в архитектуре генеративной нейронной сети: к маске сегментации, , преобразованного изображения,
, масками сегментации. Потери сегментации применяются по меньшей мере дважды в архитектуре генеративной нейронной сети: к маске сегментации, , преобразованного изображения,  , и к маске mr случайного стилевого изображения,
, и к маске mr случайного стилевого изображения, 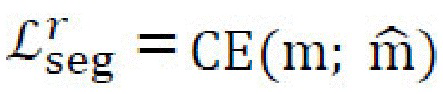 .
.
[0029] Потери скрытого восстановления. Еще два вида потерь восстановления, 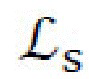 и
и 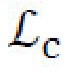 , относятся к стилевому и контентному кодам; упомянутые потери восстановления применяются к разнице между исходным и восстановленным кодами и используются по меньшей мере дважды в архитектуре генеративной нейронной сети. Во-первых, для стиля
, относятся к стилевому и контентному кодам; упомянутые потери восстановления применяются к разнице между исходным и восстановленным кодами и используются по меньшей мере дважды в архитектуре генеративной нейронной сети. Во-первых, для стиля 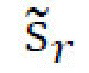 и контента
и контента 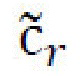 случайного стилевого изображения
случайного стилевого изображения 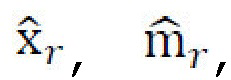 причем стиль должен соответствовать sr, а контент должен соответствовать с:
причем стиль должен соответствовать sr, а контент должен соответствовать с: 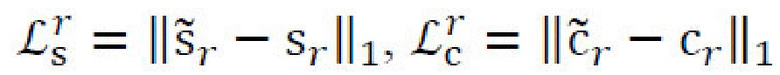 . Во-вторых, для стиля
. Во-вторых, для стиля 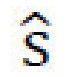 и контента
и контента 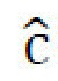 стилизованного изображения
стилизованного изображения 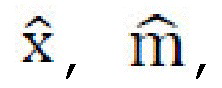 причем стиль должен соответствовать s', а контент должен соответствовать с; потери L1, но без ограничения, могут быть применены к контенту,
причем стиль должен соответствовать s', а контент должен соответствовать с; потери L1, но без ограничения, могут быть применены к контенту, 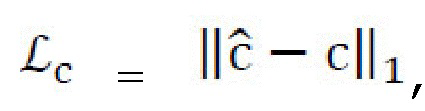 и более робастная функция потерь может быть применена к стилям для предотвращения уменьшения их до нуля:
и более робастная функция потерь может быть применена к стилям для предотвращения уменьшения их до нуля: 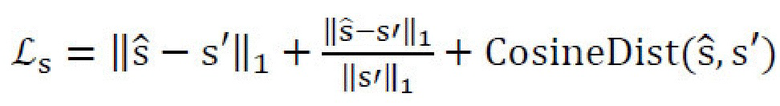 .
.
[0030] Потери распределения стилей. Для усиления структуры пространства полученных стилевых кодов, потери распределения стилей могут быть применены к пулу стилей, собранных из некоторого количества предыдущих итераций обучения. А именно, для пула данного размера Т стили {s1…sT} могут быть собраны из прошлых минигрупп с применением операции останавливающего градиента, полученные стили s и s' (которые являются частью текущего вычислительного графа) могут быть добавлены к этому пулу, и вектор средних значений, 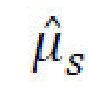 , и ковариационная матрица
, и ковариационная матрица  могут быть вычислены с использованием обновленного пула. Тогда, потери распределения стилей согласовывают эмпирические моменты результирующего распределения с теоретическими моментами декодера случайных стилевых векторов,
могут быть вычислены с использованием обновленного пула. Тогда, потери распределения стилей согласовывают эмпирические моменты результирующего распределения с теоретическими моментами декодера случайных стилевых векторов, 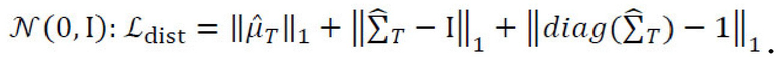 Поскольку пространство
Поскольку пространство 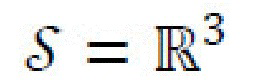 является маломерным, и целью является стандартное нормальное распределение
является маломерным, и целью является стандартное нормальное распределение 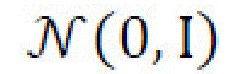 , этот упрощенный подход является достаточным для усиления структуры в пространстве скрытых кодов. После вычисления значения потерь, наиболее ранние стили удаляют из пула для сохранения его размера на уровне Т.
, этот упрощенный подход является достаточным для усиления структуры в пространстве скрытых кодов. После вычисления значения потерь, наиболее ранние стили удаляют из пула для сохранения его размера на уровне Т.
[0031] Общая функция потерь. Таким образом, общая генеративная нейронная сеть совместно обучает стилевой кодер, контентный кодер, декодер, и дискриминатор со следующей целью:
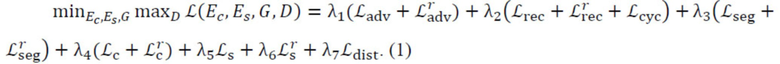
Гиперпараметры л1,…, л7 определяют относительную важность компонентов в общей функции потерь; они были определены эмпирически.
[0032] Эксперименты показали, что проекционный дискриминатор значительно улучшает результаты, в то время как удаление функции потерь сегментации иногда приводит к нежелательным «галлюцинациям», порождаемым декодером. Однако эта модель все же хорошо обучается без функции потерь сегментации. Эксперименты также показали, что функция потерь распределения стилей не является обязательной. Предполагается, что это является следствием использования как проекционного дискриминатора, так и случайных стилей во время обучения.
Адаптивная архитектура U-Net
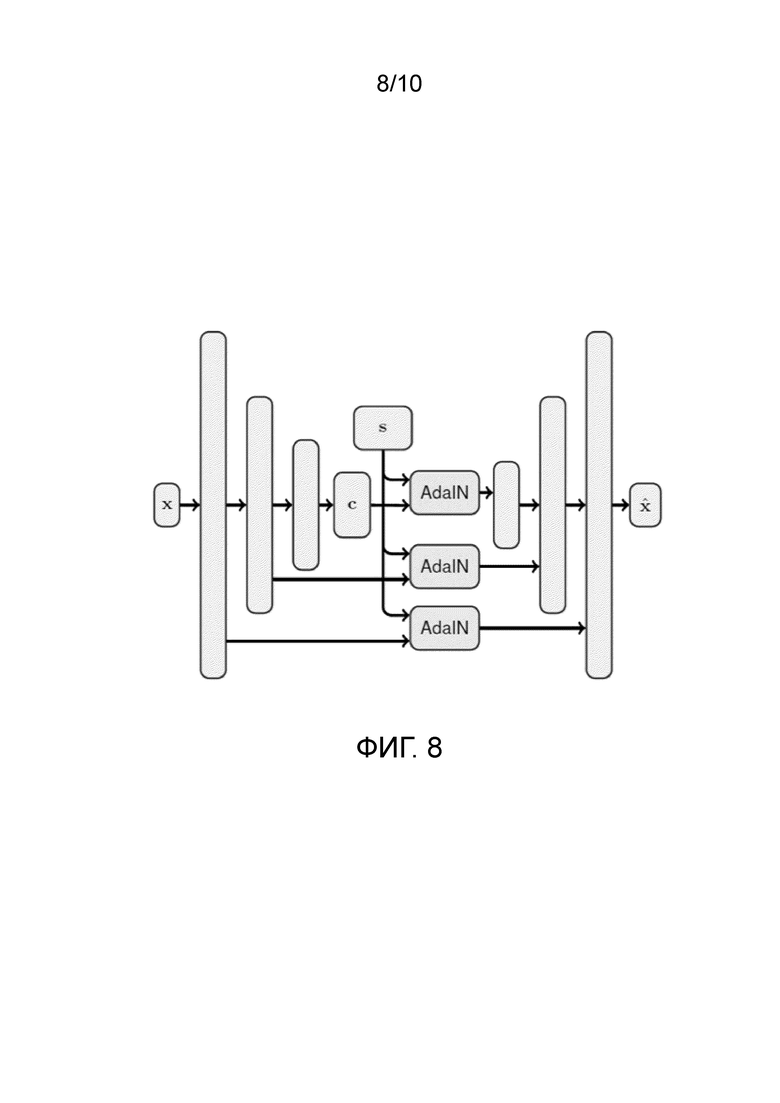
[0033] Для создания правдоподобного ландшафтного изображения времени суток, модель должна сохранять детали из исходного изображения. Таким образом, генеративная нейронная сеть может включать в себя одну или несколько плотных обходных связей (dense skip connections), выполненных с возможностью передавать высокочастотные признаки, не передаваемые контентным тензором первого изображения, декодеру. Для реализации этого, вдохновленная FUNIT архитектура кодер-декодер может быть улучшена плотными обходными связями между понижающей-дискретизацию частью Ec и повышающей-дискретизацию частью G. К сожалению, регулярные обходные связи могли бы также сохранять стиль исходных входных данных. Таким образом, в одном варианте осуществления вводится дополнительный сверточный блок с AdaIN, который применяется к обходным связям. Фиг. 8 показывает диаграмму адаптивной архитектуры U-Net: сеть кодер-декодер с плотными обходными связями и контентно-стилевое разложение (c, s) согласно одному варианту осуществления изобретения, раскрытого в данном документе.
[0034] Общая архитектура имеет следующую структуру: контентный кодер Ec отображает исходное изображение в трехмерный (3D) тензор c с использованием нескольких сверточных понижающих-дискретизацию уровней и остаточных блоков. В неограничивающем примере, стилевой кодер Es является полностью сверточной сетью, которая заканчивается глобальным объединением ресурсов и сжатием 1×1 сверточного уровня. Декодер G обрабатывает c несколькими остаточными блоками с модулями AdaIN внутри и затем повышает дискретизацию обработанного c.
Улучшающая постобработка с использованием объединяющей нейронной сети
[0035] Обучение сети, которая может эффективно работать с изображениями высокого разрешения, является сложным вследствие аппаратных ограничений, как по памяти, так и по времени вычислений. Применение полностью сверточной нейронной сети непосредственно к изображению с более высоким разрешением или использование направляемого фильтра являются применимыми технологиями в отношении изображений высокого разрешения. Хотя эти технологии в большинстве случаев демонстрируют хорошие результаты, они имеют некоторые ограничения. Полностью сверточное применение может приводить к искажению сцены вследствие ограниченного поля восприятия, которое имеет место при заходах солнца, когда должны быть изображены множественные положения солнца, или при отражениях от воды, когда может быть искажена граница между небом и поверхностью воды. Направляемый фильтр, с другой стороны, прекрасно работает с водой или солнцем, но отказывает, если мелкие детали, такие как веточки, были изменены посредством процедуры переноса стиля, или на горизонте или на любой другой высококонтрастной границе, если она подверглась сильному воздействию, что приводит к эффекту «ореола». Такие случаи могут показаться крайним случаем, который не стоит рассматривать, но они являются критическими в задаче преобразования времени суток, что приводит нас к необходимости обеспечения сохраняющего-семантику способа повышения разрешения. Также, прямое применение способов сверхвысокого разрешения и предварительно обученных моделей является невозможным вследствие значительно большего расхождения между бикубическим понижающим-дискретизацию ядром и артефактами, производимыми сетью от изображения к изображению.
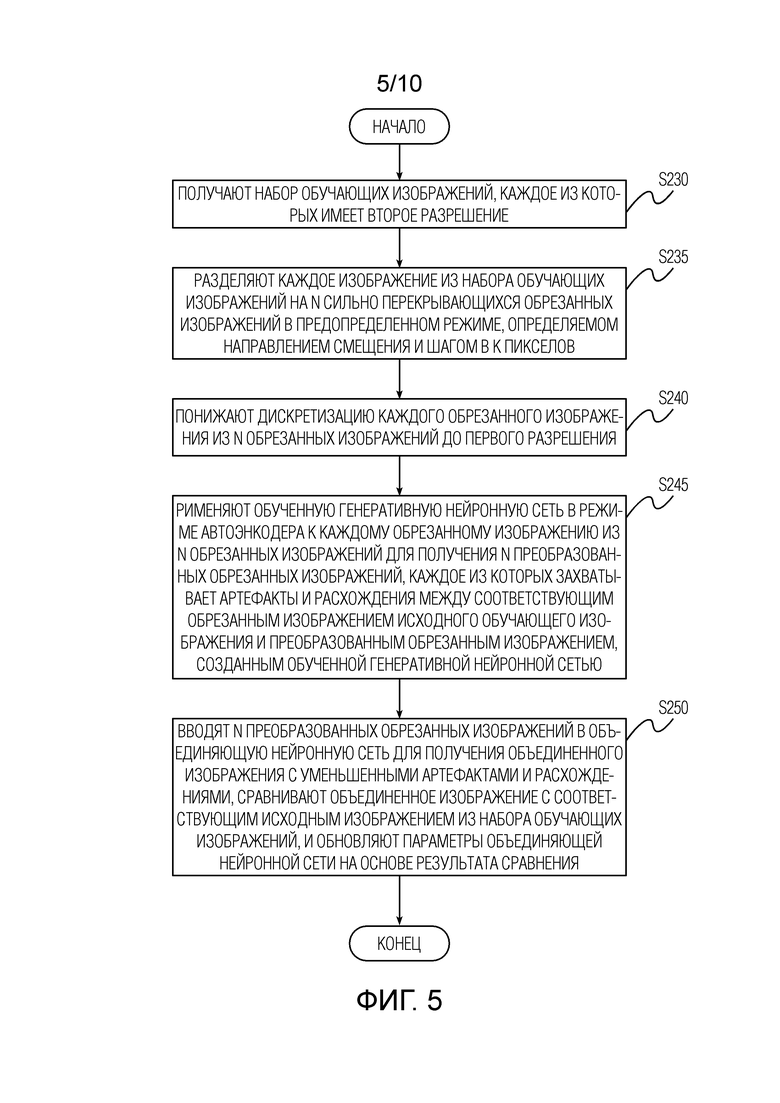
[0036] Согласно одному варианту осуществления изобретения, раскрытого в данном документе, предлагается использовать отдельную объединяющую нейронную сеть (также называемую улучшающей сетью) Genh для повышения разрешения преобразуемого изображения и одновременного удаления артефактов, которые являются «типичными» для обученного и замороженного декодера G. В одном варианте осуществления изобретения, раскрытого в данном документе, способ обучения объединяющей нейронной сети содержит следующие этапы, повторно выполняемые с некоторым количеством итераций: этап S230, на котором получают набор обучающих изображений, каждое из которых имеет второе разрешение, большее первого разрешения. Затем, способ обучения содержит этап S235, на котором разделяют каждое изображение из набора обучающих изображений на n сильно перекрывающихся обрезанных изображений в предопределенном режиме, определяемом направлением смещения и шагом в k пикселов. Значения n и k в данном документе не ограничены. Направление смещения указывает направление смещения одного изображения относительно другого сильно перекрывающегося обрезанного изображения, а шаг указывает величину смещения между обрезанными изображениями (т.е. на неперекрытую область между обрезанными изображениями). Затем, способ обучения содержит этап S240, на котором понижают дискретизацию каждого обрезанного изображения из n обрезанных изображений до первого разрешения, и этап S245, на котором применяют обученную генеративную нейронную сеть в режиме автоэнкодера к каждому обрезанному изображению из n обрезанных изображений для получения n преобразованных обрезанных изображений, каждое из которых захватывает артефакты и расхождения между соответствующим обрезанным изображением исходного обучающего изображения и преобразованным обрезанным изображением, созданным обученной генеративной нейронной сетью. Наконец, способ обучения содержит этап S250, на котором вводят n преобразованных обрезанных изображений в объединяющую нейронную сеть для получения объединенного изображения с уменьшенными артефактами и расхождениями, сравнивают объединенное изображение с соответствующим исходным изображением из набора обучающих изображений, и обновляют параметры объединяющей нейронной сети на основе результата сравнения.
[0037] В отличие от предшествующего уровня техники, несколько RGB-изображений используются в качестве входных данных вместо карт признаков. Раскрытый способ основан на использовании декодера в режиме «автоэнкодера» для получения спаренного набора данных, обучения объединяющей нейронной сети в режиме с учителем и захвата самых общих артефактов и расхождений между реальным изображением и изображением, созданным декодером. Для дополнительного улучшения обобщения по отношению к преобразуемым изображениям, декодер может быть использован в режиме «случайных стилей» для получения дополнительного неконтролируемого набора, к которому не применяются контролируемые потери (перцепционные потери и потери согласования признаков). Для краткости, ниже описаны функции потерь только для режима «автоэнкодера».
[0038] В конкретной реализации, изображение xhi высокого разрешения (1024×1024 в экспериментах) покрывают сильно перекрывающимися кадрами 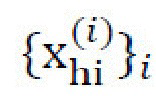 равной ширины и высоты с шагом 1 пиксел; каждый кадр только на несколько пикселов меньше изображения xhi. Разрешение кадров уменьшают билинейным ядром до разрешения, пригодного для декодера генеративной нейронной сети (в неограничивающем примере, 256×256 с коэффициентом масштабирования, равным 4), что обеспечивает набор обрезанных изображений с пониженной дискретизацией,
равной ширины и высоты с шагом 1 пиксел; каждый кадр только на несколько пикселов меньше изображения xhi. Разрешение кадров уменьшают билинейным ядром до разрешения, пригодного для декодера генеративной нейронной сети (в неограничивающем примере, 256×256 с коэффициентом масштабирования, равным 4), что обеспечивает набор обрезанных изображений с пониженной дискретизацией, 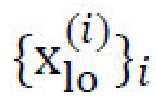 . Затем, генеративную нейронную сеть применяют к набору обрезанных изображений с пониженной дискретизацией, , что обеспечивает изображения
. Затем, генеративную нейронную сеть применяют к набору обрезанных изображений с пониженной дискретизацией, , что обеспечивает изображения 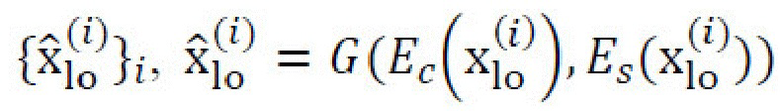 низкого разрешения. Эти кадры помещают в единственный тензор в фиксированном порядке и подают в объединяющую нейронную сеть Genh, которая выполнена с возможностью восстанавливать исходное изображение xhi с результатом
низкого разрешения. Эти кадры помещают в единственный тензор в фиксированном порядке и подают в объединяющую нейронную сеть Genh, которая выполнена с возможностью восстанавливать исходное изображение xhi с результатом 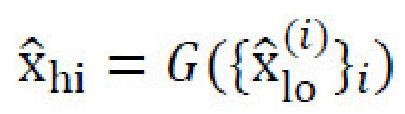 . Иллюстративное представление процесса показано на фиг. 9.
. Иллюстративное представление процесса показано на фиг. 9.
[0039] Для Genh, режим обучения pix2pixHD может быть использован с функцией перцепционных потерь, функцией потерь согласования признаков, и функцией состязательных потерь. Исходные изображения высокого разрешения используются в качестве контрольных. Genh может использовать одну или несколько следующих функций потерь во время обучения: функцию перцепционных потерь восстановления между 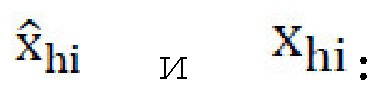
 ; функцию потерь согласования признаков между
; функцию потерь согласования признаков между 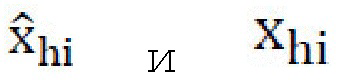 с использованием каждой карты признаков каждого дискриминатора (имеется три дискриминатора в многомасштабной архитектуре):
с использованием каждой карты признаков каждого дискриминатора (имеется три дискриминатора в многомасштабной архитектуре): 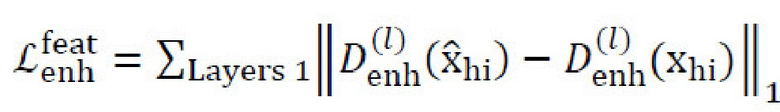 ; (3) функцию состязательных потерь на основе LSGAN:
; (3) функцию состязательных потерь на основе LSGAN: 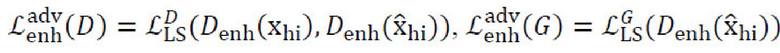 .
.
Детали реализации
[0040] Детали обучения. Конкретные детали реализации, приведенные ниже, следует рассматривать только в качестве неограничивающих примеров. В иллюстративной реализации, контентный кодер может содержать два понижающих-дискретизацию и четыре остаточных блока; после каждого понижения дискретизации, только 5 каналов могут быть использованы для обходных связей. Стилевой кодер содержит четыре понижающих-дискретизацию блока, и тогда результат с пониженной дискретизацией может быть усреднен в отношении пространственной информации в трехмерный вектор. Декодер может содержать пять остаточных блоков с AdaIN внутри и два повышающих-дискретизацию блока. Параметры AdaIN могут быть вычислены на основании стилевого вектора посредством трехуровневой сети с прямой связью. Оба дискриминатора являются многомасштабными и имеют три понижающих-дискретизацию уровня. Генеративная нейронная сеть может обучаться на протяжении некоторого числа итераций (например, около 450 тысяч итераций) с размером группы, равным 4. Для обучения, изображения могут быть подвергнуты понижению разрешения до разрешения 256×256. В конкретном примере, веса потерь эмпирически определили в виде л1=5, л2=2, л3=3, л4=1, л5=0,1, л6=4, л7=1. Оптимизатор Adam может быть использован с в1=0,5, в2=0,999, и начальной скоростью обучения, составляющей 0,0001, как для генераторов, так и для дискриминаторов, что вдвое уменьшает скорость обучения каждые 200000 итераций.
[0041] Классификатор наборов данных и времени суток. Набор данных из 20000 ландшафтных фотографий был собран из Интернета. Малая часть этих изображений была вручную помечена в соответствии с четырьмя классами (ночь, заход/восход солнца, утро/вечер, полдень, без ограничения) с использованием платформы краудсорсинга. Большее или меньшее число классов может быть использовано в других вариантах осуществления. Классификатор на основе ResNet может быть обучен на этих метках и применен к остальной части набора данных. Предсказанные метки могут быть использованы двумя способами: (1) для уравновешивания обучающего набора для моделей преобразования изображений относительно классов времени суток; (2) для обеспечения доменных меток для базовых моделей. Маски сегментации были созданы внешней моделью и приведены к 9 классам: небо, трава, земля, горы, вода, строения, деревья, дороги, и люди. Большее или меньшее число классов может быть использовано в других вариантах осуществления. Важно, что одним применением раскрытой генеративной нейронной сети является формирование отображения течения времени суток с использованием конкретного видеоизображения в качестве правила.
Другие варианты осуществления
[0042] Фиг. 6 показывает блок-схему вычислительного устройства, выполненного с возможностью выполнять способ согласно одному варианту осуществления изобретения, раскрытого в данном документе. Вычислительное устройство 300 (такое как, например, смартфон, планшетный компьютер, ноутбук, интеллектуальные часы и т.д.) содержит процессор 300.1 и память 300.2, хранящую исполняемые компьютером инструкции, которые, при исполнении процессором, побуждают процессор к выполнению способа согласно первому аспекту. Процессор 300.1 и память 300.2 связаны с возможностью взаимодействия друг с другом. В неограничивающих вариантах осуществления, процессор 300.1 может быть реализован в виде вычислительного средства, включающего в себя, но не ограниченного этим, процессор общего назначения, специализированную интегральную схему (application-specific integrated circuit - ASIC), программируемую пользователем матрицу программируемых логических вентилей (gate array - FPGA), или систему-на-кристалле (system-on-chip - SoC). Такие вычислительные устройства или другие пользовательские устройства могут также содержать память (RAM, ROM и т.д.), (сенсорный) экран, средство I/O, камеру, средство связи и т.д.
[0043] Предлагаемый способ может быть также реализован на компьютерно-читаемом носителе данных, на котором хранятся исполняемые компьютером инструкции, которые, при выполнении обрабатывающим или вычислительным средством некоторого устройства, побуждают это устройство выполнять любой этап (этапы) предлагаемого способа формирования правдоподобного представления течения времени суточного масштаба в высоком разрешении. Данные любых типов могут быть обработаны системами искусственного интеллекта, обученными с использованием описанных выше подходов. Фаза обучения может быть реализована в офлайновом режиме.
[0044] В настоящей заявке раскрыта новая модель преобразования изображений, которая не основана на доменных метках ни во время обучения, ни во время вывода. Новая схема улучшения позволяет увеличить разрешение выходных данных преобразования. Предлагаемая модель выполнена с возможностью обучаться преобразованию времени суток для ландшафтных изображений высокого разрешения. Предлагаемая модель может быть легко обобщена для других областей, например, для формирования изображений отображения течения времени на изображениях с цветами, домашними животными, людьми и т.д. Специалистам в данной области техники будет ясно, что для других областей генеративная нейронная сеть должна быть обучена на соответствующих обучающих наборах данных, например, на обучающем наборе данных изображений цветов, на обучающем наборе данных изображений домашних животных, и на обучающем наборе данных изображений людей.
[0045] Раскрытая модель выполнена с возможностью формировать изображения с использованием стилей, получаемых из изображений, а также отбираемых из априорного распределения. Привлекательным прямым применением модели является формирование отображений течения времени из единственного изображения (задача, в настоящее время решаемая, главным образом, спаренными наборами данных).
[0046] Следует ясно понимать, что не всеми техническими эффектами, упомянутыми в данном документе, можно воспользоваться во всех и каждом варианте осуществления настоящей технологии. Например, варианты осуществления настоящей технологии могут быть реализованы без использования пользователем некоторых из этих технических эффектов, в то время как другие варианты осуществления могут быть реализованы с использованием пользователем других технических эффектов или без использования каких-либо технических эффектов.
[0047] Модификации и улучшения описанных выше реализаций настоящей технологии могут быть поняты специалистами в данной области техники. Предполагается, что приведенное выше описание является иллюстративным, а не ограничивающим. Таким образом, предполагается, что объем настоящей технологии ограничен исключительно объемом прилагаемой формулы изобретения.
[0048] В то время как описанные выше реализации были описаны и показаны со ссылкой на конкретные этапы, выполняемые в конкретном порядке, следует понимать, что эти этапы могут быть объединены, подразделены, или переупорядочены, не выходя за рамки идей настоящей технологии. Соответственно, порядок и группирование этапов не являются ограничениями настоящей технологии.
| название | год | авторы | номер документа |
|---|---|---|---|
| ОБУЧЕНИЕ GAN (ГЕНЕРАТИВНО-СОСТЯЗАТЕЛЬНЫХ СЕТЕЙ) СОЗДАНИЮ ПОПИКСЕЛЬНОЙ АННОТАЦИИ | 2019 |
|
RU2735148C1 |
| Способ локального генерирования и представления потока обоев и вычислительное устройство, реализующее его | 2020 |
|
RU2768551C1 |
| СПОСОБ СОЗДАНИЯ АНИМИРУЕМОГО АВАТАРА ЧЕЛОВЕКА В ПОЛНЫЙ РОСТ ИЗ ОДНОГО ИЗОБРАЖЕНИЯ ЧЕЛОВЕКА, ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2023 |
|
RU2813485C1 |
| СПОСОБ ФОРМИРОВАНИЯ СИСТЕМЫ УПРАВЛЕНИЯ МОЗГ-КОМПЬЮТЕР | 2019 |
|
RU2704497C1 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |
| Совместная неконтролируемая сегментация объектов и подрисовка | 2019 |
|
RU2710659C1 |
| ГЕНЕРАТОРЫ ИЗОБРАЖЕНИЙ С УСЛОВНО НЕЗАВИСИМЫМ СИНТЕЗОМ ПИКСЕЛЕЙ | 2021 |
|
RU2770132C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| СПОСОБ ВИЗУАЛИЗАЦИИ 3D ПОРТРЕТА ЧЕЛОВЕКА С ИЗМЕНЕННЫМ ОСВЕЩЕНИЕМ И ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ НЕГО | 2021 |
|
RU2757563C1 |

Изобретение относится к способам и устройствам для формирования изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе контентного изображения. Технический результат заключается в повышении эффективности формирования изображений. В способе принимают контентное изображение и предопределенные стили, подлежащие применению к контентному изображению, или стилевые изображения, имеющие стили, подлежащие применению к контентному изображению; разделяют контентное изображение на n обрезанных изображений, при этом n обрезанных изображений являются обрезанными изображениями, сильно перекрывающимися в предопределенном режиме, определяемом направлением смещения и шагом в k пикселов; применяют обученную генеративную нейронную сеть с каждым из стилей к n обрезанным изображениям для получения n обрезанных изображений, рестилизованных согласно каждому из стилей; и объединяют рестилизованные n обрезанных изображений для каждого из стилей с помощью обученной объединяющей нейронной сети для получения изображений последовательности правдоподобного отображения течения времени суточного масштаба для контентного изображения. 2 н. и 16 з.п. ф-лы, 10 ил.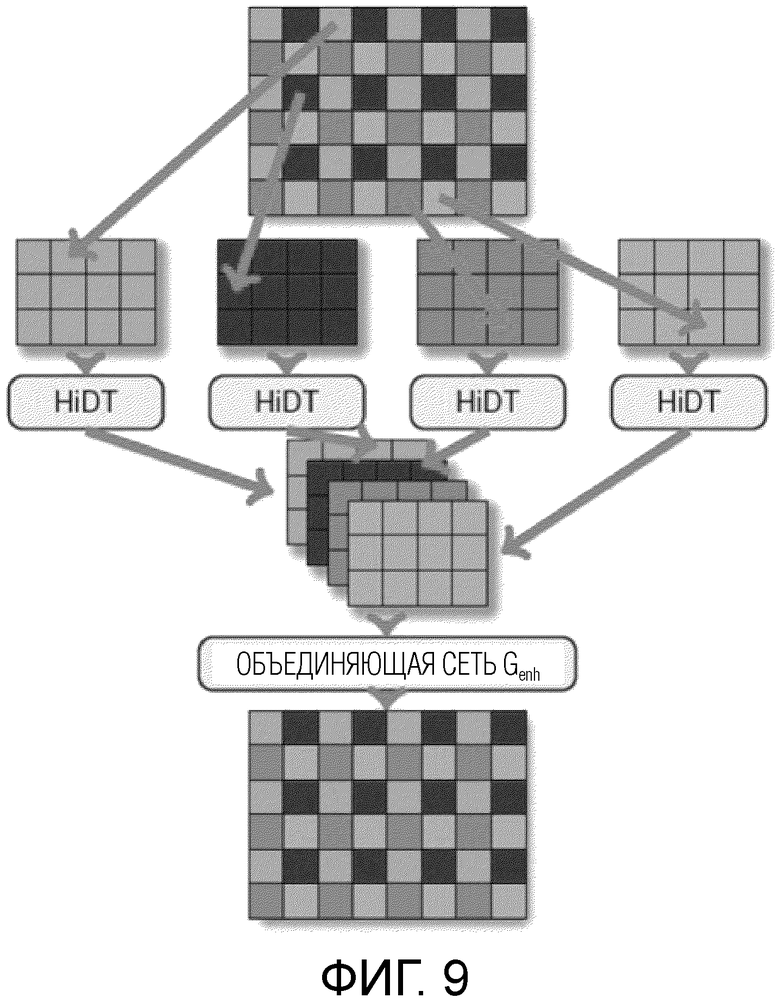
1. Способ формирования одного или нескольких изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе контентного изображения с использованием обученной генеративной нейронной сети и обученной объединяющей нейронной сети, причем способ содержит этапы, на которых:
принимают (S105) контентное изображение и (а) предопределенные один или несколько стилей, подлежащих применению к контентному изображению, или (b) одно или несколько стилевых изображений, имеющих один или несколько стилей, подлежащих применению к контентному изображению;
разделяют (S110) контентное изображение на n обрезанных изображений, при этом n обрезанных изображений являются обрезанными изображениями, сильно перекрывающимися в предопределенном режиме, определяемом направлением смещения и шагом в k пикселов;
применяют (S115) обученную генеративную нейронную сеть с каждым из одного или нескольких стилей к n обрезанным изображениям для получения n обрезанных изображений, рестилизованных согласно каждому из одного или нескольких стилей; и
объединяют (S120) рестилизованные n обрезанных изображений для каждого из одного или нескольких стилей с помощью обученной объединяющей нейронной сети для получения одного или нескольких изображений последовательности правдоподобного отображения течения времени суточного масштаба для контентного изображения.
2. Способ по п. 1, в котором генеративная нейронная сеть обучается в одном из или в комбинации следующих режимов: режим перестановки, случайный режим и режим автоэнкодера.
3. Способ по п. 1, в котором генеративная нейронная сеть содержит контентный кодер, стилевой кодер и декодер.
4. Способ по любому из пп. 1-3, в котором генеративная нейронная сеть обучается в режиме перестановки с использованием следующих этапов, повторно выполняемых с некоторым количеством итераций:
вводят (S155) первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении;
вводят (S160) второе изображение в качестве обучающего примера в стилевой кодер для получения стилевого вектора, указывающего стиль во втором изображении;
вводят (S165) контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент первого изображения и стиль второго изображения, и маски сегментации, соответствующей первому изображению;
попеременно вводят (S170) второе изображение и стилевой вектор или стилевой вектор и третье изображение в обусловленный дискриминатор, выполненный с возможностью определять, является ли изображение достаточно правдоподобным при данном стиле; и
попеременно обновляют (S175) параметры генеративной нейронной сети и обусловленного дискриминатора на основе результата определения обусловленным дискриминатором при разных итерациях для обеспечения обучения генеративной нейронной сети и обусловленного дискриминатора в состязательном режиме,
причем при обновлении параметров генеративной нейронной сети дополнительно учитывают маску сегментации,
причем первое изображение и второе изображение имеют первое разрешение.
5. Способ по любому из пп. 1-3, в котором генеративная нейронная сеть обучается в случайном режиме с использованием следующих этапов, повторно выполняемых с некоторым количеством итераций:
вводят (S180) первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении;
формируют (S185) случайный стилевой вектор из априорного распределения;
вводят (S190) контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент первого изображения, и стиль, определяемый случайным стилевым вектором, и маски сегментации, соответствующей первому изображению;
вводят (S195) случайный стилевой вектор и третье изображение в обусловленный дискриминатор, выполненный с возможностью определять, является ли изображение достаточно правдоподобным при данном стиле; и
обновляют (S200) параметры генеративной нейронной сети на основе результата определения обусловленным дискриминатором для обеспечения обучения генеративной нейронной сети и обусловленного дискриминатора в состязательном режиме,
причем при обновлении параметров генеративной нейронной сети дополнительно учитывают маску сегментации.
6. Способ по любому из пп. 1-3, в котором генеративная нейронная сеть обучается в режиме автоэнкодера с использованием следующих этапов, повторно выполняемых с некоторым количеством итераций:
вводят (S205) первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении;
вводят (S210) первое изображение в качестве обучающего примера в стилевой кодер для получения стилевого вектора, указывающего стиль в первом изображении;
вводят (S215) контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент и стиль первого изображения, и маски сегментации, соответствующей первому изображению;
сравнивают (S220) первое изображение и третье изображение; и
обновляют (S225) параметры генеративной нейронной сети на основе результата сравнения,
причем при обновлении параметров генеративной нейронной сети дополнительно учитывают маску сегментации.
7. Способ по любому из пп. 1-6, в котором генеративная нейронная сеть содержит одну или несколько плотных обходных связей, выполненных с возможностью передавать высокочастотные признаки, не передаваемые контентным тензором первого изображения, декодеру.
8. Способ по п. 1, в котором объединяющая нейронная сеть обучается с использованием следующих этапов, повторно выполняемых с некоторым количеством итераций:
получают (S230) набор обучающих изображений, каждое из которых имеет второе разрешение;
разделяют (S235) каждое изображение из набора обучающих изображений на n сильно перекрывающихся обрезанных изображений в предопределенном режиме, определяемом направлением смещения и шагом в k пикселов;
понижают (S240) дискретизацию каждого обрезанного изображения из n обрезанных изображений до первого разрешения;
применяют (S245) обученную генеративную нейронную сеть в режиме автоэнкодера к каждому обрезанному изображению из n обрезанных изображений для получения n преобразованных обрезанных изображений, каждое из которых захватывает артефакты и расхождения между соответствующим обрезанным изображением исходного обучающего изображения и преобразованным обрезанным изображением, созданным обученной генеративной нейронной сетью;
вводят (S250) n преобразованных обрезанных изображений в объединяющую нейронную сеть для получения объединенного изображения с уменьшенными артефактами и расхождениями, сравнивают объединенное изображение с соответствующим исходным изображением из набора обучающих изображений, и обновляют параметры объединяющей нейронной сети на основе результата сравнения,
причем объединенное изображение имеет второе разрешение.
9. Способ по п. 1, в котором один или несколько стилей, соответственно, соответствуют одному или нескольким временам суток, подлежащих применению к контентному изображению.
10. Вычислительное устройство (300), содержащее процессор (300.1) и память (300.2), хранящую исполняемые компьютером инструкции, которые, при исполнении процессором, побуждают процессор к выполнению способа по любому из пп. 1-9.
11. Способ формирования одного или нескольких изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе контентного изображения с использованием обученной генеративной нейронной сети, причем способ содержит этапы, на которых:
принимают контентное изображение и (a) предопределенные один или несколько стилей, подлежащих применению к контентному изображению, или (b) одно или несколько стилевых изображений, имеющих один или несколько стилей, подлежащих применению к контентному изображению;
уменьшают разрешение контентного изображения до низкого разрешения по меньшей стороне контентного изображения с сохранением соотношения сторон контентного изображения;
применяют обученную генеративную нейронную сеть с каждым из одного или нескольких стилей к уменьшенному контентному изображению для получения одного или нескольких уменьшенных контентных изображений, рестилизованных согласно каждому из одного или нескольких стилей; и
осуществляют разложение, используя пирамиду Лапласа, каждого из рестилизованных контентных изображений на высокочастотные составляющие и низкочастотную составляющую, имеющую низкое разрешение по меньшей стороне с сохранением соотношения сторон;
фильтруют низкочастотную составляющую с использованием направляемого фильтра, причем контент соответствующего рестилизованного контентного изображения используют в качестве направляющей для упомянутой фильтрации; и
формируют одно или несколько изображений последовательности правдоподобного отображения течения времени суточного масштаба на основе отфильтрованной низкочастотной составляющей и высокочастотных составляющих каждого из соответствующих рестилизованных контентных изображений, причем формирование выполняется с использованием пирамиды Лапласа.
12. Способ по п. 11, в котором генеративная нейронная сеть обучается в одном из или в комбинации следующих режимов: режим перестановки, случайный режим и режим автоэнкодера.
13. Способ по п. 11, в котором генеративная нейронная сеть содержит контентный кодер, стилевой кодер и декодер.
14. Способ по любому из пп. 11-13, в котором генеративная нейронная сеть обучается в режиме перестановки с использованием следующих этапов, повторно выполняемых с некоторым количеством итераций:
вводят первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении;
вводят второе изображение в качестве обучающего примера в стилевой кодер для получения стилевого вектора, указывающего стиль во втором изображении;
вводят контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент первого изображения и стиль второго изображения, и маски сегментации, соответствующей первому изображению;
вводят первое изображение и третье изображение, которые отфильтрованы с использованием направляемого фильтра, в дискриминатор, выполненный с возможностью определять, является ли третье изображение достаточно правдоподобным при данном стиле; и
обновляют параметры генеративной нейронной сети и дискриминатора на основе результата определения обусловленным дискриминатором при разных итерациях для обеспечения обучения генеративной нейронной сети и обусловленного дискриминатора в состязательном режиме,
причем при обновлении параметров генеративной нейронной сети дополнительно учитывают маску сегментации,
причем первое изображение и второе изображение имеют низкое разрешение.
15. Способ по любому из пп. 11-13, в котором генеративная нейронная сеть обучается в случайном режиме с использованием следующих этапов, повторно выполняемых с некоторым количеством итераций:
вводят первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении;
формируют случайный стилевой вектор из априорного распределения;
вводят контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент первого изображения, и стиль, определяемый случайным стилевым вектором, и маски сегментации, соответствующей первому изображению;
вводят первое изображение и третье изображение, которые отфильтрованы с использованием направляемого фильтра, в дискриминатор, выполненный с возможностью определять, является ли изображение достаточно правдоподобным при данном стиле; и
обновляют параметры генеративной нейронной сети на основе результата определения дискриминатором для обеспечения обучения генеративной нейронной сети и дискриминатора в состязательном режиме,
причем при обновлении параметров генеративной нейронной сети дополнительно учитывают маску сегментации.
16. Способ по любому из пп. 11-13, в котором генеративная нейронная сеть обучается в режиме автоэнкодера с использованием следующих этапов, повторно выполняемых с некоторым количеством итераций:
вводят первое изображение в качестве обучающего примера в контентный кодер для получения контентного тензора, являющегося пространственно меньшим представлением контента в первом изображении;
вводят первое изображение в качестве обучающего примера в стилевой кодер для получения стилевого вектора, указывающего стиль в первом изображении;
вводят контентный тензор, стилевой вектор в декодер для получения, с использованием адаптивной раздельной нормализации, третьего изображения, имеющего контент и стиль первого изображения, и маски сегментации, соответствующей первому изображению;
сравнивают первое изображение и третье изображение, которые отфильтрованы с использованием направляемого фильтра; и
обновляют параметры генеративной нейронной сети на основе результата сравнения,
причем при обновлении параметров генеративной нейронной сети дополнительно учитывают маску сегментации.
17. Способ по любому из пп. 11-16, в котором генеративная нейронная сеть содержит одну или несколько плотных обходных связей, выполненных с возможностью передавать высокочастотные признаки, не передаваемые контентным тензором первого изображения, декодеру.
18. Вычислительное устройство (300), содержащее процессор (300.1) и память (300.2), хранящую исполняемые компьютером инструкции, которые, при исполнении процессором, побуждают процессор к выполнению способа по любому из пп. 11-17.
| SEONGHYEON NAM и др., "End-to-End Time-Lapse Video Synthesis from a Single Outdoor Image", 01.04.2019, доступно: https://arxiv.org/pdf/1904.00680 | |||
| WEI XIONG и др., "Learning to Generate Time-Lapse Videos Using Multi-Stage Dynamic Generative Adversarial Networks", 22.09.2017, доступно: https://arxiv.org/pdf/1709.07592 | |||
| JUNTING PAN и др., "Video |

